- 投稿日:2021-03-06T23:40:54+09:00
AWSへデプロイ後に、暗号化したパスワードでログインできない現象について
AWSへデプロイ後に、bcryptで暗号化したパスワードでログインできない現象について
プログラミング初学者です。Ruby on Railsで作成したアプリをAWSのEC2インスタンスにデプロイした後で、作成したアカウントにログインできない現象が発生しました。パスワード周りのエラーの解消に丸一日かかってしまいましたので、また同じ現象で困らないためにもこの記事にまとめておきたいと思います。
発生した環境
Rubyバージョン:2.5.8
Railsバージョン:6.1.1
gem bcryptバージョン:3.1.16発生した現象
デプロイ後に新規登録したアカウントに、始めはログインできていたのですが、しばらく経ってからログインしようとすると「メールアドレスかパスワードに誤りがあります」と表示されログインできなくなりました。
試したこと
ログを確認
$ vim log/production.logいくつかのエラーログを確認しましたので、順に確認していきました。
Mysql2::Error
ActiveRecord::StatementInvalid (Mysql2::Error: Unknown column 'password_digest' in 'field list'):
bcryptでパスワードの暗号化を行なった際に、'password_digest'カラムをデータベースのusersテーブルに追加していました。mysqlにログインしたところ、確かに'password_digest'カラムは存在して値が保存されていました。
ArgumentError
ArgumentError (wrong number of arguments (given 0, expected 1)):
app/controllers/users_controller.rb:41:in `login'値が入るはずの場所に値が入っていないことが確認できました。
該当の場所には下記コードがありました。app/controllers/users_controller.rbif @user && @user.authenticate(params[:password])どうやら入力したパスワードが正常に認識されていないことがわかりました。
NoMethodError
NoMethodError (undefined method `encrypted_password=' for #User:0x000000000572e6d8):
'encrypted_password'は何のことかとわからなかったので、検索するとDeviseを導入した時に追加されるという情報がありました。確認すると、確かにGemfileに「gem 'devise'」を追加していました。そこで、encrypted_passwordを利用したパスワードの暗号化に切り替えることにしました。
password_digestからencrypted_passwordへの切り替え
まずmysqlでusersテーブルのカラム名を変更します。
mysql> alter table users change column password_digest encrypted_password char(255);user.rbを編集します。
app/models/user.rbclass User < ApplicationRecord has_secure_password #ここを削除します validates :name, {presence: true} validates :email, {presence: true, uniqueness: true} validates :image_name, {presence: true} validates :password, {presence: true} #ここも不要になるので削除します devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable, :omniauthable endusers_controller.rbを編集します。
エラーが発生していた、ログイン認証の行の認証メソッドを書き換えます。app/controllers/users_controller.rbif @user && @user.valid_password?(params[:password]パスワードを変更する部分が少々手こずりました。
params[:password]に保存されている新しいパスワードを手動で暗号化して更新しています。app/controllers/users_controller.rbif params[:password] hashed_password = BCrypt::Password.create(params[:password]) update_password_sql = "update users set encrypted_password = '#{hashed_password}' where id =#{@current_user.id};" ActiveRecord::Base.connection.execute(update_password_sql) endコードの編集が終わったらサーバーを再起動します。
nginxを再起動します。$ sudo service nginx restart続いてunicornを再起動します。unicornで走っているスレッドを確認します。
$ ps -ef | grep unicorn | grep -v grep3行の走っているスレッド番号が表示されます。
下は一行目の一例です。ユーザー名 番号 1 0 11:16 ? 00:00:00 unicorn_rails master -c /var/www/アプリのディレクトリ/config/unicorn.conf.rb -D -E production …スレッドを停止します。
$ kill 番号もう一度上記の確認コマンドを打ち込んで何も表示されなければ、スレッドが終了しています。
unicornを起動します。$ bundle exec unicorn_rails -c /var/www/アプリのディレクトリ/config/unicorn.conf.rb -D -E production確認コマンドを打ち込んでスレッド番号が表示されれば、再起動できています。
まとめ
丸一日かかってしまったので、思い出せる限り全部の工程をまとめました。
某プログラミング学習サイトでパスワードの暗号化を習い、簡単にできるものだと思っていたら思わぬ落とし穴がありました。Twitter連携などに使用するDeviseを導入することで、パスワード暗号化の機能が重複してエラーを発生するようです。簡単に習っただけでは実践には足りない、実際にエラーに遭遇することで腕を磨くものだと、今後の良い戒めになりました。
- 投稿日:2021-03-06T22:55:14+09:00
AWS Lambda 実行環境は稀に起動失敗するので、リトライ処理を意識する
一行説明
- タイトルの通りですが、AWS Lambda は偶発的に実行環境の起動失敗=実行失敗が起き得るので、リトライ処理を適宜組み込みましょう、というお話です
環境
- API Gateway 経由で API と Lambda 関数を紐付けて実行
[クライアント] --- [API Gateway] --- [Lambda]事象
- 以下、複数のパターンを確認しています
Lambda 実行ログ
- 何も出力されない
- START ログしか出力されない
12:34:56 START RequestId: 12345678-abcd-efgh-ijklmbopqrst Version: $LATEST // 本来は以下のような実行ログがつづけて出力されるが、START しか無い // 12:34:56 {"Level":"INFO","Time":"2021-01-01T12:34:56.789+0900",<自前で実装したログ出力>} // 12:34:56 END RequestId: 12345678-abcd-efgh-ijklmbopqrst // 12:34:56 REPORT RequestId: 12345678-abcd-efgh-ijklmbopqrst Duration: 212.22 ms Billed Duration: 300 ms Memory Size: 256 MB Max Memory Used: 50 MBAPI Gateway 実行ログ
- HTTP ステータスコードが 504、Lambda リクエスト ID が発行されない
Lambda invocation failed with status: 504. Lambda request id: N/AN/Aなため、この場合 Lambda の実行ログは確認できず- HTTP ステータスコードが 500、Lambda リクエスト ID が発行される
Lambda invocation failed with status: 500. Lambda request id: 1981a74b-(略)- Lambda の
ServiceExceptionが発生(12345678-abcd-efgh-ijklmbopqrst) Endpoint request URI: https://lambda.ap-northeast-1.amazonaws.com/2015-03-31/functions/arn:aws:lambda:ap-northeast-1:<accoundId>:function:<Lambda関数名>/invocations (12345678-abcd-efgh-ijklmbopqrst) Endpoint request headers: {x-amzn-lambda-integration-tag=12345678-abcd-efgh-ijklmbopqrst, Authorization=*(中略) [TRUNCATED] (12345678-abcd-efgh-ijklmbopqrst) Endpoint request body after transformations: {<リクエストボディ情報> [TRUNCATED] (12345678-abcd-efgh-ijklmbopqrst) Endpoint response headers: {Date=Mon, 01 Jan 2021 03:34:56 GMT, Content-Type=application/json, Content-Length=86, Connection=keep-alive, x-amzn-RequestId=<リクエストID>, x-amzn-ErrorType=ServiceException} (12345678-abcd-efgh-ijklmbopqrst) Endpoint response body before transformations: { "Message": "An error occurred and the request cannot be processed.", "Type": "Service" } (12345678-abcd-efgh-ijklmbopqrst) Lambda invocation failed with status: 500. Lambda request id: 1ed0cd95-a300-4e34-99c1-3d9407f9d79f発生頻度
- 連続運転試験や負荷試験などを実行した際、数万回に一回程度の割合で発生
- もし継続的に発生する場合は、サービス側の大規模な問題が発生している可能性があるため、AWS Service Health Dashboard や AWS Personal Health Dashboard で状況を確認する
原因
- Lambda 関数の一時的な問題により、当該実行環境(実行コンテキスト)において Lambda 関数の起動自体ができなかったため
- Lambda の
ServiceExceptionサービスエラーの原因や詳細は非公開回避策
- 数万回に一回の頻度だと「AWS Lambda では稀に発生しうるもの」であるため、完全な回避は不可能
- クライアント側でレスポンスコードを確認の上、500 番台(サービス側)のエラーが返ってきた場合はリトライをするほかない
- リトライ処理を組み込む場合は、インターバルを徐々に長くする「エクスポネンシャルバックオフ」アルゴリズムを推奨
- クライアントが外部のため制御できない場合、仕様書やエラーメッセージで「リトライしてね」を示す
- 投稿日:2021-03-06T21:35:56+09:00
AWS OpsWorksってなんだろ?
AWS OpsWorksってなんだろ?
CloudFormationはよく使うけど、OpsWorksは使ったことがなくてまだよくわからないです。似たようなサービスなのかなっていうフワッとした認識なので、違いやユースケースについて調べてみました!
まずは公式から
AWS OpsWorks は、Chef や Puppet のマネージド型インスタンスを利用できるようになる構成管理サービスです。Chef や Puppet は、コードを使用してサーバーの構成を自動化できるようにするためのオートメーションプラットフォームです。OpsWorks では、Chef や Puppet を使用して、Amazon EC2 インスタンスやオンプレミスのコンピューティング環境でのサーバーの設定、デプロイ、管理を自動化できます。OpsWorks には、AWS Opsworks for Chef Automate、AWS OpsWorks for Puppet Enterprise、AWS OpsWorks Stacks の 3 つのバージョンがあります。
AWS OpsWorks(Chef や Puppet を使って運用を自動化する)| AWSよりサーバーの構成を自動化できるっていうところがポイントかな?
Chef、Puppetという単語も出てきましたね。おそらくこれが分からないと理解がしづらい気がするので、先にこいつらを片付けましょう!Chefってなんだろ?
サーバの構成管理ツールのひとつ
サーバの設定とか管理を楽にしてくれるソフトウェア(のひとつ)
Chefとは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典よりまだ入り口って段階の情報ですね。
もう少し調べてみましょう。Chef(シェフ)とは、構成管理(プロビジョニング)ツールです。ユーザ作成、パッケージインストール、設定ファイル編集などの展開作業を自動化します。物理環境/仮想環境/クラウド環境などの各種インフラに対応します。
「インフラをどのように構築し、維持されるべきか」という定義は、Rubyで記述され、ソースコードのように扱います。
コードによってインフラの構成管理を行えることが、Chefの大きな特徴であり利点です。
オープンソースの運用管理・運用自動化/Chefとはよりサーバーに対して、同じ設定を実施するために、その設定をコードで記述すると。
コードで記述という点はCloudFormationと同じですが、ChefはRubyで記述する点が異なりますね。
やっぱりサーバーに対する構成管理がお仕事なのかな?もうひとつのPuppetは?
サーバの構成管理ツールのひとつ
サーバの設定とか管理を楽にしてくれるソフトウェア(のひとつ)
Puppetとは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典よりあれ?デジャヴ・・・。
また少し調べてみましょう!Puppet(パペット)は、OS設定やアプリケーションの構築を自動化するオープンソース・ソフトウェアです。物理、仮想、クラウドといったさまざまなインフラに対して、あるべき構成(OS/ミドルウエア/アプリケーションなど)をマニフェスト(manifest)に記述しておくと、サーバの台数によらずその構成どおりにインフラを自動的にセットアップする構成管理ソフトウェアです。
スタンドアロン型のPuppet は Ruby により記述されたアプリケーションですが、agent-server型は、Puppet ServerがClojureとJRuby、Puppet AgentがRubyで書かれています。Puppet Agentをインストールすると、スタンドアロン型のPuppetが同時にインストールされるようになっています。
Puppet とは?動作確認や機能、特徴などを解説 | OSSサポートのOpenStandia™【NRI】よりこっちもデジャヴってる(笑)
一応違いについても調べてみましたが、今の僕の知識ではあまり理解できませんでした(泣)
AnsibleとChefとPuppetの比較 | MacRuby
とりあえず、両方ともサーバーの構成管理ツールで、Rubyが使われてるよってことだけ覚えておきます!OpsWorksとCloudFormationの違いを教えて!
さすがはAWS!よくある質問にバッチリ書いてありました。
Q: AWS OpsWorks スタックと AWS CloudFormation では、どのような点が異なりますか?
AWS CloudFormation は土台を作るサービスで、ほぼあらゆる AWS リソースのプロビジョニングと管理を、JSON ベースのドメイン固有言語で行うことができます。
AWS OpsWorks スタックのサポート範囲は、Amazon EC2 インスタンス、Amazon EBS ボリューム、Elastic IP、Amazon CloudWatch メトリクスなど、アプリケーション志向の AWS リソースに限られています。
よくある質問 - AWS OpsWorks Stacks | AWSよりなるほど!対象範囲が異なるとのことですね。
CloudFormationはほぼすべてのサービスを作成できるけど、OpsWorksはサーバー周りだけだよってことみたいです。
初めに出てきた「サーバーの構成を自動化できる」とも合致しますね。
少し違いが分かった気がします。使い分けは?
CloudFormationがほぼすべてのサービス、OpsWorksがサーバー周りということで、ネットワーク周りをCloudFormation、サーバー周りをOpsWorksという使い方などがあるようです。ただ、併用に関するケースはあまりヒットしませんでした。詳しい方はぜひ教えて頂けるとうれしいです!
CloudFormationとOpsWorksでインフラを育てるまとめ
今回は名前は知ってるけど中身は知らないAWS OpsWorksについて調べてみました。まだ表面的なことしか分かってないけど、CloudFormationとの違いはなんとなくわかりました。最初に書いた「サーバーの構成を自動化」がOpsWorksのポイントでしたね。一歩前進です!
ChefもPuppetも使ったことないからOpsWorksも使う機会がすぐにはないかもしれませんが、サービスの概要だけでも知っておくといつか役に立つかもしれません。
そんなところで今日はおしまい!


- 投稿日:2021-03-06T17:30:19+09:00
EKSとECSの違い
勉強前イメージ
EKSはkubernetes、ECSはDockerのイメージ
調査
EKSとは?
kubernetesのマネージドサービスで、AWS上で簡単に実行できるサービス
詳細は こちらECSとは?
Elastic Container Service の略で、
Dockerコンテナを簡単に実行・停止出来る管理サービスです。
ECSを利用することによってDockerのインフラをまるっとAWSにおまかせできます。
詳細は こちらkubernetesとDockerの違い
Dockerは1台のサーバ上でコンテナを作成し、その管理をしています。
しかし、複数台のサーバで稼働するコンテナを横断的に管理することが出来ないので、
複数台のサーバにまたがったコンテナを増やさないといけない場合に対処出来ません。
それを解決するのがKubernetesで、複数台のサーバのコンテナ管理を1台の実行環境のように扱うことが出来ます。
- Kubernetes : 複数台のサーバにまたがったコンテナ管理ができる
- Docker : 1台のサーバ上でしかコンテナを管理できない
EKSとECSの違い
- EKS : Kubernetesのマネージドサービス
- ECS : AWSが開発したコンテナ管理サービス
ちなみに・・・
EKSとECSは コンテナを管理する役割として、
コントロールプレーンと呼ばれており、
コンテナが動く場所として、データプレーンと呼ばれているのが Fargate, EC2 になります。
Fargateの詳細は こちらいままで EKS+Fargate が使えなかったのですが、2019年に使えるようになりました。
下記のどの組み合わせでも使うことが出来ます。
- ECS+Fargate
- ECS+EC2
- EKS+Fargate
- EKS+EC2
勉強後イメージ
ECSはAWS独自のコンテナ管理サービスで、EKSはKubernetes(コンテナ管理サービス)のマネージドサービスってことか。
Fargateの雰囲気もなんとなくわかってきた気がする参考
- 投稿日:2021-03-06T17:04:11+09:00
AWS Gateway Load Balancer が東京リージョンに対応したらしいので試してみた
概要
AWS Gateway Load Balancerが東京リージョンに対応しました
WS Gateway Load Balancer を使うことで、FWやIDS,IPSのサードパーティの仮想ネットワークアプライアンスの可用性および、拡張性を向上させることができるようです。
今までもクラウド上に、仮想ネットワークアプライアンスを導入することは可能でしたが、可用性、拡張性といったところは課題になっていました。
例えば、ピーク時に負荷を処理するために、リソースを過剰にプロビジョニングしたり、トラヒックに基づいて手動でスケールアップ、スケールダウンしたり、もしくは、その他の補助ツールを使う必要がありました。
いずれにしても運用のオーバヘッドとコストの増加に繋がっておりましたが、AWS Gateway Load Balancerを使うことで、この課題を解決することができます。↓のページでもの概要にも書かれている通り、GWLB と GWLBE を利用することによりシンプルにスケール・可用性・サービス提供のしやすさを向上することが可能にになったらしい。
そしてこの間の通信はGeneveプロトコルを利用してレイヤー3でカプセル化され、透過的に転送することができるようだ。
[新サービス]セキュリティ製品等の新しい展開方法が可能なAWS Gateway Load Balancerが発表されたので調査してみた少々イメージがつきにくいので、り、GWLB と GWLBE を作成するところまで確認して見た。
やって見た系
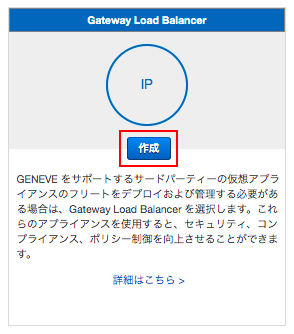
GLB
「作成」
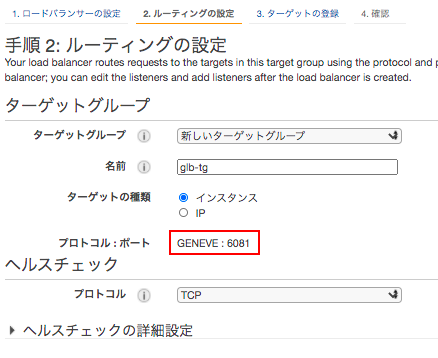
基本的な設定は通常のELBと同じで、プロトコル:ポートが、GENEVE:8081 になっているところぐらいだ。
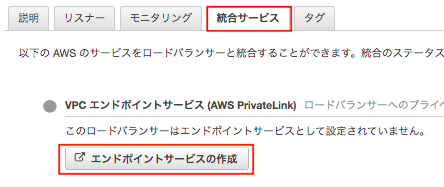
エンドポイントサービス
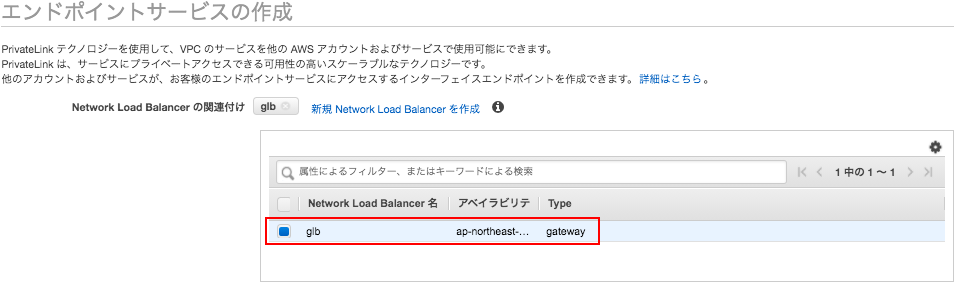
GLBが作成されたら、「統合サービス」から、「エンドポイントサービスの作成」を開き、VPCエンドポイントサービスの画面へ遷移する。
対象となるGLBを選択してエンドポイントサービスを作成する。
エンドポイントサービスが作成されたら、エンドポイントを作成するために「サービス名」をコピーしておく。
エンドポイント
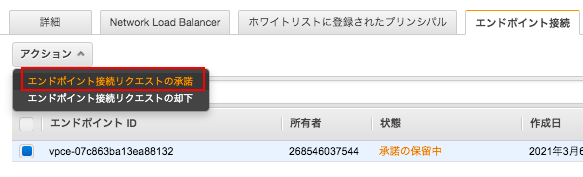
「サービスを名前で検索」から先ほど控えたエンドポイントサービスのサービス名を入れて検証する。
最後にエンドポイントサービス側で、エンドポイントのリクエストを承認する。
とりあえずはここまで。詳しい動作については追々やっていこう。
リンク


- 投稿日:2021-03-06T16:24:54+09:00
【初心者】AWS Key Management Service (AWS KMS) を使ってみる #2 (S3暗号化での利用)
1. 目的
- AWSのセキュリティ関連サービスの復習をしている。AWS KMSについて、前回の記事「【初心者】AWS Key Management Service (AWS KMS) を使ってみる」でEC2インスタンス内のファイルの暗号化、復号を試してみたが、今回はS3での動作確認を行う。
- 今ひとつKMSのメリットが理解できていないため、S3の標準機能で暗号化したバケットとの動作比較を行う。
2. やったこと
2つの空のバケットを作成する。※作業に使用したバケットは記事公開時に削除済。
- mksamba-bucket-sse-s3 (S3の標準機能での暗号化)
- mksamba-bucket-sse-kms (KMSでの暗号化)
Lambda関数からそれぞれのバケットにファイルを書き込む。
2人のIAMユーザを作成する。
- mksamba-poweruser (S3権限あり、KMS権限あり)
- mksamba-normaluser (S3権限あり、KMS権限なし)
IAMユーザの権限の違いによるバケット内のデータの見え方の違いを確認する。
バケットを誤って一般公開してしまったとして、インターネット経由でのそれぞれのバケット内のデータの見え方の違いを確認する。
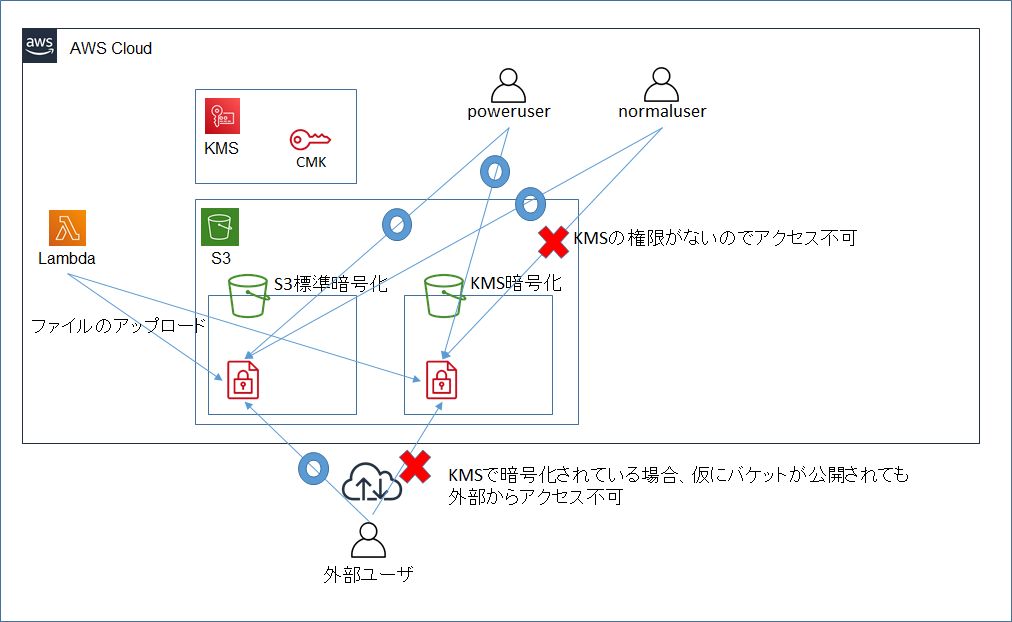
3. 構成図
4. 実施手順
4.1 2つのバケットの作成
以下の2つのバケットを作成する。
- mksamba-bucket-sse-s3 (S3の標準機能での暗号化)
- mksamba-bucket-sse-kms (KMSでの暗号化)
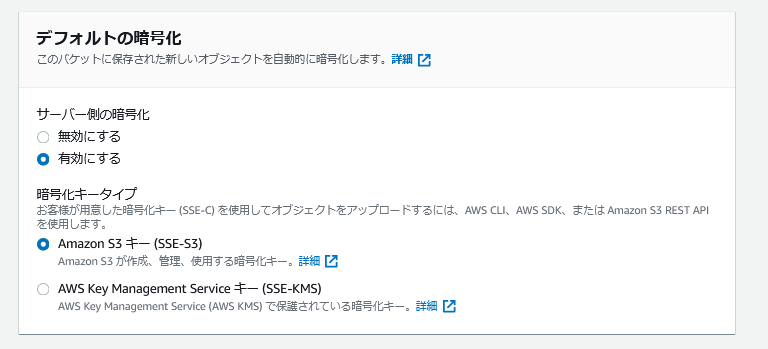
S3標準機能で暗号化する場合の設定は以下のとおり。
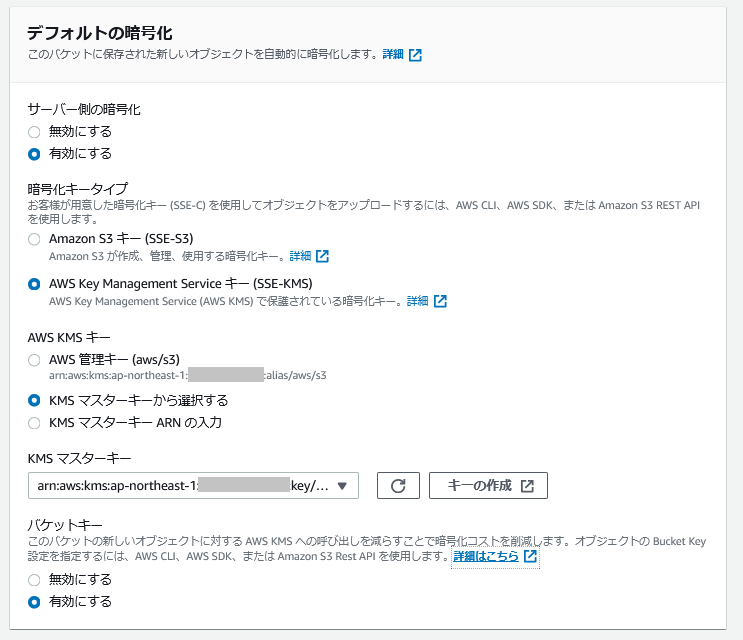
- KMSで暗号化する場合の設定は以下のとおり。
- なお、KMSでの暗号化設定時に使用する鍵(KMSマスターキー)は、事前に作成しておいた「カスタマー管理型のキー(CMK)」を用いる。また、その鍵に対するキーポリシーはデフォルト設定とする。(同一アカウント内の、KMSに関する権限を持つIAMユーザ/ロールからはアクセス可能)
4.2 バケットへのファイルの書き込み
- 2つのバケットにファイルを書き込むLambda関数を作成する。
mksamba-s3-write.pyimport datetime import boto3 s3 = boto3.resource('s3') def lambda_handler(event, context): dt_now = datetime.datetime.now() key = str(dt_now) + ".txt" #結果を保存するファイル名を"日時.txt"とする tmpfile = open('/tmp/tmp.txt', 'w', encoding='utf-8') print(str(dt_now), file=tmpfile) tmpfile.close() bucket = "mksamba-bucket-sse-s3" s3.meta.client.upload_file('/tmp/tmp.txt',bucket,key) bucket = "mksamba-bucket-sse-kms" s3.meta.client.upload_file('/tmp/tmp.txt',bucket,key)
- この関数に付与するロールの権限として、最初はAmazonS3FullAccessのみを付与する。そうすると、mksamba-bucket-sse-s3には書き込みできるが、mksamba-bucket-sse-kmsのほうには以下の書き込みエラーとなる。
[ERROR] S3UploadFailedError: Failed to upload /tmp/tmp.txt to mksamba-bucket-sse-kms/2021-02-28 15:05:16.538885.txt: An error occurred (AccessDenied) when calling the PutObject operation: Access DeniedTraceback (most recent call last): File "/var/task/lambda_function.py", line 20, in lambda_handler s3.meta.client.upload_file('/tmp/tmp.txt',bucket,key)
- ロールにKMSの権限を追加する。(AWS管理ポリシーの「AWSKeyManagementServicePowerUser」では権限不足のようで、今回は「PowerUserAccess」を追加) その後、再度Lambda関数を実行すると、ファイルが両方のバケットに保存されるようになる。
- この挙動から、KMSで暗号化されたS3バケットへの書き込み時に、KMS(の中の鍵)へのアクセス権限が必要なことが分かる。
4.3 2人のIAMユーザの権限の違いによる動作確認
- 権限の異なる2人のIAMユーザを作成する。
- mksamba-poweruser (AdministratorAccess: S3及びKMS権限あり)
- mksamba-normaluser (S3FullAccessのみ: S3権限あり、KMS権限なし)
- IAMユーザ「mksamba-poweruser」でログインした場合、両方のバケットのファイル一覧の表示、およびダウンロードが可能。
- IAMユーザ「mksamba-normaluser」でログインした場合、バケット「mksamba-bucket-sse-s3」のほうは問題なくファイル一覧の表示やファイルのダウンロードが可能。一方、バケット「mksamba-bucket-sse-kms」のほうは、ファイルの一覧の表示は可能だが、ファイルをダウンロードしようとするとエラーになる。
- mksamba-normaluser でログインした場合、バケットのリスト表示は以下のように可能。
- 次に、ファイルを選択し、ダウンロードしようとすると以下のエラー(Access Denied)となる。
- この挙動から、KMS暗号化されているバケットの場合、S3のアクセス権限があればファイルのリストの表示は可能だが、ファイルのダウンロードにはKMSのアクセス権(バケットの暗号化に使用している暗号鍵を使ったDecryptの権限)が必要なことが分かる。
4.4 バケットを公開する設定にした場合の動作確認
2つのバケットに対し、バケットを一般公開する設定を行う。設定内容は公式ドキュメント「静的ウェブサイトホスティング用に S3 バケットを設定する方法」をそのまま実施する。
- 静的ウェブサイトホスティングの有効化
- S3 パブリックアクセスブロック設定の変更(全てのチェックを外す)
- バケットポリシー(Readの許可)の追加
バケット「mksamba-bucket-sse-s3」では、上記の設定後、オブジェクト(ファイル)のURLを指定すると、誰でもダウンロード、閲覧することが可能。
バケット「mksamba-bucket-sse-kms」では、上記の設定後、オブジェクト(ファイル)のURLを指定してダウンロードしようとすると、以下のエラーとなりダウンロード不可となる。
- 上記の挙動から、SSE-S3で暗号化している場合、ファイルの取得要求をするとAWS側で自動復号されてしまうため、論理的なレベルでのアクセスに対するセキュリティの向上にはなっていないと考えられる。(AWSのデータセンターからディスクが盗まれても、暗号化されているので大丈夫、という物理的なレベルのでのセキュリティ対策にはなっている。)
- 一方SSE-KMSの場合、KMS(の中の鍵)のアクセス権限がないとファイルの復号、ダウンロードができないため、AWSアカウント内でのKMS権限を持たないユーザや、誤設定によるバケットの公開による一般ユーザからのアクセスに対してのセキュリティ対策となっている。
5. 所感
- どのようなリスクから守りたいかということを意識して暗号化の設定を選択するようにしたい。


- 投稿日:2021-03-06T14:48:19+09:00
AWS LightsailによるWordpress構築メモ
概要
ブログサイトの構築・WEB制作の学習・AWSの学習を兼ねて、価格・規模感でちょうど良さそうなLightsailを使った話。同じようなチュートリアル記事は沢山あるが、こちらは個人的に参照するためのメモ。
ひとまずWordpress導入、ドメイン取得、HTTPS化するまで書く。
導入前に公式チュートリアルも参照したが、自動翻訳なのかリンクやサービス名が文末に来てることが多くて読みづらい。併せてこの辺をざっくり読んだ ↓
使うサービスと概要
今回使うのはAWS LightsailとRoute53。
Lightsail
AWSのサービスのひとつで、低価格の仮想プライベートサーバー。
EC2よりもシンプル、レンタルサーバーより安価。VPCよりもお手軽。
ぽちぽちやるだけでOSやWordpressのインストールまでやってくれる。
月額3.50USDから使用できる。最安の料金プランの場合のみ、初月無料。Lightsail は使いやすい仮想プライベートサーバー (VPS) であり、アプリケーションやウェブサイトの構築に必要なすべてのものに加えて、コスト効率が良い月額プランを提供します。クラウドに慣れていないお客様でも、信頼している AWS インフラストラクチャを使用してすぐにクラウドにアクセスしようとしている場合も、対応できます。
Route53
こちらもAWSサービスのひとつ。ドメイン管理・DNSサービス。
Lightsailと並行したチュートリアルをよく見かけたので、試しに使ってみた。
ドメイン管理は1年あたりだいたい5~13USD。数年ぶんまとめて購入も可能。
今回はお試し利用のため、字面の信頼感等は無視して一番安かった.linkドメインにした。また、ドメイン料金とはべつにRoute53の利用料もかかる。
ホストゾーン利用料で月に0.5USD+100万クエリごとに0.4USDとのこと。
小規模サイトならクエリ利用料は誤差の範囲。
WordPressインスタンス起動まで
公式チュートリアルに沿って進める。ちょっと読みづらいがやることは簡単。
リージョンは東京が選べる。
Lightsailでのドメインの設定
こちらの記事を参照した。
HTTPS化
こちらも公式チュートリアルがある。
インスタンスのLinuxディストリビューションによって手順が異なるが、
2020年7月以降に作成されたCertified by BitnamiインスタンスであればDebian。インスタンスのディストリビューションを確認するには、 uname -a コマンドを実行します。レスポンスには、インスタンスの Linux ディストリビューションとして Ubuntu または Debian のいずれかが表示されます。
手順さえ間違えないようにすればいいだけで難しくない。
とりあえず、これでおしまい。所感・次にやること
レンタルサーバーの利用経験もなく初めて一連の流れをやったが、ここまでビビりつついろいろ調べながらやって4時間くらいかけた。思っていたよりずっと簡単だったけど、それなりに時間もかかってしまった?
この環境の維持管理費はざっくり月400円。ドメイン費用でざっくり500円。
初Wordpressなので使い倒していきたい。次はSSL更新自動化とWordpressの初期設定をば、やるべし。
- 投稿日:2021-03-06T14:35:42+09:00
[AWS SAM] API Gateway を sam deploy 後、GUI から再デプロイしないと設定が反映されないことがある
事象
- AWS SAM で API Gateway を
sam deployしても、設定がデプロイされない(デプロイ履歴にも表示されない)
- GUI からみると設定自体は更新されているが、デプロイされていないため動作に反映されていない
changeset の違い
- 事象発生時は、以下のように
AWS::ApiGateway::Deploymentが changeset に出力されないCloudFormation stack changeset ------------------------------------------------------------------------------------------------ Operation LogicalResourceId ResourceType ------------------------------------------------------------------------------------------------ * Modify TestApiGatewayStage AWS::ApiGateway::Stage * Modify TestApiGateway AWS::ApiGateway::RestApi ------------------------------------------------------------------------------------------------
- 想定通りデプロイされるときは、
AWS::ApiGateway::Deploymentが changeset に出力されるCloudFormation stack changeset ------------------------------------------------------------------------------------------------ Operation LogicalResourceId ResourceType ------------------------------------------------------------------------------------------------ + Add TestApiGateway AWS::ApiGateway::Deployment * Modify TestApiGatewayStage AWS::ApiGateway::Stage * Modify TestApiGateway AWS::ApiGateway::RestApi - Delete TestApiGatewayDeployment AWS::ApiGateway::Deployment ------------------------------------------------------------------------------------------------発生条件
- API 設定(Swagger / OpenAPI 定義等)に修正を加えず、リソースポリシーなど API Gateway 自体の設定だけ修正した場合に発生する
原因
- 「API 設定に変更が無いと API Gateway のデプロイを検知しない」という AWS SAM の制限(仕様)
- 「強制デプロイ」オプションの Issue が 2018 年頃に出ているが、2021 年時点でも未実装
- Feature: Always deploy API option · Issue #660 · aws/serverless-application-model · GitHub
回避策
- どちらも微妙な方法ですが、現状ではこのくらしかなさそうでした
sam deploy後、GUI から手動でデプロイする- API 設定に何らかの変更を加える
- ダミーパラメータを作ることで回避できないか検討しましたが、無理でした
関連情報
- AWS SAM 公式 Issue
- API Gateway Stages Deployment only gets updated when Swagger is updated · Issue #479 · aws/serverless-application-model · GitHub
- AWS::Serverless::Api deployment resource is not generated on Sub'ed Ref change · Issue #914 · aws/serverless-application-model · GitHub
- Adding "FunctionName" to AWS::Serverless::Function does not trigger an API Gateway deployment · Issue #739 · aws/serverless-application-model · GitHub
- Api Gateway Deployment not updated when AutoPublishAlias is changed · Issue #1547 · aws/serverless-application-model · GitHub
- aws sam - SAM deploys are updating API Gateway Responses but not deploying to the stage - Stack Overflow
- 投稿日:2021-03-06T14:01:02+09:00
【Lambda】S3への動画アップロードをトリガーにする時はPUTではなくマルチパートアップロード
はじめに
S3へmp4ファイルをアップロードした時に動くLambdaを作っていましたが、
動画ファイルをアップロードしても起動してくれないという問題が発生しました。
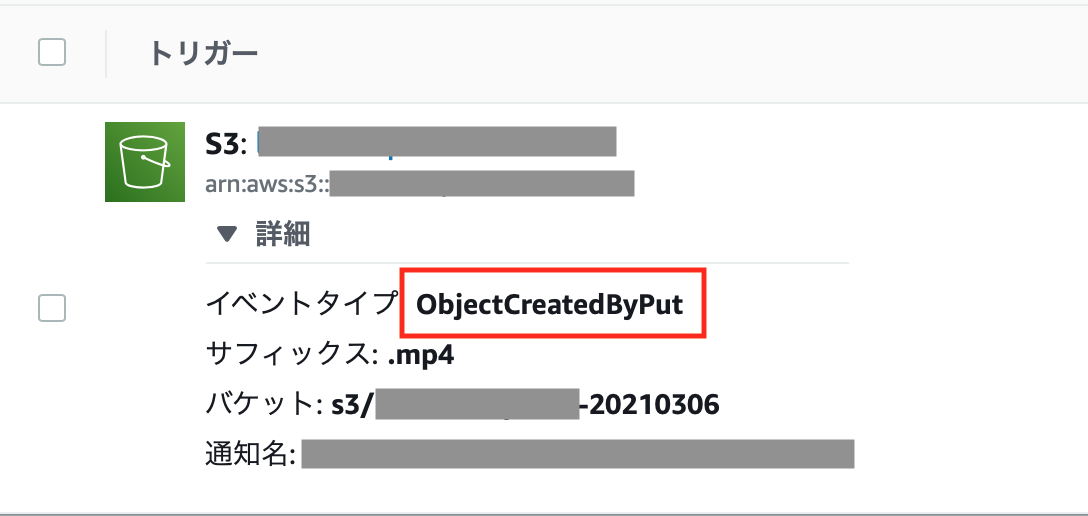
この時の設定がこちらなのですが、
アップロードだからPUTで良いだろうと深く考えずに設定していた
「イベントタイプ:ObjectCreatedByPut」に問題があったようです。
マルチパートアップロード
S3へのアップロードを調べていると、マルチアップロードという言葉が出てきました。
簡単に言うと、大きなファイルを細かく分けることで高速にアップロードできる仕組みのようです。
(こちらのページがわかりやすかったです)AWSのコンソールを使用する場合、何MB以上だとマルチパートアップロードになるのかは見つけることができませんでしたが、200MB程度の動画ファイルをアップロードする際はこのマルチパートアップロードが適用されているみたいでした。
Lambda修正
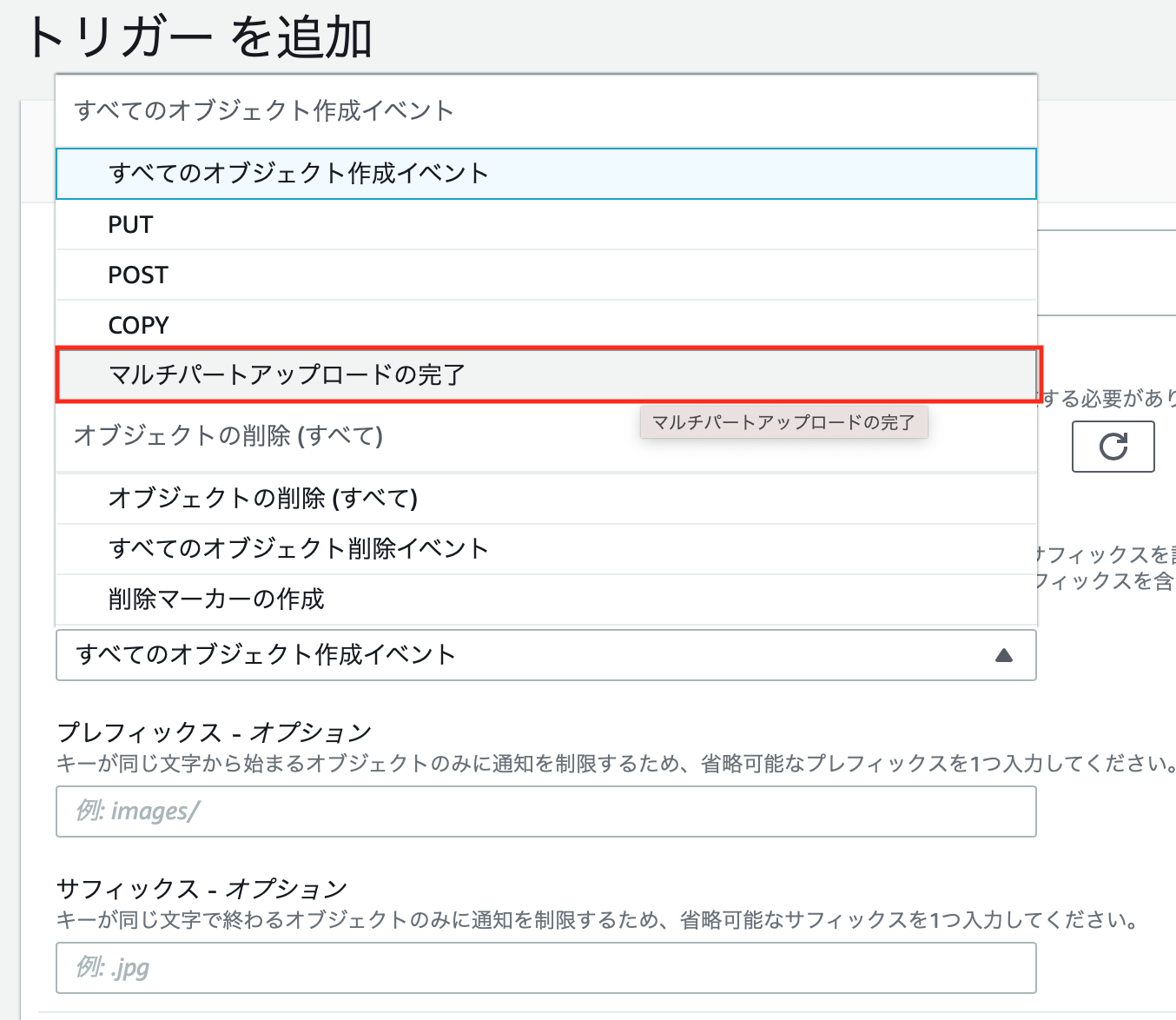
トリガーを作成するときに「マルチパートアップロードの完了」を選択すると、
無事に動画ファイルアップロード時にLambdaが起動するようになりました!
すべてのオブジェクト作成イベント
トリガー追加の選択肢を見てみると、「すべてのオブジェクト作成イベント」という、「PUT」も「マルチパートアップロードの完了」も適用されるトリガーがあります。
今回は「マルチパートアップロードの完了」でうまくいきましたが、動画ファイルといってもサイズの大小があり、必ずしもマルチパートアップロードが使用されるかわかりません。
特に問題がない場合は、「すべてのオブジェクト作成イベント」を選択しておいた方が無難なのかもしれません。参考資料

- 投稿日:2021-03-06T13:56:27+09:00
[AWS SAM] [CloudFormation] Lambda 実行ロググループを明示的に指定する
背景
- AWS SAM を使って、API Gateway + Lambda のデプロイを自動化しています
- 複数環境それぞれで Lambda 関数名を変えています
- 例では
lambda-handler-for-qiita[|-r1|-r2]の3通りを定義しています- 詳細は別記事の [AWS SAM] [CloudFormation] 環境ごとに設定値を切り替える方法 - Qiita をご参照ください
- 本ページでは、Lambda 用実行ロググループを明示的に作成・管理する際の注意点をまとめています
AWS SAM における Lambda 用実行ロググループの基礎知識
- デフォルトでは、何も指定しなくとも
/aws/lambda/{Lambda関数名}の名前で自動で CloudWatch ロググループを作ってくれます- とはいえ、以下クラスメソッド様の記事で解説されている通り、自前のテンプレートで管理した方が良いです
- 【小ネタ】AWS SAMでLambda関数を作成する場合はCloudWatch LogsのLog Groupも同時に作った方がいいという話 | Developers.IO
- 理由
- Lambda関数のLog Groupが存在する前提のテンプレートになっているとスタックの作成に失敗する可能性がある
- Lambda関数が作成するLog Groupはリテンションが無期限になっている
- AWS SAMによって作成されたスタックを削除した場合Log Groupが残り続ける
- そもそもLog GroupはLambda関数には必須のAWSリソースなのでそれも含めてテンプレートを作成した方がよい
先に Lambda 関数が作られると失敗する
- 当初、以下のように Lambda ロググループ名を
!Sub /aws/lambda/${Lambda関数}のように Lambda 関数を参照する形で指定していました# Lambda ロググループ LambdaHandlerForQiitaLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /aws/lambda/${LambdaHandlerForQiita} RetentionInDays: 180
- しかし、この書き方だと
sam build時にエラーとなる場合がありました- 理由は、Lambda 関数を
!Sub= 参照しているため Lambda 関数が先に作られている必要があるにも関わらず、Lambda ロググループのリソースが先に作成されてしまったためです
- リソースの作成順は AWS SAM が自動判断しており、検証した限りでは yaml 内での定義順は関係ありませんでした
回避策
- DependsOn 属性 を利用して、「Lambda 関数 → ロググループ」の順にリソースが作成されるよう制御
- ロググループ名は
!Sub参照が使えないため、!Joinを使って/aws/lambda/{Lambda関数名}となるよう生成
- Lambda 関数名を FunctionName プロパティ で明示的に指定しておかないと、
lambda-handler-for-qiita-A1B2C3D4E5Fのように末尾にランダムな文字列が付加され、分かりにくくなってしまうので注意# Lambda 関数名の Mapping 定義は以下も参照 # https://qiita.com/gotousua/items/48efb57cebef6d46f2ba#%E3%83%9E%E3%83%83%E3%83%94%E3%83%B3%E3%82%B0--mappings- Mappings: SystemTypeMap: general: LambdaName: lambda-handler-for-qiita Resources: # Lambda 関数 LambdaHandlerForQiita: Type: AWS::Serverless::Function Dependson: LambdaHandlerForQiitaLogGroup Properties: FunctionName: !FindInMap [ SystemTypeMap, !Ref SystemType, LambdaName ] # Lambda のログ用ロググループ LambdaHandlerForQiitaLogGroup: Type: AWS::Logs::LogGroup Properties: # Lambda より先にロググループを作るため、!Sub /aws/lambda/${LambdaHandlerForQiita} とはしない LogGroupName: !Join [ "", [/aws/lambda/, !FindInMap [ SystemTypeMap, !Ref SystemType, LambdaName ]]] RetentionInDays: 180
- 投稿日:2021-03-06T12:44:50+09:00
東京リージョンと大阪リージョンのサービス比較
大阪リージョンが2021/3/2にフルリージョン化しました!!
おめでとうございますどんなサービスが使えるのか気になったので、東京リージョンとの比較表を作成しました。
https://aws.amazon.com/jp/about-aws/global-infrastructure/regional-product-services
から抽出しました。2021/03/06時点の情報です
AWSサービス 東京 大阪 バージニア北部 AWS Amplify Y Y AWS App Mesh Y Y AWS AppSync Y Y AWS Application Discovery Service Y Y AWS Artifact Y Y Y AWS Audit Manager Y Y AWS Auto Scaling Y Y AWS Backup Y Y AWS Batch Y Y AWS Budgets Y Y AWS Certificate Manager Y Y Y AWS Chatbot Y Y AWS Cloud Map Y Y AWS Cloud9 Y Y AWS CloudFormation Y Y Y AWS CloudHSM Y Y AWS CloudTrail Y Y Y AWS CodeArtifact Y Y AWS CodeBuild Y Y AWS CodeCommit Y Y AWS CodeDeploy Y Y Y AWS CodePipeline Y Y AWS CodeStar Y Y AWS Compute Optimizer Y Y AWS Config Y Y Y AWS Control Tower Y AWS Cost Explorer Y AWS Cost and Usage Report Y AWS Data Exchange Y Y AWS Data Pipeline Y Y AWS DataSync Y Y AWS Database Migration Service Y Y Y AWS DeepComposer Y AWS DeepLens Y Y AWS DeepRacer Y AWS Device Farm AWS Direct Connect Y Y Y AWS Directory Service Y Y AWS Elastic Beanstalk Y Y Y AWS Elemental MediaConnect Y Y AWS Elemental MediaConvert Y Y AWS Elemental MediaLive Y Y AWS Elemental MediaPackage Y Y AWS Elemental MediaStore Y Y AWS Elemental MediaTailor Y Y AWS Fargate Y Y Y AWS Firewall Manager Y Y AWS Global Accelerator Y Y AWS Glue Y Y Y AWS Ground Station AWS IQ Y Y Y AWS Identity and Access Management (IAM) Y Y Y AWS IoT 1-Click Y Y AWS IoT Analytics Y Y AWS IoT Core Y Y AWS IoT Device Defender Y Y AWS IoT Device Management Y Y AWS IoT Events Y Y AWS IoT Greengrass Y Y AWS IoT SiteWise Y AWS IoT Things Graph Y Y AWS Key Management Service Y Y Y AWS Lake Formation Y Y AWS Lambda Y Y Y AWS License Manager Y Y AWS Managed Services Y Y AWS Marketplace Y Y Y AWS Migration Hub Y Y AWS Network Firewall Y Y AWS OpsWorks Stacks Y Y AWS OpsWorks for Chef Automate Y Y AWS OpsWorks for Puppet Enterprise Y Y AWS Organizations Y Y Y AWS Outposts Y Y AWS Personal Health Dashboard Y Y Y AWS PrivateLink Y Y Y AWS Proton Y Y AWS Resource Access Manager (RAM) Y Y AWS RoboMaker Y Y AWS Secrets Manager Y Y Y AWS Security Hub Y Y AWS Server Migration Service (SMS) Y Y AWS Serverless Application Repository Y Y AWS Service Catalog Y Y AWS Shield Y Y AWS Single Sign-On Y Y AWS Snowball Y Y Y AWS Snowcone Y AWS Snowmobile Y AWS Step Functions Y Y Y AWS Storage Gateway Y Y AWS Support Y Y Y AWS Systems Manager Y Y Y AWS Transfer Family Y Y AWS Transit Gateway Y Y AWS Trusted Advisor Y Y AWS VPN Y Y Y AWS WAF Y Y AWS Well-Architected Tool Y Y AWS X-Ray Y Y Y Alexa for Business Y Amazon API Gateway Y Y Y Amazon AppFlow Y Y Amazon AppStream 2.0 Y Y Amazon Athena Y Y Amazon Augmented AI (A2I) Y Y Amazon Aurora Y Y Y Amazon Braket Y Amazon Chime Y Y Amazon Cloud Directory Y Amazon CloudFront Y Y Y Amazon CloudSearch Y Y Amazon CloudWatch Y Y Y Amazon CodeGuru Y Y Amazon Cognito Y Y Amazon Comprehend Y Y Amazon Comprehend Medical Y Amazon Connect Y Y Amazon Detective Y Y Amazon DevOps Guru Y Y Amazon DocumentDB (with MongoDB compatibility) Y Y Amazon DynamoDB Y Y Y Amazon ElastiCache Y Y Y Amazon Elastic Block Store (EBS) Y Y Y Amazon Elastic Compute Cloud (EC2) Y Y Y Amazon Elastic Container Registry (ECR) Y Y Y Amazon Elastic Container Service (ECS) Y Y Y Amazon Elastic File System (EFS) Y Y Y Amazon Elastic Inference Y Y Amazon Elastic Kubernetes Service (EKS) Y Y Y Amazon Elastic MapReduce (EMR) Y Y Y Amazon Elastic Transcoder Y Y Amazon Elasticsearch Service Y Y Y Amazon EventBridge Y Y Y Amazon FSx for Lustre Y Y Amazon FSx for Windows File Server Y Y Amazon Forecast Y Y Amazon Fraud Detector Y Amazon GameLift Y Y Amazon GuardDuty Y Y Amazon Honeycode Amazon IVS Y Amazon Inspector Y Y Amazon Kendra Y Amazon Keyspaces (for Apache Cassandra) Y Y Amazon Kinesis Data Analytics Y Y Amazon Kinesis Data Firehose Y Y Y Amazon Kinesis Data Streams Y Y Y Amazon Kinesis Video Streams Y Y Amazon Lex Y Y Amazon Lightsail Y Y Amazon Location Service Y Y Amazon Lookout for Vision Y Y Amazon Lumberyard Y Y Amazon MQ Y Y Amazon Macie Y Y Amazon Managed Blockchain Y Y Amazon Managed Streaming for Apache Kafka Y Y Amazon Managed Workflows for Apache Airflow Y Y Amazon Neptune Y Y Amazon Personalize Y Y Amazon Pinpoint Y Y Amazon Polly Y Y Amazon Quantum Ledger Database (QLDB) Y Y Amazon QuickSight Y Y Amazon RDS on VMware Y Amazon Redshift Y Y Y Amazon Rekognition Y Y Amazon Relational Database Service (RDS) Y Y Y Amazon Route 53 Y Y Y Amazon SageMaker Y Y Amazon Simple Email Service (SES) Y Y Amazon Simple Notification Service (SNS) Y Y Y Amazon Simple Queue Service (SQS) Y Y Y Amazon Simple Storage Service (S3) Y Y Y Amazon Simple Workflow Service (SWF) Y Y Y Amazon Sumerian Y Y Amazon Textract Y Amazon Timestream Y Amazon Transcribe Y Y Amazon Transcribe Medical Y Y Amazon Translate Y Y Amazon Virtual Private Cloud (VPC) Y Y Y Amazon WorkDocs Y Y Amazon WorkLink Y Amazon WorkMail Y Amazon WorkSpaces Y Y Amazon WorkSpaces Application Manager Y CloudEndure Disaster Recovery Y Y Y CloudEndure Migration Y Y Y Elastic Load Balancing Y Y Y FreeRTOS Y Y VMware Cloud on AWS Y Y まだ数としては少ないようにも思いますが、今後の拡充に期待ですね。
- 投稿日:2021-03-06T08:47:16+09:00
RDSにプライベートサブネットをはる
用語確認
VPC
AWS上のプライベートなクラウド空間
サブネット
VPC内のネットワークを分割するもの。
ルートテーブル
サブネット内にあるインスタンスがどこに通信を送るのかが書かれた表のこと。ここに通信先が書かれていないサブネットは通信ができない。まとめると、サブネットごとに通信先を指定するもの。
作成手順
ルートテーブルの作成
・名前タグに任意の名前を指定
・使用するVPCを選択
・作成サブネットの作成
・名前タグに任意の名前を指定
・使用するVPCを指定
・扱うアベイラビリティゾーンを選択
・IPv4 CIDRブロックを指定(VPCの範囲内ならば何でもよい。自分は10.0.11.0/24と指定)
・作成サブネットとルートテーブルを関連付けさせる
・サブネットのアクションの編集から「ルートテーブルの関連付けの編集」を選択する。
・先ほど作成したルートテーブルのIDを選択し保存するルートテーブルの確認
・送信先が「0.0.0.0/0」となっているルートテーブルがないことを確認する。
・ターゲットがローカルのみの場合、プライベートなサブネットになっている。
- 投稿日:2021-03-06T08:46:38+09:00
40 代おじさん アタッチした EBS をマウントして使える状態にしてみた
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
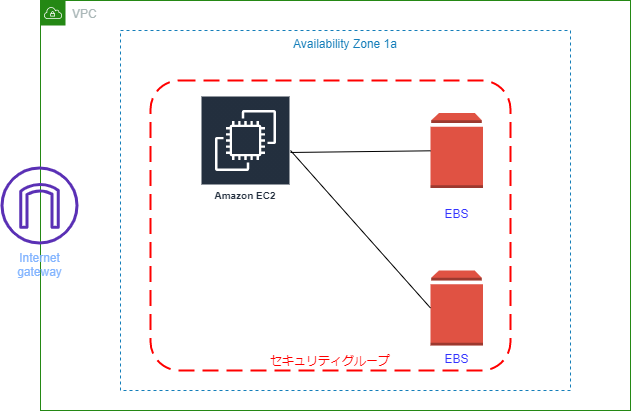
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 最終作成図
作成図構築手順
❶ EC2 インスタンス作成と同時に Apache インストール
❶ の記事は ↓
https://qiita.com/drafts/738c8f1905428e20e426/edit
❷ EBS を作成してアタッチする
❷ の記事は ↓
https://qiita.com/kou551121/items/514f2b3ac26543df3151
❸ アタッチしたあとマウントして使える状態にする3. アタッチしたあとマウントして使える状態にする
前回、EBS をアタッチしましたが実はこの状態のままでは使用できませんなので使用できる状態にしたいと思います
Tera Term を起動して EC2 にログインしてくださいsudo su -ルート権限になってください
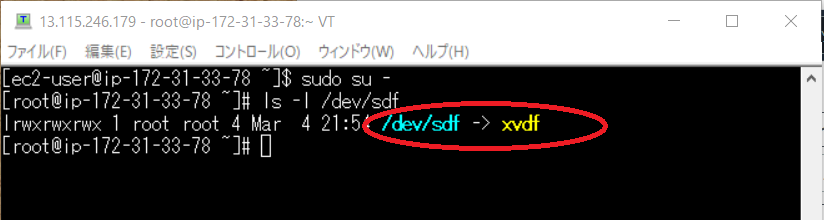
ls -l /dev/sdfコマンド打つと
/dev/sdf が xvdf のシンボリックリンクであることがわかります
ちなみにシンボリックリンクとは
Windows でいうところのショートカットのようなもので、ファイルや、ディレクトリを参照するファイルの事をいいます。
参照
https://kazmax.zpp.jp/linux_beginner/symbolic_link.html↓ のコマンドも打ってみてください
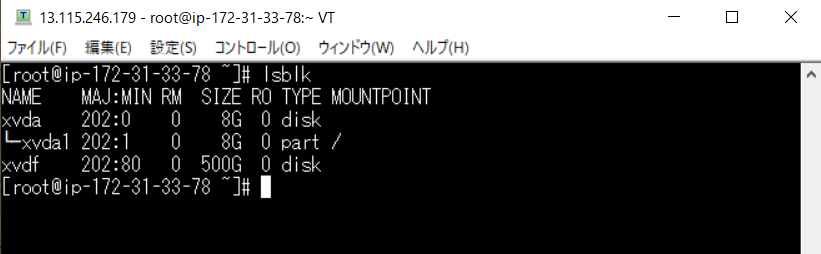
lsblk
このようになり xvda の下に xvdf があるとわかります
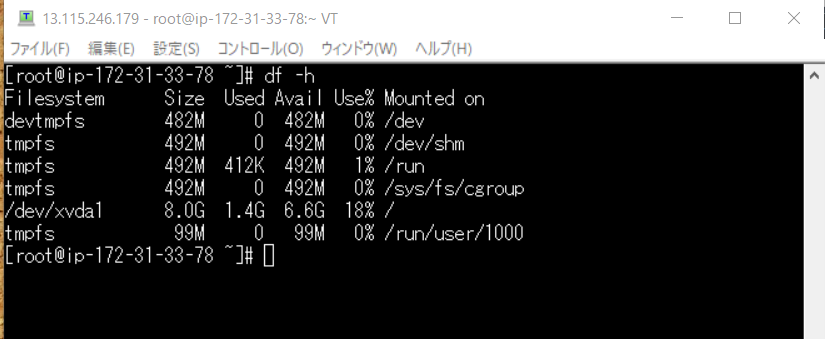
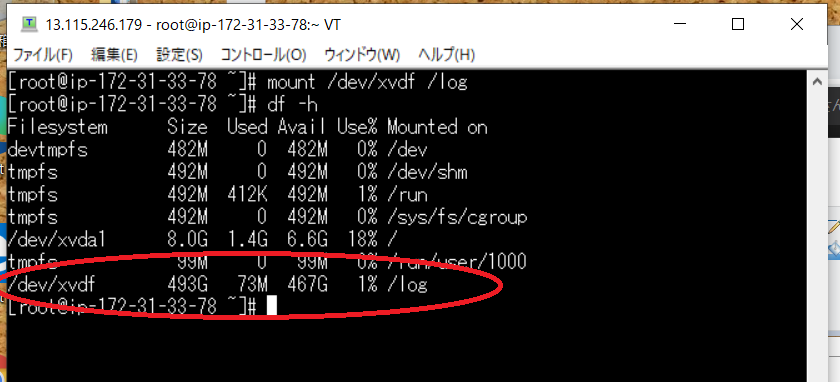
つぎの ↓ のコマンドを打ってくださいdf -h
こちらで Amazon linux ファイルシステムの一覧を見ることが出来ますが/dev/xvdf の情報が見れません
じつは linux ではマウントをしないといけないのです
マウントとは
「OS がファイルシステムを介してストレージデバイス上のファイルやディレクトリを利用できるようにすること。」みたいです
参照
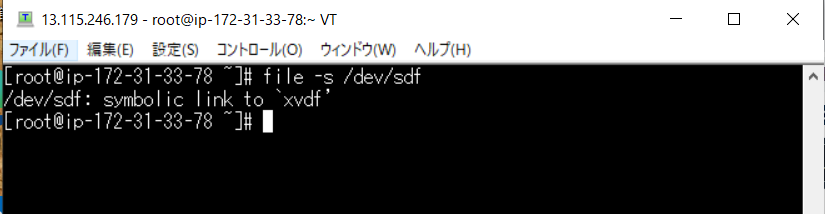
https://qiita.com/teru0x1/items/db4b64144c8d8f3f5162マウントする前にまずは前後比較をするために今の状態を見たいと思います
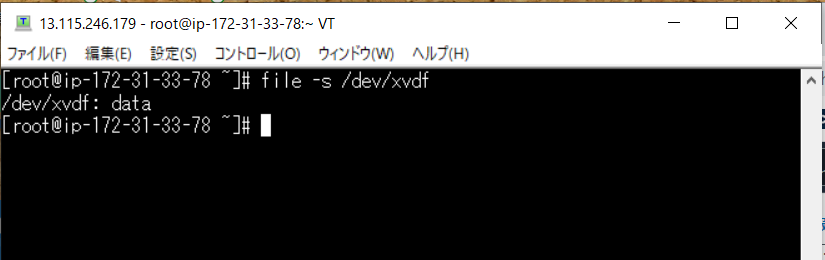
file -s /dev/sdfを打つと
/dev/sdf のシンボリックリンクが xvdf であることがわかります
次に
file -s /dev/xvdfを打つと
xvdf の中身は data となっています
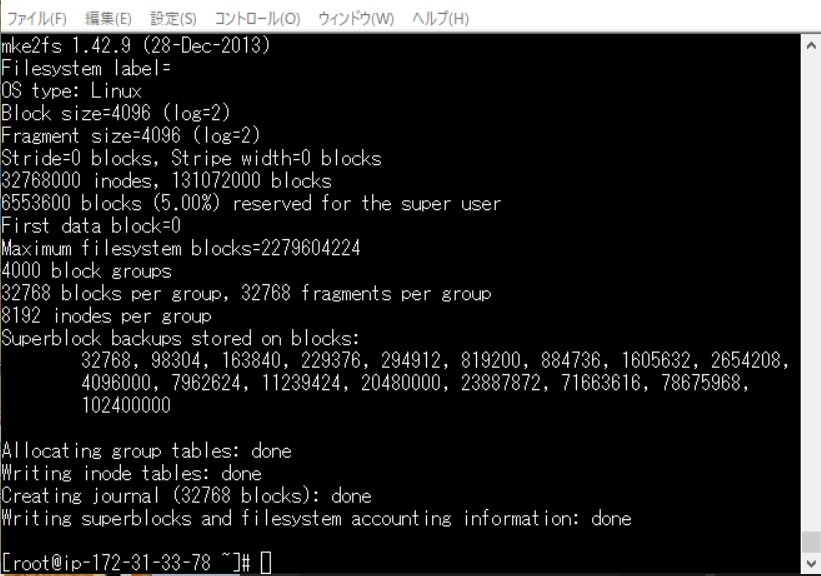
今回の流れとしてはマウントの前にファイルシステムを作成することになります。
そうするとさきほどの data の表記が変わります。mkfs -t ext4 /dev/xvdfmkfs -t ext4 でファイルシステムの名前を指定
linux では ext4 がよく使う形式みたいです
参考
https://eng-entrance.com/linux-format
/dev/xvdf で引数をしていします
このようになると思います
これでファイルシステムでストレージを使えるようになりました
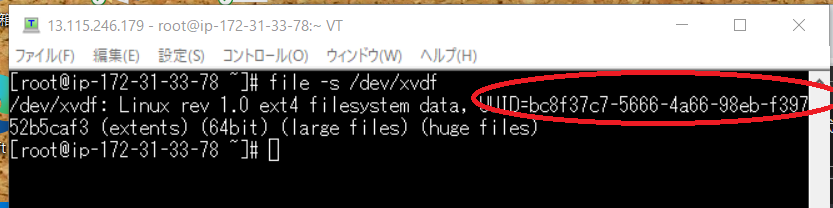
再びfile -s /dev/xvdfこちらを打ちますと
このように変わりました
UUID=xxxx-xxxx・・・・(赤枠)
こちらのものは後で使うのでコピーしておいてくださいでは次にマウントする場所を作ります
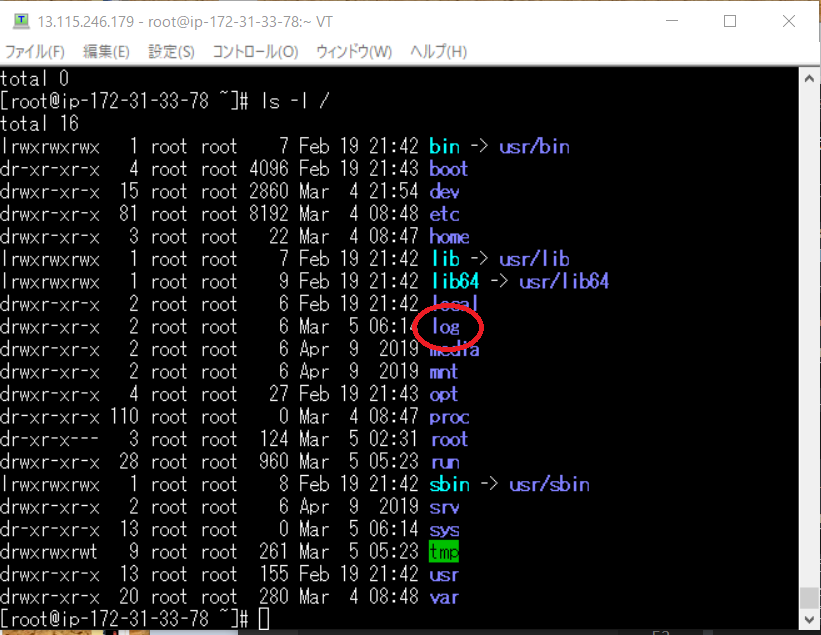
mkdir /logls -l /をしてみると
log が出来ているのが確認できます
mount /dev/xvdf /logdf -hをすると
500G ぐらいある xvdf がマウントされています
マウントまで終わりましたが再起動などするとマウントが外れるので再起動時にマウントできるように設定したいと思います
またバックアップも取ると良いのでそちらの設定も行います
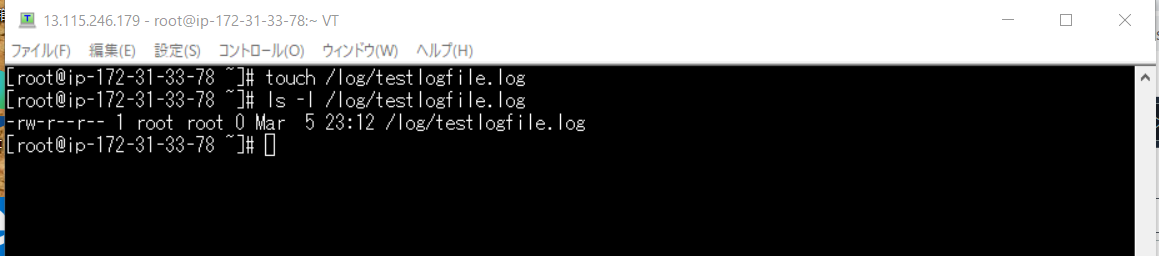
まずはバックアップのためのファイルを作成touch /log/testlogfile.log確認のために
ls -l /log/testlogfile.iog
ファイルが出来ているのが確認できます
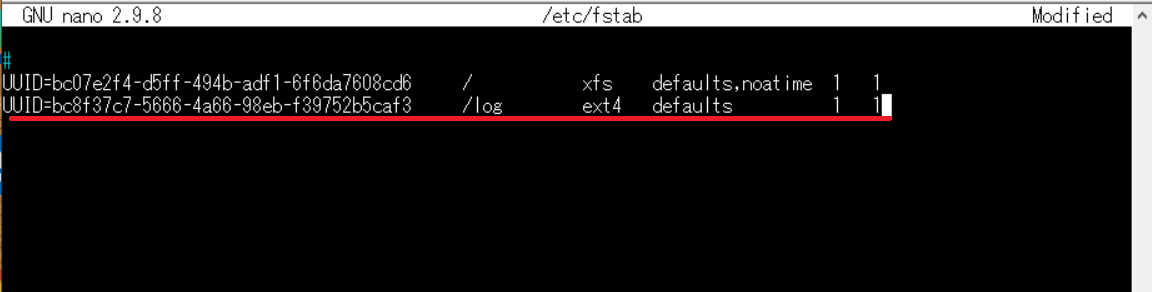
では次に再起動してマウントするように設定したいと思いますnano /etc/fstabこちらを打つと nano エディターを使うことができます。vi エディターでも良いのですが、自分は難しくて使えないためこちらを使用させていただきます
(赤線)のように UUID をいれて
/log にマウントするとして指定
ファイルシステムの名前(ext4)
defaults 最初の1はバックアップすると意味 次のは優先度を表す
参照
https://qiita.com/kihoair/items/03635447591358210772
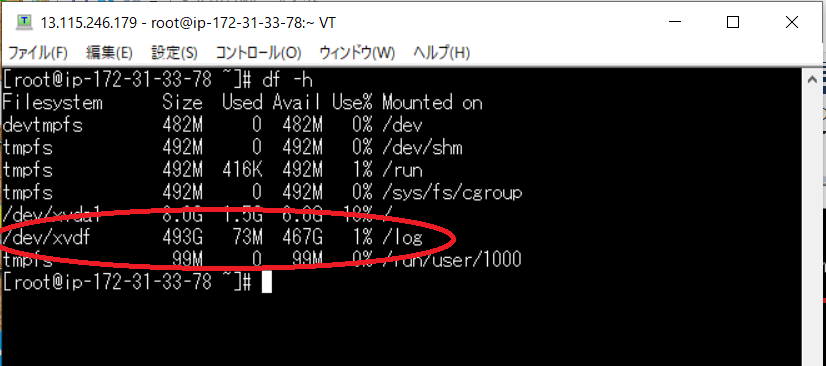
https://www.linuxmaster.jp/linux_skill/2013/06/etcfstab.htmlでは実験的に再起動をかけます
reboot接続が切れたと思うのでもう一度、入ってみてください(ルート権限になるのを忘れずに)
df -hこちらで確認をすると
再起動後もマウントされていることがわかります
最後に
今回で作成図すべて終わったと思います
せっかくなので今度は作ったものを AMI にバックアップを取って AMI から復元してみたいと思います
いや~~ なんかすごいやることが増えてきて俺少しできるようになったんでないの??
と思ってしまいます。でもまだまだです!!がんばります!!またこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/
- 投稿日:2021-03-06T01:25:13+09:00
②NiceHashマイニング収益をAWS Lambda×LINE NotifyでLINE通知する
目次
1. 背景
業務ではコーディングや、AWSに触れる機会が一切ないので、勉強がてらAWSで何かしようと思い、日々のマイニング収益を定期的に通知するシステムをAWS上に構築してみました。
※こちらの投稿は、以前に投稿した「①NiceHashマイニング収益をAWS Lambda×SNSでメール通知する」の通知方法を変更したものです。2. 構成/構築手順
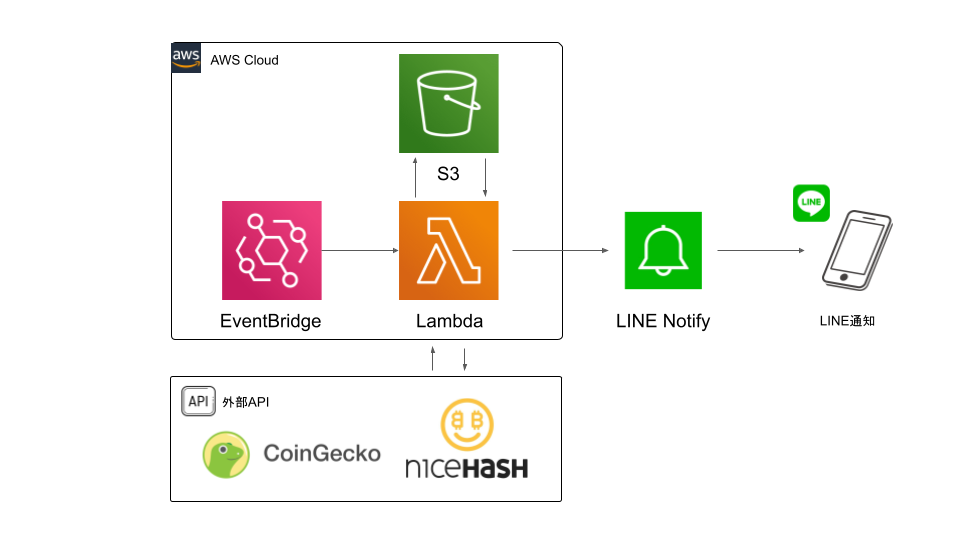
システム構成は、AWS Lambdaを中心とした基本的なサーバレスアーキテクチャです。
処理の流れ
1. EventBridge(CroudWatch Event)の日次実行cronがトリガーとなり、Lambda関数をキック
2. Lambdaでは、外部APIからマイニング収益情報を取得
3. S3バケットへ残高情報を書き込み、前日の残高情報を取得、残高の増減を算出
4. LambdaからPOSTメソッドで通知メッセージがLINE Notifyへ渡され、スマホへLINE上で通知
2-1.Lambdaの構築
2-1-1.IAMロールの作成
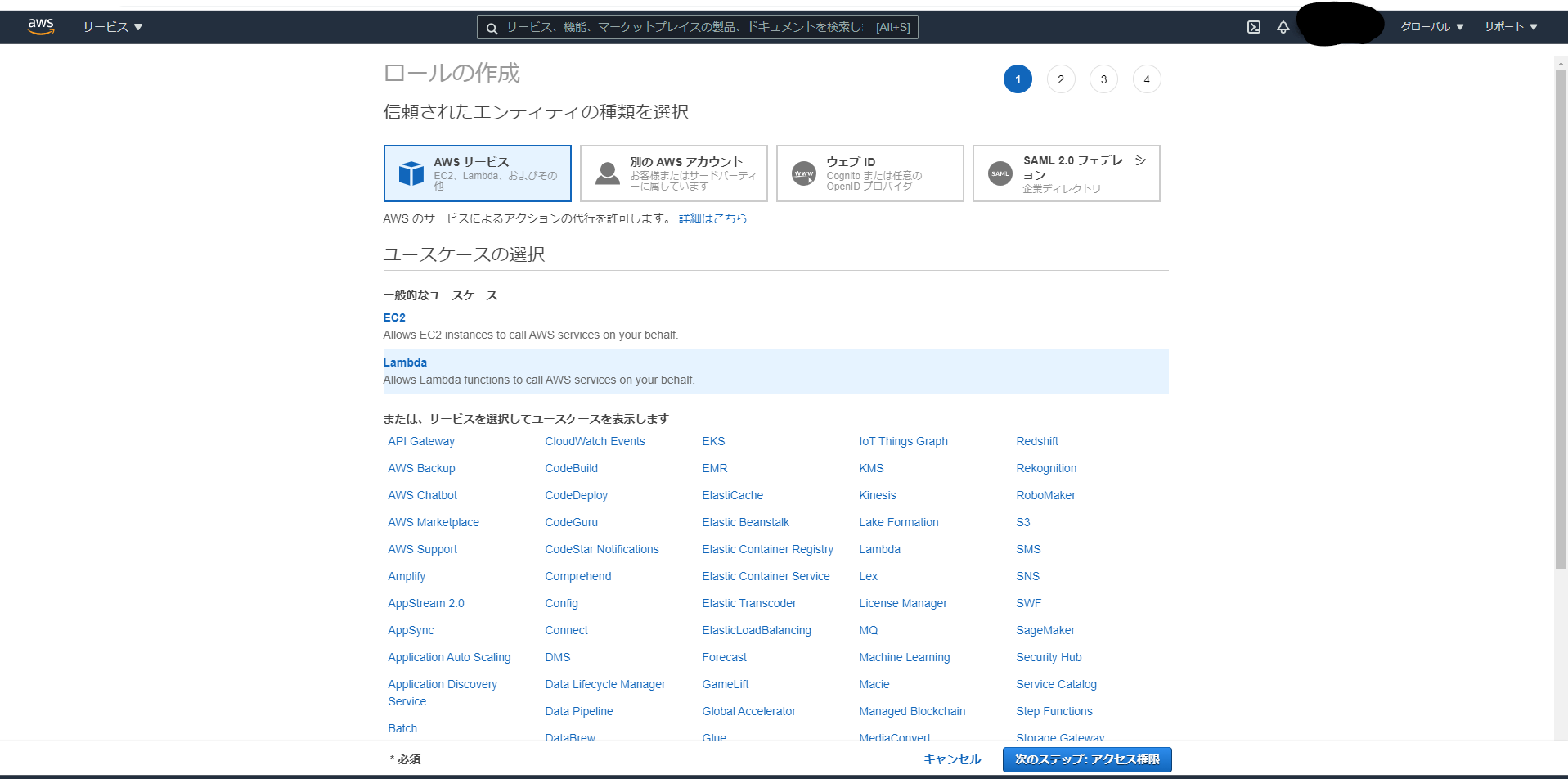
AWSサービス間を連携するために新規IAMロールを作成し必要なポリシーをアタッチする
・IAMを起動し、ユースケースLambdaを選択し「次のステップ」をクリック
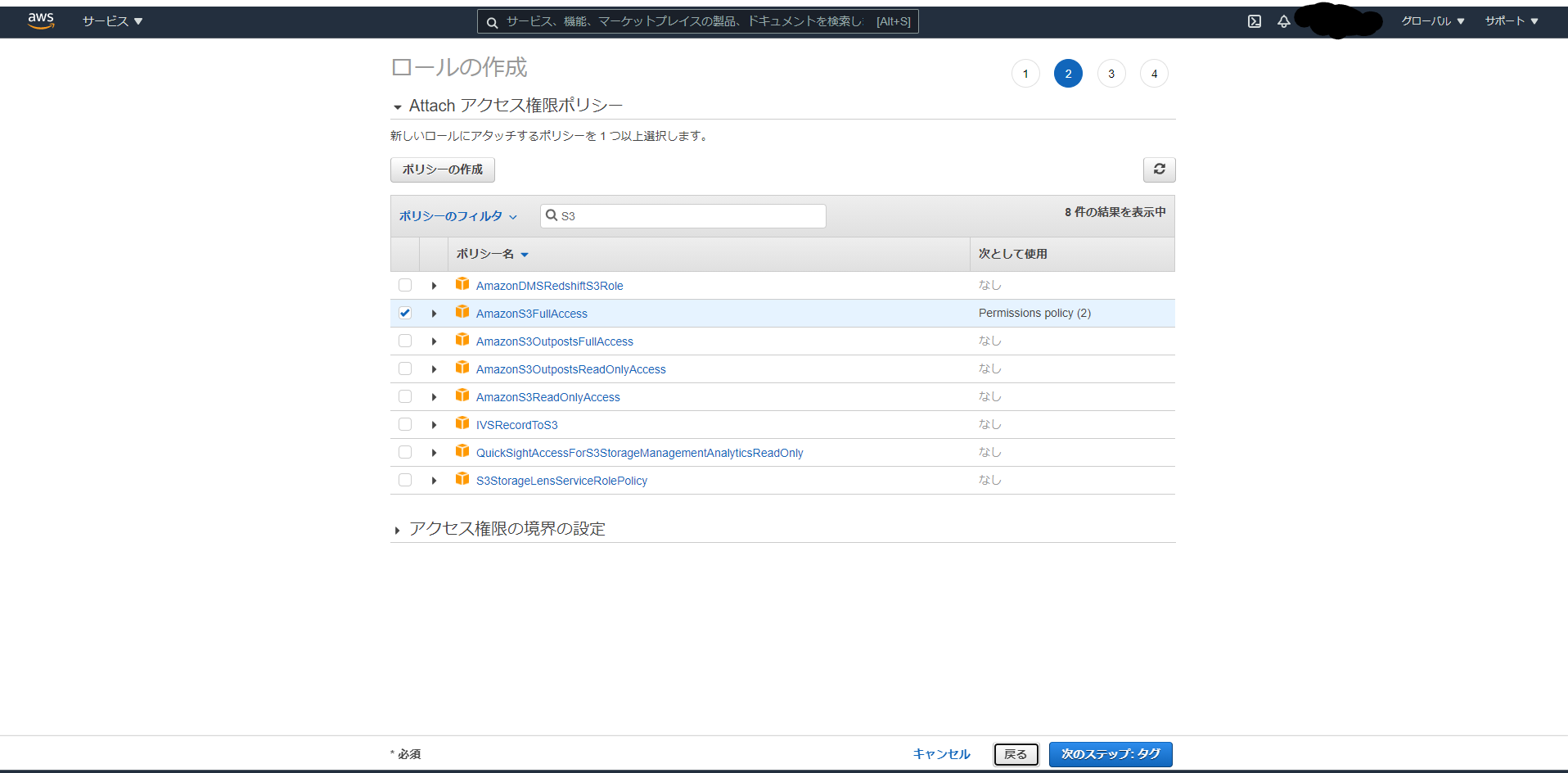
・S3バケットへ残高情報を読み書きするためにAmazonS3FullAccessポリシーをロールにアタッチし「次のステップ」をクリック
・タグの追加は不要なので何も記入せず「次のステップ」をクリック
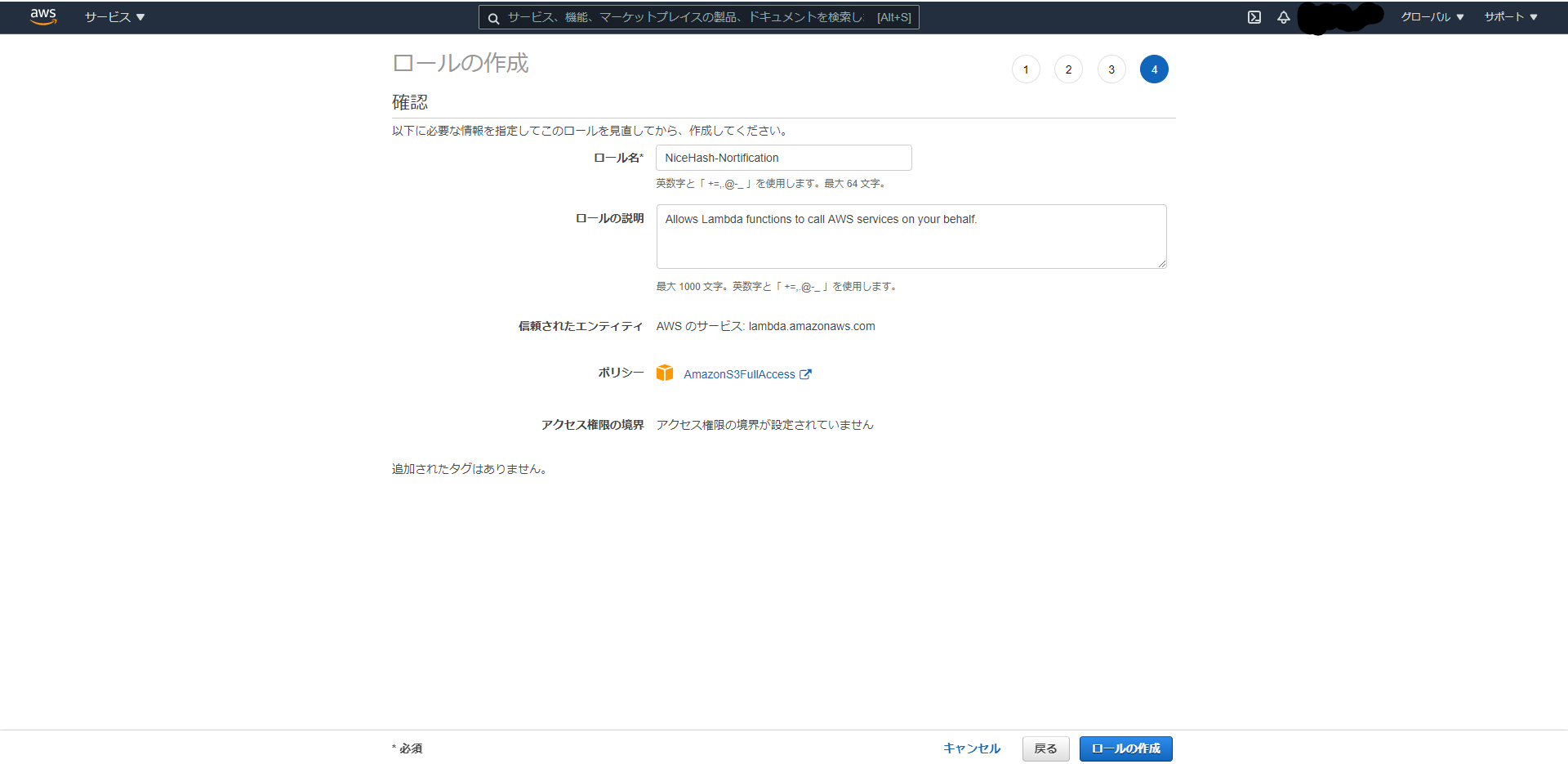
・ロール名は適当にNiceHash-Nortificationとして「ロールの作成」をクリック
2-1-2.Lambda関数の作成
呼び出されるLambda関数本体を作成する
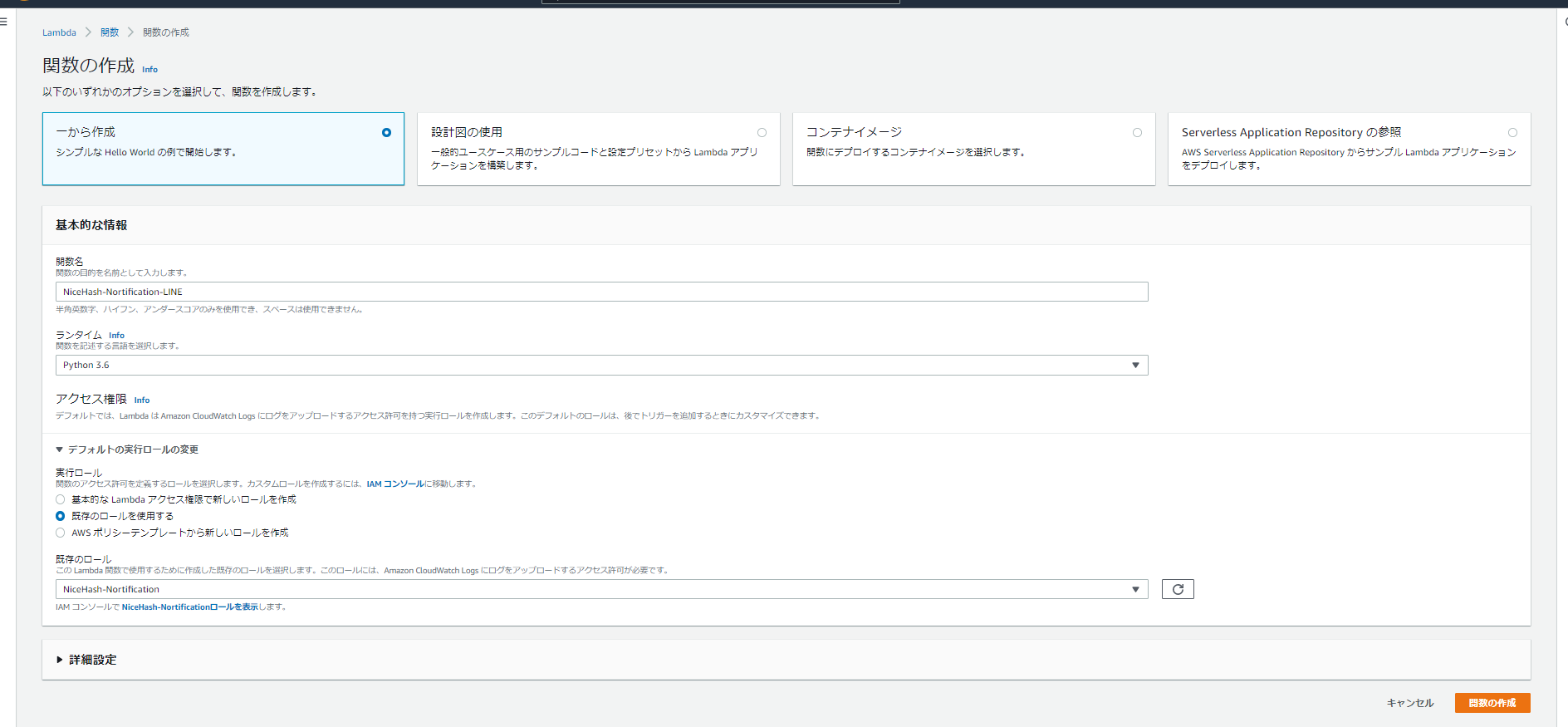
・サービスからLambdaを起動し、以下のように入力し「関数の作成」をクリック関数名:「NiceHash-Nortification-LINE」 ランタイム:「Python 3.6」#Python3系ならたぶんOK アクセス権限:「NiceHash-Nortification」#作成したIAMロール
2-1-3.ソースコードのデプロイ
Lambdaで実行するプログラムをデプロイする
・以下4つのpythonファイルを新規に作成してコードをデプロイNiceHash-Nortification-LINENiceHash-Nortification-LINE/ ├ lambda_function.py ├ nicehash.py ├ marketrate.py └ s3inout.pyLambdaで呼び出されるメインプログラム
lambda_function.pyimport os import requests import json import datetime import boto3 import nicehash import marketrate import s3inout #Function kicked by AWS Lambda def lambda_handler(event, context): #LINE Notify API LINE_NOTIFY_ACCESS_TOKEN = os.environ["LINE_NOTIFY_ACCESS_TOKEN"] HEADERS = {"Authorization": "Bearer %s" % LINE_NOTIFY_ACCESS_TOKEN} URL = "https://notify-api.line.me/api/notify" msg = create_message() data = {'message': msg} #Send a notification message to LINE with POST method requests.post(URL, headers=HEADERS, data=data) #Function to get a nortification message def create_message(): #NiceHash API host = 'https://api2.nicehash.com' organisation_id = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # hogehoge key = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # API Key Code secret = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # API Secret Key Code market='BTC' #S3 bucket bucket_name = '[bucket_name]'#hogehoge key_name = '[balance_filename]'#hogehoge #Get mining information from NiceHash API PrivateApi = nicehash.private_api(host, organisation_id, key, secret) accounts_info = PrivateApi.get_accounts_for_currency(market) balance_row = float(accounts_info['totalBalance']) #Get currency_to_JPY_rate from CoinGecko API TradeTable = marketrate.trade_table(market) rate = TradeTable.get_rate() balance_jpy = int(balance_row*rate) #S3 dealer S3dealer = s3inout.s3_dealer(bucket = bucket_name, key = key_name) pre_balance = int(S3dealer.read_from_s3_bucket()) diff = balance_jpy - pre_balance S3dealer.write_to_s3_bucket(str(balance_jpy)) #Nortification message time_text = "時刻: " + str(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))))[:19] market_text = "仮想通貨: " + market rate_text = "単位仮想通貨価値: " + str(rate) + "円" balance_text = "現在の残高: " + str(balance_jpy) + "円" pre_balance_text = "昨日の残高: " + str(pre_balance) + "円" symbol = "+" if diff > 0 else "" diff_txt = "【日次収益: " + str(symbol) + str(diff) + "円】" mon_revenue = "推定月次収益: " + str(diff*30) + "円" ann_revenue = "推定年次収益: " + str(diff*365) + "円" msg = '\n'.join([time_text,market_text,rate_text,balance_text,pre_balance_text,diff_txt,mon_revenue,ann_revenue]) return msgNiceHash API (2-2で説明)
nicehash.pyfrom datetime import datetime from time import mktime import uuid import hmac import requests import json from hashlib import sha256 import optparse import sys class private_api: def __init__(self, host, organisation_id, key, secret, verbose=False): self.key = key self.secret = secret self.organisation_id = organisation_id self.host = host self.verbose = verbose def request(self, method, path, query, body): xtime = self.get_epoch_ms_from_now() xnonce = str(uuid.uuid4()) message = bytearray(self.key, 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(str(xtime), 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(xnonce, 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(self.organisation_id, 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(method, 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(path, 'utf-8') message += bytearray('\x00', 'utf-8') message += bytearray(query, 'utf-8') if body: body_json = json.dumps(body) message += bytearray('\x00', 'utf-8') message += bytearray(body_json, 'utf-8') digest = hmac.new(bytearray(self.secret, 'utf-8'), message, sha256).hexdigest() xauth = self.key + ":" + digest headers = { 'X-Time': str(xtime), 'X-Nonce': xnonce, 'X-Auth': xauth, 'Content-Type': 'application/json', 'X-Organization-Id': self.organisation_id, 'X-Request-Id': str(uuid.uuid4()) } s = requests.Session() s.headers = headers url = self.host + path if query: url += '?' + query if self.verbose: print(method, url) if body: response = s.request(method, url, data=body_json) else: response = s.request(method, url) if response.status_code == 200: return response.json() elif response.content: raise Exception(str(response.status_code) + ": " + response.reason + ": " + str(response.content)) else: raise Exception(str(response.status_code) + ": " + response.reason) def get_epoch_ms_from_now(self): now = datetime.now() now_ec_since_epoch = mktime(now.timetuple()) + now.microsecond / 1000000.0 return int(now_ec_since_epoch * 1000) def algo_settings_from_response(self, algorithm, algo_response): algo_setting = None for item in algo_response['miningAlgorithms']: if item['algorithm'] == algorithm: algo_setting = item if algo_setting is None: raise Exception('Settings for algorithm not found in algo_response parameter') return algo_setting def get_accounts(self): return self.request('GET', '/main/api/v2/accounting/accounts2/', '', None) def get_accounts_for_currency(self, currency): return self.request('GET', '/main/api/v2/accounting/account2/' + currency, '', None) def get_withdrawal_addresses(self, currency, size, page): params = "currency={}&size={}&page={}".format(currency, size, page) return self.request('GET', '/main/api/v2/accounting/withdrawalAddresses/', params, None) def get_withdrawal_types(self): return self.request('GET', '/main/api/v2/accounting/withdrawalAddresses/types/', '', None) def withdraw_request(self, address_id, amount, currency): withdraw_data = { "withdrawalAddressId": address_id, "amount": amount, "currency": currency } return self.request('POST', '/main/api/v2/accounting/withdrawal/', '', withdraw_data) def get_my_active_orders(self, algorithm, market, limit): ts = self.get_epoch_ms_from_now() params = "algorithm={}&market={}&ts={}&limit={}&op=LT".format(algorithm, market, ts, limit) return self.request('GET', '/main/api/v2/hashpower/myOrders', params, None) def create_pool(self, name, algorithm, pool_host, pool_port, username, password): pool_data = { "name": name, "algorithm": algorithm, "stratumHostname": pool_host, "stratumPort": pool_port, "username": username, "password": password } return self.request('POST', '/main/api/v2/pool/', '', pool_data) def delete_pool(self, pool_id): return self.request('DELETE', '/main/api/v2/pool/' + pool_id, '', None) def get_my_pools(self, page, size): return self.request('GET', '/main/api/v2/pools/', '', None) def get_hashpower_orderbook(self, algorithm): return self.request('GET', '/main/api/v2/hashpower/orderBook/', 'algorithm=' + algorithm, None ) def create_hashpower_order(self, market, type, algorithm, price, limit, amount, pool_id, algo_response): algo_setting = self.algo_settings_from_response(algorithm, algo_response) order_data = { "market": market, "algorithm": algorithm, "amount": amount, "price": price, "limit": limit, "poolId": pool_id, "type": type, "marketFactor": algo_setting['marketFactor'], "displayMarketFactor": algo_setting['displayMarketFactor'] } return self.request('POST', '/main/api/v2/hashpower/order/', '', order_data) def cancel_hashpower_order(self, order_id): return self.request('DELETE', '/main/api/v2/hashpower/order/' + order_id, '', None) def refill_hashpower_order(self, order_id, amount): refill_data = { "amount": amount } return self.request('POST', '/main/api/v2/hashpower/order/' + order_id + '/refill/', '', refill_data) def set_price_hashpower_order(self, order_id, price, algorithm, algo_response): algo_setting = self.algo_settings_from_response(algorithm, algo_response) price_data = { "price": price, "marketFactor": algo_setting['marketFactor'], "displayMarketFactor": algo_setting['displayMarketFactor'] } return self.request('POST', '/main/api/v2/hashpower/order/' + order_id + '/updatePriceAndLimit/', '', price_data) def set_limit_hashpower_order(self, order_id, limit, algorithm, algo_response): algo_setting = self.algo_settings_from_response(algorithm, algo_response) limit_data = { "limit": limit, "marketFactor": algo_setting['marketFactor'], "displayMarketFactor": algo_setting['displayMarketFactor'] } return self.request('POST', '/main/api/v2/hashpower/order/' + order_id + '/updatePriceAndLimit/', '', limit_data) def set_price_and_limit_hashpower_order(self, order_id, price, limit, algorithm, algo_response): algo_setting = self.algo_settings_from_response(algorithm, algo_response) price_data = { "price": price, "limit": limit, "marketFactor": algo_setting['marketFactor'], "displayMarketFactor": algo_setting['displayMarketFactor'] } return self.request('POST', '/main/api/v2/hashpower/order/' + order_id + '/updatePriceAndLimit/', '', price_data) def get_my_exchange_orders(self, market): return self.request('GET', '/exchange/api/v2/myOrders', 'market=' + market, None) def get_my_exchange_trades(self, market): return self.request('GET','/exchange/api/v2/myTrades', 'market=' + market, None) def create_exchange_limit_order(self, market, side, quantity, price): query = "market={}&side={}&type=limit&quantity={}&price={}".format(market, side, quantity, price) return self.request('POST', '/exchange/api/v2/order', query, None) def create_exchange_buy_market_order(self, market, quantity): query = "market={}&side=buy&type=market&secQuantity={}".format(market, quantity) return self.request('POST', '/exchange/api/v2/order', query, None) def create_exchange_sell_market_order(self, market, quantity): query = "market={}&side=sell&type=market&quantity={}".format(market, quantity) return self.request('POST', '/exchange/api/v2/order', query, None) def cancel_exchange_order(self, market, order_id): query = "market={}&orderId={}".format(market, order_id) return self.request('DELETE', '/exchange/api/v2/order', query, None) if __name__ == "__main__": parser = optparse.OptionParser() parser.add_option('-b', '--base_url', dest="base", help="Api base url", default="https://api2.nicehash.com") parser.add_option('-o', '--organization_id', dest="org", help="Organization id") parser.add_option('-k', '--key', dest="key", help="Api key") parser.add_option('-s', '--secret', dest="secret", help="Secret for api key") parser.add_option('-m', '--method', dest="method", help="Method for request", default="GET") parser.add_option('-p', '--path', dest="path", help="Path for request", default="/") parser.add_option('-q', '--params', dest="params", help="Parameters for request") parser.add_option('-d', '--body', dest="body", help="Body for request") options, args = parser.parse_args() private_api = private_api(options.base, options.org, options.key, options.secret) params = '' if options.params is not None: params = options.params try: response = private_api.request(options.method, options.path, params, options.body) except Exception as ex: print("Unexpected error:", ex) exit(1) print(response) exit(0)CoinGecko API (2-2で説明)
marketrate.pyimport requests import json class trade_table: def __init__(self, market="BTC"): #currency-name conversion table self.currency_rename_table = {'BTC':'Bitcoin','ETH':'Ethereum','LTC':'Litecoin', 'XRP':'XRP','RVN':'Ravencoin','MATIC':'Polygon', 'BCH':'Bitcoin Cash','XLM':'Stellar','XMR':'Monero','DASH':'Dash'} self.market = self.currency_rename_table[market] def get_rate(self): body = requests.get('https://api.coingecko.com/api/v3/coins/markets?vs_currency=jpy') coingecko = json.loads(body.text) idx = 0 while coingecko[idx]['name'] != self.market: idx += 1 #Escape of illegal market_currency name if idx > 100: return "trade_table_err" #market-currency_to_JPY_rate else: return int(coingecko[idx]['current_price'])S3バケットへの収益情報の読み込み・書き出し(2-3で説明)
s3inout.pyimport boto3 class s3_dealer: def __init__(self, bucket = 'nice-hash-balance', key = 'balance_latest.txt'): self.bucket = bucket self.key = key #Get balance of the previous day def read_from_s3_bucket(self): S3 = boto3.client('s3') res = S3.get_object(Bucket=self.bucket, Key=self.key) body = res['Body'].read() return body.decode('utf-8') #Export balance def write_to_s3_bucket(self, balance): S3 = boto3.resource('s3') obj = S3.Object(self.bucket, self.key) obj.put(Body=balance)2-1-4.レイヤー作成
必要なモジュールをLambdaのレイヤーに取り込む
・2-1-3 記載のソースをデプロイしただけで実行するとrequestsモジュールが読み込めず以下エラーが発生してしまうため、外部モジュールをLayersへ定義する{ "errorMessage": "Unable to import module 'lambda_function': No module named 'requests'", "errorType": "Runtime.ImportModuleError" }・レイヤーファイルを作成するために、EC2でAmazon Linux AMIから新規インスタンスを作成する
・2-1-1の手順で、EC2のロールに対してS3のアクセスポリシーをアタッチ
※インターネット環境に接続されたWSLやUbuntu等のUNIXマシンであれば何でもOK
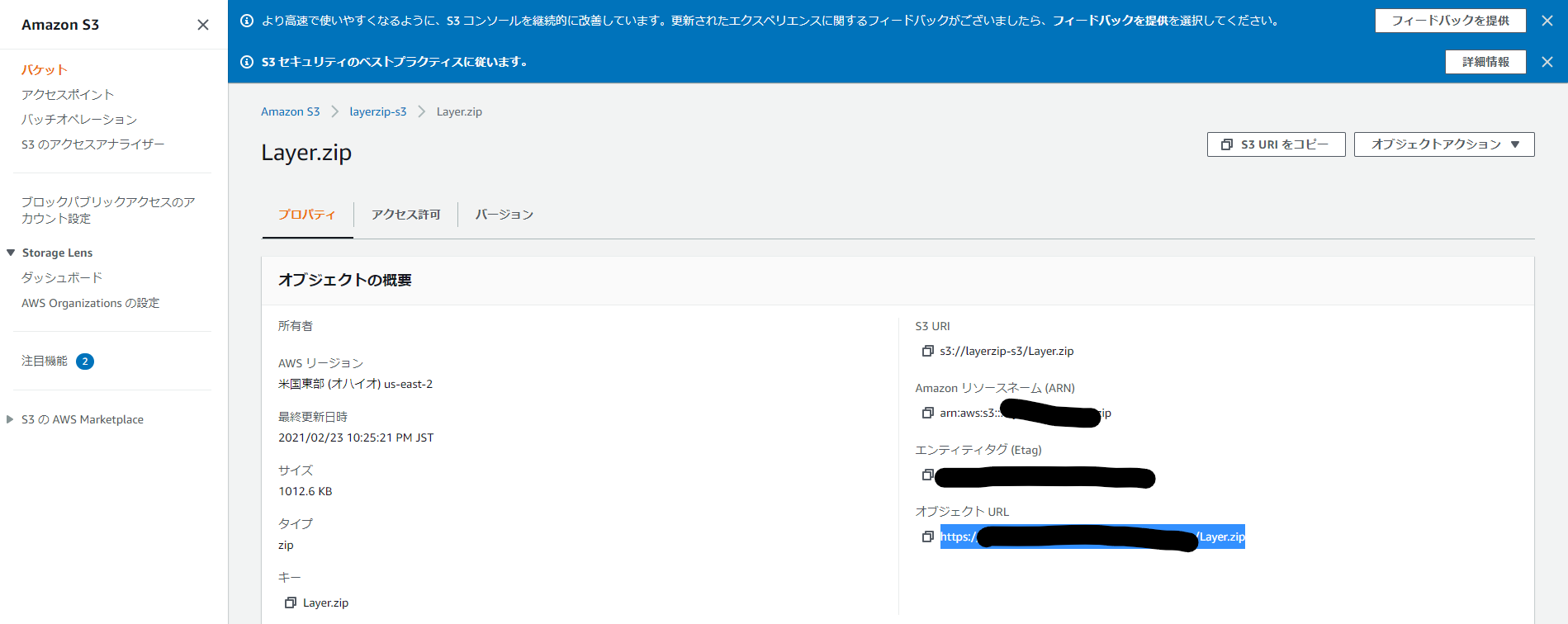
・EC2インスタンスへコンソール接続し、以下CLIコマンドを打鍵してレイヤーファイルを作成するec2-user[ec2-user@ip-xxx-xx-xx-xxx ~]$ su - [root@ip-xxx-xx-xx-xxx ~]# mkdir layer/ [root@ip-xxx-xx-xx-xxx ~]# cd layer [root@ip-xxx-xx-xx-xxx ~]# yum -y install gcc gcc-c++ kernel-devel python-devel libxslt-devel libffi-devel openssl-devel [root@ip-xxx-xx-xx-xxx ~]# yum -y install python-pip [root@ip-xxx-xx-xx-xxx ~]# pip install -t ./ requests [root@ip-xxx-xx-xx-xxx ~]# cd ../ [root@ip-xxx-xx-xx-xxx ~]# zip -r Layer.zip layer/・レイヤーファイルを、S3バケットへアップロード
ec2-user[root@ip-xxx-xx-xx-xxx ~]# chmod 777 Layer.zip [root@ip-xxx-xx-xx-xxx ~]# aws s3 cp Layer.zip s3://layerzip-s3・S3でEC2からアップロードしたレイヤーファイルのオブジェクトURLを取得
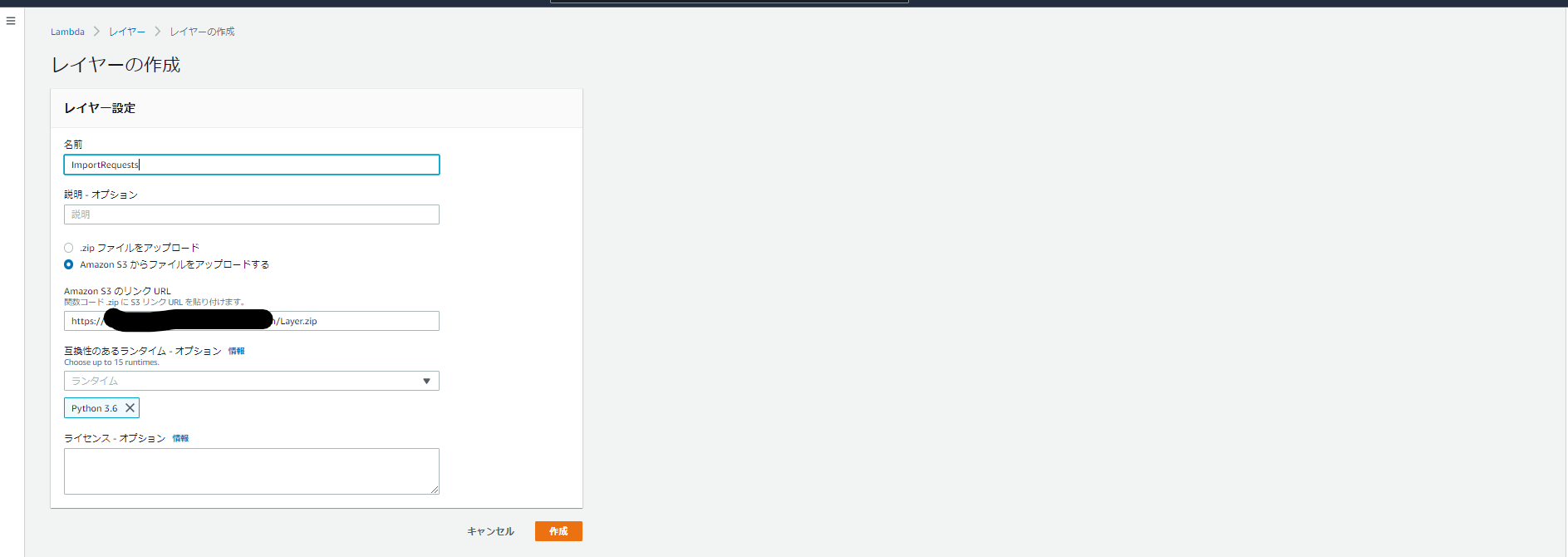
・LambdaでS3のオブジェクトURLから名前を適当に
ImportRequestsとしてレイヤーを作成
・Lambdaで「レイヤーの追加」をクリック
・カスタムレイヤーから作成した
ImportRequestsを読み込む
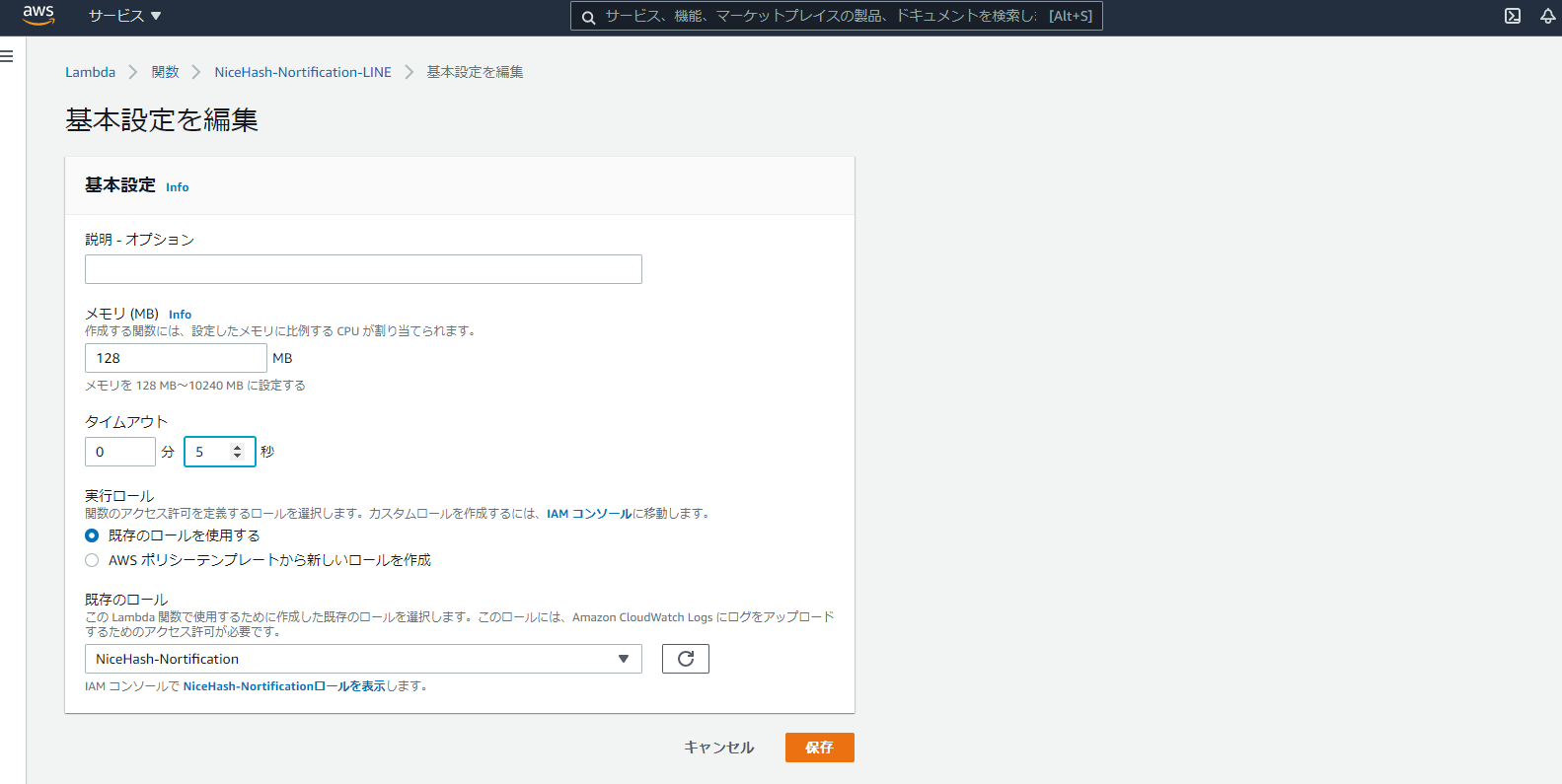
2-1-5.タイムアウト値の延長
タイムアウトエラーを回避するためにタイムアウト値を変更する
・Lambdaはデフォルトだと、メモリ:128MB、タイムアウト:3秒になっているため、タイムアウトのみ「3秒⇒ 5秒」へ変更する
2-2.APIによる収益情報取得
外部APIからマイニング収益情報を取得する
・LambdaとNiceHash APIを連携するために、NiceHashへログインしてMySettingsからAPI Keysを発行する
・NiceHash API(nicehash.py)で収益情報を取得するために、lambda_function.pyの対象箇所に発行したAPI Keys、組織IDを入力するlambda_function.py#NiceHash API host = 'https://api2.nicehash.com' organisation_id = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # hogehoge key = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # API Key Code secret = 'xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx' # API Secret Key Code・NiceHash APIのみでは、円相場の情報は取得できないため、別の外部API CoinGecko API(marketrate.py)を呼び出して、各仮想通貨市場の日本円相場を取得する。
2-3.EventBridgeによるトリガー定義
日次ジョブとしてLambdaをキックするためのトリガーを定義する
・Lambdaから「トリガーの追加」をクリック
・EventBridgeを選択し、以下のように入力し「追加」をクリック
※AWSでcronを定義する際は、crontabとの違いや時差を考慮する必要があるため注意する 1ルール:「新規ルールの作成」 ルール名:DailyTrigger ルールタイプ:スケジュール式 スケジュール式:cron(0 15 * * ? *) # 毎日0:00に実行するcron
2-4.S3バケットへの書き出し・読み込み
前日の収益との比較を行うため、S3バケットのファイルに対して書き出し・読み込みを行う
・S3バケットbucket_nameを作成して、前日の残高(円)を整数で記載したダミーファイルbalance_filename.csvを予め格納しておくbucket_name/balance_filename.csv28583・LambdaとS3のサービス間で連携するために、
lambda_function.pyの対象箇所を編集するlambda_function.py#NiceHash API #S3 bucket bucket_name = '[bucket_name]' # S3バケット名 key_name = '[balance_filename.csv]' # 残高情報が記載されたファイル名2-5.LINE NotifyによるLINE通知
2-5-1.LINE Notify アクセストークンの発行
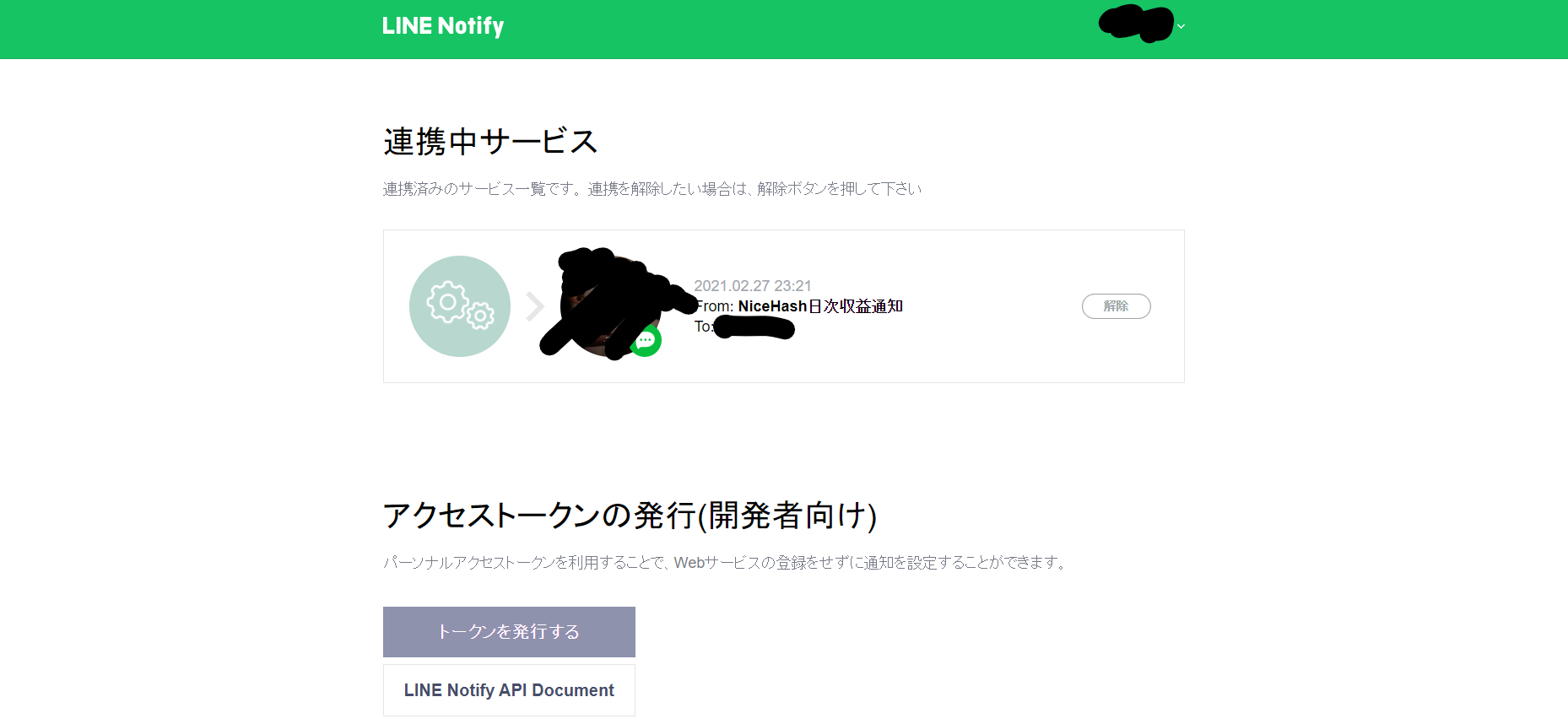
AWSへLINE Nortifyを連携するために必要なトークンを発行する
・LINE Notifyのトップページへアクセス、所有するLINEアカウントでログインして本人確認を行う
・以下のようにログインできればOK
・右上に記載されている自分の名前をクリックし、マイページへ移動
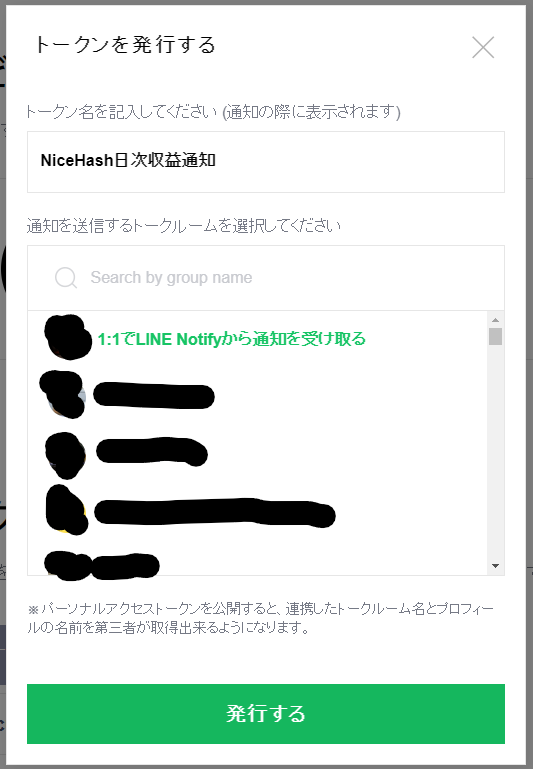
・トークンを発行するをクリック
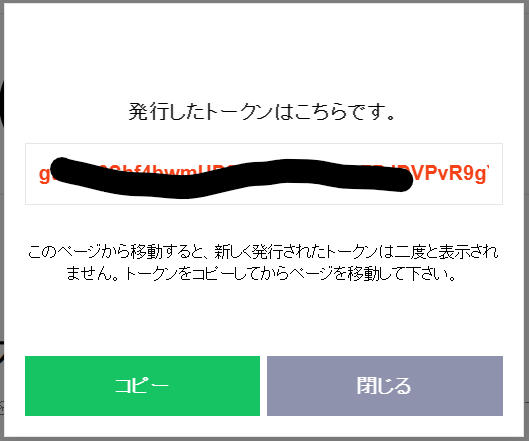
・トークン名を適当にNiceHash日次収益通知として、1:1でLINE Notifyから通知を受け取るを選択し、発行するをクリック
・発行されたトークンをコピー
・以下のように連携中サービスが追加されていればOK
2-5-2.環境変数の設定
LambdaとLINE Nortifyサービス間を連携するために環境変数を設定する
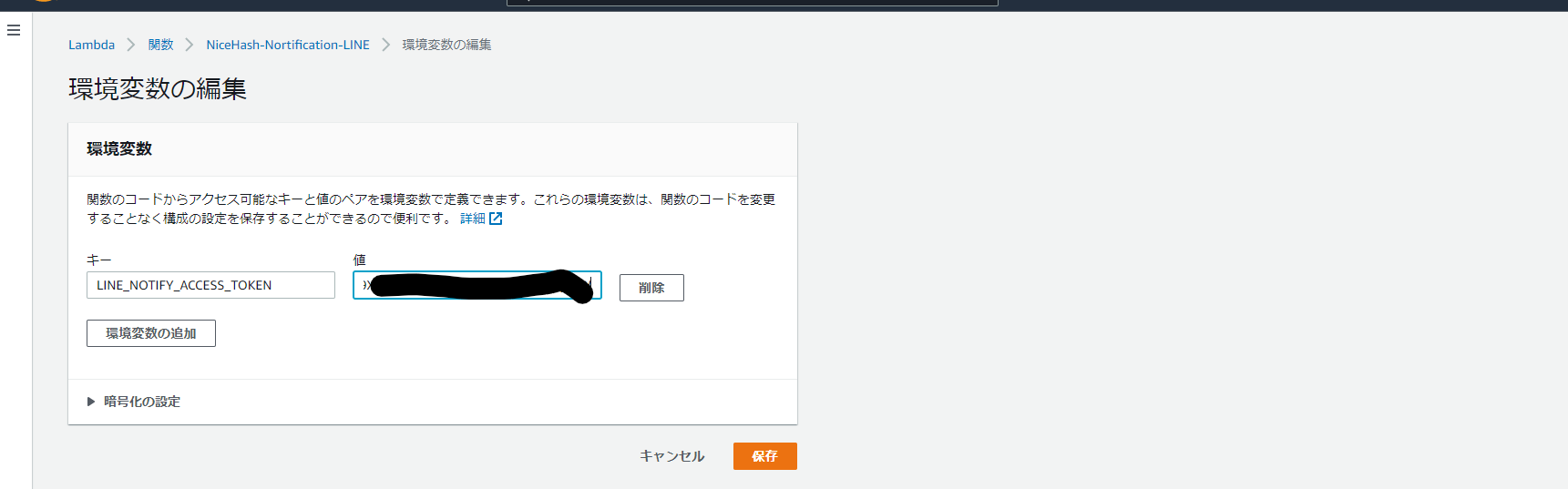
・Lambdaサービスから環境変数→設定→編集をクリック
・環境変数を以下のように入力して「保存」をクリックキー:LINE_NOTIFY_ACCESS_TOKEN 値:(2-5-1で取得したトークン)
3. 実行結果
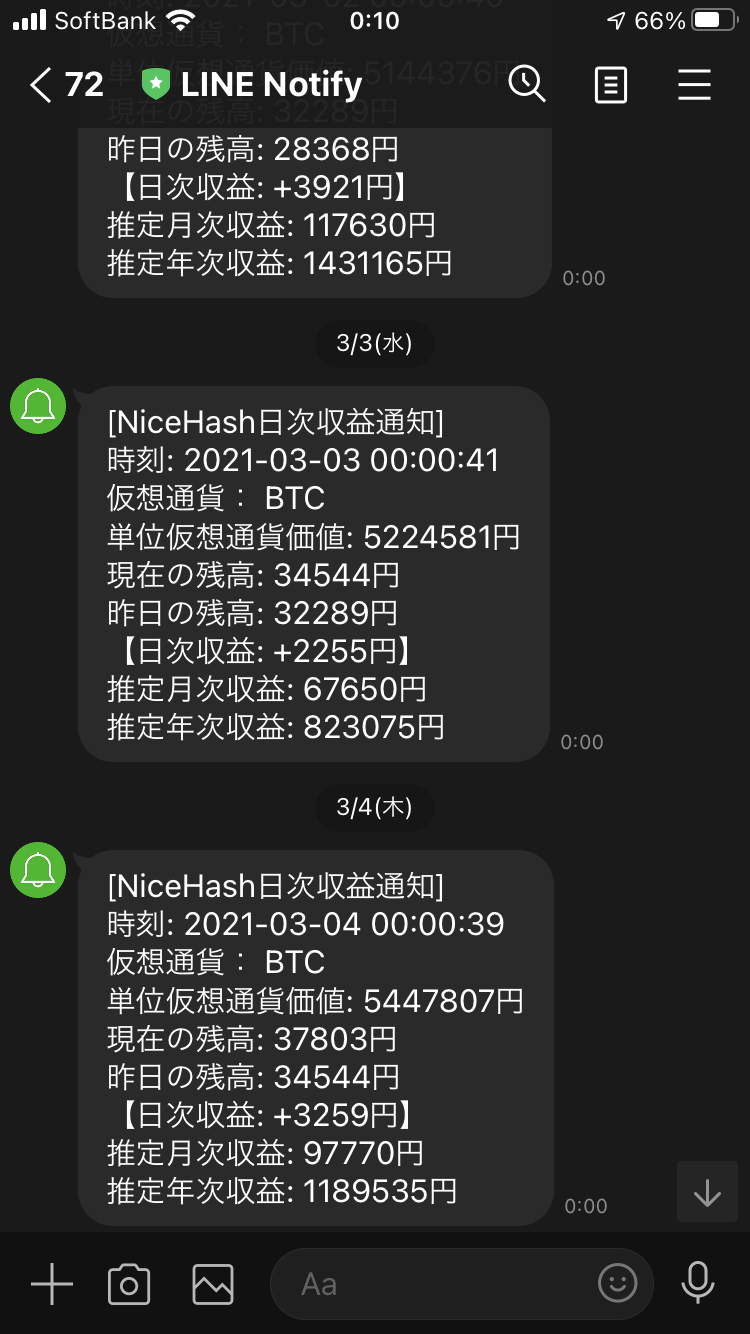
・毎日0:00になるとEventBridgeがLambdaをキックして、日次でLINE通知が来るようになりました。
(BTCの円相場 変動が激しすぎて、収益のばらつきがめちゃめちゃでかい…)4. 終わりに
・LINEの連携はとても簡単で、気軽に触れるようシンプルで分かりやすく作りこまれていました。他にも何か通知する仕組みを作ってみたいと思います。
5. 更新履歴
ver. 1.0 初版投稿 2021/03/06



- 投稿日:2021-03-06T00:25:03+09:00
【入門】Terraformプロジェクトのセットアップ
AWSコンソールでぽちぽちではなく、コードでインフラを管理する方法を学びたいと思い、学習を始めました。
今回は実際に Terraform のプロジェクトの作成、公式のチュートリアルにあるEC2インスタンスの作成までをまとめます。準備
- 公式ページ
- AWS、GCPなど、プロバイダーごとにチュートリアルが用意されてます。
- Terraformの実行環境
- homebrewなどで入れることが出来ます。
- 公式の Docker コンテナがあるので、今回はこちらを使います。
プロジェクトの作成
いったんシンプルに試すため、下記構成で作ります。
work_dir/ ├ .env ├ docker-compose.yml └ src/ └ main.tfファイルはそれぞれ下記です。
// AWS credential info AWS_ACCESS_KEY_ID = AWS_SECRET_ACCESS_KEY =docker-compose.ymlversion: "3.8" services: terraform: env_file: - .env image: hashicorp/terraform:light volumes: - ./src:/app/terraform working_dir: /app/terraformsrc/main.tfterraform { required_providers { aws = { source = "hashicorp/aws" version = "~> 3.27" } } } provider "aws" { profile = "default" region = "ap-northeast-1" } resource "aws_instance" "example" { ami = "ami-830c94e3" instance_type = "t3.micro" tags = { Name = "ExampleInstance" } }
src/main.tfのリージョン、インスタンスタイプなどはお好みで。
今回は、ami-830c94e3をt3.microサイズのインスタンスで、東京リージョンで立ち上げるように書きました。コマンドの実行
プロジェクトを作成、tfファイルを作成後に一度
initを実行します。docker-compose run --rm terraform init Creating network "mochimochi-terraform_default" with the default driver Creating mochimochi-terraform_terraform_run ... done Initializing the backend... Initializing provider plugins... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
planを実行することで、定義した内容を確認できます。$ docker-compose run --rm terraform plan Creating mochimochi-terraform_terraform_run ... done An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.example will be created + resource "aws_instance" "example" { + ami = "ami-830c94e3" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) + cpu_threads_per_core = (known after apply) + get_password_data = false + host_id = (known after apply) + id = (known after apply) + instance_state = (known after apply) + instance_type = "t3.micro" + ipv6_address_count = (known after apply) + ipv6_addresses = (known after apply) + key_name = (known after apply) + outpost_arn = (known after apply) + password_data = (known after apply) + placement_group = (known after apply) + primary_network_interface_id = (known after apply) + private_dns = (known after apply) + private_ip = (known after apply) + public_dns = (known after apply) + public_ip = (known after apply) + secondary_private_ips = (known after apply) + security_groups = (known after apply) + source_dest_check = true + subnet_id = (known after apply) + tags = { + "Name" = "ExampleInstance" } + tenancy = (known after apply) + vpc_security_group_ids = (known after apply) + ebs_block_device { + delete_on_termination = (known after apply) + device_name = (known after apply) + encrypted = (known after apply) + iops = (known after apply) + kms_key_id = (known after apply) + snapshot_id = (known after apply) + tags = (known after apply) + throughput = (known after apply) + volume_id = (known after apply) + volume_size = (known after apply) + volume_type = (known after apply) } + enclave_options { + enabled = (known after apply) } + ephemeral_block_device { + device_name = (known after apply) + no_device = (known after apply) + virtual_name = (known after apply) } + metadata_options { + http_endpoint = (known after apply) + http_put_response_hop_limit = (known after apply) + http_tokens = (known after apply) } + network_interface { + delete_on_termination = (known after apply) + device_index = (known after apply) + network_interface_id = (known after apply) } + root_block_device { + delete_on_termination = (known after apply) + device_name = (known after apply) + encrypted = (known after apply) + iops = (known after apply) + kms_key_id = (known after apply) + tags = (known after apply) + throughput = (known after apply) + volume_id = (known after apply) + volume_size = (known after apply) + volume_type = (known after apply) } } Plan: 1 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.
applyを実行することで、定義した内容が適用されます。$ docker-compose run --rm terraform apply Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes aws_instance.example: Creating... aws_instance.example: Still creating... [10s elapsed] aws_instance.example: Creation complete after 13s [id=i-056f8b4b8de00beda] Apply complete! Resources: 1 added, 0 changed, 0 destroyed.completeと表示されましたね、実際にAWSコンソールを見に行って見ると、インスタンスが生成されていると思います。
Terraformを使って、AMIから無事インスタンスを作ることができました。
他のAWSリソースの場合どうやるのか、また学んで投稿していこうと思います。
