- 投稿日:2021-01-27T23:13:06+09:00
label_map.pbtxt をつくる
Tensorflow Object Detection API に必要なlabel_map。
手作業で書き換えるのは面倒ということで、ラベルの配列から作れるコードがこちら。label_map_path = "./test.pbtxt" #保存パス categories = ["dog","cat","bird"] #ラベルの配列 end = '\n' s = ' ' class_map = {} for ID, name in enumerate(categories): out = '' out += 'item' + s + '{' + end out += s*2 + 'id:' + ' ' + (str(ID+1)) + end out += s*2 + 'name:' + ' ' + '\'' + name + '\'' + end out += '}' + end*2 with open(label_map_path, 'a') as f: f.write(out) class_map[name] = ID+1これで出力保存されます。
label_map.pbtxtitem { id: 1 name: 'dog' } item { id: 2 name: 'cat' } item { id: 3 name: 'bird' }このlabel_map.pbtxtで物体検出のラベルIDとラベル名を対応づけられます。
?
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2021-01-27T22:25:09+09:00
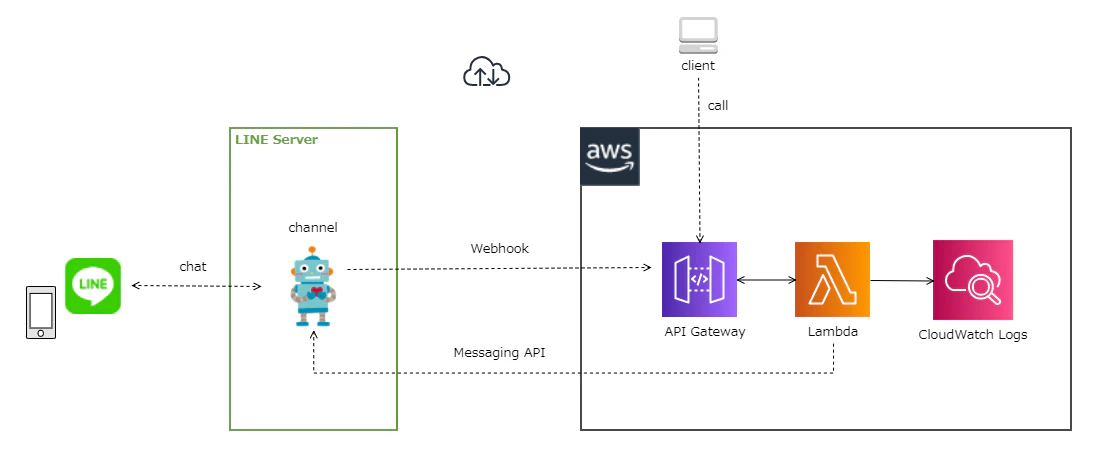
AWS ChaliceでLINE Botにメッセージのオウム返しと、任意のメッセージをプッシュさせてみる
これはなに
AWS Chaliceで簡単なLINE Botを作る手順をまとめました。
最終的に構成図にするとこんな感じになります。
LINE Botの作成
LINE Developersに登録し、LINE Developersコンソールで作業します。
プロバイダーの作成
アプリ(Bot)を提供するプロバイダーを作成します。組織名や自分の名前を付けるといいようです。
チャネルの作成
次に自分の作ったサービスとプロバイダーを関連づけるチャネルを作成します。
今回はMessaging APIをチャネルとして利用するのでこちらを選択します。
アイコン、チャネル名(Bot名)、チャネル説明など項目を設定して作成します。
チャネルが作成できたら、「チャネル基本設定」から「チャネルシークレット」。
「Messaging API設定」から「チャネルアクセストークン(長期)」をそれぞれ取得して控えておきます。ここまでできたら次はチャネルと連携するサービス(API)を準備します。
AWS Chalice
続いてAmazon API GatewayとAWS Lambdaを使ったAPIを簡単に作れるPythonフレームワークのAWS Chaliceを使ってLINE Botと連携するAPIサービスを作っていきます。
Chaliceのインストール・プロジェクトの作成
>mkdir chalice >cd chalice >virtualenv venv >venv\Scripts\activate >pip3 install chalice >chalice --version chalice 1.22.0, python 3.8.6, windows 10 >chalice new-project my_line_bot Your project has been generated in ./my_line_bot >cd my_line_botAPIの作成
インストールライブラリの指定
Lambdaデプロイ時にインストールするライブラリを記述します。
LINE BotのPython SDKを使うのでこれを指定。requirements.txtline-bot-sdk==1.18.0環境変数の設定
先ほど控えた「チャネルシークレット」と「チャネルアクセストークン(長期)」がLambdaの環境変数として展開されるよう設定します。
.chalice\config.json{ "version": "2.0", "app_name": "my_line_bot", "stages": { "dev": { "api_gateway_stage": "api", "environment_variables": { "LINE_CHANNEL_SECRET": "チャネルシークレット", "LINE_CHANNEL_ACCESS_TOKEN": "チャネルアクセストークン" } } } }API実装
チャネルの呼び出しに応じて行う処理を記述します。
app.pyimport os import json import logging import random from chalice import Chalice from chalice import BadRequestError, ForbiddenError from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import FollowEvent, MessageEvent, TextMessage, TextSendMessage, StickerMessage, StickerSendMessage app = Chalice(app_name='my_line_bot') logger = logging.getLogger() logger.setLevel(logging.INFO) # 各クライアントライブラリのインスタンス作成 handler = WebhookHandler(os.environ.get('LINE_CHANNEL_SECRET')) linebot = LineBotApi(os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')) # Webhook @app.route('/callback', methods=['POST']) def callback(): try: request = app.current_request logger.info(json.dumps(request.json_body)) # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['x-Line-Signature'] logger.info(signature) # リクエストボディを取得 body = request.raw_body.decode('utf8') # 署名を検証、問題なければhandleに定義されている関数を呼び出す handler.handle(body, signature) except InvalidSignatureError as err: logger.exception(err) raise ForbiddenError('Invalid signature.') except Exception as err: logger.exception(err) raise BadRequestError('Invalid Request.') return {} # 友達追加(一度ブロックし解除しても発火する) @handler.add(FollowEvent) def handle_follow(event): linebot.reply_message( event.reply_token, TextSendMessage(text='はじめまして!よろしくお願いします!') ) # メッセージイベント @handler.add(MessageEvent, message=TextMessage) def handle_text_message(event): # メッセージをオウム返しする linebot.reply_message( event.reply_token, TextSendMessage(text=event.message.text) ) # スタンプメッセージ @handler.add(MessageEvent, message=StickerMessage) def handle_sticker_message(event): # https://developers.line.biz/media/messaging-api/sticker_list.pdf sticker_ids = [ '52002734','52002735','52002736','52002737','52002738','52002739','52002740','52002741','52002742','52002743', ] random.shuffle(sticker_ids) sticker_message = StickerSendMessage( package_id='11537', sticker_id=sticker_ids[0] ) linebot.reply_message( event.reply_token, sticker_message ) # 通知 @app.route('/push', methods=['POST']) def push(): try: request = app.current_request logger.info(json.dumps(request.json_body)) user_id = request.json_body['user_id'] message = request.json_body['message'] # メッセージを通知 linebot.push_message( user_id, TextSendMessage(text=message) ) except Exception as err: logger.exception(err) raise BadRequestError('Invalid Request.') return {}Botと対話するユーザーからのアクションに応じて発火するWebhook用のAPI(
/callback)と、ユーザーを指定してメッセージをプッシュするAPI(/push)の二つのパスを用意しています。これで、APIは完成なのでデプロイします。
デプロイ
AWS CLIで適切な権限のあるconfigureが設定されているのが前提です。
IAMポリシーはこの辺があたってれば大丈夫そう。
https://github.com/aws/chalice/issues/59#issuecomment-603760552>cd my_line_bot >chalice deploy --profile chaliceこれでAWSにデプロイが行われAPI GatewayとLambdaが構成されました。
得られたエンドポイントをチャネルに設定します。LINE Botの設定
「Messaging API設定」の「Webhook URL」にエンドポイントを設定。
「検証」を押して「成功」と表示されればOKです。
また「Webhookの利用」をオンにします。
LINE Official Account Managerから「あいさつメッセージ」と「応答メッセージ」をオフにしておきます。
これで完成です!
「Messaging API設定」にあるQRコードから友達追加しましょう。使ってみる
LINEユーザーからのアクションに応じて、FollowEvent、MessageEventのTextMessage、MessageEventのStickerMessageがそれぞれ発火しているのがわかります。プッシュの方もやってみます。
CloudWatch Logsに先ほどまでのリクエストボディがログ出力されているので、そこからユーザーID(LINEユーザーを識別するために、プロバイダーごとに割り当てられたID)を拾って、プッシュAPIを呼び出します。$ curl -X POST -H "Content-Type: application/json" \ -d '{"user_id":"************************", "message":"何か話しましょう"}' \ https://*********.execute-api.ap-northeast-1.amazonaws.com/api/push
これでサービスから能動的にLINEユーザーに通知することもできました。
参考
https://developers.line.biz/ja/docs/messaging-api/getting-started/
https://developers.line.biz/ja/docs/messaging-api/sending-messages/#methods-of-sending-message
https://developers.line.biz/ja/reference/messaging-api/#send-reply-message
https://developers.line.biz/ja/reference/messaging-api/#sticker-message
https://qiita.com/GlobeFish/items/dbf05e0f43b93ff7a6df
https://qiita.com/t-kigi/items/21073df2bfc27e2b4999
https://keinumata.hatenablog.com/entry/2018/05/08/122348




- 投稿日:2021-01-27T21:56:22+09:00
学習に使用している参考書紹介
- 投稿日:2021-01-27T21:48:35+09:00
M1 MacにPythonの分析環境を構築する(2020-01-27現在)
個人的メモです。
2020-01-27現在、M1 Macではnumpyやpandasのpipでのinstallに問題が発生しているため、その回避のためのworkaroundを書いておきます。
いずれ公式にサポートされ、この記事は不要になると思います。RosettaでIntel(x86_64)向けバイナリを使う
iTerm2の
Open using Rosettaにチェックを入れて、普通にセットアップするだけ。参考:https://alexslobodnik.medium.com/apple-m1-python-pandas-and-homebrew-20f14828ccc7
Apple Silicon(osx-arm64)向けバイナリを使う
- homebrew: 最近Apple Silicon対応した。
/opt/homebrewに入る- python: homebrewで python@3.9 を入れる(Apple Silicon対応)
/opt/homebrew/opt/python@3.9/libexec/binにpathを通す必要あり- numpy:: homebrewでnumpyを入れる(Apple Silicon対応)
- pandas:
pip install python-dateutil pytzで依存ライブラリを入れ、pip install cythonを実行した上でpip install pandas --compile --no-binary :all: --no-use-pep517- pipenv:
pipenv --site-packagesでhomebrew下のpackageを参照できる仮想環境を作る- poetry:
poetry config virtualenvs.in-project trueでプロジェクト下に.venvを作るようにし、仮想環境を作った上で.venv/pyvenv.cfgのinclude-system-site-packagesを true にして、homebrew下のpackageを参照できるようにする。numpyとpandasはdependenciesには入れない(入れるとビルドしようとするため)
- 投稿日:2021-01-27T21:30:57+09:00
Pythonでブロックチェーンを構築④ナンスを求める
ビットコインでは新しいブロックを生成する時にPoW(プルーフオブワーク)という手法をとります。これはマイニングという計算をすることなのですが、その計算で求める値が今回実装するナンスです。
マイニングにはディフィカルティ(難易度)があり、例えば3と設定すればハッシュ関数にナンスを代入した時に先頭の3文字が0になるようにするということを意味します。
このディフカルティの数値が大きくなるほど、マイニングは難しくなり、ビットコインでもこのディフィカルティの値を変えることでマイニングの競争を調整しています。
今回はグローバル変数でこれを3と設定していきます。
「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」
https://www.udemy.com/course/python-blockchain/learn/lecture/15381372#overviewMINING_DIFFICULTY = 3また、前回までで作成したブロックチェーンクラスの表示を見やすくするpprintは別のファイルに移しても問題ないので、utilsへ移しましょう。以下のコードのことです。
def pprint(chains): for i, chain in enumerate(chains): print(f'{"="*12} Chain {i} {"="*12}') for k, v in chain.items(): if k == 'transactions': print(k) for d in v: print(f'{"-"*40}') for kk, vv in d.items(): print(f' {kk:30}{vv}') else: print(f'{k:15}{v}')そして、ブロックチェーンを呼び出すところではpprintの前にutils.を書き足します。
if __name__ == '__main__': block_chain = BlockChain() utils.pprint(block_chain.chain) block_chain.add_transaction('山本さん', '佐藤さん', 0.5) block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash = block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) utils.pprint(block_chain.chain)また、今回の処理ではここにナンスの情報も入るので、前回まで仮に5としていた部分をnonceとし、nonce = block_chain.proof_of_work()の行を追加します。
if __name__ == '__main__': block_chain = BlockChain() utils.pprint(block_chain.chain) block_chain.add_transaction('山本さん', '佐藤さん', 0.5) block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash = block_chain.hash(block_chain.chain[-1]) nonce = block_chain.proof_of_work() block_chain.create_block(nonce, previous_hash) utils.pprint(block_chain.chain)次に、proof_of_workのメソッドを追加していきます。
def valid_proof(self, transactions, previous_hash, nonce, difficulty=MINING_DIFFICULTY): guess_block = utils.sorted_dict_by_key({ 'transactions': transactions, 'nonce': nonce, 'previous_hash': previous_hash }) guess_hash = self.hash(guess_block) return guess_hash[:difficulty] == '0'*difficulty def proof_of_work(self): transactions = self.transaction_pool.copy() previous_hash = self.hash(self.chain[-1]) nonce = 0 while self.valid_proof(transactions, previous_hash, nonce) is False: nonce += 1 return nonce今回はディフカルティは3となってますが、今後書き換えられるようにdifficulty=MINING_DIFFICULTYとしてます。
guess_hashで予測した物の先頭がdifficultyの数だけ0になっているかを確かめます。
transactions = self.transaction_pool.copy()としているのは、後ほど、サーバー同士のシンクで書き換わる処理を行うためです。
今回の変更後のブロックチェーンクラスの内容はこちらです。
import hashlib import json import logging import sys import time import utils MINING_DIFFICULTY = 3 logging.basicConfig(level=logging.INFO, stream=sys.stdout) class BlockChain(object): def __init__(self): self.transaction_pool = [] self.chain = [] self.create_block(0, self.hash({})) def create_block(self, nonce, previous_hash): block = utils.sorted_dict_by_key({ 'timestamp': time.time(), 'transactions': self.transaction_pool, 'nonce': nonce, 'previous_hash': previous_hash }) self.chain.append(block) self.transaction_pool = [] return block def hash(self, block): sorted_block = json.dumps(block, sort_keys=True) return hashlib.sha256(sorted_block.encode()).hexdigest() def add_transaction(self, sender_blockchain_address, recipient_blockchain_address, value): transaction = utils.sorted_dict_by_key({ 'sender_blockchain_address': sender_blockchain_address, 'recipient_blockchain_address': recipient_blockchain_address, 'value': float(value) }) self.transaction_pool.append(transaction) return True def valid_proof(self, transactions, previous_hash, nonce, difficulty=MINING_DIFFICULTY): guess_block = utils.sorted_dict_by_key({ 'transactions': transactions, 'nonce': nonce, 'previous_hash': previous_hash }) guess_hash = self.hash(guess_block) return guess_hash[:difficulty] == '0'*difficulty def proof_of_work(self): transactions = self.transaction_pool.copy() previous_hash = self.hash(self.chain[-1]) nonce = 0 while self.valid_proof(transactions, previous_hash, nonce) is False: nonce += 1 return nonce if __name__ == '__main__': block_chain = BlockChain() utils.pprint(block_chain.chain) block_chain.add_transaction('山本さん', '佐藤さん', 0.5) block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash = block_chain.hash(block_chain.chain[-1]) nonce = block_chain.proof_of_work() block_chain.create_block(nonce, previous_hash) utils.pprint(block_chain.chain)続いて、utilsの中身はこちら
import collections def sorted_dict_by_key(unsorted_dict): return collections.OrderedDict( sorted(unsorted_dict.items(), key=lambda d:d[0])) def pprint(chains): for i, chain in enumerate(chains): print(f'{"="*12} Chain {i} {"="*12}') for k, v in chain.items(): if k == 'transactions': print(k) for d in v: print(f'{"-"*40}') for kk, vv in d.items(): print(f' {kk:30}{vv}') else: print(f'{k:15}{v}')これらの実行結果は
============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590879582.569221 transactions ============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590879582.569221 transactions ============ Chain 1 ============ nonce 2329 previous_hash 2852aa2bd46f72ba889bc8503e7c21804d1776cf30bce8819d893044aff623f9 timestamp 1590879582.598022 transactions ---------------------------------------- recipient_blockchain_address 佐藤さん sender_blockchain_address 山本さん value 0.5 ---------------------------------------- recipient_blockchain_address 佐藤さん sender_blockchain_address 田中さん value 0.1このようになりました。
次回はマイニングの処理の追加を行っていきたいと思います!
- 投稿日:2021-01-27T21:24:50+09:00
PyTorchを使って画像分類モデルを作成してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はPyTorchを用いてディープラーニングを活用した画像分類モデルを作成してみました
はじめに
仕事として、非構造化データも扱ったデータ分析ができるようにディープラーニングを活用した画像分類問題に挑戦しました。
正直、勉強始めたばかりですしので、詳しい理論については整理することができませんが、実装することはできました。使用するデータセット
今回使用したデータセットは、「CelebA」というデータセットを使いました。CelebAは、有名人の顔画像をカラー178×218ピクセルで202,599枚集めたデータセットです。
CelebAには、各画像データが40種類の属性について、該当するかどうかをまとめた属性ファイル( list_attr_celeba.txt )が付属しています。これを活用して必要な画像を抽出して実装しました。実装
今回はgoogle colabを活用して実装しました。理由としては、無料でGPUが使用できるので活用させて頂きました。
はじめに、CelebA (Large-scale CelebFaces Attributes) データセットのダウンロードと展開(解凍)を実施しました。
1. URLのリンク先に飛びます。
2. 「Google Drive」をクリック
3. 「img」ディレクトリの下の「img_align_celeba.zip」をダウンロード
4. フォルダ「data」の直下で「img_align_celeba.zip」を解凍実装コードは下記の通りになります。
# ライブラリーのインストール import os from os.path import join import sys import numpy as np import glob import pathlib import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from pathlib import Path from PIL import Image from sklearn.metrics import confusion_matrix, accuracy_score import matplotlib.pyplot as plt %matplotlib inline # google driveのマウント from google.colab import drive drive.mount('/content/drive/')次にzipファイルを解凍します。
!unzip "drive/MyDrive/CelebA_dataset/img_align_celeba.zip"取得したデータを確認します。
# CelebAデータセットのディレクトリを指定 path_dir = Path('img_align_celeba') # glob関数により取得した jpg ファイルの一覧 sorted(path_dir.glob('*.jpg'))[:10]
次に画像を確認します。
plt.figure(figsize=(20, 20)) for i, path_img in enumerate(sorted(path_dir.glob('*00001.jpg'))): name_img = path_img.name img = Image.open(path_img) plt.subplot(4, 5, i+1) plt.title(name_img) plt.imshow(img)
次は使用する画像のリサイズを行います。リサイズをする際に入力する画像のサイズをヒストグラムを用いて確認します。
# 画像サイズを集計 list_w, list_h, list_ratio = [], [], [] for path_img in path_dir.glob('*.jpg'): img = Image.open(path_img) w, h = img.size list_w.append(w) list_h.append(h) list_ratio.append(w / h) # ヒストグラムの表示 plt.figure(figsize=(20, 5)) # width plt.subplot(1, 3, 1) plt.hist(list_w, bins=10, density=True) plt.title('width') plt.xlabel('width') plt.ylabel('freq') # width plt.subplot(1, 3, 2) plt.hist(list_h, bins=10, density=True) plt.title('height') plt.xlabel('height') plt.ylabel('freq') # rate plt.subplot(1, 3, 3) plt.hist(list_ratio, bins=10, density=True) plt.title('width / height') plt.xlabel('w / h') plt.ylabel('freq')
今回は有名なデータセットを使用するため、画像サイズが綺麗に揃っておりましたが、実務で使用する際はサイズが異なっているので上記作業は必ず確認する必要がありそうです。
2の累乗を約数に含むようにサイズを設定すると良いそうなので、今回は「224 * 224」に設定しました。def load_image(path_img, size=(224, 224)): img = Image.open(path_img) # 短辺長を基準とした正方形の座標を得る x_center = img.size[0] // 2 y_center = img.size[1] // 2 half_short_side = min(x_center, y_center) x0 = x_center - half_short_side y0 = y_center - half_short_side x1 = x_center + half_short_side y1 = y_center + half_short_side img = img.crop((x0, y0, x1, y1)) img = img.resize(size) img = np.array(img, dtype=np.float32) return img # リサイズ後の画像を確認 plt.figure(figsize=(20, 20)) for i, path_img in enumerate(sorted(path_dir.glob('*00001.jpg'))): name_img = path_img.name img = load_image(path_img) plt.subplot(4, 5, i+1) plt.title(name_img) plt.imshow(img /255) # matplotlib で float32型の数値を適切に表示するために 0-1の間に収めます。
きちっとリサイズされていることが分かりますね。
次は、CelebAのデータセットを抽出します。今回は下記2パターンのデータセットを抽出しました。
- 笑っている男性
- 笑っていない男性
# outputディレクトリの指定 output_dir = f'drive/MyDrive/CelebA_dataset/' # フォルダをリストで作成 pass_list = [f'00_smiling_male/', f'01_Nonsmiling_male/'] for path in pass_list: path_train_data = join(output_dir, path) if not os.path.exists(path_train_data): os.makedirs(path_train_data) count = 0 with open("drive/MyDrive/CelebA_dataset/list_attr_celeba_ref.txt","r") as f: ### 属性ファイルを開く for i in range(202599): # 全部で202,599枚処理する line = f.readline() # 1行データ読み込み line = line.split() # データを分割 count = count+1 print(count) # 笑っている男性 if line[3]=="1" and line[16]=="-1" and line[21]=="1" and line[32]=="1" and line[36]=="-1" and line[40]=="1": image = Image.open("img_align_celeba/"+line[0]) image.save(output_dir + pass_list[0] + line[0]) # 笑っていない男性 elif line[3]=="1" and line[16]=="-1" and line[21]=="1" and line[32]=="-1" and line[36]=="-1" and line[40]=="1": image = Image.open("img_align_celeba/"+line[0]) image.save(output_dir + pass_list[1] + line[0])次は、バッチ作成関数を実装します。
* ミニバッチを生成する関数を作成。
* 画像のパスを受け取り、入力データ:x_batch, 教師ラベル:t_batchを返す関数。
* 教師ラベルはフォルダ名から計算。def make_batch(list_path_img): x_batch = [] t_batch = [] for path_img in list_path_img: img = load_image(path_img) img = np.array(img, dtype=np.float32) img = img.transpose(2, 0, 1) x_batch.append(img) t = int(str(path_img).split('/')[3][:2]) t_batch.append(t) return torch.tensor(x_batch), torch.tensor(t_batch) list_path_img = [output_dir+"00_smiling_male/"+"000012.jpg", output_dir+"00_smiling_male/"+"000023.jpg"] x_batch, t_batch = make_batch(list_path_img) print(list_path_img) print(x_batch.shape) print(t_batch) #['drive/MyDrive/CelebA_dataset/00_smiling_male/000012.jpg', 'drive/MyDrive/CelebA_dataset/00_smiling_male/000023.jpg'] #torch.Size([2, 3, 224, 224]) #tensor([0, 0])次にモデルを作成します。
- nn.Moduleというクラスを継承したクラスとしてモデルを定義。
- 3チャネルの入力画像を、Convolution 3層により 16 -> 32 -> 64 チャンネルの特徴マップに変換し、最後に全結合層により4次元のベクトルに変換するネットワークを定義。
- Convolution層の直後にはバッチ正則化を行い活性化関数 relu に通す。
class Model(nn.Module): def __init__(self): # スーパークラス(Module クラス)の初期化メソッドを実行 super().__init__() self.c0 = nn.Conv2d(in_channels=3, # 入力は3チャネル out_channels=16, # 出力は16チャネル kernel_size=3, # カーネルサイズは3*3 stride=2, # 1pix飛ばしでカーネルを移動 padding=1) # 画像の外側1pixを埋める self.c1 = nn.Conv2d(in_channels=16, # 入力は16チャネル out_channels=32, # 出力は32チャネル kernel_size=3, # カーネルサイズは3*3 stride=2, # 1pix飛ばしでカーネルを移動 padding=1) # 画像の外側1pixを埋める self.c2 = nn.Conv2d(in_channels=32, # 入力は32チャネル out_channels=64, # 出力は64チャネル kernel_size=3, # カーネルサイズは3*3 stride=2, # 1pix飛ばしでカーネルを移動 padding=1) # 画像の外側1pixを埋める self.bn0 = nn.BatchNorm2d(num_features=16) # c0用のバッチ正則化 self.bn1 = nn.BatchNorm2d(num_features=32) # c1用のバッチ正則化 self.bn2 = nn.BatchNorm2d(num_features=64) # c2用のバッチ正則化 self.fc = nn.Linear(in_features=64 * 28 * 28, # 入力サイズ out_features=4) # 各クラスに対応する4次元のベクトルに変換 def __call__(self, x): # 入力から出力を計算するメソッドを定義 h = F.relu(self.bn0(self.c0(x))) h = F.relu(self.bn1(self.c1(h))) h = F.relu(self.bn2(self.c2(h))) h = h.view(-1, 64 * 28 * 28) y = self.fc(h) # 全結合層 return y次にモデルを生成します。
model = Model() model.modules
生成したモデルの挙動を確認します。
ここで、GPUを使用する設定もします。# GPUを使用できる設定 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device)
path_img = output_dir+"00_smiling_male/"+"000033.jpg" img = load_image(path_img) plt.imshow(img /255)
この画像をモデルに通してみます。データを、PyTorchのモデルが入力画像に要求する(バッチ、チャネル、縦、横)という次元に合わせるために、np.newaxis によりバッチ次元として1次元目を挿入し、transpose メソッドにより次元の順番を変えます。
img = np.array(img, dtype=np.float32) img_ = img[np.newaxis].transpose(0, 3, 1, 2) img_.shape #(1, 3, 224, 224) x = torch.from_numpy(img_) x = x.to(device) model(x) #tensor([[-0.2852, -0.2660, 0.4112, 0.6463]], device='cuda:0',grad_fn=<AddmmBackward>)やっとここまでが事前の準備です。
これからモデルを学習します。ただし、データ数が多いのでモデルの学習にはGPUを使用しても1時間ぐらいかかります。# 一回のパラメータ更新に使うデータ数 size_batch = 64 # 学習データの学習回数 n_epoch = 5 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model = Model().to(device) opt = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # ロスと精度を保存するリスト(訓練用・テスト用) list_loss_train = [] list_loss_test = [] list_acc_train = [] list_acc_test = [] # データの分割 data_train = [] data_test = [] for path in pass_list: path_dir_data = Path(output_dir+path) list_path_img = sorted(list(path_dir_data.glob('*.jpg'))) count = 0 division_point = int(len(list_path_img)*0.9) # 学習データを90%、評価データを10% for path_img in list_path_img: count = count + 1 if count < division_point: # division_pointより小さいときは学習データに割り振る。 data_train.append(path_img) else: # division_pointより大きいときは評価データに割り振る。 data_test.append(path_img) # データ数の確認 len(data_train), len(data_test) #(18038, 2008)データの型をarrayに変換しておきます。
# データの型を変更 data_train = np.array(data_train) data_test = np.array(data_test) for epoch in range(n_epoch): print("-----------------------------------------") print('epoch: {}'.format(epoch)) print('train') perm = np.random.permutation(len(data_train)) sum_loss = 0. sum_acc = 0. # 訓練 for i in range(0, len(perm), size_batch): # ミニバッチの用意 x_batch, t_batch = make_batch(data_train[perm[i:i+size_batch]]) x_batch = x_batch.to(device) t_batch = t_batch.to(device) # 順伝播 y = model(x_batch) loss = F.cross_entropy(y, t_batch) # 逆伝播 opt.zero_grad() loss.backward() # パラメータ更新 opt.step() # ロスと精度を蓄積 sum_loss += loss.item() sum_acc += (y.max(1)[1] == t_batch).sum().item() # 進捗を表示 print(i, "/", len(perm), end="\r") sys.stdout.flush() mean_loss = sum_loss / len(data_train) mean_acc = sum_acc / len(data_train) list_loss_train.append(mean_loss) list_acc_train.append(mean_acc) print("- mean loss:", mean_loss) print("- mean accuracy:", mean_acc) # Evaluate print('test') sum_loss = 0. sum_acc = 0. with torch.no_grad(): for i in range(0, len(data_test), size_batch): x_batch, t_batch = make_batch(data_test[i:i+size_batch]) x_batch = x_batch.to(device) t_batch = t_batch.to(device) # forward y = model(x_batch) loss = F.cross_entropy(y, t_batch) sum_loss += loss.item() sum_acc += (y.max(1)[1] == t_batch).sum().item() mean_loss = sum_loss / len(data_test) mean_acc = sum_acc / len(data_test) list_loss_test.append(mean_loss) list_acc_test.append(mean_acc) print("- mean loss:", mean_loss) print("- mean accuracy:", mean_acc)
学習が完了したら結果を表示していきます。
最初に正解率の推移を見ます。# Accuracy plt.figure(figsize=(8, 5)) plt.grid(True) plt.xlabel('epoch') plt.ylabel('accuracy') plt.plot(list_acc_train) plt.plot(list_acc_test) plt.legend(['train', 'test']) plt.show()
次にLossの推移を見ます。
# Loss plt.figure(figsize=(8, 5)) plt.grid(True) plt.xlabel('epoch') plt.ylabel('loss') plt.plot(list_loss_train) plt.plot(list_loss_test) plt.legend(['train', 'test']) plt.show()
最後にConfusion Matrixを作成します。
ys = [] ts = [] for i in range(0, len(data_test), size_batch): x_batch, t_batch = make_batch(data_test[i:i+size_batch]) x_batch = x_batch.to(device) t_batch = t_batch.to(device) y = model(x_batch) y = torch.argmax(y, dim=1) # 確率の最大のインデックスを取得 ys.append(y.cpu()) ts.append(t_batch.cpu()) ys = torch.cat(ys, dim=0) ts = torch.cat(ts, dim=0) # confusion matrixを表示するための関数 from sklearn import metrics import itertools def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): """ This function prints and plots the confusion matrix. Normalization can be applied by setting `normalize=True`. """ if normalize: cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] print("Normalized confusion matrix") else: print('Confusion matrix, without normalization') print(cm) plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=45) plt.yticks(tick_marks, classes) fmt = '.2f' if normalize else 'd' thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black") plt.tight_layout() plt.ylabel('True label') plt.xlabel('Predicted label') confmat = confusion_matrix(ys, ts) confmat #array([[879, 91], # [ 88, 950]]) classes = ['smiling_male', 'Nosmiling_male'] plt.figure(figsize=(12, 12)) plot_confusion_matrix(confmat, classes=classes, normalize=True)
さいごに
最後まで読んで頂き、ありがとうございました。
今回初めてディープラーニングを活用しましたが、実装はそこまで大変ではなかったですが、学習時間が長過ぎるのが今後の問題ですね。
転移学習とかを次は勉強してみようと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。











- 投稿日:2021-01-27T21:03:07+09:00
Pythonでブロックチェーンを構築③トランザクションの追加
今回はブロックチェーンのトランザクションを追加していきます。前回のブロックチェーンのクラスが入ったファイルに送金者と受信者のブロックチェーンアドレス、送金額を含む取引(トランザクション)の情報をプールに入れるものです。
「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」
https://www.udemy.com/course/python-blockchain/learn/lecture/15381372#overviewdef add_transaction(self, sender_blockchain_address, recipient_blockchain_address, value): transaction = utils.sorted_dict_by_key({ 'sender_blockchain_address':sender_blockchain_address, 'recipient_blockchain_address':recipient_blockchain_address, 'value': float(value) }) self.transaction_pool.append(transaction) return Truevalueのところでfloatにしている理由はビットコインだと少数点である場合があるからです。
続いて、ブロックチェーンを呼び出す部分で「田中さんが佐藤さんに0.1送金」の旨の取引を追加します。
block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash=block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) pprint(block_chain.chain) # 二つ目のブロックこのように書き換えて実行すると、
============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590839663.975886 transactions [] ============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590839663.975886 transactions [] ============ Chain 1 ============ nonce 5 previous_hash a323d174ba978244a8f8e171bfbf9ebdcc095e374fa54ba0f51d6d3f430f1fe9 timestamp 1590839663.9759748 transactions [OrderedDict([('recipient_blockchain_address', '佐藤さん'), ('sender_blockchain_address', '田中さん'), ('value', 0.1)])]ここで、一つのブロックに2つ以上の記録が出来ます。
block_chain.add_transaction('山本さん', '佐藤さん', 0.5) block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash=block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) pprint(block_chain.chain) # 二つ目のブロックこれで実行すると
============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590840298.8124318 transactions [] ============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590840298.8124318 transactions [] ============ Chain 1 ============ nonce 5 previous_hash d248a17422a6a7092f62869d1b5f9f0dfdbecf30ebe74cdbbef73bc0d8e0e5cb timestamp 1590840298.812531 transactions [OrderedDict([('recipient_blockchain_address', '佐藤さん'), ('sender_blockchain_address', '山本さん'), ('value', 0.5)]), OrderedDict([('recipient_blockchain_address', '佐藤さん'), ('sender_blockchain_address', '田中さん'), ('value', 0.1)])]このように表示されます。ただ、これだと見づらいので、表示の処理の部分を書き換えます。
============ Chain 0 ============ transactions transactions [] ============ Chain 0 ============ transactions transactions [] ============ Chain 1 ============ transactions ---------------------------------------- recipient_blockchain_address 佐藤さん sender_blockchain_address 山本さん value 0.5 ---------------------------------------- recipient_blockchain_address 佐藤さん sender_blockchain_address 田中さん value 0.1これでスッキリしましたね。
本日の書き換えのまとめは以下になります。
import hashlib import json import logging import sys import time import utils logging.basicConfig(level=logging.INFO, stream=sys.stdout) class BlockChain(object): def __init__(self): self.transaction_pool = [] self.chain = [] self.create_block(0, self.hash({})) def create_block(self, nonce, previous_hash): block = utils.sorted_dict_by_key({ 'timestamp': time.time(), 'transactions': self.transaction_pool, 'nonce': nonce, 'previous_hash': previous_hash }) self.chain.append(block) self.transaction_pool = [] return block def hash(self, block): sorted_block = json.dumps(block, sort_keys=True) return hashlib.sha256(sorted_block.encode()).hexdigest() def add_transaction(self, sender_blockchain_address, recipient_blockchain_address, value): transaction = utils.sorted_dict_by_key({ 'sender_blockchain_address': sender_blockchain_address, 'recipient_blockchain_address': recipient_blockchain_address, 'value': float(value) }) self.transaction_pool.append(transaction) return True def pprint(chains): for i, chain in enumerate(chains): print(f'{"="*12} Chain {i} {"="*12}') for k, v in chain.items(): if k == 'transactions': print(k) for d in v: print(f'{"-"*40}') for kk, vv in d.items(): print(f' {kk:30}{vv}') else: print(f'{k:15}{v}') if __name__ == '__main__': block_chain = BlockChain() pprint(block_chain.chain) block_chain.add_transaction('山本さん', '佐藤さん', 0.5) block_chain.add_transaction('田中さん', '佐藤さん', 0.1) previous_hash = block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) pprint(block_chain.chain)
- 投稿日:2021-01-27T20:19:23+09:00
Pythonでブロックチェーンを構築②ブロックのハッシュを求める
引き続き、UdemyでPythonでブロックチェーンを構築する際のブロックのハッシュの実装をしていきたいと思います。
「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」
https://www.udemy.com/course/python-blockchain/learn/lecture/15381372#overviewimport collections def sorted_dict_by_key(unsorted_dict): return collections.OrderedDict( sorted(unsorted_dict.items(), key=lambda d:d[0]))ディクショナリーの中身をキーで揃えたいので、collectionsをimportします。また、OrderDictで順番を保持するメソッドを使用。
そして、これを前回作成したブロックチェーンクラスが入ったファイルで使用したいと思います。まず、
import utilsを追加。そして、ブロックを生成するところに
utils.sorted_dict_by_key()を追加しすることでブロックを作るときに常に順序良くなります。
次にハッシュメソッドを付け加えます。この後、使用する
import hashlib import jsonを追加。そして、jsonでsorted_blockを作成、sha256でハッシュ作成
def hash(self, block): sorted_block = json.dumps(block, sort_keys=True) return hashlib.sha256(sorted_block.encode()).hexdigest()json.dumpsを使用することで文字列にし、sort_keys=Trueの時に文字列をsortしてくれます。
先ほど、
utils.sorted_dict_by_key()でディクショナリーをsortしてますが、ハッシュのメソッドの部分ではsortされているか分からないので、ここでもsortしてます。以上、前回から変更した箇所がこちら
def create_block(self, nonce, previous_hash): block = utils.sorted_dict_by_key({ 'timestamp': time.time(), 'transactions': self.transaction_pool, 'nonce': nonce, 'previous_hash': previous_has self.chain.append(block) self.transaction_pool = [] return block def hash(self, block): sorted_block = json.dumps(block, sort_keys=True) return hashlib.sha256(sorted_block.encode()).hexdigest()続いて、ブロックチェーンを呼び出す部分で一つ前のブロックからハッシュを作り、前回’hash 1’としていた部分を書き換えましょう。
previous_hash=block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) pprint(block_chain.chain) # 二つ目のブロックそして、最初のブロックのハッシュ’init hash’も書き換えましょう。
def __init__(self): self.transaction_pool = [] # トランザクションの情報が入る self.chain = [] # ブロックチェーンの情報が入る self.create_block(0, self.hash({})) # 初期のブロックの作成self.hash({})として空のディクショナリーを入れます。
今回の変更をまとめたブロックチェーンクラスが入ったファイルはこちら
import hashlib import json import logging import sys import time # タイムスタンプを使用するため import utils logging.basicConfig(level=logging.INFO, stream=sys.stdout) class BlockChain(object): # ブロックチェーンのクラス def __init__(self): self.transaction_pool = [] self.chain = [] self.create_block(0, self.hash({})) def create_block(self, nonce, previous_hash): block = utils.sorted_dict_by_key({ 'timestamp': time.time(), 'transactions': self.transaction_pool, 'nonce': nonce, 'previous_hash': previous_hash }) self.chain.append(block) self.transaction_pool = [] return block def hash(self, block): sorted_block = json.dumps(block, sort_keys=True) return hashlib.sha256(sorted_block.encode()).hexdigest() def pprint(chains): #ブロックを見やすくするための処理 for i, chain in enumerate(chains): print(f'{"="*12} Chain {i} {"="*12}') for k, v in chain.items(): print(f'{k:15}{v}') if __name__ == '__main__': # ブロックチェーンを呼び出す block_chain = BlockChain() pprint(block_chain.chain) # 一つ目のブロック previous_hash=block_chain.hash(block_chain.chain[-1]) block_chain.create_block(5, previous_hash) pprint(block_chain.chain) # 二つ目のブロックこの実行結果は
============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590831143.635446 transactions [] ============ Chain 0 ============ nonce 0 previous_hash 44136fa355b3678a1146ad16f7e8649e94fb4fc21fe77e8310c060f61caaff8a timestamp 1590831143.635446 transactions [] ============ Chain 1 ============ nonce 5 previous_hash 67696f3c153f099f8a7fd6d6c7431c0322c7cbf01c418875f919cd4937cd94cc timestamp 1590831143.6355069 transactions []このようにハッシュで次のブロックへ繋いでいくイメージになります。
次回はトランザクション(取引)に進んでいきます!!!
- 投稿日:2021-01-27T19:05:21+09:00
衛星画像ファイルをNumpy Arrayの形で保存する方法(Python)
概要
こんにちは。
衛星リモートセンシングの分野では大量の画像を扱うことがありますが、GeoTiffなどの位置情報付きのものは専用のソフト(QGIS)などで扱うことが主だと思います。数十枚までならば気合で処理することもできますが、数百~数千枚になると非常に険しいのでPython等で自動化したい気持ちが湧いてきます。特にNumpy arrayの形は統計手法や機械学習手法を用いる際のベースとなるので、この形で取り込めると便利ですね。また衛星画像解析では時系列の情報も大切になりますが、変数に逐一"~_2019"と付けるのも大変です。
以上を踏まえて、画像が格納されているフォルダから画像ファイルをNumpy arrayの形で読み込み、それを辞書型配列に画像の取得年と一緒に格納するコードを書いたので、ご紹介したいと思います。環境と前提条件
- Google Colabで実行 (記事執筆時点でのバージョンはpython 3.6.9)
- ファイル名は"~YYYYMMDD~.geotiff"の様に取得年を含む形になっていることが前提条件です
- ファイルパス等についてはご自分の環境に合わせて変えて頂ければ(多分)動くと思います。Google Colabは個人的にとても便利だと感じているので、是非この機会に手を出されてみるのもオススメです!
コード
最初に必要なモノをインポートしましょう。
import.pyfrom osgeo import gdal import numpy as np import glob import os import pandas as pdファイル名を取得して年ごとに辞書型配列にしまっておきます。例では2001年から2020年までのMODIS衛星のプロダクト画像を使う準備をしています。ここを変えれば違う年についても大丈夫だと思われます。ソートをかけているのは、これが無いとファイル順がカオスになってしまうからです。ワイルドカードで特定の年に合うファイル名を探しつつ、forループでぐるぐる回しています。"/content/drive/My Drive/Colab Notebooks"はColabからDriveのファイルを使う際に特有の書き方なので、ここを変えればColab以外でも動くのではないでしょうか。
filename.pyfor y in range(2001,2021): filenames=[os.path.basename(p) for p in \ sorted(glob.glob(f'/content/drive/My Drive/Colab Notebooks/satellite_data/MODIS.2001-2020.FRP.Buryat/L3/MODIS.{y}*.geotiff', recursive=True)) \ if os.path.isfile(p)] list_of_filenames[f"{y}"]=filenames画像をnumpy行列へ格納していきます。画像が重かったり、沢山ある場合にはそこそこ時間がかかると思います。gdalでファイルを開いて、Arrayとして読み込んでいきます。グレースケール画像を使っていたのでバンドを一つしか読んでいません。前段階でソートをかけているので、日時についてはfor文で頭から順番に読んでいきます。途中でコメントアウトしてあるprint(FName)を使うことでファイル名が書かれていくと思うので、これによって順番通りに処理されているか確認されても良いかもしれません。
array.pydatabase_array={} for year in list_of_filenames.keys(): ArrayList=[] for day in range(len(list_of_filenames[f"{year}"])): FName=list_of_filenames[f"{year}"][day] #print(FName) File=gdal.Open(f'/content/drive/My Drive/Colab Notebooks/satellite_data/MODIS.2001-2020.FRP.Buryat/L3/{FName}') FileAsArray=File.GetRasterBand(1).ReadAsArray() ArrayList.append(FileAsArray) database_array[f"{year}"]=ArrayList処理が終わると、辞書型配列として画像が格納されているかと思います。
配列の格納にはそこそこ時間がかかるので、以下の様にpickleとして保存しておいてもいいかもしれません。save.pypd.to_pickle(database_array,'/content/drive/My Drive/Colab Notebooks/outputs/pickle/database_array.pkl') #再度の読み込みも簡単 #database_array=pd.read_pickle('/content/drive/My Drive/Colab Notebooks/outputs/pickle/database_array.pkl')以上が記事の内容です。初投稿なので色々と至らなかった点も多いと思いますが、今までお世話になったQiitaコミュニティへと少しでも貢献できていたら幸いです。
- 投稿日:2021-01-27T19:02:56+09:00
自動取得した株価データをBigQueryに保存
自動取得した株価データをBigQueryに保存
取得の方法はこちら → Seleniumを使い株価データを自動取得
はじめに
CSVデータはバックアップの意味も含め Cloud Storageに保存
Cloud StorageからCSVデータを一時テーブルとして作成
作成した一時テーブルのレコードを加工して本テーブルを作成Cloud Storageに保存
Cloud Storage、BigQueryを使うためパッケージをインストール
$ pip install google-cloud-bigquery $ pip install google-cloud-storageパッケージのインポート、Clientを作成
... from google.cloud import bigquery, storage from google.cloud.exceptions import NotFound ... class YahooDownload: def __init__(self): self.str_client = storage.Client() self.bq_client = bigquery.Client()CSVアップロード
GCPコンソールでバケットを作成しておく、今回はyahoo-finance-downloadという名前でバケットを作成... def upload(self): bucket = str_client.bucket("weekend-hackathon-stock") for _, v in self.download_list.iterrows(): stock_no = v["stock_no"] blob = bucket.blob(f"yahoo-finance-download/{stock_no}.T.csv") blob.upload_from_filename(f"{self.download_dir}/{stock_no}.T.csv")処理を追加
... def main(self): try: self.login() self.download() self.upload() pass except TimeoutException as ex: print(ex) pass except Exception as e: print(e) pass finally: time.sleep(5) self.driver.close() self.driver.quit()実行するとCloud Storageにアップロードされる
BigQueryに保存
BigQueryにbqコマンドを使ってバケットを作成
$ bq --location=US mk --dataset --description "yahoo_finance_download dataset using" \ weekend-hackathon:yahoo_finance_downloadポイントとしては自動取得したCSVデータの日付フォーマットがBigQueryのDATEフォーマットと一致しないため一時テーブルに日付をSTRINGで作成した後に日付を
PARSE_DATE('%Y/%m/%e', trade_at)でパースして本テーブルにデータ追加しないといけない取得CSV
日付,始値,高値,安値,終値,出来高,調整後終値 2021/1/22,423,425,423,424,5200,424 2021/1/21,425,425,422,422,2500,422BigQuery追加
... def save(self): for _, v in self.download_list.iterrows(): stock_no = v["stock_no"] # 一時テーブル準備 external_config = bigquery.ExternalConfig("CSV") external_config.source_uris = [ f"gs://weekend-hackathon-stock/yahoo-finance-download/{stock_no}.T.csv" ] external_config.schema = [ bigquery.SchemaField("trade_at", "STRING", "REQUIRED"), bigquery.SchemaField("open", "FLOAT", "REQUIRED"), bigquery.SchemaField("high", "FLOAT", "REQUIRED"), bigquery.SchemaField("low", "FLOAT", "REQUIRED"), bigquery.SchemaField("close", "FLOAT", "REQUIRED"), bigquery.SchemaField("volume", "INTEGER", "REQUIRED"), bigquery.SchemaField("adj_close", "FLOAT", "REQUIRED"), ] external_config.options.skip_leading_rows = 1 table_id = f"tmp_{stock_no}" # 一時テーブル参照結果を本テーブルに追加 job_config = bigquery.QueryJobConfig( destination = ( f"weekend-hackathon.yahoo_finance_download.{stock_no}" ), write_disposition="WRITE_TRUNCATE", ) job_config.table_definitions = {table_id: external_config} sql = f"SELECT PARSE_DATE('%Y/%m/%e', trade_at) AS trad_at, open, high, low, close, volume, adj_close FROM {table_id}" query_job = self.bq_client.query(sql, job_config=job_config) query_job.result()処理を追加
... def main(self): try: self.login() self.download() self.upload() self.save() pass except TimeoutException as ex: print(ex) pass except Exception as e: print(e) pass finally: time.sleep(5) self.driver.close() self.driver.quit()実行するとBigQueryに株価データが保存される
次回はBigQueryのデータを加工、分析しStreamlitを使いアプリっぽくします
いいね!と思ったら LGTM お願いします


- 投稿日:2021-01-27T18:33:29+09:00
create_sheetメソッドで作成されるシートの位置をへんこうする。
Pythonのライブラリであるopenpyxlを使用してExcelのシートを増やす場合
create_sheetメソッドを使用しますが
作成されるシートはブックの末尾に作成されてしまうようです。
任意の場所に作成したい場合
create_sheetメソッドのindex引数を使用します。例from openpyxl import Workbook count = input('全シート数: ') wb = Workbook() ws = wb.active ws.title = '概要_1' for i in range(2, int(count) + 1): wb.create_sheet(title=f'概要_{i}') wb.save('資料.xlsx')こちらを
ブックの先頭に作成したい場合wb.create_sheet(title=f'概要_{i}', index=0)2番目に作成したい場合wb.create_sheet(title=f'概要_{i}', index=1)こちらのように変更します。
地味ですが、覚えておくと後々便利だなと思えました。
- 投稿日:2021-01-27T18:33:29+09:00
create_sheetメソッドで作成されるシートの位置を変更する。
Pythonのライブラリであるopenpyxlを使用してExcelのシートを増やす場合
create_sheetメソッドを使用しますが
作成されるシートはブックの末尾に作成されてしまうようです。
任意の場所に作成したい場合
create_sheetメソッドのindex引数を使用します。例from openpyxl import Workbook count = input('全シート数: ') wb = Workbook() ws = wb.active ws.title = '概要_1' for i in range(2, int(count) + 1): wb.create_sheet(title=f'概要_{i}') wb.save('資料.xlsx')こちらを
ブックの先頭に作成したい場合wb.create_sheet(title=f'概要_{i}', index=0)2番目に作成したい場合wb.create_sheet(title=f'概要_{i}', index=1)こちらのように変更します。
地味ですが、覚えておくと後々便利だなと思えました。
- 投稿日:2021-01-27T17:36:17+09:00
【Python】そもそもライブラリとは? ライブラリ管理のpipとは?
背景
Python はライブラリが豊富であると言われまずが、まずはその
ライブラリとは何かと、ライブラリをインストール、管理するpipについてをまとめました。先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとして、こちらへまとめておきます。
環境
(開発)
- Python 3.9.0, 3.8.5
- Django 3.1.5
- PostgreSQL 13.1
- Nginx 1.95.5
- Gunicorn
- Putty 0.74ライブラリ? パッケージ? モジュール??
・モジュール
Python のファイル=「~.py」ファイルのことです。
Python である程度、ステップ数のあるプログラムを書く場合は、Jupitor Lab(※1) や コマンドライン ではなく、実行したい内容を書いたもの「~.py」ファイルとして保存します。
その保存された「~.py」ファイルは、他の Python プログラムからimportで呼び出して使うこともできます。これをモジュールと呼びます。
通常、このモジュールの中には幾つかのクラスや関数が含まれています。(※1)
コード、データ、そして Jupyter Notebook のファイル形式:「~.ipynb」を扱う最新の対話型開発環境(IDE)。OSS で公開されています。(参照: Project Jupyter )・パッケージ
複数のモジュールをまとめたものをパッケージと呼びます。
・ライブラリ
幾つかのパッケージをまとめて一つのライブラリとしてインストールできるようにしたものです。
また、関数、モジュール、パッケージ自体を総称して、ライブラリと呼ぶこともあります。科学技術計算でよく使われる NumPy 、グラフ描画に使われる Matplotlib 、データ解析を支援する機能を提供する Pandas 等は、すべてライブラリとして配布されています。
(注)以降、パッケージも含めて、ライブラリと総称して説明します。0. 標準ライブラリと外部ライブラリ
標準ライブラリ と 外部ライブラリ の二つの種類があります。
それぞれは以下の通りです。0-1. 標準ライブラリ
Python をインストールした時から元来含まれているライブラリのこと。追加でインストールすることなく利用できます。
(参照)Python 標準ライブラリ
0-2. 外部ライブラリ
対して Python には元来組み込まれておらず、新たに外部から読み込む必要のあるライブラリのこと。どのような外部ライブラリがあるかは、主に PyPI (The Python Package Index) のサイトで検索可能です。
利用するためには、予めコマンドプロンプトやターミナルから、(主に)下記コマンドでインストールする必要があります。
お使いの環境によってインストールのためのコマンドが異なりますため、お使いの環境に合ったコマンドをお使いください。
なお、インストールせずに利用し、プログラムを実行した場合はエラーとなります。$ pip install ライブラリ名 $ pip install scikit-learn # scikit-learn をインストールするケース1. ライブラリを利用するには
1-1. ライブラリ全体をインポートする
プログラム内でライブラリを読み込むためには、
importが必要です。
importは、ライブラリを読み込むための指示です。
この指示があることで、そのライブラリの機能が利用できるようになります。簡単ですね!また、インポートしたモジュールの関数を使うには、
ライブラリ名.関数名()と書きます。
組み込み関数を使う時と違って、関数名の前にモジュール名を書き、「.」(ドット)で繋ぎます。import ライブラリ名 import random # 引数に指定した数値の範囲でランダムに整数を返す random.randint(1,1000) # 7771-2. ライブラリを別名を付けてインポートする
ライブラリに別名を付けてインポートする場合は、以下のように書きます。
そのモジュール内の関数を使うには別名.関数名()と書きます。import ライブラリ名 as 別名 import random as rd # random を rd としてimportする rd.randint(1, 1000) # 9991-3. ライブラリから特定の関数のみをインポートする
そのライブラリから特定の関数のみをインポートする場合は、
fromを用いて以下のように書きます。
特定の関数だけをインポートした場合に、その関数を使う時は、先頭にライブラリ名を省略することができます。from ライブラリ名 import 関数名 from random import randint # random 内の randint 関数のみimportする ''' 特定の関数だけをインポートした場合に、その関数を使う時は、 先頭のライブラリ名を省略することができます。 ''' randint(1, 1000) # 4441-4. ライブラリから特定の関数のみ、別名をつけてインポートする
特定の関数だけをインポートする場合も、その関数に別名を付けることができます。
from ライブラリ名 import 関数名 as 別名 from random import randint as rd # randint 関数を rint としてimportする ''' 特定の関数だけをインポートした場合に、その関数を使う時は、 先頭のライブラリ名を省略することができます。 ''' rint(1, 1000) # 3211-5. ライブラリに含まれる関数などの属性の一覧と定義の確認方法
ライブラリに含まれる関数などの属性は
dir()で確認することができます。
numpy に含まれる属性を確認してみます。import numpy as np print(dir(np)) # ['ALLOW_THREADS', 'AxisError', 'BUFSIZE', 'CLIP', 'ComplexWarning', 'DataSource', 'ERR_CALL', 'ERR_DEFAULT', 'ERR_IGNORE', 'ERR_LOG', 'ERR_PRINT', 'ERR_RAISE', 'ERR_WARN', 'FLOATING_POINT_SUPPORT', 'FPE_DIVIDEBYZERO', (...中略...), 'var', 'vdot', 'vectorize', 'version', 'void', 'void0', 'vsplit', 'vstack', 'warnings', 'where', 'who', 'zeros', 'zeros_like']1-6. ライブラリに含まれる関数やクラスの定義の確認方法
ライブラリに含まれる関数やクラスの定義は
help()で確認できます。
pandas に含まれる DataFrame の定義を表示しています。import pandas as pd help(pd.DataFrame) # Help on class DataFrame in module pandas.core.frame: # # class DataFrame(pandas.core.generic.NDFrame, pandas.core.arraylike.OpsMixin) # | DataFrame(data=None, index: 'Optional[Axes]' = None, columns: 'Optional[Axes]' = None, dtype: 'Optional[Dtype]' = # None, copy: 'bool' = False) # | # | Two-dimensional, size-mutable, potentially heterogeneous tabular data. # | # | Data structure also contains labeled axes (rows and columns). # | Arithmetic operations align on both row and column labels. Can be # | thought of as a dict-like container for Series objects. The primary # | pandas data structure. # | # | Parameters # | ---------- # | data : ndarray (structured or homogeneous), Iterable, dict, or DataFrame # | Dict can contain Series, arrays, constants, dataclass or list-like objects. If # | # | .. versionchanged:: 0.25.0 # | If data is a list of dicts, column order follows insertion-order. # | # | index : Index or array-like # (...後略...)1-7. ライブラリのコンピュータ上のインストールされている場所を確認する
インストールされている場所は、
ライブラリ名.__file__で確認することができます。
numpy の格納場所を確認しています。import numpy print(numpy.__file__) # C:\Users\xxxxxxxx\AppData\Local\Programs\Python\Python38\lib\site-packages\numpy\__init__.pyライブラリを管理する
1. pip
何はともあれ、これ!
pip("Pip Installs Packages" または "Pip Installs Python")です。
pip を使うことで Python ライブラリを簡単にインストールしたり、管理したりすることができます。1-1. ライブラリのインストール
$ pip install ライブラリ名 $ pip install numpy # numpy をインストール1-2. ライブラリをバージョン指定してインストール
ライブラリ名とバージョン番号を
==で繋ぎます。$ pip install ライブラリ名==バージョン番号 $ pip install numpy==1.19.5 # numpy の ver.1.19.5 を指定してインストール1-3. ライブラリのアンインストール
$ pip uninstall ライブラリ名 $ pip uninstall numpy # numpy をアンインストール1-4. ライブラリのアップデート
下記 (a) または (b) で実行します。
$ pip install --upgrade ライブラリ名 # (a) $ pip install -U ライブラリ名 # (b)1-5. pip 自体のバージョンを確認する
下記 (a) または (b) で実行します。
$ pip --version # (a) $ pip -V # (b) pip 21.0 from c:\users\xxxxxxxx\appdata\local\programs\python\python38\lib\site-packages\pip (python 3.8)1-6. pip 自体のアップデート
下記 (a) または (b) でエラーとなる場合は、(c) で実行してください。
$ pip install --upgrade pip # (a) $ pip install -U pip # (b) $ python -m pip install --upgrade pip # (c) Requirement already satisfied: pip in c:\users\xxxxxxxx\appdata\local\programs\python\python38\lib\site-packages (21.0) Collecting pip Using cached pip-21.0-py3-none-any.whl (1.5 MB) Downloading pip-20.3.4-py2.py3-none-any.whl (1.5 MB) |████████████████████████████████| 1.5 MB 2.2 MB/s1-7. ライブラリのリストを全部表示する
$ pip list Package Version ------------------------ ----------- absl-py 0.11.0 aiodns 2.0.0 aiohttp 3.7.3 aiohttp-socks 0.5.5 anyio 2.0.2 argon2-cffi 20.1.0 asgiref 3.3.1 astroid 2.4.2 asttokens 2.0.4 astunparse 1.6.3 async-generator 1.10 async-timeout 3.0.1 attrs 20.3.0 Babel 2.9.0 backcall 0.2.0 Backtesting 0.3.0 beautifulsoup4 4.9.3 bleach 3.2.1 bokeh 2.2.3 boto 2.49.0 boto3 1.16.55 botocore 1.19.55 cachetools 4.2.0 cchardet 2.1.7 certifi 2020.12.5 cffi 1.14.4 chardet 3.0.4 chromedriver-binary-auto 0.1 cmdstanpy 0.9.5 colorama 0.4.3 configparser 5.0.1 contextlib2 0.6.0.post1 convertdate 2.2.0 cycler 0.10.0 Cython 0.29.21 decorator 4.4.2 defusedxml 0.6.0 Django 3.1.5 django-markdownx 3.0.1 django-ses 1.0.3 elasticsearch 7.10.1 entrypoints 0.3 ephem 3.7.7.1 et-xmlfile 1.0.1 executing 0.5.4 fake-useragent 0.1.11 fbprophet 0.7.1 flake8 3.8.4 flatbuffers 1.12 future 0.18.2 gast 0.3.3 geographiclib 1.50 geopy 2.1.0 google-auth 1.24.0 google-auth-oauthlib 0.4.2 google-pasta 0.2.0 googletransx 2.4.2 grpcio 1.32.0 h5py 2.10.0 holidays 0.10.4 icecream 2.0.0 idna 2.10 imageio 2.9.0 ipykernel 5.4.2 ipython 7.19.0 ipython-genutils 0.2.0 isort 4.3.21 Janome 0.4.1 jdcal 1.4.1 jedi 0.18.0 Jinja2 2.11.2 jmespath 0.10.0 json5 0.9.5 jsonschema 3.2.0 jupyter-client 6.1.7 jupyter-core 4.7.0 jupyter-server 1.1.3 jupyterlab 3.0.0 jupyterlab-pygments 0.1.2 jupyterlab-server 2.0.0 Keras 2.4.3 Keras-Preprocessing 1.1.2 kiwisolver 1.3.1 korean-lunar-calendar 0.2.1 lazy-object-proxy 1.4.3 LunarCalendar 0.0.9 lxml 4.6.2 Markdown 3.3.3 MarkupSafe 1.1.1 matplotlib 3.3.3 mccabe 0.6.1 mistune 0.8.4 multidict 5.1.0 nbclassic 0.2.5 nbclient 0.5.1 nbconvert 6.0.7 nbformat 5.0.8 nest-asyncio 1.4.3 notebook 6.1.6 numpy 1.19.5 oauthlib 3.1.0 openpyxl 3.0.5 opt-einsum 3.3.0 packaging 20.8 pandas 1.2.0 pandas-datareader 0.9.0 pandocfilters 1.4.3 parso 0.8.1 pickleshare 0.7.5 Pillow 8.0.1 pip 20.3.3 plotly 4.14.1 poloniexapi 0.5.7 prometheus-client 0.9.0 prompt-toolkit 3.0.8 prophet 0.1.1.post1 protobuf 3.14.0 psycopg2-binary 2.8.6 pyasn1 0.4.8 pyasn1-modules 0.2.8 pycares 3.1.1 pycodestyle 2.6.0 pycparser 2.20 pyflakes 2.2.0 Pygments 2.7.3 pylint 2.5.3 PyMeeus 0.3.7 pyparsing 2.4.7 PyPDF2 1.26.0 pyrsistent 0.17.3 PySimpleGUI 4.32.1 PySocks 1.7.1 pystan 2.17.1.0 python-dateutil 2.8.1 python-socks 1.1.2 pyti 0.2.2 pytz 2019.3 pywin32 300 pywinpty 0.5.7 pyxel 1.4.3 PyYAML 5.3.1 pyzmq 20.0.0 requests 2.25.1 requests-oauthlib 1.3.0 retrying 1.3.3 rsa 4.7 s3transfer 0.3.4 schedule 0.6.0 scipy 1.6.0 selenium 3.141.0 Send2Trash 1.5.0 setuptools 47.1.0 setuptools-git 1.2 six 1.15.0 sniffio 1.2.0 soupsieve 2.1 sqlparse 0.4.1 tensorboard 2.4.1 tensorboard-plugin-wit 1.7.0 tensorflow 2.4.0 tensorflow-estimator 2.4.0 termcolor 1.1.0 terminado 0.9.1 testpath 0.4.4 toml 0.10.1 tornado 6.1 tqdm 4.55.0 traitlets 5.0.5 tweepy 3.10.0 twint 2.1.20 typing-extensions 3.7.4.3 urllib3 1.26.2 wcwidth 0.2.5 webencodings 0.5.1 websocket-client 0.57.0 Werkzeug 1.0.1 wheel 0.36.2 wrapt 1.12.1 xlrd 2.0.1 yarl 1.6.31-8. ライブラリのリストを表示する(アップデートが必要なもの)
前項で紹介した
pip listの末尾に半角スペースを空けて-oを指定するのみです。$ pip list -o Package Version Latest Type ---------------------- -------- -------- ----- bleach 3.2.1 3.2.2 wheel boto3 1.16.55 1.16.59 wheel botocore 1.19.55 1.19.59 wheel chardet 3.0.4 4.0.0 wheel cmdstanpy 0.9.5 0.9.67 wheel colorama 0.4.3 0.4.4 wheel convertdate 2.2.0 2.3.0 wheel gast 0.3.3 0.4.0 wheel grpcio 1.32.0 1.35.0 wheel h5py 2.10.0 3.1.0 wheel idna 2.10 3.1 wheel ipykernel 5.4.2 5.4.3 wheel isort 4.3.21 5.7.0 wheel jupyter-client 6.1.7 6.1.11 wheel jupyter-server 1.1.3 1.2.2 wheel jupyterlab 3.0.0 3.0.5 wheel jupyterlab-server 2.0.0 2.1.2 wheel lazy-object-proxy 1.4.3 1.5.2 wheel nbclassic 0.2.5 0.2.6 wheel nbformat 5.0.8 5.1.2 wheel notebook 6.1.6 6.2.0 wheel openpyxl 3.0.5 3.0.6 wheel pandas 1.2.0 1.2.1 wheel Pillow 8.0.1 8.1.0 wheel plotly 4.14.1 4.14.3 wheel prompt-toolkit 3.0.8 3.0.13 wheel Pygments 2.7.3 2.7.4 wheel pylint 2.5.3 2.6.0 wheel PySimpleGUI 4.32.1 4.34.0 wheel pystan 2.17.1.0 2.19.1.1 wheel python-socks 1.1.2 1.2.0 wheel pytz 2019.3 2020.5 wheel PyYAML 5.3.1 5.4.1 wheel pyzmq 20.0.0 21.0.1 wheel setuptools 47.1.0 52.0.0 wheel tensorboard-plugin-wit 1.7.0 1.8.0 wheel tensorflow 2.4.0 2.4.1 wheel terminado 0.9.1 0.9.2 wheel toml 0.10.1 0.10.2 wheel tqdm 4.55.0 4.56.0 wheel1-9. ライブラリのリストを表示する(最新状態=アップデートが不要なもの)
前項で紹介した
pip list -oの末尾を-uへ変えるのみです。$ pip list -u Package Version ------------------------ ----------- absl-py 0.11.0 aiodns 2.0.0 aiohttp 3.7.3 aiohttp-socks 0.5.5 anyio 2.0.2 argon2-cffi 20.1.0 asgiref 3.3.1 astroid 2.4.2 asttokens 2.0.4 astunparse 1.6.3 async-generator 1.10 async-timeout 3.0.1 attrs 20.3.0 Babel 2.9.0 backcall 0.2.0 Backtesting 0.3.0 beautifulsoup4 4.9.3 bokeh 2.2.3 boto 2.49.0 cachetools 4.2.0 cchardet 2.1.7 certifi 2020.12.5 cffi 1.14.4 chromedriver-binary-auto 0.1 configparser 5.0.1 contextlib2 0.6.0.post1 cycler 0.10.0 Cython 0.29.21 decorator 4.4.2 defusedxml 0.6.0 Django 3.1.5 django-markdownx 3.0.1 django-ses 1.0.3 elasticsearch 7.10.1 entrypoints 0.3 ephem 3.7.7.1 et-xmlfile 1.0.1 executing 0.5.4 fake-useragent 0.1.11 fbprophet 0.7.1 flake8 3.8.4 flatbuffers 1.12 future 0.18.2 geographiclib 1.50 geopy 2.1.0 google-auth 1.24.0 google-auth-oauthlib 0.4.2 google-pasta 0.2.0 googletransx 2.4.2 holidays 0.10.4 icecream 2.0.0 imageio 2.9.0 ipython 7.19.0 ipython-genutils 0.2.0 Janome 0.4.1 jdcal 1.4.1 jedi 0.18.0 Jinja2 2.11.2 jmespath 0.10.0 json5 0.9.5 jsonschema 3.2.0 jupyter-core 4.7.0 jupyterlab-pygments 0.1.2 Keras 2.4.3 Keras-Preprocessing 1.1.2 kiwisolver 1.3.1 korean-lunar-calendar 0.2.1 LunarCalendar 0.0.9 lxml 4.6.2 Markdown 3.3.3 MarkupSafe 1.1.1 matplotlib 3.3.3 mccabe 0.6.1 mistune 0.8.4 multidict 5.1.0 nbclient 0.5.1 nbconvert 6.0.7 nest-asyncio 1.4.3 numpy 1.19.5 oauthlib 3.1.0 opt-einsum 3.3.0 packaging 20.8 pandas-datareader 0.9.0 pandocfilters 1.4.3 parso 0.8.1 pickleshare 0.7.5 pip 21.0 poloniexapi 0.5.7 prometheus-client 0.9.0 prophet 0.1.1.post1 protobuf 3.14.0 psycopg2-binary 2.8.6 pyasn1 0.4.8 pyasn1-modules 0.2.8 pycares 3.1.1 pycodestyle 2.6.0 pycparser 2.20 pyflakes 2.2.0 PyMeeus 0.3.7 pyparsing 2.4.7 PyPDF2 1.26.0 pyrsistent 0.17.3 PySocks 1.7.1 python-dateutil 2.8.1 pyti 0.2.2 pywin32 300 pywinpty 0.5.7 pyxel 1.4.3 requests 2.25.1 requests-oauthlib 1.3.0 retrying 1.3.3 rsa 4.7 s3transfer 0.3.4 schedule 0.6.0 scipy 1.6.0 selenium 3.141.0 Send2Trash 1.5.0 setuptools-git 1.2 six 1.15.0 sniffio 1.2.0 soupsieve 2.1 sqlparse 0.4.1 tensorboard 2.4.1 tensorflow-estimator 2.4.0 termcolor 1.1.0 testpath 0.4.4 tornado 6.1 traitlets 5.0.5 tweepy 3.10.0 twint 2.1.20 typing-extensions 3.7.4.3 urllib3 1.26.2 wcwidth 0.2.5 webencodings 0.5.1 websocket-client 0.57.0 Werkzeug 1.0.1 wheel 0.36.2 wrapt 1.12.1 xlrd 2.0.1 yarl 1.6.31-10. ライブラリをライブラリ名==バージョンで表示する
$ pip freeze absl-py==0.11.0 aiodns==2.0.0 aiohttp==3.7.3 aiohttp-socks==0.5.5 anyio==2.0.2 argon2-cffi==20.1.0 asgiref==3.3.1 astroid==2.4.2 asttokens==2.0.4 astunparse==1.6.3 async-generator==1.10 async-timeout==3.0.1 attrs==20.3.0 Babel==2.9.0 backcall==0.2.0 Backtesting==0.3.0 beautifulsoup4==4.9.3 bleach==3.2.1 bokeh==2.2.3 boto==2.49.0 boto3==1.16.55 botocore==1.19.55 cachetools==4.2.0 cchardet==2.1.7 certifi==2020.12.5 cffi==1.14.4 chardet==3.0.4 chromedriver-binary-auto==0.1 cmdstanpy==0.9.5 colorama==0.4.3 configparser==5.0.1 contextlib2==0.6.0.post1 convertdate==2.2.0 cycler==0.10.0 Cython==0.29.21 decorator==4.4.2 defusedxml==0.6.0 Django==3.1.5 django-markdownx==3.0.1 django-ses==1.0.3 elasticsearch==7.10.1 entrypoints==0.3 ephem==3.7.7.1 et-xmlfile==1.0.1 executing==0.5.4 fake-useragent==0.1.11 fbprophet==0.7.1 flake8==3.8.4 flatbuffers==1.12 future==0.18.2 gast==0.3.3 geographiclib==1.50 geopy==2.1.0 google-auth==1.24.0 google-auth-oauthlib==0.4.2 google-pasta==0.2.0 googletransx==2.4.2 grpcio==1.32.0 h5py==2.10.0 holidays==0.10.4 icecream==2.0.0 idna==2.10 imageio==2.9.0 ipykernel==5.4.2 ipython==7.19.0 ipython-genutils==0.2.0 isort==4.3.21 Janome==0.4.1 jdcal==1.4.1 jedi==0.18.0 Jinja2==2.11.2 jmespath==0.10.0 json5==0.9.5 jsonschema==3.2.0 jupyter-client==6.1.7 jupyter-core==4.7.0 jupyter-server==1.1.3 jupyterlab==3.0.0 jupyterlab-pygments==0.1.2 jupyterlab-server==2.0.0 Keras==2.4.3 Keras-Preprocessing==1.1.2 kiwisolver==1.3.1 korean-lunar-calendar==0.2.1 lazy-object-proxy==1.4.3 LunarCalendar==0.0.9 lxml==4.6.2 Markdown==3.3.3 MarkupSafe==1.1.1 matplotlib==3.3.3 mccabe==0.6.1 mistune==0.8.4 multidict==5.1.0 nbclassic==0.2.5 nbclient==0.5.1 nbconvert==6.0.7 nbformat==5.0.8 nest-asyncio==1.4.3 notebook==6.1.6 numpy==1.19.5 oauthlib==3.1.0 openpyxl==3.0.5 opt-einsum==3.3.0 packaging==20.8 pandas==1.2.0 pandas-datareader==0.9.0 pandocfilters==1.4.3 parso==0.8.1 pickleshare==0.7.5 Pillow==8.0.1 plotly==4.14.1 poloniexapi==0.5.7 prometheus-client==0.9.0 prompt-toolkit==3.0.8 prophet==0.1.1.post1 protobuf==3.14.0 psycopg2-binary==2.8.6 pyasn1==0.4.8 pyasn1-modules==0.2.8 pycares==3.1.1 pycodestyle==2.6.0 pycparser==2.20 pyflakes==2.2.0 Pygments==2.7.3 pylint==2.5.3 PyMeeus==0.3.7 pyparsing==2.4.7 PyPDF2==1.26.0 pyrsistent==0.17.3 PySimpleGUI==4.32.1 PySocks==1.7.1 pystan==2.17.1.0 python-dateutil==2.8.1 python-socks==1.1.2 pyti==0.2.2 pytz==2019.3 pywin32==300 pywinpty==0.5.7 pyxel==1.4.3 PyYAML==5.3.1 pyzmq==20.0.0 requests==2.25.1 requests-oauthlib==1.3.0 retrying==1.3.3 rsa==4.7 s3transfer==0.3.4 schedule==0.6.0 scipy==1.6.0 selenium==3.141.0 Send2Trash==1.5.0 setuptools-git==1.2 six==1.15.0 sniffio==1.2.0 soupsieve==2.1 sqlparse==0.4.1 tensorboard==2.4.1 tensorboard-plugin-wit==1.7.0 tensorflow==2.4.0 tensorflow-estimator==2.4.0 termcolor==1.1.0 terminado==0.9.1 testpath==0.4.4 toml==0.10.1 tornado==6.1 tqdm==4.55.0 traitlets==5.0.5 tweepy==3.10.0 twint==2.1.20 typing-extensions==3.7.4.3 urllib3==1.26.2 wcwidth==0.2.5 webencodings==0.5.1 websocket-client==0.57.0 Werkzeug==1.0.1 wrapt==1.12.1 xlrd==2.0.1 yarl==1.6.31-11. ライブラリをライブラリ名==バージョンで出力する
requirements.txt へ出力する際に利用すると便利です。
前項で紹介したpip freezeの末尾に半角スペースを空けて> requirements.txtを付します。
出力内容はpip freezeで表示される内容と同じです。$ pip freeze > requirements.txt
1-12. requirements.txt を用いてライブラリを一括でインストールする
開発環境を作り直す際や、本番環境を構築する際に、元の開発環境と同じライブラリ・同じバージョンをインストールする際に使います。
$ pip install -r requirements.txt1-13. 個別のライブラリの詳細内容を確認する
指定したライブラリのバージョンやインストールされている場所(パス)などが表示されます。
$ pip show ライブラリ名 $ pip show numpy # numpy の詳細内容を確認する Name: numpy Version: 1.19.5 Summary: NumPy is the fundamental package for array computing with Python. Home-page: https://www.numpy.org Author: Travis E. Oliphant et al. Author-email: None License: BSD Location: c:\users\xxxxxxxx\appdata\local\programs\python\python38\lib\site-packages Requires: Required-by: tensorflow, tensorboard, scipy, pyti, pystan, pandas, opt-einsum, matplotlib, Keras, Keras-Preprocessing, imageio, h5py, fbprophet, cmdstanpy, bokeh, Backtesting1-14. pip 依存関係を確認する
$ pip check No broken requirements found. # 問題ない場合 wagtail 2.6.1 has requirement django-modelcluster<5.0,>=4.2, but you have django-modelcluster 5.0. # 依存関係に問題がある場合2. pip-review
pip-reviewは pip でインストールした Python ライブラリに対して、アップデートの確認からアップデートの実行までを、自動かつ一括で行なうことができる優れもの。
大変便利ですので、是非インストールしておきましょう。2-1. インストール方法
$ pip install pip-review2-2. 使い方
$ pip-review --auto
注意事項
ときに、Python のバージョンや、お使いの環境、他のライブラリとで対応バージョンの相違などにより、不具合やエラーが発生します。
そのような際は、各ライブラリの Usage やリリースノート(Release history)などのドキュメントをご参照の上で、(ときにバージョンダウン等の)対応をしていただければと思います。
これは OSS を利用する上で起こりうることとして、頭の片隅に置いていただければ幸いです。
参考
(編集後記)
Python はライブラリが豊富であるとはよく言われることですが、まずはその
ライブラリとは何かと、ライブラリをインストール、管理するpipについて説明いたしました。
今後、よく使うライブラリや、便利な(おすすめ)ライブラリをまとめておくつもりです。
python には、数えきれないほど多くのライブラリが存在します。
有益なライブラリは、ぜひ積極的に活用していただき、皆様からも情報共有いただけると大変有り難いです。



- 投稿日:2021-01-27T17:30:51+09:00
[MMDetection] 環境構築&インストール編
概要
まだまだ日本語情報が少ない物体検出フレームワーク"MMDetection"について、学んだことを記録していこうと思います。
間違い等ありましたらぜひコメントで教えてください。よろしくお願いします。
公式ドキュメントはこちら。MMDetection とは
香港中文大学(CUHK)が開発している物体検出のためのライブラリであり、PyTorchで書かれている。
物体検出やセグメンテーションの最新研究で頻繁に利用されている。
モジュールを組み合わせてモデルを設計する仕組みになっており、部品の組み替えが簡単に行える。必要な環境
- Linux or macOS
- Python 3.6+
- PyTorch 1.3+
- CUDA 9.2+
- GCC 5+
- MMCV (バージョンについては下表を参照)
MMDetection ver. MMCV ver. master mmcv-full>=1.2.4, <1.3 2.8.0 mmcv-full>=1.2.4, <1.3 2.7.0 mmcv-full>=1.1.5, <1.3 2.6.0 mmcv-full>=1.1.5, <1.3 2.5.0 mmcv-full>=1.1.5, <1.3 2.4.0 mmcv-full>=1.1.1, <1.3 2.3.0 mmcv-full==1.0.5 2.3.0rc0 mmcv-full>=1.0.2 2.2.1 mmcv==0.6.2 2.2.0 mmcv==0.6.2 2.1.0 mmcv>=0.5.9, <=0.6.1 2.0.0 mmcv>=0.5.1, <=0.5.8 インストール
Dockerが使える環境であればDockerfileが公式から提供されている。
condaで環境構築するので、Anaconda等を事前にインストールする。1. condaによる仮想環境の作成
conda create -n open-mmlab python=3.7 -y conda activate open-mmlab2. PyTorchとtorchvisionのインストール
環境に応じて、公式サイトの手順に従ってインストールする。
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch3. mmcv-fullのインストール
pip install mmcv-full==1.2.64. MMDetectionをgithubからクローン
git clone https://github.com/open-mmlab/mmdetection.git cd mmdetection5. インストール
pip install -r requirements/build.txt pip install -v -e .おまけ
環境構築からインストールまで行うためのシェルスクリプト
mmdetection_env.shconda create -n open-mmlab python=3.7 -y # >>> conda init >>> __conda_setup="$(CONDA_REPORT_ERRORS=false '$HOME/anaconda3/bin/conda' shell.bash hook 2> /dev/null)" if [ $? -eq 0 ]; then \eval "$__conda_setup" else if [ -f "$HOME/anaconda3/etc/profile.d/conda.sh" ]; then . "$HOME/anaconda3/etc/profile.d/conda.sh" CONDA_CHANGEPS1=false conda activate base else \export PATH="$PATH:$HOME/anaconda3/bin" fi fi unset __conda_setup # <<< conda init <<< conda activate open-mmlab conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch -y pip install mmcv-full==1.2.6 git clone https://github.com/open-mmlab/mmdetection.git cd mmdetection pip install -r requirements/build.txt pip install -v -e .参考文献
- 投稿日:2021-01-27T17:29:24+09:00
【Python】デバッグ時に便利なIcecreamを真似てprintをオーバーライドしてみた。
はじめに
こちらの記事
デバッグ時はprintではなく、Icecreamを使うと便利
を見て自分で似たような機能を作ってみたくなったので書いてみました。
Icecreamを使った際のような表示が可能になります(つまり逆にコメントアウトをすればすぐに元に戻せるということです)。つくったもの
printer.pydef print(*args, sep=' ', end='\n', file='', flush=False): import builtins, inspect, re, sys if not file: file = sys.stdout fr = inspect.currentframe().f_back arg_names = re.split( '\s*,\s*', re.findall( 'print\(((?:.|\s)+?)\)', ''.join( inspect.getframeinfo(fr, min(1000, fr.f_lineno)).code_context))[-1]) builtins.print(*[ f'{k}: {v}' if not (re.match('[\"\'\(\[\{0-9]', k.lstrip()) or '(' in k) else str(v) for k, v in zip(arg_names, args) ], sep=sep, end=end, file=file, flush=flush)使用例
なるべく
sepやend、fileなどといった引数を取ることができます。例えば以下のようなプログラムがあったとします。
a = 1 b = "abcABC" c = [1, 2, 3] d = {"A": "a", "B": "b", "C": "c"} e = {1, 1, 2, 3, 4, 4, 4, 5} print(a, b, c, d, e)もちろん出力は
out1 abcABC [1, 2, 3] {'A': 'a', 'B': 'b', 'C': 'c'} {1, 2, 3, 4, 5}となりますね。
ここに先程の関数をインポートしてみます。すると、from printer import print a = 1 b = "abcABC" c = [1, 2, 3] d = {"A": "a", "B": "b", "C": "c"} e = {1, 1, 2, 3, 4, 4, 4, 5} print(a, b, c, d, e)outa: 1 b: abcABC c: [1, 2, 3] d: {'A': 'a', 'B': 'b', 'C': 'c'} e: {1, 2, 3, 4, 5}プログラムを書き換えることなく変数名を表示することができます。
先程説明したとおり、sepなどを指定することでprint(a, b, c, d, e, sep='\n')outa: 1 b: abcABC c: [1, 2, 3] d: {'A': 'a', 'B': 'b', 'C': 'c'} e: {1, 2, 3, 4, 5}より見やすく出力したり、
with open('log.txt', 'w') as f: print(a, b, c, d, e, file=f)外部ファイルに出力するなどといったことも、通常の
仕組み
標準ライブラリ
inspectを使うことで呼び出し元のコードを取得し、そこから正規表現で変数名を抽出、整形して出力しています。
その性質上、print(a, b, c);print(d, e)のような書き方をすると上手く変数名を抽出できないのでその点は注意してください(これは
Icecreamも同じ)。
- 投稿日:2021-01-27T17:09:27+09:00
友達の誕生日を通知するLinebot
はじめに
友達が多ければ多いほど,みんなの誕生日を記憶するのは難しいですよね.
僕は友達が多いので(嘘), 友達の誕生日を通知してくれるLinebotを作成しました.手順
- LINE Notifyにログイン
- マイページからアクセストークンを発行
- 発行したトークンをpython scriptにコピー & ペーストして,友達の誕生日を登録
- crontabを使って毎日00:00にプログラムを実行
手順1. LINE Notifyにログイン
LINEアカウントでログインしましょう.
アカウント情報はLINEアプリの「設定>アカウント」から確認できます.手順2. マイページからアクセストークンを発行
自分とLINE Notifyの1:1のやりとりなら,トークンを発行するだけでOK!!
グループとLINE Notifyのやりとりなら,グループにLINE Notifyを招待しよう手順3.
以下のコマンドを打って,誕生日通知レポジトリをクローンしましょう.
尚,このレポジトリの99%はPythonでLINEにメッセージを送るに準じます.git clone https://github.com/rikukawamura/LINEBirthdayNotify.gitmain.pyにアクセストークンと友達の誕生日を設定.
main.pyfrom line_notify_bot import LINENotifyBot import datetime # coding: UTF-8 date = str(datetime.date.today()).split('-') month, day = date[1], date[2] bot = LINENotifyBot(access_token='アクセストークンをペースト') if month=='月(e.g.01)' and day=='日(e.g.01)': bot.send( message='\n{}月{}日は{}の誕生日'.format(month, day, '名前') ) elif month=='01' and day=='01': bot.send( message='\n{}月{}日は{}の誕生日'.format(month, day, '山田太郎') )手順4.
crontabを使って毎日00:00にmain.pyを実行.
PATH=/Users/kawamurariku/.pyenv/versions/anaconda3-2019.10/condabin:/usr/local/Cellar/pyenv-virtualenv/1.1.3/shims:/Users/kawamurariku/.pyenv/shims:/Users/kawamurariku/.pyenv/bi$ 00 00 * * * python /Users/kawamurariku/LINEBirthdayNotify/main.py LANG=ja_JP.UTF-8crontabについては,以下を参考にした.
【保存版】cronでPython3を定時実行する方法&注意すべき4つのポイント出力確認
こんな感じで通知が来ると思います.
[test]の部分は,手順2.で設定した以下のトークン名が表示されます.
終わりに
今回は,LINE APIを使用して,友達の誕生日を通知するBotを作成しました.
LINEは毎日使うし,これなら友達の誕生日を忘れることもなさそうです.
他にも,あったらいいのになと思ったBotを暇があれば作りたいと思います.
最後までご閲覧ありがとうございました.



- 投稿日:2021-01-27T16:09:22+09:00
Pythonで学ぶアルゴリズム 第23弾:並べ替え(ビンソート / バケットソート)
#Pythonで学ぶアルゴリズム< ビンソート / バケットソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第23弾としてビンソート(バケットソート)を扱う.ビンソート(バケットソート)
ビンソートはバケットソートとも呼ばれる.以降ビンソートと呼ぶこととする.
ビンソート: 並べ替える要素が限定されているときに用いられるソート方法.
データ内に各要素がいくつあるのかをカウントし,そのカウント数を使って,並べ替える.そのイメージ図を次に示す.
実装
先ほどの説明をもとにPythonでの実装を行った.なお,参考文献では,決まった要素の参照リストが利用されているが,その参照リストも変えられるような実装を試みた.そのソースコードとそのときの出力を以下に示す.
ソースコード
""" 2021/01/27 @Yuya Shimizu ビンソート """ def bin_sort(data, data_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]): """ 参照リストの要素がデータにいくつあるのかをカウントし,順に並べていく """ sorted_data = [] #結果を格納する配列 for i in data_list: #要素を基準にカウントを行う count = 0 #カウントするための変数 for j in data: #各データについて調べる if j == i: count += 1 #要素が含まれていればカウント [sorted_data.append(i) for k in range(count)] #順にカウント分だけその要素を結果として配列に格納 return sorted_data if __name__ == '__main__': DATA = [9, 4, 5, 2, 8, 3, 7, 8, 3, 2, 6, 5, 7, 9, 2, 9] data_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] sorted_data = bin_sort(DATA, data_list) print(f"参照リスト: {data_list}\n\n{DATA} → {sorted_data}")出力
参照リスト: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [9, 4, 5, 2, 8, 3, 7, 8, 3, 2, 6, 5, 7, 9, 2, 9] → [2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 7, 8, 8, 9, 9, 9]ソースコード内で定義している関数では,第2引数に参照リストを渡せるが,デフォルトでは
[0,1,2,3,4,5,6,7,8,9]となるようにしている.そのため,参照リストを変更するときは,関数を扱うときに第2引数にリストの型で指定すればよい.感想
ついに,並べ替えアルゴリズムを終えた.少し長かったが,今後役立つと願おう.今回のビンソートは参考文献における"理解度check"の問題であり,様々な書き方があるとは思うが,今の私が思いつく良い方法を示した.次回からも参考文献に沿って学習を進める.残るは後1章分.また楽しみである.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社

- 投稿日:2021-01-27T15:59:18+09:00
yarr で Python で numpy データをさくっと RPC 通信するメモ
背景
numpy データ(画像データ, ボリュームデータなどサイズ大きめ)を RPC でやりとりしたい.
IPython, Jupyter-lab で C native module を autoreload するメモ
https://qiita.com/syoyo/items/0c633eda1a0bfdc31e3aにあるように, 計算モジュールが native module になっており, リロードさせたいために Python プロセスを分けたいとか,
ぱぱっと numpy データを複数 PC に送って分散処理させたいときとか.
yarr がありました.
yarr
https://pypi.org/project/yarr/
ありがとうございます. 普通に pip で入ります.
python -m pip install yarrpure Python なので Windows でも動きます.
Linux, Windows で動作確認しました.
(ただ, Win server, Linux client の場合だと通信できませんでした. Win 側でポートを開けておかないとだめ?(client 側で connection error 出してくれない))server
import yarr import numpy def proc_numpy(a): print(a) # server yarr.yarr(('localhost', 8000), [proc_numpy])client
import yarr import numpy a = numpy.random.rand(256, 512, 512) yarr.call(('localhost', 8000), 'proc_numpy', a)Voila!
さくっと numpy データ送れました.
localhost Threadripper 1950X で試したところ,
256x512x512x8(sizeof(float64)) = 512 MBで 2 秒くらいでした. ネットワークだと帯域ネックになる(~2.5 G イーサくらいまで)ので, パフォーマンスには問題ないでしょう.しくみ
中身としては
structmodule でエンコード/デコードして, socket 通信で送っているだけです.コードも 100 行ちょっとなので, 必要に応じて自前で改変できます.
問題点
ライセンスの名前がよくない...(ライセンス自体は Public domain に近いのでよいので残念)
- 投稿日:2021-01-27T15:45:33+09:00
JCLdicを使ってpythonで企業名抽出器をつくる
TL;DR
Japanese Company Lexiconを使って形態素解析(MeCab)ベースの企業名抽出器をpythonで作ります。
環境は以下を想定しています。macOS Catalina Homebrew 2.7.1 python 3.9事前準備
JCLdicのダウンロード
https://github.com/chakki-works/Japanese-Company-Lexicon
READMEからJCL_mediumのMeCab Dicをダウンロードして解凍してください。
jcl_medium_mecab.dicが必要なファイルです。MeCabインストール
mecab入ってない場合はインストールしてください。
今回はbrewでinstallします。
辞書にmecab-ipadicを使います。brew install mecab brew install mecab-ipadicMeCabのuserdict設定
MeCabのuserdict設定のためdicファイルを置くために、任意の場所にディレクトリ作成します。
今回は/usr/local/lib/mecab/dic/user_dictに作成しました。
解凍したmecab dictjcl_medium_mecab.dicを作成したディレクトリ配下に移動します。mkdir /usr/local/lib/mecab/dic/user_dict mv jcl_slim_mecab.dic /usr/local/lib/mecab/dic/user_dictmecabrcの変更
userdictを準備したら、mecabの辞書情報を変更するためにMeCabの設定ファイルであるmecabrcを登録します。
mecabrcは、install方法によって場所が変わるかもしれませんが、brewでinstallした場合/usr/local/etc/mecabrcにあります。
;でコメントになっている;userdic = <file path>を↑でおいたファイルのパスに変更します。userdic = /usr/local/lib/mecab/dic/user_dict/jcl_slim_mecab.dic動作確認
まずはconsoleで辞書が反映されているか確認しましょう。
>>> echo "ビザスクで働いています。" | mecab ビザスク 名詞,固有名詞,組織,*,*,*,株式会社ビザスク,*,* で 助詞,格助詞,一般,*,*,*,で,デ,デ 働い 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,働く,ハタライ,ハタライ て 助詞,接続助詞,*,*,*,*,て,テ,テ い 動詞,非自立,*,*,一段,連用形,いる,イ,イ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス 。 記号,句点,*,*,*,*,。,。,。 EOSビザスクが
名詞,固有名詞,組織,*,*,*,株式会社ビザスク,*,*と表示してされているのでOKです。python
次にpythonでMeCabを使う準備をします。
library install
まずpython用のライブラリをinstallします。
pip install mecab-python3これで準備は完了です。
code
以下のcodeで企業名を抽出します。
import unicodedata import MeCab # MeCabの設定 tagger = MeCab.Tagger('-r /usr/local/etc/mecabrc') def extract_company(text): # textのnormalize text = unicodedata.normalize('NFKC', text) node = tagger.parseToNode(text) result = [] while node: # node feature: 品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音 features = node.feature.split(',') if features[2] == '組織': result.append( (node.surface, features[6]) ) node = node.next return resultポイントは2つです。
1つ目は、MeCab.Taggerの引数に参照するmecabrcを-rオプションで指定しすることです。
2つ目は、テキストをparseする前に正規化することです。
JCLdicは辞書サイズと検索速度とのトレードオフの結果、全角を使わず半角のみ使っているようなのでパースするテキストを半角に正規化しておく必要があります。JCLdicでは、原型に株式会社ビザスクのような正式名称が入っているので原型を抽出することで、企業の正式名称を抽出することができます。
出力
texts = [ "ビザスクでエンジニアとして働いています。", "三菱UFJモルガンスタンレー証券とガーディアンアドバイザーズでの経歴", "キャノン株式会社で経営監理を5年経験しました。", ] for text in texts: companies = extract_company(text) print("text: ", text) for company in companies: print("キーワード: {}, 正式名称: {}".format(company[0], company[1]))text: ビザスクでエンジニアとして働いています。 キーワード: ビザスク, 正式名称: 株式会社ビザスク キーワード: エンジニア, 正式名称: 株式会社エンジニア text: 三菱UFJモルガンスタンレー証券とガーディアンアドバイザーズでの経歴 キーワード: 三菱UFJモルガンスタンレー証券, 正式名称: 三菱UFJモルガン・スタンレー証券株式会社 キーワード: ガーディアンアドバイザーズ, 正式名称: ガーディアン・アドバイザーズ株式会社 text: キャノン株式会社で経営監理を5年経験しました。 キーワード: キャノン株式会社, 正式名称: キヤノン株式会社 キーワード: 経営監理, 正式名称: 有限会社経営監理日本の会社名が多く収録されている辞書なので、一般名詞の会社名がでてくるため用途によっては使いにくいかもしれません。
その際は、抽出したくないキーワードをstopwordとして扱い、node.surfaceがstopwordだった場合スキップする処理を入れるなどの工夫が必要です。
- 投稿日:2021-01-27T15:25:33+09:00
Azure IoT EdgeのPythonモジュールでデータ収集してIoT Hubへ送信する
はじめに
横河電機のエッジコントローラe-RT3 Plus F3RP70-2L1をAzure IoT認定デバイス2に登録する担当者として、Azure IoT Edgeについて勉強しました。
その内容を数回に分けてご紹介します。
こちらで第4回目の記事となります。
これまでの記事で、エッジデバイスへのAzure IoT EdgeランタイムのインストールからサンプルのPythonモジュールをデプロイして動作確認する流れを説明しています。
- 第1回目: Ubuntu 18.04にAzure IoT Edgeランタイムをインストールする
- 第2回目: Azure IoT EdgeランタイムをインストールしたUbuntu 18.04搭載のエッジデバイスをIoT Hubへ接続する
- 第3回目: Azure IoT EdgeランタイムをインストールしたUbuntu 18.04搭載のエッジデバイスでPythonのサンプルモジュールを作成する
さて、今回はAzure IoT EdgeランタイムをインストールしたUbuntu 18.04搭載のエッジデバイスでPythonのデータ収集モジュールを作成し、収集したデータをIoT Hubへ送信してみます。
AWS IoT Greengrassのインストール手順の紹介はこちらからどうぞ!
環境
動作確認したデバイス(OS)
e-RT3 Plus F3RP70-2L(Ubuntu 18.04 32bit)+アナログ入力モジュール
モジュール構成は以下の通りです。
- e-RT3 Plus F3RP70-2L(CPUモジュール、Ubuntu 18.04 32bit)
モジュール一式を制御します。
CPUモジュールから各モジュールへアクセスし、書き込みや読み取り等を行えます。- F3AD08-6R(アナログ入力モジュール)
アナログ入力モジュールは、外部から入力されたアナログデータをディジタルデータに変換します。
- F3BU05-0D(ベースモジュール)
各モジュールをセットするベースです。
電源の供給や、モジュール間の通信はベースモジュールを介して行われます。- F3PU20-0S(電源モジュール)
電源です。ベースモジュールにセットされます。
こちらのデバイスでは
armhfアーキテクチャのパッケージが動作します。
また、Windows 10 搭載のPCでIoT Edgeモジュールの開発とデバイスの操作を行っています。
(前回までの記事と同様です。)各モジュールについてはこちらのページの左側のメニューから選択して確認いただけます。
ゴール
最終的なゴールは以下の図のような、Azure IoT EdgeランタイムをインストールしたUbuntu 18.04搭載のエッジデバイスでPythonのデータ収集モジュールとデータ書き込みモジュールを作成し、収集モジュールのデータをIoT Hubへ送信し、Power BIとWebで可視化することです。
Web AppsとPower BIでデータを可視化する手順や構成はMicrosoftの公式ドキュメント3 4を参考にし、図中のアイコンはこちらを使用しています。今回はAzure IoT EdgeランタイムをインストールしたUbuntu 18.04搭載のエッジデバイスでPythonのデータ収集モジュールを作成し、収集したデータをIoT Hubへ送信することをゴールとします。
データの収集から送信の具体的な流れは以下の通りです。
- データ収集しIoT Hubへ送信するPythonのIoT Edgeモジュールを作成し、F3RP70へデプロイする
- IoT Edgeモジュールがアナログ入力モジュールの全チャネルのデータを2秒周期で収集し、IoT Hubへ送信する
- Iot Hubへ送信されたデータをAzure IoT Explorerで確認する
※今回はDAモジュールを使用しないので、動作確認したデバイスの構成には含まれていません。
準備
今回説明する内容は、Azure IoT Edgeでモジュールを作成し、デプロイできる環境であることを前提に説明しています。
開発環境
前回までに準備した環境を使用できます。
準備の手順は基本的にはMicrosoft公式のドキュメント5 6に従っており、前回の記事でWindows 10の場合を説明しています。モジュールの作成
エッジデバイスにデプロイするIoT Edgeモジュールを作成し、Container Registryへプッシュします。
今回実装する機能は以下の通りです。
主な機能
- アナログ入力モジュールの全チャネルのデータを任意の周期で収集する
アナログ入力モジュールへアクセスするためのライブラリはIoT Edgeモジュールには含めず、CPUモジュール(ホスト)のライブラリをバインドして使用します。- 収集したデータをIoT Hubへ送信する
モジュールツイン
モジュールツインでデータの送信周期を設定できるようにします。
実際のフォーマットは以下の通りです。
今回作成するIoT Edgeモジュールのモジュールツインの設定例はモジュールツインセクションにあります。Module Twin Settings{ "ert3add2c": { "interval_sec": 2 } }ペイロードのフォーマット
Microsoftが提供する公式ドキュメント4で紹介されているIoT Edgeモジュールが送信するペイロードを参考に以下のフォーマットで作成します。Payload{ "body": { "messageID": 1, "deviceID": "{deviceID}", "datetime": "2020-01-01T00:00:00.000Z", "ch1": 123, "ch2": 234, "ch3": 345, "ch4": 456, "ch5": 567, "ch6": 678, "ch7": 789, "ch8": 890 } }各要素については以下の通りです。
messageID: 1から始まる連番deviceID: IoT EdgeモジュールのデバイスIDdatetime: データ取得時のCPUモジュールの時刻ch1-ch8: チャネル毎のデータモジュールのプロジェクトの作成
Pythonモジュールのプロジェクトを作成します。
モジュールの作成手順は、基本的には公式ドキュメントの「チュートリアル:Linux デバイス用の Python IoT Edge モジュールを開発およびデプロイする」に従います。
「モジュール プロジェクトを作成する」内の「新しいプロジェクトを作成する」から「ターゲット アーキテクチャを選択する」までの手順で、Visual Studio Code(VS Code)で新しくプロジェクトを作成します。
以上の手順の詳細が前回の記事の「モジュールの作成」内の「新しいプロジェクトを作成する」から「ターゲット アーキテクチャを選択する」でも紹介されています。今回は以下の設定でプロジェクトを作成しました。
- Solution Name: Ert3D2c
- Module Template: Python Module
- Module Name: Ert3D2cModule
また、ターゲットアーキテクチャは
arm32v7を選択します。モジュールのコードと機能
モジュールのコード
作成したプロジェクトの
main.pyを以下のコードに置き換えて保存します。
クラスと各メソッドについてコード中に簡単にコメントしています。
機能セクションで一部の機能を解説しています。main.pyimport os import json import subprocess import signal import datetime import ctypes from azure.iot.device import IoTHubModuleClient from azure.iot.device import Message DESIRED_KEY = 'desired' ERT3ADD2C_KEY = 'ert3add2c' INTERVALSEC_KEY = 'interval_sec' STATUS_KEY = 'status' FAM3AD_CHNUM = {'AD04': 4, 'AD08': 8} UNIT = 0 SLOT = 2 DEFAULT_INTERVAL_SEC = 2.0 LDCONFIGEXEC = 'ldconfig' M3LIB_PATH = '/usr/local/lib/libm3.so.1' DEVICE_ID = os.environ['IOTEDGE_DEVICEID'] OUTPUT_NAME = os.environ['IOTEDGE_MODULEID'] + 'ToIoTHub' class AdD2C(): """ ADモジュールからデータ収集する各機能が実装されたクラス。 """ def __init__(self, module_client, unit, slot): """ コンストラクタ。 """ self.__module_client = module_client self.__unit = unit self.__slot = slot self.__message_no = 1 self.__libc = ctypes.cdll.LoadLibrary(M3LIB_PATH) self.__libc.getM3IoName.restype = ctypes.c_char_p self.__chnum = self.__get_m3ad_ch_num() signal.signal(signal.SIGALRM, self.__signal_handler) def __get_m3ad_ch_num(self): """ AD08かAD04か判断する。 """ namebytes = self.__libc.getM3IoName( ctypes.c_int(self.__unit), ctypes.c_int(self.__slot)) num = 0 if namebytes is not None: num = FAM3AD_CHNUM.get(namebytes.decode(), 0) return num def __read_m3ad_ch_datas(self): """ ADモジュールの全チャネルからデータを収集する。 """ short_arr = ctypes.c_short * self.__chnum ch_datas = short_arr() self.__libc.readM3IoRegister( ctypes.c_int(self.__unit), ctypes.c_int(self.__slot), ctypes.c_int(1), ctypes.c_int(self.__chnum), ch_datas) return ch_datas def __signal_handler(self, signum, frame): """ メッセージを作成してedgeHubモジュールへ送信する。 """ bodyDict = dict( messageID=self.__message_no, deviceID=DEVICE_ID, datetime=datetime.datetime.utcnow().isoformat() + 'Z' ) ch_datas = self.__read_m3ad_ch_datas() for index, ch_value in enumerate(ch_datas): bodyDict['ch' + str(index + 1)] = ch_value bodyStr = json.dumps(bodyDict) msg = Message(bodyStr, output_name=OUTPUT_NAME) self.__module_client.send_message(msg) print(bodyStr) self.__message_no = self.__message_no + 1 def set_condition(self, desired): """ データ収集周期を設定する。 """ if ERT3ADD2C_KEY not in desired: return {STATUS_KEY: False} interval_sec = desired[ERT3ADD2C_KEY].get(INTERVALSEC_KEY, DEFAULT_INTERVAL_SEC) reported = dict() reported[ERT3ADD2C_KEY] = desired[ERT3ADD2C_KEY] if interval_sec < 0.0: reported[ERT3ADD2C_KEY][STATUS_KEY] = False else: signal.setitimer(signal.ITIMER_REAL, interval_sec, interval_sec) reported[ERT3ADD2C_KEY][STATUS_KEY] = True return reported def send_ad_data(): """ 各機能を呼び出す。 モジュールツインの変更を監視する。 """ module_client = IoTHubModuleClient.create_from_edge_environment() module_client.connect() twin = module_client.get_twin() add2c = AdD2C(module_client, UNIT, SLOT) reported = add2c.set_condition(twin.get(DESIRED_KEY, {})) module_client.patch_twin_reported_properties(reported) while True: reported = add2c.set_condition( module_client.receive_twin_desired_properties_patch() ) module_client.patch_twin_reported_properties(reported) module_client.disconnect() if __name__ == "__main__": subprocess.run([LDCONFIGEXEC]) send_ad_data()機能
一部の機能を簡単に紹介します。
ライブラリ
import ctypes今回はe-RT3の関数を使用したいことと、それがC言語のプログラムで動作するもののため、
ctypesをインポートしています。from azure.iot.device import IoTHubModuleClient from azure.iot.device import MessageAzure IoT HubデバイスSDK7のライブラリです。
定義
M3LIB_PATH = '/usr/local/lib/libm3.so.1'e-RT3のライブラリのシンボリックリンク(IoT Edgeモジュール内)です。
e-RT3の関数
getM3IoName: モジュールIDの取得
ユニット、スロットを指定してモジュールID(モジュールの名称)を取得する関数です。
C言語では以下のように使用します。char* getM3IoName (int unit, int slot);
readM3IoRegister: 入出力レジスタデータ読み出し
ユニット、スロット、読み出し開始チャネル、読み出すチャネル数、データ格納位置を指定して入出力レジスタのデータを読み出す関数です。
C言語では以下のように使用します。int readM3IoRegister(int unit, int slot, int pos, int num, unsigned short *data);その他
subprocess.run([LDCONFIGEXEC]): ライブラリのシンボリックリンクの生成
メイン関数の冒頭にあり、実際に呼び出されるのはsubprocess.run(['ldconfig'])です。
後の手順でこのIoT Edgeモジュールをデプロイする際F3RP70-2L内のライブラリを使用できるように、F3RP70-2Lの/usr/local/lib/libm3.so.1.0.1をIoT Edgeモジュールの/usr/local/lib/libm3.so.1.0.1にバインドします。
その後シンボリックリンクを生成するldconfigコマンドを実行するために、この行が初めに登場します。
実際に参照するのは生成されたシンボリックリンクの/usr/local/lib/libm3.so.1です。モジュールのプッシュ
main.pyを書き換えて保存したら、Container RegistryへIoT Edgeモジュールをプッシュします。
VS Codeのエクスプローラから
deployment.template.jsonを探して右クリックします。
表示されるメニューから「Build and Push IoT Edge Solution」を選択します。IoT EdgeモジュールのビルドとContainer Registryへのプッシュのコマンドが実行されます。
VS Code下部のターミナルに進行度と実行結果が表示されます。※もしProxy設定の不足でプッシュに失敗した場合は、前回の記事の補足の内容を確認し、VS CodeとDocker Desktopに設定を行ってください。
モジュールのデプロイ
IoT EdgeモジュールをF3RP70-2Lにデプロイします。
今回もAzure Portalを使用して設定します。Image URIの取得
Azure PortalからContainer Registryへアクセスし、左側のメニューのサービスカテゴリ内の「リポジトリ」をクリックします。
表示されるリポジトリ一覧から、デプロイしたいリポジトリのIDをクリックします。
タグが表示されるのでデプロイしたいタグをクリックします。
このとき、<version number>-arm32v7のようにバージョン番号に続くのがarm32v7であることを確認してください。「Docker pullコマンド」の隣のテキストボックスから、docker pull以降の文字列をコピーします。
こちらがImage URIにあたるもので、デプロイの際に使用します。
IoT Hubでの作業手順
モジュール
IoT Hubへ移動し、デバイスの自動管理カテゴリ内の「IoT Edge」をクリックします。
表示されるデバイスIDから、デプロイしたいデバイスを選択します。
デバイスの情報が表示されたら、画面上部の「モジュールの設定」をクリックします。今回は、前回までの記事でデプロイしたPythonModuleとSimulatedTemperatureSensorを消去し、新たに今回作成したIoT Edgeモジュールをデプロイします。
まず、コンテナーレジストリの資格情報の欄に必要な各情報が既に入力されていることを確認します。
入力が必要な場合はこちらの2. をご覧ください。
(Azure Portalで日本語表記が増えたので、前回の記事を参照する場合は適宜読み替えてください。)
次に、PythonModuleとSimulatedTemperatureSensorの右側にあるゴミ箱マークをクリックし、リストから削除してください。
IoT Edge モジュールの「+追加」をクリックし、表示されるメニューからIoT Edge モジュールをクリックします。
右側に新たにメニューが表示されるので、以下の組み合わせの通りにテキストボックスに入力・ペーストします。
モジュールの設定項目 入力する情報 IoT Edgeモジュール名 任意のモジュール名 イメージのURI Container Registryのリポジトリから取得するImage URI 再起動ポリシー 常時(デフォルトのまま) 必要な状態 実行中(デフォルトのまま) イメージのプルポリシー 空欄(デフォルトのまま)
次に、「コンテナーの作成オプション」タブをクリックし、オプションを入力します。
以下のように入力しホスト側に存在する必要なライブラリとデバイスをIoT Edgeモジュール内で使用できるようにします。
ライブラリは"Binds"、デバイスは"Devices"に設定内容をそれぞれ入力しています。Container Create Options{ "HostConfig": { "Binds": [ "/usr/local/lib/libm3.so.1.0.1:/usr/local/lib/libm3.so.1.0.1" ], "Devices": [ { "PathOnHost": "/dev/m3io", "PathInContainer": "/dev/m3io", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3sysctl", "PathInContainer": "/dev/m3sysctl", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3cpu", "PathInContainer": "/dev/m3cpu", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3mcom", "PathInContainer": "/dev/m3mcom", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3dev", "PathInContainer": "/dev/m3dev", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3ras", "PathInContainer": "/dev/m3ras", "CgroupPermissions": "rwm" }, { "PathOnHost": "/dev/m3wdt", "PathInContainer": "/dev/m3wdt", "CgroupPermissions": "rwm" } ] } }
※これらの内容は配置マニフェストの
"CreateOptions"の中に挿入されます。
Container Create Optionsについての詳細はMicrosoftのドキュメント「IoT Edge モジュールのコンテナー作成オプションを構成する方法」、設定できる内容の詳細はDockerのドキュメント「Create a container」をそれぞれご覧ください。次に、「モジュールツインの設定」タブをクリックし、モジュールツインを入力します。
初めは2秒周期に設定してみます。
入力したら青い「追加」ボタンをクリックします。Module Twin Settings{ "ert3add2c": { "interval_sec": 2 } }
ルート
「ルート」タブをクリックします。
既に入力されているPythonModuleToIoTHubに倣ってIoT EdgeモジュールからIoT Hubへデータを送信するルートの設定を行います。
以下のように名前、値を入力します。
名前 値 yourModuleToIoTHub FROM /messages/modules/yourModule/outputs/* INTO $upstream PythonModuleToIoTHubとsensorToPythonModuleの設定を右のごみ箱マークをクリックして削除します。
1.で入力した設定のみになったら上部の「確認および作成」タブか下部の「次へ: 確認および作成」ボタンをクリックします。
確認および作成
設定内容が正しいか確認します。
「検証に成功しました。」の表示があり、配置に表示されるJSON形式の設定テキスト内に入力・削除した内容が反映されていることを確認します。
問題なかったら下部の青い「作成」ボタンをクリックして設定を適用します。モジュールの動作確認
IoT Hubでデプロイの成功と動作状況を、Azure IoT ExplorerでIoT Hubへデータを送信できていることを確認します。
IoT Hubでの確認
「作成」ボタンをクリックすると自動的にIoT Edgeモジュールの情報画面に戻ります。
以下の内容を確認します。
- 「IoT Edgeランタイムの応答」が「200 -- OK」であること
- 「モジュール」のリストに表示されているのが「\$edgeAgent」、「\$edgeHub」、デプロイした「yourModule」であり、ランタイムの状態が全て「running」であること
※新たにデプロイしたIoT Edgeモジュールはランタイムの状態がrunningになるまで数分かかります。
もし上記のようにならない場合は暫く待ち、画面上部の更新ボタンをクリックし最新の情報に更新してから再度確認します。
同様に、消去した設定が反映されるのにもしばらく時間がかかります。
Azure IoT Explorerでの確認
前回の記事のモジュールの動作確認の項目と同じ手順で確認できます。
Azure IoT Explorerで受信したTelemetryが以下のようなフォーマットであれば作成したIoT Edgeモジュールが正しく動作しています。今回は8チャネルのF3AD08を使用しているため、8チャネル分のデータが送信されています。
Telemetry{ "body": { "messageID": 2034, "deviceID": "test_ert3_f3rp70", "datetime": "2021-01-26T03:50:58.445146Z", "ch1": -1, "ch2": 8, "ch3": 1, "ch4": 2, "ch5": 0, "ch6": 1, "ch7": 3, "ch8": 1 }, "enqueuedTime": "2021-01-26T03:50:58.476Z", "properties": {} }モジュールツイン
今回作成したIoT Edgeモジュールにはモジュールツインの機能を実装しています。
モジュールツインの設定手順と機能を紹介します。モジュールツインの設定手順
今回はAzure Portalからの設定手順を紹介します。
Azure Portalからモジュールセクションの1.の手順でデバイス設定を開き、モジュールのリストから変更したいIoT Edgeモジュールを選んでクリックします。
IoT Edgeモジュールの更新画面が右側に表示されるので、「モジュールツインの設定」タブをクリックします。
テキストボックスにモジュールツインを入力したり、既に入力されている場合は変更して更新します。
最後に、「確認および作成」ボタンをクリックし、設定内容に問題が無ければ更新します。
機能と設定例
周期の変更
interval_secの値を任意の値にすることでデータ収集周期を変更できます。
以下の例は収集周期を5秒に変更する場合です。Module Twin Settings{ "ert3add2c": { "interval_sec": 5 } }収集停止
データの収集を停止したい場合は
interval_secの値を0に設定します。
設定が反映されるとメッセージがIoT Hubに送信されなくなります。
IoT Edgeモジュールそのものが停止するのではないため、再度1より大きい周期を設定するとメッセージが送信されるようになります。Module Twin Settings{ "ert3add2c": { "interval_sec": 0 } }次回
今回は特に外部からデータが入力されていない状態で、IoT Edgeモジュールでアナログ入力モジュールのデータを読み出しました。
次回はさらにe-RT3 Plusにアナログ出力モジュールを実装し、データを書き込みする別のIoT Edgeモジュールを作成してデプロイします。
そのデータをアナログ入力モジュールへ入力し、IoT Hubへ送信されるデータがどのように変化するかを確かめます。→
次回参考









- 投稿日:2021-01-27T15:16:34+09:00
非情報系大学院生が一から機械学習を勉強してみた #4:最急降下法
はじめに
非情報系大学院生が一から機械学習を勉強してみました。勉強したことを記録として残すために記事に書きます。
進め方はやりながら決めますがとりあえずは有名な「ゼロから作るDeep-Learning」をなぞりながら基礎から徐々にステップアップしていこうと思います。環境はGoogle Colabで動かしていきます。第4回はニューラルネットワークによる学習の準備として最急降下法を整理します。目次
- 数値微分
- 偏微分
- 勾配
- 最急降下法
1. 数値微分
ご存知の通り微分は以下のように表せます。
$$
\frac{df(x)}{dx}=\lim_{h\rightarrow 0}\frac{f(x+h)-f(x)}{h}\tag{1}
$$
$h$を極限まで小さくすればよいので以下のような数値計算による実装が考えられます。悪い実装例def numerical_diff(f, x): h = 10e-50 return (f(x+h) - f(x)) / hこの実装は良くありません。理由は2つあります。
- 計算機内部の丸め誤差を無視している
- 差分誤差を無視している
計算機内部の丸め誤差を無視している
計算機内部ではビット演算で動いているので有効桁数が無限にある訳ではありません。したがって$10^{-50}$に設定しても計算機では$0$に丸められてしまい、微分できません。一般に$h$は$10^{-4}$程度にするのが良いと知られているそうなのでその値を使います。
差分誤差を無視している
微分は接点$x$における接線を意味しますが、数値計算の式で計算できるのはあくまで$x$と$(x+h)$の間の傾きを表現しているものにすぎません。1点目の理由から$h$を極限まで(理論的には無限小まで)小さくすることができないため真の微分値と傾きの値にどうしても誤差が生じてしまいます。
これらの解決法として誤差を小さくするために以下の式を考えます。
$$
\frac{df(x)}{dx}=\lim_{h\rightarrow 0}\frac{f(x)-f(x-h)}{h}\tag{2}
$$
式(1)を前方差分、式(2)を後方差分と呼びます。式(1)と式(2)を足します。
$$
\begin{align}
2\frac{df(x)}{dx} &= \frac{f(x+h)-f(x)}{h} + \frac{f(x)-f(x-h)}{h} \\
2\frac{df(x)}{dx} &= \frac{f(x+h)-f(x-h)}{h} \\
\frac{df(x)}{dx} &= \frac{f(x+h)-f(x-h)}{2h}\tag{3}
\end{align}
$$
式(3)を中心差分といいます。この式が最も誤差が小さくなり、数値微分の計算に使われます。
今回は中央差分式の導出のみ行いましたが、最も誤差が小さくなることをTeylor展開を使ってしっかり証明した記事がありました。
数値微分における3つの差分とその誤差についてよって、数値微分は以下のように実装できます。
数値微分def numerical_diff(f, x): h = 1e-4 return (f(x+h) - f(x-h)) / (2*h)2. 偏微分
微分の計算を変数ごとに行えば偏微分になります。すなわち
$$
\frac{\partial f(x_0)}{\partial x_0} = \frac{f(x_0+h)-f(x_0-h)}{2h}
$$
となります。詳しくは勾配で。3. 勾配
変数ごとの偏微分をまとめて計算すると勾配になります。すなわち
$$
\nabla f =
\begin{bmatrix}
\frac{\partial f(x_0)}{\partial x_0} \\
\frac{\partial f(x_1)}{\partial x_1}
\end{bmatrix}
=
\begin{bmatrix}
\frac{f(x_0+h)-f(x_0-h)}{2h} \\
\frac{f(x_1+h)-f(x_1-h)}{2h}
\end{bmatrix}
$$
となります。以下のように実装できます。勾配# 関数定義 def f(x): return x[0]**2 + x[1]**2 # 勾配 def numerical_gradient(f, x): h = 1e-4 grad = np.zeros_like(x) for idx in range(x.size): tmp_val = x[idx] # f(x+h) x[idx] = tmp_val + h fxh1 = f(x) # f(x-h) x[idx] = tmp_val - h fxh2 = f(x) grad[idx] = (fxh1 - fxh2) / (2*h) x[idx] = tmp_val return grad # 勾配計算 numerical_gradient(f, np.array([3.0, 4.0])) #array([6., 8.])上の実装例では
x.size回ループを回して変数ごとの偏微分を行っていることになります。勾配は現在地点から最小値への向きを含めた傾きと言えます。4. 最急降下法
勾配は現在地点から最小値への向きを含めた傾きなので、勾配の向きへの移動を繰り返せば最小値にたどり着けそうです(現実は局所解や傾きが0になる鞍点であることもあります)。大まかにはこの発想で最小値を探そうというのが再急降下法です。再急降下法では勾配の向きに一定距離だけ移動し、移動した新しい点で再び勾配を計算します。その新たな勾配に基づいてまた一定距離移動し移動先でまた勾配を更新し……を収束するまで繰り返します。私たちが良く知らないところに行くときちょっと歩いたら地図を見て合っているか確認し(必要なら修正し)また目的地に向かうのによく似ています。
式で表現すると以下のように書けます。
$$
x_n(k+1) = x_n(k) - \eta \frac{\partial f\left(\boldsymbol{x}(k)\right)}{\partial x_n}, ~~~n=1, ..., N\tag{4}
$$
$n$は変数数(勾配の例のように$x_0, x_1$ 2変数を用いる場合$N=2$)、$k$はイタレーション数、$\eta$は学習率です。現在の位置$x_n(k)$に対して勾配に学習率をかけて変化率を調整したものを引くことで次の位置$x_n(k+1)$を決定します。このイタレーション処理を
$$
k = k_{max}
$$
すなわちイタレーション回数が規定回数終了するか、
$$
|x_n(k+1) - x_n(k)| < \varepsilon
$$
すなわち更新量が規定量より小さくなり収束するまで繰り返します。
実装は以下のようにできます。再急降下法matplotlib.rcParams["mathtext.fontset"] = "cm" matplotlib.rcParams['contour.negative_linestyle'] = 'solid' # 再急降下法 def gradient_descent(f, init_x, lr, k_max): x = init_x x_history = [] for i in range(k_max): x -= lr * numerical_gradient(f, x) #再急降下法計算 x_history.append( x.copy() ) #データ保存 return x, np.array(x_history) # 関数定義 def f(x): return 3*x[0]**2 + x[1]**2 # 再急降下法計算 lr = 0.01 #learning rate k_max = 400 #イタレーション数 init_x = np.array([-3.0, 3.0]) #初期位置 x, x_history = gradient_descent(f, init_x, lr, k_max) # 収束確認 plt.plot(x_history[:,0], label="$x_0$") plt.plot(x_history[:,1], label="$x_1$") plt.xlabel("$k$", fontsize = 18); plt.ylabel("value", fontsize = 18); plt.legend(fontsize = 18) plt.show()
gradient_descent関数で式(4)に従って再急降下法を実装しています。x_historyで$k$回目の値を記録しています。これは後で使います。
後半で実際にパラメータを設定し再急降下法の計算を実行しています。表示させている図は各イタレーションでの$x_0, x_1$の値です。今回の関数は$(x_0, x_1) = (0,0)$で最小値をとるので共に0になれば収束したことを意味します。よって400回のイタレーションが終了するまでには$x_0, x_1$ともに収束していることが確認できました。次は計算した結果を等高線上にプロットしてみます。
再急降下法結果の確認# 輪郭(等高線)プロット関数 def plotContour(plt): # meshgrid設定 N =100 x0 = np.linspace(-4, 4, N) x1 = np.linspace(-4, 4, N) X0, X1 = np.meshgrid(x0, x1) # 目的関数値 Y = f([X0, X1]) # 等高線をプロット M = 30 levels = np.linspace(np.min(Y), np.max(Y), M) plt.contour(X0, X1, Y, colors="k", levels = levels); # 等高線をプロット fig = plt.figure() ax = fig.add_subplot(111) plotContour(ax) plt.xlabel("$x_0$", fontsize = 18); plt.ylabel("$x_1$", fontsize = 18); # 再急降下法で記録された点をプロット for i in range(k_max): ax.plot(x_history[i, 0], x_history[i, 1], "-o", color = "red", markeredgecolor = "black", markersize = 5, markeredgewidth = 0.5); plt.show()
plotContour関数で今回設定した関数$f(\boldsymbol{x}) = 3x_0^2+x_1^2$を2次元プロットします。その図上に先ほど記録したx_historyをプロットすることで再急降下法によって始点からどのように収束点まで向かっているか観測できます。図より確かにその時々の点で最も値が小さくなる方向に向かって進んでいることが確認できました。さて、なぜ機械学習で再急降下法が用いられるのでしょうか?
機械学習では教師データに沿うよう最適なパラメータ(重みとバイアス)を学習していきますが、何をもって最適とするかの評価手法が必要です。この評価手法として評価関数というものを用いて、その値が最小になることを目指します。この最小を探すという操作に再急降下法が必要になります。参考文献
ゼロから作るDeep-Learning
ゼロから作るDeep-Learning GitHub
深層学習 (機械学習プロフェッショナルシリーズ)


- 投稿日:2021-01-27T15:14:12+09:00
VSCode で def や if 等のスニペットが出なくなったら (Python)
VSCode で Python 拡張機能 (Microsoft) を有効にしている場合、def や if, for, try などの文でスニペットによる入力補完(サジェスト)が効くのですが、この機能が 2021年1月21日のバージョンで削除されました。
公式ページ (github) のリリースノートには、「コードスニペットは削除したので、もし必要なら自分で追加してね」という旨の記述があります。
- Remove code snippets (you can copy the old snippets and use them as your own snippets).
― Releases · microsoft/vscode-pythonスニペットの追加方法
Python 拡張で提供されていたスニペットをユーザースニペットとして追加すると、入力補完機能を復元できます。
手順は次の通りです。
- コマンドパレット (
Ctrl+Shift+P) にsnippetと入力し、「基本設定: ユーザースニペットの構成」を選択。pythonと入力し、"python.json" を選択。- エディタで "python.json" が開かれるので、下記 URL のスニペットをコピペする等して追加する。
― vscode-python/python.json at 2020.12.424452561 · microsoft/vscode-pythonスニペットを修正
お好みで、あまり使わないコードスニペットをコメントアウトすると、より快適になります。
また、一部のスニペットは Python 3 では若干使いにくいので、これらに少し手を加えます。def の修正と追加
"def(class method)" という名前のスニペットは Python の
@classmethodではなく、Python 公式の表現に従えばインスタンスメソッドにあたります。
そこで、これらを解りやすいように名前変更し、@classmethodの def を追加します。元の "def(class method)" と "def(static class method)" の部分を次のように書き換えます。
"def(instance method)": { "prefix": "def(instance method)", "body": ["def ${1:funcname}(self, ${2:parameter_list}):", "\t\"\"\"", "\t${3:docstring}", "\t\"\"\"", "\t${4:pass}"], "description": "a instance method" }, "def(class method)": { "prefix": "def(class method)", "body": ["@classmethod", "def ${1:funcname}(cls, ${2:parameter_list}):", "\t\"\"\"", "\t${3:docstring}", "\t\"\"\"", "\t${4:pass}"], "description": "a class method" }, "def(static method)": { "prefix": "def(static method)", "body": ["@staticmethod", "def ${1:funcname}(${2:parameter_list}):", "\t\"\"\"", "\t${3:docstring}", "\t\"\"\"", "\t${4:pass}"], "description": "a static method" },class の修正
class は object を明示的に継承しなくても定義できる為、object を消去します。
下記の例では継承も考慮して () は残してありますが、こちらも削除したほうが使いやすいかもしれません。"class": { "prefix": "class", "body": ["class ${1:classname}(${2:}):", "\t\"\"\"", "\t${3:docstring}", "\t\"\"\"", "\t${4:pass}"], "description": "a class definition" },※ この記事は自身のブログに掲載したものと同じ内容です。
- 投稿日:2021-01-27T15:13:44+09:00
Pythonで学ぶアルゴリズム 第22弾:並べ替え(ソート方法の比較)
#Pythonで学ぶアルゴリズム< ソート方法の比較 >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第22弾として今まで学んできたソートアルゴリズムの処理能力の比較および安定ソートを扱う.ソートアルゴリズムの比較
計算量での比較
表1に示すのは,各ソート方法におけるオーダー記法での処理速度である.
大前提として,「すべてにおいて最適」というような処理は存在しない.それぞれの処理に特徴がある.
例えば,表1において,下段3つのソート方法は同じ平均計算時間となっているが,ヒープソートは並列化できないことなどが理由で,あまり使われていない.マージソートは並列処理は可能だが,大量のデータをソートする際には大容量のメモリが必要となる.利用する際には,個々の処理の違いを理解し,比べられる判断力が求められる.
実データでの比較
表2では,大きな実データ(10,000~30,000)を使って,各ソート方法の処理時間を比較している.ただし,表2における値は参考文献の著者の手元にあった環境での結果である.
Pythonで標準で用意されているsortは,内部でC言語のプログラムが動いているため,大幅に高速な処理が実現できている.
表2から得られる大事なことは,「たとえオーダー記法が同じであっても,処理時間は同じにはならない」ということである.オーダー記法を学んだ一番初めに戻ると,確かに定数倍を省略してきていたことを思い出せる.オーダー記法において違いがあれば,定数倍の影響は小さく無視できるというものであったが,同じオーダー記法であるならば,その定数倍というのも大きな影響を持ち得ることは容易に理解できる.ゆえに,例えばバブルソートが選択・挿入ソートよりもかなり遅くなるということが起きている.安定ソート
ソート方法を比較するときに知っておきたいキーワードらしい...
安定ソート: 同じ値をもつデータにおけるソート前の順序がソート後も保持されていること例えば,名前の五十音順で並べられた学生のテスト結果を,点数で並べ替える場面を考える.
そのイメージ図を次に示す.
点数の高い順に並べ替えられている.上図において赤で囲んだ部分に着目すると,同じ点数である.しかし,出席番号を見ると,小さいものが上になっている.つまり,「ごうだ」と「ほねかわ」の並びの前後関係はソート前と同じである.
これが安定ソートの定義が意味していることである.
なお,今まで触れてきたソート方法の中では,「挿入ソート」「バブルソート」「マージソート」が該当する.感想
「オーダー記法が同じでも処理時間は異なる」
今まで,当たり前のようにオーダー記法において定数を省略してきていたため,忘れかけていた.ここで改めて思い出せてよかった.また,安定ソートは聞いたことなかったが,理解できた.次回は並べ替えアルゴリズムシリーズの最後の「ビンソート」である.参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社



- 投稿日:2021-01-27T14:46:23+09:00
裏でTensorflow2が動いているKerasで学習したモデルをプロトコルバッファ形式(.pb)で保存する方法
はじめに
現在主流のDeep Learningフレームワークとしては
- Tensorflow2
- PyTorch
- Keras
- etc...
といろいろありますが、作成した学習済みモデルの保存形式は以下表のとおりフレームワークごとに異なります。
フレームワーク 保存形式 備考 Tensorflow2 .pb tf2onnxを使うことでonnx形式も可能っぽい PyTorch .pt, .onnx - Keras .h5 keras2onnxを使うことでonnx形式も可能 私個人としては以下の悩みがあり、
- 個人的にKerasに慣れているのでKerasで学習したいけど、保存形式は.pbにしたい。
- .pbで保存する方法をネットで検索しても出てくる方法はTensorflowがver1の時の方法なので使えない。
上で挙げた私の悩みを皆さんもお持ちのようなので、現状私の環境で成功したコードを置いておきます。
ただ、残念なことに私自身Tensorflowに詳しくないため、質問をしていただいてもたぶん適切な回答は出来ないと思います...環境
このエントリを書いている私の環境は以下です。
- OS : Windows10 Pro x64 20H2
- CPU : Intel
- Python3 : 3.7.9
- Keras : 2.4.3
- tendorflow : 2.3.0
- tensorflow-gpu : 2.3.0
コード
import tensorflow as tf from tensorflow import keras from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 #path of the directory where you want to save your model frozen_out_path = '' # Convert Keras model to ConcreteFunction full_model = tf.function(lambda x: model(x)) full_model = full_model.get_concrete_function( tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype)) # Get frozen ConcreteFunction frozen_func = convert_variables_to_constants_v2(full_model) frozen_func.graph.as_graph_def() layers = [op.name for op in frozen_func.graph.get_operations()] # Save frozen graph to disk tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=frozen_out_path, name="mnist.pb", as_text=False) # Save its text representation tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=frozen_out_path, name="mnist.pbtxt", as_text=True)おわりに
私が.pbで保存したい理由は 学習済みモデルをOpenVINOで使いたかったからです。
そちらはもうそろそろ記事にしますので、この記事と一緒に見ていただけると嬉しいです。誤字、脱字、認識間違いなどあればご指摘をお願い致します。
- 投稿日:2021-01-27T13:36:14+09:00
M1搭載MacにおけるPytorchのインストール
概要
- M1搭載MacでのPyTorch(GPU非対応)のインストール手順をまとめています。
- torchaudioのインストールはまだうまくいっていません。
前置き
M1搭載Macでは,GPU対応のTensorflowに注目が集まりがちですが,PyTorchを使用したい方も多いかと思います。Tensorflowの導入記事は数多く見つかったのですが,PyTorchの導入記事が見つからず手間取ったので,簡単にまとめました。
2021-01-27時点で,PyTorchはGPU対応ではありませんが,CPU版の導入は可能です。方針
- M1搭載Mac対応のPython環境を提供する
miniforgeの使用を前提とします。手順
miniforgeの環境構築以下のリンク先から, arm64 (Apple Silicon) 版のインストーラ(シェルスクリプト)をダウンロードします。
https://github.com/conda-forge/miniforgeダウンロードしたら,インストーラを実行します。(基本的にすべてyes)
source ~/Downloads/Miniforge3-MacOSX-arm64.sh仮想環境を構築します。
myenvの箇所は好きな名前で良いです。2021-01-27時点で,python3.9系に対応していない有名パッケージ(例えばnumbaや,numbaに依存したlibrosaなど)があるので,python=3.8.6とするのが良いと思います。conda create -n myenv python=3.8.6 conda activate myenv普段使用するパッケージをインストールします。次のパッケージ群は私が普段使っているものなので,すべてインストールする必要はありませんが,
torchが依存しているnumpyは必ずインストールしてください。conda install numpy conda install numba conda install pandas conda install openpyxl conda install scipy conda install scikit-learn conda install matplotlib conda install seaborn conda install jupyterlabPyTorchのインストール
torchのインストール2021-01-27現在,
torchはconda install torchやpip install torchではインストールできません。
しかし,先人の方々がwheelを作成してくださっているので,それを使用すると簡単にインストールできます。
まず,wheelファイルをダウンロードします。
- 仮想環境作成時に
python=3.8.x(3.8系)を指定した方は,次のリンクからGoogle Driveのリンクに飛び,画面右上にあるダウンロードのボタンを押し,警告を無視してダウンロードしてください。
https://drive.google.com/file/d/1e-7R3tfyJqv0P4ijZOLDYOleAJ0JrGyJ/view- 仮想環境作成時に
python=3.9.x(3.9系)を指定した方は,次のリンクからGithubのページに飛び,「Download」ボタンを押してください。
https://github.com/wizyoung/AppleSiliconSelfBuilds/blob/main/builds/torch-1.8.0a0-cp39-cp39-macosx_11_0_arm64.whlダウンロードしたら,以下のコマンドで
torchをインストールできます(python3.8系か3.9系かでファイル名が異なるので,微妙にコマンドは変わります)python3.8系をダウンロードした場合pip install ~/Downloads/torch-1.8.0a0-cp38-cp38-macosx_11_0_arm64.whlpython3.9系をダウンロードした場合pip install ~/Downloads/torch-1.8.0a0-cp39-cp39-macosx_11_0_arm64.whl以上で,
torchのインストール可能です。
torchvisionのインストールこれまでの手順で
torchがインストールできていれば,次のコマンドでインストールできます。pip install torchvision
torchaudioのインストール現時点で,うまくいっていません...
pytorch-lightningのインストールPyTorchLightningは,PyTorchを効率的に書くためのラッパーパッケージです。
かなり便利なのでおすすめです。まず,依存パッケージを
conda installコマンドでインストールします。conda install future pyyaml tqdm fsspec tensorboardあとは,
pip installコマンドでpytorch-lightningをインストールしたら終了です。pip install pytorch-lightning後書き
先人の方々に感謝です。
torchaudioのインストールが残る課題になります(因みに,torchaudioが依存しているlibrosaは,pip install librosaでインストール可能です)。参考記事
- miniforgeによるPythonの環境構築
- PyTorchのM1搭載Mac対応についてのIssue
- Pytorch-lightningの公式
- 投稿日:2021-01-27T12:50:59+09:00
DynamoDBへのテストデータ作成用pythonスクリプト
はじめに
DynamoDBへ大量のテストデータを作りたいときのPythonスクリプトが欲しいなという時の参考にしていただければと思います。
実装
第一引数に、対象となるDynamoDBのテーブル名、第二引数にテストデータ数を整数で渡してあげると、動作します。
sample.pyimport json from argparse import ArgumentParser, FileType import boto3 from tqdm import tqdm def main(): p = ArgumentParser(description='jsonをDynamoDBにインポート') p.add_argument('table', help='テーブル名') p.add_argument('total', type=int, help='テストデータ数') args = p.parse_args() session = boto3.Session(profile_name="default") dynamodb = session.resource('dynamodb') table = dynamodb.Table(args.table) total = args.total with table.batch_writer() as batch: for i in tqdm(range(total)): batch.put_item( Item={ "ID": str(i), "TEST_DETAIL": "TESTDATA" } ) if __name__ == "__main__": main()
- 投稿日:2021-01-27T12:42:26+09:00
FastAPIで非同期処理に対応したLINEBOTを開発する
チャットボットは自身で開発したプログラム単独で完結できる場合は少なく、何らかのAPIを呼び出すことが多いと思います。(自然言語解析関連、ストレージ関連、翻訳や天気など各種サービス関連・・・)
したがって必然的にI/O待ち時間が発生しがちで、非同期処理との相性が良いはずなのですが、LINEBOTに関しては非同期処理のサンプルを全然見かけないので記事にしてみました。APIクライアントの非同期対応状況について
まずもってですが、根っことしてLINE Messaging APIの公式Python SDKが非同期処理に対応していないという状況があります。古いPythonバージョンがまだサポート対象であることが理由のようで、EOLは間近としてもまだしばらくかかりそうです。(2021年1月27日時点)
[Feature Request] Asynchronous/Asyncio support
ところが上のやりとりの中で、コミュニティの有志から非同期対応版のSDKが公開されていましたので、今回はありがたく利用させていただくこととします。なお本記事の内容は公式SDKが非同期対応後にもAPIクライアントのインスタンス化部分のみを差し替えればそのまま利用することができます。
aiolinebot https://github.com/uezo/aiolinebot
インストール時に公式SDKを継承して動的に非同期メソッドを追加する仕組で、原則的にすべての同期メソッドの非同期版を提供している模様です。
必要なライブラリのインストール
先に挙げたaiolinebotに加えて、FastAPIとASGIサーバもインストールします。
$ pip install fastapi uvicorn aiolinebotFastAPIとUvicornの動作確認
はじめにFastAPIとUvicornがきちんとインストールできたことを確認します。以下の通り
run.pyを作成してhttp://localhost:8000/messaging_api/handle_requestにアクセスしてみましょう。okと表示されれば動作確認完了です。run.pyfrom fastapi import FastAPI app = FastAPI() @app.post("/messaging_api/handle_request") async def handle_request(): return "ok"なおサーバーの起動方法は以下の通りです。
--debugをつけるとファイルを更新した際に自動で再読み込みが走るので開発時には便利です。$ uvicorn run:app --debugインターネットからアクセスできるようにする
LINEBOTの開発にあたっては、LINEのサーバからのHTTPリクエストを受け付けられるようにする必要があります。みんな大好きngrokをインストールしてUvicornのポート番号にルーティングしましょう。
$ ngrok http 8000ここで払い出されるドメインを使用して、先のサーバープログラムにアクセスできることを確認してください。https://xxxxx.ngrok.io/messaging_api/handle_request といった体系です。HTTPSであることと、ポート番号は不要な点に気をつけましょう。
xxxxx部分は起動都度変わってしまうので、作業が終わるまでngrokを終了しないようにしてください。トークンの取得とエンドポイントURLの登録
チャネルアクセストークンとチャネルシークレットの2種類のキーを取得し、また、Messaging APIのエンドポイントとして先のngrokのURL https://xxxxx.ngrok.io/messaging_api/handle_request を登録します。
こちらの記事を参考にしていただければすぐにできると思います→ LINEのBot開発 超入門(前編) ゼロから応答ができるまで
おうむ返しのLINEBOTを作成する
ここまでで下準備は完了です。ユーザーの発話内容をおうむ返しするLINEBOTを作ってみましょう。先程の
run.pyを以下のように書き換えます。run.pyfrom fastapi import FastAPI, Request from linebot import WebhookParser from linebot.models import TextMessage from aiolinebot import AioLineBotApi # APIクライアントとパーサーをインスタンス化 line_api = AioLineBotApi(channel_access_token="<YOUR CHANNEL ACCESS TOKEN>") parser = WebhookParser(channel_secret="<YOUR CHANNEL SECRET>") # FastAPIの起動 app = FastAPI() @app.post("/messaging_api/handle_request") async def handle_request(request: Request): # リクエストをパースしてイベントを取得(署名の検証あり) events = parser.parse( (await request.body()).decode("utf-8"), request.headers.get("X-Line-Signature", "")) # 各イベントを処理 for ev in events: await line_api.reply_message_async( ev.reply_token, TextMessage(text=f"You said: {ev.message.text}")) # LINEサーバへHTTP応答を返す return "ok"LINEアプリで話しかけてみて、たとえば「こんにちは」と話しかけると「You said: こんにちは」と応答が帰ってくれば成功です。
応答メッセージ返却のバックグラウンドタスクへの移行
先のおうむ返しBOTは、LINEBOT的には実はいわゆるアンチパターンです。
公式のLINEボット開発ガイドラインには「1000ミリ秒以内にLINEサーバーにHTTP応答を返せ」とありますが、先の実装だと受け取ったイベント(メッセージ)をすべて処理してから応答するため、1秒以内に完結しない可能性があります。
そこでFastAPIのBackgroundTaskを利用して、メッセージの処理をバックグラウンドタスクに突っ込んだらすぐにLINEヘHTTP応答を返すように修正してみます。変更点には?マークをつけておきました。run.pyfrom fastapi import FastAPI, Request, BackgroundTasks # ?BackgroundTasksを追加 from linebot import WebhookParser from linebot.models import TextMessage from aiolinebot import AioLineBotApi # APIクライアントとパーサーをインスタンス化 line_api = AioLineBotApi(channel_access_token="<YOUR CHANNEL ACCESS TOKEN>") parser = WebhookParser(channel_secret="<YOUR CHANNEL SECRET>") # FastAPIの起動 app = FastAPI() # ?イベント処理(新規追加) async def handle_events(events): for ev in events: try: await line_api.reply_message_async( ev.reply_token, TextMessage(text=f"You said: {ev.message.text}")) except Exception: # エラーログ書いたりする pass @app.post("/messaging_api/handle_request") async def handle_request(request: Request, background_tasks: BackgroundTasks): # ?background_tasksを追加 # リクエストをパースしてイベントを取得(署名の検証あり) events = parser.parse( (await request.body()).decode("utf-8"), request.headers.get("X-Line-Signature", "")) # ?イベント処理をバックグラウンドタスクに渡す background_tasks.add_task(handle_events, events=events) # LINEサーバへHTTP応答を返す return "ok"修正したら動作確認してみましょう。とはいっても体感上は何も変わらないと思います。本当にLINEサーバーへの応答が即時に返っているのか気になる方は、
handle_eventsの処理にかかる時間を極端に長くした上で、uvicornのログ"POST /messaging_api/handle_request HTTP/1.1" 200 OKがすぐに表示されて、5秒くらい経ったあとにLINEに応答メッセージが届くことが確認できると思います。run.pyimport asyncio # ?冒頭に追加 略 async def handle_events(events): await asyncio.sleep(5) # ?イベント処理前に5秒待つ for ev in events: 略なおFastAPIのバックグラウンド処理の挙動については別記事でまとめました。あわせてお読みいただけると理解が深まると思います。
FastAPIのバックグラウンド処理の多重度を同期・非同期で比較してみたよまとめ
FastAPIを使うことで、巷によくあるFlaskベースのサンプルと同じくらい簡単に非同期処理に対応したLINEBOTが作れるということをご理解頂けたかと思います。またBackgroundTasksを使えば1000ミリ秒以内のレスポンスに対応することもとても簡単です。冒頭にも書きましたとおり、特に各種外部APIと連携するチャットボットであればサーバー資源の効率的な利用につながると思います。
あとうろ覚えですがAzure Functionsだとメインスレッド以外からログを書き出せないと思いますので、バックグラウンド処理含めてメインスレッドで処理するメリットがその点からも得られると思います。ぜひ試してみてください。
- 投稿日:2021-01-27T11:58:01+09:00
Pythonのリスト内包表記の"読み方"
リスト内包表記を読む
A = [str(i) for i in range(10)] # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']変数Aは、range(10)の各値をそれぞれ文字列に変換した値が格納されたリストです。
[<値> for <変数> in <回すオブジェクト>]というような構文によって、リストを速度的にもメモリ的にも効率よく作成することができます。このような構文はリスト内包表記と呼ばれています。
内包表記という名称には「共通の性質を持った値の集まり」を説明的に表現する記述方法という意味が込められています。
例えば上記の処理で、実際にAに入る値は
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']ですが、そのように具体的に入っている値やリストをイメージするのではなく、「range(10)をfor文で回して各値を文字列に変換し、格納したもの」という説明的な表現によってAを捉えることができる表記方法ということです。
「説明的な表現」というのが実はとても大切で、プログラミングにおいて処理の本質をつかむために重要な抽象的思考力や論理的思考力を高める手助けとなります。
リスト内包表記には以下のような構文も用意されています。
A = [str(i) for i in range(10) if i % 3 == 0]rangeの後にifと条件式を追加しています。こうすることで条件式を満たす値のみを抽出することができます。形式としては以下のようになります。
[<値> for <変数> in <回すオブジェクト> if <条件式>]上記の処理では実際にA入る値は
['0', '3', '6', '9']ですが、具体的な値をイメージするのではなく、先ほどと同じように「range(10)をfor文で回して各値のうち3で割り切れるものを文字列に変換し、格納したもの」と説明的にAを捉えます。
リスト以外にも辞書型や集合型を作る際もこの内包表記を利用することができます。
# 辞書型 D = {i: i*i for i in range(10)} # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81} # 集合型 S = {i * 2 for i in range(10)} # {0, 2, 4, 6, 8, 10, 12, 14, 16, 18}いずれにしても、「共通の性質を持った集まり」を説明的に表現しています。
なぜこのような表現方法なのか
前節での「説明的な表現」というのがやはり重要です。これが活きるのは、オブジェクトを回す回数が非常に多い場合や一個一個追うと頭で処理しきれない処理がある場合にスッキリするからです。
構文の形としては、数学の影響を受けています。実は数学においても同じように膨大な大きさの集合(無限個の要素を持つ集合など)を扱ったり、手でするには途方もない計算をする場合、そもそも計算方法を捉えられない場合があるからです。
「複雑で膨大な量の処理をする」というプログラミングにおける大きなテーマを、数学と結びつけていることになります。
この節では以下の二つについて説明します。
- 可読性向上のメリット
- 数学の何に影響された?
可読性向上
では内包表記を使った具体例として業務処理「お祭りに参加した屋台のうち、ある区画に絞ってその利益を計上する」という処理が欲しいとしましょう。こうした場合Pythonでは以下のように説明的にプログラムを組めます。
(変数にはすでに値が入っているとします。雰囲気で読んでみてください。)
profits = [shop.profit() for shop in shops if shop.area == area] total = sum(profits)すこし読みづらいので、改行して整えます
profits = [shop.profit() for shop in shops if shop.area == area] total = sum(profits)profitsを使い回さないのであれば、以下のように説明的にコーディングできます。(なおかつ性能が良い)
total_profit = sum(shop.profit() for shop in shops if shop.area == area)まさに、「屋台のうち、ある区画に絞ってその利益を計上」していると読み取れるコードです。この記述の仕組みは内包表記と双子のような関係の「ジェネレータ式」によるものですが詳しい説明は割愛します。
とにかく、
<値> for <変数> in <回すオブジェクト> if <条件式>という記述で、「共通の性質を持った集まり」を説明的に表現することができるということをおさえてください。では、このような構文となった元について説明します。
数学の影響を受けているPython
実は内包表記は、数学における集合論の内包的表記の影響を受けています。
数学における集合は、さまざまな数学的対象を定義したり議論したりする際に言葉(言語)として用いられることがしばしばあります。内包的表記は、この記事の中心の話題であるリスト内包表記と同様に説明的に集合を捉えることができます。
集合の内包的表記は以下のような形となっています。補足事項はWikipediaを参照してください(https://ja.wikipedia.org/wiki/%E9%9B%86%E5%90%88#%E8%A8%98%E6%B3%95)
$$
\{ 関数(要素) | 要素 ∈ 集合, 命題(要素) \}
$$縦棒
|の左側が、集合に格納される要素となります。右側には、集合やその要素に関する関係を記述します。抽象的でわかりにくいかもしれないので、具体例を挙げます。集合 $S$ を、お祭りに参加した屋台の集まり、
要素 $s$ は、屋台、
関数 $f(s)$ を、屋台 $s$ から利益を計算する処理(※)、
命題 $P(s)$ を、「$s$ は三丁目の屋台である」
とします。
そうすると、「三丁目の屋台の利益を集めた集合」は以下のように表現できます。$$
\{ f(s) | s ∈ S, P(s) \}
$$(※ 気にしなくても良いですが、関数 $f$ は利益の値を区別するため(屋台のID, 利益)という組を出力するとします)
Pythonのリスト内包表記と照らし合わせてみます。変数名もそろえてみます。
S = shops def f(s): return s.profit() def P(s): return s.area == "三丁目" profits = [f(s) for s in S if P(s)]似ていませんか? 縦棒
|はforに対応し、$∈$ はinに対応し、命題(条件式)を使う際はifを使います。数学の影響を受けていることが伝わったでしょうか…?
最後にそのメリットを書いて終わりとします。
おわりに
気づいた方もいるかもしれませんが、数学において集合は実は数の集まりだけでなく一般的に"モノ"の集まりを扱うことができます。
よってシステム開発などで、あるデータの集まりの各データに対して一定の処理を施すような業務処理(バッチ処理)などは集合論的に考えることが可能です。
数学は頭ではイメージしきれない(イメージする必要がない)集合(無限集合など)をどうにか扱うため、対象の本質をおさえながら論理的に議論を進めることがあります。
そんな無限集合さえも扱ってしまう数学の圧倒的な道具をプログラミングにも活用することで、コードに処理の本質を表現しておくことができるのです。それができるPythonは良い言語だと思います。(RubyやJavaScriptなど多くのメジャー言語も実は数学の道具を取り入れています。その数学的な記述の傾向が強いのが関数型言語で、その中でも傑出しているのはHaskellという言語です)
これは「プログラミングに数学は必要あるのか」議論に対する「数学、特に集合はプログラミングに大いに活用できるからおすすめ!」「必要ないけど、あなたがやってるのは実は数学やで!安心して!」といういくつかの回答になりそうです。
数学がプログラミングの理解を深め、プログラミングが数学の理解を深めます。
- 投稿日:2021-01-27T11:06:13+09:00
tqdm - TypeError: 'module' object is not callable
tqdmを使おうとしたときにTypeError: 'module' object is not callableと出てしまった時の問題点と対処法。
問題点
tqdmはモジュールだから関数として呼べない。対処法
from tqdm import tqdmとするか、
import tqdm for _ in tqdm.tqdm(イテレーター)とすべし!
参考
https://stackoverflow.com/questions/39323182/tqdm-module-object-is-not-callable
- 投稿日:2021-01-27T08:29:50+09:00
discord botのDM機能で遊ぼう!
はじめに
この記事はリンク情報システムの「2021新春アドベントカレンダー Tech Connect」のリレー記事です。
engineer.hanzomonのグループメンバーによってリレーされます。(リンク情報システムのFacebookはこちらです)
15日目担当の@o-changです。
私はいつでもdiscord!!!やりたいこと
discordにはユーザー同士で直接やり取りできる、DM機能があります。
勿論botでもこの機能を使用することができます。
前回の記事で少し触った程度だったので、備忘録的にまとめておこうと思います。ソースコード自体はシンプルに、botとやりとりする機能を実装してみます。
開発環境
言語:Python3
ライブラリ:discord.pydiscord.pyを使用して実装します。
botそのものについては前々回、
Cogについては前回を参照してください。実装
メッセージを受け取った「イベント」として実行する場合と、
「コマンド」としてメッセージを受け取る場合の実装例を両方載っています。
仕組みは共通ですので、自身のbotに併せた実装をしてみてください。botの本体(イベント)
discordbot.py# コマンド拡張機能 from discord.ext import commands # discordのAPI import discord # DmCogの取り込み(./cogsにファイルを置いています) import cogs.DmCog as DmCog # コマンドプレフィックスを設定 bot = commands.Bot(command_prefix='$') # bot起動時に発生するイベント @bot.event async def on_ready(): print('-----') print(bot.user.name) print(bot.user.id) print('-----') text = f'Logged on as {bot.user}!' GameCog.setup(bot) channel = bot.get_channel(チャンネルID(数値)) await channel.send('start success') async def on_message(message): # botの発言は無視する(無限ループ回避) if message.author.bot: return elif message.content == '': await message.author.send('「$hello」 と送信してね!') # botの起動 bot.run('botのアクセストークン(文字列)')DmCogクラス(Commandコグ)
DmCog.py# exitの実装 import sys # コグクラス class DmCog(commands.Cog): # DmCogクラスのコンストラクタ。Botを受取り、インスタンス変数として保持。 def __init__(self, bot): self.bot = bot # 起動確認のコマンド @commands.command() async def test(self, message): await message.channel.send('test ok') # 終了コマンド @commands.command() async def shutdown(self, message): await message.channel.send("shutdown bot") sys.exit() # 簡単な応答をする @commands.command() async def hello(self, message): if (type(message.channel) == discord.DMChannel) and (client.user == message.channel.me): await message.author.send("World!") else: await message.channel.send("DMで送信してね!") # Bot本体側からコグを読み込む際に呼び出される関数。メンバ関数ではないです。 def setup(bot): # cogクラスにbotを渡してインスタンス化 bot.add_cog(DmCog(bot))解説
①特定のユーザーにDMを送信する方法
受け取ったメッセージのauthorにユーザー情報が入っているので、sendメソッドを利用してDMを送信できます。
簡単にですが、送信先の指定方法をまとめておきます。send.pymessage.channel.send(txt) # メッセージが入力された場所(テキストチャネル)に送信する message.author.send(txt) # メッセージの送信者にDMを送信する channel.send(txt) # 任意のチャンネルIDを使用してchannel # (番外編) txt = f'{message.author.mention} Hey!' message.channel.send(txt) # 送信者にメンションを送ることができる。author.send()との比較用。②DMを受け取る方法
discordのbotにコマンドを送る場合、botが入っているサーバーやbotのDMなど、botにメッセージを読み取る権限がある場所ならどこでもOKです。
そのため、他のコマンドと基本的に同様の記述方法で問題ありません。受け取ったコマンドの詳細を確認することで、DMが使用されているか否かを判断します。
・「コマンドが送信された場所はDMである」
・「そのDMは、bot自身のDMである」
ことを確認し、DMでコマンドを受け取ったと判断していています。追加で送信ユーザーの確認を「if(message.author() == ○○)」で行うと、特定のユーザーからのDMのみに反応することもできそうです。
おわりに
時勢柄、様々なオンラインツールに注目が集まっていますが、離れたご友人とコミュニケーションを取る場所としてdiscordを利用してみては如何でしょうか?
個人的にはチャットの自由さが気に入ってます。
Markdown形式で記述できるのが非常に楽しい…!
是非ご友人を誘って一度使ってみてください!そして面白くて便利なbotを実装して、ヒーローになりましょう!(。-`ω-)
リンク情報システム株式会社では一緒に働く仲間を随時募集しています!
また、お仕事のご依頼、ビジネスパートナー様も募集しております。お気軽にご連絡ください。