- 投稿日:2019-05-02T23:36:45+09:00
Pythonのマルチコア並列処理でクローリングを高速化
複数のサイトから情報収集する用事があり、簡単なクローラーを書いていたのだがサイトが増えると遅くてしょうがない。そこでmultiprocessingで並列処理してみたらコア数の分だけ高速化できた気がするので公開。
from multiprocessing import Pool from multiprocessing import Process import feedparser import time keyword = '' feed_urls = [ 'https://www.theverge.com/rss/index.xml', 'https://gizmodo.com/rss', 'https://www.cnet.com/rss/all/', 'https://techcrunch.com/feed/', 'https://news.ycombinator.com/rss', 'http://feeds.arstechnica.com/arstechnica/index/', 'http://feeds.mashable.com/Mashable', 'https://hub.packtpub.com/feed/' ] def function(n): count = 0 feed_result = feedparser.parse(feed_urls[n]) for entry in feed_result.entries: flag = False try: if keyword in entry.title.lower(): flag = True if keyword in entry.content.lower(): flag = True if keyword in entry.description.lower(): flag = True except: pass if flag == True: print(entry.title) print(entry.link) print() count = count + 1 return count def multi(n): p = Pool(4) #最大プロセス数 result = p.map(function, range(n)) return result def main(): global keyword print("input keyword:",end='') keyword = input().rstrip().lower() start = time.time() hit_count = 0 data = multi(len(feed_urls)) for i in data: hit_count = hit_count + i print(hit_count) print(time.time() - start) main()こちらを参考にしました。
- 投稿日:2019-05-02T23:13:51+09:00
Python+ResponderでWEBアプリケーションを構築する。
PythonのWEBフレームワーク「Responder」を使ったWEBアプリケーションを作成してみます。
「Quick Start!」, 「Feature Tour」を参考に、私自身に最低限必要なものだけを取り上げています。
- 動作環境
カテゴリ os windows10 home python Python 3.7.3 responder 1.3.1
- install
pipでインストールするだけです。
cmd.promptpip install responder
- 以下、すべて「run.py」でWEBサーバを起動します。
cmd.promptpython run.py1.hello world
run.pyimport responder api = responder.API() @api.route("/") def hello_world(req, resp): resp.text = "hello, world!" if __name__ == '__main__': api.run()2.Template Engine
- directory / file
root │ run.py │ └─templates hello.htmltemplateは、「templates」フォルダの下に作成する。
- run.py
run.pyimport responder api = responder.API() @api.route("/html/{who}") def hello_html(req, resp, *, who): resp.content = api.template('hello.html', who=who) if __name__ == '__main__': api.run()
- hello.html
hello.html<h1>Hello {{ who }}</h1>
- 確認
http://127.0.0.1:5042/html/johnにアクセスする
3.Returning JSON
- Quick Startでは、以下のようになっている。
run.pyimport responder api = responder.API() @api.route("/json/{who}") def hello_to(req, resp, *, who): resp.media = {"hello": who} if __name__ == '__main__': api.run()
- しかし、日本語だとunicodeで表示されてしまう。回避策として、json.dumpsを使う。
run.pyimport responder import json api = responder.API() @api.route("/") def hello_to(req, resp): # resp.media = {"hello": "斎藤さん"} resp.headers = {"Content-Type": "application/json; charset=utf-8"} resp.content = json.dumps({"hello": "斎藤さん"}, ensure_ascii=False) if __name__ == '__main__': api.run()4.File Upload
ここでは、staticファイルを参照する方法も載せておきます。
- ファイル・フォルダ構成
fileupload │ run.py ・・・(1) └─templates index.html ・・・(2) layout.html ・・・(3) success.html ・・・(4) static └─css main.css ・・・(5)(1) run.py
run.pyfrom pathlib import Path import responder import requests def parentdir(path='.', layer=0): return Path(path).resolve().parents[layer] BASE_DIR = parentdir(__file__,1) # ・・※1 api = responder.API( static_dir=str(BASE_DIR.joinpath('static')), ) @api.route("/") async def greet_world(req, resp): resp.content = api.template('index.html') @api.route("/upload") async def upload_file(req, resp): @api.background.task def process_data(data): file=data['file'] f = open('./{}'.format(data['file']['filename']), 'wb') f.write(file['content']) f.close() data = await req.media(format='files') process_data(data) resp.content = api.template('success.html') if __name__ == '__main__': api.run()※1・・staticファイルを使用するときは、APIを定義するときに「static_dir」を指定します。
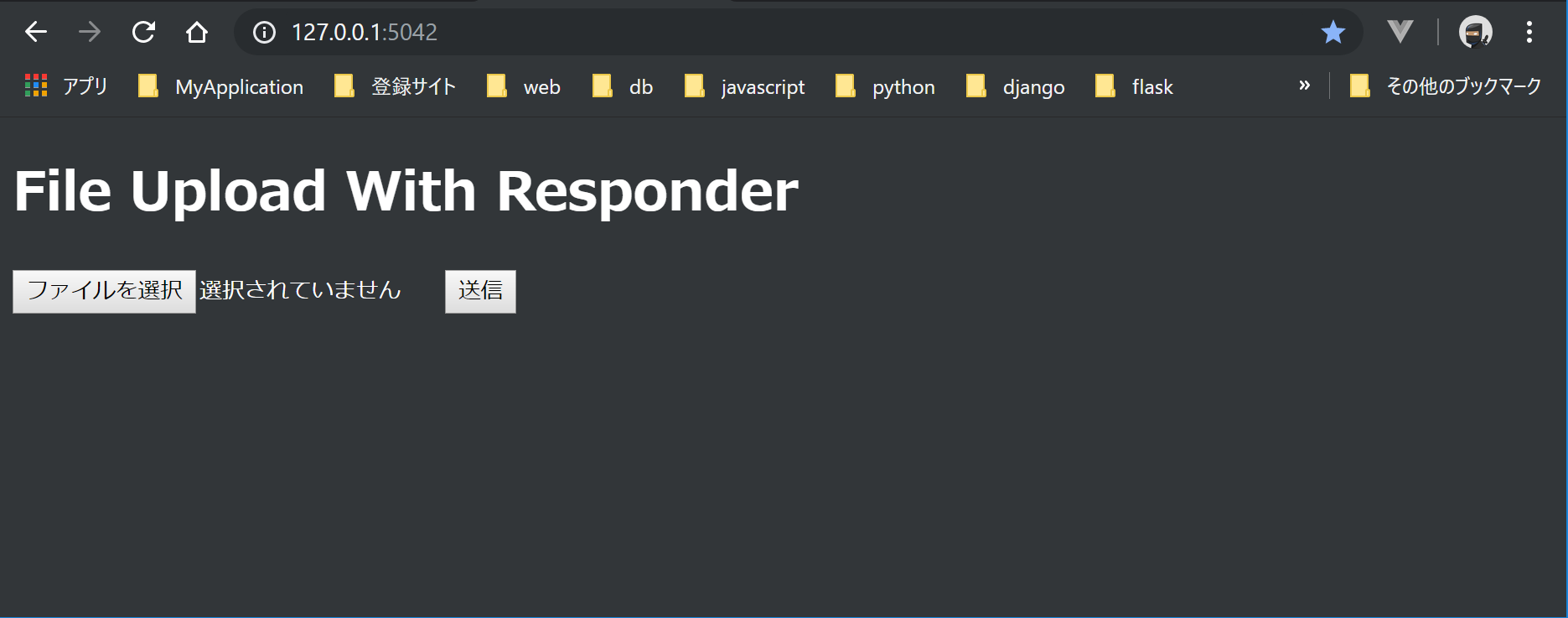
(2) index.html
index.html{% extends "layout.html" %} {% block content %} <h1>File Upload With Responder</h1> <form id="fileupload" action="/upload" method="post" enctype="multipart/form-data"> <input name="file" type="file"/> <button type="submit">送信</button> </form> {% endblock %}(3) layout.html
layout.html<!doctype html> <html> <head> <meta charset="utf-8"/> <title>{{ title }}</title> <link rel="shortcut icon" href=""> <link href="/static/css/main.css" rel="stylesheet" type="text/css" media="all"> </head> <body> {% block content %} <!-- ここにメインコンテンツを書く --> {% endblock %} </body> </html>(4) success.html
success.html{% extends "layout.html" %} {% block content %} <h1>File Upload With Responder(Result)</h1> <p>ファイルをアップロードしました。</p> <a href="#" onclick="history.back(-1); return false;">戻る</a> {% endblock %}(5) main.css
main.cssbody { background: rgb(50, 54, 57); color: white; }
- darkmode風にしています。
5.ユーザ認証
- ファイル・フォルダ構成
userauth │ run.py ・・・・(1) │ └─templates layout.html ・・・・(2) login.html ・・・・(3) logout.html ・・・・(4) top.html ・・・・(5) static └─css main.css(1)run.py
run.py# -*- coding: utf-8 -*- from pathlib import Path import responder def parentdir(path='.', layer=0): return Path(path).resolve().parents[layer] BASE_DIR = parentdir(__file__,1) api = responder.API( static_dir=str(BASE_DIR.joinpath('static')), ) users = { "admin": "password", "guest": "password" } @api.route(before_request=True) def prepare_response(req, resp): # 静的ファイルはOK if req.url.path.startswith('/static/'): return # パスがログインページならOK if req.url.path == '/login': return # セッションにusernameが保存されている場合、OK if req.session.get('username') is not None: return # 上記以外はすべて認証が必要 api.redirect(resp, '/login') @api.route("/") async def hello(req, resp): api.redirect(resp, "/login") def isauthenticated(username, password): if not username in users: return False if users.get(username) != password: return False return True @api.route("/login") class login: async def on_get(self, req, resp): # or on_get.. # getの場合 resp.content = api.template('login.html') async def on_post(self, req, resp): # or on_get.. data = await req.media() # postの場合 errmessages=[] username=data.get('username') password=data.get('password') if not isauthenticated(username, password): errmessages.append('ユーザ名またはパスワードに誤りがあります') loginredirect="/top" resp.content = api.template('login.html', errmessages=errmessages) return resp.session['username']=username api.redirect(resp, "/top") @api.route("/top") async def top(req, resp): authenticateduser = req.session.get('username') resp.content = api.template('top.html', authenticateduser=authenticateduser) @api.route("/logout") async def logout(req, resp): resp.session.pop('username') resp.content = api.template('logout.html') if __name__ == '__main__': api.run()(2)layout.html
layout.html<!DOCTYPE html> <html> <head> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta charset="utf-8"> <title></title> <meta name="description" content=""> <meta name="author" content=""> <meta name="viewport" content="width=device-width, initial-scale=1"> <link href="/static/css/main.css" rel="stylesheet" type="text/css" media="all"> <link rel="shortcut icon" href=""> </head> <body> <main> <div id="content"> {% for errmessage in errmessages %} <p class="error">{{ errmessage }}</p> {% endfor %} {% block content %} {% endblock %} </div> <nav> {% if authenticateduser %} <a href="/logout" style="color:white;">ログアウト</a> {% endif %} </nav> </main> </body> </html>(3)login.html
login.html{% extends "layout.html" %} {% block content %} <form id="loginForm" action="/login" method="post"> <h1 style="color: white;">ログイン認証</h1> <label>username:</label> <input type="text" name="username" placeholder="username" value="" required> <br/> <label>password:</label> <input type="password" name="password" placeholder="password" value="" required> <br/> <br/> <input type="submit" value="ログイン"> </form> {% endblock %}(4)logout.html
logout.html{% extends "layout.html" %} {% block content %} <h1>ログアウト</h1> <p>ご利用ありがとうございました。</p> <a href="/login" style="color:white;">ログイン</a> {% endblock %}(5)top.html
top.html{% extends "layout.html" %} {% block content %} <h1>Hello {{ authenticateduser }} さん</h1> {% endblock %}6.データベース接続
python+responderでRest APIを作るにて。
7.その他
まだまだ他にもあります。本家サイトを参考してください。
- 2019.05.03 追記
8.download file
サーバ上のファイル(CSV, PDF)をダウンロードします。
- ファイル・フォルダ構成
filedownload run.py ・・・・(1) sample.pdf 所属.csv(1).run.py
run.pyimport responder import urllib.parse api = responder.API() CONTENTTYPES = { 'plain':'text/plain', 'csv':'text/csv', 'html':'text/html', 'js':'text/javascript', 'json':'application/json', 'pdf':'application/pdf', 'xlsx':'application/vnd.ms-excel', 'ppt':'application/vnd.ms-powerpoint', 'docx':'application/msword', 'jpeg':'image/jpeg', 'png':'image/png', 'gif':'image/gif', 'bmp':'image/bmp', 'zip':'application/zip', 'tar':'application/x-tar' } def readf(filename): path='./' + filename with open(path,'rb') as f: dt = f.read() return dt @api.route("/csv/{filename}") def downloadcsv(req, resp, *, filename): downloadfilename=urllib.parse.unquote(filename, 'utf-8') resp.headers['Content-Type'] = CONTENTTYPES.get('csv') resp.headers['Content-Disposition'] = 'attachment; filename='+ filename resp.content=readf(downloadfilename) @api.route("/pdf/{filename}") def downloadpdf(req, resp, *, filename): downloadfilename=urllib.parse.unquote(filename, 'utf-8') resp.headers['Content-Type'] = CONTENTTYPES.get('pdf') resp.headers['Content-Disposition'] = 'attachment; filename='+ filename resp.content=readf(downloadfilename) if __name__ == '__main__': api.run()(2).確認
http://127.0.0.1:5042/csv/確認.csv
http://127.0.0.1:5042/pdf/sample.pdf
- 投稿日:2019-05-02T22:58:54+09:00
[ジュニア向け] ProcessingのPythonモードでプログラミング入門:その1 - ブロックくずしを作ろう
この記事について
この記事では、Processing(プロセッシング)のPython(パイソン)モードを使ってプログラミングの基本を学びます。
メインの対象読者は中高生ですが、プログラミング入門者であれば役に立ちます。
完成図
この記事ではかんたんなブロックくずしを作ります。
Processingについて
Processing(プロセッシング)を使うと簡単に画面に絵を出したりマウスの操作で絵を動かせたりできます。
なぜPythonモードか
Processsingでは通常、専用のプログラミング言語を使うのですが、この記事ではPython(パイソン)というプログラミング言語を使って書いていきます。
Pythonは簡単に書け、プログラミングの初心者からプロ中のプロまでが使う便利な言語です。ここでPythonをおぼえるとずっと役に立ちます。インストール
※子ども向け注意:ページは英語で書かれています。ここはできれば大人に手伝ってもらいましょう
Processingのインストール
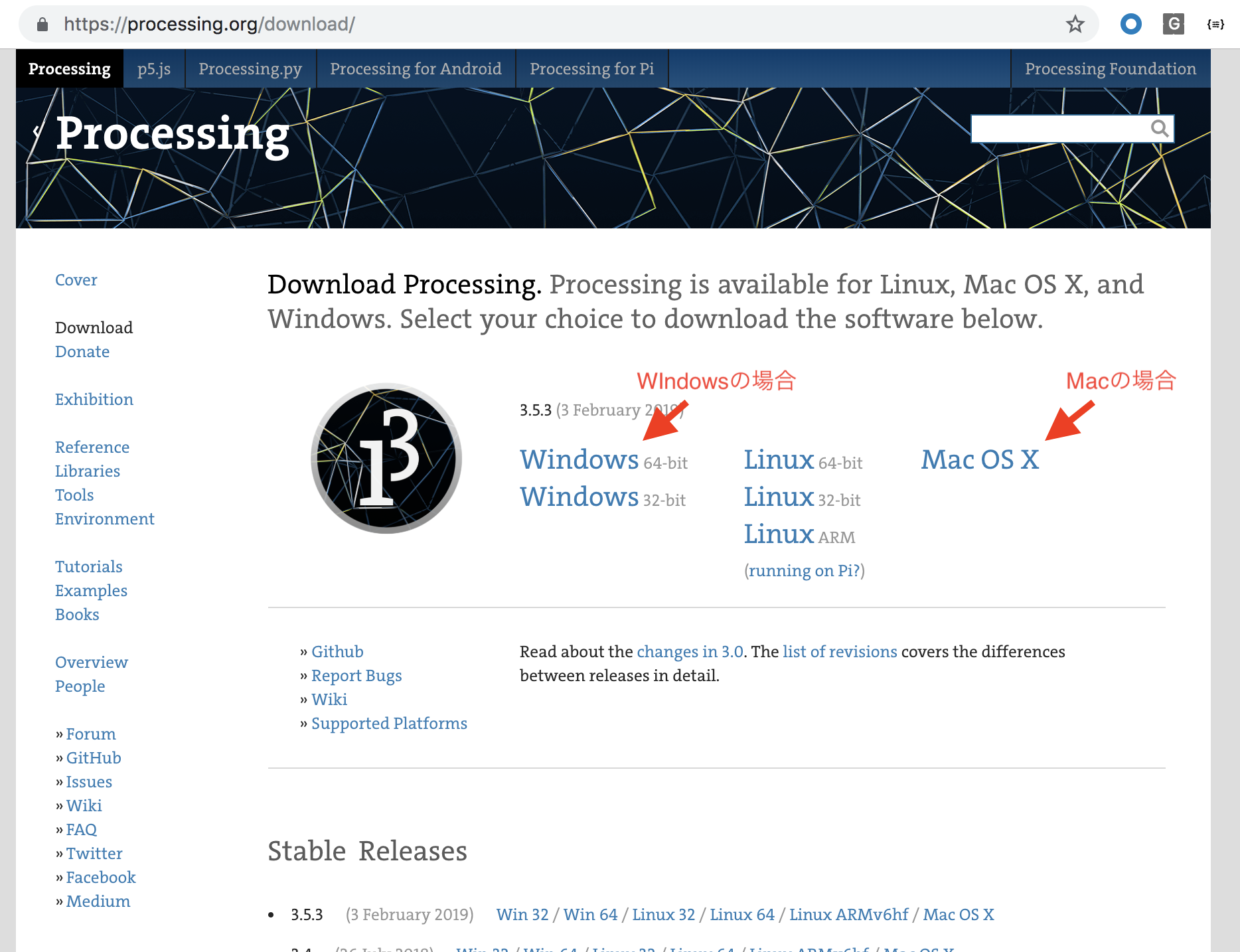
https://processing.org/ にアクセスします
以下のようなページがひらきます。左側にある「Download」というリンクをクリックします
次につかっているパソコンの種類にあわせてダウンロードします。
ダウンロードがおわると zipファイル(データが小さくなるよう加工したファイル)がダウンロードフォルダに表れます。
zipファイルをダブルクリックすると、Processingの本体ファイルが現れます。
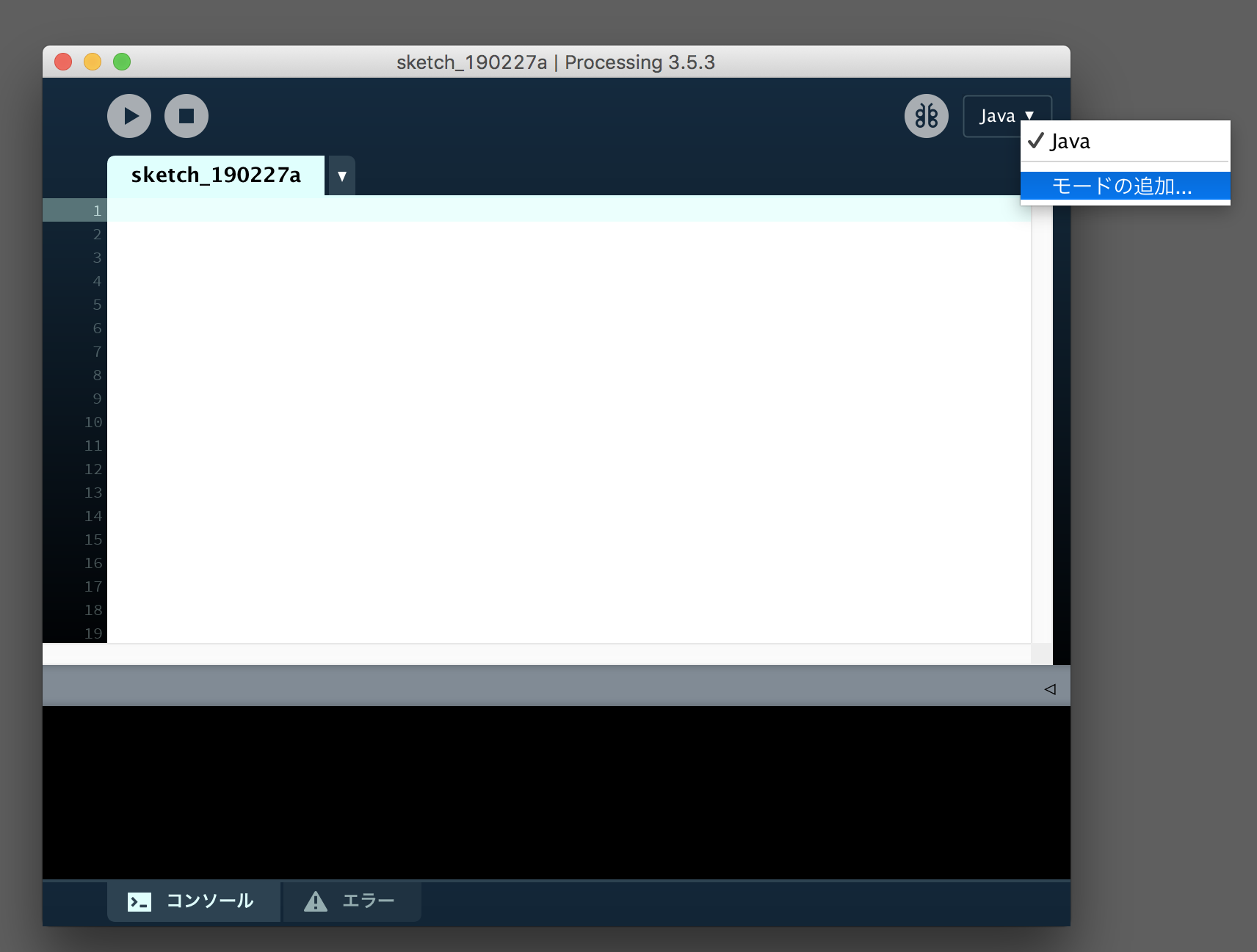
このアイコンがProcessing本体です。Pythonモードのインストール
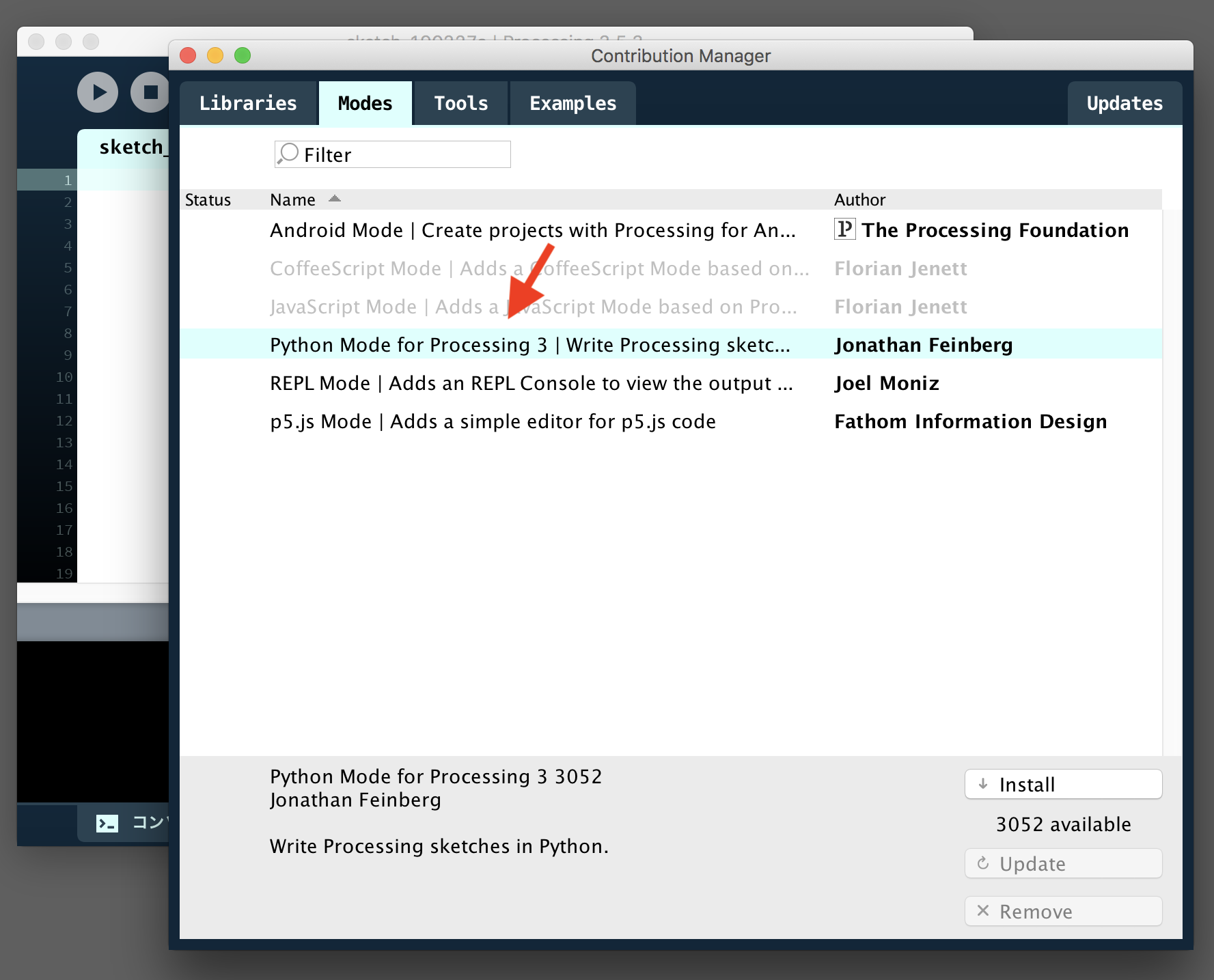
Processingのアイコンをダブルクリックすると以下のようなウィンドウが立ち上がります。右側にある「Java」となっているところをクリックすると「モードの追加..」というメニューが表示されるのでそこをクリックします。
次に出てくる画面で「Python Mode for Processing3」をクリックします
ダウンロードがおわったらその画面を閉じます。
さきほどの画面(ダブルクリックして立ち上げた状態の画面)のJavaのところをクリックして「Python」を選べればOKですPythonとProcessingの基本
プログラミング言語Pythonと、プログラミングを書いて動かすツールであるProcessingの基本について説明します。
Hello World(ハローワールド)
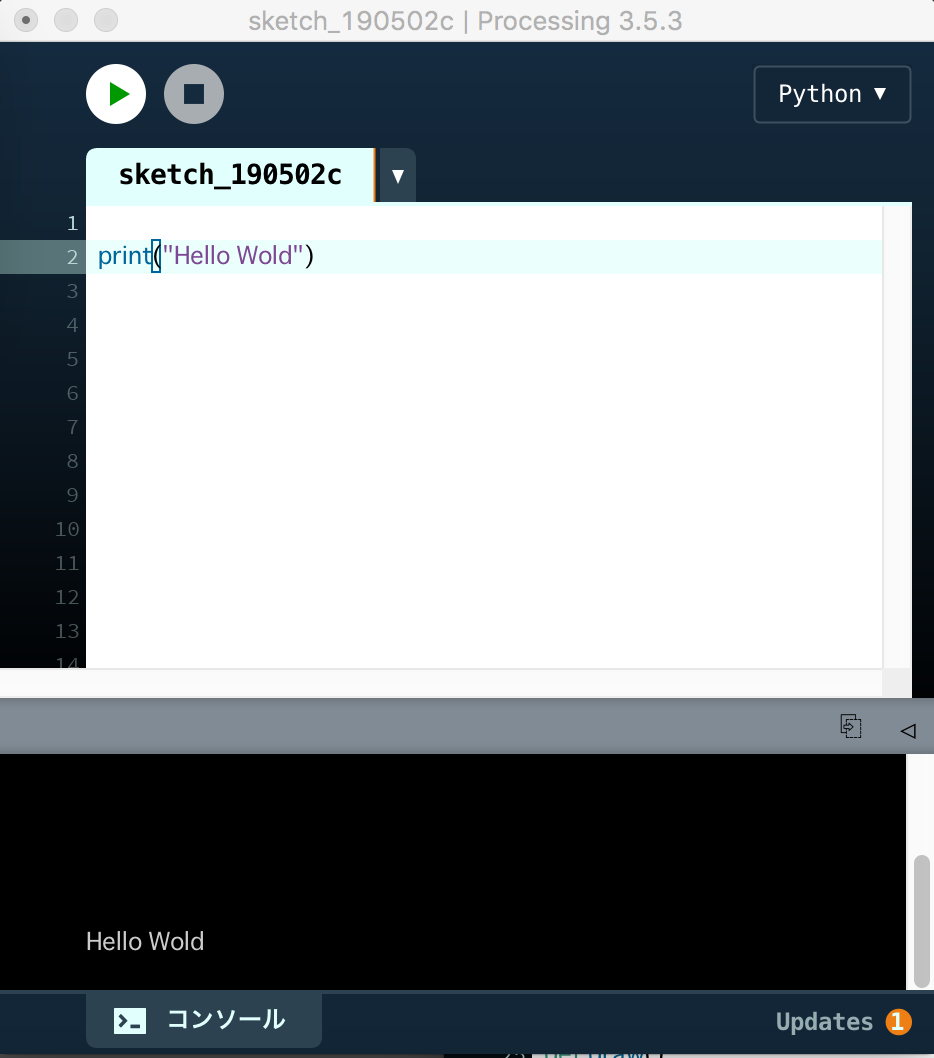
まずは最初に「Hellow World」と表示させてみましょう
print("Hello World")このように書いて▶マークの実行ボタンをおすと、エディタ画面の下半分に Hello World と表示されます
円を描く
次に円を描いてみましょう。Processingは絵やアニメーションを描くのが得意なプログラミングツールです
size(300, 300) ellipse(150, 150, 200, 200)実行ボタンを押すと、縦300ピクセル横300ピクセルの画面に、縦のx座標150、横のy座標150の位置を中心とした、高さ200ピクセル、横幅200ピクセルの円が描かれます
setup()とdraw()
Procssingのポイントは
setup()という関数とdraw()という関数です。関数については、あとで詳しく説明しますが、この時点ではプログラミングのかたまり、というようにおぼえてください。setup関数の中身は最初に一回だけ実行されます
def setup(): #..プログラムの最初に1回だけ実行されるdef draw(): # プログラムが止まるまで繰り返し繰り返し実行される。1秒間に何回も実行される例
最初に 400ピクセルx400ピクセルの画面を作り、ちょっとずつ位置どずらして円を描き続けている例です
x = 0 y = 0 def setup(): size(400,400) def draw(): global x,y x += 1 y += 1 ellipse(x, y, 100, 100)変数
変数とは、数字や文字列などを入れる箱のようなものです。(*箱というとプロのプログラマーからは違うという意見がでそうですが、ここはジュニア向けなので箱としておきます)。
x = 100 # 100という数字を変数 xに入れた name = "Taro" # Taroという文字を変数 name に入れた数字や文字だけでなく、プログラム内でつくったものも入れることができます。例えば、画面、ボタン、スーパーマリオだったらマリオなど。おいおい説明します
if文
ある条件にあてはまったかどうかで処理を分ける場合に
if 条件:という書き方をします。その条件の時に実行されるプログラムはインデント(頭に数文字分あけること)で指定します。またifの条件にはずれた時に実行される部分はelseというキーワードに続けて書きます↓の例でifの次の行が頭に数文字分あいていることに注目してください。同じ文字数分あいている数行が同じ条件の中で実行されるかたまり、という意味になります。
if x > 20: print("ここの部分はxが") print("20より大きい時に実行されます") else: print("ここはxが20以下の時に実行されます") print("ここはxがどちらの場合も実行されます")ブロックくずしを作る
ここから実際にブロックくずし作りに入っていきます
ステップ1: 円を動かす
まずは画面上に円を動かしてみましょう。「setup()とdraw()」の項目で作ったものと似ていますが、毎回draw()関数の中で
background(0)として画面全体を真っ黒に塗りつぶしている点が違います。x = 0 y = 0 def setup(): size(300, 300) def draw(): global x,y background(0) fill(255) x += 1 y += 1 ellipse(x, y, 30, 30)実行すると下のように動きます
ポイント
ellipseは楕円という意味です。中心の位置と縦横の長さを指定して円を描きますfill()は塗りつぶしを指定する命令です。()の中は色が入ります。この例の255は白を意味していますglobalは関数の外側で作られた変数を操作する時に使います。このxとyは、プログラムの頭の方で最初に作られていて、それをdraw()の中で操作するのでこの宣言が必要です+= 1は1を足すという意味です。ステップ2: プレイヤーが操作するバーを表示する。
画面上の下の方にバーを表示し、キーボードの左右の矢印で操作できるようにします
x = 0 y = 0 barX = 0 barY = 260 def setup(): size(300, 300) def draw(): global x,y background(0) fill(255) x += 1 y += 1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 1 elif keyCode == LEFT: barX -= 1実行すると下のような動きをします。右矢印を押してバーを右に動かそうとしてますが、遅くてまにあいません
ポイント
keyPressedはキーが押されて時に実行されるプロセッシングで使える関数です。今回はこの中で押されたキーのコードkeyCodeが右または左の時にボールのx座標を 1だけ足したり減らしたりしていますif 条件:に続けて別の条件のチェックをする時はelifという宣言をしますステップ3:壁でボールを反発させる
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
ポイント
- 本当は下まで来たらゲームオーバーですが、とりあえず下での反発させています
- 変数
speedXspeedYはそれぞれ横方向のスピード、縦方向のスピードをあらわしてます。- 画面の端まできたかをチェックしているのが
if x > 300 or x < 0:の部分ですspeedX = speedX * -1は-1をかけて数字を反転させています。こうすることで逆方向に進むようになりますステップ4: バーにあたったら跳ね返る
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
ポイント
if x > barX and x < barX + 60 and y > barY and y < barY + 20:の部分でバーにあたったかどうかを判断しています- バーの動く速度を最初の例よりはやめています。
ステップ5: ブロックを表示する
横3列、縦3列、合計9個のブロックを表示させます。
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 rect(blockX, blockY, 100, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
一応それっぽいものが表示されましたが、まだボールがあたっても消えません
ポイント
以下の部分で9個のブロックを表示しています。
for i in range(0, 9): #9回の繰り返し。iに 0 から8までの数字が入ってこの中の文を繰り返し実行します blockX = (i % 3) * 100 # ブロックのx座標(横の位置)。 i % 3は余りを計算しています blockY = int(i / 3) * 30 #ブロックの縦の位置 int(i/3) は3で割って切り捨てしています rect(blockX, blockY, 100, 20) # 長方形を描いていますステップ6: ブロック表示部分を関数にする
次のステップでブロックがボールにあたったら消えるにようにします。そのためにブロック表示部分を関数にして draw の外に出しておきましょう
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 showBlocks() def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3 def showBlocks(): for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 rect(blockX, blockY, 100, 20)ポイント
showBlockという関数を作ってブロック表示部分をそこにまとめました。- draw() の中で
showBlocks()という形で作った関数を実行していますステップ7: ブロックにあたったら消えるようにする
x = 40 y = 100 speedX = 2 speedY = 2 barX = 150 barY = 250 blocks = [] def setup(): size(300, 300) createBlocks() def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3 def createBlocks(): global blocks for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): global blocks for block in blocks: if block['ok']: rect(block['x'] , block['y'], 100, 20) def checkBallHit(): global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている
ポイント
- ここではリスト(配列)とディクショナリという書き方が登場しています。
- リストは、複数の変数を入れる箱です。ここでは
blocks = []という部分で宣言し、blocks.append()という命令を使って追加しています。- ディクショナリは項目名と値のセットをもつ変数です。
block = {'x': blockX, 'y': blockY, 'ok': True }の部分でひとつひとつのブロックが x, x, ok という3つの項目をもつものとして作られていますfor block in blocks:のところはblocksというリストの入っている変数をひとつひとつ取り出して実行していますいまはスッキリとはわからなくてもとりあえずそのまま書いて動かしてみてください。何度も登場するのでだんだん分かってきます。
ステップ8: ゲームオーバーとクリアの表示
ボールが下の端を超えたらゲームオーバー、全てのブロックを消したらクリアと表示します
x = 40 y = 100 speedX = 2 speedY = 2 barX = 150 barY = 250 blocks = [] def setup(): size(300, 300) createBlocks() def draw(): global x, y, speedX, speedY background(0) fill(255) checkClear() x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() if y > 300: textSize(30) text("Game Over", 70, 150) def keyPressed(): global barX if keyCode == RIGHT: barX += 5 elif keyCode == LEFT: barX -= 5 def createBlocks(): global blocks for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): global blocks for block in blocks: if block['ok']: rect(block['x'] , block['y'], 100, 20) def checkBallHit(): global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている def checkClear(): for block in blocks: if block['ok']: return textSize(30) text("Clear!!", 70, 150) noLoop()
完成版のコード
ここまでは 300x300の画面でやってきました。600x600まで大きくしたら完成です
# ボールを最初に表示する位置。xは横、yは縦の位置 x = 40 y = 200 # ボールが進むスピード。1回draw()関数が実行される時に何ピクセル進むか。縦横それぞれ定義する speedX = 2 speedY = 2 # プレイヤーが操作するバーの最初の位置 barX = 300 barY = 550 # ブロックが入るリスト(配列) blocks = [] def setup(): """最初に1回だけ実行される部分""" size(600, 600) createBlocks() def draw(): """プログラムが止まるまでくりかえしくりかえし実行される部分""" global x, y, speedX, speedY background(0) fill(255) checkClear() x += speedX y += speedY if x > 600 or x < 0: speedX = speedX * -1 if y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 100, 20) if x > barX and x < barX + 100 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() if y > 600: textSize(40) text("Game Over", 200, 300) def keyPressed(): global barX if keyCode == RIGHT: barX += 10 elif keyCode == LEFT: barX -= 10 def createBlocks(): """blocksというリスト(配列)にブロックをあらわすディクショナリを入れていく""" global blocks for i in range(0, 30): blockX = (i % 6) * 100 blockY = 10 + int(i / 6) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): """ブロックを表示する""" global blocks for block in blocks: if block['ok']: # okがTrueのものだけ表示する。それ以外は既に消えている、ということなので。 rect(block['x'] , block['y'], 100, 20) def checkBallHit(): """ブロックにボールが当たったかどうかをチェックする""" global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている def checkClear(): """全てのブロックが消えているかチェックし、消えていたらゲームを止める""" for block in blocks: if block['ok']: # ひとつでも ok にTrueが入ってるものがあればこの関数を抜ける。 return # ここまで来たということは1個もokがTrueなブロックがなかったということ。つまり全て消えている状態 textSize(40) text("Clear!!", 200, 300) # drawの実行を止める noLoop()次回はもうちょっと高度なプログラミングに挑戦する予定です。おたのしみに












- 投稿日:2019-05-02T22:58:54+09:00
[ジュニア向け] PythonとProcessingでプログラミング入門:その1 - ブロックくずしを作ろう
この記事について
この記事では、Processing(プロセッシング)のPython(パイソン)モードを使ってプログラミングの基本を学びます。
メインの対象読者は中高生ですが、プログラミング入門者であれば役に立ちます。
完成図
この記事ではかんたんなブロックくずしを作ります。
Processingについて
Processing(プロセッシング)を使うと簡単に画面に絵を出したりマウスの操作で絵を動かせたりできます。
なぜPythonモードか
Processsingでは通常、専用のプログラミング言語を使うのですが、この記事ではPython(パイソン)というプログラミング言語を使って書いていきます。
Pythonは簡単に書け、プログラミングの初心者からプロ中のプロまでが使う便利な言語です。ここでPythonをおぼえるとずっと役に立ちます。インストール
※子ども向け注意:ページは英語で書かれています。ここはできれば大人に手伝ってもらいましょう
Processingのインストール
https://processing.org/ にアクセスします
以下のようなページがひらきます。左側にある「Download」というリンクをクリックします
次につかっているパソコンの種類にあわせてダウンロードします。
ダウンロードがおわると zipファイル(データが小さくなるよう加工したファイル)がダウンロードフォルダに表れます。
zipファイルをダブルクリックすると、Processingの本体ファイルが現れます。
このアイコンがProcessing本体です。Pythonモードのインストール
Processingのアイコンをダブルクリックすると以下のようなウィンドウが立ち上がります。右側にある「Java」となっているところをクリックすると「モードの追加..」というメニューが表示されるのでそこをクリックします。
次に出てくる画面で「Python Mode for Processing3」をクリックします
ダウンロードがおわったらその画面を閉じます。
さきほどの画面(ダブルクリックして立ち上げた状態の画面)のJavaのところをクリックして「Python」を選べればOKですPythonとProcessingの基本
プログラミング言語Pythonと、プログラミングを書いて動かすツールであるProcessingの基本について説明します。
Hello World(ハローワールド)
まずは最初に「Hellow World」と表示させてみましょう
print("Hello World")このように書いて▶マークの実行ボタンをおすと、エディタ画面の下半分に Hello World と表示されます
円を描く
次に円を描いてみましょう。Processingは絵やアニメーションを描くのが得意なプログラミングツールです
size(300, 300) ellipse(150, 150, 200, 200)実行ボタンを押すと、縦300ピクセル横300ピクセルの画面に、縦のx座標150、横のy座標150の位置を中心とした、高さ200ピクセル、横幅200ピクセルの円が描かれます
setup()とdraw()
Procssingのポイントは
setup()という関数とdraw()という関数です。関数については、あとで詳しく説明しますが、この時点ではプログラミングのかたまり、というようにおぼえてください。setup関数の中身は最初に一回だけ実行されます
def setup(): #..プログラムの最初に1回だけ実行されるdef draw(): # プログラムが止まるまで繰り返し繰り返し実行される。1秒間に何回も実行される例
最初に 400ピクセルx400ピクセルの画面を作り、ちょっとずつ位置どずらして円を描き続けている例です
x = 0 y = 0 def setup(): size(400,400) def draw(): global x,y x += 1 y += 1 ellipse(x, y, 100, 100)変数
変数とは、数字や文字列などを入れる箱のようなものです。(*箱というとプロのプログラマーからは違うという意見がでそうですが、ここはジュニア向けなので箱としておきます)。
x = 100 # 100という数字を変数 xに入れた name = "Taro" # Taroという文字を変数 name に入れた数字や文字だけでなく、プログラム内でつくったものも入れることができます。例えば、画面、ボタン、スーパーマリオだったらマリオなど。おいおい説明します
if文
ある条件にあてはまったかどうかで処理を分ける場合に
if 条件:という書き方をします。その条件の時に実行されるプログラムはインデント(頭に数文字分あけること)で指定します。またifの条件にはずれた時に実行される部分はelseというキーワードに続けて書きます↓の例でifの次の行が頭に数文字分あいていることに注目してください。同じ文字数分あいている数行が同じ条件の中で実行されるかたまり、という意味になります。
if x > 20: print("ここの部分はxが") print("20より大きい時に実行されます") else: print("ここはxが20以下の時に実行されます") print("ここはxがどちらの場合も実行されます")ブロックくずしを作る
ここから実際にブロックくずし作りに入っていきます
ステップ1: 円を動かす
まずは画面上に円を動かしてみましょう。「setup()とdraw()」の項目で作ったものと似ていますが、毎回draw()関数の中で
background(0)として画面全体を真っ黒に塗りつぶしている点が違います。x = 0 y = 0 def setup(): size(300, 300) def draw(): global x,y background(0) fill(255) x += 1 y += 1 ellipse(x, y, 30, 30)実行すると下のように動きます
ポイント
ellipseは楕円という意味です。中心の位置と縦横の長さを指定して円を描きますfill()は塗りつぶしを指定する命令です。()の中は色が入ります。この例の255は白を意味していますglobalは関数の外側で作られた変数を操作する時に使います。このxとyは、プログラムの頭の方で最初に作られていて、それをdraw()の中で操作するのでこの宣言が必要です+= 1は1を足すという意味です。ステップ2: プレイヤーが操作するバーを表示する。
画面上の下の方にバーを表示し、キーボードの左右の矢印で操作できるようにします
x = 0 y = 0 barX = 0 barY = 260 def setup(): size(300, 300) def draw(): global x,y background(0) fill(255) x += 1 y += 1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 1 elif keyCode == LEFT: barX -= 1実行すると下のような動きをします。右矢印を押してバーを右に動かそうとしてますが、遅くてまにあいません
ポイント
keyPressedはキーが押されて時に実行されるプロセッシングで使える関数です。今回はこの中で押されたキーのコードkeyCodeが右または左の時にボールのx座標を 1だけ足したり減らしたりしていますif 条件:に続けて別の条件のチェックをする時はelifという宣言をしますステップ3:壁でボールを反発させる
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
ポイント
- 本当は下まで来たらゲームオーバーですが、とりあえず下での反発させています
- 変数
speedXspeedYはそれぞれ横方向のスピード、縦方向のスピードをあらわしてます。- 画面の端まできたかをチェックしているのが
if x > 300 or x < 0:の部分ですspeedX = speedX * -1は-1をかけて数字を反転させています。こうすることで逆方向に進むようになりますステップ4: バーにあたったら跳ね返る
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
ポイント
if x > barX and x < barX + 60 and y > barY and y < barY + 20:の部分でバーにあたったかどうかを判断しています- バーの動く速度を最初の例よりはやめています。
ステップ5: ブロックを表示する
横3列、縦3列、合計9個のブロックを表示させます。
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 rect(blockX, blockY, 100, 20) def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3
一応それっぽいものが表示されましたが、まだボールがあたっても消えません
ポイント
以下の部分で9個のブロックを表示しています。
for i in range(0, 9): #9回の繰り返し。iに 0 から8までの数字が入ってこの中の文を繰り返し実行します blockX = (i % 3) * 100 # ブロックのx座標(横の位置)。 i % 3は余りを計算しています blockY = int(i / 3) * 30 #ブロックの縦の位置 int(i/3) は3で割って切り捨てしています rect(blockX, blockY, 100, 20) # 長方形を描いていますステップ6: ブロック表示部分を関数にする
次のステップでブロックがボールにあたったら消えるにようにします。そのためにブロック表示部分を関数にして draw の外に出しておきましょう
x = 40 y = 0 speedX = 2 speedY = 2 barX = 150 barY = 250 def setup(): size(300, 300) def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 showBlocks() def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3 def showBlocks(): for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 rect(blockX, blockY, 100, 20)ポイント
showBlockという関数を作ってブロック表示部分をそこにまとめました。- draw() の中で
showBlocks()という形で作った関数を実行していますステップ7: ブロックにあたったら消えるようにする
x = 40 y = 100 speedX = 2 speedY = 2 barX = 150 barY = 250 blocks = [] def setup(): size(300, 300) createBlocks() def draw(): global x, y, speedX, speedY background(0) fill(255) x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y > 300 or y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() def keyPressed(): global barX if keyCode == RIGHT: barX += 3 elif keyCode == LEFT: barX -= 3 def createBlocks(): global blocks for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): global blocks for block in blocks: if block['ok']: rect(block['x'] , block['y'], 100, 20) def checkBallHit(): global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている
ポイント
- ここではリスト(配列)とディクショナリという考え方が登場しています。
- リストは、複数の変数を入れる箱です。ここでは
blocks = []という部分で宣言し、blocks.append()という命令を使って追加しています。- ディクショナリは項目名と値のセットをもつ変数です。
block = {'x': blockX, 'y': blockY, 'ok': True }の部分でひとつひとつのブロックが x, x, ok という3つの項目をもつものとして作られていますfor block in blocks:のところはblocksというリストの入っている変数をひとつひとつ取り出して実行していますいまはスッキリとはわからなくてもとりあえずそのまま書いて動かしてみてください。何度も登場するのでだんだん分かってきます。
ステップ8: ゲームオーバーとクリアの表示
ボールが下の端を超えたらゲームオーバー、全てのブロックを消したらクリアと表示します
x = 40 y = 100 speedX = 2 speedY = 2 barX = 150 barY = 250 blocks = [] def setup(): size(300, 300) createBlocks() def draw(): global x, y, speedX, speedY background(0) fill(255) checkClear() x += speedX y += speedY if x > 300 or x < 0: speedX = speedX * -1 if y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 60, 20) if x > barX and x < barX + 60 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() if y > 300: textSize(30) text("Game Over", 70, 150) def keyPressed(): global barX if keyCode == RIGHT: barX += 5 elif keyCode == LEFT: barX -= 5 def createBlocks(): global blocks for i in range(0, 9): blockX = (i % 3) * 100 blockY = int(i / 3) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): global blocks for block in blocks: if block['ok']: rect(block['x'] , block['y'], 100, 20) def checkBallHit(): global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている def checkClear(): for block in blocks: if block['ok']: return textSize(30) text("Clear!!", 70, 150) noLoop()
完成版のコード
ここまでは 300x300の画面でやってきました。600x600まで大きくしたら完成です
# ボールを最初に表示する位置。xは横、yは縦の位置 x = 40 y = 200 # ボールが進むスピード。1回draw()関数が実行される時に何ピクセル進むか。縦横それぞれ定義する speedX = 2 speedY = 2 # プレイヤーが操作するバーの最初の位置 barX = 300 barY = 550 # ブロックが入るリスト(配列) blocks = [] def setup(): """最初に1回だけ実行される部分""" size(600, 600) createBlocks() def draw(): """プログラムが止まるまでくりかえしくりかえし実行される部分""" global x, y, speedX, speedY background(0) fill(255) checkClear() x += speedX y += speedY if x > 600 or x < 0: speedX = speedX * -1 if y < 0: speedY = speedY * -1 ellipse(x, y, 30, 30) rect(barX, barY, 100, 20) if x > barX and x < barX + 100 and y > barY and y < barY + 20: speedY = speedY * -1 checkBallHit() showBlocks() if y > 600: textSize(40) text("Game Over", 200, 300) def keyPressed(): global barX if keyCode == RIGHT: barX += 10 elif keyCode == LEFT: barX -= 10 def createBlocks(): """blocksというリスト(配列)にブロックをあらわすディクショナリを入れていく""" global blocks for i in range(0, 30): blockX = (i % 6) * 100 blockY = 10 + int(i / 6) * 30 block = {'x': blockX, 'y': blockY, 'ok': True } blocks.append(block) def showBlocks(): """ブロックを表示する""" global blocks for block in blocks: if block['ok']: # okがTrueのものだけ表示する。それ以外は既に消えている、ということなので。 rect(block['x'] , block['y'], 100, 20) def checkBallHit(): """ブロックにボールが当たったかどうかをチェックする""" global speedY for block in blocks: if x > block['x'] and x < block['x'] + 100 and y > block['y'] and y < block['y'] + 20 and block['ok']: block['ok'] = False # 次から表示しないようにしている speedY = speedY * -1 # 当たったので縦方向の速度を反転させている def checkClear(): """全てのブロックが消えているかチェックし、消えていたらゲームを止める""" for block in blocks: if block['ok']: # ひとつでも ok にTrueが入ってるものがあればこの関数を抜ける。 return # ここまで来たということは1個もokがTrueなブロックがなかったということ。つまり全て消えている状態 textSize(40) text("Clear!!", 200, 300) # drawの実行を止める noLoop()次回はもうちょっと高度なプログラミングに挑戦する予定です。おたのしみに
- 投稿日:2019-05-02T22:29:42+09:00
PythonでSpotify API [アルバム情報編]
前回の記事(とにかく使ってみる編)では、とりあえずAPI使って情報の取得ができるとこまでできたので、今度は狙った情報をガンガン取得していきたいと思います。
APIのドキュメントの1番上にあったので、アルバム情報を紐解いてみましょう。
サンプルがありましたがどうもこんなかんじの情報らしい。
ちょっとだけ「...」で省略してます。{ "album_type" : "album", "artists" : [ { "external_urls" : { "spotify" : "https://open.spotify.com/artist/2BTZIqw0ntH9MvilQ3ewNY" }, "href" : "https://api.spotify.com/v1/artists/2BTZIqw0ntH9MvilQ3ewNY", "id" : "2BTZIqw0ntH9MvilQ3ewNY", "name" : "Cyndi Lauper", "type" : "artist", "uri" : "spotify:artist:2BTZIqw0ntH9MvilQ3ewNY" } ], "available_markets" : [ "AD", "AR", ...], "copyrights" : [ { "text" : "(P) 2000 Sony Music Entertainment Inc.", "type" : "P" } ], "external_ids" : { "upc" : "5099749994324" }, "external_urls" : { "spotify" : "https://open.spotify.com/album/0sNOF9WDwhWunNAHPD3Baj" }, "genres" : [ ], "href" : "https://api.spotify.com/v1/albums/0sNOF9WDwhWunNAHPD3Baj", "id" : "0sNOF9WDwhWunNAHPD3Baj", "images" : [ { "height" : 640, "url" : "https://i.scdn.co/image/07c323340e03e25a8e5dd5b9a8ec72b69c50089d", "width" : 640 }, ...], "name" : "She's So Unusual", "popularity" : 39, "release_date" : "1983", "release_date_precision" : "year", "tracks" : { "href" : "https://api.spotify.com/v1/albums/0sNOF9WDwhWunNAHPD3Baj/tracks?offset=0&limit=50", "items" : [ { "artists" : [ { "external_urls" : { "spotify" : "https://open.spotify.com/artist/2BTZIqw0ntH9MvilQ3ewNY" }, "href" : "https://api.spotify.com/v1/artists/2BTZIqw0ntH9MvilQ3ewNY", "id" : "2BTZIqw0ntH9MvilQ3ewNY", "name" : "Cyndi Lauper", "type" : "artist", "uri" : "spotify:artist:2BTZIqw0ntH9MvilQ3ewNY" } ], "available_markets" : [ "AD", "AR", ...], "disc_number" : 1, "duration_ms" : 305560, "explicit" : false, "external_urls" : { "spotify" : "https://open.spotify.com/track/3f9zqUnrnIq0LANhmnaF0V" }, "href" : "https://api.spotify.com/v1/tracks/3f9zqUnrnIq0LANhmnaF0V", "id" : "3f9zqUnrnIq0LANhmnaF0V", "name" : "Money Changes Everything", "preview_url" : "https://p.scdn.co/mp3-preview/01bb2a6c9a89c05a4300aea427241b1719a26b06", "track_number" : 1, "type" : "track", "uri" : "spotify:track:3f9zqUnrnIq0LANhmnaF0V" }, { ... } ], "limit" : 50, "next" : null, "offset" : 0, "previous" : null, "total" : 13 }, "type" : "album", "uri" : "spotify:album:0sNOF9WDwhWunNAHPD3Baj" }なるほどわからん。
遊びで使う分に使えそうなものだけ説明しますね。
URLとか名前とか、見るからに明らかなものは除きます。album_type
種類。single,album,compilationの3種類。artists
アーティストですね。複数形だしリスト形式なので、一つのアルバムに対して複数のアーティストが関与している場合には複数の値が入る様子。
例をよくみてるとわかりますが、アーティスト情報は楽曲1曲1曲にもついてます。このアーティスト情報は簡易化されたもので、詳細化されたものが別途取得できるみたいです。
artistsオブジェクトの中のid使って。available_markets
えっ売ってる国わかるの?すごくない?どうやって調べるんだろ。
「ISO 3166-1 alpha-2 country code」のリストになってます。
アルファベット2文字で国を表したもので、日本ならJP、アメリカならUSとか。image
いわゆるジャケット。サイズとURLのオブジェクトがリストになってる。popularity
0〜100の人気度(であってるのかな)。
ドキュメントによると、アルバムの人気度は収録されてる曲それぞれの人気度から抽出してるみたいです。tracks
収録曲のオブジェクトがリストになってます。artists同様簡易化されたものです。
album自体と同じような情報(名前やid、URLやartists)が入ってますね。ディスク番号やアルバム内の曲番が入ってるのが、芸がこまけーなーって思います。
いやそりゃ必要ではあるでしょうけど。今回はとりあえず、APIのドキュメントを読みながら記事におこしてみたってかんじです。
今度は、遊んでみて記事書いてみまーす。
- 投稿日:2019-05-02T20:52:07+09:00
pythonで簡単に配列を左に動かす方法
条件
a = [1,2,3,4,5]
N = 左に動かす処理を繰り返す回数
d = 配列の長さ ( [1,2,3,4,5]の場合、d = 5 )
として、配列を左にずらす処理を考えます。N = 4の時、a = [5,1,2,3,4] といった具合ですね。
全ての要素をずらしていく方法
for i in range(N): a0 = a[0] for j in range(len(a)): if n-1 == j: a[n-1] = a0 else: a[j] = a[j+1]「aの長さ分、要素を一つずらす処理」をN回繰り返していく力技です。
最初はこのコードで処理をしていました。
しかし、処理時間を考えた時、もっと早く効率のいい方法があります。先頭の要素を一番後ろにずらしていく方法
for i in range(N): a0 = a[0] a.remove(a0) a.append(a0)この処理の方がスマートで、処理時間も短いです。
- 投稿日:2019-05-02T20:51:46+09:00
【データ解析】ボストン住宅価格データセットを使ってデータ解析する
概要
- scikit-learnのサイトには、現在(2019.05.02時点)で7種類のToyデータセットが用意されています。
- そのうちの一つ「ボストン住宅価格データセット」を使ってデータ解析してみます。このデータセットはUCI ML住宅データセットを加工したデータです。
ボストン住宅価格データセットの解析
ボストン住宅価格データセットの読み込み
- 戻り値(boston)として、data(説明変数)とtarget(目的変数)が返ってきますので、変数に格納します。
#ボストン住宅価格データセットの読み込み from sklearn.datasets import load_boston boston = load_boston() #説明変数 X_array = boston.data #目的変数 y_array = boston.target説明変数の出力
for i in X_array:print(i)[ 6.32000000e-03 1.80000000e+01 2.31000000e+00 0.00000000e+00 5.38000000e-01 6.57500000e+00 6.52000000e+01 4.09000000e+00 1.00000000e+00 2.96000000e+02 1.53000000e+01 3.96900000e+02 4.98000000e+00] [ 2.73100000e-02 0.00000000e+00 7.07000000e+00 0.00000000e+00 4.69000000e-01 6.42100000e+00 7.89000000e+01 4.96710000e+00 2.00000000e+00 2.42000000e+02 1.78000000e+01 3.96900000e+02 9.14000000e+00] [ 2.72900000e-02 0.00000000e+00 7.07000000e+00 0.00000000e+00 4.69000000e-01 7.18500000e+00 6.11000000e+01 4.96710000e+00 2.00000000e+00 2.42000000e+02 1.78000000e+01 3.92830000e+02 4.03000000e+00] (省略) [ 6.07600000e-02 0.00000000e+00 1.19300000e+01 0.00000000e+00 5.73000000e-01 6.97600000e+00 9.10000000e+01 2.16750000e+00 1.00000000e+00 2.73000000e+02 2.10000000e+01 3.96900000e+02 5.64000000e+00] [ 1.09590000e-01 0.00000000e+00 1.19300000e+01 0.00000000e+00 5.73000000e-01 6.79400000e+00 8.93000000e+01 2.38890000e+00 1.00000000e+00 2.73000000e+02 2.10000000e+01 3.93450000e+02 6.48000000e+00] [ 4.74100000e-02 0.00000000e+00 1.19300000e+01 0.00000000e+00 5.73000000e-01 6.03000000e+00 8.08000000e+01 2.50500000e+00 1.00000000e+00 2.73000000e+02 2.10000000e+01 3.96900000e+02 7.88000000e+00]説明変数のカラムの説明
以下、13カラムで出力されます。(公式サイトの説明をGoogle翻訳したものをベースにしています。)
カラム 説明 CRIM 町ごとの一人当たりの犯罪率 ZN 宅地の比率が25,000平方フィートを超える敷地に区画されている。 INDUS 町当たりの非小売業エーカーの割合 CHAS チャーリーズ川ダミー変数(川の境界にある場合は1、それ以外の場合は0) NOX 一酸化窒素濃度(1000万分の1) RM 1住戸あたりの平均部屋数 AGE 1940年以前に建設された所有占有ユニットの年齢比率 DIS 5つのボストンの雇用センターまでの加重距離 RAD ラジアルハイウェイへのアクセス可能性の指標 TAX 10,000ドルあたりの税全額固定資産税率 PTRATIO 生徒教師の比率 B 町における黒人の割合 LSTAT 人口当たり地位が低い率 MEDV 1000ドルでの所有者居住住宅の中央値 目的変数の出力
print(y_array)[ 24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4 18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8 18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9 20. 21. 24.7 30.8 34.9 26.6 25.3 24.7 21.2 19.3 20. 16.6 (中略) 19.1 20.1 19.9 19.6 23.2 29.8 13.8 13.3 16.7 12. 14.6 21.4 23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7. 8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9 22. 11.9]単位は、1,000(USD)です。
説明変数、目的変数を統合してDataFrame化
import pandas as pd import numpy as np from pandas import DataFrame df = DataFrame(X_array, columns = boston.feature_names).assign(MEDV=np.array(y_array)) # ヘッダ出力 df.head以下、DataFrameの中身を確認します。
相関関係の可視化
- 説明変数の各項目(CRIMなど)と目的変数(MEDV)の相関関係を以下、可視化してみます。
- グラフ描画ライブラリのseabornをインポートします。
import seaborn as snsCRIM(犯罪率) - MEDV(住宅価格)
# CRIM(犯罪率)、MEDV(住宅価格) sns.regplot('CRIM','MEDV',data = df)
ZN(宅地比率) - MEDV(住宅価格)
# ZN(宅地比率)、MEDV(住宅価格)で可視化 sns.regplot('ZN','MEDV',data = df)
INDUS(非小売業エーカーの割合) - MEDV(住宅価格)
#INDUS(非小売業エーカーの割合)、MEDV(住宅価格)で可視化 sns.regplot('INDUS','MEDV',data = df)
CHAS(チャーリーズ川ダミー変数) - MEDV(住宅価格)
#CHAS(チャーリーズ川ダミー変数)、MEDV(住宅価格)で可視化 sns.regplot('CHAS','MEDV',data = df)
RM(1住戸あたりの平均部屋数) - MEDV(住宅価格)
#RM(1住戸あたりの平均部屋数)、MEDV(住宅価格)で可視化 sns.regplot('RM','MEDV',data = df)
- このように可視化してみると、RM(1住戸あたりの平均部屋数)は、MEDV(住宅価格)と相関関係が見て取れますが、CHAS(チャーリーズ川ダミー変数)には相関関係は見て取れそうに無いですね。
線形回帰で学習
- この記事と同様にscikit-learnを使用して学習させて見ます。
# scikit-learnの準備 from sklearn.model_selection import train_test_split # 訓練データとテストデータに8:2で分割 X_train, X_test, y_train, y_test = train_test_split(X_array, y_array, test_size=0.2, random_state=0) # 線形回帰で学習 from sklearn import linear_model model = linear_model.LinearRegression() model.fit(X_train, y_train) # 訓練データを用いた評価 print(model.score(X_train, y_train)) # テストデータを用いた評価 print(model.score(X_test, y_test))
- 残念ながら、あまり精度は高くないようです。
- 後日、非線形回帰の手法も試してみたいと思いますが、本記事ではここまでとしたいと思います。
参考にさせていただいたサイト







- 投稿日:2019-05-02T20:42:22+09:00
ケチサイエンティストへの道〜Python3で自分のバイクの最適給油タイミングを求めよう〜 ③『最適停止問題(結婚問題)を応用し,最適給油タイミングを求める』
はじめに
本記事をご覧いただき,誠にありがとうございます.
この記事は『Python3で自分のバイクの最適給油タイミングを求めよう』のシリーズ第三弾となっております.
今回は前回の続きで,『最適停止問題(結婚問題)を給油行動に適応し,数理科学的な最適給油タイミングの実装』をしていきます
(最適停止問題(結婚問題)の考え方をガソリンの給油行動に適応し,その時の効果についてシミュレーション科学的に検証しよう!).前回までの記事をご覧になられていない方は,
第一弾:自分の給油行動をモデリングしてみた
第二弾:シンプルな戦略でトータルコストの削減を狙おう
の上記2つの記事を,まずご覧になってから本記事をご覧いただくと,スムーズに理解ができるかもしれません.結論 = やり方次第で,年間ランチ一回分のコストをセーブできるよ!!笑
(給油回数がアホみたいに増えますが,365日を20日区切りに考えて,最適停止問題を適応する戦略(D20)を適応すれば,年間給油コストを1000円以上も抑えることができることがわかりました)それでは下記コンテンツをお楽しみください.
まずは,最適停止問題(結婚問題)について説明します.最適停止問題(結婚問題)とは
最適停止問題(結婚問題)とは次のような問題のことです.(Wiki参照)
1.結婚相手(一人だけ)を決めるものとする.
2.$n$人の結婚相手候補が居る.($n$は既知)
3.結婚相手候補には順位がつけられ,複数の結婚相手候補が同じ順位になることはない.
4.無作為な順番で一人ずつと付き合ってみる.次に誰と付き合うかはみな同じ確率である.
5.毎回,付き合ったあとで,その相手と結婚するかどうかを即座に決定する.
6.その結婚相手候補と結婚するかどうかは,それまで付き合ってきた相手との相対的な順位にのみ基づいて決定する.
7.別れた相手とは二度と復縁できず,結婚もできない.
8.上記1〜7の条件下で,最適な結婚相手と結婚することが本問題の目的である.つまり,後戻りができない状況で,ベストな相手と結ばれるための問題ということです.この問題を定式化しましょう.
最適停止問題の定式化
いきなり,一人目の相手と結婚するわけにもいかないので,最初の何人かは様子見でスキップすることとしましょう.そこで最初の$r-1$人の結婚相手候補はスキップします.
それ以降,現れる結婚相手候補がこれまで付き合った中で一番良い相手だったらその時点で結婚します.任意の$r$について,最良の相手と結婚する確率は
P(r) = \sum_{j=r}^{n} \Bigl( \frac{1}{n} \Bigr) \Bigl( \frac{r-1}{j-1} \Bigr) = \Bigl( \frac{r-1}{n} \Bigr) \sum_{j=r}^{n} \Bigl( \frac{1}{j-1} \Bigr)と表せます.
$n$が無限大に近づくとして,$n$分の$r$の極限を$x$,$n$分の$j$を$t$,$n$分の$1$を$dt$とすると,上記の総和は,下記の積分にて表現できます.
P(r) = x \int_{x}^{1} \frac{1}{t} dt = -x \log (x)$P(r)$の$x$に関する導関数をとり,$=0$となる$x$について解くと,最適な$x$は$\frac{1}{e}$となります.したがって,最適なスキップは$n$が増大するにつれて,$\frac{n}{e}$に近づいていき,最適な結婚相手候補を選択する確率は,$\frac{1}{e}$に近づいていきます.
簡単に言えば,最初から$e$分の$n$番目は嫌でもスキップして,それ以降に素晴らしい結婚相手候補に出逢えば結婚する戦略を取れば,0.368の確率で最適な結婚相手と結婚できるということです.
給油行動の戦略の紹介
では,最適停止問題(結婚問題)をガソリンの給油行動に落とし込みましょう.
極端なことを言ってしまえば,365日のうち,$e$分の$n$日目(135日)まではスキップして,それ以降,ガソリンの値段が最安値を更新したら一発ドカンと給油するのが,理論上,最適な給油行動と言えます.
ですが,ガソリンタンクは8Lという制約条件があり,かつ,ガス欠だと走らないので,ガソリンの残量は0Lよりも多くないといけないという制約条件があります.
そこで,
1.365日を10日区切りに考えて,最適停止問題を適応する戦略(D10)
2.365日を20日区切りに考えて,最適停止問題を適応する戦略(D20)
3.365日を30日区切りに考えて,最適停止問題を適応する戦略(D30)
4.365日を40日区切りに考えて,最適停止問題を適応する戦略(D40)
5.365日を50日区切りに考えて,最適停止問題を適応する戦略(D50)この5つの戦略を,第一弾の給油行動における各評価項目と比較し,最適停止規則による給油行動のレビューを行おうと思います.
ただし,ガソリンタンクの残量が0.8Lよりも小さくなってしまった場合は,ガス欠が怖いので,嫌でも給油するという制約条件をプラスします.
給油行動の戦略のモデリング
ここまでの説明をモデル表現すると次に示すようになります.
(ここは読み飛ばしてもらって構いません.)for i in range(0, total_days + 1): # 365日間の給油行動シミュレーション # 神様がガソリンの値段を決定します. if i == 0: gas_price = np.random.choice(gas_price_list) else: if np.random.rand() < 0.2: gas_price = np.random.choice(gas_price_list) # 毎日,ガソリンはちょっとした値段の変化があるものとしましょう. gas_price += np.random.normal(0,1) # 基本戦略の実装 if fuel_tank_STD < 0.8: fueling_litter = fuel_capa - fuel_tank_STD total_amountOfrefuel_STD += fueling_litter total_cost_STD += gas_price * fueling_litter fuel_tank_STD = fuel_capa refueling_times_STD += 1 # タンク容量が0.8L未満になってしまったら,嫌でも給油する if fuel_tank_D10 < 0.8: fueling_litter = fuel_capa - fuel_tank_D10 total_amountOfrefuel_D10 += fueling_litter total_cost_D10 += gas_price * fueling_litter fuel_tank_D10 = fuel_capa refueling_times_D10 += 1 # タンク容量が0.8L未満になってしまったら,嫌でも給油する if fuel_tank_D20 < 0.8: fueling_litter = fuel_capa - fuel_tank_D20 total_amountOfrefuel_D20 += fueling_litter total_cost_D20 += gas_price * fueling_litter fuel_tank_D20 = fuel_capa refueling_times_D20 += 1 # タンク容量が0.8L未満になってしまったら,嫌でも給油する if fuel_tank_D30 < 0.8: fueling_litter = fuel_capa - fuel_tank_D30 total_amountOfrefuel_D30 += fueling_litter total_cost_D30 += gas_price * fueling_litter fuel_tank_D30 = fuel_capa refueling_times_D30 += 1 # タンク容量が0.8L未満になってしまったら,嫌でも給油する if fuel_tank_D40 < 0.8: fueling_litter = fuel_capa - fuel_tank_D40 total_amountOfrefuel_D40 += fueling_litter total_cost_D40 += gas_price * fueling_litter fuel_tank_D40 = fuel_capa refueling_times_D40 += 1 # タンク容量が0.8L未満になってしまったら,嫌でも給油する if fuel_tank_D50 < 0.8: fueling_litter = fuel_capa - fuel_tank_D50 total_amountOfrefuel_D50 += fueling_litter total_cost_D50 += gas_price * fueling_litter fuel_tank_D50 = fuel_capa refueling_times_D50 += 1 # 10日区切りの最適停止規則 if i % days10 == 0: list_gasprice_D10 = [] refueling_flag_D10 = False list_gasprice_D10.append(gas_price) else: if (i % days10) < (days10 / np.e): list_gasprice_D10.append(gas_price) else: if refueling_flag_D10 == True: pass if gas_price < min(list_gasprice_D10): fueling_litter = fuel_capa - fuel_tank_D10 total_amountOfrefuel_D10 += fueling_litter total_cost_D10 += gas_price * fueling_litter fuel_tank_D10 = fuel_capa refueling_times_D10 += 1 refueling_flag_D10 = True # 20日区切りの最適停止規則 if i % days20 == 0: list_gasprice_D20 = [] refueling_flag_D20 = False list_gasprice_D20.append(gas_price) else: if (i % days20) < (days20 / np.e): list_gasprice_D20.append(gas_price) else: if refueling_flag_D20 == True: pass if gas_price < min(list_gasprice_D20): fueling_litter = fuel_capa - fuel_tank_D20 total_amountOfrefuel_D20 += fueling_litter total_cost_D20 += gas_price * fueling_litter fuel_tank_D20 = fuel_capa refueling_times_D20 += 1 refueling_flag_D20 = True # 30日区切りの最適停止規則 if i % days30 == 0: list_gasprice_D30 = [] refueling_flag_D30 = False list_gasprice_D30.append(gas_price) else: if (i % days30) < (days30 / np.e): list_gasprice_D30.append(gas_price) else: if refueling_flag_D30 == True: pass if gas_price < min(list_gasprice_D30): fueling_litter = fuel_capa - fuel_tank_D30 total_amountOfrefuel_D30 += fueling_litter total_cost_D30 += gas_price * fueling_litter fuel_tank_D30 = fuel_capa refueling_times_D30 += 1 refueling_flag_D30 = True # 40日区切りの最適停止規則 if i % days40 == 0: list_gasprice_D40 = [] refueling_flag_D40 = False list_gasprice_D40.append(gas_price) else: if (i % days40) < (days40 / np.e): list_gasprice_D40.append(gas_price) else: if refueling_flag_D40 == True: pass if gas_price < min(list_gasprice_D40): fueling_litter = fuel_capa - fuel_tank_D40 total_amountOfrefuel_D40 += fueling_litter total_cost_D40 += gas_price * fueling_litter fuel_tank_D40 = fuel_capa refueling_times_D40 += 1 refueling_flag_D40 = True # 50日区切りの最適停止規則 if i % days50 == 0: list_gasprice_D50 = [] refueling_flag_D50 = False list_gasprice_D50.append(gas_price) else: if (i % days50) < (days50 / np.e): list_gasprice_D50.append(gas_price) else: if refueling_flag_D50 == True: pass if gas_price < min(list_gasprice_D50): fueling_litter = fuel_capa - fuel_tank_D50 total_amountOfrefuel_D50 += fueling_litter total_cost_D50 += gas_price * fueling_litter fuel_tank_D50 = fuel_capa refueling_times_D50 += 1 refueling_flag_D50 = True # iが6ならば,土曜日であると仮定 if i % 6 == 0: # 0.15の確率でお出かけする.(土曜は少し疲れてるのであまり長距離ドライブはしたくない) if np.random.rand() < 0.15: running_distance = np.random.normal(10, 5) while running_distance <= 0: running_distance = np.random.normal(10, 5) total_running += 2 * running_distance fuel_tank_STD -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D10 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D20 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D30 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D40 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D50 -= fuel_consumptionPer1km * 2 * running_distance # iが7ならば,日曜日であると仮定 if i % 7 == 0: # 0.2の確率でお出かけする.(日曜は元気だから長距離ドライブをしてもいいかな〜って気分) if np.random.rand() < 0.2: running_distance = np.random.normal(15, 5) while running_distance <= 0: running_distance = np.random.normal(15, 5) total_running += 2 * running_distance fuel_tank_STD -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D10 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D20 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D30 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D40 -= fuel_consumptionPer1km * 2 * running_distance fuel_tank_D50 -= fuel_consumptionPer1km * 2 * running_distance # 平日は大学にしか行きません else: # うちから大学まで7.6kmです. total_running += 2 * 7.6 fuel_tank_STD -= fuel_consumptionPer1km * 2 * 7.6 fuel_tank_D10 -= fuel_consumptionPer1km * 2 * 7.6 fuel_tank_D20 -= fuel_consumptionPer1km * 2 * 7.6 fuel_tank_D30 -= fuel_consumptionPer1km * 2 * 7.6 fuel_tank_D40 -= fuel_consumptionPer1km * 2 * 7.6 fuel_tank_D50 -= fuel_consumptionPer1km * 2 * 7.6 list_days.append(i) list_totaldist.append(total_running) list_fueltank_STD.append(fuel_tank_STD) list_refueltimes_STD.append(refueling_times_STD) list_totalcost_STD.append(total_cost_STD) list_gasprice.append(gas_price) list_fueltank_D10.append(fuel_tank_D10) list_refueltimes_D10.append(refueling_times_D10) list_totalcost_D10.append(total_cost_D10) list_fueltank_D20.append(fuel_tank_D20) list_refueltimes_D20.append(refueling_times_D20) list_totalcost_D20.append(total_cost_D20) list_fueltank_D30.append(fuel_tank_D30) list_refueltimes_D30.append(refueling_times_D30) list_totalcost_D30.append(total_cost_D30) list_fueltank_D40.append(fuel_tank_D40) list_refueltimes_D40.append(refueling_times_D40) list_totalcost_D40.append(total_cost_D40) list_fueltank_D50.append(fuel_tank_D50) list_refueltimes_D50.append(refueling_times_D50) list_totalcost_D50.append(total_cost_D50) print("******************* 基本戦略(自身の給油行動)*******************") print("トータルコスト(¥):" + str(total_cost_STD)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_STD)) print("総給油量(L):" + str(total_amountOfrefuel_STD)) print("******************* 最適停止規則(D10)*******************") print("トータルコスト(¥):" + str(total_cost_D10)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_D10)) print("総給油量(L):" + str(total_amountOfrefuel_D10)) print("******************* 最適停止規則(D20)*******************") print("トータルコスト(¥):" + str(total_cost_D20)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_D20)) print("総給油量(L):" + str(total_amountOfrefuel_D20)) print("******************* 最適停止規則(D30)*******************") print("トータルコスト(¥):" + str(total_cost_D30)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_D30)) print("総給油量(L):" + str(total_amountOfrefuel_D30)) print("******************* 最適停止規則(D40)*******************") print("トータルコスト(¥):" + str(total_cost_D40)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_D40)) print("総給油量(L):" + str(total_amountOfrefuel_D40)) print("******************* 最適停止規則(D50)*******************") print("トータルコスト(¥):" + str(total_cost_D50)) print("総走行距離(Km):" + str(total_running)) print("総給油回数 :" + str(refueling_times_D50)) print("総給油量(L):" + str(total_amountOfrefuel_D50))上記プログラムでは,年間給油コスト・総走行距離,総給油回数,総給油量を評価項目とし,標準出力へ出力することとしました.
シミュレーション結果
では早速結果を見ていきましょう.
年間給油コスト・総走行距離,総給油回数,総給油量の比較
標準出力から得られたシミュレーション結果は,このようになりました.
給油にかかるトータルコストが最安値となったのは,戦略D20でした.
つまり,365日を20日区切りに考えて,最適停止問題を適応すると,年間給油コストが最安になります.現在の給油行動との年間給油コストの差額は,1000円近いので,ランチ一回分節約できることがわかりました.ただ,給油回数がどうしても多くなってしまうので,ネックですね.笑
ガソリン代の価格の推移
続いて,365日間でガソリンの価格がどのように推移していったのかを,グラフにて示します.
ガソリン価格の決定方法に関しては,
第一弾:自分の給油行動をモデリングしてみた
に詳しく記載しておりますので,御覧ください.一年間でそれなりの価格変動があったようです.
総走行距離の時間的な推移
続いて,365日間で総走行距離がどのように推移していったのかを,グラフにて示します.
多少の凸凹がありますが,基本的には総走行距離は時刻(日付)の増加に対して線形に増加していったことがわかります.
直感的な理解と一致しますね.
各戦略における給油回数の時間的な推移
続いて,各戦略において,365日間で総給油回数がどのように推移していったのかを,グラフにて示します.
左上が従来の給油戦略,右上が戦略D10,真ん中左が戦略D20,…となっております.
やっぱり給油回数を減らしたいなら,区切りを長くする必要がありますね.
ただ,それでも従来の給油行動における給油回数にはかないませんが・・・.笑各戦略におけるタンク内ガソリン残量の時間的な推移
続いて,各戦略において,365日間でタンク内ガソリン残量がどのように推移していったのかを,グラフにて示します.
左上が従来の給油戦略,右上が戦略10,真ん中左が戦略D20,…となっております.
従来の給油戦略以外は,みんなギザギザが激しいですね.
各戦略におけるトータルコストの時間的な推移
最後に,各戦略において,365日間でトータルコストがどのように推移していったのかを,グラフにて示します.
当然,給油したタイミングで,トータルコストがガツン!と増加するので,階段状になります.最終的なトータルコストだけを見たい場合は標準出力の内容だけを見たほうがわかりやすいですね.笑
Output勉強会の紹介
はじめまして,自己紹介が遅れてすみません,西山 幸寛と申します.
(恥ずかしながら,キメ顔の自分の写真です.笑)私は,愛知県立大学の同級生やOB(現在,楽天のエンジニア)たちと,『Output勉強会』という団体を運営しております.活動の様子の写真は下記の通りです.
今回,東海地方のエンジニアの卵さんたちと,交流ができる機会が欲しく,Output勉強会の存在を告知しました.興味があるかたはぜひ,ご連絡ください.
共同メンバー
Qiitaのこれまでの一連の記事の内容は,下記のメンバーとの積極的な議論の末に完成したものです.これまでの一連の記事を面白いと思っていただけたのであれば,他の2人のメンバーのQiitaの記事も御覧いただけると幸いです.
RやPythonを用いたシミュレーションや,多変量解析を強みとしている
辻和樹(Nakubaru)の記事
RubyやPHP,Pythonを用いたアプリケーション開発を強みとしている
森友哉の記事応援のほど,よろしくお願いいたします.
おわりに
今回の記事では,最適停止問題(結婚問題)の考え方をガソリンの給油行動に適応し,その時の効果についてシミュレーション科学的に検証してきました.
具体的には,次の5つの戦略を用いて,
1.365日を10日区切りに考えて,最適停止問題を適応する戦略(D10)
2.365日を20日区切りに考えて,最適停止問題を適応する戦略(D20)
3.365日を30日区切りに考えて,最適停止問題を適応する戦略(D30)
4.365日を40日区切りに考えて,最適停止問題を適応する戦略(D40)
5.365日を50日区切りに考えて,最適停止問題を適応する戦略(D50)
従来の給油行動における,年間給油コスト・総走行距離,総給油回数,総給油量を比較してきました.その結果ですが,給油回数がアホみたいに増えますが,(17回から87回に増加)
365日を20日区切りに考えて,最適停止問題を適応する戦略(D20)を適応すれば,
年間給油コストを1000円以上も抑えることができることがわかりました.笑給油回数を取るか,年間給油コストを取るか,
どっちを取るかはあなた次第ですね・・・.笑










- 投稿日:2019-05-02T19:50:49+09:00
R、Julia、Pythonの前回の実行結果変数



- 投稿日:2019-05-02T17:49:44+09:00
【まとめ】GCP無料枠で非エンジニアがアプリ(django+uwsgi+nginx+supervisor)をデプロイするまで
はじめに
さっきできました!
ついに…!ついに…!自分のドメインでWebページが見れるように!
(サイトを作ったとは言ってない)誰かが鉄は熱いうちに打てといっていたので、覚えているうちに
今回は以下の2点を目的としてまとめ記事を書こうと思います。
- 自身の振り返りとして
- 同じことをやろうとする人向けのまとめ記事として
この記事でわかること
2019/05/02時点でのGCPを介したdjangoアプリのデプロイ過程がわかります。
今回は下記を利用して、まずは独自ドメインでdjangoTOPページを見れるようにしました。
- django
- uwsgi
- nginx
- supervisor
なんせこれらでデプロイしようとすると、参考記事がいろんなところに…
しかも古かったり…(きれそう)というわけで、現時点(2019/05/02)での筆者が参照した記事やブログなりをまとめつつ
起きた問題を追記しました。
せっかくなら、皆さんの役に立てればと思い記事に。基本的に参考にしたブログや記事を載せつつ、困ったところを書きます。
各ステップでは記事を参考にしてください。筆者スペック
24歳 某事業会社にてマーケティング職
経験値としては、rails tutorialやったことあるくらい(完走はせず)
インフラとかわからなすぎて笑った手順
GCPの設定いろいろ
まずはGCPのアカウント取得から。
基本的な環境設定をここで進めていきます。以下の記事が神でした。
GCPで永久無料枠を利用してサービスを立ち上げたときにしたことの備忘録ただし、railsでの対応を書いています。
nginxの設定ファイルやサーバーが自動で起動するようにするあたりは無視しましょう。
nginxの設定まで進んだら、次のステップに進んで下さい。GCPでのSSH接続がわからねえって方はこちら
GCPでサーバーを立て、SSH接続するまで問題①sshd_config編集後にssh接続ができない…
sshを22から指定した番号へ切り替えると同時に22番を閉じました。
するとsshコマンドで、ポート切り替え後にログインできないのです…解決策
sshd_configでポート番号を変更しているため、もとの22番はNG
コマンドを下記のように変更。# 変更前 $ ssh worker@<IPアドレス> -i ~/.ssh/my-ssh-key # 変更後(ポート番号を指定すればええんや!) $ ssh -p <ポート番号> worker@<IPアドレス> -i ~/.ssh/my-ssh-keyGCEにdjangoいれる
この記事にお世話になりすぎました。
GCE + Nginx + uWSGI + Django + Supervisor を使ってDjangoアプリをデプロイ
序盤のGCP関連は、前節で対応できるはず。
ただし、以後はdjangoを利用したいため、下記のインストールあたりから参考にしてください。$ sudo apt-get install python3-pip nginx $ pip3 install django==2.0.2 uwsgi $ sudo apt-get install uwsgi uwsgi-plugin-python3 $ sudo apt-get install supervisor問題②git cloneができない…?
今回はアプリケーションはどうでもよくって、とにかく見れるようになることが主眼です。
そのため、適当なdjangoアプリをgit cloneで持ってこようという算段。「さらっとgit cloneして完了〜♪」のはずが、、全然できなかったです…
Permission denied (publickey).sshkeyまわりだとはわかりつつ、新たに追加するも失敗。
今回の対応としては、GCPが提供するプライベートGitレポジトリサービス
「Cloud Source Repositories」を利用することで回避。以下を参考にしました。
GCP Cloud Source Repositoriesを利用する手順のメモ本来であれば、ローカルでの編集のように
githubなりgitlabなりにSSH接続してpushできる方が個人的には楽です。
問題なくできるなら、通常通りsshをしましょう。いざ!NGINX!
無事にdjangoプロジェクトをcloneできたら、nginx-uwsgi-djangoのつなぎ込みです。
先程の記事を参考に進めましょう。困ったときは、下記も同じようなことを書いているので参照しました。
Django + uWSGI + nginx (uWSGIチュートリアルの和訳)基本的に記載のとおりで実施できました。
ただし、僕は後ほどエラーをだしてすごい悩んだので、
Django + uWSGI + nginx がどういった構造でクライアントからのリクエストに対応しているかは
なんとなくで理解した方がいいです。confファイルをかなりいじりますが、僕はconfの参照がうまくできずに
ずっとnginxの画面をみてました…/etc/nginx/nginx.confhttp { ~ 略 ~ include /etc/nginx/conf.d/*.conf; include /etc/nginx/sites-enabled/*; # <----- この記述がありますか? # 例 server { hogehoge } }ドメイン取得してGDSで設定
現時点では、nginxとuwsgiを使って固定IPでならdjangoのTOPページが見れています。
ここからは、独自ドメインでの設定とhttps化です。僕はお名前ドットコムでドメインを取得し、下記の記事を参考にしました。
Google Cloud DNSでIPアドレスとドメイン名を紐付けるSSL対応
残るはhttps化です。
最初にお世話になった記事へ帰ってきて、nginxを停止させて対応を進めましょう。
GCPで永久無料枠を利用してサービスを立ち上げたときにしたことの備忘録ちなみに、僕はsupervisorを使ってデーモン化していたため、
nginxの停止一つでえらく時間を消費しました。ポート番号の利用について調査するならlsofコマンドがおすすめです。
下記のコマンドでインストールした上で、調査してください。
過去にもあったんですけど、ずっと8000番を何者かが利用してくるんですよね…
(前は5年前に動かしたapacheが犯人だった)# debian ならこれでインストール sudo apt-get install lsof # ポートの利用を調べるならこれ lsof -i:<ポート番号>そのうえで、supervisorを一度停止させましょう
こんな感じになればOKuser@pjname$ sudo supervisorctl <プロジェクト名とか> STOP pid 28621, uptime 1:51:3あとは記事通りに作業を進めていくだけ。
唯一、リダイレクト処理を書く際には、defaultファイルではなく
作成した_nginx.confに書くようにしましょう。僕は新たに作成したdefaultファイルのおかげで、深い闇に落ちました。
/etc/nginx/sites-enabled/hoge_nginx.confserver_name ドメイン; return 301 https://$host$request_uri; #受け取ったpathやhostを引き継いだ状態でhttpsでリダイレクトするいかがでしょう。
このような問題が起きなければ、無事にSSL対応ができたのではないでしょうか。
最後にsupervisorを起こすか、コマンドで直接uwsgiとnginxを使って表示させてみましょう。
独自ドメインでのアクセスができるはず…!同じように初心者ながらもdjangoでなんかやりたい人の手助けになれば幸いです。
教訓
やっぱり以下の内容は大事でした。
- エラーは逃げずに読む
- コマンドを打つ前に、自身の想定した挙動と現状のギャップを理解する
エラーは逃げずに読む
結局のところ、何が起きてるかはエラーにしか存在しません。
たまに疲れてきて、同じようなコマンドを打つこともありますが、有効だった試しはないです。会社の上司と違って、何がだめだったかを明確に伝えてくれるできるやつなので
エラーはちゃんと読みましょう。コマンドを打つ前に、自身の想定した挙動と現状のギャップを理解する
上の話にも通じますが、色々と調べたり、コマンドを打つ前にすることってあるなと感じました。
「なんで?」って思考が先行しますが、
まずは想定したプロセスのうちどこで事故を起こしたのかを理解することが解決につながります。
コマンド打ちまくって反省しました…言い得て妙だと感じたのは、@jnchitoさんの記事ですね。
デバッグは「うまく動かないピタゴラ装置の原因調査」だと考えてみよう
謝辞
ここまでくるのにqiita記事やブログを大変参考にさせていただきました。
皆さんがその過程を公開してくれたおかげで、
僕は無事に自分のWebサイトを作る第1歩を踏み出せています。本当にありがとうございましたm(_ _)m
参考記事一覧
- 投稿日:2019-05-02T17:24:19+09:00
日本語による文章表現の特徴を抽出するプログラム
janomeによる日本語の形態素解析(名詞の出現頻度)
文学作品や新聞記事など日本語による文章表現から,形態素解析を通して何か特徴を抽出できないかというモチベーションから始めました。
janomeのインストール
まずは,形態素解析器のjanomeのインストールから:
janomeのインストール$ pip install janomejanomeに関するドキュメントはこちら:
- Janome v0.3 documentation (ja)メインプログラムの実行
dataディレクトリ(フォルダ)に作品ごとのテキスト形式のファイル(拡張子は.txt)を用意してから実行します。
main.pyの実行$ python main.pyメインプログラムのソースコード
とりあえず,ソースコードは以下のとおりです。
main.py# coding: UTF-8 from collections import Counter from itertools import chain from janome.tokenizer import Tokenizer import math import glob result = [] for file in glob.glob('./data/*.txt'): # ファイルからテキストを読み込む book = [] length = 0 print(file, '-'*16) for line in open(file, 'r', encoding="utf-8"): print(line, '') book.append(line) data = [] each_data = [] # 形態素解析(janome) t = Tokenizer() for b in book: tokens = t.tokenize(b) length += len(b) for token in tokens: partOfSpeech = token.part_of_speech.split(',')[0] print(token) if partOfSpeech == "名詞": each_data.append(token.surface) data.append(each_data) each_data = [] # 名詞の出現頻度(TF)を求める chain_data = list(chain.from_iterable(data)) c = Counter(chain_data) # 統計情報の表示 print("Statistics for ", file, ":") print("length = ", length) sum = 0 for cnt in c.values(): sum += cnt p = 0 for cnt in c.values(): q = cnt / sum p += - q * math.log(q) print("entropy = ", p) result_rankings = c.most_common(10) for d in result_ranking: print(d) result.append([file, length, p, result_ranking]) # 結果の表示(まとめ) for r in result: print(r) exit()メインプログラムの実行結果(一例)
いくつかの文献は,青空文庫のテキストデータを使用させていただきました。
実行結果の一例['./data\\かいじん二十めんそう.txt', 9229, 4.869249479002453, [('の', 70), ('めん', 58), ('くん', 50), ('ん', 39), ('小', 37), ('二', 32), ('そう', 28), ('十', 28), ('おばけ', 27), ('中', 26)]] ['./data\\こころ.txt', 61906, 5.73922894743357, [('私', 1098), ('の', 465), ('先生', 356), ('事', 238), ('よう', 178), ('奥さ ん', 176), ('ん', 175), ('それ', 165), ('人', 142), ('もの', 142)]] ['./data\\ごんぎつね.txt', 3851, 4.7399830961522875, [('ん', 50), ('十', 33), ('兵', 32), ('中', 17), ('うなぎ', 15), ('の', 10), ('おれ', 10), ('栗', 10), ('家', 9), ('一', 8)]] ['./data\\坊っちゃん.txt', 22895, 6.168599304143815, [('おれ', 131), ('の', 103), ('ん', 90), ('事', 76), ('君', 59), ('もの', 55), ('シャツ', 55), ('山嵐', 54), ('赤', 53), ('人', 52)]] ['./data\\宇宙旅行の科学.txt', 16832, 5.9582839368126175, [('一', 83), ('こと', 81), ('ロケット', 73), ('の', 72), ('衛星', 58), ('マイル', 50), ('人工', 50), ('二', 50), ('地球', 44), ('五', 42)]] ['./data\\斜陽.txt', 73215, 6.35525411401746, [('私', 656), ('の', 418), ('お母さま', 268), ('事', 224), ('よう', 193), ('さん', 165), ('ん', 140), ('僕', 121), ('それ', 113), ('もの', 107)]] ['./data\\日本国憲法.txt', 11862, 5.884146792014421, [('条', 105), ('これ', 79), ('こと', 67), ('法律', 57), ('議員', 49), (' 国会', 46), ('国民', 45), ('内閣', 41), ('2', 40), ('議院', 32)]] ['./data\\日本国憲法(前文).txt', 650, 4.37189439697608, [('国民', 11), ('われ', 7), ('ら', 7), ('こと', 6), ('これ', 4), (' 平和', 4), ('日本', 3), ('憲法', 3), ('もの', 3), ('つて', 3)]] ['./data\\羅生門.txt', 2766, 4.853945084977317, [('下人', 27), ('事', 19), ('老婆', 18), ('の', 17), ('よう', 13), ('それ', 9), ('雨', 8), ('上', 8), ('門', 7), ('死骸', 7)]] ['./data\\茶わんの湯.txt', 3410, 4.813071551666044, [('湯', 30), ('よう', 22), ('茶わん', 21), ('の', 19), ('こと', 17), ('も の', 16), ('それ', 13), ('とき', 13), ('空気', 13), ('これ', 12)]]展望
文書に出現するN個の名詞の出現確率
に対して,文書のエントロピーを
によって定義すると,文章の読みやすさに関係した特徴量として使えるのではないかと思って試してみました。名詞だけでなく動詞や形容詞も含めて考えるなど,まだまだ検討の余地はありそうです。



- 投稿日:2019-05-02T17:11:25+09:00
Flaskチュートリアル「Step 3: データベースを作成する」で躓いたことのメモ
Flask Tutorial
の「Step 3: データベースを作成する」で躓いたので忘れないようにやったことをメモ。init_db()を実行すると、
ValueError: script argument must be unicode.って怒られる。
db.cursor().executescript(f.read()) → db.cursor().executescript(f.read().decode('utf-8'))に書き換えればOK。
must be unicode って言ってるからunicode(utf-8)に変換して上げればOKってことね。
文字コードは難しい…。
- 投稿日:2019-05-02T16:28:29+09:00
TensorflowとNumpyを、疑問を解決しながら使ってみる。
目的
TensorflowとNumpyを、疑問を解決しながら使ってみる。
何年も前から、多くの方が、TensorflowとNumpyの使い方などを報告されています。それらを参考にして、自分が疑問に思った部分などを整理しつつ、後追いしてみます。
当面、利用目的は、CNNの実行とします。
まだ、書きはじめですが、多少、役立つと思う記載は以下。
テンソルとは?
テンソルとは?
Tensorflowの名前にも入っているtensor(テンソル)とは、なんだろうか?
ネット上で調べると、テンソル自体は、結構、難しいものであることがわかります。Tensorflowと関連づけて、テンソルの説明をされているものも多くありますが、簡単に説明しようとして頂いているが、テンソルの説明だけが、難しくなっていて、Tensorflowに対応づいていない気がします。自分としては、以下のブログ説明されているように、「多次元配列」という理解でいいと思いました。(以下のブログは、説明に成功している気がしました。)
HELLO CYBERNETICS「TensorFlowを始める前に知っておくべきテンソルのこと(追記:より一般的な話題へ)」
https://www.hellocybernetics.tech/entry/2016/12/01/223834まとめ
テンソルではまったので、まず、ひとこと、記載しました。
今後
また、何か関連する検討ができれば。
コメントなどあれば、お願いします。関連(本人)
- 投稿日:2019-05-02T16:06:18+09:00
学習まとめ Python スクレイピングからデータをCSVに出力するまで
はじめに
これまでの学習の個人的まとめです
Qittaのすべての記事ページから、
記事のタイトルとURLをスクレイピングして、データフレームに格納、それをCSVに出力する所までです結果
~60書いたコード
Qitta_pagesimport requests import numpy from bs4 import BeautifulSoup import pandas as pd from pandas import Series,DataFrame Qitta_url = "https://qiita.com/items/?page=" df = pd.DataFrame(index = [],columns = ["ページタイトル","ページURL"]) #タイトル,URL取得関数 def get_page(i): title = soup.find_all("a","u-link-no-underline")[i] return title #ページ遷移 for page_num in range(2): r = requests.get(Qitta_url + str(page_num)) soup = BeautifulSoup (r.text,"html.parser") #引数わたす,DFを作る for i in range(0,20): series = pd.Series([get_page(i).text,get_page(i).get("href")],index=df.columns) df = df.append(series,ignore_index = True) df #CSVに出力 df.to_csv("Qitta_page.csv",index = False ,encoding="utf-8")少し解説
少しでも参考になればいいです
自分の過去の記事を参照してもらえば書き方の癖はわかります#タイトル,URL取得関数 def get_page(i): title = soup.find_all("a","u-link-no-underline")[i] return title変数iを引数を持ち、スクレイピングしたリストをスライスしてtitleを戻り値とします
Python スクレイピング 備忘録⑤ N個目の要素を取得#ページ遷移 for page_num in range(2): r = requests.get(Qitta_url + str(page_num)) soup = BeautifulSoup (r.text,"html.parser")スクレイピングするページ数を設定します
range()のリストの要素をPage_numに与えてQittaのベースURLに文字を付け足しページをリクエストを繰り返します
もちろんrequestsやBeautifulSoup4の使いかたの基本も学習しました
range関数使う (参考)
Python スクレイピング 備忘録③ URLの規則性を見つけてページ遷移#引数わたす,DFを作る for i in range(0,20): series = pd.Series([get_page(i).text,get_page(i).get("href")],index=df.columns) df = df.append(series,ignore_index = True) df先ほど作ったデータがからのデータフレームに要素を代入していきます
要素は関数に引数iをわたしSeriesとして格納
それをFor文とappend関数で繰り返しデータフレームに追加していきます
Python pandas DataFrameに1行ずつSeriesを追加する (参考)
要素の追加と連結(appendメソッド, extendメソッド) (参考)#CSVに出力 df.to_csv("Qitta_page.csv",index = False ,encoding="utf-8")データフレームをCSVに出力します
PandasのデータフレームをCSVに書き込む (参考)
おわり
Pythonいいですね、環境構築楽、手軽に実行、表記も簡潔、面白いライブラリたくさん
1カ月ほどの学習でここまで成果を可視化できるとは、今後もデータ分析、機械学習などでお世話になりそう
ここまでの学習方法を簡単にまとめます
Python環境構築 ~ AnacondaとJupyterNotebook , Google Colaboratory 最初はこの2つで十分
Pythonの基本を学ぶ ~ https://www.udemy.com/python-python3/ *景品表示法違反サイト
Python 学習目的を決める~ Python 目的別チュートリアル
目的に合った教材 ~ 自分は (実践 Python データサイエンス)ここまで、そろったら実際に書きながらわからない事は調べながら”アウトプット”していく、
実際にモノを作ったり、Qittaに記事を書いたり、他人に教える以上

- 投稿日:2019-05-02T15:56:07+09:00
Filmarksから鑑賞済映画のスコア一覧を取得する
はじめに
鑑賞した映画の記録に,Filmarksというサービスを利用しています.
鑑賞時の評価を0~5の11段階(0.5刻み)のスコアで残すようにしていますが,評価の一貫性を保つのが難しいです.過去に自分がつけた評価を見ていても,「厳しくつけすぎた」とか「甘くつけすぎた」というのが多々あります.
スコア一覧を取得
現在の評価の分布を確認してみます.
Filmarksは「自分がつけたスコア毎に一覧を確認」的な操作がやり辛いので,BeautifulSoupを使用してhtmlから一覧を取得します.Jupyter Notebook を使用しました.import
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inlineスコア一覧取得
dict = {"title":[], "infobar":[]} for page in range(1, 11): rs = requests.get("https://filmarks.com/users/<ユーザ名>?view=poster", params={"page":page}) soup = BeautifulSoup(rs.content, "lxml") titles = soup.select(".c-movie-item__title > a") infobars = soup.select(".c-movie-item-infobar__item.c-movie-item-infobar__item--star.is-active > a > span") for title, infobar in zip(titles, infobars): dict["title"].append(title.string) dict["infobar"].append(infobar.string) df = pd.DataFrame(dict) df.infobar = df.infobar.str.replace('-', '0') df.infobar = df.infobar.astype("float64")鑑賞済み映画一覧のページ数はハードコードです.(自分の場合10ページあった)
データの中身を確認
df.info()
df.head(10)
直近10件分のタイトルとスコア.きちんと取れてそう.df.hist()
ヒストグラム.これが見たかった.
(昔に見た映画等スコアをつけていないものは便宜上0として処理.0.5, 5.0は実質欠番.)おわりに
「必要なら,分布がいい感じになるように過去の評価を微修正しよう」などと考えていましたが,面倒なのでやめました.(というより見ている映画がそもそも少ないので,あまり分布を気にしても仕方がない気がします)
全体のスコア平均と自分のスコアを比較したり,レビューを全て取得してきて字句解析とかすると面白そうです.



- 投稿日:2019-05-02T15:50:51+09:00
Google Edge TPUをVirtual Box上のUbuntuで動かす
1 はじめに
Google Edge TPUのUSB Acceleratorを購入しました。Virtual Box上のUbuntuで動かすのに一苦労ありましたので、ここに書き留めておきます。
2 環境
Host OS: Windows 10
Guest OS: Ubuntu 18.04 LTS
仮想化マシン:Virtual Box ver.6.0.63 手順
- Virtual Boxのインストール
- VirtualBoxにOracle VM VirtualBox Extension Packの追加
ダウンロード先:https://www.virtualbox.org/wiki/Downloads
- Virtual BoxにUbuntuのインストール
参考:https://qiita.com/ykawakami/items/4bae371932110b2e25e3- Virtual BoxのUSBフィルタを編集
4.1. 設定をクリック
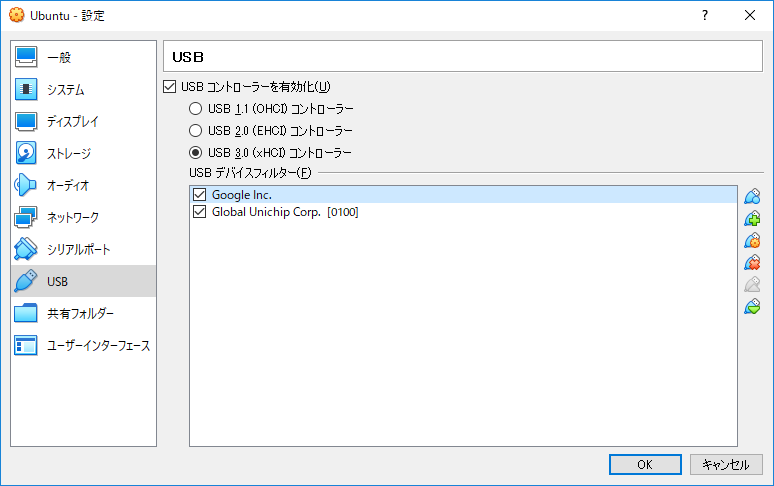
4.2. サイドバーのUSBを選択し「USBコントローラーを有効化」にチェックを入れる
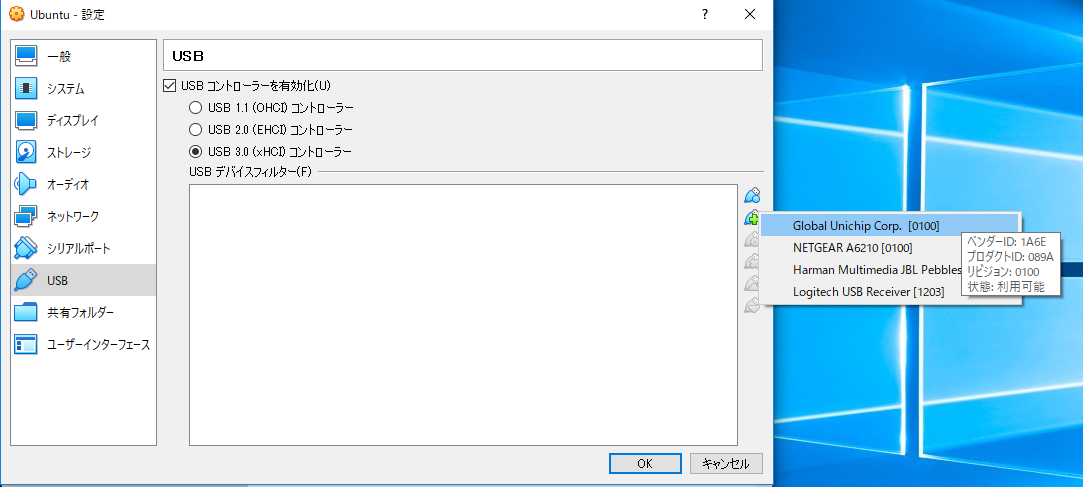
4.3. USB Acceleratorを挿入しているUSBポートに合わせ、USBコントローラーのバージョンを指定する
4.4. USBフィルタの追加をクリックし、Global Unichip Corp.[0100]を追加する
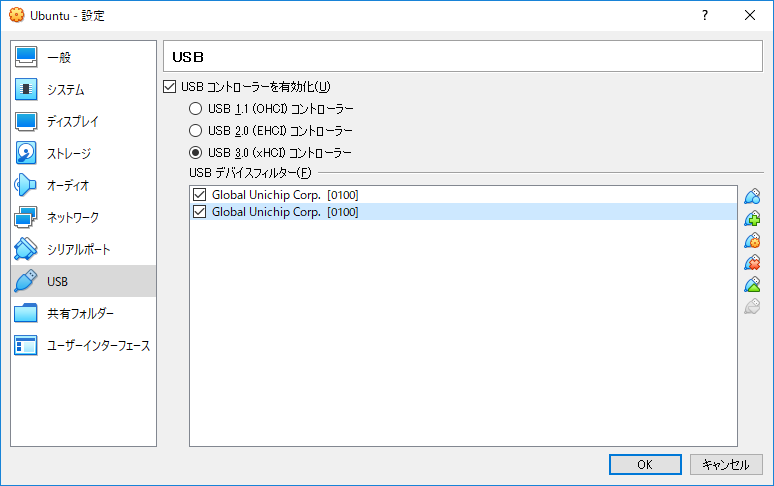
4.5. 4.4と同様の操作をし、Global Unichip Corp.[0100]を再度追加する
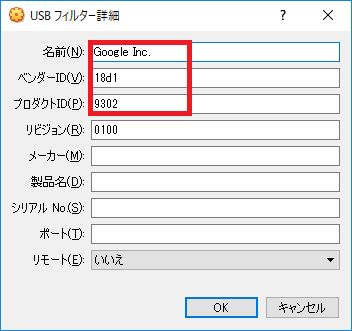
4.6. 2つのうち、1つを編集し以下のように設定する
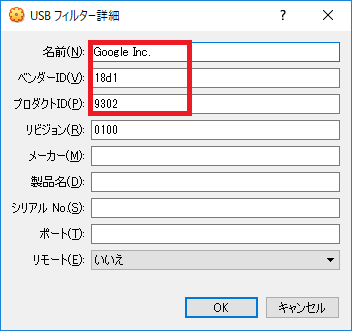
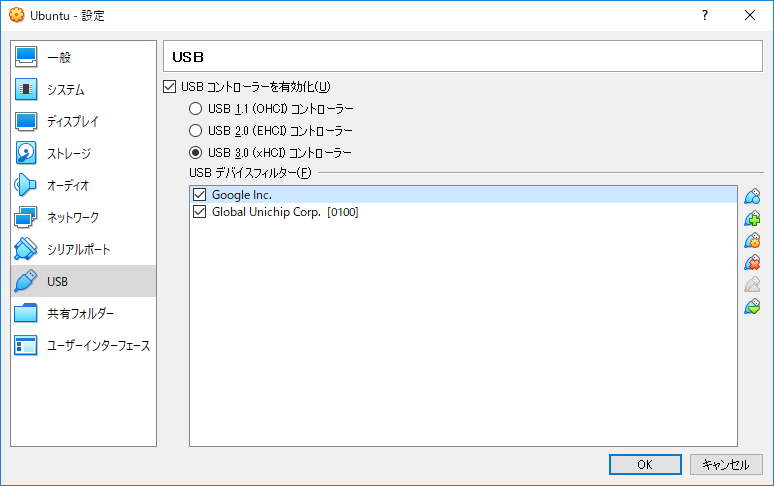
ベンダーID:18d1
プロダクトID:9302
- Ubuntuを起動
- 以下のサイトをもとにUSB Acceleratorの動作確認をする
https://coral.withgoogle.com/docs/accelerator/get-started/4 結果
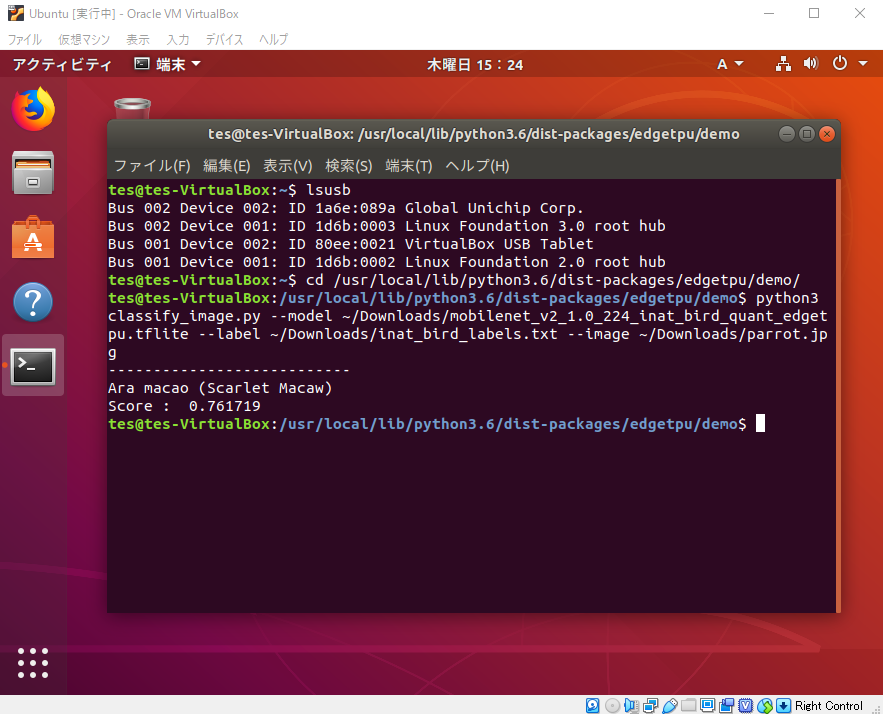
以下の通り、Virtual Box上でGoogle Edge TPUのUSB Acceleratorを動作させることができた。
5 経緯
Virtual Box上のUbuntuで動作させるに当たり、2つの問題にぶつかった。
5.1 "No Edge TPU Device detected!"エラー
これは、Virtual Box上でUSBデバイスを認識していないのが原因である。よって、USBフィルタにUSB Acceleratorを追加することで解決できた。
5.2 "RuntimeError: Failed to allocate tensors."エラー
この原因はさっぱりわからなかったが、githubのissueを見ているとサンプルプラグラム動作後にUSB AcceleratorのベンダーID、プロダクトIDが変わっているとの記載があった。また、サンプルプログラムを実行するとUSB Acceleratorがアンマウントされてしまうという現象が発生していた。このことから、試しにUSBフィルタに変更後のUSB AcceleratorのベンダーID、プロダクトIDを追加すると動作することができた。
6 補足事項
- 3で作成した仮想環境をMacBookAirのVirtual Boxにインポートしたが、USB Acceleratorを動作させることができた
- debianでも同様のことを実施したが、5.2のエラーが表示され動作させることができなかった
- 投稿日:2019-05-02T15:16:54+09:00
pandas メモ
pandas のメモです。
pandas とは
データ解析を支援する機能を提供する
Python の open source ライブラリです。csv ファイルを読み込んで、解析したりするときに頻繁に使います。
pasdas の使い方
sample1.pyimport numpy as np import pandas as pd a = np.array([10,20],[30,40]) df = pd.DataFrame(a) # 0 1 # 0 10 20 # 1 30 40 df.columns = ['A', 'B'] # A B # 0 10 20 # 1 30 40 df.index = ['C', 'D'] # A B # C 10 20 # D 30 40 df = df.rename(columns ={'A' : 'Z'}) # Z B # C 10 20 # D 30 40sample2.pydf.info() df.describe() df.head() df.isnull().sum() df.isnull().sum(axis=1)pandas で csv ファイルの読み込み
csvfileを読み込むのはシンプルです。
read_csv.pyimport pandas as pd data = pd.read_csv('-filename-')欠損値の確認
データを読み込んだ際に、欠損値(nan)がある場合があります。
確認する際に以下の関数は使えるかとchecker.pydef checker(data): null_v = data.isnull().sum() percent = 100 * null_v /len(data) output_table = pd.count([null_v, percent], axis=1) output_table = output_table.rename(columns = {0:'count(nan)' , 1:'Percent'}) return output_table最後に
pandas は使用する頻度が高いと思うので、使いこなせるようになりたいです。
今後もこの記事はアップデートしていこうと思います。
- 投稿日:2019-05-02T15:14:01+09:00
竹内関数をメモ化で高速化する工程 (Python には負けたくない)
はじめに
Ruby で竹内関数をメモ化によって、高速にしようとあれこれやります。
竹内関数とは
これです。Ruby で書くとこんな感じです。
Rubydef tarai(x, y, z) return y if x <= y tarai( tarai(x - 1, y, z), tarai(y - 1, z, x), tarai(z - 1, x, y) ) end引数をたらい回しにして、再帰しまくることにより、重い処理になっています。
迂闊に、
tarai(30, 15, 0)とかすると、後悔します。
メモ化とは
竹内関数が遅いのは、引数をたらい回しにして再帰的に関数を実行することで、引数が同じなのに、何度もなんども同じ計算をしなければならないためです。
そこで、ある引数の組合せで計算を一度してしまえば、その答えをメモしておいて、もう一度同じ引数の計算をしなければならなくなった時に、実際に計算するのでなく、メモに記録した答えを返すようにすることで、速く答えを出す、というものです。
で、何をしようというの?
Fibonacci 数を求める
fibo(n)のように引数がひとつの時には、特に問題はありません。Rubydef make_fibo cache = {} fibo = lambda do |n| return n if n < 2 cache[n] ||= fibo.call(n - 2) + fibo.call(n - 1) end end fibo = make_fibo fibo.call(100)すればOKです。
ここでは、計算結果を、引数をキーにした Hash オブジェクトcacheにメモしています。ちなみに、cacheをグローバル変数にしたくないので、lambdaを使ってクロージャを作っています。
def ... endで囲まれた空間は、局所変数の独立した 名前空間 を作るので、defで作ったメソッドは外側の局所変数をキャプチャーできず、クロージャにはなりません。その代わり、
lambda等を使ってクロージャを作る時には、def ... endの中は、局所変数に関してはクリーンルームになるので、クロージャを返すメソッドを作った上で、クロージャを作るのがオススメのはずです。多分。話が飛んでしまいましたが、Fibonacci の場合と違い、竹内関数の場合、引数が3つあります。これをどう Hash オブジェクトに登録するかです。
Python ならどうするか
Python なら、当然引数を tuple にして、dict オブジェクトに登録するはずです。
まずは、クロージャを使って、
Pythondef make_tarai: cache = {} def tarai(x, y, z): if x <= y: return y key = (x, y, z) val = cache.get(key) if val is not None: return val val = tarai( tarai(x-1, y, z), tarai(y-1, z, x), tarai(z-1, x, y) ) cache[key] = val return val return tarai tarai = make_tarai() tarai(100, 50, 0)あるいは、Python のデフォルト引数は関数を定義した時に一度だけ評価されるので、
Pythondef tarai(x, y, z, cache={}): if x <= y: return y key = x, y, z val = cache.get(key) if val is not None: return val val = tarai( tarai(x-1, y, z, cache), tarai(y-1, z, x, cache), tarai(z-1, x, y, cache), cache ) cache[key] = val return val tarai(100, 50, 0)でもOKでしょう。
tarai関数を何度実行しても、常に同じdictオブジェクトが使われるので、一度計算結果をメモしてしまえば、次にtaraiを実行した時にもそのメモが使えます。手元で計算すると、
tarai(100, 50, 0)で約0.03 秒程度です。Ruby で同じようなことをすると
Rubyの場合、デフォルト引数はメソッドを実行するたびに評価されるので、Python と違い、メソッドを実行するたびに一からメモを取り直すことになってしまいます。
どちらがいいのか私にはよく分かりません。Python が変わっているような印象ですが、どちらが勝ちで、どちらが負けという話でないことは間違いなさそうです。
そういうわけで、Ruby の場所、クロージャでいきます。
Ruby には tuple がないので、配列でやるしかありません。Rubydef make_tarai cache = {} tarai = lambda do |x, y, z| return y if x <= y cache[[x, y, z]] ||= tarai.call( tarai.call(x - 1, y, z), tarai.call(y - 1, z, x), tarai.call(z - 1, x, y) ) end end tarai = make_tarai tarai.call(100, 50, 0)できるにはできましたが、Python に比べると圧倒的に遅いです。手元で計算すると、0.09 秒前後かかってしまいました。完敗です。
Rubydef time start = Time.now result = yield diff = Time.now - start puts "Elapsed time: #{diff} secs" p result end time { tarai.call(100, 50, 0) }で時間を計算しましたが、以下略。
Python の tuple は見た目が同じなら同じオブジェクトです(少なくとも中身がintの場合)。なので高速に dict のキーを比較することができます。
それに対し、Ruby の配列は見た目が同じでも別のオブジェクトになりうるので、キーの比較に時間がかかってしまうのが大きな原因だと思います。
ここからが知恵の出しどころです。
計算結果を多重 Hash に登録する
配列をキーにするから遅いのなら、メモを多重 Hash にして、Integer である、個々の
x,y,zをキーにして、計算結果をメモすることにします。戦略的には、まず、引数
xのためのcache_x = {}を用意します。
そして、cache_x[x]は引数yのための Hash オブジェクトcache_yを返して欲しいのですが、引数xが初見であればnilが返ってきます。
そこで、cache_y = cache_x[x] ||= {}とすることで、xが初見の場合には、新たな Hash オブジェクトをcache_[x]に登録した上で、変数cache_yに代入することができます。そうすると、こんな感じになります。
Rubydef make_tarai cache_x = {} tarai = lambda do |x, y, z| return y if x <= y cache_y = cache_x[x] ||= {} cache_z = cache_y[y] ||= {} cache_z[z] ||= tarai.call( tarai.call(x - 1, y, z), tarai.call(y - 1, z, x), tarai.call(z - 1, x, y) ) end end tarai = make_tarai tarai.call(100, 50, 0)0.012 秒前後です。
やりました。Python に勝ちました。圧勝です。ちなみに、Python でこの方法を使うと少し遅くなってしまいました。恐るべし、Python の tuple 。
しかし、Ruby が勝ったとはいえ、
Rubycache_y = cache_x[x] ||= {} cache_z = cache_y[y] ||= {} cache_z[z] ||= tarai.call(...の部分がまだだるいです。どうせなら
cache[x][y][z] ||= tarai.call( ...としたいです。Hash のデフォルト値を使う
Ruby の場合、
Rubycache = Hash.new { |hash, key| hash[key] = {} }とすることで、未登録のキーに出くわしたとき、新たな Hash オブジェクトを作って、そのキーに登録するような Hash オブジェクトを作ることができます。
これを多重にすればいいわけです。Rubydef make_tarai cache = Hash.new do |hash, key| hash[key] = Hash.new do |hash, key| hash[key] = {} end end tarai = lambda do |x, y, z| return y if x <= y cache[x][y][z] = tarai.call( tarai.call(x - 1, y, z), tarai.call(y - 1, z, x), tarai.call(z - 1, x, y) ) end end tarai = make_tarai tarai.call(100, 50, 0)これでOKです。
とはいえ、このcacheの定義もだるいです。何とかスマートにしたいものです。そこで、
cacheの右辺をよく見ると、ラスボス的な{}をHash.new { |hash, key| hash[key] = ... }でラップしていけば良さそうだと分かります。メタプログラミングで何とかしましょう。メタプログラミング登場
方針としては、何重にもなった
Hash.new {}の文字列を作って、evalすることにします。引数の数が3つの場合、
{}を2回Hash.new {}でラップすればいいから、メモ化する際の引数の数をarityとすると、Rubydef make_cache(arity) seed = "{}" (arity - 1).times do seed = "Hash.new { |hash, key| hash[key] = #{seed} }" end eval(seed) endこの
make_cacheがあれば、簡単に多重 Hash を作ることができます。Rubydef make_cache(arity) seed = "{}" (arity - 1).times do seed = "Hash.new { |hash, key| hash[key] = #{seed} }" end eval(seed) end def make_tarai cache = make_cache(3) tarai = lambda do |x, y, z| return y if x <= y cache[x][y][z] ||= tarai.call( tarai.call(x - 1, y, z), tarai.call(y - 1, z, x), tarai.call(z - 1, x, y) ) end end tarai = make_tarai tarai.call(100, 50, 0)かなりいい感じになりました。でも、もっと高速を目指したいです。
いろんな事情があって、Proc オブジェクトはメソッドより遅いと聞きます。そこで、Proc オブジェクトではなく、メソッドでクロージャを作ってみます。
メソッドでクロージャを作る
すでに述べたように、
defでクロージャは作れません。そこで、defを使わずにメソッドを作ることにします。
define_methodの登場です。Rubydef make_cache(arity) seed = "{}" (arity - 1).times do seed = "Hash.new { |hash, key| hash[key] = #{seed} }" end eval(seed) end def make_tarai cache = make_cache(3) define_method(:tarai) do |x, y, z| return y if x <= y cache[x][y][z] ||= tarai( tarai(x - 1, y, z), tarai(y - 1, z, x), tarai(z - 1, x, y) ) end private :tarai end make_tarai tarai(100, 50, 0)トップレベルで
make_taraiを定義すると、定義式の中のselfはmainになります。define_methodは Module クラスのメソッドなので、一般的にはmodule ... endかclass ... endの中でしか使えないのですが、mainには同名のシングルトン・メソッドが定義されていて、実行すると、Object クラスにメソッドが登録されます。ここでは、トップクラスでメソッドを定義したときのように、private にしました。
ただ、メソッドにしてもほとんど速度は変わりません。Proc にしろ、メソッドにしろ、環境を背負っている分、遅いのでしょうか。
そこで、この辺りでクロージャに見切りをつけ、
cacheをインスタンス変数で持つ方法を試してみます。メモをインスタンス変数に格納する
Rubydef make_cache(arity) seed = "{}" (arity - 1).times do seed = "Hash.new { |hash, key| hash[key] = #{seed} }" end eval(seed) end class Tarai def initialize @cache = make_cache(3) end def call(x, y, z) return y if x <= y @cache[x][y][z] ||= call( call(x - 1, y, z), call(y - 1, z, x), call(z - 1, x, y) ) end end tarai = Tarai.new tarai.call(100, 50, 0)ついに、0.007 秒の世界に突入しました。
ぶっちぎりの速さです。関数型言語に惑わされてなのか、メモ化というとすぐにクロージャだと思い込んでいましたが、Purely Object-Oriented Programming Language である Ruby の場合、素直にオブジェクトを使えばよかったんですね。
まとめ
Ruby でメソッドをメモ化する時には、クロージャではなく、普通にインスタンスを作って、インスタンス変数にメモを格納する。
引数が複数あるときは、配列にして Hash オブジェクトのキーにするのではなく、引数の数だけ多重 Hash にする。
- 投稿日:2019-05-02T14:43:54+09:00
Numpy メモ
Numpyのメモを残しておきます。
Numpy とは
簡単にいいますと、、、
多次元配列を扱う数値ライブラリ
知っていてのメリットは、データ処理の際に高速化や省メモリ化したコードがかけるようになります。np.ndarray
ndarray は N-dimensional arrayの略であり、特徴としてはひとつのデータタイプの要素のみを持つ
Numpyの使い方
ndarray の簡単な作り方
sample1.pyimport numpy as np a = np.array([1,2]) # array([1,2]) b = np.array([[1,2],[3,4]]) # array([[1,2], # [3,4]]) c = np.array([[1,2],[3,4],[5,6]]) # array([[1,2], # [3,4], # [5,6]])sample2.pyimport numpy as np a = np.array([[1,2],[3,4]]) type(a) # <class 'numpy.ndarray'> a.shape #(2,)sample3.pyimport numpy as np a = np.zeros([3,3]) # array([[0., 0., 0.,], # [0., 0., 0.,], # [0., 0., 0.,]]) b = np.ones([3,3]) # array([[1., 1., 1.,], # [1., 1., 1.,], # [1., 1., 1.,]]) c = np.full((2,2),5) #自分の好きな形を好きな数値で作れる # array([[5,5], # [5,5]]) d = np.eye(2) #単位行列 # array([[1,0], # [0,1]])sample4.pyimport numpy as np np.random.rand(3) # array([0.63559424, 0.07561477, 0.24971466]) np.random.randn(3) # array([-0.50345217, 0.30698654, 0.71499541])
- 投稿日:2019-05-02T14:20:46+09:00
Python + HerokuでLINE BOTを作ってみた
いまさら感はありますが、
勉強のためによくあるオウム返しbotを作ってみました。まずはLine developersに登録する。
https://developers.line.biz/ja/services/messaging-api/
アプリ名 →任意のアプリ名
アプリ説明 →説明文
プラン →Developer Trial
大業種 →個人
小業種 →個人(その他)
メールアドレス →自分のメールアドレス利用規約に同意して作成。
チャネル基本設定->メッセージ送受信設定のアクセストークンの再発行ボタンを押下。
Bot情報のLINEアプリへのQRコードで友達登録しておく。
Flaskとline-bot-sdkをインストール
$ pip3 install flask $ pip3 install line-bot-sdkhttps://github.com/line/line-bot-sdk-python
にオウム返ししてくれるBotのサンプルがあるのですが、
これをそのまま使うと上手く行かないので、
こちらのサイト様からmain.pyを参考にさせて頂きました。main.py from flask import Flask, request, abort import os from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT")) app.run(host="0.0.0.0", port=port)Heroku(ヘロク)に登録する。
HerokuはPaas(パース)とよばれる、アプリケーションを実行するためのプラットフォームで、
アプリケーションを作成して簡単に動かすことが出来きます。Herokuコマンドラインインタフェース(CLI)をインストールします。CLIを使用して、アプリケーションの管理と拡張、アドオンのプロビジョニング、アプリケーションログの表示、およびアプリケーションのローカルでの実行を行います。
プラットフォーム用のインストーラをダウンロードして実行します。
$ heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/browser/XXXX Logging in... done Logged in as XXXX@XXXXアプリケーションの登録
$ heroku create {自分のアプリケーション名}
Creating ● XXXX... done
https://XXXX.herokuapp.com/ | https://git.heroku.com/XXXX.git環境変数の設定
$ heroku config:set YOUR_CHANNEL_SECRET="Channel Secretの文字列" --app {自分のアプリケーション名} $ heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="アクセストークンの文字列" --app {自分のアプリケーション名}設定の確認
$ heroku config --app {自分のアプリケーション名}Webhookの設定
管理画面から、Webhookの設定をします。
Webhook送信:利用する
Webhook URL:https://<自分のアプリケーション名>.herokuapp.com/callback
接続確認が表示されれば完了です。
PythonとFlaskのバージョンを調べる
$ flask --version設定ファイルの作成とデプロイ
同じディレクトリに作成
main.py →ソースコード
runtime.txt →Pythonのバージョンを記載
requirements.txt →インストールするライブラリの記載
Procfile →プログラムの実行方法を定義runtime.txtpython-3.7.0requirements.txtFlask==1.0.2 line-bot-sdk==1.8.0Procfile
web: python main.py
変更した内容を反映する
$ git add . $ git commit -am "make it better" $ git push heroku master上手くデプロイ出来たか確認する
$ heroku openHello Worldが表示されたら正常にデプロイされています。
ログ確認
heroku logs --tail詰まったところ
Procfileを作成した際に他二つが.txtだったので、
間違えて.txtで作成してしまっていました。
名前を付ける時にダブルクォートで囲んで保存します。Webhook URLの設定で接続確認をしたたところエラーが出ていました。
Webhookが無効なHTTPステータスコードを返しました(期待されるステータスコードは200です)
原因は分からなかったのですが、
オウム返しは上手く行っていました。ちなみに...
ログの、
WARNING: Do not use the development server in a production environment.この部分で注意されていますが、今回は試すだけなので無視して大丈夫です。
公開するときはちゃんとサーバーを立てろということですね。参考
https://jp.fujitsu.com/solutions/cloud/k5/playground/webhandson/preparation/06.html
https://qiita.com/akiko-pusu/items/dec93cca4855e811ba6c
https://qiita.com/tomboyboy/items/122dfdb41188176e45b5
https://uepon.hatenadiary.com/entry/2018/07/27/002843
- 投稿日:2019-05-02T14:05:07+09:00
Pythonを使ってzipファイルからファイルを取り出す
はじめに
Pythonのプログラム中でzipファイルからファイルを取り出したいことがあります。
この目的のためには、zipfileモジュールを使うことになります。そこで、簡単にzipfileモジュールの使い方をまとめてみました。Mac上のpython 3.6.8で動作を確認してあります。zipファイルからのファイルの抽出
zipfileモジュールを利用したいので、当然zipfileモジュールをimportします。
import zipfile
ZipFileオブジェクトを通して、zipファイルにアクセスすることになります。
例えば、zipファイルに含まれているファイルリストの取得、ファイルの取り出しなどができます。
プログラムを終了する前にcloseを呼び出さないといけないので、この面倒を避けるためにwith文を利用しています。import zipfile # zipファイルに含まれているファイル名の取得 with zipfile.ZipFile(zipファイル名) as myzip: print(myzip.filename) # zipファイル名の表示 myzip.printdir() # zipファイルに含まれているファイル名をsys.stdoutに出力 with zipfile.ZipFile(zipファイル名) as myzip: for f in myzip.namelist(): #zipファイルに含まれているファイルのリストを返す print(f) # zipファイルに含まれているファイルの取り出す with zipfile.ZipFile(zipファイル名) as myzip: myzip.extractall() # zipファイルに含まれているファイルを全て取り出す # zipファイルからファイル名を指定して取り出す with zipfile.ZipFile(zipファイル名) as myzip: myzip.extract(ファイル名) # zipファイルに含まれているファイルを取り出す # zipファイルからファイル名を指定して取り出す(パスワード付きの場合) with zipfile.ZipFile(zipファイル名) as myzip: myzip.extract(ファイル名, pwd="パスワード") # zipファイルに含まれているファイルを取り出す
内容 filename zipファイル名を保持 printdir() zipファイルに含まれているファイル名をsys.stdoutに出力 namelist() zipファイルに含まれているファイルのリストを返す extractall() zipファイルに含まれているファイルを全て取り出す extract(ファイル名) zipファイルからファイル名を指定して取り出す もしパスワードがかかっているzipファイルの場合には、extractなどの引数にpwdキーワードでパスワードを指定します。
zipファイルに含まれるテキストファイルの処理
extractなどを利用するとzipファイルからファイルを取り出すことができます。
いちいちファイルを保存してから処理をすることが面倒な場合もあります。そこでopenを利用すると、ファイルを保存することなく処理を行うことができます。import zipfile # zipファイルに含まれているテキストファイルの読み込み with zipfile.ZipFile(zipファイル名) as myzip: with myzip.open(処理をしたいファイル名) as myfile: # openを利用してファイルにアクセス print(myfile.read()) # この場合はreadで読み込みを行った
内容 open() ZipExtFileを返す。これを利用してファイルのように処理ができる zipファイルに含まれる画像ファイル(バイナリファイル)の処理
画像ファイルのようなバイナリファイルを扱う場合は、ioモジュールも利用します。
下の例では画像ファイルの処理のためにPILモジュール(Pillow)を使用しています。
ここで利用しているio.ByteIOはメモリ上でバイナリデータを扱うための機能を提供しています。import zipfile import io from PIL import Image with zipfile.ZipFile(zipファイル名) as myzip: with myzip.open(処理をしたいファイル名) as img_file: img_bin = io.BytesIO(img_file.read()) # メモリ上のデータを読み込む img = Image.open(img_bin) #読み込んだバイトストリームを利用して画像ファイルを生成実のこのサンプルを少し変更することで、ネット上にある画像フィアルをファイルとして保存することなく処理をすることができます。こんな感じになります。
import io from PIL import Image import urllib.request img_read = urllib.request.urlopen(url).read() # urlで指定され得た画像データを取得 img_bin = io.BytesIO(img_read) # メモリ上のデータを読み込む img = Image.open(img_bin) #読み込んだバイトストリームを利用して画像ファイルを生成おわりに
pythonを利用してzipファイルからファイルを取り出す方法に関してまとめてみました。ついでに、一旦ファイルとして保存することなく処理をする方法のサンプルを載せてみました。
- 投稿日:2019-05-02T13:54:52+09:00
ChainerでOctave Convolutionを実装してみた
動機
トレンドに上がっていたOctave Convolutionがなんだかよさそうだったのですが、Keras実装だったのでChainerしか知らない僕にはちょっと不便です。なので自分で実装してみることにしました。
「間違ってるよ」とか「ここはこう書くといいよ」的なアドバイスよろしくお願いします。実装
from chainer import Chain import chainer.functions as F import chainer.links as L import numpy as np class OctConv(Chain): def __init__(self, in_ch, out_ch, ksize, stride, pad, alpha0=0.25, alpha1=0.25): super().__init__() with self.init_scope(): self.h2h = L.Convolution2D(int(in_ch * (1 - alpha0)), int(out_ch * (1 - alpha1)), ksize, stride, pad) self.h2l = L.Convolution2D(int(in_ch * (1 - alpha0)), int(out_ch * alpha1), ksize, stride, pad) self.l2h = L.Convolution2D(int(in_ch * alpha0), int(out_ch * (1 - alpha1)), ksize, stride, pad) self.l2l = L.Convolution2D(int(in_ch * alpha0), int(out_ch * alpha1), ksize, stride, pad) def __call__(self, high, low): _, _, H, W = high.shape h2h = self.h2h(high) h2l = self.h2l(F.average_pooling_2d(high, ksize=2)) l2h = F.unpooling_2d(self.l2h(low), ksize=2, outsize=(H, W)) l2l = self.l2l(low) h = h2h + l2h l = h2l + l2l return h, lまだこのコードで実験していないので、後で追記します。
- 投稿日:2019-05-02T13:13:19+09:00
Jetson開発ボードでGPIOを使ってみる
はじめに
JETSON TX2の開発ボードには、RaspberryPiのピン互換のJ21があります。(ピン配置)
RaspberryPiのWiringPiように、お手軽にGPIOを操作できるライブラリとして、NVIDIAのGitHubに、Python向けのGPIOライブラリが公開されています。(こちらを見る限り、XAVIER, TX2, TX1, NANOに対応しているようです)
ここでは、LEDを点滅させるところまで試してみました。
インストール
こちらの手順に従って、インストールします。
前準備
python3の開発環境をインストール
~$ sudo apt install python3-dev python3-pipJetson.GPIOのインストール
GitHubからダウンロードしてインストール。
~$ sudu su /home/nvidia# cd /opt/nvidia/ /opt/nvidia# git clone https://github.com/NVIDIA/jetson-gpio.git /opt/nvidia# mv /opt/nvidia/jetson-gpio-master /opt/nvidia/jetson-gpio /opt/nvidia# cd jetson-gpio /opt/nvidia/jetson-gpio# python3 setup.py installgpioグループの追加と、使用するユーザをそのグループに追加
/opt/nvidia/jetson-gpio# sudo groupadd -f -r gpio /opt/nvidia/jetson-gpio# sudo usermod -a -G nvidiaudevルールをコピーして、udevに新しいルールを適応する
/opt/nvidia/jetson-gpio# cp /opt/nvidia/jetson-gpio/etc/99-gpio.rules /etc/udev/rules.d/ /opt/nvidia/jetson-gpio# udevadm control --reload-rules && sudo udevadm trigger /opt/nvidia/jetson-gpio# exit最後にスーパーユーザーから抜けます。
サンプルを試す
GPIOの出力のサンプルプログラムは、GPIO18(ピン番号12)を2秒間隔でON/OFFを繰り返します。
ここに抵抗とLEDを付けておきます。[Ctrl-C]で停止します。(自作の評価ボードPiFA-HATのD6が点滅しています)
/opt/nvidia/jetson-gpio$ cd samples/ /opt/nvidia/jetson-gpio/samples$ ./run_sample.sh Usage: ./run_sample.sh <sample application> sample_application: simple_input.py simple_output.py button_led.py button_event.py button_interrupt.py /opt/nvidia/jetson-gpio/samples$ ./run_sample.sh simple_out.py Starting demo now! Press CTRL+C to exit Outputting 1 to pin 18 Outputting 0 to pin 18 Outputting 0 to pin 18 Outputting 0 to pin 18 ^CTraceback (most recent call last): File "./simple_out.py", line 48, in <module> main() File "./simple_out.py", line 39, in main time.sleep(1) KeyboardInterrupt nvidia@tegra-ubuntu:/opt/nvidia/jetson-gpio/samples$補足
その1
./run_sample.shを使わず、直接simple_output.pyを実行するには、下記のようにします。/opt/nvidia/jetson-gpio/samples$ export PYTHONPATH="/opt/nvidia/jetson-gpio/lib/python/ /opt/nvidia/jetson-gpio/samples$ ./simple_output.pyその2
GPIOの出力のサンプルプログラムの26行目は、GPIOの番号をリストにすると、まとめてON/OFFできます。
例えば、GPIO4, 5, 8, 13, 17, 24, 25をまとめて操作する場合は下記のように修正します。修正前# Pin Definitions output_pin = 18 # BOARD pin 12, BCM pin 18修正後# Pin Definitions output_pin = [4, 5, 8, 13, 17, 24, 25]ひとりごと
18年春にTX2を入手してから、お手軽にGPIOを使う方法がないかと探していましたが、
https://github.com/anilsathyan7/JetsonTX2-GPIO
sudoを使う必要がある。https://www.jetsonhacks.com/2015/12/29/gpio-interfacing-nvidia-jetson-tx1/
良さそうだったけど、TX1用なので、ピン配置をTX2に書き換えないとならない。といった感じで、なかなか良いサンプルが見つけられず・・・
このタイミングで、NVIDIA公式からライブラリが出てくれたのは、本当に有り難い事です。
(ホントにRaspberryPi感覚で使えます)以上、ご参考になれば幸いです。

- 投稿日:2019-05-02T12:57:20+09:00
Python MatplotLib で交点の座標をグラフ中に表示する方法
日本語でのmatplotlibでのグラフ中への交点表示方法があまり探しても出てこなかったのでサンプルソースとともに載せておきます。
ここでは例として$y1 = x^3$, $y2 = 3x^2$の交点を求め, 表示しています。
import numpy as np import matplotlib.pyplot as plt x = np.array([i for i in range(10)]) y1 = x ** 3 y2 = 3 * x ** 2 # 交点の座標を取得 idx = np.argwhere(np.sign(y1 - y2) == 0) # 交点をグラフにプロット plt.plot(x[idx], y1[idx], 'ms', ms=5, label='Intersection', color='green') plt.xlabel("x") plt.ylabel("y") # 交点の座標をグラフに追記 for i in idx.ravel(): plt.text(x[i], y1[i], '({x}, {y})'.format(x=x[i], y=y1[i]), fontsize=10) plt.plot(x, y1, color='red', label='Insertion-sort') plt.plot(x, y2, color='blue', label='Merge-sort') plt.legend() plt.show()
実行結果
少し見辛いですが, 交点の座標がグラフ中に表示されていることがわかるかと思います。
表示する位置はx, yを変えてあげると見やすくなると思います。交点の座標取得では, y1とy2のxが同じである点の座標を比較して, 差が0であった時のx座標をidxに格納しています。
xのステップ数を1刻みではなく0.1刻みや0.01刻み等もっと細かくすれば, 小数点や$√$での交点の値でも取れるのではと思います。
何かご指摘やご意見等ございましたら是非お知らせください。

- 投稿日:2019-05-02T12:53:21+09:00
[PowerShell / Python]フォーマット文字列ざっくりまとめ
C/Perlとかの
printf()と比べると、PowerShellとPythonのフォーマット文字列が独特すぎてなかなかなじまないので、ざっくりと主要なものをまとめてみたpritnf()
標準ライブラリでおなじみのフォーマット文字列。
Man page of PRINTF文字列
printf "\"%8s\"\n", "hello"; # 右寄せ8桁 printf "\"%-8s\"\n", "hello"; # 左寄せ8桁出力
" hello" "hello "数値
# 数値 $val = -1; printf "%d\n", $val; # val printf "%u\n", $val; # unsigned val printf "%X\n", $val; # HEX printf "%x\n", $val; # hex printf "%4d\n", $val; # 右寄せ4桁 printf "%04d\n", $val; # 0埋め4桁 printf "%f\n", $val; # float printf "%8.3f\n", $val; # 全8桁・小数以下3桁出力
-1 18446744073709551615 FFFFFFFFFFFFFFFF ffffffffffffffff -1 -001 -1.000000 -1.000PowerShell
基本
指定の位置に
{n}(nは引数の順序)を記述する。番号は必須$name = "くれりん" Write-Output("こんにちは、{0}さん。" -f $name) $hello = "こんにちわ" Write-Output("{1}、{0}さん。" -f $name, $hello)出力
こんにちは、くれりんさん。 こんにちわ、くれりんさん。文字列
$str1 = "hello" $str2 = "world" Write-Output("'{0,8}'" -f $str1) # 右寄せ Write-Output("'{0,-8}'" -f $str1) # 左寄せ出力
' hello' 'hello '数値
$val = 254 Write-Output("{0}" -f $val) Write-Output("{0,8}" -f $val) # 8桁右寄せ Write-Output("{0:00000000}" -f $val) # 8桁0埋め Write-Output("{0:d8}" -f $val) # 8桁0埋め出力
254 254 00000254 00000254小数
$val = 21.2345678 Write-Output("{0:.0000}" -f $val) # 小数4桁 Write-Output("{0:f4}" -f $val) # 小数4桁 Write-Output("{0:0000.000}" -f $val) # 整数4桁小数3桁出力
21.2346 21.2346 0021.235※こんな感じ(↓)に、書式指定子を使った整数部と小数部の両方の桁指定はできなさそう?
Write-Output("{0:f4.3}" -f $val)基数変換
Write-Output("{0:x4}" -f $val) # hex Write-Output("{0:X4}" -f $val) # HEX出力
00fe 00FE桁区切り
カンマで3桁区切り以外にも、ハイフン付き電話番号のような特定の書式を設定するにはとても簡単にできる。
$val = 16777216 Write-Output("{0:#,#}" -f $val) # 3桁,区切り $num = 09012345678 Write-Output("{0:000-0000-0000}" -f $num) Write-Output("{0:###-####-####}" -f $num)出力 (
0でなく#を使うと0埋めされない)16,777,216 090-1234-5678 90-1234-5678
- 参考
Python
str.format()を使用する。
とくに指定がない限りPython2/Python3共通。基本
指定の位置に
{n}(nは引数の順序)を記述する。PowerShellと異なり番号は省略すると引数の順序とみなされる。name = "くれりん" print("こんにちわ、{}さん。".format(name)) hello = "こんにちわ" print("{}、{}さん。".format(hello, name)) print("{1}、{0}さん。".format(name, hello))出力
こんにちわ、くれりんさん。 こんにちわ、くれりんさん。 こんにちわ、くれりんさん。文字列
str = "hello" print("'{:<8}'".format(str)) # 左寄せ print("'{:^8}'".format(str)) # センタリング print("'{:>8}'".format(str)) # 右寄せ出力
'hello ' ' hello ' ' hello'数値
dは省略可(:>8でも大丈夫)print("{:d}".format(val)) print("{:>8d}".format(val)) # 右寄せ8桁 print("{:08d}".format(val)) # 0埋め8桁254 254 00000254小数
fは省略すると表示がおかしいval = 21.2345678 print("{:.4f}".format(val)) # 小数4桁 print("{:8.3f}".format(val)) # 全8桁・小数3桁出力
21.2346 21.235また、内部で型のチェックは行われており、小数の値に対して
dで書式指定しようとするとエラーとなるprint("{:d}".format(val)) # 整数結果
Traceback (most recent call last): File "./print2.py", line 27, in <module> print("{:d}".format(val)) # 整数 ValueError: Unknown format code 'd' for object of type 'float'キャストすれば動く
print("{:d}".format(int(val))) # 整数基数変換
val = 254 print("{:04x}".format(val)) # hex print("{:04X}".format(val)) # HEX出力
00fe 00FE桁区切り
val = 16777216 print("{:,d}".format(val))出力
16,777,216%書式
実は
printf()同等の%を使った書式も使える。(ただしformatの方が間違いにくいということでformatの使用が推奨されている)val = 21.2345678 print("%08.3f" % val) print("%08d" % val) # こっちはcastなしで大丈夫 print("%8s" % str)出力
0021.235 00000021 hellof文字列
Python3.6以降では、
formatに変わるf文字列という機能が導入されている。
それ以前のバージョンでは使用できないので注意。
基本的にformatで書かれたコードは書き直せる。…と思う。
formatでは文字列中は{}と記述し、変数は引数で指定していたが、f文字列では{}内に変数名を記述するようになる。name = "くれりん" print(f"こんにちわ、{name}さん。") # 文字列 str = "hello" print(f"'{str:<8}'") # 左寄せ print(f"'{str:^8}'") # センタリング print(f"'{str:>8}'") # 右寄せ # 数値 val = 254 print(f"{val:d}") print(f"{val:04x}") # hex print(f"{val:04X}") # HEX print(f"{val:>8}") # 右寄せ8桁 print(f"{val:08}") # 0埋め8桁 # 小数 val = 21.2345678 print(f"{val:.4f}") # 小数4桁 print(f"{val:8.3f}") # 全8桁・小数3桁 # 式 print(f"{1+5*5:d}")出力
こんにちわ、くれりんさん。 'hello ' ' hello ' ' hello' 254 00fe 00FE 254 00000254 21.2346 21.235 0026
- 投稿日:2019-05-02T12:22:09+09:00
[python] クラス図を自動生成する
モチベーション
プルリクもらったときに,ざっと構造を理解しつつ,循環参照していないかをチェックするため,クラス図を自動作成したい。
方法
Pyreverseを使うと以下のような図が出力できる(上クラス図,下パッケージ図)。
本記事の検証環境
- Windows10
- python3.7.3
- git-bash
環境構築手順
pythonとpipが使えることは前提とする。Pylintをインストールする。Pyreverseが一緒にインストールされる。pip install pylint
- 出力形式(dot, svg, png等)にかかわらず,
Graphvizが必要なので,ここからインストーラを落としてインストールする。Graphvizのbinフォルダ(筆者環境だと「C:\Program Files (x86)\Graphviz2.38\bin」)のPATHを通す。出力可能な形式を
dot -Txxxで確認する。ここでエラーが起きると,Graphvizのインストールができてないか,パスが通っていない。$ dot -Txxx Format: "xxx" not recognized. Use one of: bmp canon cmap cmapx cmapx_np dot emf emfplus eps fig gd gd2 gif gv imap imap_np ismap jpe jpeg jpg metafile pdf pic plain plain-ext png pov ps ps2 svg svgz tif tiff tk vml vmlz vrml wbmp xdot xdot1.2 xdot1.4インストールできたかテストする。
pyreverse -o png -p Pyreverse pylint/pyreverse/以下の2つのファイル(冒頭の図)がカレントディレクトリの下にできていれば,インストール完了。
- classes_Pyreverse.png
- packages_Pyreverse.png
図の出力手順
pyreverse [option] <packages>
- <packages>には変換したいパッケージ名を入れる。自作したpyファイルのファイル名・フォルダ名でもよい。フォルダを指定した場合は,そのサブフォルダ配下のすべてのpyファイルが解析される。ただし,
__init__.pyがないとエラーが起きる。- pyreverseを実行することで,package diagramとclass diagramの2つが作成される。
以下,使いそうなオプションの説明。
-oオプションは変換する画像の拡張子を制御する(指定がないとdot形式になる)。出力可能な拡張子はdot -Txxxで確認できる。pyreverse -o png pylint/pyreverse/ # 以下の二つのファイルが出力される。 # classes.png # packages.png
-pオプションは変換後のファイル名の末尾を制御する。pyreverse -p TEST pylint/pyreverse/ # 以下の二つのファイルが出力される。 # classes_TEST.dot # packages_TEST.dot
-fオプションで,出力する属性をフィルターできる。デフォルトだと,PUB_ONLY(non-publicな属性をすべて非表示)になっている。ALLにすると,すべて表示できる。ほかにもSPECIAL(コンストラクター以外の特殊メソッドをフィルターする),OTHER(protectedとprivateの属性をフィルターする)モードがある。pyreverse -o png -f ALL pylint/pyreverse/
-kオプションを指定すると,クラス図でクラス名のみを出力する(メソッドや属性を出力しない。クラスの依存関係だけ)。pyreverse -o png -k pylint/pyreverse/
-m [yn]オプションを使用すると,クラス図内のクラス名にモジュール名が追加される。pyreverse -o png -k -my pylint/pyreverse/
その他のオプションは
-hでヘルプを参照。クラスの親や子の深さを指定したりもできるらしい。最後に
参考にしたサイト




- 投稿日:2019-05-02T11:24:21+09:00
プログラム性能チューニングの入門ガイド
プログラム側の性能チューニングの中でも汎用的であり、どの言語・分野でも費用対効果が高そうな原則およびサンプルを紹介しています。
結論
以下の3つの原則を意識して、プログラムの性能チューニングおよび開発を行いましょう。
- 原則1. 計算量を小さくする
- 多重ループを改善する
- アルゴリズムを改善する
- 原則2. 高コスト処理をバッチ化する
- SQL, REST API, 外部コマンドをまとめる
- システムコール (ex. read, write)をまとめる
- 原則3. 高コストなものを再利用する
- TCP、HTTP、DB等のコネクションを再利用する
- 外部サーバからの問い合わせ結果を再利用する
- 確保したメモリ、オブジェクト、スレッド等を再利用する
なおシステムのアーキテクチャ、ハードウェア構成などのチューニング・最適化はこの記事の対象外です。(原則2,3の考え方は応用できますが、そこまでは踏み込みません)
背景
色々なシステム開発に携わっていると、設計や開発の中で性能を意識する人というのは意外と少ないように感じます。開発対象の目的や性能要件を考慮すれば明らかに後々の性能検証等で大きな問題となりそうな箇所であっても、何事もなく開発が進められたりします。
もちろん「中途半端な最適化は悪だから、後で必要な時にチューニングするべき」という格言は正しいです。しかしこの格言は設計やコーディングをしている時点である程度の性能ボトルネックについての仮説や予測を立てることも暗黙の内に期待されているのではないでしょうか?だからこそ「チューニングが必要そうなところはメソッド化やモジュール化して、後でチューニングしやすいようにしよう」という文言も添えられていることが多いのと考えています。
この事実を理解せずに性能ボトルネックについての仮説や予測を立てずにコーディングやユニットテスト等の作業を進めてしまい、いざシステムテストを実施すると致命的な性能ボトルネックが発生して右往左往してしまうのを目の当たりすることは珍しくありません。「後で必要な時に性能チューニングすれば良い」と言うのは結構ですが、そのために必要な指針(仮説や予測の立て方)、知識、スキル等を持たなければ机上の空論でしかありません。問題対応をただ単純に先延ばししているのと何ら変わりはありません。
NOTE:
Intel DPDK(ネットワークのパケットを超高速に処理するための開発キット)みたいものを開発するのであれば、当然より高度な最適化のための知識やスキルを総動員する必要があります (ex. 並列化、CPU等のAffinity、キャッシュヒット、キャッシュライン、CPUアーキテクチャ、コンパイラのオプション、ハードウェアオフロード等)。しかしこのような特殊な分野でない限りは、最優先すべき最適化は他にあります。紹介する性能チューニングの特徴
本記事では性能チューニングの中でも以下の特徴を持った原則、および代表的なテクニックのサンプルを紹介します。
- プログラム側の修正で実現できる
- 特定のプログラミング言語やライブラリに依存しない
プログラミング言語、アーキテクチャ、ハードウェア等に特化したより専門的で高度な最適化も数多く存在しますが、まずはより汎用的な原則を押さえておくべきです。
NOTE:
コンパイラの最適化オプション、Linuxカーネル等のパラメータチューニング等に物凄く精通しているのに、本記事で扱っているような基本的な性能チューニングを一切知らない/適用できない人をたまに見かけます。
そういう人は自分自身の得意分野の性能チューニングで問題の解決を試みるため、性能ボトルネック次第では極めて効果の薄い性能チューニングを施しがちになります。周りがあまり詳しくない技術者の場合「これだけやっても駄目だから仕方ない」と誤解を蔓延させるオマケ付きです。性能チューニングの原則
ここでは私自身が最も大事と考える3つの原則を紹介します。重要度は状況に応じて変わりますが、基本的に上から順番に原則を適用することをお勧めします。
- 原則1. 計算量を小さくする
- 原則2. 高コスト処理をバッチ化する
- 原則3. 高コストなものを再利用する
NOTE: 他にも加えたいところですが、あまり多すぎると実践しづらいので3つに留めています。
原則1. 計算量を小さくする
性能チューニングで最も大事なものの一つが、プログラム処理の計算量を小さくすることです。
計算量、O記法などを知らない場合は、以下の記事などを参考にしてください。[初心者向け] プログラムの計算量を求める方法
計算量オーダーの求め方を総整理! 〜 どこから log が出て来るか 〜情報系やコンピュータサイエンスを専攻している人には常識レベルの話なのですが、たとえ知っていても実践できている人は残念ながら意外と少ないです。プログラムを書いてる時でも、DB向けのSQLを書いてる時などでも計算量は常に頭の片隅で意識しておく習慣をつけておきましょう。
NOTE: ちなみにDBのSQLの場合、その時点のDBのテーブルのレコード数、統計情報などによってオプティマイザが内部実行計画を変更する可能性があるためややこしいです。このため当初は計算量がO(N)で動作していたSQLが、例えばDB統計情報の精度不足によってO(N^2)になることもあります。
大まかな基準としては計算量がO(N)以上なら「性能の阻害要因になるかも」と警戒し、O(N^2)以上の場合は「性能の阻害要因に絶対になる」くらいの意識で確認することがお勧めです。
- ループ処理
- 再帰処理
- データ構造と操作 (追加、更新、削除、参照など)
- その他 各種アルゴリズム
- SQL (ex. サブクエリ、Join/Scanなどの実行計画)
判断基準の目安例
- 計算量がO(N^2)以上、処理要素数N=数千~数万以上
- 計算量がO(N)以上、処理要素N=数十~数百以上、各要素の処理が高コスト処理に相当
- 高コスト処理については原則2を参照
補足: 計算量の係数
例えば計算回数を
3*nの式で求められる場合、計算量はO(N)となります。係数である3は無視していいわけですね。しかしプログラムの性能を考える場合はこの係数は意識することも大事です。例えば
10*nの計算回数で処理時間が10秒だった場合、係数の部分を1にできれば処理時間を1秒に改善できます。もちろん開発対象の要件等にはよりますが、この係数部分の改善が極めて重要となるケースは十分にあることは想像できると思います。後述する原則2, 原則3も、この係数部分を小さくすることに利用できます。
原則2. 高コスト処理をバッチ化する
プログラムが行う処理、要求される性能(ex. 処理時間)を考慮した場合、要求される性能を満たすために大きな阻害になる高コスト処理が存在することがあります。このような高コスト処理が何度も実行されるのは致命傷となる可能性が高いため、まとめて実行(バッチ化)することを検討しましょう。
高コスト処理と判断するかどうかはケースバイケースになります。しかし以下のような処理は「要求される性能を満たすための阻害要因となる高コスト処理」になる可能性が高いため、高コスト処理の候補として意識することをお勧めします。
- 外部コマンド実行
- プロセス生成コストが高い
- サーバへのリクエスト(REST API, SQL, RPC, etc...)
- サーバ間通信のコストが高い
- リクエストあたりの処理時間が長い、あるいは長い可能性がある
- システムコール
- I/O処理、ユーザ空間とカーネル空間の切り替えコストが高い
- 前述した2つ高コスト処理に比べればインパクトは小さめ
- 未知のライブラリ
- どのような処理をしてるかを理解するまではコストが高い可能性が残る
先ほども述べたように阻害要因になる可能性が高くても、状況によっては問題ない場合もあります。例えばある処理の支配項である「SQLのINSERT (1回あたり1msかかる)」が実行される場合のパターンを3つ考えてみます。
- 3秒以内に行う必要がある処理の中で、SQLのINSERTを高々10回しか行わない
1ms * 10 = 10msのため、性能ボトルネックになる可能性は極めて低いため問題なし- 3秒以内に行う必要がある処理の中で、SQLのINSERTが1万回行われる
1ms * 10000 = 10sのため、致命的な性能ボトルネックになるため問題あり- 60秒以内に行う必要がある処理の中で、SQLのINSERTが1万回行われる
1ms * 10000 = 10sのため、性能ボトルネックになる可能性は極めて低いため問題なし上記の3つのパターンを見ればわかるように、性能要件と処理要素数などに応じて阻害要因になるかどうかは変わります。このためここで重要なのは、阻害要因になる可能性があるもの(高コスト処理の候補)に対して大まかな概算を行い、実際に問題がありそうかどうかをざくっと見極めることです。問題がないと断定できなければ、その部分は要確認ポイントとして当たりを付けます。
高コスト処理を特定することができた場合、あとはその部分をバッチ化する方法を検討することになります。一般的に上で述べたような高コスト処理は何らかの形でまとめて実行する手段が用意されており、まとめて実行した場合に処理時間が大幅に短縮できる場合が多いです。そのような手段がない場合は、まとめて実行する手段を呼び出し先に実装してもらう必要があるかもしれません。
NOTE:
Python, Ruby等のスクリプト言語は、C/C++/Java等のコンパイル型言語と比べてステップ単位の処理が何倍~何十倍も遅いです(JavaScriptについてはV8エンジンの目覚ましい進化などにより、やや事情が異なります)。
このため処理内容と性能要件によっては、ステップ単位の処理そのものが高コスト処理として顕在化する可能性があります。このような場合はできるだけ「C言語等で高速処理されるように実装された標準関数、ライブラリ」を活用してまとめて処理するようにしましょう。例えばPythonであれば巨大な配列の生成や処理については極力Numpy等のライブラリに任せるといった具合です。判断基準の目安例
- 数十~数百以上の外部コマンドを実行している
- 外部コマンドの処理時間が長い場合、さらに注意が必要
- 数百~数千以上のHTTPリクエスト、SQLなどを送信している
- 送信先がインターネット上などの場合、さらに注意が必要
- 数千~数万以上のシステムコールを実行している
- 1秒間に数千~数万リクエストを処理したり、大量データを処理したりする場合などは要注意
- μs, ns単位の処理時間を意識する場合、さらに注意が必要
原則3. 高コストなものを再利用する
例えばプログラムの処理を行う際には、スレッドや各種コネクション(ex. HTTP, SQL)を活用して実装することも多いと思います。これらを頻繁に利用する場合、毎回新しく作成して破棄するのは思いのほか大きなコストになります。このように
高コストかつ使用頻度が高いものについては、再利用できるのであれば再利用するための仕組みを検討しましょうもちろん高コストなものというのは、プログラムの目的や性能要件などによって大きく異なります。これは原則2と同様です。例えばHTTPリクエストを10分に一回しか送信しない場合はHTTPコネクションを再利用するメリットは小さいですが、1秒に数十~数百回送信する場合はHTTPコネクションを再利用するメリットは大きいといった具合です。プログラムの用途や性能要件によっては、毎回メモリを使う度に律儀にmallocで確保してfreeで解放すること自体が大きなコストとなる場合もあり、このような場合にはmallocしたメモリ領域自体を再利用する仕組みを導入するメリットも大きいです。
代表的な再利用対象を以下に示します。
- HTTP, DB等のコネクション
- コネクションプールを活用して再利用する
- 例えばJDBC(JavaのDB API)ではTomcat JDBC Poolを活用する
- スレッド
- スレッドプールを活用して再利用する
- 例えばJavaではExecutorServiceを活用する
- サーバの問い合わせ結果
- HTTPレスポンスをキャッシュする
- DNSレスポンスを一定期間キャッシュする
- ライブラリ等にキャッシュ機構が備わっている場合、これを活用する
判断基準の目安例
- 1秒間に数十~数百以上のスレッドの生成破棄を行っている
- コネクションプールやセッションを意識せずにHTTP、SQL等を大量に発行している
- 使用している言語やライブラリによっては生成破棄が繰り返されてる可能性がある
原則を適用する流れ
最適化の原則を当てはめるのは以下の作業を行うときです。
- 実装を行う時
- 既存の実装に対してチューニングを行う時
コーディングを行う時に以下のチェックを行います。該当する原則がある場合は、後々最適化を施す必要がある箇所となり得ます。
- 各原則に該当するかどうか当たりを付ける
- 当たりを付けた箇所には以下の対応を行う
- TODOコメント、ログ埋め込み
- プログラムを動作させて性能ログを取得する
- 性能ログをもとに処理時間を確認し、確認結果から性能チューニングが実際に必要か判断する
ちなみに当たりを付ける範囲が細かいほど手間がかかるため、「これとこれが怪しい」くらいの範囲をまとめてしまっても構いません。実際にその範囲が性能の阻害要因になったタイミングで範囲を細分化して問題箇所を特定するのも一つの手です。
該当箇所には以下のような対応をしましょう。各該当箇所を何も考えずに最適化しても効果が薄く部分最適化にしかならない可能性があるため、後々の最適化を行うための準備だけに留めます。
- 処理時間を測定できるように性能関連ログを埋め込む
- TODOコメントで重要な最適化候補であることを明記する
チューニングのサンプル
ここでは各原則を実現するためのサンプルをいくつか紹介します。
ソースコードは基本的にPython3.6を前提に記述しています。NOTE: 測定結果の比較等はその都度環境(ex. OS, Host/VM/WSL)が異なるため、参考情報程度に留めてください。
原則1. 計算量を小さくする
多重ループにHashMap/Set等を活用する
あるコレクションから別のコレクションを検索するような処理では多重ループを使うことが多いです。しかし多重ループは計算量がO(N^2)、O(N^3)と大きくなるため、処理要素数が多くなると一気に性能ボトルネックとして顕在化します。
このような時には一方のコレクションからHashMapやSetを作成し、これを検索に活用することによって例えば計算量をO(N^2)からO(N)等に減らすことができます。コレクションの要素数分だけ新しいHashMap/Setを作成するコストが勿体ないと思うかもしれませんが、以下のテーブルの処理要素数を見ればそのコストは極めて小さいものだと分かります。
要素数 O(N)×2 O(N^2) 10 20 100 100 200 10,000 10,000 20,000 100,000,000 まず二重ループ処理になっている例を示します。(実行時間の測定等の処理は割愛)
bad_performance_no1.pyall_files = list(range(1, 100000)) target_files = list(range(50000, 60000)) matched_files = [] # 計算量がO(N^2) -> BAD for f in all_files: if f in target_files: matched_files.append(f) print(len(matched_files)ここで注意してもらいたいのがfor文の中にある
if f in target_files:の箇所です。この部分はループではないため処理が1回で終わっているように見えますが「リストのtarget_filesに要素sが含まれているか」を確認するために、合致する要素を見つけるまで平均でN/2の要素チェックの処理が行われることになります。Javaにおけるコレクション操作メソッドのcontains()等も同様です。このためプログラム文法上は多重ループになっていなくても、実際の処理では多重ループ相当の処理になっている場合があります。次にListからSetを作成して二重ループを改善した例を示します。(実行時間の測定等の処理は割愛)
good_performance_no1.pyNUM = 1000000 nums = list(range(1, NUM)) # TUNING: set関数によりListからSetを作成 # NOTE: //で割り算しているのは整数を保持するため expected_nums = set(range(1, NUM//2)) matched_nums = [] # 計算量がO(N)に改善 -> GOOD start = time.time() for f in nums: if f in expected_nums: matched_nums.append(f) print(len(matched_nums)ループ処理の部分の比較結果を以下に示します。
計算量 実行時間 O(N^2) 8,228 ms O(N) 4 ms 処理要素数N=10万件の場合、計算量をO(N)に改善することで約2000倍高速化できました。
このように処理対象のレコード数が数万以上の場合は、このような簡単なループ処理でも大きな改善効果があります。原則2. 高コスト処理をバッチ化する
外部コマンド大量実行をまとめる
プログラムの中で外部コマンドを実行する場合、その実行する回数が多いほどパフォーマンスが低下します。これは外部コマンド実行がプロセス生成などを伴うコストの高い処理だからです。
ここでは「/etc配下の全ファイルの総バイトサイズを表示する」ことを目的にしたプログラムを例として取り上げます。wcコマンドを
--bytesオプションを指定することにより指定したファイルのバイトサイズを出力することができます。NOTE:
ちなみにPythonを含む大半の汎用プログラミング言語では、ファイルのバイト数を取得するための標準関数等が用意されています。このためwcコマンドなんて使う必要はありません。このためこの例では「どうしても外部コマンドであるwcコマンドが必要」という前提で読み進めてください。bad_performance_no_batch.pyimport pathlib from subprocess import check_output cwp = pathlib.Path("/etc") files = [f for f in cwp.glob("**/*") if f.is_file()] total_byte = 0 for f in files: # 各ファイルに対してwcコマンドを実行 -> 極めて非効率 result = check_output(["wc", "--byte", str(f)]) size, file_path = result.split() total_byte += int(size) print("file num:", len(files)) print("total byte:", total_byte)結果は本節の最後に掲載していますが、ファイル毎にwcコマンドを実行しているため、対象ファイル数が数百~数千以上になると処理に数秒~数十秒以上かかるようになります。このため、wcコマンドの実行回数をできるだけ減らす工夫が必要となります。幸いwcコマンドは一回のコマンド実行で複数のファイルを指定することができます。このためwcコマンド実行回数をファイル数分から1回にバッチ化できます。
バッチ処理化した例を以下に示します。(実行時間の測定等の処理は割愛)
NOTE: 例にあるwcコマンド結果のパース処理はかなり雑かつ手抜きです。真似しないでください。
good_performance_with_batch.pyimport pathlib from subprocess import check_output cwp = pathlib.Path("/etc") files = [f for f in cwp.glob("**/*") if f.is_file()] # wcコマンドに全ファイルを引数として渡してバッチ処理化 args = [str(f) for f in files] # NOTE: Pythonでは*でargsのリストを引数として展開できる result = check_output(["wc", "--byte", *args]) total_byte = int(str(result).split(r"\n")[-2].split()[0]) print("file num:", len(files)) print("total byte:", total_byte)
コマンド処理のバッチ化 実行時間 なし 12,600 ms あり 338 ms 同じwcコマンドを
--bytesオプション付きで使用しているにも関わらず、バッチ処理化することにより処理時間を約1/40に短縮することができました。このようなバッチ処理を何らかの形で提供しているUnix/Linuxコマンド、各種ライブラリ(ex. SQL, HTTP, I/O)はそこそこ存在します。性能面で問題がある場合は積極的に活用しましょう。
ちなみに外部コマンドのバッチ処理化をより突き詰めたい人は、以下の記事あたりが参考になります。タイトルには「シェルスクリプト」とありますが、基本的に外部コマンドを如何に効率良く活用するかに関する記事です。
シェルスクリプトを何万倍も遅くしないためには —— ループせずフィルタしよう
続: シェルスクリプトを何万倍も遅くしないためには —— やはりパイプは速いし解りやすいI/O処理にバッファを使用する (=システムコール回数を減らす)
性能要求が高い状況化では、ファイルの読み書き、ネットワークの送受信などのI/O処理周りのシステムコールは大きなボトルネックになりがちです。このためシステムコールを減らすためにI/O処理のバッファリングが重要となります。
NOTE: 重要なのは「システムコール回数を減らすために何ができるか?」であり、その有効な手段としてI/Oバッファリングを活用しているということです。
例えばファイルの読み書きの場合であれば、それぞれの言語によって適切なバッファリングのアプローチを取ります。
- Javaの場合:BufferedReader, BufferedWriter等を使用する。
- C言語の場合:fwrite, fread関数等を使用する。
- Pythonの場合:open時にバッファリングがデフォルトで有効。
Pythonの例を以下に示します。なおPythonの場合はデフォルトでI/Oバッファが有効となっているため、あえて無効にすることでその効果を確認してみます。(実行時間の測定等の処理は割愛)
# buffering=0を指定した場合はI/Oバッファが無効となる f = open("file.txt", "wb", buffering=0) s = b"single line" for i in range(500000): f.write(s) f.close()以下の比較結果でも、I/Oバッファを有効にすると約10倍のwrite処理の性能改善があったことが分かります。
バッファ有無 実行時間 なし 2,223 ms あり 245 ms for, whileループを使わない (スクリプト型言語)
Python, Ruby, Perl等のスクリプト型言語はその動作の仕組み上、C言語やJava等のようにネイティブコードとして実行されるプログラミング言語と比較すると処理速度が非常に遅いです。特に単純な演算、ループ処理などは数十倍~数百倍くらい遅くなるケースも珍しくありません。
スクリプト言語であっても処理性能が重要になってくるような場面では、ループ処理に相当する部分を以下の手法で委譲してしまいましょう。
- 組み込み関数、言語機能を使用する
- Pythonのリスト内包表現
- map, filter, apply等の関数 (C/C++言語で実装されたものが望ましい)
- C言語等で実装されたライブラリ、モジュールを使用する
NOTE: 少し分かりづらいかもしれませんが、「スクリプト型言語のループ処理を、C言語実装にバッチ処理させている」ということから原則2に関連する手法の一つです。こういう発想をできるようにするのも大切なので日頃から意識したいものです。
例としてPythonで数値リストの総和の処理をループ処理で行った場合と、sum関数で行った場合を比較してみます。(実行時間の測定等の処理は割愛)
nums = range(50000000) # ループ処理の場合 total = 0 for n in nums: total += n # sum関数の場合 total = sum(nums)比較結果を以下に示しています。約5倍くらい高速になっています。
計算方法 実行時間 ループ処理 3,339 ms sum関数 612 ms sum関数はC言語で実装されているため高速に処理しています。join関数やmap関数などもC言語で実装されているため、うまく活用することでPython側のループ処理を回避して高速化することができます。
原則3. 高コストのものを再利用する
適切な文字列結合を選択する
プログラミング言語によっては、複数の文字列を結合して一つの文字列を作る文字列結合処理は非常にコストがかかります。
Python, Javaの場合は文字列結合のたびに新しい文字列オブジェクトが生成されるため非常に無駄が多いです。このためJavaであればStringBuilder、Pythonの場合はjoin()を活用したテクニック等を使うようにしましょう。詳細については以下の記事が参考になります。
【Java】文字列結合の速度比較
Pythonの処理速度を上げる方法 その2: 大量の文字列連結には、join()を使うちなみにJava7になってから
s = "hello" + "s" + "!!"のような1行の文字列結合に限り自動的にStringBuilderを使うように最適化してくれるようになっていますが、ループ外の変数に対する文字列結合処理にはこの最適化は適用されませんので注意しましょう。同じコネクションを再利用する
HTTP等のリクエストを送信する際にHTTPライブラリを使うと、ライブラリによっては1リクエスト毎にコネクションを生成&破棄します。例えばPythonのrequetsライブラリのrequests.get()はこのパターンに該当します。
1秒に数十~数百リクエストを送信する場合は、必ずHTTP1.1以降のPersistent Connectionで同じコネクションを使いまわすようにしましょう。
PythonのrequestsライブラリでSessionを活用した場合とそうでない場合を比較してみます。(実行時間の測定等の処理は割愛)
import requests NUM = 3000 url = 'http://localhost:8080/' # Sessionなしの場合 def without_session(): for i in range(NUM): response = requests.get(URL) if response.status_code != 200: raise Exception("Error") # Sessionありの場合 def with_session(): with requests.Session() as ses: for i in range(NUM): response = ses.get(URL) if response.status_code != 200: raise Exception("Error") without_session() with_session()比較結果を以下に示しています。同一ホスト内(Local)にWebサーバがある場合は約1.2倍、インターネット(Internet)にWebサーバがある場合は約2倍高速化しています。サーバへの接続コストが高い条件下ほど効果が大きくなることが分かりますね。
計算量 実行時間 Internet + Sessionなし 7,000 ms Internet + Sessionあり 3.769 ms Local + Sessionなし 6,606 ms Local + Sessionあり 5.538 ms その他
原則とか直接関連しない性能チューニングのトピックです。
DEBUGログ出力時に処理を発生させない
DEBUGログで固定文字列以外を使っている場合、仮にログレベルでDEBUGログを出力しないように設定していても引数を渡す部分は計算されるため処理コストがかかります。特に1秒に数千、数万回実行されるような箇所にこのようなDEBUGログがあると性能インパクトは非常に大きくなります。
計算を伴うDEBUGログ出力を入れる場合、必ずログレベルチェックのif文を組み合わせて、DEBUGログ出力を行わないログレベルの時には計算処理が発生しないようにしましょう。
l = [1, 2, 3, 4, 5] # BAD: # ログレベルに関わらず、リストの総和計算と文字列結合を実施 logging.debug("Sum=" + sum(l)) # GOOD: if logging.isdebug(): # DEBUGレベルの場合は一切実施されない logging.debug("Sum=" + sum(l)) # GOOD: 固定文字列の場合は計算が発生しないためOK logging.debug("Entered the function A")NOTE: 遅延評価されるプログラミング言語の場合はこの限りではありません。
- 投稿日:2019-05-02T11:02:20+09:00
pipインストール時のアクセス拒否の対応メモ
はじめに
掲題のことが発生したので備忘録
環境
Windows 10
Anaconda問題と対応
Anaconda環境でモジュールをpipでインストールした時に以下エラーが発生。権限の問題?
pip install pyswams Could not install packages due to an EnvironmentError: [WinError 5] アクセスが拒否されました。: 'C:\\Users\\XXX\\AppData\\Local\\Temp\\pip-uninstall-ywopbx45\\users\\XXX\\appdata\\local\\conda\\conda\\envs\\chemsyo\\lib\\site-packages\\scipy\\integrate\\lsoda.cp36-win_amd64.pyd' Consider using the `--user` option or check the permissions.--user をつけることで解決。
pip install pyswarms --user
- 投稿日:2019-05-02T10:27:10+09:00
Kerasを勉強した後にPyTorchを勉強して躓いたこと
概要
DeppLearningのフレームワークで最初にKerasを勉強した後に、Define by RunのPyTorch勉強してみて躓いたポイントをまとめてみる。
この記事の対象読者
Kerasの次にPyTorchを勉強してみようと思っている人。
はじめに
今回いくつか挙げている躓いたポイントはPyTorchに限らないものがある。またKerasといえばバックエンドはTensorFlowのものを指す。バックエンドがTensorFlowでない場合は話が当てはまらないものもあるので注意。
今回挙げたポイントは以下の5つ
1. Channel First
2. GPUへの転送
3. CrossEntropyがSoftmax+CrossEntropyになっている
4. CrossEntropyがone-hot-vectorに対応していない
5. 学習と評価を区別する以下、各ポイントの詳細について説明していく。
Channel First
PyTorchではモデルの入力と出力がChannel Firstの形式になっている。Channel Firstとは画像の次元の並びが(C, H, W)のようにChannelの次元が最初になっていること。
KerasではChannel Lastになっているため、(H, W, C)のようにChannelの次元が最後にくる。実際にモデルに入力するときは、バッチサイズも合わせた4次元で表現する必要があるため、
PyTorch:(N, C, H, W)
Keras:(N, H, W, C)
となる。記号の意味は
N:バッチサイズ
C:チャネル数
H:画像のHeight
W:画像のWidth画像を読み込む際は、OpenCVかPILを使用する場合が多いが、これらのモジュールはChannel Lastで画像を扱う仕様になっている。なので、PyTorchのモデルに入力する前に以下のコードのようにChannel Firstに変換する必要がある。
img = cv2.imread(img_path) img = img.transpose((2, 0, 1)) # H x W x C -> C x H x Wモデルの出力もChannel Firstなのでmatplotlibなどで表示したい場合はChannel Lastに変換してから表示する。
output = output.numpy() # tensor -> ndarray output = output.transpose(1, 2, 0) # C x H x W -> H x W x CGPUへの転送
KerasではGPUを使う場合、GPU側のメモリを意識することがなかったが、PyTorchではGPUを使用する場合、明示的に学習するパラメータや入力データをGPU側のメモリに転送しなければならない。
以下のコードではモデルと入力データをGPUに転送している。device = torch.device("cuda:0") # modelはnn.Moduleを継承したクラス model = model.to(device) # GPUへ転送 ・ ・ ・ for imgs, labels in train_loader: imgs, labels = imgs.to(device), labels.to(device) # GPUへ転送GPU上にあるデータCPUに転送したい場合も以下のようにコードを書く必要がある。
device = torch.device("cpu") model.to(device)CrossEntropyがSoftmax+CrossEntropyになっている
Kerasで多クラスの識別モデルを学習するときは、モデルの最終層でsoftmaxを実行してから
categorical_crossentropyでロスを計算する流れになっている。
一方PyTorchではロス関数であるtorch.nn.CrossEntropyの中でSoftmaxの計算も一緒に行っているので、モデルの最終層でSoftmaxは不要になる。たまにPyTorchのサンプルコードで最終層に
torch.nn.LogSoftmaxを置いて、ロス関数にtorch.nn.NLLLossを指定している場合がある。これは最終層を恒等関数にしてtorch.nn.CrossEntropyを使っているのと同じになる。
つまり、
torch.nn.CrossEntropy=torch.nn.LogSoftmax+torch.nn.NLLLoss
という関係になっている。
torch.nn.LogSoftmaxは名前の通りSoftmaxの計算にLogをかぶせたものになっている。LogSoftmax=log(\frac{e^{xj}}{\sum_{i=1}^{n} e^{xi}})このLogはCrossEntropyの式にあるLogを持ってきているのだが、LogとSoftmaxを先に一緒に計算しておくことで、計算結果を安定させている。
なぜLog+Softmaxが計算的に安定するかは以下のページで解説されている。
Tricks of the Trade: LogSumExpちなみに
torch.nn.NLLLossはCrossEntropyのLogを抜いた他の計算を行っている。CrossEntropyがone-hot-vectorに対応していない
Kerasではロスを計算するときに、labelは
one-hot-vector形式で渡す必要があるがPyTorchでは正解の値をそのまま渡す。例えば、3クラスの分類で正解が2番目のクラスの場合、Kerasでは
[0, 1, 0]というリストをロス関数に渡すが、PyTorchでは2という値を渡す。学習と評価を区別する
PyTorchでは、モデルを動作させるときに学習中なのか評価中なのかを明示的にコードで示す必要がある。なぜこれが必要なのかは理由が2つある。
1.学習中と評価中に挙動が変わるレイヤーがあるから
2.学習中には必要で評価中には不必要な計算があるから1は、DropOutやBatchNormalizationなどのことで、これらのレイヤーは学習中と評価中で動作が変わる。よって、コードでこれから動作するのが学習なのか評価なのかを知らせる必要がある。
具体的には以下のようなコードになる。# modelはnn.Moduleを継承したクラス model.train() # 学習モードに遷移 model.eval() # 評価モードに遷移2の不必要な計算とは計算グラフを作ることである。学習中は計算グラフを作って、誤差逆伝播法で誤差を計算グラフ上に伝播させて重みを更新する必要がある。しかし、学習以外の処理ではこの計算グラフの構築が不要になるので「計算グラフを作りません」とコードで示す必要がある。
具体的にはwith torch.no_grad()を使う。model.eval() # 評価モードに遷移 with torch.no_grad(): # この中では計算グラフは作らない output = model(imgs)まとめ
そもそもDefine and RunとDefine by Runで根本の思想が違うのでこれまでに挙げてきたポイントの他に色々と大きな違いがあるのだが、今回は個人的にコードを書く上でついつい忘れがちなところを挙げてみた。
- 投稿日:2019-05-02T10:23:44+09:00
PythonでSpotify API [とにかく使ってみる編]
音楽ストリーミングサービスもたくさん出てきていますがぼくはSpotifyを使っています。
まぁ聴きたい曲なんでも、とまではいきませんが曲のレパートリーも凄まじいし、アーティスト作成のプレイリストが楽しめることややオススメ楽曲の精度みたいのも気に入っているので。して、そのSpotifyがAPIを出していると聞いて興味が湧きました。
楽曲ごとの解析データも観れるとか、再生方法をいじれるとか、プレイリストをいじる機能もあるとか、これは(とくにどうしようとかいうビジョンがあるわけではないが)使ってみるしかない!で、本記事(色々やってみてシリーズっぽくしたい)は、
「別にこれといってやりたいことあるわけじゃないけどSpotifyのAPIとか聞いたら使ってみたいじゃん?」
という人向けだと思ってください。実際ぼくがそうなので。
登録
Spotify APIを使うにはアプリケーション登録が必要なので、やっておきましょう。
アカウントを持ってない方はここから登録してください。アプリケーション登録をするにはここにログインして、大体案内どおりでわかると思うので適当にまぁやってください。
APIとか全然わからんぼくでもまぁなんとかできたので皆さんはもっと大丈夫だと思います。
Client IDとClient Secretは必要なので控えておいてくださいね。後からでも見れますが。使ってみる!
んじゃ使ってみましょう。
とりあえずリファレンス(Welcome to Spotipy)にそって使っていきましょう。インストールはこれでいけるらしいな。ふむ。
Python開発環境を作成済みの方は以下のコマンドでAPIを使えるようにします。
pip install spotipy
環境によってはyumとか使って、まぁspotipyってのを適当にインストールしてください。どうでもいいけど、Python系のライブラリとかはみんな「py」って付けますね。
すぽちぱいってかわいいですね。発音するのはちょっと恥ずかしい。リファレンスにあった以下のコードを書いてみます。
import spotipy lz_uri = 'spotify:artist:36QJpDe2go2KgaRleHCDTp' spotify = spotipy.Spotify() results = spotify.artist_top_tracks(lz_uri) for track in results['tracks'][:10]: print 'track : ' + track['name'] print 'audio : ' + track['preview_url'] print 'cover art: ' + track['album']['images'][0]['url'] print実行ドン
spotipy.client.SpotifyException: http status: 401, code:-1 - https://api.spotify.com/v1/artists/36QJpDe2go2KgaRleHCDTp/top-tracks?country=US: No token providedエラーじゃねぇか。
調べてみるとどうも、いつだかから全てのAPI呼び出しにトークンが必要な様子。
spotipyのAPIには「Non-Authorized requests」って書いてあるんだけど、古いのかな。アプリケーション登録で使ったClient IDとClient Secretを使って以下のように書き換えます。
import spotipy import sys lz_uri = 'spotify:artist:36QJpDe2go2KgaRleHCDTp' client_id = 'Client IDの値' client_secret = 'Client Secretの値' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager) results = spotify.artist_top_tracks(lz_uri) for track in results['tracks'][:10]: print('track : ' + track['name']) print('audio : ' + track['preview_url']) print('cover art: ' + track['album']['images'][0]['url']) print()今度こそドン
track : Stairway to Heaven - Remaster audio : https://p.scdn.co/mp3-preview/8226164717312bc411f8635580562d67e191a754?cid=575190b52c754debad7825f97cf4cfec cover art: https://i.scdn.co/image/557a6058e3de72bf37ffcd2c12dd5932276df344 track : Immigrant Song - Remaster ...とれたっぽいぞ
表示は長いので割愛してます。
ともかく、APIを使ってデータを取得することができました!
いろいろ取得してみて、また記事書いてみたいと思います!!