- 投稿日:2021-02-26T22:52:53+09:00
AthenaのQueryをMysqlと同じ感覚で使ったときにひっかかった部分まとめ
AWS Athena は便利
AWS Athenaを使うと、S3内のファイルに対してSQLクエリを実行できます。環境構築やデータの前加工が不要で、簡単に利用できます。非常に便利です。
S3にログが自動で溜まるようにするのがベストですが、とりあえずログファイルをS3にアップロードするだけでも十分使えます。
普段は開発を行っていて、Athenaはちょこちょこ触るくらいであれば10$/月もいかないかと思います。安い。Athenaでできることと使い方のイメージをつかみやすい記事
→Amazon Athenaではじめるログ分析入門Mysql感覚でAthenaを触るとできないこと、違和感が起こる部分
普段はMysqlを使ってます。
AthenaのQuery環境はMysqlと完全に同じではないので、できないことがあります。
2021/02/26 時点での状況です。文字列の囲みはシングルクォーテーション
ダブルクォーテーションで囲むとエラーが出ます。
SELECT * FROM alb_logs WHERE elb_name LIKE "%elb%";↓ エラー
SYNTAX_ERROR: line 1:57: Column '%elb%' cannot be resolvedコメントアウトは /* */ のみ
「#」や、ましてや「//」は使えません。
↓ エラーline 3:1: extraneous input '#' expecting {<eof>, ~CREATE TABLE 時にカラム数があわないと、SELECT 時にエラーが出る
CREATE TABLE したときにエラーを出しておいてほしいもんですが、実際はSELECTをかけるまでエラーは出ません。
ログをカラムにばらす際の正規表現の指定がうまくいってなくて詰まりました。↓ エラー
HIVE_CURSOR_ERROR: Number of matching groups doesn't match the number of columnsまとめ
簡単に触った範囲でこれくらい出てきました。
詰まるとうっとうしいですが、それ以上にAthenaが便利なことには間違いないです。
ほかにもコツなどあればぜひ教えてください。
- 投稿日:2021-02-26T21:11:20+09:00
【AWS】ACM+Route 53+ELB+EC2でSSL化に対応する
現在、個人アプリを製作しており、
AWSの本番環境へのデプロイ及びDNS設定まで完了したので、今日はSSL化を行った。
全てAWS内で完結している為、作業はとてもシンプルだが、説明を省略している記事が多く少し迷う部分があったので、記録として残しておく。前提
・EC2インスタンスでサーバー構築している
・Route53を使ってDNS設定をしている(ドメイン設定済み)
・ELB(ALB)を使用するので、その分の費用が発生する(を許容出来る)
・VPC構成はデフォルトのものを使用する
・とにかくサクッとSSL化したい人向けざっくり手順
- AWS Certificate ManagerでSSL証明書を取得する
- ELB(ALB)を設定する
- EC2のセキュリティグループ設定を確認する
- 接続確認
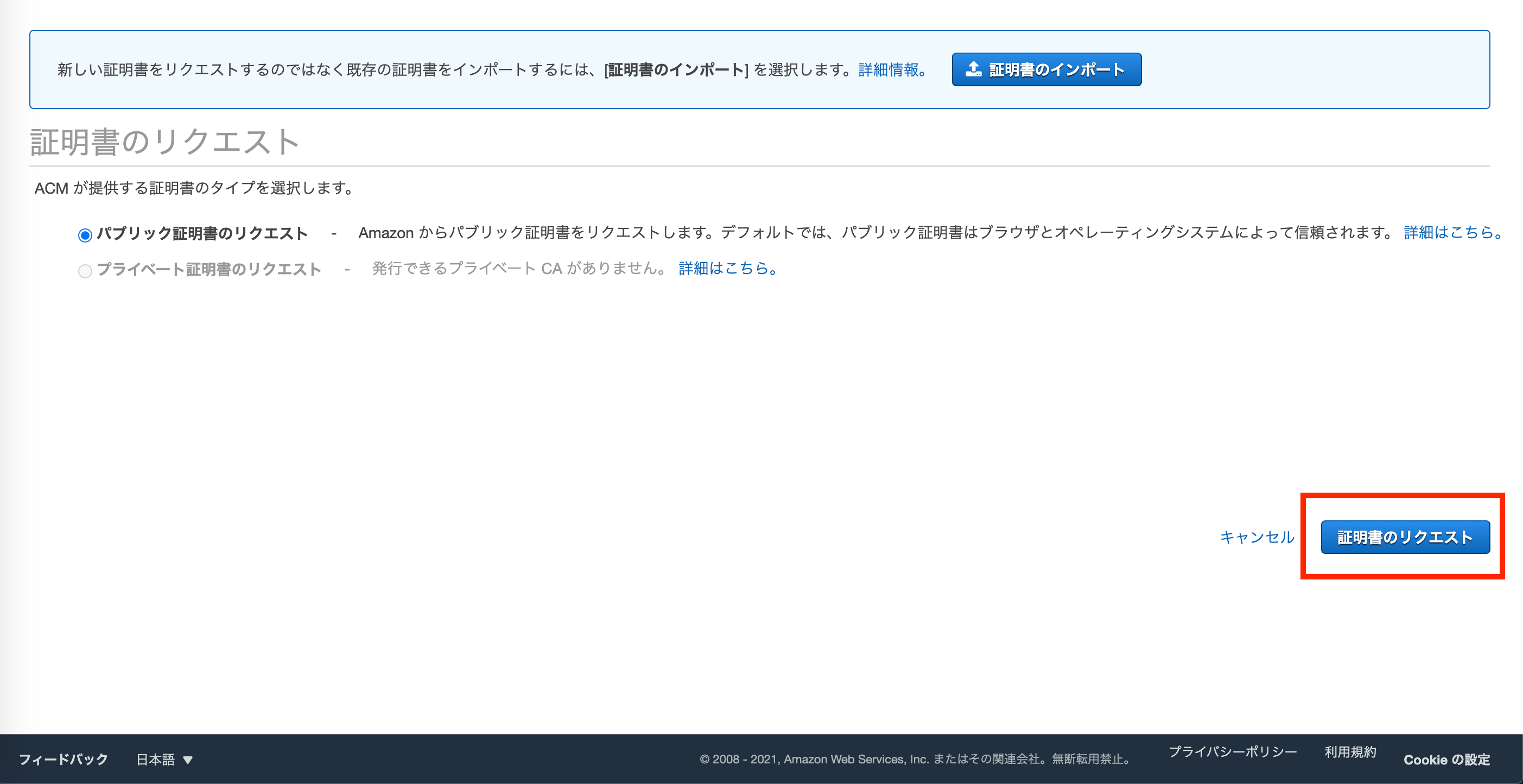
1. AWS Certificate ManagerでSSL証明書を取得する
まずはSSL証明書を取得します。
AWSコンソールでCertificate Managerの画面に遷移します。
デフォルトで
パブリック証明書のリクエストにチェックが入っています。
そのまま証明書のリクエストへ進みます。
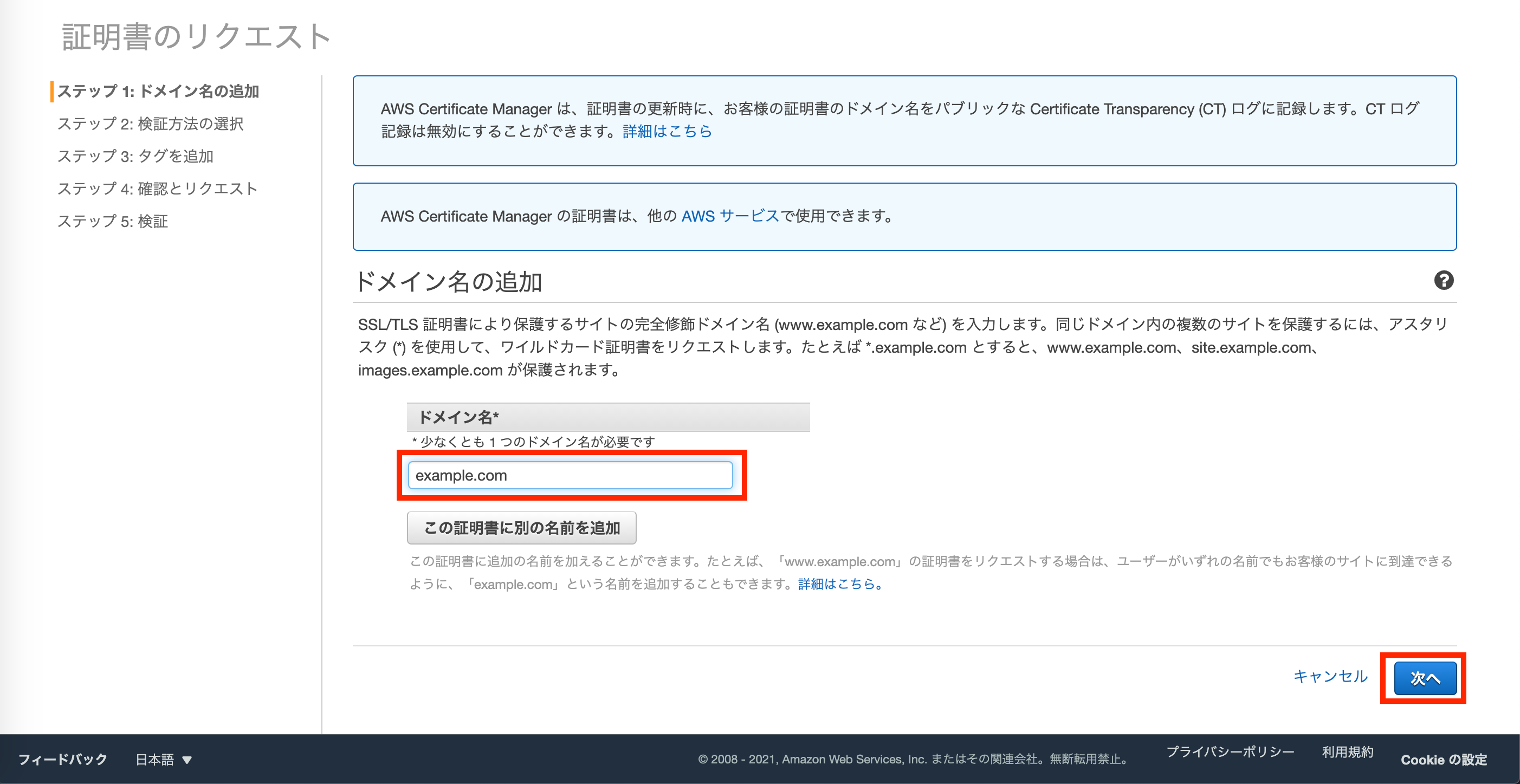
設定したいドメインを入力し、次へ進みます。
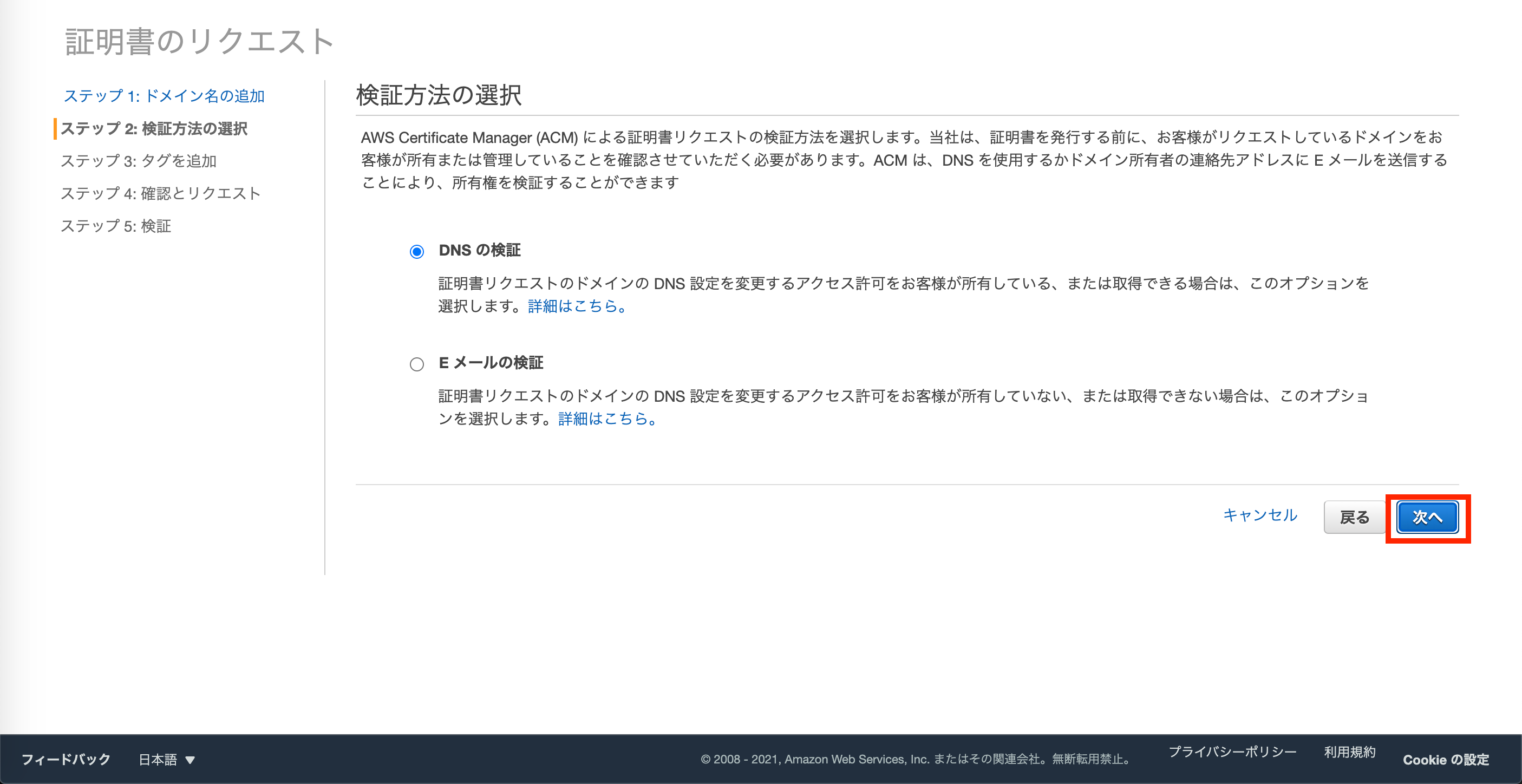
Route53でDNS設定している前提なので、
検証方法はDNSの検証を選択した状態で次へ進みます。
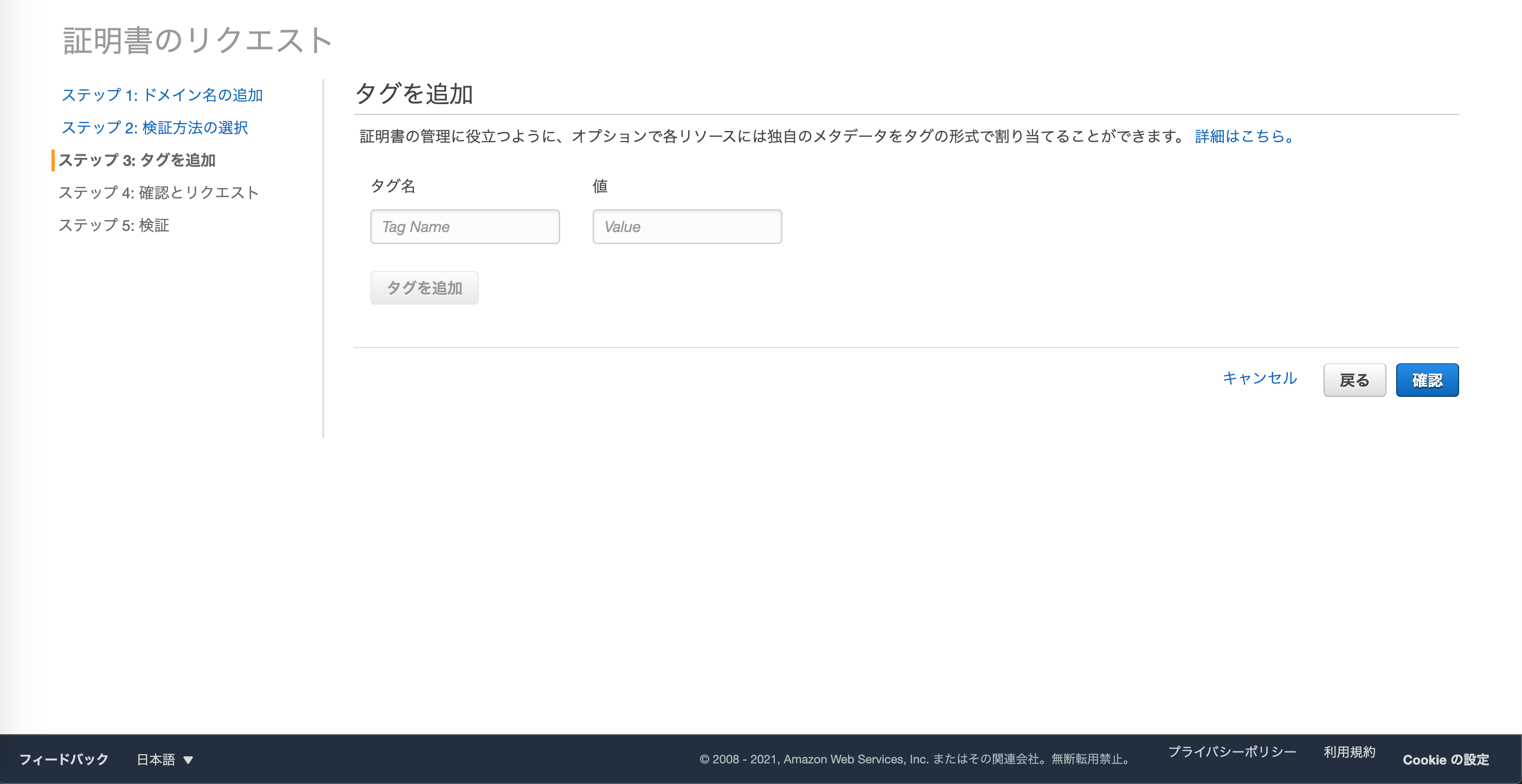
必要に応じてタグを設定しましょう。
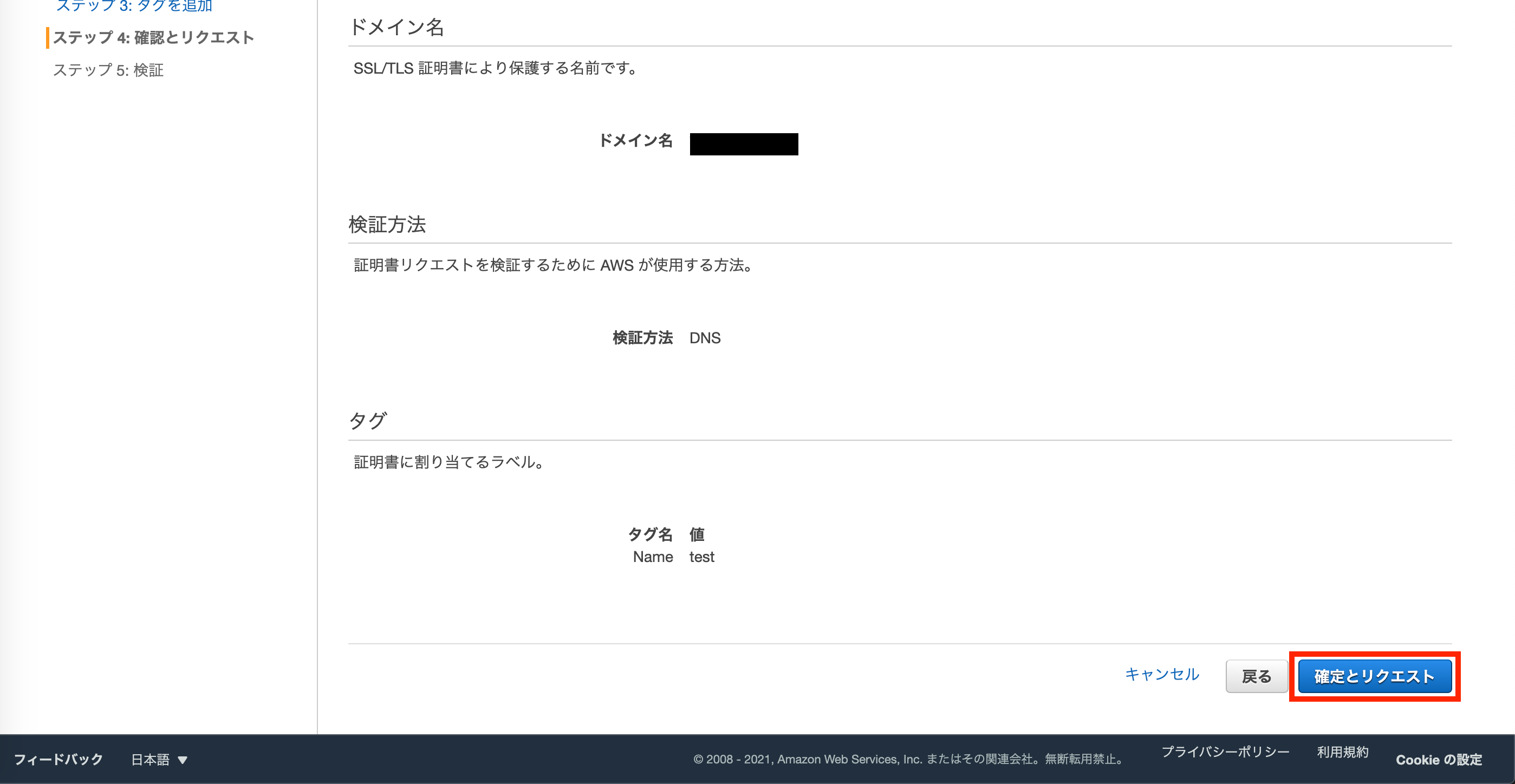
確定とリクエストを押します。
検証状態が検証保留中から成功に変わるまで待ちます。
正常に手続き出来ていれば、1分程度で直ぐに成功に変わると思います。成功になったら続行をクリック。
Certificate Managerの管理画面に遷移してきました。
赤枠のドメインあたりをクリックします。
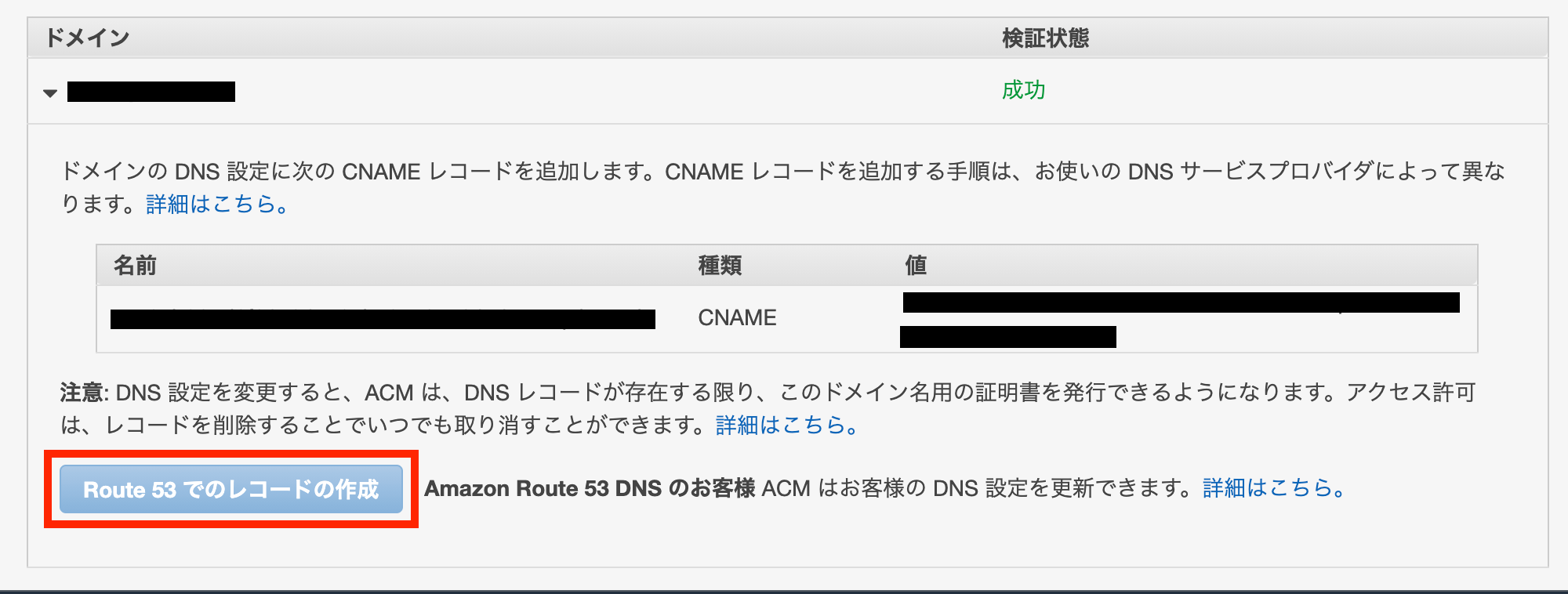
手動でRoute53にレコードを作成する事も出来るのですが、
ここから簡単にRoute53と連携させる事が出来ます。Route53でのレコードの作成をクリックします。
Route53のCNAMEレコードに登録が確認出来たら、SSL証明書取得のプロセスは完了です。2. ELB(ALB)を設定する
続いて、ELBの設定を行います。
今回の構成としてはインターネットからのトラフィックをELBでHTTPS(443)で受け、
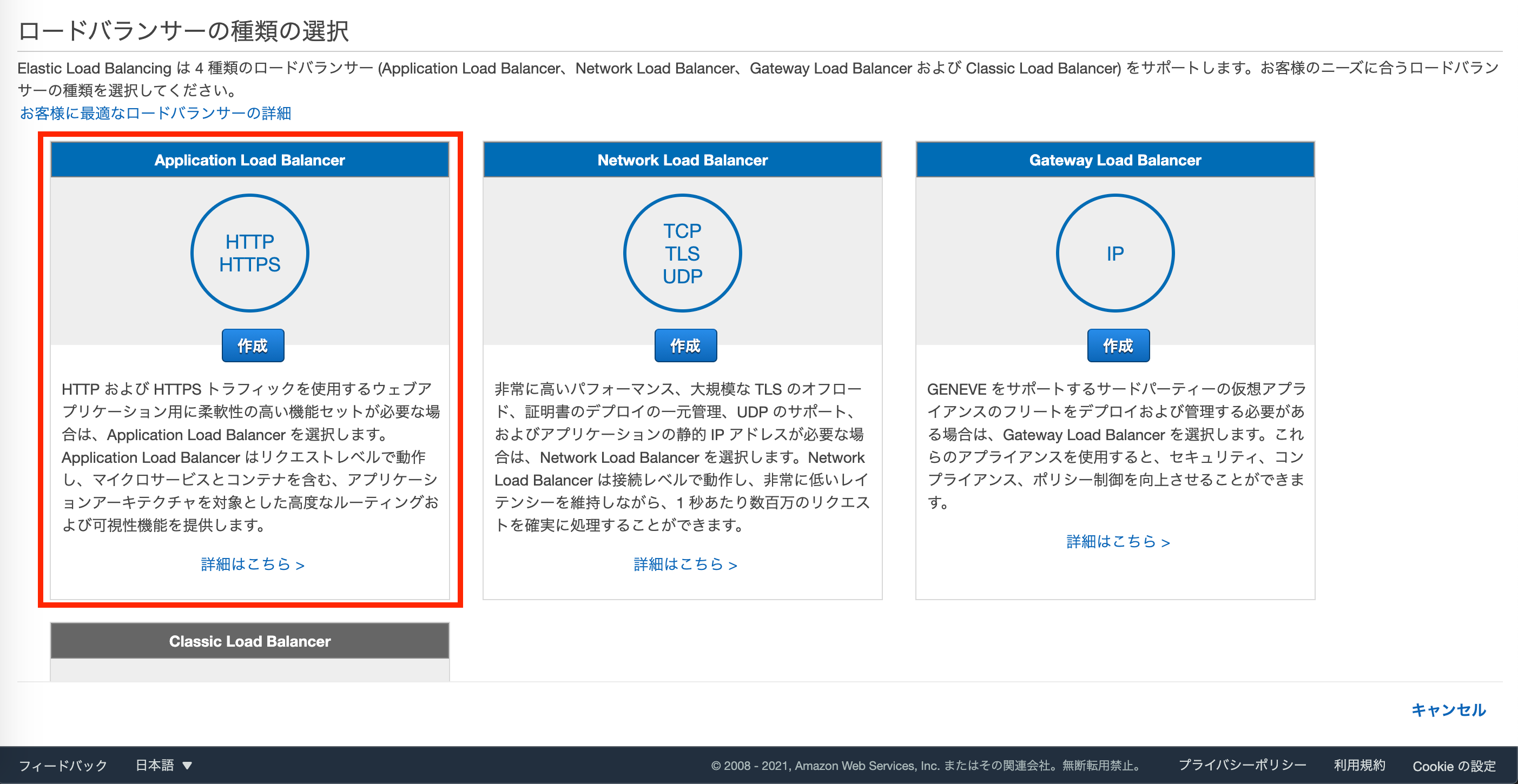
EC2にHTTP(80)で通信します。EC2のコンソールからロードバランサーを開き、Application Load Balancerを選択します。
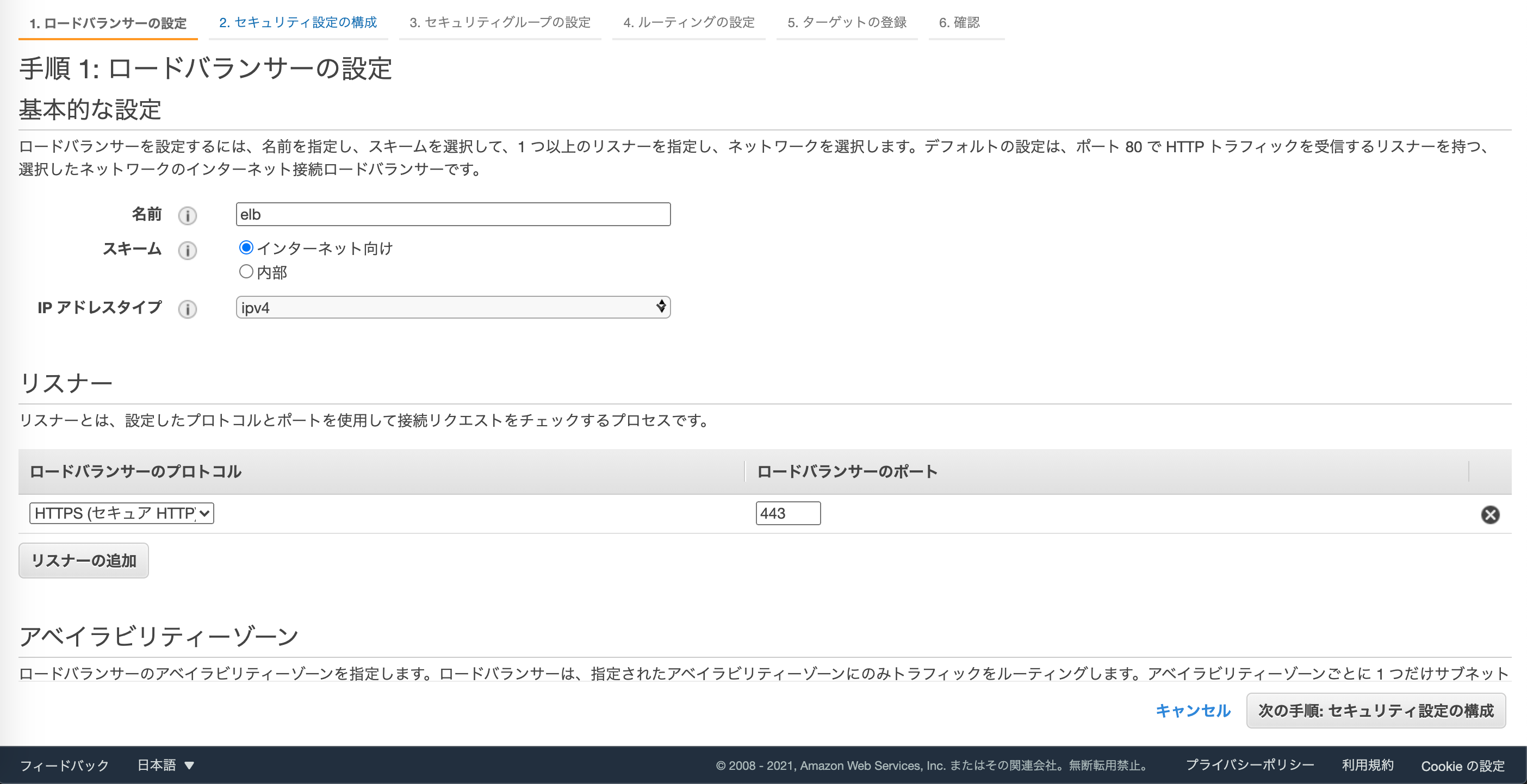
まず、基本的な設定でロードバランサーの名前を設定します。
今回の構成ではスキームはインターネット向けのままでOKです。リスナーはインターネットからALBまではHTTPS(443)になるので、HTTPS(セキュアHTTP)を選択します。
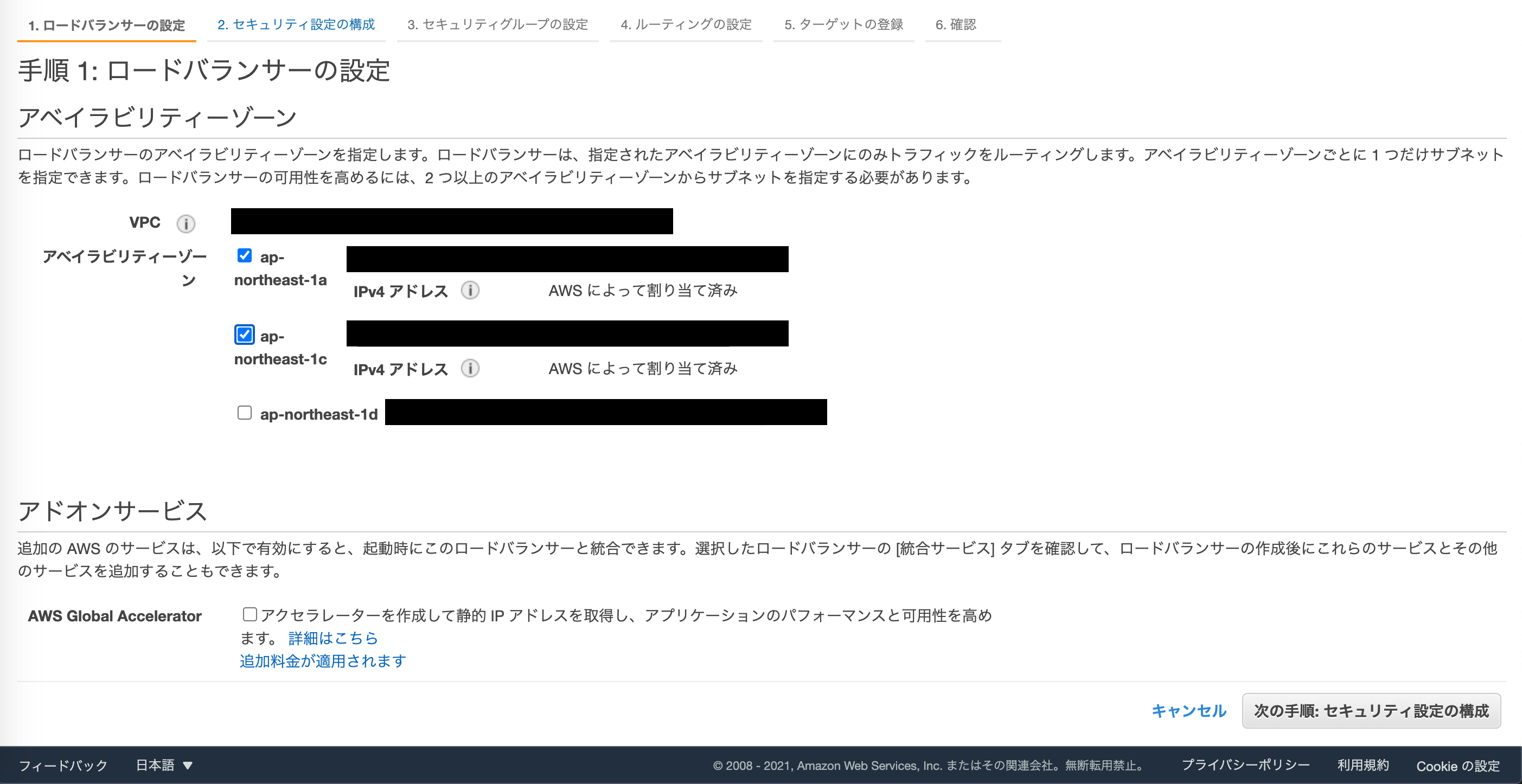
ALBを設置するVPC、サブネットを選択します。
ここではVPCについての説明は省きますが、インターネットと通信するので、プライベートではなく、パブリックサブネットを選択するようにして下さい。
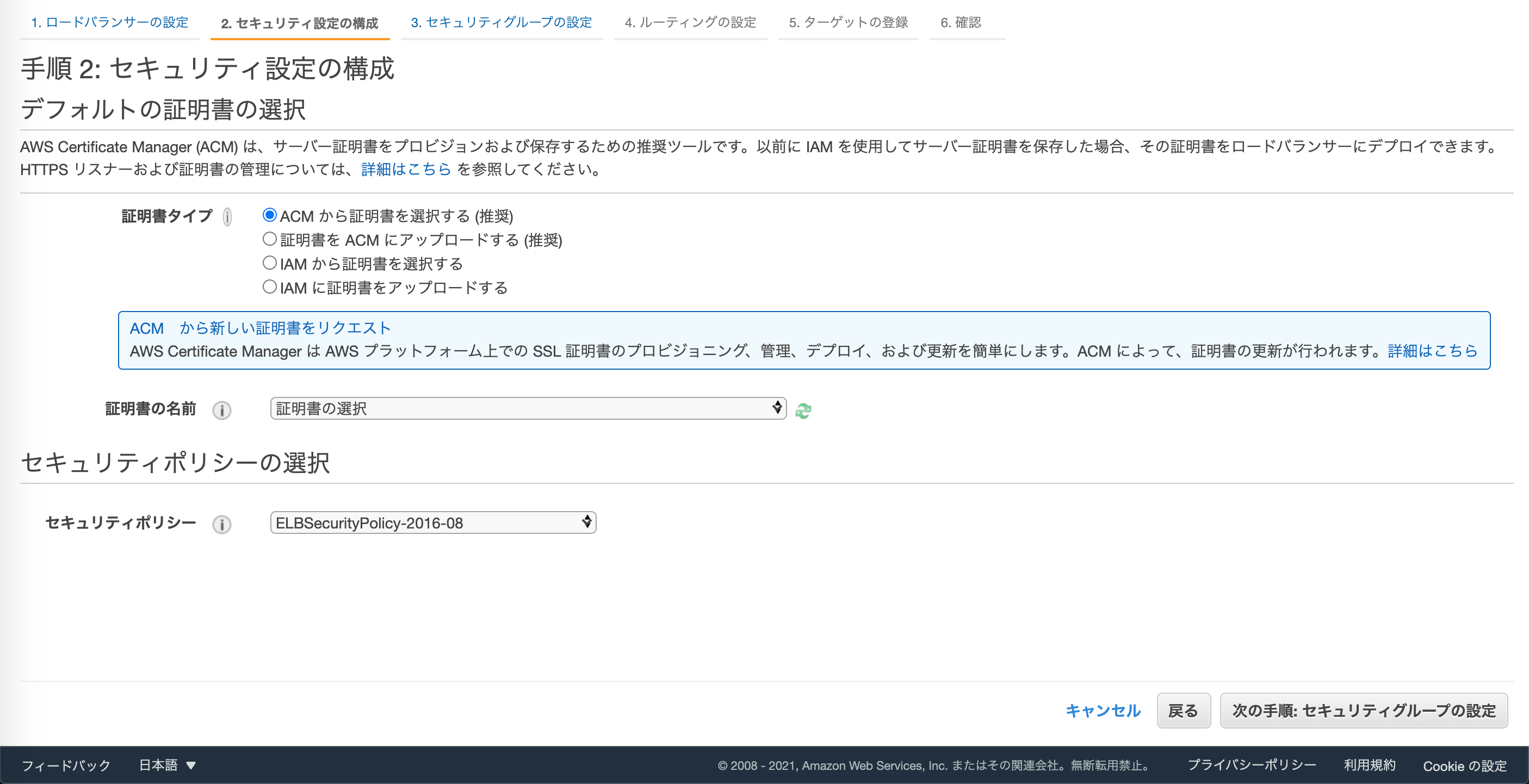
続いて、セキュリティ設定です。
証明書タイプをACMから証明書を選択するを選びます。
証明書の名前で先ほど発行した証明書を選択しましょう。セキュリティポリシーはELBSecurityPolicy-2016-08のままでOKです。
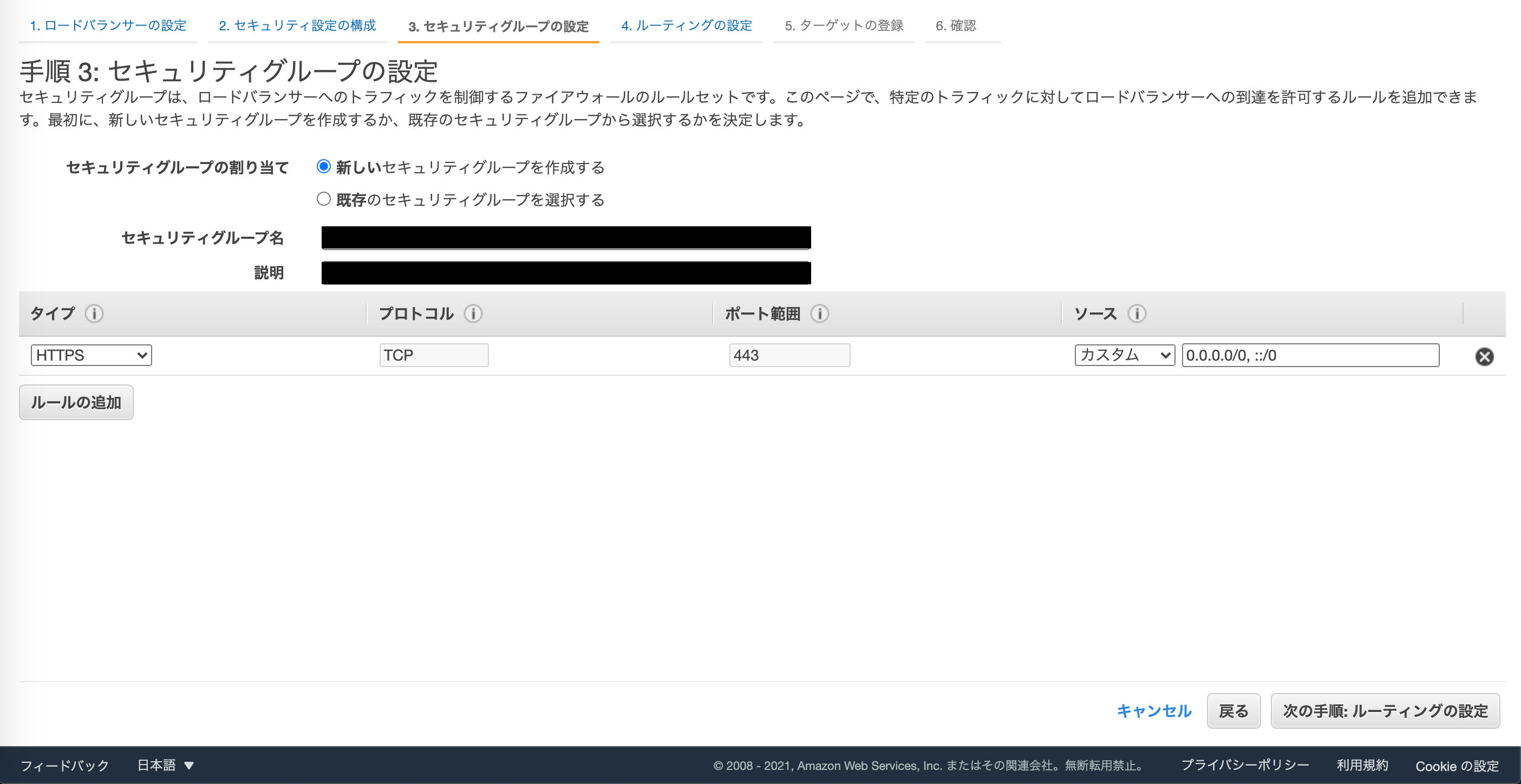
セキュリティグループの設定です。
既に設定済みのものをアタッチしても良いですが、なければここで設定しましょう。
HTTPSのインバウンドを許可するように出来ていればOKです。
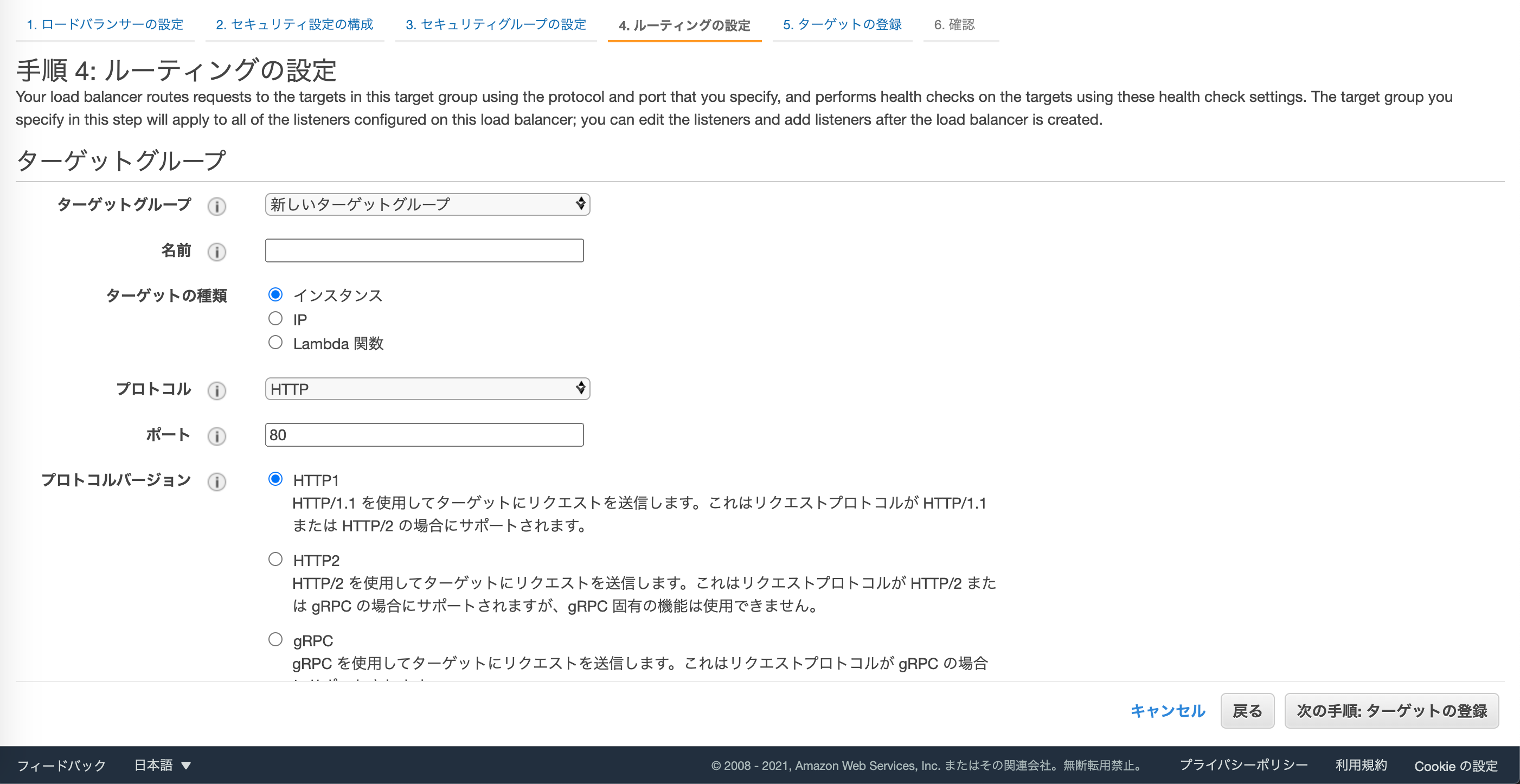
ターゲットグループを設定します。
こちらも事前に用意しているものをアタッチするのでも大丈夫です。
適用に名前をつけて、ターゲットの種類はインスタンス、プロトコルはHTTP、ポートは80でいきます。ヘルスチェックはHTTPで。
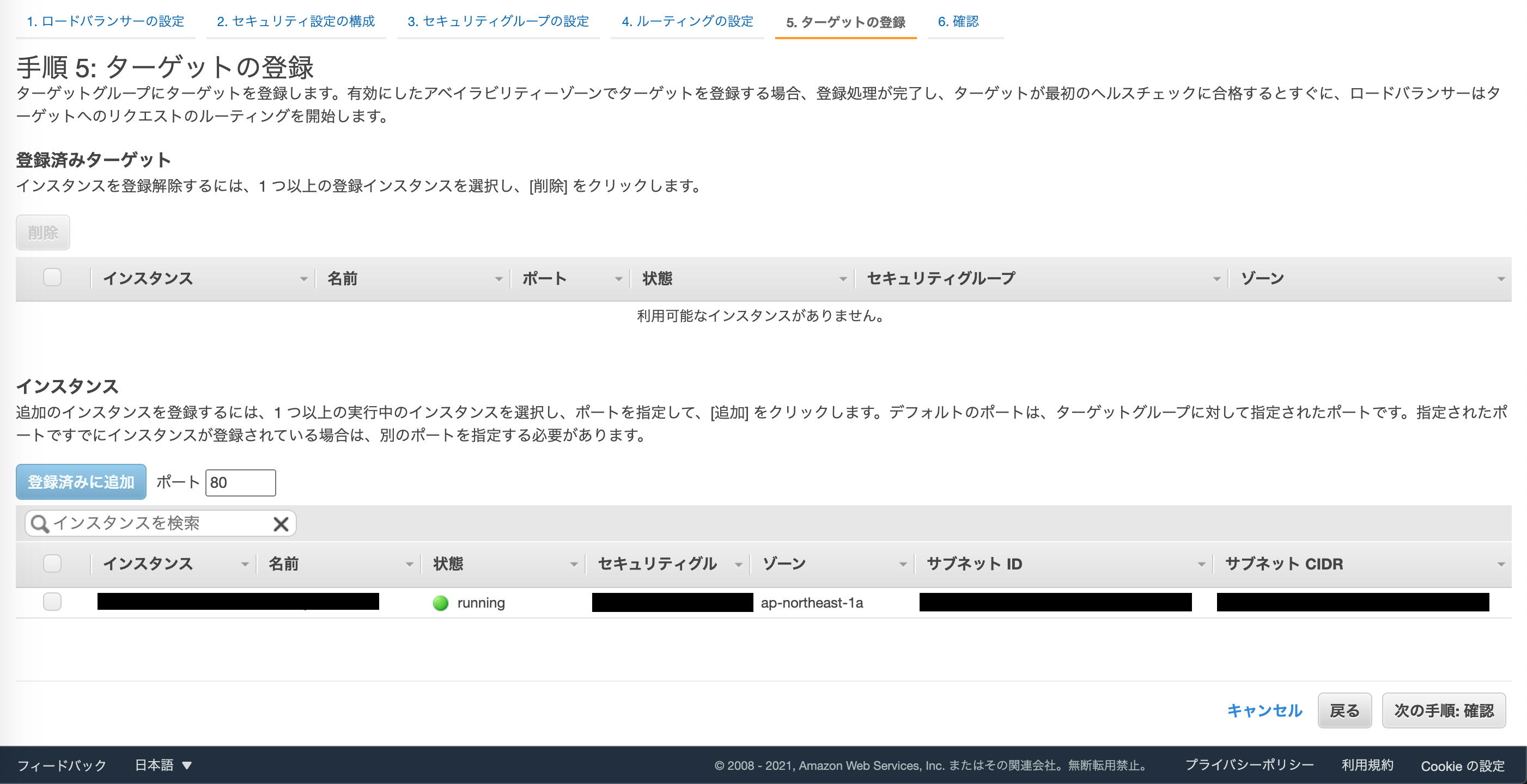
ターゲットとして登録するインスタンスにチェックを入れて、登録済みに追加します。
確認画面に遷移するので、作成を押せば完了です。elbタブに遷移しましょう。
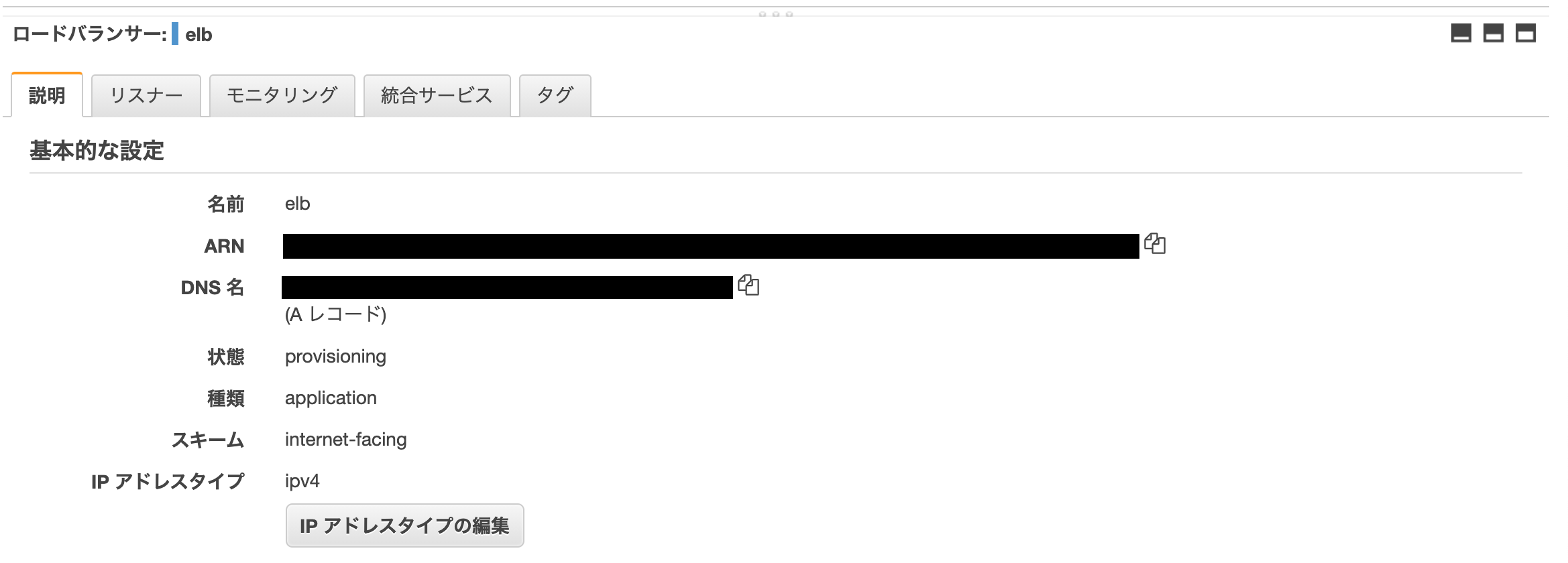
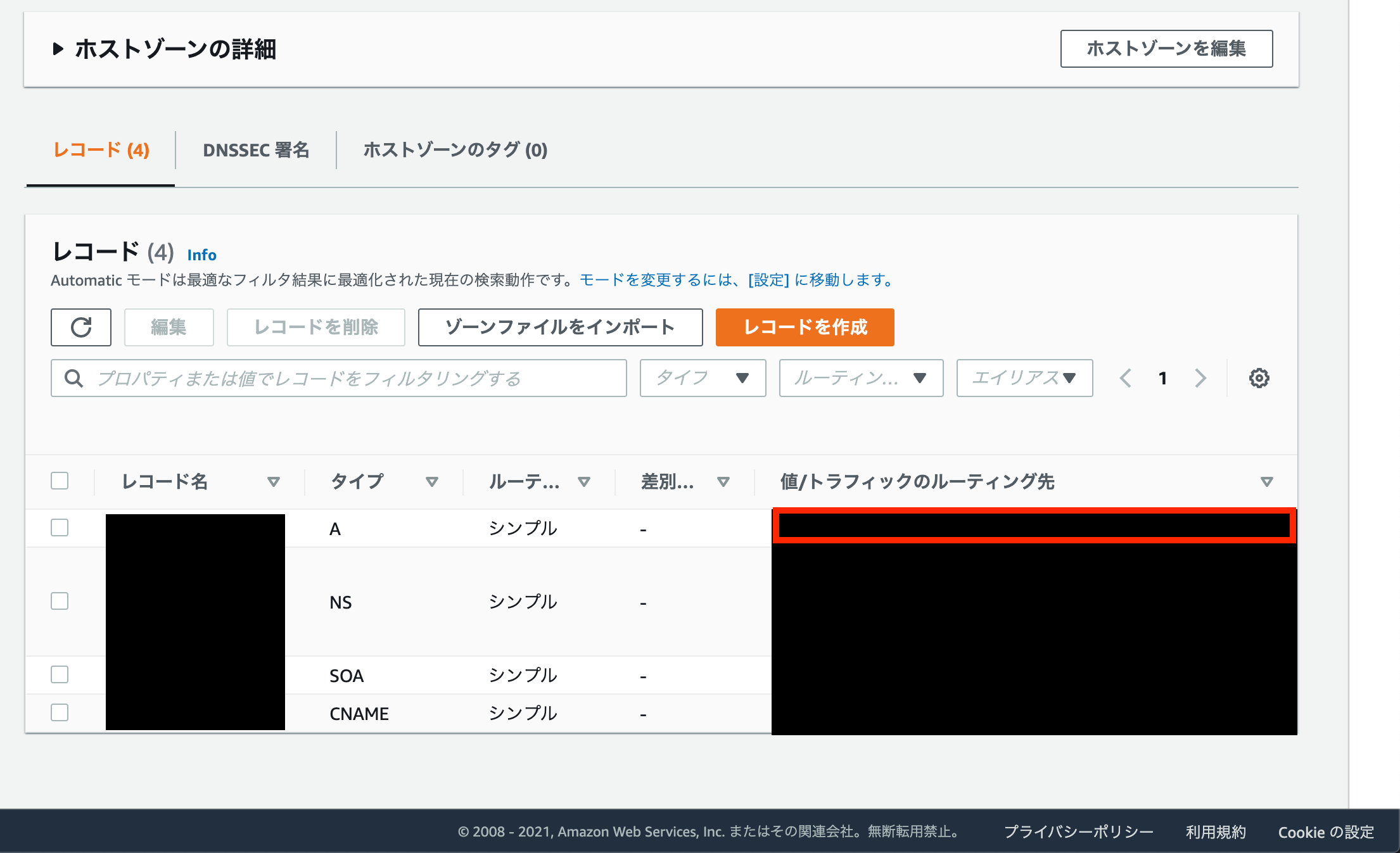
作成したALBのDNS名(Aレコード)をコピーします。
少し分かり辛くて申し訳無いです。
最後にRoute53のホストしているドメインのAレコードにコピーした値を入れます(赤枠のあたり)。お疲れ様でした。
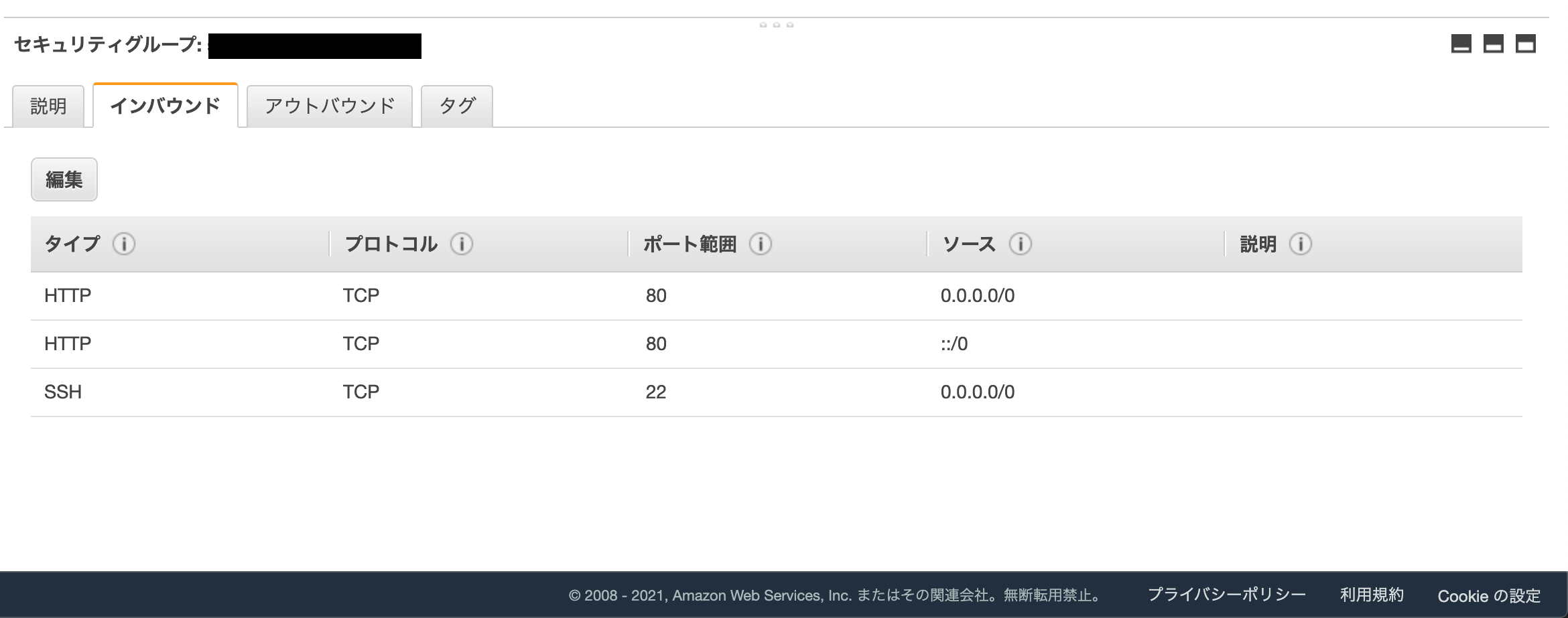
3. EC2のセキュリティグループ設定を確認する
もうほぼ対応としては完了ですが、念のため、EC2にアタッチしているセキュリティグループで、HTTP(80)のインバウンドトラフィックが許可されているかを確認しておきましょ。
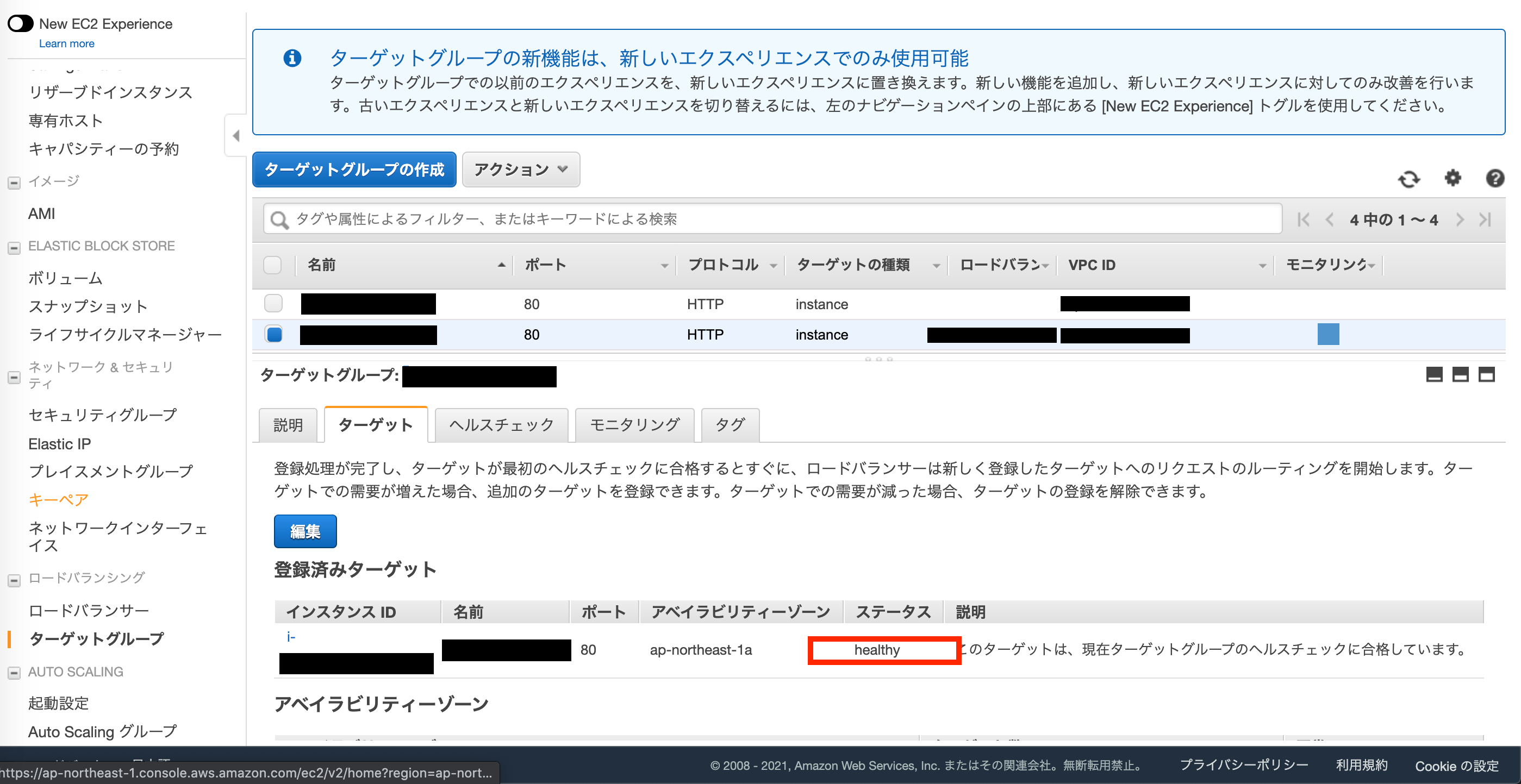
4. 接続確認
ALBがターゲットグループ(今回で言うとEC2インスタンスに対して)に
ヘルスチェックを行った結果を確認する事が出来ます。EC2メニューのターゲットグループから設定したものを選択します。healthyとなっていれば正常です。
ブラウザ(画像はchromeです)でアクセスして見ると、
SSLの鍵マークがついていますね〜、無事にSSL化する事が出来ました。お疲れ様でした。参考にさせて頂いた記事
・AWSでWebサイトをHTTPS化 その1:ELB(+ACM発行証明書)→EC2編
・ALB-EC2構成のhttps接続を構築
・AWS Certificate Managerを使って無料でSSL証明書を発行する



- 投稿日:2021-02-26T20:16:48+09:00
KaggleのNotebookでAutoGluonを使ってみる
※これは2021/02/26の記事です。指摘などありましたら気兼ねなくコメントお願いします

はじめに
「「AutoGluon-Tabular」を試してみる」という記事を読み、これを参考にしてKaggleのNotebookでAutoGluon(特にAutoGluon-Tabular)を使ってみようと試みたのですが、すんなりとはできませんでした。原因として、この一年でAutoGluon自体にいくつか変更があったことなどが考えられます。また推奨される利用方法も変わったようです。そこで、そのあたりを考慮し、「KaggleのNotebookでAutoGluonを使ってみる」というところまでを実現しました。作成したNotebookの紹介と実現するまでに発生したエラー・解決方法を備忘録として残しておきます。
結論
以下のようなNotebookを作成しました
A Beginner's Guide to AutoGluon | Kaggle
# https://github.com/awslabs/autogluon !pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluon.tabularimport pandas as pd from autogluon.tabular import TabularDataset, TabularPredictor train= TabularDataset('../input/titanic/train.csv') test = TabularDataset('../input/titanic/test.csv') label='Survived' time_limit=60 predictor = TabularPredictor(label=label).fit(train, time_limit=time_limit) submission = pd.read_csv('../input/titanic/gender_submission.csv') submission[label] = predictor.predict(test) submission.to_csv('submission.csv', index=False) submission.head()Public Scoreは0.78229と算出され、望む実装ができているようです!簡単!素晴らしい!
しかし、ちょっと不安な出力も…ひとまず棚に上げます。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. earthengine-api 0.1.252 requires google-api-python-client>=1.12.1, but you have google-api-python-client 1.8.0 which is incompatible.エラー&解決の備忘録
大きく以下2点を実施しました。
- 他環境(Google Colab)での最新の成功例で試行
- 環境依存の問題?を確認
まずは、Google Colabでの最新の成功例を試してみました。「Google ColaboratoryでAutoGluonをinstall & importする方法」、「autogluon.tabularのTabularDatasetによるデータの取得ができなくなってしまった件と解決方法について(2021/02/25に検知)」でも紹介したコードです。これは参考記事が公開されて以降のAutoGluonの変更点を考慮したものです。モジュールなどが異なります。
TabularDataset、TabularPredictorを使うためにautogluon.tabularをインポートします。このコードをすべてコピーして、実行してみたのですが以下のようなエラーが生じました。READMEを参考にしたコマンドなのですがここに原因がありそうです。
!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install --pre autogluonfrom autogluon.tabular import TabularDataset, TabularPredictor--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-2-974358aaf144> in <module> ----> 1 from autogluon.tabular import TabularDataset, TabularPredictor /opt/conda/lib/python3.7/site-packages/autogluon/tabular/__init__.py in <module> 1 import logging 2 ----> 3 from autogluon.core.dataset import TabularDataset 4 from autogluon.core.features.feature_metadata import FeatureMetadata 5 /opt/conda/lib/python3.7/site-packages/autogluon/core/__init__.py in <module> 4 from .decorator import * 5 from .utils.files import * ----> 6 from .scheduler.resource.resource import * 7 from .scheduler.scheduler import * 8 from . import metrics /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/__init__.py in <module> ----> 1 from .import remote, resource 2 from .resource import get_cpu_count, get_gpu_count 3 4 # schedulers 5 from .scheduler import * /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/remote/__init__.py in <module> 1 # remotes ----> 2 from .remote import * 3 from .ssh_helper import * 4 from .remote_manager import * /opt/conda/lib/python3.7/site-packages/autogluon/core/scheduler/remote/remote.py in <module> 9 from threading import Thread 10 import multiprocessing as mp ---> 11 from distributed import Client 12 13 from .ssh_helper import start_scheduler, start_worker /opt/conda/lib/python3.7/site-packages/distributed/__init__.py in <module> 2 import dask 3 from dask.config import config ----> 4 from .actor import Actor, ActorFuture 5 from .core import connect, rpc, Status 6 from .deploy import LocalCluster, Adaptive, SpecCluster, SSHCluster /opt/conda/lib/python3.7/site-packages/distributed/actor.py in <module> 4 from queue import Queue 5 ----> 6 from .client import Future, default_client 7 from .protocol import to_serialize 8 from .utils import iscoroutinefunction, thread_state, sync /opt/conda/lib/python3.7/site-packages/distributed/client.py in <module> 41 from tornado.ioloop import IOLoop, PeriodicCallback 42 ---> 43 from .batched import BatchedSend 44 from .utils_comm import ( 45 WrappedKey, /opt/conda/lib/python3.7/site-packages/distributed/batched.py in <module> 6 from tornado.ioloop import IOLoop 7 ----> 8 from .core import CommClosedError 9 from .utils import parse_timedelta 10 /opt/conda/lib/python3.7/site-packages/distributed/core.py in <module> 18 from tornado.ioloop import IOLoop, PeriodicCallback 19 ---> 20 from .comm import ( 21 connect, 22 listen, /opt/conda/lib/python3.7/site-packages/distributed/comm/__init__.py in <module> 24 25 ---> 26 _register_transports() /opt/conda/lib/python3.7/site-packages/distributed/comm/__init__.py in _register_transports() 16 def _register_transports(): 17 from . import inproc ---> 18 from . import tcp 19 20 try: /opt/conda/lib/python3.7/site-packages/distributed/comm/tcp.py in <module> 15 import dask 16 from tornado import netutil ---> 17 from tornado.iostream import StreamClosedError 18 from tornado.tcpclient import TCPClient 19 from tornado.tcpserver import TCPServer /opt/conda/lib/python3.7/site-packages/tornado/iostream.py in <module> 208 209 --> 210 class BaseIOStream(object): 211 """A utility class to write to and read from a non-blocking file or socket. 212 /opt/conda/lib/python3.7/site-packages/tornado/iostream.py in BaseIOStream() 284 self._closed = False 285 --> 286 def fileno(self) -> Union[int, ioloop._Selectable]: 287 """Returns the file descriptor for this stream.""" 288 raise NotImplementedError() AttributeError: module 'tornado.ioloop' has no attribute '_Selectable'
--preを外してみます。!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluonfrom autogluon.tabular import TabularDataset, TabularPredictor--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-3-974358aaf144> in <module> ----> 1 from autogluon.tabular import TabularDataset, TabularPredictor ModuleNotFoundError: No module named 'autogluon.tabular'
autogluon.tabularがないと言われていしまいました。それならとautogluon→autogluon.tabularにしてみると…成功しました!最終的に、以下のような修正で解決しました。!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install autogluon.tabular2021/02/26、Kaggleでは、
TabularDataset、TabularPredictorを使うためにautogluonではなくautogluon.tabularをインストールする必要があるということですね。色々気になっています
まとめ
「KaggleのNotebookでAutoGluonを使ってみる」というところまでを実現するために、作成したNotebookの紹介と、実現するまでに発生したエラー・解決方法を備忘録として記録しました。2021/02/26にした対応でしたが、今後もこのようなエラーが生じる恐れはあると思うので、あくまでも参考までにしていただけると幸いです。引き続きAutoGluonをはじめとするAutoMLをどんどん体験していきましょう!
- 投稿日:2021-02-26T19:53:48+09:00
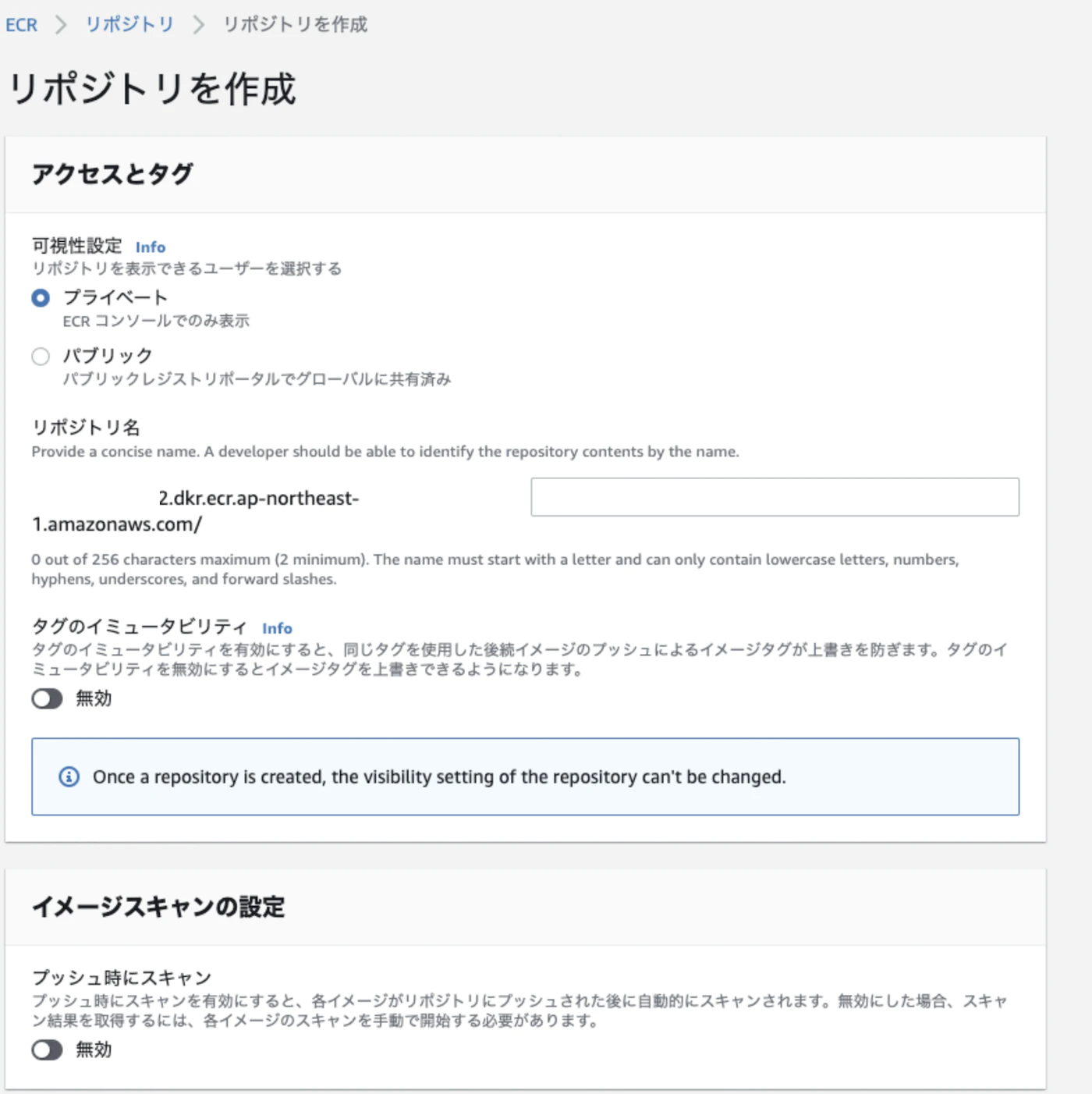
【AWS】ECRでレポジトリを作成し、イメージをプッシュする手順
1. レポジトリの作成
オレンジ色の「レポジトリを作成」をクリック
設定内容
(1) リポジトリ名
▼以下はデフォルトのまま(2) プライベート (イメージを公開したい場合はパブリックにする)
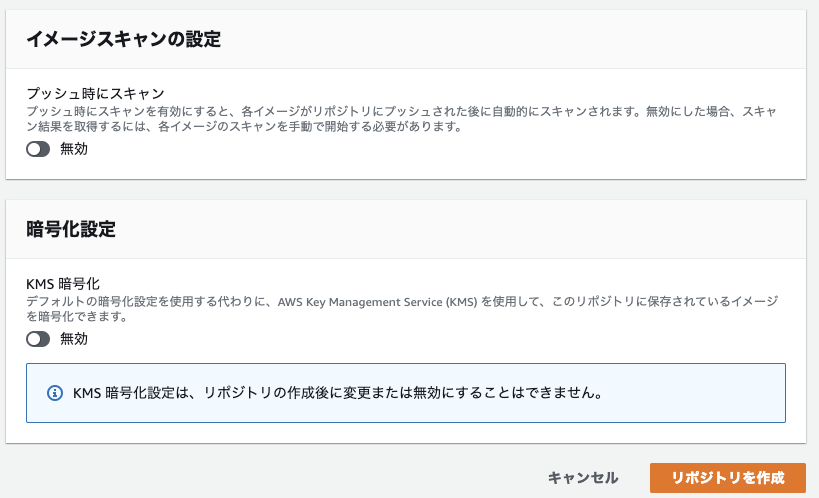
(3) タグのイミュータビリティ: 無効
(4) イメージスキャンの設定: 無効
(5) 暗号化設定: 無効
右下のオレンジ枠の「リポジトリを作成」をクリックすれば完成。たったこれだけ。
タグのイミュータビリティとは?
イメージの上書き防止機能。
dockerでイメージを作成する時は、
イメージ名:タグ名で、名前をつける。タグ名にはバージョンを指定することが一般的。タグのイミュータビリティ機能を有効にすると、タグ名が同じ場合に上書きを防いでくれる。
レポジトリ作成後は変更できない。
イメージスキャンの設定とは?
脆弱性を確認する機能。
イメージスキャンを有効にすると、イメージがECRレポジトリにプッシュされた時に、イメージの中身をスキャンし、欠陥がないか確認してくれる。
イメージスキャンの結果はAmazon EventBridgeに保存される。
無効にしている場合は、手動でスキャンを実行できる。
暗号化設定とは?
暗号化方式の指定。
デフォルトではAES-256で暗号化されているが、KMS暗号化を有効にすると、AWS Key Management Service (KMS)で指定した方法で暗号化することができる。
2020/7/29から使えるようになった比較的新しい機能。
2. イメージのビルド
docker-compose.ymlファイルとDockerfileを用意して、buildコマンドを実行する。
・
docker-compose build サービス名ECRにプッシュする前にイメージ名を変更する必要があるため、イメージ名は識別できるものにしておく。
docker-compose.ymlの中にimageディレクティブを記述する。
・
image: <イメージ名>:<タグ名>
デバッグしてからビルドする関数定義
本番環境のイメージ作成など、注意が必要な場合は、
(1)ローカルに未コミットがないか、(2)リモートレポジトリとローカルレポジトリのブランチの間に差分がないかを確認してから、イメージを作成するとうっかりミスを減らせる。
詳細はgitのハッシュ値を使ってイメージビルド前のデバッグ処理を作成する方法を参照。
3. イメージをプッシュする
作成したレポジトリにイメージをプッシュするには、
docker pushコマンドを使う。ECRへのイメージプッシュの処理手順は以下になる。
- docker経由でawsへのログイン
- docker tagでイメージ名を変更
- docker pushでイメージを送信
- ECR上でイメージが追加されたか確認
詳細は、ECRにログインし、レポジトリにイメージをプッシュするエイリアスコマンドの作成方法を参照。
ポイント1
docker pushする際に、プッシュ先のレポジトリはイメージ名で指定する。イメージ名は以下のようにする必要がある。
・
<ホスト名>/<レポジトリ名>:<タグ名>イメージ名を変更するために、
docker tagコマンドを使う。ポイント2
イメージは新たにビルドする必要がある。
元々あるイメージを再度プッシュしようとしても、変更がない場合はプッシュは行われない。
プッシュ後にECRに行って、イメージタグが追加されているか確認すること。
ECR上でプッシュした日時でイメージが確認できればOK。

- 投稿日:2021-02-26T19:38:50+09:00
AWS GuardDuty 2021年3月アップデート内容全文
English follows Japanese
いつもお世話になっております。
この通知は、Amazon GuardDuty をご利用のお客様に今後の重要な変更をお知らせするためのものです。2021年 3月12日、異常なユーザー動作を検出する既存の 13 の Amazon GuardDuty 検索タイプが廃止され、8 つの新しい検索タイプに置き換えられます。 新しい検索タイプは、GuardDuty 検出の拡張を表し、より広範かつ正確なセキュリティカバレッジを提供します。 新しい検索タイプには、異常なアクティビティのトリアージと調査に役立つ豊富なコンテキスト情報も含まれています。 潜在的なカバレッジギャップを回避するために、GuardDuty と Amazon EventBridge [1] との統合により、既存の検索タイプを基にした自動取り込みを設定しているお客様は、2021年3月12日以前に新しい検索タイプに基づいて自動化を追加する必要があります。
以下は、2021年 3月12日に GuardDuty から廃止予定の検索タイプです。
1. Persistence:IAMUser/NetworkPermissions
2. Persistence:IAMUser/ResourcePermissions
3. Persistence:IAMUser/UserPermissions
4. Recon:IAMUser/NetworkPermissions
5. Recon:IAMUser/ResourcePermissions
6. Recon:IAMUser/UserPermissions
7. ResourceConsumption:IAMUser/ComputeResources
8. Stealth:IAMUser/LoggingConfigurationModified
9. UnauthorizedAccess:IAMUser/ConsoleLogin
10. Discovery:S3/BucketEnumeration.Unusual
11. Impact:S3/PermissionsModification.Unusual
12. Impact:S3/ObjectDelete.Unusual
13. PrivilegeEscalation:IAMUser/AdministrativePermissions2021年 3月12日に GuardDuty に追加される検索タイプの種類は次のとおりです。
1. Discovery:IAMUser/AnomalousBehavior
2. InitialAccess:IAMUser/AnomalousBehavior
3. Persistence:IAMUser/AnomalousBehavior
4. PrivilegeEscalation:IAMUser/AnomalousBehavior
5. DefenseEvasion:IAMUser/AnomalousBehavior
6. CredentialAccess:IAMUser/AnomalousBehavior
7. Impact:IAMUser/AnomalousBehavior
8. Exfiltration:IAMUser/AnomalousBehavior新しい検索の詳細フィールド:
2021年 3月12日に追加される 8 つの新しい検索タイプには、フィールド resource.resourceType が AccessKey である既存の GuardDuty 検索タイプに含まれているものと同じ検索詳細フィールドが含まれます。 さらに、これらの検索タイプには豊富なコンテキストの詳細が含まれ、これらは GuardDuty コンソール及び、最上位のフィールド service.addionalInfo に含まれる json からご確認いただけます。
新しい検索タイプには、次のフィールドが含まれます。
• service.additionalInfo.userAgent.fullUserAgent // アクティビティに関連付けられた完全なユーザーエージェント
• service.additionalInfo.userAgentCategory // アクティビティに関連付けられたユーザーエージェントカテゴリ
• service.additionalInfo.unusualBehavior.isUnusualUserIdentity // アクティビティに関連付けられたユーザーが以前プロファイルされた期間に確認されたかどうかを示す Boolean 型フィールド。
• service.additionalInfo.anomalies.anomalousAPIs // アクティビティに関連付けられた異常な API のリスト。 API は、属する AWS のサービスに基づいてグループ化され、リクエストが成功したかどうか、または受信したエラー応答の詳細が提供されます。新しい検索タイプには、次の動作コンテキストも含まれます。
• ユーザーおよびアカウントレベルの動作:API、自律システム番号(ASN)、ユーザーエージェント
• アカウントレベルの動作:ユーザー名、ユーザータイプ行動コンテキストは、プロファイルされた期間中の行動頻度に基づいてグループ化されます。
• Unusual: 動作は以前見られていませんでした
• Rare: 動作は1ヶ月に1回またはそれ以下の頻度で見られました
• Infrequent: 動作は月に数回見られました
• Frequent: 動作は毎週から毎日見られました新しい結果には、次の動作コンテキストフィールドが含まれます。
• service.additionalInfo.unusualBehavior.unusualAPIsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualAPIsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualASNsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualASNsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualUserAgentsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualUserAgentsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualUserNamesAccountProfiling
• service.additionalInfo.unusualBehavior.unusualUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserTypesAccountProfilingこれらの変更が 2021年 3月12日に実施されると、追加の詳細はドキュメント [2] に記載されます。
ご質問やご不明な点がある場合は、AWS サポート [3] にお問い合わせください。
[1] https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_findings_cloudwatch.html
[2] https://docs.aws.amazon.com/guardduty/latest/ug/what-is-guardduty.html
[3] https://aws.amazon.com/support
Hello,
This notification serves to inform Amazon GuardDuty Customers of important upcoming changes to the service. On March 12, 2021, 13 existing Amazon GuardDuty finding types that detect anomalous user behavior will be deprecated in favor of 8 new finding types to replace them. The new findings types represent an enhancement to GuardDuty detections, and will provide broader, and more accurate security coverage. The new finding types will also include enriched contextual information to help triage and investigate anomalous activity. To avoid a potential coverage gap, customers that have set up automated downstream ingestion of the existing finding types via GuardDuty's integration with Amazon EventBridge [1] should add automation based on the new finding types before March 12, 2021.
Following are the finding types that will be deprecated from GuardDuty on March 12, 2021:
1. Persistence:IAMUser/NetworkPermissions
2. Persistence:IAMUser/ResourcePermissions
3. Persistence:IAMUser/UserPermissions
4. Recon:IAMUser/NetworkPermissions
5. Recon:IAMUser/ResourcePermissions
6. Recon:IAMUser/UserPermissions
7. ResourceConsumption:IAMUser/ComputeResources
8. Stealth:IAMUser/LoggingConfigurationModified
9. UnauthorizedAccess:IAMUser/ConsoleLogin
10. Discovery:S3/BucketEnumeration.Unusual
11. Impact:S3/PermissionsModification.Unusual
12. Impact:S3/ObjectDelete.Unusual
13. PrivilegeEscalation:IAMUser/AdministrativePermissionsFollowing are the finding types that will be added to GuardDuty on March 12, 2021:
1. Discovery:IAMUser/AnomalousBehavior
2. InitialAccess:IAMUser/AnomalousBehavior
3. Persistence:IAMUser/AnomalousBehavior
4. PrivilegeEscalation:IAMUser/AnomalousBehavior
5. DefenseEvasion:IAMUser/AnomalousBehavior
6. CredentialAccess:IAMUser/AnomalousBehavior
7. Impact:IAMUser/AnomalousBehavior
8. Exfiltration:IAMUser/AnomalousBehaviorNew finding details fields:
The 8 new finding types that will be added on March 12, 2021 will include the same finding detail fields that are included in existing GuardDuty finding types in which the field resource.resourceType is AccessKey. Additionally these finding types will include enriched contextual details that will be viewable in the GuardDuty console, and in the finding json under the top-level field service.additionalInfo.
The following fields will be included in the new finding types:
• service.additionalInfo.userAgent.fullUserAgent // the full user agent associated with the activity
• service.additionalInfo.userAgent.userAgentCategory // the user agent category associated with the activity
• service.additionalInfo.unusualBehavior.isUnusualUserIdentity // a Boolean field that indicates whether the user associated with the activity has been previously seen during the profiled period.
• service.additionalInfo.anomalies.anomalousAPIs // a list of anomalous APIs associated with the activity. The APIs will be grouped based on the AWS service they belong to, and provide details on whether the request was successful, or what error response was received.The new finding types will also include the following behavioral context:
• User and account level behavior: APIs, Autonomous System Numbers (ASNs), UserAgents
• Account level behavior: UserNames, UserTypesThe behavioral context will be grouped based on frequency of behavior during the profiled period:
• Unusual: the behavior was not previously seen
• Rare: the behavior was seen once a month or less
• Infrequent: the behavior was seen a few times a month
• Frequent: the behavior was seen daily to weeklyThe following behavioral context fields will be included in the new findings:
• service.additionalInfo.unusualBehavior.unusualAPIsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualAPIsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualASNsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualASNsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualUserAgentsAccountProfiling
• service.additionalInfo.unusualBehavior.unusualUserAgentsUserIdentityProfiling
• service.additionalInfo.unusualBehavior.unusualUserNamesAccountProfiling
• service.additionalInfo.unusualBehavior.unusualUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledAPIsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledAPIsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledASNsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledASNsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserAgentsAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserAgentsUserIdentityProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserNamesAccountProfiling
• service.additionalInfo.profiledBehavior.frequentProfiledUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.infrequentProfiledUserTypesAccountProfiling
• service.additionalInfo.profiledBehavior.rareProfiledUserTypesAccountProfilingOnce these changes are implemented on March 12, 2021 additional details will be provided in our documentation [2]
If you have any questions or concerns please reach out to us through AWS Support [3]
[1] https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_findings_cloudwatch.html
[2] https://docs.aws.amazon.com/guardduty/latest/ug/what-is-guardduty.html
[3] https://aws.amazon.com/supportSincerely,
Amazon Web ServicesAmazon Web Services, Inc. is a subsidiary of Amazon.com, Inc. Amazon.com is a registered trademark of Amazon.com, Inc. This message was produced and distributed by Amazon Web Services Inc., 410 Terry Ave. North, Seattle, WA 98109-5210
- 投稿日:2021-02-26T18:22:40+09:00
初めての無料ドメイン取得&Route53でフェールオーバールーティングしてみた。超ざっくりまとめてみた。
今回、人生初のドメイン取得(無料ドメイン)をしてみました!
そして、取得したドメインは、Route53でAWS上のサーバにルーティングを行っています。
※Route53はAWSのDNS(Domain Name System)サービスですまた、ルーティング先のサーバに障害があった時に、Sorryページを表示させるようにセカンダリサーバにルーティングをする(フェールオーバールーティング)ということをしてみました。
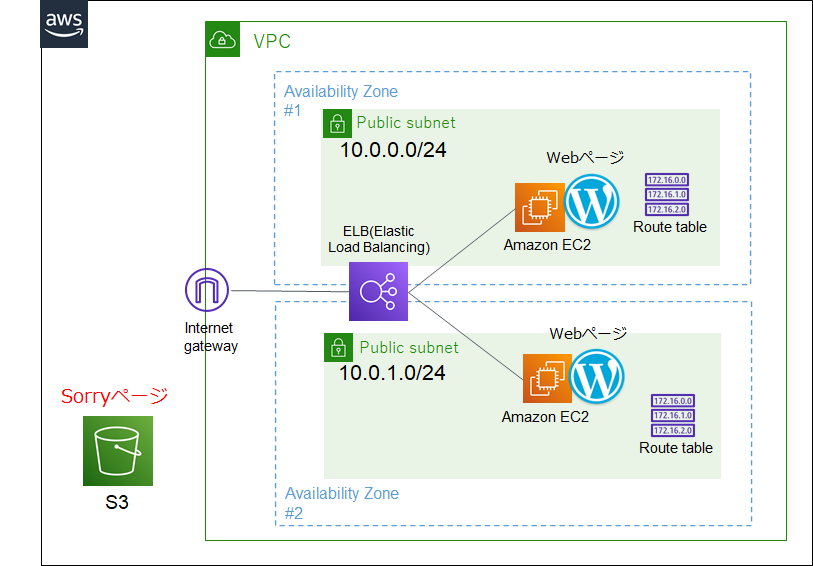
構成図(完成形)
細かい作業過程は割愛しますが環境構築で理解した基本構成の概要を自分の理解を深めるために、超ざっくりと基本要素をまとめます。
これを見れば、何の目的のために何を作るのか、一目で思い出せるはず!
初めてって、やっぱり楽しいですねー。みなさん頑張りましょう!
- 説明を極力シンプルにするために、AWSのアカウント作成、IAMユーザの登録、および以下構成は完了している状態から始めます。
- 作図には AWS 公式アイコンセットを利用してます
- 全般的に概念的な説明のみとしています。
- 詳細な設定/オペレーションを知りたい方は、他サイトをご覧ください。
- この記事や、この記事、あとはクラスメソッドさんの記事に画面キャプチャ付きで細かく説明されてました!
超ざっくりまとめ
超ざっくりと説明すと、以下を行うだけです。
1. ドメインを取得する
2. Route53にホストゾーンを登録し、フェイルオーバールーティングを設定する
※ドメイン(example.tk) やそのサブドメイン (XXX.example.tk) のルーティングを登録これだけで、さくっと作れてしまいます。
0. 事前準備
記事の内容をRoute53にフォーカスするため、以下構成は既に作成されているものとします。
S3には、障害発生時に表示する Sorryページ(html)を配置しておきます。
なお、S3に関する注意点としては
- バケット名は取得するドメインのサブドメイン(e.g. XXX.example.tk)を設定すること
- パブリックアクセスを許可しておくこと(『パブリックアクセスをすべてブロック』のチェックを外す)
- 静的webサイトホスティングを有効にする
- 公開用のhtmlファイル(Sorryページ)をS3にUploadする
- バケットポリシーの設定を実施(Web公開用のS3に設置されたファイルに誰でも参照出来る状態とするため)
上記で、S3 の URLにアクセスするとSorryページが表示できるようになります。
※詳細な手順は、ここに分かりやすく書かれています。
1. ドメインを取得する
今回は、freenomというサービスで無料で作成しました。
【URL】https://www.freenom.com
freenomでのドメイン取得は、この記事が参考になります。
※ドメイン取得は、記事を読まなくてもわかるくらいシンプルです2. Route53にホストゾーンを登録し、フェイルオーバールーティングを設定する
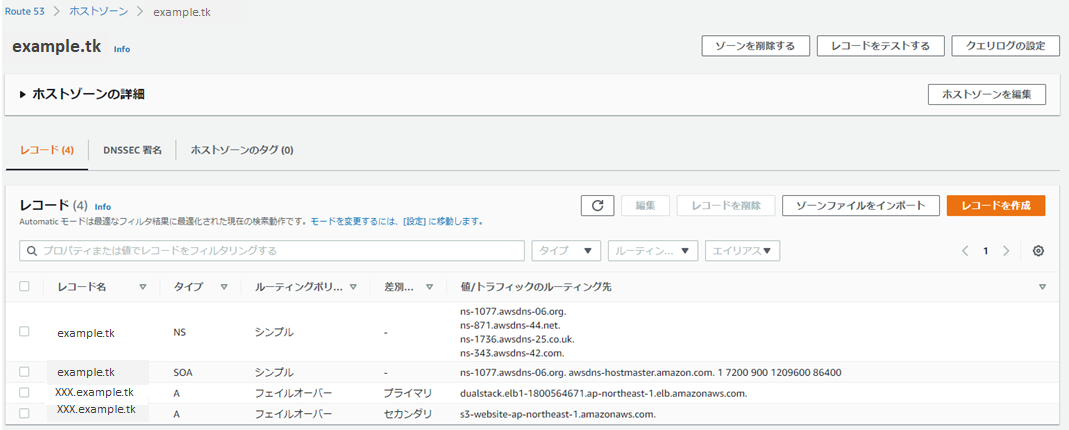
ホストゾーンは、example.com やそのサブドメイン(acme.example.com や zenith.example.com)へのルーティング情報(レコード)を登録する場所です。
以下のような情報を登録します。
上記登録レコードに関する補足
タイプ 説明 NS ネームサーバーが書かれているレコード SOA このサーバを管理する情報が書かれているレコード
詳細はここを参照A Aレコードとして、今回はフェールオーバールーティングを設定
xxx.example.tkのデフォルトのルーティング先であるプライマリ(今回はELBのホスト名)と、プライマリのヘルスチェックが失敗した時にルーティングするセカンダリ(今回はS3)を記載※NS、SOAレコードはホストゾーン作成時に自動的に作成されます
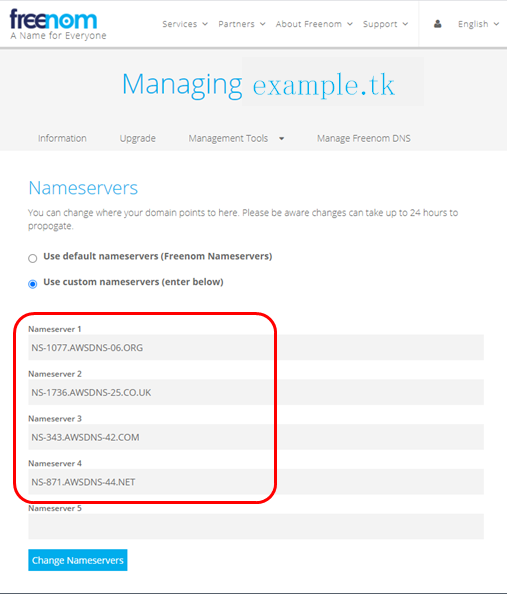
なお、ネームサーバの情報は freenom にも反映を行い、同じネームサーバを使用するようにしておく必要があります。
freenomで上記設定が反映されるのに時間がかかることがあるようです。(私の場合は1時間程度かかりました)
これで、外部(freenom)で登録したドメイン名を使用しての Route53による名前解決&ヘルスチェック失敗時のSorryページ表示ができるようになりました。
さいごに
この記事はAWS初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
このサービスは、テンポの良い/わかりやすい動画説明をもとに、気軽に実践を積み、自分の血肉とできるオンラインスクールです。
コミュニティも存在し、Slackで会員通しの情報交換/質問も気楽にできます。
書籍を購入するような値段で学習ができ、とてもお得です。(個人的な感想です)
では、また次回お会いしましょう!





- 投稿日:2021-02-26T18:07:08+09:00
【初心者】AWS Wavelengthを使ってみる #2 (Amazon EKSの利用)
1.目的
- AWS Wavelength 上で動作するサービスとしてAmazon EKSが挙げられているが、どのように設定していくのか、また、リージョンでEKSを使う場合と比較して、どのような違いがあるのかを確認する。
- AWS Wavelength の概要については以前の記事「【初心者】AWS Wavelengthを使ってみる」を参照のこと。
2.やったこと
以下の内容を実施した。※あくまで「やってみて動きました」という内容で、ベストプラクティスかどうかは微妙。
- 東京リージョンにVPCを作成し、パブリックサブネット及び Wavelength Zoneのサブネットを作成する。
- 東京リージョンにEKSクラスター(コントロールプレーン)を作成する。
- Wavelength Zone に EKSワーカーノードとなるEC2インスタンスを作成する。
- EKSクラスターとEKSワーカーノードが通信できることを確認する。
- EKSワーカーノード上にnginxコンテナを作成し、外部(キャリア網)からアクセスできることを確認する。
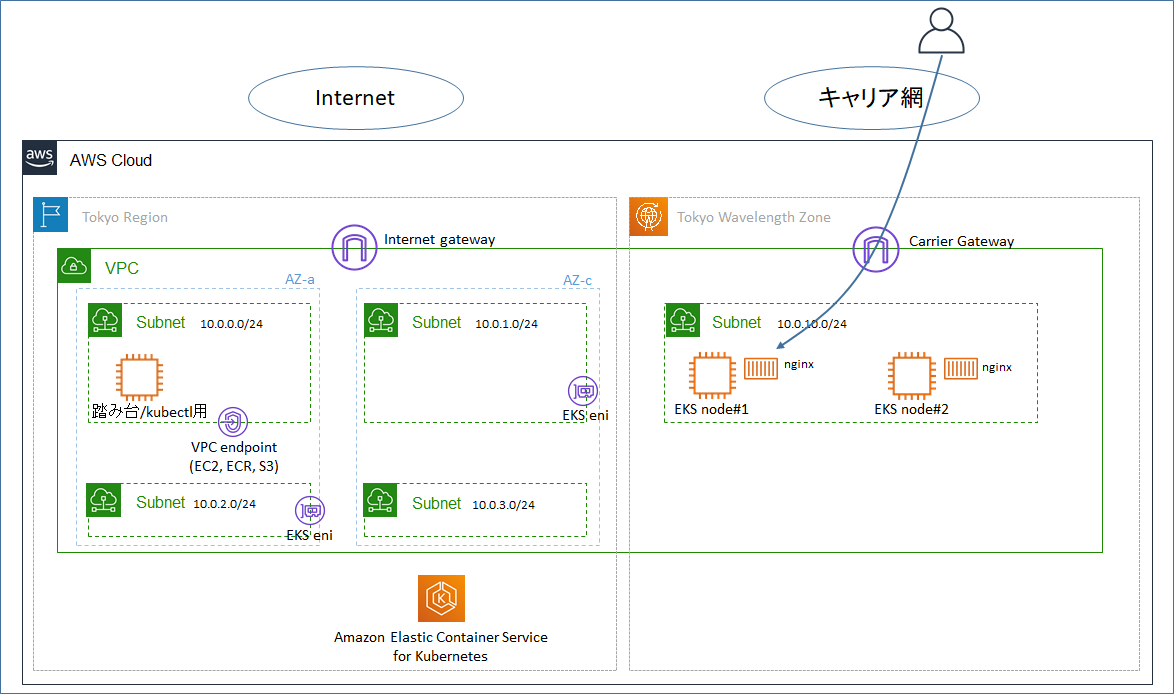
3.構成図
4.予習
公式ドキュメント「Wavelength considerations and quotas」にWavelength上でEKSを利用する場合の注意点の記載がある。それを参考に環境を構築する。
以下は2020/2時点の上記サイトでのEKSに関する注意事項の内容。
Amazon Elastic Kubernetes Service considerations
Take the following information into consideration when you run an Amazon EKS cluster:
- You must run Kubernetes 1.17 or later.
- When you create your Amazon EKS cluster, you must select an Availability Zone in the VPC, and not a Wavelength Zone.
- When you create your Amazon EKS cluster for private subnets only, you need to add VPC endpoints for Amazon ECR and Amazon Simple Storage Service. For more information, see Amazon VPC considerations.
- To create node groups in Wavelength Zones for your Amazon EKS cluster, see Launching self-managed Amazon Linux 2 nodes in the Amazon EKS User Guide.
- To apply the aws-auth ConfigMap to your Amazon EKS cluster, see Managing users or IAM roles for your cluster in the Amazon EKS User Guide.
記載事項に対して結果的には以下のような対応とした。
- Kubernetesのバージョンは1.18(執筆時点の最新)とした。
- EKSクラスターを作成する時、東京リージョンのサブネットを指定した。
- パブリックサブネットも存在しているVPCを作ったが、結果としてVPCエンドポイントも作成した。(作成しないと動作しなかった)
- Wavelength Zoneにノードグループを作成する際、「self-managed Amazon Linux nodes」の手順を使用した。
- aws-auth ConfigMapの手順を実施した。
元々、プライベートなVPC環境にEKSを構築する場合の手順(VPCエンドポイントの作成など)が準備されており、基本的にはそれらの手順を実行すればよいと理解した。
5. 作業手順
5.1 VPCの作成
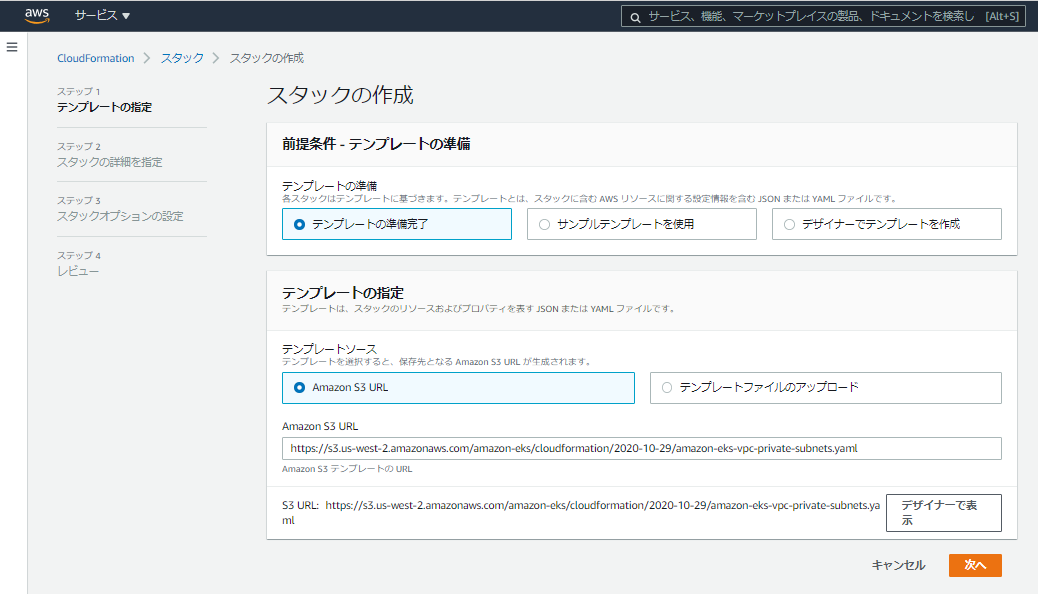
- 公式ドキュメント「Getting started with Amazon EKS – AWS Management Console and AWS CLI 」に従い、EKSを動かす用のVPCを作成する。
- 2021/2時点でのドキュメントでは、CloudFormationのスタックをCLIから実行して作成しているが、今回はマネージメントコンソールのGUIから実行し、CIDRなどのパラメータを変更する。
- CloudFormationのスタックの作成画面にて、AWSが提供するCloudFormationテンプレートを指定する。
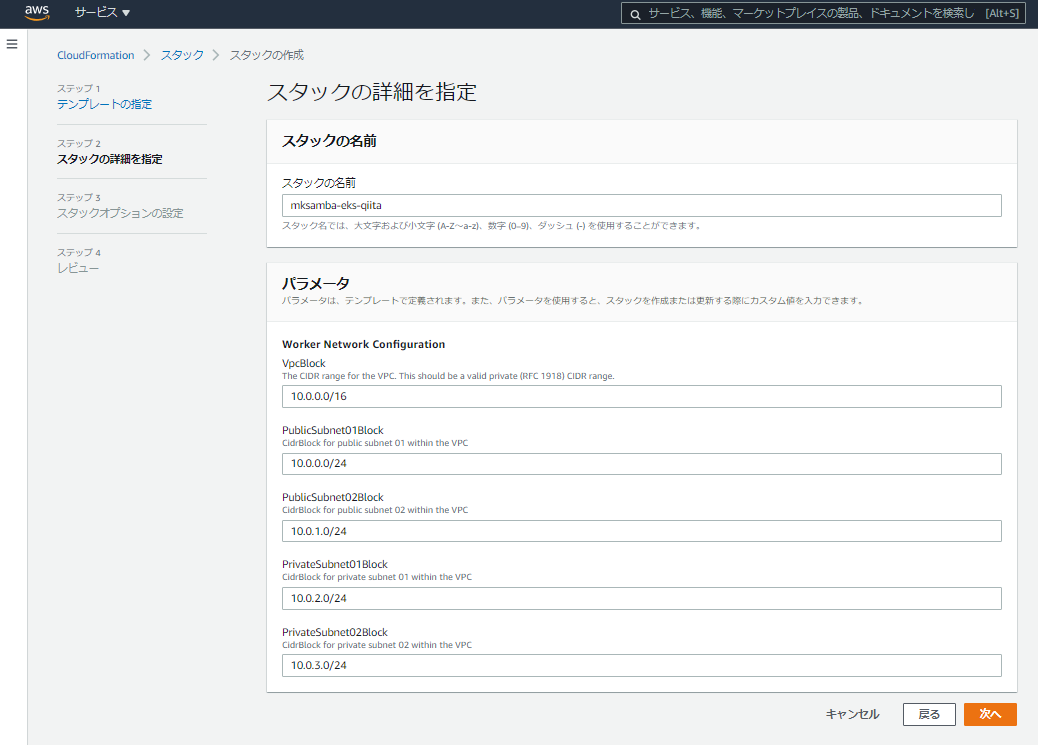
- スタック名をmksamba-eks-qiita とし、CIDRを分かりやすい体系(10.0.0.0/16ベース)に変更する。他の値は特に変更せずにスタックを生成する。
- スタックの作成が成功すると、VPC、サブネット(Public 2個、Private 2個)、InternetGateway、NatGateway(2個)、EKS用のセキュリティグループなどが作成される。
5.2 EKSクラスターロールの作成
- 引き続き公式ドキュメント「Getting started with Amazon EKS – AWS Management Console and AWS CLI 」に従い、EKSクラスター用のロールを作成する。
- 今回は「mksamba-eks-cluster-role」という名前でロールを作成している。ポイントとしては以下2点。
- アクセス権限としてポリシー「AmazonEKSClusterPolicy」がアタッチされていること。「AmazonEKSClusterPolicy」には、EC2インスタンスやELBを操作する権限が含まれる。
- 信頼されたエンティティとして、「eks.amazonaws.com」が登録されていること。
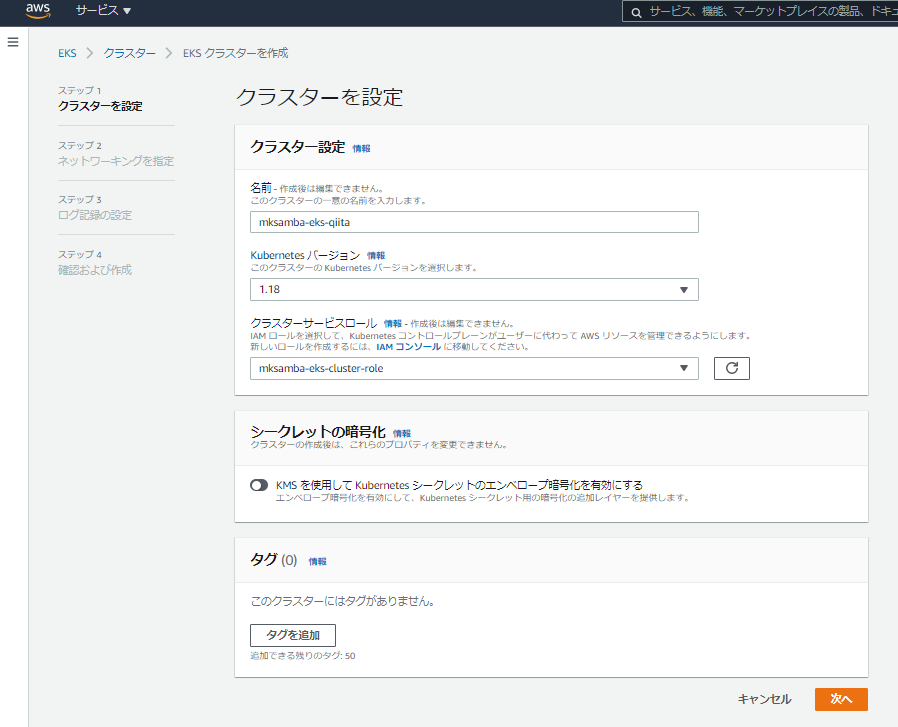
5.3 EKSクラスターの作成
- 引き続き公式ドキュメント「Getting started with Amazon EKS – AWS Management Console and AWS CLI 」に従い、EKSクラスターを作成する。
- 「EKS > クラスタ」から、クラスターの作成を行う。
- クラスタ名「mksamba-eks-qiita」を設定し、クラスターサービスロールとして先の手順で作成したロール「mksamba-eks-cluster-role」を指定する。
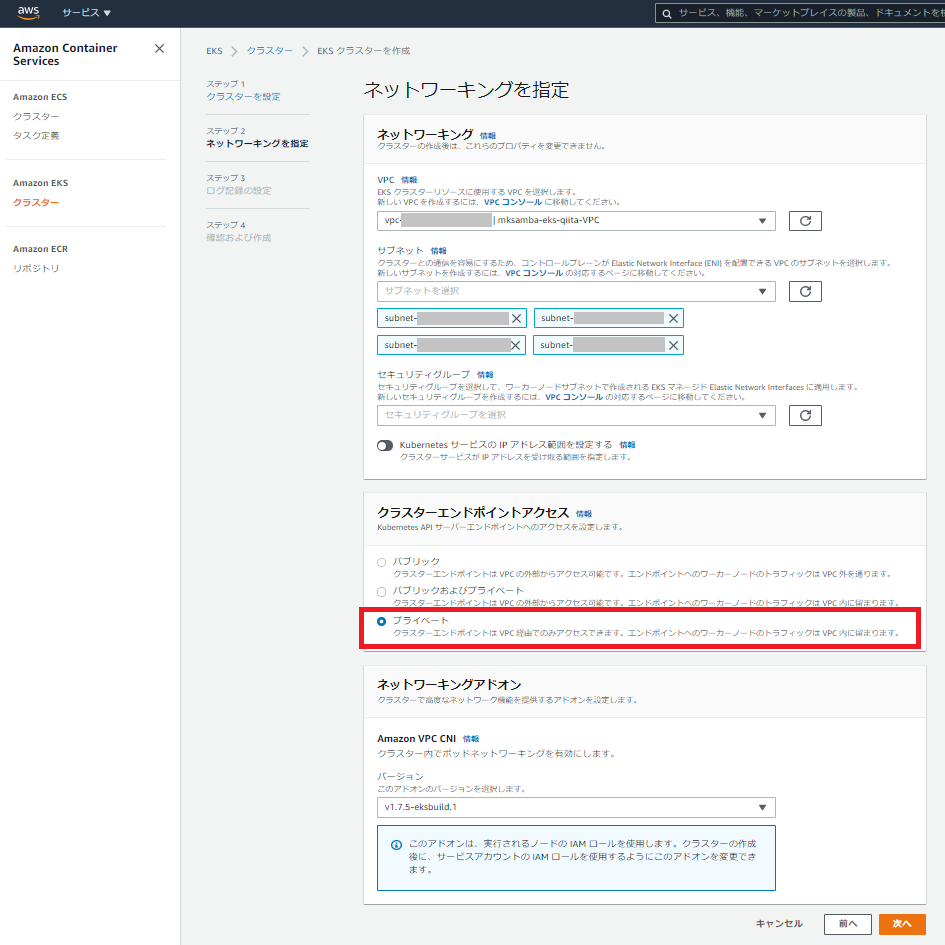
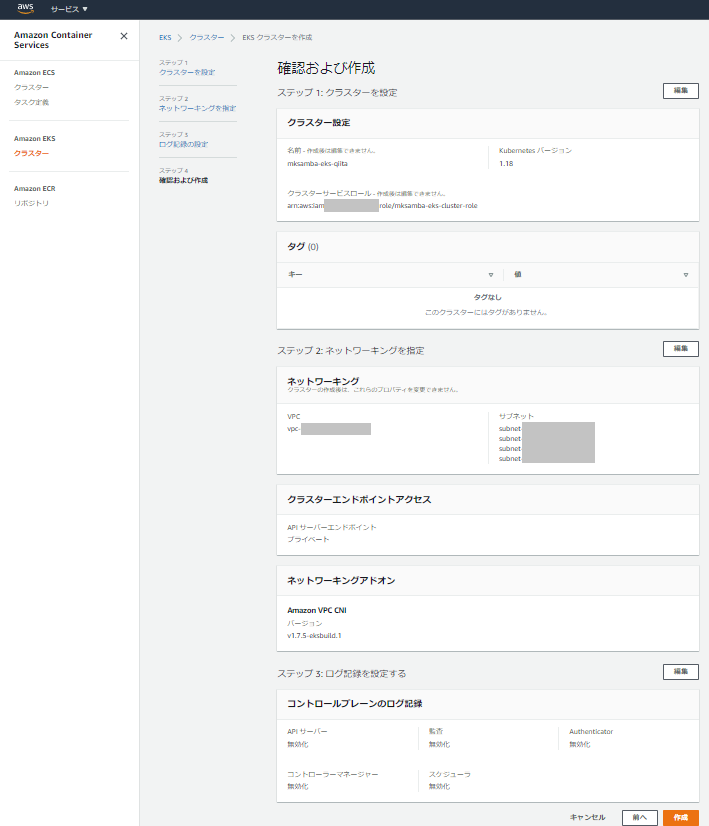
- EKSを使用するVPCとして、先の手順で作成したVPC「mksamba-eks-qiita-VPC」を指定し、サブネットもそのまま4つ選択する。今回はクラスターエンドポイントアクセスを「プライベート」にする。
- 内容を確認しEKSクラスタの作成を行う。
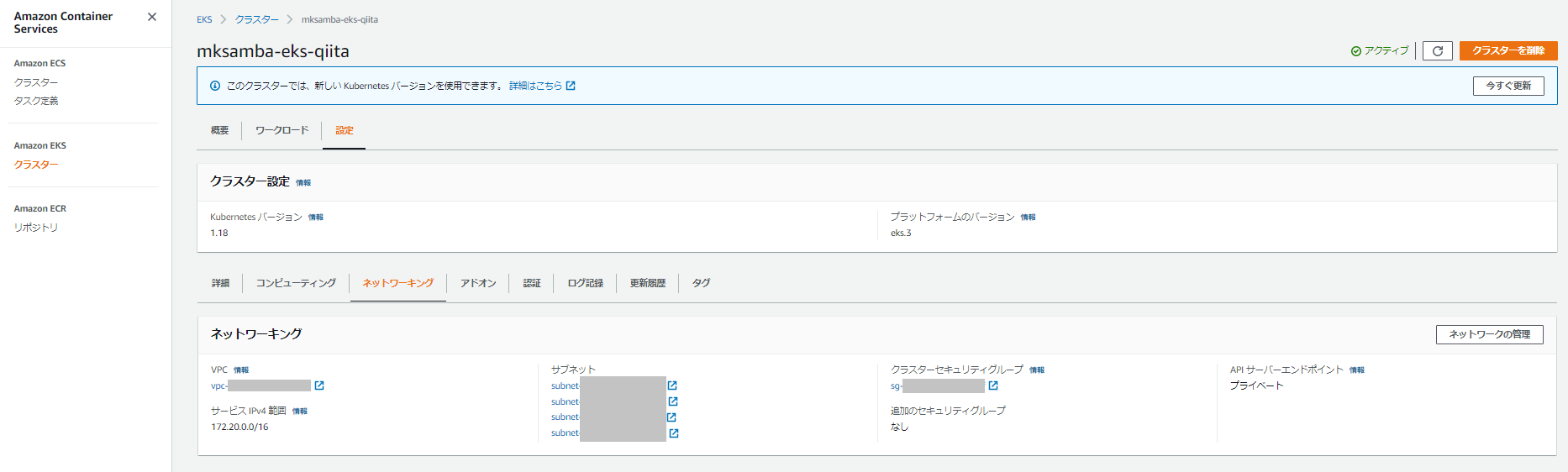
- クラスターが無事作成され、エンドポイントがプライベートになっていることを確認する。
5.4 作業用インスタンスの作成
- 作成したVPCのPublic Subnetに、作業用のインスタンス(踏み台&kubectl実行用)を作成し、aws cli(v2)、kubectl を入れておく。手順は以下(公式ドキュメント)を参照。
[ec2-user@ip-10-0-0-130 ~]$ aws --version aws-cli/2.1.27 Python/3.7.3 Linux/4.14.214-160.339.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off [ec2-user@ip-10-0-0-130 ~]$ kubectl version --short --client Client Version: v1.18.9-eks-d1db3c
- aws eks update-kubeconfig コマンドにより、今回作成したEKSクラスターの操作ができるようにする。
[ec2-user@ip-10-0-0-130 ~]$ aws eks update-kubeconfig --region ap-northeast-1 --name mksamba-eks-qiita Added new context arn:aws:eks:ap-northeast-1:XXXXXXXXXXXX:cluster/mksamba-eks-qiita to /home/ec2-user/.kube/config [ec2-user@ip-10-0-0-130 ~]$ kubectl get svc ^C ※この時点では接続不可
- EKSクラスターとの通信ができない状態のため、EKSクラスタとの接続用のセキュリティグループを変更し、VPC内からの接続を許可する(Inbound 10.0.0.0/16 に対して許可ルールの追加)。その結果、kubectl get svc ができることを確認する。
[ec2-user@ip-10-0-0-130 ~]$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 172.20.0.1 <none> 443/TCP 2d23h
- AZごとにEKSクラスターと接続するためのエンドポイントが存在していることを確認する。(エンドポイント名はEKSクラスターの管理画面で確認可能)
[ec2-user@ip-10-0-0-130 ~]$ nslookup XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.yl4.ap-northeast-1.eks.amazonaws.com Server: 10.0.0.2 Address: 10.0.0.2#53 Non-authoritative answer: Name: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.yl4.ap-northeast-1.eks.amazonaws.com Address: 10.0.2.178 Name: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.yl4.ap-northeast-1.eks.amazonaws.com Address: 10.0.1.615.5 Wavelength関連リソースの設定
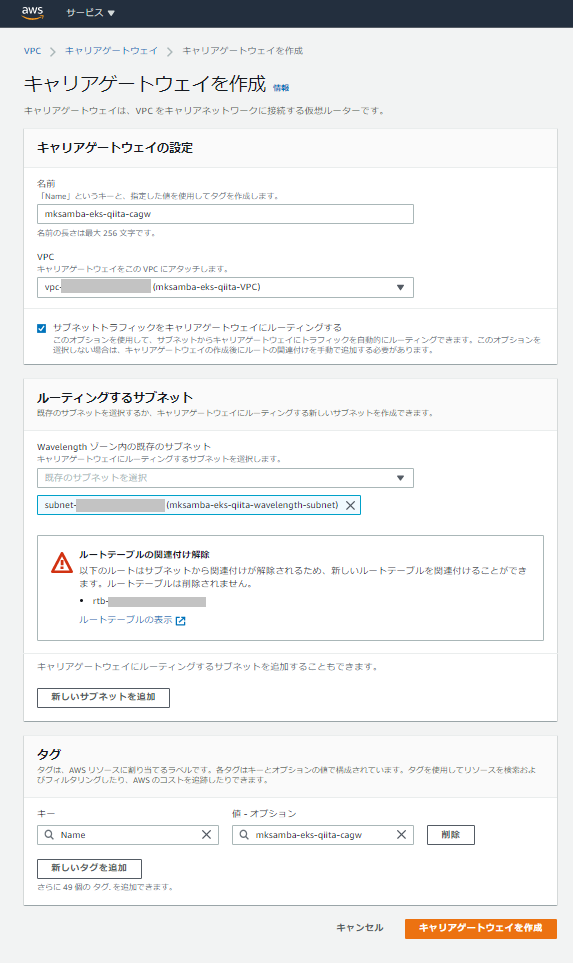
- 5.1の手順で作成した本検証用のVPCに対し、Wavelength関連のリソースの追加作成を行う。
- 東京Wavelength Zone (ap-northeast-1-wl1-nrt-wlz-1)にサブネット10.0.10.0/24を作成する。
- キャリアゲートウェイの作成、キャリアゲートウェイへのルートを含むルートテーブルの作成、サブネットへのルートテーブルの関連付けを行う。
5.6 ノードグループの作成
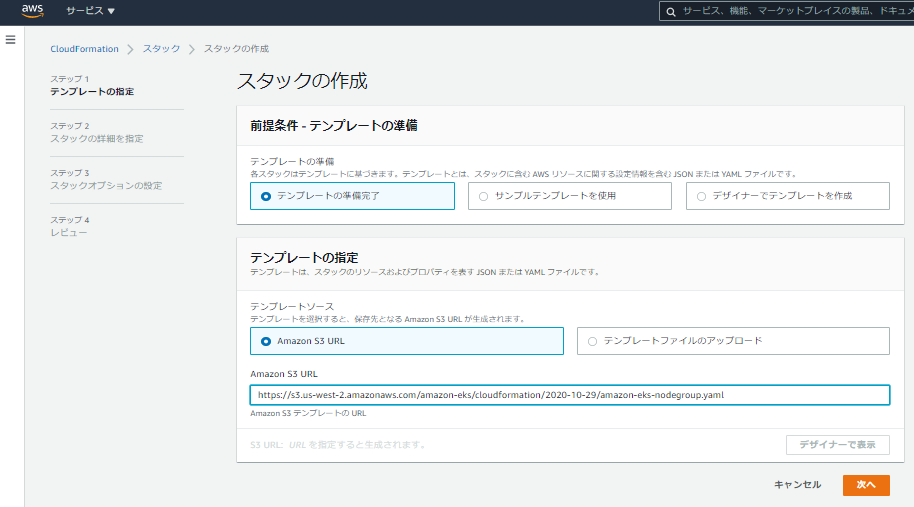
- 公式ドキュメント「セルフマネージド型 Amazon Linux ノードの起動」に従い、ノードグループを作成する。
- ノードグループを作成する用のCloudFormationテンプレートを指定してスタックを作成する。(ステップ1:テンプレートの指定)
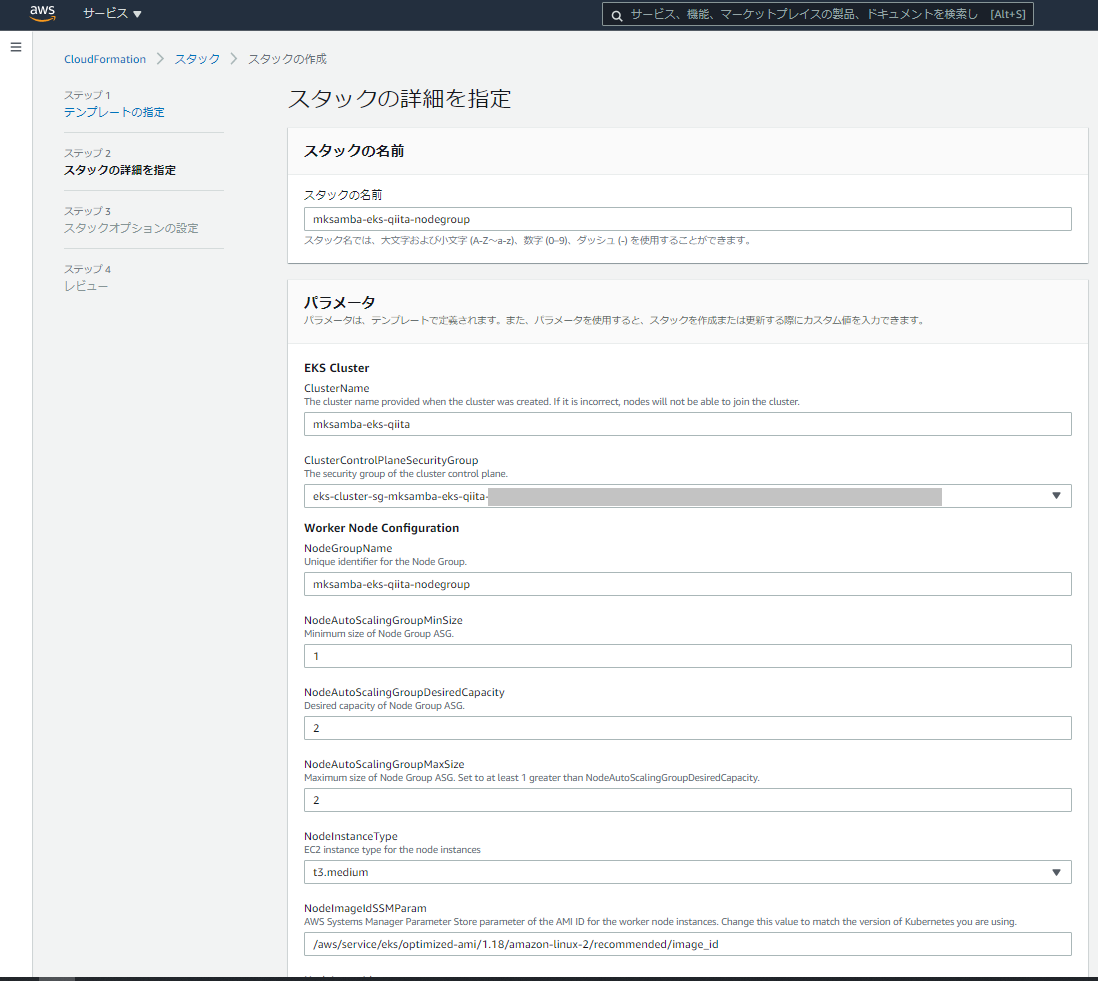
- スタック作成のためのパラメータを入力する。(ステップ2: スタックの詳細を指定)
- ClusterName: 既に作成済のEKSクラスタの名前(今回は「mksamba-eks-qiita」)
- ClusterControlPlaneSecurityGroup: EKSクラスタのセキュリティグループ。EKSクラスタを作成した時に合わせて作成されているものを指定する(今回は「eks-cluster-sg-mksamba-eks-qiita-XXXXXXXXXXX」)
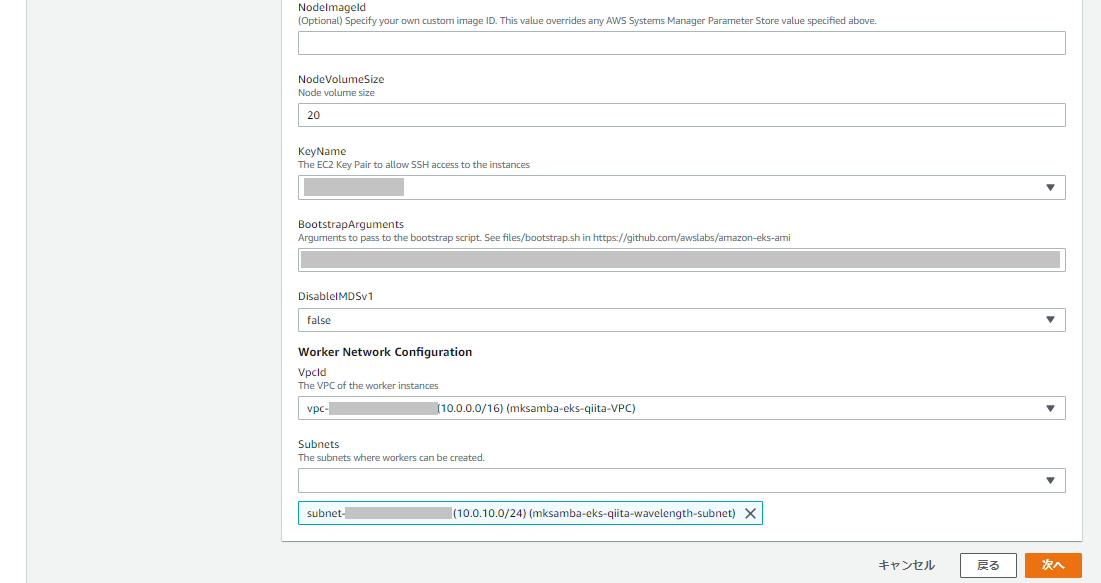
- NodeImageIdSSMParam: 埋め込まれている値の「1.17」の部分を、クラスター側のバージョンにあわせて「1.18」に変更(今回は 「/aws/service/eks/optimized-ami/1.18/amazon-linux-2/recommended/image_id」)
- BootstrapArguments: EKSクラスターのエンドポイントと認証機関の値を設定する。「--apiserver-endpoint "EKSクラスター のAPIサーバエンドポイント" --b64-cluster-ca "認証機関"」それぞれの値はEKSクラスターの管理画面で参照可能。
- Subnets: Wavelength zone に作成したサブネットを指定。
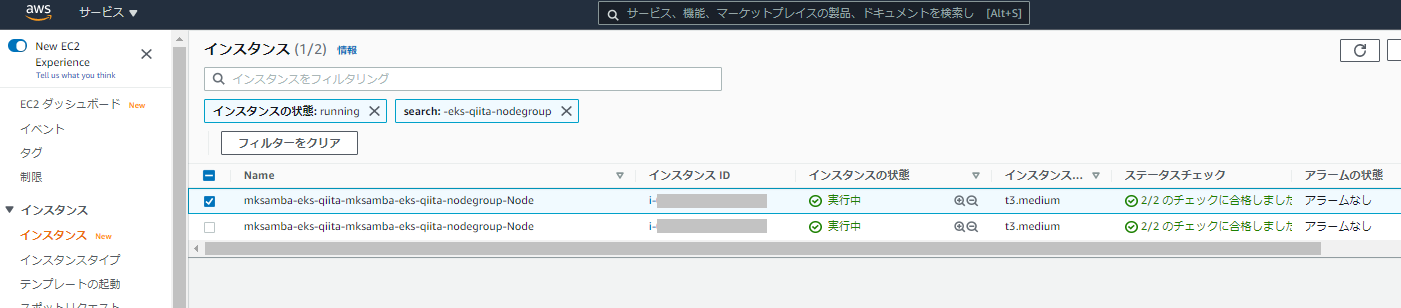
- スタックオプションは特に変更せず、設定内容を確認してスタック作成を開始する。(ステップ3: スタックオプション、ステップ4: レビュー)
- スタックの作成が完了すると、指定した数のインスタンスが起動される。
5.7 IAM オーセンティケーター設定マップの適用
- 公式ドキュメント通りに、configmapの設定を行う。
[ec2-user@ip-10-0-0-130 ~]$ cat aws-auth-cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::XXXXXXXXXXXX:role/mksamba-eks-qiita-nodegroup-NodeInstanceRole-XXXXXXXXXXXXX username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes [ec2-user@ip-10-0-0-130 ~]$ kubectl apply -f aws-auth-cm.yaml configmap/aws-auth created5.8 VPCエンドポイントの追加
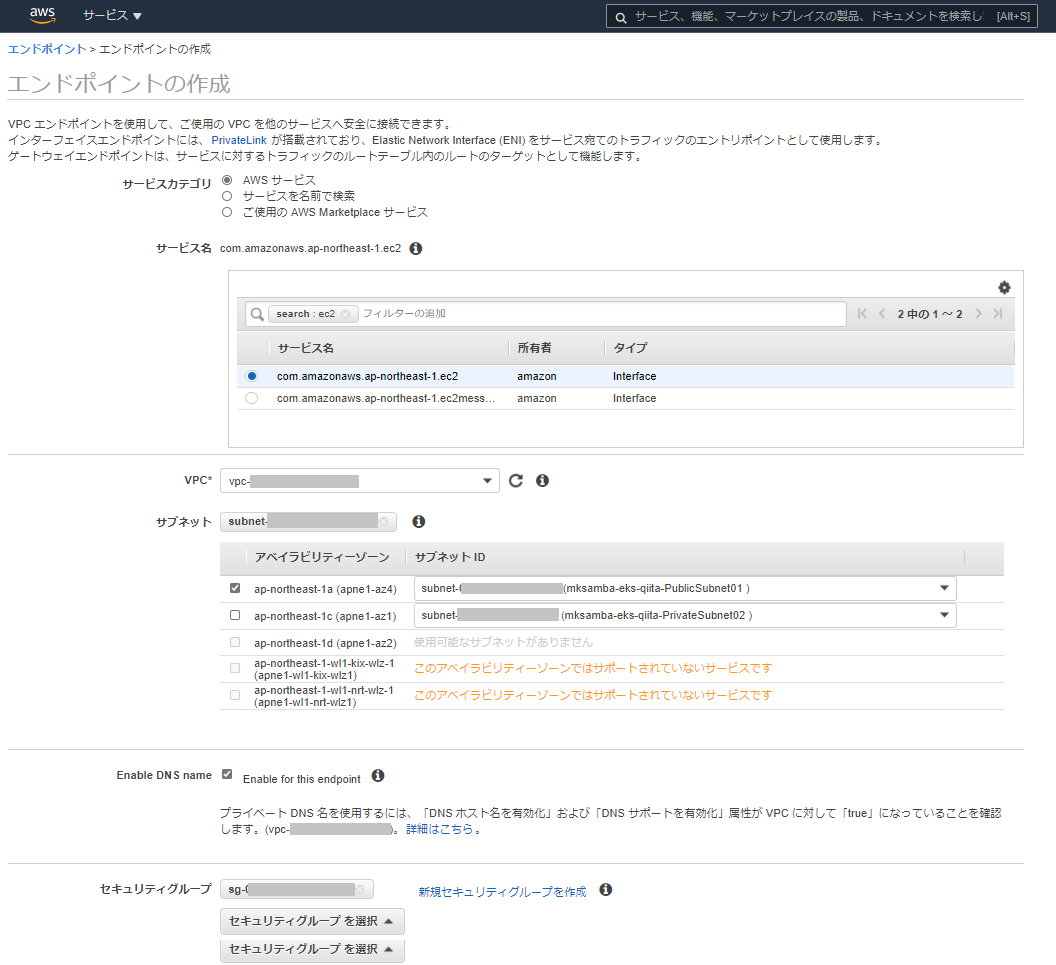
- 公式ドキュメント「プライベートクラスター」に従い、VPCエンドポイントを作成する。
- 以下の3つのインタフェースエンドポイントを作成する(画面はcom.amazonaws.ap-northeast-1.ec2のもの)。
- com.amazonaws.ap-northeast-1.ec2
- com.amazonaws.ap-northeast-1.ecr.api
- com.amazonaws.ap-northeast-1.ecr.dkr
- 今回は検証のため、1個のサブネット(東京リージョンのPublicSubnet01)のみにエンドポイントを作成している。
- エンドポイントのセキュリティグループ設定(Inbound)として、VPCのCIDR(10.0.0.0/16)を追加で許可している。
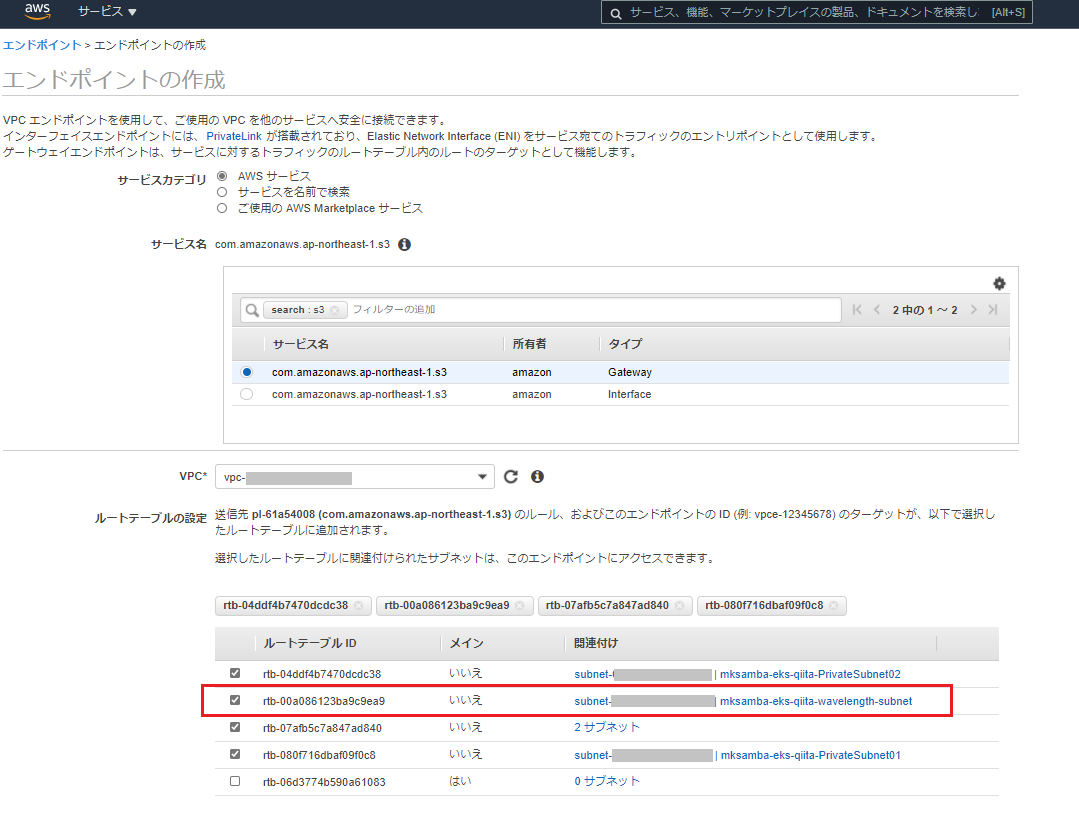
- 以下のゲートウェイエンドポイントを作成する。
- com.amazonaws.ap-northeast-1.s3
- 「ルートテーブルの追加」設定において、wavelength zoneに作成したサブネットも対象として選択する。
- エンドポイントの設定完了後、kubectl get nodes でnodeがReadyであることが確認できる。
[ec2-user@ip-10-0-0-130 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-10-0-10-132.ap-northeast-1.compute.internal Ready <none> 7m43s v1.18.9-eks-d1db3c ip-10-0-10-70.ap-northeast-1.compute.internal Ready <none> 7m42s v1.18.9-eks-d1db3c5.9 ノード(インスタンス)へのキャリアIPのアサイン
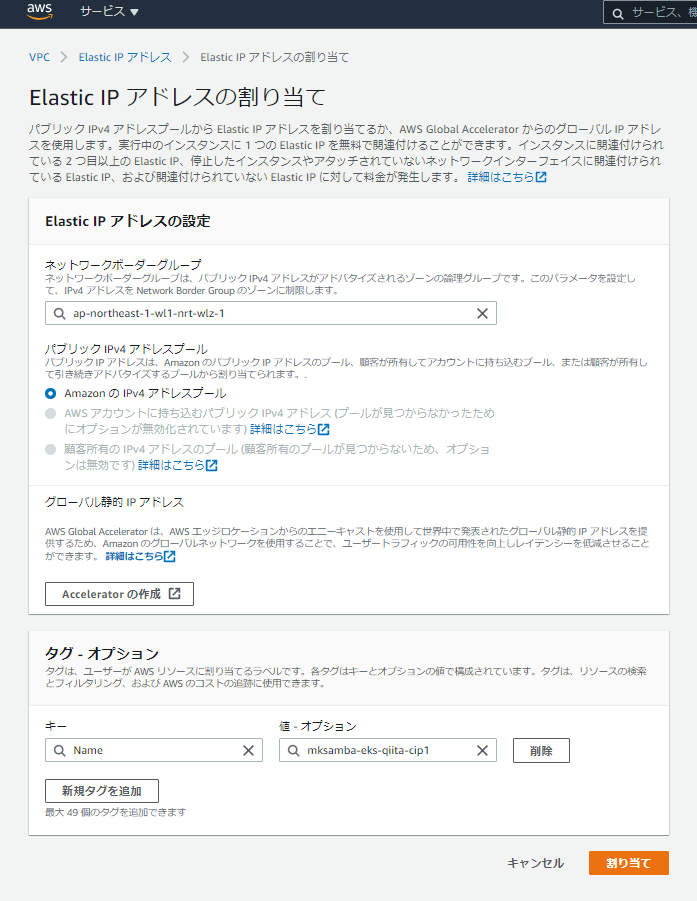
- ノードやコンテナに外部(キャリア網)からアクセスできるようにするため、キャリアIPのアサインを行う。
- Elastic IP アドレス割り当ての画面にて、ネットワークボーダーグループに「ap-northeast-1-wl1-nrt-wiz-1」を指定して割り当てを実行する。そうすると、東京Wavelength ZoneのキャリアIPが取得できる。
- 取得したキャリアIPを、Wavelengh上のワーカーノードに紐づける。
- Elastic IPアドレスの関連付けの画面で、対象のENIを指定して関連付けを行う。(ワーカーノードとなるインスタンスは、ENIを複数持つため、インスタンスIDの指定ではキャリアIPを紐づけることができない。)ENIはインスタンスの管理画面で確認可能。元々あるENI(「説明」欄が空欄のほうのENI)のIDを確認し、関連付けの画面で指定する。
5.10 NodePortでの動作確認
- nginx を Deploymentとして作成し、nodeportで公開する。
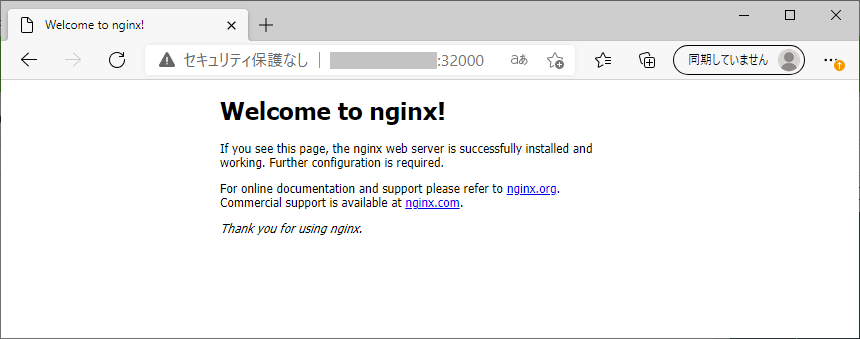
[ec2-user@ip-10-0-0-130 ~]$ cat nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx name: nginx [ec2-user@ip-10-0-0-130 ~]$ kubectl apply -f nginx-deployment.yaml deployment.apps/nginx-deployment created [ec2-user@ip-10-0-0-130 ~]$ cat nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx-service spec: type: NodePort selector: app: nginx ports: - port: 80 targetPort: 80 nodePort: 32000 [ec2-user@ip-10-0-0-130 ~]$ kubectl apply -f nginx-service.yaml service/nginx-service created
- auスマホでテザリングしたPCから、「http://キャリアIP:32000/」にアクセスして、nginxの画面が開けることを確認する。
6. 所感
- それなりに設定項目があり、結構長い記事になってしまった。もう少し手順が整理できるのかもしれない。



- 投稿日:2021-02-26T18:04:25+09:00
AWS障害が起こったときにやること覚書
2/19のAWS障害を受けて、やっておけば良かったことメモ
・対象のAZ確認
-> アナウンスではap-northeast-1cだけだったが、1a/1dのインスタンスへの疎通も問題なかったか確認すべき・対象のサービス/インスタンスにsshログインなどし、疎通状況を確認
・アナウンスされている障害範囲以外のサービスに対しても疎通確認を行う (アナウンスよりも影響範囲が広い可能性もある
-> RDSやElastiCacheなど、EC2以外に利用しているサービスについても疎通確認すべき・サポートケースを最高優先度で作成
-> 障害収束後に作成はしたが、障害発生中に作成してサポートを受けるべき・リアルタイムな障害状況はここで確認
https://status.aws.amazon.com/#AP_block
- 投稿日:2021-02-26T17:17:23+09:00
ECSのタスク定義で起きたエラーを「awslogs」で確認する方法
毎日投稿しているのですが、本当にネタが尽きない。
今友人の頼みでVue.jsとLaravel、Firebase、Stripe、AWSを使ってサイトを制作しているのですが、世の中便利になったと毎日感じております。
今日はそんなこんなでDockerで作ったコンテナを実際のサーバーで動かしたときってECRのリポジトリへプッシュしてECSでタスクやらクラスターを作成しますよね。
ただ、最近ECSでクラスターを作成し、タスクを実行するときに何回やってもエラー起きたんです。
ECSのクラスターでエラーが起きた時ってどこで起きたかが非常に分かりづらい。。。
それを解決してくれるのがawslogsです!
今日はそのawslogsをECSで使用する方法をお教えします!!
めちゃめちゃ簡単なので、ECSのタスク定義でエラーが出て困っている方はぜひご利用ください。
それでは説明していきます!!
IAMユーザーの権限
IAMユーザーで作業を行う場合、下記の権限を追加してください。
・CloudWatchFullAccess
IAMユーザーで作業を行わない場合はスキップしてください。
awslogsの設定
タスク定義で「コンテナの追加」から任意のコンテナを作成します。
その時に「ストレージとログ」で「ログドライバー」を「awslogs」にします。
すると画像のように勝手に設定されます。
このままで大丈夫です。
タスク実行画面からawslogsの確認
クラスター内でタスクの実行を行い、実行したタスクの画面の画面へ行き、コンテナ内で以下の画像のように「CloudWatchのログを表示」をクリック。
するとCloudWatch内でログが表示されます!
このようにしてクラスター内のタスクで起きたエラー内容を確認することができます。
プログラミングはエラー解決にかける時間の方が多いのでこういったところからエラー解決時間を減らしていきましょう!!
以上、「ECSのタスク定義で起きたエラーを「awslogs」で確認する方法」でした!
良ければ、LGTM、コメントお願いします。
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
あと、最近「ココナラ」で環境構築のお手伝いをするサービスを始めました。
気になる方はぜひ一度ご相談ください!
Thank you for reading


- 投稿日:2021-02-26T16:30:55+09:00
ec2でsudo以外でもパスワードなしで、インストールできるようにする
ec2userにログインしてから、
$ sudo visudoNOPASSWD:ALLで、sudo権限をパスワードなしで実行できる。
root ALL=(ALL) ALL user ALL=(ALL) NOPASSWD:ALL
- 投稿日:2021-02-26T16:17:06+09:00
量子アニーリングマシンD-Waveで良い解を出すためのコツ(前編)
この記事の概要
これまでエンジニアにとって身近に感じることが難しかった量子コンピュータですが、AWSが提供するAmazon Braketのローンチを皮切りにエンジニアにとっても身近なものとなりつつあると感じています。
そこで、量子アニーリングマシンとして世界的に最も有名でありAmazon Braketでも利用ができるD-Waveを使ってみたのですが、良い解を求めるためにチューニングする際のコツがありそうだったのでまとめてみました。
要約すると、
- チューニングポイントは「制約項の係数」「チェーン強度」「サンプリング回数」
- 制約項の係数を調整するにはPyQUBOのプレースホルダーをうまく活用する
- チェーン強度は強くするべきだが、QUBO内の値を意識しながら強くしすぎないように調整する
- サンプリング回数は多ければ多いほどいいが、金額の問題や上限が10000回であることに注意する
といった内容になります。
なお、私自身量子コンピュータについて勉強中の身ですので、間違ったことを書いている可能性もありますが、その場合は優しく指摘いただければと思います。
D-Waveを使うにあたって
D-Waveについて
知っている人は飛ばしてOKです
ここ最近は汎用的な量子計算ができるとされている「量子ゲートマシン」が界隈を賑わせている印象がありますが、D-Waveはそれとは異なり、組合せ最適化計算に特化した「量子アニーリングマシン」です。
(もしかしたら表現が不適切かもしれないですが、量子ゲートマシンと量子アニーリングマシンの対応関係は、汎用的な処理ができるパソコンと四則演算に特化した電卓の対応関係に似ているような気がしています。)組合せ最適化というジャンルで代表的に上げられるものが巡回セールスマン問題です。
このような爆発的に解の組合せが増えてしまうために逐次的に解を探索することが難しい問題を得意としているものが、D-Waveのようなマシンとなります。そんなD-waveは「D-Wave Advantage」という5760Qubitを搭載したマシンをリリースしており、トポロジ(Qubit同士の接合方式のようなもの)もより効率の良い方式となってきています。
これにより、今まで解くことができなかった規模の大きな問題にも対応できるようになりつつあります。
とは言っても、10都市強の巡回セールスマン問題を解くことができる程度ですが…。そんなD-Waveですが、PoCではあるものの企業に利用されてきていたり、今後更に搭載Qubitを増やしていく予定となっていたりと良いニュースも増えています。
というわけで、D-Waveを軽く使ってみたいなと思い触ってみたものの、なかなかいい解を導けないぞ?と思い、色々調べながら試行錯誤した結果なんとなく導き出したコツをここにまとめます。
D-Waveで求解をする流れ
流れとしては以下の通りです。
- 問題を定式化する
- 定式化したものをQUBOに変換する★1
- QUBOを入力としてD-Waveに求解させる
- Qubitに問題の埋め込みをするための前処理が行われる★2
- 量子トンネル効果を利用して求められた変数の組合せを複数回観測する★3
- 観測結果のなかで最もエネルギーが低い変数の組合せを最適な組み合わせとして出力する
この中で今回工夫してみる部分が★のところです。
★1では、制約項をQUBOに入れ込むときの係数の調整を行います。
★2では、Qubitの埋め込みをするときに、1つの変数を複数のQubitに割り当てるような動作をするのですが、論理的に同じ変数として割り当てられたQubitがバラバラにならないようにチェーン強度というものを調整します。
★3では、量子効果は確率的な現象なので必ずしも一発で正しい解が出るとは限らないので、なるべく多く観測を行うよう設定をします。詳細については後述していきます。
試しにやってみる
この記事での前提
環境
プラットフォーム:AWS(AmazonBraket)
ソルバ:D-Wave Advantage_system1.1
ノートブックインスタンス:ml.t3.medium求解対象
今回は以下のような6都市のTSPを求解します。
cities = [ ('0', (0,0)), ('1', (17,8)), ('2', (23,0)), ('3', (27,15)), ('4', (70,20)), ('5', (52,0)) ]こんな感じの格好の配置となります。
★1 制約項の係数を調整する
定式化した問題をQUBOに落とし込む際に制約項もQUBOに入れる必要があります。
そもそもQUBOというものは「制約なし二次形式二値変数最適化(Quadratic Unconstrained Binary Optimization)」の略です。(詳しくはこちら)
…え?制約なしって言ってるのに制約を考える必要があるの?と思った方は勘が鋭いですね。
実はここで言っているのは、制約を別式として明示的に設定しませんという意味なのです。
つまり、もし制約がある場合は制約を制約項として目的関数の中にうまく含める必要があります。定式化についての細かい解説は他に譲らせていただきますが、今回TSPを解くにあたっての制約はおなじみの以下2つです。
- 一度に二箇所以上へ訪問しない
\sum_{a}^{n}x_{a,i} = 1
- 各都市必ず一度だけ訪問する
\sum_{i}^{n}x_{a,i} = 1一方、TSPにおける目的関数は距離を最小化するような式となるので以下のような式となります。
この値は小さければ距離が短いことを示すので、小さければ小さいほどよいということになります。
(これを距離項と言ったりしますね。)\frac{1}{2}\sum_{i,j,a}^{n}d_{i,j}x_{a,i}(x_{a+1,j}+x_{a-1,j})この式に対して先程の2つの制約を制約項として加えるとすると、それぞれの制約項は次の通りとなります。
この値がそれぞれ0となっていることが制約を満たしていることを示します。\sum_{i}^{n}(\sum_{a}^{n}x_{a,i} - 1)^2\\ \sum_{a}^{n}(\sum_{i}^{n}x_{a,i} - 1)^2あとは距離項と制約項を足したハミルトニアン$H$をQUBO行列化します。
ハミルトニアン$H$はこのように書くことができます。H=\frac{1}{2}\sum_{i,j,a}^{n}d_{i,j}x_{a,i}(x_{a+1,j}+x_{a-1,j})+\lambda(\sum_{i}^{n}(\sum_{a}^{n}x_{a,i} - 1)^2)+\sum_{a}^{n}(\sum_{i}^{n}x_{a,i} - 1)^2)前置きが長くなりましたが、ここで重要となってくるのが$\lambda$のチューニングです。
制約項の係数である$\lambda$を調整する際に便利なのがPyQUBOです。通常、QUBO行列を生成するときにfor文を何個も書いてその中に制約項の係数を入れたり入れなかったりしながらQUBO行列を生成するのですが、可読性が悪く、どこに制約項の係数がかかってくるのかとか数式で言うとどこの部分を指しているのかとかがわかりにくいソースコードとなります。
これにより、制約項の係数をチューニングしたくても簡単にできない点が課題となります。
しかし、PyQUBOを使うことで数式をほぼそのままの形でQUBO化してくれる上に、制約項の係数のチューニングをしやすい仕掛けも備えています。
その仕掛けがプレースホルダー機能です。
プレースホルダー機能を使ってQUBO化するまでのソースはこんな感じです。# 一度に二箇所以上へ訪問しない time_const = 0.0 for i in range(n_city): time_const += Constraint((sum(x[i, j] for j in range(n_city)) - 1)**2, label="time{}".format(i)) # 各都市必ず一度だけ訪問する city_const = 0.0 for j in range(n_city): city_const += Constraint((sum(x[i, j] for i in range(n_city)) - 1)**2, label="city{}".format(j)) # 距離コスト distance = 0.0 for i in range(n_city): for j in range(n_city): for k in range(n_city): d_ij = dist(i, j, cities) distance += 1/2 * d_ij * x[k, i] * (x[(k+1)%n_city, j]+x[(k-1)%n_city, j]) # ハミルトニアン生成 A = Placeholder("A") H = distance + A * (time_const + city_const) # モデルコンパイル model = H.compile() # QUBO生成 feed_dict = {'A': 100.0} qubo, offset = model.to_qubo(feed_dict=feed_dict)このように
Aというプレースホルダーを使って制約項の係数$\lambda$を仮で置くことができます。
こうすることで後から微妙に調整してもう一回QUBOを生成したいとか、何パターンか$\lambda$を設定してQUBOを生成して求解結果がいいものを採用したいとかいう場合に、ここ↓のブロックだけを実行すれば良くなります。# QUBO生成 feed_dict = {'A': 100.0} qubo, offset = model.to_qubo(feed_dict=feed_dict)で、私自身D-Waveを実際に動かしてみるとなかなかいい解にはたどり着かず、ケースバイケースで制約項の係数をちょっとずつ調整をしたり、制約項の係数を変えた場合の解の比較をするような場面も結構あり、PyQUBOの機能に度々助けられました。
こんな感じで、PyQUBOはとても便利なのです。前編はここまで
後編では★2、★3の部分についての解説をしていきます。
特に個人的に激アツなのは★2の部分なのでぜひご覧になっていただければと思います
(後編に続く※現在執筆中)なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています。
よろしければこちらの記事も参照いただければと思います!

- 投稿日:2021-02-26T15:59:14+09:00
ec2でssh接続した際、Too many authentication failuresが出た時の解決法
% ssh -i foo.pem ec2-user@*******から
% ssh -o IdentitiesOnly=yes -i ~/.ssh/foo.pem -l ec2-user ************に変えると、ログインすることができるようになりました。
- 投稿日:2021-02-26T14:26:45+09:00
.NETでDockerを利用したローカル開発時にもAWS Profileを使ってシークレットを安全に引き渡す
はじめに
ローカル開発時に.NETのプログラムからAWSの各サービスを利用するには、認証情報としてAWSのプロファイル情報を利用するか、アクセスキーとシークレットキーを設定する必要があります。プログラムの設定ファイルなどにアクセスキーやシークレットキーを記載すると、誤ってソース管理リポジトリに公開してしまう危険があるため、可能であればAWSプロファイルを利用してAWSに接続することが推奨されます。
この記事では、Dockerを利用したローカル開発時に、AWS Profileを利用してシークレットを安全に取り扱う方法について解説します。プロファイルを利用した.NET CoreでのAWSサービスの利用
.NET CoreでAWSの各サービスを利用する場合は下記のドキュメントに記載されている通り、設定ファイル(
appsettings.json)に利用するAWSのプロファイル情報を定義し、Startup時にAddDefaultAWSOptions拡張メソッドで前述の設定内容を有効にすることが推奨されています。
https://docs.aws.amazon.com/ja_jp/sdk-for-net/v3/developer-guide/net-dg-config-netcore.html具体的には、下記のようになります。
appsettings.json{ "AWS": { "Profile": "DevProfile", "Region": "ap-northeast-1" } }Startup.cs(AWSサービスのDI設定)public class Startup { public Startup(IConfiguration configuration) { Configuration = configuration; } public IConfiguration Configuration { get; } public void ConfigureServices(IServiceCollection services) { services.AddDefaultAWSOptions(Configuration.GetAWSOptions()); services.AddAWSService<IAmazonSecretsManager>(); /// ... 略 ... } /// ... 略 ... }サービスの利用public class HomeController : ControllerBase { private readonly IAmazonSecretsManager _amazonSecretsManager; public HomeController (IAmazonSecretsManager amazonSecretsManager) { _amazonSecretsManager = amazonSecretsManager; } public async Task<string> Get() { var secret = await _amazonSecretsManager.GetSecretValueAsync(new GetSecretValueRequest { SecretId = "MySecret" }); return secret.SecretString; } }Visual StudioでIISにホストしたり、
dotnet runでWebサイトをセルフホストした場合はこれで問題ありませんが、Dockerにホストした場合はDocker内に設定ファイル(appsettings.jsonで指定した)AWSプロファイルが存在しないため、下記のような例外が発生します。AWSプロファイルからAWSの接続情報が取得できないために発生する例外Amazon.Runtime.AmazonServiceException: Unable to get IAM security credentials from EC2 Instance Metadata Service. at Amazon.Runtime.DefaultInstanceProfileAWSCredentials.FetchCredentials() at Amazon.Runtime.DefaultInstanceProfileAWSCredentials.GetCredentials() at Amazon.Runtime.DefaultInstanceProfileAWSCredentials.GetCredentialsAsync() at Amazon.Runtime.Internal.CredentialsRetriever.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.RetryHandler.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.RetryHandler.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.CallbackHandler.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.CallbackHandler.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.ErrorCallbackHandler.InvokeAsync[T](IExecutionContext executionContext) at Amazon.Runtime.Internal.MetricsHandler.InvokeAsync[T](IExecutionContext executionContext)Docker利用のAWSプロファイルの利用
アクセスキーとシークレットキーを設定してもよいのですが、せっかく機密情報を記載しなくてもよい仕組みがあるのでプロファイルを利用したいですよね。AWSプロファイルは、各ユーザーのホームディレクトリ直下の.awsディレクトリに保存されています。このディレクトリ配下の設定情報はどのOSでも共通になっているので、このフォルダーをボリュームマウントしてあげればよさそうです。
Visual Studioを利用している場合は、コンテナーオーケストレーターのサポートから
Docker Composeを追加して、
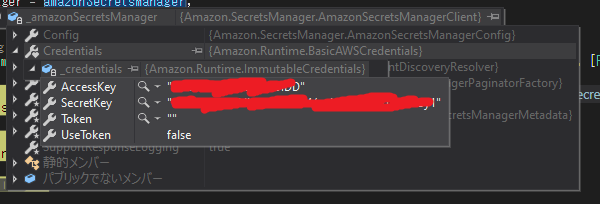
docker-compose.override.ymlにホームディレクトリ/.awsディレクトリを各コンテナのホームディレクトリにマウントする設定を追加してあげましょう。AWSプロファイル名は各開発者で異なる可能性があるので、AWSプロファイル名もこちらに書いておくと良いかもしれませんね。docker-compose.override.ymlversion: '3.4' services: app: environment: - ASPNETCORE_ENVIRONMENT=Development - ASPNETCORE_URLS=https://+:443;http://+:80 - AWS__Profile=DevProfile # 追加 ports: - "80" - "443" volumes: - ${APPDATA}/Microsoft/UserSecrets:/root/.microsoft/usersecrets:ro - ${APPDATA}/ASP.NET/Https:/root/.aspnet/https:ro - ${USERPROFILE}/.aws:/root/.aws/:ro # 追加プロファイルからアクセスキーとシークレットキーが取得できていますね。
まとめ
- AWSに接続する場合はできるだけAWSプロファイルを利用する。
- ローカルでDockerコンテナの中からAWSに接続する場合はホストの.awsディレクトリをマウントしてAWSプロファイルを利用する。

- 投稿日:2021-02-26T14:25:10+09:00
【AWS】ECRにログインし、レポジトリにイメージをプッシュするエイリアスコマンドの作成。
AWS上のdockerイメージを保存するレジストリであるECR(Amazon Elastic Container Registry)に、イメージを簡単にプッシュできるようにエイリアスコマンドを作成する。
コマンドはシェルファイルに作成する。大まかな流れは、コマンドの作成 -> 実行 -> ECRでイメージの確認となる。
目次
1. awsへのログイン処理
はじめにAWSにログインする処理を記述する。
aws-cliのawsコマンドで処理を行うが、バージョン1はAWSに直接ログインする必要があるが、バージョン2からはdocker経由でログインできる。このコマンドを実行する人の環境に合わせるため、条件分岐を使ってどちらにも対応できるようにする。
aliases.shfunction login-aws() { version=$(echo $(aws --version 2>&1) | sed -e 's/aws-cli\/\([0-9]\{1,\}\).*/\1/') if [[ $version -eq 1 ]]; then $(aws ecr get-login --no-include-email --region ap-northeast-1) elif [[ $version -ge 2 ]]; then aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com else echo "Error: could not detect aws command version." return 1 fi }1-1. aws-cliのバージョン情報を取得
$ echo $(aws --version 2>&1) aws-cli/2.0.44 Python/3.7.4 Darwin/19.6.0 exe/x86_64・
aws --version
awsはaws-cliのコマンド。バージョン情報を取得する。・
2>&1
エラーがあった場合も標準出力に表示する。
記号 内容 2 標準エラー出力 > リダイレクト(上書き) & ファイル指定子 1 標準出力 リダイレクト(>)の後には通常ファイル名がくるが、標準出力や標準エラー出力(ファイルディスクリプタと呼ぶ)を指定する場合には、ファイルじゃないよ!ということを意味する
&をつける。1-2. aws-cliのメジャーバージョン情報のみ取得する
aws-cliのバージョンが「aws-cli/2.0.44 Python/3.7.4 Darwin/19.6.0 exe/x86_64
」なら、バージョン情報の2.0.44の冒頭の2のみ取得する。sed -e 's/aws-cli\/\([0-9]\{1,\}\).*/\1/'受け取ったデータに対し、sコマンドで置換を行う。
・aws-cli/([0-9]{1,}).*
aws/cliの後に数字が1文字以上繰り返し、その後に任意の文字が1つ以上続くパターンを検出。・
\1
処理の中の一つ目のカッコ( )の中身を抽出する。
つまり、冒頭のバージョン0~99 (3桁以上もOK) を抜き出す。$ echo $(aws --version 2>&1) aws-cli/2.0.44 Python/3.7.4 Darwin/19.6.0 exe/x86_64 $ echo $(aws --version 2>&1) | sed -e 's/aws-cli\/\([0-9]\{1,\}\).*/\1/' 2sedコマンドとは?
指定のファイルや前から渡されたデータに対してコマンドを実行する。
置換、抽出、削除ができる。・
sed [オプション] コマンド [ファイルパス]・
-eオプション: expression
この後ろの引数が式になる。式が一つの場合は省略できる。・置換する
置換する場合はsコマンドを使う
sed 's/(置換前の文字パターン)/(置換後の文字パターン)/'・正規表現の詳細はこちら。
1-3. ver1の時のログイン処理
検出したaws-cliのバージョン情報が、ver1だった場合のログイン処理を記述する。
aliases.shif [[ $version -eq 1 ]]; then $(aws ecr get-login --no-include-email --region ap-northeast-1)・条件分岐
if [[ 条件式 ]]; then 処理
-ep: イコール。取得したバージョン情報が1なら処理を実行。ECRへのログインコマンド(ver.1)$ aws ecr get-login --no-include-email --region ap-northeast-1ecrのget-loginコマンドを実行。
1-4. ver2以上のログイン処理
検出したaws-cliのバージョン情報が、ver2以上だった場合のログイン処理を記述する。
v2以上ではdockerからログインできる。aliases.shelif [[ "$version" -ge 2 ]]; then aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com・
-ge: 以上。(Greater than or Equal)ver1と異なり、ecrのログインパスワードを取得して、dockerからAWSにログインする。
(1)ECRのログイパス取得$ aws ecr get-login-password --region ap-northeast-1 1xM1A1aEpJdjlVeGw3VT~~~~~~~(2)dockerからAWSにログインする$ docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com
1-5. バージョン情報が取得できなかった場合の処理
aliases.shelse echo "Error: could not detect aws command version." return 1バージョン情報が取得できなかった場合は、エラーメッセージを表示して、終了ステータス1(強制終了)で処理を終わりにする。
2. ECRにイメージをプッシュする
ECRの指定したレポジトリにイメージをプッシュ処理を記述する。
aliases.shalias push-image="login-aws && \ docker tag image:latest 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name:latest && \ docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/reposirory-name:latest"2-1. docker経由でECRにログインする
先ほど作成したAWSへのログインコマンドを実行する。
ECRへのログイン(定義した関数の実行)login-aws
&& \コマンド末尾の
&&の後に、次に実行するコマンドを記述できる。\は改行。
2-2. dockerイメージ名を変更する
ECRにイメージをプッシュするためにイメージ名を変更する必要がある。
・
ECRのエンドポイント名:タグ名ECRのエンドポイントは以下で表される。
[awsレジストリのid].dkr.ecr.[awsのリージョン].amazonaws.com・イメージ名の変更には
docker tagコマンドを使う。
- 第1引数: 現在のイメージ名:タグ名
- 第2引数: 変更後のイメージ名:タグ名
aliases.shdocker tag image:latest 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name:latest・変更前のイメージ名
image:latest↓ 変更後
111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name:latest
2-3. イメージをプッシュする
docker pushコマンドで、イメージをECRのレジストリにプッシュする。
docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name:latest"レジストリの指定はイメージ名で行う。
・
docker push [ホスト名]/[レポジトリ名]:タグ名レポジトリが深い階層にある場合は、
/でディレクトリ構造を指定する。3. コマンドの実行
3-1. シェルファイルの用意
aliases.shalias push-image="login-aws && \ docker tag image:latest 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name:latest && \ docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/reposirory-name:latest" function login-aws() { version=$(echo $(aws --version 2>&1) | sed -e 's/aws-cli\/\([0-9]\{1,\}\).*/\1/') if [[ $version -eq 1 ]]; then $(aws ecr get-login --no-include-email --region ap-northeast-1) elif [[ $version -ge 2 ]]; then aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com else echo "Error: could not detect aws command version." return 1 fi }3-2. シェルファイルのリロード
シェルファイルを変更した場合は、コマンド実行前にファイルをリロードする。
$ source aliases.sh3-3. コマンドの実行
$ push-image Login Succeeded The push refers to repository [111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/repository-name] e14d7e1febc9: Preparing df3dbc632729: Preparing ad171ae561d6: Preparing (省略) ddcd8d2fcf7e: Layer already exists 87c8a1d8f54f: Layer already exists latest: digest: sha256:8************************c size: 10326イメージのpushが完了。
4. ECRでイメージを確認
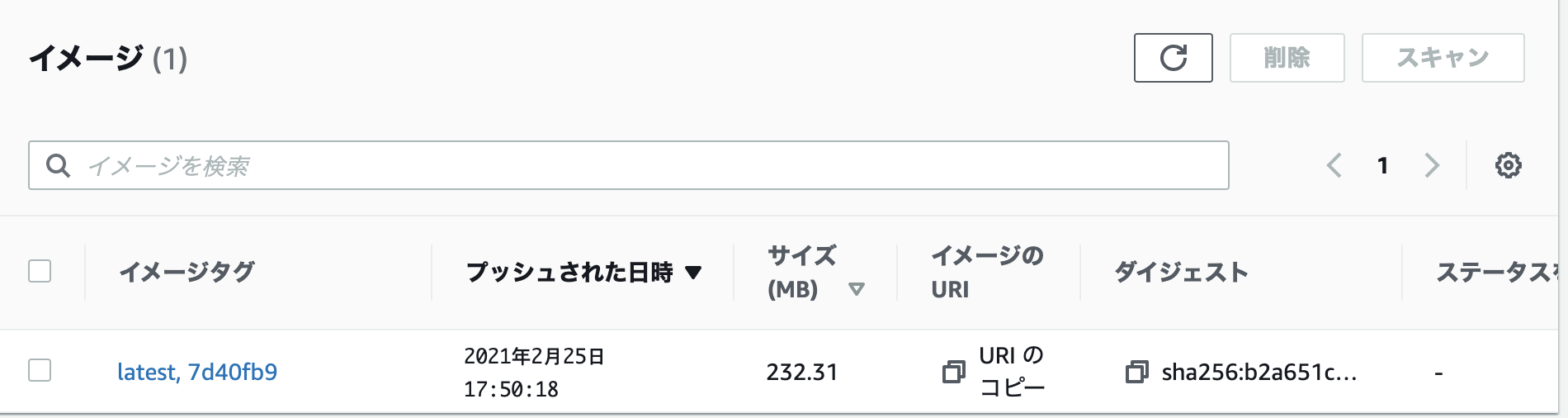
ECRの指定したレポジトリの中を確認すると、指定したタグでイメージが保存されている。
以上。
- 投稿日:2021-02-26T12:00:18+09:00
【超ざっくり】AWSのアクセスキーとシークレットアクセスキーの取得の仕方
こういう感じで、自分でアクセスキー発行して設定してねと言われた時の手順。
export AWS_ACCESS_KEY_ID=xxxx export AWS_SECRET_ACCESS_KEY=xxxxステップ
- 管理画面にログイン。
- 右上のナビゲーションバーでユーザー名を選択。
- [My Security Credentials (セキュリティ認証情報)] 選択。
- [Access keys (access key ID and secret access key)] セクションから [新しいアクセスキーの作成] を選択。
これでアクセスキーとシークレットアクセスキーが表示されるはず。あとはダウンロードするなり1Passwordなどのパスワード管理アプリなどの安全な場所に保存するなりする。
? 絶対に外部に漏らさない!GitHubにもPushしないで下さい
参考
- 投稿日:2021-02-26T10:54:52+09:00
【ECS】キャパシティプロバイダーを使ってみよう~設定編~
streampackのrisakoです。
2月中旬に入ってから花粉が一気に飛び始めましたね
今年は去年よりも飛散量が多いようで花粉症の人にとっては辛い時期になってしまいました今回は、ECSのキャパシティプロバイダについて書いて行きたいと思います。
キャパシティプロバイダーとは
「ECSにおけるタスク実行インフラを柔軟に設定できる仕組み」 です。
以下のECS設定で設定できますが、今回は「ECS on EC2 」で設定してみたいと思います。
- ECS on EC2
- ECS on Fargate
ECS on EC2を利用したことがある方は、タスク数を変更する際にEC2インスタンスもスケールアウトする必要があったかと思います。
キャパシティプロバイダーを使うことでタスク数に基づきEC2をインスタンスも自動でスケールアウトしてくれるので運用がとても楽になりますね設定
0. 事前準備
ECSクラスターにタスク定義設定とタスク作成できるようにしておく必要があります、
タスク作成ができないと、キャパシティプロバイダーを設定してもインスタンスの増減はできません。1. AutoScaling Groupを新規に作成する。
ECS on EC2で作成すると、自動でAutoScaling Groupが作成されるかと思います。
そのAutoScaling Groupとは別に、キャパシティプロバイダー用に新規で作成する必要があります。
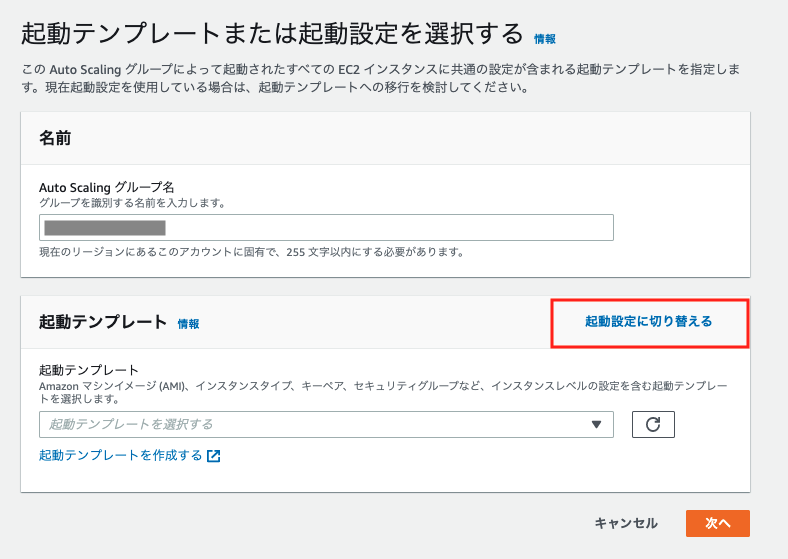
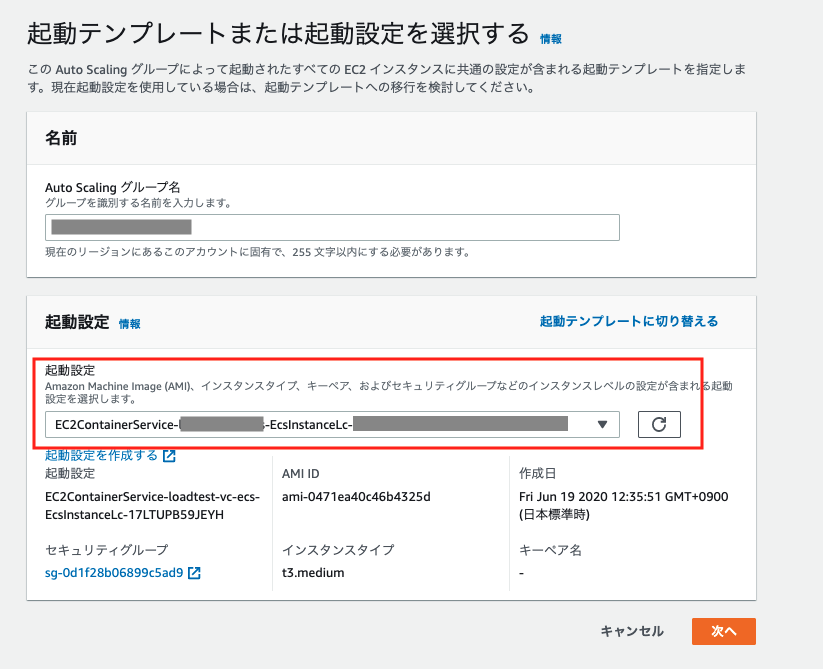
起動テンプレートではなく、起動設定で作成しましょう。
ECSクラスター作成時に作成されているAuto Scalingグループを選択します
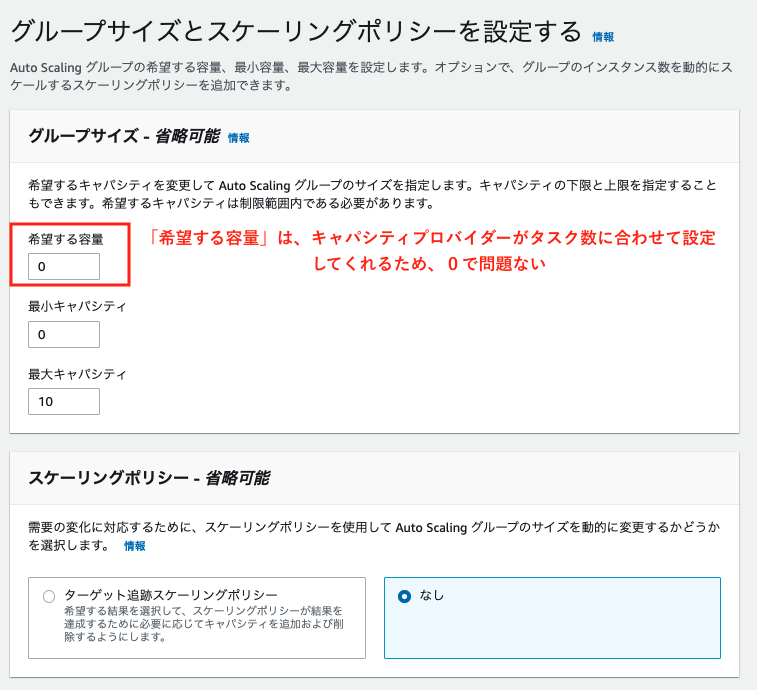
グループサイズは、最大キャパシティのみ設定します。
最大キャパシティを10にした場合は、キャパシティプロバイダーで自動スケールアウトされるインスタンスが10個までに制限されます。
2. キャパシティプロバイダー設定
- 対象ECSクラスターの「キャパシティプロバイダー」タブから作成しましょう
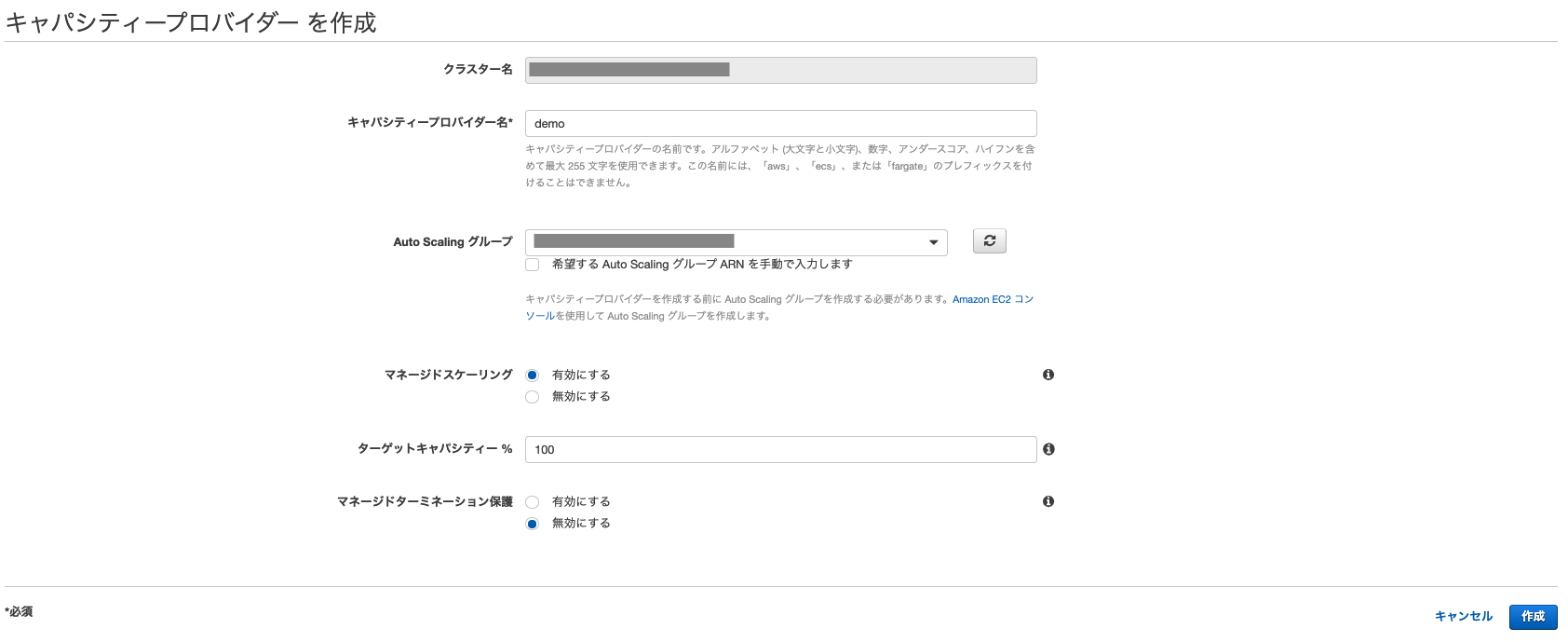
項目 値 備考 キャパシティプロバイダー名 demo 任意の名前を設定 AutoScaling グループ test-ecs 先ほど作成したAutoScaling グループを選択 マネージドスケーリング 有効 有効になっていないとタスク数に応じた自動的なスケーリングは行われな ターゲットキャパシティー% 100 ECSで使用するインスタンスの必要数(1~100)。100=全てのインスタンスが無駄なく使用される。50=本来必要なインスタンス数の倍作成する。(突発的なアクセス増加に対応できる) マネージドターミネーション 保護 無効 スケールインから保護するインスタンスがある場合には有効にする。 3.クラスターの変更
クラスター右上にある「クラスターの変更」を押下します。
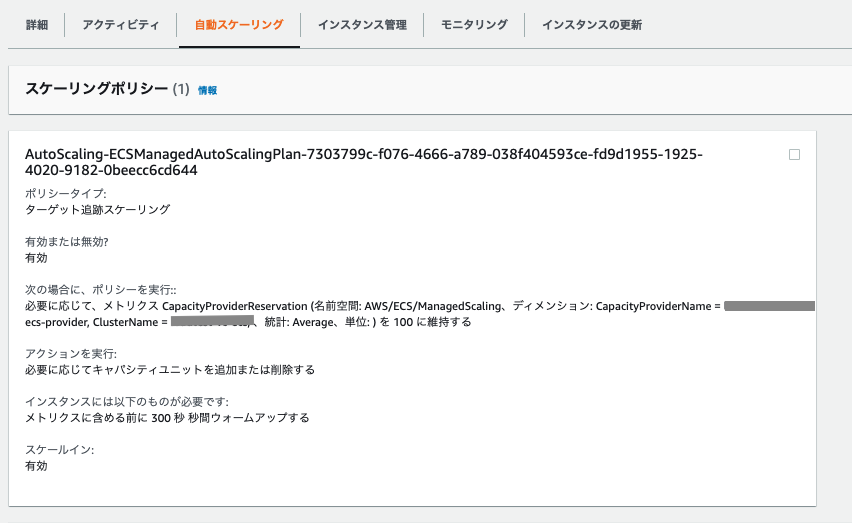
「デフォルトのキャパシティプロバイダー戦略」を、作成したキャパシティプロバイダーに設定します。
新規作成したAutoScaling Groupで以下のようなポリシーが作成されていれば、キャパシティプロバイダーの設定がされています。
4.サービス作成
今回は、サービスを新規作成する場合を想定しています。
- サービスタブの「作成」から新規作成します
- 「 起動タイプ」ではなく、「キャパシティプロバイダー戦略」で設定します
項目 値 備考 キャパシティプロバイダー戦略 Cluster default strategy 作成したキャパシティプロバイダーが選択されていることを確認 タスク定義 app 使用するタスク定義を選択する クラスター ECSクラスター名 サービス名 demo 任意のサービス名 サービスタイプ REPLICA タスクの数 2 タスクの数を変更するとキャパシティプロバイダーによりECSインスタンスが増減されます
次のページで使用するロードバランサーを指定します。
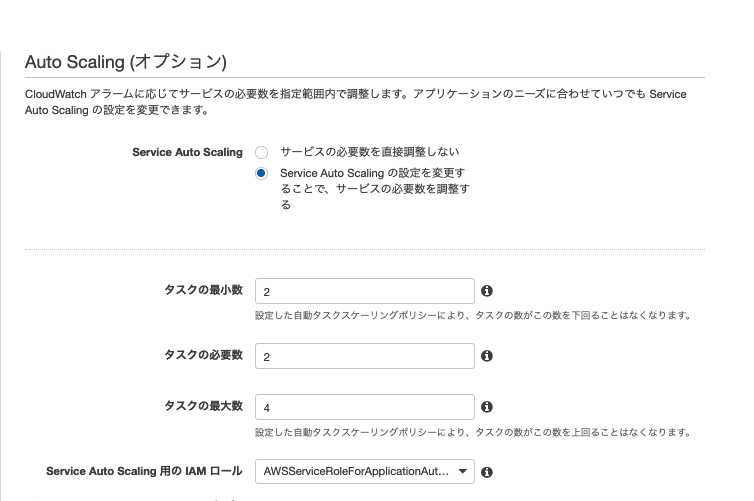
Service AutoScaling(オプション)では、「Service AutoScaling の設定を変更することで、サービスの必要数を調整する」を選択
タスクの最小数・必要数・最大数を設定します
以上でキャパシティプロバイダーの設定は完了です!
タスク数を増減させて自動でスケールアウトされるのか試してみましょう。まとめ
頻繁にECS on EC2でスケールアウトやスケールインすることがある場合はとても楽に運用できる印象でした。
今回もお読み頂きありがとうございました。



- 投稿日:2021-02-26T10:26:52+09:00
40代おっさんEC2を作成してみた➁
40代おっさんEC2を作成してみた➁
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
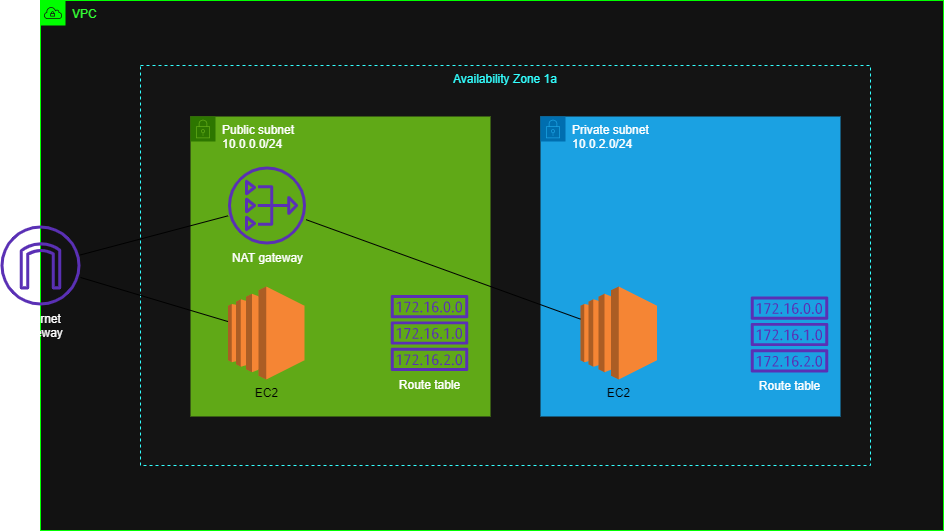
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS作成図
VPC部分については
https://qiita.com/kou551121/items/2535fe3de57a5c813687
今回はEC2を作成することをメインにしております。
EC2詳しく知りたい方は
https://qiita.com/kou551121/items/54acbecd4fa147bc4d51構築手順
❶EC2を作成する。
https://qiita.com/kou551121/items/56f2e075d33fbf345787
(❶の部分を知りたい方はこちらを)
❷セキュリティーグループの作成
❸EC2インスタンスに接続2.セキュリティーグループの作成
今現在アタッチされているセキュリティーグループはEC2作成時にデフォルトで作ったものですね(赤枠)。
ではセキュリティーグループを作りたいと思うので左をスクロールしてセキュリティーグループ(青枠)をクリック
・セキュリティーグループ画面遷移しましたらセキュリティーグループを作成(赤枠)クリック
・セキュリティーグループ名、説明を記入(赤、青枠、今回はどちらも同じにしました)
・VPCは自分が作ったVPC(Test-VPC)を選択
・終わったら下にスクロール(↓がその画面)
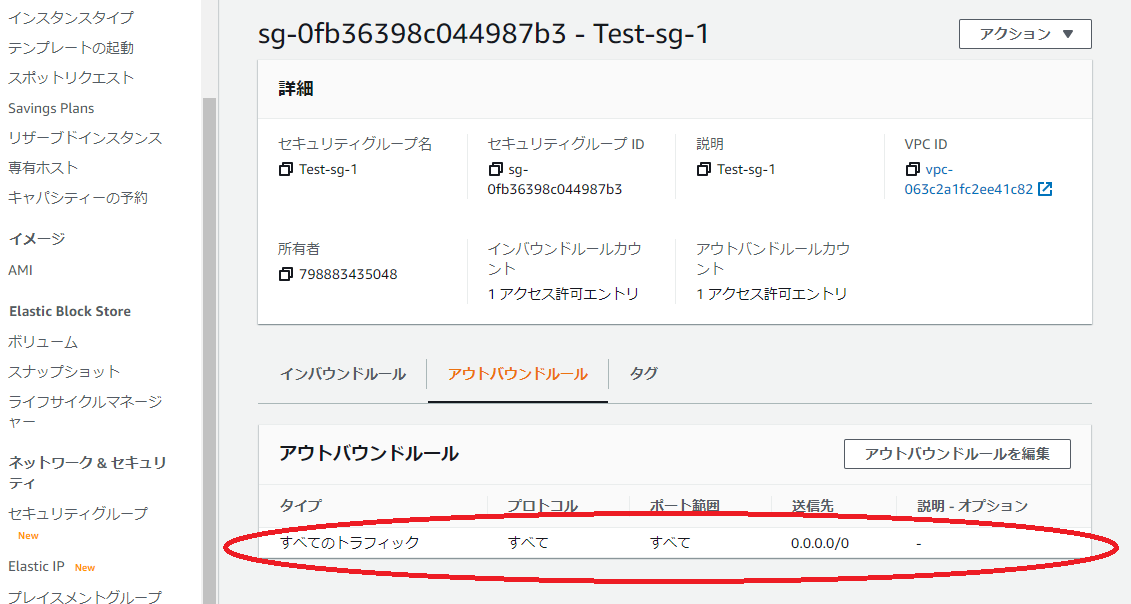
・0.0.0.0/0(赤枠)アウトバウンドルールがすべて許可されているようと言う意味です。アウトバウンドルールとは
そのセキュリティグループに関連付けられたインスタンスからどの送信先にトラフィックを送信できるかを制御するルール
トラフィックとは
インターネットやLANなどのコンピューターなどの通信回線において、一定時間内にネットワーク上で転送されるデータ量のことを意味します。
・確認したらルールの追加を押してください。
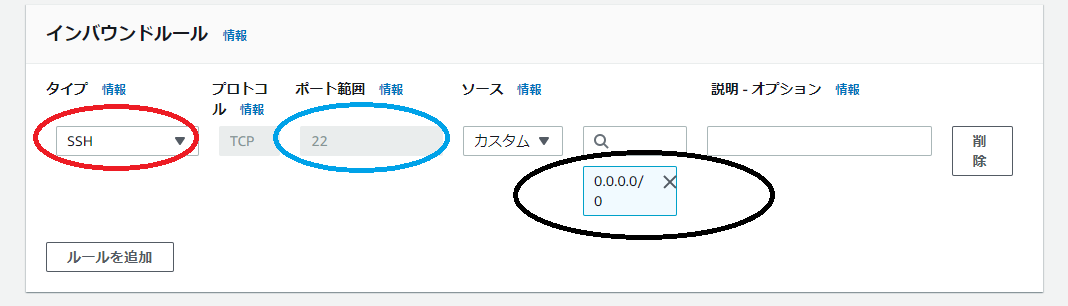
・赤枠のところをカスタムTCPからSSHへSSHとは
自分のPCからサーバーにアクセスするために必要な暗号化された通信です。
ポートとは
通信がくる入口を示しています。
・ポート番号は22番になっていることを確認
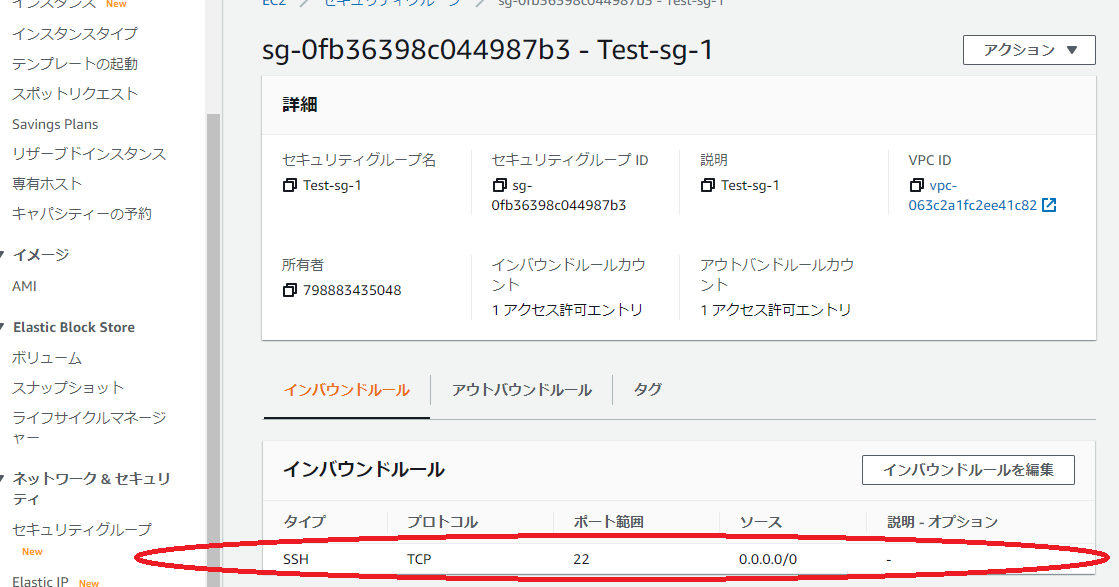
(SSHの場合は22番と基本決まっていますがそれだと悪意あるものもわかっているため、悪さできてしまいます。そのため秘密鍵や公開鍵の機能が必要となるわけです。)・0.0.0.0/0(黒枠)を選んでください。これですべてのIPからの通信ができることになります。
(説明は書いても書かなくてもよいです)
・終わったら下のほうにあるセキュリティーグループの作成をクリック
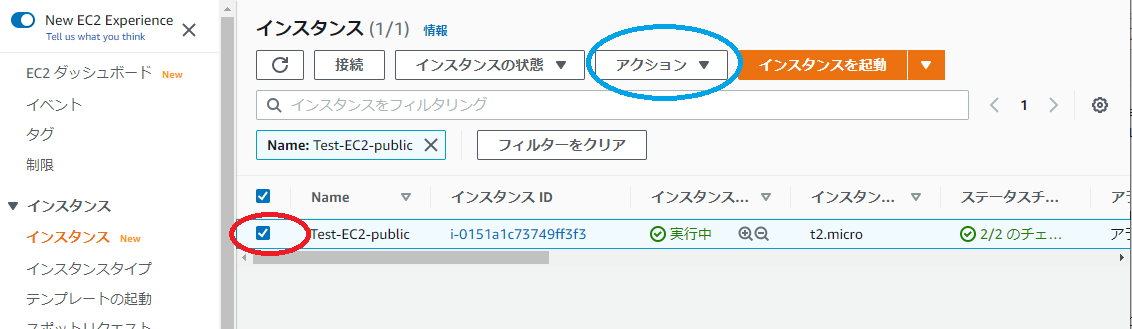
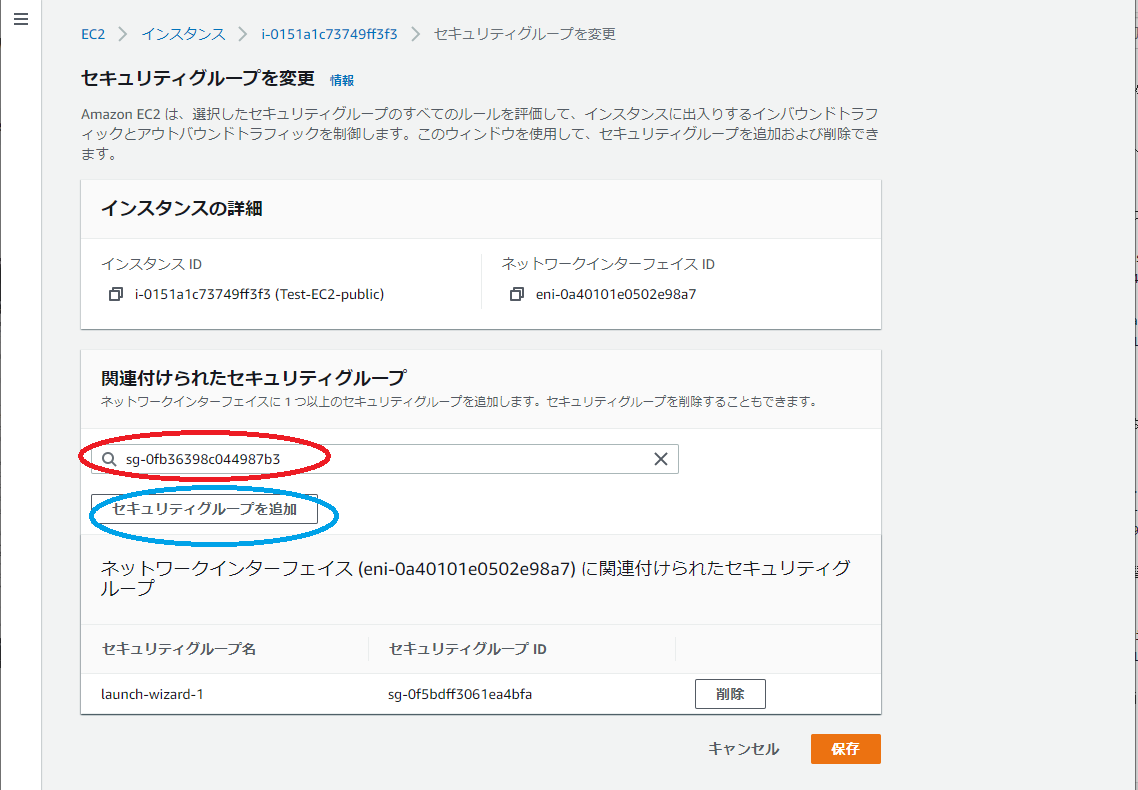
・このようになっていたら大丈夫だと思います。・では次に作ったセキュリティーグループをインスタンスにつけかえます。
・左メニューからインスタンスをクリック
・赤枠にチェック(セキュリティーグループを付け替えるインスタンス)
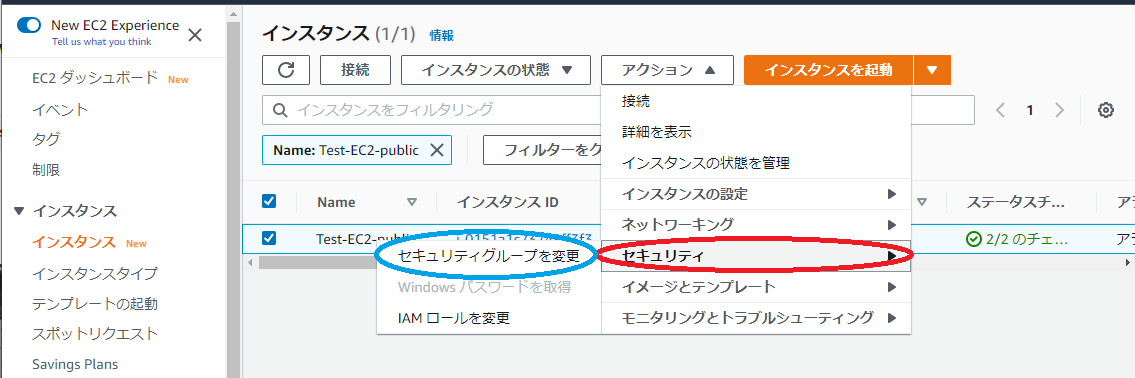
・青枠をクリックすると下に画面遷移
・赤枠セキュリティをクリックすると↑のような画面になります
・青枠のセキュリティーグループを変更をクリック
・赤枠のところに自分が作ったセキュリティグループを
・青枠を押してください。
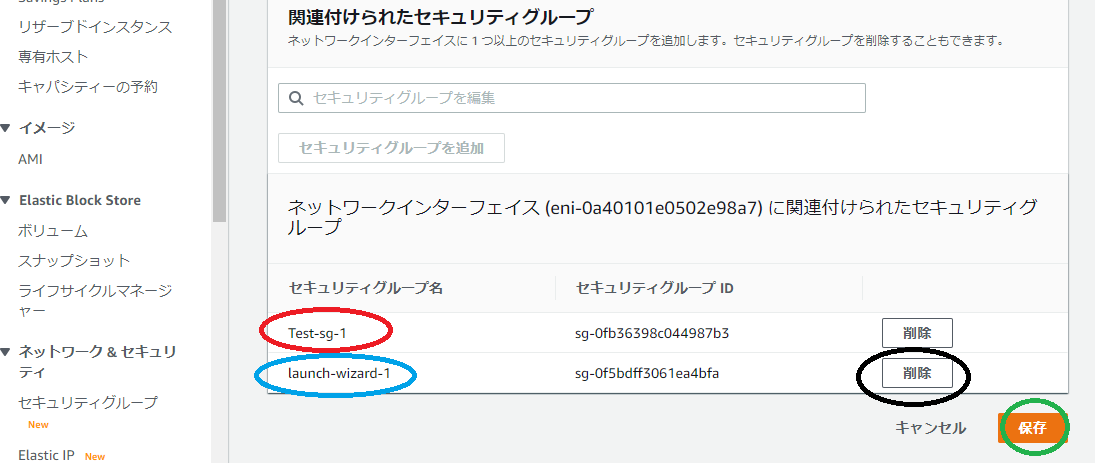
・セキュリティーグループ名が二つになったと思います。赤枠、青枠
・青枠はいらないので削除(黒枠)をクリックしてください。そうすると一つになりますのでその状態で保存(緑枠)クリック
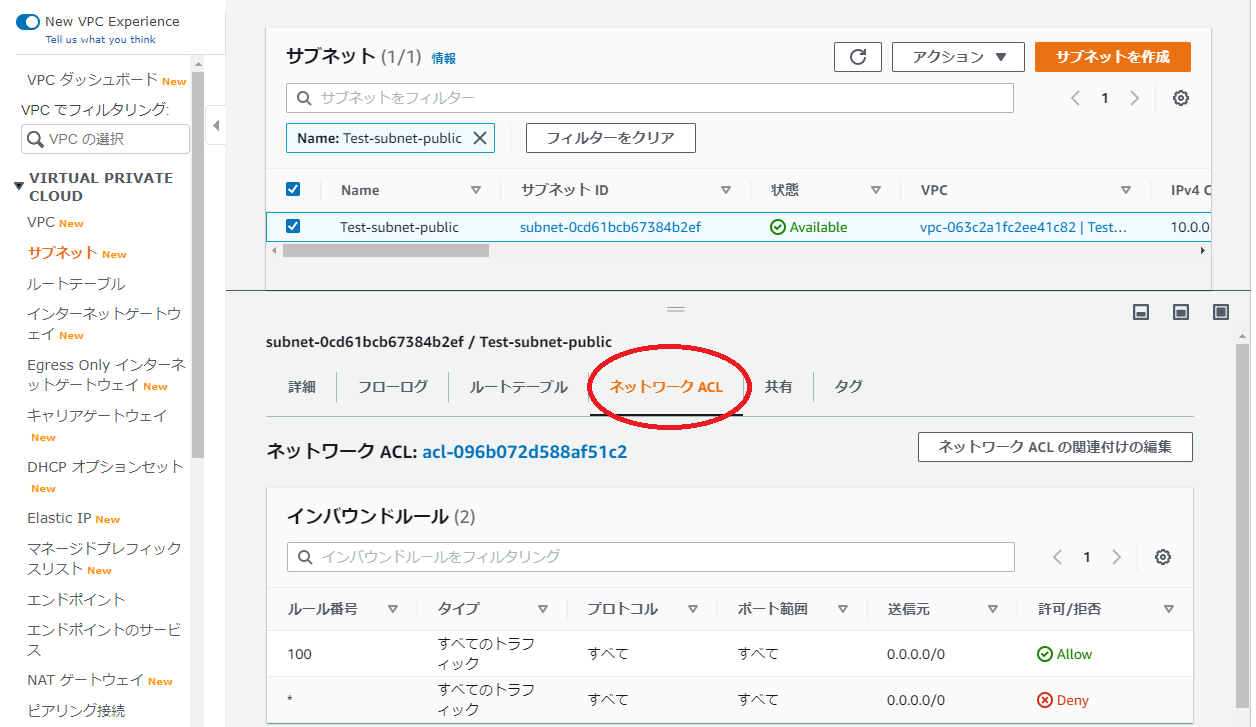
・インスタンスのセキュリティをみると赤枠のように変わっています。・次にVPCでサブネットの確認も行いためサービスをVPCに移動してください。
・ネットワークACLを開いてください(赤枠)
・イン、アウトバウンドルールがあると思いますがどちらもAllow(赤枠)になっていると思います。最後に
結構長くなったため❷セキュリティーグループの作成で今回は終わりたいと思います。次回もよろしくお願いします!
またこの記事はAWS初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/参考
https://qiita.com/noko_qii/items/d4c19ec5e891264af462
https://www.idcf.jp/words/traffic.html





- 投稿日:2021-02-26T10:00:29+09:00
【第1回】AWS戦記 ~ルートユーザへのMFA設定~
AWSアカウント作成後のルートユーザにMFA設定
こんにちは。
現在AWSアカウントを作成してほやほやの状態です。
ルートユーザのセキュリティを強化するためにルートユーザに対しMFA(Multi-Factor Authentication:多要素認証)を設定します。
メールアドレス+パスワードだけだと突破される可能性が高いですからね。ちなみに今回は多要素認証用に「Google Authenticator」」を利用します。
こちらはスマートフォンによる2段階認証を実現するために利用します。Google 認証システムで確認コードを取得する: Google Play
前提条件
・AWSアカウントが作成済みであること。
・携帯電話(スマートフォン)を所持しており、且つ「Google Authenticator」がインストール済みであること。
・AWSマネジメントコンソールへの接続はChromeを利用する。ルートユーザへのMFA設定
1.「すべてのサービス」→「セキュリティ、ID、およびコンプライアンス」→「IAM」を選択。
2.以下の画面の赤枠のリンクをクリック。
3.「MFAの有効化」をクリック。
4.「仮想 MFA デバイス」が選択された状態で「続行」をクリック。
5.スマートフォンの「Google Authenticator」を起動し、画面上に表示されたQRコードをスキャンする。
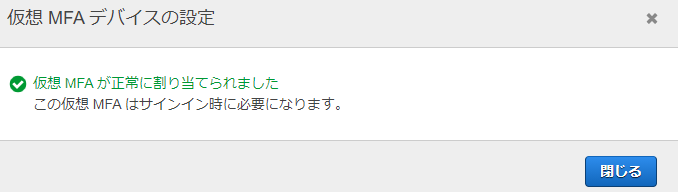
6.「Google Authenticator」上の画面に表示された6桁の数字を2回入力し、「MFAの割り当て」をクリック。
7.以下の画面が表示されれば成功。
8.MFAが有効になったか確認するため、現在利用しているブラウザとは別のブラウザ(ChromeまたはEdgeなど)でAWSにログインを試み、MFA認証が表示されることを確認。
9.スマートフォンからMFA認証の6桁の番号を入力してAWSマネジメントコンソールにログインできることを確認する。ちなみにMFA認証に利用しているデバイスが紛失された場合は登録したメールアドレスおよび連絡先電話番号でなんとかなるみたいです。
次回はIAMグループとユーザーの作成を予定しています。
ではでは。

- 投稿日:2021-02-26T06:57:14+09:00
【初投稿】AWS戦記 プロローグ
はじめに
初めまして。
いつもQiitaを参考にばかりしているのですが、自分の学習を兼ねて自分でも記事を投稿してみようと思い衝動的にアカウント作ってみました。
マークダウンの使い方の勉強も試行錯誤しながらのんびりやっていこうかな思います。自己紹介
Linux系のインフラ系システムの構築をやってます。
最近はAWS関連の仕事が増えてきました。
プログラミング言語はほとんどできないので、これから勉強していきたいです。やりたいこと
- AWSの基本的な構築(VPC周り、EC2など)
- CloudWatchによるメトリクス監視
- CloudFormation、TeraForm、Packer、AnsibleによるInfrastructure as Codeの学習
- CodeCommitによるソースコードの管理及びPipelineの構築
- プログラミング言語の習得(Python、Ruby、Goなど)
- マークダウンの書き方を覚える
- コスト監視
前提条件
・無料利用枠で納める。
・実務に使えそうな構築を目指す。
・他者が読んでもわかりやすいように書く。次回予定
項目 ゴール 備考 VPC作成 10.100.10.0/16のネットワークの作成 デフォルトVPC削除 サブネット作成 Public/Private/Protectedの作成 AZを分ける インターネットゲートウェイ作成 インターネットへ接続できること Publicに設置 NATゲートウェイ作成 Privateセグメントからインターネットへ接続できること Privateに設置 IAM 管理者グループ作成 管理者用グループ作成 IAM 管理者ユーザー作成 管理者用ユーザー作成 IAM 一般グループ作成 一般権限用グループ作成 IAM 一般ユーザー作成 一般権限用ユーザー作成 IAM MFA認証 作成したIAMユーザーに多要素認証を設定 IAMポリシー作成 EC2用UAMポリシー作成 SessionManagerやS3へのアクセス許可 IAMロール作成 EC2用IAMロール作成 SessionManagerやS3へのアクセス許可 エンドポイント作成 EC2からエンドポイント経由でAWS CLIを実行できること セキュリティグループの作成 EC2周りが操作可能になること SessionManager設定 EC2へ接続 EC2構築 EC2インスタンス(AL2)が起動し、yumアップデートできること t2.microを利用 AMI作成 構築したEC2からAMIを作成する Cloud-Initの設定も実施すること CloudWatchEvntによるEC2自動停止 自動的にEC2が停止されること SSMで設定 S3バケットの作成 EC2からファイルをGET/PUT/DELETEできること
とりあえずこんなところでしょうか。
上記以外にもRDSやVPC間のPeerig、Route53やらACMにもチャレンジしてみたいです。
最終的にはコード管理できるようになりたいなぁ。ではでは。
- 投稿日:2021-02-26T05:57:07+09:00