- 投稿日:2019-05-02T16:28:29+09:00
TensorflowとNumpyを、疑問を解決しながら使ってみる。
目的
TensorflowとNumpyを、疑問を解決しながら使ってみる。
何年も前から、多くの方が、TensorflowとNumpyの使い方などを報告されています。それらを参考にして、自分が疑問に思った部分などを整理しつつ、後追いしてみます。
当面、利用目的は、CNNの実行とします。
まだ、書きはじめですが、多少、役立つと思う記載は以下。
テンソルとは?
テンソルとは?
Tensorflowの名前にも入っているtensor(テンソル)とは、なんだろうか?
ネット上で調べると、テンソル自体は、結構、難しいものであることがわかります。Tensorflowと関連づけて、テンソルの説明をされているものも多くありますが、簡単に説明しようとして頂いているが、テンソルの説明だけが、難しくなっていて、Tensorflowに対応づいていない気がします。自分としては、以下のブログ説明されているように、「多次元配列」という理解でいいと思いました。(以下のブログは、説明に成功している気がしました。)
HELLO CYBERNETICS「TensorFlowを始める前に知っておくべきテンソルのこと(追記:より一般的な話題へ)」
https://www.hellocybernetics.tech/entry/2016/12/01/223834まとめ
テンソルではまったので、まず、ひとこと、記載しました。
今後
また、何か関連する検討ができれば。
コメントなどあれば、お願いします。関連(本人)
- 投稿日:2019-05-02T15:50:51+09:00
Google Edge TPUをVirtual Box上のUbuntuで動かす
1 はじめに
Google Edge TPUのUSB Acceleratorを購入しました。Virtual Box上のUbuntuで動かすのに一苦労ありましたので、ここに書き留めておきます。
2 環境
Host OS: Windows 10
Guest OS: Ubuntu 18.04 LTS
仮想化マシン:Virtual Box ver.6.0.63 手順
- Virtual Boxのインストール
- VirtualBoxにOracle VM VirtualBox Extension Packの追加
ダウンロード先:https://www.virtualbox.org/wiki/Downloads
- Virtual BoxにUbuntuのインストール
参考:https://qiita.com/ykawakami/items/4bae371932110b2e25e3- Virtual BoxのUSBフィルタを編集
4.1. 設定をクリック
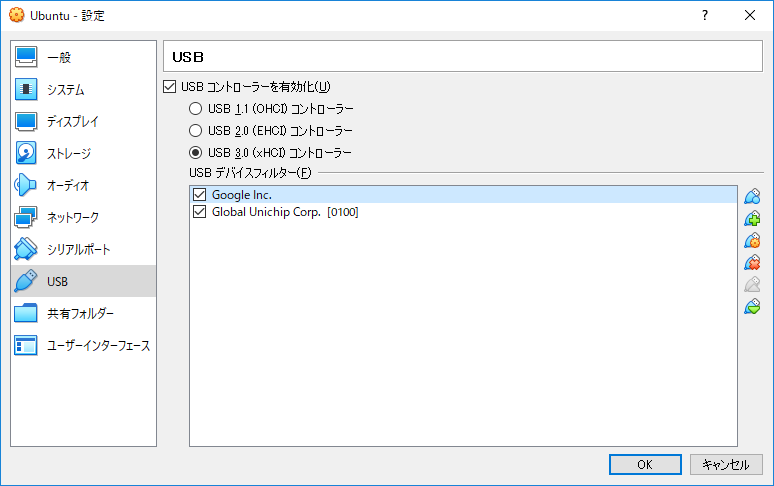
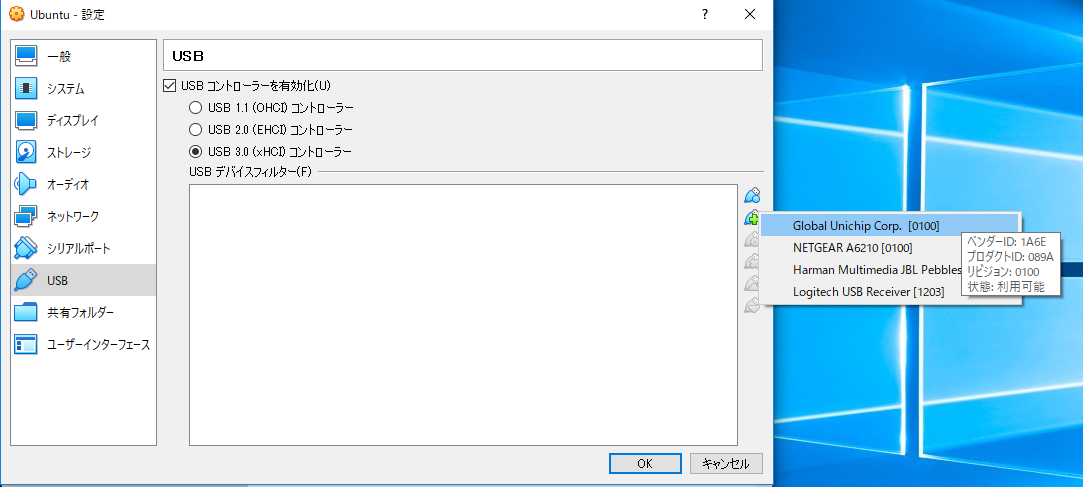
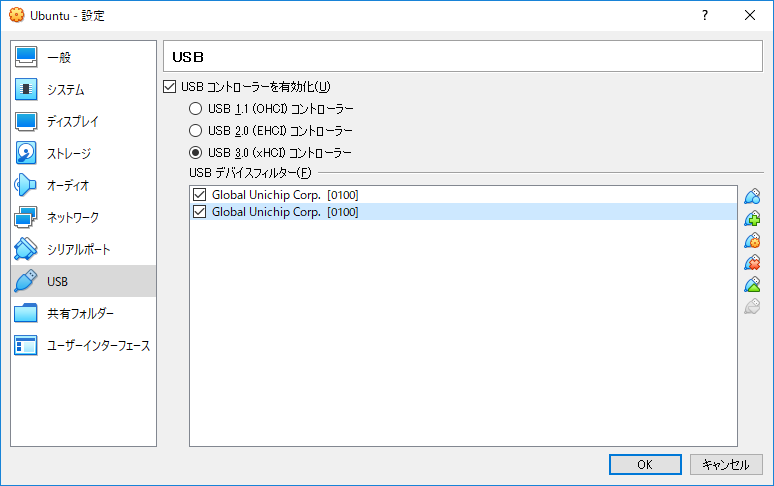
4.2. サイドバーのUSBを選択し「USBコントローラーを有効化」にチェックを入れる
4.3. USB Acceleratorを挿入しているUSBポートに合わせ、USBコントローラーのバージョンを指定する
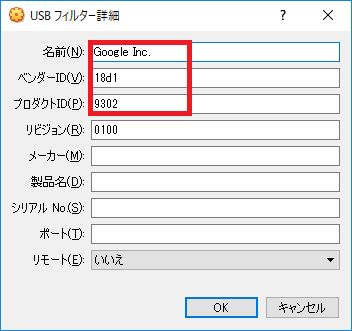
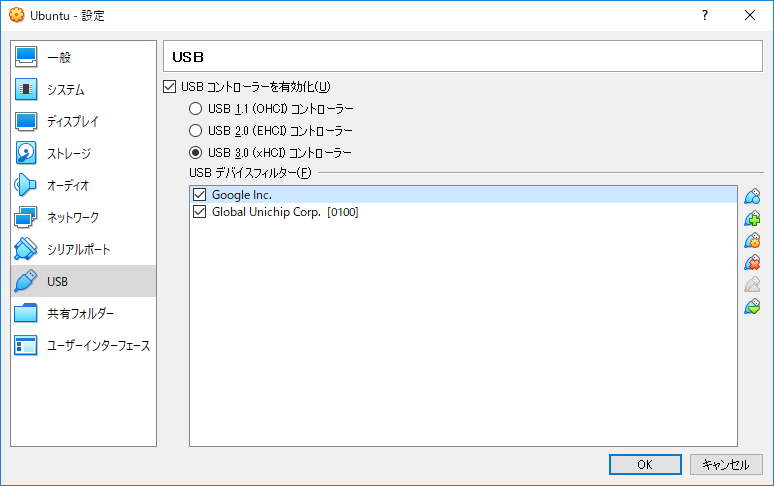
4.4. USBフィルタの追加をクリックし、Global Unichip Corp.[0100]を追加する
4.5. 4.4と同様の操作をし、Global Unichip Corp.[0100]を再度追加する
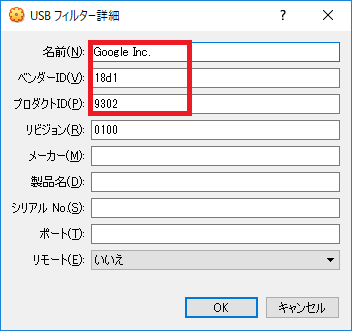
4.6. 2つのうち、1つを編集し以下のように設定する
ベンダーID:18d1
プロダクトID:9302
- Ubuntuを起動
- 以下のサイトをもとにUSB Acceleratorの動作確認をする
https://coral.withgoogle.com/docs/accelerator/get-started/4 結果
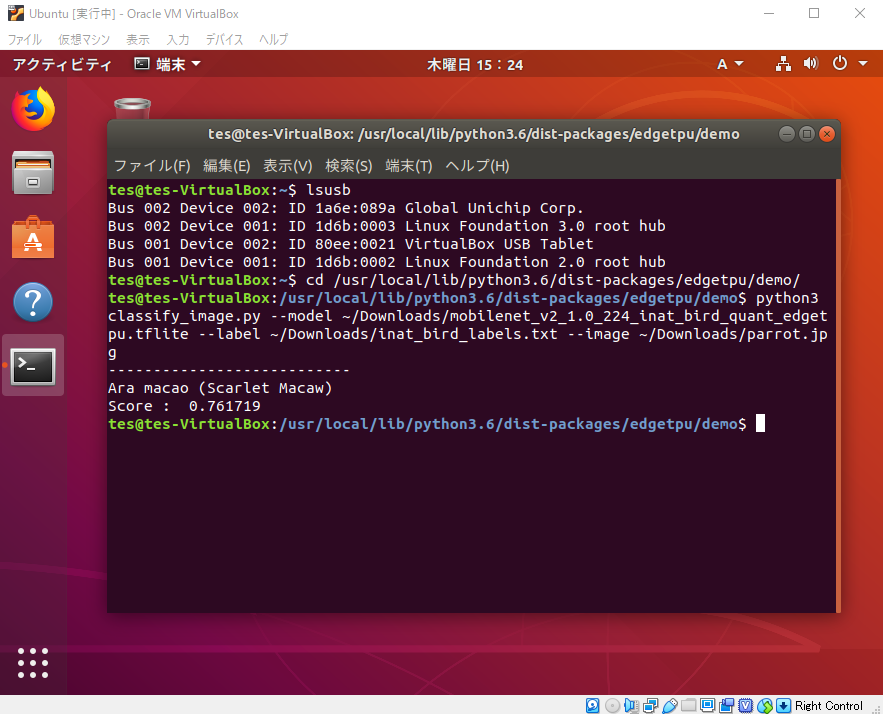
以下の通り、Virtual Box上でGoogle Edge TPUのUSB Acceleratorを動作させることができた。
5 経緯
Virtual Box上のUbuntuで動作させるに当たり、2つの問題にぶつかった。
5.1 "No Edge TPU Device detected!"エラー
これは、Virtual Box上でUSBデバイスを認識していないのが原因である。よって、USBフィルタにUSB Acceleratorを追加することで解決できた。
5.2 "RuntimeError: Failed to allocate tensors."エラー
この原因はさっぱりわからなかったが、githubのissueを見ているとサンプルプラグラム動作後にUSB AcceleratorのベンダーID、プロダクトIDが変わっているとの記載があった。また、サンプルプログラムを実行するとUSB Acceleratorがアンマウントされてしまうという現象が発生していた。このことから、試しにUSBフィルタに変更後のUSB AcceleratorのベンダーID、プロダクトIDを追加すると動作することができた。
6 補足事項
- 3で作成した仮想環境をMacBookAirのVirtual Boxにインポートしたが、USB Acceleratorを動作させることができた
- debianでも同様のことを実施したが、5.2のエラーが表示され動作させることができなかった
- 投稿日:2019-05-02T02:12:42+09:00
Kerasで基本的なRNN (LSTM) を試してみる
はじめに
Keras (TensorFlowバックエンド) のRNN (LSTM) を超速で試してみます。
時系列データを入力に取って学習するアレですね。
TensorFlowではモデル定義以外のところでいろいろコーディングが必要なので、Kerasを使って本質的な部分に集中したいと思います。動作環境
- Linux (CentOS 7)
- Python 3.6.8
- TensorFlow 1.5.0 / Keras 2.2.4
- 使っているCPUの関係で、TensorFlowは最新版だと動かないのでバージョンを落としています。
Python 3をインストールした後、以下のコマンドでTensorFlow / Kerasをセットアップします。
pip3 install tensorflow keras # CPU版 pip3 install tensorflow-gpu keras # GPU版問題設定
今回の題材は「{0.0, 1.0}からなる列の総和を出力するモデル」とします。
例えば[1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0]が入力であれば、8.0が出力されるようにします。
この問題設定は以下から拝借しました。
TensorFlowのRNNを基本的なモデルで試す - QiitaKerasでモデルを組む
KerasでのLSTMレイヤーの使い方は以下を参考にしています。
KerasでRNN(LSTM)を試してみる - Qiita各参考ページのコードの大部分を拝借&自分なりに改良していますが、自分の理解のために、なるべくコメントを入れて何をしたいかわかるようにしています。
固定長の系列を入力する場合
まずは固定長の入力がされる場合を考えます。
以下のコードでは、長さがちょうど10の{0.0, 1.0}系列が入力されたときに、その総和を出力するモデルを学習しています。rnn.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers.core import Dense from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 len_sequence = 10 # 時系列の長さ batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples, sequence_len): # 乱数で {0.0, 1.0} の列を指定された個数だけ生成する X = np.random.randint(0, 2, (nb_of_samples, sequence_len)).astype("float32") # 各行の総和を正解ラベルとする t = np.sum(X, axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 return X.reshape((nb_of_samples, sequence_len, 1)), t # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples, len_sequence) # モデル構築 model = Sequential() model.add(LSTM( num_hidden_units, input_shape=(len_sequence, input_dim), return_sequences=False)) model.add(Dense(output_dim)) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # (サンプル, 時刻, 特徴量の次元) の3次元の入力を与える。 test = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1]).astype("float32").reshape((1, 10, 1)) print(model.predict(test)) # [[7.7854743]]ポイントはデータの作り方だと思います。
時系列データを与えることになりますので、LSTMレイヤーに入力される次元数input_shapeがDNNの場合より1次元増えて、(時刻, 特徴量の次元) の2次元になります。
同様に、学習データの次元数も1つ増えて、(サンプル, 時刻, 特徴量の次元) の3次元で作成することになります。可変長の系列を入力する場合 (1)
今度は、入力される系列の長さが可変の場合を考えます。
自然言語処理の言語モデルなどを考えると、単語列や文字列の長さはどうしても変わり得るものです。いつも同じ長さの入力しかできないのでは具合が悪いでしょう。Maskingレイヤーを用いて、時系列の入力に対してマスキング(データをスキップする)処理を実装することで、可変長の入力を取り扱うことができるようになります。
長さが異なるデータを学習データ (numpy.array) として扱う際には、バッチ処理の都合上、系列の長さ(2次元目)は最大長に合わせることになります。このとき、最大長に満たない部分に特別な値を入れておくことで、パディング(長さ合わせ)を表すことができます。例えば、この「特別な値」を-1.0と決めておき[[ 1. 0. 1. 1. 0. 1. 0. -1. -1. -1.] [ 0. 1. 1. 1. 1. 0. -1. -1. -1. -1.] [ 0. 1. 0. 1. 1. 0. -1. -1. -1. -1.] [ 0. 0. 1. 0. 0. -1. -1. -1. -1. -1.] [ 0. 1. 1. 1. 1. -1. -1. -1. -1. -1.] [ 1. 0. 1. 0. 0. 0. 0. -1. -1. -1.] [ 1. 0. 1. 1. 0. 0. 1. 1. 1. 0.] [ 0. 1. 0. -1. -1. -1. -1. -1. -1. -1.] [ 1. 0. 0. 0. 1. 0. 1. -1. -1. -1.] [ 1. 1. 1. 1. 1. 1. -1. -1. -1. -1.]]といったデータを作れば、各行が順に長さ7の入力、長さ6の入力、… を表すことになります。
(実際に学習・予測に使うときには、3次元にreshapeする必要がありますが)このような学習データを乱数で作成し、予測を試すコードは以下のようになります。
rnn_dynamic_1.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Masking from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples): # 長さを対数正規分布に従って決める leng = np.around(np.random.lognormal(np.log(5.0), 0.5, (nb_of_samples, 1))).astype("int") max_sequence_len = leng.max() # 乱数で {0.0, 1.0} の列を生成する X = np.random.randint(0, 2, (nb_of_samples, max_sequence_len)).astype("float32") # 長さを超えた部分を-1.0に置き換える X[np.arange(max_sequence_len).reshape((1, -1)) >= leng] = -1.0 # 各行の-1.0を除いた総和を正解ラベルとする t = np.ma.array(X, mask=(X == -1.0)).sum(axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 return X.reshape((nb_of_samples, max_sequence_len, 1)), t # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples) # モデル構築 model = Sequential() # パディングの値を指定してMaskingレイヤーを作成する model.add(Masking( input_shape=(None, input_dim), mask_value=-1.0)) model.add(LSTM( num_hidden_units, return_sequences=False)) model.add(Dense(output_dim)) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # 任意の長さの入力を受け付ける test = np.array([1, 1, 1, 0, 1, 0, 1]).astype("float32") # (a) 長さを変えずに入力 print(model.predict(test.reshape((1, -1, 1)))) # [[4.9639335]] # (b) 後ろに適当な数の-1.0を追加して入力 print(model.predict(np.pad(test, (0, 10), "constant", constant_values=-1.0).reshape((1, -1, 1)))) # [[4.9639335]]最後の2つのprint文が同じ結果を出力することから、
-1.0がパディングとして特別扱いされていることが分かります。可変長の系列を入力する場合 (2)
入力として取り得る値が有限個であれば、Embeddingレイヤーを使うこともできます。
名前の通り、本来はword2vecのような次元圧縮(埋め込み)のタスクに用いることが想定されているようです。
Embeddingレイヤー - Keras Documentation
Using pre-trained word embeddings in a Keras model以下のページが参考になりました。
KerasでLSTMに可変長系列を入力するときはEmbedding(mask_zero=True)を使う - Qiita可変長の学習データを扱う際の注意は、先ほどと同じです。
また、入力データは非負整数(単語IDなどをイメージしてください)になり、パディングを表す値として ID: 0 が予約されます。ID: 0 はデータとしては使用できないので、0.0を ID: 1 に、1.0を ID: 2 に対応させます。そして、この対応関係をEmbeddingレイヤーに与える埋め込み行列(IDからN次元空間への変換行列)で表現します。コードは以下のようになります。
rnn_dynamic_2.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense from keras.layers.recurrent import LSTM from keras.layers.embeddings import Embedding from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples): # 長さを対数正規分布に従って決める leng = np.around(np.random.lognormal(np.log(5.0), 0.5, (nb_of_samples, 1))).astype("int") max_sequence_len = leng.max() # 乱数で {1, 2} の列を生成する X = np.random.randint(1, 3, (nb_of_samples, max_sequence_len)) # 長さを超えた部分を0に置き換える X[np.arange(max_sequence_len).reshape((1, -1)) >= leng] = 0 # 各行の2の個数を正解ラベルとする t = np.sum(X == 2, axis=1).astype("float32") # LSTM (Embedding) に与える入力は (サンプル, 時刻) の2次元になる。 return X, t # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples) # Embeddingの埋め込み行列を指定する # https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html embedding_matrix = np.array([[0.0], [0.0], [1.0]], dtype="float32") # モデル構築 model = Sequential() # Embeddingによりベクトルを変換する model.add(Embedding( input_dim=embedding_matrix.shape[0], # 入力として取り得るカテゴリ数(パディングの0を含む) output_dim=input_dim, # 出力ユニット数(本来の特徴量の次元数) weights=[embedding_matrix], # 埋め込み行列を指定 trainable=False, # 埋め込み行列を固定(学習時に更新しない) mask_zero=True)) # 0をパディング用に特別扱いする model.add(LSTM( num_hidden_units, return_sequences=False)) model.add(Dense(output_dim, activation="linear")) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # 任意の長さの入力を受け付ける test = np.array([1, 1, 1, 0, 1, 0, 1]) # {0, 1}を{1, 2}に変換してモデルに入力 # (a) 長さを変えずに入力 print(model.predict((test + 1).reshape((1, -1)))) # [[4.88129]] # (b) 後ろに適当な数の0を追加して入力 print(model.predict(np.pad((test + 1), (0, 10), "constant").reshape((1, -1)))) # [[4.88129]]最後の2つのprint文が同じ結果を出力することから、
0がパディングとして特別扱いされていることが分かります。Embeddingレイヤーは入力される特徴量を1次元(単語などのID)と想定しているので、データ作成部分が今までとは少し変わっています。今までは入力データを実数値 (float32) で与えていましたが、今回は入力データが整数値になっています。(LSTMレイヤーに与えられる特徴量は、これまでと同様に実数値になりますが)
ここまでできると、自然言語処理で何か作れるかもしれないと思えてきます。(私だけ?)
- 投稿日:2019-05-02T01:07:08+09:00
ml-agents 0.8.0 で自分のプロジェクトで機械学習させる (Windows)(Tensorflow-GPU導入編)
前段
Macでのml-agents導入はこちらを参照してほしい。
今回はWindows用、それもtensorflow-gpu を使ってやりたい。基本的に以下の本家のページの通りだが
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation-Windows.md
ハマリポイントがいくつかあったので、それには注意を促したい、というのがこの記事の趣旨だ。
あと1年後は100%忘れる自信がある私自身のためのものでもある。環境設定
1、 ml-agents をダウンロード
https://github.com/Unity-Technologies/ml-agents/tags/0.8.0
をダウンロードして、適当なところに配置2、 anaconda をインストール
ターミナルで「conda」と打って反応があれば既にインストール済み
3、 仮想環境を作る
conda info -eで[ml-agents]があれば良い。なければ↓でつくる。
conda create -n ml-agents python=3.6で仮想環境を作る(なんか聞かれたら「y」と入力)
conda activate ml-agentsで仮想環境切り替え。
4、 CUDA toolkit のインストール
Unity ML-agentsドキュメントによると、CUDA toolkitのバージョンは「9.0.176」限定であるらしいので、それをダウンロードする。ダウンロードサイト直リンク
5、cuDNN library のインストール
- NVIDIAサイトでcuDNNのサイトに行って、ダウンロードの手続きをする。ディベロッパー登録やらアンケートやらをやる必要がある。(こちらもCUDA toolkit 同様、バージョンが限定されているので要注意。「7.0.5」らしい。ダウンロードサイト直リンク )
- ダウンロードしたzipを展開すると「bin」「include」「lib」フォルダができるので、それをCUDA toolkitのインストール先である
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0に配置する。6、環境変数の設定
CUDA_HOMEという環境変数を新規に作り、C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0を設定する。
次に、Path環境変数に、以下の二つを追加する。C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\extras\CUPTI\libx64(Unity ML-agentsドキュメントには「関連するパスを置き換えろ」と書いてあるが、CUDA toolkit インストール時に書き加えられたパスを消してはいけないので注意が必要)
以下の感じにパスが張っていればOK。
7、tensorflow-gpu のインストール
3で作った仮想環境で
pip install tensorflow-gpu==1.7.1とやって tensorflow-gpu を仮想環境にインストール。
確認のために、pythonとやって、pythonを起動後、
import tensorflow as tf sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))で、tensorflow-gpu が起動するのを試してみる。
Found device 0 with properties ...とかなんとか出れば成功。出てなければ、tensorflow-gpu がインストールできていない可能性がある。
8、ML-Agents が使うライブラリをインストール
★★★ここで注意★★★
このままML-Agents の使うライブラリをインストールしようとすると、せっかくいれたtensorflow-gpu に 通常のCPUを使う tensorflow が上書きインストールされてしまう。
なので、ml-agents/setup.py を以下のように編集する必要がある。setup.py: packages=['mlagents.trainers'], # Required zip_safe=False, install_requires=[ 'mlagents_envs==0.8.0', # 'tensorflow>=1.7,<1.8', # ←ここをコメントをしておく 'Pillow>=4.2.1', 'matplotlib', 'numpy>=1.13.3,<=1.14.5', 'jupyter', :そして、改めて以下を実行して ml-agents のライブラリをインストールする。
cd ml-agents-envs pip install -e . cd .. cd ml-agents pip install -e . cd ..確認のために
mlagents-learnとやってみてちゃんとUnityロゴのアスキーアートが出ていれば成功。
念の為、先ほどのPythonを動かしてみて
import tensorflow as tf sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))で、tensorflow-gpu が正常に動いていることを確認する。(たまにCPUに切り替わってたりするので要注意)

