- 投稿日:2021-01-27T23:23:22+09:00
【AWS認定 Alexa スキルビルダー - 専門知識】に一週間で合格した話
はじめに
2021/01/23にAlexaスキルビルダーに合格しました。
勉強しようと思い立ってAlexa資格の学習を始めたのが2021/01/16(※1)なので、ちょうど一週間で資格を取得できたと言うことになります。
こちらの資格が2021/03/23で廃止となるので、私と同様に急いで取得しておきたいと言う人もいると思うので、少しでもこの記事を参考にしていただければ幸いです。
(※1 この日はセキュリティ専門知識に落ちてしまい、逆に学習意欲に満ち溢れていました。)
経歴とAWS資格歴
エンジニア歴1年、業務でのAWS歴は0年です。
ソフトバンク株式会社でソフトウェアエンジニアとして働いています。
AWS資格名 取得日 クラウドプラクティショナー 2020.6.25 ソリューションアーキテクト - アソシエイト 2020.7.25 SysOpsアドミニストレーター - アソシエイト 2020.7.26 デベロッパー - アソシエイト 2020.8.9 ソリューションアーキテクト - プロフェッショナル 2020.11.27 Alexa スキルビルダー - 専門知識 2021.1.23 試験に向けて学習したこと
※ AWSの基本的なサービスは理解しているという前提です。
※ 試験の結果については一切責任を取りません。
Alexa道場 - Amazon Developer
全くAlexaが知らない状態から、こちらの動画を参考に自分で手を動かして道場を進めていくことで、Alexaの基本的な部分を知ることができます。Exam Readiness: AWS Certified Alexa Skill Builder - Specialty (Japanese)
Alexa試験の出題傾向などを網羅的に確認することができる無料のデジタルEラーニングとなっています。3時間ほどの内容なので、受験日が近づいてきたら必ず受講していただきたい内容となっています。
因みに、Alexa for DevelopersというAlexa自体の学習用のEラーニングも準備はされていますが、日本語で公開されていません。私自身はこちらは受講せずに資格に合格しています。模擬試験
最後の学習内容としてはやはり模擬試験ではないでしょうか。メモを取りながら試験を受けて、解けなかった問題や理解が十分ではないと思われた部分に関しては、十分に理解できるところまでQiitaやその他資料等を活用して調べていくことをおすすめします。最後に
AWS12冠を目指している方にとっては、今回のAlexa資格廃止は唐突なことだったと思います。
学習次第では一週間で資格を取得することも可能ですので、諦めないでAWS12冠取得を目指して頂ければと思います。
私も次回はセキュリティ - 専門知識、7つ目のAWS資格に挑戦します。
- 投稿日:2021-01-27T22:38:36+09:00
Ruby on Rails,AWS, Docker, CircleCIでポートフォリオを作成してみた
初めに
今回はRuby on Railsをメインに、AWS,Docker,CircleCIなど近年人気の高まっているインフラ技術を使用してポートフォリオを作成してみました。
本記事では、実装した機能や苦労した点、参考にした記事などを紹介していきたいと思います。
皆様のポートフォリオ作りに少しでもお役に立てれば幸いです。
今後、ポートフォリオをアップデートした際にはこちらの記事も随時アップデートしていきます。(2021年1月26日時点)アプリの概要
レシピと料理に使った材料の投稿ができるアプリです。
レシピに乗っているあの材料はどこで手に入るんだろう??
料理初心者の誰もが感じる疑問を解消すべく、レシピ投稿機能のほか、料理に使用した材料の購入場所を投稿できるアプリを製作しました。URLは下記になります、よかったら見て行ってください!
URL: https://www.cooknavi.xyz/
(レスポンシブデザインにも対応しておりますので、スマートフォンからの閲覧も可能です!)GitHub: https://github.com/yutatsune/cooknavi
主な使用イメージ
トップページからゲストログイン(閲覧用)をクリック
「レシピを見てみる」または「材料を探してみる」をクリックし、一覧画面へ遷移します
ログインが完了したら、レシピまたは材料の一覧画面の右下から新規投稿ができます
必要な項目を入力して、投稿するをクリック
材料投稿画面にて、郵便番号を入力すると自動で住所が入力されます
材料投稿画面で入力した住所の経度・緯度を自動で取得して、GoogleMapに表示されます
投稿詳細画面でいいねをすることができます
使用技術
- フロントエンド
- jQuery 1.12.4
- HTML/CSS/Haml/Sass
- バックエンド
- ruby 2.6.5
- Ruby on Rails 6.0.0
- Google Maps API
- インフラ
- CircleCI
- Docker 19.03.13/docker-compose 1.27.4
- nginx 1.12.2
- mysql 5.7.31
- AWS ( EC2, ALB, ACM, RDS, Route53, VPC, IAM )
- その他使用ツール
- Visual Studio Code
- draw.io
インフラ構成図
VPCの構築、EC2へのデプロイ、RDSの導入、ELBの設定、ドメイン取得からのRoute53の設定、ACMでのSSL証明書の取得など基本的な部分は導入できました
今後は、S3や自動デプロイを導入していきたいです!機能一覧
機能 概要 ユーザー管理機能 新規登録・ログイン・ログアウトできます 簡単ログイン機能 トップ画面のゲストログイン(閲覧用)をクリックすることで、簡単にログインできます 投稿機能 レシピまたは材料を画像を5枚までつけて投稿できます 投稿詳細表示機能 各投稿画面が詳細ページで見ることができます 投稿編集・削除機能 投稿者本人のみ投稿編集・削除できます ユーザー一覧表示機能 登録したユーザーの一覧を見ることができます ユーザー情報編集機能 ログイン中のユーザーでアカウント本人であればプロフィール編集できます フォロー機能 ユーザー一覧画面から各ユーザーのフォローできます フォロー一覧表示機能 フォローしているまたはフォローされているユーザーを見ることができます いいね機能 投稿詳細ページからいいねすることできます いいね一覧機能 いいねした投稿の一覧を見ることができます コメント機能 投稿詳細ページから非同期通信でコメントできます 住所自動入力機能 材料投稿画面にて、郵便番号を入力するだけで住所が自動で入力されます マップ表示機能 材料投稿画面で入力した住所の経度・緯度を自動で取得し、マップで表示することができます レスポンシブデザイン スマートフォン向けの表示に対応 工夫した点
とにかく、単なるレシピ投稿アプリにならないように下記を頑張って実装しました!
- 料理に使った材料の投稿機能
- 住所自動入力機能
- GoogleMapsAPI連携
レシピを投稿したユーザーが、使った材料をどこで買ったかも投稿できるようにしました
通販でいいんじゃ。。。というツッコミはなしでお願いします笑
実際にお店で色々見たりする楽しみだってありますから!今後、新しい機能を思いついたら実装してみたいとおもいます
DB設計
各テーブルについて
テーブル名 説明 users 登録ユーザー情報 relationships フォロー・フォロワーのユーザー情報 recipes レシピの投稿情報 images レシピの投稿画像情報 comments 投稿レシピへのコメント情報 recipe_likes 投稿レシピへのいいね情報 materials 材料の投稿情報 material_images 材料の投稿画像情報 material_comments 投稿材料へのコメント情報 material_likes 投稿材料へのいいね情報 苦労した点
フロントエンド
- デザインについて
まず、デザインをどうすれば良いかで悩みました!
最終的には、フルスクリーンレイアウトやタイル型レイアウト等に落ち着きました
- JavaScript(jQuely)全般
スライドメニューやGoogleMapの表示などが大変でした!
これからも勉強を続けて、もっとカッコよく実装できるようになりたいですバックエンド
- いいね・フォロー機能のアソシエーション
投稿機能など、初めのうちに学習した機能とは違い、アソシエーションの組み方が独特でした
しかし、一度理解してしまえばあとはスムーズに実装できました
- GoogleMapsAPI連携
これがとにかく苦労しました
GoogleMapが表示されない、JavaScriptがRubyの値を参照するにはどうするかなど課題がありました
これは、gonというgemを使うことによって解決できました!
最終的に実装できて本当によかったです!
- RSpecによるテスト
意外と盲点だったのがこちら
書き方が独特で新たに覚えなければいけないことが多いです
こちらは現在進行中で更新中です!AWS
- EC2インスタンス内の環境構築
Rails6以降はYarnが必須であることがわかっていなくて、プリコンパイルのところで2日くらい詰まりました。。。
皆さんはお気をつけを!
- RDS設定
環境構築が終わった後にいざ試しに登録してみるとエラーが。。。
原因は日本語が登録できない設定になっていたことでした
これを直すには、パラメーターグループの設定を変更すれば解決するはずです
【AWS】RDSで作成したMySQLのDBに日本語が保存できないを解決 | Rails on DockerDocker
- 環境構築
Dockerはやはりこれに尽きると思います。
dockerファイルの記載やdocker-compose.ymlの設定など覚えることがたくさんありました
あと、Rails6以降はYarnとwebpackerのインストールが必須となります
【Rails6】Docker+Rails6+puma+nginx+mysql【環境構築*初心者必見】CircleCI
- 導入とyml設定
まず、GitHubとの連携の仕方がよく分からなくて苦戦しました
原因はymlファイルをgitのmasterにプッシュしてないからでした。。。
【CircleCI】CircleCI 2.0からはじめる個人での簡単なCI導入方法 - githubとの連携まで
今ではなんとか自動テストまでは導入できました
今後は自動デプロイも試していきたいです参考にした学習教材・記事
とにかく参考になりそうなものは色々と試していきました!
ここでは使ってみてよかったものを紹介していきますUI/UX
ポートフォリオのデザインに悩んだら読んでみてください!
HTMLやCSSの基礎の他、フルスクリーンレイアウトやタイル型レイアウト、レスポンシブデザインなどとても参考になりましたスライドメニューの作り方や画像のスライドショーなど、実践的に使えるテクニックが紹介されていました
jQueryを使うなら読んでみて損はないかと思います!Ruby on Rails
- いいね機能
- フォロー機能
- 住所自動入力機能
- GoogleMapsAPI連携
- Rspec
AWS
こちらの記事がすごく分かり易かったです!
画像が豊富に使われていて、初めてAWSを使う人でも問題なくできます
手順通りに行うだけで、VPC,EC2,RDS,Route53,ACMなど基本的な環境が構築可能VPCの構築やEC2の立ち上げ方など、基礎的なことを一通り学ぶことができます
まず最初にこちらを読んでみると良いのではないでしょうかDocker/docker-compose
- 【Qiita】いまさらだけどDockerに入門したので分かりやすくまとめてみた
- 入門 Docker
- 【書籍】Docker/Kubernetes 実践コンテナ開発入門(3章のdocker-composeまで読みました)
まず、学習の手始めとしてこちらを学習しました
Dockerとは何か?というところからdocker-composeの構築の仕方まで学ぶことができます私はまだ受けていないのですが、こちらの講座がわかりやすいと評判なので紹介させていただきます
CircleCI
今後の課題
- Vue.jsなどの導入
- ECSによるコンテナデプロイ
- CircleCIの自動デプロイ(CDパイプラインの構築)
- テストコードの充実
- いいね・フォロー機能のajax化
- さらなる機能の拡張
など、まだまだできるところはあると感じました!
今後の転職活動の状況と相談しながら引き続き改善していきたいと思います







- 投稿日:2021-01-27T22:25:09+09:00
AWS ChaliceでLINE Botにメッセージのオウム返しと、任意のメッセージをプッシュさせてみる
これはなに
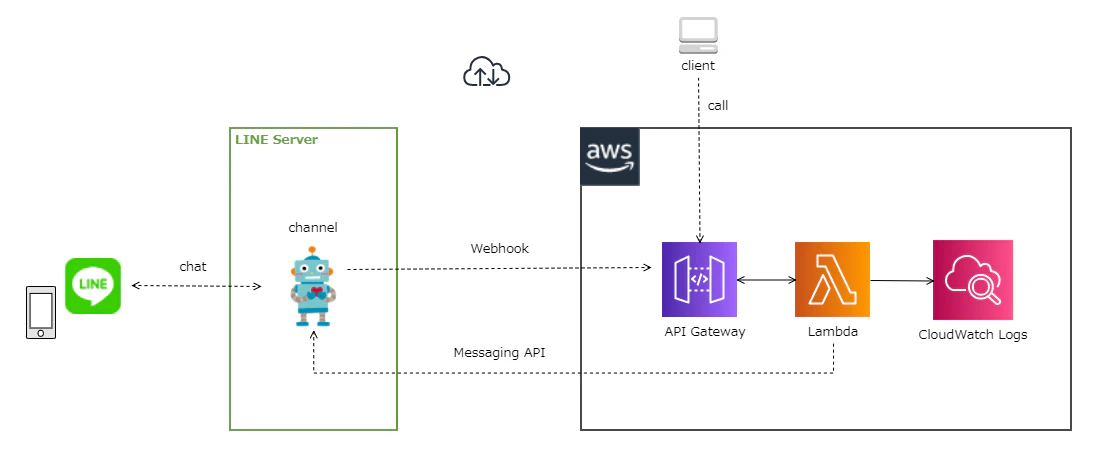
AWS Chaliceで簡単なLINE Botを作る手順をまとめました。
最終的に構成図にするとこんな感じになります。
LINE Botの作成
LINE Developersに登録し、LINE Developersコンソールで作業します。
プロバイダーの作成
アプリ(Bot)を提供するプロバイダーを作成します。組織名や自分の名前を付けるといいようです。
チャネルの作成
次に自分の作ったサービスとプロバイダーを関連づけるチャネルを作成します。
今回はMessaging APIをチャネルとして利用するのでこちらを選択します。
アイコン、チャネル名(Bot名)、チャネル説明など項目を設定して作成します。
チャネルが作成できたら、「チャネル基本設定」から「チャネルシークレット」。
「Messaging API設定」から「チャネルアクセストークン(長期)」をそれぞれ取得して控えておきます。ここまでできたら次はチャネルと連携するサービス(API)を準備します。
AWS Chalice
続いてAmazon API GatewayとAWS Lambdaを使ったAPIを簡単に作れるPythonフレームワークのAWS Chaliceを使ってLINE Botと連携するAPIサービスを作っていきます。
Chaliceのインストール・プロジェクトの作成
>mkdir chalice >cd chalice >virtualenv venv >venv\Scripts\activate >pip3 install chalice >chalice --version chalice 1.22.0, python 3.8.6, windows 10 >chalice new-project my_line_bot Your project has been generated in ./my_line_bot >cd my_line_botAPIの作成
インストールライブラリの指定
Lambdaデプロイ時にインストールするライブラリを記述します。
LINE BotのPython SDKを使うのでこれを指定。requirements.txtline-bot-sdk==1.18.0環境変数の設定
先ほど控えた「チャネルシークレット」と「チャネルアクセストークン(長期)」がLambdaの環境変数として展開されるよう設定します。
.chalice\config.json{ "version": "2.0", "app_name": "my_line_bot", "stages": { "dev": { "api_gateway_stage": "api", "environment_variables": { "LINE_CHANNEL_SECRET": "チャネルシークレット", "LINE_CHANNEL_ACCESS_TOKEN": "チャネルアクセストークン" } } } }API実装
チャネルの呼び出しに応じて行う処理を記述します。
app.pyimport os import json import logging import random from chalice import Chalice from chalice import BadRequestError, ForbiddenError from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import FollowEvent, MessageEvent, TextMessage, TextSendMessage, StickerMessage, StickerSendMessage app = Chalice(app_name='my_line_bot') logger = logging.getLogger() logger.setLevel(logging.INFO) # 各クライアントライブラリのインスタンス作成 handler = WebhookHandler(os.environ.get('LINE_CHANNEL_SECRET')) linebot = LineBotApi(os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')) # Webhook @app.route('/callback', methods=['POST']) def callback(): try: request = app.current_request logger.info(json.dumps(request.json_body)) # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['x-Line-Signature'] logger.info(signature) # リクエストボディを取得 body = request.raw_body.decode('utf8') # 署名を検証、問題なければhandleに定義されている関数を呼び出す handler.handle(body, signature) except InvalidSignatureError as err: logger.exception(err) raise ForbiddenError('Invalid signature.') except Exception as err: logger.exception(err) raise BadRequestError('Invalid Request.') return {} # 友達追加(一度ブロックし解除しても発火する) @handler.add(FollowEvent) def handle_follow(event): linebot.reply_message( event.reply_token, TextSendMessage(text='はじめまして!よろしくお願いします!') ) # メッセージイベント @handler.add(MessageEvent, message=TextMessage) def handle_text_message(event): # メッセージをオウム返しする linebot.reply_message( event.reply_token, TextSendMessage(text=event.message.text) ) # スタンプメッセージ @handler.add(MessageEvent, message=StickerMessage) def handle_sticker_message(event): # https://developers.line.biz/media/messaging-api/sticker_list.pdf sticker_ids = [ '52002734','52002735','52002736','52002737','52002738','52002739','52002740','52002741','52002742','52002743', ] random.shuffle(sticker_ids) sticker_message = StickerSendMessage( package_id='11537', sticker_id=sticker_ids[0] ) linebot.reply_message( event.reply_token, sticker_message ) # 通知 @app.route('/push', methods=['POST']) def push(): try: request = app.current_request logger.info(json.dumps(request.json_body)) user_id = request.json_body['user_id'] message = request.json_body['message'] # メッセージを通知 linebot.push_message( user_id, TextSendMessage(text=message) ) except Exception as err: logger.exception(err) raise BadRequestError('Invalid Request.') return {}Botと対話するユーザーからのアクションに応じて発火するWebhook用のAPI(
/callback)と、ユーザーを指定してメッセージをプッシュするAPI(/push)の二つのパスを用意しています。これで、APIは完成なのでデプロイします。
デプロイ
AWS CLIで適切な権限のあるconfigureが設定されているのが前提です。
IAMポリシーはこの辺があたってれば大丈夫そう。
https://github.com/aws/chalice/issues/59#issuecomment-603760552>cd my_line_bot >chalice deploy --profile chaliceこれでAWSにデプロイが行われAPI GatewayとLambdaが構成されました。
得られたエンドポイントをチャネルに設定します。LINE Botの設定
「Messaging API設定」の「Webhook URL」にエンドポイントを設定。
「検証」を押して「成功」と表示されればOKです。
また「Webhookの利用」をオンにします。
LINE Official Account Managerから「あいさつメッセージ」と「応答メッセージ」をオフにしておきます。
これで完成です!
「Messaging API設定」にあるQRコードから友達追加しましょう。使ってみる
LINEユーザーからのアクションに応じて、FollowEvent、MessageEventのTextMessage、MessageEventのStickerMessageがそれぞれ発火しているのがわかります。プッシュの方もやってみます。
CloudWatch Logsに先ほどまでのリクエストボディがログ出力されているので、そこからユーザーID(LINEユーザーを識別するために、プロバイダーごとに割り当てられたID)を拾って、プッシュAPIを呼び出します。$ curl -X POST -H "Content-Type: application/json" \ -d '{"user_id":"************************", "message":"何か話しましょう"}' \ https://*********.execute-api.ap-northeast-1.amazonaws.com/api/push
これでサービスから能動的にLINEユーザーに通知することもできました。
参考
https://developers.line.biz/ja/docs/messaging-api/getting-started/
https://developers.line.biz/ja/docs/messaging-api/sending-messages/#methods-of-sending-message
https://developers.line.biz/ja/reference/messaging-api/#send-reply-message
https://developers.line.biz/ja/reference/messaging-api/#sticker-message
https://qiita.com/GlobeFish/items/dbf05e0f43b93ff7a6df
https://qiita.com/t-kigi/items/21073df2bfc27e2b4999
https://keinumata.hatenablog.com/entry/2018/05/08/122348




- 投稿日:2021-01-27T22:20:46+09:00
AWS SAA(SAA-C02)合格までの学習内容
2020年11月にAWSソリューションアーキテクトアソシエイトに合格しました。
折角なのでどう学習して何が役に立ったかをまとめたいと思います。受験時の筆者について
- IT業界2年目
- メインの仕事はWebアプリケーションのバックエンド(PHP)
- AWSはCloudFront、EC2、S3、Lambdaぐらいしか普段は触らない
受験の動機
- 部分的にしか理解していないのでどこかのタイミングで一から勉強したかった
- GCPにも興味があるので比較するためにも一通りのこと簡単にでも知っておきたい
- ぶっちゃけ一番は個人開発時のコストを落としたいからそのために詳しくなりたい
合格に向けて使用した資料&教材
Black Beltやホワイトペーパーだけで勉強したわけではありません。
全体像を掴むために教材とオンライン講座を買っています。使用した教材
オンライン講座
AWS公式資料
受験前学習方法
1. 全容を掴む
日常的に業務で使用していてもテキストや公式資料を一読した方が良いです。
というのもAWSが提供するサービスは多岐に渡るため全て触れることは先ず有りえません。日々提供されるサービスは増え、アップデートが行われています。言葉の使い方にも癖がありますので既に多少の知識があったとしてもAWS側に寄せていく必要があります。
今後使用することがなくともどのようなものがあるか覚えておけば受験時に聞き覚えのない名称を見て右往左往することもありません。2. 使用して運用パターンを覚える
手っ取り早いのはとにかく実際に触れて覚えることです。
テキストや資料のみで覚えることも出来ますが最適な運用パターンを問う問題が多く出るので日頃から使用していることで早く正確に答えることが出来るでしょう。
よく挙がるのがUdemyの講座ですが実際に受験して合格に十分な内容だと感じました。
自信がなければ2周して扱い慣れておくことをオススメします。3. Black Beltで復習&保管する
個人的に一番重要だったのでBlack Beltです。
合格だけなら必要ないかもしれませんが高得点を狙う、業務で日常的に使用するといった場合は必読です。
テキストや講座だけでは対象範囲を絶対に網羅できません。とはいえども量が多く全てとなると負担になるかもしれません。
そこで優先的に学ぶとすれば以下、7つのカテゴリをオススメします。
- Compute
- Storage
- Databases
- Networking & Content Delivery
- Developer Tools
- Management & Governance
- Media Services
理由は3点あります。
1. 問題集や受験時に出題された内容から体感的に7割、8割は網羅出来る
2. テキストでは限界があるため省かれてしまう部分が多い(特にDatabasesやDeveloper Tools)
3. AWS公式のベストプラクティスなので業務にも活かせるテキストや講座ぐらいの内容は大体理解できていて受験のために学習時間を多くは確保できない
という場合は上記7カテゴリだけでも目を通しておくとかなり変わると思います。
例えばぶっつけ本番で
snowball
snowball edge
Snowmobile
と並べて違いがわかる方は学習する必要はありません。ほとんどのテキストでは軽く触れる程度です。
日常的に使用していて過去問や問題集で正答率が90%を狙えるのでなければ目を通しましょう!これだけは言いたい
どのテキストを使った云々という記事を見かけることは多いですがBlack Beltについて触れた記事は多くありません。
解説が公式から直接用意されているのですから活用しましょう!
別に費用が必要な訳でもなく無料で確認できるので活用しない手はありません。
- 投稿日:2021-01-27T22:04:05+09:00
AWSにアップロードできるサーバー証明書の数が上限に達したときの対処
現象
AWSにサーバー証明書をアップロードしようとしたとき、以下のようなエラーメッセージが表示されました。
cannot exceed quota for servercertificatesPerAccount: 20AWSにアップロードできるサーバー証明書は初期ではアカウントあたり20までに制限されており、その制限を超えることはできません。
対処方法
根本的にはAWS Certificate Managerを活用し、証明書をアップロードしないほうがよいと思われます。
不要なサーバー証明書の削除
以下のようなAWS-CLIを実行して不要なサーバー証明書を削除します。
aws iam delete-server-certificate --server-certificate-name <サーバー証明書の名称>証明書の名称はアップロードしている証明書の一覧から探すと良いでしょう。
以下のコマンドで表示されることができます。aws iam list-server-certificates参照:IAM でのサーバー証明書の管理 - AWS Identity and Access Management
エラーが発生するとき
以前コマンドを実行したとき、以下のようなエラーが発生しました。
An error occurred (DeleteConflict) occurred when calling the DeleteServerCertificate operation: ...<このあとはメモしそこねた>...どうやら、利用中の証明書を削除しようとしたときに発生するようです。
証明書を利用しているサービスを確認しましょう。CloudShellを使ってWebブラウザだけでAWS-CLIを使う
AWS-CLIをインストールせずともWebブラウザがあればコマンドを実行できるAWS CloudShellが便利でした。
2020年12月にリリースされたサービスです。AWSコンソールからCloudShellを選び、環境ができたらすぐに上記のコマンドが使えます。
詳しくは下記を参照してください。
- AWS CloudShell – AWS リソースへのコマンドラインアクセス | Amazon Web Services ブログ
- 待望の新サービス AWS CloudShell がリリースされました! #reinvent | Developers.IO
サーバー証明書の制限を引き上げる
方法は下記を参照してください。
- 投稿日:2021-01-27T21:18:43+09:00
Serverless Laravel を振り返る※お金のお話もあるよ!
AWS Lambda x Laravel でサーバーレス構築 ⇒ 本番リリースまで実施しました。
ベストプラクティスではなかったり、情報を見落としていたりもあると思いますが、
後々の Serverless Laraveler のために『こんな感じでしたよ』というのを残しておきます。あと費用感。とても大切。
想定される読者像
- AWS 完全に理解した!って人。
- Laravel で Serverless したい人。
- Serverless は理解しているけど『実際の費用感どうなん?』と思っている人。
背景とお気持ち
- 情報公開時にアクセス/トランザクションがスパイクするようなWEBサービスを作る
- 小規模開発なので予算は可能な限り抑えたい
- でも開発環境で本番環境と同等の検証ができるようにしたい
- あと開発環境をわざわざ Start / Stop するようなものは作りたくない
- 本番環境は可能な限り自動的にスケールしてほしい
- 最近の Lambda は VPC でも早くて、PHP もいけて、Laravel も動くらしい
- 僕は Laravel が好き
⇒これは AWS で Laravel Serverless するしかない! やろう!!!
アーキテクチャ
基本的には下記の AWS 公式の記事のようにしました。
サーバーレス LAMP スタック – Part 4: サーバーレス Laravel アプリの構築異なる点や補足等は以下の通り。
Lambda は VPC 内で動かす。
API Gateway の手前には CloudFront を通していない。
DB には Aurora Serverless を採用。
また、開発環境のみ一定時間アクセスがないとDBを止めるように設定。セッション管理で ElastiCache(Redis) を入れた。
SES からメールを送るために SMTP インターフェース用の VPC endpoint を引いている。
デプロイ作業や SSH トンネル用に、EC2 インスタンスがある。
ここ好き!ポイント
本番環境同等の検証ができる
それだけ。でも、とても嬉しい。
Aurora Serverless でDBがスケーリングする
- 開発環境:使うのは検証用の週1ぐらい、使うときには本番環境同等の検証がしたい
- 本番環境:ユーザースパイクに合わせてDB性能も勝手にスケールして欲しい
というところを叶えてくれるポイントになった Aurora Serverless。
取り分け良いのが、一定時間アクセスがないと自動的に停止する機能で、
停止時には稼働料金が掛からなくなる。ありがてぇ。
※停止後にアクセスすると1分ぐらい起動に時間は掛かるが、自動的に起動する。
※もちろん、本番環境は停止させない設定にできるLambda がとにかく安い
Google Analytics でピーク時 DAU 1500 人の利用があったが、
それでも無料利用枠の範囲内に収まったので $ 0.00 / month になっている。困ったこと
セッション管理が Cookie だと Cookie が無限増殖してクライアントがこける
決済用の外部サイトに飛んで戻ってを繰り返すと、
Cookie が無限増殖してクライアントがこける。
ElastiCache(Redis) の単一ノードでセッション管理して対応。$20.0 / month。苦い。
スケールしないし、単一障害点にもなってしまった。超苦い。Lambda が VPC 内にいるのでネットに出られない
セキュリティが担保されたり VPC 内 RDS や ElastiCache にアクセスできたりと恩恵はあるが、
AWS SES で Laravel の MAIL_DRIVER='ses' でメール送信できない、という悲しみ。
対応として、VPC endpoint から SMTP インターフェースでメール送信できるようにした。$10.0 / month。苦い。
※NAT Gateway か NAT インスタンスで対応はできるらしい。
が、NAT Gateway が $60.0/month になりそうだったり、そもそも管理対象を増やしたくなかったので見送り。X-Ray が使えなかった
そもそも PHP だと使えないみたいだった。しょんぼり。
気にしていたけど杞憂だったこと
ElastiCache のサイジング
スケールせず単一障害点になってしまったので、メモリ容量を懸念。
Google Analytics でピーク時 DAU 1500 人ぐらい。
ビビって t3.small にしていたがメモリ使用率 1% にも満たなかったので t3.micro でも数千/数万は捌けそう。
※その際は NW 速度がボトルネックになるかもAurora Serverless のサイジング
勝手にスケールするので、料金を懸念。
Google Analytics でピーク時 DAU 1500 人ぐらい。
MySQL の FOR UPDATE ロックが絡むような処理もそこそこあったが、
最後まで1番小さいサイズ( 1 ACU で t3.medium より安い)で稼働できていた。費用感
だいたいのね。
これが見たかったんでしょう?
開発環境
⇒Total: $60.0 / month
- ElastiCache(t3.micro) $20.0
- RDS(Aurora Serverless) $15.0
- EC2(t3.micro) $15.0
- VPC endpoint $10.0
本番環境
⇒Total: $120.0 / month
- RDS(Aurora Serverless) $70.0
- ElastiCache(t3.micro) $20.0
- EC2(t3.micro) $15.0
- VPC endpoint $10.0
- CloudFront $5.0
まとめない
以上。
- 投稿日:2021-01-27T20:58:30+09:00
AWS IAMのルートアカウントのみが行える操作/権限について
初投稿のため練習と学習記録を兼ねてます。
お見苦しいかと思いますが、ご容赦ください。ルートアカウントと管理者権限ってほとんど変わらない……?
IAMについて学習していくうちに「ルートアカウントとIAMユーザーの管理者権限はほぼ同じ」なんて解説されているのを見かけたので、(じゃあ設定する必要あんまりなく無い?逆に違いって何?)と思ってまとめてみました。
同じ疑問を抱いた僕のような初学者の方のお力になれれば幸いです。以下は(僕が調べられた範囲での)ルートアカウントのみ可能な操作になります。
- AWSルートアカウントのメールアドレスやパスワードの変更
- AWSアカウントのサービス(公式サポート等)の申込/キャンセル
- AWSアカウントそのものの停止
- IAMユーザーからの課金情報へのアクセスに関するactive/deactive
- 他のAWSアカウントへのRoute53のドメイン登録の移行
- コンソリデイテッドリビングの設定
- 脆弱性診断フォームの提出
- 逆引きDNS申請
それぞれ見ていきましょう。
- ・AWSルートアカウントのメールアドレスやパスワードの変更
- ・AWSアカウントのサービス(公式サポート等)の申込/キャンセル
- ・AWSアカウントそのものの停止
- 説明不要ですね。これは分かりやすいと思います。
- ・IAMユーザーからの課金情報へのアクセスに関するactive/deactive
- 通常の設定だと、IAMユーザーから課金情報へアクセスすることは出来ません。
- 各IAMユーザーに対してポリシーを設定することによりアクセス可能となります。
- ・他のAWSアカウントへのRoute53のドメイン登録の移行
- ・コンソリデイテッドリビングの設定
- ・脆弱性診断フォームの提出
- ・逆引きDNS申請
- これらについては申し訳ないのですが、知識が足りず理解が追いついていません。
- 今後追記していきたいと思います。
以上となります。
- 投稿日:2021-01-27T18:44:38+09:00
脆弱性対応の管理ポイント
私の現場では、脆弱性対応に関するフローや対応策が確立できていません。
気づいた人ベースで発信され、深刻度合いで対応するかしないかをお客様が決定します。この、「気づいた人ベース」をしっかり運用フローに乗せることを考えて行きたいと思います。
そもそも脆弱性対応をする意義
脆弱性をついたサイバー攻撃により、企業の重要な情報が外部に漏洩することや、サイト停止に伴う売上や信頼の低下を防ぐことだと思います。
攻撃側を考えると、脆弱性発生後に脆弱性の内容を元に、攻撃プログラムが作成されるため、一定の期間は要します。
この間に、攻撃を未然に防ぐことが重要になります。なので、脆弱性情報の収集は必須となってきます。統計的には、実際に攻撃までに繋がる脆弱性は2%にも満たず、攻撃プログラムが公開されるまでの日数は、2週間以内が50%を占めているそうです。
なので、全ての脆弱性を対応するのは非効率であって、深刻な脆弱性を見極めて対応していくこと重要となってきます。パッチマネジメント
システム構成を把握している前提で、構成要素ごとに関連する脆弱性情報を早く検知し、影響範囲の特定とリスクの分析によって適用の緊急性と対応用ひを判断し、判断結果を元に対応する一連の流れ。
❶検知
ベンダ、有識者、業界団体などから発信される脆弱性情報を収集し、システム構成要素に対する影響を評価❷判断
脆弱性に起因するリスクの大きさと攻撃手法の容易性を分析し、対応の緊急度と対応要否を決定する❸対応
対策方法と実施時期を確定し、攻撃を受ける前に、脆弱性によるリスクを下げる。対策
検知
検知の部分に関しては、ベンダ(AWS)の脆弱性情報サイトがあるのでそちらで、通知機能をSlack通知で検知できるようにしている。
その他は、Twitterの有識者やベンダのフォローをして、自主収集する形をとっている。このSlackへ全員を招待させることで、検知に関しては解決すると思っている。
全員に通知する必要はないかもしれないが、セキュリティ担当が確立されていないので、一旦全員に通知。判断
判断に関しては、緊急性判断は、CVSSを用いた考えが一般的。
CVSSとは、脆弱性に対するオープンで汎用的な評価手法、及び指標を指します。
1.0〜10.0の数値指標となっていて、7.0以上が緊急度:Highに値します。
緊急度:Highであり、他社でも被害が出ている状況であると、即座に対応が必須な状況であります。だが、大体的に報道される脆弱性の悪用は、直接的被害に留まらず風評被害などのに二次的な被害につながりやすいです。
実際にあった脆弱性
sudo
https://access.redhat.com/security/cve/CVE-2021-3156
CVSS 7.0 High
他社影響はなしだけど、ベンダから情報発表はあり要確認の脆弱性となる。
対応
対応策としては、パッチ適用、ワークアラウンド(設定変更やWAFによる通信遮断)、一時的なサービス停止などがあります。
これらを比較して、最良な選択をすることが大事になってくる。それでも対応結果が追跡しきれず、時間がかかってしまう場合は、システムごとの対応状況の一元管理が必要となってきます。
資産管理台帳をもとに、脆弱性対応の指示や報告を実施して、常に最新情報を集約できるようにしておくこと。情報集約度、情報鮮度、検索容易性の観点から管理や統制パターンが分かれるそうです。
・情報集約度
システムの構成情報が集中管理されているか・情報鮮度
構成情報が常に最新の状態が保たれているか・検索容易性
脆弱性を検知後、迅速に対象となるシステムを一覧化できるか踏まえて
現状、脆弱性の集約から判断や対応に関しては有識者の方で、なんとか実施できているが。
いない時を考えると恐ろしいので、運用フローには乗せて行きたい。
メインシステムは、WAFの導入をしているので大半は大丈夫である気がするが、抜け道もある気がする。
情報集約度の観点からすると、システム構成の集中管理はできていない状況なため、大規模な脆弱性が起きた場合に、迅速に対応する体制はできていない。まず、手をつけるとしたら、この「システム構成の集中管理」が第一優先だと思いました。
- 投稿日:2021-01-27T18:28:08+09:00
AWS Cognitoのユーザープールにて発行・使用されるトークンに関して調べてみた
調査結果
以下はOAuth2.0にて定義されている。
- アクセストークン
- リフレッシュ(更新)トークン以下はOpen ID Connectにて定義されている。
- IDトークン調査した経緯
AWS Cognitoで認証を行うアプリを作成する機会があったのだが、使用しているトークンがCognito特有のものなのか、一般的に定義されている仕様なのかがわからなかった。
これによって、実装時のクラス(インターフェース)分けに影響が出る可能性もあると考え、調査を行った。調査した内容
AWS Cognitoのユーザープールで使用するトークンに関して調べて見ると、以下のサイトにたどり着いた。
このサイトを読んで、Open ID Connectに準じていることが判明。
https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/amazon-cognito-user-pools-using-tokens-with-identity-providers.html次にOpen ID Connectについて、AWSのサイトに記載されているリンクから仕様を確認。
https://openid.net/specs/openid-connect-core-1_0.html仕様からOAuth2.0を拡張したものということが判明。
最後にOAuthについて以下のサイトで勉強し、調査結果にたどり着いた。
https://openid-foundation-japan.github.io/rfc6749.ja.html
https://murashun.jp/article/programming/oauth2.html
- 投稿日:2021-01-27T15:25:14+09:00
【AWS】Amazon WorkSpaces 立ち上げから費用まで
立ち上げ方
こちらのリンクが参考になりました。
・初心者でも簡単! はじめてのAmazon WorkSpaces ~ Quick Setupでの立ち上げ編~よくある質問
よくある質問
あれ?WorkSpaces作成時のメールがユーザに届かないぞ?って思った時に確認すること私はメールが届かなくて困っていたのですが、そもそも[WorkSpaces]がPENDDING状態だとメールが来ません。
[ディレクトリ]がACTIVE状態になったら起動しているのだと誤認していました。ややこしい・・・
ちなみに私はWorkSpaces起動完了後のメールが迷惑メールフォルダに入ってました。。。料金
- 投稿日:2021-01-27T15:10:07+09:00
AWS EC2 インスタンスタイプをまとめてみた
早見表
汎用 コンピューティング最適化 メモリ最適化 ストレージ最適化 高速コンピューティング A1 C4 R4 D2 G3 M4 C5 R5 H1 G4 M5 C5a R5a I3 Inf1 M5a C5ad R5ad I3en P2 M5ad C5d R5d P3 M5d C5n R5dn P3dn M5dn C6g R5n M5n C6gd R6g M6g R6gd M6gd u-xtb1 T2 X1 T3 X1e T3a z1d 概要
汎用インスタンス
汎用インスタンスは、コンピューティング、メモリ、およびネットワーキングリソースをバランスよく備えており、広範囲のワークロードに使用できます。
A1 インスタンス
これらのインスタンスは、Arm エコシステムがサポートするスケールアウト型ワークロードに最適です。
使用用途
ウェブサーバー
コンテナ化されたマイクロサービス
M5、M5a インスタンス
これらのインスタンスは、クラウドインフラストラクチャの実現に最適で、コンピューティング、メモリ、およびネットワーキングリソースをバランスよく備えており、クラウドにデプロイされる広範なアプリケーションに使用されます。
使用用途
小規模および中規模のデータベース
追加のメモリを必要とするデータ処理タスク
キャッシュフリート
SAP、Microsoft SharePoint、クラスターコンピューティング、その他のエンタープライズアプリケーションなどのバックエンドサーバー
M6g インスタンスと M6gd インスタンス
これらのインスタンスは AWS Graviton2 プロセッサを搭載しており、幅広い汎用ワークロードに対応するバランスの取れたコンピューティング、メモリ、ネットワーキングを提供します。
使用用途
アプリケーションサーバー
マイクロサービス
ゲームサーバー
中規模のデータストア
キャッシュフリート
T2、T3 インスタンス
これらのインスタンスは、ベースラインレベルの CPU パフォーマンスを維持し、ワークロードの必要に応じてより高いレベルまでバーストすることもできます。無制限インスタンスは、必要なときに、任意の期間にわたって高い CPU パフォーマンスを保持できます。
使用用途
ウェブサイトとウェブアプリケーション
コードリポジトリ
開発、ビルド、テスト、およびステージング環境
マイクロサービス
コンピューティング最適化インスタンス
コンピューティング最適化インスタンスは、高パフォーマンスプロセッサから恩恵を受けるコンピューティングバウンドな用途に最適です。
C5 および C5n インスタンス
使用用途
作業負荷のバッチ処理
メディアの変換
高性能なウェブサーバー
ハイパフォーマンスコンピューティング (HPC)
科学的なモデル
専用ゲームサーバーおよび広告エンジン
機械学習推論やその他の大量の演算を行うアプリケーション
C6g インスタンスと C6gD インスタンス
これらのインスタンスは AWS Graviton2 プロセッサを搭載しており、次のような、高度なコンピューティング集約型ワークロードの実行に最適です。
使用用途
ハイパフォーマンスコンピューティング (HPC)
バッチ処理
広告配信
動画エンコーディング
ゲームサーバー
科学的なモデル
分散分析
CPU ベースの機械学習推論
メモリ最適化インスタンス
メモリ最適化インスタンスは、メモリ内の大きいデータセットを処理するワークロードに対して高速なパフォーマンスを実現するように設計されています。
R5、R5a、および R5n インスタンス
使用用途
ハイパフォーマンスリレーショナル (MySQL) および NoSQL (MongoDB、Cassandra) データベース。
キー値タイプのデータ (Memcached および Redis) のインメモリキャッシュを提供する分散型ウェブスケールキャッシュストア。
ビジネスインテリジェンス用に最適化されたデータストレージ形式と分析機能 (SAP HANA など) を使用するインメモリデータベース。
巨大な非構造化データ (金融サービス、Hadoop/Spark クラスター) のリアルタイム処理を実行するアプリケーション。
ハイパフォーマンスコンピューティング (HPC) および電子設計オートメーション (EDA) アプリケーション。
R6g および R6gd インスタンス
これらのインスタンスは AWS Graviton2 プロセッサを搭載しており、次のようなメモリ集約型のワークロードの実行に最適です。
使用用途
オープンソースデータベース (MySQL、MariaDB、PostgreSQL など)
インメモリキャッシュ (Memcached、Redis、KeyDB など)
ハイメモリインスタンス
ハイメモリインスタンス (u-6tb1.metal、u-9tb1.metal、u-12tb1.metal、u-18tb1.metal、および u-24tb1.metal) は、インスタンスあたり 6 TiB、9 TiB、12 TiB、18 TiB、および 24 TiB のメモリを提供します。これらのインスタンスは大規模なインメモリデータベースを実行するよう設定されており、これにはクラウド内での SAP HANA インメモリデータベースの本番デプロイを含みます。ホストハードウェアに直接アクセスできるベアメタルパフォーマンスを提供します。
X1 インスタンス
使用用途
SAP HANA などのメモリ内データベース (Business Suite S/4HANA の SAP 認定サポート、Business Suite on HANA (SoH)、Business Warehouse on HANA (BW)、および Data Mart Solutions on HANA を含む)。
Apache Spark や Presto などのビッグデータ処理エンジン。
ハイパフォーマンスコンピューティング (HPC) アプリケーション。
X1e インスタンス
使用用途
高性能データベース。
SAP HANA などのメモリ内データベース。
メモリを大量に消費するエンタープライズアプリケーション。
z1d インスタンス
使用用途
電子設計オートメーション (EDA)
リレーショナルデータベースワークロード
ストレージ最適化インスタンス
ストレージ最適化インスタンスは、ローカルストレージの大規模データセットに対する高いシーケンシャル読み取りおよび書き込みアクセスを必要とするワークロード用に設計されています。ストレージ最適化インスタンスは、数万回の低レイテンシーとランダム I/O オペレーション/秒 (IOPS) をアプリケーションに提供するように最適化されています。
D2 インスタンス
使用用途
超並列処理 (MPP) データウェアハウス
MapReduce および Hadoop 分散コンピューティング
ログまたはデータ処理アプリケーション
H1 インスタンス
使用用途
MapReduce および分散ファイルシステムなどのデータ集約型ワークロード
直接アタッチされたインスタンスストレージにある大量データへのシーケンシャルアクセスを必要とするアプリケーション
大量のデータへの高スループットアクセスを必要とするアプリケーション
I3 および I3en インスタンス
使用用途
高頻度オンライントランザクション処理 (OLTP) システム
リレーショナルデータベース
NoSQL データベース
メモリ内データベース (Redis など) のキャッシュ
データウェアハウスアプリケーション
分散されたファイルシステム
高速コンピューティングインスタンス
高速コンピューティングインスタンスは、ハードウェアアクセラレーターやコプロセッサーを使用して、浮動小数点数計算、グラフィック処理、データパターンマッチングのような機能を CPU で実行されるソフトウェア以上に効率的に実行します。これらのインスタンスでは、大量の演算を行うワークロードでさらに多くの並列処理が可能となり、より高いスループットが得られます。
高度な処理機能が必要な場合は、高速コンピューティングインスタンスを使用すると、Graphics Processing Units (GPU)、Field Programmable Gate Arrays (FPGA)、AWS Inferentia などのハードウェアベースのコンピューティングアクセラレーターにアクセスできます。
GPU インスタンス
GPU ベースのインスタンスでは、数千のコンピューティングコアを持つ NVIDIA GPU にアクセスできます。これらのインスタンスを使用すると、CUDA または Open Computing Language (OpenCL) パラレルコンピューティングフレームワークを活用することにより、サイエンス、エンジニアリング、およびレンダリングアプリケーションを高速化できます。また、ゲームストリーミング、3D アプリケーションストリーミング、およびその他のグラフィックスワークロードを含む、グラフィックアプリケーションにも使用できます。
G4 インスタンス
G4 インスタンスは NVIDIA Tesla GPU を使用して、汎用 GPU コンピューティング用のコスト効率とパフォーマンスに優れたプラットフォームを CUDA を通じて提供するか、グラフィックアプリケーションを備えた機械学習フレームワークを DirectX または OpenGL を通じて提供します。G4 インスタンスは、高帯域幅ネットワーキング、強力な半精度浮動小数点機能、単精度浮動小数点機能、INT8 精度、および INT4 精度を提供します。各 GPU は 16 GiB の GDDR6 メモリを備えているため、G4 インスタンスは機械学習推論、動画トランスコード、グラフィックアプリケーション (リモートグラフィックワークステーションやクラウド内のゲームストリーミングなど) に最適です。
G4 インスタンスは、NVIDIA GRID 仮想ワークステーションをサポートします。
G3 インスタンス
G3 インスタンスは NVIDIA Tesla M60 GPU を使用し、DirectX または OpenGL を使用してグラフィックアプリケーション向けに費用対効果の高パフォーマンスのプラットフォームを提供します。また、G3 インスタンスは、最大 4096x2160 の解像度を持つ 4 つのモニターと NVIDIA GRID 仮想アプリケーションのサポートなど、NVIDIA GRID 仮想ワークステーションの機能も提供します。G3 インスタンスは、アプリケーションの例としては、3D ビジュアライゼーション、グラフィックを強化したリモートワークステーション、3D レンダリング、動画エンコード、仮想リアリティやそのほかの大規模なパラレル処理を必要とするサーバー側のグラフィックワークロードなどのアプリケーションに最適です。
G3 インスタンスは、NVIDIA GRID 仮想ワークステーションと NVIDIA GRID 仮想アプリケーションをサポートします。
G2 インスタンス
G2 インスタンスは NVIDIA GRID K520 GPU を使用し、DirectX または OpenGL を使用してグラフィックアプリケーション向けに費用対効果の高パフォーマンスのプラットフォームを提供します。NVIDIA GRID GPU は、NVIDIA の高速キャプチャおよびエンコード API オペレーションもサポートします。アプリケーションのサンプルには、動画作成サービス、3D 仮想化、グラフィックを多用したストリーミングアプリケーションなどのサーバー側のグラフィックワークロードが含まれています。
P3 インスタンス
P3 インスタンスは NVIDIA Tesla V100 GPU を使用し、CUDA または OpenCL プログラミングモデルを使用するか、Machine Learning フレームワークを使用する汎用 GPU コンピューティング用に設計されています。P3 インスタンスは高帯域幅ネットワーキング、強力な半精度、単精度、および倍精度浮動小数点機能、および GPU ごとに最大 32 GiB メモリを提供し、深層学習、数値流体力学、金融工学、耐震解析、分子モデリング、ゲノム解析、レンダリング、その他サーバー側 GPU コンピューティングワークロードに最適です。Tesla V100 GPU はグラフィックモードをサポートしません。
P3 インスタンスは NVIDIA NVLink のピアツーピア転送をサポートします。詳細については、NVIDIA NVLink を参照してください。
P2 インスタンス
P2 インスタンスは NVIDIA Tesla K80 GPU を使用し、CUDA または OpenCL プログラミングモデルを使用する汎用 GPU コンピューティング用に設計されています。P2 インスタンスは高帯域幅ネットワーキング、強力な単精度および倍精度浮動小数点機能、および GPU ごとに 12 GiB メモリを提供し、ディープラーニング、グラフデータベース、高パフォーマンスデータベース、数値流体力学、金融工学、耐震解析、分子モデリング、ゲノム解析、レンダリング、その他サーバー側 GPU コンピューティングワークロードに最適です。
P2 インスタンスは NVIDIA GPUDirect のピアツーピア転送をサポートします。詳細については、NVIDIA GPUDirect を参照してください。
引用
Amazon Elastic Compute Cloud-インスタンスタイプ
汎用インスタンス
コンピューティング最適化インスタンス
メモリ最適化インスタンス
ストレージ最適化インスタンス
高速コンピューティングインスタンス
- 投稿日:2021-01-27T14:15:05+09:00
AWS SAA(ソリューションアーキテクトアソシエイト)-C02 なんとか合格できた勉強方法
始めに
2021/1/23にAWS SAA-C02を受験し、無事に合格することがでました!
受けた感覚としては8割以上かなと思っていましたが、実際は7割5分だったので、少し残念です。。。
私の勉強方法は、先人の方々が残してくれた勉強方法をそのままやってきたのですが、私の勉強方法も少しでも参考になればいいなと思い、残しておきます。
下記、構成で書いていきます。
1.前提
2.勉強期間
3.利用した教材
4.受験当日
5.最後に1. 前提
この試験を受けた時は新社会人2年目の新米インフラエンジニアです。
AWSを触り始めて、もうすぐ1年になります。とはいっても、触ったことあるサービスはEC2やRDSなどの基本サービスから、WAFやAthena、Inspector等の浅く広く触ってきました。
受けようしたきっかけは
- AWSの知識を体系的に学びたかったから
- メンターの方から、今後のキャリアを考えるととっておいたほうがいいと言われたから
- 好奇心的にAWSを知りたかったから
- クラウド環境の設計や構築、提案は今後やっていきたいから
2. 勉強期間
前々から受験しようと思い、少しずつ勉強していましたが、本格的に勉強しはじめたのは2020年12月1日からです!
皆さんにおすすめしたいのは先に試験を受ける日を決めておくことです。
私もそうでしたが、この日に受けようと思い、試験に申しこまずにスケジュールだけをいれていたら、やっぱりいいやと思い、受けずに流してしまいました。
やはり、いつでも受けれるということで気が緩んでしまったことが原因でした。
先に試験日を決めて、緊張感を持たせる必要があるなと私は思い、12月中旬に2021年1月23日の試験を申込をしました。
そこから、本気で勉強し始めるようになりました。
結局のところ、本気で勉強した期間は1か月と20日程になります。
平日の勉強時間は朝30分と夜1時間で合計1時間30分になります。
休日の勉強時間は3時間~4時間になります。
この期間の合計勉強時間は100時間~150時間になります。3. 利用した教材
一番初めにこちらで勉強しました。
ハンズオン形式で勉強でき、各サービスの概要把握やAWSの基礎となるベストプラクティスやWell Architected Frameworkを学ぶことができます。
また、3つの模擬試験もついています。セールで安く手に入るので時期をみて、購入してください。
技術書1冊の値段と変わらないので、絶対買うことをおすすめします。一通り、上のコースで勉強した後、6つの模擬試験があるこちらのコースを買いました。
回を追うごとに難易度が上がっていき、6回全部を受けましたが、初回は5割ほどでした。。。2回目は7割、3回目は8割と積みあがっていきました。
分からない問題の復習は当たり前ですが、解答に迷った問題も見直すようにしました。
一番、公式の試験に近い形で模擬試験を受けることができるので、本番に向けて、一度うけておくと不安を和らげることができると思います。
ただ、1回2000円ほどなので、必ずしも受ける必要はないので、お金をあまりかけたくない方は受けなくてもいいと思います。
受けるときの注意点としては終わった後は問題が再度表示されないので、見直しをしたい方は一問ずつスクリーンショットをとっておくのをおすすめします。
また、問題の正解、不正解が分からないので、自分で調べる必要があります。
Udemyと公式の模擬試験を解き終わった後に、まだまだ体系的な知識が身についていないなと実感したので、こちらのテキストで見直しを行いました。
私が勉強している時は一番C02に対応している最新テキストで、分野別にサービスの特徴を見直しできたので、よかったです。しかし、2021/1/27時点で下記テキストがC02対応版の最新テキストなので、↓をおすすめします。
AWSも日に日に新しくなるので、受ける時点でなるべく最新のテキストで勉強することが大切です。
書店でパラパラとめくりましたが、こちらのほうが詳細に内容が記載されているので、よりサービスを理解できるかなと思いました。人によって、勉強しやすいテキストは異なるので、一度書店でテキストをみてみるといいと思います!
上のUdemyとテキストで勉強が終わったので、残りの期間はこちらのWEB問題集でなるべく多くの問題を解き、サービスが利用されるパターンの理解を深めました。
こちらは有料会員でSAAの問題をたくさん解くことができ、なおかつ解説も詳細なので、勉強になります。
また、無料でいくつかのSAAの問題を解けるので、一度受けてみてから、有料になるならないか決めたらいいと思います。落ちたら、15000円くらい払うのか~と考えたら、少しでも合格率を上げるほうにお金を費やしました。
4. 受験当日
当日は11時半に新宿エルタワー6Fのテストセンターでテストを受ける予定でした。
会場には40分前ほどにつき、受付をして、身分証明書2つ確認されました。
私の場合はマイナンバーカードと免許証持っていきました。
受付をすました後、テストセンターの場所が空いていたのか、予定の時間よりも早く受けることができました。試験環境は無音状態にするためのヘッドフォンがあり、それをつけて試験を受けました。
周りでは私と同様に試験を受けていましたが、ヘッドフォンつけることでまったく音が聞こえず集中して受けることができました。私の場合は最初の60分程で一通り解き、30分は見直しに使いました。
受けている時の感覚はたくさん問題を解いてきたのか、思ったより深いところまで突っ込まれず、ポンポンと解答することができました。
30分の見直しでは、見直しマークをつけたものは重点的に見直し、それ以外は複数回答か否かなどを意識して、さらっと見直しをしました。65問解き終わった後は、簡単なアンケートがあり、それが終わると試験の合格、不合格表示されます。
無事、合格の文字がみれて一安心をすることができました。
5. 最後に
あくまでも、資格を取得するという目的もありましたが、実務に使える知識を身に着けたいという思いもあったので、これで終わりではなく、引き続き勉強していきます。
試験をうけるにあたって、ある程度知識のインプットがないと、とけるものもとけないので、基本的な知識はインプットをしましょう。
そして、問題の答えを覚えるのではなく、どうして問題の答えがそうなるかを理解し、それ以外の選択肢はなぜ適用できないかも理解しておくと、合格までの道が近づくと思います。
私事ですが、4月までにソリューションアーキテクトプロフェッショナルを取得することを目標に継続して頑張ります。

- 投稿日:2021-01-27T12:50:59+09:00
DynamoDBへのテストデータ作成用pythonスクリプト
はじめに
DynamoDBへ大量のテストデータを作りたいときのPythonスクリプトが欲しいなという時の参考にしていただければと思います。
実装
第一引数に、対象となるDynamoDBのテーブル名、第二引数にテストデータ数を整数で渡してあげると、動作します。
sample.pyimport json from argparse import ArgumentParser, FileType import boto3 from tqdm import tqdm def main(): p = ArgumentParser(description='jsonをDynamoDBにインポート') p.add_argument('table', help='テーブル名') p.add_argument('total', type=int, help='テストデータ数') args = p.parse_args() session = boto3.Session(profile_name="default") dynamodb = session.resource('dynamodb') table = dynamodb.Table(args.table) total = args.total with table.batch_writer() as batch: for i in tqdm(range(total)): batch.put_item( Item={ "ID": str(i), "TEST_DETAIL": "TESTDATA" } ) if __name__ == "__main__": main()
- 投稿日:2021-01-27T12:40:13+09:00
便利なterraformコマンド3選 (備忘録)
はじめに
- tfstateで管理しているリソースのリストが見たい
- tfstateから特定のリソースを管理外にしたい
- 作成済みのリソースを狙ったtfstateの管理下にしたい
上記のような対応がしたいときにおすすめのコマンドを記載します。
tfstateで管理しているリソースのリストが見たい
terraform state list上記のコマンドで、モジュールを含むすべてのリソースを一覧表示できます。
参考: 公式ドキュメントtfstateから特定のリソースを管理外にしたい
terraform state rm [リソース名]上記のコマンドで、対象のリソースをterraform管理外に設定できます。
参考: 公式ドキュメント作成済みのリソースを狙ったtfstateの管理下にしたい
terraform import [tfstate上でどんな名前で管理するかを書く] [基本リソース名]上記のコマンドで、他の方法で作成したリソースを取得して、Terraformの管理下に置くことができます。
- 投稿日:2021-01-27T11:37:26+09:00
Set up SFTP server on Ubuntu using Public Key Auth(AWS-EC2)
This topic will guide you through how to setup an SFTP authentication mechanism using public key cryptography.
I recently set up SFTP by using the Id and Password.
↓ ↓ ↓
How to set up SFTP server on Ubuntu(AWS-EC2)
But SFTP provides an alternative method for client authentication. It's called SFTP public key authentication. This method allows users to login to your SFTP service without entering a password.Let’s get started!
Make sure that SSH and SSH-Server are installed. I assumed that you have already install the OpenSSH-server & SSH. If not then please check below link.
Install OpenSSH-Server & SSH(Step-1)Step 1:Create SFTP user account
First, we need to create a new user who will be granted only file transfer access to the server.$ sudo adduser sftp_userYou’ll be prompted to create a password for the account, followed by some information about the user. The user information is optional, so you can press ENTER to leave those fields blank.
Enter new UNIX password: Retype new UNIX password: ..... passwd: password updated successfullyYou have now created a new user that we will be granted access to the restricted directory.
In the next step we will create the directory for file transfers and set up the necessary permissions.Step 2:Creating a Directory for File Transfers
In order to restrict SFTP access to one directory, first, we have to make sure the directory complies with the SSH server’s permissions requirements, which are very particular.Specifically, the directory itself and all directories above it in the filesystem tree must be owned by root and not writable by anyone else. Consequently, it’s not possible to simply give restricted access to a user’s home directory because home directories are owned by the user, not root.
Here, we’ll create and use /var/sftp/myfolder/data/ as the target upload directory. /var/sftp/myfolder will be owned by root and will not be writable by other users.
The subdirectory /var/sftp/myfolder/data/ will be owned by sftp_user(which we created earlier), so that the user will be able to upload files to it.First, create the directories.
$ sudo mkdir -p /var/sftp/myfolder/data/Set the owner of /var/sftp/myfolder to root.
$ sudo chown root:root /var/sftp/myfolderGive root write permissions to the same directory, and give other users only read and execute rights.
$ sudo chmod 755 /var/sftp/myfolderChange the ownership on the uploads directory to sftp_user.
$ sudo chown sftp_user:sftp_user /var/sftp/myfolder/data/Here we have done the directory restriction.
So, our sftp_user will use only /data/ from the below path. sftp_user never change the directory.
/var/sftp/myfolder/data/Step 3:Genrate RSA public and Private Key
SSH key pairs can be used to authenticate a client to a server. The client creates a key pair and then uploads the public key to any remote server it wishes to access. This is placed in a file called authorized_keys within the ~/.ssh directory in the user account’s home directory on the remote server.If you’re under linuz based OS, you can use ssh-keygen to generate keys. Otherwise, for Windows, you can use PuTTY, you can refer this article to know how to process the generating.
PuTTYgen - Key Generator for PuTTY on Windows$ ssh-keygen -t rsaImmediately after running the ssh-keygen command, you'll be asked to enter a couple of values, including:
The file in which to save the private key (normally id_rsa). Just press Enter to accept the default value.
The passphrase - this is a phrase that functions just like a password (except that it's supposed to be much longer) and is used to protect your private key file. You'll need it later, so make sure it's a phrase you can easily recall.
As soon as you've entered the passphrase twice, ssh-keygen will generate your private (id_rsa) and public (id_rsa.pub) key files.Then, copy the public key to the server within the ~/.ssh folder (corresponding to which user will be authenticated).
$ cd /home/sftp_user/ $ mkdir .ssh # In case of no .ssh folder inside $ ls -a ... .ssh ... $ cd .ssh $ touch authorized_keys $ echo <your_public_key> >> authorized_keysStep 4:Change the permissions and owner
$ cd /home/sftp_user/ $ chmod 700 .ssh $ chown sftp_user:sftp_user .ssh $ cd .ssh $ chmod 600 authorized_keys $ chown sftp_user:sftp_user authorized_keysStep 5:sshd_config Settings
In this step, we’ll modify the SSH server configuration to disallow terminal access for sftp_user but allow file transfer access.Open the SSH server configuration file by using the below command.
$ sudo nano /etc/ssh/sshd_configor you can do by↓.
$ sudo vi /etc/ssh/sshd_configScroll to the very bottom of the file and append the following configuration snippet:
/etc/ssh/sshd_config
. . .Port <your_port_number> Match User sftp_user ForceCommand internal-sftp RSAAuthentication yes PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication no ChrootDirectory /var/sftp/myfolder PermitTunnel no AllowAgentForwarding no AllowTcpForwarding no X11Forwarding noThen save and close the file.[Press :wq + enter]
In the Match User [user_name], you can also use the group by using the below command.
Match Group [sftp_group]
NOTE: You need to create a new group called, sftp_group.Step 6:Restart the service
To apply the configuration changes, restart the service.$ sudo systemctl restart sshdor
$ sudo /etc/init.d/ssh restartYou have now configured the SSH server to restrict access to file transfer only for sftp_user.
Below step may be not required, but if you not able to connect successfully, then please whitelist your IP for the particular port.
Step 7:Open your sftp port in AWS-EC2 security group
If you are using AWS-EC2 instance, then you need to open the port here.
Login into your AWS account.
↓
Go to the services and then click on EC2 menu -> Running Instances.
↓
Go to the your instance.
↓
Open the Security groups.
↓
In the Inbound rules, Edit inbound rules
↓
Please do the following settings
1.Type = Custom TCP
2.Protocol = TCP
3.Port range = your_port(same as set in sshd_config file)
4.Source = You need to whitelist the IP here, if you do not want then set anywhere.
5.Description - optional = You can mention here some useful info.The last step is testing the configuration to make sure it works as intended.
Step 8:Verifying the Configuration
You can verify it within your terminal and as well as third-party software, such as WinSCP.
Please don't forgot to use your private key and passphrase(if you set).Conclusion
You’ve restricted a user to SFTP-only access by public key and also to a single directory on a server without full shell access.I hope this article helped you in setting up SFTP server on your server.
If you encountered any error then please share it with me.If this guide has been helpful to you and your team please share it with others!
Thanks & Best Regards,
Alok Rawat
- 投稿日:2021-01-27T10:18:38+09:00
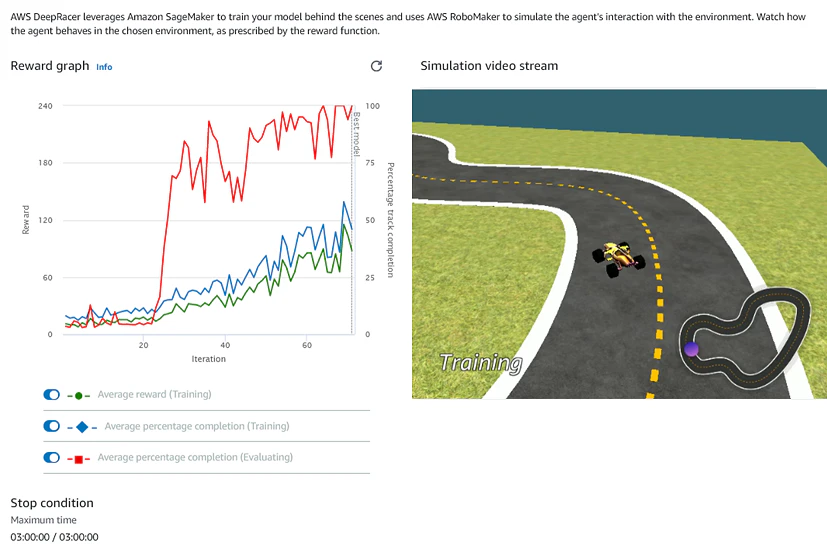
AWS DeepRacerで世界に挑む!~re:Invent 2020 AWS DeepRacerリーグ Championship Cup ファイナリストに勘所を聞いてみました~
はじめに
こんにちは、日立製作所 サービス&プラットフォームビジネスユニット Software CoE クラウドビジネス推進センタ の町野玲です。
今回はre:Invent 2020 AWS DeepRacerリーグ Championship Cup ファイナリストに選出された、当社の中村聡さんにAWS DeepRacerの勘所についてインタビューしました。AWS DeepRacerとは
AWS DeepRacerは機械学習の中でも強化学習を開発者に届けるために作られた1/18スケールのロボットカーです。コースの運転中に1秒あたり15枚の画像を撮影し、走行結果からゴールにたどり着けそうな行動を自律的に学習します。
AWS DeepRacerでモデルを学習すると、強化学習環境としてAmazon SageMakerとシミュレーション環境としてAWS RoboMakerが起動します。車が何度もコースを走り、AWS RoboMakerで経験が蓄積されていくと、そのデータがAmazon SageMakerへ送信され、モデルの学習が行われます。新しいモデルはAmazon Simple Storage Service(以降、Amazon S3)を介してAWS RoboMakerに送られ、さらに経験を蓄積します。このプロセスが何度も続き、モデルの保存にはAmazon S3、ログの保存にはAmazon CloudWatch、コンソールに動画を表示するために Amazon Kinesis Video Streamsを利用します。
〇参考:
(1) AWS Summit Online Japan 2020 DRL-01:AWS DeepRacer Workshop 2020AWS DeepRacerリーグ Championship Cup
2020年のAWS re:InventにおいてAWS DeepRacerリーグを締めくくるグローバル最終決戦「Championship Cup」が開催されました。全てのレースがオンラインで開催される今大会には、3月から続いた予選を勝ち抜いた総勢112名のファイナリストが出場し、決勝戦「Grand Prix Final」にてPo-Chun Hsuさんが優勝されました。
〇参考:
(1)AWS DeepRacer Championship Cup を応援しよう! / AWS DeepRacer が日本から購入可能に
(2)AWS DeepRacer League announces 2020 Championship Cup winner Po-Chun Hsu of Taiwanre:Invent 2020 AWS DeepRacerリーグ Championship Cup ファイナリスト インタビュー
AWS DeepRacerリーグ Championship Cup ファイナリストとして選出された当社の中村聡さんにAWS DeepRacerの勘所についてインタビューしました。
中村さんは日立製作所 アプリケーションクラウドサービス事業部 運用マネジメント本部に所属しており、ITシステムの稼働監視、業務自動化、IT資産管理、およびインフラ管理などを統合的に行うソフトウェアの業務に従事しています。Q1 レースに参加したきっかけを教えてください
中村さん:
AWS DeepRacerが発表されたre:Invent 2018 のKeyNoteを最前列で聞いていて、とても興味がわき、かねてよりずっとやってみたいなとは思っていたんです。
最初、”Deep Learning(深層学習)”や”Reinforcement Learning(強化学習)”という単語にひるんで手を出せずにいたのですが、関連ブログなどを拝見させていただいたところ、そんなに難しくないことを知り、始めてみた次第です。Q2 AWS DeepRacerの強化学習のポイントは何でしょうか?
中村さん:
まず、資金です。そして、次に資金です! と言うのは冗談として(笑)
私は大きくは以下の3つがポイントだと考えています。(1) なにを理想形とするのか?
(=最速となる理想的なレーシングライン<軌跡>やスピードの定義)
(2) 理想形への近さをどのように評価するのか?
(=報酬関数における理想形の表現)
(3) どのようにトレーニングすれば効率的に理想形へ近づけるか?
(=最適なトレーニング用ハイパーパラメータの選択)どの項目も考える内容の分野が全く異なる気がしており、しかもどの分野もかなり難しいです。ただその分、逆にそれらを解決できた時の達成感を“面白い”と感じてしまうのがAWS DeepRacerの良さかなと考えています。
Q3 今回のレースで難しかった点を教えてください
中村さん:
個人で趣味の範囲でやっており、コミュニティなどの存在も知らず、モデルを0から1人で全て考えているので、行き詰っても改善の方向性が全く思いつかなかったなんてこともありました。そんな中でも改善案を考え出さなければならないことがとても難しかったです。
また、今回のre:Invent 2020では、第一回戦は障害物をよけながらのタイムトライアルレースで、障害物をよけるモデルはまだ試作段階だったので急遽モデルを仕上げなければならなかったのですが、障害物を意識する様にモデルを作れば作るほどなぜか障害物に突進していくようになってしまうんです。(笑) そこを改善することも とても難しかったです。Q4 今後の抱負を聞かせてください
中村さん:
今現在もモデルの改良を続ており、re:Invent 2020後に作成したモデルは、トレーニング時間を従来の10分の1程度に抑えられるようになり、精度も向上してきています。この調子でより良いモデルを完成させ、次回こそはre:Inventの最終レースまで出られるよう頑張っていこうと思います!
最後に
今回はre:Invent 2020 AWS DeepRacerリーグ Championship Cup ファイナリストに選出された、当社の中村さんにAWS DeepRacerの勘所について紹介しました。今後も日立社員によるクラウドの取り組みについて発信していきます。

- 投稿日:2021-01-27T06:59:40+09:00
【AWS】EBSのマウント手順(EC2にアタッチしただけでは使えません)
はじめに
EBSはEC2にアタッチするだけでは使用できません。
アタッチしただけではOS側から"ただのディスク"としか見られていないため、
使用するにはEBSをフォーマットした上でマウントする必要があります。ここではマウントまでの手順を解説します。
※AWS, Linuxの初学者を対象にしています。
【フォーマット】
記憶装置の内部を小さな区画に分割し、管理用のデータ保管領域などを確保することにより、特定の箇所へのデータの読み書きができるよう準備する操作
IT用語事典 e-words【マウント】
周辺機器をOSなどのソフトウェアに認識させ、操作・利用可能な状態にすること
IT用語事典 e-words環境
- パソコン:Mac
- AMI:Amazon Linux 2
前提
- EC2インスタンスを作成していること。
- EBSを作成しEC2にアタッチしていること。
- ターミナルからEC2にSSH接続済みであること。
手順
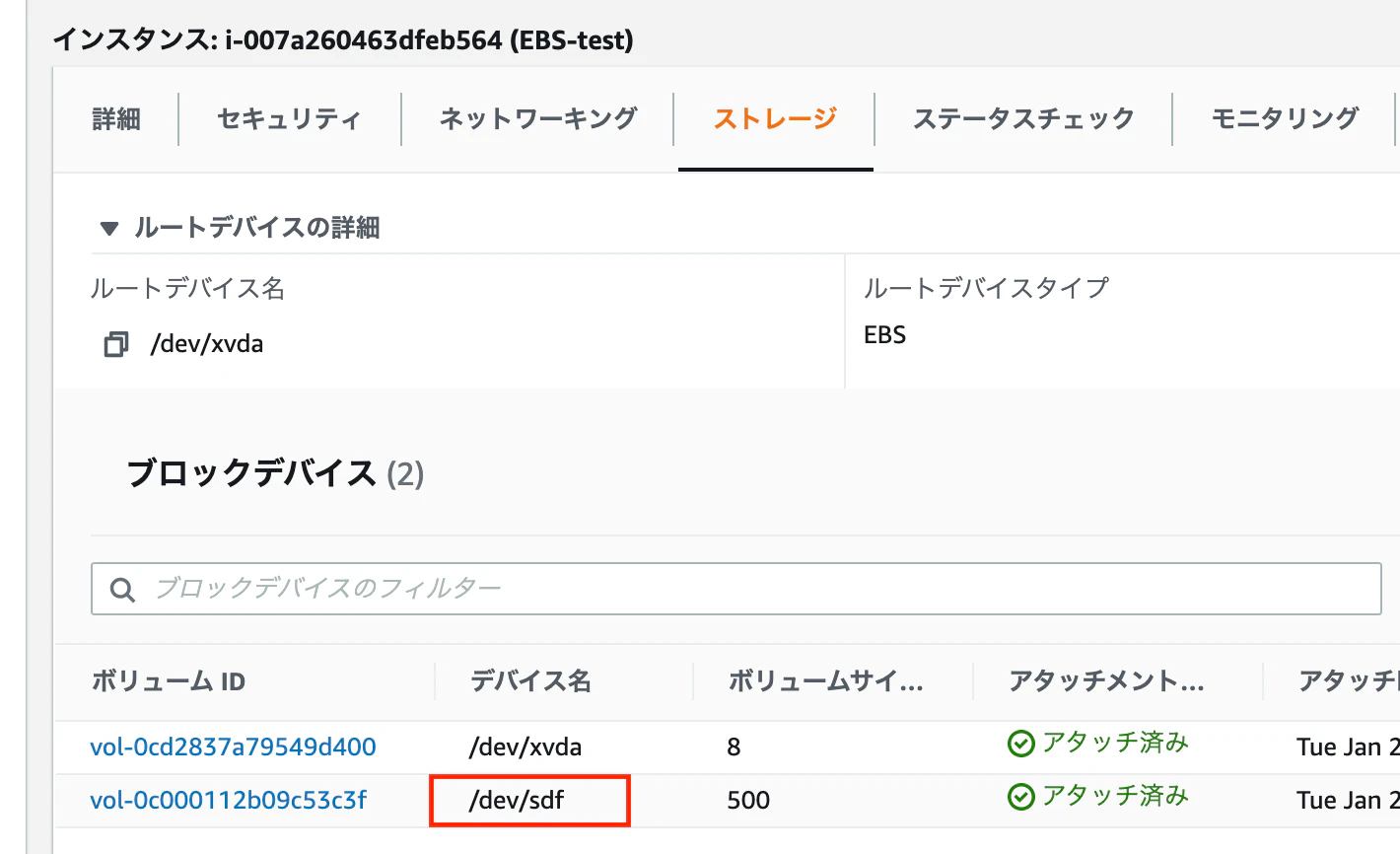
①EC2のコンソールからアタッチしたEBSのデバイス名を確認
ここですね。/dev/sdfとなっていることを確認できます。②root権限に切り替える
ここから先はroot権限が必要な操作ばかりなので切り替えます。
[ec2-user@ip-123-45-67-89 ~]$ sudo su -または
[ec2-user@ip-123-45-67-89 ~]$ sudo -i▪️参考:sudo -i と sudo su- のどちらを使うべきか?
▪️参考:AWS公式ドキュメント(公式では権限を切り替えずに以降の手順をすべて sudo で実行しています)③デバイス上にファイルシステムを作成する
ファイルシステムとは?
NTFSやFAT32など聞いたことありませんか?
「Windowsで使ってた外付けHDDをMacに接続しても認識しない!」等の経験ありませんか?
今回はその話です。
ファイルシステムとは記憶装置に保存されたデータを管理し操作するために必要な機能です。
ファイルシステムがないとEBSも外付けHDDもただの箱です。
ファイルシステムは様々な種類がありますがLinuxでは主にXFSやext4が使われているようです。
▪️参考:ファイルシステムとは?
まず現在のデバイスのファイルシステムを
fileコマンドを使って確認します。
対象が今回のようなデバイスファイルの場合は-sオプションを付ける必要があるようです。
▪️参考:wikipedia: file (UNIX)[root@ip-123-45-67-89 ~]$ file -s /dev/sdf /dev/sdf: symbolic link to `xvdf'よくわからないですが
/dev/sdfはxvdfへのシンボリックリンクですよーと出てきます。
(シンボリックリンクとはショートカットのようなものです)本体が
xvdfであるならばなぜsdfというショートカットを挟まなければいけないのか、
このあたりの理由は調べてもわかりませんでした。「こういうものだ」と処理します。
▪️参考:EC2:EBSデバイスIDの混乱(/ dev / sdfと/ dev / xvdf)実際に
lsblkコマンド(ブロックデバイスを一覧表示するコマンド)を実行してみても
接続されているデバイスはxvdfであることが確認できます。[root@ip-123-45-67-89 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 8G 0 disk └─xvda1 202:1 0 8G 0 part / xvdf 202:80 0 500G 0 disk気を取り直して、改めて現在のファイルシステムを確認します。
[root@ip-123-45-67-89 ~]# file -s /dev/xvdf /dev/xvdf: data
dataとだけ表示される場合、ファイルシステムが作られていないことを意味します。では
mkfsコマンド(ファイルシステムを作成するコマンド)でファイルシステムを作成します。
今回はext4にしたいと思いますので-tオプションで指定します。
▪️参考:【 mkfs 】コマンド――HDDなどをフォーマットする[root@ip-123-45-67-89 ~]# mkfs -t ext4 /dev/xvdf mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 32768000 inodes, 131072000 blocks 6553600 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2279604224 4000 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done長々と出てきましたが、これでファイルシステムの作成は完了です。
fileコマンドでファイルシステムを確認してみます。[root@ip-123-45-67-89 ~]# file -s /dev/xvdf /dev/xvdf: Linux rev 1.0 ext4 filesystem data, UUID=2c3d4ee5-d35f-4344-993f-9fe4303899d5 (extents) (64bit) (large files) (huge files)
ext4 filesystem dataと表示されており、
無事ext4でファイルシステムの作成ができたことを確認できます。ちなみにここで表示されている
UUIDは後ほど使いますのでどこかに控えておいてください。④マウントするディレクトリを作成する
まず
マウントの概念を理解する必要があります。
この2つの記事を読めば大まかには理解できるはずです。
▪️参考:この1ページで一通りわかる!Linuxのマウント(mount)について
▪️参考:「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典:マウント (mount)では
mkdirコマンド(ディレクトリを作成するコマンド)でマウントするディレクトリを作成します。
ディレクトリ名は自由です。今回はAWS公式ドキュメントに倣ってdataとします。[root@ip-123-45-67-89 ~]# mkdir /data
lsコマンド(ファイルやディレクトリを一覧確認するコマンド)で確認してみます。[root@ip-123-45-67-89 ~]# ls / bin boot data dev etc ...無事
dataが作成されていることを確認できます。⑤マウントする
俺お前より詳しいぜ
失礼しました。作成したdataディレクトリに/dev/xvdfをマウントします。マウントするには
mountコマンドを使います。
▪️参考:【 mount 】コマンド――ファイルシステムをマウントする[root@ip-123-45-67-89 ~]# mount /dev/xvdf /data特に何も表示されることなくしれっと完了します。
では
dfコマンド(ディスクの空き領域を調べるコマンド)を使って/dev/xvdfが表示されるかどうかを確認します。
空き領域が表示される=マウントされている を意味します。
-hオプションを付けることでギガバイトはGやメガバイトはMなど、わかりやすい単位で表示してくれます。
▪️参考:【 df 】コマンド――ディスクの空き領域を表示する[root@ip-123-45-67-89 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 482M 0 482M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 532K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 1.4G 6.7G 18% / tmpfs 99M 0 99M 0% /run/user/1000 /dev/xvdf 493G 73M 467G 1% /data
/dev/xvdfが表示されており、問題なくマウントできていることを確認できます。
これでアタッチされたEBSが使用可能ということになります。⑥再起動後も自動でマウントされるように設定する
実はマウントをしてもEC2インスタンスの停止や再起動のタイミングで外れてしまいます。
停止や再起動をしても自動で再マウントされるように設定を追加したいと思います。
/etc/fstabというファイルシステムの情報を記述するファイルを編集していきます。
OS起動時にシステムがデバイスをディレクトリにマウントしますが、
どのデバイスにどのディレクトリをマウントするかの処理は/etc/fstabファイルの記述に従って進行されます。
▪️参考:Linux豆知識 175「/etc/fstab」ファイル手順③のファイルシステム作成時に表示された
UUIDが必要になります。
メモに控えていなかった場合は再度fileコマンドで確認するか、またはblkidコマンド(ブロックデバイスの属性を表示させるコマンド)でも確認できます。[root@ip-123-45-67-89 ~]# blkid /dev/xvda1: LABEL="/" UUID="90e29211-2de8-4967-b0fb-16f51a6e464c" TYPE="xfs" PARTLABEL="Linux" PARTUUID="2c7bff30-ed75-4ab8-999f-02e40450fd0f" /dev/xvdf: UUID="2c3d4ee5-d35f-4344-993f-9fe4303899d5" TYPE="ext4"...
では
viコマンド(エディタを起動するコマンド)で/etc/fstabの編集画面を出します。
▪️参考:viコマンドについて詳しくまとめました 【Linuxコマンド集】[root@ip-123-45-67-89 ~]# vi /etc/fstab以下のような編集画面が表示されます。
# UUID=90e29211-2de8-4967-b0fb-16f51a6e464c / xfs defaults,noatime 1 1 ~ ~ ~ ~ ~ "/etc/fstab" 2L, 91Cキーボードの
iキーでINSERTモード(編集モード)にし、
2行目以降に今回追加するデバイスの情報を入力します。# UUID=90e29211-2de8-4967-b0fb-16f51a6e464c / xfs defaults,noatime 1 1 UUID=2c3d4ee5-d35f-4344-993f-9fe4303899d5 /data ext4 defaults 1 1 ~ ~ ~ ~ ~ "/etc/fstab" 2L, 91C第1フィールド:デバイス名
第2フィールド:マウントポイント
第3フィールド:ファイルシステムの種類
第4フィールド:各種オプション
第5フィールド:ファイルシステムをdumpするか否かの指定
第6フィールド:OS起動時にfsckチェックを行うか否かの指定を行う
▪️参考:Linux豆知識 175「/etc/fstab」ファイル入力後は
escキーでコマンドモードに戻り、:wqと打ちreturnキーを押して上書き保存します。以上で設定は完了です。
これでEC2が再起動をしても指定したデバイスが自動でマウントされます。終わりに
しゃーしゃーと解説しましたが私自身がAWSの初学者です。
途中でも書きましたが、本体がxvdfであるならば何故sdfと名乗る必要があるのか、
ここだけはどんなに調べてもわからず、ずっとモヤモヤしています。
詳しい方は私にマウントしてください。
- 投稿日:2021-01-27T00:56:55+09:00
yum update したら perforce が死んだ話
久しぶりに AWS サーバーにログインして yum update したら P4 が繋がんなくなったお話です。死ぬかと思った。
インスタンスを再起動 ~ p4d 復旧まで
ひとまず EC2 インスタンスを再起動するかー、とコンソールから実行。
あれ、でも P4 サーバーってどうやって起動したんだっけ・・・?としばらくググる。
P4 コマンドさえも $P4PORT を設定していないので通らない状態でした。Perforce client error:
Connect to server failed; check $P4PORT.
TCP connect to perforce:1666 failed.
perforce: host unknown.備忘録として残しておきます。
p4 set P4USER=username p4 set P4PORT=1666p4d コマンドの実行
まずは P4 サーバーのルートディレクトリ探しから。
自分の場合は /opt/perforce/servers/master/root に構築してました。
何のドキュメントを見ながら作ったのか、全く覚えてないのだが perforce ユーザー権限で作成されていた。こういうのはメモしておくべきだと激しく後悔。-bash-4.2$ ls db.bodresolve db.graphindex db.logger db.revpx db.templatesx db.bodresolvex db.graphperm db.message db.revsh db.templatewx db.bodtext db.group db.monitor db.revstg db.ticketこういった db ファイルがたくさん並んでいるのがルートディレクトリのようです。
さっそく再起動コマンドを実行する。-bash-4.2$ p4d -r /opt/perforce/servers/master/root -p 1666 -bash-4.2$しかし、なにもおこらなかった!
ログ調査
/opt/perforce/servers/master/logs/log
cd コマンドを唯々繰り返していると logs ディレクトリが存在していることに気づく。
Perforce server error: Database is at old upgrade level 36. Use 'p4d -r /opt/perforce/servers/master/root -xu' to upgrade to level 39.これだ!これだよ!
-bash-4.2$ p4d -r /opt/perforce/servers/master/root -xu Upgrades will be applied at server startup.そして再び起動コマンドを実行。
-bash-4.2$ p4d -r /opt/perforce/servers/master/root -p 1666 -d Perforce Server starting...-r で P4ROOT の指定、-p でポートの指定、-d でバックグラウンド実行となります。
P4V からの接続テスト
ssl:{address}:1666
いつも通り SSL での接続を試みる。
SSL connect to ssl:dev.nanae.online:1666 failed (既存の接続はリモート ホストに強制的に切断されました。 ).
Remove SSL protocol prefix from P4PORT or fix the TLS settings.??? SSL プロトコルで繋がんない?
tcp:{address}:1666
繋がったァァァ!?!??
TLS 設定とはなんぞや?
ついにTLS 1.0/1.1の無効化が決定!影響や確認・対応方法とは?
簡単に説明すると、TLSは「暗号化通信をするための手順書」のようなものですが、TLS 1.0/1.1などの古いバージョンには脆弱性がある(一定の条件下であれば暗号解読が可能である)ため、利用は非推奨とされていました。
どうやら脆弱性のある規格のようで。もしかすると yum update でその辺も更新されちゃったのかもしれないですね。
Perforce の設定
Perforce を調べるにもなかなかに文献が少なく苦労します。
SSL and TLS Protocol Versionsp4d -r /opt/perforce/servers/master/root -c"set ssl.tls.version.min=10"ブログにある通り、一旦 TLS v1.0 でも接続できるように設定。"p4 admin restart" だけじゃ反映されないそうな。めんどくさいので sudo reboot しました。ここでようやく SSL でも接続可能に。
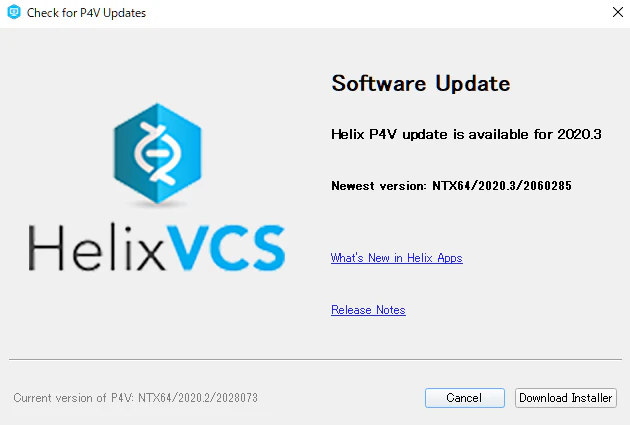
P4V クライアントの更新
Version: P4V/NTX64/2020.2/2028073
って書いてあるんで
更新ポチ。TLS 1.1 に戻しても無事繋がるようになりました。
- 投稿日:2021-01-27T00:46:52+09:00
【AWS認定】クラウドプラクティショナー&ソリューションアーキテクト - アソシエイト 合格体験記
はじめに
AWS認定 クラウドプラクティショナーとソリューションアーキテクト - アソシエイト(SAA-C02)に受かったので体験記です。
以下、略称を利用することがあります
- クラウドプラクティショナー=CLF
- ソリューションアーキテクト アソシエイト=SAA
筆者のステータス
- へっぽこエンジニア(Pythonメイン)
- ソリューションアーキテクトではない
- よく使う:EC2(SG,ELB),ECS(Fargate),RDS,Cloudwatch
- たまに使う:S3,Lambda
- 上記以外のAWSサービスについては名前も知らなかったレベル
教材
クラウドプラクティショナー編
黒本
- リンク
- 古めだが初手に読む本としてはよいと思います
- 出題範囲に被りがあるため、CLFだけ受かりたい場合もおすすめ
CLF向け問題集(udemy)
- リンク
- 1周してよく復習すればCLFに関しては安泰 問題集で覚えるタイプの人におすすめ
- 黒本では頭に入らなくても問題集で間違えると頭に入るので、個人的には役に立ったと思います
CLF向け問題集(kindle)
- リンク
- 直前に1周。udemyの問題集よりは遥かに簡単なので、あちらを解いたなら不要かも
- udemyの正答率が悪く不安な場合は解くと自信がつくのでおすすめ
ソリューションアーキテクト アソシエイト編
SAA-C02向け問題集(udemy)
- リンク
- 1周+復習。ただしこちらは復習に時間がかかった(1試験あたり少なくとも2時間程度)
- 問題文の雰囲気は似ているが出題傾向は本試とは少々異なる印象。間違えた際は答えを暗記するのではなく、サービスの仕組みや設定方法まで遡って復習するのがよいと思います
- 試験突破講座の方は未履修です
各種技術系記事
- Qiitaはじめ、Developers.io、サーバーワークスさんのブログ、はてブなど
- 問題集で間違えた部分の復習+サービスの動かし方を知る用途に利用。
1問間違えたら当該サービスの記事を3~5つは読むようにしていました受験結果、所感
試験 得点 受験日 CLF-C01 965 2020-10-04 SAA-C02 793 2021-01-16
- CLFに関してはオーバーキルだったかも…
黒本1周程度でも受かる人は受かれそうです- SAAは少々危なかった…
間違えた問題でも調べてみると大抵AWS公式のドキュメントにあったので、
多少ハンズオンを経るのが確実かもしれません- 学習期間はCLF,SAAともゆっくり1ヵ月程度。
2週間程度の期間で密度濃く取り組んだ方が本当は良いと思いますSAA取れるならCLFは不要?
- アソシエイト3冠するつもりならCLFは不要が正しい気がします
- CLFでは、SAAではあまり出ないがDVAで出そうな開発系サービスやSOAで出そうなセキュリティ系サービスにも少々触れられます
- AWSの実務経験はないが、今後のためにAWSの概要程度は抑えたいという温度感の場合はCLFもおすすめです
最後に
- CLF+アソシエイト3種+SAPの5冠までは目指す予定です(宣言)
- 取り急ぎ、DVAに受かったらまた書こうと思います

- 投稿日:2021-01-27T00:01:14+09:00
はじめてのcloudformation
そもそもcloudformationとは?
AWS cloudformation はAWSの環境構築を自動化できるサービスです。
YAMLファイルを書いてデプロイすることで、環境を構築することが出来ます。今回は、cloudformationやりたいけど、何をどうすればいいかわからない人のために
とりあえずに一歩を書いてみました。やってみる
今回作成する環境
Sample-Vpcという VPC1つと
Sample-Vpc1-Subnet1というsubnetを1つ作成します
YAMLファイルの作成
まず、
Create-Network.ymlという名前でファイルを作成します。Create-Network.ymlAWSTemplateFormatVersion: '2010-09-09' Description: "Create Network" Resources: # ------------------------------------------------------------# # VPC # ------------------------------------------------------------# SampleVPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: 10.1.0.0/16 Tags: - Key: Name Value: Sample-Vpc # ------------------------------------------------------------# # Subnet # ------------------------------------------------------------# SampleSubnet01: Type: "AWS::EC2::Subnet" Properties: VpcId: !Ref SampleVPC AvailabilityZone: ap-northeast-1a CidrBlock: 10.1.1.0/24 Tags: - Key: Name Value: Sample-Vpc1-Subnet01cloudformationの実施・確認
- AWSへログイン
AWSへログインして、cloudformationに移動します
スタックの作成で作成していきます
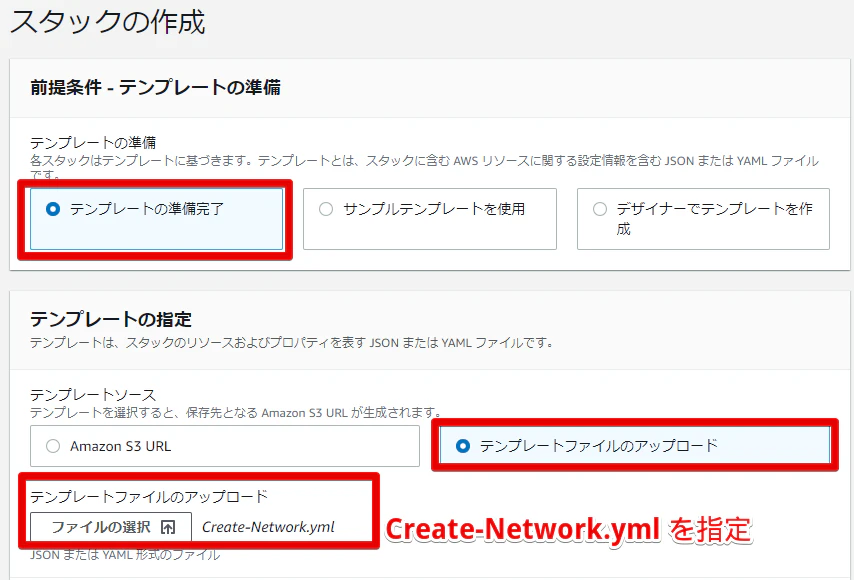
- cloudformationの設定・実施
テンプレートの準備完了からテンプレートファイルのアップロードで、先程作成した Create-Network.yml ファイルをアップロードします。
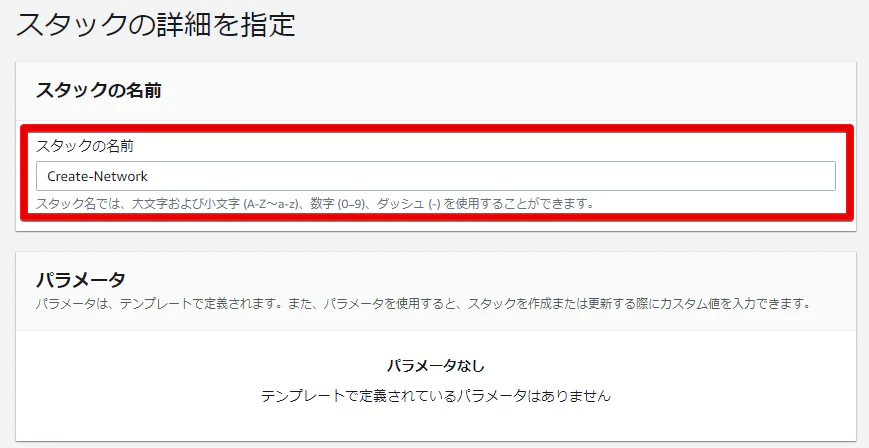
次へ進みます。
スタックの名前を記載します。
ここではCreate-Networkとします。
スタックオプションなど設定できますが、一旦最初はしなくてよいかと思います。
アクセス許可だったり、タグを付けて費用の管理をしやすくしたり出来ます。
最終確認です。
一番下まで行って特に問題なければ スタックの作成を行います。
作成を行うと、このような画面になります。
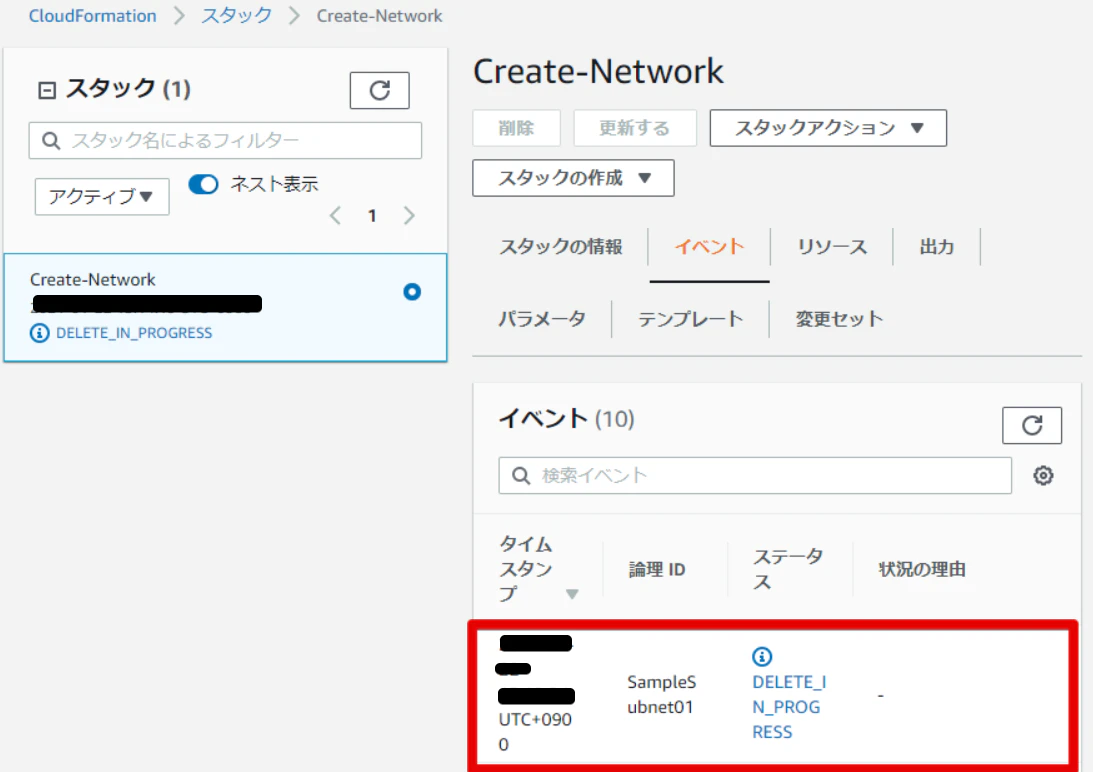
イベントのタブを開くと今なんの処理をしているか確認することが出来ます。確認CloudFormation - スタック Create-Network - Google Chro.png
- cloudformationで確認されたリソースの確認
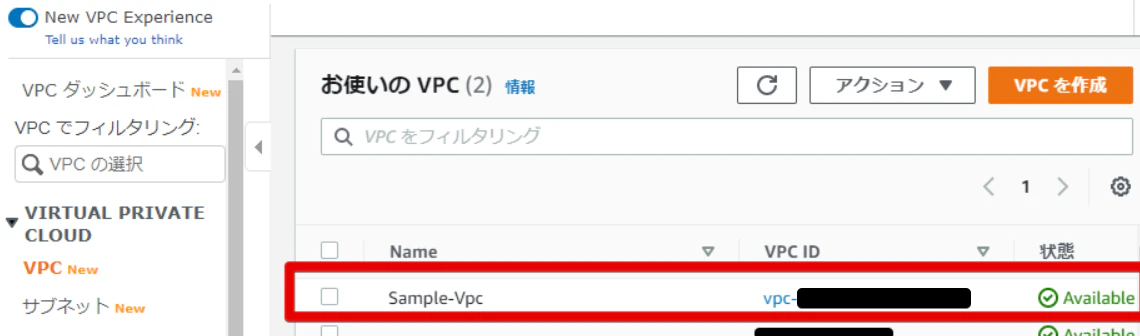
まずはVPCを確認します。
yamlファイルの以下の箇所がこのVPCの設定になっております。SampleVPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: 10.1.0.0/16 Tags: - Key: Name Value: Sample-Vpc
次はsubmet。
名前も指定されているものになっています。
yamlファイルでは以下の記載を行いました。SampleSubnet01: Type: "AWS::EC2::Subnet" Properties: VpcId: !Ref SampleVPC AvailabilityZone: ap-northeast-1a CidrBlock: 10.1.1.0/24 Tags: - Key: Name Value: Sample-Vpc1-Subnet01
cloudformationの削除・確認
作成したVPCやsubnetを削除したい場合は、cloudformationのスタックの削除を行います。
※途中でVPCやsubnetの変更を手動で行うと削除や更新ができなくなるので、cloudformationで変更を行いましょう
- 削除方法
削除したいスタックに移動し、
削除を行います。
確認が出るのでそのまま進めます。
削除を進めるとイベントにDelete が走り、削除が行われます。
すべて削除が行われたら、スタックがなくなりイベントにはDELETE_COMPLETEと出力されます
- 削除したリソースの確認
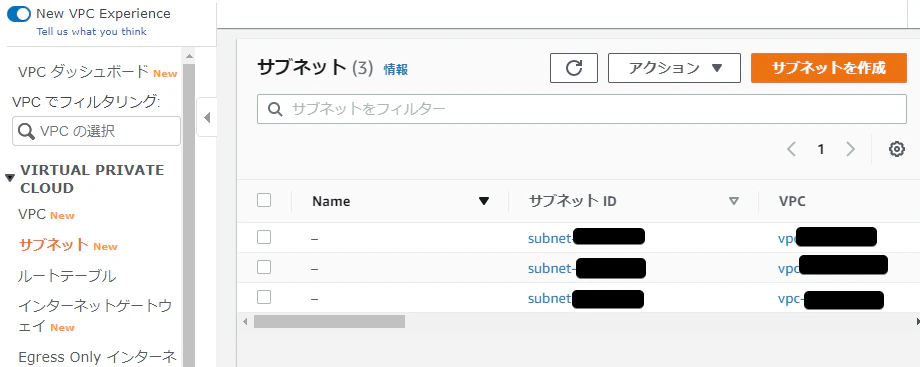
まずはVPC。
Sample-Vpcはもう削除されてありません。
お次はsubnet。
こちらもSample-Vpc1-Subnet01は削除されてないです。
こちらで、はじめてのcloudformationでの構築・削除は終わります。
勉強後イメージ
よくわからんけど、とりあえず回してみることはこれでできるかと。
後は他の人のコードとか、出来たもの見ながらいろいろ作っていきます。参考