- 投稿日:2021-01-18T22:53:11+09:00
Amazon Braket のゲート型量子コンピュータで指定できる量子回路
この記事について
- メモです。
- Amazon Braketにおいてゲート型量子コンピュータであるIonQ、Rigetti Aspen-8と量子シミュレータであるSV1シミュレータでどんな量子回路を使うことができるかを確認する方法を示します。
- 記事作成日は 2021/01/18のものなのでその時に使えている量子回路群を示しています。
なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
AmazonBraketで指定できる回路群の確認
最低限 AwsDeviceをimportする必要があります。
どのデバイスを使うか指定する必要があります。
確認したいデバイスがある場合は下のソースコードでコメントアウトを外してください。# SV1の指定 device = AwsDevice("arn:aws:braket:::device/quantum-simulator/amazon/sv1") # Rigetti Aspen-8の指定 #device = AwsDevice("arn:aws:braket:::device/qpu/rigetti/Aspen-8") # IonQの指定 # device = AwsDevice("arn:aws:braket:::device/qpu/ionq/ionQdevice")あとは以下のコードを実行するだけで確認できます。
device_properties = device.properties device_operations = device_properties.dict()['action']['braket.ir.jaqcd.program']['supportedOperations'] print('Quantum Gates supported by this device:\n',device_operations)比較
比較してみます。
上記のソースコードで確認したいデバイスでコメントを外してください。
それぞれの回路で以下のような量子回路セットを表現できます。SV1
['ccnot', 'cnot', 'cphaseshift', 'cphaseshift00', 'cphaseshift01', 'cphaseshift10', 'cswap', 'cy', 'cz', 'h', 'i', 'iswap', 'pswap', 'phaseshift', 'rx', 'ry', 'rz', 's', 'si', 'swap', 't', 'ti', 'unitary', 'v', 'vi', 'x', 'xx', 'xy', 'y', 'yy', 'z', 'zz']Rigetti Aspen-8
['cz', 'xy', 'ccnot', 'cnot', 'cphaseshift', 'cphaseshift00', 'cphaseshift01', 'cphaseshift10', 'cswap', 'h', 'i', 'iswap', 'phaseshift', 'pswap', 'rx', 'ry', 'rz', 's', 'si', 'swap', 't', 'ti', 'x', 'y', 'z']IonQ
['x', 'y', 'z', 'rx', 'ry', 'rz', 'h', 'cnot', 's', 'si', 't', 'ti', 'v', 'vi', 'xx', 'yy', 'zz', 'swap', 'i']回路設計をする際には是非参考にしてみてください。
- 投稿日:2021-01-18T20:57:31+09:00
Terraformで初期パスワードとシークレットアクセスキーを持つIAMユーザを作成する
はじめに
Terraformで複数のtfファイルを定期的にapply, destroyする必要があり、スクリプトを使って楽をしたいなぁという話になりました。
以下の流れをそれぞれスクリプトに分けて自動化したいです。
- IAMユーザーを作成
- 1. のユーザーでリソースを作成
- 1. のユーザーでリソースを削除
まずは、手動での実行がどのようなものか自分自身が理解する必要がありそうだなと。
ということで、TerraformとGnuPGを使って初期パスワードとアクセスキーを持つIAMユーザを作成してみます。
- IAMユーザを作成
- 1. のユーザーでリソースを作成
環境
$ sw_vers ProductName: macOS ProductVersion: 11.1 BuildVersion: 20C69 $ terraform -version Terraform v0.14.4 $ gpg --version gpg (GnuPG) 2.2.27 libgcrypt 1.8.7やること
- IAMユーザ作成のtfファイルを準備
- GnuPGを使って、公開鍵を作成。
gpg_keyに公開鍵を設定- Administrator権限を持つユーザで
terraform apply- 3. で作成されたパスワードやシークレットアクセスキーを複合化
- EC2インスタンス作成のtfファイルを準備
- 複合化したシークレットアクセスキーをもとに、
terrafom apply1. IAMユーザ作成のtfファイルを準備
$ tree . ├── main.tf ├── outputs.tf ├── terraform.tfvars ├── variables.tf └── version.tf最低限EC2に関するポリシーがあれば良いので、以下のように各ファイルを作成。
main.tfresource "aws_iam_user" "ec2_execution_user" { name = "ec2_execution_user" tags = { tag-key = "qiita" } } resource "aws_iam_access_key" "user_access_key" { user = aws_iam_user.ec2_execution_user.name pgp_key = var.pgp_key } resource "aws_iam_user_policy" "ec2_execution_user_role" { name = "ec2_execution_user_role" user = aws_iam_user.ec2_execution_user.name policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:*" ], "Effect": "Allow", "Resource": "*" } ] } EOF } resource "aws_iam_user_login_profile" "ec2_user_profile" { user = aws_iam_user.ec2_execution_user.name pgp_key = var.pgp_key password_reset_required = false depends_on = [aws_iam_user.ec2_execution_user] }version.tfterraform { required_providers { aws = { source = "hashicorp/aws" version = ">= 3.24.0" } } required_version = ">= 0.14.0" }outputs.tfoutput "first_password" { value = aws_iam_user_login_profile.ec2_user_profile.encrypted_password description = "IAMユーザの暗号化されたパスワード" } output "secret_access" { value = aws_iam_access_key.user_access_key.encrypted_secret description = "IAMユーザの暗号化されたシークレットキー" }variables.tfvariable "pgp_key" { description = "IAMユーザーのパスワード生成で利用するpgpの公開鍵(base64形式)" type = string }
terraform.tfvarsについては空欄にしておきます。terraform.tfvarspgp_key = ""2. GnuPGを使って、公開鍵を作成
IAMユーザを作成するにあたって、初期パスワードを暗号化して出力する必要があるため公開鍵を作成していきます。
また、日本語の公式サイトもあったのでこちらも見つつ進めます。
http://gnupg.hclippr.com/documents/howto/
gpgのインストール
$ brew install gpg鍵の出力
nameは任意の値を入力しています。$ gpg -o ./name.public.gpg --export name $ gpg -o ./name.private.gpg --export-secret-key nameBase64エンコード
公開鍵をBase64エンコードする必要があるようです。
この辺りも見る限り、AWSではBase64エンコードされたデータを扱っていると理解すれば良いのかな。
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/iam_user_login_profile#attributes-reference$ cat name.public.gpg | base64 | tr -d '\n' > name.public.gpg.base64 $ cat name.public.gpg.base64出力された値を設定
catで出力された値をコピーし、
terraform.tfvarsに設定する。terraform.tfvarspgp_key = "mQGNBGAEO6cBDADVf3FBHM…"3. Administrator権限を持つユーザで
terraform apply$ export AWS_ACCESS_KEY_ID=xxxx $ export AWS_SECRET_ACCESS_KEY=xxxxxxx $ aws sts get-caller-identity --query Account --output text [Administrator権限を持つユーザ] $ terraform init $ terraform apply … Apply complete! Resources: 4 added, 0 changed, 0 destroyed. Outputs: first_password = "xxx" secret_access = "xxx"4. 3. で作成されたパスワードやシークレットアクセスキーを複合化
まずは初期パスワードである
first_passwordを複合化します。$ export GPG_TTY=$(tty) $ echo "[first_password]" | base64 -d | gpg -r name gpg: *警告*: コマンドが指定されていません。なにを意味しているのか当ててみます ... gpg: 3072-ビットRSA鍵, ID 503Fxxxxx, 日付2021-01-17に暗号化されました "name <xxxx@icloud.com>" xxxxxxxxxx同様に、シークレットアクセスキーを複合化します。
$ echo "[secret_access]" | base64 -d | gpg -r name gpg: *警告*: コマンドが指定されていません。なにを意味しているのか当ててみます ... gpg: 3072-ビットRSA鍵, ID 503xxxxxxx, 日付2021-01-17に暗号化されました "name <xxxxx@icloud.com>" xxxxxxx5. EC2インスタンス作成のtfファイルを準備
t2.microを構築するtfファイルを作成します。$ tree . ├── main.tf └── version.tfmain.tfresource "aws_instance" "ec2_instance_t2" { ami = "ami-0cc75a8978fbbc969" instance_type = "t2.micro" tags = { tag_key = "qiita" } }version.tfterraform { required_providers { aws = { source = "hashicorp/aws" version = ">= 3.24.0" } } required_version = ">= 0.14.0" }6. 複合化したシークレットアクセスキーをもとに、
terrafom apply以前の手順で複合化したシークレットアクセスキーとアクセスキーを使ってユーザを切り替えます。
$ export AWS_ACCESS_KEY_ID=xxxx $ export AWS_SECRET_ACCESS_KEY=xxxxxxx $ aws sts get-caller-identity --query Account --output text [新しく作成したIAMユーザ]無事切り替えできました。よかった!
ではterraform applyをします。$ terraform init $ terraform apply … Apply complete! Resources: 1 added, 0 changed, 0 destroyed.こちらも無事に作成できました!
このようにGnuPGを使った暗号化・複合化の手順も自動化する必要がありそうだということがわかったので、今回の目的は達成。
- 投稿日:2021-01-18T19:45:00+09:00
AWS Lambda + カスタムランタイムでbash実行
概要
2020年12月にLambdaのコンテナ実行に対応(リンク)しているが、任意のプログラムを実行するために Lambda ランタイム APIに準拠して実装する必要がある。
(カスタムランタイムは2020年8月にAmazon Linux2に対応(リンク))このページでは、公式チュートリアルにあるbashをコンテナ経由で実行する。
既存のzipファイル化する方法とさほど変わらないがECRにdockerイメージを置いとくだけなのでデプロイが若干楽になる気がする。
以下の作業を行う。
- カスタムランタイムのためファイル用意
- Dockerfile作成
- ECRにdockerイメージをpush
- pushしたdockerイメージを使ったLambda関数を作成
- イメージの更新
CDKも対応済みだったので試してみた。
手動による作業
カスタムランタイムのためファイル用意
適当なディレクトリに
bootstrapとfunction.shを作成。
両方とも公式チュートリアルと同じコードを使用。このコードでは受け渡したEventをそのまま返している。コメントにあるようにLambdaからのイベントデータは
function.shでは、ShellScriptの引数として渡されるので、もしbash以外の環境で実行するならコマンドライン引数やファイルに一時保存するなどして引き渡せそう。また、結果はRESPONSEに代入しcurlでAWS Lambdaに渡している。
bootstrap#!/bin/sh set -euo pipefail # Initialization - load function handler source $LAMBDA_TASK_ROOT/"$(echo $_HANDLER | cut -d. -f1).sh" # Processing while true do HEADERS="$(mktemp)" # Get an event. The HTTP request will block until one is received EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") # Extract request ID by scraping response headers received above REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) # Run the handler function from the script RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA") # Send the response curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" donefunction.shfunction handler () { EVENT_DATA=$1 echo "$EVENT_DATA" 1>&2; RESPONSE="Echoing request: '$EVENT_DATA'" echo $RESPONSE }Dockerfile作成
DockerHubのリポジトリ のUsageを参考に作成。以下ではDockfileで実行権限をつけているが、最初から実行権限をつけたファイルをCOPYすればいいと思う。
DockerfileFROM public.ecr.aws/lambda/provided:al2 COPY bootstrap ${LAMBDA_RUNTIME_DIR} COPY function.sh ${LAMBDA_TASK_ROOT} RUN chmod +x ${LAMBDA_RUNTIME_DIR}/bootstrap \ && chmod +x ${LAMBDA_TASK_ROOT}/*.sh CMD [ "function.handler" ]ECRにdockerイメージをpush
ECRレポジトリを作り、「プッシュコマンドの表示」の通りビルドしてプッシュする。
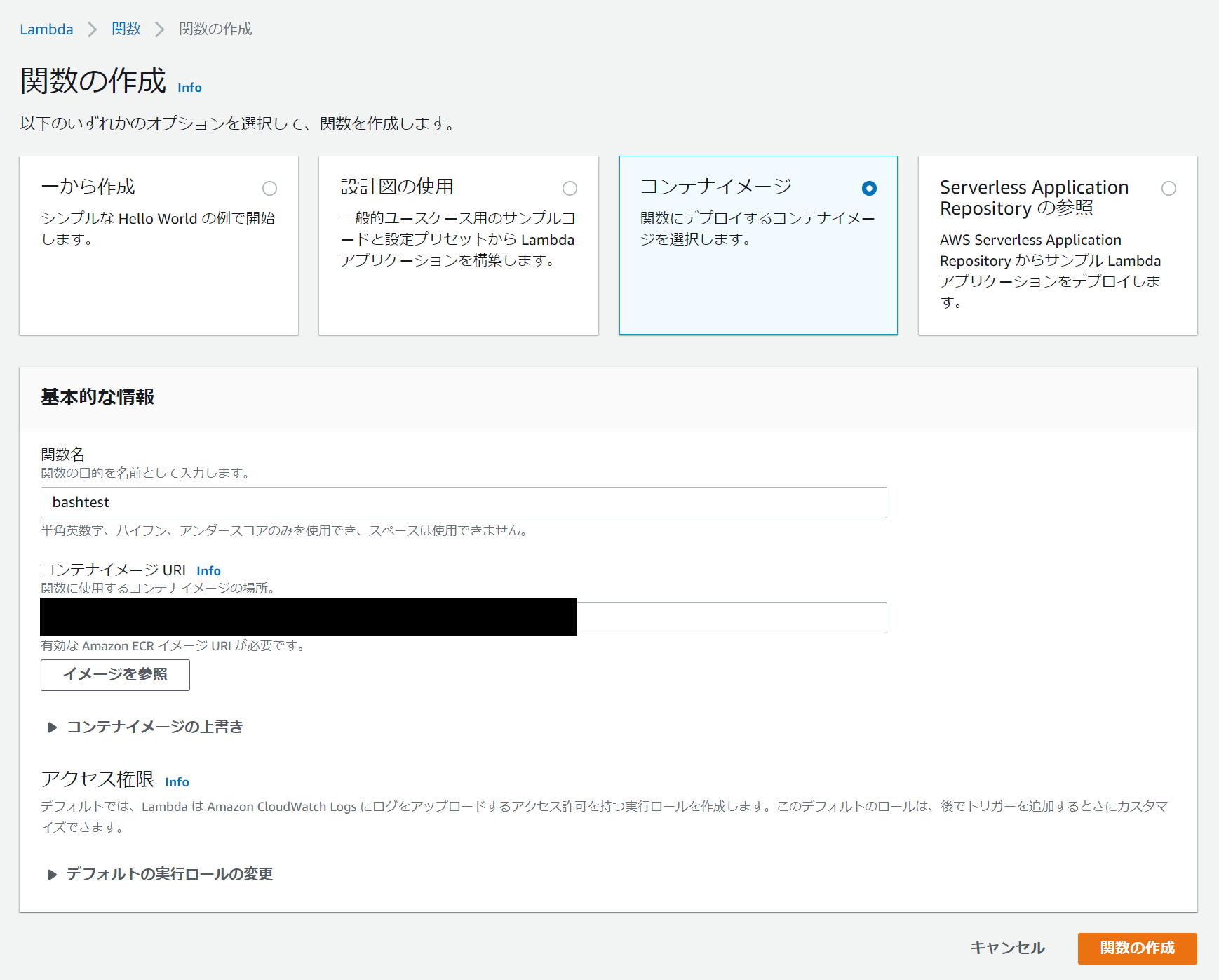
pushしたdockerイメージを使ったLambda関数を作成
コンテナイメージURIを指定して、Lambdaを作成する。
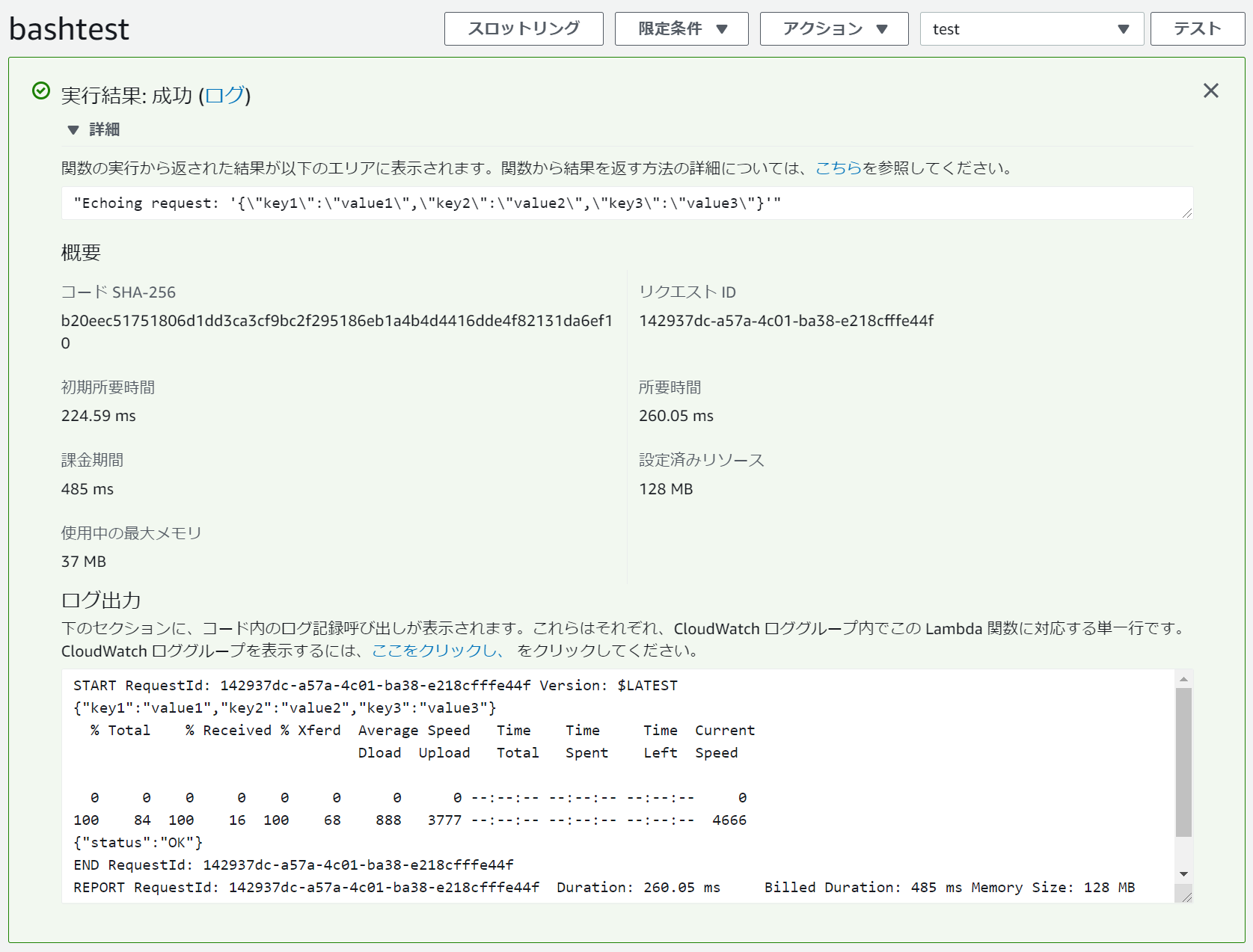
テストデータを作成する。
テストデータを実行する。Eventで渡したデータがそのまま返ってきていることを確認する。
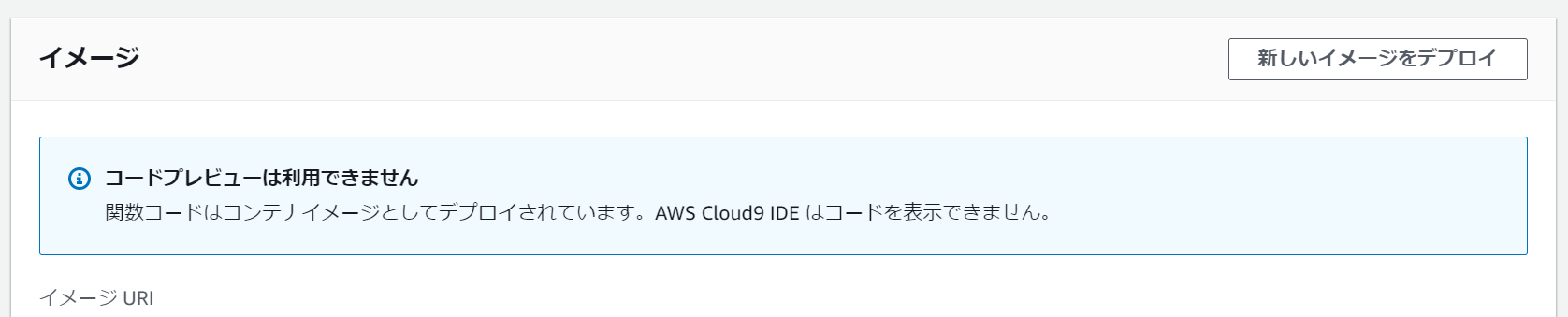
イメージの更新
Lambdaのページで「新しいイメージをデプロイ」をクリックすれば最新のイメージをpullして反映してくれた。
CDKによる作業
ドキュメントを見る限りすでに使えそうだったので試してみる。
先程の
Dockerfile、bootstrap、function.shを cdkプロジェクト下のimagesディレクトリに移した。
stackを以下のように定義した(Pythonを使用)。aws_lambda_container_test_stackfrom aws_cdk import ( core, aws_lambda, ) class AwsLambdaContainerTestStack(core.Stack): def __init__(self, scope: core.Construct, construct_id: str, **kwargs) -> None: super().__init__(scope, construct_id, **kwargs) # Lambdaを作成 aws_lambda.DockerImageFunction( self, "AssetFunction", code=aws_lambda.DockerImageCode.from_image_asset("./images") )勝手にビルドしてECRリポジトリを作ってプッシュしてLambda関数を作ってくれた。
ECRを別に作成して指定することも可能のようだった(ドキュメント参照)。

- 投稿日:2021-01-18T17:45:25+09:00
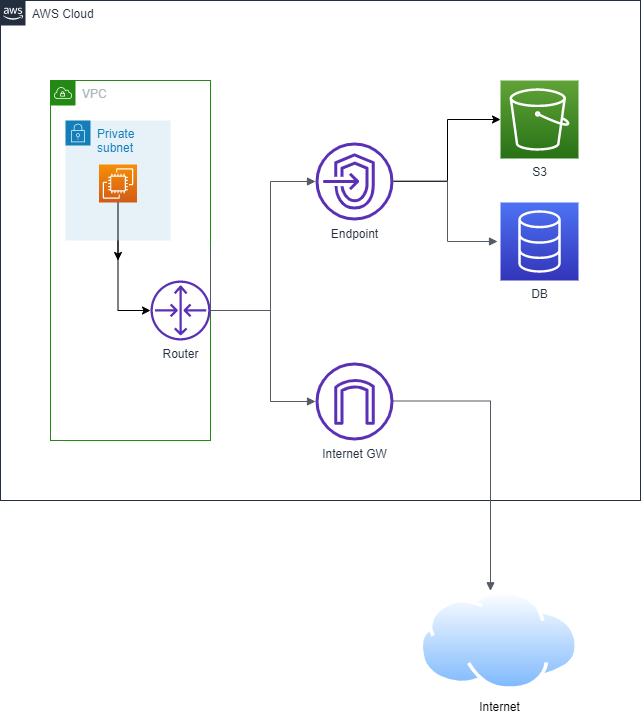
VPCエンドポイント
エンドポイントとは
インターネットを通さないで他のサービスと通信できるようにする仮想デバイス
エンドポイントを使うとできること・利点
- インターネットを通さないで外部リソース(S3,DynamoDB,別のサブネット)にアクセスできる
- データをインターネットに公開しなくて済む
- プライベートサブネットから外部リソースにアクセスできる
GW(ゲートウェイ)型
- ネットワークレイヤで動作
- サブネットに特殊なルーティングを設定してGWに向けてルーティング
- VPC内部から直接通信
構成
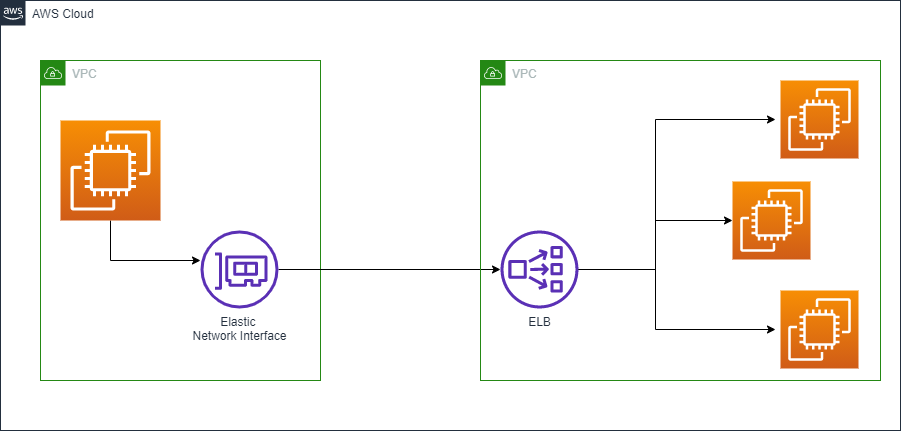
インターフェース型
- アプリケーションレイヤで動作
- AWS PrivateLinkと呼ぶ
- 実態はプライベートアドレスを持つENI(Elastic Network Interface)
構成
参考
- 投稿日:2021-01-18T17:45:25+09:00
【AWS】VPCエンドポイント
エンドポイントとは
インターネットを通さないで他のサービスと通信できるようにする仮想デバイス
エンドポイントを使うとできること・利点
- インターネットを通さないで外部リソース(S3,DynamoDB,別のサブネット)にアクセスできる
- データをインターネットに公開しなくて済む
- プライベートサブネットから外部リソースにアクセスできる
GW(ゲートウェイ)型
- ネットワークレイヤで動作
- サブネットに特殊なルーティングを設定してGWに向けてルーティング
- VPC内部から直接通信
構成
インターフェース型
- アプリケーションレイヤで動作
- AWS PrivateLinkと呼ぶ
- 実態はプライベートアドレスを持つENI(Elastic Network Interface)
構成
参考
- 投稿日:2021-01-18T17:42:17+09:00
AWS athenaでのテーブルのプレビュー結果がzero recordになった時
はじめに
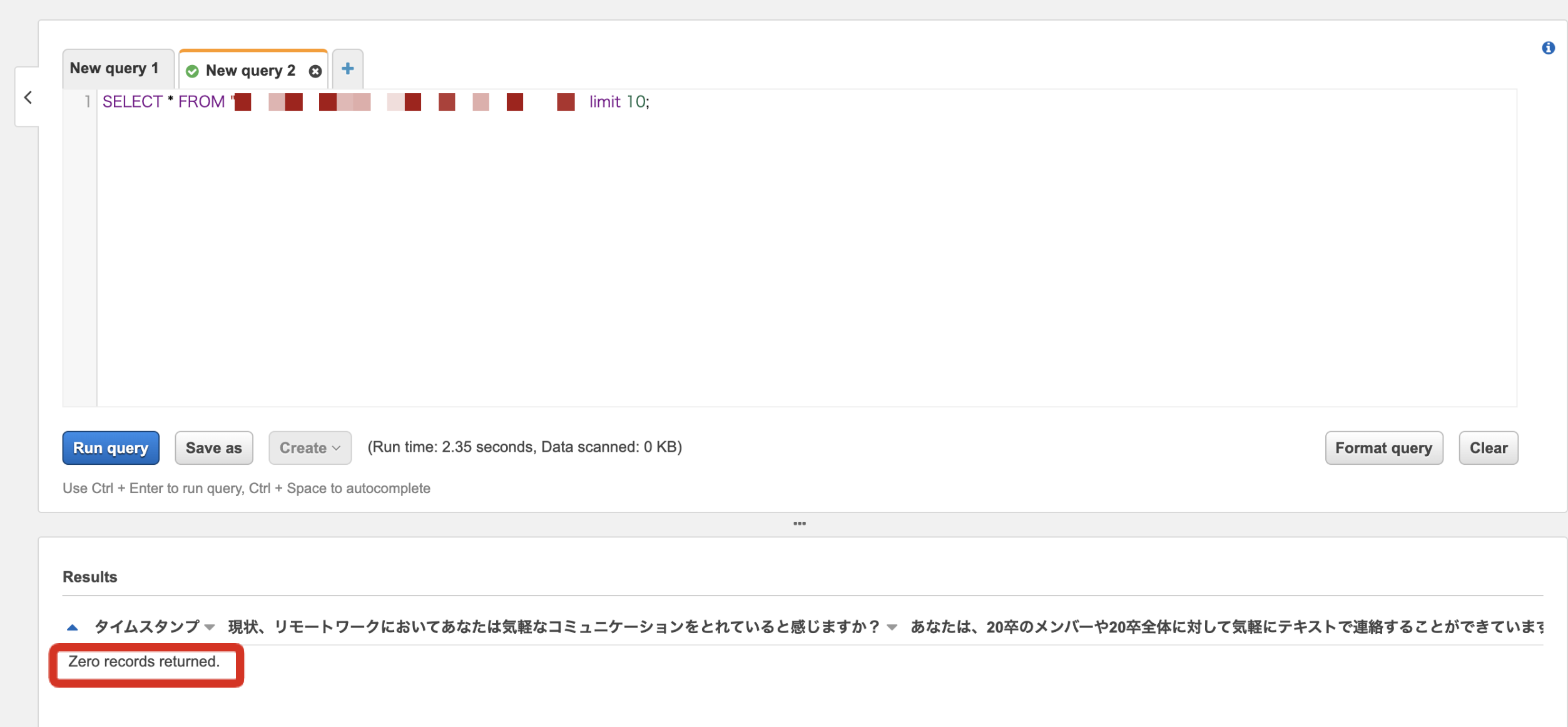
Glue catalogに作成されたテーブルをAthenaで確認する際、テーブルの中身は表示されず以下のようなメッセージが出力される場合があります。
Crawlerのパスもうまく設定したのに、中身がないと表示されるだけで原因について教えてくれないため、この現象を解決するのに時間がかかり苦労するケースがあります。この記事では
- なぜzero record状態が起こるのか
- 解決方法は何か
について説明したいと思います。
なぜzero record状態が起こるのか
Crawlerを回す際、Crawlerはパス内のデータの隙間の類似性を下に1つのテーブルを作成して返します。
この場合、Crawlerの実行のリソースとして作られるテーブルがzero recordになる原因は、パスの中の複数のファイルが持つスキーマがそれぞれ違うっていうことになります。スキーマとは?
スキーマとは、データの構造、性質や他のデータとの関連、データベースを操作する時のルールや表現法などを定義したもののことです。
(詳細はこちらをご参照ください。)
つまり、「スキーマが違う」というのは、それぞれのデータが持っている内容が違うことを意味します。1つのパスの中に違うスキーマのデータがある時、
Cralwerはどこを基準に1つに合わせたらいいかの判断ができないため、空のテーブルを返すと思われます。まずチェックするもの
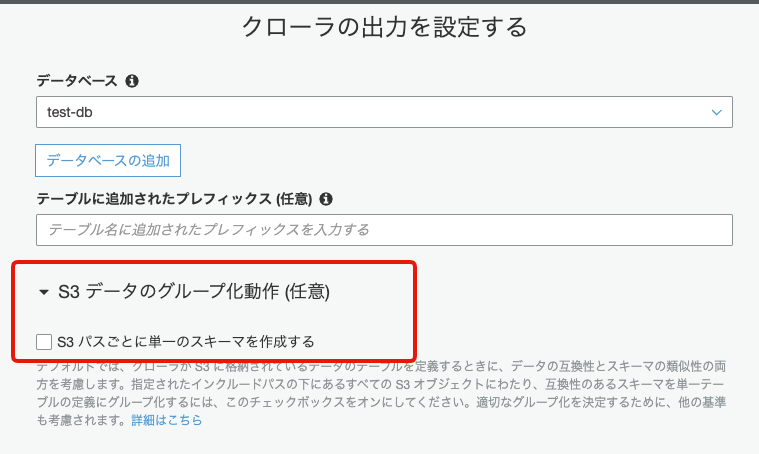
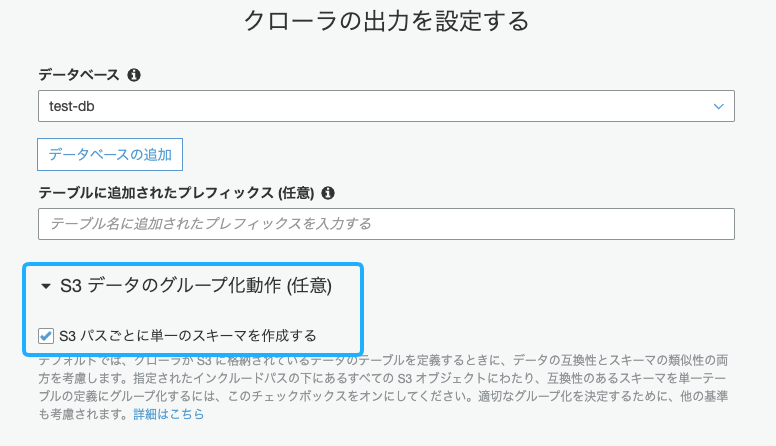
Cralwerの設定画面で、「S3パスごとに単一の」スキーマを作成する」にチェックが外されているかを確認してください。
後ほど説明いたしますが、この項目にチェックされていると、実際作りたいテーブルと違うスキーマを持つテーブルが作られるため、基本的にはチェックを外して使用することをおすすめします。解決方法
ここからは、zero recordの現象を解決するための方法をいくつか紹介したいと思います。
方法①
- 同一パスにい入っているデータソースファイルを加工してS3バケットに入れ直す方法になります
- データのスキーマが一致することが重要
- スキーマの完全一致とは「データの構造が同じ」な状態を意味する カラム名、カラムの数、カラムのデータ型が全部一致
例えば、
order_list1.csv
customer item price count date Tom aa 1000 20 2020-02-01 John bb 2000 45 2020-02-01 Jane cc 3000 3 2020-02-01 Amy dd 5000 16 2020-02-01 order_list2.csv
customer item price count date Tom dd 4000 25 2020-03-01 David ee 6000 30 2020-03-01 Judy bb 2000 5 2020-03-01 Smith ff 1500 50 2020-03-01 Amy cc 3000 35 2020-03-01 上記のようにスキーマが完全一致する場合、Glue crawlerが自動で1つのテーブル化してcatalogに追加してくれますので、zero recordはもう発生しなくなります。
方法②
「カラム名&カラムの数が一致するか?」の基準にs3パスを分ける方法です
例えば、order_list.csv
customer item price count date Tom aa 1000 20 2020-02-01 John bb 2000 45 2020-02-01 Jane cc 3000 3 2020-02-01 Amy dd 5000 16 2020-02-01 stock_list.csv
item count aa 25 bb 10 cc 5 dd 50 ee 35 order_listとstock_list単一のテーブルに併合させる必要がないため、
S3パスを分けて登録することで、それぞれ別のパスで指定すると、2つのテーブルを分けて作成できます。今回の場合、
s3://(bucket名)/(folder名)/order_list.csv s3://(bucket名)/(folder名)/stock_list.csvをそれぞれ追加すると、order_listとstock_listは別々のテーブルとして作成されます。
方法③
cralwerの設定を変更して無理やり合わせる方法もあります。
この方法は、さっきチェックを外した 「S3パスごとに単一のスキーマを作成する」を再度チェックだけでOKです。注意事項
このオプションで作られたテーブルは元のファイルとは違うカラム情報を持ってる可能性が非常に高いです。
- 同一カラムにも違う内容が入ったり
- 意図したように統合されない可能性も高いです
ので、基本オプションは「チェックを外すこと」をおすすめします。
結論
Glue CrawlerでGlue catalogにテーブルを追加する際は
1つのS3パスに入ってるパスは同じスキーマを持つ入るように設定することに気をつけましょう。
- 投稿日:2021-01-18T17:01:31+09:00
AWS Aurora(MySQL)のスロークエリログめも
概要
Aurora(MySQL)でスロークエリをテーブル(
mysql.slow_log)に記録し確認できるスロークエリログがテーブルに記録されるようにする
DBパラメータグループで以下を設定
パラメータ名 設定値 説明 log_output 1 スロークエリログを有効にするかどうか long_query_time 5 ログに記録されるクエリの最短実行時間(秒)。任意の値を設定する log_output TABLE ログの出力先(TABLE or FILE) 参考: MySQL データベースログファイル - Amazon Relational Database Service
スロークエリログを確認する
SELECT * FROM mysql.slow_log;スロークエリログをローテーションする
放っておくと無限にスロークエリログがテーブルに溜まっていくので、ログが多くなってきたらローテーションすると良い。
↓のプロシージャを実行するとログがローテーションされる
CALL mysql.rds_rotate_slow_log;
- 現在のログテーブル(
slow_log)がバックアップのログテーブル(slow_log_backup)にコピーされ、現在のログテーブルは空っぽになる。- バックアップのログテーブル(
slow_log_backup)がすでに存在する場合は、現在のログテーブルをバックアップにコピーする前に、削除される。参考: mysql.rds_rotate_slow_log - Amazon Relational Database Service
- 投稿日:2021-01-18T16:41:57+09:00
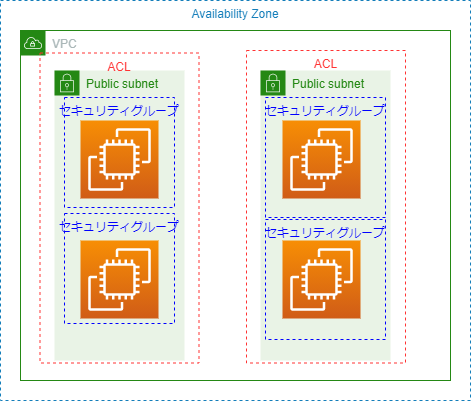
【AWS】ACL と セキュリティグループ の違い
初めに
AWSでのトラフィック制御には代表として2つある
適用範囲イメージ
ネットワークACL
- VPC/サブネットのトラフィックを制御する適用されるFW機能
セキュリティグループ
- インスタンスのトラフィックを制御するFW機能
比較
項目 ネットワークACL セキュリティグループ 単位 VPC/サブネット サーバー単位 ステート ステートレス ステートフル 設置項目 許可(In/out)と拒否(In/out) 許可のみ(In/out) デフォルト通信 すべての通信を許可(外部と通信可) 同じセキュリティグループ内のみ許可(外部と通信不可) 適用優先度 番号順にルールを適用して処理 すべてのルールを適用して処理 ステートレスとステートフル
参考
Amazon VPC でのインターネットワークトラフィックのプライバシー
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
- 投稿日:2021-01-18T16:12:05+09:00
EBSボリュームタイプの変更(gp2→gp3)
はじめに
- EBSのボリュームタイプの変更を実施したので備忘録として残します。 ※EC2インスタンスの停止させることなく、オンライン状態でのEBSボリュームタイプ変更作業です。
- AWS-CLIを用いて作業をおこないます。
実施手順
環境
OS情報 [root@localhost ~]# cat /etc/centos-release CentOS Linux release 7.9.2009 (Core) AWS-CLIバージョン [root@localhost ~]# aws --version aws-cli/2.1.19 Python/3.7.3 Linux/3.10.0-1160.11.1.el7.x86_64 exe/x86_64.centos.7 prompt/offEBSボリュームタイプ変更作業
▼EBSのボリューム IDを変数「EBS_VOLUME_ID」に格納
# EBS_VOLUME_ID="vol-1111111111111111"▼現在のEBSのボリュームタイプを確認
[root@localhost ~]# aws ec2 describe-volumes --volume-ids ${EBS_VOLUME_ID} --query Volumes[].VolumeType --output text gp2▼ボリュームタイプを「gp3」に変更
[root@localhost ~]# aws ec2 modify-volume --volume-id ${EBS_VOLUME_ID} --volume-type gp3 { "VolumeModification": { "VolumeId": "vol-1111111111111111", "ModificationState": "modifying", "TargetSize": 1000, "TargetIops": 3000, "TargetVolumeType": "gp3", "TargetThroughput": 125, "OriginalSize": 1000, "OriginalIops": 3000, "OriginalVolumeType": "gp2", "Progress": 0, "StartTime": "2021-01-17T01:31:11+00:00" } }※今回は、1TBのEBSボリュームで、ボリュームタイプの変更をおこないます。
▼EBSボリュームタイプ変更の進捗を確認
[root@localhost ~]# aws ec2 describe-volumes-modifications --volume-id ${EBS_VOLUME_ID} { "VolumesModifications": [ { "VolumeId": "vol-1111111111111111", "ModificationState": "completed", "TargetSize": 1000, "TargetIops": 3000, "TargetVolumeType": "gp3", "TargetThroughput": 125, "OriginalSize": 1000, "OriginalIops": 3000, "OriginalVolumeType": "gp2", "Progress": 100, ※ここの値が100になれば、処理が完了 "StartTime": "2021-01-17T01:31:11+00:00", "EndTime": "2021-01-17T01:52:13+00:00" } ] }ボリュームタイプ変更の実施時間:2021/01/17 10:31(日本時間)
ボリュームタイプ変更の終了時間:2021/01/17 10:52(日本時間) 処理時間→21分▼現在のEBSのボリュームタイプを確認
[root@localhost ~]# aws ec2 describe-volumes --volume-ids ${EBS_VOLUME_ID} --query Volumes[].VolumeType --output text gp3まとめ
今回は、何もデータが入っていないEBSボリュームで実施いたしました。そのため、データがたくさん入っている場合だと、もっと時間がかかるかもしれません。
また、旧世代(C1, C3, G2, I2, M1, M2, M3, R3, T1)のファミリーの場合は、処理が失敗するようなので、注意が必要のようです。参考URL
https://blog.serverworks.co.jp/reinvent2020-modify-ebs-gp2-to-gp3
- 投稿日:2021-01-18T15:35:24+09:00
RDSのDBパラメーターグループ関連のコマンドめも
はじめに
- RDSのDBパラメーターグループ関連のコマンドメモとしての備忘録
- 本手順では、AWS-CLIでの操作となります。
実施手順
DBパラメーターグループ名の一覧を出力
[root@localhost ~]# aws rds describe-db-parameter-groups --query 'DBParameterGroups[].DBParameterGroupName' [ "aurora-postgresql11", "postgresql11" ]※現在、登録してあるDBパラメーターグループは「aurora-postgresql11」「postgresql11」の2つです。
DBパラメーターグループの設定値をファイルに出力
▼DBパラメーターグループの設定値をJSON形式(デフォルト)で出力
・aurora-postgresql11 の場合 # aws rds describe-db-parameters --db-parameter-group-name aurora-postgresql11 > /tmp/aurora-postgresql1_parameters.json▼DBパラメーターグループの設定値をCSV形式(出力結果を成形した状態)で出力
# aws rds describe-db-parameters --db-parameter-group-name aurora-postgresql11 \ | jq -r '["名前","値","許可された値","変更可能","送信元","適用タイプ","データ型","説明","ApplyMethod","MinimumEngineVersion"], (.Parameters[] | [.ParameterName,.ParameterValue,.AllowedValues,.IsModifiable,.Source,.ApplyType,.DataType,.Description,.ApplyMethod,.MinimumEngineVersion]) | @csv' \ | iconv -t sjis > /tmp/aurora-postgresql11_parameters.csv※上記のコマンドは、以下のブログが参照したものである。
https://dev.classmethod.jp/articles/rds-parameter-group-export-to-csv/DBパラメーターグループの削除
・aurora-postgresql11 の場合 # aws rds delete-db-parameter-group --db-parameter-group-name aurora-postgresql11参考URL
https://dev.classmethod.jp/articles/rds-parameter-group-export-to-csv/
https://blog.manabusakai.com/2017/02/rds-parameter-group-diff/
- 投稿日:2021-01-18T12:47:24+09:00
0からRuby on Railsの環境構築【Cloud9】(Rubyのバージョン変更からRailsのインストールまで)
Ruby on Railsの環境構築(Cloud9)
本記事はRuby on Railsの環境構築を初心者の方でも迷わずできるように解説した記事です。
Ruby on Railsは、広範囲にわたる開発で使用されています。日本のスタートアップでも採用されていることが多く、食べログやnote、会計ソフトのfreeeなどもRuby on Railsによって開発されています。
そんなRuby on Railsですが、2019年8月にバージョン6.0がリリース、2020年12月にはバージョン6.1がリリースされました。また、Ruby自体も2020年12月にバージョン3.0に大型アップデートされ新しい機能が追加されています。
ここでは、Ruby 3.0とRuby on Rails 6.1.1の環境構築方法を説明していきます。
環境
- Cloud9 (Mac、Windowsどちらも対応可能です)
- Macでの環境構築方法の記事も公開しています。
- Amazon Linux2
- Cloud9の環境を立ち上げる際に、Amazon Linux2を選択している必要があります。
Rubyのバージョンを確認する
以下のURLからコンソールにサインインして、Cloud9を立ち上げましょう。
https://us-east-2.console.aws.amazon.com/console/
Cloud9上のTerminalを立ち上げて、以下のコマンドを実行してRubyのバージョンを確認しましょう。
ruby -v以下のように数字が表示されます。
ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux]ここではRubyの環境が「2.6.3」であることがわかります。
Rubyのバージョンを変更する
それではここからRubyのバージョンを変更していきます。
Rubyのバージョン管理ツールであるrvmを使います。
以下のコマンドでインストール済みのRubyのバージョンを確認します。
rvm list実行結果は以下になります。
rvm list =* ruby-2.6.3 [ x86_64 ] # => - current # =* - current && default # * - defaultまた、以下のコマンドでインストール可能なRubyのバージョンを一覧表示します。
rvm list known実行結果で、自分のインストールしたいバージョンがあることを確認してください。
rvm list known //====略==== # MRI Rubies [ruby-]1.8.6[-p420] [ruby-]1.8.7[-head] # security released on head [ruby-]1.9.1[-p431] [ruby-]1.9.2[-p330] [ruby-]1.9.3[-p551] [ruby-]2.0.0[-p648] [ruby-]2.1[.10] [ruby-]2.2[.10] [ruby-]2.3[.8] [ruby-]2.4[.6] [ruby-]2.5[.5] [ruby-]2.6[.3] ruby-head //====略====ここでインストールしたいバージョンがない場合は、rvmのアップデートをおこなう必要があります。
アップデートをするには、以下のように
getコマンドを実行します。rvm get latestrvm get latest //====略==== Thanks for installing RVM Please consider donating to our open collective to help us maintain RVM. Donate: https://opencollective.com/rvm/donate RVM reloaded!インストールしたrvmのバージョンを確認しましょう。
rvm -v rvm 1.29.10 (1.29.10) by Michal Papis, Piotr Kuczynski, Wayne E. Seguin [https://rvm.io]再度インストールしたいバージョンがあるかを確認しましょう。
rvm list known //====略==== # MRI Rubies [ruby-]1.8.6[-p420] [ruby-]1.8.7[-head] # security released on head [ruby-]1.9.1[-p431] [ruby-]1.9.2[-p330] [ruby-]1.9.3[-p551] [ruby-]2.0.0[-p648] [ruby-]2.1[.10] [ruby-]2.2[.10] [ruby-]2.3[.8] [ruby-]2.4[.10] [ruby-]2.5[.8] [ruby-]2.6[.6] [ruby-]2.7[.2] [ruby-]3[.0.0] #←インストールしたいバージョン ruby-head //====略====次に、以下のコマンドを実行してRubyのバージョンをインストールします。
<version>の部分には、インストールするバージョンを指定してください。rvm install <version>以下のように表示されれば正常にインストールされています。
ここでは
3.0を指定しています。rvm install 3.0 //===略=== ruby-2.7.2 - #generating global wrappers....... ruby-2.7.2 - #gemset created /home/ec2-user/.rvm/gems/ruby-2.7.0 ruby-2.7.2 - #importing gemsetfile /home/ec2-user/.rvm/gemsets/default.gems evaluated to empty gem list ruby-2.7.2 - #generating default wrappers.......以下のコマンドで使用するバージョンを指定しましょう。
rvm use <version> rvm use 3.0.0最後に以下のコマンドで、先ほど指定したバージョンが表示されることを確認してください。
ruby -v ruby 3.0.0p0 (2020-12-25 revision 95aff21468) [x86_64-linux]以上でRubyのバージョン変更は終了です。
Bundlerをインストール
Rubyをインストールしたら、次にBundlerをインストールします。
RubyではGemというライブラリを使いパッケージを管理しています。
Gemコマンドで簡単にインストールやアンインストールができますが、複数のGemを使うとGem同士で依存関係が生まれ、バージョン違いによる不具合が出てきます。
そこで、BundlerでGemのそれぞれのバージョンを正確に追跡し管理して、Rubyプロジェクトに一貫した環境を提供します。
それではBundlerをインストールしましょう。以下のコマンドを入力します。
gem install bundlerコマンドを実行するとインストールが始まります。
インストールされたBlundlerのバージョンを確認しましょう。
次のコマンドを入力します。
bundler -vコマンドの実行後、次のように表示されます。
bundler -v Bundler version 2.1.4「version 2.1.4」とバージョン情報が表示されました。
これでBlundlerがインストール済みであることを確認できました。
yarnをインストール
次にyarnをインストールします。
yarnはJavaScriptのライブラリの利用に必要なパッケージマネージャです。
yarnと互換性のあるnpmというパッケージマネージャもあります。しかし、Rails6ではWebpackerが標準になったことにより、yarnが必要です。
それでは、yarnのインストールを行いましょう。
次のコマンドを入力します。
npm i -g yarnyarnが実際にインストールされたかを確認するために、次のコマンドを入力します。
yarn -vコマンドを実行すると、次のように表示されます。
yarn -v 1.22.10ここでは「
1.16.0」と表示されました。バージョン情報が表示されていれば、yarnがインストールされたことが確認できます。Ruby on Railsのバージョンを確認する
ここからはRailsのバージョンを確認していきます。
Cloud9のTerminalで以下のコマンドを実行してRailsのバージョンを確認しましょう。
rails -v以下のようにデフォルトで指定されるRailsのバージョンが表示されます。
rails -v Rails 5.0.0
rails newを実行する際にバージョンを指定しないとこのバージョンでアプリケーションが作成されます。次に、インストールされているRailsのバージョンを確認しましょう。
以下のコマンドを実行して下さい。
gem list rails以下のように表示されるので、railsの項目を確認しましょう。
「5.0.0」がインストールされていることがわかるかと思います。gem list rails *** LOCAL GEMS *** rails (5.0.0) rails-dom-testing (2.0.3) rails-html-sanitizer (1.3.0) sprockets-rails (3.2.2)Ruby on Railsのインストール
いよいよ、Railsをインストールします。
Railsのインストール時に「
-v バージョン番号」とバージョンを指定してインストールできます。今回はバージョン「
6.1.1」をインストールします。次のコマンドを入力します。
gem install rails -v 6.1.1コマンドを実行すると、インストールを開始します。インストールの完了までに数分かかることがあります。
Railsをインストールしたら、Railsのバージョンを確認するために次のコマンドを入力します。
rails -vコマンドを実行すると、次の画面が表示されます。
rails -v Rails 6.1.1「
Rails 6.1.1」と表示されました。これで無事にRuby on Railsのインストールが完了しました。
※本記事はTechpitの教材を一部修正したものです。
参考
- 投稿日:2021-01-18T12:20:44+09:00
ちゃま語でツイートするSlack Bot 〜AWS Lambdaを用いたSlack Botの作り方〜
はじめに
こんな人に読んでもらいたい
ネタはホロライブ関連だけど、やってることは以下のようなことなので、役に立つかも(役に立ってほしい)。
・AWS Lambdaを用いてSlack Botを作る
・Botとの個人チャットに送信された文章を取得して、定められた動作する。(返信もする)
・twitterAPIでツイート
・AWS Lambdaをserverless-frameworkでデプロイ
・Python外部モジュールはserverless-python-requirementsで導入これは...?
ちゃま語でツイートするSlack Botを作った。ざっくり説明すると、
- Slack Botにツイートしたい文を入力する
- ちゃま語に翻訳する
- 翻訳した文をツイートする
そもそも「ちゃま語」って...?(最初にこれ書けよ
先日、マリン船長が配信で、「ちゃま語であそぼ」なるものを、はあちゃまが提案していたという旨の話をしていた。(以下の動画を参照)
https://www.youtube.com/watch?v=T2yMNE_zb54
https://www.youtube.com/watch?v=IoOeMaCzuZYちゃま語というのは、ざっくりいうと文中の「と」を「ちゃま」に置換したものだという。
例えば、「赤井はあと」->「赤井はあちゃま」
「トマト」->「ちゃままちゃま」
「となりのトトロ」->「ちゃまなりのちゃまちゃまろ」そして、「ちゃま語であそぼ」というのは以下のようなルールのローテーションリズムゲームらしい。
- 1人目が「と」を含む単語のお題を言う
- 2人目がお題をちゃま語にする(「と」を「ちゃま」にして言う)
- 3人目は1.と同じく「と」を含む単語のお題を言う。以下繰り返し。
配信を見ていた私は、ミーム汚染されていく船長とコメント欄を見ながら大爆笑しつつ、「『ちゃま語でツイートするSlack Bot』でも作って、『AWS Lambdaを用いたSlack Botの作り方』の記事を書くか〜〜」と考えた次第だ。
[追補]
以前、私は仕事で社内の請求書作成自動化Botを作った。で、その話を記事にしようと思った。(システムが扱うデータは勿論機密だけど)実装方法自体は機密ではないから…とはいえ、社内のシステムを記事にするのはちょっと…ねぇ…。一旦保留した。で、今回ちょうどいいネタが見つかったので、それを使って『AWS Lambdaを用いたSlack Botの作り方』を記事にした。
(Googleスプレッドシートの編集の自動化とか、「請求書作成自動化Bot」で使った他のことの話は後日別記事に書こうかなと思う。)本題
はじめる前に
Twitter Developerアカウントを申請・取得しておいてくださいな。(今回の作業でこれが一番めんどくさい)
serverless-frameworkでLambdaをデプロイ
まずは、serverless-frameworkを用いて、chama-language-tweet-botというLambdaを作る。
(serverless-frameworkが入ってない人はnpm install -g serverlessして入れておいて)
(awsのアカウントを設定していない人はやっておいて。「aws-cli 使い方」とか調べれば出てくるから、キーを設定して。)$ mkdir chama-language-tweet-bot $ cd chamago-tweet-bot $ npm init $ serverless create --template aws-python3 --name chama-language-tweet-bot $ ls handler.py package-lock.json serverless.yml node_modules package.jsonここまではお決まりの流れだね。(ここで、
sls deployしてちゃんと設定できているか確認してみても良いかと)
あ、私の趣味だけど、handler.pyではわかりにくいので、ここでファイル名をslackbot.pyに変更した。今回は1つの関数しか作らないからhandler.pyのままでも問題ないが、大抵1つのLambdaに複数の関数を置いたりするので、handler.pyでは分かりにくすぎる。そこで、私は普段、関数毎に.pyを作って、それぞれに関数handlerを設けて、それをhandlerにしてる。SlackBotに接続する前に
SlackBotは、設定の途中でLambda等のAPIとの接続がうまくいっているか確かめるテストがある。なので、その段階に行くまでに、テストに対応できる挙動をLambdaに作っておく必要がある。
serverless.ymlservice: chama-language-tweet-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 functions: slackbot: handler: slackbot.handler timeout: 200 events: - http: path: slackbot method: post cors: true integration: lambdaslackbot.py# coding: utf-8 import json import logging # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] return { 'statusCode': 200, 'body': 'ok' }以上のようにして、
sls deployする。そして、エンドポイントをメモする。SlackBotの作成
では、SlackBotを使っていこう。
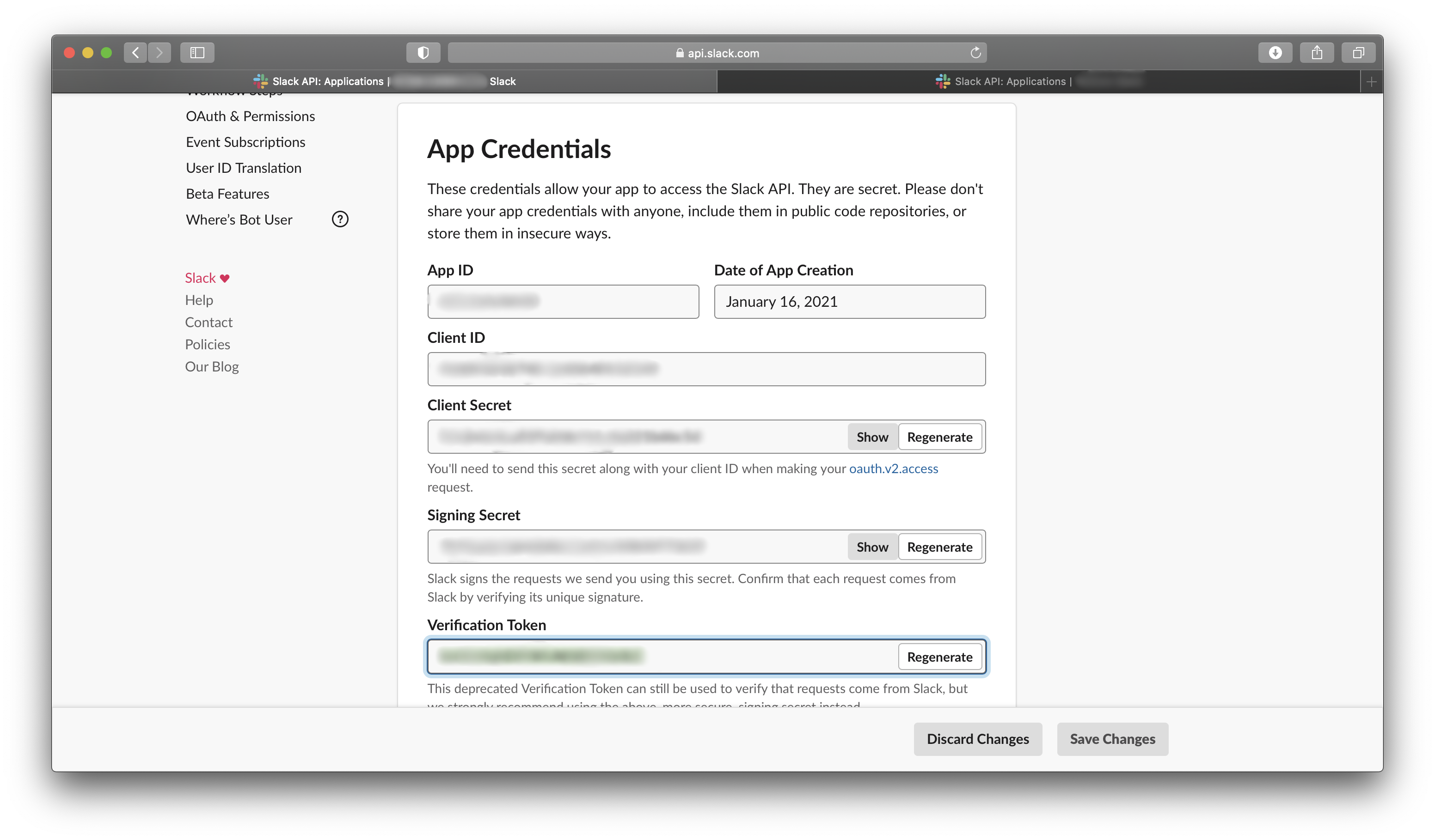
Slack API にアクセスして、「Create New App」から新しいSlack Appを作る。
名前は適当に決めて、Development Slack Workspaceでインストール先のワークスペースを決める。この時、間違っても会社のワークスペースを選択しないようにSlack Appができたら、早速App Credentialsを探して、Verification Tokenをメモしておく。
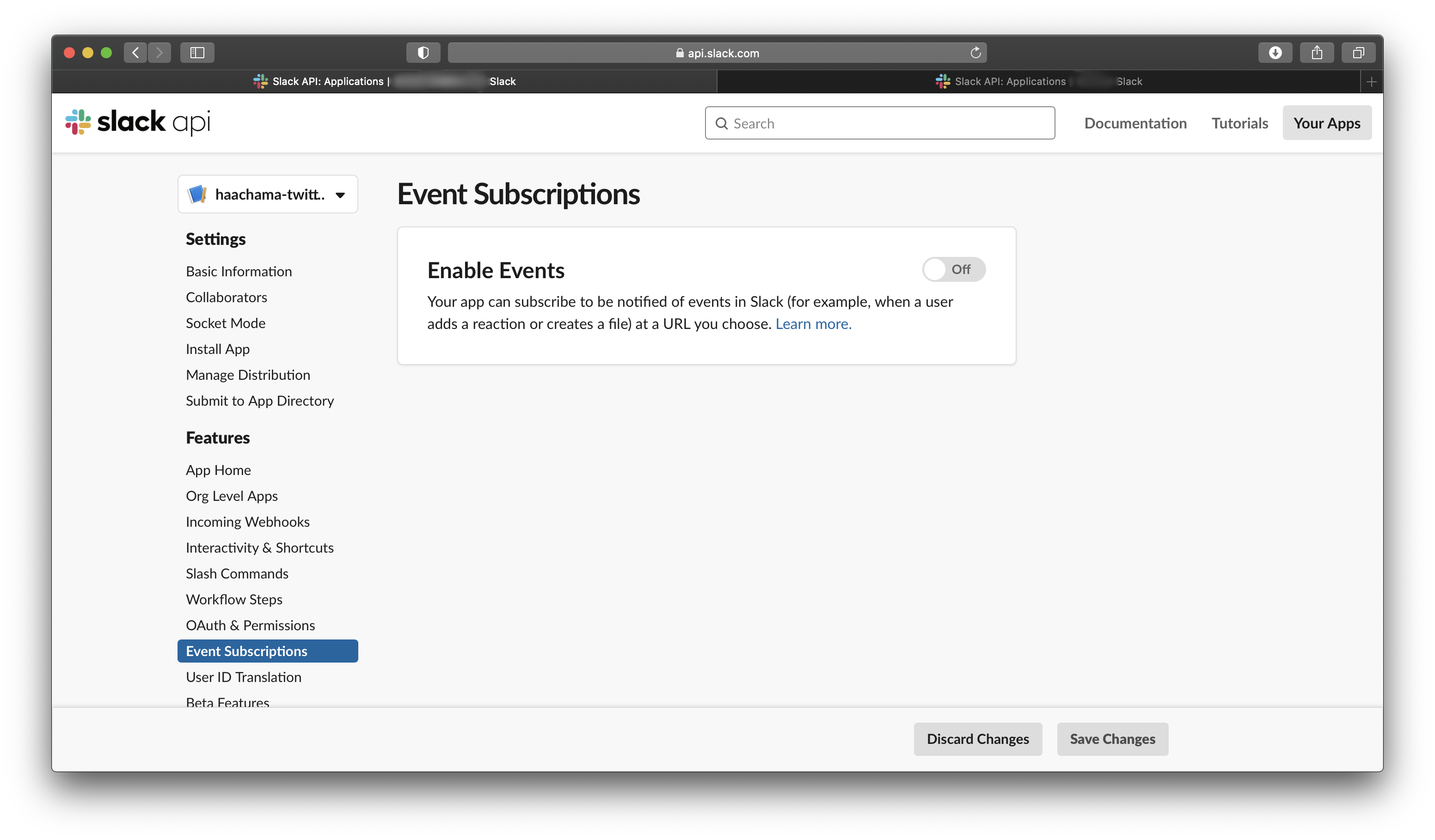
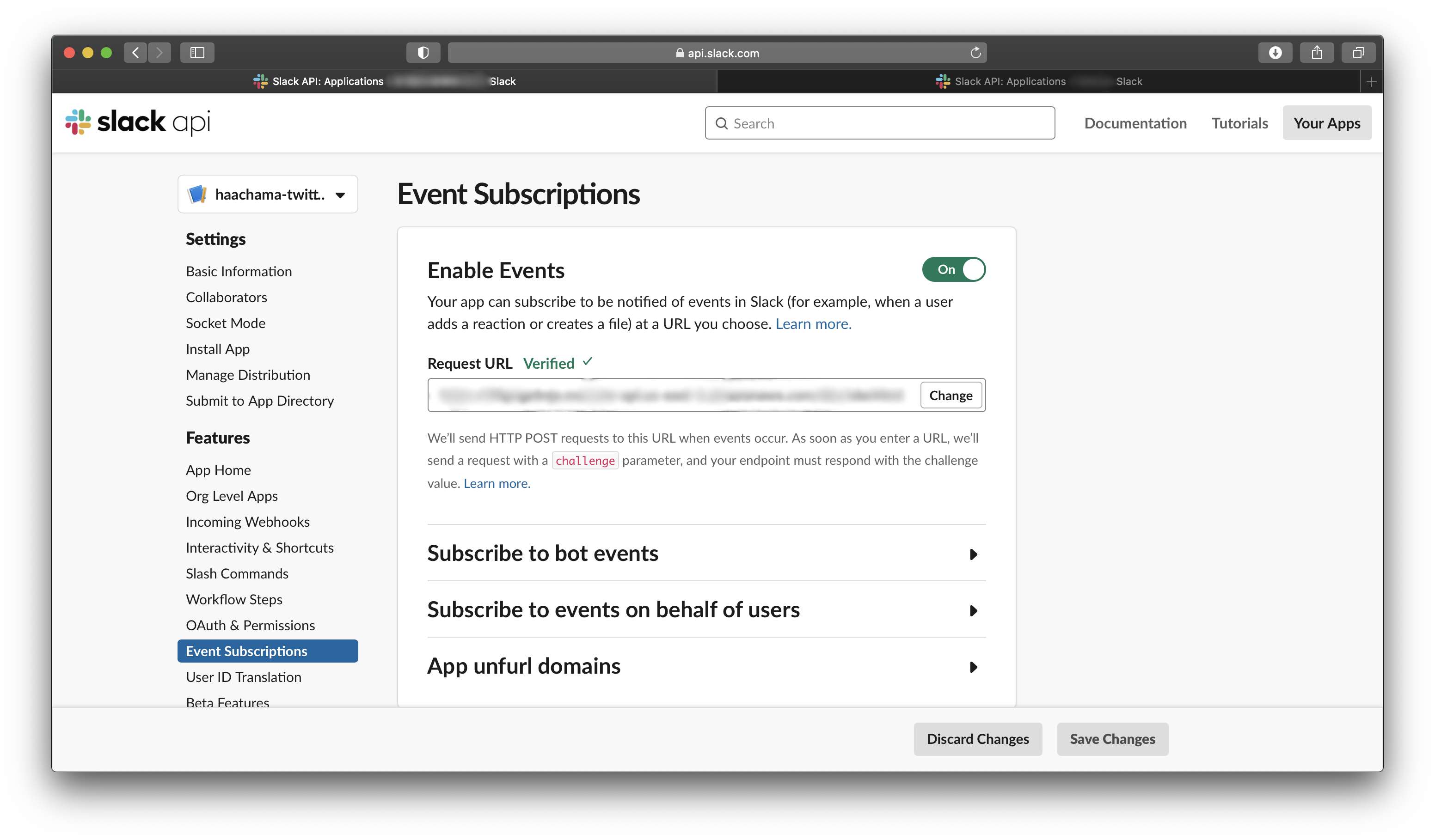
次に、Slack APIを有効にする。今回はSlack Eventというものを使うので、Event Subscriptionsを開いて、Enable Eventsをonにする。
Enable Eventsをonにしたら、Request URLにLambdaのエンドポイントを入れる。そうすると、(ここまでのLambdaがちゃんとできていれば)Verifiedとなる。これでSlackとLambdaの接続が完了する。
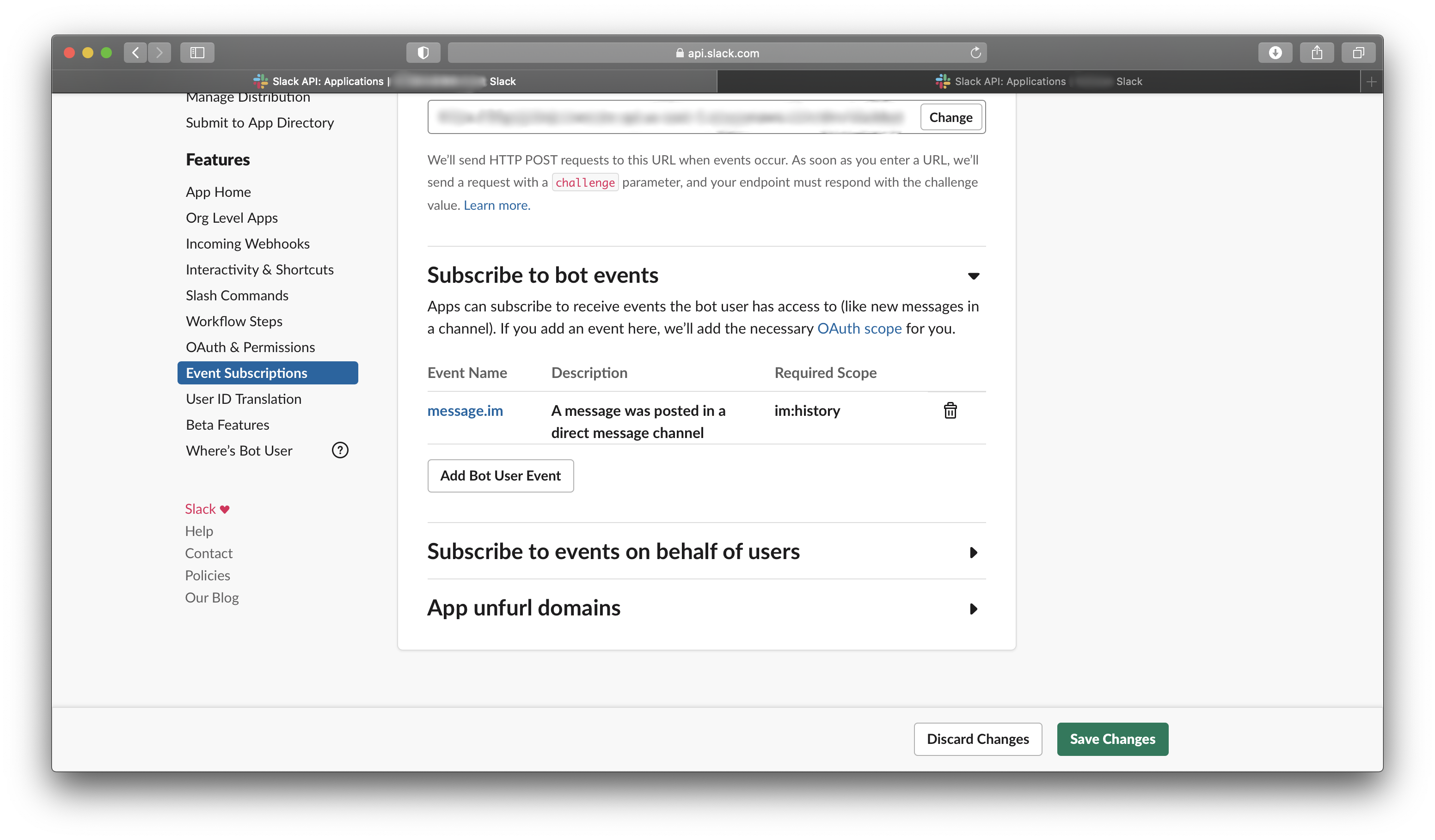
次に、Event APIの反応の種類を設定する。Add Bot User Eventから「message.im」を選択する。これは、Botとの個人チャットに投稿がなされた時に反応するという設定だ。
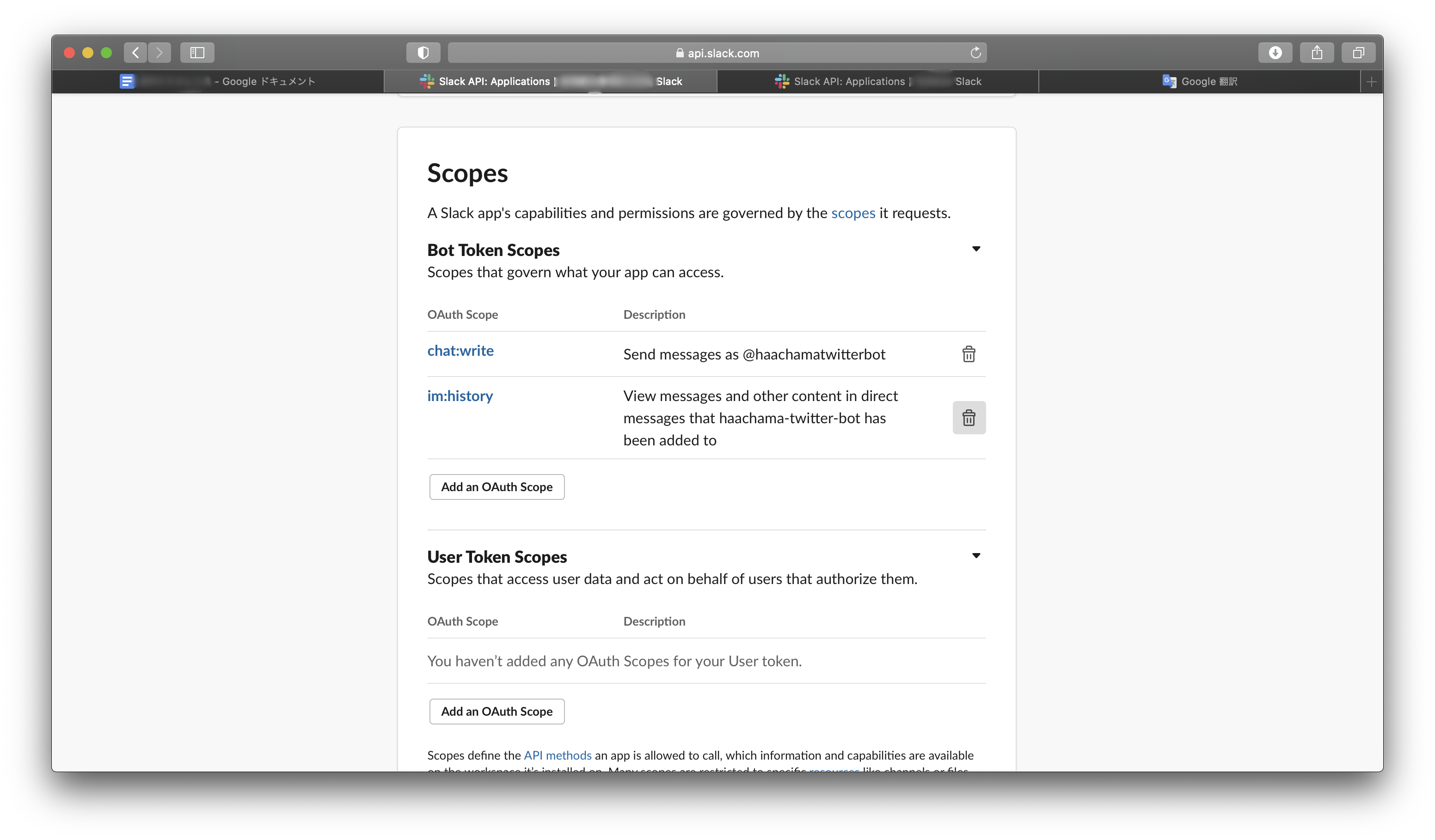
次に、Botに対して、メッセージを投稿する権限を付与する。OAuth & PermissionsからScopesを探して、そこの「Add an OAuth Scope」から「chat:write」を追加する。
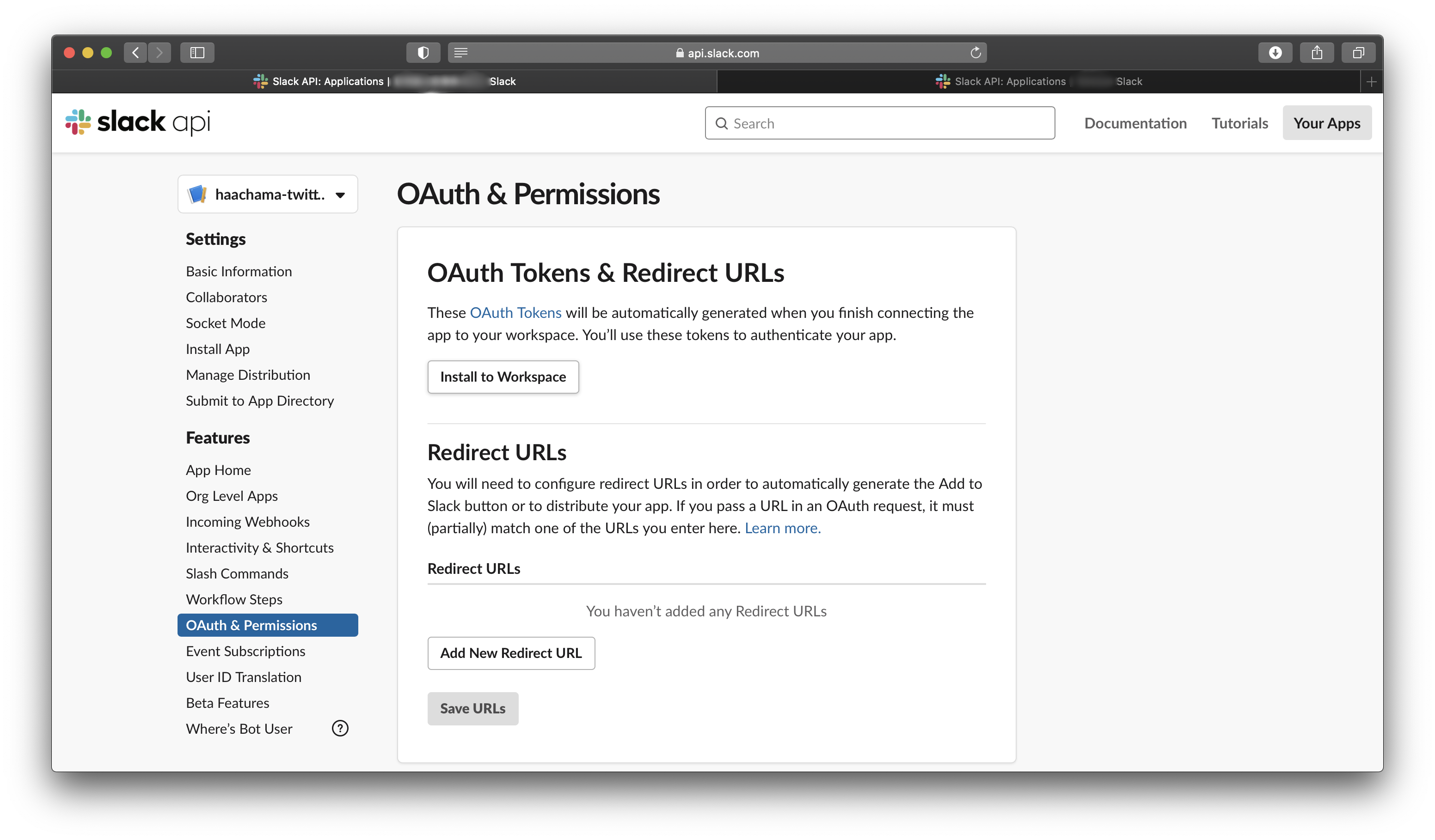
これで、SlackBotの設定が終わったので、OAuth & Permissionsの「Install to Workspace」を押して、SlackBotをワークスペースにインストールする。
そして、その後に表示されるOAuth Tokenをメモする。
さて、今度はSlackのアプリからBotの導入をしよう。
Slackのアプリの「アプリを追加する」を開いて、さっき作ったSlack Botの名前を検索し、導入する。そうしたら、Botのプロフィールを開き、「その他」から「メンバーIDをコピー」する。
これでSlack側の設定は完了!
Python外部モジュールの導入
さて、Slack Botも出来たことだし、Lambdaで使う外部モジュールを導入する。
今回使うPython外部モジュールは以下の2つ。
・tweepy
・pykakashi
今回はこれらを、プラグインserverless-python-requirementsでぶち込んでいこうと思う。ところで、LambdaにPython外部モジュールを入れる方法というのは、serverless-python-requirementsを使う他に、Dockerを使って外部モジュールをAmazon Linux環境下でビルドして、圧縮して、それをLayerにする方法とかもある。でも、serverless-python-requirementsが一番楽。Dockerで作ったLayerだと、アップロードするのがめんどくさい(サイズが大きいとS3にレイヤーをアップロードしてそこにアクセスする必要が出てくるし)。さらに、Lambdaはデプロイパッケージのサイズがかなり限られてるから、場合によってはEFSを使う必要がでてくることもある。今回はめちゃめちゃ小さいのでserverless-python-requirementsで十分だが。
さて、serverless-python-requirementsを導入する。
$ npm install --save serverless-python-requirementsそしたら、serverless.ymlに以下を追記する。
serverless.ymlplugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true基本的にはpluginsのところだけで良いんだけど、今回はpykakashiが非PureなPythonモジュールだから、customのところも書いておく必要がある。(更に言うと
sls deployする時にDockerを動かしておく必要がある。)次に、serverless.ymlとかと同階層にrequirements.txtを配置して、入れたい外部ライブラリを書く。
requirements.txttweepy pykakasiこれで、
sls deployしたら一緒に外部ライブラリも入ってくれる。キーの配置
さて、ここでキーをセットしていく。serverless.ymlにenvironmentを以下のように追記する。
serverless.ymlservice: haachama-twitter-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 environment: SLACK_BOT_USER_ACCESS_TOKEN: '' SLACK_BOT_VERIFY_TOKEN: '' TWITTER_CONSUMER_KEY: '' TWITTER_CONSUMER_SECRET: '' TWITTER_ACCESS_TOKEN: '' TWITTER_ACCESS_TOKEN_SECRET: '' BOT_USER_ID: ''それぞれの中身は、
SLACK_BOT_USER_ACCESS_TOKEN
SlackBotをワークスペースにインストールした時に表示されたOAuth TokenSLACK_BOT_VERIFY_TOKEN
SlackBotを作り始めて最初に出てきたVerification Token。TWITTER_CONSUMER_KEY
TWITTER_CONSUMER_SECRET
TWITTER_ACCESS_TOKEN
TWITTER_ACCESS_TOKEN_SECRET
TwitterDeveloperアカウントのキー。BOT_USER_ID
SlackのアプリでコピーしたBotの「メンバーID」。Lambda側の実装
SlackBotの挙動
では、Lambdaの中身を書いていく。
まず、Botとの個人チャットでBotが適切に反応するようにする。slackbot.py# coding: utf-8 import json import os import logging import urllib.request import tweepy import pykakasi # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] # tokenのチェック if not is_verify_token(event): return {'statusCode': 200, 'body': 'token error'} # 再送のチェック if "X-Slack-Retry-Num" in event["headers"]: return {'statusCode': 200, 'body': 'this request is retry'} # ボットへのメンションでない場合 if not is_app_message(event): return {'statusCode': 200, 'body': 'this request is not message'} # 自分に反応しない if event["body"]["event"]["user"] == os.environ["BOT_USER_ID"]: return {'statusCode': 200, 'body': 'this request is not sent by user'} return { 'statusCode': 200, 'body': 'ok' } def is_verify_token(event): token = event["body"]["token"] if token != os.environ["SLACK_BOT_VERIFY_TOKEN"]: return False return True def is_app_message(event): return event["body"]["event"]["type"] == "message"以上のコードでは、このようなことをしている。
- トークンの確認
- 再送の確認
- Slack Event APIは3秒以内にstatusCode:200が返ってこないと勝手に4回までリクエストを再送してしまうから、それを防ぐ。今回のLambdaは処理に3秒もかからないだろうけど、結構これのせいで暴走して、(私が)ブチ切れたことがあるので書いた。ちなみに、"X-Slack-Retry-Num"は再送回数が格納されているプロパティで、初回の送信だとそもそも"X-Slack-Retry-Num"が存在しない。今回はそれで判別した。
- 投稿されたメッセージが「Botとの個人チャットに投稿されたもの」であることを判別する
- 暴走を防ぐ
- 投稿されたメッセージがBot自身によるものである場合には反応しないようにする。もし、この部分を書かなかったら、Botが一度反応したら、自身の投稿に反応して返答することを繰り返してしまって、暴走してしまう。
そうそう。余談だが、Slackのシステムはメッセージの特定に、メッセージ固有のIDではなくて、投稿がなされたチャンネルのIDとタイムスタンプを使っているらしい(Twitterは個々のツイートにIDが振られるのにね)。だから、Botがリプライするような実装をしたいときは投稿がなされたチャンネルのIDとタイムスタンプの2つが肝要になる。
Botによる返答
今回は、投稿がなされたら、一応確認とために返答もしたいから、これも書く。
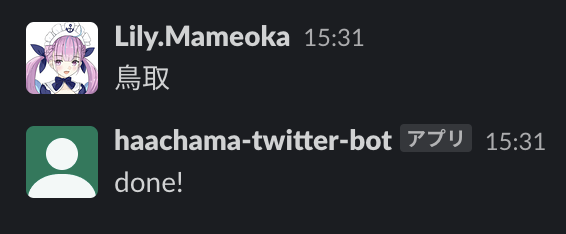
slackbot.pydef post_message_to_channel(channel, message): url = "https://slack.com/api/chat.postMessage" headers = { "Content-Type": "application/json; charset=UTF-8", "Authorization": "Bearer {0}".format(os.environ["SLACK_BOT_USER_ACCESS_TOKEN"]) } data = { "token": os.environ["SLACK_BOT_VERIFY_TOKEN"], "channel": channel, "text": message, } req = urllib.request.Request(url, data=json.dumps(data).encode("utf-8"), method="POST", headers=headers) urllib.request.urlopen(req)この関数に対して、handlerの中でチャンネルとテキストを以下のようにして渡せば、Botが「done!」と返答する。
slackbot.pychannel_id = event["body"]["event"]["channel"] post_message_to_channel(channel_id, "done!")「と」の置換とツイート
次に、「ちゃま語」に翻訳して、結果をツイートする部分を書く。
slackbot.pydef tweet(input_text): auth = tweepy.OAuthHandler(os.environ["TWITTER_CONSUMER_KEY"], os.environ["TWITTER_CONSUMER_SECRET"]) auth.set_access_token(os.environ["TWITTER_ACCESS_TOKEN"], os.environ["TWITTER_ACCESS_TOKEN_SECRET"]) api = tweepy.API(auth) kakasi = pykakasi.kakasi() kakasi.setMode('J', 'H') conv = kakasi.getConverter() input_text = conv.do(input_text) input_text = input_text.replace('と', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ど', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') api.update_status(status=input_text)slackbot.py# handlerの中で呼び出し input_text = event["body"]["event"]["text"] tweet(input_text)今回は、pykakashiで入力文を全て平仮名にして、その文の中に含まれる「と」を「ちゃま」、「ど」を「ぢゃま」に置換していく。そして、置換結果をツイートする。
「ど」を「ぢゃま」に置換するのは、はあちゃま本人の提案ではなくマリン船長の配信で出てきたものらしいが、面白いので加えた。さて、これで完成だ。
sls deployをして、テストしてみよう。
はい、できた。
漢字の変換も問題なさそうだね。
コードの全容
serverless.ymlservice: haachama-twitter-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: us-east-1 environment: SLACK_BOT_USER_ACCESS_TOKEN: '' SLACK_BOT_VERIFY_TOKEN: '' TWITTER_CONSUMER_KEY: '' TWITTER_CONSUMER_SECRET: '' TWITTER_ACCESS_TOKEN: '' TWITTER_ACCESS_TOKEN_SECRET: '' BOT_USER_ID: '' plugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true functions: slackbot: handler: slackbot.handler timeout: 200 events: - http: path: slackbot method: post cors: true integration: lambdaslackbot.py# coding: utf-8 import json import os import logging import urllib.request import tweepy import pykakasi # ログ設定 logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logging.info(json.dumps(event)) # SlackのEvent APIの認証 if "challenge" in event["body"]: return event["body"]["challenge"] # tokenのチェック if not is_verify_token(event): return {'statusCode': 200, 'body': 'token error'} # 再送のチェック if "X-Slack-Retry-Num" in event["headers"]: return {'statusCode': 200, 'body': 'this request is retry'} # ボットへのメンションでない場合 if not is_app_message(event): return {'statusCode': 200, 'body': 'this request is not message'} # 自分に反応しない if event["body"]["event"]["user"] == os.environ["BOT_USER_ID"]: return {'statusCode': 200, 'body': 'this request is not sent by user'} input_text = event["body"]["event"]["text"] channel_id = event["body"]["event"]["channel"] tweet(input_text) post_message_to_channel(channel_id, "done!") return { 'statusCode': 200, 'body': 'ok' } def post_message_to_channel(channel, message): url = "https://slack.com/api/chat.postMessage" headers = { "Content-Type": "application/json; charset=UTF-8", "Authorization": "Bearer {0}".format(os.environ["SLACK_BOT_USER_ACCESS_TOKEN"]) } data = { "token": os.environ["SLACK_BOT_VERIFY_TOKEN"], "channel": channel, "text": message, } req = urllib.request.Request(url, data=json.dumps(data).encode("utf-8"), method="POST", headers=headers) urllib.request.urlopen(req) def is_verify_token(event): token = event["body"]["token"] if token != os.environ["SLACK_BOT_VERIFY_TOKEN"]: return False return True def is_app_message(event): return event["body"]["event"]["type"] == "message" def tweet(input_text): auth = tweepy.OAuthHandler(os.environ["TWITTER_CONSUMER_KEY"], os.environ["TWITTER_CONSUMER_SECRET"]) auth.set_access_token(os.environ["TWITTER_ACCESS_TOKEN"], os.environ["TWITTER_ACCESS_TOKEN_SECRET"]) api = tweepy.API(auth) kakasi = pykakasi.kakasi() kakasi.setMode('J', 'H') conv = kakasi.getConverter() input_text = conv.do(input_text) input_text = input_text.replace('と', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ト', 'ちゃま') input_text = input_text.replace('ど', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') input_text = input_text.replace('ド', 'ぢゃま') api.update_status(status=input_text)requirements.txttweepy pykakasi(蛇足)Botの体裁を整える
テストしてみて思ったんだけど、やっぱり、Botのアイコンが初期のままでは、なんかパッとしないよね。せっかくだから描こうか。...はい、描きました。
最後にアイコン描いたのが工程の中で一番時間かかってるかもしれん。
Slack Botのアイコン設定は、Slack AppのBasic InformationのDisplay Informationからできて、こんな感じでやる。
変更したら「Save Changes」を押すのを忘れずに。
はい、良い感じになりました。やったね。この方が、「ちゃんとできてる感」がある。
(蛇足)平仮名への変換について
ところで、入力文を平仮名に変換するところは、pykakashiではなくMeCabと適当な辞書(UniDicとかneologdとか)の方が正確に出力できるんだろう。だけど、pykakashiの方が圧倒的にLambdaに組み込みやすい
のと、今回はネタなのであまり精度は要求されてないことから、pykakashiで済ませた。MeCabと辞書をLambdaに組み込む場合、MeCabと辞書をAmazon Linux環境下でビルドする必要があるので、EC2インスタンス(t2.medium以上のもの。t2.microだとメモリ不足だった)でビルドして、EFSにマウントする必要がある。LambdaでMeCab(& UniDic)を使う楽な方法はないものかな...



- 投稿日:2021-01-18T11:25:14+09:00
簡単Webサイトホスティング③特定のURLを定期的にモニタリングするCloudFormationテンプレート
はじめに
Amazon Web Services(AWS)が提供する、
Amazon CloudFrontやAmazon S3と呼ばれるサービスを組み合わせることで、 HTMLやJavaScript、画像、ビデオなどで構成される静的Webサイトの配信基盤 を安価に構築することができます。本記事では、リソースのセットアップを自動で行うことのできる、AWS CloudFormationを用いることで、これらの配信基盤を ミスなく迅速に構築 する手順をご説明します。なお、今回使用する CloudFormation テンプレートは、以下の GitHub リポジトリで公開しています。TL;DR
以下の
CloudFormationテンプレートを実行することで、 静的Webサイトのホスティング基盤を迅速かつお手軽 に実現します。下にあるボタンをクリックすると、自身のAWSアカウント(Asia Pacific Tokyo - ap-northeast-1)で、このCloudFormationテンプレートを実行することが可能となります。

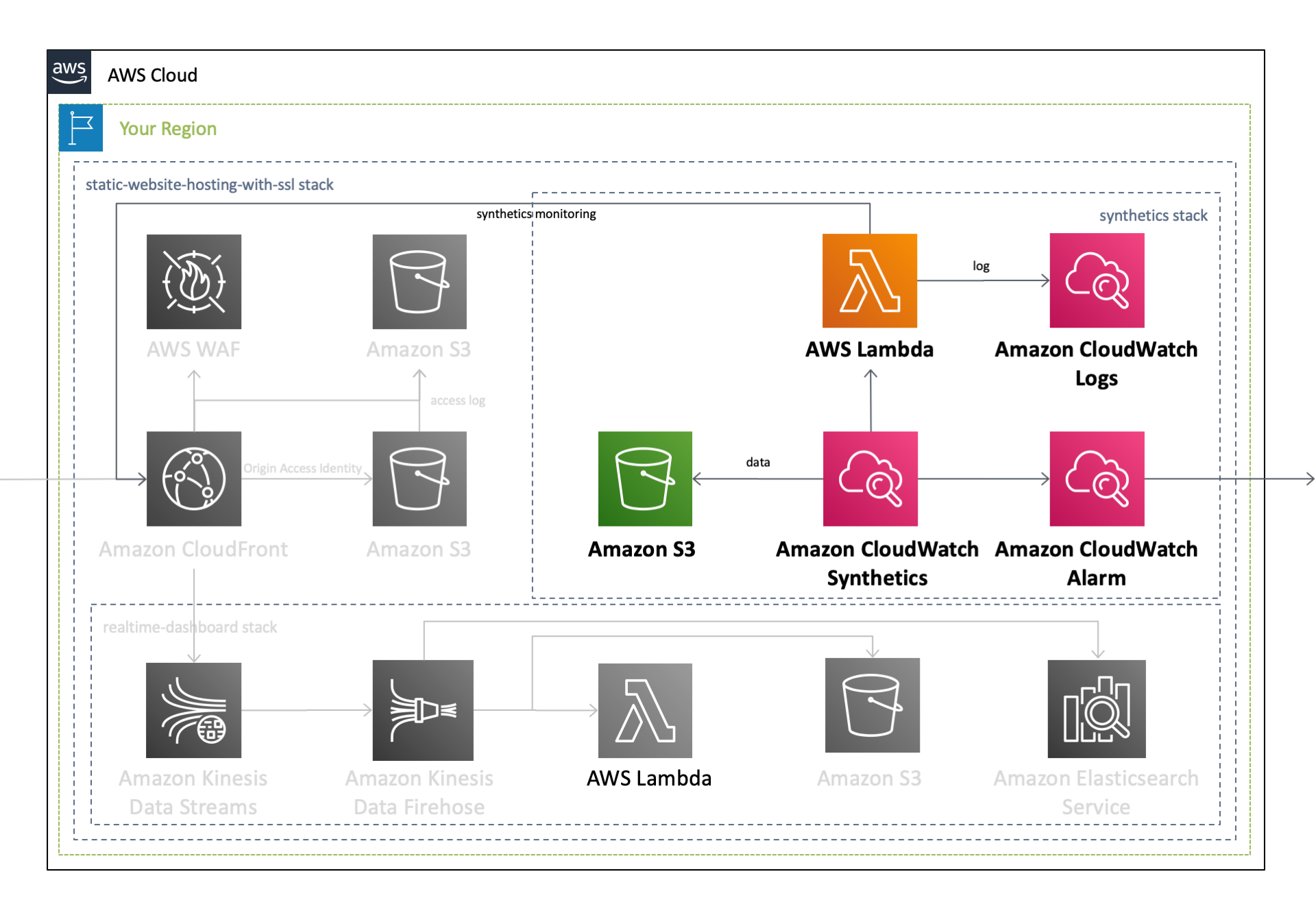
作成されるAWSリソース全体のアーキテクチャ図は、過去の記事をご覧ください。このうち本記事では、以下のリソースに焦点を当ててご説明します。
特定のURLのモニタリング
システムを運用するにあたって モニタリングは不可欠 です。モニタリングを行うことで、 システムの健全性と可用性を追求することが可能 となります。このうち、「ブラックボックスモニタリング」や「フロントエンド監視」「外形監視」と呼ばれる、 ユーザが目にする外部的な振る舞いを確認することが特に重要である とされています。なぜなら、個別のコンポーネントの正常性ではなく、アプリケーションが正常に動いているかどうかが、ユーザにとって最も重要となるからです。
これを実現させるために、AWSには Amazon CloudWatch Synthetics というサービスが用意されており、
Canaryと呼ばれるスクリプトを用いて特定のURLを定期的に監視することが可能です。Canaryは、Lambda上で実行される Node.isスクリプトで、指定したURLの可用性やレイテンシーの確認して、 UI のスクリーンショットを保存することができます。また、CloudWatch カスタムメトリクスを生成するので、可用性やレイテンシーなどの数値を継続して追跡することが可能です。IAM Role
まず、
Amazon CloudWatch Syntheticsに付与する IAM Role を設定します。このIAM Roleは、 S3バケットに対する書き込み権限 や CloudWatch Logsに対するログの書き込み権限 、 CloudWatch に対するメトリクスの送信権限 などをCloudWatch Syntheticsに付与します。Parameters: CanaryName: Type: String AllowedPattern: .+ Description: CloudWatch Synthetics Canary Name [required] Resources: IAMRoleForSynthetics: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: 'sts:AssumeRole' Description: A role required for CloudWatch Synthetics to access S3 and CloudWatch Logs. Policies: - PolicyName: !Sub 'CloudWatchLogsSynthetics-${CanaryName}-${AWS::Region}' PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - 's3:PutObject' - 's3:GetBucketLocation' Resource: !Sub arn:aws:s3:::${S3ForSynthetics}/* - Effect: Allow Action: - 'logs:CreateLogGroup' - 'logs:CreateLogStream' - 'logs:PutLogEvents' Resource: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/cwsyn-${CanaryName}-* - Effect: Allow Action: - 's3:ListAllMyBuckets' Resource: '*' - Effect: Allow Action: - 'cloudwatch:PutMetricData' Resource: '*' Condition: StringEquals: cloudwatch:namespace: CloudWatchSynthetics RoleName: !Sub 'SyntheticsRole-${CanaryName}-${AWS::Region}'Amazon S3
次に、
Amazon CloudWatch Syntheticsが取得/作成したログやスクリーンショットを保存するS3バケットを作成します。Parameters: CanaryName: Type: String AllowedPattern: .+ Description: CloudWatch Synthetics Canary Name [required] Resources: S3ForSynthetics: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: BucketName: !Sub synthetics-${CanaryName}-${AWS::Region}-${AWS::AccountId} LifecycleConfiguration: Rules: - Id: ExpirationInDays ExpirationInDays: 60 Status: Enabled PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: trueAmazon CloudWatch Synthetics
CloudWatch Synthetics の Canary を作成します。Canaryの作成自体は CloudWatch Synthetics 上で行われますが、 通常のLambda関数と同様に Lambdaサービス上で新規のLambda関数が作成 されます。下記のテンプレートでは、 指定したドメインおよびパスに対してリクエストを送信し、スクリーンショットを取得する関数 がLambda上に作成され、 5分に1回の頻度でこの関数が自動的に実行 されます。また、先ほど作成したIAM RoleおよびS3バケットの紐づけも行なっているため、Canaryの実行結果が S3バケット、CloudWatch Logs、CloudWatch メトリクスなどに書き込まれます 。
なおCanaryを作成する際には、その名前を指定する必要がありますが、 数字と小文字、一部の記号のみを使用して21文字以内でなければならない と文字制限が厳しいため、テンプレート上で Canaryの命名規則をを他のリソース名と共通化する場合は注意が必要 です。
Parameters: CanaryName: Type: String AllowedPattern: .+ Description: CloudWatch Synthetics Canary Name [required] DomainName: Type: String AllowedPattern: .+ Description: The watched domain name [required] WatchedPagePath: Type: String Default: /index.html AllowedPattern: .+ Description: The watched page path [required] Resources: Synthetics: Type: 'AWS::Synthetics::Canary' Properties: ArtifactS3Location: !Sub s3://${S3ForSynthetics} Code: Handler: pageLoadBlueprint.handler Script: !Sub > var synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); const pageLoadBlueprint = async function () { // INSERT URL here const URL = "https://${DomainName}${WatchedPagePath}"; let page = await synthetics.getPage(); const response = await page.goto(URL, {waitUntil: 'domcontentloaded', timeout: 30000}); //Wait for page to render. //Increase or decrease wait time based on endpoint being monitored. await page.waitFor(15000); await synthetics.takeScreenshot('loaded', 'loaded'); let pageTitle = await page.title(); log.info('Page title: ' + pageTitle); if (response.status() !== 200) { throw "Failed to load page!"; } }; exports.handler = async () => { return await pageLoadBlueprint(); }; ExecutionRoleArn: !GetAtt IAMRoleForSynthetics.Arn FailureRetentionPeriod: 31 Name: !Ref CanaryName RuntimeVersion: syn-nodejs-2.0 Schedule: DurationInSeconds: '0' Expression: rate(5 minutes) StartCanaryAfterCreation: true SuccessRetentionPeriod: 31CloudWatch Alarm
上記のテンプレートのみで CloudWatch Synthetics の設定は全て完了 し、5分に1回の頻度でモニタリングを開始します。この外形監視がなんらかの理由で失敗した際に通知を受け取ることができるようにするために、最後に CloudWatch Alarm を作成します。このアラームは、 Canaryの成功率が90%を下回った場合にAmazon SNSに対して通知を発行 します。
Resources: CloudWatchAlarmSynthetics: Type: 'AWS::CloudWatch::Alarm' Properties: ActionsEnabled: true AlarmActions: - !Ref SNSForAlertArn AlarmDescription: !Sub 'CloudWatch Synthetics による定期モニタリングで、${DomainName}${WatchedPagePath} への GET の *失敗率が上昇* しています。このエラーが継続する場合は、 *トラフィックの増大* もしくは *内部処理に異常が発生* している可能性があります。' AlarmName: !Sub 'Notice-${CanaryName}-Synthetics-AccessError' ComparisonOperator: LessThanThreshold DatapointsToAlarm: 1 Dimensions: - Name: CanaryName Value: !Ref CanaryName EvaluationPeriods: 1 MetricName: SuccessPercent Namespace: CloudWatchSynthetics OKActions: - !Ref SNSForAlertArn Period: 300 Statistic: Average Threshold: 90 TreatMissingData: notBreaching以上で、特定のURLに対して定期的にアクセスを行い、このエンドポイントの正常性を確認することのできる、CloudWatch Synthetics の Canary を設定することができました。これまでの記事で作成した CloudFront の URL をこの Canary の監視先に指定することで、 CloudFront が正常に動作しているかどうかを継続的に監視することが可能 となります。
関連リンク
- ワンクリックで配信基盤を構築 - CloudFormation を用いて簡単Webサイトホスティング
- CloudFrontにWAFをアタッチ - CloudFormation を用いて簡単Webサイトホスティング
- 特定のURLを定期的にモニタリングする - CloudFormation を用いて簡単Webサイトホスティング
- 投稿日:2021-01-18T11:08:42+09:00
【資格】AWSソリューションアーキテクトアソシエイト(AWS SAA-02C)2回受験から学習方法を振り返る
はじめに
受験日:2020年12月下旬
AWSソリューションアーキテクトアソシエイト(ASS-02C)を受験しました。
1回の受験で合格できず、2回目で辛うじて合格出来ました。
短時間で合格できた方々の記事が多い中、多くの時間をかけてしまった自身を振り返り、効率的に学習したい方の参考になれば、との思いで書きます。ポイント
- 試験合格が学習のゴールであるならば、世に公開されている合格エントリーを一通り読んでから計画を立てたほうが良いです。
結果、学習が行き当たりばったりだったと思います。- 学習姿勢が丸暗記型(問題)になってしまうと、理解したつもりになっていたことに気付かないまま本番に向かう事になります。
- (当たり前ですが)受験のタイミングは確固たる合格の自信をもってからです。焦ってはいけません。
- 初めて取り組む場合は、時間がかかる事を理解した上で取り組んだ方が良いです。世の合格エントリーは(短期間で)合格した内容が多いです。地道に学習し続ける事が肝要です(学校の受験生向けの内容ですね)。
受験前のスペック
- クラウドサービス全般について触ったことは無い
- 書いた時点での自身の主たる業務は2層型クラサバの保守的な業務がメイン
使用した教材
使用した教材は以下になります。
基本的に、今回使用した教材は他のレビュやエントリにも紹介されているように、限られた情報から学習する上で非常に有益だったと感じています。
特に、Udemyの講座はセール開催中を狙うとお得に購入できます。今すぐに学習をスタートさせたい場合でなく、開始時期にゆとりを持たせられる場合はセールの時期を狙うとよいでしょう。
No 教材 備考 1 Udemy AWS 認定ソリューションアーキテクト アソシエイト試験突破講座(SAA-C02試験対応版) セールで購入 2 Udemy 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集 通常価格で購入 3 AWS認定アソシエイト3資格対策 試験結果
回数 試験日 結果 1回目 2020年11月下旬 665点 2回目 2020年12月下旬 729点 学習期間 反省点
第1期(2020年8月1日から9月19日)
〇目的
触ったことが無かったことから、先ずは実際に触る → ポイントを整理する。
〇学習方法
- 今回の学習は、第1期・第2期、及び第3期に分けられます。1回目の試験は第2期後に受験しました。
- Udemy AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)にてハンズオンに重きを置いて学習。
- 本講座についている演習問題 (1回65問・計3回)を解く。
〇実際にやったこと
Udemyの講座、および問題集について、座学内容、ハンズオンの記録、問題の解説、全てをOfficeNoteに記録を取りました。
〇OfficeNoteの記録量
回数 ページ数 備考 講座・ハンズオン 206ページ 1ページで講座1セッション 演習問題 195ページ 1問1ページ(65問3セッションで計195問) 〇反省点
途中から、OfficeNoteに記録を取ることが目的化してしまっていた。気付いていたが引くに引けないような感覚になっていてひっこみがつかなくなり、とりあえずやり切りました。
ハンズオン終了時点で9月の中旬と1カ月半以上を費やす事になりました。〇良かった点
実験ノートのように、全ての座学、およびハンズオンを記録に残したことでイメージはつき易くなりました。これは試験対策とは別に大きい収穫です。
第2期(2020年10月1日から11月20日)
〇目的
第1期の終盤に説いた練習問題を通じて、ハンズオンを通しただけでは問題が解けない事を理解し、とにかく問題を多く説く事を目的としました。
〇学習方法
- Udemy 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集で問題を解き、回答解説を進めます。
- 第1期の演習問題(65問・3セット)
〇実際にやったこと
問題を解いて回答・解説を読み込んでいきます。
〇反省点
- 問題集を解き理解する事が中途半端になってしまった Udemy 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集は65問5セットに、SAA-C02用に新たに65問が追加され6セットあります。 最初の1セット目は比較的簡単で1回で合格ラインに載せられましたが、2セット目からは正答率50%台となり、1問ずつ理解しようと進めていきました。それが、自身が想像していた以上に手間がかかり、問題の答えを覚えることに意識が向いていたと思います。 肝心なのは、回答の選択肢についてこの選択肢では不正解な理由が答えられるかだと思います。これに気付くのは1回目の受験後でした。
第3期(2020年11月28日から12月25日)
〇目的
- 各問題の回答にある選択肢について、なぜこの選択肢では不正解なのかが説明できるように解説を理解を進めます。
〇学習方法
- Udemy AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)の演習問題(65問3セット)を4回転解く
- 解説を理解する上でホワイトペーパーなどの文献はOfficeNote にまとめ、絶えず振り返える
- 解説で理解がおぼつかいものは、AWS認定アソシエイト3資格対策の記述内容を読み込み、OfficeNoteにまとめる
〇第2期および1回目の受験を踏まえての改善点
- 実際の問題は基礎的な内容を軸にした問題が大半でした。問題の傾向から、Udemy AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)の演習問題に絞りました。
- 問題解説の直接的な理解はもちろんですが、他の選択肢が正答で無い理由が説明できるように理解する事を意識しました。
まとめ
2回目の受験でギリギリの点数(720点以上合格に対し729点)で合格しましたが、これは緊張から来る時間配分の大幅なミスによるところが大きいです。
とは言え、2020年中に合格出来ました。
今回の学習を通じて、出来が悪くとも、試行錯誤しながら継続する事が結果につながったと思います。
このエントリーを書きながら、学習する心構えの振り返りになりました。
次はAWS 認定 デベロッパー – アソシエイトを受験しようと思います。
- 投稿日:2021-01-18T10:14:06+09:00
Dockerでオーケストラレーションツールを使う理由
はじめに
本記事は、Dockerでなぜオーケストラレーションツールを使うのか知るための記事である。
・様々なDockerの説明で「オーケストラレーションツール」という言葉が出てくるが一体何なのか、わかりにくい。
・「オーケストラレーションツール」を理解する。オーケストラレーションツールとは
オーケストラレーションツールは、複数のDockerを動かすためツール。
オーケストラレーションツールを使う理由
オーケストラレーションツールを使う理由を知るためには、Dockerでできないことを知ることが近道である。
Dockerは特定の環境をパッケージングして、どの環境でも動くポータビリティを保証できるツールである。
Dockerができないこと、機能としてないことは以下のものがある。
- 複数のNodeに対してのデプロイ
- スケーリング
- コンテナのアップデート
- 障害時の自動復旧
- 負荷分散
つまり、オーケストラレーションツールを使う理由は、サービスを運用するためにはDockerの機能だけでは運用に問題が出てくる。
したがって、オーケストラレーションツールを使って提供できるようにするためにDockerとセットで使用するのである。よく使われるオーケストラレーションツール
docker-compose
一般的に使われるオーケストラレーションツール。
swarm
クラスタリング用ツール。
Docker Compose と Docker Swarmを合わせて使う。ECS(Elastic Container Service)
AWSが開発したオーケストレーションツール。
Kubernetes
Googleが開発したオーケストレーションツール。
おわりに
Dockerを本番のサービスで使うためには、Docker + オーケストラレーションツールを使って障害などに備えることがわかった。
Dockerの学習においては、プログラマでも必須スキルとなっているDockerだが、
本記事を加味すると、開発環境の運用ではDockerのスキルだけで問題ないが、本番のサービスを運用する段階ではオーケストラレーションツールのスキルが必要になる。
なので、プログラマに関しては Docker のスキル、インフラエンジニアに関しては Docker + オーケストラレーションツール のスキルを取得すると良いだろう。
- 投稿日:2021-01-18T10:14:06+09:00
Dockerでオーケストレーションツールを使う理由
はじめに
本記事は、Dockerでなぜオーケストレーションツールを使うのか知るための記事である。
・様々なDockerの説明で「オーケストレーションツール」という言葉が出てくるが一体何なのか、わかりにくい。
・「オーケストレーションツール」を理解する。オーケストレーションツールとは
オーケストレーションツールは、複数のDockerを動かすためツール。
オーケストレーションツールを使う理由
オーケストレーションツールを使う理由を知るためには、Dockerでできないことを知ることが近道である。
Dockerは特定の環境をパッケージングして、どの環境でも動くポータビリティを保証できるツールである。
Dockerができないこと、機能としてないことは以下のものがある。
- 複数のNodeに対してのデプロイ
- スケーリング
- コンテナのアップデート
- 障害時の自動復旧
- 負荷分散
つまり、オーケストレーションツールを使う理由は、サービスを運用するためにDockerの機能だけでは運用に問題が出てくるからである。
したがって、オーケストレーションツールを使って機能を補完して、サービスを提供できるようにするためにDockerとセットで使用するのである。よく使われるオーケストレーションツール
docker-compose
一般的に使われるオーケストレーションツール。
swarm
クラスタリング用ツール。
Docker Compose と Docker Swarmを合わせて使う。ECS(Elastic Container Service)
AWSが開発したオーケストレーションツール。
Kubernetes
Googleが開発したオーケストレーションツール。
おわりに
Dockerを本番のサービスで使うためには、Docker + オーケストレーションツールを使って障害などに備えることがわかった。
Dockerの学習においては、プログラマでも必須スキルとなっているDockerだが、
本記事を加味すると、開発環境の運用ではDockerのスキルだけで問題ないが、本番のサービスを運用する段階ではオーケストレーションツールのスキルが必要になる。
なので、プログラマに関しては Docker のスキル、インフラエンジニアに関しては Docker + オーケストレーションツール のスキルを取得すると良いだろう。
- 投稿日:2021-01-18T09:24:57+09:00
AWS SAM を使って AWS Lambda Layer を作成する
はじめに
以前に Layer を使って Lambda コンソールの AWS SDK の更新をなるだけコンソールを使って更新する方法を紹介しました(以前の記事は こちら )。今回は、同じ内容を AWS SAM を使って行いたいと思います。
開発環境を用意する
開発環境には AWS Cloud9 を利用しました。この後の作業を全く同じかたちで実行してみたい方は Cloud9 を用意してください。AWS CLI、SAM CLI が既に用意されているので、この後で必要な操作にたいして準備が必要ありません。Cloud9 の準備には Cloud9 環境を用意する を参照してください。
Lambda 関数を作成し、SAM でデプロイする
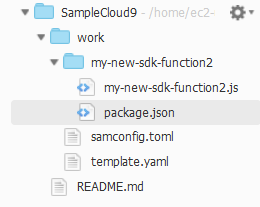
- 作業を行う work ディレクトリと、 Lambda 関数を格納する my-new-sdk-function2 ディレクトリを用意して、work ディレクトリに移動します。
mkdir -p work/my-new-sdk-function2 cd work
- Lambda 関数用の
my-new-sdk-function2.jsファイルと、SAM テンプレートを記述するtemplate.yamlファイル、SAM CLI 設定用ファイルのsamconfig.tomlを用意します。touch my-new-sdk-function2/my-new-sdk-function2.js touch template.yaml touch samconfig.toml
- my-new-sdk-function2 ディレクトリに
package.jsonファイルを用意します。cd my-new-sdk-function2 npm init -yここまでで、以下のような構成になっていると思います。
- リストから "my-new-sdk-function2.js" を選択し、編集して保存します。
const AWS = require('aws-sdk'); exports.handler = async (event) => { return AWS.VERSION; };
- リストから "template.yaml" を選択します。SAM テンプレートとしてこのファイルを編集して保存します。
AWSTemplateFormatVersion: '2010-09-09' # テンプレートフォーマットの宣言、決まり文句。 Transform: AWS::Serverless-2016-10-31 # AWS SAM テンプレートファイルであることの宣言 Description: Making Lambda Layer # このテンプレートの説明 Resources: CallVersionLambda: # リソースの論理名 Type: AWS::Serverless::Function Properties: FunctionName: my-new-sdk-function2 CodeUri: ./my-new-sdk-function2 Handler: my-new-sdk-function2.handler PackageType: Zip Runtime: nodejs12.x Timeout: 5 MemorySize: 256Resources には、"my-new-sdk-function2.js" が Lambda として実行されるように値を指定します。まずテンプレート内での名称を宣言します。ここでは
CallVersionLambdaとしました。次に Type はAWS::Serverless::Functionとします。Properties は、今回、Lambda Layer を使うので PackageTypeZipとし、それに伴い CodeUri , Handler を指定しました。
- "samconfig.toml" ファイルを選択し SAM CLI コマンドのデフォルトパラメータを設定します。バケット名は一意にする必要 ( バケットの制約と制限 - バケット命名規則 ) があるので、下で s3_bucket で指定したバケット名とは別の名前を指定してください。
version=0.1 [default.deploy.parameters] stack_name = "my-new-sdk-function2" s3_bucket = "my-new-sdk-function2" s3_prefix = "call_version_lambda" region = "ap-northeast-1" confirm_changeset = true capabilities = "CAPABILITY_IAM"ここでは、 [default.deploy.parameters] により
sum deployコマンドのパラメータ設定を宣言しています。
- "samconfig.toml" ファイルで s3_bucket に指定した S3 バケットを用意します。Cloud9 には AWS CLI が既に用意されているので、ターミナルから
aws s3 mb s3://<バケット名>コマンドで S3 バケットを用意します。aws s3 mb s3://my-new-sdk-function2
sam buildコマンドを実行してビルドします。cd ~/environment/work sam build
- ビルドが成功したら
sam deployコマンドを実行してデプロイします。sam deploy途中、changeset をデプロイするか聞かれるので
yを入力して Enter します。
最終的に "Successfully created/updated stack" と出力されたらデプロイの完了です。
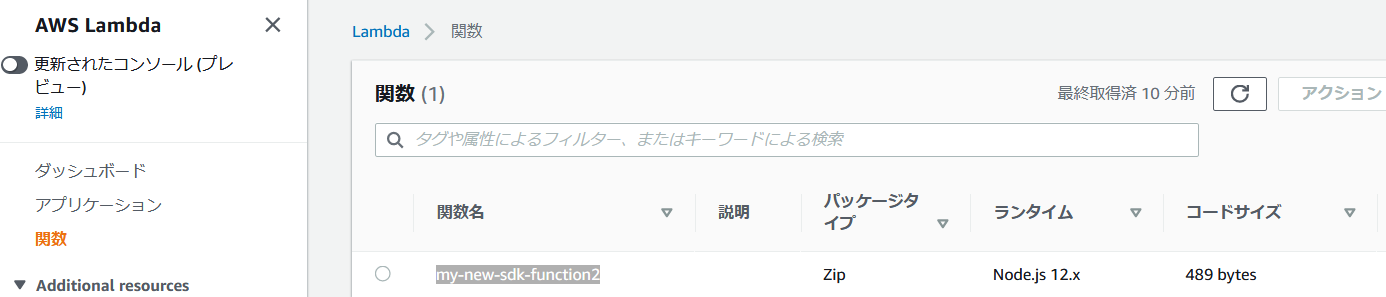
- Lambda コンソールの関数ページを開くと "my-new-sdk-function2" 関数がデプロイされていることを確認できると思います。
現在の AWS SDK のバージョンを確認する
イベントを用意して、用意した Lambda 関数を呼び出します。
- 関数一覧から "my-new-sdk-function2" のリンクを選択し、Lambda コンソールの右上にある "テスト" をクリックします。
- "イベント名" に
MyNewSdkEvent2と名付け、他はデフォルトのまま "作成" をクリックします。- もう一度 "テスト" をクリックすると先ほどデプロイした Lambda 関数が実行されます。執筆時点では 2.804.0 でした。
SAM で Lambda Layer を作成する
- SAM テンプレートを編集して Layer の設定を追加します。
template.yamlファイルを開いて次の内容に変更してください。追加した部分は、CallVersionLambda リソースのプロパティ Layers とSdkLayer リソースになります。AWSTemplateFormatVersion: '2010-09-09' # テンプレートフォーマットの宣言、決まり文句。 Transform: AWS::Serverless-2016-10-31 # AWS SAM テンプレートファイルであることの宣言 Description: Making Lambda Layer # このテンプレートの説明 Resources: CallVersionLambda: # リソースの論理名 Type: AWS::Serverless::Function Properties: FunctionName: my-new-sdk-function2 CodeUri: ./my-new-sdk-function2 Handler: my-new-sdk-function2.handler PackageType: Zip Runtime: nodejs12.x Timeout: 5 MemorySize: 256 Layers: # 追加 - !Ref SdkLayer SdkLayer: # 追加 Type: AWS::Serverless::LayerVersion Properties: Description: Newest AWS CDK ContentUri: my-new-sdk-layer/ CompatibleRuntimes: - nodejs12.x Metadata: BuildMethod: nodejs12.x # Required to have AWS SAM build this layerCallVersionLambda リソースの Layers プロパティでは、
!Refを使って Layer の宣言をしているリソース SdkLayer を参照させています。SdkLayer リソースでは Metadata 属性を追加して SAM CLI で Layer のビルド を指定しています。
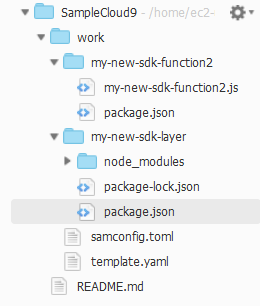
- ContentUril で指定した Layer のパッケージを追加するディレクトリを作成します。
mkdir my-new-sdk-layer
- "my-new-sdk-layer" ディレクトリに
package.jsonファイルを用意し、最新の AWS SDK をインストールします。cd my-new-sdk-layer npm init -y npm install aws-sdkここまでで、以下のような構成になっていると思います。
sam buildコマンドでビルドします。cd ~/environment/work sam build
- ビルドが成功したら
sam deployコマンドを実行してデプロイします。sam deploy途中、changeset の確認で Layer が追加されたことが分かります。確認の後、changeset をデプロイしましょう。
更新後の AWS SDK のバージョンを確認する
まえに用意した "MyNewSdkEvent2" を再度、実行します。Lambda コンソールの右上にある "テスト" をクリックしてください。関数コードペインから実行結果を確認すると更新されたことが確認できると思います。今回は 2.828.0 になりました。
以上です。




- 投稿日:2021-01-18T08:10:27+09:00
【ダメ。ゼッタイ】脱法ブランチ名やプッシュ乱用を防いでgitを治安維持する
運用規則やgitのベストプラクティスを知っててもmaster直修正しちゃいたい誘惑ってありますよね。ギリギリ踏みとどまっても今度はブランチ命名タスクが来て、次にコミット命名です。このgit運用を手抜きしたい誘惑は凄まじく、依存性もあり一度やってしまうと、もう元の生活には戻れず手抜きが横行します。
そこで、CodeCommitならばIAM絞ってとても柔軟にgit運用の統制を設定でき、社内のgit治安が良くなるという話をします。
Git Flow, Github Flowをベースに少し手を加えた以下の制約を導入したいとします。
betaはカナリアリリース用の社内独自ブランチです
- 作成できるブランチ名の制限。
master,beta,feature/*,hotfixのみ。自分の名前のブランチ名とかダメ絶対。master,betaは直コミット禁止し、プルリクのみが更新できる。- プルリクのマージはマージコミット残し必須。Fast-Fowardは不可
以下のポリシーを
HogeCorporationGitFlowPolicyとでも命名して作成し、全開発者に適用するようアタッチします。元々のCodeCommitへの操作権限を有するユーザーを前提にしています。初めてStringNotLikeを使いました。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Action": [ "codecommit:*" ], "Resource": "*", "Condition": { "StringNotLike": { "codecommit:References": [ "refs/heads/master", "refs/heads/beta", "refs/heads/feature/*", "refs/heads/hotfix" ] }, "Null": { "codecommit:References": false } } }, { "Effect": "Deny", "Action": [ "codecommit:GitPush", "codecommit:DeleteBranch", "codecommit:PutFile", "codecommit:CreateCommit", "codecommit:MergeBranchesByFastForward", "codecommit:MergeBranchesBySquash", "codecommit:MergeBranchesByThreeWay", "codecommit:MergePullRequestByFastForward", "codecommit:MergePullRequestBySquash" ], "Resource": "*", "Condition": { "StringEqualsIfExists": { "codecommit:References": [ "refs/heads/master", "refs/heads/beta" ] }, "Null": { "codecommit:References": false } } } ] }もう少し拘って以下も設定したかったのですが、よく分かりませんでした。導入できたら記事更新します。 (教えて優しい人)
- masterへのプルリクはfeature系から禁止して、betaかhotfixからのみ可
- commit名にも命名規則としてprefix必須&ホワイトリスト作成
- セルフマージ禁止(PRと承認の同一人物禁止)
参考
- https://docs.aws.amazon.com/service-authorization/latest/reference/list_awscodecommit.html
- https://docs.aws.amazon.com/codecommit/latest/userguide/how-to-conditional-branch.html
- https://dev.classmethod.jp/articles/codecommit-deny-push-mster-branch/
- https://blog.serverworks.co.jp/tech/2020/04/17/codecommit-branch/
- https://qiita.com/potyamaaaa/items/08c54072e0d9d0734ccd
- https://qiita.com/itosho/items/9565c6ad2ffc24c09364
- https://qiita.com/mint__/items/bfc58589b5b1e0a1856a
- https://qiita.com/KosukeSone/items/514dd24828b485c69a05
- 投稿日:2021-01-18T07:02:10+09:00
AWS ANS に向けての勉強 4. Route 53
参考
概要
- AWSの提供する権威DNSサービス
- 権威DNS: あるゾーンの情報を保持し、ほかのサーバに問い合わせることなく応答を返せるサービス (参考:https://jprs.jp/glossary/index.php?ID=0145)
- AWS上で高可用性、低レイテンシなアーキテクチャを実現
- マネージドサービス
DNS名前解決の基本動作
機能
権威DNS
トラフィックルーティング
加重ルーティング
レイテンシ―ルーティング
フェイルオーバールーティング
位置情報(Geolocation)ルーティング
DNSフェイルオーバー
トラフィックフロー
高可用性アーキテクチャ
運用
料金












































