- 投稿日:2021-01-14T23:46:11+09:00
pythonでUnionFind(強化版: 要素に文字列やtuple可)
はじめに
かの有名なUnionFindですが、集合の要素に文字列やtupleを扱えるものが少なかったので記事にしてみようと思います。役立つ場面にはあまり遭遇していないので、役立つかどうかはわかりませんが、興味がある方は見ていってください。
参考記事
https://note.nkmk.me/python-union-find/
https://qiita.com/white1107/items/52fd4149bb1846862e38コードの紹介
UnionFindがどういうものかについては他の記事に任せ、さっそくコードを紹介しようと思います。
UnionFind.pyimport collections class UnionFind(): def __init__(self): ''' unionfind経路圧縮あり,要素にtupleや文字列可,始めに要素数指定なし ''' self.parents = dict() #{要素:番号,} self.membersf = collections.defaultdict(lambda : set()) #setの中はtupleや文字列可 self.rootsf = set() #tupleや文字列可 self.d = dict() self.d_inv = dict() self.cnt = 0 def dictf(self,x): if x in self.d: return self.d[x] else: self.cnt += 1 self.d[x] = self.cnt self.parents[x] = self.cnt self.d_inv[self.cnt] = x self.membersf[x].add(x) self.rootsf.add(x) return self.d[x] def find(self, x): self.dictf(x) if self.parents[x] == self.dictf(x): return x else: self.parents[x] = self.d[self.find(self.d_inv[self.parents[x]])] return self.d_inv[self.parents[x]] def union(self, x, y): x = self.find(x) y = self.find(y) if self.parents[x] > self.parents[y]: x, y = y, x if x == y: return for i in list(self.membersf[y]): self.membersf[x].add(i) self.membersf[y] = set() self.rootsf.remove(y) self.parents[y] = self.d[x] def size(self, x):#xが含まれる集合の要素数 return len(self.membersf[self.find(x)]) def same(self, x, y):#同じ集合に属するかの判定 return self.find(x) == self.find(y) def members(self, x):#xを含む集合の要素 return self.membersf[self.find(x)] def roots(self):#根の要素 return self.rootsf def group_count(self):#根の数 return len(self.rootsf) def all_group_members(self):#根とその要素 return {r: self.membersf[r] for r in list(self.rootsf)} if __name__=="__main__": #デバック用 uf_s = UnionFind() uf_s.union('A', 'D') uf_s.union('D', 'C') uf_s.union('E', 'B') print(uf_s.members('D')) print(uf_s.members('E')) uf_s.union('A', 'B') print(uf_s.members('E')) print(uf_s.same('A','F')) print(uf_s.members('F')) print(uf_s.members('G')) print() uf_t = UnionFind() uf_t.union((2,3),(3,4)) uf_t.union((4,3),(5,4)) uf_t.union((1,3),(3,4)) print(uf_t.members((2,3))) print(uf_t.roots()) print(uf_t.group_count()) print(uf_t.all_group_members()) print() uf_ts = UnionFind() uf_ts.union((2,3),1) uf_ts.union((4,3),'A') uf_ts.union((1,3),(3,4)) uf_ts.union((1,3),'A') print(uf_ts.members((2,3))) print(uf_ts.roots()) print(uf_ts.all_group_members()) print(uf_ts.size('A'))テキトーなデバック用コードを下につけておきました。
説明
使い方
基本的にはよく見るUnionFind同じ使い方ができます。
find(x):xの根の取得
union(x,y):集合を合体
size(x):x要素が含まれる集合の大きさを出力
same(x,y):同じ集合に属するか判定
members(x):xが含まれる集合を出力
roots():すべての根を取得
group_count():集合の数を出力
all_group_members():すべての根とその要素を取得工夫点と利点
とにかく辞書を駆使して、要素と要素番号の対応を取りながら経路圧縮も行い集合を管理しています。なので辞書のkeyにできる要素なら型が違っていても同じように扱うことができます(文字列、tuple、整数などなど)。また、他で見るunionfindは要素数を先に指定するものが多いですが、本コードでは要素がやってくるたび初めてかどうかを確認し、初めてなら今まで使っていない番号を割り当てるようにしているので要素数の指定は不要です。
弱点
普通のunionfindに比べ、辞書等で管理している部分が多いのでメモリの消費が大きいです。また、unionfind内部でのデータのやり取りが多く計算時間も多くかかってしまいます。
例:https://atcoder.jp/contests/atc001/tasks/unionfind_a
TLEはしませんでしたが、1500msくらいでこれ以上重くなると通らないことがありそうです。おわりに
ここまでお読みいただきありがとうございました。私自身競技プログラミング初学者ですので、間違い等ございましたらご指摘よろしくお願いいたします。(加えて、本コードが役立つ問題がありましたらリンク等コメントください。)
- 投稿日:2021-01-14T22:46:28+09:00
JupyterLab3.0 デバッガ インストール方法 for Windows
Jupyter Lab3.0リリース
待望のビジュアルデバッガーが付属し使いやすくなった!
https://blog.jupyter.org/jupyterlab-3-0-is-out-4f58385e25bb単純にバージョンをあげるだけでは、デバッガ機能が有効になるわけではなく、
意外とインストールが面倒臭かったのでまとめてみる。インストールフロー
①minicondaのインストール
↓
②xeus-python(デバッガ)のインストール
↓
③Jupyter labのアップデート
↓
④インストール確認
↓
⑤ライブラリの再インストール①minicondaのインストール
xeus-pythonは、condaパッケージマネージャー用にパッケージ化されているため
conda系の環境をインストールする必要がある。
Anacondaでは競合する機能があるため、ここでは機能制限されたminicondaを使用する。
(Anacondaをインストールしていたらアンインストールする)↓各々の環境のソフトをDLインストール
https://docs.conda.io/en/latest/miniconda.html
PATHを通す(不要
システム環境変数のPathに追加
C:\Users(ユーザー名)\Miniconda3\Scripts
コマンドプロンプト上で作業をするわけでなければ必須ではなさそう。②xeus-python(デバッガ)のインストール
以降の作業はインストールした
Anaconda Prompt(miniconda3)で行うhttps://xeus-python.readthedocs.io/en/latest/installation.html
With condaのコードを順番に実行していくxeus-python_install.pyconda create -n xeus-python conda activate xeus-python # Or `source activate xeus-python` for conda < 4.6 conda install xeus-python jupyterlab -c conda-forge③Jupyter labのアップデート
②で最新の物になっているかもしれないが…念のため
Jupyterlab_update.pyconda install -c conda-forge jupyterlab = 3④インストール確認
Anaconda Prompt上でJupyter labを起動。
Xpythonの記載があればインストール成功。
⑤ライブラリの再インストール
環境が変わるため、使いたいライブラリ(pandas、numpy…)は再インストールする。
conda install pandas(pipではなくcondaでインストール)以上。
追記)起動させるたびに②xeus-python(デバッガ)のコードを事項しないとデバッガが立ち上がらない問題アリ
※デバッガのチュートリアルはこちら
https://jupyterlab.readthedocs.io/en/stable/user/debugger.html


- 投稿日:2021-01-14T22:42:58+09:00
Effective Python 学習備忘録 13日目 【13/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:79-86ページ
- 第3章:クラスと継承
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
プライベート属性よりはパブリック属性が好ましい
Pythonのクラスの属性の可視性にはパブリックとプライベートがあります。
アンダーバーを2つ付けることでプライベートとして扱われます。
classブロックの内部で宣言されるもののみ、プライベートにアクセスできます。
例えば、サブクラスからは親クラスのプライベートにアクセスできません。class MyObject(object): def __init__(self): # パブリック self.public_field = 2 # プライベート self.__private_field = 4 def get_private_field(self): return self.__private_fieldパブリックはどこからでもドット演算子でアクセスできます。
obj = MyObject() print(obj.public_field) # 2プライベートは.演算子でアクセスしようとすると例外が発生します。
print(obj.__private_field)出力結果
AttributeError: 'MyObject' object has no attribute '__private_field'
__dict__を用いてオブジェクトの属性を確認してみます。print(obj.__dict__) # {'public_field': 2, '_MyObject__private_field': 4}パブリックは同じ属性名ですが、プライベートは
__private_fieldではなく、_MyObject__private_fieldになっています。
Pythonでは、プライベート属性の振る舞いを単純な属性名の変換で行っているためおきています。
そのため、以下のようにすればプライベートにも簡単にアクセスできます。print(obj._MyObject__private_field) # 4しかし、この方法を用いても親の親のプライベートクラスにはアクセスできないです。
Pythonのプライベートは無理やり外部からアクセスできる点、多重継承になるとアクセスできなくなる点からそもそも、サブクラスを締め出すのではなく、
内部APIと属性を利用できるように考慮すべきであり、保護フィールドについてドキュメンテーションで説明した方がいいようです。
サブクラスとの名前の衝突を避けるときのみプライベートの使用を考慮すべきなようです。カスタムコンテナ型は collections.abc を継承する
カスタムコンテナ型を正しく実装するには多数のメソッドが必要になります。
そのため、自分のコンテナ型を定義するのはかなり困難です。
それらを解消するために存在するモジュールが collections.abc です。
このモジュールはコンテナ型の典型的なメソッドをすべて提供す抽象基底クラスを定義しています。
この抽象基底クラスを作って、必要なメソッドを実装し忘れていると、モジュールが指摘してくれます。from collections.abc import Sequence class BadType(Sequence): pass foo = BadType() # TypeError: Can't instantiate abstract class BadType with abstract methods __getitem__, __len__
- 投稿日:2021-01-14T21:45:21+09:00
リストの内包表記について
pythonの内容表記についてまとめる。
学習のため自分用。1.内包表記
このように処理とfor文を分けて書いていたものを最後の行のようにまとめて書くこと。
行いたい処理はfor文の前に記述する。
2.if文を使った内包表記の記述方法
内包表記ではif文を使いたい場合使いたい分の後ろに記述する。
注意するのが、elseも含まれる文の場合はfor文の前に両方記述しなければならない。
3.二次元リストを一次元化してみる。
この記述では二つのfor文が入っているがこの実行は、前から実行していくので後述のようになる。
入れ子でない限りは順番に展開していく
4.入れ子の内包表記。
この内包表記は入れ子になっている。
入れ子になっている場合、この図で言うとfor i in range(4)から実行しその処理である[row[i] for row in matrix]を行う。
またzip()関数は一度に複数の値に対して処理を行えるようにする。4.辞書型内包表記
辞書型の内包表記は全体を波括弧で覆う。
if文のみの記述は後置に記述する。
if,elseどちらも記述する場合は前置で記述。
辞書型なのでkeyと値両方の判定式を書くこと。
後述のようなzipを使った書き方もある。
またコロンをつけずに記述することで集合の内容表記も記述できます。





- 投稿日:2021-01-14T21:21:33+09:00
AWS CDK with Python
※適時更新
CDK環境の構築
CDK version: 1.83.0 (build 827c5f4)
事前準備
Python3とAWS CLIをインストールする。
AWS CLIは、プロファイルを使って、CDKを実行するAWSアカウントを切り変えるために必要(でなくもないけど)なのでインストールする。
インストール後は必要な分、プロファイルを設定しておく。brew install python3 awscli aws configure --profile プロファイル名CDKのインストールとテンプレートプロジェクトの作成
brew install aws-cdkブランクディレクトリ上でコマンドを実行する。
cdk init sample-app --language pythonセットアップ
$ python3 -m venv .venv $ source .venv/bin/activate $ pip install -r requirements.txtテンプレートの細かい修正(2021/01/12時点)
TODO
関連情報
CDK関連
- https://cdkworkshop.com/
- https://github.com/aws/aws-cdk
- https://github.com/aws-samples/aws-cdk-examples
- https://docs.aws.amazon.com/ja_jp/cdk/latest/guide/work-with-cdk-python.html
- https://docs.aws.amazon.com/ja_jp/cdk/latest/guide/tagging.html
テクニック
- https://qiita.com/mira_cocoa/items/0435cf1cfabaabeb7027
- https://qiita.com/akiraabe/items/86c995496d5ee2786088
TBD
- EC2インスタンスの作成
- AMI
- IAM
- 既存VPC
- 既存サブネット
- セキュリティグループ
- ターゲットグループ
- タグ
- 投稿日:2021-01-14T21:09:23+09:00
pytestのテストクラスの全メソッドにmonkeypatchを適用する
失敗
class TestHoge(): def setup_class(cls, monkeypatch): monkeypatch.setattr(target, 'TargetObj', MockObj)以下のエラーを返す。
TypeError: setup_class() missing 1 required positional argument: 'monkeypatch'成功
class TestHoge(): @pytest.fixture(autouse=True) def patch(self, monkeypatch): monkeypatch.setattr(target, 'TargetCls', MockCls) def test_some_func(self): ret = target.TargetCls().some_func()テストクラス内にfixtureを定義し、
autouse=Trueとすることでmonkeypatchがクラス内の全メソッドに適用される。
- 投稿日:2021-01-14T21:04:53+09:00
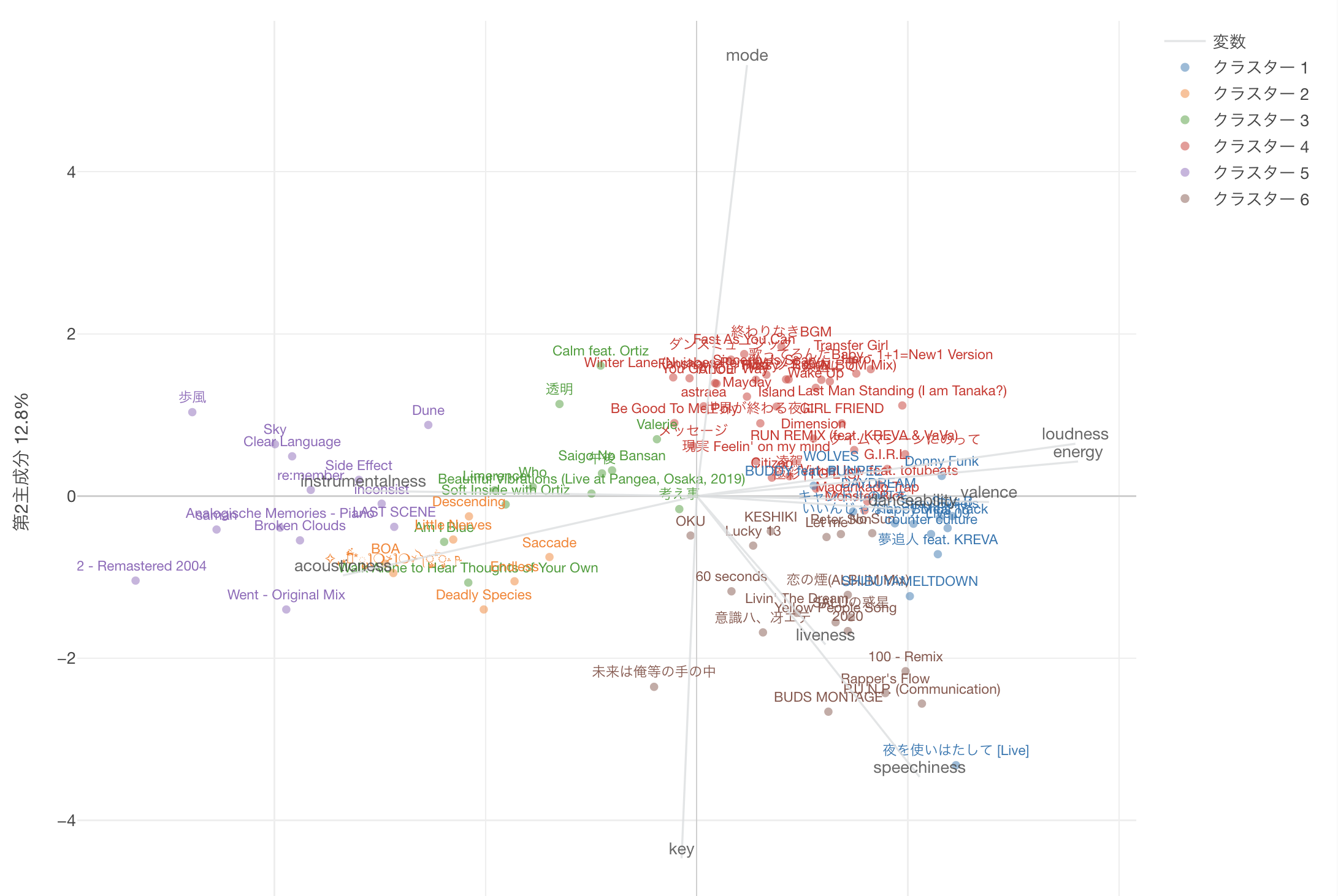
【Spotify】プレイリストで2020を振り返る - Part.2 EDA(基礎統計)、データ前処理
はじめに
SpotifyAPIでは、楽曲ごとの解析した音楽的なパラメータを返却してくれます。
それらのデータを含む楽曲リストを取得し、2020年に聴いた曲の傾向を分析してみましょう。
(年明けてしまった...)
動作環境
- Google Colaboratory
- Python 3.6
- Exploratory Public 6.3.3
事前に準備するもの
- spotifyプレイリストのCSV - Part1記事を参照ください
- Exploratory のインストール - 無料でインストール できます
やること
- EDA - データ理解
- データ前処理① - ラベル値として新規カラムを追加
- データ前処理② - 型変換(時間項目 m秒 → h:M:Sに)
EDAとは
探索的データ分析。Explanatory Data Analysisの略です。
EDAはデータ分析の一番最初のフェーズで、まずはデータに触れてみて、データを視覚化し、パターンを探したり、特徴量やターゲットの関係性/相関性の有無をくみとるのが目的です。なんで必要なの?
分析をはじめる前に、まずは ”どのようなデータセットを扱っているのか” を、理解することが重要です。
より高度な機械学習のモデルの構築をしたり、難解な問題を解決する際には、特徴量エンジニアリングを必要することが多々あり、その際に深いデータの知識と理解が求められます。
また、この段階で前処理が必要なカラムを把握しておきます。どうやってやるか
次ステップのことを考えるとpandasを使用してもよいですが、python初学者だったりするとコードを書くつまづく可能性もあります。
ここではまずは"ビジュアルから"イメージを掴んでもらえるとよいかなーと思い、ノーコードでできる方法を紹介します。データを取り込んでみる
使用するツールは、Exploratoryです。
CSVデータを取り込むだけで、以下のように各項目の欠損値の有無など、各列の要約統計量が表示されます。
便利ですね!
カラム値の相関もGUI操作で可視化できます。
loudnessとenergyの正の相関がみてとれますね。
前処理とは
前処理が必要な理由は以下のようなことが挙げられます。
- 機械学習のモデルは文字列データではなく数値データで渡す必要があるため
- 上記同様、欠損値(null)があるデータも変換しないと機械学習のモデルに渡せないため
- 精度を向上させるため、外れ値のレコードを除く などなど例えばどんなもの?
機械学習のモデルは文字列データではなく数値データで渡す
- 例. 文字列データ(曜日:Mon,Tue,Wed...)ではなく数値データ(0,1,2...)に
精度を向上させるため、外れ値のレコードを除く
- 例. シークレットトラックで無音で秒数が長いtrackの有無を確認
- 例. tempo(BPM)が倍になっている曲がないかをチェック
とはいえ
提供APIで取得できるデータは、欠損値はありませんし、機械が取り込みやすい形になっています。
ですので、前処理のお勉強教材としては、あまり適していません。またtempo(BPM)や、key(調)、time_signitune(拍子)については、一曲で1意に決まるものとは限らず、
そもそも分析対象の項目とすべきかなどの考慮が必要になります。
このあたりは、EDA時に確認するポイントになります。前処理の具体例については、別記事にまとめたいとおもいます。
この記事では、前処理の代わりに、EDAの際に人間が読みやすい値を別カラムに追加する処理を置いておきます。#調をラベル値として別カラムに :長調(major)は1, 単調(minor)は0 tracks_with_features_df.loc[tracks_with_features_df['mode'] == 1, 'a_mode'] = 'major' tracks_with_features_df.loc[tracks_with_features_df['mode'] == 0, 'a_mode'] = 'minor' #キーをラベル値として別カラムに : Cは1, C#は2 ... tracks_with_features_df.loc[tracks_with_features_df['key'] == 0, 'a_key'] = 'C' tracks_with_features_df.loc[tracks_with_features_df['key'] == 1, 'a_key'] = 'C#' tracks_with_features_df.loc[tracks_with_features_df['key'] == 2, 'a_key'] = 'D' tracks_with_features_df.loc[tracks_with_features_df['key'] == 3, 'a_key'] = 'D#' tracks_with_features_df.loc[tracks_with_features_df['key'] == 4, 'a_key'] = 'E' tracks_with_features_df.loc[tracks_with_features_df['key'] == 5, 'a_key'] = 'F' tracks_with_features_df.loc[tracks_with_features_df['key'] == 6, 'a_key'] = 'F#' tracks_with_features_df.loc[tracks_with_features_df['key'] == 7, 'a_key'] = 'G' tracks_with_features_df.loc[tracks_with_features_df['key'] == 8, 'a_key'] = 'G#' tracks_with_features_df.loc[tracks_with_features_df['key'] == 9, 'a_key'] = 'A' tracks_with_features_df.loc[tracks_with_features_df['key'] == 10, 'a_key'] = 'A#' tracks_with_features_df.loc[tracks_with_features_df['key'] == 11, 'a_key'] = 'B' #時間単位の変換:ミリ秒 → 秒 tracks_with_features_df['a_second'] = tracks_with_features_df['duration_ms'] / 1000まとめ
SpotifyAPIを使用して、楽曲のオーディオデータのデータ可視化と前処理を示しました。
次回こそ、オーディオデータから、楽曲の類似度を可視化していきます。それでは。

- 投稿日:2021-01-14T20:55:41+09:00
サンクトペテルブルクのパラドックス
本投稿ではサンクトペテルブルクのパラドックスのwikiを参照しながら私の考察をつらつらの書きなぐる.
パラドックスの内容
wikiの内容
偏りのないコイン[注釈 1]を表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円[注釈 2]、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。
つまり表が初めて出るまでに投げた回数を n とすると、2n−1円もらえるのである。10回目に初めて表が出れば512円、20回目に初めて表が出れば52万4288円、30回目に初めて表が出れば5億3687万0912円がもらえる。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか[注釈 3]。
数学的には、この種の問題では、賞金の期待値を算出し、参加費がその期待値以下であれば参加者は損しないと判断する。しかし、この問題における賞金の期待値を計算してみると、その数値は無限大に発散してしまうのである。すなわち期待値を W とすると、
$$
W=\sum _{k=1}^{\infty }\left({\frac {1}{2^{k}}}\cdot 2^{k-1}\right)={\frac {1}{2}}+{\frac {1}{2}}+{\frac {1}{2}}+{\frac {1}{2}}+\cdots =\infty
$$となる。したがって、期待値によって判断するならば、参加費(=賭け金)がいくら大金であっても参加すべきであると結論になる。
ところが実際には、このゲームでは 1/2 の確率で1円、1/4 の確率で2円、1/1024 の確率で512円の賞金が得られるに過ぎない(賞金が512円以下にとどまる確率が1023/1024)。したがって、そんなに得であるはずがないことは直観的に分かる。これが、この問題がパラドックスとされる所以である。考察
「したがって、そんなに得であるはずがないことは直観的に分かる。」この得でないと判断する理由は, 以降に出てくる「効用」によるものであり, 効用を無視すればいくら大金であっても参加したほうが良い. 例えば参加費が5億円だとすると, 効用を無視すればゲームとしては破格の金額である. しかし効用を考慮すると, 5億が莫大な額になるとしても, 殆どの場合は5億の損失であるため参加しようと思わないだけである.
もっとわかりやすくに言うと, まず100兆円配布する(100%の確率でもらえた嬉しい!). 次に100兆枚の宝くじが1つ100兆円で売られており, たった1枚のあたりを引いた人が2×100兆×100兆円を得られる賭けがある. 期待値として倍になるのでやったほうが良いか?と言われると, まぁやらないのである. 「したがって、そんなに得であるはずがないことは直観的に分かる。」とは, この時点では期待値が∞であるとか無関係に, 直観的に感じているのはこの例と同じだ.現実的な回答
wikiの内容
現実には、賞金には上限がある。例えば、胴元の財産が1億円としよう。27回続けて裏が出ると、賞金は1億円を超えてしまうので、26回裏が出た時点でゲームは打ち切りとすべきだろう。すると、期待値は
$$
{\displaystyle {\frac {1}{2}}\cdot 1+{\frac {1}{2^{2}}}\cdot 2+\cdots +{\frac {1}{2^{26}}}\cdot 2^{25}+{\frac {1}{2^{26}}}\cdot 2^{26}=14}
$$
で14円となる。同様の計算を行えば、胴元がいくら大金持ちであっても、現実的な範囲では期待値はせいぜい数十円の範囲に収まってしまうことが分かる。しかし、思考実験として「胴元が無限の支払い能力を持っている」と仮定することはでき、その場合にはいくらの参加費を支払うべきか、という問に答えられなければ、問題は完全には解決していない。
考察
ほぼこれが答えなのではないでしょうか? 例えば、胴元の財産が$2^{999999998}$円としよう。すると期待値は5億円となる。なので5億円が対等な掛け金で間違いない。ではここで我々はこの賭けに参加するだろうか?と言われるとNoである。なぜNoかというと、前述した「効用」のせいである。さらに言うと、これが対等な掛け金として認識できないのは我々の財産が少なすぎるからである。そこで我々の財産も$2^{999999998}$円としよう。すると5億円なんてはした金なので、この胴元と対等に遊ぶことができるであろう。したがって、あとは胴元の財産を∞にすれば、サンクトペテルブルクのパラドックスとなり、対等に遊ぶためには我々も∞の財産が必要なだけである。それでも∞以外の妥当な金額でこの賭けを行いたいのであれば、おとなしくあなたの財産から上限を設定し、得られた期待値を掛け金にして遊べばいいでしょう。
効用
wikiの内容
はしょります
考察
とても参考になった。
以降
すでに私の結論は出たので、以降の話は無視しました。
申し訳程度のpython要素
手抜きでこんなコードを組んで
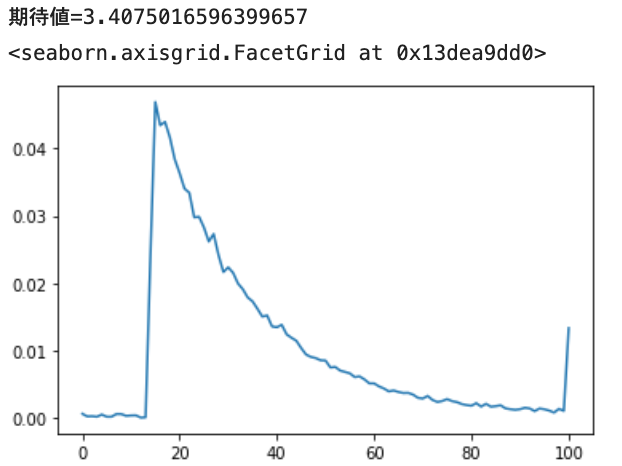
def test(N): out = 0 for i in range(N): n = 0 r = -1 while n < 0.5: n = np.random.rand() r += 1 out += 2 ** r return out / N人数と回数をてきとうに決めてサンプリングしてみましたが無駄でした。まぁ∞人でn回やって期待値求めればnがいくつでも∞になるので当然かな?人数を制限して雑にサンプリングすると曲線ぽいものは現れるが、なんか下限がそれに従うだけで、期待値はどこでもいつでも回数によらず∞で間違いないです。
結論
上限がない場合は妥当な掛け金に上限はなく、それをおかしいと思うのは我々に∞の支払い能力がないからである。∞以外で妥当な掛け金を設定したい場合は、上限を設定するしかない。
補足
wikiに書いている内容だけについてだけ否定しておく。(本当の著者の表現では理論として正しいのかもしれないが、wiki内の内容だけでは議論にすらならないように感じる)
標本抽出による解答
「大人数でこのゲームを行い、その標本抽出から期待値を算出する」について、大人数を∞にすればやるまでもなく期待値は∞になる。有限にしたら、さっきのコードでシミュレートしたように試行回数が足りな過ぎてしょーもない結果になる。人数を増やしていけば期待値が大きくなるのではなく、期待値に近づきやすくなるだけであり、その近づき方から妥当な金額とするのは不当である。(それであれば前述した100兆枚の宝くじの話でも同じようになる)よって、私の直観でこの標本抽出による解答は不当であると判断する。
[直観的にわかりやすくしておく]期待値に近づきやすいとは、宝くじの例で100人で各自が10枚セットで買って期待値求めたらおそらく0円で、この枚数を増やしていけば期待値に近づきやすくなるという意味。では、同じようにこの宝くじもセット売りで割引すべきだろうか?っと言うと、これの期待値は明らかなので買う枚数によって変化するなんてことはないから「セット売りで割引しろ!」なんて言う人もいないでしょう。ということは・・・発展的話題
「ゲームの販売店は、ゲーム1000回分をワンセットとして販売するのである。このときの価格は、約 9969 (≈ 1000 log2 1000) 円程度になる。」これは特に胴元の財産に上限を設けていない場合を仮定しているはずである。ここで胴元の財産を$2^{999999998}$円に固定すると、期待値は5億円となり、妥当な掛け金としてこの期待値を設定すると、上限を設けて胴元を有利にしたはずなのに、掛け金は上昇する(掛け金も胴元が有利になる)というおかしなことがおこる。まぁ実際は特におかしなことは起こっておらず、単にこの約 9969 (≈ 1000 log2 1000) 円程度という価格設定を不当だからである。(この胴元の財産を$2^{999999998}$円に固定し上限とし、その期待値を妥当な掛け金とすることはおそらく誰も否定しないだろうと思いますが…ここを否定する意見があればすごく興味があります)
- 投稿日:2021-01-14T20:40:08+09:00
ある日jupyter notebookが突然開けなくなった【memory error】
何が起きたか
kaggleカーネルをパクって、jupyter notebookで物体検出。
寝る前に機械学習の学習をぽちっ。
朝起きたらmemory error
そしてnotebookを再度開こうとすると、重い。そして開けない(memory error)
(写真とるの忘れた)うーん、どうしたものかと思い、とりあえずgitにpushしようとしたらエラー。
理由...150MBあるため。
えー!そんなに無いよ!と思った理由
jupyterは開けないので、止むを得ず.ipynbをvimで開いてみる。軽い
そして気が付く
200万行
ipynbをずらーっとみてみると、デバグ用に
print(images)しておいたやつが無限に表示されてる。200万行分
notebookの中だと折り畳まれるので気にならないけど、こう言うの全部メモリに記録するから起きたっぽい
ということでvimでこの200万行を消す2000000 ddそれで、あとは鍵かっこなど調整してあげれば開けた
要するに
あまり不用意にprintするのも危険なのかもしれない
- 投稿日:2021-01-14T20:36:47+09:00
pyenvでPythonをインストールできない
完全にメモです。他のPCでも実施予定なので、発生したら追記します。しばらく触っていないMacbookで発生しました。
BUILD FAILED (OS X 11.1 using python-build 20180424)色々やったので、結局何がきいたか分からなかったのですが、少なくとも有効だったのは以下です。
- OSを最新にアップデート macOS Big Sur(元のOSは忘れました…)
- XCode 12にアップデート
別のマシンで再現したら、追記します。
参考リンク
PyEnv BUILDのインストールに失敗しましたPython MacOS
Python 3.9.0、3.8.6を pyenv を使って macOS BigSur にインストールする
macOS Big Sur で pyenv Python インストールできない場合
関連記事
- 投稿日:2021-01-14T20:14:32+09:00
DBから関数名を読みだして動的に実行する
フォルダ構成
project | ├ __init__.py ├ apps.py ├ models.py ├ routes.py ├ views.pyModelをつくる
まずはmodels.pyに関数リストをあらわすクラスを規定します。
models.pyfrom django.db import models from django.db.models.signals import post_save class FuncList: func_id = models.CharField(max_length=50) callback = models.CharField(max_length=50) def get_func_id(self): return self.func_id def set_func_id(self, func_id): self.func_id = func_id self.save() def get_callback(self): return self.callback def set_callback(self, callback): self.callback = callback self.save()DBへの保存/読み出しと動的実行
views.py# DBへの保存 def save_function(**kwargs): func_list = FuncList() func_list.set_func_id(kwargs['func_id']) func_list.set_callback(kwargs['callback']) return # 動的実行 def dynamic_execution(arg1, arg2): # DBから読みだした関数を実行する関数 def execution_handler(func, **kwargs): return func(**kwargs) # DBから関数リスト取得 func_list = FuncList.objects.all() for i in range(len(func_list)): # 取得した関数を順番に実行 result = execution_handler(func=eval(func_list[i].callback), arg1=arg1, arg2=arg2) return resultあとがき
言葉足らずでしたが見に来てくださりありがとうございました。
本記事で不明な点は以下のサイトなどで補完できます。・・・多分
- 投稿日:2021-01-14T19:16:11+09:00
最適化アルゴリズムを実装していくぞ(ホタルアルゴリズム)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
ホタルアルゴリズム
ホタルアルゴリズム(Firefly Algorithm)はホタルの求愛行動に着目したアルゴリズムです。
以下の行動規則に従ってモデル化します。
- ホタルの光の強さは評価値
- 強い光を放っているホタルに他のホタルが近寄ってくる
- 魅力的であるほど、他のホタルが近寄ってくる
- 光っているホタルが近くにいないときはランダムに飛ぶ
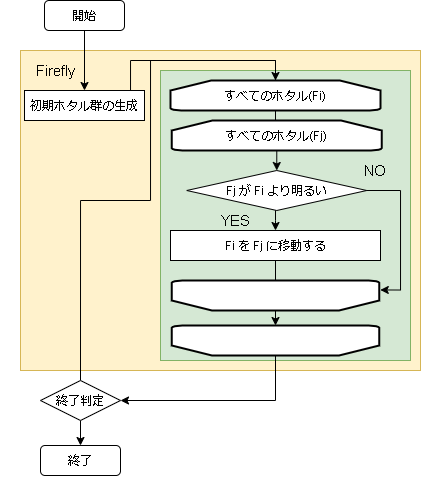
- アルゴリズムのフロー
- 用語の対応
問題 ホタルアルゴリズム 入力値の配列 ホタルの位置 入力値 ホタル 評価値 ホタルの位置における評価値(ホタルの光の強さ)
- ハイパーパラメータに関して
変数名 意味 備考 attracting_degree 誘引度($\beta_0$)(0.0~1.0) 大きいほどホタルに近づく割合が大きい absorb 光の吸収係数($\gamma$)(0.0~∞) 大きいほど光の減衰が多い(遠くのホタルが見えなくなる) alpha 乱数の反映率(0.0~1.0) 大きいほどランダムによく動く is_normalization ユークリッド距離を正規化するか 正規化するとabsorbの値が20~100ぐらいだといい感じになる ホタルの移動
ホタルの移動は2個体を比較し、相手のほうの光が強かったら近づくように移動します。
移動式は以下です。$$
d_{ij} = |\vec{x_j} - \vec{x_i}|
$$$$
attract = \beta_0e^{-\gamma d_{ij}^2}
$$$$
\vec{x_i}(t+1) = \vec{x_i}(t) + attract(\vec{x_j}(t) - \vec{x_i}(t)) + \alpha \vec{\epsilon}
$$
数式 意味 ハイパーパラメータ $i$ 対象のホタル $j$ 相手のホタル $x$ 座標 $d_{ij}$ 二人のホタルの距離(※1) $\gamma$ 光の吸収係数(定数) absorb $\beta_0$ ホタルの誘引度(定数) attracting_degree $attract$ 相手のホタルの魅力値 $t$ 時刻 $\alpha$ ランダム要素を取り入れる率(定数) alpha $\vec{\epsilon}$ 座標と同じ次元のランダム数(※2) ※1、実装はユークリッド距離ですが、他の距離でもいいらしい
※2、実装では一様分布ですが、正規分布などでもいいらしいimport random import numpy as np i = 自分のホタルのindex j = 相手のホタルのindex # 愛他のホタルの光が強かったら移動する if fireflys[i].getScore() < fireflys[j].getScore(): pos = np.asarray(fireflys[i].getArray()) pos2 = np.asarray(fireflys[j].getArray()) d = np.linalg.norm(pos2 - pos) # ユークリッド距離 attract = attracting_degree * (math.exp(-absorb * (d ** 2))) # 範囲+負の値の範囲で一様乱数 r = [] for _ in range(problem.size) t = random.randint(0, 1) if t == 0: t = -1 r.append(problem.randomVal() * t) r = np.asarray(r) # 座標を計算 pos = pos + attract * (pos2 - pos) + alpha * r # 更新 fireflys[i].setArray(pos)ユークリッド距離の正規化
$attract$ はユークリッド距離の値にかなり影響されます。
しかし、次元数が変わるとユークリッド距離の範囲も以下のように変化します。すべての次元で1離れている場合のユークリッド距離
1次元: $\sqrt{1^2} = 1$
2次元: $\sqrt{1^2 + 1^2} = 1.4142$
3次元: $\sqrt{1^2 + 1^2 + 1^2} = 1.7320$ですので、どの次元でも0~1の範囲に収まるように正規化しました。
この正規化処理は本記事オリジナルで元のアルゴリズムにはありません。import random import numpy as np # n次元の最大距離 t = [problem.MAX_VAL - problem.MIN_VAL for _ in range(problem.size)] # 最大のユークリッド距離 max_norm = np.linalg.norm(t) # iとjのホタルのユークリッド距離を出す pos1 = np.asarray(fireflys[i].getArray()) pos2 = np.asarray(fireflys[j].getArray()) d = np.linalg.norm(pos2 - pos) # ユークリッド距離を0~1の範囲で正規化 d = d / max_normホタルの魅力値に関して
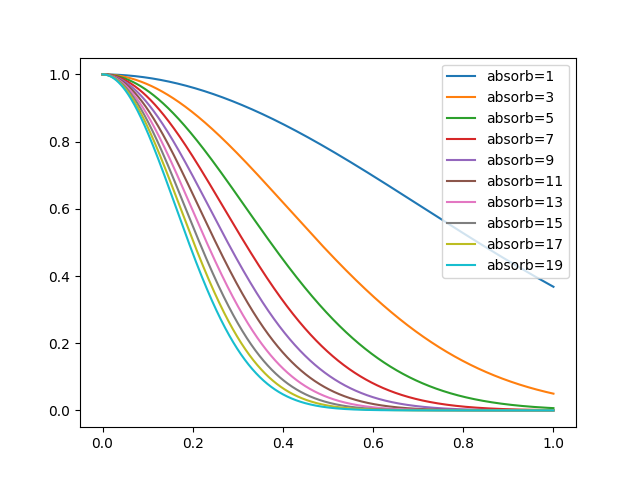
ホタルアルゴリズムで重要な $attract$ ですが、$\gamma$ (absorb)の値によってどう変化するかをグラフ化して見ました。
(attracting_degree は 1 です)
x軸が相手のホタルとのユークリッド距離で、y軸が attract 値です。
attract が大きいほど相手のホタルに近づきます。グラフを見てわかる通りある程度離れると急激に attract の値が少なくなります。
この attract値を制御しやすくするためには正規化が必要な気がしたので実装を追加しています。
コード全体
import math import random import numpy as np class Firefly(IAlgorithm): def __init__(self, firefly_max, attracting_degree=1.0, absorb=0.5, alpha=1.0, is_normalization=False, ): self.firefly_max = firefly_max self.attracting_degree = attracting_degree self.absorb = absorb self.alpha = alpha self.is_normalization = is_normalization def init(self, problem): self.problem = problem # ユークリッド距離正規化用 t = [problem.MAX_VAL - problem.MIN_VAL for _ in range(problem.size)] self.max_norm = np.linalg.norm(t) self.fireflys = [] for _ in range(self.firefly_max): self.fireflys.append(problem.create()) def step(self): for i in range(len(self.fireflys)): for j in range(len(self.fireflys)): if i == j: continue # 光が強かったら移動する if self.fireflys[i].getScore() < self.fireflys[j].getScore(): pos = self.fireflys[i].getArray() pos2 = self.fireflys[j].getArray() d = np.linalg.norm(pos2 - pos) # ユークリッド距離 if self.is_normalization: # 0~1の範囲で正規化する d /= self.max_norm # 誘引度 attract = self.attracting_degree * (math.exp(-self.absorb * (d ** 2))) # 範囲+負の値の範囲で一様乱数 r = [] for _ in range(problem.size) t = random.randint(0, 1) if t == 0: t = -1 r.append(problem.randomVal() * t) r = np.asarray(r) pos = pos + attract * (pos2 - pos) + self.alpha * r # 更新 self.fireflys[i].setArray(pos)ハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を2秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
問題 absorb alpha attract firefly_max is_normalization EightQueen 30.348200739383188 0.023361773591726337 0.2870040283132875 35 True function_Ackley 28.535248274373334 0.02020150316119749 0.3817578607938779 22 True function_Griewank 24.886474482157883 0.030874057659246265 0.2570801290508207 16 True function_Michalewicz 12.85000382821637 0.00019928439251062913 0.9311223660128144 38 True function_Rastrigin 12.146442425313117 0.0043715893301495105 0.6005897245267422 23 True function_Schwefel 19.283223050420563 0.7687804405285998 0.09958914072852465 30 False function_StyblinskiTang 22.45670196693838 0.040041083413524164 0.6313203783344563 8 True function_XinSheYang 19.93462659647029 0.7629337202966674 0.7449791915452185 12 False g2048 15.50932867945044 0.8550076810686411 0.29794958618177236 22 True LifeGame 9.681288121919476 0.46635850168820797 0.9893266181614047 42 True OneMax 3.0779446144304785 0.6083197521965231 0.8027617234478412 48 True TSP 13.999384524084206 0.08809615253769626 0.46965098629117824 21 True 実際の動きの可視化
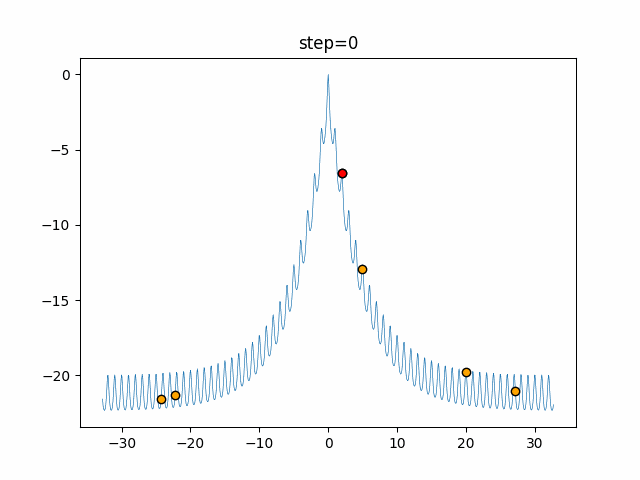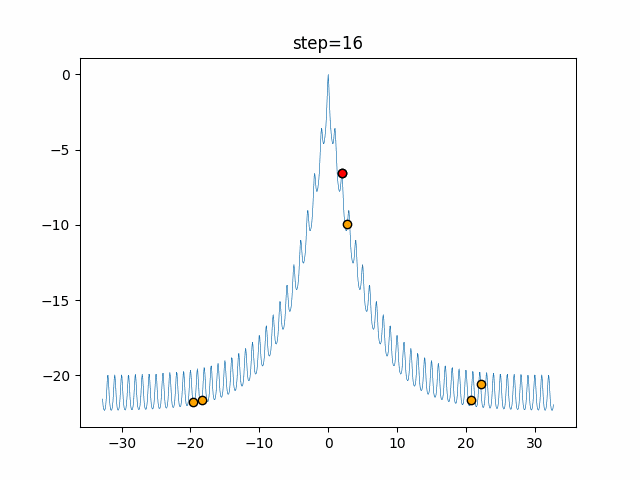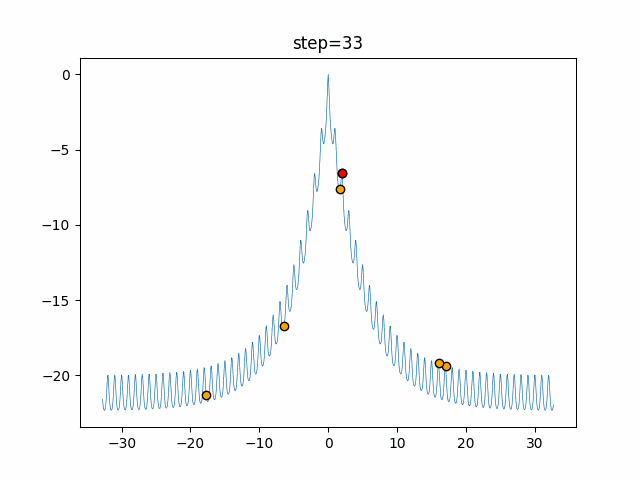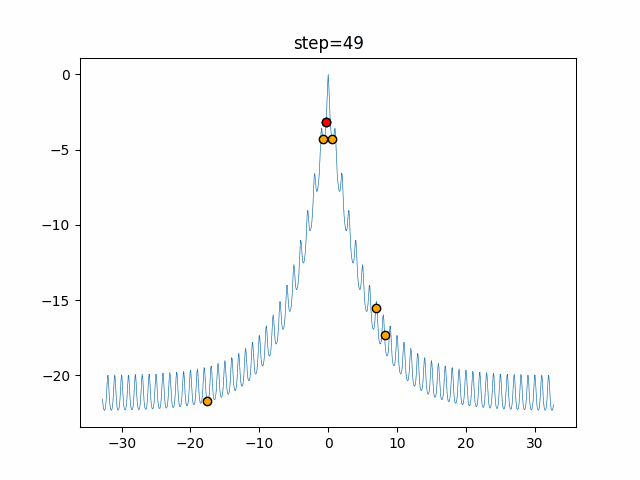
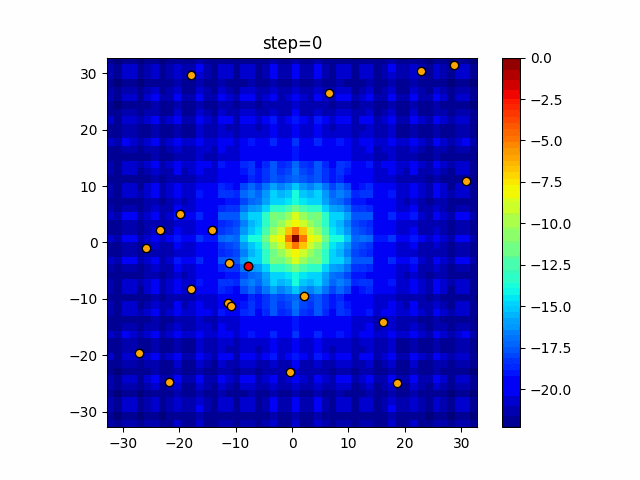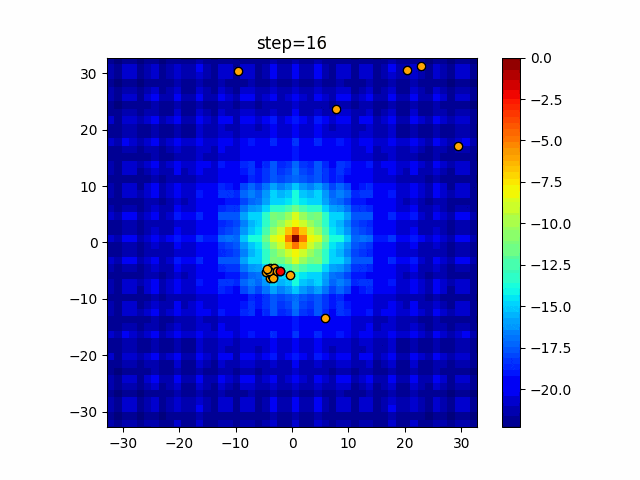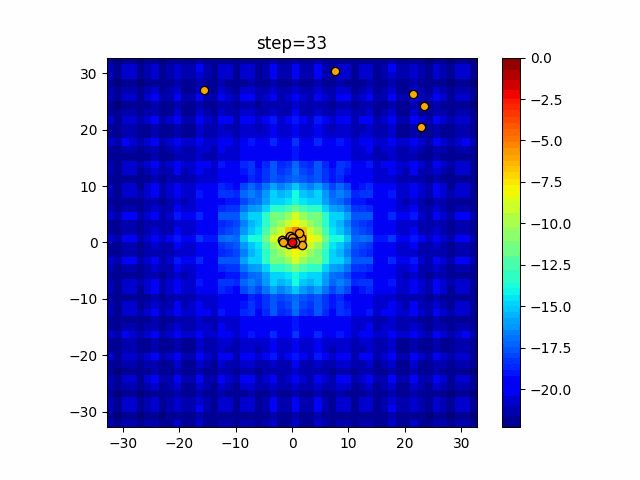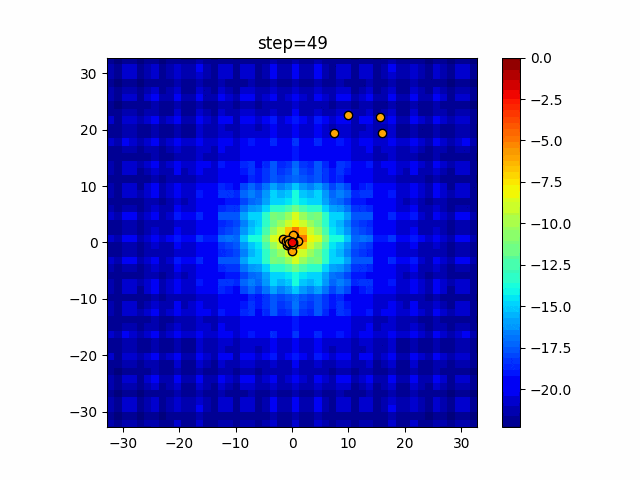
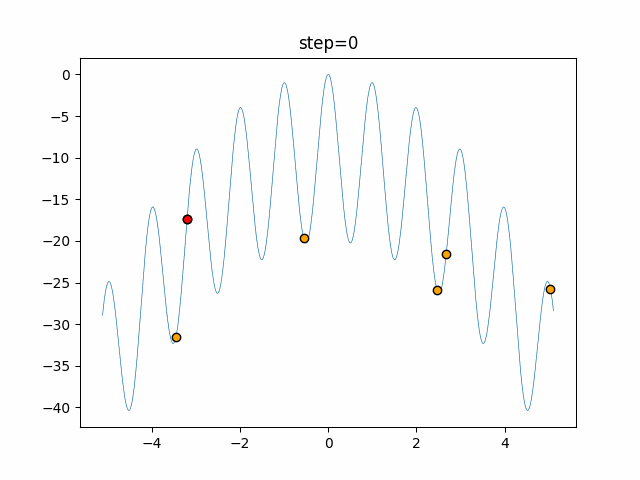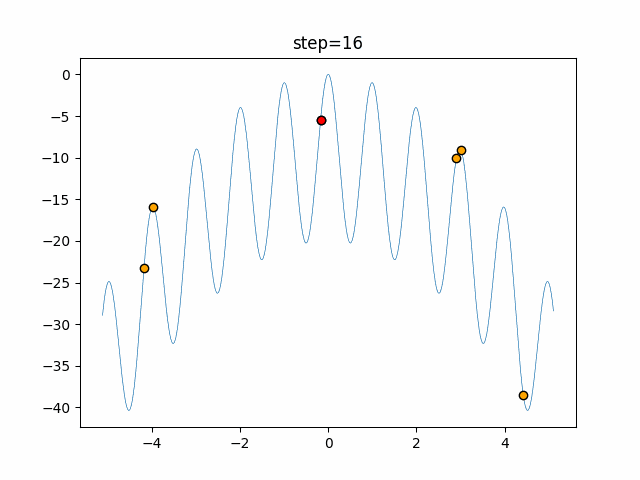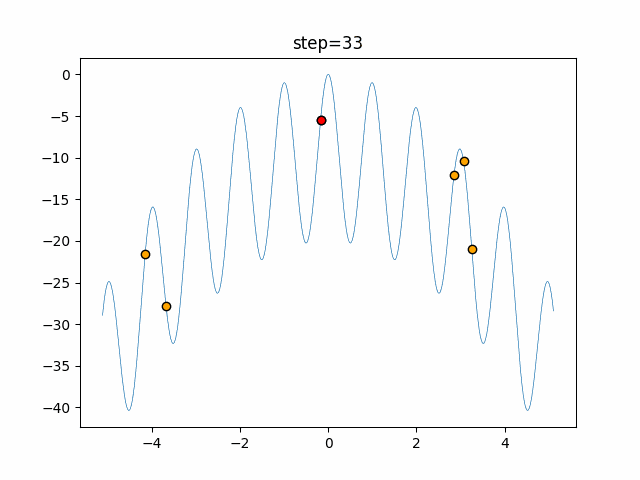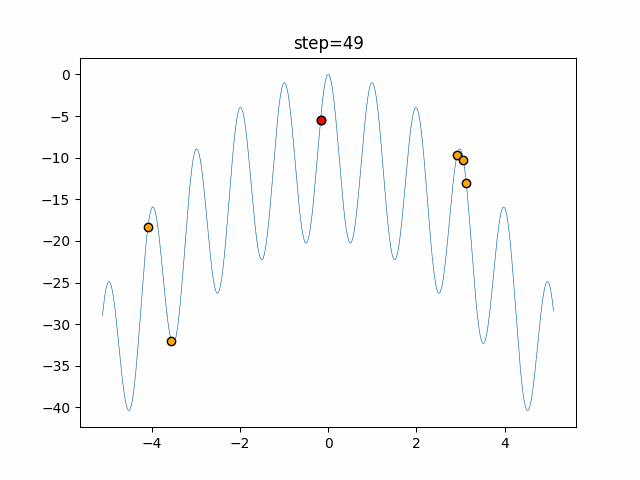
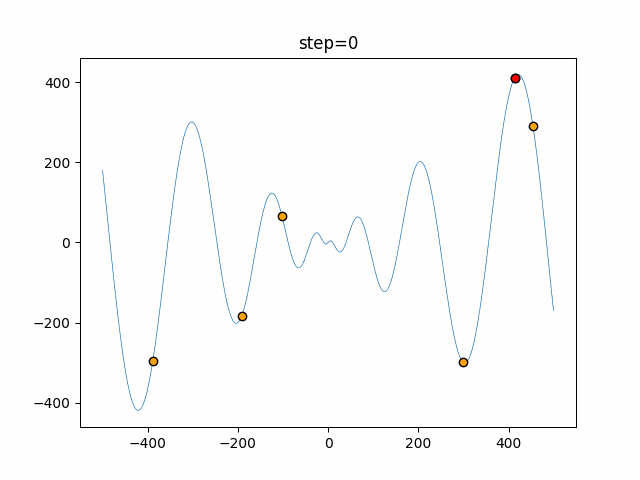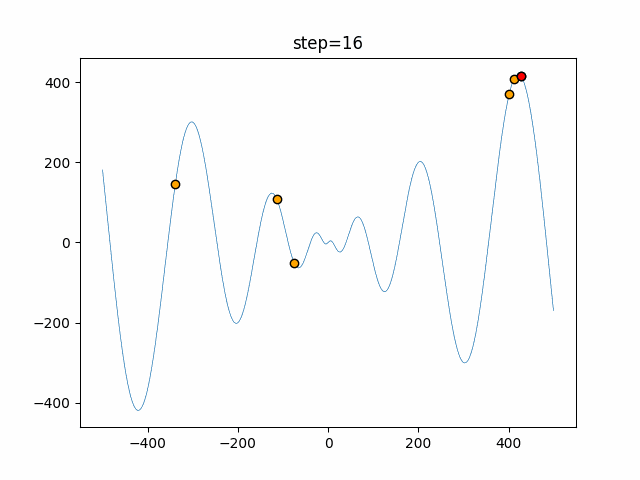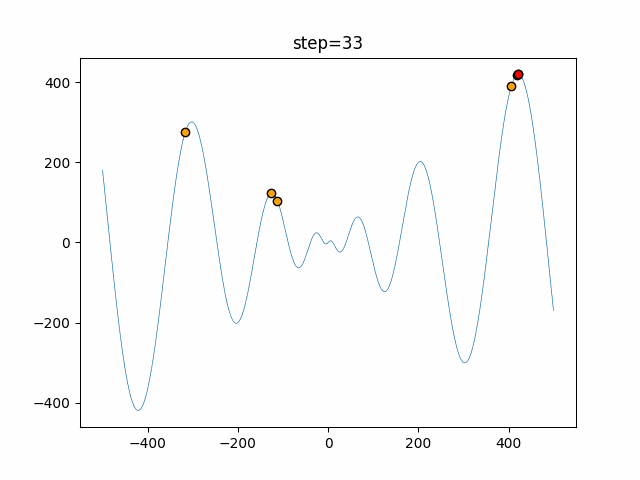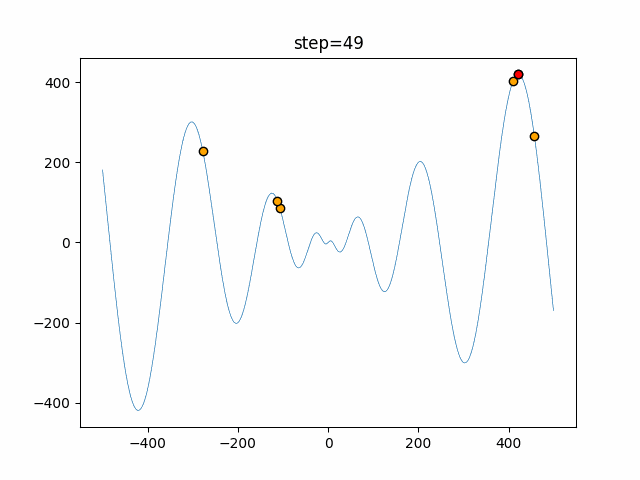
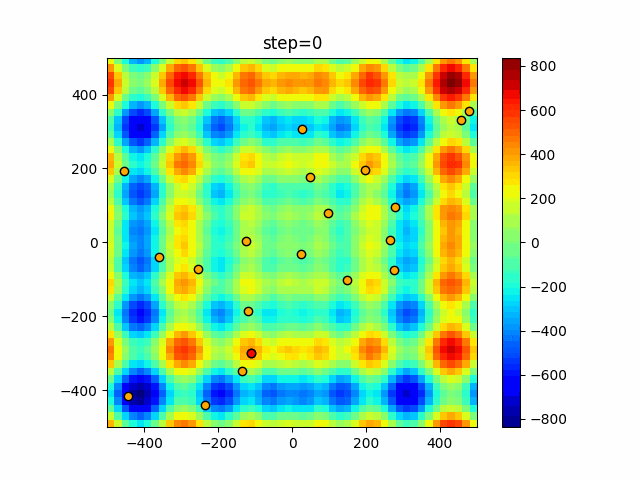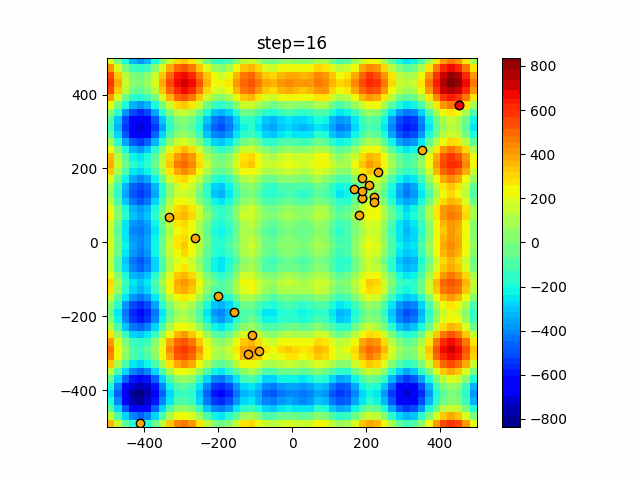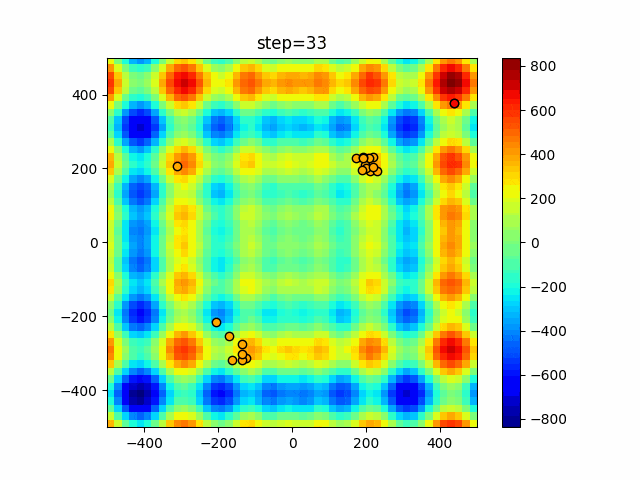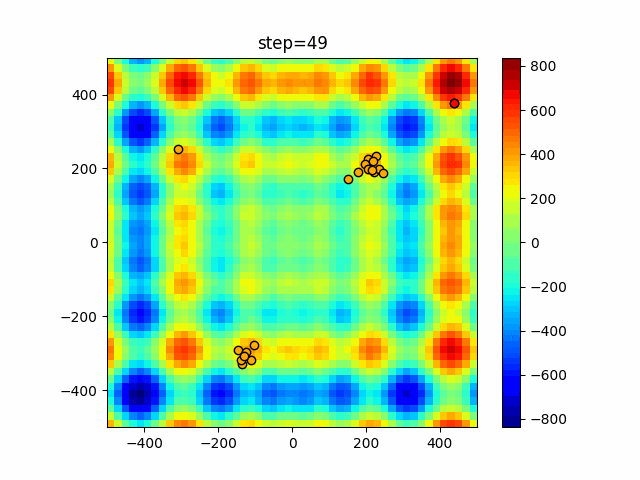
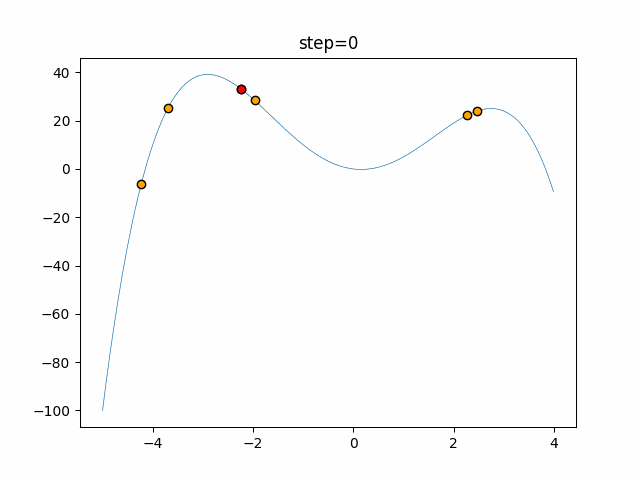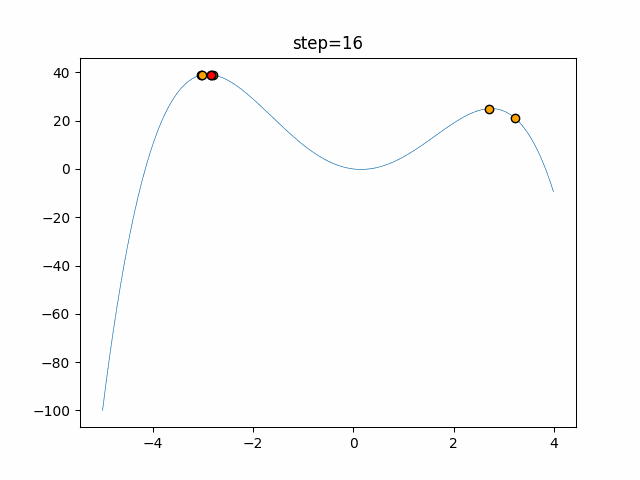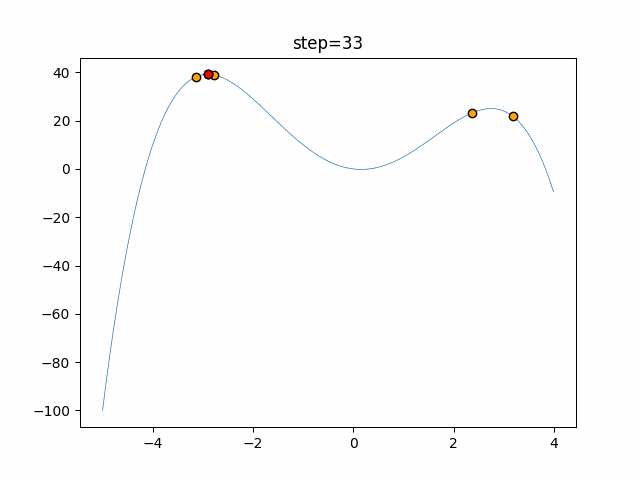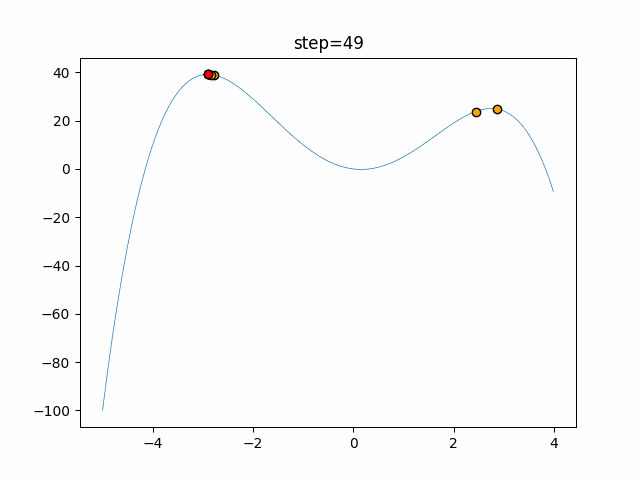
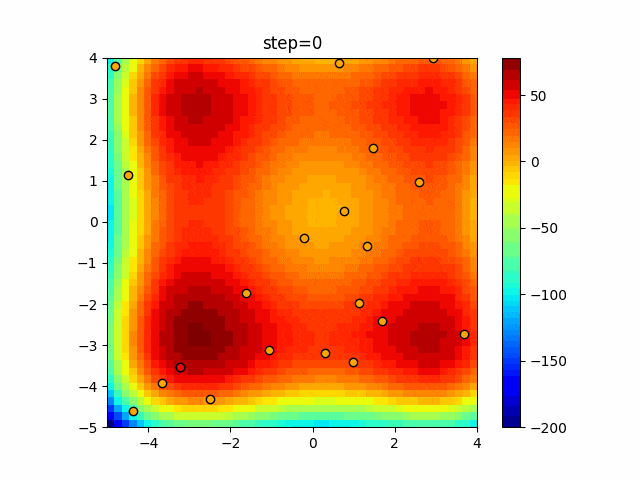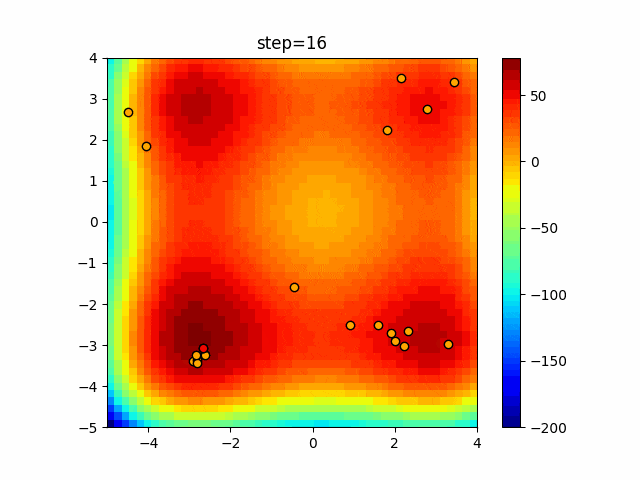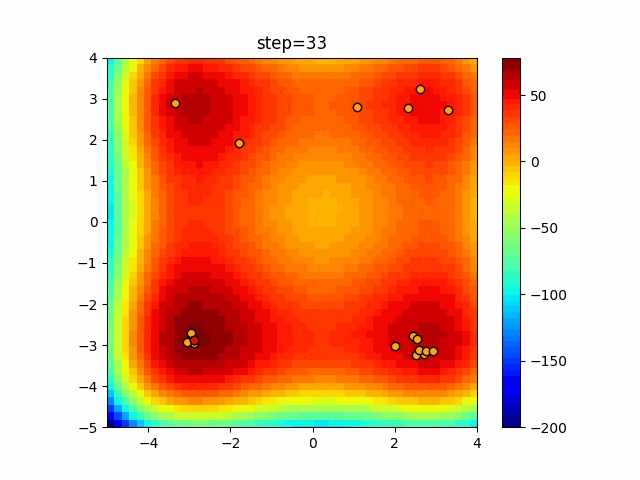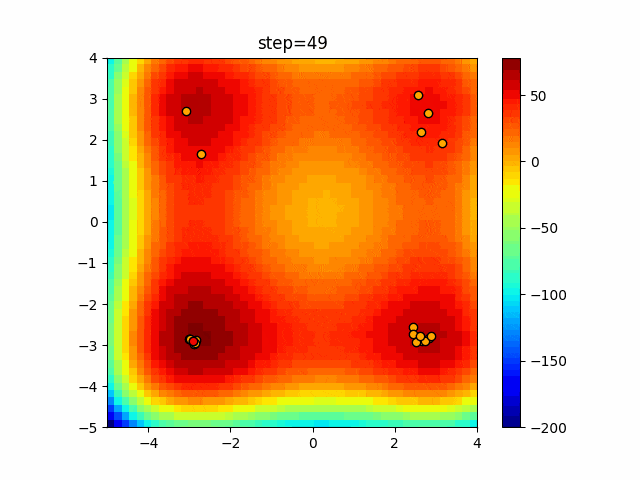
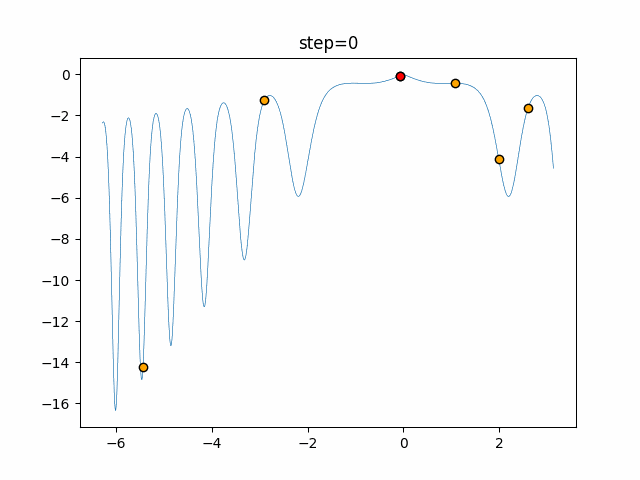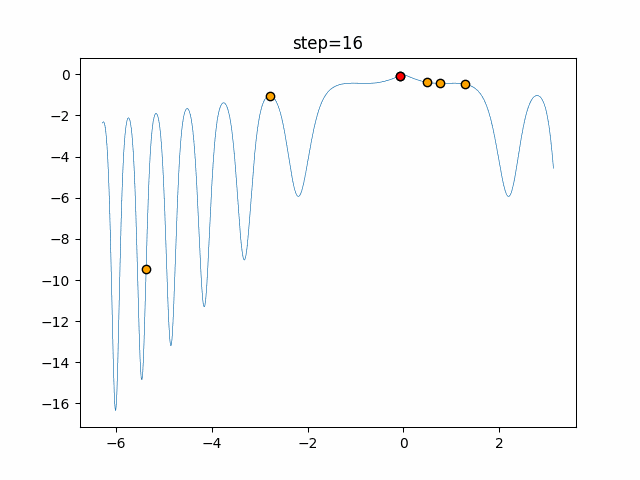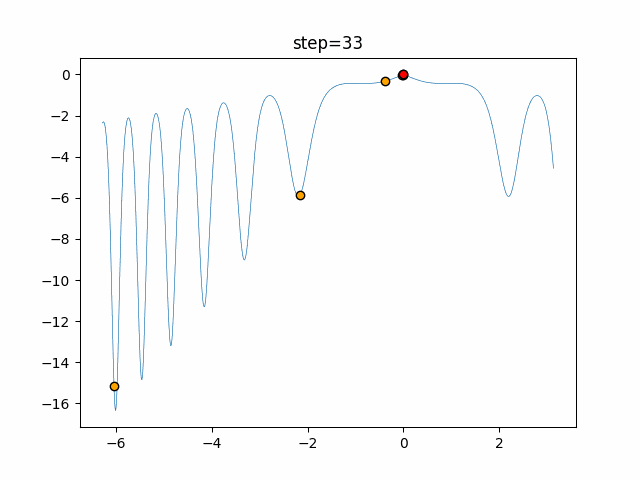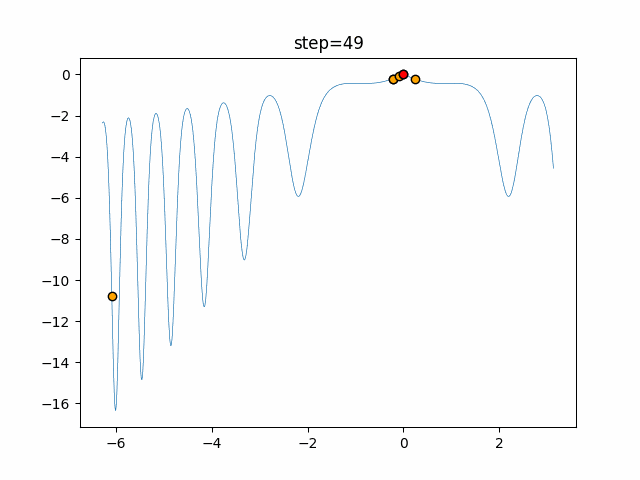
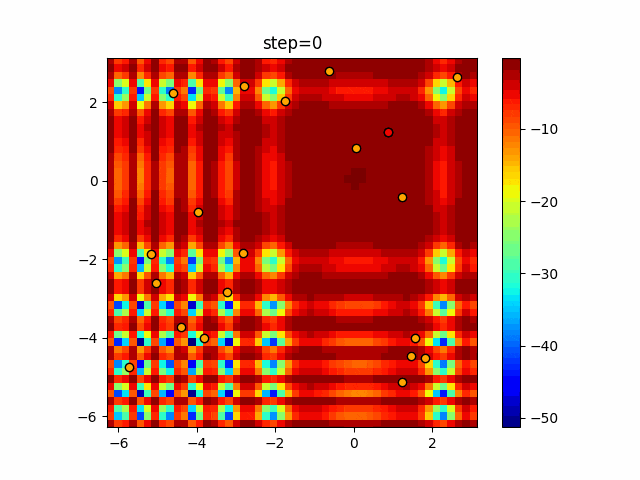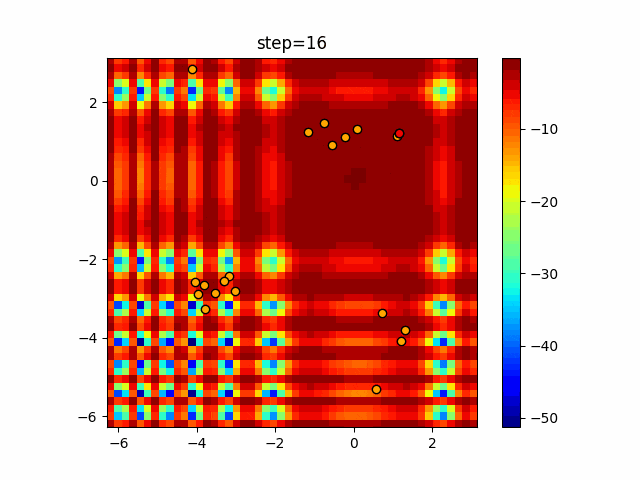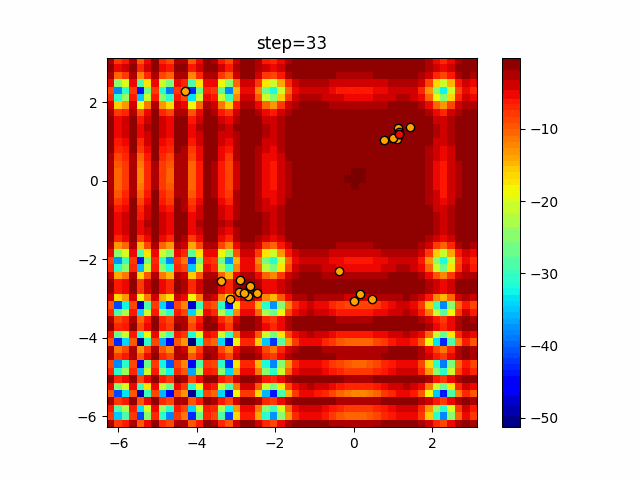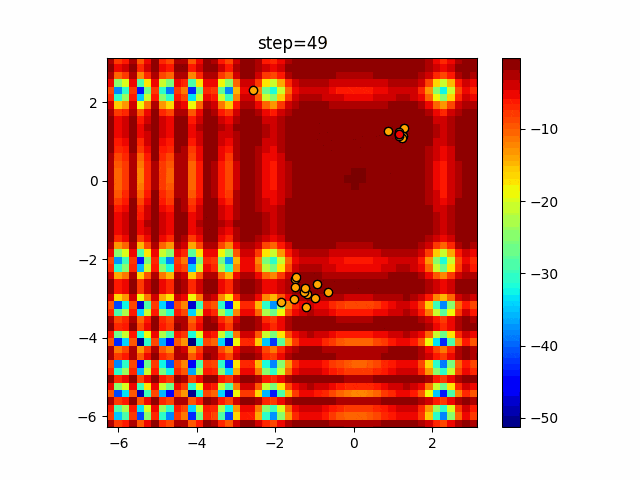
1次元は6個体、2次元は20個体で50step実行した結果です。
赤い丸がそのstepでの最高スコアを持っている個体となります。パラメータは以下で実行しました。
Firefly(N, attracting_degree=0.08, absorb=50.0, alpha=0.03, is_normalization=True)function_Ackley
- 1次元
- 2次元
function_Rastrigin
- 1次元
- 2次元
function_Schwefel
- 1次元
- 2次元
function_StyblinskiTang
- 1次元
- 2次元
function_XinSheYang
- 1次元
- 2次元
あとがき
画像はalphaを低めに設定しているので局所解からは抜け出されにくくなっています。
ふよふよ漂っている感じがホタルっぽくていいですね。
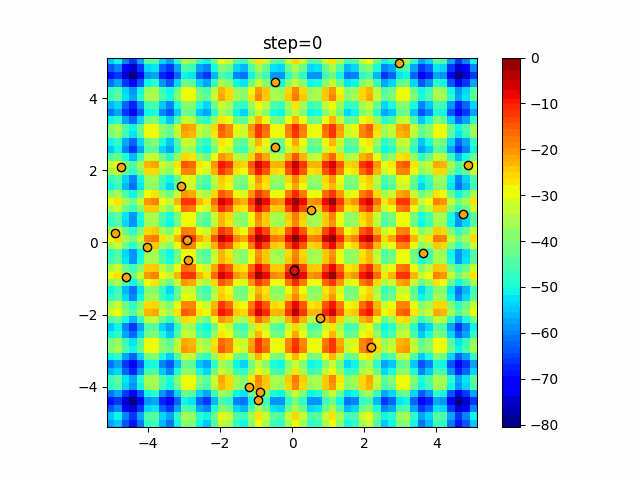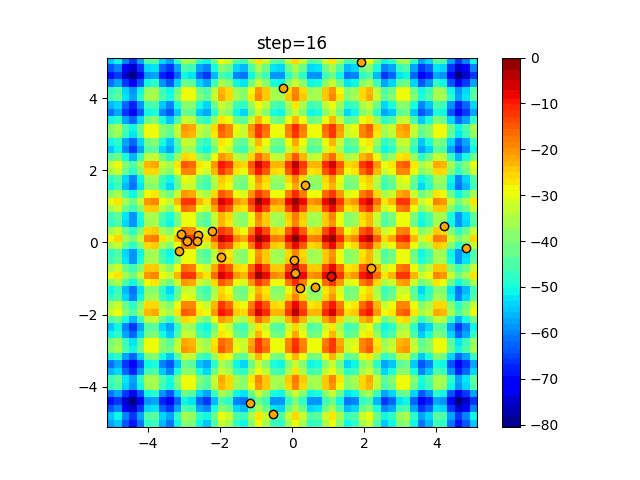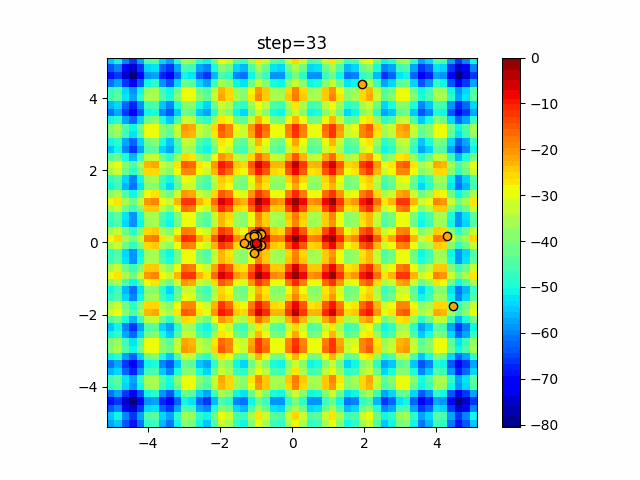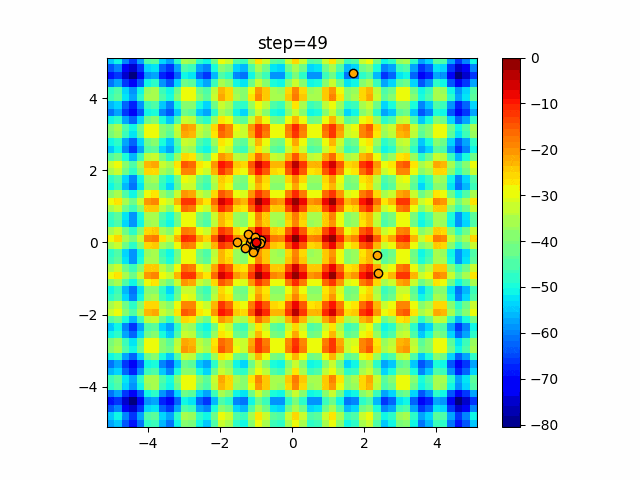
- 投稿日:2021-01-14T18:15:45+09:00
pytorch+yolov3を使ってマリオを物体検出してみた
Background
[OpenCV][C++]テンプレートマッチングを使って複数検出してみた、ではOpenCVのTemplateMatchingを使ってクリボーを検出していました。用意したクリボーの画像を上から下へ走査して形状が類似しているエリアを算出するのですが、上部の雲がクリボーと似ているらしくて雲とクリボーが一緒に出てくると雲の方が先に検出がかかってしまいました。
大雑把に類似度の高いエリアをトリミングして、その後でテンプレート画像とヒストグラムか背景差分を使って判定はできそうなのですが、今回は趣向を変えてyolov3を使った物体検出をしてみます。Device
- CPU AMD Ryzan 5 1400
- GPU GeForce GTX960
- Mother Board MSI B450 GAMING PLUS MAX B450
- Memory DDR4 8G × 4枚 = 32G
- CUDA 10.0
- cuDNN 7.4
Environment
必要なライブラリをインストールだーと思って、pytorch 公式を見るとanacondaベースで話が進んでいます。今までは
python3 -m venv [envname]で仮想環境を作ってその中で必要なパッケージをpipを使ってインストールしていたのですが、DeepLearning系のライブラリは他のパッケージとの依存性が結構ありそうなのでanaconda 使うことにします。conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorchcudaの環境は
10.0のままですが、cudatoolkitのバージョンを10.1でセットしても問題なく学習はできました。GPU周りの設定は少しバージョンが違うと動作の段階でエラーになってしまうので、本当であれば合わせた方がいいです。pytorch + yolov3
PyTorch-YOLOv3を使います。
git cloneしてデータセットとweightファイルをダウンロードします。
cocoなので相当重いです。git clone https://github.com/eriklindernoren/PyTorch-YOLOv3 cd PyTorch-YOLOv3/ sudo pip3 install -r requirements.txt cd weights/ bash download_weights.sh cd data/ bash get_coco_dataset.shその後で、動作するか確認します。
python3 test.py --weights_path weights/yolov3.weightsそれで問題なさそうであれば、デフォルト設定であるもので物体検出できるか確認します。
検出したい画像をdata/samplesに格納して、detect.pyで実行します。python3 detect.py --image_folder data/samples/ワークフォルダ直下に
outputフォルダが生成されるので、中身を見てみると物体検出でマークされた画像が格納されています。Annotation
デフォルトではcocoをデータセットとして使った学習済みのweightファイルがあり、80の物体を検出することができます。今回は開発者個人が検出させたい物体があった場合の機械学習方法を書いていきます。
流れとしては、対象の物体がある画像を100枚を用意し、それぞれの画像にどの場所に何の物体があるかをAnnotation(注釈、ラベル付け)して、最後に
train.pyで実行して学習します。データセットは、Backgroundで書いた通りSuper Mario Bros (NES) Level 1-1の動画を使います。何のデータを使って機械学習をすればいいかを考えて悩むのですが、1つの結論として著作権が大丈夫そうなゲーム動画を使うのが良さそうです。というのは現実で撮った画像よりもゲームの方が決まった固定のキャラが繰り返し登場し、形状もいくつかのパターンしかないので学習結果がすぐに得られやすいと思います。また、動画なので1秒あたり約30~60画像に落とし込むことができるので容易に取得できます。
それで、annotationをつけるのにlabelmeのツールを使います。
作業用PCはMacなので、homebrewでQt5をインストールして、pipで本体をインストールします。
brew install pyqt pip install labelmelabelmeを起動する前に、訓練用データを用意します。
今回はSuper Mario Bros (NES) Level 1-1の23-28秒の動画を抜き出し、下記の方法で連番の画像に落とし込んでいます。訓練用データ
wget https://raw.githubusercontent.com/wkentaro/dotfiles/f3c5ad1f47834818d4f123c36ed59a5943709518/local/bin/video_to_images pip install imageio imageio-ffmpeg tqdm python video_to_images your_video.mp4実行すると、
your_videoフォルダができるてその中に連番画像が格納されています。これで訓練用データが揃ったので、先程のフォルダパスを指定してlabelmeを起動します。
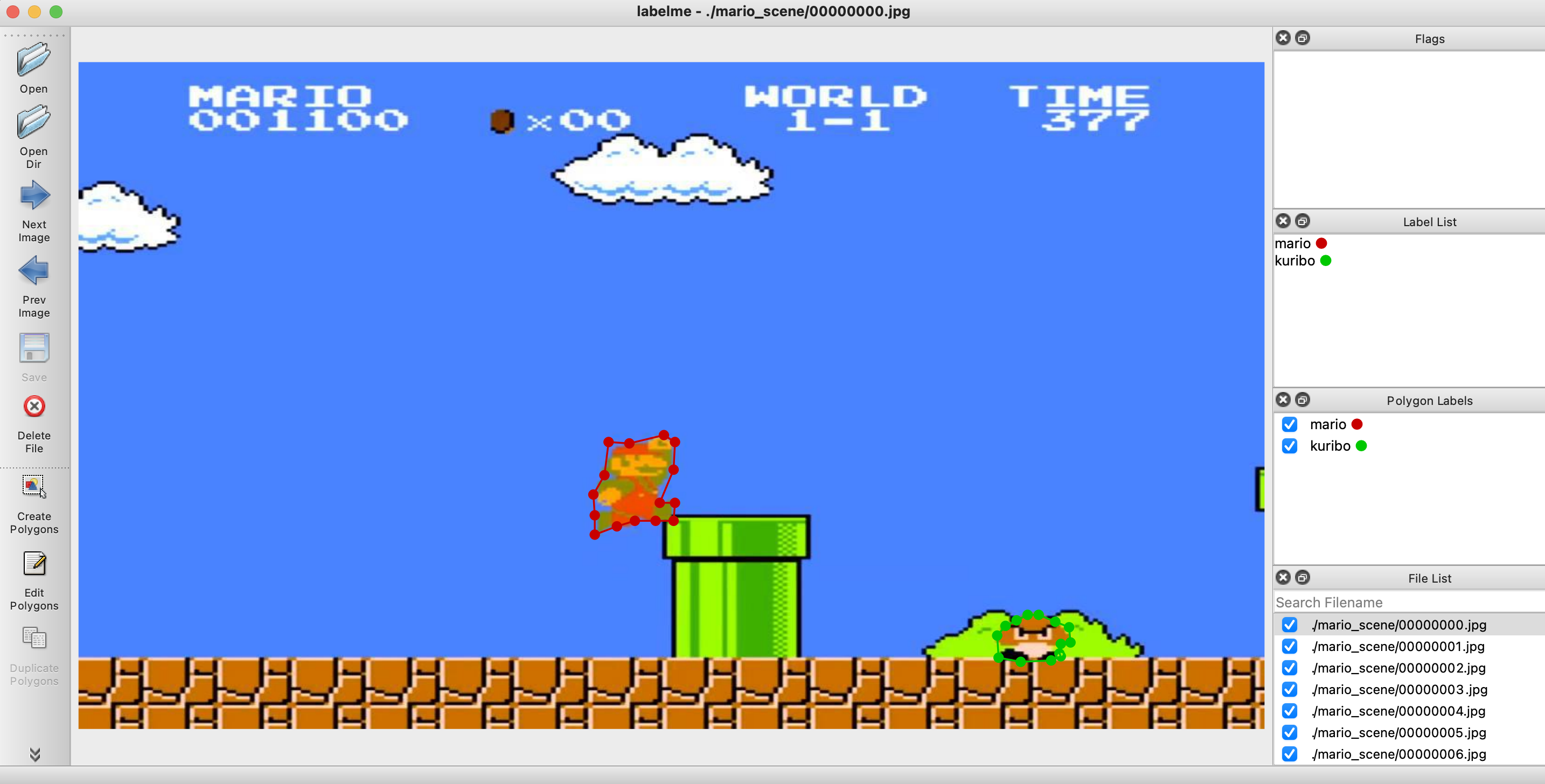
labelme ./your_videoあとは、もくもくと物体のラベルと領域を指定します。
150枚程ありました。
yolov3で学習する場合は、boundingboxと四角形で範囲指定するだけでいいのですが、後でsegmentationで学習するDNNを扱うかもしれないので無駄に領域指定してます
物体につけたラベルと領域はjsonファイルとして画像を読み込んだフォルダ先に生成されます。
完了後は、圧縮ファイルにしておきます。
tar -zcvf output.tar.gz ./your_videoTraining
訓練データが用意できたので、次は機械学習をしてみます。
まず、configファイルを作ります。ここでは
__ignore__を含めるとクラス数は3つなので、<num-classes> =3で設定します。
実行後は、config/yolov3-custom.cfgがアウトプットされます。cd config/ bash create_custom_model.sh <num-classes>
config/custom.dataを開いてクラス数を設定します。config/custom.dataclasses=3 train=data/custom/train.txt valid=data/custom/valid.txt names=data/custom/classes.names
data/custom/classes.namesを開いて物体名をリスト化します。デフォルトではtrainしか書かれてないと思います。data/custom/classes.names__ignore__ mario kuribo次に圧縮した訓練用データフォルダを直下に置いて解凍します。
tar -zxvf output.tar.gz解凍したフォルダから画像を
data/custom/images/へ移動させます。
デフォルトはdata/custom/images/に電車の画像があるので削除します。rm data/custom/images/train.jpg mv ./your_video/*.jpg data/custom/images/次にラベル情報が書かれているjsonファイルをもとに、
[クラスID] [物体の中心座標x] [物体の中心座標y] [物体の幅] [物体の高さ]に書き換えます。このとき、元データではなく全体の画像に対する比率[0,1.0]を出力します。書き換えたファイルはdata/custom/labels/に生成します。import os import json import numpy as np def treat(filepath, classes): with open(filepath, "r") as fin: src = json.load(fin) dst = [] for item in src["shapes"]: txt = item["label"] #各座標の平均値を計算 cx, cy = np.mean(np.array(item["points"]), axis=0) #画像全体の長さを1.0とした場合の比率を計算 cx_norm = cx / src["imageWidth"] cy_norm = cy / src["imageHeight"] #物体の幅・高さを計算 min_x, min_y = np.min(np.array(item["points"]), axis=0) max_x, max_y = np.max(np.array(item["points"]), axis=0) rect_width = (max_x - min_x) / src["imageWidth"] rect_height = (max_y - min_y) / src["imageHeight"] #クラスIDを検索 idx = list(filter(lambda x: x[1] == txt, classes))[0][0] #配列にして整形 dst.append([idx, cx_norm, cy_norm, rect_width, rect_height]) return dst最後に
data/custom/train.txt(訓練用)とdata/custom/valid.txt(評価用)にそれぞれdata/custom/images/に格納したファイルパスを書き込みます。比率は(訓練用):(評価用)=8:2がちょうどいいと思います。train.txtdata/custom/images/00000000.jpg data/custom/images/00000001.jpg data/custom/images/00000002.jpg data/custom/images/00000003.jpg data/custom/images/00000004.jpg data/custom/images/00000005.jpg data/custom/images/00000006.jpg data/custom/images/00000007.jpg data/custom/images/00000008.jpg data/custom/images/00000009.jpg data/custom/images/00000010.jpg data/custom/images/00000011.jpg data/custom/images/00000012.jpg data/custom/images/00000013.jpg data/custom/images/00000014.jpg data/custom/images/00000015.jpg ...設定は一通り終わったので、
train.pyを実行します。python3 train.py \ --model_def config/yolov3-custom.cfg \ --data_config config/custom.data \ --batch_size 2 \ --img_size 32 \ --epochs 200 \ --pretrained_weights weights/darknet53.conv.74
batch_sizeのデフォルトは8、img_sizeは416ですがマシン性能が弱いとメモリエラーが出てしまいます。自分のPCもGPUのメモリは4GBしかないのでアウトでした。その場合は、値を下げると正常に学習が進みます。学習結果は
checkpoints/に各エポックごとにyolov3_ckpt_{エポック数}.pthが出力されます。Detect Objects
まず、物体検出用の画像データを準備します。ここでは、Super Mario Bros (NES) Level 1-1のスタートからゴールまでの動画フレームを使います。動画から連番画像に変換する方法は訓練用データで作成したのと同様に
video_to_imagesスクリプトを使います。トータルで1501の画像を取得することができました。それで、
detect.pyを使って検出をかけてみます。python3 detect.py --image_folder ./data/mario_1-1/ \ --weights_path ./checkpoints/yolov3_ckpt_199.pth \ --model_def config/yolov3-custom.cfg \ --class_path data/custom/classes.names
--image_folderでテストしたい画像が入っているフォルダのパスを指定して、--weights_pathには学習で生成されたファイルを使います。結果はoutputファイルに格納されます。(239) Image: './data/mario_1-1/00000239.jpg' + Label: mario, Conf: 0.99997 ...
あとは、連番画像から動画に変換して完了です。
最初はffmpegでffmpeg -r 30 -i %8d.png -vcodec libx264 -pix_fmt yuv420p -r 60 out.mp4として変換をかけたのですが画質が極端に落ちてしまいました。
(ffmpegで連番画像から動画生成 / 動画から連番画像を生成 ~コマ落ちを防ぐには~を参照)なので、OpenCVを使って動画に変換しました。
import cv2 import os def main(): is_png = lambda x : os.path.splitext(x)[1] == ".png" imgs = list(filter(is_png, os.listdir())) imgs.sort() width = 480 height = 270 fps = 30 fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') writer = cv2.VideoWriter('output.mp4', fmt, fps, (width, height)) #resize for img in imgs: mat = cv2.imread(img) dst = cv2.resize(mat, dsize=(width, height)) writer.write(dst) writer.release() if __name__ == "__main__": main()Consequence
↓クリックするとyoutubeでスタートからゴールまでの検出する様子が動画で見れます。
- ファイアマリオは学習してないのですが、風貌が似ているのでmarioと識別しています。
- ちびマリオは学習していないため、高さが似ているためかクリボーと誤認識する場合があります。
- ブロック、宝箱、ノコノコなどを物体の検出対象にするとさらに精度は良くなると思います。
Reference



- 投稿日:2021-01-14T18:00:45+09:00
ID-POSデータをLDAでクラスタリング
はじめに
LDAを使って、高次元にベクトル化したPOSデータをクラスタリングできるという話。
クラスタの遷移とかも見てみた。LDA
ニュース記事などをトピック別に分けたりするときに使うあれ。
次元削減手法の一つで、文書のモデル化に適した手法で、トピックモデルとかいうやつ。
いわゆるソフトクラスタリングができて、データは複数のクラスタに属することができる。(クラスタ1の所属確率0.8、クラスタ2の所属確率0.2、みたいな)
詳しくは、他の記事とか書籍とか調べれば出てくると思う。POSデータへの適用
POSデータで商品ごとの購入回数や売り上げなどでユーザーをクラスタリングしたい場合、商品種類が多いと次元が多いデータになる。
それをkmeansのような距離を使う手法でクラスタリングする場合、次元が多いせいで計算の都合上距離が急速に大きくなってしまい、うまくクラスタリングすることができなくなってしまう。
一方LDAでは、例えば文書を分けるとき、BoW形式でベクトル化してモデルを適用したりするけど、単語数が膨大なのでかなり高次元なデータになるはず。つまりLDAのようなトピックモデルは高次元データでもクラスタリングしやすいというわけで、「おや?POSデータのクラスタリングとかにも向いてるんじゃね?」と思った。使用データ
kaggleの「eCommerce purchase history from electronics store」を使う。(出典:https://rees46.com/)
2020年4月から2020年11月までの大型家電製品および電子機器のオンラインストア購入データ。クラスタリング実行
LDAはソフトクラスタリングができるが、今回は所属確率が最も高いクラスタだけを見てハードクラスタリングとして扱う。
準備
まず必要なパッケージをimport。
# パッケージインポート import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import seaborn as sns import pandas as pd import datetime as dt import sklearn from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import StandardScaler from sklearn.cluster import KMeans from sklearn.decomposition import LatentDirichletAllocation import time import os import glob import codecs sns.set() ''' numpy 1.18.1 matplotlib 3.1.3 seaborn 0.10.0 pandas 1.0.3 sklearn 0.22.1 '''データの読み込みと加工と抽出。
file='kz.csv' df = pd.read_csv(file, dtype={'user_id':str, 'order_id':str}) df=df[['event_time', 'category_code', 'brand', 'price', 'user_id', 'order_id']] df=df.dropna() df['event_time']=df['event_time'].str[:-4] df['event_time']=pd.to_datetime(df['event_time']) df=df[df['event_time']>=dt.datetime(2020,1,1)] df=df.sort_values('event_time') # ブランドとカテゴリーを結合する df_cat_split=df['category_code'].str.split('.', expand=True) df_cat_split.loc[(pd.isna(df_cat_split[2])), 2]=df_cat_split[1] df_cat_split[3]=df_cat_split[1]+'.'+df_cat_split[2] df['category']=df_cat_split[3].values df['brand_category']=df['brand']+'.'+df['category'] # 各カラムのユニーク数 print('order_id', df['order_id'].unique().shape[0]) print('user_id', df['user_id'].unique().shape[0]) print('category_code', df['category_code'].unique().shape[0]) print('brand', df['brand'].unique().shape[0]) print('brand_category', df['brand_category'].unique().shape[0]) ''' order_id 331424 user_id 203235 category_code 123 brand 570 brand_category 1375 ''' display(df)
データを前半と後半の二つに分ける。
# データを半分に分ける df_before=df.iloc[:int(len(df)/2.),:] df_after=df.iloc[int(len(df)/2.):,:] # どちらのデータにも存在しているuser_idを抽出 df_target=pd.merge(df_before[['user_id']], df_after[['user_id']], on=['user_id'], how='inner')['user_id'].unique() df_target=pd.DataFrame(df_target, columns=['user_id']) # どちらのデータにも存在しているuser_idを対象にしたデータを作る df_before=df_before[df_before['user_id'].isin(df_target['user_id'].values)] df_after=df_after[df_after['user_id'].isin(df_target['user_id'].values)] # 2つのデータの期間とuser_idのユニーク数を表示 print('before\n', df_before['event_time'].min()) print('', df_before['event_time'].max()) print('\nafter\n',df_after['event_time'].min()) print('', df_after['event_time'].max()) print('\nUnique User Cnt', len(df_target)) ''' before 2020-01-05 04:35:21 2020-08-14 08:58:58 after 2020-08-14 08:59:17 2020-11-21 09:59:55 Unique User Cnt 15527 '''user_idごとの商品別購入金額のデータマートを作成。
価格が高いと購入のされやすさも変わると考え、重みをつけるという意味でも購入回数ではなく、購入金額のデータマートを作成した。# ピボットでマートを作る def df_pivot(df, index, columns, values, aggfunc): df_mart=df.pivot_table(index=index, columns=columns, values=values, aggfunc=aggfunc).reset_index() df_mart=df_mart.fillna(0) return df_mart # LDAに食わせる用の加工 def df_to_np(df_mart): df_data=df_mart.copy().iloc[:,1:] df_data = df_data.values return df_data row='user_id' col='brand_category' val='price' df_mart=df_pivot(df_before, row, col, val, 'sum') df_mart2=df_pivot(df_after, row, col, val, 'sum') # df_martとdf_mart2で重複していないカラム名をとってくる after=np.hstack((df_mart.columns.values, df_mart2.columns.values)) unique_after, counts_after = np.unique(after, return_counts=True) non_dep_after=unique_after[counts_after == 1] # さっきの重複していないカラム名の中で、df_martに入っていてdf_mart2に入っていないカラム名を抽出 before=np.hstack((non_dep_after, df_mart.columns.values)) unique_before, counts_before = np.unique(before, return_counts=True) dep_before=unique_before[counts_before != 1] # df_mart2にdf_mart固有のカラム名の列を追加 for col in dep_before: df_mart2[col]=0. # これでdf_martとdf_mart2のカラムがそろう df_mart=df_mart[df_mart.columns] df_mart2=df_mart2[df_mart.columns] # LDAに食わせる用の加工 df_data=df_to_np(df_mart) df_data2=df_to_np(df_mart2) display(df_mart) display(df_mart2) display(df_data) display(df_data2)
LDAでクラスタリング
2~50のクラスタ(トピック)数のモデルを作る。
対数尤度(大きいほど良い)とperplexity(小さいほど良い)はクラスタ数が大きくなるほど良くなってしまったので、適当にクラスタ数=6に設定した。(クラスタ数ってどうやって決めるんだろ?)# LDAのモデルを作る関数 def model_plot_opt(tfidf_data, topic_list, plot_enabled=True): # 定義 n_topics = list(topic_list.astype(int)) perplexities=[] log_likelyhoods_scores=[] models=[] search_params = {'n_components': n_topics} minmax_1 = MinMaxScaler() minmax_2 = MinMaxScaler() # 設定したトピック数ごとのモデルを作る for i in n_topics: print('topic_cnt:',i) lda = LatentDirichletAllocation(n_components=i,random_state=0, learning_method='batch', max_iter=25) lda.fit(tfidf_data) lda_perp = lda.perplexity(tfidf_data) log_likelyhoods_score = lda.score(df_data) perplexities.append(lda_perp) log_likelyhoods_scores.append(log_likelyhoods_score) models.append(lda) # 対数尤度とperplexityを正規化したものをプロット if plot_enabled: # 正規化 log_likelyhoods_scores_std=minmax_1.fit_transform(np.array(log_likelyhoods_scores).reshape(len(log_likelyhoods_scores),1)) perplexities_std=minmax_2.fit_transform(np.array(perplexities).reshape(len(perplexities),1)) # 図作成 plt.figure(figsize=(12, 8)) ax=plt.subplot(1,1,1) ax.plot(n_topics, log_likelyhoods_scores_std, marker='o', color='blue', label='log-likelyhoods score') ax.set_title("Choosing Optimal LDA Model") ax.set_xlabel("Numer of Topics") ax.set_ylabel("Log Likelyhood Scores&Perplexity") ax.plot(n_topics, perplexities_std, marker='x', color='red', label='perplexity') plt.legend() plt.show() return models, log_likelyhoods_scores_std, perplexities_std # モデルのリストと正規化した対数尤度とperplexityを定義 models_list, log_likelyhoods_scores_std, perplexities_std = model_plot_opt(df_data, np.linspace(2,51,50)) # 適当に6にする lda=models_list[4] print('topic_num:', lda.components_.shape[0]) ''' topic_num: 6 '''
各クラスタの特徴を見ていく。
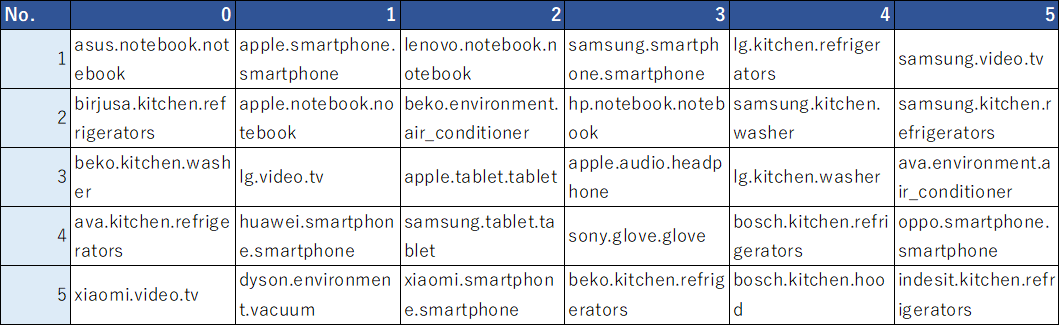
まずは各クラスタにおける、商品の出現確率上位を抽出。# 各トピックにおける、商品の出現確率上位20を取得する関数 def component(lda, features): df_component=pd.DataFrame() for tn in range(lda.components_.shape[0]): row = lda.components_[tn] words = [features[i] for i in row.argsort()[:-20-1:-1]] df_component[tn]=words words = ', '.join([features[i] for i in row.argsort()[:-20-1:-1]]) return df_component # 各トピックにおける、商品の出現確率上位5まで抽出 features = df_mart.iloc[:,1:].columns.values df_component=component(lda, features) display(df_component.iloc[:5,:])(EXCELで体裁を整えた↓)
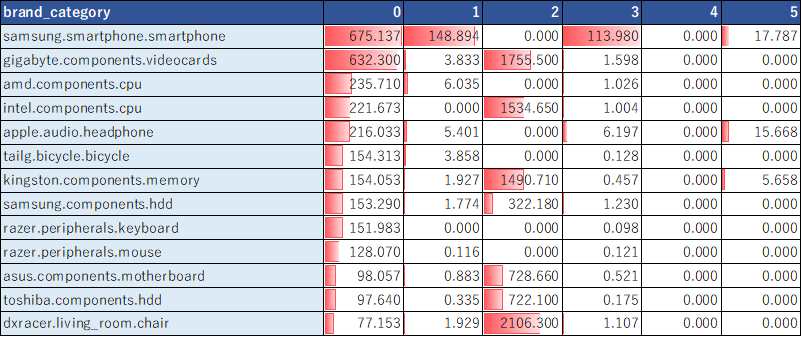
また、各クラスタにおける、商品の平均購入数を抽出。
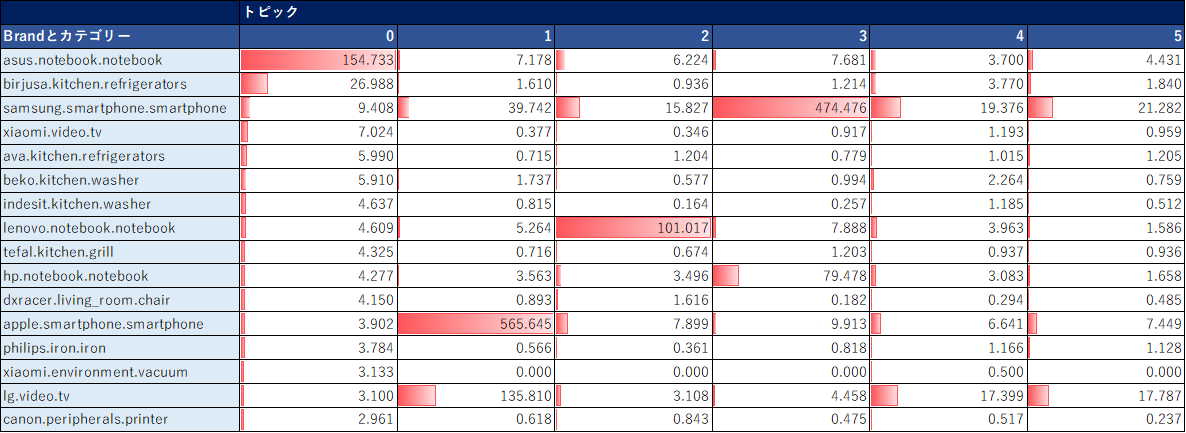
# user_idごとの所属確率が最も高いトピックを列として追加したdfを作成 def create_topic_no(df_mart, df_data, lda): df_id_cluster=df_mart[[row]] df_topic=pd.DataFrame(lda.transform(df_data)) topic=df_topic.loc[:,:].idxmax(axis=1).values df_id_cluster['topic']=topic return df_id_cluster df_id_cluster=create_topic_no(df_mart, df_data, lda) df_id_cluster2=pd.merge(df_mart, df_id_cluster, on=['user_id'], how='left') # 各トピックにおける、商品の平均購入数を抽出 display(df_id_cluster2.groupby(['topic']).mean().T)(EXCELで体裁を整えた↓)
クラスタ0はAsusのPC、1はiPhone、2はLenovoのPCの購入金額が高い、などがわかる。
user_idごとにクラスタ番号をつけてあげる。
# df_martに対してトピック番号をつけてあげる df_topic_result=df_mart.copy() top_price_brand_before=df_mart.iloc[:,1:].idxmax(axis=1).values # user_idごとの所属確率が最も高いトピックを列として追加 df_topic_result['topic_before']=create_topic_no(df_mart, df_data, lda)['topic'].values # user_idごとの購入額が最も高いブランドを列として追加 df_topic_result['top_price_brand_before']=top_price_brand_before # df_mart2に対してトピック番号をつけてあげる df_topic_result2=df_mart2.copy() top_price_brand_after=df_mart2.iloc[:,1:].idxmax(axis=1).values # user_idごとの所属確率が最も高いトピックを列として追加 df_topic_result2['topic_after']=create_topic_no(df_mart2, df_data2, lda)['topic'].values # user_idごとの購入額が最も高いブランドを列として追加 df_topic_result2['top_price_brand_after']=top_price_brand_after # df_martとdf_mart2をJOIN df_topic_result=pd.merge(df_topic_result, df_topic_result2[['user_id','topic_after','top_price_brand_after']], on=['user_id'], how='left') display(df_topic_result)
クラスタのチャートを確認。
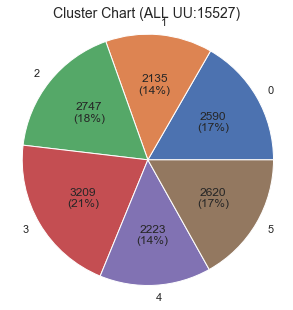
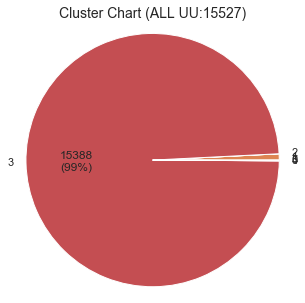
# plot Cluster Chart def pct_abs(pct, raw_data): absolute = int(np.sum(raw_data)*(pct/100.)) return '{:d}\n({:.0f}%)'.format(absolute, pct) if pct > 5 else '' def plot_chart(y_km): km_label=pd.DataFrame(y_km).rename(columns={0:'cluster'}) km_label['val']=1 km_label=km_label.groupby('cluster')[['val']].count().reset_index() fig=plt.figure(figsize=(5,5)) ax=plt.subplot(1,1,1) ax.pie(km_label['val'],labels=km_label['cluster'], autopct=lambda p: pct_abs(p, km_label['val']))#, autopct="%1.1f%%") ax.axis('equal') ax.set_title('Cluster Chart (ALL UU:{})'.format(km_label['val'].sum()),fontsize=14) plt.show() plot_chart(df_topic_result['topic_before'].values) plot_chart(df_topic_result['topic_after'].values)前半のデータのチャート
後半のデータのチャート
クラスタごとに特徴が異なるし、クラスタのユーザー数比率も偏っていないので、いい感じに分かれてるような気がする。
クラスタの遷移を確認
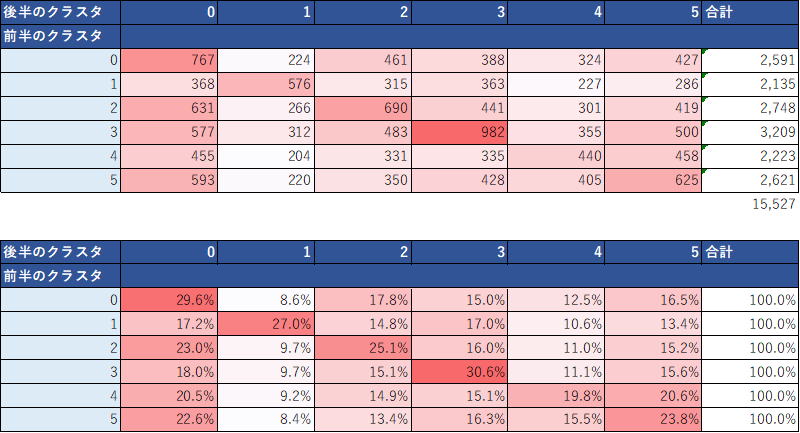
前半と後半でクラスタが遷移しているユーザーもいるので、クラスタの遷移をクロス表で見てみる。
display(df_topic_result.pivot_table(index='topic_before', columns='topic_after', values='user_id', aggfunc='count'))(EXCELで体裁を整えた↓)
例えば、クラスタ2→0への遷移や4→0へ遷移する人が多かったりする。
2→0への遷移した人たちはどういったブランドの購入が増減したのだろうか。ちょっと確認してみる。
購入回数で集計したデータフレームを作成する。row='user_id' col='brand_category' val='order_id' df_mart=df_pivot(df_before, row, col, val, 'count') df_mart2=df_pivot(df_after, row, col, val, 'count') # df_martとdf_mart2で重複していないカラム名をとってくる after=np.hstack((df_mart.columns.values, df_mart2.columns.values)) unique_after, counts_after = np.unique(after, return_counts=True) non_dep_after=unique_after[counts_after == 1] # さっきの重複していないカラム名の中で、df_martに入っていてdf_mart2に入っていないカラム名を抽出 before=np.hstack((non_dep_after, df_mart.columns.values)) unique_before, counts_before = np.unique(before, return_counts=True) dep_before=unique_before[counts_before != 1] # df_mart2にdf_mart固有のカラム名の列を追加 for col in dep_before: df_mart2[col]=0 # これでdf_martとdf_mart2のカラムがそろう df_mart=df_mart[df_mart.columns] df_mart2=df_mart2[df_mart.columns] display(df_mart) display(df_mart2)
クラスタ2→0へ遷移した人を抽出。
n=2 m=0 user_id_n_m=df_topic_result[(df_topic_result['topic_before']==n)&(df_topic_result['topic_after']==m)]['user_id'].values df_b_n_m=df_mart[df_mart['user_id'].isin(user_id_n_m)] df_a_n_m=df_mart2[df_mart2['user_id'].isin(user_id_n_m)] display(df_b_n_m) display(df_a_n_m)
後半のデータから前半のデータを引いて、ブランドごとの購入回数の増減を確認してみる。
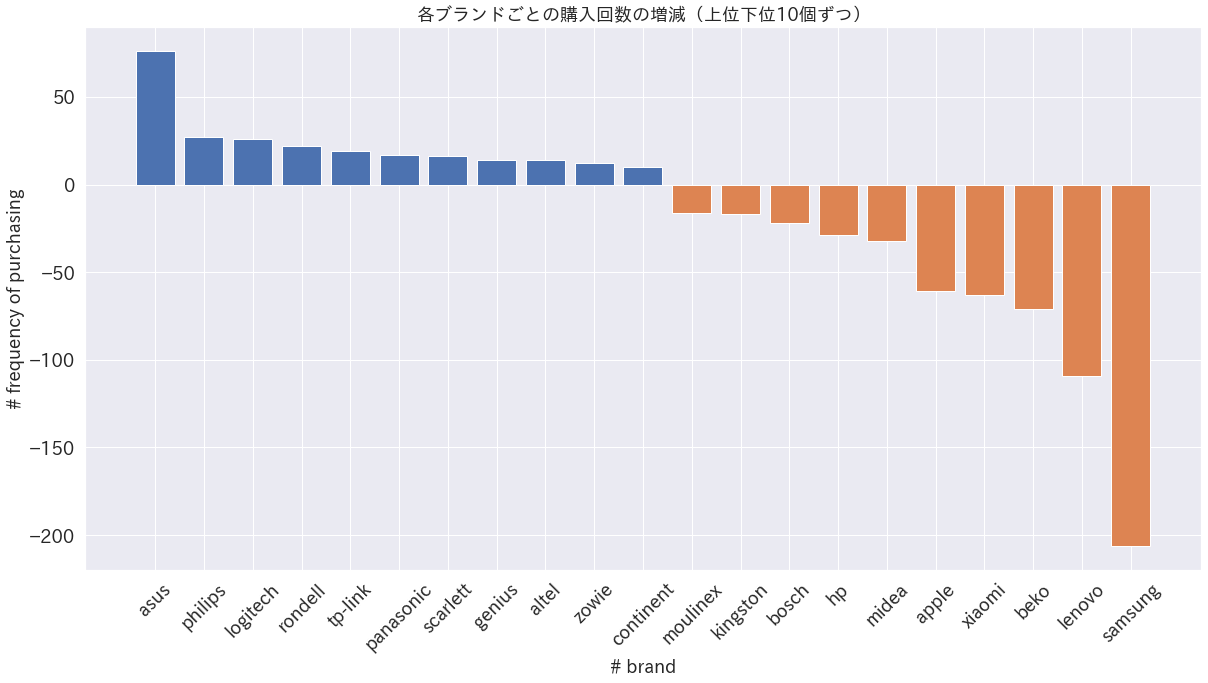
df_diff_n_m=df_a_n_m.iloc[:,1:]-df_b_n_m.iloc[:,1:] df_diff_n_m.index=df_a_n_m['user_id'].values df_diff_n_m=df_diff_n_m.T df_diff_n_m['col']=df_diff_n_m.index df_diff_n_m['brand']=df_diff_n_m['col'].str.split('.', expand=True).iloc[:,0].values df_diff_n_m=pd.DataFrame(df_diff_n_m.groupby(['brand']).sum().T.sum()).sort_values(0, ascending=False) # 各ブランドごとの購入回数の増減をプロット fig=plt.figure(figsize=(20,10)) plt.bar(df_diff_n_m.index[:11], df_diff_n_m[0][:11]) plt.bar(df_diff_n_m.index[-10:], df_diff_n_m[0][-10:]) plt.rcParams["font.family"] = "IPAexGothic" plt.tick_params(labelsize=18) plt.xticks(rotation=45) plt.xlabel('# brand', fontsize=18) plt.ylabel('# frequency of purchasing', fontsize=18) plt.title('各ブランドごとの購入回数の増減(上位下位10個ずつ)', fontsize=18) plt.show()クラスタ2→0遷移ユーザーのブランド別購入回数の増減
クラスタ2→0に遷移したユーザー群はLENOVOやSamsungの購入回数が減って、AsusやLogitechの購入回数が増えていることがわかる。これは前記のようにクラスタ別の出現確率上位などで確認したクラスタごとの特徴に沿っている。
このように時系列にユーザーの好みの変化を追ったりもできる可能性がある。
また、さらに細かく見ていかないと断定できないが、例えばユーザーのブランドスイッチングが起きてしまった可能性もあったりするので、深堀することで自社や他社のブランドがなぜ売れたか売れなかったの原因を分析していくことができるかもしれない。以上のようにLDAでクラスタリングすることで意味のある分析ができる可能性がある。
kmeansでクラスタリング
LDAでやったようなクラスタリングをkmeansでもやってみる。
結果のチャートを確認。row='user_id' col='brand_category' val='price' df_mart=df_pivot(df_before, row, col, val, 'sum') df_mart2=df_pivot(df_after, row, col, val, 'sum') # df_martとdf_mart2で重複していないカラム名をとってくる after=np.hstack((df_mart.columns.values, df_mart2.columns.values)) unique_after, counts_after = np.unique(after, return_counts=True) non_dep_after=unique_after[counts_after == 1] # さっきの重複していないカラム名の中で、df_martに入っていてdf_mart2に入っていないカラム名を抽出 before=np.hstack((non_dep_after, df_mart.columns.values)) unique_before, counts_before = np.unique(before, return_counts=True) dep_before=unique_before[counts_before != 1] # df_mart2にdf_mart固有のカラム名の列を追加 for col in dep_before: df_mart2[col]=0 # これでdf_martとdf_mart2のカラムがそろう df_mart=df_mart[df_mart.columns] df_mart2=df_mart2[df_mart.columns] # LDAに食わせる用の加工 ss=StandardScaler() df_data=ss.fit_transform(df_mart.iloc[:,1:].values) ss=StandardScaler() df_data2=ss.fit_transform(df_mart2.iloc[:,1:].values) def km_cluster(X, k): km=KMeans(n_clusters=k,\ init="k-means++",\ random_state=0) y_km=km.fit_predict(X) return y_km,km # k=6でクラスタリング y_km,km=km_cluster(df_data, 6) plot_chart(y_km)
かなり偏ってクラスタリングされてしまった。
クラスタごとの平均値を見ても多くのクラスタでSamsungが高かったり偏っている。
df_kmeans=df_mart.copy() df_kmeans['cluster']=y_km # 各トピックにおける、商品の平均購入数を抽出 df_kmeans.groupby(['cluster']).mean().T(EXCELで体裁を整えた↓)
以上のように、高次元なデータになるとやはりkmeansではうまくクラスタリングできなかった。
おわりに
POSデータをLDAでクラスタリングしてみた。
距離を指標にクラスタリングするのが難しそうなときに、トピックモデルを使うと良い結果が出るかもしれない。以上!






- 投稿日:2021-01-14T17:47:21+09:00
普通のPyTorchやTensorFlowで正規分布以外の連続値の分布を予測する
はじめに
先日、muzero-generalの実装を見ていたときに、連続値の予測としてcategoricalに予測する面白い方法がありました。
よくよく考えてみると、連続値の任意の確率分布の予測を表現できるんじゃないかな、と思って検証してみたら、上手く行きそうだったのでメモしておきます。
連続値をcategoricalに予測する
連続値の予測に MeanSquaredError を使うと基本的に「予測したい値の分布が正規分布である(さらに、関心があるのは期待値だけである)」という前提があることになります。なので例えば、山が2つあるような分布だと、その間くらいを予測してしまってちょっと都合が悪かったりします。広がり具合(分散など)もちょっとわかりません。
(関心のある)値の範囲は決まっている場合、次のような方法があります。例えば、値の範囲が 0 ~ 10 だとすると、
v=[0, 1, 2, ..., 10]という 11の値の点を決めます。
最初にp[0~10] = 0として、
例えば 3.7 という値なら p[3] = 0.3, p[4]=0.7 と表現します。0.1なら p[0]=0.9, p[1]=0.1 です。3 なら p[3]=1.0 です。要するに、値の両端に対して所属度合いを振っていく感じです。逆に、この p から元の値を計算する場合は、期待値
sum(p*v)を計算します。
コードで書くとこんな感じになります。
import numpy as np SUPPORT_SIZE = 11 VALUE_RANGE = [0., 10.] def scalar_to_support(scalars): values = np.array(scalars) min_v, max_v = VALUE_RANGE values = np.clip((values - min_v) / (max_v - min_v), 0., 1.) key_values = np.linspace(0., 1., SUPPORT_SIZE) r_index = np.searchsorted(key_values, values, side="left") # a[i-1] < x <= a[i] l_index = np.clip(r_index-1, 0, len(key_values)) left_vs = key_values[l_index] right_vs = key_values[r_index] interval = key_values[1] - key_values[0] left_ps = 1-(values - left_vs)/interval right_ps = 1-(right_vs - values)/interval vectors = np.zeros((len(values), SUPPORT_SIZE)) for i in range(len(scalars)): vectors[i, l_index[i]] = left_ps[i] vectors[i, r_index[i]] = right_ps[i] return vectors def support_to_scalar(supports): min_v, max_v = VALUE_RANGE key_values = np.linspace(min_v, max_v, SUPPORT_SIZE) supports /= supports.sum(axis=1, keepdims=True) return np.sum(supports * key_values, axis=1)※ muzeroの実装では、更に前処理として面白い変換をしていますが、それは省いています。
学習させる場合は、出力は softmax(この場合は11要素) にして、Loss関数にはCrossEntropyを使います。
確率分布を学習できるのかの検証
覚えたてのPyTorchを使って検証してみます。
定数の予測
まずは、何か1つの値を固定で予測できるかやってみます。
コード
# on jupyter notebook import torch import torch.nn.functional as F import matplotlib.pyplot as plt SUPPORT_SIZE = 101 class Net(torch.nn.Module): def __init__(self): super().__init__() self.fc = torch.nn.Linear(1, SUPPORT_SIZE) def forward(self, x): x = self.fc(x) x = F.softmax(x, dim=1) return x def get_dummy_input(batch_size): dummy_inputs = np.random.random((batch_size, 1)).astype("float32") return torch.tensor(dummy_inputs) # dummy def constant_target_value_fn(const): def fn(batch_size): return [const] * batch_size return fn def train_model(model, target_value_fn, epoch=1000, lr=0.01, batch_size=16): optimizer = torch.optim.Adam(model.parameters(), lr=lr) loss_history = [] for ep in range(epoch): target_values = target_value_fn(batch_size) target_supports = torch.tensor(scalar_to_support(target_values)) # optimizer.zero_grad() outputs = model(get_dummy_input(batch_size)) losses = torch.mean(- target_supports * torch.log(outputs)) losses.backward() optimizer.step() loss_history.append(losses.item()) plt.plot(loss_history) plt.show() ####################### model = Net() train_model(model, constant_target_value_fn(4.8)) outputs = model(get_dummy_input(5)).detach().numpy() print(f"期待値={np.mean(support_to_scalar(outputs))}") vs = np.mean(outputs, axis=0) plt.plot(vs)対象範囲を0~10、出力ベクトルのサイズを101にして、4.8 という定数を予測させてみました。
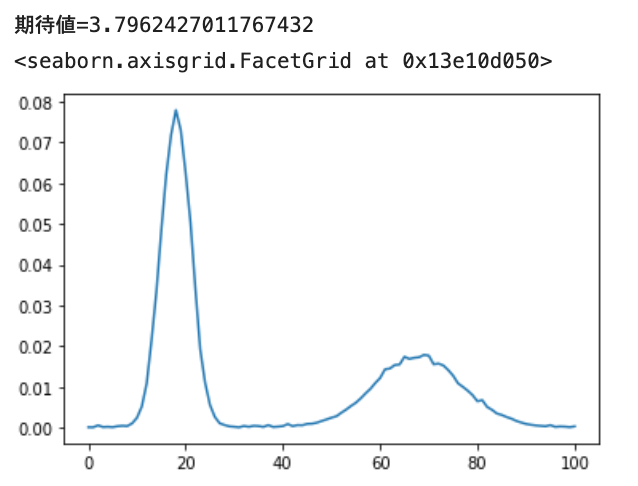
予測結果はこうなりました。問題なさそうです。
期待値=4.804064254500373
※ 横軸が0~100になってますが、0~10だと思ってください。以降も同じ。
正規分布の予測
次に正規分布(loc=4.8, scale=0.9)を学習させてみます。
コード
from scipy import stats def norm_fn(loc, scale): def fn(batch_size): dist = stats.norm(loc=loc, scale=scale) return dist.rvs(batch_size) return fn model = Net() distribution_fn = norm_fn(4.8, 0.9) train_model(model, distribution_fn, epoch=1000, batch_size=1024) outputs = model(get_dummy_input(5)).detach().numpy() print(f"期待値={np.mean(support_to_scalar(outputs))}") vs = np.mean(outputs, axis=0) plt.plot(vs)
いい感じ。
混合正規分布の予測
次に2つの正規分布 Normal(loc=1.8, scale=0.3, 確率=0.6) と Normal(loc=6.8, scale=0.9, 確率=0.4) を学習させてみます。
コード
from collections import Counter def multi_norm_fn(loc_scale_prob_list): def fn(batch_size): values = [] for loc, scale, prob in loc_scale_prob_list: dist = stats.norm(loc=loc, scale=scale) values.append(dist.rvs(batch_size)) ps = np.array([p for _, _, p in loc_scale_prob_list]) ps = ps / np.sum(ps) count = Counter(np.random.choice(range(len(values)), size=batch_size, p=ps)) ret = [] for i, cnt in count.items(): ret += list(values[i][:cnt]) return ret return fn model = Net() distribution_fn = multi_norm_fn([ [1.8, 0.3, 0.6], [6.8, 0.9, 0.4], ]) train_model(model, distribution_fn, epoch=1000, batch_size=1024) outputs = model(get_dummy_input(5)).detach().numpy() print(f"期待値={np.mean(support_to_scalar(outputs))}") vs = np.mean(outputs, axis=0) plt.plot(vs)
おー、ちゃんと2山できますね。あと、裾野の広さも表現されています。
指数分布の予測
最後に指数分布(loc=1.4, scale=2.0)です。
※ 普通の指数分布(2)を1.4だけ右に平行移動したものになります。
コード
def exp_fn(loc, scale): def fn(batch_size): dist = stats.expon(loc, scale) return dist.rvs(batch_size) return fn model = Net() distribution_fn = exp_fn(1.4, 2.0) train_model(model, distribution_fn, epoch=1000, batch_size=1024) outputs = model(get_dummy_input(5)).detach().numpy() print(f"期待値={np.mean(support_to_scalar(outputs))}") vs = np.mean(outputs, axis=0) plt.plot(vs)
1.4 辺りからピークが立ち上がり、徐々に落ちていくのが表現されています。また、10以上の値がそれなりにあることも表しています。
余談
あと、角度みたいに循環する連続値の予測にはかなりぴったりかな、と思います。
10度と350度は実は近いんだよ、というのがちょっと工夫すれば表現できそうです。さいごに
ということで、連続値予測はCategoricalにCrossEntropyでもOK、というのが確認できました。
こういうテクニックは最近の書籍などを読むと載っているのかもしれませんが、個人的に新しかったのでメモしておきます。


- 投稿日:2021-01-14T17:41:12+09:00
Udemy「Djangoの基礎をマスターして、3つのアプリを作ろう! やってみた結果」
年末年始は勉強をするまたとないチャンスです。
特に、みんながお正月で一家団欒を楽しんでいるときに自分を追い込んで勉強することは周りと差がつけられるといった意味でも非常に価値があります。
今回は、時間たっぷりなそのタイミングを狙って,新しいことにチャレンジしようと、「Djangoの基礎をマスターして、3つのアプリを作ろう!」をやりました。
・・・・・・・・・・・・・・・・
動画詳細はこちら↓
【徹底的に解説!】Djangoの基礎をマスターして、3つのアプリを作ろう!(Django2版 / 3版を同時公開中です)
https://px.a8.net/svt/ejp?a8mat=2TR3YZ+3ENG0Y+3L4M+BW8O2&a8ejpredirect=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdjango-3app%2F
・・・・・・・・・・・・・・・・djangoの講義に関して
基本的に、Djangoチュートリアルではイメージができなかった部分を非常に丁寧に解説してくれていますので、
これからweb開発でDjangoを使用しようとしている方のスタートの教材としてなかなか良いのではないかと思います。もちろん、講義の前にPython、HTML/CSS、Web系の知識(HTTP、ブラウザ、サーバーなど)を簡単にキャッチアップしておくと理解が早いですが。。。内容としては、Python初学者の私でも、数日で全レッスンを終えられました。全体的にとてもわかりやすかったです。
話し方に関しても、講師の方が聞き取りやすい声でとても良かった。また、この講義を視聴するか迷っている方に関しては、この講義ではデプロイ方法の説明を除けば、Djangoの全体像が俯瞰できます。
なので、 「どうすればアプリが動くの?」 「アプリ作成に必要な手順は?」といった疑問といった疑問を抱えている方は、だいぶスッキリするはずです。また、全体像がわかっていることから、トラブルは概ね検索すればすぐに解決できるレベルになります。
そのためDjangoの仕組み部分や環境部分でつまずくことはなくなるはずです。ただし説明が冗長になっていたり、ときどきミスが映り込んでいるため、学習速度の遅延につながってしまいました。その点だけが非常に惜しかったです。
少なからず、全体の感想としては満足していますし、この講座を受講してよかったと心から思っています。Djangoのように日本語情報が少ない講座は多くの人に需要があると思いますし、学習者が増えれば界隈も盛り上がると思います。
繰り返しになりますが、どのチュートリアルよりも圧倒的にわかりやすく、初心者に寄り添った内容になっています。 Pythonに触れる前、Railsを公式チュートリアルで独学して挫折し、Web構築を諦める寸前でしたが、この講義のおかげでDjangoの面白さ、便利さを実感し、再び開発に向き合おうと思えるようになりました。
残念だった点
・・・・・・・・・・・・・・・・
以下は残念だった点になります。
懸念点としては、基礎の部分の解説や調べ方については解り易かったのですが、実際使用できるアプリという意味ではTodoアプリまでで、最後のアプリはSNSというよりも個人ブログのような内容で、編集や削除がありませんでした。そのため、いつ作成したかわからないので、これらのDjangoの解説がなく、実際にアプリとして使えないところが残念でした。
デプロイの部分は、有料の物をご案内いただいてますが、ポートフォリオ等に使う程度であれば、Herokuは最高5つまでデプロイ可能なので、そちらのデプロイ方法を掲載していただきたかったかなといった印象です。ただ、現在はDockerを使ってのデプロイや環境構築ができたほうが良いといったことも主流ですので、自分で考えながらそこのところの実装ができたといった意味ではいい意味で考えさせられて良かったんじゃないかなと思います。
とはいっても、Djangoの2系と3系に触れられているのは凄くいいことですし、実務では古い2系の方を使って開発をするといった可能性も十分にありえるので、その2つをカバーできる点に関しては良かったと思います。
【学んだことが活きたときに関して】
この講座を通じて、画面の作成が非常に楽になりました。
デフォルトでテンプレートみたいなのを用意してくれているみたいで、それを使えば一瞬でいい感じのデザインの画面を作るといったことをこの動画で理解することができたためですね。Webアプリを作るときにデザインの調整が苦手でcssといつも格闘しているのですが、Djangoのテンプレートをそのまま使う場合は大幅に時間を削減できます。
また他のフレームワークと違って,ファイルが少なく,スッキリしているので、非常に開発がしやすくなりましたね。色々書きましたが、教材としては凄くおすすめです。動画詳細
・・・・・・・・・・・・・・・・
動画詳細はこちら↓
【徹底的に解説!】Djangoの基礎をマスターして、3つのアプリを作ろう!(Django2版 / 3版を同時公開中です)
https://px.a8.net/svt/ejp?a8mat=2TR3YZ+3ENG0Y+3L4M+BW8O2&a8ejpredirect=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdjango-3app%2F
・・・・・・・・・・・・・・・・
- 投稿日:2021-01-14T16:52:33+09:00
Splunk 外部pythonでファイルをダウンロードして取り込む
これのベストプラクティスはなんなんだろう?
とりあえずできたので、紹介します。前提条件
前回のCSV
を利用するためにAppsseikaを作成。
ディレクトリ構成はこんな感じtree├── bin │ ├── README │ ├── dl.py │ └── seika_dl.sh ├── data │ ├── seika_20210113.csv │ └── seika_20210114.csv ├── default │ ├── app.conf │ └── data │ └── ui │ ├── nav │ │ └── default.xml │ └── views │ └── README ├── local │ ├── app.conf │ ├── inputs.conf │ └── props.conf └── metadata ├── default.meta └── local.metainputs.conf
inputs.conf[script://$SPLUNK_HOME/etc/apps/seika/bin/seika_dl.sh] disabled = false index = main interval = 0 20 * * * sourcetype = csv [monitor:///Applications/Splunk/etc/apps/seika/data] disabled = false sourcetype = seika_csv crcSalt= /Applications/Splunk/etc/apps/seika/data
seika_dl.shのintervalは午後8時に実施
検証の時にはinterval = 0 * * * *毎分0秒に実施に変更していました。
ここのsourcetypeは使われないので適当
monitorのsoucetypeは今回のため作成したものを使用
crcSaltをつけることで、ファイルができたら強制的に読み込むようにしている。seika_dl.sh
bin/配下の二つのスクリプトはchmod 755済seika_dl.shcd $SPLUNK_HOME/etc/apps/seika/data /opt/anaconda3/bin/python ../bin/dl.pyデータ格納用フォルダーに移動したのち、ダウンロード用scriptを起動しているだけのもの
/usr/bin/env/ pythonで行けるかと思ったら、Splunk内のpythonが起動してしまうため、フルパスで記載。
dl.pyは前回のにシバンをつけただけ。
pandas入れて欲しいよ〜props.conf
props.conf[seika_csv] INDEXED_EXTRACTIONS = csv KV_MODE = none LINE_BREAKER = ([\r\n]+) NO_BINARY_CHECK = true SHOULD_LINEMERGE = false TIMESTAMP_FIELDS = date TIME_FORMAT = %Y-%m-%d category = Structured disabled = false pulldown_type = true読み込みやすいようにpython側で加工しているのでシンプル
python側でdate列を一番左にしておくと時間の設定も多分いらない。検索
SPL
miyagi.splindex=main sourcetype=seika_csv area="宮城" category="野菜" | stats sum(*_price) as *_price by date, product_name結果
解説
- trellis表示は
stats byの引数を第1:X軸 第2:カテゴリーとすると、このように綺麗に表示できる。- ['high_price','middle_price','low_price']の3つをグラフにするので
(*_price) as *_priceで省略して記述している。まとめ
まだ二日分なのでつまらないけど、データが集まってくるといろいろ使えそうな感じまで持っていけた。
本格運用するのであれば、データそのものはローカルに保存しない方法を検討したほうがいいんだろうなと思いました。
- 投稿日:2021-01-14T16:41:17+09:00
Pybind11でC++関数をPythonから実行する(Windows & Visual Studio Codeな人向け) 環境構築編
Pybind11を使ってC++の関数をPythonから呼び出せるようにする環境を構築する方法を説明します。WindowsかつVisual Studio Code(以下、VSCode)
を使っている人向けの記事があまりなかったので、いろいろ調べたことをまとめておきます。
デバッグ編は後日投稿します。0. 環境
以下の環境で確認しています。CMake以下のインストール方法はこの記事で説明します。
- OS: Windows 10 Home 20H2
- エディター: Visual Studio Code 1.52.1
- Python: 3.7 (Anaconda 3 2019.7)
- この記事でインストールするもの
- CMake: 3.19.2
- msvc: 2019 Release
- pybind11: 2.6.1
1. 環境構築
1.1. CMakeのインストール
CMakeとは、C++等をビルドする際の設定を様々なコンパイラーで利用できるようにするツールです。が、私自身よく分かっていないので、詳しくはこちらをみてください。
ダウンロード ページからWindows win64-x64 Installerをダウンロードし、インストールします。
また、VSCode用の拡張機能CMake ToolsもVSCodeにインストールしておきます。端末がオフラインの場合はこちらを参考にしてください。
1.2. msvcのインストール
msvcとは、Microsoft製C++コンパイラです。Visual StudioのC++コンパイラー部分です。
インストール方法は、端末がオンラインの場合はこちらを、オフラインの場合はこちらをご覧ください。
1.3. Pybind11のインストール
オンライン環境なら、
pipでインストールします。Powershell> pip install pybind11オフライン環境の場合は、
PyPIのダウンロード ページからpybind11-x.y.z-py2.py3-none-any.wh(x, y, zは数字)をダウンロードしてから、pipでインストールします。Powershell> pip install ダウンロード先/pybind11-2.5.0-py2.py3-none-any.whl #2.5.0部分は適宜読み替え後で使うので、公式のサンプルもダウンロードします。オンライン環境(かつGitをインストール済み)なら、Powershell上でダウンロードしたい場所まで移動し、
Powershellgit clone --recursive https://github.com/pybind/cmake_example.gitとしてダウンロードします。オフライン環境の場合は、公式のサンプルの
Clone or downloadボタンを押します。また、pybind11フォルダーも同様にダウンロードします。
【重要】(2021/1修正。現時点ではワーニングが出ないため削除。)cmake_example/pybind11/include/pybind11以下のファイルを、C:\ProgramData\Anaconda3\include\pybind11以下のファイルで置き換えます。置き換える前のファイルは古いみたいで、コンパイルは通りますが、warning: 'void PyThread_delete_key_value(int)' is deprecated [-Wdeprecated-declarations]というワーニングが大量に出ます。2. やってみるさ( ■ 一 ■)
先ほどダウンロードした
cmake_exmpleフォルダーから、pybind11、src、CMakeLists.txtを適当なフォルダー(以下、project_rootとします)にコピーします。なお、パス名に日本語が含まれるとConfigureとGenarateができないため、半角英数字(スペースと記号もOK)にしてください。(コンパイラーにg++を使うと日本語はダメだけど、msvcならOKみたい)フォルダー構成project_root ├ pybind11 │ ├ docs │ ├ include │ │ └pybind11 │ │ └・・・ │ └・・・ ├ src │ └main.cpp └ CMakeLists.txtコンパイル エラー(なぜかはわからない)になるため、
main.cppの#ifdef VERSION_INFO~#endif部分をコメントアウトor削除。project_root/src/main.cpp#include <pybind11/pybind11.h> int add(int i, int j) { return i + j; } namespace py = pybind11; PYBIND11_MODULE(cmake_example, m) { (略) m.def("add", &add, R"pbdoc( Add two numbers Some other explanation about the add function. )pbdoc"); (略) //コンパイルエラー(なぜかはわからない)になるので以下をコメントアウトor削除 //#ifdef VERSION_INFO // m.attr("__version__") = MACRO_STRINGIFY(VERSION_INFO); //#else // m.attr("__version__") = "dev"; //#endif }project_root/CMakeLists.txtcmake_minimum_required(VERSION 2.8.12) project(cmake_example) add_subdirectory(pybind11) pybind11_add_module(cmake_example src/main.cpp)
project_rootをVSCodeで開き、コマンド パレット(Ctrl+p)からCMake Toolsを使ってビルドします。
Cmake: Select VariantでDebugを選択Cmake: Select a KitでVisal Studio Build Tools 2019 Release - amd64を選択Cmake: Select a Kitを実行なお、上記はVSCodeのステータスバー(下部の青いバー)をクリックして設定することもできます。
成功すれば、
./build/Debugフォルダーにcmake_example.cp37-win_amd64.pydが作成されます。VSCodeでCtrl+pでターミナルを開き、試してみましょう。Powershell> python # Pythonを起動 >>> from build.Debug.cmake_example import add >>> add(1,2) 3 >>> exit() # Powershellに戻る
add関数を呼び出せていれば成功です。3. トラブルシューティング
3.1. ConfigureとGenarate
3.1.1.cmake -G "MinGW Makefiles" ..ができない
パス名に日本語が含まれるとConfigureとGenarateができません。パス名は大人しく半角英数字(スペースと記号もOK)にしましょう。日本語に対応して欲しいですね。(コンパイラーにg++を使うと日本語はダメだけど、msvcならOKみたい)3.2. ビルド時
3.2.1. warning: 'void PyThread_delete_key_value(int)' is deprecated [-Wdeprecated-declarations]
上で書きましたが、(2021/1修正。現時点ではワーニングが出ないため削除。)cmake_example/pybind11/include/pybind11以下のファイルを、C:\ProgramData\Anaconda3\include\pybind11以下のファイルで置き換えます。置き換える前のファイルは古いみたいで、コンパイルは通りますが、warning: 'void PyThread_delete_key_value(int)' is deprecated [-Wdeprecated-declarations]というワーニングが大量に出ます。3.2.2. error: '::hypot' has not been declared
2018年12月以前にリリースされたPythonの各バージョンを使っていると、このエラーでビルドが失敗します。原因はpyconfig.hで、次のように修正します。
Pythonインストール先/include/pyconfig.h#define COMPILER "[gcc]" - #define hypot _hypot ←この行を削除する。 #define PY_LONG_LONG long long #define PY_LLONG_MIN LLONG_MIN #define PY_LLONG_MAX LLONG_MAXこの問題は公式でも議論されており、プルリクエスト後、マージされています(実際のコミット)。
4. おわりに
最後まで読んでいただき、ありがとうございます。
この記事では公式のサンプルを使っただけでしたが、他の人の記事を参考に、main.cppやCMakeLists.txtを修正してみてください。
C++に疎いため、たったこれだけの事が出来るようになるまでに時間がかかりました。これからC++デビューしたいと思います。参考
以下の記事を参考にさせていただきました。
Mingw-w64のインストール方法
CMakeの解説
CMake Toolsの使い方
Pybind11の使い方
- 投稿日:2021-01-14T16:36:09+09:00
メモ:カスタマイズ特殊名一覧
Python 言語リファレンス - 3. データモデル
"__" で始まるカスタマイズするための特殊名の一覧
(実装したい機能の名前が出てこない時に探す)3.3.1 基本的なカスタマイズ
object.__new__(cls, [...])
object.__init__(self, [...])
object.__del__(self)
object.__repr__(self)
object.__str__(self)
object.__bytes__(self)
object.__format__(self, fmtspec)
object.__lt__(self, other)
object.__le__(self, other)
object.__eq__(self, other)
object.__ne__(self, other)
object.__gt__(self, other)
object.__ge__(self, other)
object.__hash__(self)
object.__bool__(self)3.3.2 属性値アクセスをカスタマイズする
object.__getattr__(self, name)
object.__getattribute__(self, name)
object.__setattr__(self, name, value)
object.__delattr__(self, name)
object.__dir__(self)
object.__get__(self, instance, owner=None)
object.__set__(self, instance, value)
object.__delete__(self, instance)
object.__set_name__(self, owner, name)
object.__slots__3.3.3 クラス生成をカスタマイズする
object.__init_subclass__(cls)
object.__mro_entries__(self, bases)
object.__prepare__(metacls, name, bases)3.3.4 インスタンスのカスタマイズとサブクラス チェック
class.__instancecheck__(self, instance)
class.__subclasscheck__(self, instance)3.3.5 ジェネリック型をエミュレートする
object.__class_getitem__(cls, key)
3.3.6 呼び出し可能オブジェクトをエミュレートする
object.__call__(self[, args...])
3.3.7 コンテナをエミュレートする
object.__len__(self)
object.__length_hint__(self)
object.__getitem__(self, key)
object.__setitem__(self, key, value)
object.__delitem__(self, key)
object.__missing__(self, key)
object.__iter__(self)
object.__reserved__(self)
object.__contains__(self, item)3.3.8 数値型をエミュレートする
object.__add__(self, other)
object.__sub__(self, other)
object.__mul__(self, other)
object.__matmul__(self, other)
object.__truediv__(self, other)
object.__floordiv__(self, other)
object.__mod__(self, other)
object.__divmod__(self, other)
object.__pow__(self, other [,modulo])
object.__lshift__(self, other)
object.__rshift__(self, other)
object.__and__(self, other)
object.__xor__(self, other)
object.__or__(self, other)object.__radd__(self, other)
object.__rsub__(self, other)
object.__rmul__(self, other)
object.__rmatmul__(self, other)
object.__rtruediv__(self, other)
object.__rfloordiv__(self, other)
object.__rmod__(self, other)
object.__rdivmod__(self, other)
object.__rpow__(self, other [,modulo])
object.__rlshift__(self, other)
object.__rrshift__(self, other)
object.__rand__(self, other)
object.__rxor__(self, other)
object.__ror__(self, other)object.__iadd__(self, other)
object.__isub__(self, other)
object.__imul__(self, other)
object.__imatmul__(self, other)
object.__itruediv__(self, other)
object.__ifloordiv__(self, other)
object.__imod__(self, other)
object.__ipow__(self, other [,modulo])
object.__ilshift__(self, other)
object.__irshift__(self, other)
object.__iand__(self, other)
object.__ixor__(self, other)
object.__ior__(self, other)object.__neg__(self)
object.__pos__(self)
object.__abs__(self)
object.__invert__(self)object.__complex__(self)
object.__int__(self)
object.__float__(self)
object.__index__(self)object.__round__(self [,ndigits])
object.__trunc__(self)
object.__floor__(self)
object.__ceil__(self)3.3.9 with 文とコンテキストマネージャー
object.__enter__(self)
object.__exit__(self, exc_type, exc_value, traceback)3.4.1 待機可能オブジェクト
object.__await__(self)
3.4.3 非同期イテレータ
object.__aiter__(self)
object.__anext__(self)3.4.3 非同期コンテキストマネージャー
object.__aenter__(self)
object.__aexit__(self, exc_type, exc_value, traceback)
- 投稿日:2021-01-14T15:29:41+09:00
【データサイエンス備忘録】DataFrame型の中身の確認【python】
- 投稿日:2021-01-14T15:29:41+09:00
【データサイエンス備忘録】 DataFrame型の中身の確認 【python】
- 投稿日:2021-01-14T15:19:46+09:00
pythonでグラフ描く度に調べてるので、最もシンプルな使い方だけまとめとく
pythonでグラフ描く度に調べてるので、最もシンプルな使い方だけまとめとく
jupyter notebook使ってます。
jupyter notebookじゃないのなら「%matplotlib inline」は不要2次元グラフ
# ライブラリのインポート %matplotlib inline import matplotlib.pyplot as plt import numpy as np # グラフ描画したい関数 def func(x): return x**2 # 変数準備 # np.arange(開始, 終了, ステップ) x = np.arange(0.0, 10.0, 0.1) y = func(x) # グラフに描画 plt.plot(x, y);
3次元グラフ
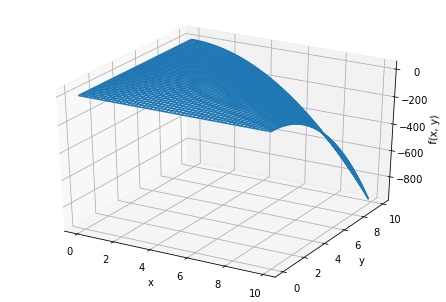
# ライブラリのインポート %matplotlib inline from mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt import numpy as np # グラフ描画したい関数 def func(x, y): return x * y * (10 - x - y) # 変数準備 x = np.arange(0.0, 10.0, 0.1) y = np.arange(0.0, 10.0, 0.1) X, Y = np.meshgrid(x, y) Z = func(X, Y) # 描画 fig = plt.figure() ax = Axes3D(fig) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("f(x, y)") ax.plot_wireframe(X, Y, Z) plt.show()

- 投稿日:2021-01-14T14:46:44+09:00
地域メッシュコードを緯度経度に変換するPythonコード
はじめに
位置が地域メッシュコードで提供されているビッグデータを扱う機会があり、プログラムで扱いやすい緯度経度の形に変換する関数を作成したので共有します。
参考にしたサイト
この記事は、こちらのブログに掲載されている第三次メッシュまでの変換コードを8分の1地域メッシュにまで対応させたものです。
地域メッシュコードとは
Wikipediaの記事によると、
地域メッシュ(ちいきメッシュ)とは、統計に利用するために、緯度・経度に基づいて地域をほぼ同じ大きさの網の目(メッシュ)に分けたものである。メッシュを識別するためのコードを地域メッシュコードと言う。 地図の製作や提供においては、地域メッシュごとに紙地図を用意し、あるいはデジタル的な地図データファイルを用意することが行われる。とされており、JIS X 0410で規格化されています。Esriジャパンのサイトにわかりやすくまとまっています。
実行環境
- docker-anacondaイメージ
- Python 3.8.5
メッシュコードから緯度経度に変換する関数
def get_latlon(meshCode): # 文字列に変換 meshCode = str(meshCode) # 1次メッシュ用計算 code_first_two = meshCode[0:2] code_last_two = meshCode[2:4] code_first_two = int(code_first_two) code_last_two = int(code_last_two) lat = code_first_two * 2 / 3 lon = code_last_two + 100 if len(meshCode) > 4: # 2次メッシュ用計算 if len(meshCode) >= 6: code_fifth = meshCode[4:5] code_sixth = meshCode[5:6] code_fifth = int(code_fifth) code_sixth = int(code_sixth) lat += code_fifth * 2 / 3 / 8 lon += code_sixth / 8 # 3次メッシュ用計算 if len(meshCode) >= 8: code_seventh = meshCode[6:7] code_eighth = meshCode[7:8] code_seventh = int(code_seventh) code_eighth = int(code_eighth) lat += code_seventh * 2 / 3 / 8 / 10 lon += code_eighth / 8 / 10 # 1/2メッシュ用計算 if len(meshCode) >= 9: code_nineth = meshCode[8:9] code_nineth = int(code_nineth) if code_nineth % 2 == 0: lon += 0.00138888 if code_nineth > 2: lat += 0.00416666 # 1/4メッシュ用計算 if len(meshCode) >= 10: code_tenth = meshCode[9:10] code_tenth = int(code_tenth) if code_tenth % 2 == 0: lon += 0.00138888 / 2 if code_tenth > 2: lat += 0.00416666 / 2 # 1/8メッシュ用計算 if len(meshCode) >= 11: code_eleventh = meshCode[10:11] code_eleventh = int(code_eleventh) if code_eleventh % 2 == 0: lon += 0.00138888 / 2 / 2 if code_eleventh > 2: lat += 0.00416666 / 2 / 2 return lat, lon関数の使い方
Pythonに詳しい方でしたら見ればわかると思いますが、
lat,lon = get_latlon(60413212422)のようにすると、
latに緯度が、lonに経度が代入されます。
- 投稿日:2021-01-14T14:14:33+09:00
Dartsを使ってみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は時系列モデルを統一的なAPIで使用できるライブラリー(Darts)があったので使ってみました。
はじめに
過去に時系列解析に関する記事を整理しておりますので、興味ある方はそちらも参照して頂けますと幸いです。
Dartsとは
時系列モデルを分析する際は、様々なライブラリのAPIを理解して、それに合わせてデータ整形し、モデルを評価する必要がありました。
しかし、スイスの企業Unit8が2020年6月末に公開したDartsは上記のような課題を解決するライブラリです。簡単に言うと時系列データに関する様々なモデルをscikit-learnのように統一的に扱うことができます。現在は下記モデルが対応しているようです。
- Exponential smoothing
- ARIMA & auto-ARIMA
- Facebook Prophet
- Theta method
- FFT (Fast Fourier Transform)
- Recurrent neural networks (vanilla RNNs, GRU, and LSTM variants)
- Temporal convolutional network
- Transformer
- N-BEATS
Dartsを使ってみた
ライブラリーのインストールは下記で簡単にできます。
pip install u8dartsまずは「AirPassengers」のデータを使って分析を行っていきます。
# 必要なライブラリーのインポート import darts from darts import TimeSeries import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline from darts.metrics import mape, mase from darts.utils.statistics import check_seasonality, plot_acf, plot_residuals_analysis import warnings warnings.filterwarnings("ignore") import logging logging.disable(logging.CRITICAL) # https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/AirPassengers.html df = pd.read_csv('AirPassengers.csv') # データの中身を確認 df.head()
次にDartsのTimeSeries型に変換します。
# DartsのTimeSeriesに変換 series = TimeSeries.from_dataframe(df, time_col='Month', value_cols='#Passengers')ExponentialSmoothing(指数平滑法)
初めに、HyndmanとAthanasopoulosによる指数平滑法を試してみます。今回は各手法の詳細は省きます。
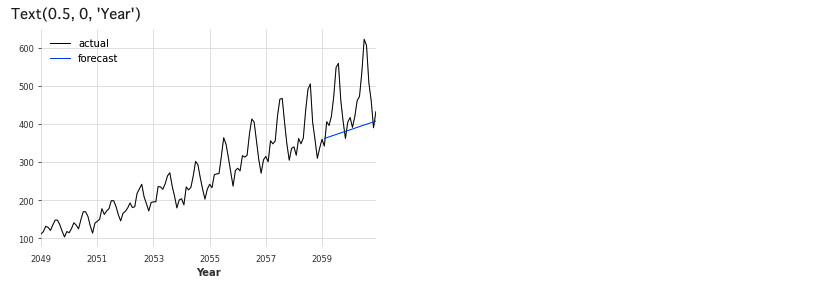
# Jan-59以前と以後に分割 train, val = series.split_after(pd.Timestamp('Jan-59')) from darts.models import ExponentialSmoothing # モデル生成 model_es = ExponentialSmoothing() # 学習 model_es.fit(train) # 予測 (predictには予測数を入れることに注意) historical_fcast_es = model_es.predict(len(val)) # 可視化 series.plot(label='actual', lw=1) historical_fcast_es.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Year')
NaiveSeasonal
次にNaiveSeasonalと言う手法を試してみます。パラメータKが重要らしいので、適切に設定しないと上手く予測できないようです。
# 自己相関を求める plot_acf(train, m = 12, alpha = .05) # NaiveSeasonal from darts.models import NaiveSeasonal # モデル生成 seasonal_model = NaiveSeasonal(K=12) # 学習 seasonal_model.fit(train) # 予測 seasonal_forecast = seasonal_model.predict(len(val)) # 可視化 series.plot(label='actual', lw=1) seasonal_forecast.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Year')
12ヶ月周期を考慮したモデルを採用しております。
NaiveDrift
次は、NaiveDriftを使ってみます。
# NaiveDrift from darts.models import NaiveDrift # モデル生成 drift_model = NaiveDrift() # 学習 drift_model.fit(train) # 予測 drift_forecast = drift_model.predict(len(val)) # 可視化 series.plot(label='actual', lw=1) drift_forecast.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Year')
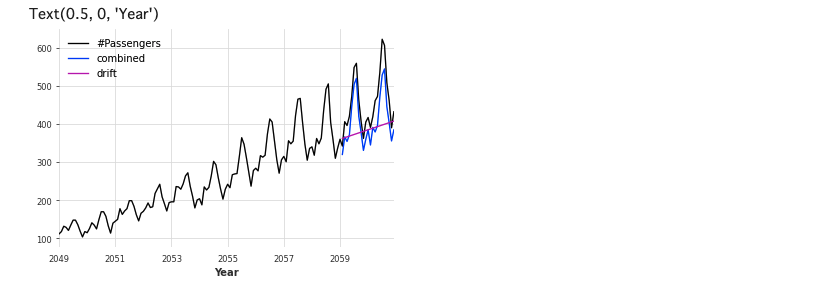
適切に予測できていないので、NaiveSeasonalとNaiveDriftを組み合わせたモデルを使ってみます。
combined_forecast = drift_forecast + seasonal_forecast - train.last_value() series.plot() combined_forecast.plot(label='combined') drift_forecast.plot(label='drift') plt.legend() plt.xlabel('Year')
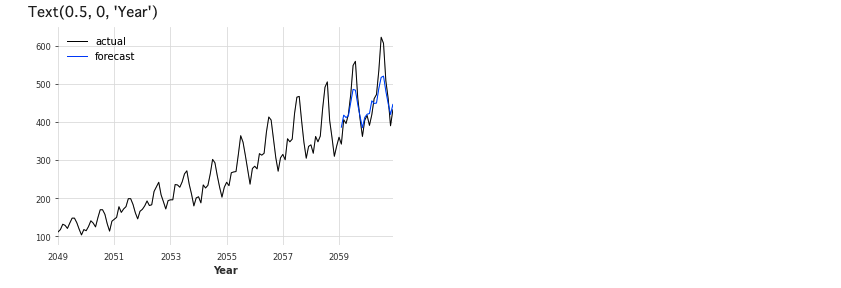
Prophet
次はFacebookが開発した時系列予測のオープンソースソフトウェア(OSS)ライブラリ「Prophet」です。詳細は割愛します。
# Prophet from darts.models import Prophet # モデル生成 model_P = Prophet() # 学習 model_P.fit(train) # 予測 prediction = model_P.predict(len(val)) # 可視化 series.plot(label='actual', lw=1) prediction.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Year')
Theta(シータ法)
次はHyndman & Billahの時系列予測手法「シータ法」です。
# Search for the best theta parameter, by trying 50 different values # Theta from darts.models import Theta thetas = 2 - np.linspace(-10, 10, 50) best_mape = float('inf') best_theta = 0 for theta in thetas: model = Theta(theta) model.fit(train) pred_theta = model.predict(len(val)) res = mape(val, pred_theta) if res < best_mape: best_mape = res best_theta = theta # Theta # モデル生成 best_theta_model = Theta(best_theta) # 学習 best_theta_model.fit(train) # 予測 pred_best_theta = best_theta_model.predict(len(val)) # 可視化 series.plot(label='actual', lw=1) pred_best_theta.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Year')
Transformer Model
2017年12月頃にGoogleチームにより発表され世間の注目を集めた、時系列データ処理に革新をもたらしたモデルです。
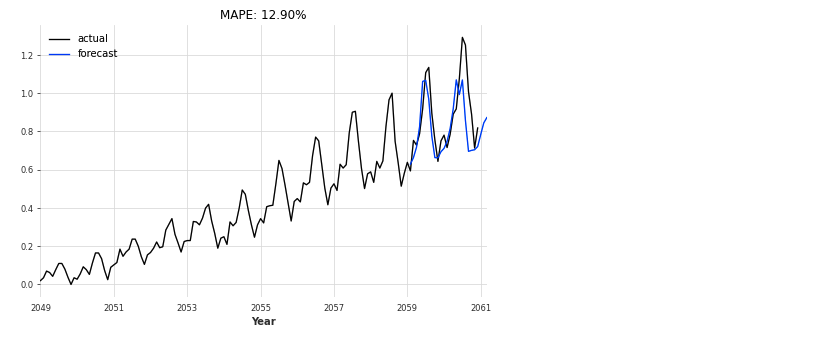
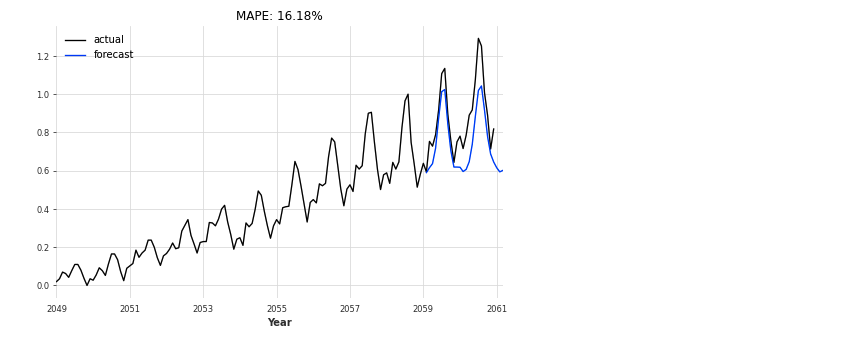
データの与え方を少し工夫する必要がありますが、これも簡単に使えます。#Transformer Model from darts.models import TransformerModel # Normalize the time series scaler = Scaler() train_scaled = scaler.fit_transform(train) val_scaled = scaler.transform(val) series_scaled = scaler.transform(series) N_EPOCHS = 1000 NR_EPOCHS_VALIDATION_PERIOD = 10 # Number of previous time stamps taken into account. SEQ_LENGTH = 10 # number of output time-steps to predict OUTPUT_LEN = 1 # Number of layers in encoder/decoder NUM_LAYERS = 6 my_model = TransformerModel( batch_size = 32, input_length = SEQ_LENGTH, input_size = 1, output_length = OUTPUT_LEN, output_size = 1, n_epochs = N_EPOCHS, model_name = 'air_transformer', log_tensorboard=True, nr_epochs_val_period = NR_EPOCHS_VALIDATION_PERIOD, model = None, d_model = 64, nhead = 32, num_encoder_layers = 6, num_decoder_layers = 6, dim_feedforward = 2048, dropout = 0.1, activation = "relu", custom_encoder = None, custom_decoder = None, random_state=42, ) my_model.fit(training_series=train_scaled, val_training_series=val_scaled, verbose=True) def eval_model(model, n, series, val_series): pred_series = model.predict(n=n) plt.figure(figsize=(8,5)) series.plot(label='actual') pred_series.plot(label='forecast') plt.title('MAPE: {:.2f}%'.format(mape(pred_series, val_series))) plt.legend(); eval_model(my_model, 26, series_scaled, val_scaled)
LSTM
LSTM(long short-term memory:長短期記憶)とは、ニューラルネットワークの中間層の構造の一つで、自身の出力を、再帰的に入力するような構造を持ったものです。
# LSTM # Number of previous time stamps taken into account. SEQ_LENGTH = 12 # Number of features in last hidden state HIDDEN_SIZE = 25 # number of output time-steps to predict OUTPUT_LEN = 1 # Number of stacked rnn layers. NUM_LAYERS = 1 LSTM_model = RNNModel( model='LSTM', output_length=OUTPUT_LEN, hidden_size=HIDDEN_SIZE, n_rnn_layers=NUM_LAYERS, input_length=SEQ_LENGTH, dropout=0.4, batch_size=16, n_epochs=400, optimizer_kwargs={'lr': 1e-3}, model_name='Air_RNN', log_tensorboard=True, random_state=42 ) LSTM_model.fit(train_scaled, val_training_series=val_scaled, verbose=True) eval_model(LSTM_model, 26, series_scaled, val_scaled)
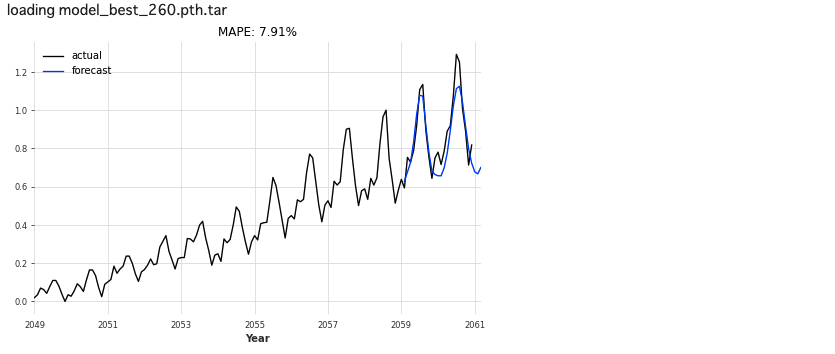
bestLSTM_model = RNNModel.load_from_checkpoint(model_name='Air_RNN', best=True) eval_model(bestLSTM_model, 26, series_scaled, val_scaled)
GRU
GRUは,LSTMの代替となる手法です。GRUのメリットは、LSTMと比較してパラメーター数が少ないので計算時間が抑えられるといった点があります。性能としてはLSTMと同程度らしいです。
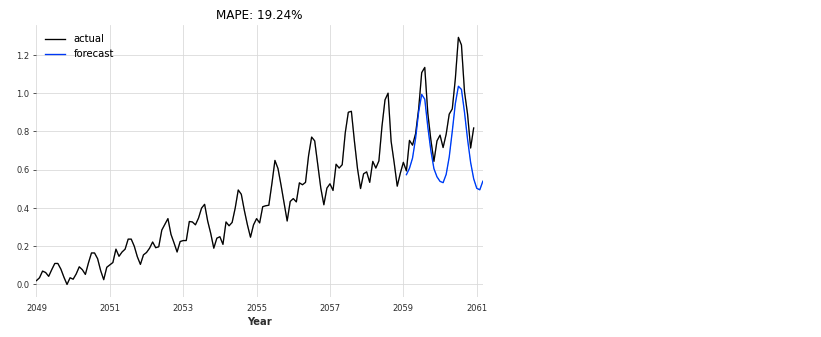
# GRU gru_model = RNNModel( model='GRU', output_length=OUTPUT_LEN*4, input_length=SEQ_LENGTH, hidden_size=HIDDEN_SIZE, n_rnn_layers=NUM_LAYERS, batch_size=64, n_epochs=1500, dropout=0.2, model_name='Air_GRU_out12', log_tensorboard=True, random_state=42 ) gru_model.fit(train_scaled, val_training_series=val_scaled, verbose=True) eval_model(gru_model, 26, series_scaled, val_scaled)
さいごに
最後まで読んで頂き、ありがとうございました。
こんな便利なライブラリーがあるとは知りませんでした。PyCaretといい、世の中便利なライブラリーが多いですね。きちっと理論を理解し、自分でも実装できるようになる必要があるとは思いますが、製造現場で普及させるには簡単に使えることも重要かなと思っております。訂正要望がありましたら、ご連絡頂けますと幸いです。




- 投稿日:2021-01-14T13:55:24+09:00
Pythonを使ってn!の相乗平均を求める
はじめに
現在独学でRailsを勉強している初学者です。趣味で数値計算などにPythonを利用してます。
今回$n$が無限大のときの$n!$の相乗平均、つまり\lim_{n \to \infty} \frac{\sqrt[n]{n!}}{n}\\をPythonでなんとか求めていきたいと思います。
相乗平均って?
平均といえば、ある$n$個のデータ$x_1, x_2, ..., x_n$を全て足し合わせて$n$で割った値を求める相加平均を思い浮かべると思います。それに対し相乗平均$\mu$は
\mu = \sqrt[n]{x_1x_2...x_n}\\で求めることができます。成長率や利率の計算などによく使われます。
本題
さて、前述で示したn!の相乗平均を求めていこうと思います。上式を使うと$\sqrt[n]{n!}$で求められますが、無限大に飛ばしたとき収束しなさそうなので$n$で除したものを無限大に飛ばしたときを考えます。つまり$\mu$が全体の何%の位置にあるか調べます。したがって
\lim_{n \to \infty} \frac{\sqrt[n]{n!}}{n}\\を求めていきます。
解いてみる
まず数を$n$にれてみてどの値に収束しそうなのか、matplotlibを使ってグラフをプロットしていきたいと思います。
sympyを使うと$2000!$でも楽々計算できます。標準モジュールのmathを使うと桁数が大きすぎるとエラーが返ってきます。plot.pyimport matplotlib.pyplot as plt import sympy def fun(n): n1 = sympy.factorial(n) n2 = n1 ** (1/n) n3 = n2/n return n3 x = list(range(1,2000,10)) y = [] for i in x: y.append(fun(i)) print(x) print(y) plt.plot(x,y) plt.ylim([0.36,0.4])
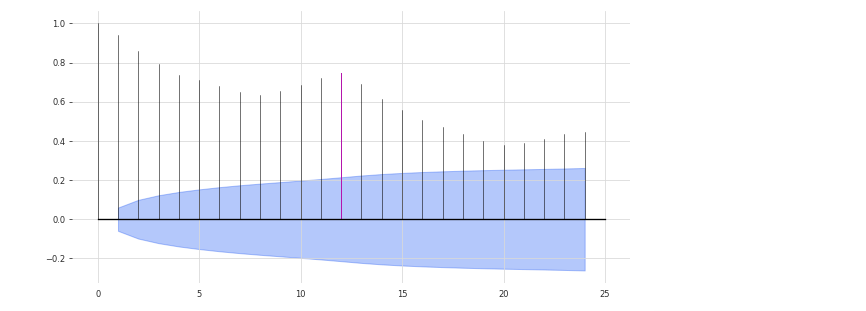
グラフを見ると0.37あたりで収束しそうな気がします。
ここで上式がある値$a$に収束すると仮定します。また上式のままでは解きにくいので対数をとると、\log \lim_{n \to \infty} \frac{\sqrt[n]{n!}}{n} = \log a\\ \lim_{n \to \infty} \log \frac{\sqrt[n]{n!}}{n} = \log a\\整理すると、
\begin{align} \lim_{n \to \infty} \log \frac{\sqrt[n]{n!}}{n} &= \lim_{n \to \infty} (\log {\sqrt[n]{n!}}-\log {n})\\ &= \lim_{n \to \infty} \Bigl( \frac{1}{n}\log {n!}-\log {n}\Bigr)\\ &= \lim_{n \to \infty} \Bigl( \frac{1}{n}\sum_{k=1}^{n} \log k-\log {n}\Bigr) \end{align}\\ここで
\sum_{k=1}^{n} \log kについて考えていきます。
区分級数の極限が出てきたらはさみうちの定理が利用できそうだと予想できます。ここで\begin{align} f(x) &= \log({x-1})\\ g(x) &= \log {x} \end{align}導入します。理由はこれから示します。以上3つの式を再度matplotlibを使ってプロットします。
plot2.pywith np.errstate(invalid='ignore'): x = np.arange(-1, 11, 0.01) y1 = np.log(x) y2 = np.log(x-1) fig = plt.figure() plt.xlim([-1, 11]) plt.ylim([-2, 4]) plt.xlabel('x') plt.ylabel('y', rotation=0) plt.gca().set_aspect('equal') plt.grid() plt.plot(x, y1, label="g(x)") plt.plot(x, y2, label="f(x)", color="green") x = list(range(1,11,1)) y3 = [] for i in x: y3.append(np.log(i)) print(y3) plt.bar(x, y3, width = 1.0, align="edge",color="orange", edgecolor="black", label="Σlogk") plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=8) plt.show() fig.savefig("log.jpg")
プロットを見てわかるように$\sum_{k=1}^{n} \log k$が$f(x)$と$g(x)$の積分値の間にあることがわかります。よって、
\int_{2}^{n}\log({x-1})dx< \sum_{k=1}^{n} \log k < \int_{2}^{n}\log {x} dx\\上記の対数関数の定積分は部分積分を使えば解けます。しかしここではPythonを使っていくのが目的なので、
integral.pyimport sympy as sym from sympy.plotting import plot sym.init_printing(use_unicode=True) from sympy import log n, x, y = sym.symbols("n x y") logx1 = log(x) logx2 = log(x-1) q1 = sym.integrate(logx1, (x, 2, n+1)) q2 = sym.integrate(logx2, (x, 2, n+1)) print(q1) print(q2)-n + (n + 1)*log(n + 1) - 2*log(2) + 1 #log(x)定積分の解 -n + (n + 1)*log(n) - log(n) + 1 #log(x-1)定積分の解さらにそれぞれ$n$ で割って$\log {n}$引きます。つまり、最初の式に直します。
\frac{1}{n}-1< \frac{1}{n}\sum_{k=1}^{n} \log k-\log {n} < \log \Bigl(1+\frac{1}{n}\Bigr)+\frac{1}{n}\log(n+1)+\frac{1}{n}-\frac{2}{n}\log2\\極限もsympy を使って求めます。
integral.pyimport sympy as sym from sympy.plotting import plot sym.init_printing(use_unicode=True) from sympy import log n, x, y = sym.symbols("n x y") logx1 = log(x) logx2 = log(x-1) q1 = sym.integrate(logx1, (x, 2, n+1)) q2 = sym.integrate(logx2, (x, 2, n+1)) q11 = q1/n-log(n) q22 = q2/n-log(n) oo = sympy.oo lim_q11 = sym.limit(q11, n, oo) lim_q22 = sym.limit(q22, n, oo) print(lim_q11) print(lim_q22)-1 -1よってはさみうちの定理より、
\lim_{n \to \infty} \Bigl( \frac{1}{n}\sum_{k=1}^{n} \log k-\log {n}\Bigr)=\lim_{n \to \infty} \log \frac{\sqrt[n]{n!}}{n} = -1 \\ところで、収束値を$a$とおきました。
\lim_{n \to \infty} \log \frac{\sqrt[n]{n!}}{n} = \log a\\ \begin{align} a&= \lim_{n \to \infty} \frac{\sqrt[n]{n!}}{n}\\ &= \frac{1}{e}\\ &= 0.367... \end{align}\\お疲れ様でした。やっと収束が出ました。最初に適当な数字を代入して予測した収束値と合ってます。
自然対数$e$が出てくる美しい解です。最後に
いかがでしたか?Pythonの数値計算用のモジュールを利用して解きましたが、もっとスマートな解き方もあると思います。またこの問題は高校数学の範囲内で解くことができます。
別解を考えてみるのも楽しいかもしれません。参考


- 投稿日:2021-01-14T13:34:04+09:00
I tried to paste
Windows の GUI emacs で Python のコードをとりあえず見るための設定。
elpy introduction © Copyright 2014, Jorgen Schäfer Revision 4032c725.
https://elpy.readthedocs.io/en/latest/introduction.html;; .emacs.d/init.el ;; =================================== ;; MELPA Package Support ;; =================================== ;; Enables basic packaging support (require 'package) ;; Adds the Melpa archive to the list of available repositories (add-to-list 'package-archives '("melpa" . "http://melpa.org/packages/") t) ;; Initializes the package infrastructure (package-initialize) ;; If there are no archived package contents, refresh them (when (not package-archive-contents) (package-refresh-contents)) ;; Installs packages ;; ;; myPackages contains a list of package names (defvar myPackages '(better-defaults ;; Set up some better Emacs defaults elpy ;; Emacs Lisp Python Environment flycheck ;; On the fly syntax checking material-theme ;; Theme ) ) ;; Scans the list in myPackages ;; If the package listed is not already installed, install it (mapc #'(lambda (package) (unless (package-installed-p package) (package-install package))) myPackages) ;; =================================== ;; Basic Customization ;; =================================== (setq inhibit-startup-message t) ;; Hide the startup message (load-theme 'material t) ;; Load material theme (global-linum-mode t) ;; Enable line numbers globally ;; ==================================== ;; Development Setup ;; ==================================== ;; Enable elpy (elpy-enable) ;; Enable Flycheck (when (require 'flycheck nil t) (setq elpy-modules (delq 'elpy-module-flymake elpy-modules)) (add-hook 'elpy-mode-hook 'flycheck-mode)) ;; User-Defined init.el ends hereコンパイルもできた。
Cf.
(ちょっと)貼ってみる
https://qiita.com/dauuricus/private/744cf1f0b13eb0542f19
- 投稿日:2021-01-14T11:35:32+09:00
[Day 9]モデルの作成
January 14, 2021
←前回:Day 8 TemplateViewでテンプレートを表示する注意書き
この記事は単一の記事ではありません。
日記として書いているため、初見の方にはお役に立てないかと思います。
「Djangoを学びたい」とのことでありましたら[Day 1]Djangoの開発環境から読むことをおすすめします。はじめに
今回のテーマは「モデルの作成」です。
ここまで非常に初歩ですが、ViewとTemplateについて見てきました。
残りはModelですね。
Djangoではモデルに様々な情報をもたせることでデータベースとの連携やバリデーション処理をスマートに行える仕組みを持っています。
今回は掲示板ということで簡単なモデルを作って学習することにしましょう。threadアプリケーションの追加
まずはthreadアプリケーションを作ります。これは掲示板のスレッドに関することを処理するアプリケーションです。
(venv)$ ./manage.py startapp threadbaseアプリケーションと同様にthread/urls.pyの追加、mysite/settings.pyにアプリケーションの追加、mysite/urls.pyにURLの追加を行います。
この辺りはbaseアプリケーションと同様です。
[Day 4]アプリケーション作成参考までにmysite/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django.contrib.sites', 'django.contrib.sitemaps', 'debug_toolbar', 'base', + 'thread', ]mysite/urls.pyurlpatterns = [ path('admin/', admin.site.urls), path('', include('base.urls')), + path('thread/', include('thread.urls')), ]thread/urls.pyfrom django.urls import path from . import views app_name = 'thread' urlpatterns = [ ]これでアプリケーションの追加処理はOKです。
モデル追加
threadアプリケーションのモデルは以下の様なものを想定します。
まずは掲示板の最低限の機能を有するように以下のようなモデルを考えます。thread/models.pyfrom django.db import models class TopicManager(models.Manager): # Topic操作に関する処理を追加 pass class CommentManager(models.Manager): # Comment操作に関する処理を追加 pass class CategoryManager(models.Manager): # Category操作に関する処理を追加 pass class Category(models.Model): name = models.CharField( 'カテゴリー名', max_length=50, ) url_code = models.CharField( 'URLコード', max_length=50, null=True, blank=False, unique=True, ) sort=models.IntegerField( verbose_name='ソート', default=0, ) objects = CategoryManager def __str__(self): return self.name class Topic(models.Model): user_name = models.CharField( 'お名前', max_length=30, null=True, blank=False, ) title = models.CharField( 'タイトル', max_length=255, null = False, blank = False, ) message = models.TextField( verbose_name='本文', null=True, blank=False, ) category = models.ForeignKey( Category, verbose_name='カテゴリー', on_delete=models.PROTECT, null=True, blank=False, ) created = models.DateTimeField( auto_now_add=True, ) modified = models.DateTimeField( auto_now=True, ) objects = TopicManager() def __str__(self): return self.title class Comment(models.Model): id = models.BigAutoField( primary_key=True, ) no = models.IntegerField( default=0, ) user_name = models.CharField( 'お名前', max_length=30, null=True, blank=False, ) topic = models.ForeignKey( Topic, on_delete=models.PROTECT, ) message = models.TextField( verbose_name='投稿内容' ) pub_flg = models.BooleanField( default=True, ) created = models.DateTimeField( auto_now_add=True, ) objects = CommentManager() def __str__(self): return '{}-{}'.format(self.topic.id, self.no)簡単な解説
ここからは上記の(thread/models.py)説明に入ります。
そのため、本家のurlを載せておきます。
本家
以降、リンクに飛ばなくてもいいように説明書きを下に載せておきますが、本家と全く同じなので本家に飛んで参照することをおすすめします。
モデルフィールド
モデルの各クラスのプロパティはモデルフィールドで規定していきます。
公式のモデルフィールドリファレンスにモデルフィールドの種類がまとまっています。Djangoではモデルが持つ関連情報はできるだけ一箇所にまとめることを理想としていて、データベース格納時のデータ型、リレーションに関する情報、デフォルト値、nullの許容等の情報を付与していきます。多くのWeb開発ではAPIの設計、データベース設計を終えた後に実装に入ると思いますので、設計を素直にモデルに書き起こしていく作業となります。
nullとblank
nullとblankが出てきました。nullはデータベース上でNULLを許容するかどうか?であり、blankはユーザーが入力項目として必須項目にするかどうかということです。具体的にはblankにFalseを当てるとフォームでインプットタグにrequiredが付きます。
IDの自動生成
さて、IDに関する記述がないのに気づきましたか?IDに関しては明記しない場合はDjangoによって自動生成されます。その場合はデータ型はintとなりPrimary Keyが設定されます。
外部キー
今回、1対多の関係を構築するためにトピックはカテゴリーのidをコメントはトピックのidを保有しています。このような場合DjangoではForeignKeyを用います。その場合、外部キーとして保有してるモデルが削除された場合の削除方法をon_deleteで指定します。種類としては以下のようなものがあります。models.CASCADE : 外部キーのモデルと一緒に参照しているモデルも削除される
models.PROTECT : 保護される(参照されている場合には削除できない)
models.SET_NULL : 外部キーのモデルが削除された場合IDはNULLとなる
models.SET_DEFAULT : デフォルトで設定されている値がセットされる。
オススメはPROTECTでしょうか。CASCADEは少々リスクが高いですが、設計次第では問題ないと思います。
マネージャーについて
また、今回はTopicManagerとCommentManager,CategoryManagerを用意し、各モデルのobjectsと紐づけました。今後、各モデルに関する操作に関わる処理はこのマネージャーに追加していき、ビューからはその処理を呼び出し、モデルに作用するようにします。慣れない内はViewで多くの処理をしてしまい肥大化しがちですが、モデルが担うビジネスロジックの処理はモデルで行うべきかと(自戒をこめて)考えています。
と、ここまで丁寧に説明してもらえましたが、私はよくわからなかったです。
しかしながら、Djangoのモデルというものがどういうものかは理解でしました。おわりに
今回はモデルの作成をしました。大学でSQLを触ったことがあるのでモデルの性質は少し理解することができました。
それではまたまた
- 投稿日:2021-01-14T11:31:37+09:00
WindowsでPythonの仮想開発環境を作る
はじめに
pythonをWindowsで使いたいな~と思って色々調べていたんですが、環境構築のところで右往左往してしまったので、備忘録としてアウトプットしておきます。VScodeでコードを書きます。
環境
・Windows 10 Home
・Visual Studio Code前提として、python自体がWindowsにインストールされていることを確認してください。
インストールはこちらからできます。python japanの公式ページです。コマンドを打っていく
Windowsの場合は、powershellを管理者として開いて、
Set-ExecutionPolicy RemoteSignedというコマンドを打ちます。これはスクリプトの実行をローカルファイルのみ許可するというものです。他にもオプションがありますので、気になった方はこちらを参考にしてみてください。
その後、VScodeのターミナルで、作業をしたいディレクトリを作成し、移動します。
$ mkdir test $ cd testtestディレクトリ直下に仮想環境を作ります。実際、詰まってしまったのはここだけなのですが、私の環境では以下の通りコマンドを打ったら素直に仮想環境に入ってくれました。
$ py -m venv myenv $ myenv/Scripts/Activate.ps1「myenv」は任意の文字列に変更してください。
サイトによっては、pyがpythonだったりpython3だったり、とにかくたくさんコマンドが並んでいて、打っても動かなかったり怒られたりして困っていました。
じゃあなんでpyコマンドなら動くのかと、python japanのページを眺めていたら、こんな記述がありました。
Windows版のPythonでは、python コマンドを使うより、Pythonランチャー py がおすすめです。通常、Python をコマンドラインから実行するときには、Pythonをインストールしたディレクトリを環境変数というシステム設定に記録する必要がありますが、py は、設定をしなくとも実行できます。
pythonコマンドを使いたかったらそれぞれの環境でパスを通してくださいね、ただしpyコマンドならデフォルトで使えますよって認識で良いのかな?
とにかく上記のように入力すると、ターミナルの左側に(myenv)と表示されるはずです。これで仮想環境に入ることができました。
ちなみに仮想環境から抜けるためのコマンドは、
$ deactivateです。
続けてVScode側の設定をする必要がありますが、既に記事にしてくださっている方がいらっしゃいましたので、こちらを参考に設定を行ってみてください。Djangoを仮想環境で動かすという内容ですが、その他フレームワークの場合でも同様の設定をすれば大丈夫だと思います。
- 投稿日:2021-01-14T11:27:54+09:00
Q. ジェネリクスみたいに[]から値取るやつやりたいか?
Q. ジェネリクスみたいに[]から値取るやつやりたいか?
A. はい。(
__class_getitem__を使う)class Hello: def __class_getitem__(self, v): return v print(Hello["sh1ma"])
- 投稿日:2021-01-14T11:26:12+09:00
Big Surで "macOS 11 or later required !" が出たり、pyarrow2.0.0 がinstallできなかったりしたときの対処メモ
はじめに
定期的にやってくる環境周りのトラブルですが、今回はMacのOSを Big Sur にUpgradeしたことに起因したものでした。
困ったことの要約
- Big Sur で pyenv で python を使っていたら
macOS 11 or later required !という謎のエラーが出て pythonがcrashした- 上記はpython3.9.1 にすると解消するのだが、すると
pyarrowが対応していなくて Installできない- grpcio が Installできない
- numpy 周りでエラーになる!
ということが発生したので、そのworkaroundを書いておきます。
いずれ不要になるとは思いますが、今現在で言えば結構厄介です。個々の対処法
macOS 11 or later required !への対処再現方法
こんな感じです。
% python -c "import tkinter; r = tkinter.Tk()" macOS 11 or later required ! zsh: abort python -c "import tkinter; r = tkinter.Tk()"Tkなんて使わないよ! と思うでしょうが、 matplotlib か何かが使おうとしたりします。
※ んーそれを回避した方が良かったかもしれないな...対処法
(たぶん BigSurにしてから)pyenv経由でInstallしたようなPythonで発生していたようですが、 pythonを3.9.1にすることで解消されました。brew で pyenv を入れている場合は以下のような感じになります。
% brew install tcl-tk # これが必要なのか、は未確認ですがそう書いてあるところがあった % brew upgrade pyenv % pyenv install -l | grep 3.9 # 3.9系を探す 3.9.0 3.9-dev 3.9.1 miniconda-3.9.1 miniconda3-3.9.1 % pyenv install 3.9.1 # 3.9.1 が一番新しいのでそれにする治るか確認
% pyenv local 3.8.7 # エラーが出るVersion % python -c "import tkinter; r = tkinter.Tk()" macOS 11 or later required ! zsh: abort python -c "import tkinter; r = tkinter.Tk()" % pyenv local 3.9.1 % python -c "import tkinter; r = tkinter.Tk()" ### エラーが出ない! ###python3.9系になんてできないときは...?
とは言っても、気軽に3.9系にUpdateできるプロジェクトばかりではないでしょうし、その場合は正規のInstaller経由でInstallしたPythonなら大丈夫だとかなんだとか(未確認)。
pyarrow2.0.0 が python3.9 に対応していない!
pyarrow は どうも
pyathenaのpandas拡張 のようなライブラリから必要とされているようで、それらを使っていると影響を受けます。普通に pip や poetry などではInstallできなかったので、3.8系のwheelを強引にInstallします(たぶんちゃんと動いている)。
cp38な部分をcp39にするとどうも良いらしい。酷い方法ですが、仕方ない...% curl -LO https://files.pythonhosted.org/packages/14/75/9f116c8d0774ed170c59c87649d3e74dbdaf3318d72a09171c6f4634c7a7/pyarrow-2.0.0-cp38-cp38-macosx_10_13_x86_64.whl % mv pyarrow-2.0.0-cp38-cp38-macosx_10_13_x86_64.whl pyarrow-2.0.0-cp39-cp39-macosx_10_13_x86_64.whl % pip install pyarrow-2.0.0-cp39-cp39-macosx_10_13_x86_64.whlこれで、poetry や pipenv などで Installしようとしても既にInstall済みなので何もされずエラーにならなくなります。
grpcio が Installできない
BigSur周りのトラブルの初期に出くわしたので、どういう発生条件か忘れてしまいましたが、これも事前に以下のようにして入れておくと良かったです。
% pip install --upgrade pip setuptools wheel % pip install --no-cache-dir --force-reinstall -Iv grpcio==1.34.0numpy 周りでエラーになる!
どうも Accelerator がどうとか、そういう理由でエラーになるようでした。
Install時ではなく、実行時にエラーになるのでちょっと性質が悪いです。
こんな感じでInstallしておくことで、回避できました。% brew install openblas % OPENBLAS="$(brew --prefix openblas)" pip install numpyまとめると
最近は poetry で 管理していますが、結局こんな手順でInstallしておくとなんとか通りました。
% pyenv local 3.9.1 % poetry run pip install --upgrade pip setuptools wheel % poetry run pip install --no-cache-dir --force-reinstall -Iv grpcio==1.34.0 % curl -LO https://files.pythonhosted.org/packages/14/75/9f116c8d0774ed170c59c87649d3e74dbdaf3318d72a09171c6f4634c7a7/pyarrow-2.0.0-cp38-cp38-macosx_10_13_x86_64.whl % mv pyarrow-2.0.0-cp38-cp38-macosx_10_13_x86_64.whl pyarrow-2.0.0-cp39-cp39-macosx_10_13_x86_64.whl % poetry run pip install pyarrow-2.0.0-cp39-cp39-macosx_10_13_x86_64.whl % OPENBLAS="$(brew --prefix openblas)" poetry installさいごに
ビルドエラーとか人類の時間を奪う敵だと思います。