- 投稿日:2021-01-18T23:45:20+09:00
特定の範囲をトリミングした後に1回だけFFT (Python)
はじめに
前回の記事
音圧レベルFFT
の末尾に書いたように,ハンマで叩いた音は叩く力に依存して大きく聞こえたり小さく聞こえたりします.そのため,周波数分析する際も音圧レベルが変動すると想定されますので,力が入力された瞬間周辺のデータのみを解析することが望ましいです.やること
・全データから,特定の力(任意値)が入力された瞬間周辺基準にトリミングし,音圧レベルFFTを行なう.
FFT条件
・解析対象は,ホワイトノイズ環境下で外壁タイルを1秒間に1回の頻度で10秒間加振した時の打音データ(前回と同じ)です.
・サンプリングレート fs:8192 Hz
・解析上限周波数:3200 Hz
・FFTブロックサイズ block_size:8192 点
・ライン数:3200 本
・オーバーラップ overlap:0.75
・周波数分解能 df:1.0 Hz
・1回のFFTにかかる時間:1.0 sec
・打音計測マイクのチャンネル本数:1 ch
・何 [N] の力をトリミング対象とするのか?:30 N(任意値で構いません)
(fs・blocksizeが何なのかについては下記のサイトを参考にしてください.個人的に,これが一番わかりやすいです)
NTi-audioトリミング関数(非効率コード)
force_base_trimming.pyimport numpy as np import scipy.signal as ss def force_base_trimming(data, block_size, goal_power): impact_peak_index_and_number = ss.find_peaks(data[:, 0], height = 0.1, distance = 2000) # まず加振ハンマの時間波形のデータからピーク検出.これはタプル型.0.1よりも高い値をピークと判断. impact_peak_number_only = impact_peak_index_and_number[1] # こいつはなぜかdict型.検出したインデックスのときの力はどんな値を取るのか変換 impact_peak_number_only_to_array = list(impact_peak_number_only.values())[0] nearest_peak_index_of_array = np.argsort(np.abs(impact_peak_number_only_to_array - goal_power)) border_index = impact_peak_index_and_number[0][nearest_peak_index_of_array[0]] # ソートしたうちの0番目のインデックス➡一番目標値に近しいインデックスが摘出される trimmed_data = data[np.int(border_index - (block_size / 2) + np.int(border_index + (block_size / 2) + 1), :] "TODO:ダブルハンマしたときの例外処理を書く➡re-take" calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100) # サンプリングデータ数が100個ずつにしたときのピークをカウント if calculate_peak_in_trimmed_data[0].shape[0] == 1: print('ダブルハンマなし {:.3f} N'.format(max(trimmed_data[:, 0]))) # トリムした加振ハンマの最大値を小数点以下第3位まで表示される else: print('ダブルハンマリング \n 1回目の再取得スタート') border_index = impact_peak_index_and_number[0]nearest_peak_index_of_array[1]] trimmed_data = data[np.int(border_index - (block_size / 2) + 1):np.int(border_index + (block_size / 2) + 1), :] print('1回目の再取得完了') calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100) if calculate_peak_in_trimmed_data[0].shape[0] == 1: print("1回目の再取得verにダブルはない") else: print('1回目の再取得verにダブルはまだある \n 2回目の再取得スタート') border_index = impact_peak_index_and_number[0]nearest_peak_index_of_array[2]] trimmed_data = data[np.int(border_index - (block_size / 2) + border_index + (block_size / 2) + 1), :] print('2回目の再取得完了') calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100) if calculate_peak_in_trimmed_data[0].shape[0] == 1: print("2回目の再取得verにダブルはない") else: print("2回目の再取得verにダブりがまだあるけど再取得しない.あきらめる.別の目標加振力を設定したほうが良い") return trimmed_data # print('2回目の再取得verにダブルはない')のところのifに対する戻り値 return trimmed_data # 2つめのifに対する戻り値 return trimmed_data # 初めのifに対する戻り値 return trimmed_data # defの戻り値どんな処理をしてる?(イメージ)
1⃣計測した力データを特定の数ずつに分割する.(今回は2000個のデータ群を1つの塊として扱い,複数の塊を生産)
2⃣2000個の中で0.1(任意値)を超える最大値を1つ探す.探し終わったら,別の2000個を対象に最大値を探す.終わったら次,次,次...
3⃣複数ある最大値のうち30 N(任意値)に一番近い力はどれか検索
4⃣任意値に近い力の配列番号を音圧信号の配列番号に照らし合わせ,配列番号を基準にFFT 1 ブロックの半分左右にオフセットし,トリミングする.(このようにすることで,ウィンドウ関数による音圧振幅の補正を最小限にすることができる.オリジナルデータが一番歪みにくい位置はウィンドウ関数の頂点と力が入力された瞬間がちょうど重なるとき.)
5⃣手順4⃣がダブルハンマ(短時間に2回以上加振してしまうこと.この信号をFFTすると正しく解析できない.)なのか検知するために,トリミングしたデータ(8192個)を対象に100個ずつ分割
6⃣100個の中0.1(任意値)を超える最大値を1つ探す.探し終わったら,別の100個を対象に最大値を探す.終わったら次,次,次...
7⃣複数ある最大値のうち0.1を超えるピークが2つ以上あるならそれなりに大きい力が2つ入力されていると判断できる.
8⃣ダブルハンマと見なし,2番目に近い30 Nのピークを基準にトリミング,ダブルハンマなのか再度検知,の繰り返し結果
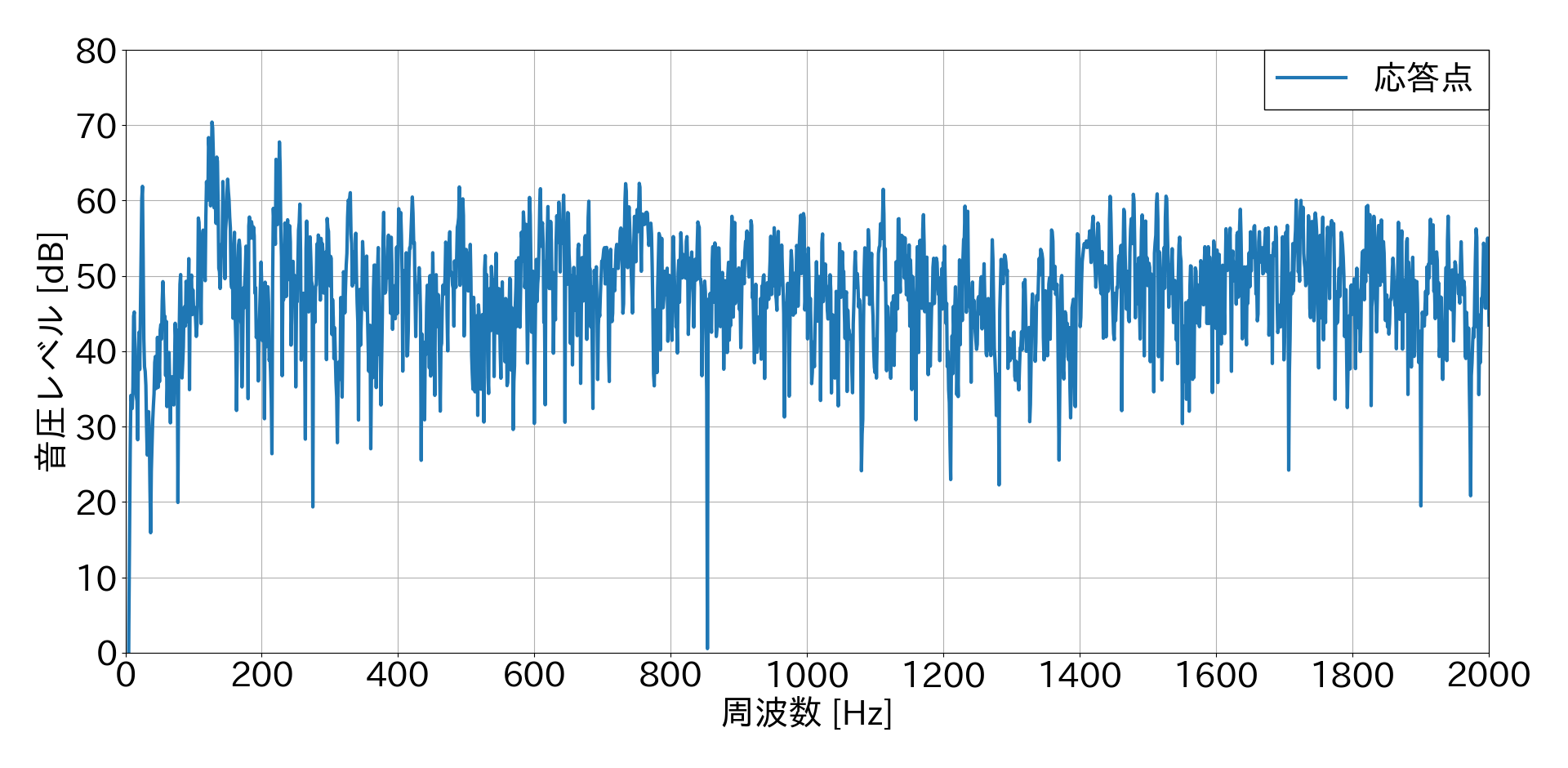
力が入力された瞬間周辺1秒間のデータをトリミングし,1回だけFFTした結果
全データを対象に複数回FFTした結果(トリミングしない)
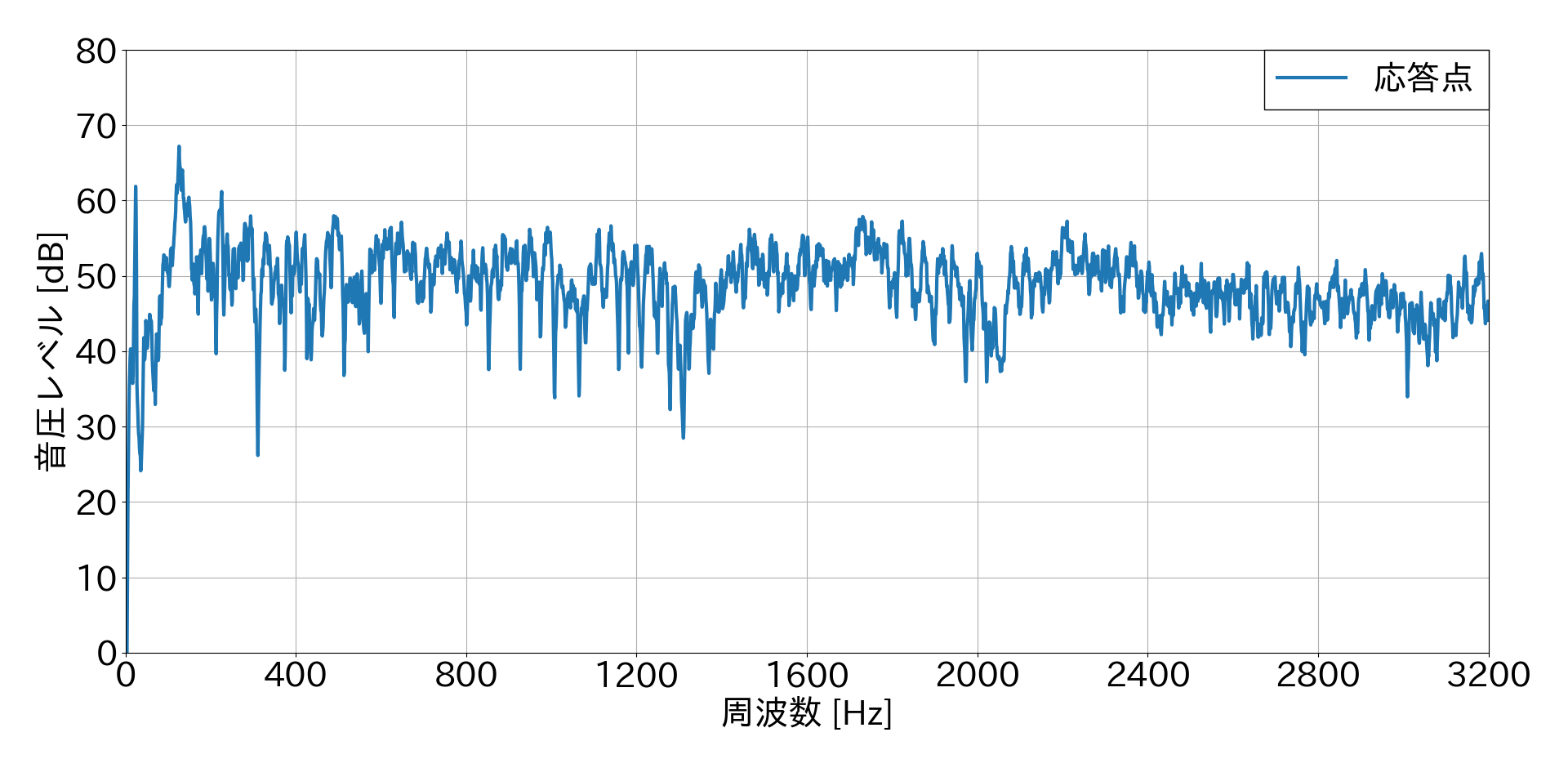
静粛環境下で同じタイルを加振し,同じ方法で1回だけFFTした結果(参考までに)
この結果から,1回だけFFTした結果の方が比較的ノイジーな音圧レベル結果となることが分かりました.しかし,特定の力が入力された瞬間の応答としてはこちらの方がふさわしいと思います.複数回FFTした結果の方がきれいなグラフになるのは,平均しているからだと思います.(間違えてたらすみません?.)
また,騒音環境下での結果と静粛環境下での結果を比較すると,ノイズに打音が埋もれていることが確認できるかと思います.静粛環境下での固有振動数は750 Hz・1400 Hzで約55 dBとなりはっきりとしたピークがありますが,騒音環境下では固有振動数のピークを確認することが困難であると思われます.まとめ
ウィンドウ関数によって打音(インパルス応答)が大きく補正されないように,ウィンドウ関数の頂点と打音の最大振幅がちょうど重なるようなトリミング方法を紹介しました.その結果,複数回FFTの結果とどれほど違いが出るのかも確認しました(したつもり).正直「よくこんなコードを公開しようと思ったな?」と指摘されるほど下手なコードです.「もっとこうした方が良いのでは?」などの意見があれば嬉しいです.

- 投稿日:2021-01-18T23:27:29+09:00
wordcloudで巡る文学作品の旅【Colab&MeCab&neologd】
はじめに
wordcloud(ワードクラウド)とは、文章を解析して頻出の単語ほど大きく表示するものです。
最近よく見る、こういうものです
ちなみに、これはとある文学作品のwordcloudです。
何の作品かわかりますでしょうか??環境
環境はGoogle Colaboratory、言語はPython。
形態素解析はMeCabで、辞書はneologdを使用。
別に、新語に強いneologd使う必要ないかもだけど、せっかくだし。なお、今回は青空文庫の作品を対象にしました
青空文庫は、著作権が消滅した作品や著者が許諾した作品のテキストを公開しているインターネット上の電子図書館である。
参考:Wikipedia実装
まずは、必要なものをインストール。
# MeCabとneologdのインストール !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc !echo `mecab-config --dicdir`"/mecab-ipadic-neologd" # wordcloudで使う日本語フォントのインストール !apt-get -y install fonts-ipafont-gothic次に、必要なライブラリをインポート。
import re import MeCab from wordcloud import WordCloud import matplotlib.pyplot as plt tagger = MeCab.Tagger("-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd")次に、関数を定義。
def format_aozora(text): """青空文庫の文章(1行テキスト)から、ルビや空白などの不要な文字を削除する""" text = re.sub('[.+?]', '', text) text = re.sub('《.+?》', '', text) text = re.sub('|', '', text) text = re.sub('\s', '', text) return text def get_nouns(text): """1行テキストを入力すると、形態素解析した結果、名詞のリストを返す""" node = tagger.parseToNode(text) nouns = [] while node: if 36 <= node.posid <=67: # 名詞のみ取得 nouns.append(node.surface) node = node.next return nouns def plot_wordcloud(text, stop_words, background_color='black'): """1行テキストを入力すると、stopwordsを除いたwordcloudを表示する""" wordcloud = WordCloud( font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf', width=900, height=600, background_color=background_color, stopwords=set(stop_words), max_words=200, min_font_size=10, collocations = True ).generate(text) plt.figure(figsize=(15,12)) plt.axis("off") plt.imshow(wordcloud) plt.savefig("word_cloud.png") plt.show()青空文庫のデータには、本文の内容とは直接関係のないルビや空白などが含まれていて、それらの文字を削除するのがformat_aozora関数です。
1行テキストのデータにできたら、get_nouns関数に入れてあげます。
この関数は、形態素解析をして名詞のみをリストで返します。
文章中で重要になってくる単語は名詞が多いハズ。
ちなみに、node.posidは品詞を表す数値で、名詞は36~67になります。最後に、名詞のみのリストから1行テキストを作成し、plot_wordcloudに入れればwordcloudを表示します。
インプラントは、textは1行テキスト、stop_wordsは表示したくない単語のリスト、background_colorはwordcloudの背景色でデフォルト黒にしています。
好みによって背景色を変えても面白いかも?
なお、stop_wordsは、wordcloudを表示しながら決めていくことになります。
例えば、「こと」とか「それ」とか、よく使われているけど重要じゃないと判断したらstop_wordsで指定。使い方 〜wordcloudで巡る文学作品の旅〜
今回は、青空文庫から5つの作品を対象にwordcloudを作成してみました。
以下テキストファイルは、青空文庫のページから各作品のリンク先にある「テキストファイル(ルビあり)」をダウンロードしたものです。
各作品のwordcloudを見て、どういったキーワードが作中でよく使われているか、そこからイメージできることは何か、もあわせて書いてみました。【注】ちなみに、自分は文学は大の苦手で、以下有名作品は全く読んだことありません。いや、読んだかもしれんが記憶にない。ので、妙な考察してるかもしれませんがご了承下さい。
その壱 『こころ 夏目漱石』
txt_file = 'kokoro.txt' with open(txt_file, encoding='shift-jis') as f: text = f.read() text = format_aozora(text) nouns = get_nouns(text) text=" ".join(nouns) stop_words = ['それ', 'もの', 'よう', 'そこ', 'ため', 'そう', 'これ', 'ところ', 'うち'] plot_wordcloud(text, stop_words)使い方はこんな感じ。
青空文庫からダウンロードしたテキストファイル(上の場合、kokoro.txt)を読み取り1行テキスト(text)に。
それを、get_nouns関数に入れて形態素解析&名詞のリストを取得。
そのリストをスペースで繋げて再び1行テキストに。
表示したくないストップワードも結果を見ながらリストで指定。
最後にplot_wordcloudでwordcloudの表示!以下、txt_fileとstop_wordsが異なるだけです。
1行テキストを用意してあげれば何でも良いので、いろんな素材で試してみて下さい
まず最初は夏目漱石の『こころ』
記事冒頭のものは、こちら「こころ」のwordcloudでした。
「先生」や「奥さん」という言葉がひときわ大きく表示されており、作中でキーとなる人物である予感。
それらに比べて小さいですが、「病気」「心持」「医者」というワードもあって、何か精神的な暗さも彷彿とさせます。タイトルの「こころ」に繋がるものなのだろうか?その弐 『人間失格 太宰治』
txt_file = 'ningen_shikkaku.txt' with open(txt_file, encoding='shift-jis') as f: text = f.read() text = format_aozora(text) nouns = get_nouns(text) text=" ".join(nouns) stop_words = ['もの', 'それ', 'たち', 'よう', 'これ', 'そう', 'ほう', 'みたい'] plot_wordcloud(text, stop_words)
人間失格、映画化もされましたね。
「自分」というのがデカく出てきてますが、これは主人公の一人称の呼び方なんだろうか?
人間失格だからか「人間」というワードもあります。
「堀木」って、友人ですかね?
「ヨシ子」「ツネ子」は女性の名前っぽいけど、主人公の彼女?奥さん?お母さん??
というか、「ヒラメ」って?
その参 『羅生門 芥川龍之介』
txt_file = 'rashomon.txt' with open(txt_file, encoding='shift-jis') as f: text = f.read() text = format_aozora(text) nouns = get_nouns(text) text=" ".join(nouns) stop_words = ['よう', 'それ', 'これ', 'さっき', 'しよう'] plot_wordcloud(text, stop_words)
続いて、芥川龍之介の『羅生門』
「下人」という聞き慣れない言葉がデカデカとあります。調べてみると、この下人というのは身分の低い人のことを指すとのこと。
ついで、「老婆」というワード。下人の老婆ってこと?
それから「死骸」「梯子(はしご)」「餓死」「死人」という不穏なワードが…。
タイトルの「羅生門」も。
全体的に不吉な感じのイメージですな。その肆 『吾輩は猫である 夏目漱石』
txt_file = 'wagahaiwa_nekodearu.txt' with open(txt_file, encoding='shift-jis') as f: text = f.read() text = format_aozora(text) nouns = get_nouns(text) text=" ".join(nouns) stop_words = ['もの', 'よう', 'これ', 'それ', 'ところ', 'そう', 'さん', 'うち', 'ため', 'どこ'] plot_wordcloud(text, stop_words)
4つ目は『吾輩は猫である』
「主人」が一番大きいですね。猫の飼い主のことでしょうか?
続いて「吾輩」。これは主人公の一人称ですね、きっと。
「迷亭」ってなんぞ。
「細君」「人間」「寒月」も多く使われているようです。その伍 『銀河鉄道の夜 宮沢賢治』
txt_file = 'gingatetsudono_yoru.txt' with open(txt_file, encoding='shift-jis') as f: text = f.read() text = format_aozora(text) nouns = get_nouns(text) text=" ".join(nouns) stop_words = ['よう', 'それ', 'そう', 'とき', 'こと', 'どこ', 'こっち', 'そこ', 'とこ', 'いま', 'もの', 'そっち', 'さっき', 'たち', 'ここ'] plot_wordcloud(text, stop_words)
最後に、宮沢賢治の『銀河鉄道の夜』
「ジョバンニ」「カムパネルラ」といった聞き慣れないカタカナがトップ。
これ、調べたら主人公と友人の名前だそうな。。
あとは、「汽車」「銀河」「天の川」といった、いかにも銀河鉄道の夜らしい、情景が目に浮かぶようなキーワードが並んでいます。
「ザネリ」??まとめ
いかがだったでしょうか?
今回はGoogle Colabでwordcloudを作成してみました。
この記事では青空文庫を題材にしました。
こうやってみると、文学嫌いの自分でも、キーワードの先が気になってしまい、なんだか読んでみたくなる気がしないでもない。。実際の業務では、ユーザのコメントなどを解析して重要なキーワードの把握に役立てたりできると思います。
単に、頻出ワードを表にして並べるより、見た目のインパクトがありますよね
また、ツイッターやslackなどの会話を集めて分析するのも面白いと思います。
自分は、会社のslackの内容をwordcloudにして見せたところ、なかなか好評だったようです。皆さんも是非、色々と試してみて下さいね






- 投稿日:2021-01-18T23:22:31+09:00
flask_migrateでテーブル名を変更した場合
flask_migrateを利用して、pythonコード内でテーブル名の変更を行う場合は必ずdb migrate / db upgradeしようね、という話です。
例えば
class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True) description = db.Column(db.String(120), index=True) def __repr__(self): return '<User %r>'%self.usernameと、Flask_SQLAlchemyを利用して、テーブルを定義した後に、
class UserData(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True) description = db.Column(db.String(120), index=True) def __repr__(self): return '<User %r>'%self.usernameのようにテーブル名(クラス名)を変更した場合、
flask db migrate flask db upgradeとしないと
sqlalchemy.exc.ProgrammingError: (psycopg2.errors.UndefinedTable) relation "user_data" does not existといった風に「テーブルがないよ!」と怒られます。
pythonコード内で変更したからといってそれを暗黙のうちに差分変更してくれるわけではないので、
明示的にflask db migrate / flask db upgradeする必要があるようです。gitみたいですね。
- 投稿日:2021-01-18T22:56:48+09:00
JenkinsAPI使ってPythonからちょこちょこと
まだ環境が固まっておらずちょっと書いてみたものです。
テストクラスはしかかり中です。Jenkinsの情報をちょっと取得したい
要はJenkins画面を解放せずともChatOpsで情報をとれるようにしたいわけなのですが
まだ環境固まっておらず、とりあえず実験的にJenkinsAPIを叩いて
JOB情報取ってきたり、JOB起動できるようにしてみました。ChatOps提供あればJOB起動のコードは書かなくてもOKになるはずなのですけどね。
#!/opt/anaconda3/bin/python3 # -*- coding: utf-8 -*- '''RocketChat Jenkins情報取得 Jenkins情報をRocketChatのチャンネルに提供する Jenkinsの設定によりCSRF対策が行われている そのためauth情報だけでなくJenkins-Crumb情報が必要となる。 1.adminのTOKEN情報 → adminユーザコンソールからパーソナルアクセストークンを生成する。 都度生成なのでメモるのを忘れないようにする。 2.Jenkins-Crumb情報取得方法 → コマンドを発行する必要がる。以下実行してその戻りにより得られる adminのTOKEN設定が設定になっている。 curl -u 'admin:ADMINS_TOKEN' 'http://xxxxxxx/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,":",//crumb)' 3.結果送信は自前ライブラリを使用する様にして下さい。ここでは実装しません。 RocketChatChannelManager -> sendMessageToRocketChat(channel, msg)1 Todo: ''' ################################################ # library ################################################ import json import requests import pandas as pd import sys from datetime import datetime from dateutil import parser from pprint import pprint from pytz import timezone ################################################ # 環境変数取得 ################################################ # # # HEADERS定義 # headers = { # 'Jenkins-Crumb': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'} # 認証定義 # AUTH = ('admin', 'xxxxxxxxxxxxxxxxxxxxxxxxxxxx26fa') # # URL = 'http://xxx.xxx.xxx.xxx:3000' # ################################################ # RocketChatJenkinsManager ################################################ class RocketChatJenkinsManager(object): def __init__(self, HEADERS, AUTH, URL): # 引数チェック 型 if not isinstance(HEADERS, dict): print(f'引数:HEADERSの型が正しくありません dict <-> {type(HEADERS)}') raise TypeError # 引数チェック 型 if not isinstance(AUTH, tuple): print(f'引数:AUTHの型が正しくありません tuple <-> {type(AUTH)}') raise TypeError # 引数チェック 型 if not isinstance(URL, str): print(f'引数:URLの型が正しくありません str <-> {type(URL)}') raise TypeError # インスタンス生成 self.HEADERS = HEADERS self.AUTH = AUTH self.URL = URL def exchangeUnixtimeToTimestamp(self, unixtime): '''unixtimeをtimestampに変換する Args: unixtime: float Returns: timestamp: str Raises: TypeError Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.exchangeUnixtimeToTimestamp(1610870939803) -> '2021/01/17 17:08:59' Note: ''' # 引数チェック 型 #if not isinstance(unixtime, int): # print(f'引数:unixtimeの型が正しくありません int <-> {type(unixtime)}') # raise TypeError timestamp_succsessful = float(unixtime) return datetime.fromtimestamp(timestamp_succsessful/1000.).strftime('%Y/%m/%d %H:%M:%S') def getJenkinsJobList(self): '''Jenkins 利用可能JOB一覧を取得する 利用可能JenkinsJOB一覧をPandas DataFrameで返す。 Args: 無し Returns: pd.DataFrame Jobname, Params, JobDescription, ExecCount, URL Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> df = jenkins.getJenkinsJobList() Note: ''' # Columns定義(データ取得) columns_in_df = ['JobName', 'JobDescription', 'ExecCount', 'URL','Params'] # Columns定義(データ出力) columns_out_df = ['JobName', 'Params', 'JobDescription', 'ExecCount', 'URL'] # API定義 ENDPOINT = '/api/json' QUERY = '?depth=1&tree=jobs[displayName,description,lastCompletedBuild[number,url],actions[parameterDefinitions[name]]]' API = f'{self.URL}{ENDPOINT}{QUERY}' # 取得処理 try: response = requests.post( API, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # 仮の入れ物を用意 _list1 = [] _list2 = [] # 取得responseから情報取得 ## Job基本情報取得 for _ in response.json()['jobs']: _list1.append([_['displayName'], _['description'], _['lastCompletedBuild']['number'], _['lastCompletedBuild']['url']]) ## 可変であるパラメータ取得 _list3 = [] for __ in _['actions']: if (__ != {}) & (__ != {'_class': 'com.cloudbees.plugins.credentials.ViewCredentialsAction'}): _key = '' for ___ in __['parameterDefinitions']: _key += f"param: {___['name']} " _list3.append(_key) _list2.append(_list3) ## 出力フォーマット処理 df1 = pd.DataFrame(_list1) df2 = pd.DataFrame(_list2) df = pd.concat([df1, df2], axis=1) df.columns = columns_in_df # 出力微調整 return df[columns_out_df] def execJenkinsJobListNoParameters(self, jobname): '''指定したJenkinsJOB(パラメータなし)をリモート実行する ここでの役割はJenkinsJobをリモート実行するのみであり そのJob実行結果はハンドリングしていない。 そもそも非同期実行の仕組みになっている。 Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Return: response: <Response [201]> 実行スケジュールに渡しました Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.execJenkinsJobListNoParameters('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/build' API = f'{self.URL}{ENDPOINT}' # Job投入 try: response = requests.post( API, headers=self.HEADERS, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # Jobリモート投入成功を伝える print(f'{jobname}をリモート実行しました') print(response) return '201' def execJenkinsJobListWithParameters(self, jobname): '''指定したJenkinsJOB(パラメータ設定あり)をリモート実行する ここでの役割はJenkinsJobをリモート実行するのみであり そのJob実行結果はハンドリングしていない。 そもそも非同期実行の仕組みになっている。 Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Return: response: <Response [201]> 実行スケジュールに渡しました Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.execJenkinsJobListWithParameters('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/buildWithParameters' API = f'{self.URL}{ENDPOINT}' # Job投入 try: response = requests.post( API, headers=self.HEADERS, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # Jobリモート投入成功を伝える print(f'{jobname}をリモート実行しました') print(response) return '201' def _lastBuildTimestamp(self, jobname): '''指定したJenkinsJOB(パラメータ設定あり)の最終実行時間を取得する Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Retur: timestamp: str 最後の成功Build時間 YYYY/MM/DD HH:MM:SS Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.lastSuccessfulBuildTimestamp('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/lastBuild/api/json' API = f'{self.URL}{ENDPOINT}' # JOBパラメータ定義 params = ( ('pretty', 'true'), ) # Job投入 try: response = requests.post( API, headers=self.HEADERS, params=params, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # unixtimeをtimestampへ変換して戻す return(self.exchangeUnixtimeToTimestamp(response.json()['timestamp'])) def _lastSuccessfulBuildTimestamp(self, jobname): '''指定したJenkinsJOB(パラメータ設定あり)の最終成功時間を取得する Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Retur: timestamp: str 最後の成功Build時間 YYYY/MM/DD HH:MM:SS Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.lastSuccessfulBuildTimestamp('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/lastSuccessfulBuild/api/json' API = f'{self.URL}{ENDPOINT}' # JOBパラメータ定義 params = ( ('pretty', 'true'), ) # Job投入 try: response = requests.post( API, headers=self.HEADERS, params=params, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # unixtimeをtimestampへ変換して戻す return(self.exchangeUnixtimeToTimestamp(response.json()['timestamp'])) def _lastFailedBuildTimestamp(self, jobname): '''指定したJenkinsJOB(パラメータ設定あり)の最終失敗時間を取得する Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Retur: timestamp: str 最後の成功Build時間 YYYY/MM/DD HH:MM:SS Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.lastFailedBuildTimestamp('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/lastFailedBuild/api/json' API = f'{self.URL}{ENDPOINT}' # JOBパラメータ定義 params = ( ('pretty', 'true'), ) # Job投入 try: response = requests.post( API, headers=self.HEADERS, params=params, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # unixtimeをtimestampへ変換して戻す return(self.exchangeUnixtimeToTimestamp(response.json()['timestamp'])) def getJobInformation(self, jobname): '''指定したJenkinsJOB(パラメータ設定あり)の実行情報を取得する Args: jobname: str JenkinsJob名、ただしパラメータ定義のないJob Return: joburl: str job情報: DataFrame Raises: API実行時のエラー Examples: >>> jenkins = RocketChatJenkinsManager(HEADERS, AUTH, URL) >>> jenkins.getJobInformation('test_hubot') Note: ''' # 引数チェック 型 if not isinstance(jobname, str): print(f'引数:jobnameの型が正しくありません str <-> {type(jobname)}') raise TypeError # API定義 ENDPOINT = f'/job/{jobname}/api/json' API = f'{self.URL}{ENDPOINT}' # JOBパラメータ定義 params = ( ('pretty', 'true'), ) # Job投入 try: response = requests.post( API, headers=self.HEADERS, params=params, auth=self.AUTH,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # JobLinkPath生成 joburl = f"{response.json()['url']}" # 基本情報をまとめる _list = [] _list.append([f"Job名", f"{response.json()['displayName']}"]) _list.append([f"Job詳細", f"{response.json()['description']}"]) _list.append([f"HealthReport", f"{response.json()['healthReport'][0]['description']}"]) _list.append([f"JobStatus Color", f"{response.json()['color']}"]) # _list.append([f"Job最新実行:失敗判定", f"{response.json()['lastUnstableBuild']}"]) _list.append([f"Job最終BuildNo.", f"{response.json()['lastBuild']['number']}"]) _list.append([f"Job最終Build時間", f"{self._lastBuildTimestamp(jobname)}"]) _list.append([f"Job最終成功BuildNo.", f"{response.json()['lastSuccessfulBuild']['number']}"]) _list.append([f"Job最終成功Build時間", f"{self._lastSuccessfulBuildTimestamp(jobname)}"]) _list.append([f"Job最終失敗BuildNo.", f"{response.json()['lastFailedBuild']['number']}"]) _list.append([f"Job最終失敗Build時間", f"{self._lastFailedBuildTimestamp(jobname)}"]) # DataFrame生成 df = pd.DataFrame(_list) df.columns = ['項目', 'ステータス'] return joburl, df
- 投稿日:2021-01-18T22:36:19+09:00
JCLdicを使ってpythonで企業名抽出器をつくる
TL;DR
Japanese Company Lexiconを使って形態素解析(MeCab)ベースの企業名抽出器をpythonで作ります。
環境は以下を想定しています。macOS Catalina Homebrew 2.7.1 python 3.9事前準備
JCLdicのダウンロード
https://github.com/chakki-works/Japanese-Company-Lexicon
READMEからJCL_mediumのMeCab Dicをダウンロードして解凍してください。
jcl_medium_mecab.dicが必要なファイルです。MeCabインストール
mecab入ってない場合はインストールしてください。
今回はbrewでinstallします。
辞書にmecab-ipadicを使います。brew install mecab brew install mecab-ipadicMeCabのuserdict設定
MeCabのuserdict設定のためdicファイルを置くために、任意の場所にディレクトリ作成します。
今回は/usr/local/lib/mecab/dic/user_dictに作成しました。
解凍したmecab dictjcl_medium_mecab.dicを作成したディレクトリ配下に移動します。mkdir /usr/local/lib/mecab/dic/user_dict mv jcl_slim_mecab.dic /usr/local/lib/mecab/dic/user_dictmecabrcの変更
userdictを準備したら、mecabの辞書情報を変更するためにMeCabの設定ファイルであるmecabrcを登録します。
mecabrcは、install方法によって場所が変わるかもしれませんが、brewでinstallした場合/usr/local/etc/mecabrcにあります。
;でコメントになっている;userdic = <file path>を↑でおいたファイルのパスに変更します。userdic = /usr/local/lib/mecab/dic/user_dict/jcl_slim_mecab.dic動作確認
まずはconsoleで辞書が反映されているか確認しましょう。
>>> echo "ビザスクで働いています。" | mecab ビザスク 名詞,固有名詞,組織,*,*,*,株式会社ビザスク,*,* で 助詞,格助詞,一般,*,*,*,で,デ,デ 働い 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,働く,ハタライ,ハタライ て 助詞,接続助詞,*,*,*,*,て,テ,テ い 動詞,非自立,*,*,一段,連用形,いる,イ,イ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス 。 記号,句点,*,*,*,*,。,。,。 EOSビザスクが
名詞,固有名詞,組織,*,*,*,株式会社ビザスク,*,*と表示してされているのでOKです。python
次にpythonでMeCabを使う準備をします。
library install
まずpython用のライブラリをinstallします。
pip install mecab-python3これで準備は完了です。
code
以下のcodeで企業名を抽出します。
import unicodedata import MeCab # MeCabの設定 tagger = MeCab.Tagger('-r /usr/local/etc/mecabrc') def extract_company(text): # textのnormalize text = unicodedata.normalize('NFKC', text) node = tagger.parseToNode(text) result = [] while node: # node feature: 品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音 features = node.feature.split(',') if features[2] == '組織': result.append( (node.surface, features[6]) ) node = node.next return resultポイントは2つです。
1つ目は、MeCab.Taggerの引数に参照するmecabrcを-rオプションで指定しすることです。
2つ目は、テキストをparseする前に正規化することです。
JCLdicは辞書サイズと検索速度とのトレードオフの結果、全角を使わず半角のみ使っているようなのでパースするテキストを半角に正規化しておく必要があります。JCLdicでは、原型に株式会社ビザスクのような正式名称が入っているので原型を抽出することで、企業の正式名称を抽出することができます。
出力
texts = [ "ビザスクでエンジニアとして働いています。", "三菱UFJモルガンスタンレー証券 M&A部 アソシエート リンカーンインターナショナル ヴァイスプレジデント ガーディアンアドバイザーズ パートナー", "キヤノン株式会社 部長/経営監理室", "など、主力商品のプロダクトマーケティングに従事してきました。そして、会員サービスを一元化した「My Sony Club」の企画立案及び立ち上げを陣頭指揮してきました。また、シナジーマーケティングでは、クライアント企業様へCRMを中心としたマーケティングおよびマーケティング・コミュニケーション領域の支援をしてきました。" ] for text in texts: companies = extract_company(text) print("text: ", text) for company in companies: print("キーワード: {}, 正式名称: {}".format(company[0], company[1]))text: ビザスクでエンジニアとして働いています。 キーワード: ビザスク, 正式名称: 株式会社ビザスク キーワード: エンジニア, 正式名称: 株式会社エンジニア text: 三菱UFJモルガンスタンレー証券 M&A部 アソシエート リンカーンインターナショナル ヴァイスプレジデント ガーディアンアドバイザーズ パートナー キーワード: 三菱UFJモルガンスタンレー証券, 正式名称: 三菱UFJモルガン・スタンレー証券株式会社 キーワード: M&A, 正式名称: 株式会社M&A キーワード: アソシエート, 正式名称: 株式会社アソシエート キーワード: リンカーンインターナショナル, 正式名称: リンカーン・インターナショナル株式会社 キーワード: ヴァイス, 正式名称: 株式会社ヴァイス キーワード: ガーディアンアドバイザーズ, 正式名称: ガーディアン・アドバイザーズ株式会社 text: キヤノン株式会社 部長/経営監理室 キーワード: キヤノン株式会社, 正式名称: キヤノン株式会社 キーワード: 経営監理, 正式名称: 有限会社経営監理 text: など、主力商品のプロダクトマーケティングに従事してきました。そして、会員サービスを一元化した「My Sony Club」の企画立案及び立ち上げを陣頭指揮してきました。また、シナジーマーケティングでは、クライアント企業様へCRMを中心としたマーケティングおよびマーケティング・コミュニケーション領域の支援をしてきました。 キーワード: Sony, 正式名称: Sony合同会社 キーワード: シナジーマーケティング, 正式名称: シナジーマーケティング株式会社 キーワード: クライアント, 正式名称: 有限会社クライ・アント キーワード: CRM, 正式名称: 株式会社C.R.M.日本の会社名が多く収録されている辞書なので、一般名詞の会社名がでてくるため用途によっては使いにくいかもしれません。
その際は、抽出したくないキーワードをstopwordとして扱い、node.surfaceがstopwordだった場合スキップする処理を入れるなどの工夫が必要です。
- 投稿日:2021-01-18T22:07:30+09:00
LaTeX,Pythonのtips in修論
筆者(物性物理系M2)が修論を書くのに使った小ネタをテンプレとしてメモしておきます.
LaTeX
環境はpLaTeX,
\documentclass[a4paper,10pt]{jsarticle}とします.図
preamble\usepackage[dviout]{graphicx} \usepackage{here} %[H] オプションを使用する場合図の挿入
\begin{figure}[ht] %オプション h:その場, t:ページ上端, b:ページ下端, p:専用ページを作成 % H:その場で強制出力 \centering \includegraphics[keepaspectratio, width=0.8\linewidth]{fig1.png} %オプション keepaspectratio:アス比を固定, width,height:サイズ指定 % 0.8\linewidthなど紙幅との比や 8cmなど単位付き長さでの指定 \caption{キャプション} \label{fig:1} %相互参照用のラベル \end{figure}昔はTeXで画像を扱うならepsと相場が決まっていましたが,今はPDFが一番速いです.その他の場合でもdvipdfmxでPDFに変換されるのでPNGやJPEGならそのまま使って問題ありません.
http://www.yamamo10.jp/~yamamoto/comp/latex/make_doc/insert_fig/index.php#CONTEMPORARY
\includegraphics...の行を増やせば並ぶだけ適当に並べてくれますが,こちらでちゃんとコントロールして2カラムにしたい場合等は\begin{figure}[ht] \begin{tabular}{cc} \begin{minipage}[t]{0.45\hsize} \centering \includegraphics[keepaspectratio, width=\linewidth]{fig2.png} \caption{キャプション1} \label{fig:2} \end{minipage} & \begin{minipage}[t]{0.45\hsize} \centering \includegraphics[keepaspectratio, width=\linewidth]{fig3.png} \caption{キャプション2} \label{fig:3} \end{minipage} \end{tabular} \end{figure}のようにtabular環境を使います.
図に文字を回り込ませたいときはwrapfigure環境を使います.
abstructなどページ制限があるときなんかに便利.
普通のfigureと混ぜて使うと出力される順番がおかしくなったりするので注意が必要です.
オプション等の詳細は次を参照. http://www.yamamo10.jp/~yamamoto/comp/latex/make_doc/insert_fig/index.php#WRAPFIG\begin{wrapfigure}{R}{0.5\hsize} \centering \includegraphics[keepaspectratio, width=\linewidth]{fig4.png} \caption{キャプション3} \label{fig:4} \end{wrapfigure}表
表です.罫線を全部引いたりするとダサいのでほどほどにしておきます.
\begin{table}[ht] \centering \caption{キャプション} \begin{tabular}{c|ccc} \hline X & A & B & C\\ \hline \hline 1 & a & b & c \\ 2 & s & t & u \\ 3 & p & q & r \\ \hline \end{tabular} \label{tab:1} \end{table}
{c|ccc}のところは項目数と左右中央寄せ(l,r,c),縦罫線の設定です.
横罫線は\hlineで引きます.相互参照
図表や数式中に
\label{<適当な文字列>}を入れておくと\ref{<その文字列>}で図表番号を出力できます.執筆中に順序を入れ替えたりしても問題ないよう,手でベタ打ちするのではなく相互参照を使いましょう.
そのラベルが図なのか表なのか数式なのかは環境から自動で判断してくれますが,ユーザー側が判別しやすいようにfigやtabなどをprefixにつけておくと良いです.
なお,1度目のタイプセットでlabelの位置やら番号やらを書き出して,それをrefで参照することになるので2回以上のタイプセットが必要になります.目次や数字が入ることでページ数が変化することもありうるので万全を期すならば3回タイプセットしておくと安全です1.図表番号を章立てにする
図表番号はjsarticleでは通し番号が付けられますが,sectionごとにリセットする場合は次のようにします.
preamble\makeatletter % sectionが変わるごとにfigureカウンタをリセット \@addtoreset{figure}{section} % 図番号の出力を「<章番号>.<図番号>」にする \renewcommand{\thefigure}{\thesection.\arabic{figure}} % \@addtoreset{table}{section} \renewcommand{\thetable}{\thesection.\arabic{table}} \makeatother参考: [LaTeX] 図表数式番号を通し番号にする・章ごとに分ける
参考文献の参照
参考文献管理はthebibliography環境,またはBibTeXを使うのが一般的.
thebibliography環境を使用する場合はpreamble\usepackage{cite}\begin{thebibliography}{99} \bibitem{label1} hogehoge. \bibitem{label2} fugafuga. \end{thebibliography}のようにして
\cite{<ラベル名>}で参照します.
\cite{label1,label2}のように2つ以上並べたり\cite[pp12--34]{label1}のようにページ数などを付記することが可能.PDFにハイパーリンクを埋め込む
hyperref パッケージを使用すると相互参照にハイパーリンクが張られるので長いPDFを生成する場合,ワンクリックであっちこっち飛べて便利.
リンク文字列の色などの設定が可能.(デフォルトは赤とか緑なのでだいぶ見づらいと思う.)preamble\usepackage[dvipdfmx]{hyperref} \usepackage{pxjahyper} \hypersetup{ setpagesize=false, bookmarksnumbered=true, bookmarksopen=true, colorlinks=true, linkcolor=black, citecolor=black, }参考: ハイパーリンク付きLaTeX文書
自作カウンタの参照
自分で定義したカウンタも相互参照することができます.
subscriptという名前のカウンタを作成し,呼ばれたときの挙動を定義しておきます.preamble\newcounter{subscript} \setcounter{subscript}{0} \renewcommand{\thesubscript}{\arabic{subscript}} \newcommand{\subscript}{\refstepcounter{subscript}\thesubscript}$$ T_{\subscript\label{sub:hoge}} = hoge $$ $$ T_{\subscript\label{sub:fuga}} = fuga $$ $$ T_{\subscript\label{sub:piyo}} = piyo $$ $T_{\ref{sub:fuga}}$ はfugaです.
SI単位
preamble\usepackage{siunitx}
\si{kg.m/s^2}のように使用.
°は\si{\degree},℃は\si{\degreeCelsius}などまた、$\rm\LaTeX$ では
\AAでÅを印字できますが,これは「上リング付きA」2で,テキスト環境で使う想定のものなので\si内で使用するとLaTeX Warning: Command \r invalid in math mode on input line XXのような警告が出ます.
\angstromを使えば警告は出なくなります.参考:
SI単位(国際単位系) - siunitxパッケージのマクロ
command \r invalid化学式
上付き,下付きは数式環境でしか使えないが元素記号はローマン体なのでいちいち
$\mathrm{H}_2\mathrm{O}$のようにしなければいけなくてとても面倒.
パッケージを使用すると楽.preamble\usepackage[version=3]{mhchem}
\ce{SrTiO3},\ce{HSO4-}などのようにすると自動で上付き,下付きなどを適用してくれます(1桁に限る.SO42-等ではどこで区切るか決定できないので自分で上付き,下付きを設定する).
数式環境内でもローマン体にしてくれるし,テキスト環境でも上付き^,下付き_が効く.$\mathrm{FeSe}_ {1-x} \mathrm{Te}_ {x}$のような変数が入った置換系などで
\ce{FeSe_{$1-x$}Te_{$x$}}のようにすると1-xのマイナスがハイフンになってしまうようなので$\ce{FeSe}_{1-x}\ce{Te}_x$のようにしたほうが良い.mhchemパッケージの環境で数式モードにして
— ❄雪下❄ (@Mopepe51) January 5, 2021-を使うとマイナスじゃなくてハイフンになってる?
上が
\ce{FeSe_{$1-x$}Te_{$x$}}
下が
$\mathrm{FeSe}{1-x}\mathrm{Te}{x}$ pic.twitter.com/FODodQtwHN参考: TeXによる化学組版 - TeX Alchemist Online
マクロ内容の確認
このマクロ,どう動作するんだっけ?と気になることがあります.
$\rm\LaTeX$マクロであれなlatex.ltxを開いて検索すれば良いのですが再定義していたりパッケージで定義されたものだったりすると探すのも面倒です.
現環境での定義内容を確認するには,\show<トークン>のようにすればログにマクロを展開した結果が出力されます.例えば上で出てきた
\AAでやってみると> \AA=macro: ->\r A. l.11 \show\AA ?のように出力されます.
Aにアクセント記号\rを付けたものであるということがわかります.
マクロ以外のトークン(例えば&では>alignment tab character &.など)でも可.
またレジスタ数値などを出力する\showtheなど色々なデバッグ用コマンドも用意されています(以下略. 参考: TeX プログラムのデバッグで絶望する前に知るべきこと (1) - マクロツイーター )その他
- 「1から5まで」のように範囲を書くときは「~」
\simではなくen-dash--を使おう(~はニアリーイコールの記号). LaTeXで論文作成のいろいろ #ダッシュとハイフンの使い分けbibliographyを端折る
BibTeXを使わずに3参考文献を書く時は
\begin{thebibliography}{99} \bibitem{Josephson} B. D. Josephson, Phys. Lett. 1, 251-253 (1962). \end{thebibliography}のようにすればよいのですが,このままだと特に書式のないテキストで
[1] B. D. Josephson, Phys. Lett. 1, 251-253 (1962).
のように書き出されます.私の分野の書式にあわせようとすると
[1] B. D. Josephson, Phys. Lett. 1, 251-253 (1962).
のように雑誌名をイタリック,巻数をボールドにしたいのですが,いちいちB. D. Josephson, \textit{Phys. Lett.} \textbf{1}, 251-253 (1962).と毎度書くのはもちろん,
\newcommand{\paper}[4]{#1 \textit{#2} \textbf{#3} #4}とマクロを定義して\paper{B. D. Josephson,}{Phys. Lett.,}{1,}{251-253 (1962).}とするのもカッコを書くのが面倒4だったので\defを使ってもう少し入力数を減らしてみました.$\rm\LaTeX$では基本的に
\newcommandを使うべきなのですが,\defを使うと便利な場面もあります.
\def特有の機能のうちにパターンマッチングが使えるというものがあり,\def\paper#1;#2;#3;#4.{#1\textit{#2}\textbf{#3}#4.} \paper B. D. Josephson,;Phys. Lett.,;1,;251-253 (1962).のようにすると
B. D. Josephson,,Phys. Lett.,,1,,251-253 (1962)がそれぞれ#1,#2,#3,#4 に格納され展開されます.便利ですね.横着するためだけに($\rm\LaTeX$ではなく)$\rm\TeX$を書かないといけないのであまり真似しないほうが良いと思いますが.
Python
%matplotlib inline import numpy as np import matplotlib.pyplot as plt import pandas as pdあたりは前置きなく使用します.
グラフ
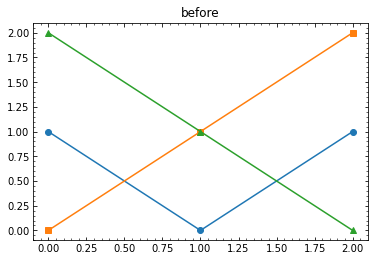
目標はこんな感じのグラフです.
[出典 : E. Snider, et al. "Room-temperature superconductivity in a carbonaceous sulfur hydride." Nature 586, 373–377 (2020).]目盛り設定
デフォルトの設定だと目盛りが外向き・補助目盛り無しなので表示させます.
plt.rcParams['font.family'] ='sans-serif' #フォント選択 plt.rcParams['font.size'] = 12 #フォントの大きさ plt.rcParams["xtick.minor.visible"] = True #補助目盛りの追加 plt.rcParams["ytick.minor.visible"] = True plt.gca().xaxis.set_tick_params(which='both', direction='in',bottom=True, top=True) plt.gca().yaxis.set_tick_params(which='both', direction='in',left=True, right=True)
その他の設定項目.備忘録 Matplotlibのグラフの見た目の調整
マーカーを白抜きにする
markerfacecolorを"None"にするとマーカーが枠線だけになる."white"だと後ろが透過しない.
markeredgecolorを設定すれば線と別の色で描画もできる.
散布図plt.scatterの場合はそれぞれ引数名がedgecolors,facecolorになる.plt.plot([0, 1, 2], [1, 0, 1], marker="o", markersize=10) plt.plot([0, 1, 2], [0, 1, 2], marker="s", markerfacecolor="None", markersize=10) plt.plot([0, 1, 2], [2, 1, 0], marker="^", markeredgecolor="C3", markerfacecolor="white", markersize=10) plt.scatter([0, 1, 2], [0, 2, 1], marker="v", edgecolors="C4", facecolor='None', s=100)matplotlib グラフ作成Tips (3) 白抜き記号と矢印
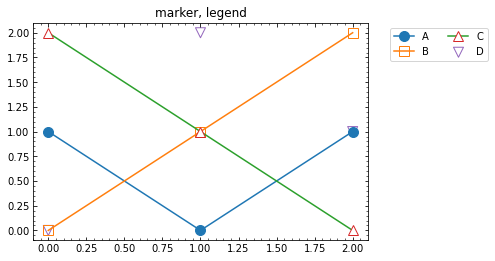
凡例をグラフ外部に表示する
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left", ncol=2)matplotlibの凡例(legend)レイアウト関連メモ
重ねてプロット
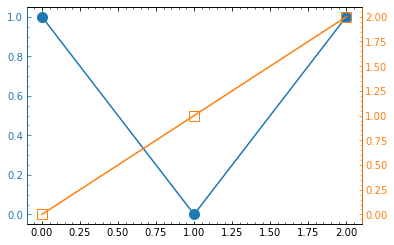
第2軸と重ねて書く場合.
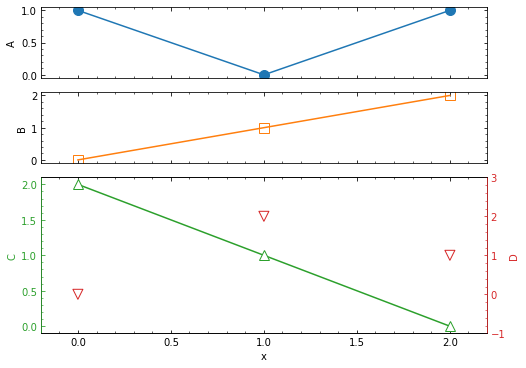
プロット色に合わせて軸の色も変えようとすると結構面倒です.fig = plt.figure() ax1 = fig.subplots() plt.rcParams['font.family'] ='sans-serif' plt.rcParams['font.size'] = 10 plt.rcParams["xtick.minor.visible"] = True plt.rcParams["ytick.minor.visible"] = True ax1.xaxis.set_tick_params(which='both', direction='in',bottom=True, top=True) # 1軸 目盛色の変更 ax1.yaxis.set_tick_params(which='both', direction='in',left=True, color="C0") # 目盛ラベル色の変更 ax1.tick_params(axis="y", colors="C0") ax2 = ax1.twinx() # 2軸 目盛色の変更 ax2.tick_params(axis="y", which='both', direction='in', right=True, color="C1") # 目盛ラベル色の変更 ax2.tick_params(axis='y', colors="C1") # 枠線色の変更 ax2.spines['left'].set_color("C0") # ax2のほうが"上"にあるのでax2を変える ax2.spines['right'].set_color("C1") ax1.plot([0, 1, 2], [1, 0, 1], marker="o", markersize=10, color="C0") ax2.plot([0, 1, 2], [0, 1, 2], marker="s", markerfacecolor="None", markersize=10, color="C1") plt.show()
[Python]matplotlibで左右に2つの軸があるグラフを書く方法
時系列データを複数縦に並べてプロットしたい,しかもそのうち2つは2軸で重ねて描画したいなんていうときはこんな感じ.
fig = plt.figure(figsize=(8, 6)) plt.rcParams['font.family'] ='sans-serif' #フォント選択 plt.rcParams['font.size'] = 10 #フォントの大きさ plt.rcParams["xtick.minor.visible"] = True #補助目盛りの追加 plt.rcParams["ytick.minor.visible"] = True #plt.gca().xaxis.set_tick_params(which='both', direction='in',bottom=True, top=True) #plt.gca().yaxis.set_tick_params(which='both', direction='in',left=True, right=True) # 画面を4x1に分割 ax1 = plt.subplot2grid((4,1), (0,0)) # (0,0) の画面に描画 ax2 = plt.subplot2grid((4,1), (1,0)) # (1,0) の画面に描画 ax3 = plt.subplot2grid((4,1), (2,0), rowspan=2) # (2,0) から2つ縦にぶち抜いた画面に描画 ax4 = ax3.twinx() # ax3に重ねて描画 ax1.xaxis.set_tick_params(which='both', direction='in', bottom=True, top=True, labelbottom=False) ax1.yaxis.set_tick_params(which='both', direction='in', left=True, right=True) ax2.xaxis.set_tick_params(which='both', direction='in', bottom=True, top=True, labelbottom=False) ax2.yaxis.set_tick_params(which='both', direction='in', left=True, right=True) ax3.xaxis.set_tick_params(which='both', direction='in', bottom=True, top=True) ax3.yaxis.set_tick_params(which='both', direction='in', color="C2") ax4.spines['left'].set_color("C2") ax4.yaxis.set_tick_params(which='both', direction='in', color="C3") ax4.tick_params(axis='y', colors="C3") ax4.spines['right'].set_color("C3") ax1.plot([0, 1, 2], [1, 0, 1], marker="o", color="C0", markersize=10, label="A") ax1.set_ylabel("A") ax2.plot([0, 1, 2], [0, 1, 2], marker="s", color="C1", markerfacecolor="None", markersize=10, label="B") ax2.set_ylabel("B") ax3.plot([0, 1, 2], [2, 1, 0], marker="^", color="C2", markerfacecolor="white", markersize=10, label="C") ax3.tick_params(axis='y', colors="C2") ax3.set_xlabel("x") ax3.set_ylabel("C", color="C2") ax4.scatter([0, 1, 2], [0, 2, 1], marker="v", edgecolors="C3", facecolor='None', s=100, label="D") ax4.set_ylabel("D", color="C3") ax4.set_ylim(-1,3) plt.xlim(-0.2, 2.2) ax1.set_xlim(*plt.xlim()) #ax1,ax2のx軸をあわせる ax2.set_xlim(*plt.xlim()) plt.show()
2軸にするのをx軸にしたい場合は
twinx()をtwiny()にします.平滑化
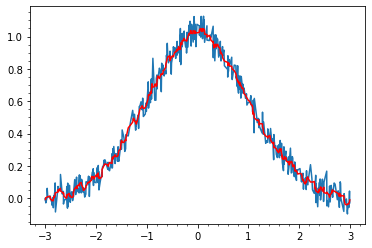
ノイズを移動平均で平滑化する場合はnp.convolveが使える.
def gauss(x, a=1, mu=0, sigma=1): return a * np.exp(-(x - mu)**2 / (2*sigma**2)) x = np.array(sorted([np.random.rand()*6-3 for _ in range(500)])) y = np.array([gauss(i)+np.random.randn()*0.05for i in x]) width = 7 plt.plot(x,y) plt.plot(x, np.convolve(y, np.ones(width)/width, mode='same'), color="red")
時系列データの場合,未来のデータを見るわけにはいかないのでずらします.
plt.plot(x,y) plt.plot(x[width-1:], np.convolve(y, np.ones(width)/width, mode='valid'), color="red")
このパターンはPandasのrolling関数でも書けます.
plt.plot(x, y) plt.plot(x, pd.Series(y).rolling(11).mean(), color="red")Pandasだと同様に指数平滑移動平均もできる.
plt.plot(x, y) plt.plot(x, pd.Series(y).ewm(span=width).mean(), color="red")波形データならFFTするとか他にも色々ありますね.時系列及び波形データの平滑化3手法(smoothing)
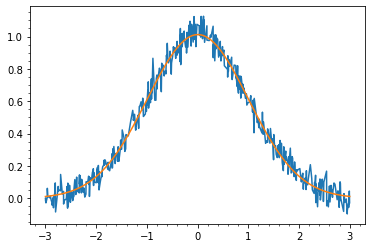
曲線フィット
最小二乗法で曲線のパラメーターフィットを行います.
from scipy.optimize import curve_fit def gauss(x, a=1, mu=0, sigma=1): return a * np.exp(-(x - mu)**2 / (2*sigma**2)) x = np.array(sorted([np.random.rand()*6-3 for _ in range(500)])) y = np.array([gauss(i, 1, 0, 1)+np.random.randn()*0.05for i in x]) popt, pcov = curve_fit(gauss, x, y)
curve_fit関数に「第1引数にx,残りがパラメーターである関数」,x,y を与えると最適パラメーターと共分散行列が返されます.共分散行列の対角成分はそれぞれのパラメーターの分散なので平方根を取れば標準偏差が得られます.
plt.plot(x,y) plt.plot(np.linspace(-3,3,1000), gauss(np.linspace(-3,3,1000), *popt)) plt.show() perr = np.sqrt(np.diag(pcov)) for i in range(3): print(f"{popt[i]:.3f}±{perr[i]:.3f}") # 1.012±0.005 # 0.004±0.006 # 0.996±0.006
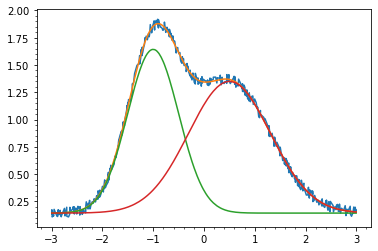
パラメーターの初期値や範囲を与えてやればそれなりに複雑な関数もフィットできます.
def two_gauss(x, a1, m1, s1, a2, m2, s2, e): return gauss(x, a1, m1, s1) + gauss(x, a2, m2, s2) + e y2 = np.array([two_gauss(i, 1.5, -1, 0.5, 1.2, 0.5, 0.8, 0.1) + np.random.rand()*0.1 for i in x]) p,q = curve_fit(two_gauss, x, y2, [2, -1.5, 0.5, 1.5, 1, 1, 0], bounds=((0, -np.inf, 0, 0, -np.inf, 0, 0), (np.inf, np.inf, np.inf, np.inf, np.inf, np.inf, np.inf)) ) plt.plot(x,y2) plt.plot(x, two_gauss(x, *p)) plt.plot(x, gauss(x, p[0], p[1], p[2])+p[6]) plt.plot(x, gauss(x, p[3], p[4], p[5])+p[6])
曲線で補間する
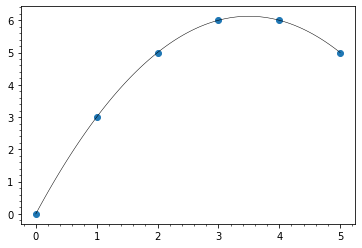
適切な関数で表せればそれで良いですが,それができず適当な曲線でつなぎたいだけという場合はスプラインでつないでしまいます.
from scipy.interpolate import make_interp_spline, BSpline x = [0,1,2,3,4,5] y = [0,3,5,6,6,5] smooth = make_interp_spline(x, y) plt.scatter(x, y) plt.plot(np.linspace(0,5,100), smooth(np.linspace(0,5,100)), color="black", linewidth=0.5)
make_interp_spline(x, y)でx,yを制御点とするB-スプライン曲線を表す関数ができるので適当なxの値でプロットすれば曲線が引けます.
他の曲線による補間もいろいろあります. Scipy.interpolate を使った様々な補間法
DataFrameの操作
温度を変えながら抵抗を測ってR-Tプロットするというとき,降温時は速度を固定していないので邪魔です.
そんなときに昇温期間だけにトリムするコード.df = pd.read_csv("data.csv") df = df.iloc[1:, :] #2行目の単位の行があるとfloatにできないので削除 df = df.astype('float64') cond = df.index>=df["Temperature"].idxmin() plt.plot(df[cond]["Temperature"], df[cond]["Resistance"])トリム条件は
&や|で繋げられる.(真偽値のarrayの演算なのでbool演算ではなくビット演算)# 変分はdiffで取れる cond = (df.index>=df["Temperature"].idxmin()) & (df["Temperature"].diff() > 0.02) cond = (df.index>=df["Temperature"].idxmin()) | ((df["Time"] > 100) & (df["Time"]<2000))水平部分の抽出
こんな時系列データ(ノイズ±0.01くらい乗ってる)から水平部分のyの値のset(これだと{10, 15, …, 37, 38, 38.5, 39})を取得するの、どうするのが早いかな pic.twitter.com/MX7oSuIeaU
— ❄雪下❄ (@ykstprg) January 6, 2021水平部分のyの値を取ってきたい.
width = 0.01 z = plt.hist(y, bins=np.arange(0, 40, width)-width/2) plt.ylim(0,50) threshold=300 print((z[1][:-1]+width/2)[z[0]>threshold]) # [ 2.5 5. 10. 15. 20. 25. 30. 33. 35. 35.5 36. 36.5 37. 37.5]
widthとthresholdを適当に変えるといい感じになる.
https://texwiki.texjp.org/?LaTeX%E5%85%A5%E9%96%80%2F%E7%9B%B8%E4%BA%92%E5%8F%82%E7%85%A7%E3%81%A8%E3%83%AA%E3%83%B3%E3%82%AF#h84e81eb ↩
ノルウェー語などで使用される記号.ドイツ語なんかで言うウムラウト付き文字のようなもの.もっと雑に言えば日本語でいう半濁音みたいな? ↩
過去のパワポなどから持ってくるものが多いので
B. D. Josephson, Phys. Lett. 1, 251-253 (1962).というような文字列を持ってくるのが一番楽だったんですよね. ↩ブレースってShiftが必要だしキーボードの端にあるしで入力しづらくて好きではないんですよね. ↩
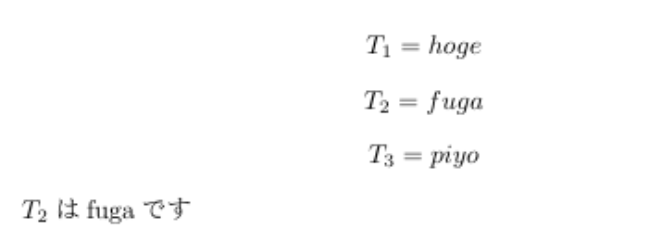

- 投稿日:2021-01-18T21:52:12+09:00
VBAユーザがPython・Rを使ってみた:文字列操作(続)
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
文字列操作
以前の記事では、PythonとRの文字列操作についてVBAとの比較をしましたが、その続きで、Rの文字列操作のパッケージ
stringrを使ってみます。参考記事に「R標準の
baseパッケージが提供する関数でも文字列処理は可能だが、stringrのほうが統一的なインターフェイスに合理的な挙動で使いやすい。」とありますが、実際に使ってみると、確かに、関数のネーミングと引数の順序に統一性があって、感動的に使いやすいです。
参考:stringr — Rの文字列をまともな方法で処理する文字列の結合
R(stringr)
Rlibrary(stringr) s1 <- "abc" s2 <- "def" s3 <- "ghij" str_c(s1, s2, s3) # "abcdefghij"文字列の長さ
R(stringr)
Rs <- "abcdefghij" str_length(s) # 10文字列の取り出し
R(stringr)
Rs <- "abcdefghij" str_sub(s, 1, 2) # "ab" str_sub(s, -2, -1) # "ij" str_sub(s, 4, 6) # "def"文字列の検索
R(stringr)
Rs <- "abcdefghij" t <- str_c(s, s, sep="") # "abcdefghijabcdefghij" str_detect(s, "def") # TRUE str_detect(t, "def") # TRUE str_count(s, "def") # 1 str_count(t, "def") # 2 str_locate(s, "def") # start end # [1,] 4 6 str_locate(t, "def") # start end # [1,] 4 6 class(str_locate(t, "def")) # "matrix" str_locate_all(t, "def") # [[1]] # start end # [1,] 4 6 # [2,] 14 16 class(str_locate_all(t, "def")) # "list"文字列の置換
R(stringr)
Rs <- "abcdefghij" t <- str_c(s, s, sep="") # "abcdefghijabcdefghij" str_replace(s, "def", "DEF") # "abcDEFghij" str_replace(t, "def", "DEF") # "abcDEFghijabcdefghij" str_replace_all(t, "def", "DEF") # "abcDEFghijabcDEFghij"文字列の変換
大文字と小文字の変換
R(stringr)
Rs <- "abcDEFghij" str_to_upper(s) # 大文字に # "ABCDEFGHIJ" str_to_lower(s) # 小文字に # "abcdefghij" str_to_title(s) # 先頭のみ大文字・それ以外は小文字に # "abcdefghij" str_to_sentence(s) # 先頭のみ大文字・それ以外は小文字に # "Abcdefghij" ss <- "abc def ghij" str_to_title(ss) # "Abc Def Ghij" str_to_sentence(ss) # "Abc def ghij" t <- "" for (i in 1:str_length(s)) { stemp = str_sub(s,i,i) if (stemp == str_to_lower(stemp)) { stemp = str_to_upper(stemp) } else if (stemp == str_to_upper(stemp)) { stemp = str_to_lower(stemp) } t <- str_c(t, stemp) } t # 大文字・小文字の入れ替え # "ABCdefGHIJ" s == str_to_upper(s) # すべて大文字かどうかの判定 # FALSE s == str_to_lower(s) # すべて小文字かどうかの判定 # FALSE全角と半角の変換
R(stringr)
R文字列の反転
R(stringr)
Rs <- "abcdefghij" t <- "" for (i in 1:str_length(s)) { t <- str_c(t, str_sub(s, -i, -i)) } t # "jihgfedcba"文字列の繰り返し
R(stringr)
Rstr_dup("A", 3) # "AAA" str_dup("def", 3) # "defdefdef"スペース
スペースの文字列
R(stringr)
Rstr_c("-", str_dup(" ", 3), "-") # "- -" # "- -" s <- str_c(str_dup(" ", 2), "d", str_dup(" ", 3), "e", str_dup(" ", 4), "f", str_dup(" ", 5)) str_c("-", s, "-") # "- d e f -"前後の不要なスペースの削除
R(stringr)
Rstr_trim(s, side="left") # "d e f " str_trim(s, side="right") # " d e f" str_trim(s, side="both") # "d e f"文字列ベクトルについて
stringrパッケージの関数は、文字列(1個の文字列)だけでなく、文字列のベクトルやデータフレームでも使えます。
例えば、3個の文字列からなる文字列ベクトルにstr_length関数を使うと、その各要素の文字列に対してそれぞれstr_length関数を使った結果の数値3個からなるベクトルが返ります。R(stringr)
Rs1 <- "abcdefghij" s2 <- "cdefghijkl" s3 <- "efghijklmn" ss <- c(s1, s2, s3) ss # [1] "abcdefghij" "cdefghijkl" "efghijklmn" str_c(ss, "_1") # [1] "abcdefghij_1" "cdefghijkl_1" "efghijklmn_1" str_length(ss) # [1] 10 10 10 str_sub(ss, 1, 2) # [1] "ab" "cd" "ef" str_sub(ss, -2, -1) # [1] "ij" "kl" "mn" str_sub(ss, 2, 3) # [1] "bc" "de" "fg" str_detect(ss, "def") # [1] TRUE TRUE FALSE str_count(ss, "def") # [1] 1 1 0 str_locate(ss, "def") # start end # [1,] 4 6 # [2,] 2 4 # [3,] NA NA str_locate_all(ss, "def") # [[1]] # start end # [1,] 4 6 # # [[2]] # start end # [1,] 2 4 # # [[3]] # start end # str_replace(ss, "def", "DEF") # [1] "abcDEFghij" "cDEFghijkl" "efghijklmn" str_replace_all(ss, "def", "DEF") # [1] "abcDEFghij" "cDEFghijkl" "efghijklmn" str_to_upper(ss) # [1] "ABCDEFGHIJ" "CDEFGHIJKL" "EFGHIJKLMN" str_to_lower(ss) # [1] "abcdefghij" "cdefghijkl" "efghijklmn" str_to_title(ss) # [1] "Abcdefghij" "Cdefghijkl" "Efghijklmn" str_to_sentence(ss) # [1] "Abcdefghij" "Cdefghijkl" "Efghijklmn" ss == str_to_upper(ss) # [1] FALSE FALSE FALSE ss == str_to_lower(ss) # [1] TRUE TRUE TRUE str_dup(ss, 2) # [1] "abcdefghijabcdefghij" "cdefghijklcdefghijkl" "efghijklmnefghijklmn" tt <- str_c(" ", ss, " _1 ") tt # [1] " abcdefghij _1 " " cdefghijkl _1 " " efghijklmn _1 " str_trim(tt) # [1] "abcdefghij _1" "cdefghijkl _1" "efghijklmn _1" str_trim(tt, side="left") # [1] "abcdefghij _1 " "cdefghijkl _1 " "efghijklmn _1 " str_trim(tt, side="right") # [1] " abcdefghij _1" " cdefghijkl _1" " efghijklmn _1"ベクトルやデータフレームについては、また別の記事でまとめたいと思います。
まとめ
一覧
各言語で使用する文字列操作関数等を一覧にまとめます。比較のために、EXCELでの計算も示しました。
s1 = "abc"
s2 = "def"
s3 = "ghij"
s = "abcdefghij"
t = "abcdefghijabcdefghij"
u = "abcDEFghij"
v = "abcDEFghij"
w = " d e f "
とします。また、EXCELのセルにそれぞれ
A1セル:="abc"
A2セル:="def"
A3セル:="ghij"
A4セル:="abcdefghij"
A5セル:="abcdefghijabcdefghij"
A6セル:="abcDEFghij"
A7セル:="abcDEFghij"
A8セル:=" d e f "
が入力されているものとします。文字列の基本的操作
Python R R(stringr) VBA EXCEL 結果 結合 s1 + s2 + s3 paste0(s1, s2, s3)
paste(s1, s2, s3, sep="")str_c(s1, s2, s3) s1 & s2 & s3 =A1&A2&A3
=CONCATENATE(
A1,A2,A3)abcdefghij 長さ len(s) nchar(s) str_length(s) Len(s) =LEN(A4) 10 反転 s[::-1] StrReverse(s) jihgfedcba 繰り返し 'A' * 3 str_dup("A", 3) String(3, "A") =REPT("A",3) AAA 繰り返し 'def' * 3 str_dup("def", 3) =REPT("def",3) defdefdef 文字列の取り出し
Python R R(stringr) VBA EXCEL 結果 左から s[8:10]
s[0:2]
s[:2]substr(s, 1, 2)
substring(s, 1, 2)str_sub(s, 1, 2) Left(s, 2) =LEFT(A4,2) ab 右から s[len(s)-2:len(s)]
s[-2:]substr(s,
nchar(s)-2+1,
nchar(s))str_sub(s, -2, -1) Right(s, 2) =RIGHT(A4,2) ij 途中 s[3:6] substr(s, 4, 6) str_sub(s, 4, 6) Mid(s, 4, 3) =MID(A4,4,3) def 注意)「途中」の文字列の取り出しについて、Python, Rの関数では取り出す文字列を「どこからどこまで」と指定しますが、VBA, EXCELの関数では「どこから何文字分」と指定します。
文字列の検索
Python R R(stringr) VBA EXCEL 結果 検索 s.find('def') str_locate(s, "def") InStr(1, s, "def") =FIND("def",A4,1)
=SEARCH("def",A4,1)3,4 後ろからの検索 t.rfind('def') InStrRev(t, "def") 13,14 カウント t.count('def') str_count(t, "def") 2 注意)
str_detect,str_locate関数については、上記参照。文字列の置換
Python R R(stringr) VBA EXCEL 結果 置換 s.replace('def', 'DEF') sub("def", "DEF", s) str_replace(s, "def", "DEF") Replace(s, "def", "DEF") =SUBSTITUTE(
A4,"def","DEF")
=REPLACE(A4,
FIND("def",A4),
LEN("def"),"DEF")abcDEFghij 最初の1つだけ置換 sub("def", "DEF", t) str_replace(t, "def", "DEF") abcDEFghij
abcdefghijすべて置換 t.replace('def', 'DEF') gsub("def", "DEF", t) str_replace_all(t, "def", "DEF") Replace(t, "def", "DEF") =SUBSTITUTE(
A5,"def","DEF")abcDEFghij
abcDEFghij文字列の変換
Python R R(stringr) VBA EXCEL 結果 大文字に u.upper() toupper(u) str_to_upper(u) UCase(u) =UPPER(A6) ABCDEFGHIJ 小文字に u.lower() tolower(u) str_to_lower(u) LCase(u) =LOWER(A6) abcdefghij 先頭のみ大文字・それ以外は小文字に u.capitalize() str_to_title(u)
str_to_sentence(u)StrConv(u, vbProperCase) =PROPER(A6) Abcdefghij 大文字と小文字を入れ替え u.swapcase() chartr("A-Za-z", "a-zA-z", u) ABCdefGHIJ 大文字かどうかの判定 u.isupper() u == toupper(u) u == str_to_upper(u) False 小文字かどうかの判定 u.islower() u == tolower(u) u == str_to_lower(u) False 全角に chartr("A-Za-z", "A-Za-z", u) StrConv(u, vbWide) =JIS(A6) abcDEFghij 半角に chartr("A-Za-z", "A-Za-z", v) StrConv(v, vbNarrow) =ASC(A7) abcDEFghij 文字列のスペース
Python R R(stringr) VBA EXCEL 結果 スペース ' ' * 3 str_dup(" ", 3) Space(3) =REPT(" ",3) " " 両側スペース削除 w.strip(' ') str_trim(s, side="both") Trim(w) =TRIM(A8) "d e f" 左スペース削除 w.lstrip(' ') str_trim(s, side="left") LTrim(w) "d e f " 右スペース削除 w.rstrip(' ') str_trim(s, side="right") RTrim(w) " d e f" 注意)EXCELのTRIM関数は文字列の中のスペースも1つを除いて削除されて
d e fとなります。プログラム全体
参考までに使ったプログラムの全体を示します。
Python, VBAのコードは前回の記事参照。R(stringr)
Rlibrary(stringr) # 文字列の結合 s1 <- "abc" s2 <- "def" s3 <- "ghij" str_c(s1, s2, s3) # "abcdefghij" # 文字列の長さ s <- "abcdefghij" str_length(s) # 10 # 文字列の取り出し s <- "abcdefghij" str_sub(s, 1, 2) # "ab" str_sub(s, -2, -1) # "ij" str_sub(s, 4, 6) # "def" # 文字列の検索 s <- "abcdefghij" t <- str_c(s, s, sep="") # "abcdefghijabcdefghij" str_detect(s, "def") # TRUE str_detect(t, "def") # TRUE str_count(s, "def") # 1 str_count(t, "def") # 2 str_locate(s, "def") # start end # [1,] 4 6 str_locate(t, "def") # start end # [1,] 4 6 class(str_locate(t, "def")) # "matrix" str_locate_all(t, "def") # [[1]] # start end # [1,] 4 6 # [2,] 14 16 class(str_locate_all(t, "def")) # "list" # 文字列の置換 s <- "abcdefghij" t <- str_c(s, s, sep="") # "abcdefghijabcdefghij" str_replace(s, "def", "DEF") # "abcDEFghij" str_replace(t, "def", "DEF") # "abcDEFghijabcdefghij" str_replace_all(t, "def", "DEF") # "abcDEFghijabcDEFghij" # 文字列の大文字・小文字の変換 s <- "abcDEFghij" str_to_upper(s) # 大文字に # "ABCDEFGHIJ" str_to_lower(s) # 小文字に # "abcdefghij" str_to_title(s) # 先頭のみ大文字・それ以外は小文字に # "abcdefghij" str_to_sentence(s) # 先頭のみ大文字・それ以外は小文字に # "Abcdefghij" ss <- "abc def ghij" str_to_title(ss) # "Abc Def Ghij" str_to_sentence(ss) # "Abc def ghij" t <- "" for (i in 1:str_length(s)) { stemp = str_sub(s,i,i) if (stemp == str_to_lower(stemp)) { stemp = str_to_upper(stemp) } else if (stemp == str_to_upper(stemp)) { stemp = str_to_lower(stemp) } t <- str_c(t, stemp) } t # 大文字・小文字の入れ替え # "ABCdefGHIJ" s == str_to_upper(s) # すべて大文字かどうかの判定 # FALSE s == str_to_lower(s) # すべて小文字かどうかの判定 # FALSE # 文字列の反転 s <- "abcdefghij" t <- "" for (i in 1:str_length(s)) { t <- str_c(t, str_sub(s, -i, -i)) } t # "jihgfedcba" # 文字列の繰り返し str_dup("A", 3) # "AAA" str_dup("def", 3) # "defdefdef" # 文字列のスペース str_c("-", str_dup(" ", 3), "-") # "- -" # "- -" s <- str_c(str_dup(" ", 2), "d", str_dup(" ", 3), "e", str_dup(" ", 4), "f", str_dup(" ", 5)) str_c("-", s, "-") # "- d e f -" # 文字列の前後のスペース削除 str_trim(s, side="left") # "d e f " str_trim(s, side="right") # " d e f" str_trim(s, side="both") # "d e f" # 文字列ベクトル s1 <- "abcdefghij" s2 <- "cdefghijkl" s3 <- "efghijklmn" ss <- c(s1, s2, s3) ss # [1] "abcdefghij" "cdefghijkl" "efghijklmn" str_c(ss, "_1") # [1] "abcdefghij_1" "cdefghijkl_1" "efghijklmn_1" str_length(ss) # [1] 10 10 10 str_sub(ss, 1, 2) # [1] "ab" "cd" "ef" str_sub(ss, -2, -1) # [1] "ij" "kl" "mn" str_sub(ss, 2, 3) # [1] "bc" "de" "fg" str_detect(ss, "def") # [1] TRUE TRUE FALSE str_count(ss, "def") # [1] 1 1 0 str_locate(ss, "def") # start end # [1,] 4 6 # [2,] 2 4 # [3,] NA NA str_locate_all(ss, "def") # [[1]] # start end # [1,] 4 6 # # [[2]] # start end # [1,] 2 4 # # [[3]] # start end # str_replace(ss, "def", "DEF") # [1] "abcDEFghij" "cDEFghijkl" "efghijklmn" str_replace_all(ss, "def", "DEF") # [1] "abcDEFghij" "cDEFghijkl" "efghijklmn" str_to_upper(ss) # [1] "ABCDEFGHIJ" "CDEFGHIJKL" "EFGHIJKLMN" str_to_lower(ss) # [1] "abcdefghij" "cdefghijkl" "efghijklmn" str_to_title(ss) # [1] "Abcdefghij" "Cdefghijkl" "Efghijklmn" str_to_sentence(ss) # [1] "Abcdefghij" "Cdefghijkl" "Efghijklmn" ss == str_to_upper(ss) # [1] FALSE FALSE FALSE ss == str_to_lower(ss) # [1] TRUE TRUE TRUE str_dup(ss, 2) # [1] "abcdefghijabcdefghij" "cdefghijklcdefghijkl" "efghijklmnefghijklmn" tt <- str_c(" ", ss, " _1 ") tt # [1] " abcdefghij _1 " " cdefghijkl _1 " " efghijklmn _1 " str_trim(tt) # [1] "abcdefghij _1" "cdefghijkl _1" "efghijklmn _1" str_trim(tt, side="left") # [1] "abcdefghij _1 " "cdefghijkl _1 " "efghijklmn _1 " str_trim(tt, side="right") # [1] " abcdefghij _1" " cdefghijkl _1" " efghijklmn _1"参考
- 投稿日:2021-01-18T21:37:36+09:00
Cutmix はテーブルデータに対しても有効か?
初めに
通常,教師あり学習は,高精度を達成するため,十分な量のラベル付きデータを必要とします.しかし,人手による注釈は,非常に多くの時間と労力を要します.これを解決する方法の一つとして,人工的にデータをかさ増しする data augmentation があります.
しかし,data augmentation は,画像ありきに語られることがほとんどで,テーブルデータに適用できる手法は,そう多くありません.そこで,本記事は,テーブルデータに適用できる data augmentation を紹介し,実験を行い,それらの性能を検証します.
Mixup
mixup: Beyond Empirical Risk Minimization
Mixup は,2017 年に提案された手法で,ICLR に採択されました.二つの入力を混ぜ合わせることで,新たな入力を生成します.
import random as rn from sklearn.utils import check_random_state def mixup(x, y=None, alpha=0.2, p=1.0, random_state=None): n, _ = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = random_state.beta(alpha, alpha) shuffle = random_state.choice(n, n, replace=False) x = l * x + (1.0 - l) * x[shuffle] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, y画像の他に,音声やテーブルデータに対して Mixup を適用しても性能が向上したことが論文中で報告されています.
Cutmix
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
Cutmix は,2019 年に提案された手法で,ICCV に採択されました.入力の一部分をもう一方の入力で置き換えることで,新たな入力を生成します.
import random as rn import numpy as np from sklearn.utils import check_random_state def cutmix(x, y=None, alpha=1.0, p=1.0, random_state=None): n, w, h, _ = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = random_state.beta(alpha, alpha) r_w = int(w * np.sqrt(1.0 - l)) r_h = int(h * np.sqrt(1.0 - l)) x1 = random_state.randint(w - r_w) y1 = random_state.randint(h - r_h) x2 = x1 + r_w y2 = y1 + r_h shuffle = random_state.choice(n, n, replace=False) x[:, x1:x2, y1:y2] = x[shuffle, x1:x2, y1:y2] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, yCutmix は,画像に対して適用した結果しか論文中で報告されていません.これを,テーブルデータに対して適用するとどうなるのでしょうか.
テーブルデータは,特徴(年齢や国籍等)の順序に意味はありません.そこで,もう一方の入力で置き換える部分を無作為に選ぶことにします.
import random as rn import numpy as np from sklearn.utils import check_random_state def cutmix_for_tabular(x, y=None, alpha=1.0, p=1.0, random_state=None): n, d = x.shape if n is not None and rn.random() < p: random_state = check_random_state(random_state) l = random_state.beta(alpha, alpha) mask = random_state.choice([False, True], size=d, p=[l, 1.0 - l]) mask = np.where(mask)[0] shuffle = random_state.choice(n, n, replace=False) x[:, mask] = x[shuffle, mask] if y is not None: y = l * y + (1.0 - l) * y[shuffle] return x, y実験
今回は,次のデータを使って実験を行います.これは,遺伝子発現パターンから化合物の作用機序を予測するマルチラベル分類問題です.
Mechanisms of Action (MoA) Prediction | Kaggle
詳細は,以下のコードを確認して下さい.
Logloss は,次のようになりました.
Local Public Private Baseline 0.01696 0.01921 0.01679 Mixup 0.01682 0.01910 0.01674 Cutmix 0.01681 0.01915 0.01676 Mixup, Cutmix 共に性能の向上を確認することができました.
終わりに
Cutmix は,テーブルデータに対しても有効な手法です.
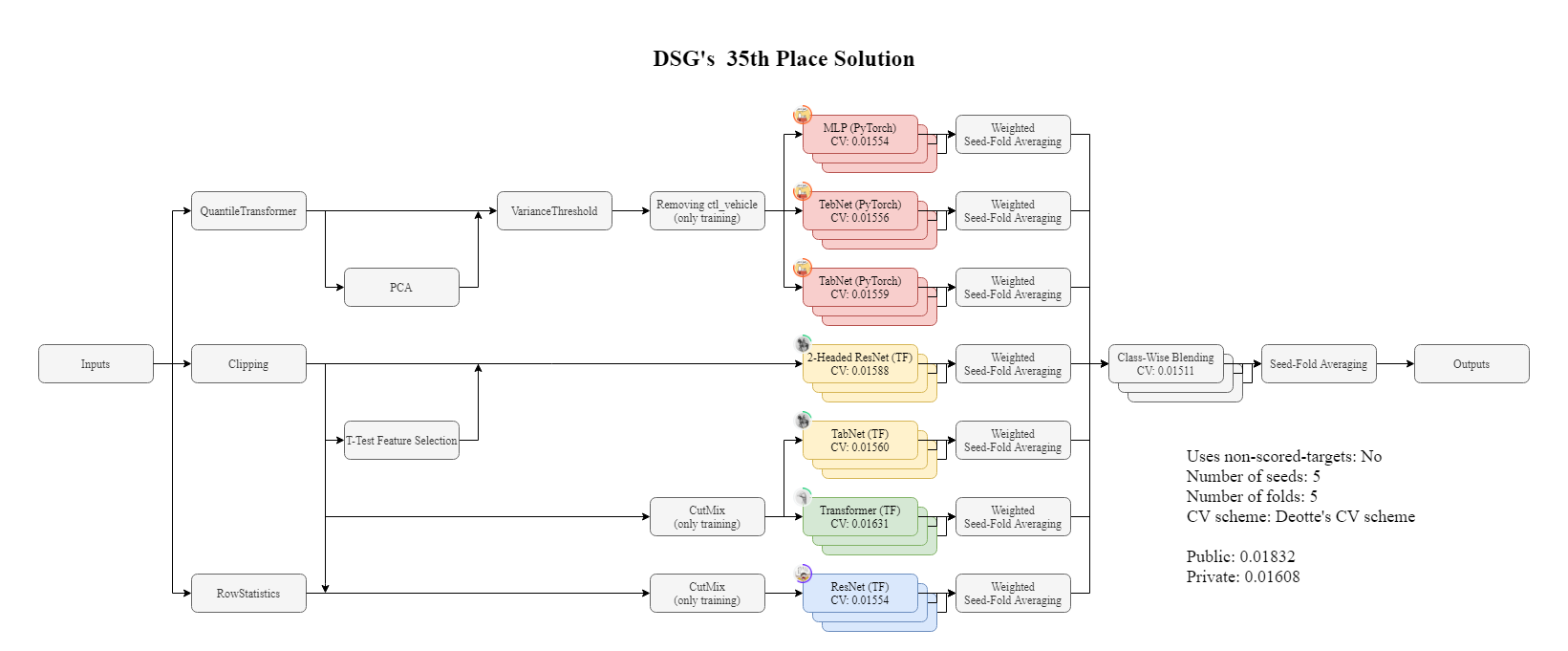
最後に,上記大会で Cutmix を用いて 35 位になった解法を公開しているので,興味のある方は,ご覧下さい.
Mechanisms of Action (MoA) Prediction | Kaggle
- 投稿日:2021-01-18T20:34:46+09:00
Range Requestsに対応したPythonの簡易HTTPサーバ
以下のコマンドでPythonに同梱されている簡易的なHTTPサーバを起動することができます。
$ python -m http.server 8080しかし、このHTTPサーバはRange Requestsに対応していません。動画の再生をローカルで試すには不都合でした。
似たことを指摘している人はほかにもいました。
- Safariで動画を表示する際、サーバーのHTTP Range Request対応が必須になっている - Qiita
- Pythonのhttp.serverはRange Requestに対応してなかった - Qiita (iOS Safariで動画が再生できない)
そこで、このHTTPサーバにRange Requestの機能を加えたPythonスクリプトを書きました。これによりChromeで動画のシークができるようになりました。
このスクリプトには以下の記事で書いた、ブラウザキャッシュを効かないようにするコードも含んでいます。ローカルでウェブアプリ開発するときに簡易的に便利に使えるHTTPサーバです。
Pythonスクリプト
import http.server import socketserver import os import re import urllib import sys def main(port): httpServer = ThreadingHTTPServer(('', port), RangeRequestNoCacheHTTPRequestHandler) httpServer.serve_forever() class ThreadingHTTPServer(socketserver.ThreadingMixIn, http.server.HTTPServer): pass RANGE_BYTES_RE = re.compile(r'bytes=(\d*)-(\d*)?\Z') class RangeRequestNoCacheHTTPRequestHandler(http.server.SimpleHTTPRequestHandler): # overriding def send_head(self): if 'Range' not in self.headers: self.range = None return super().send_head() try: self.range = self._parse_range_bytes(self.headers['Range']) except ValueError as e: self.send_error(416, 'Requested Range Not Satisfiable') return None start, end = self.range path = self.translate_path(self.path) if os.path.isdir(path): parts = urllib.parse.urlsplit(self.path) print(parts) if not parts.path.endswith('/'): self.send_response(301) new_parts = (parts[0], parts[1], parts[2] + '/', parts[3], parts[4]) new_url = urllib.parse.urlunsplit(new_parts) self.send_header("Location", new_url) self.end_headers() return None for index in "index.html", "index.htm": index = os.path.join(path, index) if os.path.exists(index): path = index break f = None try: f = open(path, 'rb') except IOError: self.send_error(404, 'Not Found') return None self.send_response(206) ctype = self.guess_type(path) self.send_header('Content-type', ctype) self.send_header('Accept-Ranges', 'bytes') fs = os.fstat(f.fileno()) file_len = fs[6] if start != None and start >= file_len: self.send_error(416, 'Requested Range Not Satisfiable') return None if end == None or end > file_len: end = file_len self.send_header('Content-Range', 'bytes %s-%s/%s' % (start, end - 1, file_len)) self.send_header('Content-Length', str(end - start)) self.send_header('Last-Modified', self.date_time_string(fs.st_mtime)) self.end_headers() return f def _parse_range_bytes(self, range_bytes): if range_bytes == '': return None, None m = RANGE_BYTES_RE.match(range_bytes) if not m: raise ValueError('Invalid byte range %s' % range_bytes) if m.group(1) == '': start = None else: start = int(m.group(1)) if m.group(2) == '': end = None else: end = int(m.group(2)) + 1 return start, end # overriding def end_headers(self): # ブラウザキャッシュを無効にするコード self.send_header('Cache-Control', 'max-age=0') self.send_header('Expires', '0') super().end_headers() # overriding def copyfile(self, source, outputfile): try: if not self.range: return super().copyfile(source, outputfile) start, end = self.range self._copy_range(source, outputfile, start, end) except BrokenPipeError: # ブラウザ上で動画をシークすると # ブラウザは動画ファイルのレスポンス受信を中断して # このエラーが発生してしまうので、 # これを無視する pass def _copy_range(self, infile, outfile, start, end): bufsize = 16 * 1024 if start != None: infile.seek(start) while True: size = bufsize if end != None: left = end - infile.tell() if left < size: size = left buf = infile.read(size) if not buf: break outfile.write(buf) port = int(sys.argv[1]) main(port)実行
以下のようなコマンドでこのスクリプトを起動すると、8080番ポートにアクセスできるようになります。
$ python server.py 8080
- 投稿日:2021-01-18T20:29:01+09:00
PDFのページを結合,すぐコピペシリーズ
PDFファイルの結合
PDFの結合をたまに使うので、すぐに使える状態で自分用に。
PyPDF2のpipインストールが必要。
以上。merge_pdf.pyimport PyPDF2 # 別々のpdfファイルを結合します def merge_pdf(pdf_files): merger = PyPDF2.PdfFileMerger() for pdf in pdf_files: merger.append(pdf) merger.write("merge.pdf") merger.close() if __name__ == "__main__": pdf_files = ["a.pdf","b.pdf"] merge_pdf(pdf_files)
- 投稿日:2021-01-18T20:28:34+09:00
[python]ライブラリramkanのインストールでエラーになる
ramkanはローマ字/仮名変換用のライブラリ。
インストールする際にエラーが起きたので忘備録。エラー内容
ramkanのインストール
$ pip3 install romkanするとこういうエラーが起きる。
Collecting romkan==0.2.1 Downloading romkan-0.2.1.tar.gz (10 kB) ERROR: Command errored out with exit status 1: command: /home/scaruadmin/venv/bin/python3 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-8y_m14tz/romkan_f9a5712add8043608044b16dab0fc01c/setup.py'"'"'; __file__='"'"'/tmp/pip-install-8y_m14tz/romkan_f9a5712add8043608044b16dab0fc01c/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-xw46by6f cwd: /tmp/pip-install-8y_m14tz/romkan_f9a5712add8043608044b16dab0fc01c/ Complete output (7 lines): Traceback (most recent call last): File "<string>", line 1, in <module> File "/tmp/pip-install-8y_m14tz/romkan_f9a5712add8043608044b16dab0fc01c/setup.py", line 12, in <module> README = open(os.path.join(here, 'README.rst')).read() File "/opt/rh/rh-python36/root/usr/lib64/python3.6/encodings/ascii.py", line 26, in decode return codecs.ascii_decode(input, self.errors)[0] UnicodeDecodeError: 'ascii' codec can't decode byte 0xe3 in position 181: ordinal not in range(128) ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.解決策
pythonの言語設定が問題っぽい。
$ sudo vim ~/.bashrcファイルに↓を追加して保存。
export LC_ALL=en_US.UTF-8bashの再起動
$source ~/.bashrcおしまい
参考
PythonのUnicodeDecodeErrorの対処方法 - Python入門
前提知識など
.bash_profileと.bashrcのまとめ - Qiita
よく使う Vim のコマンドまとめ - Qiita追記
Docker使ってる場合は、bashの設定じゃなくてdockerに言語設定してもいいかもしれない。
Docker: コンテナのlocaleを設定したい - Qiita
- 投稿日:2021-01-18T20:16:10+09:00
pythonで三重ループと条件分岐を一行で記述したい
はじめに
たかしくん問題を実装してるときに出会った知見メモ。
pulpを使うときに多重のfor文を一文で記述する必要があり勉強しました。
まだまだ記述の力不足を感じます。。。メモ
三重ループ
for x in range(4): for y in range(3): for z in range(2): print(x,y,z) >>0 0 0 >>0 0 1 >>0 1 0 >>0 1 1 >>0 2 0 >>0 2 1 ...は
[(x,y,z) for x in range(4) for y in range(3) for z in range(2)] >>[(0, 0, 0), >> (0, 0, 1), >> (0, 1, 0), >> (0, 1, 1), >> (0, 2, 0), >> (0, 2, 1), ...三重ループ+条件分岐1つ
for x in range(4): if x ==3: for y in range(3): for z in range(2): print(x,y,z) >>3 0 0 >>3 0 1 >>3 1 0 >>3 1 1 >>3 2 0 >>3 2 1は
[(x,y,z) for x in range(4) if x == 3 for y in range(3) for z in range(2)] >>[(3, 0, 0), (3, 0, 1), (3, 1, 0), (3, 1, 1), (3, 2, 0), (3, 2, 1)]三重ループ+条件分岐2つ
for x in range(4): if x ==3: for y in range(3): for z in range(2): if z == 1: print(x,y,z) >>3 0 1 >>3 1 1 >>3 2 1は
[(x,y,z) for x in range(4) if x == 3 for y in range(3) for z in range(2) if z == 1] >>[(3, 0, 1), (3, 1, 1), (3, 2, 1)]さいごに
for文が回る順序がややこしいね
- 投稿日:2021-01-18T20:08:01+09:00
【Python】matplotlibでfont familyとfont
- 投稿日:2021-01-18T19:54:48+09:00
pythonistaでScroll Viewの実装方法
はじめに
地図をスクロールしながら見ている時の様に、
大きな画像の一部を画面に表示して、スクロールさせる。
これは uiライブラリのscroll View を、使用すれば実装できます。環境
ios + pythonista3
使用ライブラリ
ui ライブラリのviewを使用します。
import ui
pythonistaのドキュメントは、それなりに丁寧に記載されているので 初心者でもある程度
分かります。
英語が優しいのか、自動翻訳様のお力を全面的にお借りしている身でも なんとか理解できました。とりあえず実装してみる
scrollview_image.py#! python3 # # 20210118 ver001 scrollviewに大きな画像を見て表示してスクロールを実装。 # import ui #scrllviewやimageviewを表示するライブラリ class epaint(ui.View): def __init__(self): w,h = ui.get_screen_size()#uiライブラリのメソッド。画面のサイズを取得して、w、hに代入。 #スロールする元の大きなが画像のViewを作成する。この段階では何も表示されない。 self.bv = ui.ImageView()#bvってオブジェクトは、ui.ImageViewだよって宣言して作成した。 self.bv.frame = (0, 0, 3264,2448)#ImageViewの枠サイズを宣言。中に入る画像はこのサイズに延ばされる。 # ちなみに、frameの行は無くても可。無い場合は元の画像サイズでViewが作成される。 self.bv.image = ui.Image.named('test:Peppers')#テスト画像を呼び出して表示(pythonista3内包) self.bv.bg_color = 'red'#背景色を設定。無くても可。 #ScrollViewを作成。スクロールビューは、画面に表示する枠と理解する。 self.sv = ui.ScrollView()#svってオブジェクトは、ui.ScrollViewだよって宣言。 self.sv.width = w*0.8#画面の8割の幅に表示枠を設定。 self.sv.height = h*0.75#画面の75%の高さに枠を設定。 self.sv.content_size = (3500,2500)#ScrollViewの元画像を入れる枠のサイズを設定する。 #中に入れるViewのサイズと同じか大きくする。左上に配置される。ImageViewと違って引き延ばされない。 self.sv.scroll_enabld = False # スクロールがTrue有効・False無効。デフォルトTrue self.sv.add_subview(self.bv)#svにbvを入れる事で ScrollViewの元が画像をcontentsに代入した。 self.add_subview(self.sv)#selfにsvを入れる事で表示させるViewはsvと宣言した。 v = epaint() # クラスを変数に代入。インスタンス化。 v.present('fullscreen')#フルスクリーンでui表示する。説明
スクロールビューもイメージビューもuiライブラリのViewオブジェクトの一種。
viewオブジェクトは、レタッチソフトとかのレイヤみたいなイメージです。
(ちゃんと順番もあります。)ここが難しいところですが、ScrollViewの元画像は Viewなら何でもOK。
イメージ意外にButtonも配置できます。何個でも配置できます。
ScrollViewのcontentsで元画像の枠のサイズを決めて、ScrollViewを作成してから
Viewを代入するとcontentsの所に配置されます。
配置座標を指定しないと原点の左上になります。
(座標指定の仕方も、そのうちアップします)uiライブラリの座標系は 左上が(0,0)x方向は右方向に増加しますが、
y方向は下が増加方向です。普通の座標系とちょっと違うので 最初は戸惑うかも。最後に、Viewは宣言しただけでは、表示されないのでaddで表示しています。
注意点
・uiオブジェクトの座標系は、左上が原点で右下に向かって増加する。
・Viewには順番がある。タッチイベントの競合。
これは、ScrollView以外にもタッチイベントを使うViewが混在すると
一番上のタッチイベントを使うViewだけが タッチイベントを受け取ります。
具体的には 手書きのパスを取得するviewとScrollViewを両方同時には
使えない。
・Viewには順番がある。順番を入れ替えるメソッドもある。これを利用して
画面を切り替える事もできます。
・元画像のcontentsには 画像の他にボタンとかも入れられます。
ボタンを入れると 画面に入りきらないボタンをスクロールして、押す様な
uiを作る事が出来ます。最後に
最終的に 拙記事「写真を読み込んで手書きスケッチ。zoom機能付。作ってみた。」の
機能を分解して 紹介していこうと思います。
このツールを作っていて pythonistaでScrollViewについての記事が無くて
本当に苦労したので 最初に紹介しました。
内容的には swiftとかと一緒だったようで、イメージを理解するには
そちらの記事も参考なると思います。
- 投稿日:2021-01-18T19:54:48+09:00
pythonistaでScroll Viewの実装方法1
はじめに
地図をスクロールしながら見ている時の様に、
大きな画像の一部を画面に表示して、スクロールさせる。
これは uiライブラリのscroll View を、使用すれば実装できます。環境
ios + pythonista3
使用ライブラリ
ui ライブラリのviewを使用します。
import ui
pythonistaのドキュメントは、それなりに丁寧に記載されているので 初心者でもある程度
分かります。
英語が優しいのか、自動翻訳様のお力を全面的にお借りしている身でも なんとか理解できました。とりあえず実装してみる
scrollview_image.py#! python3 # # 20210118 ver001 scrollviewに大きな画像を見て表示してスクロールを実装。 # import ui #scrllviewやimageviewを表示するライブラリ class epaint(ui.View): def __init__(self): w,h = ui.get_screen_size()#uiライブラリのメソッド。画面のサイズを取得して、w、hに代入。 #スロールする元の大きなが画像のViewを作成する。この段階では何も表示されない。 self.bv = ui.ImageView()#bvってオブジェクトは、ui.ImageViewだよって宣言して作成した。 self.bv.frame = (0, 0, 3264,2448)#ImageViewの枠サイズを宣言。中に入る画像はこのサイズに延ばされる。 # ちなみに、frameの行は無くても可。無い場合は元の画像サイズでViewが作成される。 self.bv.image = ui.Image.named('test:Peppers')#テスト画像を呼び出して表示(pythonista3内包) self.bv.bg_color = 'red'#背景色を設定。無くても可。 #ScrollViewを作成。スクロールビューは、画面に表示する枠と理解する。 self.sv = ui.ScrollView()#svってオブジェクトは、ui.ScrollViewだよって宣言。 self.sv.width = w*0.8#画面の8割の幅に表示枠を設定。 self.sv.height = h*0.75#画面の75%の高さに枠を設定。 self.sv.content_size = (3500,2500)#ScrollViewの元画像を入れる枠のサイズを設定する。 #中に入れるViewのサイズと同じか大きくする。左上に配置される。ImageViewと違って引き延ばされない。 self.sv.scroll_enabld = False # スクロールがTrue有効・False無効。デフォルトTrue self.sv.add_subview(self.bv)#svにbvを入れる事で ScrollViewの元が画像をcontentsに代入した。 self.add_subview(self.sv)#selfにsvを入れる事で表示させるViewはsvと宣言した。 v = epaint() # クラスを変数に代入。インスタンス化。 v.present('fullscreen')#フルスクリーンでui表示する。説明
スクロールビューもイメージビューもuiライブラリのViewオブジェクトの一種。
viewオブジェクトは、レタッチソフトとかのレイヤみたいなイメージです。
(ちゃんと順番もあります。)ここが難しいところですが、ScrollViewの元画像は Viewなら何でもOK。
イメージ意外にButtonも配置できます。何個でも配置できます。
ScrollViewのcontentsで元画像の枠のサイズを決めて、ScrollViewを作成してから
Viewを代入するとcontentsの所に配置されます。
配置座標を指定しないと原点の左上になります。
(座標指定の仕方も、そのうちアップします)uiライブラリの座標系は 左上が(0,0)x方向は右方向に増加しますが、
y方向は下が増加方向です。普通の座標系とちょっと違うので 最初は戸惑うかも。最後に、Viewは宣言しただけでは、表示されないのでaddで表示しています。
注意点
・uiオブジェクトの座標系は、左上が原点で右下に向かって増加する。
・Viewには順番がある。タッチイベントの競合。
これは、ScrollView以外にもタッチイベントを使うViewが混在すると
一番上のタッチイベントを使うViewだけが タッチイベントを受け取ります。
具体的には 手書きのパスを取得するviewとScrollViewを両方同時には
使えない。
・Viewには順番がある。順番を入れ替えるメソッドもある。これを利用して
画面を切り替える事もできます。
・元画像のcontentsには 画像の他にボタンとかも入れられます。
ボタンを入れると 画面に入りきらないボタンをスクロールして、押す様な
uiを作る事が出来ます。最後に
最終的に 拙記事「写真を読み込んで手書きスケッチ。zoom機能付。作ってみた。」の
機能を分解して 紹介していこうと思います。
このツールを作っていて pythonistaでScrollViewについての記事が無くて
本当に苦労したので 最初に紹介しました。
内容的には swiftとかと一緒だったようで、イメージを理解するには
そちらの記事も参考なると思います。
- 投稿日:2021-01-18T19:44:35+09:00
[Python] 前処理の小技
サンプルデータ作成
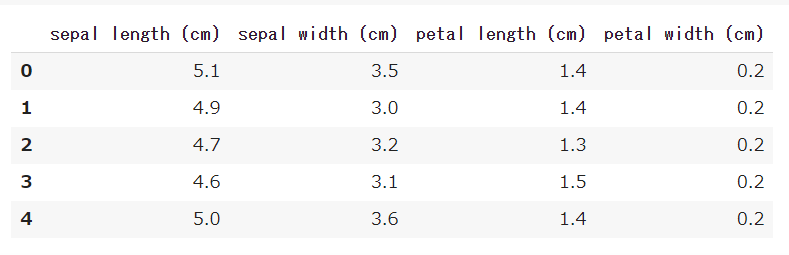
irisデータからDataFrameを作成
import pandas as pd from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names)
辞書からDataFrameを作成
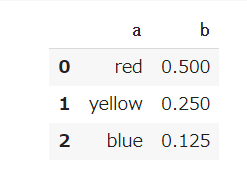
import pandas as pd input = {'a': ['red', 'yellow', 'blue'], 'b': [0.5, 0.25, 0.125]} df = pd.DataFrame(input)
データ読み込み
import pandas as pd # エクセル df = pd.read_excel('ファイル名.xlsx') # CSV df = pd.read_csv('zenkoku.csv', low_memory=False)データ確認
統計量
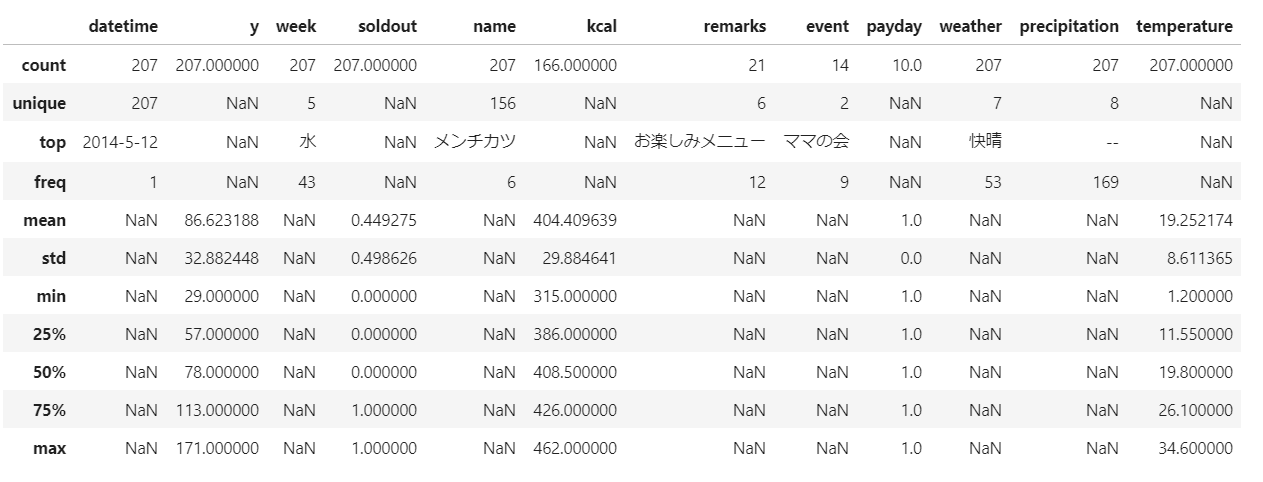
train.describe(include='all')
ペアプロット
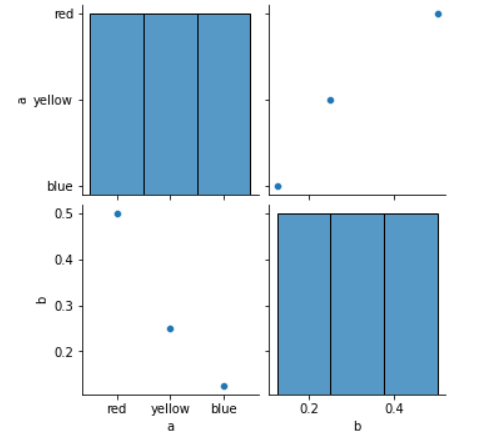
import seaborn as sns sns.pairplot(df, vars=df.columns, hue="target")
nullチェック
df.isnull().sum()
各列のUnique数(Distinct)
df.nunique()
頻度
df.value_counts()
ヒストグラム
df3['列名'].plot.hist(bins=40)
ソート
# index順 df.sort_index()データ加工
One Hot Encoding
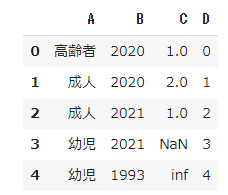
import pandas as pd import numpy as np df = pd.DataFrame({'A': ['高齢者', '成人', '成人', "幼児", "幼児"], 'B': [2020,2020,2021,2021,1993], 'C': [1.0, 2.0, 1.0, np.nan, np.inf], "D":[0,1,2,3,4]})
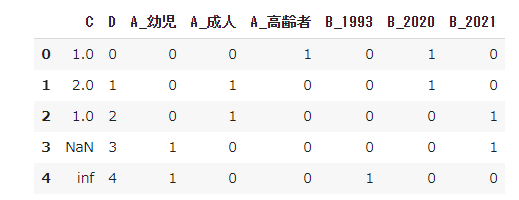
pd.get_dummies(df, columns=["A", "B"])
# OneHot化 df = pd.get_dummies(df, columns=["列名"], drop_first=True) # 条件に当てはまる行のみ取得 df = df[df['列名'] == 値] # 「カレー」というワードを含むnameを1、含まないnameを0にラベルづけ train['curry'] = train['name'].apply(lambda x : 1 if x.find("カレー") >=0 else 0)DataFrameの扱い
# Dataframeを縦に結合 pd.concat([df1, df2, df3], axis=0, ignore_index=True) # Dataframeを横に結合 pd.concat([df1, df2, df3], axis=1)列の扱い
# 列名変更 df = df.rename(columns={'変更前':'変更後'}) # 列追加 df = df.assign('列名'='値') # 列削除 df = df.drop('列名', axis=1)NULL(NaN)の扱い
# 一つでもNULLを含む行を削除 df = df.dropna(how='any') # NULLを置換 df = df.fillna({'列名': 値})One Hot Decode
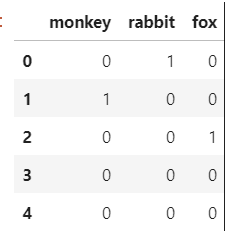
animals = pd.DataFrame({"monkey":[0,1,0,0,0],"rabbit":[1,0,0,0,0],"fox":[0,0,1,0,0]})
def get_animal(row): for c in animals.columns: if row[c]==1: return c animals.apply(get_animal, axis=1)
出力
# csv出力 df.to_csv('ファイル名.csv', index=False)参考
- https://qiita.com/ao_log/items/fe9bd42fd249c2a7ee7a
- https://qiita.com/chusan/items/d7b210243f3b646375ba
- https://stackoverflow.com/questions/38334296/reversing-one-hot-encoding-in-pandas/38334528
- One-HotエンコーディングならPandasのget_dummiesを使おう | Shikoan's ML Blog
- https://www.renom.jp/ja/notebooks/tutorial/preprocessing/category_encoding/notebook.html
- https://qiita.com/uratatsu/items/8bedbf91e22f90b6e64b



- 投稿日:2021-01-18T19:40:23+09:00
matplotlibのspecgramの謎を解明する
研究でmatplotlibのspecgramと格闘したときに得た知識をここに残しておこうと思います。
主に次のトピックについてです。
- どうしてグラフの周波数の上限が周波数サンプルの半分になるのか
- 周波数サンプルとデータの長さが一致しないとどうなるのか
- どうして返される周波数データの長さは129なのか
基本的な変数については次のqiita記事がすごく参考になると思います。
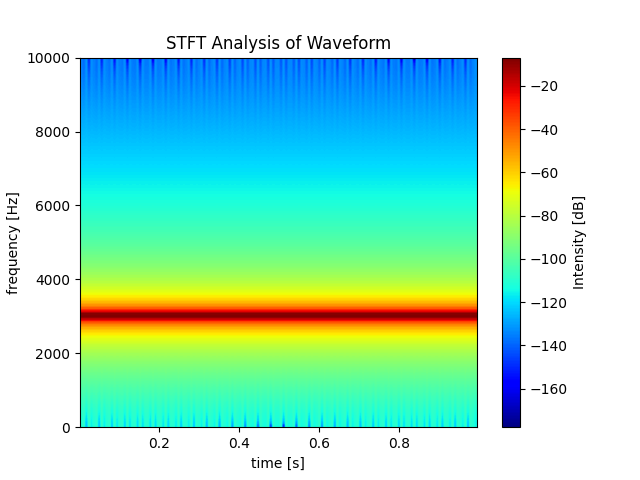
matplotlibのspecgramまずはダミーデータで可視化
まずはダミーデータで試してみましょう。以下では周波数3000のサイン波を可視化しています。サイン波のデータの長さは20000としており、1秒間でこのデータが観測されたということにしています。
import matplotlib.pyplot as plt import numpy as np # freq_sampleの単位はHz freq_sample = 20000 # データの長さとfreq_sampleの関係を把握していることが重要 x = np.linspace(0, 2*np.pi, freq_sample) sin_signal = np.sin(3000*x) fs = freq_sample amplitude = 1 data = amplitude * sin_signal list_data = data.tolist() Pxx, freqs, bins, im = plt.specgram(list_data, Fs=fs, cmap = 'jet', mode='magnitude') x1, x2, y1, y2 = plt.axis() plt.axis((x1, x2, y1, y2)) plt.xlabel("time [s]") plt.ylabel("frequency [Hz]") plt.colorbar(im).set_label('Intensity [dB]') plt.title(f"STFT Analysis of Waveform") plt.show()当たり前ですが、周波数3000のところで赤くなっていますね。
どうしてグラフの周波数の上限が周波数サンプルの半分になるのか
コードでは
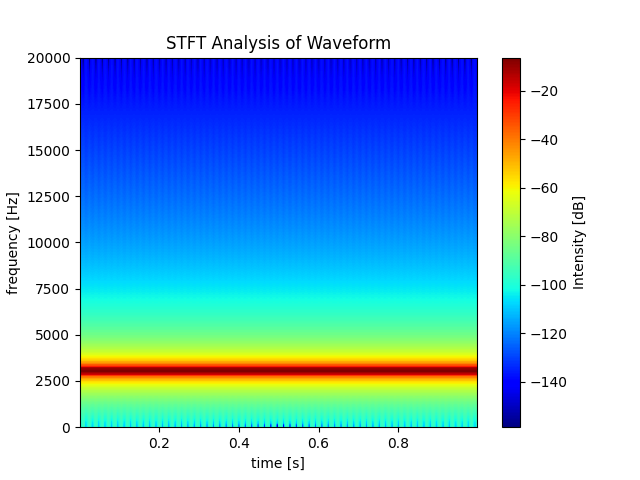
frequency_sampleは20000Hzにしてあるのに、グラフではy軸の上限は10000Hzとなっています。これはspecgramにおいてはサンプルは0が下限で、サンプル周波数の半分が上限ということが決まっているようです。この周波数の上限のほうをナイキスト周波数(Nyquist frequency)と呼ぶらしいです。試しにfreq_sampleを40000にすると、たしかに上限が半分の20000になっています。
freq_sample = 40000 x = np.linspace(0, 2*np.pi, freq_sample) sin_signal = np.sin(3000*x)
参考になったのは以下のstackoverflowでした。
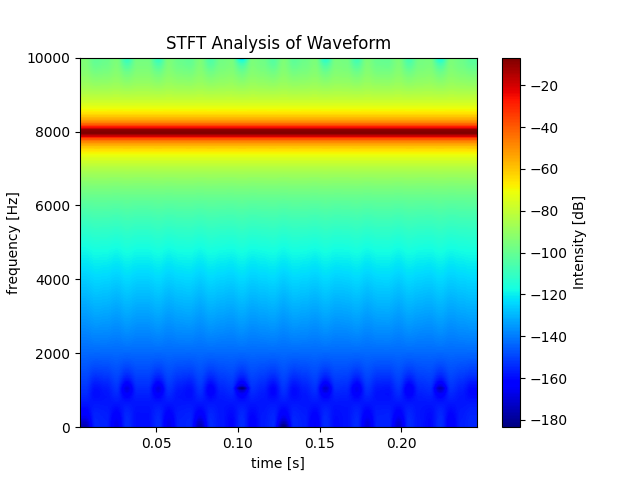
周波数サンプルとデータの長さが一致しないとどうなるのか
周波数サンプル > データの長さ:周波数が大きくなり、時間が短くなる
周波数サンプルは20000のまま、データの長さを5000にするとどうなるでしょうか。
freq_sample = 20000 x = np.linspace(0, 2*np.pi, 5000) sin_signal = np.sin(3000*x)8000Hzのところが赤くなってしまいました。sin関数は変わっていないのですが、サンプルが変わってしまったため周波数が大きくなってしまっています。さらに、時間単位のx軸にも注目すると、さっきは1秒間だったものが0.25秒に縮まっています。
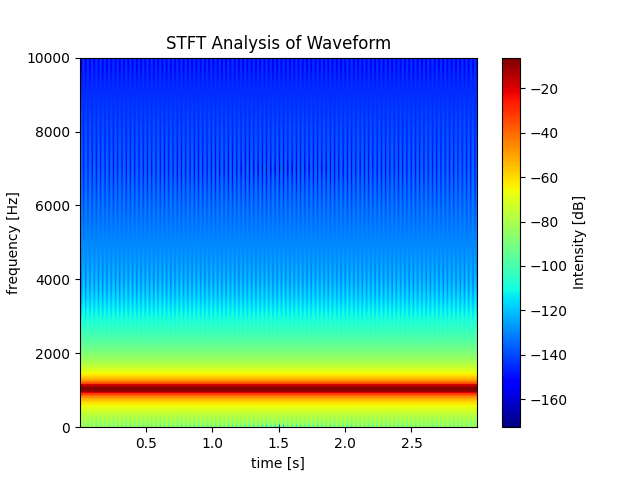
周波数サンプル < データの長さ:周波数が小さくなり、時間が長くなる
データの長さを逆に60000とかにするとどうなるでしょうか。
freq_sample = 20000 x = np.linspace(0, 2*np.pi, 60000) sin_signal = np.sin(3000*x)
今度は1000Hzあたりになってしまいました。さらに、時間軸も3.0秒に伸びます。
どうして返される周波数データの長さは129なのか
Pxx, freqs, bins, im = plt.specgram(lstrip, Fs=fs, cmap = 'jet', mode='magnitude') print("freqs:") print(freqs.shape) print("Pxx") print(Pxx.shape) >> output: freqs: (129,) Pxx (129, 311)これは離散フーリエ変換を行うときのサンプル数が固定で
256になっており、オーバーラップするのが128個になることから256 // 2 + 1 = 129となるそうです。129は中途半端な数字ですし、変えられないのがちょっと面倒ですね、、、
参考になったのは以下のstackoverflowです。
Python - How to save spectrogram output in a text file?
結論
グラフを作るのにおいて単位はすごく大事になってくると思うので、周波数サンプルとデータの長さの関係についてはしっかり考慮する必要があります。
- 投稿日:2021-01-18T19:20:11+09:00
python xlwings: 最終行のセルを求める
pythonのxlwingsで特定の列から要素のある最終行の値を取得・代入する方法です。
途中要素のない行が挟まっても求められます。Book1.xlsx
行/列 A B C 1 品名 数 2 りんご 2 3 4 みかん 0 5 いちご 5 参考
xlwings.Range 簡易リファレンス
xlwings function to find the last row with data (stackoverrun)
- 投稿日:2021-01-18T18:43:29+09:00
数学は共通テストをグラフで。
実行環境
- Mac OS Catanalina
- バージョン 10.15.6
- 言語 : Python
- Spyder
きっかけ
グラフとPythonを使って身近なものに触れたかった。
実際にやってみる
数学Ⅱ・数学B 大1問〔1〕(1)問題A
問題
関数 y = sin θ+√3 cos(θ) (0 <= θ <= π/2)の最大値を求めよ。matplotlibの基本的なグラフ設定を列挙〜散布図と連続曲線〜
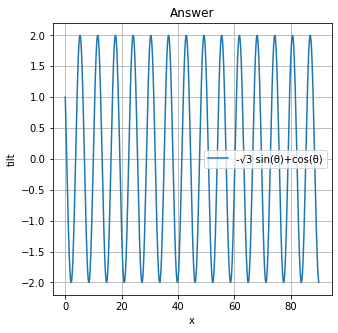
を参考にして、考えます。ここでは、問題通りに考えるのではなく、微分を利用してグラフにして考えようと思います。sin x+√{3}*cos(x)を微分すると......import sympy x = sympy.Symbol('x') print(sympy.diff(sympy.sin(x)+sympy.sqrt(3)*sympy.cos(x)))本当はθなのですが、ここでは、次にグラフにしたいため、xにしています。
出力結果
-sqrt(3)*sin(x) + cos(x)数学らしく書くと、
-√{3} *sin(x)+cos(x)です。
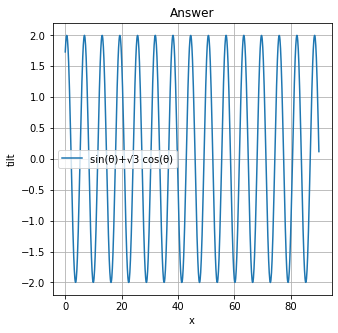
プログラムimport matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 90, 900) y = -np.sqrt(3)*np.sin(x)+np.cos(x) # グラフの大きさ指定 plt.figure(figsize=(5, 5)) # グラフの描写 plt.plot(x, y, '-', label='-√3 sin(θ)+cos(θ)') # plt.plot(x, y, label='first', linestyle='-') # でも同じ plt.title('Answer') # タイトル plt.xlabel('x') # x軸のラベル plt.ylabel('tilt') # y軸のラベル plt.grid(True) # gridの表示 plt.legend()上のプログラムを実行すると、こんな感じになるはずです。明らかに極地が多いですね。では、元の問題のグラフを書きましょう(方向転換)。
下のプログラムを実行した結果です。import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 90, 900) y = np.sqrt(3)*np.cos(x)+np.sin(x) # グラフの大きさ指定 plt.figure(figsize=(5, 5)) # グラフの描写 plt.plot(x, y, '-', label='sin(θ)+√3 cos(θ)') # plt.plot(x, y, label='first', linestyle='-') # でも同じ plt.title('Answer') # タイトル plt.xlabel('x') # x軸のラベル plt.ylabel('tilt') # y軸のラベル plt.grid(True) # gridの表示 plt.legend()答えは見た目で2という感じがします。(実際、答えもそうです。)少し最後が感覚的(曖昧)になってしまいましたが、答えをグラフ・Pythonで得られました。
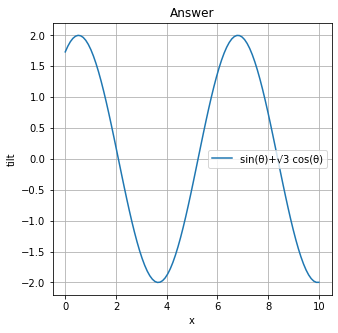
拡大版
こんな感じです。
```
プログラムimport matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 10, 100) y = np.sqrt(3)*np.cos(x)+np.sin(x) # グラフの大きさ指定 plt.figure(figsize=(5, 5)) # グラフの描写 plt.plot(x, y, '-', label='sin(θ)+√3 cos(θ)') # plt.plot(x, y, label='first', linestyle='-') # でも同じ plt.title('Answer') # タイトル plt.xlabel('x') # x軸のラベル plt.ylabel('tilt') # y軸のラベル plt.grid(True) # gridの表示 plt.legend()参考文献
- 投稿日:2021-01-18T18:29:03+09:00
[Python/tkinter] GUIに結びついている変数を整理する
※個人用
概要
tkinterはPythonで簡易的にGUIを作るのに都合が良いライブラリであるが、GUIごとにソースコードが必要で、全体的に冗長で、コーディング中に何をしているか忘れることがある。
変数と結合している部分をまとめて、フォーム全体で管理するフィールドの数を減らすことで、それを対処したい。
適用範囲
デザインテーマを一律にかけられるよう、tkinter.ttkの部品のみを使用するものとする。
(対象部品:ttk.Entry, ttk.Combobox, ttk.Radiobutton, ttk.Checkbox)ソースコード
簡単なコードです。
DataBindings.pyimport tkinter as tk import tkinter.ttk as ttk from tkinter import (StringVar) class DataBindings: def __init__(self): # GUI用の連想配列を定義する self._dict_params = {} def register_entry(self, source, default): # Entry:文字列の場合。 # テキストボックス(Entry)のほか、それを親として継承しているComboboxにも適用が出来る。 self._dict_params[source] = StringVar() self._dict_params[source].set(default) source.configure(textvariable=self._dict_params[source]) def register_radiobutton(self, parent, child): # Radiobutton:ラジオボタンの場合。 # ラジオボタンは、親に該当するttk.Frameなどの部品と連動して配置されるので、 # 一律性を保つため、連想配列にはttk.Frameを登録する。 if parent not in self._dict_params: self._dict_params[parent] = StringVar() self._dict_params[parent].set(child['value']) child.configure(variable=self._dict_params[parent]) def register_checkbox(self, source): # Checkbox:チェックボックスの場合。 self._dict_params[source] = StringVar() self._dict_params[source].set('False') source.configure(variable=self._dict_params[source]) def value(self, source): # 値を取り出す return self.get_variable(source).get_variable(source).get() def variable(self, source): # 変数を取り出す actual_source = source if isinstance(source, ttk.Radiobutton): actual_source = source.master return self._dict_params[actual_source]コード例# import, 各種宣言, Tk.tk()などは省略 # self._bindings_setting = DataBindings() # テキストボックスの設定 self._ui_category_label = ttk.Entry(frame) self._ui_category_label.pack() self._bindings_setting.register_entry(self._ui_category_label, '合格-A') # 変数取得、値取得 variable_entry = self._bindings_setting.variable(self._ui_category_label) value_entry = self._bindings_setting.value(self._ui_category_label) # コンボボックスの設定 self._ui_category_type = ttk.Combobox(frame, width=10, values=['合格', '不合格'], state='readonly', justify='left') self._ui_category_type.pack() self._bindings_setting.register_entry(self._ui_category_type, '合格') # 変数取得、値取得 variable_combobox = self._bindings_setting.variable(self._ui_category_type) value_combobox = self._bindings_setting.value(self._ui_category_type)ちなみに、同じ内容をヘルパークラスなしでやると、次のような感じとなり、コードの行数は減るものの、フィールドの数が増えるので、(個人的には)少し管理が面倒に感じます。
コード例(ヘルパークラスなし)# import, 各種宣言, Tk.tk()などは省略 # # テキストボックスの設定 self._ui_category_label = ttk.Entry(frame) self._ui_category_label.pack() self._text_textbox = StringVar() # self._text_textbox(値)を管理する必要が出てくる self._text_textbox.set('合格-A') self._bindings_setting.register_entry(self._ui_category_label, textvariable=self._text_textbox) # 変数取得はself._text_textbox、値取得はself._text_textbox.get()で行う # コンボボックスの設定 self._ui_category_type = ttk.Combobox(frame, width=10, values=['合格', '不合格'], state='readonly', justify='left') self._ui_category_type.pack() self._text_combobox = StringVar() # self._text_combobox(値)を管理する必要が出てくる self._text_combobox.set('合格-A') self._bindings_setting.register_entry(self._ui_category_type, '合格', textvariable=self._text_combobox) # 変数取得はself._text_combobox、値取得はself._text_combobox.get()で行う
- 投稿日:2021-01-18T17:58:28+09:00
VSCode+Pythonでmicro:bitを触ってみる
micro:bitのプログラムをVSCodeとPythonで書いてみたメモです。
ビジュアルプログラミング環境で作れるのがmicro:bitの特長であって、わざわざPythonで書きたい人がいるかは怪しいですが...。
使用環境はこんな感じ。
- MacOS Catalina 10.15.7
- VSCode 1.52.1
- Python 3.9.0
VSCodeにはPythonの拡張機能がすでに入っている前提での解説です。
1. uflashのインストール
micro:bitにPythonプログラムを書き込むためのツールです。
$ pip install uflashこのあと導入するVSCodeの拡張機能が"uflash"コマンドを使用するようなので、ちゃんと使えるか確認しておきます。
$ uflash --version uflash 1.3.0バージョンが出ればOKです。
2. VSCode拡張機能のインストール
micro:bitに対応した拡張機能をVSCodeに入れます。
拡張機能の検索欄で「micro:bit」と検索し、↓の拡張機能をインストールします。
インストールしたあとは一応VSCodeを再起動しておきましょう。
これで環境の構築は完了です。3. Pythonファイルの作成
適当な場所に新しいディレクトリを作成し、その中にPythonファイルを作成します。
ここではディレクトリ名を「microbit」、Pythonファイル名を「main.py」としました。
作成したディレクトリをVSCodeにドラック&ドロップし、VSCode上でPythonファイルを開きます。
拡張機能がうまく入っていれば右上に「Build current file to Micro:Bit」というボタンが出てきます。それではmicro:bit用のコードを書いてみます。
from microbit import * while True: if button_a.is_pressed(): display.show(Image.HAPPY) else: display.show(Image.ANGRY)4. 補完が効かない問題
ここまででも最低限micro:bitへ書き込みができるのですが、まだVSCode上でmicro:bit用の関数に赤線が出てくる上に補完も効きません。
補完を働かせるにはVSCodeのコマンドパレット(Cmd+Shift+P)を開き、以下のコマンドを実行します。Fetch micro:bit modulesコマンド実行直後はまだ赤線が消えませんがソースファイルを一度保存すると反映されて赤線が消えます。
5. micro:bitへの書き込み
micro:bitをPCに接続し、「Build current file to Micro:Bit」ボタンを押すとmicro:bit本体のオレンジ色LEDが点滅し始め、点滅が終わると書き込み完了です。
書き込み完了後、本体のAボタンを押したり離したりすると5×5LEDマトリクスに表示される顔の表情が変わります。余談
micro:bitは単体でもLED/ボタン/センサが内蔵されていて、複数台揃えれば無線通信も可能なので工夫次第で面白いものが作れそうです。
大学の学祭で体験会をやったことがありますが、ビジュアルプログラミング環境MakeCodeを使えばプログラミング未経験の小学生でも楽しく使うことができる印象でした。
Pythonを使う場合でも日本語のドキュメントがしっかりしているので比較的始めやすいのではないでしょうか。
だいたいの子供向けプログラミング教材が1万円以上することを考えると、本体だけなら3000円前後で買える上にビジュアル開発環境もテキスト開発環境もサポートしているmicro:bitは有力な選択肢になりそうです。参考文献
- uflash - PyPI
https://pypi.org/project/uflash/- micro:bit - Visual Studio Marketplace
https://marketplace.visualstudio.com/items?itemName=PhonicCanine.micro-bit- BBC micro:bit MicroPython ドキュメンテーション
https://microbit-micropython.readthedocs.io/ja/latest/
- 投稿日:2021-01-18T17:10:21+09:00
君たちに問う!君たちはプログラマか!!
まず最初に規約違反よけのため、Pythonの小話を一つ。
デコレータはただのシンタックスシュガーです。なのでdef printer(f): def decorator(*args, **kwargs): return f(*args, **kwargs) return decorator def add(x, y): return x + y """ printer(add)(1, 2) # print(3)される ↑ @printer def add(x, y): return x + y と同等 """ここまで小ネタ
以下
main()あなたの属性に興味がありません
- 「元引き込もりが」
- 「文系が」
- 「JKが」
- 「プログラミング初心者が」
これらのタイトル・見出しは多くの場合不要です。あなたの年齢・性別・学歴・出身・その他の属性によってプログラムの動作が変わるなら別ですが。(参照透過性)
noteと間違えていませんか?
あなたやあなたの周りで起きた話には関心がありません。私が関心を持っているのはプログラミング言語やソフトウェアアーキテクチャ、その他の技術です。(特に新しい技術!)
ノートと間違えていませんか?
Qiitaはあなたのノートではありません。
「Python学習 2日目」なんてタイトルの記事を見たくはありません。
ただし、技術を学習する過程で躓いた箇所や、得た知見などはぜひ共有してください!魅力的なタイトルもお忘れなく。
- 投稿日:2021-01-18T15:58:27+09:00
【メモ】多品種輸送問題(あたらしい数理最適化)を実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はあたらしい数理最適化の書籍を買ったので、実務で使えそうな部分をアレンジして実装してみました。
はじめに
業務で最適化を使う機会が増えたので、「あたらしい数理最適化」という書籍を購入したので、実務で使えるように勉強中です。
詳細を載せると問題があるかもしれないので、詳しい内容を知りたい方は書籍を購入してください。多品種輸送問題の実装
今回は複数の製品を運ぶための輸送問題を実装しました。使用したライブラリーはmypulpを使いました。書籍ではgurobiが使われているのですが、有料のため無料で使えるmypulpを選定しました。
pythonで数理最適化を実装する際は、pulpが良く使われると思いますが、gurobiと書き方が少し違うので、gurobiと同じような書き方で実装できるmypulpを選定しております。また実務で使う際は、制約条件とかのデータをcsvで読み込ませて使うことが多いと思いましたので、一部改変しております。
pythonの実装コードは下記です。
# 必要なライブラリーを読み込む import pandas as pd from mypulp import *次に多品種輸送問題を解くためのコードを書いていきます。
下記では、制約条件や目的関数を記載しております。def mctransp(I, J, K, c, d, M): """多品種輸送問題 Arg: I(set) : 顧客番号 J(list) : 工場番号 K(list) : 製品番号 c(dict) : Key:(顧客番号,工場番号,製品番号), Value:輸送費 d(dict) : Key:(顧客番号,製品番号), Value:需要量 M(dict) : Key:工場番号, Value:生産容量 Returns: a model, ready to be solved. """ # モデルの定義 model = Model(name = "Multi-product_transportation_problem") # 変数を格納する辞書xを作成 # 変数は輸送費用を表す辞書cのキーが存在する場合にだけ生成 x = {} for i,j,k in c: x[i,j,k] = model.addVar(vtype="C") model.update() arcs = tuplelist([(i,j,k) for (i,j,k) in x]) # 顧客の需要制約 for i in I: for k in K: model.addConstr(quicksum(x[i,j,k] for (i,j,k) in arcs.select(i,"*",k)) == d[i,k]) # 工場の容量制約 for j in J: model.addConstr(quicksum(x[i,j,k] for (i,j,k) in arcs.select("*",j,"*")) <= M[j]) # 目的関数 model.setObjective(quicksum(c[i,j,k]*x[i,j,k] for (i,j,k) in x), GRB.MINIMIZE) model.update() model.__data = x return model次は各条件を取得するための関数です。
書籍では、ハードコーディングされていたのですが、csvファイルから読み込む方式へ変更した方が使いやすいと思って少しアレンジしております。def get_data(): """インプットデータ取得 Return: I(set) : 顧客番号 J(list) : 工場番号 K(list) : 製品番号 c(dict) : Key:(顧客番号,工場番号,製品番号), Value:輸送費 d(dict) : Key:(顧客番号,製品番号), Value:需要量 M(dict) : Key:工場番号, Value:生産容量 """ # 工場で製造可能な製品を抽出 df_p = pd.read_csv('constraints/Multi-product_transportation_problem/produce.csv') # DataFrameをdictへ変換 produce = df_p.set_index('factory').T.to_dict('list') # Nanを削除 for key in produce.keys(): produce[key] = {x for x in produce[key] if x==x} # 顧客と商品の需要量を抽出 df_d = pd.read_csv('constraints/Multi-product_transportation_problem/demand.csv') # 顧客番号と製品番号のタプル(組)を作成 D = list(zip(df_d[df_d.columns[0]], df_d[df_d.columns[1]])) # 顧客番号と製品番号のタプル(組)をキーとし、需要量を値とする辞書を作成 d = dict(zip(D, df_d[df_d.columns[2]])) # 顧客番号Iを生成 I = set([i for (i,k) in d]) # 工場の番号リストJと生産容量Mをmultidictを用いて作成 J, M = multidict({1:3000, 2:3000, 3:3000}) # 製品番号リストKと重量weightをmultidictを用いて作成 K, weight = multidict({1:5, 2:2, 3:3, 4:4}) # 顧客と商品の輸送費用を抽出 df_c = pd.read_csv('constraints/Multi-product_transportation_problem/cost.csv') # 顧客番号と製品番号のタプル(組)を作成 C = list(zip(df_c[df_c.columns[0]], df_c[df_c.columns[1]])) # 顧客番号と製品番号のタプル(組)をキーとし、輸送費用を値とする辞書を作成 cost = dict(zip(C, df_c[df_c.columns[2]])) # weightとcostから製品毎の輸送費用を計算し、辞書cに保管 c = {} for i in I: for j in J: for k in produce[j]: c[i, j, k] = cost[i, j] * weight[k] return I, J, K, c, d, M最後に最適化を解きます。
if __name__ == "__main__": I, J, K, c, d, M = get_data() model = mctransp(I, J, K, c, d, M) # 最適化の実行 model.optimize() print("Opt value:", model.ObjVal) # Opt value: 43536.0ご参考までに使用したcsvファイルを記載します。
# 工場で製造可能な製品を抽出 df_p = pd.read_csv('constraints/Multi-product_transportation_problem/produce.csv') # DataFrameをdictへ変換 produce = df_p.set_index('factory').T.to_dict('list') # Nanを削除 for key in produce.keys(): produce[key] = {x for x in produce[key] if x==x} # produce # {1: {2.0, 4.0}, 2: {1.0, 2.0, 3.0}, 3: {2.0, 3.0, 4.0}}
# 顧客と商品の需要量を抽出 df_d = pd.read_csv('constraints/Multi-product_transportation_problem/demand.csv') # 顧客番号と製品番号のタプル(組)を作成 D = list(zip(df_d[df_d.columns[0]], df_d[df_d.columns[1]])) # 顧客番号と製品番号のタプル(組)をキーとし、需要量を値とする辞書を作成 d = dict(zip(D, df_d[df_d.columns[2]])) # d # d = {(1,1):80, (1,2):85, (1,3):300, (1,4):6, # (2,1):270, (2,2):160, (2,3):400, (2,4):7, # (3,1):250, (3,2):130, (3,3):350, (3,4):4, # (4,1):160, (4,2):60, (4,3):200, (4,4):3, # (5,1):180, (5,2):40, (5,3):150, (5,4):5 # }
# 顧客と商品の輸送費用を抽出 df_c = pd.read_csv('constraints/Multi-product_transportation_problem/cost.csv') # 顧客番号と製品番号のタプル(組)を作成 C = list(zip(df_c[df_c.columns[0]], df_c[df_c.columns[1]])) # 顧客番号と製品番号のタプル(組)をキーとし、輸送費用を値とする辞書を作成 cost = dict(zip(C, df_c[df_c.columns[2]])) # cost # cost = {(1,1):4, (1,2):6, (1,3):9, # (2,1):5, (2,2):4, (2,3):7, # (3,1):6, (3,2):3, (3,3):4, # (4,1):8, (4,2):5, (4,3):3, # (5,1):10, (5,2):8, (5,3):4, # }
さいごに
最後まで読んで頂き、ありがとうございました。
製造現場において最適化が求められることは多いので、引き続き数理最適化を勉強していこうと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。

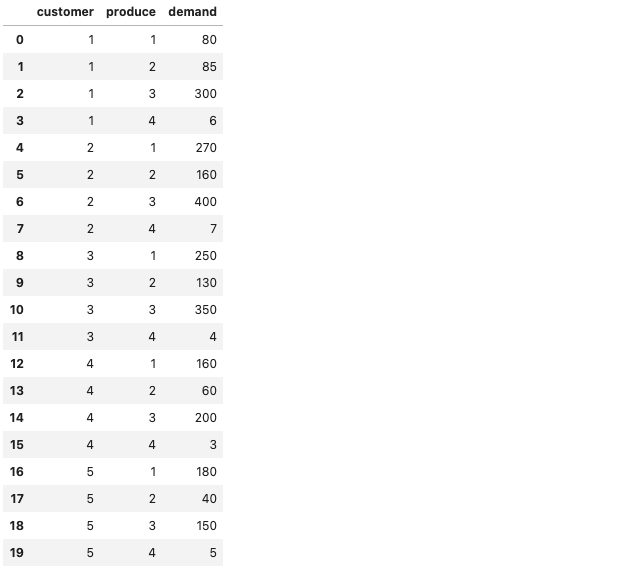
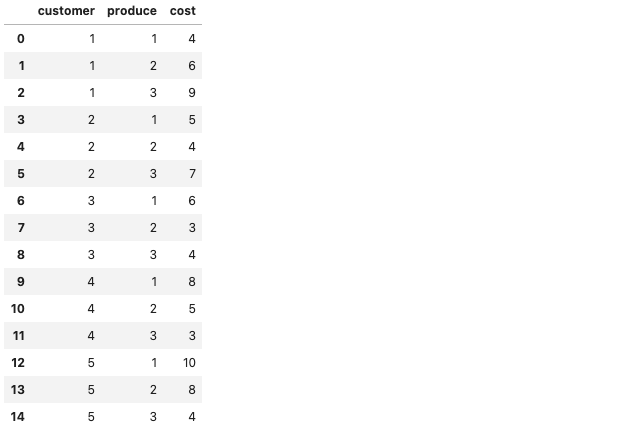
- 投稿日:2021-01-18T15:32:33+09:00
マストドンBot作成メモ:その4 まとめ
あらすじ
Mastodonで、通常のトゥートと、リプライされたら特定の単語を含む場合に特定の返信をするbot、クラウドというか自機内だけでなくてとにかくサーバー上でネットワーク上で自動で動くやつ!を作るべく奮闘しました。
同じくそういうのが作りたい方はこの記事だけ見たら事足りるかもしれません。
私ががんばった変遷を一から見ていきたい方は↓からどうぞ。
マストドンBot作成時のメモ:その1 通常Toot(ローカル)編 - Qiita■ ますとどんbot作る方が覚悟しておくべきこと
たぶんお金をかけずに保守管理していくことは無理!
ご自宅に鯖など持ってる方はできるのかもしれないですが…、
こんな頭の弱いページを参考にしてくださる方は
軽い気持ちで作ろうと思っていらっしゃる気がするので、
とにかく費用がかかることは覚悟してください。
さくらVPSの値段が月額1500円ぐらい?
他にもVPSで色々するなら良いかもですが、あとはとにかく自己満足。■ ますとどんBotつくりかたまとめ!
かんたん(たぶん)にまとめます。
とりあえずサーバーを用意する
ファイルをupしたり(viは最小限しか使わない…)ライブラリをインストールしたり
crontab(スケジューリングしてつぶやくためのやつ)したりするサーバーを用意します。
私はさくらVPSを利用しました。私のローカル!のメインの環境はWindows10です。
コマンドプロンプトでできるのかは知りませんが、私はTera Termを利用しています。
PythonとかpipとかMastodon.pyとかをインストールします…。
わからなかったら、CentOS!(調べたいこと)!インストール![検索] で
たぶん何かが出てくると思います。わからなかったら、私でわかることなら聞いてね。CUI…あの黒い画面にひたすら英字打つ感じのやつを未経験の方は難しいかも?
TeraTerm 使い方 [検索] とかなさってください。あとコマンドとか
Tera Termでよく使うコマンドのメモ | Online Inc.あと次の項目でも参考にさせていただくんですが、
とにかく↓の記事を御覧ください。VPSではないですがMastodon.pyのインスコとかも参考に!
ご注文はMastodonBotですか? 今すぐ動かしてみたい初めての方に☕ - Qiitasetup.pyを用意する
ご注文はMastodonBotですか? 今すぐ動かしてみたい初めての方に☕ - Qiita
これは完全に↑の記事さん(?)のコードを利用させていただきます。
setup.pyのコードをコピーして、保存して、、
こちらをサーバー上(ローカルでもできますが)でpython setup.pyってすると、client.secretとuser.secretという二つのファイルが作られます。
こちら、トゥートするために必要なファイルです。何でかわからないけどインスタンスがmstdn.jpだとエラー出た。
自分とこのインスタンスだとできたのに! なんで!?data.txtに書かれたトゥートをランダムで呟くbot.py
上記の記事さまに記載されているbot.pyでとりあえず試してみてください。
チノちゃん!ってトゥートするはずなので… わたしもココアさんすき!それでとりあえずは、適当なトゥート内容を呟くためのdata.txtを作ってください。
内容は本当に適当でいいです。決めれないひとのために用意しときますよぉ~っ!data.txt通常トゥート01 通常トゥート02 通常トゥート03 通常トゥート04 通常トゥート05 通常トゥート06 通常トゥート07 通常トゥート08 通常トゥート09 通常トゥート10\ドヤ!/
とりあえずランダムに呟けるかの試しなのでこんなので大丈夫です。
一行が一トゥートです。違くしたい方は自分で考えて!
それで、ランダムに呟くためのbot.pyの内容が下記のとおりです。bot.py# -- coding: utf-8 -- from mastodon import Mastodon import random hogebot = Mastodon( client_id = 'client.secret', #app情報 access_token = 'user.secret', #ログイントークン api_base_url = 'https://hogehoge.com' #インスタンス名 ) # 通常Tootファイルの指定 path = 'data.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() content = random.choice(l) # Toot!! hogebot.toot(content) print('【投稿完了】' + str(content)) # 確認用一番上のは、私はUTF-8を使うのでおまじないです。インスタンス名のみ書き換えて、
data.txt と client.secret と user.secret と四つを同じ場所に置いて、python bot.pyをすると動くはずです。
ちなみに最後のprint文は、結果が見たいタイプの私が書き足しただけなので消して大丈夫です。
(というか、最終的にcronで動かすことになったとき一々mailが来るみたいだし
消したほうがいいのかもしれない)(mailを来なくする方法もあるみたいだけど…)
あとhogebotという変数…変数?名はかわいそうなので、
かわいい名前をつけてあげてください。2箇所あります。reply_pattern.txtに書かれた感じにリプライするreply.py
先にreply_pattern.txtの内容を書きます。
reply.textこんにちは::こんにちは01 こんにちは::こんにちは02 こんにちは::こんにちは03 こんにちは::こんにちは04 こんにちは::こんにちは05 こんばんは::こんばんは01 こんばんは::こんばんは02 こんばんは::こんばんは03 こんばんは::こんばんは04 こんばんは::こんばんは05また適当なんですけど…
「こんにちは」と言うと「こんにちはn」とリプライして、
「こんばんは」と言うと「こんばんはn」とリプライする内容です。
これも一行で一つのかたまりで、
::の前が相手が言ってきた語句のパターン、後ろがbot側のリプライする内容です。
あっ反応語句は正規表現できるようにしたいな… 後で考えよう…reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random import re import os.path def main(content,st,id,disname): # 呟きファイルの指定 path = 'reply_pattern.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() count = len(l) - 1; selectedList = [] hogeToot = '' nameChanged = '' # 反応語句を含む行を抽出 while count >= 0: tmpList = l[count].split('::') if tmpList[0] in st['content']: selectedList.append(tmpList) count -= 1 # 抽出したリストからランダムに一つ選ぶ if len(selectedList) != 0: count = len(selectedList) - 1; replyNo = random.randint(0,count) hogeToot = selectedList[replyNo][1] if hogeToot == '': hogeToot = '{name}さんごめんなさい、聞こえませんでした' # {name}をおなまえに変換する nameChanged = re.sub("\{name\}",disname,hogeToot) # ↓何もトゥートがなかったときの処理、そのうち変える print("【リプライ】" + nameChanged) #確認用 mastodon.status_reply(st, nameChanged, id, visibility='public') #公開範囲 # 「公開」 -> 'public' # 「未収載」 -> 'unlisted' # 「非公開」 -> 'private' # 「ダイレクト」-> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://hogehoge.com") #インスタンス notif = mastodon.notifications() #通知を取得 count = len(notif) - 1 while True: # 逆(古い方)からTootを数える(0/最後まできたらbreak) if count >= 0: if notif[count]['type'] == 'mention': # Toot形成... と思われる content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] disname = notif[count]['status']['account']['display_name'] idStr = str(notif[count]['status']['id']) # Toot!!/log.txtが存在する際(二回目以降の実行時)のみ呟く if os.path.exists('log.txt'): main(content, st, id, disname) else: # 最後まで通知を拾い終わったらnotificationsをclear mastodon.notifications_clear() if not os.path.exists('log.txt'): f = open('log.txt', 'w') f.write('1') f.close() break count -= 1その3までの記事では書くのを忘れていたんですが、
最後のほうに もしその垢が既に通知を受け取りまくっていたら…というときの処理を追加しました。
もしそうだったら、下手したら何百とかリプ爆する可能性があるので…。
初めて実行したときに一旦全ての通知をクリアし、log.txtというファイルを作ります。
(なのでそのときまでに受け取った通知には返事をしません)
log.txtがあるとき(2回目以降の実行時)はふつうにリプライする~という処理をします。このファイルも、インスタンス名を変えるだけで動く…はず!
crontabに登録する
crontabは、好きな時間に好きなファイルやコマンドなどを実行できる機能?ですね。
最短1分ずつ実行できて、毎週何曜日とか、何時何分に実行とか、そういうのができます。
詳しくはcrontabで調べてね!crontab -eで編集画面にいけます。vi…と同じなのかな…????
0 * * * * cd /root/mstdn && python ./bot.py * * * * * cd /root/mstdn && python ./reply.py私とてもハマったのですが、なんかcdで移動してからじゃないと実行できないみたいでした。
これで動くはず! おつかれさまでした!!
- 投稿日:2021-01-18T15:16:09+09:00
Streamlitでリストの初期化を防ぐ
はじめに
備忘録です。
何か他にもいい方法があったら教えて下さい。本題
Streamlitを使用すると、簡単に描画アプリを作成することができます。
また、Rerunボタンを押すことで、すぐにソースコードの変更を反映できます
ここで問題が発生しました。
例えば以下のようにinputをリストで保持したい場合import streamlit as st lst = [] input = st.text_input('何か入力して下さい') lst.append(input) st.table(lst)appの出力はこのようになります。
ここで何かを入力してみます。
aaaが反映されたことがわかります。
次に新しくbbbを追加してみます。
bbbは追加されましたが、すでにあったaaaは反映されていませんでした。なのでコードを修正してみました。チェックボックスがチェックされていると入力が止まるような
感じにしてみました。lst = [] i = 0 while True: input = st.text_input('何か入力して下さい', key=str(i)) lst.append(input) i += 1 if st.checkbox('stop'): break st.table(lst)出力は以下のようになりました。
streamlitで入力をループにするにはよくないっぽいです。(できたとしても入力欄が無限に出力されそう)
原因
原因としてはStreamlitでRerunを実行すると、全てのデータをロードしてしまうからでした。
Rerunはボタンを押さなくても、入力欄での追加・変更がされるだけでも自動的に行われます。
そこでStreamlitのcache機能を使用します。Cacheとは
cacheはStreamlitのデコレーターです。
関数の前に@st.cacheをつけることで使用することができます。
簡単に言うとcacheを利用できるので、一度使った関数は引数が変わらないと変更が行われない感じです。
(変更される条件は他にも複数存在します。詳しくはドキュメントを参考にしてみて下さい。)改善
それではcacheを使用してコードを変更してみます。
@st.cache(allow_output_mutation=True) def cache_lst(): lst = [] return lst lst = cache_lst() input = st.text_input('何か入力して下さい') if st.checkbox('clear'): caching.clear_cache() lst = cache_lst() elif input: lst.append(input) st.table(lst)すると、以下のようにリストに値が保持できていることがわかります。
また、clearのチェックボックスをチェックするとリストを初期化することができます。
これを使うことで、要素の削除や変更を行うことができます。
また、このときリストはimmutableなので、要素の変更を行う際に代入をする形をとると変更が反映されません。@st.cache(allow_output_mutation=True) def cache_lst(): lst = [] return lst lst = cache_lst() input = st.text_input('何か入力して下さい') if st.checkbox('clear'): caching.clear_cache() lst = cache_lst() elif input: lst.append(input) if st.checkbox('delete'): delete = st.selectbox('削除する要素を選択して下さい', options=lst) if st.button('Delete'): lst.remove(delete) st.success(f'Delete : {delete}') if st.checkbox('change'): change_from = st.selectbox('変更する要素を選択して下さい', options=lst) change_index = lst.index(change_from) change_to = st.text_input('何に変更しますか') if st.button('Change'): lst.remove(change_from) lst.insert(change_index, change_to) st.success(f'Change {change_from} to {change_to}') st.table(lst)
削除した時
変更した時
※削除・変更・追加をする際はinput欄に文字が入っていると勝手に追加されることがあるので注意して下さい参考
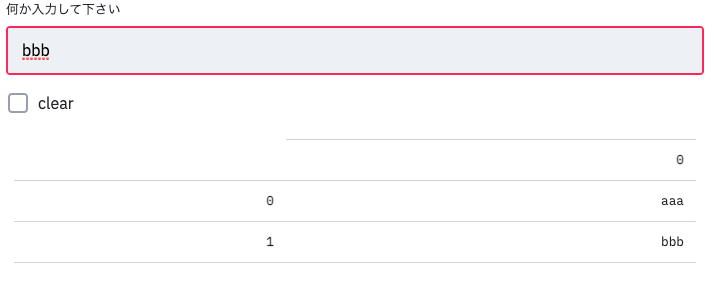

- 投稿日:2021-01-18T15:14:27+09:00
Python + chatwork + google extension = 簡単に面白いチャット BOT を作り方
前提
以下の準備できること
- ChatWork関連
- Chatwork Webhook
- Chatwork チャネル
- Python関連
- http.server、socketserver、json、requests、ChatBotのインストール
- ngrok関連
- ngrokのインストール
スクリプトの実装
Pythonで200 OKを返すようなサーバーを作る
webhookchatwork.pyimport http.server import socketserver import json import requests class MyHandler(http.server.BaseHTTPRequestHandler): def do_POST(self): self.send_response(200) self.end_headers() content_leng = int(self.headers.get("content-length")) req_body = self.rfile.read(content_leng).decode("utf-8") json_object = json.loads(req_body) print(json_object) # ローカルの環境に3000ポートを設定 with socketserver.TCPServer(("", 3000), MyHandler) as httpd: httpd.serve_forever()Ngrokでローカルホストをインターネットに公開する
- ngrokのインストール
- ngrokを実行
- 上記の
webhookchatwork.pyに3000ポートを利用しているので下記に実行ngrok http 3000結果:
Chatwork webhookとNgrokに連携
ここまでローカルの
webhookchatwork.pyのファイルはインターネットに公開しました。
チャットワークから投稿する時webhookchatwork.pyに受け取るように設定しなければなりません。
上記の赤枠にngrokのURLを記入
記入した後Chatwork webhookとNgrokに連携できると思います。
確認:
webhookchatwork.pyを実行:python3 webhookchatwork.py
- ルームにwebhookの登録した人を投稿してみる

- ngrokの実行しているに確認
200 OKに返しまた。

ChatBotのスクリプト
ChatBotの処理は二つがあります
- チャットワークに返事すること
webhookchatwork.pyAPIKEY = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # ChatworkのAPI tokenから取得 ENDPOINT = 'https://api.chatwork.com/v2' ROOMID = 'XXXXXXXXX' # 投稿したいルーム post_message_url = '{}/rooms/{}/messages'.format(ENDPOINT, ROOMID) headers = { 'X-ChatWorkToken': APIKEY } def checkAssignee(assigneenum): # 返事する人 if assigneenum ==3987766: assigneename = 'Aさん' elif assigneenum ==4388605: assigneename = 'Bさん ' return assigneename # # チャットワークに送信- start def sendtoChatworkRemind(answer,fromaccountid,sendtouser): headers = { 'X-ChatWorkToken': APIKEY } params = { 'body': '[To:'+str(fromaccountid)+']'+ sendtouser+ '\n' + str(answer) } requests.post(post_message_url, headers=headers, params=params) # チャットワークに送信 - end
- トレニングすること
webhookchatwork.pychatbot = ChatBot('EventosChatBot') trainer = ListTrainer(chatbot) traningjson = [] print(json_object['webhook_event']['body'].find("[To:2555387]Chat Bot Eventos")) if "[To:2555387]Chat Bot Eventos" in json_object['webhook_event']['body'] : fromaccountid = json_object['webhook_event']['from_account_id'] reponse = json_object['webhook_event']['body'].replace("[To:2555387]Chat Bot Eventos\n","") sendtouser = checkAssignee(fromaccountid) if "教えさせてください ]:)" in json_object['webhook_event']['body'] : for item in json_object['webhook_event']['body'].split("\n"): if "質問 :" in item: print(item.strip().replace("● 質問 : ","")) if item.strip().replace("● 質問 : ","") != "": traningjson.append(item.strip().replace("● 質問 : ","")) else: traningjson.append("") if "回答 :" in item: print(item.strip().replace("● 回答 : ","")) if item.strip().replace("● 回答 : ","") != "": traningjson.append(item.strip().replace("● 回答 : ","")) else: traningjson.append() trainer.train(traningjson) answer = "教えていただき、ありがとうございます (bow)" sendtoChatworkRemind(answer,fromaccountid,sendtouser) else: answer = chatbot.get_response(reponse) sendtoChatworkRemind(answer,fromaccountid,sendtouser)Google extensionに作り
誰でもchatbotにトレニングできるようにGoogle extensionを作成しましょう
- googel extension開発の方法
- トレニングのソースコード
content_scropts.jssetTimeout(function(){ $("#__chatworkInputTools_toolbarIcons").prepend('<li class="_showDescription __chatworkInputTools_toolbarIcon" id="teachChatbot" role="button" aria-label="info: Surround selection with [chatbotEV] tag"><span class="btnDanger" style="padding: 3px 4px; font-size: 10px; border-radius: 3px; position: relative; top: -2px;">chatbotEV</span></li>'); $("#teachChatbot").click(function(){ $("#_chatText").val('[To:2555387]Chat Bot Eventos \n教えさせてください ]:) \n[info]\n ● 質問 : \n ● 回答 : \n[/info]'); }) },1000);結果:
OKです。最後にテストしてみる
トレイニング:
ちゃんと勉強になっています
返事:
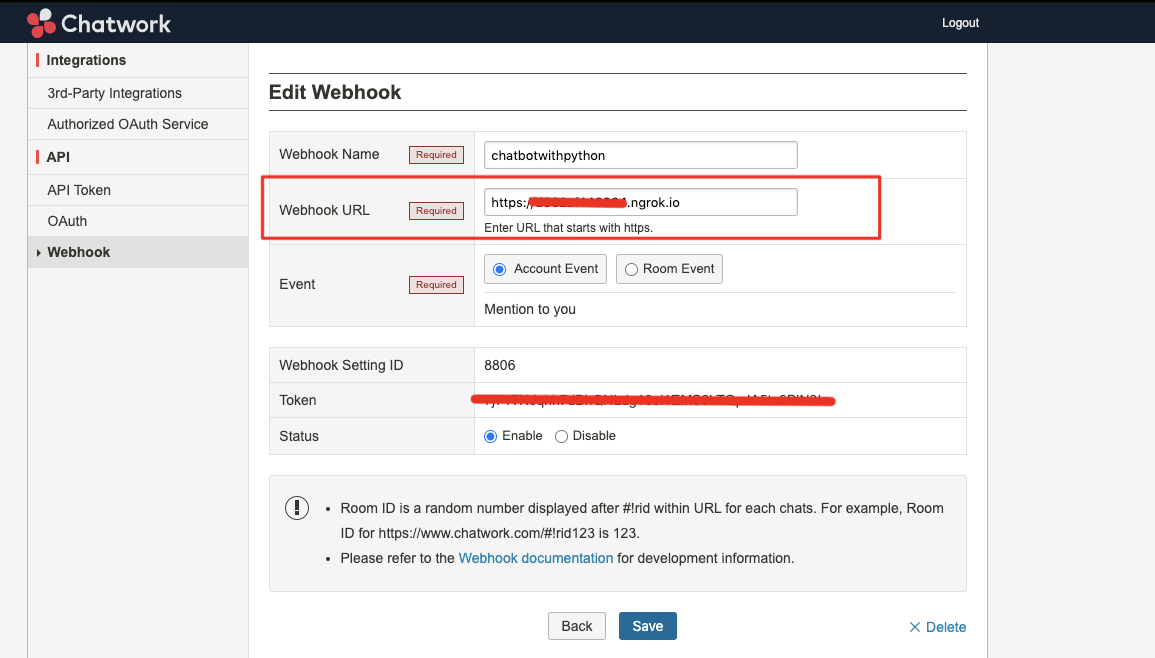

- 投稿日:2021-01-18T13:17:25+09:00
【データサイエンス備忘録】 欠損値の取扱 【python】
欠損値の有無を確認する。
isnull()関数を使用する。
DataFrameが代入された変数.isnull()
もし欠損値が含まれていればTrue、含まれていなければFalseとなる。欠損値の個数を確認する
isnull()関数とsum()関数を使用する。
DataFrameが代入された変数.isnull().sum()欠損値の削除
dropna()関数を使用する。
DataFrameが代入された変数.dropna()
dropna()関数を利用した後は、別の変数に代入するか、inplace=Trueというdropnaの引数を付け加え、実行したらそのまま変数を書き換える。
data = data.dropna()data.dropna(inplace=True)data = data.dropna(inplace=True)特定のカラムが欠損値を含むデータを削除する場合は、
DataFrame.dropna(subset=[‘カラム名’])欠損値の補完
fillna()関数で特定のカラムの欠損値をある値で補完する。
DataFrameを代入した変数['カラム'].fillna(値)特定のカラムの平均値で欠損値を補完する。
DataFrameを代入した変数['カラム'].mean()
- 投稿日:2021-01-18T12:55:21+09:00
【PHP】IoTデバイスからPOST送信されたときに送信元IPアドレスを取得する【ESP32】
はじめに
IoTデバイスをIPアドレスを使って識別しようとしている方,デバイスのIPアドレスをサーバ側で取得したい方向けになります.
環境
- IoTデバイス(ESP32)
- ファームウェア(MicroPython1.3)
- サーバ(Ubuntu18.04)
- Webサーバ(Apache2)
- PHP(PHP7.4)
※Apache2を起動して/var/www/html/にPHPプログラム(今回はreceive.php)を置いておくことが前提です.
ソースコード(ESP32)
今回はESP32で適当なJSONデータのPOST送信をし,サーバで送信元のIPアドレスを取得してレスポンスとしてそのIPアドレスを返すようなプログラムにしました.
post.pyimport urequests import ujson #送信先のURLの指定 #"XXX.XXX.XXX.XXX"にURLを入れる url = 'http://XXX.XXX.XXX.XXX/receive.php' #データをDICT型で宣言 obj = {"value" : 123, "text" : "abc"} #jsonデータで送信するという事を明示的に宣言 header = {'Content-Type' : 'application/json'} #オブジェクトをJSONに変換し,HTTPリクエストをPOSTとして送信 res = urequests.post( url, data = ujson.dumps(obj).encode("utf-8"), headers = header ) #サーバ側からのレスポンスを受け取って表示(jsonのデコードも一緒にしている) print (res.json()) #終了 res.close()ソースコード(サーバ)
送信元のIPアドレスは
$_SERVER[REMOTE_ADDR]に入っているのでそれを変数に入れるなりする.receive.php<?php //送られてきたPOSTデータを受け取って,JSONデータをデコードして$inに入れる. $json_string = file_get_contents('php://input'); $in = json_decode(stripslashes($json_string),true); //送られてきたデータを取り出す $value = $in["value"]; // = 123 $text = $in["text"]; // = abc //$_SERVER変数を使って送信元のIPアドレスを取得する //レスポンスを取得したIPアドレスとし,それをJSONとして再度エンコード //そして送信元(ESP32)へ返す. $ipAddress = $_SERVER['REMOTE_ADDR']; //AWS ELBを使用している場合はELBのIPアドレスを取得してしまうので //以下のようにして元のIPアドレスを取得する if (array_key_exists('HTTP_X_FORWARDED_FOR', $_SERVER)) { $ipAddress = array_pop(explode(',', $_SERVER['HTTP_X_FORWARDED_FOR'])); } //IPアドレスをエンコードして返す echo json_encode($ipAddress); ?>実行結果
micropythonのWEB REPLで実行したところ,IPアドレスが返ってきました.
>>> execfile("post.py") >>> YYY.YYY.YYY.YYY // <- ESP32のIPアドレス参考
この記事は以下の記事を参考に書いています
[1]
ESP32からMicropythonでHTTPリクエスト(POST)でデータを送信し,PHP(サーバ)で受け取る
- 投稿日:2021-01-18T12:20:44+09:00
ちゃま語でツイートするSlack Bot 〜AWS Lambdaを用いたSlack Botの作り方〜
はじめに
こんな人に読んでもらいたい
ネタはホロライブ関連だけど、やってることは以下のようなことなので、役に立つかも(役に立ってほしい)。
・AWS Lambdaを用いてSlack Botを作る
・Botとの個人チャットに送信された文章を取得して、定められた動作する。(返信もする)
・twitterAPIでツイート
・AWS Lambdaをserverless-frameworkでデプロイ
・Python外部モジュールはserverless-python-requirementsで導入これは...?
ちゃま語でツイートするSlack Botを作った。ざっくり説明すると、
- Slack Botにツイートしたい文を入力する
- ちゃま語に翻訳する
- 翻訳した文をツイートする
そもそも「ちゃま語」って...?(最初にこれ書けよ
先日、マリン船長が配信で、「ちゃま語であそぼ」なるものを、はあちゃまが提案していたという旨の話をしていた。(以下の動画を参照)
https://www.youtube.com/watch?v=T2yMNE_zb54
https://www.youtube.com/watch?v=IoOeMaCzuZYちゃま語というのは、ざっくりいうと文中の「と」を「ちゃま」に置換したものだという。
例えば、「赤井はあと」->「赤井はあちゃま」
「トマト」->「ちゃままちゃま」
「となりのトトロ」->「ちゃまなりのちゃまちゃまろ」そして、「ちゃま語であそぼ」というのは以下のようなルールのローテーションリズムゲームらしい。
- 1人目が「と」を含む単語のお題を言う
- 2人目がお題をちゃま語にする(「と」を「ちゃま」にして言う)
- 3人目は1.と同じく「と」を含む単語のお題を言う。以下繰り返し。
配信を見ていた私は、ミーム汚染されていく船長とコメント欄を見ながら大爆笑しつつ、「『ちゃま語でツイートするSlack Bot』でも作って、『AWS Lambdaを用いたSlack Botの作り方』の記事を書くか〜〜」と考えた次第だ。
[追補]
以前、私は仕事で社内の請求書作成自動化Botを作った。で、その話を記事にしようと思った。(システムが扱うデータは勿論機密だけど)実装方法自体は機密ではないから…とはいえ、社内のシステムを記事にするのはちょっと…ねぇ…。一旦保留した。で、今回ちょうどいいネタが見つかったので、それを使って『AWS Lambdaを用いたSlack Botの作り方』を記事にした。
(Googleスプレッドシートの編集の自動化とか、「請求書作成自動化Bot」で使った他のことの話は後日別記事に書こうかなと思う。)本題
はじめる前に
Twitter Developerアカウントを申請・取得しておいてくださいな。(今回の作業でこれが一番めんどくさい)
serverless-frameworkでLambdaをデプロイ
まずは、serverless-frameworkを用いて、chama-language-tweet-botというLambdaを作る。
(serverless-frameworkが入ってない人はnpm install -g serverlessして入れておいて)
(awsのアカウントを設定していない人はやっておいて。「aws-cli 使い方」とか調べれば出てくるから、キーを設定して。)$ mkdir chama-language-tweet-bot $ cd chamago-tweet-bot $ npm init $ serverless create --template aws-python3 --name chama-language-tweet-bot $ ls handler.py package-lock.json serverless.yml node_modules package.jsonここまではお決まりの流れだね。(ここで、
sls deployしてちゃんと設定できているか確認してみても良いかと)
あ、私の趣味だけど、handler.pyではわかりにくいので、ここでファイル名をslackbot.pyに変更した。今回は1つの関数しか作らないからhandler.pyのままでも問題ないが、大抵1つのLambdaに複数の関数を置いたりするので、handler.pyでは分かりにくすぎる。そこで、私は普段、関数毎に.pyを作って、それぞれに関数handlerを設けて、それをhandlerにしてる。SlackBotに接続する前に
SlackBotは、設定の途中でLambda等のAPIとの接続がうまくいっているか確かめるテストがある。なので、その段階に行くまでに、テストに対応できる挙動をLambdaに作っておく必要がある。
serverless.ymlservice: chama-language-tweet-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 functions: slackbot: handler: slackbot.handler timeout: 200 events: - http: path: slackbot method: post cors: true integration: lambdaslackbot.py# coding: utf-8 import json import logging # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] return { 'statusCode': 200, 'body': 'ok' }以上のようにして、
sls deployする。そして、エンドポイントをメモする。SlackBotの作成
では、SlackBotを使っていこう。
Slack API にアクセスして、「Create New App」から新しいSlack Appを作る。
名前は適当に決めて、Development Slack Workspaceでインストール先のワークスペースを決める。この時、間違っても会社のワークスペースを選択しないようにSlack Appができたら、早速App Credentialsを探して、Verification Tokenをメモしておく。
次に、Slack APIを有効にする。今回はSlack Eventというものを使うので、Event Subscriptionsを開いて、Enable Eventsをonにする。
Enable Eventsをonにしたら、Request URLにLambdaのエンドポイントを入れる。そうすると、(ここまでのLambdaがちゃんとできていれば)Verifiedとなる。これでSlackとLambdaの接続が完了する。
次に、Event APIの反応の種類を設定する。Add Bot User Eventから「message.im」を選択する。これは、Botとの個人チャットに投稿がなされた時に反応するという設定だ。
次に、Botに対して、メッセージを投稿する権限を付与する。OAuth & PermissionsからScopesを探して、そこの「Add an OAuth Scope」から「chat:write」を追加する。
これで、SlackBotの設定が終わったので、OAuth & Permissionsの「Install to Workspace」を押して、SlackBotをワークスペースにインストールする。
そして、その後に表示されるOAuth Tokenをメモする。
さて、今度はSlackのアプリからBotの導入をしよう。
Slackのアプリの「アプリを追加する」を開いて、さっき作ったSlack Botの名前を検索し、導入する。そうしたら、Botのプロフィールを開き、「その他」から「メンバーIDをコピー」する。
これでSlack側の設定は完了!
Python外部モジュールの導入
さて、Slack Botも出来たことだし、Lambdaで使う外部モジュールを導入する。
今回使うPython外部モジュールは以下の2つ。
・tweepy
・pykakashi
今回はこれらを、プラグインserverless-python-requirementsでぶち込んでいこうと思う。ところで、LambdaにPython外部モジュールを入れる方法というのは、serverless-python-requirementsを使う他に、Dockerを使って外部モジュールをAmazon Linux環境下でビルドして、圧縮して、それをLayerにする方法とかもある。でも、serverless-python-requirementsが一番楽。Dockerで作ったLayerだと、アップロードするのがめんどくさい(サイズが大きいとS3にレイヤーをアップロードしてそこにアクセスする必要が出てくるし)。さらに、Lambdaはデプロイパッケージのサイズがかなり限られてるから、場合によってはEFSを使う必要がでてくることもある。今回はめちゃめちゃ小さいのでserverless-python-requirementsで十分だが。
さて、serverless-python-requirementsを導入する。
$ npm install --save serverless-python-requirementsそしたら、serverless.ymlに以下を追記する。
serverless.ymlplugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true基本的にはpluginsのところだけで良いんだけど、今回はpykakashiが非PureなPythonモジュールだから、customのところも書いておく必要がある。(更に言うと
sls deployする時にDockerを動かしておく必要がある。)次に、serverless.ymlとかと同階層にrequirements.txtを配置して、入れたい外部ライブラリを書く。
requirements.txttweepy pykakasiこれで、
sls deployしたら一緒に外部ライブラリも入ってくれる。キーの配置
さて、ここでキーをセットしていく。serverless.ymlにenvironmentを以下のように追記する。
serverless.ymlservice: haachama-twitter-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 environment: SLACK_BOT_USER_ACCESS_TOKEN: '' SLACK_BOT_VERIFY_TOKEN: '' TWITTER_CONSUMER_KEY: '' TWITTER_CONSUMER_SECRET: '' TWITTER_ACCESS_TOKEN: '' TWITTER_ACCESS_TOKEN_SECRET: '' BOT_USER_ID: ''それぞれの中身は、
SLACK_BOT_USER_ACCESS_TOKEN
SlackBotをワークスペースにインストールした時に表示されたOAuth TokenSLACK_BOT_VERIFY_TOKEN
SlackBotを作り始めて最初に出てきたVerification Token。TWITTER_CONSUMER_KEY
TWITTER_CONSUMER_SECRET
TWITTER_ACCESS_TOKEN
TWITTER_ACCESS_TOKEN_SECRET
TwitterDeveloperアカウントのキー。BOT_USER_ID
SlackのアプリでコピーしたBotの「メンバーID」。Lambda側の実装
SlackBotの挙動
では、Lambdaの中身を書いていく。
まず、Botとの個人チャットでBotが適切に反応するようにする。slackbot.py# coding: utf-8 import json import os import logging import urllib.request import tweepy import pykakasi # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] # tokenのチェック if not is_verify_token(event): return {'statusCode': 200, 'body': 'token error'} # 再送のチェック if "X-Slack-Retry-Num" in event["headers"]: return {'statusCode': 200, 'body': 'this request is retry'} # ボットへのメンションでない場合 if not is_app_message(event): return {'statusCode': 200, 'body': 'this request is not message'} # 自分に反応しない if event["body"]["event"]["user"] == os.environ["BOT_USER_ID"]: return {'statusCode': 200, 'body': 'this request is not sent by user'} return { 'statusCode': 200, 'body': 'ok' } def is_verify_token(event): token = event["body"]["token"] if token != os.environ["SLACK_BOT_VERIFY_TOKEN"]: return False return True def is_app_message(event): return event["body"]["event"]["type"] == "message"以上のコードでは、このようなことをしている。
- トークンの確認
- 再送の確認
- Slack Event APIは3秒以内にstatusCode:200が返ってこないと勝手に4回までリクエストを再送してしまうから、それを防ぐ。今回のLambdaは処理に3秒もかからないだろうけど、結構これのせいで暴走して、(私が)ブチ切れたことがあるので書いた。ちなみに、"X-Slack-Retry-Num"は再送回数が格納されているプロパティで、初回の送信だとそもそも"X-Slack-Retry-Num"が存在しない。今回はそれで判別した。
- 投稿されたメッセージが「Botとの個人チャットに投稿されたもの」であることを判別する
- 暴走を防ぐ
- 投稿されたメッセージがBot自身によるものである場合には反応しないようにする。もし、この部分を書かなかったら、Botが一度反応したら、自身の投稿に反応して返答することを繰り返してしまって、暴走してしまう。
そうそう。余談だが、Slackのシステムはメッセージの特定に、メッセージ固有のIDではなくて、投稿がなされたチャンネルのIDとタイムスタンプを使っているらしい(Twitterは個々のツイートにIDが振られるのにね)。だから、Botがリプライするような実装をしたいときは投稿がなされたチャンネルのIDとタイムスタンプの2つが肝要になる。
Botによる返答
今回は、投稿がなされたら、一応確認とために返答もしたいから、これも書く。
slackbot.pydef post_message_to_channel(channel, message): url = "https://slack.com/api/chat.postMessage" headers = { "Content-Type": "application/json; charset=UTF-8", "Authorization": "Bearer {0}".format(os.environ["SLACK_BOT_USER_ACCESS_TOKEN"]) } data = { "token": os.environ["SLACK_BOT_VERIFY_TOKEN"], "channel": channel, "text": message, } req = urllib.request.Request(url, data=json.dumps(data).encode("utf-8"), method="POST", headers=headers) urllib.request.urlopen(req)この関数に対して、handlerの中でチャンネルとテキストを以下のようにして渡せば、Botが「done!」と返答する。
slackbot.pychannel_id = event["body"]["event"]["channel"] post_message_to_channel(channel_id, "done!")「と」の置換とツイート
次に、「ちゃま語」に翻訳して、結果をツイートする部分を書く。
slackbot.pydef tweet(input_text): auth = tweepy.OAuthHandler(os.environ["TWITTER_CONSUMER_KEY"], os.environ["TWITTER_CONSUMER_SECRET"]) auth.set_access_token(os.environ["TWITTER_ACCESS_TOKEN"], os.environ["TWITTER_ACCESS_TOKEN_SECRET"]) api = tweepy.API(auth) kakasi = pykakasi.kakasi() kakasi.setMode('J', 'H') conv = kakasi.getConverter() input_text = conv.do(input_text) input_text = input_text.replace('と', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ど', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') api.update_status(status=input_text)slackbot.py# handlerの中で呼び出し input_text = event["body"]["event"]["text"] tweet(input_text)今回は、pykakashiで入力文を全て平仮名にして、その文の中に含まれる「と」を「ちゃま」、「ど」を「ぢゃま」に置換していく。そして、置換結果をツイートする。
「ど」を「ぢゃま」に置換するのは、はあちゃま本人の提案ではなくマリン船長の配信で出てきたものらしいが、面白いので加えた。さて、これで完成だ。
sls deployをして、テストしてみよう。
はい、できた。
漢字の変換も問題なさそうだね。
コードの全容
serverless.ymlservice: haachama-twitter-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 environment: SLACK_BOT_USER_ACCESS_TOKEN: '' SLACK_BOT_VERIFY_TOKEN: '' TWITTER_CONSUMER_KEY: '' TWITTER_CONSUMER_SECRET: '' TWITTER_ACCESS_TOKEN: '' TWITTER_ACCESS_TOKEN_SECRET: '' BOT_USER_ID: '' plugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true functions: slackbot: handler: slackbot.handler timeout: 200 events: - http: path: slackbot method: post cors: true integration: lambdaslackbot.py# coding: utf-8 import json import os import logging import urllib.request import tweepy import pykakasi # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] # tokenのチェック if not is_verify_token(event): return {'statusCode': 200, 'body': 'token error'} # 再送のチェック if "X-Slack-Retry-Num" in event["headers"]: return {'statusCode': 200, 'body': 'this request is retry'} # ボットへのメンションでない場合 if not is_app_message(event): return {'statusCode': 200, 'body': 'this request is not message'} # 自分に反応しない if event["body"]["event"]["user"] == os.environ["BOT_USER_ID"]: return {'statusCode': 200, 'body': 'this request is not sent by user'} input_text = event["body"]["event"]["text"] channel_id = event["body"]["event"]["channel"] tweet(input_text) post_message_to_channel(channel_id, "done!") return { 'statusCode': 200, 'body': 'ok' } def post_message_to_channel(channel, message): url = "https://slack.com/api/chat.postMessage" headers = { "Content-Type": "application/json; charset=UTF-8", "Authorization": "Bearer {0}".format(os.environ["SLACK_BOT_USER_ACCESS_TOKEN"]) } data = { "token": os.environ["SLACK_BOT_VERIFY_TOKEN"], "channel": channel, "text": message, } req = urllib.request.Request(url, data=json.dumps(data).encode("utf-8"), method="POST", headers=headers) urllib.request.urlopen(req) def is_verify_token(event): token = event["body"]["token"] if token != os.environ["SLACK_BOT_VERIFY_TOKEN"]: return False return True def is_app_message(event): return event["body"]["event"]["type"] == "message" def tweet(input_text): auth = tweepy.OAuthHandler(os.environ["TWITTER_CONSUMER_KEY"], os.environ["TWITTER_CONSUMER_SECRET"]) auth.set_access_token(os.environ["TWITTER_ACCESS_TOKEN"], os.environ["TWITTER_ACCESS_TOKEN_SECRET"]) api = tweepy.API(auth) kakasi = pykakasi.kakasi() kakasi.setMode('J', 'H') conv = kakasi.getConverter() input_text = conv.do(input_text) input_text = input_text.replace('と', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ど', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') api.update_status(status=input_text)requirements.txttweepy pykakasi(蛇足)Botの体裁を整える
テストしてみて思ったんだけど、やっぱり、Botのアイコンが初期のままでは、なんかパッとしないよね。せっかくだから描こうか。...はい、描きました。
最後にアイコン描いたのが工程の中で一番時間かかってるかもしれん。
Slack Botのアイコン設定は、Slack AppのBasic InformationのDisplay Informationからできて、こんな感じでやる。
変更したら「Save Changes」を押すのを忘れずに。
はい、良い感じになりました。やったね。この方が、「ちゃんとできてる感」がある。
(蛇足)平仮名への変換について
ところで、入力文を平仮名に変換するところは、pykakashiではなくMeCabと適当な辞書(UniDicとかneologdとか)の方が正確に出力できるんだろう。だけど、pykakashiの方が圧倒的にLambdaに組み込みやすい
のと、今回はネタなのであまり精度は要求されてないことから、pykakashiで済ませた。MeCabと辞書をLambdaに組み込む場合、MeCabと辞書をAmazon Linux環境下でビルドする必要があるので、EC2インスタンス(t2.medium以上のもの。t2.microだとメモリ不足だった)でビルドして、EFSにマウントする必要がある。LambdaでMeCab(& UniDic)を使う楽な方法はないものかな...



- 投稿日:2021-01-18T10:45:53+09:00
pythonでスプレッドシートとSlackを連携させてBOTを作ってみる2/2(python+gspread+slackbot)
はじめに
前回の記事では、Slack上でスプレッドシートにあらかじめ登録されている単語をBOTに送信すると、その意味を返してくれるというところまで実装しました。
今回はその続きです。
やりたいこと
単語の登録
登録されている単語の一覧出力
単語の削除
これら全てSlack上で完結させる
コードを書いていく
コードを追加するのはmy_mention.pyだけです。
my_mention.py@respond_to('登録:(.*)') def mention_func2(message, entry_word): entry_list = entry_word.split() entry_len = len(entry_list) values_list = worksheet.col_values(1) if entry_len == 2: gyou = len(values_list) # 選択したワークシートの行数を取得 worksheet.update_cell(gyou+1, 1, entry_list[0]) worksheet.update_cell(gyou+1, 2, entry_list[1]) message.reply('「'+ entry_word +'」'+'を登録しました。') else: message.reply('単語とその意味を同時に登録してください。例→PC パソコン') # メンション @respond_to('一覧') def mention_func3(message): values_list = worksheet.col_values(1) message.reply('これまで次のような単語が登録されています。→→→→' + '、'.join(values_list)) @respond_to('削除:(.*)') def mention_func4(message, delete_word): values_list = worksheet.col_values(1) tof = delete_word in values_list if tof == True: cells = worksheet.find(delete_word) # 入力結果に一致する座標を取得 worksheet.delete_row(cells.row) # 選択した行を削除する message.reply('「' + delete_word + '」'+'を削除しました。') else: message.reply('削除しようとしましたが、見つかりませんでした。「一覧」と送信して確認してください。') # メンション気を付けたこと
- 登録
単語と意味を同時に入力して登録したかったので、「登録:○○ △△」と送信したら、○○を単語、△△をその意味としてスプレッドシートに書き込むようにします。
split()を使って、entry_listには○○と△△を分割したリストを渡します。登録ミスをしてしまったときに片方だけスプレッドシートに入力されるということを避けるため、entry_listに格納されている要素がちゃんと2つあるかどうかをentry_lenで確認します。
しっかりと要素が2つ入っていたら、スプレッドシートの操作を行い、空いている行に格納します。
やはりこのあたりはもう少しスマートに書きたいなとつくづく思うのですが、私のような初心者は実装できただけでも万々歳です...改善案があったら教えてください。
- 一覧の出力
message.replyはリストそのものの出力には対応していないようなので、join()を使って文字列に変換します。'、'は要素と要素の間を「、」で区切るという意味です。
- 削除
検索と同じような動作をさせています。特に詰まったところはありませんでした。
さいごに
今回のBOT実装を通して、pythonやその周辺のライブラリについてかなり勉強になりました。Slackとどのように連携するのか気になっていたところがすっきりしたので、また気が向いたら違うものを実装しようと思います。