- 投稿日:2021-01-11T23:24:58+09:00
sympyとDecimalは仲悪いみたい
Decimalオブジェクトをfrom sympy import * from decimal import * getcontext().prec = 100 # Decimalの精度100桁 弟子丸 = Decimal(1)/ Decimal(3) x = Symbol("x") print("decimal:", 弟子丸) print("sympy.nsolve:", nsolve(x-弟子丸, x, 1, prec=100)) # =0 について解く 初期予測値 精度これを
Python 3.8.3 (default, Jul 2 2020, 17:30:36) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32な環境で実行した結果が次の通り結果decimal: 0.3333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333 sympy.nsolve: 0.3333333333333333148296162562473909929394721984863281250000000000000000000000000000000000000000000000
decimalオブジェクトをsympyに渡すと、精度が落とされてしまうようだ。
ちなみにこれはnsolveだけの問題ではなく、evalfを使っても同様。expr = x print("sympy.evalf:", expr.evalf(100, subs={x:d}))結果sympy.evalf: 0.3333333333333333148296162562473909929394721984863281250000000000000000000000000000000000000000000000次のように、未計算のオブジェクトを渡し、
sympyに解かせれば、確かにsympyでもちゃんとした精度を得られる。y = Symbol("y") expr = x/y print("sympy.evalf:", expr.evalf(100, subs={x:Decimal(1), y:Decimal(3)}))結果sympy.evalf: 0.3333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333
- 投稿日:2021-01-11T23:19:10+09:00
rembgを用いて白背景+人物動画を黒背景動画にした話
概要
ffmpeg、rembg、opencvを使って、白背景+人物の動画を黒背景+人物動画にした。
背景
結婚式の余興で、香水のパロディー動画を作成することになった。
香水のMVのように黒背景で人が歌っている動画を作成したかったが、黒い布を買うといった手間をかけたくなかった。白背景ならどこでも撮影可能なので、白背景をなんとか黒背景にしたかった。どんな感じになったか
これが、
こんな感じになった。素晴らしい精度です。rembgすごい。他の人物切り抜き方法も色々試しましたが、これが一番自然でした。※モザイク化には、https://www.facepixelizer.com/jp/
を使わせていただきました。前提
- pythonがインストールされている。
- rembgがインストールされている。(このインストールがやっかいです。別で解説してもいいかも)
- opencvがインストールされている。
- ffmpegがインストールされ、PATHが通っている。
手順
- 動画ファイル用意(MP4等、FPSは必要以上あげない(処理が重くなる))
- 動画ファイルを画像ファイルに分解。
コマンド例(rawフォルダに動画のコマ画像が出力される):ffmpeg -i ~~.mp4 -vcodec png raw\image_%05d.png
- rembgを用いて画像ファイルの人物を切り抜く。動画の全画像を対象とするので、結構時間がかかる。
コマンド例:rembg -a -ae 15 -o output1\image_252.png raw\image_00001.png
https://github.com/danielgatis/rembg
を用いるが、導入がけっこう大変だった。pytorch、torchvisionのバージョン等が難しい。
pyenvやcondaの仮想環境で構築するのがいいと思う。
人物を切り抜いたあとの透明な部分を違う画像もしくは任意の色で塗りつぶす。
opencvでやった。画像を動画化
コマンド例:ffmpeg -f image2 -r 30 -i image_%03d.png -r 30 -an -vcodec libx264 -pix_fmt yuv420p video.mp4
使用したスクリプト
フォルダ構成
今回使用したスクリプトのフォルダ構成は以下の通り。
root/ ├ raw_video/ # 未加工動画を保存するフォルダ ├ formatted_video/ #toMP4.pyでFPS、画質を調整した動画を保存するフォルダ ├ output/ # 最終的に生成される動画を保存するフォルダ ├ mask/ # 背景用黒画像を保存するフォルダ └ black.png # 動画のサイズに合わせて、1920x1080の黒画像を用意。黒でなくても問題はない。 ├ tmp1/ # formatted_videoの動画を画像化したものを保存するフォルダ ├ tmp2/ # tmp1の画像をrembgで白背景を透明にした画像を保存するフォルダ ├ tmp3/ # tmp2の画像とをmask/black.pngの画像をopencvで合成し、黒背景にした画像を保存するフォルダ ├ toMP4.py # raw_videoの動画のFPS、画質を調整して、formatted_videoフォルダに入れるスクリプト └ main.py # 一連の処理を行うスクリプト
フルHD、30FPSのMP4ファイルにするコード(toMP4.py)
ffmpegのコマンドをpythonで生成し、実行するスクリプト。
import os base_dir = "raw_video" output_dir = "formatted_video" fns = os.listdir(base_dir) print(len(fns)) for f in fns: print(f) cmd = "ffmpeg.exe -i {} -s hd1080 -c:v libx264 -c:a copy -r 30 {} -y".format( base_dir + "\\" + f, output_dir + "\\" + f + "__.mp4") os.system(cmd)一連の処理を行うコード(main.py)
- 動画ファイルを画像ファイルに分解。
- rembgを用いて画像ファイルの人物を切り抜く。動画の全画像を対象とするので、結構時間がかかる。
- 人物を切り抜いたあとの透明な部分を違う画像もしくは任意の色で塗りつぶす。
- 画像を動画化
import os import shutil import cv2 import matplotlib.pylab as plt base_dir = "formatted_video" tmp1_dir = "tmp1" tmp2_dir = "tmp2" tmp3_dir = "tmp3" output_dir = "output" fns = os.listdir(base_dir) print(len(fns)) for f in fns: bn = os.path.basename(f) print(f) # フォルダ作成 shutil.rmtree(tmp1_dir) os.makedirs(tmp1_dir) shutil.rmtree(tmp2_dir) os.makedirs(tmp2_dir) shutil.rmtree(tmp3_dir) os.makedirs(tmp3_dir) # os.makedirs(output_dir) # # 動画ファイルを画像ファイルに分解 p1 = base_dir + "\\" + f p2 = tmp1_dir + "\\" + bn + "_%05d.png" cmd1 = "ffmpeg -i {} -vcodec png {}".format(p1, p2) print(cmd1) os.system(cmd1) # rembgを用いて画像ファイルの人物を切り抜く fn2s = os.listdir(tmp1_dir) for f2 in fn2s: if(f2[-3:] != "png"): continue p3 = tmp1_dir + "\\" + f2 p4 = tmp2_dir + "\\" + f2 cmd2 = "rembg -a -ae 15 -o {} {}".format(p4, p3) print(cmd2) os.system(cmd2) # 人物を切り抜いたあとの透明な部分を違う画像もしくは任意の色で塗りつぶす fn2s = os.listdir(tmp2_dir) for f2 in fn2s: if(f2[-3:] != "png"): continue print('{}/{}'.format(tmp2_dir, f2)) frame = cv2.imread('mask/black1.png') png_image = cv2.imread('{}/{}'.format(tmp2_dir, f2), cv2.IMREAD_UNCHANGED) # アル ファチャンネル込みで読み込む # png_image[:, :, 3:] = np.where(png_image[:, :, 3:] > 200, 255, 0) x1, y1, x2, y2 = 0, 0, png_image.shape[1], png_image.shape[0] frame[y1:y2, x1:x2] = frame[y1:y2, x1:x2] * (1 - png_image[:, :, 3:] / 255) + \ png_image[:, :, :3] * (png_image[:, :, 3:] / 255) # plt.imshow(frame) # plt.show() cv2.imwrite('{}/{}'.format(tmp3_dir, f2), frame) # 画像を動画化 cmd3 = "ffmpeg -f image2 -r 30 -i {} -r 30 -an -vcodec libx264 -pix_fmt yuv420p {}.mp4 -y".format( tmp3_dir + "\\" + bn + "_%05d.png", output_dir + "\\" + bn + "_bg_blk") os.system(cmd3) # breakデバッグ用に、余計なコードも入ってます。
rembgのインストール
- Anacondaで仮想環境を作る。(python=3.8)
- conda install pytorch===1.7.0 torchvision===0.8.1 torchaudio cpuonly -c pytorch
- pip install rembg==1.0.18
- pip install numpy==1.19.3 → rembgインストール時、numpy 1.19.4がインストールされるが、うまく動かなかったため、1.19.3にした。
- ついでにopencvもインストールしとく。pip install opencv-python
- 仮想環境上で、rembg -o 〇〇.png ✕✕.pngを実行し、✕✕.jpg画像の人物以外が透過された〇〇.pngファイルが出力されていればOK。
最後に
あくまで自分のメモ程度の内容なので、わからにくい部分もあるかと思いますが、ご了承ください。


- 投稿日:2021-01-11T23:18:13+09:00
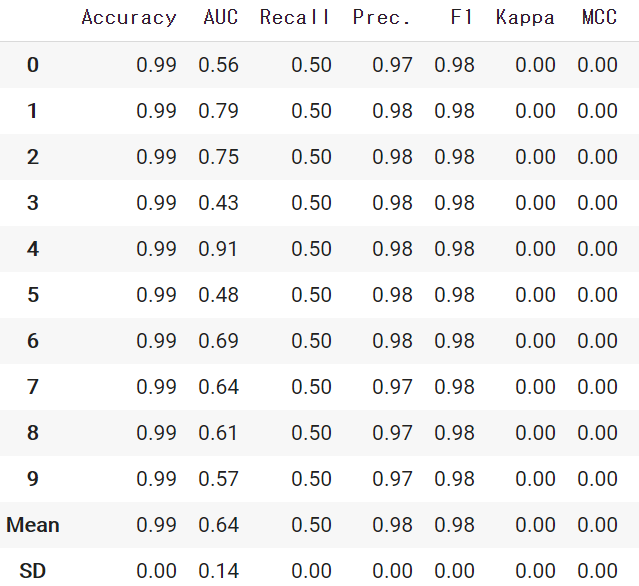
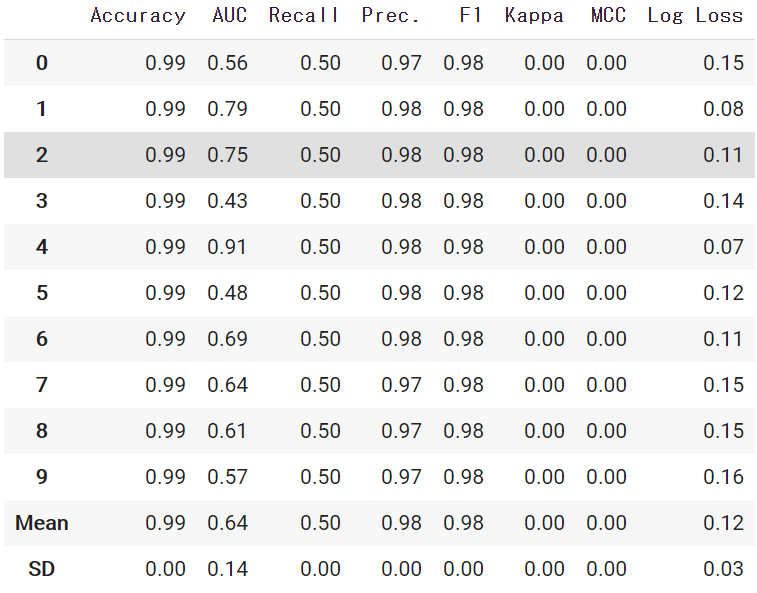
pycaretに任意の評価指標を追加するadd_metricメソッドの調査
はじめに
pycaretで評価指標のloglossを使おうと思ったのですが、デフォルトではloglossが無かったので、追加する方法を調査しました。
以前まで、評価指標を追加することができなかったのですが、2020年10月のアップデート(version 2.2.0)で評価指標を任意に追加できるようになったようです。環境とバージョン
- PyCaret 2.2.0
- Google Colaboratory
pycaretとは
pycaretとは、機械学習の前処理からモデリングまで自動でしてくれる機械学習ライブラリです。
デフォルトで使える評価指標
add_metricメソッドについて
add_metricメソッドを使用することで、scikit_learnで利用可能な任意の評価指標や、make_scorer関数を使用した独自の評価指標を扱うことができるようになります。
from pycaret.classification import add_metric from sklearn.metrics import log_loss add_metric('logloss', 'Log Loss', log_loss, greater_is_better = False)add_metric()の引数の説明です。
- id: 1つ目の引数
- str型
- 評価指標のID
- name: 2つ目の引数
- str型
- 評価指標を表示する際の名称
- score_func: 3つ目の引数
- type型
- 追加したい評価指標
- 今回の場合は、sklearnから引っ張ってきたlog_lossを入れています
- greater_is_better: 4つ目の引数
- bool型
- デフォルト=True
- score_funcが数値が高いほうが良い指標なのか、低いほうが良い指標なのかを表します。
- Trueでは高いほうが、Falseでは低いほうが良いということになります。
では、再度評価指標を確認してみます。
無事にloglossを追加することできました。
参考サイト
https://pycaret.readthedocs.io/en/latest/api/clustering.html
- 投稿日:2021-01-11T23:09:13+09:00
Power Automate Desktop カナ英数の半角全角変換
概要
データ収集から入力までの自動化をする場合、半角全角の表記揺れ修正は課題の一つになります。
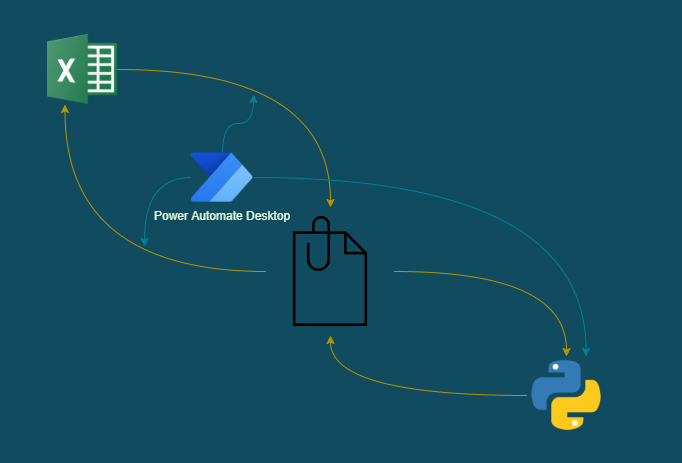
その中で正規表現での修正が難しいと思われるカナ英数の半角to全角変換を行います。Power Automate Desktop(以下PAD)の「クリップボードアクション」を用いてpythonとデータ交換を行い、ライブラリを利用して半角全角表記の修正方法を考えてみました。
デモは、下記テストデータの半角全角表記が滅茶苦茶な住所っぽいデータを全角に変換しています。前提条件
Windows10pro 20H2
Power Automate Desktop 2.2.20339.22608
.pyファイルが実行できることPython 3.8.5
pandas 1.1.4
mojimoji 0.0.11Pythonライブラリとして日本語文字列を高速に半角・全角変換できるライブラリ「mojimoji」及び「Pandas」を利用させて頂いております。
Pythonはディストリビューションではなくhttps://www.python.org/のインストーラーを使っています。
ライブラリは個別にインストールしています。
2021年1月の情報です。フローイメージ
PADのクリップボードアクションとPandasのデータフレームをクリップボードで入出力できる機能を利用してデータ交換を行います。1.変換したい列のデータをクリップボードにコピー
2.クリップボードからPandasデータフレームに読み込み
3.mojimojiで半角→全角変換処理
4.クリップボードに格納
5.Excelにペースト準備
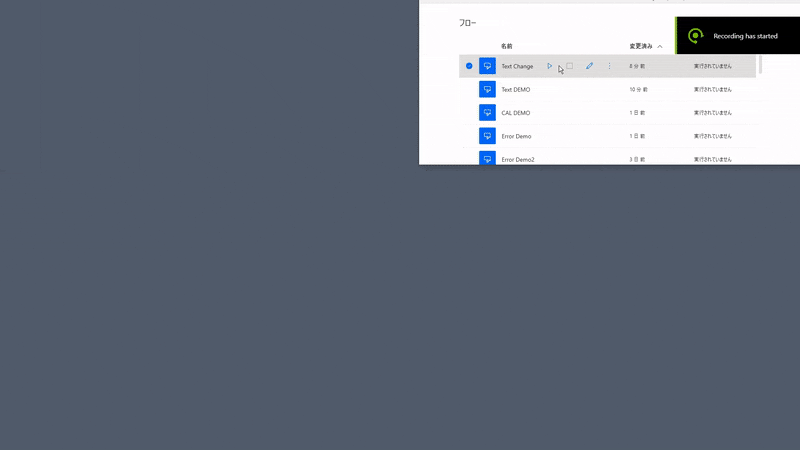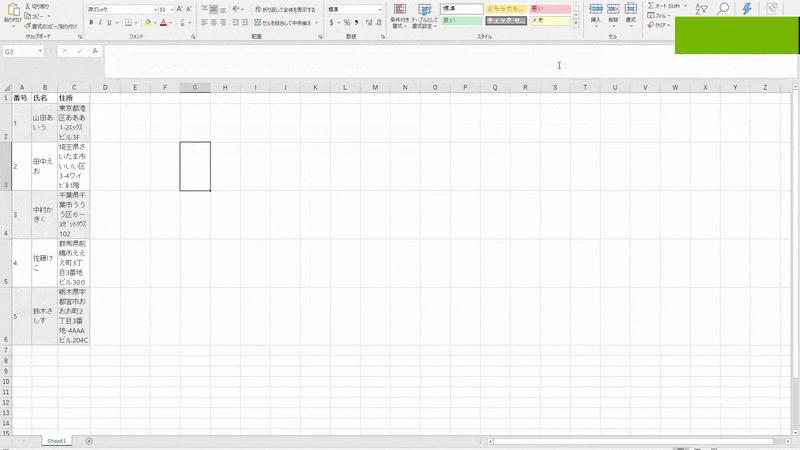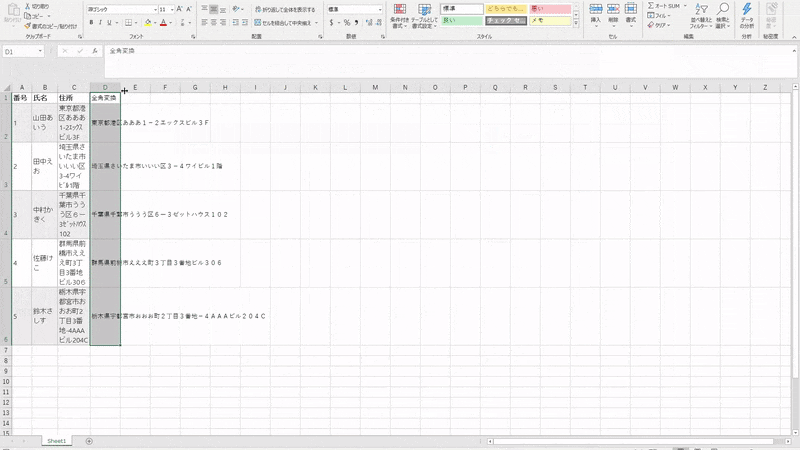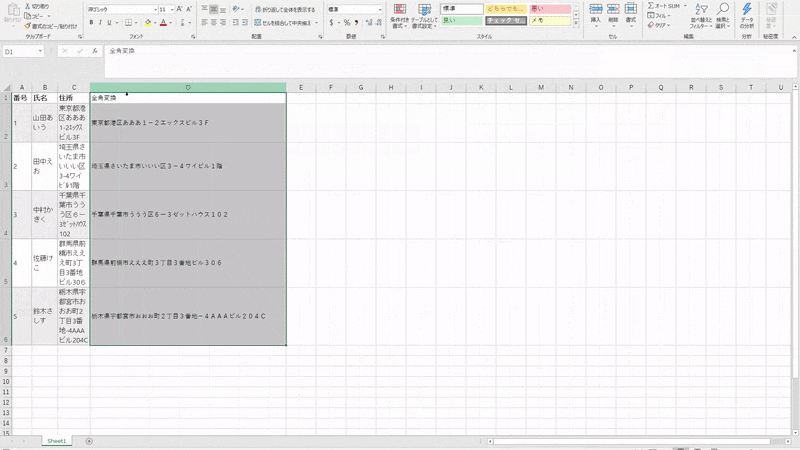
テストデータを用意します。
番号 氏名 住所 1 山田あいう 東京都港区あああ1-2エックスビル3F 2 田中えお 埼玉県さいたま市いいい区3-4ワイビル1階 3 中村かきく 千葉県千葉市ううう区6ー3ゼットハウス102 4 佐藤けこ 群馬県前橋市えええ町3丁目3番地ビル306 5 鈴木さしす 栃木県宇都宮市おおお町2丁目3番地-4AAAビル204C 空のExcelに上記テーブルデータを貼り付けてdummytest.xlsxとしてデスクトップに保存してください。
mojimoji及びpandasをvenvではないpython実行環境にインストールが必要です。
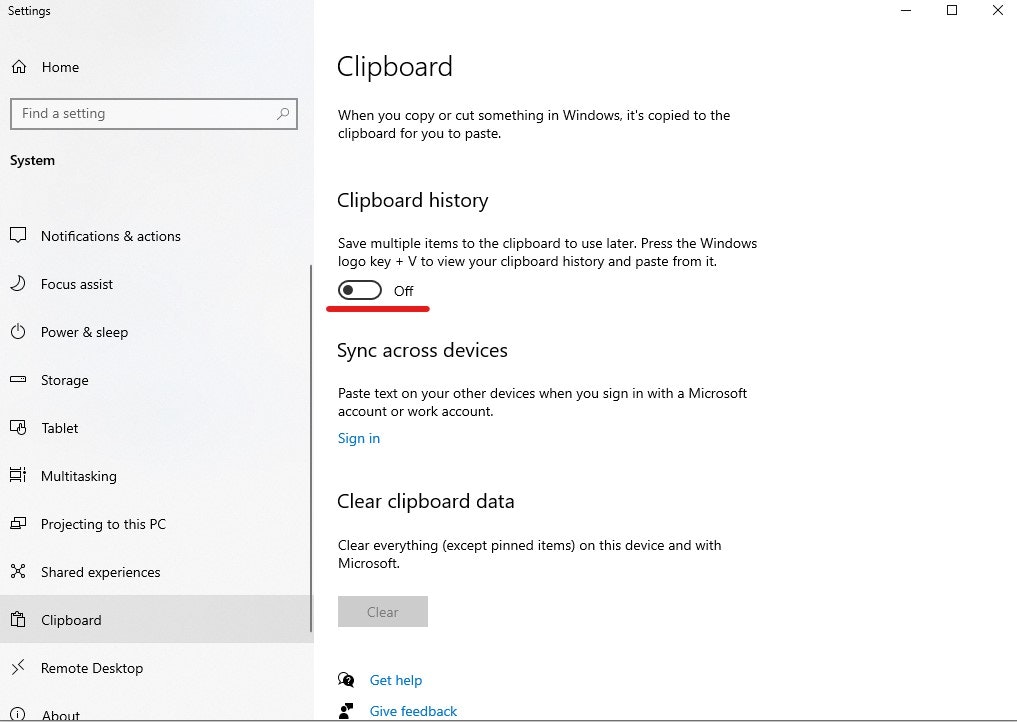
% py -m pip install pandas % py -m pip install mojimojiクリップボードの履歴がオンになっているとPADの「クリップボードの内容ををクリア」アクションがうまく動作しないようなのでオフにしておきます。設定>システム>クリップボード。
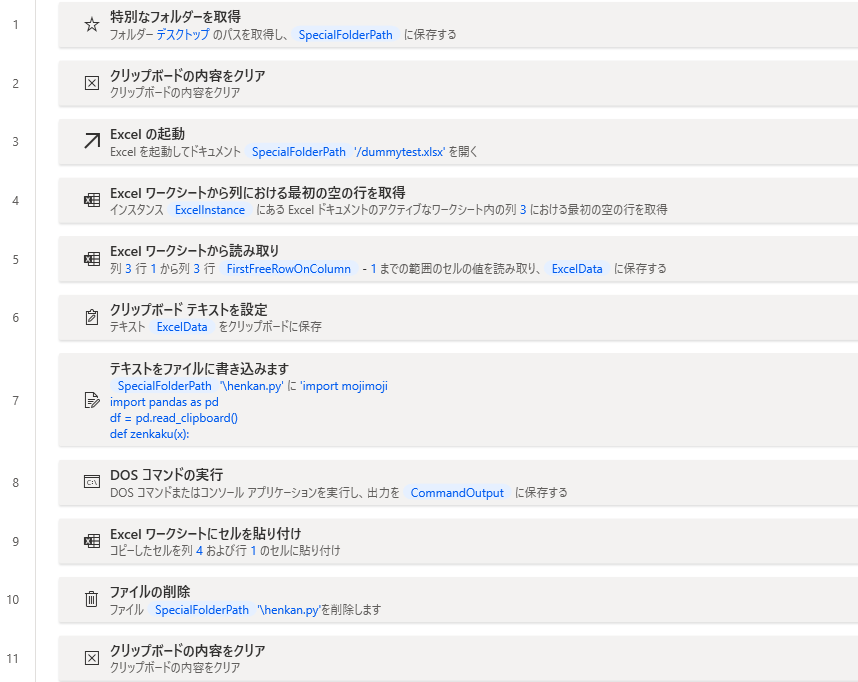
フロー作成
- 特別なフォルダーを取得
クリップボードの内容をクリア
Excelの起動 パスは
%SpecialFolderPath%/dummytest.xlsx
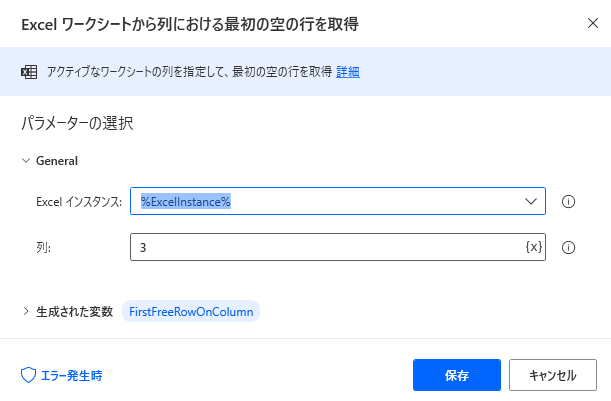
準備で用意したテストデータを指定しています。Excelワークシートから列における最初の空の行を取得
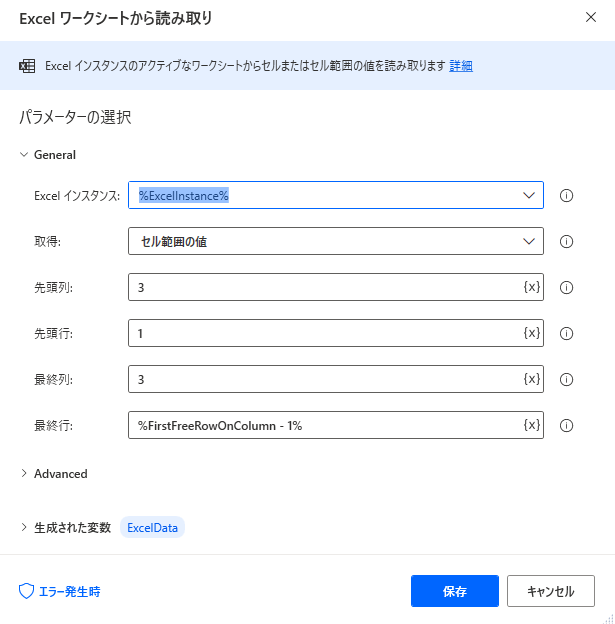
Excelワークシートから読み取り
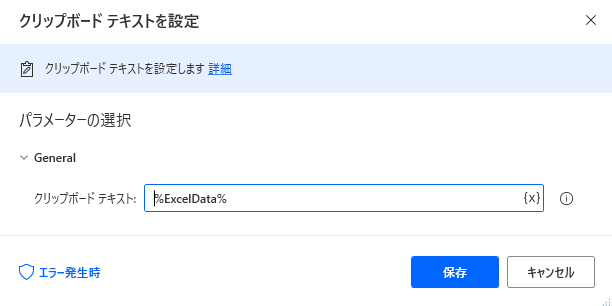
クリップボードテキストを設定
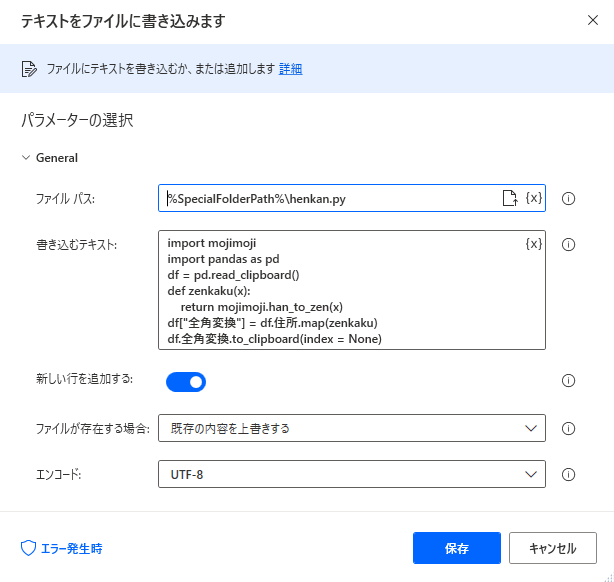
テキストをファイルに書き込みます
ここでPythonスクリプトを作成するのですが、現在のPADの仕様では複数行のテキストが「書き込むテキスト」に記入できません。
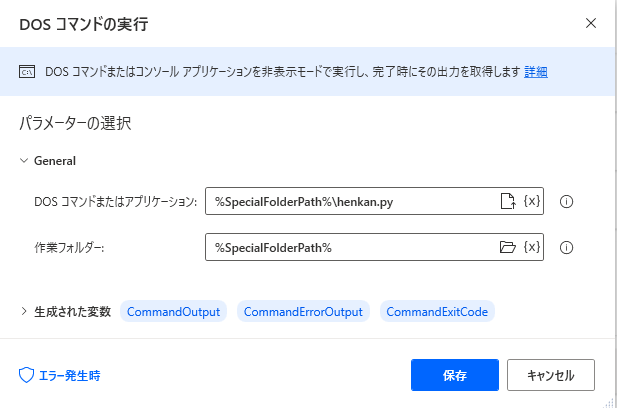
以前書いた記事になりますがご参考にしていただければ幸いです。henkan.pyimport mojimoji import pandas as pd df = pd.read_clipboard() def zenkaku(x): return mojimoji.han_to_zen(x) df["全角変換"] = df.住所.map(zenkaku) df.全角変換.to_clipboard(index = None)8 . DOSコマンドの実行
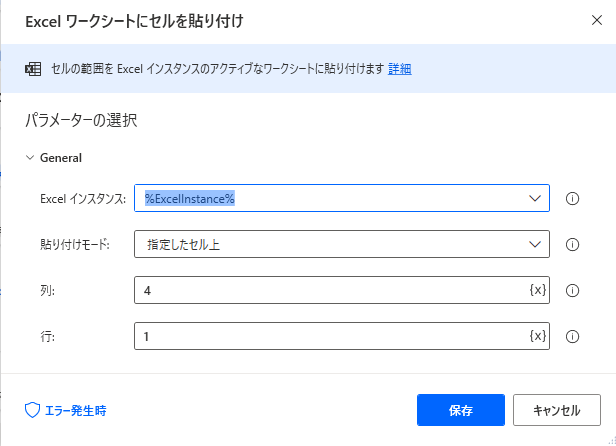
pythonスクリプトを実行し、半角全角変換処理をしたデータフレーム(テーブル)をクリップボードに格納します。9 . Excelワークシートにセルを貼り付け
アクション名は「Excelワークシートにセルを貼り付け」となっていますがセルにクリップボードの内容をペーストすることができます。
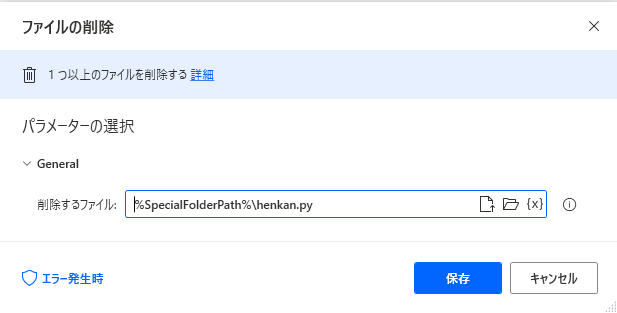
10 . ファイルの削除
pythonスクリプトを削除します。
11 . クリップボードの内容をクリアフロー全体像
たったこれだけ(;'∀')PowerAutomateDesktopRobinFolder.GetSpecialFolder SpecialFolder: Folder.SpecialFolder.DesktopDirectory SpecialFolderPath=> SpecialFolderPath Clipboard.Clear _ Excel.LaunchAndOpen Path: $'''%SpecialFolderPath%/dummytest.xlsx''' Visible: True ReadOnly: False LoadAddInsAndMacros: False Instance=> ExcelInstance Excel.Advanced.GetFirstFreeRowOnColumn Instance: ExcelInstance Column: 3 FirstFreeRowOnColumn=> FirstFreeRowOnColumn Excel.ReadCells Instance: ExcelInstance StartColumn: 3 StartRow: 1 EndColumn: 3 EndRow: FirstFreeRowOnColumn - 1 ReadAsText: False FirstLineIsHeader: False RangeValue=> ExcelData Clipboard.SetText Text: ExcelData File.WriteText File: $'''%SpecialFolderPath%\\henkan.py''' TextToWrite: $'''import mojimoji import pandas as pd df = pd.read_clipboard() def zenkaku(x): return mojimoji.han_to_zen(x) df[\"全角変換\"] = df.住所.map(zenkaku) df.全角変換.to_clipboard(index = None)''' AppendNewLine: True IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.UTF8 System.RunDOSCommand DOSCommandOrApplication: $'''%SpecialFolderPath%\\henkan.py''' WorkingDirectory: $'''C:\\Users\\Aphrodite\\Desktop''' StandardOutput=> CommandOutput StandardError=> CommandErrorOutput ExitCode=> CommandExitCode Excel.Advanced.PasteAt Instance: ExcelInstance Column: 4 Row: 1 File.Delete Files: $'''%SpecialFolderPath%\\henkan.py''' Clipboard.Clear _まとめ
PADとPandas間でクリップボードによるデータの伝達が可能です。
Pythonの素晴らしいライブラリを利用させていただけるおかげで(自分にとって)難題が一つ解決しました。
他にも素晴らしいライブラリがたくさんあるのでpython連携は色々出来そうです。
そのためにもテキストアクションを通常方法で複数行が使えるように修正して欲しいです。(Winautomationは可能)
クリップボード関連のアクションを持っているRPAツールであれば同様の方法が可能と思われます。手動で変換するのであればExcelのJIS関数でも可能です。
私は関数を多用したフォーマットはなるべく使いたくないという理由と、正規表現を使ってPAD内だけで実現を考えましたがうまくいかなかったため、今回の方法をとりました。本当は入力段階で強制されているのが一番だと思います。(;'∀')
参考
追記
PADに実装されているPython2からunicodedata.normalizeも試してみましたが文字数がおかしくなるので断念しました。
参考 文字コード地獄秘話 第3話:後戻りの効かないUnicode正規化

- 投稿日:2021-01-11T23:01:38+09:00
クラスの関数にダブルアンダースコア使用時(Private属性)の呼び出し方について
クラス内の関数にダブルアンダースコアを指定してPrivate属性としてみたが、関数を呼び出す時に嵌ったので記録・・・。
<追記(pep8より参照):尚、一般的には、アンダースコアを名前の先頭に二つ付けるやり方は、サブクラス化されるように設計されたクラスの属性が衝突したときに、それを避けるためだけに使うべきです。>class HogeHoge: def __init__(self): pass def __FugaFuga(self): iam = "king" return iamこの時の__FugaFugaの返り値”king”をPrintしたいが、
iam = _HogeHoge__FugaFuga() print(iam) # iam = _HogeHoge__FugaFuga() # NameError: name '_HogeHoge__FugaFuga' is not defined
NameErrorで_HogeHoge__FugaFugaは見つからないと・・・HogeHoge = HogeHoge() iam = HogeHoge.__FugaFuga() # iam = HogeHoge.__FugaFuga() # AttributeError: 'HogeHoge' object has no attribute '__FugaFuga'ではクラスと関数を分離すると関数
__FugaFugaが見つかりません・・・。
成功例:class HogeHoge: def __init__(self): pass def __FugaFuga(self): iam = "common people" return iam HogeHoge = HogeHoge() iam = HogeHoge._HogeHoge__FugaFuga() print(iam)実行結果:
C:\Users\***\test>python main.py common peopleクラス
HogeHogeの関数が_HogeHoge__FugaFugaとなるようです。下記のサイトの記事を参考にさせていただきました。
Pythonのアンダースコア( _ )を使いこなそう!
pythonのカプセル化とマングリングについて
PEP8:Python コードのスタイルガイド
- 投稿日:2021-01-11T22:55:01+09:00
新型コロナウイルス感染症に関する相模原市発表資料(発生状況等)のPDFをCSVに変換
import datetime import pathlib import re from urllib.parse import urljoin import pandas as pd import pdfplumber import requests from bs4 import BeautifulSoup def fetch_file(url, dir="."): r = requests.get(url) r.raise_for_status() p = pathlib.Path(dir, pathlib.PurePath(url).name) p.parent.mkdir(parents=True, exist_ok=True) with p.open(mode="wb") as fw: fw.write(r.content) return p url = "https://www.city.sagamihara.kanagawa.jp/shisei/koho/1019191.html" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") tag = soup.find( "a", href=re.compile(".pdf$"), onclick=re.compile("新型コロナウイルス感染症による新たな患者の確認") ) link = urljoin(url, tag.get("href")) path_pdf = fetch_file(link) with pdfplumber.open(path_pdf) as pdf: dfs = [] for page in pdf.pages: if page.page_number == 1: # cropでテキスト取得 crop = page.within_bbox((400, 44, page.width, 60)) update = crop.extract_text() for table in page.extract_tables(): df_tmp = pd.DataFrame(table) row, col = df_tmp.shape # 列が11 if col == 11: # 表の一番先頭に未満が含まれない if "未満" not in table[0][0]: dfs.append(df_tmp) df = ( pd.concat(dfs) .iloc[1:] .set_axis( ["症例No.", "年代", "性別", "職業等", "場所", "居住地", "症状", "発症日", "陽性判明日", "感染経路等", "備考"], axis=1, ) ) df # 前後の空白文字、正規化 for col in df.select_dtypes(include=object).columns: df[col] = df[col].str.replace("\s", "").str.normalize("NFKC") dt_now = datetime.datetime.now() def str2date(s: pd.Series) -> pd.Series: df = ( s.str.extract("(\d{1,2})月(\d{1,2})日") .rename(columns={0: "month", 1: "day"}) .fillna(0) .astype(int) ) df["year"] = dt_now.year tmp = pd.to_datetime(df, errors="coerce") df["year"] = df["year"].mask(tmp > dt_now, df["year"] - 1) return pd.to_datetime(df, errors="coerce") df["発症日YMD"] = str2date(df["発症日"]) df["陽性判明日YMD"] = str2date(df["陽性判明日"]) y, m, d = map(int, re.findall("\d+", update)) dt_update = datetime.datetime(2018 + y, m, d) df.to_csv(f'sagamihara{dt_update.strftime("%Y%m%d")}.csv', encoding="utf_8_sig")
- 投稿日:2021-01-11T22:37:10+09:00
備忘録:Anaconda起動してPythonの仮想環境入ってMongoDBにローカル接続
※備忘録
開発中アプリに移動
terminalにてcdとかでディレクトリ内に入る。
Anacondaを起動↓
base(現在の場所)から、仮想環境(私の場合は作成した名前がpy3_aaaa)へ移動する為、下記を入力$ (base) lancai@oja % source activate py3_aaaa #py3_aaa:作成した仮想環境名↓今回の開発環境が
APIなので
uvicorn prog:app --reload --host 0.0.0.0 --port 8100の
progをapiに置き換えたもの(下記)を入力$ (base) lancai@oja % uvicorn api:app --reload --host 0.0.0.0 --port 8000これで接続完了となる!
MongoDBにローカル接続できない時に確認すること
開発中のアプリディレクトリ
..>src>db>connect.py内に、
設定したusernameとpasswordが記述されているか確認。なければ追記する。pythonfrom pymongo import MongoClient # DB接続 def get_connect(): # mongoDBローカル接続 client = MongoClient("mongodb://(※ここにusername):(ここにpassword)@localhost:27017/") # 使用DB (DBを指定) db = client.(※ここにDB名が入る) return dbterminalにて下記コマンド入力
terminal$ uvicorn api:app --reload --host 0.0.0.0 --port 8000【補足】MongoDBに設定したusernameなどの情報を確認する方法
①terminalにて開発中アプリの
docker-composer.ymlファイルが置いてある場所へ移動②↓terminalにてcat”で参照する。
terminal$ cat docker-compose.yml③↓
environment:部分に記載してある^^terminalenvironment: MONGODB_USERNAME: ***** MONGODB_PASSWORD: ***** MONGODB_HOSTNAME: *****db # VIRTUAL_HOST: "" # LETSENCRYPT_HOST: "" # LETSENCRYPT_EMAIL: "*********@gmail.com"
- 投稿日:2021-01-11T22:31:17+09:00
VBAユーザがPython・Rを使ってみた:文字列操作
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
文字列操作
文字列の結合
Python
Python3s1 = 'abc' s2 = 'def' s3 = 'ghij' print(s1 + s2 + s3) # abcdefghijPythonでは算術演算と同じ
+演算子を使います。ちなみに*演算子は文字列の繰り返しに使います(後述)。R
Rs1 <- "abc" s2 <- "def" s3 <- "ghij" paste0(s1, s2, s3) # "abcdefghij" paste(s1, s2, s3) # "abc def ghij" paste(s1, s2, s3, sep="") # "abcdefghij"Rの
paste関数はデフォルトでスペースが入ります。VBA
VBAs1 = "abc" s2 = "def" s3 = "ghij" Debug.Print s1 & s2 & s3 ' abcdefghij文字列の長さ
Python
Python3s = 'abcdefghij' print(len(s)) # 10R
Rs <- "abcdefghij" nchar(s) # 10 length(s) # 1Rの
length関数は文字列の長さではなく、文字列ベクトルの要素数を返します。VBA
VBAs = "abcdefghij" Debug.Print Len(s) ' 10文字列の取り出し
Python
Python3s = 'abcdefghij' print(s[0:2]) print(s[:2]) # ab print(s[8:10]) print(s[len(s)-2:len(s)]) print(s[-2:]) # ij print(s[3:6]) # defPythonでは、エクセルのLEFT、RIGHTのような関数はないようです。
R
Rs <- "abcdefghij" substr(s, 1, 2) # "ab" substring(s, 1, 2) # substrとほぼ同じ # "ab" substr(s, nchar(s)-2+1, nchar(s)) # "ij" substr(s, 4, 6) # "def"VBA
VBAs = "abcdefghij" Debug.Print Left(s, 2) ' ab Debug.Print Right(s, 2) ' ij Debug.Print Mid(s, 4, 3) ' def文字列の検索
Python
Python3s = 'abcdefghij' print(s.find('def')) # 3 t = s + s # 'abcdefghijabcdefghij' print(t.rfind('def')) # 13 print(t.count('def')) # 2 print('def' in t) # True print('def' not in t) # FalseR
Rs <- "abcdefghij" match("def", s) #完全一致 # NA "def" %in% s #完全一致 # FALSE grep("def", s) #部分一致(パターンマッチ) # 1 # これはsという文字列ベクトルの1番目の要素(いまは要素は1つしかないが)に部分一致があったということ(1文字目ということではない) regexpr("def", s) # [1] 4 # attr(,"match.length") # [1] 3 # attr(,"index.type") # [1] "chars" # attr(,"useBytes") # [1] TRUE regexpr("def", s)[1] # [1] 4 t <- paste(s, s, sep="") t # [1] "abcdefghijabcdefghij" gregexpr("def", t) # [[1]] # [1] 4 14 # attr(,"match.length") # [1] 3 3 # attr(,"index.type") # [1] "chars" # attr(,"useBytes") # [1] TRUEVBA
VBAs = "abcdefghij" Debug.Print InStr(1, s, "def") ' 4 Debug.Print InStr(1, s, "DEF") ' 0 t = s & s ' abcdefghijabcdefghij Debug.Print InStrRev(t, "def") '後ろから検索 ' 14文字列の置換
Python
Python3s = 'abcdefghij' print(s.replace('def', 'DEF')) # 'abcDEFghij' t = s + s # 'abcdefghijabcdefghij' print(t.replace('def', 'DEF')) # 'abcDEFghijabcDEFghij'R
Rs <- "abcdefghij" sub("def", "DEF", s) # "abcDEFghij" t <- paste(s, s, sep="") # "abcdefghijabcdefghij" sub("def", "DEF", t) # 最初の1つだけ置換 # "abcDEFghijabcdefghij" gsub("def", "DEF", t) # すべて置換 # "abcDEFghijabcDEFghij"VBA
VBAs = "abcdefghij" Debug.Print Replace(s, "def", "DEF") ' abcDEFghij t = s & s ' abcdefghijabcdefghij Debug.Print Replace(t, "def", "DEF") ' abcDEFghijabcDEFghij文字列の変換
大文字と小文字の変換
Python
Python3s = 'abcDEFghij' print(s.upper()) # 大文字に # ABCDEFGHIJ print(s.lower()) # 小文字に # abcdefghij print(s.capitalize()) # 先頭のみ大文字・それ以外は小文字に # Abcdefghij print(s.swapcase()) # 大文字と小文字を入れ替え # ABCdefGHIJ print(s.isupper(), s.islower(), s.upper().isupper(), s.lower().islower()) # False False True TrueR
Rs <- "abcDEFghij" toupper(s) # 大文字に chartr("a-z", "A-Z", s) # 大文字に # "ABCDEFGHIJ" tolower(s) # 小文字に chartr("A-Z", "a-z", s) # 小文字に # "abcdefghij" paste0(substr(toupper(s),1,1), substr(tolower(s),2,nchar(s))) # 先頭のみ大文字・それ以外は小文字に # "Abcdefghij" chartr("A-Za-z", "a-zA-z", s) #大文字・小文字を入れ替え # "ABCdefGHIJ" s == toupper(s) #すべて大文字かどうかの判定 # FALSE s == tolower(s) #すべて小文字かどうかの判定 # FALSEVBA
VBAs = "abcDEFghij" Debug.Print UCase(s) ' 大文字に Debug.Print StrConv(s, vbUpperCase) ' 大文字に ' ABCDEFGHIJ Debug.Print LCase(s) ' 小文字に Debug.Print StrConv(s, vbLowerCase) ' 小文字に ' abcdefghij Debug.Print UCase(Left(s, 1)) & Right(LCase(s), Len(s) - 1) ' 先頭のみ大文字・それ以外は小文字に Debug.Print StrConv(s, vbProperCase) ' 先頭のみ大文字・それ以外は小文字に ' Abcdefghij全角と半角の変換
Python
Python3Pythonには全角・半角を変換する組み込み関数はなさそうです。
R
Rs <- "abcDEFghij" chartr("A-Za-z", "A-Za-z", s) # 半角を全角に # "abcDEFghij" chartr("A-Za-z", "A-Za-z", chartr("A-Za-z", "A-Za-z", s)) # 全角を半角に # "abcDEFghij"VBA
VBA' Abcdefghij s = "abcDEFghij" Debug.Print StrConv(s, vbWide) ' 全角へ ' abcDEFghij Debug.Print StrConv(StrConv(s, vbWide), vbNarrow) ' 半角へ ' abcDEFghij文字列の反転
Python
Python3s = 'abcdefghij' print(s[::-1]) # jihgFEDcba t = '' for i in range(len(s)): t = t + s[len(s)-i-1] print(t)Pythonでは、リストのスライス表記を使って文字列の反転ができます。
R
Rs <- "abcdefghij" t <- "" for (i in 1:nchar(s)) { t <- paste0(t, substr(s, nchar(s)-i+1, nchar(s)-i+1)) } t # "jihgfedcba"VBA
VBAs = "abcdefghij" Debug.Print StrReverse(s) ' jihgfedcbaVBAには文字列を反転させる関数があります。
文字列の繰り返し
Python
Python3print('A' * 3) # AAA print('def' * 3) # defdefdefPythonでは文字列に算術演算子
*を使って文字列を繰り返すことができます。R
Rrep("A", 3) # "A" "A" "A" paste(rep("A", 3), collapse="") # "AAA" paste(rep("def", 3), collapse="") # "defdefdef"まず、
rep("A", 3)で"A"という文字列を要素とする長さ3の文字列ベクトルを作成します。その各要素をpaste関数で結合しているだけです。VBA
VBADebug.Print String(3, "A") ' AAA Debug.Print String(3, "def") ' ddd Dim i As Integer s = "" For i = 1 To 3 s = s & "def" Next i Debug.Print s ' defdefdef
String(3, "def")は"defdefdef"とはなりません。スペース
スペースの文字列
Python
Python3s = ' ' * 3 print('-' + s + '-') # - - s = ' '*2 + 'd' + ' '*3 + 'e' + ' '*4 + 'f' + ' '*5 print('-' + s + '-') # - d e f -R
Rs <- paste(rep(" ", 3), collapse="") paste("-", s, "-", sep="") # "- -" s <- paste("-", paste(rep(" ", 2), collapse=""), "d", paste(rep(" ", 3), collapse=""), "e", paste(rep(" ", 4), collapse=""), "f", paste(rep(" ", 5), collapse=""), "-", sep="") s # "- d e f -"VBA
VBAs = Space(3) Debug.Print "-" & s & "-" ' - - s = Space(2) & "d" & Space(3) & "e" & Space(4) & "f" & Space(5) Debug.Print "-" & s & "-" ' - d e f -前後の不要なスペースの削除
Python
Python3s = ' '*2 + 'd' + ' '*3 + 'e' + ' '*4 + 'f' + ' '*5 print(s.strip(' ')) # 'd e f' print(s.lstrip(' ')) # 'd e f ' print(s.rstrip(' ')) # ' d e f'R
RRにはトリム関数がないようです。
VBA
VBAs = Space(2) & "d" & Space(3) & "e" & Space(4) & "f" & Space(5) Debug.Print "-" & Trim(s) & "-" ' -d e f- Debug.Print "-" & LTrim(s) & "-" ' -d e f - Debug.Print "-" & RTrim(s) & "-" ' - d e f-アスキーコード
最後は、文字のアスキー(ASCII)コードです。
Python
Python3print(ord('A'), ord('Z'), ord('a'), ord('z')) # 65 90 97 122 print(chr(65), chr(90), chr(97), chr(122)) # A Z a zR
Rcat(charToRaw("A"), charToRaw("Z"), charToRaw("a"), charToRaw("z")) #16進数 # 41 5a 61 7a cat(strtoi(charToRaw("A"), 16L), strtoi(charToRaw("Z"), 16L), strtoi(charToRaw("a"), 16L), strtoi(charToRaw("z"), 16L)) # 65 90 97 122 cat(as.raw(65), as.raw(90), as.raw(97), as.raw(122)) #16進数 # 41 5a 61 7a cat(rawToChar(as.raw(65)), rawToChar(as.raw(90)), rawToChar(as.raw(97)), rawToChar(as.raw(122))) # A Z a z charToRaw("AZaz") #16進数 # 41 5a 61 7a strtoi(charToRaw("AZaz"), 16L) # 65 90 97 122 as.raw(c(65, 90, 97, 122)) #16進数 # 41 5a 61 7a rawToChar(as.raw(c(65, 90, 97, 122))) # "AZaz"VBA
VBADebug.Print Asc("A"), Asc("Z"), Asc("a"), Asc("z") ' 65 90 97 122 Debug.Print Chr(65), Chr(90), Chr(97), Chr(122) ' A Z a zまとめ
一覧
各言語で使用する文字列操作関数等を一覧にまとめます。比較のために、EXCELでの計算も示しました。
s1 = "abc"
s2 = "def"
s3 = "ghij"
s = "abcdefghij"
t = "abcdefghijabcdefghij"
u = "abcDEFghij"
v = "abcDEFghij"
w = " d e f "
とします。また、EXCELのセルにそれぞれ
A1セル:="abc"
A2セル:="def"
A3セル:="ghij"
A4セル:="abcdefghij"
A5セル:="abcdefghijabcdefghij"
A6セル:="abcDEFghij"
A7セル:="abcDEFghij"
A8セル:=" d e f "
が入力されているものとします。文字列の基本的操作
Python R VBA EXCEL 結果 文字列の結合 s1 + s2 + s3 paste0(s1, s2, s3) s1 & s2 & s3 =A1&A2&A3 abcdefghij paste(s1, s2, s3, sep="") =CONCATENATE(A1,A2,A3) abcdefghij 文字列の長さ len(s) nchar(s) Len(s) =LEN(A4) 10 文字列の反転 s[::-1] StrReverse(s) jihgfedcba 文字列の繰り返し 'A' * 3 String(3, "A") =REPT("A",3) AAA 文字列の繰り返し 'def' * 3 =REPT("def",3) defdefdef 文字列の取り出し
Python R VBA EXCEL 結果 左から s[0:2] substr(s, 1, 2) Left(s, 2) =LEFT(A4,2) ab s[:2] substring(s, 1, 2) ab 右から s[len(s)-2:len(s)] substr(s, nchar(s)-2+1, nchar(s)) Right(s, 2) =RIGHT(A4,2) ij s[-2:] Right(s, 2) =MID(A4,4,3) ij 途中 s[3:6] substr(s, 4, 6) Mid(s, 4, 3) def 文字列の検索
Python R VBA EXCEL 結果 文字列の検索 s.find('def') InStr(1, s, "def") =FIND("def",A4,1) 3,4 =SEARCH("def",A4,1) 3,4 文字列の後ろからの検索 t.rfind('def') InStrRev(t, "def") 13,14 文字列の個数の検索 t.count('def') 2 文字列の置換
Python R VBA EXCEL 結果 置換 s.replace('def', 'DEF') sub("def", "DEF", s) Replace(s, "def", "DEF") =SUBSTITUTE(A4,"def","DEF") abcDEFghij =REPLACE(A4,FIND("def",A4),LEN("def"),"DEF") abcDEFghij 最初の1つだけ置換 sub("def", "DEF", t) abcDEFghijabcdefghij すべて置換 t.replace('def', 'DEF') gsub("def", "DEF", t) Replace(t, "def", "DEF") =SUBSTITUTE(A5,"def","DEF") abcDEFghijabcDEFghij 文字列の変換
Python R VBA EXCEL 結果 大文字に u.upper() toupper(u) UCase(u) =UPPER(A6) ABCDEFGHIJ 小文字に u.lower() tolower(u) LCase(u) =LOWER(A6) abcdefghij 先頭のみ大文字・それ以外は小文字に u.capitalize() StrConv(u, vbProperCase) =PROPER(A6) Abcdefghij 大文字と小文字を入れ替え u.swapcase() chartr("A-Za-z", "a-zA-z", u) ABCdefGHIJ 大文字かどうかの判定 u.isupper() u == toupper(u) False 小文字かどうかの判定 u.islower() u == tolower(u) False 全角に chartr("A-Za-z", "A-Za-z", u) StrConv(u, vbWide) =JIS(A6) abcDEFghij 半角に chartr("A-Za-z", "A-Za-z", v) StrConv(v, vbNarrow) =ASC(A7) abcDEFghij 文字列のスペース
Python R VBA EXCEL 結果 スペース ' ' * 3 Space(3) =REPT(" ",3) スペース削除 w.strip(' ') Trim(w) =TRIM(A8) "d e f" w.lstrip(' ') LTrim(w) "d e f " w.rstrip(' ') RTrim(w) " d e f" EXCELのTRIM関数は文字列の中のスペースも1つを除いて削除されて
d e fとなります。文字列のアスキー(ASCII)コード
Python R VBA EXCEL 結果 AのASCIIコード ord('A') strtoi(charToRaw("A"), 16L) Asc("A") =CODE("A") 65 ZのASCIIコード ord('Z') strtoi(charToRaw("Z"), 16L) Asc("Z") =CODE("Z") 90 aのASCIIコード ord('a') strtoi(charToRaw("a"), 16L) Asc("a") =CODE("a") 97 zのASCIIコード ord('z') strtoi(charToRaw("z"), 16L) Asc("z") =CODE("a") 122 ASCIIコード65の文字 chr(65) rawToChar(as.raw(65)) Chr(65) =CHAR(65) A ASCIIコード90の文字 chr(90) rawToChar(as.raw(90)) Chr(90) =CHAR(90) Z ASCIIコード97の文字 chr(97) rawToChar(as.raw(97)) Chr(97) =CHAR(97) a ASCIIコード122の文字 chr(122) rawToChar(as.raw(122)) Chr(122) =CHAR(122) z プログラム全体
参考までに使ったプログラムの全体を示します。
Python
Python3# 文字列の結合 s1 = 'abc' s2 = 'def' s3 = 'ghij' print(s1 + s2 + s3) # abcdefghij # 文字列の長さ s = 'abcdefghij' print(len(s)) # 10 # 文字列の取り出し s = 'abcdefghij' print(s[0:2]) print(s[:2]) # ab print(s[8:10]) print(s[len(s)-2:len(s)]) print(s[-2:]) # ij print(s[3:6]) # def # 文字列の検索 s = 'abcdefghij' print(s.find('def')) # 3 t = s + s # 'abcdefghijabcdefghij' print(t.rfind('def')) # 13 print(t.count('def')) # 2 print('def' in t) # True print('def' not in t) # False # 文字列の置き換え s = 'abcdefghij' print(s.replace('def', 'DEF')) # 'abcDEFghij' t = s + s # 'abcdefghijabcdefghij' print(t.replace('def', 'DEF')) # 'abcDEFghijabcDEFghij' # 文字列の大文字・小文字の変換 s = 'abcDEFghij' print(s.upper()) # 大文字に # ABCDEFGHIJ print(s.lower()) # 小文字に # abcdefghij print(s.capitalize()) # 先頭のみ大文字・それ以外は小文字に # Abcdefghij print(s.swapcase()) # 大文字と小文字を入れ替え # ABCdefGHIJ print(s.isupper(), s.islower(), s.upper().isupper(), s.lower().islower()) # False False True True # 文字列の全角・半角の変換 # 全角・半角の変換の組み込み関数はなさそう # 文字列の反転 s = 'abcdefghij' print(s[::-1]) # jihgFEDcba t = '' for i in range(len(s)): t = t + s[len(s)-i-1] print(t) # 文字列の繰り返し print('A' * 3) # AAA print('def' * 3) # defdefdef # 文字列のスペース s = ' ' * 3 print('-' + s + '-') # - - s = ' '*2 + 'd' + ' '*3 + 'e' + ' '*4 + 'f' + ' '*5 print('-' + s + '-') # - d e f - # 文字列の前後のスペース削除 s = ' '*2 + 'd' + ' '*3 + 'e' + ' '*4 + 'f' + ' '*5 print(s.strip(' ')) # 'd e f' print(s.lstrip(' ')) # 'd e f ' print(s.rstrip(' ')) # ' d e f' # アスキー(ASCII)コード print(ord('A'), ord('Z'), ord('a'), ord('z')) # 65 90 97 122 print(chr(65), chr(90), chr(97), chr(122)) # A Z a zR
R# 文字列の結合 s1 <- "abc" s2 <- "def" s3 <- "ghij" paste0(s1, s2, s3) # "abcdefghij" paste(s1, s2, s3) # "abc def ghij" paste(s1, s2, s3, sep="") # "abcdefghij" # paste関数はデフォルトでスペースが入る # 文字列の長さ s <- "abcdefghij" nchar(s) # 10 length(s) # 1 # length関数は文字列の長さではなく、文字列ベクトルの要素数を返す # 文字列の取り出し s <- "abcdefghij" substr(s, 1, 2) # "ab" substring(s, 1, 2) # substrとほぼ同じ # "ab" substr(s, nchar(s)-2+1, nchar(s)) # "ij" substr(s, 4, 6) # "def" # 文字列の検索 s <- "abcdefghij" match("def", s) #完全一致 # NA "def" %in% s #完全一致 # FALSE grep("def", s) #部分一致(パターンマッチ) # 1 # これはsという文字列ベクトルの1番目の要素(いまは要素は1つしかないが)に部分一致があったということ(1文字目ということではない) regexpr("def", s) # [1] 4 # attr(,"match.length") # [1] 3 # attr(,"index.type") # [1] "chars" # attr(,"useBytes") # [1] TRUE regexpr("def", s)[1] # [1] 4 t <- paste(s, s, sep="") t # [1] "abcdefghijabcdefghij" gregexpr("def", t) # [[1]] # [1] 4 14 # attr(,"match.length") # [1] 3 3 # attr(,"index.type") # [1] "chars" # attr(,"useBytes") # [1] TRUE # 文字列の置き換え s <- "abcdefghij" sub("def", "DEF", s) # "abcDEFghij" t <- paste(s, s, sep="") # "abcdefghijabcdefghij" sub("def", "DEF", t) # 最初の1つだけ置換 # "abcDEFghijabcdefghij" gsub("def", "DEF", t) # すべて置換 # "abcDEFghijabcDEFghij" # 文字列の大文字・小文字の変換 s <- "abcDEFghij" toupper(s) # 大文字に chartr("a-z", "A-Z", s) # 大文字に # "ABCDEFGHIJ" tolower(s) # 小文字に chartr("A-Z", "a-z", s) # 小文字に # "abcdefghij" paste0(substr(toupper(s),1,1), substr(tolower(s),2,nchar(s))) # 先頭のみ大文字・それ以外は小文字に # "Abcdefghij" chartr("A-Za-z", "a-zA-z", s) #大文字・小文字を入れ替え # "ABCdefGHIJ" s == toupper(s) #すべて大文字かどうかの判定 # FALSE s == tolower(s) #すべて小文字かどうかの判定 # FALSE # 文字列の全角・半角の変換 s <- "abcDEFghij" chartr("A-Za-z", "A-Za-z", s) # 半角を全角に # "abcDEFghij" chartr("A-Za-z", "A-Za-z", chartr("A-Za-z", "A-Za-z", s)) # 全角を半角に # "abcDEFghij" # 文字列の反転 s <- "abcdefghij" t <- "" for (i in 1:nchar(s)) { t <- paste0(t, substr(s, nchar(s)-i+1, nchar(s)-i+1)) } t # "jihgfedcba" # 文字列の繰り返し rep("A", 3) # "A" "A" "A" paste(rep("A", 3), collapse="") # "AAA" paste(rep("def", 3), collapse="") # "defdefdef" # 文字列のスペース s <- paste(rep(" ", 3), collapse="") paste("-", s, "-", sep="") # "- -" s <- paste("-", paste(rep(" ", 2), collapse=""), "d", paste(rep(" ", 3), collapse=""), "e", paste(rep(" ", 4), collapse=""), "f", paste(rep(" ", 5), collapse=""), "-", sep="") s # "- d e f -" # 文字列の前後のスペース削除 # トリム関数はなさそう # アスキー(ASCII)コード cat(charToRaw("A"), charToRaw("Z"), charToRaw("a"), charToRaw("z")) #16進数 # 41 5a 61 7a cat(strtoi(charToRaw("A"), 16L), strtoi(charToRaw("Z"), 16L), strtoi(charToRaw("a"), 16L), strtoi(charToRaw("z"), 16L)) # 65 90 97 122 cat(as.raw(65), as.raw(90), as.raw(97), as.raw(122)) #16進数 # 41 5a 61 7a cat(rawToChar(as.raw(65)), rawToChar(as.raw(90)), rawToChar(as.raw(97)), rawToChar(as.raw(122))) # A Z a z charToRaw("AZaz") #16進数 # 41 5a 61 7a strtoi(charToRaw("AZaz"), 16L) # 65 90 97 122 as.raw(c(65, 90, 97, 122)) #16進数 # 41 5a 61 7a rawToChar(as.raw(c(65, 90, 97, 122))) # "AZaz"VBA
VBASub test_string() Dim s1 As String Dim s2 As String Dim s3 As String Dim s As String Dim t As String ' 文字列の結合 s1 = "abc" s2 = "def" s3 = "ghij" Debug.Print s1 & s2 & s3 ' abcdefghij ' 文字列の長さ s = "abcdefghij" Debug.Print Len(s) ' 10 ' 文字列の取り出し s = "abcdefghij" Debug.Print Left(s, 2) ' ab Debug.Print Right(s, 2) ' ij Debug.Print Mid(s, 4, 3) ' def ' 文字列の検索 s = "abcdefghij" Debug.Print InStr(1, s, "def") ' 4 Debug.Print InStr(1, s, "DEF") ' 0 t = s & s ' abcdefghijabcdefghij Debug.Print InStrRev(t, "def") '後ろから検索 ' 14 ' 文字列の置き換え s = "abcdefghij" Debug.Print Replace(s, "def", "DEF") ' abcDEFghij t = s & s ' abcdefghijabcdefghij Debug.Print Replace(t, "def", "DEF") ' abcDEFghijabcDEFghij ' 文字列の大文字・小文字の変換 s = "abcDEFghij" Debug.Print UCase(s) ' 大文字に Debug.Print StrConv(s, vbUpperCase) ' 大文字に ' ABCDEFGHIJ Debug.Print LCase(s) ' 小文字に Debug.Print StrConv(s, vbLowerCase) ' 小文字に ' abcdefghij Debug.Print UCase(Left(s, 1)) & Right(LCase(s), Len(s) - 1) ' 先頭のみ大文字・それ以外は小文字に Debug.Print StrConv(s, vbProperCase) ' 先頭のみ大文字・それ以外は小文字に ' Abcdefghij ' 文字列の全角・半角の変換 ' Abcdefghij s = "abcDEFghij" Debug.Print StrConv(s, vbWide) ' 全角へ ' abcDEFghij Debug.Print StrConv(StrConv(s, vbWide), vbNarrow) ' 半角へ ' abcDEFghij ' 文字列の反転 s = "abcdefghij" Debug.Print StrReverse(s) ' jihgfedcba ' 文字列の繰り返し Debug.Print String(3, "A") ' AAA Debug.Print String(3, "def") ' ddd Dim i As Integer s = "" For i = 1 To 3 s = s & "def" Next i Debug.Print s ' defdefdef ' 文字列のスペース s = Space(3) Debug.Print "-" & s & "-" ' - - s = Space(2) & "d" & Space(3) & "e" & Space(4) & "f" & Space(5) Debug.Print "-" & s & "-" ' - d e f - ' 文字列の前後のスペース削除 s = Space(2) & "d" & Space(3) & "e" & Space(4) & "f" & Space(5) Debug.Print "-" & Trim(s) & "-" ' -d e f- Debug.Print "-" & LTrim(s) & "-" ' -d e f - Debug.Print "-" & RTrim(s) & "-" ' - d e f- ' アスキー(ASCII)コード Debug.Print Asc("A"), Asc("Z"), Asc("a"), Asc("z") ' 65 90 97 122 Debug.Print Chr(65), Chr(90), Chr(97), Chr(122) ' A Z a z End Sub参考
- 投稿日:2021-01-11T22:24:18+09:00
PySimpleGuiで入力に応じてグラフを表示・更新する
はじめに
PysimpleGuiで入力に応じてグラフを表示・更新するプログラムを組んでみました。
入力に応じてグラフを表示させるところまでは、なんとなくで書けたのですが、gui上でパラメーターを変えたときに、グラフ内容を更新させる…というところに苦労しました。
githubに掲載されているコードを参考にそれっぽいものが作れましたので公開します。あまり他にいい題材も思いつかなかったので、データは厚生労働省が発表している、コロナウイルスの感染者データを使います。
https://www.mhlw.go.jp/stf/covid-19/open-data.htmlやること
コロナウイルスの陽性者数、累積死亡者、日別死亡者、pcr検査数等を入力した期間に応じてgui上にプロットする。パラメーターを変えた際はgui上のグラフを更新する。
コード
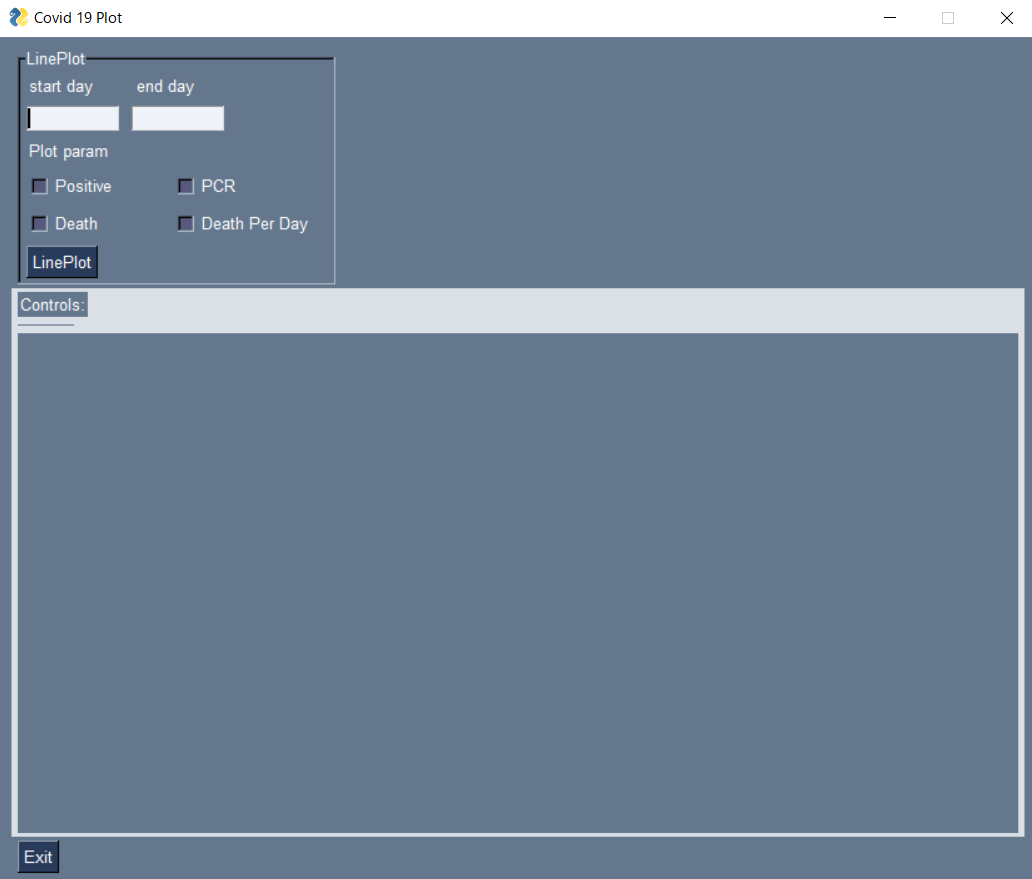
import PySimpleGUI as sg import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2Tk from datetime import datetime import matplotlib.dates as mdates class Toolbar(NavigationToolbar2Tk): def __init__(self, *args, **kwargs): super(Toolbar, self).__init__(*args, **kwargs) class GuiWindow: def __init__(self): self.line_plot_frame = sg.Frame(layout=[ [sg.Text('start day', size=(9, 1)), sg.Text('end day', size=(10, 1))], [sg.InputText('', size=(10, 1)), sg.InputText('', size=(10, 1))], [sg.Text('Plot param')], [sg.CBox('Positive', size=(10, 1), key='-positive-'), sg.CBox('PCR', size=(10, 1), key='-pcr-')], [sg.CBox('Death', size=(10, 1), key='-death-'), sg.CBox('Death Per Day', size=(12, 1), key='-death_per_day-')], [sg.B('LinePlot')]], title='LinePlot', relief=sg.RELIEF_SUNKEN, vertical_alignment='top') self.graph_area = sg.Column(layout=[ [sg.T('Controls:')], [sg.Canvas(key='controls_cv')], [sg.Canvas(key='fig_cv', size=(400 * 2, 400))]], background_color='#DAE0E6', pad=(0, 0), ) self.controls = sg.B('Exit') self.layout = [[self.line_plot_frame], [self.graph_area], [self.controls]] self.window = sg.Window('Covid 19 Plot', self.layout) def clear_plot(self): if self.window['fig_cv'].TKCanvas.children: for child in self.window['fig_cv'].TKCanvas.winfo_children(): child.destroy() # if canvas_toolbar has child if self.window['controls_cv'].TKCanvas.children: for child in self.window['controls_cv'].TKCanvas.winfo_children(): child.destroy() def plot_on_canvas(self, fig): figure_canvas_agg = FigureCanvasTkAgg(fig, master=self.window['fig_cv'].TKCanvas) figure_canvas_agg.draw() toolbar = Toolbar(figure_canvas_agg, self.window['controls_cv'].TKCanvas) toolbar.update() figure_canvas_agg.get_tk_widget().pack(side='left', fill='both', expand=2) def event_loop(self, df_data): # plot用のクラスをインスタンス化 graph_generator = GraphGenerator(df_data) while True: event, values = self.window.read() if event in (sg.WIN_CLOSED, 'Exit'): # always, always give a way out! break elif event == 'LinePlot': # プロットするパラメーターを設定 param_list = [] if values['-pcr-']: param_list.append('pcr') if values['-positive-']: param_list.append('positive') if values['-death-']: param_list.append('death') if values['-death_per_day-']: param_list.append('death_per_day') # 表示期間の設定 start_day = datetime.strptime(values[0], '%Y/%m/%d') end_day = datetime.strptime(values[1], '%Y/%m/%d') fig = graph_generator.line_plot(start_day, end_day, param_list) self.clear_plot() self.plot_on_canvas(fig) class GraphGenerator: def __init__(self, df): self.df = df def line_plot(self, start_day, end_day, param_list): df_covid = self.df[self.df['published_day'] <= end_day] df_covid = df_covid[df_covid['published_day'] >= start_day] df_covid = df_covid.set_index('published_day') df_covid = df_covid[param_list] sns.set() fig, ax = plt.subplots() sns.lineplot(data=df_covid) ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d')) ax.xaxis.set_major_locator(mdates.MonthLocator()) plt.tight_layout() return fig def job(): # dataframeの読み込み df_positive = pd.read_csv('https://www.mhlw.go.jp/content/pcr_positive_daily.csv') df_pcr = pd.read_csv('https://www.mhlw.go.jp/content/pcr_tested_daily.csv') df_death = pd.read_csv('https://www.mhlw.go.jp/content/death_total.csv') # 日付でmerge df = pd.merge(df_positive, df_pcr, on='日付', how='outer') df = pd.merge(df, df_death, on='日付', how='outer') # リネーム df = df.rename(columns={'日付': 'published_day', 'PCR 検査陽性者数(単日)': 'positive', 'PCR 検査実施件数(単日)': 'pcr', '死亡者数': 'death'}) df.fillna(0, inplace=True) df['published_day'] = pd.to_datetime(df['published_day']) # 死亡者の累積和を単純配列に直す death_per_day = [] for i, death_total in enumerate(df['death'].values): if i == 0: death = death_total else: death = death_total - df['death'].values[i - 1] death_per_day.append(death) df['death_per_day'] = death_per_day window = GuiWindow() window.event_loop(df) job()GUI表示画面
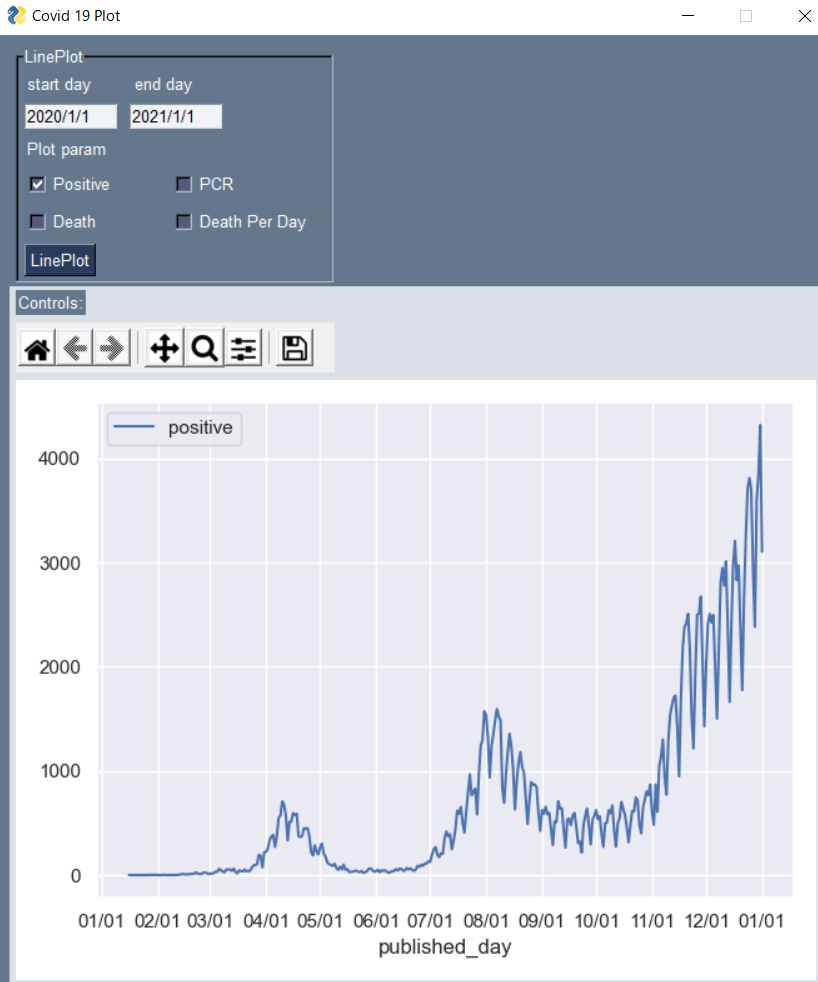
プロット
2020/1/1~2021/1/1まで陽性者数の推移をみてみます。
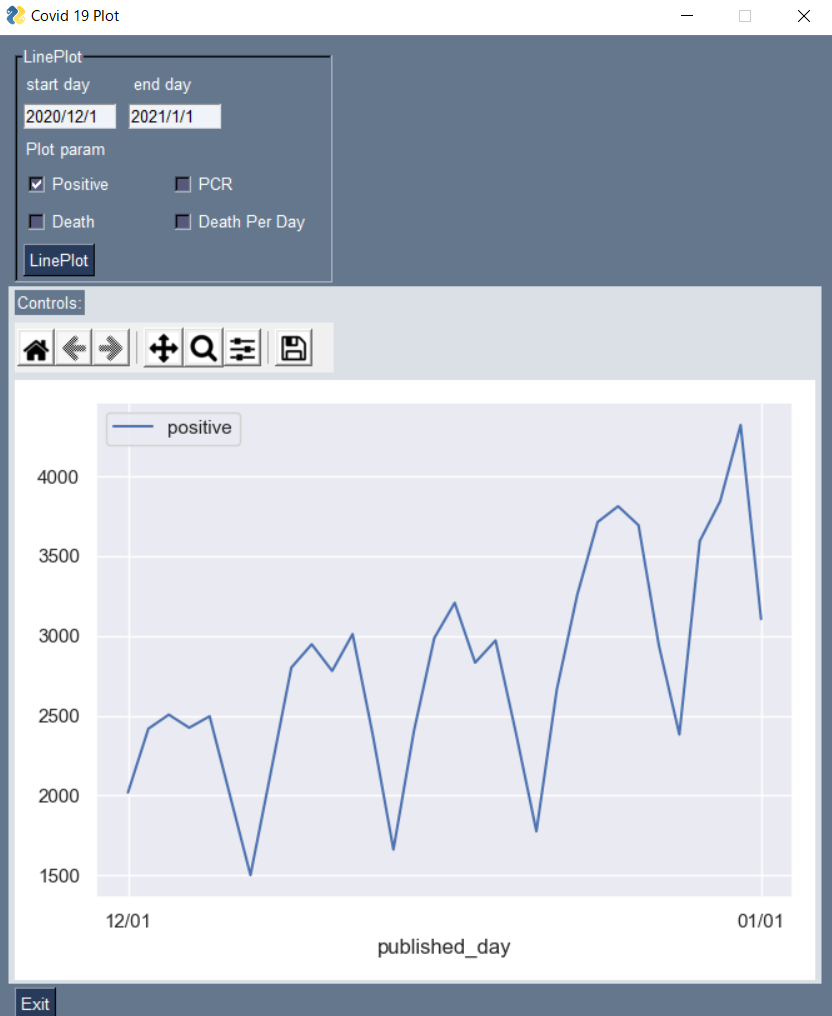
2020/12/1~で期間を絞り込んでみます。
LinePlotのボタンを押すとグラフが更新されます。
苦労した点
冒頭でも書いた通り、グラフを表示させるところまでは順調にいったのですが、
そこから次に見たい値を更新するのに苦労しました。
PySimpleGuiのupdateメソッドを使うのかな、と試行錯誤したのですが、gui上のグラフではアップデートメソッドは使えない模様です。
一度destroyメソッドでグラフを消去してから再表示する、というのが一つのやり方であるみたいです。
クラス内のこの関数でグラフとツールバーの初期化を行っています。def clear_plot(self): if self.window['fig_cv'].TKCanvas.children: for child in self.window['fig_cv'].TKCanvas.winfo_children(): child.destroy() # if canvas_toolbar has child if self.window['controls_cv'].TKCanvas.children: for child in self.window['controls_cv'].TKCanvas.winfo_children(): child.destroy()今後の課題
画像だとわかりづらいかもしれませんが、グラフを表示させる際に、gui上の画面がちらつく現象が起きています。原因不明なので対処したい。折れ線だけではなく、別の種類のグラフも表示させてみる、等。
それと、今回はPySimpleGuiのWindowを一つのクラスとしてまとめましたが、もうちょっと細分化した方がコードが読みやすくなると思います。この辺りはクラス設計にかかわるところで、引き続き勉強していきたいと思いました。アドバイス等ありましたらいただきたく思います。
- 投稿日:2021-01-11T22:10:16+09:00
[備忘録]pythonでQRコードと説明を同じ画像に書く方法
出来上がるもの
準備
colab上で動作させるために必要なものをインストールします。
必要なライブラリのインストール
pip install qrcode pillow用意したサンプルで日本語の文字列を画像に書き込むためフォントをインストール
!apt-get -y install fonts-ipafont-gothicスクリプト実部
import qrcode import PIL.Image import PIL.ImageDraw import PIL.ImageFont imgpath = "qr.png" # 画像の保存場所とファイル名 text = "もどる" # QRコードに組み込みたい情報 # 今回は日本語の表記を追加したいので日本語フォントを用意 fontname = "/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf" # 表記する文字のサイズ fontsize = 36 # 表記する文字サイズを取得する関数 def getTextSize(_text="test", _fontname="", _fontsize=36): canvasSize = (1, 1) backgroundRGB = (255, 255, 255) img = PIL.Image.new("RGB", canvasSize, backgroundRGB) draw = PIL.ImageDraw.Draw(img) font = PIL.ImageFont.truetype(_fontname, _fontsize) textWidth, textHeight = draw.textsize(_text, font=font) return textWidth, textHeight # QRコードを作成し、文字表記を下部中央に追記する def makeQRimg(_imgpath, _text, _fontname="", _fontsize=36): # 誤り訂正レベルを最大に、余白は仕様上の最小幅 qr = qrcode.QRCode( error_correction=qrcode.constants.ERROR_CORRECT_H, border=4, ) qr.add_data(_text) qr.make() img = qr.make_image().convert("RGB") textSize = getTextSize(_text, _fontname, _fontsize) textTopLeft = (img.size[0]/2 - textSize[0]/2, img.size[1] - textSize[1]) draw = PIL.ImageDraw.Draw(img) font = PIL.ImageFont.truetype(_fontname, _fontsize) draw.text(xy=textTopLeft, text=_text, fill=(0, 0, 0), font=font) # QRコードを保存 img.save(_imgpath) # 実行 makeQRimg(imgpath, text, fontname, fontsize) # 作成したQRコードをIPython上で表示 from IPython.display import Image, display_png display_png(Image(imgpath))

- 投稿日:2021-01-11T21:49:45+09:00
【初心者向け】NumeraiのHPの見方+サブミット+便利リンク集
はじめに
はじめまして。
tit_BTCQASH と申します。(https://twitter.com/tit_BTCQASHNumeraiというプロジェクトでわかりにくい点とその解説、予測結果のサブミットまでを一気通貫して紹介します。(https://numer.ai/tournament
Numeraiは株価の予測結果をもとに運用するヘッジファンドの手伝いをするプロジェクトです。
私たちは自分でデータを用意する必要はなく、チームから与えられたデータを最適化し、その予測結果を提出することが求められます。
(日本ではblog_UKIさんの記事 機械学習による株価予測 はじめようNumerai
https://qiita.com/blog_UKI/items/fb401725288e58c92bd6
が有名ですので、詳細はそちらをご一読ください。)さて、本記事ではNumeraiのホームページの見方から、Google Colaboratoryを用いた予測結果の提出方法まで、できるだけ丁寧に解説します。
わからない点、加筆した方がよい点は遠慮なくtwitter等までご連絡ください。本記事の目次
①Numeraiのホームページの見方
②Numeraiチームから与えられた特徴量(説明変数)と株価データを最適化し、予測を提出する方法
③numerai関連の便利リンク集(追記予定 コメントください)
④DIAGNOSTICSの見方
⑤Numeraiに望むこと
⑥さいごに①Numeraiのホームページの見方
NumeraiのホームページのURLは https://numer.ai/tournament
です。色々とコンテンツがありますが、一つ一つ解説していきます。頻出する用語について
NMRトークン:Numeraiで使用する掛け金に相当するERC-20ベースの仮想通貨のことです。
NMRはNumeraiのペイアウトや、Numeraiへの技術的貢献をすることで発行されます。最初にNMRトークンを手に入れるためには取引所で購入するのが手っ取り早いです。
ただし、日本の取引所では取り扱いがないため購入は不可能です。NMRトークンを取り扱っている取引所はこちらのリンクに一覧があります。
https://coinmarketcap.com/ja/currencies/numeraire/
DEX系の取引所では、UniswapやCoinlistを使用することもできます。
Uniswap:https://uniswap.org/
Coinlist:https://coinlist.co/dashboardNMRトークンはNumerai以外にもerasureで使用することができます。https://erasure.world/
correlation:提出した株価の予測結果と、解答の相関係数のこと 大きければ大きいほど報酬が増えます。
Reputation:correlationの20ラウンド平均値
MMC:Meta Model Contributionの略。自分のモデルから、MMCモデル(Numeraiに提出されている予測結果を加重平均したモデル)の寄与を除いたものが、どれだけ解答との相関があるかを表す相関係数。MMCモデルに比べて優位な結果では+のMMCとなります。
ステーク:NMRを預け入れること
Payouts:賭けたNMRに応じて貰える報酬のことHP上部
DOCS:Numeraiのドキュメントへのリンク(英語版)ドキュメント内にはNumeraiのルールなどが解説されています。日本語への翻訳も進んでおり、https://jp.docs.numer.ai/
に翻訳版がありますが、翻訳は途中のようです。CHAT:Numeraiに関する情報や、雑談、フィードバック等のチャットスペースです。英語のみ対応(日本語版はなし。)
FORUM:Numeraiに関する議論をするスペース コミュニティとの情報共有化がメイン。英語のみ対応(日本語版はなし)
LEADERBOARD:Numeraiに提出した株価の予測結果のランキング
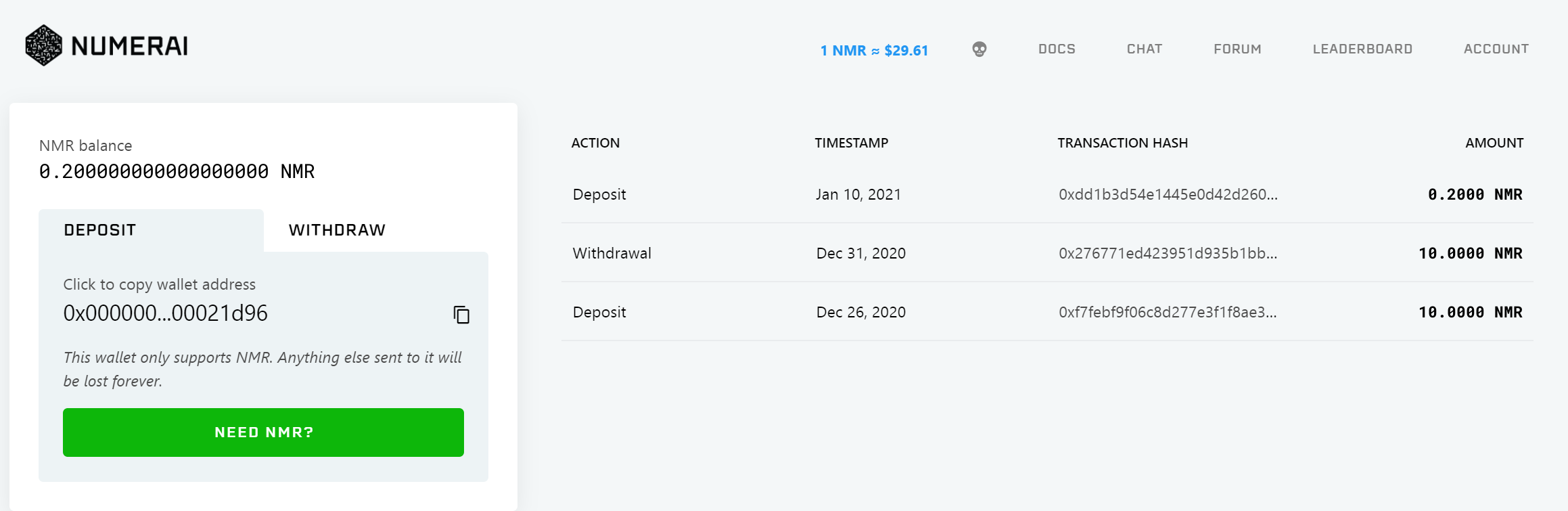
ACCOUNT:WALLET MODELS SETTINGS LOGOUT の4つのリンクがあります。
WALLET:NMRトークンの入出金に関するページです。Wallet addressにあるアドレスにBinance等で入手したNMRトークンを送付すると、預入ができます。withdrawタブでは、NMRトークンに引き出しができます。
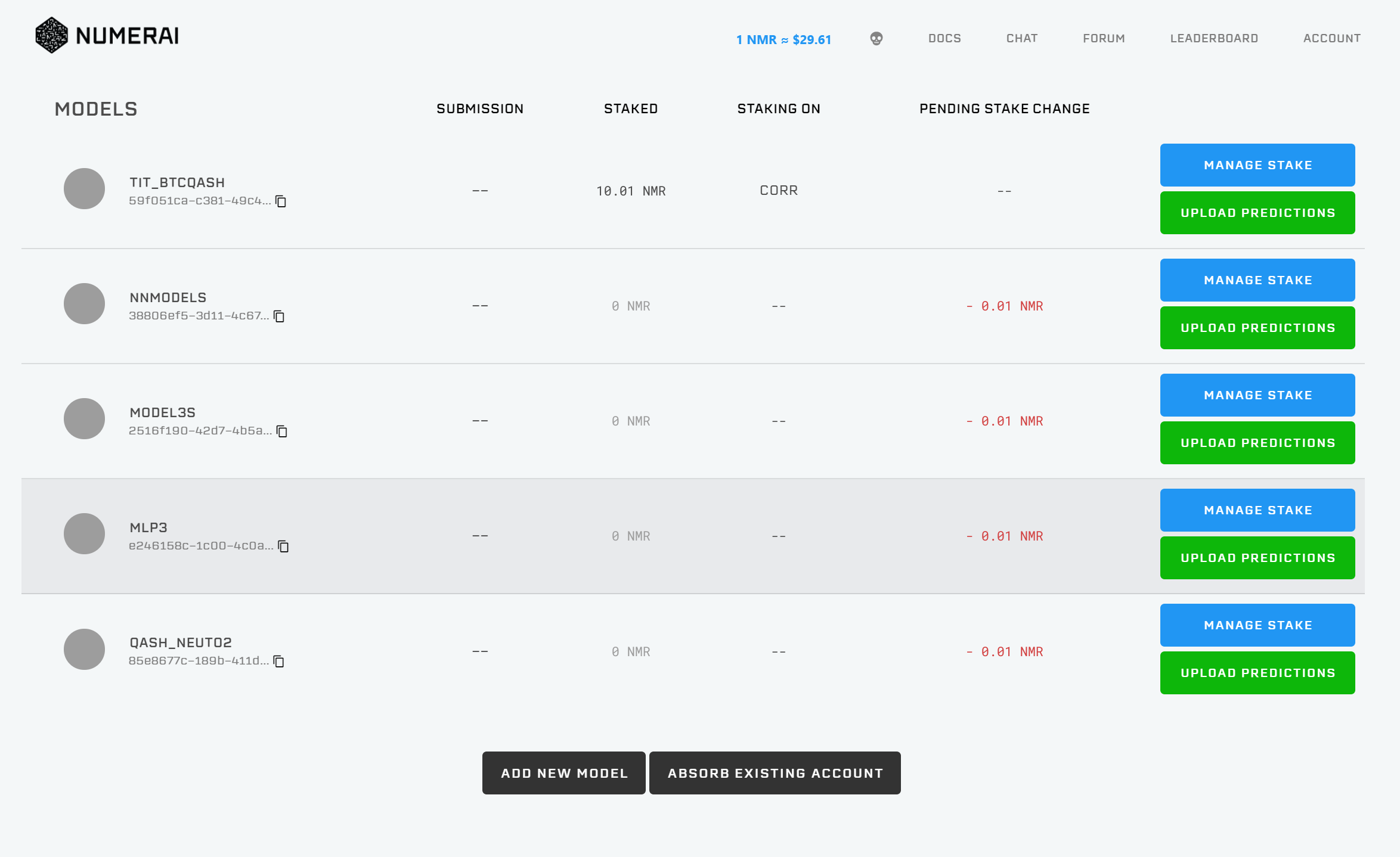
MODELS:Numeraiに提出するモデルの追加・削除をするページです。ADD NEW MODEL/ABSORB EXISTING ACCOUNTを押すことで、モデルの追加/削除ができます。
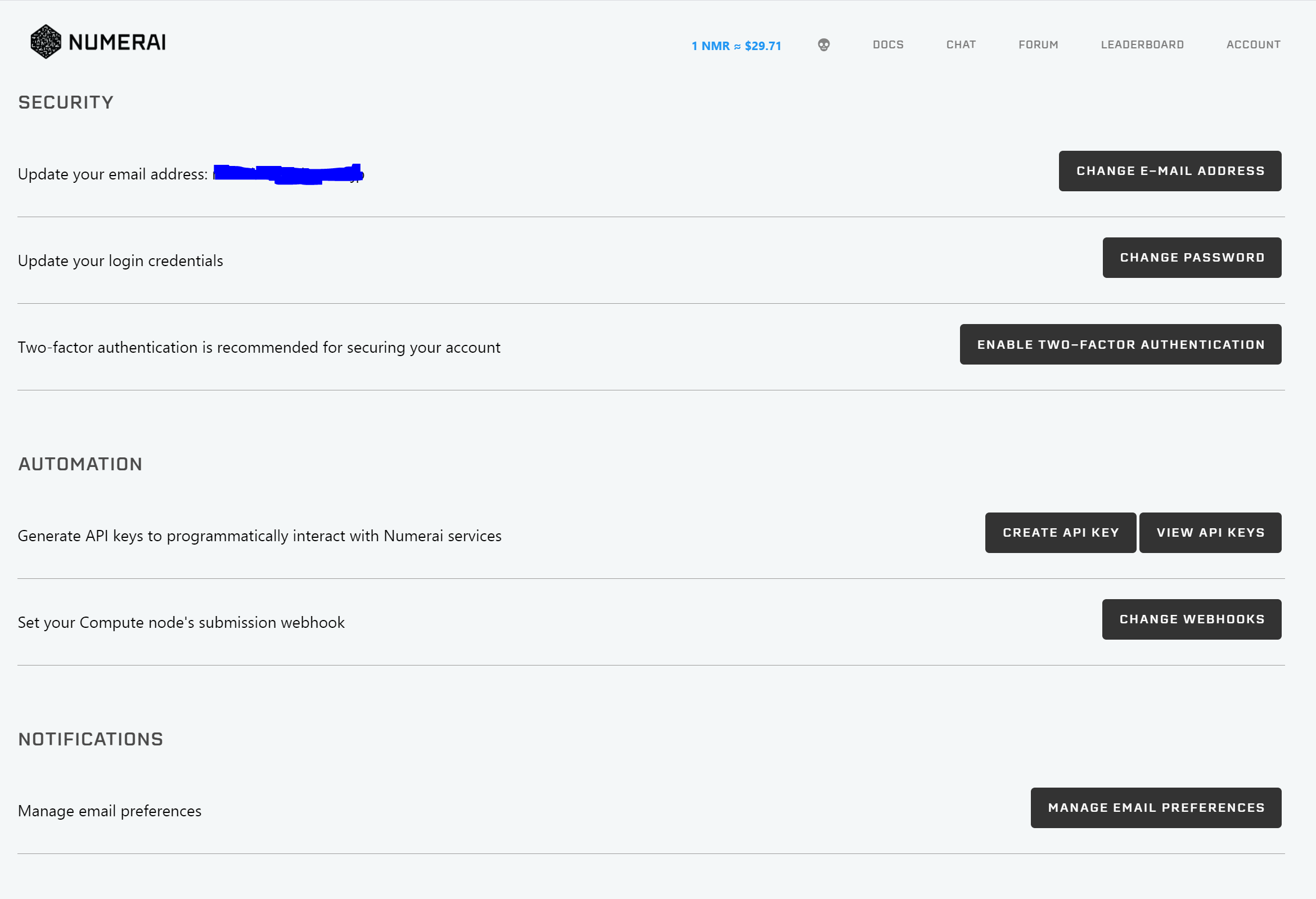
SETTINGS:E-mail,Password,2段階認証の設定や、APIキーの設定に関するページです。
HP下部
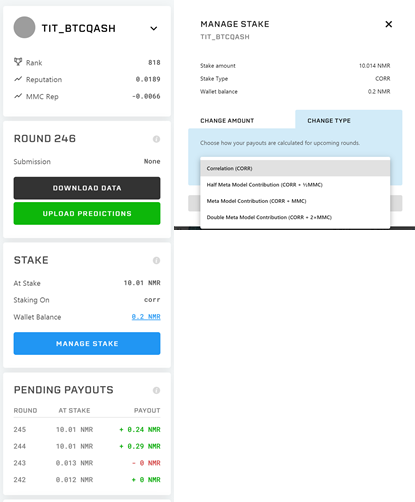
モデル情報:モデル(今回はTIT_BTCQASH)のランキング、Reputation、MMC Repに関するページです。↓ボタンを押すとモデルの切り替えができます。
データ情報:最新のラウンドのデータダウンロードリンクと、予測結果のアップロードリンク。
ステークNMRトークンの預け入れに関する設定 Manage Stakeから、今回のラウンドに賭けるNMRの量を設定することができます。
CorrやCorr+MMCなど、異なる種類のステーク方法が用意されており、例えばCorrではcorrelationにのみNMRを賭け、Corr+MMCではcorrelationとMMCにNMRを賭けることができます。
Pending Payouts ラウンド毎の払い出し予測値の表。貰える予定の報酬量についてのまとめです。
②Numeraiチームから与えられた特徴量(説明変数)と株価データを最適化する方法
何もわからない状態で、Numeraiのデータを提出する場合、katsu1110さんの記事
https://www.kaggle.com/code1110/numerai-tournament
や、Carlo Lepelaarsさんの記事
https://www.kaggle.com/carlolepelaars/how-to-get-started-with-numerai
が非常に参考になります。
今回、私が紹介する記事では、上記の記事や公式が出しているExample modelから一歩踏み込んだ解説(コードでどこを改良するか、など)と、ボタンを押せば予測データが手に入るサンプルコードの提供をしたいと思います。
本記事を読んで、少しでもモデルの提出数が増えるといいなあ、と思っています。
(良いcorrの上げ方などを見つけたら、こっそり教えてください)今回紹介したコードは、Google colaboratory上で動かせます。Runボタンを押せば、提出ファイルができるようにしてあるので、
使用してみてください。
https://colab.research.google.com/drive/1u5Cc3NlJQZJwJNmOrPjjqBchk928gT4C?usp=sharingコードを解説する前の基礎編
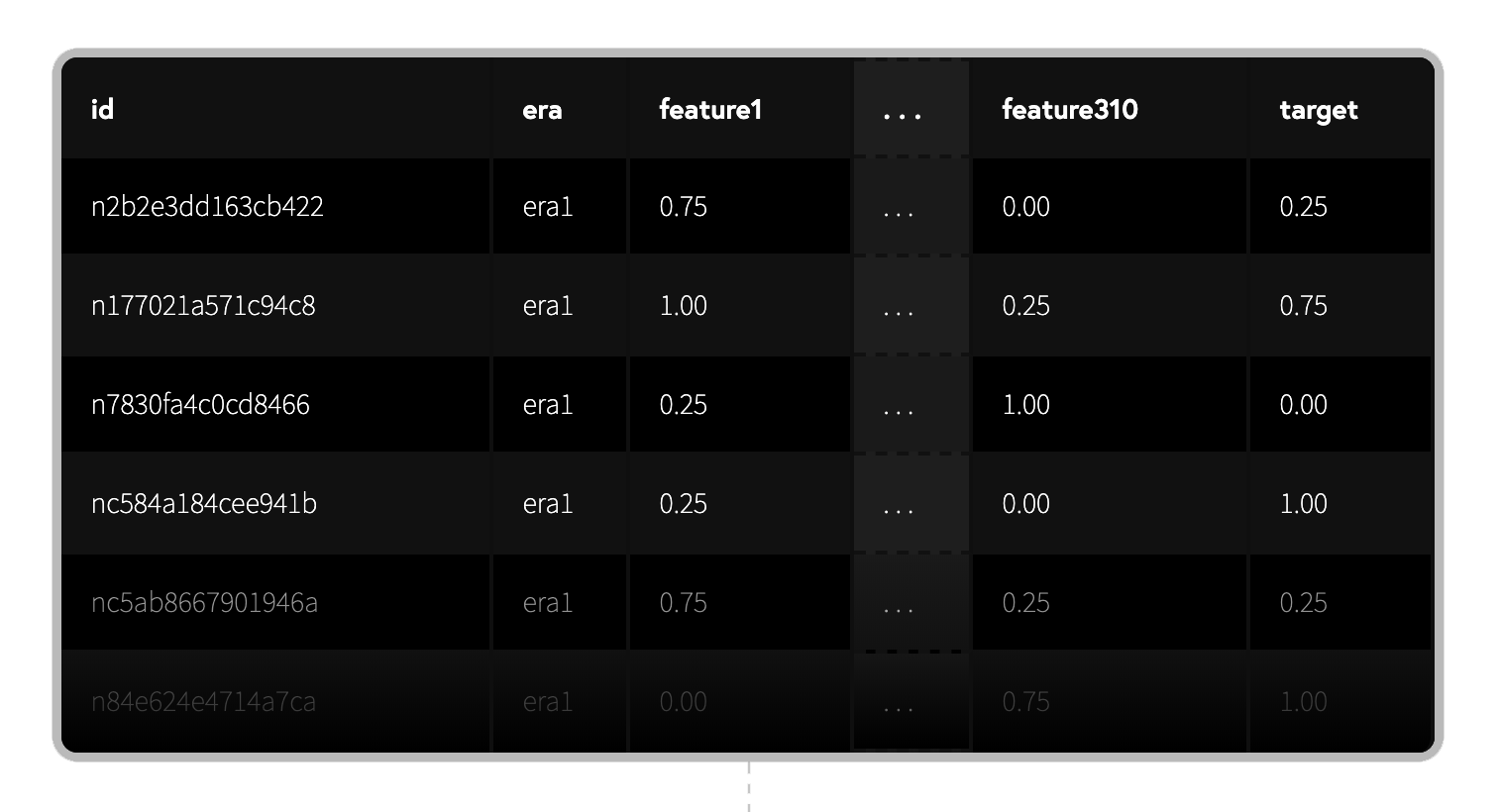
i)Numeraiデータセットの構造
データセットは最新のラウンドのデータダウンロードリンクからダウンロードできます。(本記事上部参照)
前述したUKIさんの記事(https://qiita.com/blog_UKI/items/fb401725288e58c92bd6
に詳しい解説がのっていますので、簡単に中身について記述しておきます。numerai_training_data.csvはトレーニング用のデータが入っているcsvファイルです。
numerai_tournament_data.csvはバリデーション(検証)用のデータが入っているcsvファイルです。
(csvファイルの中身)
id:暗号化された株に関するラベル。
era:データが収集された期間に関するラベル。eraが同じなら、同じ期間に収集されたデータであることを表します。
data_type:train,validation,test,liveの4つの値があります。trainはトレーニング用のデータ、validationは検証用のデータ、testはNumeraiがテストする用のデータ、liveは現ラウンドのデータとなっています。
feature:ビン化された特徴量。0,0.25,0.5,0.75,1の5分位となっている。featureは"feature_intelligence", "feature_wisdom", "feature_charisma", "feature_dexterity", "feature_strength", "feature_constitution"とタグ付けされたものがあり、グループ化されています。
target:ビン化された教師データ。0,0.25,0.5,0.75,1の5分位となっています。numerai_training_data.csvではtargetデータがあたえられているが、numerai_tournament_data.csvのliveデータではNANになっています。ii)データ提出までの流れ
①データの読み込み
②特徴量エンジニアリング
③機械学習
④モデルの強さについて
⑤予測結果を書きこんだcsvファイルの用意
⑥neutrizeの方法①データの読み込み
Carlo Lepelaarsさんの記事からデータ読み込み部分を引用(一部編集)させていただきます。
download_current_data(DIR)を呼び出すと、DIRで指定したディレクトリに最新ラウンドのデータをダウンロードします。
train, val, test = load_data(DIR, reduce_memory=True)を呼び出すと、train, val, testデータに分けてデータを格納します。!pip install numerapi import numerapi NAPI = numerapi.NumerAPI(verbosity="info") import numpy as np import random as rn import pandas as pd import seaborn as sns import lightgbm as lgb import matplotlib.pyplot as plt from scipy.stats import spearmanr, pearsonr from sklearn.metrics import mean_absolute_error import os DIR = "/kaggle/working" def download_current_data(directory: str): """ Downloads the data for the current round :param directory: The path to the directory where the data needs to be saved """ current_round = NAPI.get_current_round() if os.path.isdir(f'{directory}/numerai_dataset_{current_round}/'): print(f"You already have the newest data! Current round is: {current_round}") else: print(f"Downloading new data for round: {current_round}!") NAPI.download_current_dataset(dest_path=directory, unzip=True) def load_data(directory: str, reduce_memory: bool=True) -> tuple: """ Get data for current round :param directory: The path to the directory where the data needs to be saved :return: A tuple containing the datasets """ print('Loading the data') full_path = f'{directory}/numerai_dataset_{NAPI.get_current_round()}/' train_path = full_path + 'numerai_training_data.csv' test_path = full_path + 'numerai_tournament_data.csv' train = pd.read_csv(train_path) test = pd.read_csv(test_path) # Reduce all features to 32-bit floats if reduce_memory: num_features = [f for f in train.columns if f.startswith("feature")] train[num_features] = train[num_features].astype(np.float32) test[num_features] = test[num_features].astype(np.float32) val = test[test['data_type'] == 'validation'] test = test[test['data_type'] != 'validation'] return train, val, test # Download, unzip and load data download_current_data(DIR) train, val, test = load_data(DIR, reduce_memory=True)②特徴量エンジニアリング
Numeraiデータセットの特徴量はそれぞれの相関が低く、特徴量エンジニアリングをしなくとも、ある程度の結果が出せます。
また、PDAなどの手法を用いて特徴量を削減すると、Corrが低くなる傾向があり、あまりよくありません。(*あくまで、私が検証した結果です。Corrが良くなる可能性を否定しているわけではありません)
Numeraiにおいて効果的なことは、特徴量を増やしつつ、特徴量同士の相関を減らすことだと考えています。
公式曰く、特徴量を310個から3100個に増やす(https://twitter.com/numerai/status/1347361350205415425
らしいので、これからは特徴量エンジニアリングすら不要になるかもしれませんが、どうやって特徴量を扱うかを軽く紹介します。まずは、trainデータを眺めていると、"feature_intelligence", "feature_wisdom", "feature_charisma", "feature_dexterity", "feature_strength", "feature_constitution"の6種類に大別されることがわかります。
Carlo Lepelaarsさんの記事からコードを引用しますが、これらのfeatureの平均値や偏差、歪度などは有用な特徴量になります。
そこで、train = get_group_stats(train)を呼び出し、trainデータなどにこれらの特徴量を追加します。def get_group_stats(df: pd.DataFrame) -> pd.DataFrame: for group in ["intelligence", "wisdom", "charisma", "dexterity", "strength", "constitution"]: cols = [col for col in df.columns if group in col] df[f"feature_{group}_mean"] = df[cols].mean(axis=1) df[f"feature_{group}_std"] = df[cols].std(axis=1) df[f"feature_{group}_skew"] = df[cols].skew(axis=1) return df train = get_group_stats(train) val = get_group_stats(val) test = get_group_stats(test)メモリに余裕があるPCをお持ちの方は、featureの差分データや、交互作用特徴量、などを入れるとよい特徴量になります(20%くらいはcorrが上がります)。
Google colaboratoryでRunをかけるとクラッシュするので、コードのみを載せますが、from sklearn import preprocessing ft_corr_list=['feature_dexterity7', 'feature_charisma18', 'feature_charisma63', 'feature_dexterity14']#ft_corr_listは交互作用特徴量を作りたいものを入れる。 interactions.fit(train[ft_corr_list], train["target"]) X_train_interact = pd.DataFrame(interactions.transform(train[ft_corr_list])) X_best_val_inter =pd.DataFrame(interactions.transform(val[ft_corr_list])) X_best_test_inter =pd.DataFrame(interactions.transform(test[ft_corr_list])) train=pd.concat([train,X_train_interact],axis=1) val=val.reset_index().drop(columns='index') val=pd.concat([val,X_best_val_inter],axis=1) test=test.reset_index().drop(columns='index') test=pd.concat([test,X_best_test_inter],axis=1)を追加すればよいです。
Kaggle等で使われるような特徴量エンジニアリングがそのままNumeraiでは使えるので、train,val,testのデータを弄ることで、良いCorr、シャープレシオが得られます。
Numeraiでよい結果を得るために必要な作業の一つが、特徴量エンジニアリングなので、この部分がやりこみ要素の一つです。③機械学習
Numeraiデータセットを機械学習にかける上で検討する必要があるのは、
i)どんな機械学習の手法を用いるか(LightGBM,XGBoost,NLPなど)
ii)どんなハイパーパラメーターを使用するか
iii)予測結果のスタッキングをするか
などです。今回は、計算時間を考えてLightGBMを使用します。trainデータの中でもidやera,data_typeは機械学習に必要がないので除き、
残りのfeature_○○を説明変数、targetを教師データとして学習させます。学習させたデータを用いて、valに含まれるValidationデータやLiveデータについても予測データを作ります。i)~iii)について検討すればCorr等の値がよくなりますので、この部分もやりこみ要素の一つです。
dtrain = lgb.Dataset(train[train.columns.drop('id').drop('era').drop('data_type').drop('target')].fillna(0), label=train["target"]) dvalid = lgb.Dataset(val[train.columns.drop('id').drop('era').drop('data_type').drop('target')].fillna(0), label=val["target"]) best_config ={"objective":"regression", "num_leaves":31,"learning_rate":0.01,"n_estimators":2000,"max_depth":5,"metric":"mse","verbosity": 10, "random_state": 0} model = lgb.train(best_config, dtrain) train.loc[:, "prediction"] = model.predict(train[train.columns.drop('id').drop('era').drop('data_type').drop('target')]) val.loc[:,"prediction"]=val["target"] val.loc[:,"prediction"] = model.predict(val[train.columns.drop('id').drop('era').drop('data_type').drop('target')])④モデルの強さについて
Validationデータにおける、モデルの強さを推定するために、spearman, payout, numerai_sharpe, maeを算出します。spearman, payout, numerai_sharpeは大きければ大きいほど良いです。
この中でも、まずはspearmanの値が大きい(0.025以上が目安)条件を見つけるといいモデルが作れます。
(*Corr重視だけだといろいろと問題が起きることもあります。
Numeraiになれている方には異論があると思いますが、あくまでも「はじめて」予測結果をサブミットする人向けの記事なので、このくらいの表現にさせてください)用語の説明は以下です。
spearman:Correlationの平均値 高いほど良い(目安は0.022~0.04)
payout:平均リターン
numerai_sharpe:平均リターンを標準偏差で割った比率のこと。高いほど良い(目安は1以上)
mae:平均絶対誤差def sharpe_ratio(corrs: pd.Series) -> np.float32: """ Calculate the Sharpe ratio for Numerai by using grouped per-era data :param corrs: A Pandas Series containing the Spearman correlations for each era :return: A float denoting the Sharpe ratio of your predictions. """ return corrs.mean() / corrs.std() def evaluate(df: pd.DataFrame) -> tuple: """ Evaluate and display relevant metrics for Numerai :param df: A Pandas DataFrame containing the columns "era", "target_kazutsugi" and a column for predictions :param pred_col: The column where the predictions are stored :return: A tuple of float containing the metrics """ def _score(sub_df: pd.DataFrame) -> np.float32: """Calculates Spearman correlation""" return spearmanr(sub_df["target"], sub_df["prediction"])[0] # Calculate metrics corrs = df.groupby("era").apply(_score) print(corrs) payout_raw = (corrs / 0.2).clip(-1, 1) spearman = round(corrs.mean(), 4) payout = round(payout_raw.mean(), 4) numerai_sharpe = round(sharpe_ratio(corrs), 4) mae = mean_absolute_error(df["target"], df["prediction"]).round(4) # Display metrics print(f"Spearman Correlation: {spearman}") print(f"Average Payout: {payout}") print(f"Sharpe Ratio: {numerai_sharpe}") print(f"Mean Absolute Error (MAE): {mae}") return spearman, payout, numerai_sharpe, mae feature_spearman_val = [spearmanr(val["prediction"], val[f])[0] for f in feature_list] feature_exposure_val = np.std(feature_spearman_val).round(4) spearman, payout, numerai_sharpe, mae = evaluate(val)⑤予測結果を書きこんだcsvファイルの用意
neutrize用ファイルをsubmission_file.csvに書き込みます。このファイルは、id,predictionカラムが必須であり、idはValidationデータ、testデータ(+Liveデータ)の順番であることが求められます。順番が異なるとNumerai側ではじかれるので気を付けてください。test.loc[:, "prediction"] =0 test.loc[:, "prediction"] = model.predict(test[feature_list]) test[['id', "prediction"]].to_csv("submission_test.csv", index=False) val[['id', "prediction"]].to_csv("submission_val.csv", index=False) test=0 val=0 directory = "/kaggle/working" full_path = f'{directory}/numerai_dataset_{NAPI.get_current_round()}/' test_path = full_path + 'numerai_tournament_data.csv' tournament_data = pd.read_csv(test_path) tournament_data_id=tournament_data['id'] tournament_data_id2=tournament_data['feature_dexterity7'] tournament_data_id=pd.concat([tournament_data_id,tournament_data_id2],axis=1) val=pd.read_csv("submission_val.csv") test=pd.read_csv("submission_test.csv") test_val_concat=pd.concat([val[['id', "prediction"]],test[['id', "prediction"]]],axis=0).set_index('id') tournament_data_id=tournament_data_id.set_index('id') conc_submit=pd.concat([tournament_data_id,test_val_concat],axis=1).drop(columns='feature_dexterity7').reset_index() conc_submit=conc_submit.rename(columns={'index': 'id'}) conc_submit.to_csv("submission_file"+".csv", index=False)⑥neutrize
Example_model(Numeraiが公式に配布しているサンプルモデル)と自分のモデルを線形回帰することで、
単一の特徴量と予測結果の相関性を下げつつ、シャープレシオの改善ができます。ただ、やりすぎるとCorrが大幅に下がるので、0.3~0.5程度がよいと思います。
どんなモデルをneutrizeするか、どのくらいneutrizeするか、という部分がやりこみ要素の一つです。def neutralize(series,by, proportion): scores = series.values.reshape(-1, 1) exposures = by.values.reshape(-1, 1) exposures = np.hstack((exposures, np.array([np.mean(series)] * len(exposures)).reshape(-1, 1))) correction = proportion * (exposures.dot(np.linalg.lstsq(exposures, scores)[0])) corrected_scores = scores - correction neutralized = pd.Series(corrected_scores.ravel(), index=series.index) return neutralized by=pd.read_csv('/kaggle/working/numerai_dataset_'+str(NAPI.get_current_round())+'/example_predictions.csv') neut=pd.read_csv("submission_file.csv") neut=pd.DataFrame({'prediction':neutralize(neut['prediction'],by['prediction'], 0.3)})#ここを弄ると、Neutralizeの量を変化させることができる。 conc=pd.concat([by.drop(columns="prediction"),neut],axis=1) conc.to_csv("neutralized_submission_file.csv", index=False)#提出ファイル得られたneutralized_submission_file.csvをNumeraiホームページのUpload predictions から提出すれば完了です。
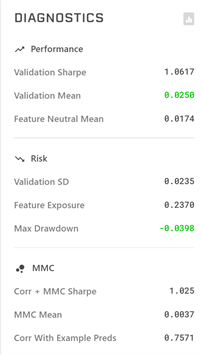
DIAGNOSTICSの見方
Validation Sharpe:Validationデータでのシャープレシオ 1以上だと良い
Validation Mean: ValidationデータでのCorr平均値 0.025~くらいあると良い
Feature Neutral Mean:全特徴量についてneutralizeした時のCorr平均値(あまり参考にしていない)
Validation SD:Validationデータと予測値のEra毎の相関性の標準偏差(あまり参考にしていない)
Feature Exposure:特徴量と予測結果がどれだけバランスがとれているかを表す指標 小さいほど良い
Max Drawdown 最大ドローダウン -0.05以下くらいが目安
Corr + MMC Sharpe:CorrとMMCを合わせたシャープレシオ
MMC Mean:MMCの平均値
Corr With Example Predsサンプルモデルとの相関 0.5~0.8程度が目安numerai関連の便利リンク集(追記予定 コメントください)
自分がどのくらいの順位か簡易的にわかるツール
https://dashboard.numeraipayouts.com/
ペイアウトの合計を算出するツール
https://apps.apple.com/app/id1522158691
Numerai Advent Calendar 2020(Corrを上げる方法などの情報集 @kunigakuさん主催)
https://adventar.org/calendars/5031Numeraiに望むこと
①NMRは草コインであるため、価格が安定しません。20~60USD程度で価格が振れるので、参入時期によってはNumeraiに提出したモデルが優秀でも、NMRトークンが値下がり、損失を出す可能性があります。トークン価格が安定してくれると嬉しいです。
②日本語文献が少ない。フォーラムを追っていないと、機能の変更があってもすぐに対応ができません。(例えば、パラメーターの計算方法が変更になった時 https://forum.numer.ai/t/model-diagnostics-update/902
日本語記事の拡充や、ホームページが日本語化されると嬉しいです。(現状、対応中らしいですが・・・。)さいごに
私自身は800位程度と、そこまで上位ではないですが、+のリターンになっています。
https://numer.ai/tit_btcqash
今回載せたコードとはかなり異なりますが、Corrをある程度維持しつつ、Neutralizeを7種類かけたモデルを使用しています。
3NMRくらいくれたらコードの入った.ipynbファイルを渡すので、興味ある人がいればお声かけください。チップ用
NMR:0x0000000000000000000000000000000000021d96

- 投稿日:2021-01-11T21:47:15+09:00
Poetry での AssertionError は pyproject.toml を変更すると直る可能性がある
https://github.com/python-poetry/poetry/issues/1051 に書いてある。
pyproject.tomlの[tool.poetry]にあるnameフィールドと同名のモジュールをインストールすることはできない。 Poetry がもともとモジュール開発を意識して作られたことから、納得できる。[tool.poetry] + name = "mypulp" - name = "pulp" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"]私の場合は
PuLPモジュールを試すときにpulpというディレクトリでpoetry initを実行した。初期値を使ったため pyproject.toml の中のモジュール名がpulpになっていたためpoetry経由でpulpのインストールができなかった。ちなみに、
pipであれば問題なくインストールできる。
- 投稿日:2021-01-11T21:35:14+09:00
cuiでのラズパイwifi設定と設定ようscript
目的
遠隔に設置したラズパイ(ak20でネットワークにつなげている)に予備のwifiネットワークに繋げるようにネットワークの設定を行う。
または、ラズパイのネットワークの設定にあらかじめお客さんのネットワーク設定を入れておくやり方
wifiの設定ファイルの編集sudo vim /etc/wpa_supplicant/wpa_supplicant.conf/etc/wpa_supplicant/wpa_supplicant.confctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 country=JP network={ ssid="W03_aaaaa" #wifiの名前 psk="aaaa" #wifiのパスワード key_mgmt=WPA-PSK } network={ ssid="W03_bbbb" #wifiの名前 psk="bbbbb" #wifiのパスワード key_mgmt=WPA-PSK priority=3 #優先度 大きいほうに優先してつなぐ default 0 disabled=1 #自動接続するかどうか 1だと自動接続しない default 0 }script
上記参考にwpaを書き換えるスクリプトを書くことでお客さん用のラズパイ設定が楽になります。(⚠️sudo権限じゃないと実行できない)
add_wifi_ssid.pyimport fire def main(ssid: str, password: str): file = "/etc/wpa_supplicant/wpa_supplicant.conf" with open(file, 'a') as f: text = "network={\nssid=\"" + ssid + "\"\npsk=\"" + password + "\"\nkey_mgmt=WPA-PSK\n}" print(text, file=f) if __name__ == '__main__': fire.Fire(main)その他
cuiでwifiを切り替えるコマンドnetworksetup -setairportnetwork en0 $ssid $password
- 投稿日:2021-01-11T20:38:53+09:00
【slackapi + Python】ステータス確認やメッセージ送信などのメゾットをまとめてみた
この記事では、Python3でslackapiを使うためのテンプレっぽいものの備忘録です。扱うリクエストは、以下です。
- chat.postMessage (公式ドキュメント)
- users.profile.set (公式ドキュメント)
- users.setPresence (公式ドキュメント)
- users.getPresence (公式ドキュメント)
- users.list (公式ドキュメント)
公式ドキュメントでその他のリクエストも参考にできます。
前提, 環境
- slackアプリを作成済み
Class SlackFunctionsを作る。
OAuth Tokenが2種類
slackapi -> YourApp -> Install app
を開くと2つトークンがあります。
- OAuth Access Token
- Bot User OAuth Access Token
リクエストの種類によって必要になるトークンが違うので、そこもうまく簡略化できるようにしたいと思いました。
定義する場所は任意ですが、今回は「.env」に格納しておきました。
.envSLACK_OAUTH_TOKEN='xoxp-{YOUR_TOKEN}' SLACK_USER_TOKEN='xoxb-{YOUR_TOKEN}'pythonファイルで使う時にはdotenvのインポートが必要です。
slackapi_functions.pyfrom dotenv import load_dotenv import os load_dotenv() slack_oauth_token = os.environ['SLACK_OAUTH_TOKEN'] slack_user_token = os.environ['SLACK_USER_TOKEN']ついでにslackapiを使うためのインポートも!
slackapi_functions.pyimport requests # リクエストを送るため import json # レスポンスをJsonとして受け取る。 from slack import WebClient # SlackapiのWebClientClass SlackFunctions初期化
slackapi_functions.pyclass SlackFunctions: def __init__(self): self._headers = {'Content-Type': 'application/json'}chat.postMessage
slackapi_functions.pydef post_message(self, channel, message): params = {"token": slack_user_token, "channel": channel, "text": message} r = requests.post('https://slack.com/api/chat.postMessage', headers=self._headers, params=params)メッセージを送るリクエストです。
#generalに送る →post_message("#general","hello!")
DMでユーザーに送る →post_message("{USERS_ID}", "Wake UP!")users.profile.set
slackapi_functions.pydef profile_set(self, text, emoji): params = { "token": slack_oauth_token, "profile": json.dumps({ "status_text": text, "status_emoji": emoji }) } r = requests.post('https://slack.com/api/users.profile.set', params=params)カスタムステータスのテキストと絵文字を設定するリクエストです。
profileという変数にstatus_text, status_emojiがあるのでその2つだけを設定する際にはこのまま使えます。users.setPresence
slackapi_functions.pydef set_presence(self, status): # statue: 'away' OR 'auto' params = { "token": slack_user_token, "presence": status } r = requests.post('https://slack.com/api/users.setPresence', params=params)こちらは、実際にactiveかawayかについてのリクエストです。
強制的にawayにすることはできますが、強制的にactiveにすることはできません。
なので、presenceの引数は"away"か"auto"だけです。users.getPresence
slackapi_functions.pydef get_presence(self, user): params = {"token": slack_user_token, "user":user} r = requests.post('https://slack.com/api/users.getPresence', headers=self._headers, params=params) return r.json()ユーザーのステータス(activeかawayか)を返してくるリクエストです。
帰ってきたステータスを使いたかったので、返り値を付けました。users.list
slackapi_functions.pydef users_list(self): params = {"token": slack_user_token} r = requests.post(' https://slack.com/api/users.list', headers=self._headers, params=params) return r.json()workspace内の全ユーザー(BOTやプラグインアプリも含む)情報を返してくるリクエストです。
情報量が多いので、自分はレスポンスを加工してから返すfunctionにしてました。def users_list(self): params = {"token": slack_user_token} r = requests.post(' https://slack.com/api/users.list', headers=self._headers, params=params) rjson = r.json() id_list = [] name_list = [] for i in range(0, len(rjson["members"])): id_list.append(rjson["members"][i]["id"]) name_list.append(rjson["members"][i]["profile"]["display_name"]) return id_list, name_list使い方
まず、
slackapi_functions.pyをインポートyour_slackapp.pyimport slackapi_functions SF = slackapi_functions.SlackFunctions()あとは、Class名とFunction名で使えます!
your_slackapp.pySF.post_message("#international-team", "Hello, this is your app!") SF.change_status_message("I am focused!", :computer:) SF.set_presence('away') user_status = SF.get_presence(YOUR_ID) accounts_info = SF.users_list()
- 投稿日:2021-01-11T19:43:07+09:00
selenium ケーススタディ まとめ python pyCharm
Seleniumで困ったことのまとめ
最近、seleniumを入力作業の自動化をする仕組みを作りそれにあたって困ったことなどこの記事でまとめていこうかなと思います。何をimportするとかは書いたらpycharmが勝手に教えてくれるので省略
reCAPTCHAや二段階認証の回避
chromeにてユーザープロファイルに対象のサイトのログイン情報を記憶させ、seleniumでユーザープロファイル指定、ドライバー初期化にて回避する。
# main.py from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument("--user-data-dir=C:\Users\Yoshi\AppData\Local\Google\Chrome\User Data") options.add_argument("--profile-directory=Profile 7") driverPath = "C:\Program Files (x86)\WebDriver\chromedriver_win32\chromedriver_87.exe" driver = webdriver.Chrome(executable_path=driverPath, options=options)Send.keyが遅い......
execute_scriptを使ってテキストボックスに値を入力します。
# webドライバー初期化は省きます targetId = "targetId" inputVal = "inputVal" # 改行を含めて文字列を入力したいとき↓ # inputVal = inputVal.replace('\n', '\\n') driver.execute_script(f'document.getElementById("{targetId}").value="{inputVal}";')要素の存在チェックを行う
# webドライバー初期化は省きます if len(driver.find_elements(By.ID, "element")) > 0: print("あるよ。")Conform Alert box のOKボタンを押す
# webドライバー初期化は省きます # クリックするのは何でもよいComform Alertとの表示のトリガーとなるものをクリック driver.find_element_by_xpath("xpath").click() Alert(driver).accept() # OK Alert(driver).dismiss() # キャンセルtype fileに画像を送る
# webドライバー初期化は省きます productImgFilePath = r"C:\work\RakumaAutoApp\1.jpg" driver.find_element_by_xpath("xpath").send_keys(productImgFilePath)xpathの確認方法
chromeだけ、たぶんほかのブラウザも大体おんなじ感じだと思う
・F12で開発者用画面を開く
・何でもよいから選択
対象要素右クリ、Copyを見れば見つかる。
まとめ
今回の入力作業自動化のプログラム作成で初めてPythonを触り、いい勉強になった。Seleniumも何かと何もせずに勝手にブラウザ動かしてなんかしてくれるのできもちいい。
- 投稿日:2021-01-11T19:31:41+09:00
Visual Studio Code ( VS Code ) で jupyter notebook 環境を構築 Mac版
Visual Studio Code ( VS Code ) で jupyter notebook 環境を構築 Mac版
目的
Python開発環境の作業メモとして記載。
ANACONDAのライセンスが変わり、当面は問題無いのですが、ANACONDAを使わないPythonのローカル開発環境へ移行してみました。
jupyter notebookは Visual Studio Code ( VS Code ) とそのJupyter Extension for Visual Studio Code (Jupyter 拡張)を使うことにしてみました。
手順は簡単ですが使い方のメモとしても記載しておくことにしました。
Pythonの開発環境としては、pyenvとpyenv-virtualenvを利用しています。(別記事)Mac環境
OS : Mac OS Big Sur(11.1)
Xcode : App StoreではインストールしていないVisual Studio Code ( VS Code ) をインストール
Visual Studio Codeサイトからダウンロードし、インストール
Visual Studio Code Insidersをインストール
Visual Studio Codeサイト Insidersからダウンロードし、インストール!
起動すると警告が出ますが「開く」
Jupyter Extension for Visual Studio Code (Jupyter 拡張)をインストール
https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter
Jupyter Extension for Visual Studio Codeサイト Insidersからダウンロードし、インストール!
Visual Studio Code.appを開くようにポップアップが出ます
Visual Studio Code が起動し、そのウインドウ内でJupyterが開かれます
インストール を押します
使い方
Visual Studio Code を起動します
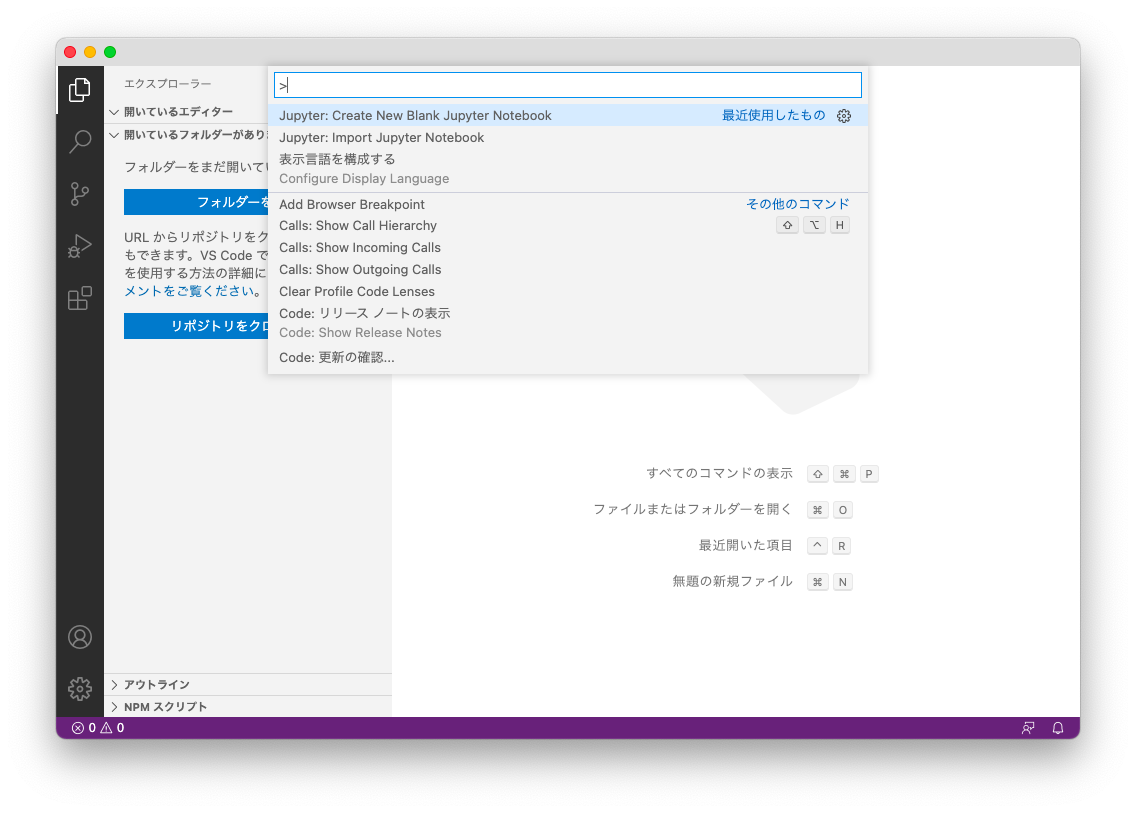
全てのコマンドを表示 commandキー+shiftキー+pキー を押します
jupyter: Create New Blank Jupyter Notebook を選びます
インストールが必要なものがあれば、ポップアップ表示されますので、インストールしてください
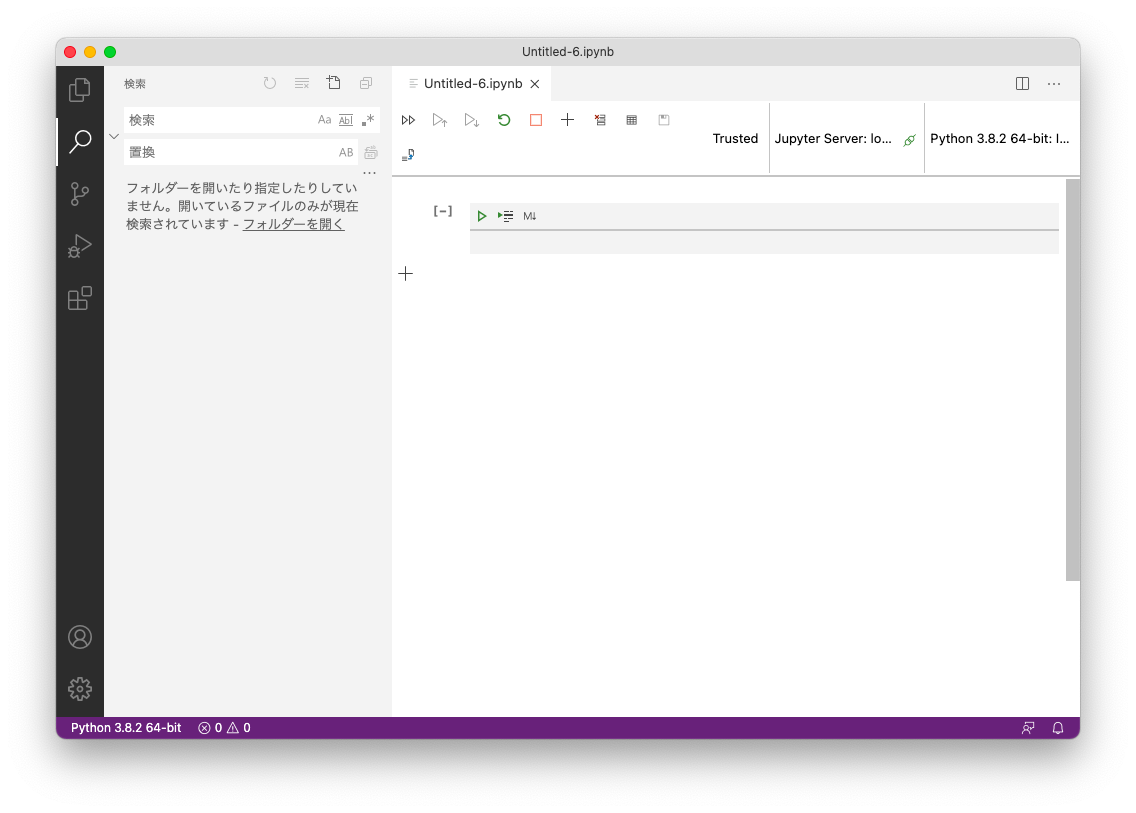
Visual Studio Code 内にJupyter Notebookが起動します
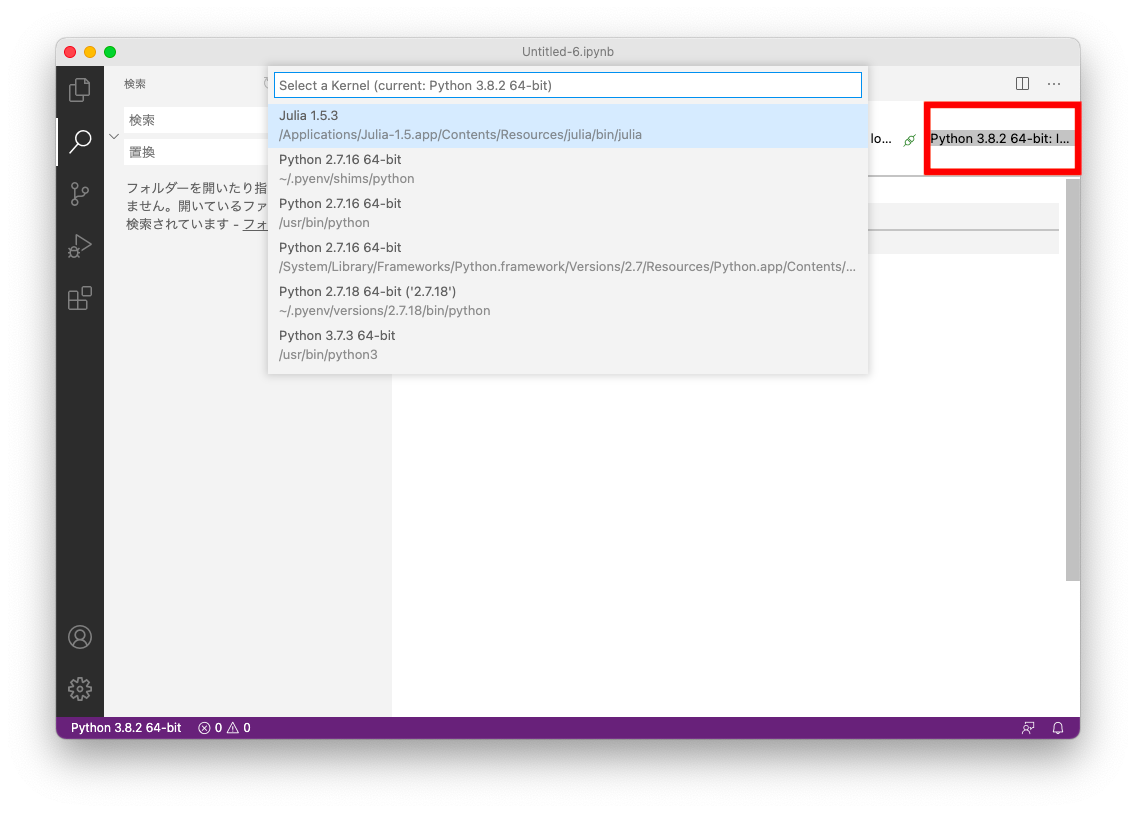
右上に利用しているPython環境が表示されており、こちらをクリックすると、実行するPython環境を切り替えることができます



- 投稿日:2021-01-11T19:13:37+09:00
Flaskで作るSNS Flask(Blueprint,bcrypt)編
TL;DL
Udemyの下記講座の受講記録
Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~
https://www.udemy.com/course/flaskpythonweb/この記事ではFlaskのBluePrintによるアプリケーション管理とbcryptによるパスワードの暗号化について記載する。
BluePrintとは
作成したアプリケーションを機能などの単位別にグループ分けして管理したい場合に利用する機能。
例えば、個人情報管理機能(site1)とデータ照会機能(site2)のモジュールを別々に管理したい場合に、BluePrintを使用して分割管理することで、アプリケーションとしての見た目は1つでも、内部管理的には複数のアプリケーションとして分割管理することが可能となる。
基本構造
構文
1.管理したいアプリケーションをBluePrintオブジェクトとして作成する。
フォーマット サンプル 作成されるURL例 BluePrint(サイトの名称, __name__, url_prefix='/urlとして利用する文字列') mysite1_bp = Blueprint('mysite1', name, url_prefix='/site1') http://www.xxxx/site1/hello from flask import Blueprint, render_template '''BlurPrintインスタンスの作成''' mysite1_bp = Blueprint('mysite1', __name__, url_prefix='/site1') @mysite1_bp.route('/hello') def hello(): return render_template('mysite1/hello.html')2.init.py でアプリケーションにBluePrintオブジェクトを登録する。
from flask import Flask def create_app(): app = Flask(__name__) from flaskr.mysite1.views import mysite1_bp from flaskr.mysite2.views import mysite2_bp app.register_blueprint(mysite1_bp) app.register_blueprint(mysite2_bp) return app3.setup.py でinit.pyに定義したアプリケーション情報を取得し、アプリを起動する。
from flaskr import create_app from flask import render_template app = create_app() # __init__.appより取得 @app.route('/') def home(): return render_template('home.html') if __name__ == '__main__': app.run(host='0.0.0.0', port=5000, debug=True)パスワードの暗号化(bcrypt)
Flask-Bcryptを利用してパスワードを暗号化する。
: inport時は「flask_bcrypt」と単語感がアンダースコアである点に注意 >>> from flask_bcrypt import Bcrypt : bcryptオブジェクトの作成 >>> bcrypt = Bcrypt() >>> testpass = 'password' : パスワードのハッシュ化 >>> hashed_password = bcrypt.generate_password_hash(password=testpass) >>> hashed_password b'$2b$12$3B0I.CHMIEya1OdyI/m44Od7I.TKhRLiOA.EMMWQP3MgUXgr9dkYG' : ハッシュ化パスワードとの正誤比較 >>> bcrypt.check_password_hash(hashed_password, 'password') True >>> bcrypt.check_password_hash(hashed_password, 'pass') Falseサンプル
from flask_bcrypt import generate_password_hash, check_password_hash class User(UserMixin, db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) email = db.Column(db.String(64), unique=True, index=True) username = db.Column(db.String(64), index=True) password = db.Column(db.String(128)) def __init__(self, email, username, password): self.email = email self.username = username # フォームから渡されたpasswordの値を暗号化して変数に格納する。 self.password = generate_password_hash(password) def validate_password(self, password): # 関数に渡されたパスワードが正しいか比較する。 return check_password_hash(self.password, password)
- 投稿日:2021-01-11T18:51:37+09:00
自習” A Beginner's Guide to Getting User Input in Python”の和訳
元記事URL https://hackernoon.com/a-beginners-guide-to-getting-user-input-in-python-141q312q
自習用の翻訳なので、自己責任でご利用ください。
A Beginner's Guide to Getting User Input in Python(初心者向けガイド Pythonでデータを入力する方法)
January 8th 2021
2021年1月8日
@aswinbarath
Aswin Barath
Budding Software Engineer
@aswinbarath
オースウィン・バラス
新人ソフトウエアエンジニアGetting input from the user is what makes a program more interactive with the user.
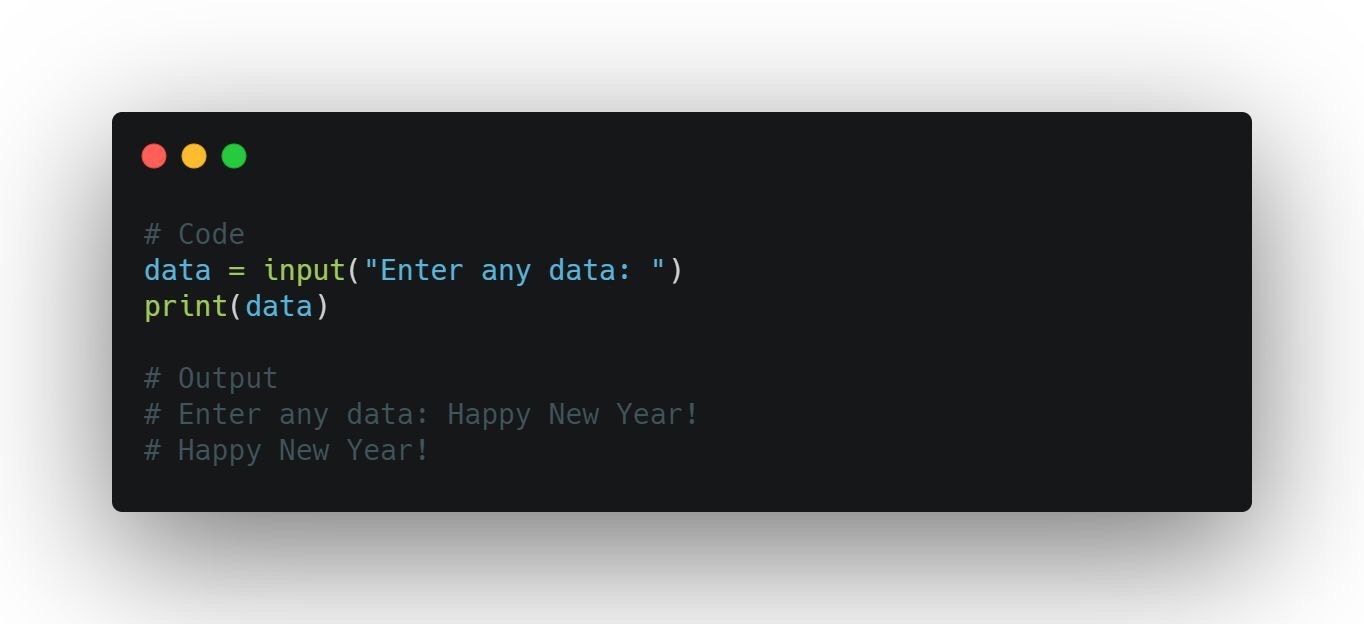
ユーザから入力を受け付けることは、ユーザにとってプログラムをよりインタラクティブなものにします。Hence, in python we have an input function: input(), to receive input from the user.
ですから、ユーザからの入力を受け取るために、Pythonには入力のための関数input()があります。Take a look at an example.
次のサンプルコードを見てください。
Output:
画面出力は次のようになります。Enter any data:Happy new year! Happy new year!Input Function Under the Hood(入力関数の内部の動き)
When input() function is encountered by python, the program will pause until the user enters data.
Pythonインタプリタがinput()関数を実行すると、ユーザがデータを入力するまでプログラムは一時停止します。Later, any input entered by the user will be converted into a string. Let’s see another example to understand this point.
その後に、ユーザが何かしらのデータを入力すると、そのデータは文字列オブジェクトに変換されます。これを理解するために、次のサンプルコードを見てください。
Output:
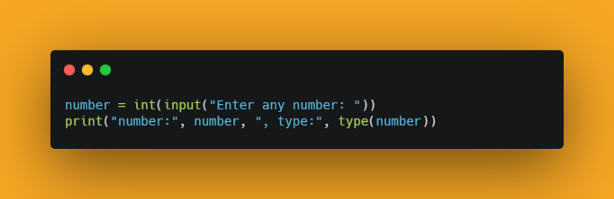
画面出力は次のようになります。Enter any text: Have a great year ahead. text: Have a great year ahead. , type: <class 'str'> Enter any number: 2021 number: 2021 , type: <class 'str'>So, in these cases make sure that you convert the input to your preferred data type using its corresponding constructors. Let’s see that example too.
このため、以上の場合には対応するコンスタラクタ(入門者が読むならば、ここでは変換手段)を使って入力されたデータを望むデータ型に変換する必要があります。次のサンプルコードも見てください。
Output:
画面出力は次のようになります。Enter any number: 2021 number: 2021 , type: <class 'int'>So, code along and have fun :)
と、いうことで、コーディングを楽しみましょう!(^v^)


- 投稿日:2021-01-11T18:48:30+09:00
Flaskで作るSNS Flask(flask_loginによるログイン処理)編
TL;DL
Udemyの下記講座の受講記録
Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~
https://www.udemy.com/course/flaskpythonweb/この記事ではFlask_loginによるログイン処理について記載する。
flask_login
Flaskアプリケーションでログイン処理をかんたんに実装することができるライブラリ
https://flask-login.readthedocs.io/en/latest/フォルダ構成
login_sample
├── flaskr
│ ├── __init__.py
│ ├── forms.py
│ ├── models.py
│ ├── templates
│ │ ├── _formhelpers.html
│ │ ├── base.html
│ │ ├── home.html
│ │ ├── login.html
│ │ ├── register.html
│ │ ├── user.html
│ │ └── welcome.html
│ └── views.py
└── setup.py※ここではログイン処理に必要なもののみ抜粋して記載する。
ライブラリインストール
(flaskenv) (base) root@e8cf64ce12e9:/home/venv/flaskenv/login_sample# pip install flask_loginコード
__init__.py
・「login_maneager.login_view」にログイン処理のメソッドを登録する。ここではアプリケーション名をBlueprintで「app」という名称に設定しているので、「app.login」となる。
・「login_manager.login_message」にはリダイレクトされたときに表示するフラッシュメッセージを登録する。指定しない場合はデフォルトメセージが利用される。
・LoginManagerを利用する場合は、「login_manager.init_app([name])」メソッドで初期化してアプリケーションを登録する。import os from flask import Flask from flask_sqlalchemy import SQLAlchemy from flask_migrate import Migrate from flask_login import LoginManager # Flask-LoginとFlaskアプリケーションをつなぐ処理。 login_manager = LoginManager() # ログインする際に実行される処理 アプリケーション名.login login_manager.login_view = 'app.login' # ログイン画面にリダイレクトされた際に表示されるメッセージ login_manager.login_message = 'ログインしてください' base_dir = os.path.abspath(os.path.dirname(__name__)) # db作成 db = SQLAlchemy() # Migration用インスタンス作成 migrate = Migrate() def create_app(): # Flaskアプリケーション作成 app = Flask(__name__) # DB定義 app.config['SECRET_KEY'] = 'mysite' app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + \ os.path.join(base_dir, 'data.sqlite') app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # アプリにBlueprintオブジェクトを登録 from flaskr.views import bp app.register_blueprint(bp) # DBを使用するアプリケーションを初期化 db.init_app(app) # migrationするflaskアプリとDBを初期化 migrate.init_app(app, db) # loginManagerを初期化 login_manager.init_app(app) return appviews.py
・「@login_required」デコレータをつけることで、該当のメソッドを実行する前にログインしているか確認し、ログインしていなければメソッドは実行されずに__init__.pyでlogin_manager.login_viewに定義されているメソッドを実行する。
・login_user関数にユーザー名を渡すことでログイン処理を実行する。第2引数にremember=Trueを渡すことで、ブラウザを閉じてもsession情報を残す事ができる。
・「request.args.get('next')」メソッドでは、リクエスト元画面で遷移先として指定していたrouteを取得することができる。これにより、直接遷移先を再指定しなくても意図した画面に遷移することが可能となる。from flask import Blueprint, request, render_template, redirect, url_for from flask_login import login_user, login_required, logout_user from flaskr.forms import LoginForm, RegisterForm from flaskr.models import User bp = Blueprint('app', __name__, url_prefix='') @bp.route('/') def home(): return render_template('home.html') # login_requiredにより、login_userが実行されていない場合以下の関数は実行されない。 # ログインしていない場合は、__init__.pyのlogin_viewに指定されている処理に遷移する。 @bp.route('/welcome') @login_required def welcome(): return render_template('welcome.html') @bp.route('/login', methods=['GET', 'POST']) def login(): form = LoginForm(request.form) if request.method == 'POST' and form.validate(): user = User.select_by_email(form.email.data) if user and user.validate_password(form.password.data): # login_user関数にユーザー名を渡すことでログイン処理を実行する。 # remember=Trueとすることで、ブラウザを閉じてもsession情報を残す事が可能。 login_user(user, remember=True) # このログインメソッドを呼び出した処理が本来の遷移先として指定していた # ページ(url)を取得する。 next = request.args.get('next') if not next: next = url_for('app.welcome') return redirect(next) return render_template('login.html', form=form)models.py
ポイント
・「@login_manager.user_loader」デコレータをつけたload_userメソッドでユーザーIDを取得して返すことにより、ログイン済みユーザーであることを確認する。この処理で返されるユーザー情報(userオブジェクト)が、home.htmlで利用されている「current_user」となる。
・UserMixinはflask-loginで必要なものをまとめたクラスであり、class定義時に必ず継承する必要がある。from flaskr import db, login_manager # __init__.pyからインポートされる from flask_bcrypt import generate_password_hash, check_password_hash from flask_login import UserMixin # セッションに保存されたログインユーザーを返すためにtemplateから呼ばれる。 @login_manager.user_loader def load_user(user_id): return User.query.get(user_id) # UserMixinはFlask-Loginを利用するユーザーに必須のオブジェクトを定義したもの class User(UserMixin, db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) email = db.Column(db.String(64), unique=True, index=True) username = db.Column(db.String(64), index=True) password = db.Column(db.String(128)) def __init__(self, email, username, password): self.email = email self.username = username self.password = generate_password_hash(password) def validate_password(self, password): return check_password_hash(self.password, password) def add_user(self): with db.session.begin(subtransactions=True): db.session.add(self) db.session.commit() @classmethod def select_by_email(cls, email): return cls.query.filter_by(email=email).first()login.html
{% from "_formhelpers.html" import render_field %} {% extends "base.html" %} {% block content %} <!-- get_flashed_messages()でリダイレクトされた際にメッセージを表示する。 表示するメッセージは__init__.py のlogin_manager.login_messageで定義 --> {% for message in get_flashed_messages() %} {{ message }} {% endfor%} <form method='POST'> {{ form.csrf_token }} {{ render_field(form.email) }} {{ render_field(form.password) }} {{ form.submit()}} </form> {% endblock %}home.html
{% extends 'base.html' %} {% block content %} <div> {% if current_user.is_authenticated %} <p>ログイン済み {{ current_user.username }}</p> {% else %} <p>ログイン or 登録してください。</p> {% endif %} </div> {% endblock %}
- 投稿日:2021-01-11T18:40:27+09:00
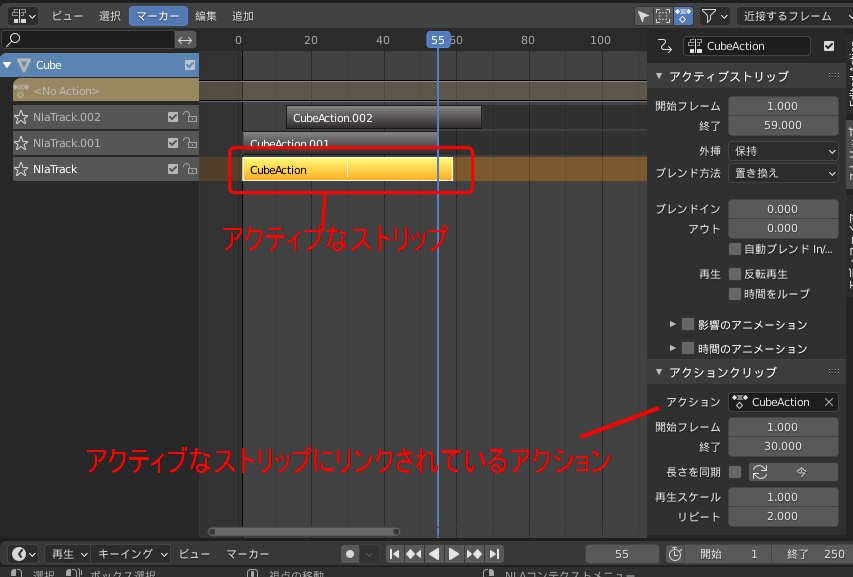
アクティブなストリップの範囲をプレビュー範囲に設定
Blenderには アクションをストリップという単位で範囲指定して
複数のモーションを重ね合わせたり、ループさせたりするノンリニアアニメーション(NLA)という機能があります
また、FBX等の書き出し時にストリップを1つのモーションとして書き出すこともできます。
ゲーム等の繰り返しモーションを作成する時に
ストリップの長さでリピートさせて動きをチェックすることが多いので作成した
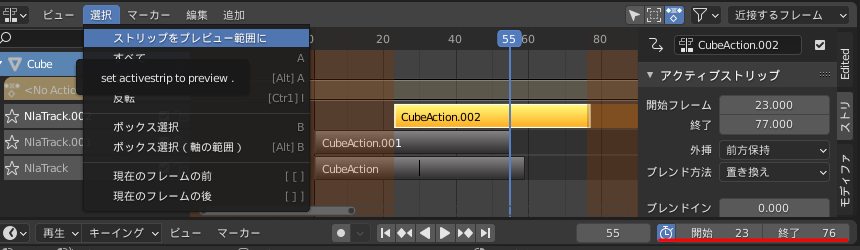
指定したストリップの範囲をタイムラインのプレビューに設定するアドオンですノンリニアアニメーションエディッタの 選択メニューに「ストリップうをプレビュー範囲に」の項目を追加します
2.7時代に仕事で使用していたものを2.8以降に対応するように修正しました
y_StripTime_to_preview.pybl_info = { "name": "set activeStripTime to preview", "description": "アクティブなストリップの範囲をプレビュー範囲に設定", "author": "Yukimi", "version": (0,3), "blender": (2,80, 0), "location": "NLA", "warning": "", "wiki_url": "", "tracker_url": "", "category": "Animation"} import bpy def Striptime_to_preview(context): active_track = context.active_object.animation_data.nla_tracks.active if not active_track :return() for strip in active_track.strips: if strip.active: active_strip = strip if active_strip == "":return() #ストリップの情報を取得 frame_start = strip.frame_start frame_end = strip.frame_end repeat = strip.repeat #リピートの一回目のみをプレビュー context.scene.use_preview_range = True context.scene.frame_preview_end = frame_start + int(( frame_end - frame_start)/ repeat) -1 context.scene.frame_preview_start = frame_start class NLA_OT_StripTimeToPreview(bpy.types.Operator): ''' set activestrip to preview ''' bl_idname = "action.striptime_to_preview" bl_label = "set activeStripTime to preview" def execute(self, context): Striptime_to_preview(context) return {'FINISHED'} classes = (NLA_OT_StripTimeToPreview,) ################################################### def menu_func(self, context): self.layout.operator("action.striptime_to_preview", text="ストリップをプレビュー範囲に" ) def register(): for cls in classes: bpy.utils.register_class(cls) bpy.types.NLA_MT_select.prepend(menu_func) def unregister(): bpy.types.NLA_MT_select.remove(menu_func) for cls in reversed(classes): bpy.utils.unregister_class(cls) if __name__ == "__main__": register()
- 投稿日:2021-01-11T18:12:47+09:00
pythonの*(アスタリスク)引数について(とitertools.starmap)
これは何?
mapについてpythonの公式ドキュメント1見ていたとき
map() と starmap() の違いは function(a,b) と function(*c) の差に似ています。
という記述があり、何だコレってなったのがきっかけ。
function(a,b) と function(*c) の差
を知るのが目的
アスタリスク引数の効果
Qiita記事2にすごくよくまとまっていた。
function(a,b) と function(*c) の差と言っているのが、以下のうちどちらかわからない。def sum1(a,b): return a+b def sum2(*c): ret = 0 for n in c: ret += n return ret a = 1 b = 2 c = [a,b] sum1(a,b) # > 3 # pattern1 sum1(*c) # > 3 # pattern2 sum2(*c) # > 3pattern1はアンパックであり、
sum1(*c) = sum1(c[0], c[1])で、len(c) = 2だから(sum1の引数の数と一致するから)うまく動く。pattern2は可変長の引数に対する処理で、
len(c)がいくつであってもうまく動く。関数の*引数についてはよくわかったが、せっかくなので、starmap()について見てみる。
itertools.startmap()
公式ドキュメント1にあるように
list(starmap(pow, [[2,3],[3,4],[4,5]])) # --> 32 9 1000となる。
これは$2^{3}, 3^{4}, 4^{5}$のように
第2引数、$[a,b,c,\cdots]$に対して
$a[0]^{a[1]},b[0]^{b[1]},c[0]^{c[1]}, \cdots$を計算していることがわかる。
同じようにlist(starmap(sum, [[2,3],[3,4],[4,5]]))とすれば、$2+3, 3+4, 4+5$を計算してくれるだろうと思っていたが
TypeError: 'int' object is not iterableと出てくる。
int object…?list(starmap(sum, [[2,3,4],[3,4,5],[4,5,6]]))とすると
TypeError: sum() takes at most 2 arguments (3 given)だと…。
なるほど、3 givenということは、2, 3, 4の3つを引数だと思ったのか。
sum([2,3,4])ではなく、sum(2,3,4)として扱われたということか。[2,3]のときも
sum(2,3)として扱われて、第1引数が2でintが入っていたためTypeError: 'int' object is not iterableこのErrorが出たのか。
公式ドキュメント3によるとPython3.8以降ではsum(iterable, /, start=0)らしくて、第2引数で下駄を履かせられるようになったらしい。
話をもとに戻して、$2+3, 3+4, 4+5$とを計算するためには
list(starmap(sum, [[[2,3]],[[3,4]],[[4,5]]])) # [5, 7, 9]とすれば良い。
つまりstarmapはstarmap(func, [funcに入れる引数, funcに入れる引数,...])と理解すれば良さそう
- 投稿日:2021-01-11T17:55:02+09:00
Google Colaboratoryで簡単な画像処理してみました。
はじめに
この記事は、pythonましてやPCにすらあまり触ったことのない逆に珍しい高専生(編入学生)が、書いている内容の薄い記事です。他の方の記事を参考にさせていただいている点がかなり多いです。温かな目で見ていただけたら嬉しいです。
必要な環境
- google colaboratory
- OpenCV
画像をアップロードして表示
今回は任意の画像が使いやすいようにアップロードして処理することにします。
files.upload()を使うことでアップロードすることができます。
コマンドを実行するとアップロードフォームが表示されるのでアップロードしてください。
その後ファイル名を取得しておきます。Uploadfrom google.colab import files uploaded_file = files.upload() img = next(iter(uploaded_file))画像表示
オリジナルの表示
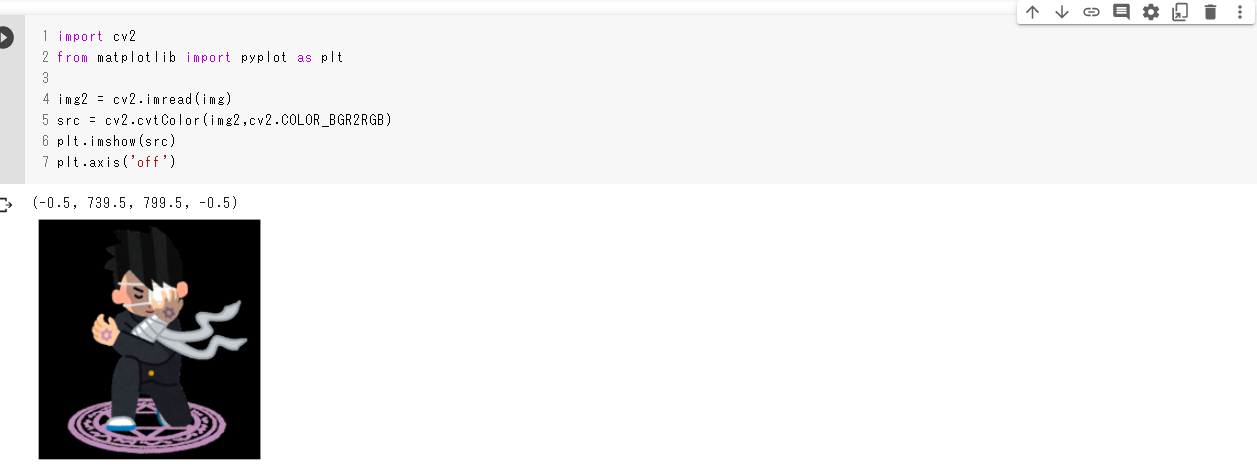
OpenCVを使って画像を読み込みますが、OpenCVでの画像の色はRGBではなくBGRで扱われているため、一般的なRGBに変換します。その後、
matplotlibを使って画像を表示します。画像表示import cv2 from matplotlib import pyplot as plt img2 = cv2.imread(img) #RGB変換 src = cv2.cvtColor(img2,cv2.COLOR_BGR2RGB) #画像の表示 plt.imshow(src) #値の非表示 plt.axis('off')これでオリジナルの画像が表示されます。
色の反転
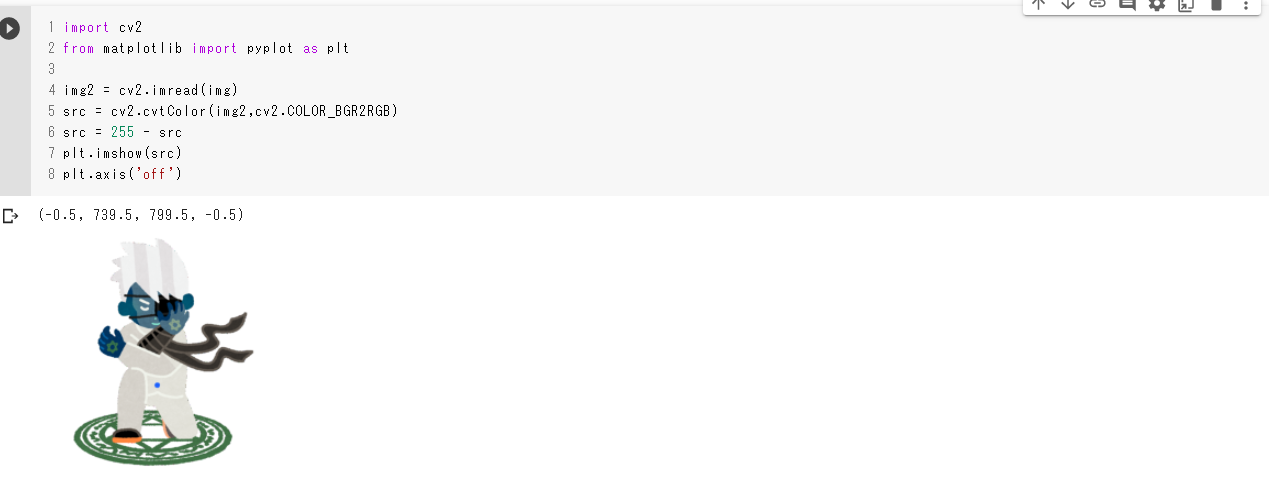
色の反転は簡単で
src = 255 - srcを入れるだけです。これは元の色の値を白(255)から引くことによって値が反転する事を利用しています。色の反転import cv2 from matplotlib import pyplot as plt img2 = cv2.imread(img) src = cv2.cvtColor(img2,cv2.COLOR_BGR2RGB) #反転 src = 255 - src plt.imshow(src) plt.axis('off')実行結果
グレースケールへの変換と表示
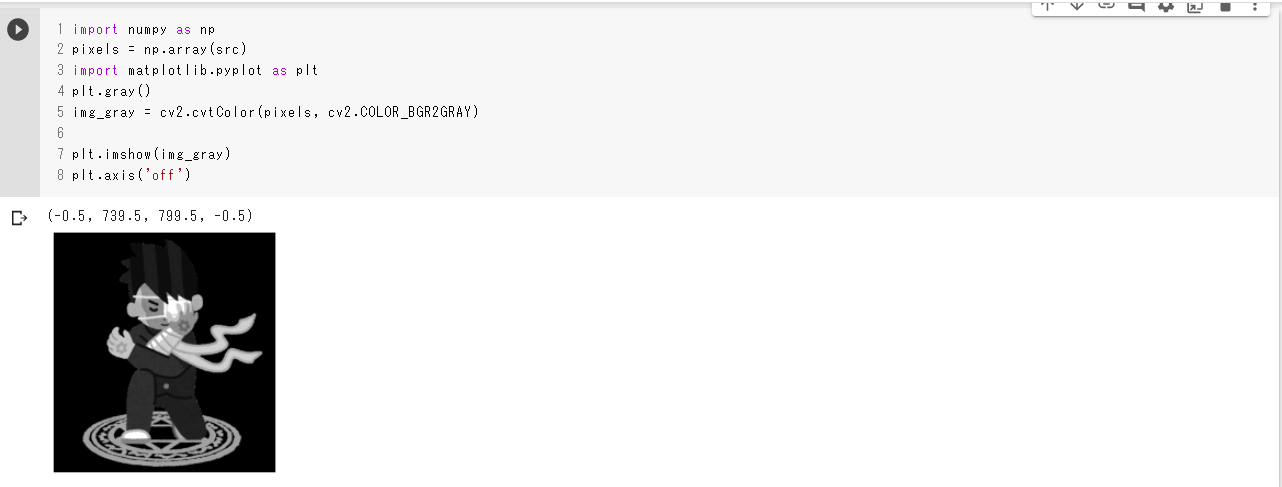
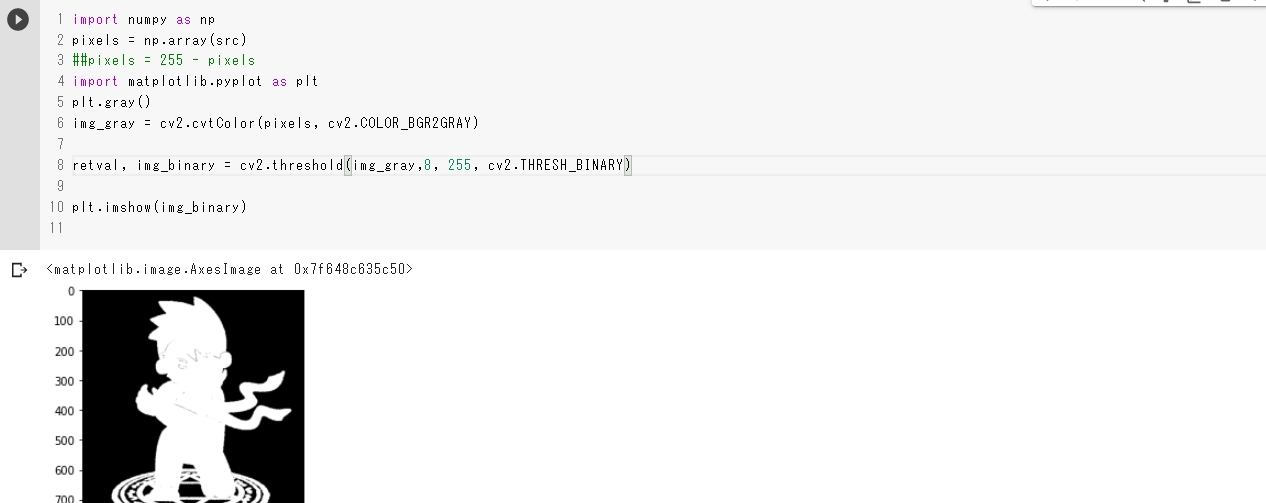
グレースケールへの変換は
cv2.cvtColor(pixels, cv2.COLOR_BGR2GR)で変換できます。
オリジナルと違う点はそこだけです。グレースケールimport numpy as np pixels = np.array(src) import matplotlib.pyplot as plt #グレースケールに変換 img_gray = cv2.cvtColor(pixels, cv2.COLOR_BGR2GRAY) plt.imshow(img_gray) plt.axis('off')実行結果
二値化
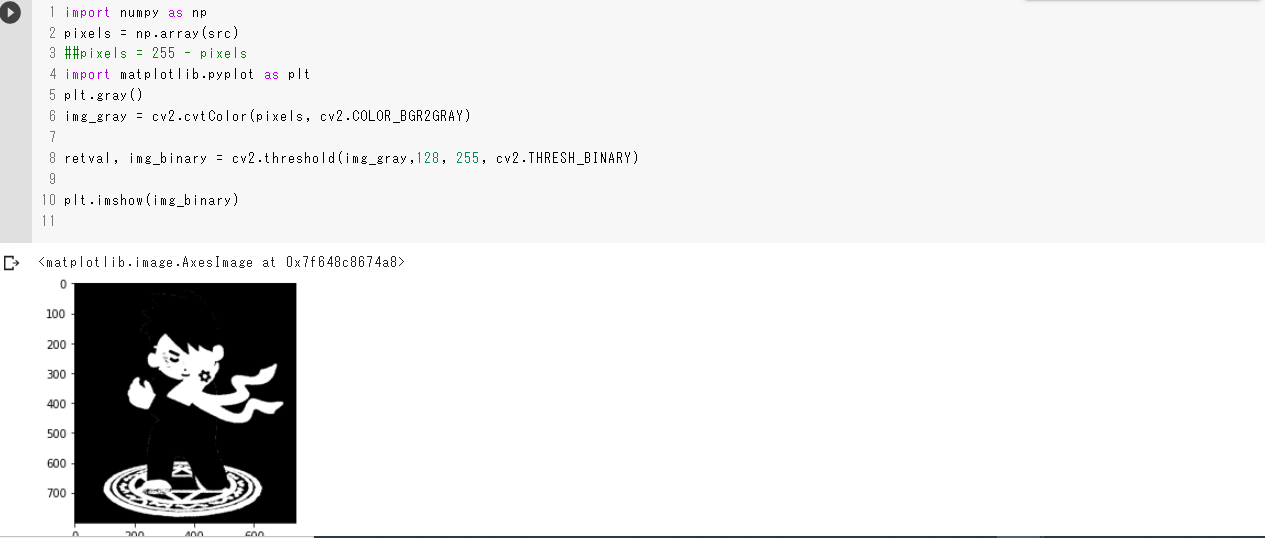
最後に二値化です。二値化は先にグレースケールに変換してから、
cv2.threshold(img_gray,128, 255, cv2.THRESH_BINARYで二値化します。128の部分はしきい値と言い、ここの値より明るい数値は白(255)に、暗い数値は黒(0)になります。しきい値の値が二値化するにあたって重要になってきます。二値化import numpy as np pixels = np.array(src) import matplotlib.pyplot as plt] #グレースケールへ変換 img_gray = cv2.cvtColor(pixels, cv2.COLOR_BGR2GRAY) #二値化 retval, img_binary = cv2.threshold(img_gray,128, 255, cv2.THRESH_BINARY) plt.imshow(img_binary)実行結果
しきい値=128
しきい値=8
参考資料
- 投稿日:2021-01-11T17:34:25+09:00
ANACONDAやめました MacにPython開発環境構築 pyenvとpyenv-virtualenvのインストール
ANACONDAやめました MacにPython開発環境構築 pyenvとpyenv-virtualenvのインストール
目的
Python開発環境の作業メモとして記載。
ANACONDAのライセンスが変わり、当面は問題無いのですが、ANACONDAを使わないPythonのローカル開発環境へ移行してみました。
Pythonの開発環境としては、pyenvとpyenv-virtualenvを利用、pythonのバージョンが切替可能とする方法を選択しました。
pyenvとpyenv-virtualenvのインストールは、楽なのでhomebrewを使います。Mac環境
OS : Mac OS Big Sur(11.1)
Xcode : App Storeではインストールしていないインストール
homebrewのアップデート
taguchi@MasamacAir ~ % brew update Updated 2 taps (homebrew/core and homebrew/cask). ==> New Formulae acl2 grpcui ocaml-zarith act gtkmm4 oci-cli aerc guile@2 odin aida-header gulp-cli oha airshare h2spec omake 省略 iphoney yandexradio java yourkit-java-profiler jeromelebel-mongohub zoom-in jing zoomus-outlook-plugin kekadefaultapppyenvのインストール
taguchi@MasamacAir ~ % brew install pyenv Error: homebrew-core is a shallow clone. homebrew-cask is a shallow clone. 省略 ==> readline readline is keg-only, which means it was not symlinked into /usr/local, because macOS provides BSD libedit. For compilers to find readline you may need to set: export LDFLAGS="-L/usr/local/opt/readline/lib" export CPPFLAGS="-I/usr/local/opt/readline/include" For pkg-config to find readline you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/readline/lib/pkgconfig"pyenv-virtualenvのインストール
taguchi@MasamacAir ~ % brew install pyenv-virtualenv Error: Your CLT does not support macOS 11. It is either outdated or was modified. Please update your CLT or delete it if no updates are available. Update them from Software Update in System Preferences or run: softwareupdate --all --install --force If that doesn't show you an update run: sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install Alternatively, manually download them from: https://developer.apple.com/download/more/. Error: An exception occurred within a child process: SystemExit: exitpyenv-virtualenvをインストールしようとしたが、エラーになった、対応
taguchi@MasamacAir ~ % softwareupdate --all --install --force sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install taguchi@MasamacAir ~ % sudo rm -rf /Library/Developer/CommandLineTools Password: taguchi@MasamacAir ~ % sudo xcode-select --install 省略リトライ pyenv-virtualenvをインストール
taguchi@MasamacAir ~ % brew install pyenv-virtualenv Error: homebrew-core is a shallow clone. homebrew-cask is a shallow clone. To `brew update`, first run: 省略 ==> ./install.sh ==> Caveats To enable auto-activation add to your profile: if which pyenv-virtualenv-init > /dev/null; then eval "$(pyenv virtualenv-init -)"; fi ==> Summary ? /usr/local/Cellar/pyenv-virtualenv/1.1.5: 22 files, 65.6KB, built in 5 secondspyenvの設定
taguchi@MasamacAir ~ % echo 'export PYENV_ROOT="${HOME}/.pyenv"' >> ~/.zprofile taguchi@MasamacAir ~ % echo 'export PATH="${PYENV_ROOT}/bin:$PATH"' >> ~/.zprofile taguchi@MasamacAir ~ % echo 'eval "$(pyenv init -)"' >> ~/.zprofile taguchi@MasamacAir ~ % echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.zprofilepyenv環境設定
使えるバージョンを確認
taguchi@MasamacAir ~ % pyenv install --list Available versions: 2.1.3 2.2.3 2.3.7 2.4.0 省略Python 3.9.1 と 2.7.18 をインストール
Python 3.9.1
taguchi@MasamacAir ~ % pyenv install 3.9.1 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.9.1.tar.xz... -> https://www.python.org/ftp/python/3.9.1/Python-3.9.1.tar.xz Installing Python-3.9.1... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.9.1 to /Users/taguchi/.pyenv/versions/3.9.1Python 2.7.18
taguchi@MasamacAir ~ % pyenv install 2.7.18 python-build: use openssl from homebrew python-build: use readline from homebrew Downloading Python-2.7.18.tar.xz... -> https://www.python.org/ftp/python/2.7.18/Python-2.7.18.tar.xz Installing Python-2.7.18... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-2.7.18 to /Users/taguchi/.pyenv/versions/2.7.18Pythonのバージョン切替方法
開発用のディレクトリ毎に利用するPythonのバージョンを変える(localコマンド)
使い方
cd <開発用ディレクトリ> pyenv local <この開発用ディレクトリで利用するPythonのバージョン>実行例
デフォルトはPython 2.7.16 だが 開発ディレクトリpy2で利用するPythonのバージョンを 2.7.18 に変更するtaguchi@MasamacAir ~ % cd ~/test/py2 taguchi@MasamacAir py2 % python --version Python 2.7.16 taguchi@MasamacAir py2 % pyenv local 2.7.18 taguchi@MasamacAir py2 % python --version Python 2.7.18python --version の表示が変わらないとき
1)よくある 他のディレクトリに移動してから再度戻る、ログアウトしてログインし直してから再度確認してみてください
2).zprofileや/etc/paths でパス/usr/local/binが/usr/binより優先されているかを確認してくださいシステム全体で利用するPythonのバージョンを変える(globalコマンド)
pyenv global <システム全体で利用するPythonのバージョン>実行例
デフォルトはPython 2.7.16 だが システム全体で利用するPythonのバージョンを 3.9.1 に変更するtaguchi@MasamacAir ~ % python --version Python 2.7.16 taguchi@MasamacAir ~ % pyenv global 3.9.1 taguchi@MasamacAir ~ % python --version Python 3.9.1pyenv-virtualenv環境設定
pyenv-virtualenvを使うと、開発環境が分けられます。
ライブラリ等が異なるなどの際に便利です。
私は、色々試したい場合にはpyenv-virtualenv、開発環境の構成が複雑な場合や開発環境を共有する場合はDocker(ローカルPCやクラウド上)やVirtualBox(ローカルPC)と使い分けています。使い方
pyenv virtualenv <利用するPythonのバージョン> <Python開発環境の名前、自分でわかるように付ける>実行例
Pythonのバージョン 2.7.18 の開発環境 GANtest1 を作る、開発ディレクトリは ~/test/GANtest1taguchi@MasamacAir ~ % mkdir ~/test/GANtest1 taguchi@MasamacAir ~ % cd ~/test/GANtest1 taguchi@MasamacAir GANtest1 % pyenv virtualenv 2.7.18 GANtest1 taguchi@MasamacAir GANtest1 % pyenv local GANtest1 taguchi@MasamacAir GANtest1 % python --version Python 2.7.18作成した開発環境が不要になったら、以下で消すことができます
使い方pyenv uninstall <Python開発環境の名前>実行例
taguchi@MasamacAir ~ % pyenv uninstall GANtest1 taguchi@MasamacAir ~ % rm -r ~/test/GANtest1
- 投稿日:2021-01-11T17:29:03+09:00
VSCodeでPythonの環境を「楽に」整える
初めに
こんにちは。今回の投稿は覚え書き兼共有といった感じです。
見た感じ同じような投稿はQiitaでは長いこと投稿されていなかったようなので、投稿します。あと、初投稿なので試行錯誤になるうえ、たぶん間違いが何か所かあることが予想されるうえ、わかりにくいと思います。ごめんなさい。目次
- VSCodeをインストール
- 拡張機能をインストール <- ここで終了
- 実行する
1. VSCodeをインストール
- ブラウザでVSCodeと検索してもいいですし、これをクリックしてもらってもいいです。とりあえずホームページに行きます。
- 上のほうにある今すぐダウンロードをクリックして、お使いのOSに合わせてダウンロードボタンを押します。
- インストーラーを起動し、案内されるがままに設定をあなた好みの物にしながら本体をインストールします。
- インストールされたら、起動します。
1編は以上です。多分わかりにくいと思います。(笑)
2. 拡張機能をインストール
順当にいけばVSCodeは起動されているはずなので、もし起動されていなかったら起動してください。
Ctrl + Shift + x(Windowsの場合) を押すか、左サイドバーにある4つのブロックの1つが離れていったみたいなデザインのボタンをクリックします。マウスホバーしたらExtensionsと表示されます。- すると上のほうにSearch Extentions in ...(Marketplace)と表示されると思うので、そこでPythonと入力し、一番上のものをクリックします。たぶんこれと同じものが表示されると思います。それ以外はやめておいたほうがいいです。
- Installボタンを押します。
- 次の拡張機能をインストールします。2-2のところで、今度はJupyter(これ)と検索します。Installしてください。
3. 実行する
拡張子が
.pyであるパイソンのファイルを書けば、おそらく右上に緑の矢印が表示されると思います。それをクリックすれば、ターミナルが起動して実行結果が表示されます。以上になります!楽しいVSCodeLifeを!w
- 投稿日:2021-01-11T17:08:41+09:00
Python ctypes で CUDA Driver API を呼び出すメモ
背景
CUDA Driver API を python からぺろっと叩きたい.
pybind11 とか cfffi だとネイティブコードのビルドが必要になりめんどい. pure python(標準 python 機能)でやりたい(CI ビルドとかだと CUDA SDK インストールとかめんどい)
ctypes を使います.
https://docs.python.org/3/library/ctypes.html
CUDA Driver API(ドライバが入っていれば使える API)を想定します.
CUDA Runtime API(CUDA SDK or ランタイムのインストールが必要になる)は扱いません(API 面倒いし)動かす Kernel は PTX 形式で生成されているものとします.
python で CUDA を叩くことで, たとえば PTX コードをテンプレートにしておいて, python 側で動的に書き換えてコンパイル(ターゲット GPU に合わせて最適なパラメータを設定)するとかができるようになります.Clang で CUDA コードを NVPTX に変換するメモ
https://qiita.com/syoyo/items/4e60543aded0210fde49dll/so のありか
Windows
C:\Windows\System32\nvcuda.dll通常は
nvcuda.dllだけで良い
(CUDA は NVIDIA driver インストールすれば自動で入っているので, ロードできなかったら NV GPU が挿さっていない PC(e.g. Intel 内臓/Xe or AMD GPU) であろう)Linux(Ubuntu)
Ubuntu ですと
/usr/lib/x86_64-linux-gnu/あたりにあります.さわりだけ
from ctypes import * cu = cdll.LoadLibrary("/usr/lib/x86_64-linux-gnu/libcuda.so") print(cu) ret = cu.cuInit(0) assert ret == 0 # CUDA_SUCCESS ver = c_int() ret = cu.cuDriverGetVersion(byref(ver)) assert ret == 0 # CUDA_SUCCESS print("CUDA version", ver)CUDA version c_int(11020)Voila!
ポインタのところは
byrefを使うといいようです.あとはいろいろ API 呼び出していけば OK のはずです!
その他
PTX Compiler API
PTX Compiler API のメモ
https://qiita.com/syoyo/items/cfaf0f7dd20b67cc734estatic lib しか提供されていないので, 一旦なんらかの dll を作る必要がありますが, これによりドライバにある PTX compile では満足できない場合, クライアントサイドでの PTX compile も pure Python でできるようになります!
Runtime API
cuSparse など, runtime API の上に作られたライブラリを使いたいときもあります.
一応だいたいの dll/so は再配布可能なので,
https://docs.nvidia.com/cuda/eula/index.html
必要であれば自身のアプリに同梱するなどして対応しましょう
(e.g. CI 環境で毎回 CUDA SDK インストールとかめんどい)TODO
- numpy との連携を考える(Python buffer protocol で連携になるかしらん)
- 投稿日:2021-01-11T16:54:13+09:00
やってみたら簡単!ディープラーニング・オセロを作って自分を負かすまで強くした話(その1)
オセロのAIアルゴリズムをディープラーニングで作成し、私が勝てないぐらいまでには強くなった、という話です。
また私の場合は2ヶ月ぐらいかかってしまいましたが、実装自体はそんなに難しくなかったので、実装方法についても説明したいと思います。
この記事でわかることは、ディープラーニングでオセロのAIアルゴリズムを作る方法です。基本的な考え方は他のボードゲームも同じなので、流用できると思います。
対象読者は、TensorFlowなどディープラーニングのライブラリを使い始めて、MNISTの数字分類など基本的な処理はできたけれど、それ以外の問題だとやり方がわからない、というような方です。
きっかけ
私の所属するエンジニアと人生コミュニティで、リバーシチャレンジなるものが開催されたことがきっかけです。このコンテストは「リバーシならどこにこだわっても良い」というルールでした。
私は、ちょうど少しまえに「将棋AIで学ぶディープラーニング」という本を読んでいて、いつかボードゲームのAIを作ってみたいなと思っていたところだったので、エントリーすることにしました。
わりと気楽にエントリーして、ディープラーニングのモデルを簡単に作ってAIに打たせてみよう、ぐらいの気持ちからスタートしたのですが、途中からだんだん「自分に勝つぐらいにしたい」と思い始めて、改善をしていったのでした。
私のオセロの腕について
「自分を負かしたっていっても、あなたのオセロの腕はどうなのよ?」という疑問もあると思います。
ハッキリ言えば弱いです。
ディープラーニングと対戦を繰り返す中で私も少しずつ強くなりましたが、だいたいこんなことを考えて打っています。
(私の思考)
1. 最初は真ん中あたりの4x4マスから抜けないように打つと良さそう
2. 盤面の端にあるマスは取られづらいからなるべく取りたい
3. 四隅は絶対に取られないので、なんとしても取りたい
4. 先読みは面倒だからしない出来たもの
モデルの作成と訓練はTensorFlowを使いましたが、最終的にはiOSアプリ(AppStoreには出していません)になりました。GitHubからcloneすれば手元で動かすことができます。
TokyoYoshida/reversi-charenge
機能としては、AIと対戦できるほか、メンテナンスモードにすると自由に盤面を作ることができます。勝ち負けの判定機能は作っていないので、最後に自分の石の数を数える必要があります。
AIの強さは、だいたい私と対戦して8割ぐらいはAIが勝つぐらいです。なぜかたまに私が自分の石の色だけになる完全勝利をすることもあります。理由は不明ですが、このAIは先読みしないのと、後半まで自分の石をあまり増やさずに最後に追い上げる傾向があることが関係しているのかもしれません。
対戦結果の例
私が黒、AIが白です。
・最後に追い上げられて、ほぼ真っ白になってしまいました。
・隅を3つも取ったのに負けてしまった。。
対戦していくうちに、四隅だけを取ろうとしても必ずしも勝てないことや、あまり自分の石が多すぎると、パスしかできなくなってしまうことがあることがわかりました。
作り方の概要
作り方の説明に入っていきます。
盤面のデータを画像として渡すと、次に打つ手を予想してくれるようなニューラルネットのモデルを作り、訓練することでオセロAIを作ることができます。
「次の手の予想」とは、オセロは8x8マスあるので「64マスのどこが最善かを予想する分類問題」ということになります。
※画像といってもピクセルデータではなく盤面を表現した配列ですこれは、AlphaGoのSLポリシーネットワークの仕組みを模したもので、教師あり学習を使って棋譜データから盤面の画像とその時に打った手をニューラルネットに学習させることで、盤面を与えると次の手を予想してくれるようになるというものです。
AlphaGoの場合はさらに様々な手法を組み合わせていますが、今回はSLポリシーネットワークだけを作りました。おまけとしてモンテカルロ木探索も組み合わせたものも作りましたが、これはAlphaGoとはだいぶ異なる方法になっています。
参考:
AlphaGoの論文(原題:Mastering the game of Go with deep neural networks and tree search)
AlphaGoを模したオセロAIを作る(1): SLポリシーネットワーク作り方の手順は次のとおりです。
1.学習データを作る
2.モデルを作る
3.訓練する
----(今回の説明はここまで)----
4.UIを作る(ついでにモンテカルロ木探索をする)本記事はその1なので訓練するところまでの説明ですが、オセロの手をAIに予想させるところまでは作ります。
また、実装はPythonを使いGoogle Colaboratory上で動作させていますが、Pythonが動作する環境なら何でも良いです。
1.学習データを作る
これが一番大変な作業だったりします。1つ1つ説明します。
・棋譜データをダウンロードする
学習データは、フランスのオセロ連盟が公開しているオセロの棋譜データベースWTHORを使うので、データをダウンロードしておきます。
・棋譜データをcsvに変換する
ダウンロードした棋譜データはバイナリフォーマットになっているため、これを変換用サイトでcsvに変換します。出力形式を選べますが今回は「全項目出力」を使いました。
参考:オセロの棋譜データベースWTHORの読み込み方
(このツールを作った方の記事です。)棋譜データをcsvに変換したら、1つのファイルにマージします。
csvデータをデコードする
データセットをcsvで読み込み、ヘッダ行を削除します。
NoteBookimport pandas as pd import re import numpy as np # csvの読み込み df = pd.read_csv("wthor棋譜データ.csv") # ヘッダ行の削除 df = df.drop(index=df[df["transcript"].str.contains('transcript')].index)読み込んだデータのうち、
transcriptという列が実際の棋譜の情報です。
文字列が並んでいるのが分かりますが、1つの列値が1試合分のデータとなっています。
文字列は
f5f6e6・・・と続いていますが、2文字で1手となっていて次のようにエンコードされています。
1文字目 ・・・ 列(a,b,c・・・h)
2文字目 ・・・ 行(1,2,3・・・8)
例えばf5なら、左から6列目、上から5行目ということです。このまま
transcriptに1試合のデータがすべて入っているのは分かりづらいので、
1行=1手となるように展開します。あわせて、文字列をデコードして列番号と行番号に変換します。NoteBook# 正規表現を使って2文字ずつ切り出す transcripts_raw = df["transcript"].str.extractall('(..)') # Indexを再構成して、1行1手の表にする transcripts_df = transcripts_raw.reset_index().rename(columns={"level_0":"tournamentId" , "match":"move_no", 0:"move_str"}) # 列の値を数字に変換するdictonaryを作る def left_build_conv_table(): left_table = ["a","b","c","d","e","f","g","h"] left_conv_table = {} n = 1 for t in left_table: left_conv_table[t] = n n = n + 1 return left_conv_table left_conv_table = left_build_conv_table() # dictionaryを使って列の値を数字に変換する def left_convert_colmn_str(col_str): return left_conv_table[col_str] # 1手を数値に変換する def convert_move(v): l = left_convert_colmn_str(v[:1]) # 列の値を変換する r = int(v[1:]) # 行の値を変換する return np.array([l - 1, r - 1], dtype='int8') transcripts_df["move"] = transcripts_df.apply(lambda x: convert_move(x["move_str"]), axis=1)こんな感じのデータになりました。
棋譜データを学習データに変換する
1手1手のデータを盤面に展開して学習の入力データにします。
学習データは、入力データとしてオセロの盤面、教師データとしてその時の1手です。
たとえば、最初の例にあるオセロの盤面を学習データにした場合は、次の図のようになります。
shapeは、それぞれ次のようになります。
学習データ = (バッチ数, 2(チャンネル。自分の石の配置と敵の石の配置), 8(行), 8(列))
予想データ = (バッチ数, 64(8x8の盤面の位置で左上が0番目で右下が63番目))注意点は、入力データのチャンネルは黒→白という並びではなく、自分の石→敵の石という並びになっていることです。このようにすることで、黒が打ったデータも、白が打ったデータもこの並び方に従っていれば学習データとして利用できるようにしています。
盤面に展開するためには、1手を打ったら敵の石をひっくり返す処理を入れて、その時の盤面を記録していきます。
パスの場合は次のデータも同じプレイヤーの手になります。単純に黒の番、白の番、、と交互に読んでしまうと盤面がおかしくなるのでパスの時の判定処理を入れます。
NoteBook# 盤面の中にあるかどうかを確認する def is_in_board(cur): return cur >= 0 and cur <= 7 # ある方向(direction)に対して石を置き、可能なら敵の石を反転させる def put_for_one_move(board_a, board_b, move_row, move_col, direction): board_a[move_row][move_col] = 1 tmp_a = board_a.copy() tmp_b = board_b.copy() cur_row = move_row cur_col = move_col cur_row += direction[0] cur_col += direction[1] reverse_cnt = 0 while is_in_board(cur_row) and is_in_board(cur_col): if tmp_b[cur_row][cur_col] == 1: # 反転させる tmp_a[cur_row][cur_col] = 1 tmp_b[cur_row][cur_col] = 0 cur_row += direction[0] cur_col += direction[1] reverse_cnt += 1 elif tmp_a[cur_row][cur_col] == 1: return tmp_a, tmp_b, reverse_cnt else: return board_a, board_b, reverse_cnt return board_a, board_b, reverse_cnt # 方向の定義(配列の要素は←、↖、↑、➚、→、➘、↓、↙に対応している) directions = [[-1,0],[-1,1],[0,1],[1,1],[1,0],[1,-1],[0,-1],[-1,-1]] # ある位置に石を置く。すべての方向に対して可能なら敵の石を反転させる def put(board_a, board_b ,move_row, move_col): tmp_a = board_a.copy() tmp_b = board_b.copy() global directions reverse_cnt_amount = 0 for d in directions: board_a ,board_b, reverse_cnt = put_for_one_move(board_a, board_b, move_row, move_col, d) reverse_cnt_amount += reverse_cnt return board_a , board_b, reverse_cnt_amount # 盤面の位置に石がないことを確認する def is_none_state(board_a, board_b, cur_row, cur_col): return board_a[cur_row][cur_col] == 0 and board_b[cur_row][cur_col] == 0 # 盤面に石が置けるかを確認する(ルールでは敵の石を反転できるような位置にしか石を置けない) def can_put(board_a, board_b, cur_row, cur_col): copy_board_a = board_a.copy() copy_board_b = board_b.copy() _, _, reverse_cnt_amount = put(copy_board_a, copy_board_b, cur_row, cur_col) return reverse_cnt_amount > 0 # パスする必要のある盤面かを確認する def is_pass(is_black_turn, board_black, board_white): if is_black_turn: own = board_black opponent = board_white else: own = board_white opponent = board_black for cur_row in range(8): for cur_col in range(8): if is_none_state(own, opponent, cur_row, cur_col) and can_put(own, opponent, cur_row, cur_col): return False return True # 変数の初期化 b_tournamentId = -1 # トーナメント番号 board_black = [] # 黒にとっての盤面の状態(1試合保存用) board_white = [] # 白にとっての盤面の状態(1試合保存用) boards_black = [] # 黒にとっての盤面の状態(全トーナメント保存用) boards_white = [] # 白にとっての盤面の状態(全トーナメント保存用) moves_black = [] # 黒の打ち手(全トーナメント保存用) moves_white = [] # 白の打ち手(全トーナメント保存用) is_black_turn = True # True = 黒の番、 False = 白の番 # ターン(黒の番 or 白の番)を切り変える def switch_turn(is_black_turn): return is_black_turn == False # ターンを切り替え # 棋譜のデータを1つ読み、学習用データを作成する関数 def process_tournament(df): global is_black_turn global b_tournamentId global boards_white global boards_black global board_white global board_black global moves_white global moves_black if df["tournamentId"] != b_tournamentId: # トーナメントが切り替わったら盤面を初期状態にする b_tournamentId = df["tournamentId"] board_black = np.zeros(shape=(8,8), dtype='int8') board_black[3][4] = 1 board_black[4][3] = 1 board_white = np.zeros(shape=(8,8), dtype='int8') board_white[3][3] = 1 board_white[4][4] = 1 is_black_turn = True else: # ターンを切り替える is_black_turn = switch_turn(is_black_turn) if is_pass(is_black_turn, board_black, board_white): # パスすべき状態か確認する is_black_turn = switch_turn(is_black_turn) #パスすべき状態の場合はターンを切り替える # 黒の番なら黒の盤面の状態を保存する、白の番なら白の盤面の状態を保存する if is_black_turn: boards_black.append(np.array([board_black.copy(), board_white.copy()], dtype='int8')) else: boards_white.append(np.array([board_white.copy(), board_black.copy()], dtype='int8')) # 打ち手を取得する move = df["move"] move_one_hot = np.zeros(shape=(8,8), dtype='int8') move_one_hot[move[1]][move[0]] = 1 # 黒の番なら黒の盤面に手を打つ、白の番なら白の盤面に手を打つ if is_black_turn: moves_black.append(move_one_hot) board_black, board_white, _ = put(board_black, board_white, move[1], move[0]) else: moves_white.append(move_one_hot) board_white, board_black, _ = put(board_white, board_black, move[1], move[0]) # 棋譜データを学習データに展開する transcripts_df.apply(lambda x: process_tournament(x), axis= 1)上のコードを実行したとき、各変数は次のような状態になっています。
boards_black ・・・ 黒が手を打つ直前の盤面の状態
boards_white ・・・ 白が手を打つ直前の盤面の状態
moves_black ・・・ 黒が打った手
moves_white ・・・ 白が打った手これらを使って学習データを作ります。
黒と白の盤面と打ち手をつなげて1つのデータにするだけです。NoteBookx_train = np.concatenate([boards_black, boards_white]) y_train = np.concatenate([moves_black, moves_white]) # 教師データは8x8の2次元データになっているので、64要素の1次元データにreshapeする y_train_reshape = y_train.reshape(-1,64)学習データが出来ました。
私はWTHORから20年分のデータをダウンロードしてこの処理をしましたが、535万盤面のデータになりました。まだダウンロードしていないデータも合わせるとさらに強いAIが作れるはずです。
2.モデルを作る
いよいよモデルを作ります。
入力データは、上で説明したとおりshape=(バッチ数,2,8,8)の配列です。これを先頭でPermute(転置)をしていますがこれはTensorFlowの都合です。Conv2DにChannels First(batch, C, H, W)と指定すれば大丈夫だろうと思っていたらなぜかConv2DがChannels Firstを受け付けてくれなかったので、急きょChannels Last(batch, H, W, C)に変換しています。(これがわかっていたら最初からそういうデータを用意すればよかったです..)
続けて、カーネルサイズ3の畳み込み層を12層と、カーネルサイズ1の畳み込み層、最後にバイアス層を入れてSoftMax関数にかけています。結果として出力はshape=(バッチ数,64)の配列になります。64の要素にはオセロのマスごとに次の手の確率が0〜1の数字で入ります。1に近いほど良い手ということになります。
バイアス層ですが、tf.kerasにはバイアス層がなかったのでBiasクラスとして自作しています。
NoteBookimport tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from keras.engine.topology import Layer class Bias(keras.layers.Layer): def __init__(self, input_shape): super(Bias, self).__init__() self.W = tf.Variable(initial_value=tf.zeros(input_shape[1:]), trainable=True) def call(self, inputs): return inputs + self.W model = keras.Sequential() model.add(layers.Permute((2,3,1), input_shape=(2,8,8))) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu')) model.add(layers.Conv2D(1, kernel_size=1,use_bias=False)) model.add(layers.Flatten()) model.add(Bias((1, 64))) model.add(layers.Activation('softmax'))モデルが出来たらコンパイルをします。
オプティマイザはAlphaGoと同じSGD、損失関数は分類問題なので、
categorical_crossentropyを使用します。NoteBookmodel.compile(keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False), 'categorical_crossentropy', metrics=['accuracy'])3.訓練する
訓練をします。
訓練は、Google Colabだとタイムアウトが厳しいので、Google AI Platformのインスタンス上で実行しました。
try〜exceptで囲って途中で中断しても学習したモデルを保存するようにしてあります。このあたりのことは、Google Colaboratoryで利用していたノートブックをGoogle AI Platformで実行し、さらにコマンドラインからも実行する方法にまとめてあります。
NoteBooktry: model.fit(x_train, y_train_reshape, epochs=600, batch_size=32, validation_split=0.2) except KeyboardInterrupt: model.save('saved_model_reversi/my_model') print('Output saved')AI Platformのインスタンス(NVIDIA Tesla T4 GPU)で、6時間ほど学習して4エポックほど学習したところ、val_accuracyが0.59になったので、そこで学習を止めました。
AplhaGoは2840万盤面に対して学習しaccuracyが57%だったそうです。
モデルの訓練で苦労したところと対策
最初の頃は、モデルの訓練を12時間もしたもののAccuracyが0.25程度にとどまり、実際に対戦しても弱々でどうしたものかと思っていました。
原因を調べたところ、次のような問題が見つかりました。
- 棋譜データから盤面を展開する処理にバグがあった。このため間違った盤面を学習させていた
- モデルのPermuteの指定方法が間違っていた。これによって、おかしな画像を学習させていた
- Bias層の後で、reshapeして(8,8)にしてしまっていた。8分類問題になってしまっていた
ディープラーニングは、意味のないデータを読み込ませてもなんとなく答えを出してしまうので、間違いがあることに気づきにくいです。また、処理の途中の状態を抜き出してチェックしても、それが正しいのか間違っているのかは判断しづらいです。
そこで、次のような手順で調査をしました。
1. ディープラーニングの出力の質に対する基準を設定する
今回は「私に勝つ」ということが基準でした。Accuracy(正確さ)についての基準値も設定しました。Accuracyが0.25というのは他の方のオセロAIに比べても低いので、他の事例から推測して少なくとも0.35は超えてほしいと考えていました。
逆に言うとこのような基準がないと調査することもなかったので、上のような問題は見つけることが出来なかったと思います。
2. モデルの問題の原因となりうる箇所をMECEに分類しておく
大分類としてはデータ、モデル、パラメータがあります。これらをツリー状に整理した上で、ツリーの枝を1つ1つを掘り下げていきます。
これを意識しないで手当たりデータや実装を差し替えたりすると、どこまでが正しくてどこからがおかしいのか、というように範囲を狭めることができなくなってしまいます。
3. データ加工からモデルの出力までの全体を少しずつ細分化して原因を見つける
2.と同じような話ですが、こちらはデータの流れに注目して細分化していきます。
例えば、ニューラルネットにすべて0などの単純な値を入力してみて、特定の層の出力を確認してみるといったことをすると、問題に気がつくことがあります。(全くわからないことの方が多かったですが...)AIに打ち手を予想させてみる
学習が終わったら、打ち手の予想ができる状態になっています。試しに予想してみましょう。
NoteBook# オセロの初期の盤面データを与える board_data = np.array([[ [[0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,1,0,0,0], [0,0,0,1,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0]], [[0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,1,0,0,0,0], [0,0,0,0,1,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0]]]],dtype=np.int8) # 打ち手を予想する model.predict(board_data) # 出力結果 # array([[2.93197723e-11, 1.42428486e-10, 7.34781472e-11, 2.39318716e-08, # 1.31301447e-09, 1.50736756e-08, 9.80145964e-10, 2.52176102e-09, # 3.33402395e-09, 2.05685264e-08, 2.49693510e-09, 3.53782520e-12, # 8.09815548e-10, 6.63711930e-08, 2.62752469e-08, 5.35828759e-09, # 4.46924164e-10, 7.42555386e-08, 2.38477658e-11, 3.76452749e-06, # 6.29236463e-12, 4.04659602e-07, 2.37438894e-06, 1.51068477e-10, # 1.81150719e-11, 4.47054616e-10, 3.75479488e-07, 2.84151619e-14, # 3.70454689e-09, 1.66316525e-07, 1.27947108e-09, 3.30583454e-08, # 5.33877942e-10, 5.14411222e-11, 8.31681668e-11, 6.85821679e-13, # 1.05046523e-08, 9.99991417e-01, 3.23126500e-07, 1.72151644e-07, # 1.01420455e-10, 3.35642431e-10, 2.22305030e-12, 5.21605148e-10, # 5.75579229e-08, 9.84997257e-08, 3.62535673e-07, 4.41284129e-08, # 2.43385506e-10, 1.96498547e-11, 1.13820758e-11, 3.01558468e-14, # 3.58017758e-08, 8.61415117e-09, 1.17988044e-07, 1.36784823e-08, # 1.19627297e-09, 2.55619081e-10, 9.82019244e-10, 2.45560993e-12, # 2.43100295e-09, 8.31343083e-09, 4.34338648e-10, 2.09913722e-08]], # dtype=float32)出力結果は、マスごとの配列なので、最大値をとると打ち手を取得することができます。
NoteBooknp.argmax(model.predict(board_data)) # 出力結果 # 37左上から37番目が最善手のようですね。
最後に
いずれ、その2を書きたいと思います。
その2は、iOSデバイス上での動作となります。ディープラーニングをiOSデバイスで動作させる方法や、ミニマックス法やモンテカルロ木探索を取りれようとして失敗した話などを書こうと思います。
(書かなかったらすいません)
また、NoteではiOS開発、とくにCoreML、ARKit、Metalなどについて定期的に発信しています。
https://note.com/tokyoyoshidaTwitterでも発信しています。
https://twitter.com/jugemjugemjugem




- 投稿日:2021-01-11T16:33:43+09:00
Pythonをはじめよう ~Windows10での環境構築~
Python やりましょう。
Python やって損ないと思います。
スクリプト言語なので、学習しやすく、コーディングもラクです。
インタプリタ言語で、実行も容易。
人気 No.1 言語のひとつで、コミュニティも活発。
しかも、Web アプリ開発からディープラーニングまで、できることも多いです。
もう一度言います。Python やりましょう。環境構築
仮想環境使いましょう。
Python はライブラリをめっちゃ使うので、仮想環境でやると管理がラクです。
ここでは、
- 生の Python + pyenv + Poetry
- Anaconda
のふたつを紹介します。
なお、対象 OS は Windows10 です。生の Python + pyenv + Poetry
Web アプリつくるとかならこっちです。
Python インストール
まずは Python をインストールします。
コードを機械語に翻訳するインタプリタです。
PythonJapan のサイトが便利ですので利用しましょう。
このサイトにアクセスして、最新の安定版のインストーラをダウンロードしましょう。
2021 年 1 月現在、3.9.1 のインストーラ、つまりpython-3.9.1-amd64.exeですね。
ダウンロードが完了したら、インストールしましょう。
インストーラを実行します。
色々初期設定する画面に入りますが、ほとんどの項目は特に触らないで大丈夫だと思います。
ただ、Add Python 3.x to PATHという項目のチェックボックスが出てきたら、チェックを入れてください。
PowerShell やコマンドプロンプトから Python を操作できるようにするためです。インストールが完了したら、
Closeで閉じます。
正常にインストールできているか確かめましょう。
PowerShell を起動して、python -Vというコマンドを実行します。
3.9.1などと、バージョンが表示されれば OK です。
pyenv インストール
プロジェクトによって Python のバージョンを変えたいときがあるそうです(僕はまだないけど)。
そんなときに pyenv を使うと、同じ PC 内で複数のバージョンの Python を使えます。
つまり、Python のバージョン管理ツールです。pyenv は、UNIX 系のサービスですので、代わりに Windows 版の
pyenv-winを使用します。
PowerShell で以下のコマンドを実行します。pip install pyenv-win --target $HOME\.pyenv次に、以下のコマンドを実行して、PYENV 環境変数を追加します。
[System.Environment]::SetEnvironmentVariable('PYENV',$env:USERPROFILE + "\.pyenv\pyenv-win\","User")管理者権限の PowerShell で、以下のコマンドを実行します。
[System.Environment]::SetEnvironmentVariable('PATH', $HOME + "\.pyenv\pyenv-win\bin;" + $HOME + "\.pyenv\pyenv-win\shims;" + $env:Path,"Machine")一度 PowerShell を閉じ、もう一度起動して、設定を反映させます。
pyenv のインストールと初期設定が完了したので、正常に反映されているか確認します。
PowerShell で、以下のコマンドを実行します。
pyenv --versionバージョンが出力されれば OK です。
現在の Python を、pyenv で管理します。
pyenv rehashpyenv のコマンド
- pyenv の更新
pip install --upgrade pyenv-win
- pyenv のサポートしているバージョンのリスト
pyenv install -l
- 任意のバージョンのインストール
pyenv install 3.9.0
- 任意のバージョンのグローバル化(PC の共通バージョンに)
pyenv global 3.9.0
- 任意のバージョンのローカル化(プロジェクト内でのバージョン)
pyenv local 3.9.0
- 任意のバージョンのアンイストール
pyenv uninstall 3.9.0Poetry インストール
Python のひとつの特徴として、
外部ライブラリが重要というものが挙げられます。
外部ライブラリとは、簡単に言うと拡張機能のことです。
pip などで外部ライブラリをインストールし、使用するのが一般的です。
しかし、ライブラリをインストールしすぎると、管理が大変です。
そこで、プロジェクトごとにライブラリを管理するツールが、Poetry です。PowerShell で、以下のコマンドを実行します。
(Invoke-WebRequest -Uri https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py -UseBasicParsing).Content | pythonPowerShell を一度閉じ、設定を反映させます。
もう一度起動して、poetry --versionというコマンドを実行します。
バージョンが表示されたら OK です。
初期設定として、以下のコマンドを実行しましょう。
poetry config virtualenvs.in-project trueプロジェクト内に virtualenv の仮想環境が作成されるようになりました。
Poetry のコマンド
- Poetry の更新
poetry self update
- プロジェクトのひな形生成
poetry new MyProject01MyProject01 ├── pyproject.toml ├── README.rst ├── myproject01 │ └── __init__.py └── tests ├── __init__.py └── test_my_package.py
- プロジェクトにライブラリを追加(ここでは numpy)
poetry add numpy
- プログラムの実行
myproject01 ディレクトリにmain.pyを作成します。main.pyimport numpy as np x = np.array([1, 2, 3]) print(x.size)myproject01 ディレクトリで、以下のコマンドを実行します。
poetry run python main.py
Anaconda
統計分析とか機械学習とかやるならこっちです。
Anaconda とは、Pyhon インタプリタに、科学計算によく使われる外部ライブラリ、そして開発に便利な IDE が付属した、ディストリビューションです。
Anaconda だけインストールすれば、すぐに開発環境が整います。ダウンロード
まず、このサイトにアクセスします。
スクロールすると、こんな画面が出てきます。
64-Bit Graphical Installerをクリックして、インストーラをダウンロードします。インストール
インストーラを起動します。
色々初期設定する画面に入りますが、こちらもほとんどの項目は特に触らないで大丈夫だと思います。
ただ、Add Anaconda 3 to the system PATH environment variableという項目のチェックボックスが出てきたら、チェックを入れてください。
PowerShell やコマンドプロンプトから Python を操作できるようにするためです。インストールが完了したら、スタート画面の
Anaconda3 (64-bit)からAnaconda Powershell Prompt(Anaconda3)を起動しましょう。
そして、以下のコマンドを実行します。ipython
IPython とは、Anaconda に付属している、python シェルです。
コードを打ち込んで実行できます。
とりあえず、exit()でシェルから抜けましょう。
エディタ・IDE
プログラミングを行うには、今インストールしてきたもの以外に、「テキストエディタ」もしくは「統合開発環境」と呼ばれるものが必要です。
これらは、「コードを書く」ためのソフトです。
テキストエディタは最低限の機能で、統合開発環境、通称 IDE は多機能という感じです。
メモ帳という、Windows 標準のものもありますが、使いにくいので、別途インストールしましょう。おすすめは、
PyCharmです。
Python 専用の IDE で、非常に優秀なソフトです。
有料版と無料版がありますが、基本的には無料版で事足りると思います。フレームワークでの開発などとなってくると有料版が良いと思いますが。JetBrains Toolbox のインストール
PyCharm は、
JetBrainsというチェコの企業が開発しています。
JetBrains 社は、ほかにもIntellij IDEAやRubyMineといった、便利な IDE を開発しています。
それらを管理するためのソフトがJetBrains Toolboxです。
公式サイトからインストールするより、Toolbox を使うほうが便利なので、利用しましょう。
このサイトから、インストーラをダウンロードします。
インストーラを実行すると、簡単にインストールできます。PyCharm のインストール
Toolbox を起動して、
PyCharm Communityをinstallします。PyCharm の初期設定
初回起動時は少し戸惑いがちなので、解説します。
起動したら、+のマークをクリック。
Locationは、プロジェクトの保存場所です。特に理由がなければ、C ドライブのドキュメントもしくは D ドライブにPythonなどとディレクトリを作成しておいて、その中にプロジェクトを作成しましょう。
その下のVirtualenvは、生の Python + pyenv + Poetryならそのままで、Anacondaならcondaに変更しましょう。
あとは、CREATEでプロジェクトを作ります。PyCharm以外の選択肢
また、Anaconda を利用している場合は、
JupyterLabやSpyderなどの IDE が付属していますので、そちらでも構いません。
あと、変態な人は是非 Vim をお使いください。Vim 最高 Vim 最高 Vim 最高 Vim 最高環境構築終了です!!おめでとうございます!!!
環境構築は、プログラミングで一番挫折しやすいところです。
なので、失敗は当たり前。
うまくいかなかったら、もう片方の方法や、別のサイトで紹介されている方法で試してみてください。参考
Windows 10 で Python のインストールから Poetry と pyenv の利用
最後まで読んでいただき、ありがとうございました!
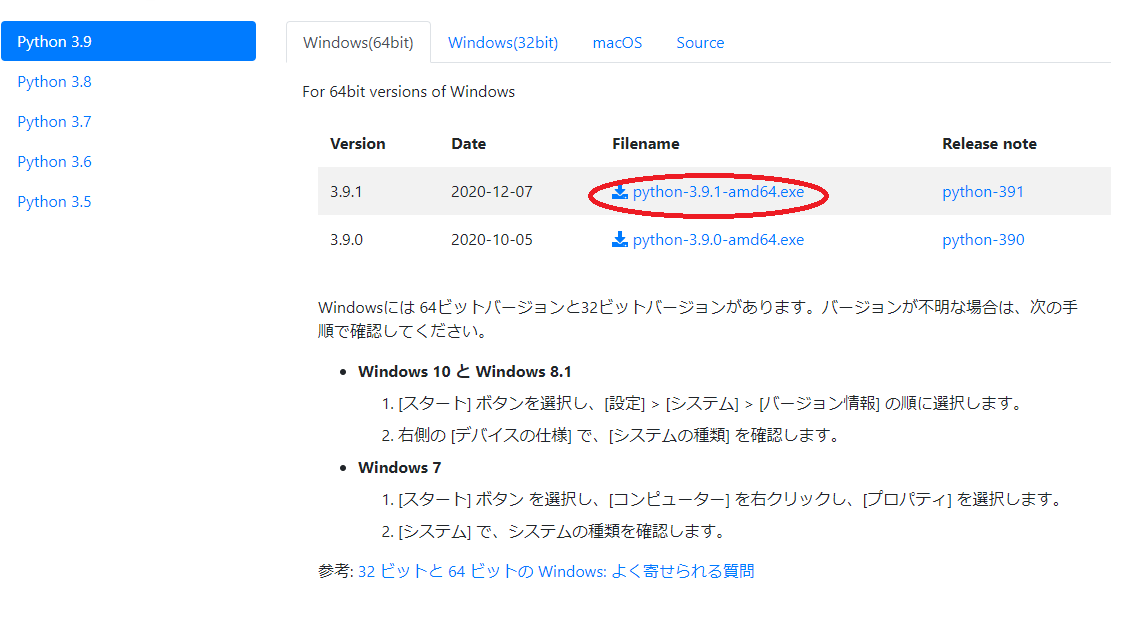




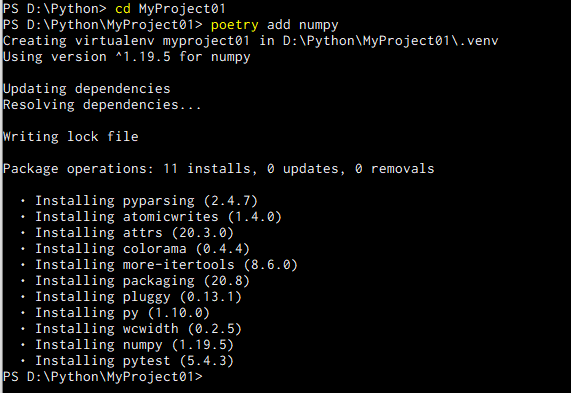

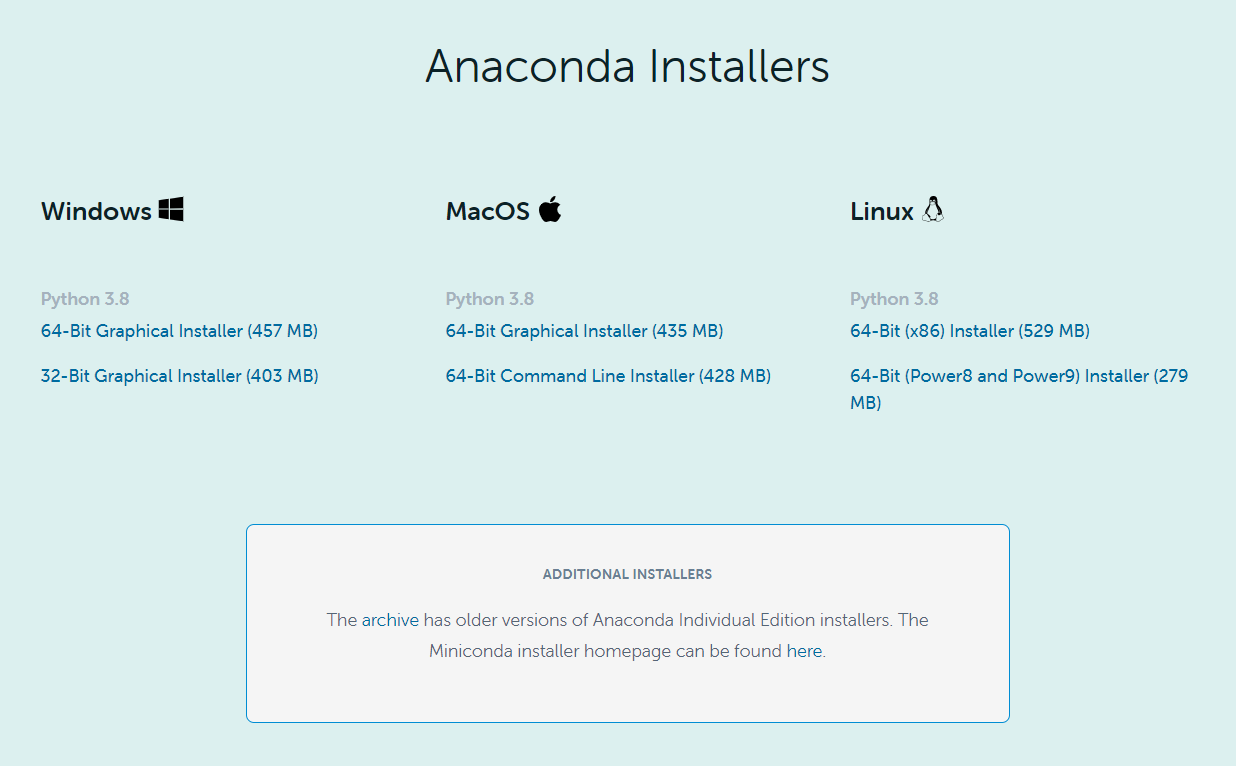

- 投稿日:2021-01-11T16:25:00+09:00
Colaboratoryでセルをファイル出力する
Colaboratory セル ファイル 出力でググっても出てこなかったので。元ネタ: Cell magics@ipython
やり方
yesno.py%%writefile yesno.py #!/usr/bin/env python import re def main(): check=input('YesかNoを入力してください :') print(YN(check)) def YN(string): if re.match('(?i)ye?s?',string): return 'YESです' elif re.match('(?i)no?',string): return 'NOです' else: return 'Yes/Noじゃないよ' if __name__ == '__main__': main()
%%writefile yesno.pyがコマンド
!cat -n yesno.pyで確認すると1 #!/usr/bin/env python 2 3 import re 4 5 def main(): 6 check=input('YesかNoを入力してください :') 7 print(YN(check)) 8 9 def YN(string): 10 if re.match('(?i)ye?s?',string): 11 return 'YESです' 12 elif re.match('(?i)no?',string): 13 return 'NOです' 14 else: return 'Yes/Noじゃないよ' 15 16 if __name__ == '__main__': 17 main()コマンドの直後からファイル出力されるので、シバンを記述する場合は気を付ける。
これにより
check.pyimport yesno if yesno.YN(('Yes')) == 'YESです': print('Yeah')結果:
Yeahと使えるようになる。
まとめ
Pythonの勉強をColaboratoryでやっているとローカルファイルを元に書いてある課題をどうやってやるのか困る時があります。
Pythonでファイルをダウンロードすると合わせて使うと、大体はColaboratoryでできると思います。
- 投稿日:2021-01-11T16:14:41+09:00
VBAユーザがPython・Rを使ってみた:基本的な算術演算
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
基本的な算術演算
四則演算
まず、四則演算(加算・減算・乗算・除算)です。四則演算の演算子
+,-,*,/はどの言語でも共通です。Python
Python3print( 1 + 2 ) # 加算 print( 3 - 4 ) # 減算 print( 5 * 6 ) # 乗算 print( 7 / 8 ) # 除算Python2では、除数(割る数)と被除数(割られる数)が整数の場合に
/で除算すると切り捨て除算となります。R
Rprint( 1 + 2 ) # 加算 print( 3 - 4 ) # 減算 print( 5 * 6 ) # 乗算 print( 7 / 8 ) # 除算VBA
VBADebug.Print 1 + 2 ' 加算 Debug.Print 3 - 4 ' 減算 Debug.Print 5 * 6 ' 乗算 Debug.Print 7 / 8 ' 除算べき乗と整数の割り算
次に、べき乗(累乗)、整数の除算(商(整数商)と剰余(余り))の計算です。言語によって演算子が違います。
Python
Python3print( 2 ** 3 ) # べき乗 print( 5 // 3 ) # 整数商 print( 5 % 3 ) # 剰余 print( divmod(5, 3) ) # 整数商と剰余Pythonの
divmod関数はtupleを返します。divmod(5, 3)の結果はtuple(1, 2)となります。R
Rprint( 2 ^ 3 ) # べき乗 print( 5 %/% 3 ) # 整数商 print( 5 %% 3 ) # 剰余VBA
VBADebug.Print 2 ^ 3 ' べき乗 Debug.Print 5 \ 3 ' 整数商 Debug.Print 5 Mod 3 ' 剰余 Debug.Print Int(5 / 3) ' 整数商(Int関数で整数部分を取得)VBAの整数商の計算「5 \ 3」のバックスラッシュ「\」は半角円マークです。
符号反転と絶対値
最後に、符号反転と絶対値の計算です。
Python
Python3print( -2 ) # 符号反転 print( abs(-2) ) # 絶対値R
Rprint( -2 ) # 符号反転 print( abs(-2) ) # 絶対値VBA
VBADebug.Print -2 ' 符号反転 Debug.Print Abs(-1) ' 絶対値まとめ
一覧
各言語で使用する演算子・関数等を一覧にまとめます。比較のために、EXCELでの計算も示しました。
演算 例 Python R VBA EXCEL 結果 加算 $1+2$ 1 + 2 1 + 2 1 + 2 =1+2 3 減算 $3-4$ 3 - 4 3 - 4 3 - 4 =3-4 -1 乗算 $5*6$ 5 * 6 5 * 6 5 * 6 =5*6 30 除算 $7/8$ 7 / 8 7 / 8 7 / 8 =7/8 0.875 べき乗 $2^3$ 2 ** 3 2 ^ 3 2 ^ 3 =2^3 8 整数商 $5/3$ 5 // 3 5 %/% 3 5 ¥ 3 =QUOTIENT(5,3) 1 剰余 $5/3$ 5 % 3 5 %% 3 5 Mod 3 =MOD(5,3) 2 divmod(5, 3) (1, 2) 符号反転 $-2$ -2 -2 -2 =-2 -2 絶対値 $|-2|$ abs(-2) abs(-2) Abs(-2) =ABS(-2) 2 VBAの「¥」は円マーク(全角の円マークを入れていますが、実際には半角の円マークです。)。
プログラム全体
参考までに使ったプログラムの全体を示します。
Python
Python3# 四則演算 print( 1 + 2 ) # 加算 print( 3 - 4 ) # 減算 print( 5 * 6 ) # 乗算 print( 7 / 8 ) # 除算 # べき乗と整数の割り算 print( 2 ** 3 ) # べき乗 print( 5 // 3 ) # 整数商 print( 5 % 3 ) # 剰余 print( divmod(5, 3) ) # 整数商と剰余 # 符号反転と絶対値 print( -2 ) # 符号反転 print( abs(-2) ) # 絶対値R
R# 四則演算 print( 1 + 2 ) # 加算 print( 3 - 4 ) # 減算 print( 5 * 6 ) # 乗算 print( 7 / 8 ) # 除算 # べき乗と整数の割り算 print( 2 ^ 3 ) # べき乗 print( 5 %/% 3 ) # 整数商 print( 5 %% 3 ) # 剰余 # 符号反転と絶対値 print( -2 ) # 符号反転 print( abs(-2) ) # 絶対値VBA
VBASub test() ' 四則演算 Debug.Print 1 + 2 ' 加算 Debug.Print 3 - 4 ' 減算 Debug.Print 5 * 6 ' 乗算 Debug.Print 7 / 8 ' 除算 ' べき乗と整数の割り算 Debug.Print 2 ^ 3 ' べき乗 Debug.Print 5 \ 3 ' 整数商 Debug.Print 5 Mod 3 ' 剰余 Debug.Print Int(5 / 3) ' 整数商(Int関数で整数部分を取得) ' 符号反転と絶対値 Debug.Print -2 ' 符号反転 Debug.Print Abs(-1) ' 絶対値 End SubVBAの整数商の計算「5 \ 3」のバックスラッシュ「\」は半角円マークです。
参考
- 投稿日:2021-01-11T16:13:46+09:00
Mac上でPython+OpenCVを利用した動画処理
Mac上のOpenCVで動画処理のプログラムを作成する際に、いくつかハマった点があったので、その備忘録です。
初めに
作成したプログラムは、入力した動画の、1フレームごとの画像に対して任意の画像処理を行い、処理後の画像を再び動画として保存するもの。動画処理の流れは、以下のようになっている。
- ローカルに保存されている動画を読み込む
- 1フレームずつ画像処理
- 動画ファイルとして書き込み
実行環境
- macOS Catalina(ver 10.15.3)
- python 3.8
opencv-pythonのインストールは、以下コマンドで行う。
pip install opencv-pythonソースコードの全体像
作成したソースコードの全体像は以下の通り。動画に対する処理は、67行目の
processed_frame = cv2.flip(frame, -1)にある、上下左右の反転を行うもの。こちらのプログラムを実行することで、入力した動画を上下左右反転させた動画を作成できる。上下左右の反転処理を、任意の画像処理に置き換えることで、Pythonで様々な動画処理ができるようになる。
./main.pyimport os import cv2 import argparse class MovieIter(object): """ 動画のIterator """ def __init__(self, moviefile, inter_method=cv2.INTER_AREA): if os.path.isfile(moviefile): # mp4ファイルが存在するとき print("[Loading]\tLoading Movie") self.org = cv2.VideoCapture(moviefile) self.framecnt = 0 self.inter_method = inter_method def __iter__(self): return self def __next__(self): self.end_flg, self.frame = self.org.read() if not self.end_flg: # 動画の最後に到達したらループを終了する raise StopIteration() self.framecnt += 1 return self.frame def __del__(self): self.org.release() def get_size(self) -> (int, int): """動画の解像度を返す Returns: (int, int): (w, h) """ return ( int(self.org.get(cv2.CAP_PROP_FRAME_WIDTH)), int(self.org.get(cv2.CAP_PROP_FRAME_HEIGHT)), ) def get_fps(self) -> float: """動画のFpsを返す Returns: float: fps """ return self.org.get(cv2.CAP_PROP_FPS) def main(movie_path, save_path): # 入力する動画を定義 input_movie = MovieIter(movie_path) input_moveie_size = input_movie.get_size() # 出力する動画ファイルの定義 fourcc = cv2.VideoWriter_fourcc(*"mp4v") output_movie = cv2.VideoWriter( os.path.join(save_path, "output.mp4"), # 保存するパス fourcc, # コ-ディック input_movie.get_fps(), # 動画のfps input_moveie_size, # 動画の解像度 ) for frame in input_movie: processed_frame = cv2.flip(frame, -1) # 上下左右反転 # 動画の解像度が異なると保存できないので確認する assert processed_frame.shape[:2][::-1] == input_moveie_size output_movie.write(processed_frame) # リリースして動画を保存 output_movie.release() if __name__ == "__main__": parser = argparse.ArgumentParser(description="動画を処理するプウログラム") parser.add_argument("movie_path", help="処理を行う動画のURL") parser.add_argument("--save_path", default="results", help="生成した画像を保存するディレクトリのパス") args = parser.parse_args() main(args.movie_path, args.save_path)実行時のコマンドは以下の通り。処理に成功すると、
${処理する動画のパス}の上下左右が反転した動画が作成され、--save_pathに指定したフォルダに保存される。python main.py ${処理する動画のパス} --save_path ${処理後の動画を保存するパス}ハマったところ
動画に書き込む画像サイズの指定
ハマりポイントの1つ目は、ソースコード57行目の
cv2.VideoWriter()に指定する画像のサイズと、71行目のoutput_movie.write(processed_frame)で書き込む画像のサイズが異なると、動画の書き出しに失敗する点である。~~~省略~~~~ output_movie = cv2.VideoWriter( os.path.join(save_path, "output.mp4"), # 保存するパス fourcc, # コ-ディック input_movie.get_fps(), # 動画のfps input_moveie_size, # 動画の解像度 ← ココ! ) ~~~省略~~~~一般的にopencvの画像サイズは、
(height, width, chnnel)の順で定義されている。しかし一方でcv2.VideoWriter()で指定する画像のサイズは(width, height)の順で定義する必要がある。なので、普段のノリで「画像サイズは(height, width)の順だね〜」と思って指定すると、定義時と書き込み時の画像サイズの違いにより、動画の書き出しに失敗する現象が発生する。しかも困ることに、上記のような、サイズの違いによる動画の書き出しに失敗する現象が起きても、opencvはエラーやワーニングを返してこない。それにより、「プログラムは正常なのに、なぜ保存できないんだろう..」と無駄に時間を浪費してしまい、画像サイズの指定ミスに気づくのにかなり時間がかかってしまった。
解決策として、以下のようにassertで確認する処理を入れておいた。
~~~省略~~~~ # 動画の解像度が異なると保存できないので確認する assert processed_frame.shape[:2][::-1] == input_moveie_size ~~~省略~~~~グレースケールの動画を作成する場合
作成する動画の形式がグレースケールの場合は、
cv2.VideoWriter()の5つ目の引数に、0を指定する必要がある。これも指定し忘れると、上記の件と同様に、エラー・ワーニングなしで、ただ動画の書き出しに失敗する現象が起きる。~~~省略~~~~ output_movie = cv2.VideoWriter( os.path.join(save_path, "output.mp4"), # 保存するパス fourcc, # コ-ディック input_movie.get_fps(), # 動画のfps input_moveie_size, # 動画の解像度 ← ココ! 0 # ← ココ! ) ~~~省略~~~~動画のコーデックの指定
2つ目は、ソースコード58行目の動画のコーデック形式に、実行環境に応じた対応している形式を指定する必要がある点である。
~~~省略~~~~ # 出力する動画ファイルの定義 fourcc = cv2.VideoWriter_fourcc(*"mp4v") # ← ココ! ~~~省略~~~~「opencv python 動画」などで検索して上位に出てくる記事だと、
cv2.VideoWriter_fourcc(*'XVID')と指定されていることが多く、筆者もそれに倣ってそのまま.avi形式で保存を試したが、うまく書き出しが行われなかった。バージョンによっては、MacOS上で.avi形式で保存することもできるようだが、mp4形式で保存をするのが最も安定すると思われる。Mac上での各形式の動作状況が、有志により以下のリンクにまとめられている。プログラムを書く前に、自分の使いたい形式がMac上でうまく動作するかを確認した方が良い。
- OpenCV Video Writer on Mac OS X · GitHub終わりに
形式違いやサイズ違いで保存に失敗してるなら、ワーニングくらい出して欲しいですね...
参考