- 投稿日:2021-01-18T23:30:21+09:00
M1 Mac Homebrew,Tensorflow,keras,pillow,...etc導入
M1搭載Macにて現時点で躓いてきた点がいくつもあったので一応残す(長くなりそう)
2021.01.24 追記
結局M1でやりたいこと全てやるには、M1に対応するのを待ったほうが
良さそうだったので、とりあえず、X86向けの仮想環境を作成してそこでpython動かす
が、途中までやったのはそのままにしたい為、x86用仮想環境を作成したので
どう作るかわからない方は、以下記事を参考にとりあえずの仮想環境を作成してみて下さい
https://qiita.com/inosuke-hashibira/items/690b5792e39d07daab8e目次
①:TensorFlow macos導入時に公式からpythonダウンロードしていて厄介なことになった
②:pipが効かない(homebrew)
③:Kerasがimportできない(解決したが何かと曖昧)
④:Pillowがimportできない(matplotlibがinstallできない)
順番にどう解決していったかリアルを載せます
①:TensorFlow macos導入時に公式からpythonダウンロードしていて厄介なことになった
これに関しては、すでに記事にしているので以下の記事参考ください
↓↓
https://qiita.com/inosuke-hashibira/items/0d0e50d4e49fc2f78b42
(ざっくり言うと、余分なpythonの消し方です)
②:pipが効かない(homebrew)
これに関してもすでに記事にしているので以下を参考ください
↓↓
https://qiita.com/inosuke-hashibira/items/ba7e0e5579f66389f8d7
③:Kerasがimportできない(from tensorflow import keras)
(環境python3.8.2)
これがかなり曖昧。
自分がこれに引っかかっていた状況としては、
・https://qiita.com/tomoyaeibu/items/46f2f3384a370df71d5e
上記の記事にて、TensorFlow macosインストール済み(仮想環境も構築)
・②にて、ターミナルをRosettaを使用して開く設定になっているやったこと
1.ターミナルを「Rosetta使用して開く」を解除
2.①の時と同じやり方、同じインストール先でもう一度TensorFlow macos入れる
(binフォルダが更新される)※下記コードが①記事と同じコードです/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/apple/tensorflow_macos/master/scripts/download_and_install.sh)"3.brewでpython3.9インストール(関係ないはず)
結局3.8.2使用してるし関係ないはず...homebrew updataみたいな文言が出たからもしかしたら...
4.reboot(再起動)以上の4つがやったことです
Rosettaは最初に外し、2のをやって念の為3をやって、これまた念の為4をやって,ダメでまた2をやったら
みたいに半ばヤケクソにやってたらできました。笑
わかる方、いたらコメントください。笑
④Pillowがimport出来ない(matplotlibがインストールできない)
pip3 install matplotlib(上記によりpillow8.1.0が一緒に入ります)
で上手くいかないといった記事をよく見かけましたが自分は問題なく行きました
しかし、
from PIL import Image
でエラーを吐きました(libjpegと言うものが必要)
そこで行うのが以下のコマンドですbrew install libjpeg確認で
brew listでjpegがあれば正常にインストールできて
from PIL import Image これも上手くいくと思いますおそらく、pip3 instal matplotlib が失敗した人もこれで解決するかな。多分
ちなみに
brew installの時は、ターミナルを、Rosettaを使用して開いていて
pip installの時は、Rosetta解除してます
何か解決できないことや
事細かにわかったことがあれば教えて下さい
- 投稿日:2021-01-18T22:24:32+09:00
Mac(M1)TensorFlow導入(自分でpythonを入れてしまった人におすすめ)
この記事自体は、
1ヶ月程前に書き上げました
そこから、この後Keras、Pillowで躓きそれを回避したので
その記事のURL載せておきます
https://qiita.com/inosuke-hashibira/items/b660d895d45455689143概要
とある記事を参考にTensorflow導入開始
しかし、AnacondaやPython公式からpythonをインストールすると
かなり躓くことがわかったので実際に回避したやり方を残すーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
回避方法に移る前にぶつかったエラーとしては
pip3 list で確認するとTensorFlow-macos は存在するが
import tensorflowをすると No module となる
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーちなみに以下が「とある記事」になる
https://qiita.com/tomoyaeibu/items/46f2f3384a370df71d5e
特に個別でインストールしていなければ、上の記事だけでTensorFlow導入可能です環境
M1 MacBook Pro
エラーの原因(推測)
そもそも,エラーの原因がプロンプトで
which python3とした時に出力が
/usr/bin/python3とならないこと。
ちなみに不具合時の出力は/Library/Frameworks/Python.framework/Versions/3.7/bin/python3だった。使用してるpythonが違う?(素人に詳細はわからん...)
じゃあ、/Library/Frameworks/Python.framework/Versions/3.7/bin/python3
これを消せばいいか?ってなった以下、やったこと(2パターン)
その1 ファイルをコマンドや手探りで削除する
以下、記事参照
https://code-graffiti.com/how-to-uninstall-official-python3-on-mac/bash_profileの部分はやらなくていいです
(bash_profile1が見つからなかった)その2 Mac初期化(その1がだめだった時の最終手段)
以下、記事参照
https://www.sin-space.com/entry/m1mac-recovery参照記事内で実際にやったことを以下に記す(参照記事と見比べながら見るとわかる)
1.再起動
2.R + Command +電源ボタンを押しながら起動を待つ(M1でもこれでやった)
3.左上の復旧アシスタントからMacを消去を選択
4.従って、消去実行
5.「ターミナルからmacos復元する」のストレージの初期化が完了したら...という文章から従ってやった
6.あとは従って進めていくだけです全て完了したら、一番上に載せた記事を参考にTensorFlowを導入して下さい
もっと楽な方法ないかな...
- 投稿日:2021-01-18T21:37:36+09:00
Cutmix はテーブルデータに対しても有効か?
初めに
通常,教師あり学習は,高精度を達成するため,十分な量のラベル付きデータを必要とします.しかし,人手による注釈は,非常に多くの時間と労力を要します.これを解決する方法の一つとして,人工的にデータをかさ増しするデータ拡張(data augmentation)があります.
しかし,データ拡張は,画像ありきに語られることがほとんどで,テーブルデータに適用できる手法は,そう多くありません.そこで,本記事は,テーブルデータに適用できるデータ拡張を紹介し,実験を行い,それらの性能を検証します.
Mixup
mixup: Beyond Empirical Risk Minimization
Mixup は,2017 年に提案された手法で,ICLR に採択されました.二つの入力を混ぜ合わせることで,新たな入力を生成します.
import random as rn from sklearn.utils import check_random_state def mixup(x, y=None, alpha=0.2, p=1.0, random_state=None): n, _ = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = random_state.beta(alpha, alpha) shuffle = random_state.choice(n, n, replace=False) x = l * x + (1.0 - l) * x[shuffle] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, y画像の他に,音声やテーブルデータに対して Mixup を適用しても性能が向上したことが論文中で報告されています.
Cutmix
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
Cutmix は,2019 年に提案された手法で,ICCV に採択されました.入力の一部分をもう一方の入力で置き換えることで,新たな入力を生成します.
import random as rn import numpy as np from sklearn.utils import check_random_state def cutmix(x, y=None, alpha=1.0, p=1.0, random_state=None): n, h, w, _ = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = np.random.beta(alpha, alpha) r_h = int(h * np.sqrt(1.0 - l)) r_w = int(w * np.sqrt(1.0 - l)) x1 = np.random.randint(h - r_h) y1 = np.random.randint(w - r_w) x2 = x1 + r_h y2 = y1 + r_w shuffle = random_state.choice(n, n, replace=False) x[:, x1:x2, y1:y2] = x[shuffle, x1:x2, y1:y2] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, yCutmix は,画像に対して適用した結果しか論文中で報告されていません.これを,テーブルデータに対して適用するとどうなるのでしょうか.
テーブルデータは,特徴(年齢や国籍等)の順序に意味がありません.そこで,もう一方の入力で置き換える部分を無作為に選ぶことにします.
import random as rn import numpy as np from sklearn.utils import check_random_state def cutmix_for_tabular(x, y=None, alpha=1.0, p=1.0, random_state=None): n, d = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = random_state.beta(alpha, alpha) mask = random_state.choice([False, True], size=d, p=[l, 1.0 - l]) mask = np.where(mask)[0] shuffle = random_state.choice(n, n, replace=False) x[:, mask] = x[shuffle, mask] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, y実験
今回は,次のデータセットを使って実験を行います.これは,遺伝子発現パターンから化合物の作用機序を予測するマルチラベル分類問題です.
Mechanisms of Action (MoA) Prediction | Kaggle
実験の詳細は,以下のコードを確認して下さい.
Logloss は,次のようになりました.
Local Public Private Baseline 0.01604 0.01906 0.01666 Mixup 0.01605 0.01905 0.01668 Cutmix 0.01604 0.01901 0.01663 Public, Private 共に Cutmix でスコアが向上することを確認できました.
終わりに
Cutmix は,テーブルデータに対しても有効な手法です.
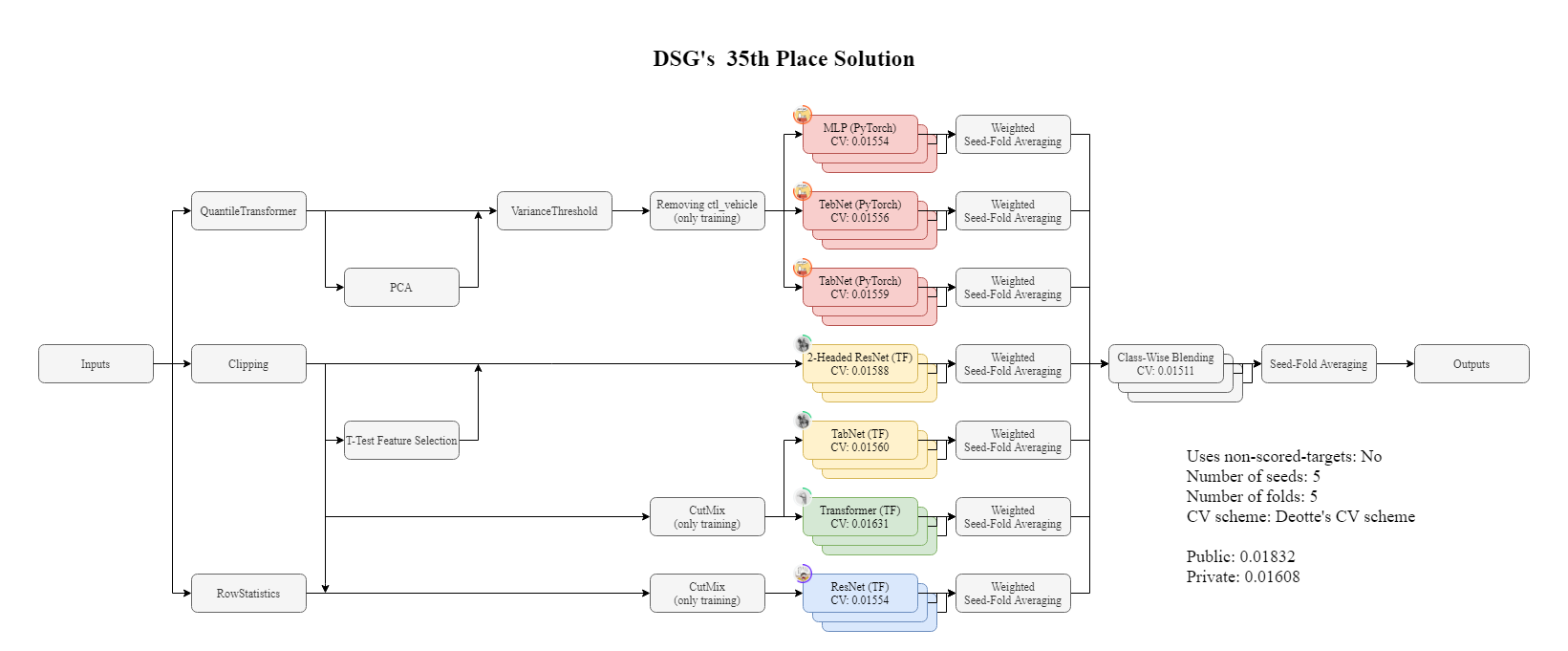
最後に,上記大会で Cutmix を用いて 35 位になった解法を公開しているので,興味のある方は,ご覧下さい.
Mechanisms of Action (MoA) Prediction | Kaggle