- 投稿日:2021-01-17T23:57:19+09:00
VPCと周辺知識についてまとめてみた
※ 現在学習中で間違った内容を記載している可能性が大いにあります。もし間違いがありましたら、遠慮なくご指摘くださいませ。
VPCとは?
AWS アカウント内の仮想ネットワーク環境。1 アカウント、1 リージョンに 5 つまで VPC を作成可能。VPC 内部ではさらに細かくネットワークを分けて(サブネット)運用する。使用できるアドレスの範囲は/16~/28 となっている。つまり、第 3 オクテットと第 4 オクテットのはじめの 4 桁は自由に使える。
サブネットとは?
VPC 内部にさらにネットワークを細かく分ける。具台的には、災害などで一つの AZ がダメになっても、他の AZ に分けておくことができれば対応できる。そのため、サブネットを同じ構成で複数の AZ に冗長的に設置する。また、サブネットは AZ を跨いで作成することはできない。
パブリックサブネット
- インターネット接続可(デフォルトゲートウェイにインターネット接続が設定されている)
- 外部に公開しても良いインスタンス
プライベートサブネット
- インターネット接続不可(デフォルトゲートウェイにインターネット接続が設定されていない)
- 外部に公開できないインスタンス(RDS などのデータベース)
ルートテーブルとは?
サブネットに関連付けて使用するもので、サブネットから外に出る通信をどこ(ターゲットで表記)に向けて発信するか決めるルール。
- ターゲットが local な場合はその VPC 内全てに接続できる
- ターゲットが InternetGateway は外部に向けて接続できる/される
インターネットゲートウェイとは(IGW)?
VPC 内の AWS リソース(EC2 など)とインターネットを繋げるもの。AWS 側が負荷分散などを自動でスケールしてくれるので、可用性が高い。
- 使い方
- サブネットのルートテーブルのターゲットに設定して使用する。
NATgateway とは?
プライベートサブネットからインターネット接続したい時に使用する。ただし、アウトバウンドはできるが、インバウンドはできない。(発信はできるが受信はできない)ちなみに、パブリックサブネットはデフォルトでインターネット接続が設定されているが、プライベートサブネットはデフォルトでインターネット接続が設定されていない。また、インターネットゲートウェイと同様に負荷が高まると自動で負荷分散してくれる。
使い方
- プライベートサブネットのルートテーブルのターゲットに設定して使用する。(NATゲートウェイはプライベートIPをEIPに変換してインターネットゲートウェイに接続する)そのため、パブリックサブネットにアタッチする必要がある。
ENI とは?
仮想ネットワークインターフェイス(NIC)のこと。そもそも NIC とは...
- 有線の LAN ケーブルを挿す場所のようなイメージ
- インターフェイス=接点なので、パソコンがインターネット接続するための接点というイメージ(結構曖昧...)
それが仮想化されていて、それぞれ EC2 などにアタッチされており、IP アドレスを割り当てている。一つのインスタンスに複数の ENI を割り当てて IP を複数保持し、一つのインスタンスで複数サイトを運用したりもできる。ENI と IGW が繋がることで、インターネット接続可能となる
パブリック IP、EIP とは?
外部のリソース同士が接続するためには、パブリック IP か EIP が必要。パブリック IP は、サブネットの設定で、パブリック IP の自動割当を有効にしていれば、インスタンス作成時に自動で割り当てられる。ただし、停止 → 起動で毎回パブリック IP が変わるので、EIP を設定することで、IP アドレス を固定できる。
ちなみに EC2 はプライベート IP で内部のインスタンスと接続し、パブリック IP で外部のインターネットなどと接続できる。
- 使い方
- EIPをEC2などのインスタンスに紐付けることで使用できる。
セキュリティグループとは?
AWS の仮想ファイアーウォールサービスのことで、EC2 レベルで設定できる。(厳密には EC2 の ENI 単位らしい)ホワイトリスト型で(許可したもの以外は受け付けない)、インバウンドとアウトバウンドの設定ができる。ステートフル型なので、戻りの通信許可設定は必要ない。
ネットワーク ACL とは?
サブネット単位で設定するファイアーウォールのこと。ブラックリスト型でデフォルトでは、インバウンドもアウトバウンドも全て許可されているので、許可したくないものを設定する。ステートレス型なので、戻りの通信も許可する必要がある。(外部からの攻撃があった場合などに、EC2 単位でなくサブネット単位で IP を指定してブロックしたりする時に使う)
- 投稿日:2021-01-17T23:41:26+09:00
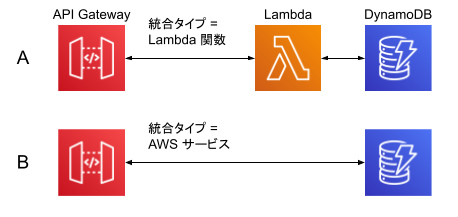
Amazon API GatewayのAWS 統合を使い、AWS Lambdaを通さずにAmazon DynamoDBへアクセスする
Amazon API Gateway の「AWS 統合(AWS integration)」を使うことで、下の図のBのようにAWS Lambdaを通さずAmazon DynamoDBにアクセスができます。
これにより、例えば DynamoDB の中にあるItemをGET /items/IDのように読み出す程度の実装を、素早く行うことが可能です。「Lambda 統合」を利用した場合のPros/Cons
Amazon API Gateway から Amazon DynamoDB 等の AWS サービスへのアクセスで利用されるパターンが、AWS Lambdaを経由する「Lambda プロキシ統合(Lambda proxy integration)」でしょう。構成は先の図のAになり、API Gatewayの設定では「統合タイプ = Lambda関数」を使用します。
クライアントからのリクエストや、呼び出し先AWSサービスからのレスポンスの加工をプログラムできるので便利ですが、管理対象が一つ増えるわけです。
API Gateway の "マッピングテンプレート"
API Gateway の AWS 統合を設定すると、「統合リクエスト」内の "マッピングテンプレート" で作ったJSONをAWSサービスのAPIに投げ込むことができます。また、AWSサービスからのレスポンスJSONを「統合レスポンス」で受けて、"マッピングテンプレート" で整形し直すことができます。
即ち、この "マッピングテンプレート" でLambdaで書くような変換実装ができるわけです。
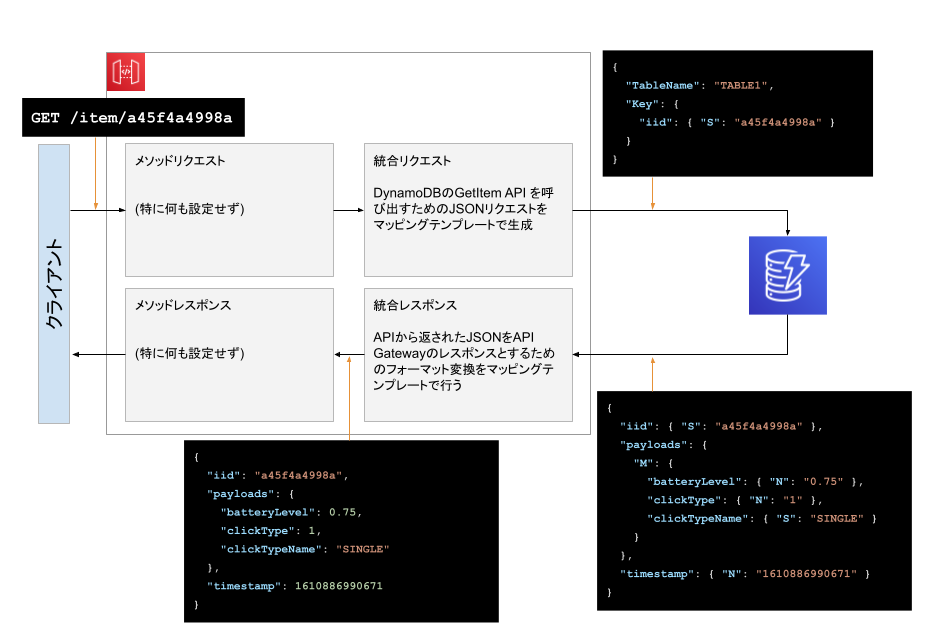
DynamoDB の GetItem を API Gateway で実装する
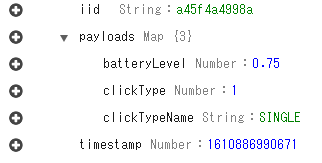
今回は DynamoDBの
TABLE1に以下のようなデータが入っているとして、これをGET /items/{iid}で値を取得するようにします。
DynamoDB JSON 形式で表示
{ "iid": { "S": "a45f4a4998a" }, "payloads": { "M": { "batteryLevel": { "N": "0.75" }, "clickType": { "N": "1" }, "clickTypeName": { "S": "SINGLE" } } }, "timestamp": { "N": "1610886990671" } }全体の流れ
API Gateway リソースの作成
GET /items/{iid}を作り、パス名をこの後のマッピングテンプレートで参照できるようにします。
GET メソッドのセットアップ
項目 設定内容 統合タイプ AWS サービス AWS リージョン (DynamoDBのあるリージョン) AWS サービス DynamoDB AWS サブドメイン <空> HTTP メソッド POST アクションの種類 アクション名の使用 アクション GetItem実行ロール (後述で作成したロールのARN) コンテンツの処理 パススルー デフォルトタイムアウトの使用 チェックをつける ここでのポイントはアクションの GetItem と HTTP メソッドの POST です。これらの情報は API リファレンスから得ることができます。
アクションは API 名になります。HTTP メソッドは当該の API リファレンスを参照することで得られますが、一番手っ取り早いのは Examples を見る事です。例えば DynamoDB の GetItem の Examples を見れば HTTP メソッドがPOSTであることが判明します。ロールの作成
後日、改めて詳細。ポイントだけ。
- 信頼されたエンティティのID プロバイダーを
apigateway.amazonaws.com- ポリシーでAmazon DynamoDB の GetItem に Allow されていること
統合リクエストの設定
統合リクエストでは、クライアントからのリクエストをDynamoDBのGetItem APIリクエストに変換します。
マッピングテンプレートで以下のように設定します。
項目 設定内容 リクエスト本文のパススルー なし マッピングテンプレートの追加で Content-Type に
application/jsonを入力、その後表示されるテキストエリアに以下を入力して保存します。マッピングテンプレート{ "TableName": "TABLE1", "Key": { "iid": { "S": "$input.params('iid')" } } }これは先ほど設定した「アクション(= API)」のリクエストボディです。
そのため、例えば Scanなら、以下のような形になります。Scanの場合{ "TableName": "TABLE1", "Limit": 10 }マッピングテンプレートの開発TIPS
マッピングテンプレートには、テンプレートエンジンであるApache Velocityが利用されています。それに加えて、API Gatewayで独自に設定されている変数を組み合わせてJSONを構築していきます。
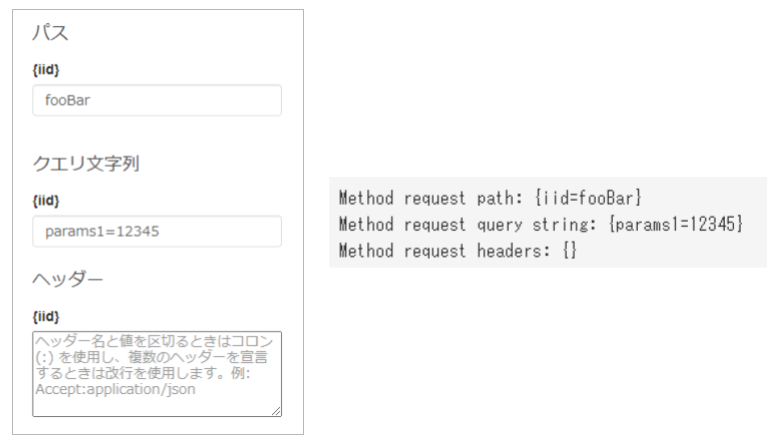
クライアントからのリクエストの中身を見る方法は「テスト」を利用します。以下のように入力をしてテストをすると "Method request" に値が表示されます。これをマッピングテンプレートで読み出します。
読み出し方は$input.params('NAME')です。パスとQueryStringとで名前が競合した場合はパス側が優先されます。詳しくは $input変数を参照ください。
DynamoDB 内に Item が存在していれば、テスト結果は以下のようになります。
ここまでくれば、リクエスト側は完了です。
統合レスポンスの設定
統合レスポンスでは、DynamoDBからのレスポンスをクライアントに返すための整形を行います。
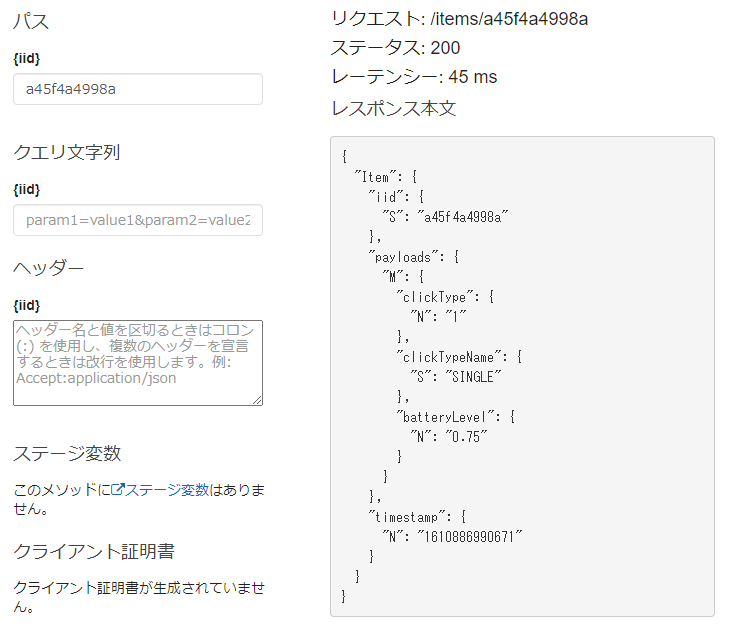
統合レスポンスを開くとすでに "メソッドレスポンスのステータス" = 200 の行があるので、その行を開いた後にマッピングテンプレートを開きます。その中の application/json をクリックすると表示されるテキストエリアに以下を入力して保存します。
マッピングテンプレート{ "iid": "$input.path('$').Item.iid.S", "timestamp": $input.path('$').Item.timestamp.N "payloads": { "clickType": $input.path('$').Item.payloads.M.clickType.N, "clickTypeName": "$input.path('$').Item.payloads.M.clickTypeName.S", "batteryLevel": $input.path('$').Item.payloads.M.batteryLevel.N, } }この状態でテストすると、レスポンス本文が以下のように変化します。今までは何も入力しない = DynamoDB からのレスポンスをパススルーしていたのが、マッピングテンプレートによって整形されたわけです。
統合レスポンスにおける
$input統合レスポンスでの
$inputは、DynamoDB からのレスポンスです。$input.path('$')とすれば、それ以降はJSONのパスを直接指定できます。何度も書くのは面倒なのでApache Velocity(VTL; Velocity Template Language)の set を使って、変数に入れることができます。
setで簡略化#set($inputRoot = $input.path('$')) { "iid": "$inputRoot.Item.iid.S", "timestamp": $inputRoot.Item.timestamp.N "payloads": { "clickType": $inputRoot.Item.payloads.M.clickType.N, "clickTypeName": "$inputRoot.Item.payloads.M.clickTypeName.S", "batteryLevel": $inputRoot.Item.payloads.M.batteryLevel.N, } }繰り返しには foreach を使う方法もあります。VLTとAPI Gatewayの変数リファレンスを見ながら、サンプルを見ることで理解が深まるかと思います。
VLTの if で 404 対応をしてみる
このマッピングテンプレートだと Item が存在しなかった場合、以下のようにキーだけが存在するJSONとなってしまうため、返す内容を変更します。
404対応マッピングテンプレート#if($input.path('$') == "{}") {} #set($context.responseOverride.status = 404) #else { "iid": "$input.path('$').Item.iid.S", "timestamp": $input.path('$').Item.timestamp.N "payloads": { "clickType": $input.path('$').Item.payloads.M.clickType.N, "clickTypeName": "$input.path('$').Item.payloads.M.clickTypeName.S", "batteryLevel": $input.path('$').Item.payloads.M.batteryLevel.N, } } #endItemが存在しなかった場合、DynamoDBからは
{}という文字が送られてきます。これを if で判定し、{}であれば、改めて{}という文字を返し、同時に HTTP レスポンスコードも 404 に変更しています。テストしてみるとレスポンス本文は
{}で、HTTP レスポンスコード(ステータス)も404となりました。
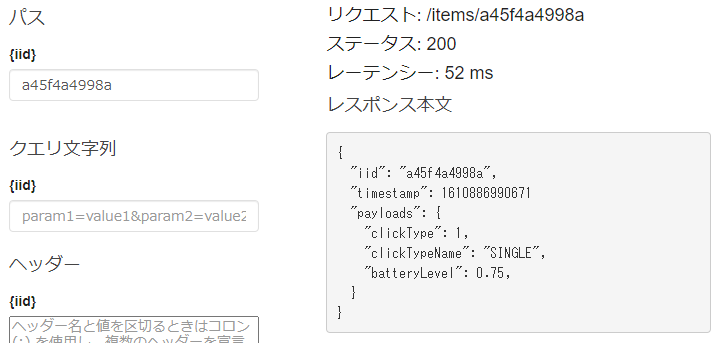
curl からの実行例
デプロイ後にcurlからは以下のように実行できるようになります。
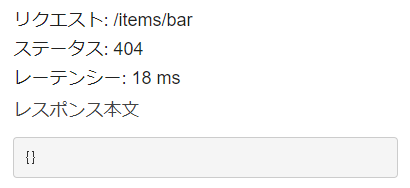
$ curl -v https://XXXXX.execute-api.REGION.amazonaws.com/prod/items/a45f4a4998a < HTTP/2 200 { "iid": "a45f4a4998a", "timestamp": 1610886990671 "payloads": { "clickType": 1, "clickTypeName": "SINGLE", "batteryLevel": 0.75, } } $ curl -v https://XXXXX.execute-api.REGION.amazonaws.com/prod/items/bar < HTTP/2 404 {}まとめと、この後
クライアントからのリクエスト、そして、AWSサービスからのレスポンスが単純であればLambdaを使わずともAPI化が可能です。DynamoDBを例として挙げましたが、基本的にはどのサービスでも対応可能です。
一方で、例えば処理中に他の情報を参照したり、複雑な変換をする場合はLambda統合が有利にもなるため、両方を試しておいて目的に応じて使い分けましょう。Lambda統合への切り替えも容易ですので、API化の第一歩として知っておいて損は無いのではないでしょうか。
アクセス制御を忘れずに
今後ですが、このままですとAPIエンドポイントが無防備です。API Gateway での REST API へのアクセスの制御と管理に沿って、いずれかのアクセス制御を行いましょう。
参考資料
- Developers.IO / Amazon API Gateway で AWS Service Proxy を使って DynamoDB にアクセスする
- Amazon API Gateway 開発者ガイド / API Gateway マッピングテンプレートとアクセスのログ記録の変数リファレンス
- Apache Velocity / Velocity User Guide (VLT)
EoT

- 投稿日:2021-01-17T23:27:22+09:00
AWS Lightsail 入門4 基本設定(CentOS 7)
本記事の内容
- Lightsailインスタンス(CentOS 7)に対して、OSの基本設定を行う。
前提条件
- Lightsailインスタンス(CentOS 7)を作成済み。
※他のOS・バージョンでは、コマンドが異なる場合があります。
作業の進め方
ブラウザ版ターミナルか、SSHクライアントでコマンドを入力していく。
次の例では、コマンド
cat /etc/redhat-releaseを入力し、OSのバージョンを確認している。$ cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)※入力するコマンドには、プロンプト
$を含めない。管理者(root)への切替
本記事で入力するコマンドは、管理者権限が必要なものが多い。
最初にrootに切り替えておく。(末尾のハイフンを忘れずに)$ sudo su -管理者権限が必要なコマンドは、プロンプトを
#で表記する。スワップ領域の追加
Lightsailの最安プラン(3.5ドル)はメモリが512MBと少ない。
メモリが不足してもプログラムを実行できるよう、スワップ領域を追加する。※SSDをメモリの代わりに使うので、速度的には遅くなる。
本設定はメモリが一時的に不足したときのためのエラー防止策で、日常的に不足するならメモリ量が十分な上位プランを選択した方が良い。スワップ領域の確認(追加前)
$ free -h total used free shared buff/cache available Mem: 485M 98M 260M 8.4M 126M 365M Swap: 0B 0B 0BSwapの[total]が0Bとなっており、スワップ領域が割り当てられていない。
スワップファイルの作成・有効化
ディスク上に1GBのスワップファイルを作成し、有効化する。
※複数のコマンドを1行にまとめているので、コピー漏れに注意。# dd if=/dev/zero of=/swapfile bs=1M count=1024 && chmod 600 /swapfile && mkswap /swapfile && swapon /swapfile1GB以外で作成する場合は
count=nを変更する。例えばcount=2048では、2GBになる。※スワップのサイズを増やせばメモリ不足のリスクは減るが、ファイル保存先として使えるディスク容量は少なくなる。
Lightsail最安プランのディスクは20GBなので、バランスを考えて設定する。スワップ領域の確認(追加後)
$ free -h total used free shared buff/cache available Mem: 485M 96M 6.0M 8.4M 382M 367M Swap: 1.0G 0B 1.0GOS起動時の自動マウント設定
OS起動時、自動的にスワップ領域が有効化されるようにする。
# echo "/swapfile swap swap defaults 0 0" >> /etc/fstabパッケージの更新
導入済みのパッケージを更新する。
内容を確認しながら進める場合は、オプション-yを外す。# yum -y update最後に「Complete!」と出力されれば更新完了。
念のため、更新可能なパッケージが残っていないか確認する。$ yum check-update Loaded plugins: fastestmirror Determining fastest mirrors * base: d36uatko69830t.cloudfront.net * extras: d36uatko69830t.cloudfront.net * updates: d36uatko69830t.cloudfront.netOSの再起動
パッケージの更新を確実に反映するため、Lightsail管理画面よりインスタンスを再起動する。
コマンド
sudo rebootで再起動しても問題なかったが、EC2ではOSコマンド以外の方法が推奨されている。インスタンスからオペレーティングシステムの再起動コマンドを実行する代わりに、Amazon EC2 コンソール、コマンドラインツール、または Amazon EC2 API を使用してインスタンスを再起動することをお勧めします。Amazon EC2 コンソール、コマンドラインツール、または Amazon EC2 API を使用してインスタンスを再起動する場合、インスタンスが数分以内に完全にシャットダウンしないと、ハードリブートが実行されます。
インスタンスの再起動 - Amazon Elastic Compute Cloud
Lightsailは管理画面での手順のみで、コマンドによる再起動については言及されていなかった。
Amazon Lightsail インスタンスの開始、停止、または再起動 | Lightsail ドキュメントタイムゾーンの変更
デフォルトは時刻がUTCで表示されるため、日本時間に変更する。
時刻の確認(変更前)
$ date Sun Jan 17 10:42:45 UTC 2021日本時間に変更
# timedatectl set-timezone Asia/Tokyo時刻の確認(変更後)
$ date Sun Jan 17 19:42:52 JST 2021まとめ
Lightsailの最安プランで、CentOSを使用する場合の基本設定を紹介した。
特に、メモリは512MBと少ないので、スワップ領域の追加は忘れずに行っておきたい。
- 投稿日:2021-01-17T22:12:20+09:00
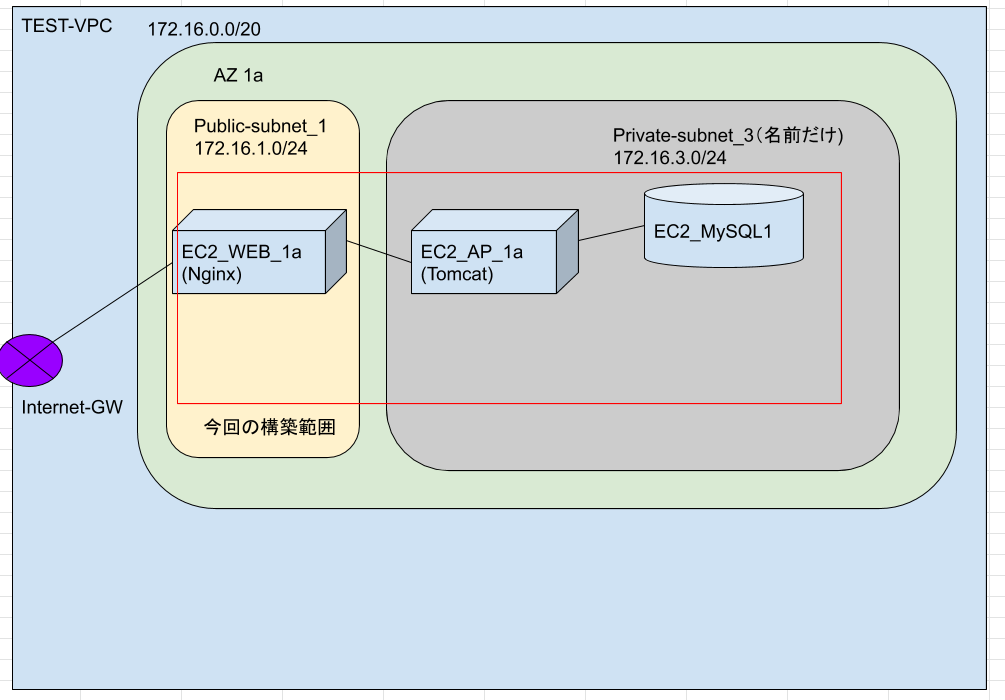
AWS_WEB3層環境構築②
前回の記事
https://qiita.com/shinichi_yoshioka/items/7226b9ebaad06c569c80
前回の続きをやっていく。
APサーバとDBサーバはプライベートサブネットに構築する。
プライベートサブネット配置のEC2インスタンス作成にあたって、
"パブリックIP自動割り当てを無効"にしたが
TomcatやMySQLをインストールするのに一時的にインターネットに繋ぎたい。
そもそもプライベートサブネット配置のEC2インスタンスにssh接続できなくて詰んでいる。
対処法を調べたところ、3通りぐらい把握した。
①ElasticIP(EIP)を一時的に割り当て →これは実質パブリックサブネットと変わらない。
②前回構築したWEBサーバを踏み台としてアクセスする →SSH接続はできるが、TomcatやMySQLをインストールするのに面倒。
③NATゲートウェイをパブリックサブネットに配置する →これが一番良いやり方。ちなみにNATゲートウェイの料金は、東京リージョンで1hあたり0.062USDらしい。
https://aws.amazon.com/jp/vpc/pricing/
施行錯誤の環境構築で時間がかかると思ったので、今回はEIPを使い、一時的にパブリック化する方法を選んだ。
(2台目のDBサーバを構築する際は、NATゲートウェイを使おうと思う)
EIPはAWSアドレスプールから払い出される固定のパブリックIPのこと。
セキュリティグループも一時的に開けないとダメだし、ルートテーブルもインターネットゲートウェイへ向ける。
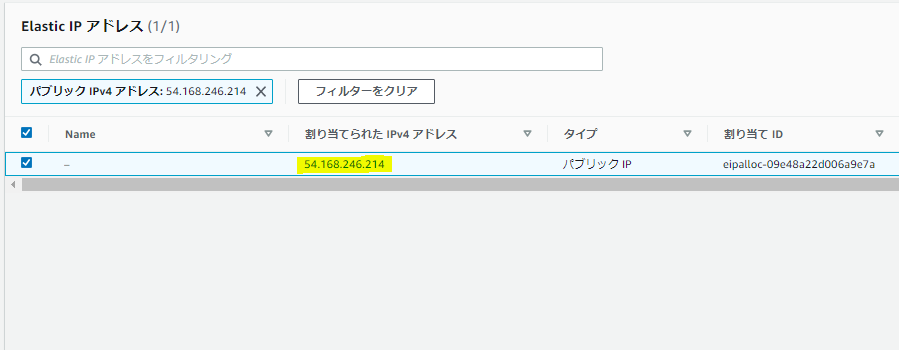
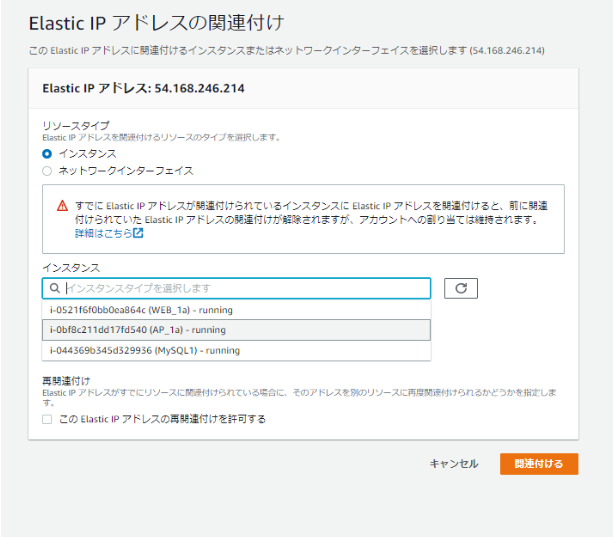
構築が落ち着いたら、封鎖するので許してほしい。◆EIPの作成とアタッチ
サービス[VPC]のElasticIPから[Elastic IPアドレスの割り当て]から、
AmazonのIPv4アドレスプールから割り当てを行う。
割り当てられたアドレスをクリックすると、EC2インスタンスに関連付けできる。
ちなみにEIPはEC2インスタンスにアタッチ中は課金されないが、
EIPの払い出しだけしていてEC2にアタッチされていないと課金されるらしい。
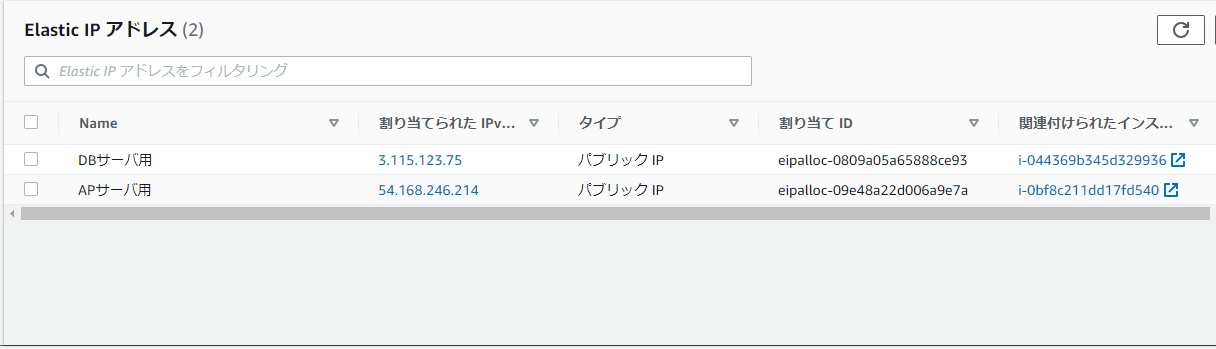
ここでは、APサーバとDBサーバそれぞれにEIPを割り当てる。
こんな感じ。
とりあえず、各EC2インスタンスにSSH接続できることは確認した。
AP/DBサーバの構築後処理は以下。
①EIPをデタッチし、EIPを解放
②ルートテーブルからインターネットゲートウェイを削除し、最低限に絞る
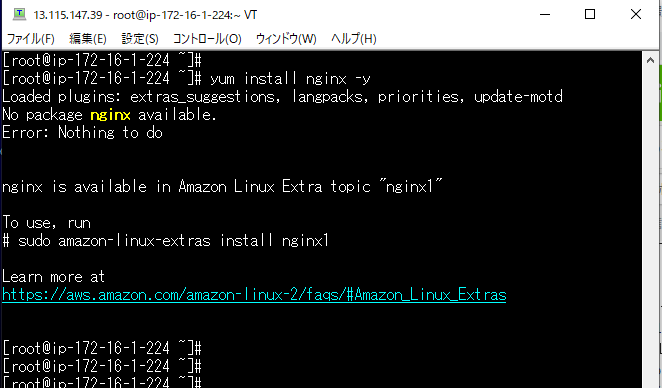
③セキュリティグループを必要なプロトコルのみに絞る◆Nginxのインストール
対象:WEBサーバ
sudo su -
yum update -y
yum install nginx -y
ここでエラーが。
どうやら、AmazonLinuxはインストール方法が違うらしい。
以下コマンドでインストールが開始されたことを確認した。
amazon-linux-extras install nginx1 -y
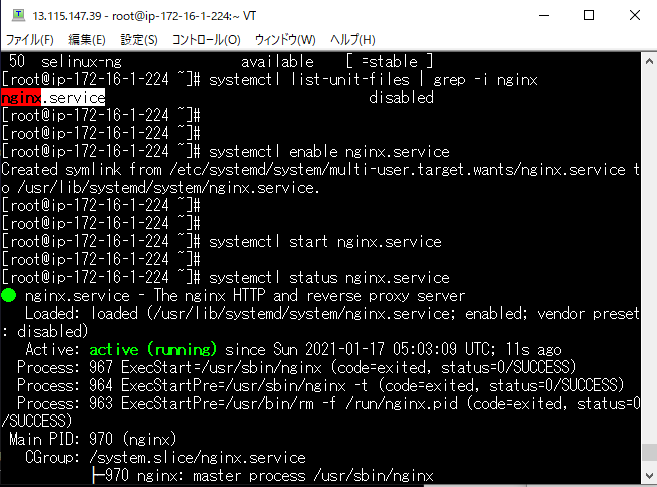
Nginxの自動起動を有効化にし、サービスを起動。
ステータスがactive(running)になっていることを確認した。
systemctl enable nginx.service
systemctl start nginx.service
systemctl status nginx.service
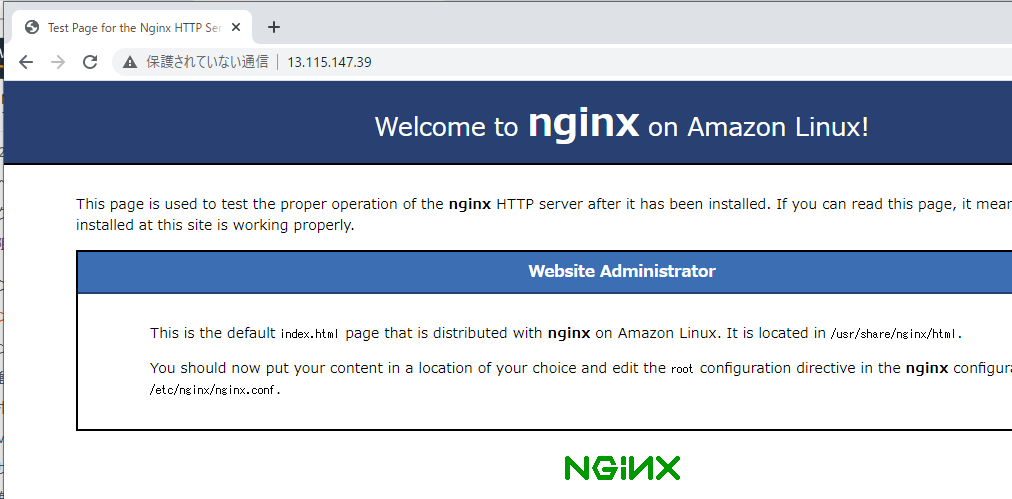
ブラウザに以下のように入力し、Nginxのテストページが表示されることを確認した。
http://WEBサーバのパブリックアドレス◆Tomcatのインストール
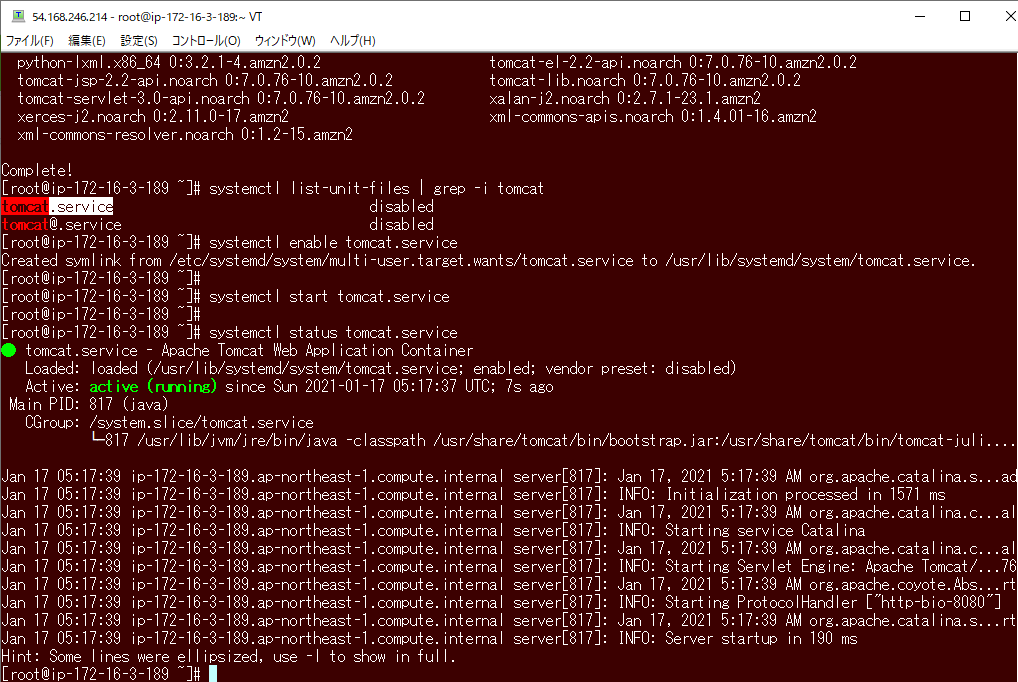
対象:APサーバ
sudo su -
yum update -y
yum install tomcat -y
systemctl enable tomcat.service
systemctl start tomcat.service
systemctl status tomcat.service
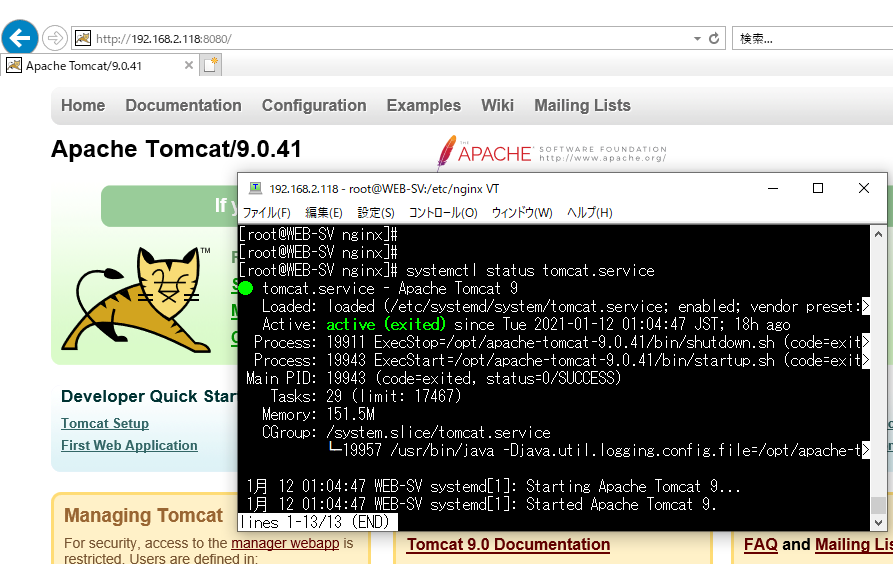
tomcatのサービスは正常に動いているが、Web App Containerとしての正常性確認のやり方が不明(調べ中)
過去に自宅VirtualBoxにTomcatを入れて正常性確認をしたが、これはApache Tomcat(WEBサーバ)であって
上記のWeb App Containerとは違う認識。
◆MySQLのインストール
対象:DBサーバ
sudo su -
yum update -y
yum install mysql -y
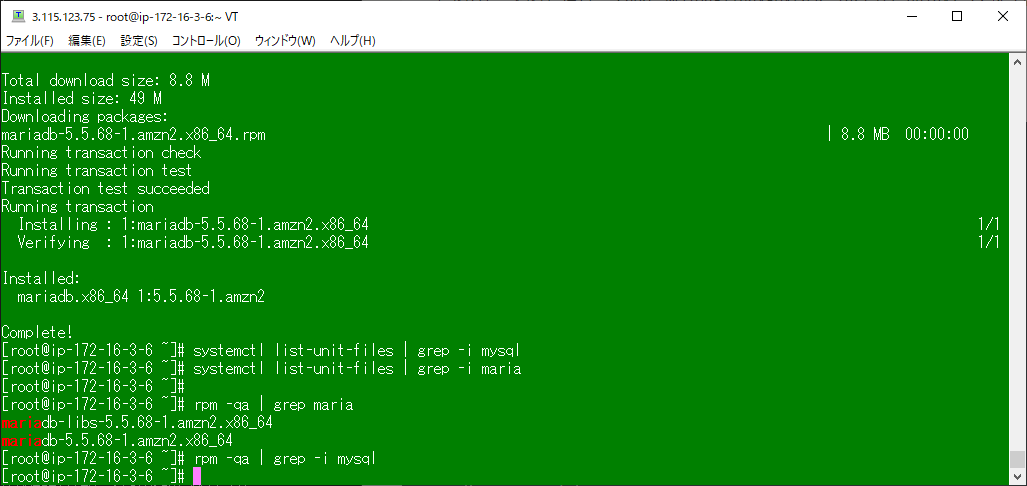
Mysqlをインストールしようとしたら、MariaDBが入ったのだが・・・。
他のEC2インスタンスを確認したところ、Amazon Linuxにはデフォルトでmariadb-libs-5.5.68-1.amzn2.x86_64が入っていて
MySQL互換のMariaDBをインストールしてしまった。
MySQLとMariaDBで競合をおこさないようにアンインストールしておく。
yum remove mariadb-libs -y
rpm -qa | grep -i maria
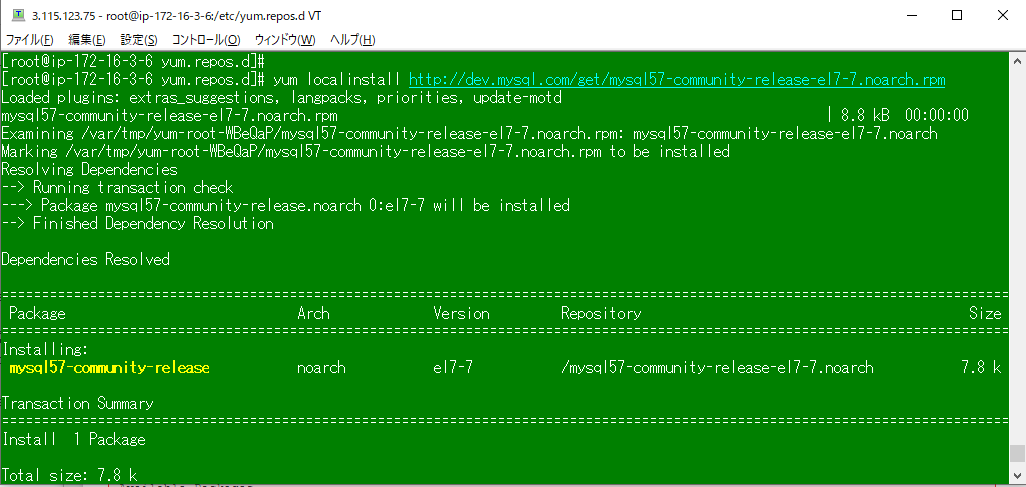
何も表示されないことを確認した。次にMySQLをyumでインストールするため、MySQL公式のリポジトリを追加した。
yum localinstall http://dev.mysql.com/get/mysql57-community-release-el7-7.noarch.rpm -y
yum info mysql-community-server
にて、MySQLのyumリポジトリ追加を確認。
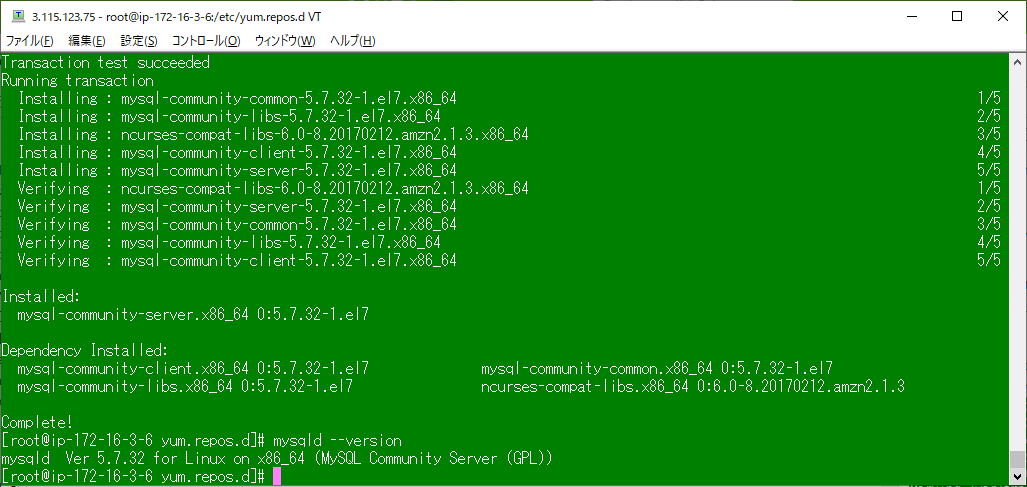
yum -y install mysql-community-server
mysqld --version
にてMySQLのインストールを確認。
他のサービスと同様にmysqld.serviceが正常に動いていることを確認した。
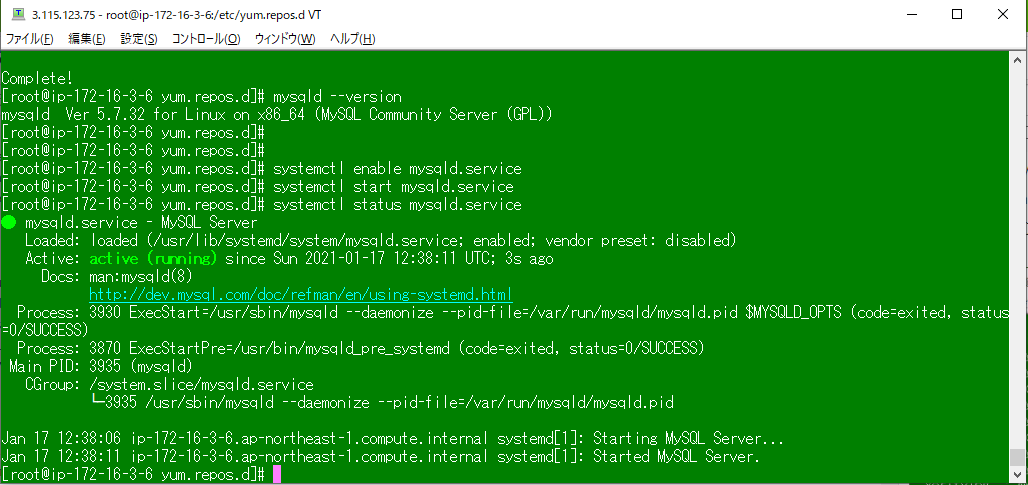
systemctl enable mysqld.service
systemctl start mysqld.service
systemctl status mysqld.service
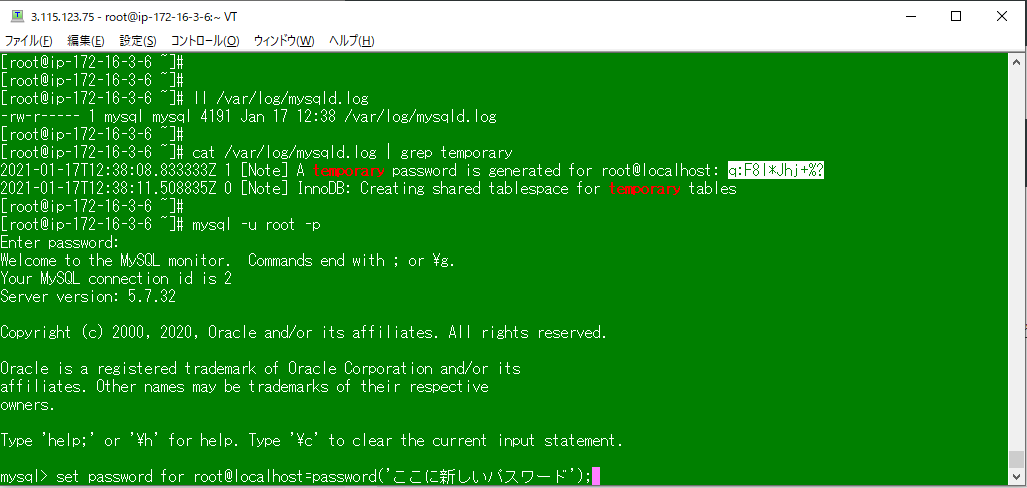
MySQLのrootユーザの初期パスワードは、/var/log/mysqld.logに記載されている。
cat /var/log/mysqld.log | grep temporary
一時的なパスワードなので、rootユーザにログイン後に任意のパスワードに変える。
mysql -u root -p
白塗りの一時パスワードを入力し、rootユーザにログイン。
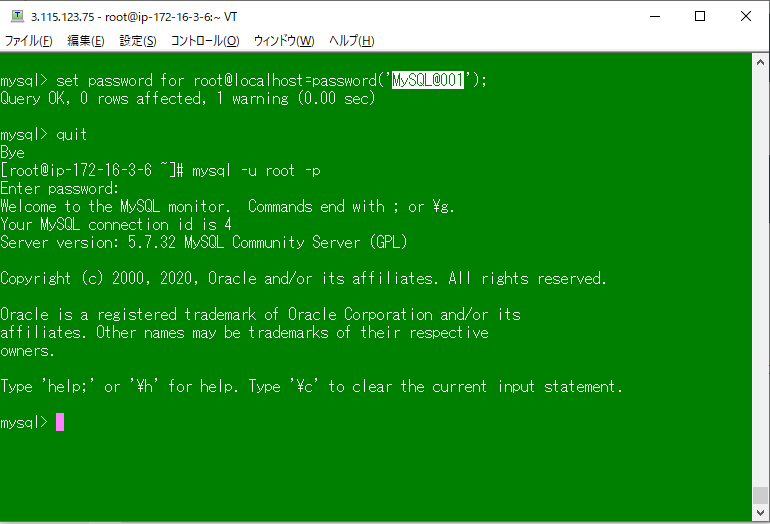
set password for root@localhost=password('ここに新しいパスワード');
Query OKと出れば変更完了だが、初期のパスワードポリシーが結構厳しめで
パスワードは大文字・小文字・数字・記号とかにしないとはじかれると思う。
パスワード変更後はいったんMySQLから抜けて、新パスワードでログインできることを確認した。
長くなってしまったので、第2回はここまで。
久々に有意義な休日を過ごせたと思う。(いつもはゲームして、YouTube見て、見てるうちに寝ちゃって1日終わる)
次回は、APサーバにMySQLドライバーを入れて、WEBサーバとAPサーバとDBサーバを連携したい。
イメージでは、WEBサーバのnginx.confにリバースプロキシの設定を入れて、
Tomcatのserver.xmlにDBサーバのアドレスを記載すれば
連携できるのではないかと思っている。
正直ここから先は何もわかっていないので、次回の記事は結構先になりそうだ。
- 投稿日:2021-01-17T20:54:35+09:00
【AWSデプロイ】S3設定にてExcon::Error::Forbiddenエラーが発生する
はじめに
Railsでポートフォリオ作成しAWSにてデプロイ後、S3を使って画像をアップロードする設定を行っていましたが、本番環境にてS3にアップロードされない事態が発生。
環境
・Rails 6.0.0
・Ruby 2.6.5
・Unicorn 5.4.1状況
S3の設定をおこない、ローカル環境で無事にS3にアップロードされたことを確認。
本番環境の環境変数をevnに設定してデプロイをおこなったが
画像投稿を行ってもS3にアップロードされなかった。問題解決のために行ったこと
まずはどのようなエラーが起こっているか確認するため
config/environments/production.rb
を
config.consider_all_requests_local = true
に変更。
これにより、ローカルの時のようにエラー文が画面に表示されるようになります。するとExcon::Error::Forbiddenというエラーが発生していることが判明。
どうやら環境変数の設定がうまくいっていないよう・・・sudo vim /etc/environmentにて入力内容を確認
ターミナルAWS_ACCESS_KEY_ID='#####アクセスキー######' AWS_SECRET_ACCESS_KEY='##########シークレットアクセスキー##########'入力ミスはしていなさそう・・・
env | grep AWSで確認
ターミナルenv | grep AWS AWS_ACCESS_KEY_ID=#####アクセスキー###### AWS_SECRET_ACCESS_KEY=##########シークレットアクセスキー##########'あれ??
シークレットアクセスキーの最後に’がついている・・?なんで?もう一度sudo vim /etc/environmentで丁寧に確認してみると・・
ターミナルAWS_ACCESS_KEY_ID='#####アクセスキー######' AWS_SECRET_ACCESS_KEY='##########シークレットアクセスキー##########'図で表現できませんが、
AWS_SECRET_ACCESS_KEY='##########シークレットアクセスキー##########'の最後に
スペースが一つ入っていました・・・AWS_SECRET_ACCESS_KEY='##########シークレットアクセスキー##########' を
AWS_SECRET_ACCESS_KEY='##########シークレットアクセスキー##########'に直す。変更を反映させるために一度ログアウトし入り直す。
env | grep AWSで確認
ターミナルenv | grep AWS AWS_ACCESS_KEY_ID=#####アクセスキー###### AWS_SECRET_ACCESS_KEY=##########シークレットアクセスキー##########これでもう一度画像投稿を行ったところ、
無事S3にアップロードされました。さいごに
スペース一つに数日間悩まされました。
ネットで同じような事例がなく、かなり遠回りをしたので
同じような状況で苦しんでいる人の助けになればと思い投稿しました。
- 投稿日:2021-01-17T20:50:54+09:00
AWSのインスタンスタイプ(TとかGとか)の意味まとめ
EC2 Instance Types (主要メンバー)
R
- RAMのR インメモリキャッシュがたくさん要るアプリケーションならこれ!
C
- CPUのC 演算処理、DB用でCPUがほしいならこれ!
M
- mediumのM 中間の性能 通常のappはこれでおけ!
I
- I/OのI DBの性能がほしいならこれ!
G
- GPUのG 動画像処理や機械学習するならこれ!
T2/T3
- burst可能なインスタンス! 上限あり
T2/T3 unlimited
- 無限にburst可能! 料金に注意!!
Ultimate AWS Certified Solutions Architect Associate 2021
https://www.udemy.com/course/aws-certified-solutions-architect-associate-saa-c02/
- 投稿日:2021-01-17T20:35:12+09:00
ワンランク上のTerraform使いになるための小技
前提
AWSをTerraformで構成する場合、を前提とした小技を記述します。
リモートステート
何も設定せずにTerraformをデプロイすると、ローカルに
tfstateファイルが生成されます。
tfstateはデプロイしたクラウドの実リソースの構成情報が記述されています。この手のファイルはプライベートに扱うべきで、Gitで管理するべきではありません。また、複数人でTerraformを管理する場合、このtfstateを複数の作業PCで共有する必要があります。
そこで、クラウド上にリモートステートとしてアップロードし、必要に応じて管理する。という方法が推奨されています。
具体的にはAWS S3がよく利用されます。
また、DynamoDBを追加することで、複数人での同時書き込みによる競合の発生を防ぐこともできます。terraform { backend "s3" { bucket = "tfstate" key = "terraform.tfstate" region = "ap-northeast-1" } }Data Only Module
モジュールは複数のリソースで構成される機能を1つにまとめておくものですが、リソースを含めない用途があります。
Data Only Module では指定した条件(tags="staging"を持つaws_vpc,aws_subnet)に合致するリソースを参照し、出力値としてvpcのidを持つモジュールを定義します。
これにより、柔軟なモジュール実装を可能にします
例では Tags にマッチするものを参照していますが、
他に aws_vpc では state を参照することで、available なVPCのみを参照したりできます。
また、リモートステートやリテラルで参照も可能です。DataOnlyModuleを定義data "aws_vpc" "main" { tags = { Environment = "Staging" } } data "aws_subnet" "main" { tags = { Environment = "Staging" } } output "vpc_id" { id = data.aws_vpc.main.id }https://www.terraform.io/docs/modules/composition.html#data-only-modules
SSMパラメータストア
AWSのSSMパラメータストアを利用することでプロジェクトやリソースをまたいだグローバル変数を扱えます。
SSMパラメータストアへ代入resource "aws_ssm_parameter" "main" { name = "/dev/network/cidrblock" value = aws_vpc.main.cidrblock type = "String" }SSMパラメータストアから参照data "aws_ssm_parameter" "cidr" { name = "/dev/network/cidrblock" } resource "aws_vpc" "main" { cidr_block = data.aws_ssm_parameter.cidr.value tags = { Name = "test" } }Count引数
リソースに対し
count引数を与えると、与えた数だけ同じリソースが作成されます。
作成する数に応じて一部パラメータを変える必要があるときはcount.indexを参照。リソースを3つ複製resource "aws_vpc" "main" { count = 3 cidr_block = "10.${count.index}.0.0/16" }また、三項演算子と
countを組み合わせることでリソースの作成の可否を制御できます。
terraform:リソースの作成を制御
resource "aws_vpc" "main" {
count = var.create_vpc ? 1:0
cidr_block = "10.0.0.0/16"
}
組み込み関数
Terraformには様々な組み込み関数が用意されています。利用するうえで動作を確認したい場合
terraform consoleで対話式に動作を確認できます。マルチリージョン
複数のリージョンでリソースを作成する際に、デフォルトのリージョンと明示的に指定した場合のリージョンを設定することができます。
以下ではデフォルトがap-northeast-1で明示的にvirginiaを指定するとus-east-1に作成されますリージョンを定義provider "aws" { alias = "virginia" region = "us-east-1" } provider "aws" { region = "ap-north-east" }リージョンを参照resource "aws_vpc" "at_virginia" { provider = "aws.virginia" cidr_block = "10.0.0.0/16" } resource "aws_vpc" "at_tokyo" { cidr_block = "10.0.0.0/16" }
- 投稿日:2021-01-17T19:12:10+09:00
なぜサーバーレスアーキテクチャを選んだか(AWS Lambdaアプリケーション)
背景
自社新システムの開発のバックエンドを担当することになった際にサーバーレスアーキテクチャを選定したので、メリット・デメリットなどを合わせてなぜサーバーレスアーキテクチャにしたのか書きたいと思います。
前提
クラウドはAWSを利用しているのでAWS Lambdaを使用する前提です。
また、言語はRuby(2.5系)を使用しています。サーバーレス(AWS Lambda)のメリット・デメリット
メリット
- インフラ構築の工数が削減できる
- サーバーを管理する必要がないのでEC2インスタンスの構成などを考えること自体が不要です。(※VPCは設定できます)
- アプリケーションエンジニアがシステムの大部分を管理できます。
- 自動スケーリング
- 水平にスケーリングするため、パフォーマンスを維持できます。
- メモリ圧迫により「サーバー落ち」が起きて再起動するまで利用できなくなるなどの心配がありません。
- 従量課金制
- リクエストに比例して課金されるため、システムを使わない間は課金されません。
- 耐障害性
- AWS Lambdaは各リージョンの複数のアベイラビリティーゾーンで管理されるため信頼性が高いです。
デメリット
- サーバーレスの経験を持っている人材が比較的少ない印象のため、属人化する可能性があります。
- デフォルトだとエラーログがcloudwatch Logs頼みになってしまいます。
- クラウドベンダーに依存しやすいです。
- AWSからGCPへの移行などがしづらい印象があります。
今回は利用するユーザが限定的かつ小規模な社内システムのため従量課金の方が金額的に妥当であり、
障害対応のリスクが少ない、AWS Lambdaを積極的に利用してきた、属人化はドキュメントを残すことで回避できる、などの理由からサーバーレス構成に決定しました。AWS Lambdaとは
FaaS(Function as a Service)の代表格とも言えます。
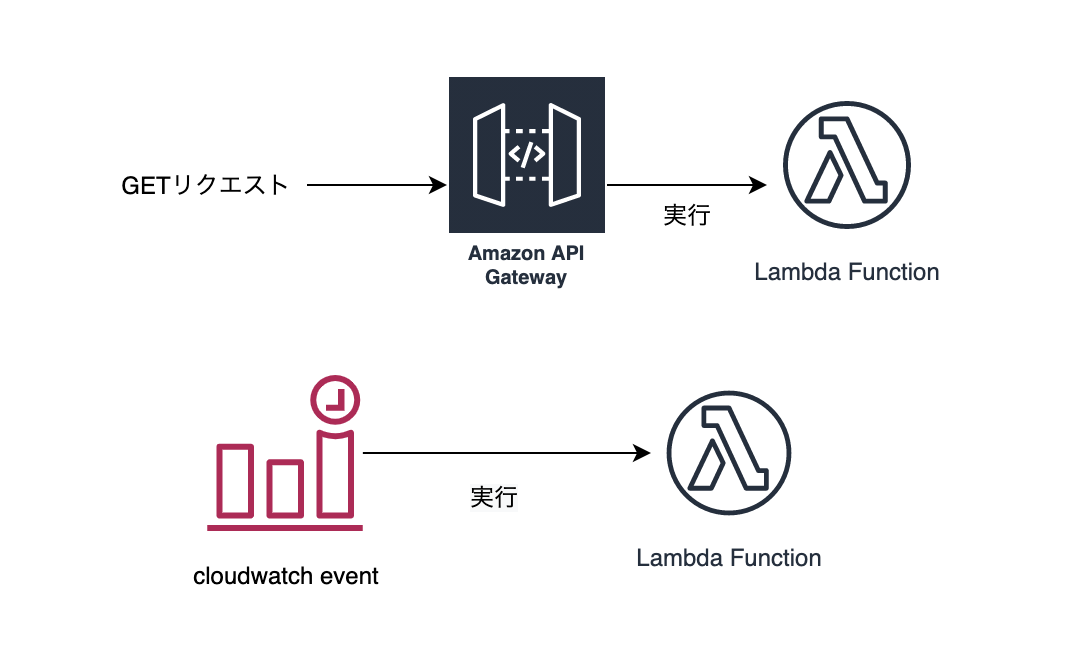
責務は「イベントに応じて関数を実行する」だけなのでサーバの管理が不要なのが特徴です。
サーバーレスと謳っていますが、あくまで管理不要というだけで裏ではコンテナが立ち上がっていて、そのコンテナ上で関数が実行されます。API Gatewayをイベントトリガーに設定すればREST APIを構築したりできます。
関数単体でも使用できますし、アプリケーションとしても構築できます。
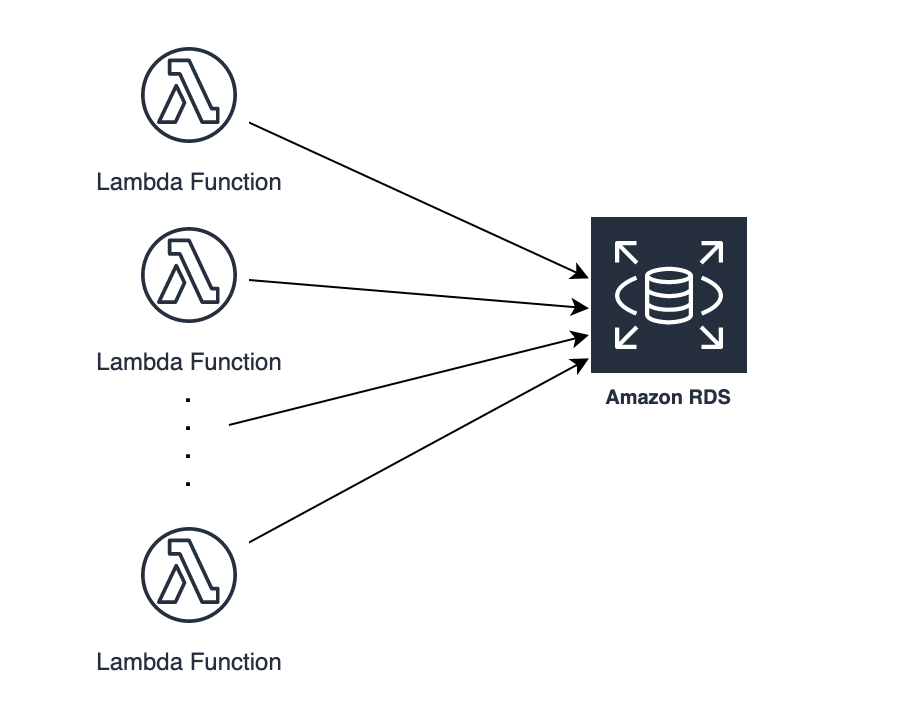
AWS Lambda × RDS
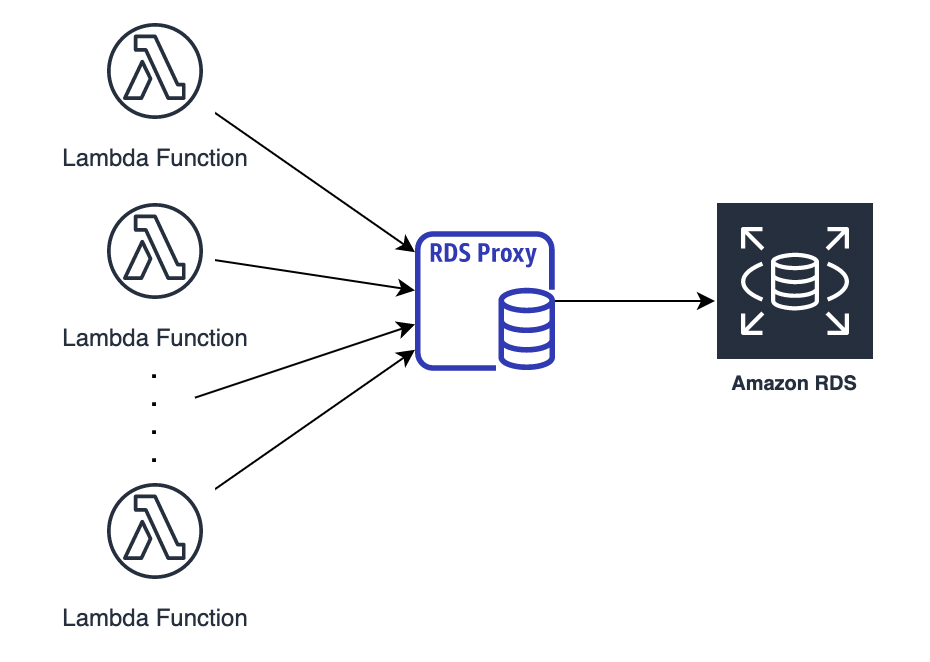
アンチパターンであったRDSとの組み合わせもRDS Proxyがリリースされたことで解消されました。
lambdaはリクエスト毎にコンテナを立ち上げるため、アプリケーションで直接RDSにコネクションを貼ってしまうと、例えば1000リクエスト同時に来たとすると1000コネクションを貼ることになります。
これだとDBのメモリがコネクション過多により不足してしまうので、RDSproxyを経由してコネクションをプーリングすることで大量アクセスによるDBのコネクション負荷を抑えることができます。
今回のシステムではこのRDS Proxyを使用しています。
Ruby on Jets
AWS Lambdaによるアーキテクチャのメリットやデメリットが分かったので、次はアプリケーションのフレームワークを探してみました。
弊社ではRubyonRailsが馴染み深いため、「Railsライク」なフレームワークを探していたところ、RubyonJetsというフレームワークを見つけました。そこでgithubのスター数、最終更新日、トレンド性、ドキュメントの充実性を加味して決定しました。
Ruby on Jetsの特徴
使ってみてわかったのが本当にRailsライクで、Railsを書いている感覚でアプリケーションが作成できます。
以下に特徴を挙げます。
routes.rbに定義したもの→API Gatewayで定義- controllerのアクション毎に関数が作成されます
- IAMロール、ポリシー、VPC、メモリ割当、タイムアウト時間、同時実行数などの設定をconfig/application.rbで管理できます
- ORMがActiveRecord
- ActiveSupportやActiveModelのメソッドを使用可能
- ローカルではjets serverコマンドでpumaを立ち上げて動作確認できます
また、嬉しかった点としてはstaging環境やその他のテスト環境を簡単に作成できることです。
環境を作成するというよりかは関数を複製するイメージに近いのでproductionとかなり近い環境を作成することができます。
具体的にはJETS_ENVという環境変数をstagingやproductionに変えるだけで環境の作成と切り替えが可能です。まとめ
小規模なアプリケーションにAWS lambdaはとても有効だと思います。
フレームワークを探していてRuby on Railsに慣れているという方には、Ruby on Jetsがおすすめです。Ruby on Jetsのdocker-composeでの環境構築からデプロイまでをまとめたのでリンクを貼っておきます。
参考
- 投稿日:2021-01-17T18:33:07+09:00
CloudEndure Disaster Recoveryの利用方法紹介
CloudEndure Disaster Recoveryの紹介
今回はCloudEndure Disaster Recoveryについて、ご紹介させていただきます。
CloudEndureは2018年末にAWS社が買収されました。CloudEndure Disaster Recoveryはサービス名のとおり災害対策を目的にしたソリューションです。
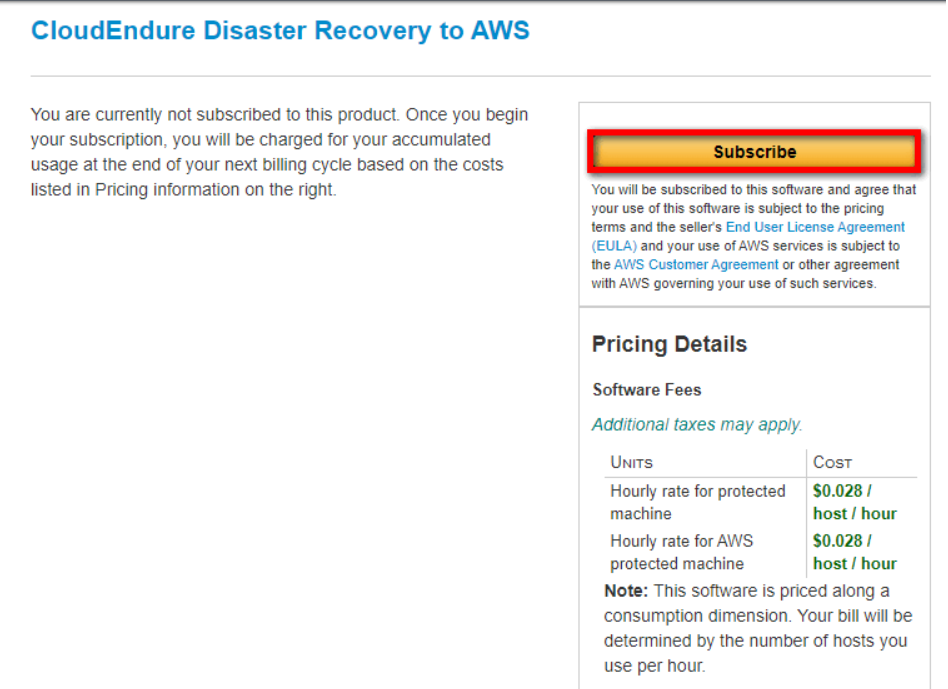
参考紹介ページ:CloudEndure Disaster Recovery実際の料金:CloudEndure Disaster Recovery自体の料金はレプリケーション対象EC2が1台につき0.028USD/時間の従量課金(1ヶ月20USD程度)になっております。
*Reference: https://aws.amazon.com/jp/cloudendure-disaster-recovery/pricing/構築手順
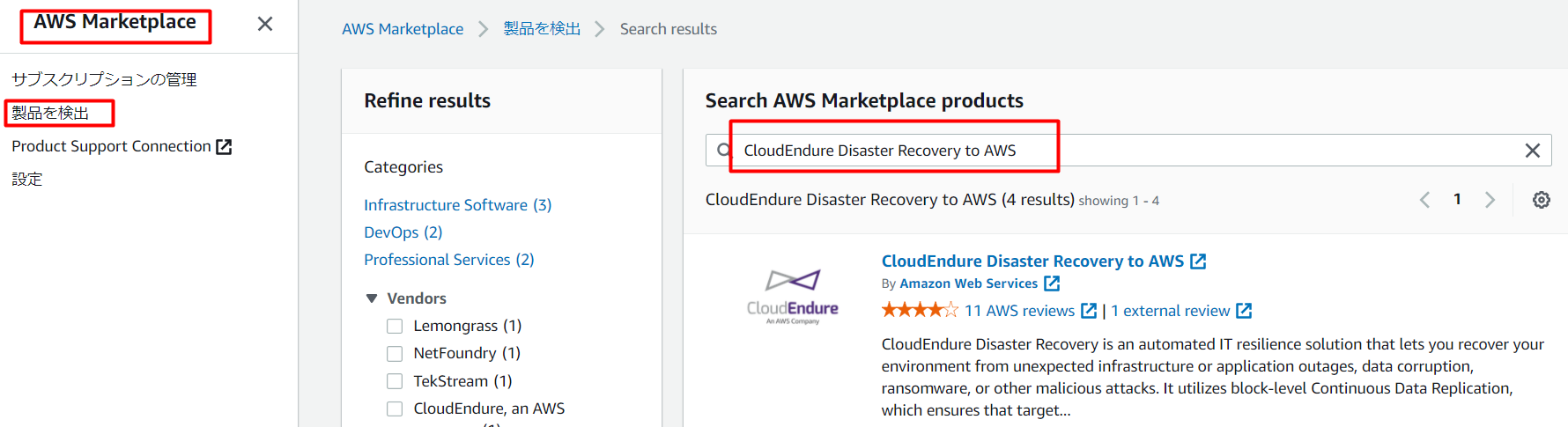
▲サブスクリプションの登録
「AWSのマネジメントコンソール画面」から「AWS Marketplace」にアクセスし、「製品を検出」から「CloudEndure Disaster Recovery to AWS」を選択しクリックします。
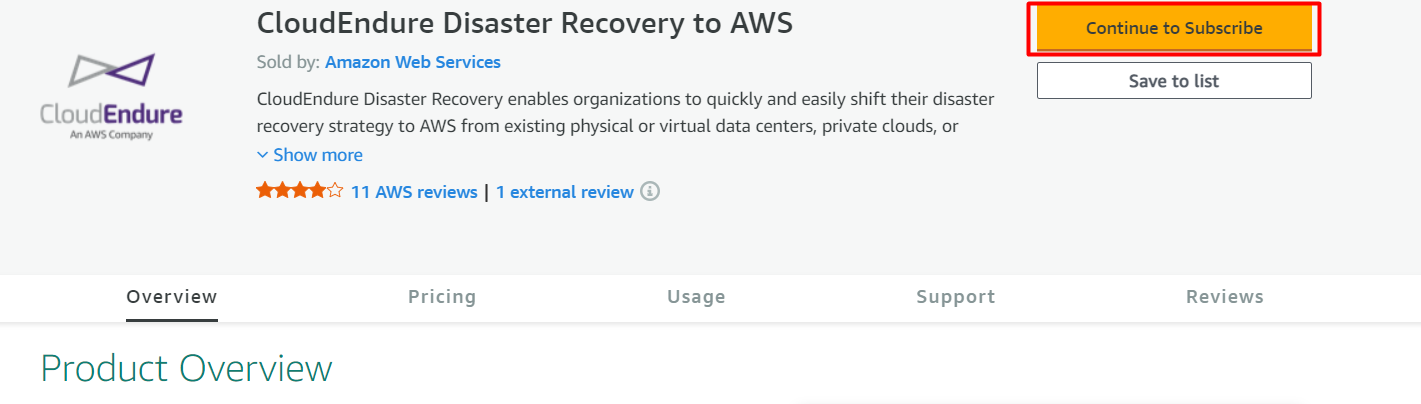
▲次の画面で「Continue to Subscribe」をクリックします。画面遷移したら、アカウントのサインイン及びメールを確認してください。
▲CloudEndure Disaster Recovery
サインインしてください。
https://console.cloudendure.com/#/signIn
▲今回はDefault Projectを利用します。
▲IAMユーザを作成し、アクセスキーを設定します。
「SetUp&Info」⇒「AWS CREDENTIALS」⇒「these permissions」の順番クリックし、次のページに遷移したら、内容をコピーしてください。
参考:
IAMユーザー作成の手順▲「REPLICATION SETTINGS」タグをクリックし、必要の項目を設定してください。
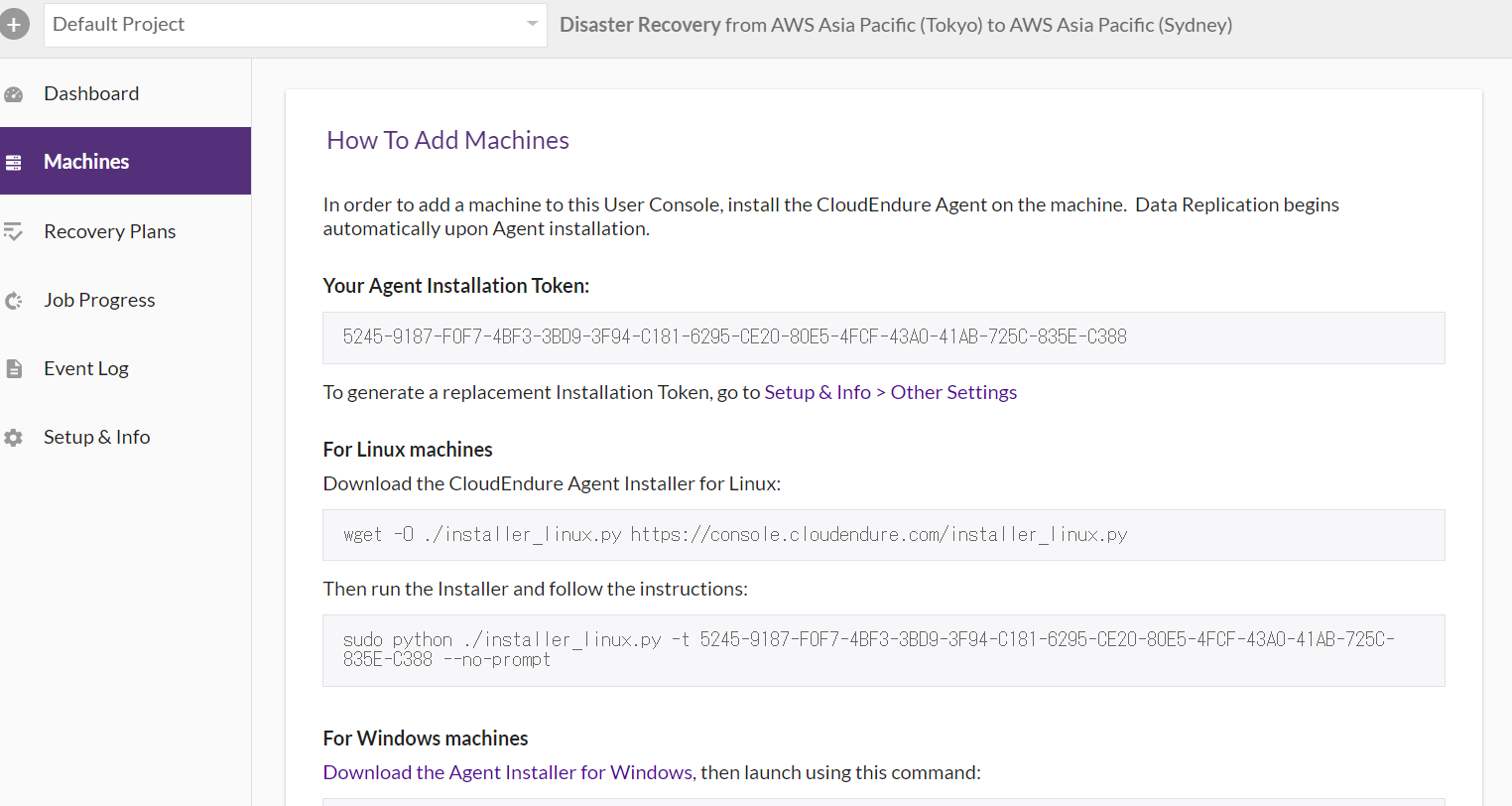
▲DRするEC2にCloudEndureエージェントのインストールします。
Linux:
-2GB以上の空きディスク容量
-Python 2(2.4以上)またはPython 3(3.0以上)Windows:
-2GB以上の空きディスク容量
-NETFramework 4.5以上
-WMI(Windows Management Instrumentation)の有効化▲CloudEndureエージェントのインストールした後、CloudEndureの画面を確認してください。
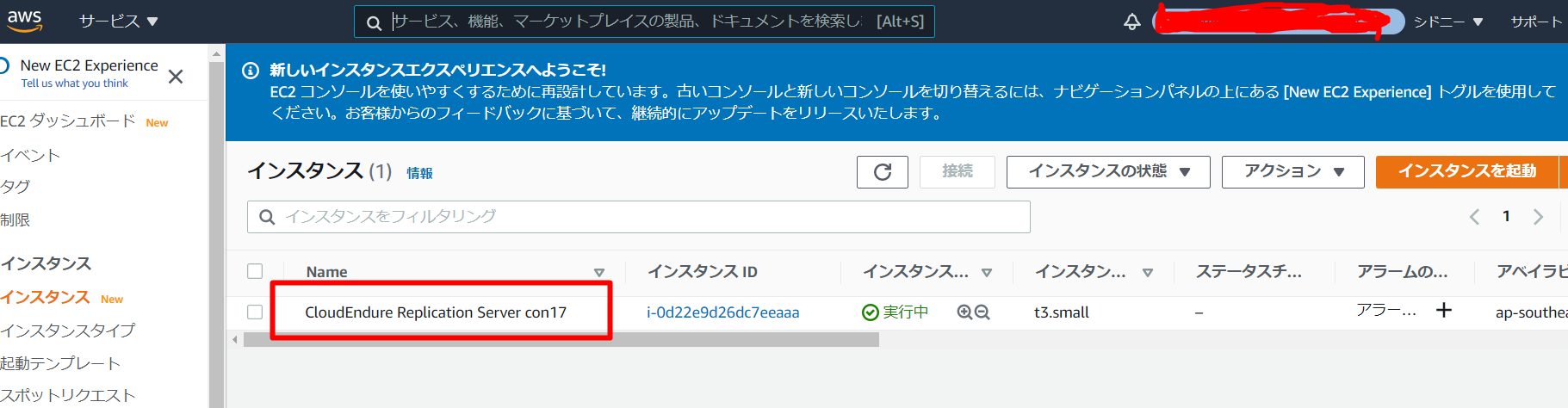
DRのターゲットのリージョン画面で、レプリケーション用管理サーバが起動できたことを確認します。
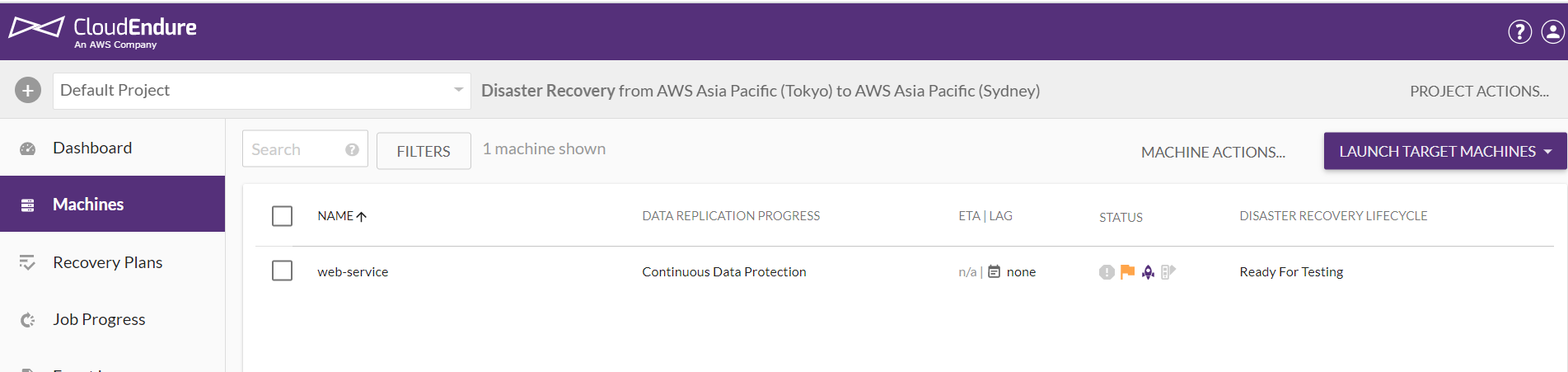
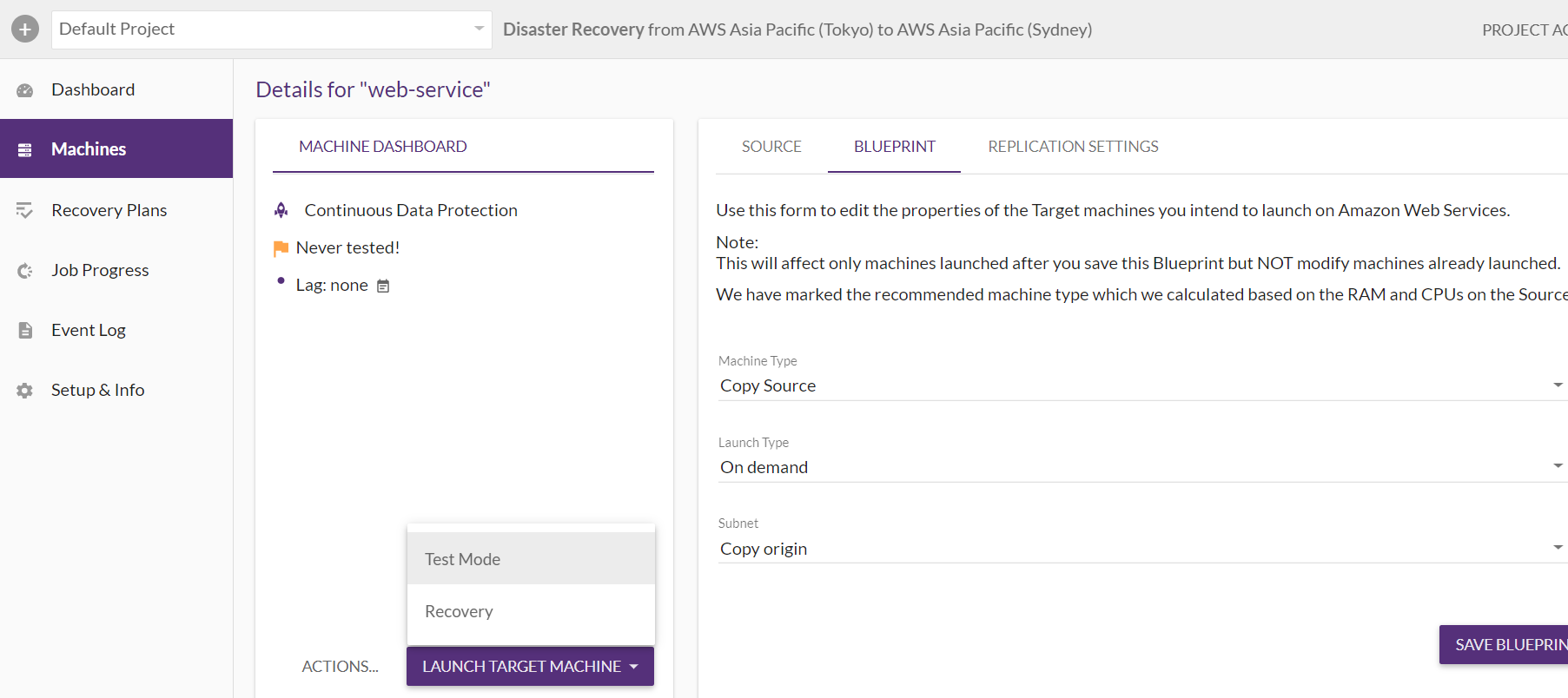
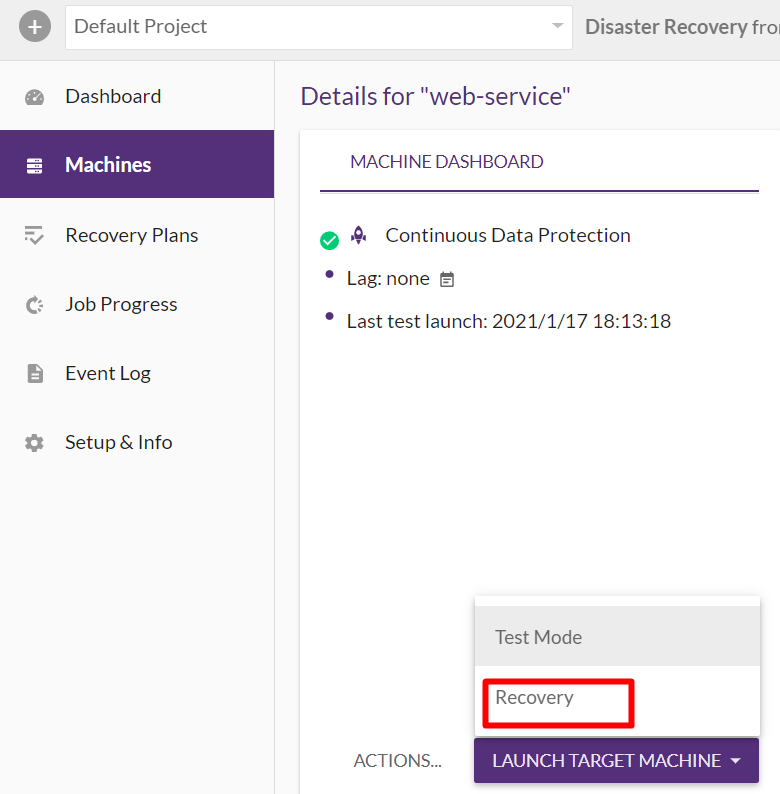
▲BLUEPRINTの設定およびTest Modeを実行します。
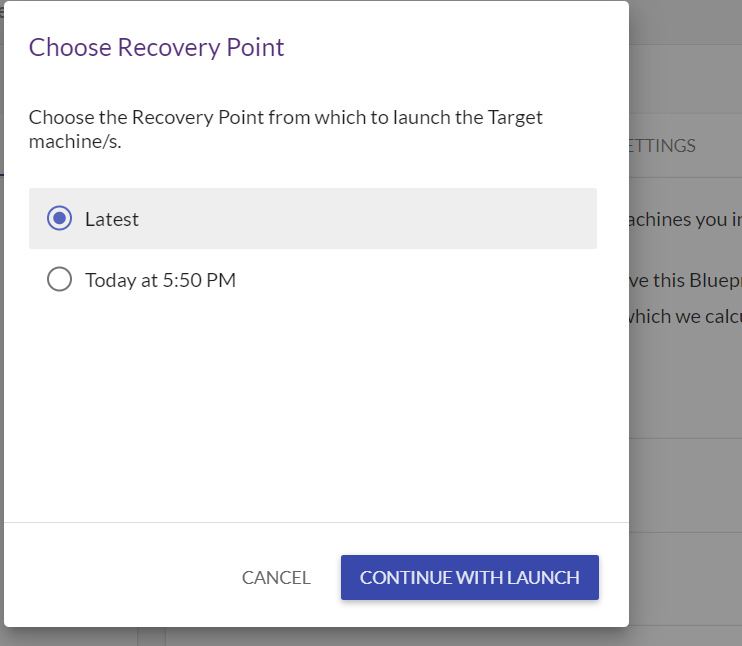
▲Recovery Pointを選択してください。
▲テスト実行状況を確認します。
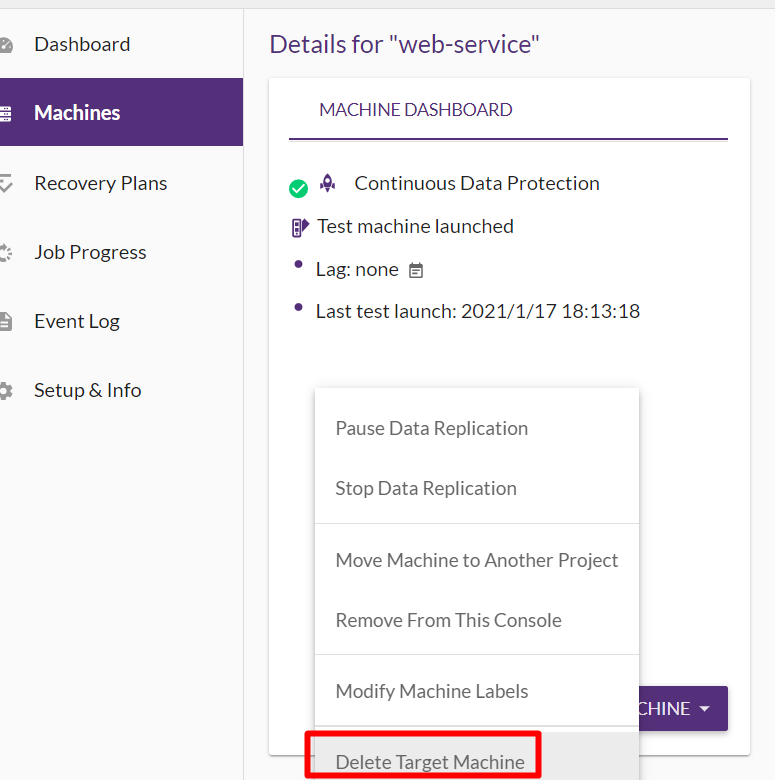
▲テストマシンを削除します。
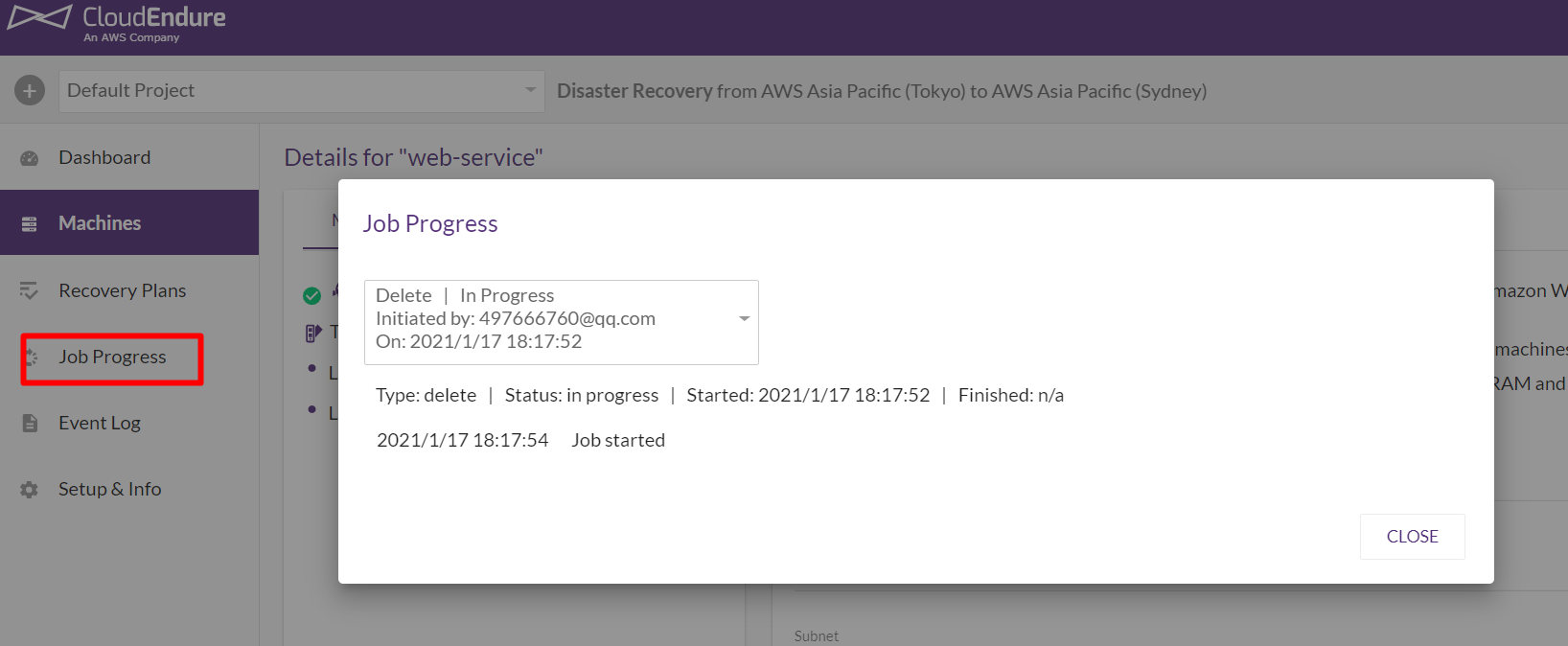
▲「Job Progess」で実行状況を確認することができます。
▲本番フェイルオーバー



- 投稿日:2021-01-17T18:09:40+09:00
【合格体験記】AWS認定SysOpsアドミニストレーター–アソシエイト(SOA-C01)
本記事の概要
AWS認定SysOpsアドミニストレーター–アソシエイト(SOA-C01) を取得したので勉強方法を備忘録として投稿します。
AWS-SOAを受けようと思っている方や、現在勉強している方がこの記事を参考の一つにしていただけたら幸いです。使用した教材
WEBサイト
・awsWEB問題集で学習しようUdemy
・Ultimate AWS Certified SysOps Administrator Associate 2021WHIZLABS
・AWS Certified SysOps Administrator Associate勉強の流れ
AWSについては、AWS-SAAを取得済みということもあり
大体のサービスについては理解している状態からのスタートです。まずはkoiwaclubさんのawsWEB問題集とりかかりました。
半分くらいまで解いていると、CloudWatchの理解度がSAAの範囲だけでは補えないと思い、
UdemyのUltimate AWS Certified SysOps Administrator Associate 2021を実施。こちらは全部やるのではなく、
CloudWatchとCloudFormationのセクションに絞って実施しました。
すべて通してやろうとするとかなりの量なので、
SAAを取得している方は自分が不安なサービスのみに絞るほうがいいと思います。
Udemyの最後には模擬試験(65問)があるのでそれも是非解きましょう!Udemyの講座終了後は、再度WEB問題集に取り掛かり1週終了。
WEB問題集終了後は、SAA試験の際もお世話になったWHIZLABSのセクション毎問題を実施。
WHIZLABSのSysOps用コースは、セクション毎の問題が少なめなので全問完璧に正解できるまで繰り返し内容を理解しました。WHIZLABSが終わったらあとは試験日までawsWEB問題集を繰り返し解いて試験問題になれましょう。
試験結果
受験日:2021年1月11日
スコア:782
合格ライン:720
結果:passSOAはSAAの時とは違い、WEB問題集やWHIZLABSで実施した問題がそのまま出題されたので自身があったのですが、あまり点数は伸びず...
受験してみて
勉強期間は1ヶ月ほどでしたが、個人的にはSAAよりも解きやすい試験だと感じました。
アソシエイト3冠まで残すはAWS認定デベロッパー–アソシエイトのみ!
次もがんばります!この記事を開いていただき、また、
ここまで読んでいただきありがとうございました。
- 投稿日:2021-01-17T18:05:27+09:00
Amazon Transcribeをストリーミングで実行する
はじめに
- Amazon Transcribe は音声データをテキスト化する(文字起こしとも言われる)サービスです
- 音声ファイルを準備してバッチ処理するタイプと、音声をストリーミングして、リアルタイム(逐次的に)処理するタイプがあります
- 日本語については、2020年11月にリアルタイム処理タイプに対応しました
- AWSコンソール上ではブラウザの音声をTranscribeへストリーミングすることで機能を確認することができます。レスポンス良くテキスト化されます
- 実際の業務等ではマネジメントコンソールで使うことはなく、アプリケーション等に組み込むことになると思います
- ということで、サンプル的にストリーミング処理を実装してみました
- そして自分への備忘も兼ねて処理内容の解釈を記述します
- なお、SDK v3はpreviewなので、これからリリースされる正式バージョンと異なる(動作しない)可能性があります
環境
- Ubuntu 20.04 on WSL2
- Node.js v14.15.4
- AWS SDK for JavaScript version 3(preview)
サンプルコード
下記コードをタタキ台として説明します
実行手順
オーディオファイルを準備する
- バッチ処理ではなくリアルタイムストリーム処理、と言ったわりには音声ファイルを準備します
音声入力部分も何らかのストリームにする想定ですが、今回はTranscribeとのストリーム部分にフォーカスし、シンプルにしました
- (手元ではKinesisVideoStreamからの音声をTranscribeへパイプできることまで確認しています)
オーディオファイルの仕様
- 符号付き16ビット PCM 8KHz RAW(ヘッダ無)
- 指定がある場合はリトルエンディアンを選択
Audacity を利用して変換するのが簡単です
実行環境の準備
- Node.jsの環境作成
- 各自準備してください
- githubからソースファイルを手元へコピー
git cloneなどで- パッケージインストール
npm install実行
- ニュース動画の音声で試してみました
- 下記のようになります
- 音声が30秒ぐらいで、処理時間も30秒+αかかります
- アナウンサーの発声ということもあってか、正確にテキスト化されています
来月 な の か?部分が正確には来月七日ですが、他は誤変換もなく素晴らしい精度です$ node transcription.js sample_audio.raw 0.08: きょう 東京 都心 は ぽかぽか 陽気 と なり 最高 気温 は 昨日 より 十 一 度、 以上 高い 十 八、 七 度 と か 8.39: 四 月 中旬 並み の 暖か さ と なり まし た 11.98: 江戸川 区 の 葛西 臨海 公園 に は 多く の 家族 連れ の 姿 が。 17.54: 東京 都 で は 緊急 事態 宣言 の 解除 が 予定 さ れ て いる 来月 な の か? まで 23.15: 上野 動物 園 や 葛西 臨海 水 族 園 など 都立 の 動物 園 や 水 族 館 を 臨時 休業 に し て い ますコードの解説
対象ソースファイル
const parseTranscribeStream...部分
- Transcribeからのレスポンス解釈部です
- Transcribeからのレスポンスオブジェクトを表示用に編集しています
IsPartial == trueの場合は変換途中を示していますので表示から省いています
- 条件を外して実行してみると挙動がわかると思います
const audioSource = createReadStream部分
- 音声ファイルを読み込みしています
- highWaterMarkで一度に読み込むサイズを1KBに抑えています
- 大きいサイズを送信するとTranscribe側がエラーを返すことがあります
const audioStream = async function*部分
- 音声ファイルのデータ片を所定のオブジェクト形式に変換しています
const command = new StartStreamTranscriptionCommand部分
- Transcribeとのリアルタイムストリーム開始コマンドを作成しています
- 日本語、PCM形式、8KHzであることを伝えています
- 入力は前段で定義したストリームを指定しています
- 処理が開始すると、入力ストリームから順次データを受け取り、処理する記述です
const client = new TranscribeStreamingClient部分
- Transcribeとのリアルタイムストリーム開始リクエストクライアントを作成しています
- パラメータ
requestHandlerでセッションタイムアウトを5秒指定しています
- これを指定しないと音声データ送信が終了しても5分ぐらい通信が切断されません
- SDK内部でコネクションプールしていますが、データ終了時にクローズせず、プールしたままになっているようです
- SDKはまだpreviewなので改善するかもしれません
const response = await client.send(command)部分
- Transcribeとのリアルタイムストリーム開始リクエストしています
- SDK v3では基本的に「コマンド作成」して、client.send()する記述になるようですね
const transcriptsStream = Readable.from(response.TranscriptResultStream)部分
- Transcribeからのレスポンスを受け取るストリームを宣言しています
transcriptsStream.pipe(parseTranscribeStream).pipe(stdout)部分
- ストリームをパイプで接続しています
- Transcribeからのレスポンスを冒頭で記述したレスポンス解釈部へ
- レスポンス解釈部のアウトプットを標準出力へ
まとめ
- Node.jsの非同期ストリーム処理によってシンプルに実装できる印象です
- そのぶん、どこで何が処理されているか理解しておかないとハマるかもしれません
- この実装だと、HTTP/2 Streaming 動作になると思います
- 実は SDK v2で WebSockets Streaming も試していたのですが、途中でv3に気づいて移ってきました
- あまり詳しくないのですが、HTTP/2ストリーミングだと送信ごとに毎回署名してるようなので効率は落ちるのでしょうかね

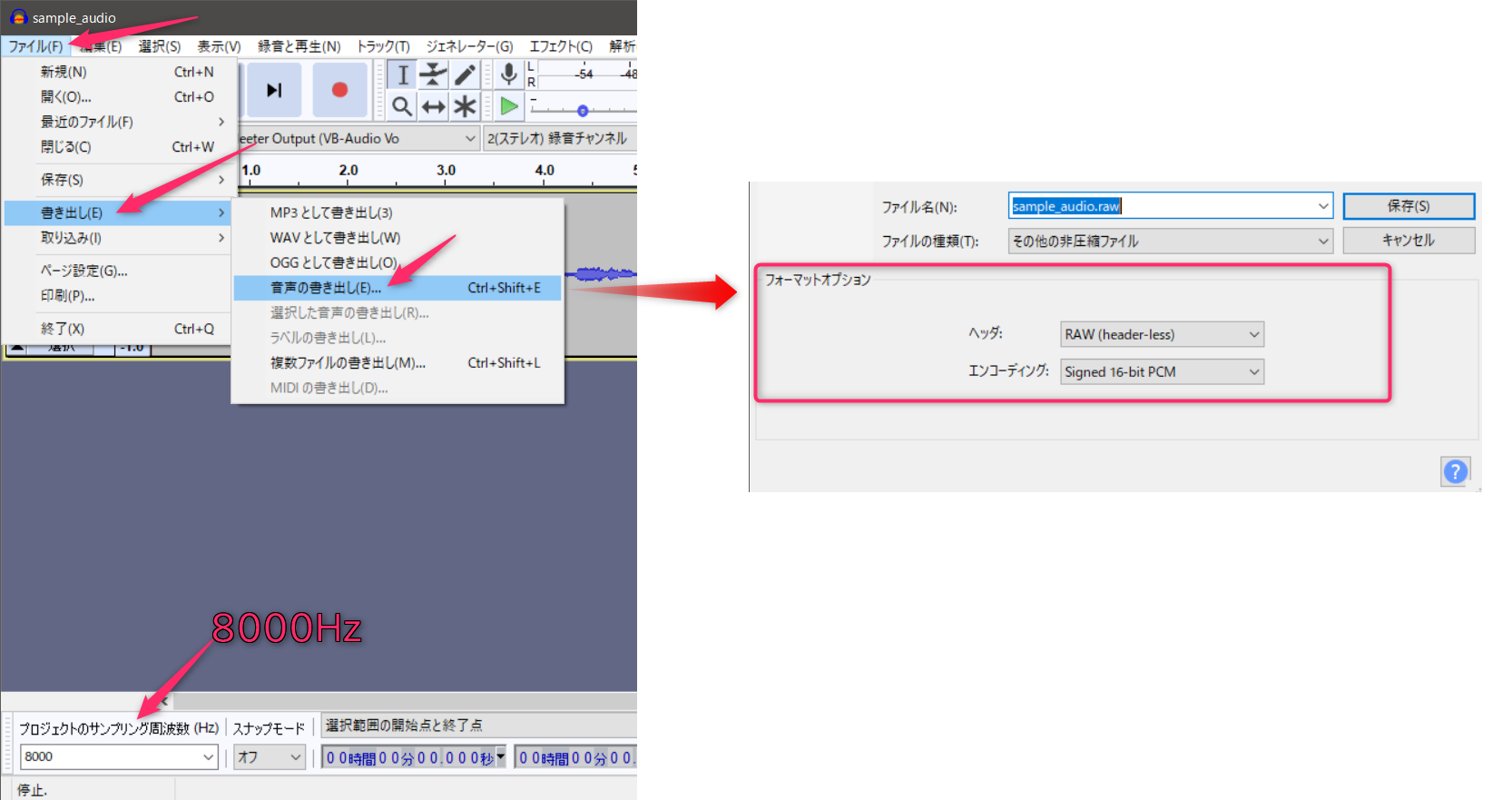
- 投稿日:2021-01-17T17:11:19+09:00
AWSソリューションアーキテクトアソシエイト(SAA-C02)合格体験記【オマケ:半額で受験する方法】
結論: SAA試験はほぼUdemyだけで、約1ヶ月で合格できました?
始めに
僕は、2020年6月9日に
AWS認定ソリューションアーキテクトアソシエイト試験(以下、SAA)試験に合格することができました。
本記事では、試験合格に向けて学習した教材や、知っておくとお得な特典等についてご紹介します。↓合格時のスコアです(結構ギリギリ・・^^;)
試験前の知識レベルについて
既に、AWS認定 クラウドプラクティショナー という資格試験に合格していました。(AWSの一番入門編の資格)
なのでAWSの基礎についてはそれとな~く理解できているようなレベルでした。ちなみにクラウドプラクティショナーの試験合格前は、
AWS?何それ美味しいの?レベルからのスタートで、書籍やUdemyでAWSの基礎を学びました。
それから次第にクラウドプラクティショナー合格を目指すようになり、
勉強期間は、ゆるく進めていたので正味1ヶ月半くらいだったと思います。
入門編の試験ともあって、あまり深い知識が問われず、難易度は低かったです。(試験時間も50分くらい余りました)AWSの基礎学習や試験対策に向けて参考にしていた教材は↓の通りです。
クラウドプラクティショナー試験勉強時に利用した教材
〜〜基礎学習〜〜
- 【Udemy】AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
→実際に手を動かしながらAWSでのインフラ構築を学べ、非常にわかりやすい- 【書籍】Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版
→良書として有名な本で、わかりやすいです。ただ、上記のUdemy講座で学ぶ内容と結構被っている気もするので、買うのはどちらかでよいと思います。- 【書籍】図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書
→カラー印刷&イラストが多めで、AWSの概要のイメージを掴みやすい〜〜試験対策〜〜
- 【書籍】AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
→試験範囲を体系的に学べる- 【Udemy】この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
→模擬試験です。全7回分ありますが、3回分までやりました。上記の教材でAWSの基礎固めと試験対策を進め、
2020年4月29日に無事にクラウドプラクティショナーに合格することができました。
それから続けて、SAA試験を受験することにしました。SAA試験を受けた感想
それでは本題の、SAA試験の話に戻ります。
実際にSAA試験を受験してみてまず感じたのが、
「めちゃめちゃ難しい」、、でした。
4択の選択問題でしたが、自信を持って答えを絞り切れないくらい悩ましい問題が多く、試験時間も3分くらいしか余りませんでした^^;(試験時間は140分)
やっぱり、クラウドプラクティショナーの試験よりもだいぶ深い知識が求める印象。。
試験本番の内容については書けないのですが、模擬試験とかを解いていると問題文が長い!と感じることもしばしば。(200文字くらいあったり)
やはり、試験問題の難易度に近い模擬試験等での対策は必須だなと感じました。SAA試験勉強時に利用した教材
次に、SAA試験対策に利用した教材をご紹介します。
1日2~3時間学習するようにし、約1ヶ月間行いました。
また、基本的には試験の最新のバージョンであるSAA-C02版に対応している教材を選びました。Udemy
- ①これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
→ハンズオンでAWSのインフラ構築を行いながら、SAA試験範囲を学べる。模試3回分付き。
- ②【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
→模擬試験6回分。難易度高め①の教材で試験範囲の学習を済ませた後に、②の模擬試験に取り組みました。
初見でこの模擬試験に挑戦してみたら、点数は50%台くらいしか取れませんでした^^;(72%が合格ライン)
模試のレベル感としては、実際の試験と同等か、やや難しいくらいの印象でした。
模試は念のため全6回分に挑戦し、更に2週して各模試で8〜9割得点できるまで復習しました。半額で受験する方法(※条件あり)
最後に、SAA試験の受験料15,000円(税別)を半額にできる方法をご紹介します。
受験前に、もし既に他のAWS認定試験に合格していれば、その特典として
受験料が50%offになる公式のクーポンがもらえます。僕は、SAA試験の受験前にクラウドプラクティショナーに合格していたので、この特典を利用させていただきました?
また、この度SAA試験にも合格することができたので、次回AWS認定試験を受ける時に利用できる受験料50%offクーポンを更に新しくもらうことができました。AWS公式模試を無料で受験できるクーポンももらえる
更に、受験料半額の特典に加え、AWSの公式模試(通常2,000円/税別)に無料で挑戦できるクーポンももらえます。
僕も、SAA受験前に公式模試を受けてみました。
とは言えこの模試は、25問題しかなく、解答がありません。
模試終了後に、得点だけ教えてもらえるような形になります。
難易度はそれほど高くなく、9割以上取ることができました。
無料クーポンが使えるなら、受けてみるのもいいかもしれませんね、、!
ちなみにこれらの特典は、AWS Certificationのページにログインして、
「特典」のタブを開いたところから確認することができます。
最後に
本記事では、SAA試験合格までに利用した教材や、知っておくとお得な特典等についてご紹介いたしました。
SAA試験の受験を考えられている方にとって、少しでもこの記事がお役に立てれば幸いです!

- 投稿日:2021-01-17T17:02:17+09:00
自動デプロイに失敗してwe are sorry
前書き
プログラミングをしていて最も見たくないエラーに遭遇してしまった。
初学者の自分にとってポートフォリオが公開できないことはすなわち死に直結するからである。
少しの間デプロイせずに開発していたところ自動デプロイのやり方を忘れてしまいエラーになった。前提
・ローカルでは問題なく動いている
・ローカル→GiuHubへのpushのし忘れはない(mergeまで確認)
・GitHubからEC2への反映(git pull origin master)のし忘れはない
・EC2サーバー側でエラーログの内容を確認し、原因を探す
・Nginxは正しく起動しているか
・EC2サーバー側の環境変数は正しく設定できているか
・EC2インスタンスの再起動を行ってみる結論
ただの勘違い。ローカルでやるべき
bundle exec cap production deploy ローカル開発環境のディレクトリで実行するこれだけで自動デプロイが完了した。
そもそもbundle exec cap production deployは自動デプロイを実行するコマンドなのだが何を思ったのかEC2ターミナルで行っていた。
開発環境の変更データを本番に反映するコマンドなのでEC2ターミナルで行っても反映されるはずがないのだ。なぜなら本番環境だから。こんな感じで怒られます↓[ec2-user@ip-000-00-00-00 ~]$ bundle exec cap production deploy Could not locate Gemfile or .bundle/ directory終わりに
そんなとこでつまづくなよ、、って言われそうですがこの経験が実務で活きると信じて今日も頑張ります。
- 投稿日:2021-01-17T16:58:27+09:00
初心者向け! Rails6+CircleCI+Capistrano+AWS(EC2)で自動デプロイ
はじめに
先日、ポートフォリオ作成後、AWSにCapistranoとCircleCIを使ってCIツールによる自動デプロイを実装できたので、備忘録として残しておこうと思います。
なお、前述したとおり備忘録としてなので参考になる保証はありません。
前提
・Railsアプリが作成できていること
・EC2にCapistranoで自動デプロイを実現できていること以上の条件に当てはまる場合にのみCIツールによるCapistranoの自動デプロイを行います。
開発環境
ローカル
・Rails6
・MySQL5.6.50
・Docker
・docker-compose本番
・EC2
・RDS(MariaDB)
・Unicorn
・Nginx
・Capistrano本願環境にはDockerとdocker-composeは用いていません。
手順
①CircleCIにEC2にログインするための秘密鍵を設定する
②.circleci/config.ymlにssh接続の記述をし、ログインできるか確かめる
③githubのmasterブランチにmergeもしくはpushしたときにCapistranoによるデプロイを行う1)CircleCIにEC2ログインの秘密鍵を設定する
多くの人はここで詰まる事が多く、筆者自身も2時間くらいつまりました。
まず、どの鍵が必要なのかがわからないということでつまります。
必要なのは、sshからEC2へログインする時に使うキーペアと呼ばれる鍵です。インスタンスを作成する時に
pemファイル形式でダウンロードする秘密鍵をCircleCIにも登録します。ここで1つ注意点があり、CircleCIで使えるのは
pem形式のみということです。
OPENSSH形式の場合はpem形式にする必要があるので下記の記事を参考に実行してみてください。(筆者の場合は最初からpem形式だったため、この辺は詳しくないので。。。)ということなので、ターミナルの
sshディレクトリに移って、以下のコマンドを実行します。ターミナル.ssh % cat XXXXXXXXXXXXX.pem # ご自身のEC2にログインする際のキーペアすると以下のように非常に長い暗号が出力されます。
ターミナル-----BEGIN RSA PRIVATE KEY----- WWIEXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX # まだまだありますが割愛 -----END RSA PRIVATE KEY-----%これを
-----BEGIN RSA PRIVATE KEY-----から-----END RSA PRIVATE KEY-----%までコピーします。もしくは以下のような方法で一括コピーも可能です。
ターミナル.ssh % pbcopy < ~/.ssh/XXXXXXXXX.pemこのコマンドを使うことで先ほどの長い暗号をコピーすることができます。
1-2)CircleCIにキーペア登録
CircleCIのprojectに移り、project settingにを開きます。(右上の歯車アイコンをクリック)
すると以下のように設定画面に遷移するので、メニューバーの
SSH Keysを選択して、鍵を設定します。
ページが切り替わったら、スクロールして以下の
Add SSH Keyをクリックしましょう。
クリックすると以下のようになるので、
HostnameとPrivate Keyを入力して、Add SSH Keyをクリックします。
HostnameにはElasticIPを入れてもいいですが、筆者の場合は独自ドメインを取得していたためwww.myapp.comのような形で記入しました。続いて
Private Keyには、先ほどコピーした暗号を貼り付けます。
しばらくすると、元の画面に戻ると思います。すると、
Fingerprintなる項目に数字と文字と「:」の文字列が存在していると思います。それをコピーしてメモなどに保存しておきましょう。CircleCI(GUI)での設定は以上です。
2).Circlci/cofig.ymlの記述
次にCircleCIでSSH接続できるか確認します。
以下のように存在している記述のsteps:- checkoutの下などに記述を加えます。
筆者の場合はCapistranoの前はHerokuとCIパイプラインを構築してたため記述を加え、git pushしました。.circleci/config.yml- add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX"この記述を加え確認しましょう。
以下のように成功していたらOKです。
3)githubのmasterブランチにmergeもしくはpushしたときにCapistranoによるデプロイを行う
ここからが実際に、CIツールによるCapistrano自動デプロイの実装です。
まずこちらが成功したコードです。
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@1.1.0 jobs: build: docker: - image: circleci/ruby:2.6.5-node-browsers environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - run: gem install bundler -v 2.1.4 - run: name: Which bundler? command: bundle -v - ruby/install-deps deploy: docker: - image: circleci/ruby:2.6.5-node-browsers environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2.1 build-deploy: jobs: - build - deploy: requires: - build filters: branches: only: master筆者が参考にしたのは参考文献にもある記事と公式ですが、難しかったです(笑)
1つずつ解説すると、dockerのimageは自分のrubyのバージョンに合わせ、bundlerの自分のバージョンに合わせるような記述をしました。
まず
jobとしてコードチェックのためのbuildを行い、bundlerのインストールするようにします。そして
deploy jobではCapistranoを走らせるようにして、どのSSHに接続するかを指定しています。
これが先ほど設定したり、記述したadd_ssh_keys:という記述に当たります。その下のコマンドで実際にCapistranoが走るという構図になっています。
そして
workflowsではonly: masterとしてmasterブランチにpushもしくはmergeがあった場合に行うように設定しています。詳しい説明は下記の記事や、記事内で参考にしていた文献に書いてありますので、そちらの方も合わせて読むとより理解しやすいと思います。
結構、苦労しましたが、なんとか実装できました。
皆さんも頑張ってください。参考文献

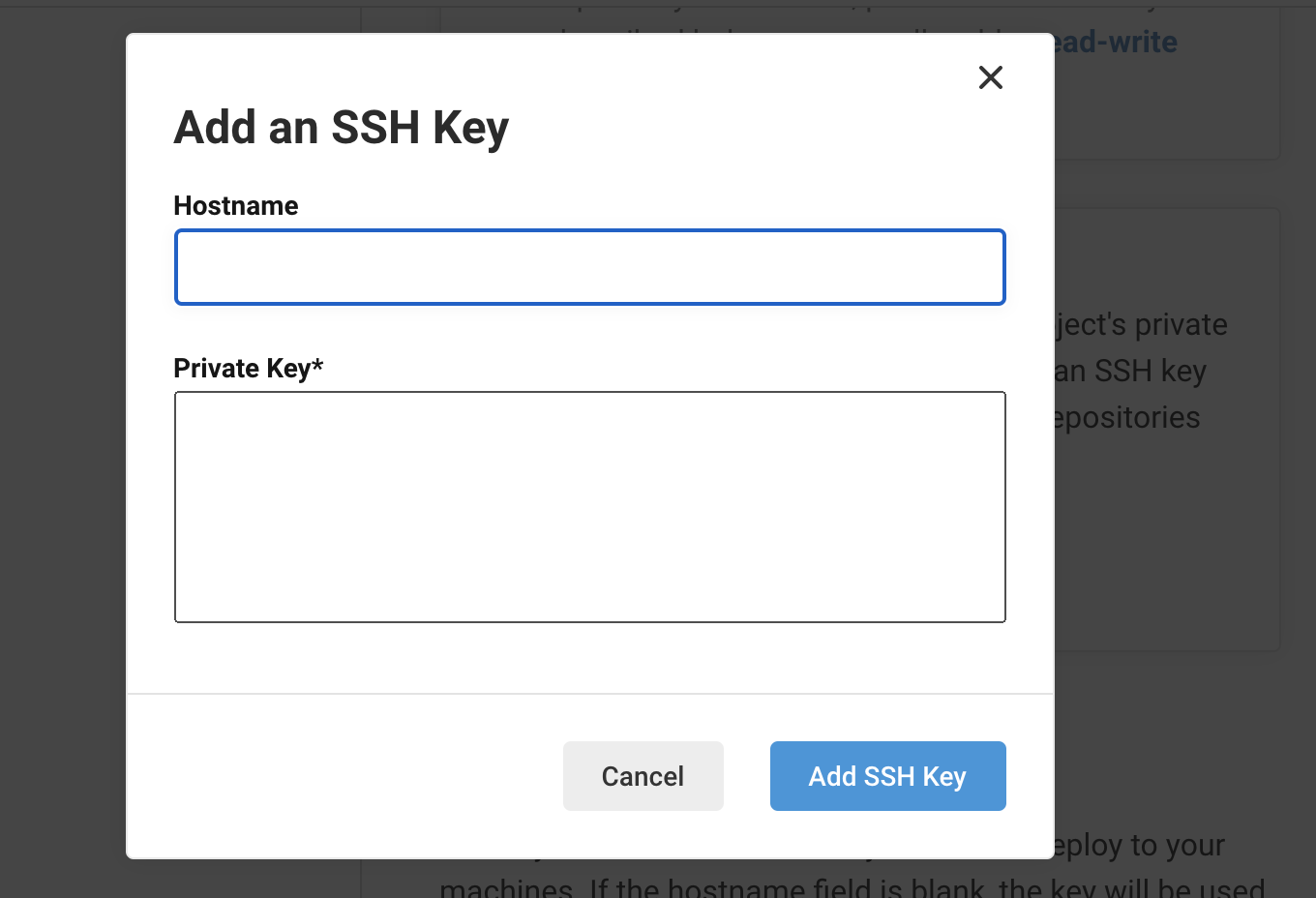

- 投稿日:2021-01-17T16:30:40+09:00
【個人開発】鉛筆画の作画プロセスを生成するAI「スケッチメーカー」を作りました!
スケッチメーカーでAIに鉛筆画のスケッチを描いてもらいました!
— 2z / AIメーカー (@2zn01) January 15, 2021
スケッチメーカーでは画像をアップロードすると、それをもとにAIが鉛筆画のスケッチを描いてくれます! https://t.co/zRKASfmkuX #スケッチメーカー pic.twitter.com/clsHWlpcUZ
明けましておめでとうございます。
趣味でWebサービスの個人開発をしている、2z(Twitter: @2zn01 )です。普段は以下のようなサービスを開発・運営していますので、興味があるものがございましたら、ぜひとも使ってみて頂けると嬉しいです!
AIメーカー
https://aimaker.io/
誰でも簡単にAIを作ったり、試したりできるサービスです。
使ったAIを活用するためのAPIも提供していますので、ぜひご活用ください。waifu2x-multi
https://waifu2x.me/
画像・動画を高画質化・拡大・ノイズ除去できるサービスです。文字起こすくん
https://text.aimaker.io/recognize-bot/
画像、音声、動画をアップするだけで簡単に文字起こし・書き起こしできるサービスです。話者の識別も可能になりました!テロップメーカー
https://text.aimaker.io/recognize-video/
動画をアップロードするだけで、動画内の音声を認識して文字起こしを行い、自動で動画に字幕・テロップをつけるサービスです。こちらも話者の識別が可能になりました!今回作ったもの
今回はこの「AIメーカー」で鉛筆画の作画プロセスを生成するAIを試せる「スケッチメーカー」という機能を作りましたので、ご紹介します。
- スケッチメーカー
https://aimaker.io/sketch-art【お知らせ】
— 2z / AIメーカー (@2zn01) January 15, 2021
画像からAIが鉛筆画のスケッチをしてくれる「スケッチメーカー」という機能をリリースしました!?
写真やイラスト、Twitterのアイコンからもスケッチできるので、ぜひ試してみてくださいー!?
頑張って作ったので、いいねやRTしてくれると嬉しいです!?https://t.co/KWGHS8g2qt何ができるの?
画像をアップロードすると、その画像を鉛筆画として作画した際のプロセスを動画もしくはGIFアニメーションで生成することができます。
言葉で説明するよりも、実際に見てもらった方が分かりやすいと思います。
以下のように、画像をアップロードすると、画像を鉛筆画として作画するプロセスの動画が生成することができます。
スケッチメーカーでAIに鉛筆画のスケッチを描いてもらいました!
— 2z / AIメーカー (@2zn01) January 15, 2021
スケッチメーカーでは画像をアップロードすると、それをもとにAIが鉛筆画のスケッチを描いてくれます! https://t.co/zRKASfmkuX #スケッチメーカー pic.twitter.com/clsHWlpcUZ他にもこんな感じで生成することができます。
スケッチメーカーでAIに鉛筆画のスケッチを描いてもらいました!
— 2z / AIメーカー (@2zn01) January 15, 2021
スケッチメーカーでは画像をアップロードすると、それをもとにAIが鉛筆画のスケッチを描いてくれます! https://t.co/KFdaCgvcey #スケッチメーカー #いらすとや pic.twitter.com/paDt5a5xl9システム構成図
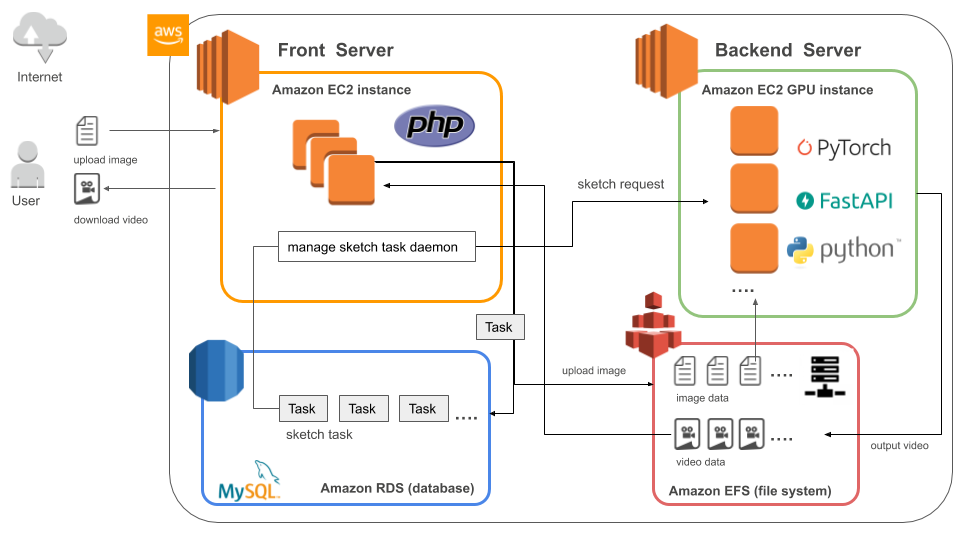
スケッチメーカーのシステム構成図は以下の通りです。
Amazon Web Services(以下、AWS)を使ってサービスを構築しました。
大きな構成としては、主にユーザからのリクエストを受け付けるフロントサーバと機械学習の処理を取り扱うバックエンドサーバの2つです。
使用技術
Linux
クラウドのホスティングはAWSで、EC2でサーバを立てています。
サーバのOSはLinuxでフロントサーバ側はAmazon Linux2、バックエンドサーバ側はUbuntuを使っています。Apache
webサーバはApacheを使っています。
Nginxもありますが、Apacheは普段から使っており、設定方法も把握しているため、いつも通りの安定の選択としました。MySQL(Amazon RDS)
データベースはMySQL(Amazon RDS)を使用しています。
NFS(Amazon EFS)
各インスタンスでファイルを共有するため、NFS(ネットワークファイルシステム)として、Amazon EFSを使用しています。
PHP
フロントサーバのプログラムはPHPを使って実装しています。
Python
バックエンドサーバのプログラムはPythonを使っています。
また、フロントサーバ側からバックエンド処理を呼び出すためのAPIは、「FastAPI」というフレームワークを使って実装しています。
- FastAPI
https://fastapi.tiangolo.com/ja/仕組み
画像から鉛筆画の作画プロセスを生成する部分に関しては、以下の論文・コードをご覧ください。
- 論文
Sketch Generation with Drawing Process Guided by Vector Flow and Grayscale- コード
GitHub上にコードも公開されています。
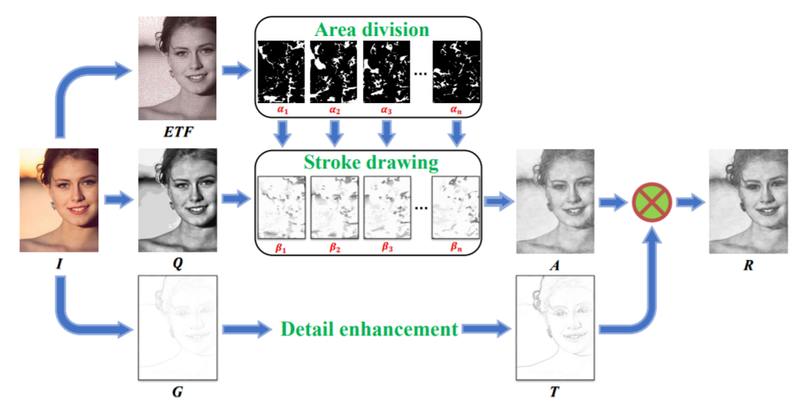
TZYSJTU / Sketch-Generation-with-Drawing-Process-Guided-by-Vector-Flow-and-Grayscale論文によると、与えられた画像(I)をもとに3つの処理(ETF、Q、G)が行われ、最終的には出力(R)を得るという流れとなります。
また、そのプロセスで進捗を画像で出力していくことで、作画プロセス(制作過程)を見ることができます。
そして、最後に作画プロセスごとに出力されたすべての画像(コマ)を結合することで、動画およびアニメーションGIFを生成することができます。
もう少し詳しく仕組みを知りたい方は、日本語で記事を書いている方がいらっしゃいましたので、以下の記事をご覧ください。
最後に
今回は鉛筆画の作画プロセスを生成するAI「スケッチメーカー」について、ご紹介しました。
以下のURLよりぜひ試して遊んでみてください!■URL
https://aimaker.io/sketch-art/実際に試して頂いた方のスケッチはTwitterのハッシュタグ「 #スケッチメーカー 」から見ることができます。皆さんもぜひ試して頂いた際には、試した結果をTwitterにシェアして頂けると嬉しいです!
また、このサービスに少しでも興味をもって頂けましたら、ぜひともフォローやいいね、リツイートで応援お願いします!
スケッチメーカーでAIに鉛筆画のスケッチを描いてもらいました!
— 2z / AIメーカー (@2zn01) January 15, 2021
スケッチメーカーでは画像をアップロードすると、それをもとにAIが鉛筆画のスケッチを描いてくれます! https://t.co/zRKASfmkuX #スケッチメーカー pic.twitter.com/clsHWlpcUZ


- 投稿日:2021-01-17T15:48:54+09:00
AWS Lambda Layersでsam buildを行うとファイルの階層が変わりimportエラーになる問題
概要
sam deploy刷る前にsam buildをするだけでLambda Functionからimportできなくなってしまったので原因を調べました。
対象コード
Lambda Layer Template
Resources: SystemSharedLayer: Type: AWS::Serverless::LayerVersion Properties: ContentUri: src/layers/system_shared CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8Lambda Layer Src構造
src └── layers └── system_shared ├── python │ └── hogehoge.py └── requirements.txt呼び出し側
import hogehoge.pyLamnda Function側での展開パス
sam buildしなかった場合
/opt └── python/ └── hogehoge.pysam buildした場合
/opt └── python/ └── python/ ← 余計なパスが付与される └── hogehoge.py解決策
仕様が一貫していないので諦めてtemplate側の階層指定を切り替える
Resources: SystemSharedLayer: Type: AWS::Serverless::LayerVersion Properties: ContentUri: src/layers/system_shared/python CompatibleRuntimes: - python3.8 Metadata: BuildMethod: python3.8
- 投稿日:2021-01-17T15:40:42+09:00
LocalStackとSAM LocalでStep Functions(lambda)をローカル環境で実行してみる
はじめに
Step Functionsの開発を行っていたときに、ローカル上で実行確認が取りたいなと思ったのですが、そのための方法がパッと出てこず少し困ったので、その方法をまとめておきます。
目的
ローカル環境でStep Functionsの実行確認を行う。
そのために、SAM Localで実行しているlambdaをLocalStackのStep Functionsから呼び出し実行する。実行環境
環境
- macOS Catalina 10.15.7
- aws-cli 1.18.185
- sam-cli 1.12.0
事前準備
ここでは詳細に書きませんが、aws-cliとsam-cliが実行できる環境が必要です。
また、LocalStackを使用するので、そのためのcredential情報をセットしてください。$ vi ~/.aws/credentials/.aws/credentials[localstack] aws_access_key_id = dummy aws_secret_access_key = dummy$ vi ~/.aws/config/.aws/credentials[profile localstack] region = ap-northeast-1 output = textやってみる
LocalStackの準備
まずはLocalStackのコンテナを立てていきます。
GitHubのページに幾つかの方法が記載されていますが 今回はdocker-composeで行っていきます。$ git clone https://github.com/atlassian/localstack.git $ cd localstackこの時、後々SAMで立てたlambdaをLocalStackのStep Functionsから呼び出す必要があるので、それらを呼び出せるようにlambdaのエンドポイントを指定する環境変数をdocker-compose.ymlに追記しておきます
docker-compose.ymlversion: '2.1' services: localstack: container_name: "${LOCALSTACK_DOCKER_NAME-localstack_main}" image: localstack/localstack network_mode: bridge ports: - "4566:4566" - "4571:4571" - "${PORT_WEB_UI-8080}:${PORT_WEB_UI-8080}" environment: - SERVICES=${SERVICES- } - DEBUG=${DEBUG- } - DATA_DIR=${DATA_DIR- } - PORT_WEB_UI=${PORT_WEB_UI- } - LAMBDA_EXECUTOR=${LAMBDA_EXECUTOR- } - LAMBDA_ENDPOINT=http://host.docker.internal:3001 ##追記 - STEPFUNCTIONS_LAMBDA_ENDPOINT=http://host.docker.internal:3001 ##追記 - KINESIS_ERROR_PROBABILITY=${KINESIS_ERROR_PROBABILITY- } - DOCKER_HOST=unix:///var/run/docker.sock - HOST_TMP_FOLDER=${TMPDIR} volumes: - "${TMPDIR:-/tmp/localstack}:/tmp/localstack" - "/var/run/docker.sock:/var/run/docker.sock"追記したら、コンテナを立てておきましょう
$ docker-compose up -dlambda関数の作成
今回はStep Functionsでlambdaを実行できることを確認したいだけなので、lambda関数自体は非常に単純なものにします。
ということで、以下の2つの関数を作成していきます。
- HelloWorldFunction :{入力パラメータ}+HelloWorld!!を出力する関数
- GoodByeFunction :{入力パラメータ}+GoodBye!!を出力する関数sam initでlambda関数を作成する
それでは適当なディレクトリにlambda関数を作成していきます。
sam initで作成していきます。ダイアログの通りですが、runtimeはpython3.6、sfn-testというプロジェクト名で作成しています。$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore3.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8.al2 13 - java8 14 - dotnetcore2.1 Runtime: 9 Project name [sam-app]: sfn-test Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) 4 - Step Functions Sample App (Stock Trader) Template selection: 1 ----------------------- Generating application: ----------------------- Name: sfn-test Runtime: python3.6 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sfn-test/README.mdこれで必要なファイル群が作成されました。
ディレクトリ構成は以下の通りです。$ tree . . └── sfn-test ├── README.md ├── __init__.py ├── events │ └── event.json ├── hello_world │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests ├── __init__.py └── unit ├── __init__.py └── test_handler.pylambdaを実行してみる
この状態で一度、lambda関数をsamで実行してみます。
$ cd sfn-test $ sam local invoke --profile localstack {"statusCode":200,"body":"{\"message\": \"hello world\"}"}デフォルト値の出力がされました。問題なさそうです。
lambda関数の編集
今回は、入力を受け取ってから
{入力}+HelloWorld!!・{入力}+GoodBye!!を返すことが目的なので、lambda関数の中身を編集しておきます。
まずはHelloWorldFunctionを作成します。 以下がapp.py中身です。
入力された値を受け取って、HelloWorld!!と返すだけの単純なものであることが分かるかと思います。app.pydef lambda_handler(event, context): print(str(event["input"]) + " HelloWorld!!") return event2つ目のlambda関数を作成
2つ目の
{入力}+GoodBye!!の方のlambda関数も同様に作成しておきます。
今回は、同じディレクトリにもう一つ関数を作成しておきます。~/sfn-test $ tree . . ├── README.md ├── __init__.py ├── events │ └── event.json ├── good_bye ##追加 │ ├── __init__.py ##追加 │ └── app.py ##追加 ├── hello_world │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests ├── __init__.py └── unit ├── __init__.py └── test_handler.pyこちらのlambdaも入力を受け取って、GoodBye!!と返すだけの単純なものです。
good_bye/app.pydef lambda_handler(event, context): print(str(event["input"]) + " GoodBye!!") return eventtemplate.yamlの編集
先ほど作成した2つの関数を呼び出せるように、template.yamlを修正していきます。
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sfn-test Sample SAM Template for sfn-test Resources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.6 GoodByeFunction: Type: AWS::Serverless::Function Properties: CodeUri: good_bye/ Handler: app.lambda_handler Runtime: python3.6
Resources内に、HelloWorldFunctionとGoodByeFunctionを定義します。
CodeUri、Handlerで関数のパスを指定しているので、ここを工夫すれば別ディレクトリに作成してある関数も呼び出すことができます。start-lambda
ここまででlambdaの準備はOKです!
Step Functionsから呼び出せるように、lambdaを実行しておきましょう。$ sam local start-lambda --profile localstack Starting the Local Lambda Service. You can now invoke your Lambda Functions defined in your template through the endpoint. 2021-01-17 14:55:11 * Running on http://127.0.0.1:3001/ (Press CTRL+C to quit)エンドポイントはデフォルトで
http://127.0.0.1:3001/なので、Step Functionsからもこのエンドポイントで呼び出すことができます。ステートマシンの作成
lambdaの準備ができたので、次はStep Functionsのステートマシンを作成していきます。
定義ファイルをdefine.jsonという名前で作成します。
lambdaを実行しているのとは別のターミナルを開いて、以下を実行していきましょう。$ touch define.jsondefine.json{ "StartAt": "HelloWorld", "States": { "HelloWorld": { "Type": "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:HelloWorldFunction", "Parameters": { "input": "hogehoge" }, "Next": "GoodBye" }, "GoodBye": { "Type": "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:GoodByeFunction", "End": true } } }ResourceのところにlambdaのARNを指定することで呼び出すことができます。ローカルで呼び出す場合はFunction名を正しくセットしておけば問題ないはずです。
定義内容は単純で、HelloWorldFunctionの後にGoodByeFunctionを呼び出すだけです。lambda内で出力することになる
inputというパラメータにはhogehogeという文字列を渡しています。それでは、aws-cliでLocalStackのコンテナ上にStep Functionsを作成していきます。
$ aws stepfunctions create-state-machine \ --name TestState \ --definition file://define.json \ --role-arn "arn:aws:iam::000000000000:role/DummyRole" \ --endpoint http://localhost:4566
TestStateという名前のステートマシンを、先ほど作成した定義ファイル通りにLocalStackのエンドポイントである4566のポートで作成しています。
すると、以下のように出力されるはずです。{ "stateMachineArn": "arn:aws:states:us-east-1:000000000000:stateMachine:TestState", "creationDate": 1610863591.321 }これでStep FunctionsのARNが作成されました。あとはこれを呼び出せば実行できるはずです!
実行してみる
今回は、aws-cliで先ほどのステートマシンを実行してみます。
$ aws stepfunctions start-execution \ --state-machine arn:aws:states:us-east-1:000000000000:stateMachine:TestState \ --endpoint http://localhost:4566すると、lambdaを実行しているターミナルが動き、結果が出力されていくはずです。
Starting the Local Lambda Service. You can now invoke your Lambda Functions defined in your template through the endpoint. 2021-01-17 14:55:11 * Running on http://127.0.0.1:3001/ (Press CTRL+C to quit) Invoking app.lambda_handler (python3.6) Skip pulling image and use local one: amazon/aws-sam-cli-emulation-image-python3.6:rapid-1.12.0. Mounting /sfn-test/hello_world as /var/task:ro,delegated inside runtime container ・ ・ ・ hogehoge HelloWorld!! ・ ・ ・ Mounting /sfn-test/good_bye as /var/task:ro,delegated inside runtime container ・ ・ ・ hogehoge GoodBye!! ・ ・ ・無事、2つのlambdaを実行できました!
ARNを呼び出しているだけなので、アプリケーションからSDKなどで呼び出すこともできます。
実際にはこの形で、アプリケーションからStep Functionsと連携が取れるかをローカル環境で確認するために利用できそうです。最後に
ということで、LocalStackとSAM Localを利用して、Step Functions(lambda)のローカル環境での実行確認が行えました。
AWS上にデプロイする前に、実行確認が取りたい場合などには有効利用できそうですね。本記事は以上です。
どなたかの参考になれば幸いです!
- 投稿日:2021-01-17T15:30:18+09:00
GreengrassでIoT入門
はじめに
この記事は、趣味で宇宙開発を行う団体「リーマンサット・プロジェクト」がお送りする新春アドベントカレンダーの 1/26 分の投稿になります。
リーマンサットでは人工衛星の開発を行っていますが、地球と軌道上を周回する衛星とで通信を行う、今の地球上で最もスケールの大きいIoTプロジェクトだと言っても良いと思います。
今回はIoT関連ということで、AWSさんが開発されているGreengrassというソフトウェアについて簡単な解説記事を書こうと思います。特にV2に関しては、re:Invent2020で発表されたばかりであまり情報がないため、そちらを中心に書いていきます。Greengrassについて
ざっくりいうと、AWSの機能を一部エッジデバイスで実行可能にし、エッジデバイス向けの機能を足したソフトウェアになります。
例えば、
- Lambdaをエッジデバイスで実行する
- ECRに登録してあるコンテナイメージを実行する
- SageMakerで作成したMLModelをデプロイする
などになります。またMQTT BrokerであるAWS IoT Coreと通信し、あるトピックにメッセージがpublishされた際にエッジデバイス上で特定のLambdaを起動する、といった使い方もできます。機能全般についてはBlackbeltの記事が詳しいです。
ユースケースとしては、主に工場などがあるそうです。おそらく一台マシンパワーが強めのマシンをエッジに置いておいて、他のデバイスを制御・管理する、といった使い方になるのだと思います。
GreengrassV1とV2について
Greengrassは長らくV1で改良が続けられていましたが、re:Invent2020の時期にGreengrass V2が発表されました。
実行できる機能については大きな違いはありませんが、公式の解説によると、大きな違いは
1. Apache2.0のOSS公開をしているため、直接ソースコードをカスタマイズ可能
2. ランタイム構成がモジュール化されており、ユースケースやHWによって組み合わせの変更が可能
3. ローカル開発ツールの充実化
4. フリートマネジメント機能の改良
になります。
実際に動かしてみたい方は、getting-startedを見られると良いと思います。手順自体はそれほど難しくないので、一時間あれば充分にできると思います。筆者は、AWS EC2 Ubuntu20 aarch64で試しました。フリートマネジメント機能以外を1つずつ簡単に見ていくと
Apache2.0のOSS公開をしているため、直接ソースコードをカスタマイズ可能
Githubのレポジトリでソースコードが公開されていました。
おそらくランタイムのコア機能を司るnucleusレポジトリを見てみると、javaで構成されたソースコードが確認できます。
たしかにIoTの環境に応じてソースコードから改変可能、というのは強みかもしれません。ランタイム構成がモジュール化されており、ユースケースやHWによって組み合わせの変更が可能
GreengrassV1は高機能ではありますが、それをモジュール化し分割して必要な分だけデプロイが可能になっているようです。
公式より複数のコンポーネントが提供されており、これを必要な分だけ選択してデプロイが可能になります。
ローカル開発ツールの充実化
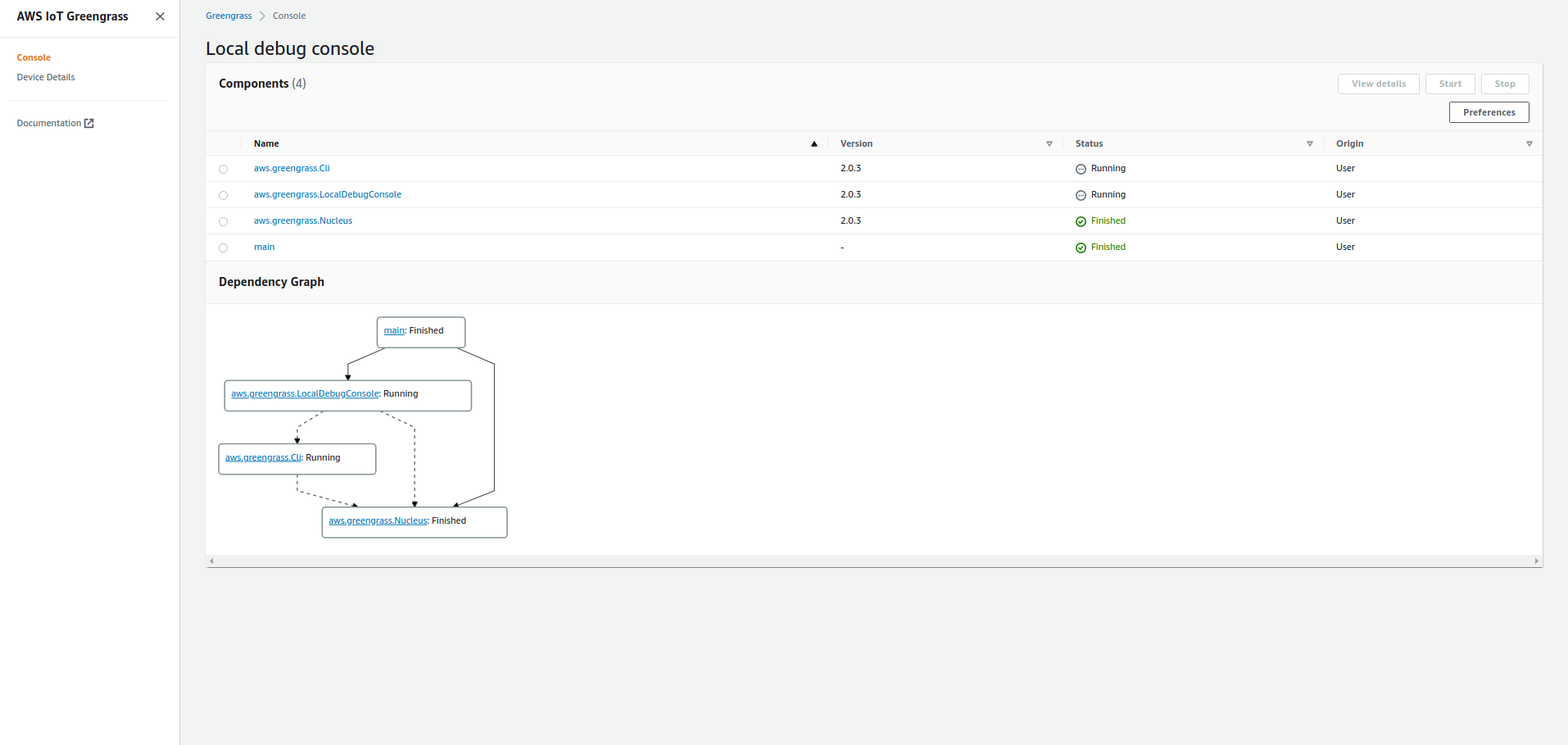
greengrass-cliやlocal debug consoleが開発用のデバイスで使用可能になっています。
greengrass-cliでは今現在デプロイされているコンポーネントの確認などが行なえます。
このgreengrass-cli自体も、プロダクション用のデバイスにはデプロイしない、といった選択も可能になっています。$ sudo /greengrass/v2/bin/greengrass-cli component list Components currently running in Greengrass: Component Name: DeploymentService Version: 0.0.0 State: RUNNING Configuration: null Component Name: UpdateSystemPolicyService Version: 0.0.0 State: RUNNING Configuration: null **省略** Component Name: aws.greengrass.Cli Version: 2.0.3 State: RUNNING Configuration: {"AuthorizedPosixGroups":null} Component Name: aws.greengrass.LocalDebugConsole Version: 2.0.3 State: RUNNING Configuration: {"bindHostname":"localhost","port":"1441","websocketPort":"1442"}local debug consoleでは、greengrass-cliで参照可能な情報がGUIで表示されるようになっています。
その他
GreengrassV1では、pre-builtされたバイナリを実行する形式ですが、今回からはモジュール化に伴いjavaが必須になっているようです。
自動スクリプトでsystemdへの登録まで実施してくれるので、実際見てみるとjavaで起動していることがわかります。$ sudo systemctl status greengrass.service ● greengrass.service - Greengrass Core Loaded: loaded (/etc/systemd/system/greengrass.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2021-01-04 01:24:07 UTC; 3h 22min ago Main PID: 5459 (loader) Tasks: 56 (limit: 4600) Memory: 493.3M CGroup: /system.slice/greengrass.service ├─5459 /bin/sh -x /greengrass/v2/alts/current/distro/bin/loader └─5649 java -Dlog.store=FILE -Droot=/greengrass/v2 -jar /greengrass/v2/alts/current/distro/lib/Greengrass.jar --setup-system-service false動かしてみる
getting startedの手順で動かしてみました。
環境:AWS EC2 Ubuntu20 arm64
手順通りやれば基本的にできますが、注意点としてはデバイスに
- aws cli のインストール
- jre v8以上のインストール
が必要になります。最終的に成功しているかどうかは、AWS IoTのGUIコンソールより確認できます。下記の感じになると思います。
Lambda関数などをデプロイするサンプルはまだ無いようなので、ここのリンクより必要な設定値等を抜き出しつつ、作成していく必要がありそうです。
おわりに
AWSと宇宙といえば、Groud Stationがありますが、これを使用して「人工衛星にLambda関数をデプロイし、地上からMQTTメッセージをpublishするとIoTCoreとGroundStationを経由して、人工衛星にデプロイ済みのLambda関数を動的に起動する」みたいなことができると、わくわくするIoTシステムができそうですね!
次は @ishikawa-takumi の記事になります。お楽しみに!
- 投稿日:2021-01-17T15:25:47+09:00
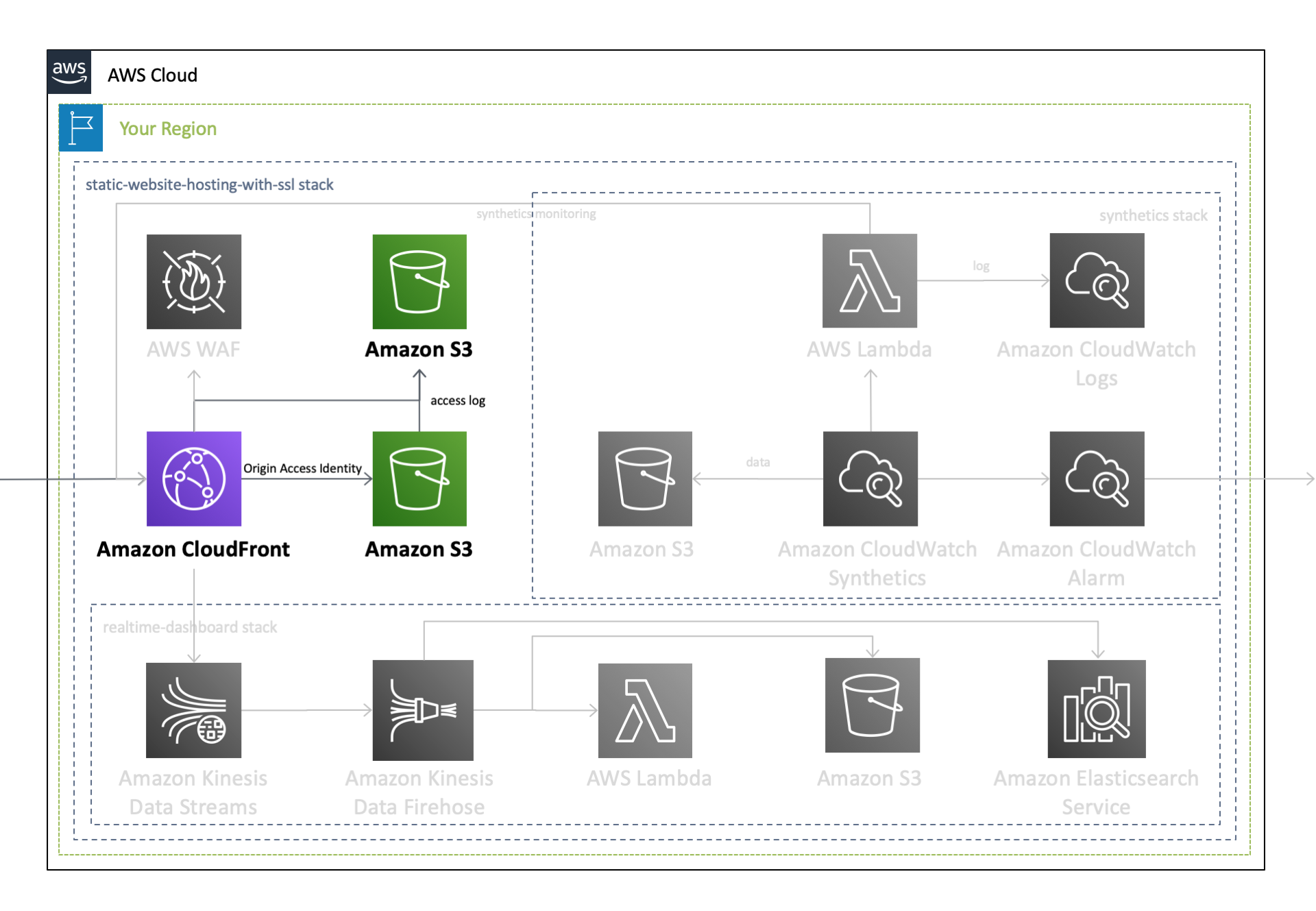
簡単Webサイトホスティング②CloudFrontにWAFをアタッチするCloudFormationテンプレート
はじめに
Amazon Web Services(AWS)が提供する、
Amazon CloudFrontやAmazon S3と呼ばれるサービスを組み合わせることで、 HTMLやJavaScript、画像、ビデオなどで構成される静的Webサイトの配信基盤 を安価に構築することができます。本記事では、リソースのセットアップを自動で行うことのできる、AWS CloudFormationを用いることで、これらの運用基盤を ミスなく迅速に構築 する手順をご説明します。なお、今回使用する CloudFormation テンプレートは、以下の GitHub リポジトリで公開しています。TL;DR
以下の
CloudFormationテンプレートを実行することで、 静的Webサイトのホスティング基盤を迅速かつお手軽 に実現します。下にあるボタンをクリックすると、自身のAWSアカウント(Asia Pacific Tokyo - ap-northeast-1)で、このCloudFormationテンプレートを実行することが可能となります。

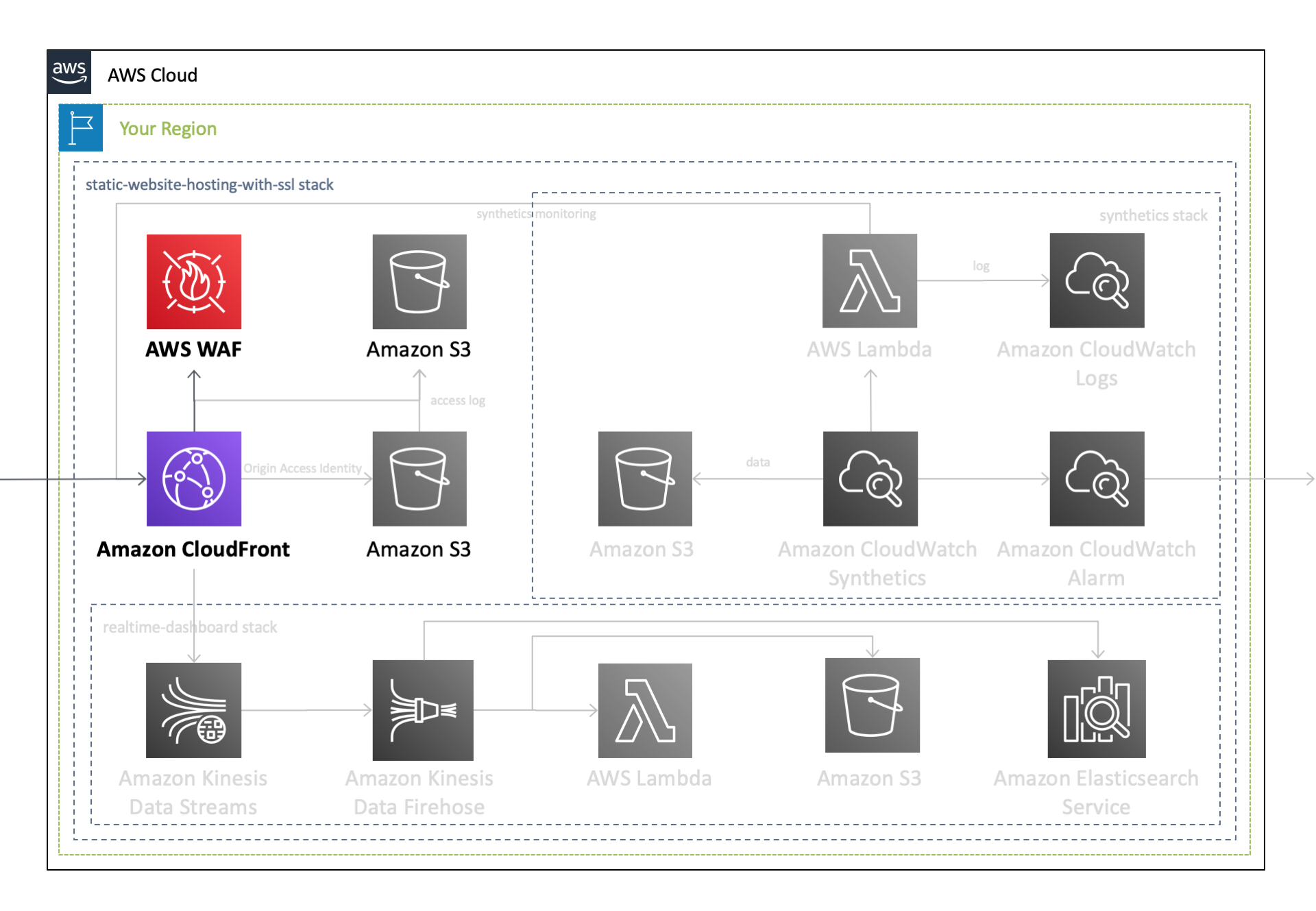
作成されるAWSリソース全体のアーキテクチャ図は、前回の記事をご覧ください。このうち本記事では、以下のリソースに焦点を当ててご説明します。
Amazon CloudFront への AWS WAF のアタッチ
AWS WAFは、Webの脆弱性からWebアプリケーションを保護する Web Application Firewall で、 SQLインジェクションやクロスサイトスクリプティングなどの 一般的な攻撃パターンをブロック します。静的Webサイトのホスティング機能の一部を担う CloudFrontに AWS WAFをアタッチすることで、CloudFrontへの リクエストのモニタリング 、およびコンテンツへの アクセスのコントロール を可能とします。
AWS WAF
以下のテンプレートを用いて、AWS WAFを設定します。
Resources: WebACL: Type: AWS::WAFv2::WebACL Properties: DefaultAction: Allow: {} Description: !Sub ACL for ${LogicalNamePrefix} Name: !Ref LogicalNamePrefix Rules: - Name: AWSManagedRulesCommonRuleSet OverrideAction: Count: {} Priority: 1 Statement: ManagedRuleGroupStatement: Name: AWSManagedRulesCommonRuleSet VendorName: AWS VisibilityConfig: CloudWatchMetricsEnabled: true MetricName: AWSManagedRulesCommonRuleSet SampledRequestsEnabled: false - Name: AWSManagedRulesAdminProtectionRuleSet OverrideAction: Count: {} Priority: 2 Statement: ManagedRuleGroupStatement: Name: AWSManagedRulesAdminProtectionRuleSet VendorName: AWS VisibilityConfig: CloudWatchMetricsEnabled: true MetricName: AWSManagedRulesAdminProtectionRuleSet SampledRequestsEnabled: false - Name: AWSManagedRulesKnownBadInputsRuleSet OverrideAction: Count: {} Priority: 3 Statement: ManagedRuleGroupStatement: Name: AWSManagedRulesKnownBadInputsRuleSet VendorName: AWS VisibilityConfig: CloudWatchMetricsEnabled: true MetricName: AWSManagedRulesKnownBadInputsRuleSet SampledRequestsEnabled: false - Name: AWSManagedRulesAmazonIpReputationList OverrideAction: Count: {} Priority: 4 Statement: ManagedRuleGroupStatement: Name: AWSManagedRulesAmazonIpReputationList VendorName: AWS VisibilityConfig: CloudWatchMetricsEnabled: true MetricName: AWSManagedRulesAmazonIpReputationList SampledRequestsEnabled: false Scope: REGIONAL VisibilityConfig: CloudWatchMetricsEnabled: true MetricName: !Ref LogicalNamePrefix SampledRequestsEnabled: false WebACLAssociation: Type: AWS::WAFv2::WebACLAssociation Properties: ResourceArn: !Ref TargetResourceArn WebACLArn: !GetAtt WebACL.Arn本テンプレートでは、 Default Action を
Allowに設定しており、 Ruleに一致しないリクエストは全て許可 します。また、WAFv2から導入された以下の マネージドルールを有効化 して、これらの ルールに一致するリクエストをカウント します。なお、 CloudWatchへメトリクスを送信 しますが、リクエストのサンプルの保存は行いません。
優先順位 ルール名 内容 1 AWSManagedRulesCommonRuleSet 一般的に適用可能なルール 2 AWSManagedRulesAdminProtectionRuleSet 公開されている管理ページへの外部アクセスをブロックするためのルール 3 AWSManagedRulesKnownBadInputsRuleSet 無効であることがわかっており脆弱性の悪用または発見に関連するリクエストパターンをブロックするルール 4 AWSManagedRulesAmazonIpReputationList Amazon 内部脅威インテリジェンスに基づくルール Amazon CloudFront
先ほど作成した
AWS WAFをAmazon CloudFrontにアタッチします。前回のテンプレートに以下の記述を追加します。Resources: CloudFront: Type: 'AWS::CloudFront::Distribution' Properties: DistributionConfig: WebACLId: !GetAtt WebACL.Id以上で、 マネージドルールを有効化したAWS WAFを作成して、CloudFrontにアタッチ することができました。これにより、CloudFront へのリクエストは、 AWS WAF で検査されたのちに CloudFront ディストリビューションで処理 されます。
関連リンク
- ワンクリックで配信基盤を構築 - CloudFormation を用いて簡単Webサイトホスティング
- CloudFrontにWAFをアタッチ - CloudFormation を用いて簡単Webサイトホスティング
- 投稿日:2021-01-17T14:20:23+09:00
SecretManagerのパラメータを ECS Taskからクロスアカウントで取得する際の手順の罠
概要
SecretManagerのパラメータをECS Taskからクロスアカウントで取得しようとした場合、
AWSの公式手順のやり方では取得できなかったので掲載します。詳細
どれだけググってもこの説明をしているページがなかったのでここに掲載します。
クロスアカウントを用いてSecretManagerからパラメータを取得しようとする場合、AWSで公式の手順が紹介されています。
要はIAM roleとKMS(CMK)とSecretManagerのそれぞれで権限指定が必要と言っているのですが、SecretManagerで権限を指定してもECS Task定義の環境変数経由でクロスアカウントのSecretManagerのパラメータを取得することができませんでした。{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowUseOfTheKey", "Effect": "Allow", "Action": "secretsmanager:GetSecretValue", "Principal" : { "AWS" : "arn:aws:iam::Dev_Account:user/SecretsUser" }, "Resource": "*", "Condition": { "ForAnyValue:StringEquals": { "secretsmanager:VersionStage": "AWSCURRENT" } } } ] }で、以下のように変えたら取得できるようになりました。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowUseOfTheKey", "Effect": "Allow", "Action": "secretsmanager:GetSecretValue", "Principal" : { "AWS" : "arn:aws:iam::Dev_Account:role/AWSLierECSTaskRole" }, "Resource": "*" } ] }
注意: ステップ 5 のポリシーでは、AWSCURRENT バージョンステージへの参照が明示的に必要です。
と書かれているのに、これは罠ですよね・・・
続く「これは、シークレットが次のように SecretsUser によって取得される場合は常に明示的に要求する必要があります。」と言うのは、タスクはそうじゃないよということかもしれませんが・・・
手順としても割と最近掲載されたものなので、誰かの一助になればと。
- 投稿日:2021-01-17T13:34:03+09:00
AWS ECSでDocker環境を試してみる
概要
AWS資格取得に向けて利用してみたAWSサービスの具体的な利用方法についての投稿です。
今回はAWS上でのDocker利用、 Amazon ECS(Amazon Elastic Container Service)を利用してみる編です。15分程度でDockerを利用したWebアプリケーションが公開できます。資格試験の勉強法は記事は以下を参照。
AWS初心者がAWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法
AWS初心者がAWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に合格した時の勉強法できるようになること
- AWS ECSでのWebアプリケーションの公開
およその作業時間
- 15分
- ECSの「今すぐ始める」メニューをやってみます
- すべてデフォルト値でも構築できその場合、5クリック5分で完了します^^;
必要な知識
- Docker
- AWS ECS
手順の概要
ではやってみましょう。
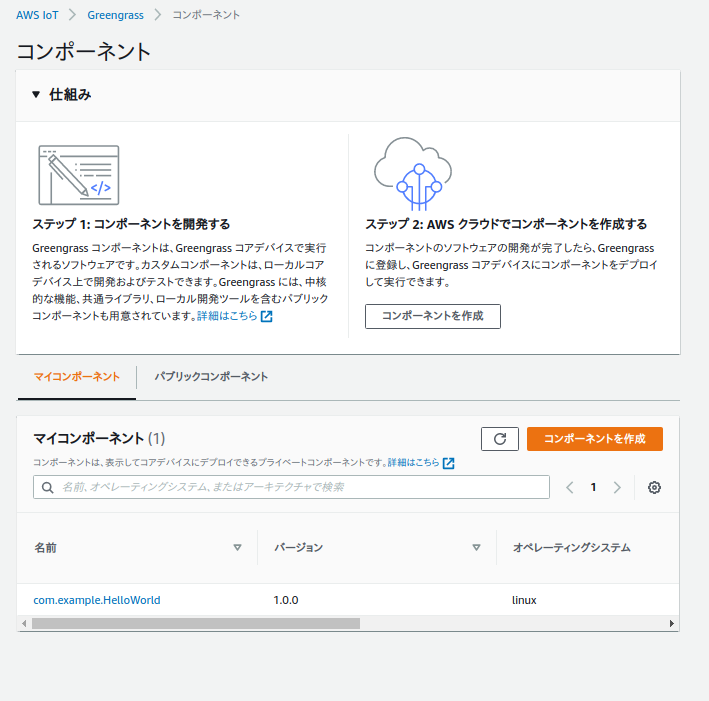
とは言うものの、ECSの「今すぐ始める」メニューのウィザードに従って入力するだけです。
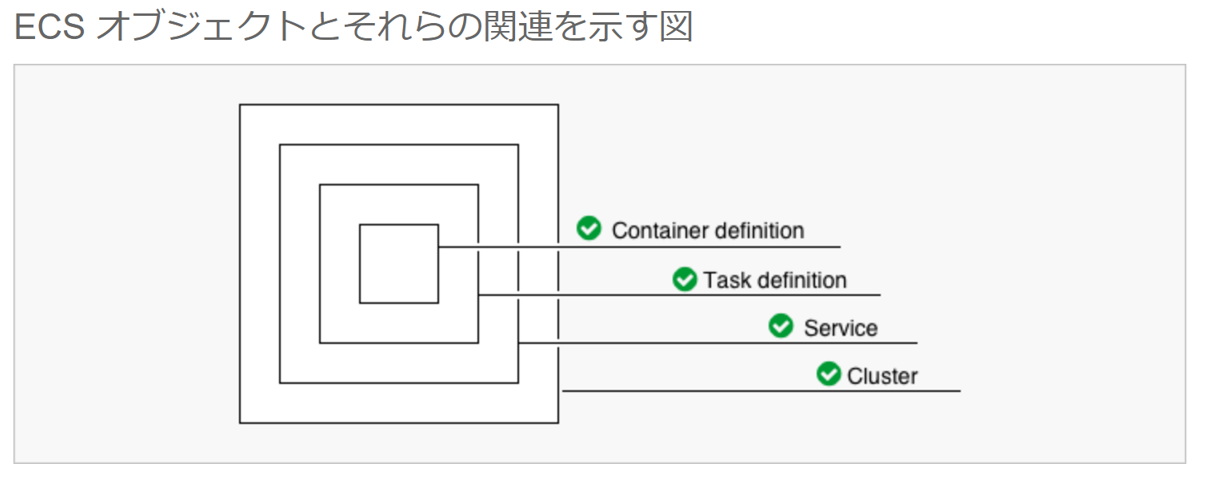
最初に全体像だけ説明すると、ECSの概念としては、
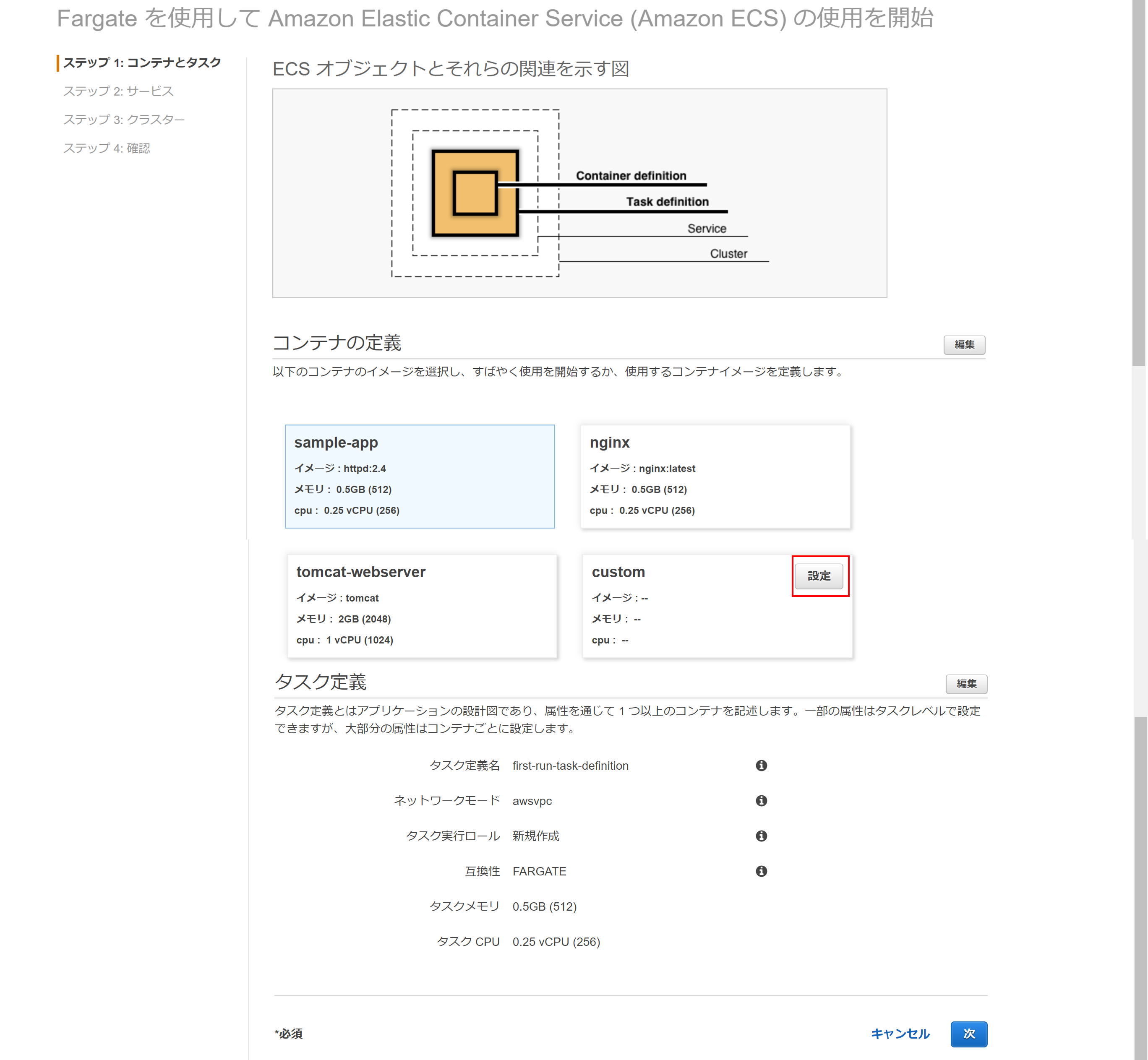
図のように、Container definition、Task definition、Service、Clusterの4つがあり、こらをウィザードに従って3画面で設定してきます。
では、始めます。
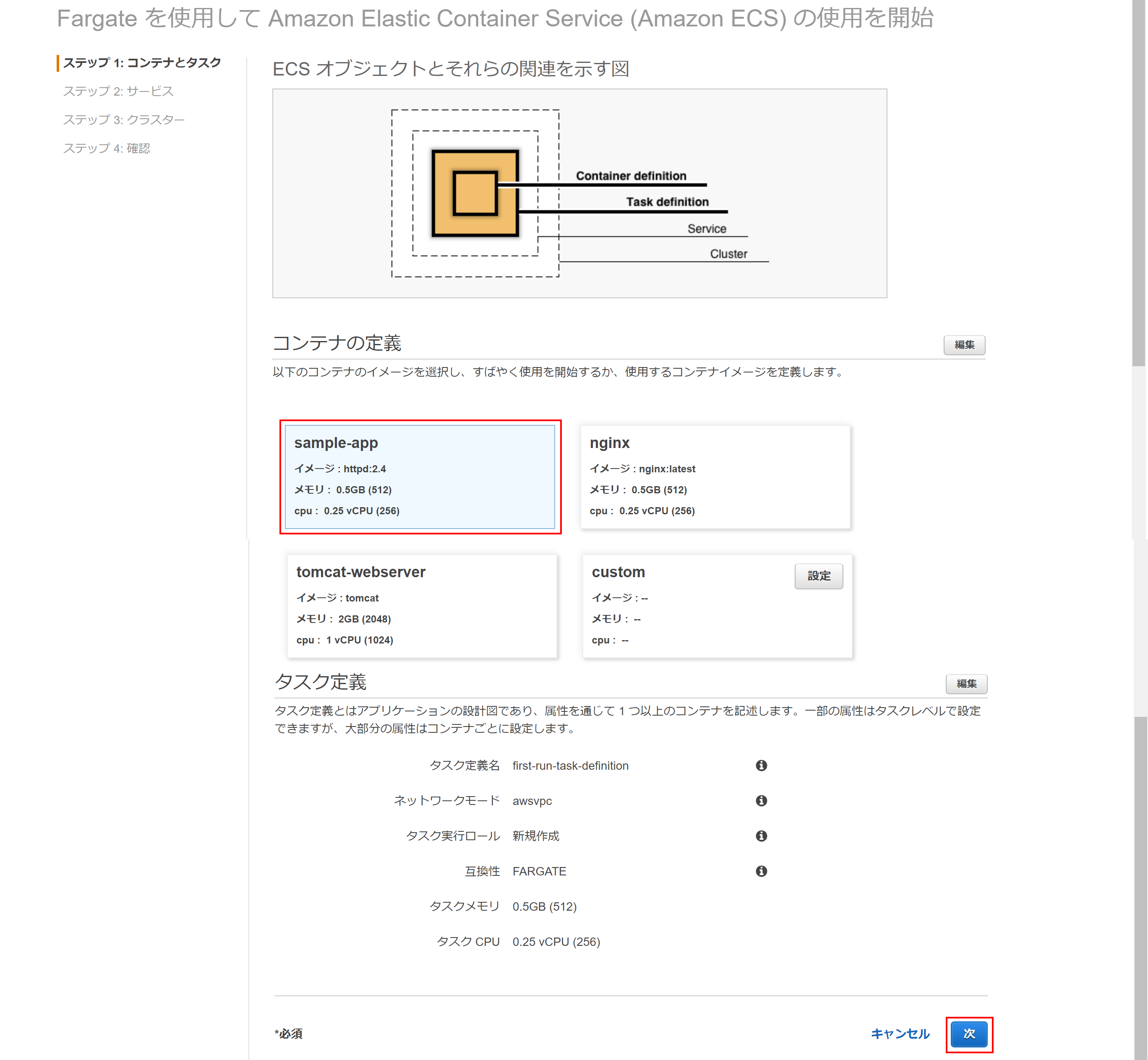
ECSの初期画面、またはクラスターの今すぐ始めるをクリックして開始します。
または
今すぐ始めるをクリックして開始します。(クリック1回目)Container definition/Task definition設定
最初の画面でContainer definitionとTask definition設定を行います。
コンテナ定義では、デフォルトでhttpd、nginx、tomcatが用意されています。(今回はhttpdを選択)
コンテナ定義、タスク定義いずれも右上に編集ボタンが用意されており、一部パラメータのカスタマイズは可能です。
とりあえず今回はデフォルトのまま次をクリック。(クリック2回目)
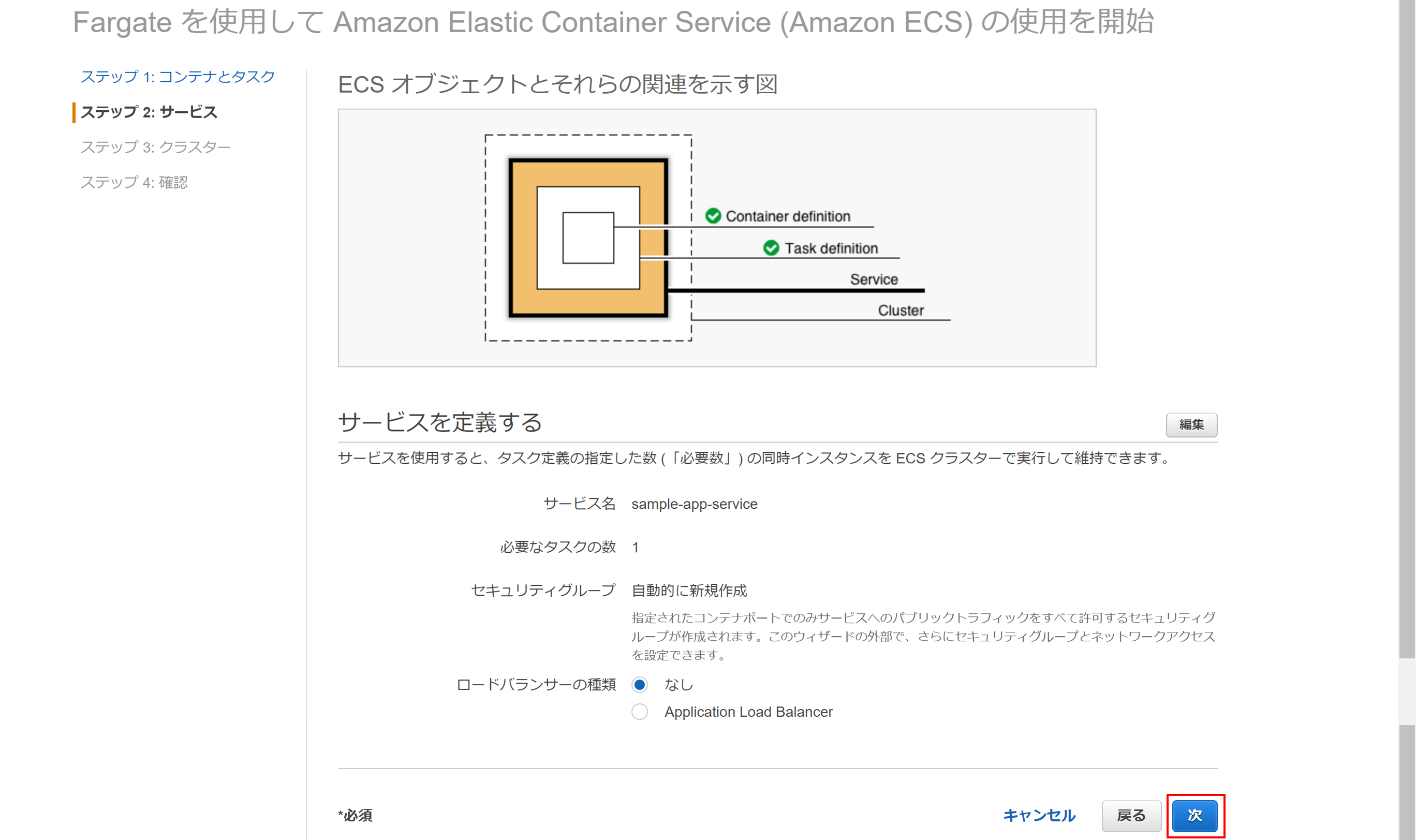
Service設定
次はサービス設定です。ロードバランサーとしてALBを組み込めるようですが、とりあえずなしのまま次をクリック。(クリック3回目)
Cluster設定
最後にクラスター設定です。と言ってもクラスター名だけなのでデフォルトのまま次をクリック。(クリック4回目)
確認画面
確認画面が表示されるので、確認して作成をクリック。
以上!クリック5回で作成完了です!!
作成画面
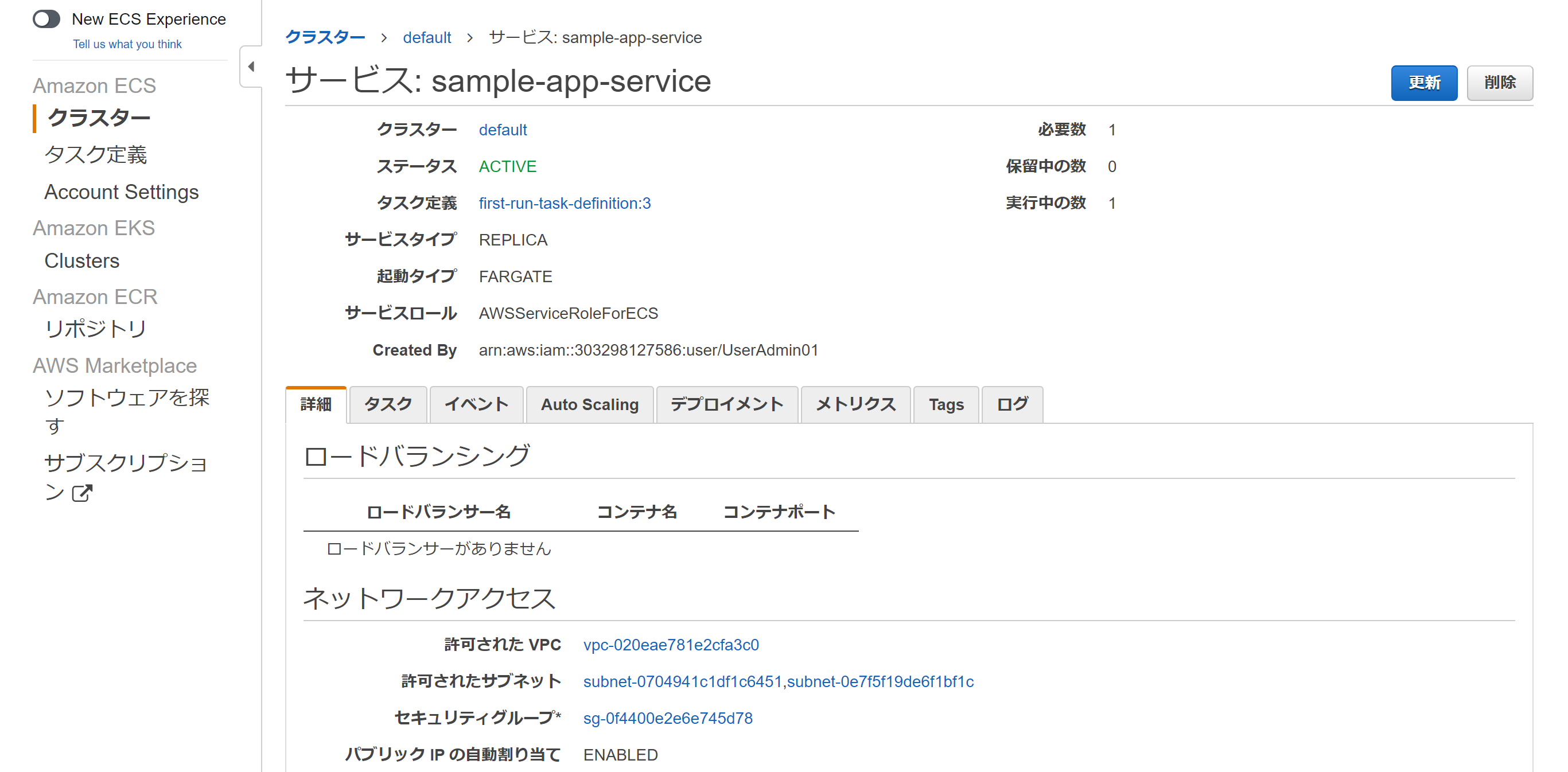
内部的にはCloudFormationを使っているようなので、頑張ってVPCから作ってくれていて問題がなければ2,3分後に作成されます。
2,3分後、、、
サービスの表示をクリックしてみましょう。
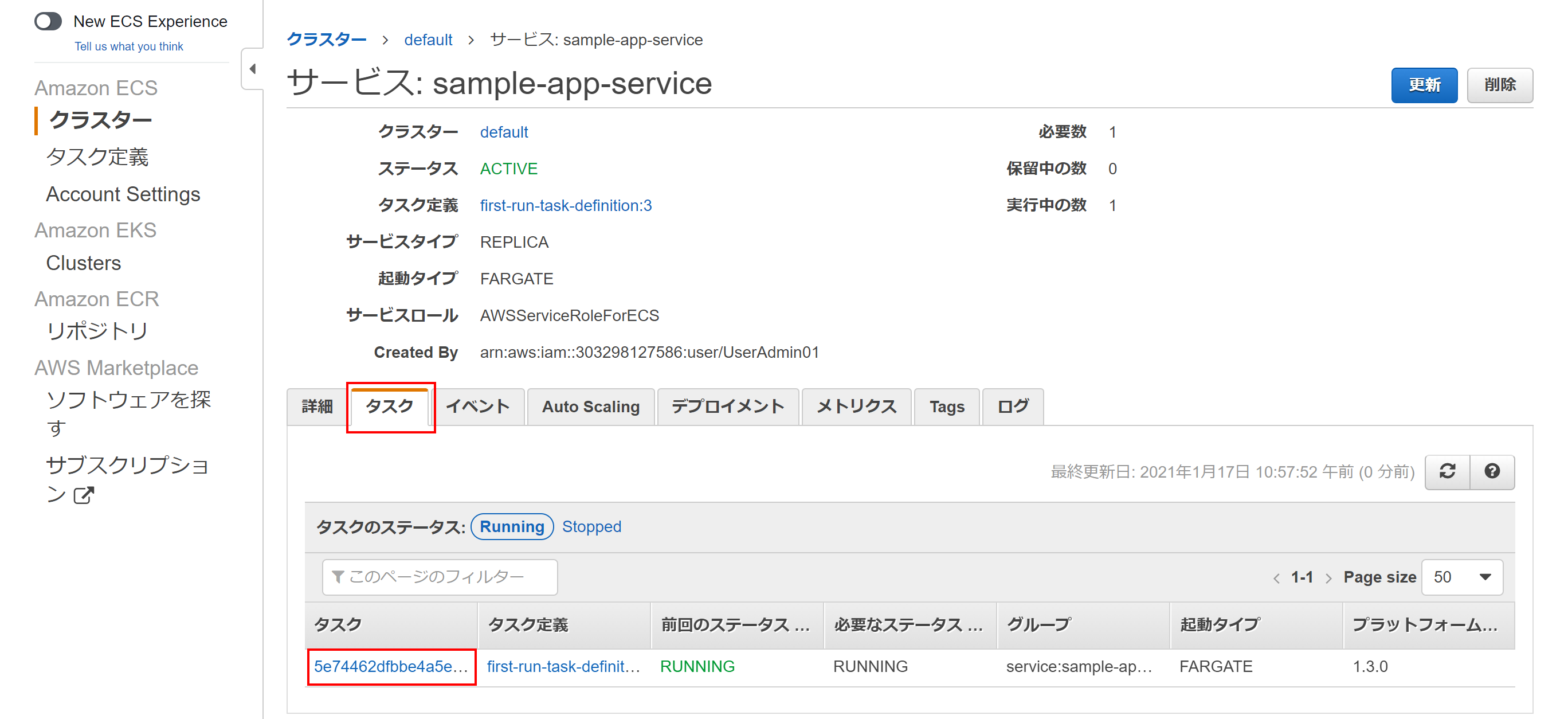
作成されたVPCやサブネット、セキュリティグループの情報が確認できす。
タスクタブから作成されたタスクをクリックすると
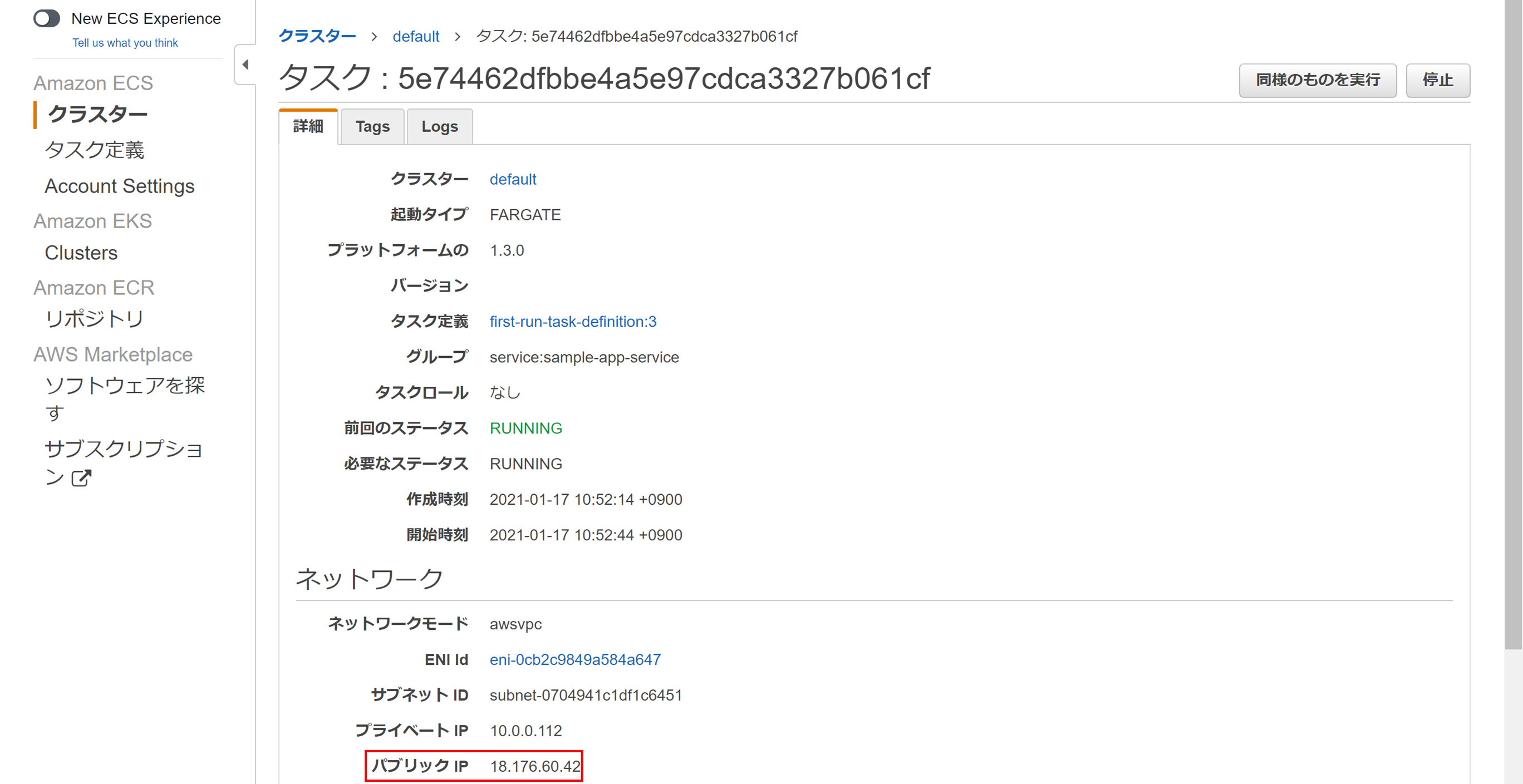
パブリックIPが割り当てられているので、
http://{割り当てられていたパブリックIP}/
でアクセスしてみます。
↓が表示されていれば問題なく作成できています。
AWS ECSでのWebアプリケーションの公開完了です!
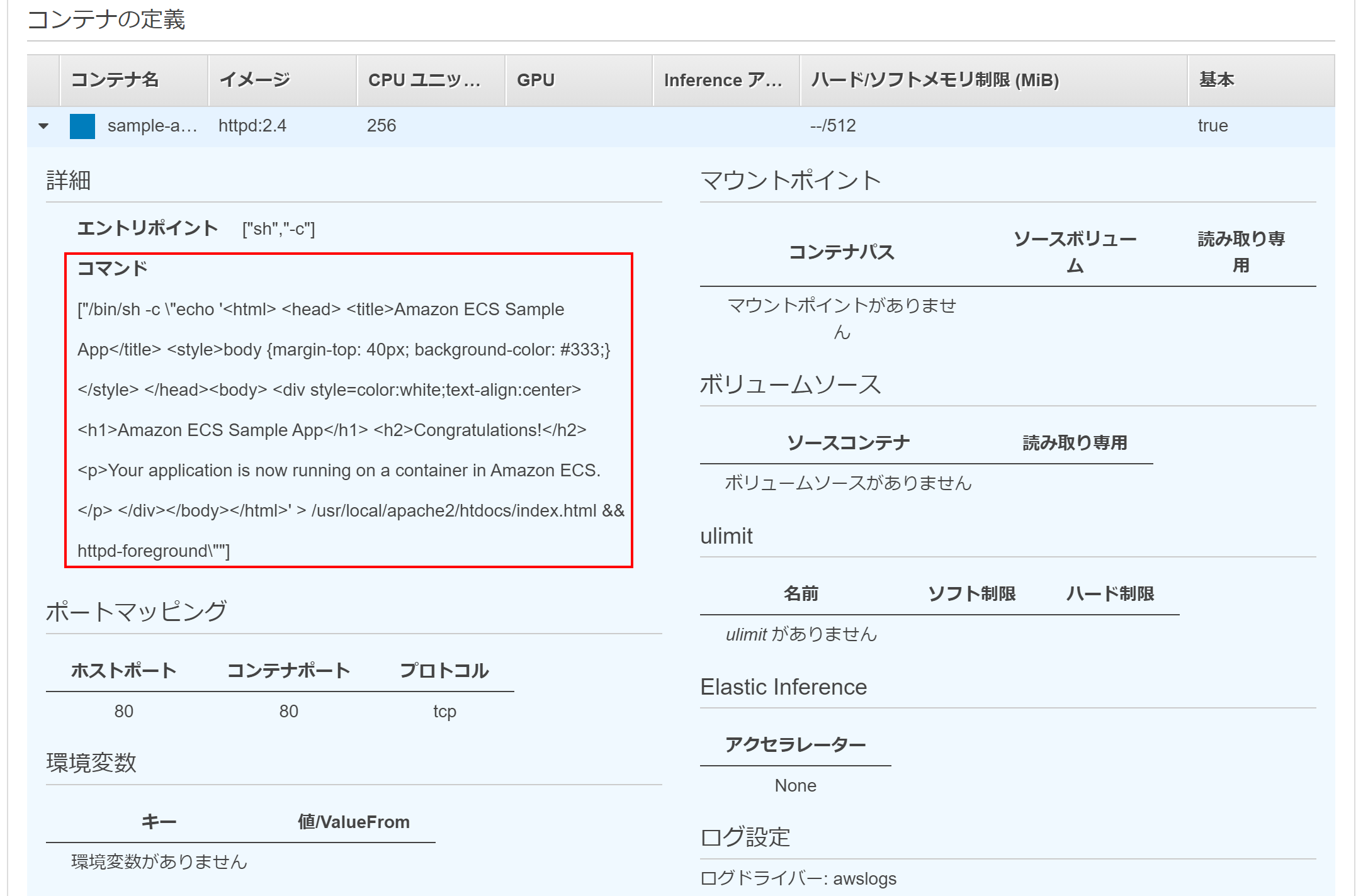
実体としては、コンテナ定義の中に定義されている以下のようです。
はい、クリック5回完了です。
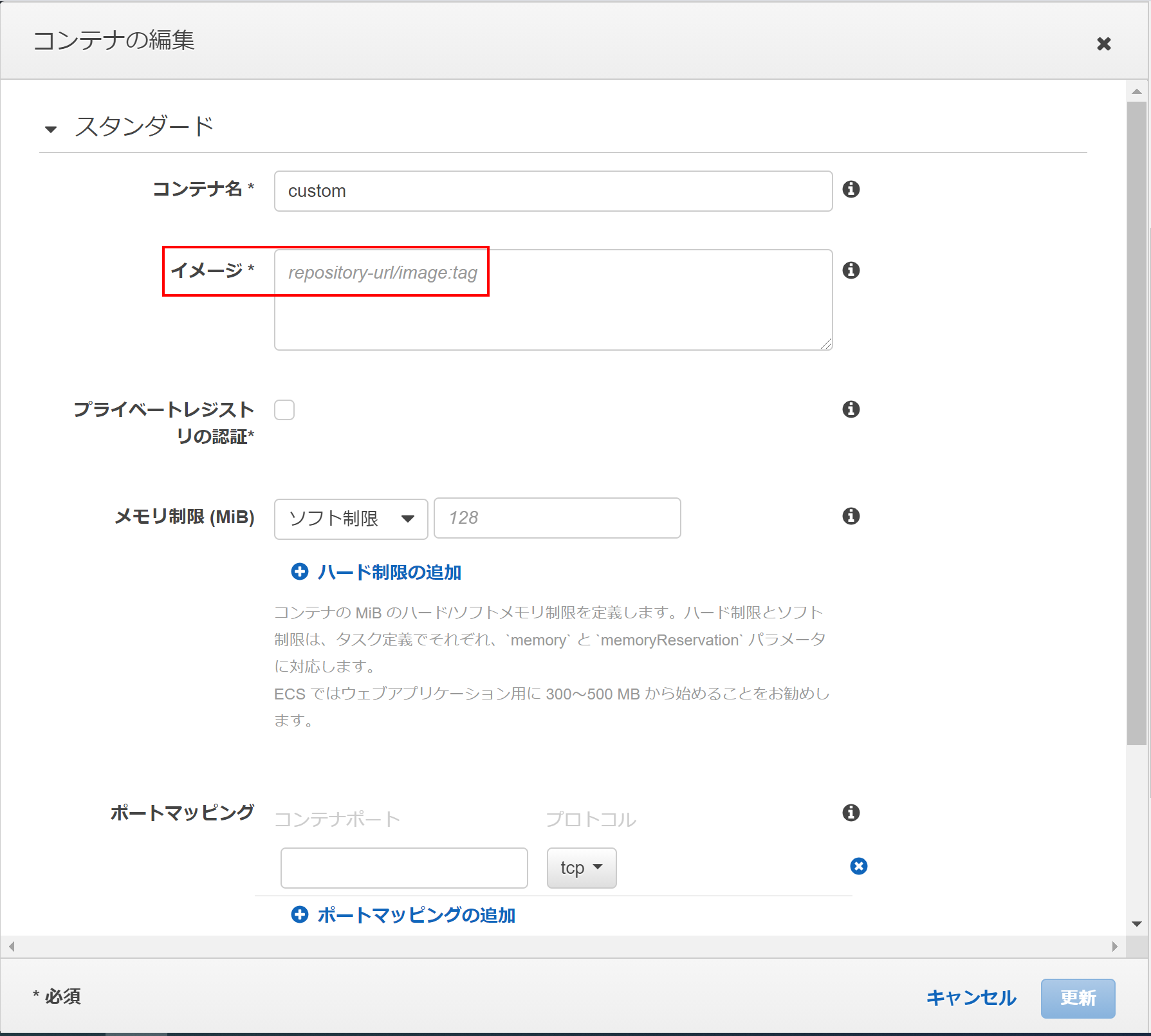
あとはコンテナ定義などいじくり倒しましょう^^補足1:自作Webアプリケーションのコンテナイメージの設定
Container definition設定のcustomで自分で作成した今回のようなhttp(80ポート)のWebアプリケーションのコンテナイメージを指定するだけで簡単にWebアプリケーションの公開ができそうですね。
開いた画面でコンテナのイメージを設定
補足2:作成したWebアプリケーションの削除
クラスターメニューのクラスターの削除から簡単にできます。
CloudFormationを使っているのでVPCからコンテナのタスク定義までまるっと削除されます。
まとめ
想像したよりずっと簡単に作成できました。
今のままだとデフォルト設定のままなので今後は設定内容等、もう少し詳しくみてみます(^^)






- 投稿日:2021-01-17T12:30:55+09:00
AWS IAM ユーザーの作成方法
APIやサービスを新しく利用するときに、チュートリアルなど読むと、
「以下の JSON を参考に AWS IAM ユーザーを作成してください」
と、できて当然に書かれていて、素人の私はいつも四苦八苦しております。(できて当然なことなんでしょうけど)公式サイトに書いてあるとおりといえば、そうなんですけど、
恥ずかしながら素人の私は毎回すんなりできないので、「AWS IAM ユーザーの作成方法」を備忘録として残します。
条件
・ユーザーコンソールで作成
・APIなど外部からのアクセスに利用
・ポリシーをJSONで作成手順
AWS マネジメントコンソール にサインイン
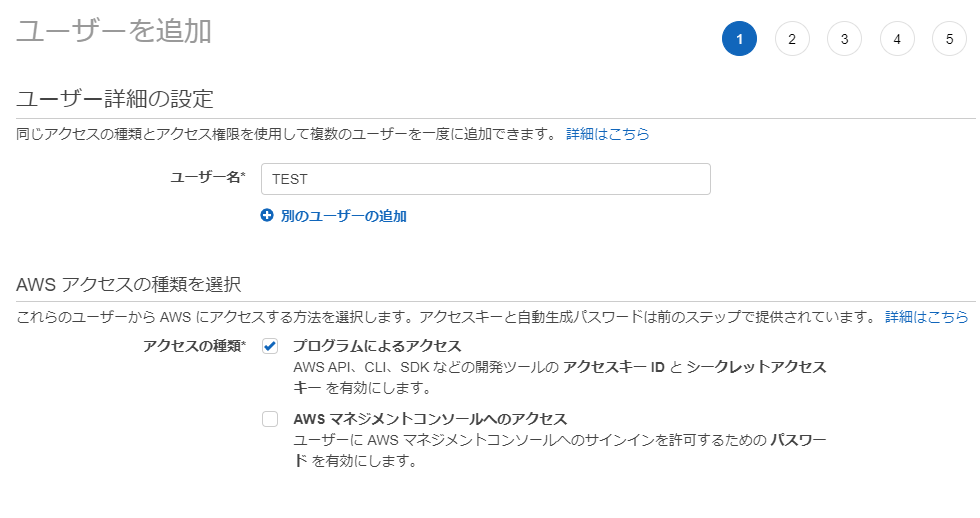
IAM (https://console.aws.amazon.com/iam/ ) を開く。[ユーザー] > [ユーザーを追加]
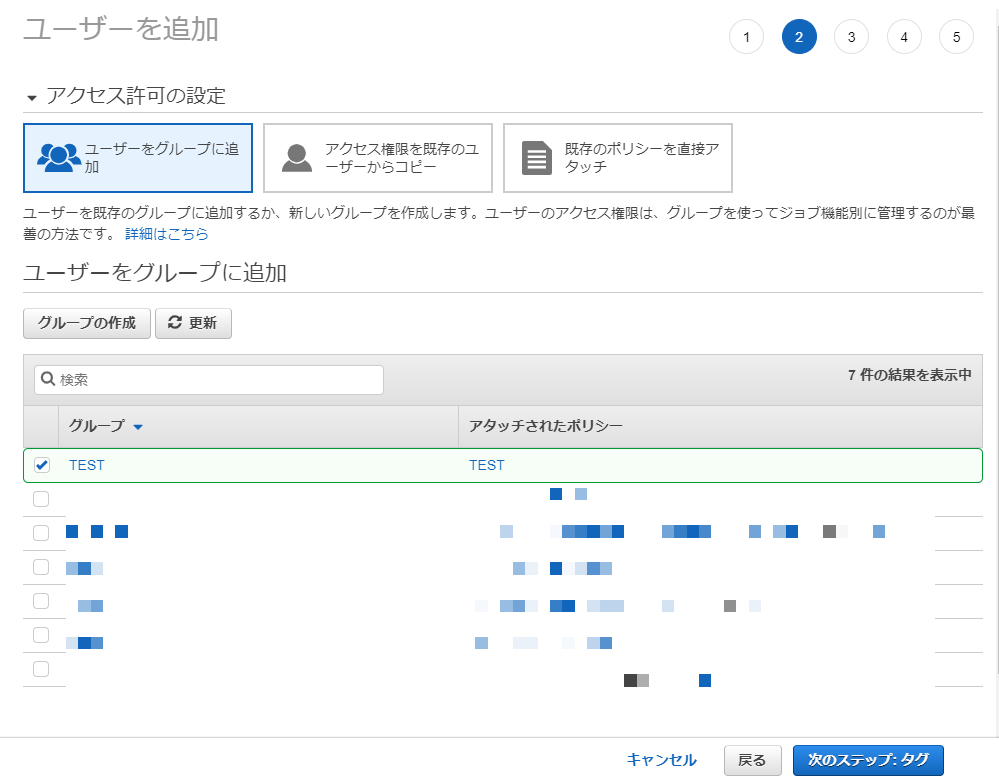
次へ
アクセス許可の設定
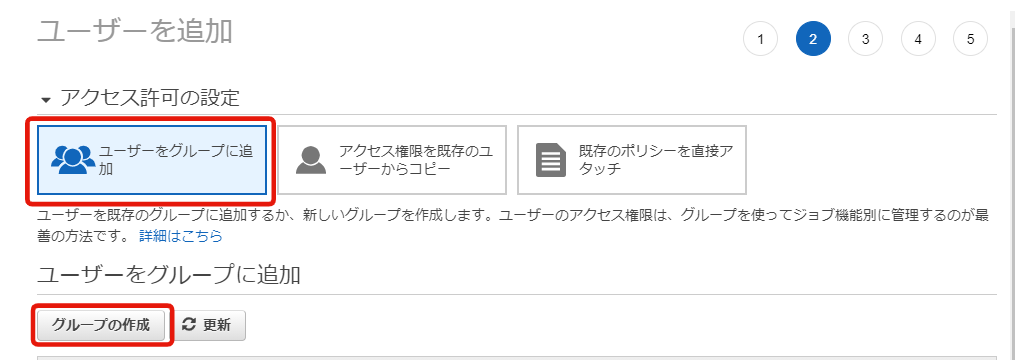
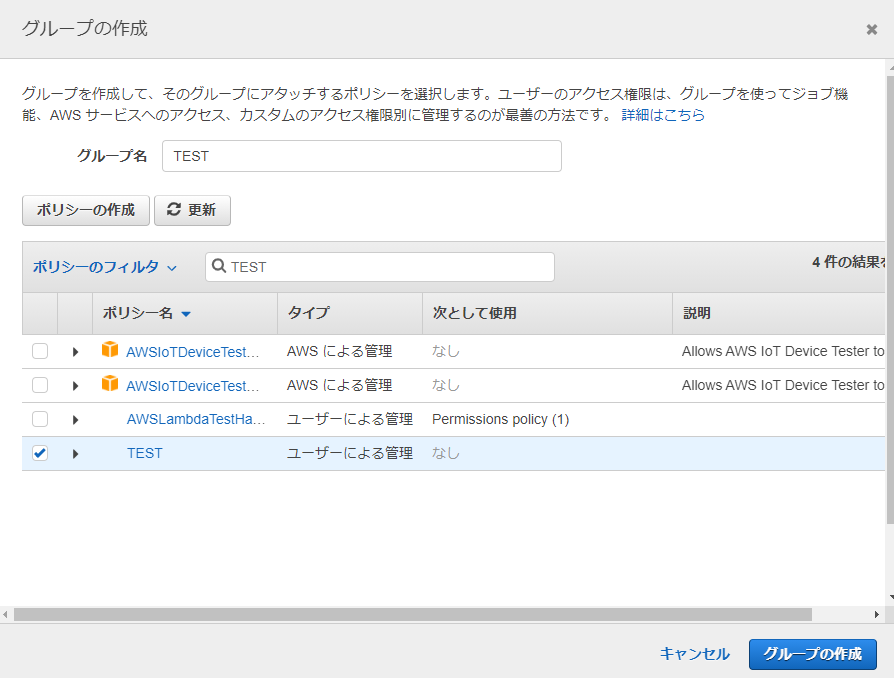
[ユーザーをグループに追加] > [グループの作成]
グループの作成
・グループ名を入力
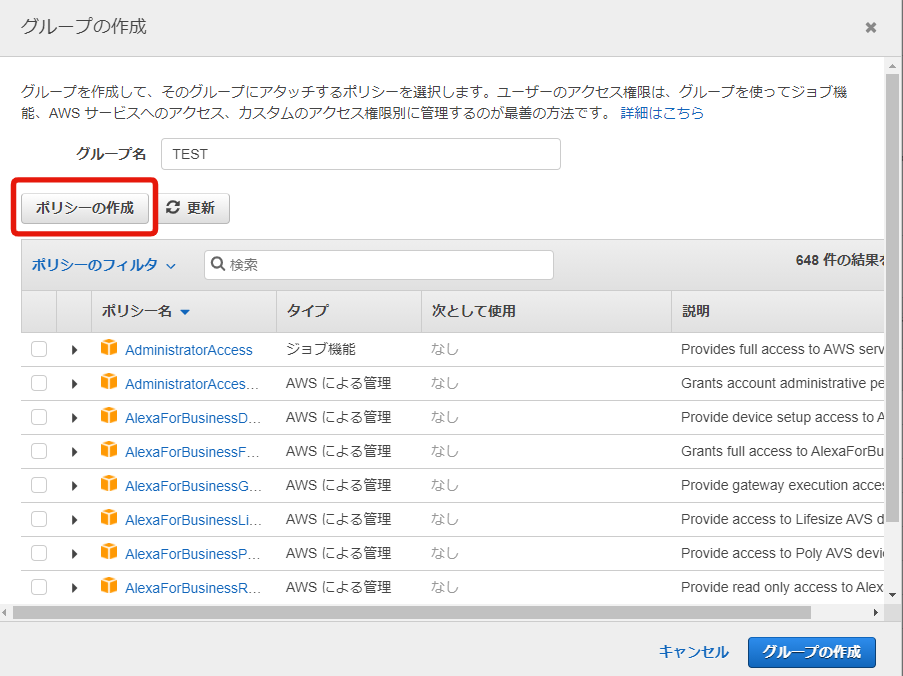
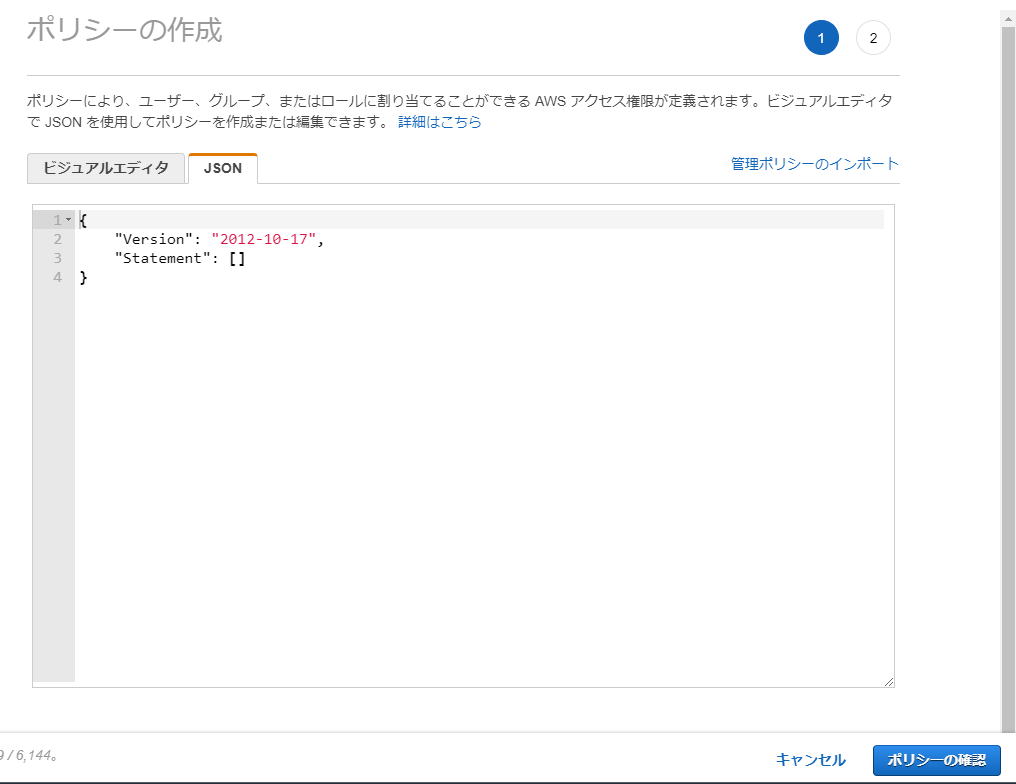
・[ポリシーの作成]をクリック
JSONの場合は、ここに入力
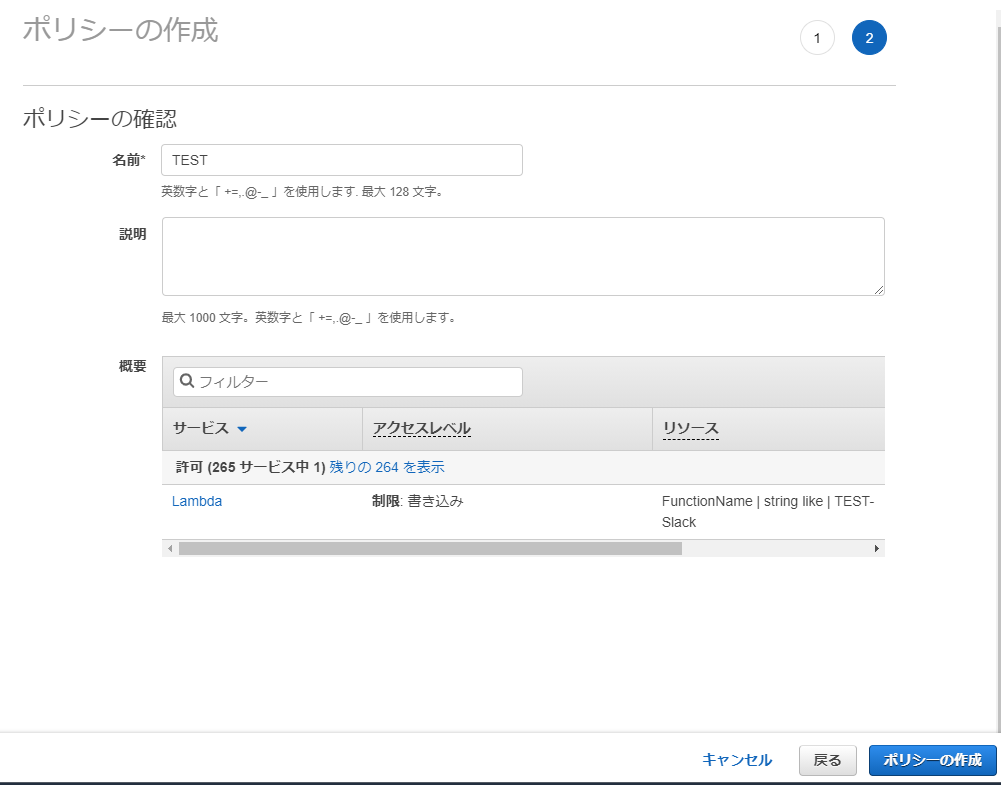
ポリシーの確認
[グループの作成]に戻る。
いま作ったポリシーを選択し、[グループの作成]をクリック
[ユーザーをグループに追加]に戻る。
今作成したグループを選択し、
[次のステップ: タグ] をクリック
必要ならば入力し、[次のステップ: 確認] をクリック
最終確認し、よければ、[ユーザーの作成]をクリック
ユーザーの作成が成功すれば、
アクセスキーIDと、シークレットアクセスキーが発行される。
以上です。
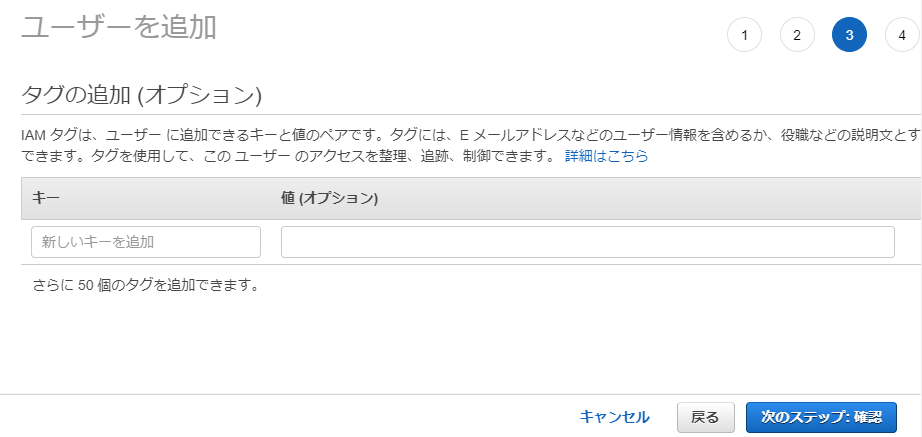
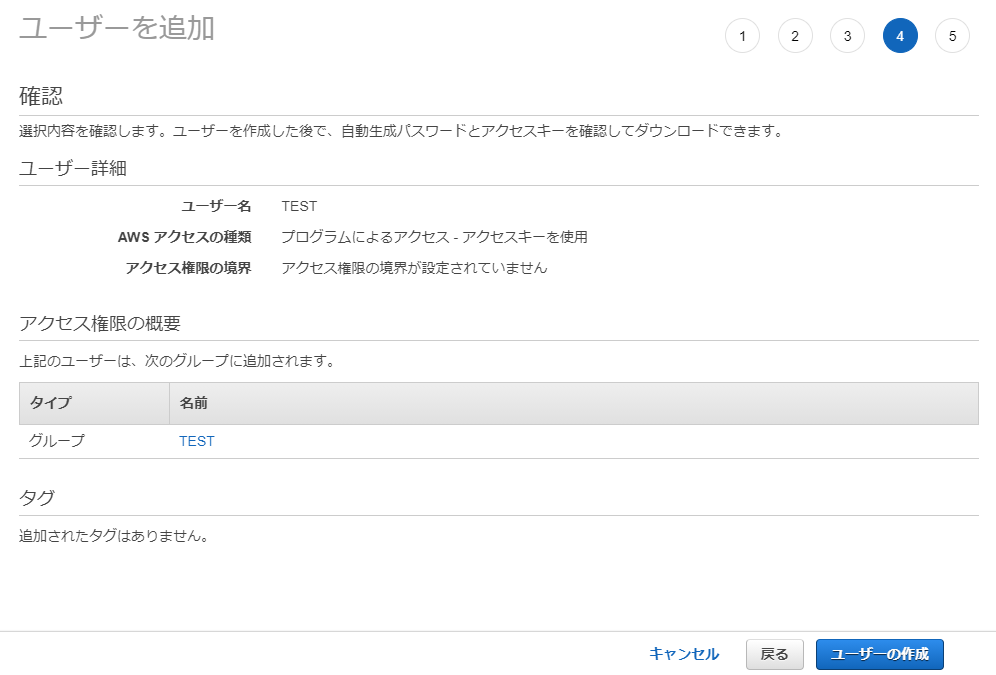
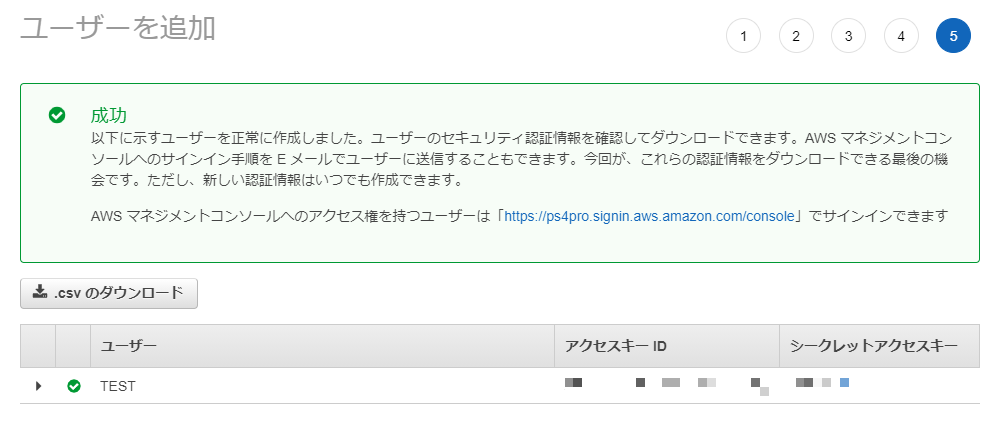
- 投稿日:2021-01-17T11:23:12+09:00
AWS の Mac instanceでディスク拡張する方法
メモ書き程度に
ec2-user@ip-172-31-37-115 ~ % df -h Filesystem Size Used Avail Capacity iused ifree %iused Mounted on /dev/disk2s5 30Gi 10Gi 11Gi 49% 488248 312036152 0% / devfs 186Ki 186Ki 0Bi 100% 642 0 100% /dev /dev/disk2s1 30Gi 6.0Gi 11Gi 36% 157508 312366892 0% /System/Volumes/Data /dev/disk2s4 30Gi 2.0Gi 11Gi 16% 1 312524399 0% /private/var/vm map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home ec2-user@ip-172-31-37-115 ~ % sudo su sh-3.2# diskutil list /dev/disk0 (internal, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *121.3 GB disk0 /dev/disk1 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *137.4 GB disk1 1: EFI EFI 209.7 MB disk1s1 2: Apple_APFS Container disk2 32.0 GB disk1s2 /dev/disk2 (synthesized): #: TYPE NAME SIZE IDENTIFIER 0: APFS Container Scheme - +32.0 GB disk2 Physical Store disk1s2 1: APFS Volume Macintosh HD - Data 6.5 GB disk2s1 2: APFS Volume Preboot 80.0 MB disk2s2 3: APFS Volume Recovery 529.0 MB disk2s3 4: APFS Volume VM 2.1 GB disk2s4 5: APFS Volume Macintosh HD 11.0 GB disk2s5 sh-3.2# diskutil repairdisk /dev/disk1 Repairing the partition map might erase disk1s1, proceed? (y/N) y Started partition map repair on disk1 Checking prerequisites Checking the partition list Adjusting partition map to fit whole disk as required Checking for an EFI system partition Checking the EFI system partition's size Checking the EFI system partition's file system Checking the EFI system partition's folder content Checking all HFS data partition loader spaces Checking booter partitions Reviewing boot support loaders Checking Core Storage Physical Volume partitions The partition map appears to be OK Finished partition map repair on disk1 sh-3.2# diskutil list /dev/disk0 (internal, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *121.3 GB disk0 /dev/disk1 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *137.4 GB disk1 1: EFI EFI 209.7 MB disk1s1 2: Apple_APFS Container disk2 32.0 GB disk1s2 /dev/disk2 (synthesized): #: TYPE NAME SIZE IDENTIFIER 0: APFS Container Scheme - +32.0 GB disk2 Physical Store disk1s2 1: APFS Volume Macintosh HD - Data 6.5 GB disk2s1 2: APFS Volume Preboot 80.0 MB disk2s2 3: APFS Volume Recovery 529.0 MB disk2s3 4: APFS Volume VM 2.1 GB disk2s4 5: APFS Volume Macintosh HD 11.0 GB disk2s5 sh-3.2# diskutil apfs resizeContainer /dev/disk1s2 0 Started APFS operation Aligning grow delta to 105,226,698,752 bytes and targeting a new physical store size of 137,229,197,312 bytes Determined the maximum size for the targeted physical store of this APFS Container to be 137,228,169,216 bytes Resizing APFS Container designated by APFS Container Reference disk2 The specific APFS Physical Store being resized is disk1s2 Verifying storage system Using live mode Performing fsck_apfs -n -x -l -S /dev/disk1s2 Checking the container superblock Checking the EFI jumpstart record Checking the space manager Checking the space manager free queue trees Checking the object map Checking volume Checking the APFS volume superblock The volume Macintosh HD - Data was formatted by newfs_apfs (1412.141.1) and last modified by apfs_kext (1412.141.1) Checking the object map Checking the snapshot metadata tree Checking the snapshot metadata Checking the extent ref tree Checking the fsroot tree Checking volume Checking the APFS volume superblock The volume Preboot was formatted by diskmanagementd (1412.141.1) and last modified by apfs_kext (1412.141.1) Checking the object map Checking the snapshot metadata tree Checking the snapshot metadata Checking the extent ref tree Checking the fsroot tree Checking volume Checking the APFS volume superblock The volume Recovery was formatted by diskmanagementd (1412.141.1) and last modified by apfs_kext (1412.141.1) Checking the object map Checking the snapshot metadata tree Checking the snapshot metadata Checking the extent ref tree Checking the fsroot tree Checking volume Checking the APFS volume superblock The volume VM was formatted by diskmanagementd (1412.141.1) and last modified by apfs_kext (1412.141.1) Checking the object map Checking the snapshot metadata tree Checking the snapshot metadata Checking the extent ref tree Checking the fsroot tree Checking volume Checking the APFS volume superblock The volume Macintosh HD was formatted by diskmanagementd (1412.141.1) and last modified by apfs_kext (1412.141.1) Checking the object map Checking the snapshot metadata tree Checking the snapshot metadata Checking the extent ref tree Checking the fsroot tree Verifying allocated space The volume /dev/disk1s2 appears to be OK Storage system check exit code is 0 Growing APFS Physical Store disk1s2 from 32,002,498,560 to 137,229,197,312 bytes Modifying partition map Growing APFS data structures Finished APFS operation sh-3.2# diskutil list /dev/disk0 (internal, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *121.3 GB disk0 /dev/disk1 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *137.4 GB disk1 1: EFI EFI 209.7 MB disk1s1 2: Apple_APFS Container disk2 137.2 GB disk1s2 /dev/disk2 (synthesized): #: TYPE NAME SIZE IDENTIFIER 0: APFS Container Scheme - +137.2 GB disk2 Physical Store disk1s2 1: APFS Volume Macintosh HD - Data 6.5 GB disk2s1 2: APFS Volume Preboot 80.0 MB disk2s2 3: APFS Volume Recovery 529.0 MB disk2s3 4: APFS Volume VM 2.1 GB disk2s4 5: APFS Volume Macintosh HD 11.0 GB disk2s5 sh-3.2# df -h Filesystem Size Used Avail Capacity iused ifree %iused Mounted on /dev/disk2s5 128Gi 10Gi 109Gi 9% 488248 1339640632 0% / devfs 186Ki 186Ki 0Bi 100% 644 0 100% /dev /dev/disk2s1 128Gi 6.0Gi 109Gi 6% 157713 1339971167 0% /System/Volumes/Data /dev/disk2s4 128Gi 2.0Gi 109Gi 2% 1 1340128879 0% /private/var/vm map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home
- 投稿日:2021-01-17T11:13:10+09:00
AWS_WEB3層環境構築①
AWSでWEB3層の環境構築に挑戦。
とりあえず、作りたい環境は以下の図のような感じ。
APサーバの/etc/hostsかtomcatのserver.xmlを更新することによって、
参照するDBがMySQL1からMySQL2に切り替わるかを検証したい。
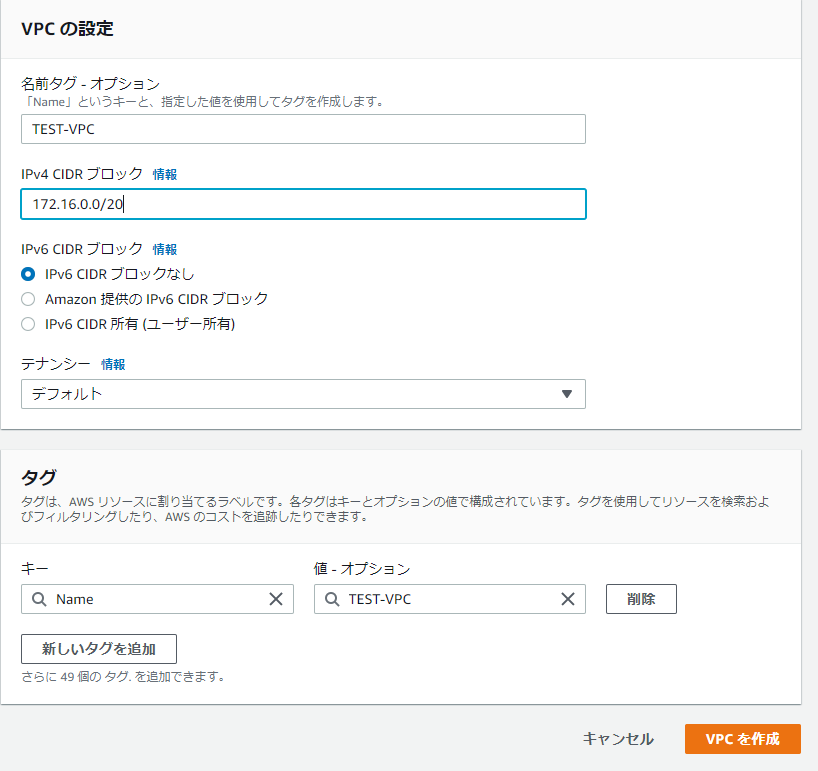
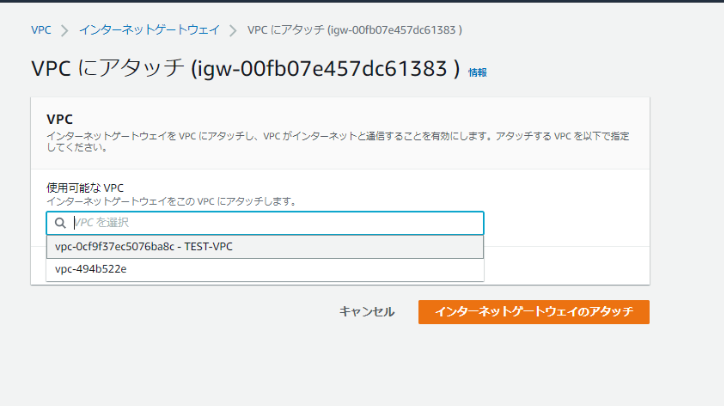
①VPC
サービスから[VPC]を選択。
左ペインの[VPC]から[VPCを作成]。
※VPCダッシュボードからウィザードでの作成もできるみたいだ
サブネットは172.16.0.0/20とした。
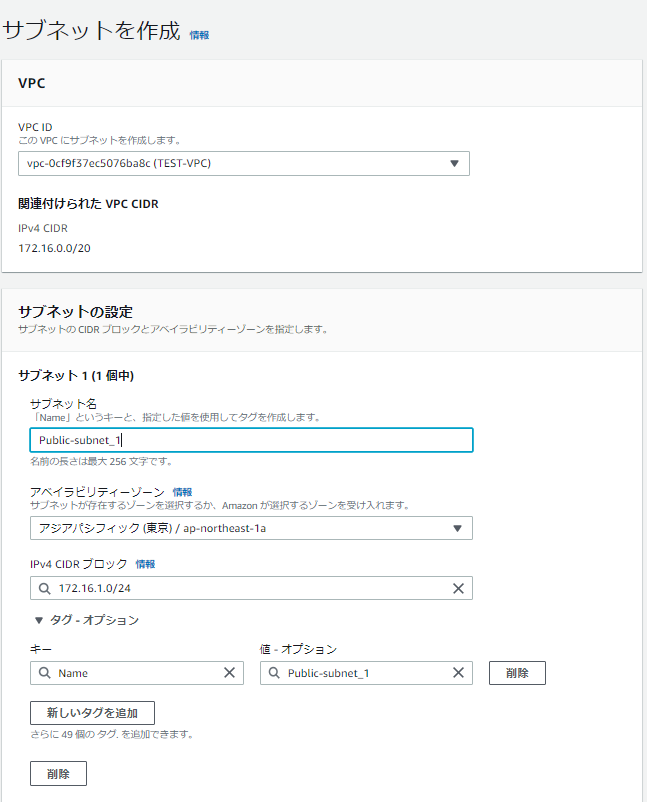
②サブネット
左ペインの[サブネット]から[サブネットを作成]。
先ほど作成したVPCを選択。
アベイラビリティゾーンは東京リージョン1aを選択。
サブネットは172.16.1.0/24とした。
③インターネットゲートウェイ
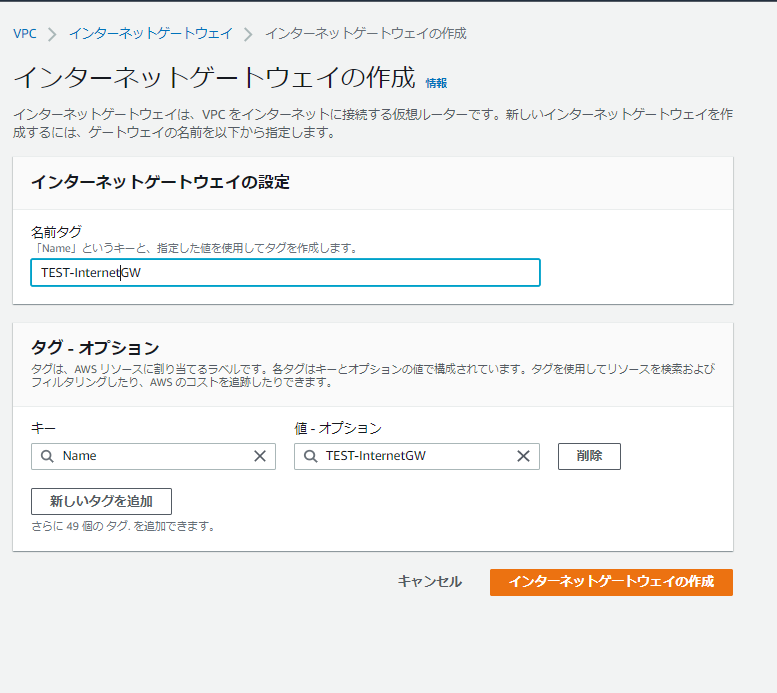
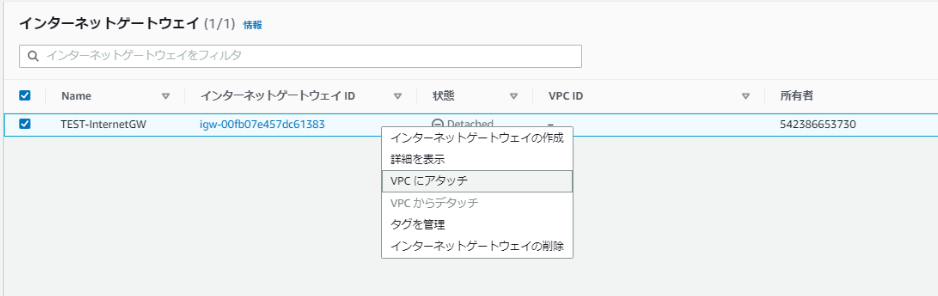
左ペインの[インターネットゲートウェイ]から[インターネットゲートウェイの作成]。
作成したら、VPCに関連付けする。
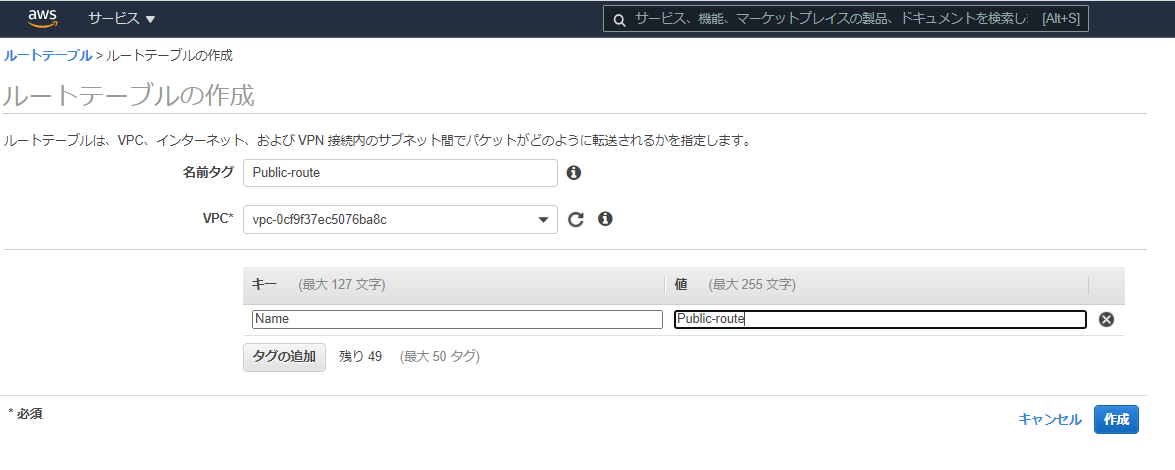
④ルートテーブル
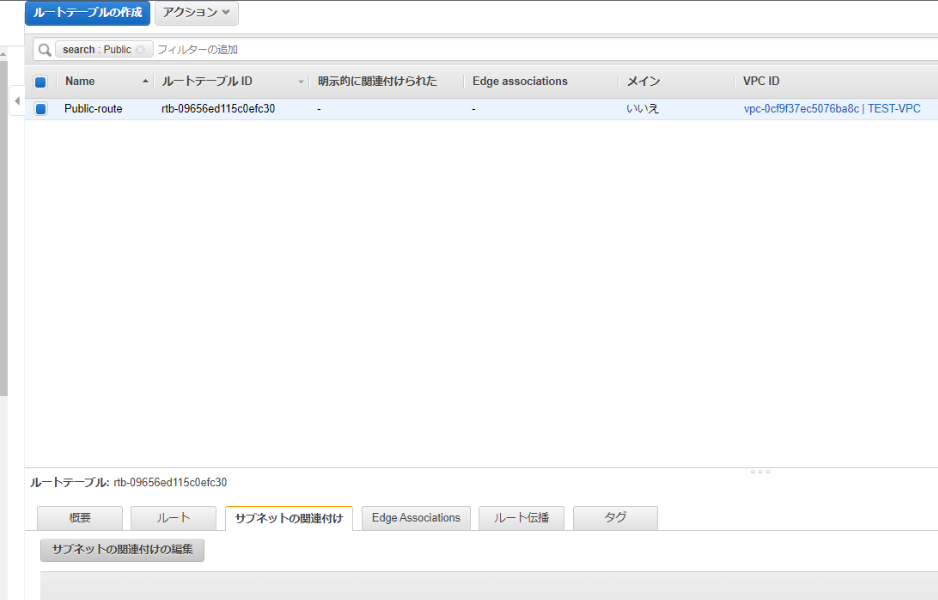
左ペインの[ルートテーブル]から[ルートテーブルの作成]。
名前つけて、VPCに関連付けする。
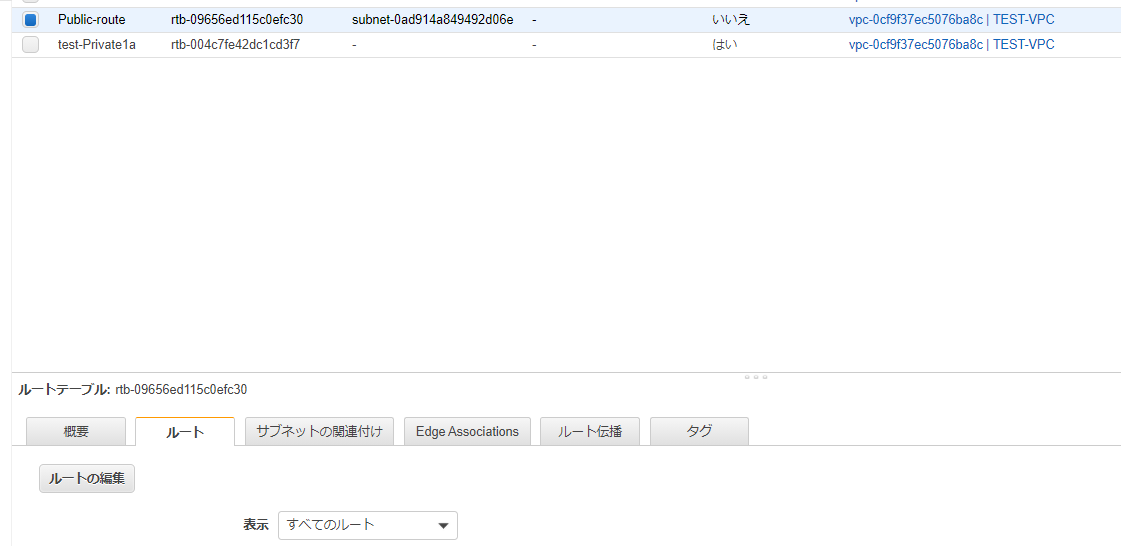
ルートテーブル(箱)ができたら、中身を編集する。
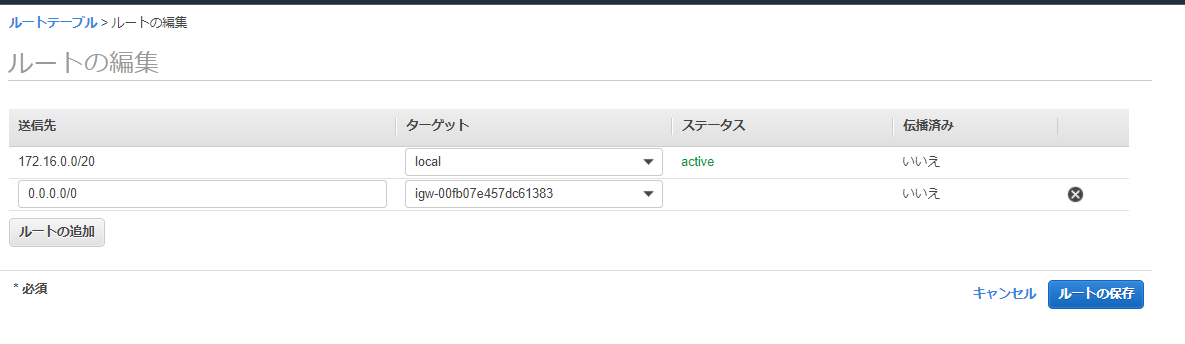
[ルート]タブから[ルートの編集]
送信先にすべてのネットワーク(0.0.0.0/0)を入力し、ターゲットには作成したインターネットゲートウェイを選択する。
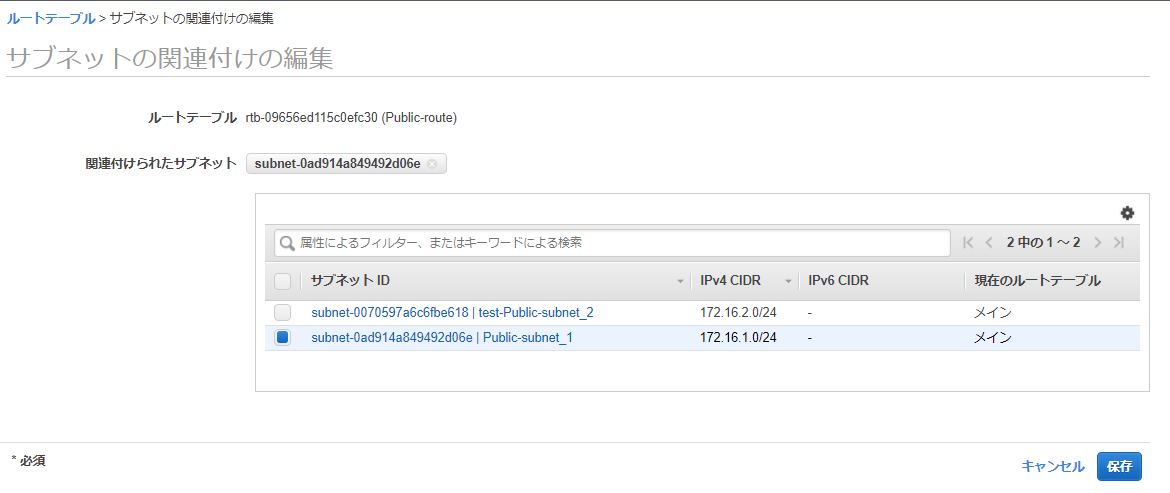
次はルートテーブル(箱)とサブネットを関連付けさせる。
[サブネットの関連付け]タブの[サブネットの関連付けの編集]から、
ルートテーブルとサブネット(パブリック)を関連付けする。
⑤EC2インタンス
土台ができたので、仮想サーバを立てる。
AWSマネージメントコンソールのサービスから[EC2]を選択。
※上記手順で[VPC]を開いているため、ブラウザの別タブで開くことをおすすめする。左ペインの[インスタンス]から[インスタンスの起動]。
無料枠のAmazon Linux2を選択。
インスタンスタイプはt2microを選択して、次のステップ。
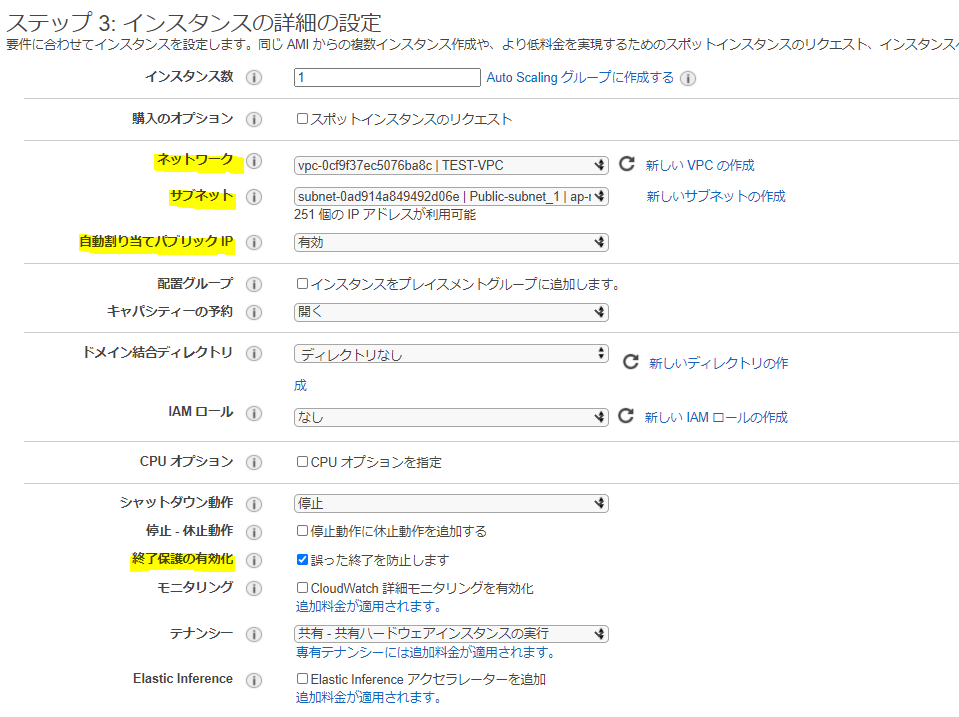
ステップ3では以下の項目を変更し、次のステップ。
・ネットワークで作ったVPCを関連付けする
・サブネットも同様に作ったPublic-subnetを関連付けする
・自宅PCからsshするため、自動割り当てパブリックIPを有効
・終了保護の有効化はチェックをしておく(※AWSにおいて、インスタンスの終了=破壊なので要注意)
ステップ4ではEBS(EC2インスタンスのディスクにあたり、ネットワーク経由で保存データにアクセスしている)は汎用SSD 8Gのまま。
[終了時に削除]にチェックが入っていないと、インスタンスを消したあともEBS分で課金されるので要注意。
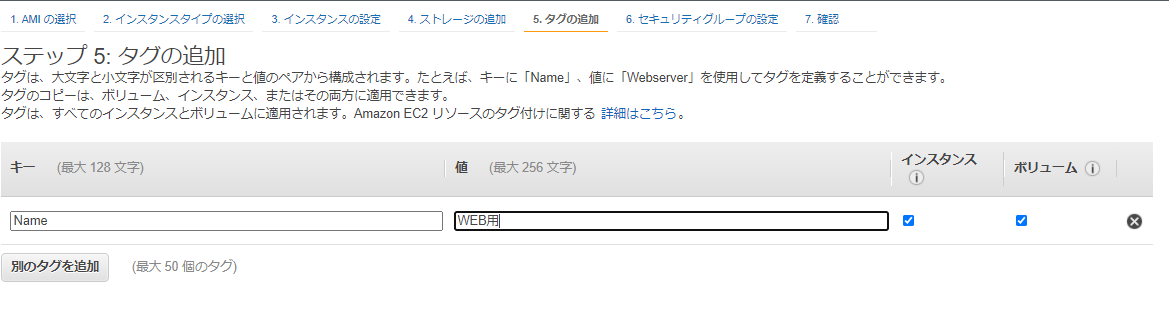
タグにはNameキーで"WEB用"とつけておく。
名前つけておかないと、インスタンスが増えてきたときに意味不明になる。
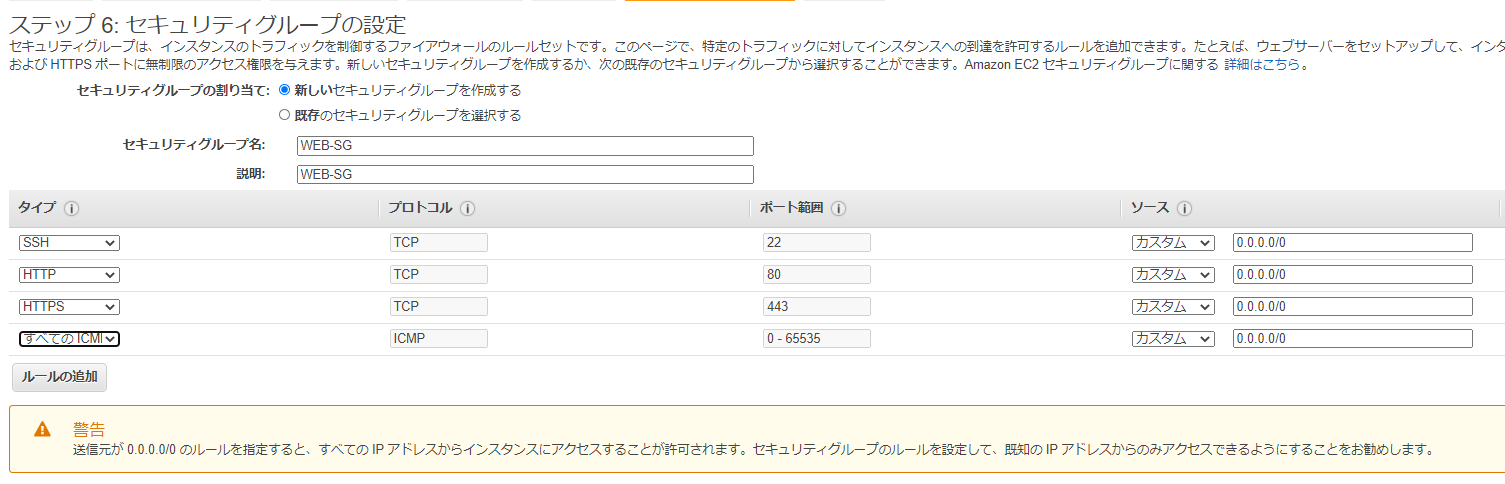
セキュリティグループでは、新しいセキュリティグループを作成し、名前もわかりやすいのをつけておく。
※セキュリティグループの名前は作成後に変更できない仕様。代替手段として、セキュリティグループをコピーして別名で新規作成するしかない。
ここではWEBサーバ用なので、以下プロトコルをフルオープン(0.0.0.0/0)で開ける。
・HTTP(80)
・HTTPS(443)
・SSH(22)
・ICMP(疎通確認ping用)
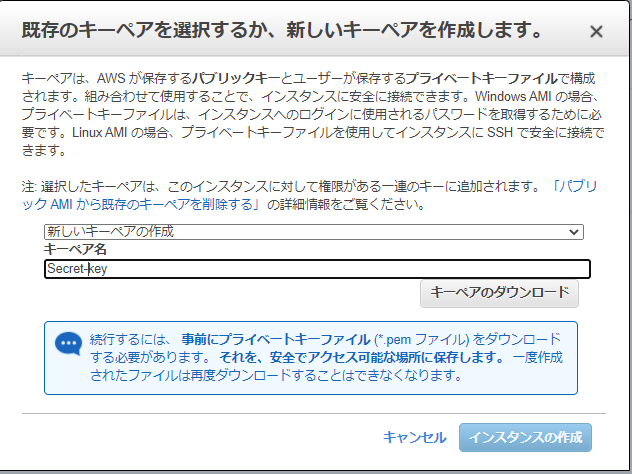
最後にキーペアを新規作成して、ダウンロードする。※EC2インスタンスにアクセスする際に必要になるため、大事に保管する。紛失しても何とかなるが。
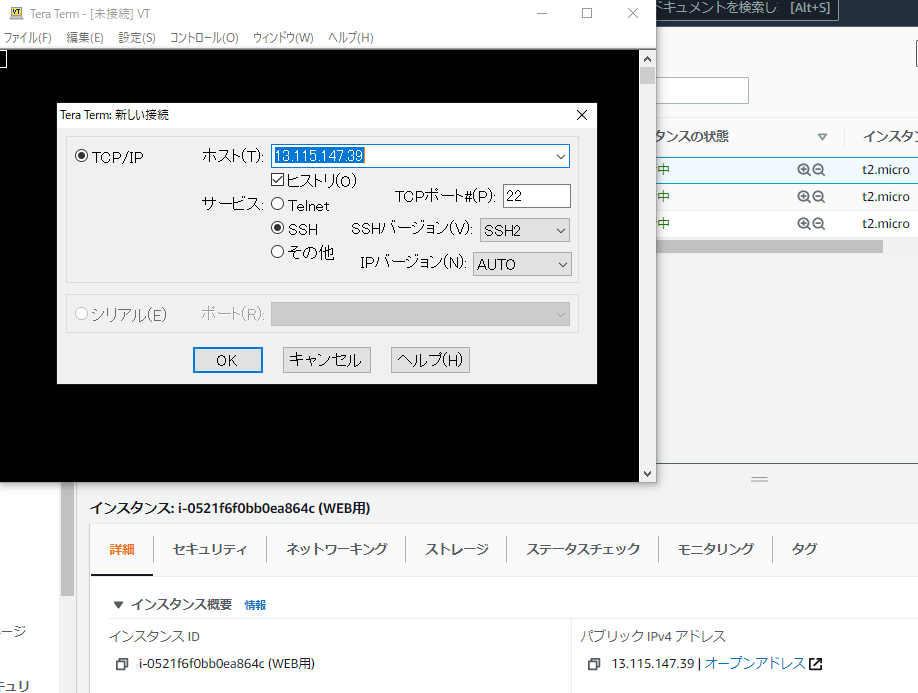
⑥SSHでEC2インスタンスにアクセス
TeraTermで、ホスト名にEC2のパブリックIPアドレスを入力し、SSH接続する。
※パブリックアドレスはEC2インスタンスの[詳細]タブから確認できる
AmazonLinuxの初期ユーザはec2-user
※OSによりAWSでの初期ユーザが異なるため注意
ディストリビューション/初期ユーザ
Ubuntu Ubuntu
RHEL ec2-user
CentOS centos
秘密鍵の項目で、先ほどダウンロードしたキーペアを選択することで、EC2インスタンスへSSH接続ができたことが確認できた。
長くなってしまったので、初回はここまでで一回切る。
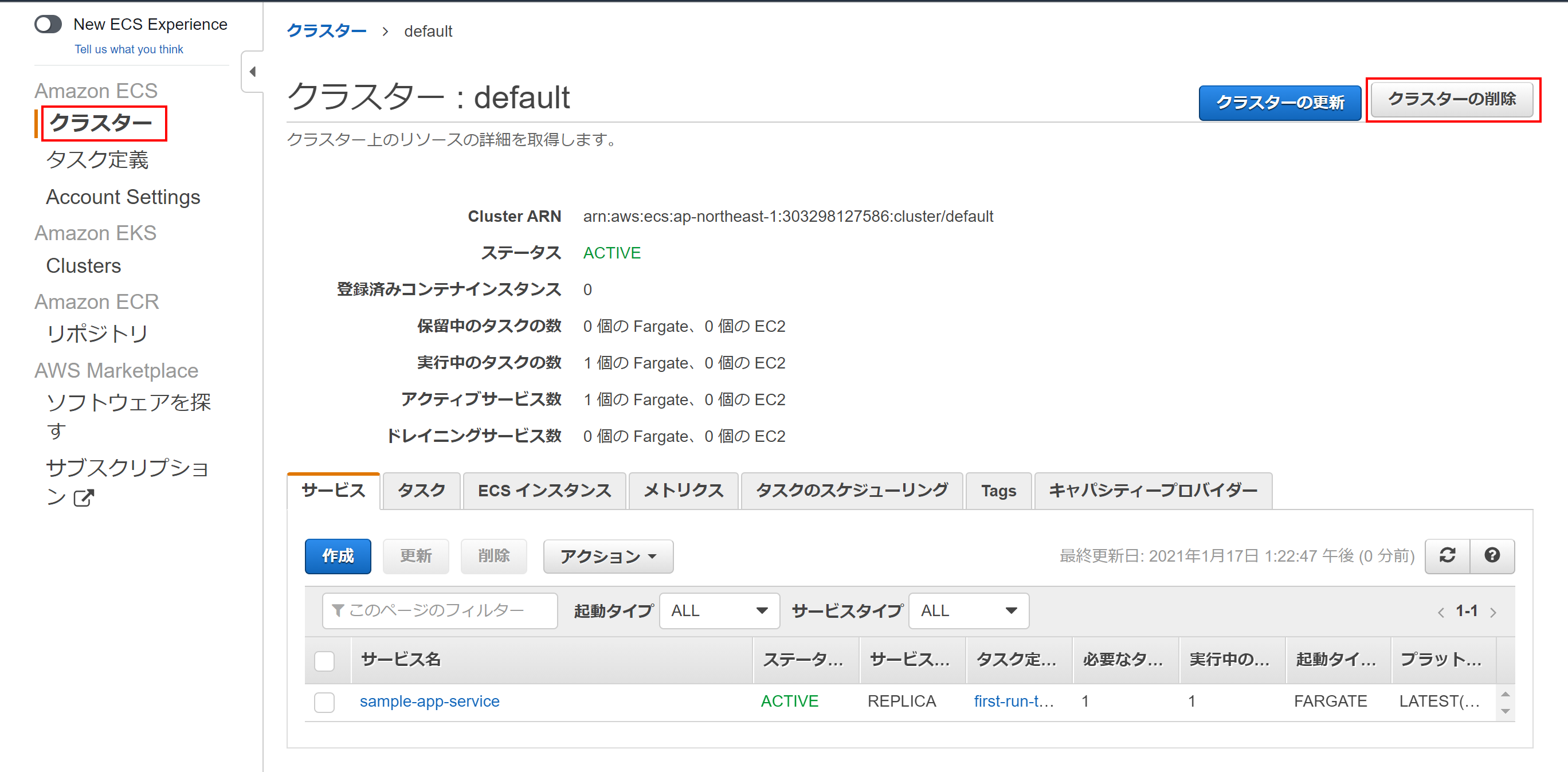
次回は、プライベートサブネットに配置予定のAPサーバ/DBサーバのEC2インスタンスを構築。
WEBサーバにはnginxのインストールとnginx.confの作成。
APサーバにはtomcatのインストールとMySQLドライバーのインストール。
DBサーバにはMySQLのインストールをしたいと思う。
次回で全部できるかな・・・つづく
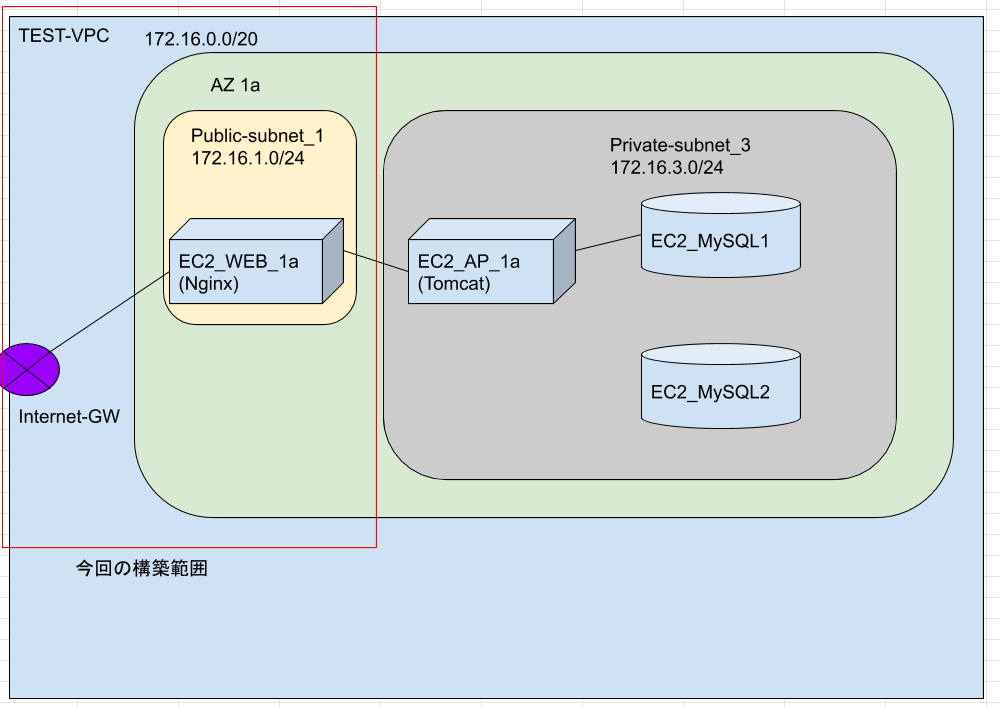


- 投稿日:2021-01-17T10:54:36+09:00
Cloud9でWordPress環境を構築 3
WordPressの学習&AWSに触れるのを目的として
AWS Cloud9でWordPress環境を構築するまでの備忘録。環境構築完了。ここまでやったこと
- Cloud9環境立ち上げ
- MySQLセットアップ
- Apache、MySQLサービス起動
- スナップショット作成
この記事の目次
- WordPressセットアップ
- 前準備
- インストール
基本これに従う。
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/sample-wordpress.htmlWordPressセットアップ
前準備
WordPressをダウンロード&展開する。
wget http://wordpress.org/latest.tar.gz tar -xzvf latest.tar.gz
wp-config-sample.phpをwp-config.phpに名前変更して利用する。cd wordpress mv wp-config-sample.php wp-config.php
wp-config.php内の3箇所をMySQLで作成したデータベースに合わせる。define( 'DB_NAME', 'データベース名' ); define( 'DB_USER', 'ユーザ名' ); define( 'DB_PASSWORD', 'パスワード' );Amazonのサイトに記載はないが、セキュリティ的な対応をしておく。
次の値をサイトでランダムに生成して書き換える。
https://api.wordpress.org/secret-key/1.1/salt/define('AUTH_KEY', 'XXXXX'); define('SECURE_AUTH_KEY', 'XXXXX'); define('LOGGED_IN_KEY', 'XXXX'); define('NONCE_KEY', 'XXXX'); define('AUTH_SALT', 'XXXX'); define('SECURE_AUTH_SALT', 'XXXX'); define('LOGGED_IN_SALT', 'XXXX'); define('NONCE_SALT', 'XXXX');インストール
index.phpをエディタで開いてメインメニューバーからRunを実行する。
メインメニューバーのPreview > Preview Running Application を実行する。
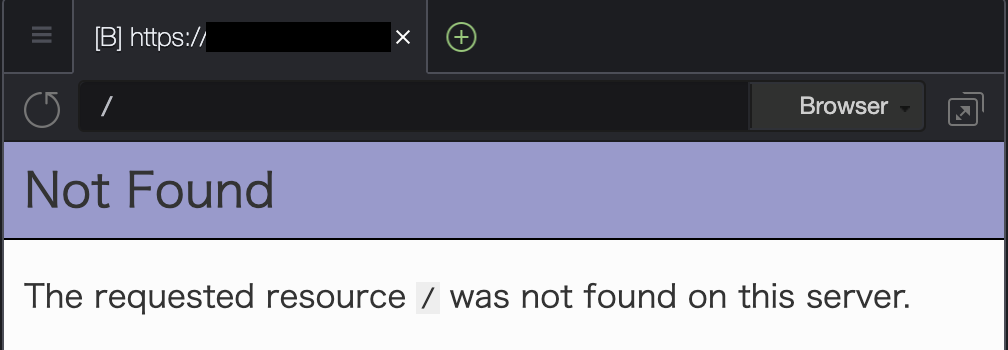
Not Foundのエラー画面が出る。これは正常。
ブラウザのパスに
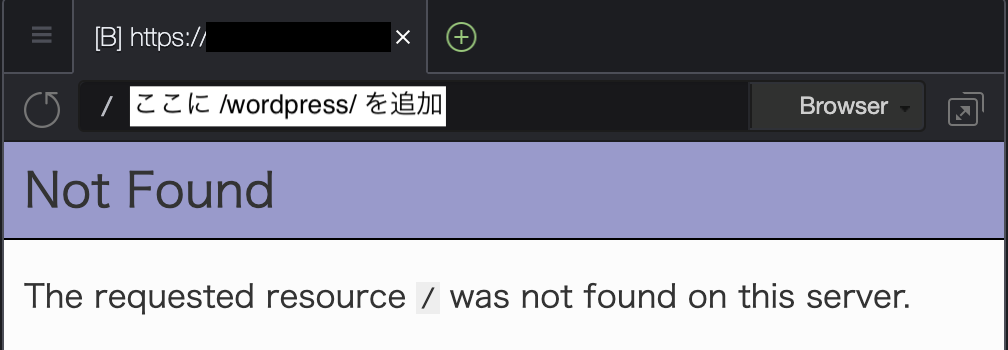
/wordpress/を追加する。
これでインストール画面が出るらしいが、ずっとぐるぐるして画面が表示されない。
追加するURLを
/wordpress/readme.htmlに変更する。画面が表示される。
(ここが分からず、色々いじって何回かCloud9の環境を作成しなおした……)
install.phpへのリンクをクリックしてインストールを進める。
ようやくWordPressのインストールまで完了した。
AWSの用語が分からなかったり、プリインストールのMySQLが動かなかったりで
結構時間がかかってしまった……。今後はこの環境を使ってWordPressの学習を進める。

- 投稿日:2021-01-17T00:43:22+09:00
【Ruby on Rails】EC2でwheneverを使ってcrontabを設定する時のハマったことの解決
wheneverというのはRuby on Railsのgemであり、crontabを設定する時によく使われています。
使い方
使い方はGithubホームページに詳しく記載されていますが、主に使うのは下記になります。
Gemfileに追加
Gemfilegem 'whenever', require: falseインストール
bundle exec wheneverize .schedule.rbファイルの内容を確認する
whenever開発環境でcrontabを更新する
whenever --update-crontab --set environment='development'Capistranoに入れる
config/deploy.rbset :whenever_roles, -> { :app }Capfilerequire 'whenever/capistrano'ハマったことなどの解決
EC2では動かない
EC2にデプロイの後、crontabが動かず、ログ確認したらBundleバージョンが間違いなどの問題
job_typeを以下に設定すれば良い
config/schedule.rbset :output, environment == 'development' ? 'log/crontab.log' : '/deploy/apps/<アプリ名/shared/log/crontab.log' job_type :rake, 'export PATH="$HOME/.rbenv/bin:$PATH"; eval "$(rbenv init -)"; cd :path && RAILS_ENV=:environment bundle exec rake :task :output'時間通りに動かない
タイムゾーンが間違い可能性が高いです。
タイムゾーン設定方法は:
config/schedule.rbrequire 'active_support/core_ext/time' def local(time) Time.zone = 'Asia/Tokyo' Time.zone.parse(time).localtime($system_utc_offset) end every 1.day, at: local('6:00 am') do # 日本時間毎朝6時に実行 rake '<task>' endcrontabのログにExecJS::RuntimeUnavailable エラーが出たとき
Could not find a JavaScript runtime. See https://github.com/rails/execjs for a list of available runtimes. (ExecJS::RuntimeUnavailable)Gemfileに
mini_racerを追加すればいいです。therubyracerでも大丈夫ですが、Macにはインストールが難しいのでmini_racerを使います。
- 投稿日:2021-01-17T00:23:35+09:00
AWSのControl TowerマスターアカウントからStackSetsを展開してみた
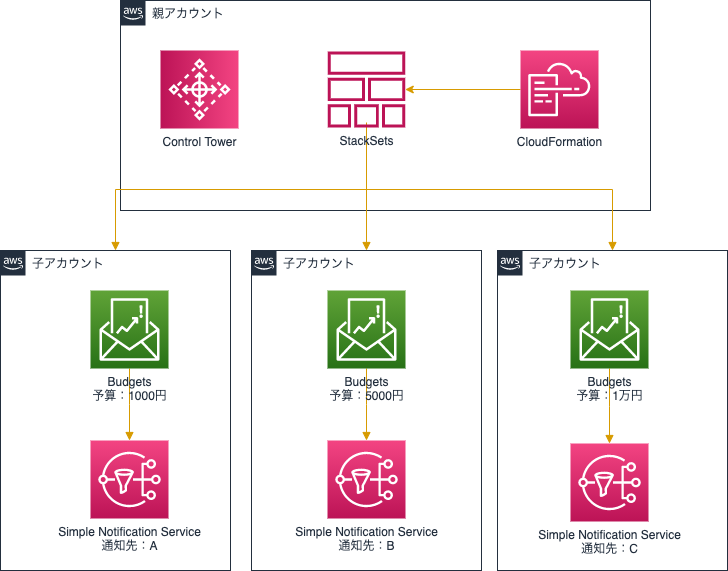
構成
以下の構成により、Control TowerマスターアカウントでStackSetsを展開します。
※アカウント自体はControl Towerのアカウント登録により作成します。
アカウント払い出し時に、管理者がアカウントに予算を作成した上で使用者にアカウントを渡すことを想定しています。
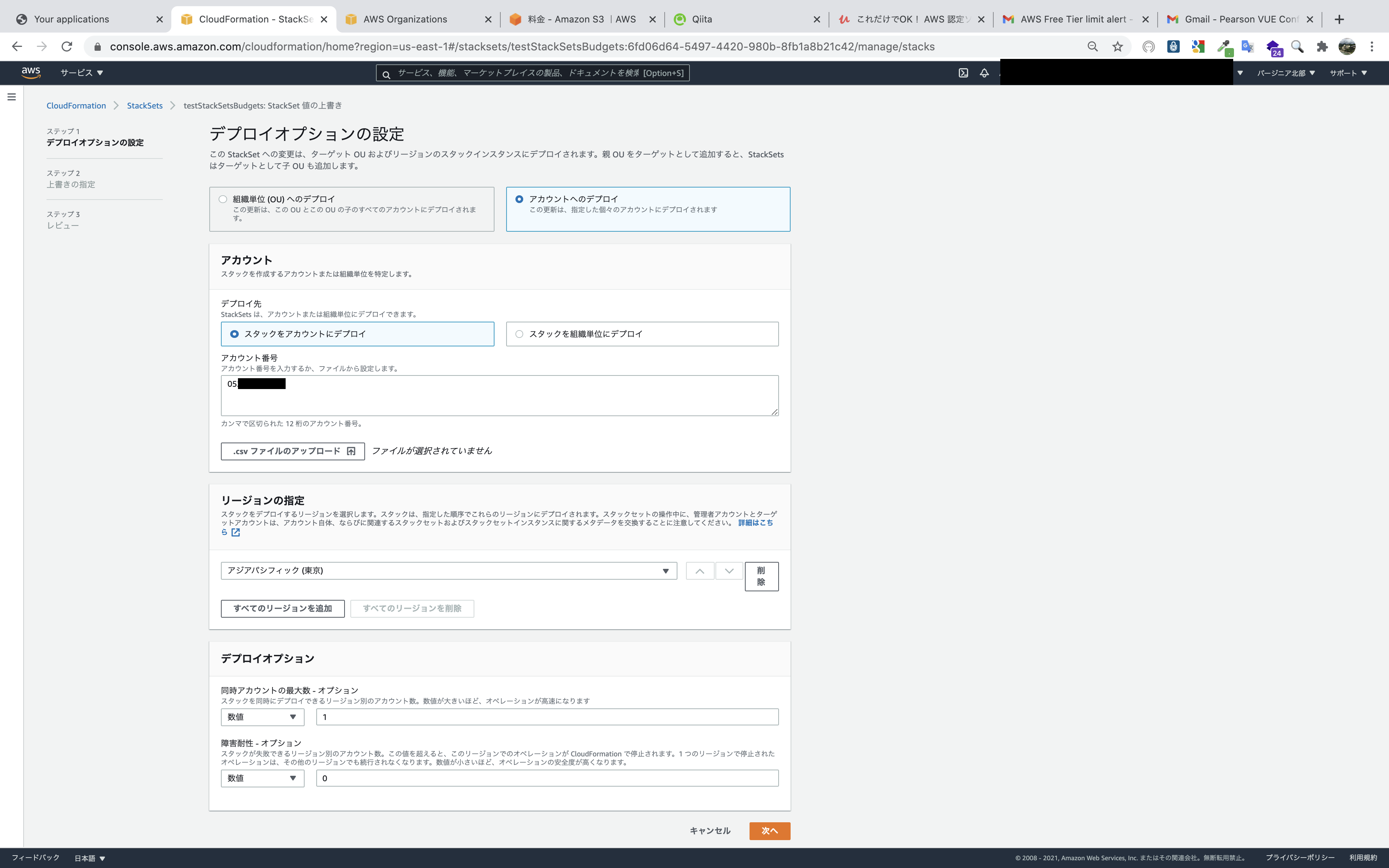
使用者ごとに予算額、通知先が異なるためStackSetsで一気に展開することは不可能なので、StackSetsを後から更新して対応します。流れとしては、まず、ターゲットをOU(組織単位)としてStackSetsを作成し、自動デプロイ機能を有効化します。
そして、Control Towerのアカウント登録機能を使用してアカウントを作成(このときOUも指定する仕様になっています)。
そうすると、アカウント作成完了時にはそのアカウントにはBudgetsも作成されていることに。しかし、これだとStackSets作成時のパラメータ設定通りの予算額と通知先になってしまい、各アカウントでカスタマイズできていないので、パラメータの上書きで対応します。
注意点として、StackSets作成時に入力したメールアドレス宛にSNSトピックのサブスクリプション確認メールが届くので、その確認を行ってからパラメーターの上書きを行うこと(そうしないと上書きを行っても保留中のサブスクリプションが置換されず残ったままになります。)。この構想だと最初に指定したメールアドレスにアカウント作成のたびに確認メールが届くことになりますが、他の方法が思いつかなかったためその点は許容します。
なお、最初のメールアドレスを自分で確認できないメールアドレスにしてしまうと作業が進まないので、アカウント作成担当者のメールアドレスに設定します。StackSets作成
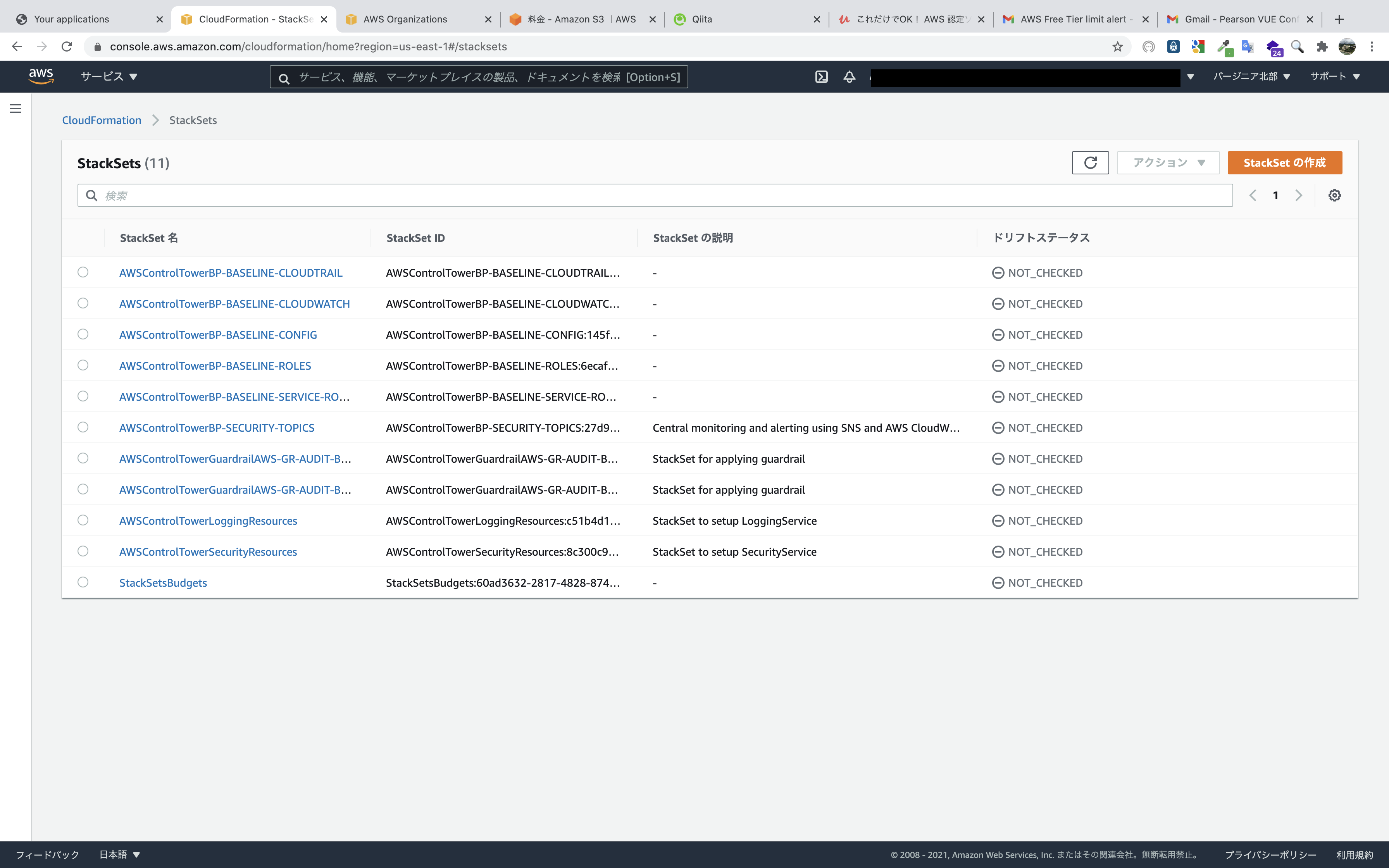
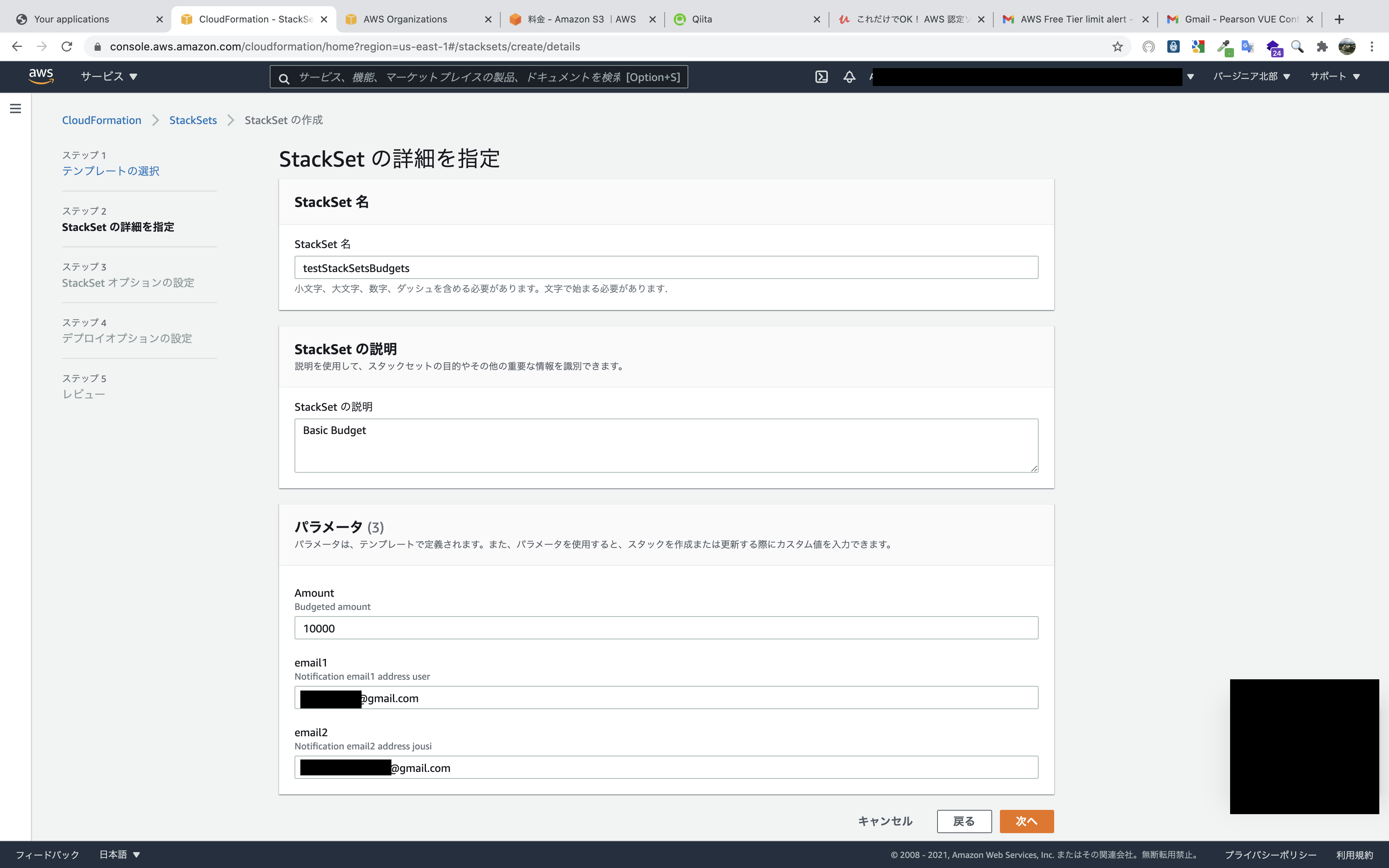
Control TowerマスターアカウントのCloudFormationのStackSets画面に移り、
StackSetの作成をクリック。
準備していたテンプレートをアップロードします。
テンプレートは記事の最後に掲載。
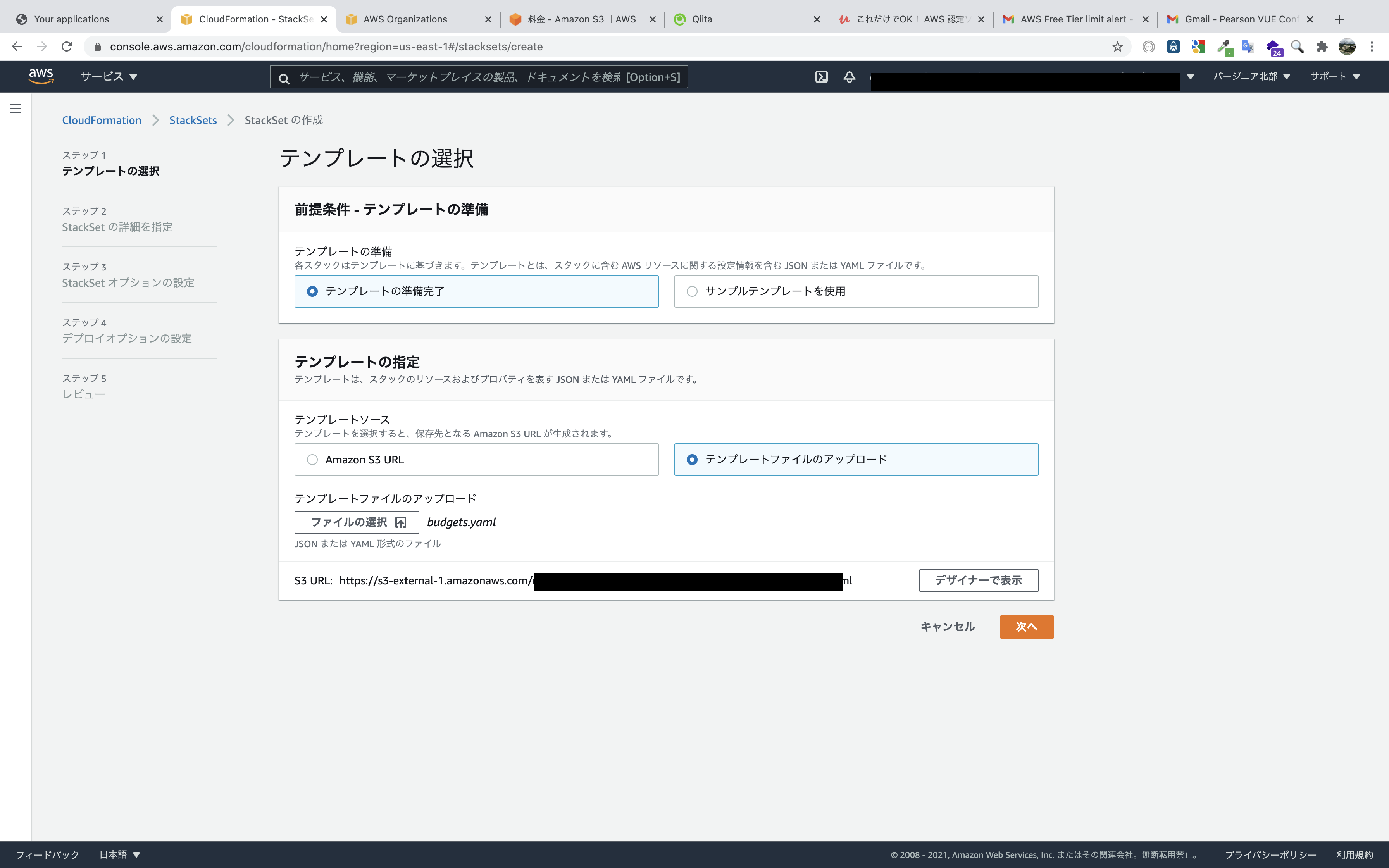
StackSetの名前や、パラメータを入力します。
予算額とメールアドレレスはともに変更予定なので適当なものでも構いませんが、メールアドレスはサブスクリプションの確認メールのリンクをクリックする必要があるので、自分が使用できる実在するメールアドレスを入力します。
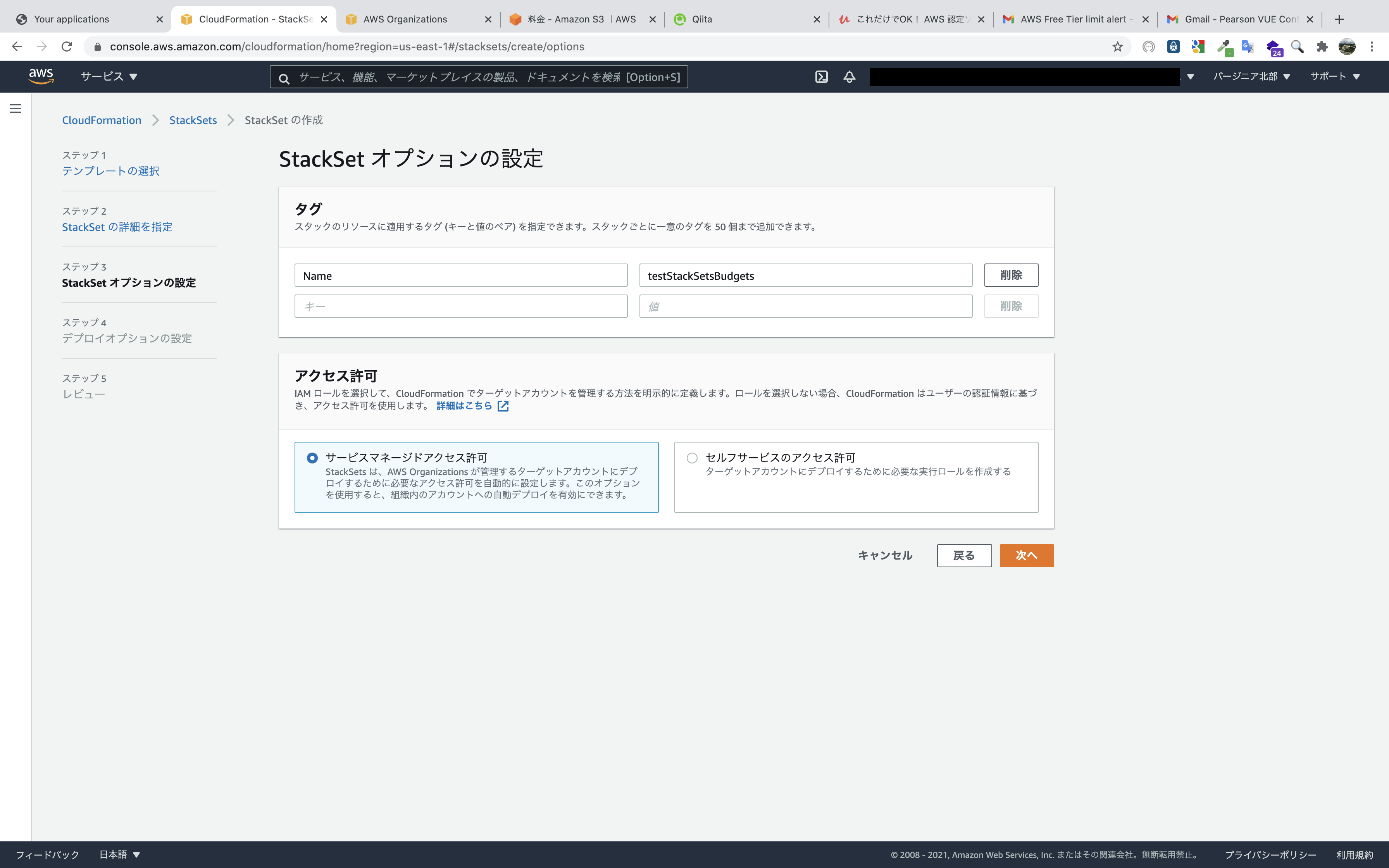
タグはなくても構いませんが、アクセス許可は
サービスマネージドアクセス許可を選択します。
理由としては二つです。① StackSet展開用のIAMロールを自分で作成する必要がない
セルフサービスのアクセス許可だと、管理アカウントとターゲットアカウントの両方でIAMロールを手動で作成する必要があります。
② 自動デプロイが使用できる
自動デプロイを有効化すると、指定したOUに追加・削除されると自動でStackSetが展開・削除されます。
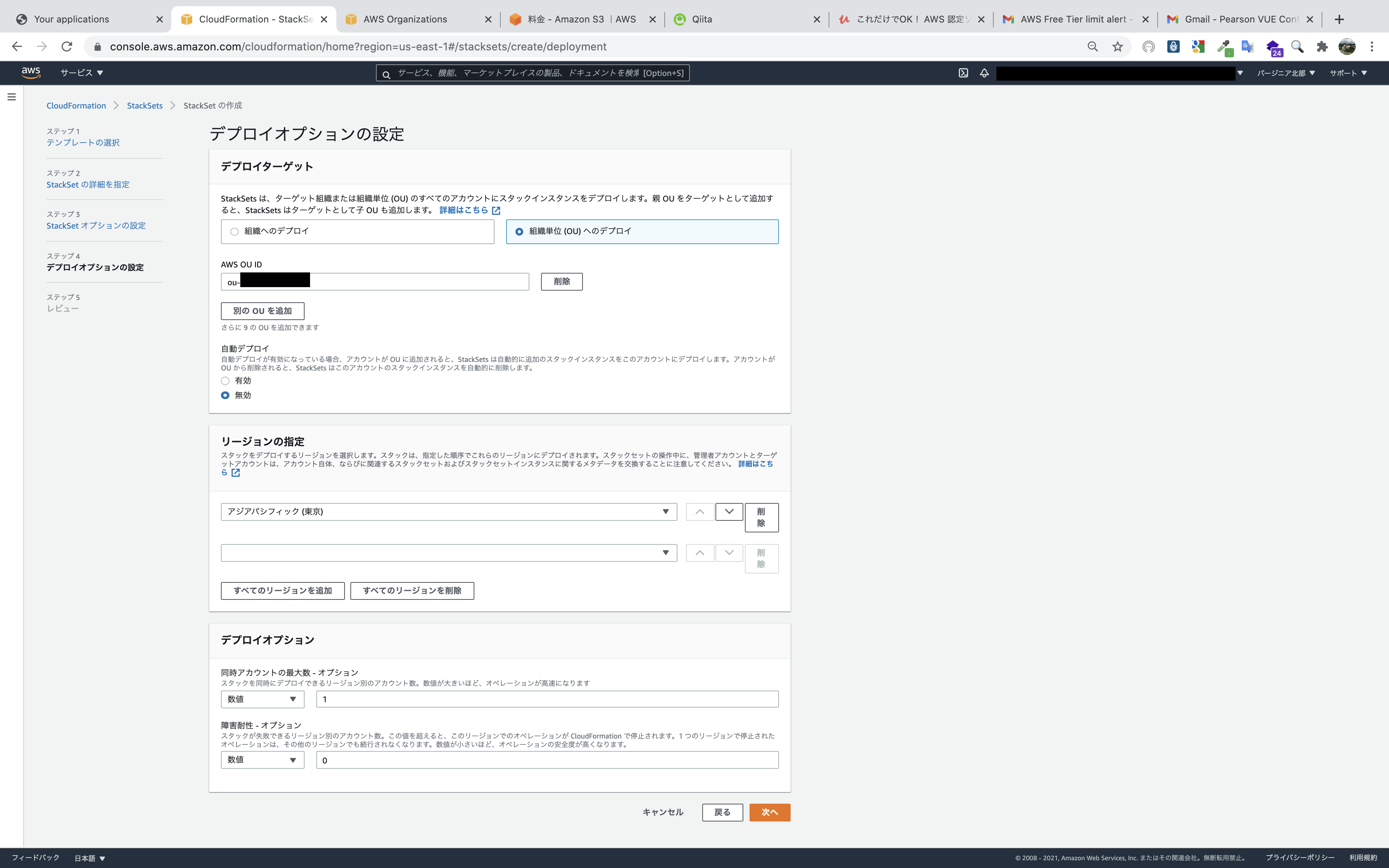
デプロイターゲットのOUを入力します(以下の写真のように、あらかじめ確認しておきます。)。
写真では自動デプロイが無効になっていますが、有効にします。
有効を選択すると、スタックインスタンスを削除する時に実際のリソースを残すかどうか選択できます。
リソースを残す設定にすると、スタックインスタンスを削除しても実際のリソースは残り、StackSetsの管理下から外れるという結果になります。
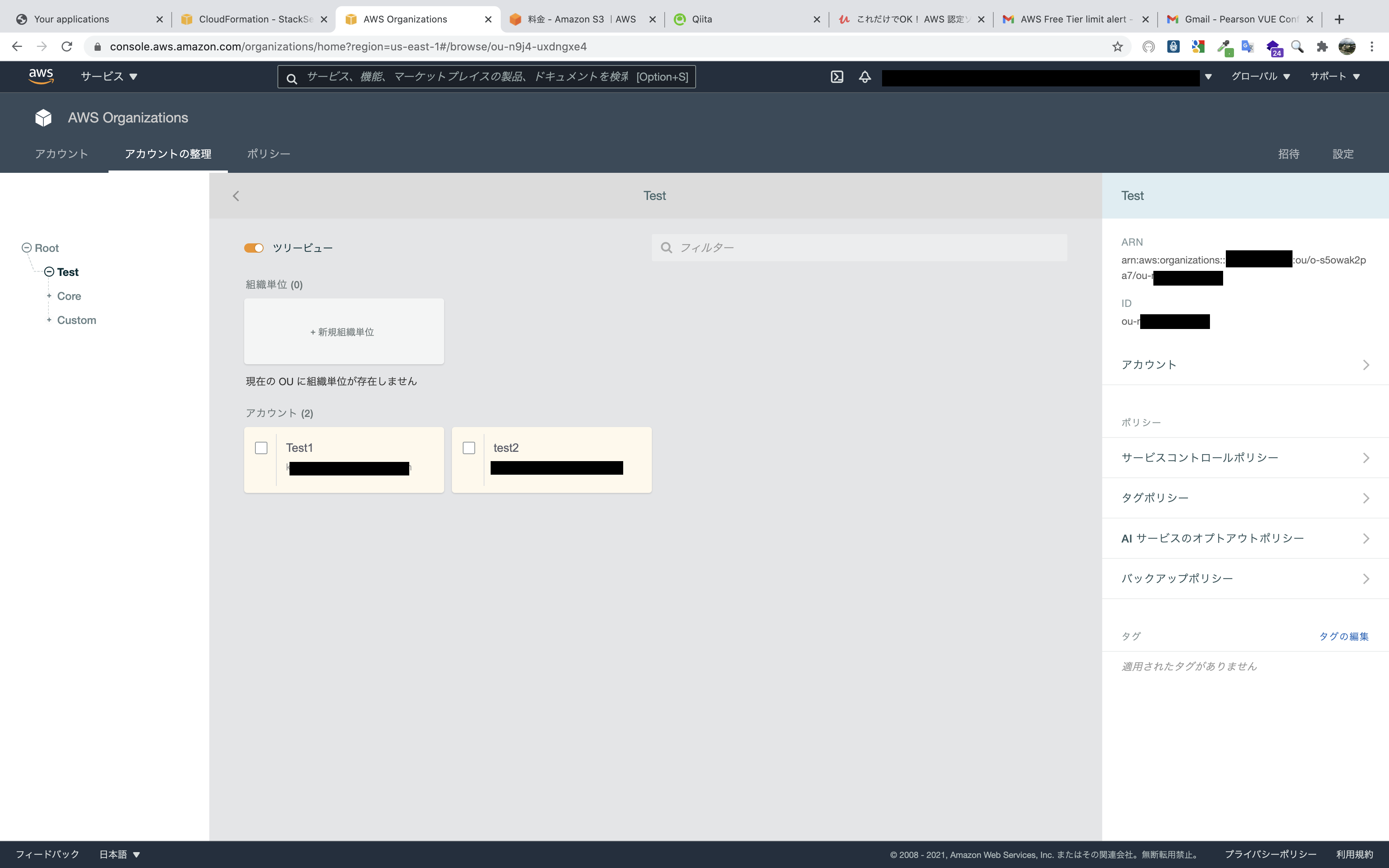
AWS OrganizationsでOUのIDを確認できます。
最後は今まで設定した事項を確認して作成するだけです。
作成を開始した様子です。
作成中です。
2分ほどで作成が完了しました。
そのときの写真をとり忘れましたが、エラーのときは状況の理由欄に理由が記載されます。
各アカウントにBudgetsとSNSトピックが作成されましたが、各アカウントの予算額等はパラメーターで入力した一律の値です。
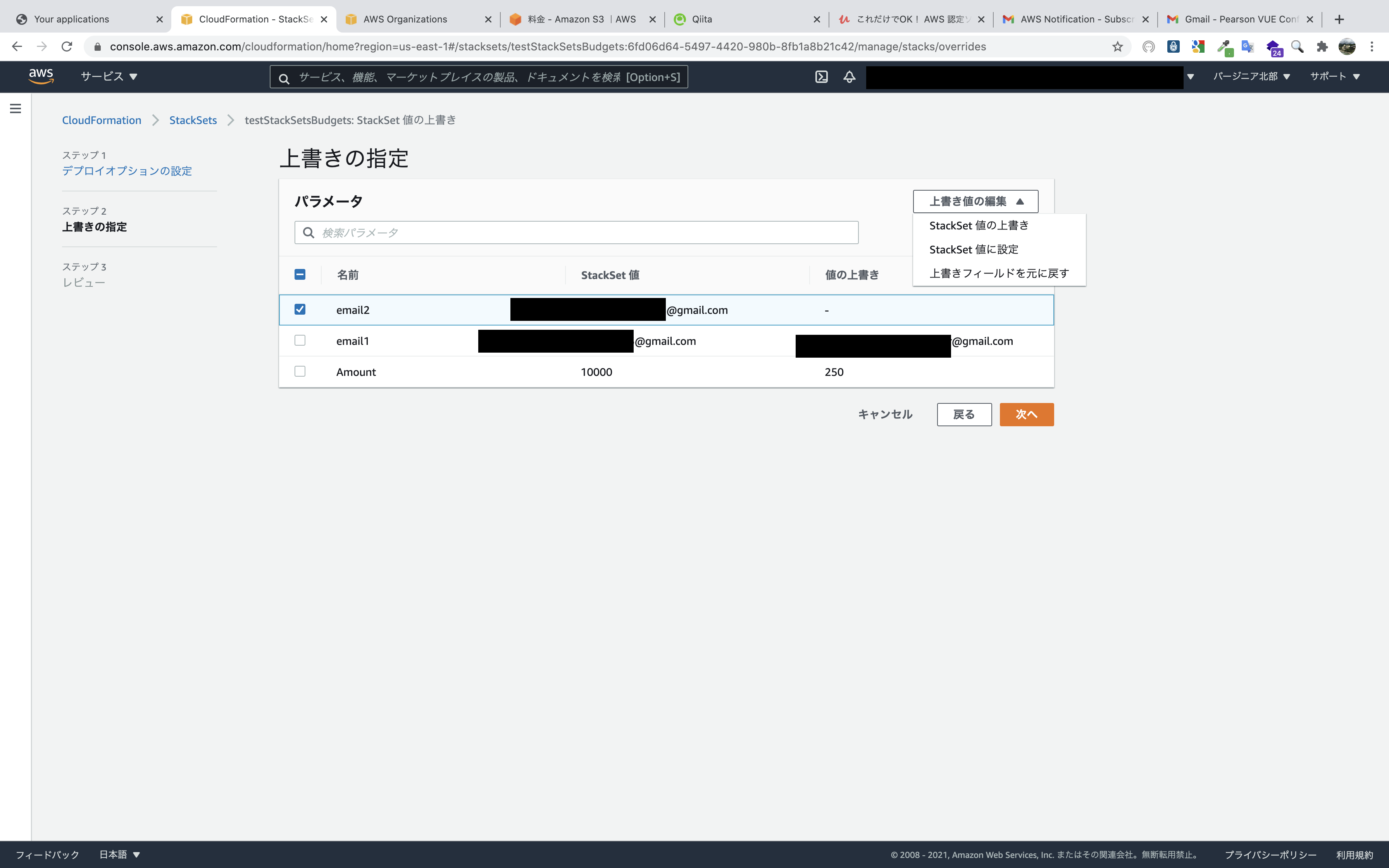
各アカウント用にカスタマイズするために、アクション,StackSetのパラメータを上書きをクリックします。
OU単位へのデプロイとアカウントへのデプロイがありますが、個別にカスタマイズしたいのでアカウントへのデプロイを選択します。
アカウント番号を入力するのであらかじめ調べておきます。
リージョンは既に展開済みのリージョンを選択します(展開したリージョンしか選べないようになっていると思います。)。
上書きするパラメータを選択して、
上書き値の編集から該当のアクションを選択して入力します。
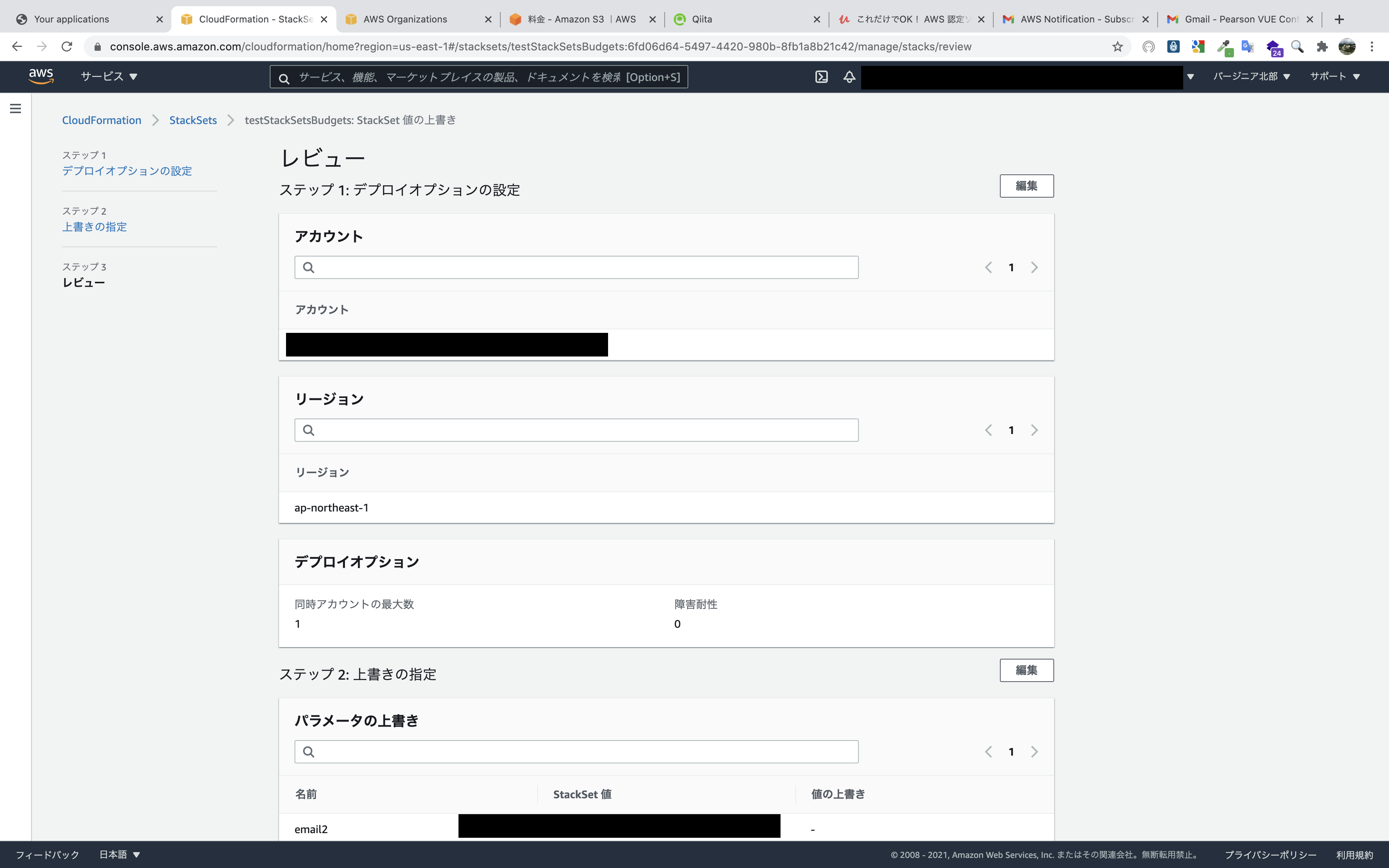
設定した項目を確認したら完了です。
これで指定したアカウントへカスタマイズされたBudgetsとSNSが作成されました。
あとはアカウントの数だけ繰り返します。
最初のStackSetsの展開さえ行えば、ターゲットのOUにアカウントが追加されたら自動デプロイされます。
そのたびにパラメータの上書きが必要ですが、各アカウントにサインインして手動でポチポチするよりかは早く設定できると思います。テンプレート
Description: "Basic Budget" Parameters: Amount: Type: String Default: 100 Description: Budgeted amount email1: Type: String Description: Notification email1 address email2: Type: String Description: Notification email2 address Resources: Budget: Type: AWS::Budgets::Budget Properties: Budget: BudgetName: test1 BudgetLimit: Amount: !Ref Amount Unit: USD TimeUnit: MONTHLY BudgetType: COST NotificationsWithSubscribers: - Notification: NotificationType: FORECASTED ComparisonOperator: GREATER_THAN Threshold: 50 ThresholdType: PERCENTAGE Subscribers: - Address: !Ref SNS1 SubscriptionType: SNS - Notification: NotificationType: FORECASTED ComparisonOperator: GREATER_THAN Threshold: 70 ThresholdType: PERCENTAGE Subscribers: - Address: !Ref SNS1 SubscriptionType: SNS - Notification: NotificationType: FORECASTED ComparisonOperator: GREATER_THAN Threshold: 100 ThresholdType: PERCENTAGE Subscribers: - Address: !Ref SNS2 SubscriptionType: SNS SNS1: Type: AWS::SNS::Topic Properties: Subscription: - Endpoint: !Ref email1 Protocol: email TopicName: StackSetsBudgets1 SNS2: Type: AWS::SNS::Topic Properties: Subscription: - Endpoint: !Ref email1 Protocol: email - Endpoint: !Ref email2 Protocol: email TopicName: StackSetsBudgets2 SNSPolicy1: Type: AWS::SNS::TopicPolicy Properties: PolicyDocument: Id: MyTopicPolicy Version: '2012-10-17' Statement: - Sid: My-statement-id Effect: Allow Principal: Service: budgets.amazonaws.com Action: SNS:Publish Resource: !Ref SNS1 Topics: - !Ref SNS1 SNSPolicy2: Type: AWS::SNS::TopicPolicy Properties: PolicyDocument: Id: MyTopicPolicy Version: '2012-10-17' Statement: - Sid: My-statement-id Effect: Allow Principal: Service: budgets.amazonaws.com Action: SNS:Publish Resource: !Ref SNS2 Topics: - !Ref SNS2個人的なメモ(ここからは蛇足です)
検証時にへーと思ったことを書いていきます。
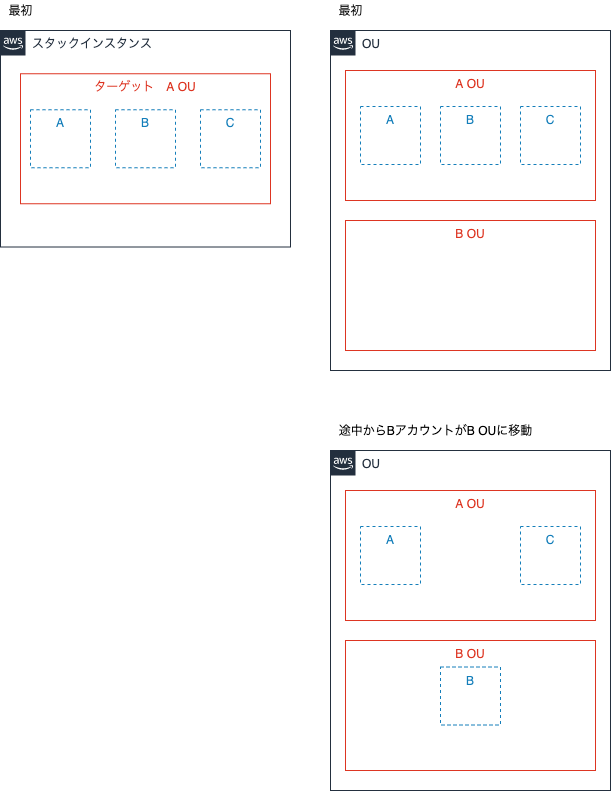
スタックインスタンスが認識しているOUと実際のOUが異なる場合がある
このように、StackSetでターゲットとなっているOUにいるアカウントが、別のOUに移動したときのスタックインスタンスの更新や削除時の挙動について調べてみました。
ちなみに自動デプロイ機能を使わないでStackSetsを展開したらどうなるか検証していた時に発見したものです。
とりあえずStacksetにドリフト検出をしてみました。
私の予想ではリソースが変更していないとはいえ、OUが変更されているからドリフト検出されると思っていたのですが、予想に反してドリフト検出されませんでした。
そこで、どのような挙動になるか確認するために更新や削除を行ってみます。
まず、StackSetにA OUを指定して更新してみます。B OU所属のBアカウントも更新されました。
次に、B OUを指定して削除してみます。スタックインスタンスにB OUが見つかりませんとエラーが出ます。よって、Bアカウントは実際は
B OUに所属しているが、スタックインスタンスではBアカウントはA OUとして認識されていそうなことがわかりました。
とても紛らわしいので、自動デプロイ機能を使わない場合でアカウントの所属OUを変更するときは、その前に該当のスタックインスタンスのみを削除したいですが、サービスマネージドアクセス許可でStackSetを作成していると、OU単位でしか削除できません。
サービスマネージドアクセス許可のStackSetは、自動デプロイを有効化した方がよさそうです。パラメータの上書きアクションでスタックインスタンス以外のアカウントは追加できない
デプロイ対象のアカウントやOUを選択できるので、スタックインスタンスにない新たなアカウントを追加できるのではないかと思い試してみましたが、エラーで作成できませんでした。
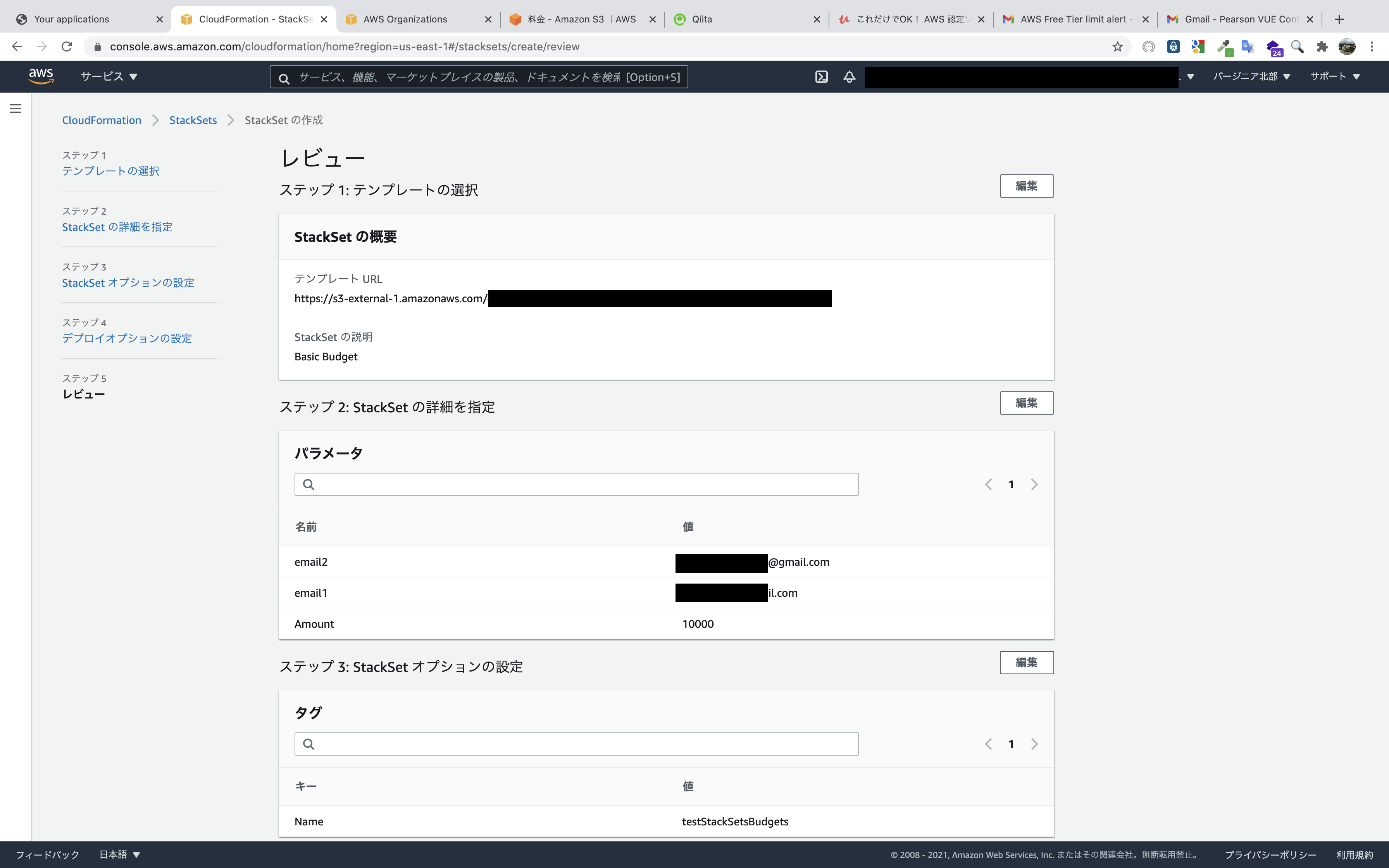
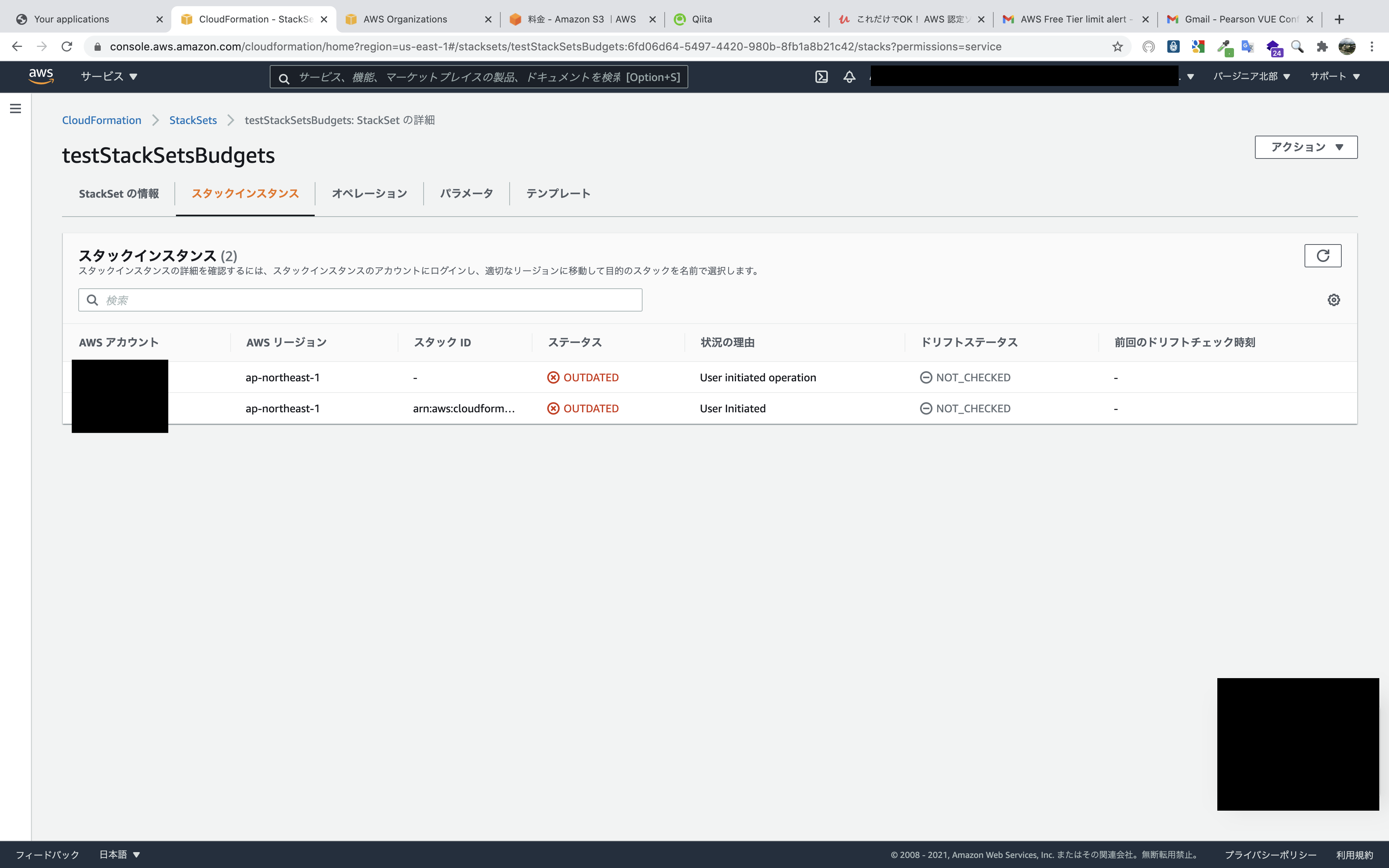
- 投稿日:2021-01-17T00:16:17+09:00
簡単Webサイトホスティング①ワンクリックで運用基盤を構築するCloudFormationテンプレート
はじめに
Amazon Web Services(AWS)が提供する、
Amazon CloudFrontやAmazon S3と呼ばれるサービスを組み合わせることで、 HTMLやJavaScript、画像、ビデオなどで構成される静的Webサイトの運用基盤 を安価に構築することができます。本記事では、リソースのセットアップを自動で行うことのできる、AWS CloudFormationを用いることで、これらの運用基盤を ミスなく迅速に構築 する手順をご説明します。なお、今回使用する CloudFormation テンプレートは、以下の GitHub リポジトリで公開しています。TL;DR
以下の
CloudFormationテンプレートを実行することで、 静的Webサイトのホスティング基盤を迅速かつお手軽 に実現します。下にあるボタンをクリックすると、自身のAWSアカウント(Asia Pacific Tokyo - ap-northeast-1)で、このCloudFormationテンプレートを実行することが可能となります。
作成されるAWSリソースとそのアーキテクチャ図はこちら。
この
CloudFormationテンプレートは、Nested Stackの構成となっており、下記のAWSサービスを単体で作成することも可能です。
作成されるAWSサービス 個別のCloudFormationテンプレート 作成されるサービス Synthetics 作成した運用基盤の 外形監視 を行います Real-time Dashboard CloudFront の アクセスログをリアルタイムに解析 します WAF 作成した運用基盤に WAF を導入 します なお、 上記の Nested Stack のリソースの作成は必須ではなく、これらが無くても正常に動作 します。 静的Webサイトのホスティングに必要となるのは、 Amazon CloudFront と Amazon S3 のみ であり、本記事ではこの部分に焦点を当ててご説明します。
アーキテクチャ
このテンプレートの設定内容は以下の通りです。なお、以下のYAMLコードは、AWSCloudFormationTemplates/static-website-hosting-with-ssl で公開しているCloudFormationテンプレートから、本記事用に一部抜粋したものです。本記事作成用に一部改変を行なっていること、またリポジトリの最新のコードを常に反映している訳ではないことをご了承ください。詳細は、GitHubの当該リポジトリをご覧ください。
- README(EN) - aws-cloudformation-templates/static-website-hosting-with-ssl
- README(JP) - aws-cloudformation-templates/static-website-hosting-with-ssl
Amazon S3
Amazon S3は、ユーザがデータを安全にかつ容量無制限に保存可能な オブジェクトストレージ で、本アーキテクチャでは、 オリジンWebサーバ としての役割を担います。このS3の中に、HTMLやJavaScript、画像、ビデオなどの 静的ファイルが格納 されており、ユーザからのHTTPSリクエストに従って、これらのコンテンツが配信されます。
なお、S3自体に備わっている
静的Webサイトホスティング機能を有効化することで、S3のみを用いてWebサイトのホスティングを実現することも可能です。しかし、 S3に以下のような制限 があることから、本テンプレートでは CloudFront と組み合わせて静的Webサイトのホスティングを実現 しています。
- S3単独では秒間数千リクエストを超える 大規模なトラフィックに耐えられない
- S3単独では カスタムドメインを用いたHTTPS通信が実現できない
- S3の権限設定ミスを悪用した Ghostwriter攻撃 を受ける可能性がある
S3バケットに関するCloudFormationテンプレートは以下の通りです。
Resource: S3ForWebHosting: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: AccessControl: Private BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: example.com LifecycleConfiguration: Rules: - Id: NonCurrentVersionExpiration NoncurrentVersionExpirationInDays: 90 Status: Enabled LoggingConfiguration: !If DestinationBucketName: !Ref S3ForAccessLog LogFilePrefix: S3-example.com/ PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: true VersioningConfiguration: Status: Enabledバケット内が空である場合のみS3バケットの削除が可能となるため、S3バケットには、
UpdateReplacePolicyおよびDeletionPolicyを指定して、 リソース置換時およびリソース削除時は、リソースを保持する 設定にしています。また、上述のように CloudFront と組み合わせて静的Webサイトホスティングを実現するため、 規定ACLはprivateにした上で、 パブリックアクセスを全て禁止 にしています。なお、のちほどご説明する
Origin Access Identityが、 AES256によるバケット暗号化のみをサポートしていること、AWS の基本的なセキュリティのベストプラクティス標準 にて S3バケットのサーバサイド暗号化を求められている ことから、 AES256によるサーバサイド暗号化を有効化 しています。Parameters: DomainName: Type: String AllowedPattern: .+ Description: The CNAME attached to CloudFront [required] Resources: S3BucketPolicy: Type: 'AWS::S3::BucketPolicy' Properties: Bucket: !Ref S3ForWebHosting PolicyDocument: Version: 2012-10-17 Id: !Ref S3ForWebHosting Statement: - Effect: Allow Principal: AWS: !Sub arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${CloudFrontOriginAccessIdentity} Action: - 's3:GetObject' Resource: !Sub arn:aws:s3:::${S3ForWebHosting}/* - Effect: Deny Principal: '*' Action: 's3:*' Resource: - !GetAtt S3ForWebHosting.Arn - !Join - '' - - !GetAtt S3ForWebHosting.Arn - /* Condition: Bool: aws:SecureTransport: false CloudFrontOriginAccessIdentity: Type: 'AWS::CloudFront::CloudFrontOriginAccessIdentity' Properties: CloudFrontOriginAccessIdentityConfig: Comment: !Sub access-identity-${DomainName}S3のバケットポリシーでは、 Origin Access Identity を用いた CloudFront からのアクセスを許可 しています。また、AWS の基本的なセキュリティのベストプラクティス標準 にて Secure Socket Layer を使用するためのリクエストが必要 とされているため、 SSLを用いないS3バケットへのアクセスを禁止 しています。
また、上述のS3バケットとは別に、 ログを蓄積するためのS3バケットを作成 します。このバケットの規定ACLには、
LogDeliveryWriteを指定しています。Resources: S3ForAccessLog: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: AccessControl: LogDeliveryWrite BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: !Sub logs-${AWS::Region}-${AWS::AccountId} LifecycleConfiguration: Rules: - Id: ExpirationInDays ExpirationInDays: 60 Status: Enabled PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: true S3BucketPolicyForAccessLog: Condition: CustomLogBucketName Type: 'AWS::S3::BucketPolicy' Properties: Bucket: !Ref S3ForAccessLog PolicyDocument: Version: 2012-10-17 Id: !Ref S3ForAccessLog Statement: - Effect: Deny Principal: '*' Action: 's3:*' Resource: - !GetAtt S3ForAccessLog.Arn - !Join - '' - - !GetAtt S3ForAccessLog.Arn - /* Condition: Bool: aws:SecureTransport: false本テンプレートで作成するS3バケットは、AWS の基本的なセキュリティのベストプラクティス標準 の以下の項目に準拠しています。
No. ルール 実行内容 S3.1 S3 バケットでは、パブリックアクセスブロック設定を有効にする必要があります パブリックアクセスを禁止します S3.2 S3 バケットでは、パブリック読み取りアクセスを禁止する必要があります パブリックアクセスを禁止します S3.3 S3 バケットでは、パブリック書き込みアクセスを禁止する必要があります パブリックアクセスを禁止します S3.4 S3 バケットでは、サーバー側の暗号化を有効にする必要があります AES256によるサーバ側暗号化を行います S3.5 S3 バケットでは、Secure Socket Layer を使用するためのリクエストが必要です バケットボリシーを用いて、SSL通信以外のリクエストを拒否します CloudFront
CloudFrontは、コンテンツを低遅延、高速かつ安全に配信することが可能な コンテンツ配信ネットワーク(CDN)で、 AWS Certificate Manager(ACM)で作成/インポートされたSSL/TLS証明書を簡単に紐付けることができます 。
ユーザからのHTTPリクエストは、まず最初にこのCloudFrontが受信し、 CloudFrontがキャッシュしていないコンテンツのみ を、オリジンWebサーバの役割を担う S3バケットに問い合わせる ため、CloudFrontを用いることで S3バケットへのトラフィックを大幅に低減することが可能 です。
また、 CloudFrontへは GET/HEAD リクエストのみ許可 され、 S3バケットへはCloudFrontからのリクエストのみが許可 されるため、 AWSリソースおよびS3バケット上のコンテンツは安全に保護 されます。
Parameters: CertificateManagerARN: Default: '' Type: String Description: The ARN of an SSL Certifiation attached to CloudFront DomainName: Type: String AllowedPattern: .+ Description: The CNAME attached to CloudFront [required] CloudFrontDefaultTTL: Default: 86400 MinValue: 0 Type: Number Description: CloudFront Default TTL [required] CloudFrontMinimumTTL: Default: 0 MinValue: 0 Type: Number Description: CloudFront Minimum TTL [required] CloudFrontMaximumTTL: Default: 31536000 MinValue: 0 Type: Number Description: CloudFront Maximum TTL [required] Resources: CloudFront: Type: 'AWS::CloudFront::Distribution' Properties: DistributionConfig: Aliases: - !Ref DomainName Comment: !Sub CDN for ${DomainName} DefaultCacheBehavior: AllowedMethods: - GET - HEAD DefaultTTL: !Ref CloudFrontDefaultTTL ForwardedValues: QueryString: false MaxTTL: !Ref CloudFrontMaximumTTL MinTTL: !Ref CloudFrontMinimumTTL SmoothStreaming: false TargetOriginId: !Ref S3ForWebHosting ViewerProtocolPolicy: redirect-to-https DefaultRootObject : index.html Enabled: true HttpVersion: http2 IPV6Enabled: false Logging: Bucket: !GetAtt S3ForAccessLog.DomainName Prefix: !Sub CloudFront-${DomainName}/ Origins: - DomainName: !GetAtt S3ForWebHosting.DomainName Id: !Ref S3ForWebHosting S3OriginConfig: OriginAccessIdentity: !Join - '' - - origin-access-identity/cloudfront/ - !Ref CloudFrontOriginAccessIdentity ViewerCertificate: AcmCertificateArn: !Ref CertificateManagerARN MinimumProtocolVersion: TLSv1.1_2016 SslSupportMethod: sni-only本テンプレートでは、 任意のカスタムドメイン とこれに 関連するSSL/TLS証明書 をCloudFrontディストリビューションに紐づけます。また、ディストリビューションが コンテンツがキャッシュする時間(TTL)を自由に指定 することが可能です。
以上で、Amazon S3 バケットと Amazon CloudFront ディストリビューションを用いた、 静的Webサイトの配信基盤を構築 することができました。 トラフィックの大部分はCloudFrontで処理 され、またCloudFrontとS3との間の通信に
Origin Access Identityが使用されるために、 オリジンWebサーバの役割を担うS3バケットと、その中に保存されている静的コンテンツは安全に保護 されます。また、任意のカスタムドメインを紐付けて、このドメインに対して HTTPS通信 を行うこともできます。これらのトラフィックの ログは、指定したS3バケットに一定期間保存 されます。
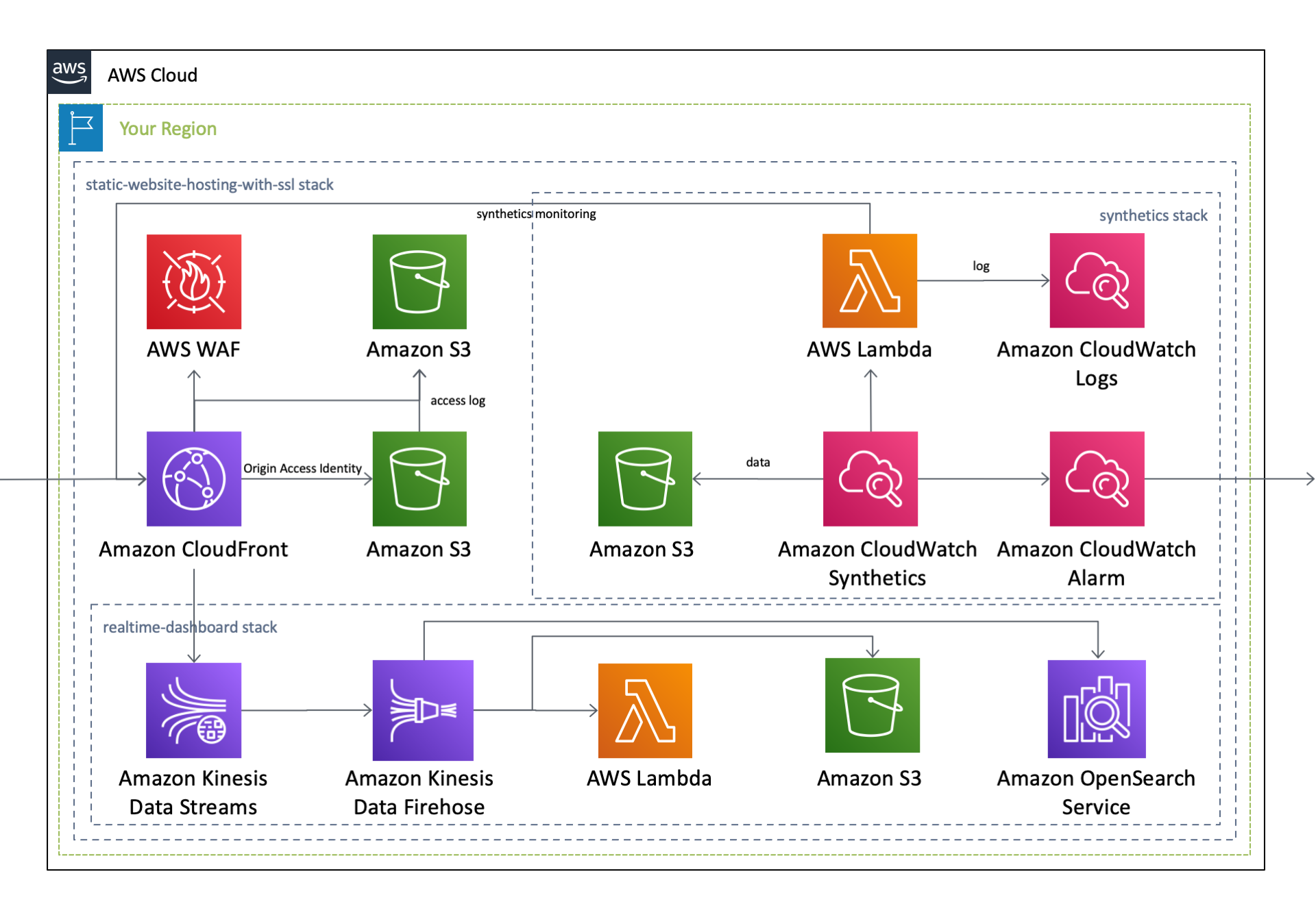
- 投稿日:2021-01-17T00:16:17+09:00
簡単Webサイトホスティング①ワンクリックで配信基盤を構築するCloudFormationテンプレート
はじめに
Amazon Web Services(AWS)が提供する、
Amazon CloudFrontやAmazon S3と呼ばれるサービスを組み合わせることで、 HTMLやJavaScript、画像、ビデオなどで構成される静的Webサイトの配信基盤 を安価に構築することができます。本記事では、リソースのセットアップを自動で行うことのできる、AWS CloudFormationを用いることで、これらの運用基盤を ミスなく迅速に構築 する手順をご説明します。なお、今回使用する CloudFormation テンプレートは、以下の GitHub リポジトリで公開しています。TL;DR
以下の
CloudFormationテンプレートを実行することで、 静的Webサイトのホスティング基盤を迅速かつお手軽 に実現します。下にあるボタンをクリックすると、自身のAWSアカウント(Asia Pacific Tokyo - ap-northeast-1)で、このCloudFormationテンプレートを実行することが可能となります。
作成されるAWSリソースとそのアーキテクチャ図はこちら。
この
CloudFormationテンプレートは、Nested Stackの構成となっており、下記のAWSサービスを単体で作成することも可能です。
作成されるAWSサービス 個別のCloudFormationテンプレート 作成されるサービス Synthetics 作成した運用基盤の 外形監視 を行います Real-time Dashboard CloudFront の アクセスログ を リアルタイムに解析 します WAF 作成した配信基盤に WAF を導入 します なお、 上記の Nested Stack のリソースの作成は必須ではなく 、これらが無くても正常に動作します。 静的Webサイトのホスティングに必要となるのは、 Amazon CloudFront と Amazon S3 のみ であり、本記事ではこの部分に焦点を当ててご説明します。
アーキテクチャ
このテンプレートの設定内容は以下の通りです。なお、以下のYAMLコードは、AWSCloudFormationTemplates/static-website-hosting-with-ssl で公開しているCloudFormationテンプレートから、本記事用に一部抜粋したものです。本記事作成用に一部改変を行なっていること、またリポジトリの最新のコードを常に反映している訳ではないことをご了承ください。詳細は、GitHubの当該リポジトリをご覧ください。
- README(EN) - aws-cloudformation-templates/static-website-hosting-with-ssl
- README(JP) - aws-cloudformation-templates/static-website-hosting-with-ssl
Amazon S3
Amazon S3は、ユーザがデータを安全にかつ容量無制限に保存可能な オブジェクトストレージ で、本アーキテクチャでは、 オリジンWebサーバ としての役割を担います。このS3の中に、HTMLやJavaScript、画像、ビデオなどの 静的ファイルが保存 されており、ユーザからのHTTPSリクエストに従って、これらのコンテンツが配信されます。
なお、S3自体に備わっている
静的Webサイトホスティング機能を有効化することで、S3のみを用いてWebサイトのホスティングを実現することも可能です。しかし、 S3に以下のような制限 があることから、本テンプレートでは CloudFront と組み合わせて静的Webサイトのホスティングを実現 しています。
- S3単独では秒間数千リクエストを超える 大規模なトラフィックに耐えられない
- S3単独では カスタムドメインを用いたHTTPS通信が実現できない
- S3の権限設定ミスを悪用した Ghostwriter攻撃 を受ける可能性がある
S3バケットに関するCloudFormationテンプレートは以下の通りです。
Resource: S3ForWebHosting: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: AccessControl: Private BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: example.com LifecycleConfiguration: Rules: - Id: NonCurrentVersionExpiration NoncurrentVersionExpirationInDays: 90 Status: Enabled LoggingConfiguration: DestinationBucketName: !Ref S3ForAccessLog LogFilePrefix: S3-example.com/ PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: true VersioningConfiguration: Status: Enabledバケット内が空である場合のみS3バケットの削除が可能となるため、S3バケットには、
UpdateReplacePolicyおよびDeletionPolicyを指定することで、 リソース置換時およびリソース削除時は、リソースを保持する 設定にしています。また、上述のように CloudFront と組み合わせて静的Webサイトホスティングを実現するため、 規定ACLをprivateにした上で、 パブリックアクセスを全て禁止 にしています。なお、のちほどご説明する
Origin Access Identityが、 AES256によるバケット暗号化のみをサポート していること、AWS の基本的なセキュリティのベストプラクティス標準 にて S3バケットのサーバサイド暗号化を求められている ことから、 AES256によるサーバサイド暗号化を有効化 しています。Parameters: DomainName: Type: String AllowedPattern: .+ Description: The CNAME attached to CloudFront [required] Resources: S3BucketPolicy: Type: 'AWS::S3::BucketPolicy' Properties: Bucket: !Ref S3ForWebHosting PolicyDocument: Version: 2012-10-17 Id: !Ref S3ForWebHosting Statement: - Effect: Allow Principal: AWS: !Sub arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${CloudFrontOriginAccessIdentity} Action: - 's3:GetObject' Resource: !Sub arn:aws:s3:::${S3ForWebHosting}/* - Effect: Deny Principal: '*' Action: 's3:*' Resource: - !GetAtt S3ForWebHosting.Arn - !Join - '' - - !GetAtt S3ForWebHosting.Arn - /* Condition: Bool: aws:SecureTransport: false CloudFrontOriginAccessIdentity: Type: 'AWS::CloudFront::CloudFrontOriginAccessIdentity' Properties: CloudFrontOriginAccessIdentityConfig: Comment: !Sub access-identity-${DomainName}S3のバケットポリシーでは、 Origin Access Identity を用いた CloudFront からのアクセスを許可 しています。また、AWS の基本的なセキュリティのベストプラクティス標準 にて Secure Socket Layer を使用するためのリクエストが必要 とされているため、 SSLを用いないS3バケットへのアクセスを禁止 しています。
また、上述のS3バケットとは別に、 ログを蓄積するためのS3バケットを作成 します。このバケットの規定ACLには、
LogDeliveryWriteを指定しています。Resources: S3ForAccessLog: Type: 'AWS::S3::Bucket' UpdateReplacePolicy: Retain DeletionPolicy: Retain Properties: AccessControl: LogDeliveryWrite BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: !Sub logs-${AWS::Region}-${AWS::AccountId} LifecycleConfiguration: Rules: - Id: ExpirationInDays ExpirationInDays: 60 Status: Enabled PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: true S3BucketPolicyForAccessLog: Condition: CustomLogBucketName Type: 'AWS::S3::BucketPolicy' Properties: Bucket: !Ref S3ForAccessLog PolicyDocument: Version: 2012-10-17 Id: !Ref S3ForAccessLog Statement: - Effect: Deny Principal: '*' Action: 's3:*' Resource: - !GetAtt S3ForAccessLog.Arn - !Join - '' - - !GetAtt S3ForAccessLog.Arn - /* Condition: Bool: aws:SecureTransport: false本テンプレートで作成するS3バケットは、AWS の基本的なセキュリティのベストプラクティス標準 の以下の項目に準拠しています。
No. ルール 実行内容 S3.1 S3 バケットでは、パブリックアクセスブロック設定を有効にする必要があります パブリックアクセスを禁止します S3.2 S3 バケットでは、パブリック読み取りアクセスを禁止する必要があります パブリックアクセスを禁止します S3.3 S3 バケットでは、パブリック書き込みアクセスを禁止する必要があります パブリックアクセスを禁止します S3.4 S3 バケットでは、サーバー側の暗号化を有効にする必要があります AES256によるサーバ側暗号化を行います S3.5 S3 バケットでは、Secure Socket Layer を使用するためのリクエストが必要です バケットボリシーを用いて、SSL通信以外のリクエストを拒否します Amazon CloudFront
CloudFrontは、コンテンツを低遅延、高速かつ安全に配信することが可能な コンテンツ配信ネットワーク(CDN)で、AWS Certificate Manager(ACM)で作成/インポートされた SSL/TLS証明書を簡単に紐付ける ことができます。
ユーザからのHTTPリクエストはまず最初にこのCloudFrontが受信し、 CloudFrontがキャッシュしていないコンテンツのみをオリジンWebサーバの役割を担うS3バケットに問い合わせるため、 S3バケットへのトラフィックを大幅に低減することが可能 です。
また、 GET/HEAD リクエストのみ許可 され、 かつS3バケットへは Origin Access Identity (OAI)と呼ばれる、特別なCloudFrontユーザからのリクエストのみが許可 されるため、 AWSリソースおよびS3バケット上のコンテンツは安全に保護 されます。
Parameters: CertificateManagerARN: Default: '' Type: String Description: The ARN of an SSL Certifiation attached to CloudFront DomainName: Type: String AllowedPattern: .+ Description: The CNAME attached to CloudFront [required] CloudFrontDefaultTTL: Default: 86400 MinValue: 0 Type: Number Description: CloudFront Default TTL [required] CloudFrontMinimumTTL: Default: 0 MinValue: 0 Type: Number Description: CloudFront Minimum TTL [required] CloudFrontMaximumTTL: Default: 31536000 MinValue: 0 Type: Number Description: CloudFront Maximum TTL [required] Resources: CloudFront: Type: 'AWS::CloudFront::Distribution' Properties: DistributionConfig: Aliases: - !Ref DomainName Comment: !Sub CDN for ${DomainName} DefaultCacheBehavior: AllowedMethods: - GET - HEAD DefaultTTL: !Ref CloudFrontDefaultTTL ForwardedValues: QueryString: false MaxTTL: !Ref CloudFrontMaximumTTL MinTTL: !Ref CloudFrontMinimumTTL SmoothStreaming: false TargetOriginId: !Ref S3ForWebHosting ViewerProtocolPolicy: redirect-to-https DefaultRootObject : index.html Enabled: true HttpVersion: http2 IPV6Enabled: false Logging: Bucket: !GetAtt S3ForAccessLog.DomainName Prefix: !Sub CloudFront-${DomainName}/ Origins: - DomainName: !GetAtt S3ForWebHosting.DomainName Id: !Ref S3ForWebHosting S3OriginConfig: OriginAccessIdentity: !Join - '' - - origin-access-identity/cloudfront/ - !Ref CloudFrontOriginAccessIdentity ViewerCertificate: AcmCertificateArn: !Ref CertificateManagerARN MinimumProtocolVersion: TLSv1.1_2016 SslSupportMethod: sni-only本テンプレートでは、 任意のカスタムドメイン とこれに 関連するSSL/TLS証明書 をCloudFrontディストリビューションに紐づけます。また、ディストリビューションが コンテンツをキャッシュする時間(TTL)を自由に指定 することが可能です。
以上で、Amazon S3 バケットと Amazon CloudFront ディストリビューションを用いた、 静的Webサイトの配信基盤を構築 することができました。 トラフィックの大部分はCloudFrontで処理 され、またCloudFrontとS3との間の通信に
Origin Access Identityが使用されるために、 オリジンWebサーバの役割を担うS3バケットと、その中に保存されている静的コンテンツは安全に保護 されます。また、任意のカスタムドメインを紐付けて、このドメインに対して HTTPS通信 を行うこともできます。これらのトラフィックの ログは、指定したS3バケットに一定期間保存 されます。関連リンク
- ワンクリックで配信基盤を構築 - CloudFormation を用いて簡単Webサイトホスティング
- CloudFrontにWAFをアタッチ - CloudFormation を用いて簡単Webサイトホスティング