- 投稿日:2021-03-06T23:30:22+09:00
複数の画像を敷き詰めてプロットする方法をいつも忘れちゃう(ML向け)
はじめに
画像データをこういう感じにプロットするやり方をいつも忘れてしまう自分用メモです。
前提
データセットはこのようなディレクトリ構成になっていることを想定しています。
├─Dataset
│ ├─classA
│ │ ├─classAの画像たち
│ ├─classB
│ ├─classC
│ ├─classD
│ ├─classF
│ └─...
...ソースコード
show_class_images.pyimport glob import os import matplotlib.pyplot as plt from PIL import Image # データセットの親ディレクトリ DATA_PARENT_DIR = '親ディレクトリを指定' # 子ディレクトリのリスト data_dir_list = glob.glob(DATA_PARENT_DIR + '\*') # ディレクトリ数 class_num = len(data_dir_list) # 1ディレクトリあたりに敷き詰める画像数 SHOW_FILE_NUM = 6 fig = plt.figure(figsize=(12, 12)) # subplot用のカウント cnt = 1 for data_dir in data_dir_list: filepath_list = glob.glob(data_dir + '\*') dirname = os.path.basename(data_dir) # ディレクトリ内のファイル for i in range(SHOW_FILE_NUM): filepath = filepath_list[i] filename = os.path.basename(filepath) img = Image.open(filepath) # 6*6の1マス分を指定(cnt)してプロット ax = fig.add_subplot(class_num, SHOW_FILE_NUM, cnt) plt.imshow(img) # 目盛りを消す ax.axis('off') # ディレクトリ名(クラス名)+ファイル名をタイトルに出す plt.title(os.path.join(dirname, filename)) # 描画用カウントアップ cnt += 1 plt.show() # 保存する fig.savefig('./subplot.png')引用
データセットはこちらからお借りしました。ありがとうございました。
DiceRecognitionDatasetForML

- 投稿日:2021-03-06T23:07:18+09:00
MacでPythonの環境作りからTableauでTabPyを利用するまで
はじめに
最近、プログラミングに触れることも少なくなったのだけど、TableauでTabPyを利用する必要がでたので、Pythonを書く訳ではないもののPythonの環境作りをして、TabPyを利用できる準備をしてみた。
TabPyとは、BIツールであるTableauからPythonの機械学習モデルを呼び出せる仕組み。随分、プログラミング環境も整える機会も減ってしまったので、まずは
brewをインストールして必要なパッケージを揃えてきいく。目次
1.Pythonの環境準備
2.TabPyのインストール
3.おまけ(TableauでのTabPy活用1.Pythonの環境準備
Pythonの環境は以下で実現
# pyenvの準備 $ brew install pyenv $ echo 'eval "$(pyenv init -)"' >> ~/.zshrc $ exec $SHELL -l # インストールできるVersionを確認 $ pyenv install --list # インストールできるVersionを確認 $ pyenv install --list # pythonのインストール $ pyenv install 3.7.9 $ pyenv global 3.7.9 $ eval "$(pyenv init -)" $ python --version Python 3.7.2 # anacondaのインストール $ pyenv install anaconda3-2020.11 $ pyenv global anaconda3-2020.112.TabPyのインストール
TabPyのインストールは、Githubを参考に。
https://github.com/tableau/TabPy
以下に手順はあったので容易にインストールはできる。
https://github.com/tableau/TabPy/blob/master/docs/server-install.md#pipを最新に $ python -m pip install --upgrade pip #TabPyをインストール $ pip install tabpy #TabPyの起動確認 $ tabpy #以下のような起動メッセージがでれば起動完了(portなどは後のTableauで利用する [INFO] (app.py:app:105): Web service listening on port 90043.おまけ(TableauでのTabPy活用
最終的に実施したかったのは、TableauでのTabPyを利用したかったので、上記で起動したTabPyに接続をする。
Tableau DesktopからTabpy Serverに接続
- Tableau Desktopを起動
ヘルプ→設定とパフォーマンス→分析の拡張機能の接続を選択TabPy/External APIを選択して、サーバをlocalhost、ポートが9004であることを確認して、テスト接続を実施OKを押して接続が完了
Pythonの環境作りやTabPyの起動までは意外とさまよった部分はあったのだが、結果として整理してみると意外とさらっと終わる手順であった。

- 投稿日:2021-03-06T22:46:16+09:00
【Python】 2つのListを並行処理する方法
概要
- 2つのListを並行処理する方法
1: for文を使用する方法
2: zip関数を使用する方法
※ 2 の方が可読性が上がるので、2 を使用することを推奨。検証環境
OS:18.04.5 LTS
Python:3.6.9方法
2つのlistをで並行処理
1: for文を使用する方法
基本形
for 変数1, 変数2 in enumerate( list_1 ): print('{0}, {1}').format(変数2, list_2[変数1])実行結果
list_1 = [1,2,3,4,5,6,7,8,9,10]; list_2 = ['1','2','3','4','5','6','7','8','9','10']; # 並行処理 for i, j in enumerate( list_1 ): print('{0}, {1}'.format( j, list_2[i] )); # 結果 1, 1 2, 2 3, 3 4, 4 5, 5 6, 6 7, 7 8, 8 9, 9 10, 102: zip関数を使用する方法
基本形
for 変数1, 変数2 in zip(list_1, list_2): print('{0}, {1}'.format( 変数1, 変数2 ))実行結果
list_1 = [1,2,3,4,5,6,7,8,9,10] list_2 = ['1','2','3','4','5','6','7','8','9','10'] # 並行処理 for i, j in zip(list_1, list_2): print('{0}, {1}'.format( i, j )) # 結果 1, 1 2, 2 3, 3 4, 4 5, 5 6, 6 7, 7 8, 8 9, 9 10, 10
- 投稿日:2021-03-06T20:51:34+09:00
PythonのPytestでTDDするときimportがエラーになる
あらすじ
Pytestを使っていて気が付いたことです。
これは入門者泣かせですね。別なのかよ
F5デバッグや、Debug testでは正常にインポートされますが、Run testすると下記のエラーが出ました。E ModuleNotFoundError: No module named `??????????`Pythonでは、
importするときの Base Directory として、sys.path内にリストされたアドレスを使います。Pylintや
F5デバッグ、Debug testでは、settings.jsonのpython.envFile内に記述した、PYTHONPATH=./が Base Directory です。ところが
Run testでは、Base Directory を決める際に、実行するテストのあるディレクトリから上に向かって検索し、__init__.pyが無い最初のディレクトリを Base Directory として登録するようです。Note: Good Integration Practices
環境
.vscode/extensions.json{ "recommendations": [ "ms-python.python", "visualstudioexptteam.vscodeintellicode", "oderwat.indent-rainbow", "kameshkotwani.google-search" ] }.vscode/launch.json{ "version": "0.2.0", "configurations": [ { "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal", "justMyCode": true } ] }.vscode/settings.json{ "python.testing.pytestEnabled": true, "python.formatting.provider": "black", "python.envFile": "${workspaceFolder}/.env", }Excelsior!
- 投稿日:2021-03-06T20:17:58+09:00
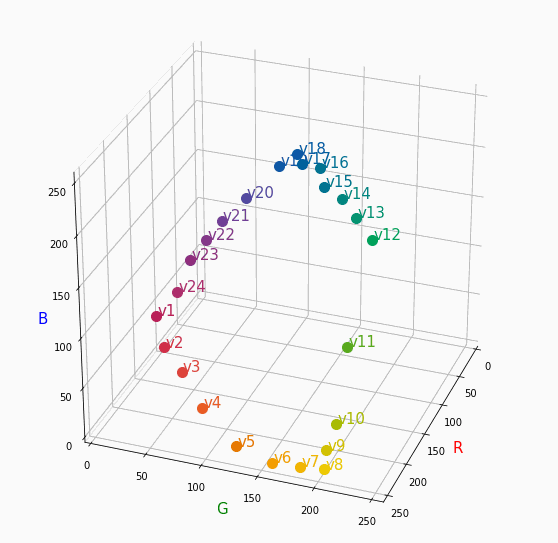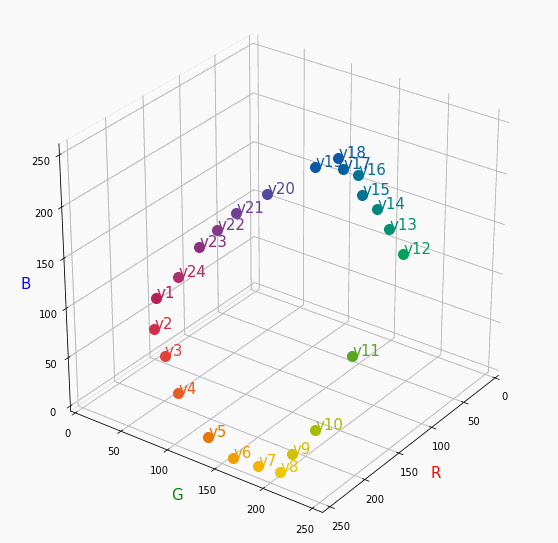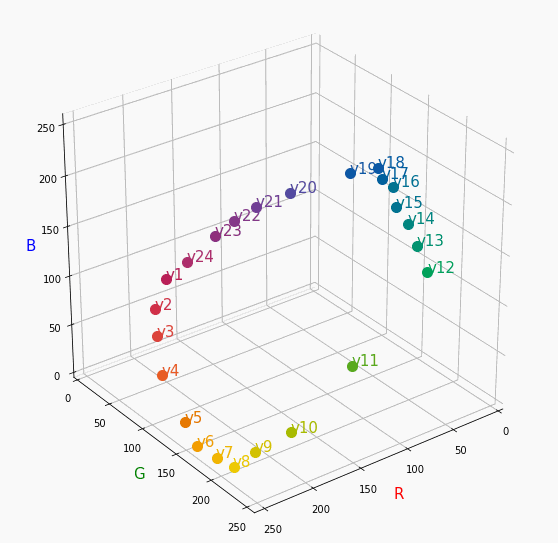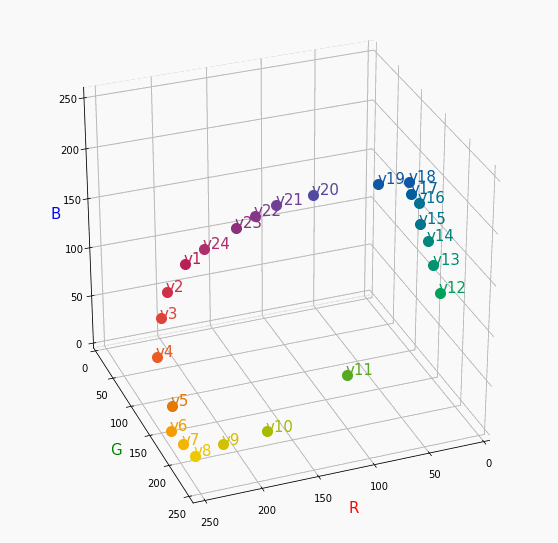
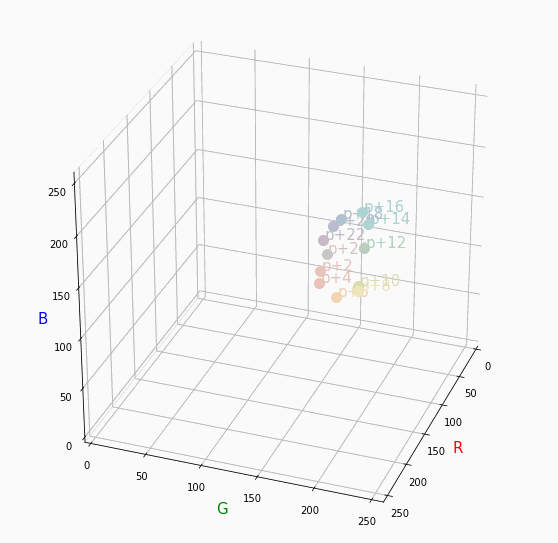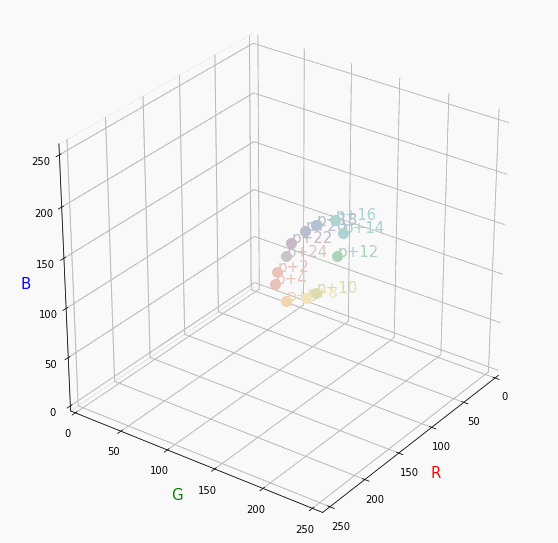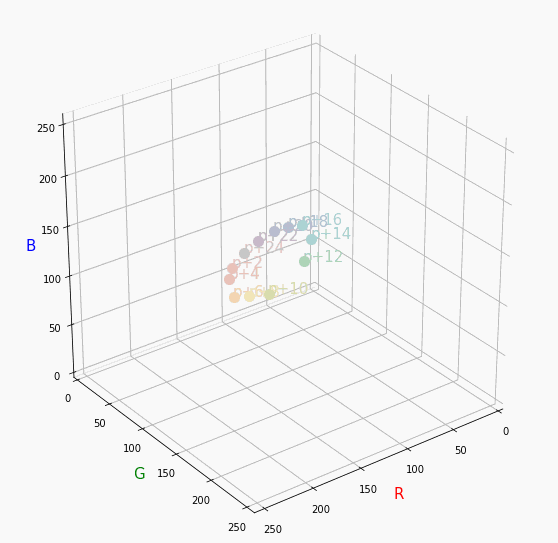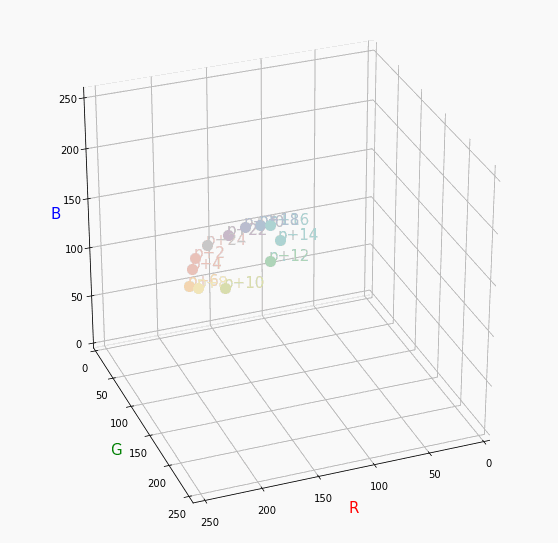
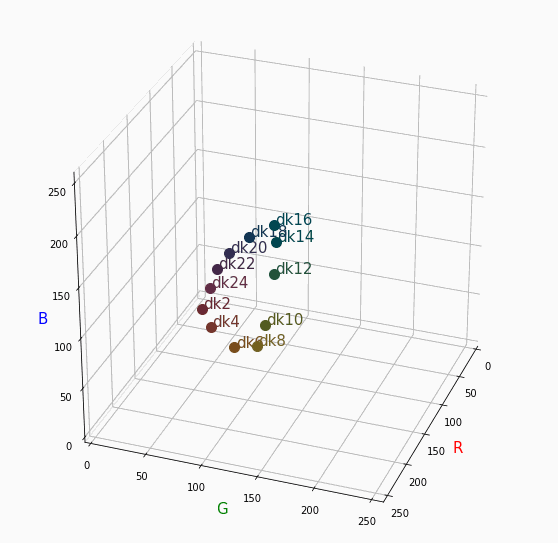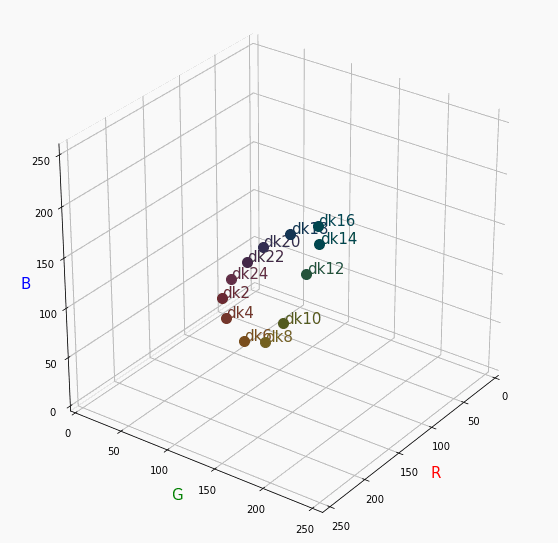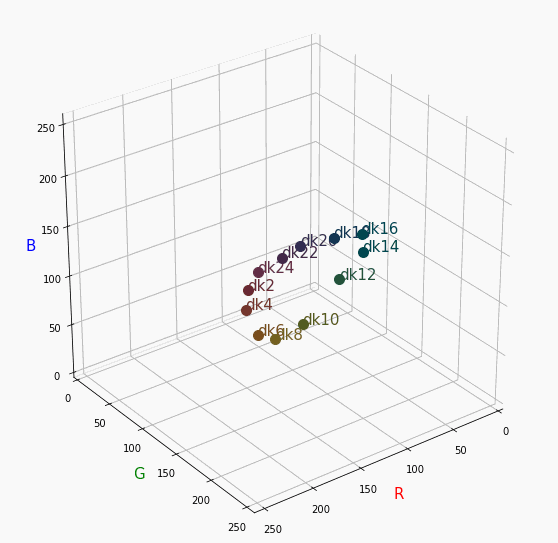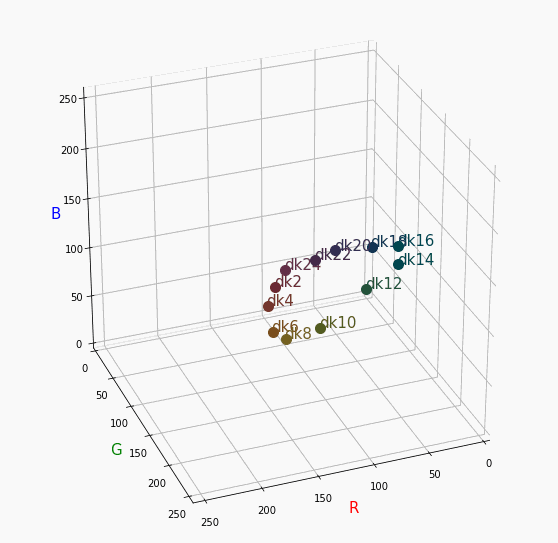
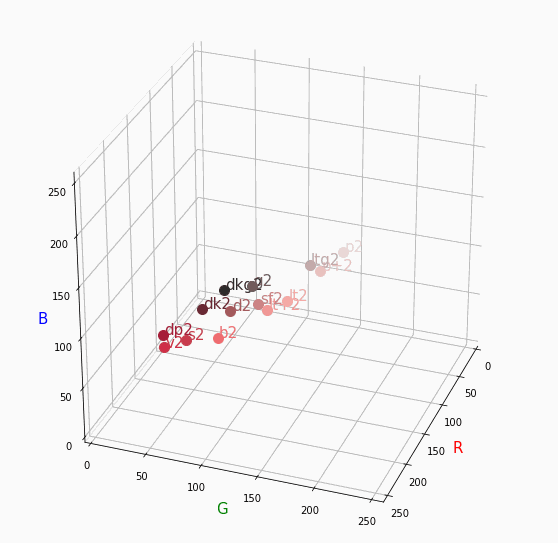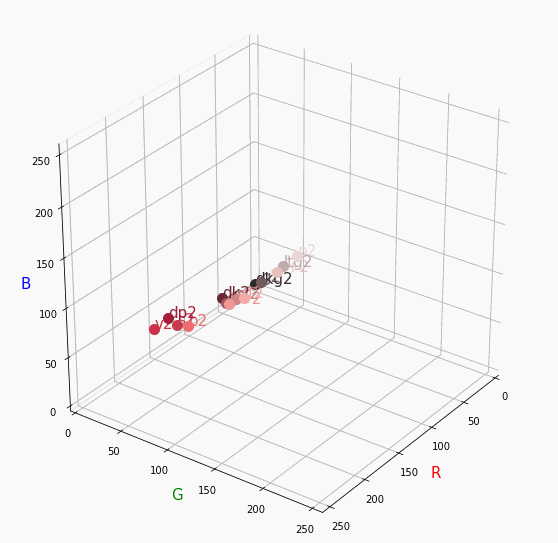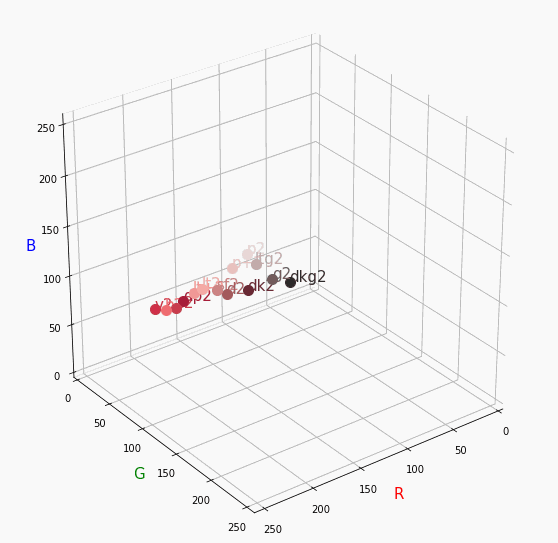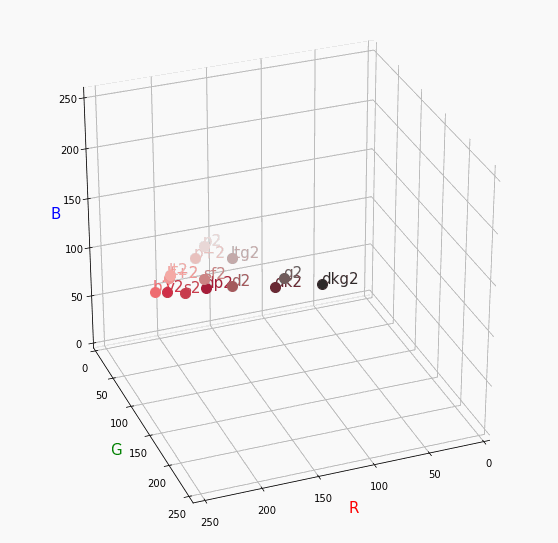
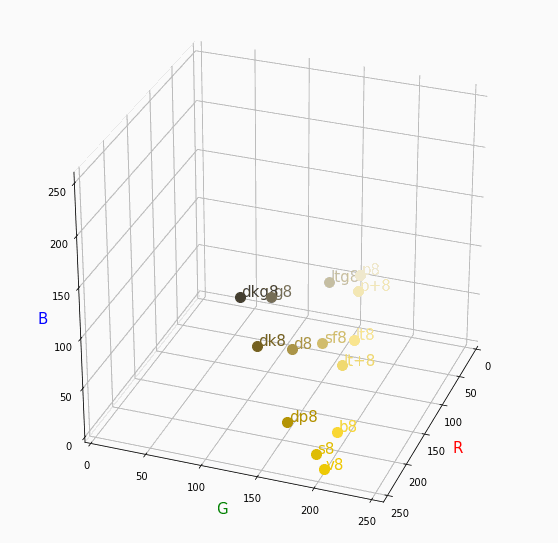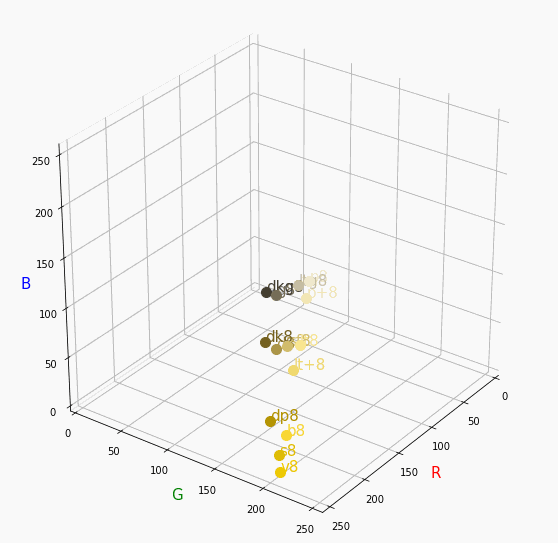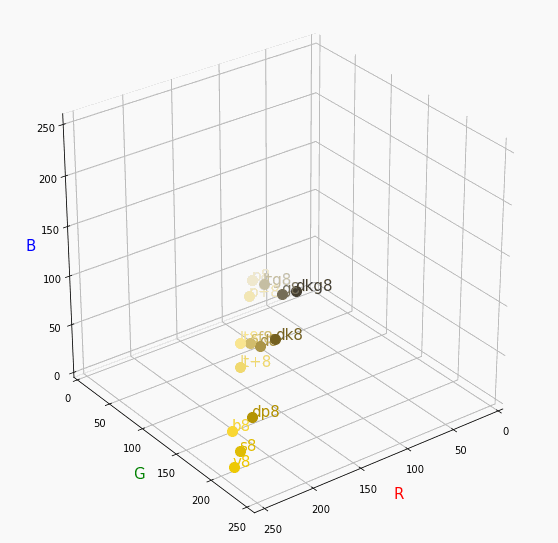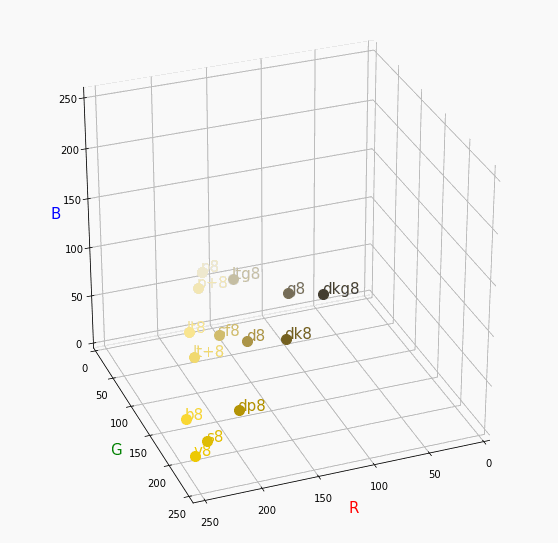
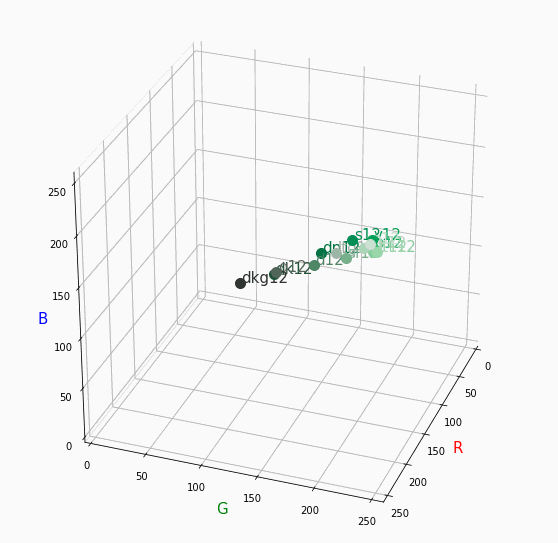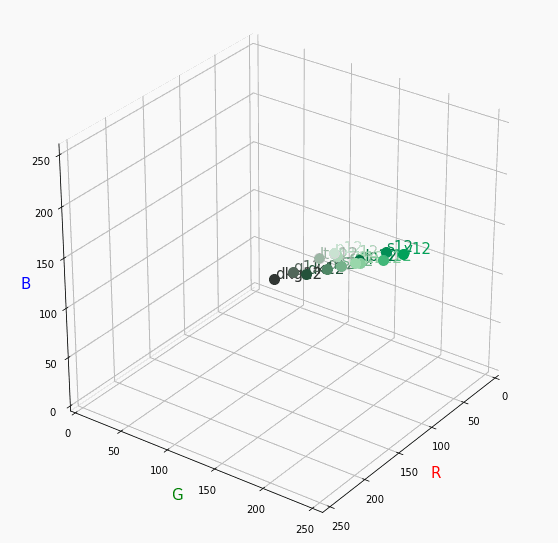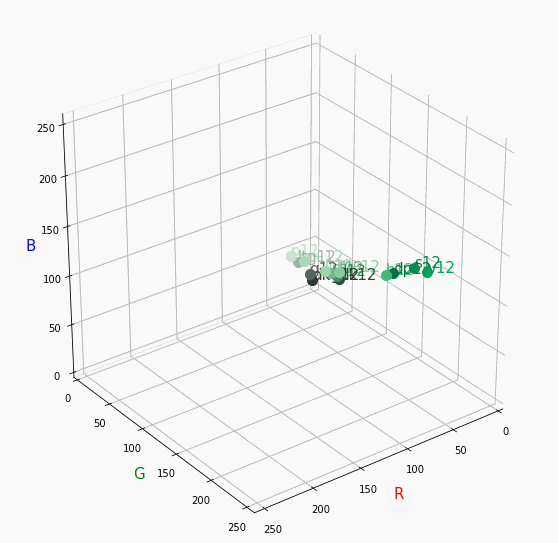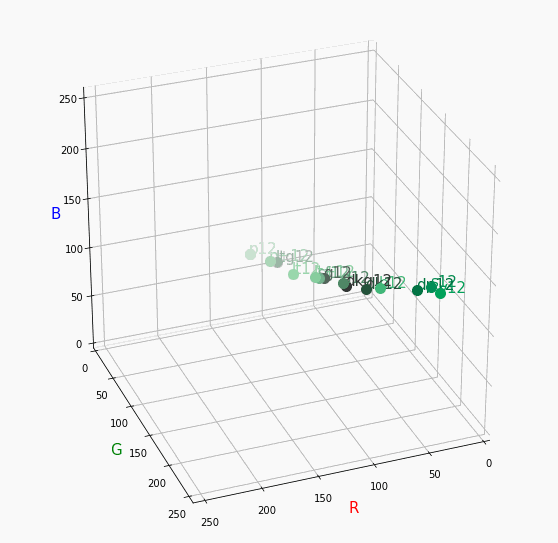
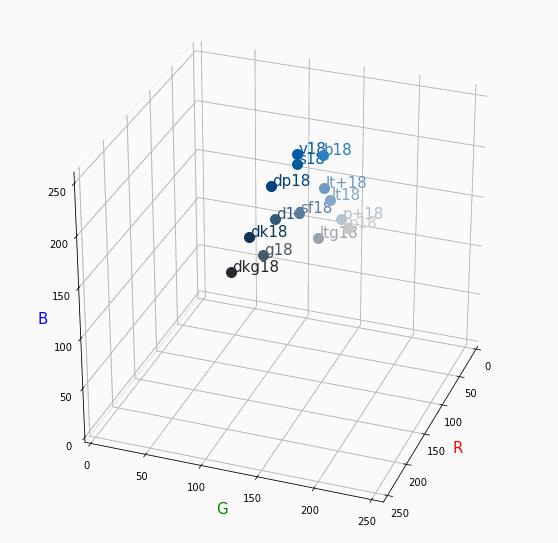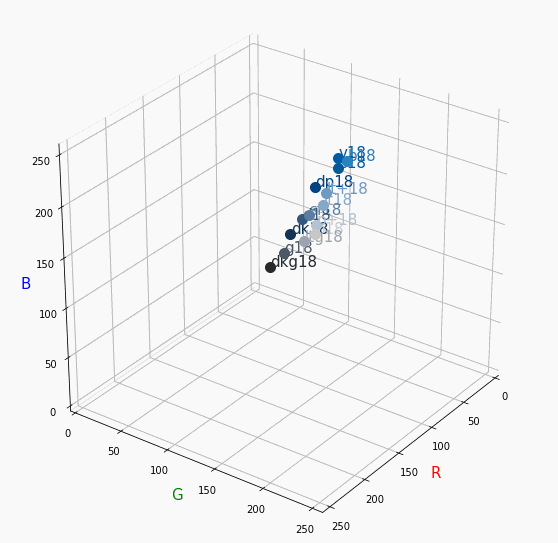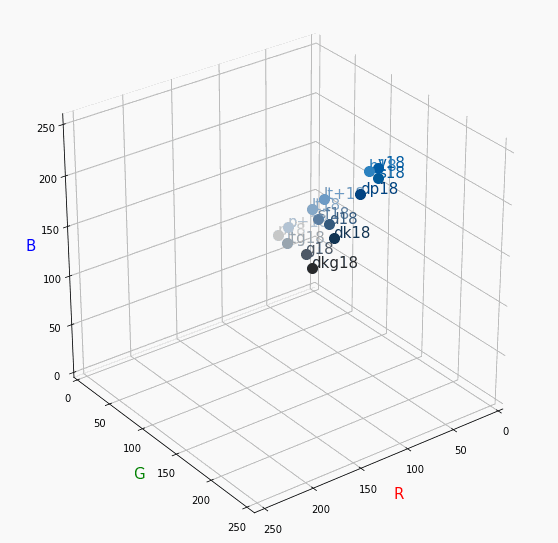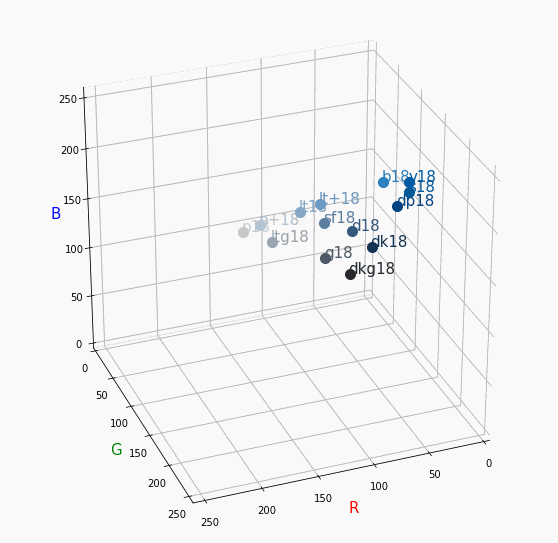
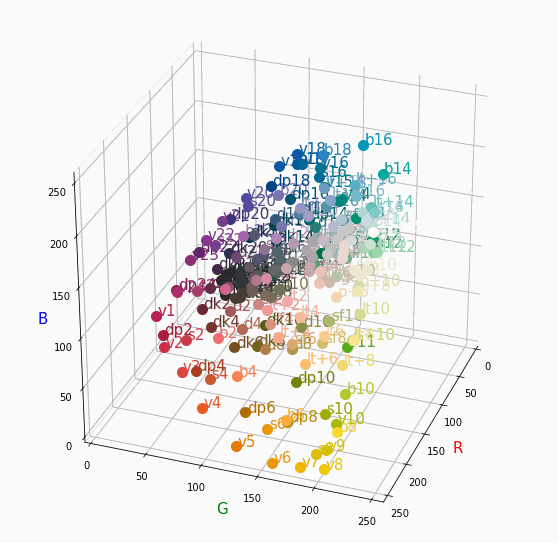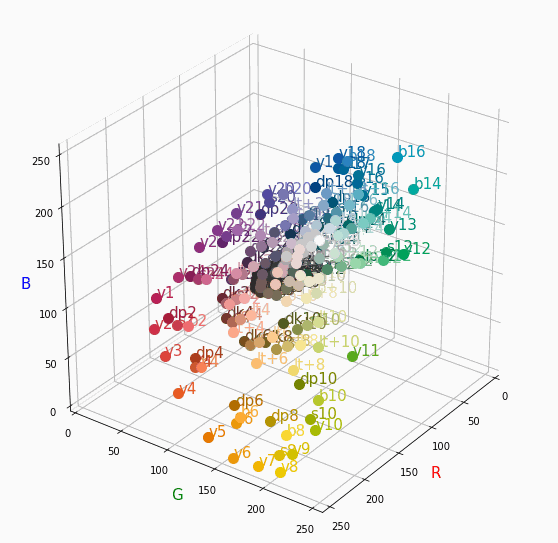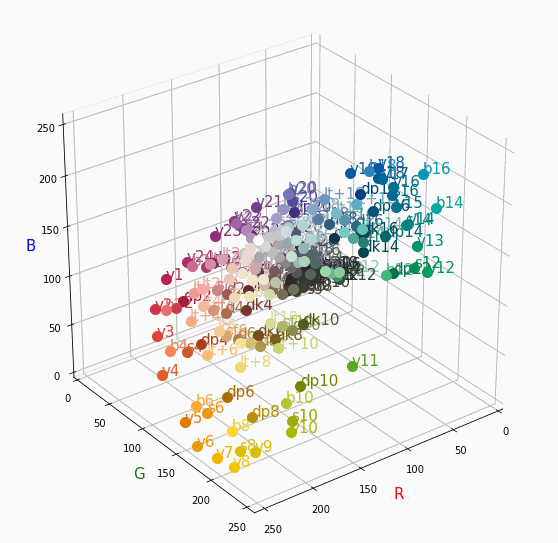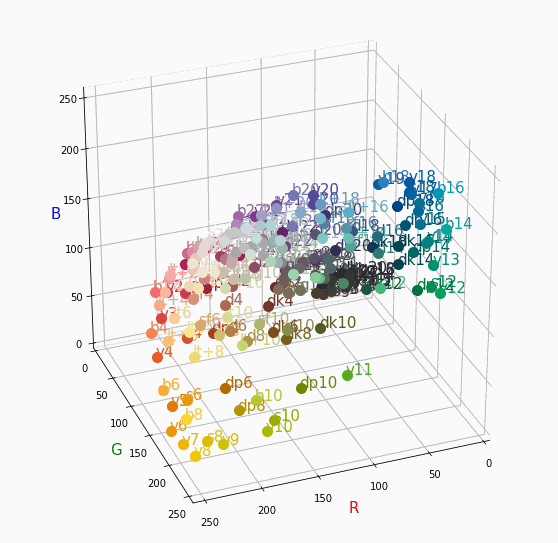
PCCSをRGBの3D散布図で可視化してみた
はじめに
色彩検定の勉強をし始めると、はじめにPCCSという色の表記方法に出会います。
自分はRGBの表記しか知らなかったので、「PCCSとRGBってどんな関係なの?」
「同じ色相のままトーンを変えるとRGBはどう変化するの?」といった疑問が沸きました。
そこで、RGBの3D散布図にすれば関係がわかるのでは?と思い立ち、実際にやってみました。PCCSとRGBの対応関係
こちらの記事から得ました。
PCCSの3D散布図
Pythonでmatplotlibを用いて可視化しました。
- BeautifulSoupでスクレイピングし対応関係を表に
- 表から欲しいデータを取り出し、matplotlibとAxes3Dで3D散布図に
- BytoIOとImageを用いてgifとして保存
360度回転もできるのですが、5GB以下にしたかったので20度~70度で回転させてます。
同じトーンで表示
Vivid
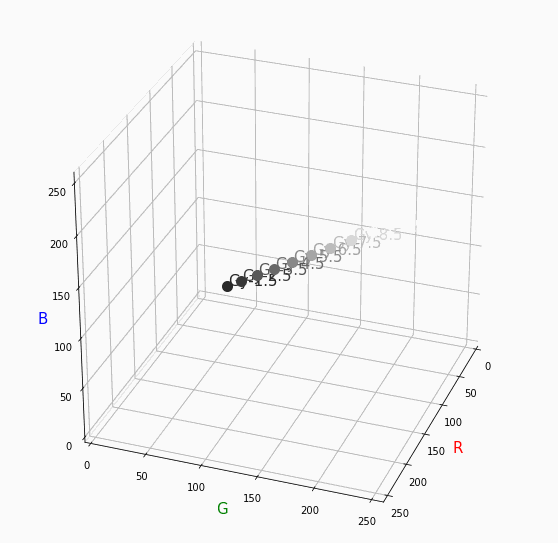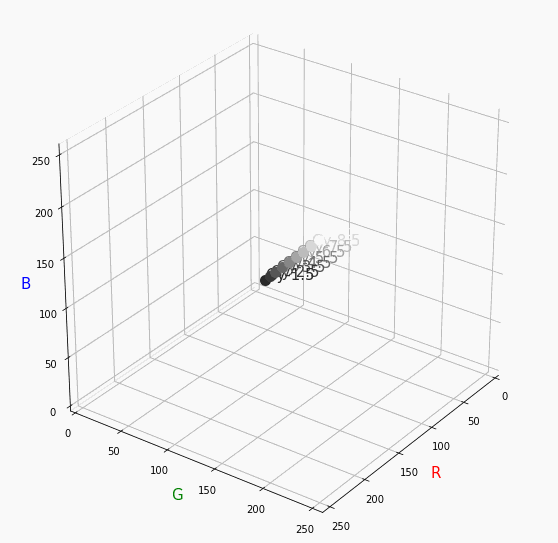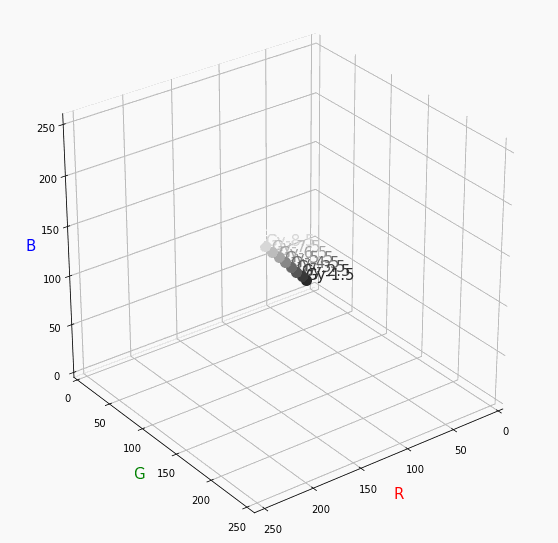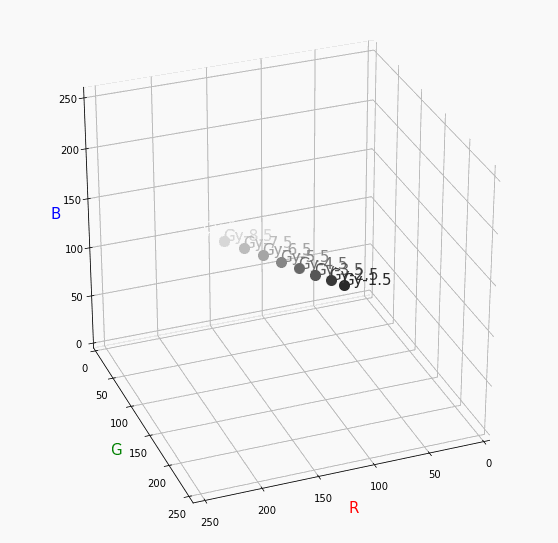
まずはVividの色相環。
色相環というだけあって、三次元で表しても順番に一周しているのが見て取れます。
個人的にはもっときれいな円形になってると思ってました。Nuetral
無彩色。
R, G, Bがすべて同じ値を取るのでこういった直線に並びます。
つまり、この直線に近くなるほど彩度が低くなるということです。
また、画面手前に来るほど明度が高くなるということもうかがえます。Pale
Vivid、Nuetralが分かればあとはなんとなく想像つくと思います。
Paleは明度が高いのでかなり画面手前で円を描きます。
逆に彩度は落ちるので一つ前のNuetralの直線に集まります。dark
最後に一つだけ。
Darkは明度が低いので画面奥になり、かつ彩度も低い方なのでNuetralの直線に近い位置で円を描きます。同じ色相で表示
心理4原色でトーンを変えて表示。
2 : R
8 : Y
12 : G
18 : B
すべてトーン図通りのきれいな同一平面のグラフが得られました。
分かったこと
- Vividの表から色相ごとのRGBのイメージがつかめる。
- 同じ色相ならトーンは同じ平面上にある。
- 彩度を落とすとR=G=Bに近づく。その逆もしかり。
- 明度を上げるとR, G, Bは255に近づく。その逆もしかり。
3D散布図により、PCCSや色の三属性について、RGBにおけるざっくりとしたイメージがつかめました。
最後に
全部表示させてみる。
きれいになると思ったのに暗めの色が邪魔してる。。。軸の色を変えられればもっと見やすくなるかも、と思ったが、Axes3Dの扱い方がむずかしく、わからなかったので一旦保留。
Munsell ⇒ RGBの変換もやる価値がありそう。
コードはいつか上げるかも。
参考
- 投稿日:2021-03-06T20:17:58+09:00
PCCSをRGBの3D散布図で可視化
はじめに
色彩検定の勉強をし始めると、はじめにPCCSという色の表記方法に出会います。
自分はRGBの表記しか知らなかったので、
「PCCSとRGBってどんな関係なの?」
「同じ色相のままトーンを変えるとRGBはどう変化するの?」
といった疑問が沸きました。
そこで、RGBの3D散布図にすれば関係がわかるのでは?と思い立ち、実際にやってみました。
PCCSとRGBの対応関係
こちらの記事から得ました。
PCCSの3D散布図
Pythonでmatplotlibを用いて可視化しました。
- BeautifulSoupでスクレイピングし対応関係を表に
- 表から欲しいデータを取り出し、matplotlibとAxes3Dで3D散布図に
- BytoIOとImageを用いてgifとして保存
360度回転もできるのですが、5GB以下にしたかったので20度~70度で回転させてます。
同じトーンで表示
Vivid
まずはVividの色相環。
色相環というだけあって、三次元で表しても順番に一周しているのが見て取れます。
個人的にはもっときれいな円形になってると思ってました。Nuetral
無彩色。
R, G, Bがすべて同じ値を取るのでこういった直線に並びます。
つまり、この直線に近くなるほど彩度が低くなるということです。
また、画面手前に来るほど明度が高くなるということもうかがえます。Pale
Vivid、Nuetralが分かればあとはなんとなく想像つくと思います。
Paleは明度が高いのでかなり画面手前で円を描きます。
逆に彩度は落ちるので一つ前のNuetralの直線に集まります。dark
最後に一つだけ。
Darkは明度が低いので画面奥になり、かつ彩度も低い方なのでNuetralの直線に近い位置で円を描きます。
同じ色相で表示
心理4原色でトーンを変えて表示。
2 : R
8 : Y
12 : G
18 : B
すべてトーン図通りのきれいな同一平面のグラフが得られました。
分かったこと
- Vividの表から色相ごとのRGBのイメージがつかめる。
- 同じ色相ならトーンは同じ平面上にある。
- 彩度を落とすとR=G=Bに近づく。その逆もしかり。
- 明度を上げるとR, G, Bは255に近づく。その逆もしかり。
3D散布図により、PCCSや色の三属性について、RGBにおけるざっくりとしたイメージがつかめました。
最後に
全部表示させてみる。
きれいになると思ったのに暗めの色が邪魔してる。。。軸の色を変えられればもっと見やすくなるかも、と思ったが、Axes3Dの扱い方がむずかしく、わからなかったので一旦保留。
Munsell ⇒ RGBの変換もやる価値がありそう。
コードはいつか上げるかも。
参考









- 投稿日:2021-03-06T20:17:58+09:00
PCCSを3D散布図で可視化
はじめに
色彩検定の勉強をし始めると、はじめにPCCSという色の表記方法に出会います。
自分はRGBの表記しか知らなかったので、
「PCCSとRGBってどんな関係なの?」
「同じ色相のままトーンを変えるとRGBはどう変化するの?」
といった疑問が沸きました。
そこで、RGBの3D散布図にすれば関係がわかるのでは?と思い立ち、実際にやってみました。
PCCSとRGBの対応関係
こちらのサイトから得ました。
PCCSの3D散布図
Pythonでmatplotlibを用いて可視化しました。
- BeautifulSoupでスクレイピングし対応関係を表に
- 表から欲しいデータを取り出し、matplotlibとAxes3Dで3D散布図に
- BytoIOとImageを用いてgifとして保存
360度回転もできるのですが、5GB以下にしたかったので20度~70度で回転させてます。
同じトーンで表示
Vivid
まずはVividの色相環。
色相環というだけあって、三次元で表しても順番に一周しているのが見て取れます。
個人的にはもっときれいな円形になってると思ってました。Nuetral
無彩色。
R, G, Bがすべて同じ値を取るのでこういった直線に並びます。
つまり、この直線に近くなるほど彩度が低くなるということです。
また、画面手前に来るほど明度が高くなるということもうかがえます。Pale
Vivid、Nuetralが分かればあとはなんとなく想像つくと思います。
Paleは明度が高いのでかなり画面手前で円を描きます。
逆に彩度は落ちるので先ほどのNuetralの直線に集まります。dark
最後に一つだけ。
Darkは明度が低いので画面奥になり、かつ彩度も低い方なのでNuetralの直線に近い位置で円を描きます。
同じ色相で表示
心理4原色でトーンを変えて表示。
2 : R
8 : Y
12 : G
18 : B
すべてトーン図通りのきれいな同一平面のグラフが得られました。
分かったこと
- Vividの表から色相ごとのRGBのイメージがつかめる。
- 同じ色相ならトーンは同じ平面上にある。
- 彩度を落とすとR=G=Bに近づく。その逆もしかり。
- 明度を上げるとR, G, Bは255に近づく。その逆もしかり。
3D散布図により、PCCSや色の三属性について、RGBにおけるざっくりとしたイメージがつかめました。
最後に
全部表示させてみる。
きれいになると思ったのに暗めの色が邪魔してる。。。軸の色を変えられればもっと見やすくなるかも、と思ったが、Axes3Dの扱い方がむずかしく、わからなかったので一旦保留。
Munsell ⇒ RGBの変換もやる価値がありそう。
コードはいつか上げるかも。
参考
- 投稿日:2021-03-06T20:10:31+09:00
B - Bingo, C - Takahashi's Information, C - 山崩し
B - Bingo
O(N)
実装問題です。pythonimport math import heapq import itertools from functools import reduce # main def main(): A = [] Field = [[False] * 3, [False] * 3, [False] * 3] for i in range(0, 3): a = list(map(int, input().split())) A.append(a) N = int(input()) B = [0] * N for i in range(0, N): B[i] = int(input()) for b in B: for i in range(3): for j in range(3): if A[i][j] == b: Field[i][j] = True bingo = False if Field[0][0] and Field[1][1] and Field[2][2]: bingo = True if Field[0][2] and Field[1][1] and Field[2][0]: bingo = True for i in range(3): if Field[i][0] and Field[i][1] and Field[i][2]: bingo = True for i in range(3): if Field[0][i] and Field[1][i] and Field[2][i]: bingo = True if bingo: print("Yes") else: print("No") # エントリポイント if __name__ == '__main__': main()C - Takahashi's Information
O(1)
問題文から下記の要素が推測できる。
引き算をして各要素が等しいか判定。a_1 + b_1, a_1 + b_2, a_1 + b_3 \\ a_2 + b_1, a_2 + b_2, a_2 + b_3 \\ a_3 + b_1, a_3 + b_2, a_3 + b_3 \\pythonimport math import heapq import itertools from functools import reduce # main def main(): C = [] for _ in range(0, 3): row = list(map(int, input().split())) C.append(row) ok = True if C[0][0] - C[0][1] != C[1][0] - C[1][1] or C[1][0] - C[1][1] != C[2][0] - C[2][1]: ok = False if C[0][1] - C[0][2] != C[1][1] - C[1][2] or C[1][1] - C[1][2] != C[2][1] - C[2][2]: ok = False if ok: print("Yes") else: print("No") # エントリポイント if __name__ == '__main__': main()C - 山崩し
O(N*(2N-1))
全探索の問題です。
実装問題。5 ....#.... ...##X... ..#####.. .#X#####. #########配列の下から判定すると上手くいきますね。
pyhtonimport math import heapq import itertools from functools import reduce # main def main(): N = int(input()) field = [] for _ in range(0, N): S = str(input()) field.append(S) for i in range(N-1, 0, -1): for j in range(0, 2*N-1): if field[i][j] == 'X': if j-1>=0 and field[i-1][j-1] == '#': field[i-1] = field[i-1][:j-1] + 'X' + field[i-1][j:] if field[i-1][j] == '#': field[i-1] = field[i-1][:j] + 'X' + field[i-1][j+1:] if j+1<2*N-1 and field[i-1][j+1] == '#': field[i-1] = field[i-1][:j+1] + 'X' + field[i-1][j+2:] for i in range(0, N): print(field[i]) # エントリポイント if __name__ == '__main__': main()
- 投稿日:2021-03-06T19:49:29+09:00
【Python】Listを文字列として出力する方法
概要
1:文字列を含むlistを文字列に変換
2:数値を含むlistを文字列に変換検証環境
OS:18.04.5 LTS
Python:3.6.9方法
文字列を含むlistを文字列に変換
list = ['v','e','r','i','f','y'] print(''.join(list)) # 実行結果 verify数値を含むリストを文字列に変換
list = [0,1,2,3,4,5] print(''.join(map(str,list))) # 実行結果 012345data = [0,1,2,3,4,5] print(*data, sep='') # 実行結果 012345
- 投稿日:2021-03-06T18:46:52+09:00
Pandasの使い方3
1 この記事は
DataFrame型データの各種操作方法をメモする。
2 内容
2-1 DataFrame型の各列に関数を作用させてデータを生成する。
DataFrame型dfの列C > 8 かつ 列D<90のとき、D1列に1を書き込む作業を行う。
sample.pyimport pandas as pd import numpy as np import scipy.stats #関数定義 DataFrame型xの列C > 8 かつ 列D<90のとき、D1列に1を書き込む def judge(x): x.loc[ ( (x['C'] > 8 ) & (x['D']<90) ) , 'D1'] = 1 return x['D1'] #dataを定義する。 dat = [ [100,'2019-07-01',2,7,0,0], [100,'2019-07-02',4,77,0,0], [100,'2019-07-03',8,8,0,0], [100,'2019-07-04',16,89,0,0], [200,'2020-07-06',100,9,0,0], [200,'2019-07-05',200,99,0,0], [200,'2019-07-04',400,123,0,0], [200,'2019-07-03',200,345,0,0], ] #datをDataFrame型変数dfに格納する。 df = pd.DataFrame(dat,columns=["A","B","C","D","D1","D2"]) #A,B列をindexに指定する。 df=df.set_index(["A","B"]) #DataFrame dfをindex Aでgroupbyさせる。df.groupby("A")に関数judgeを作用させる。judgeはseries型で返却されるので、to_frameでDataFrame型に変換し、dfのD1列に書き込む。 df['D1']= df.groupby("A").apply(lambda x:judge(x).to_frame('any')) print("df",df)実行結果
df C D D1 D2 A B 100 2019-07-01 2 7 0 0 2019-07-02 4 77 0 0 2019-07-03 8 8 0 0 2019-07-04 16 89 1 0 200 2020-07-06 100 9 1 0 2019-07-05 200 99 0 0 2019-07-04 400 123 0 0 2019-07-03 200 345 0 0
- 投稿日:2021-03-06T17:26:44+09:00
ROSの勉強 第20弾:環境の地図作成
#プログラミング ROS< 環境の地図作成 >
はじめに
1つの参考書に沿って,ROS(Robot Operating System)を難なく扱えるようになることが目的である.その第20弾として,「環境の地図作成」を扱う.
環境の地図作成
まず,地図を作成する対象環境を以下に示す.
ここでは,turtlebotを動かし,センサデータから地図作成を行う.前回(https://qiita.com/Yuya-Shimizu/items/f69b18e8dd2cee392e79 )で学んだrosbagが大いに活躍する.
手順
以下では,動画像を使って手順を示す.
手順1
対象環境にセンサを搭載したロボットを配置(gazeboの起動)
手順2
ロボットを動かす準備と,データを記録する準備(teleopとrosbag)
実行したコマンドは以下のとおりである.~$ rosbag record -O data.bag /scan /tf~$ roslaunch turtlebot3_teleop turtlebot3_teleop_key.launchこれで,data.bagに/scanと/tfのデータを記録する準備ができた.
手順3
データ収集(ロボットを動かす)
しばらく適当にデータを収集し続ける.データ収集後,
rosbag record~を実行しているターミナル(端末)上でCtrl-cを押して,データの記録終了.そのとき,data.bagというファイルができている.このファイルの情報を詳しく見ることができる.
こんな感じである.
手順4
データから地図を生成する(gmappingとrosbag)
ターミナル1~$ rosrun gmapping slam_gmappingターミナル2~$ rosbag play --clock data.bagターミナル3~$ rosrun robot_state_publisher robot_state_publisherはじめは,ターミナル1と2だけ実行していたが,これではうまく地図を生成できていなかった.どうやら,rvizのとき同様,robotからmapにデータがうまく変換がされていないようだ.そこで,rvizのときの解決策と同じようにターミナル3を実行してから行ってみたところ,うまくいった.必ず,シミュレータを停止して,ターミナル3を実行してから,ターミナル1,ターミナル2という順で実行する.
これで,地図の作成ができた.手順5
地図データの保存(map_server)
~$ rosrun map_server map_saverこのとき,手順4でのターミナル2は起動したままとする.なぜなら,そのデータを今から保存しようとしているため.保存が完了すると,地図の画像データと,メタデータを含むyamlファイルが得られる.以下にそれらを示す.
map.yamlimage: map.pgm resolution: 0.050000 origin: [-100.000000, -100.000000, 0.000000] negate: 0 occupied_thresh: 0.65 free_thresh: 0.196地図の質を向上させる
先ほど得られた地図の画像については,デフォルトではサイズが4000*4000であったため,非常に小さく表示されてしまっていた.また,地図自体もあまりよくないらしい.そこで,ある設定をこなすだけでよくなる方法をここで示しておく.
rosparam set /slam_gmapping/angularUpdate 0.1 rosparam set /slam_gmapping/linearUpdate 0.1 rosparam set /slam_gmapping/lskip 10 rosparam set /slam_gmapping/xmax 10 rosparam set /slam_gmapping/xmin -10 rosparam set /slam_gmapping/ymax 10 rosparam set /slam_gmapping/ymin -10これらを,gmapping実行前に設定する.
rosparam setにより,gmappingのパラメータを変更している.上記のものは,新しいスキャンデータを地図に取り込むまでにロボットが動かないといけない回転量(angularUpdate)と並進移動の量(linearUpdate),LaserScanメッセージを処理するときに飛ばして読む光線の数(lskip),地図の広さ(xmin, xmax, ymin, ymax)を変更している.以下にそのときの結果を示す.
map2.yamlimage: map2.pgm resolution: 0.050000 origin: [-10.000000, -10.000000, 0.000000] negate: 0 occupied_thresh: 0.65 free_thresh: 0.196上の地図を見ても分かるように,地図の広さの指定により程よい大きさの地図画像が生成された.非常に見やすくなった.このあたりの設定は,ここでは示さないが,launchファイルなどにまとめておくと便利かもしれない.
感想
rvizのときもそうだったが,今回も気づきにくい(明示的にエラーとは示してくれない)ものが,原因となってうまく地図の作成ができず,1日2日悩んだ.何とか解決できてよかった.何か別の空間や形式に持っていくときには,何かしらの変換が必要で,そのための変換器のようなものが必要になることもあるということを頭に入れて,意識しておいた方がいいと身をもって感じた.なお,上では示さなかったが,リアルタイム(bagファイルに保存しない)で地図を作成することも可能で,その場合,ロボットを動かしているときに,
slam_gmappingを起動するだけである.しかしながら,ロボットの計算負荷を減らすために,データをいったん記録することがお勧めらしい.ただし,rosbagで保存するかどうかにかかわらず,結果的には同じような地図ができるらしい.今回扱ったgmappingについての詳細は,論文が2つある.ここにそのURLを示しておく.
論文1: Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters
(https://www.researchgate.net/publication/3450390_Improved_Techniques_for_Grid_Mapping_With_Rao-Blackwellized_Particle_Filters )
論文2: Improving Grid-based SLAM with Rao-Blackwellized Particle Filters By Adaptive Proposals and Selective Resampling
(https://www.researchgate.net/publication/221067958_Improving_Grid-based_SLAM_with_Rao-Blackwellized_Particle_Filters_By_Adaptive_Proposals_and_Selective_Resampling )また,余談だがQiitaの記事を作成する際に,どうやら10MBを超える画像は貼り付けられないらしい.そういう公式の発表を見たわけではないが,10MBを超えたgifデータだけ貼り付けられず,圧縮して軽量化することで,貼り付けられた.
参考文献
プログラミングROS Pythonによるロボットアプリケーション開発
Morgan Quigley, Brian Gerkey, William D.Smart 著
河田 卓志 監訳
松田 晃一,福地 正樹,由谷 哲夫 訳
オイラリー・ジャパン 発行









- 投稿日:2021-03-06T16:53:22+09:00
[Python]辞書を1行ずつファイルに書き込む
keyとvalueの組を1行ずつファイル出力するプログラム
パッケージのimportなどは不要dic = dict(key1="val1", key2="val2", key3="val3") #ファイル出力 with open("output.csv", mode='w') as f: f.writelines("\n".join(str(k)+","+str(v) for k,v in dic.items())) # key1,val1 # key2,val2 # key3,val3注意点
joinの中に二重リストや二重タプルを入れることはできません.
また異なる型をjoinで結合しようとするとエラーを吐くため,結合前に各変数をstr型に変換してあげないといけません.
- 投稿日:2021-03-06T16:43:07+09:00
Git Bashで対話モードのPythonのコマンド履歴と補完を有効化する
- 投稿日:2021-03-06T16:18:55+09:00
WaniCTF complex writeup ( Ghidra を使用した静的解析 )
Ghidraを勉強した記録として残しておく。
stack strings の問題だけど byte だけではなく,qword, dword, word も登場する。complexの入手先
表層解析で得られる文字列 Incorrect を検索
main関数だundefined8 main(void) { int iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78); if (local_10 != 0) { if (local_10 == 1) { puts("Incorrect"); return 1; } if (local_10 == 2) { printf("Correct! Flag is %s\n",local_48); return 0; } } local_c = local_c + 1; } while( true ); }check関数のリターンが 2 だと Correct! になるようだ。
check関数
void check(undefined4 param_1,undefined8 param_2) { switch(param_1) { case 0: check_0(param_2); break; case 1: check_1(param_2); break; case 2: check_2(param_2); break; case 3: check_3(param_2); break; case 4: check_4(param_2); break; case 5: check_5(param_2); break; case 6: check_6(param_2); break; case 7: check_7(param_2); break; case 8: check_8(param_2); break; case 9: check_9(param_2); break; case 10: check_10(param_2); break; case 0xb: check_11(param_2); break; case 0xc: check_12(param_2); break; case 0xd: check_13(param_2); break; case 0xe: check_14(param_2); break; case 0xf: check_15(param_2); break; case 0x10: check_16(param_2); break; case 0x11: check_17(param_2); break; case 0x12: check_18(param_2); break; case 0x13: check_19(param_2); } return; }心を折りにきてるな。負けるもんか。(正直,心折れそう)
一つずつ落ち着いてみていく。
check_13関数だけ 2 を返してるundefined8 check_13(long param_1) { undefined8 local_68; undefined8 local_60; undefined8 local_58; undefined8 local_50; undefined4 local_48; undefined local_44; undefined8 local_38; undefined8 local_30; undefined8 local_28; undefined8 local_20; undefined4 local_18; undefined local_14; int local_c; local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37; local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52; local_c = 0; while( true ) { if (0x24 < local_c) { return 2; } if (((int)*(char *)((long)&local_38 + (long)local_c) ^ (uint)*(byte *)(param_1 + local_c)) != (int)*(char *)((long)&local_68 + (long)local_c)) break; local_c = local_c + 1; } return 1; }local_38のstack strings
local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37;と,local_68のstack strings
local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52;を xor すれば flag みたいです。
本当?
main関数に戻ってみるint iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78);check関数に渡してる local_78 は,acStack67のコピーだけど。。。
acStack67への代入はどこにも無い。型を変更して,デコンパイル誤りを正す。
int iVar1; size_t sVar2; char local_78 [48]; char local_48 [48]; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(local_48 + 0x2a,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,local_48 + 5,0x25);check関数(check_13関数)に渡すのは,"FLAG{"の 5バイトを除いた 0x25バイトですね。
stack strings のところの逆アセンブルはこんな感じ
0010139c 48 b8 37 .. MOV RAX,0x3131393431333637 001013a6 48 ba 35 .. MOV RDX,0x3435313837393235 001013b0 48 89 45 d0 MOV qword ptr [RBP + local_38],RAX 001013b4 48 89 55 d8 MOV qword ptr [RBP + local_30],RDX 001013b8 48 b8 36 .. MOV RAX,0x3635313836343636 001013c2 48 ba 34 .. MOV RDX,0x3834303131353334 001013cc 48 89 45 e0 MOV qword ptr [RBP + local_28],RAX 001013d0 48 89 55 e8 MOV qword ptr [RBP + local_20],RDX 001013d4 c7 45 f0 .. MOV dword ptr [RBP + local_18],0x34323435 001013db c6 45 f4 37 MOV byte ptr [RBP + local_14],0x37 001013df 48 b8 53 .. MOV RAX,0x6e44564d6e575f53 001013e9 48 ba 47 .. MOV RDX,0x576a48545b585747 001013f3 48 89 45 a0 MOV qword ptr [RBP + local_68],RAX 001013f7 48 89 55 a8 MOV qword ptr [RBP + local_60],RDX 001013fb 48 b8 5e .. MOV RAX,0x535d45675d57535e 00101405 48 ba 6b .. MOV RDX,0x675a42444550416b 0010140f 48 89 45 b0 MOV qword ptr [RBP + local_58],RAX 00101413 48 89 55 b8 MOV qword ptr [RBP + local_50],RDX 00101417 c7 45 c0 .. MOV dword ptr [RBP + local_48],0x415e5543 0010141e c6 45 c4 52 MOV byte ptr [RBP + local_44],0x52ソルバー ( Ghidra Script ) を作ってみる
def qword_parse(value): return([(value & 0x00000000000000ff) / 0x1,(value & 0x000000000000ff00) / 0x100,(value & 0x0000000000ff0000) / 0x10000,(value & 0x00000000ff000000) / 0x1000000,(value & 0x000000ff00000000) / 0x100000000,(value & 0x0000ff0000000000) / 0x10000000000,(value & 0x00ff000000000000) / 0x1000000000000,(value & 0xff00000000000000) / 0x100000000000000]) def dword_parse(value): return([(value & 0x000000ff) / 0x1,(value & 0x0000ff00) / 0x100,(value & 0x00ff0000) / 0x10000,(value & 0xff000000) / 0x1000000]) def word_parse(value): return([(value & 0x00ff) / 0x1,(value & 0xff00) / 0x100]) # step 1 local_38 extract local_38 = [] addr = toAddr(0x0010139c) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013a6) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013b8) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013c2) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013d4) inst = getInstructionAt(addr) local_38.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013db) inst = getInstructionAt(addr) local_38.append(inst.getOpObjects(1)[0].getValue()) #print(local_38) #print(''.join(map(chr,local_38))) # step 2 local_68 extract local_68 = [] addr = toAddr(0x001013df) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013e9) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013fb) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101405) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101417) inst = getInstructionAt(addr) local_68.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x0010141e) inst = getInstructionAt(addr) local_68.append(inst.getOpObjects(1)[0].getValue()) #print(local_68) #print(''.join(map(chr,local_68))) # step 2 xor ans = [] i = 0 while i < 0x25: ans.append(local_38[i] ^ local_68[i]) i = i + 1 #print(ans) print(''.join(map(chr,ans)))もっと美しくコードを書ければいいのに。。。
- 投稿日:2021-03-06T16:18:55+09:00
WaniCTF Complex Writeup Using Ghidra
Ghidraを勉強した記録として残しておく。
stack strings の問題だけど byte だけではなく,qword, dword, word も登場する。complexの入手先
表層解析で得られる文字列 Incorrect を検索
main関数だundefined8 main(void) { int iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78); if (local_10 != 0) { if (local_10 == 1) { puts("Incorrect"); return 1; } if (local_10 == 2) { printf("Correct! Flag is %s\n",local_48); return 0; } } local_c = local_c + 1; } while( true ); }check関数のリターンが 2 だと Correct! になるようだ。
check関数
void check(undefined4 param_1,undefined8 param_2) { switch(param_1) { case 0: check_0(param_2); break; case 1: check_1(param_2); break; case 2: check_2(param_2); break; case 3: check_3(param_2); break; case 4: check_4(param_2); break; case 5: check_5(param_2); break; case 6: check_6(param_2); break; case 7: check_7(param_2); break; case 8: check_8(param_2); break; case 9: check_9(param_2); break; case 10: check_10(param_2); break; case 0xb: check_11(param_2); break; case 0xc: check_12(param_2); break; case 0xd: check_13(param_2); break; case 0xe: check_14(param_2); break; case 0xf: check_15(param_2); break; case 0x10: check_16(param_2); break; case 0x11: check_17(param_2); break; case 0x12: check_18(param_2); break; case 0x13: check_19(param_2); } return; }心を折りにきてるな。負けるもんか。(正直,心折れそう)
一つずつ落ち着いてみていく。
check_13関数だけ 2 を返してるundefined8 check_13(long param_1) { undefined8 local_68; undefined8 local_60; undefined8 local_58; undefined8 local_50; undefined4 local_48; undefined local_44; undefined8 local_38; undefined8 local_30; undefined8 local_28; undefined8 local_20; undefined4 local_18; undefined local_14; int local_c; local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37; local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52; local_c = 0; while( true ) { if (0x24 < local_c) { return 2; } if (((int)*(char *)((long)&local_38 + (long)local_c) ^ (uint)*(byte *)(param_1 + local_c)) != (int)*(char *)((long)&local_68 + (long)local_c)) break; local_c = local_c + 1; } return 1; }local_38のstack strings
local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37;と,local_68のstack strings
local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52;を xor すれば flag みたいです。
本当?
main関数に戻ってみるint iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78);check関数に渡してる local_78 は,acStack67のコピーだけど。。。
acStack67への代入はどこにも無い。型を変更して,デコンパイル誤りを正す。
int iVar1; size_t sVar2; char local_78 [48]; char local_48 [48]; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(local_48 + 0x2a,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,local_48 + 5,0x25);check関数(check_13関数)に渡すのは,"FLAG{"の 5バイトを除いた 0x25バイトですね。
stack strings のところの逆アセンブルはこんな感じ
0010139c 48 b8 37 .. MOV RAX,0x3131393431333637 001013a6 48 ba 35 .. MOV RDX,0x3435313837393235 001013b0 48 89 45 d0 MOV qword ptr [RBP + local_38],RAX 001013b4 48 89 55 d8 MOV qword ptr [RBP + local_30],RDX 001013b8 48 b8 36 .. MOV RAX,0x3635313836343636 001013c2 48 ba 34 .. MOV RDX,0x3834303131353334 001013cc 48 89 45 e0 MOV qword ptr [RBP + local_28],RAX 001013d0 48 89 55 e8 MOV qword ptr [RBP + local_20],RDX 001013d4 c7 45 f0 .. MOV dword ptr [RBP + local_18],0x34323435 001013db c6 45 f4 37 MOV byte ptr [RBP + local_14],0x37 001013df 48 b8 53 .. MOV RAX,0x6e44564d6e575f53 001013e9 48 ba 47 .. MOV RDX,0x576a48545b585747 001013f3 48 89 45 a0 MOV qword ptr [RBP + local_68],RAX 001013f7 48 89 55 a8 MOV qword ptr [RBP + local_60],RDX 001013fb 48 b8 5e .. MOV RAX,0x535d45675d57535e 00101405 48 ba 6b .. MOV RDX,0x675a42444550416b 0010140f 48 89 45 b0 MOV qword ptr [RBP + local_58],RAX 00101413 48 89 55 b8 MOV qword ptr [RBP + local_50],RDX 00101417 c7 45 c0 .. MOV dword ptr [RBP + local_48],0x415e5543 0010141e c6 45 c4 52 MOV byte ptr [RBP + local_44],0x52ソルバー ( Ghidra Script ) を作ってみる
def qword_parse(value): return([(value & 0x00000000000000ff) / 0x1,(value & 0x000000000000ff00) / 0x100,(value & 0x0000000000ff0000) / 0x10000,(value & 0x00000000ff000000) / 0x1000000,(value & 0x000000ff00000000) / 0x100000000,(value & 0x0000ff0000000000) / 0x10000000000,(value & 0x00ff000000000000) / 0x1000000000000,(value & 0xff00000000000000) / 0x100000000000000]) def dword_parse(value): return([(value & 0x000000ff) / 0x1,(value & 0x0000ff00) / 0x100,(value & 0x00ff0000) / 0x10000,(value & 0xff000000) / 0x1000000]) def word_parse(value): return([(value & 0x00ff) / 0x1,(value & 0xff00) / 0x100]) # step 1 local_38 extract local_38 = [] addr = toAddr(0x0010139c) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013a6) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013b8) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013c2) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013d4) inst = getInstructionAt(addr) local_38.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013db) inst = getInstructionAt(addr) local_38.append(inst.getOpObjects(1)[0].getValue()) #print(local_38) #print(''.join(map(chr,local_38))) # step 2 local_68 extract local_68 = [] addr = toAddr(0x001013df) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013e9) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013fb) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101405) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101417) inst = getInstructionAt(addr) local_68.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x0010141e) inst = getInstructionAt(addr) local_68.append(inst.getOpObjects(1)[0].getValue()) #print(local_68) #print(''.join(map(chr,local_68))) # step 3 xor ans = [] i = 0 while i < 0x25: ans.append(local_38[i] ^ local_68[i]) i = i + 1 #print(ans) print(''.join(map(chr,ans)))もっと美しくコードを書ければいいのに。。。
- 投稿日:2021-03-06T16:18:55+09:00
WaniCTF complex をGhidraで静的解析してみた
Ghidraを勉強した記録として残しておく。
stack strings の問題だけど byte だけではなく,qword, dword, word も登場する。complexの入手先
表層解析で得られる文字列 Incorrect を検索
main関数だundefined8 main(void) { int iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78); if (local_10 != 0) { if (local_10 == 1) { puts("Incorrect"); return 1; } if (local_10 == 2) { printf("Correct! Flag is %s\n",local_48); return 0; } } local_c = local_c + 1; } while( true ); }check関数のリターンが 2 だと Correct! になるようだ。
check関数
void check(undefined4 param_1,undefined8 param_2) { switch(param_1) { case 0: check_0(param_2); break; case 1: check_1(param_2); break; case 2: check_2(param_2); break; case 3: check_3(param_2); break; case 4: check_4(param_2); break; case 5: check_5(param_2); break; case 6: check_6(param_2); break; case 7: check_7(param_2); break; case 8: check_8(param_2); break; case 9: check_9(param_2); break; case 10: check_10(param_2); break; case 0xb: check_11(param_2); break; case 0xc: check_12(param_2); break; case 0xd: check_13(param_2); break; case 0xe: check_14(param_2); break; case 0xf: check_15(param_2); break; case 0x10: check_16(param_2); break; case 0x11: check_17(param_2); break; case 0x12: check_18(param_2); break; case 0x13: check_19(param_2); } return; }心を折りにきてるな。負けるもんか。(正直,心折れそう)
一つずつ落ち着いてみていく。
check_13関数だけ 2 を返してるundefined8 check_13(long param_1) { undefined8 local_68; undefined8 local_60; undefined8 local_58; undefined8 local_50; undefined4 local_48; undefined local_44; undefined8 local_38; undefined8 local_30; undefined8 local_28; undefined8 local_20; undefined4 local_18; undefined local_14; int local_c; local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37; local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52; local_c = 0; while( true ) { if (0x24 < local_c) { return 2; } if (((int)*(char *)((long)&local_38 + (long)local_c) ^ (uint)*(byte *)(param_1 + local_c)) != (int)*(char *)((long)&local_68 + (long)local_c)) break; local_c = local_c + 1; } return 1; }local_38のstack strings
local_38 = 0x3131393431333637; local_30 = 0x3435313837393235; local_28 = 0x3635313836343636; local_20 = 0x3834303131353334; local_18 = 0x34323435; local_14 = 0x37;と,local_68のstack strings
local_68 = 0x6e44564d6e575f53; local_60 = 0x576a48545b585747; local_58 = 0x535d45675d57535e; local_50 = 0x675a42444550416b; local_48 = 0x415e5543; local_44 = 0x52;を xor すれば flag みたいです。
本当?
main関数に戻ってみるint iVar1; size_t sVar2; char local_78 [48]; char local_48 [5]; char acStack67 [37]; char acStack30 [14]; int local_10; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(acStack30,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,acStack67,0x25); local_c = 0; do { if (0x13 < local_c) { return 0; } local_10 = check(local_c,local_78,local_78);check関数に渡してる local_78 は,acStack67のコピーだけど。。。
acStack67への代入はどこにも無い。型を変更して,デコンパイル誤りを正す。
int iVar1; size_t sVar2; char local_78 [48]; char local_48 [48]; int local_c; printf("input flag : "); __isoc99_scanf(&DAT_00101dc2,local_48); sVar2 = strlen(local_48); if (((sVar2 != 0x2b) || (iVar1 = strncmp(local_48,"FLAG{",5), iVar1 != 0)) || (iVar1 = strcmp(local_48 + 0x2a,"}"), iVar1 != 0)) { puts("Incorrect"); return 1; } strncpy(local_78,local_48 + 5,0x25);check関数(check_13関数)に渡すのは,"FLAG{"の 5バイトを除いた 0x25バイトですね。
stack strings のところの逆アセンブルはこんな感じ
0010139c 48 b8 37 .. MOV RAX,0x3131393431333637 001013a6 48 ba 35 .. MOV RDX,0x3435313837393235 001013b0 48 89 45 d0 MOV qword ptr [RBP + local_38],RAX 001013b4 48 89 55 d8 MOV qword ptr [RBP + local_30],RDX 001013b8 48 b8 36 .. MOV RAX,0x3635313836343636 001013c2 48 ba 34 .. MOV RDX,0x3834303131353334 001013cc 48 89 45 e0 MOV qword ptr [RBP + local_28],RAX 001013d0 48 89 55 e8 MOV qword ptr [RBP + local_20],RDX 001013d4 c7 45 f0 .. MOV dword ptr [RBP + local_18],0x34323435 001013db c6 45 f4 37 MOV byte ptr [RBP + local_14],0x37 001013df 48 b8 53 .. MOV RAX,0x6e44564d6e575f53 001013e9 48 ba 47 .. MOV RDX,0x576a48545b585747 001013f3 48 89 45 a0 MOV qword ptr [RBP + local_68],RAX 001013f7 48 89 55 a8 MOV qword ptr [RBP + local_60],RDX 001013fb 48 b8 5e .. MOV RAX,0x535d45675d57535e 00101405 48 ba 6b .. MOV RDX,0x675a42444550416b 0010140f 48 89 45 b0 MOV qword ptr [RBP + local_58],RAX 00101413 48 89 55 b8 MOV qword ptr [RBP + local_50],RDX 00101417 c7 45 c0 .. MOV dword ptr [RBP + local_48],0x415e5543 0010141e c6 45 c4 52 MOV byte ptr [RBP + local_44],0x52ソルバー ( Ghidra Script ) を作ってみる
def qword_parse(value): return([(value & 0x00000000000000ff) / 0x1,(value & 0x000000000000ff00) / 0x100,(value & 0x0000000000ff0000) / 0x10000,(value & 0x00000000ff000000) / 0x1000000,(value & 0x000000ff00000000) / 0x100000000,(value & 0x0000ff0000000000) / 0x10000000000,(value & 0x00ff000000000000) / 0x1000000000000,(value & 0xff00000000000000) / 0x100000000000000]) def dword_parse(value): return([(value & 0x000000ff) / 0x1,(value & 0x0000ff00) / 0x100,(value & 0x00ff0000) / 0x10000,(value & 0xff000000) / 0x1000000]) def word_parse(value): return([(value & 0x00ff) / 0x1,(value & 0xff00) / 0x100]) # step 1 local_38 extract local_38 = [] addr = toAddr(0x0010139c) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013a6) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013b8) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013c2) inst = getInstructionAt(addr) local_38.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013d4) inst = getInstructionAt(addr) local_38.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013db) inst = getInstructionAt(addr) local_38.append(inst.getOpObjects(1)[0].getValue()) #print(local_38) #print(''.join(map(chr,local_38))) # step 2 local_68 extract local_68 = [] addr = toAddr(0x001013df) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013e9) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x001013fb) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101405) inst = getInstructionAt(addr) local_68.extend(qword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x00101417) inst = getInstructionAt(addr) local_68.extend(dword_parse(inst.getOpObjects(1)[0].getValue())) addr = toAddr(0x0010141e) inst = getInstructionAt(addr) local_68.append(inst.getOpObjects(1)[0].getValue()) #print(local_68) #print(''.join(map(chr,local_68))) # step 2 xor ans = [] i = 0 while i < 0x25: ans.append(local_38[i] ^ local_68[i]) i = i + 1 #print(ans) print(''.join(map(chr,ans)))もっと美しくコードを書ければいいのに。。。
- 投稿日:2021-03-06T16:02:10+09:00
色々めんどくさいので作りながら学ぶDjango2
Djangoにアプリを作っていきます。
プロジェクト下にCRMというアプリを作成していきます。
$ python manage.py startapp cms
上記のCMSというディレクトリが作成されました。
モデルの作成
DBの定義にしたいDBモデルをcms/models.pyに入れていきます。
from django.db import models class Book(models.Model): """書籍""" name = models.CharField('書籍名', max_length=255) publisher = models.CharField('出版社', max_length=255, blank=True) page = models.IntegerField('ページ数', blank=True, default=0) def __str__(self): return self.name class Impression(models.Model): """感想""" book = models.ForeignKey(Book, verbose_name='書籍', related_name='impressions', on_delete=models.CASCADE) comment = models.TextField('コメント', blank=True) def __str__(self): return self.comment感想は書籍に紐づく、モデルとしています。
モデルを有効化します
CMSをインストールしたことをプロジェクトに教えてあげる必要があります。
これを applepie/settings.py の INSTALLED_APPS の最後に 'cms.apps.CmsConfig', という文字列で追加します。
cms/apps.pyを一度開いてみると、cmsconfigが定義されています。
確認した上でこの設定を親に反映させていきます。
以下コマンドを入力してマイグレファイルを作成していきます
>python manage.py makemigrations cms Migrations for 'cms': cms\migrations\0001_initial.py - Create model Book - Create model ImpressionこのファイルがどんなSQLなのか中身を確認します。
python manage.py sqlmigrate cms 0001 BEGIN; -- -- Create model Book -- CREATE TABLE "cms_book" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "name" varchar(255) NOT NULL, "publisher" varchar(255) NOT NULL, "page" integer NOT NULL); -- -- Create model Impression -- CREATE TABLE "cms_impression" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "comment" text NOT NULL, "book_id" integer NOT NULL REFERENCES "cms_book" ("id") DEFERRABLE INITIALLY DEFERRED); CREATE INDEX "cms_impression_book_id_b2966102" ON "cms_impression" ("book_id"); COMMIT;dbに反映していないファイルを反映させます。
>python manage.py migrate cms Operations to perform: Apply all migrations: cms Running migrations: Applying cms.0001_initial... OKページの確認
python manage.py runserverでサーバーを起動させます。
起動後http://127.0.0.1:8000/admin/ にブラウザでアクセスします。初回に入力したスーパーユーザーでログインを行ってください。
ログインすると下のような状態になっています。
ユーザーとグループしかない状態です。
cmsモデルをadmin上で編集できるようにします
cms/admin.pyに管理サイト表示したいモデルを追加します。
from django.contrib import admin from cms.models import Book, Impression admin.site.register(Book) admin.site.register(Impression)
CMSの項目が追加されているのが確認ができました。
管理サイトの一覧ページをカスタマイズ
cms/admin.pyを修正します
from django.contrib import admin from cms.models import Book, Impression # admin.site.register(Book) # admin.site.register(Impression) class BookAdmin(admin.ModelAdmin): list_display = ('id', 'name', 'publisher', 'page',) # 一覧に出したい項目 list_display_links = ('id', 'name',) # 修正リンクでクリックできる項目 admin.site.register(Book, BookAdmin) class ImpressionAdmin(admin.ModelAdmin): list_display = ('id', 'comment',) list_display_links = ('id', 'comment',) raw_id_fields = ('book',) # 外部キーをプルダウンにしない(データ件数が増加時のタイムアウトを予防) admin.site.register(Impression, ImpressionAdmin)
こんな感じになりました。
見た目を良くします
Bootstrapを使用します
*jQueryがない場合はインスコする必要あり。applepie └── cms └── static └── cms ├── css │ ├── bootstrap.min.css │ └── bootstrap.min.css.map └── js ├── bootstrap.bundle.min.js ├── bootstrap.bundle.min.js.map ├── jquery-3.4.1.min.js └── jquery-3.4.1.min.map上記のようにファイルを配置します。
Bootstrapを入れ込みます
applepie>pip install django-bootstrap4 Collecting django-bootstrap4 Downloading django_bootstrap4-2.3.1-py3-none-any.whl (24 kB) Collecting beautifulsoup4<5.0.0,>=4.8.0 Downloading beautifulsoup4-4.9.3-py3-none-any.whl (115 kB) |████████████████████████████████| 115 kB 939 kB/s Requirement already satisfied: django<4.0,>=2.2 in c:\users\8140\appdata\local\programs\python\python39\lib\site-packages (from django-bootstrap4) (3.1) Collecting soupsieve>1.2; python_version >= "3.0" Downloading soupsieve-2.2-py3-none-any.whl (33 kB) Requirement already satisfied: asgiref~=3.2.10 in c:\users\8140\appdata\local\programs\python\python39\lib\site-packages (from django<4.0,>=2.2->django-bootstrap4) (3.2.10) Requirement already satisfied: sqlparse>=0.2.2 in c:\users\8140\appdata\local\programs\python\python39\lib\site-packages (from django<4.0,>=2.2->django-bootstrap4) (0.4.1) Requirement already satisfied: pytz in c:\users\8140\appdata\local\programs\python\python39\lib\site-packages (from django<4.0,>=2.2->django-bootstrap4) (2021.1) Installing collected packages: soupsieve, beautifulsoup4, django-bootstrap4 Successfully installed beautifulsoup4-4.9.3 django-bootstrap4-2.3.1 soupsieve-2.2しっかり入ったことが確認できました
applepie>pip freeze -l appdirs==1.4.4 asgiref==3.2.10 beautifulsoup4==4.9.3 distlib==0.3.1 Django==3.1 django-bootstrap4==2.3.1 django-cors-headers==3.4.0 django-templated-mail==1.1.1 djangorestframework==3.11.1 djoser==2.0.3 filelock==3.0.12 pathtools==0.1.2 Pillow==8.1.0 pytz==2021.1 six==1.15.0 soupsieve==2.2 sqlparse==0.4.1 virtualenv==20.4.2 watchdog==0.10.3applepie/setting.pyのINSTALLED_APPS に 'bootstrap4' を追加します。
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'cms.apps.CmsConfig', # cms アプリケーション 'bootstrap4', # django-bootstrap4 )CRUD
ざっとつくります。
ファンクションが必要なので、`cms/views.py' にひな形を作ります。登録、修正は編集としてひとまとめにしています
from django.shortcuts import render from django.http import HttpResponse def book_list(request): """書籍の一覧""" return HttpResponse('書籍の一覧') def book_edit(request, book_id=None): """書籍の編集""" return HttpResponse('書籍の編集') def book_del(request, book_id): """書籍の削除""" return HttpResponse('書籍の削除')







- 投稿日:2021-03-06T15:59:43+09:00
1年間でpythonで収益化してみた
今日からpythonの勉強を始める
目標としてはこの1年で自分で案件を獲得し収益を生み出すこと多くのサイトを閲覧しこの1年の大まかな計画を立てる
その中でこのサイトの手順が最も有効だと考えた【初心者必見】プログラミング未経験から3年間のpython学習ロードマップ
基本的にこの手順に乗っ取って頑張ってみようと思う
- 投稿日:2021-03-06T15:59:43+09:00
1年間でpython収益化してみた
今日からpythonの勉強を始める
目標としてはこの1年で自分で案件を獲得し収益を生み出すこと多くのサイトを閲覧しこの1年の大まかな計画を立てる
その中でこのサイトの手順が最も有効だと考えた【初心者必見】プログラミング未経験から3年間のpython学習ロードマップ
基本的にこの手順に乗っ取って頑張ってみようと思う
- 投稿日:2021-03-06T15:36:34+09:00
PuLPで変数を沢山作るときはLpVariable.dictsを使おう
最適化をやっていると、変数を一度に沢山作る機会があります。pythonで最適化をやる際におそらく一番使われるPuLPで、その書き方を強調して書いてあるものが少なかったので、ご参考になればと思い書いときます。
3行サマリ
- 変数はpulp.LpVariablle.dictsで作成する
- 式の表現はlpSumを使う
がおすすめです。
LpVariable.dictsを使うべき理由
書き方がいくつかあるなかで、なぜLpvariable.dictsが良いのかというと、、、
理由1:リストの何番目とか分からなくなるので
他の代表的な書き方に「for文や内包表記で変数のリストを作成する」というものがあると思います。
でも、商品Aにだけこの制約を加えたい、だとか地点Bから地点Cに行くことだけは避けたい、みたいな制約を入れたいときってありますよね。リストで作成していると、その商品や地点ってリストの何番目?となるわけです。
一説によると人間が短期記憶できる数は7個程度とも言われていますし1、インドのPuri族には数を表す概念は1,2,沢山のみだそうです2。つまり数という概念は人間にとって分かりやすいものではないというわけです。私も5を超えるとだいたい途中で分からなくなって2~3回数え直します
ということで、リストの何番目かを考えるのはいまの人類には高度すぎるため、なるべく苦手なことに脳を使わないですむように辞書を用いるのが良いと思います。
理由2:公式のexampleもそれを使っているので
Docsにある例もそうですし、githubにおいてある例もそうなっています。
自分もそこまで沢山知っているわけではないですが、最適化の文脈だと辞書で作るのがひとつのスタンダードであると思います。例えばgurobiのexampleもそうでした3。長いものには巻かれときましょう。
例
ということで、じゃあ具体的にこう書くのがいいだろう、と私が考えているものを例を用いて見ていきます。
標準的なナップサック問題を解きます。題材は駄菓子にしましょう。遠足でよくある、300円までで一番魅力的な駄菓子パーティーを組む問題です。数式で書くと
\begin{align} \max ~ & \sum_{i\in I}Value_i \cdot x_i \\ s.t. ~ & \sum_{i\in I}Price_i \cdot x_i <= 300 \\ & x_i \in \{0,1\} \end{align}です。$x_i$はおかし$i$を買うならば1、買わないならば0をとる変数とします。金額の合計が300円を超えないように、価値が最大になるように買う商品を選ぶわけです。同じおかしを複数個買うようなパーティーが最強であるわけがないので、$x_i$は整数でなくてBinaryにしています。これを以降ではKnapSnack問題と呼びます。
データの取得
価格が分からないと問題が解けないので、そのデータを取得します。みんな大好き、やおきんさんのオンラインショップからスクレイピングします4。ここは記事の本題とは関係ないので、お急ぎの型は最適化パートまで飛んでも大丈夫です。
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd df = pd.DataFrame() for i in range(19): url = f'https://dagasiya.com/shop/shopbrand.html?page={i}&search=&sort=&money1=&money2=500&prize1=&company1=&content1=&originalcode1=&category=&subcategory=' res = requests.get(url) soup = BeautifulSoup(res.text, "html.parser") name = soup.find_all('p', class_='itemName') price = soup.find_all('p', class_='itemPrice') df_page = pd.DataFrame({ 'Name': [i.text for i in name], 'Price': [i.text for i in price] }) df = df.append(df_page) df = df.drop_duplicates('Name') df['Value'] = np.abs(np.random.randn(len(df))) df['Price'] = df['Price'].str[:-1].astype(int)スクレイピングは本記事の本題ではないので、さっとさらうだけにします5。
- 高すぎる駄菓子はロマンがないので、500円以下のものに絞ります
- urlのmoney2=500のところが該当します
- requestsを用いてhtmlを取得します
- BeautifulSoupを用いてパース(文字列を分かりやすい形に整理)します
- 商品名と価格に対応するcssのclassをもつ要素をすべて取得します
- 取得した結果を、pandasのDataFrameに格納します
- 以上を検索結果ページ数(19ページ)分繰り返します
さらに、最適化の都合で以下の操作を加えます。
- 同じ商品名のものがあるとどっちがどっちか分からなくなるので、商品名が重複しているものは片方省きます
- 「一番魅力的なパーティー」の定義は非常に難しい問題ですが、ここでは適当に乱数で個々の商品の価値をつけています
- 価格が「450円」のような形で取得されたので、円を削除してint型に変形します
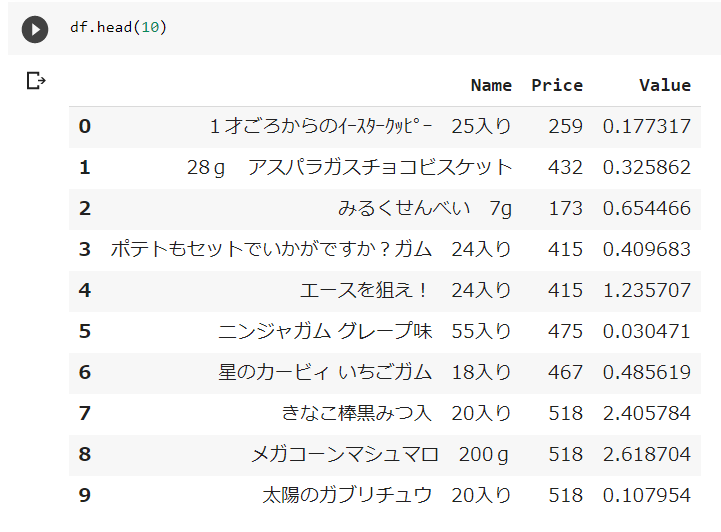
できあがったDataFrameがこちらです。
さて、困ったことに、20個入りなどの単位でしか売ってません。まあそりゃオンラインで駄菓子1個単位で打ってたら商売成り立たないか。。
まあ個数当たりの金額にしたりするのは面倒なので、無視してこのままいきましょう。
最適化の実行
price = df.set_index('Name')['Price'].to_dict() value = df.set_index('Name')['Value'].to_dict()まず、最適化に用いる定数を辞書として用意します。別にpandasのまま処理してもいいのだけど、公式のexampleと対応するように辞書にしています。
ここではkeyが商品名で、valueがそれぞれ価格や価値であるような辞書ができます。valueが被っていてイケてないですね。。すみません
では本題のPuLPの部分です。
# 問題の作成 prob = pulp.LpProblem(name='KnapSnack', sense=-1) # 変数の作成 x = pulp.LpVariable.dicts('x', df['Name'], cat='Binary') # 目的関数の追加 prob += pulp.lpSum([x[i] * value[i] for i in x.keys()]) # 制約の追加 prob += pulp.lpSum([x[i] * price[i] for i in x.keys()]) <= 30 * 300 # 求解 sol = prob.solve() # 解けているかを確認 print(pulp.LpStatus[sol]) # Optimal # 最適解を確認 print(pulp.value(prob.objective)) # 61.213647083559061. 問題の作成
2. 変数の作成:'x'が変数の名前、次に辞書のkeyに対応するもの、最後にBinary変数を指定しています。これで、keyが商品名でvalueがPuLPの変数である辞書が作成されます
3. 目的関数の追加:基本的にはlpSumを使うことになるでしょう。リスト内包表記で足し上げる要素を羅列するのをよく見ます
4. 制約の追加:先ほど見たように単位がバグってたので、一クラス分(30人×300円)を買う問題に変更していますw
5. 求解ということで、シンプルに記述できました。以下で変数の作り方について補足します。
変数の作成
LpVariable.dicts(name, indexs, lowBound=None, upBound=None, cat='Continuous', indexStart=[])引数は、nameが変数名です。indexsが辞書のkeyになるもので、文字列のリストを渡します。
他は色んなところに書いてあるのと同じなので略します。
結果
そういえば結果です。こいつらが最強のおかしパーティーです。
商品名 価格 ポイント 13 うまい棒鉛筆3種(HB・B・2B)各3本セット + 特典 475 1.958077 19 つけつけペロスティックチョコ 6入り 311 0.360806 2 新サワーコーラグミ 60入り 518 1.042587 18 ペンシルカルパス 20入り 518 0.017585 23 ガブリチュウ・グレープ 20入り 518 0.144169 3 オレンジマーブルガム 24入り 311 0.260376 4 ドラえもんマーブルガム 24入り 311 0.464725 12 もちっときなこ餅 20入り 518 0.310539 20 カジリッチョ サイダー味 20入り 518 0.962775 12 フルーツモンスターレインボー味 12入り 518 0.909126 5 BR 出前寿司セット 1個 385 1.410559 9 BR 富士山と神社 1個 385 0.937255 18 BR スポーツセット 1個 385 0.180035 0 BR お寿司 1個 385 1.340095 1 BR お料理 1個 385 0.490019 12 こんぺいとう 20個入 518 0.438453 14 塩吉原羊かん 12入り 259 1.477365 16 ミニしみチョココーン ミルクチョコ 10入り 432 1.221638 8 ましゅろー 30入り 259 1.519683 21 もちもちきなこ 12入り 518 0.700150 8 変わり味 ギョギョギョガム 20入り 518 0.291298 1 ゾンBのもとガム 18入り 467 1.365611 2 ドラQラのもとガム 18入り 467 0.864054 18 うまい棒お箸 小 とんかつソース 1膳 317 0.239067 19 うまい棒お箸 大 とんかつソース 1膳 317 0.755195 11 うまい棒フォーク タコヤキ 1本 317 0.292592 14 うまい棒フォーク チーズ 1本 317 0.891636 20 フライドポテト 30入り 518 1.119859 18 うまい棒プチマスコット・メンタイ 1個 288 1.381736 19 うまい棒プチマスコット・ソース 1個 288 0.615968 8 うまい棒やさいサラダ味 30本 259 0.981209 10 うまい棒とんかつソース味 30本 259 1.491541 まあ結局価値のところを乱数で出しているので大して意味のある結果にはなっていませんが、やっぱりうまい棒は強いですね。うまい棒最強。あとお寿司がしれっと混ざっているのは笑いました。
おまけ
実は他にもこんなのがあるけど、あまり推奨されてないんじゃないかな、というものです。
自作で変数のリストを作る
散々本記事で書いている通りです。や、手元でサッと作るだけとか、規模が大きくないとかなら問題ないとは思います。
LpVariable.matrix
LpVariable.dictsと同じノリで変数の行列を作ってくれるメソッドがあります。しかし、辞書のほうが良いということで機能としてはあるもののドキュメントには載っていません6。
lpDot
lpSumと同じノリで内積($\sum_i x_i p_i$みたいな)を計算してくれる関数が存在します。しかしこれも辞書とは相性が悪いので(リストとかだとi番目同士を掛けるけど、辞書に対しては...)、こちらもドキュメントに載っていません。
まあ色々な条件のもとでの実験の結果で、適切な解釈はだいぶ違うのでしょうが。https://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A7%E3%83%BC%E3%82%B8%E3%83%BB%E3%83%9F%E3%83%A9%E3%83%BC_(%E5%BF%83%E7%90%86%E5%AD%A6%E8%80%85) ↩
ちゃちゃっと調べただけなので少し古い論文ですが、こちらなどが参考です。https://opera.repo.nii.ac.jp/?action=repository_action_common_download&item_id=6500&item_no=1&attribute_id=19&file_no=1 ↩
https://www.gurobi.com/documentation/9.1/examples/diet_py.html ↩
こちらのページです:https://dagasiya.com/shop/shopbrand.html?page=1&search=&sort=&money1=&money2=500&prize1=&company1=&content1=&originalcode1=&category=&subcategory= ↩
ちなみに余談ですが、やおきんさんのオンラインショップはスクレイピングするのにちょうどいい題材だと感じました(複雑すぎることもないし、きれいなコードで作られている気がしました)。スクレイピング初心者におすすめです。 ↩
ドキュメントにないのはそれはそれで分かりにくいので、載せたうえで非推奨とかって書いてほしいものですけどね。 ↩
- 投稿日:2021-03-06T15:35:56+09:00
MLPG:Maximum Likelihood Parameter Generationとは
MLPG
Maximum Likelihood Parameter Generationについて書きます。
DeepLearningなど機械学習では
\begin{align} \boldsymbol{y} &= f_\theta (\boldsymbol{x}) \\ \theta &= argmin_\theta[ Loss(\boldsymbol{y}, \hat{\boldsymbol{y}}) ] \end{align}のように、入力$\boldsymbol{x}$から関数$f$を通して$\boldsymbol{y}$を出力するモデルを考えたりします。
このとき教師データ$\hat{\boldsymbol{y}}$と出力$\boldsymbol{y}$間のLossを最小化する関数パラメータ$\theta$を求めるのが学習ブロックです。ただ、この特徴量$\boldsymbol{x}$は大抵が時刻$t$における特徴量です。
できれば前後の時刻との相関というか時間変化も捉えて学習した方が良さそうですよね???
(とは言え、MLPGでは「生成した特徴量の、時間方向の連続性が破綻してて音質が悪い!」のを防ぐことが目的で、音声の時間変化成分に含まれる個人性を捉えれるかどうかは別だと思います。せいぜい近傍10〜20msしか捉えられないので。)なので例えば
\begin{align} \boldsymbol{x} &= [\boldsymbol{x_1}^T, \boldsymbol{x_2}^T, \cdots, \boldsymbol{x_T}^T]^T \\ &(\boldsymbol{x_t} = [x_{1t}, x_{2t}, \cdots, x_{Dt}]^T) \end{align}という静的特徴量$\boldsymbol{x}$に動的特徴量を含んだ特徴量$\boldsymbol{X}$
\begin{align} \boldsymbol{X} &= [\boldsymbol{X_1}^T, \boldsymbol{X_2}^T, \cdots, \boldsymbol{X_T}^T]^T \\ &(\boldsymbol{X_t} = [\boldsymbol{x_t}^T, \Delta\boldsymbol{x_t}^T]) \end{align}を扱います。
それで\begin{align} \boldsymbol{Y} &= f_\theta (\boldsymbol{X}) \\ \theta &= argmin_\theta[ Loss(\boldsymbol{y}, \hat{\boldsymbol{y}}) ] \\ &= argmin_\theta[ Loss(\boldsymbol{RY}, \hat{\boldsymbol{y}}) ] \end{align}というように、静的・動的特徴量$\boldsymbol{X}$を入力したら出力$\boldsymbol{Y}$を求めるモデルを考えます。
そのモデルのパラメータ$\theta$ は $\boldsymbol{RY} (= y)$ と $\hat{\boldsymbol{y}}$のロスを最小化するように学習します。ここで重要なのは静的・動的特徴量と静的特徴量間の変換行列$\boldsymbol{R}$をどうやって産むかということです。
次節以降、もう少し具体的に必要な行列とかに関する算出方法のメモとコードを記します。
ちょいと数学
ここでやるのは$\boldsymbol{X} = \boldsymbol{Wx}$ なる変換行列$\boldsymbol{W}$ と
$\boldsymbol{x} = \boldsymbol{RX}$ なる変換行列$\boldsymbol{R}$を求めることです。X = Wx について
※今回は$\Delta\boldsymbol{x}$までしか扱いません。記事や図、コードを書くのが楽なので。さらに$\Delta\Delta\boldsymbol{x}$も考慮したって理屈は同じです。
では本題
記事では$\boldsymbol{x}$とか$\boldsymbol{y}$とか入り混じってますが、
大文字と小文字間の変換なので意味は変わりません。ごめんなさい。図にしてみました!
この行列$\boldsymbol{W}$が言いたいところは
\Delta\boldsymbol{y_t} = -0.5\boldsymbol{y_{t-1}} + 0.5\boldsymbol{y_{t+1}}だよっていうだけです。
x = RX について
\boldsymbol{R} = (\boldsymbol{W}^T\Sigma^{-1}\boldsymbol{W})^{-1}\boldsymbol{W}^T\boldsymbol{\Sigma}^{-1}$\boldsymbol{\Sigma}$は$\boldsymbol{X}$の共分散行列です。
「W」算出の実装しまーす
import scipy.sparse import numpy as np def computeW(T, D): for t in range(T): w0 = scipy.sparse.lil_matrix((D, D * T)) w1 = scipy.sparse.lil_matrix((D, D * T)) w0[0:, t * D:(t + 1) * D] = scipy.sparse.diags(np.ones(D), 0) if t >= 1: tmp1 = np.zeros(D) tmp1.fill(-0.5) w1[0:, (t - 1) * D:t * D] = scipy.sparse.diags(tmp1, 0) if t < T-1: tmp1 = np.zeros(D) tmp1.fill(0.5) w1[0:, (t + 1) * D:(t + 2) * D] = scipy.sparse.diags(tmp1, 0) W_t = scipy.sparse.vstack([w0, w1]) if t == 0: W = W_t else: W = scipy.sparse.vstack([W, W_t]) W = scipy.sparse.csr_matrix(W) return Wでは解説しまーす。
方針は、2D行DT列の行列を1まとまりとして考えます。
最初のD行が静的特徴量、次のD行が動的特徴量に関連します。w0 = scipy.sparse.lil_matrix((D, D*T))これは、D行DT列のゼロ行列w0を生成します。時刻tにおける静的特徴量に関連する行ブロックです。
次のw1は動的特徴量の算出を担当します。例えば音声だとDはメルケプストラムなどで39次元とかありますし、Tは発話単位のフレーム数で1000次元くらいあるので素直にnumpy.arrayを使うと1521000個の要素を持ちます。大変な事ですね。
なのでscipyのスパース行列を利用します。
- どのインデックスに0以外の値を持つか
- そこにどの値が入ってるか
という情報だけを格納します。なので今回みたいな0が大半を占める行列を扱う時にはもってこいなわけです。w0[0:, t*D:(t+1)*D] = scipy.sparse.diags(np.ones(D), 0)さっき乗せた図の各マスはD行D列の対角行列で、対角要素はマス目の数字です。
まず、「1」が入ってるところに注目してください。
時刻tにおけるブロック(2D行TD列)の上段で、t*D:(t+1)*D列に「1」が割り当てられてます。
つまり、そこのマス(D行D列のサブ行列)が単位行列になります。
上記のコードはそれを意味してます。if t >= 1: tmp1 = np.zeros(D) tmp1.fill(-0.5) w1[0:, (t - 1) * D:t * D] = scipy.sparse.diags(tmp1, 0)今度は「-0.5」に注目します。
まぁやりたいことは、「1」のときと同じなので、さっきの図を見ながら呼んでくれればわかるかと思います。if t < T-1: tmp1 = np.zeros(D) tmp1.fill(0.5) w1[0:, (t + 1) * D:(t + 2) * D] = scipy.sparse.diags(tmp1, 0)今度は「0.5」です。詳細は今までと同じ感じです。
次、
W_t = scipy.sparse.vstack([w0, w1]) if t == 0: W = W_t else: W = scipy.sparse.vstack([W, W_t]) W = scipy.sparse.csr_matrix(W)w0とv1を垂直結合します。最初に「2D行DT列を1まとまりとして」と言いました。
これで1まとまりのブロックの完成です。あとはそれをT回繰り返してがっちゃんこすれば
2DT行DT列の行列$\boldsymbol{W}$の完成です。やったー!!!「R」算出の実装しまーす
def covar_matrix(Y, T, D): Y_mat = Y.reshape(T, int(len(Y)/T)) S_vec = np.var(Y_mat, axis=0) M = len(S_vec) diagonal_t = 1.0/S_vec S_inv = np.zeros((T, M, M)) for t in range(T): S_inv[t] = np.diag(diagonal_t) S_inv = scipy.sparse.block_diag(S_inv, format='csr') return S_invまず$\Sigma^{-1}$を求めます。共分散行列の逆行列です。ただし簡易化するために今回は対角行列化したただの分散行列にします。
対角行列の逆行列は、対角成分の逆数をとれば良いだけなのでめっちゃ簡単です。次、
def computeR(W, S_inv): R1 = W.T.dot(S_inv).dot(W) R1 = scipy.sparse.linalg.inv(R1) R2 = W.T.dot(S_inv) R = R1.dot(R2) return R\boldsymbol{R} = (\boldsymbol{W}^T\Sigma^{-1}\boldsymbol{W})^{-1}\boldsymbol{W}^T\boldsymbol{\Sigma}^{-1}を計算してます。
全体コード
import scipy.sparse import numpy as np def computeW(T, D): for t in range(T): w0 = scipy.sparse.lil_matrix((D, D * T)) w1 = scipy.sparse.lil_matrix((D, D * T)) w0[0:, t * D:(t + 1) * D] = scipy.sparse.diags(np.ones(D), 0) if t >= 1: tmp1 = np.zeros(D) tmp1.fill(-0.5) w1[0:, (t - 1) * D:t * D] = scipy.sparse.diags(tmp1, 0) if t < T-1: tmp1 = np.zeros(D) tmp1.fill(0.5) w1[0:, (t + 1) * D:(t + 2) * D] = scipy.sparse.diags(tmp1, 0) W_t = scipy.sparse.vstack([w0, w1]) if t == 0: W = W_t else: W = scipy.sparse.vstack([W, W_t]) W = scipy.sparse.csr_matrix(W) return W def covar_matrix(Y, T, D): Y_mat = Y.reshape(T, int(len(Y)/T)) S_vec = np.var(Y_mat, axis=0) M = len(S_vec) diagonal_t = 1.0/S_vec S_inv = np.zeros((T, M, M)) for t in range(T): S_inv[t] = np.diag(diagonal_t) S_inv = scipy.sparse.block_diag(S_inv, format='csr') return S_inv def computeR(W, S_inv): R1 = W.T.dot(S_inv).dot(W) R1 = scipy.sparse.linalg.inv(R1) R2 = W.T.dot(S_inv) R = R1.dot(R2) return R def super2static(Y, W, T, D): S_inv = covar_matrix(Y, T, D) R = limitationR(W, S_inv) return R.dot(Y) def static2super(y, T, D): y_ = y.reshape(T*D, 1) W = computeW(T, D) Y = W.dot(y_) return Y, WDeepLearningに組み込む
よく見るのはMSE基準による最適化です。
L = \frac{1}{T}(\boldsymbol{y} - \hat{\boldsymbol{y}})^T(\boldsymbol{y} - \hat{\boldsymbol{y}})単に教師データ$\boldsymbol{y}$と生成データ$\hat{\boldsymbol{y}}$の誤差を
フレーム方向に(データ数方向に)平均してます。ただこのとき、$\boldsymbol{y}$はある関数$f$を介して入力$\boldsymbol{x}$から生成されたデータとします。
$\boldsymbol{x}$はミニバッチ学習などを採用していれば、無造作に選ばれたN個のデータからなるので
n番目のデータとn+1番目のデータに繋がりはありません。MGE基準の最適化
こいつはMinimum-Generation-Errorのことで、
\begin{align} L &= \frac{1}{T}(\boldsymbol{RY} - \hat{\boldsymbol{y}})^T(\boldsymbol{RY} - \hat{\boldsymbol{y}}) \\ \boldsymbol{Y} &= f(\boldsymbol{x}) \end{align}のように、静的・動的特徴量を出力するモデルに対して、本来欲しい静的特徴量間の誤差を用いて最適化します。
※もし音声変換ならモデルの入力は$\boldsymbol{X}$などなので、この状況下では
- ミニバッチ単位では無く、1塊のデータ単位での学習(例えば1発話など)
※その都度$\boldsymbol{Y}$から制約行列$\boldsymbol{R}$を推定
になります。
これが「Generation」の由来でしょうかね。今回はscipyのスパース行列でMLPGを実装しましたが、DeepLearningをPyTorchで実装するならMLPGもそれに対応させる必要があります。
それは疲れたのでまたいつかやります。まとめ
ということで今回はMLPGとMGE基準についてメモを書きました。
細かいミスはごめんなさい。
勘違いや誤りがあれば教えていただけると幸いです。。。

- 投稿日:2021-03-06T14:53:59+09:00
Python,AI関連の英語語源の調査
概要
(特に分野を限定するものではないですが、)英語がなんとなくしっくりこない場合に語源を調べたりすると思う。
いま現在であれば、以下のサイトの語源が詳しいことがよく知られている。
etymonline.com を使う場合の注意事項
以下の注意事項がある(逐次追加)
- 予備知識が必要。主に、ヨーロッパの歴史を少し知らないと、なんのことかわからない場合がある。
予備知識
ヨーロッパの時代区分
(↓ Wikipediaを参考にしたと思う。)
時代 境界 古代 西ローマ帝国の滅亡 中世 東ローマ帝国の滅亡、ルネサンス、大航海時代、宗教改革 近世 市民革命(特にフランス革命)、産業革命 近代 ここでポイントは、以下。
- 中世の一部は、「暗黒時代」とも呼ばれており、あまり、どんどん文明とかが発展するようないい時代ではなかったらしい。民族の移動とかの影響のためか?。このあたりが日本とかとは、すこし、ノリの違うところか。(←歴史の話なので、違う意見や、見解の見直しなど、いろいろあるが。。。。)
以下は、中世の様子。えって、感じ。
Wikipedia(https://en.wikipedia.org/wiki/Middle_Ages)より引用。
語源調査結果
(20回に1回ぐらい、調べて良かったと思うことあり。そのあたりのよかった単語を、紹介する。後報)
まとめ
特にありません。


- 投稿日:2021-03-06T14:42:03+09:00
PyTorchのチュートリアルA 60 MINUTE BLITZをやってみた
PyTorchのチュートリアルA 60 MINUTE BLITZをやってみました
https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html1. インストール
公式ページに行くと環境に合わせたインストールコマンドを教えてもらえます
https://pytorch.org/get-started/locally/
上記ではPython版Stable versionをWindows + CUDA10.1環境にpipでインストールする場合のコマンドが表示されています。公式ではcondaでのインストールを推奨しているようですがpipでインストールに失敗したことがないのでpipでも大丈夫だと思います。なお、python2系は対応してないのでpython3系環境にインストールしましょう。正常にインストールされていれば以下を実行出来る筈です
python>>> import torch >>> x = torch.rand(5, 3) >>> print(x) tensor([[0.4095, 0.9509, 0.5004], [0.7022, 0.7838, 0.8452], [0.6560, 0.2921, 0.4012], [0.1274, 0.6157, 0.4293], [0.2008, 0.7606, 0.0061]])CUDAが有効になっているか確認しておきます
python>>> import torch >>> torch.cuda.is_available() True問題ないようです
2. tensorの扱い方
np.array的な感じで使えるようになっています
https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor-tutorial-py2-1. torch.tensorを作る
ゼロ埋め、1埋めのtensorを作る
python>>> torch.ones(2, 2) tensor([[1., 1.], [1., 1.]]) >>> torch.zeros(2, 2) tensor([[0., 0.], [0., 0.]])乱数でtensorを作る
python>>> torch.rand(2, 2, dtype=torch.float) tensor([[0.0020, 0.1918], [0.4320, 0.5111]])listからtensorを作る
python>>> import torch >>> import numpy as np >>> data = [[1, 2],[3, 4]] >>> x_data = torch.tensor(data) >>> x_data tensor([[1, 2], [3, 4]])np.ndarrayからtensorを作る
python>>> arr = np.array([[1, 2],[3, 4]]) >>> x_data = torch.tensor(arr) >>> x_data tensor([[1, 2], [3, 4]], dtype=torch.int32)python>>> x_data = torch.from_numpy(arr) >>> x_data tensor([[1, 2], [3, 4]], dtype=torch.int32)ちなみにtorch.from_numpy()で作った場合には元のnumpy.ndarrayに何やら仕込んでくれるようで、元になったnumpy.ndarrayオブジェクトの計算結果を作ったtensorに反映することが出来ます。
python>>> n = np.ones(5) >>> t = torch.from_numpy(n) >>> t2 = torch.tensor(n) >>> print(f"t: {t}") >>> print(f"n: {t2}") >>> print(f"n: {n}", '\n') t: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: [1. 1. 1. 1. 1.] >>> np.add(n, 1, out=n) >>> print(f"t: {t}") >>> print(f"n: {t2}") >>> print(f"n: {n}") t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64) n: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: [2. 2. 2. 2. 2.]tensorからnp.ndarrayを作る
numpy.arrayを作りたい場合は以下で作れます
pythonarr = np.array(x_data) arrnumpy()メソッドを使ってnumpy.arrayを作ることもできます
pythonarr = x_data.numpy() arrこちらもnumpy()メソッドで作ったnumpy.ndarrayっぽいオブジェクトには何やら仕込まれているようで、元になったオブジェクトへの変更を反映することが出来ます。
python>>> t = torch.ones(5) >>> n = t.numpy() >>> arr = np.array(t) >>> print(f"t: {t}") >>> print(f"n: {n}") >>> print(f"arr: {arr}", '\n') t: tensor([1., 1., 1., 1., 1.]) n: [1. 1. 1. 1. 1.] arr: [1. 1. 1. 1. 1.] >>> t.add_(1) >>> print(f"t: {t}") >>> print(f"n: {n}") >>> print(f"arr: {arr}") t: tensor([2., 2., 2., 2., 2.]) n: [2. 2. 2. 2. 2.] arr: [1. 1. 1. 1. 1.]2-2. tensorをcudaで扱えるようにする
PyTorchは同じ環境でCPUとGPUの両方が使えるようになっていて、どちらを使うのかをtensorやmodelのモード切り替えで明確にする仕組みのようです。
GPUで扱う
to('cuda')で切り替える際にCUDAデバイスへの割り当てが行われて、どのCUDAデバイスに割り当てられているかが表示されるようになります
python>>> tensor = torch.tensor([[1, 2], [1, 2]]) >>> if torch.cuda.is_available(): >>> tensor = tensor.to('cuda') >>> tensor tensor([[1, 2], [1, 2]], device='cuda:0')to('cuda')の代わりにcuda()でも同じです
python>>> tensor = tensor.cuda() >>> tensor tensor([[1, 2], [1, 2]], device='cuda:0')CPUで扱う
CPUで扱うように戻すことも出来ます
python>>> tensor = tensor.to('cpu') >>> tensor tensor([[1, 2], [1, 2]])python>>> tensor = tensor.cuda() >>> tensor tensor([[1, 2], [1, 2]])2-3. tensorの一部を書き換える
python>>> tensor = torch.ones(4, 4) >>> tensor[:, 1] = 0 >>> tensor[3, 2] = 4 >>> print(tensor) tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 4., 1.]])2-4. tensorの計算
使えるメソッドは以下にまとまっています
https://pytorch.org/docs/stable/torch.htmlスカラー和
python>>> arr = np.arange(6).reshape(2, 3) >>> tensor = torch.tensor(arr) >>> print(tensor, '\n') tensor([[0, 1, 2], [3, 4, 5]], dtype=torch.int32) >>> print(tensor + 5, '\n') >>> print(tensor, '\n') tensor([[ 5, 6, 7], [ 8, 9, 10]], dtype=torch.int32) tensor([[0, 1, 2], [3, 4, 5]], dtype=torch.int32) >>> tensor = tensor + 5 >>> print(tensor) tensor([[ 5, 6, 7], [ 8, 9, 10]], dtype=torch.int32)要素ごとの積
python>>> tensor = torch.ones(4, 4) >>> tensor[:, 1] = 0 >>> print(tensor, '\n') tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]]) >>> # This computes the element-wise product >>> print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n") >>> # Alternative syntax: >>> print(f"tensor * tensor \n {tensor * tensor}") tensor.mul(tensor) tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]]) tensor * tensor tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])行列積
python>>> print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n") tensor.matmul(tensor.T) tensor([[3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.]]) >>> # Alternative syntax: >>> print(f"tensor @ tensor.T \n {tensor @ tensor.T}") tensor @ tensor.T tensor([[3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.]])3. autogradについて
逆誤差伝搬による微分を実現するtorch.autogradの動作を解説してくれています
https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-pytorch.autogradのAPIリファレンス
https://pytorch.org/docs/stable/autograd.html3-1. 勾配の算出とoptimize
学習済みresnet18モデルに乱数で作ったデータをつっこんで勾配を算出してみましょう
モデルの読み込みとデータの作成
pythonimport numpy as np import torch, torchvision import matplotlib.pyplot as plt model = torchvision.models.resnet18(pretrained=True) data = torch.rand(1, 3, 64, 64) labels = torch.rand(1, 1000) arr = np.array(data) im = np.stack([arr[0, k, :, :] for k in range(3)], axis=2) plt.imshow(im) plt.show() plt.plot(labels[0]) plt.show()
乱数なので画像もlabelも当然意味をなさない値が入っていますがとりあえずやってみるだけなので気にしないで進めます予測を実行
modelにデータを放り込めば推定してくれます
pythonprediction = model(data) # forward pass print(prediction.shape) plt.plot(prediction[0].detach(), label='prediction') plt.plot(labels.numpy()[0], label='labels') plt.legend() plt.show()
乱数で作った画像を放り込まれたモデルが気の毒になりますlossを算出
lossを算出します
python>>> loss = (prediction - labels).sum() >>> loss.backward() # backward pass >>> loss tensor(-503.5731, grad_fn=<SumBackward0>)勾配算出の為に何やら付いてますね
optimizerを作ってパラメーターを更新する
python>>> optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9) >>> optim.step() #gradient descentこれでパラメーターの更新が完了です
実際の学習では乱数ではなく何かが写ったまともな画像と正解ラベルをバッチ枚数ごとに放り込んでいって、学習データ全体がepoch回学習されるように繰り返すわけですね。この辺、実際の画像でデモした方が分かりやすい気がするんですがこの手のライブラリを作るような人にはこれで充分ということなのかも知れません。
3-2. autogradの動作
以下のような関数を微分することを考えてみます
Q = 3a^3 + b^2a, bで偏微分すると以下のようになります
\frac{\delta Q}{\delta a} = 9a^2 \\ \frac{\delta Q}{\delta b} = 2bこれをtorch.autogradにやってもらいましょう
a, bをつくる
pythonimport torch a = torch.tensor([2., 3.], requires_grad=True) b = torch.tensor([6., 4.], requires_grad=True)a, bの関数Qをつくる
python>>> Q = 3 * a ** 3 - b ** 2 >>> Q tensor([-12., 65.], grad_fn=<SubBackward0>)Qの偏微分を実行
先程と同様にbackward()すれば偏微分が実行されますが、torchはloss functionのようなスカラー量が求まる関数しか偏微分できませんので、Qをどう足し合わせるか指定してやる必要があります。行列を引数として渡してやれば内積して得られた値を使ってやってくれますので、以下ではそれぞれ1倍して足し合わせた値を使ってやってくれます。
python>>> external_grad = torch.tensor([1., 1.]) >>> Q.backward(gradient=external_grad) >>> # check if collected gradients are correct >>> print(9*a**2 == a.grad, a.grad) >>> print(-2*b == b.grad, b.grad) tensor([False, False]) tensor([18.0000, 40.5000]) tensor([False, False]) tensor([-6., -4.])a, bを微分して得られる9a^2と-2bが得られているのが分かります
3-3. 微分を算出しないノードを指定する
requires_gradを省略するかrequires_grad=Falseにすると偏微分が算出されなくなります。偏微分の算出は計算コストが掛かりますので、学習する必要がないパラメーターについては偏微分を算出しないように設定するのが良いようです。
pythonx = torch.rand(5, 5) y = torch.rand(5, 5) z = torch.rand((5, 5), requires_grad=True) a = x + y print(f"Does `a` require gradients? : {a.requires_grad}") b = x + z print(f"Does `b` require gradients?: {b.requires_grad}")3-4. モデルの微分を算出しないように設定する
学習済みモデルを別のモデルに組み込んで学習をかけるような場合にモデルの学習を行わないようにするには以下のようにしてやります。model.parameters()で偉えるモデルのそれぞれのパラメーターにあたるtensorのrequires_gradをFalseにしてやるわけですね。
pythonfrom torch import nn, optim model = torchvision.models.resnet18(pretrained=True) # Freeze all the parameters in the network for param in model.parameters(): param.requires_grad = False model.fc = nn.Linear(512, 10) # Optimize only the classifier optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)4. CNNをやってみる
ようやく実際のneural networkのデモに到着しました
https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html#sphx-glr-beginner-blitz-neural-networks-tutorial-py4-1. ネットワークをつくる
PyTorchでは以下のような書き方でネットワークをつくるようです。クラスとして扱うのはtensorflowと同様ですが、こちらの方が書き方の自由度は高そうです。
pythonimport torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 1 input image channel, 6 output channels, 3x3 square convolution # kernel self.conv1 = nn.Conv2d(1, 6, 3) self.conv2 = nn.Conv2d(6, 16, 3) # an affine operation: y = Wx + b self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features net = Net() print(net)畳み込み2層と全結合2層+出力1層のネットワークが構築されました
outputNet( (conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=576, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )4-2. パラメーターの確認方法
parameters()メソッドでパラメーターを取得できます。weight, biasの順で入っているので5層だと10個のパラメーターがあることになります。
python>>> params = list(net.parameters()) >>> print(len(params)) 10parameters()はtorch.tensor形式のパラメーターをlistに入れて出してくれるので、例えば1層目のweightは以下のようにすれば見られます
python>>> print(params[0].size(), '\n') # conv1's .weight >>> print(params[0]) torch.Size([6, 1, 3, 3]) Parameter containing: tensor([[[[-0.2333, 0.2431, 0.1944], [ 0.0508, 0.0473, 0.0961], [ 0.2589, -0.0621, -0.3103]]], [[[-0.1810, -0.3264, 0.2296], [ 0.1090, -0.1363, 0.2106], [-0.1993, 0.1884, 0.2740]]], [[[-0.1940, 0.2546, -0.1444], [ 0.2365, -0.2924, 0.0217], [ 0.3072, -0.0517, -0.1252]]], [[[ 0.3191, -0.2198, -0.1129], [-0.1344, -0.0281, 0.3153], [-0.2891, 0.1994, -0.2489]]], [[[ 0.2201, 0.1512, -0.2975], [-0.2770, 0.1493, 0.0099], [ 0.0210, 0.3213, 0.2986]]], [[[-0.0330, -0.3037, -0.0267], [-0.2693, -0.1042, -0.0520], [-0.0537, -0.2117, -0.0070]]]], requires_grad=True)4-3. 推定する
乱数で入力データを作ってネットワークに通してみます。ネットワーク自体も初期値として入力した乱数がパラメーターとして入っているだけの意味をなさないものなので、まあなんか出てきましたというだけの出力になりますが、とりあえずのデモという事ですね。
python>>> input = torch.randn(1, 1, 32, 32) >>> out = net(input) >>> print(out.shape, '\n') >>> print(out) torch.Size([1, 10]) tensor([[-0.0469, 0.0536, 0.0633, -0.0827, -0.0329, 0.0237, -0.0360, 0.0352, -0.0768, -0.1269]], grad_fn=<AddmmBackward>)inputってpythonの標準関数に同じ名前のものがあるので使わない方が良い気がするんですが、まあチュートリアルなので気にせずいきましょう。
4-4. lossを算出する
以下ではloss functionとしてmseを使ってlossを算出しています
pythonoutput = net(input) target = torch.randn(10) # a dummy target, for example target = target.view(1, -1) # make it the same shape as output criterion = nn.MSELoss() loss = criterion(output, target) print(loss)lossを定義するときに勾配算出の為の関数も登録されます
python>>> print(loss.grad_fn) # MSELoss >>> print(loss.grad_fn.next_functions[0][0]) # Linear >>> print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU <MseLossBackward object at 0x0000020A362DF908> <AddmmBackward object at 0x0000020A362DF708> <AccumulateGrad object at 0x0000020A362DF908>4-5. 勾配の算出
autogradは前回の勾配を覚えておいてbackward()したときに今回の勾配と足し合わせて返してくれますが、CNNだとその必要はないのでzero_grad()により前回の勾配を消してから微分します
python>>> net.zero_grad() # zeroes the gradient buffers of all parameters >>> print('conv1.bias.grad before backward') >>> print(net.conv1.bias.grad) conv1.bias.grad before backward tensor([0., 0., 0., 0., 0., 0.]) >>> loss.backward() >>> print('conv1.bias.grad after backward') >>> print(net.conv1.bias.grad) conv1.bias.grad after backward tensor([ 0.0004, 0.0189, 0.0209, -0.0024, 0.0032, 0.0082])4-6. 学習の反映
例えばSGDなら以下のようにすれば更新できます
pythonlearning_rate = 0.01 for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate)一般的なoptimizerはクラスを用意してくれていますのでそれを使えば良いようです
https://pytorch.org/docs/stable/optim.htmloptimizerの定義からlossの算出、パラメーターの更新までを通してやると以下のようになります
pythonimport torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) # in your training loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criterion(output, target) loss.backward() optimizer.step() # Does the update5. まとめ
PyTorchの挙動を強く意識させる内容になっていて、tensorflowなどで既にneural networkに慣れている人向けのチュートリアルかもしれません。おかげでautogradの挙動への理解は結構進みましたが初めて触る人がここから入るとちょっと分かりにくいかも。




- 投稿日:2021-03-06T14:42:03+09:00
PyTorchのチュートリアルをやってみた
PyTorchのチュートリアルA 60 MINUTE BLITZをやってみました
https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html1. インストール
公式ページに行くと環境に合わせたインストールコマンドを教えてもらえます
https://pytorch.org/get-started/locally/
上記ではPython版Stable versionをWindows + CUDA10.1環境にpipでインストールする場合のコマンドが表示されています。公式ではcondaでのインストールを推奨しているようですがpipでインストールに失敗したことがないのでpipでも大丈夫だと思います。なお、python2系は対応してないのでpython3系環境にインストールしましょう。正常にインストールされていれば以下を実行出来る筈です
python>>> import torch >>> x = torch.rand(5, 3) >>> print(x) tensor([[0.4095, 0.9509, 0.5004], [0.7022, 0.7838, 0.8452], [0.6560, 0.2921, 0.4012], [0.1274, 0.6157, 0.4293], [0.2008, 0.7606, 0.0061]])CUDAが有効になっているか確認しておきます
python>>> import torch >>> torch.cuda.is_available() True問題ないようです
2. tensorの扱い方
np.array的な感じで使えるようになっています
https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor-tutorial-py2-1. torch.tensorを作る
ゼロ埋め、1埋めのtensorを作る
python>>> torch.ones(2, 2) tensor([[1., 1.], [1., 1.]]) >>> torch.zeros(2, 2) tensor([[0., 0.], [0., 0.]])乱数でtensorを作る
python>>> torch.rand(2, 2, dtype=torch.float) tensor([[0.0020, 0.1918], [0.4320, 0.5111]])listからtensorを作る
python>>> import torch >>> import numpy as np >>> data = [[1, 2],[3, 4]] >>> x_data = torch.tensor(data) >>> x_data tensor([[1, 2], [3, 4]])np.ndarrayからtensorを作る
python>>> arr = np.array([[1, 2],[3, 4]]) >>> x_data = torch.tensor(arr) >>> x_data tensor([[1, 2], [3, 4]], dtype=torch.int32)python>>> x_data = torch.from_numpy(arr) >>> x_data tensor([[1, 2], [3, 4]], dtype=torch.int32)ちなみにtorch.from_numpy()で作った場合には元のnumpy.ndarrayに何やら仕込んでくれるようで、元になったnumpy.ndarrayオブジェクトの計算結果を作ったtensorに反映することが出来ます。
python>>> n = np.ones(5) >>> t = torch.from_numpy(n) >>> t2 = torch.tensor(n) >>> print(f"t: {t}") >>> print(f"n: {t2}") >>> print(f"n: {n}", '\n') t: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: [1. 1. 1. 1. 1.] >>> np.add(n, 1, out=n) >>> print(f"t: {t}") >>> print(f"n: {t2}") >>> print(f"n: {n}") t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64) n: tensor([1., 1., 1., 1., 1.], dtype=torch.float64) n: [2. 2. 2. 2. 2.]tensorからnp.ndarrayを作る
numpy.arrayを作りたい場合は以下で作れます
pythonarr = np.array(x_data) arrnumpy()メソッドを使ってnumpy.arrayを作ることもできます
pythonarr = x_data.numpy() arrこちらもnumpy()メソッドで作ったnumpy.ndarrayっぽいオブジェクトには何やら仕込まれているようで、元になったオブジェクトへの変更を反映することが出来ます。
python>>> t = torch.ones(5) >>> n = t.numpy() >>> arr = np.array(t) >>> print(f"t: {t}") >>> print(f"n: {n}") >>> print(f"arr: {arr}", '\n') t: tensor([1., 1., 1., 1., 1.]) n: [1. 1. 1. 1. 1.] arr: [1. 1. 1. 1. 1.] >>> t.add_(1) >>> print(f"t: {t}") >>> print(f"n: {n}") >>> print(f"arr: {arr}") t: tensor([2., 2., 2., 2., 2.]) n: [2. 2. 2. 2. 2.] arr: [1. 1. 1. 1. 1.]2-2. tensorをcudaで扱えるようにする
PyTorchは同じ環境でCPUとGPUの両方が使えるようになっていて、どちらを使うのかをtensorやmodelのモード切り替えで明確にする仕組みのようです。
GPUで扱う
to('cuda')で切り替える際にCUDAデバイスへの割り当てが行われて、どのCUDAデバイスに割り当てられているかが表示されるようになります
python>>> tensor = torch.tensor([[1, 2], [1, 2]]) >>> if torch.cuda.is_available(): >>> tensor = tensor.to('cuda') >>> tensor tensor([[1, 2], [1, 2]], device='cuda:0')to('cuda')の代わりにcuda()でも同じです
python>>> tensor = tensor.cuda() >>> tensor tensor([[1, 2], [1, 2]], device='cuda:0')CPUで扱う
CPUで扱うように戻すことも出来ます
python>>> tensor = tensor.to('cpu') >>> tensor tensor([[1, 2], [1, 2]])python>>> tensor = tensor.cuda() >>> tensor tensor([[1, 2], [1, 2]])2-3. tensorの一部を書き換える
python>>> tensor = torch.ones(4, 4) >>> tensor[:, 1] = 0 >>> tensor[3, 2] = 4 >>> print(tensor) tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 4., 1.]])2-4. tensorの計算
使えるメソッドは以下にまとまっています
https://pytorch.org/docs/stable/torch.htmlスカラー和
python>>> arr = np.arange(6).reshape(2, 3) >>> tensor = torch.tensor(arr) >>> print(tensor, '\n') tensor([[0, 1, 2], [3, 4, 5]], dtype=torch.int32) >>> print(tensor + 5, '\n') >>> print(tensor, '\n') tensor([[ 5, 6, 7], [ 8, 9, 10]], dtype=torch.int32) tensor([[0, 1, 2], [3, 4, 5]], dtype=torch.int32) >>> tensor = tensor + 5 >>> print(tensor) tensor([[ 5, 6, 7], [ 8, 9, 10]], dtype=torch.int32)要素ごとの積
python>>> tensor = torch.ones(4, 4) >>> tensor[:, 1] = 0 >>> print(tensor, '\n') tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]]) >>> # This computes the element-wise product >>> print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n") >>> # Alternative syntax: >>> print(f"tensor * tensor \n {tensor * tensor}") tensor.mul(tensor) tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]]) tensor * tensor tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])行列積
python>>> print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n") tensor.matmul(tensor.T) tensor([[3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.]]) >>> # Alternative syntax: >>> print(f"tensor @ tensor.T \n {tensor @ tensor.T}") tensor @ tensor.T tensor([[3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.], [3., 3., 3., 3.]])3. autogradについて
逆誤差伝搬による微分を実現するtorch.autogradの動作を解説してくれています
https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-pytorch.autogradのAPIリファレンス
https://pytorch.org/docs/stable/autograd.html3-1. 勾配の算出とoptimize
学習済みresnet18モデルに乱数で作ったデータをつっこんで勾配を算出してみましょう
モデルの読み込みとデータの作成
pythonimport numpy as np import torch, torchvision import matplotlib.pyplot as plt model = torchvision.models.resnet18(pretrained=True) data = torch.rand(1, 3, 64, 64) labels = torch.rand(1, 1000) arr = np.array(data) im = np.stack([arr[0, k, :, :] for k in range(3)], axis=2) plt.imshow(im) plt.show() plt.plot(labels[0]) plt.show()
乱数なので画像もlabelも当然意味をなさない値が入っていますがとりあえずやってみるだけなので気にしないで進めます予測を実行
modelにデータを放り込めば推定してくれます
pythonprediction = model(data) # forward pass print(prediction.shape) plt.plot(prediction[0].detach(), label='prediction') plt.plot(labels.numpy()[0], label='labels') plt.legend() plt.show()
乱数で作った画像を放り込まれたモデルが気の毒になりますlossを算出
lossを算出します
python>>> loss = (prediction - labels).sum() >>> loss.backward() # backward pass >>> loss tensor(-503.5731, grad_fn=<SumBackward0>)勾配算出の為に何やら付いてますね
optimizerを作ってパラメーターを更新する
python>>> optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9) >>> optim.step() #gradient descentこれでパラメーターの更新が完了です
実際の学習では乱数ではなく何かが写ったまともな画像と正解ラベルをバッチ枚数ごとに放り込んでいって、学習データ全体がepoch回学習されるように繰り返すわけですね。この辺、実際の画像でデモした方が分かりやすい気がするんですがこの手のライブラリを作るような人にはこれで充分ということなのかも知れません。
3-2. autogradの動作
以下のような関数を微分することを考えてみます
Q = 3a^3 + b^2a, bで偏微分すると以下のようになります
\frac{\delta Q}{\delta a} = 9a^2 \\ \frac{\delta Q}{\delta b} = 2bこれをtorch.autogradにやってもらいましょう
a, bをつくる
pythonimport torch a = torch.tensor([2., 3.], requires_grad=True) b = torch.tensor([6., 4.], requires_grad=True)a, bの関数Qをつくる
python>>> Q = 3 * a ** 3 - b ** 2 >>> Q tensor([-12., 65.], grad_fn=<SubBackward0>)Qの偏微分を実行
先程と同様にbackward()すれば偏微分が実行されますが、torchはloss functionのようなスカラー量が求まる関数しか偏微分できませんので、Qをどう足し合わせるか指定してやる必要があります。行列を引数として渡してやれば内積して得られた値を使ってやってくれますので、以下ではそれぞれ1倍して足し合わせた値を使ってやってくれます。
python>>> external_grad = torch.tensor([1., 1.]) >>> Q.backward(gradient=external_grad) >>> # check if collected gradients are correct >>> print(9*a**2 == a.grad, a.grad) >>> print(-2*b == b.grad, b.grad) tensor([False, False]) tensor([18.0000, 40.5000]) tensor([False, False]) tensor([-6., -4.])a, bを微分して得られる9a^2と-2bが得られているのが分かります
3-3. 微分を算出しないノードを指定する
requires_gradを省略するかrequires_grad=Falseにすると偏微分が算出されなくなります。偏微分の算出は計算コストが掛かりますので、学習する必要がないパラメーターについては偏微分を算出しないように設定するのが良いようです。
pythonx = torch.rand(5, 5) y = torch.rand(5, 5) z = torch.rand((5, 5), requires_grad=True) a = x + y print(f"Does `a` require gradients? : {a.requires_grad}") b = x + z print(f"Does `b` require gradients?: {b.requires_grad}")3-4. モデルの微分を算出しないように設定する
学習済みモデルを別のモデルに組み込んで学習をかけるような場合にモデルの学習を行わないようにするには以下のようにしてやります。model.parameters()で偉えるモデルのそれぞれのパラメーターにあたるtensorのrequires_gradをFalseにしてやるわけですね。
pythonfrom torch import nn, optim model = torchvision.models.resnet18(pretrained=True) # Freeze all the parameters in the network for param in model.parameters(): param.requires_grad = False model.fc = nn.Linear(512, 10) # Optimize only the classifier optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)4. CNNをやってみる
ようやく実際のneural networkのデモに到着しました
https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html#sphx-glr-beginner-blitz-neural-networks-tutorial-py4-1. ネットワークをつくる
PyTorchでは以下のような書き方でネットワークをつくるようです。クラスとして扱うのはtensorflowと同様ですが、こちらの方が書き方の自由度は高そうです。
pythonimport torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 1 input image channel, 6 output channels, 3x3 square convolution # kernel self.conv1 = nn.Conv2d(1, 6, 3) self.conv2 = nn.Conv2d(6, 16, 3) # an affine operation: y = Wx + b self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features net = Net() print(net)畳み込み2層と全結合2層+出力1層のネットワークが構築されました
outputNet( (conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=576, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )4-2. パラメーターの確認方法
parameters()メソッドでパラメーターを取得できます。weight, biasの順で入っているので5層だと10個のパラメーターがあることになります。
python>>> params = list(net.parameters()) >>> print(len(params)) 10parameters()はtorch.tensor形式のパラメーターをlistに入れて出してくれるので、例えば1層目のweightは以下のようにすれば見られます
python>>> print(params[0].size(), '\n') # conv1's .weight >>> print(params[0]) torch.Size([6, 1, 3, 3]) Parameter containing: tensor([[[[-0.2333, 0.2431, 0.1944], [ 0.0508, 0.0473, 0.0961], [ 0.2589, -0.0621, -0.3103]]], [[[-0.1810, -0.3264, 0.2296], [ 0.1090, -0.1363, 0.2106], [-0.1993, 0.1884, 0.2740]]], [[[-0.1940, 0.2546, -0.1444], [ 0.2365, -0.2924, 0.0217], [ 0.3072, -0.0517, -0.1252]]], [[[ 0.3191, -0.2198, -0.1129], [-0.1344, -0.0281, 0.3153], [-0.2891, 0.1994, -0.2489]]], [[[ 0.2201, 0.1512, -0.2975], [-0.2770, 0.1493, 0.0099], [ 0.0210, 0.3213, 0.2986]]], [[[-0.0330, -0.3037, -0.0267], [-0.2693, -0.1042, -0.0520], [-0.0537, -0.2117, -0.0070]]]], requires_grad=True)4-3. 推定する
乱数で入力データを作ってネットワークに通してみます。ネットワーク自体も初期値として入力した乱数がパラメーターとして入っているだけの意味をなさないものなので、まあなんか出てきましたというだけの出力になりますが、とりあえずのデモという事ですね。
python>>> input = torch.randn(1, 1, 32, 32) >>> out = net(input) >>> print(out.shape, '\n') >>> print(out) torch.Size([1, 10]) tensor([[-0.0469, 0.0536, 0.0633, -0.0827, -0.0329, 0.0237, -0.0360, 0.0352, -0.0768, -0.1269]], grad_fn=<AddmmBackward>)inputってpythonの標準関数に同じ名前のものがあるので使わない方が良い気がするんですが、まあチュートリアルなので気にせずいきましょう。
4-4. lossを算出する
以下ではloss functionとしてmseを使ってlossを算出しています
pythonoutput = net(input) target = torch.randn(10) # a dummy target, for example target = target.view(1, -1) # make it the same shape as output criterion = nn.MSELoss() loss = criterion(output, target) print(loss)lossを定義するときに勾配算出の為の関数も登録されます
python>>> print(loss.grad_fn) # MSELoss >>> print(loss.grad_fn.next_functions[0][0]) # Linear >>> print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU <MseLossBackward object at 0x0000020A362DF908> <AddmmBackward object at 0x0000020A362DF708> <AccumulateGrad object at 0x0000020A362DF908>4-5. 勾配の算出
autogradは前回の勾配を覚えておいてbackward()したときに今回の勾配と足し合わせて返してくれますが、CNNだとその必要はないのでzero_grad()により前回の勾配を消してから微分します
python>>> net.zero_grad() # zeroes the gradient buffers of all parameters >>> print('conv1.bias.grad before backward') >>> print(net.conv1.bias.grad) conv1.bias.grad before backward tensor([0., 0., 0., 0., 0., 0.]) >>> loss.backward() >>> print('conv1.bias.grad after backward') >>> print(net.conv1.bias.grad) conv1.bias.grad after backward tensor([ 0.0004, 0.0189, 0.0209, -0.0024, 0.0032, 0.0082])4-6. 学習の反映
例えばSGDなら以下のようにすれば更新できます
pythonlearning_rate = 0.01 for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate)一般的なoptimizerはクラスを用意してくれていますのでそれを使えば良いようです
https://pytorch.org/docs/stable/optim.htmloptimizerの定義からlossの算出、パラメーターの更新までを通してやると以下のようになります
pythonimport torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) # in your training loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criterion(output, target) loss.backward() optimizer.step() # Does the update5. まとめ
PyTorchの挙動を強く意識させる内容になっていて、tensorflowなどで既にneural networkに慣れている人向けのチュートリアルかもしれません。おかげでautogradの挙動への理解は結構進みましたが初めて触る人がここから入るとちょっと分かりにくいかも。
- 投稿日:2021-03-06T14:01:00+09:00
連続した数値を1桁区切りで配列にする
num = 12345 num_arr = [int(n) for n in list(str(num))] print(num_arr) #=> [1, 2, 3, 4, 5]
- 投稿日:2021-03-06T13:57:06+09:00
[Python] 既存のPowerpointのテキストをフォーマットを変えずに変更する python-pptx
python-pptxでPowerPointのレポートを操作したい時、事前にテンプレートを用意しておいて文字のフォーマットはそのままで内容の一部を変更したいことがあります。思ったよりも面倒でしたので、こちらの備忘録として残します。
動作を確認するために、以下のようにフォーマットされた文字列のあるPPTファイルの一部(「。。。」)を今日の日付(2021/3/6)で変換するコードを書いてみました。元の文字は影をつけたり、下線をつけたりと、いろいろと装飾してあります。
なお、既存の文字を置き換える方法は、python-pptxの作者であるScannyさんがこちらで説明していますので、その関数(モジュール)はそのまま利用します。
https://github.com/scanny/python-pptx/issues/285
replace_paragraph_text_retaining_initial_formattingという名前の長い関数がそうです。私が工夫したポイントとしては、元のファイルの中から該当するparagraphオブジェクトを探すところです。このオブジェクトの関係がいろいろとややこしいのですが、こちらを参考にさせていただきました。
https://www.relief.jp/docs/python-pptx-font-color.htmlimport pptx, re from pptx.util import Cm, Pt, Inches def replace_paragraph_text_retaining_initial_formatting(paragraph, new_text): p = paragraph._p # the lxml element containing the <a:p> paragraph element # remove all but the first run for idx, run in enumerate(paragraph.runs): if idx == 0: continue p.remove(run._r) paragraph.runs[0].text = new_text prs = pptx.Presentation("元のファイル.pptx") slide=prs.slides[0] #先頭のページを選択 for shp in slide.shapes: if shp.has_text_frame: if "日付は" in shp.text: #変更する文字列の一部でマッチさせる new_text=re.sub('。。。', '2021年3月6日', shp.text) #置き換え replace_paragraph_text_retaining_initial_formatting(shp.text_frame.paragraphs[0], new_text) prs.save('変更後のファイル.pptx')

- 投稿日:2021-03-06T12:55:34+09:00
MacでSelenum+PyautoGUIを使ってZoomに自動出席
自動でZoom出席する
半年ほど前にSeleniumでZoomに自動で出席できないかトライしてみた(オンライン授業にPython+Seleniumで自動出席したい!)のですが、Seleniumのみではシステムダイアログをクリック出来ず、Zoom会議に参加することはできませんでした。
その後、@hima_zin331さんの「PythonでZoomミーティングに自動入室しよう」という記事を拝見しました。
この記事ではWindowsにてSelenium+Pywinautoを用いてZoomにログインし、指定時間画面録画後に自動でZoomを退出しています。当時の私はSeleniumで遊ぶことが目的だったのでSeleniumのみで出席することを考えていたのですが、本記事ではSelenium以外のライブラリを利用して、MacでもZoomに自動出席ができないかを検討します。
なお、本プログラムはあくまで知的好奇心を満たす為のものです。本プログラムを利用して発生したあらゆる損失や不利益について当方は一切の責任を負いません。環境
macOS Big Sur 11.2.2
Python 3.8.6
PyautoGUI 0.9.52
Google Chrome 88.0.4324.192(Official Build) (x86_64)PyautoGUIについて
今回改めて自動出席プログラムに挑戦しようと考えた最大の理由がPyautoGUIの存在です。
PyAutoGUIは、Python のモジュールの一つで、マウスやキーボード操作を自動化することが出来ます。イメージマッチングが簡単に利用でき、クロスプラットフォームなのでMac、Windows、Linuxで利用出来ます。参考
事前準備
- Zoomをインストール、ログインの後に以下の様に設定を変更する。
- ミーティング接続時に、自動的にコンピュータオーディオに接続
- ミーティングの参加時にマイクをミュートに設定
- command+Shift+5を押して、Macの画面撮影録画バーを表示する。「画面全体を収録」か「選択部分を収録」をクリックし、録画はせずに閉じる。(macOS Mojave以降の機能です。)録音には「なし」か「内臓マイク」を選択できます。 Zoomの音声を録音したい場合はBackground Musicなどを利用します。ただし、OSbigSurは非対応の為、スナップショットバージョンを利用します。 詳細は公式ページを参照して下さい。
brew tap homebrew/cask-versions brew install --cask background-music-pre
- ターミナルから
crontab -eを入力して、Zoomに入室したい時間にautozoom.pyを起動するようにcronを設定します。 次の例では3月4日の21時に実行し、ログを書き出します。 ただし、/usr/sbinにPATHを通さないとPyautoGUIがエラーを吐いて実行できないので注意が必要です。
cronでPyautoGUIを使うには何かと工夫が必要だったので、MacでのPyAutoGUIの注意点にまとめておきます。 pythonのフルパスはwhich pythonで取得出来ます。 cronが利用できない場合はtime.sleep()で軌道までの時間を無理矢理時間を潰すのもアリかもしれないです。PATH=/usr/sbin:/usr/bin:/bin 0 21 3 4 * cd autozoom.pyのフルパス && pythonのフルパス autozoom.pyのフルパス ログ書き出したいファイルのフルパス 2>&1
- システム環境設定から「セキュリティとプライバシー」タブをクリックして「プライバシー」を開いて下記の項目を設定し、ターミナルを再起動する。
- アクセシビリティに「AEServer」(OSのバージョンによっては名称が異なるかも)、「/usr/sbin/cron」を追加
- フルディスクアクセスに「ターミナル」、「/usr/sbin/cron」を追加
- 画面収録に「ターミナル」、「/usr/sbin/cron」を追加
以下のような写真を撮影する。(cmd+shift+4で任意範囲のスクリーンショットが撮影できます。)ファイル名をopenzoom.pngに変更し、後述のautozoom.pyと同じフォルダに入れておく。
必要なライブラリのインストール(ターミナルに入力する)
#ブラウザ操作関連 pip3 install selenium pip3 install chromedriver-binary #PyautoGUI関連 #OSによってインストール方法が異なりますが、Macの場合は以下の様にインストール出来ます。 pip3 install pyobjc-core pip3 install opencv_python pip3 install pyobjc pip3 install pyscreeze pip3 install pyautoguiコード
autozoom.pyimport datetime import os import pyautogui import chromedriver_binary from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.add_argument('--disable-dev-shm-usage') import time import pyscreeze from pyscreeze import ImageNotFoundException pyscreeze.USE_IMAGE_NOT_FOUND_EXCEPTION = True browser = webdriver.Chrome() browser.implicitly_wait(3) browser.get("入室するZoomのURL") time.sleep(5) nowTime = 0 maxTime = 15 p=None while True: time.sleep(1) nowTime+=1 print(nowTime) if(nowTime>maxTime): print(nowTime,maxTime) break try: p = pyautogui.locateCenterOnScreen('openzoom.png',grayscale=False,confidence=0.7) pyautogui.moveTo(p.x/2,p.y/2) if(p is not None): sc = pyautogui.screenshot() break except ImageNotFoundException: print("Image not found") if(p is None): print("None and exit") sc = pyautogui.screenshot() name = 'screenshot%s.png' % (datetime.datetime.now().strftime('%Y-%m%d_%H-%M-%S-%f')) sc.save(name) exit() else: pyautogui.click(p.x/2, p.y/2) pyautogui.hotkey('command','shift','5') time.sleep(3) pyautogui.hotkey('enter') time.sleep(600) pyautogui.hotkey('command','ctrl','esc') time.sleep(3) pyautogui.hotkey('enter') pyautogui.hotkey('command','q') time.sleep(3) pyautogui.hotkey('enter')コードの説明詳細
各種ライブラリ類のインポート
autozoom.pyimport datetime import os import pyautogui import chromedriver_binary from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.add_argument('--disable-dev-shm-usage') import time import pyscreeze from pyscreeze import ImageNotFoundException pyscreeze.USE_IMAGE_NOT_FOUND_EXCEPTION = Trueseleniumのオプションで--disable-dev-shm-usageを指定するとメモリ不足のクラッシュを防げるらしいので利用します。
また、pyscreezeのImageNotFoundExceptionを利用することで、target.pngが見つからなかったときにImageNotFoundExceptionが発生するようにしています。ブラウザ起動、「zoom.usを開く」をクリックしてZoomに入室
autozoom.pybrowser = webdriver.Chrome() browser.implicitly_wait(3) browser.get("入室するZoomのURL") time.sleep(5) nowTime = 0 maxTime = 15 p=None while True: time.sleep(1) nowTime+=1 print(nowTime) if(nowTime>maxTime): print(nowTime,maxTime) break try: p = pyautogui.locateCenterOnScreen('openzoom.png',grayscale=False,confidence=0.7) if(p is not None): break except ImageNotFoundException: print("Image not found") if(p is None): print("None and exit") sc = pyautogui.screenshot() name = 'screenshot%s.png' % (datetime.datetime.now().strftime('%Y-%m%d_%H-%M-%S-%f')) sc.save(name) exit() else: pyautogui.moveTo(p.x/2,p.y/2) pyautogui.click(p.x/2, p.y/2)ブラウザーを起動して、ZoomURLを開きます。1秒ごとに画面内にtarget.pngがあるかどうかを判定し、発見した場合はwhileをbreak、lauchボタンにカーソルを動かしてクリックして、Zoomに入室します。
入室後は設定通りにオーディオに自動接続し、ミュート状態になります。
PyautoGUIには一部Macで座標系が2倍になる不具合があり、p.x/2、p.y/2としていますが、座標系が正しい場合は/2は不要です。
ちなみに、カーソルを動かさずとも(pyautogui.moveTo(p.x/2,p.y/2))クリックできるが、アクセシビリティでターミナル、cron、AEServerなどが許可されていないとカーソルが動かないことを利用して、正しく動作しているか確認します。
maxTime秒(=15秒)以内に発見できなかった場合はスクリーンショットを撮影して、プログラムを終了します。撮影されたスクリーンショットがデフォルトのデスクトップの画像の場合は、画面収録にcronやターミナルが追加されていないので環境設定を確認してください。画面録画、待機、退室処理
pyautogui.hotkey('command','shift','5') time.sleep(3) pyautogui.hotkey('enter') time.sleep(600) pyautogui.hotkey('command','ctrl','esc') time.sleep(3) pyautogui.hotkey('enter') pyautogui.hotkey('command','q') time.sleep(3) pyautogui.hotkey('enter')Zoom入室後はMacのデフォルトの画面録画開始のショートカット(command+shift+5)で画面録画のツールバーを呼び出し、enterキーで画面録画を開始します。(Mac以外のOSや、Mojave以前のOSを利用する場合は画面録画ツールにショートカット設定すれば同様に利用できると思います。)
time.sleep()で録画する間待機(サンプルでは600[秒]=10[分])し、画面録画終了のショートカット(command+ctrl+esc)で録画を終了します。
最後にcommand+qで退室ボタンを表示させ、enteキーで退室します。Zoomの設定で退室の確認通知は設定でoffにすることもできます。終わりに
PyautoGUIのイメージマッチング機能が便利すぎて感動しました。
locateCenterOnScreenの1行でイメージマッチングして座標を返すなんて便利すぎないかい、PyautoGUIくん?笑
そして、実は先日までOSがHighSierraでした。画面収録が機能がなかったので、いっちょBigSurアプデするかーにと思った結果、なんだかんだでOSをクリーンインストールしたのですが、セキュリティとプライバシーの機能変更にかなり戸惑いました。HighSierraにはフルディスクアクセスとか無かったんですよね。
思ったように動くようになってよかったです。
- 投稿日:2021-03-06T12:53:22+09:00
pythonで自作クラスの大小判定(ソート)を行う
やりたかったこと
pythonで簡単なクラスを定義して,そのクラスの中のある変数を基準にしてインスタンスが入っているリストのソートを行いたかったです.
どうやるんだっけ?となったのでやり方をメモしておきます.
作成したクラス
class Node: # 木のノードを表すクラス def __init__(self, value: int, left = None, right = None): self.value: int = value # ソートの基準としたい値 self.left = left # 左の子ノード self.right = right # 右の子ノードこのクラスのvalueというint型の変数をもとに大小判定をしてリストをソートしたいです.
ソートするためにこのクラスのインスタンスのリストを適当に作成しておきます.
> import numpy as np > nodes = [Node(np.random.randint(10)) for i in range(10)] > print([node.value for node in nodes]) [6, 1, 7, 9, 8, 6, 4, 9, 6, 7]この
nodesというリストを単純にソートしてみると...> sorted(nodes) TypeError: '<' not supported between instances of 'Node' and 'Node'このようにTypeErrorがでてソートすることができません.
Nodeインスタンス間の比較演算<がサポートされていないというエラーがでています.やり方1: クラスに
__lt__メソッドを定義するclass Node: # 木のノードを表すクラス def __init__(self, value: int, left = None, right = None): self.left = left # 左の子ノード self.right = right # 右の子ノード self.value: int = value # ソートの基準としたい値 def __lt__(self, other): # 自作クラスで大小を判別するための関数 return self.value < other.value上記のように
__lt__メソッド(less than)を定義します.引数には
selfとotherを受け取ります.
self.valueがother.valueより小さい時にはTrueをそうで無い時はFalseを返すようにします.このように定義することでインスタンス間の大小を比較できるようになります.
(そのほかにも__eq__(equal)や__gt__(greater than)などの比較演算を定義できますが,ソートなら__lt__を定義しておけば十分でした.)実際にソートしてみると...
> sorted_nodes = sorted(nodes) > print([node.value for node in sorted_nodes]) [1, 4, 6, 6, 6, 7, 7, 8, 9, 9]正しくソートされていました!
やり方2: ソート時に比較する際のキーを渡す
pythonの
sorted関数ではオプション引数としてkeyを渡すことができます.
このkeyを渡すとこれを基準にソートを行なってくれます.次のようにlambda式を使って書けます.
> sorted_nodes = sorted(nodes, key=lambda x: x.value) > print([node.value for node in sorted_nodes]) [1, 4, 6, 6, 6, 7, 7, 8, 9, 9]こちらも正しくソートされていました.
まとめ
上記2つのやり方どちらでもソートを行うことができます.
単純にソートをしたいだけならやり方2の方が早く書けると思います.
ただ優先度付きキューなどに入れたい場合やり方1を用いないとできないと思います.
参考
- 投稿日:2021-03-06T12:44:09+09:00
【音声生成+機械学習】ポケモンの鳴き声をWaveGANで生成する
はじめに
ゲーム「ポケットモンスター」シリーズにおいてはポケモンの鳴き声は電子音のようなSEとして表現されています。ほぼ全てのポケモンに固有の鳴き声が割り当てられており、本編をプレイしたことがある方にとっては馴染み深いものも多いと思われます。以下の動画はそれらの例です。
これらの音声をデータセットにし、機械学習の手法の1つ"WaveGAN"でポケモンの鳴き声を生成しました。以下は生成例です。
機械学習で音声を生成する手法「WaveGAN」でポケモンの鳴き声を出力させてみましたhttps://t.co/Izt2nq9Q3e pic.twitter.com/fqzEFwSqoH
— zassou (@zassouEX) March 12, 2021
本記事ではこれに用いた手法を紹介していきます。
WaveGAN
音声の生成にはWaveGANという手法を使っています。これはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法をベースにしたもので、以下のように構成されています。
この手法では、音声を生成するニューラルネットワーク(Generator)と、音声を識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。Generatorは音声データを生成し(これを偽物音声と呼ぶことにします)、それによってDiscriminatorをデータセット中の本物の音声データ(本物音声と呼ぶことにします)だと誤認させることを目指して学習を進めます。一方でDiscriminatorはGeneratorに騙されないよう、より正確に音声データの真贋を見極めるよう学習します。
二つのニューラルネットワークがお互いに鍛え合うことで、Generatorは徐々に学習データに近い音声を生成できるようになっていきます。
要するにGenerator VS Discriminatorです。データセット
データセットには全国図鑑でNo.001のフシギダネ〜No.898のバドレックスまで全部のポケモンの鳴き声(.wav形式、サンプリングレート16000Hz)を用います。同じ種類のポケモンでもフォルムチェンジで鳴き声が変わるようであればそれもデータセットに含めます。ただしメガシンカ、ダイマックス時の鳴き声は学習全体に与える影響を考え除外しました。
Generatorの作成
Generatorの役割は、入力に乱数で構成された数列(これを乱数列と表現することにします)をとり、それを元にして音声を生成することです。生成した音声をDiscriminatorに入力した時、本物音声だと騙せるように学習していきます。
入力する乱数列の長さは20とし、出力する音声は長さ65536の時系列データ(約4秒程度)とします。入力を1次元転置畳み込み層(TransConv1D)に通していき最終的に音声を出力します。
Discriminatorの作成
Discriminatorは入力された音声が本物音声なのか、Generatorによって生成された偽物音声なのかを正しく識別できるよう目指して学習を進めます。要は音声認識器を作ります。
入力する音声は長さ65536の時系列データとし、出力はどれだけ本物らしいかを表す値(範囲は0~1)とします。入力を1次元畳み込み層(Conv1D)とPhase Shuffle(後述)に通していき最終的な判断結果を得ます。
checkerboard artifacts
GANによる画像生成において、Generatorが転置畳み込みによって出力した画像にはcheckerboard artifactsという、市松模様のような周期的なパターンが出現することがあります。
引用元 : Deconvolution and Checkerboard Artifacts
一部の特例をのぞいて、一般的にほとんどの学習データの画像においてはこのようなパターンは現れないため、Discriminatorはこの模様を含む画像が入力された時、それを偽物画像だと判定するように学習が進みます。
音声生成でもcheckerboard artifactsのようなパターン(以下ではこれを単にcheckerboard artifactsと呼ぶことにします)が生成されることがあり、ノイズのような形で知覚できるようです。音声においてcheckerboard artifactsは常に特定の位相でのみ発生するそうで、このことが原因でDiscriminatorが意図しない学習をしてしまい、結果的にモデル全体がうまく機能しなくなることがあるようです。
そこでDiscriminatorにPhase Shuffleという操作を行う層を導入します。
Phase Shuffle
checkerboard artifactsによってDiscriminatorが意図しない学習をしてしまうのを防止するため、Phase Shuffleを実行する層を導入します。
Phase Shuffleを行う層ではまず入力された特徴量に対し、$m$要素ずらす操作を実行します(ただし$m\in [-n,n]$、$n$はハイパーパラメーターで、今回は$n=2$に設定)。$m$はPhase Shuffleを実行するたびにランダムに$[-n,n]$の範囲から選び出す整数です。さらに、$m$要素ずらした結果空いた箇所をReflection Paddingによって埋めます。
Phase Shuffle層はDiscriminator中の、各畳み込み層の直後にそれぞれ配置します。
この操作によってDiscriminatorの学習がうまくいく理由として、WaveGANの論文中では以下のように言及されています。
"Intuitively speaking, phase shuffle makes the discriminator’s job more challenging by requiring invariance to the phase of the input waveform."
(直訳 : 直感的に言えば、phase shuffleは、入力波形の位相に不変性を要求することで、Discriminatorの仕事をより困難にします。)
自分的な解釈ですが、おそらくcheckerboard artifactsが常に特定の位相でのみ発生するところを、Phase Shuffleによってより多様な位相で発生するようにすることで意図通りの学習が進むようにしているものと思われます。学習方法・誤差関数
GeneratorとDiscriminatorの損失関数はWGAN-GPとしました。WGAN-GPの定義は以下です。
- Generatorの損失関数
-E[d_{fake}]
- Discriminatorの損失関数
E[d_{fake}] - E[d_{real}] + \lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]乱数列をGeneratorへ入力、ミニバッチの数$M$(今回は$M=16$と設定)だけ音声を生成します。それらをDiscriminatorに入力し、どれくらい本物らしいかを示す値をそれぞれの入力音声に対し$M$個出力させます。これを$d_{fake}$とします。
また、本物音声を$M$個Discriminatorに入力し、その時の$M$個の出力を$d_{real}$とします。$E$はミニバッチに対して平均をとる操作です。Discriminatorの損失関数の第3項はgradient penaltyと呼ばれている項です。詳しい解説はこちら。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.5と0.9に設定しました。
全体像
以上のようにして作成したGeneratorとDiscriminatorを図のように組み合わせ、WaveGANを構成します。
学習+音声生成
今回はミニバッチ数16、エポック数は500に設定しました。
ポケモンの鳴き声を用いて学習を行い、Generatorに音声を生成させます。学習途中における出力は次のようになりました。学習途中における出力です。ノイズのような音声から学習を経るごとに出力が変化しているのがわかります。 pic.twitter.com/bHJR0qYWdG
— zassou (@zassouEX) March 12, 2021ソースコード
実装したコードはこのリポジトリにあります。
https://github.com/zassou65535/WaveGAN余談
GANは本来音声の生成よりも、画像の生成や画像間の変換で有名な手法です。
GANによる画像生成や変換に関しても解説記事を書いているので是非こちらもどうぞ。画像変換 :
機械学習で画像を変換する手法「UGATIT」でメルアイコン変換器を作りました。https://t.co/stNnKuSf0Z pic.twitter.com/vk99ZXOX9g
— zassou (@zassouEX) December 1, 2020画像生成 :
機械学習で画像を生成する手法「GAN」を用いてメルアイコン生成器 version2を作りましたhttps://t.co/D84EkyL7LA pic.twitter.com/Fyt9cb1ysn
— zassou (@zassouEX) August 8, 2020まとめ
WaveGANによって音声を生成しました。一般に画像に関する分野でよく使われている手法が、音声においても通用するのは興味深いですね。
機械学習で音声を生成する手法はWaveGANだけでなくSpecGAN、GANSynth、WaveNetなど多種多様な方法がこれまでに提案されています。いずれも長さ数秒程度の音声の出力が可能で、短めのサウンドエフェクトなどの生成に向いているかと思われます。皆さんもどんどん音声生成しましょう。参考
Adversarial Audio Synthesis
PyTorch reimplementation of WaveGAN
Synthesizing Audio with Generative Adversarial Networks
Deconvolution and Checkerboard Artifacts




- 投稿日:2021-03-06T12:14:36+09:00
yukicoder contest 285 参戦記
yukicoder contest 285 参戦記
★2.5とはいえども4つもあればどれかは解けるんじゃないかと思って考えていたら意識が飛んで、起きたら25時過ぎだった(笑).
A 1415 100の倍数かつ正整数(1)
書くだけ……といいつつ、最初はちゃんと問題文を読んでいなくて、
print(abs(N) // 100)で出して WA を食らった(馬鹿). まあ、100で割れば答えが出ますよね.N = int(input()) if N < 0: print(0) else: print(N // 100)B 1416 ショッピングモール
一目で店員数が多い店から入れていけばいいことは分かるはず.
from math import log2 n, *A = map(int, open(0).read().split()) A.sort(reverse=True) result = 0 for i in range(n): result += int(log2(i + 1)) * A[i] print(result)F 1420 国勢調査 (Easy)
コンテスト後に解いた. 連立一次方程式と同じで、関係する未知数のどれかが1個分かればドミノ倒しのように全部定まるので、まず Union Find で関係しているグループを求める. グループが求めれたらどれか一つを0として、ドミノ倒しで全部求めれば良い. 求まったら最後に矛盾したものがなかったかをチェックして、矛盾があったら -1 を、無かったら求まった答えを出力する.
from sys import setrecursionlimit, stdin def find(parent, i): t = parent[i] if t < 0: return i t = find(parent, t) parent[i] = t return t def unite(parent, i, j): i = find(parent, i) j = find(parent, j) if i == j: return parent[j] += parent[i] parent[i] = j readline = stdin.readline setrecursionlimit(10 ** 6) N, M = map(int, readline().split()) parent = [-1] * N d = {i: {} for i in range(N)} vs = [] for _ in range(M): A, B = map(lambda x: int(x) - 1, readline().split()) Y = int(readline()) vs.append((A, B, Y)) d[A][B] = Y d[B][A] = Y unite(parent, A, B) result = [-1] * N q = [i for i in range(N) if parent[i] < 0] for i in q: result[i] = 0 while q: a = q.pop() for b in d[a]: if result[b] != -1: continue result[b] = result[a] ^ d[a][b] q.append(b) for A, B, Y in vs: if result[A] ^ result[B] == Y: continue print(-1) exit() print(*result, sep='\n')