- 投稿日:2021-01-22T23:31:13+09:00
【Python】それぞれのオブジェクトがリストを持つ(共有しないようにする)には?
Python初学者です!
とある教材のコード課題を解いていてなかなか理解できなかったので、記事にすることにしました。
頑張って現時点で理解できているだけの用語と知識で言語化してみました。
もし、説明でおかしなところや理解がまだまだ浅い部分がありましたらつよつよエンジニアの皆さんよりご指摘いただけると幸いです><!!
(2021-01-22 @shiracamus さんよりご教授いただきましたので追記します!ありがとうございますm(_ _)m)
使用環境
macOS BigSur バージョン11.1
Google Colaboratory課題
というわけで早速、その課題です。
Q. 次のクラスはバグを持っている。
複数インスタンスを行った場合addメソッドを呼び出すと、それぞれのオブジェクトにリストが共有されている。
これをデバッグし、正常に動作させよ。class Sample: li = [] def __init__(self, name): self.name = name def add(self, name): self.li.append(name) a = Sample('test1') b = Sample('test2') a.add('test1 a') b.add('test2 b') print(a.li) # 出力結果 # ['test1 a', 'test2 b']原因
これをどのようにすればいいのでしょうか。
まず、出力結果から考えると問題文の通り、
['test1 a', 'test2 b']と出力されているのが分かります。本来は、どのような出力を期待していたのかというと、 コードを見る限り
print(a.li)で['test1 a']のみを出力したいのだと推測できます。このようなことが起きている原因がどこにあるのかというと、
a.add('test1 a')にもb.add('test2 b')においても同じリストli = []が使われているからだと考えられます。ではなぜ、同じリストが使われてしまっているのでしょうか??
それはコンストラクタ外に変数が記述されている(=インスタンス変数ではなく、クラス変数になっている)からです。
これを理解するために必要な3つの知識をまとめます。
(私はこの3つのことをよく理解していませんでした・・・)重要事項
①コンストラクタ
コンストラクタとはインスタンスが生成されるときに自動的に呼び出されるメソッドのことで、対象のクラスのインスタンスを初期化するために利用します。
※厳密には、「コンストラクタから呼び出される初期化メソッド」という方が正しいそうです。コンストラクタは
「__init__」で定義します。そしてクラスの中の関数の第一引数には「self」と指定します。それぞれインスタンスを生成する際には、それぞれのデータを持たせたいわけですからこれによって初期化されるようになればいいわけです。
②インスタンス変数
(2021-01-22 @shiracamus さんよりご教授いただきましたので追記します!ありがとうございますm(_ _)m)
そしてこれを実装する際にもう一つ大事な概念、メソッド上で定義する変数のことをインスタンス変数と言います。
インスタンス変数は、それぞれのインスタンス(オブジェクト)ごとに独立しているという性質を持っています。
さらに、そのインスタンス変数にはself(インスタンス自身)をつけるのがルールです。
基本の書き方は以下のようになります。
def __init__(self, 引数): self.インスタンス変数 = 引数なのでコンストラクタでインスタンス変数を定義するには、
self.li = []と書くのが良さそうです。③クラス変数
クラス変数とははじめに書いていたようにclass直下に定義している変数のことです。
また、このクラス変数は全てのインスタンスで共有されるという性質を持っています。
だから、最初のコードではリストがa,bどちらのインスタンスにも共有されてしまったのです!(なるほど
)
②③をまとめると、
1. インスタンスに変数を代入した場合は、インスタンスに変数が作られる(クラス変数とは別)
2. インスタンスに変数を代入しなければ、クラス変数を参照するこの辺りはよく混同しやすいそうで、以下の記事も参考にさせていただきました!
(@7shi さんありがとうございます)
『Pythonでクラス変数とインスタンス変数を取り違えてハマった』解決方法
ということで、以上のことを抑えたらコードを書いてみます。
class Sample: def __init__(self, name): self.name = name self.li = [] def add(self, name): self.li.append(name) a = Sample('test1') b = Sample('test2') a.add('test1 a') b.add('test2 b') a.add('test3 a') b.add('test4 b') print(a.li) print(b.li) ## 出力結果 ## ['test1 a', 'test3 a'] ## ['test2 b', 'test4 b']出力結果もそれぞれのインスタンスに対してリストが生成されています
__init__にてインスタンス変数を作ると、それぞれのインスタンス(aとb)毎に初期化されたliという空のリストが渡されているからですね!まだまだなれませんが数をこなして慣れていきますっ!
では、次回もよろしくお願いします!
- 投稿日:2021-01-22T22:17:31+09:00
【2】Docker-compose + Django の環境で管理画面からアプリのでデータベース管理をする
概要
- Docker-composoe + Django環境で作業環境を整えます。
- Djangoは専用の管理画面からデータベースの操作(作成や編集など)が行えます。
- つまりPHPMyAdminなどが不要!!
環境
- Docker + Docker-compose が利用できること。
- Python3.6
- Django3.1(最新)
前提
- Docker-compose + Django + MySQL + Nginx + uwsgi を使った環境の初期設定 が完了していること
- djangoが起動中である
- データベースへアクセスできる
- 管理画面へアクセスできる
- または、同等の環境であること
手順
アプリケーションの作成
- アプリケーションの作成
$ docker-compose exec django manage.py sampleコンフィグの修正
src/app/settings.pyを編集する
- INSTALLED_APPS に作成したアプリケーションを追加する
- sample: フォルダ名
- SampleConfig:
src/app/sample/apps.pyに書いてあるclass名src/app/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'sample.apps.SampleConfig', # 追加 ]モデルの作成
src/app/sample/models.pyを編集するsrc/app/sample/models.pyfrom django.db import models class Test1(models.Model): class Meta: verbose_name_plural = "テスト1" test1_name = models.CharField("テスト名",max_length=25) test1_value = models.CharField("テスト値",max_length=25) def __str__(self): return self.test1_name class Test2(models.Model): class Meta: verbose_name_plural = "テスト2" test1= models.ForeignKey(Test1, on_delete=models.PROTECT) test2_name = models.CharField("テスト名",max_length=25) test2_value = models.CharField("テスト値",max_length=25) def __str__(self): return self.test2_name管理画面の設定
src/app/sample/admin.pyを編集するfrom django.contrib import admin # Register your models here. from order.models import Test1, Test2 admin.site.register(Test1) admin.site.register(Test2)マイグレーション
- マイグレーションファイルを作成して実行
$ docker-compose exec django ./manage.py makemigrations $ docker-compose exec django ./manage.py migrate確認
- 下記へログインするとモデルで作成したデータベースが操作できる
http://<IP>:8000/admin
- 投稿日:2021-01-22T22:17:31+09:00
【2】Django の管理画面からアプリケーションのデータベース管理をする
概要
- Docker-composoe + Django環境で作業環境を整えます。
- Djangoは専用の管理画面からデータベースの操作(作成や編集など)が行えます。
- つまりPHPMyAdminなどが不要!!
環境
- Docker + Docker-compose が利用できること。
- Python3.6
- Django3.1(最新)
前提
- Docker-compose + Django + MySQL + Nginx + uwsgi を使った環境の初期設定 が完了していること
- djangoが起動中である
- データベースへアクセスできる
- 管理画面へアクセスできる
- または、同等の環境であること
手順
アプリケーションの作成
- アプリケーションの作成
$ docker-compose exec django manage.py sampleコンフィグの修正
src/app/settings.pyを編集する
- INSTALLED_APPS に作成したアプリケーションを追加する
- sample: フォルダ名
- SampleConfig:
src/app/sample/apps.pyに書いてあるclass名src/app/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'sample.apps.SampleConfig', # 追加 ]モデルの作成
src/app/sample/models.pyを編集するsrc/app/sample/models.pyfrom django.db import models class Test1(models.Model): class Meta: verbose_name_plural = "テスト1" test1_name = models.CharField("テスト名",max_length=25) test1_value = models.CharField("テスト値",max_length=25) def __str__(self): return self.test1_name class Test2(models.Model): class Meta: verbose_name_plural = "テスト2" test1= models.ForeignKey(Test1, on_delete=models.PROTECT) test2_name = models.CharField("テスト名",max_length=25) test2_value = models.CharField("テスト値",max_length=25) def __str__(self): return self.test2_name管理画面の設定
src/app/sample/admin.pyを編集するsrc/app/sample/admin.pyfrom django.contrib import admin # Register your models here. from order.models import Test1, Test2 admin.site.register(Test1) admin.site.register(Test2)マイグレーション
- マイグレーションファイルを作成して実行
$ docker-compose exec django ./manage.py makemigrations $ docker-compose exec django ./manage.py migrate確認
- 下記へログインするとモデルで作成したデータベースが操作できる
http://<IP>:8000/admin
- 投稿日:2021-01-22T21:52:39+09:00
Sarsa、Actor-Critic法の解説および倒立振子問題を解く
はじめに
Q学習以外のTD学習であるSarsa、Actor-Critic法を紹介していく。Q学習についてはこの記事、倒立振子問題についてはこの記事で紹介した。
理論
Sarsa(State-Action-Reward-State-Action)
SarsaはQ学習でQ値を更新する部分を少し変更した(実装の面では似た)理論である。具体的には以下の通りである。
Q学習
$$Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_{t+1}+\gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1})-Q(s_t,a_t))$$
Sarsa$$Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_{t+1}+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t))$$
この二つは将来に関する項が異なっている。Q学習では状態$s_{t+1}$における最大の価値を採用しているが、Sarsaでは実際に次の行動$a_{t+1}$を決め、価値$Q(s_{t+1}$,$a_{t+1})$を採用している。Q学習では次の行動をQ値の更新後に決定し、Sarsaでは次の行動をQ値の更新前に決定する。Q学習は価値が最大となるような行動で状態更新する(Valueベース)ことから方策オフ型のアルゴリズム、Sarsaは戦略に基づいた行動で状態更新する(Policy)ことから方策オン型のアルゴリズムと呼ばれている。この二つに良し悪しはなく、考えるモデルによって変わる。Actor Critic法
Actor Critic法はValueベースとPolicyベースを組み合わせた手法である。Sarsaでは行動決定と状態更新は同一のQテーブルで行われていたが、Actor Critic法では行動決定Actorと状態更新Criticを異なるテーブルで行い、これらを相互に更新し学習する。Q値の更新は以下のように行う。
$$Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_{t+1}+\gamma V(s_{t+1})-Q(s_t,a_t))$$実装
倒立振子問題(CartPole)を例にそれぞれの方法で学習させる。この問題に関する細かな条件はここを参照した(「はじめに」ある記事にも書いた)。Q学習のコードはいくつかのファイルに分けて書いたが、解説には不便であったので一つにまとめて書く。小分けに紹介し、コード全体はGitHubを参照していただきたい。
Sarsa
まず、ライブラリーの呼び出し、定数、パラメータの設定、観測値の離散化などを行う。
import os, sys import numpy as np import matplotlib.pyplot as plt from matplotlib import animation import gym # 定数 MAX_STEPS = 200 # 最大のステップ数 NUM_EPISODES = 2000 # 最大の試行回数 NUM_DIZITIZED = 6 # 各状態の分割数 # 学習パラメータ GAMMA = 0.99 # 時間割引率 ETA = 0.5 # 学習係数 # 離散化 def bins(clip_min, clip_max, num): # 観測した状態デジタル変換する閾値を求める return np.linspace(clip_min, clip_max, num + 1)[1:-1] def analog2digitize(observation): #状態の離散化 cart_pos, cart_v, pole_angle, pole_v = observation digitized = [ np.digitize(cart_pos, bins=bins(-2.4, 2.4, NUM_DIZITIZED)), np.digitize(cart_v, bins=bins(-3.0, 3.0, NUM_DIZITIZED)), np.digitize(pole_angle, bins=bins(-0.5, 0.5, NUM_DIZITIZED)), np.digitize(pole_v, bins=bins(-2.0, 2.0, NUM_DIZITIZED)) ] return sum([x * (NUM_DIZITIZED**i) for i, x in enumerate(digitized)])これで学習方法(パラメータを除く)などに依存しない部分の設定ができたので次に進む。
Qテーブルの更新や行動決定に関するクラスを作成する。class Sarsa: def __init__(self, num_states, num_actions): self.num_actions = num_actions self.q_table = np.random.uniform(low=-1, high=1, size=(NUM_DIZITIZED**num_states, num_actions)) # Qテーブル更新 def update_Qtable(self, observation, action, reward, observation_next, action_next): state = analog2digitize(observation) state_next = analog2digitize(observation_next) td = reward + GAMMA * self.q_table[state_next, action_next] - self.q_table[state, action] self.q_table[state, action] += ETA * td def decide_action(self, observation, episode): state = analog2digitize(observation) # ε-greedy法で行動を選択する epsilon = 0.5 * (1 / (episode + 1)) if epsilon <= np.random.rand(): # 最も価値の高い行動を行う。 action = np.argmax(self.q_table[state][:]) else: # 適当に行動する。 action = np.random.choice(self.num_actions) return actionQ学習と本質的に異なる部分はQテーブル更新の将来に関する項のみである。最後に学習の実行、報酬の設定、エピソードごとの報酬などの描画、最後のエピソードの描画を行う。
class Env(): def __init__(self, env, sarsa_class): self.env = env self.sarsa_class = sarsa_class def run(self): # 状態数を取得 num_states = self.env.observation_space.shape[0] # 行動数を取得 num_actions = self.env.action_space.n sarsa = self.sarsa_class(num_states, num_actions) step_list = [] mean_list = [] std_list = [] for episode in range(NUM_EPISODES): observation = self.env.reset() # 環境の初期化 frames = [] # 初期行動を求める action = sarsa.decide_action(observation, 0) for step in range(MAX_STEPS): if episode == NUM_EPISODES-1: frames.append(self.env.render(mode='rgb_array')) # 行動a_tの実行により、s_{t+1}, r_{t+1}を求める observation_next, _, done, _ = self.env.step(action) # 初期行動を求める action_next = sarsa.decide_action(observation_next, episode+1) # 報酬を与える if done: # ステップ数が200経過するか、一定角度以上傾くとdoneはtrueになる if step < 195: reward = -1 # 失敗したので-1の報酬を与える else: reward = 1 # 成功したので+1の報酬を与える else: reward = 0 # Qテーブル, Vを更新する sarsa.update_Qtable(observation, action, reward, observation_next, action_next) # 観測値を更新する observation = observation_next # 行動を更新する action = action_next # 終了時の処理 if done: step_list.append(step+1) print('{}回目の試行は{}秒持ちました。(max:200秒)'.format(episode, step + 1)) break if episode == NUM_EPISODES-1: plt.figure() patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=50) anim.save('movie_cartpole_v0_{}.gif'.format(episode+1), "ffmpeg") es = np.arange(0, len(step_list)) plt.clf() plt.plot(es, step_list) plt.savefig("reward.png") for i, s in enumerate(step_list): if i < 100: mean_list.append(np.average(step_list[:i+1])) std_list.append(np.std(step_list[:i+1])) else: mean_list.append(np.average(step_list[i-100:i+1])) std_list.append(np.std(step_list[i-100:i+1])) mean_list = np.array(mean_list) std_list = np.array(std_list) plt.clf() plt.plot(es, mean_list) plt.fill_between(es, mean_list-std_list, mean_list+std_list, alpha=0.2) plt.savefig("mean_var.png") if __name__ == "__main__": env = gym.make("CartPole-v0") env = Env(env, Sarsa) env.run()行動を決めるところに気をつける。
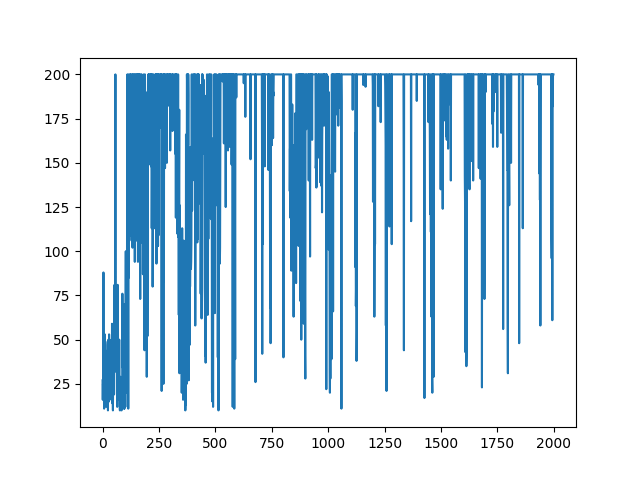
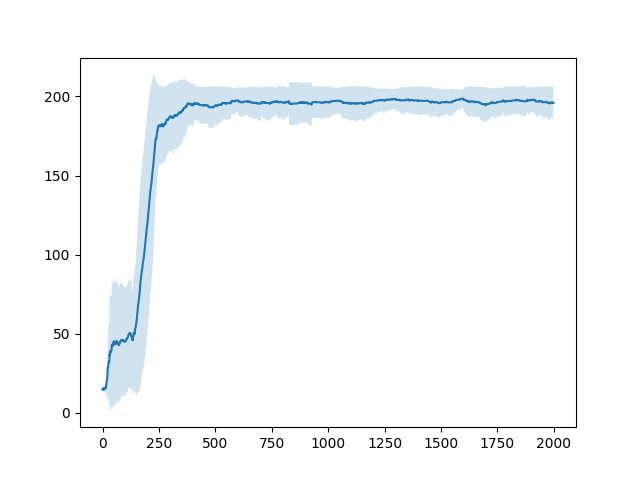
これによって得られた最後のエピソードは以下のようになった。
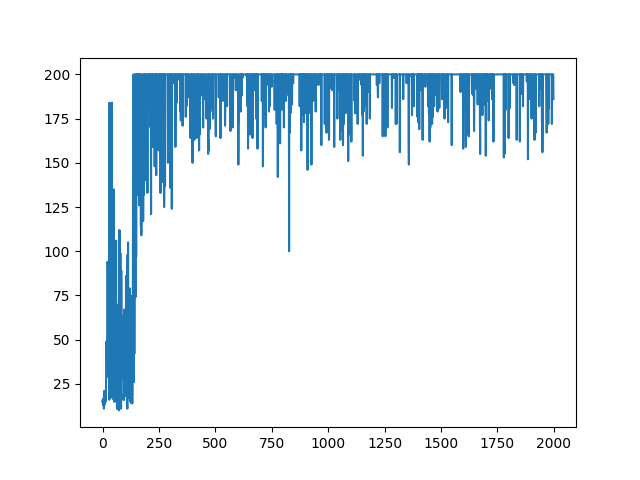
エピソードごとの報酬の遷移は以下のようになった。
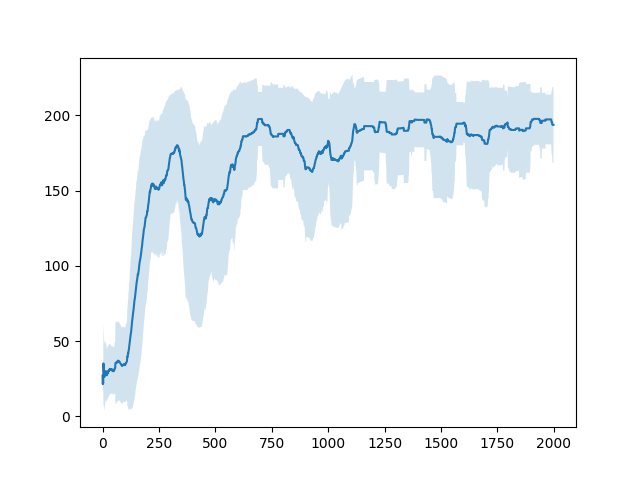
直近100エピソードの報酬の平均およびそのばらつき(標準偏差)は以下のようになった。
この結果はQ学習や後に見せるActor-Critic法で行った結果と比べて悪い。これはSarsaが他の手法に比べて戦略的に失敗するような行動を起こすことが多いからだと考えられます(これは私の考察なのでそもそもコードにmsがあったなどさまざまな原因が考えられます。その可能性を防ぐため、いくつか他の人が書いたコードと比較しましたが学習法の誤りは発見できませんでした。)。Actor-Critic法
Actor-Critic法で学習させたコードを紹介する。Sarsaのコードを改変して作ったので同じ部分は省略する。
この手法では以下のように行動を選択するQテーブルと状態を評価するVを定義する。# 行動選択 class Actor: def __init__(self, num_states, num_actions): self.num_actions = num_actions self.q_table = np.random.uniform(low=-1, high=1, size=(NUM_DIZITIZED**num_states, num_actions)) def decide_action(self, observation, episode): state = analog2digitize(observation) # ε-greedy法で行動を選択する epsilon = 0.5 * (1 / (episode + 1)) if epsilon <= np.random.rand(): # 最も価値の高い行動を行う。 action = np.argmax(self.q_table[state][:]) else: # 適当に行動する。 action = np.random.choice(self.num_actions) return action # 状態評価 class Critic: def __init__(self, num_states): self.V = np.zeros(NUM_DIZITIZED**num_states)Sarsaとは異なり、Qテーブル、Vのどちらも更新しなければいけないので、Qテーブルを定義したクラスには更新に関する関数は書かなかった。この関数は次の部分に加えた。
# Actor Critic 学習 class ActorCritic(): def __init__(self, env, actor_class, critic_class): self.env = env self.actor_class = actor_class self.critic_class = critic_class def run(self): # 状態数を取得 num_states = self.env.observation_space.shape[0] # 行動数を取得 num_actions = self.env.action_space.n actor = self.actor_class(num_states, num_actions) critic = self.critic_class(num_states) # Qテーブル, Vの更新 def update_Qtable_V(observation, action, reward, observation_next): state = analog2digitize(observation) state_next = analog2digitize(observation_next) td = reward + GAMMA * critic.V[state_next] - critic.V[state] actor.q_table[state, action] += ETA * td critic.V[state] += ETA * td step_list = [] mean_list = [] std_list = [] for episode in range(NUM_EPISODES): observation = self.env.reset() # 環境の初期化 frames = [] for step in range(MAX_STEPS): if episode == NUM_EPISODES-1: frames.append(self.env.render(mode='rgb_array')) # 行動を求める action = actor.decide_action(observation, episode) # 行動a_tの実行により、s_{t+1}, r_{t+1}を求める observation_next, _, done, _ = self.env.step(action) # 報酬を与える if done: # ステップ数が200経過するか、一定角度以上傾くとdoneはtrueになる if step < 195: reward = -1 # 失敗したので-1の報酬を与える else: reward = 1 # 成功したので+1の報酬を与える else: reward = 0 # Qテーブル, Vを更新する update_Qtable_V(observation, action, reward, observation_next) # 観測値を更新する。 observation = observation_next """途中までだよ"""Sarsaと行動を決める部分も変更した。これによって得られた最後のエピソードは次のようになった。
エピソードごとの報酬の遷移は以下のようになった。
直近100エピソードの報酬の平均およびそのばらつき(標準偏差)は以下のようになった。
一つ目の図からGameAI Gym本来の学習終了が達成されなかったことがわかった。また、二つ目の図からこの手法が最も早く学習が収束したことがわかった。学習の収束とは学習終了の早さではなく、エピソード数に対する報酬の平均の増加の速さとした。参考文献

- 投稿日:2021-01-22T21:43:18+09:00
Pythonで学ぶアルゴリズム 第20弾:並べ替え(マージソート)
#Pythonで学ぶアルゴリズム< ヒープソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第20弾としてマージソートを扱う.マージソート
マージソートはまず,リストを順に半分ずつにしてバラバラにする.そのイメージ図を次に示す.
上図の最下層,つまりバラバラになったものを次は,逆に統合していく.このときに大きさを比較しながら統合していくことで,すべての要素が再構築されるときには並べ替えられた状態になっているという原理である.そのイメージ図を次に示す.
実装
再帰を使わずに実装を試みようとしたが,うまくいかなかったため,再帰を利用したコードとそのときの出力を以下に示す.
コード
merge_sort.py""" 2021/01/22 @Yuya Shimizu マージソート:リストを半分ずつ分割 → 並べ替えしながら再構築 """ def merge_sort(data): if len(data) <= 1: return data mid = len(data) // 2 #半分の位置を計算 # 再帰的に分割 left = merge_sort(data[:mid]) #左側を分割 right = merge_sort(data[mid:]) #右側を分割 #統合 return merge(left, right) def merge(left, right): result = [] i, j = 0, 0 while (i < len(left)) and (j < len(right)): if left[i] <= right[j]: #左<=右のとき result.append(left[i]) #左側から1つ取り出して追加 i += 1 else: result.append(right[j]) #右側から1つ取り出して追加 j += 1 # 残りをまとめて追加 if i < len(left): result.extend(left[i:]) #左側の残りを追加 if j < len(right): result.extend(right[j:]) #右側の残りを追加 return result if __name__ == '__main__': data = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sorted_data = merge_sort(data) print(f"{data} → {sorted_data}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]計算量
2つのリストを統合する処理は,できあがるリストの長さのオーダーで処理できるので,オーダー記法で表すと$O(n)$である.また統合する段数を考えると,$n$個のリストを1つになるまで統合する場合,1度の統合で2つのリストを統合することになるので,その段数は$log_2n$となる.したがって,全体の計算時間をオーダー記法で表すと$O(nlogn)$となる.
感想
今回は,再帰を使わずに何とかしようと試みたが,うまくいかなく残念であった.もう少し粘ってもよかったのだが,いまはとりあえずアルゴリズムを理解することが本筋であるため,次に進もうと思う.ただ,今回も初めて使うものがあった.
extend()である.これはリストの末尾に追加するときに使う.+と似ているが,文字列を追加するときに使うと,1文字ずつ追加してしまうようだ.append()と+ぐらいしかリストには使ってきていなかったため,良い学びとなった.次回はクイックソートである.参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社


- 投稿日:2021-01-22T21:12:57+09:00
Practical Guide to Wavelet Analysis in Python
以前、wavelet解析について別の場所に書いた。質問を受けた事を機会にgithubにコードを上げると共に、ここに内容を再録する。
Torrence and Compo [1998]のwavelet解析手法と、そのツールは我々の分野でよく使われる。私もMiyama and Miyazawa [2014]をで使用している。その関連した発表をAOGS 2014でした時に、Torrence and Compo [1998] はスケールが大きいほうを過大評価するバイアスがあり、それに関する論文(Liu et al. 2007と関連するweb pageを教えていただいた。
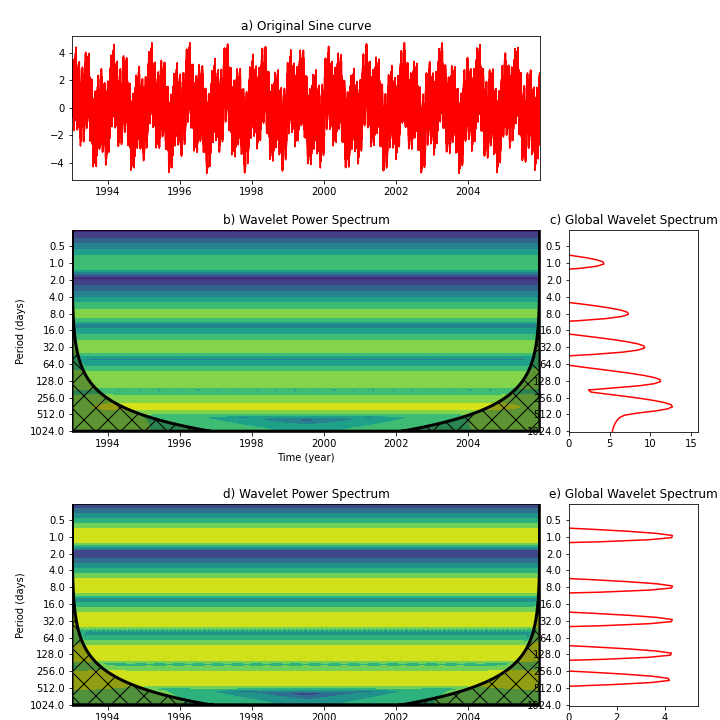
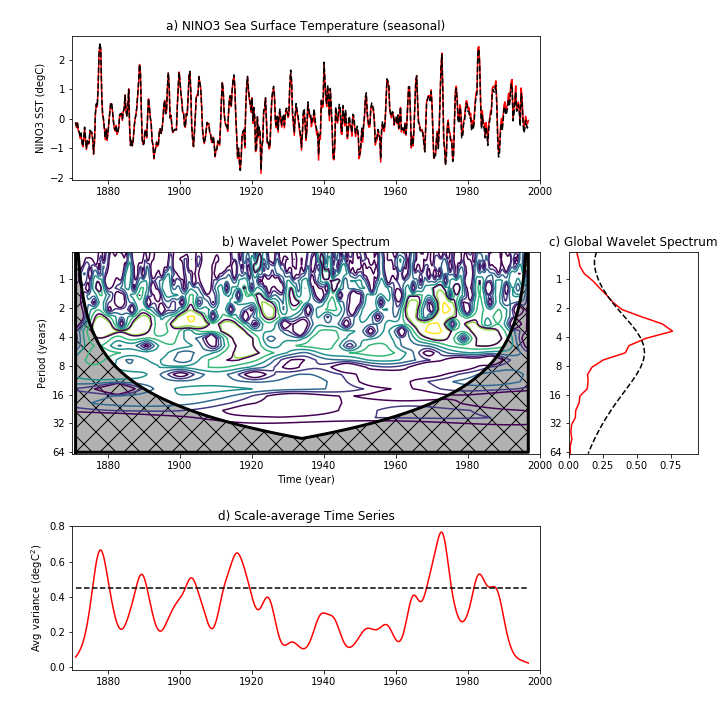
下の図はLiu et al. 2007のFig.2に対応する、1,8,32,128,365日のsineカーブの単純な重ね合わせ(a)のシグナルにwavelet解析をかけたものである。Torrence and Compo [1998] の手法(b,c)ではスケールが大きい(長周期)のほうがシグナルが大きいと解析されてしまう。一方、Liu et al. [2007]はスペクトルをスケールで割ることを提案しており、これであれば(d,e)、各周期が同じくらいの強さであるという合理的な結果が出る。
上記の図を作るwavelet解析のツールをpythonに翻訳し、Jupyter Notebookにしたものはこちら。
https://github.com/tmiyama/WaveletAnalysis/blob/main/wavelet_test_sine.ipynb
さらに、NINO SST3のwavelet解析した(Liu et al. 2007のFig 4に対応)物をJupyter Notebookしたものはこちら。
https://github.com/tmiyama/WaveletAnalysis/blob/main/wavelet_test_ElNino3_Liu.ipynb
- 投稿日:2021-01-22T20:59:00+09:00
いろいろな最適化アルゴリズムを比較してみた
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
比較について
比較はアルゴリズムの優劣をつける事ではなく、アルゴリズム毎の解きやすい問題・解きにくい問題の傾向を把握するために実施しています。
最適化アルゴリズムにはノーフリーランチ定理という考えがあり、汎用的ではありますが決して万能ではありません。
ですのでこの比較はあくまで参考程度に見てください。結果
各問題の詳細に関しては問題編を見てください。
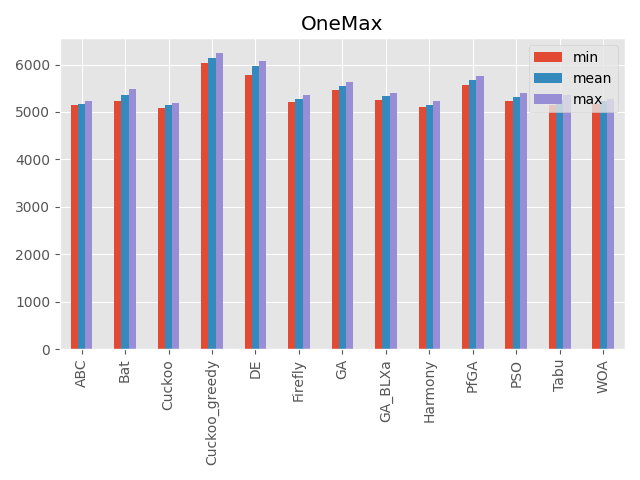
OneMax
パラメータ 最大評価値 難しさ 10000次元 10000 ☆ 局所解はなく、最適解も広い範囲であります。
なので次元数を大きく設定しました。
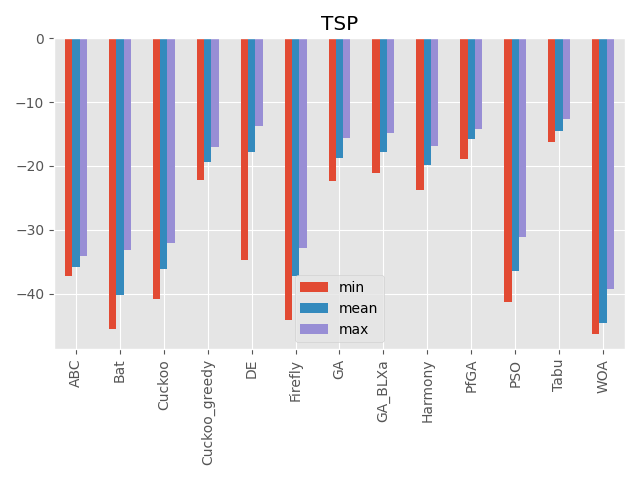
巡回セールスマン問題
パラメータ 最大評価値 難しさ 80次元(80都市) 0に近い値 ☆☆☆ 各入力が都市を回る順番を表しています。
1つの入力の値を変えただけで全部の入力値に影響があるのが特徴です。
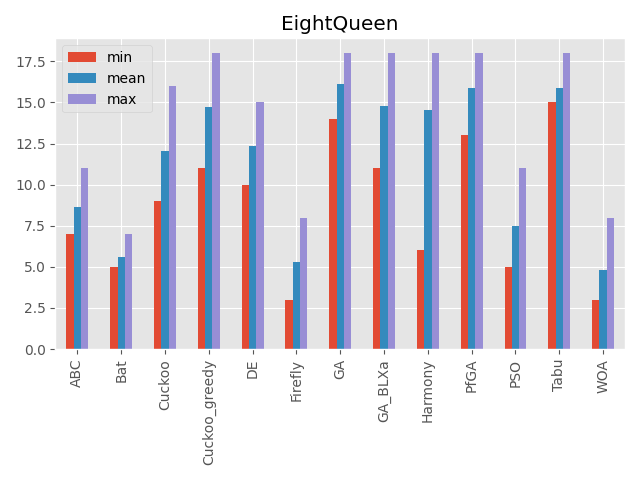
エイト・クイーン
パラメータ 最大評価値 難しさ 20次元(20クイーン) 20 ☆☆☆ 2次元のクイーンの座標を入力としています。
入力の次元により意味が変わる事が特徴です。
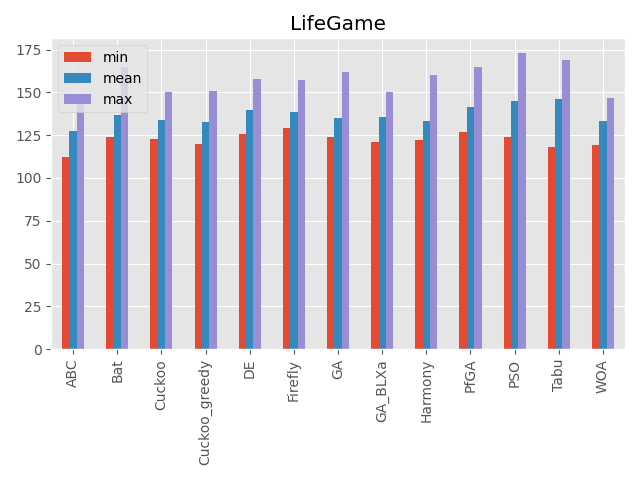
ライフゲーム
パラメータ 最大評価値 難しさ 400次元(20×20)、5ターン 400に近い値 ☆☆☆ 入力と結果の関係が特殊なルールで決まります。
入力値の良し悪しがすぐに判断できません。
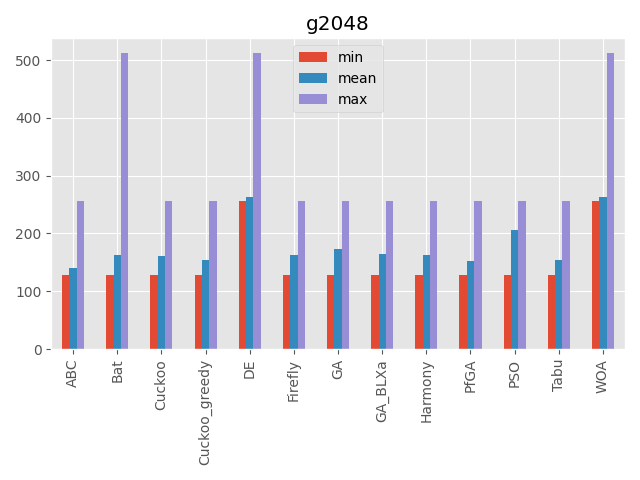
2048
パラメータ 最大評価値 難しさ 350次元(350ターン) 不明 ☆☆☆ 入力が時系列を表しています。
ある入力値を変えるとそれ以降の入力値の意味が変わるのが特徴です。
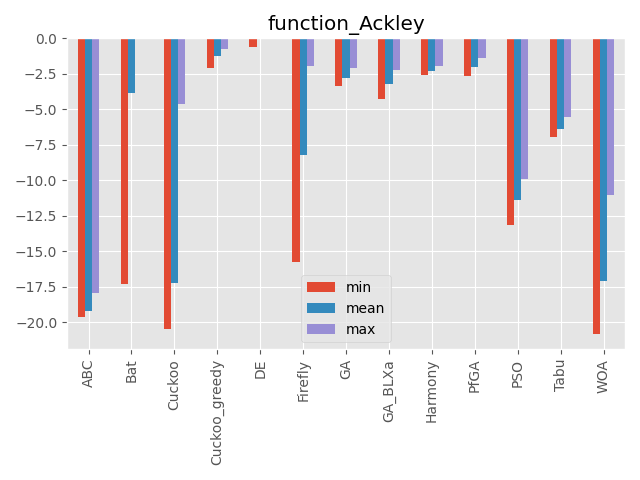
Ackley function
パラメータ 最大評価値 難しさ 50次元 0 ☆☆ 多数の局所解はありますが、局所解の深さはそこまで深くありません。
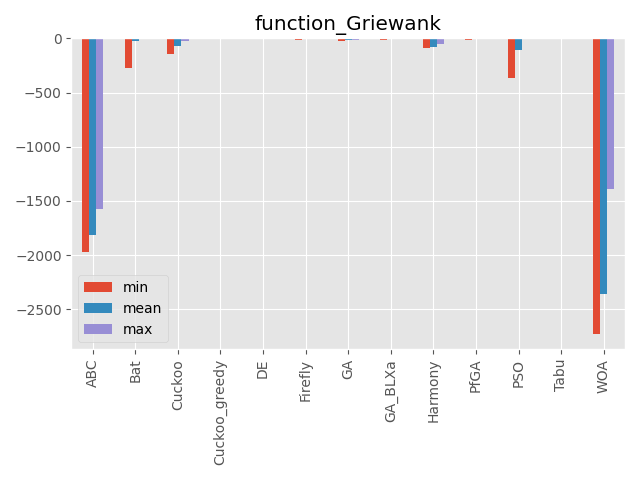
Griewank function
パラメータ 最大評価値 難しさ 100次元 0 ☆? 単峰性関数に見える…。
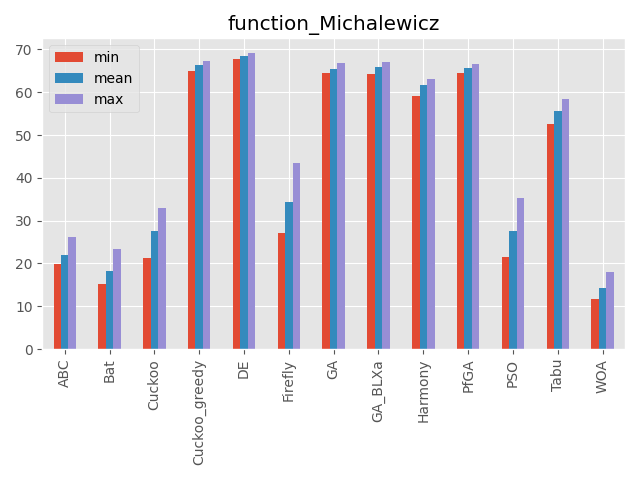
Michalewicz function
パラメータ 最大評価値 難しさ 70次元 不明 ☆☆ 次元数だけ局所解が増える関数。
最適解が中心にないのも特徴です。
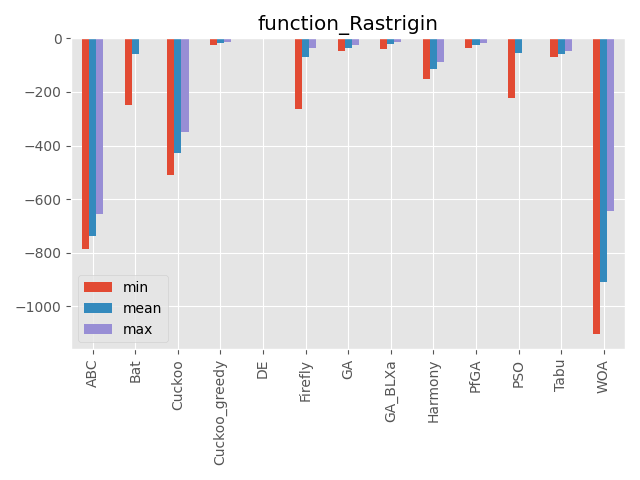
Rastrigin function
パラメータ 最大評価値 難しさ 70次元 0 ☆☆ 局所解が多数あります。
その局所解も深いものが多いです。
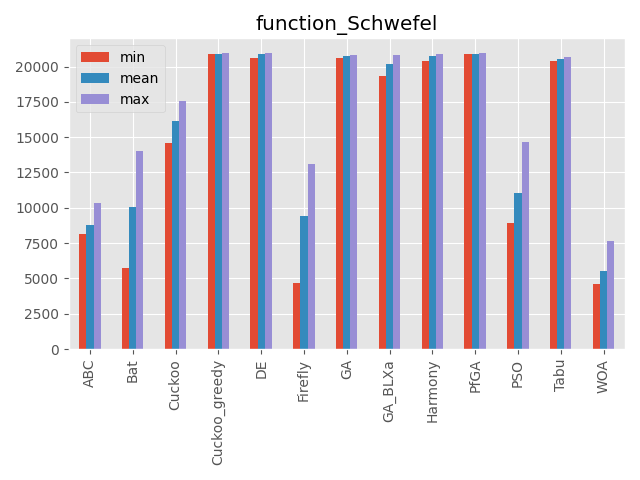
Schwefel function
パラメータ 最大評価値 難しさ 50次元 20,949.145 ☆☆ 深い局所解と最適解が離れているのが特徴です。
また最適解が中心にありません。
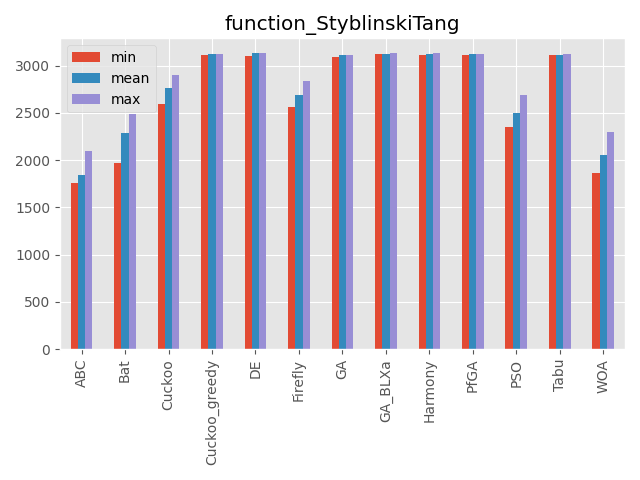
StyblinskiTang function
パラメータ 最大評価値 難しさ 80次元 3,133.2932 ☆☆ 最適解と局所解が広い範囲で広がっています。
また最適解が中心にありません。
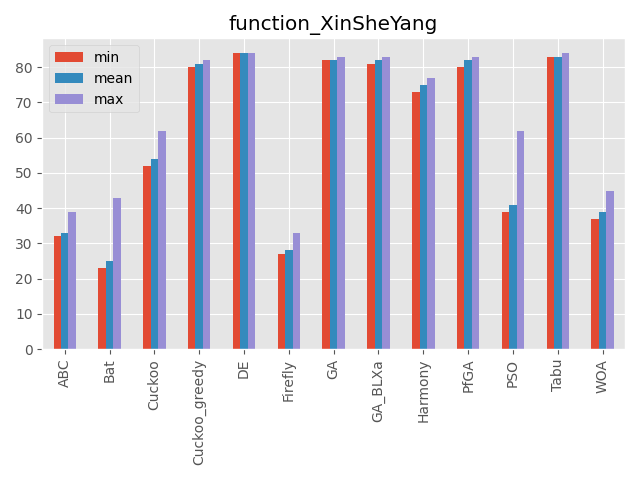
XinSheYang function
パラメータ 最大評価値 難しさ 200次元 0 ☆☆ かなり面白い形をしている関数です。
最適解が中心にありません。
評価値がものすごく小さい値なので小数の桁数で比較しています。(指数表記時の指数部を使っています)
比較まとめ
こうしてみると、カッコウ探索(ε-greedy版)、差分進化、遺伝的アルゴリズムとパラメータフリーGA、ハーモニーサーチ、タブーサーチあたりが全体的にいい感じですね。
コウモリアルゴリズムは安定はしていないですが、一部の問題でいい評価を出しています。
またくじらさんアルゴリズムは2048ではいい結果を出していますね。GA_BLXaは遺伝的アルゴリズムの実数値版ですが、シンプルな遺伝的アルゴリズムとあまり結果が変わらないように見えます(一部は悪くなっている)
比較方法
比較方法ですが、2段階に分けています。
1段階目はハイパーパラメータを探索するフェーズ、
2段階目は実際に測定するフェーズです。どちらの段階でも実際に探索させる動作は同じものを使っており、コードは以下です。
def run(problem, algorithm, timeout): # 問題の初期化、乱数は固定する random.seed(1) problem.init() random.seed() # アルゴリズムの初期化 algorithm.init(problem) # timeout になるまで loop t0 = time.time() while time.time() - t0 < timeout: algorithm.step() # 最大スコアを返す return algorithm.getMaxScore()問題の初期化は同じ問題になるように乱数を固定しています。
また試行回数ですが、アルゴリズム毎で1stepでの探索回数に差がでるので時間で回数を決めています。
- ハイパーパラメータの探索
ハイパーパラメータの探索では optuna を使用して値を求めています。
各アルゴリズムの探索時間は5秒とし、これを100回繰り返してハイパーパラメータを求めています。
OneMaxを遺伝的アルゴリズムで学習する例は以下です。import optuna # optuna用の関数を作成 def objective_degree(prob_cls, alg_cls, timeout): def objective(trial): if alg_cls.__name__ == GA.__name__: # optunaの探索範囲を指定 algorithm = GA( trial.suggest_int('individual_max', 2, 50), trial.suggest_categorical('save_elite', [False, True]), trial.suggest_categorical('select_method', ["ranking", "roulette"]), trial.suggest_uniform('mutation', 0.0, 1.0), ) (略) if prob_cls.__name__ == OneMax.__name__: problem = OneMax(10000) (略) score = run(problem, algorithm, timeout) return score return objective # 学習する対象を指定 prob_cls = OneMax alg_cls = GA # optunaによる探索 study = optuna.create_study(direction="maximize") study.optimize(objective_degree(prob_cls, alg_cls, timeout=5), n_trials=100) # optunaの結果を取得 print(study.best_params) print(study.best_value)
- 実際の測定
optunaで学習したハイパーパラメータを用いて実際に結果を計測しています。
計測方法は同じく5秒間探索してその間の最高評価値を結果としています。
これを100回繰り返して集計した結果をもとにグラフ化しています。# optunaで探索したハイパーパラメータでアルゴリズムを作成 algorithm = alg_cls(**study.best_params) # 問題を作成 if prob_cls.__name__ == OneMax.__name__: problem = OneMax(10000) (略) # 100回探索して結果を集計 results = [] for _ in range(100): score = run(problem, algorithm, timeout=5) results.append(score) # 結果の表示 print("min : {}".format(min(results))) print("max : {}".format(max(results)))実際の表示はグラフ化するためにもう少しいろいろ書いています。
詳しく見たい人はgithubにコードが置いてあります。
- 投稿日:2021-01-22T20:29:45+09:00
Python でのスクレイピング 入門
はじめに
今PythonでWebページのスクレイピングの勉強をしているので、スクレイピングをする際の必要不可欠な部分をまとめました。自分と同じように皆さんがPythonでスクレイピングをする時の参考になれば幸いです。
対象者
- Python初心者でPythonでスクレイピングをしたい人
- Pythonのスクレイピングの書き方を忘れた人
自動で Web ブラウザ(GoogleChrome)を起動
webdriver.Chrome()
bash# chromedriverをインストール $ brew install --cask chromedriverpythonfrom selenium import webdriver driver = webdriver.Chrome() driver.get("指定のurl")自動でテキスト入力
python# HTMLのid属性 ele = driver.find_element_by_id("id名") # またはname属性 ele = driver.find_element_by_name("name名") # テキスト入力 ele.send_keys(入力したい値) # ボタンクリック ele.click()現在表示しているページのソースコードを取得
page_source
pythonhtml = driver.page_source.encode('utf-8')url 取得
urllib.request.urlopen
pythonimport urllib.request url = urllib.request.urlopen("指定のurl")または
requests.get
pythonimport requests url = requests.get("指定のurl")※ python は後者を推奨
HTML および XML ファイルの解析
BeautifulSoup
python# pythonの標準で"html.parser"("lxml"や"html5lib"などもある) from bs4 import BeautifulSoup soup = BeautifulSoup(url.text, "html.parser")テキスト取得
find, find_all
python# findは''に囲まれた文字列を返す elem = soup.find('a').text # find_allはforを使い全ての''に囲まれた値を文字列で返す elems = soup.find_all('a') for elem in elems: print(elem.text)最後に
今回はPythonでWebページをスクレイピングする際に必要となるモジュールやメソッドを紹介しました。次回からは実際に何かしらのWebページをスクレイピングしていこうと思います。
参考サイト
- 投稿日:2021-01-22T19:54:12+09:00
Dockerを使って爆速でGPUを設定する方法
はじめに
機械学習をやろうと思ったら、まずやってくるのが GPUの設定 ですよね。ドライバインストールしてCUDAとcudnnインストールして、、、。これが本当にめんどくさい!そんな方には Dockerを用いた設定をオススメします。マジで爆速です。しかも、PyTorchやTFによって環境を別で設定できますし、使わなくなったらその環境をすぐに削除できます。ひと通りカバーした記事があまりなかったので残しておきます。困っている方の参考になればと思います。
*ミスがありましたら、ぜひご指摘お願いします
手順
1. NVIDIA driver のインストール
2. Docker のインストール
3. NVIDIA container toolkit のインストール
1. NVIDIA Driverのインストール
$ nvidia-smi$ sudo apt-get --purge remove nvidia-* $ sudo apt autoremove$ sudo add-apt-repository ppa:graphics-drivers/ppa $ ubuntu-drivers devices$ sudo apt-get install nvidia-driver-4502. Dockerのインストール
- aptのindex更新
$ sudo apt-get update
- 前提ソフトウェアをインストール
$ sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
- Dockerの公式GPG公開鍵のインストール
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - OK
- 公開鍵のフィンガープリントを確認
$ sudo apt-key fingerprint 0EBFCD88 pub rsa4096 2017-02-22 [SCEA] 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid [ unknown] Docker Release (CE deb) <docker@docker.com> sub rsa4096 2017-02-22 [S]*「0EBFCD88」は鍵ID
- repositoryの追加
$ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"$ sudo apt-get update
- Docker CE のインストール
$ sudo apt-get install -y docker-ce
- この状態だと、
$ sudo docker psのようにsudoを付加しないと実行できないので変更# dockerグループの情報表示 $ getent group docker # Dockerグループにユーザ追加 $ sudo gpasswd -a [username] docker # 権限を付与 $ sudo chgrp docker /var/run/docker.sock # 追加されているか確認 $ id [username] # 再起動 $ sudo reboot
- エラーが消えているか確認
$ docker ps
- これでエラーが出なかったらOK
$ sudo docker run hello-world3. NVIDIA container toolkit
- インストール
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit $ sudo systemctl restart docker
- 確認
$ nvidia-container-cli info4. DockerでGPUを使う
- イメージをpull
$ docker pull nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04
- docker上でNVIDIAドライバが認識されていればOK
$ docker run --gpus all nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04 nvidia-smi
- イメージを元にコンテナを作成する
- 以下は、CUDA:10.0、cudnn:7を使用する場合
$ docker run -it -d --gpus all --name gpu_env nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04 bash$ docker ps
- コンテナに入る
$ docker exec -it gpu_env bash5. コンテナで作業
root@cf3868e92ebf:/# nvidia-smi root@cf3868e92ebf:/# nvcc -Vroot@cf3868e92ebf:/# apt-get updateroot@cf3868e92ebf:/# apt-get install -y python3 python3-piproot@cf3868e92ebf:/# pip3 install torch torchvisionroot@cf3868e92ebf:/# python3 Python 3.6.9 (default, Oct 8 2020, 12:12:24) [GCC 8.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> >>> import torch >>> print(torch.cuda.is_available()) True >>>
- コンテナを抜ける
root@cf3868e92ebf:/# exitその他(dockerコマンド)
- ローカルにあるイメージの一覧表示
$ docker images
- 起動中のコンテナ表示
$ docker ps
- コンテナの起動
$ docker start CONTAINER
- コンテナの停止
$ docker stop CONTAINER
- 起動中のコンテナに入る
$ docker exec -it CONTAINER bash
- コンテナの名前変更
$ docker rename OLD_CONTAINER_NAME NEW_ONTAINER_NAME
- コンテナの削除
$ docker rm CONTAINER参考文献
- 投稿日:2021-01-22T19:43:39+09:00
重複する行を順序を保ったまま整理したい
経緯
.gitignoreが秘伝のタレ状態になると、対象が重複することがある。### C ### # Prerequisites *.d # Object files *.o *.ko *.obj *.elf # Linker output *.ilk *.map *.exp ### C++ ### # Prerequisites *.d # <- 重複 # Compiled Object files *.slo *.lo *.o # <- 重複 *.obj # <- 重複 # Precompiled Headers *.gch *.pch # Linker files *.ilk # <- 重複このせいで修正したつもりが「あれ、
.gitignoreが反映されないな」みたいな時間の無駄が発生する。
ググると、「ソートしてから(^.*$)(\n(^\1$)){1,}で検索!」みたいな情報が出てくるんだが、
そうやって消すと順序が破壊されて「この*.mapって何のために無視してるんだっけ?」が起きる。面倒だけど、スクリプトにしておく。
実装
コピペしてさっと動かしたいので、Python3.6の標準ライブラリだけで。
arrange-duplicate-lines.py#!/usr/bin/env python3 from argparse import ArgumentParser from logging import basicConfig, getLogger, DEBUG, INFO from pathlib import Path from re import compile, escape, match basicConfig(level=INFO) logger = getLogger(__name__) def main(): parser = ArgumentParser(description='Remove or comment out duplicate lines, keeping them in order.') parser.add_argument('path', type=Path, help='Input file path.') delete_or_comment = parser.add_mutually_exclusive_group() delete_or_comment.add_argument('--delete', '-d', action='store_true', help='Flag to remove duplicate lines.') delete_or_comment.add_argument('--comment', '-c', type=str, default='#', help='The character to comment out duplicate lines.') parser.add_argument('--output', '-o', type=Path, default=None, help='Path to save.') args = parser.parse_args() result = [] with open(args.path, mode='r', encoding='utf_8') as f: pattern_commented = compile(r'^{0}.*$'.format(escape(args.comment))) pattern_blank = compile(r'^\s+$') for i, line in enumerate(f): if match(pattern_commented, line) or match(pattern_blank, line): logger.debug(f'L{i:04}: [ AS IS ] {line}') result.append(line) else: if line not in result: logger.debug(f'L{i:04}: [ HIT ] {line}') result.append(line) else: if not args.delete: logger.debug(f'L{i:04}: [COMMENT] {line}') result.append(f'{args.comment} {line}') else: logger.debug(f'L{i:04}: [ DELETE ] {line}') logger.debug('\n'.join(result)) if args.output: with open(args.output, mode='w') as f: f.writelines(result) logger.info(f'Save: {args.output}') logger.info('Completed!') if __name__ == "__main__": main()せっかくなので、空行と元々コメントされているところはそのまま残し、重複行を削除するかコメントアウトするか選べるようにした。
結果
$ python3 arrange-duplicate-lines.py .gitignore -d -o .gitignore.deletegitignore.delte### C ### # Prerequisites *.d # Object files *.o *.ko *.obj *.elf # Linker output *.ilk *.map *.exp ### C++ ### # Prerequisites # Compiled Object files *.slo *.lo # Precompiled Headers *.gch *.pch # Linker files$ python3 arrange-duplicate-lines.py .gitignore -c '###' -o .gitignore.commentgitignore.comment### C ### # Prerequisites *.d # Object files *.o *.ko *.obj *.elf # Linker output *.ilk *.map *.exp ### C++ ### ### # Prerequisites ### *.d # Compiled Object files *.slo *.lo ### *.o ### *.obj # Precompiled Headers *.gch *.pch # Linker files ### *.ilk愚直、ゆえに、もし
*.txtとlog-*.txtみたいな意味的な重複は残してしまうが、まぁ良しとしよう。
gitignore.io の名誉のために付記しておくと、
https://www.toptal.com/developers/gitignore/api/c,c++のように一緒に指定した場合は上記のように重複が削除された状態で生成されるのを確認しました。
- 投稿日:2021-01-22T19:35:31+09:00
Django の Form Class でセッション情報を利用する
概要
フォームのバリデーションを行う際にセッション情報を使いたかったのですが、Django のフォームクラスではリクエストオブジェクトを参照することができません。
セッション情報をコンテキストとしてフォームの hidden 属性で渡したりできますが、、いかんせん格好悪い。ということで、フォームクラスのメソッドをオーバーライドしてリクエストオブジェクトを渡す方法を紹介します。
動作環境は Python 3.8, Django 3.1.1 です。
forms.py
フォームクラスはデフォルトのキーワード引数として initial や data といったパラメータしか受け取れません。
なので、__init__メソッドをオーバーライドして、フォームのインスタンス生成時に request パラメータを引数として受け取るようにします。
https://github.com/django/django/blob/master/django/forms/forms.py#L64forms.pyclass MyForm(forms.form): def __init__(self, request, *args, **kwargs): self.request = request super(MyForm, self).__init__(*args, **kwargs)views.py
フォームクラスで request をインスタンス引数として受け取るようにしたので、ビュー側でフォームインスタンスを生成する際にリクエストオブジェクトを渡すようにします。
関数ビュー
シンプルにリクエストオブジェクトを引数で渡せばOK。
views.pydef my_form_view(request): form = MyForm(request=request, data=request.POST)クラスビュー
FormView の継承元である FormMixin には、フォームインスタンス生成時にキーワード引数として渡す値を指定するための
get_form_kwargs()というメソッドがあります。initial や data といったパラメータを渡します。
https://github.com/django/django/blob/3.0/django/views/generic/edit.py#L35このメソッドをオーバーライドして、ビュー側から request データを kwargs としてフォームインスタンスに渡すようにします。
views.pyclass MyFormView(FormView): form_class = MyForm def get_form_kwargs(self): kwargs = super(MyFormView, self).get_form_kwargs() kwargs['request'] = self.request return kwargsこれでフォームクラスでもリクエストオブジェクトを参照できるようになりました。
あとは、clean メソッドなどで
self.request.session.get('foo')のようにしてセッション情報を取得できます!
- 投稿日:2021-01-22T19:33:42+09:00
[python]文章校正とおみくじの2つのミニプログラムを作ってみる
目的
pythonの練習問題を通して、pythonの記法に慣れる。
現在pyQにて学習中問題1の仕様 文章校正ファイルを作成しよう
ファイルを読み込んで、いくつかの文章校正ルールでチェックするプログラムを作ります。
校正ルール一覧:
【ルール1: NGワード】NGワードが含まれている場合は、メッセージを表示します。
NGワード一覧ファイル input/ngwords.txt の中に入っているNGワードが含まれている場合は、"NGワード「", ng_word, "」が文章に含まれています。"と表示します。【ルール2: 1文の長さ】1文の長さをチェックして、50文字以上の場合は”1文が長過ぎます(50文字以上)", 対象の文章)とメッセージを表示します。
【ルール3: 1文内の読点の数】1文内の読点( 、 )の数をチェックし、1文内に3つ以上の読点がある場合は"読点の数が多すぎます(3以上)", 対象の文章) と表示します。
メッセージは、「NGワード」、「1文の長さ」、「1文内の読点の数」の順で表示します。input/ngword見れる,することができる,最高の,死,障害input/letter.txtまるちゃんです。最近、暖かくなってきましたね。みなさん、お元気ですか。風が暖かくて着ていた服を脱いだのですが、置くところがなかったので、ずっと持っていて、重かったので手が痛くなりました。キューは、たまに死にたくなることもあるけどキューは元気です。こないだ仕事で、障害がでたんで、悲しくなって、最高のおまんじゅうをたくさん食べました。おまんじゅうを食べて元気を出しましょう。あと、後輩の面倒が見れるようになりました。成長したねってパイ先輩に褒めてもらったので、うれしくて、また、おまんじゅうを食べました。お手紙下さいね。待ってます。回答
f = open ("input/letter.txt","r",encoding="utf-8") letters = f.read() f.close() sentences = letters.split("。") f2 = open("input/ngwords.txt","r",encoding="utf-8") ngwordfile = f2.read() f2.close() ngwords = ngwordfile.split(",") for ngword in ngwords: for sentence in sentences: if ngword in sentence: print("NGワード「", ngword, "」が文章に含まれています。") for sentence in sentences: if len(sentence)>=50: print("1文が長過ぎます(50文字以上)", sentence) if sentence.count("、")>= 3: print("読点の数が多すぎます(3以上)", sentence)学び
含むは、対象物 in 範囲を使う
for sentence in sentences問題2の仕様 おみくじを作ろう
おみくじを10回引いて「大吉」が出たら「n回目に大吉が出ました」と表示するプログラムを作ります。
1回も大吉が出なかった場合は、「残念でした」と表示してください。回答
import random candidates = ["大吉", "中吉", "小吉", "吉", "凶", "大凶"] num = 0 numofhits = 0 results = [] for num in range(10): result = random.choice(candidates) num = num + 1 results.append(result) if result == "大吉": print(num,"回目に大吉が出ました") if num == 10 and results.count("大吉") == 0: print("残念でした")学び
randomなどの関数を使用する場合は、importする
関数ごとではなく一括でimportする方法は、現状不明。
「かつ」はand
javascriptと違う部分まとめ
ブール演算子
a and b
# a も b も真であれば真
a or b
# a または b が真であれば真
not a
# a が偽であれば真比較演算子
a is b
# a が b と等しい
a is not b
# a が b と異なる
a in b
# a が b に含まれる (a, b は共に文字列、または、b はリストやタプル)
a not in b
# a が b に含まれない (a, b は共に文字列、または、b はリストやタプル)それ以外の演算子は、
こちらがとてもシンプルでわかりやすくまとめてあります!
- 投稿日:2021-01-22T19:22:36+09:00
はじめてのディープラーニング??一日目
前提
学習をはじめて・触って8時間程度なのでおそらく間違っている所多々
完璧ではなく流れを理解しようとしている
やさしい世界
最後の数値から???ってなってるので一旦寝て考える再度考える戦法ディープラーニング
項目
・ディープラーニングの概要
・データの読み込みと前処理
・訓練データとテストデータ
・モデルの構築
・学習モデルの評価、予測ディープラーニングの概要
::::::::::::::::::::まず踏まえておきたいワード:::::::::::::::::::
・人工 ニューラルネットワーク
コンピューター 上 の モデル 化 さ れ た 神経 細胞 ネットワーク・人工 ニューロン
コンピューター 上 の モデル 化 さ れ た 神経 細胞
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::ディープラーニングとは?
・ニューラルネットワーク(NN)というパターン認識をするように設計された、人間や動物の脳神経回路をモデルとしたアルゴリズムを多層構造化したもの
・多数の層からなるニューラルネットワークの学習参照
https://www.deeplearningbook.org/contents/intro.html
*絵心ないです
上記のように様々な外的参照データによって出力されていますその集合体(ネットワーク)が人口ニューラルネットワークです。
人工 ニューラルネットワーク について解説します 。
こちら の 図 に ニューラルネットワークの例を示しますがニューロンが層状に並んでいます.
ニューロンは 前 の 層 の すべて の ニューロン と 後 の 層 の すべて の ニューロン と 接続 さ れ て い ます 。 ニュラルネットワーク に は 複数 の 入力 と 複数 の 出力数値 を 入力 し 情報 を 伝播 さ せ 結果 を 出力 し ます 。
出力は確率などの予測 値 として 解釈 可能 で ネットワーク により 予測 を 行う こと が 可能 です
また ニューロン や 層 の 数 を 増やす こと で ニューラルネットワークは高い表現力を発揮するようになります。
以上 の よう に ニューラルネットワーク は シンプル
な 機能 しか 持た ない ニューロン が 層 を 形成 し 層 の 間 で 接続 が 行わ れる こと により 形作ら れ ます 。
*絵心下さい(とにかく沢山のものが集まり層を形成し各自がつながりあってる感じの絵です)
ニューラルネットワークは出力と正解の誤差が小さくなるように重みとバイアスを調整し
バックプロパゲーションと言うアルゴリズムを使い学習していきます。
各パラメーターが繰り返し調整されることでネットワークは次第に学習し適切な予測が行われます。データの読み込みと前処理
import numpy as np from sklearn import datasets #ライブラリーのインポートを行います。 iris = datasets.load_iris() print(iris.data[:10]) print(iris.target[:10]) print(iris.data.shape)from sklearn import datasets
=sklearnからdatasetsをインポートしています。iris=花のデータです。
print(iris.data[:10]) print(iris.target[:10])
=頭から10個のデータを表示してもらいます。print(iris.data.shape)
=データの形状を表示します。出力結果.[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1]] [0 0 0 0 0 0 0 0 0 0] (150, 4)このデータから上から4種類の値、ラベル、データ数、列数
というデータの中身がわかります。前処理
from sklearn import preprocessing from keras.utils import np_utils scaler = preprocessing.StandardScaler() scaler.fit(iris.data) x = scaler.transform(iris.data) print(x[:10]) y = np_utils.to_categorical(iris.target) print(t[:10])from sklearn import preprocessing
=前処理をインポートStandardScaler
=標準化のために使われるscaler.fit(iris.data)
=irisのデータに対してfitを行う(標準化パラメータ)標準化とは、データから平均値を引いて標準偏差で割ったもの
x が標準化されたirisデータ
iris.targetデータをcategorical化します。
1or0だけの表現に変換出力結果.[[-0.90068117 1.01900435 -1.34022653 -1.3154443 ] [-1.14301691 -0.13197948 -1.34022653 -1.3154443 ] [-1.38535265 0.32841405 -1.39706395 -1.3154443 ] [-1.50652052 0.09821729 -1.2833891 -1.3154443 ] [-1.02184904 1.24920112 -1.34022653 -1.3154443 ] [-0.53717756 1.93979142 -1.16971425 -1.05217993] [-1.50652052 0.78880759 -1.34022653 -1.18381211] [-1.02184904 0.78880759 -1.2833891 -1.3154443 ] [-1.74885626 -0.36217625 -1.34022653 -1.3154443 ] [-1.14301691 0.09821729 -1.2833891 -1.44707648]] [[1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.]]参照
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.htmlhttps://keras.io/ja/utils/np_utils/
訓練データとテストデータ
データを訓練用データとテスト用データに分けていきます。
なぜデータを分ける必要があるのか?A、ディープラーニングではデータの精度を高める事が非常に大切になっていきます。
そのためデータを分けておく必要があります。(今回は二つなだけ)
もしデータ全てを訓練用データとして使用した場合、過度に適合したデータが完成してしまい逆に精度が低くなってしまうfrom sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, t, train_size=0.75) print(x_train[:10]) print(x_train.shape) print(x_test.shape)sklearn.model_selection.train_test_split
=参照ソース↓
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.htmlなぜ、train_size=0.75にしたの?
=K-分割交差検証(Cross Validation)出力結果.[[ 0.55333328 -1.28296331 0.70592084 0.92230284] [-0.65834543 1.47939788 -1.2833891 -1.3154443 ] [ 0.67450115 0.32841405 0.87643312 1.44883158] [-1.87002413 -0.13197948 -1.51073881 -1.44707648] [ 2.12851559 -0.13197948 1.61531967 1.18556721] [-0.41600969 -1.28296331 0.13754657 0.13250973] [-1.38535265 0.32841405 -1.22655167 -1.3154443 ] [-0.7795133 1.01900435 -1.2833891 -1.3154443 ] [-1.14301691 0.09821729 -1.2833891 -1.3154443 ] [ 0.67450115 -0.82256978 0.87643312 0.92230284]] (112, 4) (38, 4)データをわけることができました。
モデルの構築
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(32, input_dim=4)) model.add(Activation('relu')) model.add(Dense(32)) model.add(Activation('relu')) model.add(Dense(3)) model.add(Activation('softmax')) model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy']) print(model.summary())~~~~~~~~入力層~~~~~~~~~
model.add(Dense(32, input_dim=4))
で、入力=4(4種類の値)中間層32のニューロンmodel.add(Activation('relu')
活性化関数=relu(「0」を基点として、0以下なら「0」、0より上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数)を代入
~~~~~~~~~~~中間層~~~~~~~~~~~~~~~model.add(Dense(32))
=32のニューロンを結合model.add(Activation('relu'))
=活性化関数を代入
~~~~~~~出力層~~~~~~~~~model.add(Dense(3))
=三つの出口を作ってあげていますmodel.add(Activation('softmax'))
=3つ以上の出口を作るときはsoftmax使うっぽいです~~~~~~~~~~~~~~~~~~~~
↓
コンパイルしてます。
参照
Sequentilal
=https://keras.io/ja/models/sequential/Dense
=https://keras.io/ja/layers/core/#denseActivation:
=https://keras.io/ja/layers/core/#activationsoftmax関数を直感的に理解したい
=https://qiita.com/rtok/items/b1affc619d826eea61fd脳死で覚えるkeras入門
=https://qiita.com/wataoka/items/5c6766d3e1c674d61425出力結果.Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 32) 160 _________________________________________________________________ activation (Activation) (None, 32) 0 _________________________________________________________________ dense_1 (Dense) (None, 32) 1056 _________________________________________________________________ activation_1 (Activation) (None, 32) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 99 _________________________________________________________________ activation_2 (Activation) (None, 3) 0 ================================================================= Total params: 1,315 Trainable params: 1,315 Non-trainable params: 0 _________________________________________________________________ None学習
his = model.fit(x_train, y_train, epochs=30, batch_size=9)epochs=30, batch_size=9
30回データを使う
9個のまとまりEpoch 1/30 13/13 [==============================] - 0s 1ms/step - loss: 1.1210 - accuracy: 0.4930 Epoch 2/30 13/13 [==============================] - 0s 1ms/step - loss: 1.0056 - accuracy: 0.5040 Epoch 3/30 13/13 [==============================] - 0s 1ms/step - loss: 0.8827 - accuracy: 0.7040 Epoch 4/30 13/13 [==============================] - 0s 1ms/step - loss: 0.8044 - accuracy: 0.8141 Epoch 5/30 13/13 [==============================] - 0s 1ms/step - loss: 0.7981 - accuracy: 0.8031 Epoch 6/30 13/13 [==============================] - 0s 1ms/step - loss: 0.7140 - accuracy: 0.7751 Epoch 7/30 13/13 [==============================] - 0s 1ms/step - loss: 0.6903 - accuracy: 0.7695 Epoch 8/30 13/13 [==============================] - 0s 1ms/step - loss: 0.6953 - accuracy: 0.7973 Epoch 9/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5926 - accuracy: 0.8374 Epoch 10/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5871 - accuracy: 0.8065 Epoch 11/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5614 - accuracy: 0.8400 Epoch 12/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5210 - accuracy: 0.8147 Epoch 13/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5227 - accuracy: 0.8099 Epoch 14/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5048 - accuracy: 0.8354 Epoch 15/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4412 - accuracy: 0.8697 Epoch 16/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4572 - accuracy: 0.7845 Epoch 17/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4188 - accuracy: 0.8345 Epoch 18/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4476 - accuracy: 0.8292 Epoch 19/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3701 - accuracy: 0.8872 Epoch 20/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3487 - accuracy: 0.9335 Epoch 21/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3967 - accuracy: 0.8826 Epoch 22/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3888 - accuracy: 0.9157 Epoch 23/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3478 - accuracy: 0.9062 Epoch 24/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3379 - accuracy: 0.9389 Epoch 25/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3224 - accuracy: 0.9245 Epoch 26/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3235 - accuracy: 0.9022 Epoch 27/30 13/13 [==============================] - 0s 2ms/step - loss: 0.3205 - accuracy: 0.9212 Epoch 28/30 13/13 [==============================] - 0s 2ms/step - loss: 0.3049 - accuracy: 0.9498 Epoch 29/30 13/13 [==============================] - 0s 2ms/step - loss: 0.2916 - accuracy: 0.9244 Epoch 30/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3103 - accuracy: 0.9376参照
=https://keras.io/ja/models/sequential/#fit学習モデルの評価、予測
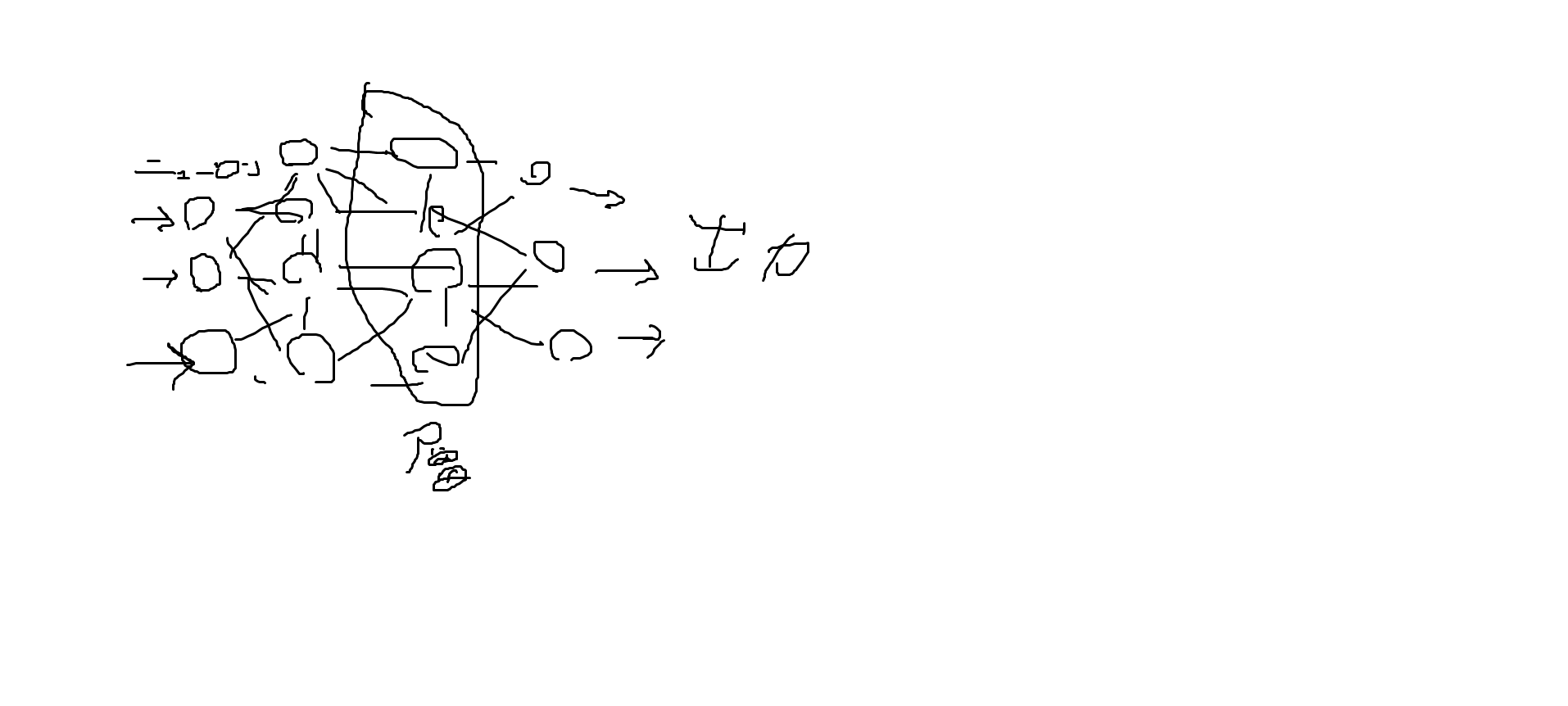
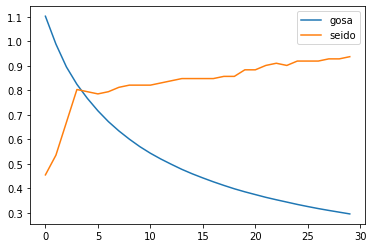
import matplotlib.pyplot as plt hist_loss = history.history['loss'] hist_acc = history.history['acc'] plt.plot(np.arange(len(hist_loss)), hist_loss, label='gosa') plt.plot(np.arange(len(hist_acc)), hist_acc, label='seido') plt.legend() plt.show()
このようなグラフができました。
パット見、回数が増えれば精度があがっているので問題なさそう。。評価
loss, accuracy = model.evaluate(x_test, t_test) print(loss, accuracy)2/2 [==============================] - 0s 3ms/step - loss: 0.3002 - accuracy: 0.8421 0.30019232630729675 0.84210526943206790.84....................
2/2 [==============================] - 0s 3ms/step - loss: 0.3002ん・・・・?????
予測
model.predict(x_test)array([[0.9570871 , 0.03468084, 0.00823214], [0.9415316 , 0.0529235 , 0.00554489], [0.09786918, 0.8637411 , 0.0383897 ], [0.00380978, 0.08060622, 0.91558397], [0.00516732, 0.05931339, 0.93551934], [0.05471139, 0.3572611 , 0.5880275 ], [0.01959354, 0.37794194, 0.60246444], [0.9635058 , 0.03082733, 0.00566692], [0.01309439, 0.07551848, 0.91138715], [0.0096556 , 0.07231863, 0.91802573], [0.95494115, 0.03726008, 0.00779877], [0.9562635 , 0.03845736, 0.00527913], [0.9641995 , 0.02395629, 0.0118442 ], [0.52867496, 0.4659895 , 0.00533543], [0.9613784 , 0.03035152, 0.00827017], [0.04043853, 0.31576672, 0.6437947 ], [0.01528158, 0.10288678, 0.88183165], [0.9151587 , 0.07728348, 0.00755785], [0.01373726, 0.2678833 , 0.71837944], [0.01790639, 0.11440011, 0.8676935 ], [0.93540496, 0.05014379, 0.01445119], [0.00815325, 0.06253443, 0.92931235], [0.05771529, 0.4806437 , 0.461641 ], [0.06256435, 0.44442546, 0.49301007], [0.08182625, 0.7663055 , 0.15186824], [0.08219455, 0.3012668 , 0.6165387 ], [0.9779156 , 0.0143037 , 0.0077807 ], [0.9344322 , 0.0505922 , 0.01497557], [0.06872862, 0.33931345, 0.59195787], [0.9520358 , 0.03229078, 0.01567345], [0.09619313, 0.8281841 , 0.07562277], [0.0197491 , 0.2699217 , 0.7103293 ], [0.9632427 , 0.02939309, 0.00736426], [0.02244722, 0.27921143, 0.6983413 ], [0.0239581 , 0.19942115, 0.7766208 ], [0.05605358, 0.609517 , 0.3344295 ], [0.94509476, 0.04353072, 0.01137454], [0.9617277 , 0.03190768, 0.00636464]], dtype=float32)となりました。
多分どこかで間違えてる気がしかしないです。
また明日挑戦します。
おわり
感想
サイゼまじ愛してるLOVEだからキャッシュレス対応して(勉強の道のりはまだまだ長い・・・・)
圧倒的感謝資料
AIパーフェクトマスター講座 -Google Colaboratoryで隅々まで学ぶ実用的な人工知能/機械学習-
https://www.udemy.com/course/ai-master/
- 投稿日:2021-01-22T19:22:36+09:00
ディープラーニング合宿一日目
前提
学習をはじめて・触って8時間程度なのでおそらく間違っている所多々
完璧ではなく流れを理解しようとしている
やさしい世界
最後の数値から???ってなってるので一旦寝て考える再度考える戦法ディープラーニング
項目
・ディープラーニングの概要
・データの読み込みと前処理
・訓練データとテストデータ
・モデルの構築
・学習モデルの評価、予測ディープラーニングの概要
::::::::::::::::::::まず踏まえておきたいワード:::::::::::::::::::
・人工 ニューラルネットワーク
コンピューター 上 の モデル 化 さ れ た 神経 細胞 ネットワーク・人工 ニューロン
コンピューター 上 の モデル 化 さ れ た 神経 細胞
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::ディープラーニングとは?
・ニューラルネットワーク(NN)というパターン認識をするように設計された、人間や動物の脳神経回路をモデルとしたアルゴリズムを多層構造化したもの
・多数の層からなるニューラルネットワークの学習参照
https://www.deeplearningbook.org/contents/intro.html
*絵心ないです
上記のように様々な外的参照データによって出力されていますその集合体(ネットワーク)が人口ニューラルネットワークです。
人工 ニューラルネットワーク について解説します 。
こちら の 図 に ニューラルネットワークの例を示しますがニューロンが層状に並んでいます.
ニューロンは 前 の 層 の すべて の ニューロン と 後 の 層 の すべて の ニューロン と 接続 さ れ て い ます 。 ニュラルネットワーク に は 複数 の 入力 と 複数 の 出力数値 を 入力 し 情報 を 伝播 さ せ 結果 を 出力 し ます 。
出力は確率などの予測 値 として 解釈 可能 で ネットワーク により 予測 を 行う こと が 可能 です
また ニューロン や 層 の 数 を 増やす こと で ニューラルネットワークは高い表現力を発揮するようになります。
以上 の よう に ニューラルネットワーク は シンプル
な 機能 しか 持た ない ニューロン が 層 を 形成 し 層 の 間 で 接続 が 行わ れる こと により 形作ら れ ます 。
*絵心下さい(とにかく沢山のものが集まり層を形成し各自がつながりあってる感じの絵です)
ニューラルネットワークは出力と正解の誤差が小さくなるように重みとバイアスを調整し
バックプロパゲーションと言うアルゴリズムを使い学習していきます。
各パラメーターが繰り返し調整されることでネットワークは次第に学習し適切な予測が行われます。データの読み込みと前処理
import numpy as np from sklearn import datasets #ライブラリーのインポートを行います。 iris = datasets.load_iris() print(iris.data[:10]) print(iris.target[:10]) print(iris.data.shape)from sklearn import datasets
=sklearnからdatasetsをインポートしています。iris=花のデータです。
print(iris.data[:10]) print(iris.target[:10])
=頭から10個のデータを表示してもらいます。print(iris.data.shape)
=データの形状を表示します。出力結果.[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1]] [0 0 0 0 0 0 0 0 0 0] (150, 4)このデータから上から4種類の値、ラベル、データ数、列数
というデータの中身がわかります。前処理
from sklearn import preprocessing from keras.utils import np_utils scaler = preprocessing.StandardScaler() scaler.fit(iris.data) x = scaler.transform(iris.data) print(x[:10]) y = np_utils.to_categorical(iris.target) print(t[:10])from sklearn import preprocessing
=前処理をインポートStandardScaler
=標準化のために使われるscaler.fit(iris.data)
=irisのデータに対してfitを行う(標準化パラメータ)標準化とは、データから平均値を引いて標準偏差で割ったもの
x が標準化されたirisデータ
iris.targetデータをcategorical化します。
1or0だけの表現に変換出力結果.[[-0.90068117 1.01900435 -1.34022653 -1.3154443 ] [-1.14301691 -0.13197948 -1.34022653 -1.3154443 ] [-1.38535265 0.32841405 -1.39706395 -1.3154443 ] [-1.50652052 0.09821729 -1.2833891 -1.3154443 ] [-1.02184904 1.24920112 -1.34022653 -1.3154443 ] [-0.53717756 1.93979142 -1.16971425 -1.05217993] [-1.50652052 0.78880759 -1.34022653 -1.18381211] [-1.02184904 0.78880759 -1.2833891 -1.3154443 ] [-1.74885626 -0.36217625 -1.34022653 -1.3154443 ] [-1.14301691 0.09821729 -1.2833891 -1.44707648]] [[1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.]]参照
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.htmlhttps://keras.io/ja/utils/np_utils/
訓練データとテストデータ
データを訓練用データとテスト用データに分けていきます。
なぜデータを分ける必要があるのか?A、ディープラーニングではデータの精度を高める事が非常に大切になっていきます。
そのためデータを分けておく必要があります。(今回は二つなだけ)
もしデータ全てを訓練用データとして使用した場合、過度に適合したデータが完成してしまい逆に精度が低くなってしまうfrom sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, t, train_size=0.75) print(x_train[:10]) print(x_train.shape) print(x_test.shape)sklearn.model_selection.train_test_split
=参照ソース↓
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.htmlなぜ、train_size=0.75にしたの?
=K-分割交差検証(Cross Validation)出力結果.[[ 0.55333328 -1.28296331 0.70592084 0.92230284] [-0.65834543 1.47939788 -1.2833891 -1.3154443 ] [ 0.67450115 0.32841405 0.87643312 1.44883158] [-1.87002413 -0.13197948 -1.51073881 -1.44707648] [ 2.12851559 -0.13197948 1.61531967 1.18556721] [-0.41600969 -1.28296331 0.13754657 0.13250973] [-1.38535265 0.32841405 -1.22655167 -1.3154443 ] [-0.7795133 1.01900435 -1.2833891 -1.3154443 ] [-1.14301691 0.09821729 -1.2833891 -1.3154443 ] [ 0.67450115 -0.82256978 0.87643312 0.92230284]] (112, 4) (38, 4)データをわけることができました。
モデルの構築
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(32, input_dim=4)) model.add(Activation('relu')) model.add(Dense(32)) model.add(Activation('relu')) model.add(Dense(3)) model.add(Activation('softmax')) model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy']) print(model.summary())~~~~~~~~入力層~~~~~~~~~
model.add(Dense(32, input_dim=4))
で、入力=4(4種類の値)中間層32のニューロンmodel.add(Activation('relu')
活性化関数=relu(「0」を基点として、0以下なら「0」、0より上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数)を代入
~~~~~~~~~~~中間層~~~~~~~~~~~~~~~model.add(Dense(32))
=32のニューロンを結合model.add(Activation('relu'))
=活性化関数を代入
~~~~~~~出力層~~~~~~~~~model.add(Dense(3))
=三つの出口を作ってあげていますmodel.add(Activation('softmax'))
=3つ以上の出口を作るときはsoftmax使うっぽいです~~~~~~~~~~~~~~~~~~~~
↓
コンパイルしてます。
参照
Sequentilal
=https://keras.io/ja/models/sequential/Dense
=https://keras.io/ja/layers/core/#denseActivation:
=https://keras.io/ja/layers/core/#activationsoftmax関数を直感的に理解したい
=https://qiita.com/rtok/items/b1affc619d826eea61fd脳死で覚えるkeras入門
=https://qiita.com/wataoka/items/5c6766d3e1c674d61425出力結果.Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 32) 160 _________________________________________________________________ activation (Activation) (None, 32) 0 _________________________________________________________________ dense_1 (Dense) (None, 32) 1056 _________________________________________________________________ activation_1 (Activation) (None, 32) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 99 _________________________________________________________________ activation_2 (Activation) (None, 3) 0 ================================================================= Total params: 1,315 Trainable params: 1,315 Non-trainable params: 0 _________________________________________________________________ None学習
his = model.fit(x_train, y_train, epochs=30, batch_size=9)epochs=30, batch_size=9
30回データを使う
9個のまとまりEpoch 1/30 13/13 [==============================] - 0s 1ms/step - loss: 1.1210 - accuracy: 0.4930 Epoch 2/30 13/13 [==============================] - 0s 1ms/step - loss: 1.0056 - accuracy: 0.5040 Epoch 3/30 13/13 [==============================] - 0s 1ms/step - loss: 0.8827 - accuracy: 0.7040 Epoch 4/30 13/13 [==============================] - 0s 1ms/step - loss: 0.8044 - accuracy: 0.8141 Epoch 5/30 13/13 [==============================] - 0s 1ms/step - loss: 0.7981 - accuracy: 0.8031 Epoch 6/30 13/13 [==============================] - 0s 1ms/step - loss: 0.7140 - accuracy: 0.7751 Epoch 7/30 13/13 [==============================] - 0s 1ms/step - loss: 0.6903 - accuracy: 0.7695 Epoch 8/30 13/13 [==============================] - 0s 1ms/step - loss: 0.6953 - accuracy: 0.7973 Epoch 9/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5926 - accuracy: 0.8374 Epoch 10/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5871 - accuracy: 0.8065 Epoch 11/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5614 - accuracy: 0.8400 Epoch 12/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5210 - accuracy: 0.8147 Epoch 13/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5227 - accuracy: 0.8099 Epoch 14/30 13/13 [==============================] - 0s 1ms/step - loss: 0.5048 - accuracy: 0.8354 Epoch 15/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4412 - accuracy: 0.8697 Epoch 16/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4572 - accuracy: 0.7845 Epoch 17/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4188 - accuracy: 0.8345 Epoch 18/30 13/13 [==============================] - 0s 1ms/step - loss: 0.4476 - accuracy: 0.8292 Epoch 19/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3701 - accuracy: 0.8872 Epoch 20/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3487 - accuracy: 0.9335 Epoch 21/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3967 - accuracy: 0.8826 Epoch 22/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3888 - accuracy: 0.9157 Epoch 23/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3478 - accuracy: 0.9062 Epoch 24/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3379 - accuracy: 0.9389 Epoch 25/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3224 - accuracy: 0.9245 Epoch 26/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3235 - accuracy: 0.9022 Epoch 27/30 13/13 [==============================] - 0s 2ms/step - loss: 0.3205 - accuracy: 0.9212 Epoch 28/30 13/13 [==============================] - 0s 2ms/step - loss: 0.3049 - accuracy: 0.9498 Epoch 29/30 13/13 [==============================] - 0s 2ms/step - loss: 0.2916 - accuracy: 0.9244 Epoch 30/30 13/13 [==============================] - 0s 1ms/step - loss: 0.3103 - accuracy: 0.9376参照
=https://keras.io/ja/models/sequential/#fit学習モデルの評価、予測
import matplotlib.pyplot as plt hist_loss = history.history['loss'] hist_acc = history.history['acc'] plt.plot(np.arange(len(hist_loss)), hist_loss, label='gosa') plt.plot(np.arange(len(hist_acc)), hist_acc, label='seido') plt.legend() plt.show()
このようなグラフができました。
パット見、回数が増えれば精度があがっているので問題なさそう。。評価
loss, accuracy = model.evaluate(x_test, t_test) print(loss, accuracy)2/2 [==============================] - 0s 3ms/step - loss: 0.3002 - accuracy: 0.8421 0.30019232630729675 0.84210526943206790.84....................
2/2 [==============================] - 0s 3ms/step - loss: 0.3002ん・・・・?????
予測
model.predict(x_test)array([[0.9570871 , 0.03468084, 0.00823214], [0.9415316 , 0.0529235 , 0.00554489], [0.09786918, 0.8637411 , 0.0383897 ], [0.00380978, 0.08060622, 0.91558397], [0.00516732, 0.05931339, 0.93551934], [0.05471139, 0.3572611 , 0.5880275 ], [0.01959354, 0.37794194, 0.60246444], [0.9635058 , 0.03082733, 0.00566692], [0.01309439, 0.07551848, 0.91138715], [0.0096556 , 0.07231863, 0.91802573], [0.95494115, 0.03726008, 0.00779877], [0.9562635 , 0.03845736, 0.00527913], [0.9641995 , 0.02395629, 0.0118442 ], [0.52867496, 0.4659895 , 0.00533543], [0.9613784 , 0.03035152, 0.00827017], [0.04043853, 0.31576672, 0.6437947 ], [0.01528158, 0.10288678, 0.88183165], [0.9151587 , 0.07728348, 0.00755785], [0.01373726, 0.2678833 , 0.71837944], [0.01790639, 0.11440011, 0.8676935 ], [0.93540496, 0.05014379, 0.01445119], [0.00815325, 0.06253443, 0.92931235], [0.05771529, 0.4806437 , 0.461641 ], [0.06256435, 0.44442546, 0.49301007], [0.08182625, 0.7663055 , 0.15186824], [0.08219455, 0.3012668 , 0.6165387 ], [0.9779156 , 0.0143037 , 0.0077807 ], [0.9344322 , 0.0505922 , 0.01497557], [0.06872862, 0.33931345, 0.59195787], [0.9520358 , 0.03229078, 0.01567345], [0.09619313, 0.8281841 , 0.07562277], [0.0197491 , 0.2699217 , 0.7103293 ], [0.9632427 , 0.02939309, 0.00736426], [0.02244722, 0.27921143, 0.6983413 ], [0.0239581 , 0.19942115, 0.7766208 ], [0.05605358, 0.609517 , 0.3344295 ], [0.94509476, 0.04353072, 0.01137454], [0.9617277 , 0.03190768, 0.00636464]], dtype=float32)となりました。
多分どこかで間違えてる気がしかしないです。
また明日挑戦します。
おわり
感想
サイゼまじ愛してるLOVEだからキャッシュレス対応して(勉強の道のりはまだまだ長い・・・・)
圧倒的感謝資料
AIパーフェクトマスター講座 -Google Colaboratoryで隅々まで学ぶ実用的な人工知能/機械学習-
https://www.udemy.com/course/ai-master/
- 投稿日:2021-01-22T18:41:20+09:00
Python による Microsoft Graph API を利用した全グループ情報を取得してみました
概要
Microsoft Graph API を利用してAzureActiveDirectoryから全グループ情報を取得するための Python プログラムです。
Access Token の取得については、このプログラム を使用しています。
全ユーザ情報の取得については こちら を参照ください。実行環境
macOS Big Sur 11.1
python 3.8.3実行プログラム
GetAzureADGroups.pyimport json import requests import argparse import time from GetAzureAccessToken import get_azure_access_token # Azureアクセスのためのアクセストークンの取得オリジナル関数 # 全User情報の取得 def get_ad_all_groups(access_token): # Microsoft Graphを実行するためのヘッダ情報 headers = { 'Authorization': 'Bearer %s' % access_token } # 全グループの id, ddisplayName, mail の取得のURL UsersGet_URL = "https://graph.microsoft.com/v1.0/groups?$count=true&$select=id,displayName,mail&$orderby=displayName" # 全Users情報取得のGetリクエスト res1 = requests.get( UsersGet_URL, headers=headers ) # requrest処理をクローズする res1.close # res1をjsonファイルに整形しユーザ情報の取得 print("取得した全グループ情報:") for num, item in enumerate(res1.json()['value']): print(item) return num+1 if __name__ == '__main__': parser = argparse.ArgumentParser(description='AzureActiveDirectoryの全Group情報の取得') args = parser.parse_args() start = time.time() access_token = get_azure_access_token() num = get_ad_all_groups(access_token) get_time = time.time() - start print("") print(f"全グループ数:{num}") print("取得時間:{0}".format(get_time) + " [sec]") print("")プログラムの実行
最初にヘルプを表示してみます。
$ python GetAzureADGroups.py -h usage: GetAzureADGroups.py [-h] AzureActiveDirectoryの全Group情報の取得 optional arguments: -h, --help show this help message and exitでは、全グループ情報を取得してみます。
$ python GetAzureADGroups.py 取得した全グループ情報: 中略 {'id': 'ae666666-9196-4586-8788-5521024bbbbb', 'displayName': 'PSG0', 'mail': None} {'id': 'b8811111-2986-4615-8823-11bbdd56d000', 'displayName': 'PSG1', 'mail': None} {'id': 'de999999-5059-4656-9512-7800bd514444', 'displayName': 'PSG2', 'mail': None} 中略 全グループ数:28 取得時間:0.5144941806793213 [sec]参考情報
以下の情報を参考にさせていただきました。感謝いたします。
- 投稿日:2021-01-22T18:03:19+09:00
Python による Microsoft Graph API を利用した全ユーザ情報を取得してみました
概要
Microsoft Graph API を利用してAzureActiveDirectoryから全ユーザ情報を取得するための Python プログラムです。
Access Token の取得については、このプログラム を使用しています。
全グループ情報の取得については こちら を参照ください。実行環境
macOS Big Sur 11.1
python 3.8.3実行プログラム
GetAzureADUsers.pyimport json import requests import argparse import time from GetAzureAccessToken import get_azure_access_token # Azureアクセスのためのアクセストークンの取得オリジナル関数 # 全User情報の取得 def get_ad_all_users(access_token): # Microsoft Graphを実行するためのヘッダ情報 headers = { 'Authorization': 'Bearer %s' % access_token } # 全メンバーの id, ddisplayName の取得のURL UsersGet_URL = "https://graph.microsoft.com/v1.0/users?$count=true&$select=id,displayName,mail&$orderby=displayName" # 全Users情報取得のGetリクエスト res1 = requests.get( UsersGet_URL, headers=headers ) # requrest処理をクローズする res1.close # res1をjsonファイルに整形しユーザ情報の取得 print("取得した全ユーザ情報:") for num, item in enumerate(res1.json()['value']): print(item) return num+1 if __name__ == '__main__': parser = argparse.ArgumentParser(description='AzureActiveDirectoryの全User情報の取得') args = parser.parse_args() start = time.time() access_token = get_azure_access_token() # Access_tokenの取得 num = get_ad_all_users(access_token) # 全ユーザ情報の取得 get_time = time.time() - start print("") print(f"全ユーザ数:{num}") print("取得時間:{0}".format(get_time) + " [sec]") print("")プログラムの実行
最初にヘルプを表示してみます。
$ python GetAzureADUsers.py -h usage: GetAzureADUsers.py [-h] AzureActiveDirectoryの全User情報の取得 optional arguments: -h, --help show this help message and exitでは、全ユーザ情報を取得してみます。
$ python GetAzureADUsers.py 取得した全ユーザ情報: 中略 {'id': 'c3333333-e7e7-4949-8989-5539d465ffff', 'displayName': '山田 太郎', 'mail': 'yamada@hogehoge.com'} {'id': '25999999-c8c8-4242-baab-e477b1990000', 'displayName': '鈴木 一郎', 'mail': 'suzuki@hogehoge.com'} {'id': '3f666666-e5e5-4444-8558-0fe4ef0cceee', 'displayName': '木下 藤吉', 'mail': 'kinoshita@hogehoge.com'} 中略 全ユーザ数:100 取得時間:0.7425880432128906 [sec]参考情報
以下の情報を参考にさせていただきました。感謝いたします。
Azure AD ユーザーアカウントの棚卸しに便利なスクリプト
Microsoft Graph を使ってみよう : Graph エクスプローラー
- 投稿日:2021-01-22T15:50:09+09:00
複数のExcelファイルのデータを1つのJSON形式ファイルとして書込みしてみます
はじめに
AWS SDK for Python(boto3) を使って、プログラムをほぼ変更せずに Cloudian と S3 へのアクセスが可能となります。 クレデンシャル情報の定義を変更するだけで、オブジェクトストレージをハイブリッド(オンプレミス:Cloudian、AWS:S3)で使いたい方への参考になればと、、、
概要
複数の同一書式のExcelファイルのデータをJSON形式に変換し、1ファイル1レコードとして、オブジェクトストレージCloudian/S3 に1つのファイルとして書込む Python プログラムです。
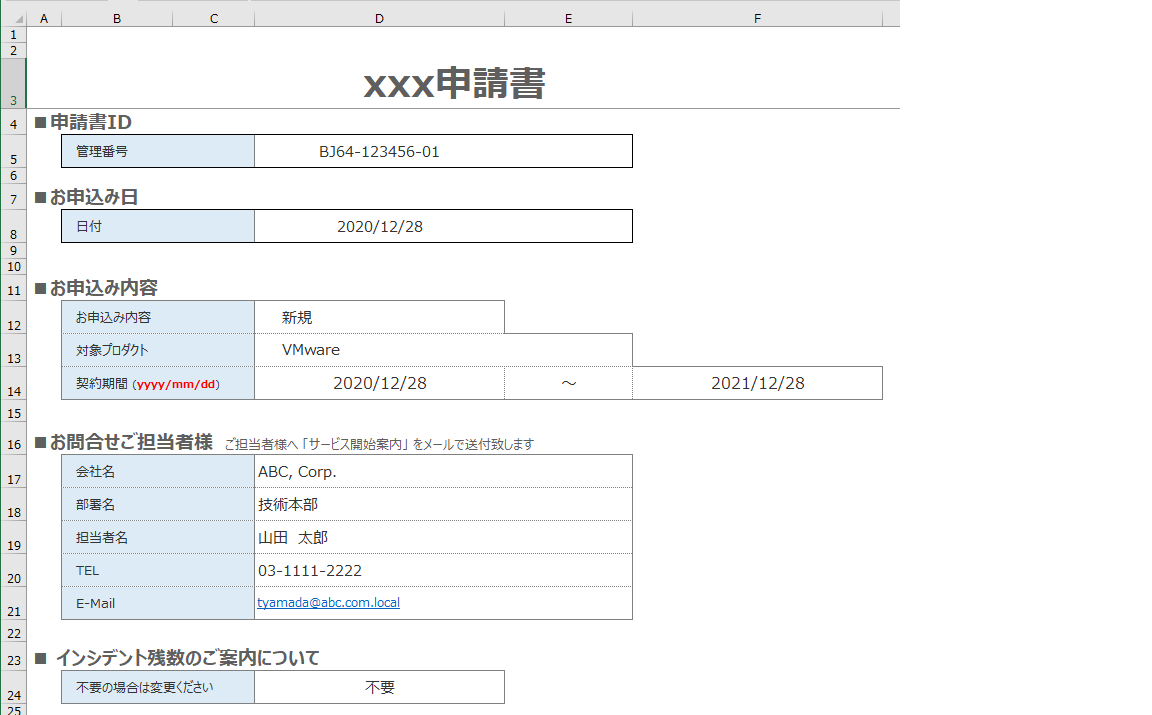
そのExcelファイルのフォルダ(Path)と変換後のJSONファイルをパラメータで指定します。同一書式の申請書等の複数のExcelファイルを一括してJSON形式への変換を想定し、なんちゃってRPAとして使えるかもと想定しております。変換するデータ項目についてはプログラム内の「OrderedDict」を参照ください。
パラメータは以下の3種類となります。
--rpath : 複数Excelファイルが存在するディレクトリ(Path)を指定
--wfile : JSON変換データを書き込むファイル名を指定
--mode : 変換データの出力先の指定 lo:ローカルへの出力、 s3:Cloudian/S3への出力(デフォルト:lo)プログラム実行時に、パラメータ「-h」を指定することにより表示されるヘルプも参照ください。
実行環境
macOS Big Sur 11.1
python 3.8.3クレデンシャル情報の定義
今回はクレデンシャル情報を .zshenv に定義してプログラムを実行しています。接続先に合わせて定義ください。
# AWS S3 export AWS_ACCESS_KEY_ID=xxxxxxxxxxxxx export AWS_SECRET_ACCESS_KEY=yyyyyyyyyyyyyyyyy export AWS_DEFAULT_REGION=ap-northeast-1 # Cloudian #export AWS_ACCESS_KEY_ID=aaaaaaaaaaaaaaaaaa #export AWS_SECRET_ACCESS_KEY=bbbbbbbbbbbbbbbbbbbb #export AWS_DEFAULT_REGION=pic実行プログラム
Cloudianへデータ出力する場合は endpoint_url を記載ください(プログラム内を参照ください)。
ManyExcelSample-openpyxl.pyimport json import time from datetime import date, datetime from collections import OrderedDict import argparse import string import boto3 import pprint import sys import openpyxl import pathlib BUCKET_NAME = 'boto3-cloudian' # 複数のExcelファイルの取得 def excels_to_json(rpath) : xlsx_files = list(pathlib.Path(rpath).glob('*.xlsx')) # xlsxファイル群のリスト作成 many_excel_list = [] for i in xlsx_files: rfile = '%s%s' % (rpath, i.name) # パス+xlsxファイル many_excel_list.append([excel_to_json(rfile)]) # JSONデータの作成 return many_excel_list, len(xlsx_files) # 対象Excelファイルから送信JSONデータの作成 def excel_to_json(rfile) : excel_rfile = openpyxl.load_workbook(rfile) # Excelのロード sheet = excel_rfile['申請書'] # ExcelのSheet名 excel_list = OrderedDict({ "file_name": rfile, # 変換Excelファイル名 "time": generate_time(), # データ変換時間 "manage_id": sheet.cell(row = 5, column = 4).value, # 管理ID "date": json_trans_date(sheet.cell(row = 8, column = 4).value), # 申込日 "class": sheet.cell(row = 12, column = 4).value, # 申込み区分 "product": sheet.cell(row = 13, column = 4).value, # 対象製品 "from_date": json_trans_date(sheet.cell(row = 14, column = 4).value), # 期間(From) "to_date": json_trans_date(sheet.cell(row = 14, column = 6).value), # 期間(To) "comp": sheet.cell(row = 17, column = 4).value, # 会社名 "dept": sheet.cell(row = 18, column = 4).value, # 部署 "name": sheet.cell(row = 19, column = 4).value, # 担当者 "tel": sheet.cell(row = 20, column = 4).value, # 電話番号 "email": sheet.cell(row = 21, column = 4).value, # メールアドレス "guide": sheet.cell(row = 24, column = 4).value, # 案内有無 }) return excel_list # データ生成時間 def generate_time(): dt_time = datetime.now() gtime = json_trans_date(dt_time) return gtime # date, datetimeの変換関数 def json_trans_date(obj): # 日付型を文字列に変換 if isinstance(obj, (datetime, date)): return obj.isoformat() # 上記以外は対象外. raise TypeError ("Type %s not serializable" % type(obj)) # メイン(ローカル出力用) def lo_openpyxl(rpath, wfile) : print('Excelファイルと同じディレクトリにJSONファイルを生成') excel_dict, count = excels_to_json(rpath) pprint.pprint(excel_dict) with open(wfile, mode = 'w', encoding = 'utf-8') as f: f.write(json.dumps(excel_dict, ensure_ascii = False, indent = 4)) return count # メイン(Cloudian/S3 出力用) def s3_openpyxl(rpath, wfile) : print('Cloudian/S3 にJSONファイルを生成') excel_dict, count = excels_to_json(rpath) # client = boto3.client('s3', endpoint_url='http://s3-pic.networld.local') # Cloudianへのアクセス時 client = boto3.client('s3') # S3へのアクセス時 client.put_object( Bucket=BUCKET_NAME, Key=wfile, Body=json.dumps(excel_dict, ensure_ascii = False, indent = 4) ) return count if __name__ == '__main__': parser = argparse.ArgumentParser(description='複数のExcelデータファイルをopenpyxlを使用して、1つのJSONデータファイルを生成') parser.add_argument('--rpath', type=str, default='./', help='複数Excelファイルが存在するディレクトリ(Path)を指定') parser.add_argument('--wfile', type=str, help='JSON変換データを書き込むファイル名を指定') parser.add_argument('--mode', type=str, default='lo', help='lo(変換データをローカル出力)/ s3(変換データをCloudian/S3出力)') args = parser.parse_args() if not args.wfile: print("\n\r 書き込むJSONファイルを指定ください \n\r") sys.exit() start = time.time() if (args.mode == 's3'): count = s3_openpyxl(args.rpath, args.wfile) else : count = lo_openpyxl(args.rpath, args.wfile) convert_time = time.time() - start print("") print(f"データ変換Excelファイル数:{count}") print("データ変換時間:{0}".format(convert_time) + " [sec]") print("")複数の同一書式のExcelファイル
今回、2つの同一書式Excelファイルを用意しています(何かの申請書を想定)。
$ ls -al *.xlsx -rwxrwxrwx@ 1 hoge staff 14012 12 30 14:27 001-ABC_SampleForm.xlsx* -rwxrwxrwx@ 1 hoge staff 14007 12 30 14:27 002-XYZ_SampleForm.xlsx*
プログラムの実行
最初にヘルプを表示してみます。
$ python ManyExcelSample-openpyxl.py -h usage: ManyExcelSample-openpyxl.py [-h] [--rpath RPATH] [--wfile WFILE] [--mode MODE] 複数のExcelデータファイルをopenpyxlを使用して、1つのJSONデータファイルを生成 optional arguments: -h, --help show this help message and exit --rpath RPATH 複数Excelファイルが存在するディレクトリ(Path)を指定 --wfile WFILE JSON変換データを書き込むファイル名を指定 --mode MODE lo(変換データをローカル出力)/ s3(変換データをCloudian/S3出力)次に、プログラムと同一フォルダにある複数のExcelファイルのダータをLocalのJSONファイル出力してみます。
$ python ManyExcelSample-openpyxl.py --wfile abc.json : 出力内容は割愛 : データ変換Excelファイル数:2 データ変換時間:0.03844475746154785 [sec]作成されたJSONデータを確認してみます。
$ cat abc.json [ [ { "file_name": "./002-XYZ_SampleForm.xlsx", "time": "2021-01-22T14:40:01.478800", "manage_id": "BJ74-456789-02", "date": "2020-12-27T00:00:00", "class": "新規", "product": "Azure", "from_date": "2021-01-01T00:00:00", "to_date": "2021-03-31T00:00:00", "comp": "XYZ, Inc.", "dept": "IoTソリューション部", "name": "磯野 カツオ", "tel": "06-333-4567", "email": "katsuo@xyz.com.local", "guide": "ご案内を希望します" } ], [ { "file_name": "./001-ABC_SampleForm.xlsx", "time": "2021-01-22T14:40:01.494818", "manage_id": "BJ64-123456-01", "date": "2020-12-28T00:00:00", "class": "新規", "product": "VMware", "from_date": "2020-12-28T00:00:00", "to_date": "2021-12-28T00:00:00", "comp": "ABC, Corp.", "dept": "技術本部", "name": "山田 太郎", "tel": "03-1111-2222", "email": "tyamada@abc.com.local", "guide": "不要" } ] ]今度は、それらのExcelファイルデータを Cloudian/S3 にJSONファイル出力してみます。
$ python ManyExcelSample-openpyxl.py --wfile abc.json --mode s3 データ変換Excelファイル数:2 データ変換時間:0.2519500255584717 [sec]参考情報
以下の情報を参考にさせていただきました。感謝いたします。
まとめ
今回は、AWS SDK for Python(boto3) を使って、オブジェクトストレージ Cloudian / S3 へ Excelデータ を JSONデータに変換し保存することを確認できました。
こちらの記事 も参照ください。
- 投稿日:2021-01-22T15:45:49+09:00
多項式回帰分析
0.はじめに
初めまして。Qiita初投稿です。
現在、エンジニアへの転職へ向けてpythonによるデータ分析などを学習しています。
自身の備忘録として書いていますので、間違いや気になるところなどあればご指摘頂けるとありがたいです。
1.単回帰分析と多項式回帰分析
どちらも2つの量的データの関係を予測する分析手法ですが、
・単回帰分析 一次式を用いて直線的に予測
・多項式回帰分析 多項式を用いて曲線的に予測
の違いがあります。
式で書くと、
単回帰分析・・・y = wx + b
多項式回帰分析・・・ y = w0x0 + w1x1 + w2x2 + ... + b02.pythonでの実装
1.データの読み込み
sklearnのデータセット boston.data を使って実装してみます。
(参考【データ解析】ボストン住宅価格データセットを使ってデータ解析する)まずは、データの読み込みから、
import pandas as pd from sklearn.datasets import load_boston #説明変数となるデータ boston = load_boston() boston_df = pd.DataFrame(boston.data, columns=boston.feature_names) #目的変数の追加 boston_df['MEDV'] = boston.target2.データの可視化
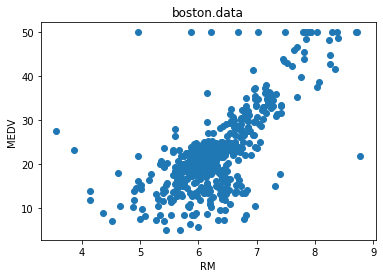
説明変数にRM(平均部屋数)、目的変数にMEDV(住宅価格)を使用しています。
import matplotlib.pyplot as plt #平均部屋数RMと住宅価格MEDVの散布図 x = boston_df['RM'] y = boston_df['MEDV'] plt.scatter(x, y) plt.title('boston.data') plt.xlabel('RM') plt.ylabel('MEDV') plt.show()
3.学習用データとテストデータに分割する
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)4.モデルの作成
PolynomialFeaturesの引数degreeに任意の値を指定することで、N項の多項式にすることができる。
以下では、degree=1(1項なので単回帰分析)、degree=4(4項の多項式分析)を試している。from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline x_train = np.array(x_train).reshape(-1, 1) y_train = np.array(y_train) #degree=1で単回帰分析 model_1 = Pipeline([ ('poly', PolynomialFeatures(degree=1)), ('linear', LinearRegression()) ]) model_1.fit(x, y) #degreeの値に任意の値を指定することで、多項式分析に(以下は4項) model_2 = Pipeline([ ('poly', PolynomialFeatures(degree=4)), ('linear', LinearRegression()) ]) model_2.fit(x, y)5.散布図と回帰モデルの可視化
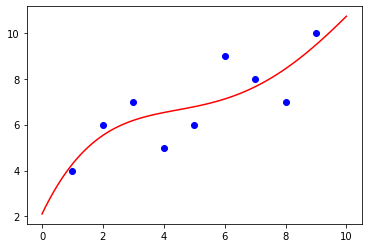
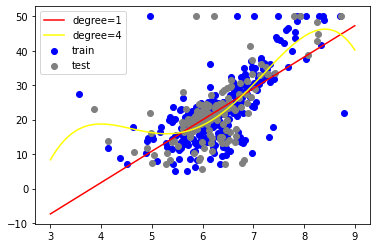
fig, ax = plt.subplots() ax.scatter(x_train, y_train, color='blue', label='train') ax.scatter(x_test, y_test, color='gray', label='test') x_ = np.linspace(3, 9, 100).reshape(-1, 1) plt.plot(x_, model_1.predict(x_), color='red', label='degree=1') plt.plot(x_, model_2.predict(x_), color='yellow', label='degree=4') plt.legend() plt.show()
degreeの値を増やせば、もっとグニャグニャの線になり、学習データに対して適合した線になっていくが、増やし過ぎると過学習になってしまうので、調整が必要。
この他、正則化によって過学習を抑える方法もある。

- 投稿日:2021-01-22T15:41:17+09:00
tkinterのEntryから取得した値をリストの末尾に追加する
背景
クラスがよくわかっていなかったので、自らの勉強を兼ねて書いてみた。
クラスのコードを試しに書いてみる
試しに、以下のような簡単なクラスを書いてみる。
tkclass.pyclass x: def __init__(self,x): #クラスを実行したときに必ず実行されるメソッド self.x = x def go(self): self.x = x #__init__で取得した変数xを引き継いでいる。 print(x)ここで、Xというのがクラスの名前である。
また、クラス内での関数はメソッドと呼ばれる。ただ、ここでxの内容を入れてもこのままでは呼び出されない。
ここで、インスタンスというものを定義するtest.pyyobidashi =x(10)このyobidashiが、インスタンス名(クラスを呼び出したいときの名前)である。
(10)は、xに入れたい引数を入れている。test.pyyobidashi =x(10) yobidashi.go()実際にインスタンスを呼び出したいときは、インスタンス名.メソッド名(引数が必要な場合は引数)で呼び出すことができる。
ここでは、yobidashi.go()で、yobidashiインスタンスのうち、goメソッドだけ呼び出している出力結果としてはこうなる。
test.py10Tkinterでクラスを作ってみる
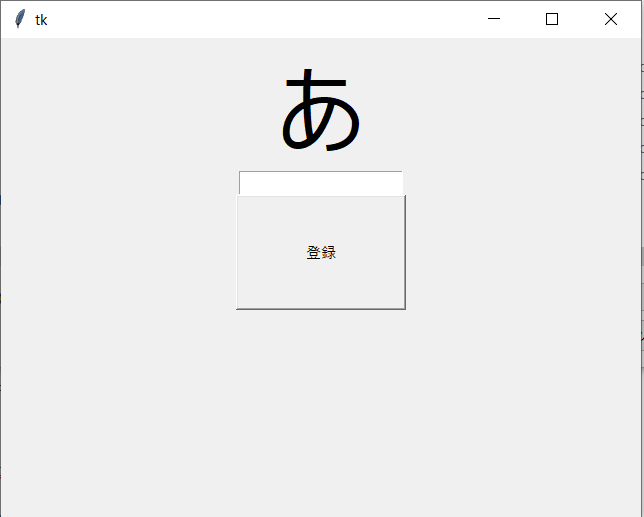
内容としては、EntryBoxに入れた文字を指定されたリストの末尾に代入し、その文字をStringVar()でラベルを更新する
test.pyimport tkinter as tk #客リスト namelist=[] #commandにクラスのメソッドを当ててみるテスト class disp(): e=0 l=0 #土台を作成 def tki(self): global e global l root = tk.Tk() root.geometry("640x480") l = tk.StringVar() l.set("あ") la = tk.Label(textvariable=l,font=("Meiryo UI",60)) la.pack() e = tk.Entry(width=20) e.pack() bt = tk.Button(text="登録",width=20,height=5,command=self.nameappend) bt.pack() root.mainloop() #list_append def nameappend(self): global e global l global namelist get1 = e.get() namelist.append(get1) if str(get1) == "": l.set("名前を入力してください!") else: l.set(str(get1)+"さんを名前リストに追加しました") print(namelist) #インスタンス作成 d = disp() d.tki()出来上がりイメージ
参考サイト
buttonのcommandにクラスのメソッドを割り当てる方法 https://www.shido.info/py/tkinter5.html
super()の使い方 https://teratail.com/questions/85379


- 投稿日:2021-01-22T15:40:56+09:00
[Python]リストの最後から順に取り出す
はじめに
気まぐれでアルゴリズムの問題を解くことがあるのですが、このときは普段利用しないPythonを選択しています。
その中で、Pythonにおいて「リストの最後から順に要素を取り出す」という操作をどうしたらいいのかで悩みました。Python自体、めったに利用することがなく、基本的なfor文の書き方すら頭から抜け落ちることもあるため、
基礎から学び直しつつ、最後に「リストの最後から順に要素を取り出す」にチャレンジします。また、こちらは、エンジニアの新たな学びキャンペーンに向けた記事となります。
まず基本的なfor文から
for 変数 in データの集まり: 実行する処理適当なリストを作成し、そのリストについて操作してみます。
a = ["hoge", "foo", "bar", "fuga"] for i in range(4): print(a[i]) # hoge # foo # bar # fugafor i in range(len(a)): print(a[i]) # hoge # foo # bar # fuga拡張for文のように書く
他言語でいうところの拡張for文のように処理することもできます
ここではiはインデックスではなく、リスト内のリテラルとなりますfor i in a: print(i) # hoge # foo # bar # fuga飛ばし飛ばしで要素を取得する
print(list(range(0, 10, 3))) # [0, 3, 6, 9]0を出発点、10を終了点として、3飛ばしで要素を取得することができるメソッドのようです。
リストの最後から次々に取り出す
前述 #飛ばし飛ばしで要素を取得するを利用して、
リストの最後のインデックスを出発点、リストの最初を到達点、-1ずつ飛ばしていくという引数指定をしてみます。a = ["hoge", "foo", "bar", "fuga"] for i in range(len(a), 0, -1): print(a[i]) # Traceback (most recent call last): # File "Main.py", line 3, in <module> # print(a[i]) # IndexError: list index out of rangeエラー文を読むと、リストのインデックスの当て方が間違っていたようです。
今回はリストの個数は4ですが、厳密には0番から3番目までに要素が格納されています。
従って、出発点はlen(a)-1ではないかと想像します。
また、第二引数である到達点について、「この数字に達する直前の数」まで適用するため、ここに記載すべきは0ではなく-1であると想像します。そこで以下のようなソースコードに書き換えました。
a = ["hoge", "foo", "bar", "fuga"] for i in range(len(a)-1, -1, -1): print(a[i]) # fuga # bar # foo # hoge「リストの最後から順に取り出す」という、意図していた挙動が確認できました。
しかし-1が引数に複数含まれていて、なんとも見づらいですね。リストの最後から次々に取り出す(別解)
別解というよりもこちらのほうがスタンダードな気配さえするのですが、
reverseでリストの順序を逆転させることができるようで、これを使えばさらに簡単に目的が達成できそうです。
とはいえ、もともと用意していたリストの順序そのものが変わってしまうので、一癖はあるのかなと感じます。a = ["hoge", "foo", "bar", "fuga"] a.reverse() for i in a: print(i)もとのリストの順序を変えずに済む方法も、こちらに紹介されていたので、これに沿って書き直してみます。
a = ["hoge", "foo", "bar", "fuga"] for i in reversed(a): print(i) print(a) # fuga # bar # foo # hoge # ['hoge', 'foo', 'bar', 'fuga']おわりに
Udemy学習応援ということで、本記事で扱ったUdemy講座の内容について、最後に触れます。
『【基礎を全解説】はじめての人の無料で学べるPython超入門!』はタイトルの通り、初心者向けの講座となっています。
他言語を少しやったことのある人向けというよりは、今からプログラム言語に初めて触れる人を対象にしており、
環境構築の方法や、変数とは何か?といったところから解説されていて、本当に土台から学べるコースになっています。さらに無料であることも大きなポイントかと思います。
他言語の習得済みの方にとっては物足りない内容だろうなと感じる一方で、
真に初心者な方にとっては強力な教材であると感じます。このコースの習得後に、例えばPaizaのPythonコースといった、初心者向けでありながらも やや発展的&演習問題つきの教材、
あるいは私は存じ上げないのですがUdemyの発展的教材に向かうのが良いかなと思います。参考
参考
- 投稿日:2021-01-22T14:21:25+09:00
テキストデータをキーワードで区切ってブロックごとに配列に入れる
同じテキストデータにいろいろ書きこんじゃったけどそれぞれのデータを区分して配列に入れたいとき、ありますよね。
a.pyfilename = 'yourtxt.txt' keyword = '区切る言葉' with open(filename, 'r', encoding='utf-8') as f: text = f.read().splitlines() sp_num =[] sp_txt =[] a = 0 num = 0 while num != len(text): num = text.index(keyword,a,len(text)) sp_txt = list(text[a:num]) print(sp_txt) a = num+1while文でテキストファイルの終わるまで繰り返す。
キーワードがあるたびに次のキーワードの一つ前までの単語をリスト化して配列に入れます。
そもそもsplitlinesして読み込んだファイルを行ごとに分割しているのですが、これはテキストデータが結構箇条書きっていうのは大きいです。
長文の場合は少し変わってくるかと思います。
- 投稿日:2021-01-22T14:06:53+09:00
AtCoder Tips
入力について
https://qiita.com/kyuna/items/8ee8916c2f4e36321a1c
round(元の数字,(桁数))
ただし、端数がちょうど0.5なら切り捨てと切り上げのうち結果が偶数となる方へ丸める。
round(0.5)
→0
round(1.5)
→2
round(2.5)
→2
round(3.5)
→4
round(4.5)
→4sys
sys.exit()
処理を終了させる。
Pythonimport sys sys.exit()math
math.sqrt()
Pythonimport math math.sqrt(数字)math.log(数字、底)
Pythonimport math math.log(数字,底)sort
リスト.sort()
→小さい順に並べる。リスト.sort(reverse=True)
→大きい順に並べる。join
python'間に挿入する文字列'.join([連結したい文字列のリスト])
- 投稿日:2021-01-22T13:40:31+09:00
モーフィングの練習
きっかけ
- VS嵐のコーナーで、人の顔や物が別の人の顔へ変化していくというものがあった。
これをそのままゲームにしたいと思った。- また、私の好きな黒崎真音 さんが神田沙也加 さんに似ているという話から、似ている人がモーフィングされたらどうなるのか興味を持った。
モーフィングの参考
というかコピペで利用させていただいた。
顔モーフィング
ありがとうございます。準備
- anacondaを利用して環境構築する
- モーフィングしたい画像を収集する
実装
コードの概要
- morphing.py
- 画像ファイルパスを二つ、出力先フォルダパスを引数で与える
- 1%~99%まで係数を与えて徐々に変化していく画像を100枚作る
- creategif.py
- 画像があるフォルダを引数で与える(上記morphing.pyで出力されたフォルダ)
- 作成された画像のフォルダで実行し、画像を繋ぎ合わせてアニメーション化する
作ったコード(ほぼコピペ)
morphing.pyimport argparse import cv2 import numpy as np import random import dlib from imutils import face_utils import sys import os import shutil def Face_landmarks(image_path): print("[INFO] loading facial landmark predictor...") detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") image = cv2.imread(image_path) size = image.shape gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) rects = detector(gray, 0) if len(rects) > 2: print("[ERR] too many faces fount...") # print("[Error] {} faces found...".format(len(rect))) sys.exit(1) if len(rects) < 1: print("[ERR] face not found...") # print("[Error] face not found...".format(len(rect)) sys.exit(1) for rect in rects: (bX, bY, bW, bH) = face_utils.rect_to_bb(rect) print("[INFO] face frame {}".format(bX, bY, bW, bH)) shape = predictor(gray, rect) shape = face_utils.shape_to_np(shape) points = shape.tolist() # (0,0),(x,0),(0,y),(x,y) points.append([0, 0]) points.append([int(size[1]-1), 0]) points.append([0, int(size[0]-1)]) points.append([int(size[1]-1), int(size[0]-1)]) # (x/2,0),(0,y/2),(x/2,y),(x,y/2) points.append([int(size[1]/2), 0]) points.append([0, int(size[0]/2)]) points.append([int(size[1]/2), int(size[0]-1)]) points.append([int(size[1]-1), int(size[0]/2)]) cv2.destroyAllWindows() return points def Face_delaunay(rect,points1 ,points2 ,alpha ): points = [] for i in range(0, len(points1)): x = ( 1 - alpha ) * points1[i][0] + alpha * points2[i][0] y = ( 1 - alpha ) * points1[i][1] + alpha * points2[i][1] if rect[2] < x: print(rect[2], x) x = rect[2]-0.01 elif rect[3] < y: print(rect[3], y) y = rect[3]-0.01 points.append((x,y)) triangles, delaunay = calculateDelaunayTriangles(rect, points) cv2.destroyAllWindows() return triangles, delaunay def calculateDelaunayTriangles(rect, points): subdiv = cv2.Subdiv2D(rect) for p in points: subdiv.insert(p) triangleList = subdiv.getTriangleList() delaunayTri = [] pt = [] for t in triangleList: pt.append((t[0], t[1])) pt.append((t[2], t[3])) pt.append((t[4], t[5])) pt1 = (t[0], t[1]) pt2 = (t[2], t[3]) pt3 = (t[4], t[5]) if rectContains(rect, pt1) and rectContains(rect, pt2) and rectContains(rect, pt3): ind = [] for j in range(0, 3): for k in range(0, len(points)): if(abs(pt[j][0] - points[k][0]) < 1.0 and abs(pt[j][1] - points[k][1]) < 1.0): ind.append(k) if len(ind) == 3: delaunayTri.append((ind[0], ind[1], ind[2])) pt = [] return triangleList,delaunayTri def rectContains(rect, point) : if point[0] < rect[0] : return False elif point[1] < rect[1] : return False elif point[0] > rect[0] + rect[2] : return False elif point[1] > rect[1] + rect[3] : return False return True def betweenPoints(point1, point2, alpha) : points = [] for i in range(0, len(points1)): x = ( 1 - alpha ) * points1[i][0] + alpha * points2[i][0] y = ( 1 - alpha ) * points1[i][1] + alpha * points2[i][1] points.append((x,y)) return points def Face_morph(img1, img2, img, tri1, tri2, tri, alpha) : """モーフィング画像作成 Args: img1 : 画像1 img2 : 画像2 img : 画像1,2のモーフィング画像(Output用画像) tri1 : 画像1の三角形 tri2 : 画像2の三角形 tri : 画像1,2の間の三角形 alpha: 重み """ # 各三角形の座標を含む最小の矩形領域 (バウンディングボックス)を取得 # (左上のx座標, 左上のy座標, 幅, 高さ) r1 = cv2.boundingRect(np.float32([tri1])) r2 = cv2.boundingRect(np.float32([tri2])) r = cv2.boundingRect(np.float32([tri])) # バウンディングボックスを左上を原点(0, 0)とした座標に変換 t1Rect = [] t2Rect = [] tRect = [] for i in range(0, 3): tRect.append(((tri[i][0] - r[0]),(tri[i][1] - r[1]))) t1Rect.append(((tri1[i][0] - r1[0]),(tri1[i][1] - r1[1]))) t2Rect.append(((tri2[i][0] - r2[0]),(tri2[i][1] - r2[1]))) # 三角形のマスクを生成 # 三角形の領域のピクセル値は1で、残りの領域のピクセル値は0になる mask = np.zeros((r[3], r[2], 3), dtype = np.float32) cv2.fillConvexPoly(mask, np.int32(tRect), (1.0, 1.0, 1.0), 16, 0) # アフィン変換の入力画像を用意 img1Rect = img1[r1[1]:r1[1] + r1[3], r1[0]:r1[0] + r1[2]] img2Rect = img2[r2[1]:r2[1] + r2[3], r2[0]:r2[0] + r2[2]] # アフィン変換の変換行列を生成 warpMat1 = cv2.getAffineTransform( np.float32(t1Rect), np.float32(tRect) ) warpMat2 = cv2.getAffineTransform( np.float32(t2Rect), np.float32(tRect) ) size = (r[2], r[3]) # アフィン変換の実行 # 1.src:入力画像、2.M:変換行列、3.dsize:出力画像のサイズ、4.flags:変換方法、5.borderMode:境界の対処方法 warpImage1 = cv2.warpAffine( img1Rect, warpMat1, (size[0], size[1]), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REFLECT_101 ) warpImage2 = cv2.warpAffine( img2Rect, warpMat2, (size[0], size[1]), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REFLECT_101 ) # 2つの画像に重みを付けて、三角形の最終的なピクセル値を見つける #print(warpImage1.shape, warpImage2.shape) imgRect = (1.0 - alpha) * warpImage1 + alpha * warpImage2 # マスクと投影結果を使用して論理AND演算を実行し、 # 三角形領域の投影されたピクセル値を取得しOutput用画像にコピー #print("mask:",mask) #print("imgRect:",imgRect) #print("r:",r) img[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] = img[r[1]:r[1]+r[3], r[0]:r[0]+r[2]] * ( 1 - mask ) + imgRect * mask if __name__ == '__main__' : # モーフィングする画像取得 filename1 = sys.argv[1] filename2 = sys.argv[2] print(sys.argv) img1 = cv2.imread(filename1) img2 = cv2.imread(filename2) # 画像をfloat型に変換 img1 = np.float32(img1) img2 = np.float32(img2) print("img1:",img1.shape) print("img2:",img2.shape) # 長方形を取得 size = img1.shape rect = (0, 0, size[1], size[0]) #print(rect) # 顔の特徴点を取得 points1 = Face_landmarks(filename1) points2 = Face_landmarks(filename2) # 1~99%割合を変えてモーフィング for cnt in range(1, 100): alpha = cnt * 0.01 # 画像1,2の特徴点の間を取得 points = betweenPoints(points1,points2,alpha) # ドロネーの三角形(座標配列とpoints要素番号)を取得 triangles, delaunay = Face_delaunay(rect,points,points2,alpha) # モーフィング画像初期化 imgMorph = np.zeros(img1.shape, dtype = img1.dtype) # ドロネー三角形の配列要素番号を読込 for (i, (x, y, z)) in enumerate(delaunay): # ドロネー三角形のピクセル位置を取得 tri1 = [points1[x], points1[y], points1[z]] tri2 = [points2[x], points2[y], points2[z]] tri = [points[x], points[y], points[z]] # モーフィング画像を作成 Face_morph(img1, img2, imgMorph, tri1, tri2, tri, alpha) # モーフィング画像をint型に変換し出力 imgMorph = np.uint8(imgMorph) os.makedirs(sys.argv[3], exist_ok=True) stroutfile = sys.argv[3] + '/picture-%s.png' cv2.imwrite(stroutfile % str(cnt).zfill(3),imgMorph) strcopyfilezero = sys.argv[3] + '/picture-000.png' strcopyfilehund = sys.argv[3] + '/picture-100.png' shutil.copyfile(filename1, strcopyfilezero) shutil.copyfile(filename2, strcopyfilehund)creategif.pyfrom PIL import Image import glob import sys images = [] for i in range(100): file_name = sys.argv[1] + '/picture-' + str(i).zfill(3) + '.png' im = Image.open(file_name) images.append(im) images[0].save(sys.argv[1] + '/image.gif' , save_all = True , append_images = images[1:] , duration = 100 , loop = 0)実装がうまくいかなかった点
顔モーフィング の筆者は関数の役割毎にファイルを分けており、
face_landmarks.Face_landmarks(filename1)のように記載していた
pythonを使ったことが無いので、別ファイルの関数呼び出しが分からず、全部一つのファイルにまとめ、
Face_landmarks(filename1)とした。
調べればよいが、とりあえず実行してみたかったので飛ばした。"import dlib"が記載されていなかったりしてエラーが出る
- ライブラリの宣言は重要
範囲外を触っているというエラーが出た
calculateDelaunayTriangles()subdiv = cv2.Subdiv2D(rect) for p in points: subdiv.insert(p)
- subdiv.insert(p)でエラー発生
- 渡した二つの画像サイズが違うため起こっていた
- 最初は安直にrectの値を+1して範囲に収まるようにしていたが、
ほかの箇所でエラーが出てしまった- ペイントでピクセルサイズを合わせる
結果
入力画像

出力画像をgifに整形
ということで、失敗した。
口が認識できていない?色、角度の問題か?
参考にさせていただいた著者の方、真音さん、沙也加さんごめんなさい。グレーにして再挑戦
入力画像

出力画像
こっちはほぼ成功!
なぜ失敗したのか
カラーに対応していないコードだった?
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- ここでグレーに変換している
- 特徴点の検出がうまくできていない?
このアルゴリズムの欠点
- 顔の特徴点が全て取れないと進めない
- 眉毛が前髪で全く見えなかったり、顔の輪郭が手で隠れているとダメみたい。




- 投稿日:2021-01-22T13:16:12+09:00
Pythonでテキストファイルの行数を取得する方法
Pythonでテキストファイルの行数を取得
import subprocess cmd = "wc -l [テキストファイル名]" c = subprocess.check_output(cmd.split()).decode().split()[0] print(c) #行数990002のファイルにかかった時間 0.05637836456298828 (sec)他に以下でも取得できる
print(len(open('[テキストファイル名]').readlines())) #行数990002のファイルにかかった時間 0.2346503734588623 (sec) print(sum(1 for line in open('[テキストファイル名]'))) #行数990002のファイルにかかった時間 0.1792283058166504 (sec)それぞれかかる時間を比較すると、一番上の方法が最も速いが、何度も取得する必要がなければ大差は無い。
- 投稿日:2021-01-22T13:09:52+09:00
無償のSpark実行環境であるDatabricks Community Editionの申し込み方法
概要
無償でSpark実行環境として利用できるDatabricks Community Editionの環境構築方法を共有します。
合わせて、無償で提供されているDatabricksの学習コンテンツの申し込みもおすすめします。Databricks Community Editionとは
Sparkによるビッグデータ処理やPythonやRによるデータ分析を実施可能なデータ統合データプラットフォーム(レイクハウス)のサービスであるDatabricksの無償環境です。
引用元:Databricks - 統合データ分析Databricks環境構築
Try Databricksから申し込みを実施します。
引用元:Try Databricks下記にて、"COMMUNITY EDITION"を選択します。
引用元:Try Databricks届いたメールのリンクを設定します。
パスワードを設定します。
Databricksに接続できることを確認します。
"Clusters"を選択後、"+Create Cluster"を選択します。
"Cluster Name"に適切な名前を入力し、"Create Cluster"を選択します。
数分後に、クラスターが作成されたことを確認します。
"Workspace"を選択後右クリックし、"Create" -> "Notebook"を選択します。
"Name"に適切な名前を入力し、"Default Language"にて"Python"を選択して、"Create"を選択します。
左上にある"Detached"を選択後、作成済みのクラスターを選択します。
"print("Hello World")"と入力後、右にある"▶︎"を選択します。
"Hello Worldと表示されたことを確認します。


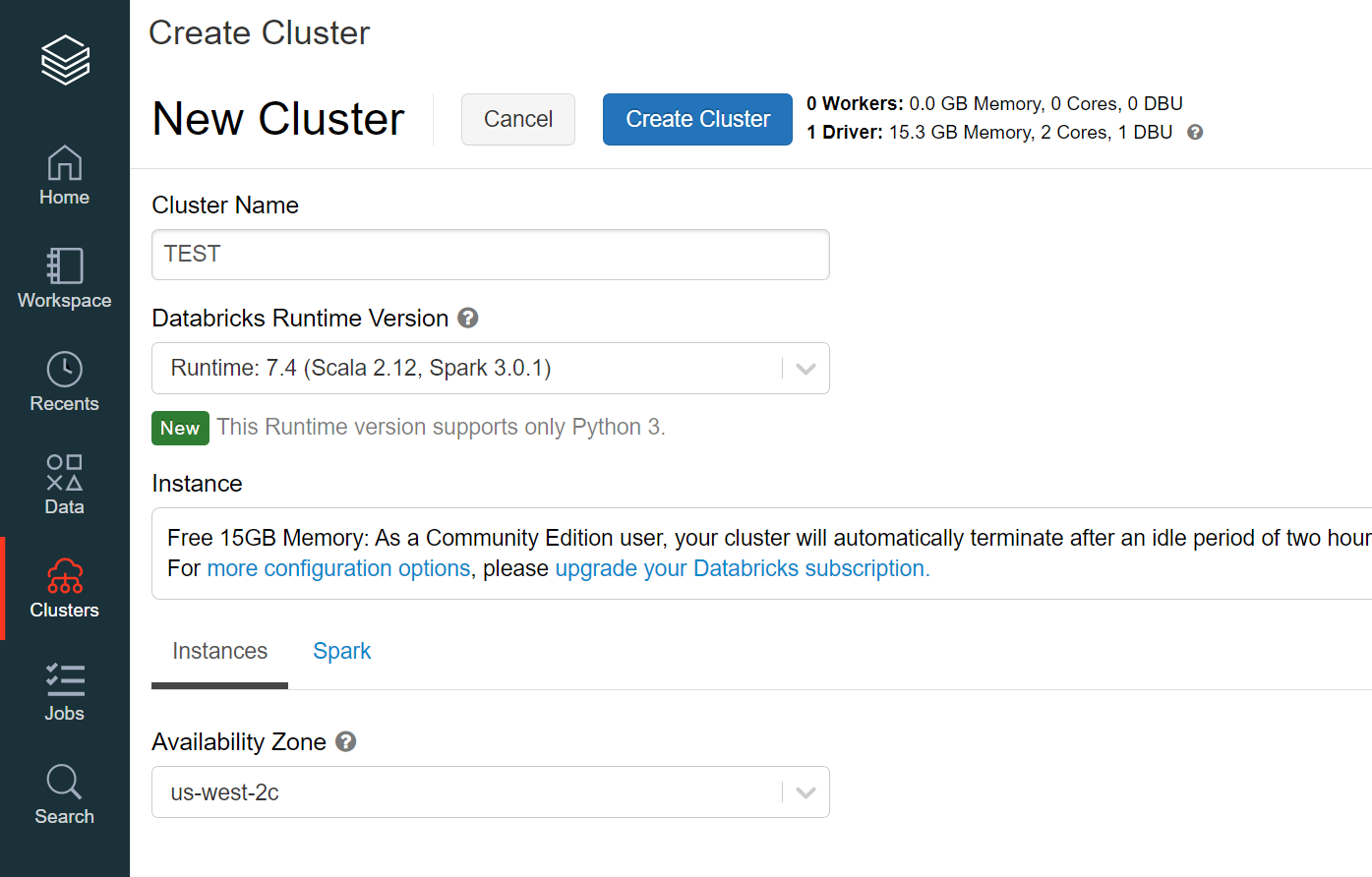
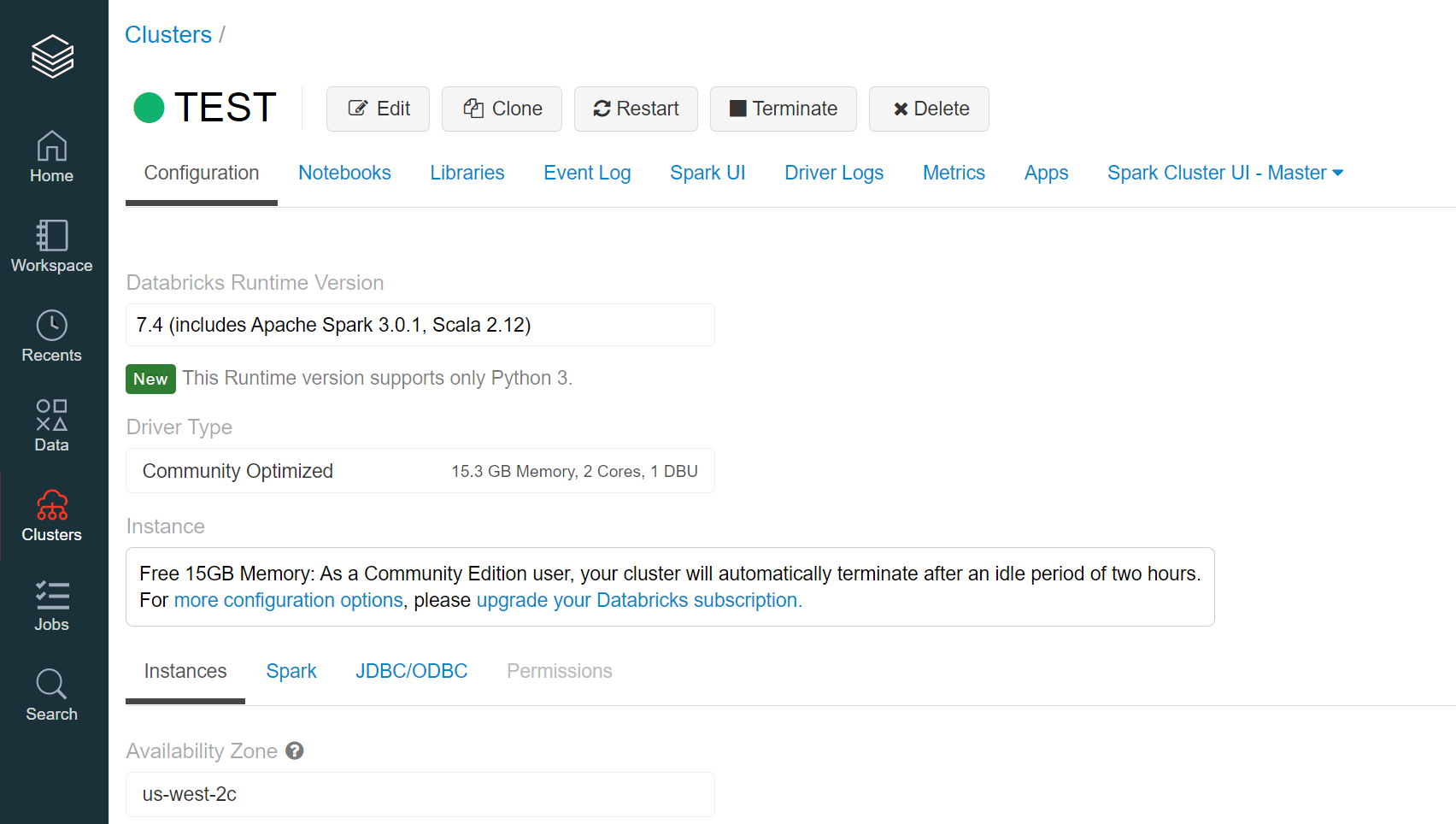


- 投稿日:2021-01-22T12:02:34+09:00
TensorFlowでカスタム訓練ループをfitに組み込むための便利な書き方
TensorFlow(Keras)でバッチ単位の訓練をカスタマイズしつつ、fitで訓練する便利な書き方を見つけたので紹介していきます。
きっかけ
Kerasの作者のツイッター見てたら面白い書き方していました。
This is the key part: the training loop. pic.twitter.com/M96XQlyNkS
— François Chollet (@fchollet) January 10, 2021例はVAEでしたが、もっと簡単に超解像の問題で追ってみました。
元のNotebook:https://colab.research.google.com/drive/1veeJMSRE7yzE3q-OulyPqbsuAuk00yxK?usp=sharing
環境:TensorFlow 2.3.1
問題意識
TensorFlowでちょっと複雑なモデルを訓練すると、独自の訓練ループを書いたほうが便利なことがあります。GANやVAEのように複数のモデルを訓練するケースがそうですね。次のような書き方です。
@tf.function # 高速化のためのデコレーター def train_on_batch(X, y): with tf.GradientTape() as tape: pred = model(X, training=True) loss_val = loss(y, pred) graidents = tape.gradient(loss_val, model.trainable_weights) optim.apply_gradients(zip(graidents, model.trainable_weights)) acc.update_state(y, pred) return loss_val自分が昔書いた記事のカスタム訓練ループから、バッチ単位の関数です。データ全体をforループでバッチ単位に切り出して、
for step, (X, y) in enumerate(trainset): loss_val = train_on_batch(X, y)こんな感じに回す、PyTorchみたいな書き方です。この書き方は便利ですが、TensorFlow(Keras)のいいところを損なっています。それは、
「Kerasの便利なcompile→fitというAPIを使えない」
ということです。バッチ単位の処理をカスタムしつつ、fitで訓練したいという需要に応えたのが今回紹介する書き方です。
モデル設定
今回はCIFAR-10の超解像の訓練をします。超解像のようにロスとは別の評価関数(PSNR)を使う問題のほうが、この書き方のありがたみがわかります。CIFAR-10でいきます。
- 入力:16×16の画像
- 出力:32×32の画像
入力画像を2倍に拡大する超解像の問題です。論文ではSingle Image Super-Resolution(SISR)と言われる問題です。
もともとCIFAR-10は32×32の解像度なので、半分のサイズ(16×16)にリサイズしたものを入力に入れ、オリジナル画像を教師データとして訓練すればいいだけです。問題としてはシンプルです。
PSNR
超解像の問題ではPSNRという評価指標をよく使います。単位はdBです。ロスの値を直接見るよりも、PSNRを見たほうが直感的にイメージしやすくなります。PSNRは以下の定義です。
$$PSNR=10\log_{10}\frac{MAX_I^2}{MSE} $$
$MSE$は平均2乗誤差、$MAX_I$は画素の最大値を表します。0-1スケールなら$MAX_I=1$、0-255スケールなら$MAX_I=255$です。このコードでは0-1スケールで説明します。
PSNRの実装はTensorFlowの組み込み関数を使いましょう。
tf.image.psnr(highres_pred, highres_true, 1.0) # 1.0=MAX_Iこれでサンプル単位のPSNRが計算されます。ホワイトノイズに対して計算すると次のようになります。
x = np.random.uniform(size=(5, 32, 32, 3)) y = np.random.uniform(size=(5, 32, 32, 3)) psnr = tf.image.psnr(x, y, 1.0) print(psnr) # tf.Tensor([7.8894033 7.6707745 7.8617544 7.8076196 7.8329306], shape=(5,), dtype=float32)コード
先に全体のコードを示します
import tensorflow as tf import tensorflow.keras.layers as layers import numpy as np # CuDNNの初期化エラー対策のためにメモリを制限する # 参考:https://qiita.com/masudam/items/c229e3c75763e823eed5 gpus = tf.config.experimental.list_physical_devices('GPU') if gpus: try: # Currently, memory growth needs to be the same across GPUs for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) logical_gpus = tf.config.experimental.list_logical_devices('GPU') print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs") except RuntimeError as e: # Memory growth must be set before GPUs have been initialized print(e) class SuperResolutionModel(tf.keras.models.Model): def __init__(self, **kwargs): super().__init__(**kwargs) # 複数モデルを入れ子にすることもOK self.model = self.create_model() # トラッカーを用意する(訓練、テスト共通で良い) self.loss_tracker = tf.keras.metrics.Mean(name="loss") self.psnr_tracker = tf.keras.metrics.Mean(name="psnr") def create_model(self): inputs = layers.Input((16, 16, 3)) x = layers.Conv2D(64, 3, padding="same")(inputs) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.UpSampling2D(2)(x) x = layers.Conv2D(32, 3, padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.Conv2D(3, 3, padding="same", activation="sigmoid")(x) return tf.keras.models.Model(inputs, x) # なくてもエラーは出ないが、訓練・テスト間、エポックの切り替わりで # トラッカーがリセットされないため、必ずmetricsのプロパティをオーバーライドすること # self.reset_metrics()はこのプロパティを参照している @property def metrics(self): return [self.loss_tracker, self.psnr_tracker] def train_step(self, data): low_res_input, high_res_gt = data with tf.GradientTape() as tape: high_res_pred = self.model(low_res_input) loss = tf.reduce_mean(tf.abs(high_res_gt - high_res_pred)) # 全体(self)に対する偏微分か、特定モデル(self.model)に対する微分かは場合により変わる # このケースではどちらでも同じだが、GANでは使い分ける必要がある grads = tape.gradient(loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) psnr = tf.reduce_mean(tf.image.psnr(high_res_pred, high_res_gt, 1.0)) # エポックの切り替わりのトラッカーのリセットは、self.reset_metrics()で自動的に行われる self.loss_tracker.update_state(loss) self.psnr_tracker.update_state(psnr) return { "loss": self.loss_tracker.result(), "psnr": self.psnr_tracker.result(), } def test_step(self, data): low_res_input, high_res_gt = data high_res_pred = self.model(low_res_input) loss = tf.reduce_mean(tf.abs(high_res_gt - high_res_pred)) psnr = tf.reduce_mean(tf.image.psnr(high_res_pred, high_res_gt, 1.0)) # 訓練・テストの切り替わりのトラッカーのリセットは、self.reset_metrics()で自動的に行われる self.loss_tracker.update_state(loss) self.psnr_tracker.update_state(psnr) return { "loss": self.loss_tracker.result(), "psnr": self.psnr_tracker.result(), } def main(): (X_train, _), (X_test, _) = tf.keras.datasets.cifar10.load_data() # high res images X_train_highres = X_train.astype(np.float32) / 255.0 X_test_highres = X_test.astype(np.float32) / 255.0 # low res images X_train_lowres = tf.image.resize(X_train_highres, (16, 16)) X_test_lowres = tf.image.resize(X_test_highres, (16, 16)) model = SuperResolutionModel() model.compile(optimizer=tf.keras.optimizers.Adam()) model.fit(X_train_lowres, X_train_highres, validation_data=(X_test_lowres, X_test_highres), batch_size=128, epochs=10) if __name__ == "__main__": main()モデルは適当に作りました(軽いのでCPUでも訓練できます)。ポイントをかいつまんで説明します。
トラッカーを用意する
コンストラクタのここに注目。
# トラッカーを用意する(訓練、テスト共通で良い) self.loss_tracker = tf.keras.metrics.Mean(name="loss") self.psnr_tracker = tf.keras.metrics.Mean(name="psnr")これはロスの値と、PSNRの値を記録するためのトラッカーです。バッチ単位で各値が積み重なっていき、fitのログではバッチ間の平均が表示されます。
metrics.Meanとしているのはバッチ間の平均を取るためです。このトラッカーを
train_step, test_stepでアップデートしていきます。train_step, test_step
この関数は、Kerasの
fitやevaluateの中で呼ばれるバッチ単位の処理を記述する部分です。ここをカスタマイズすることで、fitのAPIを利用しつつ独自の処理を定義できます。def train_step(self, data): low_res_input, high_res_gt = data with tf.GradientTape() as tape: high_res_pred = self.model(low_res_input) loss = tf.reduce_mean(tf.abs(high_res_gt - high_res_pred)) grads = tape.gradient(loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) psnr = tf.reduce_mean(tf.image.psnr(high_res_pred, high_res_gt, 1.0)) self.loss_tracker.update_state(loss) self.psnr_tracker.update_state(psnr) return { "loss": self.loss_tracker.result(), "psnr": self.psnr_tracker.result(), }細かい書き方はこれまでのカスタム訓練と同じです。異なる点がいくつかあります。
1つ目は、オプティマイザを外部から与えず、モデルのもの(インスタンス変数)を使うこと。オプティマイザはモデル内で一切記述していませんが、
compileが呼ばれたときに自動で登録されます。2つ目は、train_stepを
@tf.functionのデコレーターで囲まなくてよいこと。このデコレーターは訓練をグラフモードで高速に実行するために必要ですが、そもそもmodelのfitがデフォルトでグラフモードとして実行されるため、ステップ単位の処理を書くだけでOKです。fit自体が@tf.functionで囲まれているようなものです。metricsのプロパティを実装する
これはなくても動いてしまいますが、全てのトラッカーをリストで入れるように実装してください。後述のトラッカーのリセットの関係で必要になります。
@property def metrics(self): return [self.loss_tracker, self.psnr_tracker]ログの結果をdictで返す
見ればそのとおりですが、Kerasのログに対応する値を書いていきます。
self.loss_tracker.update_state(loss) self.psnr_tracker.update_state(psnr) return { "loss": self.loss_tracker.result(), "psnr": self.psnr_tracker.result(), }出力はこうなります。
391/391 [==============================] - 3s 9ms/step - loss: 0.0559 - psnr: 23.7072 - val_loss: 0.0414 - val_psnr: 25.4800 Epoch 2/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0375 - psnr: 26.1364 - val_loss: 0.0365 - val_psnr: 26.3191 Epoch 3/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0354 - psnr: 26.5446 - val_loss: 0.0343 - val_psnr: 26.7604 Epoch 4/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0343 - psnr: 26.7636 - val_loss: 0.0338 - val_psnr: 26.8522 Epoch 5/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0339 - psnr: 26.8342 - val_loss: 0.0333 - val_psnr: 26.9524 Epoch 6/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0335 - psnr: 26.9146 - val_loss: 0.0334 - val_psnr: 26.9208 Epoch 7/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0332 - psnr: 26.9717 - val_loss: 0.0328 - val_psnr: 27.0393 Epoch 8/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0330 - psnr: 27.0053 - val_loss: 0.0326 - val_psnr: 27.0906 Epoch 9/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0328 - psnr: 27.0457 - val_loss: 0.0324 - val_psnr: 27.1292 Epoch 10/10 391/391 [==============================] - 3s 8ms/step - loss: 0.0328 - psnr: 27.0496 - val_loss: 0.0329 - val_psnr: 27.0406fitでプログレスバーをいい感じに出してくれますし、訓練データに対してもPSNRを計算してくれるのがとてもいいですね。
validationの部分は「val_」と自動的にプレフィックスをつけてくれます。
Q1:評価関数のリセットはしているのですか?
ここで疑問なのは「評価関数(トラッカー)って訓練テスト共通で用意しているけど、訓練・テストの切り替わりや、エポックの切り替わりでバッチ単位のログをリセットしているのですか?」ということです。これ気になってTensorFlowのソースを読んでみました。
結論は、metricsのプロパティにトラッカーが登録されていれば、リセットの処理を書かなくても自動的にリセットされます。もともと
tf.keras.model.Modelsにはreset_metricsという関数が組み込まれています(参考)。エポックの開始時、訓練・テストの切替時にreset_metricsが自動的に呼び出されます。この関数の実装を見てみると、for m in self.metrics: m.reset_states()とありました。ここで参照しているのはModelのmetricsのプロパティです。したがって、metricsにトラッカーを登録する必要があるのです。
もし登録しなくてもエラーは特に出ませんが、リセットが行われずに訓練・テスト間でログが使い回されるはずです。ここだけ注意が必要です。
Q2:self.trainable_weightsとself.model.trainable_weightsって何が違うんですか?
このケースでは1つしかモデルがないので特に変わりませんが、GANのように複数のモデルをfitで扱うケースだと意識する必要があります。
前者は入れ子にしているモデルの訓練可能な係数全て、後者は特定モデルの訓練可能な係数全てを表します。GANの場合使い分けが必要ですね。
Q3:ずっとfitにtf.functionがかかているとデバッグで困る。デバッグのときはEagerモードで動かしたい
コンパイル時に
run_eagerly=Trueと指定しましょう。model.compile(optimizer=tf.keras.optimizers.Adam(), run_eagerly=True)これでEagerモードに簡単に切り替えられます。train_stepの中でprintをするとテンソルの値が出てくるのでデバッグに最適です。
まとめ
バッチ単位の訓練のカスタマイズと、fitのAPIは両立できるということが示せました。これはかなり便利な書き方だと思います。ぜひ活用してみてください。
- 投稿日:2021-01-22T11:58:17+09:00
【python】毒島、閏秒はdatetime.datetimeで変換できないってよ!
背景
先日、「閏秒(うるう秒:以下、すべて漢字表記します)」のレコードを持つデータを扱う機会があり、その際の対処について調べた結果をまとめておきます。
タイトルは、映画『桐島、部活やめるってよ』のパロディです Pythonなので大蛇⇒ニシキヘビ⇒毒⇒毒島...すみません...
先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとしても、こちらへまとめておきます。環境
- Windows 10 Pro
- Python 3.9.0, 3.8.5
- Django 3.1.4
- PostgreSQL 13.1
- Nginx 1.95.1
- Gunicorn
- Putty 0.74
0.閏秒とは
Wikipedia - 閏秒 より引用:
閏秒は、現行の協定世界時 において、世界時のUT1との差を調整するために追加もしくは削除される秒である 。この現行方式のUTCは1972年に始まった。2019年までに実施された計27回の閏秒(★注1)は、いずれも1秒追加による調整であった。 直近の閏秒の挿入は、2017年1月1日午前9時直前に行われた。
(★注1) 末尾に実施日の一覧も掲載しています。
1.現象
nofrag, frag = t.split('.') nofrag_dt = datetime.datetime.strptime(nofrag, "%Y-%m-%dT%H:%M:%S") dt = nofrag_dt.replace(microsecond=int(frag))ValueError: second must be in 0..59『値エラー:秒は0~59であるべき』が発生。
↓
当然じゃん……ん!?で、フリーズ……恐る恐るデータを見てみると…
『なんということでしょう~ データを開けるとそこには、2016-12-31 23:59:60.202915というレコードが隠されていました~』(大改造!!劇的ビフォーアフター風に)
という結果です。その文字列を解析してdatetimeオブジェクトに変換するために、上記のコードを使用したところで値エラーに...
2.原因
Python公式ドキュメント - time --- 時刻データへのアクセスと変換 -- time.strftime では、うるう秒をサポートしていると記載あり
⇒ ”値60は閏秒を表すタイムスタンプで有効で、値61は歴史的な理由からサポートされています” との注釈入り上述の通り、Python のドキュメントでは、
%Sは [0, 61] を受け入れるので、これは問題ではないと思いますね。
しかし、上記のタイムスタンプでこのエラーが発生します。なんと、秒数が59を超える場合、ここでの問題は .strftime での扱いではなく、datetime.datetime へ変換できないことだったようです。
%Sのドキュメントには、次のように記載あり:time モジュールとは異なり、datetime モジュールは閏秒をサポートしていません。
上述の時間文字列
"2016-12-31T23:59:60.202915"は、時刻が UTC(協定世界時)における(現時点では最後の(直近の)閏秒)であることを意味します。3.対処
以下の変換論理を用いて、datetime.datetime で扱えるようにします。参考元コードは某所よりお借りしてきました。
【注意】:現地時間での変換では失敗する可能性があります。(例:DST(夏時間)への遷移中)
import time from calendar import timegm from datetime import datetime, timedelta time_string = '2016-12-31T23:59:60.202915' time_string, dot, us = time_string.partition('.') utc_time_tuple = time.strptime(time_string, "%Y-%m-%dT%H:%M:%S") dt = datetime(1970, 1, 1) + timedelta(seconds=timegm(utc_time_tuple)) if dot: dt = dt.replace(microsecond=datetime.strptime(us, '%f').microsecond) print(dt)4.結果
2017-01-01 00:00:00.202915閏秒の表記が、
2017-01-01 00:00:00.202915へ変換されました。⇒ 上記例
2016-12-31 23:59:60.202915は、JST(日本標準時)における2017-01-01 08:59:60.202915に相当します。※JST=UTC+9時間
参考
閏秒の実施:
(編集後記)
データ分析・解析の前処理では、例外レコードを扱う機会も多いかと思いますが、こういった歴史的にも特殊な事柄に関連する事象を、つい忘れがちです。
(00~59に当てはまらないため)例外だからエラーデータとして弾いてしまおう…とすると、正しい分析・解析に至らない可能性もあります。
何が原因なのか、このレコードが発生した背景・理由や、レコードの必要性や妥当性を、今一度考えるきっかけにしたいと思います。
- 投稿日:2021-01-22T11:50:34+09:00
pythonで2Dセグメント木実装
はじめに
pythonで実装した2Dセグメント木について記事が見当たらなかったので紹介しようと思います。
参考文献
https://qiita.com/tomato1997/items/da9a7a73f2301aa48896
https://www.hamayanhamayan.com/entry/2017/12/09/015937
http://algoogle.hadrori.jp/algorithm/2d-segment-tree.html
https://ei1333.github.io/luzhiled/snippets/structure/segment-tree.html2Dセグメント木とは
ある矩形領域に対して、和や最小最大などなどの値をlogオーダーで取り出し可能とするものです。ある一点の値の変更もlogオーダーで可能です。
例として4×4の配列を扱います。セグメント木に乗せる関数はminとしました。(以下、0-indexedで説明します)
木の構築
言葉での説明は難しいので図を見てください。右下の黒枠が元の配列です。親子に対応する部分の一部を色で塗ってみました。左または上の方が親要素になっています。
木の構築はO(NM)です。値の更新
例えば(1,2)の値を0にする場合、以下の図のような部分が更新されます。
値の更新はO(logNlogM)です。区間の値の取得
[0,3)×[0,3)を取得する場合、見なければいけない領域は図の色を付けた部分です。
この場合は[0,2)×[0,2)、[0,2)×[2,3)、[2,3)×[0,2)、[2,3)×[2,3)の4か所だということが分かります。
値の取得はO(logNlogM)です。コード
上の考察を用いてpythonにて実装しました。
segki2D.pyimport sys import math sys.setrecursionlimit(10**7) class segki2D(): DEFAULT = { 'min': 1 << 60, 'max': -(1 << 60), 'sum': 0, 'prd': 1, 'gcd': 0, 'lmc': 1, '^': 0, '&': (1 << 60) - 1, '|': 0, } FUNC = { 'min': min, 'max': max, 'sum': (lambda x, y: x + y), 'prd': (lambda x, y: x * y), 'gcd': math.gcd, 'lmc': (lambda x, y: (x * y) // math.gcd(x, y)), '^': (lambda x, y: x ^ y), '&': (lambda x, y: x & y), '|': (lambda x, y: x | y), } def __init__(self, N, M, ls2D, mode='min'): """ 葉の数N*M, 要素ls2D, 関数mode (min,max,sum,prd(product),gcd,lmc,^,&,|) """ self.default = self.DEFAULT[mode] self.func = self.FUNC[mode] self.N = N self.M = M self.KN = (N - 1).bit_length() self.KM = (M - 1).bit_length() self.N2 = 1 << self.KN self.M2 = 1 << self.KM self.dat = [[self.default] * (2**(self.KM + 1)) for i in range(2**(self.KN + 1))] for i in range(self.N): for j in range(self.M): self.dat[self.N2 + i][self.M2 + j] = ls2D[i][j] self.build() def build(self): for j in range(self.M): for i in range(self.N2 - 1, 0, -1): self.dat[i][self.M2 + j] = self.func(self.dat[i << 1][self.M2 + j], self.dat[i << 1 | 1][self.M2 + j]) for i in range(2**(self.KN + 1)): for j in range(self.M2 - 1, 0, -1): self.dat[i][j] = self.func(self.dat[i][j << 1], self.dat[i][j << 1 | 1]) def leafvalue(self, x,y): # (x,y)番目の値の取得 return self.dat[x + self.N2][y + self.M2] def update(self, x, y, value): # (x,y)の値をvalueに変える i = x + self.N2 j = y + self.M2 self.dat[i][j] = value while j > 1: j >>= 1 self.dat[i][j] = self.func(self.dat[i][j << 1], self.dat[i][j << 1 | 1]) j = y + self.M2 while i > 1: i >>= 1 self.dat[i][j] = self.func(self.dat[i << 1][j], self.dat[i << 1 | 1][j]) while j > 1: j >>= 1 self.dat[i][j] = self.func(self.dat[i][j << 1], self.dat[i][j << 1 | 1]) j = y + self.M2 return def query(self, Lx, Rx, Ly, Ry): # [Lx,Rx)×[Ly,Ry)の区間取得 Lx += self.N2 Rx += self.N2 Ly += self.M2 Ry += self.M2 vLx = self.default vRx = self.default while Lx < Rx: if Lx & 1: vLy = self.default vRy = self.default Ly1 = Ly Ry1 = Ry while Ly1 < Ry1: if Ly1 & 1: vLy = self.func(vLy, self.dat[Lx][Ly1]) Ly1 += 1 if Ry1 & 1: Ry1 -= 1 vRy = self.func(self.dat[Lx][Ry1], vRy) Ly1 >>= 1 Ry1 >>= 1 vy = self.func(vLy, vRy) vLx = self.func(vLx,vy) Lx += 1 if Rx & 1: Rx -= 1 vLy = self.default vRy = self.default Ly1 = Ly Ry1 = Ry while Ly1 < Ry1: if Ly1 & 1: vLy = self.func(vLy, self.dat[Rx][Ly1]) Ly1 += 1 if Ry1 & 1: Ry1 -= 1 vRy = self.func(self.dat[Rx][Ry1], vRy) Ly1 >>= 1 Ry1 >>= 1 vy = self.func(vLy, vRy) vRx = self.func(vy, vRx) Lx >>= 1 Rx >>= 1 return self.func(vLx, vRx)使用例
AOJ School of Killifish 値の更新はない問題です。
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=1068
http://judge.u-aizu.ac.jp/onlinejudge/review.jsp?rid=5153232#1
Atcoder ABC106D AtCoder Express 2 オーバーキル感ありますが当然普通の二次元累積和も扱えます
https://atcoder.jp/contests/abc106/tasks/abc106_d
https://atcoder.jp/contests/abc106/submissions/19563643おわりに
ここまでお読みいただきありがとうございました。私自身競技プログラミング初学者ですので、間違い等ございましたらご指摘よろしくお願いいたします。また、LGTMしていただけると励みになります。
- 投稿日:2021-01-22T11:34:23+09:00
matplotlibで予測結果を3D表示
はじめに
深層学習で予測した結果のうち誤差が大きいものと,誤差が小さいものに特徴はあるのか可視化して確認したかったので,3Dグラフにプロットしてみました.
* 予測に失敗:赤
* 予測に成功:青
で示しています.使ったライブラリ
- matplotlib
- pandas
- Pillow
3D表示
Matplotlib公式が色分けの散布図の表示の仕方を載せていたので参考にしました.
mplot3d tutorial — Matplotlib 2.0.2 documentation使うデータ
x, y, z, TFとラベル付けしました.
描画
plot3d.pyimport pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from io import BytesIO from PIL import Image import_path = './test.csv' def main(): fig = plt.figure(figsize=(10.0, 9.0)) ax = fig.add_subplot(111, projection='3d') data = pd.read_csv(import_path, header=0) print(data) for index, row in data.iterrows(): print('\rindex = {}/{}, TorF = {} '.format(index,len(data), str(row['TF'])),end="") color = 'r' marker = 'x' if str(row['TF']) == 'True': color = 'b' marker = 'o' ax.scatter(row['x'], row['y'], row['z'], c = color, marker = marker) print('\n---Finished Loading---') ax.set_xlabel("x", fontsize=20) ax.set_ylabel("y", fontsize=20) ax.set_zlabel("z", fontsize=20) ax.view_init(30, 0) plt.savefig('./output2D-1.png') ax.view_init(30, 90) plt.savefig('./output2D-2.png') ax.view_init(30, 180) plt.savefig('./output2D-3.png') if __name__ == '__main__': main()描画した結果
3D表示を回転させる
GIFアニメにすることで回転させてみました.
こちらの記事を参考にさせていただきました.
3D 散布図を回転 GIF アニメーションにする - Qiitaplot3d.pyimport pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from io import BytesIO from PIL import Image import time import datetime import_path = './test.csv' def render_frame(ax, angle): print('\rangle = {}'.format(angle),end="") ax.view_init(30, angle) buf = BytesIO() plt.savefig(buf, bbox_inches='tight', pad_inches=0.0) return Image.open(buf) def main(): start = time.time() fig = plt.figure(figsize=(10.0, 9.0)) ax = fig.add_subplot(111, projection='3d') data = pd.read_csv(import_path, header=0) for index, row in data.iterrows(): print('\rindex = {}/{}, TorF = {} '.format(index,len(data), str(row['TF'])),end="") color = 'r' marker = 'x' if str(row['TF']) == 'True': color = 'b' marker = 'o' ax.scatter(row['x'], row['y'], row['z'], c = color, marker = marker) ax.set_xlabel("x", fontsize=20) ax.set_ylabel("y", fontsize=20) ax.set_zlabel("z", fontsize=20) print('\n---Finished Loading---\n') images = [render_frame(ax, angle) for angle in range(50)] images[0].save('output3D.gif', save_all=True, append_images=images[1:], duration=100, loop=0) # 経過時間の集計 process_time = time.time() - start td = datetime.timedelta(seconds=process_time) print('PROCESS TIME = {}'.format(td)) if __name__ == '__main__': main()GIFアニメ
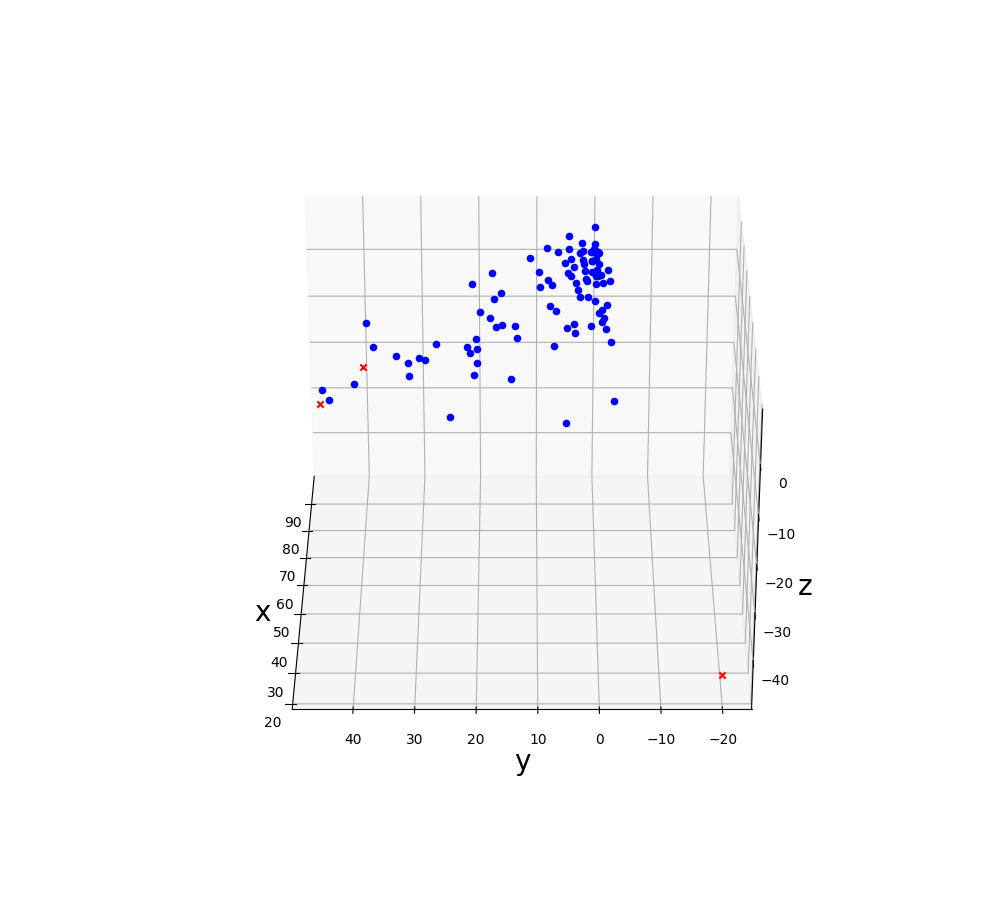
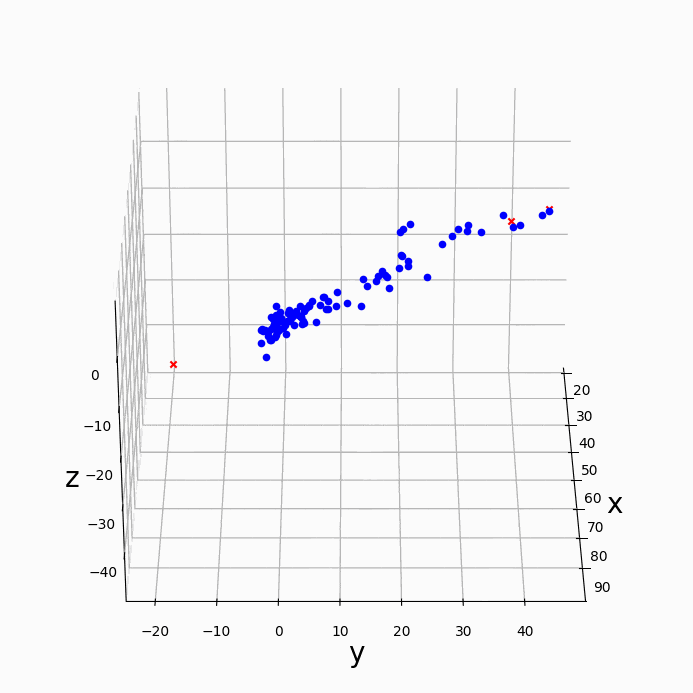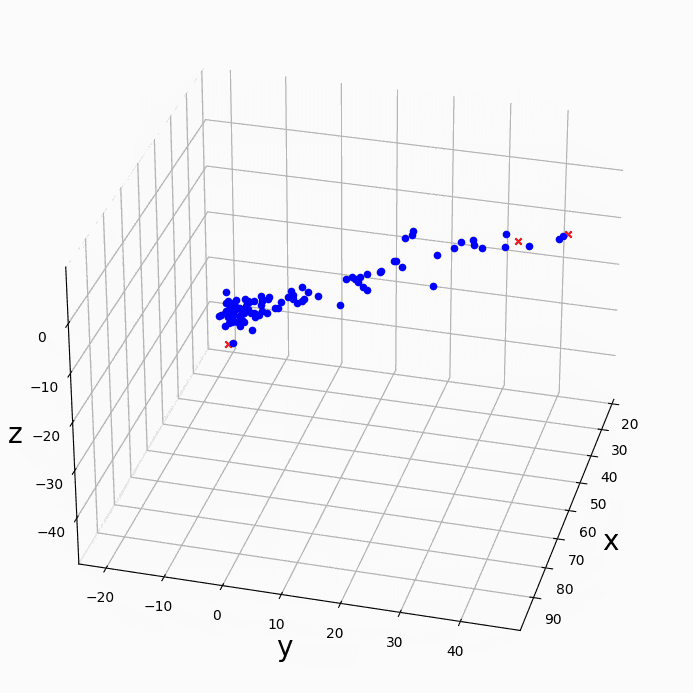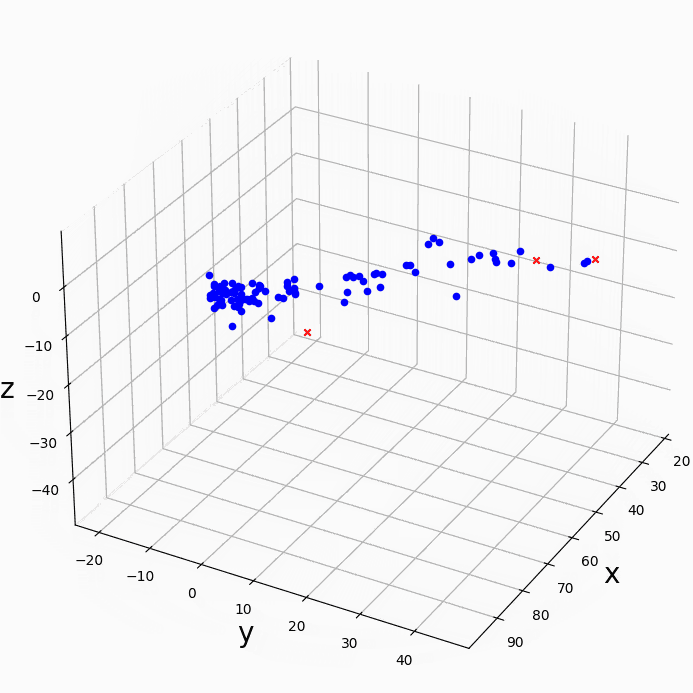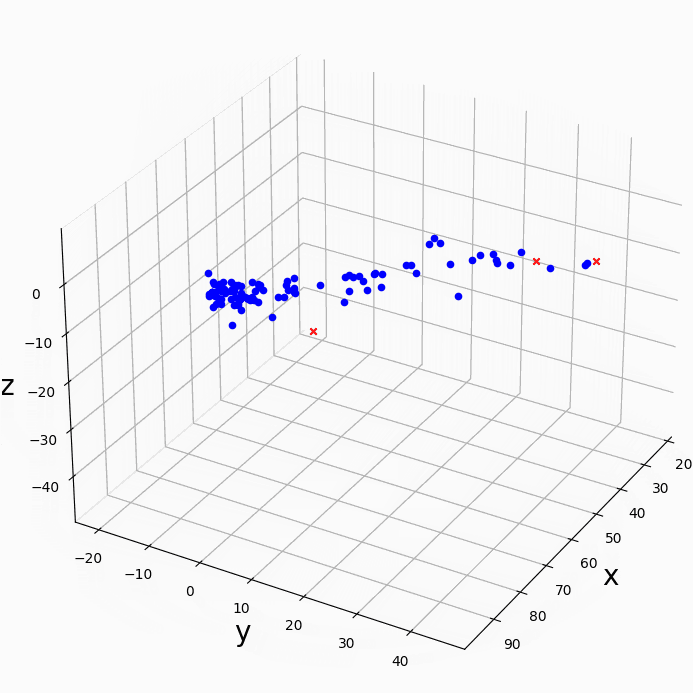
- 投稿日:2021-01-22T11:25:45+09:00
AWSでWebアプリを公開する方法(Python+Flask)
はじめに
この記事は、私がPythonとFlaskで作成したWebアプリをAWSで公開するまでの方法を記したものになります。
なので、自作のWebアプリをAWSでWeb上に公開したい人などにとっては特に参考になる点があると思います。また、最近の流行りで機械学習のモデルを作成したが、それをどうすれば良いかわからないという人も記事に従ってやってもらえれば、Web上に公開でき、ネットワークといったインフラ側の知識も身につきますので、そういう人にも読んでもらえればなと思います。
最後に紹介までにですが、
今回私が作成したアプリケーションは機械学習を用いた画像認識アプリなので、是非使ってその感想などをいただけますと幸いです。(以下そのURL)
https://www.body-score-checker.ml本記事の流れ
・前提
・アプリのディレクトリ構成と一部コードの紹介
・公開までの流れ
1.全体像の把握
2.実際の手順
・1人でWebアプリケーションを作成してみて感じたこと前提
この記事を読むのに当たっての前提の共有をしたいと思います。
・Webアプリの実装方法やそれぞれコードの詳しい解説は省略します。
・AWS初心者なため、アーキテクチャがベストプラクティスではないことはご了承ください。アプリのディレクトリ構成と一部コードの紹介
実際のアプリ構成は、以下のようになっています。
Flask |_ app.py |_ cnn_model.py |_ photos-newmodel-light.hdf5 |_ templates |_ flask_api_index.html(メインのhtmlファイル) |_ result.html(結果を表示するページhtmlファイル) |_ static |_ css |_main.css |_ images(htmlファイルに挿入する画像) |_xxxx.jpg細かい説明は省略しますが、
app.pyとcnn_model.py は参考になる部分もあると思うので、載せておきます。実際のコード(一部)
app.pyimport numpy as np from PIL import Image import cnn_model from flask import Flask, render_template, request app = Flask(__name__) @app.route('/') def index(): return render_template('./flask_api_index.html') @app.route('/result', methods=['POST']) def result(): body_list = ["筋肉型","標準型","痩せ型","肥満型"] # submitした画像が存在したら、画像データをモデル用に整形 try : if request.files['image']: img_file = request.files['image'] temp_img = Image.open(request.files['image']) temp_img = temp_img.convert("RGB") #色空間をRGBに #今回は、モデルの精度を上げるために(64,64)で画像を学習させています。 temp_img = temp_img.resize((64,64)) temp_img = np.asarray(temp_img) im_rows = 64 im_cols = 64 im_color = 3 in_shape = (im_rows,im_cols,im_color) nb_classes = 4 img_array = temp_img.reshape(-1,im_rows,im_cols,im_color) img_array = img_array / 255 model = cnn_model.get_model(in_shape,nb_classes) #学習済みモデルを呼び出す model.load_weights("photos-newmodel-light.hdf5") predict = model.predict([img_array])[0] index = predict.argmax() body_shape = body_list[index] body_score = 90*predict[0]+70*predict[1]+40*predict[2]+40*predict[3] body_score = int(body_score) return render_template('./result.html', title='結果',body_score=body_score,body_shape=body_shape,img_file=img_file) except: return render_template('./flask_api_index.html') if __name__ == '__main__': app.debug = True app.run(host='localhost', port=8888)cnn_model.py# 簡単にモデルを作成できるので、kerasを用います。 import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop # CNNのモデルを定義する def def_model(in_shape, nb_classes): model = Sequential() model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=in_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(nb_classes, activation='softmax')) return model # コンパイル済みのCNNのモデルを返す def get_model(in_shape,nb_classes): model = def_model(in_shape, nb_classes) model.compile( loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) return model公開までの流れ
1.全体像の把握
手順に従って進めていけば、最終的には以下のアーキテクチャでアプリを公開できます。
2.実際の手順
(1)AWSのアカウントを作成する
(2)AWSのサーバー上でpython環境の構築
(3)gitからフォルダをcloneする
(4)パブリックIPアドレスを固定化する
(5)独自ドメインの取得
(6)パブリックIPアドレスと購入ドメインの紐付け
(7)ミドルウェアをインストールする
(8)プロキシパスの設定
(9)HTTPをHTTPSにする(1)AWSのアカウントを作成する
ここは、下記の参考書を読めば一撃で理解できると思うので、割愛します。
AWSをはじめようあるいは、以下の資料でも大丈夫だと思います。
AWS EC2でインスタンスを立てる(2)AWSのサーバー上でpython環境の構築
$ sudo yum -y update $ sudo yum install python36-devel python36-libs python36-setuptools $ mkdir body_checker $ python -m venv body_checker $ source body_checker/bin/activate (body_checker)$ pip install --upgrade pip (body_checker)$ pip install flask 以下それぞれのアプリに必要なライブラリをインストール参考資料
Amazon AWS(EC2)でのFlask環境の作成方法(3)gitからフォルダをcloneする
まず、ローカルで作成したフォルダを自分のgithubのリポジトリにあげてください。(githubのアカウント作成の説明などは省略します)
今回行う操作は、EC2上でsshを使ってgit clone して、欲しいフォルダなどを一括で取得するというものです。
手順
1.EC2上で公開鍵・秘密鍵の生成
2.特定のフォルダ(私でいうflaskというフォルダ)だけgit cloneする1に関しては、以下の記事がとても参考になります。
GitHubでssh接続する手順~公開鍵・秘密鍵の生成から~2に関しては、以下のコマンドで大丈夫だと思います。
(body_checker)$git init (body_checker)$git config core.sparsecheckout true (body_checker)$git remote add origin リポジトリのURL(https~) (body_checker)$vim flask(git cloneしたいフォルダやファイル) > .git/info/sparse-checkout (body_checker)$git pull origin masterちなみに、私は「git pull origin masetr」でエラーが出たので、masterをmainにしたら出来ました。
参考資料
git sparse checkout で clone せずに一部のサブディレクトリだけを pull/checkout する(4)パブリックIPアドレスを固定化する
この理由としては、EC2においてIPアドレスはインスタンスが停止すると毎回変わってしまうからです。
それを防ぐために、ElasticIPという静的な(勝手に変わらない)IPアドレスをサーバーに固定のIPアドレスとしてつけましょう。
手順
1.「Elastic IP」メニューから「新しいアドレスの割り当て」をクリック
2. ElasticIPをインスタンスに紐付ける(5)独自ドメインの取得
これは、私のサイト(https://www.body-score-checker.ml) でいうbody-score-cheker.mlの部分です。
これは以下のサイトで無料で作成できます。
Freenom(6)パブリックIPアドレスと購入ドメインの紐付け
この作業はRoute53というサービスを使います。
注意事項
全体像では、Route53からALBを経由してDNSを解決していますが、ここでは直接ドメインをEC2のElastic IPに紐づけてDNSを解決してます。ALBを使用したDNS解決は、(9)で説明しています。
目的としては、最初は簡単なアーキテクチャにして、なるべく早くwebでアプリを見れるようにするためです。以下のサイトがわかりやすかったので、そちらを参照して進めてみてください。
AWS Route 53を使って独自ドメインのWebページを表示させてみよう(7)ミドルウェアをインストールする
全体像の図でも示している通り、Apacheをインストールします。
以下インストールの方法
EC2インスタンスにApache HTTP Serverをインストールするミドルウェアをインストールする理由は、クライアントからのアクセスとflaskサーバーの仲介役を担ってもらうためです。
以下のその簡単な流れ
・「Application Load Balancer」でクライアントからのリクエストがポート80番に送られます。
・Apacheはポート80番に対応するので、そのアクセスを受け取ると静的コンテンツをクライアントに返します。(flask_api_index.htmlなど)
・もし動的な操作が必要な場合は、Apacheからflaskサーバー(ポート番号:8888)にリクエストが送られます。
・そこで、先ほど立てたflaskサーバーが動作する。(私の場合だと、送られてきた画像を機械学習のモデルに入れて点数を算出する。)(8)プロキシパスの設定
(6)で通信の簡単な流れを説明しましたが、そこで「Apacheからflaskサーバーにリクエストが送られます。」とありますが、これはこちらで設定する必要があります。
それが、プロキシパスの設定です。・confファイルを修正する
$ sudo vi /etc/httpd/conf.d/vhost.conf・修正内容
NameVirtualHost *:80 DocumentRoot "/var/www/html/" ServerName body-score-checker.ml ProxyRequests Off ProxyPass / http://localhost:8888/ ProxyPassReverse / http://body-score-checker.ml/・httpd再起動
$ sudo service httpd restartここまでで、Web上でアプリケーションが動作するようになると思います。
・以下実行コマンド(body_checker)$ python app.pyまた、sshでの接続が切れても、serverを立ち上げたままにするためには以下のコマンドを使用します。
(body_checker)$ nohup python app.py &以下参考資料
SSH切断した後でもVPS上でPythonを実行したままにする方法(9)通信方式をHTTPからHTTPSにする
基本的にはこれで問題なくWeb上で動作するのですが、私の場合は個人の画像を取り扱うのでhttpからhttpsに通信方式を変えています。
このタイミングで、全体像の真ん中にあるALB(Application Load Balancer)を導入しています。ロードバランサーの作成は以下の資料が参考になると思います。
Application Load Balancer を作成する
AWS ELBでWebサーバの負荷分散を実現!ロードバランサーの作成が終わったので、最後に通信方式をHTTPからHTTPSにします。
Application Load Balancer を使い HTTP リクエストを HTTPS にリダイレクトするにはどうすればよいですか?
[新機能]Webサーバでの実装不要!ALBだけでリダイレクト出来るようになりました!1人でWebアプリケーションを作成してみて
このように最後まで1人で作成してみて感じる事は、Webアプリケーションの仕組みを体系的に理解するには自分で手を動かして全て触ることが一番いいということです。
今回は私は、フロントからバックエンドまで全て自分でコードを書いて実装しましたが、Web上で実際にどのような処理が行われているのかなど、そうゆう大局の部分の理解がかなり捗ったと思います。
なので、これからももっといろんな技術に触れてみたいと思います。もしご指摘等ありましたら、バシバシ言っていただけると私自身の勉強になりますのでお願いいたします。
そして、最後まで読んでくださりありがとうございます。少しでも何か参考になる部分がありましたら幸いです。最後に、このアプリやこの記事を作るにあたって参考にした記事を紹介して終わりにしたいと思います。
バナナの食べ頃を機械学習モデルで判定するWEBアプリを作ってみた