- 投稿日:2021-01-24T23:50:39+09:00
とりあえず仮想環境作成してpython動かしたい
概要
M1チップ搭載Macを購入したが、
現状、色々とM1(ARMアーキテクチャ)対応しておらずだったので
とりあえず、x86向けでもいいのでpython動かしたい。
できるとこまで、M1用で構築したので、それを崩したくない。
そこで仮想環境を作ることにしました。環境
Macbook M1
python3.7(x86)で動く仮想環境作ります手順
1.pythonインストール
今回は公式サイトから、MacOsのPython3.7の最新のものを
インストールしました
↓公式サイトURL
https://www.python.org/downloads/mac-osx/
(お持ちのPCのOSに合うものをインストールください)2.仮想環境をしまう、フォルダの作成
今回はプロンプトで作成していきます(testというフォルダ作成)
プロンプトを起動後、現在位置を確認するとわかりやすいかも。pwdで、確認します
mkdir testをすると、上で確認したフォルダに、testというフォルダを作成します。
cd testで、作成したフォルダに移動します
3.仮想環境の作成
作成した、testフォルダに移動した上で
python3.7 -m venv test_venvこれをすると、test_venvという仮想環境フォルダができます
4.仮想環境へ切り替える(アクティブする)
この記事と同じフォルダ名で作成した場合は下記コードから
ユーザー名を変えるだけで、切り替えれますsource "/Users/ユーザー名/test/test_venv/bin/activate"別名で作った場合は、ユーザー名、test(仮想環境をしまうフォルダ),test_venv(仮想環境フォルダ)
を合うように変えて下さい切り替わっていれば、
プロンプト入力の先頭に
(test_venv) が付与されますあとは、欲しいモジュールをpip3等でインストールして下さい
- 投稿日:2021-01-24T22:55:44+09:00
【django】アプリ作成手順
UdemyでDjango入門講座を受講したので、
Djangoアプリケーション作成する手順の備忘録として記載環境
OS : Mac Python : 3.7.4 Django : 3.1.5 エディタ : VScodeプロジェクト名、アプリケーション名
本記事では、以下の名前で作成
プロジェクト名 : project アプリケーション名 : employeeプロジェクト作成
プロジェクト作成するディレクトリで以下のコマンドを実行
django-admin startproject projectアプリケーション作成
上記コマンドを実行すると、projectディレクトリが作成される。
projectディレクトリ内のmanage.pyが格納されている場所までcdで遷移して、
以下のコマンドを実行格納先 : */project/manage.py cd projectアプリケーション作成python manage.py startapp employee正常にコマンドが実行されると、projectディレクトリ内にemployeeフォルダが作成される
ついでに、DB反映コマンドや、スーパーユーザ作成しておくと良い
参考:【メモ】【自分用】Djangoコマンド初期設定
settings.py
「settings.py」が格納されている場所まで遷移し、初期設定を行う
格納先 : */project/project/settings.py cd projectINSTALLED_APPSに'employee.apps.EmployeeConfig',の1行を追記
※'アプリ名.apps.アプリ名(先頭大文字)Config'settings.pyINSTALLED_APPS = [ 'employee.apps.EmployeeConfig', ←ここ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]LANGUAGE_CODEを'ja'に変更
TIME_ZONEを'Asia/Tokyo'に変更settings.pyLANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'urls.py(project配下)
settings.pyと同じディレクトリ内のurls.pyを修正
格納先 : */project/project/urls.pyurls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('employee.urls')), ]urls.py(employee配下)
employeeディレクトリ配下にurls.pyを新規作成し、修正
格納先 : */project/employee/urls.py cd ../employeeurls.pyfrom django.urls import path from . import views app_name = 'employee' urlpatterns = [ path('', views.IndexView.as_view(), name='index') ]views.py
TemplateViewを表示させるよう修正
views.pyはemployee配下に格納されているので遷移不要格納先 : */project/employee/views.pyviews.pyfrom django.views import generic class IndexView(generic.TemplateView): template_name = 'employee/employee_list.html'テンプレートhtml作成
まずは以下になるようにディレクトリを作成
作成後 : */project/employee/templates/employee/employee配下にtemplatesフォルダを作成、
templates配下にemployeeフォルダを作成base.html
上記で作成した、employeeへ遷移し、base.htmlを新規作成
cd */project/employee/templates/employeeBootstrapのテンプレートを使用
base.html<!doctype html> <html lang="ja"> <head> <title>社員管理システム</title> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous"> </head> <body> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.5.1.slim.min.js" integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/js/bootstrap.min.js" integrity="sha384-OgVRvuATP1z7JjHLkuOU7Xw704+h835Lr+6QL9UvYjZE3Ipu6Tp75j7Bh/kR0JKI" crossorigin="anonymous"></script> </body> </html>employee_list.html
base.htmlと同じディレクトリ内にemployee_list.htmlを新規作成
employee_list.html<!doctype html> {% extends 'employee/base.html' %} {% block content %} トップページ {% endblock %}動作確認
上記まで作成したら、manage.pyが格納されている場所までcdで遷移して、
以下のコマンドを実行サーバ起動python manage.py runserverサーバが起動したら、以下へアクセスし確認する
http://127.0.0.1:8000/「トップページ」が表示されていればテンプレートは完成
あとは、必要に応じて作成していく。
- 投稿日:2021-01-24T22:41:56+09:00
pythonとArduinoで始めるIoT開発<部屋が寒いと思う皆さん!部屋の温度可視化してみませんか?>
はじめに
私は最近部屋がすごく寒いなーと感じています.
一体今の部屋の温度は何度なんだろう?昨日と比べて何度違うんだろうと感じている人いませんか?
そんな人の悩みを解決すべく温度を可視化するシステムを構築してみましたのでご覧いただけると幸いです.システムの構成
Arduino UNO(マイコンだったらなんでも大丈夫です.)
今回はArduinoUNOを使っていますが...
PC (Windows or Mac or Linux or ワンボード)
基本的になんでも大丈夫です.
温度センサ DHT11温度センサー温度センサDHT11
類似商品と今回のシステムの比較
はい.世の中には既存に色々なシステムがあります.その中でも今回はスイッチボットさんの温度計を紹介したいと思います.
上の写真がスイッチボットさんの温度計になります.はいスマートでいいですね.本当にそう思います.
が,しかし...こちらの商品電池を交換しなくちゃならないらしいです.いや聞いた話なので本当かどうかはわかりませんが...
めんどくさがり屋の自分としては電池の交換はしたくないので自作をしました.
既存システムとの差別化は電池を交換しなくていい所!
自分の部屋の温度を他人に知られない...笑(会社に)
多分この2つが差別化できる所だと思います.※スイッチボットさんと比較していますが,スイッチボットさんを誹謗中傷するものではございません.
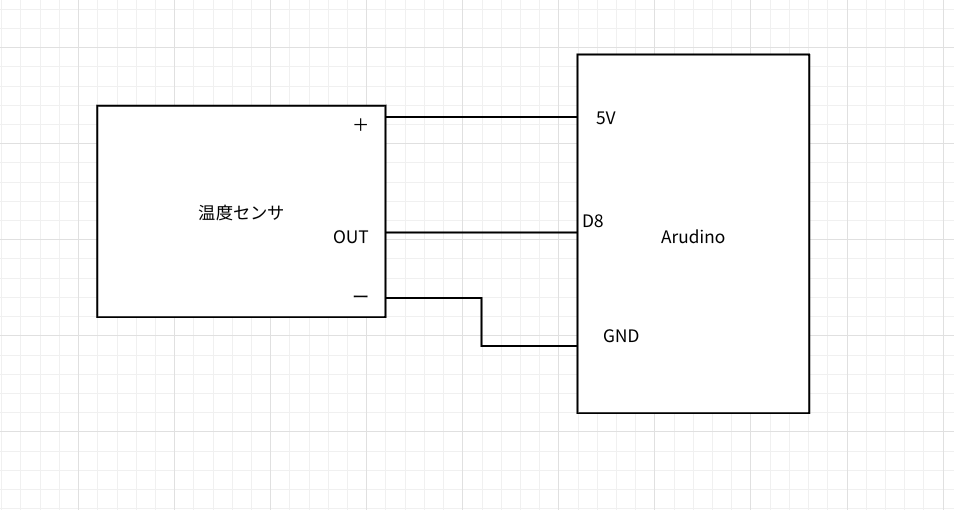
あくまでも個人的な意見です.回路図
作った回路図は本当に対して難しくないので誰でも実践できると思うのでやってみてください.
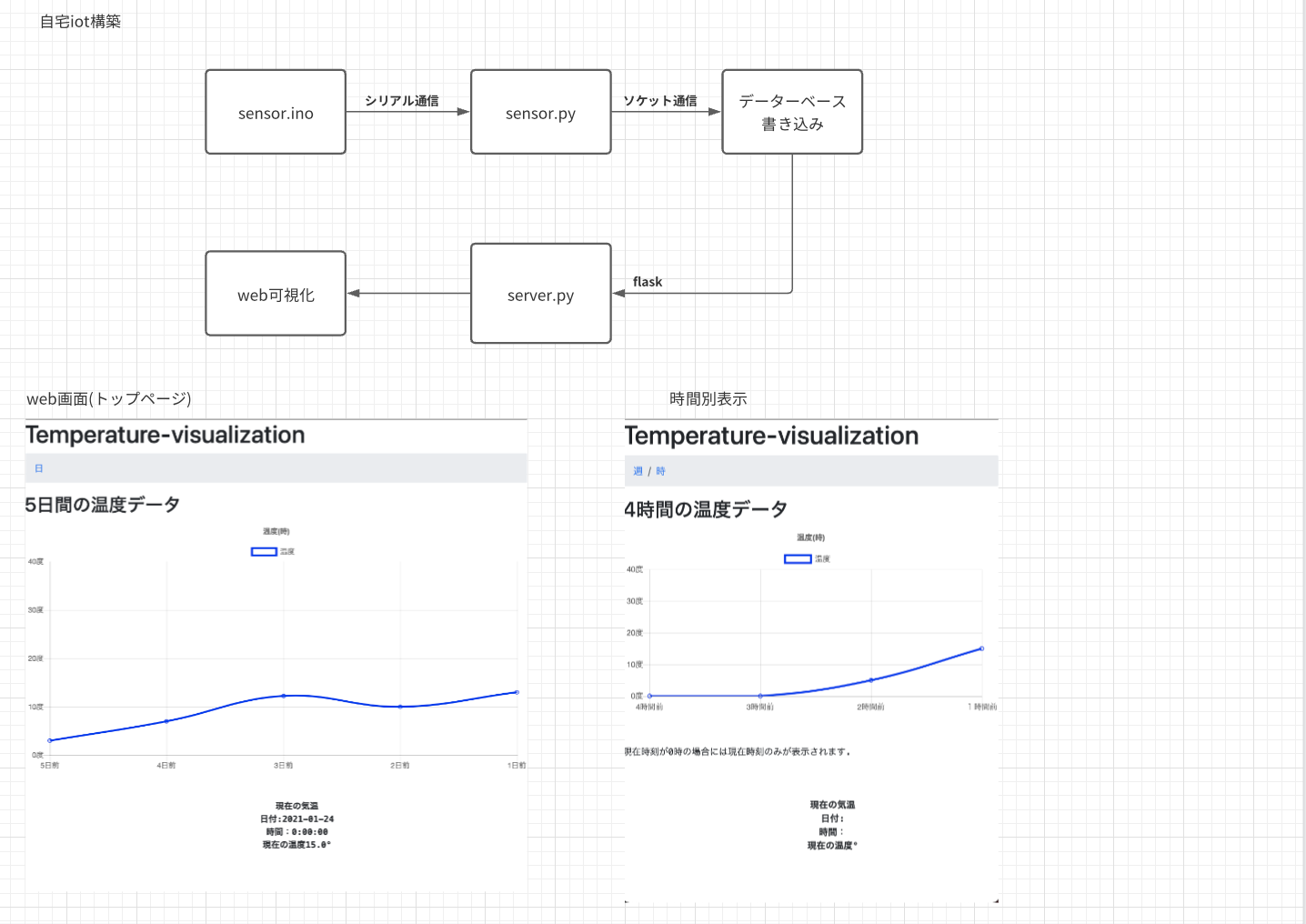
システム構成図
システムの説明
一応システムの説明をすると,
sensor.ino
1,まず,マイコンで温度を計測する.
sensor.py
2,それをUSB(シリアル通信)を使ってpcで受け取る(pythonで表示).
3,pcで受け取ったデータをデータベースに書き込む
大体,通信的なことも入れるとローカル上だと2秒に1回書き込んでいます.
外部のサーバを通すともう少し書き込みスピードは変わるかもしれません.
server.py
4,書き込まれたデータをflaskで可視化する
現在可視化対応しているもの:
・過去5日間の平均温度の可視化
・最新の温度計測結果の表示
設計だと,画面をリロードするとデータが更新される設計になっています.
以上!本当に難しいことはなにもしていません.
データベースの設計
設計っていうかただデータベースに送っているだけなので現状は大したことはありません.
day time temperature こんな感じになっています.
一つ注意点
データは無限に入れられる分ではないのでそこはデータが溜まってきたときに
考えなければいけない問題の一つであるかなと考えています.現状設計では考えていませんが,5ヶ月を超えたデータは消していこうかなと思っています.
コード
Arduino側のコード
一つだけ注意点というかこのコードは外部のライブラリを参照していますのでそのライブラリをインストールしないと使うことができません.
上記からダウンロードしてありがたく使わせていただきました.
sensor.ino
sensor.ino#include "DHT.h" //ライブラリインクルード #define DHT_Pin 8 #define DHT_Type DHT11 DHT dht(DHT_Pin, DHT_Type); float tempC = 0.0f; void setup() { Serial.begin(9600); dht.begin(); } void loop() { delay(2000); tempC = dht.readTemperature(); if (isnan(humidity) || isnan(tempC)) { return; } Serial.println(tempC); } //参考URL //https://omoroya.com/arduino-lesson11/pythonシリアル通信
sensor.py
sensor.pyimport serial import time import datetime import mysql.connector as mydb ser = serial.Serial('/dev/tty.usbmodem14101', 9600) conn = mydb.connect( host='127.0.0.1', port='3306', user='root',#ユーザidの記入 password='',#パスワードの記入 database='temperature'#データベースの名前を記入 ) # コネクションが切れた時に再接続してくれるよう設定 conn.ping(reconnect=True) # 接続できているかどうか確認 print(conn.is_connected()) while (1): s=str(ser.readline()) s1=s.replace("b'", '') s2=s1.replace("r", '') s3=s2.replace("n", '') s4=s3.replace("\\", '') s5=s4.replace("'", '') dt_now = datetime.datetime.now() print("現在時刻:"+str(dt_now)) print(str(s5)+"°") # コネクションが切れた時に再接続してくれるよう設定 conn.ping(reconnect=True) # 接続できているかどうか確認 print(conn.is_connected()) cur = conn.cursor() cur.execute("INSERT INTO `test` (`day`, `temperature`)"+ "VALUES"+ "("+"'"+str(dt_now)+"'"+","+str(s5)+")") conn.commit() cur.close() conn.close() time.sleep(0.1)コードのワンポイント解説
win系だとCOMを使うらしいのでwinでやる方はお調べになると良いのでは?と思います.
MacやLinux OSで実装される方は下記の書き方で大丈夫だと思います.ser = serial.Serial('/dev/tty.usbmodem14101', 9600)シリアル通信やソケット通信を行うと不要な文字などもついてくるのでそちらを整形してあげるとうまく使えるようになります
s=str(ser.readline()) s1=s.replace("b'", '') s2=s1.replace("r", '') s3=s2.replace("n", '') s4=s3.replace("\\", '') s5=s4.replace("'", '')温度可視化(Flask)
server.py
server.pyfrom flask import Flask, render_template #追加 import pymysql #追加 import time import datetime from flask import render_template, url_for from flask import request import numpy import json app = Flask(__name__) @app.route('/') def hello(): #db setting db = pymysql.connect( host='127.0.0.1', user='root', password='', db='temperature', charset='utf8', cursorclass=pymysql.cursors.DictCursor, ) cur = db.cursor() cur1 = db.cursor() cur2 = db.cursor() cur3 = db.cursor() cur4 = db.cursor() cur5 = db.cursor() cur6 = db.cursor() day = datetime.date.today() day1 = datetime.date.today() - datetime.timedelta(days=1) day2 = datetime.date.today() - datetime.timedelta(days=2) day3 = datetime.date.today() - datetime.timedelta(days=3) day4 = datetime.date.today() - datetime.timedelta(days=4) day5 = datetime.date.today() - datetime.timedelta(days=5) print(day1) print(day2) print(day3) print(day4) print(day5) #sql = "SELECT avg(temperature) as temperature FROM `temperature`" sql = "SELECT * FROM `temperature` WHERE `day`="+"'"+str(day)+"'" +"ORDER BY `time` DESC LIMIT 1" sql1="SELECT day , DATE_FORMAT(time, '%H') as time, avg(temperature) as avg FROM temperature WHERE day='2021-01-18' GROUP BY DATE_FORMAT(time, '%H');" tday1="select avg(temperature) as temperature from temperature WHERE day='"+str(day1)+"';" tday2="select avg(temperature) as temperature from temperature WHERE day='"+str(day2)+"';" tday3="select avg(temperature) as temperature from temperature WHERE day='"+str(day3)+"';" tday4="select avg(temperature) as temperature from temperature WHERE day='"+str(day4)+"';" tday5="select avg(temperature) as temperature from temperature WHERE day='"+str(day5)+"';" cur.execute(sql) cur1.execute(sql1) cur2.execute(tday1) cur3.execute(tday2) cur4.execute(tday3) cur5.execute(tday4) cur6.execute(tday5) members = cur.fetchall() members1 = cur1.fetchall() today1 = cur2.fetchall() today2 = cur3.fetchall() today3 = cur4.fetchall() today4 = cur5.fetchall() today5 = cur6.fetchall() cur.close() cur1.close() cur2.close() cur3.close() cur4.close() cur5.close() cur6.close() db.close() print(today1) print(today2) print(today3) print(today4) print(today5) return render_template('hello.html', title='トップページ', members=members,members1=members1,today1=today1,today2=today2,today3=today3,today4=today4,today5=today5) @app.route('/hello.html') def hello1(): #db setting db = pymysql.connect( host='127.0.0.1', user='root', password='', db='temperature', charset='utf8', cursorclass=pymysql.cursors.DictCursor, ) cur = db.cursor() cur1 = db.cursor() cur2 = db.cursor() cur3 = db.cursor() cur4 = db.cursor() cur5 = db.cursor() cur6 = db.cursor() day = datetime.date.today() day1 = datetime.date.today() - datetime.timedelta(days=1) day2 = datetime.date.today() - datetime.timedelta(days=2) day3 = datetime.date.today() - datetime.timedelta(days=3) day4 = datetime.date.today() - datetime.timedelta(days=4) day5 = datetime.date.today() - datetime.timedelta(days=5) print(day1) print(day2) print(day3) print(day4) print(day5) #sql = "SELECT avg(temperature) as temperature FROM `temperature`" sql = "SELECT * FROM `temperature` WHERE `day`="+"'"+str(day)+"'" +"ORDER BY `time` DESC LIMIT 1" sql1="SELECT day , DATE_FORMAT(time, '%H') as time, avg(temperature) as avg FROM temperature WHERE day='2021-01-18' GROUP BY DATE_FORMAT(time, '%H');" tday1="select avg(temperature) as temperature from temperature WHERE day='"+str(day1)+"';" tday2="select avg(temperature) as temperature from temperature WHERE day='"+str(day2)+"';" tday3="select avg(temperature) as temperature from temperature WHERE day='"+str(day3)+"';" tday4="select avg(temperature) as temperature from temperature WHERE day='"+str(day4)+"';" tday5="select avg(temperature) as temperature from temperature WHERE day='"+str(day5)+"';" cur.execute(sql) cur1.execute(sql1) cur2.execute(tday1) cur3.execute(tday2) cur4.execute(tday3) cur5.execute(tday4) cur6.execute(tday5) members = cur.fetchall() members1 = cur1.fetchall() today1 = cur2.fetchall() today2 = cur3.fetchall() today3 = cur4.fetchall() today4 = cur5.fetchall() today5 = cur6.fetchall() cur.close() cur1.close() cur2.close() cur3.close() cur4.close() cur5.close() cur6.close() db.close() print(today1) print(today2) print(today3) print(today4) print(today5) return render_template('hello.html', title='日別部屋の温度可視化', members=members,members1=members1,today1=today1,today2=today2,today3=today3,today4=today4,today5=today5) #変更 @app.route('/hello1.html') def hello2(): #db setting db = pymysql.connect( host='127.0.0.1', user='root', password='', db='temperature', charset='utf8', cursorclass=pymysql.cursors.DictCursor, ) now = datetime.datetime.now() now1=now - datetime.timedelta(hours=1) now4=now - datetime.timedelta(hours=2) now6=now - datetime.timedelta(hours=3) now8=now - datetime.timedelta(hours=4) now3=now1.strftime('%H')#20 now2=now4.strftime('%H')#19 now5=now6.strftime('%H')#18 now7=now8.strftime('%H')#17 day = datetime.date.today() cur = db.cursor() cur1 = db.cursor() cur2 = db.cursor() cur3 = db.cursor() cur4 = db.cursor() t1day="SELECT * FROM `temperature` WHERE `day`="+"'"+str(day)+"'" +"ORDER BY `time` DESC LIMIT 1" t1day1="select avg(temperature) as temperature from temperature WHERE day="+"'"+str(day)+"'"+ "and time>="+"'"+str(now2)+":00:00"+"'"+" and time<="+"'"+str(now3)+":00:00"+"'"+";" t1day2="select avg(temperature) as temperature from temperature WHERE day="+"'"+str(day)+"'"+ "and time>="+"'"+str(now5)+":00:00"+"'"+" and time<="+"'"+str(now2)+":00:00"+"'"+";" t1day3="select avg(temperature) as temperature from temperature WHERE day="+"'"+str(day)+"'"+ "and time>="+"'"+str(now7)+":00:00"+"'"+" and time<="+"'"+str(now5)+":00:00"+"'"+";" t1day4="select avg(temperature) as temperature from temperature WHERE day="+"'"+str(day)+"'"+ "and time>="+"'"+str(now7)+":00:00"+"'"+" and time<="+"'"+str(now5)+":00:00"+"'"+";" cur.execute(t1day) cur1.execute(t1day1) cur2.execute(t1day2) cur3.execute(t1day3) cur4.execute(t1day4) test1 = cur1.fetchall() test2 = cur2.fetchall() test3 = cur3.fetchall() test4 = cur3.fetchall() test5 = cur.fetchall() cur.close() cur1.close() cur2.close() cur3.close() cur.close() db.close() print(t1day1) print(test1) print(t1day2) print(test2) print(t1day3) print(t1day4) return render_template('hello1.html', title='時別部屋の温度可視化', test1=test1,test2=test2,test3=test3,test4=test4,test5=test5) if __name__ == '__main__': app.run(debug=True, port=8085)ピンポイントコード解説
データベースの集計はこんな感じで集計を行いました.select avg(temperature) as temperature from temperature WHERE day='"+str(day1)+"'debug=Trueflaskのデバックモードがオンになっていますので実際に運用する時はdebug=Falseにしましょう.
温度可視化(Flaskフロント)
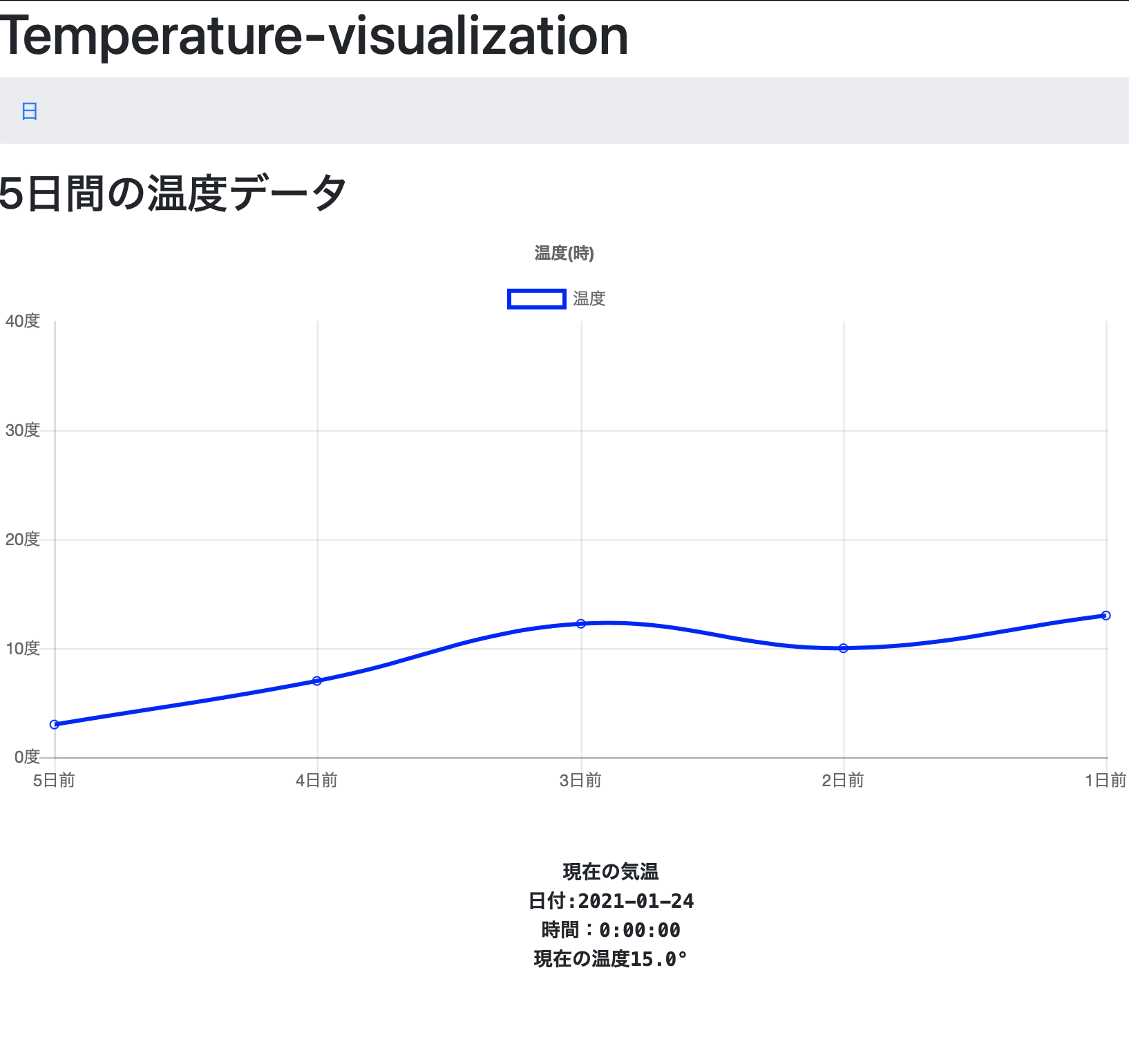
hello.html(日別ページ)
hello.html{% extends "layout.html" %} {% block content %} <script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.7.2/Chart.bundle.js"></script> <h1>Temperature-visualization</h1> <nav aria-label="breadcrumb"> <ol class="breadcrumb"> <li class="breadcrumb-item"><a href="hello.html">日</a></li> <!--<li class="breadcrumb-item"><a href="hello.html">週</a></li>--> <!--<li class="breadcrumb-item"><a href="hello3.html">月</a></li>--> </ol> </nav> <h2>5日間の温度データ</h2> <canvas id="myLineChart"></canvas> <center> <br> <pre> <b> <b>現在の気温</b> 日付:{% for member in members %}{{ member.day}}{% endfor %} 時間:{% for member in members %}{{ member.time}}{% endfor %} 現在の温度{% for member in members %}{{ member.temperature}}{% endfor %}° </pre> </b> </center> <script> var today1 = "{% for today1 in today1 %}{{today1.temperature}}{% endfor %}" var today2 = "{% for today2 in today2 %}{{today2.temperature}}{% endfor %}" var today3 = "{% for today3 in today3 %}{{today3.temperature}}{% endfor %}" var today4 = "{% for today4 in today4 %}{{today4.temperature}}{% endfor %}" var today5 = "{% for today5 in today5 %}{{today5.temperature}}{% endfor %}" var ctx = document.getElementById("myLineChart"); var myLineChart = new Chart(ctx, { type: 'line', data: { labels: ['5日前', '4日前', '3日前', '2日前', '1日前'], datasets: [ { label: '温度', data: [today5, today4, today3, today2, today1], borderColor: "rgba(0,0,255,1)", backgroundColor: "rgba(0,0,0,0)" } ], }, options: { title: { display: true, text: '温度(時)' }, scales: { yAxes: [{ ticks: { suggestedMax: 40, suggestedMin: 0, stepSize: 10, callback: function(value, index, values){ return value + '度' } } }] }, } }); </script> {% endblock %}ピンポイントアドバイス
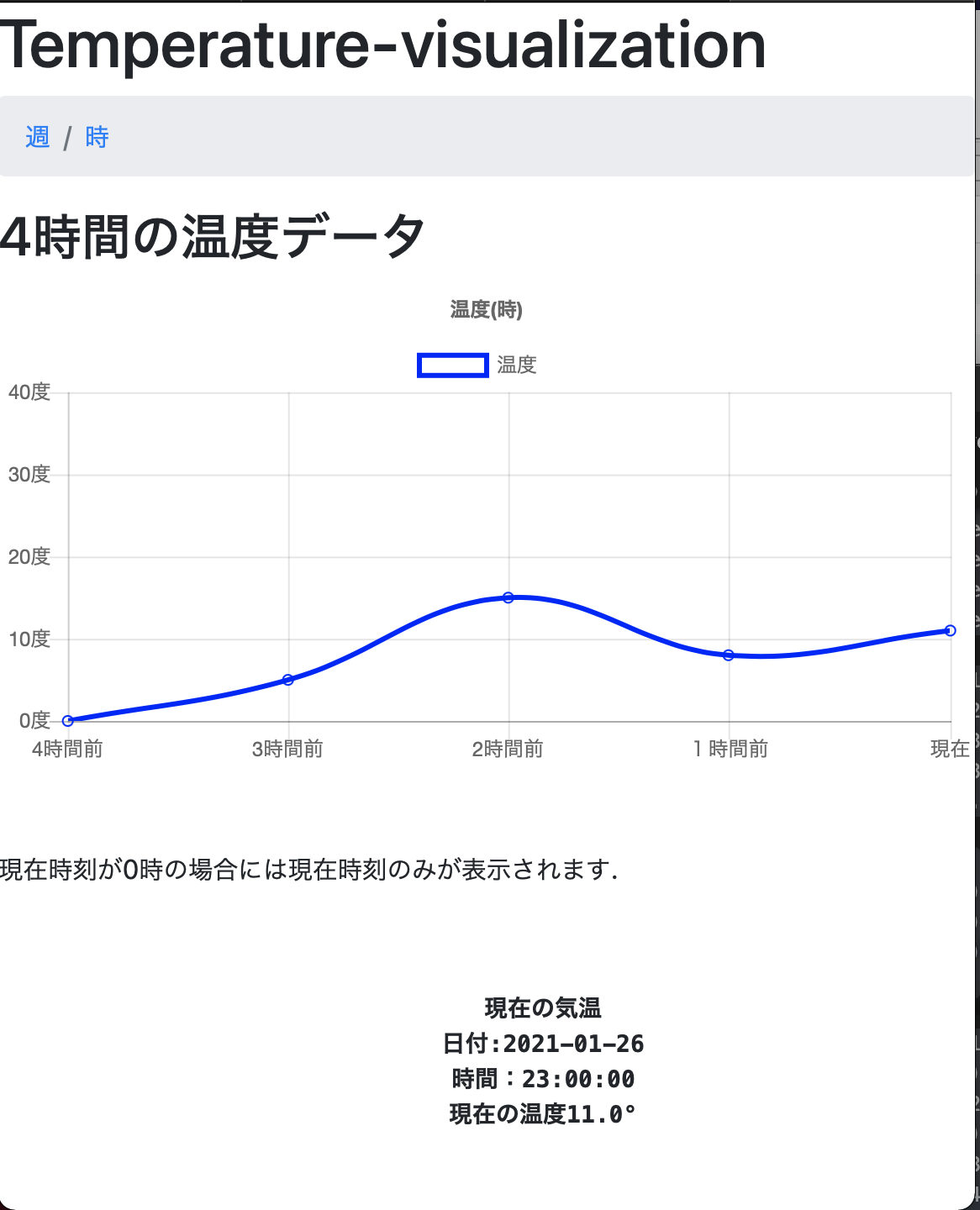
flask上でjsにpythonの変数を移行する為には以下のやり方をするとできますので参考にしていただけると良いかなと思います.var today1 = "{% for today1 in today1 %}{{today1.temperature}}{% endfor %}" var today2 = "{% for today2 in today2 %}{{today2.temperature}}{% endfor %}" var today3 = "{% for today3 in today3 %}{{today3.temperature}}{% endfor %}" var today4 = "{% for today4 in today4 %}{{today4.temperature}}{% endfor %}" var today5 = "{% for today5 in today5 %}{{today5.temperature}}{% endfor %}"hello1.html(時別ページ)
hello1.html{% extends "layout.html" %} {% block content %} <script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.7.2/Chart.bundle.js"></script> <h1>Temperature-visualization</h1> <nav aria-label="breadcrumb"> <ol class="breadcrumb"> <li class="breadcrumb-item"><a href="hello.html">週</a></li> <li class="breadcrumb-item"><a href="hello1.html">時</a></li> <!--<li class="breadcrumb-item"><a href="hello3.html">月</a></li>--> </ol> </nav> <h2>4時間の温度データ</h2> <canvas id="myLineChart"></canvas> <br> <br> <p>現在時刻が0時の場合には現在時刻のみが表示されます.</p> <center> <br> <pre> <b> <b>現在の気温</b> 日付:{% for test5 in test5 %}{{ test5.day}}{% endfor %} 時間:{% for test5 in test5 %}{{ test5.time}}{% endfor %} 現在の温度{% for test5 in test5 %}{{ test5.temperature}}{% endfor %}° </pre> </b> </center> <script> var t1 = "{% for test1 in test1 %}{{test1.temperature}}{% endfor %}" var t2 = "{% for test2 in test2 %}{{test2.temperature}}{% endfor %}" var t3 = "{% for test3 in test3 %}{{test3.temperature}}{% endfor %}" var t4 = "{% for test4 in test4 %}{{test4.temperature}}{% endfor %}" var t = "{% for test5 in test5 %}{{test5.temperature}}{% endfor %}" var ctx = document.getElementById("myLineChart"); var myLineChart = new Chart(ctx, { type: 'line', data: { labels: ['4時間前','3時間前', '2時間前', '1時間前','現在'], datasets: [ { label: '温度', data: [t4, t3, t2, t1,t], borderColor: "rgba(0,0,255,1)", backgroundColor: "rgba(0,0,0,0)" } ], }, options: { title: { display: true, text: '温度(時)' }, scales: { yAxes: [{ ticks: { suggestedMax: 40, suggestedMin: 0, stepSize: 10, callback: function(value, index, values){ return value + '度' } } }] }, } }); </script> {% endblock %}layout.html
layout.html<html> <head> <title>{{ title }}</title> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/css/bootstrap.min.css" integrity="sha384-GJzZqFGwb1QTTN6wy59ffF1BuGJpLSa9DkKMp0DgiMDm4iYMj70gZWKYbI706tWS" crossorigin="anonymous"> <script src="http://guide.withabout.net/guide/gp332/459916/Chart.min.js"></script> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.6/umd/popper.min.js" integrity="sha384-wHAiFfRlMFy6i5SRaxvfOCifBUQy1xHdJ/yoi7FRNXMRBu5WHdZYu1hA6ZOblgut" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/js/bootstrap.min.js" integrity="sha384-B0UglyR+jN6CkvvICOB2joaf5I4l3gm9GU6Hc1og6Ls7i6U/mkkaduKaBhlAXv9k" crossorigin="anonymous"></script> </head> <body> {% block content %} {% endblock %} </body> </html>グラフの可視化にはchart.jsを利用しています.この辺は皆さんでやる場合お好きなものをお使いになると良いのではないかなと思います.
画面UI
日別ページ
時別ページ
最後に
今回はスイッチボットさんの温度計を見て自分で自作してみました.手直しする部分は多いですが,案外実システムとwebシステムの融合って難しくないのでは?と感じられた方も多いのではないでしょうか.
皆さんも楽しいお家IoT開発をされてみてはいかがでしょうか.一応コードはgithubにあげてありますのでそちらも確認いただけると幸いです.
github
https://github.com/S-mishina/Temperature-visualization
- 投稿日:2021-01-24T22:40:50+09:00
Matplotlib入門
Matplotlib入門
Matplotlibはデータの可視化とカスタマイズに最も柔軟性のあるインターフェースpyplotを提供します。
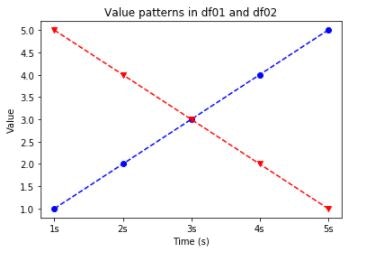
pyplotの簡単な使用方法は以下:import pandas as pd df01 = pd.DataFrame( {'time': ['1s', '2s', '3s', '4s', '5s'], 'value': [1, 2, 3, 4, 5]}) df02 = pd.DataFrame( {'time': ['1s', '2s', '3s', '4s', '5s'], 'value': [5, 4, 3, 2, 1]} )# matplotlib.pyplotをインポート import matplotlib.pyplot as plt # FigureとAxesオブジェクトを作成 fig, ax = plt.subplots() # df01のvalueをtimeに対してプロット ax.plot(df01['time'], df01['value']) # df02のvalueをtimeに対してプロット ax.plot(df02['time'], df02['value']) # プロット表示 plt.show()
プロットのカスタマイズ
マーカー、線のスタイル、線の色を設定できます。
また、タイトル、X軸の名称、Y軸の名称も設定できます。設定可能なフォーマットは matplotlib.pyplot.plot にあります。
# マーカー、線のスタイル、線の色を設定 ax.plot(df01["time"], df01["value"], color='b', marker='o', linestyle='--') ax.plot(df02["time"], df02["value"], color='r', marker='v', linestyle='--') # X軸の名称を設定 ax.set_xlabel('Time (s)') # Y軸の名称を設定 ax.set_ylabel('Value') # タイトルを設定 ax.set_title('Value patterns in df01 and df02') plt.show()
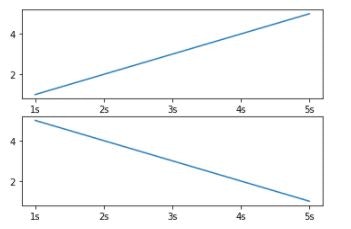
サブプロット
プロットにデータを追加しすぎると、場合によってはプロットが煩雑になりすぎて、パターンが見えなくなってしまうことがあります。
その場合はサブプロットを使用します。 matplotlib.pyplot.subplot# 2行1列のサブプロットを作成 fig, ax = plt.subplots(2, 1) ax[0].plot(df01['time'], df01['value']) ax[1].plot(df02['time'], df02['value']) plt.show()

- 投稿日:2021-01-24T22:01:05+09:00
VBAユーザがPython・Rを使ってみた:簡単なプログラムの例
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。今回は、簡単なプログラムをそれぞれの言語で書いてみたいと思います。
目次
簡単なプログラムの例
簡単な定義の数列を書き出すプログラムの例です。
偶数と奇数
0から10までの偶数(even number)と奇数(odd number)をそれぞれ定義どおり計算して書き出すプログラムを書いてみます。
定義:
偶数は、2で割り切れる整数のこと。
奇数は、2で割り切れない整数のこと。Python
Python3# 0から10までの偶数を書き出す for n in range(0, 10+1): if n % 2 == 0: print(n) # 0 # 2 # 4 # 6 # 8 # 10 # 0から10までの奇数を書き出す for n in range(0, 10+1): if n % 2 == 1: print(n) # 1 # 3 # 5 # 7 # 9R
R# 0から10までの偶数を書き出す for (n in 0:10) { if (n %% 2 == 0) { print(n) } } # [1] 0 # [1] 2 # [1] 4 # [1] 6 # [1] 8 # [1] 10 # 0から10までの奇数を書き出す for (n in 0:10) { if (n %% 2 == 1) { print(n) } } # [1] 1 # [1] 3 # [1] 5 # [1] 7 # [1] 9VBA
VBADim n As Integer ' 0から10までの偶数を書き出す For n = 0 To 10 If n Mod 2 = 0 Then Debug.Print n End If Next n ' 0 ' 2 ' 4 ' 6 ' 8 ' 10 ' 0から10までの奇数を書き出す For n = 0 To 10 If n Mod 2 = 1 Then Debug.Print n End If Next n ' 1 ' 3 ' 5 ' 7 ' 9別の書き方
いくつか別の書き方をしてみます。
リスト内法表記
Pythonのリスト内法表記を使うとこのように簡潔に書けます。
Python3[n for n in range(0, 10+1) if n % 2 == 0] # [0, 2, 4, 6, 8, 10] [n for n in range(0, 10+1) if n % 2 == 1] # [1, 3, 5, 7, 9]これらはそれぞれ次のコードと等価です:
Python3nums = [] for n in range(0, 10+1): if n % 2 == 0: nums.append(n) nums # [0, 2, 4, 6, 8, 10] nums = [] for n in range(0, 10+1): if n % 2 == 1: nums.append(n) nums # [1, 3, 5, 7, 9]ベクトルの演算
Rのベクトルの演算を使うとこのように書けます。
Rv <- 0:10 v %% 2 == 0 # TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE v[v %% 2 == 0] # 0 2 4 6 8 10 v %% 2 == 1 # FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE v[v %% 2 == 1] # 1 3 5 7 9Pythonでも、Numpy の numpy.ndarray を使うと同じように書けます。
Python3import numpy as np v = np.arange(0, 10+1) print(v % 2 == 0) # [ True False True False True False True False True False True] list(v[v % 2 == 0]) # [0, 2, 4, 6, 8] print(v % 2 == 1) # [False True False True False True False True False True False] list(v[v % 2 == 1]) # [1, 3, 5, 7, 9]等差数列として
定義からそのまま計算したものではなくなりますが、等差数列になることを考えれば、もちろんこのようにも書けます。
Python3list(range(0, 10+1, 2)) # [0, 2, 4, 6, 8, 10] list(np.arange(0, 10+1, 2)) # [0, 2, 4, 6, 8, 10] list(range(1, 10+1, 2)) # [1, 3, 5, 7, 9] list(np.arange(1, 10+1, 2)) # [1, 3, 5, 7, 9]Rseq(0, 10, by=2) # 0 2 4 6 8 10 seq(1, 10, by=2) # 1 3 5 7 9一般項を求めてリスト内法表記で
また、一般項を考えればもちろんこのようにも書けます。
$a_n = a_1 + (n-1)*2$Python3[0 + (n-1)*2 for n in range(1,10+1) if 0 + (n-1)*2 <= 10] # [0, 2, 4, 6, 8, 10] [1 + (n-1)*2 for n in range(1,10+1) if 1 + (n-1)*2 <= 10] # [1, 3, 5, 7, 9]一般項を求めてベクトルの演算で
Python3import numpy as np v = 0 + np.arange(0, 10+1) * 2 list(v[v <= 10]) # [0, 2, 4, 6, 8, 10] v = 1 + np.arange(0, 10+1) * 2 list(v[v <= 10]) # [1, 3, 5, 7, 9]Rv <- 0 + 0:10 * 2 v[v <= 10] # 0 2 4 6 8 10 v <- 1 + 0:10 * 2 v[v <= 10] # 1 3 5 7 9素数
1から50までの素数(prime number)を書き出してみます。
定義:
素数は、1より大きい自然数で、正の約数が1と自分自身のみであるもののこと。正の約数の個数が2である自然数と言い換えることもできる。Python
Python3# 1から50までの素数を書き出す for n in range(1, 50+1): count = 0 for m in range(1, n+1): if n % m == 0: count += 1 if count == 2: print(n, end=' ') print() # 改行 # 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47R
R# 1から50までの素数を書き出す for (n in 1:50) { count <- 0 for (m in 1:n) { if (n %% m == 0) { count = count + 1 } } if (count == 2) { cat(n, "") } } # 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47VBA
VBADim n As Integer Dim m As Integer Dim count As Integer ' 1から50までの素数を書き出す For n = 1 To 50 count = 0 For m = 1 To n If n Mod m = 0 Then count = count + 1 End If Next m If count = 2 Then Debug.Print n; End If Next n Debug.Print "" ' 改行 ' 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47等差数列
初項 $a_1=1$、公差 $d=2$ の等差数列(arithmetic sequence)の最初の10項を書き出してみます。
定義:
初項 $a_1$、公差 $d$ の等差数列 $a_n$ は、次の漸化式で定義される:\begin{eqnarray*} a_n &=& a_1 &(n = 1) \\ a_n &=& a_{n-1} + d \quad &(n \geq 2) \end{eqnarray*} \\Python
Python3# 初項a1=1、公差d=2の等差数列の最初の10項を書き出す a1 = 1 d = 2 for n in range(1, 10+1): if n == 1: an = a1 else: an += d print(an, end=' ') print() # 改行 # 1 3 5 7 9 11 13 15 17 19R
R# 初項a1=1、公差d=2の等差数列の最初の10項を書き出す a1 <- 1 d <- 2 for (n in 1:10) { if (n == 1) { an <- a1 } else { an <- an + d } cat(an, "") } # 1 3 5 7 9 11 13 15 17 19VBA
VBADim n As Integer Dim a1 As Integer Dim d As Integer Dim an As Integer ' 初項a1=1、公差d=2の等差数列の最初の10項を書き出す a1 = 1 d = 2 For n = 1 To 10 If n = 1 Then an = a1 Else an = an + d End If Debug.Print an; Next n Debug.Print "" ' 改行 ' 1 3 5 7 9 11 13 15 17 19別の書き方
別の書き方をしてみます。
等比数列なので
Python、Rには等比数列を作る関数がありますので、
Python3list(range(a1, a1+(10-1)*d+1, d)) # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]Rseq(a1, a1+(10-1)*d, by=2) # 1 3 5 7 9 11 13 15 17 19一般項を求めてリスト内法表記で
一般項は $a_n = a_1 + (n-1)d$ ですので、
Python3a1 = 1 d = 2 [a1 + (n-1)*d for n in range(1, 10+1)] # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]一般項を求めてベクトルの演算で
Python3a1 = 1 r = 2 import numpy as np ns = np.arange(1, 10+1) print(ns) # [ 1 2 3 4 5 6 7 8 9 10] v = a1 + (ns - 1) * d list(v) # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19] v = a1 + (np.arange(1, 10+1) - 1) * d list(v) # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]Ra1 <- 1 d <- 2 ns <- 1:10 a1 + (ns - 1) * d # 1 3 5 7 9 11 13 15 17 19 a1 + (1:10 - 1) * d # 1 3 5 7 9 11 13 15 17 19等比数列
初項 $a_1=1$、公差 $r=2$ の等比数列(geometric sequence)の1000以下の項を書き出してみます。
定義:
初項 $a_1$、公比 $r$ の等差数列 $a_n$ は、次の漸化式で定義される:\begin{eqnarray*} a_n &=& a_1 &(n = 1) \\ a_n &=& a_{n-1} * r \quad &(n \geq 2) \end{eqnarray*} \\Python
Python3# 初項a1=1、公比r=2の等比数列の1000以下の項を書き出す a1 = 1 r = 2 an = a1 while an <= 1000: print(an, end=' ') an *= r print() # 改行 # 1 2 4 8 16 32 64 128 256 512R
R# 初項a1=1、公比r=2の等比数列の1000以下の項を書き出す a1 <- 1 r <- 2 an <- a1 while (an <= 1000) { cat(an, "") an <- an * r } # 1 2 4 8 16 32 64 128 256 512VBA
VBADim n As Integer Dim a1 As Integer Dim r As Integer Dim an As Integer ' 初項a1=1、公比r=2の等比数列の1000以下の項を書き出す a1 = 1 r = 2 an = a1 Do While an <= 1000 Debug.Print an; an = an * r Loop Debug.Print "" ' 改行 ' 1 2 4 8 16 32 64 128 256 512別の書き方
別の書き方をしてみます。
一般項を求めてリスト内法表記で
一般項は $a_n = a_1 r^{n-1}$ ですので、
Python3a1 = 1 r = 2 [a1 * r**(n-1) for n in range(1, 20+1) if a1 * r**(n-1) <= 1000] # [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]注意)
range(1, 20+1)の20は適当に大きな数。以下も同様。一般項を求めてベクトルの演算で
Python3a1 = 1 r = 2 import numpy as np ns = np.arange(1, 20+1) print(ns) # [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20] v = a1 * r**(ns - 1) list(v[v <= 1000]) # [1, 2, 4, 8, 16, 32, 64, 128, 256, 512] v = a1 * r**(np.arange(1, 20+1) - 1) list(v[v <= 1000]) # [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]Ra1 <- 1 r <- 2 ns <- 1:20 v <- a1 * r^(ns - 1) v[v <= 1000] # 1 2 4 8 16 32 64 128 256 512 v <- a1 * r^(1:20 - 1) v[v <= 1000] # 1 2 4 8 16 32 64 128 256 512フィボナッチ数
フィボナッチ数(Fibonacci number)を書き出す例です。Python チュートリアル にある例です。
定義:
フィボナッチ数列 $F_n (n \geq 0)$ は、次の漸化式で定義される:\begin{eqnarray*} F_0 &=& 0 &(n = 0) \\ F_1 &=& 1 &(n = 1) \\ F_{n+2} &=& F_n + F_{n+1} \quad &(n \geq 0) \end{eqnarray*} \\Python
Pythonでは、複数同時の代入 (multiple assignment) ができるので、他の言語より少し簡単に書けます。Python3# フィボナッチ数列の1000以下の項を書き出す f0 = 0 f1 = 1 fn = f0 fnp1 = f1 while fn <= 1000: print(fn, end=' ') fnp2 = fn + fnp1 fn = fnp1 fnp1 = fnp2 print() # 改行 # 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 fn, fnp1 = f0, f1 while fn <= 1000: print(fn, end=' ') fn, fnp1 = fnp1, fn+fnp1 print() # 改行 # 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987R
R# フィボナッチ数列の1000以下の項を書き出す f0 <- 0 f1 <- 1 fn <- f0 fnp1 <- f1 while (fn <= 1000) { cat(fn, "") fnp2 <- fn + fnp1 fn <- fnp1 fnp1 <- fnp2 } # 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987VBA
VBADim f0 As Integer Dim f1 As Integer Dim fn As Integer Dim fnp1 As Integer Dim fnp2 As Integer ' フィボナッチ数列の1000以下の項を書き出す f0 = 0 f1 = 1 fn = f0 fnp1 = f1 Do While fn <= 1000 Debug.Print fn; fnp2 = fn + fnp1 fn = fnp1 fnp1 = fnp2 Loop Debug.Print "" ' 改行 ' 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
- 投稿日:2021-01-24T21:54:30+09:00
RHEL8にjupyter notebookをインストール
pythonの設定
このサイトに準じて行う。
RHEL8には標準でPython3.6が提供されいるので、これを呼出やすいようにする。pipも同様。
これをしないと単にpython,pipと入力しただけではコマンドが見つからないと表示されてしまう。なお、Anacondaは別途インストールする。
jupyter notebookのインストール
jupyter notebookは手動でインストールする必要がある。
下記のとおり行う。sudo pip install notebookターミナルでjupyter notebookと入力して、立ち上がればOK。
- 投稿日:2021-01-24T21:16:25+09:00
AtCoder参加したったー (ABC189編)
こんにちは!バイオインフォマティクス系オタク修士学生のroadricefieldです!ひさびさにABCに参加したあと記事を書きたい気分と時間があるのでABC189の参戦記録を書きます!
A問題
与えられる3文字が同じ文字かそうでないかを調べるだけです.私はそれぞれの文字が一文字目と一致するかどうかで判定しました.
私の解答
S = input() C1 = S[0] for i in range(3): if S[i] != C1: print("Lost") quit() print("Won")i = 0 のときが完全に無駄な処理ですがまあどうでもいいでしょう.
B問題
高橋くんが入力のお酒を1杯ずつ飲んで行くので0で初期化した変数(vとします.)に高橋くんが飲んだアルコールの体積をひたすら足していきます.1杯飲んだらvがXを超えていないかどうかを判定して,もし超えていたならばその時点で高橋くんが飲んだお酒の杯数を出力して終了すればよいです.最後までvがXを超えなければ
-1を出力して終了です.公式の解説にもある通り,何度も浮動小数点演算を繰り返していると誤差がたまっていくので本当はv = Xでもv > Xとなってしまう場合があります.なのでN, X = map(int, input().split()) now = 0 for i in range(N): v, p = map(float, input().split()) #入力を浮動小数として受ける now += v*(p/100) if now > X: print(i + 1) quit() print(-1)のような書き方だと
WAとなります.(私もまんまとひっかかりました.)これを防ぐには浮動小数点ではなく整数だけで計算すればいいです.そのために高橋くんのお酒の強さXを実際の100倍にしておき,vには実際の体積の100倍,つまり入力のV × Pを整数のまま足していきます.
私の解答
N, X = map(int, input().split()) X *= 100 now = 0 for i in range(N): v, p = map(int, input().split()) now += v*p if now > X: print(i + 1) quit() print(-1)C問題
C問題にしては難しくね!!??問題文を読み替えるとつまりは「配列Aからある一つ区間を取る.その区間の最小値と区間の長さの積(Pとする.)が最大となるときを探してその値を出力せよ」ということです.
私の方針は以下のとおりです.
- 空配列
candiを用意する.- 0で初期化した変数
pを用意する.- 配列Aから要素を一つ選んで
startとする.
p += start.startの左隣の要素がstart以上ならばp += start.startよりも小さい要素が現れるまでさらに左の要素とstartを比較して,それがstart以上であればp += startすることを繰り返す.startの右隣の要素がstart以上ならばp += start.startよりも小さい要素が現れるまでさらに右の要素とstartを比較して,それがstart以上であればp += startすることを繰り返す.pをcandiに加える.- 2~9を配列Aのすべての要素について行う.
candiの最大値を出力する.
上記のような操作を行うことである配列Aに属する要素を最小値とする区間のとり方でPが最大となるときのPを集めていってその最大値を出力するという方針です.「ある配列Aに属する要素を最小値とする区間のとり方でPが最大となるとき」とは選んだ要素が最小値である限り区間を左右に伸ばせるだけ伸ばしたときです.
この計算量は一つの要素につき最大で配列A全体の長さであるN回比較と
pへの加算を行い,それを配列の要素数N回繰り返すので計算量はO(N2)となります.制約ではNは104以下とのことなので計算見積もりは最大で108となります.これ,Python間に合うのか?不安だったのでC++を使いました.私の解答
#include<iostream> using namespace std; int main(){ int N; cin >> N; int A[N]; for(int i=0;i<N;i++){ cin >> A[i]; } int now_max = 0; int start; int ref1; int ref2; int j; int p; for(int i=0;i<N;i++){ ref1 = 10000000; start = A[i]; p = 0; j = i; while(ref1 >= start and j >= 0){ p += start; j--; ref1 = A[j]; } j = i+1; ref2 = A[j]; while(ref2 >= start and j < N){ p += start; j++; ref2 = A[j]; } if(p > now_max) now_max = p; } cout << now_max << endl; return 0; }上記のコードでは
candi配列はつくらず,startを変えて計算するたびにそれまでの最大値now_maxとpを比較して更新していっています.こちらのほうが最後に改めて最大値を探す計算を行わない分速いはずです.(たぶん......)D問題
N = 1,2,3のときで具体的な答えを計算していると下のように処理すれば答えを出せることに気づきました.
私の解答
N = int(input()) S = [] for _ in range(N): S.append(input()) ans = 2**(N+1) - 1 minus = [] for i in range(N): if S[i] == "AND": minus.append(2**(i+1)) for d in minus: ans -= d print(ans)雑ですみません......
最後に
C問題が難しくて肝を冷やしました.規則性に気づくのに時間がかかってD問題も終了15分前に
ACしました.当然私の実力ではE問題に挑戦しても解けないと思ったのでD問題をACした時点でセブイレに行ってビールを買いました.今,ラブライブ虹ヶ咲学園スクールアイドル同好会のセブンイレブンイメージガール総選挙というのをやっていて,午後ティーを買えば推しの歩夢ちゃんと栞子ちゃんに投票できるのにそれを失念していてビールのみを買ってしまいました.こうしていてはいられないのでセブイレで午後ティーを買ってきます.ここまで読んでくださり,ありがとうございました!
- 投稿日:2021-01-24T21:12:10+09:00
投稿記事の Markdown 中のコードをファイルとして取り出す
Qiita は、全体は小さいけど、多数のファイルで構成されたソースコードを記事に入れようと思うと
- 記事にするときも手間
- 利用するときも手間
なので、そういうものは記事にしにくい側面があります。そこで、(Qiita で完結する前提で)手間を軽減したいわけですが、ファイルから Markdown にするものと、その逆があれば少しは良くなるでしょう。既に誰かやっててもよさそうな気がしますが、探せなかったので作ることにしました。
変換処理は
ファイルから Markdown へ
- テキスト ファイルの前後に「```」の行を追加
- ファイルの種類に応じたコードの挿入
- 種類の判定が必要
- ファイル内行頭「```」
- 元のコードをうまく表示する法方を見つけられなかったので「\」を先頭に追加
Markdown からファイルへ
- Markdown の「```」から「```」までをテキスト ファイルにする
- ファイル内行頭「```」を復元
の簡素なものにしています。
Python スクリプト: ファイルから Markdown へ
f2m.py#!/usr/bin/env python import os import sys import argparse makefiles = ('gnumakefile', 'makefile') type_map = { 'c++': ('.c', '.cc', '.cpp', 'c++', '.h', '.hh', '.hpp', 'h++'), 'makefile': ('.mak', '.mk'), 'markdown': ('.md',), 'python': ('.py',), } suffix_map = {} for k in type_map: for x in type_map[k]: suffix_map[x] = k parser = argparse.ArgumentParser() parser.add_argument('-o', '--output', default=None) parser.add_argument('files', metavar='FILE', type=str, nargs='+') args = parser.parse_args() md = '' for fn in args.files: fn = fn.replace('&', '&') fn = fn.replace(' ', ' ') ct = 'text' sfx = os.path.splitext(fn)[1] if fn.lower() in makefiles: ct = 'makefile' elif sfx in suffix_map: ct = suffix_map[sfx.lower()] md = md + ('\n```%s:%s\n' % (ct, fn)) for line in open(fn).readlines(): if len(line) > 3 and line[:3] == '```': line = '\\' + line md = md + line md = md + '```\n' o = args.output if o is None or o == '-': o = sys.stdout else: o = open(o, 'w') o.write(md)
Python スクリプト: Markdown からファイルへ
m2f.py#!/usr/bin/env python import os import sys import argparse import urllib.request parser = argparse.ArgumentParser() parser.add_argument('-o', '--outputdir', metavar='DIR', default=None) parser.add_argument('markdown', metavar='URL/FILE', type=str, default=None) args = parser.parse_args() lines = [] if args.markdown is None: lines = sys.stdin.readlines() elif args.markdown == '-': lines = sys.stdin.readlnes() elif args.markdown.split(':')[0] in ('http', 'https'): with urllib.request.urlopen(args.markdown) as res: lines = [] for line in res.read().decode().split('\n'): lines.append(line + '\n') else: lines = open(args.markdown).readlines() odir = args.outputdir if odir is None: odir = '.' if odir[-1] != '/': odir += '/' index = 0 output = None for line in lines: if len(line) > 3 and line[:3] == '```': if output is None: code = line[3:].split(':', 1) mode = code[0].strip().lower() fname = '' if len(code) > 1: fname = code[1].strip() if len(fname) == 0: fname = 'code:%d.%s' % (index, mode) index += 1 fname = fname.replace(' ', ' ') fname = fname.replace('&', '&') path = odir + fname os.makedirs(os.path.dirname(path), exist_ok=True) print(path) output = open(path, 'w') continue output.close() output = None continue if output is None: continue if len(line) > 4 and line[:4] == '\\```': line = line[1:] output.write(line)こちらの記事の取得例
$ python3 m2f.py -o sample https://qiita.com/ikiuo/items/2dc82e76337010f935a1.md sample/main.swift sample/zlibwrapper.m sample/project-Bridging-Header.h
- 投稿日:2021-01-24T21:06:12+09:00
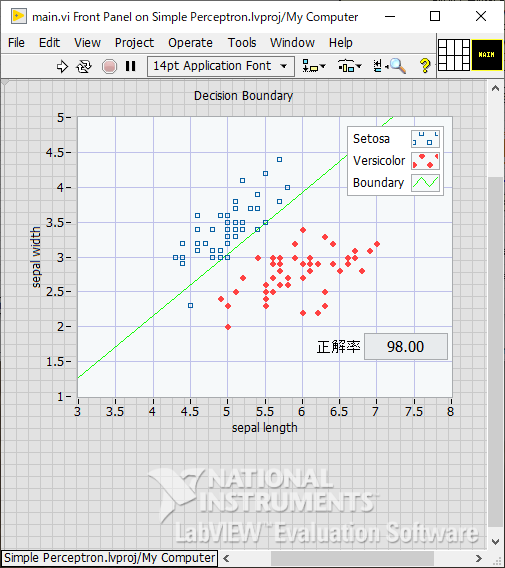
LabVIEWを使って単純パーセプトロンによる分類をやってみた
本記事の内容
LabVIEW Community Editionを使い、Irisデータセットに対して、単純パーセプトロンによる分類をおこないました。
下記サイトをゴッソリ参考にさせていただき、標準関数のみを使用して分類処理を作成しています。"機械学習の元祖「パーセプトロン」とは?"
https://rightcode.co.jp/blog/information-technology/simple-perceptron処理の流れ
次の流れで処理をおこなっています。
1.データセットの読込、2.教師データの作成、3.散布図用データの作成、4.確率的勾配降下法による重みの更新、5.境界直線データの生成
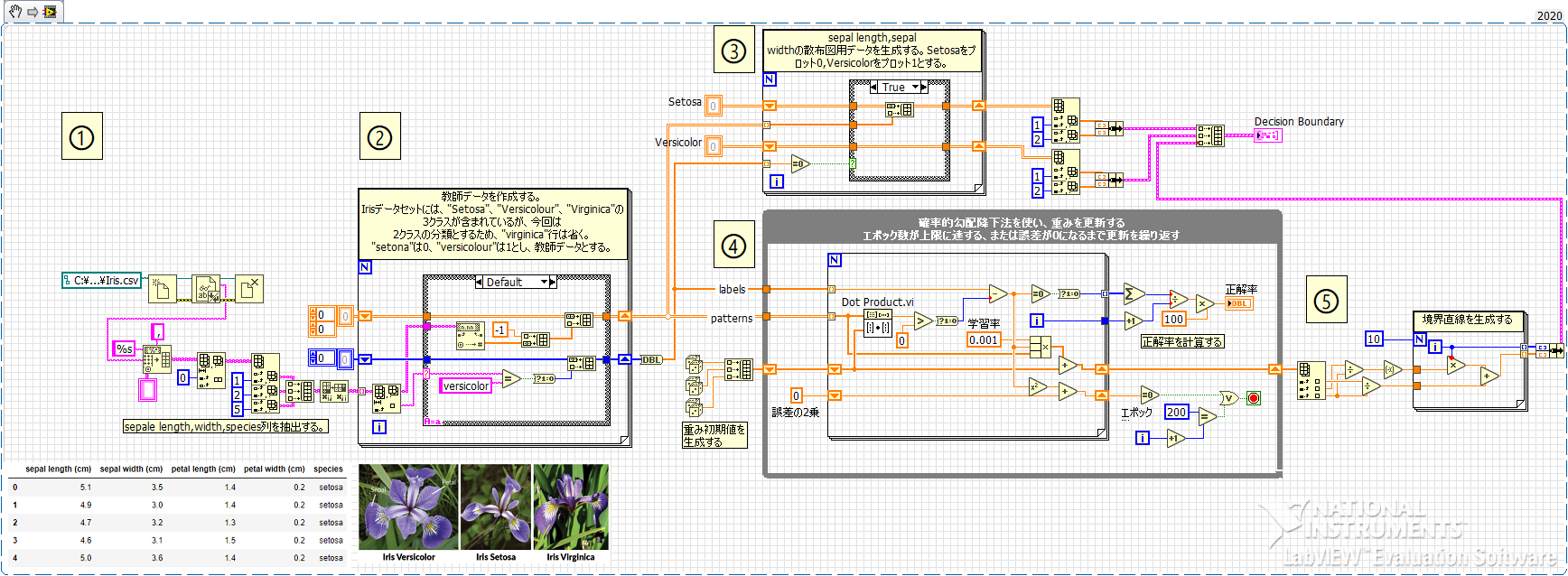
順番に処理を説明します。1.データセットの読込
あらかじめ下記処理で保存しておいたCSVファイルを読み込みます。
Irisデータセットは4次元のデータですが、結果のプロットを簡単にするため、sepal lenght(cm)とsepal width(cm)の2つのデータをのみを使用します。from sklearn.datasets import load_iris import pandas as pd iris = load_iris() iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) iris_df["species"] = [iris.target_names[i] for i in iris.target] iris_df.to_csv("./Iris.csv")
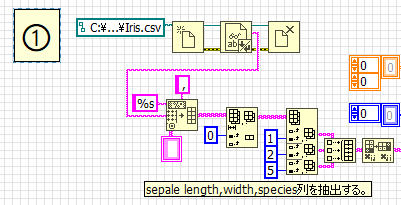
2.教師データの作成
2クラス分類とするため、virginica行を削除して教師データを作成しています。setonaは0、versicolorは1とラベリングします。
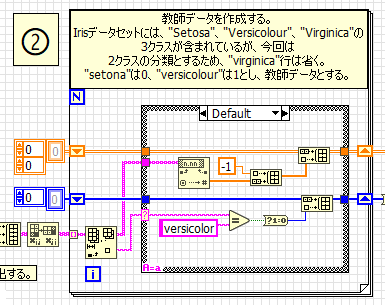
3.散布図用データの作成
Sepal lenghおよびSepal widthを要素とするクラスタを、SetosaとVersicolorそれぞれで作成し、Build array関数で結合した後でXYグラフへ入力することによって、プロットを分けてグラフ表示することが可能となります。
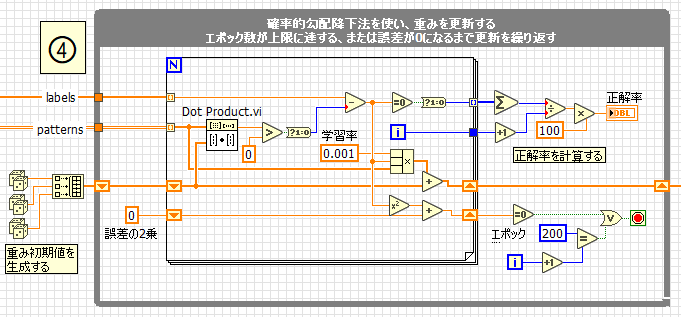
4. 確率的勾配降下法による重みの更新
-w0 + w1 × Sepal length + w2 × Sepal width をstep関数(0より大きければ1を、それ以外は0を出力)に入力した値がラベリングした値と一致するように、重みw0,w1,w2を更新する。 誤差が0になるか、エポック数が上限に達するまで処理を繰り返します。
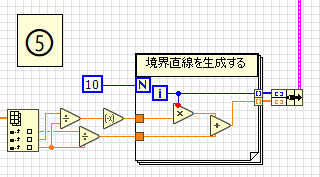
5.境界直線データの生成
重み値を使って境界直線データを生成します。
ループ回数10回は適当に決めた値です。
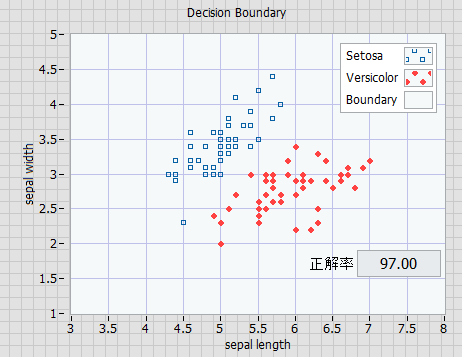
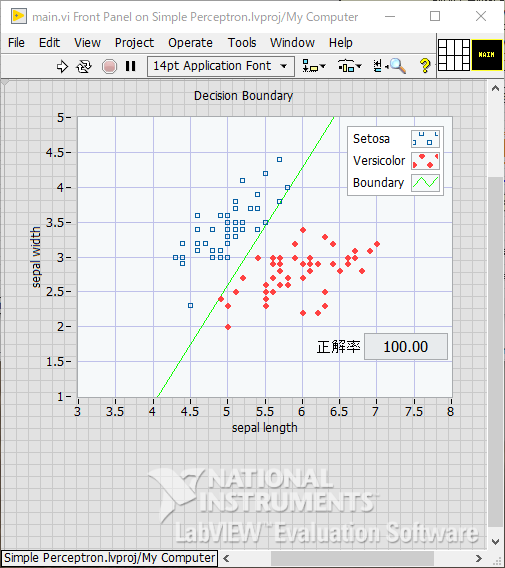
結果
エポック数の上限を200とすることで、繰り返し試行した場合においても正解率はほぼ100%となりました。
まれに100%未満となる。重みの初期値によって結果が変わります。
おわりに
本記事ではLabVIEWを使ってパーセプトロンによる分類をおこないました。
LabVIEWの標準関数を使用することでまったく問題なく処理を実装することができました。
- 投稿日:2021-01-24T20:54:09+09:00
PythonのスクレイピングでJリーガーの個人能力値をエクセルに書き出してみた
Pythonの勉強がてら、大好きなJリーグに関連するデータをスクレイピングにより取得してみました。
Mac
Python 3.6.5プログラム
Football LABには、チームデータから選手個人の細かいデータが掲載されているので、ここからデータを取得しました。
https://www.football-lab.jp/
今回は、こちらの表をエクセルに書き出していきます。
スクレイピングに必要な情報は、Chromeのデータソース表示から取得します。
早速ですが、実行コードはこちらです。
import sys import openpyxl as px import requests from openpyxl.styles import PatternFill from bs4 import BeautifulSoup def teamcrawling(division): if division == 'J1': id = '#footerj1' elif division == 'J2': id = '#footerj2' elif division == 'J3': id = '#footerj3' req = requests.get('https://www.football-lab.jp/') top_soup = BeautifulSoup(req.text, 'html.parser') html_attributes = top_soup.select('{} li a'.format(id)) team_permalinks = [] for ha in html_attributes: team_permalinks.append(ha.get('href').strip('/')) return team_permalinks def pagecrawling(soup): table = soup.select('.statsTbl10 tr') standing = [] for row in table: tmp = [] for item in row.find_all('td'): if item.a: tmp.append(item.text[0:len(item.text)]) else: tmp.append(item.text) standing.append(tmp) #配列の要素数をカウント length = len(standing) #開始位置を指定 n = 0 #分割する変数の個数を指定 s = 16 #配列を指定した個数で分割していくループ処理 for i in standing: # print(standing[n:n+s:1]) n += s #カウント数が配列の長さを超えたらループ終了 if n >= length: break del standing[0:2] # チーム名を取得する team_name = soup.find('div', id='teamHeader').find('span', class_='jpn').text data = { team_name: standing } return data def write_excel(team_data_list): # エクセルを取得 wb = px.Workbook() ws = wb.active # エクセル2行目以降に取得したデータを出力 for i, data in enumerate(team_data_list): for team_name, player_data in data.items(): # データを出力するチーム名のシートを作成 wb.create_sheet(title=team_name) ws = wb[team_name] # エクセル1行目のヘッダーを出力 headers = ['ポジション', '背番号', '選手名', '出場', '先発', '出場時間', '攻撃', 'パス', 'クロス', 'ドリブル', 'パスレシーブ', 'シュート', 'ゴール', '奪取', '守備', 'セーブ'] for i, header in enumerate(headers): # ヘッダー値を設定 ws.cell(row=1, column=1+i, value=header) # セルを塗りつぶす fill = PatternFill(patternType='solid', fgColor='e0e0e0', bgColor='e0e0e0') ws.cell(row=1, column=1+i).fill = fill for n, pd in enumerate(player_data): for y, d in enumerate(pd): ws.cell(row= 2+n, column= 1+y, value= d) # 不要なSheetシートを削除 del wb['Sheet'] # エクセルファイルの保存 filename = 'J_player_data.xlsx' wb.save(filename) def main(): divisions = { 1: 'J1', 2: 'J2', 3: 'J3' } print('データを取得したいリーグを選択してください。') for key, value in divisions.items(): print('{0}: {1}'.format(key, value)) try: user_input = int(input()) except KeyboardInterrupt: sys.exit() try: team_permalinks = teamcrawling(divisions[user_input]) except: print('半角で「1」「2」「3」のいづれかを入力してください。') sys.exit() team_data_list = [] for tp in team_permalinks: url = 'https://www.football-lab.jp/' + tp; r = requests.get(url) soup = BeautifulSoup(r.text, 'html.parser') # 各チームのデータを「team_data_list」に格納 team_data_list.append(pagecrawling(soup)) # エクセルデータを作成 write_excel(team_data_list) if __name__ == '__main__': main()必要なライブラリをインストールして、
python ファイル名で実行すると、J1〜J3のどのリーグの選手データを取得するか問われます。
例えば、J1を選択するだけで、自動的でチーム名を取得して、各チームごとにシートを作成し、そこに選手データを書き出します。
こんな感じで一気に選手データを取得できました。
今後は、機械学習でこのようなデータをどのように活用できるかを勉強していきたいと思います。
サッカー好きエンジニアに役立てれば幸いです。




- 投稿日:2021-01-24T20:42:26+09:00
コーディングテストの前に解くべき10のアルゴリズム問題
10 Algorithms To Solve Before your Python Coding Interviewという記事が良記事だったので、オリジナルの物も含めてアウトプットしたいと思います。ソースコードはこちらです。
Strings Manipulation
1. Reverse Integer
# Given an integer, return the integer with reversed digits. # Note: The integer could be either positive or negative. def solution(x): string = str(x) if string[0] == '-': return int('-'+string[:0:-1]) else: return int(string[::-1]) print(solution(-231)) # => -123 print(solution(345)) # => 543文字列を逆順にして出力する問題です。pythonにおけるスライスの使い方がキーとなります。スライスの基本構文は
s[<start>:<end>:<step>]となり、値が0の場合は省力できます。したがって、文字列を逆順にしたいときはs[::-1]となります。以下が使用例です。>>> word = 'python' >>> word[0:2] 'py' >>> word[:2] 'py' >>> word[2:] 'thon' >>> word[::-1] 'nohtyp' >>> word[:0:-1] 'nohty' >>> word[:] 'python'また、文字列を別の文字列に変えたい場合は元の文字列をコピーして付け足します。(以下、
pythonをjsonに変える例)>>> word 'python' >>> word[0:4] = 'js' <= このような書き方はできない! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment >>> word = 'js' + word[4:] >>> word 'json'2. Average Words Length
# For a given sentence, return the average word length. # Note: Remember to remove punctuation first. sentence1 = "Hi all, my name is Tom... I am originally from Australia." sentence2 = "I need to work very hard to learn more about algorithms in Python!" def solution1(sentence): for p in "!?',;.": sentence = sentence.replace(p, '') words = sentence.split() sum = 0 for word in words: sum += len(word) return round(sum / len(words),2) # solution1をリファクタリング def solution2(sentence): for p in "!?',;.": sentence = sentence.replace(p, '') words = sentence.split() return round(sum(len(word) for word in words)/len(words),2) # mapメソッドを使う方法 def solution3(sentence): for p in "!?',;.": sentence = sentence.replace(p, '') words = sentence.split() return round(sum(map(len, words))/len(words), 2) print(solution1(sentence1)) # => 3.82 print(solution1(sentence2)) # => 4.08mapメソッド
ここで
mapメソッドについて見ていきましょう。mapメソッドは、『リストやタプルの要素を順に処理して新たなオブジェクトとして取得する』ための関数です。以下の形式で使用します。map(関数, イテレート可能なオブジェクト)これによってfor文などを使わずにリストやタプルの中身をまとめて計算することができ、そのスピード自体も速くなるみたいです。1
ラムダ式やlist関数とセットで使うことが多いようです。以下は「ECサイトにおいて買い物かごの合計価格を消費税込みで取得する」といったときの計算にmapメソッドを使う例です。>>> basket = {"pen": 100, "notebook": 300, "eraser": 200, "textbook": 1000} >>> sum_with_tax = sum(map(lambda price: price*1.1, basket.values())) >>> sum_with_tax 1760.03. Add Strings
# Given two non-negative integers num1 and num2 represented as string, return the sum of num1 and num2. # You must not use any built-in BigInteger library or convert the inputs to integer directly. #Notes: #Both num1 and num2 contains only digits 0-9. #Both num1 and num2 does not contain any leading zero. num1 = '364' num2 = '1836' # Approach 1: def solution(num1,num2): eval(num1) + eval(num2) return str(eval(num1) + eval(num2)) print(solution(num1,num2)) #Approach2 #Given a string of length one, the ord() function returns an integer representing the Unicode code point of the character #when the argument is a unicode object, or the value of the byte when the argument is an 8-bit string. def solution(num1, num2): n1, n2 = 0, 0 m1, m2 = 10**(len(num1)-1), 10**(len(num2)-1) for i in num1: n1 += (ord(i) - ord("0")) * m1 m1 = m1//10 for i in num2: n2 += (ord(i) - ord("0")) * m2 m2 = m2//10 return str(n1 + n2) print(solution(num1, num2))4. First Unique Character
標準ライブラリを使わない場合
# Given a string, find the first non-repeating character in it and return its index. # If it doesn't exist, return -1. # Note: all the input strings are already lowercase. def solution1(word): frequency = {} for i in word: if i not in frequency: frequency[i] = 1 else: frequency[i] +=1 for i in range(len(word)): if frequency[s[i]] == 1: return i return -1 print(solution1('alphabet')) # => 1 print(solution1('barbados')) # => 2 print(solution1('ppaap')) # => -1ある文字列に対して最初のユニークな文字のインデックスを、なければ-1を返すプログラムです。
frequencyという空のdictを定義し、文字列をfor文で回し、キーの重複がなければバリューに1を持たせて追加し、重複があれば(すでに1以上のバリューが入っているとき)バリューに1を足します。setdefault
上記の作業はdictに定義されている
setdefault関数を使えば簡潔に書けます。setdefaultは以下のようにキーと初期値を引数に持ち、キーが存在しれいればそのバリューを返し、初期値をバリューとして新たに要素を追加します。『居酒屋さんで最初の飲み物を注文、基本はビール』みたいな場面で使えます。>>> order = {'Alice': 'beer', 'Bob': 'water', 'Mike': 'beer'} >>> order.setdefault('Bob', 'beer') 'water' >>> order.setdefault('Pence', 'beer') 'beer' >>> order {'Alice': 'beer', 'Bob': 'water', 'Mike': 'beer', 'Pence': 'beer'} >>> order.items() dict_items([('Alice', 'beer'), ('Bob', 'water'), ('Mike', 'beer'), ('Pence', 'beer')])defaultdict([default_factory[, ...]])2
pythonの標準ライブラリ、collectionsに定義されている
defaultdictを使うとdictのような振る舞いをするオブジェクトを生成することができます。このdefault_factoryにlistを用いると先ほどのキーバリューの組み合わせを簡単にグループ分けし、dictの形式で返すことができます。>>> from collections import defaultdict >>> d = defaultdict(list) >>> for k, v in order.items(): ... d[v].append(k) ... >>> d defaultdict(<class 'list'>, {'beer': ['Alice', 'Mike', 'Pence'], 'water': ['Bob']}) >>> len(d["beer"]) 3 >>> sorted(d.items()) [('beer', ['Alice', 'Mike', 'Pence']), ('water', ['Bob'])]Counter([iterable-or-mapping])3
最後に
collectionsに定義されているCounterクラスによる実装を紹介します。Counterはdictのサブクラスでキーに要素を、バリューにその個数を保存します。>>> cnt = Counter() >>> for word in ['red', 'blue', 'red', 'green', 'blue', 'blue']: ... cnt[word] += 1 >>> cnt Counter({'blue': 3, 'red': 2, 'green': 1})標準ライブラリを使ってリファクタリング
setdefaultを使う方法をsolution2,defaultdictを使う方法をsolution3,Counterを使う方法をsolution4とします。import collections def solution2(word): frequency = {} for i in word: frequency.setdefault(i, 0) frequency[i] += 1 for i in range(len(word)): if frequency[word[i]] == 1: return i return -1 def solution3(word): frequency = collections.defaultdict(int) for i in word: frequency[i] += 1 for i in range(len(word)): if frequency[word[i]] == 1: return i return -1 def solution4(word): # build hash map : character and how often it appears count = collections.Counter(word) # <-- gives back a dictionary with words occurrence count #Counter({'l': 1, 'e': 3, 't': 1, 'c': 1, 'o': 1, 'd': 1}) # find the index for idx, ch in enumerate(word): if count[ch] == 1: return idx return -15. Valid Palindrome
# Given a non-empty string s, you may delete at most one character. Judge whether you can make it a palindrome. # The string will only contain lowercase characters a-z. s = 'radkar' def solution(s): for i in range(len(s)): t = s[:i] + s[i+1:] if t == t[::-1]: return True return s == s[::-1] print(solution(s)) # => TrueArrays
6. Monotonic Array
# Given an array of integers, determine whether the array is monotonic or not. A = [6, 5, 4, 4] B = [1,1,1,3,3,4,3,2,4,2] C = [1,1,2,3,7] def solution1(nums): return (all(nums[i] <= nums[i + 1] for i in range(len(nums) - 1)) or all(nums[i] >= nums[i + 1] for i in range(len(nums) - 1))) def solution2(nums): return nums == sorted(nums) or nums == sorted(nums, reverse=True) print(solution1(A)) # => True print(solution1(B)) # => False print(solution1(C)) # => Trueこの問題でのポイントはallメソッドです。
all(iterable)と使い、iterableの全ての要素が真ならTrueを返します。反対のメソッドにanyメソッドというのもあります。また、この問題のように降順、昇順に並び替えるというのはsolution2のようにsorted()を使えば簡単にできます。7. Move Zeroes
#the non-zero elements. array1 = [0,1,0,3,12] array2 = [1,7,0,0,8,0,10,12,0,4] def solution1(nums): for i in nums: if 0 in nums: nums.remove(0) nums.append(0) return nums def solution2(nums): new_nums = [num for num in nums if num != 0] for i in range(nums.count(0)): new_nums.append(0) return new_nums def solution3(nums): zeros = [] non_zeros = [] for n in nums: if n == 0: zeros.append(n) else: non_zeros.append(n) return non_zeros + zeros print(solution1(array1)) # => [1, 3, 12, 0, 0] print(solution1(array2)) # => [1, 7, 8, 10, 12, 4, 0, 0, 0, 0]
removeとappendを適切に使うことで0を配列の最後に、それ以外の要素の配置を変えないように並び替える問題です。array.remove(x)で最初のxのみを消去、array.append(x)で配列の最後にxを挿入します。8. Fill The Blanks
# Given an array containing None values fill in the None values with most recent # non None value in the array array1 = [1,None,2,3,None,None,5,None] def solution1(array): valid = 0 res = [] for i in array: if i is not None: res.append(i) valid = i else: res.append(valid) return res def solution2(array): last = 0 for i in range(len(array)): if array[i] is None: array[i] = last else: last = array[i] return array print(solution1(array1)) # => [1, 1, 2, 3, 3, 3, 5, 5]9. Matched & Mismatched Words
#Given two sentences, return an array that has the words that appear in one sentence and not #the other and an array with the words in common. sentence1 = 'We are really pleased to meet you in our city' sentence2 = 'The city was hit by a really heavy storm' def solution(sentence1, sentence2): set1 = set(sentence1.split()) set2 = set(sentence2.split()) return sorted(list(set1^set2)), sorted(list(set1&set2)) print(solution(sentence1, sentence2)) # => (['The', 'We', 'a', 'are', 'by', 'heavy', 'hit', 'in', 'meet', 'our', 'pleased', 'storm', 'to', 'was', 'you'], ['city', 'really'])二つの文章の単語から「どちらか一方に含まれる単語」と「共通して含まれる単語」を配列にして返すという問題です。このように「かつ」、「または」という問題は
setクラスで集合の概念を使います。以下、SNSで「共通の友達を探す」といった場面です。>>> my_friends = {"A", "C", "D"} >>> A_friends = {"B", "D", "E", "F"} >>> my_friends & A_friends {'D'}10. Prime Numbers Array
# Given k numbers which are less than n, return the set of prime number among them # Note: The task is to write a program to print all Prime numbers in an Interval. # Definition: A prime number is a natural number greater than 1 that has no positive divisors other than 1 and itself. n = 35 def solution(n): prime_nums = [] for num in range(n): if num > 1: # all prime numbers are greater than 1 for i in range(2, num): if (num % i) == 0: # if the modulus == 0 is means that the number can be divided by a number preceding it break else: prime_nums.append(num) return prime_nums solution(n)参考文献
- 投稿日:2021-01-24T20:25:20+09:00
pydicomで圧縮されたDICOM画像を見る
目的
圧縮されたDICOM画像をpydicomで読み込み表示させる.
普通にpydicomで圧縮されたDICOM画像を読み込もうとすると,以下のようなエラーを吐いたので参考までに.エラーに対する解決方法を書きましたが読むのが面倒くさい方は,
面倒な人向けと環境に載っているものと同じバージョンのライブラリをインポートして完成版でコンパイルしてみてください.環境
・Windows 10
・Visual Studio Code・pip 21.0
・numpy 1.19.5
・matplotlib 3.3.1
・Pillow 7.2.0
・opencv-python 4.4.0.42
・pydicom 2.1.2
・pylibjpeg 1.1.1
・pylibjpeg-libjpeg 1.1.0
・pylibjpeg-openjpeg 1.0.1注意事項
Macでも同じことをしようとしましたが,gdcmがインポートできませんでした.
調べたら他に方法があるかもしれないので,見つけた方はぜひ教えて下さい.エラー内容
1つ目のエラー
`RuntimeError: The following handlers are available to decode the pixel data however they are missing required dependencies: GDCM (req. GDCM)`コマンドプロンプトで
pip install gdcmをインポートで解決
2つ目のエラー
`RuntimeError(msg + ', '.join(pkg_msg))`コマンドプロンプトで
pip install pylibjpegをインポートで解決
3つ目のエラー
`ImportError: DLL load failed: 指定されたモジュールが見つかりません。`コマンドプロンプトで
pip install pylibjpegをインポートしてコンパイルしたところ3つ目のエラーが...
いろいろ調べて試した結果,pydicomのバージョンをアップデートしたところ治りました.コマンドプロンプトで
pip install -U pydicomを入力
私の場合,pydicom-2.0.0 → pydicom-2.1.2にバージョンアップしました.もう一度,コンパイル.
ここで,pylibjpeg-libjpegのモジュールが無いと言われたら,コマンドプロンプトでpip install pylibjpeg-libjpegを入力し,もう一度コンパイル.これで無事,画像が表示されました!
面倒な人向け
コマンドプロンプトでとりあえず以下を入力しておく.
1.pip install pydicom
2.pip install numpy
3.pip install matplotlib
4.pip install gdcm
5.pip install pylibjpeg
6.pip install pylibjpeg-libjpeg
7.pip install Pillow
8.pip install opencv-python完成版
import pydicom import numpy as np from matplotlib import pyplot as plt import pylibjpeg path = "パスを入力" compressed_Data = pydicom.read_file(path) #表示 plt.imshow(compressed_Data.pixel_array, cmap = "gray") plt.show()
- 投稿日:2021-01-24T19:01:17+09:00
高画質なGANでいろいろ生成してみた(ポケモン、ピカチュウ、漢字、動物)【Colab付】
GANとは
GANというのは、Generative Adversarial Network (敵対的生成ネットワーク) の略です。
簡単に言うと、AIどうしを戦わせて、画像や音声などを生成する技術です。
より詳しく説明すると、AIを2つ用意して、一方に画像などの生成をさせる役 (generatorと呼ばれる)、もう一方は画像が本物か生成されたものかを判別する役 (discriminatorと呼ばれる)をさせます。理論的なところを知りたい方は、こちらのシリーズの記事が非常にわかりやすかったです。
今さら聞けないGAN(1) 基本構造の理解PGGANとは
その中でも、PGGANを使いました。
PGGANはProgressive Growing GANの略で、Progressive GANとも呼ばれます (GitHubの検索とかのときのために統一してほしい...)。
画質を少しずつ向上させることによって、以前のものより高画質な画像を生成できるようになります。こちらのサイトが、実例付きで非常にわかりやすいと思います。
メルアイコン生成器 version2を作った話作品集
あまり、GANで色々つくってみたみたいな記事が存在しなかったので、自分でつくってみました。
とりあえず、今のGANがどれだけのものを生成できるのかを見てほしいです。
しかも、個人で画像仕分けができる程度の300~1000枚程度しか画像を用意してません。
本来、GANの研究とかだと1万枚から100万枚程度、あるいはそれ以上の画像を使うので、精度はあまり期待しないでください...
一番下に作り方とか載せるので、作りたくなったらまねしてみてください!一番末尾に実際に用いたコード(Colab)を載せているので最後まで見ていってくださいm(_ _)m
下では学習順 (PGGANなので画質が低い順) に並べてあります。
ポケモン
https://bohemia.hatenablog.com/entry/2016/08/13/132314
https://www.monthly-hack.com/entry/201612170000
https://tech.ledge.co.jp/entry/2020/07/02/120000
などなどあるように、n番煎じ(特に1番上すごい)ですが、画質が低いGANが多かったので、PGGANで画質上げたれって感じでやりました!公式イラストを使いました。ダウンロードした際に、外縁の透過部分が白だったり黒だったりしてたみたいで、白い枠が残ってしまっています。申し訳ないです(前処理しろ)。
↓これをもとに絵を描けそう!!
左の真ん中の
とか
とか。好みが出ますが(笑)
こいつもかっこいい。
ここにはいないけど、
こいつも結構お気に入り。とさかとくちばしと、ちょっとぽっちゃりなのがかわいい。ピカチュウ
技術が上がっているので、https://www.inoue-kobo.com/ai_ml/gan-pikachu/index.html より精度があげられるといいなという目標で。
ネット上の様々なイラストを使わせていただきました。ありがとうございます。
そこそこだけど、かわいいのが描けて嬉しい。
アンノーン
画像が28枚しか用意できない状況で、どうなるかというのも興味があったので(オーグメンテーションしてもよかったが、あまり効果ない気がする)
集合体恐怖症の方は、ちょっと飛ばしてください。ごめんなさい。↓実在するアンノーンが多いですが、アンノーンBの下の穴にも目がある... Vと混ざっていそうです。
↓モード崩壊(同じような画像ばかり生成されてしまうGANの学習失敗パターンの一例)してしまった...画像28枚は無理か...
↓回転させた画像なども加えて再チャレンジ
↓結局モード崩壊した...
ひらがな
文字をGANに読み込ませたらどうなるんだろうと。単純な興味です。
学習させたのは、PCに入っている明朝フォントのデータです。
https://github.com/uchidalab/font2img で、pngに変換しました。
なるほどなあ(語彙力)。実在するひらがなが多めですね。
似たような字があるときに、あいまいに書いてることがあっておもしろいです。さ、ち、ろとか。は、ほ、まとか。
でも、逆向きの字が出てくる理由がわかりません。データセットには逆向きの字は与えていません(コード内で勝手に鏡像反転して学習してる説がある)。カタカナ
同じく実在するカタカナか、それに近い文字が多いですね。
てか〃と゜が多すぎる。〃つければ、カタカナっぽくてdiscriminatorを騙せるということでしょうか??
時々、三つ〃をつけてるの面白いですね!笑
あと、セが苦手??ヒと混ざってる?アルファベット
フォントはCenturyです。
↓キリル文字感がすごい。
↓gがたいへんなことに
なるほど。アルファベットどうしが結構混ざるようです(さっきのはaとgとuが混ざっていたのですね)。あと、震えた手で書いているような揺らいだ感じになるのも興味深いですね。
漢字
JIS規格のすべての漢字
縦横にたくさん書けば、discriminator騙せると思ってるでしょ。
常用漢字のみ
すべての漢字だと複雑すぎるのかなと思って、常用漢字だけにしました。多少簡単な字も入ってきたかもしれないけど、それでもこれです笑
古文書
漢字の画像データは漢字字体規範史データセットからいただきました。本当にありがとうございます。
ノイズが多かったので、前処理しています(参考: 画像のノイズ除去)。
昔の人の達筆の字っぽい。本物だと言われたら、信じる。
虎
Google検索で虎、トラ、tigerを検索して画像を集めました (詳細は後で説明)。以降は同様に画像を集めています。
顔の特徴がとらえられるようになっていくのが、わかると思います!
どうでもいい話ですが、Googleでtigerを検索してダウンロードしていたのですが、タイガーウッズ氏の画像も一緒にダウンロードされたので、仕分けしながら笑ってました。
キツネ
アイコンにしてるくらい好きなので。
いろんな顔のキツネがいて結構難しかった。
野菜
それっぽくはあるけど、よく見ると荒い。
夜景
あまりうあまくいっていませんが、水面に写るビル群みたいな画像もありますね(一番上の左から4番目とその2個下など)。画像がもっとほしい。
初心者でも簡単にGANを作る方法
ここまで、紹介してきたGANですが、Google Colaboratoryを使うことで、いずれもみなさんのPCで簡単・無料で作ることができます。所要時間はColabの連続使用の制限により2~3日間程度です。
画像を集める方法(インターネット検索)
Colabで利用可能なものをご用意しました。google images downloadを利用していますが、現在300枚程度を上限にそれ以上ダウンロードできないバグが発生しているようです (直し方がわかる方は教えて下さると助かります)。
https://colab.research.google.com/drive/1igIULkva1BjKg62WfFK6p7Rv1UOEpzIj?usp=sharingGANを学習させる
GANは自分で実装してもいいですが(勉強にもなるし)、今回は、ネット上に公開されているものを用います。
PGGANは、progressive gan pytorchまたはpggan pytorchと検索すると色々出てくるので、お好きなものを使ってください(PyTorchでなくても大丈夫です)。
私は初心者に優しそうな
https://github.com/odegeasslbc/Progressive-GAN-pytorch
を使いました。フォルダに入れておけば全部自動でやってくれるので。
少しいじってみた感じ、デフォルトのハイパーパラメータが一番よさそうです。
Colabの雛形も用意しておくので、ご自由にご利用ください。
https://colab.research.google.com/drive/1k6eq9GxYDxr74f-yxOxf2AFQBDLzesvR?usp=sharing次回予告?
今までは、PGGANを用いてきましたが、より新しいStyleGANを用いたほうが精度があがるかもしれません ( やや複雑な仕組みになっていて、画像を増やさないと変えても意味がないかもしれませんが...)。時間ができたら、またそちらを用いた方法も紹介したいなと思っております。





























- 投稿日:2021-01-24T18:59:58+09:00
【Python】リスト結合_備忘録
【構文】joinメソッド
i.join(iterable)
i:区切り文字
iterable:連結対象のリストdata = ['りんご','ゴリラ','ラッコ','コアラ'] print('⇒ '.join(data)) #結果:りんご⇒ ゴリラ⇒ ラッコ⇒ コアラdata1 = [1,2,3,4] print('⇒ '.join(data)) #結果:TypeError: sequence item 0: expected str instance, int found数値型リストをそのまま連結することができないためstr型に変更する必要がある。
※リスト内包表記data1 = [1,2,3,4] print('の'.join([str(i) for i in data1]))
- 投稿日:2021-01-24T18:38:05+09:00
Pythonのunittestで「Exception has occurred: SystemExit」が出る
Pythonのunittestで「Exception has occurred: SystemExit」が出たときの対応。
エラーが出る理由
文法等に誤りがあるわけではなく、例えば、デバッグモードで起動する等実行環境に問題があると、このエラーが出ます。unittestではデバッグモードで起動されることを想定していないようです。
デバッグなしで起動するとこのエラーは出てきません。デバッグモードでもエラーをなくす方法
if __name__ == "__main__": unittest.main()これを
if __name__ == "__main__": unittest.main(exit=False)に書き換えるとエラーが出なくなります。
参考URL
https://stackoverflow.com/questions/9202772/tests-succeed-still-get-traceback
- 投稿日:2021-01-24T17:54:54+09:00
【Python】Atomで競技プログラミング用、linterの導入(警告非表示))【Mac】
【Python】Atomで競技プログラミング用の環境構築(input()使えます!)【Mac】
〜こちらの記事の続き〜
別に単体の記事としても成立します。linterを導入したい。
linterとは静的エラーチェックをいろいろやってくれるやつ。
デバッグ実行時前に、単純なスペルミスや構文チェックができたら嬉しい。いろいろググったら、pylintというのがいいらしんだが、
pylintを導入すると、規約どおりのコードではない!と不要な警告が出まくるらしい。
競技プログラミングのコードは、規約に従ってなくても問題ないし、
- 単純なスペルミスや構文チェック
このチェックだけがしたい。
警告非表示とかでググっても、「pylintrc」ファイルをいじってねという記事しか見つからず、いじっても全然うまくいかなかったw
他いろいろググっても解決方法が見つからなかったので記事にしておく。手順
①linter-pylamaをatomからインストール。
②Ignore Errors And Warningsの箇所で、「W,C」と入力。
③Use PyLint のみにチェック、それ以外はチェック外す。以上!!!
なんかエラーが出たら、前提となるものが色々足りないので、適当にインストールすればOK。
(atomでのパッケージインストール→linter、pip→pylamaとかそのあたり。ググればいろいろでてくる)実際の動き
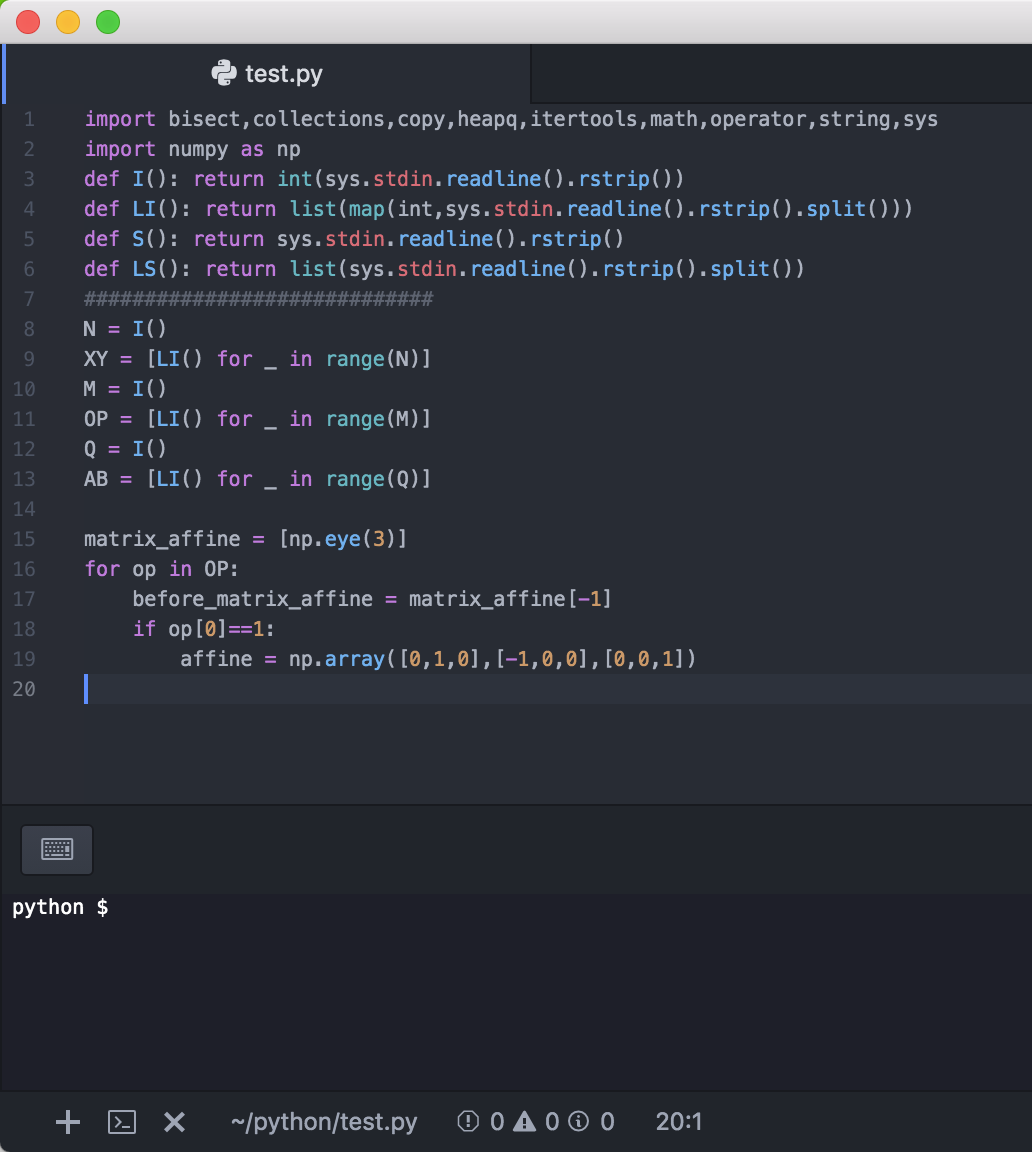
通常
警告0件。なんかスペルミスしてみる。
ファイルを保存したタイミングで、スペルミスの箇所が赤波線で表示された。
フッタをみると、エラーが1件と表示されている。
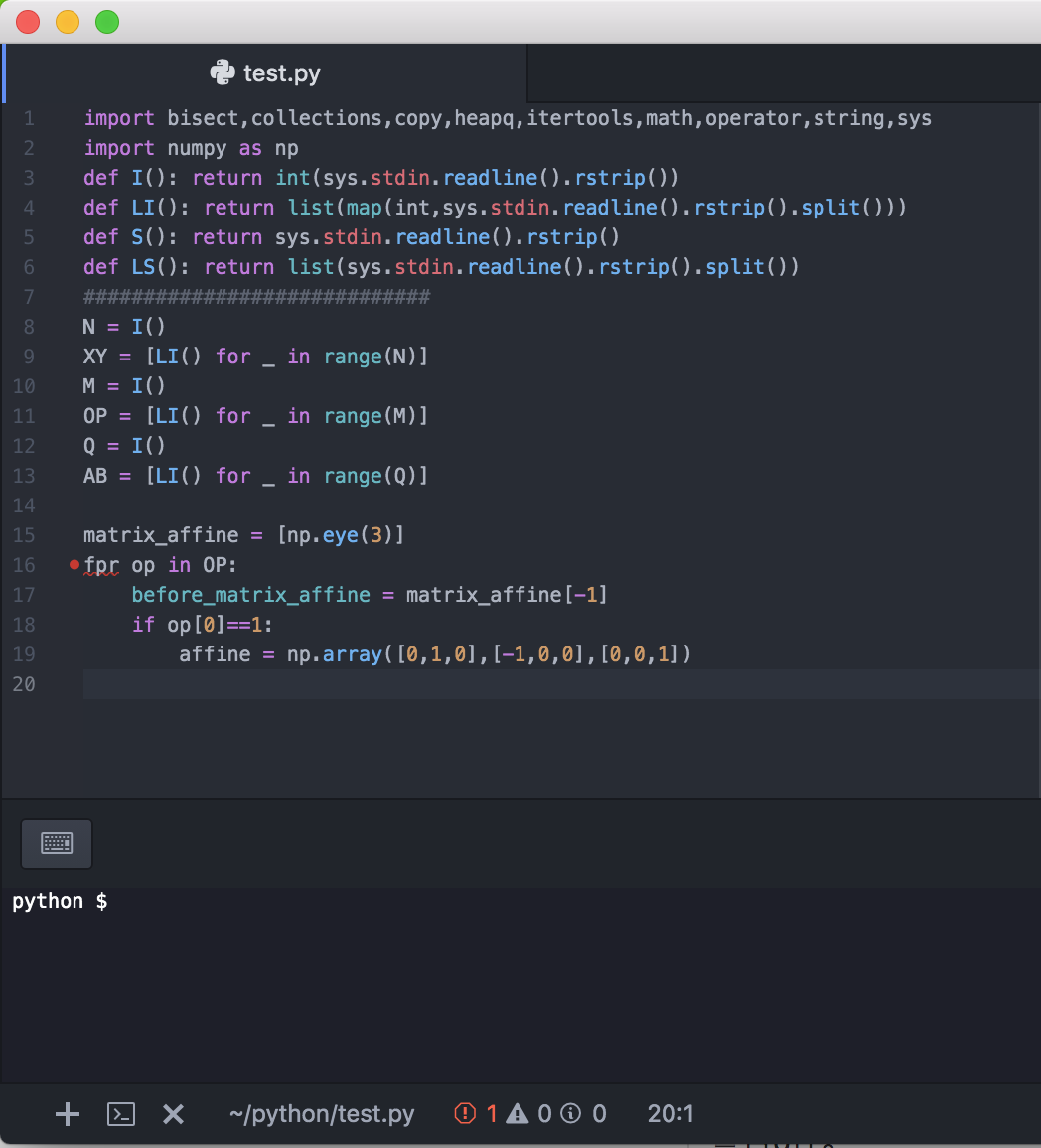
if文の最後にコロン忘れた。
赤波線の行を疑えばコロンミスに気付く。
以上!!!
- 投稿日:2021-01-24T17:40:36+09:00
Rhinoceros + Grasshopper + Pythonではじめる3Dモデリング
はじめに
最近、3DモデリングツールであるRhinocerosを使って遊んでいます。自分はデザイン全くわからないマンなのですが、サンプルを引っ張ってくるとそれなりに綺麗なものができるので、楽しいです。
※Rhinoceros公式より拝借今回の記事は、3DモデリングツールであるRhinocerosと、そのプラグインGrasshopper、そしてPythonを使って、3Dモデリングのチュートリアル的な内容を書きました。
お断りなのですが、自分自身は全くのデザイン初心者かつ、今回紹介するツールの熟達者ではありません。ですが、ツールを全く触ったことのない方でも比較的簡単な入門の記事として書いたので、読んでいただけると幸いです。
この記事を読んで3Dモデリングの世界に一歩踏み込んでいただけたらなと思います。
想定読者
Robert McNeel & Associatesが開発している、デザイン性の高い3次元モデルデータを作成できる3Dモデリングソフトウェア。機械設計、金型設計、試作、製造、建築、宝飾、マルチメディア、FEM・CFD等解析などマルチに使われているそうです。
公式ページにギャラリーがあります。とにかくいろいろできる。
※建築レンダリングモデルサンプル より
ガッチガチに建築レンダリングもできます。すごい。
Grasshopperとは
Rhinoceros上で動作するプラグインのモデリング支援ツール。電池みたいなコンポーネントをガッションガッション組み合わせることで、幾何学模様などを表現できます。
質量・速度・摩擦・風などの力学的な法則もシュミレートでき、屋内の日当たり分析や室温・風環境を解析したりもできるそう。友人はこれで卒業制作で作った建造物の日光シュミレートをしていて、隣から見てすげー、となっていました。
Rhinoceros / GrasshopperでPython?
二つのツールを使うことで、モデリングが可能です。が、本業はエンジニアなので、ぽちぽちコンポーネントを組み合わせるのではなく、コーディングである程度デザインができると嬉しい。
なんと、RhinocerosやGrasshopperではプログラミング言語によるコーディングがサポートされています。既存コンポーネントではデザインが難しい場合、プログラムを自分で書くことでコンポーネントを自作でき、より自由度の高いデザインが可能になります。
全て把握できませんでしたが、調べた限りでは
C#やVisual Basic、Pythonが正式サポートされているみたいです。この記事では、使用人口が多い
Pythonを扱おうと思います。補足:pythonの実行環境について
ここで、Rhinoceros / GrasshopperでPythonを使う方法は大きく分けて二通りあります。
- Rhinocerosの
EditPythonScriptにPythonコードを書き、Rhinocerosでスクリプトを直接走らせる- GrassHopperのプラグイン
Gh_CPythonを通して、Grasshopper上でPythonを実行させる1はPython2系のため、普段、python3.xxを使っている方はとっつきにくいかもしれません。
(Rhinoの実行環境は .NET Frameworkで、相性がいいironPythonが走る。ironPythonはまだPython3.xxをサポートしていない)Rhinoceros 6からGrasshopperが標準搭載されたこともあり、現在は2.のGH_CPythonがスタンダードかも?今回の記事も、2.の方法でPythonを実行していきます。
参考:RhinocerosとGrasshopperでPythonを使う方法
チュートリアル
用語の説明が終わったところで、今回の記事では
Rhinoceros + Grasshopper + Pythonではじめる3Dモデリングことはじめとして、
Rhinocerosのインストール
Grasshopper上でPythonの実行
Rhinocerosに簡単な図形を描画するスクリプトを書く
ことを行います。
つくるもの
環境
-801010.svg?logo=Rhinoceros&style=flat)
Rhinoceros
インストール
Rhinocerosは製品版、教育版、評価版の3つの入手法があります。仕事等で長く使う場合は製品版を購入することをお勧めしますが、価格は144,000円と、もちろんプロ仕様です(当たり前ですが、お高い..)。教育版もやや高めですが、社会人価格だと本当に手が出しづらい価格帯になってくるので、ゴリゴリ触りたい学生は多少無理しても買った方がいいと思います!
学生が羨ましい!今回は軽く使いたいので、Rhinoceros 7の評価版をダウンロードします。評価版はダウンロードから90日間であれば、製品版の全ての機能を無料で試すことができます。
※注意:M1 macは今(2021/01/24)のところ動作しないみたいです。 サポートを待つしかない。
評価版のダウンロード方法ですが、
まずRhinocerosを販売しているAppliCraftのページに行き、メールアドレスなどを入力して登録します。
ライセンスコード・ダウンロードリンクが記載されたメールが届きます。ダウンロードリンクから公式ダウンロードページにアクセスし、Rhino 7評価版をダウンロードします。
インストールし、ライセンスコードを入力すると、使えるようになります。
Rhinocerosを開いて、図のようになっていると使える状態になっています。
今回はGrasshopperで書いたPythonスクリプトを動かすチュートリアルのため、Rhinocerosの詳しい使い方は他に譲ります。
公式ページにwindows/macのチュートリアルがあるので、まずはここで雰囲気を掴むのがGoodかも。
https://www.rhino3d.com/tutorials/
Grasshopper
続いて、Grasshopperです。Rhinoceros7ではGrasshopperプラグインは標準搭載されています。
上部のツールバーから、[ツール]→[Grasshopper]と選択すると、Grasshopperプラグインが起動し、作業スペースが作られます。これでGrasshopperの起動は完了です。
Grasshopper単体のチュートリアルはこれまた公式ページにwindows/macのチュートリアルがあるので、ここで雰囲気を掴むのがGood。
Grasshopper + Python
ここからが本記事の主題です。
Grasshopper上でPythonスクリプトを実行するには、Pythonコンポーネントを用います。
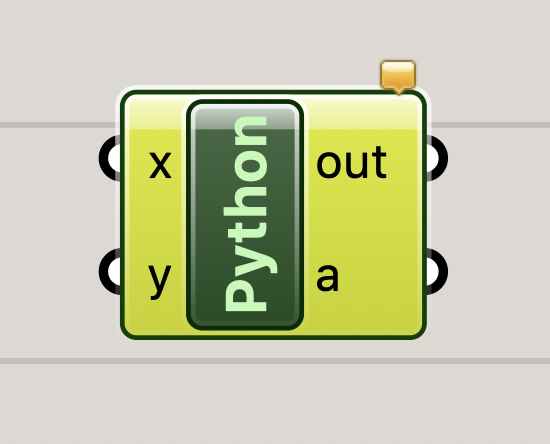
Python コンポーネントは、[math]タブ→[script]からドラッグ&ドロップするか、何もないところでダブルクリックして検索窓を表示し、"Python"と入力すると呼び出すことができます。
基本的には、左側が入力(引数みたいな感じ)、右側が出力になっています。
左側の入力、右側の出力は好きな数増やすことができます。初期状態では、右側にある[a]は出力、[out]にはエラーメッセージが出力されます。Hello,world
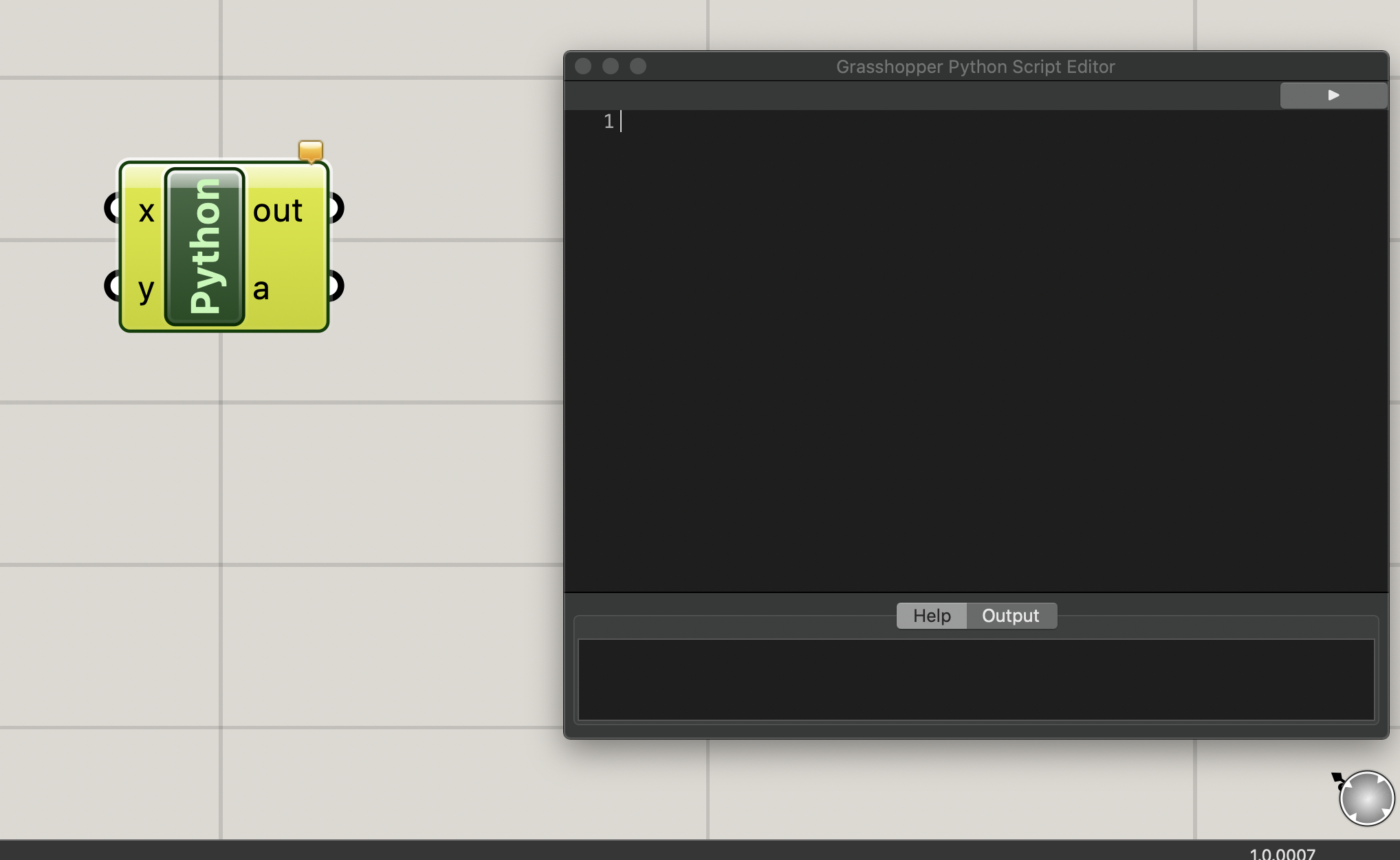
では、hello,worldと出力するスクリプトを書いてみます。スクリプトを書くにはpythonコンポーネントをダブルクリックすると、コードを書くことができるeditorが表示されます。ここに、コードをガリガリ書いていくことになります。
sample-script1a = "hello, world"コードを書いたら、Grasshopperに戻ります。コードでは"a"に"hello world"を出力するように書いたので、それを表示させます。
[Params]タブから[input]→[Panel](螺旋のアイコン)をドラッグ&ドロップ or 検索窓で"Panel"を入力すると、表示用のコンポーネントが呼び出せます。呼び出せたら、Pythonコンポーネントと、表示用のコンポーネントを接続します。
pythonコンポーネントをダブルクリックすると、スクリプトが実行され、"hello, world"が表示されます。簡単な入出力
続いて2つ入力をとり、掛け算した値を出力するサンプルです。
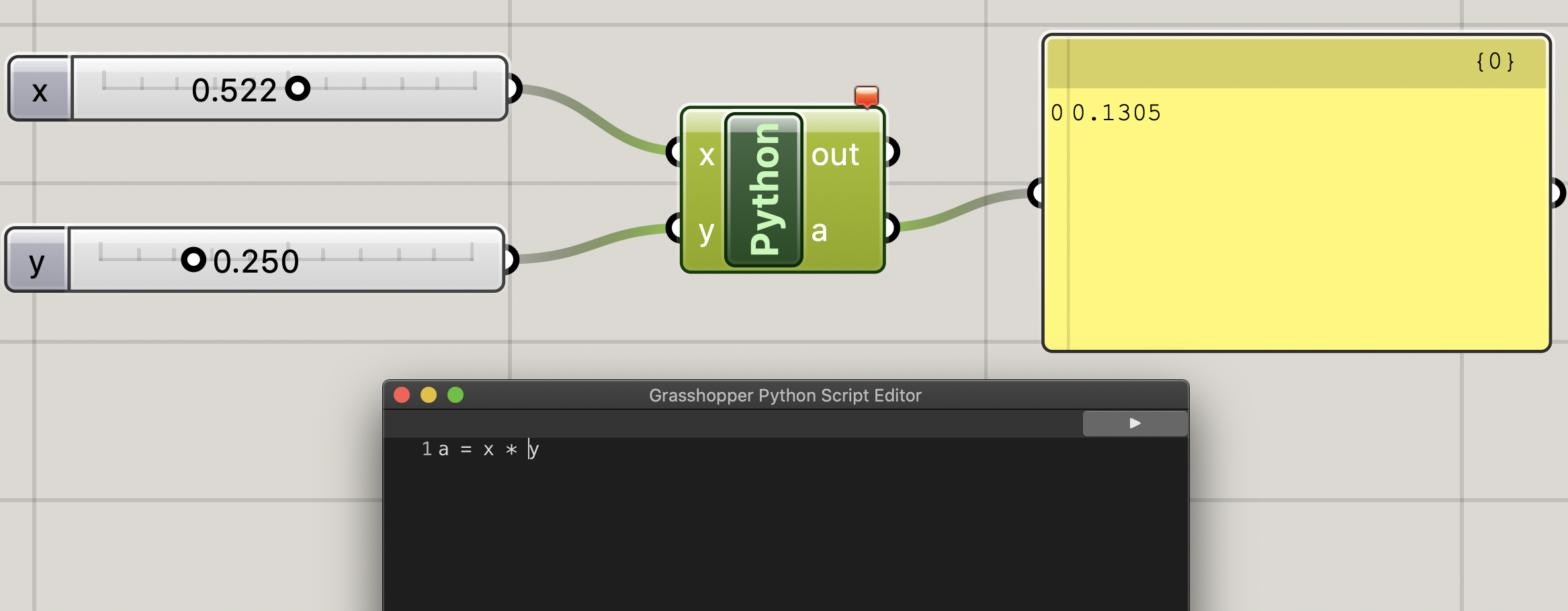
今回は入力側の数値は、スライダーで変えてみたいと思います。再度editorを開き、以下のように書き換えます。
sample-script2a = x * yコードを書いたら、[params]タブから[input]→[Slider]をドラッグ&ドロップ or 検索窓で"Slider"を入力し、スライダーコンポーネントを2つ呼び出します。
それぞれのスライダーをpythonコンポーネントと接続すると、二つのスライダーで指定した値の乗算値が出力されます。
コンポーネントは様々にあるので、入力値を増やしたり、スライダー以外のものに変えてみたり、上限値を変えたり、いろいろ遊んでみてください。Rhinocerosのコンポーネントを使う
続いては、Rhinoceros側に出力するコードを書きます。三次元空間に各辺100の空間に点を打ち、正方形を描画します。
入力値を変える
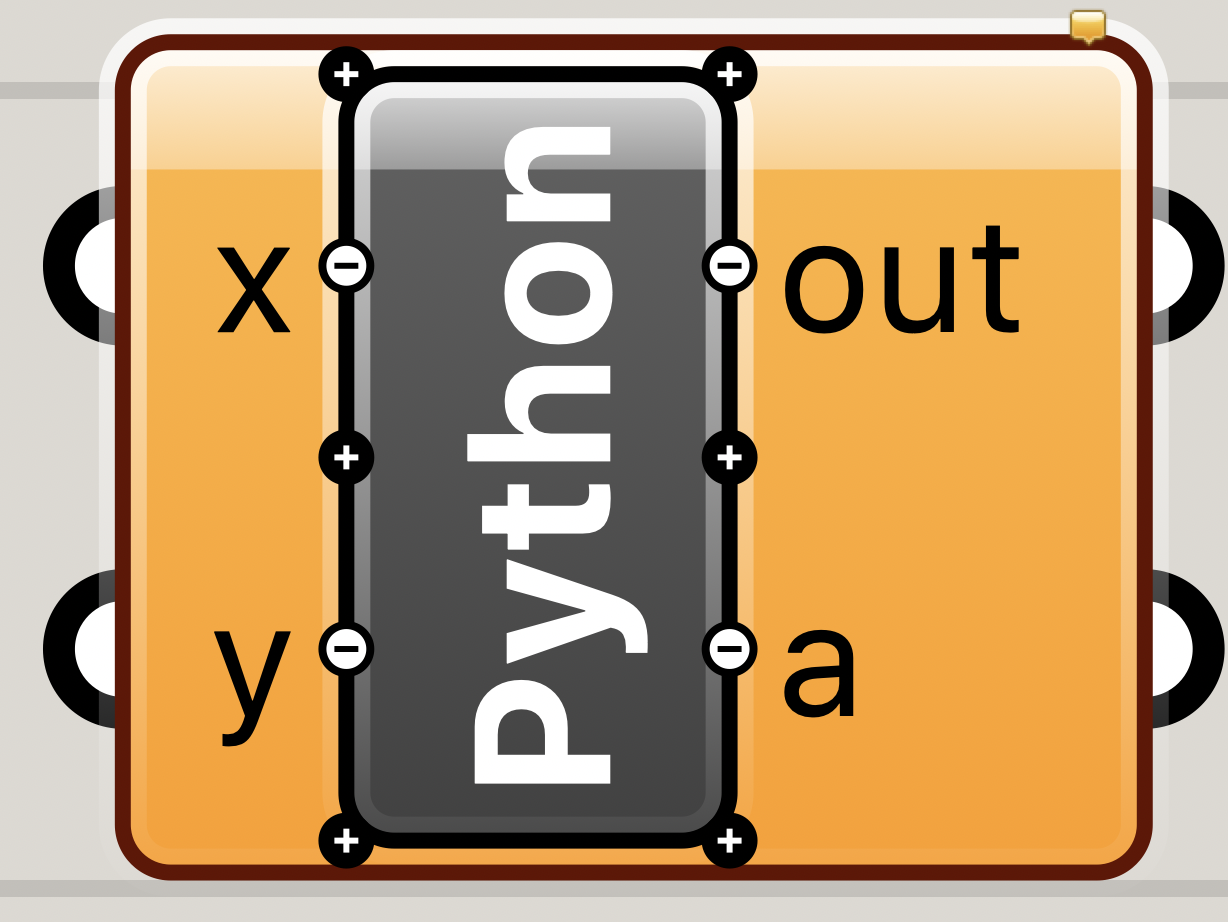
まずは、Pythonコンポーネントの入力の数を減らします。入力値を増やす/減らすためにはコンポーネントの
+ -を弄るとできます。また、入力の名前もrangeに変えておいてください(コンポーネントの入力部分を左クリックで変えられます)。
入力用のコンポーネントを作る
特定の範囲の値を生成してくれる
rangeコンポーネントがあるので、それを使ってみます。
検索窓で"range"と入力して、rangeコンポーネントを呼び出し、pythonコンポーネントと接続します。このときにPythonコンポーネントを左クリックし、[List Access]を選択しておいてください(Item Accessだとruntime errorが起こる)。
続いて、範囲を指定するコンポーネントをrangeコンポーネントに接続します。検索窓で"100"と入力すると、上限値が100のsliderコンポーネントを呼び出すことができます。呼び出せたら、rangeコンポーネントと接続します。
このような形になっていればOKです。
スクリプトを書く
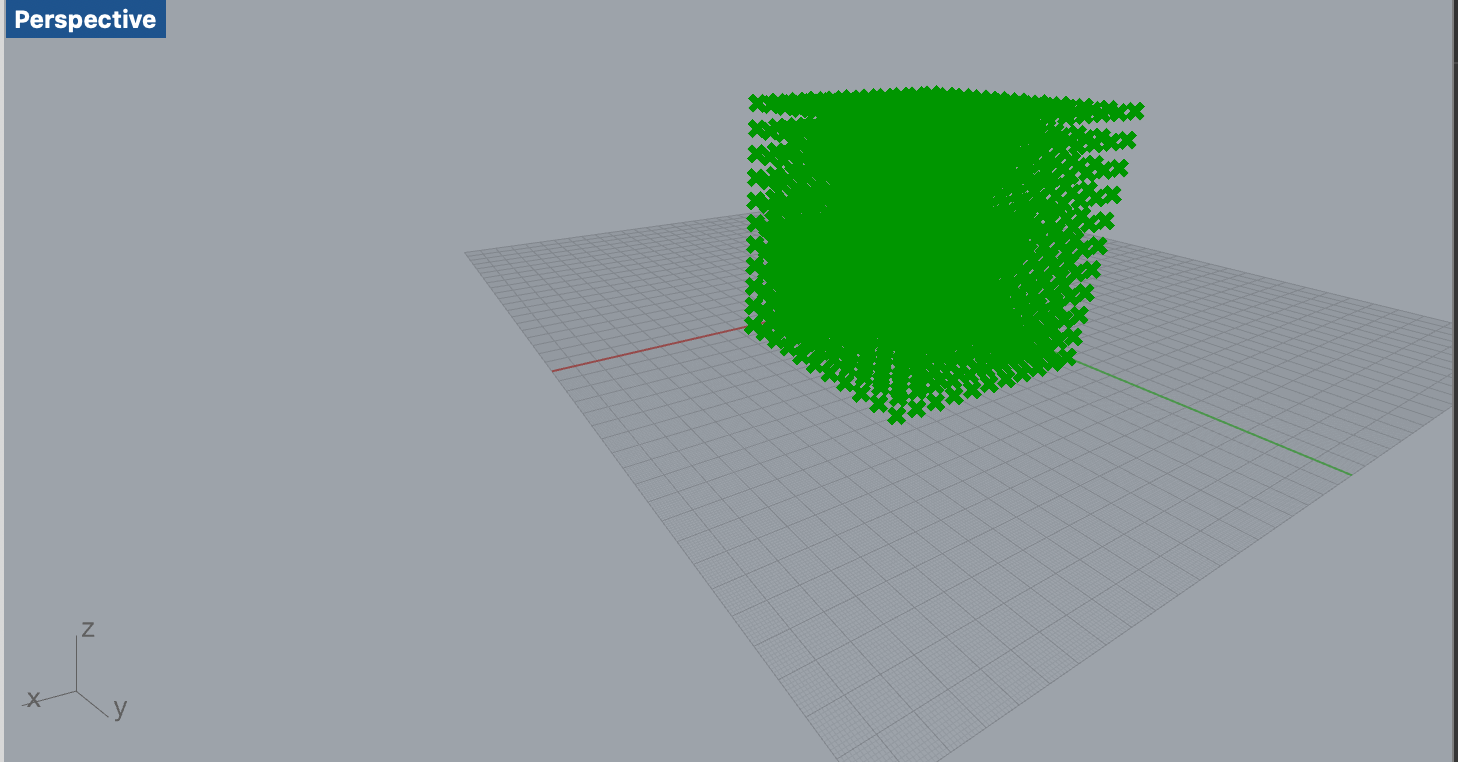
コードを以下のように書き換えます。
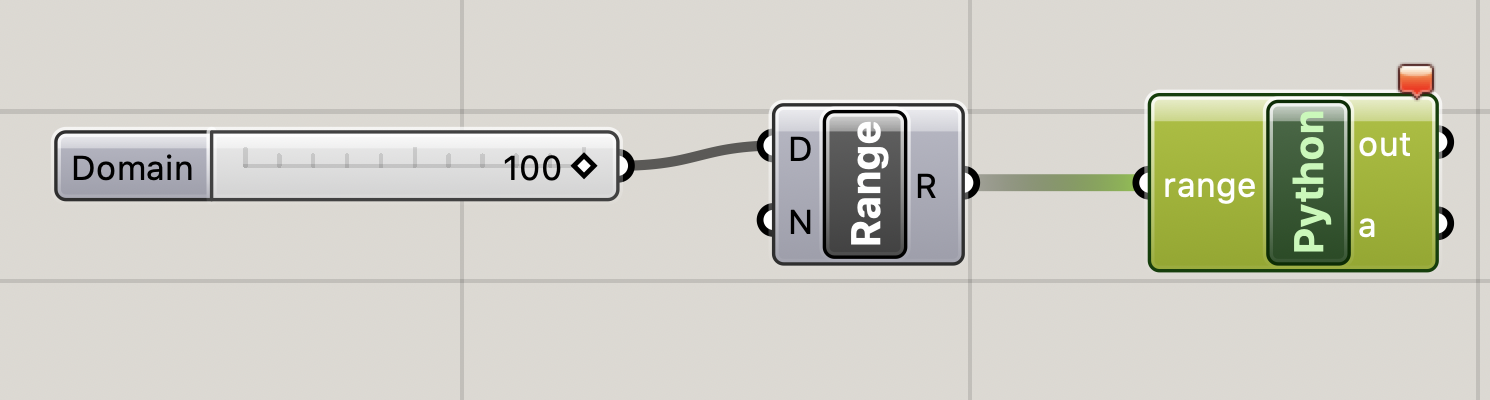
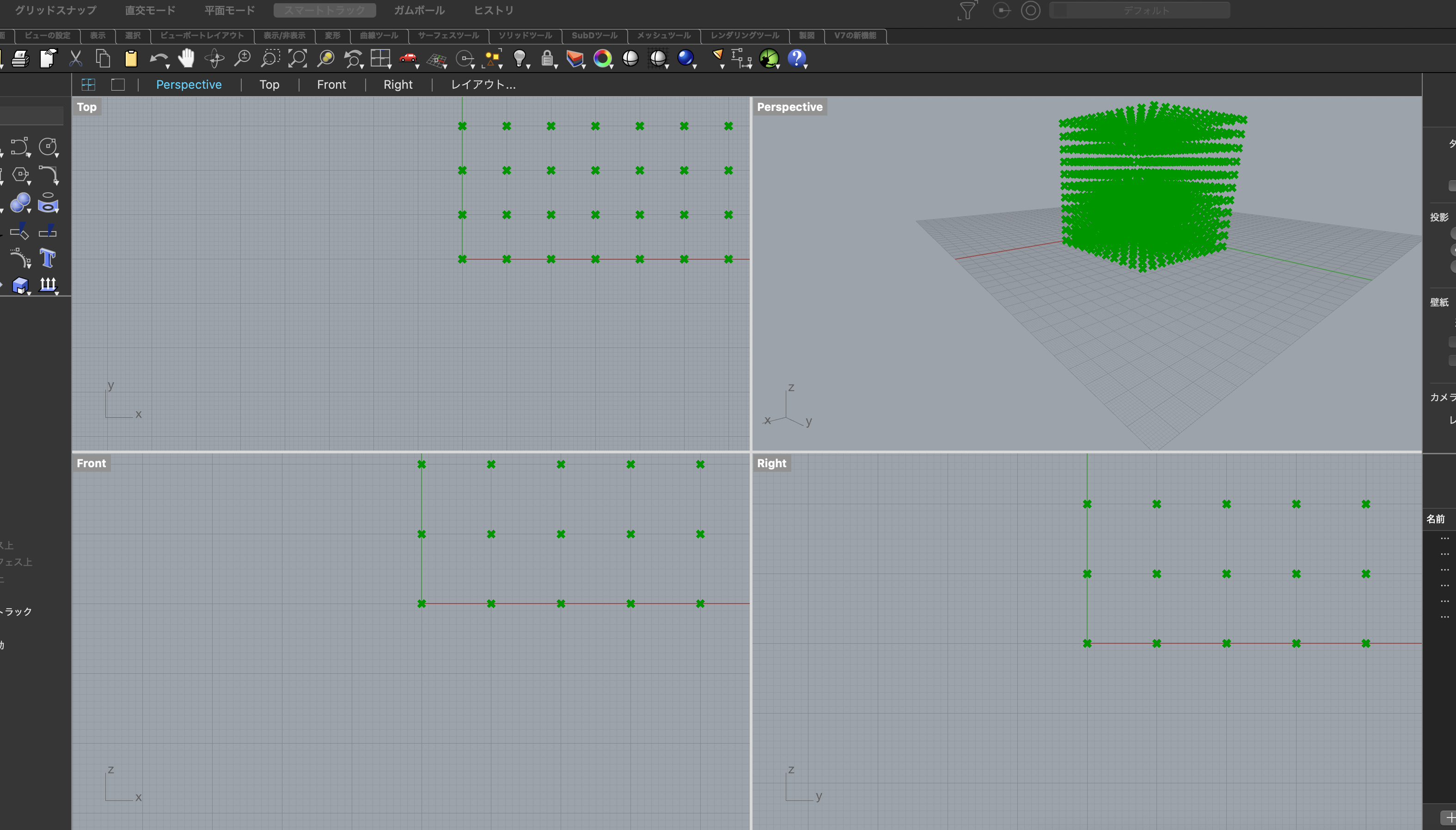
Rhinocerosのコンポーネントを使うために
rhinoscriptsyntaxライブラリを、描画用にRhiro.Geometoryをimportしています。sample-script3import rhinoscriptsyntax as rs import Rhino.Geometry as rg points = [] for x in range: for y in range: for z in range: point = rg.Point3d(x, y, z) points.append(point) a = pointsざっくりな説明ですが
rangeをforで回し、生成した座標を配列の中に突っ込み、その配列を出力しています。
Rhinoceros側のPerpectiveに描画されました。マウスでグリグリ回したり、ズームなどして確認してみてください。rangeを変えたりすると、大きさを変えたりいろいろ遊べます。
おわりに
今回の記事では、Rhinoceros + Grasshopper + Pythonではじめる3Dモデリングことはじめということで、基本中の基本のチュートリアルを行いました。自分自身も触り始めなので凝ったデザインはまだできませんが、他の人が作ったモデルなどをみていると、その可能性に非常にワクワクします。
ここから先はGrasshopper×Pythonのサンプルコードで遊んだりしながら、次の段階へステップアップができると思います。日本語情報はまだ少ないですが、
書籍やサンプルコードを読む
ちょっとコードやコンポーネントを変えてみる
作ったモデルをforumに投稿する
みたいな流れで勉強していくと、自由にモデリングができるようになっていけるのではないかと思います(自分は他の方が書いたものをなぞる段階ですが..)。
最近では、Rhinoceros×Grasshopper(×programming language)のスキルへの需要も高いそうです。この機会に、3Dモデリングで遊んでみるのもいかがでしょうか?
最後に、自分のメモ用として、書籍やサイトの情報を残しておきます。
- 書籍
- サイト
- Rhino公式
- Grasshopper公式
- Youtube
参考資料





- 投稿日:2021-01-24T17:30:22+09:00
Mac(M1)でpython環境構築(はじめて環境構築をする人向け)
Mac(M1)へ買い換えたので環境構築を行います
5年ぶりくらいにMacを買い換えたのでpython環境構築をする必要があり、せっかくなのでまとめました。
Macで、はじめてpythonの環境構築を行う人に役立てばと思います。そしてQiitaでの投稿ははじめてなので、見辛いかもしれません。。。
今後memoの感覚で投稿できたらと思います。以下を使用していきます
Mac(BigbSur Apple M1チップ)
Xcode
Homebrew
pip3
venv(仮想環境構築)まず全体の流れ
- 仮想環境構築とは
- Xcodeをインストール
- Homebrewをインストール
- 仮想環境作成 virtualenvをインストール
- pythonをインストール
1.仮想環境構築とは
pythonを使用していくにあたり、さまざまなパッケージ(モジュールをまとめたもの)をインストールします。
python初心者のころは(まだ初心者ですが)いろんなチュートリアルを見ては、いろんなパッケージファイルをインストールしてしまい、気づけばとんでもない数のパッケージファイルをインストールしてたってことにもなりかねません。そこで!仮想環境というものを作成し、その中でpythonを管理していきます。
そうすることで、作りたいものごとにパッケージを管理することができるよになります。使わなくなった、失敗した環境に関してはなにも考えずに消してしまえばOKなので安心です。
仮想環境の作り方は4.仮想環境作成にて説明します。
では、必要なものをインストールしていきましょう!2.Xcodeインストール
まずはAppStoreでXcodeをインストール
(サイズが11.6GBもあるため少し時間かかります。嘘でしょ。)
一度起動して「Xcode and iOS SDK License Agreement」が表示されるので
[Agree]をクリックします。※Xcodeを全てインストールする必要はなくApple製品のアプリ開発をしなければ以下コマンドで「Command Line Developper Tools」をインストールするだけでOK
terminal$ xcode-select --installこれでXcodeのインストールは完了
3.Homebrewのインストール
HomebrewはAppleStoreなどでインストールできない必要なものをインストールするためのツールです。(アイコンがビールで可愛いです。)Homebrewへアクセスし記載されてあるコマンドをターミナルへコピペ!
と、言いたいところなのですが、Homebrew_alternativeに書いているようにM1チップ版のインストールはopt/homebrewに展開する手順になるそう。
将来的にIntel/M1両対応が完了すれば従来通り/usr/localで利用できるようになるよう。待ってもいられないのでこちらでM1Mac用環境構築を綺麗にまとめられてたので参考にし、インストール行いました。% cd /opt #ディレクトリ移動 % sudo mkdir homebrew #rootユーザでディレクトリ作成 % sudo chown -R $USER . #ログインユーザに所有権設定 % curl -L https://github.com/Homebrew/brew/tarball/master | tar xz --strip 1 -C homebrew #Homebrewインストール % vi ~/.zshrc export PATH=/opt/homebrew/bin:$PATH #Homebrewへのパスを追加 % source ~/.zshrc #シェルに反映 % brew -v #反映されているか確認 % brew update #更新インストールできているかチェックするために
brew doctorを実行
Your system is ready to brew.になれば、おめでとうございます。
インストール完了です。4.仮想環境作成
1.仮想環境構築とはで説明したように直接Mac下にpythonをインストールすると後々、めんどくさいことになるので、仮想環境という箱を作成し、その中に使用するだけのモジュールをインストールしてあげます。
仮想環境を作成する方法は色々あるのですが、今回はvenvを使用します。
(venvはPython3.4以降であれば標準で使用できます)venvで仮想環境を作成
terminalpython3 -m venv myenvvenvで仮想環境を実行
terminalsource myenv/bin/activateこれで作成した仮想環境内に入ることができました
ターミナルのUser名の前に(myenv)と仮想環境名が入っていることを確認してください。
仮想環境内で作業している時はpythonコマンドは自動的に正しいバージョンのpythonを参照しに行くのでpython3コマンドの代わりにpythonが使用できます。以上で仮想環境構築は終了です。
pip install hogehogeでいろんなモジュールをインストールして試してみたください。また作成した仮想環境を削除したい時は作成したフォルダを削除するだけです。
簡単ですね!仮想環境を初期化したい場合は
deactivateで仮想環境から抜けて以下コマンドを実行すれば初期化されます。terminalpython3 -m venv --clear myenv他にも色々なコマンドがあるので、便利そうなものがあれば、またまとめたいと思います!

- 投稿日:2021-01-24T17:23:52+09:00
Power Automate Desktop 「Pythonスクリプトの実行」アクションで最大値 最小値を求める
概要
Power Automate Desktopの「Pythonスクリプトの実行」アクションを試してみます。ちょっとした配列の処理は、外部のPythonを呼び出さなくてもこのアクションから実行できると利便性が上がると思い試しました。しかし2021年1月時点ではMicrosoftのDocsやlearnにあまり情報がなくハマりポイントがあったので記録しておきます。
環境など
Windows10 20H2
Power Automate Desktop 2.2.20339.22608
組込みされているPython
2021年1月時点の情報です。試したこと
PADの配列から最大値、最小値を求めます。
使ってみる
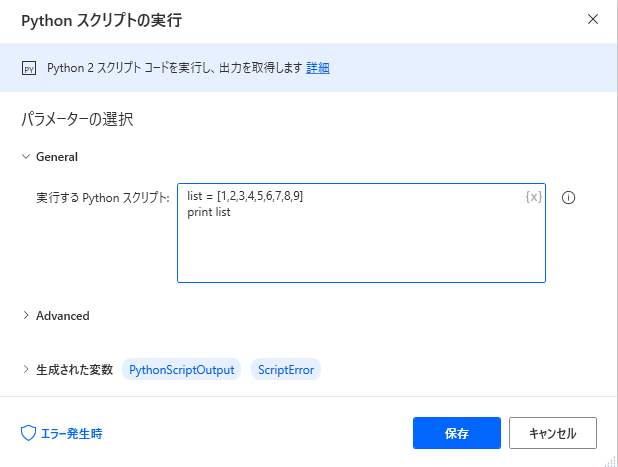
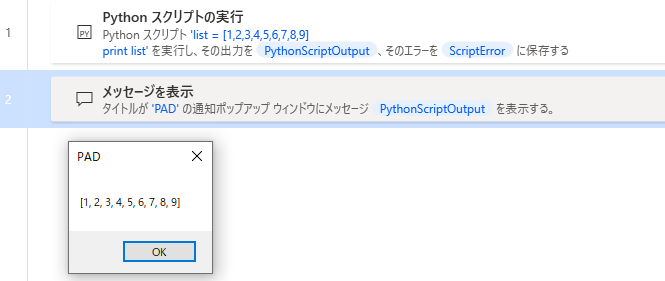
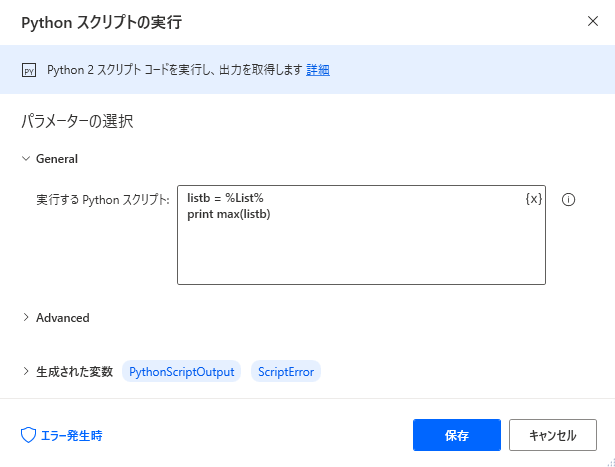
最初に「Pythonスクリプトの実行」アクションにPythonスクリプトを書いて試してみます。
配列も直接スクリプト内に書いてみます。
配列が表示されます。
最大値を求めてみます。
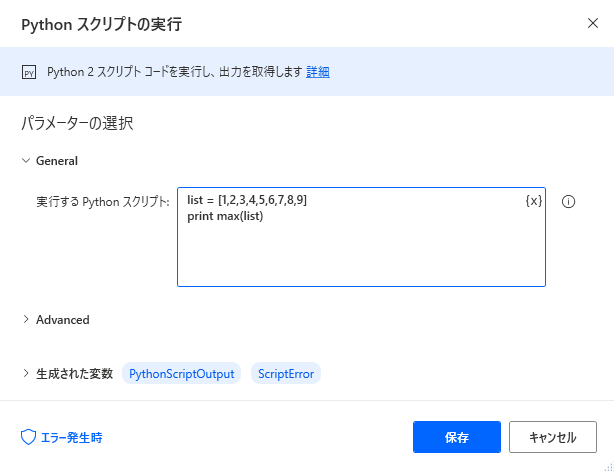
問題なく実行出来そうです。次に、PADで作成した配列を「Pythonスクリプトの実行」に渡して試します。
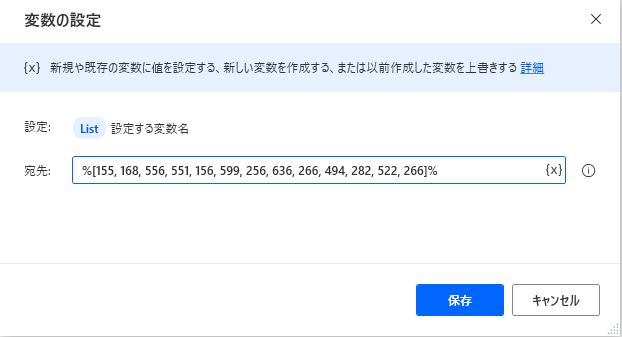
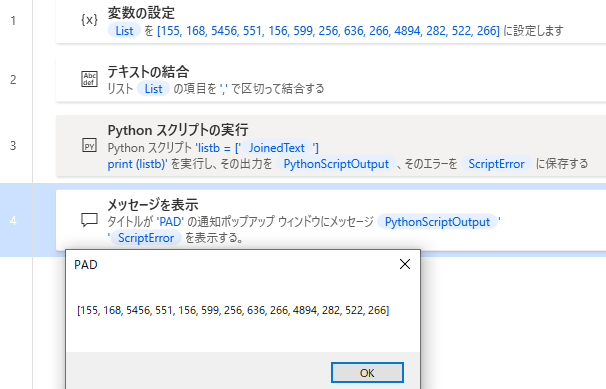
アクション1行目に「変数の設定」を利用してリストを作成します。
「新しいのリスト作成」アクションを使わなくても1行で配列作成が可能です。
宛先:の内容です。
%[155, 168, 5456, 551, 156, 599, 256, 636, 266, 4894, 282, 522, 266]%
「Pythonスクリプトの実行」の変数listbをPADの変数に変えてみます。
ダメです。ここでハマりました。
TypeError: int is not iterable 数値は反復できません。??
関数maxを外して実行してみると
配列ごとを渡したつもりなのですが単体の値になっているようです。回避策
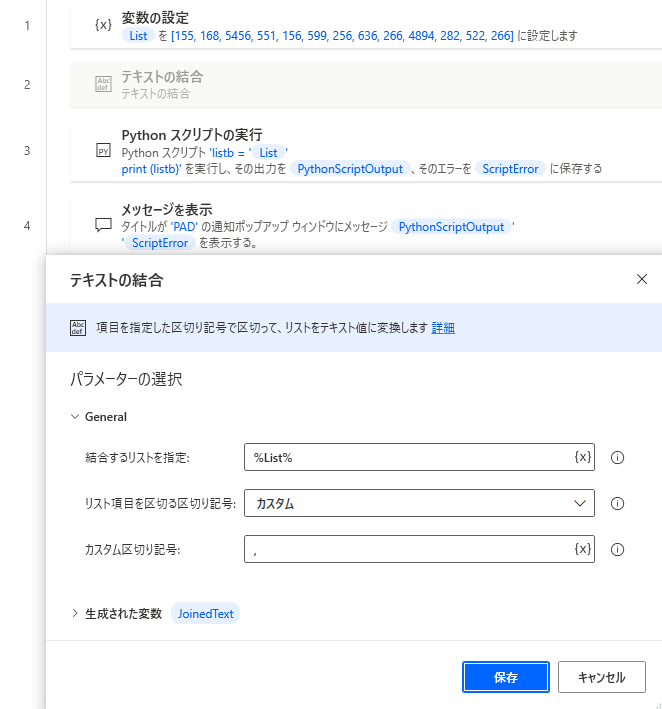
配列が単体値になってしまうなら、先に配列ごと単体テキストにしてからpythonに渡すことにしました。
カンマ区切りでテキストの結合を行います。
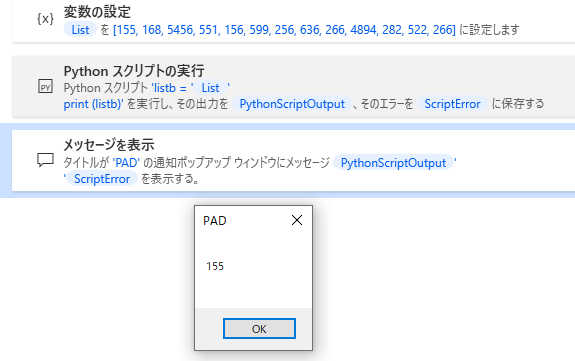
pythonスクリプトを修正します。
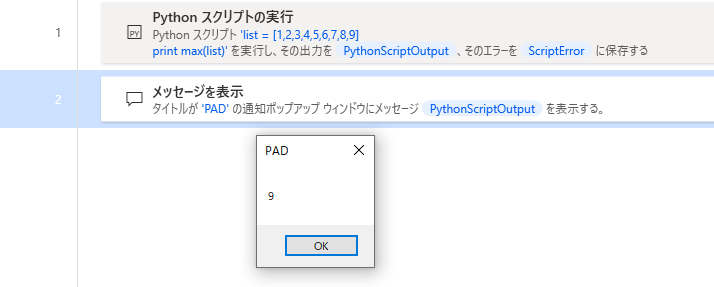
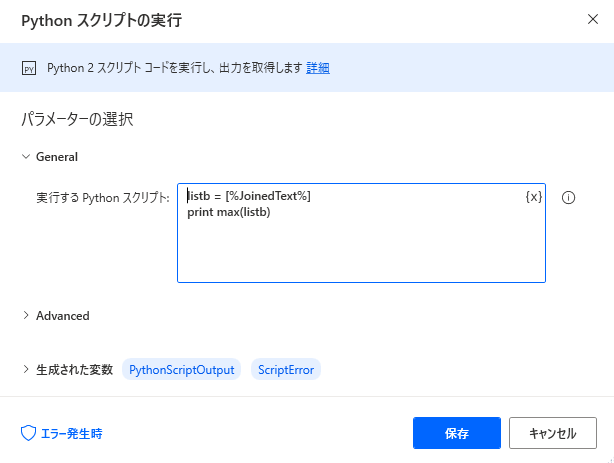
上手くいきそうです。
max関数を追加します。
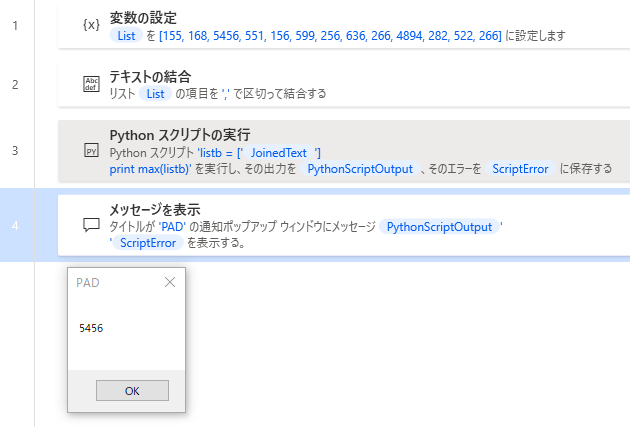
PADの配列から最大値を取り出すことができました。
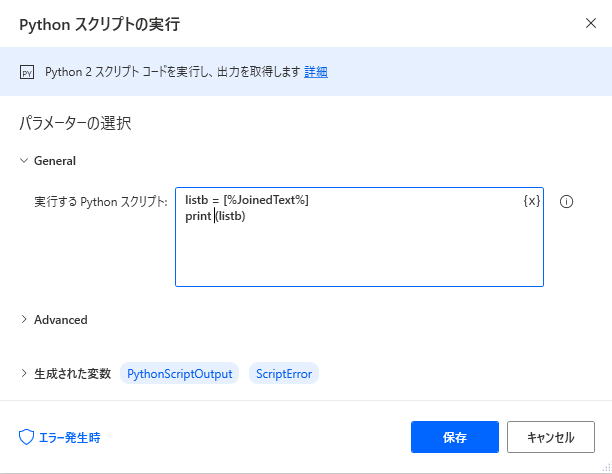
min関数を使えば最小値を取得できます。PowerAutomateDesktopSET List TO [155, 168, 5456, 551, 156, 599, 256, 636, 266, 4894, 282, 522, 266] Text.JoinWithCustomDelimiter List: List CustomDelimiter: $''',''' Result=> JoinedText System.RunPythonScript PythonCode: $'''listb = [%JoinedText%] print max(listb)''' ScriptOutput=> PythonScriptOutput ScriptError=> ScriptError Display.ShowMessage Title: $'''PAD''' Message: $'''%PythonScriptOutput% %ScriptError%''' Icon: Display.Icon.None Buttons: Display.Buttons.OK DefaultButton: Display.DefaultButton.Button1 IsTopMost: True ButtonPressed=> ButtonPressedまとめ
現時点では直接配列をPythonスクリプトの実行に渡せませんでした。
配列を渡せることで利便性が上がります。参考
Microsoft learn :Power Automate Desktop でのスクリプトの作成
https://docs.microsoft.com/ja-jp/learn/modules/pad-scripting/

- 投稿日:2021-01-24T17:17:23+09:00
AWS S3バケットの指定フォルダ直下のフォルダとファイルをLambdaで取得する
Amazon Web ServiceのS3バケットの指定フォルダ直下のフォルダとファイル一覧を取得するLambda関数を作ってみました。
サンプルコード
まずはコードから。Pythonです。
ListFoldersAndFiles.pyimport json import boto3 def lambda_handler(event, context): S3Bucket = "{your-bucket-name}" S3KeyPrefix = "" dirDepth = 1 folders = [] files = [] result = "" # Get requesting path from query string and normalize it. try: path = event['queryStringParameters']['path'] if path is not None: S3KeyPrefix = path if (len(S3KeyPrefix) > 0) and (S3KeyPrefix[0] == "/"): S3KeyPrefix = S3KeyPrefix[1:] if (len(S3KeyPrefix) > 0) and (S3KeyPrefix[-1] == "/"): S3KeyPrefix = S3KeyPrefix[:-1] if (len(S3KeyPrefix) > 0): dirDepth = len(S3KeyPrefix.split('/')) + 1 except Exception as e: print(e) # Create instances. s3 = boto3.resource('s3') bucket = s3.Bucket(S3Bucket) objs = bucket.meta.client.list_objects(Bucket = bucket.name, Prefix = S3KeyPrefix, Delimiter = "/") try: # Enumrate subfolders. for o in objs.get('CommonPrefixes'): folder = o.get('Prefix') folders.append(folder) subFolders = bucket.meta.client.list_objects(Bucket = bucket.name, Prefix = folder, Delimiter = "/") if (subFolders is not None) and (subFolders.get('CommonPrefixes') is not None): for f in subFolders.get('CommonPrefixes'): subFolder = f.get('Prefix') if len(subFolder.split('/')) == dirDepth + 1: folders.append(subFolder) # Enumrate files. oFiles = bucket.meta.client.list_objects_v2(Bucket = bucket.name, Prefix = S3KeyPrefix) for f in oFiles.get('Contents'): file = f.get('Key') if (file[-1] != '/') and (len(file.split('/')) <= dirDepth): files.append(file) except Exception as e: result += "No such folder : " + S3KeyPrefix # Get results. folders = sorted(folders) result += "\n".join(folders) + "\n" files = sorted(files) result += "\n".join(files) + "\n" return { 'statusCode': 200, 'body': result }気をつけた点は、取得しようとするパスの前後に「/」が入っていたり入っていなかったりしても大丈夫にした点と、「/」の数で指定ディレクトリ直下のフォルダ・ファイルのみ取得するようにした点でしょうか。
不恰好ですが、バケットのルートとそれ以外で取得できるフォルダが違ったりしていたので力技で書いてます。この関数につけるロール
Lambda関数を作成する際にデフォルトのロールを選んで、その後以下のインラインポリシーを追加します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your-bucket-name" ] }, { "Sid": "AllObjectActions", "Effect": "Allow", "Action": "s3:*Object", "Resource": [ "arn:aws:s3:::your-bucket-name/*" ] } ] }テストイベント
テストイベントに以下の行を追加し、検索パスを指定します。
{ "queryStringParameters": { "path": "path-to-folders" } }
- 投稿日:2021-01-24T17:14:44+09:00
pythonでexcelデータを読み込むときの下準備【技術的負債対応用】
要約
エクセルファイルをpythonで処理するときは、余計な情報を削除しよう。
エクセルマクロを作るときは書式の作り込みはできるだけ避けよう。きっかけ
数千行、十列程度のエクセルファイルに対して作業を行っていたのだが、異様にファイル操作が重かった。
デバッグ中にエクセルファイルを読み込むだけで10分以上かかり、事実上デバッグ不可能となっていた。
調査した結果、またブラックボックス化されたマクロが悪さをしていたたことがわかった。出来事
まずはこのコードと出力結果を見てほしい。
誤差レベルのサイズのマクロと、ある細工を除けば、格納されているデータは全く同じ3つのエクセルファイルに対して、全セルの数値を合計した値を出力しただけのプログラムだ。import openpyxl as pyxl import datetime as dt def read_and_sum(path: str): book = pyxl.open(path) ans = 0 sheet = book.worksheets[0] for row in range(500): for col in range(10): ans += sheet.cell(row+1, col+1).value book.close() return ans if __name__ == '__main__': start = dt.datetime.now() print(read_and_sum("testcase1.xlsx")) check1 = dt.datetime.now() print(read_and_sum("testcase2.xlsm")) check2 = dt.datetime.now() print(read_and_sum("testcase3.xlsm")) end = dt.datetime.now() print(f"例1:{(check1 - start).total_seconds()}sec") print(f"例2:{(check2 - check1).total_seconds()}sec") print(f"例3:{(end - check2).total_seconds()}sec")出力結果
2494558 2494558 2494558 例1:0.034934sec 例2:0.045877sec 例3:12.923414sec原因
ファイルの中身は同じでも、ファイル容量はこれほどの差ができている。
この時点でピンときている人も多いと思うけど、3つのエクセルファイルの差は書式設定にある。
testcase1のエクセルファイルはこのように、
0~1000の数値を500行10列の範囲に書いただけのデータだ。
case2は、1セル目のフォント、サイズを変更し、文字太字にして、
次のマクロを適用した。Sub create_testcase() Dim src As Range Dim row As Long Dim col As Long Set src = ActiveSheet.Cells(1, 1) src.Copy For row = 1 To 500 For col = 1 To 10 If (row + col) Mod 2 = 1 Then ThisWorkbook.Sheets(1).Cells(row, col).PasteSpecial Paste:=xlPasteFormats End If Next Next End Sub石松模様に書式をコピーした結果が下の通り。
case3は、上記のfor文のrowの上限を5000,colの上限を1000に変更しただけだ。見た目はcase2のものと全く同じだが、不要な書式データを大量に埋め込んである。
これが極端な速度のからくりだった。余談
私の遭遇したExcelファイルは、特定シートの書式を消すだけでファイルサイズが10MB以上減る、素晴らしい出来栄えになっていた。
先人がマクロを作ったとき、セルの書式ごとコピーしていたのだと予想している。
書式を消したところ10分以上読み込みがかかり、諦めたエクセルファイルが100秒で読み込めるようになった。
このクソマクロを作ったのは誰だぁっ!詳細検証
書式の多さがどこに影響しているかを調べるために、先程の速度計測用のソースを次のように書き換えた。
import openpyxl as pyxl import datetime as dt def read_and_sum(path: str): start = dt.datetime.now() book = pyxl.open(path) ans = 0 sheet = book.worksheets[0] check1 = dt.datetime.now() for row in range(500): for col in range(10): ans += sheet.cell(row+1, col+1).value check2 = dt.datetime.now() book.close() end = dt.datetime.now() print(f"ファイル読み込み時間:{(check1 - start).total_seconds()}") print(f"セル操作時間:{(check2 - check1).total_seconds()}") print(f"後処理時間:{(end - check2).total_seconds()}") return ans if __name__ == '__main__': print("例1:") print(read_and_sum("testcase1.xlsx")) print("例2:") print(read_and_sum("testcase2.xlsm")) print("例3:") print(read_and_sum("testcase3.xlsm"))出力結果は下記のようになる。
例1: ファイル読み込み時間:0.03194 セル操作時間:0.003001 後処理時間:0.0 2494558 例2: ファイル読み込み時間:0.040884 セル操作時間:0.001993 後処理時間:0.0 2494558 例3: ファイル読み込み時間:13.107952 セル操作時間:0.003989 後処理時間:0.0 2494558どのファイルでも読み込み時間がほとんどであるため、
書式がセルの操作時間に影響を及ぼしているかどうかはよくわからなかった。まとめ
- Pythonでexcelファイルを操作するときは、高速化のために余計な書式はなるべく削除しよう。
- VBAのマクロも技術的負債になるかどうかを意識して作成しよう。

- 投稿日:2021-01-24T17:01:55+09:00
Pythonで任意のクラスにmapとto_listを実装する(プライベート用)
これめんどくさくない?
いきなりですがPythonの仕様上こう書くのってめんどくさくないですか?
list(map(lambda x: x + 1, [0, 1, 2])) # => [1, 2, 3]あとから,listで括りなおすのとかmapの引数が先に関数なのとか,わりとややこしいように思います。
つまり他の言語みたいに,下のように書きたい!
[0, 1, 2].map(lambda x: x + 1).to_list() # => [1, 2, 3]これをやるためのいい方法を見つけてしまったので記事にします(きちんとした開発には不向きな方法なので,個人的な範囲での利用をオススメします)。
classにメソッドを追加できないの?
Pythonではclassにメソッドを追加するための方法として、次のような方法があります、
# クラスを定義しインスタンスを生成 class Bomb: pass my_bomb = Bomb() # 追加したいメソッドを関数として定義しクラスのプロパティに追加 def explosion(self): print("大爆発!") Bomb.explosion = explosion # 追加したメソッドが生成済みのオブジェクトからも利用できる my_bomb.explosion() # => 大爆発!この方法は自分で定義したclassであればうまくいきますが。list, object等の組み込みclassではうまく行きません。
object.to_list = lambda self: list(self) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-4-9c86e5ed31fa> in <module>() ----> 1 object.to_list = lambda self: list(self) TypeError: can't set attributes of built-in/extension type 'object'forbiddenfruitを使う
そこでforbiddenfruitを使います。名前の通り、禁断の果実なので、あまり多用しないように笑
pip install forbiddenfruitとしたのち、
from forbiddenfruit import curse def to_list(self): return list(self) curse(object, 'to_list', to_list)とすることで、任意のobjectにto_listメソッドが実装されます。
同様にcurse(object, 'map', lambda self, f: map(f, self))とすることで、mapメソッドが実装されます。
すると、
[0, 1, 2].map(lambda x: x + 1).to_list() # => [1, 2, 3]となり成功です。ただし、もとからto_listやmapなどが実装されている場合、どうなるかわかりませんので、objectではなく、もっと限られたクラスで実装すべきだとはおもいます(iterableのbase classってないよね?)
- 投稿日:2021-01-24T17:00:29+09:00
備忘録:Xserver上のPython, Jupyter notebookをローカル(Mac)から使う
はじめに
ブログで導入したXserverをもっと有効活用出来ないか?
→ ローカルでの解析をサーバーで出来ればもっと重たい処理も出来て便利なのでは、と考えました。そこで、MacからXserver上のJupyter notebookが使えるようになるまでの環境構築について調べた備忘録です。
同様なことを記事にしている優秀な参考サイトはたくさんありましたので、実際自分が環境構築した際につまずいたところを記録として残します。何かの参考になれば幸いです。
MacのターミナルからXserverにssh接続
下記の記事を参考に無事接続出来ました。ありがとうございます。
Linuxbrewインストール
下記記事が大変参考になりました。
【Xserver】Linuxbrewインストール&アップデート
下記コマンドよりインストールを始めましたが、LinuxbrewはHomebrewに統合されたようでした。
sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"Warning: Linuxbrew has been merged into Homebrew. Please migrate to the following command: /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"途中、下記メッセージが出てましたが、Returnすると続けてインストールを開始しました。
残念ですが、ユーザー XXXXXX は sv**** 上で sudo を実行できません。約1時間くらいかかりましたが、無事インストールされました。
インストール完了時のメッセージとして、PATHの設定などがありましたので、メッセージに従い設定しています。
brew doctorで確認してみると、下記エラーが表示されました。
[XXXXXX@sv**** ~]$ brew doctor Error: Please update your system cURL. Minimum required version: 7.41.0 Your cURL version: 7.29.0 Your cURL executable: /usr/bin/curl検索したところ、同じ事例がありましたので、その解決策で無事にエラーは出なくなりました。素晴らしい。
Xserver上のHomebrew(Linuxbrew)実行時にサーバー側の(古いバージョンの)cURLを参照しないようにしたい
解決策: .bash_profile に下記を追加。
export HOMEBREW_FORCE_BREWED_CURL="1"2021年1月23日インストール時点では下記Versionがインストールされています。
[XXXXXX@sv**** ~]$ brew --version Homebrew 2.7.5 Homebrew/linuxbrew-core (git revision cd05cb; last commit 2021-01-23)pyenv, Anacondaのインストール
同じサイトが大変分かりやすく参考になりました。インストール時に特に違いはありませんでした。
Anaconda3-2020.11をインストールしました。Pythonは3.8.5でした。
[XXXXXX@sv**** ~]$ pyenv install anaconda3-2020.11 [XXXXXX@sv**** ~]$ pyenv versions * system (set by /home/XXXXXX/.pyenv/version) anaconda3-2020.11 [XXXXXX@sv**** ~]$ pyenv global anaconda3-2020.11 [XXXXXX@sv**** ~]$ python -V Python 3.8.5仮想環境構築
折角?Anacondaをインストールしたので、仮想環境を構築します。
ただ、仮想環境を構築して必要なライブラリを追加するなら、別にAnacondaを入れなくていい気がして今ひとつしっくりきません(condaが使えるのはメリットですが)。どうなんでしょう?conda create -n envname python=3.8 numpy pandas matplotlibconda activate envnameしかし構築した仮想環境をactivateしたところ、下記メッセージが出て切り替えが出来ませんでした。
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. To initialize your shell, run $ conda init <SHELL_NAME> Currently supported shells are: - bash - fish - tcsh - xonsh - zsh - powershell See 'conda init --help' for more information and options. IMPORTANT: You may need to close and restart your shell after running 'conda init'.conda initを調べてみると、下記記事がありましたので参考にしました。
IMPORTANT: You may need to close and restart your shell after running 'conda init'.
[XXXXXX@sv**** ~]$ conda init bash [XXXXXX@sv**** ~]$ source .bashrcこれによりコマンドライン先頭に(base)が付くようになりました。
(base) [XXXXXX@sv**** ~]$再度、仮想環境をactivateすると無事切り替わりました。
(base) [XXXXXX@sv**** ~]$ conda activate envname (envname) [XXXXXX@sv**** ~]$ conda info -e # conda environments: # base /home/XXXXXX/.pyenv/versions/anaconda3-2020.11 envname * /home/XXXXXX/.pyenv/versions/anaconda3-2020.11/envs/envnameサーバーで Jupyter notebook を使いたい
設定の仕方は下記を参考にしました。ありがとうございます。
・SSH先のサーバ上のjupyter notebookをローカルPCで操作する
基本的な設定方法は参考サイト通りです。最終的な設定を残します。
【サーバーの設定】
サーバーの仮想環境にjupyterを追加。(まだ入れてなければ)conda install jupyter.jupyter/jupyter_notebook_config.py に下記を追加。パスワードは別途設定しています。ポート番号は任意です。
c = get_config() c.NotebookApp.open_browser = False c.NotebookApp.ip = '0.0.0.0' c.NotebookApp.port = 9999 c.NotebookApp.allow_remote_access = True c.NotebookApp.password = 'sha1:0000...'【ローカルの設定】
.ssh/config に LocalForward 9000 localhost:9999 を追加。Host xsrv Hostname XXXXXX.xsrv.jp Port 10022 User XXXXXX IdentityFile ~/.ssh/id_xserver_rsa LocalForward 9000 localhost:9999 ServerAliveInterval 60設定は以上。再度下記でログイン後、jupyter notebookを起動。
ssh xsrvローカルのブラウザに下記を打ち込み、設定したパスワード入力して無事ローカルでjupyter notebookが使えるようになりました。
http://localhost:9000今後、色々試していこうと思います。
- 投稿日:2021-01-24T16:11:58+09:00
AWSからLandsat8のデータを大量にダウンロードする方法
背景
衛星画像と深層学習を使用して、湖水のクロロフィル濃度を推定する研究行っています。
最近では、衛星画像から物体検出のアルゴリズムで深層学習が使われていることがあるようですが、
深層学習にはとにかく大量のデータが必要!今回使用する衛星画像データは、AWS からダウンロードしてきました。AWSで提供されているLandsat8のデータは、L1プロダクトでGeotiff形式です。Geotiff形式なので、緯度経度からピクセルの値(DN値)を抽出できます!その方法はまた別の記事衛星画像から緯度経度を指定してその地点からピクセル値を抽出する方法にのってます!
今回はまず、大量にトレーニング用のデータをダウンロードするプログラミングについて、自分のために( ..)φメモとしてと、同じように衛星画像データ大量に欲しい人向けにこの記事を書きます!AWSのLandsat8のデータダウロード先URL
Landsat8のデータは、↓のように、1つのURL先にいくつかのファイルが掲載されていますが、それはある1日で取得した衛星画像のデータすべてです。(バンド1~11の画像データと、メタファイルとBQAファイルというものなど)
詳しい話は割愛しますが、自分が欲しい場所の衛星画像は、Path と Row を指定して検索できます。
詳しくはこちら。→Accessing Landsat on AWS
まず、自分の欲しい場所と日にちのデータのURLリストを作成してください。
こんな感じ。
これをURL.csvとします。
今回のプログラミング
download.pyimport os import wget #ダウンロード先のディレクトリPath作成 download_dir = 'D:/landsat8/' # extensions = ['_B1.TIF', '_B2.TIF', '_B3.TIF', '_B4.TIF', '_B5.TIF', '_B6.TIF', '_B7.TIF', '_B8.TIF', '_B9.TIF', '_B10.TIF', '_B11.TIF', '_BQA.TIF', '_MTL.txt'] with open("D:/URL.csv") as URL: #readlines で、URLを1行ずつリストに格納 URLs = URL.readlines() for URL in URLs: #for文で、1URLごとすべてのファイルを、ディレクトリをわけて格納 #(1URLごとに1ディレクトリ作成。その中にバンド1~11,BQA,metafileをダウンロード格納) for i in extensions: r = URL.split('/') name = r[8] html = URL.find("index.html") new_dir = download_dir + name if os.path.isdir(new_dir) == False: os.mkdir(new_dir) url = URL[0:html] +name+i print(url) wget.download(url=url, out=new_dir)これで、↓みたいにシーン毎のフォルダが作成され、その配下にバンド別の衛星画像データがダウンロード格納されます。
ちなみに、これ全部ダウンロードするのに時間めっちゃかかります。普通のパソコンだと3日ぐらいかかるんじゃないかな??研究用のサーバ使用したけどそれでも1日はかかったかな?
今回便利だったモジュールやメソッド
wget
wget は、LinuxをはじめとするUNIX系のOSで多く利用されているHTTP, HTTPS, FTP, FTPSといったプロトコルを使用し、インターネット上のファイルを取得できるコマンドですが、Pythonでもモジュールがあります!Linuxのwgetコマンドのように、便利なオプションはあまりないようですが、十分使えます。例えば、
Linuxコマンドだったら、URL先にいくつかファイルがあって、その中の指定の拡張子だけのファイルをダウンロードしたい場合は、オプションで簡単に指定してwgetでダウンロードできます。Pythonじゃあそんなことできないためめんどくさいプログラミングを?でしてるわけなんですよ。readlines()
ファイルの内容を読みだす時に活用するメソッドで、似たようなのにread, readlineがあります。
それぞれの違いはリンク先で確認お願いいたします。find()
指定した文字列の位置を取得する方法です。osモジュールは、OSに依存しているさまざまな機能を利用するためのモジュールです。
主にファイルやディレクトリ操作が可能で、ファイルの一覧やpathを取得できたり、新規にファイル・ディレクトリを作成することができます終わりに
以上、長くなりましたが、これでAWSから大量に衛星画像データをダウンロードできるはずです。
もっと良い方法あったら教えてください^^/

- 投稿日:2021-01-24T16:08:00+09:00
pythonでAWSのリソース情報を取得してyamlファイルを編集してみた
はじめに
仕事で特定のyamlファイルをコピーして、EC2のIPアドレスなどの特定の箇所を編集してplaybookを実行することがあり、手作業だとミスが起きると思いプログラムでAWSのリソースを取得して、その値でyamlファイルを書き換えられないか試してみた。
実施したこと
引数として
- 編集したいyamlのファイル名
- EC2のタグ(Name)の値
- AWSのプロファイル
を渡してあげて、AWSのプロファイルの設定で、EC2タグの値に紐づくECインスタンスを取得して
yamlファイルを編集する。yamlファイルのイメージ
- hosts: target_test tasks: - name: install git yum: name=git state=latest instance: private_ip: 0.0.0.0 public_ip: 0.0.0.0 ip: 0.0.0.0↑のprivate_ipと、public_ipを編集する。
作成したソース
#!/usr/bin/python # -*- coding: utf-8 -*- import ruamel import ruamel.yaml import sys import boto3 from boto3.session import Session yaml = ruamel.yaml.YAML() args = sys.argv file_name = args[1] tag_value = args[2] profile = args[3] # プロファイルの内容でAWSのリソースにアクセスするように設定 session = Session(profile_name=profile) def read_file(file_name): """ ファイル読み込み 引数 file_name: ファイル名 返り値 loadしたyamlデータ """ with open(file_name, 'r') as file: data = yaml.load(file) return data def fetch_ec2_instance(tag_value): """ ec2インスタンス取得 引数 tag_value: ファイル名 返り値 Name=tag_valueのインスタンス """ ec2 = session.client("ec2") # Nameタグでフィルター instances = ec2.describe_instances( Filters=[ {'Name': 'tag-key', 'Values': ['Name']}, {'Name': 'tag-value', 'Values': [tag_value]} ] )['Reservations'] if len(instances) == 0: raise Exception("インスタンスが存在しません。 Name:{}".format(tag_value)) return instances[0] def edit_data(data, instance): """ パブリックIP、プライベートIPの修正 引数 data: yamlデータ instance: ec2インスタンス """ data[0]["instance"]["private_ip"] = instance['Instances'][0]['PrivateIpAddress'] data[0]["instance"]["public_ip"] = instance['Instances'][0]['PublicIpAddress'] def write_data(file_name, data): """ yamlデータ書き込み file_name: 書き込むファイル名 data: yamlデータ """ with open(file_name, 'w') as file: yaml.dump(data, stream=file) data = read_file(file_name) instance = fetch_ec2_instance(tag_value) edit_data(data, instance) write_data(file_name, data)ruamelを使用して、yamlファイルの編集をしてます。
PyYamlもあるのですが、その場合yamlファイルの順序が保障されてないためruamelを使用してます。以下コマンドで実行
python {pythonのソースファイル名} {編集ファイル名} {Nameタグの値} {プロファイル}参考
ruamelについて
https://dev.classmethod.jp/articles/getting-started-with-pyyaml-and-ruamel-yaml/デフォルトのプロファイル以外を使用する
https://qiita.com/inouet/items/f9723d7ae7d8d134280b
- 投稿日:2021-01-24T15:48:41+09:00
単回帰データ
データセットの読み込み
データセットには、説明変数と目的変数が含まれています。
説明変数:何かの原因となっている変数
目的変数:その原因を受けて発生した結果である変数import numpy as np from sklearn import datasets boston = datasets.load_boston() boston_df = pd.DataFrame(boston.data, columns=boston.feature_names) boston_df["PRICE"] = boston.target # target: 目的変数 boston_df.head()結果.CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT PRICE 0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.0 1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.6 2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.7 3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.4 4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2説明変数が住宅の特徴となり、目的変数が価格にであることがわかります
ラベルの意味がわかんないんで説明してもらいます。
説明
print(boston.DESCR)結果... _boston_dataset: Boston house prices dataset --------------------------- **Data Set Characteristics:** :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. :Attribute Information (in order): - CRIM per capita crime rate by town - ZN proportion of residential land zoned for lots over 25,000 sq.ft. - INDUS proportion of non-retail business acres per town - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) - NOX nitric oxides concentration (parts per 10 million) - RM average number of rooms per dwelling - AGE proportion of owner-occupied units built prior to 1940 - DIS weighted distances to five Boston employment centres - RAD index of accessibility to radial highways - TAX full-value property-tax rate per $10,000 - PTRATIO pupil-teacher ratio by town - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town - LSTAT % lower status of the population - MEDV Median value of owner-occupied homes in $1000's :Missing Attribute Values: None :Creator: Harrison, D. and Rubinfeld, D.L. This is a copy of UCI ML housing dataset. https://archive.ics.uci.edu/ml/machine-learning-databases/housing/ This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic prices and the demand for clean air', J. Environ. Economics & Management, vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics ...', Wiley, 1980. N.B. Various transformations are used in the table on pages 244-261 of the latter. The Boston house-price data has been used in many machine learning papers that address regression problems. .. topic:: References - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.意味がわかりました。
データセットの詳細を見たいので色々表示してもらいます。boston_df.describe()CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT PRICE count 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 mean 3.613524 11.363636 11.136779 0.069170 0.554695 6.284634 68.574901 3.795043 9.549407 408.237154 18.455534 356.674032 12.653063 22.532806 std 8.601545 23.322453 6.860353 0.253994 0.115878 0.702617 28.148861 2.105710 8.707259 168.537116 2.164946 91.294864 7.141062 9.197104 min 0.006320 0.000000 0.460000 0.000000 0.385000 3.561000 2.900000 1.129600 1.000000 187.000000 12.600000 0.320000 1.730000 5.000000 25% 0.082045 0.000000 5.190000 0.000000 0.449000 5.885500 45.025000 2.100175 4.000000 279.000000 17.400000 375.377500 6.950000 17.025000 50% 0.256510 0.000000 9.690000 0.000000 0.538000 6.208500 77.500000 3.207450 5.000000 330.000000 19.050000 391.440000 11.360000 21.200000 75% 3.677083 12.500000 18.100000 0.000000 0.624000 6.623500 94.075000 5.188425 24.000000 666.000000 20.200000 396.225000 16.955000 25.000000 max 88.976200 100.000000 27.740000 1.000000 0.871000 8.780000 100.000000 12.126500 24.000000 711.000000 22.000000 396.900000 37.970000 50.000000from sklearn.model_selection import train_test_split # 訓練データとテストデータに分割 x_train, x_test, t_train, t_test = train_test_split(boston.data, boston.target, random_state=0)from sklearn import linear_model # RM(部屋数)の列を取得 x_rm_train = x_train[:, [5]] x_rm_test = x_test[:, [5]] model = linear_model.LinearRegression() # 線形回帰モデル model.fit(x_rm_train, t_train) # モデルの訓練LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)a = model.coef_ # 係数 b = model.intercept_ # 切片 print("a: ", a) print("b: ", b)a: [9.31294923] b: -36.180992646339206import matplotlib.pyplot as plt plt.scatter(x_rm_train, t_train, label="Train") plt.scatter(x_rm_test, t_test, label="Test") y_reg = a * x_rm_train + b # 回帰直線 plt.plot(x_rm_train, y_reg, c="red") plt.xlabel("Rooms") plt.ylabel("Price") plt.legend() plt.show()
線上にええ感じになってるのでええ感じになってる
次回へ続く
- 投稿日:2021-01-24T15:37:13+09:00
画像から情報(Exif,GPSなど)を削除する
iPhoneで撮影した写真をQiitaにアップする際に、念のためExif,GPSなどの情報を削除しておきます。
情報削除を行うコード
PythonでPillowを使用して、画像を貼り付けて保存する。
reimage.pyfrom PIL import Image import argparse def conv(image_path: str, new_name: str): print(f"convert: {image_path} -> {new_name}") new_im = None with Image.open(image_path) as im: new_im = Image.new("RGBA", im.size, (255, 255, 255, 0)) new_im.paste(im) new_im.save(new_name, "png") parser = argparse.ArgumentParser() parser.add_argument("-i", "--input") parser.add_argument("-o", "--output") args = parser.parse_args() output = args.input if args.output: output = args.output conv(args.input, output)実行コマンド
python3 reimage.py -i 画像パス (-o 新しい画像パス、無ければ元画像に上書き)
- 投稿日:2021-01-24T15:32:02+09:00
Python3エンジニア認定データ分析試験を受けようと考えている人達へ
Python3エンジニア認定データ分析試験を受けました
合格したので、試験を受けるためにやってきたことを書いておきます。
今後この資格を受けようと考えている人達のためになれば幸いです。結論から
- 転職などでは役にはたたないと思う(ある転職サイトの資格欄が選択式だったのですが、この資格はありませんでした。)
- Python初心者, データ分析のライブラリについて勉強したことがない方は行う価値あり。(環境構築、ライブラリの使い方が一通り分かるため)
なぜ受講したのか
主に以下3点です。
1. 環境構築や機械学習に興味があった。
2. 業務でPythonを使用しており、ライブラリの勉強がしたかった。
3. 2020年春から基本情報などを受けようとしたが、コロナで中止された為、CBT方式の資格を考えた試験範囲
Python3エンジニア認定データ分析試験は下記内容で問題が出題されます。l
章 節 問題数 問題割合 1 データエンジニアの役割 2 5.00% 2 Pythonと環境 1 実行環境構築 1 2.50% 2 Pythonの基礎 3 7.50% 3 Jupyter Notebook 1 2.50% 3 数学の基礎 1 数式を読むための基礎知識 1 2.50% 2 線形代数 2 5.00% 3 基礎解析 1 2.50% 4 確率と統計 2 5.00% 4 ライブラリによる分析実践 1 NumPy 6 15.00% 2 pandas 7 17.50% 3 Matplotlib 6 15.00% 4 scikit-learn 8 20.00% 5 応用: データ収集と加工 0 0% 勉強内容
使用した教材はPythonによるあたらしいデータ分析の教科書のみ(画像はAmazonのものを使用しています)
2週間かけて、試験範囲のところを読みました。Codeが分からないところはJupyter NoteBookで実行して、理解しました。
その後、PRIME STUDYで模擬試験を受講。
私の感想だと、この教材のみ勉強すれば合格できると考えています。
以上です!!
この資格を受けてよかった点
- 環境構築など、今まで疎かにしていたところが明確に理解できた。
- 今まで使用していたライブラリでも、使っていない機能を知れた
- 機械学習の導入として、最適かなと感じました。ただこれだけだと
反省点
模擬試験で安心していたのですが、過去問ではないため、出題内容が少し違いました。
そのため結構ギリギリで合格した形でした。私が元々知識が薄かった環境構築とJupyter Notebookが正解率が一番低かったです。
どれか得意な分野を作るのではなく、きちんと全体的に勉強した方がよいかなと(当たりまえか・・・)。今後について
今後は統計の勉強と基本情報と応用情報の勉強をしていきたいと考えてます。
それが終わったらコンペに出たいですね!
また何かあったら、記事にしていく予定なので、宜しくお願いします。

- 投稿日:2021-01-24T15:25:18+09:00
Pythonのunittestでmock_openを使った時、openを複数回呼び出すコードは、assert_has_callsではなくcall_args_listで検証すると学びました
「Pythonの
unittestを使ったコードにおいて、関数呼び出しの引数は、モックのassert_xxx系のメソッドで常に検証できる」という思い込みが粉砕されたので、アウトプットします。
だいぶハマったので再発防止の目的です。モックのassert_xxx系のメソッドとは、公式ドキュメントの以下にあるメソッドを指しています(例:
assert_called_once_with)。
https://docs.python.org/ja/3/library/unittest.mock.html#unittest.mock.MockPythonのunittest.mockでめっちゃハマりました。なんとか突破
— nikkie (@ftnext) January 23, 2021
私の知っている範囲の some_mock.assert_xxx メソッド呼び出しでは、アサートできない引数のパターンが存在していました。
mock. call_args_list を検証して解決。
全部assert_xxxで書けるという思い込みが粉々にされました環境
macOS
Python 3.8.6
- pytest 6.0.1(テストランナーとして使用。テストコードは
unittestを使っています)テストコードを書きたいコード(イメージ)
同名のファイルを複数回
openするコード1です。
ファイルの読み書き無しでテストが実行できるよう、openにモックを当てて、モックを呼び出す引数を検証しようと考えました。DATA_FILE = "./data/loaded_files.json" with open(DATA_FILE) as f: loaded = json.load(f) # 処理(省略) with open(DATA_FILE, 'w', encoding='utf-8') as f: json.dump(loaded, f, indent=2, ensure_ascii=False)mock_openについて少し
テストの実装には、
unittest.mockにあるmock_openを使います。
https://docs.python.org/ja/3/library/unittest.mock.html#mock-openopen() の利用を置き換えるための mock を作るヘルパー関数。 open() を直接呼んだりコンテキストマネージャーとして利用する場合に使うことができます。
サンプルコード(
mock_openのドキュメントより)>>> from unittest.mock import mock_open, patch >>> m = mock_open() >>> with patch("__main__.open", m): # 対話モードで実行しているので __main__ を指定 ... with open("foo", "w") as h: ... h.write("some stuff") ... >>> m.assert_called_once_with("foo", "w")
openを呼び出す際の引数を検証できました。[TL; DR] 書くべきと分かったテストコード
from unittest.mock import call, mock_open, patch # 以下はTestCaseのメソッドの中に書いています m = mock_open(read_data='{"spam": 42}') with patch("builtins.open", m): sut.main() # テスト対象のメソッド実行 self.assertEqual( m.call_args_list, [ call("./data/loaded_files.json"), call("./data/loaded_files.json", "w", encoding="utf-8"), ], )?
m.call_args_listをassertEqualするというのがポイントでした。
call_args_listは「モックの呼び出しを順に記録したリスト」(要素はcallオブジェクト)です。
https://docs.python.org/ja/3/library/unittest.mock.html#unittest.mock.Mock.call_args_list
補足:
mock_openのread_data引数について
ドキュメントに「mock が呼ばれるたびに read_data は先頭に巻き戻されます」とあるのを見て、「書き込みモードでも影響はないだろう」と判断しました。
読み取り/書き込みのモードで分けることはせずに、openに一括でモックを当てています。
当初書いたコード
openは2回呼び出されるので、モックmのassert_has_callsで検証しようとしました。
https://docs.python.org/ja/3/library/unittest.mock.html#unittest.mock.Mock.assert_has_calls呼び出しでは mock_calls のリストがチェックされます。
from unittest.mock import mock_open, patch # 以下はTestCaseのメソッドの中に書いています m = mock_open(read_data='{"spam": 42}') with patch("builtins.open", m): sut.main() # テスト対象のメソッド実行 m.assert_has_calls( [ call("./data/loaded_files.json"), call("./data/loaded_files.json", "w", encoding="utf-8"), ] )通らないAssertion
E AssertionError: Calls not found. E Expected: [call('./data/loaded_files.json'), E call('./data/loaded_files.json', 'w', encoding='utf-8')] E Actual: [call('./data/loaded_files.json'), E call().__enter__(), E call().read(), E call().__exit__(None, None, None), E call('./data/loaded_files.json', 'w', encoding='utf-8'), E call().__enter__(), E call().__exit__(None, None, None)]
mock_openで当てたモックが複数回呼び出された時、どうやらassert_has_callsでは検証できないようです2。
以下に示すように1回だけ呼び出した場合はassert_has_callsで検証できるので、今ひとつ解せません。
(これがPythonのバグなのか仕様なのかまでは踏み込めていません)>>> from unittest.mock import call, mock_open, patch >>> m = mock_open() >>> with patch("__main__.open", m): ... with open("foo") as h1: ... h1.read() ... '' >>> m.mock_calls [call('foo'), call().__enter__(), call().read(), call().__exit__(None, None, None)] >>> m.assert_has_calls([call("foo")]) >>> # 書き込みモードでも同一のファイルをopenする >>> with patch("__main__.open", m): ... with open("foo", "w") as h2: ... h2.write("egg") ... >>> m.mock_calls [call('foo'), call().__enter__(), call().read(), call().__exit__(None, None, None), call('foo', 'w'), call().__enter__(), call().write('egg'), call().__exit__(None, None, None)] >>> # mock_callsに call('foo') があるにもかかわらずAssertionError >>> m.assert_has_calls([call("foo"), call("foo", "w")]) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/unittest/mock.py", line 950, in assert_has_calls raise AssertionError( AssertionError: Calls not found. Expected: [call('foo'), call('foo', 'w')] Actual: [call('foo'), call().__enter__(), call().read(), call().__exit__(None, None, None), call('foo', 'w'), call().__enter__(), call().write('egg'), call().__exit__(None, None, None)]
mock_openでのみ発生(Mockについては発生しない)モックについて同じメソッドを複数回呼び出したときは、
assert_has_callsで検証できました(MagicMockで検証した例)。>>> from unittest.mock import call, MagicMock >>> m = MagicMock() >>> m.awesome_method("foo") <MagicMock name='mock.awesome_method()' id='4387550112'> >>> m.awesome_method("foo", 42) <MagicMock name='mock.awesome_method()' id='4387550112'> >>> m.awesome_method.mock_calls [call('foo'), call('foo', 42)] >>> m.awesome_method.assert_has_calls([call("foo"), call("foo", 42)])別の方法:
assert_any_call3https://docs.python.org/ja/3/library/unittest.mock.html#unittest.mock.Mock.assert_any_call
モックが特定の引数で呼び出されたことがあるのをアサート
>>> # AssertionErrorになった対話モードの続き >>> m.assert_any_call("foo", "w") >>> m.assert_any_call("foo")
- 投稿日:2021-01-24T15:10:21+09:00