- 投稿日:2021-01-14T23:28:55+09:00
AMAZON CONNECT でIVRを試してみた(その2)
はじめに
前回は問い合わせフローだけで作ってみたが、今度はLambdaを使って
動的に音声レスポンスを変えてみることにした。
流れは、次のとおり
1. 電話かける
2. 発信元番号がS3にあるmembersファイルに合致する場合、メッセージを返す(Amazon Connect から Lambda 関数を呼び出す)
3. Lambdaから返した戻り地を音声として流す。という簡単な流れ
S3にファイルを作る
ファイル内容は、こんな感じのCSV
member_phone_number, message 09012345678,ゴールドランク 05012345678,シルバーランク 07012345678,ブロンズランクAmazon Connectから呼び出すLambda関数を作成する
sampleimport os import io import json import csv import urllib import boto3 def lambda_handler(event, context): # バケット名 S3_BUCKET_NAME = 'xxxxxxxxxxxxxxxxxx' # 会員情報のランクを書いたファイル名 FIle_NAME = 'members.csv' # 渡されるパラメタより相手先番号を取得 phone_number = replace_PhoneNumber(event['Details']['ContactData']['CustomerEndpoint']['Address']) user_message = 'あなた会員ではありません'; # S3のファイルオブジェクトより会員電話番号と合致したものを会員ランクとして返す for csv_rec in csv.DictReader(get_s3file(S3_BUCKET_NAME, FIle_NAME)): if csv_rec['member'] == phone_number: user_message = csv_rec['message'] result = { 'Message' : user_message } print(result['Message']) return result # S3 から指定ファイルオブジェクトを返す def get_s3file(bucket_name, key): s3 = boto3.resource('s3') s3obj = s3.Object(bucket_name, key).get() return io.TextIOWrapper(io.BytesIO(s3obj['Body'].read())) # AMAZON CONNECT の発信元番号は、+81の国番号付きでくるから置き換え def replace_PhoneNumber(phone_number): return phone_number.replace('+81', '0')この取得部分ですが、
event['Details']['ContactData']['CustomerEndpoint']['Address']
Amazon Connect のlambda呼び出し時のパラメタは下記の形式で渡されます。
https://docs.aws.amazon.com/ja_jp/connect/latest/adminguide/connect-lambda-functions.html
を参考にしていて、色々設定できそうですが、今回は試してません。
{
"Details": {
"ContactData": {
"Attributes": {},
"Channel": "VOICE",
"ContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX",
"CustomerEndpoint": {
"Address": "+1234567890",
"Type": "TELEPHONE_NUMBER"
},
"InitialContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX",
"InitiationMethod": "INBOUND | OUTBOUND | TRANSFER | CALLBACK",
"InstanceARN": "arn:aws:connect:aws-region:1234567890:instance/c8c0e68d-2200-4265-82c0-XXXXXXXXXX",
"PreviousContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX",
"Queue": {
"ARN": "arn:aws:connect:eu-west-2:111111111111:instance/cccccccc-bbbb-dddd-eeee-ffffffffffff/queue/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee",
"Name": "PasswordReset"
},
"SystemEndpoint": {
"Address": "+1234567890",
"Type": "TELEPHONE_NUMBER"
}
},
"Parameters": {
"sentAttributeKey": "sentAttributeValue"
}
},
"Name": "ContactFlowEvent"
}Lambda 関数を問い合わせフローからの呼び出し
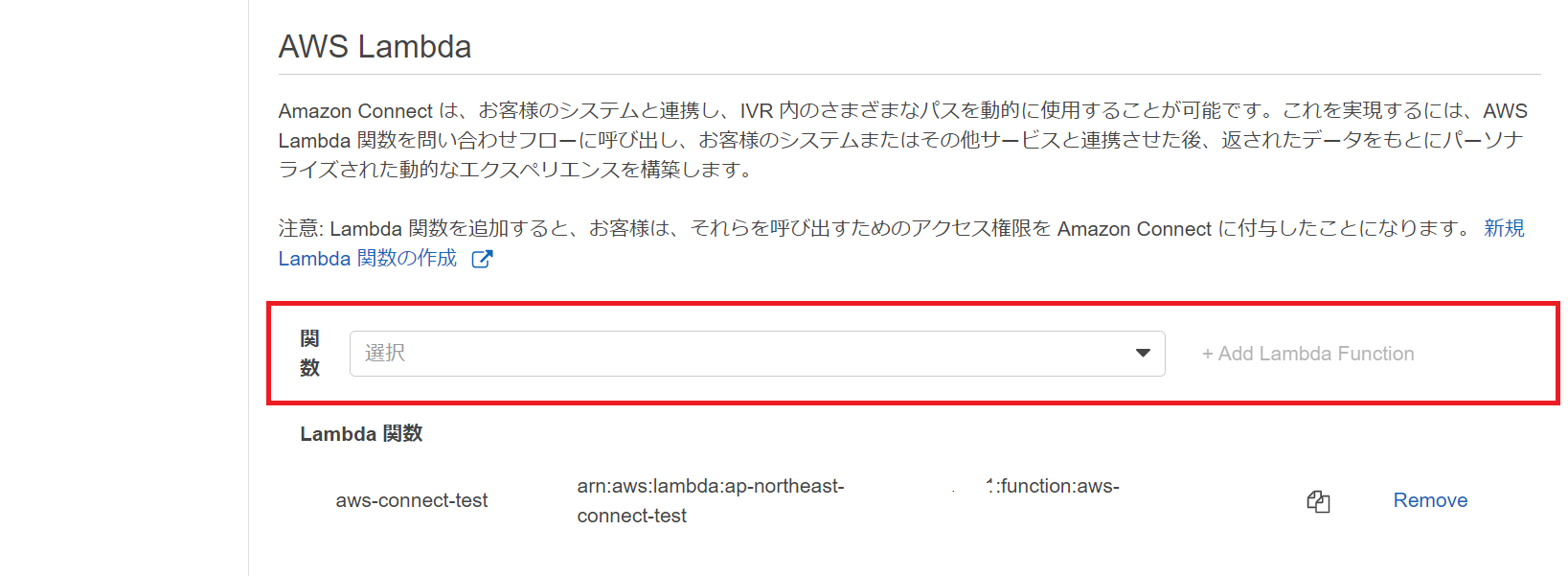
Amazon Connectの問い合わせフローを作成し、下記の部分を開く
AWS Lambdaの選択から今回利用する関数を選択して、[+Add Lambda Function]をクリックしたら、Lambda関数が追加されます
問い合わせフロー
あとは、下記のように問い合わせフローを作って、AWSLambdaを呼び出して、関数の戻りを
次のプロンプトで再生する。
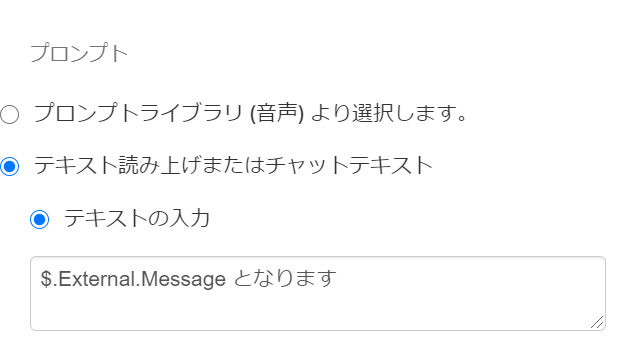
Lambdaの呼び出しは、[関数を選択する]より追加したLamdba関数を選択するだけでOK
あとは、Lambdaより戻した変数をそのままプロント再生で、[$.External.変数名]で
利用できます。
今回は、これで電話を掛けた方の会員ランク名を音声で返します。
まとめ
今回は、最も単純な方法で試してみました。
思った以上に簡単で、少し複雑なものが作れそうです。Amazon Connect は、Lambdaから返した変数を属性に保存して利用します。
属性は、利用方法で定義済み属性、ユーザ定義属性、外部属性とあり、関数を呼ぶごとに上書きされるような一時的利用する外部属性と、一度、Lambdaから返した変数を保存し、使いまわし、問い合わせフローで上書きできるユーザ定義属性があります。
このあたりは、属性へのアクセス方法も含めて、マニュアル読むのが一番です。https://docs.aws.amazon.com/ja_jp/connect/latest/adminguide/use-attributes-cust-exp.html



- 投稿日:2021-01-14T23:13:34+09:00
AWS Lightsail 入門2 SSH接続(RLogin)
本記事の内容
- Windows 10 PCにSSHクライアント「RLogin」を導入し、Lightsailインスタンス(Linux)に接続する。
前提条件
- Windows PC(本記事はWindows 10 Pro バージョン 20H2で作成)
- Lightsailインスタンスを作成済み。
SSHクライアント接続のメリット
Lightsailはブラウザ版のターミナルでも接続できるが、SSHクライアントを使用することで次のメリットがある。
- 一度設定すれば、必要なときにすぐ接続できる。(ブラウザ版ではAWSへのサインインや2段階認証、画面遷移が必要)
- 各SSHクライアントの便利な機能が使える。
- 細かな設定が行える。
RLoginとは
Windows用のSSHクライアントは複数あるが、今回は「RLogin」を導入する。
RLoginには次のようなメリットがある。
- 単一の実行ファイル「RLogin.exe」で動作。「RLogin.ini」を作成すればレジストリを使用せずに設定を管理できるため、導入や複数PCでの設定共有がしやすい。
- 接続先をタブでグループ分けできるため、多くのサーバーを扱う場合でも探しやすい。
- SFTPのファイル転送機能がある。WinSCPやFFFTPのように、GUIでファイルのアップロード・ダウンロードが行える。
- 歴史が長く、現在も開発が継続されている。(1998年~2021年1月現在)
接続情報の取得
SSHクライアントからの接続に必要な以下の情報を、Lightsail管理画面で確認・取得する。
- インスタンスのパブリックIP
- インスタンスのOSユーザー名
- SSHプライベートキー(秘密鍵)
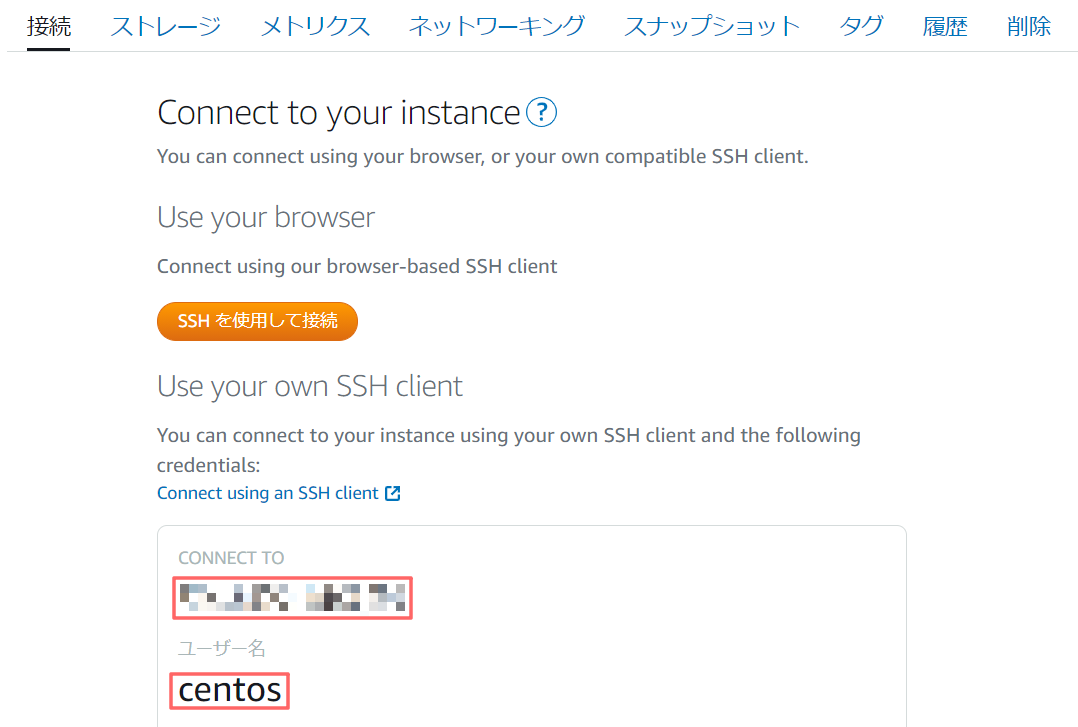
パブリックIPとOSユーザー名の確認
Lightsail管理画面を開き、接続対象のインスタンスを選択する。
[接続]タブの下に、パブリックIPとOSユーザー名が表示される。
※パブリックIPが分かれば、世界中のどこからでも接続や攻撃を試みることができてしまうので、必要なければ公開しない。
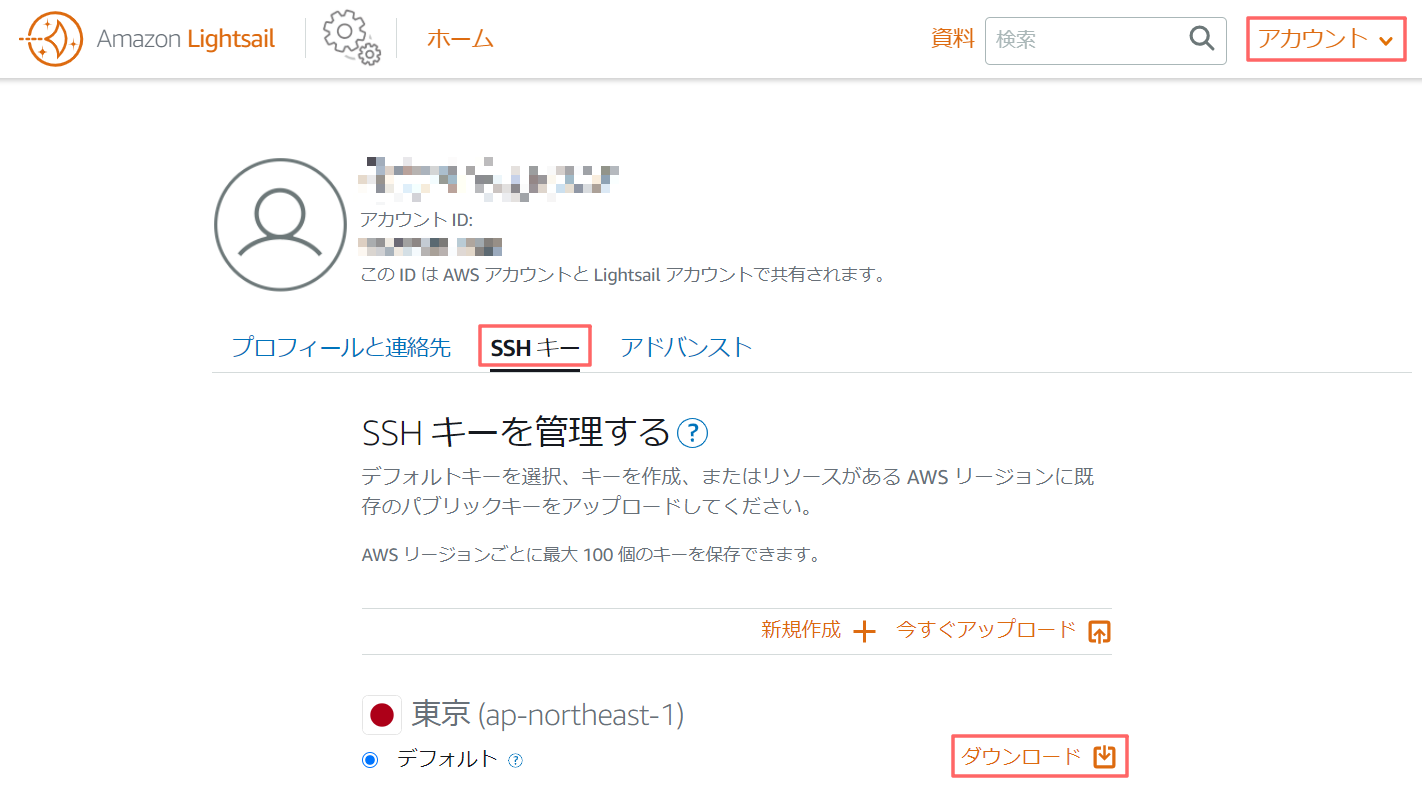
SSHプライベートキーのダウンロード
Lightsail管理画面右上の[アカウント]よりアカウントページを表示。
[SSH キー]タブを選択し、対象リージョン(今回は東京)の[ダウンロード]を選択。
「LightsailDefaultKey-ap-northeast-1.pem」がダウンロードされる。
※SSHプライベートキーは、パスワードと同様に自身であることを証明する重要なファイルのため、他人に配布しないよう注意。
RLoginの導入・起動
下記サイトよりRLoginをダウンロードし、PCに導入する。
RLogin > 1.3 インストールおよびアンインストール
- [実行プログラム(64bit)]より「rlogin_x64.zip」をダウンロードし、任意の場所に展開。
- 「RLogin.exe」と同じフォルダにファイル「RLogin.ini」を作成。(内容は空で良い)
- 「RLogin.exe」を実行。
※「RLogin.ini」を作成すると設定をレジストリに保存しなくなるため、設定のバックアップや複数PCでの共有が容易になる。
ただし、ファイル破損のリスクや動作が遅くなるデメリットもあるとのこと。RLoginからLightsailインスタンスへの接続
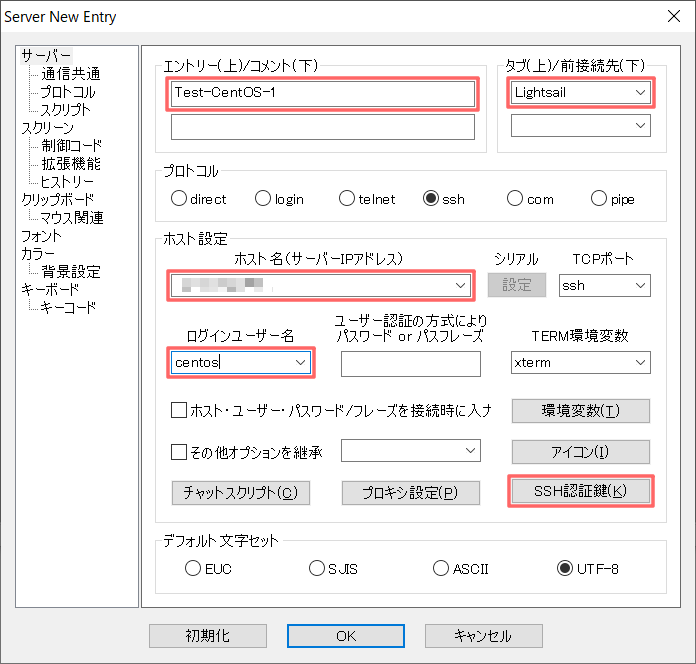
RLoginを起動後、接続一覧で[新規]を選択。
下記項目を入力後、[OK]を選択。
- [エントリー]: インスタンス名(表示用のため値は任意)
- [タブ]: 接続一覧のグループ名(任意)
- [ホスト名]: インスタンスのパブリックIP
- [ログインユーザー名]: インスタンスのOSユーザー名
- [SSH認証鍵]: ダウンロード済みのSSHプライベートキーを選択。
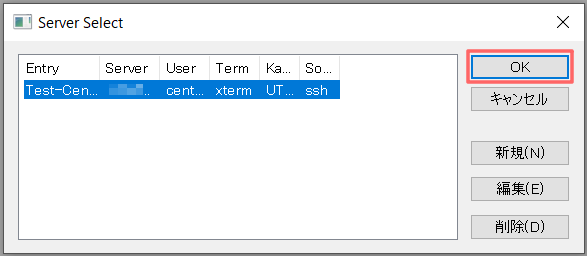
接続一覧より上記で登録した行を選択し、[OK]を選択。
※初回は確認ダイアログが表示されるが、[接続する]、[はい]を選択。
インスタンスにSSH接続され、コマンド入力が可能になる。


- 投稿日:2021-01-14T23:07:23+09:00
AWSの今月の使用料を毎日slackに通知する
はじめに
AWSには「CostExplorer」というAWSのコスト関連を管理&分析してくれるサービスがあります。
このサービスで現在のAWS使用料も把握することもできます。
私はプライベートで色々試すことが多いので、常に使用料を把握しておきたいのですが、確認の度にAWSにログインするのがとても面倒でした。
なので、毎日slackに使用料を通知するようにしました。やりたいこと
LambdaとEventBridgeを使って、月初からその日までの合計使用料を毎日0時にslackに通知する
事前準備
- 通知するslackチャンネルを作成しておく
- Incoming Webhookの設定を行い、URLを取得しておく
【2020年度版】Slack通知はSlack AppのIncoming Webhooksを使おう!やり方を解説やってみる
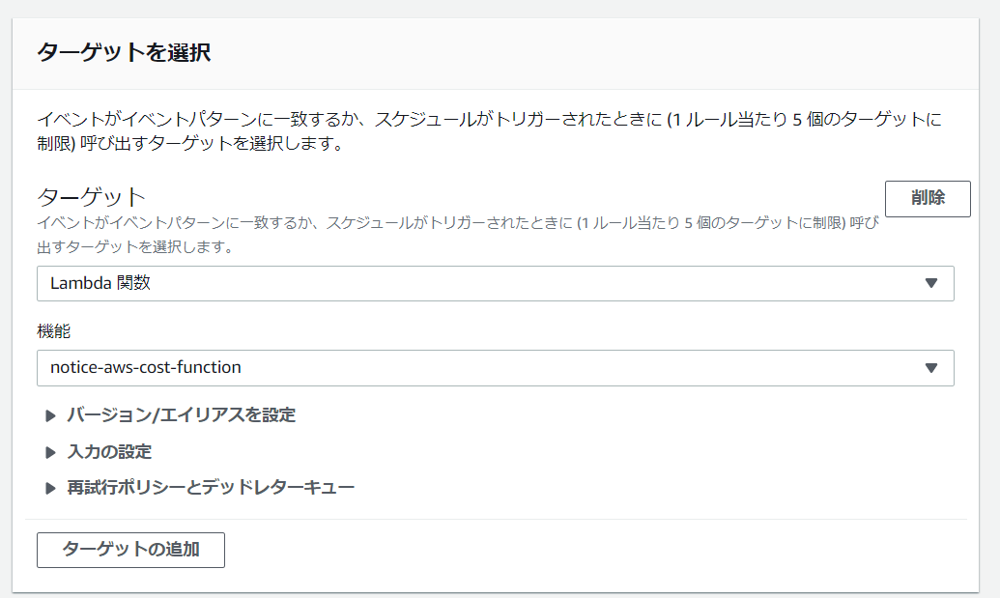
1. Lambda関数を作成
「CostExplorerから今月の使用料を取得して、slackにそのデータを通知する」という内容でLambda関数で作成します。
「名前」と「利用する言語」を入力して、Lambda関数を作成
以下のように関数のコードを編集
from datetime import datetime import json import os import urllib import boto3 SLACK_WEBHOOK_URL = "https://hooks.slack.com/services/YYYYYY/XXXXXXXX" # slackのwebhook url SLACK_CHANNEL_NAME = "#notice_aws_cost" # 通知先のslackチャンネル名 def lambda_handler(event, context): today = datetime.now() # UTC時間 # Cost Explorerから今月の使用料を取得 client = boto3.client('ce') response = client.get_cost_and_usage( TimePeriod={ 'Start': str(today.strftime('%Y-%m')) + '-01', 'End': today.strftime('%Y-%m-%d') }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ] ) billing_dollers = response["ResultsByTime"][0]["Total"]["AmortizedCost"]["Amount"] msg = f"""{today.strftime("%Y/%m/%d")}時点での今月の合計請求額をお知らせします。 合計請求額:{billing_dollers} USD""" post_slack(msg) def post_slack(msg): # メッセージデータを作成 post_data = { "username": "noticeBot", #ユーザー名 "icon_emoji": ":money_with_wings:", #アイコン "text": msg, #メッセージ(※メンションを付与してる) "channel": SLACK_CHANNEL_NAME #チャンネル } encode_post_data = ("payload=" + json.dumps(post_data)).encode('utf-8') # Request(post)を作成 request = urllib.request.Request( SLACK_WEBHOOK_URL, data=encode_post_data, method="POST" ) # 送信 urllib.request.urlopen(request)以下、コード内容の補足説明
# Cost Explorerから今月の使用料を取得 client = boto3.client('ce') response = client.get_cost_and_usage( TimePeriod={ 'Start': str(today.strftime('%Y-%m')) + '-01', 'End': today.strftime('%Y-%m-%d') }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ] ) billing_dollers = response["ResultsByTime"][0]["Total"]["AmortizedCost"]["Amount"]CostExplorerのGetCostAndUsageというAPIを利用して、今月の1日から今日までの合計使用料を取得してます。
今回は月の使用料を取得してますが、日ごとの使用料も取得できます。また、サービスの合計ではなく各々のサービス使用料なども取得することができます。
GetCostAndUsage - AWS Cost Explorer Service
Serverlessで日々のAWSコストを算出するdef post_slack(msg): # メッセージデータを作成 post_data = { "username": "noticeBot", #ユーザー名 "icon_emoji": ":money:", #アイコン "text": msg, #メッセージ(※メンションを付与してる) "channel": SLACK_CHANNEL_NAME #チャンネル } encode_post_data = ("payload=" + json.dumps(send_data)).encode('utf-8') # Request(post)を作成 request = urllib.request.Request( SLACK_WEBHOOK_URL, data=encode_post_data, method="POST" ) # 送信 urllib.request.urlopen(request)slackにメッセージを送信する関数です。
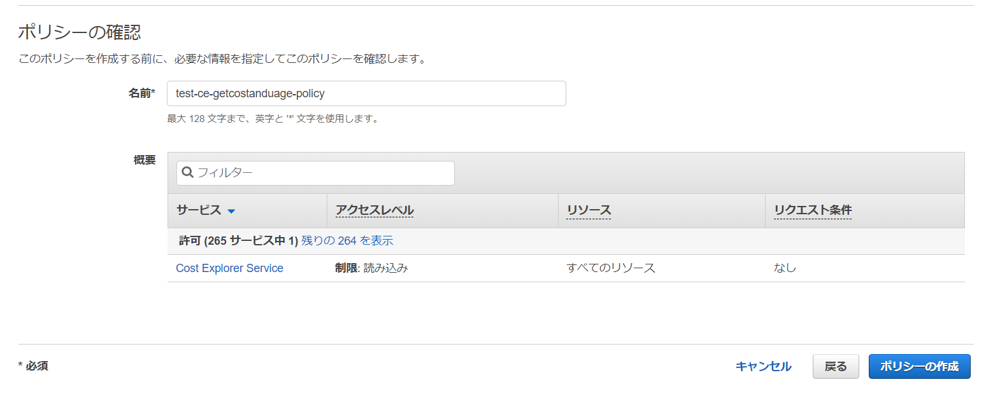
SLACK_CHANNEL_NAME、SLACK_WEBHOOK_URL変数には、各自適した値を代入してください。2. IAM Roleにポリシーを追加
Lambdaを作成すると自動でIAM Roleも一緒に作成されます。
そのIAM Roleには、Cost ExplorerのGetCostAndUsageの利用権限が付与されていません。
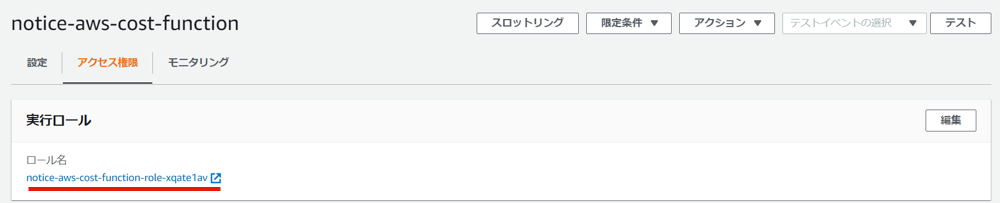
今の状態でLambdaを実行するとエラーになりますので、権限を付与します。Lambdaのアクセス権限タブを開き、実行ロールのリンクにアクセス
インラインポリシーの追加
以下のようにJSONを記述し、名前をつけて作成{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "ce:GetCostAndUsage", "Resource": "*" } ] }
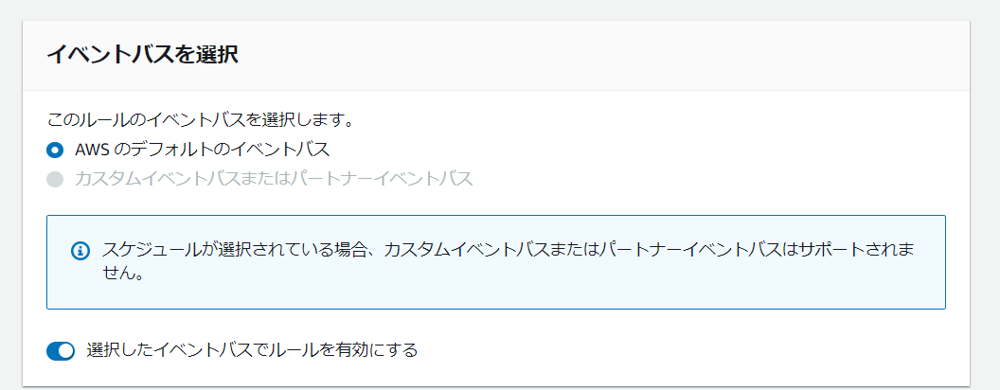
3. EventBridgeルールを作成
Lambda関数を作成したことで、使用料をslackに通知できるようになりました。
しかし、Lambdaには定期実行という仕組みがないので、毎日0時に実行することはできません。
それを実現するためにEventBridge ルールを作成します。
EventBridgeとは簡単に言うと、何かイベントが発火したらそれをトリガーにして、予め設定してるAWSリソースを実行してくれるサービスです。
Amazon EventBridge とは - Amazon EventBridgeEventBridge ルールを以下の設定で作成
これで毎日0時にAWSの使用料がslackに通知されるようになりました。
注意
cron式に「0 0 * * ? *」ではなく「0 15 * * ? *」と指定してるのは、cronが東京時間(UTC+9)ではなく標準時間(UTC+0)で動くので帳尻を合わせてます。最後に
実はこのプログラム、実行されるたびに$0.01課金されます。
(CostExplorerのAPIを叩くときに$0.01のコストが発生)
無料で似たような事をしたいという方は、Budgetsを調べてみてください。





- 投稿日:2021-01-14T21:24:51+09:00
AWSマネジメントコンソールで Unified search service is unavailable Try your search again later. が出たときの対応

- 投稿日:2021-01-14T21:21:56+09:00
ブラウザからAWSのIoT Coreにつなぐ
背景
AWSのIoT Coreにブラウザから接続するのにクラスメソッドさんのAWS IoTのMQTT over WebSocketにHTMLから接続してみたが非常に参考になるのですが、Paho mqtt clientのバージョンが古いため、最新版(v1.1.0)で試しました。
最新版にするメリットは、reconnectの処理が実装されているらしいということです。
本記事はpaho-mqttを使用してみたところ、色々とハマりどころがありましたので、そのまとめです。最初に結果
reconnectの試験をするために、次の2種類を試しましたが、結果は次のとおりでした。
- PCのWiFiをOFFする ⇒ 再接続してくれる
- PCをスリープさせる ⇒ 再接続に失敗する
- reconnectが成功したときもsubscribeしてくれないので、改めてsubscribeする必要があります。最新版(v1.1.0)を入手する
最新版はgithubで管理されています。
https://github.com/eclipse/paho.mqtt.javascript使用方法
JavaScriptからrequireして利用したかったので、このようにしました。ここでのポイントは2つ。
-Paho.MQTT.clientではなくなっていて、Paho.clientにする必要がありました。※動いたコードから抜き出したコードなので動かないかも...
const Paho = require("paho-mqtt/paho-mqtt-min.js"); const CryptoJS = require("crypto-js"); const moment = require("moment"); let connected = false; let endpoint = createEndpoint( 'ap-northeast-1', // Your Region 'yourendpoint.iot.ap-northeast-1.amazonaws.com', // Require 'lowercamelcase'!! 'YOUR_AWS_ACCESS_KEY', 'YOUR_AWS_SECRET_ACCESS_KEY') ); let clientId = 'your client id'; let client = new Paho.Client(endpoint,clientId); client.onConnectionLost = onConnectionLost; client.onMessageArrived = onMessageArrived; let connectOptions = { useSSL: true, timeout: 3, mqttVersion: 4, reconnect: true, onSuccess: function() { if(connected !== true) { // 最初の接続時の処理 console.log("onConnect"); client.subscribe("/World"); } else { // 再接続時の処理 console.log("reconnect"); client.subscribe("/World"); } onFailure: function(e) { callback(e); } }; client.connect(connectOptions); function onConnectionLost(responseObject) { if (responseObject.errorCode !== 0) console.log("onConnectionLost:"+responseObject.errorMessage); }; function onMessageArrived(message) { console.log("onMessageArrived:"+message.payloadString); client.disconnect(); }; function SigV4Utils(){} SigV4Utils.sign = function(key, msg) { var hash = CryptoJS.HmacSHA256(msg, key); return hash.toString(CryptoJS.enc.Hex); }; SigV4Utils.sha256 = function(msg) { var hash = CryptoJS.SHA256(msg); return hash.toString(CryptoJS.enc.Hex); }; SigV4Utils.getSignatureKey = function(key, dateStamp, regionName, serviceName) { var kDate = CryptoJS.HmacSHA256(dateStamp, 'AWS4' + key); var kRegion = CryptoJS.HmacSHA256(regionName, kDate); var kService = CryptoJS.HmacSHA256(serviceName, kRegion); var kSigning = CryptoJS.HmacSHA256('aws4_request', kService); return kSigning; }; function createEndpoint(regionName, awsIotEndpoint, accessKey, secretKey) { var time = moment.utc(); var dateStamp = time.format('YYYYMMDD'); var amzdate = dateStamp + 'T' + time.format('HHmmss') + 'Z'; var service = 'iotdevicegateway'; var region = regionName; var secretKey = secretKey; var accessKey = accessKey; var algorithm = 'AWS4-HMAC-SHA256'; var method = 'GET'; var canonicalUri = '/mqtt'; var host = awsIotEndpoint; var credentialScope = dateStamp + '/' + region + '/' + service + '/' + 'aws4_request'; var canonicalQuerystring = 'X-Amz-Algorithm=AWS4-HMAC-SHA256'; canonicalQuerystring += '&X-Amz-Credential=' + encodeURIComponent(accessKey + '/' + credentialScope); canonicalQuerystring += '&X-Amz-Date=' + amzdate; canonicalQuerystring += '&X-Amz-SignedHeaders=host'; var canonicalHeaders = 'host:' + host + '\n'; var payloadHash = SigV4Utils.sha256(''); var canonicalRequest = method + '\n' + canonicalUri + '\n' + canonicalQuerystring + '\n' + canonicalHeaders + '\nhost\n' + payloadHash; var stringToSign = algorithm + '\n' + amzdate + '\n' + credentialScope + '\n' + SigV4Utils.sha256(canonicalRequest); var signingKey = SigV4Utils.getSignatureKey(secretKey, dateStamp, region, service); var signature = SigV4Utils.sign(signingKey, stringToSign); canonicalQuerystring += '&X-Amz-Signature=' + signature; return 'wss://' + host + canonicalUri + '?' + canonicalQuerystring; }
- 投稿日:2021-01-14T19:10:38+09:00
EKSにHashiCorp Vault with ConsulをHA構成でデプロイしてSecret管理させてみる
はじめに
みなさん、KubernetesのSecretはどのように管理されていますか?
よく聞くOSSツールといえば、Kubesec、Sealed Secrets、External Secretsなどがあります。
それらとAWSのSecrets Manager等のクラウドマネージドサービスを連携して使う方法もありますね。
今回は、データストレージにHashiCorp Consulを使用するHashiCorp VaultクラスタをEKS上に作成して、hashicorp/vault-k8sを用いたサイドカー構成でSecret管理をさせてみたいと思います。
また、VaultはOSS版であってもWeb UIが提供されているのでそちらも合わせて構築したいと思います。やりたいこと
- UIで秘匿情報を管理できる
- アプリケーションのデプロイ時にその秘匿情報を自動で埋め込んで欲しい
- 秘匿情報はひとつのVaultサーバに登録するだけで、複数クラスタ間で共有できる
- 今回はこれは確認しません
注意事項
- EKSの構築については触れません
- 構築の際はIAMの知識が必要です
- ConsulとVaultの原理や仕様は本筋から逸れるため本記事では説明しません
- Kubernetesクラスタ上にどのように構築するかということに重きを置いています
- 本文が非常に長くなってしまいました
使用した環境
- Amazon EKS
- Clusterバージョン 1.17
- HashiCorp Vault v1.6.1
- HashiCorp Consul v1.9.1
基本方針
Vaultの公式ドキュメントVault on Kubernetes Deployment GuideにあるHelmチャートを用いる方法でデプロイを行います。
参考アーキテクチャ
Vaultの公式ドキュメントVault on Kubernetes Reference Architectureで紹介されているアーキテクチャの参考を簡単にまとめます。
- VaultのストレージとしてConsulを使用する
- つまり、Vault Server PodとConsul Server Podが必要
- また、Consul Client Podをデプロイし、Vault Server Podはそれを介してConsul Serverを検索する
- 運用簡素化のため、Consul Client PodはDaemonSetでデプロイすることが望ましい
- 可能であれば、Vault/Consul専用のクラスタを作成する
- セキュリティ担保や高可用性のため
- 難しい場合であっても(マルチテナントクラスタ上にデプロイする場合であっても)、専用のノードを作成するのが望ましい
- PersistentVolumesおよびPersistentVolumeClaimsを使用したストレージ永続化
- ノード要件
- Consul
- 2-4 CPU / 8-16 GB RAM / 50GB Disk / e.g. m5.large, m5.xlarge
- 8-16 CPU / 32-64 GB RAM / 100GB Disk / e.g. m5.2xlarge, m5.4xlarge
- Vault
- 2 CPU / 4-8 GB RAM / 25GB Disk / e.g. m5.large
- 4-8 CPU / 16-32GB RAM / 50GB Disk / e.g. m5.xlarge, m5.2xlarge
- Consul Server PodとVault Server Podはアベイラビリティゾーン間で均質に分散すること
- 5つのConsul Server Pod (StatefulSet)
今回のアーキテクチャ
今回は複数のVault Server Pod (StatefulSet)によるHA構成、Consulを用いたデータ永続化、Web UI有効化を行います。
データ永続化については、他にも様々なストレージの選択肢があるので必要に応じて使い分けてください。
また、VaultとConsulのそれぞれのWeb管理画面へのServiceとしてInternal NLBを自動生成するように設定します。
最終的に同一クラスタ内のアプリケーションにVaultを介して秘匿情報を埋め込むことにチャレンジします。
以下はイメージ図です(色々省いてます)。
Vaultのデータ永続化用のConsulをデプロイする
Consulの公式ドキュメントを参考にしながらデプロイを行います。
Helmリポジトリのセットアップ
Helmリポジトリの追加
公式Helmリポジトリが提供されているのでそれを追加します。
追加したらチャートを検索しましょう。
今回は記事を書いている時点で最新のチャートバージョン0.28.0を使用することにします。$ helm repo add hashicorp https://helm.releases.hashicorp.com $ helm search repo hashicorp/consul NAME CHART VERSION APP VERSION DESCRIPTION hashicorp/consul 0.28.0 1.9.1 Official HashiCorp Consul ChartHelmチャートの内容確認
リポジトリを追加したらチャートの中身を確認してみましょう。
helm fetchでチャートをダウンロードしてhelm templateで内容を標準出力に出します。
今回は標準出力をlessにパイプで渡しています。$ helm fetch hashicorp/consul --version 0.28.0 $ helm template consul-0.28.0.tgz | less中身を確認すると、大まかにServiceAccount系リソース、ConfigMap系リソース、Service系リソース、Pod系リソース、PodDisruptionBudgetリソースを確認できます。
- Pod系リソース
- Consul Server PodとしてのStatefulSet
- Consul Client PodとしてのDaemonSet
- テスト用のConsul Pod
- Service系リソース
- Consul Server PodへのClusterIP
- Web UI用
- Consul Server PodへのHeadless Service
- Consul Server PodおよびConsul Client Podへの53番ポートClusterIP
- ServiceAccount系リソース
- Consul Server用のServiceAccount (serverと呼ぶことにする)
- ServiceAccount server用のRoleとそれを付与するRoleBinding
- Consul Client用のServiceAccount (clientと呼ぶことにする)
- ServiceAccount client用のRoleとそれを付与するRoleBinding
- ConfigMap系リソース
- Consul Server Pod用のConfigMap
- Consul Client Pod用のConfigMap
- PodDisruptionBudget
app: consulラベルが付与されたPodに対してのPodDisruptionBudgetvalues.ymlの更新
ファイル生成
変更可能なパラメータ確認のためオリジナルのvalues.ymlを生成しておきます。
$ helm show values hashicorp/consul --version 0.28.0 > values-origin.yml更新内容
今回は必要なディレクティブのみ抜き出してyamlを作成します。
先に生成したvalues-origin.ymlを更新してもOKです。
global.datacenter: Consul datacenterとしての名前 (好きに指定)server.storageClass: EBSのStorageClassを指定 (後述)ui.service: Web UI用の内部NLBを生成するように指定syncCatalog.enabled: Kubernetesのリソースを同期できるようにtrueを指定values.ymlglobal: datacenter: booklive-dc1 server: storageClass: gp2 ui: service: type: 'LoadBalancer' annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-internal: "true" syncCatalog: enabled: trueデプロイ
EBSのPersistentVolumeClaimはDynamic Provisioningで生成する
公式Helmチャートを使用してConsulをKubernetesにデプロイするには、Dynamic Provisioningが可能なStorageClassがクラスタにデプロイされている必要があります。
2021年1月現在、EFSはDynamic Provisioningに対応していませんので、今回はEBSを利用したいと思います。
EBSのDynamic Provisioningはデフォルトでデプロイされているgp2StorageClassを使用すれば可能です。Consul Server Podの実際のmanifestを覗いてどのようにPersistentVolumeをコンテナにマウントするのかを念のため確認しておきます。
先ほどfetch済みのmanifestで確認します。
次のコマンドを実行後、kind: StatefulSetのmetadata.name: RELEASE-NAME-consul-serverを探してください。$ helm template consul-0.28.0.tgz | lessすると、そのmanifest内に次のような内容が見つかると同時に、外部PersistentVolumeClaimのマウントは見つからないことが分かります。
volumeClaimTemplates: - metadata: name: data-default spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Giつまり、Consul Server PodはDynamic Provisioningを利用して動的にPersistentVolumeClaimを作成してくれるので、別途作成する必要がないということです。
Consulのデプロイ
先に紹介したvalues.ymlを使用してデプロイします。
$ helm install -f values.yml consul hashicorp/consul --version 0.28.0 NAME: consul LAST DEPLOYED: Thu Jan 14 11:38:22 2021 NAMESPACE: default STATUS: deployed REVISION: 1 NOTES: Thank you for installing HashiCorp Consul! Now that you have deployed Consul, you should look over the docs on using Consul with Kubernetes available here: https://www.consul.io/docs/platform/k8s/index.html Your release is named consul. To learn more about the release if you are using Helm 2, run: $ helm status consul $ helm get consul To learn more about the release if you are using Helm 3, run: $ helm status consul $ helm get all consul
defaultnamespaceにconsul用のpersistentvolumeclaimsとpersistentvolumesが生成され(少し時間がかかります)、consul-consul-...というPodが正常にRunningしていれば問題なくデプロイできています。Vaultをデプロイする
1. 名前空間の作成
default名前空間を使用するのは推奨されませんので、新規に作成します。
今回はvaultという名前空間を作成して、Vaultリソースは全てこの名前空間にapplyします。namespace.ymlapiVersion: v1 kind: Namespace metadata: name: vault$ kubectl apply -f namespace.yml2. Helmリポジトリのセットアップ
Helmリポジトリの追加
公式Helmリポジトリが提供されているのでそれを追加します。
追加したらチャートを検索しましょう。
今回は記事を書いている時点で最新のチャートバージョン0.9.0を使用することにします。$ helm repo add hashicorp https://helm.releases.hashicorp.com $ helm search repo hashicorp/vault NAME CHART VERSION APP VERSION DESCRIPTION hashicorp/vault 0.9.0 1.6.1 Official HashiCorp Vault ChartHelmチャートの内容確認
リポジトリを追加したらチャートの中身を確認してみましょう。
helm fetchでチャートをダウンロードしてhelm templateで内容を標準出力に出します。
今回は標準出力をlessにパイプで渡しています。$ helm fetch hashicorp/vault --version 0.9.0 $ helm template vault-0.9.0.tgz | less中身を確認すると、大まかにServiceAccount系リソース、Service系リソース、Pod系リソース、MutatingWebhookConfigurationリソースを確認できます。
- Pod系リソース
- Vault Server PodとしてのStatefulSet
- vault-agent-injector Pod (hashicorp/vault-k8s)としてのDeployment
- Service系リソース
- Vault Server PodへのClusterIP
- Vault Server PodへのHeadless Service
- vault-agent-injectorへのClusterIP (vault-agent-injector-svc)
- MutatingWebhookConfigurationリソース
- vault-agent-injector-svcへのMutating Admission Webhook
- Pod等のリソース作成時・更新時にvault-agent-injectorが呼ばれるようになる
- vault-agent-injectorが特定の
spec.template.metadata.annotationsに反応できるようになる- ServiceAccount系リソース
- Vault Server Pod用のServiceAccount (vaultと呼ぶことにする)
- ServiceAccount vaultに
system:auth-delegatorのClusterRoleを割り当てるClusterRoleBinding- MutatingWebhookConfigurationのget/list/watch/patchができるClusterRole (injector-roleと呼ぶことにする)
- vault-agent-injector用のServiceAccount (injectorと呼ぶことにする)
- ServiceAccount injectorにClusterRole injector-roleを割り当てるClusterRoleBinding
values.ymlの生成
パラメータはなるべくコード化しておきたいので、この時点でvalues.ymlを生成しておきます。
ただし、600行近くあります。$ helm show values hashicorp/vault --version 0.9.0 > values.ymlvalues.ymlの更新
公式HelmチャートではありますがデフォルトではHA構成になっていなかったりするので、設定を書き換えていきます。
各ディレクティブの説明は公式ドキュメントを参照してください。HAモードの有効化
HAモードはデフォルトで無効になっています。
HAモードを有効化するとVault Server Pod (StatefulSet)はreplicasに指定した数だけデプロイされます。
ha:で検索したらすぐに見つかります。Beforeserver: ha: enabled: false replicas: 3Afterserver: ha: enabled: true replicas: 3Vault Server Podのリソース制限
injector (vault-k8s)とVault本体のリソース制限をそれぞれできます。
本番で稼働させるには、参考アーキテクチャで紹介されているスペックが必要になるかもしれません。
今回は特に指定しません。Defaultinjector: resources: {} # resources: # requests: # memory: 256Mi # cpu: 250m # limits: # memory: 256Mi # cpu: 250m server: resources: {} # resources: # requests: # memory: 256Mi # cpu: 250m # limits: # memory: 256Mi # cpu: 250mStatefulSetとしてのデータ永続化
今回はVaultのデータのみ永続化するので、
server.dataStorage.enabledがtrueになっていることを確認します。server: dataStorage: enabled: true auditStorage: enabled: falseまた、HA構成にする場合は、ストレージスタンザの設定を必要に応じて書き変えます。
デフォルトではConsulが有効になっています。
HOST_IPの箇所だけ、ConsulServerへ名前解決できるService名に書き換えておきます。server: ha: config: | ui = true listener "tcp" { tls_disable = 1 address = "[::]:8200" cluster_address = "[::]:8201" } storage "consul" { path = "vault" address = "consul-consul-server.default.svc.cluster.local:8500" } service_registration "kubernetes" {}Auto Unseal
今回はこの設定は行いませんが、AWSの場合、credentialsとKMSを使用してVault ServerのAuto Unsealを実現できます。
紹介までに方法を記載しておきます。
まず、credentialsをvalues.ymlに渡すためのsecretを作成します。
このとき、次のIAMポリシー権限を持つIAMユーザーのキーを使用するようにしてください。
kms:Encryptkms:Decryptkms:DescribeKey$ kubectl -n vault create secret generic vault-aws-key \ > --from-literal=AWS_ACCESS_KEY_ID=AAAAAAAAAAAAAAAA \ > --from-literal=AWS_SECRET_ACCESS_KEY=BBBBBBBBBBBBBBBBB作成が終えたら、secretをvalues.ymlから読み込むように設定します。
seal "awskms"内のkms_key_idにはAWS KMSのKey IDを調べて記載します。server: extraSecretEnvironmentVars: - envName: AWS_ACCESS_KEY_ID secretName: vault-aws-key secretKey: AWS_ACCESS_KEY_ID - envName: AWS_SECRET_ACCESS_KEY secretName: vault-aws-key secretKey: AWS_SECRET_ACCESS_KEY ha: config: | seal "awskms" { region = "ap-northeast-1" kms_key_id = "aaa-bbb-ccc-ddd-eee-111" }Web UIの有効化
デフォルトではWeb UIは無効化されているので有効化し、Vault Server Podへの疎通のためにLoadBalancer Serviceを作成するように書き換えます。
EKSを使用している場合、type: LoadBalancerを指定すればCLBまたはNLBを自動生成できるので、それでリソースの作成を行います。
今回は内部NLBを作成します。ui: enabled: true publishNotReadyAddresses: true activeVaultPodOnly: true serviceType: "LoadBalancer" serviceNodePort: null externalPort: 80 # loadBalancerSourceRanges: # - 10.0.0.0/16 # - 1.78.23.3/32 # loadBalancerIP: annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-internal: "true"3. デプロイ
設定したvalues.ymlを使用してhelm installを実行します。
$ helm install vault hashicorp/vault --namespace vault -f values.yml --version 0.9.0 NAME: vault LAST DEPLOYED: Thu Jan 14 12:27:55 2021 NAMESPACE: vault STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Thank you for installing HashiCorp Vault! Now that you have deployed Vault, you should look over the docs on using Vault with Kubernetes available here: https://www.vaultproject.io/docs/ Your release is named vault. To learn more about the release, try: $ helm status vault $ helm get manifest vaultStatefulSetのreplicasを3に設定したので、vault-{number}が3つとvault-agent-injectorという合計4つのPodが作成されていれば問題ありません。
$ kubectl -n vault get pod NAME READY STATUS RESTARTS AGE vault-0 0/1 Running 0 12s vault-1 0/1 Running 0 12s vault-2 0/1 Running 0 12s vault-agent-injector-b55d65869-mlxtt 1/1 Running 0 12sWeb UIに疎通可能なELB (NLB)が生成されていることも確認できます。
$ kubectl -n vault get service vault-ui NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vault-ui LoadBalancer 172.20.223.44 aaaaabbbbb-cccccddddd.elb.ap-northeast-1.amazonaws.com 8200:32040/TCP 5m10s4. Vaultの初期設定
HA構成の場合、コマンドラインでVaultをUnsealにする必要があります。
kubectl execでVault Server Podのどれかひとつにinitコマンドを実行します。
このとき、Unseal KeyとInitial Tokenを取得します(以降も大切な情報ですので安全な場所で保管します)。$ kubectl -n vault exec -it vault-0 -- vault operator init Unseal Key 1: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa Unseal Key 2: bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb Unseal Key 3: cccccccccccccccccccccccccccccccccccccccccccc Unseal Key 4: dddddddddddddddddddddddddddddddddddddddddddd Unseal Key 5: eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee Initial Root Token: s.fffffffffffffffffffffff Success! Vault is initialized Recovery key initialized with 5 key shares and a key threshold of 3. Please securely distribute the key shares printed above.AWS KMSによるAuto Unsealを有効にしていれば、Unseal Keyを入力せずにこのタイミングで使える状態になります。
ただし、今回はマニュアルでUnsealを行います。
次のコマンドをすると対話形式でUnseal Keyを聞かれるので、operator initで取得した5つのUnseal Keyのうち任意のひとつを入力します。$ kubectl -n vault exec -it vault-0 -- vault operator unseal Unseal Key (will be hidden):これを全部で3回繰り返すとVaultはUnseal状態になり使用可能になります。
3回目にSealed Keyがfalseになったことを確認できればOKです。
※ 3回入力するUnseal Keyは全て別のものを使用してください$ kubectl -n vault exec -it vault-0 -- vault operator unseal Unseal Key (will be hidden): Key Value --- ----- Seal Type shamir Initialized true Sealed false Total Shares 5 Threshold 3 Version 1.6.1 Storage Type consul Cluster Name vault-cluster-**** Cluster ID HA Enabled true HA Cluster n/a HA Mode standby Active Node Address <none> $ kubectl -n vault get pod NAME READY STATUS RESTARTS AGE vault-0 1/1 Running 0 2m38s vault-1 1/1 Running 0 2m38s vault-2 1/1 Running 0 2m38s vault-agent-injector-6fcf464c66-9k8ch 1/1 Running 0 2m38sここまで終えると
NLBのDNS名にブラウザからアクセスしてみましょう。
するとログイン画面が表示されるので、kubectl execで取得したInitial Root Tokenを入力し、Sign Inを実行します。
実行後、次のような画面が表示されれば初期設定完了です。
5. ロール/認証情報の設定
ログイン認証
Vaultの長所は細かく権限管理できるところです。
これは管理画面のログイン認証においても例外ではなく、ログインユーザーが持つポリシーによって可能な作業が制御されます。
先ほど初期設定のためにRoot Tokenを使用しましたが、このTokenにはrootポリシーが付与されていて何でもできるため、安全に管理する必要があります。
そのため、必要な権限に応じてポリシーを作成していく必要があります。
デフォルトではrootポリシーとdefaultポリシーがありますが、rootポリシーは使い回すことができず、一方でdefaultポリシーはできることが少な過ぎます。
そこで、今回は強めの権限を持ったadminというポリシーを作成しておきます。
まず、Top > Policiesに遷移してCreate ACL policyをクリックします。
Nameにadminを入力し、Policyに次の設定をコピーし、Create policyを実行します。# Configure auth methods path "sys/auth" { capabilities = [ "read", "list" ] } # Configure auth methods path "sys/auth/*" { capabilities = [ "create", "update", "read", "delete", "list", "sudo" ] } # Manage auth methods path "auth/*" { capabilities = [ "create", "update", "read", "delete", "list", "sudo" ] } # Display the Policies tab in UI path "sys/policies" { capabilities = [ "read", "list" ] } # Create and manage ACL policies from UI path "sys/policies/acl/*" { capabilities = [ "create", "read", "update", "delete", "list" ] } # Create and manage policies path "sys/policies/acl" { capabilities = [ "read", "list" ] } # Create and manage policies path "sys/policies/acl/*" { capabilities = [ "create", "read", "update", "delete", "list" ] } # List available secrets engines to retrieve accessor ID path "sys/mounts" { capabilities = ["read"] } # Create and manage entities and groups path "identity/*" { capabilities = [ "create", "read", "update", "delete", "list" ] } # List, create, update, and delete key/value secrets path "kv/*" { capabilities = ["create", "read", "update", "delete", "list", "sudo"] } # Manage secrets engine path "sys/mounts/*" { capabilities = ["create", "read", "update", "delete", "list", "sudo"] }次にユーザー・パスワード認証を有効化します。
Top > Access > Auth Methods > Enable new methodを押します。
今回はUsername & Passwordを設定してみます。
Nextを押すと詳細設定ができますが今回はデフォルトのままEnable Methodを押します。
Methodの作成が完了したら、次の画面に移動してCreate userを押します。
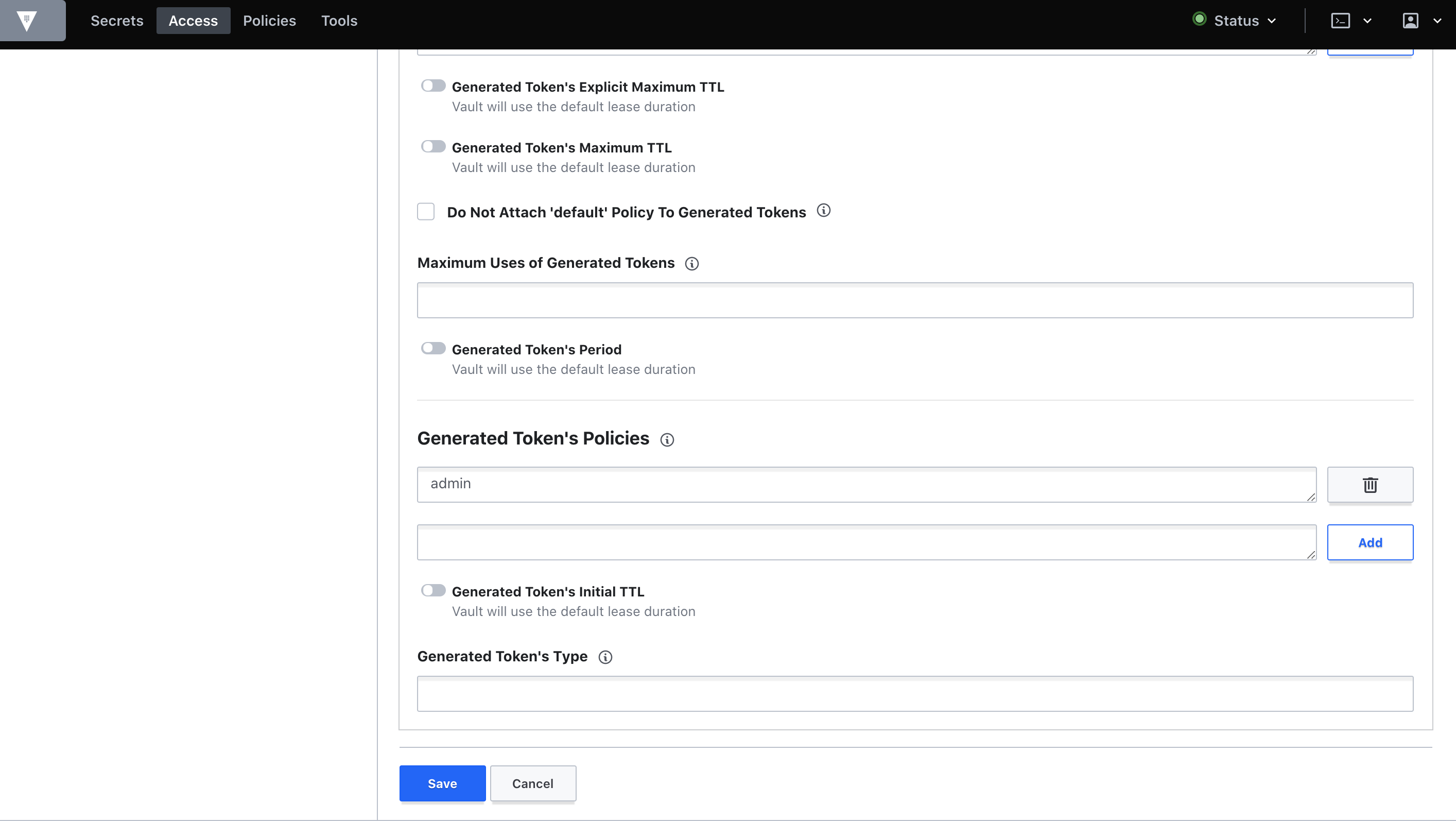
ユーザー作成画面では、今回はUsername=admin,Password=adminpasswordを入力し、隠れている詳細設定のアコーディオンを開くためにTokensをクリックします。
Generated Token's Policiesに先ほど作成したポリシーの
adminを入力しAddをクリックします。
ここまで完了したらSaveをクリックしてユーザー作成完了です。
以後、adminユーザーで作業を行うため、一度ログアウトしてログインし直します。
読み取り専用アプリケーションポリシー
アプリケーションからはSecretの読み取りのみ許可したいことがほとんどだと思われます。
そのため、Read Onlyなポリシーも作成しておきます。
今回は、readonly-secretという名前で登録しました。path "kv/*" { capabilities = ["read"] }Kubernetes認証メソッドの有効化とロールの作成
KubernetesのServiceAccountとVaultのポリシーを関連づけるための設定です。
まず、Access > Auth MethodsからEnable new methodを押します。
Infra > Kubernetesを選択しNextを押します。
デフォルトのままEnable Methodを押し、Kubernetes Authentication Methodを有効化します。
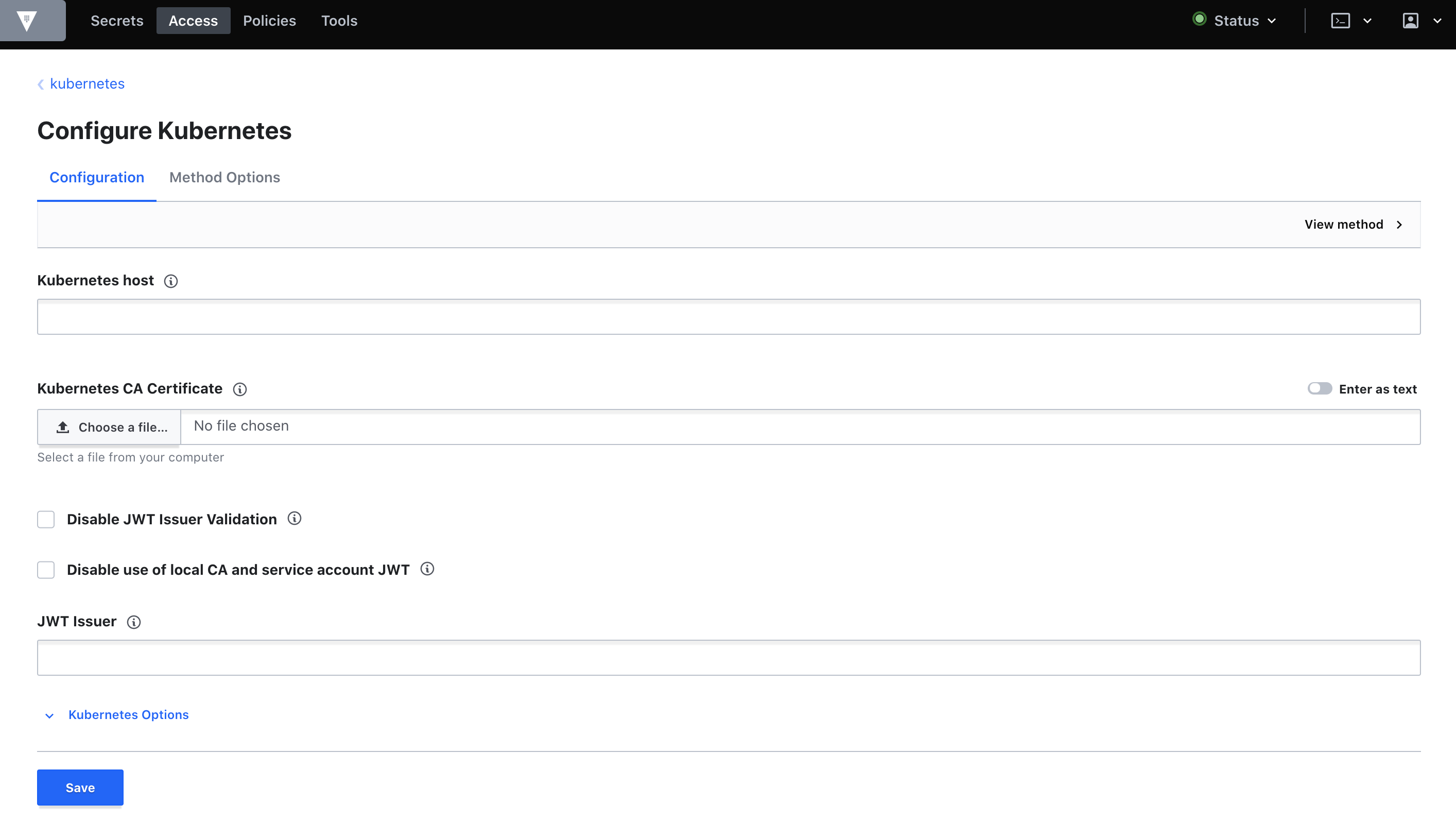
有効化が終わったら、Configure Kubernetesという画面に遷移するので必要情報を入力します。
それぞれのキーに対して、次のコマンドを実行して得られた値を入力します。
- Kubernetes host
- ここで得られるIPを
$IPとするとhttps://$IP:443の形式で入力してください$ kubectl -n vault exec -it vault-0 -- sh -c 'echo $KUBERNETES_PORT_443_TCP_ADDR'
- Kubernetes CA Certificate
- 入力時は
Enter as textを有効にしてから入力してください$ kubectl -n vault exec -it vault-0 -- cat /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- Token Reviewer JWT
- このJWTはVault起動時に作成されるvaultというServiceAccountに紐づくSecretとしてデプロイされています
$ kubectl -n vault exec -it vault-0 -- cat /var/run/secrets/kubernetes.io/serviceaccount/token入力が済んだらSaveを押して保存します。
ここまで終えたら、次の画面まで移動してCreate roleを押します。
今回は、sample-app-roleという名前で全てのServiceAccountと全てのnamespaceを許可します。
また、Generated Token's Policiesにはreadonly-secretポリシーを追加しておきます。
6. Secret情報の登録
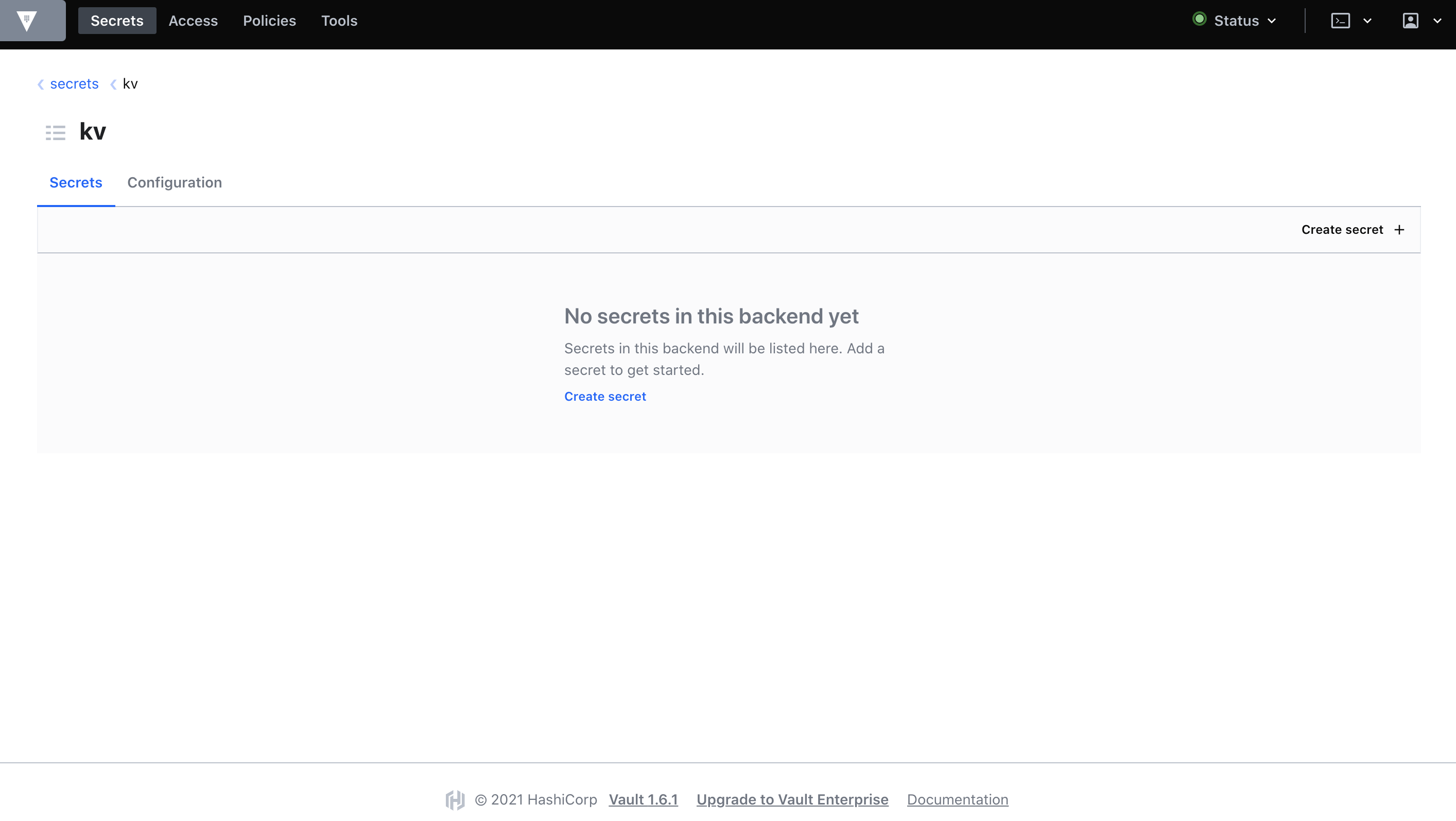
今回はKey-Value形式のSecretを有効にします。
まずは、Top > Secrets > Enable new engine > Generic/KV > Next > (特に何もせずに) Enable Engineを実行します。
すると、Key-Value形式のSecretを登録できるようになるので、Create secretからSecretを登録します。
今回は、
secret/test-secretというSecretにKey=username,Value=testuserとKey=password,Value=passwordを登録してみます。
readonly-secretのポリシーにkv/*のreadを許可しているのは、今作成したkv配下の読み込み権限を与えるためです。
コンシューマアプリケーションからSecret情報を取得してみる
サンプルアプリケーション構築
サンプルアプリケーションのマニフェストは次の通りです。
Nginxコンテナの/vault/secrets/test-secretというファイルに秘匿情報が埋め込まれます。sample-app.yml--- apiVersion: v1 kind: Namespace metadata: name: sample-app --- apiVersion: apps/v1 kind: Deployment metadata: name: sample-app namespace: sample-app spec: replicas: 1 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app annotations: # Enables the Vault Agent Injector service vault.hashicorp.com/agent-inject: "true" vault.hashicorp.com/agent-inject-status: update # Vault Kubernetes authentication role vault.hashicorp.com/role: sample-app-role # agent-inject-secret-FILEPATH prefixes the path of the file, written to the /vault/secrets directory. # The value is the path to the secret defined in Vault. vault.hashicorp.com/agent-inject-secret-test-secret: kv/secret/test-secret vault.hashicorp.com/agent-inject-template-test-secret: | {{- with secret "kv/secret/test-secret" -}} USERNAME={{ .Data.data.username }} PASSWORD={{ .Data.data.password }} {{- end -}} spec: containers: - name: nginx-container image: nginx:1.19デプロイと確認
ファイルを作成したらデプロイします。
デプロイ後にREADY2/2とSTATUSがRunningになっていればOKです。$ kubectl apply -f sample-app.yml $ kubectl -n sample-app get pod NAME READY STATUS RESTARTS AGE sample-app-6f4f9b46fd-l8wgd 2/2 Running 1 60sなぜ2/2かというとvault-agentコンテナが埋め込まれているためです。
sample-app.ymlにvault.hashicorp.com/agent-inject: "true"アノテーションがあるので、Vaultクラスタと一緒にデプロイしておいたvault-agent-injectorによってMutating Admission Webhookが発火し、Vaultと通信できるAgentがsample-app Podのサイドカーとして埋め込まれる仕組みです。最終的にNginxコンテナにパスワードが埋め込まれていることを次のように確認できます。
$ kubectl -n sample-app exec -it sample-app-6f4f9b46fd-l8wgd -c nginx-container -- cat /vault/secrets/test-secret USERNAME=testuser PASSWORD=passwordローカル開発でも同じ場所に同じ形式でファイルを置いておけば、アプリケーションに秘匿情報を埋め込まず、かつビルド時に秘匿情報を渡すこともなく、.envのような使い方で実装を進められます。
まとめ
やりたかったことのうち次の2つを確認できました。
- UIで秘匿情報を管理できる
- アプリケーションのデプロイ時にその秘匿情報を自動で埋め込んで欲しい
3つ目の複数クラスタでVaultの情報を共有するためにはVault専用クラスタを作成するのが一番いいと考えられます。
その場合、Vault Helmのvalues.ymlにて「Vault Server Podは起動せず、外部Vault Serverを使用する」というような設定が可能なので、それを利用します。
そうすると、Ingector Agentのみを起動することができます。そして、良くも悪くも柔軟な権限管理や様々な秘匿情報の管理に対応しているので、様々なケースに対応できると思います。
高機能であるが故に覚えないといけないことも多いというのも事実です。
まだまだ分かっていない点も多いので本番運用に向けて色々調べていく所存です。おまけ
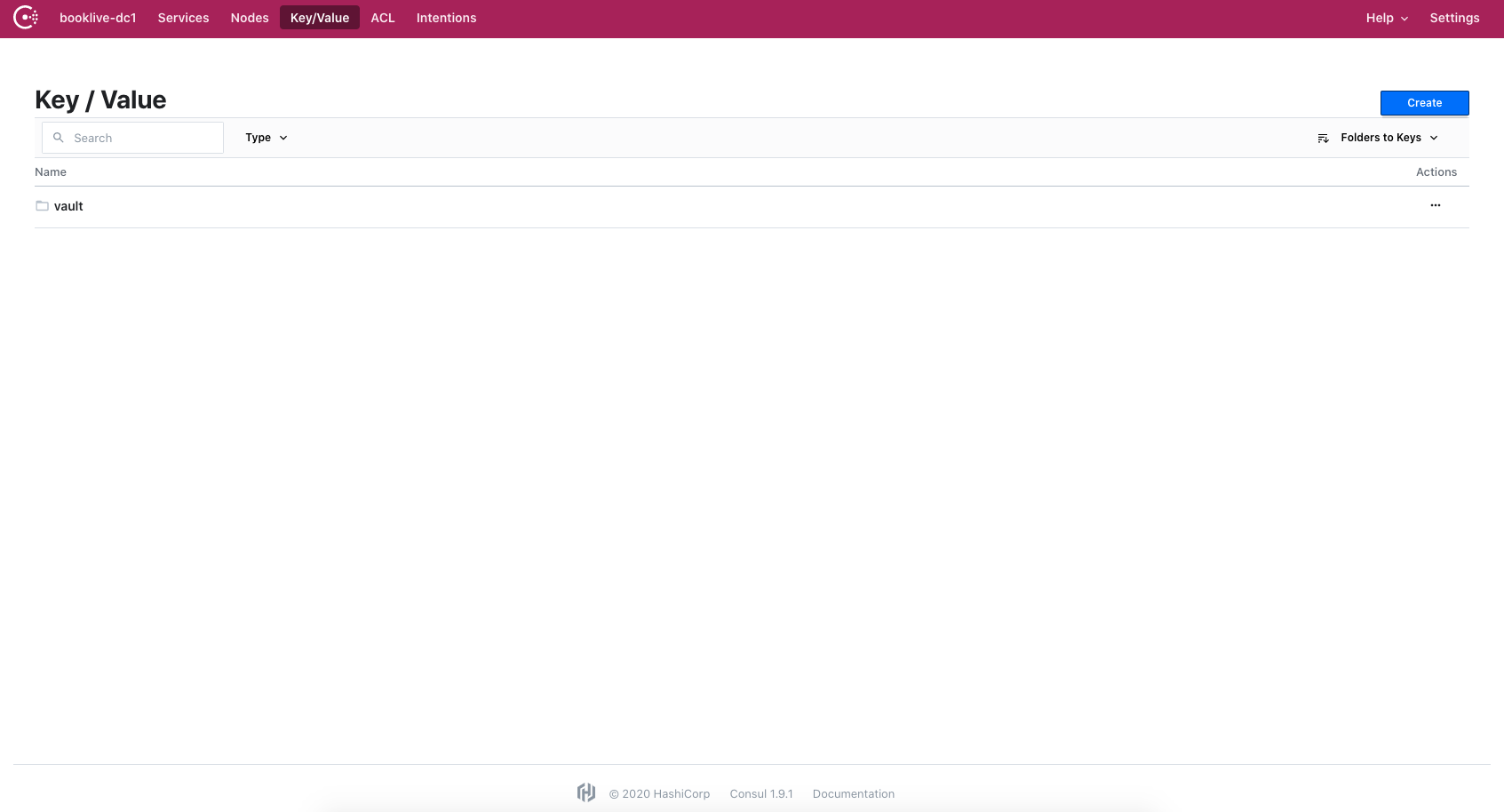
ついでに、データストレージとして使用しているConsulサーバにアクセスするとKey/Valueの項目にvaultのデータが格納されていることも確認できます。
更新情報
- 2021/01/15
- 説明不足の箇所や文脈がおかしいところの文章を修正しています
- 構築内容に変更はありません








- 投稿日:2021-01-14T19:01:01+09:00
Udemy「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得 」は初学に最適な件
どのエンジニアに対しても実はインフラ側の知識は必要なものです。今回は、初学者にとって最適なUdemyのコースに関して解説していきます。
本講座「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得 」では、インフラにあまり詳しくない方でも、インフラの基礎を身につけることができます。
これからDockerの基礎を固めたいといった方や、Kubernetesを理解したいといった方でも、AWSの基礎はきちんと知識として持っていおいたほうがいいでしょう。
AWSに触れるのが初めてな方も、サーバやネットワークの知識も合わせて学びたい方にも、こちらの講義はハンズオン形式でしっかり理解していけるので非常におすすめです。
動画詳細
・・・・・・・・・・・・・・・・
動画詳細はこちら↓
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
https://px.a8.net/svt/ejp?a8mat=3BBLME+FWR3TE+3L4M+BW8O2&a8ejpredirect=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Faws-and-infra%2F
・・・・・・・・・・・・・・・・講義内容
この講座では、受講者のあなたが実際にAWSアカウントを作成し、ECやS3などを構築して、WordPressで自分のサイトを公開する、といった、実践的な内容になっています。
また、勉強の進め方に関しても冒頭で解説してくれているので、とても学習しやすいです。AWSは触ったことないし、サーバやネットワーク構築もろくにしたことないといった方でも、サーバやネットワーク構築もイラストを用いて丁寧に解説してくれるので、インフラ初心者の方でも安心できる内容となっています。
このコースでの学習を勧めていけば、AWSの基礎を網羅できるのでおすすめです。
私も実際にDockerを勉強する際やKubernetesを勉強する際は役に立ちました。実際に実務ではもっと大事な覚えたほうがいいことが多いですが、AWSの基礎が実務での経験とリンクしてきちんとした知識として定着していく瞬間は多いです。
良かったことろその1
まずこの講座は、ハンズオン形式なので理解しやすいです。
AWSアカウントを作成するところから丁寧に解説してくれますし、受講した際に自分のアカウントを作成するので理解の深まりも早いです。また、AWSでは、一般的なサーバ構築、ネットワーク構築では使わないAWS独自の概念や言語が数多くでてきますが、ハンズオン形式なので理解スピードが非常に高いのもメリットです。
良かったことろその2
図を用いてサーバからネットワーク構築まで図解で分かりやすく解説ので、サーバ構築やネットワーク構築をあまりしたことがなく、自身がないという方にもおすすめです。
この講座を受講していただければ、AWSの概念だけでなく、どこにいっても使える基本的な構築方法をインプットでき、特にサーバやネットワーク構築の流れ、構成の工程をイラストで分かりやすく解説してくれます。
良かったことろその3
この講座では、AWSの基礎を網羅することができ、具体的には以下のようなことを学習できます。
・AWSの基礎
・EC2 →サーバインスタンス
・IAM →アクセス管理
・S3 →ストレージ
・Route53 →DNS
・RDS →DB
・ELB →負荷分散
・VPC →仮想空間
・CloudWatch →リソース管理、監視このようにAWSの基礎をしっかりと学ぶことができるので、とてもおすすめです。
私はこの講座を受けたあとにKubernetesやDockerを勉強したのですが、この講座で培った知識が活きてきました。特に、AWSのアルゴリズムのようなものの概要を理解させてくれる動画になっているので、これから他のインフラの学習をしたいといった方にもおすすめです。動画詳細
・・・・・・・・・・・・・・・・
動画詳細はこちら↓
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
https://px.a8.net/svt/ejp?a8mat=3BBLME+FWR3TE+3L4M+BW8O2&a8ejpredirect=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Faws-and-infra%2F
・・・・・・・・・・・・・・・・
- 投稿日:2021-01-14T16:42:51+09:00
[AWS]codecommitにpushされたらs3に静的コンテンツをリリースする環境を作成しよう
説明
AWSでCI/CD環境を一度作成してみたかったので、作成してみました。
このような記事は腐るほどありますが、自分のメモのために記事としてまとめます。概要
awsのサービス「CodeCommit」と「CodeBuild」を使用します。CodeCommitやCodeBuildなどの細かい説明は省きますが、CodeCommitはソース管理サービス(gitを使用)で、CodeBuildはビルドサービス(テストやビルドの自動化)です。
今回はCodeCommitに資源がpushされたらCodeBuildが動いてs3に資源がリリースされるところ(派生でCloudFrontでキャッシュさせるところ)まで作成してみます。
準備
CodeCommitのリポジトリ作成
※作成手順は割愛。リポジトリ作成してからローカルにclone(iamのcodecommitのキー作成を忘れずに。)までします。
適当なhtmlとbuildspec.ymlもコミットしておくことにします。(後ほどCodeBuildというサービスで使います)
test.html<!DOCTYPE html> <html lang=“ja”> <head> <meta charset=“UTF-8” /> <title>test page</title> </head> <body> <h1>ci/cdのテストページです</h1> </body> </html>バケット名は次で作るs3バケット(test-bucket-20201218)と揃えておきます。
buildspec.ymlversion: 0.1 phases: build: commands: - aws s3 sync --delete src s3://test-bucket-20201218静的コンテンツ格納のs3作成
静的コンテンツを格納、ホスティングさせるS3バケットを作成します。
CodeBuildの作成
ここからちょっと丁寧目に書きます。
ビルドプロジェクトの作成を押します。
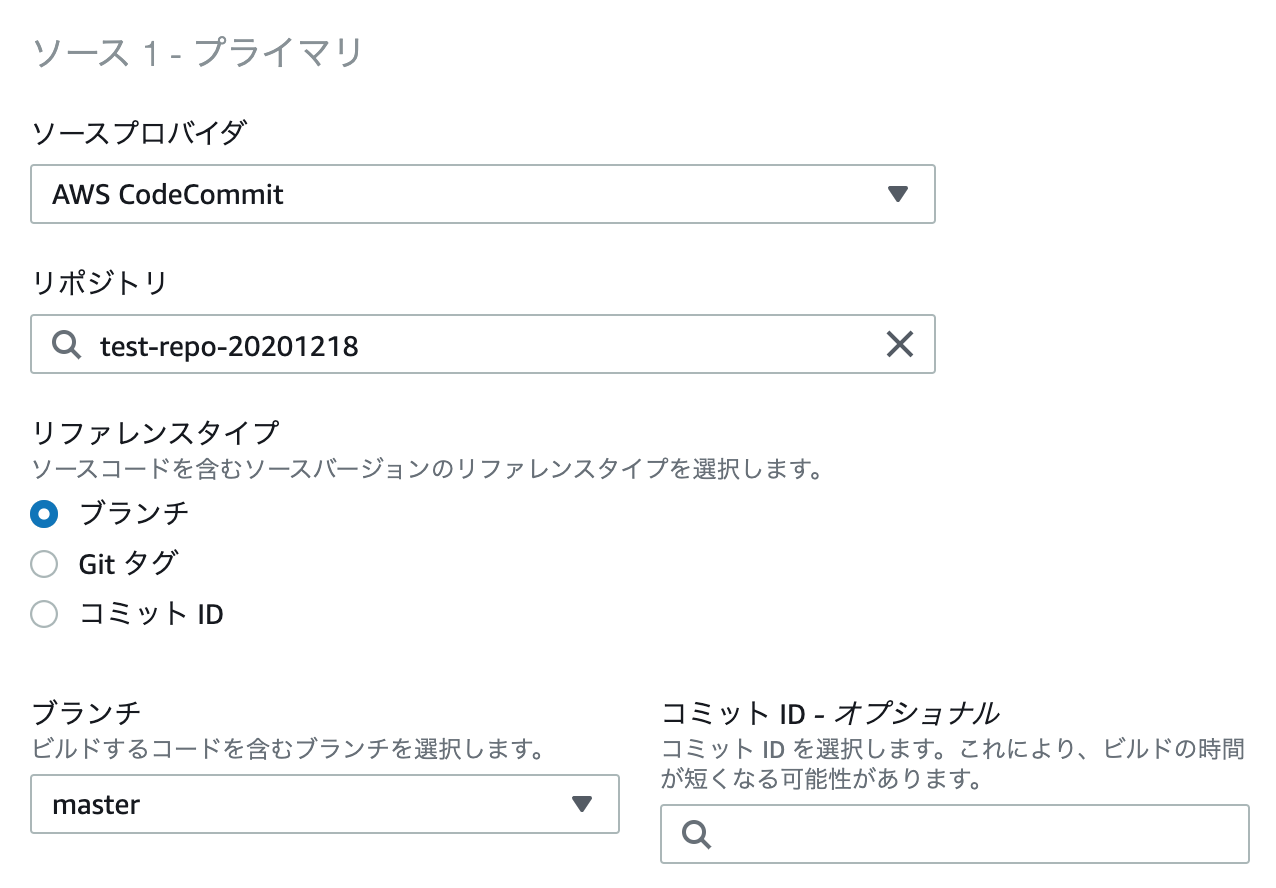
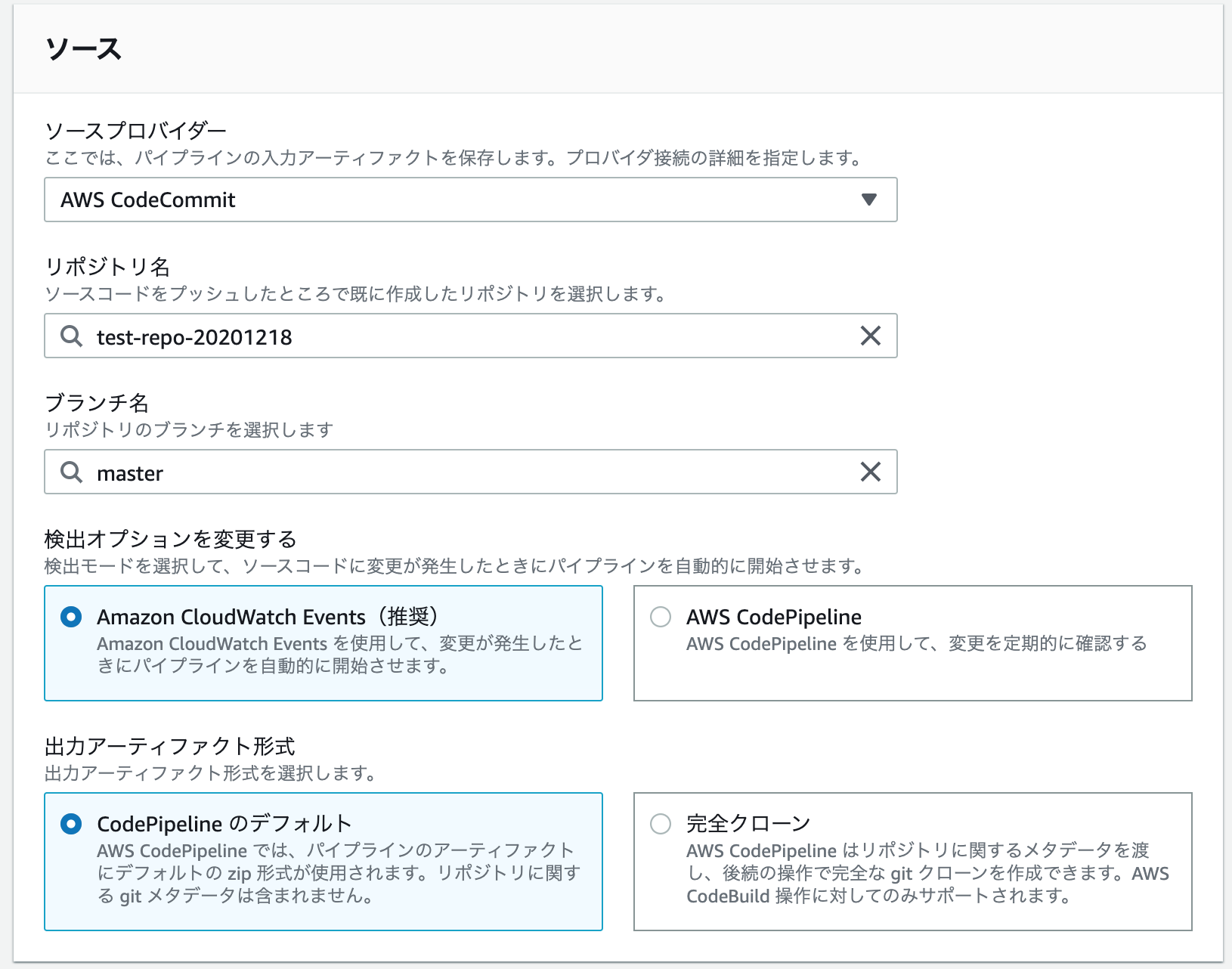
ソースプロバイダはCodeCommitにして、リポジトリを入力するとブランチを入力できる欄が現れます。(今回はmasterにしておきます。)
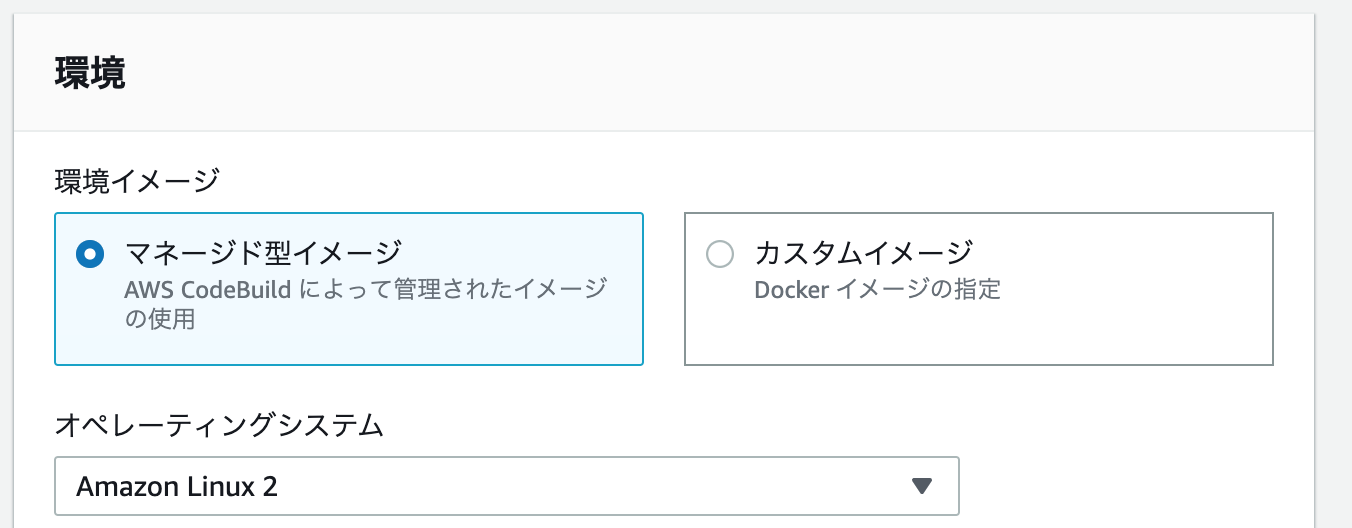
環境はlinuxを選択します。
ランタイム他の設定です。
ロール名はデフォルトで設定されているものを使用しました。
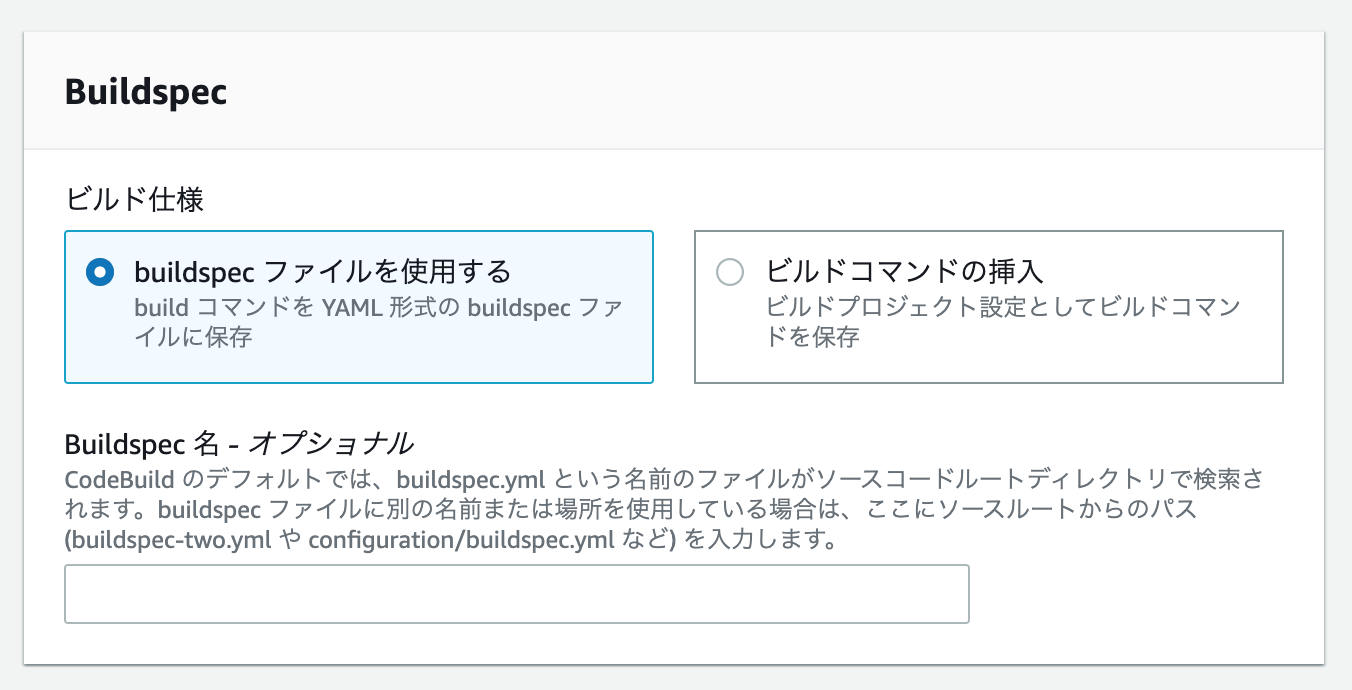
さらに今回はbuildspec.ymlをリポジトリのルートディレクトリ直下に置きますのでここは書くことはないです。
次はアーティファクトをS3に指定します。
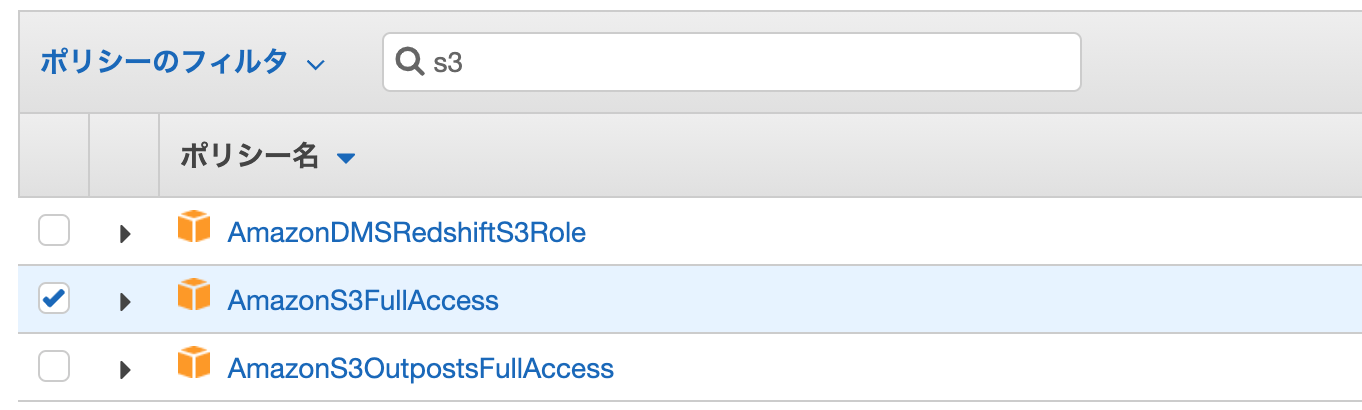
ここまででCodeBuildは作成できましたが、S3へアップロードする権限がないので付与してあげましょう。
今回はS3へのFullAccessをアタッチします。
CodePipileneの作成
そして、CodePipilineの設定をしましょう。
CodeCommitへのpushをトリガーにCodeBuildが動作する設定をしてあげます。パイプラインを作成するを押します。
パイプライン名、ロールの設定をします。
次はソースのプロバイダなどの設定。以下の通り設定します。
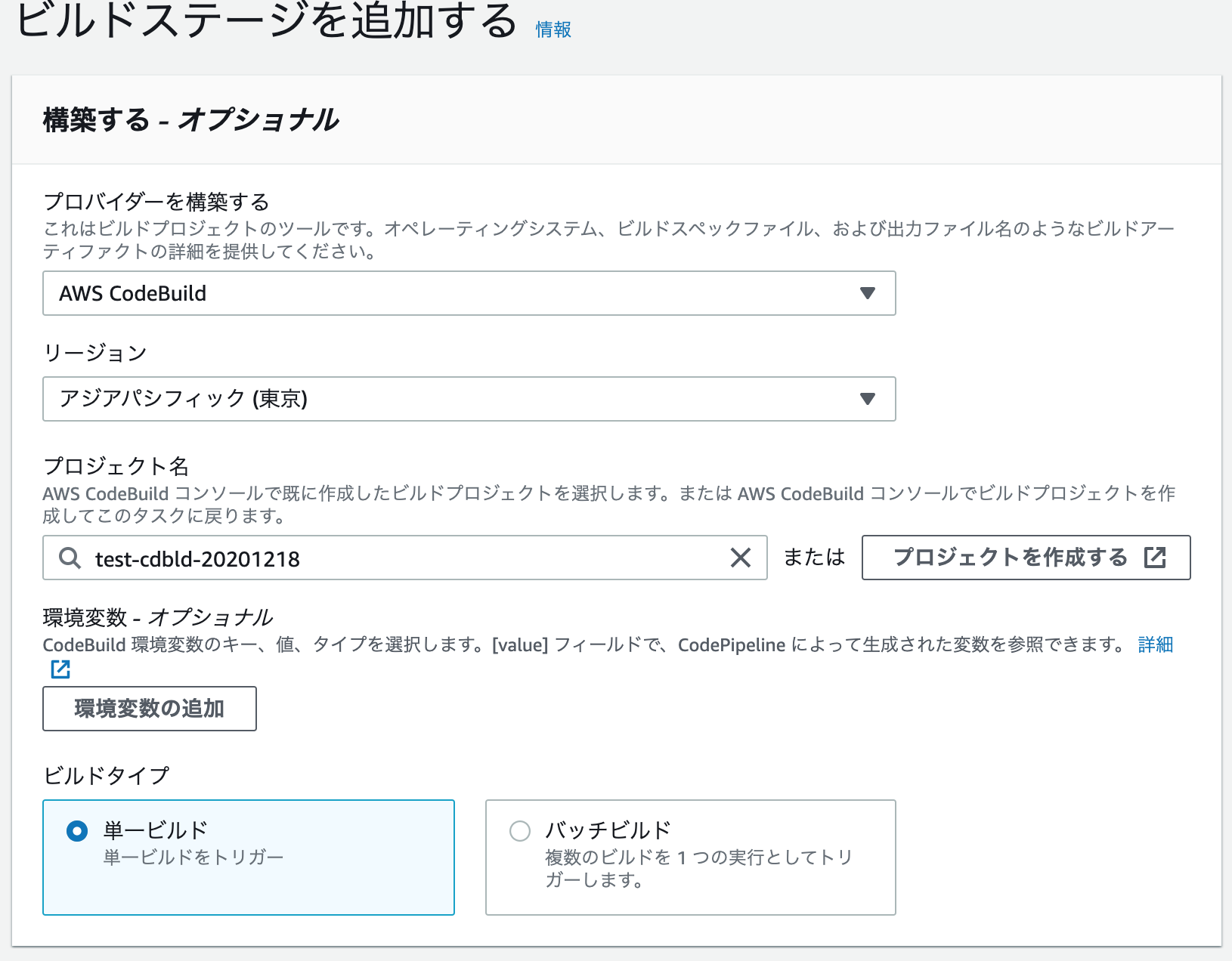
ビルドステージには先程作成したcodebuildのプロジェクトを指定します。
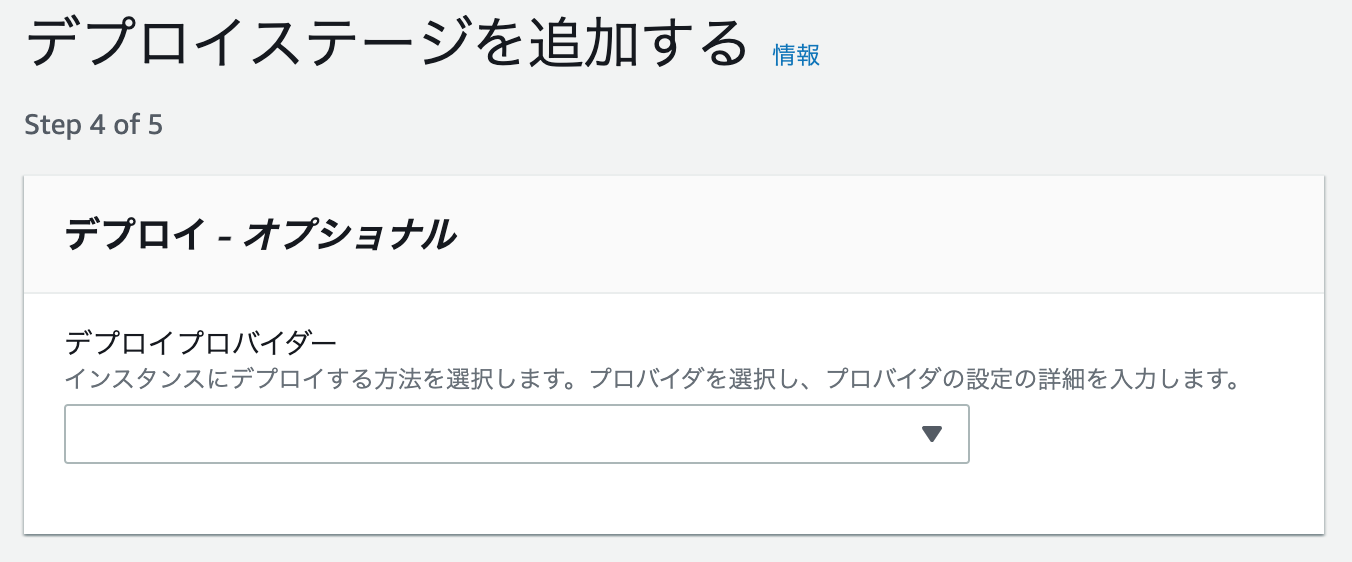
デプロイステージは特に設定しません。
buildspec.ymlの中でs3にputすることを書いているからです。
これでcpdepipelineが完成しました!
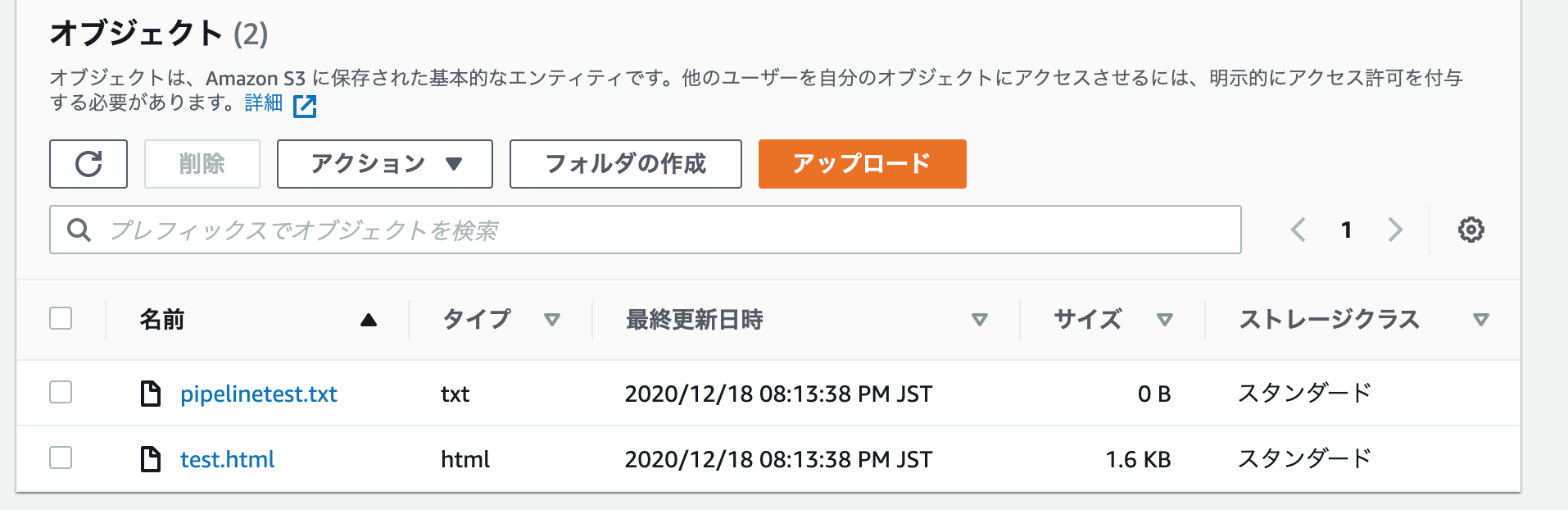
試しに0byteのテキストファイルをgit pushしてみました。きちんとs3が更新されています。
何度か失敗していますが、これはbuildspec.ymlに
aws s3 sync --delete src s3://test-bucket-20201218
と書いてあるのにリポジトリにsrcフォルダを用意しなかったからです。
ひとまずこれでgitのpushを契機にS3へのアップロードはできるようになりました!!ヤッター
cloudfrontの設定
次回に回します。
codedeployも使ってみたいなぁ・・・あとcloudformationも。







- 投稿日:2021-01-14T16:19:45+09:00
Chrome + ELB(ALB) で接続が異常に遅い問題
はじめに
https通信にしたくてELBを構成しブラウザ(Chrome)からhttps://ドメイン名/でアクセスするとレスポンスは返ってはくるが1分以上かかるという現象に遭遇しましたので備忘録確認した事
Chromeのデベロッパーツールで何がそんなに時間がかかっているのかを確認
initial connectionというのがやたら長いGoogleで検索 initial connection 遅い
下記の記事がヒット
https://qiita.com/TakenoriHirao/items/a3ace404d785e6a4db22
原因
ELB(ALB)では2つのサブネットを設定するが、プライベートなサブネットを設定するとこの現象が起きるらしい

- 投稿日:2021-01-14T11:29:28+09:00
AWS概要 ネットワーキングについて
概要
もはや何番煎じているか分かりません。
1月から個人的に始めている未経験AWSチャレンジの一環として、CP試験に向けての個人的なメモとして記述します。※は書き方を模索中ですが、問題を通して思った感想になります
ネットワーキング
Amazon CloudFront(CDN=コンテンツ・デリバリー・ネットワーク)
CDN=サーバーの代わりに表示やら・負担分散してくれるサーバーたち
・ディストリビューションという単位で管理される
・オリジンサーバー =オリジナルコンテンツサーバー
・エッジサーバー =コンテンツをキャッシュして、ユーザーへ直接配信サーバー
※ディストリビューションには独自のドメインを設定できるAmazonRoute53
DNS(Domain Name System)=ドメインの取得ができる
Route53にもヘルスチェック機能があり、EC2に不可が検知されるとS3のソーリページに
ルーティングさせるなどの、名称通りのRouteの設定も出来ます。※SSL証明書「https://」のユーザーとWebアプリ間の暗号化
1 AWS Certificate Manager(ACM)で証明書の作成
2 ELB(ロードバランサー:インターネットGWからアクセスを割り振る仕組み)に証明書を設定
3 Route53でDNSして、晴れて自分のWebアプリ感が出てくる※AWSでサービスを作る場合は、公式にDNSはRoute53を使用する事とあるので、
お仕事などでAWSに触れるならば、必ず出てくるであろう仕組みですね
- 投稿日:2021-01-14T08:22:19+09:00
【GCP・AWS・Azure】3大クラウドの仮想マシンの比較をしてみた
ネットを探すと、関連した記事がたくさん見つかりますが、備忘録的にまとめました。
※表の作成に慣れておらず。。見づらくてすみません。
名前 課金体系 仮想マシンの起動速度 マシンタイプ スポットVMの有無 作成時のステップ数 ブラウザから仮想マシンのOSログインの不可 停止時のインスタンスタイプ変更 起動時のインスタンスタイプ変更 リージョン変更・移動 ゾーン変更・移動 ライブマイグレーション シリアルコンソール 自動シャットダウン CPU メモリ CPU/メモリカスタマイズ 性能指標値 GPU FPGAAWS AWS Amazon EC2 従量課金制、秒 (最低1分) と時間単位が混在 3分〜4分20秒 コア数、メモリ、ディスクのセットから選択する方法をとっているため、あらかじめ用意されたマシンタイプの種類から選ぶ 有 6ステップ 不可 ○ × × × × × × vCPU: 1〜128(論理プロセッサ448というのもある) 0.5〜12TB × ECU あり (EC2: P3/P2/G3, Elastic GPU) あり (f1 インスタンス) Azure Azure Virtual Machine 従量課金制、 分単位 (秒切り捨て) 3〜4分 コア数、メモリ、ディスクのセットから選択する方法をとっているため、あらかじめ用意されたマシンタイプの種類から選ぶ 無 16ステップ 可 ○ × × × × ○ ○ vCPU: 1〜128 0.75〜27TB × ACU あり (VM: NC/NCv2/ND/NV) 無 GCP Compute Engine 従量課金制、秒 (最低1分) 約40秒 カスタムマシンにより設定できるようになっているため、コア数、メモリ、ディスクを別々に設定することが可能 有 2ステップ 可 ○ × × ○(インスタンスにローカル SSD がつながっていると NG 、コマンドラインまたは API からしかできないといった制限あり) ○ ○ × 仮想CPU: 0.2〜160 (2019/04/03 early access ながら vCPU 208・416が登場) 0.6〜11TB ○ (カスタムタイプ, 拡張メモリ) GCEU あり (GCE, Dataproc, GKE) 無 ====
説明
・スポットインスタンス
「常に使えるとは限らない、突然落ちるかもしれないけど、安い」という仮想マシン・ライブマイグレーション
「仮想マシンを再起動することなく (動作させたまま)、現在のホストから新しいホストに移動する」・シリアルコンソール
/etc/fstab の修正をミスしたり iptables の設定をしくじって接続できなくなった場合、 OS の起動が失敗してしまいます。Azure・GCP ではブラウザ上でシリアル接続が可能・自動シャットダウン
お試しで仮想マシンを起動したいときがあります。 そしてもう不要なのに削除し忘れて余分な請求が来てしまう・拡張メモリ
GCP には「拡張メモリ」という仕組みがあり、 「メモリは vCPU あたり 0.9GB〜6.5GB の範囲」を超えて追加が可能・性能指標値
CPU 速度の指標値
AWSのCPUが一番高性能。料金も加えて考えたとき、コストパフォーマンスがいいのはGCPというお話もある。・FPGA
Field Programmable Gate Array の略で、 プログラミング可能なハードウェア回路。GPU と同じく、簡単な計算を複数並列で行うような用途に向いています====
ネットワーク
グローバルIPアドレス固定化 内部IPアドレス固定化 複数 NIC ○ ○ (VPC の場合) ○ ○ ○ ○ ○ ○ ○ ディスク・ストレージ
ストレージ HDD/SSD 選択可否 ストレージ冗長化の有無 ストレージ共有 ストレージ動的拡張 ストレージ最大数 1ストレージの最大容量 ストレージバックアップ ストレージ自動バックアップ ストレージストライピング 一時ストレージ EBS 可 ◯ × ◯ Linux: 40、Windows: 17〜26 16TB ◯ ◯ ◯ ○ インスタンスストア Managed Disk, Azure Disk Storage 可 ◯ × × (インスタンス停止が必要) 4TB ◯ ○ 一時ディスク 永続ディスク 可 ◯ 永続ディスクを読み取り専用で利用すれば〇 ◯ 4〜16 64TB(共有したときの最大容量も64TB) ◯ ◯ △ (できるが、推奨ではない) ◯ ローカル SSD (375GB×8本) その他
Iaasの監視 オートスケーリング EC2 Systems Manager Amazon EC2 Auto Scaling Azure Monitor マネージドインスタンスグループ 検討するときのポイント
課金体系、選べるコアやメモリ等のオプション、OSの種類、GPUへの対応、ネットワークの帯域、長期契約による割引などの観点から検討し、要件に合致することを確認
Linux Windows FreeBSD その他 AWS Amazon Linux Amazon Linux 2 Ubuntu RHEL SUSE Windows Server 2003 Azure CentOS Debian Ubuntu RHEL Windows Server 2008 2012 GCP CentOS. Debian Ubuntu CoreOS RHEL SUSE Windows Server 2008 特徴
AWS インフラを提供するIaaS(Infrastructure as a Service)の種類が豊富で、OSやミドルウェアの制限が少ないのも特徴です。こんな時に使ったほうがいい
AWS 日本語のナレッジをたくさん参照したい。商用ライセンスの正式サポートが必須。一定負荷のサーバーを長期にわたって利用する Azure GCP サーバーを細かくカスタマイズしたい起動速度が圧倒的に早いライブマイグレーションもできる 料金比較もしたいのですが、難しい・・
AWS:https://aws.amazon.com/jp/ec2/pricing/on-demand/
Azure:https://azure.microsoft.com/ja-jp/pricing/details/virtual-machines/linux/
GCP:https://cloud.google.com/compute/vm-instance-pricing?hl=ja
- 投稿日:2021-01-14T06:19:41+09:00
AWS から"0.09$"請求されてめちゃくちゃあせった話
はじめに
私は現在、エンジニアへの転職のために、Railsチュートリアルの勉強をしており、
AWSのcloud9にて環境構築を実施していました。
その際に、awsからの支払い通知メールに大変ビビったお話(無料分で十分なはずなのに!)についてご紹介できればと思います。AWSより警告メール受信...
Railsチュートリアルの環境構築のために、初めてAWSのcloud9を設定し、学習を開始。
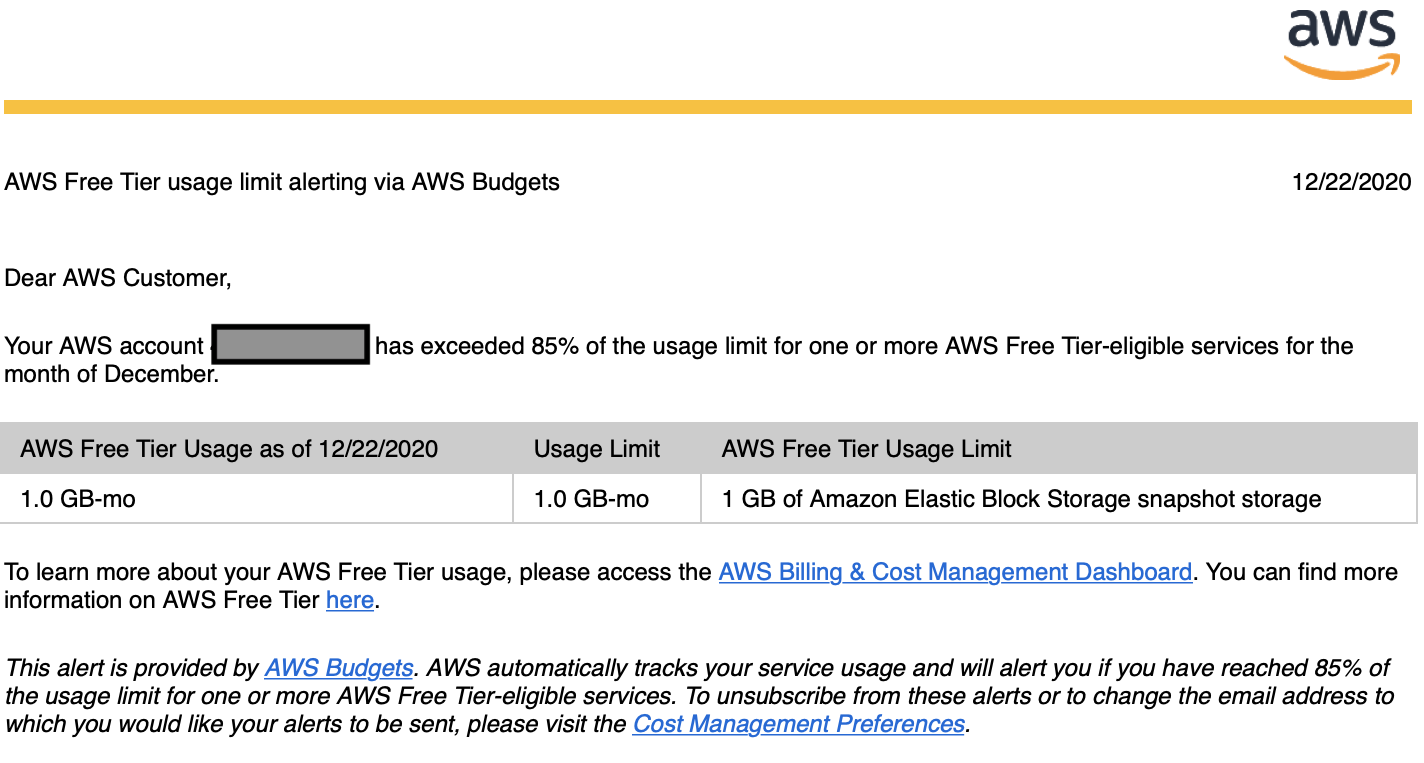
しばらくすると、下記メールが届く。
英語で書いてあったため最初はスルーしていたが、何やら容量オバーとの記載があり不安になり確認。
何やらスナップショットの容量がいっぱいになっているとのこと。
AWS Cost Explorerにて請求金額を確認(まず何を見ればいいのかも分からなかった...)
詳細を確認すると、やはり下記の通り、スナップショットのデータ容量が無料分の枠をオーバーし、0.07$の請求が確定していることを確認。
金額は大したことはないのですが、何が原因で容量が無料分をオーバーしているのか分からずにかなりビビりました...。
スナップショットの容量を確認
スナップショットとは:ボリューム(データディスク
)のバックアップのようなもの
スナップショット作成を実行した時のデータボリュームの状態を保存しておき、その時点からデータボリュームに書き込みなどがされて状態が変わったらその差分をすべて記録しているもの、のようです。AWS EC2より、スナップショットを確認すると、身に覚えのないスナップショットが2つ存在していることを確認!(ボリューム容量を変えたり、新規作成した際に、残ってしまったのかも。)
実はこの前に下記URLのような容量オーバーのエラーが発生していたため、
ボリュームの容量を10→30GBへ変更したり、何個かボリュームの追加/削除を繰り返していたため、
それが原因なのかも。Cloud 9にてRailsチュートリアル環境設定時の容量オーバーに関して
https://qiita.com/t4141sjglobal/items/7839a0edeac29eef4744スナップショット削除
とりあえず、不安だったため、保有しているスナップショットは全て削除!!
(ただし、データのバックアップのようなものだそうですので、保険としてひとつは残しておいた方が
いいのかな?今回はRailチュートリアルの内容だったので、バックアップは不要と考えた)
下記が参考になると思います!Amazon EC2のスナップショットを削除しようとしたらエラーになった話
https://dev.classmethod.jp/articles/error-remove-snapshot-ec2/
AWSでAMIが勝手にスナップショット作ってて課金されてた件
https://www.durianhunter.com/archives/awssnapshot.htmlちなみにスナップショットに料金は
EBS スナップショット 1 か月に格納されたデータ 1 GB あたり 0.05USD
みたいです。その後
スナップショット削除後しばらくは、AWSからのメールに怯えていましたが(やはり初めての体験なので
すごくドキドキする笑)、これ以上請求額が増える事もなく、無事にお支払いが完了しました。
毎日、aws cost explolerを見てました...。やっておいた方がいい事
最後になりますが、初学者の方で、awsの料金体制が分からず不安な夜を過ごしている方は、
ぜひ、下記の請求アラームの作成を実施しておいてください!
私も今回のことがあり、設定しました!AWS の予想請求額をモニタリングする請求アラームの作成
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.html最後までご覧頂きましてありがとうございました。
現在、ポートフォリオにおける使用技術の選定の段階に入りましたので、
また不明点は投稿していきたいと考えております
。

- 投稿日:2021-01-14T06:19:41+09:00
AWS から"$0.09"請求されてめちゃくちゃあせった話
はじめに
私は現在、エンジニアへの転職のために、Railsチュートリアルの勉強をしており、
AWSのcloud9にて環境構築を実施していました。
その際に、awsからの支払い通知メールに大変ビビったお話(無料分で十分なはずなのに!)についてご紹介できればと思います。AWSより警告メール受信...
Railsチュートリアルの環境構築のために、初めてAWSのcloud9を設定し、学習を開始。
しばらくすると、下記メールが届く。
英語で書いてあったため最初はスルーしていたが、何やら容量オバーとの記載があり不安になり確認。
何やらスナップショットの容量がいっぱいになっているとのこと。
AWS Cost Explorerにて請求金額を確認(まず何を見ればいいのかも分からなかった...)
詳細を確認すると、やはり下記の通り、スナップショットのデータ容量が無料分の枠をオーバーし、0.07$の請求が確定していることを確認。
金額は大したことはないのですが、何が原因で容量が無料分をオーバーしているのか分からずにかなりビビりました...。
スナップショットの容量を確認
スナップショットとは:ボリューム(データディスク
)のバックアップのようなもの
スナップショット作成を実行した時のデータボリュームの状態を保存しておき、その時点からデータボリュームに書き込みなどがされて状態が変わったらその差分をすべて記録しているもの、のようです。AWS EC2より、スナップショットを確認すると、身に覚えのないスナップショットが2つ存在していることを確認!(ボリューム容量を変えたり、新規作成した際に、残ってしまったのかも。)
実はこの前に下記URLのような容量オーバーのエラーが発生していたため、
ボリュームの容量を10→30GBへ変更したり、何個かボリュームの追加/削除を繰り返していたため、
それが原因なのかも。Cloud 9にてRailsチュートリアル環境設定時の容量オーバーに関して
https://qiita.com/t4141sjglobal/items/7839a0edeac29eef4744スナップショット削除
とりあえず、不安だったため、保有しているスナップショットは全て削除!!
(ただし、データのバックアップのようなものだそうですので、保険としてひとつは残しておいた方が
いいのかな?今回はRailチュートリアルの内容だったので、バックアップは不要と考えた)
下記が参考になると思います!Amazon EC2のスナップショットを削除しようとしたらエラーになった話
https://dev.classmethod.jp/articles/error-remove-snapshot-ec2/
AWSでAMIが勝手にスナップショット作ってて課金されてた件
https://www.durianhunter.com/archives/awssnapshot.htmlちなみにスナップショットに料金は
EBS スナップショット 1 か月に格納されたデータ 1 GB あたり 0.05USD
みたいです。その後
スナップショット削除後しばらくは、AWSからのメールに怯えていましたが(やはり初めての体験なので
すごくドキドキする笑)、これ以上請求額が増える事もなく、無事にお支払いが完了しました。
毎日、aws cost explolerを見てました...。やっておいた方がいい事
最後になりますが、初学者の方で、awsの料金体制が分からず不安な夜を過ごしている方は、
ぜひ、下記の請求アラームの作成を実施しておいてください!
私も今回のことがあり、設定しました!AWS の予想請求額をモニタリングする請求アラームの作成
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.html最後までご覧頂きましてありがとうございました。
現在、ポートフォリオにおける使用技術の選定の段階に入りましたので、
また不明点は投稿していきたいと考えております
。