- 投稿日:2021-01-17T23:39:02+09:00
ゼロから作るDeep Learning❷で素人がつまずいたことメモ:7章
はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep Learning❷ーー自然言語処理編」の7章で私がつまずいたことのメモです。
実行環境はmacOS Catalina + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 )
7章 RNNによる文章生成
この章は、前章でつくった言語モデルによる文章生成と、seq2seqという新しいモデルの解説です。なお、今回も自分で実装する時間が取れなかったので、本の実装を試すレベルに留まっています。ご了承ください。
7.1 言語モデルを使った文章生成
PTBコーパスから作った言語モデルでは、英語が苦手な私は結果の良し悪しがよくわからないので、前章で作った青空文庫の言語モデルで試してみました。
まず、前章でパープレキシティが105.19だったRNNLMを試すため、
ch07/generate_text.pyを少し変更します。★の部分が変更点です。ch07/generate_text.py# coding: utf-8 import sys sys.path.append('..') from rnnlm_gen import RnnlmGen from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更 corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更 vocab_size = len(word_to_id) corpus_size = len(corpus) model = RnnlmGen(vocab_size=vocab_size) # ★語彙数指定(省略時はRnnlmの既定値=PTBの値になる) model.load_params('../ch06/Rnnlm.pkl') # start文字とskip文字の設定 start_word = 'あなた' # ★you start_id = word_to_id[start_word] skip_words = [] # ★前処理していないのでskip文字はなし skip_ids = [word_to_id[w] for w in skip_words] # 文章生成 word_ids = model.generate(start_id, skip_ids) # ★日本語なので空白なしで連結、<eos>は句点+改行に置換 eos_id = word_to_id['<eos>'] txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids]) txt = txt.replace('\n。\n', '\n') # 空行の除去 txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去 print(txt)そして「あなた」から生成した文章の結果です。何回か実行してみました。
パープレキシティ105.19版あなたたちがかえって進んで来るんだから、しばらくすると、あの女の汽車のなかの紳士の方ですから、それでも江戸られまいといって、もう少し聞いたときは、まだ紀元前したかはぎとらと見えないのです。 かれはこのままで静かに渡ったらいないので、ごちゃごちゃのなけりゃとわらって、私はどうしてもぱみじんにくだけ文学調子で入り口のうちころす話しを与えたのです。 お嬢さんたちは失望尽そうとしパープレキシティ105.19版あなたに割り込んでそこにハトのお口へ送ったんですが、。 「それがその帰り、この家はぽんぽんするに』」 「くらいじゃありませんか」 「そうです」 「それから助からない。 」 「どうだ、手荒なんだか?」ジョバンニは楽器の頭の毛状の藁を通って思わず、飛んでしまいました。 それから海苔とというのはいいもといって金色のようパープレキシティ105.19版あなたの楯に追いついた。 二人は返さずにいった。 ところがむずかしい否ふさいを、いつでも寝ていた。 ところが鏡の外で躁狂の頸はなんともいえぬまるで意味かも知れませんから、無声という音は次第で、どんな風には白難症の超然たる元々でいた何だか酒のこの藪のたった右の木には細長いこちらが正門の寸方がすぎて飯前たこチラッとたまりません。 そこでなんとなく文章にはなりかけていますね。使っているコーパスが小説なので、何か小説っぽい文章ができています。
2番目の結果はカッコのつじつまがざっくり合っていて、カッコの開始と終了の関係をきちんと記憶できていることがわかります。
それにしても2番目の結果の「ハトのお口へ送ったんですが」から「ジョバンニは楽器の頭の毛状の藁を通って思わず、飛んでしまいました。」への展開、意味はさっぱりわかりませんがジワります
つづいて、前章でパープレキシティ73.66まで下がった改良版を試してみます。以下、
ch07/generate_better_text.pyの変更版です。★の部分が変更点です。ch07/generate_better_text.py# coding: utf-8 import sys sys.path.append('..') from common.np import * from rnnlm_gen import BetterRnnlmGen from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更 corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更 vocab_size = len(word_to_id) corpus_size = len(corpus) model = BetterRnnlmGen(vocab_size=vocab_size) # ★語彙数指定(省略時はBetterRnnlmの既定値になる) model.load_params('../ch06/BetterRnnlm.pkl') # start文字とskip文字の設定 start_word = 'あなた' # ★you start_id = word_to_id[start_word] skip_words = [] # ★前処理していないのでskip文字はなし skip_ids = [word_to_id[w] for w in skip_words] # 文章生成 word_ids = model.generate(start_id, skip_ids) # ★日本語なので空白なしで連結、<eos>は句点+改行に置換 eos_id = word_to_id['<eos>'] txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids]) txt = txt.replace('\n。\n', '\n') # 空行の除去 txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去 print(txt) model.reset_state() start_words = '人生 の 意味 は' # ★the meaning of life is start_ids = [word_to_id[w] for w in start_words.split(' ')] for x in start_ids[:-1]: x = np.array(x).reshape(1, 1) model.predict(x) word_ids = model.generate(start_ids[-1], skip_ids) word_ids = start_ids[:-1] + word_ids # ★日本語なので空白なしで連結、<eos>は句点+改行に置換 txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids]) txt = txt.replace('\n。\n', '\n') # 空行の除去 txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去 print('-' * 50) print(txt)以下、「あなた」から始まる文章の生成結果です。
パープレキシティ73.66版あなたにも知らずに、もぎ取ってしまった。 もっともこれからがぼくの気になれるのか、その人なら仕事にだきしめた時眼がかんかんつく。 slip'麭の御代と云う家族死の事、しらになる。 人が金を快楽を棄てる道具のつくのを天下と肩身のように水に残さん上なら、自ら世帯人種の歴史を読んで、四の二文字を見ても愉快だ。 お腹の代表パープレキシティ73.66版あなたが、私に話し給えと云った。 (僕はそんな碁だ。 あるところで、上野と来たのは門口行灯袴を持って続いている。 今年の夜中ぼろしで出るので勝手には行かない。 減る、手が高射泣きついて、まあ今ではとても楽がないくらいだ。 今は呑気だから、教師が上等な手段より持ち方を折ったじゃありませんか」 「なぜ」 「いいえまだパープレキシティ73.66版あなたには行った事実があるので、目まいがしてそんなに来られたかな。 まだ病人なのか知らない。 いくら泳げてもどうしてもびかかってきたではありませんか。 この二十四。 私は床の上をぐるぐる回って、不安の顔を見合わせて客を捜している。 先生は二人とも午近く性、座敷へ帰ったまま歩き出した。 奥に東京へ二人で参れた頃の、次は少し賑やかなんとなく、前の結果よりも日本語になっている感じはします。
なお、1つ目の結果で突然「slip'」という言葉が出てきたのでコーパスを調べてみたら、「吾輩は猫である」の中に
many a slip ' twixt the cup and the lip と 云う 西洋 の 諺 くらい は 心得 て いる だろ うという文章がありました。ここでしか使われていないので、やはりPTBコーパスのようにレアな単語の前処理をしないとダメですね続いて本と同じように「人生の意味は」の続きを語らせてみた結果です。
パープレキシティ73.66版人生の意味は心の歴史と同じように思われたからだから、庭は終わるには落ちつかなかったのである。 あることは名文家に関係通りあるものだ。 砂の焼けたレンズが、圧力に打たれてもよいのだろうか。 あれほどが月々問題を見て、偽りをにやにや茶托に結んでいたから、これは精神的世界に大した刺激ではない。 ただ腹に目の結んだものであるパープレキシティ73.66版人生の意味は作家の広告違だからきたなくなった。 それで未来を茶器をかためて、かえって死なないような気がした。 三四郎はこうざあい。 東京でも早く円を入れて一、五長を根堀りした人がぬすまれたと思って、いよいよこうなるというだけであった。 三四郎はその婦人の神様から主人と丸鞄の下にすわって、授業をするのもじっとしていた。パープレキシティ73.66版人生の意味はちょうどと、第二の遠いところを択んだのである。 しかしこういう顔が済んだ時、その言葉に。 私は今日午町へ行ったに始まった。 友達の生活な男は宿へ出ない歌い籠は、歴々と縞物のお光だから、今催促したと生きていたので、取り巻かれた十三飯をくれた母の顔であった。 先生はまたちょいと蔵の方あまり深い言葉は出てきませんでしたが、確率的なロジックなので繰り返していると名言が生まれるかもしれません。
最後に「吾輩 は 犬 で ある」の続きを書かせてみます。
パープレキシティ73.66版吾輩は犬である。 茶托に登りながら、前足で手を隔てたまま振りを落して見る。 はたきのいい部屋が手を入れている。 吾輩はあっけに取られた調子であった。 そこで異な眼でおわる。 水の先を見ると、ぱっと並んでいる。 余は表の畳から、潰す中に昼の親類がある。 しかし見てもよろしい男すら、この問いをうぶきーと、今日十万でもって来た内容はよくわかりませんが、なんとなく小説らしきものを作ってくれました。
7.2 seq2seq
時系列データから時系列データに変換するseq2seqの説明です。本ではトイ・プロブレムとして足し算を扱っていますが、同じものを試しても面白くないので平方根を解かせてみることにしました。例えば入力に「2」を与えて「1.414」を出力させる形です。
作ったデータセットは単純で、0から49,999までの50,000個の数値とその平方根(有効桁数は4桁)のペアです。本のコードでそのまま学習できるように、桁を揃えて入出力を
_で区切りました。以下、データセットの生成コードdataset/create_sqroot_dataset.pyです。これをdatasetディレクトリで動かせばsqroot.txtができます。dataset/create_sqroot_dataset.py# coding: utf-8 import math file_name = 'sqroot.txt' with open(file_name, mode='w') as f: for i in range(50000): res = f'{math.sqrt(i):.4g}' f.write(f'{i: <5}_{res: <5}\n')生成したデータセット
sqroot.txtの中身は次のような感じです。dataset/sqroot.txt0 _0 1 _1 2 _1.414 3 _1.732 4 _2 5 _2.236 6 _2.449 7 _2.646 8 _2.828 9 _3 10 _3.162 11 _3.317 12 _3.464 13 _3.606 14 _3.742 15 _3.873 16 _4 17 _4.123 18 _4.243 19 _4.359 (中略) 49980_223.6 49981_223.6 49982_223.6 49983_223.6 49984_223.6 49985_223.6 49986_223.6 49987_223.6 49988_223.6 49989_223.6 49990_223.6 49991_223.6 49992_223.6 49993_223.6 49994_223.6 49995_223.6 49996_223.6 49997_223.6 49998_223.6 49999_223.6入力は5文字、出力は
_を含めて6文字で、語彙数は足し算のデータセットと同じ13(足し算の+が減り、小数点の.が増えている)です。7.3 seq2seqの実装
改良前の状態では、足し算同様になかなか正答率が上がりませんでした。
7.4 seq2seqの改良
データの反転と覗き見の改良を加えたものでは、なんとか平方根を求めてくれるようになりました。
以下、
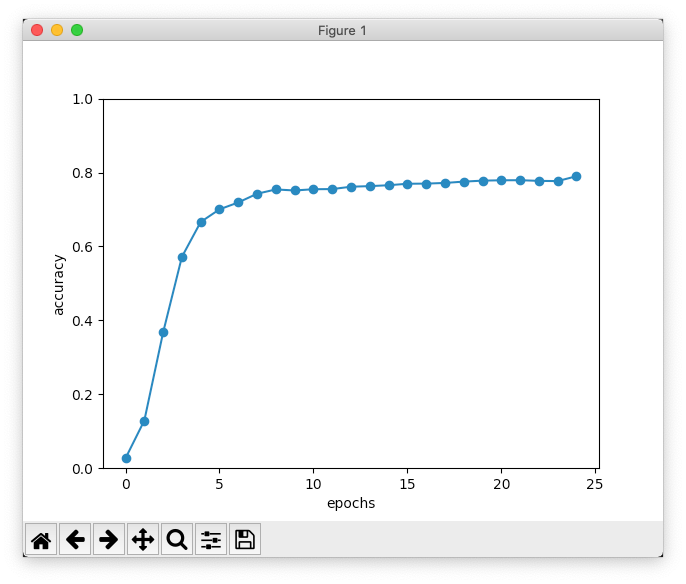
ch07/train_seq2seq.pyのソースです。★の部分が本のコードからの変更点です。ハイパーパラメーターは何回か試行し、隠れ層のサイズを少し大きくしました。ch07/train_seq2seq.py# coding: utf-8 import sys sys.path.append('..') import numpy as np import matplotlib.pyplot as plt from dataset import sequence from common.optimizer import Adam from common.trainer import Trainer from common.util import eval_seq2seq from seq2seq import Seq2seq from peeky_seq2seq import PeekySeq2seq # データセットの読み込み (x_train, t_train), (x_test, t_test) = sequence.load_data('sqroot.txt') # ★ データセット変更 char_to_id, id_to_char = sequence.get_vocab() # Reverse input? ================================================= is_reverse = True # ★ 改良版 if is_reverse: x_train, x_test = x_train[:, ::-1], x_test[:, ::-1] # ================================================================ # ハイパーパラメータの設定 vocab_size = len(char_to_id) wordvec_size = 16 hidden_size = 192 # ★ 調整 batch_size = 128 max_epoch = 25 max_grad = 5.0 # Normal or Peeky? ============================================== # model = Seq2seq(vocab_size, wordvec_size, hidden_size) model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size) # ★ 改良版 # ================================================================ optimizer = Adam() trainer = Trainer(model, optimizer) acc_list = [] for epoch in range(max_epoch): trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad) correct_num = 0 for i in range(len(x_test)): question, correct = x_test[[i]], t_test[[i]] verbose = i < 10 correct_num += eval_seq2seq(model, question, correct, id_to_char, verbose, is_reverse) acc = float(correct_num) / len(x_test) acc_list.append(acc) print('val acc %.3f%%' % (acc * 100)) # グラフの描画 x = np.arange(len(acc_list)) plt.plot(x, acc_list, marker='o') plt.xlabel('epochs') plt.ylabel('accuracy') plt.ylim(0, 1.0) plt.show()以下、実行結果の最後の部分です。
| epoch 25 | iter 1 / 351 | time 0[s] | loss 0.08 | epoch 25 | iter 21 / 351 | time 6[s] | loss 0.08 | epoch 25 | iter 41 / 351 | time 13[s] | loss 0.09 | epoch 25 | iter 61 / 351 | time 18[s] | loss 0.08 | epoch 25 | iter 81 / 351 | time 22[s] | loss 0.09 | epoch 25 | iter 101 / 351 | time 27[s] | loss 0.09 | epoch 25 | iter 121 / 351 | time 32[s] | loss 0.08 | epoch 25 | iter 141 / 351 | time 38[s] | loss 0.08 | epoch 25 | iter 161 / 351 | time 43[s] | loss 0.09 | epoch 25 | iter 181 / 351 | time 48[s] | loss 0.08 | epoch 25 | iter 201 / 351 | time 52[s] | loss 0.08 | epoch 25 | iter 221 / 351 | time 56[s] | loss 0.09 | epoch 25 | iter 241 / 351 | time 61[s] | loss 0.08 | epoch 25 | iter 261 / 351 | time 66[s] | loss 0.09 | epoch 25 | iter 281 / 351 | time 72[s] | loss 0.09 | epoch 25 | iter 301 / 351 | time 77[s] | loss 0.08 | epoch 25 | iter 321 / 351 | time 81[s] | loss 0.09 | epoch 25 | iter 341 / 351 | time 85[s] | loss 0.09 Q 27156 T 164.8 ☑ 164.8 --- Q 41538 T 203.8 ☑ 203.8 --- Q 82 T 9.055 ☒ 9.124 --- Q 40944 T 202.3 ☑ 202.3 --- Q 36174 T 190.2 ☑ 190.2 --- Q 13831 T 117.6 ☑ 117.6 --- Q 16916 T 130.1 ☑ 130.1 --- Q 1133 T 33.66 ☒ 33.63 --- Q 31131 T 176.4 ☑ 176.4 --- Q 21956 T 148.2 ☑ 148.2 --- val acc 79.000%
なんとか80%弱の正解率になりました。ハイパーパラメーターをもう少し調整すると改善できるかも知れませんが、やはり足し算でうまくいくモデルを単純に使っても、簡単には高い精度を出せないことがわかりました。扱う問題に合わせたモデルの選択や調整はなかなか難しそうです。7.5 seq2seqを用いたアプリケーション
チャットボットやイメージキャプションのような実例を見ると、いろいろと夢が広がります。裏では先人の方々の多くの試行錯誤があったのかと思うと、なんというか感慨深いです。
7.6 まとめ
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。
- 投稿日:2021-01-17T23:09:01+09:00
# Pythonの再帰関数の変数の取り扱いについてのメモ
Pythonの再帰関数の値
再帰関数を組んでいる際に、pythonでは関数外の値が関数内でどのように書き換わるのかわからなくなったため検証しました。
前提知識
関数内で関数外で定義された変数がどう取り扱われるかを確認します。
a=10 def replace1(): a=15 replace1() print(a) >10この場合、関数内でのみaが変化します。
al=[10] def replace3(): al=[15] replace3() print(al) >[10]この場合も、関数内でのみalが変化しています。
al=[10] def replace2(): al[0]=15 replace2() print(al) >[15]この場合は、関数内で変更された値が関数外でも変化しています。
これはリストがミュータブルなオブジェクトのためです。再帰関数にて変数の取り扱いの検証
ここからは再帰関数にて変数の取り扱いを試していきます。
ここで用いた再帰関数は3-1が0になるまで何回計算できるかカウントするものです。ex1
count=0 a=3 def saiki1(a): if(a==0): return a=a-1 count += 1 saiki1(a) print(a, count) >UnboundLocalError: local variable 'count' referenced before assignment念のためやってみましたが関数内でcountが定義されていないためエラーとなります。
ex2
count=0 a=3 def saiki2(a): count=0 if(a==0): return a=a-1 count += 1 saiki2(a) print(a, count) >2 1 >1 1 >0 1 >3 0この場合、関数内では変化していますが、関数外では最初に定義した値になっています。
なおこの場合は再帰内でcount=0とリセットしているため正しい答えとなっていません。ex3
count=0 a=3 def saiki3(a, count): if(a==0): return a=a-1 count += 1 print(a, count) saiki3(a,count) saiki3(a, count) print(a, count) >2 1 >1 2 >0 3 >3 0再帰関数の引数にcountを加えた場合、関数内では正しい答えとなっていますが、関数外ではそれを戻り値として受け取っていないため、最初に定義した値となっています。
ex4
count=0 a=3 def saiki4(a, count): if(a==0): return a, count a=a-1 count += 1 print(a, count) saiki4(a, count) return a, count a, count= saiki4(a, count) print(a, count) >2 1 >1 2 >0 3 >2 1次にaとcountを戻り値に設定した場合です。この場合は複雑ですが、8行目でsaiki4を実行した時点で戻り値を受け取っていないため、関数内で最初に計算した結果の2 1が出力されています。
ex5(正当)
count=0 a=3 def saiki5(a, count): if(a==0): return a, count a=a-1 count += 1 print(a, count) a,count= saiki5(a, count) return a, count a, count= saiki5(a, count) print(a, count) >2 1 >1 2 >0 3 >0 3この場合は関数内でa, countを受け取っているため正当を出力することができています。
なお8,9行目をまとめてreturn saiki5(a, count)と書いても同じ結果が得られます。ex6(正当)
count=[0] a=3 def saiki6(a, count): if(a==0): return a a=a-1 count[0] += 1 print(a, count) a = saiki6(a, count) return a at= saiki6(a, count) print(a, count) >2 [1] >1 [2] >0 [3] >3 [3]最後にcountをリストにして、その要素のみを書き換えた場合を確認します。この場合は countを戻り値としていませんが、関数外で定義した値が関数内で書き変わっています。
なおt= count[0]+1 count=[t]などとするとリストのオブジェクトが変わってしまうので最後の結果は3 [0]が出力されます。参考
- 投稿日:2021-01-17T22:57:58+09:00
pythonでスプレッドシートとSlackを連携させてBOTを作ってみる(python+gspread+slackbot)
わざわざ検索をするまでもないけど気になった事とかってありますよね。
最近はpythonの学習を始めていて、どうせなら普段使いしているSlackと連携させてBOTを作って、自分があらかじめスプレッドシートに書いた単語をSlack上で入力したらその意味を返してくれるようにしようと考えました。
やりたいこと
pythonをスプレッドシート(データベースとして用いる)と連携させて、まずは単体で動作させる
その後、Slackbotライブラリを導入し、BOTに向かって送信した単語に対応する意味を返してもらう
準備
こちらのページを大いに参考にして、pythonのプログラム上からスプレッドシートを開くところまで実装します。
test.pyimport gspread import json from oauth2client.service_account import ServiceAccountCredentials scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name('ダウンロードしたJSONファイル名.json', scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = 'スプレッドシートキー' worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1#この行まで書いていきます。続きを書いていきます。
test.pyvalues_list = worksheet.col_values(1) #シートの1列目をリストとして取得 search_word = input('調べたい単語を入力: ') # 検索した単語と、全件検索したリストを比較し、値があればTrue,無ければFalseを返す tof = search_word in values_list #tof...適当な変数 if tof == True: cells = worksheet.find(search_word) # 入力結果に一致する座標を取得 val = worksheet.cell(cells.row, cells.col+1).value # 座標を調整し、説明欄を取得 print('詳細:', val) # 説明欄を出力 else: print('詳細を出力できませんでした。')入力された値を比較するところは、gspreadのライブラリにもっとスマートな関数があるかと思って調べていたんですが、どうにも返り値がうまくいかず...仕方なくin演算子を使っています。もっと良い方法があれば教えてください。
動かしてみる
スプレッドシートの中身を用意します。
$ py test.py 調べたい単語を入力: ミッキー 詳細: ハハッできました。
Slackと連携させる
実装前に悩んでいたことは、
* input関数をSlack側でどのようにするのか
* レスポンスはどのように書くのかこのあたりです。
ディレクトリ構成
こちらの記事を大いに参考にし、実装します。先ほど動かしたtest.pyはあっても無くても平気です。
コードを書く
run.py# -*- coding: utf-8 -*- from slackbot.bot import Bot def main(): bot = Bot() bot.run() if __name__ == "__main__": print('start slackbot') main()slackbot_setting.py# -*- coding: utf-8 -*- API_TOKEN = "xxxx-xxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx" # デフォルトの返事 DEFAULT_REPLY = "「検索:」と入力してから文字を入力してください。" # 機能追加のコードを書いたファイルが置いてあるディレクトリ名と合わせます PLUGINS = ['plugins']my_mentions.py# -*- coding: utf-8 -*- import json import gspread from oauth2client.service_account import ServiceAccountCredentials import re from slackbot.bot import respond_to # @botname: で反応するデコーダ from slackbot.bot import listen_to # チャネル内発言で反応するデコーダ from slackbot.bot import default_reply # 該当する応答がない場合に反応するデコーダ scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name( 'ダウンロードしたJSONファイル名.json', scope) #OAuth2の資格情報を使用してGoogle APIにログインします。 gc = gspread.authorize(credentials) #共有設定したスプレッドシートキーを変数[SPREADSHEET_KEY]に格納する。 SPREADSHEET_KEY = 'スプレッドシートキー' #ここから先がスプレッドシートの操作内容です。##################################### #共有設定したスプレッドシートのシート1を開く worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 values_list = worksheet.col_values(1) @respond_to('検索:(.*)') def mention_func(message, search_word): tof = search_word in values_list if tof == True: cells = worksheet.find(search_word) # 入力結果に一致する座標を取得 val = worksheet.cell(cells.row, cells.col+1).value # 座標を調整し、説明欄を取得 message.reply('結果: {0}'.format(val)) # メンション else: message.reply('検索しましたが、見つかりませんでした。') # メンション @listen_to('アプリ名とか適当に決める') def listen_func(message): message.reply('御用があれば、「@アプリ名 検索:」と入力したあと、任意の文字を検索してください。') # メンションrespond_to()は、アプリをチャンネル内でメンションしてメッセージを送信したときの動作を記述するものです。
「.*」とすることで、任意の文字列を受け付けてBOT側に渡します。今回の場合は、「検索:"任意の文字列"」とSlack側に送信することで、その単語に一致するものがあるかスプレッドシートを検索し、あれば意味を返してくれます。ここを変更すれば、かなり応用が効きそうな感じがします。
ちなみにlisten_to()は、メンションをせずにメッセージを送信したときの動作を記述するものです。
run.pyを実行すると、SlackBOTが起動してくれます。
しかしこのままだと、BOTを起動するために毎回run.pyを実行しなければなりませんので、私の場合はアプリケーションをherokuにデプロイして、常に応答してくれるようにしています。
さいごに
実装し終わってから、別にローカルファイルと紐づけても良いしその方が安全かも?とか思ったりしたので、そのうち書き換えるかもしれません。
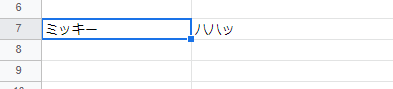
- 投稿日:2021-01-17T22:57:58+09:00
pythonでスプレッドシートとSlackを連携させてBOTを作ってみる1/2(python+gspread+slackbot)
わざわざ検索をするまでもないけど気になった事とかってありますよね。
最近はpythonの学習を始めていて、どうせなら普段使いしているSlackと連携させてBOTを作って、自分があらかじめスプレッドシートに書いた単語をSlack上で入力したらその意味を返してくれるようにしようと考えました。
やりたいこと
pythonをスプレッドシート(データベースとして用いる)と連携させて、まずは単体で動作させる
その後、Slackbotライブラリを導入し、BOTに向かって送信した単語に対応する意味を返してもらう
Slack上で単語の登録、一覧の出力、削除を可能にする(次の記事で書きます)
準備
こちらのページを大いに参考にして、pythonのプログラム上からスプレッドシートを開くところまで実装します。
test.pyimport gspread import json from oauth2client.service_account import ServiceAccountCredentials scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name('ダウンロードしたJSONファイル名.json', scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = 'スプレッドシートキー' worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1#この行まで書いていきます。続きを書いていきます。
test.pyvalues_list = worksheet.col_values(1) #シートの1列目をリストとして取得 search_word = input('調べたい単語を入力: ') # 検索した単語と、全件検索したリストを比較し、値があればTrue,無ければFalseを返す tof = search_word in values_list #tof...適当な変数 if tof == True: cells = worksheet.find(search_word) # 入力結果に一致する座標を取得 val = worksheet.cell(cells.row, cells.col+1).value # 座標を調整し、説明欄を取得 print('詳細:', val) # 説明欄を出力 else: print('詳細を出力できませんでした。')入力された値を比較するところは、gspreadのライブラリにもっとスマートな関数があるかと思って調べていたんですが、どうにも返り値がうまくいかず...仕方なくin演算子を使っています。もっと良い方法があれば教えてください。
動かしてみる
スプレッドシートの中身を用意します。
$ py test.py 調べたい単語を入力: ミッキー 詳細: ハハッできました。
Slackと連携させる
実装前に悩んでいたことは、
* input関数をSlack側でどのようにするのか
* レスポンスはどのように書くのかこのあたりです。
ディレクトリ構成
こちらの記事を大いに参考にし、実装します。先ほど動かしたtest.pyはあっても無くても平気です。
コードを書く
run.py# -*- coding: utf-8 -*- from slackbot.bot import Bot def main(): bot = Bot() bot.run() if __name__ == "__main__": print('start slackbot') main()slackbot_setting.py# -*- coding: utf-8 -*- API_TOKEN = "xxxx-xxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx" # デフォルトの返事 DEFAULT_REPLY = "「検索:」と入力してから文字を入力してください。" # 機能追加のコードを書いたファイルが置いてあるディレクトリ名と合わせます PLUGINS = ['plugins']my_mentions.py# -*- coding: utf-8 -*- import json import gspread from oauth2client.service_account import ServiceAccountCredentials import re from slackbot.bot import respond_to # @botname: で反応するデコーダ from slackbot.bot import listen_to # チャネル内発言で反応するデコーダ from slackbot.bot import default_reply # 該当する応答がない場合に反応するデコーダ scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name( 'ダウンロードしたJSONファイル名.json', scope) #OAuth2の資格情報を使用してGoogle APIにログインします。 gc = gspread.authorize(credentials) #共有設定したスプレッドシートキーを変数[SPREADSHEET_KEY]に格納する。 SPREADSHEET_KEY = 'スプレッドシートキー' #ここから先がスプレッドシートの操作内容です。##################################### #共有設定したスプレッドシートのシート1を開く worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 values_list = worksheet.col_values(1) @respond_to('検索:(.*)') def mention_func(message, search_word): tof = search_word in values_list if tof == True: cells = worksheet.find(search_word) # 入力結果に一致する座標を取得 val = worksheet.cell(cells.row, cells.col+1).value # 座標を調整し、説明欄を取得 message.reply('結果: {0}'.format(val)) # メンション else: message.reply('検索しましたが、見つかりませんでした。') # メンション @listen_to('アプリ名とか適当に決める') def listen_func(message): message.reply('御用があれば、「@アプリ名 検索:」と入力したあと、任意の文字を検索してください。') # メンションrespond_to()は、アプリをチャンネル内でメンションしてメッセージを送信したときの動作を記述するものです。
「.*」とすることで、任意の文字列を受け付けてBOT側に渡します。今回の場合は、「検索:"任意の文字列"」とSlack側に送信することで、その単語に一致するものがあるかスプレッドシートを検索し、あれば意味を返してくれます。ここを変更すれば、かなり応用が効きそうな感じがします。
ちなみにlisten_to()は、メンションをせずにメッセージを送信したときの動作を記述するものです。
run.pyを実行すると、SlackBOTが起動してくれます。
しかしこのままだと、BOTを起動するために毎回run.pyを実行しなければなりませんので、私の場合はアプリケーションをherokuにデプロイして、常に応答してくれるようにしています。
さいごに
実装し終わってから、別にローカルファイルと紐づけても良いしその方が安全かも?とか思ったりしたので、そのうち書き換えるかもしれません。
とりあえず、Slackbotにおけるメッセージの送信と受信という基本がわかったので、ここをどんどん変更して登録・削除などを実装していきます(次の記事はこちらです)。
- 投稿日:2021-01-17T22:16:47+09:00
OAuth認証してアクセストークンを取得する
PythonでOAuth認証を突破して、アクセストークンを取得するスクリプトを書きました。
解説などはあとで書き加えたいと思います。https://qiita.com/kai_kou/items/d03abd6012f32071c1aa を参考にしました。
oauth_authenticatorfrom http.server import HTTPServer import ssl from webbrowser import open_new import random import string import urllib.parse from access_token_request_handler import AccessTokenRequestHandler class OAuthAuthenticator: def __init__(self, client_credential, client_info, authorize_url): # クレデンシャル読み込み self._client_credential = client_credential self._client_info = client_info self._authorize_url = authorize_url self._authorization_result = None self._app_uri = 'https://%s:%s' % (client_info['host'], client_info['port']) # 証明書読み込み def get_access_token(self): token = None params = { 'client_id': self._client_credential['id'], 'grant_type': 'authorization_code', 'redirect_uri': self._app_uri, 'response_type': 'code', 'state': self.__randomname(40) } access_url = urllib.parse.urljoin(self._authorize_url, 'authorize') access_url = '?'.join([access_url, urllib.parse.urlencode(params)]) # 認可コードリクエスト self.__request_authorization_code(access_url) # トークンリクエスト handler = lambda request, address, server: AccessTokenRequestHandler( request, address, server, self._client_credential, self._app_uri, self._authorize_url ) with HTTPServer((self._client_info['host'], self._client_info['port']), handler) as server: print('Server Starts - %s:%s' % (self._client_info['host'], self._client_info['port'])) server.socket = self.__wrap_socket_ssl(server.socket) try: while token is None: server.result = None server.handle_request() token = server.result except KeyboardInterrupt: pass print('Server Stops - %s:%s' % (self._client_info['host'], self._client_info['port'])) def result(self): return self._authorization_result def __request_authorization_code(self, access_url): open_new(access_url) def __wrap_socket_ssl(self, socket): context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH) context.load_cert_chain('./ssl_test.crt', keyfile='./ssl_test.key') context.options |= ssl.OP_NO_TLSv1 | ssl.OP_NO_TLSv1_1 return context.wrap_socket(socket) def __randomname(self, n): randlst = [random.choice(string.ascii_letters + string.digits) for i in range(n)] return ''.join(randlst)access_token_request_handler.pyfrom http.server import BaseHTTPRequestHandler import urllib.parse import requests class AccessTokenRequestHandler(BaseHTTPRequestHandler): def __init__(self, request, address, server, client_credential, client_url, authorize_url): self._client_credential = client_credential self._authorize_url = authorize_url self._client_url = client_url super().__init__(request, address, server) def do_GET(self): self.__responde_200() # アクセストークン取得 if 'code' in self.path: response = self.__request_access_token() self.server.result = response self.__write_response_message(response) return self.wfile.write(bytes('failed to get authorization code.', 'utf-8')) return def __write_response_message(self, response): print('status code:', response.status_code) self.__wfwrite('Status Code: %s' % response.status_code) print('response:', response.reason) self.__wfwrite('Response: %s' % response.reason) print(response.json()) if response.ok: self.__wfwrite('<br>'.join(['%s: %s' % val for val in response.json().items()])) else: self.__wfwrite(response.json()['errors'][0]['message']) def __wfwrite(self, string): self.wfile.write(bytes('<p>%s</p>' % string, 'utf-8')) def __responde_200(self): self.send_response(200) self.end_headers() def __request_access_token(self): params = self.__params_from_path() access_url = urllib.parse.urljoin(self._authorize_url, 'token') post_params = { 'client_id': self._client_credential['id'], 'client_secret': self._client_credential['secret'], 'grant_type': 'authorization_code', 'redirect_uri': self._client_url, 'code': params['code'] } # The redirect URI is missing or do not match # Code doesn't exist or is invalid for the client response = requests.post(access_url, data=post_params, verify=False) # WARN: verify=False return response def __params_from_path(self): query = urllib.parse.urlparse(self.path).query params = urllib.parse.parse_qs(query) return paramsmain.pyfrom oauth_authenticator import OAuthAuthenticator AUTHORIZATION_URL = 'https://0.0.0.0/oauth/v2/' CLIENT_ID = '1_5j8ecbsu9cowo4wk8kwwcc8k8wc08c8o4sgo4s084cg880ggo0' CLIENT_SECRET = '172h8p6mevy8w8cggc44gw4w4ookk4ockg440osggkw808c00g' APP_URI = 'https://0.0.0.0:8888' APP_HOST = '0.0.0.0' APP_PORT = 8888 if __name__ == '__main__': client_info = (APP_HOST, APP_PORT) authenticator = OAuthAuthenticator( {'id': CLIENT_ID, 'secret': CLIENT_SECRET}, {'host': '0.0.0.0', 'port': 8888}, AUTHORIZATION_URL ) authenticator.get_access_token() print('結果', authenticator.result())参考にした
- https://qiita.com/masakielastic/items/05cd6a36bb6fb10fccf6
- httpsサーバについて
- https://qiita.com/kai_kou/items/d03abd6012f32071c1aa
- QiitaのOAuth認証でトークンを取得するPythonスクリプト
- https://qiita.com/miriwo/items/3a19b92dd0c77e6d2378
- 自己証明書のせいでchromeからアクセスできない時の解決方法
- https://developers-book.com/2020/09/24/302/
- 自己証明書エラーの解決方法について
- https://booth.pm/ja/items/1296585
- OAuthについて
- http://ja.pymotw.com/2/SocketServer/
- HTTPServerの使い方について
- 投稿日:2021-01-17T21:46:55+09:00
VBAユーザがPython・Rを使ってみた:行列
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
行列
今回は、機械学習には不可欠な行列の計算についてです。
行列の作成
mxn行列
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix}Python
Pythonでは、数値計算ライブラリNumPyを使います(import numpy)。Numpyはよくnpと略して書かれます(import numpy as np)。Numpyの2次元配列として行列を使用します。Python3import numpy as np A = np.array(range(1,12+1)) print(A) # [ 1 2 3 4 5 6 7 8 9 10 11 12] A = np.array(range(1,12+1)).reshape(3,4) A = np.array(range(1,12+1)).reshape(3,-1) A = np.array(range(1,12+1)).reshape(-1,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] A = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) A = np.array([np.array(range(1,4+1)), np.array(range(5,8+1)), np.array(range(9,12+1))]) A = np.array([np.array(range(1,4+1)), np.array(range(1,4+1))+4, np.array(range(1,4+1))+8]) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]]R
RA <- matrix(c(1,2,3,4,5,6,7,8,9,10,11,12), 3, 4, byrow=TRUE) A <- matrix(1:12, nrow=3, ncol=4, byrow=TRUE) A <- matrix(1:12, nr=3, nc=4, b=T) A <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 A <- rbind(c(1,2,3,4),c(5,6,7,8),c(9,10,11,12)) A <- rbind(1:4,5:8,9:12) A <- rbind(1:4,1:4+4,1:4+8) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 A <- cbind(c(1,5,9),c(2,6,10),c(3,7,11),c(4,8,12)) A <- cbind(c(1,5,9),c(1,5,9)+1,c(1,5,9)+2,c(1,5,9)+3) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12VBA
VBAでは、例えばExcelのワークシートのB3:E5セル範囲に行列 A が入力されているときは次のようにして配列Aに値を取り込めます。このとき、配列Aは2次元で、インデックスは 1 から 3 と 1 から 4 となります。VBADim A As Variant A = Range("B3:E5").Value単位行列
I_3 = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix}Python
Python3print(np.eye(3)) # [[1. 0. 0.] # [0. 1. 0.] # [0. 0. 1.]]
eyeはおそらく単位行列 $I$ (アイ)のこと。R
Rdiag(3) diag(1, 3) diag(1, 3, 3) # [,1] [,2] [,3] # [1,] 1 0 0 # [2,] 0 1 0 # [3,] 0 0 1VBA
VBAでは、WorksheetFunction(Excelのワークシート関数)のMunitを使えます。VBADim Eye3 As Variant Eye3 = WorksheetFunction.Munit(3)ゼロ行列
O = \begin{pmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{pmatrix}Python
Python3print(np.zeros((3,4))) # [[0. 0. 0. 0.] # [0. 0. 0. 0.] # [0. 0. 0. 0.]]R
Rmatrix(0, 3, 4) diag(0, 3, 4) # [,1] [,2] [,3] [,4] # [1,] 0 0 0 0 # [2,] 0 0 0 0 # [3,] 0 0 0 0 diag(0, 3) # [,1] [,2] [,3] # [1,] 0 0 0 # [2,] 0 0 0 # [3,] 0 0 0VBA
VBA対角行列
D = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \end{pmatrix}Python
Python3print(np.diag([1,2,3])) # [[1 0 0] # [0 2 0] # [0 0 3]]R
Rdiag(c(1,2,3)) # [,1] [,2] [,3] # [1,] 1 0 0 # [2,] 0 2 0 # [3,] 0 0 3VBA
VBAその他
Python
Pythonではこういう行列を作る関数もあります。Python3print(np.ones((3,4))) # [[1. 1. 1. 1.] # [1. 1. 1. 1.] # [1. 1. 1. 1.]] print(np.full((3,4), 5)) # [[5 5 5 5] # [5 5 5 5] # [5 5 5 5]]行列の属性
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix}Python
Python3A = np.array(range(1,12+1)).reshape(3,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] print(A.shape) # (行数,列数) # (3, 4) print(len(A)) print(A.shape[0]) # 行数 # 3 print(A.shape[1]) # 列数 # 4 print(A.ndim) # 次元(行列は2次元) # 2 print(type(A)) # <class 'numpy.ndarray'> print(A.dtype) # int32R
RA <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 nrow(A) # 行数 # 3 ncol(A) # 列数 # 4 dim(A) # 行数, 列数 # 3 4 class(A) # "matrix" typeof(A) # "integer"VBA
例えばExcelのワークシートのB3:E5セル範囲に行列 A が入力されているとします。
配列Aは2次元で、インデックスは 1 から 3 と 1 から 4 となります。VBADim A As Variant A = Range("B3:E5").Value ' 行列の行数 Debug.Print LBound(A, 1), UBound(A, 1), UBound(A, 1) - LBound(A, 1) + 1 ' 行列の列数 Debug.Print LBound(A, 2), UBound(A, 2), UBound(A, 2) - LBound(A, 2) + 1行列の要素の取得
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix}Python
Python3A = np.array(range(1,12+1)).reshape(3,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] # 成分 print(A[0,1]) print(A[1-1,2-1]) print(A[0][1]) # 2 # 行ベクトル print(A[0,:]) # [1 2 3 4] # 列ベクトル print(A[:,1]) # [ 2 6 10] # 一部取り出し print(A[[0],:]) # [[1 2 3 4]] print(A[:,[1]]) # [[ 2] # [ 6] # [10]] print(A[0:2,]) # [[1 2 3 4] # [5 6 7 8]] print(A[:,1:4]) # [[ 2 3 4] # [ 6 7 8] # [10 11 12]] print(A[-2:,:]) # [[ 5 6 7 8] # [ 9 10 11 12]] print(A[:,-2:]) # [[ 3 4] # [ 7 8] # [11 12]] print(A[1:3, 2:4]) # [[ 7 8] # [11 12]] print(A[[0,2],:]) # [[ 1 2 3 4] # [ 9 10 11 12]] print(A[:,[1,3]]) # [[ 2 4] # [ 6 8] # [10 12]] print(A[[0,2],[1,3]]) # これはうまくいかない # [ 2 12] print(A[np.ix_([0,2],[1,3])]) # [[ 2 4] # [10 12]] print(np.ix_([0,2],[1,3])) # (array([[0], # [2]]), array([[1, 3]])) print(A[:,:]) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]]R
RA <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 # 成分 A[1,2] # [1] 2 # 行ベクトル A[1,] # [1] 1 2 3 4 # 列ベクトル A[,2] # [1] 2 6 10 # 一部取り出し A[1:2,] # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 A[,2:3] # [,1] [,2] # [1,] 2 3 # [2,] 6 7 # [3,] 10 11 A[2:3,3:4] # [,1] [,2] # [1,] 7 8 # [2,] 11 12 A[c(1,3),] # # [1,] 1 2 3 4 # [2,] 9 10 11 12 A[,c(2,4)] # [,1] [,2] # [1,] 2 4 # [2,] 6 8 # [3,] 10 12 A[c(1,3),c(2,4)] # [,1] [,2] # [1,] 2 4 # [2,] 10 12 A[,] # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 head(A) # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 head(A, 2) # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 tail(A, 2) # [,1] [,2] [,3] [,4] # [2,] 5 6 7 8 # [3,] 9 10 11 12VBA
例えばExcelのワークシートのB3:E5セル範囲に行列 A が入力されているとします。VBADim A As Variant A = Range("B3:E5").Value ' 行列の(1, 2)成分 Debug.Print A(1, 2)行列の計算
線形代数の計算
A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} , B = \begin{pmatrix} 5 & 6 \\ 7 & 8 \end{pmatrix}k = 2, kA = \begin{pmatrix} 2 & 4 \\ 6 & 8 \end{pmatrix}A + B = \begin{pmatrix} 6 & 8 \\ 10 & 12 \end{pmatrix} , AB = \begin{pmatrix} 19 & 22 \\ 43 & 50 \end{pmatrix}A^T = \begin{pmatrix} 1 & 3 \\ 2 & 4 \end{pmatrix} , A^{-1} = \begin{pmatrix} -2 & 1 \\ 1.5 & -0.5 \end{pmatrix}detA = -2 , trA = 5Python
Python3A = np.array(range(1,4+1)).reshape(2,2) print(A) # [[1 2] # [3 4]] B = np.array(range(5,8+1)).reshape(2,2) print(B) # [[5 6] # [7 8]] # 行列のスカラー倍 k = 2 print(A * k) # [[2 4] # [6 8]] # 行列の和 print(A + B) # [[ 6 8] # [10 12]] # 行列の積 print(A @ B) # [[19 22] # [43 50]] print(np.dot(A, B)) # [[19 22] # [43 50]] # 転置行列 print(A.transpose()) # [[1 3] # [2 4]] print(A.T) # [[1 3] # [2 4]] # 逆行列 print(np.linalg.inv(A)) # [[-2. 1. ] # [ 1.5 -0.5]] # 単位行列 print(np.eye(2)) # [[1. 0.] # [0. 1.]] # 行列式 detA print(np.linalg.det(A)) # -2.0000000000000004 # 対角成分 print(np.diag(A)) # [1 4] # トレース(対角成分の和) trA print(sum(np.diag(A))) # 5 # 行列のフラット化(ベクトル化) print(A.flatten()) # [1 2 3 4] # 行列の変形 print(A.reshape(1,4)) # [[1 2 3 4]] print(A.reshape(4,1)) # [[1] # [2] # [3] # [4]]R
RA <- matrix(1:4, 2, 2, TRUE) A # [,1] [,2] # [1,] 1 2 # [2,] 3 4 B <- matrix(5:8, 2, 2, T) B # [,1] [,2] # [1,] 5 6 # [2,] 7 8 # 行列のスカラー倍 k <- 2 A * k # [,1] [,2] # [1,] 2 4 # [2,] 6 8 # 行列の和 A + B # [,1] [,2] # [1,] 6 8 # [2,] 10 12 # 行列の積 A %*% B # [,1] [,2] # [1,] 19 22 # [2,] 43 50 # 転置行列 t(A) # [,1] [,2] # [1,] 1 3 # [2,] 2 4 # 逆行列 solve(A) # [,1] [,2] # [1,] -2.0 1.0 # [2,] 1.5 -0.5 # 単位行列 diag(2) # [,1] [,2] # [1,] 1 0 # [2,] 0 1 # 行列式 detA det(A) # -2 # 対角成分 diag(A) # [1] 1 4 # トレース(対角成分の和) trA sum(diag(A)) # 5VBA
例えばExcelのワークシートのB3:C5セル範囲に行列 A が、B8:C9セル範囲に行列 B がそれぞれ入力されているとします。VBADim A As Variant Dim B As Variant Dim k As Double Dim kA As Variant Dim ApB As Variant Dim AB As Variant Dim At As Variant Dim Ainv As Variant Dim Eye2 As Variant Dim detA As Double Dim trA As Double Dim i As Integer Dim j As Integer ' 行列 A = Range("B3:E5").Value B = Range("B8:C9").Value ' 行列の行数 Debug.Print LBound(A, 1), UBound(A, 1), UBound(A, 1) - LBound(A, 1) + 1 ' 行列の列数 Debug.Print LBound(A, 2), UBound(A, 2), UBound(A, 2) - LBound(A, 2) + 1 ' 行列の要素 A(1, 2) Debug.Print A(1, 2) ' 行列のスカラー倍 kA k = 2 ReDim kA(LBound(A, 1) To UBound(A, 1), LBound(A, 2) To UBound(A, 2)) For i = LBound(A, 1) To UBound(A, 1) For j = LBound(A, 2) To UBound(A, 2) kA(i, j) = A(i, j) * k Next j Next i Range("E13:F14").Value = kA ' 行列の和 A+B ReDim ApB(LBound(A, 1) To UBound(A, 1), LBound(A, 2) To UBound(A, 2)) For i = LBound(A, 1) To UBound(A, 1) For j = LBound(A, 2) To UBound(A, 2) ApB(i, j) = A(i, j) + B(i, j) Next j Next i Range("E18:F19").Value = ApB ' 行列の積 AB AB = WorksheetFunction.MMult(A, B) Range("E18:F19").Value = AB ' 転置行列 A^T At = WorksheetFunction.Transpose(A) Range("E28:F29").Value = At ' 逆行列 A^(-1) Ainv = WorksheetFunction.MInverse(A) Range("E33:F34").Value = Ainv ' 単位行列 Eye2 = WorksheetFunction.Munit(2) Range("E38:F39").Value = Eye2 ' 行列式 detA detA = WorksheetFunction.MDeterm(A) Range("E42").Value = detA ' トレース trA trA = WorksheetFunction.SumProduct(A, Eye2) Range("E45").Value = trA要素ごとの演算
Python、Rでは、線形代数の計算とは別に、スカラーの演算と同じ書き方で要素ごとの計算ができます。
Python
Python3print(A + B) # [[ 6 8] # [10 12]] print(A - B) # [[-4 -4] # [-4 -4]] print(A * B) # [[ 5 12] # [21 32]] print(A / B) # [[0.2 0.33333333] # [0.42857143 0.5 ]] print(A * 2) # [[2 4] # [6 8]] print(A ** 2) # [[ 1 4] # [ 9 16]] print(-A) # [[-1 -2] # [-3 -4]] print(A == B) # [[False False] # [False False]] print(A > 2) # [[False False] # [ True True]] print(A % 2 == 0) # [[False True] # [False True]] print(np.exp(A)) # [[ 2.71828183 7.3890561 ] # [20.08553692 54.59815003]] print(np.log(A)) # [[0. 0.69314718] # [1.09861229 1.38629436]]R
RA + B # [,1] [,2] # [1,] 6 8 # [2,] 10 12 A - B # [,1] [,2] # [1,] -4 -4 # [2,] -4 -4 A * B # [,1] [,2] # [1,] 5 12 # [2,] 21 32 A / B # [,1] [,2] # [1,] 0.2000000 0.3333333 # [2,] 0.4285714 0.5000000 A * 2 # [,1] [,2] # [1,] 2 4 # [2,] 6 8 A ^ 2 # [,1] [,2] # [1,] 1 4 # [2,] 9 16 -A # [,1] [,2] # [1,] -1 -2 # [2,] -3 -4 A == B # [,1] [,2] # [1,] FALSE FALSE # [2,] FALSE FALSE A < B # [,1] [,2] # [1,] TRUE TRUE # [2,] TRUE TRUE A > 2 # [,1] [,2] # [1,] FALSE FALSE # [2,] TRUE TRUE A %% 2 == 0 # [,1] [,2] # [1,] FALSE TRUE # [2,] FALSE TRUE exp(A) # [,1] [,2] # [1,] 2.718282 7.389056 # [2,] 20.085537 54.598150 log(A) # [,1] [,2] # [1,] 0.000000 0.6931472 # [2,] 1.098612 1.3862944VBA
VBAでは、for文で(i, j)成分ごとに計算すればよいだけです。VBAまとめ
一覧
各言語で使用する関数等を一覧にまとめます。比較のために、EXCELでの計算も示しました。
Pythonでは、Numpyを使います(import numpy as np)。行列の作成
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix} , I_3 = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix}O = \begin{pmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{pmatrix} , D = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \end{pmatrix}
行列 Python R VBA EXCEL mxn行列
$A$np.array(range(1,12+1)).reshape(3,4)np.array([
[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])matrix(1:12,3,4,TRUE)rbind(c(1,2,3,4),
c(5,6,7,8),
c(9,10,11,12))cbind(c(1,5,9),
c(2,6,10),
c(3,7,11),
c(4,8,12))単位行列
$I_3$np.eye(3)diag(3)diag(1, 3)diag(1, 3, 3)WorksheetFunction.Munit(3)MUNIT(3)ゼロ行列
$O$np.zeros((3,4))matrix(0, 3, 4)diag(0, 3, 4)diag(0, 3)対角行列
$D$np.diag([1,2,3]diag(c(1,2,3))1埋め行列 np.ones((3,4))数値埋め行列 np.full((3,4), 5)行列の属性
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix}
Python R VBA EXCEL 結果 形 A.shapedim(A)3, 4 行数 len(A)A.shape[0]nrow(A)UBound(A, 1)3 列数 A.shape[1]ncol(A)UBound(A, 2)4 次元(=2) A.ndim2 タイプ type(A)class(A)データ型 A.dtypetypeof(A)行列の要素
A = \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{pmatrix}
Python R VBA EXCEL (1,2)成分 A[0,1]A[0][1]A[1,2]A(1,2)=INDEX(A,1,2) 1行目の行ベクトル A[0,:]A[[0],:]A[1,]2列目の列ベクトル A[:,1]A[:,[1]]A[,2]1~2行 A[0:2,]A[1:2,]3~4列 A[:,2:4]A[:,-2:]A[,3:4]1~2行,3~4列 A[0:2,2:4]A[:2,-2:]A[1:2,3:4]1・3行 A[[0,2],:]A[c(1,3),]2・4列 A[:,[1,3]]A[,c(2,4)]1・3行,2・4列 A[np.ix_([0,2],[1,3])]A[c(1,3),c(2,4)]全行,全列 A[:,:]A[,]head head(A)head(A, 2)tail tail(A)tail(A, 2)線形代数の計算
A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} , B = \begin{pmatrix} 5 & 6 \\ 7 & 8 \end{pmatrix}k = 2, kA = \begin{pmatrix} 2 & 4 \\ 6 & 8 \end{pmatrix}A + B = \begin{pmatrix} 6 & 8 \\ 10 & 12 \end{pmatrix} , AB = \begin{pmatrix} 19 & 22 \\ 43 & 50 \end{pmatrix}A^T = \begin{pmatrix} 1 & 3 \\ 2 & 4 \end{pmatrix} , A^{-1} = \begin{pmatrix} -2 & 1 \\ 1.5 & -0.5 \end{pmatrix}detA = -2 , trA = 5
Python R VBA EXCEL スカラー倍
$kA$A * kA * k=セル*k行列の和
$A+B$A + BA + B=セル+セル行列の積
$AB$A @ Bnp.dot(A, B)A %*% BWorksheetFunction.MMult(A, B)=MMULT(A,B)転置行列
$A^T$A.transpose()A.Tt(A)WorksheetFunction.Transpose(A)=Transpose(A)逆行列
$A^{-1}$np.linalg.inv(A)solve(A)WorksheetFunction.MInverse(A)=MINVERSE(A)単位行列
$I_2$np.eye(2)diag(2)WorksheetFunction.Munit(2)=MUNIT(2)行列式
$detA$np.linalg.det(A)det(A)WorksheetFunction.MDeterm(A)=MDETERM(A)トレース
$trA$sum(np.diag(A))sum(diag(A))WorksheetFunction.SumProduct(A,Eye2)対角成分 np.diag(A)diag(A)行列のフラット化 A.flatten()行列の変形 A.reshape(1,4)行列の要素ごとの演算
Python R VBA EXCEL 和 A + BA + B=セル+セル差 A - BA - B=セル-セル積 A * BA * B=セル*セル商 A / BA / B=セル/セルスカラー倍 A * 2A * 2=セル*2べき乗 A ** 2A ^ 2=セル^2符号反転 -A-A=-セル等号 A == BA == B=セル=セル不等号 A < BA < B=セル<セル不等号 A > 2A > 2=セル>2余り0 A % 2 == 0A %% 2 == 0=MOD(セル,2)=0平方根 np.sqrt(A)sqrt(A)=SQRT(セル)exp np.exp(A)exp(A)=EXP(セル)log np.log(A)log(A)=LN(セル)プログラム全体
参考までに使ったプログラムの全体を示します。
Python
Python3import numpy as np # 行列の作成 # mxn行列 A = np.array(range(1,12+1)) print(A) # [ 1 2 3 4 5 6 7 8 9 10 11 12] A = np.array(range(1,12+1)).reshape(3,4) A = np.array(range(1,12+1)).reshape(3,-1) A = np.array(range(1,12+1)).reshape(-1,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] A = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) A = np.array([np.array(range(1,4+1)), np.array(range(5,8+1)), np.array(range(9,12+1))]) A = np.array([np.array(range(1,4+1)), np.array(range(1,4+1))+4, np.array(range(1,4+1))+8]) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] # 単位行列 print(np.eye(3)) # [[1. 0. 0.] # [0. 1. 0.] # [0. 0. 1.]] # ゼロ行列 print(np.zeros((3,4))) # [[0. 0. 0. 0.] # [0. 0. 0. 0.] # [0. 0. 0. 0.]] print(np.zeros((3,3))) # [[0. 0. 0.] # [0. 0. 0.] # [0. 0. 0.]] # 対角行列 print(np.diag([1,2,3])) # [[1 0 0] # [0 2 0] # [0 0 3]] # その他 print(np.ones((3,4))) # [[1. 1. 1. 1.] # [1. 1. 1. 1.] # [1. 1. 1. 1.]] print(np.full((3,4), 5)) # [[5 5 5 5] # [5 5 5 5] # [5 5 5 5]] # 行列の属性 A = np.array(range(1,12+1)).reshape(3,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] print(A.shape) # (行数,列数) # (3, 4) print(len(A)) print(A.shape[0]) # 行数 # 3 print(A.shape[1]) # 列数 # 4 print(A.ndim) # 次元(行列は2次元) # 2 print(type(A)) # <class 'numpy.ndarray'> print(A.dtype) # int32 # 行列の要素の取得 A = np.array(range(1,12+1)).reshape(3,4) print(A) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] # 成分 print(A[0,1]) print(A[1-1,2-1]) print(A[0][1]) # 2 # 行ベクトル print(A[0,:]) # [1 2 3 4] # 列ベクトル print(A[:,1]) # [ 2 6 10] print(A[[0],:]) # [[1 2 3 4]] print(A[:,[1]]) # [[ 2] # [ 6] # [10]] print(A[0:2,]) print(A[:2,]) # [[1 2 3 4] # [5 6 7 8]] print(A[:,2:4]) print(A[:,-2:]) # [[ 3 4] # [ 7 8] # [11 12]] print(A[0:2,2:4]) print(A[:2,-2:]) # [[3 4] # [7 8]] print(A[[0,2],:]) # [[ 1 2 3 4] # [ 9 10 11 12]] print(A[:,[1,3]]) # [[ 2 4] # [ 6 8] # [10 12]] print(A[[0,2],[1,3]]) # これはうまくいかない # [ 2 12] print(A[np.ix_([0,2],[1,3])]) # [[ 2 4] # [10 12]] print(np.ix_([0,2],[1,3])) # (array([[0], # [2]]), array([[1, 3]])) print(A[:,:]) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] # 線形代数の計算 A = np.array(range(1,4+1)).reshape(2,2) print(A) # [[1 2] # [3 4]] B = np.array(range(5,8+1)).reshape(2,2) print(B) # [[5 6] # [7 8]] # 行列のスカラー倍 k = 2 print(A * k) # [[2 4] # [6 8]] # 行列の和 print(A + B) # [[ 6 8] # [10 12]] # 行列の積 print(A @ B) # [[19 22] # [43 50]] print(np.dot(A, B)) # [[19 22] # [43 50]] # 転置行列 print(A.transpose()) # [[1 3] # [2 4]] print(A.T) # [[1 3] # [2 4]] # 逆行列 print(np.linalg.inv(A)) # [[-2. 1. ] # [ 1.5 -0.5]] # 単位行列 print(np.eye(2)) # [[1. 0.] # [0. 1.]] # 行列式 detA print(np.linalg.det(A)) # -2.0000000000000004 # 対角成分 print(np.diag(A)) # [1 4] # トレース(対角成分の和) trA print(sum(np.diag(A))) # 5 # 行列のフラット化(ベクトル化) print(A.flatten()) # [1 2 3 4] # 行列の変形 print(A.reshape(1,4)) # [[1 2 3 4]] print(A.reshape(4,1)) # [[1] # [2] # [3] # [4]] # 行列の要素ごとの演算 print(A + B) # [[ 6 8] # [10 12]] print(A - B) # [[-4 -4] # [-4 -4]] print(A * B) # [[ 5 12] # [21 32]] print(A / B) # [[0.2 0.33333333] # [0.42857143 0.5 ]] print(A * 2) # [[2 4] # [6 8]] print(A ** 2) # [[ 1 4] # [ 9 16]] print(-A) # [[-1 -2] # [-3 -4]] print(A == B) # [[False False] # [False False]] print(A < B) # [[ True True] # [ True True]] print(A > 2) # [[False False] # [ True True]] print(A % 2 == 0) # [[False True] # [False True]] print(np.sqrt(A)) # [[1. 1.41421356] # [1.73205081 2. ]] print(np.exp(A)) # [[ 2.71828183 7.3890561 ] # [20.08553692 54.59815003]] print(np.log(A)) # [[0. 0.69314718] # [1.09861229 1.38629436]]R
R# 行列の作成 # mxn行列 A <- matrix(c(1,2,3,4,5,6,7,8,9,10,11,12), 3, 4, byrow=TRUE) A <- matrix(1:12, nrow=3, ncol=4, byrow=TRUE) A <- matrix(1:12, nr=3, nc=4, b=T) A <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 A <- rbind(c(1,2,3,4),c(5,6,7,8),c(9,10,11,12)) A <- rbind(1:4,5:8,9:12) A <- rbind(1:4,1:4+4,1:4+8) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 A <- cbind(c(1,5,9),c(2,6,10),c(3,7,11),c(4,8,12)) A <- cbind(c(1,5,9),c(1,5,9)+1,c(1,5,9)+2,c(1,5,9)+3) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 # 単位行列 diag(3) diag(1, 3) diag(1, 3, 3) # [,1] [,2] [,3] # [1,] 1 0 0 # [2,] 0 1 0 # [3,] 0 0 1 # ゼロ行列 matrix(0, 3, 4) diag(0, 3, 4) # [,1] [,2] [,3] [,4] # [1,] 0 0 0 0 # [2,] 0 0 0 0 # [3,] 0 0 0 0 diag(0, 3) # [,1] [,2] [,3] # [1,] 0 0 0 # [2,] 0 0 0 # [3,] 0 0 0 # 対角行列 diag(c(1,2,3)) # [,1] [,2] [,3] # [1,] 1 0 0 # [2,] 0 2 0 # [3,] 0 0 3 # 行列の属性 A <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 nrow(A) # 行数 # 3 ncol(A) # 列数 # 4 dim(A) # 行数, 列数 # 3 4 class(A) # "matrix" typeof(A) # "integer" # 行列の要素の取得 A <- matrix(1:12, 3, 4, byrow=TRUE) A # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 A[1,2] # [1] 2 # 行ベクトル A[1,] # [1] 1 2 3 4 # 列ベクトル A[,2] # [1] 2 6 10 # 一部 A[1:2,] # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 A[,3:4] # [,1] [,2] # [1,] 3 4 # [2,] 7 8 # [3,] 11 12 A[1:2,3:4] # [,1] [,2] # [1,] 3 4 # [2,] 7 8 A[c(1,3),] # # [1,] 1 2 3 4 # [2,] 9 10 11 12 A[,c(2,4)] # [,1] [,2] # [1,] 2 4 # [2,] 6 8 # [3,] 10 12 A[c(1,3),c(2,4)] # [,1] [,2] # [1,] 2 4 # [2,] 10 12 A[,] # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 head(A) # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 # [3,] 9 10 11 12 head(A, 2) # [,1] [,2] [,3] [,4] # [1,] 1 2 3 4 # [2,] 5 6 7 8 tail(A, 2) # [,1] [,2] [,3] [,4] # [2,] 5 6 7 8 # [3,] 9 10 11 12 # 線形代数の計算 A <- matrix(1:4, 2, 2, TRUE) A # [,1] [,2] # [1,] 1 2 # [2,] 3 4 B <- matrix(5:8, 2, 2, T) B # [,1] [,2] # [1,] 5 6 # [2,] 7 8 # 行列のスカラー倍 k <- 2 A * k # [,1] [,2] # [1,] 2 4 # [2,] 6 8 # 行列の和 A + B # [,1] [,2] # [1,] 6 8 # [2,] 10 12 # 行列の積 A %*% B # [,1] [,2] # [1,] 19 22 # [2,] 43 50 # 転置行列 t(A) # [,1] [,2] # [1,] 1 3 # [2,] 2 4 # 逆行列 solve(A) # [,1] [,2] # [1,] -2.0 1.0 # [2,] 1.5 -0.5 # 単位行列 diag(2) # [,1] [,2] # [1,] 1 0 # [2,] 0 1 # 行列式 detA det(A) # -2 # 対角成分 diag(A) # [1] 1 4 # トレース(対角成分の和) trA sum(diag(A)) # 5 # 行列の要素ごとの演算 A + B # [,1] [,2] # [1,] 6 8 # [2,] 10 12 A - B # [,1] [,2] # [1,] -4 -4 # [2,] -4 -4 A * B # [,1] [,2] # [1,] 5 12 # [2,] 21 32 A / B # [,1] [,2] # [1,] 0.2000000 0.3333333 # [2,] 0.4285714 0.5000000 A * 2 # [,1] [,2] # [1,] 2 4 # [2,] 6 8 A ^ 2 # [,1] [,2] # [1,] 1 4 # [2,] 9 16 -A # [,1] [,2] # [1,] -1 -2 # [2,] -3 -4 A == B # [,1] [,2] # [1,] FALSE FALSE # [2,] FALSE FALSE A < B # [,1] [,2] # [1,] TRUE TRUE # [2,] TRUE TRUE A > 2 # [,1] [,2] # [1,] FALSE FALSE # [2,] TRUE TRUE A %% 2 == 0 # [,1] [,2] # [1,] FALSE TRUE # [2,] FALSE TRUE sqrt(A) # [,1] [,2] # [1,] 1.000000 1.414214 # [2,] 1.732051 2.000000 exp(A) # [,1] [,2] # [1,] 2.718282 7.389056 # [2,] 20.085537 54.598150 log(A) # [,1] [,2] # [1,] 0.000000 0.6931472 # [2,] 1.098612 1.3862944VBA
VBASub test_matrix() Dim A As Variant Dim B As Variant Dim k As Double Dim kA As Variant Dim ApB As Variant Dim AB As Variant Dim At As Variant Dim Ainv As Variant Dim Eye2 As Variant Dim detA As Double Dim trA As Double Dim i As Integer Dim j As Integer ' 行列 A = Range("B3:E5").Value print_matrix (A) B = Range("B8:C9").Value print_matrix (B) ' 行列の行数 Debug.Print LBound(A, 1), UBound(A, 1), UBound(A, 1) - LBound(A, 1) + 1 ' 行列の列数 Debug.Print LBound(A, 2), UBound(A, 2), UBound(A, 2) - LBound(A, 2) + 1 ' 行列の要素 A(1, 2) Debug.Print A(1, 2) ' 行列のスカラー倍 kA k = 2 ReDim kA(LBound(A, 1) To UBound(A, 1), LBound(A, 2) To UBound(A, 2)) For i = LBound(A, 1) To UBound(A, 1) For j = LBound(A, 2) To UBound(A, 2) kA(i, j) = A(i, j) * k Next j Next i Call print_matrix(kA) Range("E13:F14").Value = kA ' 行列の和 A+B ReDim ApB(LBound(A, 1) To UBound(A, 1), LBound(A, 2) To UBound(A, 2)) For i = LBound(A, 1) To UBound(A, 1) For j = LBound(A, 2) To UBound(A, 2) ApB(i, j) = A(i, j) + B(i, j) Next j Next i Call print_matrix(ApB) Range("E18:F19").Value = ApB ' 行列の積 AB AB = WorksheetFunction.MMult(A, B) Call print_matrix(AB) Range("E18:F19").Value = AB ' 転置行列 A^T At = WorksheetFunction.Transpose(A) Call print_matrix(At) Range("E28:F29").Value = At ' 逆行列 A^(-1) Ainv = WorksheetFunction.MInverse(A) Call print_matrix(Ainv) Range("E33:F34").Value = Ainv ' 単位行列 Eye2 = WorksheetFunction.Munit(2) Call print_matrix(Eye2) Range("E38:F39").Value = Eye2 ' 行列式 detA detA = WorksheetFunction.MDeterm(A) Debug.Print detA Range("E42").Value = detA ' トレース trA trA = WorksheetFunction.SumProduct(A, Eye2) Debug.Print trA Range("E45").Value = trA End Sub Sub print_matrix(M As Variant) ' 行列の表示用 Dim i As Integer Dim j As Integer Dim s As String If IsArray(M) Then s = "" For i = LBound(M, 1) To UBound(M, 1) For j = LBound(M, 2) To UBound(M, 2) s = s & vbTab & M(i, j) Next j s = s & vbCrLf Next i Debug.Print s End If End Sub参考
- 投稿日:2021-01-17T20:54:38+09:00
[Blender] Modeling tips まとめ Mesh Modeling編
目次
30.複数のオブジェクトを同時に編集する
31.頂点間に辺を挿入する
32.辺をスライドさせる
33.頂点をマージする
34.距離が近い頂点を自動でマージする
35.辺を融解する
36.カーソルの位置まで面を押し出す
37.編集モードでミラーを使う
38.オブジェクトを変形させずに辺の角度をかえる
39.面に垂直な向きに動かす
40.面を規則的に埋める30.複数のオブジェクトを同時に編集する
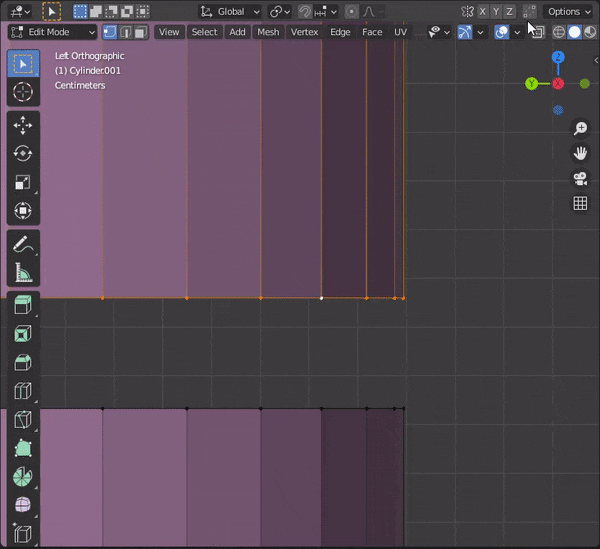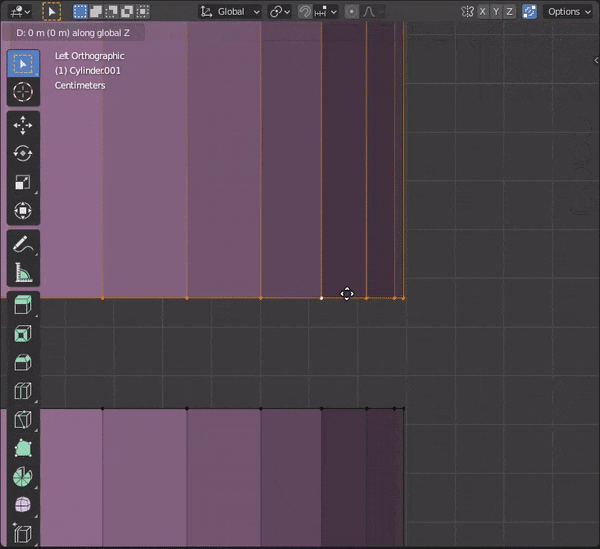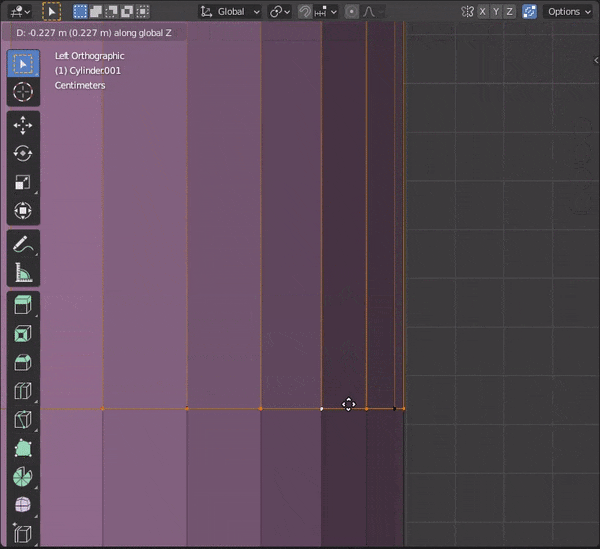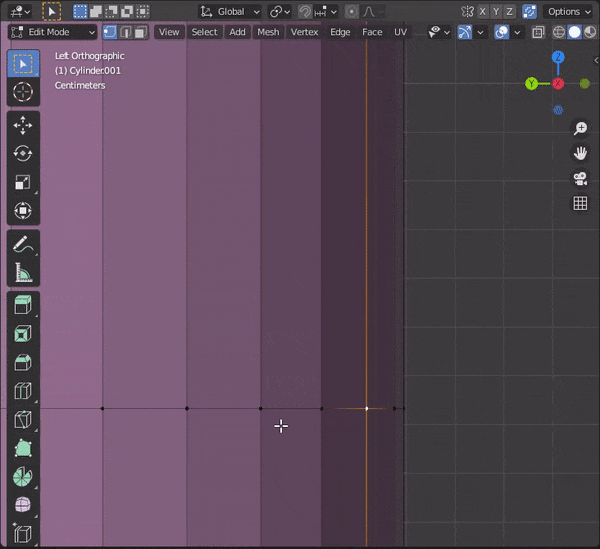
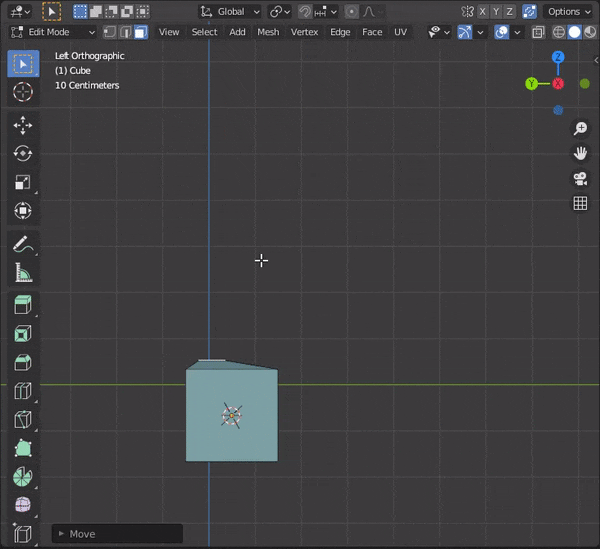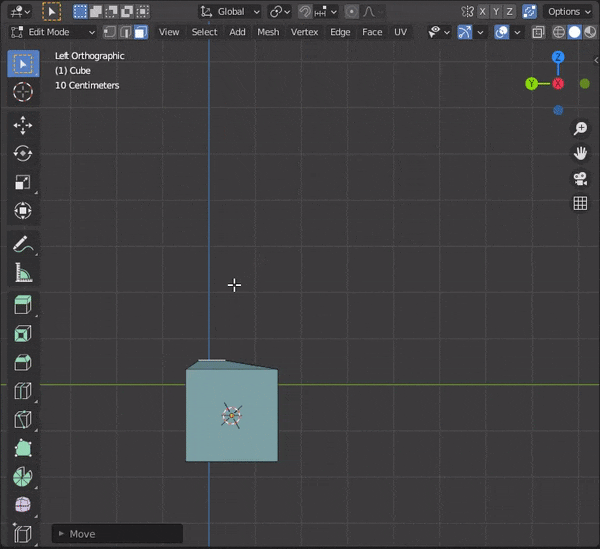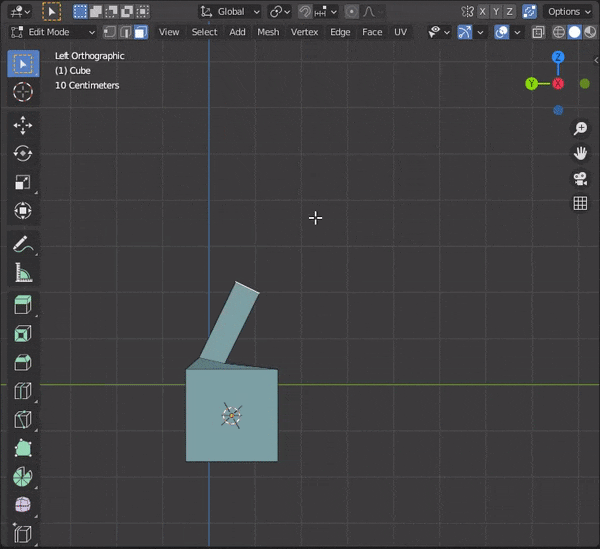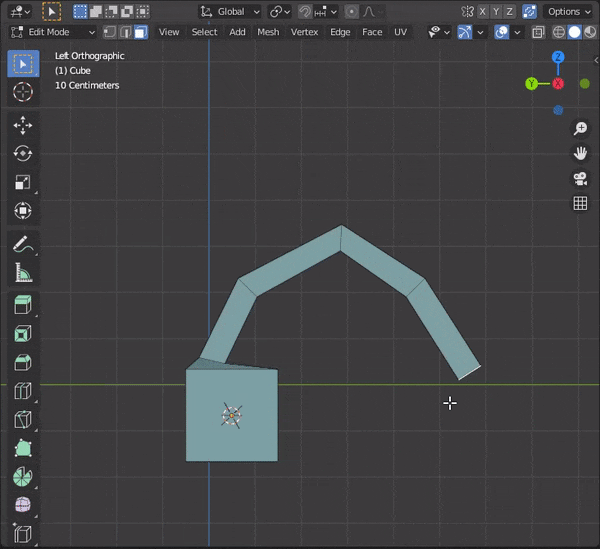
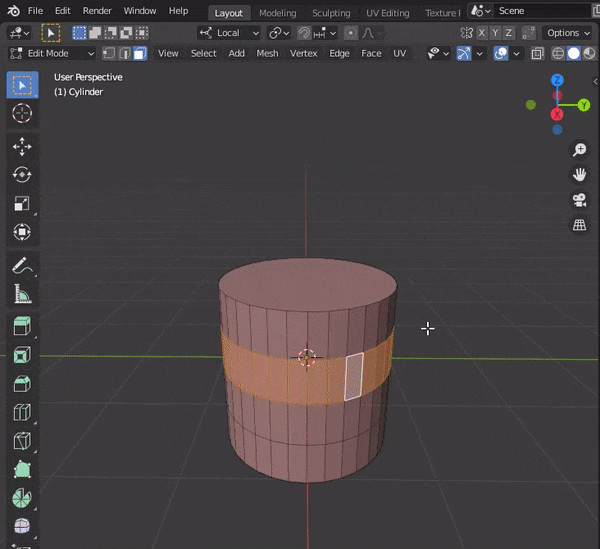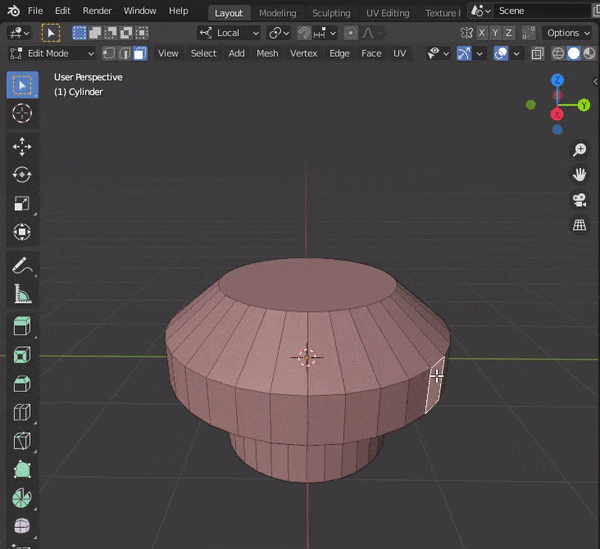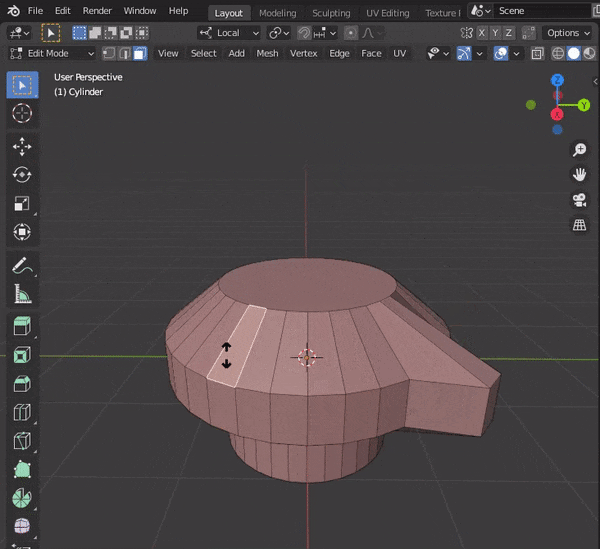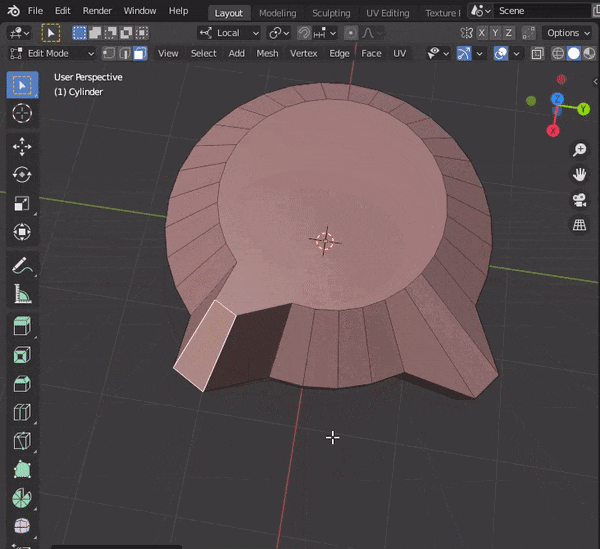
[SHIFT]を押しながら複数のオブジェクトを選択し、[TAB]キーを押して編集モードにする。
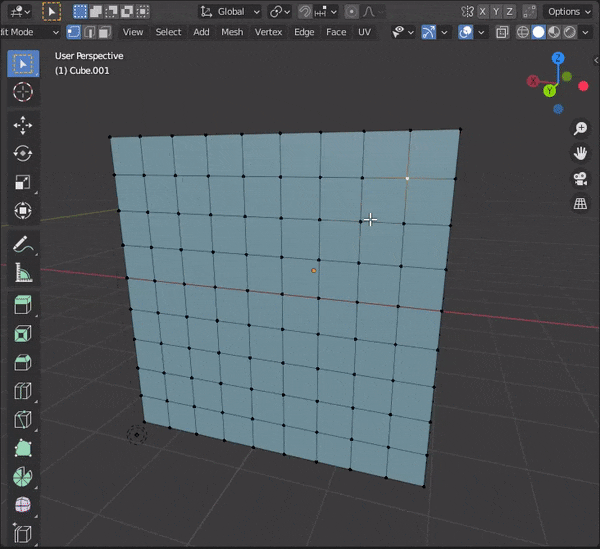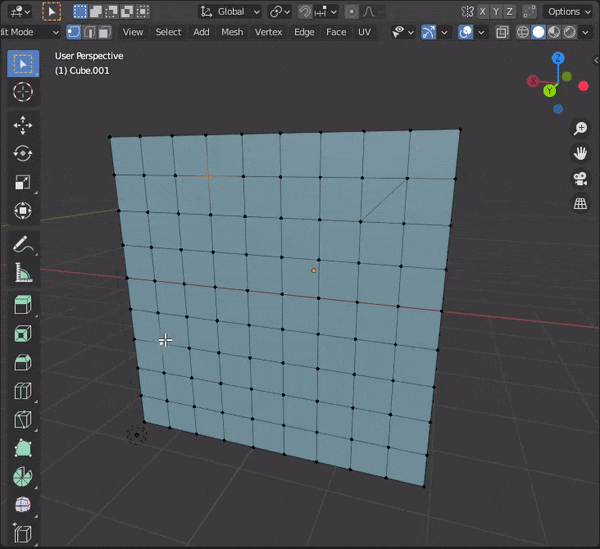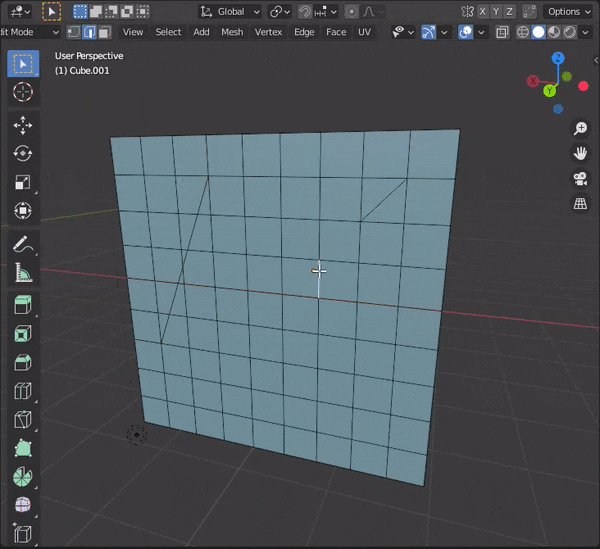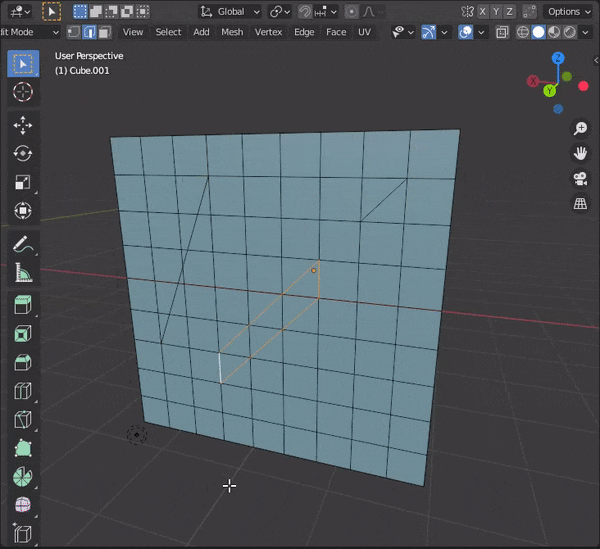
31.頂点間に辺を挿入する
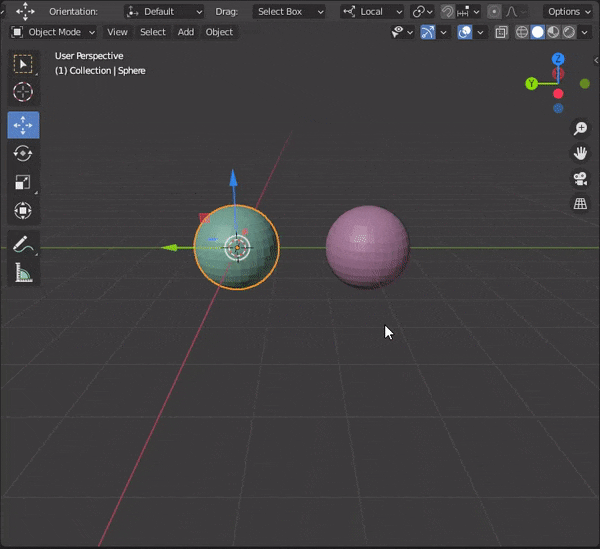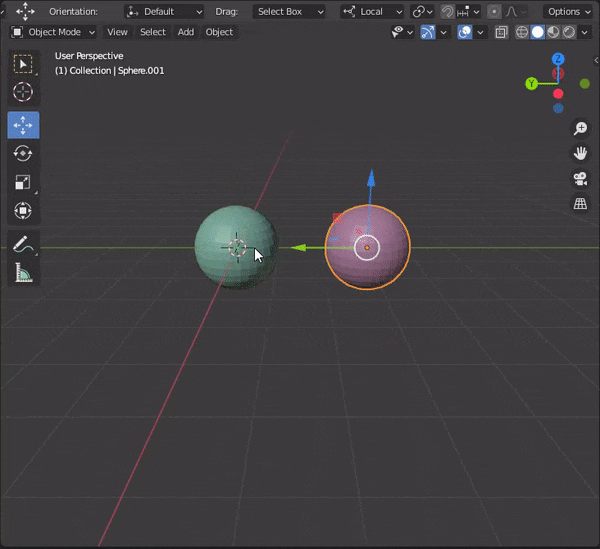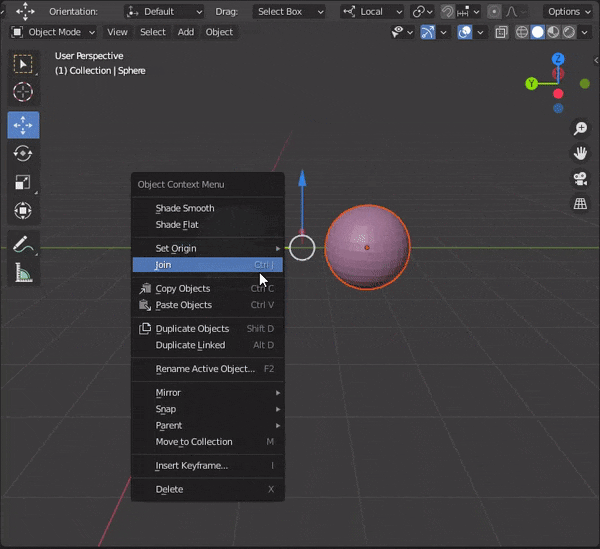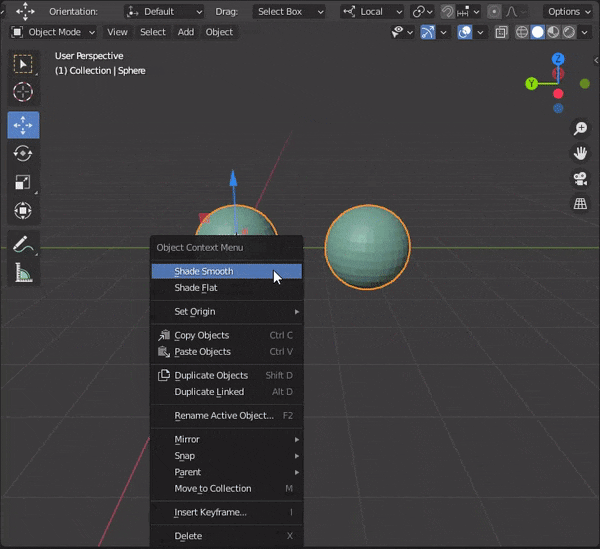
頂点などを2つ選択して、[J]キーを押す
32.辺をスライドさせる
①スライドさせたい辺を選択
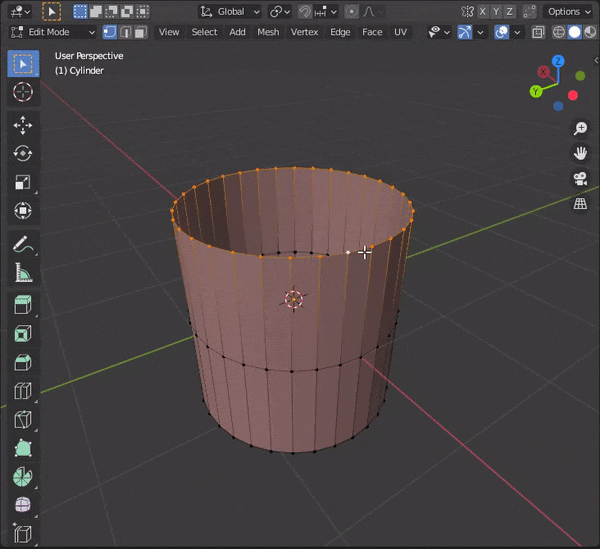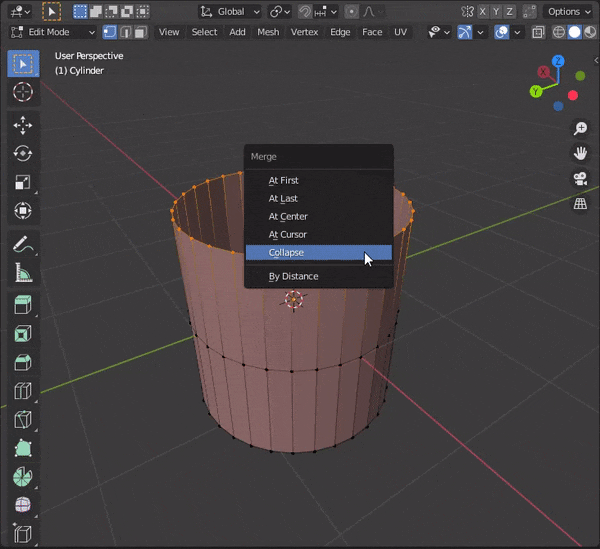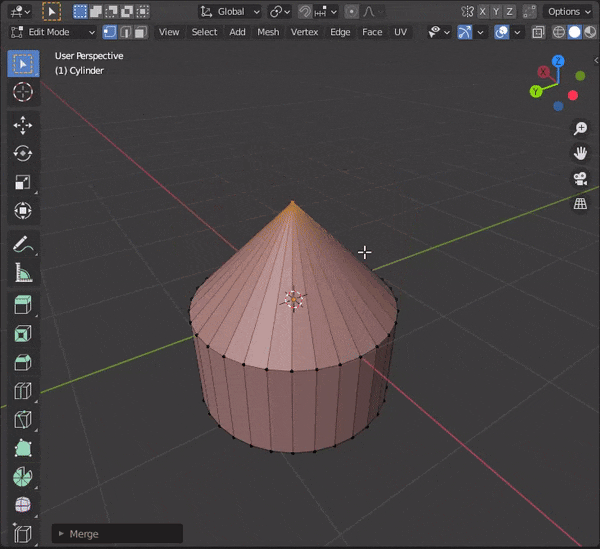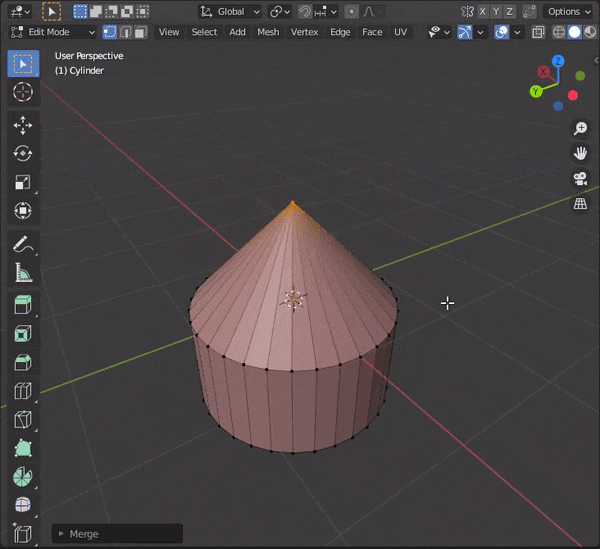
②[G]をダブルタップ33.頂点をマージする
複数頂点を選択して[M]キーを押し、モードを選択
At First :最初に選択した頂点にマージする
At Last :最後に選択した頂点にマージする
At Center:選択した頂点の中心にマージする
At Cursor:カーソルの位置にマージする
Collapse :つながっている頂点の中央にマージする
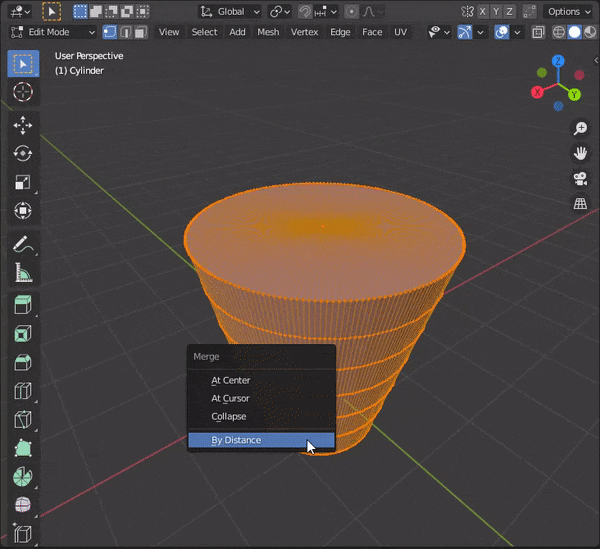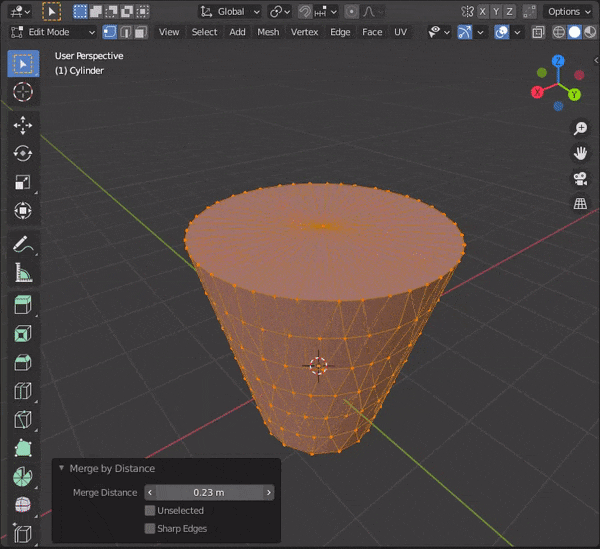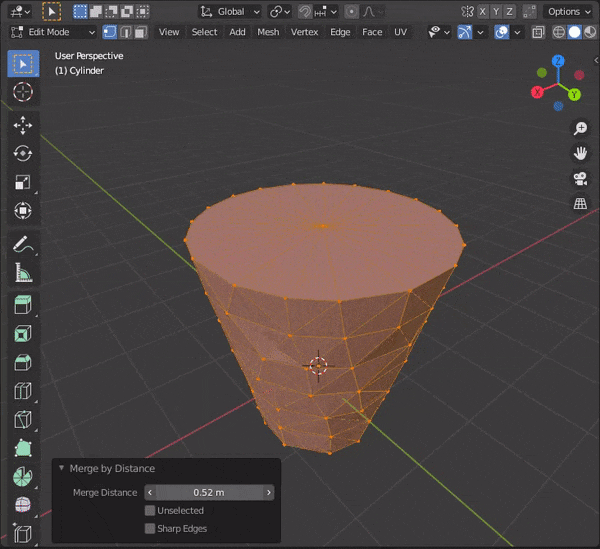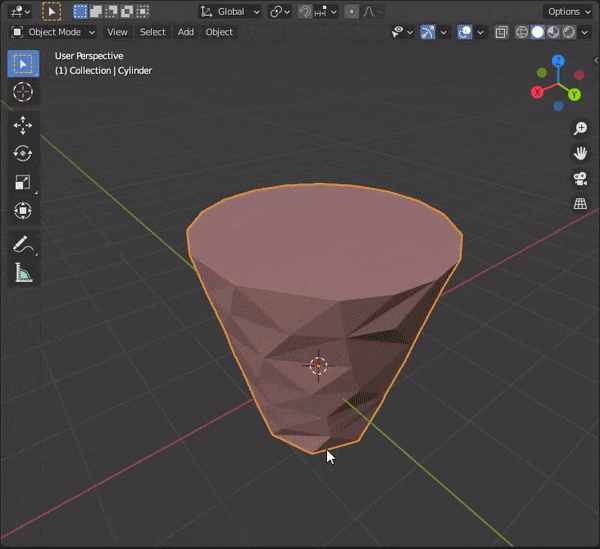
By Distance:頂点の距離に応じてマージする
34.距離が近い頂点を自動でマージする
Auto Marge Verticesのマークをクリックして頂点を近づける。
※マークがない場合は、view→Toolsettingにチェックをいれる
35.辺を融解する
①[X]キーを押す
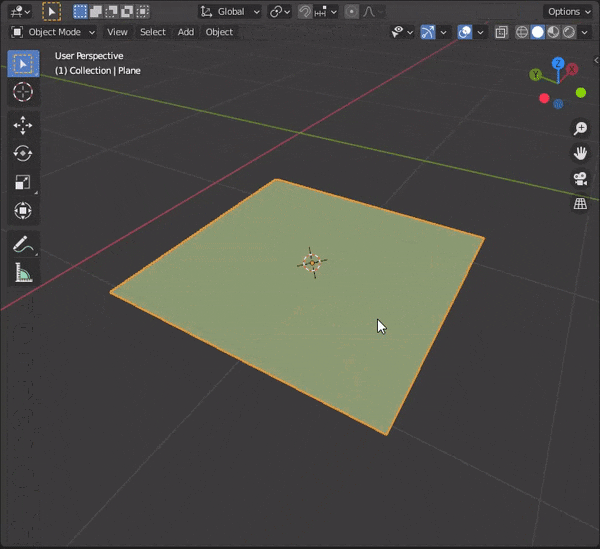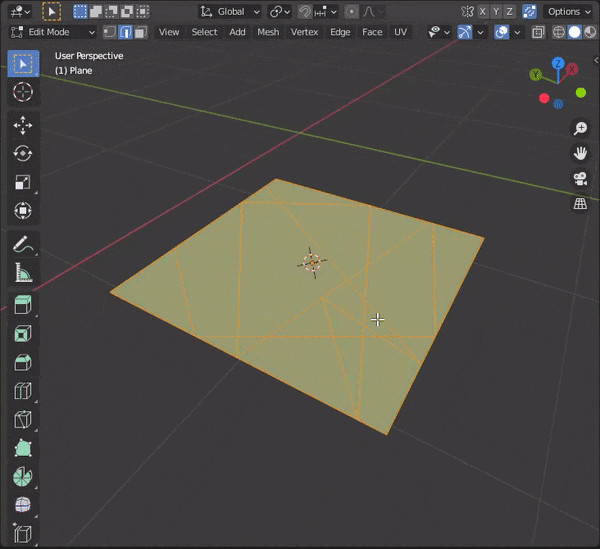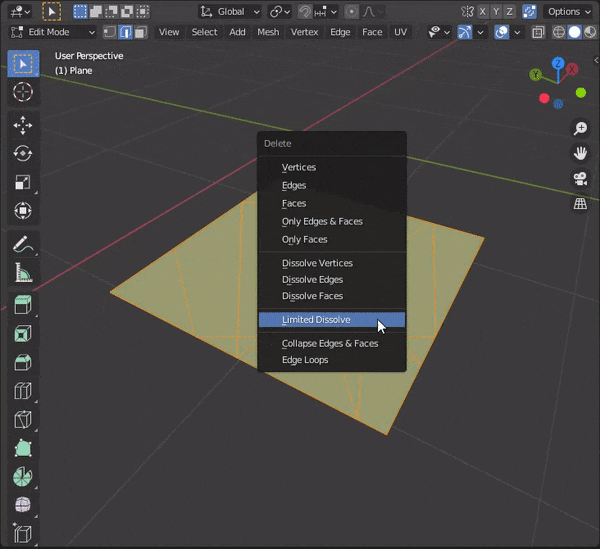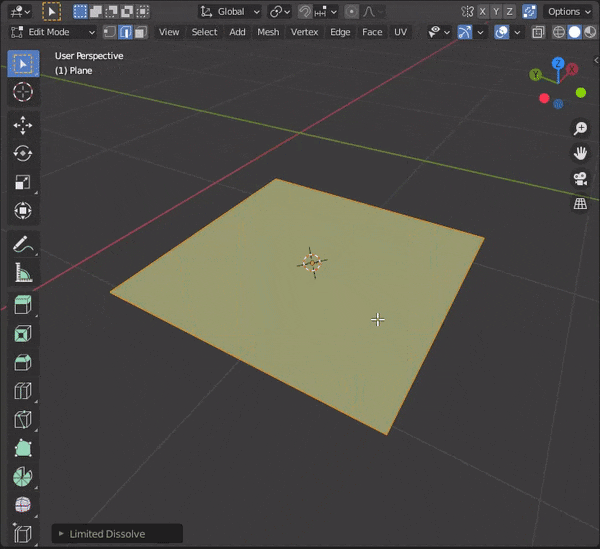
②Dissolve Edgesを押すまたは、
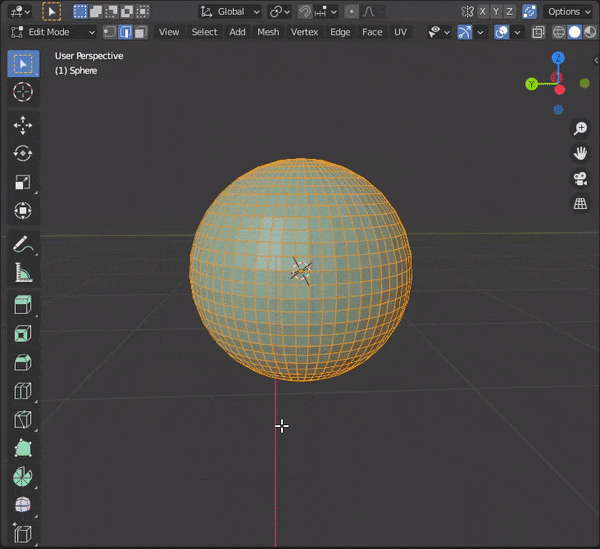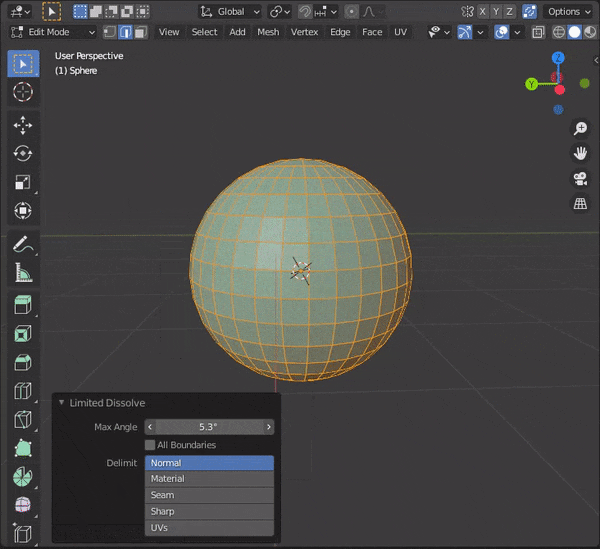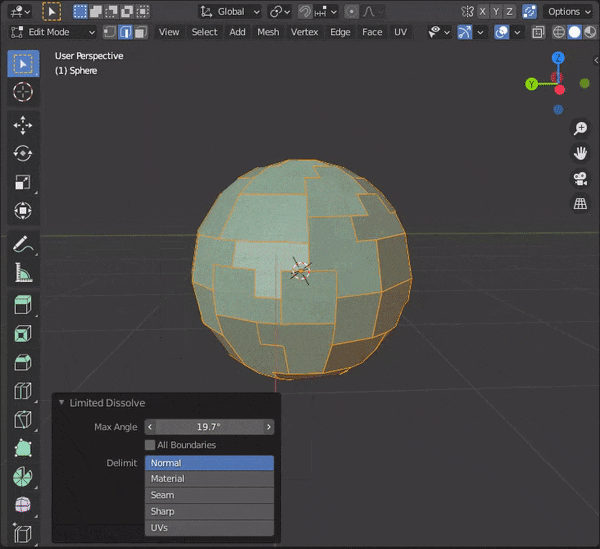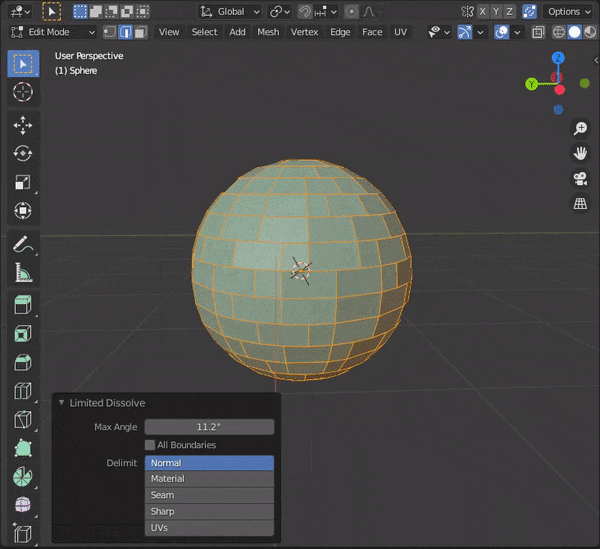
[CTRL + X]を押す
以下のように、Limitted Dissolveで限定的に辺を融解することもできる
36.カーソルの位置まで面を押し出す
①面を選択
②[CTRL + マウス右クリック]でカーソルの位置まで面を押し出す
37.編集モードでミラーを使う
①2つのオブジェクトを[CTRL + J]で1つのオブジェクトにする
②右クリック→Set Origin → Origin to Geometoryでオブジェクトの原点を変更する
③編集モードでTransformation OrientationをLocalにする
④ミラーさせたい軸を選択する
⑤編集する
38.オブジェクトを変形させずに辺の角度をかえる
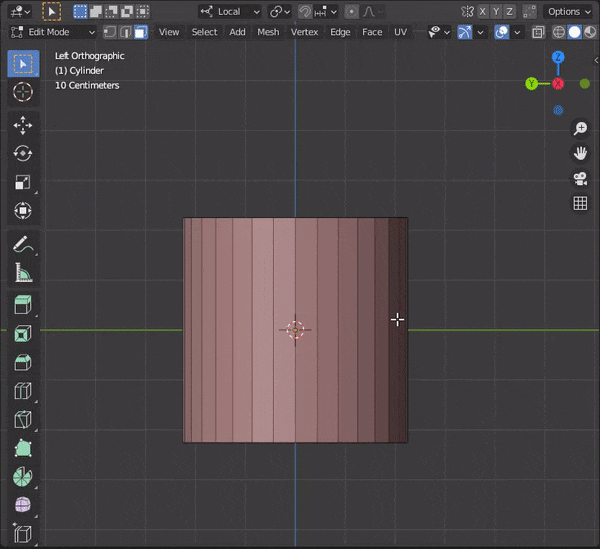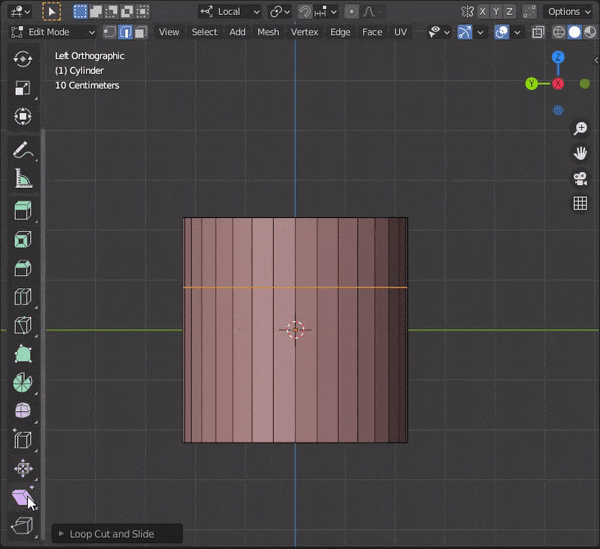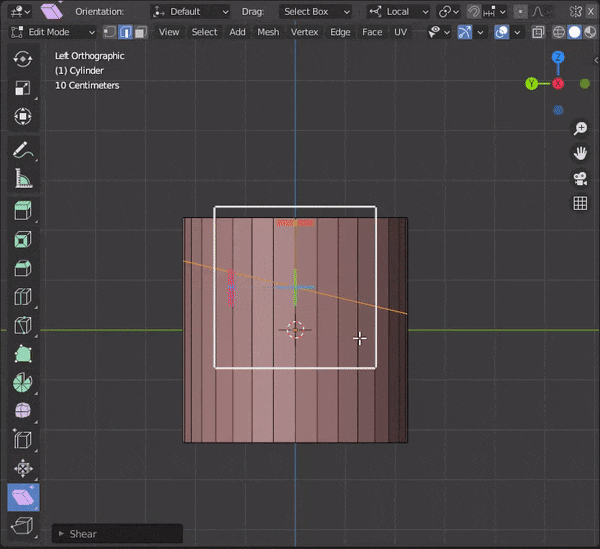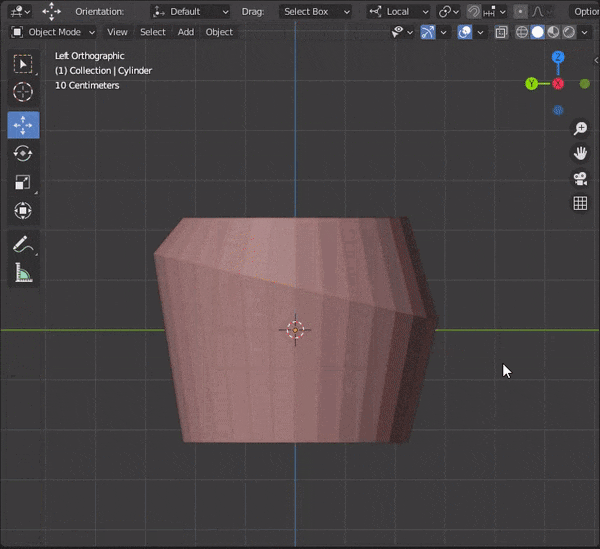
辺を選択して、Shearのパネルを押して編集する。
39.面に垂直な向きに動かす
[ALT + S]で面に垂直な方向に動かすことができる
40.面を規則的に埋める
①埋めたい部分を選択
②[CTRL + F] → Grid Fillを選択

- 投稿日:2021-01-17T20:30:19+09:00
Docker-compose + Django + MySQL + Nginx + uwsgi を使った環境の初期設定
概要
- 表題を利用した環境を作る必要があったので、メモします。
- 合わせて日本語化など
環境
- Docker + Docker-compose が利用できること。
- Python3.6
- Django3.1(最新)
手順
ディレクトリの構成
- 下記構成でディレクトリとファイルを作成します。
./WORKDIR |--- docker-compose.yml # Docker-compose本体 |---.gitignore # git対象外用(今回は作るだ、gitを使うときに利用する) |---nginx |---nginx.conf # nginxの設定ファイル |---uwsgi_params # uwsgi用パラメータ |---django |---Dockerfile # Dockerfile |---requirements.txt # pipでインストールするリスト |---.env # django用の環境変数 |---mysql |---.env # mysql用の環境変数 |---sql |---init.sql # DB起動時(初回のみ)に流すスクリプトファイルの作成と編集
docker-compose.ymldocker-compose.ymlversion: '3' services: nginx: image: nginx:1.13 ports: - "8000:8000" volumes: - ./nginx/nginx.conf:/etc/nginx/nginx.conf - ./nginx/uwsgi_params:/etc/nginx/uwsgi_params - ./static:/static depends_on: - django mysql: image: mysql:5.7 command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci ports: - "3306:3306" env_file: - ./mysql/.env volumes: - ./mysql:/var/lib/mysql - ./sql:/docker-entrypoint-initdb.d django: build: ./django command: uwsgi --socket :8001 --module app.wsgi --py-autoreload 1 --logto /tmp/mylog.log volumes: - ./src:/code - ./static:/static expose: - "8001" env_file: - ./django/.env depends_on: - mysql
.gitignoremysql/*
django/DockerfileFROM python:3.6 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code ADD requirements.txt /code/ RUN pip install -r requirements.txt ADD . /code/
django/requirements.txtdjango/requirements.txtDjango uwsgi PyMySQL
django/.envdjango/.envMYSQL_ROOT_PASSWORD=root MYSQL_DATABASE=db MYSQL_USER=bbt-user MYSQL_PASSWORD=password
nginx/nginx.confnginx/nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; upstream django_8001 { ip_hash; server django:8001; } server { listen 8000; server_name 127.0.0.1; charset utf-8; location /static { alias /static; } location / { uwsgi_pass django_8001; include /etc/nginx/uwsgi_params; } } server_tokens off; }
nginx/uwsgi_paramsuwsgi_param QUERY_STRING $query_string; uwsgi_param REQUEST_METHOD $request_method; uwsgi_param CONTENT_TYPE $content_type; uwsgi_param CONTENT_LENGTH $content_length; uwsgi_param REQUEST_URI $request_uri; uwsgi_param PATH_INFO $document_uri; uwsgi_param DOCUMENT_ROOT $document_root; uwsgi_param SERVER_PROTOCOL $server_protocol; uwsgi_param REQUEST_SCHEME $scheme; uwsgi_param HTTPS $https if_not_empty; uwsgi_param REMOTE_ADDR $remote_addr; uwsgi_param REMOTE_PORT $remote_port; uwsgi_param SERVER_PORT $server_port; uwsgi_param SERVER_NAME $server_name;
mysql/.envmysql/.envMYSQL_ROOT_PASSWORD=root MYSQL_DATABASE=db MYSQL_USER=bbt-user MYSQL_PASSWORD=password TZ='Asia/Tokyo'
sql/init.sqlsql/init.sqlGRANT ALL PRIVILEGES ON db.* TO 'user'@'%'; FLUSH PRIVILEGES;構築
- プロジェクトを作成する。
$ docker-compose run django django-admin.py startproject app .
- 下記が作成される。
./WORKDIR |--- docker-compose.yml |---.gitignore |---nginx |---nginx.conf |---uwsgi_params |---django |---Dockerfile |---requirements.txt |---.env |---src |---app |---__init.py__ # pythonであることの意味(編集しない) |---asgi.py # 利用しない |---settings.py # django本体の設定ファイル |---urls.py # URL処理をする |---wsgi.py # wsgiファイル |---manage.py # 管理用コマンド |---mysql |---.env |--- ~~ # 複数作成されるが編集しないため割愛 |---sql |---init.sql
src/app/settings.pyを編集する#### 追加 import os import pymysql STATIC_ROOT = '/static' pymysql.install_as_MySQLdb() #### 修正 ALLOWED_HOSTS = ['*'] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': os.environ.get('MYSQL_DATABASE'), 'USER': os.environ.get('MYSQL_USER'), 'PASSWORD': os.environ.get('MYSQL_PASSWORD'), 'HOST': 'mysql', 'PORT': '3306', } } LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'
- DBのマイグレーション
$ docker-compose run django ./manage.py makemigrations $ docker-compose run django ./manage.py migrate
- CSSを反映する
起動
$ docker-compose up -d参考
- Django+Nginx+MySQLの開発環境をDockerで構築する
- 自分用に修正しただけでほぼお世話になってます。
- 投稿日:2021-01-17T20:28:46+09:00
【pytorch-lightning入門】torchvision.transformsの使い方と自前datasetの自由な作り方♬
いろいろなデータを使いたいということで、自前datasetの作り方をいろいろ試してみたので、まとめておきます。
denoising, coloring, ドメイン変換などをやるためには、必須な技術です。今回は、二つの要素をまとめます。
一つは、torchvision.transformsの各種クラスの使い方と自前クラスの作り方、もう一つはそれらを利用した自前datasetの作り方です。
後半は、以下の参考がありますが、試行錯誤を随分したので、その結果を載せることとします。【参考】
①pyTorchのtransforms,Datasets,Dataloaderの説明と自作Datasetの作成と使用
②PyTorchでDatasetの読み込みを実装してみた
③TORCHVISION.TRANSFORMSやったこと
・transformsの整理
・autoencoderに応用する
・自前datasetの作り方
①data-labelの場合
②data1-data2-labelのような場合・transformsの整理
transformは以下のようにpytorch-lighitningのコンストラクタで出現(定義)していて、setupでデータ処理を簡単に定義し、Dataloaderで取得時にその処理を実行しています。
以下では、MNISTデータに対して、transforms.Normalize((0.1307,), (0.3081,))を実行しています。最初は、この数字は何というところからのまとめをしたいと思います。
※結論は、この数字は平均と標準偏差で、各画像数値をこの平均と標準偏差に入るように再規格化するという呪文でした
(画像なら暗すぎるものを明るくしたり、明るすぎるものを暗めにするなどの、輝度調整という処理になります)
実際、この数字がどこから来たかは今回は不明です。
全体の画像からそれぞれの平均の平均や標準偏差を求めて調整が筋ですが、そこまでやっている証拠は見つけられませんでした⇒以下の参考⑤を見ると、チャンネルごとの平均をそれぞれから引き、そのチャンネルの標準偏差で除しているようです。
しかし記述統計的にはそうすべきです。しかし、今回の興味の中心からはずれるので、パスすることにします。
※なお、研究テーマ的には、これを色々適応しつつ、精度への寄与をまじめに計測するのは面白いと思いますし、物体検出では重要なテーマ(必須で自分の対象にたいしてやるべき)だと思いますclass LitAutoEncoder(pl.LightningModule): def __init__(self, data_dir='./'): super().__init__() self.data_dir = data_dir # Hardcode some dataset specific attributes self.num_classes = 10 self.classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') self.dims = (1, 28, 28) channels, width, height = self.dims self.transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 32)) self.decoder = nn.Sequential(nn.Linear(32, 128), nn.ReLU(), nn.Linear(128, 28 * 28)) def forward(self, x): # in lightning, forward defines the prediction/inference actions embedding = self.encoder(x) return embedding ... def setup(self, stage=None): #train, val, testデータ分割 # Assign train/val datasets for use in dataloaders mnist_full =MNIST(self.data_dir, train=True, transform=self.transform) n_train = int(len(mnist_full)*0.8) n_val = len(mnist_full)-n_train self.mnist_train, self.mnist_val = torch.utils.data.random_split(mnist_full, [n_train, n_val]) self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform) def train_dataloader(self): self.trainloader = DataLoader(self.mnist_train, shuffle=True, drop_last = True, batch_size=32, num_workers=0) # get some random training images return self.trainloader ...そして、このtransformsは、上記の参考③にまとめられていました。
ここでは、全てを試していませんが、当面使いそうな以下の表の機能を動かしてみました。
機能 備考 rotate(x, angle) 角度に基いて回転する to_grayscale(x) grayscaleに変換する vflip(x) 上下フリップを行う hflip(x) 左右フリップを行う Resize(imageSize) 指定されたサイズにResizeを行う Normalize(self.mean, self.std) 指定された平均と標準偏差で画像を規格化する Compose() ()内の一連の変換をまとめて実行する ToTensor() torchTensorに変換する ToPILImage() PILImageに変換する
TORCHVISION.TRANSFORMSのクラス等
Compose(transforms) CenterCrop(size) ColorJitter(brightness=0, contrast=0, saturation=0, hue=0) FiveCrop(size) Grayscale(num_output_channels=1) Pad(padding, fill=0, padding_mode='constant') RandomAffine(degrees, translate=None, scale=None, shear=None, resample=0, fillcolor=0) RandomApply(transforms, p=0.5) RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant') RandomGrayscale(p=0.1) RandomHorizontalFlip(p=0.5) RandomPerspective(distortion_scale=0.5, p=0.5, interpolation=2, fill=0) RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2) RandomRotation(degrees, resample=False, expand=False, center=None, fill=None) RandomSizedCrop(*args, **kwargs) RandomVerticalFlip(p=0.5) Resize(size, interpolation=2) TenCrop(size, vertical_flip=False) GaussianBlur(kernel_size, sigma=(0.1, 2.0)) Transforms on PIL Image only; RandomChoice(transforms) RandomOrder(transforms) Transforms on torch.*Tensor only; LinearTransformation(transformation_matrix, mean_vector) Normalize(mean, std, inplace=False) output[channel] = (input[channel] - mean[channel]) / std[channel] RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False) ConvertImageDtype(dtype: torch.dtype) Conversion Transforms; ToPILImage(mode=None) ToTensor Generic Transforms; Lambda(lambd) Functional Transforms; Example: you can apply a functional transform with the same parameters to multiple images like this:... Example: you can use a functional transform to build transform classes with custom behavior:... adjust_brightness(img: torch.Tensor, brightness_factor: float) → torch.Tensor adjust_contrast(img: torch.Tensor, contrast_factor: float) → torch.Tensor adjust_gamma(img: torch.Tensor, gamma: float, gain: float = 1) → torch.Tensor adjust_hue(img: torch.Tensor, hue_factor: float) → torch.Tensor adjust_saturation(img: torch.Tensor, saturation_factor: float) → torch.Tensor ...以下省略コードは、おまけに掲載しておきます。
クラスの書き方は、以下の参考④を参考にしています。
また、各種のtransformの実行結果が参考⑤に掲載されています。
さらに、gaussian noizeの載せ方は、参考⑥を参考にしていますし、同じコードが参考⑦にも掲載されています。
自前のtransform関数をtransforms.Lambda(関数名)から使えることが、参考⑤に記載されていますが、今回は使用していません。
※PIL.ImageOps.equalize(image, mask=None)なども使えそうfrom PIL import ImageFilter img = Image.open("sample.jpg") def blur(img): """ガウシアンフィルタを適用する。 """ return img.filter(ImageFilter.BLUR) transform = transforms.Lambda(blur) img = transform(img) img【参考】
④vision/docs/source/transforms.rst
⑤Pytorch – torchvision で使える Transform まとめ
⑥How to add noise to MNIST dataset when using pytorch
ということで、以下のような参考⑦のようなことがsample augmentationとして簡単に実行できます。
⑦Pytorch Image Augmentation using Transforms.・autoencoderに応用する
pytorch-lightningのコードは以下の通りです。
以下のコードでは、画像のリサイズは行っていませんが、Networkを変更すれば行えます。
autoencoderへの応用
class LitAutoEncoder(pl.LightningModule): def __init__(self, data_dir='./'): super().__init__() self.data_dir = data_dir # Hardcode some dataset specific attributes self.num_classes = 10 self.classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') #self.classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') self.dims = (3, 32, 32) self.mean = [0.5,0.5,0.5] #[0.485, 0.456, 0.406] #[0.5,0.5,0.5] self.std = [0.25,0.25,0.25] #[0.229, 0.224, 0.225] #[0.5,0.5,0.5] self.imageSize = (32,32) self.p=0.5 self.scale=(0.01, 0.05) #(0.02, 0.33) self.ratio=(0.3, 0.3) #(0.3, 3.3) self.value=0 self.inplace=False #channels, width, height = self.dims self.transform = transforms.Compose([ transforms.Resize(self.imageSize), # 画像のリサイズ transforms.ToTensor(), transforms.Normalize(self.mean, self.std), transforms.RandomErasing(p=self.p, scale=self.scale, ratio=self.ratio, value=self.value, inplace=self.inplace), MyAddGaussianNoise(0., 0.5) ]) self.encoder = Encoder() self.decoder = Decoder() def forward(self, x): # in lightning, forward defines the prediction/inference actions embedding = self.encoder(x) return embedding結果
どちらも、1epockでの出力だが、ノイズありの方が出力画像は改善している。
処理無し 上記のcomposeでtransforms適用後 ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) Resize(self.imageSize), ToTensor(), Normalize(self.mean, self.std), RandomErasing(...), MyAddGaussianNoise(0., 0.5) 入力 
入力 
出力 
出力 
・自前datasetの作り方
これは、上記では世の中で公開されているデータセットをダウンロードして利用する場合は、簡単に以下のコードで自前のDirに置いて、以下のようにそれを読み込む形でデータをtransformsすればよいが、自前データではファイルや画像を形式に合わせて読み込むところから実施する。
cifar10_full =CIFAR10(self.data_dir, train=True, transform=self.transform)
普通のdataset, Dataloaderの使い方コード
def prepare_data(self): # download CIFAR10(self.data_dir, train=True, download=True) CIFAR10(self.data_dir, train=False, download=True) def setup(self, stage=None): #train, val, testデータ分割 # Assign train/val datasets for use in dataloaders cifar10_full =CIFAR10(self.data_dir, train=True, transform=self.transform) n_train = int(len(cifar10_full)*0.8) n_val = len(cifar10_full)-n_train self.cifar10_train, self.cifar10_val = torch.utils.data.random_split(cifar10_full, [n_train, n_val]) self.cifar10_test = CIFAR10(self.data_dir, train=False, transform=self.transform) def train_dataloader(self): self.trainloader = DataLoader(self.cifar10_train, shuffle=True, drop_last = True, batch_size=32, num_workers=0) # get some random training images return self.trainloader def val_dataloader(self): return DataLoader(self.cifar10_val, shuffle=False, batch_size=32, num_workers=0) def test_dataloader(self): self.testloader = DataLoader(self.cifar10_test, shuffle=False, batch_size=32, num_workers=0) return self.testloader①data-labelの場合
まずは、参考②の通り基本が大切です。
前回のmediapipeの学習のところで、以下のようなdatasetを作成して利用しました。
以下では、csvファイルからデータを読み取り、座標に変換して、out_dataとその分類であるout_labelを提供するものでした。
前回のmediapipe_handsデータのためのdatasetコード
class HandsDataset(torch.utils.data.Dataset): def __init__(self, data_num, transform=None): self.transform = transform self.data_num = data_num self.data = [] self.label = [] df = pd.read_csv('./hands/sample_hands7.csv', sep=',') print(df.head(3)) #データの確認 df = df.astype(int) x = [] for j in range(self.data_num): x_ = [] for i in range(0,21,1): x__ = [df['{}'.format(2*i)][j],df['{}'.format(2*i+1)][j]] x_.append(x__) x.append(x_) y = df['42'][:self.data_num] #以下のfloat() とlong()の指定は今回の肝です self.data = torch.from_numpy(np.array(x)).float() print(self.data) self.label = torch.from_numpy(np.array(y)).long() print(self.label) def __len__(self): return self.data_num def __getitem__(self, idx): out_data = self.data[idx] out_label = self.label[idx] if self.transform: out_data = self.transform(out_data) return out_data, out_label今回は、自前イメージデータを自前datasetとして提供する場合を示します。
結果は以下の通りです。
自前イメージデータのためのdatasetコード
class ImageDataset(torch.utils.data.Dataset): def __init__(self, data_num, transform=None): self.transform = transform self.data_num = data_num self.data = [] self.label = [] x = [] y = [] from_dir = './face/mayuyu/' sk = 0 for path in glob.glob(os.path.join(from_dir, '*.jpg')): image = Image.open(path) x.append(np.array(image)/255.) y.append(sk) sk += 1 self.data = torch.from_numpy(np.array(x)).float() self.label = torch.from_numpy(np.array(y)).long() def __len__(self): return self.data_num def __getitem__(self, idx): out_data = self.data[idx] out_label = self.label[idx] if self.transform: out_data = self.transform(out_data) return out_data, out_label mean, std = [0.5,0.5,0.5], [0.25,0.25,0.25] model = ImageDataset(10, transform = transforms.Normalize(mean, std)) for i in range(10): image = model.data[i] print(model.label[i], image) plt.title('label_{}'.format(model.label[i])) plt.imshow(image) plt.pause(1) plt.close()②data1-data2-labelのような場合
このコードでは、いわゆるcifar10のdatasetをダウンロードして、gray化し、元のカラー画像と同時にdatasetを提供するものである。このとき元のlabelは当然必要なシーンがあるので、それも同時に提供する。
基本は、上記の参考①でout_dataとしてgray画像、out_labelとしてカラー画像を出力するdatasetのコードを示しているが、ここに本来のlabelも同時に出力するものである。
また、コードは極力分かり易さを心がけた。
利用も今まで同様の以下のコードでデータ数、trans1, trans2に応じた処理されたデータ群に対して、batch数に応じたデータ数で使える。
つまり、実行結果のとおり、以下のコードの場合、32個のデータ生成をして、そこから4個ずつ取り出して使うこととなる。dataset = ImageDataset(32,transform1 = trans1, transform2 = trans2) testloader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=0)
Cifar10データを処理データと処理無しデータ,そしてlabel提供のためのdatasetコード
import numpy as np import torch import torchvision from torch.utils.data import DataLoader, random_split from torchvision import transforms import cv2 import matplotlib.pyplot as plt from torchvision.datasets import CIFAR10 from PIL import Image class ImageDataset(torch.utils.data.Dataset): def __init__(self, data_num, transform1 = None, transform2 = None,train = True): self.transform1 = transform1 self.transform2 = transform2 self.ts = torchvision.transforms.ToPILImage() self.ts2 = transform=transforms.ToTensor() self.data_dir = './' self.data_num = data_num self.data = [] self.label = [] # download CIFAR10(self.data_dir, train=True, download=True) CIFAR10(self.data_dir, train=False, download=True) self.data =CIFAR10(self.data_dir, train=True, transform=self.ts2) def __len__(self): return self.data_num def __getitem__(self, idx): out_data = self.ts(self.data[idx][0]) out_label = np.array(self.data[idx][1]) if self.transform1: out_data1 = self.transform1(out_data) if self.transform2: out_data2 = self.transform2(out_data) return out_data1, out_data2, out_label trans1 = torchvision.transforms.ToTensor() trans2 = torchvision.transforms.Compose([torchvision.transforms.Grayscale(), torchvision.transforms.ToTensor()]) dataset = ImageDataset(32,transform1 = trans1, transform2 = trans2) testloader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=0) ts = torchvision.transforms.ToPILImage() for out_data1, out_data2, out_label in testloader: print(len(out_label),out_label) for i in range(len(out_label)): image = out_data1[i] image_gray = out_data2[i] im = ts(image) im_gray = ts(image_gray) #print(out_label[i]) plt.imshow(np.array(im_gray), cmap='gray') plt.title('{}'.format(out_label[i])) plt.pause(1) plt.clf() plt.imshow(np.array(im)) plt.title('{}'.format(out_label[i])) plt.pause(1) plt.clf() plt.close()
実行結果は以下のとおり
>python dataset_cifar10_original.py Files already downloaded and verified Files already downloaded and verified 4 tensor([0, 3, 2, 6], dtype=torch.int32) tensor(0, dtype=torch.int32) tensor(3, dtype=torch.int32) tensor(2, dtype=torch.int32) tensor(6, dtype=torch.int32) 4 tensor([2, 2, 9, 5], dtype=torch.int32) tensor(2, dtype=torch.int32) tensor(2, dtype=torch.int32) tensor(9, dtype=torch.int32) tensor(5, dtype=torch.int32) 4 tensor([3, 6, 1, 7], dtype=torch.int32) tensor(3, dtype=torch.int32) tensor(6, dtype=torch.int32) tensor(1, dtype=torch.int32) tensor(7, dtype=torch.int32) 4 tensor([3, 9, 4, 9], dtype=torch.int32) tensor(3, dtype=torch.int32) tensor(9, dtype=torch.int32) tensor(4, dtype=torch.int32) tensor(9, dtype=torch.int32) 4 tensor([7, 8, 4, 4], dtype=torch.int32) tensor(7, dtype=torch.int32) tensor(8, dtype=torch.int32) tensor(4, dtype=torch.int32) tensor(4, dtype=torch.int32) 4 tensor([6, 7, 9, 0], dtype=torch.int32) tensor(6, dtype=torch.int32) tensor(7, dtype=torch.int32) tensor(9, dtype=torch.int32) tensor(0, dtype=torch.int32) 4 tensor([4, 1, 9, 2], dtype=torch.int32) tensor(4, dtype=torch.int32) tensor(1, dtype=torch.int32) tensor(9, dtype=torch.int32) tensor(2, dtype=torch.int32) 4 tensor([6, 9, 6, 3], dtype=torch.int32) tensor(6, dtype=torch.int32) tensor(9, dtype=torch.int32) tensor(6, dtype=torch.int32) tensor(3, dtype=torch.int32)まとめ
・transformsで遊んでみた
・自前datasetを作って遊んでみた
・自前データを利用した自前datasetが作成できるようになった
・いろいろな処理を施して、その結果得られる各種datasetを同時に提供できるdataset及びそのDataloaderの利用の仕方を学んだ・これを利用して、改めてdenoizing, coloring, 画像拡大、画像合成などの学習と利用アプリを作りたい
おまけ
import torchvision.transforms.functional as TF import random import matplotlib.pyplot as plt import cv2 from PIL import Image import numpy as np import torch import torchvision class MyRotationTransform:MyRotationTransform """Rotate by one of the given angles.""" def __init__(self, angles): self.angles = angles def __call__(self, x): angle = random.choice(self.angles) return TF.rotate(x, angle) class MyGrayscaleTransform: """GrayScale by this class.""" def __init__(self): pass def __call__(self, x): #return TF.rgb_to_grayscale(x) return TF.to_grayscale(x) class MyVflipTransform: """Vertical flip by this class.""" def __init__(self): pass def __call__(self, x): return TF.vflip(x) class MyHflipTransform: """Vertical flip by this class.""" def __init__(self): pass def __call__(self, x): return TF.hflip(x) from torchvision import transforms class MyNormalizeTransform: """normalization by the image.""" def __init__(self): self.imageSize = (512,512) self.mean = [0.485, 0.456, 0.406] self.std = [0.229, 0.224, 0.225] def __call__(self, x): img = self.transform = transforms.Compose([ transforms.Resize(self.imageSize), # 画像のリサイズ transforms.ToTensor(), # Tensor化 transforms.Normalize(self.mean, self.std), # 標準化 ]) return img(x) class MyErasingTransform: """normalization by the image.""" def __init__(self): self.imageSize = (512,512) self.p=0.5 self.scale=(0.02, 0.33) self.ratio=(0.3, 3.3) self.value=0 self.inplace=False def __call__(self, x): self.transform = transforms.Compose([ transforms.Resize(self.imageSize), # 画像のリサイズ transforms.ToTensor(), # Tensor化 transforms.RandomErasing(p=self.p, scale=self.scale, ratio=self.ratio, value=self.value, inplace=self.inplace) ]) return self.transform(x) class MyAddGaussianNoise(object): def __init__(self, mean=0., std=0.1): self.std = std self.mean = mean def __call__(self, tensor): return tensor + torch.randn(tensor.size()) * self.std + self.mean def __repr__(self): return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std) trans2 = torchvision.transforms.Compose([torchvision.transforms.Grayscale(), torchvision.transforms.ToTensor()]) ts = torchvision.transforms.ToPILImage() trans3 = MyGrayscaleTransform() trans4 = MyHflipTransform() trans5 = MyNormalizeTransform() trans6 = MyErasingTransform() trans7 = transforms.Compose([ transforms.ToTensor(), #transforms.Normalize((0.1307,), (0.3081,)), MyAddGaussianNoise(0., 0.1) ]) angle_list =[i for i in range(-10,10,1)] #[-30, -15, 0, 15, 30] rotation_transform = MyRotationTransform(angles=angle_list) x = Image.open('./face/mayuyu/2.jpg') while 1: y = rotation_transform(x) #z = trans5(x) z = trans7(y) plt.imshow(ts(z)) plt.pause(0.1) #z = trans3(x) #plt.imshow(z, cmap='gray') #plt.pause(0.1) #plt.imshow(np.array(ts(trans2(y))), cmap='gray') #plt.pause(0.1) plt.clf()
- 投稿日:2021-01-17T19:55:28+09:00
全力回避フラグちゃん!のサムネイル画像をRGB 値でヒストグラムにしてみた【ヒストグラム】【可視化】
はじめに
はてなブログのほうで,全力回避フラグちゃん!の動画のサムネイル画像を主観に基づいて手動で分類してみた
という名目で,主観に基づき,手動でサムネイルを分類しましたが,やっぱりデータに基づいて自動で分類したいと思い,まずは分類に使用するための情報を取得して表示してみました.ということで,各サムネイル画像からRGB 値のヒストグラムを取得して表示しました.プログラム内ではそれを特徴量として$k$-means という手法により自動的にクラスタリングしていますが,その結果をうまく伝えられそうにないため,本記事ではそこまで説明しません.
今まで書いた記事はこちら↓↓
- 「全力回避フラグちゃん!」チャンネルの動画をグラフ化するとどうなるのか?【Python】【グラフ化】
- 全力回避フラグちゃん! の動画再生数の分布を調べてみた【Python】【グラフ化】
- 全力回避フラグちゃん!の動画の再生数と評価/コメント数をグラフにしたらどうなるのか?【Python】【グラフ化】
- 全力回避フラグちゃん!で少しわかるYouTube Data API Channels リソースから取得できる主な情報
- 全力回避フラグちゃん!のチャンネルの人気は本当にほぼフラグちゃんで成り立っているのか?【検証】【可視化】
- 全力回避フラグちゃん!の動画を再生回数と高評価でスコアリングしてランキング化してみた【正規化】【ランキング】注意事項
2021/1/16 18:30時点で公開されているすべての動画のサムネイル229本が対象です.
なお,$k$-means 初心者で,これから学習していってちゃんと理解して使えるようになるので,今回の記事は多分に誤りが含まれている可能性があります.その際は,コメントで指摘していただけると幸いです.1用いたデータセット/手法
「全力回避フラグちゃん!」チャンネル上に公開されている各動画のサムネイル画像全229本の,hqdefault.jpg という下記でいうところのhigh サイズのサムネイル画像を使用しました.
ご存じの方も多いでしょうが,YouTube のサムネイル画像は全部で5種類ほどサイズが存在します.
- default (120 x 90)
- medium (320 x 180)
- high (480 x 360)
- standard (640 x 480)
- maxres (1280 x 720)
今回使用したサイズはhigh です.理由は,できるだけサイズが大きいものをなんとなく使用したかったからです.maxres および standard は,存在しない動画があったので今回採用を見送りました.
画像の前処理
対象としたサムネイル画像はサイズが均等であるため,リサイズする必要は(おそらく)ないのですが,以下のサムネイル画像を保存等していただくとわかる通り,high サイズの画像は上下に黒い枠線があります.
https://i.ytimg.com/vi/j-sUiMkkA0A/hqdefault.jpg
そこで,プログラム内では黒に枠線を事前に全画像においてスライスしたものを使用しています.また,サイズ的な問題ではなく,サムネイル画像自体にも上下に黒の枠線2 が入っているサンプルもあるため,そこも含めてスライスしました.
スライス後の画像サイズはすべて 216 x 480 です.画像の上下がスライスされています.
用いたクラスタリング手法 (おまけ)
結果が微妙なのと,見せ方が難しいため,おまけと思ってください.
クラスタリングの手法としては,$k$-Means を用いました.特徴量はサムネイル画像のRGB 値です.上記で引用しているはてなブログで書いていますが,主観に基づき手動でクラスタリングした場合,分類の数は6だったので,本プログラム内でもハイパーパラメーターとして$k = 6$ としています.使用したプログラム
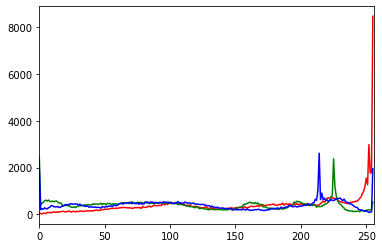
サムネイルクラスタリングプログラムimport cv2 import numpy as np from matplotlib import pyplot as plt import glob from PIL import Image from natsort import natsorted from sklearn import datasets from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.cluster import KMeans datasets = [] image_path = "thumbnail\\high\\*.jpg" target_path = "thumbnail\\target\\*.jpg" cluster_path = "thumbnail\\kmeans\\" #画像スライス用のパラメーター first = 68 second = 216 #クラスターの数 k = 6 for image in natsorted(glob.glob(image_path)): file = image[14:] # GBRにてカラーで読み込み image_bgr = cv2.imread(image, cv2.IMREAD_COLOR) # RGBに変換 image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB) # debug #plt.imshow(image_bgr), plt.axis("off") #plt.show() # 画像の上をスライス image_rgb_cropped = image_rgb[first:,:] image_bgr_cropped = image_bgr[first:,:] # 画像の下をスライス target_image = image_rgb_cropped[:second,:] target_image_cv = image_bgr_cropped[:second,:] cv2.imwrite("thumbnail\\target" + file, target_image_cv) features = [] colors = ("r","g","b") for i, channel in enumerate(colors): histogram = cv2.calcHist([target_image], [i], None, [256], [0,256]) features.extend(histogram) plt.plot(histogram, color = channel) plt.xlim([0, 256]) plt.show() features = StandardScaler().fit_transform(histogram) pca = PCA(n_components=0.99, whiten=True) features_pca = pca.fit_transform(features) observation = np.array(features_pca).flatten() features = StandardScaler().fit_transform(histogram) cluster = KMeans(n_clusters=k, random_state=0, n_jobs=-1) model = cluster.fit(features_pca) i = 0 for image in natsorted(glob.glob(target_path)): cluster_file = image[17:] cluster_img = Image.open(image) save_name = "cluster" + str(model.labels_[i]) + "_" + cluster_file cluster_img.save(cluster_path + save_name) i = i + 1RGB 値のヒストグラム
上記のプログラムを実行すると,サムネイル画像のRGB 値のヒストグラムが表示されます.ヒストグラムは分布を表すので,これでRGB 値のどの値がどれほどあるのかがわかります.
その結果が以下の図になります.
結果を簡単に見てみると,かなり強い赤色がかなり使用されているように見えます.
そこで,サムネイル画像に戻ってみると,以下の画像のように文字や背景に赤色が使用されており,加えて文字の協調で赤色が使用されているサムネイル画像が多く,おそらく正しい結果になっているだろうということがわかります.3
また,対比型のサムネイル画像が全体の6割以上を占めており,その際に使用される対比を説明する文字枠の背景色が黄色 (R255 G241 B0)であるため,255 に近いR の値が多いのかもしれません.4
大きな赤文字があるサムネイル画像.血しぶきも赤色
https://i.ytimg.com/vi/UpwW9R1_MpA/hqdefault.jpgおびただしいほどの赤字
https://i.ytimg.com/vi/-LF7JROdkeo/hqdefault.jpg対比型のサムネイル画像に使用されている黄色の文字枠
https://i.ytimg.com/vi/xrKHkpVl6qo/hqdefault.jpgということで,どうやらサムネイル画像には強い赤色が多く使用されていることがわかりました.
簡単なまとめ
- サムネイル画像RGB 値にて,ヒストグラムにして可視化した
- 可視化の結果,強い赤色が多く使用されていることが分かった
- 赤色は文字の協調や背景,対比式の説明の文字欄に使用されているため,分布として多いのではないか
- ただ,上記を特徴量として用いた際の$k$-Means の結果は微妙だった (結果は割愛.気になる人はサムネイル画像を集めて,自分で確かめてみてください.)
今後の予定
サムネイルの書き手分類とかもクラスタリングでやってみたいですね.
そのまえに,ちゃんと勉強しないと...今回紹介した動画
今回は省略します.
おわりに
ここまで読んでいる人はいないと思いますが,もしいたらまずは,以下のリンクから全力回避フラグちゃん! チャンネルとフラグちゃんのTwitter をフォローしてください.この記事を読むより大切なことです.
大事なことなのでもう一度,チャンネル登録とTwitter のフォローをよろしくお願いいたします.関連リンク
- 全力回避フラグちゃん! https://www.youtube.com/channel/UCo_nZN5yB0rmfoPBVjYRMmw/videos
- 株式会社Plott / Plott Inc. https://plott.tokyo/#top
- フラグちゃんのTwitter https://twitter.com/flag__chan
- Github https://github.com/uky007/flag_analysis
- Python機械学習クックブック (Chris Albon 著,中田 秀基 訳,オライリー・ジャパン) https://www.oreilly.co.jp/books/9784873118673/
- 投稿日:2021-01-17T19:04:18+09:00
【Effective Python勉強メモ】1章:Python流思考(Pythonic Thinking)
はじめに
こちらはEffective Pythonを読んで個人的に勉強になった項目のメモ書きになります。
書籍の"まえがき"には「項目間は自由に拾い読みしていいよ」と書いてあるのですが、前から順番に読んでみます。
なお、2020/07/26に第二版が発売されているようですが、ここでは2016年に発売された書籍を扱いますのでご了承ください。
Effective Python ―Pythonプログラムを改良する59項目 (日本語) 大型本 – 2016/1/231章:Python流思考(Pythonic Thinking)
Pythonプログラマは、明示すること、複雑さよりは単純さを選ぶこと、可読性を最大化することを好みます。
他の言語に馴染んだプログラマは、Pythonをあたかも、C++、Javaあるいは一番よく知っている言語と同じであるかのように書こうとするものです。後で1章を読み進めてからこの前書きを読み返してみたんですが、知らなかった仕様・表現も出てきたりして、"Python流"を把握できてなかったなと思いました。
項目2:PEP8スタイルガイドに従う
- 式と文(一部項目を抜粋)
- 長さを使って(if len(somelist) == 0)空値([]や''など)かどうかをチェックしない。
- if not somelistを使って、空値が暗黙にFalseと評価されることを使う
うっ、これ結構やっちゃってる気がします。。ごめんなさいもうしません。。
項目5:シーケンスをどのようにスライスするか知っておく
スライスでは、リストの境界を越えた添字のstartとendも適切に扱われます。したがって、入力シーケンスを考慮して最大長を設定したコードもたやすく書けます。
下記は実行可能です。
シーケンス長に関わらず20要素までは取り出すというコードがスライスで簡単に実現できるということですね。a = ['a', 'b', 'c', 'd', 'e', 'f'] a[:20]実行結果
['a', 'b', 'c', 'd', 'e', 'f']あと下記は恥ずかしながら知りませんでした。。
代入するスライスの長さは同じでなくても構いません。代入の前後でスライスの値は保全されています。
試しにやってみます。
a = ['a', 'b', 'c', 'd', 'e', 'f'] a[2:4] = [1, 2, 3, 4, 5] print(a)実行結果
['a', 'b', 1, 2, 3, 4, 5, 'e', 'f']ほんとだ、できた。
項目6:1つのスライスでは、start, end, strideを使わない
# somelist[start:end:stride] a[2::2] a[-2::-2] a[-2:2:-2] a[2:2:-2]要点は、スライス構文のstride部分が極端に人を惑わせるということです。(中略)このような問題を避けるには、startやendの添字と一緒にstrideを使わないことです。
項目8:リスト内包表記には、3つ以上の式を避ける
項目7では、mapやfilterの代わりにリスト内包表記を使うことを推奨していますが、式が多くなった場合はリスト内包表記は適切でないとしています。
例えば下記のような場合です。my_lists = [[[1, 2, 3], [4, 5, 6]]] flat = [x for sublist1 in my_lists for sublist2 in sublist1 for x in sublist2]節約した行数は、後の面倒さを納得させられるものではありません。
本当にこれですよね。
項目12:forとwhileループの後のelseブロックは使うのを避ける
ループでbreak文が実行されると、実はelseブロックがスキップされます。
知らなかった。。(書こうとしたこともなかったんですけど)
for i in range(3): print('loop: %d' % i) # ループ内でbreakしない else: print('Else block!')実行結果
loop: 0
loop: 1
loop: 2
Else block!for i in range(3): print('loop: %d' % i) if i == 1: # ループ内でbreakする break else: print('Else block!')実行結果
loop: 0
loop: 1ほんとだ…!
ループの直後のelseブロックは振る舞いが直感的でないから使わないべき、と書いてあります。まとめ
個人的にぐっときたポイントを書き出してみました。
- 項目2:PEP8スタイルガイドに従う
- 長さを使って空値をチェックしない。
- 項目5:シーケンスをどのようにスライスするか知っておく
- スライスでは、境界外の添字が許される
- スライスへの代入は、元のシーケンスの指定範囲の長さが違っていても実行可能
- 項目6:1つのスライスでは、start, end, strideを使わない
- スライスでは、できるだけ正のstride値をstartかendのうちどちらか一方のみと一緒に使うようにする
- 項目8:リスト内包表記には、3つ以上の式を避ける
- 3つ以上の式を使うリスト内包表記は、読むのが難しく、避けるべきだ。
- 項目12:forとwhileループの後のelseブロックは使うのを避ける
- ループの後のelseブロックは、ループ本体でbreak文が実行されなかった場合にのみ実行される。
- ループの直後のelseブロックは振る舞いが直感的でなく、誤解を生みやすいので使わない。
おわりに
1章から既に思い当たる節が色々あって勉強になりました。
この後もまとめていきたいと思います。
全ての項目をまとめているわけではないので、気になる方は書籍の購入をご検討ください(回し者ではありません)

- 投稿日:2021-01-17T17:26:26+09:00
pythonで逆辞書を作る最速の方法は?
TL;DR
pythonのdictのkey,valueを逆にしたものを生成したい場合は、以下が最速。
d = dict(zip(list('abc'), range(3))) # 例として適当な辞書を生成 d2 = dict(zip(d.values(), d.keys())) # 逆本題
pythonを書いていると、既存のdictのkey,valueを逆にしたものを生成したい場合があったりします。例えば、
{'a': 0, 'b': 1, 'c': 2}に対する
{0: 'a', 1: 'b', 2: 'c'}です。そこで、逆版を最速で得るやり方を幾つか試してみました。
準備
d = dict(zip([f'key{i}' for i in range(10000)], range(10000))) # 適当な辞書1. forループ
%%timeit d2 = dict() for k in d: d2[d[k]] = k結果: 1.09 ms ± 57.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2. zipで値とキーを結合
%timeit dict(zip(d.values(), d.keys()))結果: 525 µs ± 21.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
3. 辞書内包表記
%timeit {v:k for k,v in d.items()}結果: 661 µs ± 23 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
結果
結果、2. zipで値とキーを結合 が最速となりました。pythonの内部の挙動は不勉強でよく分かりませんが、forループが効いているように感じます。pythonのforループは一回ごとに型チェックが入るので遅い、というのは色々な所で指摘されています。
ただ、2位である辞書内包表記とあまり差がないので、()のネストが深い分可読性が落ちることを考慮して、3.でも良いかも知れません。
以上。
- 投稿日:2021-01-17T16:56:00+09:00
SenseHat でIMUを使ったゲーム
今度のsense hatゲームは、IMU(慣性測定ユニット)を試してみました。
本体を傾けると、赤いピクセルが動きます。これで緑のピクセルをすべて取るとクリア。最右列の青いピクセルは、時間制限です。
ただ今回苦労したのは、IMUではなく、同時に初めて使ったPythonのスレッドです。
IMUの方は、ジョイスティックと同様、結構簡単でした。メインループと並行して時間制限をカウントするスレッドを動かしてみましたが、相互の制御(ゲームクリアならスレッドを停止し、タイムオーバーしたらメインループを停止)の方法が分かりませんでした。
threading.Event()による制御を知り、解決できました。from sense_hat import SenseHat, ACTION_PRESSED, ACTION_HELD, ACTION_RELEASED from time import sleep from random import randint from copy import copy import threading sense = SenseHat() sense.clear() red = (255, 0, 0) blue = (0, 0, 255) yellow=(255,255,0) purple=(128,0,128) green=(0,255,0) indigg=(75,0,130) orange=(255,128,0) black=[0,0,0] sense.set_rotation(0) ncol = 8 nrow = 8 col_max = ncol - 2 row_max = nrow - 1 event = threading.Event() def setdisturbs(num_disturbs, initpos): disturbs = list() for i in range(0,num_disturbs): while True: candi = (randint(0, col_max), randint(0, row_max)) if candi == initpos: continue duplicated = False for j in disturbs: if candi == j: duplicated = True break if duplicated: continue disturbs.append(candi) break color_disturb = green for i in disturbs: sense.set_pixel(i[0], i[1], color_disturb) def timecount(interval): col = ncol - 1 for row in range(row_max): sense.set_pixel(col, row, blue) if event.wait(interval): break event.set() speed = 0.2 num_disturbs = 10 interval = 3 ballpos = (ncol/2, nrow/2) sense.set_pixel(ballpos[0], ballpos[1], red) ballvec = (0, 0) setdisturbs(num_disturbs, ballpos) t1 = threading.Thread(target=timecount, args=(interval,)) t1.start() success = False while True: if event.is_set(): break acceleration = sense.get_accelerometer_raw() x = acceleration['x'] y = acceleration['y'] z = acceleration['z'] x=int(round(x, 0)) y=int(round(y, 0)) z=int(round(z, 0)) #print("x={0}, y={1}, z={2}".format(x, y, z)) ballvec = (x, y) # if x == -1: #left # ballvec = (-1, 0) # elif y == -1: #top # ballvec = (0, -1) # elif x == 1: #right # ballvec = (1, 0) # elif y == 1: #bottom # ballvec = (0, 1) # else: # ballvec = (0, 0) sense.set_pixel(ballpos[0], ballpos[1], black) ballpos = (max(min(ballpos[0] + ballvec[0], col_max), 0), max(min(ballpos[1] + ballvec[1], row_max), 0)) sense.set_pixel(ballpos[0], ballpos[1], red) #print("col={0}, row={1}".format(ballpos[0], ballpos[1])) num_colorpx = 0 cur_px = sense.get_pixels() for px in cur_px: if px == [0,252,0]: # green num_colorpx = num_colorpx + 1 if num_colorpx == 0: event.set() success = True break sleep(speed) if success: sense.show_letter("O") else: sense.show_letter("X") sleep(2) sense.clear()

- 投稿日:2021-01-17T16:36:45+09:00
Tk.textでログ表示させるときのハマりポイント
初めに
職場でメモリリーク問題でトラブった調査してたら予想外の罠が見つかったので投稿します。
ちょっと乱文になると思うのですがご容赦ください。環境
OS:Windows10
Anaconda PowerShell Prompt(base) PS C:\Users\95315> python -V Python 3.6.10 :: Anaconda, Inc. (base) PS C:\Users\95315> conda -V conda 4.9.2 (base) PS C:\Users\95315>conda list … tk 8.6.8 hfa6e2cd_0 …何がしたかったのか
https://tkdocs.com/tutorial/text.html
上記ページのExample: Logging Windowの節を参考して欲しいのですがロガーの内容を引っ張ってTk.textで表示するプログラムを作ってました。
要は下のコードです。from tkinter import * from tkinter import ttk root = Tk() log = Text(root, state='disabled', width=80, height=24, wrap='none') log.grid() def writeToLog(msg): numlines = int(log.index('end - 1 line').split('.')[0]) log['state'] = 'normal' if numlines==24: log.delete(1.0, 2.0) if log.index('end-1c')!='1.0': log.insert('end', '\n') log.insert('end', msg) log['state'] = 'disabled'何が起きたのか
ロガーの表示内容がある行数を超えると頭から削除してたんですが、それでもメモリ消費量がモリモリ増えて最終的にPC毎メモリ不足で落ちるというヤバげな挙動を示しており頭が痛い不具合が出ておりました…。
何がマズかったのか
色々探してたら以下のリファレンスがちょっと古いものの原因を記してました。
https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/text-undo-stack.htmlThe Text widget has a built-in mechanism that allows you to implement undo and redo operations that can cancel or >reinstate changes to the text within the widget.
要はTk.textはオプションでundo/redoスタックを持つよ。便利だね。
そうだね。勝手にONにしてスタック数無制限っぽい挙動をしなければ良かったね。んでどう直したか
要はスタックを無効にするだけです。ぶっちゃけさっきのコードで言えばこう直します。
from tkinter import * from tkinter import ttk root = Tk() log = Text(root, state='disabled', width=80, height=24, wrap='none',undo=False) log.grid() def writeToLog(msg): numlines = int(log.index('end - 1 line').split('.')[0]) log['state'] = 'normal' if numlines==24: log.delete(1.0, 2.0) if log.index('end-1c')!='1.0': log.insert('end', '\n') log.insert('end', msg) log['state'] = 'disabled'undo=Falseを追加するだけっすね。
俺はこの一行のためになんて時間を…
とまぁ割とえげつない話だったので記事にでもしとこう。そうでないと溜飲が下がらん。
というわけで記事にした次第です。終わりに
公式からリンク張ってあるようなTKDocsでもこういうことがあるので、もはや何を信用してよいやら…
とりあえず一つのソースだけじゃなくて多角的に色々探るってのは大事だと思った次第です。
だからTkinterはクソとかそういうつもりはないです。というかPythonでGUIはどれも色々あるし標準で用意されてるTkinter使ってもいいんじゃないっすかね。
こういうトラブルがいくつか埋まってるのが気になるなら良さげなライブラリ使うのも一考ですが。
後はまぁ集合知でこういうトラブルあったよということはQiitaの記事にジャンジャン書いていいんじゃないでしょうか。
辛いトラブル引いたときはまぁQiitaに書くネタが出来たとでも思えば多少は気が晴れます。
んでここからが怖い話なんですが、メモリリーク要因はまだもう一件残っててそっちも探して潰さないといけないんですよ…フフフ
とまぁあまり引っかかる人はいないと思うので読み物としてそういうことあるんだと思っていただければ幸いです。
ここまで読んでくださりありがとうございました。
- 投稿日:2021-01-17T15:51:52+09:00
LightGBM(実装・パラメータの自動調整(Optuna))
はじめに
LightGBMの実装とパラメータの自動調整(Optuna)をまとめた記事です。
LightGBMとは
LightGBMとは決定木とアンサンブル学習のブースティングを組み合わせた勾配ブースティングの機械学習。
(XGBoostを改良したフレームワーク。)XGBoostのリリース:2014年
LightGBMのリリース:2016年※アンサンブル学習:以下を参照
https://qiita.com/hara_tatsu/items/336f9fff08b9743dc1d2LightGBMの特徴
①予測精度が高い
一般的にディープラーニングを除いた機械学習の中ではXGBoostと並んで最高の予測精度。②モデルの訓練に掛かる時間が比較的短い
同等の予測精度を誇るXGBoostよりも計算コストが少ない。
(LightGBMが「Light(軽い)」と言われる所以。)③過学習しやすい
複雑な決定木構造になるため、パラメータを適切に調整しないと過学習となる可能性が高い。実装
今回は、【SIGNATE】の自動車の評価を題材にします。
以下リンク。
https://signate.jp/competitions/122データの前処理
データを読み込んで、「文字列」を「数値」に変更します。
pyhon.pyimport pandas as pd import numpy as np # データの読み込み df = pd.read_csv('train.tsv', delimiter = '\t') df = df.drop('id', axis = 1) # 説明変数 df = df.replace({'buying': {'low': 1, 'med': 2, 'high': 3, 'vhigh': 4}}) df = df.replace({'maint': {'low': 1, 'med': 2, 'high': 3, 'vhigh': 4}}) df = df.replace({'doors': {'2': 2, '3': 3, '4': 4, '5': 5, '5more': 6}}) df = df.replace({'persons': {'2': 2, '4': 4, 'more': 6}}) df = df.replace({'lug_boot': {'small': 1, 'med': 2, 'big': 3}}) df = df.replace({'safety': {'low': 1, 'med': 2, 'high': 3}}) # 目的変数 df = df.replace({'class': {'unacc': 0, 'acc': 1, 'good': 2, 'vgood': 3}})訓練データと評価データに分類
python.pyfrom sklearn.model_selection import train_test_split train_set, test_set = train_test_split(df, test_size=0.2, random_state = 0) #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('class', axis=1) y_train = train_set['class'] #評価データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('class', axis=1) y_test = test_set['class'] print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape) (691, 6) (173, 6) (691,) (173,)LightGBMの実装
LightGBMのデータセットに変換
python.pyimport lightgbm as lgb # 訓練データ lgb_train = lgb.Dataset(X_train, y_train) # 評価データ lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)モデルの学習
※2値分類の場合
'objective': 'binary',
'metric': 'binary_error' #評価指標:正答率※回帰の場合
'objective': 'regression',
'metric': 'rmse'python.py# パラメータの設定 parms = { 'task': 'train', #トレーニング用 'boosting': 'gbdt', #勾配ブースティング決定木 'objective': 'multiclass', #目的:多値分類 'num_class': 4, #分類するクラス数 'metric': 'multi_error', #評価指標:正答率 'num_iterations': 1000, #1000回学習 'verbose': -1 #学習情報を非表示 } # モデルの学習 model = lgb.train(parms, #訓練データ train_set=lgb_train # 評価データ valid_sets=lgb_eval, early_stopping_rounds=100)結果の確認
python.py# 結果の予測 y_pred = model.predict(X_test) # 予測確率を整数へ y_pred = np.argmax(y_pred, axis=1) from sklearn import metrics print(metrics.classification_report(y_test, y_pred)) # 結果 precision recall f1-score support 0 1.00 0.99 1.00 114 1 0.93 0.98 0.95 42 2 0.75 0.67 0.71 9 3 1.00 1.00 1.00 8 accuracy 0.97 173 macro avg 0.92 0.91 0.91 173 weighted avg 0.97 0.97 0.97 173正答率: 97%
Optunaでパラメータの調整
次に「Optuna」を利用してパラメータの最適化をします。
Optunaとは
Optuna はパラメータの最適化を自動化するためのソフトウェアフレームワークです。パラメータの値に関する試行錯誤を自動的に行いながら、優れた性能を発揮するパラメータの値を自動的に発見する。
(Tree-structured Parzen Estimator というベイズ最適化アルゴリズムの一種を用いています。)※インストール方法
pip install optuna詳細はこちらから
①ホームページ
https://preferred.jp/ja/projects/optuna/
②ドキュメント
https://optuna.readthedocs.io/en/stable/index.htmlOptunaの実装
自動で最適化されるパラメータは以下の7つになります。
lambda_l1
lambda_l2
num_leaves
feature_fraction
bagging_fraction
bagging_freq
min_child_samplesそれでは実装していきます。
python.py# optuna経由でLightGBMをインポート from optuna.integration import lightgbm as gbm # 固定するパラメータ params = { "boosting_type": "gbdt", 'objective': 'multiclass', 'num_class': 4, 'metric': 'multi_error', "verbosity": -1, } # Optunaでのパラメータ探索 model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval], verbose_eval=100, early_stopping_rounds=100, ) # 最適なパラメータの表示 best_params = model.params print("Best params:", best_params) Best params: { 'objective': 'multiclass','num_class': 4, 'metric': 'multi_error', 'verbosity': -1, 'boosting_type': 'gbdt', 'feature_pre_filter': False, 'lambda_l1': 0.0, 'lambda_l2': 0.0, 'num_leaves': 31, 'feature_fraction': 0.8999999999999999, 'bagging_fraction': 1.0, 'bagging_freq': 0, 'min_child_samples': 20, 'num_iterations': 1000, 'early_stopping_round': 100 }結果の確認
python.pyY_pred = model.predict(X_test, num_iteration=model.best_iteration) y_pred = np.argmax(Y_pred, axis=1) from sklearn import metrics print(metrics.classification_report(y_test, y_pred)) precision recall f1-score support 0 1.00 0.99 1.00 114 1 0.95 0.98 0.96 42 2 0.78 0.78 0.78 9 3 1.00 1.00 1.00 8 accuracy 0.98 173 macro avg 0.93 0.94 0.93 173 weighted avg 0.98 0.98 0.98 173おわりに
正解率 97% → 98% へ向上しました!
前回のランダムフォレストよりも予測精度は高いですね!!
※ランダムフォレスト((実装・パラメーターまとめ))
https://qiita.com/hara_tatsu/items/581db994ec8866afe8f8
- 投稿日:2021-01-17T15:50:54+09:00
【強化学習】Ape-X の高速な実装を簡単に!
内部実装の技術的な話は Zenn に記事を投稿しました。
興味のある方はそちらをお読みください。1. はじめに
以前紹介記事も書いていますが、強化学習の経験再生 (Experience Replay) 用のReplay Bufferのライブラリを開発して公開しています。
Experience Replay は強化学習で広く利用されているにも関わらず、多くの人がネット上等に公開されているコードをコピペしたりスクラッチで書き直したりと車輪の再発明に時間を費やしている状況は良くないと思い開発と公開を続けています。しかも意外とハマりどころがあり、非効率的な実装や同じ轍を踏むバグに遭遇したりと、深層学習に興味がある研究者・開発者たちにとっては頭の痛い問題であるので、サクッと利用可能なライブラリがあることは重要だと思っています。
(もちろんRLlibなど強化学習全体を内包した素晴らしいライブラリはありますが、実装されていないアルゴリズムを自作して乗せようとなるとなかなか骨が折れるため、強化学習のアルゴリズムの研究者には使い勝手が良くはないと思っています。また、先日公開されたDeepMind製のReverbは直接の競合相手ですが、あちらはもっと大規模なスケールが前提で、こちらは現状単一コンピュータでの利用が想定されています。)
主題からそれるので、ここでは詳しくは記載しませんが、深層学習のフレームワーク非依存で、かつ高い自由度と効率性を主眼に開発をしています。興味が湧いた方はぜひ利用してみて、レポジトリにスターをつけたり issue を立てたりとフィードバックしてもらえるととても嬉しいです。
2. Ape-X
強化学習を短い時間で学習させる手法のひとつとして分散学習の Ape-X が提案されています。ざっくり言うと、環境の探索とネットワークの学習を分離して、かつ複数の探索を同時に実行する方法です。
細かい解説や実装は Qiita 上にもしっかり書かれた素晴らしい記事がありました。
これらの実装でも、Replay Buffer やプロセス間データ通信をフルスクラッチで書かれているように思います。再利用する際に、「自分はTensorFlow派ではなくてPyTorch派なんだけど・・・」となるとコピペして関係する部分を全部書き直すのは大変だと思っています。
3. cpprb のインストール
今回の Ape-X 向けの機能は、 v9.4.2 以降が必要です。
3.1 Linux/Windows
PyPI からそのままバイナリをインストールできます。
pip install cpprb3.2 macOS
残念ながらデフォルトで利用される clang ではコンパイルができないため、Homebrew なり MacPorts なりで、gcc を用意してもらいインストール時に手元でコンパイルしてもらうことが必要です。
/path/to/g++はインストールした g++ のパスに置き換えてください。CC=/path/to/g++ CXX=/path/to/g++ pip install cpprb参考: 公式サイトのインストール手順
4. cpprb を利用した Ape-X サンプル実装コード
cpprb を利用した際の Ape-X のサンプル実装を以下に掲載します。深層学習のモデル(ネットワーク)部分は含んでいない Ape-X の骨格の部分のコードです。モックの
MyModelの部分を変えてもらって、必要に応じて TensorBoard などの可視化を入れたりモデルの保存を加えたりすることで、実際に利用できるようになると思います。(その辺りの実装は、普段から強化学習を研究開発している方たちにとって難しくはないと思います。)apex.pyfrom multiprocessing import Process, Event, SimpleQueue import time import gym import numpy as np from tqdm import tqdm from cpprb import ReplayBuffer, MPPrioritizedReplayBuffer class MyModel: def __init__(self): self._weights = 0 def get_action(self,obs): # Implement action selection return 0 def abs_TD_error(self,sample): # Implement absolute TD error return np.zeros(sample["obs"].shape[0]) @property def weights(self): return self._weights @weights.setter def weights(self,w): self._weights = w def train(self,sample): # Implement model update pass def explorer(global_rb,env_dict,is_training_done,queue): local_buffer_size = int(1e+2) local_rb = ReplayBuffer(local_buffer_size,env_dict) model = MyModel() env = gym.make("CartPole-v1") obs = env.reset() while not is_training_done.is_set(): if not queue.empty(): w = queue.get() model.weights = w action = model.get_action(obs) next_obs, reward, done, _ = env.step(action) local_rb.add(obs=obs,act=action,rew=reward,next_obs=next_obs,done=done) if done: local_rb.on_episode_end() obs = env.reset() else: obs = next_obs if local_rb.get_stored_size() == local_buffer_size: local_sample = local_rb.get_all_transitions() local_rb.clear() absTD = model.abs_TD_error(local_sample) global_rb.add(**local_sample,priorities=absTD) def learner(global_rb,queues): batch_size = 64 n_warmup = 100 n_training_step = int(1e+4) explorer_update_freq = 100 model = MyModel() while global_rb.get_stored_size() < n_warmup: time.sleep(1) for step in tqdm(range(n_training_step)): sample = global_rb.sample(batch_size) model.train(sample) absTD = model.abs_TD_error(sample) global_rb.update_priorities(sample["indexes"],absTD) if step % explorer_update_freq == 0: w = model.weights for q in queues: q.put(w) if __name__ == "__main__": buffer_size = int(1e+6) env_dict = {"obs": {"shape": 4}, "act": {}, "rew": {}, "next_obs": {"shape": 4}, "done": {}} n_explorer = 4 global_rb = MPPrioritizedReplayBuffer(buffer_size,env_dict) is_training_done = Event() is_training_done.clear() qs = [SimpleQueue() for _ in range(n_explorer)] ps = [Process(target=explorer, args=[global_rb,env_dict,is_training_done,q]) for q in qs] for p in ps: p.start() learner(global_rb,qs) is_training_done.set() for p in ps: p.join() print(global_rb.get_stored_size())見ていただければわかるように、グローバル・バッファとして利用している
MPPrioritizedReplayBuffer(Multi-Process サポートな Prioritized Replay Buffer) は複数プロセスから、特に意識することなくアクセスすることができます。内部データを共有メモリに乗せているので プロキシ (multiprocessing.managers.SyncManager等) や、キュー (multiprocessing.Queue等) よりも高速なプロセス間データ共有を実現しています。また、データの不整合が起きないようにするロックも各メソッドの内部で実行しているので、複数 explorer + 単一 learner という基本構成をユーザーが守っている限り、手動でロックをかける必要はありません。しかもバッファ全体をロックするわけではなく、データの整合性を保つために必要な最小限のクリティカル・セクションだけをロックしているので下手にグローバル・バッファ全体をロックするよりも非常に効率的です。(特に深層学習のネットワークが小さいとか、シミュレーターなどの環境の計算負荷が軽いなどの状況下ではその差は大きくなり、厳密な試験ではないですが手元で開発している際には単純なグローバル・バッファ全体のロックと比較して、explorerの速度が3-4倍、learnerの速度が1.2-2倍程度になりました。)
5. おまけ
友人が cpprb を利用して、TensorFlow 2.x 向けの強化学習ライブラリ tf2rl を開発しています。
そちらも興味があればよろしくおねがいします。作者本人の紹介記事 → tf2rl: TensorFlow2 Reinforcement Learning
- 投稿日:2021-01-17T15:48:54+09:00
AWS Lambda Layersでsam buildを行うとファイルの階層が変わりimportエラーになる問題
概要
sam deploy刷る前にsam buildをするだけでLambda Functionからimportできなくなってしまったので原因を調べました。
対象コード
Lambda Layer Template
Resources: SystemSharedLayer: Type: AWS::Serverless::LayerVersion Properties: ContentUri: src/layers/system_shared CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8Lambda Layer Src構造
src └── layers └── system_shared ├── python │ └── hogehoge.py └── requirements.txt呼び出し側
import hogehoge.pyLamnda Function側での展開パス
sam buildしなかった場合
/opt └── python/ └── hogehoge.pysam buildした場合
/opt └── python/ └── python/ ← 余計なパスが付与される └── hogehoge.py解決策
仕様が一貫していないので諦めてtemplate側の階層指定を切り替える
Resources: SystemSharedLayer: Type: AWS::Serverless::LayerVersion Properties: ContentUri: src/layers/system_shared/python CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8
- 投稿日:2021-01-17T15:23:15+09:00
mac python 環境構築時のエラー
macにpython環境を構築する際に発生したエラーの対処方法が調べても出てきにくかったのでまとめました.
pythonのインストール時に以下のコマンドをターミナルに入力しました.
$ pyenv install 3.9.1すると,以下のようなエラーが出てきました.
Last 10 log lines: checking for python3.9... python3.9 checking for --enable-universalsdk... no checking for --with-universal-archs... no checking MACHDEP... "darwin" checking for gcc... clang checking whether the C compiler works... no configure: error: in `/var/folders/9y/b18s20496nz6mc47pmf2czdm0000gn/T/python-build.20210117143950.2739/Python-3.9.1': configure: error: C compiler cannot create executables See `config.log' for more details xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrungcc(XcodeのCommand Line Tools)をインストールすると解決しました.
1.Xcodeを開き,左上(りんごマーク横)の
Xcodeタブ>Open Developer Tool>More Developer Tools...2.Xcodeのapple IDでログイン
3.Command Line Tools for Xcode 12.0.dmg(任意のバージョン)をダウンロード
4.インストール
5.インストールの確認
gcc -dumpversion 12.0.0以上の操作をしたところ,エラーがなくなりpythonをインストールできました.
pyenv install 3.9.1 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.9.1.tar.xz... -> https://www.python.org/ftp/python/3.9.1/Python-3.9.1.tar.xz Installing Python-3.9.1... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.9.1 to /Users/shogo/.pyenv/versions/3.9.1
- 投稿日:2021-01-17T15:04:23+09:00
[Blender] Blender Modeling tips まとめ(11~20)
目次
11.見たい範囲のみを表示する
12.3D viewportを4分割する
13.スプラッシュスクリーンの表示/非表示
14.Tooltipsの表示/非表示
15.検索機能
16.計算した値を代入する
17.複数のパネルの数値を同時に変更する
18.数値をデフォルト値に戻す
19.微調整ができるようにする
20.パネルをピンで常に表示する11.見たい範囲のみを表示する
①[ALT + B]を押して、みたい範囲を選択
※もとにもどす場合はもう一度[ALT + B]を押す12.3D viewportを4分割する
①[ALT + CTRL + Q]を押す
②Nキーを押す
④View/Quad Viewを開く
⑤Lock→視座の決定
⑥Box→物体を動かしたときの視点の決定※もとのviewにもどす場合はもう一度[ALT + CTRL + Q]を押す
13.スプラッシュスクリーンの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④Display/Splash Screenを押す表示
①Blenderアイコンを押す
②Splash Screenを押す14.Tooltipsの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsのチェックを外す※基本は非表示で知りたい時だけ表示させる方法
[ALT]を押しながらパネルにカーソルをあわせる表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsにチェックをいれる15.検索機能
[F3]を押せば検索が可能になる
※[F3]で検索できない場合は、
①Editを押す
②Menu Searchを押す※パネルの上で右クリックからショートカットの設定やお気に入りへの追加をしておくと便利
16.計算した値を代入する
パネル上で数値計算をすれば計算結果が反映される
17.複数のパネルの数値を同時に変更する
①パネル上で左クリックをしながらドラッグする
②数値を入力する
18.数値をデフォルト値に戻す
①カーソルをパネルにあわせる
②[back space]を押す
19.微調整ができるようにする
[shift]キーをおしながら動かすことで細かい調整が可能になる
20.パネルをピンで常に表示する
①表示したいパネルの上で右クリック
②PINにチェックをいれる※ピンを外すときは、ピンのマークをクリックする
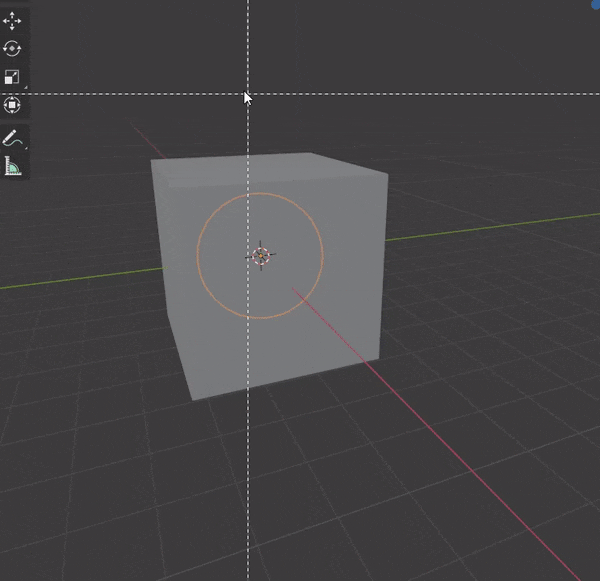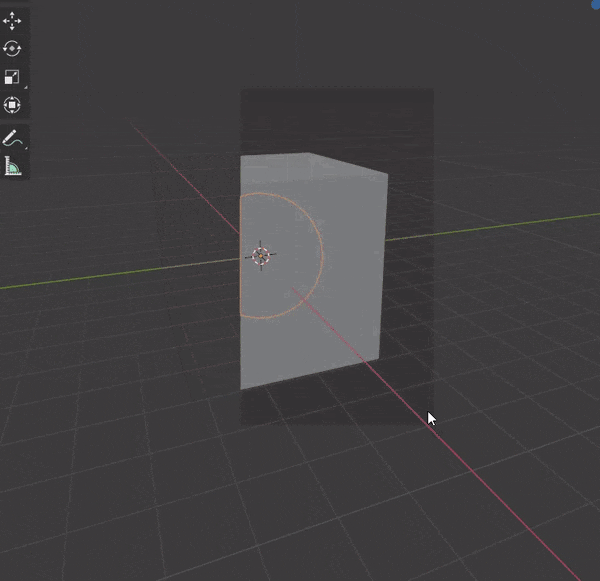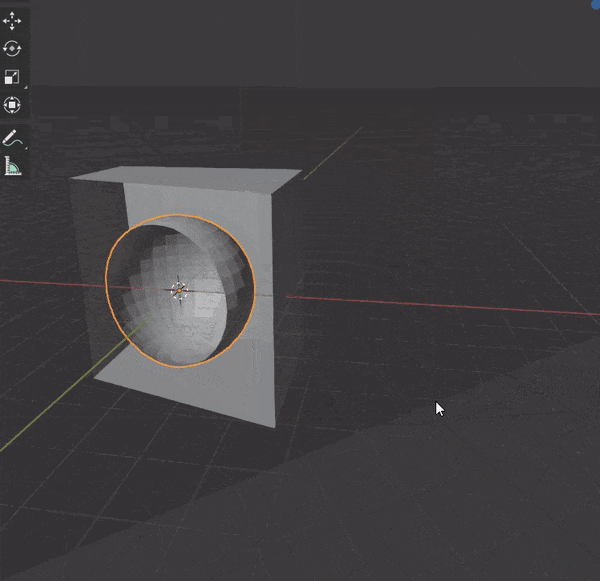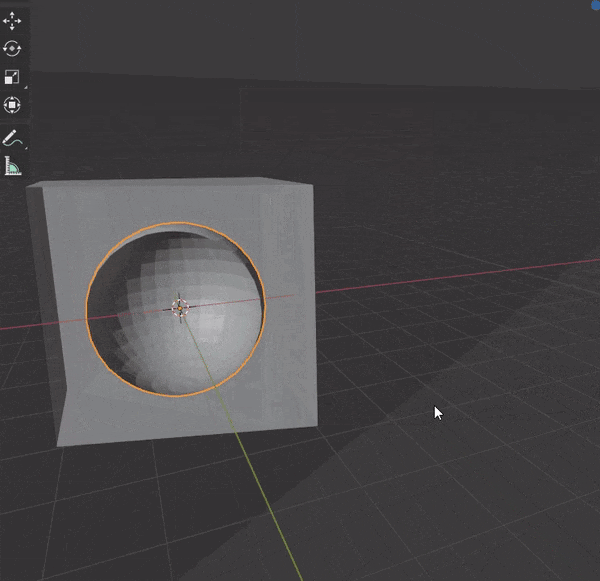
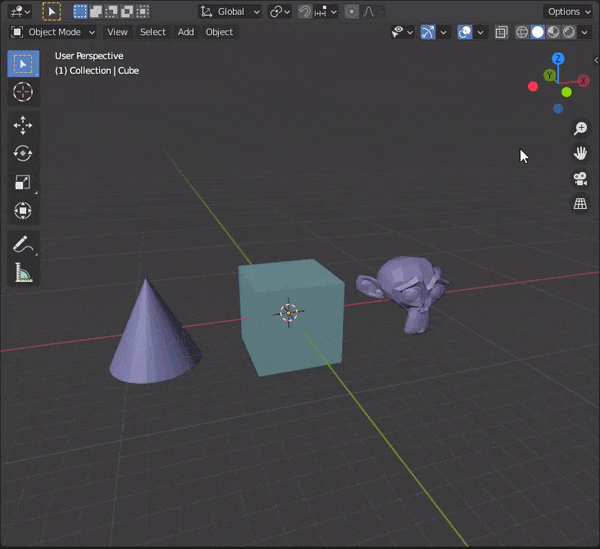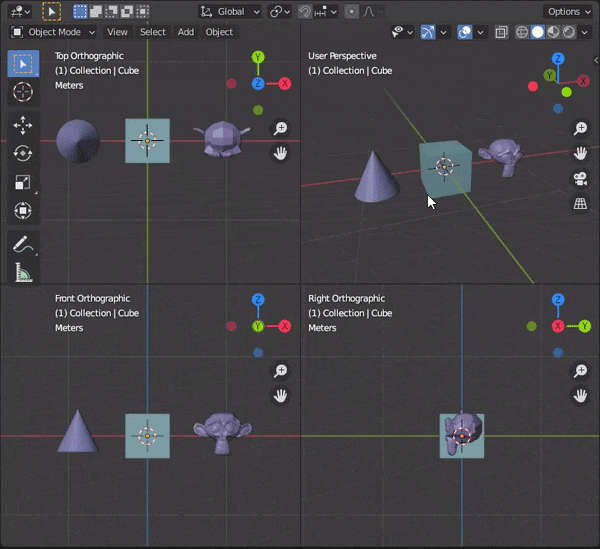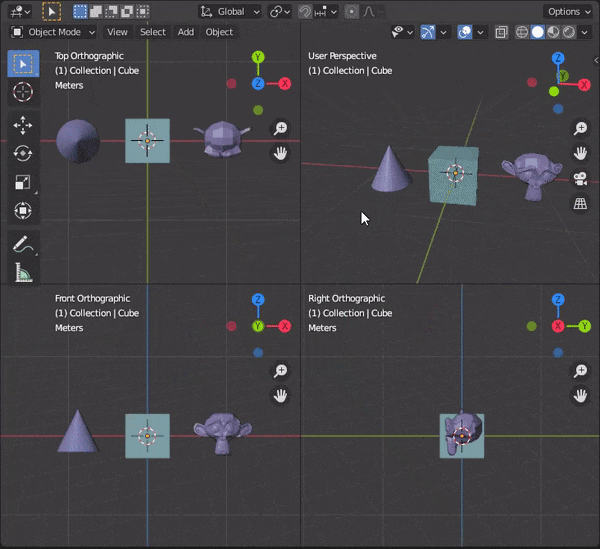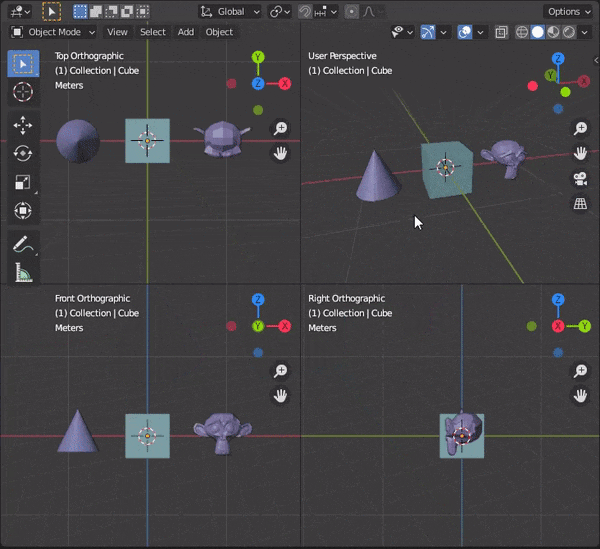
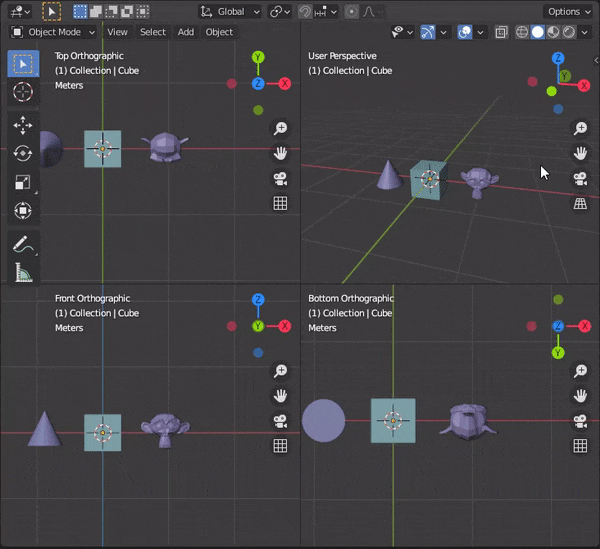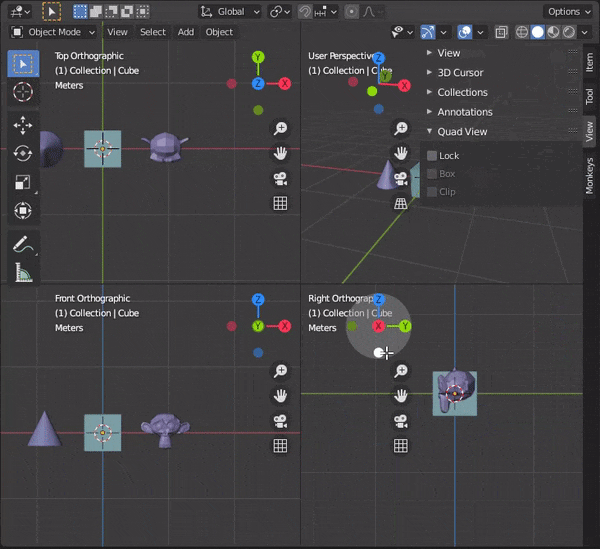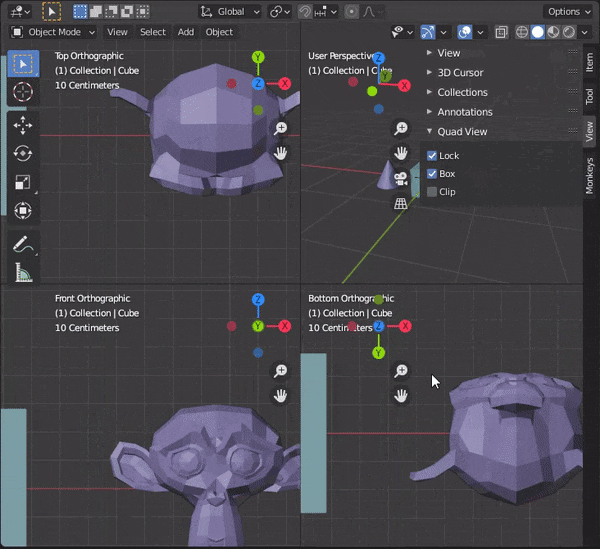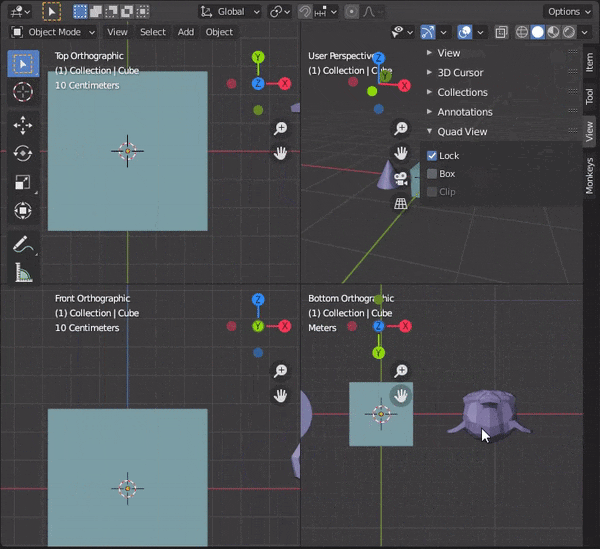
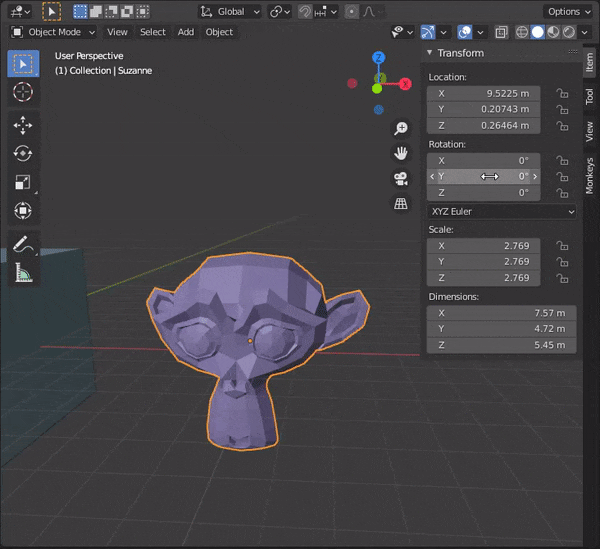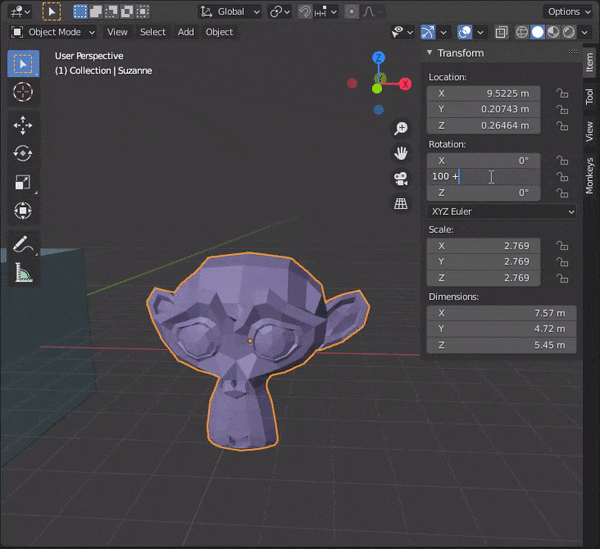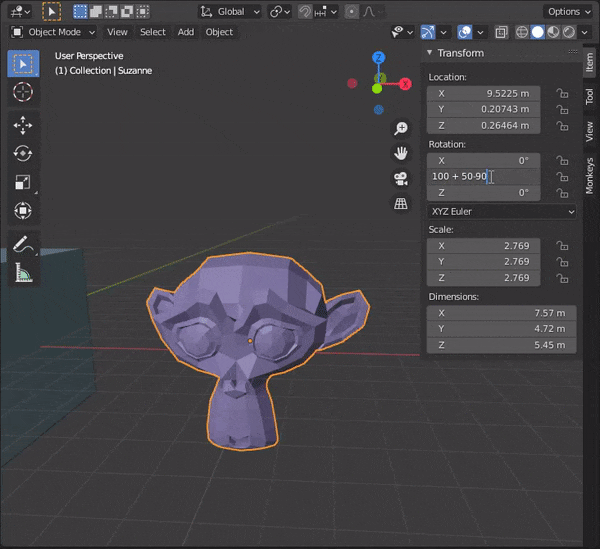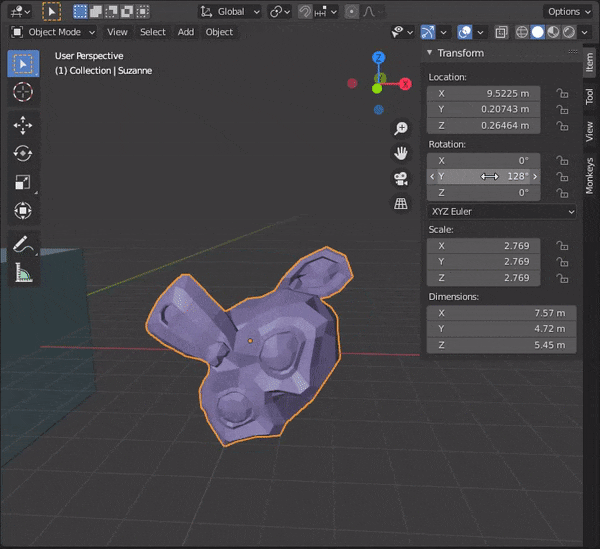
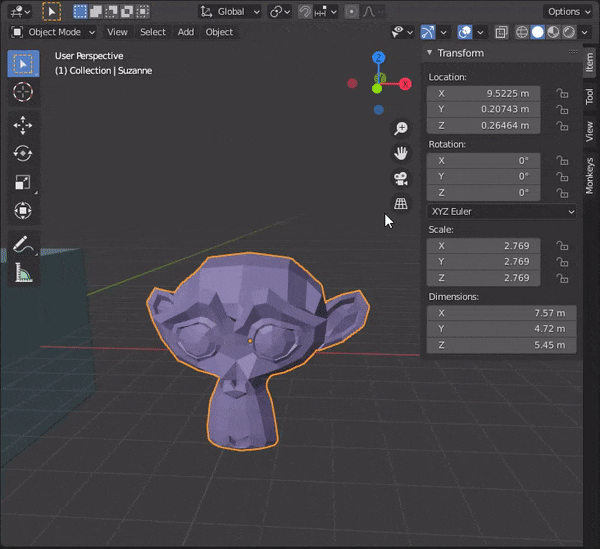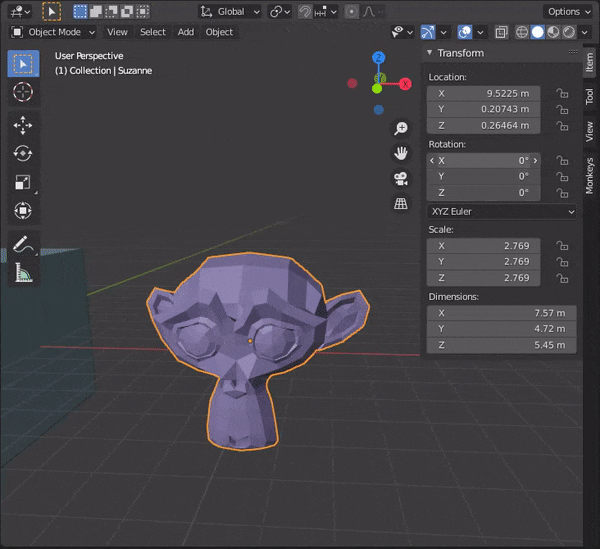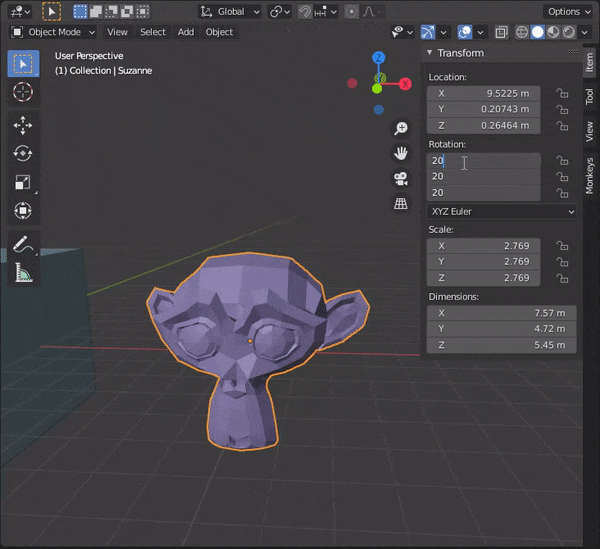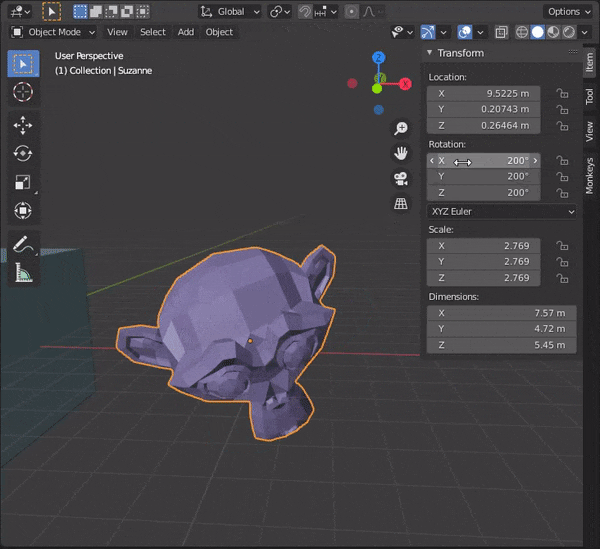

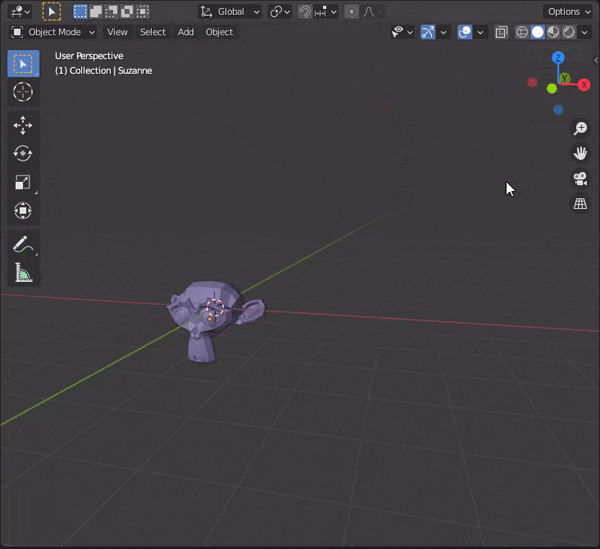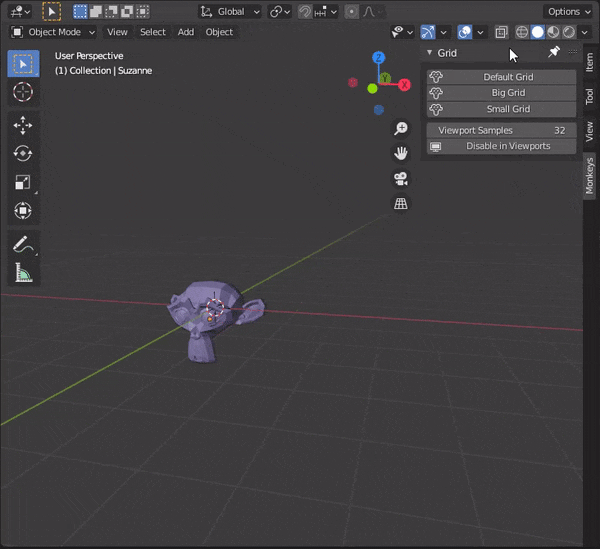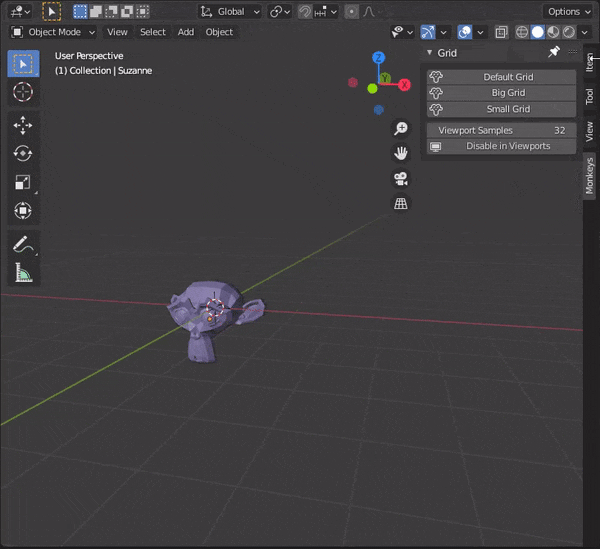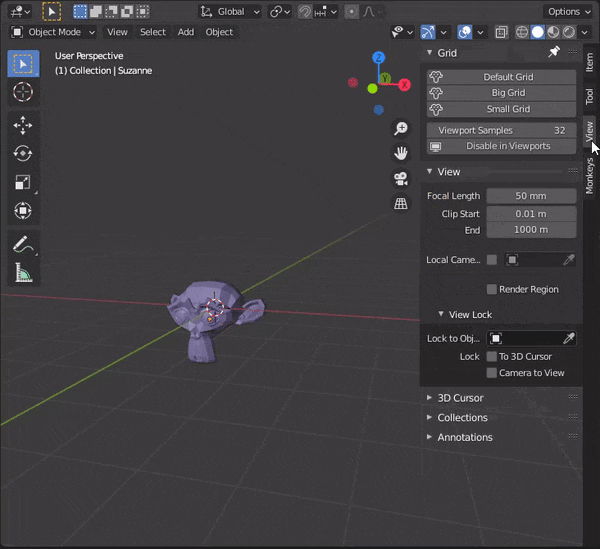
- 投稿日:2021-01-17T15:04:23+09:00
[Blender] Blender Modeling tips まとめ User Interface編Part2
目次
11.見たい範囲のみを表示する
12.3D viewportを4分割する
13.スプラッシュスクリーンの表示/非表示
14.Tooltipsの表示/非表示
15.検索機能
16.計算した値を代入する
17.複数のパネルの数値を同時に変更する
18.数値をデフォルト値に戻す
19.微調整ができるようにする
20.パネルをピンで常に表示する11.見たい範囲のみを表示する
①[ALT + B]を押して、みたい範囲を選択
※もとにもどす場合はもう一度[ALT + B]を押す12.3D viewportを4分割する
①[ALT + CTRL + Q]を押す
②Nキーを押す
④View/Quad Viewを開く
⑤Lock→視座の決定
⑥Box→物体を動かしたときの視点の決定※もとのviewにもどす場合はもう一度[ALT + CTRL + Q]を押す
13.スプラッシュスクリーンの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④Display/Splash Screenを押す表示
①Blenderアイコンを押す
②Splash Screenを押す14.Tooltipsの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsのチェックを外す※基本は非表示で知りたい時だけ表示させる方法
[ALT]を押しながらパネルにカーソルをあわせる表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsにチェックをいれる15.検索機能
[F3]を押せば検索が可能になる
※[F3]で検索できない場合は、
①Editを押す
②Menu Searchを押す※パネルの上で右クリックからショートカットの設定やお気に入りへの追加をしておくと便利
16.計算した値を代入する
パネル上で数値計算をすれば計算結果が反映される
17.複数のパネルの数値を同時に変更する
①パネル上で左クリックをしながらドラッグする
②数値を入力する
18.数値をデフォルト値に戻す
①カーソルをパネルにあわせる
②[back space]を押す
19.微調整ができるようにする
[shift]キーをおしながら動かすことで細かい調整が可能になる
20.パネルをピンで常に表示する
①表示したいパネルの上で右クリック
②PINにチェックをいれる※ピンを外すときは、ピンのマークをクリックする
- 投稿日:2021-01-17T15:04:23+09:00
[Blender] Modeling tips まとめ User Interface編Part2
目次
11.見たい範囲のみを表示する
12.3D viewportを4分割する
13.スプラッシュスクリーンの表示/非表示
14.Tooltipsの表示/非表示
15.検索機能
16.計算した値を代入する
17.複数のパネルの数値を同時に変更する
18.数値をデフォルト値に戻す
19.微調整ができるようにする
20.パネルをピンで常に表示する11.見たい範囲のみを表示する
①[ALT + B]を押して、みたい範囲を選択
※もとにもどす場合はもう一度[ALT + B]を押す12.3D viewportを4分割する
①[ALT + CTRL + Q]を押す
②Nキーを押す
④View/Quad Viewを開く
⑤Lock→視座の決定
⑥Box→物体を動かしたときの視点の決定※もとのviewにもどす場合はもう一度[ALT + CTRL + Q]を押す
13.スプラッシュスクリーンの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④Display/Splash Screenを押す表示
①Blenderアイコンを押す
②Splash Screenを押す14.Tooltipsの表示/非表示
非表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsのチェックを外す※基本は非表示で知りたい時だけ表示させる方法
[ALT]を押しながらパネルにカーソルをあわせる表示
①Editを押す
②Preferencesを押す
③Interfaceを押す
④tooltipsにチェックをいれる15.検索機能
[F3]を押せば検索が可能になる
※[F3]で検索できない場合は、
①Editを押す
②Menu Searchを押す※パネルの上で右クリックからショートカットの設定やお気に入りへの追加をしておくと便利
16.計算した値を代入する
パネル上で数値計算をすれば計算結果が反映される
17.複数のパネルの数値を同時に変更する
①パネル上で左クリックをしながらドラッグする
②数値を入力する
18.数値をデフォルト値に戻す
①カーソルをパネルにあわせる
②[back space]を押す
19.微調整ができるようにする
[shift]キーをおしながら動かすことで細かい調整が可能になる
20.パネルをピンで常に表示する
①表示したいパネルの上で右クリック
②PINにチェックをいれる※ピンを外すときは、ピンのマークをクリックする
21.オペレーターパネルを再表示する
[F9]をおせば表示可能
※もしファンクションキーが使えない場合は
①Editを押す
②Preferencesを押す
③KeyMapを押す
④Redo Lastと検索する
⑤オリジナルのショートカットを割り当てる
22.機能をもっとよくしりたいとき(blender manualをひらく)
[F1]キーを押す
または、
パネル上で右クリック→Online Manualを押す

- 投稿日:2021-01-17T14:38:59+09:00
Flaskで作るSNS Flask(Ajax)編
TL;DL
Udemyの下記講座の受講記録
Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~
https://www.udemy.com/course/flaskpythonweb/この記事ではAjaxによる非同期通信について記載する。
Ajaxとは
・Ajax(Asynchronous JavaScript and XML)とは、HTML、CSS、Javascriptなどの複合技術である。ウェブアプリケーションにおいてより早くページを表示すること、ページの全体を再読み込みすることなくインターフェースを部分部分で更新することが可能となる。
→画面遷移せずにページのコンテンツを更新したい場合に利用する。<公式>
https://flask.palletsprojects.com/en/1.1.x/patterns/jquery/・jQueryを使用するために、googleのCDNを利用する。
Ajax API
https://developers.google.com/speed/libraries3.x snippet:
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>コードサンプル
構成
sample
├── app.py
└── templates
└── index.htmlapp.py
from flask import Flask, request, render_template, jsonify app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') @app.route('/_add_numbers') def add_numbers(): # request.args.get(クエリパラメータ、[デフォルト値]、[値の型]) a = request.args.get('a', 0, type=int) b = request.args.get('b', 0, type=int) # jsonify({key:value}): 引数に与えられた辞書形式データをJsonに変換する。 # またその際にheaderの"content-type"を'application/json'に変換してくれる。 return jsonify({'result': a+b}) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000, debug=True)index.html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script> <script> $(function(){ $('a#calculate').bind('click', function(){ $.getJSON('/_add_numbers', { a: $('input[name="a"]').val(), b: $('input[name="b"]').val() }, function(data){ $("#result").text(data.result) }); }); }); </script> <h1>Jquery Sample</h1> <p> <input type="text" size=5 name='a'>+ <input type="text" size=5 name='b'>= <span id='result'>?</span> </p> <a href="#" id='calculate'>Calculate</a>処理の流れ
1. app.pyのルートディレクトリの処理を実行し、index.htmlを画面表示する。
2. 「calculate」リンクを押下すると、clickイベントに反応してgeJSON処理を実行する。
getJSON処理でフィールドa、bから入力値を取得し、「app.py」で定義している「/add_numbers」ルートの処理を実行する。(=イベント処理)
3. add_numbers処理では、requestでクエリパラメータからa、bの値を取得し、jsonifyモジュールを利用してJSON形式で結果をindex.htmlに返す。
4. イベント処理の結果をgetJSON()の第三引数であるイベントハンドラーに渡す。("function(data)"のdata)
5. addnumbersから受け取った結果をid=resultのタグのテキストに反映する。画面イメージ
JQueryのメソッド
$('HTML要素').bind( eventType [, eventData], handler(eventObject) )
内容 説明 .bind() HTML要素に以降の処理を紐付ける eventType 処理を起動するキーとなるDOMイベント。カンマ区切りで複数指定可能。'click''submit'など eventData 任意。eventHandlerに渡すデータを定義可能。(関数OK) handler(eventObject) eventTypeに低付議しているイベントが発生した場合に実行する処理を定義する。eventDataを定義している場合、handlerの引数として受け取ることが可能。(引数に使用する名称は任意) $.getJSON( url [, data] [, success(data, textStatus, jqXHR)] )
内容 説明 url リクエスト送信先URLを指定する。 data サーバーに送信するデータを指定する。サーバーに送信する前にURLエンコードが施される。 callback リクエストの送信が成功した場合に実行されるコールバック関数。リクエスト送信先URLからreturnされた値を関数の引数として受け取ることができる。
- 投稿日:2021-01-17T13:45:11+09:00
C#にpythonで作った処理を組み込む【pythonnet準備+確認編 2021年1月最新】
概要
pythonで作った処理(主にはtensorflow, pytorch等のディープラーニング系)をGUIから動かして結果を表示したいということがあると思います。
PyQtでもいけるかもなんですが、C#を扱える人の方が周りに多いので組み込むことができると嬉しいと思い調べたところ、
以下の先人の方々が使い方をまとめていただいていますのでそれを元に実際にtensorflowで作ったモデルを使ってアプリを作るところまでの手順を記事したいと思います。
本記事はまずは準備と動作確認編です。
(2021年1月現在、pythonnet自体のソースコードの更新がありますので最新の手順を載せます)
C#初心者なので間違っているところもあるかもしれませんがあしからずご了承ください・・・参考①:.NET (C#)からpythonを呼び出す
参考②:Pythonnetを使って.NetからPythonコードを実行してみました(Hallo World編)
0.前提
開発の環境
visualstudio2019 community Version 16.7.7
NuGet パッケージ マネージャー 5.7.0
Anaconda Navigator 1.9.12C#の環境
.NET Framework 4.7.2pythonの環境
Python 3.7.6
tensorflow 2.3.0
numpy 1.18.5前提知識
・pythonでpip等で環境構築ができ、コーディングできる人
・C#が少しわかる人1.pythonnetの導入
Nugetで導入
python3.7であればNugetを使って簡単に導入できます(2021/01/10現在)
⇒2.呼び出して使うまで飛ばしてください自分でビルドして導入
以下の記事を参考にさせていただきました。
pythonnetの古いソースコードであれば以下の記事を参考にしていただければと思います。参考:.NET (C#)からpythonを呼び出す
参考:Pythonnetを使って.NetからPythonコードを実行してみました(Hallo World編)
2021年1月10日現在の最新のソースコードでのビルド方法をここでは記述します。
1.pythonnetのgithubリポジトリから最新コードをcloneし、pythonnet.slnを開く
2.プロジェクトPython.Runtimeのプロジェクト プロパティを開き、コンパイルシンボルを手入力する。
python3.8を使いたい場合はPYTHON38;WINDOWSと入力。3.7の場合はPYTHON38を37に変更してください。
ちなみにruntime.csの中身を見るとコンパイルシンボルの設定の方法がわかるようになっています。
WINDOWSを入力していないとdllの中身がpython38となり、実際に使うときにはpython3.8を探しに行くのでうまくdllを読み込めなくなります。
3.ソリューションエクスプローラーのPython.Runtimeで右クリックしてビルドを選択する
うまくビルドが通るとルートフォルダの
src\runtime\bin\Debug\netstandard2.0
に
Python.Runtime.dll
が生成されていると思います。2.C#からpythonnetを呼び出して使ってみる
参考:.NET (C#)からpythonを呼び出す
先人の方のコードの書き方をほぼ真似するだけですが、フォームにラベルを配置してnumpyのバージョン表示、numpyでの簡単な計算をするアプリを作ってみようと思います。1.フォームのソリューションを作る
2.プラットホームの変更
プラットホームがx64になっていることを確認してください。
3.参照の追加
先ほど作成したDLLファイルを参照します
Python.Runtimeが追加されていることを確認してください。
4.サンプルコード作成
こんな感じでフォームを作ってください。
参考:.NET (C#)からpythonを呼び出す
後は先人の方のコードを参考に書くだけです。Form.csusing System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Drawing.Imaging; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; using System.IO; using System.Runtime.InteropServices; using Python.Runtime; namespace pythonnet_numpy_version { public partial class Form1 : Form { /// <summary> /// pythonライブラリを共有して使うための変数 /// </summary> public dynamic np; public Form1() { InitializeComponent(); } /// <summary> /// プロセスの環境変数PATHに、指定されたディレクトリを追加する(パスを通す)。 /// </summary> /// <param name="paths">PATHに追加するディレクトリ。</param> public static void AddEnvPath(params string[] paths) { var envPaths = Environment.GetEnvironmentVariable("PATH").Split(Path.PathSeparator).ToList(); foreach (var path in paths) { if (path.Length > 0 && !envPaths.Contains(path)) { envPaths.Insert(0, path); } } Environment.SetEnvironmentVariable("PATH", string.Join(Path.PathSeparator.ToString(), envPaths), EnvironmentVariableTarget.Process); } // フォームが呼び出されるときに処理させる private void Form1_Load(object sender, EventArgs e) { // *-------------------------------------------------------* // * python環境の設定 // *-------------------------------------------------------* // python環境にパスを通す // TODO: 環境に合わせてパスを直すこと var PYTHON_HOME = Environment.ExpandEnvironmentVariables(@@"%userprofile%\Anaconda3\envs\tensorflow-2-3-0"); // pythonnetが、python本体のDLLおよび依存DLLを見つけられるようにする AddEnvPath( PYTHON_HOME, Path.Combine(PYTHON_HOME, @"Library\bin") ); // python環境に、PYTHON_HOME(標準pythonライブラリの場所)を設定 PythonEngine.PythonHome = PYTHON_HOME; // pythonの処理をする=numpyの定義とバージョンをラベルに表示させる using (Py.GIL()) { // numpyのインポート np = Py.Import("numpy"); // numpyのバージョンを変数に格納 dynamic np_version = np.__version__; // string型にして文字列と連結させラベルに表示 labelNumpyVersion.Text = "numpyバージョン:" + np_version.ToString(); } } // ボタンをクリックするとnumpyのメソッドを使って簡単な計算をしてラベルに表示 private void buttonCalc_Click(object sender, EventArgs e) { // 簡単な計算をして変数に格納 dynamic result = np.cos(np.pi / 3); // ToStringしなくても文字列にくっつけると勝手に型を変えてくれる labelResult.Text = "np.cos(np.pi / 3)=" + result; } } }基本は参考にしている記事の通りに書くだけですが、1つポイントとしてフォームアプリの場合は色々なコントロールでnumpyを使いたいのでインポートしたときに格納するメンバー変数を定義しておく必要があります。
まとめると以下の通りになります。(使い方によってはアクセス修飾子の適切な設定はあるかもです・・・とりあえずpublicにしときました)メンバー変数の定義
hogehoge.cspublic partial class Form1 : Form { /// <summary> /// pythonライブラリを共有して使うための変数 /// </summary> public dynamic np;numpyの定義
hogehoge.cs// pythonの処理をする=numpyの定義とバージョンをラベルに表示させる using (Py.GIL()) { // numpyのインポート np = Py.Import("numpy");numpyの使用
hogehoge.cs// 簡単な計算をして変数に格納 dynamic result = np.cos(np.pi / 3);3.終わりに
pythonからプログラミングを始めた俄かでC#を勉強してまだ数ヶ月でpythonnetをビルドするところで半日くらいかかってしまい心が折れそうでしたが何とか形できてホッとしています。
次はtensorflowとopencvを使ってC#側で画像を読み込んでpythonでセグメンテーションのモデルで推論した結果をC#のpictureboxに表示するアプリを作る記事を書こうと思います。
以上です。
不明点、おかしい点ありましたらコメントよろしくお願いします。
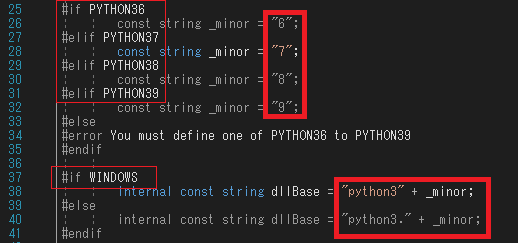

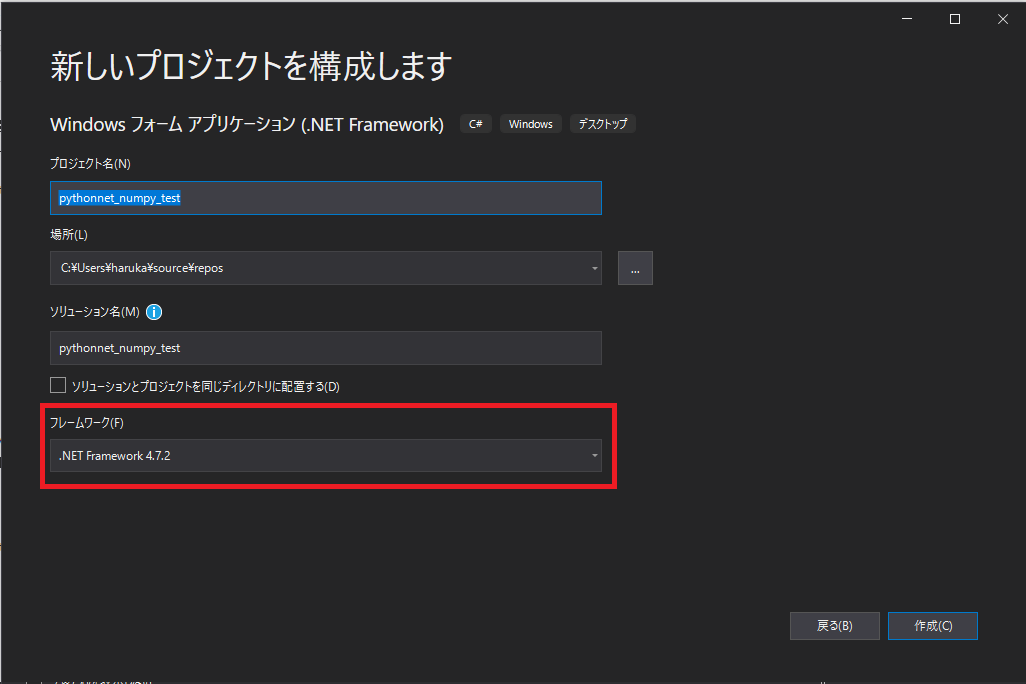
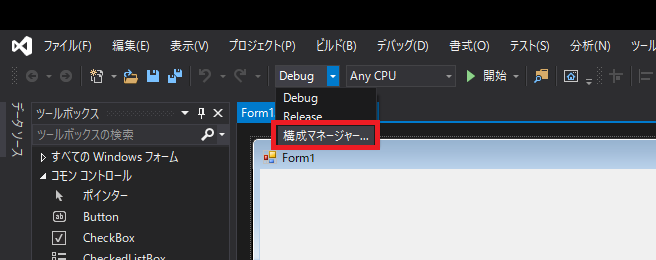
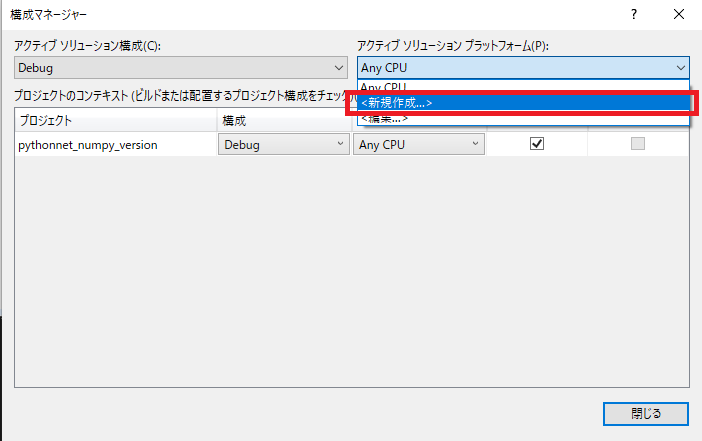
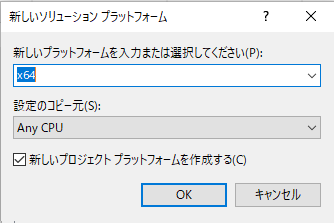

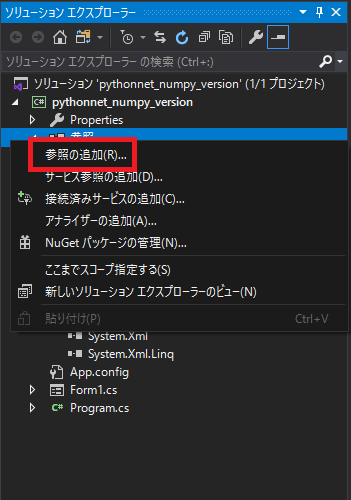
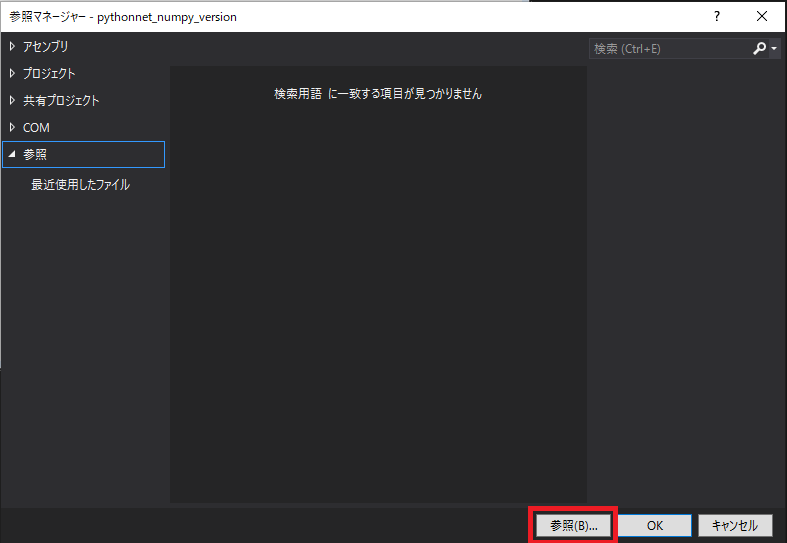
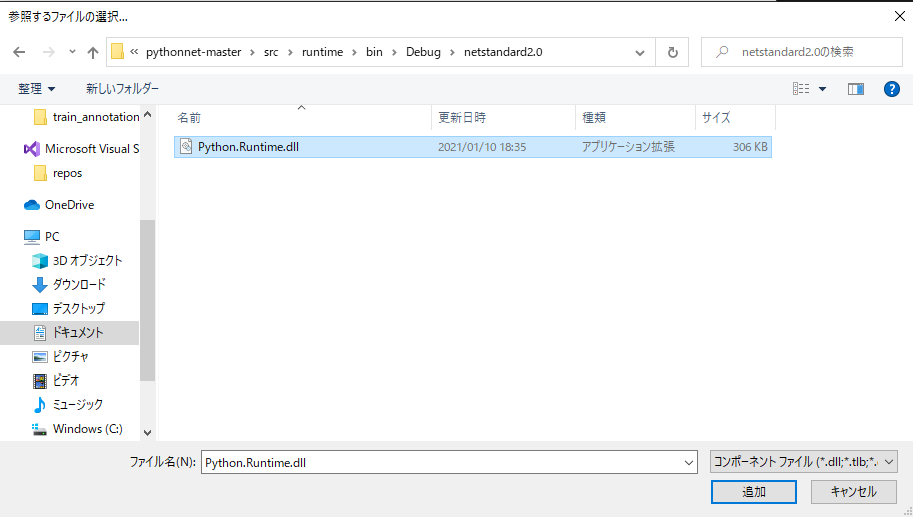

- 投稿日:2021-01-17T12:55:43+09:00
Python+NumpyのIntelコンパイラを使ったbuildではまっている人を救うかもしれない魔法の言葉(?)
何の話?
Python+Numpyをソースコードからインテルコンパイラを使ったBuildに小一時間はまったので、備忘録的なメモです。分かっている人にはかなりくだらない話です。一方で初心者ははまりやすいです。日本語環境特有の問題のため、海外のサイトなどの情報を漁っても出てきません。
ただ、Python+Numpyを使うだけであれば、PIPを使えば苦労なく終わります。とある事情でPIPが使えなかったのです。環境
- CentOS 7.6
- Intel Compiler 19
- Python 3.9.1
- Numpy 1.19.5
Buildはどうやるの?
基本的に、Pythonはconfigure+Makeで終わりです。特にはまることもありません。
一方Numpyのbuildではまりました。基本的なのやり方は、
インテルの公式サイト
に詳しく書かれています。setup.py を使います。何にはまったの?
Numpyをbuildする際に、Intel CompilerのVersionがマッチしないといったエラーがでます。
これは日本語環境特有の問題でした。あなたを救う魔法の言葉
LANG=C
LANG=C python3 setup.py config--compiler=intelem --fcompiler=intelem build_clib --compiler=intelem --fcompiler=intelem build_ext --compiler=intelem --fcompiler=intelem install教訓
他人が作ったプログラムをソースコードからBuildする場合は、言語環境に気をつけましょう。
おしまい。
- 投稿日:2021-01-17T12:28:26+09:00
整数型で高方程式を解く (重解なし) Manager編
Manager編
前回の整数型で高方程式を解くまで、並列処理部分はmultiprocessingのpoolを使ってきました。各プロセスが終了毎にランダムな順序でreturnされてきます。単に並列処理する場合はいいのですが、順序の並べ直しが必要で処理時間にロスがありました。そこで今回は、multiprocessingのmanagerを使ってプログラムを書き直しました。2度手間の並べ直しが無くなった分、計算時間は半分以下になりました。
前回の整数型で高方程式を解くの中で、10次方程式と10000次方程式のプログラムを書き直し、以下に示しました。Raspberry Pi 4Bのメモリー2Gの機種で、Raspberry Pi OS with DESKTOP(2020-DEC-02, 32bit版OS)のThonnyを使っています。USBにディスク等は接続していません。SwapはデフォルトのSDカード100MBです。
10次方程式
eq-10ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0 xx_to = 12 aa00= 3628800.0 aa01=-10628640.0 aa02= 12753576.0 aa03=-8409500.0 aa04= 3416930.0 aa05=-902055.0 aa06= 157773.0 aa07=-18150.0 aa08= 1320.0 aa09=-55.0 aa10= 1.0 r_f = 1000000 ji_su = 10 y_zoom = 0 #### Input End #### ksu=[] ksu.append( int((r_f**10)*aa00) ) ksu.append( int((r_f**9) *aa01) ) ksu.append( int((r_f**8) *aa02) ) ksu.append( int((r_f**7) *aa03) ) ksu.append( int((r_f**6) *aa04) ) ksu.append( int((r_f**5) *aa05) ) ksu.append( int((r_f**4) *aa06) ) ksu.append( int((r_f**3) *aa07) ) ksu.append( int((r_f**2) *aa08) ) ksu.append( int((r_f**1) *aa09) ) ksu.append( int((r_f**0) *aa10) ) initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 2 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)10000次方程式
eq-10000ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0.940 xx_to = 1.060 ksu_init = [] ksu_temp = 0.94999 for i in range(10000): ksu_temp += 0.00001 ksu_init.append(ksu_temp) r_f = 200000 ji_su = 10000 y_zoom = 2500 #### Input End #### initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 15 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom ksu=[] for i in range(len(ksu_init)): ksu.append( int(r_f*ksu_init[i]) ) p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") time.sleep(5) for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)最後までご覧いただき、ありがとうございました。
今回はQiitaの主旨に同意して投稿していますので、公開したプログラムはコピー、改変などでのご使用は自由です。著作権に関する問題も発生しません。
ただし、Raspberry Pi 4Bを使う場合にはCPUに特に大きめのヒートシンクが必須です。LAN通信の頻度の少ない今回のプログラムのような場合、LANチップは熱くなりません。しかし計算時間が継続するとCPUの激しい発熱で分かるように相当電力を使っています。電源UCB Cタイプの後ろにある黒い小さなチップも熱くなりますので、ファンでの風流も必要です。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
- 投稿日:2021-01-17T12:28:26+09:00
整数型で高次方程式を解く (重解なし) Manager編
Manager編
前回の整数型で高方程式を解くまで、並列処理部分はmultiprocessingのpoolを使ってきました。各プロセスが終了毎にランダムな順序でreturnされてきます。単に並列処理する場合はいいのですが、順序の並べ直しが必要で処理時間にロスがありました。そこで今回は、multiprocessingのmanagerを使ってプログラムを書き直しました。2度手間の並べ直しが無くなった分、計算時間は半分以下になりました。
前回の整数型で高方程式を解くの中で、10次方程式と10000次方程式のプログラムを書き直し、以下に示しました。Raspberry Pi 4Bのメモリー2Gの機種で、Raspberry Pi OS with DESKTOP(2020-DEC-02, 32bit版OS)のThonnyを使っています。USBにディスク等は接続していません。SwapはデフォルトのSDカード100MBです。
10次方程式
eq-10ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0 xx_to = 12 aa00= 3628800.0 aa01=-10628640.0 aa02= 12753576.0 aa03=-8409500.0 aa04= 3416930.0 aa05=-902055.0 aa06= 157773.0 aa07=-18150.0 aa08= 1320.0 aa09=-55.0 aa10= 1.0 r_f = 1000000 ji_su = 10 y_zoom = 0 #### Input End #### ksu=[] ksu.append( int((r_f**10)*aa00) ) ksu.append( int((r_f**9) *aa01) ) ksu.append( int((r_f**8) *aa02) ) ksu.append( int((r_f**7) *aa03) ) ksu.append( int((r_f**6) *aa04) ) ksu.append( int((r_f**5) *aa05) ) ksu.append( int((r_f**4) *aa06) ) ksu.append( int((r_f**3) *aa07) ) ksu.append( int((r_f**2) *aa08) ) ksu.append( int((r_f**1) *aa09) ) ksu.append( int((r_f**0) *aa10) ) initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 2 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)10000次方程式
eq-10000ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0.940 xx_to = 1.060 ksu_init = [] ksu_temp = 0.94999 for i in range(10000): ksu_temp += 0.00001 ksu_init.append(ksu_temp) r_f = 200000 ji_su = 10000 y_zoom = 2500 #### Input End #### initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 15 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom ksu=[] for i in range(len(ksu_init)): ksu.append( int(r_f*ksu_init[i]) ) p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") time.sleep(5) for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)最後までご覧いただき、ありがとうございました。
今回はQiitaの主旨に同意して投稿していますので、公開したプログラムはコピー、改変などでのご使用は自由です。著作権に関する問題も発生しません。
ただし、Raspberry Pi 4Bを使う場合にはCPUに特に大きめのヒートシンクが必須です。LAN通信の頻度の少ない今回のプログラムのような場合、LANチップは熱くなりません。しかし計算時間が継続するとCPUの激しい発熱で分かるように相当電力を使っています。電源UCB Cタイプの後ろにある黒い小さなチップも熱くなりますので、ファンでの風流も必要です。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
- 投稿日:2021-01-17T12:28:26+09:00
整数型で高次方程式を解く(重解なし) Manager編
Manager編
前回の整数型で高方程式を解くまで、並列処理部分はmultiprocessingのpoolを使ってきました。各プロセスが終了毎にランダムな順序でreturnされてきます。単に並列処理する場合はいいのですが、順序の並べ直しが必要で処理時間にロスがありました。そこで今回は、multiprocessingのmanagerを使ってプログラムを書き直しました。2度手間の並べ直しが無くなった分、計算時間は半分以下になりました。
前回の整数型で高方程式を解くの中で、10次方程式と10000次方程式のプログラムを書き直し、以下に示しました。Raspberry Pi 4Bのメモリー2Gの機種で、Raspberry Pi OS with DESKTOP(2020-DEC-02, 32bit版OS)のThonnyを使っています。USBにディスク等は接続していません。SwapはデフォルトのSDカード100MBです。
10次方程式
eq-10ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=0 for j in range(0, ji_su +1): Y += Ksu[j]*(X**j) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0 xx_to = 12 aa00= 3628800.0 aa01=-10628640.0 aa02= 12753576.0 aa03=-8409500.0 aa04= 3416930.0 aa05=-902055.0 aa06= 157773.0 aa07=-18150.0 aa08= 1320.0 aa09=-55.0 aa10= 1.0 r_f = 1000000 ji_su = 10 y_zoom = 0 #### Input End #### ksu=[] ksu.append( int((r_f**10)*aa00) ) ksu.append( int((r_f**9) *aa01) ) ksu.append( int((r_f**8) *aa02) ) ksu.append( int((r_f**7) *aa03) ) ksu.append( int((r_f**6) *aa04) ) ksu.append( int((r_f**5) *aa05) ) ksu.append( int((r_f**4) *aa06) ) ksu.append( int((r_f**3) *aa07) ) ksu.append( int((r_f**2) *aa08) ) ksu.append( int((r_f**1) *aa09) ) ksu.append( int((r_f**0) *aa10) ) initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 2 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)10000次方程式
eq-10000ji-int-manager.pyimport time from multiprocessing import Manager, Process def f0(list0, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list0.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list0.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f1(list1, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list1.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list1.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f2(list2, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list2.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list2.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) def f3(list3, r_f, ji_su, y_zoom, X_init, X_end, Ksu): Ypre=0 for X in range( int(X_init), int(X_end)+1 ): Y=1 for j in range( 0, 10000): Y *= (X-Ksu[j]) if X == int(X_init): Ypre=Y list3.pop(0) if Ypre * Y > 0: Ypre=Y else: if Y == 0: Y=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) else: Ypre=Y list3.append(( X/r_f, Y/(r_f**(ji_su-y_zoom)) )) if __name__=="__main__": with Manager() as manager: list0 = manager.list(range(1)) list1 = manager.list(range(1)) list2 = manager.list(range(1)) list3 = manager.list(range(1)) #### Input Start #### xx_from = 0.940 xx_to = 1.060 ksu_init = [] ksu_temp = 0.94999 for i in range(10000): ksu_temp += 0.00001 ksu_init.append(ksu_temp) r_f = 200000 ji_su = 10000 y_zoom = 2500 #### Input End #### initial_time=time.time() print(f"Calcilation Start") print(f" Please wait for 15 minutes.") Xfrom = int(r_f*xx_from) Xto = int(r_f*xx_to) Xrange = Xto - Xfrom ksu=[] for i in range(len(ksu_init)): ksu.append( int(r_f*ksu_init[i]) ) p0 = Process(target=f0, args=(list0,r_f,ji_su,y_zoom,Xfrom+0*Xrange/4,Xfrom+1*Xrange/4,ksu)) p0.start() p1 = Process(target=f1, args=(list1,r_f,ji_su,y_zoom,Xfrom+1*Xrange/4,Xfrom+2*Xrange/4,ksu)) p1.start() p2 = Process(target=f2, args=(list2,r_f,ji_su,y_zoom,Xfrom+2*Xrange/4,Xfrom+3*Xrange/4,ksu)) p2.start() p3 = Process(target=f3, args=(list3,r_f,ji_su,y_zoom,Xfrom+3*Xrange/4,Xfrom+4*Xrange/4,ksu)) p3.start() p0.join() p1.join() p2.join() p3.join() print(f"Calcilation Finished") print(f"") print(f"Time :") print(str(time.time() - initial_time)) print(f"Answers :") time.sleep(5) for i in range(len(list0)): print(list0[i]) for i in range(len(list1)): print(list1[i]) for i in range(len(list2)): print(list2[i]) for i in range(len(list3)): print(list3[i]) time.sleep(10)最後までご覧いただき、ありがとうございました。
今回はQiitaの主旨に同意して投稿していますので、公開したプログラムはコピー、改変などでのご使用は自由です。著作権に関する問題も発生しません。
ただし、Raspberry Pi 4Bを使う場合にはCPUに特に大きめのヒートシンクが必須です。LAN通信の頻度の少ない今回のプログラムのような場合、LANチップは熱くなりません。しかし計算時間が継続するとCPUの激しい発熱で分かるように相当電力を使っています。電源UCB Cタイプの後ろにある黒い小さなチップも熱くなりますので、ファンでの風流も必要です。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
- 投稿日:2021-01-17T11:03:56+09:00
3種類の文字だけで無限長さの「繰り返しのない文字列」を作れるか?【BFS】【DFS】
概要
「3種類の文字だけで無限長さの『繰り返しのないの文字列』を作れるか?」という問いについて考えました。(「繰り返し」は次節で説明するこの問題独自の定義です)
証明できていませんが、一定程度の長さ(10000)までは繰り返しのない数列が作れることをプログラムで確認しました。繰り返しのある/ない文字列
ある文字列のなかに同一の部分文字列(長さ1以上)が隣り合って存在しているとき、その文字列は繰り返しのある文字列であるとします。
繰り返しのある文字列の例を示します。(繰り返し部分を太字にしています)
- abcbca
- aab
- abcdefbcdbcdabcd
逆にある文字列が繰り返しのある文字列でない時、繰り返しのない文字列とします。繰り返しのない文字列の例を示します。
- aba
- abcbac
- abcdabce
同じ部分文字列が登場していても隣り合っていない場合は繰り返しのない文字列となることに注意してください。
使える文字の種類が限られるとき、繰り返しのない文字列はどのくらいの長さまで作れるか?
使える文字が1種類のとき
使える文字列が1種類(例えば"a")のとき、繰り返しのない文字列は何文字の長さまで作ることができるでしょうか?
長さ1のとき、以下のように繰り返しのない文字列を作ることができます
- a
長さが2のとき、繰り返しのない文字列を作ることはできません。具体的には、1種類の文字を使って作れる長さ2の文字列は"aa"のみですが、これは繰り返しのある文字列です。
よって、使える文字が1種類のとき、繰り返しのない文字列を作れる最大長さは1です。
使える文字が2種類のとき
使える文字列が2種類(例えば"a","b")のとき、繰り返しのない文字列は何文字の長さまで作ることができるでしょうか?
長さ1のとき、以下のように繰り返しのない文字列を作ることができます。
- a
長さ2のとき、以下のように繰り返しのない文字列を作ることができます。
- ab
長さ3のとき、以下のように繰り返しのない文字列を作ることができます。
- aba
長さ4のとき、繰り返しのない文字列を作ることはできません。具体的には2種類の文字で作れる長さ4の文字列は"aaaa","aaab","aaba","aabb","abaa","abab","abba","abbb"および、これの"a"と"b"を入れ替えたものですが、これらはすべて繰り返しを含みます。
よって、使える文字が2種類のとき、繰り返しのない文字列を作れる最大長さは3です。
使える文字が3種類のとき
使える文字列が3種類(例えば"a","b","c")のとき、繰り返しのない文字列は何文字の長さまで作ることができるでしょうか?
地道に手を動かしてみると、少なくとも長さ10までは以下のように繰り返しのない文字列を作れることがわかります。
長さ 繰り返しのない文字列の例 1 a 2 ab 3 aba 4 abac 5 abacb 6 abacba 7 abacbab 8 abacbabc 9 abacbabca 10 abacbabcab なんだかこの調子でいくらでも長く、繰り返しのない文字列を作れそうです。
本当でしょうか? 以下、3種類の文字が使える場合についてもう少し考えてみます。文字列長を固定したときに繰り返しのない文字列を何通り作れるか
3種類の文字が使えるときに繰り返しのない文字列を無限に作れるか?という問いの答えを直接的に証明することは難しかったです。(有名な問題だったりするのでしょうか? だれか知っていたら教えてほしいです)
そこで、とりあえず文字列長Lのときに、繰り返しのない文字列が何通り作れるか調べてグラフを書いてみることにしました。繰り返しのある文字列の判定
準備として、ある文字列が繰り返しを含むかどうかを判定する関数を作ります。
pythonの場合、隣り合う同じ長さの部分文字列は整数$i,j$を用いて、
text[j:j+i], text[j+i:j+2*i]のように書けます。
ただし、$i$は部分文字列の長さ、$j$は一番左の文字のindexを0としたときの左側の部分文字列の開始位置のindexです。
あとは$i,j$の取りうる範囲をループで回して、この部分文字列の異同を判定すればよいです。
与えられた文字列の長さをLとすると、$i,j$の取りうる範囲は
$1\leq i \leq L/2$
$0\leq j \leq L-2i$
です。
$i,j$をこれらの範囲で動かして、text[j:j+i]とtext[j+i:j+2*i]を比較すれば、ある文字列が繰り返しを含むかどうかがわかります。#textが繰り返しを含むときTrueを返し、含まないときFalseを返す def is_repeat(text): for i in range(1,len(text)//2+1): for j in range(len(text)-2*i+1): if text[j:j+i]==text[j+i:j+2*i]: #print(j,j+i,text[j:j+i]) return True return Falseただ、上記関数の計算量はざっくり$O(L^2)$で、ちょっと多いです。
文字列Aが繰り返しのない文字列であるとき、Aの端に一文字足したA'の繰り返し判定は、少ない計算量で行えます。足した1文字を含む部分文字列についてだけ検討すれば良いので、計算量は$O(L)$です。
def is_added_text_repeat(text,char): text = char + text for i in range(1,len(text)//2+1): if text[:i]==text[i:2*i]: return True return False次小節で説明するように、繰り返しのない文字列を生成するときには、既知の繰り返しのない文字列に1文字ずつ足すという操作をするので、こちらの判定方法が使えます。
1文字ずつ追加しながら繰り返しのない文字列かどうかを判定する
文字列長Lと繰り返しのない文字列の個数の関係を調べるために、繰り返しのない文字列を総当りで作っていきます。
これは既知の繰り返しのない文字列の端(プログラムでは先頭)に、1文字足したものが、繰り返しを含むかどうかを調べる、ということを順次行うことで達成されます。(1度繰り返しが生じると、以降何文字足しても繰り返しを含むままなので、繰り返しのある文字列に1文字足したものを考える必要はありません)Lが少ないものから優先的に生成したいので、幅優先探索で実装します。
また、初期値は"ab"に固定しており、文字の入れ替えによる重複を無視しています(つまり実際の個数はこれの6倍です)。from collections import deque #lengthの長さまでの繰り返しのない文字列の個数を出力する def without_repeat_text_bfs(length): unit = ["a","b","c"] q = deque(["ab"]) cnt = {2:1} prev = "ab" while q: tmp = q.popleft() if len(tmp) > len(prev): print(len(prev),cnt.get(len(prev),0)) prev = tmp if len(prev) >= length: continue for u in unit: if prev[0] == u: continue if is_added_text_repeat(prev,u): continue l = len(prev)+1 cnt[l] = cnt.get(l,0)+1 q.append(u+prev) print(length, cnt.get(length,0))出力は下記のような感じです。
>>>without_repeat_text_bfs(55) 2 1 3 2 4 3 5 5 6 7 7 10 8 13 9 18 10 24 ...L=55までの繰り返しのない文字列の個数をグラフにしたものが以下です。
なんか指数関数っぽいので縦軸の対数をとってみました。
ほぼ直線になったのでどうやら指数関数的に増加するようです。
これがどこかで急に0になるということは考えにくいので、Lがどんなに大きくても、繰り返しのない文字列を作ることができそうです(証明されたわけではありません)。繰り返しのない文字列が作れることを何文字まで確定できるか?
無限に作れそうだ、とはいってもL=55までだとさすがに少ない気がするので、もう少し大きいLまで、少なくとも1つは繰り返しのない文字列があることを確認しようと思います。
前節の関数で、個数を愚直に求めると計算時間がかかりすぎるのですが、少なくとも1個見つけるだけであれば、深さ優先探索によって、もう少し効率的に計算できそうです。def without_repeat_text_dfs(length): unit = ["a","b","c"] q = deque(["ab"]) prev = "" while q and len(prev) < length: prev = q.pop() for u in unit: if prev[0] == u: continue if is_added_text_repeat(prev,u) == False: if len(u+prev) >= length: return u+prev q.append(u+prev)上記関数を使って調べた結果、L=10000までは繰り返しのない文字列が見つかることを確認できました。
おわりに
繰り返しのある(ない)文字列というものを定義して、使える文字の種類が限られるときに、繰り返しのない文字列がどのくらいの長さまで作れるかを検証しました。
使える文字の種類が1種類、2種類のときは有限長さまでしか作れませんでした。3種類のときは、証明はできませんでしたが、グラフの形状から無限長さまで作れそうだということが推測できました。また、少なくとも長さ10000以下のときは繰り返しのない文字列が存在することが確かめられました。
(推測が正しいとして)1種類、2種類では有限なのに3種類になった瞬間に急に無限に発散するというのはちょっと興味深いです。あらゆる地図が4色あれば隣接する領域が同じ色にならないように塗り分けられるという、四色定理というものがありますが、関係していたりするのでしょうか?(単純に四色定理の1次元版、ということではないですが)。 というかすでに証明済みの問題だったりするのでしょうか? もしわかる方いたら情報いただけると嬉しいです。
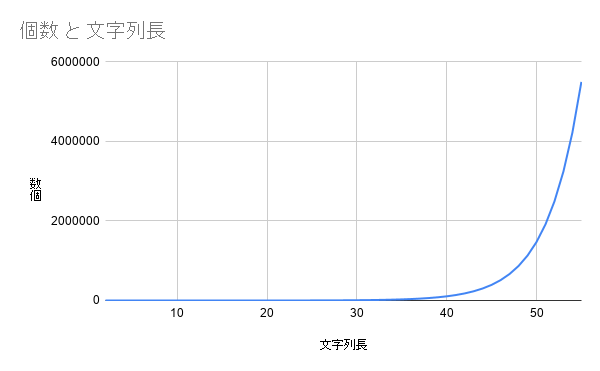
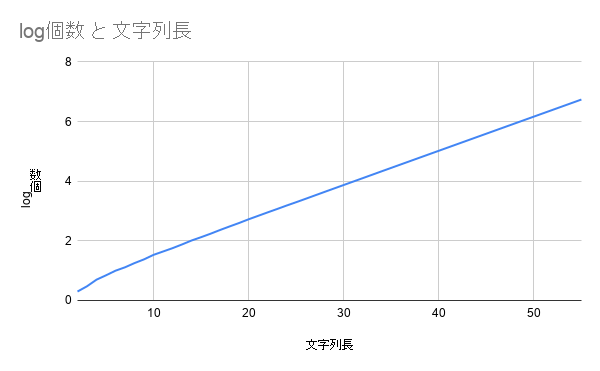
- 投稿日:2021-01-17T10:44:24+09:00
VBAユーザがPython・Rを使ってみた:条件分岐
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
条件分岐
条件分岐(主に、If文)についてです。
Python
Python3x = 0 if x == 0: print(0) # 0 if x == 0: print(0) else: print(1) # 0 if x == 0: print(0) elif x == 1: print(1) elif x == 2: print(2) else: print(3) # 0 if x in (0,1,2): print(x) else: print(3) # 0Pythonにはswitch文、case文はなさそうです。
なお、Pythonでは、If文のまとまり(ブロック)を(次のRのように{}で囲んだり、VBAのようにIfではじまってEnd Ifで閉じたり、というような方法ではなく)インデント(字下げ)で表現します(If文に限らず、他の制御構文(繰り返しのFor文)でも同様です。)。R
Rx <- 0 if (x == 0) { print(0) } # 0 if (x == 0) { print(0) } else { print(1) } # 0 if (x == 0) { print(0) } else if (x == 1) { print(1) } else if (x == 2) { print(2) } else { print(3) } # 0 if (x %in% c(0,1,2)) { print(x) } else { print(3) }Rには、
switch関数がありますが、使いづらそうです(参考:R-Tips)。VBA
VBAx = 0 If x = 0 Then Debug.Print 0 End If ' 0 If x = 0 Then Debug.Print 0 Else Debug.Print 1 End If ' 0 If x = 0 Then Debug.Print 0 ElseIf x = 1 Then Debug.Print 1 ElseIf x = 2 Then Debug.Print 2 Else Debug.Print 3 End If ' 0 Select Case x Case 0 Debug.Print 0 Case 1 Debug.Print 1 Case 2 Debug.Print 2 Case Else Debug.Print 3 End Select ' 0 Select Case x Case 0, 1, 2 Debug.Print x Case Else Debug.Print 3 End Select ' 0 Select Case x Case 0 To 2 Debug.Print x Case Else Debug.Print 3 End Select '0 Select Case x Case Is <= 2 Debug.Print x Case Else Debug.Print 3 End Select ' 0 Debug.Print Switch(x = 0, 0) ' 0 Debug.Print Switch(x = 0, 0, 1, 1) ' 0 Debug.Print Switch(x = 0, 0, 1, 1, 2, 2) ' 0VBAにはSelect Case文があります。Switch関数もあります。
まとめ
一覧
各言語で使用する演算子等を一覧にまとめます。比較のために、EXCELでの計算も示しました。
条件分岐
Python R VBA EXCEL If文 if P:
...elif Q:
...elif R:
...else:
...if (P) {
...} else if (Q) {
...} else if (R) {
...} else {
...}If P Then
...ElseIf Q Then
...ElseIf R Then
...Else
...End If=IF(P,...,IF(Q,...,IF(R,...,...)))Switch文 Select Case XCase p
...Case q
...Case r
...Case Else
...End Select=SWITCH(X,p,...,q,...,r,...,...)プログラム全体
参考までに使ったプログラムの全体を示します。
Python
Python3# 条件分岐 x = 0 if x == 0: print(0) # 0 if x == 0: print(0) else: print(1) # 0 if x == 0: print(0) elif x == 1: print(1) elif x == 2: print(2) else: print(3) # 0 if x in (0,1,2): print(x) else: print(3) # 0R
R# 条件分岐(If) x <- 0 if (x == 0) { print(0) } # 0 if (x == 0) { print(0) } else { print(1) } # 0 if (x == 0) { print(0) } else if (x == 1) { print(1) } else if (x == 2) { print(2) } else { print(3) } # 0 if (x %in% c(0,1,2)) { print(x) } else { print(3) } # 0VBA
VBASub test_conditional_branch() Dim x As Integer ' 条件分岐 x = 0 If x = 0 Then Debug.Print 0 End If ' 0 If x = 0 Then Debug.Print 0 Else Debug.Print 1 End If ' 0 If x = 0 Then Debug.Print 0 ElseIf x = 1 Then Debug.Print 1 ElseIf x = 2 Then Debug.Print 2 Else Debug.Print 3 End If ' 0 Select Case x Case 0 Debug.Print 0 Case 1 Debug.Print 1 Case 2 Debug.Print 2 Case Else Debug.Print 3 End Select ' 0 Select Case x Case 0, 1, 2 Debug.Print x Case Else Debug.Print 3 End Select ' 0 Select Case x Case 0 To 2 Debug.Print x Case Else Debug.Print 3 End Select '0 Select Case x Case Is <= 2 Debug.Print x Case Else Debug.Print 3 End Select ' 0 Debug.Print Switch(x = 0, 0) ' 0 Debug.Print Switch(x = 0, 0, 1, 1) ' 0 Debug.Print Switch(x = 0, 0, 1, 1, 2, 2) ' 0 End Sub参考
- 投稿日:2021-01-17T10:43:19+09:00
PocketSphinxのPythonパッケージの扱いに苦戦した話
PocketSphinxとは
PocketSphinxは連続音声認識を行う音声認識エンジンです。
英語しか対応していないので、日本語には向かないようです。
(強引に対応させる手があるようですが、話が脱線するので割愛します。。。)実行環境
今回は以下の環境で動作確認を行いました。
- Windows10
- Anaconda(Python 3.7.9)
パッケージインストール
pip install pocketsphinxで終わり、とはならないです。。。
PocketSphinxをインストールするには、swigとBuild Tool(C++)が必要になります。swigはこちらを参考にインストールできました。
Build Toolはこちらからダウンロードできます。準備ができたら、pipでPocketSphinxをインストールします。
pip install pocketsphinxサンプルコード実行
PocketSphinxのサンプルコードは以下のようになっています。
この通り実行すると、英単語を検知してくれます。sample.pyimport os from pocketsphinx import LiveSpeech, get_model_path model_path = get_model_path() speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'en-us'), lm=os.path.join(model_path, 'en-us.lm.bin'), dic=os.path.join(model_path, 'cmudict-en-us.dict') ) for phrase in speech: print(phrase)LiveSpeechのデフォルト値は以下のようになっているそうです。
verbose = False logfn = /dev/null or nul audio_file = site-packages/pocketsphinx/data/goforward.raw audio_device = None sampling_rate = 16000 buffer_size = 2048 no_search = False full_utt = False hmm = site-packages/pocketsphinx/model/en-us lm = site-packages/pocketsphinx/model/en-us.lm.bin dict = site-packages/pocketsphinx/model/cmudict-en-us.dict参照先ディレクトリの理解
PocketSphinxでは、このようなエラーが出る事象が発生しました。
この事象の原因を整理していきます。RuntimeError: new_Decoder returned -1hmm / lm / dictで使用している
model_pathは以下のように設定しています。model_path = get_model_path()このパスをprintしてみるとこのようになります。
C:\Users\<UserName>\.conda\envs\pocketsphinx\lib\site-packages\pocketsphinx\model(pocketsphinx) C:\Users\<UserName>\.conda\envs\pocketsphinx\Lib\site-packages\pocketsphinx\model>tree /f C:. │ cmudict-en-us.dict │ en-us.lm.bin │ └─en-us feat.params mdef means noisedict README sendump transition_matrices variancesどうやら、pipでインストールしたパッケージの中にデフォルトの辞書データ諸々が含まれているようです。
このパスが間違っているとRuntimeErrorが発生するようです。余談
このエラーの話は検索すると情報があるのですが、わざわざen-usをダウンロードするように書かれていたり、
そもそも、エラーが回避できていないコードがあったりしました。
(極めつけは、そもそもPythonとして、パスの置換に失敗しているコードも出てきました。。。)
当初、自分もパスの確認を怠ったのもあり、ますます謎が深くなった事象でした。自作辞書データの適用
今回はこのようなディレクトリ構成になっています。
model\sample.dictが自作辞書データです。(pocketsphinx) C:\Users\<UserName>\Documents\pocketsphinx_sample>tree /f C:. │ exmaple.py └─model sample.dict次に、LiveSpeechの引数を見ると、以下の引数を設定すればよさそうです。
lmについては、Falseを設定する方法もドキュメントに記載されていますが、何故かRuntimeErrorになるので、対象としています。hmm=os.path.join(model_path, 'en-us'), lm=os.path.join(model_path, 'en-us.lm.bin'), dic=os.path.join(model_path, 'cmudict-en-us.dict')exmaple.pyimport os from pocketsphinx import LiveSpeech, get_model_path model_path = get_model_path() my_model_path = 'C:\\Users\\<UserName>\\Documents\\pocketsphinx_sample\\model' speech = LiveSpeech( hmm=os.path.join(model_path, 'en-us'), lm=os.path.join(model_path, 'en-us.lm.bin'), dic=os.path.join(my_model_path, 'sample.dict'), ) for phrase in speech: print(phrase)残った疑問点
自分の目的としては辞書データを読み込んでくれればよいので、これで目的は達成できました。
しかし、lm=Falseでエラーになる原因が不明な状態なままです。
また、gram(文法ファイル)を読み込ませるjsgfという引数を書いているサンプルコードも見られましたが、
PocketSphinxのGithubでコードを確認しても、そのような引数はなさそうでした。
文法ファイルの読み込み方も今後必要になれば確認が必要です。参考
http://rinatz.github.io/swigdoc/install.html
https://pypi.org/project/pocketsphinx/
https://visualstudio.microsoft.com/ja/thank-you-downloading-visual-studio/?sku=BuildTools
https://stackoverflow.com/questions/44339312/new-decoder-returned-1-when-trying-to-run-pocketsphinx-on-raspberry-pi/51346264#51346264