- 投稿日:2021-02-26T23:52:30+09:00
dictのdictをDataFrameにする
- 投稿日:2021-02-26T23:47:22+09:00
Pythonで可変長引数を利用するには
可変長引数とは
可変長引数とは、名前の通り長さが可変な引数である。要するに引数が固定ではなく、任意の個数を受け取ることができる。これだけではわかりかねると思うので、実際のコードを例に見ていこう。
*args
def main(*args): print(args) main(1, "one", ["one", "two"], {"one", "two"}) # 実行結果 -> (1, 'one', ['one', 'two'], {'two', 'one'})
*argsは任意の数の引数を受け取り、その内容をargsという*(アスタリスク)を外した形でアクセスすると受け取った引数をタプル型で展開してくれる。*以降は任意の文字列でもよいが、特別な理由がなければ*argsとする場合が多い。**kwargs
def main(**kwargs): print(kwargs) main(int=1, str="one", list=["one", "two"], dict={"one", "two"}) # 実行結果 -> {'int': 1, 'str': 'one', 'list': ['one', 'two'], 'dict': {'one', 'two'}}
**kwargsは任意の数のキーワード引数を受け取り、その内容をkwargsという**(アスタリスクx2)を外した形でアクセスすると受け取った引数を辞書型で展開してくれる。こちらも**特別な理由がなければ**kwargsとする場合が多い。実際の例
これらの可変長引数の実例を見たい場合は、Pythonのサードパーティー製のライブラリがオススメ。特にHTTPリクエスト関連でよく使う
requestsはコードリーディングをするのに最適なので、是非一度読んでみることをオススメする。Github(psf/requests) -> https://github.com/psf/requests/tree/master/requests
- 投稿日:2021-02-26T23:39:01+09:00
yukicoder contest 284 参戦記
yukicoder contest 284 参戦記
A 1406 Test
0点から100点までの101パターン、平均点が整数になるかをチェックすればいいだけ.
N, *A = map(int, open(0).read().split()) if N == 1: print(101) exit() a = sum(A) result = 0 for i in range(100 + 1): if (i + a) % N == 0: result += 1 print(result)
- 投稿日:2021-02-26T23:37:17+09:00
with 構文で使っているメソッドをmockする
with構文で使っているメソッドをmockしたい
Unittest を書いていて with でリソースを取得している箇所のmockをすることを考えました。
以下のように書けばmockができるので、参考にしてください。withが使えるということは?
withが使えるということは、以下のようなメソッドがクラスに定義されていて、
withの開始、終了でそれぞれのメソッドが呼ばれますclass someClass: # with の開始で呼ばれる def __enter__(self): return self # with の終了で呼ばれる def __exit__(self, exception_type, exception_value, traceback): passUnittest を書いてみる
以下のようなソースのUnittestを書こうと思いました。
tempfile.TemporaryDirectory()をmockしてtmp_dir_name固定の値にしたい
- テストするソース
class processFile(): def process(self): tempfile.TemporaryDirectory() as tmp_dir_name: # テンポラリのディレクトリでなにか処理
- テスト
@mock.patch("tempfile.TemporaryDirectory") def test_process_temp_dir_test(self, mock_TemporaryDirectory): proess_file = processFile() mock_TemporaryDirectory.return_value.__enter__.return_value = "/tmp"こんな感じに書いてあげると、
tmp_dir_nameを/tmpに固定できます。
- 投稿日:2021-02-26T23:20:31+09:00
Pythonでポアソン分布
前回の二項分布に引き続き今回はポアソン分布オブジェクトを作成したいと思います。素人なので間違いがあったら教えていただけると嬉しいです。
ポアソン分布って何
導出方法から見ると、ポアソン分布は二項分布の「全試行回数」が無限大になったバージョンだと考えていいと思います。
ポアソン分布の確率質量関数の導出方法
- 二項分布の確率質量関数を用意する
- 全試行回数n→∞、確率p→0 の場合の極限を求める
式変形はこちらの記事がわかりやすいです。
https://note.com/konpyu/n/ncede5754aba8ポアソン分布の確率質量関数
上記の方法で導出されたポアソン分布の確率質量関数は以下のようになります。
単位区間(時間 or 空間)内における平均発生回数がλ回である事象が単位区間内にk回発生する確率(eはネイピア数):
P(k)=e^{-\lambda}\dfrac{\lambda^k}{k!}なんで無限大にするのか
「地震の発生回数」のように人為的な試行が行われていないもの(つまり「全試行回数」が無いもの)を二項分布として扱うために「単位時間内に無限に試行が行われた」と仮定してるんじゃないかと考えると個人的にはしっくりきました。
こちらでも同じような説明がありました
https://bellcurve.jp/statistics/course/6984.htmlどんなときに便利か
ポアソン分布で近似できる現象の例としては「一年間の地震の発生回数」、「ウェブサイトへの一時間あたりのアクセス数」などがあります。分母が無限(と仮定できる)もの全般に使える...と言いたいところですが、実際にあてはまるのは以下のような条件を満たす場合が多いようです。
(希少性):時間幅 ⊿t の間に着目している事象がちょうど1回起こる確率が {\displaystyle \lambda \Delta t+o(\Delta t)}{\displaystyle \lambda \Delta t+o(\Delta t)}、2回以上起こる確率が {\displaystyle o(\Delta t)}o(\Delta t)
(定常性):事象の起きる確率は、どの時間帯で同じ
(独立性):事象の起きる確率は、それ以前に起こった事象の回数や起こり方には無関係
ここで、o(⊿t) は ⊿t に対して高位の無限小を表しており、⊿t のスケールに注目したときに無視できる微小量であることを表す。(Wikipediaより抜粋)
Pythonでポアソン分布してみた
確率質量関数を求める関数とグラフを描画する関数を持つクラスを作ってみます。ポイントはコンストラクタの引数が事象の平均発生回数λ(
known_average)一個だけということです。
ちなみに今回は使いませんでしたがnumpyのnumpy.random.poisson()という関数でもポワソン分布の確率質量を求めることができます。import math import numpy as np import matplotlib.pyplot as plt class PoissonDistribution: """ 二項分布 Attributes ---------- known_average : int 単位区間内における事象Aの平均発生回数. """ def __init__(self, known_average): self.known_average = known_average def get_probability_mass(self, parameter_of_interest): """ 事象Aがk回起きる確率密度を求める. Parameters ---------- parameter_of_interest : int 確率質量を求めたい回数k(確率変数). Returns ------- probability_mass : float kの確率質量. """ probability_mass = (math.e ** (-self.known_average) * self.known_average ** parameter_of_interest) / math.factorial(parameter_of_interest) return probability_mass def draw_graph(self, min, max): """ グラフを描画してpng形式で保存する. Parameters ---------- min : int グラフの左端(回数). max : int グラフの右端(回数). """ x = np.arange(min, max + 1, 1) y = [] for k in range(min, max + 1): y.append(self.get_probability_mass(k)) plt.plot(x, y) plt.savefig('graph.png')実行
# 単位区間内における発生回数が5回の事象Aのポアソン分布オブジェクトを作成する. poisson_distribution = PoissonDistribution(5) # 事象Aが単位区間内において3回起きる場合の確率質量を計算する. print(poisson_distribution.get_probability_mass(3)) # このポアソン分布を左端が0回、右端が20回(k=0,1,2 ... 20)のグラフに描画する. poisson_distribution.draw_graph(0, 20)結果
0.14037389581428059 #単位区間内における発生回数が5回の事象Aが3回起きる確率質量

- 投稿日:2021-02-26T23:00:41+09:00
PythonでIDを取得してオブジェクトに戻す
TL;DR
PythonでIDを取得してオブジェクトに戻す小技の紹介です.
IDを取得する
Pythonではid関数を使うことでオブジェクトのIDを取得することができます.
これはオブジェクトを一意に表すIDです.>>> val = 5 >>> id(val) 140725152520080 型にもあります >>> val = int >>> id(val) 140725152283920オブジェクトに戻す
一意に表すIDであればIDからオブジェクトを取得できるのでは?という話です.
_ctypesモジュールのPyObj_FromPtrという関数を使用します.
>>> import _ctypes >>> val = 5 >>> id(val) 140725152520080 >>> _ctypes.PyObj_FromPtr(140725152520080) 5インスタンスオブジェクトでも.
>>> import _ctypes >>> class Test: ... def __init__(self, val): ... self.val = val ... >>> test = Test(10) >>> test.val 10 >>> id(test) 2441514736128 >>> test_from_id = _ctypes.PyObj_FromPtr(2441514736128) >>> test_from_id.val 10使い道
マルチプロセスを使う際,プロセス間通信の引数はシリアライズ可能である必要があります.
インスタンスオブジェクトを渡す際は引っかかることが多いかと思います.
id関数と_ctypes.PyObj_FromPtrを使うことで,IDだけ渡して,渡した先で復元するということができます.また,IDの値はint値なのでオブジェクトの代わりに保持しておく,ということができます.
(ポインタなので変わらんじゃんという話もありますが...)懸念
スコープなのか呼び出し階層なのかは分かりませんが,IDの値が別のオブジェクトになっていることもあります.
なるべく同じスコープ,短い呼び出し階層で使うことをお勧めします.まとめ
Pythonにはこういったメタ関数が多くあるので面白いですよね.
ご参考になれば幸いです.
- 投稿日:2021-02-26T22:38:55+09:00
Python の開発環境問題には direnv が最高だった件
よくある悩み
- 「Python で開発するけどローカル環境汚したくないんだよなー」
- 「Python コンテナ立てて VSCode でアタッチしてもいいけど拡張機能の管理がめんどいなー」
- 仁義なき
virtualenvvspipenvvsvenv派閥争いそんなあなたに direnv
https://github.com/direnv/direnv
一言でいうと、ディレクトリ毎に環境を分けるもの
つまり何 ??
venv と組み合わせると、direnv を有効化したディレクトリに移動しただけで venv を
activateすることが可能また、環境変数も同様に自動でセットすることが可能
使い方
インストール
Mac の場合は
brew install direnv、Windows は知らん設定
~/.zshrcに追記$EDITOR で指定するのは自分の好きなやつ
export EDITOR=/usr/local/bin/nvim eval "$(direnv hook zsh)"有効化
target_dirでやってみるmkdir target_dir cd target_dir python -m venv venv echo "source venv/bin/activate" > .envrc direnv allow
direnv はディレクトリに移動した際に自動で
.envrcを読み込む
.envrcの編集はdirenv editでやってもいいし、直接編集してからdirenv allowで有効かしてもいい
export HOGE=hogeと記述しておくと、そのディレクトリ配下にいる間だけその環境変数が有効化される設定完了!! ?
これで
target_dirに移動すると、勝手に venv が有効化するゾ!!
- 投稿日:2021-02-26T22:33:49+09:00
numpyでシフト演算を使って符号無し⇒符号有りに変換する
TL;DR
numpyの符号無しのndarrayをシフト演算を使って符号有りに変換する方法の紹介です.
numpyのシフト演算
numpyは要素毎にシフト演算することができる.
シフト演算も例外できる.>>> import numpy as np >>> val = np.arange(5) >>> val array([0, 1, 2, 3, 4]) >>> val << 4 array([ 0, 16, 32, 48, 64], dtype=int32) >>> val >> 1 array([0, 0, 1, 1, 2], dtype=int32)符号無し => 符号有りに変換
astype
astype関数を使って符号無しから符号有りに変換することはできる.
8bitであれば,uint8からint8に変換すれば問題ない(16bit/32bit/64bitも同様).>>> import numpy as np >>> val = np.asarray([255, 0, 127, 128], dtype=np.uint8) >>> val array([255, 0, 127, 128], dtype=uint8) >>> val.astype(np.int8) array([ -1, 0, 127, -128], dtype=int8)しかし,4bitや12bitといったデータを扱う場合こうはいかない.
(4bitや12bitといった型は存在しないため)
要素数が少ない場合は2進変換->10進変換をfor文でループしたり,frompyfuncを使えば良いが,要素数が多いと時間がかかる(numpyの意味がない).
np.whereを使うとしても要素数が多いと時間はかかってくる(インデックスアクセスが遅くなる).そこでシフト演算を使うことで解決を図る.
シフト演算
numpyでは型の上限のbitまで左シフトしてから右シフトすると符号有りに変換される.
最上位bit=符号bitに情報が残るようである.符号有り8bitで詳しく説明する.
1を2進で表すと以下 1 → 00000001 これを7bit左シフト 000000001 << 7 > 10000000 10進で表すと 10000000 → -128 7bit左シフトした分を右シフト 10000000 >> 7 > 00000001 (理論的にはこっち) > 10000001 (実際はこっち) 10進で表すと 00000001 → 1 10000001 → -1つまり,4bitだと8bit,12bitだと16bitで情報を持つことになるので,4bit左シフトして右シフトすると符号有りに変換できる.
(24bitだと32bitなので8bitシフトになる)>>> import numpy as np >>> val = np.arange(pow(2, 4), dtype=np.int8) >>> val array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], dtype=int8) >>> val << 4 >> 4 array([ 0, 1, 2, 3, 4, 5, 6, 7, -8, -7, -6, -5, -4, -3, -2, -1], dtype=int8)まとめ
この特性を活かすことで,シフト演算を使って高速に4bitや12bitを符号無しから符号有りに変換できます.
(4bitや12bitといっていますが,何bitでもOKです)
ぜひ試してみてください.
- 投稿日:2021-02-26T22:26:10+09:00
A.I.VOICE 琴葉 茜・葵 exVOICE」収録音声一覧(PDFファイル)をCSVに変換
ダウンロード
wget https://aivoice.jp/pdf/exVOICE_kotonoha.pdftabula-javaでコマンド変換
JAVAをインストール
# tabula-javaをダウンロード wget https://github.com/tabulapdf/tabula-java/releases/download/v1.0.4/tabula-1.0.4-jar-with-dependencies.jar -O tabula.jar java -jar tabula.jar -o akane.csv -p 1-7 -l exVOICE_kotonoha.pdf java -jar tabula.jar -o aoi.csv -p 8-14 -l exVOICE_kotonoha.pdfpdfplumberで変換
インストール
pip install pandas pip install pdfplumberCSV変換
import pdfplumber import pandas as pd with pdfplumber.open("exVOICE_kotonoha.pdf") as pdf: data = [] for page in pdf.pages: table = page.extract_table() data.extend(table) dft = pd.DataFrame(data, columns=data[0]) dfg = dft.groupby((df["通しNo"] == "通しNo").cumsum()) dfs = [g.iloc[1:].reset_index(drop=True) for _, g in dfg] for i, df in enumerate(dfs): df.to_csv(f"a_i_voice{i}.csv", encoding="utf_8_sig")
- 投稿日:2021-02-26T21:41:06+09:00
VSCodeプラグインを活用してdocstringを簡単に書こう
やりたいこと
Pythonにdocstringをできるだけ簡単に記述したい。
※VSCodeを使用することを前提にしています。環境
VSCode: 1.53.2
Python Docstring Generator: 0.5.4プラグインの設定
Python Docstring Generatorのインストール
VSCodeのExtensionsで"docstring"を検索すると上位に出てくるので選択してインストール。
docstring設定の変更(必要に応じて)
⌘+,(windowsの場合はctrl+,)を押下して設定画面を開くと、Python Docstring Generatorの設定を変更できます。
デフォルトはGoogleフォーマットです。使い方
docstringを挿入する箇所(classやdefの次の行)に、
”””を入力しEnterを押すだけで自動で挿入されます。
注意
methodのdocstring(ファイルの先頭)はインデントされてしまうバグ有り。終わりに
Python Docstring Generatorを使用するとPythonファイルへのdocstringの記述がとても簡単になります。
docstringの書き方は参考ページの内容がわかりやすいと思います。
参考ページ
GoogleスタイルのPython Docstringの入門
Pythonのdocstringの書き方
[Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)Python Docstring Generator


- 投稿日:2021-02-26T21:37:09+09:00
Pythonで学ぶ制御工学 第8弾:時間応答(1次遅れ系)
#Pythonで学ぶ制御工学< 時間応答(1次遅れ系) >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第8弾として「時間応答(1次遅れ系)」を扱う.時間応答(1次遅れ系)
時間応答の1次遅れ系について,図を使っての説明を以下に示す.
続いては,台車を例に1次遅れ系を導出する.
このようにして,1次遅れ系の形にした時に,対応する部分がゲイン及び時定数となる.
実装
ここでは,適当なゲインと時定数を指定し,ステップ応答の図を出力するプログラムを実装する.なお,出力する図は3つあり,ステップ応答・時定数を変化させたステップ応答・ゲインを変化させたステップ応答である.
ソースコード
step.py""" 2021/02/26 @Yuya Shimizu 時間応答(1次遅れ系) """ from control.matlab import * import matplotlib.pyplot as plt import numpy as np from for_plot import * #自分で定義した関数をインポート ##1次遅れ系のステップ応答 T, K = 0.5, 1 #時定数とゲインの設定 P = tf([0, K], [T, 1]) #1次遅れ系 y, t = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) fig1, ax1 = plt.subplots() ax1.plot(t, y) plot_set(ax1, 't', 'y') #グリッドやラベルを与える関数(自作のfor_plotライブラリより) plt.title(f"T={T}, K={K}") plt.show() ##1次遅れ系のステップ応答(時定数Tを変化させる) K = 1 T = (1, 0.5, 0.1) #3種類の時定数を用意 #図示の準備 fig2, ax2 = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(T)): P = tf([0, K], [T[i], 1]) #1次遅れ系 y, t = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) ax2.plot(t, y, ls=next(LS), label=f"T={T[i]}") plot_set(ax2, 't', 'y', 'best') plt.title(f"T={T}, K={K}") plt.show() ##1次遅れ系のステップ応答(ゲインKを変化させる) T = 0.5 K = (1, 2, 3) #3種類の時定数を用意 #図示の準備 fig3, ax3 = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(K)): P = tf([0, K[i]], [T, 1]) #1次遅れ系 y, t = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) ax3.plot(t, y, ls=next(LS), label=f"K={K[i]}") plot_set(ax3, 't', 'y', 'best') plt.title(f"T={T}, K={K}") plt.show()出力①:ステップ応答
出力②:時定数を変化させたステップ応答
出力③:ゲインを変化させたステップ応答
結果
定常値の63.2%に到達する時間が時定数.すなわち,時定数Tを小さくすると応答が早くなり,逆に大きくすると応答が遅くなることが予想できる.実際に上での図からも分かる.Tが小さいほど,早く収束している.また,図に示してはないが,Tを負値にすると,一定値に収束せず,発散してしまう.ゲインKは定常値を変化させる.なぜなら,最終値の定理より,次の式が成り立つからである.
$lim_{t->\infty}\ y(t) = lim_{s->0}\ sY(s)$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = lim_{s->0}\ s\frac{K}{1+Ts}\frac{1}{s}$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = lim_{s->0}\ \frac{K}{1+Ts}$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = K$追加
ソースコード:部分分数分解
Apart.py""" 2021/02/26 @Yuya Shimizu 部分分数分解 """ import sympy as sp sp.init_printing() s = sp.Symbol('s') T = sp.Symbol('T', real=True) P = 1/((1 + T*s)*s) Apart = sp.apart(P, s)#部分分数分解 print(f"{P}\n ↓\n{Apart}")出力
1/(s*(T*s + 1)) ↓ -T/(T*s + 1) + 1/sソースコード:逆ラプラス変換
inverse_Laplace_tf.py""" 2021/02/26 @Yuya Shimizu 逆ラプラス変換 """ import sympy as sp sp.init_printing() s = sp.Symbol('s') t = sp.Symbol('t', positive=True) T = sp.Symbol('T', real=True) P = 1/((1 + T*s)*s) Inverse = sp.inverse_laplace_transform(1/s - 1/(s+1/T), s, t) #逆ラプラス変換 print(f"1/s - 1/(s+1/T)\n ↓\n{Inverse}")出力
1/s - 1/(s+1/T) ↓ 1 - exp(-t/T)感想
時間応答が何たるかを学んだ.今回は1次遅れ系ということで,時定数やゲインの意味と特徴を知り,また時定数やゲインが制御対象によって中身は変わるということを知った.またPythonでの実装を通して,グラフでの意味のとらえ方にも触れることができた.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社





- 投稿日:2021-02-26T21:13:02+09:00
Python for Windowsをインストールして、仮想環境を作ってみた
インストーラのダウンロード
以下のサイトから、Pythonのインストーラをダウンロードします。
私はpython-3.9.1-amd64.exeをダウンロードしました。
Pythonのインストール
ダウンロードしたインストーラを実行します。
するとこのような画面が開きますので、Add Python 3.x to PATHにチェックを入れ、Install Nowをクリックしましょう。もしAdd Python 3.x to PATHにチェックを入れ忘れてしまったら、慌てずもう一度インストールしましょう。何度繰り返しても大丈夫です。
インストール中
インストールは大体1~2分で終了しました。
インストール完了
以下の画面が表示されればインストールは完了です。
PowerShellの環境設定
PowerShellでスクリプトの実行を許可しておきます。
スタートメニューでWindows PowerShellを起動し、Set-ExecutionPolicy RemoteSigned -Scope CurrentUser -Force!と入力します。
このコマンドは一番最初に一度だけ実行してください。
二回目以降は不要です。


- 投稿日:2021-02-26T21:08:50+09:00
【selenium, beautifulsoup, API 】スクレイピング基本3パターンの使い分け!
本記事では、スクレイピングでWEBページの情報を取得するための方法、基本3パターンについて説明しております。
スクレイピングをするにあたって"どの手法を用いるのが最適なのか"を考えたことはありますか?
本記事を読めば無駄のない最適なスクレイピング手法が身に付きます!スクレイピング3パターン
スクレイピングのパターンは殆ど以下の3つだと考えて良いかと思います。
・ selenium
・ request & beautifulsoup
・ 各サイトのAPI使い分ける際に考える点
これら3パターンを使い分けるに当たって考える点は以下です。
・ 取得可能かどうか
・ 取得の速さ
・ ブロックのされにくさ
ほんとこれだけなので、シンプルですね。
上の3つの取得手法について、まとめてみるとこのようになります。
取得可能かどうか 取得の速さ ブロックのされにくさ selenium ◎ △ ◯ request & beautifulsoup ◯ ◎ ◯ API △ ◎ ◎ ここから分かることは、
selenium → 何でも取得できて万能だけど遅い
request & beautifulsoup → かなり早く取得できるけど、取得できないサイトがある
API → サイトが提供していないとそもそも使えない。だけど、サイトが許容しているからブロックに対しての安全性は高い。速い。
このような特徴があることを知っておいてください!3パターン使い分け
では、3パターンを使い分ける上での考え方です。次のように考えていきましょう。
1. APIが使えないか?
2. APIで無理そうなら、request&beautifulsoupが使えないか?
3. これらが無理なら、仕方ない、seleniumでやろう。
こんな流れで考えてください。
seleniumはよく使うのですが、最終手段です。
- 投稿日:2021-02-26T21:05:10+09:00
Python boot camp by Dr.Angela day7
これまでに学習したこと
For Loop, While Loop, if/else, Lists, Strings, Range, Module...etc.
を使用して簡単なゲームを作ってみよう!ということで、アルゴリズムを書きました。せっかくなのでwebアプリとしてブラウザで楽しめるようにフレームワークに移植し、改変してみました(予定)。Mission>> Hangman game
正解wordの中に入っている文字を当てていくゲーム。
フリーサイト→ https://hangmanwordgame.com/?fca=1&success=0#/
外れたら、Hangman(首つり人間)の絵がどんどん書き足されていき、絵が完成するまでにすべての単語を推測し、当てることが出来なかったらGAMEOVERとなる。なお、推測できる文字は1度に1アルファベットのみで、途中で単語が分かったとしてもwordに使用されるアルファベット全てを入力&推測しないと正解にはさせない仕様。昔からあるゲームで、ヴィクトリア朝時代にまで遡れるらしい...
詳細はwikiへ→ https://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%B3%E3%82%B0%E3%83%9E%E3%83%B3_(%E3%82%B2%E3%83%BC%E3%83%A0)ゲーム原型として以下のような出力をするプログラムを作成しました。
・与えられた単語の中からランダムに正解ワードが選定される
・文字数は最初にヒントとして空欄「 _ (アンダースコア)」で与えられる
・すべての空欄がアルファベットで埋まるまで永遠に入力を聞いてくる
→ これでは勝敗がつくゲームではないので次に回数制限を設けて手直ししたものが2番目のコード。
苦戦したところは相変わらず、型変換ですね・・・。import random #正解リストを作成 word_list = ["centos", "kali", "ubuntu"] #正解リストから正解を1つランダムに決める chosen_word = random.choice(word_list) select = list(chosen_word) #入力前の変数に「_」を文字数分セット ans = [] for _ in range(len(chosen_word)): ans += "_" #正解ワードの文字数ヒント表示 print("The word is ", " ".join(ans), "\n") #check関数を作成 def check(): #標準入力した文字が正解ワードに含まれていればそのindexを取り出す if guess in select: index = [i for i, x in enumerate(select) if x == guess] for y in index: #取り出したindexをint型変換 idx = int(y) #ansリストから該当indexの「_」を削除 del ans[y] #ansリストの該当indexに正解した標準入力を追加 ans.insert(idx,guess) #ans2はリストなので結合してstr型変換 currans = " ".join(ans) print(currans) else: #標準入力した文字が正解ワードに含まれていない場合以下を出力 print("No exist in this word") #すべての「_」が文字で埋まるまでcheck関数を回す while "_" in ans: guess =str(input("Input an alphabet you guess: ")) print("") #check関数の呼び出し check() #すべての空欄(_)が文字列で埋まった場合、以下を出力 else: print("\nYou got it!!")[i for i, x in enumerate(select) if x == guess]
→ if直後の条件に一致した場合、該当の値を持つindexを返す次に回数制限を設けたver.
#check関数まで上記と同じ #初期値、最大試行回数の指定 times = 1 max_times = 5 #check関数を回す条件・範囲を指定 while times < max_times: guess =str(input("Input an alphabet you guess: ")) #試行回数、残り試行回数の表示 print(f"Challenge {times} times :: Remain {int(max_times)-int(times)} times") print("") #回数のインクリメント times += 1 #check関数の呼び出し check() #空欄(_)がある場合、負け if "_" in ans: print("\nYou lose...") #全て当てられて空欄(_)がない場合、勝ち! else: print("\nYou won !!")Mission>> 図を挿入したい!
では図を入れてみます。
#check関数まで上記と同じ times = 1 max_times = 6 lives = 6 stages = [''' +---+ | | O | /|\ | / \ | | ========= ''', ''' +---+ | | O | /|\ | / | | ========= ''', ''' +---+ | | O | /|\ | | | ========= ''', ''' +---+ | | O | /| | | | =========''', ''' +---+ | | O | | | | | ========= ''', ''' +---+ | | O | | | | ========= ''', ''' +---+ | | | | | | ========= '''] while times < max_times: guess =str(input("Input an alphabet you guess: ")) print(f"Challenge {times} times :: Remain {int(max_times)-int(times)} times\n") print("") check() print(stages[lives]) times += 1 if "_" in ans: print("\nYou lose...") else: print("\nYou won !!")上記のように複数行にわたって図を入れたい場合は「'''」(トリプルコーテーション)を使います。
Mission>> webアプリ化したい!
今回はスマホからも遊べるように、herokuにデプロイできるDjangoで作ってみます!
まずHerokuのアカウント作成から→ https://signup.heroku.com/dc
- 投稿日:2021-02-26T20:49:33+09:00
【Python】自作モジュールでも使える特殊なloggerを簡潔に書きたい時【logging】
特殊なloggerとは?
loggingと言えばlogging.iniとかloggingConfigDictとかいろいろあるけど、
例えば、googleのCloud LoggingとかにAI Platformのログを貯めたい時にこんな書き方をします。loggingの書き方import logging import google.cloud.logging_v2 from google.cloud.logging_v2.handlers import CloudLoggingHandler from google.cloud.logging_v2.resource import Resource client = google.cloud.logging_v2.Client(project=os.environ["PROJECT_ID"]) handler = CloudLoggingHandler(client, resource=Resource( "ml_job", { "task_name": "hoge", "project_id": os.environ["PROJECT_ID"], "job_id": os.environ["CLOUD_ML_JOB_ID"] } ) ) LOGGER = logging.getLogger(__name__) LOGGER.setLevel(logging.INFO) LOGGER.addHandler(handler)ちょっとこれはlogging.iniに書けんなーと思って、
だけどちゃんとモジュールを呼んだらLoggingして欲しい訳です。結構苦しみましたが、うまく動作した例を紹介します。成功例
以下のようにファイルを整理
main.pyfrom logger import get_logger, set_logger from module import module set_logger() LOGGER = get_logger() def another(): LOGGER.info("another") def main(): LOGGER.info("start") another() module() LOGGER.info("end") if __name__ == "__main__": main()module.pyfrom logger import get_logger # 呼び出したいモジュール def module(): global LOGGER LOGGER = get_logger() LOGGER.info("test") module2() def module2(): LOGGER.info("test2")logger.pyimport logging def set_logger(): global LOGGER LOGGER = logging.getLogger(__name__) LOGGER.setLevel(logging.INFO) ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) formatter = logging.Formatter("%(levelname)s - %(message)s") ch.setFormatter(formatter) LOGGER.addHandler(ch) #今回は簡単な例としてStreamHandlerを使用。 def get_logger(): return LOGGERまず説明すると、Entrypointとなるmain.pyには必ず
set_logger()を付け加えます。
するとlogger側でLOGGERの設定ができる事になります。
そして、get_logger()からLOGGERを取り出し、使用することができます。
ここまでは、単純なloggingと変わりません。問題は別モジュールを呼び出した時、Entrypointで設定したLOGGERはどうやっても読めませんし、
かと言ってもう一度宣言をすると、二重でログを吐くことが分かっています。
なので、モジュールにおいては、get_logger()だけを使用し、そのLOGGERをGrobal設定することで、
モジュールファイル内のLOGGER全てで設定したLOGGERを使用することができます。別の方法
別の方法があれば教えてください...もっと...もっと簡潔に書きたい...
参考文献
(あまり参考にできなかったですが、以下の方法もあるみたいです)
- 投稿日:2021-02-26T20:47:36+09:00
Networkタブの情報をスクレイピングする方法
概要
多くの場合、サイトを表示した場合にそのサイト内で(サーバ・クライアントサイド問わず)外部サーバへリクエストを行い、ページがレンダリングされますが、この時のリクエストした先の情報をスクレイピングしたくなったため、まとめます。
簡潔に流れをまとめると
- seleniumを導入
- 以下のscriptを書く
- おしまい
手順
seleniumを導入
これはいろいろなサイトで説明があるため省略しますが、macの方はbrewで導入可能です。
$ brew install chromedriver$ pip install seleniumスクリプトを書く
以下のスクリプトを実行します。
※自分の場合、「"chromedriver"は開発元を検証できないため開けません。」と表示されたため、「キャンセル」ボタンを押して「システム環境設定」をクリックし、「セキュリティとプライバシー」を選択して許可しました。import json from selenium import webdriver driver = webdriver.Chrome("/hoge/hoge/chromedriver") driver.get("{スクレイピングしたい先のサイトのURL}") scriptToExecute = "var performance = window.performance || window.mozPerformance || window.msPerformance || window.webkitPerformance || {}; var network = performance.getEntries() || {}; return JSON.stringify(network);" data = driver.execute_script(scriptToExecute) json = json.loads(str(data))あとはjsonの中にobjectが配列で入っているためいい感じに取り出します。
- 投稿日:2021-02-26T20:42:27+09:00
DateFrameを2つのkeyで昇順にソートする方法
1 この記事は何?
DateFarme型を2つのkeyで昇順に並べ替える方法を節毎します。
下記は、行名Aを第1keyで昇順に並べ替え、行名Dateを第2Keyで昇順に並べ替えをしています。
2 どうやってやるの?
下記のコードの通り実施してみてください。
exampleimport pandas as pd import numpy as np import scipy.stats idx = pd.IndexSlice #dataを定義する。 dat = [ [1,'2019-07-01',2], [1,'2019-09-02',4], [1,'2019-06-01',8], [3,'2018-07-02',16], [3,'2019-07-03',100], [3,'2016-07-01',200], [2,'2020-07-01',400], [2,'2019-07-01',200], ] #datをDataFrame型変数dfに格納する。 df = pd.DataFrame(dat,columns=["A","Date","C"]) print("df",df) print("第1keyを「A」、第2keyを「Date」で並べ替える。") df1=df.groupby(["A"]).apply(lambda x: x.sort_values(["Date"], ascending = True)).reset_index(drop=True) df1実行結果
exampledf A Date C 0 1 2019-07-01 2 1 1 2019-09-02 4 2 1 2019-06-01 8 3 3 2018-07-02 16 4 3 2019-07-03 100 5 3 2016-07-01 200 6 2 2020-07-01 400 7 2 2019-07-01 200 第1keyを「A」、第2keyを「Date」で並べ替える。 A Date C 0 1 2019-06-01 8 1 1 2019-07-01 2 2 1 2019-09-02 4 3 2 2019-07-01 200 4 2 2020-07-01 400 5 3 2016-07-01 200 6 3 2018-07-02 16 7 3 2019-07-03 100

- 投稿日:2021-02-26T20:24:36+09:00
[vscode]リモート環境のjupyterにワンクリックでホストのブラウザからアクセスする
はじめに
vscodeのpython extensionはjupyter notebook形式に対応していて、vscodeのタブをjupyter notebook風に利用することができます。
参考:VS CodeのPython拡張がJupyterをネイティブサポートしたそうなので早速使ってみた。しかし2021年2月現在、
- 複数ペインでnotebookを開いた場合にフォーカスが安定しない
- 読み込みに時間がかかる
- 黒背景が見づらい
などパフォーマンス面でいくつかの課題があります。今のところ、ブラウザでjupyter-labを開いた時ほど安定感はないかなと思います。
ストレスフリーに使いたければブラウザからアクセスしたいところですが、ブラウザからリモート環境にアクセスするにはサーバのポートの設定などを変更しなければならず面倒だとされています。また作業ディレクトリを毎回変更して起動しなければならないのもやや面倒です。
できれば1クリックで実現したいところです→できます!
方法
- VS Codeでリモート環境のフォルダーを開く
- タブから"ターミナル(T)"→"新しいターミナル"を選択
ターミナルで
jupyter labを起動ターミナル上に出力されたurlをctrl+クリック
以上で、使い慣れたブラウザ版jupyterをワンクリックで利用することができました。

- 投稿日:2021-02-26T20:16:48+09:00
KaggleのNotebookでAutoGluonを使ってみる
※これは2021/02/26の記事です。指摘などありましたら気兼ねなくコメントお願いします

はじめに
「「AutoGluon-Tabular」を試してみる」という記事を読み、これを参考にしてKaggleのNotebookでAutoGluon(特にAutoGluon-Tabular)を使ってみようと試みたのですが、すんなりとはできませんでした。原因として、この一年でAutoGluon自体にいくつか変更があったことなどが考えられます。また推奨される利用方法も変わったようです。そこで、そのあたりを考慮し、「KaggleのNotebookでAutoGluonを使ってみる」というところまでを実現しました。作成したNotebookの紹介と実現するまでに発生したエラー・解決方法を備忘録として残しておきます。
結論
以下のようなNotebookを作成しました
A Beginner's Guide to AutoGluon | Kaggle
# https://github.com/awslabs/autogluon !pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluon.tabularimport pandas as pd from autogluon.tabular import TabularDataset, TabularPredictor train= TabularDataset('../input/titanic/train.csv') test = TabularDataset('../input/titanic/test.csv') label='Survived' time_limit=60 predictor = TabularPredictor(label=label).fit(train, time_limit=time_limit) submission = pd.read_csv('../input/titanic/gender_submission.csv') submission[label] = predictor.predict(test) submission.to_csv('submission.csv', index=False) submission.head()Public Scoreは0.78229と算出され、望む実装ができているようです!簡単!素晴らしい!
しかし、ちょっと不安な出力も…ひとまず棚に上げます。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. earthengine-api 0.1.252 requires google-api-python-client>=1.12.1, but you have google-api-python-client 1.8.0 which is incompatible.エラー&解決の備忘録
大きく以下2点を実施しました。
- 他環境(Google Colab)での最新の成功例で試行
- 環境依存の問題?を確認
まずは、Google Colabでの最新の成功例を試してみました。「Google ColaboratoryでAutoGluonをinstall & importする方法」、「autogluon.tabularのTabularDatasetによるデータの取得ができなくなってしまった件と解決方法について(2021/02/25に検知)」でも紹介したコードです。これは参考記事が公開されて以降のAutoGluonの変更点を考慮したものです。モジュールなどが異なります。
TabularDataset、TabularPredictorを使うためにautogluon.tabularをインポートします。このコードをすべてコピーして、実行してみたのですが以下のようなエラーが生じました。READMEを参考にしたコマンドなのですがここに原因がありそうです。
!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install --pre autogluonfrom autogluon.tabular import TabularDataset, TabularPredictor--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-2-974358aaf144> in <module> ----> 1 from autogluon.tabular import TabularDataset, TabularPredictor /opt/conda/lib/python3.7/site-packages/autogluon/tabular/__init__.py in <module> 1 import logging 2 ----> 3 from autogluon.core.dataset import TabularDataset 4 from autogluon.core.features.feature_metadata import FeatureMetadata 5 /opt/conda/lib/python3.7/site-packages/autogluon/core/__init__.py in <module> 4 from .decorator import * 5 from .utils.files import * ----> 6 from .scheduler.resource.resource import * 7 from .scheduler.scheduler import * 8 from . import metrics /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/__init__.py in <module> ----> 1 from .import remote, resource 2 from .resource import get_cpu_count, get_gpu_count 3 4 # schedulers 5 from .scheduler import * /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/remote/__init__.py in <module> 1 # remotes ----> 2 from .remote import * 3 from .ssh_helper import * 4 from .remote_manager import * /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/remote/remote.py in <module> 9 from threading import Thread 10 import multiprocessing as mp ---> 11 from distributed import Client 12 13 from .ssh_helper import start_scheduler, start_worker /opt/conda/lib/python3.7/site-packages/distributed/__init__.py in <module> 2 import dask 3 from dask.config import config ----> 4 from .actor import Actor, ActorFuture 5 from .core import connect, rpc, Status 6 from .deploy import LocalCluster, Adaptive, SpecCluster, SSHCluster /opt/conda/lib/python3.7/site-packages/distributed/actor.py in <module> 4 from queue import Queue 5 ----> 6 from .client import Future, default_client 7 from .protocol import to_serialize 8 from .utils import iscoroutinefunction, thread_state, sync /opt/conda/lib/python3.7/site-packages/distributed/client.py in <module> 41 from tornado.ioloop import IOLoop, PeriodicCallback 42 ---> 43 from .batched import BatchedSend 44 from .utils_comm import ( 45 WrappedKey, /opt/conda/lib/python3.7/site-packages/distributed/batched.py in <module> 6 from tornado.ioloop import IOLoop 7 ----> 8 from .core import CommClosedError 9 from .utils import parse_timedelta 10 /opt/conda/lib/python3.7/site-packages/distributed/core.py in <module> 18 from tornado.ioloop import IOLoop, PeriodicCallback 19 ---> 20 from .comm import ( 21 connect, 22 listen, /opt/conda/lib/python3.7/site-packages/distributed/comm/__init__.py in <module> 24 25 ---> 26 _register_transports() /opt/conda/lib/python3.7/site-packages/distributed/comm/__init__.py in _register_transports() 16 def _register_transports(): 17 from . import inproc ---> 18 from . import tcp 19 20 try: /opt/conda/lib/python3.7/site-packages/distributed/comm/tcp.py in <module> 15 import dask 16 from tornado import netutil ---> 17 from tornado.iostream import StreamClosedError 18 from tornado.tcpclient import TCPClient 19 from tornado.tcpserver import TCPServer /opt/conda/lib/python3.7/site-packages/tornado/iostream.py in <module> 208 209 --> 210 class BaseIOStream(object): 211 """A utility class to write to and read from a non-blocking file or socket. 212 /opt/conda/lib/python3.7/site-packages/tornado/iostream.py in BaseIOStream() 284 self._closed = False 285 --> 286 def fileno(self) -> Union[int, ioloop._Selectable]: 287 """Returns the file descriptor for this stream.""" 288 raise NotImplementedError() AttributeError: module 'tornado.ioloop' has no attribute '_Selectable'
--preを外してみます。!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluonfrom autogluon.tabular import TabularDataset, TabularPredictor--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-3-974358aaf144> in <module> ----> 1 from autogluon.tabular import TabularDataset, TabularPredictor ModuleNotFoundError: No module named 'autogluon.tabular'
autogluon.tabularがないと言われていしまいました。それならとautogluon→autogluon.tabularにしてみると…成功しました!最終的に、以下のような修正で解決しました。!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluon.tabular2021/02/26、Kaggleでは、
TabularDataset、TabularPredictorを使うためにautogluonではなくautogluon.tabularをインストールする必要があるということですね。色々気になっています
まとめ
「KaggleのNotebookでAutoGluonを使ってみる」というところまでを実現するために、作成したNotebookの紹介と、実現するまでに発生したエラー・解決方法を備忘録として記録しました。2021/02/26にした対応でしたが、今後もこのようなエラーが生じる恐れはあると思うので、あくまでも参考までにしていただけると幸いです。引き続きAutoGluonをはじめとするAutoMLをどんどん体験していきましょう!
- 投稿日:2021-02-26T20:04:30+09:00
「画像でゴミ分類!」アプリ作成日誌day9~テストの追加~
一言でいうと
Djangoで作成したアプリにSeleniumを使ったテストを追加しました!
これまでの経緯
「画像でゴミ分類!」という画像を入れたらそれが何ゴミか分類してくれるwebアプリを作成しました。いったん完成していたのですが、テストが大事とかテスト駆動開発いいよねという記事に感化されてこのアプリにもテストを導入します。
<これまでの記事一覧>
- 「画像でゴミ分類!」アプリ作成日誌day1~データセットの作成~
- 「画像でゴミ分類!」アプリ作成日誌day2~VGG16でFine-tuning~
- 「画像でゴミ分類!」アプリ作成日誌day3~Djangoでwebアプリ化~
- 「画像でゴミ分類!」アプリ作成日誌day4~Bootstrapでフロントエンドを整える~
- 「画像でゴミ分類!」アプリ作成日誌day5~Bootstrapでフロントエンドを整える2~
- 「画像でゴミ分類!」アプリ作成日誌day6~ディレクトリ構成の修正~
- 「画像でゴミ分類!」アプリ作成日誌day7~サイドバーのスライドメニュー化~
- 「画像でゴミ分類!」アプリ作成日誌day8~herokuデプロイ~
テスト手法
Seleniumを使ったUIテストを行いたいので、DjangoのLiveServerTestCaseを利用します。
Jupyterで動作確認
Seleniumについてまだ勉強中なので、いきなりwebアプリ上に書くのではなく、Jupyterで挙動を確認しながらコードを書いていきます。
まずは、chromeを起動しましょう
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys DRIVER_PATH = r'chromedriver.exeのパス' # ブラウザの起動 driver = webdriver.Chrome(executable_path=DRIVER_PATH)そして開発用サーバーにアクセス。ここは開発用サーバーを立ち上げておく必要があります。
driver.get('http://localhost:8000/garbage')まずは、タイトルを取得してみましょう
driver.title # '画像でゴミ分類!'次に、要素を取得してみましょう
driver.find_element_by_class_name("sample-img").get_attribute('outerHTML') # '<img src="/static/garbage/media/gif/waiting.278078bec7bd.gif" alt="画像1" class="mt-3 sample-img waiting" id="waiting-gif">'outerHTMLを見ると無事取得できていることがわかります。ただ、実はこのクラスに所属するものは複数あるので、そんなときは
find_elements_by_class_nameと複数形で使うとリストで取得できます。len(driver.find_elements_by_class_name("sample-img")) # 3では画像をクリックする処理を書きます
driver.find_elements_by_class_name("sample-img")[1].click()簡単ですね。
今度は遷移先のページでタグを取得してみます。
num_tr = len(driver.find_elements(By.XPATH, '//tr'))書き方がちょっと変わりましたが、XML Pathで要素を指定しているだけで、やってることは同じですね。
これを用いてテストするには以下のようにすればいいです。
assert 6 == num_tr, "表の行数が一致しません"では、一度トップページに戻って文字検索時のテストを書いていきます。
まずは、検索ボックスを取得してみましょうdriver.get('http://localhost:8000/garbage') driver.find_elements(By.XPATH, '//input[@name="word"]') # [<selenium.webdriver.remote.webelement.WebElement (session="d795b92e9edbbd43c50a2be08e0b75e1", element="54b9e56a-2624-4a33-9f5f-be8fe77a6e5e")>, # <selenium.webdriver.remote.webelement.WebElement (session="d795b92e9edbbd43c50a2be08e0b75e1", element="1ccd154e-326f-4e5c-8004-9258ec03bb39")>]あれ、2つ出てくるのはなんででしょうか。これは、スマホ対応時のサイドバーとPC時の左メニューの分ですね。
PC時の左メニューのほうだけを使います。文字列として針を入力してみましょう。
search_box = driver.find_elements(By.XPATH, '//input[@name="word"]')[1] search_box.send_keys('針')そして、Enterキーを押します。この後は先ほどと同じく表の行数をチェックするようにしようかと思います。
search_box.send_keys(Keys.ENTER) len(driver.find_elements(By.XPATH, '//tr')) # 14testコードの追加
これまで書いたコードをwebアプリ上に移植します。
まず、test.pyを削除してその代わりにtests/test_views.pyを追加します。
まずはおまじないです。LiveServerTestCaseクラスをオーバーライドしてドライバーなどの場所を教えます。from django.test import LiveServerTestCase from selenium.webdriver.chrome.webdriver import WebDriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys class TestClickSample(LiveServerTestCase): @classmethod def setUpClass(cls): super().setUpClass() cls.selenium = WebDriver(executable_path=r'garbage\tests\chromedriver.exe') @classmethod def tearDownClass(cls): cls.selenium.quit() super().tearDownClass()まずは、ページを開いてタイトルがあってるかを確認をしておきましょう。
def test_open_page(self): """ページを開いてタイトルがあってるかを確認 """ self.selenium.get('http://localhost:8000/garbage') self.assertEquals("画像でゴミ分類!", self.selenium.title)次にサンプル画像をクリックしたときの処理を記述して、モデルの挙動が正しいかを確認できるようにします。
def test_click_sample(self): """モデルの動きが正常かを確認 サンプル画像をクリックした際の挙動を確認 """ self.selenium.get('http://localhost:8000/garbage') self.selenium.find_elements_by_class_name("sample-img")[1].click() num_tr = len(self.selenium.find_elements(By.XPATH, '//tr')) self.assertEquals(6, num_tr)最後に文字検索時の挙動をテストします。
def test_search(self): """文字検索時の挙動をテスト """ self.selenium.get('http://localhost:8000/garbage') search_box = self.selenium.find_elements(By.XPATH, '//input[@name="word"]')[1] search_box.send_keys('針') search_box.send_keys(Keys.ENTER) num_tr = len(self.selenium.find_elements(By.XPATH, '//tr')) self.assertEquals(14, num_tr)テスト実行してみましょう。
Creating test database for alias 'default'... System check identified no issues (0 silenced). ---------------------------------------------------------------------- Ran 3 tests in 10.380s OK無事テストが通ったようです!
参考文献
- 大高 隆(2019)『動かして学ぶ!Python Django開発入門』翔泳社
- Djangoを始めよう! 〜チュートリアル⑤〜
- Seleniumで要素を選択する方法まとめ
- 投稿日:2021-02-26T19:12:51+09:00
AtCoderのARC113bを解説を読めない者が解くとこうなる
はじめに
こんにちは、麻菜結です。はじめての競技プログラミング解説記事になるのですが、この記事は作問者が思い描いたきれいな解答を咀嚼しながら解説するものではなく、私がコンテスト時間内に半泣き&戸惑いながらACをとってしまった解法を解説する記事となります。
この記事の読者として想定するのは、多かれ少なかれプログラミングを教える立場にある人です。アルゴリズムのコツがつかめないやつってどのあたりでつまずいちゃうんだろうという一例をあげる記事となります。以下見苦しい文章が続きます。よろしくお願いします。問題文
正の整数A, B, Cが与えられます。A^B^Cの10進法での1の位を求めてください。
AtCoder Regular Contest 113 B A^B^C
思考
じゃあどんなふうに考えようかと言うと、「この解答ってAの1桁目に依存するよな」と考えます。どういうことかというと、例えば5にどんな数をかけようと1桁目は0か5になります、このようにAの1桁目に注目することを思い浮かびます。
さらに、「BとCがどんな数になろうとしょせんはA * A * ...になるからAの1桁目 * Aの1桁目 * ...ででた数字の1桁目にしか解答はありえないよな」となります。さらに踏み込んだ考え方が出来そうですが、愚かにもこのあたりで思考の限界が来てしまい、実装の為の検証に入ります。検証
検証ですが、0から9までのそれぞれの数字でどのような1桁目になるかを検証するために以下のようなプログラムを組みます。
import sys A = int(sys.argv[1]) for i in range(1, 10): for j in range(1, 10): x = A ** (i ** j) print(f"LastDigit({A} ** {i} ** {j}) -> {str(x)[-1]}")もし上のソースコードを実行する方は、コンピュータにそこそこな負荷をかけますのでほどほどな所で
[Ctrl]+[C]をしてください。コマンドライン引数から数字を与えた任意の数字AをA^(i^j)[1 <= i,j <= 9]するプログラムです。それぞれを実行すると以下のような傾向が見えてきます。
単一の数字しかないもの 2種類の数字がでるもの 4種類の数字がでるもの 0 → 0 4 → 4, 6 2 → 2, 4, 6, 8 1 → 1 9 → 1, 9 3 → 1, 3, 7, 9 5 → 5 7 → 1, 3, 7, 9 6 → 6 8 → 2, 4, 6, 8 これでとりあえず0, 1, 5, 6なら即断していいのがわかりましたね。
コンピュータの世界は答えさえ合っていれば数学のように証明が無くてもOKなのが楽ですね。
では、数字が2種類でるものを検証しましょう。
$ python exp_test 4
LastDigit(4 ** 1 ** 1) -> 4 LastDigit(4 ** 1 ** 2) -> 4 LastDigit(4 ** 1 ** 3) -> 4 LastDigit(4 ** 1 ** 4) -> 4 LastDigit(4 ** 1 ** 5) -> 4 LastDigit(4 ** 1 ** 6) -> 4 LastDigit(4 ** 1 ** 7) -> 4 LastDigit(4 ** 1 ** 8) -> 4 LastDigit(4 ** 1 ** 9) -> 4 LastDigit(4 ** 2 ** 1) -> 6 LastDigit(4 ** 2 ** 2) -> 6 LastDigit(4 ** 2 ** 3) -> 6 LastDigit(4 ** 2 ** 4) -> 6 LastDigit(4 ** 2 ** 5) -> 6 LastDigit(4 ** 2 ** 6) -> 6 LastDigit(4 ** 2 ** 7) -> 6 LastDigit(4 ** 2 ** 8) -> 6 LastDigit(4 ** 2 ** 9) -> 6 LastDigit(4 ** 3 ** 1) -> 4 LastDigit(4 ** 3 ** 2) -> 4 LastDigit(4 ** 3 ** 3) -> 4 LastDigit(4 ** 3 ** 4) -> 4 LastDigit(4 ** 3 ** 5) -> 4 LastDigit(4 ** 3 ** 6) -> 4 LastDigit(4 ** 3 ** 7) -> 4 LastDigit(4 ** 3 ** 8) -> 4 LastDigit(4 ** 3 ** 9) -> 4 LastDigit(4 ** 4 ** 1) -> 6 LastDigit(4 ** 4 ** 2) -> 6 LastDigit(4 ** 4 ** 3) -> 6 LastDigit(4 ** 4 ** 4) -> 6 LastDigit(4 ** 4 ** 5) -> 6 LastDigit(4 ** 4 ** 6) -> 6 LastDigit(4 ** 4 ** 7) -> 6 LastDigit(4 ** 4 ** 8) -> 6 LastDigit(4 ** 4 ** 9) -> 6 LastDigit(4 ** 5 ** 1) -> 4 LastDigit(4 ** 5 ** 2) -> 4 LastDigit(4 ** 5 ** 3) -> 4 LastDigit(4 ** 5 ** 4) -> 4 LastDigit(4 ** 5 ** 5) -> 4 LastDigit(4 ** 5 ** 6) -> 4 LastDigit(4 ** 5 ** 7) -> 4 LastDigit(4 ** 5 ** 8) -> 4 LastDigit(4 ** 5 ** 9) -> 4 LastDigit(4 ** 6 ** 1) -> 6 LastDigit(4 ** 6 ** 2) -> 6 LastDigit(4 ** 6 ** 3) -> 6 LastDigit(4 ** 6 ** 4) -> 6 LastDigit(4 ** 6 ** 5) -> 6 LastDigit(4 ** 6 ** 6) -> 6 LastDigit(4 ** 6 ** 7) -> 6 ^C
長いので折り畳み&途中停止していますが、Bの値が偶数の時は6, 奇数の値の時は4となっており、それが延々と続きそうなのでBが偶数の時と奇数の時で判断できます。書きませんが9の場合は偶数→1, 奇数→9です。
4種類のやつを検証します。
$ python exp_test 2
LastDigit(2 ** 1 ** 1) -> 2 LastDigit(2 ** 1 ** 2) -> 2 LastDigit(2 ** 1 ** 3) -> 2 LastDigit(2 ** 1 ** 4) -> 2 LastDigit(2 ** 1 ** 5) -> 2 LastDigit(2 ** 1 ** 6) -> 2 LastDigit(2 ** 1 ** 7) -> 2 LastDigit(2 ** 1 ** 8) -> 2 LastDigit(2 ** 1 ** 9) -> 2 LastDigit(2 ** 2 ** 1) -> 4 LastDigit(2 ** 2 ** 2) -> 6 LastDigit(2 ** 2 ** 3) -> 6 LastDigit(2 ** 2 ** 4) -> 6 LastDigit(2 ** 2 ** 5) -> 6 LastDigit(2 ** 2 ** 6) -> 6 LastDigit(2 ** 2 ** 7) -> 6 LastDigit(2 ** 2 ** 8) -> 6 LastDigit(2 ** 2 ** 9) -> 6 LastDigit(2 ** 3 ** 1) -> 8 LastDigit(2 ** 3 ** 2) -> 2 LastDigit(2 ** 3 ** 3) -> 8 LastDigit(2 ** 3 ** 4) -> 2 LastDigit(2 ** 3 ** 5) -> 8 LastDigit(2 ** 3 ** 6) -> 2 LastDigit(2 ** 3 ** 7) -> 8 LastDigit(2 ** 3 ** 8) -> 2 LastDigit(2 ** 3 ** 9) -> 8 LastDigit(2 ** 4 ** 1) -> 6 LastDigit(2 ** 4 ** 2) -> 6 LastDigit(2 ** 4 ** 3) -> 6 LastDigit(2 ** 4 ** 4) -> 6 LastDigit(2 ** 4 ** 5) -> 6 LastDigit(2 ** 4 ** 6) -> 6 LastDigit(2 ** 4 ** 7) -> 6 LastDigit(2 ** 4 ** 8) -> 6 LastDigit(2 ** 4 ** 9) -> 6 LastDigit(2 ** 5 ** 1) -> 2 LastDigit(2 ** 5 ** 2) -> 2 LastDigit(2 ** 5 ** 3) -> 2 LastDigit(2 ** 5 ** 4) -> 2 LastDigit(2 ** 5 ** 5) -> 2 LastDigit(2 ** 5 ** 6) -> 2 LastDigit(2 ** 5 ** 7) -> 2 LastDigit(2 ** 5 ** 8) -> 2 LastDigit(2 ** 5 ** 9) -> 2 LastDigit(2 ** 6 ** 1) -> 4 LastDigit(2 ** 6 ** 2) -> 6 LastDigit(2 ** 6 ** 3) -> 6 LastDigit(2 ** 6 ** 4) -> 6 LastDigit(2 ** 6 ** 5) -> 6 LastDigit(2 ** 6 ** 6) -> 6 LastDigit(2 ** 6 ** 7) -> 6 LastDigit(2 ** 6 ** 8) -> 6 LastDigit(2 ** 6 ** 9) -> 6 LastDigit(2 ** 7 ** 1) -> 8 LastDigit(2 ** 7 ** 2) -> 2 LastDigit(2 ** 7 ** 3) -> 8 LastDigit(2 ** 7 ** 4) -> 2 LastDigit(2 ** 7 ** 5) -> 8 LastDigit(2 ** 7 ** 6) -> 2 LastDigit(2 ** 7 ** 7) -> 8 LastDigit(2 ** 7 ** 8) -> 2 ^C
難しそうに見えますが、4種類のパターンが続いていくのが推測されます。
条件 パターン B%4 → 1 X. ある数に定まる(2) B%4 → 2 Y. 1番目だけ別の数字で後は同じ数字(4, 6) B%4 → 3 Z. Cが奇数か偶数かによって定まる(2, 8) B%4 → 0 W. ある数に定まる(6) 以上は2の場合です。
他の数字は以下のようになります。
X Y Z W 3 3 9,1 7,3 1 7 7 9,1 3,7 1 8 8 4,6 2,8 6 パターンXの場合はA、パターンWの場合はAが偶数の時6、奇数の時1が解答になってますね。さて、そろそろ実装に移っていきますか。
プログラム
一回整理しましょう。解答はフローチャートっぼくにまとめると以下のようになります。
そして、図とすこし違いますが、解答のプログラムが以下のモノになります。
A, B, C = [int(e) for e in input().split()] ans = 0 l_A = str(A)[-1] if(l_A in ["0", "1", "5", "6"]): ans = {"0":0, "1":1, "5":5, "6":6}[l_A] elif(l_A in ["4", "9"]): l_A += "+" if B%2 == 0 else "" ans = {"4+":6, "9+":1, "4":4, "9":9}[l_A] elif(B % 4 == 1): ans = {"2":2, "3":3, "7":7, "8":8}[l_A] elif(B % 4 == 2): if(C == 1): ans = {"2":4, "3":9, "7":9, "8":4}[l_A] else: ans = {"2":6, "3":1, "7":1, "8":6}[l_A] elif(B % 4 == 3): if(C % 2 == 0): ans = {"2":2, "3":3, "7":7, "8":8}[l_A] else: ans = {"2":8, "3":7, "7":3, "8":2}[l_A] elif(B % 4 == 0): ans = {"2":6, "3":1, "7":1, "8":6}[l_A] print(ans)おわりに
本当にお疲れさまでした。自分の恥をさらすような記事で、読んでいて「あちゃー」と思っている人もいるかもしれませんが、そうなった人は自分よりもできない人なんかいくらでもいるんだという事実を誇らしく思ってください。
逆に皆さんはどんなふうに競技プログラミングに慣れていきましたか?いつまでも初心者から脱せない感じがモチベをじわじわ削っていく気がします。精進します。最後まで読んでくださってありがとうございました。書きたいネタが出来たらまたかきます。

- 投稿日:2021-02-26T19:09:07+09:00
文系の非エンジニアがiPadだけでpythonと機械学習の勉強をする②環境構築編 Google Colaboratoryの場合
はじめに
前回はAzure Notebookを使ってpythonの学習環境を作ってみましたが、残念なことにAzure Notebookのサービスが終了してしまったので別の環境が必要になりました。
前回の記事の作成後、会社で受講したe-learningでGoogle Colaboratoryの存在を知ったので、こちらで改めて環境を構築したいと思います。準備するもの
- Googleアカウント
勉強する人のスペック
- G検定合格(2020.3)
- コードは10年以上書いてない
- VB6.0,PL/SQL,COBOL
- 大学時代は作者の気持ちを考えていました
- e-learningでpythonを受講(2020.8)
Google Colaboratryとは?
以下はGoogle Colaboratoryにアクセスして最初に表示される説明文です。
Colaboratory(略称: Colab)は、ブラウザから Python を記述、実行できるサービスです。次の特長を備えています。
環境構築が不要
GPU への無料アクセス
簡単に共有
Colab は、学生からデータ サイエンティスト、AI リサーチャーまで、皆さんの作業を効率化します。手順
Googleアカウントにサインインする
Googleアカウントがあれば特に問題はありません。
普通にサインインしましょうGoogle Colaboratryにアクセスする
Google Colaboratryにアクセスするとこのような画面が表示されます。
↑で書いたので説明文は、[キャンセル]を選択した時に表示されるものですね。
ここでは[ノートブックを新規作成]を選択します。
作成されたノートブックは[Untitled0.ipynb]という名前になります。
今回は学習用ということで、[pythonlearning.ipynb]に名称を変更します。
これでノートブック作成完了。pythonのコードを学習する環境が整いました。コードを書いてみる
ノートブックを開いた初期状態はこのような感じです。
[+コード]を選択すると、コード編集用の領域が追加されます。
例によってあれを書いてみましょうprint("Hellow")コードを実行する
コードがかけたら実行します。
コード編集領域の左端の矢印をタップするか、shift+enterで実行できます。
iPadなのでタップでも操作できますね。忘れていました。print("Hellow") Hellowここまでのまとめ
今回はAzure Notebookの代わりにGoogle Colaboratryを使って
- Notebookの作成
- コードの編集と実行
の方法を確認しました。研修を受けてから少し時間が空いてしまったので、基礎的なコードを復習しながら学んでいきたいと思います。
今回は学習環境の再作成ということであまり複雑なことはしませんでしたが、無料で学習できる環境に不自由しないということには愕きました。
それだけ機械学習の分野には関心が集まり、人もお金も集中している、ということだと思います。

- 投稿日:2021-02-26T19:04:10+09:00
Python OpenCV で日本語を含むパス及びファイルが読み取れない問題
OpenCVでは日本語のパスに対応していない!?
cv2.VideoCaptureを普通に実行していると普通に動いたが、pyinstallerでexe化すると文字化けしてエラーが出てしまった。(違いがよくわからないが)調べてみるとOpenCVではANSI文字列以外、つまり日本語のパスに対応していない模様。なのでcv2.imread,cv2.imwrite,cv2.VideoCapture等で日本語を含むパスを指定するには工夫が必要。
こちらではnumpyを噛ませて解決してましたが、なんか難しそうだしcv2.VideoCaptureでのやり方もよくわからない。こちらでファイルをリネームすればいいというのを採用。解決方法
対象ファイルのディレクトリに移動して、一時的に対象ファイルの名前を変更して処理する。
コード例(
cv2.imread)
- 対象ファイルがあるディレクトリに移動
- 対象ファイルの名前を変更
- 対象ファイルを読み取る
- 対象ファイルの名前を戻す
import cv2 import os def imread(path): tmp_dir = os.getcwd() # 1. 対象ファイルがあるディレクトリに移動 if len(path.split("/")) > 1: file_dir = "/".join(path.split("/")[:-1]) os.chdir(file_dir) # 2. 対象ファイルの名前を変更 tmp_name = "tmp_name" os.rename(path.split("/")[-1], tmp_name) # 3. 対象ファイルを読み取る img = cv2.imread(tmp_name) # 4. 対象ファイルの名前を戻す os.rename(tmp_name, path.split("/")[-1]) # カレントディレクトリをもとに戻す os.chdir(tmp_dir) return imgはじめに
os.getcwd()でカレントディレクトリを取得、最後に戻す。その後対象ファイルが存在するディレクトリに移動するが、すでにそのディレクトリにいる場合は何もしない。os.chdir(path)でpathディレクトリに移動できる。コード例(
cv2.imwrite)
cv2.imwriteで画像を保存するときは
1. 保存するディレクトリに移動
2. 対象ファイルを保存
3. 対象ファイルの名前を戻す
とするとよいimport cv2 import os def imwrite(path, img): tmp_dir = os.getcwd() # 1. 保存するディレクトリに移動 if len(path.split("/")) > 1: file_dir = "/".join(path.split("/")[:-1]) os.chdir(file_dir) # 2. 対象ファイルを保存 tmp_name = "tmp_name.png" cv2.imwrite(tmp_name, img) # 3. 対象ファイルの名前を戻す if os.path.exists(path.split("/")[-1]): # ファイルが既にあれば削除 os.remove(path.split("/")[-1]) os.rename(tmp_name, path.split("/")[-1]) # カレントディレクトリをもとに戻す os.chdir(tmp_dir)
cv2.imwriteではデフォルトで既存の画像を上書きするのでこちらもその仕様にした。存在するファイルの名前に変更することはできないので、存在する場合は削除してから名前を変更するようにした。コード例(
cv2.VideoCapture)
cv2.VideoCaptureの場合は少し注意が必要。ファイルを読み取った後cap.release()としないと名前を変えることはできないので、処理が終わった後に名前を戻す。それにより関数化ができない。
- 対象ファイルがあるディレクトリに移動
- 対象ファイルの名前を変更
- 対象ファイルを読み取る
- 対象ファイルの名前を戻す
import cv2 import os path = "C:/Users/***/Desktop/フォルダ/画像.bmp" # 1. 対象ファイルがあるディレクトリに移動 file_dir = "/".join(path.split("/")[:-1]) os.chdir(file_dir) # 2. 対象ファイルの名前を変更 tmp_name = "tmp_name" os.rename(path.split("/")[-1], tmp_name) # 3. 対象ファイルを読み取る cap = cv2.VideoCapture(tmp_name) ''' 任意の処理 ''' # 4. 対象ファイルの名前を戻す cap.release() os.rename(tmp_name, path.split("/")[-1])
cap.release()しないとPermissionError: [WinError 32] プロセスはファイルにアクセスできません。別のプロセスが使用中です。というエラーが出るので注意。プログラムで使用中だから
もうちょいくわしく
エラー挙動
cv2.imreadを日本語を含むパスを指定した場合の挙動を確認import cv2 path = "C:/Users/sd18080/Desktop/フォルダ/画像.bmp" img = cv2.imread(path) print(img)結果
Noneエラーすら表示されない…!
OpenCVではそもそも存在しないファイルを参照しようとしてもエラーが出ないよう。
試しに上記をpath="aaaaa"と適当に存在しないファイルを設定した場合も同様の結果となった。
cv2.VideoCaptureのエラー挙動
cv2.VideoCaptureは存在しないファイルを指定するとエラーが表示されるimport cv2 path = "C:/Users/***/Desktop/フォルダ/画像.bmp" cap = cv2.VideoCapture(path)これを実行すると
warning: Error opening file (/build/opencv/modules/videoio/src/cap_ffmpeg_impl.hpp:908) warning: C:\Users\***\Desktop\繝輔か繝ォ繝\逕サ蜒・bmp (/build/opencv/modules/videoio/src/cap_ffmpeg_impl.hpp:909) [ERROR:0] VIDEOIO(cvCreateFileCapture_Images(filename.c_str())): raised OpenCV exception: OpenCV(3.4.8) C:\projects\opencv-python\opencv\modules\videoio\src\cap_images.cpp:246: error: (-5:Bad argument) CAP_IMAGES: can't find starting number (in the name of file): C:\Users\***\Desktop\繝輔か繝ォ繝€\逕サ蜒・bmp in function 'cv::icvExtractPattern'となってどうやら文字コードUTF-8→Shift_JISに文字化けしているみたい。
最後に
numpyかませる方法がよくわからない、こっちのほうが簡単って思ってまとめました。参考になれば幸いです。
cv2.VideoCaptureに関しては日本語が入っているときも普通に読み込めることがあって挙動が安定しなくて「?」という感じです。自分はpythonで実行したときには普通に読み込めたがpyinstallerでexe化したものを実行したらエラーが出ました。pyinstallerを実行する時にUnicodeDecodeErrorで'utf-8'がどうちゃらっていうエラーが出ててそれをこちらのようにライブラリを書き換えるという力技をしたせいだと思ったので沼りました。この記事のようにすれば万事解決です。
cv2.VideoCaptureは日本語でも大丈夫なことがあるということについてなにか分かる人がいれば教えてくれれば幸いです。参考
[1] Python OpenCV の cv2.imread 及び cv2.imwrite で日本語を含むファイルパスを取り扱う際の問題への対処について - Qiita, 2018, https://qiita.com/SKYS/items/cbde3775e2143cad7455,
[2] Python - imwriteでのファイル名の文字化け|teratail, 2020, https://teratail.com/questions/268813,
[3] pythonスクリプトをexeに変換する(つまづきポイントまとめ) - Qiita, 2018, https://qiita.com/pocket_kyoto/items/80a1ac0e46819d90737f,
- 投稿日:2021-02-26T18:58:26+09:00
Jackknife法とサンプル数バイアス
はじめに
平均0、分散$\sigma^2$のガウス分布に従う確率変数$\hat{x}$を考えます。確率変数の2次と4次のモーメントはそれぞれ
$$
\left< \hat{x}^2 \right> = \sigma^2
$$$$
\left< \hat{x}^4 \right> = 3 \sigma^4
$$です。したがって、以下のような量を考えると分散依存性が消えます。
$$
U \equiv \frac{\left< \hat{x}^4 \right>}{\left< \hat{x}^2 \right>^2} = 3
$$これは尖度(kurtosis)と呼ばれ、ガウス分布で0とするような定義もありますが、本稿ではガウス分布で3となる上記の定義を用います。
実際に上記の量を計算して3になるか確認してみましょう。平均0、分散$\sigma^2$のガウス分布に従うN個の確率変数$\hat{x}_1, \hat{x}_2, \cdots, \hat{x}_N$を生成し、そこから
\left<x^2 \right>_N = \frac{ \sum_i \hat{x}_i^2}{N}\left<x^4 \right>_N = \frac{\sum_i \hat{x}_i^4}{N}を計算します。そこから
U_N = \frac{\left< x^4 \right>_N}{\left< x^2 \right>_N^2}を計算してみましょう。
まず、平均0、分散1の正規分布に従う乱数は
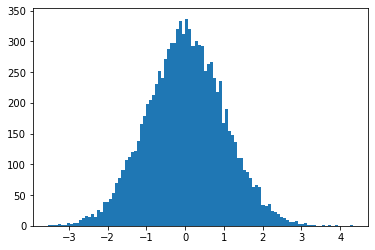
numpy.random.randnで生成することができます。import numpy as np import sympy from matplotlib import pyplot as plt x = np.random.randn(10000) fig, ax = plt.subplots(facecolor='w') n, bins, _ = ax.hist(x, bins=100)
ガウス分布になっていますね。では$N$個のデータを受け取って尖度を計算する関数
simple_estimatorを作って、$U_N$を計算します。$U_N$も確率変数になるので、それをn_trials回平均することで、$U_N$の期待値を計算し、$N$依存性を見てみましょう。def simple_estimator(r): r2 = r ** 2 r4 = r ** 4 return np.average(r4)/np.average(r2)**2 samples = np.array([16,32,64,128,256]) n_trials = 128**2 for n in samples: u = [simple_estimator(np.random.randn(n)) for _ in range(n_trials)] print(f"{n} {np.average(u)}")結果はこんな感じになります。
16 2.665024406056554 32 2.8310461207614 64 2.9117517962292196 128 2.9536867076886937 256 2.974102994397855明らかに$N$依存性が見えます。この依存性は何か、そしてどうやって回避するのかを検討するのが本稿の目的です。
コードは以下に置いてあります。
また、以下のリンクからコードをGoogle Colabで開くことができます。
サンプル数によるバイアス
サンプル数依存性の起源
まず、先ほどの$N$依存性をプロットしてましょう。$N$が大きいほど$3$に近づいているので、$U_N$を$1/N$に対してプロットしてみます。
samples = np.array([16,32,64,128,256]) y = [] n_trials = 128**2 for n in samples: u = [simple_estimator(np.random.randn(n)) for _ in range(n_trials)] y.append(np.average(u)) x = 1.0/samples y_theory = [3.0 for _ in x] fig, ax = plt.subplots() plt.xlabel("1 / N") plt.ylabel("U_N") ax.plot(x,y,"-o",label="Simple") ax.plot(x,y_theory,"-", label="3", color="black") plt.show()結果は以下の通りです。
きれいに$1/N$の依存性が見えます。これがどこから来ているか調べるため、2次のモーメント$\left< x^2 \right>_N$と4次のモーメント$\left< x^4 \right>_N$の$N$依存性を見てみましょう。2次のモーメントは1、4次のモーメントは3になるはずです。
samples = np.array([16,32,64,128,256]) n_trials = 128**2 y = [] for n in samples: r2 = [] r4 = [] for _ in range(n_trials): r = np.random.randn(n) r2.append(np.average(r**2)) r4.append(np.average(r**4)) print(f"{n} {np.average(r2)} {np.average(r4)}")結果はこうなります。
16 1.0069638341496114 3.052695056865599 32 1.0009326403631478 3.0048770596574004 64 1.0011522697373576 3.0051207850152353 128 1.0009699343712042 3.000195653356738 256 1.000964117125373 3.0086579096740012次のモーメントは1、4次のモーメントは3であり、特に$N$依存性は見えません。
さて、尖度の定義は
$$
U \equiv \frac{\left< \hat{x}^4 \right>}{\left< \hat{x}^2 \right>^2} = 3
$$でしたから、$\left< \hat{x}^2 \right>$から$1/\left< \hat{x}^2 \right>^2$を計算する必要があります。こいつの$N$依存性を見てみましょう。
samples = np.array([16,32,64,128,256]) n_trials = 128**2 y = [] for n in samples: r2_inv2 = [] for _ in range(n_trials): r = np.random.randn(n) r2_inv2.append(1.0/np.average(r**2)**2) print(f"{n} {np.average(r2_inv2)}")16 1.5399741991666933 32 1.21947965805206 64 1.0998402893078216 128 1.0501167786713717 256 1.0252452060315502$N$依存性が出てきました。つまり、$\left< \hat{x}^2 \right>$はちゃんと計算できているが、$1/\left< \hat{x}^2 \right>^2$の計算で変なバイアスが入るということです。これは、確率変数の期待値にバイアスがなくても、確率変数の期待値の(非線形)関数にはバイアスが入るからです。
確率変数の期待値の関数
確率変数$\hat{r}$を考えます。期待値は$\left<\hat{r}\right> = \bar{r}$、分散は$\left<(\hat{r}-\bar{r})^2\right> = \sigma^2_r$であるとしましょう。
この変数の期待値$\bar{r}$の関数$f(\bar{r})$を計算したいとします。いま、真の期待値$\bar{r}$は知らないので、この確率変数を$N$個($\hat{r}_1, \hat{r}_1, \cdots, \hat{r}_N$)観測して、その平均を期待値の推定値としましょう。
\bar{r}_N \equiv \frac{1}{N} \sum_i \hat{r}_iこうして得られた期待値の推定値から、期待値の関数$f(\bar{r}_N)$が計算できます。この時、真の値$f(\bar{r})$との差を
\Delta_N = \left<f(\bar{r}_N) - f(\bar{r}) \right>で定義しましょう。$\bar{r}_N$の定義から、
\begin{aligned} \bar{r}_N & = \frac{1}{N} \sum_i \hat{r}_i \\ &= \bar{r} + \underbrace{\frac{1}{N} \sum_i (\hat{r}_i - \bar{r})}_{\varepsilon} \\ &= \bar{r} + \varepsilon \end{aligned}となります。ただし$\varepsilon$は真の平均からのずれの平均です。$\varepsilon$が小さいと思って$f(\bar{r}_N)$をテイラー展開すると、
f(\bar{r}_N) - f(\bar{r}) = f'(\bar{r}) \epsilon + \frac{1}{2}f''(\bar{r})\epsilon^2 + O(\varepsilon^3)となります。この量の期待値を取るのですが、まず、明らかに$\left< \varepsilon \right>= 0$です。
次に$\left< \varepsilon^2 \right>$ですが、
\begin{aligned} \left< \varepsilon^2 \right> &= \left< \left(\frac{1}{N} \sum_i (\hat{r}_i - \bar{r})\right)^2 \right> \\ &= \frac{\sum_i\sum_j (\hat{r_i} - \bar{r})(\hat{r_j} - \bar{r})}{N^2} \\ &= \frac{\sum_i (\hat{r_i} - \bar{r})^2}{N^2} \\ &= \frac{\sigma^2_r}{N} \end{aligned}となります。以上から、真の値からのバイアス$\Delta_N$は
\Delta_N = \frac{f''(\bar{r})\sigma_r^2}{2N} + O(1/N^2)となり、これが先ほど見た$1/N$依存性です。
直観的には、もともと左右対称の分布を持つ確率変数$\hat{r}$に対して、非線形関数$f$を通すことで分布が歪むのがサンプル数に起因するバイアスが出てくる原因と理解できます。
尖度の場合
さて、バイアスの$N$依存性が求まったので、実際に尖度の計算で確認してみましょう。
今、確率変数$\hat{r_i}$にあたるのは、平均0、分散$\sigma^2$のガウス分布に従う確率変数の二乗、つまり
\hat{r_i} = \hat{x}_i^2です。したがって、$\bar{r} = \sigma^2$です。$\hat{r}_i$の分散は
\begin{aligned} \left< (\hat{r}_i - \bar{r})^2 \right> &= \left< \hat{r}_i^2 \right> - \left< \hat{r}_i \right>^2 \\ &= \left< \hat{x}_i^4 \right> - \left< \hat{x}_i^2 \right>^2 \\ &= 3 \sigma^4 - \sigma^4 \\ &= 2 \sigma^2 \end{aligned}です。いま、$1/\left< x^2 \right>_N$のバイアスを考えたいので$f(r) = 1/r^2$です。なので、
f''(\bar{r}) = \frac{6}{\bar{r}^4}です。
これらを先ほど求めたバイアスに代入すると、
\Delta_N = \frac{6}{N\sigma^4} + O(1/N^2)となります。確かめてみましょう。
samples = np.array([16,32,64,128,256]) n_trials = 128**2 y = [] var = 1.0 for n in samples: r2_inv2 = [] for _ in range(n_trials): r = np.random.randn(n) r2_inv2.append(1.0/np.average(r**2)**2) print(f"{n} {np.average(r2_inv2)} {var**-2 + 6.0/n/var**2}")結果は以下の通りです。
16 1.5230564202615229 1.375 32 1.2212774912873294 1.1875 64 1.1007142526829008 1.09375 128 1.0438091495295474 1.046875 256 1.0261846279126134 1.0234375サンプル数$N$が大きくなるにつれて、バイアスも考慮した理論値に近づいていることがわかります。
いま、分散が$1$の場合でしたが、念のために分散が別の値を取る時も確認しておきましょう。一般の平均や分散を持つガウス分布に従う乱数は
numpy.random.normalで作ることができます。samples = np.array([16,32,64,128,256]) n_trials = 128**2 y = [] var = 2.0 for n in samples: r2_inv2 = [] for _ in range(n_trials): r = np.random.normal(loc=0.0, scale=np.sqrt(var), size = n) r2_inv2.append(1.0/np.average(r**2)**2) print(f"{n} {np.average(r2_inv2)} {var**-2 + 6.0/n/var**2}")結果は以下の通りです。
16 0.3789599570753983 0.34375 32 0.3068478643660296 0.296875 64 0.27515116352287705 0.2734375 128 0.2625408567464121 0.26171875 256 0.2560667526445651 0.255859375サンプル数依存性を正しく推定できています。
Jackknife法
Jackknife Resampling
さて、一般に期待値の非線形関数を計算しようとすると、サンプル数$N$に対して$1/N$のバイアスが乗ることがわかりました。$N$が十分に大きければバイアスを小さくできますが、$N$に対してリニアにしか減らないので面倒です。
そこで、$N$依存性を調べて、$N$無限大に外挿することを考えます。先ほど見たように、かなりきれいに$1/N$依存性が見えるので、$1/N$に対してプロットして線形フィットして$1/N \rightarrow 0$に外挿すれば良いことになりますが、これをいちいちやるのも面倒です。そこで、二点だけを使って外挿することを考えましょう。
今、データが$N$個あるとします。これを全て使って推定した値を$\theta(N)$としましょう。$\theta(N)$には、以下のような$N$依存性があります.
$$
\theta(N) = \theta(\infty) + a/N
$$さて、$N$個のうち、$B$個だけを使わず、$N-B$個しかデータが無いと思って$\theta(N-B)$を推定します。すると、
$$
\theta(N-B) = \theta(\infty) + a/(N-B)
$$です。この二つから比例係数$a$を消去すると、
$$
\theta(\infty) = \frac{N\theta(N) - (N-B)\theta(N-B)}{B}
$$となります。
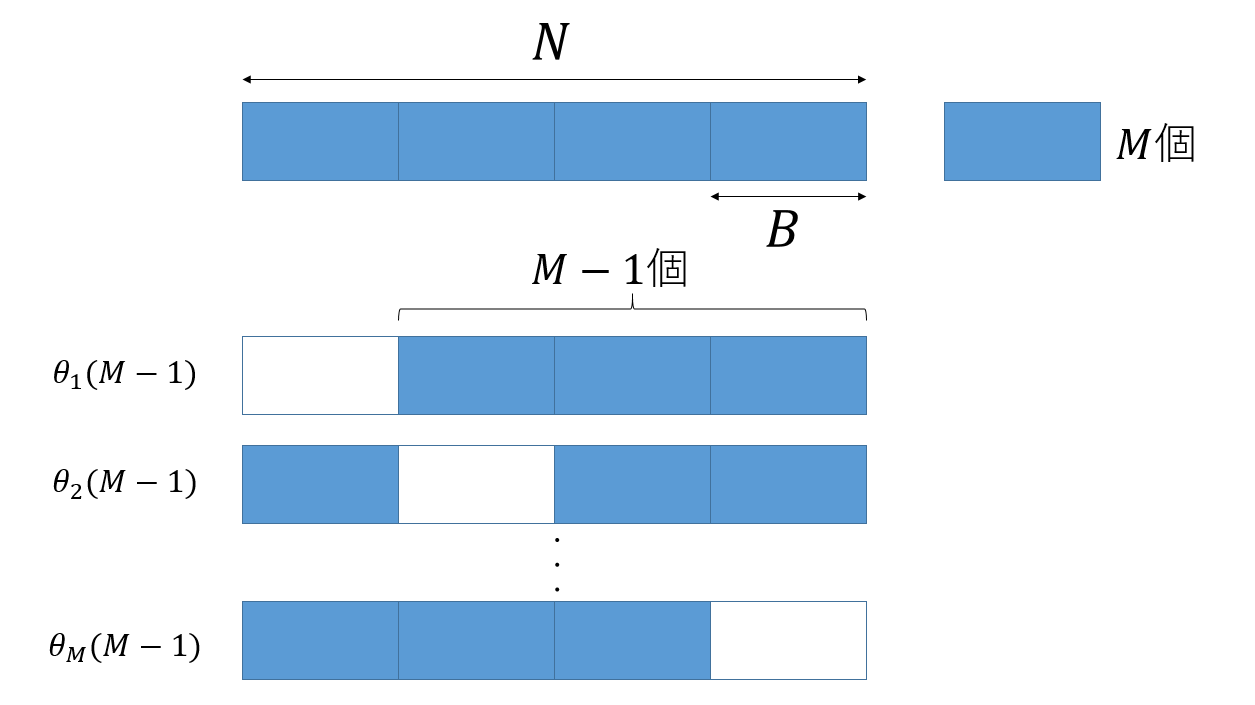
ただ、せっかく$N$個のデータがあるのに、$B$個のデータを全く使わないのはもったいないです。そこで、データを$M( = N/B)$個のブロックにわけ、それぞれ$B$個のデータを使わずに計算した値を$M$個作り、その平均を取ることで$\theta(N-B)$を推定しましょう。
$M$個のブロック全てを使った推定値を$\theta(M)$とし、$i$番目のブロックを使わずに作った推定値を$\theta_i(M-1)$とします。
そして、
$$
\theta(M-1) = \sum_i \frac{\theta_i(M-1)}{M}
$$とすれば、全てのデータを使いつつ、かつサンプル数の少ない場合の推定値を得ることができます。
ブロックに分けた場合の$M$依存性も
$$
\theta(M) - \theta(\infty) \sim 1/M
$$であるため、先ほどと同様な議論により、
$$
\theta(\infty) = M \theta(M) - (M-1) \theta(M-1)
$$として、データの無限大外挿ができることになります。これがJackknife法と呼ばれる手法です。
Jackknife法の実装
Jackknife法を実装してみましょう。$N$個のデータを$B$個ずつのブロック(ビン)に分ける必要がありますが、ここでは適当に$N$の因数のうち$\sqrt{N}$に一番近いものをビンサイズとします。
def jackknife_estimator(r): divs = np.array(sympy.divisors(n)) idx = np.abs(divs-np.sqrt(len(r))).argmin() bin_size = divs[idx] r2 = r ** 2 r4 = r ** 4 u_all = np.average(r4)/np.average(r2)**2 r2 = [np.average(r2[i:i+bin_size]) for i in range(0, len(r), bin_size)] r4 = [np.average(r4[i:i+bin_size]) for i in range(0, len(r), bin_size)] u_jn = [] m = len(r) // bin_size for i in range(m): r2_i = np.average(np.delete(r2,i)) r4_i = np.average(np.delete(r4,i)) u_jn.append(r4_i/r2_i**2) return m*u_all - (m-1)*np.average(u_jn)実行してみましょう。
samples = np.array([16,32,64,128,256]) n_trials = 128**2 for n in samples: u = [jackknife_estimator(np.random.randn(n)) for _ in range(n_trials)] print(f"{n} {np.average(u)}")16 2.9620721493242543 32 2.977947785672 64 2.9937291906193657 128 2.9961565664465897 256 3.004119961488022
- データをB個ずつM個のビン(ブロック)に分け
- そのうちM-1個を使って計算したものをM個作り
- その平均を計算し
- バイアスを除いた値を推定する
ということをやっているだけですが、$N=16$という非常に少ないデータ数でもかなり精度良く推定が出来ており、効率的に$1/N$バイアスを除くことができています。
なお、
resamplingといライブラリを使うと同じことができます。!pip install resample import resample def jackknife_estimator_resample(r): divs = np.array(sympy.divisors(n)) idx = np.abs(divs-np.sqrt(len(r))).argmin() bin_size = divs[idx] m = len(r) // bin_size sample = np.zeros((m, 2)) sample[:, 0] = [np.average(r[i:i+bin_size]**2) for i in range(0, len(r), bin_size)] sample[:, 1] = [np.average(r[i:i+bin_size]**4) for i in range(0, len(r), bin_size)] def f(vals): return np.average(vals[:, 1]) / np.average(vals[:, 0])**2 return resample.jackknife.bias_corrected(f, sample) samples = np.array([16,32,64,128,256]) n_trials = 128**2 for n in samples: u = [jackknife_estimator_resample(np.random.randn(n)) for _ in range(n_trials)] print(f"{n} {np.average(u)}")結果は同様ですが、ナイーブな実装よりは速いようです。
まとめ
確率変数の期待値の関数を求めたい場合、関数が非線形だと、サンプル数$N$に対して$1/N$のバイアスがのってきます。このバイアスを異なるサンプル数の推定値を二つ作ることで取り除く手法がJackknife法です。
Jackknife法は原理が簡単なわりにとても便利なのですが、僕にはその「気持ち」の理解に苦しみました。本稿が同様に理解に苦しんでいる人の助けになれば幸いです。
謝辞
Jackknife法やサンプル数バイアスについてはsmoritaさんや、yomichiさんに教わりました。特にコードはsmoritaさんの書いたコードを参考させていただきました。なお、本稿に間違いなどありましたら全て筆者の責任です。

- 投稿日:2021-02-26T18:32:40+09:00
機械学習アルゴリズムメモ 線形回帰編
線形回帰とは
線形回帰は回帰に用いられるアルゴリズムです。
データには線形の相関があると仮定して直線(高次元では超平面)を求めます。【回帰】
データに対して適当に超平面を引きます。超平面とは、データの重み付き和のことであり以下の数式で表すことができます。
\hat{y} = \sum_{i=0}^{p-1} w_ix + b超平面を求めたのち、学習データの正解値との平均二乗誤差を求め、それを最小化するように係数wと切片bの値を調整します。
MSE(w) = \frac{1}{n} \sum_{i=0}^{n} (y_i - \hat{y_i}) ^ 2scikit-learnでの使い方
【回帰】
from sklearn.linear_model import LinearRegression lr = LinearRegression() print(lr.coef_) # 重み print(lr.intercept_) # 切片 lr.fit(X_train, y_train) lr.score(X_test, y_test)パラメータ
よく使うパラメータはありません。
scikit-learnにて正則化を行いたい場合は別途モデルが用意されています。メリット
線形代数を理解していれば、ホワイトボックス的に利用できます。
2次元平面では直線でしか表すことができないが、入力特徴量が多い多次元平面では複雑なモデルを構築できる。(逆に適合しすぎるというデメリットでもあります)デメリット
データの特徴量が少ないと過少適合し、データの特徴量が多いと過剰適合します。
- 投稿日:2021-02-26T18:26:00+09:00
Pythonでロジスティック回帰①
はじめに
データの基礎分析を学ぶために、default of credit card clients Data Setに対して、Rで基礎分析結果をCSV出力①全体編、Rで基礎分析結果をCSV出力②量的変数編、Rで基礎分析結果をCSV出力③質的変数編にて基礎分析を行ってみた。本記事では、分析を行ってきたデータを用いて、クレジットカードのデフォルト(債務不履行)が起きるかどうかの分類モデルをPythonで扱ってみる。試行する中で気づいたこと、知ったことなどを書きながら進める。知見が乏しいので、間違っている部分や改善すべき部分などあれば、ぜひコメントお願いいたします。
ロジスティック回帰
今回のデータからデフォルトするかどうかの判定を行いたい。そこで、このような目的変数が二値になるようなモデルでよく使われるロジスティック回帰を試してみる。
ライブラリのインポート
まず今回使用するライブラリをインポートする。ロジスティック回帰を行うためのライブラリは scikit-learn に含まれている。
importLibrary.pyimport numpy as np import pandas as pd # For Logistic Regression from sklearn.model_selection import train_test_split from sklearn.metrics import roc_curve, roc_auc_score from sklearn.linear_model import LogisticRegressionデータの読み込み
default of credit card clients Data Setのデータを読み込む。また量的変数と質的変数で前処理が異なるので、それぞれのカラム名を取得しておく。
readCsv.pydf = pd.read_csv("c:/Users/t_honda/Desktop/Default/data/default_of_credit_card_clients.csv", header=1, index_col=0) col = df.columns.values quantity_col = col[[0, 4, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]] quality_col = col[[1, 2, 3, 5, 6, 7, 8, 9, 10]]データの前処理
基礎分析は終えているので、それらに基づいてデータを処理する。
量的変数の前処理
量的データのスケールが異なるので、標準化を行う。StandardScaler は出力が numpy.array形式となるが、あとで前処理をした質的データと結合して扱いたいので、出力を DataFrame形式で受け取れるようにしている。
(本題とは異なるので詳細は書かないが、プログラムを書いている際にSettingWithCopyWarningというエラーに悩まされた。SettingWithCopyWarningの対応に関しては、pandas の SettingWithCopyWarning で苦労した話を参考にした。下記プログラムのように、.copy()を使えば問題ない。)quantity.pyfrom sklearn.preprocessing import StandardScaler df_quantity = df[quantity_col].copy() # SettingWithCopyWarning を避けるためにコピー df_quantity[quantity_col] = StandardScaler().fit_transform(df_quantity) # 標準化後のデータを numpy.array ではなく DataFrame で受け取る質的変数の前処理
質的データをダミー変数化する。基礎分析の結果、未定義のカテゴリが複数ある項目があるためそれらの処理を行う。具体的には、EDUCATIONはカテゴリとして 1: graduate school, 2: university, 3: high school, 4: others とデータの説明には書いてあるが、0, 5, 6 のデータも存在する。それらをまとめて 4: others に入れてもよいかもしれないが、ここではそれら未定義のものを1つのカテゴリとした。そのため、5, 6 というデータを 0 に置換している。
replaceEducation.pydf_quality = df[quality_col].copy() df_quality["EDUCATION"] = df_quality["EDUCATION"].replace({5: 0}).replace({6: 0}) # 0, 5, 6 の3種類未定義カテゴリがあるため、それらは 0 に統合PAY_0 - 6 というデータも同様に未定義カテゴリ(-2, 0)が存在するため、-2 を 0 に置換している。またこれらデータは -1 から 8 までの値をとるが、PAY_5, PAY_6 は 1 というカテゴリに属するデータを持っていないため、そのまま処理するとカテゴリが一つ少なくなり、かつずれてしまう。そこでこれらのカテゴリを pd.Categorical() でカテゴリを統一したうえで、ダミー変数にする。
replacePay.py# -2, 0 の2種類未定義カテゴリがあるため、それらは 0 に統合 df_quality["PAY_0"] = df_quality["PAY_0"].replace({-2: 0}) df_quality["PAY_2"] = df_quality["PAY_2"].replace({-2: 0}) df_quality["PAY_3"] = df_quality["PAY_3"].replace({-2: 0}) df_quality["PAY_4"] = df_quality["PAY_4"].replace({-2: 0}) df_quality["PAY_5"] = df_quality["PAY_5"].replace({-2: 0}) df_quality["PAY_6"] = df_quality["PAY_6"].replace({-2: 0}) pay_categories = set(df_quality["PAY_0"].unique().tolist() + df_quality["PAY_2"].unique().tolist() + df_quality["PAY_3"].unique().tolist() + df_quality["PAY_4"].unique().tolist() + df_quality["PAY_5"].unique().tolist() + df_quality["PAY_6"].unique().tolist()) df_quality["PAY_0"] = pd.Categorical(df_quality["PAY_0"], categories=pay_categories) df_quality["PAY_2"] = pd.Categorical(df_quality["PAY_2"], categories=pay_categories) df_quality["PAY_3"] = pd.Categorical(df_quality["PAY_3"], categories=pay_categories) df_quality["PAY_4"] = pd.Categorical(df_quality["PAY_4"], categories=pay_categories) df_quality["PAY_5"] = pd.Categorical(df_quality["PAY_5"], categories=pay_categories) df_quality["PAY_6"] = pd.Categorical(df_quality["PAY_6"], categories=pay_categories) df_quality_dummies = pd.get_dummies(df_quality, columns=quality_col, drop_first=True)前処理したデータを統合し学習
これまでで量的変数と質的変数の前処理を実行したので、それらを統合して訓練用データとテスト用データに分割する。
concat.pyX = pd.concat([df_quantity, df_quality_dummies], axis=1) Y = df["default payment next month"] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)ロジスティック回帰モデルを使って学習・予測。AUCスコアを出す。
train.pylr = LogisticRegression(max_iter=2000) lr.fit(X_train, Y_train) THRESHOLD = 0.50 Y_pred = np.where(lr.predict_proba(X_test)[:,1] > THRESHOLD, 1, 0) print("Prediction:", np.count_nonzero(Y_pred==1)) print(" Test:", np.count_nonzero(np.array(Y_test)==1)) print("AUC Score:", roc_auc_score(Y_test, Y_pred)) # Prediction: 673 # Test: 1297 # AUC Score: 0.6571462858317605通常ロジスティック回帰は0.50をしきい値として判定をするが、上記コードではTHRESHOLDを変更することでしきい値を変えることができる。しきい値0.50では実際と比べてデフォルト判定数が非常に少ないため、ためしにTHRESHOLD=0.30とした場合の結果を以下に示す。
threshold.pyTHRESHOLD = 0.30 Y_pred = np.where(lr.predict_proba(X_test)[:,1] > THRESHOLD, 1, 0) print("Prediction:", np.count_nonzero(Y_pred==1)) print(" Test:", np.count_nonzero(np.array(Y_test)==1)) print("AUC Score:", roc_auc_score(Y_test, Y_pred)) # Prediction: 1115 # Test: 1297 # AUC Score: 0.6957317062174753しきい値を変えることで、実際の判定とほぼ同じ数の判定をした。しかし、AUCスコア自体はそこまで大きく変動していないため、精度に関してはあまり良いとは言えない。次回の記事では、ロジスティック回帰の精度向上に努めてみようと思う。
- 投稿日:2021-02-26T17:42:16+09:00
【2021 pixivpy】ログイン認証変更の解決方法について
PixivPyの認証方法が変更
2021年2月下旬頃、pixivpyの認証方法が変更されました。
従来では、pixivのユーザー名・パスワードがauth認証として必要でしたが、
今後はrefresh_tokenを用いることで動作するそうです。refresh_tokenの取得方法
pixiv_auth.py#!/usr/bin/env python from argparse import ArgumentParser from base64 import urlsafe_b64encode from hashlib import sha256 from pprint import pprint from secrets import token_urlsafe from sys import exit from urllib.parse import urlencode from webbrowser import open as open_url import requests # Latest app version can be found using GET /v1/application-info/android USER_AGENT = "PixivAndroidApp/5.0.234 (Android 11; Pixel 5)" REDIRECT_URI = "https://app-api.pixiv.net/web/v1/users/auth/pixiv/callback" LOGIN_URL = "https://app-api.pixiv.net/web/v1/login" AUTH_TOKEN_URL = "https://oauth.secure.pixiv.net/auth/token" CLIENT_ID = "MOBrBDS8blbauoSck0ZfDbtuzpyT" CLIENT_SECRET = "lsACyCD94FhDUtGTXi3QzcFE2uU1hqtDaKeqrdwj" def s256(data): """S256 transformation method.""" return urlsafe_b64encode(sha256(data).digest()).rstrip(b"=").decode("ascii") def oauth_pkce(transform): """Proof Key for Code Exchange by OAuth Public Clients (RFC7636).""" code_verifier = token_urlsafe(32) code_challenge = transform(code_verifier.encode("ascii")) return code_verifier, code_challenge def print_auth_token_response(response): data = response.json() try: access_token = data["access_token"] refresh_token = data["refresh_token"] except KeyError: print("error:") pprint(data) exit(1) print("access_token:", access_token) print("refresh_token:", refresh_token) print("expires_in:", data.get("expires_in", 0)) def login(): code_verifier, code_challenge = oauth_pkce(s256) login_params = { "code_challenge": code_challenge, "code_challenge_method": "S256", "client": "pixiv-android", } open_url(f"{LOGIN_URL}?{urlencode(login_params)}") try: code = input("code: ").strip() except (EOFError, KeyboardInterrupt): return response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "code": code, "code_verifier": code_verifier, "grant_type": "authorization_code", "include_policy": "true", "redirect_uri": REDIRECT_URI, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def refresh(refresh_token): response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "grant_type": "refresh_token", "include_policy": "true", "refresh_token": refresh_token, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def main(): parser = ArgumentParser() subparsers = parser.add_subparsers() parser.set_defaults(func=lambda _: parser.print_usage()) login_parser = subparsers.add_parser("login") login_parser.set_defaults(func=lambda _: login()) refresh_parser = subparsers.add_parser("refresh") refresh_parser.add_argument("refresh_token") refresh_parser.set_defaults(func=lambda ns: refresh(ns.refresh_token)) args = parser.parse_args() args.func(args) if __name__ == "__main__": main()①上記のコードを実行。
②Pixivログインページでブラウザが開きます。
③開発コンソール(F12)を開き、[ネットワーク]タブに切り替えます。
④検索ボックスに
callback?を入力⑤Pixivにログインする。
⑥ログイン後、空白のページが表示。
callback?state=...&code=...。
codeパラメータの値をpixiv_auth.pyのプロンプトにコピーして、Enterキーを押します。⑦refresh_token表示がされる。
⚠️ codeの有効期限は非常に短いため、手順5と7の間の処理は素早くすること。
auth認証をrefresh_tokenに変更で動作
# api.login(_USERNAME, _PASSWORD) api.auth(refresh_token=_REFRESH_TOKEN)
ソース元


Due to #158 reason, password login no longer exist. Please use
api.auth(refresh_token=REFRESH_TOKEN)instead
Due to #158 reason, password login no longer exist. Please useapi.auth(refresh_token=REFRESH_TOKEN)insteadTo get
refresh_token, see @ZipFile Pixiv OAuth Flow or OAuth with Selenium/ChromeDriver
Pixiv API for Python (with Auth supported)
- 投稿日:2021-02-26T17:42:16+09:00
【Pythonライブラリ pixivpy】ログイン認証変更(2021)
pixivpyの認証方法が変更
2021年2月下旬頃、pixivpyの認証方法が変更されました。
従来では、pixivのユーザー名・パスワードがauth認証として必要でしたが、
今後はrefresh_tokenを用いることで動作するそうです。refresh_tokenの取得方法
pixiv_auth.py#!/usr/bin/env python from argparse import ArgumentParser from base64 import urlsafe_b64encode from hashlib import sha256 from pprint import pprint from secrets import token_urlsafe from sys import exit from urllib.parse import urlencode from webbrowser import open as open_url import requests # Latest app version can be found using GET /v1/application-info/android USER_AGENT = "PixivAndroidApp/5.0.234 (Android 11; Pixel 5)" REDIRECT_URI = "https://app-api.pixiv.net/web/v1/users/auth/pixiv/callback" LOGIN_URL = "https://app-api.pixiv.net/web/v1/login" AUTH_TOKEN_URL = "https://oauth.secure.pixiv.net/auth/token" CLIENT_ID = "MOBrBDS8blbauoSck0ZfDbtuzpyT" CLIENT_SECRET = "lsACyCD94FhDUtGTXi3QzcFE2uU1hqtDaKeqrdwj" def s256(data): """S256 transformation method.""" return urlsafe_b64encode(sha256(data).digest()).rstrip(b"=").decode("ascii") def oauth_pkce(transform): """Proof Key for Code Exchange by OAuth Public Clients (RFC7636).""" code_verifier = token_urlsafe(32) code_challenge = transform(code_verifier.encode("ascii")) return code_verifier, code_challenge def print_auth_token_response(response): data = response.json() try: access_token = data["access_token"] refresh_token = data["refresh_token"] except KeyError: print("error:") pprint(data) exit(1) print("access_token:", access_token) print("refresh_token:", refresh_token) print("expires_in:", data.get("expires_in", 0)) def login(): code_verifier, code_challenge = oauth_pkce(s256) login_params = { "code_challenge": code_challenge, "code_challenge_method": "S256", "client": "pixiv-android", } open_url(f"{LOGIN_URL}?{urlencode(login_params)}") try: code = input("code: ").strip() except (EOFError, KeyboardInterrupt): return response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "code": code, "code_verifier": code_verifier, "grant_type": "authorization_code", "include_policy": "true", "redirect_uri": REDIRECT_URI, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def refresh(refresh_token): response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "grant_type": "refresh_token", "include_policy": "true", "refresh_token": refresh_token, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def main(): parser = ArgumentParser() subparsers = parser.add_subparsers() parser.set_defaults(func=lambda _: parser.print_usage()) login_parser = subparsers.add_parser("login") login_parser.set_defaults(func=lambda _: login()) refresh_parser = subparsers.add_parser("refresh") refresh_parser.add_argument("refresh_token") refresh_parser.set_defaults(func=lambda ns: refresh(ns.refresh_token)) args = parser.parse_args() args.func(args) if __name__ == "__main__": main()①上記のコードを実行。
②Pixivログインページでブラウザが開きます。
③開発コンソール(F12)を開き、[ネットワーク]タブに切り替えます。
④検索ボックスに
callback?を入力⑤Pixivにログインする。
⑥ログイン後、空白のページが表示。
callback?state=...&code=...。
codeパラメータの値をpixiv_auth.pyのプロンプトにコピーして、Enterキーを押します。⑦refresh_token表示がされる。
⚠️ codeの有効期限は非常に短いため、手順5と7の間の処理は素早くすること。
auth認証をrefresh_tokenに変更で動作
# api.login(_USERNAME, _PASSWORD) api.auth(refresh_token=_REFRESH_TOKEN)
ソース元
Due to #158 reason, password login no longer exist. Please use
api.auth(refresh_token=REFRESH_TOKEN)instead
Due to #158 reason, password login no longer exist. Please useapi.auth(refresh_token=REFRESH_TOKEN)insteadTo get
refresh_token, see @ZipFile Pixiv OAuth Flow or OAuth with Selenium/ChromeDriver
Pixiv API for Python (with Auth supported)https://gist.github.com/ZipFile/c9ebedb224406f4f11845ab700124362
https://github.com/upbit/pixivpy/commit/249eb51f202ba83868ec358ed7bab4163c0f8cc6
- 投稿日:2021-02-26T17:42:16+09:00
【Pythonライブラリ pixivpy】ログイン認証変更の対処法について(2021)
pixivpyってなんぞ?
Pythonを使って人気サイトpixivにてタグ検索やイラスト保存できる
優れライブラリのことです。
https://github.com/upbit/pixivpy筆者もhttps://twitter.com/PixSns
にてpixiv デイリーランキング上位3位を自動ツイートしてます。
pixiv絵師様について知っていただければ嬉しい!と思い活動中。pixivpyの認証方法が変更
2021年2月下旬頃、pixivpyの認証方法が変更されました。
従来では、pixivのユーザー名・パスワードがauth認証として必要でしたが、
今後はrefresh_tokenを用いることで動作するそうです。refresh_tokenの取得方法
pixiv_auth.py#!/usr/bin/env python from argparse import ArgumentParser from base64 import urlsafe_b64encode from hashlib import sha256 from pprint import pprint from secrets import token_urlsafe from sys import exit from urllib.parse import urlencode from webbrowser import open as open_url import requests # Latest app version can be found using GET /v1/application-info/android USER_AGENT = "PixivAndroidApp/5.0.234 (Android 11; Pixel 5)" REDIRECT_URI = "https://app-api.pixiv.net/web/v1/users/auth/pixiv/callback" LOGIN_URL = "https://app-api.pixiv.net/web/v1/login" AUTH_TOKEN_URL = "https://oauth.secure.pixiv.net/auth/token" CLIENT_ID = "MOBrBDS8blbauoSck0ZfDbtuzpyT" CLIENT_SECRET = "lsACyCD94FhDUtGTXi3QzcFE2uU1hqtDaKeqrdwj" def s256(data): """S256 transformation method.""" return urlsafe_b64encode(sha256(data).digest()).rstrip(b"=").decode("ascii") def oauth_pkce(transform): """Proof Key for Code Exchange by OAuth Public Clients (RFC7636).""" code_verifier = token_urlsafe(32) code_challenge = transform(code_verifier.encode("ascii")) return code_verifier, code_challenge def print_auth_token_response(response): data = response.json() try: access_token = data["access_token"] refresh_token = data["refresh_token"] except KeyError: print("error:") pprint(data) exit(1) print("access_token:", access_token) print("refresh_token:", refresh_token) print("expires_in:", data.get("expires_in", 0)) def login(): code_verifier, code_challenge = oauth_pkce(s256) login_params = { "code_challenge": code_challenge, "code_challenge_method": "S256", "client": "pixiv-android", } open_url(f"{LOGIN_URL}?{urlencode(login_params)}") try: code = input("code: ").strip() except (EOFError, KeyboardInterrupt): return response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "code": code, "code_verifier": code_verifier, "grant_type": "authorization_code", "include_policy": "true", "redirect_uri": REDIRECT_URI, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def refresh(refresh_token): response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "grant_type": "refresh_token", "include_policy": "true", "refresh_token": refresh_token, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def main(): parser = ArgumentParser() subparsers = parser.add_subparsers() parser.set_defaults(func=lambda _: parser.print_usage()) login_parser = subparsers.add_parser("login") login_parser.set_defaults(func=lambda _: login()) refresh_parser = subparsers.add_parser("refresh") refresh_parser.add_argument("refresh_token") refresh_parser.set_defaults(func=lambda ns: refresh(ns.refresh_token)) args = parser.parse_args() args.func(args) if __name__ == "__main__": main()①上記のコードを実行。
②Pixivログインページでブラウザが開きます。
③開発コンソール(F12)を開き、[ネットワーク]タブに切り替えます。
④検索ボックスに
callback?を入力⑤Pixivにログインする。
⑥ログイン後、空白のページが表示。
callback?state=...&code=...。
codeパラメータの値をpixiv_auth.pyのプロンプトにコピーして、Enterキーを押します。⑦refresh_token表示がされる。
⚠️ codeの有効期限は非常に短いため、手順5と7の間の処理は素早くすること。
auth認証をrefresh_tokenに変更で動作
# api.login(_USERNAME, _PASSWORD) # 従来ではpixivのID/PWが必要だった。 api.auth(refresh_token=_REFRESH_TOKEN) # 新auth認証ではrefresh_tokenでok。
ソース元
Due to #158 reason, password login no longer exist. Please use
api.auth(refresh_token=REFRESH_TOKEN)instead
Due to #158 reason, password login no longer exist. Please useapi.auth(refresh_token=REFRESH_TOKEN)insteadTo get
refresh_token, see @ZipFile Pixiv OAuth Flow or OAuth with Selenium/ChromeDriver
Pixiv API for Python (with Auth supported)https://gist.github.com/ZipFile/c9ebedb224406f4f11845ab700124362
https://github.com/upbit/pixivpy/commit/249eb51f202ba83868ec358ed7bab4163c0f8cc6
- 投稿日:2021-02-26T17:29:14+09:00
機械学習アルゴリズムメモ k-近傍法編
機械学習アルゴリズムメモをシリーズ化します。
初学者なので間違ってたらご指摘お願いします。
メモ程度なので簡潔にまとめます。k-近傍法とは
k-近傍法は分類および回帰に用いられるアルゴリズムです。
シンプルで分かりやすくホワイトボックス的に使うことができます。【分類】
テストデータが与えられるとそれに近い学習データを見つけ出し、テストラベルを学習データのラベルの多数決で予測します。
【回帰】
テストデータが与えられるとそれに近い学習データを見つけ出し、テストデータの値を学習データの値の平均として予測します。
scikit-learnでの使い方
【分類】
from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=3) clf.fit(X_train, y_train) clf.score(X_test, y_test)【回帰】
from sklearn.neighbors import KNeighborsRegressor clf = KNeighborsRegressor(n_neighbors=3) clf.fit(X_train, y_train) clf.score(X_test, y_test)パラメータ
scikit-learnでのパラメータ名 概要 初期値 特性 n_neighbors 近傍データ数 5 大きくすると単純なモデル、小さくすると複雑なモデルになる。 ※このメモではよく使うパラメータのみ紹介します。
メリット
モデルが理解しやすく単純であるため、パラメータをそこまでいじらなくてもよい結果が出ることが多いです。
デメリット
特徴量、サンプル数が多くなると予測に時間がかかります。
疎なデータセットに対しては性能が悪いです。