- 投稿日:2021-01-22T22:49:26+09:00
営業マンがEC2に挑戦したら/etc/fstabに返り討ちにされた話
所属する会社がAWSに力を入れているため、実際に触ってみようということで、
- Amazon LinuxにApacheをインストールして、PCからhttp接続
- EBSを新たにアタッチ、マウントして使用する
- バックアップを保存し、EC2インスタンスをまるごと削除し、復元する。
という課題にチャレンジしました。
ハンズオン形式でしたので、「まずは最後までサクッと経験しよう」の期待とは裏腹に、トラブりましたので顛末を書いてみようと思います。
数カ月後に読み返した際に、かわいいなぁと思えるように。想定していたプロセス
- EC2インスタンスをたてる
- ・AMIはAmazon Linux 2
- ・ユーザデータにApacheのインストール、起動、再起動後も有効とするシェルスクリプトを記載
- ・セキュリティグループにHTTPを設定
- ターミナルでEC2の起動確認をする
- ・ssh接続でEC2インスタンスに接続
- ・Apacheが正常に起動しているか確認(systemctl statusコマンド)
- ・起動ログを確認してユーザデータに記載した内容を確認(cat /var/log/cloud-init-output.log)
- EBSをアタッチ・マウントする
- ・同一のAZにボリュームを作成する
- ・作成したEC2インスタンスにアタッチする(デバイスには /dev/sdf と入力)
- ・ファイルシステムを作成する(mkfs -s /dev/xvdf)
- ・ファイルシステムの型を確認し、UUID=~~~をメモしておく(mkfs -s /dev/xvdf)
- ・マウントするディレクトリを作成する(mkdirコマンド)
- ・マウントする(mount /dev/xvdf マウント先ディレクトリ)
- ・ディスク情報を確認し、マウントされたことを確認する(de -hコマンド)
- ・削除後、復元した際に自動でマウントする設定をする(vi /etc/fstab)
- ・マウントを解除する(umount マウント先ディレクトリ)
- ・再起動する(reboot コマンド)
- ・ssh接続で再度EC2インスタンスに接続
この先もまだプロセスがありましたが・・・
エラーが起きた箇所
マウントを解除して、再起動後、ssh接続ができませんでした。
コマンドを打ってもプロンプトが現れてくれません。振り返る
rebootもumountもシンプルで間違えていないよなと。
vi /etc/fstabでミスしたのはほぼ間違いなさそうそうでした。原因と対処
とりあえず出てきたエラーや状況をコピペして暗中模索。。
AWSマネジメントコンソールから直接ログを見ることができることを知り、ログを見てみると
emergency mode 〜なんちゃら〜
と出力されており、下記ページにたどり着きました。EC2 Linux インスタンスが起動せず、緊急モードになるのはなぜですか?
詳細は上記にあるので、流れだけ書くと下記の手順で復旧できました。
1. 復旧したいEC2インスタンスを停止し、ルートボリューム(デフォルトでアタッチされているボリューム)をデタッチ
2. 同一AZで新しくEC2インスタンス(救世主)を起動し、1でデタッチしたボリュームをセカンダリ(2つ目)としてアタッチ
3. 救世主にSSH接続し、マウント先ディレクトリを作成、マウントする
4.vi /etc/fstabで教わったとおりに書き換えて保存する!
5. ボリュームをアンマウントし、救世主からセカンダリボリュームをデタッチする
6. 復旧したいEC2インスタンスにアタッチして、起動
7. SSHできることを確認!(涙学べたこと
正直なことろ、viコマンドで再度/etc/fstabを書き換える際は復旧に必死で、
「どこを間違えたのか」
という最も大事なことをわからず復旧してしまったことは、最大の後悔です。
しかし、文字ひとつですべてが動かなくなる怖さを学べましたし、よしとしようかなと。今度は冷静に原因分析しないとなと思った次第です。
おわりに
Markdownというもの初めてだったので、
https://qiita.com/Qiita/items/c686397e4a0f4f11683d
を見ながら記述しました。纏めていただいておりとても助かりました、感謝です!
- 投稿日:2021-01-22T19:00:17+09:00
AWS EKS 盛り盛り構成インストールガイド ~完結編~
EKS構築手順 完結編
前提
前編のつづきとなっていますので、そちらを閲覧されてからどうぞ
https://qiita.com/lapolapo/items/99bda7f4c8cf1b517448やりたいこと
- 既存PrivateVPCでEKSを使いたい
- ALBも使いたい
- EFSも使うんだ
- Apache + PHP7.4 のいわゆるWEBサーバを作る(CacheやDBはElasticacheやらRDSを使う)
- HTTPSも使いたい
- AutoScalingを考えるとコンテンツはNASに置いておきたい
作業の流れ
- [前回] Cluster作成
- [前回] aws-load-balancer-controllerのインストール
- [前回] EFSドライバーのインストール
- [今回] 各種設定ファイルの作成
- [今回] サービスの起動
- [今回] DNS登録と動作確認
各種サービス用の設定ファイルを作成する
EFS用の設定ファイルを作成
$ mkdir php74-apache && cd php74-apache $ vi php74h-storageclass.yaml \ php74h-pv.yaml \ php74h-claim.yaml ## php74h-storageclass.yaml は、クラスターに割り当てるストレージの定義 ## php74h-pv.yaml は、永続化ボリュームの設定 ## php74h-claim.yaml は、上記で設定したもののを使用するための請求php74h-storageclass.yamlapiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: php74h-sc provisioner: efs.csi.aws.comphp74h-pv.yamlapiVersion: v1 kind: PersistentVolume metadata: name: php74h-pv spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: php74h-sc csi: driver: efs.csi.aws.com volumeHandle: fs-5b708f7bphp74h-claim.yamlapiVersion: v1 kind: PersistentVolumeClaim metadata: name: php74h-claim spec: accessModes: - ReadWriteMany storageClassName: php74h-sc resources: requests: storage: 5GiALB用の設定ファイルを作成
$ vi php74h-ingress.yaml \ php74h-service.yaml ## php74h-ingress.yaml は、ALBとターゲットグループの設定 ## php74h-service.yaml は、PodとALBを外部と接続する設定php74h-ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: php74h-ingress annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/tags: CmBillingGroup=Solution alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-1:687521589547:certificate/d049801f-89b5-4062-8156-dcaaaaaaaaae ## 証明書のARN alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]' alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}' spec: rules: - host: eks.taterole.jp ## 自分の設定したいドメインを設定する http: paths: - path: /* backend: serviceName: php74h-http servicePort: 80 - path: /* backend: serviceName: php74h-https servicePort: 443php74h-service.yamlapiVersion: v1 kind: Service metadata: name: php74h-service labels: app: php74h spec: ports: - port: 80 protocol: TCP type: NodePort selector: app: php74hPod用の設定ファイルを作成
$ vi php74h-pod.yaml ## php74h-pod.yaml は、Podの設定 ## volumes:のセクションにEFSをマウントする設定が入っているので要注目php74h-pod.yamlapiVersion: apps/v1 kind: Deployment metadata: name: php74h spec: selector: matchLabels: app: php74h replicas: 1 template: metadata: labels: app: php74h spec: containers: - name: php74h-container image: php:7.4-apache ports: - name: php74h-port containerPort: 80 volumeMounts: - name: documentroot mountPath: /var/www/htm volumes: - name: documentroot persistentVolumeClaim: claimName: php74h-claimサービスの起動
起動させる
$ cd .. $ kubectl apply -f ./php74h-apache persistentvolumeclaim/php74h-claim created ingress.extensions/php74h-ingress created deployment.apps/php74h created persistentvolume/php74h-pv created service/php74h-service created storageclass.storage.k8s.io/php74h-sc created customresourcedefinition.apiextensions.k8s.io/targetgroupbindings.elbv2.k8s.aws configured mutatingwebhookconfiguration.admissionregistration.k8s.io/aws-load-balancer-webhook configured role.rbac.authorization.k8s.io/aws-load-balancer-controller-leader-election-role unchanged clusterrole.rbac.authorization.k8s.io/aws-load-balancer-controller-role configured rolebinding.rbac.authorization.k8s.io/aws-load-balancer-controller-leader-election-rolebinding uncha clusterrolebinding.rbac.authorization.k8s.io/aws-load-balancer-controller-rolebinding unchanged service/aws-load-balancer-webhook-service unchanged deployment.apps/aws-load-balancer-controller unchanged certificate.cert-manager.io/aws-load-balancer-serving-cert unchanged issuer.cert-manager.io/aws-load-balancer-selfsigned-issuer unchanged validatingwebhookconfiguration.admissionregistration.k8s.io/aws-load-balancer-webhook configuredドメインまわりの設定
ALBのhostnameを確認する
$ kubectl get ingress NAME CLASS HOSTS ADDRESS PORTS AGE php74h-ingress <none> eks.taterole.jp k8s-default-php74hin-bdcfd7b35a-687748344.ap-northeast-1.elb.amazonaws.com 80 121m管理コンソールでもCLIでもいいので設定
→ eks.taterole.jp に dualstack.k8s-default-php74hin-aaaaaaaa5a-681111114.ap-northeast-1.elb.amazonaws.com を結びつける
注意:初期設定でphp74h-ingress.yaml 内で指定したドメインとパス以外は404に飛ばすようになっているので、DNS設定しないとコンテンツが見えません適当にコンテンツを配置する
→ EFSにphpinfo的なものを置いておくといいかもフザウザで確認する
→ HTTPでもHTTPSでもアクセスできることを確認しておく
おつかれさまでした。
- 投稿日:2021-01-22T18:12:24+09:00
AWS EKS 盛り盛り構成インストールガイド (Apache2 + PHP7.4 + EFS + ALB + HTTPS)
EKS構築手順
前提
ちょっとだけ中級者向け(AWSで一般的な環境が構築できる方以上向けの記事)です
やりたいこと
- 既存PrivateVPCでEKSを使いたい
- ALBも使いたい
- EFSも使うんだ
- Apache + PHP7.4 のいわゆるWEBサーバを作る(CacheやDBはElasticacheやらRDSを使う)
- HTTPSも使いたい
- AutoScalingを考えるとコンテンツはNASに置いておきたい
作業の流れ
[事前] AWSでPrivateVPCをつくる
→ 172.16.0.0/16 → 既存のIPを使っているだけなので、読み替えてください[事前] Public-subnetとPrivate-subnetをつくる
→ Public-subnet(ap-northeast-1a:172.16.1.0/24, ap-northeast-1c:172.16.51.0/24) グローバルIP付与可能+InternetGateWayあり
→ Private-subnet(ap-northeast-1a:172.16.101.0/24, ap-northeast-1c:172.16.151.0/24) プライベートのみアクセス可能だが外部への通信はNatgatewayを介して可能[事前] Public-SubnetにEKSをコントロールするためのEC2を配置
[事前] eksctlのインストール
→ https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/getting-started-eksctl.html[この記事] Cluster作成
[この記事] aws-load-balancer-controllerのインストール
[この記事] EFSドライバーのインストール
[次回] 満を持してPodを作成していく
clusterの作成
taterole-test.yaml ファイルを配置
taterole-test.yaml
taterole-test.yamlapiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: taterole-test region: ap-northeast-1 version: "1.18" vpc: id: "vpc-0cb0c0d9201725a89" cidr: "172.16.0.0/16" subnets: private: ## NATGatewayあり ap-northeast-1a: id: "subnet-0351c84fd49393355" cidr: "172.16.101.0/24" ap-northeast-1c: id: "subnet-07b2bfb24b1154028" cidr: "172.16.151.0/24" public: ## InternetGateWayあり ap-northeast-1a: id: "subnet-0f281e8620e7368bf" cidr: "172.16.1.0/24" ap-northeast-1c: id: "subnet-01b715a5b4dd43efc" cidr: "172.16.51.0/24" managedNodeGroups: - name: web1 instanceType: t3.small ## K8sワーカーノードの設定です。任意のインスタンスタイプにしてください。 desiredCapacity: 1 ## 希望台数です。任意の台数にしてください minSize: 1 ## 最小台数です。任意の台数にry maxSize: 1 ## 最大台数です。任意のry privateNetworking: true ssh: publicKeyName: ssh-key-file ## なんかあったときのために、ワーカーノードにログインする為のSSH鍵を指定しておく allow: true labels: {role: worker} tags: Type: eks-worker ## タグを好きにつけられますclusterの立ち上げ
eksctlコマンドでclusterをつくる
$ eksctl create cluster -f taterole-test.yaml --with-oidc → 20分くらいかかるaws-load-balancer-controllerのインストール
iam-policy.jsonのダウンロード
$ curl -o iam-policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/main/docs/install/iam_policy.jsoniamポリシーの作成
$ aws iam create-policy \ --policy-name AWSLoadBalancerControllerIAMPolicy \ --policy-document file://iam-policy.jsonサービスアカウントの作成
$ eksctl create iamserviceaccount \ --cluster=taterole-test \ --namespace=kube-system \ --name=aws-load-balancer-controller \ --attach-policy-arn=arn:aws:iam::<YOUE-AWS-ID>:policy/AWSLoadBalancerControllerIAMPolicy \ --approve [!] no IAM OIDC provider associated with cluster, try 'eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=taterole-test' と、怒られた場合は以下を実行する $ eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=taterole-test --approvecert-managerのインストール
$ kubectl apply --validate=false -f https://github.com/jetstack/cert-manager/releases/download/v1.0.2/cert-manager.yamlAWS Load Balancer Controller のインストール
以下の部分をviで修正する
--cluster-name の部分を自分の my-cluster-name を、自分の設定したいCluster名に変更
ServiceAccountのセクションをまるごと削除$ curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/main/docs/install/v2_0_1_full.yaml $ vi v2_0_1_full.yaml $ kubectl apply -f v2_0_1_full.yamlインストールの確認
$ kubectl get pods -n kube-system | grep aws-load-balancer-controller aws-load-balancer-controller-594b77dc87-cmwgp 1/1 Running 0 91mEFSドライバーのインストール
Amazon EFS CSI ドライバーをデプロイ
$ kubectl apply -k "github.com/kubernetes-sigs/aws-efs-csi-driver/deploy/kubernetes/overlays/stable/?ref=master" → 下記のように、efs-csi-controllerが再起動を繰り返しインストールが完了しない不具合があるので、helmでインストールする $ kubectl get pod --all-namespac NAMESPACE NAME READY STATUS RESTARTS AGE kube-system aws-node-jwqzh 1/1 Running 0 101m kube-system coredns-86f7d88d77-5tpzk 1/1 Running 0 105m kube-system coredns-86f7d88d77-sjxwp 1/1 Running 0 105m kube-system efs-csi-controller-5c8f98ddfd-rf5jd 2/3 CrashLoopBackOff 7 14m kube-system efs-csi-controller-5c8f98ddfd-xqvsb 2/3 CrashLoopBackOff 7 14m kube-system efs-csi-node-prjmd 3/3 Running 0 14m kube-system kube-proxy-fw8wdhelmのインストール
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 > get_helm.sh % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 11213 100 11213 0 0 37754 0 --:--:-- --:--:-- --:--:-- 37627 $ chmod 700 get_helm.sh $ ./get_helm.sh WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/ec2-user/.kube/config WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/ec2-user/.kube/config Helm v3.5.0 is available. Changing from version v3.4.2. Downloading https://get.helm.sh/helm-v3.5.0-linux-amd64.tar.gz Verifying checksum... Done. Preparing to install helm into /usr/local/bin helm installed into /usr/local/bin/helmhelm で Amazon EFS CSI ドライバーをデプロイ
$ helm install aws-efs-csi-driver https://github.com/kubernetes-sigs/aws-efs-csi-driver/releases/download/v0.3.0/helm-chart.tgz WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/ec2-user/.kube/config WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/ec2-user/.kube/config NAME: aws-efs-csi-driver LAST DEPLOYED: Thu Jan 21 17:16:16 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: To verify that aws-efs-csi-driver has started, run: kubectl get pod -n kube-system -l "app.kubernetes.io/name=aws-efs-csi-driver,app.kubernetes.io/instance=aws-efs-csi-driver" $ kubectl get pod -n kube-system -l "app.kubernetes.io/name=aws-efs-csi-driver,app.kubernetes.io/instance=aws-efs-csi-driver" NAME READY STATUS RESTARTS AGE efs-csi-node-glkgs 3/3 Running 0 44mクラスターのVPCID取得
$ aws eks describe-cluster --name taterole-test --query "cluster.resourcesVpcConfig.vpcId" --output text vpc-0cb0c0d9201725a89VPIのCIDR範囲を取得
$ aws ec2 describe-vpcs --vpc-ids vpc-0cb0c0d9201725a89 --query "Vpcs[].CidrBlock" --output text 172.16.0.0/16EKSクラスター→EFSセキュリティグループの作成
$ aws ec2 create-security-group --description taterole-efs-test-sg --group-name taterole-efs-sg --vpc-id vpc-0cb0c0d9201725a89 { "GroupId": "sg-091e5e23e775a4f4b" }EFSインバウンドルールを追加して、VPC のリソースが EFS と通信できるようにする
$ aws ec2 authorize-security-group-ingress --group-id sg-091e5e23e775a4f4b --protocol tcp --port 2049 --cidr 172.16.0.0/16EFSファイルシステムの作成
$ aws efs create-file-system --creation-token taterole-efs { "OwnerId": "<YOUE-AWS-ID>", "CreationToken": "taterole-efs", "FileSystemId": "fs-5b708f7b", "FileSystemArn": "arn:aws:elasticfilesystem:ap-northeast-1:<YOUE-AWS-ID>:file-system/fs-5b708f7b", "CreationTime": "2021-01-21T17:03:50+09:00", "LifeCycleState": "creating", "NumberOfMountTargets": 0, "SizeInBytes": { "Value": 0, "ValueInIA": 0, "ValueInStandard": 0 }, "PerformanceMode": "generalPurpose", "Encrypted": false, "ThroughputMode": "bursting", "Tags": [] }EFSマウントターゲットの作成 ap-northeast-1a (サブネット毎に実行する)
$ aws efs create-mount-target --file-system-id fs-5b708f7b --subnet-id subnet-0351c84fd49393355 --security-group sg-091e5e23e775a4f4b { "OwnerId": "<YOUE-AWS-ID>", "MountTargetId": "fsmt-e09902c1", "FileSystemId": "fs-5b708f7b", "SubnetId": "subnet-0351c84fd49393355", "LifeCycleState": "creating", "IpAddress": "172.16.101.9", "NetworkInterfaceId": "eni-03a2229e1a0a08857", "AvailabilityZoneId": "apne1-az4", "AvailabilityZoneName": "ap-northeast-1a", "VpcId": "vpc-0cb0c0d9201725a89" }EFSマウントターゲットの作成 ap-northeast-1c (サブネット毎に実行する)
$ aws efs create-mount-target --file-system-id fs-5b708f7b --subnet-id subnet-07b2bfb24b1154028 --security-group sg-091e5e23e775a4f4b { "OwnerId": "<YOUE-AWS-ID>", "MountTargetId": "fsmt-e69902c7", "FileSystemId": "fs-5b708f7b", "SubnetId": "subnet-07b2bfb24b1154028", "LifeCycleState": "creating", "IpAddress": "172.16.151.53", "NetworkInterfaceId": "eni-0e51080afba62675e", "AvailabilityZoneId": "apne1-az1", "AvailabilityZoneName": "ap-northeast-1c", "VpcId": "vpc-0cb0c0d9201725a89" }
あとはPodを作成してサービス提供の準備をしていくだけです。
今回はとりあえずここまで
- 投稿日:2021-01-22T17:48:26+09:00
【初心者メモ】冗長化して稼働率を高くするには
AWSインフラ構築学習で、稼働率向上のための具体的な冗長化に初めて取り組んだので、そこで学んだ用語等をメモしておきます。修正点やアドバイス等ございましたら教えていただければ幸いです。
参考講座:AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得https://www.udemy.com/course/aws-and-infra/
そもそも稼働率とは
トラブルなく無事に使えている期間を示すもの。
インフラ設計観点の大切な項目である可用性(サービスを継続的に利用できるか)を表す指標のひとつ。
稼働率の計算には、平均故障間隔(MTBF)や平均修理時間(MTTR)が用いられる。○平均故障間隔(Mean Time Between Failure)
故障と故障の間隔を表すもの。
○平均修理間隔(Mean Time To Repair)
修理に必要な時間を表すもの。
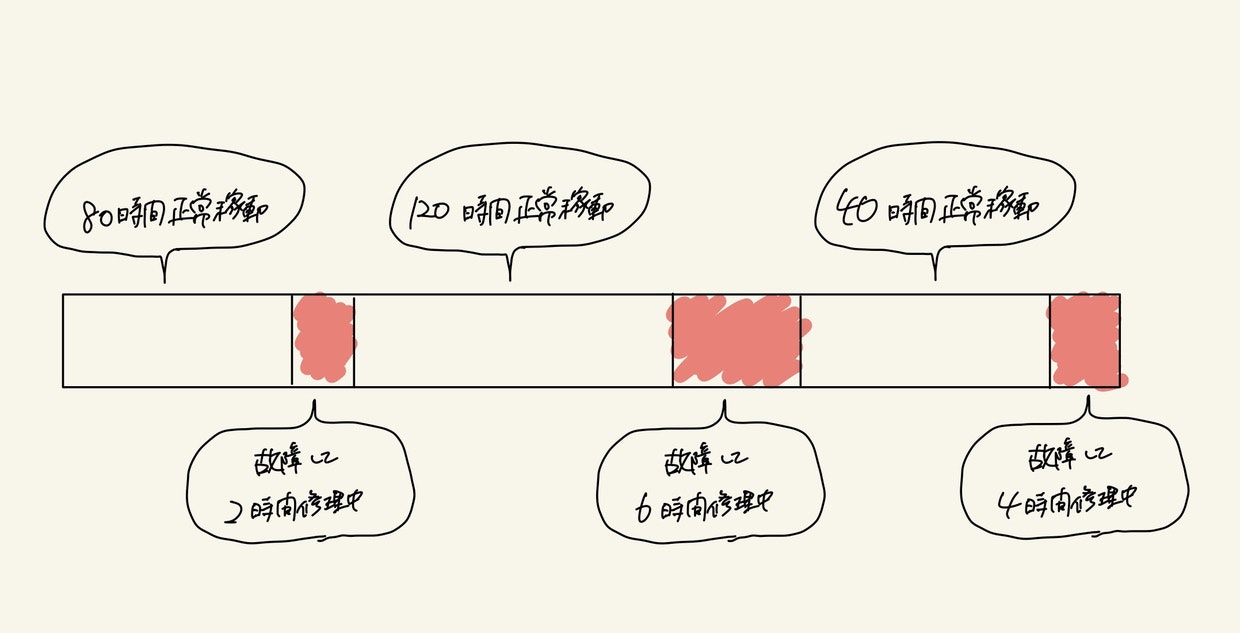
こんな稼働状況があったら、
平均故障間隔は→(80時間+120時間+40時間)÷3 = 80時間
平均修理時間は→(2時間+6時間+4時間)÷3 = 4時間つまり「平均80時間くらいの間隔で故障する」ということと、「だいたい平均すると4時間が復旧時間として必要」ということが言える。
稼働率の求め方
稼働率は、システムが正常稼働していた割合なので
稼働時間(MTBF)÷全運転時間(MTBF+MTTR)で求められる。
今回の場合は、稼働時間240時間÷全運転時間252時間 = 約95%となる稼働率を上げるための基本的な考え方
そこで、稼働率を高くするためには
①障害発生間隔を長くする or ②平均復旧時間を短くする
の2つが考えられる。そのための手法の一つに冗長化がある。
○冗長化
システムの構成要素を多重化すること。
ある構成要素で障害が発生しても、処理を引き継げるようにすることで稼働率を高める。「冗長」という言葉は、通常「無駄が多い」のようなネガティブなニュアンスが伴うことがありますが、システムの世界では、冗長であることは「より耐久性が高く、堅牢である」という良い意味を持っている。
○単一障害点(Single Poing Of Failure)
冗長化で重要なのがSPOFの考え方。
SPOFとは、システム構成要素のうち、多重化されておらずそこが停止すると全体が停止してしまう部分のこと。
このSPOFを無くすために、二重化まではやることが多いが、それ以上どの程度コストをかけて冗長化するかは、予算制約と、求める信頼性水準とのせめぎ合い次第らしい。稼働率を上げる具体的な方法
AWSで取り組める主な方法は2つ
①要素を組み合わせて、全体の稼働率を高める
②負荷を適切なプロビジョニングで回避する
①要素を組み合わせて、全体の稼働率を高める
サーバが2台ある構成。
Active-Active:構成要素が同時に稼働する
Active-Stanby:稼働するのはActiveのみで残りは待機しているActive-Active構成のメリットはダウンタイム時間の短さで、この構成は複数のサーバが同時に動いているため、そのうち一つが動作不能に陥ったとしても、残りのサーバが処理を継続することで、システム全体の停止を防ぐことができる。
それだけ聞いて、全てActive-Activeにしておけば良いのではないかと考えてしまったが、
Webサーバはそれで良くても、DB等のデータを持つものはデータの生合成を保つために同期が必要で、動作が遅くなる等の事象が発生する。そういう時にはActive-Stanbyにしたりするようだ。②負荷を適切なプロビジョニングで回避する
アクセス数等を予測し、適切にリソースを準備(プロビジョニング)することで、負荷を捌けるようにする方法。ここでは、スケールアップ・スケールアウトが用いられる。
○スケールアップ
・個々の要素の性能を向上させること。
ある程度の規模まではスケールアップがコスパ良いが、一定範囲を超えると悪化する。○スケールアウト
・個々の要素の数を増やすこと
ある程度の規模を超えそうであれば、スケールアウトで対応する。
基本用意するのがN+1構成。安心なのはN=2構成。
(サービス提供に必要な最低限のサーバ台数をNとする)まとめ
最近アプリケーション制作でも、SQL発行数を減らせるようなコード作りを意識し始めました。
初心者ながら少しでも負荷を下げたり、スムーズな稼働のためにできることはやっていきたいなと思いました。

- 投稿日:2021-01-22T17:48:26+09:00
【初心者メモ】冗長化して稼働率を高くするとは
AWSインフラ構築学習で、稼働率向上のための具体的な冗長化に初めて取り組んだので、そこで学んだ用語等をメモしておきます。修正点やアドバイス等ございましたら教えていただければ幸いです。
参考講座:AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得https://www.udemy.com/course/aws-and-infra/
そもそも稼働率とは
トラブルなく無事に使えている期間を示すもの。
インフラ設計観点の大切な項目である可用性(サービスを継続的に利用できるか)を表す指標のひとつ。
稼働率の計算には、平均故障間隔(MTBF)や平均修理時間(MTTR)が用いられる。○平均故障間隔(Mean Time Between Failure)
故障と故障の間隔を表すもの。
○平均修理間隔(Mean Time To Repair)
修理に必要な時間を表すもの。
こんな稼働状況があったら、
平均故障間隔は→(80時間+120時間+40時間)÷3 = 80時間
平均修理時間は→(2時間+6時間+4時間)÷3 = 4時間つまり「平均80時間くらいの間隔で故障する」ということと、「だいたい平均すると4時間が復旧時間として必要」ということが言える。
稼働率の求め方
稼働率は、システムが正常稼働していた割合なので
稼働時間(MTBF)÷全運転時間(MTBF+MTTR)で求められる。
今回の場合は、稼働時間240時間÷全運転時間252時間 = 約95%となる稼働率を上げるための基本的な考え方
そこで、稼働率を高くするためには
①障害発生間隔を長くする or ②平均復旧時間を短くする
の2つが考えられる。そのための手法の一つに冗長化がある。
○冗長化
システムの構成要素を多重化すること。
ある構成要素で障害が発生しても、処理を引き継げるようにすることで稼働率を高める。「冗長」という言葉は、通常「無駄が多い」のようなネガティブなニュアンスが伴うことがありますが、システムの世界では、冗長であることは「より耐久性が高く、堅牢である」という良い意味を持っている。
○単一障害点(Single Poing Of Failure)
冗長化で重要なのがSPOFの考え方。
SPOFとは、システム構成要素のうち、多重化されておらずそこが停止すると全体が停止してしまう部分のこと。
このSPOFを無くすために、二重化まではやることが多いが、それ以上どの程度コストをかけて冗長化するかは、予算制約と、求める信頼性水準とのせめぎ合い次第らしい。稼働率を上げる具体的な方法
AWSで取り組める主な方法は2つ
①要素を組み合わせて、全体の稼働率を高める
②負荷を適切なプロビジョニングで回避する
①要素を組み合わせて、全体の稼働率を高める
サーバが2台ある構成。
Active-Active:構成要素が同時に稼働する
Active-Stanby:稼働するのはActiveのみで残りは待機しているActive-Active構成のメリットはダウンタイム時間の短さで、この構成は複数のサーバが同時に動いているため、そのうち一つが動作不能に陥ったとしても、残りのサーバが処理を継続することで、システム全体の停止を防ぐことができる。
それだけ聞いて、全てActive-Activeにしておけば良いのではないかと考えてしまったが、
Webサーバはそれで良くても、DB等のデータを持つものはデータの生合成を保つために同期が必要で、動作が遅くなる等の事象が発生する。そういう時にはActive-Stanbyにしたりするようだ。②負荷を適切なプロビジョニングで回避する
アクセス数等を予測し、適切にリソースを準備(プロビジョニング)することで、負荷を捌けるようにする方法。ここでは、スケールアップ・スケールアウトが用いられる。
○スケールアップ
・個々の要素の性能を向上させること。
ある程度の規模まではスケールアップがコスパ良いが、一定範囲を超えると悪化する。○スケールアウト
・個々の要素の数を増やすこと
ある程度の規模を超えそうであれば、スケールアウトで対応する。
基本用意するのがN+1構成。安心なのはN=2構成。
(サービス提供に必要な最低限のサーバ台数をNとする)まとめ
最近アプリケーション制作でも、SQL発行数を減らせるようなコード作りを意識し始めました。
初心者ながら少しでも負荷を下げたり、スムーズな稼働のためにできることはやっていきたいなと思いました。
- 投稿日:2021-01-22T17:30:53+09:00
AWSでEFSをマウントしたときにFilesystemが127.0.0.1になる理由
AWS(Qiitaも)ド素人が勉強していて気になったので調べた結果を共有します。
EFSマウントヘルパーを使用してマウントした場合
[root@ip-hogehoge ~]# df -hP Filesystem Size Used Avail Use% Mounted on devtmpfs 482M 0 482M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 524K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 1.7G 6.4G 21% / tmpfs 99M 0 99M 0% /run/user/1000 127.0.0.1:/ 8.0E 0 8.0E 0% /home/ec2-user/efs ←127.0.0.1:/ってなに? tmpfs 99M 0 99M 0% /run/user/0Filesystemが
127.0.0.1:/ってなんぞ?
調べてもパッと出てこなかった・・・・
これが瞬時に理解できないの自分だけ?NFSクライアントを使用してマウントした場合
[root@ip-hogehoge ~]# df -hP Filesystem Size Used Avail Use% Mounted on devtmpfs 482M 0 482M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 472K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 1.7G 6.4G 21% / tmpfs 99M 0 99M 0% /run/user/1000 tmpfs 99M 0 99M 0% /run/user/0 fs-hogehoge.efs.ap-northeast-1.amazonaws.com:/ 8.0E 0 8.0E 0% /home/ec2-user/efsNFSクライアントを利用した場合は、NFSを利用する際に表示される見なれた形式(ホスト名)になっています。
調べてみた
結論
NFSクライアントはstunnelを利用しているから。
stunnelとは、Wikiより
stunnel は、フリーなマルチプラットフォーム対応のプログラムであり、汎用TLS/SSLトンネリングサービスを提供する。
stunnel は、TLSやSSLにネイティブで対応していないクライアントサーバシステムに安全な暗号化されたコネクションを提供するのに利用できる。AWSのマニュアルを読んでもあまり記載が無かったが、PDFのユーザガイドには記載があった。
https://docs.aws.amazon.com/ja_jp/efs/latest/ug/efs-ug.pdf
のP.166、167あたり。転送中のデータの暗号化を使用する場合、NFS クライアント設定が変更されます。アクティブに
マウントされたファイルシステムを検査する場合、次の例に示すように、localhost または 127.0.0.1 に
マウントされたことが表示されます。
- 投稿日:2021-01-22T17:03:04+09:00
ACMのSSL証明書に切り替えてみた
やりたいこと
やりたいことは、AWSベースで作成したウェブサイトのSSL証明書をまとめて管理したいため、ACM(AWS Certificate Manager)で取得したSSL証明書を利用すること。
ACMのSSL証明書をそのままでウェブサイトにインストールができないため、ALB(Application Load Balancer)も導入する。
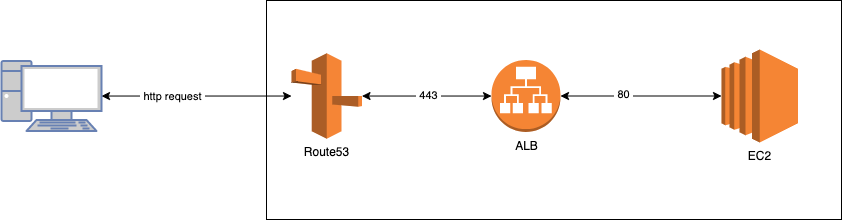
構成イメージ
Route53はhttpsのリクエスト受け取って、ALBに送信する。
ALBに設定しているリスナーのルールに従って対象のインスタンスに送信する。ACMのSSL証明書をALBに登録するので、基本はHTTPS:443のリクエスト受信する想定です。ただ、80番のリクエストにも対応しておきたいため、ALBのHTTP:80のリスナーにHTTPS:443にリダイレクトするようにしている。
やり方の参考:https://aws.amazon.com/jp/premiumsupport/knowledge-center/elb-redirect-http-to-https-using-alb/事前準備
①対象ウェブサイトはRoute53で管理しているドメインで立ち上げたもの。
②SSL証明書をACMから取得しておく。ALBの設定
SSL証明書の登録
HTTPS:443のリソナーに取得したSSL②をインポートする。
参考:https://aws.amazon.com/jp/premiumsupport/knowledge-center/associate-acm-certificate-alb-nlb/ターゲットグループの作成
今回作成したのはTarget typeがInstanceになっているもの。
参考:https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/create-target-group.html
リスナーにルールの追加
HTTPS:443のルールを編集し、IF−THENのルールを追加する。
例えば、example.comのリクエストが来たら、exampleターゲットに転送。IF ホストがexample.com
THEN
転送先
example: 1 (100%)Route53の設定
ここの目的はALBとRoute53連携できるように設定する。
レコードの編集&追加
ALBの画面には当該DNS名の情報はあり、あとで確認するため、先にコピしておく。
Route53画面にある当該ホストゾーンの詳細から、Aレコードを編集&追加する。
(元々インスタンスIPに関連するAレコードがありまして、それをALBに変更すれば良いですが、テスト&確認しながら行いたいため、そのAレコードのルーティングポリシーを加重に変更してから、新規でALBのAレコード(ルーティングポリシーも加重にする)を追加する形にした。重みの調整でALBに行くか、本来の固定IPに行くかのコントロールできるのは自分の狙い。)ALBのAレコードを作成する時に、「ターゲットのヘルスを評価」という項目があり、ONにする場合、予想している動きになる可能性があります。その時に以下の資料を参考になれると思います。ちなみに、今回はOFFにした。
ヘルスチェックが設定されている場合に Amazon Route 53 がレコードを選択する方法
複雑な Amazon Route 53 構成におけるヘルスチェックの動作レコードのテスト
Route53の画面には「レコードをテストする」機能があるので、自分の設定が正しいかを確認したい時に使えると思います。
最後: 確認する
CloudWatch、ALBのターゲットのモニタニングでリクエストの集計を確認できます。
また、普通にサイトにアクセスして、対象インスタンスのaccess.logにはALBのIPからのアクセスが出てきましたら、それでOKだと思います。
- 投稿日:2021-01-22T14:20:52+09:00
色々なAWSの画像認識サービス(最初は静止画の分析から)
AWS画像認識サービスを調べたり触る機会がありましたので、ちょっとした解説です。
前提として、以下があるので、ご注意ください。
- 動作確認は、主にlinux(ubuntu)を使い、awsのcliやpythonライブラリ(boto3)を活用しました。
- 2020年1月頃に調べたり動作確認した内容が含まれています。
目次
1.はじめに
2.AWS画像認識サービス
2.1.RekognitionとRekognition Videoを触ってみた
2.2.好みの画像分析が作成できるRekognitionカスタムラベルとSageMaker
3.おわりに
a.参考リンク1. はじめに
人の行動を分析することをやりたくて、有名で身近にあるAWSの画像認識サービスを調べていきました。
画像から人や物(服や帽子も)が検出され、ものの名前や、顔のオブジェクトの座標や年齢等のデータが得られるので、
得られたデータをもとに、マーケティング等の色々な分析や、お店でのVIPお客様対応等の支援等、幅広い活用が聞かれます。精度的に、どうしても判断しにくい画像になってくると、検出漏れや誤検出、というのはありますので、
そういったことが起きにくくするか、起きても許容される形で活用するのが、難易度が低く進めやすいかと思います。
例えば、人を特定しても、犯人と断定せず、容疑者として抽出し、管理者等が確認して、決定づける。という感じですね。ちなみにですが、私は、オフィスで人同士の距離が近いかどうかを、推定する検証を行いました。
人の顔検出データ(顔パーツの座標等)をもとに大まかな位置を推定し、DataBaseに記録し、ユーザによる確認や追跡を支援する。といった感じです。2. AWS画像認識サービス
画像認識の中身の話になりますが、AWSの画像認識のサービスには、主に、以下があります。
サービス名 概要 認識対象 備考 Rekognition 静止画の分析 ラベル、カスタムラベル(任意)、コンテンツの節度、テキスト抽出、顔検出と分析、顔検出と検証、有名人の認識、Personal Protective Equipment (PPE) の検出 SageMakerと同様にユーザが画像認識モデルの作成が可能(カスタムラベル) Rekognition Video 映像の分析 ラベル、顔検出と分析、顔検索、人物追跡、不適切コンテンツ、有名人の認識、テキスト検出 リアルタイムのライブストリーミング分析の場合、顔検出や顔探索のみのようです SageMaker ユーザが何を分析するかのモデルを作成し、そのモデルを活用して画像の分析 ユーザ作成モデルによる画像認識(任意) 2.1. RekognitionとRekognition Videoを触ってみた
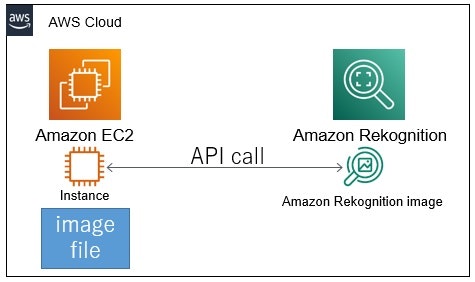
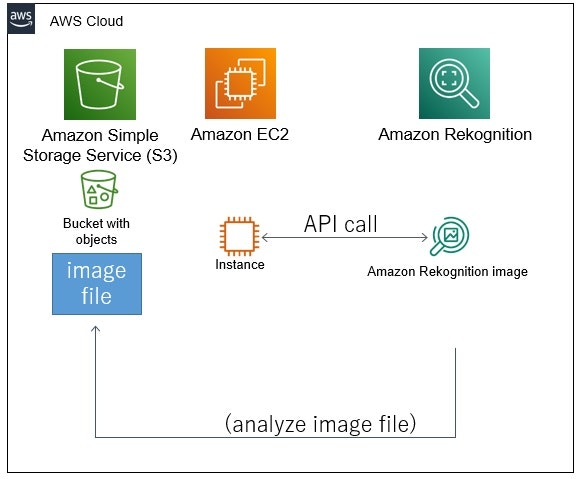
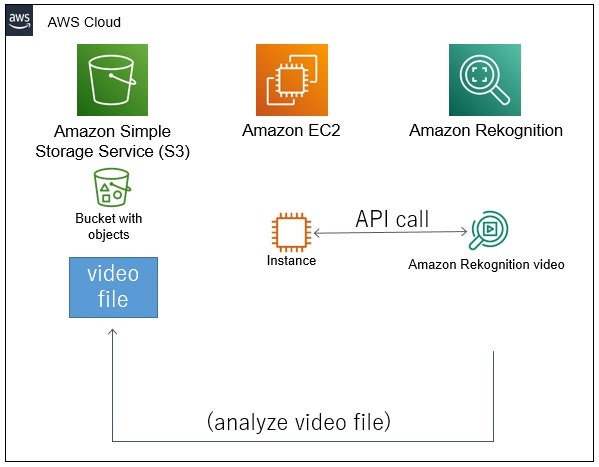
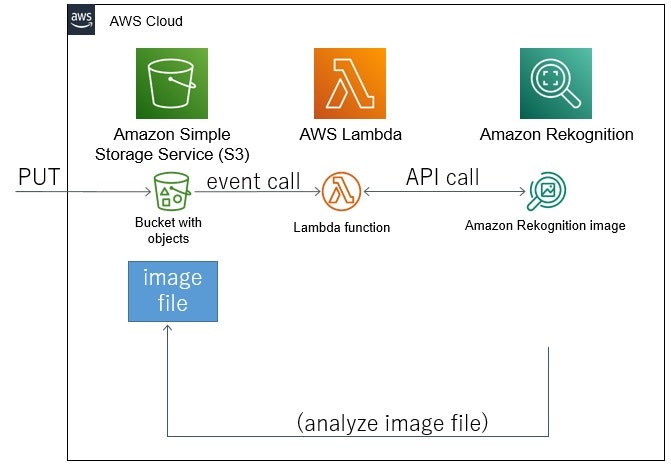
以下のようなイメージの構成で、画像認識を試しました。
EC2のローカルにある画像ファイルを、Rekognitionへ送信(バイト配列で)して画像認識。
S3にある画像ファイルを、Rekognitionで画像認識。
S3にある映像ファイルを、Rekognition Videoで画像認識。
S3にある映像ファイルをKinesis Video Streamsにアップロードして、Rekognition Videoで画像認識。(Kinesis Video Streamsを使うことで、カメラ映像もリアルタイムで画像認識させることも可能です)
S3に画像ファイルをPUTし、S3のPUTイベントコールから実行されたLambda関数から、Rekognitionで画像認識。
これらのように、簡単に試した範囲ですが、
Rekognitionの認識結果について、
顔検出と分析(detect-faces)のデフォルトモードでは、顔の矩形座標や、顔パーツ(5点:両目、鼻、口の左右の端)の座標、あと顔向きや輝度、シャープネス、顔のスコアの情報が取得できました。
そして、詳細モード(ALL)では、上記に加え、顔のパーツが他25点(眉や顎等含め)、年齢幅、性別、スマイルや感情等、口や目等、ひげや眼鏡といった情報も取得できました。ラベルのdetect-labelsでは、シーンのスコアや、人や服等だと矩形座標やスコアが取得できました。
Rekognition Videoの認識結果について、
顔検出やラベルでは、2FPS(約500ms毎)で、フレーム画像から顔やラベルを検出をした結果が取得できました。
人物追跡では、顔は5FPS(約200ms毎)で、人は15FPS(約66ms毎)で、フレーム画像から顔や人検出した結果が取得できました。
なお、人には、番号が振られており、番号により人の追跡を見分けられるようです。そして、顔は、検出された人に紐づいていました。RekognitionやRekognition Videoの入力サイズについて、
映像の連続するフレーム画像を、リアルタイムに順次処理できるか気になり、入力方法を調べたのですが、画像の入力方法によって許容サイズが異なるようです。
以下のように大きいサイズを指定したい場合、S3経由でなければいけません。
サービス名 入力方法 許容サイズ 備考 Rekognition S3 15 MB Rekognition バイト配列 5 MB Rekognition Video S3 10 GB か 6 時間 Rekognition Video Kinesis Video なし※1 リアルタイム対応可能 ※Rekognition Videoの場合、映像ファイルをバイト配列で送信して入力する方法はできなかったです。S3経由でした。
※1 長時間は未検証ですが記載を見つけられなかったので制限がないと思われます。また解像度についても、画像認識に影響があるようです。
QAにも、RekognitionやRekognition Videoについての記載があり、それぞれ以下のようです。Rekognitionの解像度について、
Amazon Rekognition は縦横両方のサイズが 80 ピクセル以上の画像に対応していますが、QVGA (320x240) より解像度が低い場合は顔や物体、不適切なコンテンツを認識しない可能性が高くなります。
上記引用の通りですが、
縦横80ピクセル以上で、VGA (640x480) 以上が推奨されてます。
QVGA (320x240) 未満は、顔等の対象を認識しなくなる可能性が高いそうです。通常は、画像内に表示されている最小の物体または顔が、画像の短い辺のサイズ (ピクセル) の 5% 以上になるようにしてください。
こちらも、上記引用の通り、
検出対象(物体や顔等)が、画像の縦か横の短いピクセルサイズの、5%以上必要のようです。
実際に、360°カメラの解像度6080x3040で顔検出しましたが、小さい顔が検出されず、画像の解像度を小さく変更すると検出されましたので、対象によっては事前に加工が必要ですね。Rekognition Videoの解像度について、
推奨の解像度は 720p (1280×720 ピクセル) から 1080p (1920x1080 ピクセル) までです。他のアスペクト比における同等の解像度でも最適な結果が得られます。解像度が低すぎる場合 (QVGA または 240p) や低画質な動画の場合は、結果の質にマイナスの影響が出る可能性があります。
上記引用の通り、
推奨の解像度があり、解像度が低すぎる場合だと、よくないようです(検出漏れ等の精度に影響すると思われます)。2.2. 好きな画像分析が作成できるAWSのサービス
好きなものを画像認識させるといったカスタマイズができるのは、Rekognitionのカスタムラベルと、SageMakerのようです。
画像認識モデル作成に注目すると、それぞれ以下の違いがあるようですね。(私は触ったことがないので、あくまでも資料を見たり、聞いた話です。)
サービス名 特徴 備考 Rekognitionカスタムラベル ラベル付け等のRekognitionの既存機能をベースに、少ないデータで効率的な画像認識モデルを作成 SageMakerのラベル付け支援(Ground Truth)も利用可能 SageMaker 開発者やデータサイエンティスト向けの各種ツール(統合開発環境(Studio)、ラベル付け支援(Ground Truth)、エッジデバイス管理(Edge Manager)等)を活用し、高精度の画像認識モデルを作成 課金については、以下の違いがあります。
Rekognitionは、推論リソースの数と時間当たりで決まっているのですが、SageMakerは、EC2のインスタンスを起動することもありインスタンスタイプに依存した料金となるようです。
Rekognitionは、開始すると時間当たり$4程度かかってしまいますが、SageMakerの場合、EC2インスタンスタイプによって料金が決まるため、
例えばですが、1時間に数回で、24時間監視したいといった、あまり頻繁に映像分析を行わない場合は、お得に活用できそうです。
サービス名 フェーズ 料金 Rekognitionカスタムラベル 学習 $1/時間 Rekognitionカスタムラベル 画像認識 $4/時間*推論リソース数 SageMaker 学習・分析・画像認識 EC2インスタンスタイプに依存 4. おわりに
というように複数のサービスがあり、どれを活用していくか、悩ましいところがありますが、最初は、Web上にデモも用意され、すぐ使えるRekognitionの静止画の分析(ラベル検出等)を試してみるのがよさそうです。
次に、既存のRekognitionが画像認識に対応していなければ、カスタムラベルで、画像認識モデルを作成し利用したり。
凝った分析や最適な精度や料金によるサイジング等、突き詰めていく場合、SageMakerを利用する。といったユーザの活用スタイルによって順に進めていくのがよさそうに思えています。今後、自分でも、カスタムラベルで好みの画像認識モデルを作成してみたいと思います。
5. 参考リンク

- 投稿日:2021-01-22T14:18:14+09:00
パッケージ mysql-server は利用できません。 というエラーについて
こんにちは!
独学でRailsアプリを作成し、AWS EC2上に手動でデプロイしたとき想像以上に大変だったので、出会った主なエラーとその解決方法を複数の記事に分けて記します。同じ様にエラーで悩んでいる方にとって参考になれば幸いです。環境
ローカル環境
・Ruby 2.7.2
・Ruby on Rails 6.0.3
・MySQL 8.0.2
EC2上の環境
・OS:Amazon Linux 2今回はこの記事を参考にデプロイしました。
https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view事象
EC2インスタンスにSSH通信でログインし以下のコマンドでパッケージをインストールしました。
$ sudo yum -y install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-release sqlite sqlite-develパッケージのインストールが進んでいく中ログの中に気になるメッセージがありました。
パッケージ mysql-server は利用できません。どういうことでしょうか。このままではMySQLを使うことができないことは自分でも理解できました。
解決方法
原因を突き止めるべく調べてみると、どうやらEC2インスタンスにはデフォルトでMariaDBが入っており、それと競合することからこのメッセージが出たということがわかりました。
つまり、MariaDBを削除すればMySQLがインストールできるのではないかと考え、以下のコマンドを実行しました。$ sudo yum remove mariadb-libs $ rm -rf /var/lib/mysql/ $ sudo yum localinstall http://dev.mysql.com/get/mysql57-community-release-el7-7.noarch.rpm $ sudo yum -y install mysql-community-server手順としては以下の通りです。
①MariaDBライブラリ
②データフォルダの削除
③MySQL公式のyumリポジトリの追加
④MySQLのインストールそしてバージョン確認のコマンドを実行して、正常に出力されれば成功です。
$ mysqld --version最後までお読みいただきありがとうございました。
参考
https://weblabo.oscasierra.net/installing-mysql57-centos7-yum/
https://qiita.com/riekure/items/d667c707e8ca496f88e6
- 投稿日:2021-01-22T14:07:52+09:00
AWS初心者が3回目でやっとソリューションアーキテクト-アソシエイトに合格【5ヵ月】
スペック
・基本的なIT用語はわかる
・ネットワークわからん(TCP/IPってなに?)
・EC2インスタンスの作り方だけ知ってる
・クラウドってなんかすごいらしいね
・資格はIパスのみ使用した教材・使い方
動画
概要をつかむのに利用しました。全てUdemyです。参考書と並行して一番最初にやるべき。
下2つのうちのどちらかをやれば良いと思います。上2つはなくても良かったかな。
あまりのんびりやらず、早いとこ問題集を解く段階まで行くのをおすすめします。Amazon Web Services マスターコース VPC編
Amazon Web Services マスターコース EC2編
→AWSに欠かせないサービスであるVPC、EC2についてそれぞれ詳しく解説されています。こちらは下2つのコースでも解説されているので受ける必要はなかったかなと思います。この辺りの内容に不安がある方は受けてみても良いかもしれません。最速で学ぶ AWS認定ソリューションアーキテクトアソシエイト入門完全攻略コース
→だいたいの内容はこちらで網羅できますが、ハンズオンがEC2周りに限られているのでより多くのハンズオンをしたい方には次のコースの方がおすすめです。個人的には聞き取りやすさとか見やすさの点でこちらの方が気に入ってました。これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
→かなりボリューミーですが、主要サービス以外のハンズオンもついているので多数ある覚えなければいけないサービスも頭に入りやすかったです。ただ、動画を最新の情報にするためにつぎはぎされていたり少し聞き取りづらい部分がありました。参考書
AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
→オレンジと白の表紙の本。(改訂版が発売予定らしいので新しい方のリンクを貼っています)
動画と並行して読むとかなりわかりやすいです。私は日中動画を見て、寝る前に読んでました。あとは動画でイメージがつきにくかったところを辞書的に引いて読んでました。巻末に模擬試験一回分ついているのも良いです。
黒本も有名みたいですが本屋で見た感じだと私はこちらの方が初心者にはわかりやすいと思いました。内容が古いことがデメリットでしたが改訂版出るみたいなのでその心配もなくなりましたね。公式サイト
AWS 認定 ソリューションアーキテクト – アソシエイト
→こちらで試験の概要などを確認します。サンプル問題は問題文の長さや難易度が本試験と同じなので見ておくと良いと思います。AWS サービス別資料
→BlackBeltというAWS公式のセミナーの動画や資料があります。調べたいことがある時やスキマ時間に見ていました。問題集
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
→主要教材。とにかくこれを解きまくってました。最初はAWSだけでなくIT用語も何言ってるかわからなかったので、調べながら問題を読みました。なんとなくで解答を選ぶのではなく、一問ずつなぜこれが正解なのか、不正解の選択肢はなぜ不正解なのかを答えられるようにしないと厳しいです。本試験では模擬試験より明らかに難しい問題が出ます。AWS認定資格 無料WEB問題集&徹底解説
→一周だけやりましたが、Udemyの問題集だけで良いかと。余力があったらやるくらいで大丈夫です。内容やボリューム的には悪くないですが、無料ということもあり情報の更新がされていなかったり誤りがあったりするのでUdemyの方がおすすめです。公式模試
AWS認定試験に備える
→本試験の申し込みページから公式の模擬試験を申し込めます。2000円で20問の模試が受けられます。本試験と同様解答は分かりませんが、問題のスクショは可能です。本試験の問題の雰囲気を知るために受けてみるのも良いですが、絶対必要というわけではないです。実際に行った学習の流れ
結構だらだらやっていました。
学習期間:2020/7月~12月(約5ヵ月)
7月
Amazon Web Services マスターコース VPC編
Amazon Web Services マスターコース EC2編
最速で学ぶ AWS認定ソリューションアーキテクトアソシエイト入門完全攻略コース
実際の案件で使われるような構成の簡易版のものを構成してみる
8月
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
9月
模擬試験問題集の解き直し
10月
模擬試験問題集の解き直し
AWS認定資格 無料WEB問題集&徹底解説
一回目の受験→680点で不合格
11月
模擬試験問題集の解き直し
二回目の受験→624点で不合格(少しさぼったら露骨に点数落ちました)
12月
模擬試験問題集の解き直し
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
三回目の受験→730点で合格!(ギリギリ…)まとめ
のんびりやりすぎたので実際は集中してやれば1~2ヵ月くらいで合格できたんじゃないかなと思います(言い訳)。ネットワークとかインフラとかわかる方はもっと短くてもいけると思います。
早めに概要を掴んで、ひたすら問題を解き続けることが大事です。
ただ、初心者の方はなかなかイメージを掴みづらいと思うので、ハンズオンで実際に触りながら学んでいくのがおすすめです。ハンズオンは時間がかかりますが、実際に触ることで頭に入りやすくなるのでかえって近道になります。
過去問がなく、試験を受けた際もどの問題が合っていたかわからないのでしんどかったですが、なんとか合格できてよかったです。読んでくださった皆様が無事合格することを祈っております。
- 投稿日:2021-01-22T12:53:04+09:00
draw.io(diagrams)は無料で汎用的に使える作画ツール
よくみるAWSの構成図、クラウドを触るようになってから何で描いているんだろうと気になっていました。
案件に参画してみると、draw.io(現在はdiagrams)というツールで作画していることが判明しました。
使ってみてお気に入りになったツールの一つです。draw.io(diagrams)とは
無料で使える、構成図やレイアウト図などが描ける作画ツールです。
こちらから利用できます。
AWSを使用する構成図や資料作りに大変重宝しています。
使い方の概要はferretの記事が参考になるかと思います。AWS公式ドキュメントの図をリメイクしてみた
AWSのDirect Connectの公式ドキュメントにあるこの図のアイコンが古かったので、新しいアイコンで作ってみました。
https://docs.aws.amazon.com/ja_jp/directconnect/latest/UserGuide/Welcome.htmlこれが
こうなりました。
色味の微妙な違いはご容赦ください。元ネタと同じ色が使いたい!という方へ
私はGoogle Chromeの拡張機能にあるColorPick Eyedropperを使って調べています。
参考になれば。


- 投稿日:2021-01-22T11:25:45+09:00
AWSでWebアプリを公開する方法(Python+Flask)
はじめに
この記事は、私がPythonとFlaskで作成したWebアプリをAWSで公開するまでの方法を記したものになります。
なので、自作のWebアプリをAWSでWeb上に公開したい人などにとっては特に参考になる点があると思います。また、最近の流行りで機械学習のモデルを作成したが、それをどうすれば良いかわからないという人も記事に従ってやってもらえれば、Web上に公開でき、ネットワークといったインフラ側の知識も身につきますので、そういう人にも読んでもらえればなと思います。
最後に紹介までにですが、
今回私が作成したアプリケーションは機械学習を用いた画像認識アプリなので、是非使ってその感想などをいただけますと幸いです。(以下そのURL)
https://www.body-score-checker.ml本記事の流れ
・前提
・アプリのディレクトリ構成と一部コードの紹介
・公開までの流れ
1.全体像の把握
2.実際の手順
・1人でWebアプリケーションを作成してみて感じたこと前提
この記事を読むのに当たっての前提の共有をしたいと思います。
・Webアプリの実装方法やそれぞれコードの詳しい解説は省略します。
・AWS初心者なため、アーキテクチャがベストプラクティスではないことはご了承ください。アプリのディレクトリ構成と一部コードの紹介
実際のアプリ構成は、以下のようになっています。
Flask |_ app.py |_ cnn_model.py |_ photos-newmodel-light.hdf5 |_ templates |_ flask_api_index.html(メインのhtmlファイル) |_ result.html(結果を表示するページhtmlファイル) |_ static |_ css |_main.css |_ images(htmlファイルに挿入する画像) |_xxxx.jpg細かい説明は省略しますが、
app.pyとcnn_model.py は参考になる部分もあると思うので、載せておきます。実際のコード(一部)
app.pyimport numpy as np from PIL import Image import cnn_model from flask import Flask, render_template, request app = Flask(__name__) @app.route('/') def index(): return render_template('./flask_api_index.html') @app.route('/result', methods=['POST']) def result(): body_list = ["筋肉型","標準型","痩せ型","肥満型"] # submitした画像が存在したら、画像データをモデル用に整形 try : if request.files['image']: img_file = request.files['image'] temp_img = Image.open(request.files['image']) temp_img = temp_img.convert("RGB") #色空間をRGBに #今回は、モデルの精度を上げるために(64,64)で画像を学習させています。 temp_img = temp_img.resize((64,64)) temp_img = np.asarray(temp_img) im_rows = 64 im_cols = 64 im_color = 3 in_shape = (im_rows,im_cols,im_color) nb_classes = 4 img_array = temp_img.reshape(-1,im_rows,im_cols,im_color) img_array = img_array / 255 model = cnn_model.get_model(in_shape,nb_classes) #学習済みモデルを呼び出す model.load_weights("photos-newmodel-light.hdf5") predict = model.predict([img_array])[0] index = predict.argmax() body_shape = body_list[index] body_score = 90*predict[0]+70*predict[1]+40*predict[2]+40*predict[3] body_score = int(body_score) return render_template('./result.html', title='結果',body_score=body_score,body_shape=body_shape,img_file=img_file) except: return render_template('./flask_api_index.html') if __name__ == '__main__': app.debug = True app.run(host='localhost', port=8888)cnn_model.py# 簡単にモデルを作成できるので、kerasを用います。 import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop # CNNのモデルを定義する def def_model(in_shape, nb_classes): model = Sequential() model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=in_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(nb_classes, activation='softmax')) return model # コンパイル済みのCNNのモデルを返す def get_model(in_shape,nb_classes): model = def_model(in_shape, nb_classes) model.compile( loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) return model公開までの流れ
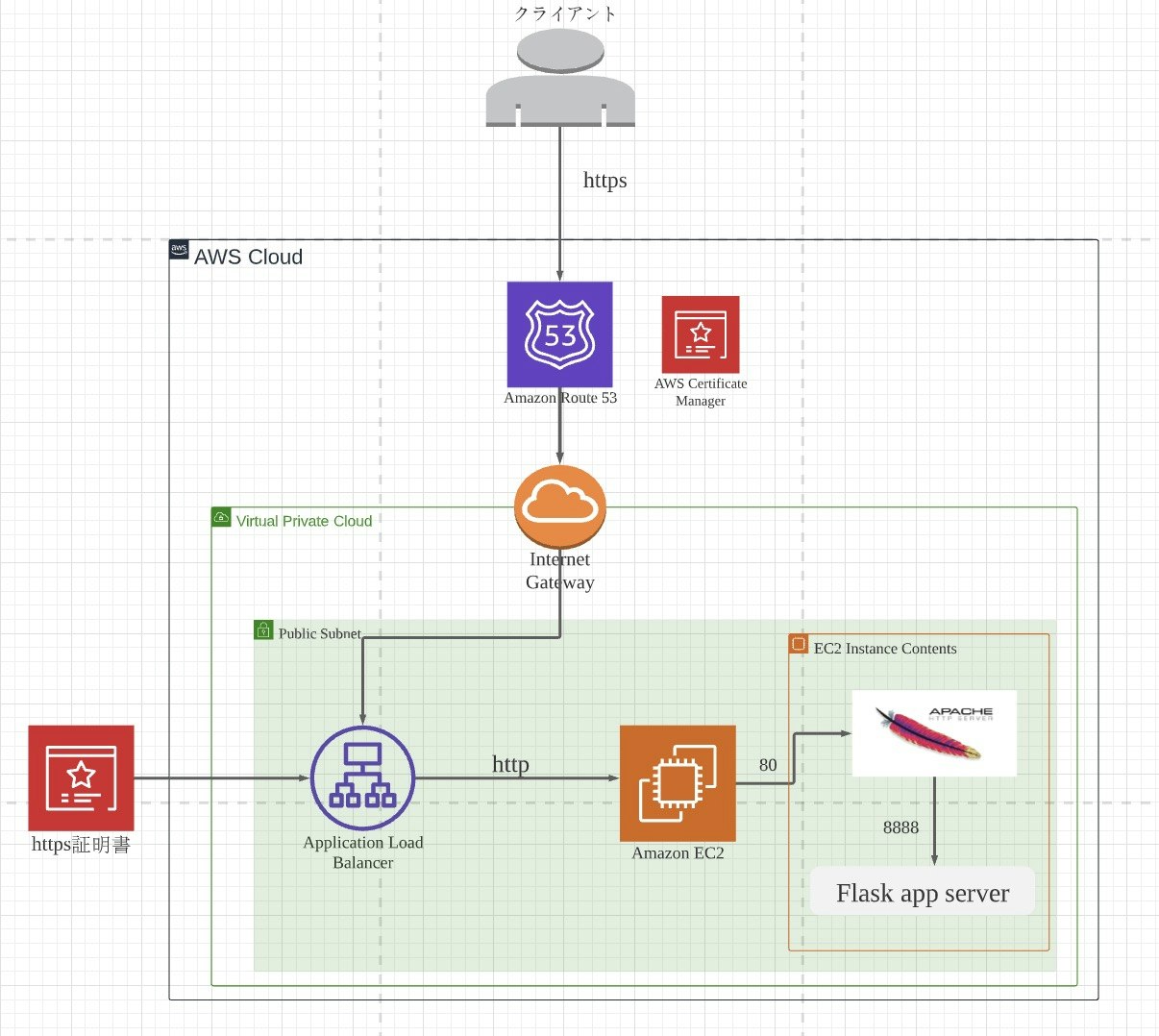
1.全体像の把握
手順に従って進めていけば、最終的には以下のアーキテクチャでアプリを公開できます。
2.実際の手順
(1)AWSのアカウントを作成する
(2)AWSのサーバー上でpython環境の構築
(3)gitからフォルダをcloneする
(4)パブリックIPアドレスを固定化する
(5)独自ドメインの取得
(6)パブリックIPアドレスと購入ドメインの紐付け
(7)ミドルウェアをインストールする
(8)プロキシパスの設定
(9)HTTPをHTTPSにする(1)AWSのアカウントを作成する
ここは、下記の参考書を読めば一撃で理解できると思うので、割愛します。
AWSをはじめようあるいは、以下の資料でも大丈夫だと思います。
AWS EC2でインスタンスを立てる(2)AWSのサーバー上でpython環境の構築
$ sudo yum -y update $ sudo yum install python36-devel python36-libs python36-setuptools $ mkdir body_checker $ python -m venv body_checker $ source body_checker/bin/activate (body_checker)$ pip install --upgrade pip (body_checker)$ pip install flask 以下それぞれのアプリに必要なライブラリをインストール参考資料
Amazon AWS(EC2)でのFlask環境の作成方法(3)gitからフォルダをcloneする
まず、ローカルで作成したフォルダを自分のgithubのリポジトリにあげてください。(githubのアカウント作成の説明などは省略します)
今回行う操作は、EC2上でsshを使ってgit clone して、欲しいフォルダなどを一括で取得するというものです。
手順
1.EC2上で公開鍵・秘密鍵の生成
2.特定のフォルダ(私でいうflaskというフォルダ)だけgit cloneする1に関しては、以下の記事がとても参考になります。
GitHubでssh接続する手順~公開鍵・秘密鍵の生成から~2に関しては、以下のコマンドで大丈夫だと思います。
(body_checker)$git init (body_checker)$git config core.sparsecheckout true (body_checker)$git remote add origin リポジトリのURL(https~) (body_checker)$vim flask(git cloneしたいフォルダやファイル) > .git/info/sparse-checkout (body_checker)$git pull origin masterちなみに、私は「git pull origin masetr」でエラーが出たので、masterをmainにしたら出来ました。
参考資料
git sparse checkout で clone せずに一部のサブディレクトリだけを pull/checkout する(4)パブリックIPアドレスを固定化する
この理由としては、EC2においてIPアドレスはインスタンスが停止すると毎回変わってしまうからです。
それを防ぐために、ElasticIPという静的な(勝手に変わらない)IPアドレスをサーバーに固定のIPアドレスとしてつけましょう。
手順
1.「Elastic IP」メニューから「新しいアドレスの割り当て」をクリック
2. ElasticIPをインスタンスに紐付ける(5)独自ドメインの取得
これは、私のサイト(https://www.body-score-checker.ml) でいうbody-score-cheker.mlの部分です。
これは以下のサイトで無料で作成できます。
Freenom(6)パブリックIPアドレスと購入ドメインの紐付け
この作業はRoute53というサービスを使います。
注意事項
全体像では、Route53からALBを経由してDNSを解決していますが、ここでは直接ドメインをEC2のElastic IPに紐づけてDNSを解決してます。ALBを使用したDNS解決は、(9)で説明しています。
目的としては、最初は簡単なアーキテクチャにして、なるべく早くwebでアプリを見れるようにするためです。以下のサイトがわかりやすかったので、そちらを参照して進めてみてください。
AWS Route 53を使って独自ドメインのWebページを表示させてみよう(7)ミドルウェアをインストールする
全体像の図でも示している通り、Apacheをインストールします。
以下インストールの方法
EC2インスタンスにApache HTTP Serverをインストールするミドルウェアをインストールする理由は、クライアントからのアクセスとflaskサーバーの仲介役を担ってもらうためです。
以下のその簡単な流れ
・「Application Load Balancer」でクライアントからのリクエストがポート80番に送られます。
・Apacheはポート80番に対応するので、そのアクセスを受け取ると静的コンテンツをクライアントに返します。(flask_api_index.htmlなど)
・もし動的な操作が必要な場合は、Apacheからflaskサーバー(ポート番号:8888)にリクエストが送られます。
・そこで、先ほど立てたflaskサーバーが動作する。(私の場合だと、送られてきた画像を機械学習のモデルに入れて点数を算出する。)(8)プロキシパスの設定
(6)で通信の簡単な流れを説明しましたが、そこで「Apacheからflaskサーバーにリクエストが送られます。」とありますが、これはこちらで設定する必要があります。
それが、プロキシパスの設定です。・confファイルを修正する
$ sudo vi /etc/httpd/conf.d/vhost.conf・修正内容
NameVirtualHost *:80 DocumentRoot "/var/www/html/" ServerName body-score-checker.ml ProxyRequests Off ProxyPass / http://localhost:8888/ ProxyPassReverse / http://body-score-checker.ml/・httpd再起動
$ sudo service httpd restartここまでで、Web上でアプリケーションが動作するようになると思います。
・以下実行コマンド(body_checker)$ python app.pyまた、sshでの接続が切れても、serverを立ち上げたままにするためには以下のコマンドを使用します。
(body_checker)$ nohup python app.py &以下参考資料
SSH切断した後でもVPS上でPythonを実行したままにする方法(9)通信方式をHTTPからHTTPSにする
基本的にはこれで問題なくWeb上で動作するのですが、私の場合は個人の画像を取り扱うのでhttpからhttpsに通信方式を変えています。
このタイミングで、全体像の真ん中にあるALB(Application Load Balancer)を導入しています。ロードバランサーの作成は以下の資料が参考になると思います。
Application Load Balancer を作成する
AWS ELBでWebサーバの負荷分散を実現!ロードバランサーの作成が終わったので、最後に通信方式をHTTPからHTTPSにします。
Application Load Balancer を使い HTTP リクエストを HTTPS にリダイレクトするにはどうすればよいですか?
[新機能]Webサーバでの実装不要!ALBだけでリダイレクト出来るようになりました!1人でWebアプリケーションを作成してみて
このように最後まで1人で作成してみて感じる事は、Webアプリケーションの仕組みを体系的に理解するには自分で手を動かして全て触ることが一番いいということです。
今回は私は、フロントからバックエンドまで全て自分でコードを書いて実装しましたが、Web上で実際にどのような処理が行われているのかなど、そうゆう大局の部分の理解がかなり捗ったと思います。
なので、これからももっといろんな技術に触れてみたいと思います。もしご指摘等ありましたら、バシバシ言っていただけると私自身の勉強になりますのでお願いいたします。
そして、最後まで読んでくださりありがとうございます。少しでも何か参考になる部分がありましたら幸いです。最後に、このアプリやこの記事を作るにあたって参考にした記事を紹介して終わりにしたいと思います。
バナナの食べ頃を機械学習モデルで判定するWEBアプリを作ってみた