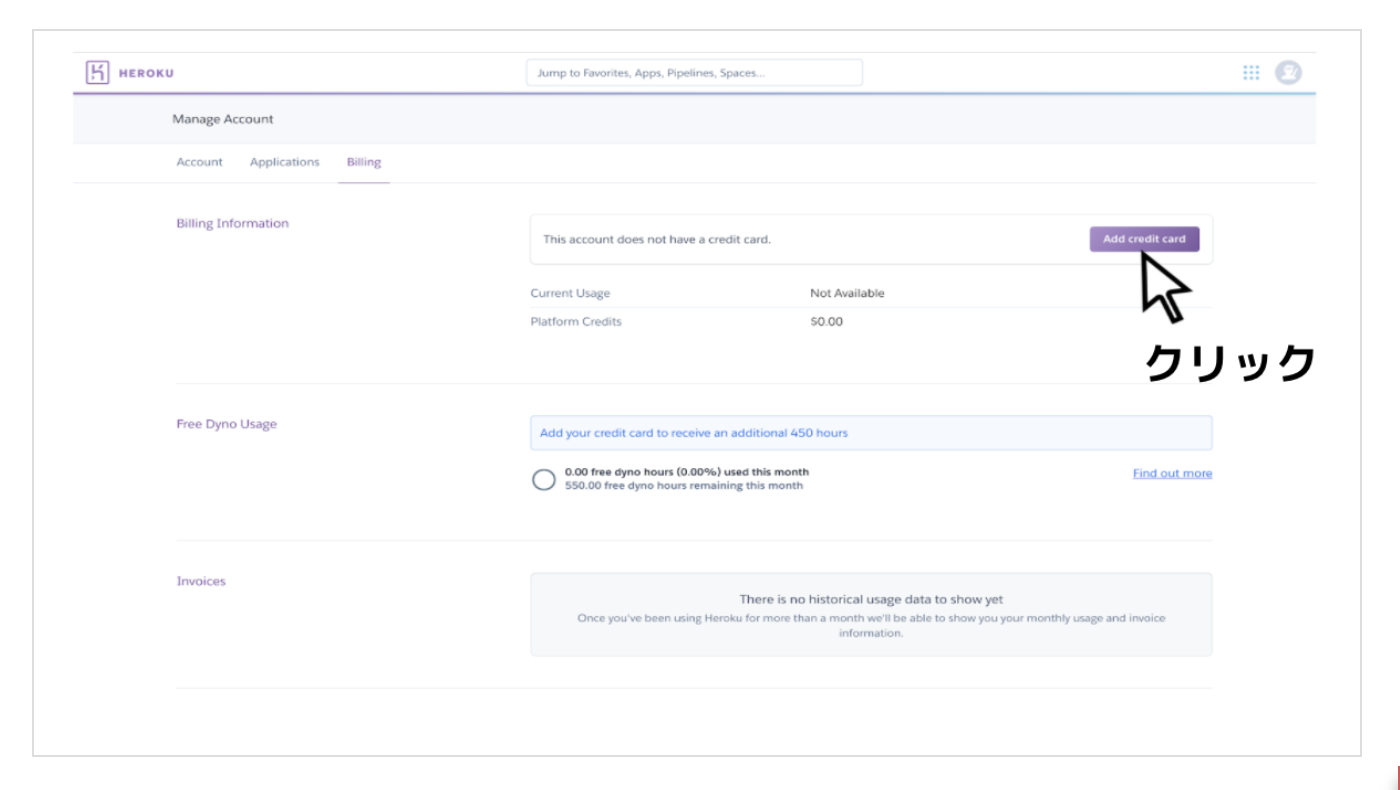
echo 'if which rbenv >/dev/null;then eval"$(rbenv init -)";fi' >> ~/.bash_profile
このコマンドを追加することで、ターミナル起動時にrbenvを自動的に起動させます。
最後に、sourceというコマンドを使って追加した内容を反映します。
source ~/.bash_profile
.bash_profileに追加した内容を反映できました。
これでrbenvコマンドを利用するのに必要なPATHが通りました。
Rubyの環境構築
次にRubyをインストールします。
Rubyをインストールする前に、インストールできるRubyのバージョンを確認します。
先ほどインストールしたrbenvを使って次のコマンドを入力してください。
rbenv install -l
コマンドを実行すると、最新の安定版のバージョンが一覧で表示されます。
rbenv install -l
2.5.8
2.6.6
2.7.2
3.0.0
jruby-9.2.13.0
maglev-1.0.0
mruby-2.1.2
rbx-5.0
truffleruby-20.2.0
truffleruby+graalvm-20.2.0
Only latest stable releases for each Ruby implementation are shown.
Use 'rbenv install --list-all' to show all local versions.
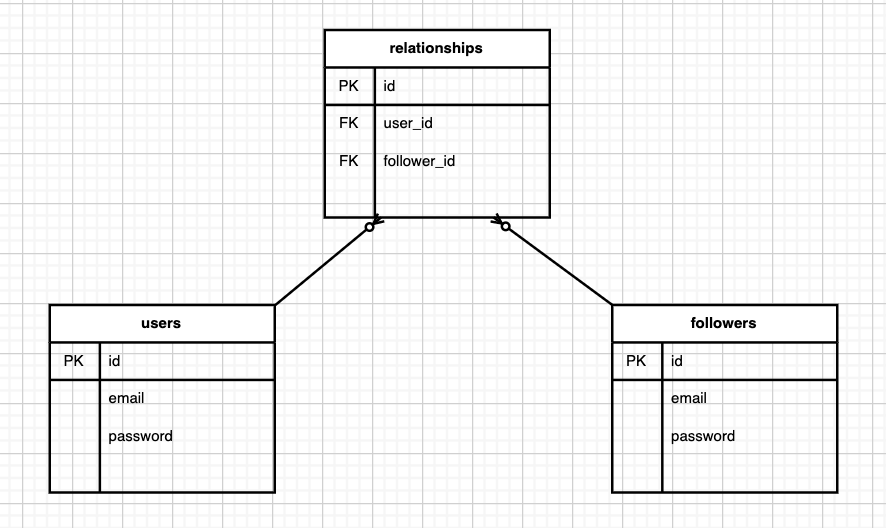
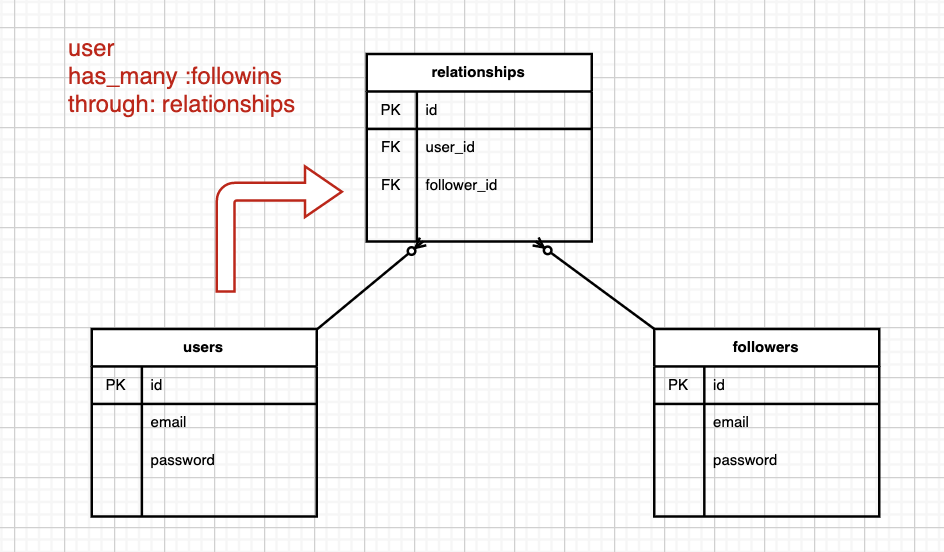
moduleApimoduleV1# class ApplicationController < ActionController::API # Note: here is not ::BASEclassApplicationController<ActionController::BaseincludeDeviseTokenAuth::Concerns::SetUserByTokenprotect_from_forgerywith: :null_sessionrespond_to:jsonendendendend
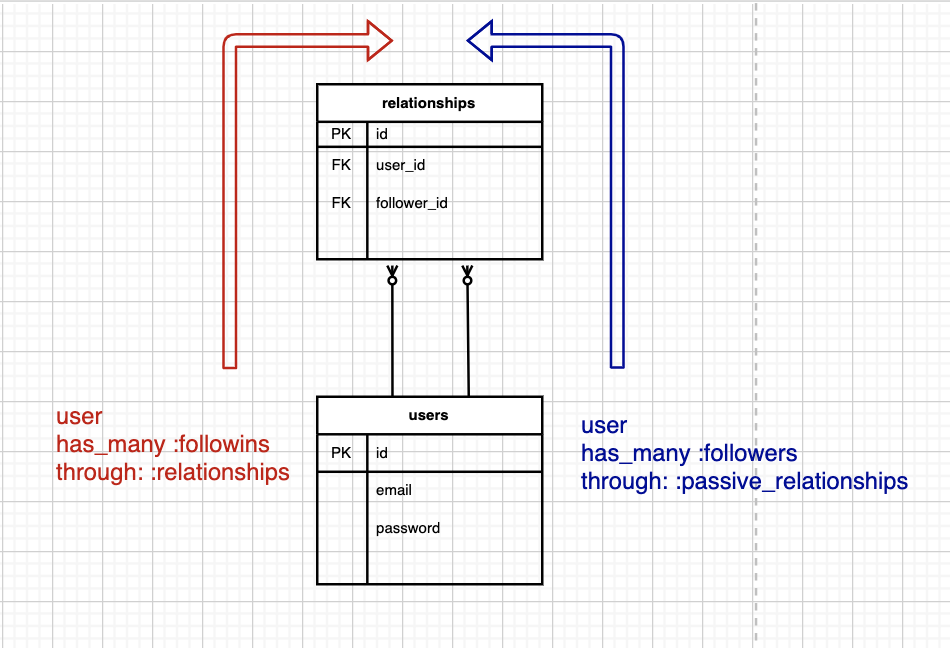
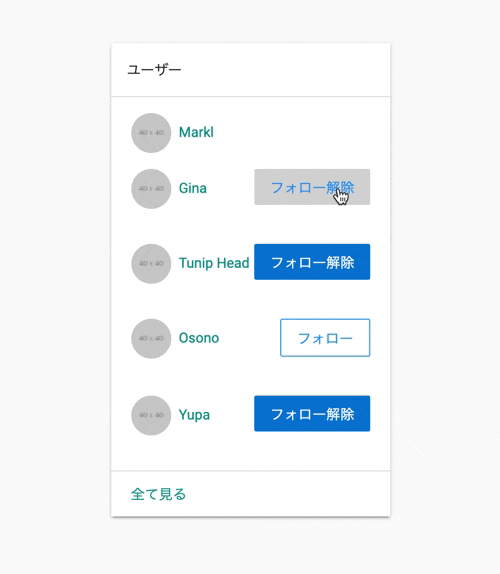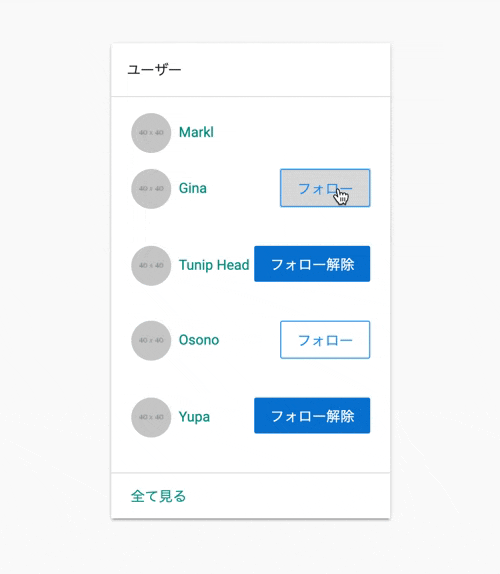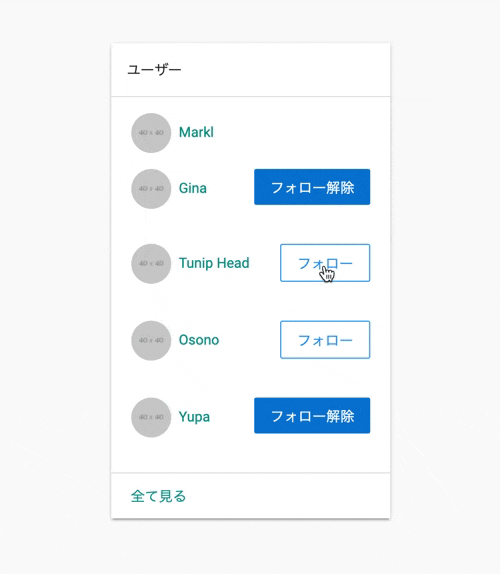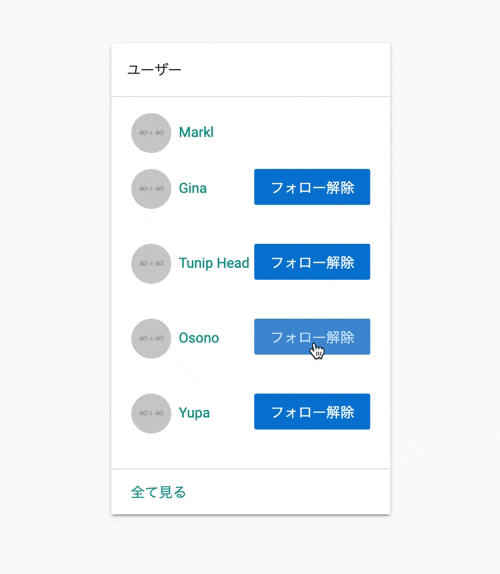
# もともとボタンのあったビューファイル-iflogged_in?&¤t_user!=userdivid="follow-button-#{user.id}"-ifcurrent_user.following?(user)=render'relationships/unfollow_button',user: user-else=render'relationships/follow_button',user: user
Please be careful when adding paths here otherwise it will make the compilation slow, consider adding specific paths instead of whole parent directory if you just need to reference one or two modules
========================================
Your Yarn packages are out of date!
Please run `yarn install --check-files` to update.
========================================
$ yarn install --check-files
上記を実行でOK
新規アプリ作成
Railsプロジェクト用のenvironmentディレクトリを作る
$ cd # プロジェクトのホームディレクトリに移動
$ mkdir environment # environmentディレクトリを作成
$ cd environment/ # 作成したenvironmentディレクトリに移動
都道府県のリストを用意するため、prefectureモデルを作成します。
ここで、いつものrails g model :モデル名コマンドに--skip-migrationというオプションを付けます。 --skip-migrationはマイグレーションファイルの作成をスキップしてくれるオプションです。都道府県に関する情報はデータベースに保存しないためです。