- 投稿日:2021-01-24T23:33:54+09:00
CloudWatchイベントでスケジュールされたECSタスクをAWS SDK for Javaで直接起動する
TL; DR
CloudWatchイベントでスケジュールされたECSタスクを、AWS SDK for Javaを利用して直接起動する機会があったので、備忘録がてら知見としてまとめます。
環境
- AWS CLI:
2.1.16- Kotlin:
1.3.50- AWS SDK for Java:
2.8.7AWS CLI
やること自体はとても単純ですので、簡単にAWS CLIで動作確認していきます。
まず、list-targets-by-ruleでCloudWatchイベントでスケジュールされたECSタスクのパラメータを取得します。
$ aws events list-targets-by-rule --rule "batch-schedule"レスポンスを確認すると、
Arnにクラスター名、EcsParameters以下にECSタスクの起動に必要なパラメータが色々設定されているのが分かります。{ "Targets": [ { "Id": "batch-schedule", "Arn": "arn:aws:ecs:ap-northeast-1:{アカウントID}:cluster/{クラスター名}", "RoleArn": "arn:aws:iam::{アカウントID}:role/{ロール名}", "EcsParameters": { "TaskDefinitionArn": "arn:aws:ecs:ap-northeast-1:{アカウントID}:task-definition/{ファミリー名}:{リビジョン番号}", "TaskCount": 1, "LaunchType": "FARGATE", "NetworkConfiguration": { "awsvpcConfiguration": { "Subnets": [ "{サブネットID}" ], "SecurityGroups": [ "{セキュリティグループID}" ], "AssignPublicIp": "DISABLED" } }, "PlatformVersion": "1.3.0" } } ] }後は上記で取得したパラメータを使ってrun-taskを実行するだけです。
$ aws ecs run-task \ --cluster "arn:aws:ecs:ap-northeast-1:{アカウントID}:cluster/{クラスター名}" \ --task-definition "arn:aws:ecs:ap-northeast-1:{アカウントID}:task-definition/{ファミリー名}:{リビジョン番号}" \ --launch-type "FARGATE" \ --network-configuration "awsvpcConfiguration={subnets=[{サブネットID}],securityGroups=[{セキュリティグループID}],assignPublicIp=DISABLED}"AWS SDK for Java
上記と同じことをAWS SDKで実行すると下記のようになります。
build.gradle.ktsdependencies { ... implementation("software.amazon.awssdk:ecs") implementation("software.amazon.awssdk:cloudwatchevents") }import software.amazon.awssdk.services.cloudwatchevents.CloudWatchEventsClient import software.amazon.awssdk.services.cloudwatchevents.model.ListTargetsByRuleRequest import software.amazon.awssdk.services.ecs.EcsClient import software.amazon.awssdk.services.ecs.model.AwsVpcConfiguration import software.amazon.awssdk.services.ecs.model.NetworkConfiguration import software.amazon.awssdk.services.ecs.model.RunTaskRequest import software.amazon.awssdk.services.ecs.model.RunTaskResponse fun runTask(): RunTaskResponse { // CloudWatchイベントでスケジュールされたECSタスクのパラメータを取得 val cloudWatchEvents = CloudWatchEventsClient.builder().build() val listTargetsByRuleRequest = ListTargetsByRuleRequest.builder() .rule("batch-schedule") .build() val listTargetsByRuleResponse = cloudWatchEvents.listTargetsByRule(listTargetsByRuleRequest) val eventRule = listTargetsByRuleResponse.targets().first() val ecsParameters = eventRule.ecsParameters() // CloudWatch Eventsのパッケージで定義されたNetworkConfigurationを元に // ECSのパッケージで定義されたNetworkConfigurationを作成する val networkConfiguration = ecsParameters.networkConfiguration().awsvpcConfiguration().let { NetworkConfiguration.builder().awsvpcConfiguration( AwsVpcConfiguration.builder() .subnets(it.subnets()) .securityGroups(it.securityGroups()) .assignPublicIp(it.assignPublicIp().name) .build() ).build() } // ECSタスクを実行する val ecs = EcsClient.builder().build() val runTaskRequest = RunTaskRequest.builder() .cluster(eventRule.arn()) .taskDefinition(ecsParameters.taskDefinitionArn()) .launchType(ecsParameters.launchType().name) .networkConfiguration(networkConfiguration) .build() return ecs.runTask(runTaskRequest) }NetworkConfigurationの詰め替えが若干面倒ではありますが、ListTargetsByRuleで取得したパラメータを元にRunTaskを実行するだけなのは特に変わらないですね。
まとめ
実際はClientをシングルトンにしたり色々やると思いますが、記事にするにあたって諸々簡略化しました。
AWS CLIもAWS SDKも結局はAWS APIをコールしてるだけなので、AWS APIにもっと慣れ親しんだ方が理解が早そうだなぁと思う今日この頃です。
- 投稿日:2021-01-24T22:58:20+09:00
EC2 [Amazon linux] -> S3 ファイルアップロード
EC2 -> S3
aws s3 cp [転送したいファイル] s3://[バケット名]
- 投稿日:2021-01-24T22:51:31+09:00
AWSメモ
責任共有モデル 顧客側は以下のリソースに対するセキュリティに責任があります。 -Amazon Machine Images(AMI) -アプリケーション -転送中のデータ -保管中のデータ -データストア -資格情報 -ポリシーと構成 共有統制 インフラストラクチャレイヤーとお客様レイヤーの両方に適用される統制です。ただし、コンテキストや観点は完全に異なります。共有統制では、AWS がインフラストラクチャに対する要件を提供し、お客様は AWS のサービスの使用に対して独自の統制を実装する必要があります。以下に例を示します。 パッチ管理 AWS がインフラストラクチャの不具合に対するパッチ適用および修復に責任を負いますが、お客様はゲスト OS およびアプリケーションのパッチ適用に責任を負います。 構成管理 AWS がインフラストラクチャデバイスの構成を保守しますが、お客様は独自のゲストオペレーティングシステム、データベース、アプリケーションの構成に責任を負います。 意識とトレーニング AWS が AWS の従業員のトレーニングを実施しますが、お客様の従業員のトレーニングはお客様が実施する必要があります。 クラウドでのセキュリティには、7 つの設計原則があります。 強力なアイデンティティ基盤の実装: 最小権限の原則を実装し、役割分担を徹底させ、各 AWS リソースとの通信において適切な認証を実行します。アイデンティティ管理を一元化し、長期にわたる静的な認証情報に依存しないようにすることを目的とします。 トレーサビリティの実現: ご使用の環境に対して、リアルタイムで監視、アラート、監査のアクションと変更を行うことができます。ログとメトリクスの収集をシステムに統合して、自動的に調査しアクションを実行します。 全レイヤーでセキュリティを適用する: 複数のセキュリティコントロールを使用して深層防御アプローチを適用します。ネットワークのエッジ、VPC、ロードバランシング、すべてのインスタンスとコンピューティングサービス、オペレーティングシステム、アプリケーション、コードなど、すべてのレイヤーに適用します。 セキュリティのベストプラクティスを自動化する: 自動化されたソフトウェアベースのセキュリティメカニズムにより、スケール機能を改善して、安全に、より速く、より費用対効果の高いスケールが可能になります。バージョン管理されているテンプレートにおいてコードとして定義および管理されるコントロールを実装するなど、セキュアなアーキテクチャを作成します。 伝送中および保管中のデータの保護: データを機密性レベルに分類し、暗号化、トークン分割、アクセスコントロールなどのメカニズムを適宜使用します。 **データに人の手を入れない: データに直接アクセスしたりデータを手動で処理したりする必要を減らしたり、排除したりするメカニズムとツールを使用します。これにより、機密性の高いデータを扱う際の誤処理、変更、ヒューマンエラーのリスクを軽減します。 セキュリティイベントに備える: 組織の要件に合わせたインシデント管理および調査のポリシーとプロセスを導入し、インシデントに備えます。インシデント対応シミュレーションを実行し、自動化されたツールを使用して、検出、調査、復旧のスピードを上げます。 VPC ルート テーブル内の各ルートは、送信先とターゲットを指定します。 たとえば、サブネットがインターネットゲートウェイ経由でインターネットにアクセスできるようにするには、サブネットルートテーブルに次のルートを追加します。 送信先 ターゲット 0.0.0.0/0 igw-12345678901234567 ルートの宛先は 0.0.0.0/0 です。これは、すべての IPv4 アドレスを表します。ターゲットは、VPC にアタッチされているインターネットゲートウェイです。 ゲートウェイルートテーブル ルートテーブルは、インターネットゲートウェイまたは仮想プライベートゲートウェイに関連付けることができます。ルートテーブルがゲートウェイに関連付けられている場合、ゲートウェイルートテーブルと呼ばれます。 カスタマーゲートウェイ+VPG ターゲットゲートウェイを作成する VPC とオンプレミスネットワークの間に VPN 接続を確立するには、接続の AWS 側でターゲットゲートウェイを作成する必要があります。 ターゲットゲートウェイは、仮想プライベートゲートウェイまたはトランジットゲートウェイにすることができます。 仮想プライベートゲートウェイの作成 仮想プライベートゲートウェイを作成するとき、オプションで、Amazon 側のゲートウェイのプライベート自律システム番号 (ASN) 指定できます。ASN は、カスタマーゲートウェイに指定した BGP ASN とは異なっている必要があります。 仮想プライベートゲートウェイを作成した後は、VPC にアタッチする必要があります。 VPCのDNSに関する設定 VPCのDNSに関する設定として、「DNS Resolution」、「DNS Hostname」、「DHCP Options Sets」がありますので、以下簡単に記載します。 DNS Resolution VPC に対して DNS 解決がサポートされているかどうかを示します。 この属性が false の場合、Amazon が提供する VPC の DNS サービス (パブリック DNS ホスト名を IP アドレスに解決します) が有効になりません。この属性が true の場合、Amazon が提供する DNS サーバー (IP アドレス 169.254.169.253) へのクエリ、またはリザーブド IP アドレス (VPC IPv4 ネットワークの範囲に 2 をプラスしたアドレス) へのクエリは成功します。 DNS Hostname VPCの設定として、本設定をtrueまたはfalseで設定できます。trueにすることで、VPC内に起動されるインスタンスに名前解決可能なFQDNが付与されます。 VPC 内に起動されるインスタンスが パブリック DNS ホスト名を取得するかどうかを示します。この属性が true の場合、VPC 内のインスタンスは DNS ホスト名を取得します。それ以外の場合は取得しません。インスタンスが DNS ホスト名を取得するようにする場合は、enableDnsSupport 属性も true に設定する必要があります。 DHCP Options Sets DHCPのオプションフィールドに関するパラメータ(DNSサーバやドメイン名等)を指定する設定項目です。作成したDHCP Options SetsをVPCに関連づけることで設定します。 IPアドレスの予約 サブネットのネットワークアドレスをのぞいた最初の3つのアドレスはAWS側で予約されているため使用できません。 例えば/24であれば第4オクテットが1、2、3のIPアドレスが使用できないことになります。 またオンプレミスのネットワークと同様に、ネットワークアドレス、ブロードキャストアドレスはEC2インスタンスなどに割り当てることができません。 そのため合計で5個のIPアドレスがデフォルトで使用されます。 VPC CIDRの拡張 拡張にあたっては、制限事項がありますのでいくつか紹介します。 追加可能なCIDRのサイズは、/28から/16の間です。 すでに割り当てているCIDRと重複する範囲で割り当てはできません。 ピアリング接続があるVPCの場合、ピアリングしたVPCと重複するCIDRは割り当てできません。 プライマリCIDRの範囲によって、割り当て可能なセカンダリCIDRの範囲は制限されます。 例えば、プライマリCIDRの範囲が10.0.0.0/8の場合、 172.16.0.0/12および192.168.0.0/16の範囲は割り当てできません。(他のRFC 1918の範囲は追加不可) プライマリCIDRが10.0.0.0/15の範囲内にある場合、10.0.0.0/16の範囲のCIDRブロックは追加できません。 198.19.0.0/16の範囲のCIDRブロックは追加できません。 VPCピアリング(+ PrivateLink) VPCピアリングとVPC PrivateLinkの違い 今日は、VPC同士の通信に使えるという機能としては同じで、混同しやすいこの2つのサービスの違いを整理したいと思います。 VPCピアリングとは リージョン間VPCピアリング以外のピアリングの場合通信が一度インターネットを経由します。 異なるVPC間を1対Nで接続することができます。接続したVPC間は、あたかも同じVPC内であるかのように通信することができます。 故に、CIDRブロックが一致または重複する VPC 間ではこの機能は使えません。 VPC ピアリング接続を使用すると、データの転送が容易になります。 たとえば、複数の AWS アカウントがある場合、これらのアカウント間で VPC をピアリングし、ファイル共有ネットワークを作成できます。また、VPC ピア接続を使用して、他の VPC からお客様のいずれかの VPC に存在するリソースへのアクセスを許可することもできます。 異なるAWSアカウント間でも接続可能です。 リージョン間 VPC ピア接続(インターリージョンVPCピアリング) 異なるリージョンにあるVPC同士も接続可能です (リージョン間 VPC ピア接続、インターリージョンVPCピアリングとも呼ばれます)。 これにより、異なる AWS リージョンで実行されている EC2 インスタンス、Amazon RDS データベース、Lambda 関数などの VPC リソースが、ゲートウェイ、VPN 接続、または個別のネットワークアプライアンスを必要とせずに、プライベート IP アドレスを使用して互いにやり取りできます。 トラフィックはプライベート IP 空間に残ります。 すべてのリージョン間トラフィックは暗号化され、単一障害点または帯域幅のボトルネックは存在しません。 トラフィックは、常にグローバル AWS バックボーンにとどまり、パブリックインターネットを通過することがないため、一般的なエクスプロイトや DDoS 攻撃などの脅威を減らすことができます。 また、リージョン間 VPC ピア接続を利用すると、シンプルで費用対効果の高い方法により、リージョン間でリソースを共有したり、地理的な冗長性のためにデータをレプリケートしたりできます。 クォーター デフォルト50、ハードクォーター:125があるため、Transit VPCを使う Transit VPC(転送ゲートウェイ) トランジットゲートウェイは、Virtual Private Cloud (VPC) とオンプレミスネットワークを相互接続するために使用できる中継ハブです。詳細については、Amazon VPC トランジットゲートウェイを参照してください。Site-to-Site VPN 接続は、トランジットゲートウェイのアタッチメントとして作成できます。 PrivateLinkとは PrivateLinkを使うと、通信がAWSのネットワーク内で完結してインターネットに出ないので、要件を満たすことができます。 PrivateLinkはインターフェースタイプのVPCエンドポイント VPCのコンソールにエンドポイント、エンドポイントのサービスというメニューがあります。 事前にNLBを作成することが必須です。 その上で対向となるVPCに「インターフェースVPCエンドポイント」を作成し、NLBとの接続を設定します。 PrivateLinkを使うことでインターネットに出る必要がなくなるため「IGW、NATデバイス、VPNコネクション、パブリックIP」の導入・設定が不要になり、環境設計が必要なコンポーネントを減らすことができます。また、セキュリティ要件の厳しいシステムやクローズドな環境での稼動が必須となるシステムをAWS上に構築する際に役立ちます。 VPCエンドポイント VPCと他のサービス間の通信を可能にするVPCコンポーネント(仮想デバイス)です。VPCエンドポイントをVPCに作成することで、VPC内のインスタンスとVPC外のサービスの間で通信ができるようになります。 VPCエンドポイント(ゲートウェイとインターフェース) S3とDynamoDBがゲートウェイ その他のAWSサービスがインタフェースに対応している(ENIが必要?) ゲートウェイタイプを使用する場合はルーティング設定が必要です。 図に示したルートテーブルにあるように、Destinationとして「使用するサービスのエンドポイント(この場合は東京リージョンのS3のpl-id(プレフィックスリストID))」、Targetとして「作成したVPCエンドポイントのID(vpce-id)」を指定します。 このルートを設定することでVPC内部からVPC外のサービスへの通信ができるようになります。 Gateway VPCのルートテーブルを書き換えてVPCエンドポイントのゲートウェイ経由でAWSのAPIエンドポイントへアクセスする。 ゲートウェイVPCエンドポイントではAWSのAPIへはパブリックIPへ向いており、アクセス制御はゲートウェイのアクセスポリシーで行います。 S3のエンドポイントがグローバルIPのままであるということは、ゲートウェイ型のVPCエンドポイントの1つの特徴です。 接続元のEC2インスタンスはプライベートIPのみにも関わらず、ゲートウェイ型のVPCエンドポイントが何らか上手いことやってくれて、そのままS3にアクセスできるようにしてくれます。ただし、エンドポイントのIPはグローバルIPとなるので、ネットワークACLでローカルのIPのみという制限を加えると、エンドポイントを利用しても通信が出来なくなります。 Interface サービスのエンドポイントとENIをPrivateLinkと呼ばれるものでリンクされます。 DNSを使ってENIのプライベートIPに<サービス名>.<リージョン>.amazonaws.comのようなAレコードが設定されます。 インターフェイスVPCエンドポイントではENIに対してアクセスするため、アクセス制御はセキュリティグループで行います。 VPCピアリングとの使い分け PrivateLinkのユースケースを検討する際にはVPCピアリングとどう使い分けるのかが問題になると思います。両VPCのネットワーク構成や利用用途、あるいは現行の運用方法などを考慮してVPCピアリングとPrivateLinkのどちらを利用するのが適切であるかを検討しましょう。 VPC Flow Logs VPC内のNetwork Interface間のIPトラフィックをキャプチャすることができる VPC、サブネット、あるいはネットワークインターフェイス(ENI)のいずれかに作成します。 ENIが特定できる場合は、不要なトラフィックをキャプチャしないようにENIに対してVPC フローログを設定します。 VPC Flow Logs データはCloudWatch Logsに格納され、自由に可視化することが出来ます。CloudWatch Logsに格納される、ということはあらかじめ特定のトラフィックを設定しておくことでアラートを発生させることもできる VPC FLow Logsの中身 ログ見方 ${action}フィールドのACCEPTは、セキュリティグループおよびネットワーク ACLで許可されたトラフィックを表します。 REJECTは、セキュリティグループまたはネットワーク ACLで許可されていないトラフィックを表します。 制限事項 EC2 Classicには使えない VPC Peeringには使えない タグ付けはできない 一度Flow Logsを作成したら変更はできない(IAMロールの変更等)。変更する場合は一度削除してから作り直す リソースレベルのアクセス許可はできない。Flow Logsを使用する際は全てのリソースに対してワイルドカードにてLogsに対して権限を付与する必要がある VPC での IPv6 の使用開始 https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/get-started-ipv6.html IPv6 CIDR ブロックと 1 つのパブリックサブネットを持つデフォルトでない VPC を作成します。 特定のポートのみからトラフィックを許可するセキュリティグループをインスタンスに作成します。 サブネット内に Amazon EC2 インスタンスを起動し、起動時に IPv6 アドレスをインスタンスに関連付けます。IPv6 アドレスはグローバルに一意であり、インスタンスがインターネットと通信できるようにします。 VPC の IPv6 CIDR ブロックをリクエストできます。このオプションを選択すると、IPV6 CIDR ブロックをアドバタイズする場所であるネットワーク境界グループを設定できます。ネットワーク境界グループを設定すると、CiDR ブロックがこのグループに制限されます。 ステップ 1: VPC を作成する /16 (65,536 個の IP アドレス)の IPv4 CIDR ブロックを持つ VPC を作成し、/56 の IPv6 CIDR ブロックを VPC と関連付けます。 IPv6 CIDR ブロックのサイズ (/56) は固定されており、IPv6 アドレスの範囲は、Amazon の IPv6 アドレスのプールから自動的に割り当てられます (独自の IPv6 アドレス範囲を指定することはできません)。 インターネットゲートウェイをこの VPC にアタッチします。インターネットゲートウェイの詳細については、「インターネットゲートウェイ」を参照してください。 /24 の IPv4 CIDR ブロックと、/64 の IPv6 CIDR ブロックを持つサブネットを VPC 内に作成します。IPv6 CIDR ブロックのサイズは固定されています (/64)。 カスタムルートテーブルを作成し、サブネットに関連付けると、サブネットとインターネットゲートウェイ間でトラフィックが転送されます。ルートテーブルに関する詳細については、「ルートテーブル」を参照してください。 VPNの種類と用語 【基準1】インターネット経由かそうでないか ■インターネットを経由する → 「インターネットVPN」(開かれたネットワークでの利用を想定) ■インターネットを経由しない → 「IP-VPN」など(閉じられたネットワークでの利用を想定) 【基準2】インターネットVPNでどのプロトコル(通信の規格)が使われているか ■IPsecを使用するVPN → IPsec-VPN(より深い階層「ネットワーク層」で動作する) ■SSLを使用するVPN → SSL-VPN(より浅い階層「セッション層」で動作する) SSL-VPNとは、暗号化にSSL技術を使用したリモートアクセスVPNのことです。 リモートアクセスVPNには IPsecによるリモートアクセスVPNと、SSLによるリモートアクセスVPNの大きく2つがあります IPSec-VPNとは? によるリモートアクセスVPNの場合、クライアントPCに必ずVPN Clientのソフトウェアをインストールする 必要がある IPSec-VPNだけが、以下3点を満たすことができるVPNです。 安全性を維持できる 暗号化のプロトコルを取り入れています。「暗号化」そのものは複雑な構造をしています。IPSecの場合では、安全性を確かめ改ざんされていないか確認するプロトコルで成り立っています。 トンネリングができる 離れた場所を、疑似的につなぐプロトコルを取り入れています。 どのアプリでも動作する より深い階層(ネットワーク層)で動作しているため可能になります。SSL-VPNでは動作しない場合があります。 SSL SSLによるリモートアクセスVPNの場合はWebブラウザさえあれば通信可能です SSL VPNはLambda RDSにアクセスできない ネットワークACLとセキュリティグループの違い ネットワークACL ネットワークACLはサブネット単位で設定します。 サブネット以下の全インスタンスが影響を受けます。各サブネットは必ずいずれか一つのネットワークACLと紐付ける必要があります。設定しない場合デフォルトのネットワークACLが勝手に紐付きます。 ネットワークACLは許可ルール、拒否ルール両方設定します。ルール毎にルール番号を設定し、番号の低い順から評価されます。 ネットワークACLのルールに設定するのは、ポートとCIDRです。インバウンドルールであれば、ポート〇〇のCIDR xx.xx.xx.xx/24 からのインバウンドトラフィックを許可(拒否)するとか、アウトバウンドルールであればポート▲▲のCIDR yy.yy.yy.yy/32 へのアウトバウンドトラフィックを許可(拒否)するとかいったルールを書いていきます。 セキュリティグループ セキュリティグループはインスタンス単位で設定します。 各インスタンスには少なくとも 1 つのセキュリティグループを紐付ける必要があります。言い換えれば複数個のセキュリティグループを紐付けることも可能です。 セキュリティグループはデフォルト通信拒否です。許可ルールのみを設定していきます。 セキュリティグループも同様にポートとCIDRを指定してルールを書いていきます。CIDRの代わりにセキュリティグループIDを指定することもできます。 両方で細かく設定すると変更が面倒 ネットワークACL、セキュリティグループ両方で許可されたトラフィックのみが通信許可されます。もし途中で通信要件が変わった場合、ネットワークACL、セキュリティグループ両方で細かいを設定をしていると両方の設定を変更しない限り疎通できません。それが面倒なので、より細かな設定ができるセキュリティグループでのみ細かい設定をしてネットワークACLは全許可などゆるい設定にしていることが多いです。 ★ EC2 インスタンスを別のサブネット、アベイラビリティーゾーン、VPC に移動する方法 既存のインスタンスを別のサブネット、アベイラビリティーゾーン、または VPC に移動することができません。 代わりに、ソースインスタンスから新しい Amazon マシンイメージ (AMI) を作成して、手動でインスタンスを移行できます。次に、目的のサブネット、アベイラビリティーゾーン、または VPC で新しい AMI を使用して新しいインスタンスを起動します。最後に、ソースインスタンスを新しいインスタンスに任意の Elastic IP アドレスを再割り当てします。 各サービスの 既存データの暗号化について RDS 暗号化オプションはDBインスタンスの作成時にのみ有効にすることができる 作成後のインスタンスでは有効にすることができません。 ただし、暗号化されていないスナップショットのコピーは暗号化することが可能です。 S3 デフォルトの暗号化を有効にした後、設定した暗号化は将来のアップロードにのみ適用されます。 既存のオブジェクトを適切に暗号化するには、コピーオブジェクトまたはコピーパート API を使用できます。 同じ名前のオブジェクトをコピーし、サーバー側で暗号化することでオブジェクトデータを暗号化します。 削除した S3 オブジェクトを復元する方法 削除されたオブジェクトを復元するには、オブジェクトが削除される前にオブジェクトを含むバケットでバージョニングが有効になっている必要があります S3 バケットから削除されたオブジェクトを復元する方法 削除したオブジェクトを復元するには、削除マーカーを削除する必要があります。 復元するオブジェクトの削除マーカーの横にあるチェックボックスを選択し、次に [削除] を選択します。 S3にアクセスしたIPアドレスの特定方法について CloudTrailを使用する デフォルトではバケットレベルの操作のみ証跡を作成しているが、任意のS3バケットに対してデータレベルで証跡を作成することもできる。 CloudFrontに自動的にキャッシュされたS3のファイルを削除する方法 S3 オブジェクトを無効にする S3 オブジェクト無効にして、CloudFront ディストリビューションのキャッシュからレスポンスを削除できます。オブジェクトがキャッシュから削除されると、次のリクエストでは、 Amazon S3 から直接オブジェクトを取得します。 オブジェクトのバージョニングを使う Snowball CloudWatch Agent CloudWatch エージェントによって収集されたメトリクスは、カスタムメトリクスとして請求されます。 基本的な設定の流れ 1.EC2にインストールされたCloudWatch AgentがログをCloudWatchに書き込めるように適切なIAMロールを設定する 2.EC2にCloudWatch Agentをインストールする 3.CLIやEC2やSSMからCloudWatch Agentを起動する EBS EBSのパフォーマンス向上の手段としては大きく二つあります。 EBS最適化インスタンス: 通常EC2とEBS間の通信は他のネットワークトラフィックと共存していますが、EBS最適化(EBS optimization)インスタンスに設定することでEC2とEBS間に専用のネットワークスループットが確保され、他のネットワークトラフィックの影響を最小化することが出来ますので、EBSのパフォーマンスが安定的に引き出せます。 Provisioned IOPS: 作成時にIOPSレートを指定出来るボリュームです。最小200〜最大4000IOPSの範囲で指定可能です。なおその性質から上記のEBS最適化インスタンスと組み合わせて使用することが推奨されています。 ★既存のインスタンスの EBS 最適化の有効化 インスタンスが実行中の場合は、まず停止する必要があります。 Amazon Data Lifecycle Manager Amazon Data Lifecycle Manager を使用して、EBS スナップショットと EBS-backed AMI の作成、保持、削除を自動化できます。スナップショットと AMI 管理を自動化すると、次のことができるようになります。 定期的なバックアップスケジュールを実施して貴重なデータを保護する。 定期的に更新できる標準化された AMI を作成する。 監査担当者または社内のコンプライアンスが必要とするバックアップを保持する。 古いバックアップを削除してストレージコストを削減する。 分離されたアカウントにデータをバックアップする災害対策バックアップポリシーを作成する。 AWS Shield ELB(ALB,CLB),CloudFront, Route53の DDoS 対策を提供するサービスです。 Standardは全てのAWSアカウントで無償、主要なDDoS攻撃対策やモニタリングが提供されます。 Advancedは月額$3000で、DoS攻撃発生時の各種支援、DDoSにより生じたAWS課金の補填 - DDoS履歴の詳細レポート提供(L3、L4、L7) 特徴 AWS Shield Standard AWS Shield Advanced アクティブな監視 ネットワークフロー監視 ○ ○ 自動化されたアプリケーション(レイヤー7)トラフィックの監視 - ○ DDoS対策 SYNフラッドやUDPリフレクション攻撃などの一般的なDDoS攻撃から保護します。 ○ ○ 追加のDDoS軽減能力へのアクセス - ○ 可視性と報告 レイヤ3/4アタック通知と攻撃フォレンジックレポート - ○ レイヤ3/4/7攻撃履歴レポート - ○ DDoS対応チームのサポート 重大度が高いイベントでのインシデント管理 - ○ 攻撃時のカスタム軽減 - ○ 攻撃後の分析 - ○ コスト保護 Route 53、CloudFront、およびELB DDoSの料金に関連する払い戻し - ○ AWS GuardDuty(脅威検出サービス) AWSのアカウント、ワークロード、および Amazon S3 に保存されたデータを保護するために、悪意のあるアクティビティや不正な動作を継続的にモニタリングする脅威検出サービス なぜGuardDutyが必要か? インターネット上のリソースに対する攻撃リスク AWSアカウントへの攻撃リスク から保護するため GuardDutyの原理と動作 各種AWSのログを収集している 分析するためのCloudTrailやVPC Flow Logsのログについては、利用者が有効化していなくてもAWSがバックグラウンドで取得している情報を使うため、GuardDutyを利用するためにそれぞれを有効化する必要はありません。 AWSへのAPIコールを記録するCloudTrailのイベントログ VPC内のトラフィックを記録するVPC Flow Logs 各種リソースからのDNSログ ログを機械学習とAIで分析している 不正なIPの情報など既存の脅威情報を活用している 通常の利用と異なるリクエストなどを検知している リスクレベルを10段階で評価する などの複数の AWS データソース全体で何百億件ものイベントを分析します 信頼できるIPリストでホワイトリストを作る 信頼できるIPリストを使えば、IPアドレスのホワイトリストを作成できます。ホワイトリストに登録されると、Findingは発生しません。 AWS SystemManager AWSおよびオンプレミスのサーバ群を管理する多機能なツールセットの総称です。いろいろな観点でのグルーピングと関連リソースの整理の方法があると思いますが、すっきりまとめると以下のような感じになるかと思います。 共有リソース SSM Documents Parameter Store グループ化 OpsCenter Resource Groups スケジューリング Maintenance Windows オペレーション Run Command Automation Distributer Session Manager 構成情報の集約・監査 State Manager Inventory Patch Manager Automation Automationは、自動化ワークフローを構築して、インスタンスおよびAWSリソースを管理する機能です。 AWSが定義済のワークフローだけでなく、独自のカスタムワークフローを作成することも可能です。 定義したワークフローの進捗は、CloudWatch Events経由の通知やAWS Systems Managerコンソールから確認することが可能です。 SSM Automationを使ってWindows Update実行を自動化など AWS SystemManager PatchManager AWS でインフラストラクチャを表示および制御するために使用できる AWS のサービスです。 Systems Manager コンソールを使用すると、複数の AWS のサービスのオペレーションデータを表示して、AWS リソース間でオペレーションタスクを自動化することができます。Systems Manager は、マネージドインスタンスをスキャンして、ポリシーの違反が検出された場合にはレポート (または是正策の措置) を行うことで、セキュリティを維持するのに役立ちます。 パッチベースライン インスタンスにパッチ適用を行う際のルールを定義するものである OSごとに事前定義済みのパッチベースラインが存在する 事前定義済みのパッチベースラインは変更できないが、カスタムベースラインを作成することができる OSごとにデフォルトのベースラインを設定する 1つのパッチベースラインに複数のパッチグループをアタッチすることができる パッチグループ インスタンスと特定のパッチグループの関連付けを行うためのコンポーネントである 1つのパッチグループには複数のOSのEC2インスタンスを所属させることができる 1つのパッチグループを複数のパッチベースラインにアタッチすることができるが、OSごとに1つまでである パッチグループにEC2インスタンスを所属させない状態も取りうる どのパッチベースラインにも登録しない状態でパッチグループを作成することはできない 1台のインスタンスを複数のパッチグループに所属させることはできない パッチを適用するインスタンスの選択 パッチマネージャーによるスキャン(およびインストール)を実行する際のターゲットの指定の仕方として以下の3種がある インスタンスID指定 タグ指定 パッチグループ指定 パッチグループ指定以外の方法でターゲットを指定し、ターゲットがどのパッチグループにも所属していない場合、使用されるパッチベースラインはOSごとのデフォルトベースラインとなる パッチグループ指定の場合、パッチグループが登録しているパッチベースラインが選択される インスタンスログの CloudWatch Logs への送信 インスタンスのメトリクスとログを収集するには、SSM エージェント を使用する代わりに、Amazon CloudWatch エージェント を設定して使用できます。SSM エージェント よりも CloudWatch エージェント を使用したほうが、EC2 インスタンスのメトリクスを多く収集できます。また、CloudWatch エージェント を使用すると、オンプレミスのサーバーからもメトリクスを収集できます。 ALB+CLB+NLB ロードバランサーの種類 インターネットロードバランサー インターネットに接続するロードバランサーは、インターネット経由でクライアントからのリクエストを受け取り、ロードバランサーに登録されている EC2 インスタンス全体に分散します。 内部ロードバランサー 内部ロードバランサーは、プライベートサブネット内の EC2 インスタンスへのトラフィックをルーティングします。 ロードバランサーのタイプ ALB: レイヤー 7 CLB NLB: レイヤー 4, Pre-warming不要 アベイラビリティーゾーン/サブネット ELB を使用すると、サブネットを追加することができるので、それぞれのアベイラビリティーゾーンにロードバランサーノードが作成されます。 ELB には少なくとも1つのサブネットが接続されている。 ELB には、AZ ごとに1つのサブネットしか接続できません。既にアタッチされた AZ でサブネットをアタッチすると、既存のサブネットが置き換えられます。 各サブネットは、少なくとも a/27 ビットマスクを持つ CIDR ブロックを持ち、ELB がバックエンドインスタンスとの接続を確立するために使用する少なくとも8つの空き IP アドレスを持っている必要があります。 高可用性を実現するには、インスタンスが単一のサブネット内にある場合でも、1つのサブネットを AZ ごとに少なくとも2つの AZ にアタッチすることをお勧めします。 サブネットは ELB からアタッチまたはデタッチすることができ、それに応じてサブネット内のインスタンスへの要求の送信を開始または停止します。 リスナー リスナーは、HTTP、HTTPS、SSL、TCP プロトコルをサポートします。 HTTPS または SSL 接続に x.509 証明書が必要であり、ロードバランサーは証明書を使用して接続を終了し、クライアントから要求を復号化してからバックエンドインスタンスに送信します リスナールールは上から順番に評価されます パスが/admin/*かつ送信元が許可CIDRの場合、ターゲットグループAに転送 パスが/admin/*の場合、固定レスポンス403を返す デフォルトアクションでターゲットグループAに転送 Classic Load Balancerのレスポンスコードのメトリクス レスポンスメトリクス HTTP 400: BAD_REQUEST 原因 1: クライアントが HTTP 仕様を満たさない誤った形式のリクエストを送信しました。たとえば、リクエストの URL にスペースを含めることはできません。 原因 2: クライアントが HTTP CONNECT メソッドを使用しました。このメソッドは Elastic Load Balancing でサポートされていません。 HTTP 405: METHOD_NOT_ALLOWED 原因: リクエストヘッダー内のメソッドの長さが 127 文字を超えています。 HTTP 408: Request timeout 原因 1: ネットワークの中断またはリクエストの構造の問題 (ヘッダーの形式が完全ではない、指定されたコンテンツのサイズが実際に送信されたコンテンツのサイズと一致しないなど)。 原因 2: クライアントとの接続が閉じています (ロードバランサーは応答を送信できません)。 HTTPCode_ELB_4XX HTTPCode_ELB_5XX HTTP 502: Bad gateway インスタンスからの応答の形式が適切でないか、ロードバランサーに問題があります。 HTTP 504: Gateway Timeout (3)のリクエストがタイムアウトした場合です。このタイムアウト時間は通常60秒です。 このケースに対応する場合、アプリケーションが60秒以内にレスポンスを返すように何らかの対応を行うのが第一選択ですが、サポートに依頼することによりタイムアウト時間を延長することができる。 HTTP 503: Service Unavailable 原因 1: ロードバランサーにリクエストを処理する能力が不足しています。 原因 2: 登録されたインスタンスがありません。 原因 3: 正常なインスタンスがありません。 HTTPCode_Backend_4XX : (1)〜(4)までのステップを全て正常に完了したのだが、3のレスポンスが400系レスポンスであり、その結果(4)のレスポンスが400系として完了した場合、これはHTTPCode_Backend_4XXとしてカウントされます。存在しないリソースにアクセスして404がとなった場合や、Web APIに於いて必須のパラメータが足りなかった場合の400レスポンス等、クライアント側の「リクエストの仕方」に問題がある場合、400系のレスポンスを返すのが一般的 HTTPCode_Backend_5XX : (1)〜(4)までのステップを全て正常に完了したのだが、(3)のレスポンスが500系レスポンスであり、その結果(4)のレスポンスが500系として完了した場合 その他のメトリクス RequestCount HTTPCode_Backend_*の合計がRequestCountです。 SurgeQueueLength ELBは、バックエンドインスタンスがリクエストの処理能力を超えた場合に備えて、surge queueという待ち行列を備えています。 例えば、EC2インスタンス上のApache httpdのMaxClientsが飽和し、新たなコネクションを受け付けられない時、ELBはリクエストを一旦このキューに格納し、バッファリングを行います。 このキューの容量は1024で、それ以上のリクエストが来た場合は、バックエンドにリクエストのルーティングは行わず(行えず)、HTTPCode_ELB_5XXとしてレスポンスを行います。 このメトリクスは、このキューにたまったリクエストの数を表します。また、一般的には平均(average)や最大値(max)による集計が適切です。突発的なリクエスト増がなければ、このメトリクスは0を維持します。 SpilloverCount surge queueがあふれ、HTTPCode_ELB_5XXが返った数を表します。 この分のリクエストは、前述の通りRequestCountには含まれず、サーバサイドにもログが残らないので、気をつけておかなければ気付けない障害となりがちです。 クラシックロードバランサー の SSL ネゴシエーション設定 セキュリティポリシーと呼ばれる Secure Socket Layer (SSL) ネゴシエーション設定を使用して、クライアントとロードバランサー間の SSL 接続をネゴシエートします。セキュリティポリシーは、SSL プロトコル、SSL 暗号、およびサーバーの優先順位オプションを組み合わせたものです。 SSL プロトコル SSL プロトコルは、クライアントとサーバーの間の安全な接続を確立し、クライアントとロードバランサーの間で受け渡しされるすべてのデータのプライバシーを保証します。 Secure Sockets Layer (SSL) と Transport Layer Security (TLS) はインターネットなどの安全性の低いネットワークでの機密データの暗号化に使用される暗号プロトコルです。TLS プロトコルは SSL プロトコルの新しいバージョンです。Elastic Load Balancing のドキュメントでは、SSL プロトコルも TLS プロトコルも SSL プロトコルと呼びます。 SSL プロトコル 以下のバージョンの SSL プロトコルがサポートされています。 TLS 1.2 TLS 1.1 TLS 1.0 SSL 3.0 非推奨の SSL プロトコル カスタムポリシーで以前に SSL 2.0 プロトコルを有効にした場合、セキュリティポリシーを事前に定義されたデフォルトのセキュリティポリシーに更新することをお勧めします。 SSL証明書の更新について ELBのサーバ証明書更新にはset-load-balancer-listener-ssl-certificateAPIを利用します。 オプションには、ロードバランサ名と更新後サーバ証明書のARN(手順1)を指定する必要があります。 AWSでは、ELBやCloudFrontに紐付けるサーバ証明書はIAMで一括管理されています。サーバ証明書のアップロードにはIAMのupload-server-certificate APIを利用します。 aws elb set-load-balancer-listener-ssl-certificate \ --load-balancer-name <ロードバランサ名> \ --load-balancer-port 443 \ --ssl-certificate-id <更新後サーバ証明書のARN> ELBのログについて ELBはリクエストに関する詳細情報を収集するアクセスログを取得することができます。 各ログには、リクエストを受け取った時刻、クライアントの IP アドレス、レイテンシー、リクエストのパス、サーバーレスポンスなどの情報が含まれます。 ユーザーはこれらのアクセスログを使用して、トラフィックパターンの分析や、問題のトラブルシューティングを行うことができます。 Elastic Load Balancing がロードバランサーのトラフィックを不均等にルーティングするのはなぜですか? 以下の場合、ELB はトラフィックをターゲットに不均等にルーティングすることがあります。 クライアントが、TTL の有効期限が切れた DNS レコードを持つロードバランサーノードの誤った IP アドレスに、リクエストをルーティングしている。 スティッキーセッション (セッションアフィニティ) が、ロードバランサーに対して有効になっている。スティッキーセッションでは Cookie を使用して、クライアントが Cookie の有効期間にわたって同じインスタンスへの接続を維持するため、時間の経過とともに不均衡が発生する可能性があります。 利用可能な正常なインスタンスが、アベイラビリティーゾーン間で均等に分散されていない。 特定のキャパシティータイプのインスタンスが、アベイラビリティーゾーン間で均等に分散されていない。 クライアントとインスタンスの間に、存続期間の長い TCP 接続がある。 Perfect Forward Secrecy Perfect Forward Secrecy(PFS)は暗号化通信のセキュリティを高めるための仕組み(概念)です。 万が一、暗号化通信に用いる鍵が漏洩してしまった場合、キャプチャして保存していた通信内容は過去に渡って復号化されてしまう可能性があります。そこで、一時的な情報であるセッションキーを暗号化通信に利用します。これにより、万が一、鍵が漏洩してしまった場合でも、通信内容が復元される可能性を低くするわけです。 Server Order Preference 暗号化通信の技術は常に進化しており、同時に脆弱性も新しく発見されていきます。しかし、常に最新の技術を利用すれば良いとも限りません。 サーバサイドは兎も角、クライアントサイド、すなわちブラウザが最新のセキュリティ方式に対応していなければ通信そのものが出来なくなってしまいます。古いブラウザを利用せざるを得ないこともあります(最新のOS/ブラウザにアップデートすることは必要かと思いますが)。 Server Order Preferenceを有効にすることで、ELBは適切な暗号化技術を選択して適用します。TLS1.2に対応していないブラウザからのアクセスであれば、TLS1.0で適切な暗号化技術を組み合わせて通信を行うようになるため、自動的に最適なセキュリティ対策を行ってくれると考えてよいでしょう。 ただし、古いOSやブラウザからのアクセスであれば対応する暗号化技術も古いため、セキュリティは弱くなります。可能な限り最新のOS/ブラウザを利用した方が良いことは変わりません。 x-forwarded-for X-Forwarded-For (XFF) ヘッダーは、 HTTP プロキシ又はロードバランサーを通過してウェブサーバーへ接続したクライアントの、送信元 IP アドレスを特定するために事実上の標準となっているヘッダーです。 AWS Config AWS リソースの【設定】を評価、監査、審査できるサービス AWS リソースとは、AWS で使用できるエンティティであり、Amazon Elastic Compute Cloud (EC2) インスタンス、Amazon Elastic Block Store (EBS) ボリューム、セキュリティグループ、Amazon Virtual Private Cloud (VPC) などを指します https://docs.aws.amazon.com/ja_jp/config/latest/developerguide/resource-config-reference.html AWS Trusted Advisor AWS サービスに対して実施されるもの コストの最適化、セキュリティ、耐障害性、パフォーマンス、サービスの制限といった AWS のベストプラクティスに基づく 5 つのカテゴリにわたるチェックと推奨事項を提供します。 レポートをだすことも可能です。 Amazon Inspector EC2 インスタンスへ実施するもの 意図しないネットワークアクセスや、EC2 インスタンス上の脆弱性をチェックできます Amazon Inspector では、自動的にアプリケーションを評価し、露出、脆弱性、ベストプラクティスからの逸脱がないかどうかを確認できます AWS WAF 一般的なWebアプリケーションに対する攻撃手法としてSQLインジェクションやXSS(クロスサイトスクリプティング)などがありますが、これらの脅威から保護します。(もっといろんな攻撃から保護することが多いですがここでは省略) 使えるサービス AWS WAFは下記にインテグレートしてサービスとして利用します。 CloudFront ALB API Gateway ルール ルールとは、WAFの動作する様々な条件の定義で、例えば下記のような条件で1つのルールとなりました。 指定したIPからのアクセスを拒否する XSSとなるような文字列を拒否する 特定のIPのみ/adminパスへのアクセスを許可する 過剰なリクエストがあるIPを拒否する CloudFront キャッシュヒット率の改善方法 オリジンが一意のオブジェクトを返すクエリ文字列パラメータのみを転送するようにCloudFront を設定するなどしてキャッシュを改善できます。 Cache-Control max-age ディレクティブをオブジェクトに追加し、max-ageに対して最も長い実用的な値を指定するようにオリジンを設定する レポート 使用状況レポート リクエストとデータ転送の傾向を追跡 HTTP/S の要求数、HTTP/S で転送されたデータ、CloudFront のエッジロケーションからユーザーに転送されたデータ、CloudFront からオリジンに転送されたデータがこのグラフに表示されます。 ビューワーレポート エンドユーザーの詳細トを表示できます。 デバイス – コンテンツにアクセスするユーザーが最も頻繁に使用するデバイスのタイプ (デスクトップやモバイルなど)。 ブラウザ – Chrome や Firefox など、コンテンツにアクセスするときに、ユーザーが最も頻繁に使用するブラウザの名前 (または名前とバージョン)。このレポートには、上位 10 件のブラウザが表示されます。 オペレーティングシステム – Linux、Mac OS X、Windows など、コンテンツにアクセスするときにビューワーが最も頻繁に実行するオペレーティングシステムの名前 (または名前とバージョン)。このレポートには、上位 10 件のオペレーティングシステムが表示されます。 ロケーション – コンテンツに最も頻繁にアクセスするビューワーの場所 (国、または米国の州/準州)。このレポートには、上位 50 件の国、または米国の州/準州が表示されます。 トップリファラーレポート エンドユーザーがどのドメインからウェブサイトを参照したかを確認する キャッシュ統計レポート CloudFront エッジロケーションに関連する統計をグラフ表示できます。 キャッシュ統計グラフには、トータルのリクエスト、結果の種類別に分類されたビューワーリクエストの割合、ビューワーに転送されたバイト数、HTTP ステータスコード、ダウンロードが完了しなかった GET リクエストの割合が表示されます。 Amazon CloudFront 人気オブジェクトレポート 最も人気のあるオブジェクトを追跡 Route53 パブリックホストゾーンとプライベートホストゾーン パブリックホストゾーン VPC外で名前解決をしてくれるもの インターネット上に公開されたDNSにメインレコードを管理するコンテナです。 インターネットのDNSドメインに対するトラフィックのルーティング方法を定義するものです プライベートホストゾーン VPC内のみで名前解決をしてくれるもの ヘルスチェックの作成と DNS フェイルオーバーの設定 ヘルスチェックでは、ウェブアプリケーション、ウェブサーバー、その他のリソースの正常性とパフォーマンスを監視します。 3 種類の Amazon Route 53 ヘルスチェックを作成できます。 ウェブサーバーなどの指定するリソースのヘルスチェック IP アドレスあるいはドメイン名で特定するエンドポイントをモニタリングするヘルスチェック 指定された一定の間隔で、Route 53 は、自動リクエストをインターネット経由でアプリケーションやサーバーなどのリソースに送信して、そのリソースが到達可能、使用可能、機能中であることを確認します。オプションで、ユーザーが行ったものと同様のリクエスト (特定の URL へのウェブページのリクエストなど) を行うように、ヘルスチェックを設定できます。 そのほかのヘルスチェックのステータス 他のヘルスチェックが正常あるいは異常であるかを Route 53 が判断するかについてをモニタリングするヘルスチェック この方法が便利な状況のひとつが、複数のウェブサーバーなどの同じ機能を実行する複数のリソースがあるときに、最低限のリソースが正常であるかどうかに重点を置く場合です Amazon CloudWatch アラームのステータス アラームをモニタリングする CloudWatch と同じデータストリームをモニタリングするヘルスチェック データストリームがアラームの状態を [OK] と示している場合、ヘルスチェックは正常と見なされます。 データストリームが状態を [アラーム] と示している場合、ヘルスチェックは異常と見なされます。 アラームの状態を判断するための十分な情報がデータストリームから提供されない場合、ヘルスチェックのステータスは [ヘルスチェックステータス] の設定 (正常、異常、または最後の既知の状態) によって決まります (Route 53 API では、この設定は InsufficientDataHealthStatus です)。 ルーティングポリシー シンプルルーティングポリシー – ドメインで特定の機能を実行する単一のリソースがある場合に使用します。たとえば、example.com ウェブサイトにコンテンツを提供する 1 つのウェブサーバーなどです。 フェイルオーバールーティングポリシー – アクティブ/パッシブフェイルオーバーを構成する場合に使用します。 位置情報ルーティングポリシー – ユーザーの位置に基づいてトラフィックをルーティングする場合に使用します。 地理的近接性ルーティングポリシー – リソースの場所に基づいてトラフィックをルーティングし、必要に応じてトラフィックをある場所のリソースから別の場所のリソースに移動する場合に使用します。 レイテンシールーティングポリシー – 複数の AWS リージョンにリソースがあり、レイテンシーの最も小さいリージョンにトラフィックをルーティングする場合に使用します。 複数値回答ルーティングポリシー – ランダムに選ばれた最大 8 つの正常なレコードを使用して Route 53 が DNS クエリに応答する場合に使用します。 加重ルーティングポリシー – 指定した比率で複数のリソースにトラフィックをルーティングする場合に使用します。 Route 53 がエンドポイントをモニタリングするヘルスチェックのステータスを決定する方法 18% を超えるヘルスチェッカーがエンドポイントを正常であるとレポートした場合、Route 53 はそのエンドポイントを正常と見なします。 ヘルスチェッカーが正常であるエンドポイントが 18% 以下であるとレポートした場合、Route 53 はそのエンドポイントを異常と見なします。 HTTP/HTTPS ヘルスチェック – Route 53 が、エンドポイントとの TCP 接続を 4 秒以内に確立できることが必要です。加えて、接続後 2 秒以内に、HTTP ステータスコード 2xx または 3xx でエンドポイントが応答する必要があります。 TCP ヘルスチェック - – Route 53 が、エンドポイントとの TCP 接続を 10 秒以内に確立できることが必要です。 HTTP/HTTPS ヘルスチェックと文字列一致 – HTTP/HTTPS ヘルスチェックと同様に、Route 53 はエンドポイントとの TCP 接続を 4 秒以内に確立し、そのエンドポイントが接続後 2 秒以内に 2xx または 3xx の HTTP ステータスコードで応答する必要があります。 AWS のコストと使用状況レポート(AWS Billing and Cost Management ) サービス、料金、リザーブドインスタンス、Savings Plans などに関するメタデータを含む、AWS のコストと使用状況に関する最も包括的なデータを提供します 子サービス? AWS Cost Explorer:グラフでのコストの分析 AWS Budgets:予算を設定し閾値を超えたらアラートを上げて通知してくれるサービス AWS Cost & Usage Report:AWS のコストと定期的にレポートティングしてくれるサービス AWS Billing Dashboard Cost Allcation Tags(コスト配分タグ):どのAWSアカウントを追加委、どの程度課金が発生したかを識別するためにタグをふ ダッシュボード ダッシュボードでは、次のグラフを表示できます。 利用額の概要 サービス別の今月の初めから今日までの消費 過去 1 か月のトップサービス (消費別) EC2 インスタンスタイプとサイズとネットワーク速度 インスタンスファミリー T3・T2 「バースト」できることが特長のインスタンスタイプです。負荷が少ないときに「CPUクレジット」を貯めておくと、突発的に負荷が高まったときに貯めたCPUクレジットを消費して対応できる。たとえば、「ある時間だけ負荷が集中する」といった傾向が見えているWebサイトなど。 M5・M4 CPUやメモリ、ネットワークをバランスよく提供する C5・C4 「コンピューティング負荷の高いワークロードに最適化」 インスタンスサイズとは 搭載しているメモリや vCPU の数を表しています。また、ネットワークパフォーマンスに違いが出てきます。 EC2 インスタンスのリタイアメント通知 インスタンスをホストしている基盤のハードウェアで回復不可能な障害が検出されたときに通知されます。 予定されたリタイア日になると、インスタンスは AWS によって停止または削除されますので、対応は必須になります。 対応方法は対象インスタンスを停止・起動のみ EC2間のネットワーク高速化と拡張ネットワーキングとプレイスメントグループ 拡張ネットワーキング インスタンス間レイテンシーを実現します。 プレイスメントグループ 単一のアベイラビリティーゾーン内のインスタンスを論理的にグループ化したものです。サポートされているインスタンスタイプとともにプレイスメントグループを使用すると、アプリケーションが低レイテンシーの 10 Gbps (ギガビット/秒) ネットワークに参加できるようになります。 どちらもインスタンス間における低レイテンシな通信を実現するための機能オプション AWS EC2 で Ping応答を得られるようにする設定 Amazon Web Service EC2 のデフォルトではPing応答が返されません。それはSecurity Group でICMP応答が有効になっていない為です。 インスタンスメタデータの取得 http://169.254.169.254/latest/meta-data/ EC2のログを取得する方法 CloudWatchAgentをインストールする CloudWatchLogsに対するIAMを与える InsufficientInstanceCapacityエラー 原因 インスタンスを起動したり、停止したインスタンスを再起動したりする際にこのエラーが発生する場合、現在 AWS にはリクエストに対応するために必要とされる十分なオンデマンドキャパシティーがありません。 ソリューション この問題を解決するには、以下の手順を実行します。 数分間待ってからリクエストを再度送信します。容量は頻繁に変化します。 インスタンス数を減らして新しいリクエストを送信します。たとえば、15 インスタンスを起動する 1 つのリクエストを行っている場合、代わりに 5 つのインスタンスに対する 3 つのリクエストを作成するか、1 つのインスタンスに対する 15 のリクエストを作成してみてください。 インスタンスを起動する場合は、アベイラビリティーゾーンを指定しないで新しいリクエストを送信します。 インスタンスを起動する場合は、別のインスタンスタイプを使用して新しいリクエストを送信します (これは後で* サイズを変更できます)。詳細については、「インスタンスタイプを変更する」を参照してください。 クラスタープレイスメントグループにインスタンスを起動すると、容量不足エラーが発生する場合があります。 インスタンスの種類 スケジュールドリザーブドインスタンス EC2インスタンスの買い方です。 日次、週次、月次と3パターンのスケジューリングされた買い方があり、月に数回のバッチ用などで買うことができる オンデマンドインスタンス リザーブドインスタンス スケジュールされたリザーブドインスタンス スポットインスタンス ハードウェア専有インスタンス スタンダードとコンバーチブル リザーブドインスタンス の違い 以下に、スタンダードとコンバーティブル リザーブドインスタンス の違いを示します。 スタンダード リザーブドインスタンス コンバーティブルリザーブドインスタンス リザーブドインスタンス の変更 一部の属性は変更できます。詳細については、「リザーブドインスタンス の変更」を参照してください。 一部の属性は変更できます。詳細については、「リザーブドインスタンス の変更」を参照してください。 リザーブドインスタンス の交換 交換できません。 期間内で、インスタンスファミリー、インスタンスタイプ、プラットフォーム、スコープやテナンシーなどの新しい属性の別の コンバーティブルリザーブドインスタンス に交換することができます。詳細については、「コンバーティブルリザーブドインスタンス の交換」を参照してください。 リザーブドインスタンスマーケットプレイス で販売する リザーブドインスタンスマーケットプレイス で販売できます。 リザーブドインスタンスマーケットプレイス では販売できません。 リザーブドインスタンスマーケットプレイス で購入 リザーブドインスタンスマーケットプレイス で購入することができます。 リザーブドインスタンスマーケットプレイス では購入できません。 インスタンスストアボリュームのバックアップ 1.新しい EBS ボリュームを作成して、インスタンスストアボリュームのデータをその EBS ボリュームにコピーする。 2. EBS ボリュームに保存されている個々のファイルをAmazon S3 CLI を最大限に活用してバックアップする。 EC2のステータスについて EC2インスタンスを立ち上げたばかりのときにステータス情報がデータ不足の場合は、ボリューム上でチェックがまだ進行中である可能性がある。 Connection Draining ソフトウェアのメンテナンスなどで使える機能です。 ELBから切り離してもリクエスト中のインスタンスへ指定秒数の間は通信は切れません。 min 1s デフォルト300s max 3600s ステータスチェックに失敗したインスタンスのトラブルシューティング まず、アプリケーションで問題が発生しているかどうかを確認します。インスタンスでアプリケーションが正常に実行されていないことを確認した場合は、ステータスチェック情報とシステムログを確認します。 ステータスチェック情報の確認 システムログの取得 インスタンスのステータスチェックに失敗した場合は、インスタンスを再起動してシステムログを取得できます。ログから判明したエラーが問題のトラブルシューティングに役立つ場合があります。再起動すると、ログから不要な情報が消去されます。 メモリ不足: プロセスの終了 インスタンスコンソール出力 コンソール出力は問題を診断する際に役立つツールで、特に、カーネルの問題やサービス設定の問題のトラブルシューティングを行うときに便利です。これらの問題が発生すると、SSH デーモンの開始前にインスタンスが停止したり、インスタンスに到達不能になったりする可能性があります。 Linux/Unix の場合、マシンに接続されている物理的なモニターに通常表示されるようなコンソール出力がインスタンスコンソール出力に表示されます。 コンソール出力は、インスタンス遷移状態 (開始、停止、再起動、終了) の直後に投稿されたバッファされた情報を返します。表示される出力は、継続的には更新されず、更新する価値があると思われる場合にのみ更新されます。 Windows インスタンスの場合は、インスタンスコンソール出力に直近のシステムイベントログエラーが 3 つ表示されます。 AutoScaling クールダウン(Cooldown) 新しいインスタンスが追加されるまでの待ち時間(新しいインスタンスの処理が開始されるまでの待ち時間) 再大容量を超えて複数ゾーンに渡ったインスタンス数について Auto Scalingは、常に古いインスタンスを止める前に新しいインスタンスを起動するため、 最大容量に近づくとリバランスを妨害したり処理を止めてしまうかもしれません。 この問題を避けるために、システムは一時的にリバランスの間、10%だけ(または1インスタンス)指定された最大容量を超えることができます 複数ゾーンに渡ったインスタンスの配分とバランス Auto Scalingは、Auto Scalingグループ内における複数のアベイラビリティゾーンで、インスタンスの均等な配分を試みます。 Auto Scalingは、最小のインスタンス構成でアベイラビリティゾーン内のインスタンス起動を試みます。 もし、起動に失敗すると、 Auto Scalingは、他のアベイラビリティゾーンで起動するまで試みます。 何かしらの操作や状態によって、Auto Scalingグループ内のバランスが保たれなくなったとき、Auto Scalingは、以下のような状態のときにリバランスによって釣り合いを取ります。 Auto Scalingグループのためにアベイラビリティゾーンを変える要求を出した場合。 TerminateInstanceInAutoScalingGroupによってバランスを失った場合。 不十分な容量のアベイラビリティゾーンが、回復して利用可能な容量を得た場合。 Auto Scalingは、古いインスタンスを終了させる前に新しいインスタンスを起動するため、リバランスにおいてアプリケーションの性能に悪影響を及ぼすことはありません。 CloudWatch を使用したインスタンスのモニタリング 基本モニタリング データは自動的に 5 分間無料で取得できます。 詳細モニタリング 1 分間のデータを取得できます。追加料金がかかります。 NAT NAT ゲートウェイ プライベートサブネットのインスタンスからはインターネットや他の AWS のサービスに接続できるが、インターネットからはこれらのインスタンスとの接続を開始できないようにすることができます。 NAT ゲートウェイを作成するには、NAT ゲートウェイの常駐先のパブリックサブネットを指定する必要があります。 NAT ゲートウェイに関連付ける Elastic IP アドレスも、ゲートウェイの作成時に指定する必要があります。NAT ゲートウェイに関連付けた Elastic IP アドレスを変更することはできません プライベートサブネットの 1 つ以上に関連付けられているルートテーブルを更新し、インターネット向けトラフィックを NAT ゲートウェイに向かわせる必要があります。これにより、プライベートサブネットのインスタンスがインターネットと通信できるようになります。 NAT ゲートウェイのルールと制限 NAT ゲートウェイは、プロトコルとして TCP、UDP、ICMP をサポートします。 NAT ゲートウェイにセキュリティグループを関連付けることはできません。セキュリティグループは、プライベートサブネットのインスタンスに対して使用し、それらのインスタンスに出入りするトラフィックを管理できます。 ★NATゲートウェイのトラブルシューティング インスタンスがインターネットにアクセスできない 問題 NAT ゲートウェイを作成し、手順に従ってテストしましたが、ping コマンドが失敗するか、プライベートサブネットのインスタンスがインターネットにアクセスできません。 原因 この問題の原因として、次のいずれかが考えられます。 NAT ゲートウェイでトラフィックを処理する準備が整っていません。 ルートテーブルが正しく構成されていません。 セキュリティグループまたはネットワーク ACL がインバウンドトラフィックまたはアウトバウンドトラフィックをブロックしています。 サポートされていないプロトコルを使用しています。 Egress-Only インターネットゲートウェイ NAT ゲートウェイは IPv6 トラフィックでサポートされていないため、送信専用 (Egress-Only) インターネットゲートウェイを使用します Egress-Only インターネットゲートウェイは水平にスケールされ、冗長で、高度な可用性を持つ VPC コンポーネントで、IPv6 経由での VPC からインターネットへの送信を可能にし、インスタンスとの IPv6 接続が開始されるのを防ぎます。 IPv6 アドレスはグローバルに一意であるため、デフォルトではパブリックアドレスになっています。インスタンスにインターネットにアクセスさせる場合で、インターネット上のリソースにインスタンスとの通信を開始させないようにする場合は、Egress-Only インターネットゲートウェイを使用できます。これを行うには、Egress-Only インターネットゲートウェイを VPC で作成し、次にすべての IPv6 トラフィック (::/0) または特定の IPv6 アドレスの範囲をポイントするルートテーブルに、Egress-Only インターネットゲートウェイへのルートを追加します。ルートテーブルに関連付けられるサブネットの IPv6 トラフィックは、Egress-Only インターネットゲートウェイにルーティングされます。 AWS Health リソースのパフォーマンスと AWS のサービスとアカウントの可用性をリアルタイムで可視化します。 AWS リソースのヘルス状態が変化したときにアラートや通知がトリガーされ、ほぼ瞬時にイベントが可視化されます。 AWS HealthのイベントのモニタリングAmazon CloudWatch Events Amazon CloudWatch Events イベントの変更を検出し対応することができます。 AWS Health次に、作成したルールで指定した値とイベントが一致すると、CloudWatch イベント で 1 つ以上のターゲットアクションが呼び出されます。 AWS Lambda 関数 Amazon Kinesis Data Streams Amazon Simple Queue Service(Amazon SQS) キュー 組み込みターゲット (CloudWatch アラームアクション) Amazon Simple Notification Service (Amazon SNS) トピック AWS Service Health DashBoard https://status.aws.amazon.com/ AWSサービス全体の障害情報を表示 AWS Personal Health Dashboard AWS Personal Health Dashboard では、お客様に影響するイベントが AWS で発生している場合に、アラートおよび改善のためのガイダンスを提供します。Service Health Dashboard は AWS の サービスの全般的なステータスを表示しますが、Personal Health Dashboard では、ご利用の AWS リソースの基礎となる AWS のサービスのパフォーマンスおよび可用性に関するパーソナライズされた表示を利用できます。 組織内で起きるAWSのメンテナンス情報などを マネジメントアカウントに集約、 全て確認できるのはとても便利ですね。 組織ビューの作成は特にコスト掛からないので、Organizations環境であればすぐに有効化して良いと思います。 CloudFormation 変更セットとは? スタック実行前に変更箇所を確認することができる機能です。 スタック実行前に変更されるリソースやパラメータを確認できるので、スタック実行することによって意図せずリソースが削除されたりする事故が防げます。 ドリフトとは? スタック実行後に手動操作などで変更されたリソースを確認できる機能です。 初期の構築ではCloudFormationを利用するが、後のアップデートではUpdate Stackを実行せずに手動で変更したりCloudFormation以外の手段で変更してしまうことが多々あります。 一旦別の手段へ変更してしまうと、テンプレートとの差が分からなくなりCloudFormationを利用した構成管理が行えなくなり、大きな問題になっていました。 実際のリソースとCloudFormationテンプレートの内容に乖離があることをドリフトと言い、それが可視化できる様になりました ドリフト検出のステータス ドリフトのステータスにはいくつかの種類があります。 ドリフト検出オペレーションステータス: ドリフトの操作の現在のステータスを記述する。 スタックドリフトステータス: そのリソースのドリフト状態に基づいて、スタック全体のドリフト状態を記述します。 リソースドリフトステータス: 個々のリソースのドリフト状況を記述します。 ヘルパースクリプト cfn-init リソースメタデータの取得と解釈、パッケージのインストール、ファイルの作成、およびサービスの開始で使用します。 cfn-signal CreationPolicy または WaitCondition でシグナルを送信するために使用し、前提となるリソースやアプリケーションの準備ができたときに、スタックの他のリソースを同期できるようにします。 使いみちとしては、AutoScalingグループ内のEC2インスタンスの更新時などに 新インスタンスのデプロイに失敗した(=成功シグナルを時間内に受信できなかった)場合はインスタンスを更新せずにロールバックする、などがありそうです。 (例)リソースの作成開始から10秒以内にCloudFormationにシグナルが飛ばない場合にはスタックがロールバックするcfn-signal Resources: ServerInstance: Type: AWS::EC2::Instance CreationPolicy: ResourceSignal: // ココ重要 Count: 1 Timeout: PT10S // ココ重要 Metadata: Comment: Install a simple web app UserData: Fn::Base64: !Sub | #!/bin/bash -xe /opt/aws/bin/cfn-init -v \ --stack ${AWS::StackName} \ --resource ServerInstance \ --region ${AWS::Region} # signal the status from cfn-init /opt/aws/bin/cfn-signal -e $? \ --stack ${AWS::StackName} \ --resource ServerInstance \ --region ${AWS::Region} InstanceSecurityGroup: Type: 'AWS::EC2::SecurityGroup' cfn-get-metadata 特定のキーへのリソースまたはパスのメタデータを取得するために使用します。 cfn-hup メタデータへの更新を確認し、変更が検出されたときにカスタムフックを実行するために使用します。 リソース属性 CreationPolicy 属性 CreationPolicy 属性をリソースに関連付けて、AWS CloudFormation が指定数の成功シグナルを受信するかまたはタイムアウト期間が超過するまでは、ステータスが作成完了にならないようにします。 リソースにシグナルを送信するには、cfn-signal ヘルパースクリプトまたは SignalResource API を使用できます 現在、作成ポリシーをサポートしている AWS CloudFormation リソースは、 AWS::AutoScaling::AutoScalingGroup、AWS::EC2::Instance、および AWS::CloudFormation::WaitCondition のみです。 (例) スタックの作成に進む前にリソース設定アクションを待機する場合は、CreationPolicy 属性を使用します。 たとえば、EC2 インスタンスにソフトウェアアプリケーションをインストールして設定する際に、先に進む前にこのアプリケーションを起動して実行する場合があります。このような場合、インスタンスに CreationPolicy 属性を追加すると、アプリケーションがインストールされ設定された後に、インスタンスに成功シグナルを送信します。 DeletionPolicy 属性 https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-attribute-deletionpolicy.html DeletionPolicy 属性を使用すると、スタックが削除された際にリソースを保持または (場合によっては) バックアップできます。 削除 この削除ポリシーは、あらゆるリソースタイプに追加することができます。デフォルトでは、DeletionPolicy を指定しない場合、AWS CloudFormation はリソースを削除します。ただし、以下の点を考慮する必要があります。 Retain AWS CloudFormation はスタックを削除する際、リソースやコンテンツを削除せず保持します。この削除ポリシーは、あらゆるリソースタイプに追加することができます。 { "AWSTemplateFormatVersion" : "2010-09-09", "Resources" : { "myS3Bucket" : { "Type" : "AWS::S3::Bucket", "DeletionPolicy" : "Retain" } } } DependsOn 属性 DependsOn 属性を使用すると、特定のリソースが他のリソースに続けて作成されるように指定できます。 DependsOn 属性をリソースに追加した場合、そのリソースの作成は必ず、DependsOn 属性で指定したリソースの作成後に行われます。 依存スタックには、ターゲットプロパティ !Ref および !GetAtt の形式で暗黙的な依存関係もあります。たとえば、リソース A のプロパティでリソース B への !Ref を使用する場合、次のルールが適用されます。 リソース B はリソース A の前に作成されます。 リソース A はリソース B の前に削除されます。 リソース B はリソース A の前に更新されます。 DependsOn 属性が必要なとき VPC ゲートウェイのアタッチメント VPC 内の一部のリソースはゲートウェイ (インターネットゲートウェイまたは VPN ゲートウェイのいずれか) を必要とします。 VPC、ゲートウェイ、ゲートウェイアタッチメントを AWS CloudFormation テンプレートで定義する場合、ゲートウェイを必要とするリソースはすべて、そのゲートウェイアタッチメントに依存することになります。 たとえば、パブリック IP アドレスが割り当てられている Amazon EC2 インスタンスは、同じテンプレートで VPC リソースと InternetGateway リソースも宣言されている場合、VPC ゲートウェイのアタッチメントに依存します。 現在、次のリソースは、関連付けられたパブリック IP アドレスを持ち、VPC 内にある場合、VPC ゲートウェイのアタッチメントに依存します。 Auto Scaling グループ Amazon EC2 インスタンス Elastic Load Balancing ロードバランサー Elastic IP アドレス Amazon RDS データベースインスタンス インターネットゲートウェイを含む Amazon VPC のルート UpdatePolicy 属性 UpdatePolicy 属性を使用して AWS::AutoScaling::AutoScalingGroup、AWS::ElastiCache::ReplicationGroup、AWS::Elasticsearch::Domain、AWS::Lambda::Alias のリソースに対する更新を処理する方法を指定できます AutoScalingReplacingUpdate ポリシー ローリング更新中、AWS CloudFormation がローリング更新を完了する前に、一部の Auto Scaling プロセスが Auto Scaling グループに変更を行うことがあります。 これらの変更により、ローリング更新が失敗する場合があります。ローリング更新中の Auto Scaling プロセスの実行を防止するには、SuspendProcesses プロパティを使用します AutoScalingRollingUpdate ポリシー プロパティ MaxBatchSize:AWS CloudFormation が更新するインスタンスの最大数を指定します。 MinSuccessfulInstancesPercent:更新を成功させるために成功のシグナルを送信する必要があるインスタンスの、 Auto Scaling ローリング更新における割合を指定します。0~100 の値を指定できます。AWS CloudFormation は、10% ごとに丸められます。たとえば、成功の最小割合が 50 の 5 つのインスタンスを更新する場合、3 つのインスタンスが成功のシグナルを送信する必要があります。 PauseTime:インスタンスにソフトウェアアプリケーションを起動する時間を与えるために、それらのインスタンスのバッチに変更を加えた後 AWS CloudFormation が一時停止する時間の長さ。たとえば、Auto Scaling グループ内のインスタンスの数をスケールアップする場合は PauseTime を指定する必要があります。 SuspendProcesses:スタックの更新中に Auto Scaling プロセスが停止されるように指定します。プロセスを停止すると、Auto Scaling がスタックの更新に干渉しなくなります。たとえば、Amazon EC2 Auto Scaling がアラームに関連付けられたスケーリングポリシーを実行しないようにアラームを停止できます。 UpdateReplacePolicy 属性 スタック更新オペレーションでリソースを置き換えるときに、リソースの既存の物理インスタンスを保持したり、必要に応じてバックアップしたりします。 UpdateReplacePolicy では、AWS CloudFormation で古いリソースを保持するか、必要に応じて古いリソースのスナップショットを作成するかを指定できます。 UpdateReplacePolicy は、スタックの更新時に置き換えるリソースにのみ適用されるという点で、DeletionPolicy 属性とは異なります。 RDS ストレージサイズを増やすことはできますが、減らすことはできません。 途中でインスタンスタイプを縮小することが可能です。 Amazon RDS での高可用性 (マルチ AZ) Amazon RDS のマルチ AZ 配置では、異なるアベイラビリティーゾーンに同期スタンバイレプリカが自動的にプロビジョニングされて維持されます。 プライマリ DB インスタンスは複数のアベイラビリティーゾーンにまたがって、スタンバイレプリカに同期してレプリケートされます。 セキュリティグループによるアクセスコントロール セキュリティグループにより DB インスタンスに対する送受信トラフィックへのアクセスを制御します。Amazon RDS では、VPC セキュリティグループ、DB セキュリティグループ、EC2-Classic セキュリティグループという 3 種類のセキュリティグループを使用します。 VPC セキュリティグループ VPC 内の DB インスタンスと EC2 インスタンスへのアクセスを制御します。 DB セキュリティグループ VPC 内にない EC2-Classic DB インスタンスへのアクセスを制御します。 EC2-Classic セキュリティグループ EC2 インスタンスへのアクセスを制御します。EC2-Classic セキュリティグループの詳細については、 Amazon EC2 ドキュメントの「 EC2-Classic 」を参照してください。 マルチAZの書き込み性能 マルチ AZ 配置を使用する DB インスタンスでは、同期データレプリケーションが発生するため、シングル AZ 配置より書き込みとコミットのレイテンシーが増加する場合があります。 AWS はアベイラビリティーゾーン間でのネットワーク接続レイテンシーが低くなるように設計されていますが、配置がスタンバイレプリカにフェイルオーバーした場合はレイテンシーに変化が見られる可能性があります。 本番稼働用ワークロードの場合、高速で一貫したパフォーマンスを実現できるようにプロビジョンド IOPS 用に最適化されたプロビジョンド IOPS および DB インスタンスクラスを使用することをお勧めします。 DB インスタンスをマルチ AZ 配置にする シングル AZ 配置の DB インスタンスをマルチ AZ 配置に変更すると (エンジンは Amazon Aurora 以外)、Amazon RDS でいくつかのことが実行されます。 まず、Amazon RDS は配置から、プライマリ DB インスタンスのスナップショットを撮ります。 その後、他のアベイラビリティーゾーンにスナップショットを復元します。その後、Amazon RDS によりプライマリ DB インスタンスと新しいインスタンスとの間に同期レプリケーションが設定されます。 Amazon RDS のフェイルオーバープロセス DB インスタンスの計画的な機能停止または計画外の機能停止が発生すると、マルチ AZ を有効にした場合は、Amazon RDS により別のアベイラビリティーゾーン内のスタンバイレプリカに自動的に切り替えられます。 フェイルオーバーが完了するまでにかかる時間は、データベースアクティビティや、プライマリ DB インスタンスが使用できなくなった時点の他の条件によって異なります。 フェイルオーバー時間は通常 60~120 秒です。 ただし、大規模なトランザクションや長期にわたる復旧プロセスによって、フェイルオーバー時間が増加する場合があります。フェイルオーバーが完了してから、新しいアベイラビリティーゾーンが RDS コンソールに反映されるまでさらに時間がかかる場合があります。 注記 DB インスタンスを再起動するときに手動でフェイルオーバーを強制的に実行することができます。詳細については、「DB インスタンスの再起動」を参照してください。 フェイルオーバーの条件 Amazon RDS はフェイルオーバーを自動的に処理するため、管理者が操作しなくても可能な限りすみやかにデータベース操作を再開できます。次のいずれかの条件が発生した場合、プライマリ DB インスタンスがスタンバイレプリカに自動的に切り替えられます。 * アベイラビリティーゾーンの機能停止 * プライマリ DB インスタンスのエラー * DB インスタンスのサーバータイプ変更 * DB インスタンスのオペレーティングシステムでソフトウェアのパッチ適用中 * DB インスタンスの手動フェイルオーバーが [Reboot with failover] を使用して開始された フェイルオーバーの判断 マルチ AZ DB インスタンスがフェイルオーバーされたかどうかを判断する方法は複数あります。 * DB イベントサブスクリプションは、フェイルオーバーが開始されたことを E メールまたは SMS で通知するように設定できます。イベントの詳細については、「Amazon RDS イベント通知の使用」を参照してください。 * Amazon RDS コンソールまたは API オペレーションを使用して DB イベントを表示できます。 * Amazon RDS コンソールおよび API オペレーションを使用して、マルチ AZ 配置の現在の状態を表示できます。 Aurora DB クラスター Amazon Aurora DB クラスターは、1 つ以上の DB インスタンスと、これらの DB インスタンスのデータを管理する 1 つのクラスターボリュームで構成されます。 Aurora クラスターボリュームは、複数のアベイラビリティーゾーンにまたがる仮想データベースストレージボリュームです。各アベイラビリティーゾーンには DB クラスターデータのコピーが保存されます。Aurora DB クラスターは 2 種類の DB インスタンスで構成されます。 インスタンスの種類 プライマリ DB インスタンス 読み書きオペレーションをサポートし、クラスターボリュームに対するすべてのデータ変更を実行します。各 Aurora DB クラスターには 1 つのプライマリ DB インスタンスがあります。 Aurora レプリカ プライマリ DB インスタンスと同じストレージボリュームに接続し、読み取りオペレーションのみをサポートします。各 Aurora DB クラスターは、プライマリ DB インスタンスに加えて 15 Aurora までのレプリカを持つことができます。 個別のアベイラビリティーゾーンに Aurora インスタンスレプリカを配置することで、高可用性を維持します。 プライマリ DB インスタンスが使用できない場合、Aurora は、Aurora レプリカに自動的にフェイルオーバーします。Aurora レプリカのフェイルオーバー優先順位を指定することができます。 RDSのスワップメモリの原因調査方法について 空きメモリが十分に割り当てられているにもかかわらず、Amazon RDS DB インスタンスが大量のスワップメモリを使用しています。十分なメモリがあるのにスワップメモリが使用される理由を調べるために。 FreeableMemory と SwapUsage の両方の Amazon CloudWatch メトリクスを調べて、RDS DB インスタンスの全体的なメモリ使用パターンを把握します 拡張モニタリングを有効にして、1 秒のわずかな間隔でメトリクスを確認します。拡張モニタリングはホストレベルで統計情報を収集し、CloudWatch は 60 秒ごとにハイパーバイザーレベルからデータを収集します。拡張モニタリングを使用すると、1 秒間だけ発生した増減を識別し、個々のプロセスで使用されている CPU とメモリを確認できます。 Performance Insights を有効にして SQL を識別し、RDS DB インスタンスで過度のスワップやメモリを消費しているイベントを待つこともできます RDSのスナップショット 日次で指定した時間帯に実施されます AWS DMS(Database Migration Serive) データベースの移行を支援するサービス 同じデータベースエンジン間の移行だけでなく、異なるデータベースエンジン間もサポートしている ただし、エンジンが異なると、データ型やプロシージャの際を変換する必要があるので、AWS SCTと組み合わせて意向を実施する必要がある AWS SCT データベースエンジン間でスキーマ変換を行うツール 各種RDBMSやDWHアプライアンス製品を指定することができる S3 耐久性 データを単一の AZ 内の複数のデバイスにわたって冗長に保存します レプリケーション レプリケーションを使用すると、Amazon S3 バケット間でオブジェクトを自動で非同期的にコピーできます。 オブジェクトのレプリケーションに設定されたバケットは、同じ AWS アカウントが所有することも別のアカウントが所有することもできます。オブジェクトを異なる AWS リージョン間でコピーすることも、同じリージョン内でコピーすることもできます。 オブジェクトのレプリケーションを有効にするには、レプリケーション設定をレプリケート元バケットに追加します。最小設定では、以下を指定する必要があります。 * Amazon S3 がオブジェクトをレプリケートするレプリケート先バケット。 * ユーザーに代わってオブジェクトをレプリケートするために Amazon S3 が引き受けることができる AWS Identity and Access Management (IAM) ロール レプリケーションを使用する理由 レプリケーションは、以下の場合に役立ちます。 メタデータを保持しながらオブジェクトをレプリケートする レプリケーションを使用すると、元のオブジェクトの作成時刻やバージョン ID などのすべてのメタデータを保持するオブジェクトのコピーを作成できます。この機能は、レプリカがソースオブジェクトと同じであることを確認する場合に重要です。 オブジェクトを異なるストレージクラスにレプリケートする レプリケーションを使用すると、オブジェクトをレプリケート先バケットの S3 Glacier、S3 Glacier Deep Archive、または別のストレージクラスに直接配置できます。データを同じストレージクラスにレプリケートし、レプリケーション先バケットのライフサイクルポリシーを使用して、オブジェクトが古くなるにつれてより冷たいストレージクラスに移動することもできます。 オブジェクトのコピーを別の所有権で保持する レプリケート元オブジェクトの所有者に関係なく、レプリカの所有権をレプリケート先バケット所有者である AWS アカウントに変更するように Amazon S3 に指示できます。これは所有者オーバーライドオプションと呼ばれます。このオプションを使用すると、オブジェクトのレプリカへのアクセスを制限できます。 15 分以内にオブジェクトをレプリケート S3 Replication Time Control (S3 RTC) を使用して、予測可能な時間枠内で、同じ AWS リージョンまたは異なるリージョン間でデータをレプリケートできます。S3 RTC は、Amazon S3 内に保存されている新規オブジェクトの 99.99% を 15 分以内にレプリケートします(サービスレベルアグリーメントに基づく)。詳細については、「S3 Replication Time Control (S3 RTC) を使用してコンプライアンス要件を満たす」を参照してください。 レプリケーションの要件 レプリケーションには以下が必要です。 送信元バケット所有者は、自分のアカウントに対して送信元と送信先の AWS リージョンを有効にする必要があります。レプリケート先のバケット所有者は、自分のアカウントでレプリケート先リージョンを有効にしている必要があります。AWS リージョンの有効化または無効化の詳細については、AWS 全般のリファレンスの「AWS のサービスエンドポイント」を参照してください。 レプリケート元とレプリケート先の両方のバケットで、バージョニングを有効にする必要があります。 Amazon S3 には、ユーザーに代わってレプリケート元バケットのオブジェクトをレプリケート先バケットにレプリケートするアクセス許可が必要です。 ソースバケット所有者がバケット内のオブジェクトを所有していない場合、オブジェクト所有者は、オブジェクトアクセスコントロールリスト (ACL) を使用して、バケット所有者に READ 権限と READ_ACP 権限を付与する必要があります。 レプリケート元バケットでオブジェクトロックが有効になっている場合は、レプリケート先バケットでも S3 オブジェクトロックが有効になっている必要があります クロスアカウントのレプリケーションの追加要件 保存先バケット所有者は、レプリケート元バケット所有者に、バケットポリシーを使用してオブジェクトをレプリケートするためのアクセス許可を付与する必要があります S3の分析 S3アクセスログ バケットに対する詳細ログが記録される アクセスログはセキュリティやアクセス監査に役立つ S3の請求についての理解にも役立つ ストレージクラス分析 Amazon S3 分析のストレージクラス分析を使用することにより、ストレージアクセスパターンを分析し、適切なデータをいつ適切なストレージクラスに移行すべきかを判断できます。この新しい Amazon S3 分析機能は、アクセス頻度の低い STANDARD ストレージをいつ STANDARD_IA (IA: 小頻度アクセス) ストレージクラスに移行すべきかを判断できるように、データアクセスパターンを確認します S3 Select Athena クエリの機能も対応フォーマットも多い 複数のファイルを対象にできる S3 Select 単一ファイルを対象 CSVとJSON(LD JSONもOKの模様)に対応 少しだけお手軽 クエリの機能が少ない。ORDER BYすらできない AWS CLI を使用してバケットを削除する バケットのバージョニングが有効化されていない場合にのみ、AWS CLI を使ってコンテンツオブジェクトがあるバケットを削除できます。バケットのバージョニングが有効化されていない場合には、rb (remove bucket) AWS CLI command with --force パラメータを使用して空ではないバケットを取り除くことができます。このコマンドは、すべてのオブジェクトを削除した後にバケットを削除します。 $ aws s3 rb s3://bucket-name --force rmは空にする 低価格なストレージについて Glacier Glacier Deep Archive ストレージ料金(東京) 0.005USD/GB 0.002USD/GB ストレージ料金(バージニア) 0.004USD/GB 0.00099USD/GB 最小保存期間 90日 180日 迅速取り出し時間 250 MB 以下の取り出しの場合、通常 1~5 分以内 - 標準取り出し時間 3~5時間 12時間以内 一括取得時間 5~12時間 48時間以内 暗号化 サーバーサイド Amazon S3 が管理するキーによるサーバー側の暗号化 (SSE-S3) Amazon S3 が管理するキーによるサーバー側の暗号化 (SSE-S3) を使用すると、各オブジェクトは一意のキーで暗号化されます。 さらにセキュリティを強化するために、キー自体が、定期的に更新されるマスターキーで暗号化されます。Amazon S3 のサーバー側の暗号化では、最強のブロック暗号の一つである、256 ビットの高度暗号化規格 (AES-256) を使用してデータを暗号化します。詳細については、「Amazon S3 で管理された暗号化キーによるサーバー側の暗号化 (SSE-S3) を使用したデータの保護」を参照してください。 AWS Key Management Service (SSE-KMS) に保存されたカスタマーマスターキー (CMK) によるサーバー側の暗号化。 AWS Key Management Service (SSE-KMS) に保存されているカスタマーマスターキー (CMK) によるサーバー側の暗号化は、SSE-S3 と似ていますが、このサービスを使用した場合はいくつかの追加の利点があり、追加の料金がかかります。Amazon S3 のオブジェクトへの不正アクセスに対する追加の保護を提供する CMK を使用するための個別のアクセス許可があります。 SSE-KMS は、CMK がいつ誰によって使用されたかを示す監査証跡も提供します。 さらに、カスタマー管理の CMK を作成および管理したり、ユーザー、サービス、およびリージョンに固有の AWS 管理の CMK を使用できます。詳細については、「AWS Key Management Service (SSE-KMS) に保存された CMK によるサーバー側の暗号化を使ったデータの保護」を参照してください。 お客様が指定したキーによるサーバー側の暗号化 (SSE-C) お客様が指定したキーによるサーバー側の暗号化 (SSE-C) を使用する場合は、お客様が暗号化キーを管理します。Amazon S3 は、ディスクに書き込む際の暗号化とオブジェクトにアクセスする際の復号を管理します クライアントサイド暗号化 (CSE) クライアントサイドの暗号化(Client Side Encryption(以降、CSEと略す))はお客様が用意したキーによって、クライアント内で暗号化したオブジェクトをS3に登録しますので、暗号化されたオブジェクトはユーザー以外に復号化が不可能です。 S3 Inventory S3 Inventoryは、S3に保管されたオブジェクトの一覧を定期的に出力してくれる機能です。レポーティング目的の為、定期的にバケット内のファイル一覧が必要な場合等、便利に使えそうです。 バージョニングな有効なバケットへの Amazon S3 リクエストに対する HTTP 503 レスポンスが著しく増加する HTTP 503 の数が著しく増加し、バージョニングを有効にしたバケットへの Amazon S3 PUT または DELETE オブジェクトリクエストに対して受信されるレスポンスが低下する場合は、数百万のバージョンがあるバケットに 1 つ以上のオブジェクトがある可能性があります。数百万のバージョンを持つオブジェクトがある場合、Amazon S3 は、過剰なリクエストトラフィックからお客様を保護するため (同じバケットに対して行われた他のリクエストを妨害する可能性があります)、バケットへのリクエストを自動的に調整します。 数百万のバージョンがある S3 オブジェクトを確認するには、Amazon S3 インベントリツールを使用します。インベントリツールは、バケット内のオブジェクトのフラットファイルリストを提供するレポートを生成します。詳細については、「 Amazon S3 インベントリ」を参照してください。 Amazon S3 チームでは、同じ S3 オブジェクトを繰り返し上書きし、そのオブジェクトに対して数百万のバージョンを作成する可能性のあるアプリケーションを調査して、アプリケーションが意図どおり動作しているかどうか調査することをお客様にお勧めしています。1 つ以上の S3 オブジェクトに対して数百万のバージョンを必要とするユースケースについては、AWS サポートの AWS サポートチームにご相談ください。当該ユースケースのシナリオに応じた最適なソリューションを判断できるよう当社がお手伝いをします。 この問題を回避するには、次のベストプラクティスを検討してください。 ライフサイクル管理の「NonCurrentVersion」有効期限ポリシーと「ExpiredObjectDeleteMarker」ポリシーを有効にして、以前のバージョンのオブジェクトを期限切れにし、バケット内に関連するデータオブジェクトが存在しないマーカーを削除します。 ディレクトリ構造をできるだけフラットにして、各ディレクトリ名を一意にします。 Amazon S3 分析 – ストレージクラス分析 Amazon S3 分析のストレージクラス分析を使用することにより、ストレージアクセスパターンを分析し、適切なデータをいつ適切なストレージクラスに移行すべきかを判断できます。 イベント通知の設定 Amazon S3 通知機能により、バケット内で特定のイベントが発生したときに、通知を受けることができます。 Amazon S3 は、イベントの発行先として次の宛先をサポートしています。 Amazon Simple Notification Service (Amazon SNS) のトピック Amazon Simple Queue Service (Amazon SQS) キュー AWS Lambda IAM ポリシーの種類 IDベースかリソースベースか AWSにおけるアクセス権限を付与する方法は2種類あります。 項番 種類 概要 ① IDベース いわばIAMのこと。「誰がどのリソースに対して○○できる」 ② リソースベース 例えばS3のバケットポリシー。「このリソースに対して誰が○○できる」 IAMポリシーとは IAMポリシーについて説明していきます。IAMポリシーとは、IAMユーザや後述のIAMロールにアタッチすることができる、AWSリソースへの操作権限を設定する機能です。IAMポリシーにも大きく分けて3種類あります。 AWS管理ポリシー AWSが提供するIAMポリシーです。各サービスに対して大まかな制御ポリシーが設定できます。 カスタマー管理ポリシー ユーザがJSONファイルなどを利用して設定するポリシーです。IPアドレスの制御など、AWS管理ポリシーよりも細やかな制御が可能です。 インラインポリシー インラインポリシーは特定のIAMユーザやIAMロール専用に作成されるポリシーです。AWS管理ポリシーやカスタマー管理ポリシーは1つのポリシーを作成すれば多くのIAMユーザなどにアタッチすることができますが、インラインポリシーは1つのIAMユーザなど、1対1でのアタッチしかできません。 ユーザーベースのポリシー ユーザーベースのポリシーは、IAMユーザー、IAMグループ、IAMロールに関連づけるポリシーになります。 リソースベースのポリシー リソースベースのポリシーはユーザーベースのポリシーと似ていますが、関連づける先がユーザーではなく「AWSサービス」であるという点が異なります。 (ざっくり言うと、操作する主体(≒ユーザー)ではなく、操作を行われるモノ(AWSリソース)に関連づけるポリシーです) よく使われているリソースベースのポリシーは、S3のバケットポリシーと思います。 以下にS3のバケットポリシーの例を示します。 { "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": {"AWS": "arn:aws:iam::777788889999:user/bob"}, "Action": [ "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::example-bucket/*" } } この例では、「AWSアカウント:777788889999のIAMユーザー:bob」 が 「example-bucket S3バケット配下」に「操作:PutObject、PutObjectAcl」を「許可する」事を意味しています。 リソースベースのポリシーはS3、Lambda(DynamoDBはなし)等の一部のAWSサービスのみに対応しています。 対応しているAWSサービスは IAM と連携する AWS サービス の表において、「リソースベース」がYesになっている行です https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_aws-services-that-work-with-iam.html AWSアカウントの認証情報レポートとは AWSアカウント内の全てのユーザーとユーザーの認証情報ステータス(MFA、最終ログイン時間、パスワード利用有無等)をCSVでダウンロードできます。 レポートは4時間ごとに1回作成となります。 第三者にIAM渡すとき AWSでは第三者に一時的なアクセス権限を付与する際はIAMロールを利用することが推奨されています。 IAMユーザーは一時的に利用するものではないためです。IAMロールによって、たとえば、AWS アカウントのユーザーに、通常はないリソースに対するアクセス許可を付与したり、ある AWS アカウントのユーザーに、別のアカウントのリソースに対するアクセス許可を付与したりできます。 これによって、リソースを監査できるように、アカウントへのアクセス権を第三者に付与することができます。 AWS IAM Access Analyzer AWS IAM Access Analyzer は、外部エンティティと共有されている Amazon S3 バケットや IAM ロールなど、組織とアカウントのリソースを識別するのに役立ちます。これにより、セキュリティ上のリスクであるリソースとデータへの意図しないアクセスを特定できます。 IDフェデレーションの概要 一言で言うと外部で管理されたIDを使って認証して、AWSのサービスの使用許可を制御(認可)しよう。ということです。 2つのドメインでIDフェデレーションを実現すると、一方のドメインで認証を受けたエンドユーザーは、他方のドメインでもログインしないでそのリソースにアクセスできる。 例えば複数の企業が、あるプロジェクトに共同で取り組む場合、IDフェデレーションを実現すれば、各社のエンドユーザーが簡単に相手企業のリソースにアクセスしたり、自社のリソースを共有したりできるようになる。 IDフェデレーションの重要な構成要素が「シングルサインオン」(SSO)だ。 SSOは、エンドユーザーが1つのクレデンシャル(ログイン資格)情報で、複数のシステムやアプリケーションにアクセスできるようにする認証メカニズムだ。 IDフェデレーションとSSOは同一の技術だと考えられることもあるが、必ずしもそうではない。 ただしIDフェデレーションは、複数ドメイン間でエンドユーザーを認証するために、SSOに大きく依存する。 IDフェデレーションが求められるようになった主な背景としては、Office365やGoogle Apps、salceforce.comをはじめとしたビジネス向けクラウドサービスの普及が挙げられる。これらを利用するたびに、個別にIDとパスワードを入力してログインしなければならないとなると、ユーザーの利便性が低下するだけでなく、パスワード漏れによるセキュリティリスクを招き入れかねない SAMLとは SAMLでは認証情報を提供する側をIdentity Provider(IdP)と呼び、認証情報を利用する側(一般的にアプリケーションサービス側)をService Provider (SP)と呼びます。 SAMLによる認証フロー(SP Initiated) ユーザーがSPにアクセスすると、SPはそのリクエストをSAML認証要求と共に、IdPへとリダイレクトします。 IdPはこの認証要求に基づき、ユーザーの認証処理を実行します。IdPでのユーザー認証が成功すると、IdPはSPに対して認証情報やユーザーの属性等の情報を発行します。 これらの情報を「アサーション」といい、SPはこのアサーションを元に、アクセス制御を行います。両者の間ではパスワードのやり取りが行われないため、非常に安全な方法だと言えます。 SAMLによる認証フロー(IdP Initiated) IdPを起点とした場合、ユーザーは、まずIdPにログイン(認証)し、次にIdPに対して SPの利用を要求します。 IdPはSPにアクセスするための情報(SAMLアサーション)を 作成し、ユーザー(ブラウザー)に渡します。ユーザー(ブラウザー)は、受け取った 情報をSPに渡します。SPは受け取った情報の内容を確認し、ユーザーにサービスの 利用を許可(認可)します。 SAML2.0ベースのフェデレーション SAML2.0ベースのフェデレーション:外部のLDAP等のIDプロバイダーを利用するタイプ SAML 2.0 ベースのフェデレーションを使用するには、事前に組織の IdP と AWS アカウントを設定して相互に信頼する必要があります。 1. 組織のユーザーが、クライアントアプリを使用して、組織の IdP に認証を要求します。 2. IdP がユーザーを組織の ID ストアに対して認証します。 3. IdP はユーザーに関する情報を使用して SAML アサーションを構築し、クライアントアプリにアサーションを送信します。 4. クライアントアプリが、AWS STS AssumeRoleWithSAML API を呼び出して、SAML プロバイダーの ARN、引き受けるロールの ARN、および IdP からの SAML アサーションを渡します。 5. API は一時的なセキュリティ認証情報を含むレスポンスをクライアントアプリに返します。 6. クライアントアプリでは、一時的なセキュリティ証明書を使用して Amazon S3 API オペレーションを呼び出します。 ウェブIDフェデレーション ウェブIDフェデレーション:モバイルデバイスでAWSの外の認証情報を使って認証しAWSサービスを使うタイプ ウィブIDフェデレーションをAWS STSを使って実現するイメージは以下の通り。 Amazon Cognitoを使用する場合 AWS Organizations SCP(Service Control Policy)とは SCPは組織に含まれる複数のAWSアカウントに対してざっくりとした権限制御を行うための仕組みです。 また、IAMでは不可能な各アカウントのルートユーザーに制限をかけることができます。 OU(組織単位) OUはAWSアカウントをグループ化するための概念です。 これによって、ポリシーの適用などの管理作業を大幅に簡素化できます。 ポリシー OUもしくはアカウントに割り当てるポリシーを独立したリソースとして定義できます。 OUにポリシーを割り当てるとそのOUに所属するアカウントにポリシーが適用されます。 また、すでに述べたとおり下位のOUにポリシーが継承されます。 IAMとの関係 アクセス権の管理はOrganizationsの登場以前にはIAMによって管理されていました。 SCPを利用する場合、リクエストを実行できるかはどのように決まるのでしょうか? ざっくり書くと、SCPとIAMの両方で許可されている場合に実行可能です。 もう少し具体的に書くと、「双方で明示的に許可され」なおかつ「いずれでも明示的に拒否されていない」場合に権限を有していると評価されます。 SCP を使用した戦略 組織内のサービス制御ポリシー (SCP) は、次のいずれかとして構成できます。 拒否リスト – デフォルトでアクションは許可され、どのサービスとアクションを禁止するかを指定できます 許可リスト – デフォルトでアクションは禁止され、どのサービスとアクションを許可するかを指定できます (例) この例では、影響を受けるアカウントのユーザーが Amazon DynamoDB サービスのいかなるアクションも実行しないようにします。組織の管理者は、FullAWSAccess ポリシーをデタッチして、これを代わりにアタッチできます。この SCP は、引き続きすべての他のサービスとそのアクションを許可します。 { "Version": "2012-10-17", "Statement": [ { "Sid": "AllowsAllActions", "Effect": "Allow", "Action": "*", "Resource": "*" }, { "Sid": "DenyDynamoDB", "Effect": "Deny", "Action": "dynamodb:*", "Resource": "*" } ] } 「Root Userの権限を制限できる」 ただし、以下のアクションはSCPで制限されません。 ルート認証情報の管理。アタッチされている SCP に関係なく、アカウントの root ユーザーはいつでも次の操作を実行できます。 ルートユーザーのパスワードの変更 ルートアクセスキーの作成、更新、削除 ルートユーザーの多要素認証の有効化または無効化 ルートユーザーの x.509 キーの作成、更新、または削除 ルートユーザーとしての Enterprise サポートプランへの登録 ルートユーザーとしてのアカウントの解約 (AWS サポートにチケットを送信する代わりにアカウント内から) ルートユーザーとしての AWS サポートレベルの変更 CloudFront キーの管理 CloudFront プライベートコンテンツの信頼された署名者の機能 AWS アカウントメールの上限/rDNS の変更 アカウント AWS リソースを含む標準の AWS アカウント。1 つのアカウントにポリシーをアタッチして、そのアカウントのみ制御することができます。 組織には 2 種類のアカウントがあります。1 つは管理アカウントとして指定されたアカウント、もう 1 つはメンバーアカウントです。 管理アカウントは、組織の作成に使用するアカウントです。組織の管理アカウントから、以下の操作を実行できます。 組織にアカウントを作成する 組織に他の既存のアカウントを招待する 組織からアカウントを削除する 招待を管理する 組織内のエンティティ (ルート、 OUs 、または アカウント) にポリシーを適用する 管理アカウントには支払いアカウントだけでなく、メンバーアカウントによって発生したすべての料金を支払う責任があります。組織の管理アカウントを変更することはできません 組織に属する残りのアカウントは、メンバーアカウントと呼ばれます。アカウントが組織のメンバーになることができるのは、一度に 1 つのみです。 AWS で使用できる のサービスAWS Organizations AWS Organizations では、複数の AWS アカウントを 1 つの組織に統合することにより、大規模なアカウント管理作業を行うことができます。アカウントを統合すると、他の AWS サービスの使用が簡単になります。選択した AWS Organizations サービスで、AWS で利用できるマルチアカウント管理サービスを利用して、組織のメンバーであるすべてのアカウントでタスクを実行できます。 一括請求 一括請求には次の利点があります。 1つの請求書 – 複数のアカウントに対して1つの請求書を受け取るだけで済みます。 簡単な追跡 – 複数のアカウントでの料金を追跡し、コストと使用状況の統合データをダウンロードできます。 使用状況の結合 – 組織内のすべてのアカウントの使用量を結合し、料金のボリューム割引、リザーブドインスタンスの割引、および Savings Plans を共有できます。その結果、会社、部門、またはプロジェクトでの料金が個々のスタンドアロンアカウントと比較して低くなります。詳細については、「従量制割引」を参照してください。 追加料金なし – 一括請求は追加コストなしで提供されます。 組織をメンバーアカウントとして残したり、メンバーアカウントを管理アカウントとして削除しようとすると、「アクセスが拒否されました」というメッセージが表示される メンバーアカウントでの請求を IAM ユーザーアクセスで有効にした後でのみ、メンバーアカウントを削除できます アカウントがスタンドアロンアカウントとして動作するために必要な情報を持っている場合にのみ、組織からアカウントを削除できます ■すべての機能 この機能セットは AWS Organizations を使用するにあたって推奨されており、一括請求機能も含まれています。組織を作成する際、デフォルトではすべての機能が有効化されています。すべての機能が有効になっていると、サービスコントロールポリシー (SCP) などの AWS Organizations で利用できる高度なアカウント管理機能を使用できます。SCP は組織内のすべてのアカウントの最大使用アクセス権限を一元的に管理できる機能を提供し、アカウントが組織のアクセスコントロールガイドラインに沿って活動することを確実にできます。 ■一括請求機能 すべての組織ではこの機能サブセットがサポートされ、これによって組織内のアカウント管理を一元化するために使用できる基本的な管理ツールが提供されます 一括請求機能のみを使用してOrganizationsを起動した場合、後から「すべての機能」を有効にできます。 AWS Storage Gateway AWS Storage Gateway は、オンプレミスから実質無制限のクラウドストレージへのアクセスを提供するハイブリッドクラウドストレージサービスです。 お客様は Storage Gateway を使用して、ストレージ管理を簡素化し、主要なハイブリットクラウドストレージのユースケースでコストを削減できます。 これには、バックアップをクラウドに移動すること、クラウドストレージを利用したオンプレミスのファイル共有を使用すること、およびオンプレミスアプリケーションに AWS のデータへの低レイテンシーアクセスを提供することが含まれます。 こうしたユースケースをサポートするため、Storage Gateway では、ファイルゲートウェイ、ボリュームゲートウェイ、テープゲートウェイの 3 つのゲートウェイタイプが提供されます。 プレイバック攻撃とCHAP認証 AWS Storage Gateway では、iSCSI イニシエータは iSCSI ターゲットとしてボリュームに接続します。Storage Gateway は、チャレンジハンドシェイク認証プロトコル (CHAP) を使用して iSCSI とイニシエータの接続を認証します。 ファイルゲートウェイ ファイルゲートウェイ は、Amazon Simple Storage Service (Amazon S3) へのファイルインターフェイスをサポートし、サービスと仮想ソフトウェアアプライアンスを組み合わせます。 ネットワークファイルシステム (NFS) やサーバーメッセージブロック (SMB) などの業界標準のファイルプロトコルを使用して、Amazon S3 でオブジェクトを保存および取得できます。 ソフトウェアアプライアンス(ゲートウェイ)は、オンプレミス環境に仮想マシン(VM)として導入され、 VMware ESXi、Microsoft Hyper-V、Linux Kernelベースの仮想マシン(KVM)ハイパーバイザー。ゲートウェイは、S3 内のオブジェクトへのアクセスをファイルまたはファイル共有のマウントポイントとして提供します。ファイルゲートウェイ では、次のことを実行できます。 NFS バージョン 3 または 4.1 プロトコルを使用して、ファイルを直接保存し取得できます。 SMB ファイルシステムのバージョン 2 および 3 のプロトコルを使用してファイルを直接保存および取得できます。 データには、 Amazon S3 任意の AWS クラウドアプリケーションまたはサービス。 ライフサイクルポリシー、地域間レプリケーション、バージョン管理を使用して、S3 データを管理できます。ファイルゲートウェイ を S3 上のファイルシステムマウントとして考えることができます。 ファイルゲートウェイ は Amazon S3 のファイルストレージを簡素化し、既存のアプリケーションを業界標準ファイルシステムプロトコルと統合して、オンプレミスのストレージに代わるコスト効率の高いシステムを提供します。 また、透過的なローカルキャッシュを通じてデータへの低レイテンシーアクセスを提供します。A ファイルゲートウェイ とのデータ転送を管理 AWSは、ネットワーク混雑からアプリケーションをバッファリングし、並列でデータを最適化およびストリームし、帯域幅消費を管理します。ファイル・ゲートウェイは、 AWS 次のようなサービスがあります。 を使用した共通アクセス管理 AWS Identity and Access Management (IAM) AWS Key Management Service (AWS KMS) を使用した暗号化 Amazon CloudWatch (CloudWatch) を使用したモニタリング AWS CloudTrail (CloudTrail) を使用した監査 AWS マネジメントコンソール と AWS Command Line Interface (AWS CLI) を使用したオペレーション 請求情報とコスト管理 ボリュームゲートウェイ ボリュームゲートウェイは、オンプレミスのアプリケーションサーバーから iSCSI (Internet Small Computer System Interface) デバイスとしてマウントできる、クラウドベースのストレージボリュームを提供します。 キャッシュボリューム データを Amazon Simple Storage Service (Amazon S3) に保存し、頻繁にアクセスするデータサブセットのコピーをローカルに保持します。 プライマリストレージのコストを大幅に削減し、ストレージをオンプレミスで拡張する必要を最小限に抑えます。 また、頻繁にアクセスするデータへのアクセスを低レイテンシーに保つことができます。 ゲートウェイがキャッシュストレージとして使用するディスク アプリケーションがデータを AWS のストレージボリュームに書き込むとき、ゲートウェイは最初にデータをキャッシュストレージに使用されるオンプレミスのディスクに保存します。次に、ゲートウェイはデータを Amazon S3 にアップロードします。キャッシュストレージは、オンプレミスで耐久性の高い保存場所として、アップロードバッファから Amazon S3 へのアップロードを保留中のデータを保存する働きをします。 ゲートウェイがアップロードバッファとして使用するディスク ゲートウェイは、受け取ったデータを Amazon S3 にアップロードする前に、アップロードバッファと呼ばれる待機領域にいったん保存します。 ゲートウェイはこのバッファからデータを暗号化 Secure Sockets Layer (SSL) 接続で AWS にアップロードし、そこでデータは暗号化されて Amazon S3 に保存されます。 データのバックアップを復元する Amazon EBS スナップショットをゲートウェイストレージボリュームに復元できます。また、16 TiB までのスナップショットの場合、新しい Amazon EBS ボリュームの場合は、開始点としてスナップショットを使用できます。この新しい Amazon EBS ボリュームを Amazon EC2 インスタンスにアタッチできます。 保管型ボリューム データセット全体への低レイテンシーアクセスが必要な設定は、最初にすべてのデータをローカルに保存するようにオンプレミスのゲートウェイを設定します。 次に、このデータのポイントインタイムスナップショットを非同期的に Amazon S3 にバックアップします。 この設定は、ローカルデータセンターや Amazon Elastic Compute Cloud (Amazon EC2) に復元できる、耐久性が高く低コストのオフサイトバックアップを提供します。たとえば、障害復旧のための代替容量が必要な場合は、Amazon EC2 にバックアップを復元できます。 データのバックアップを復元する Amazon EBS スナップショットをオンプレミスのゲートウェイストレージボリュームに復元できます。このスナップショットから新たに Amazon EBS ボリュームを作成し、それを Amazon EC2 インスタンスにアタッチすることもできます テープゲートウェイ テープゲートウェイは、クラウドベースの仮想テープストレージを提供します。テープゲートウェイは、VMware ESXi、KVM、または Microsoft Hyper-V ハイパーバイザーで実行される VM としてオンプレミス環境にデプロイ テープゲートウェイを使用すると、バックアップデータをコスト効果や耐久性の高い方法で GLACIER または DEEP_ARCHIVE にアーカイブできます。テープゲートウェイは仮想テープインフラストラクチャとして、お客様事業での需要に応じシームレスにスケーリングができ、物理テープインフラストラクチャのプロビジョニング、スケーリング、保守といった運用の負担を解消 オンプレミスで VM アプライアンスとして、ハードウェアアプライアンスとして、または AWS で Amazon EC2 インスタンスとして実行できます。EC2 インスタンスにゲートウェイをデプロイして、AWS の iSCSI ストレージボリュームをプロビジョニング AWS SSO まず社内の Active Directory を AWS Directory Service を使って AWS SSO に接続します。 社内のディレクトリを接続するには AWS Directory Service の AD Connector を使用する方法と、AWS Directory Service for Microsoft Active Directory (Microsoft AD) とオンプレミスの Active Directory と信頼関係を設定する方法の2つ選択肢があります。 AWS Directory Service Microsoft Active Directory (AD) を AWS の他のサービスと併用するための複数の方法を提供します ユースケース AD 認証情報で AWS アプリケーションとサービスにサインインする Amazon EC2 インスタンスを管理する Office 365 およびその他のクラウドアプリケーションに SSO する SQS タスク Attribute Nameは キューから取得可能なメッセージのおおよその数を取得します。 ApproximateNumberOfMessages キュー内の、遅延が発生したためにすぐに読み取ることができないメッセージのおおよその数を取得します。これは、キューが遅延キューとして設定されている場合、またはメッセージが遅延パラメータとともに送信された場合に発生することがあります。 ApproximateNumberOfMessagesDelayed 処理中のメッセージのおおよその数を取得します。メッセージがクライアントに送信されたが、まだ削除されていない場合、または表示期限に達していない場合、メッセージは処理中とみなされます。 ApproximateNumberOfMessagesNotVisible AWSサポート デベロッパー ビジネス エンタープライズ ケースの重要度と応答時間* 平日の月曜日~金曜日、日本時間の午前9時から午後6時まで利用できます。 24時間年中無休 24時間年中無休でいつでも利用できます。しかも緊急事態には15分以内に初回応答 料金 月額29米ドル 月額100米ドル 最低でも15,000米ドル Elastic Beanstalk ログファイルをカスタマイズ Elastic Beanstalk が収集するデフォルトのログファイルとストリームがアプリケーションまたはユースケースのニーズを満たさない場合は、次のオプションを検討して、ログファイルの収集とストリーミングをカスタマイズします。 ログバンドルにカスタムログを含める ログをローテーションする (オプション:ベストプラクティス) ログを CloudWatch にストリーミングする AWS Direct Connect AWS Direct Connect はオンプレミスから AWS への専用ネットワーク接続の構築をシンプルにするクラウドサービスソリューションです。 AWS Direct Connect を使用すると、AWS とデータセンター、オフィス、またはコロケーション環境との間にプライベート接続を確立することができます。 これにより、多くの場合、ネットワークのコストを削減し、帯域幅のスループットを向上させ、インターネットベースの接続よりも安定したネットワークエクスペリエンスをお客様に提供することが可能となりました。 Direct Connect Gateway Direct Connect Gatewayには以下の特徴があります。 Direct Connect GatewayをいずれかのAWSリージョンに作成すると、AWSの全リージョン *1に複製され、相互接続できる Direct Connect Gatewayには複数のVIFおよびVGWが接続できる 従来あった、VIFとVGWは同一リージョンに1対1で設定する *2という制約を緩和することができます。 ユースケース オンプレミスと海外リージョンのVPCとのプライベート接続 例えば、東京のDirect ConnectロケーションのVIFを、Direct Connect Gatewayを経由してオレゴンリージョンのVPCと接続することができます。 Direct Connect Gateway内のリージョン間通信はAWSのプライベートネットワークを経由するので、高速でセキュアな通信環境が期待できますね。 また、複数の海外Direct ConnectロケーションとVPCとのプライベート接続も可能です。 複数VPCとのプライベート接続 これまでVIFと接続するVPCは最大で1つだったため、複数のVPCでDirect Connectを利用するためには複数のVIFを用意する必要がありました。Direct Connect Gatewayに複数のVGWを接続することで、1つのVIFで複数のVPCと通信することが可能です。ただし、後述の制約により、アカウントをまたぐことが出来ない点に注意しましょう。 制約 便利に使えるDirect Connect Gatewayですが、いくつか制約もあります。設計上重要なものをピックアップしました。 Direct Connect Gatewayを介したVPC(VGW)同士の通信は不可 Direct Connect Gatewayを介したVIF同士の通信は不可 異なるAWSアカウントのVIFおよびVGWの接続は不可 移行について 既に構築済みのDirect Connect接続でDirect Connect Gatewayを利用するためには、どうすれば良いでしょうか。 作成済みVIFにあとからDirect Connect Gatewayを追加することはできないため、VIFを再作成する必要があります。 また、従来東京リージョンでは10124で固定だったAmazon側のASN *3が、Direct Connect GatewayではPrivate ASNの範囲で自由に指定する形になったため、指定したASNに合わせてカスタマールーターのBGPのコンフィグを調整する必要があります。 BGPのピアIPとパスフレーズはVIF再作成時に任意に指定できるため、移行前と同じ設定にしても問題ないでしょう。 Amazon Simple Workflow Service 複数のサーバーでバッチ等の自動処理を行う時に、その順番や振り分け先の管理を行うワークフローサービス 場所を問わない 諸事情によりどうしてもAWSにすぐに移行できないサーバー、というものが出てきます。SWFを使うとオンプレやAWS以外のデータセンターにあるサーバーも管理対象に入れられるので本当に処理のみに注力することができます。 人間の判断も入れられる これもSWFの大きな特徴のひとつです。人間の判断が必要な場合(選択肢があったり、承認フローが必要だったり)は、人間が処理をするまでワークフローは待ってくれます。これで定期的な自動処理だけではなく日常使用するようなフローにもSWFが使えますね。 ユースケース オンプレを含めたバッチジョブ、人間の判断が混ざるワークフロー 仮想マシンの移行 VM Import/Export VM Import/Exportを使うとオンプレミスの仮想マシンイメージをEC2に移行することができます。移行に際して大きな変更を加える必要が無い点は魅力的ですが、利用できる仮想化ソフトウェアやOSは限定されていることに注意が必要です。移行元のオンプレミスで稼働しているシステムと要件が合致しているか確認する必要があります。 → あまり使わない?非推奨? AWS Server Migration Service AWS Server Migration Serviceを利用するとVMware vSphere または Microsoft Hyper-V/SCVMM上で動いている仮想マシンをAWSに移行することができます。 オンプレミスの仮想化環境にAWS Server Migration Service Connectorを導入して、AWS Server Migration Service Connector経由でAWS環境に仮想マシンのデータを転送します。こちらもVM Import/Export同様、移行要件が合致しているかどうかはしっかりと確認する必要があるでしょう。 CloudTrail 異常な API アクティビティを自動検出 API コールは AWS CloudTrail によって記録されます OpsWorks AWS OpsWorks は Chef や Puppetを使用して EC2インスタンスやオンプレミス環境のサーバーの構成、デプロイ、管理を自動化する事が可能 AWS OpsWorks スタックは、既存の EC2 インスタンスや独自のデータセンターで実行中のサーバーを含むあらゆる Linux サーバーまたは Windows サーバーにおいて、ソフトウェア構成、パッケージのインストール、データベースのセットアップおよびコードのデプロイといった運用タスクを自動化するのに役立ちます。 アプリケーションやサーバーを AWS 上とオンプレミスで管理できるようにします Auto Healing AWS X-Ray リクエスト動作の確認 AWS X-Ray では、アプリケーション全体で転送されるユーザーリクエストがトレースされます。アプリケーションを構成する個々のサービスやリソースによって生成されるデータが集計されるため、アプリケーションの実行状況をエンドツーエンドで確認できます。 アプリケーションの問題の検出 AWS X-Ray を使うと、アプリケーションの実行状況についてのインサイトを収集して、問題の根本原因を調べることができます。X-Ray のトレース機能を使ってリクエストのパスをたどると、パフォーマンスの問題の原因と、問題に関係するアプリケーション内の場所を特定できます。また、X-Ray には注釈機能があり、トレースにメタデータを付加できます。これにより、トレースデータにタグを付けてフィルタリングすることができるため、パターンを発見して、問題を診断できます。 アプリケーションのパフォーマンスの向上 AWS X-Ray を使うと、パフォーマンスのボトルネックを特定できます。X-Ray のサービスマップにより、アプリケーション内のサービスやリソースの関係をリアルタイムで表示できます。高いレイテンシーが発生している場所を簡単に検出し、サービスのノードとエッジのレイテンシーのディストリビューションを視覚化し、アプリケーションのパフォーマンスに影響を与える特定のサービスやパスをドリルダウンすることができます。 AWS との連携 AWS X-Ray は、Amazon EC2、Amazon EC2 Container Service (Amazon ECS)、AWS Lambda、AWS Elastic Beanstalk と連携します。Java、Node.js、および .NET で記述し、上記のサービスにデプロイされたアプリケーションに、X-Ray を使用できます。 AWS KMSとCloudHSMの違いは? ■AWS KMS AWS管理のサーバを共有で利用し、そこで暗号化キーを管理します。 システム的に他の組織へのアクセス制限はされていますが、物理的には同じサーバ上に存在します。 CloudHSMに比べると安価に利用することができます。 キーポリシー キーポリシーは AWS KMS でカスタマーマスターキー (CMK) へのアクセスを制御するための主要な方法です。 ■CloudHSM 専用のハードウェアで暗号化キーを保管します。 CloudHSMの方がより安心してキーを管理することが可能です。 KMSに比べると高価です Amazon Redshift Amazon Redshift は、クラウド内のフルマネージド型、ペタバイト規模のデータウェアハウスサービスです。数百ギガバイトのデータから開始して、ペタバイト以上まで拡張できます。これにより、お客様のビジネスと顧客のために新しい洞察を得る目的でデータを使用できるようになります。 拡張 VPC ルーティング Amazon Redshift 拡張された VPC ルーティングを使用すると、 は、 Amazon Redshift サービスに基づく Virtual Private Cloud (VPC) を通じて、クラスターとデータリポジトリ間のすべての COPY および UNLOAD トラフィックをAmazon VPC強制します ノード構成 シングルノード構成 他のドライブとデータが冗長化されている場合、単一ドライブでの障害は自動復旧されサービス利用可能です。 自動復旧ができない場合スナップショットからの復旧が必要です。 マルチノード構成 ノード内でドライブが冗長されているので1つのドライブに障害が発生したとしても、 冗長化による別のドライブの複製されたデータにより入出力が行われ、処理が続行されますのでサービス利用可能です。 他のドライブにデータの移動ができない場合はノード交換が自動的に行われデータは別のノードから復元されますが ノード交換が終わるまではサービス利用不可となります。 複数ノードが利用可能になることで、単一ノード障害への耐久性が向上しますが、複数AZや複数リージョンの構成ができません。 スナップショット Redshiftがスナップショット用の無料ストレージを提供してますが、クラスターのストレージ容量を利用することになります。 スナップショットの空き容量の上限に達すると、通常の料金で追加のストレージに課金されてしまいます。 このため、自動スナップショットを保存し、それに応じて保存期間を設定する必要がある日数を評価し、不要になった手動スナップショットを削除する必要があります。 クロスリージョンスナップショット 別リージョンにコピーしておくことも可能です。なお、データ転送コストが発生する。 IPV6 やること EC2にCIDRブロックをVPCおよび、サブネットにひもづける インスタンスタイプを新インスタンスに変更する AWS Marketplace お客様は、数回クリックするだけで事前設定されたソフトウェアをすばやく起動し、ソフトウェアソリューションを Amazon マシンイメージ (AMI) 形式、SaaS (Software-as-a-Service) 形式、およびその他の形式で選択できます Regognition(機械学習を使用して画像と動画の分析を自動化) 機械学習の専門知識を必要とせずに、実績のある高度にスケーラブルな深層学習テクノロジーを使用して、アプリケーションに画像およびビデオ分析を簡単に追加できるようになります。
- 投稿日:2021-01-24T22:46:57+09:00
AWS ソリューションアーキテクト 資格取得タイムトライアル 2日目
目次
- AWS ソリューションアーキテクト 資格取得タイムトライアル 1日目
- AWS ソリューションアーキテクト 資格取得タイムトライアル 2日目 ★今回の内容
本日(2021/01/24)の学習時間
- 16:45〜17:45までの約1時間
以下勉強内容
AWS Direct Connect
VPCピアリング
異なるVPCをプライベートネットワークでつなぐサービス
AWS Transit Gateway
外部接続するVPCが増えた場合に管理が煩雑になるが、それを一元管理するためのゲートウェイ
VPCエンドポイント
通常はインターネット接続が必要な他AWSサービスへのアクセスやAPI呼び出しを、プライベートネットワークからAWSサービスにアクセスするためのもので、方法は以下の2種類ある
ゲートウェイ型(ネットワークレイヤー)
ルートテーブルにターゲットを追加する(S3やDynamoDBなど)
インターフェース型(アプリケーションレイヤー)
AWSプライベートリンクとも呼ばれている。API呼び出しに対してプライベート接続できる(CloudWatchやSQS)
Elastic Load Balancing(ELB)
EC2などの不可分散に利用されるサービスで、以下3種類がある。ELBに紐づいているEC2インスタンスを「バックエンドインスタンス」と呼ぶ。
Classic Load Balancer(CLB)
リクエストのバックエンドインスタンスへ振り分け、指定されたポートに転送する標準的な機能を提供する
Application Load Balancer(ALB)
レイヤー7で動作し、HTTP・HTTPSのリクエストを特定のサーバーに振り分ける
Network Load Balancer(NLB)
レイヤー4で動作し、低レイテンシー高スループットで送信元アドレスを保持するため、レスポンスはクライアントへ返却する
高可用性: トラフィックを複数のAZへ分散することができる自動スケーリング: 自動スケーリングする機能が備わっているので冗長性が確保されている。しかしVPCサブネットのIPアドレスが自動的に割り振られるため、通常ELBへの接続はエンドポイントと呼ばれる割り当てられたDNSへ行う。ヘルスチェックとモニタリング: バックエンドインスタンスが正常に動作しているかチェックを行う。チェックに失敗したEC2インスタンスへの振り分けは停止して他の正常に動作しているインスタンスへのみ振り分けを行う。
- 投稿日:2021-01-24T21:36:07+09:00
個人で作成したAMIを使ってEC2(Windows)を起動したら、IAMロールが割り当てられているのに他サービスにアクセスできない事象が発生した件について
はじめに
表題にある通り、AWSから提供されているAMIをベースとして個人でAMIを作成し、そのAMIを使ってEC2(Windows Server 2019)を起動したら、IAMロールが割り当てられているにも関わらず、EC2からAWSの各サービスにアクセスできない事象が発生しました。
本記事は、現象の要因や対処等を備忘録としてまとめたものです。問題詳細
使用したAMIの詳細
ベースとしたAMIは以下です。
Windows_Server-2019-Japanese-Full-Base-2020.12.09 - ami-027a63125bb60c403
Microsoft Windows Server 2019 with Desktop Experience Locale Japanese AMI provided by Amazon上記AMIでEC2を起動後に個別にアプリをインストールし、AWSコンソールの「イメージを作成」で新しいAMIを作成しました。
現象内容
新しく作成したAMIを使ってEC2を立ち上げた後、EC2にログインしてAWS CLIで各種サービスにアクセスできることを確認しようとしたのですが、なぜかうまくいかず、「aws configure list」で確認すると、Access KeyやSecret Access Keyが割り当てられていない状態でした。
コンソールで見ると、ちゃんとIAMロール割りつけられているんですけどねぇ。。。
原因
違う方法でIAMのCredentialを確認してみると
いろいろ調べてもなかなか解決策が見つからずでしたが、こちらのサイトにある確認手順を試したところ、以下の結果となりました。 http://169.254.169.254 に接続できないんですねぇ。
ちなみに、Access KeyなどのCredential情報はメタデータから取得しているみたいですねぇ。勉強になります。で、なぜ http://169.254.169.254 に接続できないのかですが、ヒント(というか答え)が別のサイトにありました。どうもルーティングテーブルがおかしくなって、 http://169.254.169.254 にアクセス出来なくなるようです。この情報を元に、こちらの環境のルーティングテーブルを確認してみました。
おかしいですねぇ。EC2は10.1.0.0/24のサブネットに配置しているので、デフォルトのルーティングはオレンジ線に表示された設定になっているのですが、169.254.169.xxx向けのルーティングはゲートウェイが10.0.24.1になっていて、デフォルトとは異なった先で、かつ、違うネットワークアドレスのゲートウェイに接続に行くような設定になっています。とりあえずルーティングテーブルを変更
ここのサイトには、ルーティングテーブルを削除して再起動とあったのですが、とりあえず手動で再作成してみたところ、、、、
http://169.254.169.254 にアクセス出来て、Credential取れました。s3にもアクセスできました。
ここのサイトの記載にあったように、ルーティングテーブルがおかしくなっていたことが原因だったようです。原因調査
なぜルーティングテーブルがおかしくなったのか
一応解決はしましたが、なぜルーティングテーブルがおかしくなったのかという疑問が残ります。
先程のおかしかったルーティングテーブルを再度見直してみたところ、ふと思い当たる節がありました。0.0.0.0 0.0.0.0 10.1.0.1 10.1.0.130
169.254.169.xxx 255.255.255.255 10.0.24.1 10.1.0.130VPC/Subnetの設定です。
AMI作成時
VPC:10.0.0.0/16
Public Subnet:10.0.24.0/24
作成したAMIを使ってEC2を起動した時
VPC:10.1.0.0/16
Public Subnet:10.1.0.0/24
おそらくですが、AMI作成時に設定されていたルーティングテーブルがそのままAMIに記録されたことよって、作成したAMIを使って別環境でEC2起動した際に、AMI作成時のルーティングテーブルがそのまま使用されて、http://169.254.169.254 に接続できなくなってしまったようです。
対処
ルーティングテーブルの削除
リンク先のサイトにもあるように、該当ルートを削除し、再起動することにより正常なルーティング情報が自動的にセットされるようなので、169.254.169.xxx向けのルーティングテーブルを全て削除した上で、AMIを作成します。
削除後のルーティングテーブルです。こんな感じですね。
この状態でAMIを作成します。対処したAMIでEC2起動
作成したAMIでEC2を起動します。
起動後に169.254.169.xxxに接続できるか確認します。
問題なく、169.254.169.xxxに接続できました。
これで、各サービスへのアクセス権も付与されました。結論
自分で作成したAMIを使用する場合は、ネットワーク構成に気を付けてください。
AMIを作成する場合は、いろいろなネットワーク構成を考慮して、ルーティングテーブルを削除した上で作成するのが賢明なのかもしれません。











- 投稿日:2021-01-24T20:20:19+09:00
AWS_WEB3層環境構築③
前回の記事
https://qiita.com/shinichi_yoshioka/items/e358f57a3ecb7735c091
前々回(初回)の記事
https://qiita.com/shinichi_yoshioka/items/7226b9ebaad06c569c80
構成図
前回の続きをやっていく。
VSCodeすら使ったことなかったが、VSCodeの拡張機能にdrawioというものがあって、
カッコ良いアイコンなどが使えるのを教えてもらった。
さっそく使ってみたが、色のセンスはお察しだ。初回記事ではDBの切り替えをしたいと書いたが、まずは正常な状態を作りたい。
WEBサーバにはリバースプロキシの設定(To:APサーバ)をし、APサーバでJSPを使って、
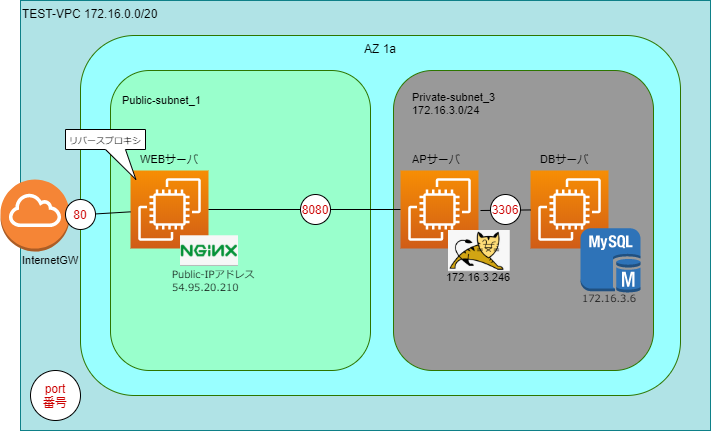
DBを参照できることを正常な状態とすることにした。◆リバースプロキシの設定
対象:WEBサーバ
/etc/nginx/conf.d 配下にserver.confというファイルを作る。cd /etc/nginx/conf.d vi server.confserver.confの中身は、APサーバのプライベートアドレス:ポート番号(8080)を指定した。
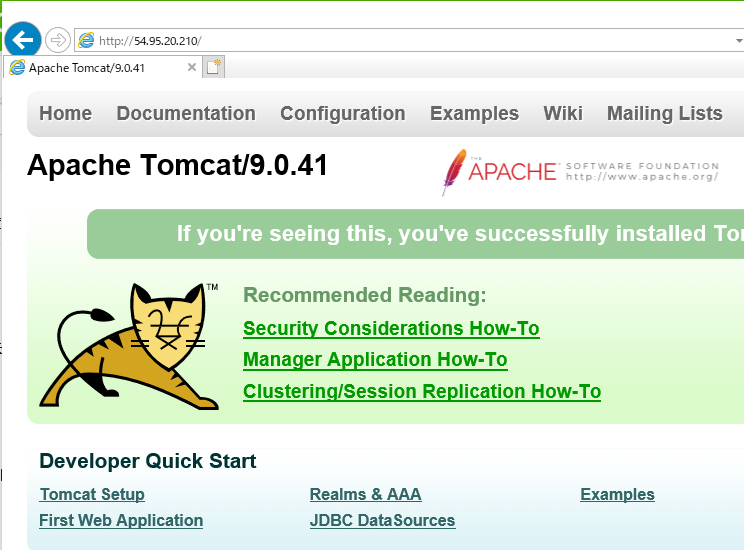
#server.conf server{ location / { proxy_pass http://172.16.3.246:8080/; } }nginxのサービスを再起動(systemctl restart nginx)して、ブラウザにWEBサーバのパブリックアドレスを入力し、
APサーバのtomcatのページが表示されることを確認した。
[自宅PC]-[Internet]-[WEBサーバ]-[APサーバ] ←ここまでのイメージ
◆JDBC for MySQLのインストール
対象:APサーバ
APサーバにJDBCドライバーをインストールしようと思ったのだが、AmazonLinux用がなかった^^;;;
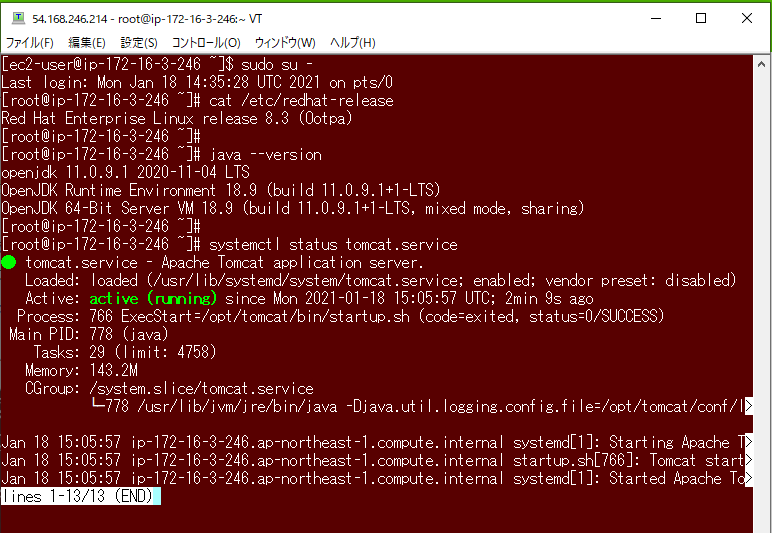
ということで、前回作ったAPサーバはぶっ壊して、再度RedHatで作りなおして、Tomcatのインストールまでは済んだとこ。
これがクラウドの良いところである。(オンプレでOS選定ミスってたら、首飛んでた)
EIPを使っていたので、記事の不整合もない!
OSやJavaのバージョン、Tomcatの状態はこんな感じ。
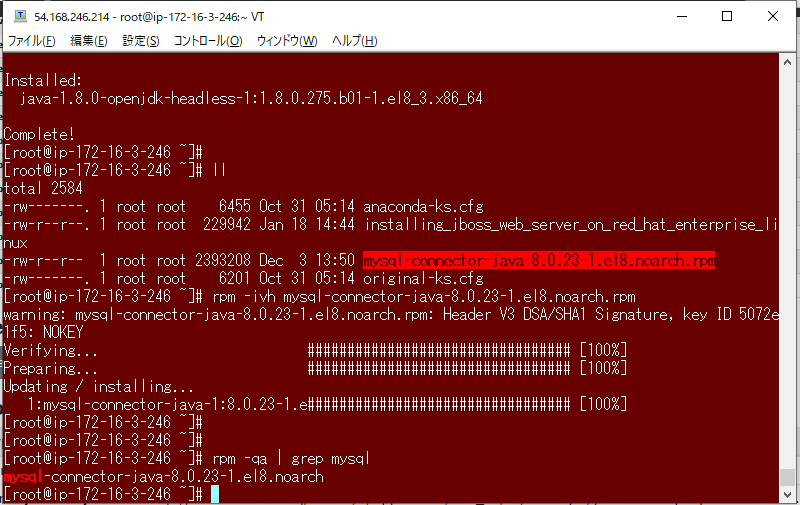
MySQLコミュニティサーバからJDBCドライバーのRPM(RHEL用)をダウンロードしインストールしようとしたが、
依存関係でopenjdk-headlessが必要と言われた。
yumでopenjdk-headlessをインストール後に、mysql-connector-javaをRPMコマンドでインストールした。wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.23-1.el8.noarch.rpm yum install java-1.8.0-openjdk-headless -y rpm -ivh mysql-connector-java-8.0.23-1.el8.noarch.rpm rpm -qa | grep mysql
◆サンプルデータベースの用意
対象:DBサーバ
参照するためのDBを用意するため、以下からworld databaseをインポートすることにした。
https://dev.mysql.com/doc/index-other.html
まずはDBサーバにssh接続し、wgetコマンドにてダウンロードした。
gz形式だったため、gunzipコマンドにて解凍した。wget https://downloads.mysql.com/docs/world.sql.gz gunzip world.sql.gz次にMySQLにログインし、SOURCEコマンドにて、world.sqlをインポートした。
mysql> SOURCE root/world.sql;/rデータベースに"world"がインポートされた。
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | TEST | | auth | | mysql | | performance_schema | | sys | | world | +--------------------+データベースをworldに切り替え、テーブルが存在することを確認した。
mysql> use world; mysql> show tables; +-----------------+ | Tables_in_world | +-----------------+ | city | | country | | countrylanguage | +-----------------+ 3 rows in set (0.00 sec)MySQLはデフォルトで、外部からのアクセスを許可されていないため、
以下の権限追加をした。
権限追加後は、FLUSHにて権限を再読み込みした。
※*(すべてのデータベース).*(すべてのテーブル)を認識できるようにユーザ名@接続元IPアドレス(APサーバ)へ権限を与えるmysql> GRANT all ON *.* TO root@'172.16.3.246' IDENTIFIED BY 'MySQLのパスワード'; mysql> FLUSH PRIVILEGES; ←権限関係の再読み込み◆JDBCドライバの配置とサンプルJSPの作成
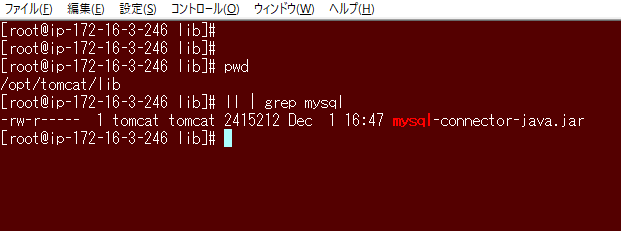
対象:APサーバ
JDBCドライバーは/lib配下に配置しないとダメらしく、初期配置から移動させた。mv /usr/share/java/mysql-connector-java.jar /opt/tomcat/lib/
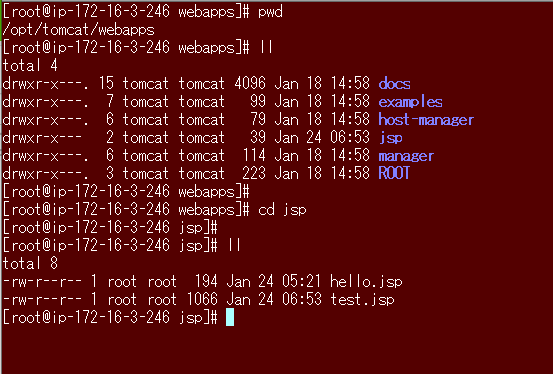
JSPについては初心者でggりまくった結果、JSPも配置が重要らしく、
/opt/tomcat/webapps配下にjspディレクトリを作成し、パーミッションを750にし、所有者はtomcatに変更した。cd /opt/tomcat/webapps mkdir jsp chown tomcat:tomcat jsp chmod 750 jsp
/opt/tomcat/webapps/jsp配下には、test.jspを作成したが、
JSPの知識がなさすぎて、以下URLを参考にさせていただいた。
https://michael-e29.hatenadiary.org/entry/20111107/1320630444jdbc:mysql://172.16.3.6:3306/world
↑DBサーバのアドレス:ポート番号/データベース名
※worldはデータベース名。
※ID,Name,CountryCode,District,Populationはデータベースのカラム名###test.jspの中身### <%@ page contentType="text/html; charset=utf-8" import="java.sql.*" %> <html> <head> <title>DB参照テスト</title> </head> <body> <h1>DB参照テスト</h1> <tr> <td>ID</td> <td>Name</td> <td>CountryCode</td> <td>District</td> <td>Population</td> </tr> <% Class.forName("com.mysql.jdbc.Driver"); Connection conn=DriverManager.getConnection("jdbc:mysql://172.16.3.6:3306/world?" + "user=root&password=MySQL@001&useUnicode=true&characterEncoding=utf-8"); Statement st=conn.createStatement(); ResultSet res = st.executeQuery("select * from city;"); while(res.next()){ out.println("<tr>"); out.println("<td>" + res.getString("ID") + "</td>"); out.println("<td>" + res.getString("Name") + "</td>"); out.println("<td>" + res.getString("CountryCode") + "</td>"); out.println("<td>" + res.getString("District") + "</td>"); out.println("<td>" + res.getString("Population") + "</td>"); out.println("</tr>"); } st.close(); conn.close(); %> </table> </body> </html>APサーバとDBサーバの連携の準備ができたので、APサーバのTomcatサービスを再起動。
あとDBサーバのmysqldサービスを再起動し、ブラウザにJSPのパスを入力する。
ちなみにJSPファイルを置いたパスは /opt/tomcat/webapps/jsp/test.jsp だが、
ブラウザでは/webapps/配下を入力する。
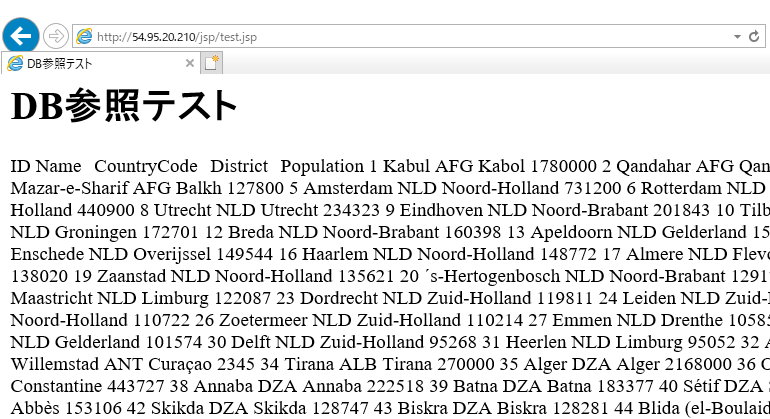
http://WEBサーバのパブリックアドレス/jsp/test.jsp
ぐちゃぐちゃだけど、一応DB参照できたので
一応WEB3層構成はできた・・・。
めちゃ時間かかったけど、つまづきながらハマりながら色々覚えれたので良かったです。
次回はNATゲートウェイの作成と、AnsibleでJSP内の文字列を置換することで
参照するDBを切り替えようと思います。つづく
- 投稿日:2021-01-24T20:14:39+09:00
EC2インスタンスのJupyter Notebookにローカルのブラウザから接続する
初めに
atmaCup オンサイトデータコンペ #9 に参加するにあたって、AWSのg4dnを動かしたいと思った。
(Azure使いたい!枠で参加表明しているので、計算資源には困らない)
手順を残しておこうと思い、自分用のメモとしてこの記事を書くことにした。
メモなので、雑に書いてる。本来、ある程度自動化するべき内容なのだろうけど...。
手順など
GPUインスタンスを初めて作るときは、予めGタイプのインスタンスを作れるようにしておくこと
インスタンスを作成する
コンソールから上げた。Deep Learning AMI を選ぶ。Deep Learning AMI (Ubuntu 18.04) Version 39.0を選択した。
接続
二つの方法で実施(Windowsから接続する。)
- git bashから接続する
- Remote Development をインストールして、EC2へ接続する
設定など
AWSの公式ドキュメントを読みながら実施。
Anacondaが入っていて、すでに仮想環境がいくつか作られているので、それを使うのが楽だと思う。
Jupyter のほうも、AWSのドキュメント(https://docs.aws.amazon.com/ja_jp/dlami/latest/devguide/setup-jupyter.html) にきっちり書いてあるので、これを見れば設定できるはず。
EC2インスタンスとローカルの間にトンネルを作るためにgit bashから操作した。
それも書かれていた。(https://docs.aws.amazon.com/ja_jp/dlami/latest/devguide/setup-jupyter-configure-client-linux.html)
$ ssh -i /c/Users/ユーザ名/.ssh/証明書.pem -N -f -L 8888:localhost:8888 ubuntu@xxxxx接続確認
https://localhost:8888に接続して、接続できるか確認する。オレオレ証明書を使っていたら、警告が出るが無視。

- 投稿日:2021-01-24T18:59:50+09:00
Amazon GuardDutyをはじめてみた
はじめに
Amazon GuardDutyはAWSのリージョン別脅威検出サービスです。
CloudTrailログ、VPCフローログ、DNSログなど複数のAWSデータソースにより何百億件ものイベントを分析します。
今回はGuard Dutyがどのようなものかコンソールにより有効化してみて、最後にCloudFormationでも作成してみます。GuardDuty有効化(コンソール)
サービスロールのアクセス権限を見てみます。
分析するのに、権限がこれだけでいいのでしょうか?
とりあえず有効化してみます。
最初の画面です。
GuardDutyは有効化されると、分析をすぐに開始するようです。
時間を置いても何も検出されていないので、潜在的に悪意のあるアクティビティは検出されていないことがわかりました。
また、抑制ルールを作成して対処する必要のない脅威検出結果を自動的にアーカイブでき、影響を与える脅威検出結果を簡単に認識できるようにできます。
コストが可視化されているようです。
私が有効化しているデータソースはCloudTrailとVPCフローログですが、両方とも保留中となっています。
使用日数が7日未満の新しく有効になったGuardDuty,データソースの場合はコストは保留中と表示されるからです。
なお、この画面に表示されている見積もりは、過去7から30日間の使用料に基づく1日の平均コストになります。ところで、
S3データイベントとは何でしょうか?
他のデータソースはイメージできますが、これがよくわからなかったので調べてみました。
簡単に言うと、S3に対するデータアクセスイベントのようで、S3に対する悪意あるアクティビティを検出できるようです。
GetObject、ListObjects、DeleteObject、およびPutObjectAPI操作がS3データイベントの例です。
なぜかサービルロールの権限がパワーアップしています。
また、結果のサンプルを生成をクリックすることで、検出結果のサンプルが見られます。
GuardDutyは検出結果に重大度が付されており、青が低、黄が中、赤が高です。
数字で表すと0.1から8.9の範囲で、大きいほどセキュリティリスクが高いことを示します。
信頼しているIPリストと悪意あるIPリストを作成できるみたいです。
DNSログやVPCフローログの分析の際に活用できそうです。
S3保護はデフォルトで有効になっています。
S3保護により、オブジェクトレベルのAPIオペレーションを監視して、S3バケット内のデータの潜在的なセキュリティリスクを特定するようです。
こちらは、複数アカウントを管理するための画面です。
GuardDutyの管理者アカウントになり、メンバーアカウントを管理することができます。
管理者アカウントは、メンバーアカウントのGuardDutyの有効化・一時停止や、抑制ルール・IPリストなどを作成管理できます。
メンバーアカウントは、これらの機能にアクセスできなくなります。S3バケットのブロックパブリックアクセスをオフにして検出するか試してみる
空のS3バケットを新規作成して検出されるか試してみます。
結果は検出されましたが、15分かかりました。
GuardDuty有効化(CloudFormation)
めちゃくちゃ短いです。
AWSTemplateFormatVersion: 2010-09-09 Description: Enable Amazon GuardDuty Resources: GuardDuty: Type: AWS::GuardDuty::Detector Properties: Enable: true
EventBridgeとSNSを組み合わせて検出された重要度によって通知をすることもできますが、今回はしません。
GuardDutyを有効化していない場合は作成に成功しますが、GuardDutyを停止している場合に作成すると、既にDetectorが存在すると言われてエラーになります。おわりに
簡単に全リージョンに有効化できそうです。
それにしても途中からサービスロールのアクセス権限が増えたのはどうしてでしょうか。













- 投稿日:2021-01-24T18:12:51+09:00
AWS ベストプラクティス 読んでみた
はじめに
AWSのベストプラクティスを読んだり読まなかったり。
IAM でのセキュリティのベストプラクティス抜粋
インラインポリシーではなくカスタマー管理ポリシーを使用する
- インラインポリシー : IAM アイデンティティ (ユーザー、グループ、またはロール) に埋め込まれたポリシー
- カスタマー管理ポリシー : スタンドアロンポリシー、arn:aws:iam::〜の形でpolicyを利用できる
推奨理由
- 再利用可能性
- 1つの管理ポリシーを複数のプリンシパルエンティティ (ユーザー、グループ、ロール) にアタッチすることができます。
- 一元化された変更管理
- 管理ポリシーを変更すると、変更はポリシーがアタッチされているすべてのプリンシパルエンティティに適用されます。
カスタマー管理ポリシーの方が管理が楽ってことのようです。
厳密に細かくポリシーを記載したい場合は、インラインポリシーの使用が便利とのこと。個人的には、管理ポリシーの方が記述量が減ってわかりやすくなるので、よく再利用するポリシーについてはこちらを利用し、少し変わったポリシーをアタッチしたい場合はインラインポリシーを使うようなイメージですかね?
S3のベストプラクティス抜粋
- https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/security-best-practices.html
- https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/optimizing-performance.html
頻繁にアクセスされるコンテンツにキャッシュを使用する
キャッシュ導入が成功すると、レイテンシーが低くなり、データ転送速度が速くなります。また、アプリケーションでキャッシュを使用すると Amazon S3 にリクエストを直接送信する回数も減るため、リクエストにかかる費用を削減できます。
キャッシュの導入
- Amazon CloudFront(CDN)
- オブジェクトにアクセスするユーザーの近くにデータをキャッシュできます。
- Amazon ElastiCache
- マネージド型のインメモリキャッシュ
- これにより、GET レイテンシーが数桁減少し、ダウンロードスループットが大幅に向上します。
- ElastiCache を使用するには、アプリケーションのロジックを変更して、アクセス数の多いオブジェクトをキャッシュに保存し、Amazon S3 にそのオブジェクトをリクエストする前にキャッシュを確認するようにします。
- AWS Elemental MediaStore
- Amazon S3 の動画ワークフローとメディア配信のために特別に作成されたキャッシュおよびコンテンツ配信システムです。
DynamoDBのベストプラクティス抜粋
- https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/best-practices.html
- https://aws.amazon.com/jp/blogs/news/make-a-new-years-resolution-follow-amazon-dynamodb-best-practices/
まだ、私には早かったw
- 投稿日:2021-01-24T18:12:21+09:00
【初心者向け】S3, Athena, QuickSightを使用してcsvデータを可視化する
はじめに
この記事ではデータをAWS上で分析・可視化するための1つの方法を紹介いたします。
実際に手順の通りに手を動かしていただき、各サービスの理解を深めていただければ幸いです。
作業で発生する料金は1$かかるかかからないかくらいになりますのでご安心ください。(無料枠を使用した場合)
以下は作業の流れです。
- 可視化する対象のデータを入手する
- 対象のデータをAWSへアップロードする
- 対象のデータのカラム情報を登録する
- 対象のデータを可視化サービスに取り込む
- 対象のデータを可視化する
各AWSサービスの紹介
今回使用するAWSサービスについて簡単に説明いたします。
Amazon S3(Simple Storage Service)について
S3はAWSが提供するオブジェクトストレージサービスになります。
特徴
高い可用性
S3は内部で自動的にストレージリソースをスケールアップ・スケールダウンするので我々はストレージのリソースを気にする必要がありません。高い耐久性
S3は99.99999999999%(9 x 11)の耐久性を実現しております。デフォルトで最低3つのAZのデバイスにデータを保存しているためデータの損失に強い。優れたセキュリティ
データの暗号化はもちろん、ACL・バケットポリシーを用いることで許可されたユーザーにのみデータを提供することができる。高いコストパフォーマンス
大きなファイルを保存してもそれほど料金がかからない ex. 500GBのデータを標準ストレージに保存してもストレージの保存料金は1297円/月 ほど(2021年1月24日時点)無制限の容量
S3バケットに容量制限はないのでいくらでもデータを保存することができます。様々なAWSサービスとの連携
AWSの中でも1,2番目に古いサービスであり、様々なAWSサービスと連携することが容易です。料金
すべてではありませんが、料金の大半を占める項目をピックアップいたします。
※東京リージョン 2021年 1月 24日時点
ストレージ料金
標準S3
区分 料金 最初の 50 TB/月 0.025USD/GB 次の 450 TB/月 0.024USD/GB 500 TB/月以上 0.023USD/GB リクエスト料金
PUT、COPY、POST、LIST リクエスト (1,000 リクエストあたり):0.0047USD
GET、SELECT、他のすべてのリクエスト (1,000 リクエストあたり):0.00037USD
DELETEは無料
データ転送
以下のデータは料金の対象になりません(以下、料金サイトから抜粋)
- インターネットから転送されたデータ
- インスタンスが S3 バケットと同じ AWS リージョンにある(同じ AWS リージョン内の別のアカウントを含む)場合、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスに転送されたデータ
- Amazon CloudFront (CloudFront) に転送されたデータ
つまり、課金されるのはS3からの送信のみでS3へのアップロードの際には料金が発生しません。また、同一リージョン内のAWSサービスとのデータ転送の際にも料金は発生致しません。S3からインターネットへデータを送信する際には気をつけた方が良さそうです。
区分 料金 1 GB/月まで 0.00USD/GB 次の 9.999 TB/月 0.114USD/GB 次の 40 TB/月 0.089USD/GB 次の 100 TB/月 0.086USD/GB 150 TB/月以上 0.084USD/GB Amazon Athenaについて
AWSが提供するフルマネージドサービスで、S3にあるデータファイルに対してクエリを実行することの出来るクエリサービスになります。クエリはPrestoSQLベースとなっております。
つまり、S3を配置してしまえば、それだけでそのデータの分析を始められることができます。フルマネージドサービスなのでサーバーの管理は不要ですし、データをRDBにインポートさせる手間も必要ありません。
特徴
クエリを発行するごとに料金が発生する
アドホックなケースでクエリを発行する場合はDBを用意するよりも安くなるケースが多いです。高速なクエリ
マネージドサービスであるためクエリを実行するクラスターの管理が自動化されており、パフォーマンスが最適化されております。そのため大規模なデータセットに対しても高いパフォーマンスを発揮いたします。サーバーの管理が不要
データを入手してからすぐに分析のフェーズに入れるのでとても楽です。余計なことを考えなくて済むのは大きく感じます。料金
スキャンされたデータ 1 TB あたり 5USD (2021年1月24日 東京リージョン)
これのみです。クエリを実行した分だけ料金が発生します。
1ドル=107円換算で1GBあたり約0.522円ほどになります。
QuickSightについて
AWSが提供するBI(Business Inteligence)サービスです。
特徴
サーバーレス
BIツールとなるとサーバーを自前で用意して運用するケースが多いのですが、QuickSightではサーバーの管理が不要ですぐに始められます。SPICE
SPICEはQuickSightが持つインメモリ計算エンジンです。取り込んだデータのキャッシュとしても捉えることができます。ML Insights
機械学習と自然言語処理を利用してインサイトを提供することができます。従量課金制
QuickSightでは主に利用するユーザー数によって料金が発生するため安価に可視化を始めることができます。料金
※Enterprise Editionの場合
作成者のユーザーあたり 18USD
閲覧者のユーザーあたり 最大5USD
SPICEの容量追加 1GBあたり $0.38 /月
1.データの入手
今回は日本の人口推移のデータを使用し、データの可視化を行います。
こちらからcsvファイルをダウンロードしてください。
このcsvファイルは文字コードがSJISかつダブルクォーテーションの引用符つきのcsvファイルになります。また、最後の2行のデータの備考コメントとなります。
後の作業に影響があるためデータを整形していきます。文字コードをutf8へ変更
% nkf -w --overwrite c01.csvダブルクォーテーションの削除 最後の行を削除×2 data.csvとして書き出し
cat c01.csv | sed "s/\"//g" | sed -e "$d" | sed -e "$d" > data.csv2.S3へデータをアップロード
AWSアカウントにログインしていただき、サービス一覧からS3へ遷移してください。
任意のバケット、プレフィックスを作成し先ほどダウンロードして加工したファイルdata.csvをアップロードしてください。
本記事では s3://inu-is-dog/japan-population/data.csv へアップロードしております。
3. Athena でテーブル情報を登録する
サービス一覧からAthenaへ遷移してください。初めてAthenaを開かれる方はAthenaのクエリ結果をどこに保存するのか問われるかと思いますが適宜設定してください。
次にAthenaで以下のクエリを実行してください。S3の配置場所(LOCATIONの部分)は3の手順でファイルを配置したS3パスへ変更してください。
CREATE EXTERNAL TABLE IF NOT EXISTS default.japan_population ( code string, prefecture string, era_name string, japanese_calender int, year int, comment string, all_population bigint, man_population bigint, woman_population bigint ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SerDeProperties ("field.delim" = ",", "escapeChar"="\\", "quoteChar"="\"") STORED AS TEXTFILE LOCATION 's3://inu-is-dog/japan-population/' TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1')このクエリはS3に配置されたcsvのカラム情報をテーブル情報として登録するためのクエリになります。
クエリを実行するとdefaltのデータベースにjapan_populationのテーブルが追加されるはずです。
テーブルが追加されたことを確認しましたら、テーブルの中身を正しく読み込めているのかを確認します。
以下のクエリを実行してデータを読み取れれば成功です。
SELECT * FROM default.japan_population LIMIT 100;
4. QuickSightでデータセットを作成する
AWSのサービス一覧からQuickSightへ遷移してください。
初めてQuickSightを使用する場合はアカウントの設定が必要かと思います。適宜設定してください。
まず、QuickSightがS3、Athenaと連携できるように設定します。
右上の人型のマークをクリック > QuickSightの管理をクリック
※リージョンはバージニア北部へ変更すること
QuickSightのAWSサービスへのアクセスの追加または削除をクリック
S3とAthenaにチェックが入っていることとファイルを格納しているS3バケットが対象となっているのかを確認する
チェックが入っていなければチェックをいれて更新する
リージョンを東京へ戻し
データセット > 新しいデータセット > Athena をクリックする
画像
任意のデータソース名をつけデータソースを作成
データベース:default
テーブル:japan_population
で選択する
今回はSPICEにデータを保存したいので"迅速な分析のために SPICE へインポート"を選択し、Visualizeを選択するとするとデータのインポートが始まりますので完了まで待ちます。
これで可視化の準備は完了です。
5. QuickSightでデータを可視化する
インポートが完了したら分析の画面に移ります。
最初にグラフが1つ用意されておりますので、フィールドリストから必要なものをドラッグ&ドロップで追加します。
今回は
- ビジュアルタイプ:積み上げ面折れ線グラフ
- Xのフィールド:year
- 値:all_population
- 色:prefecture
として都道府県ごとの人口の推移を観察できるようにしましょう。
このような図となるはずです。
Prefectureの中に都道府県以外に全国、人口集中地区、人口集中地区以外の地区も混ざっていることがわかります。
これらの値は都道府県の値の中でも特別な値なので排除しましょう。
Prefectureの判例の中で右クリックしてこれらの値をグラフから取り除きます。また、判例で表示しきれないものはotherとしてまとめられてしまいますのでこれも非表示にしてみます。
それらしいグラフになってきました。
あとは左上の"追加"から新たなグラフやタイトルを追加したり、テーマから色味を変えてみてダッシュボードらしく整備していきます。
最後にこの可視化した内容を第三者と共有するためにダッシュボードの共有をおこないます。
右上の共有から"ダッシュボードの公開"を選択します。
任意のダッシュボード名を入力し公開します。
ダッシュボードを誰に公開するのかはダッシュボードのアクセス管理から行います。
これでデータを可視化した結果のダッシュボードを公開することができました。
最後に
これで一通りの作業は完了となります。
今回は、サーバーレスの環境でデータを分析・可視化を行うことができました。
AthenaもQuickSightもマネージドサービスなので初心者にとっては始めやすいものなんだということが伝われば幸いです。
しかし、マネージドサービスが万能かというとそういうわけではありません。AWSが大半を管理しているからこそカスタマイズしにくかったりする部分があるのでその辺りはケースバイケースなので注意が必要です。

















- 投稿日:2021-01-24T17:30:26+09:00
【AWS】EC2を間違えて終了(削除)してしまわないよう、終了保護の設定をする
はじめに
本記事では、AWSのマネジメントコンソールからEC2インスタンスの管理をする時に、
誤操作でうっかりインスタンス(サーバー)を「終了」(削除)してしまわないように対策する方法をご紹介します。
(インスタンスを一度削除してしまうと、もう復元することはできないので要注意です。。!)
画像の例では、EC2のマネジメントコンソールで「Test」という名前のインスタンスを選択した状態で、「インスタンスの状態」タブを開いています。
すると、①インスタンスを停止
②インスタンスを終了等を選択できるようになります。
インスタンスを停止したい時は①を選択しますが、
例えばここで間違えて②を選択してしまうと、インスタンスが削除されてしまいます。
大事なデータやアプリが全部消えてしまっては、一大事。。誤操作でインスタンスを削除してしまわないように対策する設定をしていきましょう!
終了保護の設定をする
以下の順にクリックしていきます。
EC2のマネジメントコンソールの「アクション」タブ > 「インスタンスの設定」 > 「終了保護を設定」
あとは、終了保護の設定画面で、「有効化」にチェックを入れて、「保存」ボタンをクリックすれば設定は完了です!
終了保護が設定できたか確認
それでは、ちゃんと終了保護設定が反映されているかを確認してみます。
先ほどと同様に、「インスタンスの状態」タブを開いて、「インスタンスの終了」をクリックしてみます。(クリックできちゃう)すると赤い背景色で、「インスタンスxxxxxの終了に失敗しました」というエラーメッセージが表示され、ちゃんとインスタンスの終了から保護されていることがわかります。
もし逆に、インスタンスを終了したい時は、終了保護設定を無効にすればOKです。
インスタンスの新規作成時にも、終了保護設定ができる
なお、「インスタンスを起動」ボタンをクリックして、
インスタンスを新規作成する時の
「ステップ3:インスタンスの詳細の設定」のページでも終了保護設定の有効化を設定することができます。
最後に
今回は、EC2インスタンスを終了(削除)から保護をする設定方法をご紹介しました。
もし更に対策を万全にするのであれば、この他にもインスタンスのバックアップやスナップショップを取ったり、AMIを残しておくと安全です!それでは、この記事が少しでもお役に立てば幸いです。





- 投稿日:2021-01-24T17:17:23+09:00
AWS S3バケットの指定フォルダ直下のフォルダとファイルをLambdaで取得する
Amazon Web ServiceのS3バケットの指定フォルダ直下のフォルダとファイル一覧を取得するLambda関数を作ってみました。
サンプルコード
まずはコードから。Pythonです。
ListFoldersAndFiles.pyimport json import boto3 def lambda_handler(event, context): S3Bucket = "{your-bucket-name}" S3KeyPrefix = "" dirDepth = 1 folders = [] files = [] result = "" # Get requesting path from query string and normalize it. try: path = event['queryStringParameters']['path'] if path is not None: S3KeyPrefix = path if (len(S3KeyPrefix) > 0) and (S3KeyPrefix[0] == "/"): S3KeyPrefix = S3KeyPrefix[1:] if (len(S3KeyPrefix) > 0) and (S3KeyPrefix[-1] == "/"): S3KeyPrefix = S3KeyPrefix[:-1] if (len(S3KeyPrefix) > 0): dirDepth = len(S3KeyPrefix.split('/')) + 1 except Exception as e: print(e) # Create instances. s3 = boto3.resource('s3') bucket = s3.Bucket(S3Bucket) objs = bucket.meta.client.list_objects(Bucket = bucket.name, Prefix = S3KeyPrefix, Delimiter = "/") try: # Enumrate subfolders. for o in objs.get('CommonPrefixes'): folder = o.get('Prefix') folders.append(folder) subFolders = bucket.meta.client.list_objects(Bucket = bucket.name, Prefix = folder, Delimiter = "/") if (subFolders is not None) and (subFolders.get('CommonPrefixes') is not None): for f in subFolders.get('CommonPrefixes'): subFolder = f.get('Prefix') if len(subFolder.split('/')) == dirDepth + 1: folders.append(subFolder) # Enumrate files. oFiles = bucket.meta.client.list_objects_v2(Bucket = bucket.name, Prefix = S3KeyPrefix) for f in oFiles.get('Contents'): file = f.get('Key') if (file[-1] != '/') and (len(file.split('/')) <= dirDepth): files.append(file) except Exception as e: result += "No such folder : " + S3KeyPrefix # Get results. folders = sorted(folders) result += "\n".join(folders) + "\n" files = sorted(files) result += "\n".join(files) + "\n" return { 'statusCode': 200, 'body': result }気をつけた点は、取得しようとするパスの前後に「/」が入っていたり入っていなかったりしても大丈夫にした点と、「/」の数で指定ディレクトリ直下のフォルダ・ファイルのみ取得するようにした点でしょうか。
不恰好ですが、バケットのルートとそれ以外で取得できるフォルダが違ったりしていたので力技で書いてます。この関数につけるロール
Lambda関数を作成する際にデフォルトのロールを選んで、その後以下のインラインポリシーを追加します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your-bucket-name" ] }, { "Sid": "AllObjectActions", "Effect": "Allow", "Action": "s3:*Object", "Resource": [ "arn:aws:s3:::your-bucket-name/*" ] } ] }テストイベント
テストイベントに以下の行を追加し、検索パスを指定します。
{ "queryStringParameters": { "path": "path-to-folders" } }
- 投稿日:2021-01-24T16:08:00+09:00
pythonでAWSのリソース情報を取得してyamlファイルを編集してみた
はじめに
仕事で特定のyamlファイルをコピーして、EC2のIPアドレスなどの特定の箇所を編集してplaybookを実行することがあり、手作業だとミスが起きると思いプログラムでAWSのリソースを取得して、その値でyamlファイルを書き換えられないか試してみた。
実施したこと
引数として
- 編集したいyamlのファイル名
- EC2のタグ(Name)の値
- AWSのプロファイル
を渡してあげて、AWSのプロファイルの設定で、EC2タグの値に紐づくECインスタンスを取得して
yamlファイルを編集する。yamlファイルのイメージ
- hosts: target_test tasks: - name: install git yum: name=git state=latest instance: private_ip: 0.0.0.0 public_ip: 0.0.0.0 ip: 0.0.0.0↑のprivate_ipと、public_ipを編集する。
作成したソース
#!/usr/bin/python # -*- coding: utf-8 -*- import ruamel import ruamel.yaml import sys import boto3 from boto3.session import Session yaml = ruamel.yaml.YAML() args = sys.argv file_name = args[1] tag_value = args[2] profile = args[3] # プロファイルの内容でAWSのリソースにアクセスするように設定 session = Session(profile_name=profile) def read_file(file_name): """ ファイル読み込み 引数 file_name: ファイル名 返り値 loadしたyamlデータ """ with open(file_name, 'r') as file: data = yaml.load(file) return data def fetch_ec2_instance(tag_value): """ ec2インスタンス取得 引数 tag_value: ファイル名 返り値 Name=tag_valueのインスタンス """ ec2 = session.client("ec2") # Nameタグでフィルター instances = ec2.describe_instances( Filters=[ {'Name': 'tag-key', 'Values': ['Name']}, {'Name': 'tag-value', 'Values': [tag_value]} ] )['Reservations'] if len(instances) == 0: raise Exception("インスタンスが存在しません。 Name:{}".format(tag_value)) return instances[0] def edit_data(data, instance): """ パブリックIP、プライベートIPの修正 引数 data: yamlデータ instance: ec2インスタンス """ data[0]["instance"]["private_ip"] = instance['Instances'][0]['PrivateIpAddress'] data[0]["instance"]["public_ip"] = instance['Instances'][0]['PublicIpAddress'] def write_data(file_name, data): """ yamlデータ書き込み file_name: 書き込むファイル名 data: yamlデータ """ with open(file_name, 'w') as file: yaml.dump(data, stream=file) data = read_file(file_name) instance = fetch_ec2_instance(tag_value) edit_data(data, instance) write_data(file_name, data)ruamelを使用して、yamlファイルの編集をしてます。
PyYamlもあるのですが、その場合yamlファイルの順序が保障されてないためruamelを使用してます。以下コマンドで実行
python {pythonのソースファイル名} {編集ファイル名} {Nameタグの値} {プロファイル}参考
ruamelについて
https://dev.classmethod.jp/articles/getting-started-with-pyyaml-and-ruamel-yaml/デフォルトのプロファイル以外を使用する
https://qiita.com/inouet/items/f9723d7ae7d8d134280b
- 投稿日:2021-01-24T15:32:49+09:00
AWS CloudFormationを使ってS3で静的WEBサイトをホストするメモ
前提
AWS CLIのプロファイル作成済み
https://qiita.com/pino2/items/c0ede5c2b23f7f898a99S3で静的WEBサイトをホストするCloudFormaitonテンプレート作成
ここにあったのでコピペ
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/quickref-s3.htmlスタック作成
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-cfn-cli-deploy.html
> aws cloudformation deploy --template /path_to_template/my-template.json --stack-name my-new-stack[スタック名]-s3bucket-~
の名前でパブリックアクセス可能なバケットができた。WEBサイト表示
S3バケットにindex.htmlをアップロード
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8" /> <meta name="description" content="Hello" /> <title>Hello</title> </head> <body> Hello!! </body> </html>管理コンソール>バケット>プロパティ>「静的ウェブサイトホスティング」に記載のURLをクリックしたらアップロードしたhtmlが表示された。
- 投稿日:2021-01-24T15:29:18+09:00
AWS CLIを初めて使うメモ
AWS CLI
インストール
https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.htmlIAMロール作成
ルートユーザ使用はおすすめしないみたいなので、IAMロール作成。
既存のポリシーを直接アタッチでAdministratorAccessをチェック
(本当はAdminでなく権限絞った方が良いらしい)
認証情報のCSVをダウンロードしておく。AWS CLIのプロファイル作成
適当なプロファイル名をつけてプロファイル作成。
$ aws configure --profile PROFILE1 AWS Access Key ID[None]: アクセスキーID AWS Secret Access Key[None]: シークレットアクセスキー Default region name[None]: ap-northeast-1 Default output format[None]: json確認
aws sts get-caller-identity --profile PROFILE1毎回指定しなくてすむようにprofileを環境変数に設定しておく(以下Macの場合)
vi ~/.bash_profile.bash_profileに追記
export AWS_PROFILE=PROFILE1
- 投稿日:2021-01-24T15:06:39+09:00
[AWS CloudFormation] Amazon SNS プッシュ通知環境構築
前提
- 通知先デバイスのOSはAndroid
- 通知先デバイスは1台 ※複数台に通知する場合はトピックを使用
- Mobileアプリの環境構築、実装については本記事では言及しない
構成要素
Amazon SNSを使用してプッシュ通知を行う場合、以下の構成となる
準備
Amazon SNSからFCM経由でMolblieアプリにプッシュ通知を行うためには、
通知先のデバイスを特定するためのデバイストークンと、
Firebaseのプロジェクトを特定するためのサーバーキーが必要となる
そのため以下の準備を行う
Firebaseに任意のプロジェクトを作成
Firebase Cloud MessagingにMoblieアプリを登録
Firebaseの以下からサーバーキーを取得する
Mobileアプリからデバイストークンを取得
※取得方法については参考記事等を参照
※デバイストークンはMobileアプリのインストール毎に変化するマネジメントコンソールでの環境構築
プッシュ通知から、
プラットフォームアプリケーションの作成をクリック
任意のアプリケーション名を入力
プッシュ通知プラットフォームはFCMを選択
APIキーに準備で取得したサーバーキーを入力
プラットフォームアプリケーションをクリック
アプリケーションエンドポイントの作成をクリック
デバイストークンに準備で取得したデバイストークンを入力
アプリケーションエンドポイントの作成をクリック
マネジメントコンソールからのプッシュ通知テストでは、
配信プロトコルごとにカスタムペイロードを選択
メッセージの内容は、
Mobileアプリがバックグラウンドでもプッシュ通知するためには以下のようなフォーマットとなる
※android_channel_idはMobileアプリの実装に合わせる{ "GCM": "{ \"notification\": { \"body\": \"message body\", \"title\": \"message title \", \"sound\":\"default\" ,\"click_action\": \"FLUTTER_NOTIFICATION_CLICK\", \"android_channel_id\":\"1\"} , \"data\" : {\"key1\" : \"value\", \"key2\" : \"value\" } }" }CloudFormationでの環境構築
Amazon Simple Notification Service リソースタイプのリファレンスからわかるように、
マネジメントコンソールで作成したプラットフォームアプリケーション、アプリケーションエンドポイントはCloudFormationに対応していない
今回は、カスタムリソースを使用してプラットフォームアプリケーションを作成し、
Lambdaにてアプリケーションエンドポイントを追加するカスタムリソースにはcfn-responseモジュールが必要となる、cfn-responseモジュールについては以下を参照
cfn-responseモジュール
今回は、cfn-responseモジュールをLayer化して使用しているカスタムリソースによるプラットフォームアプリケーション作成
以下、プラットフォームアプリケーションを作成するためのテンプレート
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > child stack (SNS) Globals: Function: Timeout: 3 Runtime: python3.8 Handler: function.lambda_handler Parameters: StackName: Type: String CfnResponseArn: # cfn-responseモジュールLayer Type: String ApiKey: # プラットフォームアプリケーション生成に必要なAPIキー(サーバーキー) Type: String Resources: CreatePlatformApplicationRole: # カスタムリソース生成時に実行されるLambdaに付与するロール Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole Path: / Policies: - PolicyName: CreatePlatformApplicationPolicy # SNS操作用ポリシー PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: sns:* Resource: '*' CreatePlatformApplicationFunction: # カスタムリソース生成時に実行されるLambda Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${StackName}_CreatePlatformApplicationFunction Role: !GetAtt CreatePlatformApplicationRole.Arn CodeUri: create-platform-application/ Layers: - !Ref CfnResponseArn # プラットフォームアプリケーションを生成するカスタムリソース CreatePlatformApplication: Type: Custom::CreatePlatformApplication Properties: ServiceToken: !GetAtt 'CreatePlatformApplicationFunction.Arn' # リソースを生成するLambda Arn PlatformApplicationName: !Sub ${StackName}_sample # プラットフォームアプリケーション名 PlatformApplicationArn: !Sub arn:aws:sns:${AWS::Region}:${AWS::AccountId}:app/GCM/${StackName}_sample # プラットフォームアプリケーションArn ApiKey: !Ref ApiKey # プラットフォームアプリケーション生成に必要なAPIキー(サーバーキー) Outputs: PlatformApplicationArn: # 生成したプラットフォームアプリケーションを他テンプレートで使用できるようにOutput Value: !Sub arn:aws:sns:${AWS::Region}:${AWS::AccountId}:app/GCM/${StackName}_sample以下、カスタムリソース生成時に実行されるLambda
import json import boto3 from cfnresponse import CfnResponse def lambda_handler(event, context): try: sns = boto3.client('sns') if event['RequestType'] == 'Create': # リソース生成時 # プラットフォームアプリケーションの生成 response = sns.create_platform_application( Name = event['ResourceProperties']['PlatformApplicationName'], Platform = 'GCM', Attributes = { 'PlatformPrincipal': '', 'PlatformCredential': event['ResourceProperties']['ApiKey'] } ) CfnResponse.send(event, context, CfnResponse.SUCCESS, {}) elif event['RequestType'] == 'Delete': # リソース削除時 # プラットフォームアプリケーションの削除 response = sns.delete_platform_application( PlatformApplicationArn = event['ResourceProperties']['PlatformApplicationArn'] ) CfnResponse.send(event, context, CfnResponse.SUCCESS, {}) else: CfnResponse.send(event, context, CfnResponse.SUCCESS, {}) except Exception as e: CfnResponse.send(event, context, CfnResponse.FAILED, {})Lambdaによるアプリケーションエンドポイントの追加
以下、アプリケーションエンドポイントを追加するLambdaとそのテンプレート
Parameters: StackName: Type: String PlatformApplicationArn: Type: String Resources: SetEndpointFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub '${StackName}_SetEndpointFunction' CodeUri: set-endpoint/ Environment: Variables: PlatformApplicationArn: !Ref PlatformApplicationArn # プラットフォームアプリケーションArn Policies: - Version: '2012-10-17' Statement: - Effect: Allow Action: sns:* Resource: '*'import os import json import boto3 platformApplicationArn = os.getenv('PlatformApplicationArn') sns = boto3.client('sns') def add_endpoint(token): # アプリケーションエンドポイントの追加 # ※既存のtokenの場合はendpoint(Arn)返却のみされる endpoint = sns.create_platform_endpoint( PlatformApplicationArn = platformApplicationArn, Token = token )プッシュ通知を行うLambda
以下、プッシュ通知のLambda実装は以下のようになる
import os import boto3 import json sns = boto3.client('sns') platformApplicationArn = os.getenv('PlatformApplicationArn') # デバイストークンから通知先のendpoint(Arn)を取得する def get_targetEndpoint(deviceToken): try: # ※既存のtokenの場合はendpoint(Arn)返却のみされる endpoint = sns.create_platform_endpoint( PlatformApplicationArn = platformApplicationArn, Token = deviceToken ) except: raise ValueError(f'get_targetEndpoint error') return endpoint['EndpointArn'] def publish_notification(deviceToken): try: payload = { 'notification': { 'body': 'message body', 'title': 'message title', 'click_action': 'FLUTTER_NOTIFICATION_CLICK', 'android_channel_id': '1' }, 'data': { 'key1': value1, 'key2': value2 } } message = json.dumps({ "GCM": json.dumps(payload) }) response = sns.publish( TargetArn = get_targetEndpoint(deviceToken), Message = message, MessageStructure = 'json' ) except: raise ValueError(f'publish_notification error')参考







- 投稿日:2021-01-24T14:44:21+09:00
VPCのコンポーネント
はじめに
AWSのVPCについて学んだことを備忘録を兼ねてまとめて行こうと思う。
今回も細かいとこよりイメージ優先で書いて行来ます。ルートテーブル
- サブネット間の通信を制御するもの
- サブネットから出る通信をどこに向けるかを決めるもの
- イメージは下記のような感じになる
送信先 ターゲット 10.0.0.0/21 local 0.0.0.0/0 インターネット ※適用されるルールについては、より明確に記述したものから優先される。上の例だと、localの方がルールとしては強い
インターネットゲートウェイ
- パブリックサブネットがインターネットに接続するために必要なコンポーネント
- これをサブネットにアタッチすることで、VPCがインターネットに接続することができる
- インターネットゲートウェイはアタッチされたサブネットのルートテーブルを参照する
- とあるサブネットをインターネットにつなげたい場合下記のようなイメージとなる
送信先 ターゲット 10.0.0.0/21 local 0.0.0.0/0 internet gateway NAT ゲートウェイ
- プライベートサブネットをネットに接続させるコンポーネント
- 基本的にアウトバウンド(外への通信)のみで、インバウンド(外からの通信)は許可されていない
- とあるプライベートサブネットをネットにつなげたい場合下記のようなイメージとなる
送信先 ターゲット 10.0.0.0/21 local 0.0.0.0/0 NAT gateway ENI
- AWSのインスタンスにアタッチすることで、IPアドレスを扱える?ようになるイメージかな?
- 例えばEC2はlocalリソースへの通信用のプライベートIPアドレスと外部通信用のパブリックIPアドレスを保持している
- パブリックIPアドレスはインスタンスが停止したり、再起動したりすると変更してしまう
- パブリックIPアドレスを固定したい場合はElasticIPアドレスをENIにアタッチする
セキュリティーグループ
- インスタンスごとに設定するファイアーウォール
- アウトバウンドのみ設定が必要(ステートフル型)
Network ACL
- サブネットごとに設定するファイアーウォール
- 新規作成したものはデフォルトで全ての通信が拒否となっているため、注意(デフォルトは全ての通信が許可されている)
- インバウンド、アウトバウンドどちらも設定が必要(ステートレス型)
- 役割としては、補助的なセキュリティ強化につかう
まとめ
結構複雑なので、遠ざけがちでしたが、わかってくるとおもしろいですね~
- 投稿日:2021-01-24T13:24:08+09:00
【AWS】VPC Lambdaを構築したときのメモ
普段、インフラを構築する機会が滅多にないけど、最近VPC Lambdaを構築する機会があったので、色々学んだ事をメモしておく。
やりたかったこと
- Lambdaからピアリングで他のVPCにあるAPIとの接続
- Lambdaからインターネット経由で外部APIとの接続
本記事の内容
- Lambdaを置くPrivateサブネットのCIDR設計
- Privateサブネットからの疎通確認
- SessionManager越しのSSHアクセス
背景
今までLambdaをVPC内に置く必要はなかったが、LambdaからVPCピアリングでAPIにリクエストする必要が出たのでLambdaをVPCのサブネットに含む構成に変えることになった。
ネットワーク構成は以下の図の通り。
Lambdaからインターネット経由で外のAPIにアクセスする必要もあるためPublicサブネット内にNATインスタンスを用意している。
LambdaのサブネットのCIDR
VPC Lambdaはアンチパターンと言われていたイメージがあったので、Lambdaを置くサブネットのCIDR設計の際に以下のような心配をした。
- 新しいENIを作成してアタッチするときにコールドスタートが起こる恐れ
- リクエストの増加につれて、多くのENIが作成されIPが枯渇する恐れ
しかし、調べたら2019年9月からLambda関数がVPCに接続する方法が改善されていた。(参考:[発表] Lambda 関数が VPC 環境で改善されます)。
以前はVPCのネットワークインターフェースをLambda実行環境に直接マッピングする方法だったのが、現在はVPCのネットワークインターフェースはHyperplane ENIにマッピングされ、Lambda関数はそれを使用して接続する仕組みに変わっている。↓ 2019年9月まで
↓ 2019年9月以降
記事の中で自分が懸念していた事柄が改善されている旨がちゃんと記載されていた。
ネットワークインターフェースの作成は、Lambda 関数が作成されるか、VPC 設定が更新されるときに発生します。 関数が呼び出されると、実行環境は事前に作成されたネットワークインターフェイスを使用するだけで、そこへのネットワークトンネルをすばやく確立します。 これにより、コールドスタートでのネットワークインターフェイスの作成と接続にこれまで発生していた遅延が劇的に削減されます。
ネットワークインターフェイスは実行環境全体で共有されるため、通常、関数ごとに必要なネットワークインターフェイスはほんの少数です。 アカウント内の関数にまたがるすべての一意のセキュリティグループ:サブネットの組み合わせには、個別のネットワークインターフェイスが必要です。 組み合わせがアカウント内の複数の関数で共有されている場合、関数間で同じネットワークインターフェイスを再利用します。
関数のスケーリングは、ネットワークインターフェースの数に直接関係しなくなり、Hyperplane ENI は、多数の同時関数実行をサポートするようにスケールできます
念のため、Lambdaに並列実行数が500リクエスト以上行う検証をしてみたが、最初に作られたネットワークインターフェース1つが常に再利用されていた。
(またCIDRの設計では、VPCピアリングする場合に接続先のVPCとCIDRが被らないように注意が必要ということも当然なことだけど学びました。)
Privateサブネット内のLambdaからの疎通がうまくいかなかったときの原因とやったこと
Privateサブネット内のLambdaから、ピアリング先や外部との疎通がうまくいかなくてハマった時のことを書いておく。
結論から言うと、以下がそれぞれ原因だった。
- ピアリング先との原因 → Lambdaのエイリアスのversion指定が古いのを指定していた
- 外部との原因 → NATインスタンスの設定で送信元/送信先を確認する設定を無効にしていなかった
疎通できない原因ってわかると大体あっけないものですよね
解決のためにやったこと
原因は先程書いたとおりだったが、解決のためにやったことを書いておく。
ピアリング先との疎通確認
1.Lambdaのいるサブネットに仮でEC2インスタンスを立てて、そこからピアリング先と疎通確認 → 問題なく疎通できた → サブネットの設定は問題なさそう
2.じゃあ原因はLambdaからのアクセスか?
3.仮で新たにテスト用のLambda(以下のtest.js)を作成してレスポンス返ってくるか確認した。
→ 疎通できたのでLambdaからのアクセスも問題なさそうtest.jsvar http = require('http') exports.handler = (event, context, callback) => { const options = { hostname: event.Host, port: 80 } const response = {}; http.get(options, (res) => { response.httpStatus = res.statusCode callback(null, response) }).on('error', (err) =>{ callback(null, err.message); }) };4.じゃあ原因はAPIGatewayからLambda????
うーん。
5.改めてLambdaの設定を眺めると、指定しているエイリアスのversionがおかしい。。!
→ エイリアスを指定してLambdaを見てみるとVPCに関連付けされていなかった。。。つまり古い構成のままになってしまっていた。。。という結末でした。
外部との疎通確認
- EC2 instanceの作成時にNAT用のAMIを使用しているか再確認
- private, publicのサブネットのNACL、インスタンスのセキュリティグループを全許可にして試す
- privateサブネット内に仮で作ったインスタンスからwww.google.comにpingもcurlも失敗 → この時点でセキュリティグループやNACLの設定の問題じゃなさそう

- publicサブネット内のNATインスタンスへpingは成功 → VPC内の疎通は問題なさそう
- tracerouteを使ってrouteの経路を見てみる
- netstatで、TCP接続のステータスを確認 → establishedになっていない
完全に外との疎通が全くできていなさそうなことから、NATインスタンスがNATの役目を果たしていないよなーと思って、改めてAWSのNATの公式ドキュメントを読み直した。
そしたら、、、EC2 インスタンスは、送信元/送信先チェックをデフォルトで実行します。つまり、そのインスタンスは、そのインスタンスが送受信する任意のトラフィックの送信元または送信先である必要があります。しかし、NAT インスタンスは、送信元または送信先がそのインスタンスでないときにも、トラフィックを送受信できなければなりません。したがって、NAT インスタンスでは送信元/送信先チェックを無効にする必要があります。
ここを見落としていました。
ドキュメントに従って設定したら疎通できました。
SessionManager越しにSSHアクセスする
SessionManagerを使えば、もうbastionは不要になると聞いて初めてSessionManagerを使ってみた。
SessionManagerを利用するには以下が必須条件。
- EC2インスタンスに
AmazonSSMManagedInstanceCoreのロールが付与されていること- EC2インスタンスにSSMエージェントがインストールされていること
ロールの付与
IAMにいき、以下のように
AmazonSSMManagedInstanceCoreポリシーをアタッチする。
上記のロールをEC2インスタンスのロールに付与する。
SSM エージェントのインストール
SSMエージェントは、以下のEC2インスタンスとAmazon Machine Images (AMIs)ではデフォルトでインストールされている。
- Amazon Linux
- Amazon Linux 2
- Amazon Linux 2 ECS-Optimized AMIs
- Ubuntu Server 16.04, 18.04, and 20.04
ただし上記以外のAMIを利用した場合は手動でインストールする必要があります
。
ロールを付与した後に、
インスタンスのアクション > 接続 > セッションマネージャー
を開くと、セッションマネージャーがインスタンスに接続できていないかどうかがわかる。もし以下の図のように、接続できていないならそのインスタンスにSSMエージェントがインストールされていないと思われる。
bastion不要になる、22番ポートをセキュリティグループで許可しなくて済むと思っていたけど、SSMエージェントをインストールするために初めは必要なんだね。
とはいえ、SSMエージェントをインストールする手順はすぐ簡単にできる。
※試してるだけなので、ユーザーはデフォルトのec2-userです、お許しください// SSHでインスタンスに入る $ssh -i "test-key.pem" ec2-user@(インスタンスのIP) // SSMエージェントをインストール $sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm // SSMエージェントのステータスを確認してみる $sudo status amazon-ssm-agent // 実行結果 amazon-ssm-agent start/running, process 2774このあと、AWSコンソールからSessionManagerを開いてみると、、、
表示されているー!
インスタンスのアクション > 接続 > セッションマネージャー
を開いても、SessionManagerがインスタンスに接続できる状態に変わっている!
セッションを開始するを押すと、無事にインスタンスに入れた。
ここまで確認できたら、SSMエージェントのインストールのために許可した22番ポートやbastionを削除するのを最後に忘れずにやっておわりです。
注意事項としてはエージェントの起動に多少時間がかかるところ。
設定が問題なくても、EC2内のエージェントが起動直後で立ち上がっていないとセッションマネージャーの画面にいっても何も表示されない。自分の場合は10分以上待ってようやく表示されたので、もしSSMエージェントのインストールや、ロールの設定も済んでいるのに表示されない場合は10分以上様子を見た方がいい。おわりに
どれも基本的な内容かなと思いますが、
普段インフラを触ることがあまりない自分にとっては勉強になったことをまとめました!間違っている点などあればご指摘お願いします











- 投稿日:2021-01-24T13:23:04+09:00
CloudWatch Logs Insights 新人演習
新しく AWS の CloudWatch Logs Insights を使い始める人に向けての演習資料を目指します。
CloudWatch Logs Insights とは
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
ログファイルの監視、保存、アクセスができます。
CloudWatch Logs Insights を使用して、ログデータをインタラクティブに検索および分析できます。クエリを実行することで、運用上の問題に効率的かつ効果的に対応できます。
EC2 instance の Apache access_log とか tomcat log を収集・保存して、AWSコンソール上でクエリによる参照・分析ができます。
なにが嬉しいの
- 各EC2 instanceに loginせずにログを参照できる
- ログ参照できる権限でログインしてると、ログ参照以外の操作もできたりして、いろいろとあやうい
- 負荷分散・高可用性で複数台並列構成にしているとき、ワンストップで全部のログを調査分析できる
- 2台ならまだいいけど、運用の 2n台、3n台構成だとうんざりでしょ?
- クエリがそれなりに強力
- ログの各フィールドを adhoc に構造化したりとか
クラウド破産は怖くない?
ほい、料金表。
https://aws.amazon.com/jp/cloudwatch/pricing/無料利用枠
ログ 5 GB データ (取り込み、ストレージのアーカイブ、Logs Insights クエリによってスキャンされたデータ)
従量料金
分析 (Logs Insights のクエリ) スキャンしたデータ 1 GB あたり 0.0076USD
料金の例
ウェブアプリケーションのアクセスログ 1 GB x 30 日 = 30 GB
CloudWatch の月額料金 = 12.53 USD上記は無料枠の 5GB は引いてます。あなたの時給の 0.x時間分ですね。
ログ調査は直近のログだけで済む場合が殆どなので、スキャンデータの範囲を限定すれば怖くない。1 日間~10 年間の保持期間を選択することができます
Administrator が調査可能範囲とコストを秤にかけて、適切な保持期間にしてるし、コンソールのデフォールトだと直近1時間がスキャン範囲なので、そこまでびくびくしなくていいです。
はじめの一歩
- AWSコンソールにログイン
- CloudWatch > CloudWatch Logs Insights
- 調査対象の loggroupを選択 (例: homura/tomcat/current)
[Run Query]
fields @timestamp, @message | sort @timestamp desc | limit 20対象ロググループの最新ログが20行表示されます。
クエリーは、pipe で単純な処理を連結して組み立ててます。json処理する jq にちょっと感じが似てるか。疑似SQLで表現しなおすと、こんな感じでしょう。
SELECT timestamp_, message_ FROM 'homura/tomcat/current' ORDER BY timestamp_ DESC LIMIT 20;各行の詳細を行頭の
▶をクリックして表示させてみましょう。▶ 2 2021-01-23T14:56:02.045+09:00 @40000000600bba7b34e32194 SCIM [HTTP Response Header]:Content-Type=application/scim+json;charset=UTF-8 Field Value @ingestionTime 1611381366827 @log <account>:homura/tomcat/current @logStream 101a @message @40000000600bba7b34e32194 SCIM [HTTP Response Header]:Content-Type=application/scim+json;charset=UTF-8 @timestamp 1611381362045
fieldsで指定した以外の属性も見えました。@ingestionTime は、ログイベントが CloudWatch Logs によって受信された時間を示します。
@logstreamはログ発生元を表すための文字列で、各instance の aws-cloudwatch-agent の設定ファイル由来です。
設定のデフォールトは instance-id ですが、AutoScaleとかしないでずっと同じ少数の instance を使う開発・試験環境では、
instanceの pet-nameで設定していることもあるでしょう。二歩目では
fieldsに@logStreamも追加することにしましょう。SEVERE/ERRORログの特定
500 Internal Server Errorなどが返ってきてるという想定で、ログ調査演習してみましょう。
fields @timestamp, @logStream, @message | filter @message like /(SEVERE|ERROR)/ | sort @timestamp desc | limit 10みつかりました?
該当がでてこなったら、ログの探索範囲を広げてみましょう。初期値は過去1hになっているので、3h, 12hと。
もっと過去までみるなら Custom から4weekまでは簡単に指定できます。
hitすると、時間軸とhit数のヒストグラムも出てくるので、いつから出始めたのか、頻度はどれくらいか、すぐに把握できます。
- あるデプロイの直後からなら、そのデプロイでの変更点が第1容疑者
- 毎正時に出ているなら、なにかの定期実行jobかな
SEVERE/ERRORログの直後のstack trace
Exceptionが出てるかも。その stack trace からExceptionの発生場所をつきとめましょう。
起点とする
ERROR行がこうだとすると@logStream 101b @message @40000000600a66f41b958bdc 22-Jan-2021 05:47:22.461 INFO [ajp-nio-8009-exec-9] com.example.servlet.ScimUsersServlet.httpMethod end(69ms)--->HTTP 500 INTERNAL_SERVER_ERROR @timestamp 1611294447291fields @timestamp, @logStream, @message | filter @logStream = "101b" | filter @timestamp >= 1611294447291 | sort @timestamp asc | limit 30
ERROR行と、同じ logStream(同じinstance)ERROR行のtimsstampの直後の30行- timsstamp の昇順ソート
at javax.のライブラリや、at org.apache.のミドルウェアのところじゃなくて、開発・試験中の package が出ていれば、その Class と行番号からソースでの調査が始められます。
stack trace がやたらと長いときには、limit行数を調整します。Export results
うまく拾えたら、 コンソールの
Export resultsを使いましょう。ここでは markdown 結果を貼っておきます。
CSVでのクリップ|ダウンロードもできます。
@timestamp @logStream @message 2021-01-22 05:47:27.291 101b @40000000600a66f41b958bdc 22-Jan-2021 05:47:22.461 情報 [ajp-nio-8009-exec-9] com.example.servlet.ScimUsersServlet.httpMethod end(69ms)--->HTTP 500 INTERNAL_SERVER_ERROR 2021-01-22 05:48:46.663 101b @40000000600a6748232cff4c at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52) 2021-01-22 05:48:46.663 101b @40000000600a67482331ae84 at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) 2021-01-22 05:48:46.663 101b @40000000600a674822dc1474 java.lang.NullPointerException 2021-01-22 05:48:46.663 101b @40000000600a67482336c734 at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) 2021-01-22 05:48:46.663 101b @40000000600a6748233e77f4 at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:199) 2021-01-22 05:48:46.663 101b @40000000600a67482343a814 at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) 2021-01-22 05:48:46.663 101b @40000000600a674823486ebc at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:478) 2021-01-22 05:48:46.663 101b @40000000600a674822e1f45c at com.example.common.service.mybatis.MybatisUserServiceImpl.getSystemSqlSession(MybatisUserServiceImpl.java:277) 2021-01-22 05:48:46.663 101b @40000000600a674822e53c34 at com.example.common.service.mybatis.MybatisUserService3Impl.getUser(MybatisUserService3Impl.java:430) 2021-01-22 05:48:46.663 101b @40000000600a674822e9f33c at com.example.common.service.mybatis.MybatisUserService3Impl.getUser(MybatisUserService3Impl.java:422) 2021-01-22 05:48:46.663 101b @40000000600a6748234d4504 at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140) 2021-01-22 05:48:46.663 101b @40000000600a67482351f43c at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87) 2021-01-22 05:48:46.663 101b @40000000600a67482356c2b4 at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:342) 2021-01-22 05:48:46.663 101b @40000000600a6748235da084 at org.apache.coyote.ajp.AjpProcessor.service(AjpProcessor.java:486) 2021-01-22 05:48:46.663 101b @40000000600a674823628284 at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66) 2021-01-22 05:48:46.663 101b @40000000600a6748236735a4 at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:868) 2021-01-22 05:48:46.663 101b @40000000600a6748236cbbb4 at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1459) 2021-01-22 05:48:46.663 101b @40000000600a674822f009d4 at com.example.documentservice.servlet.documentmanagerservlet.UserService3.login(UserService3.java:1341)
調査Issue にはこの結果をそのまま貼ればいいでしょう。
それとは別に Slack とかにも貼るなら、com.example.*の開発package部分だけの短縮版がいいでしょう。長すぎる log が貼られるとチャンネル自体が読みづらくなってしまうので。
@timestamp @logStream @message 2021-01-22 05:47:27.291 101b @40000000600a66f41b958bdc 22-Jan-2021 05:47:22.461 情報 [ajp-nio-8009-exec-9] com.example.servlet.ScimUsersServlet.httpMethod end(69ms)--->HTTP 500 INTERNAL_SERVER_ERROR 2021-01-22 05:48:46.663 101b @40000000600a674822dc1474 java.lang.NullPointerException 2021-01-22 05:48:46.663 101b @40000000600a674822e1f45c at com.example.common.service.mybatis.MybatisUserServiceImpl.getSystemSqlSession(MybatisUserServiceImpl.java:277) 2021-01-22 05:48:46.663 101b @40000000600a674822e53c34 at com.example.common.service.mybatis.MybatisUserService3Impl.getUser(MybatisUserService3Impl.java:430) 2021-01-22 05:48:46.663 101b @40000000600a674822e9f33c at com.example.common.service.mybatis.MybatisUserService3Impl.getUser(MybatisUserService3Impl.java:422) 2021-01-22 05:48:46.663 101b @40000000600a674822f009d4 at com.example.documentservice.servlet.documentmanagerservlet.UserService3.login(UserService3.java:1341)
いかがでしたか。ssh login して grep , less でログ調査してる時代じゃないでしょう?
`@messageフィールドを adhoc に構造化する演習はまたこんど。



- 投稿日:2021-01-24T01:33:50+09:00
AWS基礎から学習①-EC2の環境構築-
今回、AWSの基礎を学び直す目的でEC2の環境構築と接続まで行ったので、その過程と自分なりに気になったポイントを書いていこうと思います。
自分用の備忘録として残していますが、これからAWSの基礎学習を始める方の参考になればと思います。
今回は踏み台用EC2を使って作業用EC2にログインするところまで。環境
・MacOS
※macOsとwindowsでは操作方法が異なる部分があるので、ご注意してください。
・AWSサービス(2021/1/22時点)
※各種設定画面は都度アップデートされていますので画像と異なる場合があります。目次
1.VPCの作成
2.サブネットの作成
3.インターネットゲートウェイの作成とアタッチ
4.サブネットのルートテーブルの設定
5.EC2(踏み台サーバー)の作成
6.EC2(踏み台サーバー)に接続
7.EC2(作業サーバー)の作成
8.EC2(作業サーバー)の作成
9.構成図の拡張
10.まとめ目標構成図
構成図の概要
今回作成する構成図は踏み台サーバーを使って作業サーバーにログインする構成となっています。この構成のポイントは作業サーバーにアクセスするためには必ず踏み台サーバーを経由しなければならない点です。このサーバーがあると誰がどの作業サーバーにアクセスしたかを監視することができるため、セキュリティを高めることが出来ます。
1.VPCの作成
まずEC2を起動する場所を確保するため、VPCから作成していきます。
各種設定を行います。
名前タグ:作成するVPCに任意の名前を与えます。
例→ test-vpcIPv4 CIDR ブロック:こちらはAWSが指定する○.○.○.○/16〜○.○.○.○/28のプライベートIPアドレスの範囲で設定します。
■プライベートIPアドレス(○.○.○.○)
・10.0.0.0 - 10.255.255.255 (10.0.0.0/8)
・172.16.0.0 - 172.31.255.255 (172.16.0.0/12)
・192.168.0.0 - 192.168.255.255 (192.168.0.0/16)※プライベートアドレスを使う理由としてはIPアドレスが競合することを防ぐためです。AWSでもプライベートアドレスを使うことが推奨されているのでこちらに従っていきましょう。
またCIDRについての内容を書いてしまうと長くなってしますので、割愛させていただきますが、AWS内のネットワークから自分が使うVPCのネットワークの範囲を借りるようなイメージです。
以下の記事でわかりやすく解説されているので合わせて確認してみてください。https://wa3.i-3-i.info/word11989.html
引用:「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典2.サブネットの作成
次にサブネットの作成を行います。
先程作成したVPCを選択し、「パブリックサブネット」、「プライベートサブネット」の2つのサブネットの各種設定を行います。・パブリックサブネット…直接インターネット接続可能なサブネット
・プライベートサブネット…直接インターネット接続不可なサブネット1つ目のパブリックサブネット
2つ目のサブネット
サブネット名:任意の名前を設定します
例→ test-public-subnet
アベイラビリティーゾーン:アジアパシフィック(東京)/ap-northeast-1a
を選択します。
IPv4 CIDR ブロック:VPCで指定した範囲内で更に範囲を設定していきます。
サブネットはパブリックとプライベートが判断できる名前としておきましょう。3.インターネットゲートウェイの作成とアタッチ
次にサブネットがインターネットに接続できるようするためにインターネットゲートウェイを作成します。
名前タグ:インターネットゲートウェイの名前を設定します。
例→ test-internetgateway
作成後、作成したVPCにインターネットゲートゲートウェイをアタッチ(VPCにインターネットに接続するため入り口を用意)するためにアクションからVPCにアタッチを選択。
作成したVPCを指定し、インターネットゲートウェイにアタッチをクリックする。
アタッチ後、状態を確認しアタッチされたことを確認します。4.サブネットのルートテーブルの設定
VPCにインターネットゲートウェイをアタッチしてもサブネットはインターネットには接続できませんのでルートテーブルでサブネットがインターネットに接続できるように設定します。
(※自分の経験談ですが、ここを設定し忘れてEC2と接続出来ない!ということが多々あるので忘れないようにしましょう。)
パブリックサブネットのルートテーブルタブをクリックし、上記赤枠で囲まれたルートテーブルクリックし、設定画面に移ります。
上記ルートタブのルートの編集をクリック。
送信先:0.0.0.0/0(インターネット)
ターゲット:作成したインターネットゲートウェイを指定
ルートの保存をします。
ルートテーブルにインターネットゲートウェイが設定されたことを確認。
これでパブリックサブネットがインターネットと接続可能になります。ここで注意したいのは、先ほど編集したルートテーブルがプライベートサブネットにも適用されてしまう点です。これは各サブネットを明示的に関連付けを行わなかったためです。
そこで
①パブリックサブネット用のルートテーブルの追加
②各ルートテーブルをサブネットの関連付け
を行います。①プライベートサブネット用のルートテーブルの追加
まずはVPCメニューのルートテーブルをクリックし、下記画面のルートテーブルを作成をクリックします。
名前タグ:任意の名前を設定
VPC:作成したVPCを選択
2つの値を設定し、作成ボタンで作成します。
作成後、最初に作成されたルートテーブル(※パブリックサブネット用)Nameが設定されていないので区別しやすいように設定します。②各ルートテーブルをサブネットの関連付け
ルートテーブルを作成後、それぞれをサブネットの関連付けを行います。
・パブリックサブネットのルートテーブル
・プライベートサブネットのルートテーブル
それぞれ選択後保存ボタンで設定を保存します。
これでプライベートサブネットのルートテーブルからインターネットへの接続設定がなくなっているかと思います。
現時点の構成図
5.EC2インスタンスの作成
次は本命のEC2インスタンスを作成を行います。
AWSのEC2サービス画面からインスタンスの起動ボタンをクリック。
AMIを選択していきますが、ここではさまざまなOSを選択することが出来ます。
今回は標準のAmazonLinux2を選択します。
次にインスタンスタイプを選択します。
インスタンスタイプは簡単に言うとEC2の性能を選択する画面になります。
今回は無料枠のt2.micro選択します。
その他を選択すると課金対象となってしまうので気をつけてください。
各パラメータの名称は以下の通り・「t2」部分…インスタンスファミリー
→「t」が各用途に応じて変更する。(機械学習用など)
→「2」世代を表す。値が大きいほど性能の高いものになります。・「micro」部分…インスタンスサイズ
→EC2のメモリ、vCPUの数を表しており、EC2の性能を表している。
ネットワーク:作成したVPCを選択
サブネット:パブリックサブネットを選択
自動割り当てパブリックIP:有効
その他のパラメータはデフォルトのままとしステップを進めていきます。
ステップ6でセキュリティグループを作成します。
・セキュリティグループ名:任意の名前を設定する。例:test-securitygroup
・タイプ:SSH
・プロトコル:TCP
・ポート範囲:22
・ソース:カスタム、0.0.0.0/0
※今回はどのIPアドレスからでもSSHでアクセスできますが、警告メッセージが推奨するようにアクセスできるIPアドレスを設定するのがおすすめです。例えば自分のPCのみから接続させたい場合はPCのIPアドレスを設定しておきます。
セキュリティグループ作成後、起動ボタンをクリック。
セキュリティグループでタイプSSHを選択しているためキーペアを作成します。キーペア名を設定しキーペアを任意の場所にダウンロードします。
※キーペアを紛失した場合、再度キーペアの作成と別手順を実施する必要が出てきますので注意してください。
下記参照urlにキーペアを紛失した場合の手順が書かれているので確認してみてください。https://aws.amazon.com/jp/premiumsupport/knowledge-center/user-data-replace-key-pair-ec2/
AWSより引用キーペアダウンロード後、インスタンスを作成します。
インスタンスが起動するまで少しかかるのでその間に次のElasticIPの設定を行います。ElasticIPの設定
EC2は何も設定をしていないと停止して再起動するとIPアドレスが変更されてしまい、何かと不便になるのでIPアドレスを固定します。
(例:アクセスを制限したいときなど)EC2メニューのネットワーク&セキュリティ>Elastic IPをクリックします。
ElasticIPアドレスの割り当てを行います。
ネットワークボーダーグループ:デフォルトの「ap-northeast-1」を設定
おそらく東京リージョンはこの設定になる。
パブリックIPv4アドレスプール:AmazonのIPv4アドレスプールを選択
その他の設定はオンプレミス用途で使われるので一般の人はおそらくあまり使用しないと思います。
ElasticIP割り当て後、
アクション>ElasticIPアドレスの関連付けを選択。
インスタンス:起動したEC2を選択。
他はそのままで関連付ける。
ElasticIPアドレスの設定は以上です。6.EC2(踏み台サーバー)に接続
ここで一旦踏み台サーバーに接続できるか確認します。
MacのLaunchpadから
Launchpad>その他>ターミナル の順でターミナルを開きます。キーペアの権限設定
ここで先程ダウンロードしたキーペアのあるフォルダまで移動します。
(※すみません、Linuxコマンドについては割愛させていただきます。)
このままEC2に接続をするとキーペアファイルの権限の弱さが原因で接続できないので権限の設定を行います。
ちなみに接続しようとすると下記のように警告されます。
下記のコマンドでキーペアの権限を変更します。
chmod 400 test-keypair.pem
-rw-r--r-- → -r-------
に変更しました。
この変更で具体的に
・所有者権限:読み込み、書き込み可→読み込み可
・グループ権限:読み込み可→権限なし
・その他:読み込み可→権限なし
と権限が厳しく設定されました。これでEC2へ接続可能となります。
コマンドで設定したElasticIPアドレスのEC2に接続します。
パブリックIPv4アドレスまたはElasticIPアドレス(両方同じ)をコピーし、
EC2への接続コマンド:
ssh -i [キーペア] ec2-user@[ElasticIPアドレス]
で接続する。
上記のようにターミナルでec2-user@〇〇となっていたら接続成功です。現在の構成図
7.EC2(作業サーバー)の作成
踏み台サーバーへの接続が確認できた段階で、作業サーバーを作成していきます。
EC2の作成については一度行っているので相違点の部分だけピックアップします。
■サブネットの設定
・サブネット:作成したプライベートサブネットを指定します。
・自動割り当てパブリックIP:使用しないのでそのままとします。
※インターネットへ接続しないEC2のため今回は無効としています。
■セキュリティグループの設定
ここではSSH接続できるIPアドレスを踏み台サーバーのEC2のみに限定しています。○.○.○.○/32でアクセス可能にしたいIPアドレスを指定することが出来ます。
アクセス可能なIPアドレスを指定することでその他のアクセスを拒否しセキュリティを高めます。
※IPアドレスは同じVPC内からのアクセスのため作業サーバーのプライベートIPアドレスを指定します。
プライベートIPアドレスはEC2インスタンス設定画面の下記通りに確認。
その他の設定はデフォルトです。
キーペアも同じものを使用します。(新しく作成しても構いません。)8.EC2(作業サーバー)に接続
作業サーバーのEC2が起動出来たら、次に踏み台サーバーから作業サーバーに接続するためのキーペアをローカルのPCから踏み台サーバーに置きます。
再度ターミナルでキーペアのあるフォルダまで移動し、下記コマンドでキーペアを踏み台サーバーにコピーします。
コマンド:
scp -i [キーペア] [キーペア] ec2-user@[ElasticIPアドレス]:/tmp/
これで踏み台サーバーからキーペアを使って作業サーバーにアクセス出来ます。
そして先程と同じように踏み台サーバーにアクセスします。
ssh -i [キーペア] ec2-user@[ElasticIPアドレス]
そして今度は作業用サーバーから踏み台サーバーにアクセスします。
キーペアがある場所に移動:
cd /tmp/
作業サーバーへ接続:
ssh -i [キーペア] ec2-user@[作業サーバープライベートIPアドレス]これで踏み台サーバーから作業サーバーへのアクセスが出来ました。
最終的な構成図
9.構成図の拡張
①今回作成した作業サーバーは一つだけでしたが、複数台の作業サーバーを使う場合は下図のようになって一つの踏み台サーバーから各作業サーバーにログインできるように構成していきます。
あとは踏み台サーバーに監視用のソフトウェアをインストールすることで誰がどの作業サーバーにアクセスしたか確認できるようになると実際のシステム運用に近づいて面白そうですね。
②作業サーバーはインターネットにアクセスできないようになっています。完全なオフラインでの作業サーバーの作成の業務場面は少ないと思います。作業サーバーにもインターネットに接続できる構成にする際は下記のようにNATゲートウェイを採用し、内部からインターネットに接続は可能として、外部からのアクセスは遮断する構成が一般的となので実運用に近づけるなら抑えておきたい構成の一つです。
10.まとめ
以上が今回の踏み台サーバーと作業サーバーのEC2環境構築でした。
基本的な構成でしたが、自分としてはこの環境構築でVPC、EC2の基礎をかなり勉強できたなと感じています。
最初に試したときは、VPCのところでインターネット接続するためにサブネットのルートテーブルの設定を行いますが、あまり理解していない状態で設定したら案の定、インターネットに繋がらなかったりで大変でした。。ですが改めて環境構築してみてAWSで簡単にインフラの環境構築が出来てしまうのはすごいと思いました。インフラの現場に実際には行ったことはありませんがこの作業は本来配線を一つ一つ確認して組むとかだと思うので、それをボタンと数値の入力でポチポチしてできてしまうのはなんて画期的なんだと。
インフラをやったことがない人でも気軽に扱えるというのは大変助かりますね。
実務ではかなり慎重にやらないといけないとは思いますが。。
これからの時代インフラとアプリを両方担当するのが主流となってきそうなので、大変ですが頑張って勉強してついていきたいですね。以上です。
長くなりましたが、ここまで読んでいただきありがとうございました。
AWSを勉強する方の参考になれば幸いです。



















































- 投稿日:2021-01-24T01:33:50+09:00
AWS 基礎から学習①~EC2の環境構築~
今回、AWSの基礎を学び直す目的でEC2の環境構築と接続まで行ったので、その過程と自分なりに気になったポイントを書いていこうと思います。
自分用の備忘録として残していますが、これからAWSの基礎学習を始める方の参考になればと思います。
今回は踏み台用EC2を使って作業用EC2にログインするところまで。環境
・MacOS
※macOsとwindowsでは操作方法が異なる部分があるので、ご注意してください。
・AWSサービス(2021/1/22時点)
※各種設定画面は都度アップデートされていますので画像と異なる場合があります。目次
1.VPCの作成
2.サブネットの作成
3.インターネットゲートウェイの作成とアタッチ
4.サブネットのルートテーブルの設定
5.EC2(踏み台サーバー)の作成
6.EC2(踏み台サーバー)に接続
7.EC2(作業サーバー)の作成
8.EC2(作業サーバー)の作成
9.構成図の拡張
10.まとめ目標構成図
構成図の概要
今回作成する構成図は踏み台サーバーを使って作業サーバーにログインする構成となっています。この構成のポイントは作業サーバーにアクセスするためには必ず踏み台サーバーを経由しなければならない点です。このサーバーがあると誰がどの作業サーバーにアクセスしたかを監視することができるため、セキュリティを高めることが出来ます。
1.VPCの作成
まずEC2を起動する場所を確保するため、VPCから作成していきます。
各種設定を行います。
名前タグ:作成するVPCに任意の名前を与えます。
例→ test-vpcIPv4 CIDR ブロック:こちらはAWSが指定する○.○.○.○/16〜○.○.○.○/28のプライベートIPアドレスの範囲で設定します。
■プライベートIPアドレス(○.○.○.○)
・10.0.0.0 - 10.255.255.255 (10.0.0.0/8)
・172.16.0.0 - 172.31.255.255 (172.16.0.0/12)
・192.168.0.0 - 192.168.255.255 (192.168.0.0/16)※プライベートアドレスを使う理由としてはIPアドレスが競合することを防ぐためです。AWSでもプライベートアドレスを使うことが推奨されているのでこちらに従っていきましょう。
またCIDRについての内容を書いてしまうと長くなってしますので、割愛させていただきますが、AWS内のネットワークから自分が使うVPCのネットワークの範囲を借りるようなイメージです。
以下の記事でわかりやすく解説されているので合わせて確認してみてください。https://wa3.i-3-i.info/word11989.html
引用:「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典2.サブネットの作成
次にサブネットの作成を行います。
先程作成したVPCを選択し、「パブリックサブネット」、「プライベートサブネット」の2つのサブネットの各種設定を行います。・パブリックサブネット…直接インターネット接続可能なサブネット
・プライベートサブネット…直接インターネット接続不可なサブネット1つ目のパブリックサブネット
2つ目のサブネット
サブネット名:任意の名前を設定します
例→ test-public-subnet
アベイラビリティーゾーン:アジアパシフィック(東京)/ap-northeast-1a
を選択します。
IPv4 CIDR ブロック:VPCで指定した範囲内で更に範囲を設定していきます。
サブネットはパブリックとプライベートが判断できる名前としておきましょう。3.インターネットゲートウェイの作成とアタッチ
次にサブネットがインターネットに接続できるようするためにインターネットゲートウェイを作成します。
名前タグ:インターネットゲートウェイの名前を設定します。
例→ test-internetgateway
作成後、作成したVPCにインターネットゲートゲートウェイをアタッチ(VPCにインターネットに接続するため入り口を用意)するためにアクションからVPCにアタッチを選択。
作成したVPCを指定し、インターネットゲートウェイにアタッチをクリックする。
アタッチ後、状態を確認しアタッチされたことを確認します。4.サブネットのルートテーブルの設定
VPCにインターネットゲートウェイをアタッチしてもサブネットはインターネットには接続できませんのでルートテーブルでサブネットがインターネットに接続できるように設定します。
(※自分の経験談ですが、ここを設定し忘れてEC2と接続出来ない!ということが多々あるので忘れないようにしましょう。)
パブリックサブネットのルートテーブルタブをクリックし、上記赤枠で囲まれたルートテーブルクリックし、設定画面に移ります。
上記ルートタブのルートの編集をクリック。
送信先:0.0.0.0/0(インターネット)
ターゲット:作成したインターネットゲートウェイを指定
ルートの保存をします。
ルートテーブルにインターネットゲートウェイが設定されたことを確認。
これでパブリックサブネットがインターネットと接続可能になります。ここで注意したいのは、先ほど編集したルートテーブルがプライベートサブネットにも適用されてしまう点です。これは各サブネットを明示的に関連付けを行わなかったためです。
そこで
①パブリックサブネット用のルートテーブルの追加
②各ルートテーブルをサブネットの関連付け
を行います。①プライベートサブネット用のルートテーブルの追加
まずはVPCメニューのルートテーブルをクリックし、下記画面のルートテーブルを作成をクリックします。
名前タグ:任意の名前を設定
VPC:作成したVPCを選択
2つの値を設定し、作成ボタンで作成します。
作成後、最初に作成されたルートテーブル(※パブリックサブネット用)Nameが設定されていないので区別しやすいように設定します。②各ルートテーブルをサブネットの関連付け
ルートテーブルを作成後、それぞれをサブネットの関連付けを行います。
・パブリックサブネットのルートテーブル
・プライベートサブネットのルートテーブル
それぞれ選択後保存ボタンで設定を保存します。
これでプライベートサブネットのルートテーブルからインターネットへの接続設定がなくなっているかと思います。
現時点の構成図
5.EC2インスタンスの作成
次は本命のEC2インスタンスを作成を行います。
AWSのEC2サービス画面からインスタンスの起動ボタンをクリック。
AMIを選択していきますが、ここではさまざまなOSを選択することが出来ます。
今回は標準のAmazonLinux2を選択します。
次にインスタンスタイプを選択します。
インスタンスタイプは簡単に言うとEC2の性能を選択する画面になります。
今回は無料枠のt2.micro選択します。
その他を選択すると課金対象となってしまうので気をつけてください。
各パラメータの名称は以下の通り・「t2」部分…インスタンスファミリー
→「t」が各用途に応じて変更する。(機械学習用など)
→「2」世代を表す。値が大きいほど性能の高いものになります。・「micro」部分…インスタンスサイズ
→EC2のメモリ、vCPUの数を表しており、EC2の性能を表している。
ネットワーク:作成したVPCを選択
サブネット:パブリックサブネットを選択
自動割り当てパブリックIP:有効
その他のパラメータはデフォルトのままとしステップを進めていきます。
ステップ6でセキュリティグループを作成します。
・セキュリティグループ名:任意の名前を設定する。例:test-securitygroup
・タイプ:SSH
・プロトコル:TCP
・ポート範囲:22
・ソース:カスタム、0.0.0.0/0
※今回はどのIPアドレスからでもSSHでアクセスできますが、警告メッセージが推奨するようにアクセスできるIPアドレスを設定するのがおすすめです。例えば自分のPCのみから接続させたい場合はPCのIPアドレスを設定しておきます。
セキュリティグループ作成後、起動ボタンをクリック。
セキュリティグループでタイプSSHを選択しているためキーペアを作成します。キーペア名を設定しキーペアを任意の場所にダウンロードします。
※キーペアを紛失した場合、再度キーペアの作成と別手順を実施する必要が出てきますので注意してください。
下記参照urlにキーペアを紛失した場合の手順が書かれているので確認してみてください。https://aws.amazon.com/jp/premiumsupport/knowledge-center/user-data-replace-key-pair-ec2/
AWSより引用キーペアダウンロード後、インスタンスを作成します。
インスタンスが起動するまで少しかかるのでその間に次のElasticIPの設定を行います。ElasticIPの設定
EC2は何も設定をしていないと停止して再起動するとIPアドレスが変更されてしまい、何かと不便になるのでIPアドレスを固定します。
(例:アクセスを制限したいときなど)EC2メニューのネットワーク&セキュリティ>Elastic IPをクリックします。
ElasticIPアドレスの割り当てを行います。
ネットワークボーダーグループ:デフォルトの「ap-northeast-1」を設定
おそらく東京リージョンはこの設定になる。
パブリックIPv4アドレスプール:AmazonのIPv4アドレスプールを選択
その他の設定はオンプレミス用途で使われるので一般の人はおそらくあまり使用しないと思います。
ElasticIP割り当て後、
アクション>ElasticIPアドレスの関連付けを選択。
インスタンス:起動したEC2を選択。
他はそのままで関連付ける。
ElasticIPアドレスの設定は以上です。6.EC2(踏み台サーバー)に接続
ここで一旦踏み台サーバーに接続できるか確認します。
MacのLaunchpadから
Launchpad>その他>ターミナル の順でターミナルを開きます。キーペアの権限設定
ここで先程ダウンロードしたキーペアのあるフォルダまで移動します。
(※すみません、Linuxコマンドについては割愛させていただきます。)
このままEC2に接続をするとキーペアファイルの権限の弱さが原因で接続できないので権限の設定を行います。
ちなみに接続しようとすると下記のように警告されます。
下記のコマンドでキーペアの権限を変更します。
chmod 400 test-keypair.pem
-rw-r--r-- → -r-------
に変更しました。
この変更で具体的に
・所有者権限:読み込み、書き込み可→読み込み可
・グループ権限:読み込み可→権限なし
・その他:読み込み可→権限なし
と権限が厳しく設定されました。これでEC2へ接続可能となります。
コマンドで設定したElasticIPアドレスのEC2に接続します。
パブリックIPv4アドレスまたはElasticIPアドレス(両方同じ)をコピーし、
EC2への接続コマンド:
ssh -i [キーペア] ec2-user@[ElasticIPアドレス]
で接続する。
上記のようにターミナルでec2-user@〇〇となっていたら接続成功です。現在の構成図
7.EC2(作業サーバー)の作成
踏み台サーバーへの接続が確認できた段階で、作業サーバーを作成していきます。
EC2の作成については一度行っているので相違点の部分だけピックアップします。
■サブネットの設定
・サブネット:作成したプライベートサブネットを指定します。
・自動割り当てパブリックIP:使用しないのでそのままとします。
※インターネットへ接続しないEC2のため今回は無効としています。
■セキュリティグループの設定
ここではSSH接続できるIPアドレスを踏み台サーバーのEC2のみに限定しています。○.○.○.○/32でアクセス可能にしたいIPアドレスを指定することが出来ます。
アクセス可能なIPアドレスを指定することでその他のアクセスを拒否しセキュリティを高めます。
※IPアドレスは同じVPC内からのアクセスのため作業サーバーのプライベートIPアドレスを指定します。
プライベートIPアドレスはEC2インスタンス設定画面の下記通りに確認。
その他の設定はデフォルトです。
キーペアも同じものを使用します。(新しく作成しても構いません。)8.EC2(作業サーバー)に接続
作業サーバーのEC2が起動出来たら、次に踏み台サーバーから作業サーバーに接続するためのキーペアをローカルのPCから踏み台サーバーに置きます。
再度ターミナルでキーペアのあるフォルダまで移動し、下記コマンドでキーペアを踏み台サーバーにコピーします。
コマンド:
scp -i [キーペア] [キーペア] ec2-user@[ElasticIPアドレス]:/tmp/
これで踏み台サーバーからキーペアを使って作業サーバーにアクセス出来ます。
そして先程と同じように踏み台サーバーにアクセスします。
ssh -i [キーペア] ec2-user@[ElasticIPアドレス]
そして今度は作業用サーバーから踏み台サーバーにアクセスします。
キーペアがある場所に移動:
cd /tmp/
作業サーバーへ接続:
ssh -i [キーペア] ec2-user@[作業サーバープライベートIPアドレス]これで踏み台サーバーから作業サーバーへのアクセスが出来ました。
最終的な構成図
9.構成図の拡張
①今回作成した作業サーバーは一つだけでしたが、複数台の作業サーバーを使う場合は下図のようになって一つの踏み台サーバーから各作業サーバーにログインできるように構成していきます。
あとは踏み台サーバーに監視用のソフトウェアをインストールすることで誰がどの作業サーバーにアクセスしたか確認できるようになると実際のシステム運用に近づいて面白そうですね。
②作業サーバーはインターネットにアクセスできないようになっています。完全なオフラインでの作業サーバーの作成の業務場面は少ないと思います。作業サーバーにもインターネットに接続できる構成にする際は下記のようにNATゲートウェイを採用し、内部からインターネットに接続は可能として、外部からのアクセスは遮断する構成が一般的となので実運用に近づけるなら抑えておきたい構成の一つです。
10.まとめ
以上が今回の踏み台サーバーと作業サーバーのEC2環境構築でした。
基本的な構成でしたが、自分としてはこの環境構築でVPC、EC2の基礎をかなり勉強できたなと感じています。
最初に試したときは、VPCのところでインターネット接続するためにサブネットのルートテーブルの設定を行いますが、あまり理解していない状態で設定したら案の定、インターネットに繋がらなかったりで大変でした。。ですが改めて環境構築してみてAWSで簡単にインフラの環境構築が出来てしまうのはすごいと思いました。インフラの現場に実際には行ったことはありませんがこの作業は本来配線を一つ一つ確認して組むとかだと思うので、それをボタンと数値の入力でポチポチしてできてしまうのはなんて画期的なんだと。
インフラをやったことがない人でも気軽に扱えるというのは大変助かりますね。
実務ではかなり慎重にやらないといけないとは思いますが。。
これからの時代インフラとアプリを両方担当するのが主流となってきそうなので、大変ですが頑張って勉強してついていきたいですね。以上です。
長くなりましたが、ここまで読んでいただきありがとうございました。
AWSを勉強する方の参考になれば幸いです。
- 投稿日:2021-01-24T01:04:42+09:00
AWS java SDKでDynamoDBテーブル情報を取得してみる
この記事について
将来的に書く予定の「JavaFX で DynamoDB Viewer作ってみた」記事の1ステップ。
結構大きな話になると思うので、少しずつ技術ポイント毎に記事を書いて、ある一定程度の要件を満たせた段階で前述まとめ記事書く予定。第一回記事:DynamoDBの情報を読み込んでJavaFXで表示してみる
第二回記事:JavaFXで動的にテーブル列を設定する※前回の記事が基本になってます。メソッドなど再説明していない部分があります。
今回の進捗
今回終了時のソースはこちら。Github
今回つけた機能
- localDynamoDb対応
- テーブルリスト表示
- 選択したテーブルの構造から検索条件に主キー情報を自動設定
- ついでにレコード件数とテーブルサイズも表示
- 検索条件無指定も可能に
- パーティションキーとソートキーを表の冒頭に表示
それぞれのポイント
localDynamoDb対応
各dynamoDB機能(Scan、Query)のベースとなるAbstructクラスを準備し、そのクラス中でConnectorの分岐を行う。それぞれの継承先では気にしなくて良い様に。
テーブルリスト表示
基本は公式サンプル。読み込みクラスである ListTablesRequest では検索条件が指定できなさそうなので、java側でフィルタリング。
※読み込み条件を指定できる手法が見つかったら変更予定。選択したテーブルの構造から検索条件に主キー情報を自動設定(ついでにレコード件数とテーブルサイズも表示)
同じく公式サンプル から DescribeTable 機能を使用。
TableDescription 形式の情報が取得可能。以下の情報が解る。
- tableName:テーブル名
- tableArn:ARN
- tableStatus:ステータス
- itemCount:レコード数
- tableSizeBytes:テーブルサイズ
- provisionedThroughput:プロビジョン済みスループット
- readCapacityUnits:読み込みキャパシティ
- writeCapacityUnits:書き込みキャパシティ
- attributeDefinitions:属性定義のリスト
- keySchema:キー情報
検索条件無指定も可能
検索条件がある時はQuery、全読み込みはScanを使う
パーティションキーとソートキーを頭に表示
今回一番面倒だった部分。
DynamoDBは、RDBの様にテーブル構造が明確に定義されているわけではない。取得されるデータのフィールド順は不定。そのままだと表にした時にデータの把握がしにくい。パーティションキー、ソートキーを冒頭にセットしたい。
その為にフィールド情報を以下の情報から組み立てる必要がある。今回はキーのフィールド名とデータ型情報は最初の2つから。それ以外のフィールド名とデータ型は実データから取得するようにした。
- TableDescription.keySchema から取得できるKeySchemaElementクラス。
KeySchemaElement.keyTypeでpartitionKey(HASH)とsortKey(RANGE)が解る。
KeySchemaElement.attributeNameでフィールド名が解る。- TableDescription.attributeDefinitions から取得できる各フィールドのAttributeDefinitionクラス。
AttributeDefinition.attributeTypeでEnumのScalarAttributeTypeクラスで文字列か数値かが解る。
AttributeDefinition.attributeNameでフィールド名が解る。
※全フィールドがある訳ではない。キーやインデックスに使用していないフィールドは無いと思われる。- 検索結果(QueryResponse、ScanResponseのitems)から List>が取得できる。
AttributeValueにはhasSs,hasNsなどがあり、ある程度のデータ型が解る。
しかし文字型と数値型などが解らず、一旦toStringで文字列を取得後「AttributeValue(N=」で始まるかなどで判断。次回予定
- テーブル表示内容のコピー(キー値の取得など)
- 検索結果の複数表示(タブ表示で複数テーブル検索結果切り替え)

- 投稿日:2021-01-24T00:43:42+09:00
EC2インスタンスにパブリックIPが付与されなかった話
EC2にパブリックIPが付与されてない
ある時EC2をパブリックサブネットに立ち上げた時のこと。
EC2インスタンスにPublic IPが付与されていないことを発見↓AWS認定のソリューションアーキテクトでもよく出てくるこの事象。
この原因について、試験での答えは大体こう⇨「サブネットのパブリックIPv4アドレスの自動割り当てが有効になっていない」了解了解、座学で知ってます。サブネットを確認しましょう。
あれ、サブネットの設定では自動割り当てが有効になっているな、、、↓
原因
EC2インスタンスの起動時の設定が間違ってました。
押し間違えで自動割り当てパブリックIPを「無効化」にしてしまってたようです。
悩んだ挙句しょうもないミス。あるあるですね。対処法
EC2のコンソールで有効化するとこを探します。が、、、、ない!
EC2のバブリックIPの自動割り当て設定は後から変更できないようです。
そうなると、対処法は2つ。
1. 今のEC2を終了して、新しいEC2を正しい設定で起動。
2. ElasticIPアドレスをEC2にアタッチする
今回は ElasticIPを付与することにします。
ElasticIPを付与後、無事パブリックIPアドレスが付与されました↓
感想
たかが自動割り当ての初期設定を間違えただけで、静的IPである必要もないのにElasticIPをアタッチしないといけないのは若干大袈裟な気が、、、
ElasticIPは一応有料で、EC2からデタッチした後に解放をしないと料金が発生しますしね。
参考: https://aws.amazon.com/jp/premiumsupport/knowledge-center/elastic-ip-charges/EC2のみならず、リソースの作成時でないと変更できない設定が色々とあるので、意外と初期設定は大事だと感じました。
(今回スクショしたリソースなどは全て削除済なので、IPやIDが丸出しですがご心配なく)



