- 投稿日:2021-01-11T22:06:17+09:00
RailsにてデプロイしたところPayjp::InvalidRequestErrorが発生する
はじめに
Railsでポートフォリオ作成し、AWSにてデプロイしたところPayjpを使ったクレジット登録が完了できず
エラーとなりました。
環境
・Rails 6.0.0
・Ruby 2.6.5
・Unicorn 5.4.1状況
Payjpでのクレジットカード登録で、決済ページから決済処理に入るタイミングでエラーが出ました。
tail -f log/production.logでログを確認すると
Payjp::InvalidRequestError (No such token: tok_acd40b5df50c7656e3bed4444890):
というエラーがありました。問題解決のために行ったこと
エラー文の通り、Payjpの設定に問題があるのかと推測。
ローカルでは問題なく動いていたので
環境変数の問題かと思いevnにPAYJP_SECRET_KEYを設定し直したりしましたが
変化ありませんでした。ローカルのコード記述を変えてみたり散々いじりましたが
そもそもローカルでは正常に動いているのでもっと根本的な問題では?と方針変更ターミナルを再起動→変化なし
Unicon、Nginxを再起動→変化なし自分がやった解決手順
上記の流れでアセットコンパイルも再起動することにしました。
・rake assets:clobberでまずアセットパイプラインをクリーンにする
→このとき Please runyarn install --check-filesto update.が出たので
yarn install --check-files
・bundle exec rake assets:precompile RAILS_ENV=productionでアセットパイプラインのプリコンパイルを実行
・Unicon、Nginxを再起動無事に立ち上がりました!!
さいごに
まさかのPayjpは無関係という結果でした。
ネットで同じような事例がなく、かなり遠回りをしたので
同じような状況で苦しんでいる人の助けになればと思い投稿しました。


- 投稿日:2021-01-11T22:01:31+09:00
CodeCommitエンドポイントでPrivateサブネットからgit cloneしてみる
はじめに
- 今回は
- Privateサブネット内にある
- EC2インスタンスから
- VPCエンドポイントを使って
- AWS CodeCommitにアクセスし
- リソースを
git clone- してみます
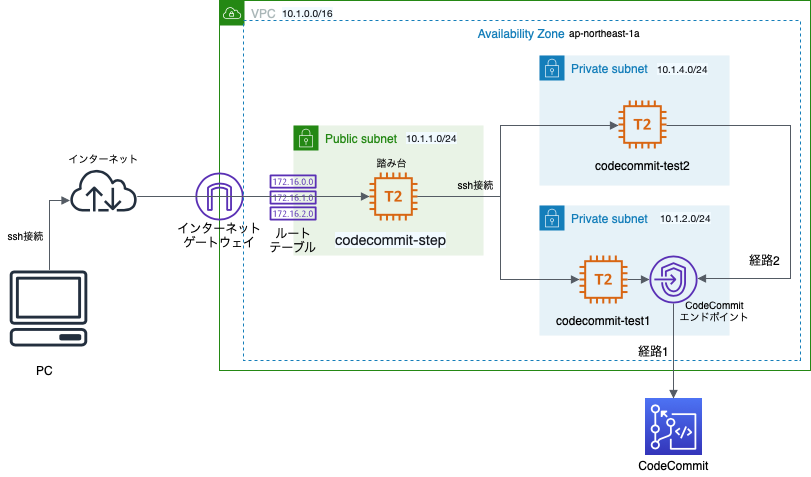
構造図
- Publicサブネット × 1
- SSHアクセス用の踏み台インスタンス × 1
- Privateサブネット × 2
- VPC(CodeCommit)エンドポイントを置くサブネット × 1
- 〃 を置かないサブネット × 1
git cloneをテストする用インスタンス × 1 ずつ
つまづきそうなところ
- セキュリティグループの設定
- インバウンド、アウトバウンドの設定を理解していないと沼る危険性があります
- 筆者は時間を溶かしました...
- 本記事では設定の目的を簡潔に添えているため、理解されていない方は一読することを推奨します
- また、間違いがありましたらご指摘ください
- IAMユーザ認証の作成
git cloneする際には「ユーザ名」と「PW」を求められます- IAMでユーザの認証情報を作成する必要があります
- ドキュメント(ステップ3)を参考にご作成ください
手順
1. ネットワークを構築する
- VPC、Publicサブネット、Privateサブネットを作ります
- 作成手順は過去記事: 「Amazon VPCでシンプルなネットワークを構築する」を参照
- VPCの「DNSホスト名」「DNS 解決」はどちらも有効
2. EC2インスタンスを生成する
- 作成手順は過去記事: 「Amazon EC2を起動し、MacのターミナルからSSH接続してみる」を参照
- セキュリティグループ以外は特筆すべき設定はなし
セキュリティグループ
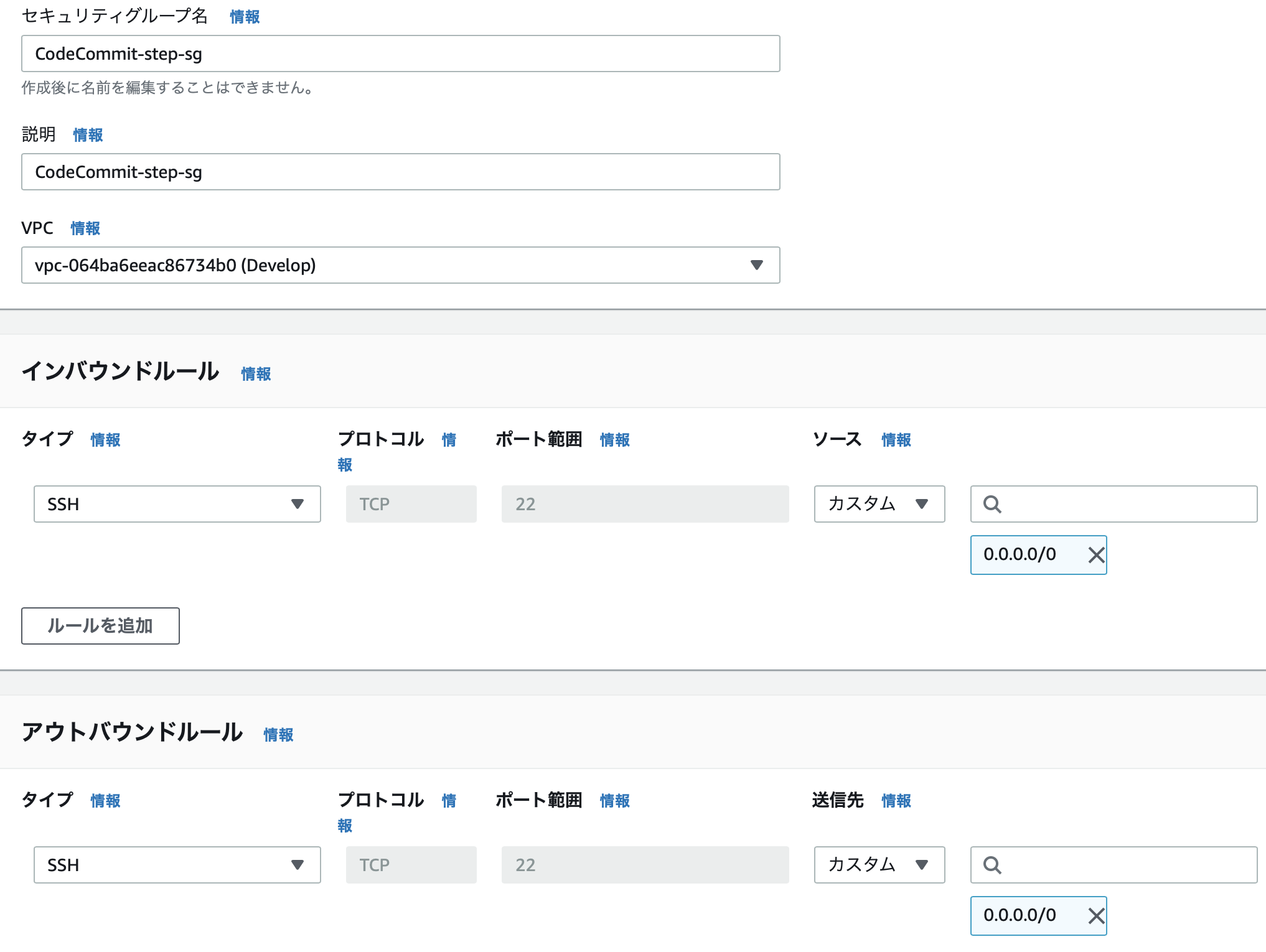
CodeCommit-step-sg(踏み台サーバ用)
- インバウンド: SSH
- ローカルPCからのSSHアクセスを許可
- アウトバウンド: SSH
- Privateサブネット内のサーバへのSSHアクセスを許可
CodeCommit-clong-sg(git cloneテストサーバ用)
- インバウンド: SSH
- 踏み台サーバからのSSHアクセスを許可するため
- アウトバウンド: HTTPS
- HTTPSによる
git cloneを許可するため(SSHによるgit cloneがしたい場合はSSHを許可)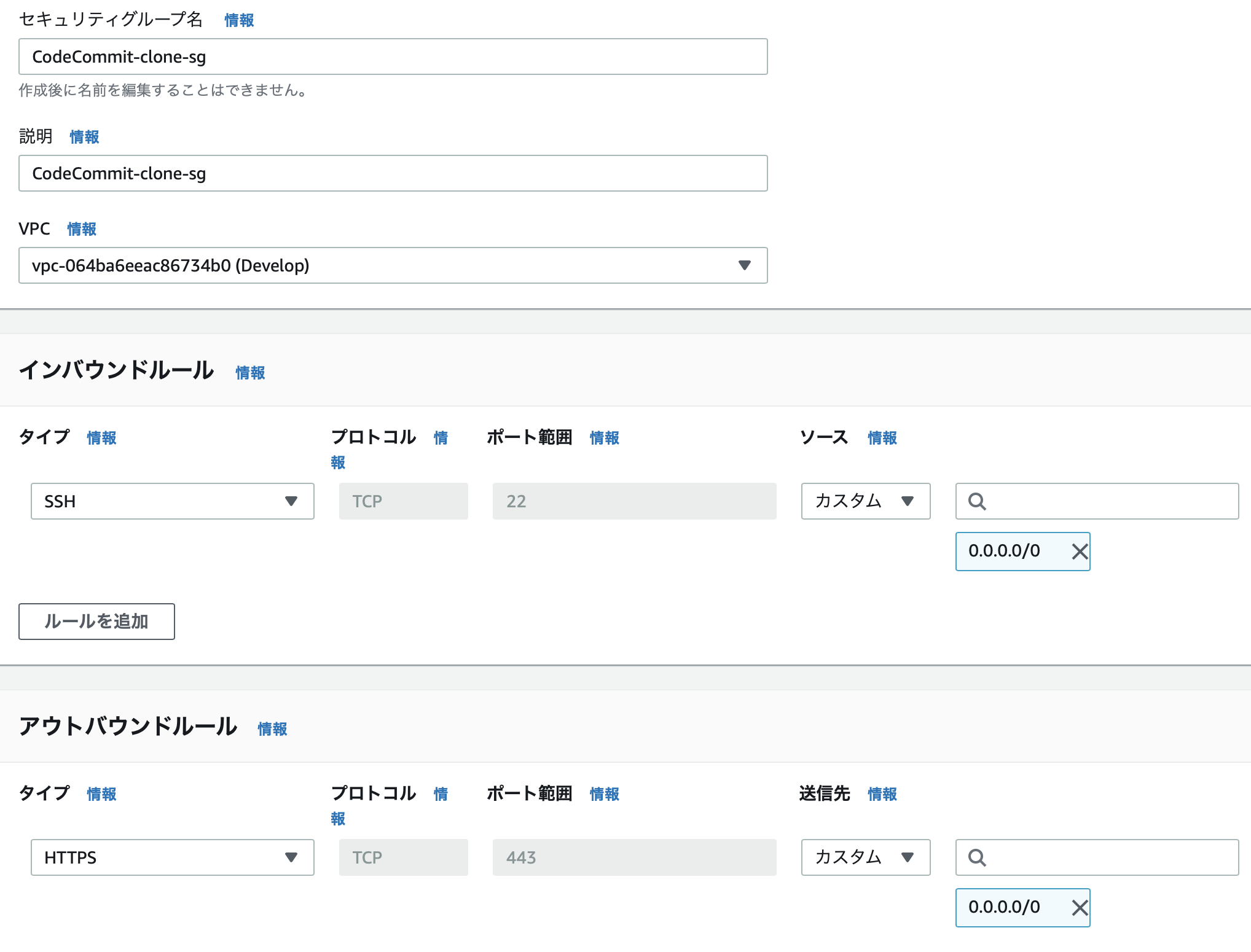
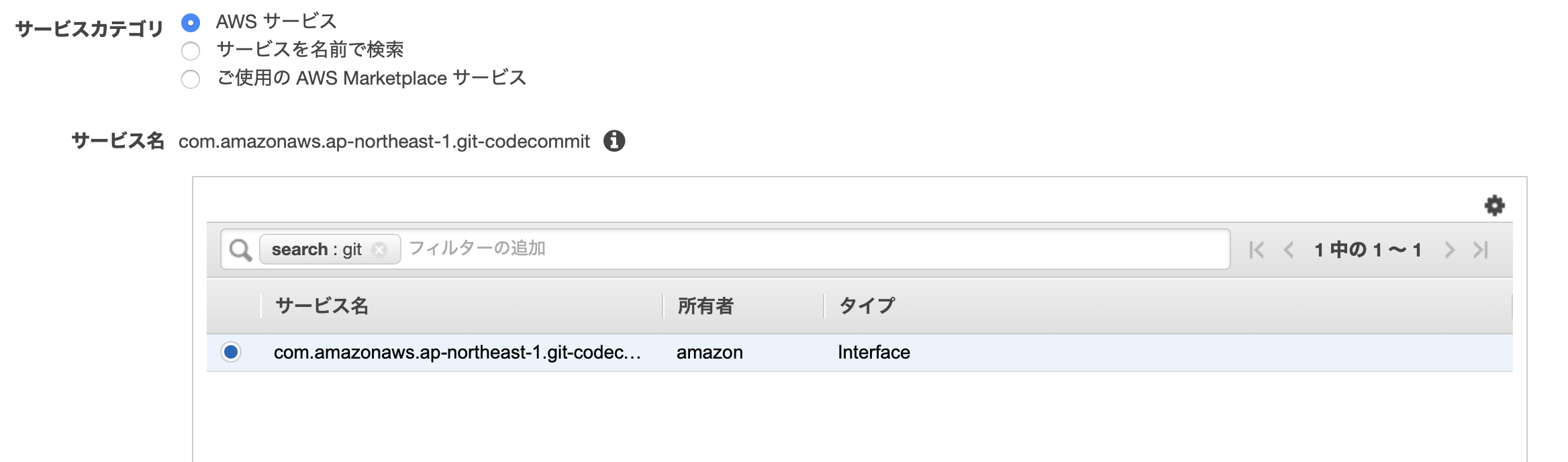
3. VPCエンドポイントを作成する
- サービスカテゴリ: AWSサービス
サービス名: com.amazonaws.ap-northeast-1.git-codecommit(
gitで検索すれば出る)
VPC: 10.1.0.0/16
サブネット: 10.1.2.0/24
Enable DNS name: 有効にする
セキュリティグループ
- インバウンド: HTTPS
- Privateサブネット内のサーバからHTTPSアクセスを許可するため
- アウトバウンド: HTTPS
- CodeCommitへの
git cloneを許可するため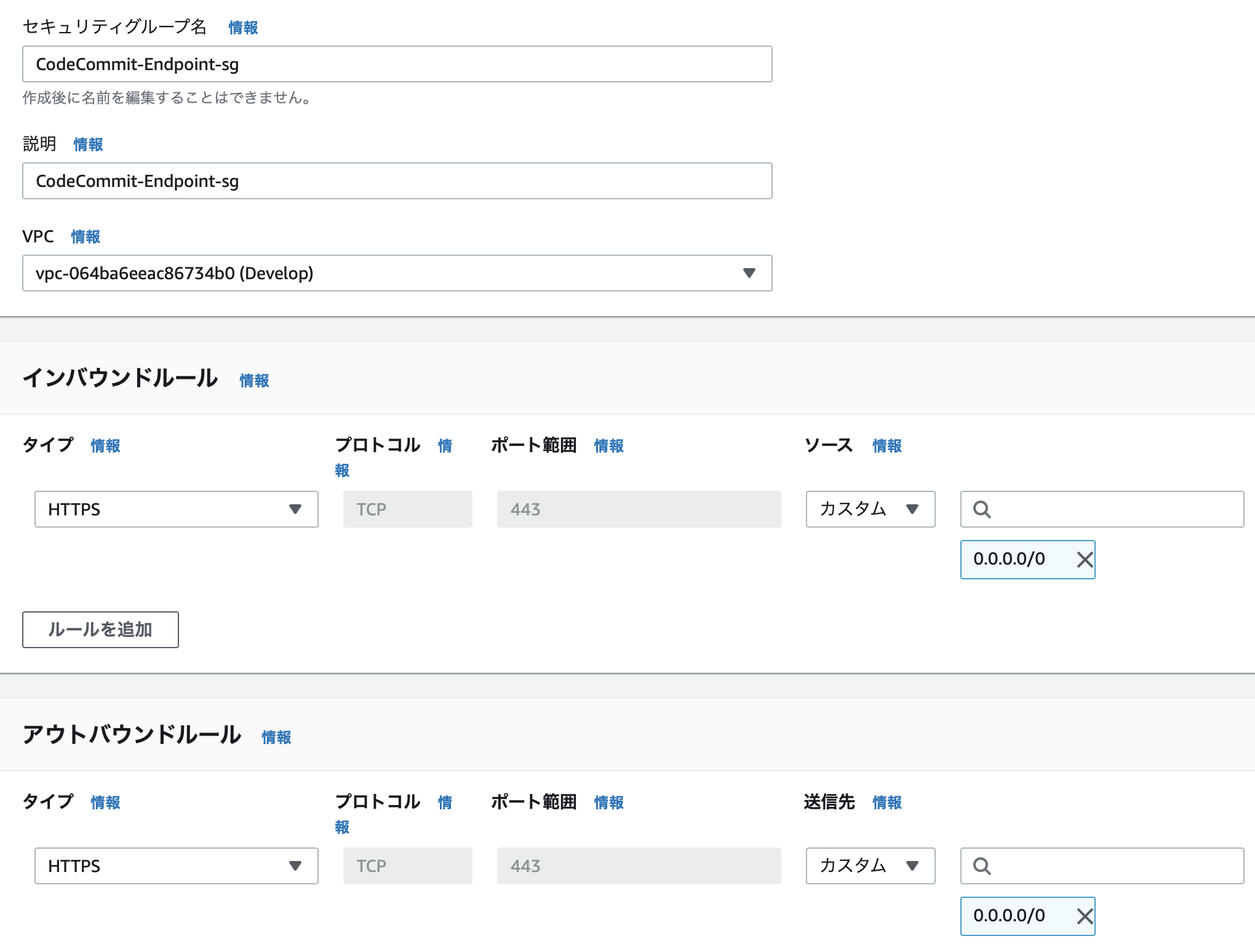
4. EC2インスタンスにgitをインストールする
- Privateサブネットのインスタンスに入れていく
Amazon Linuxn 2にはExtras Library と呼ばれるパッケージ群が存在
- インターネットに繋がなくてもgit等をインストール可能
- 中身は
amazon-linux-extrasで確認可能(アウトバウンドにHTTPを追加する必要あり)いざgitを入れていく
sudo yum update -y
- 成功
sugo yum install git -y
- 応答がない...
amazon-linux-extrasから
yum installするためにはS3エンドポイントを設定する必要がある
- パッケージはS3に保存されているため
S3エンドポイントを配置する
- サービスカテゴリ: AWSサービス
- サービス名: com.amazonaws.ap-northeast-1.s3
- ルートテーブルの設定: Privateサブネットのルートテーブル
リベンジ
sudo yum install git -y
- 無事にインストール完了
5. CodeCommitにリポジトリを作る
- リポジトリを作成
- リポジトリ名、説明: endpoint-test
- ファイルの作成
- ファイル名: endpoint-test.text
- 内容: endpoint-test
6. IAMで「AWS CodeCommit の HTTPS Git 認証情報」を生成
- IAM
- ユーザー
- リポジトリを作成したユーザを選択
- 「認証情報」タブ
- 「AWS CodeCommit の HTTPS Git 認証情報」で「認証情報を生成」
- これがgit cloneの際に要求される「Username」と「Password」になる
- 保存しておく(取り扱いには注意する)
7.
git clone(HTTPS)
- [CodeCommit]
- リポジトリ → URLのクローン(HTTPS)
- [ローカルのターミナル]
- Privateサブネットのインスタンスにsshアクセス
- 踏み台サーバを経由
- [PrivateサブネットのEC2サーバ内]
git clone <CodeCommitリポジトリのHTTPS URL>
- Username, Password: 認証情報を参照して入力
- codecommit-test1、codecommit-test2のどちらも
git clone可能- 完了
おわりに
- Privateサブネット内のEC2インスタンスからVPCエンドポイントを利用して
git cloneすることができました- 理解が浅く不安な点もあるので、ご指摘等ございましたらどしどしコメントください
参考資料
- Git 認証情報を使用した HTTPS ユーザーのセットアップ
- インターフェイス VPC エンドポイント (AWS PrivateLink)
- Codecommit の VPC エンドポイント対応を確認する
- 投稿日:2021-01-11T21:21:48+09:00
【Tips】AWSのVPC Reachability Analyzerでどんなエラーが検出できるかを調べてみた
はじめに
AWS の VPC Reachability Analyzerはめちゃくちゃ便利。
構築するときに「なんでこれ通信通らないんだ……!ぐぬぬ……!」と時間が格段に減ったと思う。しかし、これってどんなところまで調べることができるのだろう?
と思い、いくつかのパターンを確認してみた。VPC Reachability Analyzer 自体の使い方はクラスメソッド先生の記事で詳しく図付きで解説されているので、そちらを見てもらえれば。
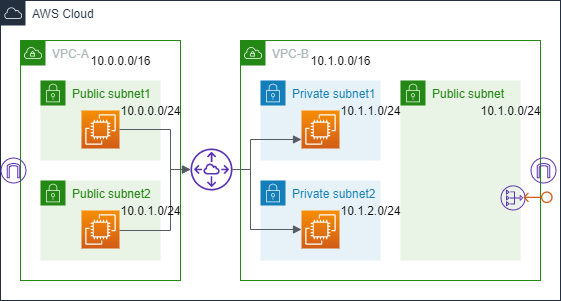
AWS構成図
今回分析をかける構成は以下のような感じだ。
冗長化しているのにNLB使わないとか、こんな構成はあまり取らないだろうが、おためしで作った構成ということで。
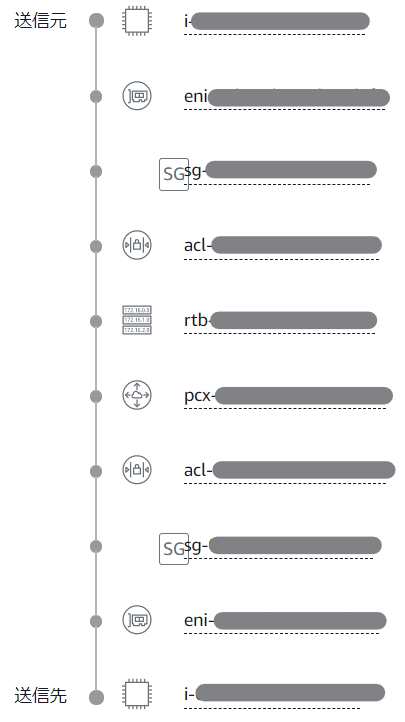
VPC Reachability Analyzer の分析成功時は以下のように出力される。
さて、以下は、上記の図を各標題に記載した状態に変更した場合の分析結果だ。
VPC Peeringのルーティングをしなかった場合
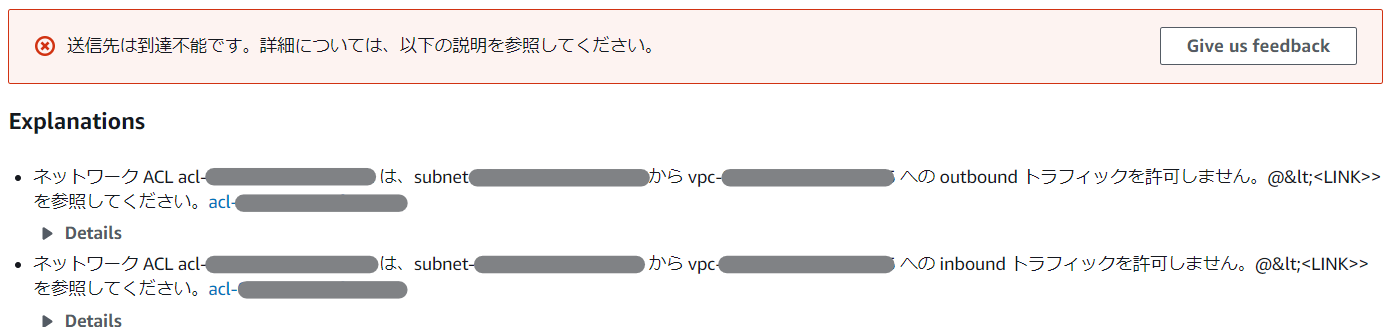
VPC-B側のNACLでインバウンドを制限した場合
VPC-B側のセキュリティグループでインバウンドを制限した場合
VPC-B側のEC2インスタンスで対象ポートをListenしているデーモンを停止した場合
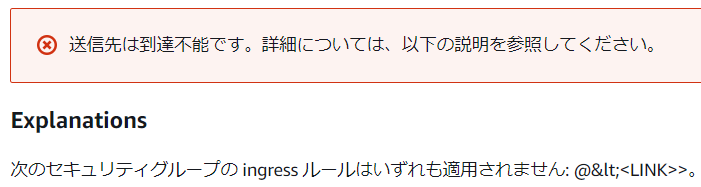
なんと、これは「到達可能」扱いになった。
わざわざポートまで指定しているのだからこれも検知してくれてもよさそうなものなのだが……。VPC-B側のEC2インスタンスを停止した場合
まとめ
割と良い感じに色々な通信エラー部分を拾ってくれる。
ただ、デーモン停止は拾ってくれないので、あくまでも「エンドポイントまでの到達」を検査するようだ。
仮に到達可能になった時は、エンドポイントの内部に問題があると考えるのが良さそう、といったところか。


- 投稿日:2021-01-11T19:36:36+09:00
AWSでGPU必須のバッチ処理を動かす
まとめ
- 使うべきサービスは AWS Batch
- GPUあり/なしで挙動が変わるライブラリに注意
- DockerHubにGPUあり版のイメージがある場合はそれをbaseにすると楽
- 例: PyTorch
背景
- 以下の要件を満たすシステムをAWS上に組みたい
- 毎日/毎週1回のみ動かし、他の時間は課金しないで欲しい
- スポットインスタンスが使えると嬉しい
- GPUは必須
- 例: https://zenn.dev/miyatsuki/articles/0d66daf6615962
- それができそうなサービスがいろいろあるがどれを使えばいいのかよくわからない
- Fargate
- ECS
- SageMaker
- AWS Batch (採用)
なぜAWS Batch?
- Fargate
- GPUが使えないのでNG
- CPUだけなら、Fargateでもいいと思います
- ECS
- GPUインスタンスを立ち上げ続ける必要があるのでNG
- SageMaker
- (サービスがありすぎてよくわからない。。。)
- AWS Batch
- 特定時間のみ起動して終わったらインスタンスを閉じてくれる
- スポットインスタンスも使える
- GPUインスタンスも使える
AWS Batchの使い方
- ECR (Elastic Container Registory) に動かしたいコンテナのイメージをpushする
- AWS Batchのコンピューティング環境を作る
- マネージド型を選択
- インスタンスの設定 -> スポット
- オンデマンド料金 -> 予算をみて適当に設定。50%だとそんなに待たされることはなかったです。
- 許可されたインスタンスタイプ -> GPUが使えるインスタンスを選択。g4dn.xlargeが最安なので、これから様子をみてみるのも良いかもしれません
- EC2設定のイメージタイプ -> Amazon Linux 2 (GPU)
- AWS Batchのジョブキューを作る
- コンピューティング環境は2.で作った物を選ぶ
- AWS Batchのジョブ定義を作る
- プラットフォーム -> EC2
- イメージ -> 1でpushしたもの
- コマンド -> バッチで実行したい物をCMDの引数として使えるように書く。元のイメージのCMDは上書きされるので、イメージ側に記載している場合でも改めて設定が必要
- メモリ -> 2GBで足りない場合は増やす
- GPUの数 -> 1
- AWS Batchのジョブを投げる
- ジョブ画面から新しいジョブを作成をクリック
- ジョブ定義とジョブキューは4と3で作った物を選択
- 最後の送信を押すと、ジョブがsubmitされる
- AWS Batchのジョブ実行を見守る
- ダッシュボード画面からジョブの実行状況が見られるので見守る
コンテナイメージについて
コンテナ側がGPU Readyになっていても、イメージファイル内のソフトウェアがGPU対応してないと、結局CPUで動作してしまう。個人的に注意すべきと思う点は下記。
- pip installした際に、PCの状況をみてGPUなし版を入れてくるライブラリがある
- PyTorchなど
- このようなライブラリのGPU版が必要な場合は、DockerHubからGPU版が入ったイメージをpullしてくると楽
- 投稿日:2021-01-11T18:40:32+09:00
【AWS】IAMユーザーのログインパスワードを忘れた場合の対処法
参考記事
https://dev.classmethod.jp/articles/iam-user-password-reset/
こちらの記事を参考にさせていただきました。
- 投稿日:2021-01-11T17:15:40+09:00
クラウド上にコールセンターを作れるAmazon Connect入門 【用語解説】
はじめに
Amazon Connectとは、クラウド上にコールセンターを安価に構築できるサービスです。
普通にコールセンターを作ろうとするとPBXという高額な機械が必要ですが、Amazon Connectであれば初期費用ゼロで構築できます。
運用費は従量課金で安く (3,000ー4,000円/月) 利用できます。
固定電話不要で、ブラウザとマイクがあれば、電話として使えるのも特徴です。また電話だけでなく、音声データを解析し、声紋認証や感情分析などができたり、CRM連携も標準で付いています。
本記事では、そんなAmazon Connectを実際に使うときに、知っておいた方が良い予備知識 (用語) を解説します。
対象読者
- はじめてAmazon Connectを触る方
- 用語の整理をしたい方
YouTube動画
文字だけでなく、動画での解説もしています。
Amazon Connect以外のAWSサービスについても解説しているので、今日のある方はこちらもみていただけると嬉しいです。
【YouTube動画】クラウド上にコールセンターを開設できるAmazon Connect入門!!
Amazon Connectの用語解説
Amazon Connectは以下のような構成で、電話の発信および着信ができます。
まず、用語について解説した後に発信・着信時の処理の流れをみていきます。
電話番号
Amazon Connectでは、インスタンスを作成すると、050番号、0120番号、080番号などを取得できます。
電話番号は枯渇しやすいので、取得できない場合はサポートに連絡する必要があります。
問い合わせフロー
問合せフローは電話番号を受信した時にどういう処理をするか設定できます。
デフォルトでいくつか使えるフローもありますし、自分で新しく作ることもできます。設定はGUIででき、Lambdaを起動したり、音声データを録音したり、解析したりできます。
キュー
キューは発信や着信を一時的に保持するために使います。
ユーザーはどこかのキューに属し、キューに入った電話が割り振られて、ユーザーに着信します。
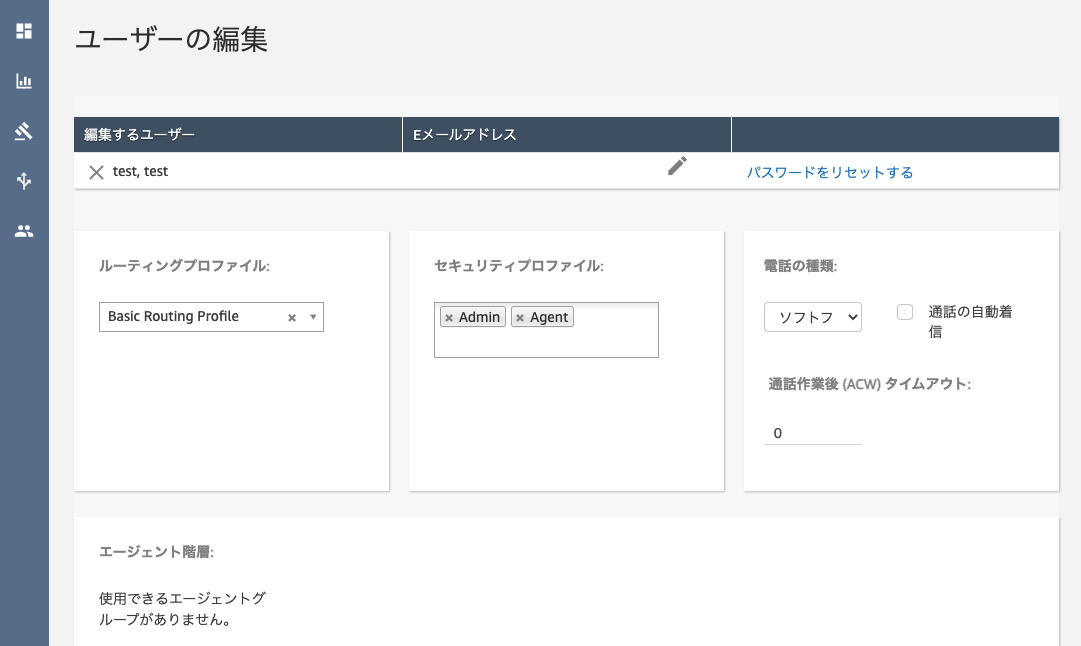
ルーティングプロファイル
ルーティングプロファイルはキューの優先順位を決めるために使います。
ユーザー (エージェント, オペレーター)
電話対応する人のことです。
ユーザーは1つのルーティングプロファイルしか持てないため、ルーディングプロファイルとユーザーの関係は1対nです。エージェントとも呼ばれます。
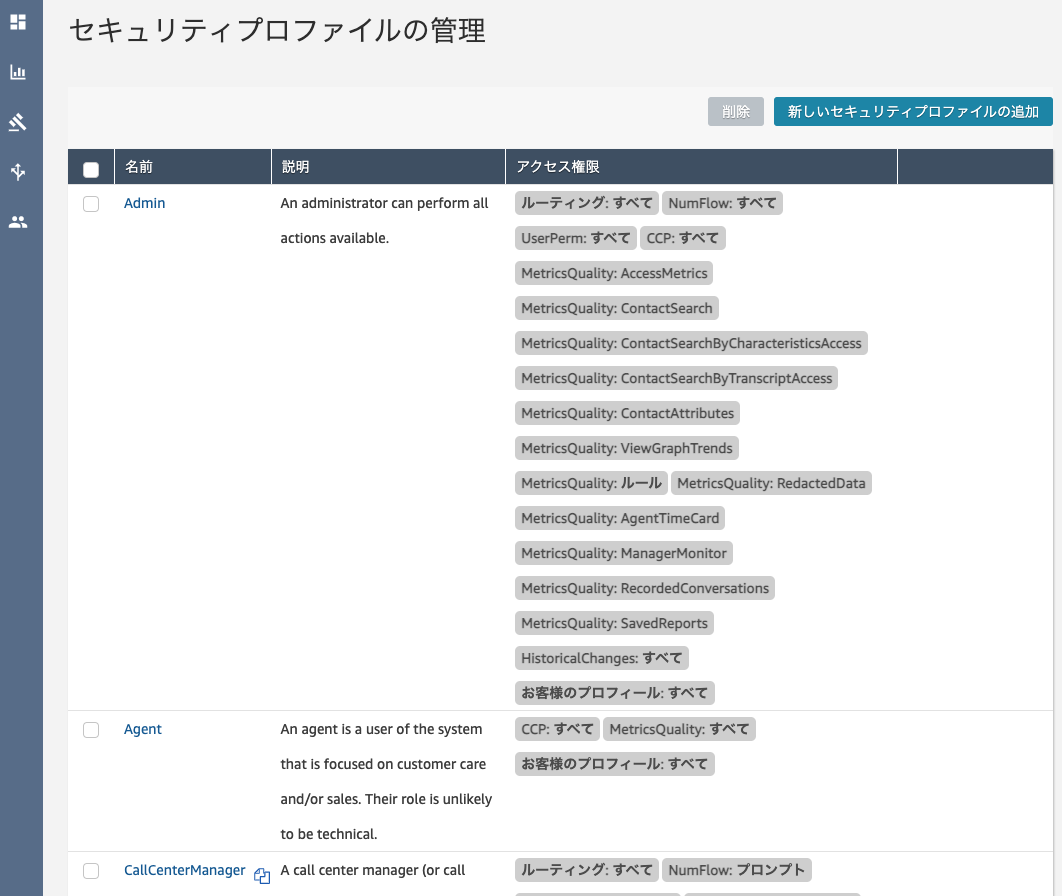
セキュリティプロファイル
セキュリティ上の権限のことで、ユーザーをadminやoperatorといったグループに分け、各グループに対して権限を設定できます。ユーザーとセキュリティプロファイルはn対1の関係になっています。
アウトバウンド
コールセンターは電話の受信だけでなく送信もでき、これをアウトバウンドといいます。
ルーティングプロファイルはデフォルトのアウトバウンドキューを1つ設定できます。
そのルーティングプロファイルに所属するユーザーが電話をかける場合は、その番号を使って発信します。
また、キューにもアウトバウンドの電話番号を1つ設定できます。Amazon Connectの処理の流れ
発信時・着信時で処理の流れが異なるので、2つに分けて解説します。
発信時 (お客様 -> ユーザー(エージェント、オペレーター))
お客様が、ある電話番号に着信すると、電話番号に紐づいた問合せフローの処理が実行されます。
問合せフロー内でユーザーに割り当てるか、キューに割り当てるか設定できます。
ユーザーに割り当てた場合は、そのユーザーに電話がかかります。
キューに割り当てられた場合は、ルーティングプロファイルを元に優先順位付けされた後、ユーザーに電話がかかります。また、ユーザーにはAgentやAdminなどのRoleがあり、それに対応する権限がセキュリティプロファイルで設定されています。
着信時 (ユーザー(エージェント、オペレーター) -> お客様)
ユーザー (エージェント, オペレーター) があるお客様に着信すると、ユーザーの属するキューからお客様に向けて着信されます。
この場合にも、間にコンタクトフローを挟み、Lambdaを実行したり、録音したりができます。まとめ
今回は、Amazon Connectを設定する前に知らないと挫折する用語に関して説明しました。
少しでも用語が整理できればなと思います。



- 投稿日:2021-01-11T16:20:24+09:00
AWS認定ソリューションアーキテクト – プロフェッショナル 合格体験記
はじめに
みなさんこんにちは!
SOMPOホールディングスでチーフエンジニアをしているy-sugichanです。今回、AWS認定ソリューションアーキテクト-プロフェッショナル試験に合格したので、勉強法などを残しておきたいと思います。
みなさまのご参考になれば幸いです。まずは結果から
スコア:819(750で合格)
試験結果詳細:全セクション「十分な知識を有する」
→苦手な分野がなくて良かったです…私について
- エンジニア歴13年
- 主にWEBアプリ開発を経験
- AWSの実務は3年以上5年未満くらい
- サーバーレスやElasticBeanstalksなどでの開発メイン。GlueやAthenaとかも使ってました。
- CloudFormationのテンプレートも書いてたり(今は中々機会が・・・
- 家ではAlexaスキルを作って遊んだりもしてました(Lambda+DynamoDB)
- AWS認定ソリューションアーキテクト-アソシエイト取得済み
- インフラエンジニアとしてキャリアを積んだわけではないのでそこらへんは未熟
取ろうと思った動機
正直、アソシエイトで体系的な学習はしたので「あとは実務でいいかな~」と思っていたのですが
- チーム内でAWSを主に担当しているのにアソシエイトだけでいいのか自問自答
- 先日、AWS Dev Dayに登壇したものの、周りの人がすごい人ばかり
- プロフェッショナルってついてた方がかっこいい(?)
- おうち時間も増えてきたので自己研鑽に良い機会
などなどがあります。特に二つ目は大きな動機かもしれません。
取得してみて
自分の知識の浅さといいますか、すぐググって解決してた実務を見直すきっかけになりました。
「こんなに細かいところ(バケットポリシーはこっちの書き方は無効なので不正解です等)まで覚えて正解しないといけないのか…」と、勉強初期は絶望していた記憶があります。また、試験内容のセクションも明確になっており、ユースケースに則った問題が多いので
- これはコスト削減を聞かれているのか→どういう施策があるか
- これは可用性について聞かれているのか→どういうアーキテクチャにするか
- これは移行について聞かれているのか→どういうソリューション・サービスが使えるか
といったあたりをしっかり考えて答えられるようになるのもメリットでしょうか。
実務でも直面しそうなケースを、ベストプラクティスに従って解答できる力を求められていると思います。勉強期間と教材
勉強期間
12月頭に本格開始して、1月9日に受験しました。1ヶ月少々です。
その前は、実務でわからないところをBlack Beltやドキュメントで確認したり。
ただ、年末年始に11連休があり、勉強時間の確保ができたため、合計時間は150時間くらいだと思います(体感土日は3~4時間やれたものの、平日は業務があって中々厳しかったです…
が、後述するBlack BeltのYou Tubeを垂れ流すだけでもいい勉強になったと思っています!教材
【書籍】
正直、日本語の教材が出たのも受験しようと思ったキッカケです(小声
セクションごとのサンプル問題と解説が非常に充実しており、「え、こんな長文で出るの(愕然)」というヤバさも実感できます。【公式】
- Black Belt
- AWS サービス別資料のYou Tubeリンクが非常に便利です!知識があいまいなサービスは必ず見た方が良いです。
- AWS Well-Architected
- まだ読まれていない方はAWS Well-Architectedの5つの柱を一読しましょう。問題で何を聞かれているのか?を理解できるため、遠回りなようで捗ります。
- 各サービス公式ドキュメント
- 実務でもお世話になる公式ドキュメントに必ず答えがあります。ですが全部読むのは絶望しかないので、Black Beltなどを見ていて「これなんだろう」と深堀りしたいときだけで十分だと思います。
他にも色々あると思いますが、色々手を出すより書籍とBlack Beltの中身を完璧にする方が良いと個人的に思います。
ただ問題文が長文なので、慣れるためにUdemyの問題集なども良いかもしれません
(買ったけどやってないです…また、公式模擬試験について、私は受ける時間がありませんでしたが、最初に苦手分野を知るために受けるのはありだと思います。
勉強方法
ここからは具体的に試験までの流れに沿って勉強方法を記載してみます。
試験内容の把握
まずは試験内容です。これは公式の試験ガイドで明確に示されています。
試験時間:180分(3時間)
問題数:75問
分野 試験における比重 分野 1: 組織の複雑さに対応する設計 12.5% 分野 2: 新しいソリューションの設計 31% 分野 3: 移行の計画 15% 分野 4: コスト管理 12.5% 分野 5: 既存のソリューションの継続的な改善 29% 合計 100% 長文問題を一問2分~3分以内で解かないといけないため、気合が必要です(白目
個人的に移行だけでも15%あるというのが、実務では中々触れない部分なので厳しかったです。
逆に自分の苦手分野は重点的に勉強しようとなるので、ここは最初に必ず見たほうがいいと思います。
(私は組織の複雑さ~と移行について自信なしでした)合格体験記の調査
これは色々なところにありますがQiitaに書いてある皆さんの記事を信じましょう。
私は信じて合格しました。書籍での勉強開始
書籍については、まず模擬試験までの各章を一通りこなしました。
そして、問題文の長さと全然解けない自分に絶望しつつも、負けずに地道に繰り返しました。
※ちなみに試験前日に確認したときも普通に間違えました(てへっ土日は基本的にこれ→ドキュメントを読むの繰り返しです。
並行してBlack Beltをひたすら見る
平日は仕事で疲れていることも多いと思うので、お風呂上がりやご飯を食べながら、まったりYou TubeでBlack Beltを見るというのがイチオシです!
余裕があれば深堀りする、疲れてるならとりあえずインプットだけしておく、これだけで何だか頑張った気持ちになれます(大事でも本当に疲れてたら寝ましょう。私は何度かBlack Beltを見ながら寝落ちしてました…
ドキュメントを読む
ドキュメントを単体で読むことはなく、書籍やBlack Beltでの勉強に補足する感じです。
AWS Well-Architectedを読んでいない場合は、書籍での勉強開始前に読んでおいたほうが良いと思います。書籍の模擬試験実施
書籍についている模擬試験を3時間きっちり、時間を測って(水なども飲まず)実施しました。
試験の10日前に実施しましたが、6割しか解けませんでした…
ここで年末年始休暇だったので挽回できたのですが、本来はもっと早めに模擬試験をやっておいた方がいいと思います。
そうしないと、このあとの「間違えたところを再学習」で時間が足りなくなると思われます…間違えたところを再学習
間違いが多すぎたので非常に時間がかかりました。
前述したとおり、もう少し早めに実施した方がいいです。
特に模擬試験で「え、何このサービス・・・知らん・・・」というのも出てくるので、そういった意味でも早めが良いかと。ここでは、書籍と公式のドキュメントをフル活用しました。
再度、書籍の模擬試験を実施する
模擬試験の一週間後(きっと忘れてるだろう頃)に、もう一度模擬試験を実施しました。
やっぱり忘れてましたが、なんとか5問の間違いで済みました。
この内容を100%理解していれば、おそらく当日も合格できると思います。当日について
以下、もう一度受けるなら・・・というふりかえりです。
- 180分も集中力は続かない
- 時間を犠牲にしても、少し休んだ方が良いかもしれません。ずっと長文を読んでいると脳が疲弊します。
- 数問、まったくわからない問題が出るため、見切りを早くした方が良い
- 文章が長いだけで解くのは簡単な問題もあるため、「長いから」というだけで見切るのは危険です。知らない単語が出たりしたら、時間を使うよりフラグを立てて次の問題に行ったほうがいいです。
- 時間は30分程度しか余らないため、見直しフラグは立てすぎない
- 戻ってきて「見直しばかりじゃん!」となります。なりました。
- 難易度は書籍と同等なので自分を信じる
- 日本語訳が適当すぎるので英語が不出来な私ですら英語に切り替えた
- 日頃から英語ドキュメントに慣れておきましょう…
信じるといいながら、終わったあとのアンケート回答中は「微妙だなー」という手応えでした。
スコアがそれをよく表していると思います(泣)最後に
色々なところで「AWS認定でトップクラスに難しい」「長文がつらい」と言われているとおりでした。
個人的にはOrganizationなど、もっと手を動かしておけばよかったかなと思います。
あと、せめて2ヶ月はじっくりやるべきでした・・・非常に多くのことを学ぶことができたので、資格名のとおり「プロフェッショナル」を目指す方なら取得を目指すのが良いと思います!
昨今、中々外に出ることもできず、周りを見るとIT業界は恵まれていると感じることも多いです。
こういった機会に、自分の知識を棚卸ししつつ、資格取得を目指すのも良いなと感じた次第です。以上、お読みいただきありがとうございました!
- 投稿日:2021-01-11T16:15:38+09:00
【Heroku】デプロイしたRailsアプリにAWSのS3を紐付ける
参考URL
https://qiita.com/params_bird/items/dc2a3868f4a2caf0504c
基本的に、上記URLの記事を参考にさせていただきました。
変更した部分
上記記事の後半部分、ターミナルにてコマンドを入力する箇所が、記事の通りにやってもできなかったので、そこだけ私が行った手順を記します。
$ heroku config --app デプロイしているアプリ名https://reasonable-code.com/heroku-config/ (上記コマンドはこちらの記事から)
$ heroku config:set S3_ACCESS_KEY="ココに先ほどメモしたアクセスキーを入力" --app デプロイしているアプリ名 $ heroku config:set S3_SECRET_KEY="同様に、シークレットキーを入力" --app デプロイしているアプリ名 $ heroku config:set S3_BUCKET="バケットの名前を入力" --app デプロイしているアプリ名 $ heroku config:set S3_REGION="リージョンの名前を入力" --app デプロイしているアプリ名最初に紹介したURLと違う部分は、【 --app デプロイしているアプリ名】です。
これを付け加えることで、無事にコマンドを実行することができて、Herokuにデプロイしているアプリから、画像を保存することができるようになりました。
- 投稿日:2021-01-11T16:10:09+09:00
【AWS 手動デプロイ】2回目以降の手順
◆ 目次
1. コマンド
2. かんたんにコマンド説明付き
3. rails db:seedする時の注意1) コマンド
実行場所:[ec2-user@●●●●●<リポジトリ名>]$ 前提: mariaDB起動中 1. githubを最新の状態にする 2. git pull origin master 3. rails db:drop RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 4. rails db:create RAILS_ENV=production 5. rails db:migrate RAILS_ENV=production 6. rails db:seed RAILS_ENV=production 7. rails assets:precompile RAILS_ENV=production 8. ps aux | grep unicorn 9. kill プロセス番号 10. RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D*mariaDB起動の有無確認コマンド
sudo systemctl status mariadb //確認 sudo systemctl start mariadb //起動させる sudo systemctl restatus mariadb //停止→起動2) かんたんにコマンド説明付き
1. githubを最新の状態にする
2. git pull origin master
ec2のWEBアプリケーションを最新の状態にする* migrationfileの変更があった場合のみ -----
3. rails db:drop RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1
起動中のDBを削除する。
* DISABLE_DATABASE_ENVIRONMENT_CHECK=1のオプションをつける必要がある。
4. rails db:create RAILS_ENV=production
DBを再作成
5. rails db:migrate RAILS_ENV=production
migrationfileを反映する
6. rails db:seed RAILS_ENV=production
* seedするデータがなければ不要
---------------------------------------------------
7. rails assets:precompile RAILS_ENV=production
アセットファイルをコンパイルする
8. ps aux | grep unicorn
9. kill プロセス番号
Railsを再起動するためプロセスをきる
10. RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D
Railsを再起動する**補足
RAILS_ENV=production・・・本番環境でコマンド実行する時につくオプションのこと
3) rails db:seedするときの注意
1. 下記コマンドの本番環境で実行する時につくオプションの記述を忘れるとyarnのエラーが出るので注意。
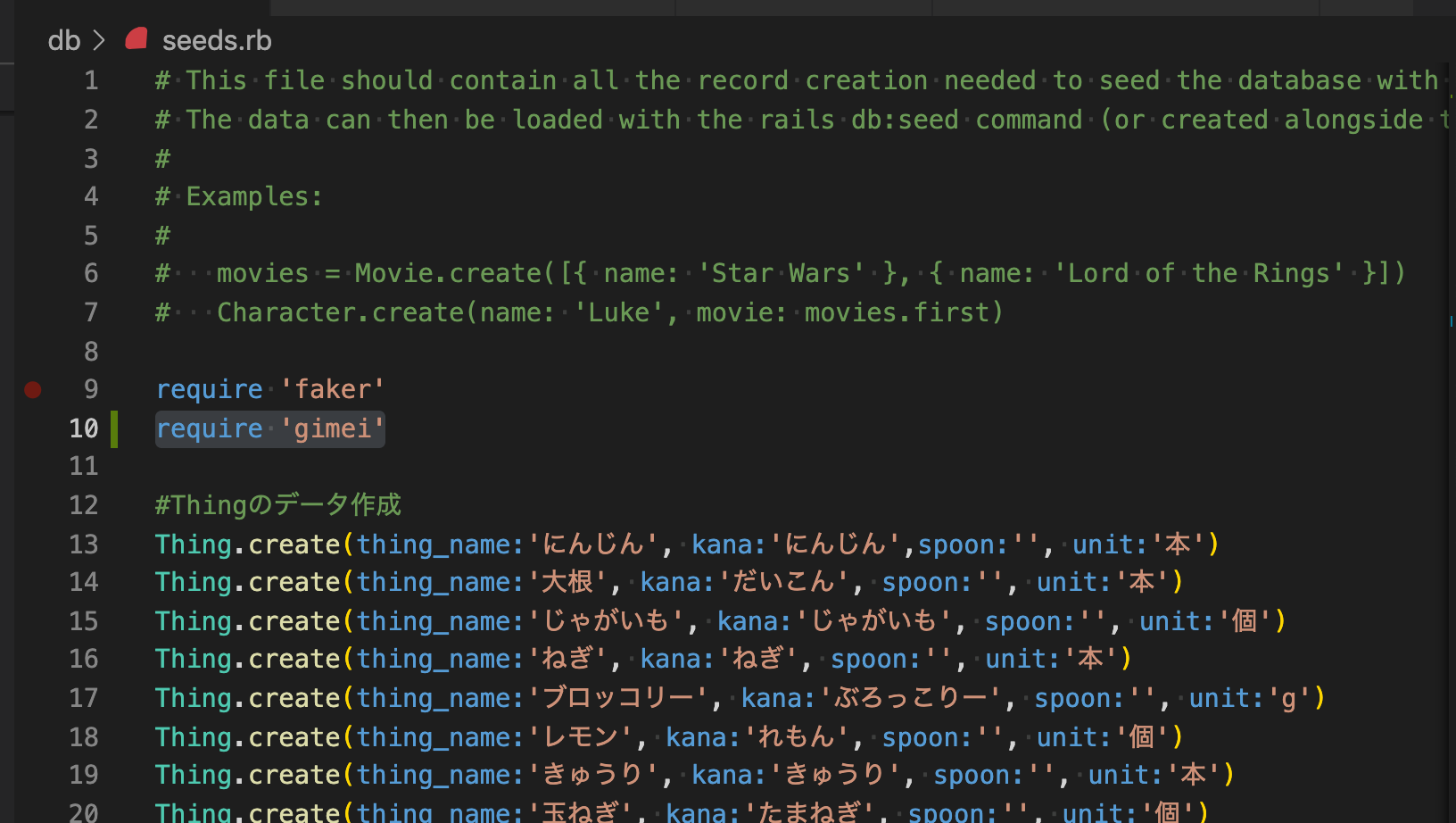
rails db:seed RAILS_ENV=productionrails db:seed warning Integrity check: Flags don't match error Integrity check failed error Found 1 errors. ======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ======================================== To disable this check, please change `check_yarn_integrity` to `false` in your webpacker config file (config/webpacker.yml). yarn check v1.22.5 info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command.2. seed.rbに[require]の記述が漏れててもエラー出ます
10行目記述もれのエラーと↑のダブルパンチで大変惑わされました。
rails db:seed RAILS_ENV=production rails aborted! NameError: uninitialized constant Gimei /var/www/cooktime/db/seeds.rb:44:in `block in <main>' /var/www/cooktime/db/seeds.rb:40:in `times' /var/www/cooktime/db/seeds.rb:40:in `<main>' /var/www/cooktime/bin/rails:9:in `<top (required)>' /var/www/cooktime/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Tasks: TOP => db:seed (See full trace by running task with --trace)以上
- 投稿日:2021-01-11T15:20:20+09:00
Amazon SageMaker Distributed Training
はじめに
Amazon SageMaker で分散学習をするためのライブラリが追加されました。データ並列処理とモデル並列処理に対応しています。それぞれの特徴を見てみましょう。この記事は、こちらのドキュメント を日本語で要約したものです。
Data Parallel
AWS blog によると、モデルの学習に GPU インスタンスを使用し、AllReduce には GPU インスタンスに搭載された CPU を使用することで、専用のパラメータサーバを用意しなくても良いようです。
バランスフュージョンバッファを使用して帯域幅を最適化
SageMaker の分散データ並列ライブラリは、パラメータサーバに似た通信パターンを採用し、複数の GPU からの勾配の平均化に伴うデータ転送量とステップ数を削減しています。また、バランスフュージョンバッファと呼ばれる新しい技術を使用して、クラスタ内の全ノードで利用可能な帯域幅を最適に利用しています。
従来のパラメータサーバの主な欠点は、利用可能なネットワーク帯域幅を最適に利用できないことです。パラメータサーバは変数を原子単位として扱い、各変数を1つのサーバに配置します。勾配は backward パスの間に順次利用可能になるため、任意の瞬間に、異なるサーバから送受信されるデータ量に不均衡が生じます。あるサーバはより多くのデータを受信して送信していますが、あるサーバはより少なく、あるサーバは全く送信しないなどです。この問題は、パラメータサーバの数が増えるにつれて悪化します。
SageMaker のデータ分散ライブラリでは、バランスフュージョンバッファを導入することでこれらの問題に対処しています。バランスフュージョンバッファは、バッファのサイズがしきい値を超えるまで勾配を保持するGPU 内のバッファです。N個のパラメータサーバを持つ場合、バッファがしきい値を超えると、バランスフュージョンバッファは CPU メモリにコピーされ、N個のパーツに分割され、i番目のパーツが i番目のパラメータサーバに送信されます。各サーバは、バランスフュージョンバッファから全く同じサイズのデータを受け取ることになります。i番目のサーバは、すべてのワーカーからバランスフュージョンバッファの i番目のパーツを受け取り、それらを合計し、その結果をすべてのワーカーに送り返します。すべてのサーバが各バランスフュージョンバッファの平均化に同程度使われるため、サーバの帯域幅は効率的に利用されます。
効率的な AllReduce オーバーラッピングとバックワードパスによる GPU 使用率の最適化
SageMaker の分散データ並列ライブラリは、AllReduce 演算と backward パスの最適なオーバーラップを実現し、GPU 利用率を大幅に向上させ、CPU と GPU 間のタスクを最適化することで、ほぼ直線的なスケール効率と学習時間の高速化を実現します。このライブラリは、GPU が勾配を計算している間にAllReduce を並列に実行するため、GPU の追加サイクルを奪うことなく、ライブラリの高速化を実現しています。
CPU の活用:ライブラリは CPU を利用して勾配の AllReduce を行い、このタスクを GPU からオフロードします。
GPU 使用率の向上:クラスタの GPU は勾配の計算に集中しているため、学習中は GPU の使用率が向上します。
Data Parallel FAQ
Q. このライブラリを使用する場合、allreduce を行う CPU インスタンスはどのように管理されますか? 別の CPU-GPU クラスタを作成する必要はありますか。もしくは SageMaker が追加の C5 インスタンスを作成しますか?
A. ライブラリは GPU インスタンスで利用可能な CPU を使用します。追加の C5 や CPU インスタンスは起動されません。SageMaker 学習ジョブが 8 ノードの ml.p3dn.24xlarge クラスターの場合、8 個の ml.p3dn.24xlarge インスタンスのみが使用されます。追加のインスタンスはプロビジョニングされません。
Q. ハイパーパラメータ H1(学習率、バッチサイズ、オプティマイザなど)を設定したひとつのml.p3.24xlarge インスタンスで5日間かかる学習ジョブがあります。SDP を有効にして 5倍の大きなクラスタを使用すれば、およそ5倍のスピードアップを経験するのに十分でしょうか? それとも、SDP を有効にした後に、その学習ハイパーパラメータを再検討する必要があるのでしょうか?
A. ライブラリを有効にすると、全体のバッチサイズが変わります。新しい全体的なバッチサイズは、使用するトレーニングインスタンスの数に応じて線形にスケーリングされます。その結果、収束を確実にするためには、学習率などのハイパーパラメータを変更する必要があります。
Q. ライブラリは Spot Training に対応していますか?
A. はい、マネージドスポットトレーニングを利用することができます。SageMaker の学習ジョブでチェックポイントファイルのパスを指定します。スクリプト修正の概要の最後のステップ で説明したように、学習スクリプトでチェックポイントの保存/復元を有効にします。
Q.このライブラリのバランスフュージョンバッファと PyTorch Distributed Data Parallel (DDP)の "Gradient Buckets "の違いは何ですか?
主な違いは、DDP のフュージョンバッファは AllReduce に使用され、ライブラリのバランスフュージョンバッファはパラメータサーバ型同期に使用されます。このライブラリは、パラメータサーバ型の勾配の同期でフュージョンバッファをシャードする最初のフレームワークです。
PyTorch DDP のドキュメントより。"通信効率を向上させるために、Reducer はパラメータグラデーションをバケットに整理し、1度に 1つずつバケットを減らしていきます。バケットサイズは、DDP コンストラクタで bucket_cap_mb 引数を設定することで設定できます。パラメータグラデーションからバケットへのマッピングは、バケットサイズの制限値とパラメータサイズに基づいて、構築時に決定されます。モデルパラメータは、だいたい与えられたモデルから Model.parameters() の逆順でバケットに割り当てられます。逆順を使用する理由は、DDP は勾配がほぼその順番で backward の間に準備が整うことを期待しているからです。"
Q. シングルホスト、マルチデバイスでの利用は可能ですか?
A. 可能です。しかし、2つ以上のノードでは、ライブラリの AllReduce 動作により、パフォーマンスが大幅に向上します。また、シングル・ホストでは、NVLink がすでにノード内の AllReduce 効率に貢献しています。
Q: PyTorch Lightning で使えますか?
A. 使えません。ただし、PyTorch 用のライブラリの DDP を使えば、機能を実現するためのカスタム DDP を書くことができます。
Q. 学習データセットはどこに保存すればいいですか?
A. 学習データセットは、S3 バケットや FSx ドライブに保存できます。学習ジョブのためにサポートされている様々な入力ファイルシステムについては、このドキュメント を参照してください。
Q. 学習データはFSx for Lustre に保存しておく必要がありますか? EFS や S3 は使用できますか?
A. 学習開始までの時間を短縮するために、FSxの使用をおすすめしますが、必須ではありません。
Q. CPU ノードでも利用できますか?
A. 使えません。現時点では ml.p3.16xlarge、ml.p3dn.24xlarge、ml.p4d.24xlarge のインスタンスをサポートしています。
Q. サポートされているフレームワークやフレームワークのバージョンを教えてください。
A. 現在、PyTorch v1.6 と Tensorflow v2.3.1 をサポートしています。Tensorflow 1.x をサポートしています。
Model Parallel
モデル並列では、モデルの計算グラフ、モデルのパラメータとアクティブ化のサイズ、およびリソースの制約(時間とメモリの比較など)によって、最適な分割戦略が決定されます。
異なるデバイスが異なるデータサンプルのフォワードパスとバックワードパスを同時に処理できる効率的な計算スケジュールを構築するパイプラインを実装することで、並列化を実現しています。
自動モデル分割
ライブラリは、メモリのバランスをとり、デバイス間の通信を最小限に抑え、パフォーマンスを最適化するパーティショニング・アルゴリズムを使用します。速度やメモリを最適化するために、自動パーティショニングアルゴリズムを調整することができます。モデルの構成に熟知しており、より効率的な分割が可能な場合、手動でモデル分割することも可能です。
モデルの自動分割は、最初の学習ステップである smp.step-decorated 関数が最初に呼び出されたときに実行されます。この呼び出しの間、ライブラリはまず GPU メモリを圧迫しないよう CPU RAM 上にモデルのバージョンを構築し、モデルグラフを解析して分割を決定します。この決定に基づいて、各モデルのパーティションが GPU 上にロードされます。このような解析とパーティショニングのステップがあるため、最初の学習ステップは時間がかかる場合があります。
いずれのフレームワークでも、ライブラリはAWSインフラストラクチャに最適化された独自のバックエンドを介してデバイス間の通信を管理します。
自動パーティショニング設計はフレームワークの特性に合わせて行われます。たとえば、TensorFlow は特定の操作を別のデバイスに割り当てることができますが、PyTorch はモジュールレベルで割り当てが行われ、各モジュールは複数の操作で構成されています。
パイプライン実行スケジュール
SageMaker の分散モデル並列ライブラリのコア機能として、モデル学習中にデバイス間で計算とデータ処理の順番を決定するパイプライン実行があります。パイプラインとは、GPU ごとに異なるデータサンプルを同時に計算させることでモデル並列化を実現し、シーケンシャルな計算による性能低下を克服するための手法です。
パイプラインは、ミニバッチをマイクロバッチに分割して構成されており、マイクロバッチは 1つずつ学習パイプラインに供給され、ライブラリランタイムによって定義された実行スケジュールに従って実行されます。マイクロバッチは、与えられた学習ミニバッチのより小さなサブセットです。パイプラインスケジュールは、タイムスロットごとにどのデバイスでどのマイクロバッチを実行するかを決定します。
たとえば、パイプラインスケジュールとモデルパーティションに応じて、GPU i がマイクロバッチ b で計算を実行し、GPU i+1 がマイクロバッチ b+1 で計算を実行することで、両方の GPU を同時にアクティブにしておくことができます。1 回の forward または backward パスの間に、パーティショニングの決定に応じて、1 つのマイクロバッチの実行フローが同じデバイスを複数回割り当てられることがあります。たとえば、モデルの先頭にある操作はモデルの末尾にある操作と同じデバイスに配置され、その間の操作は別のデバイスにあるため、このデバイスは 2回使用されることになります。
ライブラリにはシンプルとインターリーブの 2種類のパイプラインスケジュールがあり、SageMaker Python SDK の pipeline パラメータを使って設定できます。多くの場合、インターリーブされたパイプラインの方が GPU をより効率的に利用することで、より良いパフォーマンスを得ることができます。
インターリーブパイプライン
インターリーブパイプラインでは、可能な限りマイクロバッチの backward 処理が優先されます。これにより、アクティベーションに使用したメモリをより早く解放し、メモリをより効率的に使用することができます。また、マイクロバッチの数をより多くスケーリングして、GPU のアイドル時間を短縮することもできます。定常状態では、各デバイスは forward 処理と backward 処理を交互に実行します。これは、あるマイクロバッチの backward 処理が、別のマイクロバッチの forward 処理が終了する前に実行される可能性があることを意味します。
上図は、2つの GPU を用いたインターリーブパイプラインの実行スケジュールの一例です。F0 はマイクロバッチ0 の forward 処理、B1はマイクロバッチ1 の backward 処理を表しています。Update はパラメータのオプティマイザ更新を表します。GPU0 は可能な限り常に backward 処理を優先する(たとえば、F2 の前に B0 を実行する)ことで、アクティベーションに使用したメモリを先にクリアできるようにしています。
シンプルパイプライン
インターリーブパイプラインとは対照的に、シンプルパイプラインは、backward 処理を開始する前に、各マイクロバッチの forward 処理の実行を終了します。これは、forward 処理と backward 処理のステージをそれ自体の中でのみパイプライン化することを意味します。次の図は、2つのGPUを使用した場合の動作例を示しています。
フレームワークごとのパイプライン実行
フレームワークごとにパイプライン実行方法が異なります。ここでは、Tensorflow と PyTorch それぞれについて説明します。
Tenforflow のパイプライン実行
次の画像は、自動モデル分割を使用してモデル並列ライブラリで分割された TensorFlow グラフの例です。グラフが分割されると、各サブグラフは B回(変数を除く)複製されます(Bはマイクロバッチの数)。この図では、各サブグラフは 2回(B=2)複製されています。サブグラフの各入力には SMPInput オペレーションが挿入され、各出力には SMPOutput オペレーションが挿入されます。これらの操作は、ライブラリのバックエンドと通信して、テンソルを相互に転送します。
次の画像は、2つのサブグラフを B=2 で分割し、勾配演算を加えた例です。SMPInput op の勾配がSMPOutput op の勾配になり、その逆も同様です。これにより、バックプロパゲーション時に勾配を逆流させることができます。
上図は、B=2 マイクロバッチと 2サブグラフのインターリーブパイプライン実行スケジュールの例を示しています。各デバイスは、GPU 利用率を向上させるために、サブグラフのレプリカの 1つを順次実行します。B が大きくなるにつれて、アイドルタイムスロットの割合はゼロに近づきます。特定のサブグラフレプリカで(forward または backward の)計算を行う時はいつでも、パイプライン層は対応する青色のSMPInput 操作に信号を送り、実行を開始します。
1つのミニバッチ内のすべてのマイクロバッチからの勾配が計算されると、ライブラリはマイクロバッチ間の勾配を結合し、パラメータに適用することができます。
PyTorch のパイプライン実行
パイプラインは概念的には PyTorch と似たような考え方をしています。しかし、PyTorch は静的なグラフを使用しないため、モデル並列ライブラリに PyTorch 用の機能では、より動的なパイプラインのパラダイムを使用しています。
TensorFlow と同様に、各バッチはいくつかのマイクロバッチに分割され、各デバイス上で一度に一つずつ実行されます。ただし、実行スケジュールは各デバイス上で起動された実行サーバを介して処理されます。他のデバイスに配置されているサブモジュールの出力が現在のデバイス上で必要になるたびに、サブモジュールへの入力テンソルとともに、リモートデバイスの実行サーバに実行要求が送られます。実行サーバは、与えられた入力でこのモジュールを実行し、その応答を現在のデバイスに返します。
リモートサブモジュールの実行中はカレントデバイスがアイドル状態なので、現在のマイクロバッチのローカル実行は一時停止し、ライブラリランタイムはカレントデバイスがアクティブに作業できる別のマイクロバッチに実行を切り替えます。マイクロバッチの優先順位は、選択したパイプラインスケジュールによって決まります。インターリーブされたパイプラインスケジュールでは、計算の backward ステージにいるマイクロバッチが可能な限り優先されます。
Model Parallel 使用前のチェックポイント
Amazon SageMaker の分散モデル並列ライブラリを使用する前に、以下のヒントと落とし穴を確認してください。このリストには、フレームワーク全体に適用可能なヒントが含まれています。TensorFlow とPyTorch 特有の Tips については、それぞれ Modify a TensorFlow Training Script と Modify a PyTorch Training Script を参照してください。
バッチサイズとマイクロバッチ数
ライブラリは、バッチサイズを大きくすると最も効率的です。モデルがひとつのデバイス内に収まるが、小さなバッチサイズでしか学習できないような場合は、モデル並列を適用する際にバッチサイズを大きくすることができます。モデル並列化により、大きなモデルのメモリを節約できるため、これまでメモリに収まらなかったバッチサイズを使用してトレーニングを行うことができりためです。
マイクロバッチの数が小さすぎたり大きすぎたりすると、パフォーマンスが低下することがあります。ライブラリは各デバイスで各マイクロバッチを順次実行するため、マイクロバッチサイズ(バッチサイズをマイクロバッチ数で割った値)は、各 GPU を十分に利用するのに十分な大きさでなければなりません。同時に、パイプラインの効率はマイクロバッチの数に応じて向上するため、適切なバランスを取ることが重要です。一般的には、2~4個のマイクロバッチを試してみて、バッチサイズをメモリ限界まで大きくしてから、より大きなバッチサイズとマイクロバッチ数で実験するのが良い出発点です。マイクロバッチの数が増えるにつれて、インターリーブパイプラインを使用する場合は、より大きなバッチサイズが可能になるかもしれません。
バッチサイズは常にマイクロバッチの数で割る必要があります。データセットのサイズによっては、エポックごとの最後のバッチのサイズが他のバッチよりも小さくなることがあることに注意してください。そうでない場合は、Tensorflow の場合 tf.Dataset.batch() コールで
drop_remainder=Trueを設定するか、PyTorch の場合 DataLoader でdrop_last=Trueを設定して、この最後の小さなバッチを使用しないようにします。データパイプラインに別の API を使用している場合は、マイクロバッチの数で割り切れない場合は、最後のバッチを手動でスキップする必要があるかもしれません。手動パーティショニング
手動パーティショニングを使用する場合は、トランスアーキテクチャの埋め込みテーブルなど、モデル内の複数の操作やモジュールで消費されるパラメータに注意してください。同じパラメータを共有するモジュールは、正確性を保つために同じデバイスに配置する必要があります。自動分割を使用すると、ライブラリは自動的にこの制約を適用します。
データの準備
モデルが複数の入力を取る場合は、データパイプラインのランダム操作(例えば、シャッフル)を smp.dp_rank() でシード設定するようにしてください。データセットがデータ並列デバイス間で決定論的にシャードされている場合、シャードが smp.dp_rank() でインデックス化されていることを確認してください。これは、モデルパーティションを構成するすべてのランクで見られるデータの順序が一貫していることを確認するためです。
smp.DistributedModel から返す Tensor
Tensorflow の場合 smp.DistributedModel.call、PyTorch の場合 smp.DistributedModel.forward 関数から返されたテンソルは、その特定のテンソルを計算したランクから他のすべてのランクにブロードキャストされます。不要な通信やメモリのオーバヘッドやパフォーマンスの低下につながるため、call メソッドや forward メソッドの外で必要とされないテンソル(例えば中間活性化)は返されるべきではありません。




- 投稿日:2021-01-11T15:20:20+09:00
効率的に分散学習する! Amazon SageMaker Distributed Training
はじめに
Amazon SageMaker で分散学習をするためのライブラリが追加されました。データ並列処理とモデル並列処理に対応しています。それぞれの特徴を見てみましょう。この記事は、こちらのドキュメント を日本語で要約したものです。
Data Parallel
AWS blog によると、モデルの学習に GPU インスタンスを使用し、AllReduce には GPU インスタンスに搭載された CPU を使用することで、専用のパラメータサーバを用意しなくても良いようです。
バランスフュージョンバッファを使用して帯域幅を最適化
SageMaker の分散データ並列ライブラリは、パラメータサーバに似た通信パターンを採用し、複数の GPU からの勾配の平均化に伴うデータ転送量とステップ数を削減しています。また、バランスフュージョンバッファと呼ばれる新しい技術を使用して、クラスタ内の全ノードで利用可能な帯域幅を最適に利用しています。
従来のパラメータサーバの主な欠点は、利用可能なネットワーク帯域幅を最適に利用できないことです。パラメータサーバは変数を原子単位として扱い、各変数を1つのサーバに配置します。勾配は backward パスの間に順次利用可能になるため、任意の瞬間に、異なるサーバから送受信されるデータ量に不均衡が生じます。あるサーバはより多くのデータを受信して送信していますが、あるサーバはより少なく、あるサーバは全く送信しないなどです。この問題は、パラメータサーバの数が増えるにつれて悪化します。
SageMaker のデータ分散ライブラリでは、バランスフュージョンバッファを導入することでこれらの問題に対処しています。バランスフュージョンバッファは、バッファのサイズがしきい値を超えるまで勾配を保持するGPU 内のバッファです。N個のパラメータサーバを持つ場合、バッファがしきい値を超えると、バランスフュージョンバッファは CPU メモリにコピーされ、N個のパーツに分割され、i番目のパーツが i番目のパラメータサーバに送信されます。各サーバは、バランスフュージョンバッファから全く同じサイズのデータを受け取ることになります。i番目のサーバは、すべてのワーカーからバランスフュージョンバッファの i番目のパーツを受け取り、それらを合計し、その結果をすべてのワーカーに送り返します。すべてのサーバが各バランスフュージョンバッファの平均化に同程度使われるため、サーバの帯域幅は効率的に利用されます。
効率的な AllReduce オーバーラッピングとバックワードパスによる GPU 使用率の最適化
SageMaker の分散データ並列ライブラリは、AllReduce 演算と backward パスの最適なオーバーラップを実現し、GPU 利用率を大幅に向上させ、CPU と GPU 間のタスクを最適化することで、ほぼ直線的なスケール効率と学習時間の高速化を実現します。このライブラリは、GPU が勾配を計算している間にAllReduce を並列に実行するため、GPU の追加サイクルを奪うことなく、ライブラリの高速化を実現しています。
CPU の活用:ライブラリは CPU を利用して勾配の AllReduce を行い、このタスクを GPU からオフロードします。
GPU 使用率の向上:クラスタの GPU は勾配の計算に集中しているため、学習中は GPU の使用率が向上します。
Data Parallel FAQ
Q. このライブラリを使用する場合、allreduce を行う CPU インスタンスはどのように管理されますか? 別の CPU-GPU クラスタを作成する必要はありますか。もしくは SageMaker が追加の C5 インスタンスを作成しますか?
A. ライブラリは GPU インスタンスで利用可能な CPU を使用します。追加の C5 や CPU インスタンスは起動されません。SageMaker 学習ジョブが 8 ノードの ml.p3dn.24xlarge クラスターの場合、8 個の ml.p3dn.24xlarge インスタンスのみが使用されます。追加のインスタンスはプロビジョニングされません。
Q. ハイパーパラメータ H1(学習率、バッチサイズ、オプティマイザなど)を設定したひとつのml.p3.24xlarge インスタンスで5日間かかる学習ジョブがあります。SDP を有効にして 5倍の大きなクラスタを使用すれば、およそ5倍のスピードアップを経験するのに十分でしょうか? それとも、SDP を有効にした後に、その学習ハイパーパラメータを再検討する必要があるのでしょうか?
A. ライブラリを有効にすると、全体のバッチサイズが変わります。新しい全体的なバッチサイズは、使用するトレーニングインスタンスの数に応じて線形にスケーリングされます。その結果、収束を確実にするためには、学習率などのハイパーパラメータを変更する必要があります。
Q. ライブラリは Spot Training に対応していますか?
A. はい、マネージドスポットトレーニングを利用することができます。SageMaker の学習ジョブでチェックポイントファイルのパスを指定します。スクリプト修正の概要の最後のステップ で説明したように、学習スクリプトでチェックポイントの保存/復元を有効にします。
Q.このライブラリのバランスフュージョンバッファと PyTorch Distributed Data Parallel (DDP)の "Gradient Buckets "の違いは何ですか?
主な違いは、DDP のフュージョンバッファは AllReduce に使用され、ライブラリのバランスフュージョンバッファはパラメータサーバ型同期に使用されます。このライブラリは、パラメータサーバ型の勾配の同期でフュージョンバッファをシャードする最初のフレームワークです。
PyTorch DDP のドキュメントより。"通信効率を向上させるために、Reducer はパラメータグラデーションをバケットに整理し、1度に 1つずつバケットを減らしていきます。バケットサイズは、DDP コンストラクタで bucket_cap_mb 引数を設定することで設定できます。パラメータグラデーションからバケットへのマッピングは、バケットサイズの制限値とパラメータサイズに基づいて、構築時に決定されます。モデルパラメータは、だいたい与えられたモデルから Model.parameters() の逆順でバケットに割り当てられます。逆順を使用する理由は、DDP は勾配がほぼその順番で backward の間に準備が整うことを期待しているからです。"
Q. シングルホスト、マルチデバイスでの利用は可能ですか?
A. 可能です。しかし、2つ以上のノードでは、ライブラリの AllReduce 動作により、パフォーマンスが大幅に向上します。また、シングル・ホストでは、NVLink がすでにノード内の AllReduce 効率に貢献しています。
Q: PyTorch Lightning で使えますか?
A. 使えません。ただし、PyTorch 用のライブラリの DDP を使えば、機能を実現するためのカスタム DDP を書くことができます。
Q. 学習データセットはどこに保存すればいいですか?
A. 学習データセットは、S3 バケットや FSx ドライブに保存できます。学習ジョブのためにサポートされている様々な入力ファイルシステムについては、このドキュメント を参照してください。
Q. 学習データはFSx for Lustre に保存しておく必要がありますか? EFS や S3 は使用できますか?
A. 学習開始までの時間を短縮するために、FSxの使用をおすすめしますが、必須ではありません。
Q. CPU ノードでも利用できますか?
A. 使えません。現時点では ml.p3.16xlarge、ml.p3dn.24xlarge、ml.p4d.24xlarge のインスタンスをサポートしています。
Q. サポートされているフレームワークやフレームワークのバージョンを教えてください。
A. 現在、PyTorch v1.6 と Tensorflow v2.3.1 をサポートしています。Tensorflow 1.x をサポートしています。
Model Parallel
モデル並列では、モデルの計算グラフ、モデルのパラメータとアクティブ化のサイズ、およびリソースの制約(時間とメモリの比較など)によって、最適な分割戦略が決定されます。
異なるデバイスが異なるデータサンプルのフォワードパスとバックワードパスを同時に処理できる効率的な計算スケジュールを構築するパイプラインを実装することで、並列化を実現しています。
自動モデル分割
ライブラリは、メモリのバランスをとり、デバイス間の通信を最小限に抑え、パフォーマンスを最適化するパーティショニング・アルゴリズムを使用します。速度やメモリを最適化するために、自動パーティショニングアルゴリズムを調整することができます。モデルの構成に熟知しており、より効率的な分割が可能な場合、手動でモデル分割することも可能です。
モデルの自動分割は、最初の学習ステップである smp.step-decorated 関数が最初に呼び出されたときに実行されます。この呼び出しの間、ライブラリはまず GPU メモリを圧迫しないよう CPU RAM 上にモデルのバージョンを構築し、モデルグラフを解析して分割を決定します。この決定に基づいて、各モデルのパーティションが GPU 上にロードされます。このような解析とパーティショニングのステップがあるため、最初の学習ステップは時間がかかる場合があります。
いずれのフレームワークでも、ライブラリはAWSインフラストラクチャに最適化された独自のバックエンドを介してデバイス間の通信を管理します。
自動パーティショニング設計はフレームワークの特性に合わせて行われます。たとえば、TensorFlow は特定の操作を別のデバイスに割り当てることができますが、PyTorch はモジュールレベルで割り当てが行われ、各モジュールは複数の操作で構成されています。
パイプライン実行スケジュール
SageMaker の分散モデル並列ライブラリのコア機能として、モデル学習中にデバイス間で計算とデータ処理の順番を決定するパイプライン実行があります。パイプラインとは、GPU ごとに異なるデータサンプルを同時に計算させることでモデル並列化を実現し、シーケンシャルな計算による性能低下を克服するための手法です。
パイプラインは、ミニバッチをマイクロバッチに分割して構成されており、マイクロバッチは 1つずつ学習パイプラインに供給され、ライブラリランタイムによって定義された実行スケジュールに従って実行されます。マイクロバッチは、与えられた学習ミニバッチのより小さなサブセットです。パイプラインスケジュールは、タイムスロットごとにどのデバイスでどのマイクロバッチを実行するかを決定します。
たとえば、パイプラインスケジュールとモデルパーティションに応じて、GPU i がマイクロバッチ b で計算を実行し、GPU i+1 がマイクロバッチ b+1 で計算を実行することで、両方の GPU を同時にアクティブにしておくことができます。1 回の forward または backward パスの間に、パーティショニングの決定に応じて、1 つのマイクロバッチの実行フローが同じデバイスを複数回割り当てられることがあります。たとえば、モデルの先頭にある操作はモデルの末尾にある操作と同じデバイスに配置され、その間の操作は別のデバイスにあるため、このデバイスは 2回使用されることになります。
ライブラリにはシンプルとインターリーブの 2種類のパイプラインスケジュールがあり、SageMaker Python SDK の pipeline パラメータを使って設定できます。多くの場合、インターリーブされたパイプラインの方が GPU をより効率的に利用することで、より良いパフォーマンスを得ることができます。
インターリーブパイプライン
インターリーブパイプラインでは、可能な限りマイクロバッチの backward 処理が優先されます。これにより、アクティベーションに使用したメモリをより早く解放し、メモリをより効率的に使用することができます。また、マイクロバッチの数をより多くスケーリングして、GPU のアイドル時間を短縮することもできます。定常状態では、各デバイスは forward 処理と backward 処理を交互に実行します。これは、あるマイクロバッチの backward 処理が、別のマイクロバッチの forward 処理が終了する前に実行される可能性があることを意味します。
上図は、2つの GPU を用いたインターリーブパイプラインの実行スケジュールの一例です。F0 はマイクロバッチ0 の forward 処理、B1はマイクロバッチ1 の backward 処理を表しています。Update はパラメータのオプティマイザ更新を表します。GPU0 は可能な限り常に backward 処理を優先する(たとえば、F2 の前に B0 を実行する)ことで、アクティベーションに使用したメモリを先にクリアできるようにしています。
シンプルパイプライン
インターリーブパイプラインとは対照的に、シンプルパイプラインは、backward 処理を開始する前に、各マイクロバッチの forward 処理の実行を終了します。これは、forward 処理と backward 処理のステージをそれ自体の中でのみパイプライン化することを意味します。次の図は、2つのGPUを使用した場合の動作例を示しています。
フレームワークごとのパイプライン実行
フレームワークごとにパイプライン実行方法が異なります。ここでは、Tensorflow と PyTorch それぞれについて説明します。
Tenforflow のパイプライン実行
次の画像は、自動モデル分割を使用してモデル並列ライブラリで分割された TensorFlow グラフの例です。グラフが分割されると、各サブグラフは B回(変数を除く)複製されます(Bはマイクロバッチの数)。この図では、各サブグラフは 2回(B=2)複製されています。サブグラフの各入力には SMPInput オペレーションが挿入され、各出力には SMPOutput オペレーションが挿入されます。これらの操作は、ライブラリのバックエンドと通信して、テンソルを相互に転送します。
次の画像は、2つのサブグラフを B=2 で分割し、勾配演算を加えた例です。SMPInput op の勾配がSMPOutput op の勾配になり、その逆も同様です。これにより、バックプロパゲーション時に勾配を逆流させることができます。
上図は、B=2 マイクロバッチと 2サブグラフのインターリーブパイプライン実行スケジュールの例を示しています。各デバイスは、GPU 利用率を向上させるために、サブグラフのレプリカの 1つを順次実行します。B が大きくなるにつれて、アイドルタイムスロットの割合はゼロに近づきます。特定のサブグラフレプリカで(forward または backward の)計算を行う時はいつでも、パイプライン層は対応する青色のSMPInput 操作に信号を送り、実行を開始します。
1つのミニバッチ内のすべてのマイクロバッチからの勾配が計算されると、ライブラリはマイクロバッチ間の勾配を結合し、パラメータに適用することができます。
PyTorch のパイプライン実行
パイプラインは概念的には PyTorch と似たような考え方をしています。しかし、PyTorch は静的なグラフを使用しないため、モデル並列ライブラリに PyTorch 用の機能では、より動的なパイプラインのパラダイムを使用しています。
TensorFlow と同様に、各バッチはいくつかのマイクロバッチに分割され、各デバイス上で一度に一つずつ実行されます。ただし、実行スケジュールは各デバイス上で起動された実行サーバを介して処理されます。他のデバイスに配置されているサブモジュールの出力が現在のデバイス上で必要になるたびに、サブモジュールへの入力テンソルとともに、リモートデバイスの実行サーバに実行要求が送られます。実行サーバは、与えられた入力でこのモジュールを実行し、その応答を現在のデバイスに返します。
リモートサブモジュールの実行中はカレントデバイスがアイドル状態なので、現在のマイクロバッチのローカル実行は一時停止し、ライブラリランタイムはカレントデバイスがアクティブに作業できる別のマイクロバッチに実行を切り替えます。マイクロバッチの優先順位は、選択したパイプラインスケジュールによって決まります。インターリーブされたパイプラインスケジュールでは、計算の backward ステージにいるマイクロバッチが可能な限り優先されます。
Model Parallel 使用前のチェックポイント
Amazon SageMaker の分散モデル並列ライブラリを使用する前に、以下のヒントと落とし穴を確認してください。このリストには、フレームワーク全体に適用可能なヒントが含まれています。TensorFlow とPyTorch 特有の Tips については、それぞれ Modify a TensorFlow Training Script と Modify a PyTorch Training Script を参照してください。
バッチサイズとマイクロバッチ数
ライブラリは、バッチサイズを大きくすると最も効率的です。モデルがひとつのデバイス内に収まるが、小さなバッチサイズでしか学習できないような場合は、モデル並列を適用する際にバッチサイズを大きくすることができます。モデル並列化により、大きなモデルのメモリを節約できるため、これまでメモリに収まらなかったバッチサイズを使用してトレーニングを行うことができりためです。
マイクロバッチの数が小さすぎたり大きすぎたりすると、パフォーマンスが低下することがあります。ライブラリは各デバイスで各マイクロバッチを順次実行するため、マイクロバッチサイズ(バッチサイズをマイクロバッチ数で割った値)は、各 GPU を十分に利用するのに十分な大きさでなければなりません。同時に、パイプラインの効率はマイクロバッチの数に応じて向上するため、適切なバランスを取ることが重要です。一般的には、2~4個のマイクロバッチを試してみて、バッチサイズをメモリ限界まで大きくしてから、より大きなバッチサイズとマイクロバッチ数で実験するのが良い出発点です。マイクロバッチの数が増えるにつれて、インターリーブパイプラインを使用する場合は、より大きなバッチサイズが可能になるかもしれません。
バッチサイズは常にマイクロバッチの数で割る必要があります。データセットのサイズによっては、エポックごとの最後のバッチのサイズが他のバッチよりも小さくなることがあることに注意してください。そうでない場合は、Tensorflow の場合 tf.Dataset.batch() コールで
drop_remainder=Trueを設定するか、PyTorch の場合 DataLoader でdrop_last=Trueを設定して、この最後の小さなバッチを使用しないようにします。データパイプラインに別の API を使用している場合は、マイクロバッチの数で割り切れない場合は、最後のバッチを手動でスキップする必要があるかもしれません。手動パーティショニング
手動パーティショニングを使用する場合は、トランスアーキテクチャの埋め込みテーブルなど、モデル内の複数の操作やモジュールで消費されるパラメータに注意してください。同じパラメータを共有するモジュールは、正確性を保つために同じデバイスに配置する必要があります。自動分割を使用すると、ライブラリは自動的にこの制約を適用します。
データの準備
モデルが複数の入力を取る場合は、データパイプラインのランダム操作(例えば、シャッフル)を smp.dp_rank() でシード設定するようにしてください。データセットがデータ並列デバイス間で決定論的にシャードされている場合、シャードが smp.dp_rank() でインデックス化されていることを確認してください。これは、モデルパーティションを構成するすべてのランクで見られるデータの順序が一貫していることを確認するためです。
smp.DistributedModel から返す Tensor
Tensorflow の場合 smp.DistributedModel.call、PyTorch の場合 smp.DistributedModel.forward 関数から返されたテンソルは、その特定のテンソルを計算したランクから他のすべてのランクにブロードキャストされます。不要な通信やメモリのオーバヘッドやパフォーマンスの低下につながるため、call メソッドや forward メソッドの外で必要とされないテンソル(例えば中間活性化)は返されるべきではありません。
- 投稿日:2021-01-11T14:59:22+09:00
【ギリ初心者向け】Laravel Docker AWS(EC2) Webアプリ(PHP)を0から簡単にデプロイする方法(無料)② ーDocker開発環境構築編(Laravel)ー
0.概要
何度もいいますが、知らない単語が出た瞬間ググってください!!!!!
①の全体像編がこちらにあるのでこちらを一読してからだと理解がスムーズかと!!!
https://qiita.com/SG_Sg/items/6b8ce48567b6b6602805
今回で作成するは具体的にいうと赤いとこ
Dokcerを利用してLaravel(PHP)のプロジェクトを作成(dockerの説明)
さて具体的にDockerをを利用して環境構築したいが、、、、
「Dockerってなんやねん」「Docker使うメリットなんやねん」「開発現場でどうやって使うねん」
疑問だらけのため、ざっっくり説明してからにしよう!(最初いくらググってもマジでちょっと何言ってるかわかんないっすねって感じでした)
Dockerとは??等細かいところはググってくださいな、、1.Dockerのメリット、なぜプロのエンジニアは使うのか
①MACを汚さずに環境とプロジェクト、プログラムを作れる!
どういうことかって???
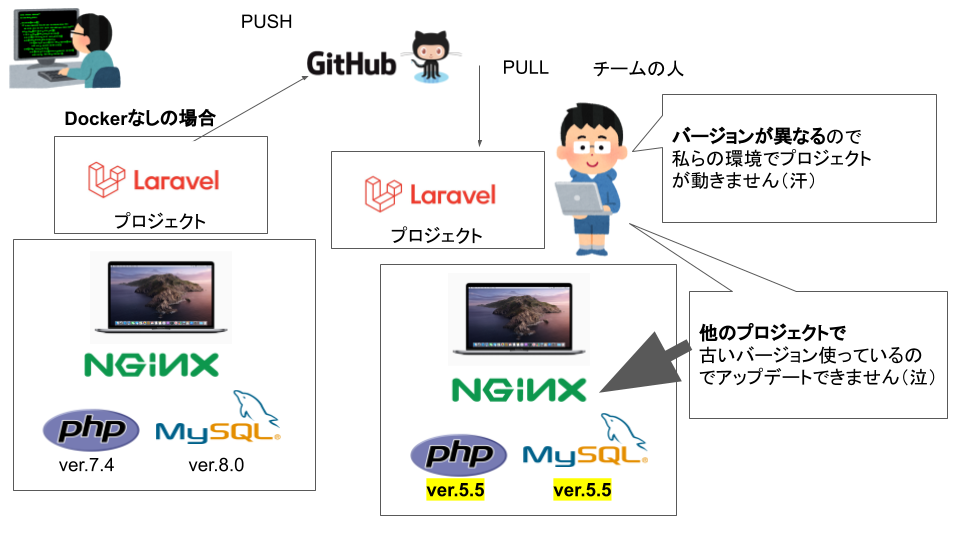
Dockerを使わずにプロジェクトをつくるとどうなるかみてみよう!!
こんな風にバージョン違いだったり他のPCの環境に依存してしまう!!Dockerを使うプロジェクトをつくるとどうなるかみてみよう!!
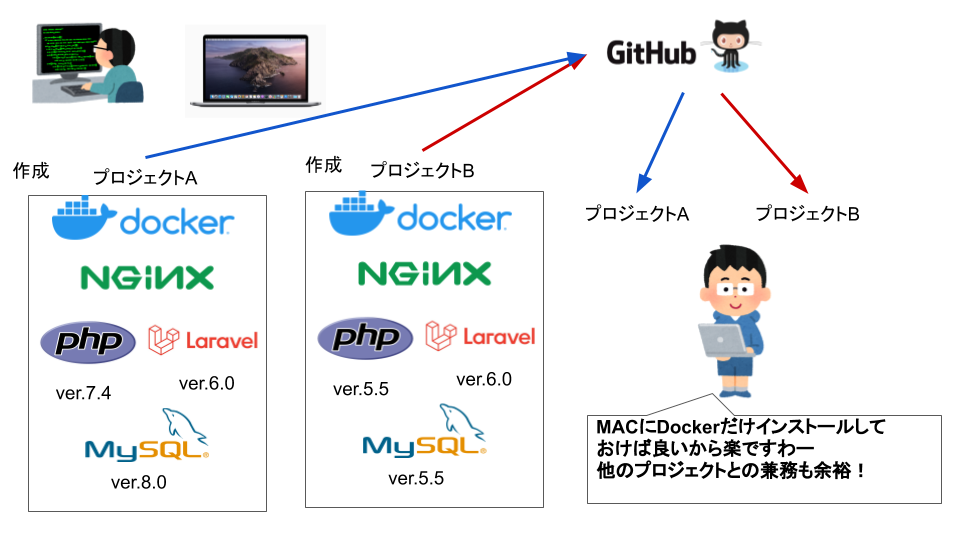
Dockerを使えばDockerの中に環境をインストールしてプロジェクトごとgithub上にのっけるイメージ
Docker内に必要な環境をインストールするから
Macに必要な環境をインストールしなくて良い!!2.まずはいろいろ準備(GitとかDockerをインストールとか)
以下デフォルトのターミナル使ってるよ!
①githubアカウントの作成
https://github.com
②Gitの初期設定
すみません。。「Mac git初期設定」でググってください汗
最終的に下記のように表示されればokです。MacBook-Pro% git config --list | grep user user.name=[githubname] user.email=67626524+[githubname]@users.noreply.github.com③GithubSSH接続設定
これも「Mac Github SSH接続」とかでググってね!エラーとかがでたらまたそのエラー文をぐぐるんや!!!MacBook-Pro% ssh -T github.com Hi [githubの名前]! You've successfully authenticated, but GitHub does not provide shell access.こんなかんじに
successfullyの文字が出れば大体いける!④ docker, docker-compose(起動したり停止できたりするやつ)のインストール
Docker for Macをインストール
https://docs.docker.com/docker-for-mac/install
インストール確認(なにかインストールしたら必ずインストールされてるか確認!)MacBook-Pro% docker --version Docker version 20.10.0, build 7287ab3 MacBook-Pro% docker-compose --version docker-compose version 1.27.4, build 40524192Docker起動確認
これで準備完了なはず!!3.Dockerプロジェクトを作る!!
3-1.github動作確認まで
①プロジェクト(ディレクトリ)を作成する
私はホームディレクトリに「LaravelProjext」をつくってその中に「docker-test」ディレクトリを作成!!このへんはご自由に!!!MacBook-Pro % mkdir LaravelProject MacBook-Pro % cd LaravelProject MacBook-Pro LaravelProject % mkdir docker-test MacBook-Pro LaravelProject % cd docker-test MacBook-Pro docker-test %②リモートリポジトリを作る
作り方は「giuhubリモートリポジトリ 作成」でググろう!!
「DockerLaravelTestProject」を作成
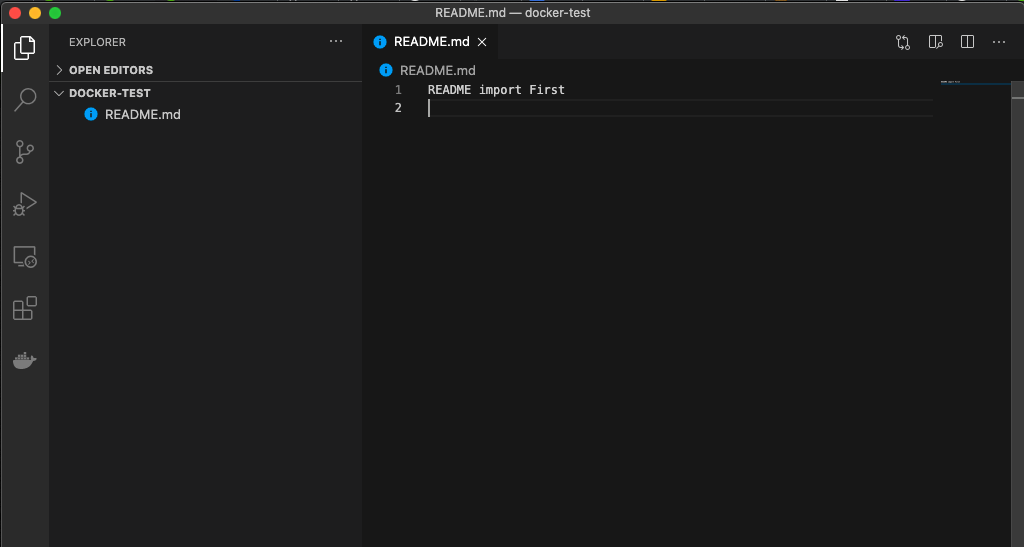
②リモートリポジトリにテストプッシュ!Gitが機能しているかの確認
//README.mdファイルを作成 MacBook-Pro docker-test % echo "README import First" >> README.md //git管理できるようにする MacBook-Pro docker-test % git init //ステージングにaddする! MacBook-Pro docker-test % git add . //commitする!! MacBook-Pro docker-test % git commit -m "first commit README" //push先のリモートリポジトリをGithubに!!(SSHで接続 ※URLはSSH) MacBook-Pro docker-test % git remote add origin git@github.com:SugiKoki/DockerLaravelTestProject.git //リモートリポジトリ先を確認!しっかりgithubのプロジェクトになっている MacBook-Pro docker-test % git remote -v origin git@github.com:SugiKoki/DockerLaravelTestProject.git (fetch) origin git@github.com:SugiKoki/DockerLaravelTestProject.git (push) //gitのブランチを確認 MacBook-Pro docker-test % git branch * master //gitのブランチ(master)にプッシュ MacBook-Pro docker-test % git push -u origin master kokisugi@sugihirokinoMacBook-Pro docker-test %③VScodeで確認する
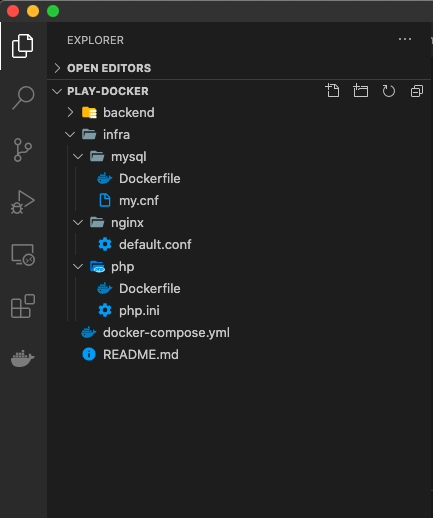
しっかりディレクトリの中に書かれていることを確認!!これで作業できる!!!!3-2.最終ゴールの確認
ファイル構成はこんな感じをめざすよ!!
backendの中が実際にプログラミングするところ!!3-3.アプリケーションサーバー(app)を作る(入れる)
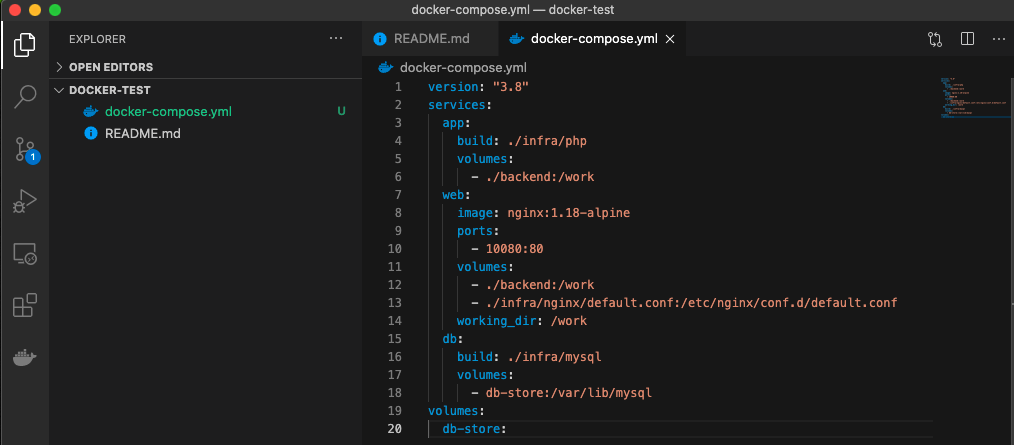
①docker-compose.yml を作成する
MacBook-Pro docker-test % touch docker-compose.ymlVScodeでディレクトリを開いて以下のようにする
以下が内容version: "3.8" services: app: build: ./infra/php volumes: - ./backend:/work web: image: nginx:1.18-alpine ports: - 10080:80 volumes: - ./backend:/work - ./infra/nginx/default.conf:/etc/nginx/conf.d/default.conf working_dir: /work db: build: ./infra/mysql volumes: - db-store:/var/lib/mysql volumes: db-store:上のappってとこがアプリケーションサーバー
真ん中のwebってとこがwebサーバー
下のdbがデータベースサーバー
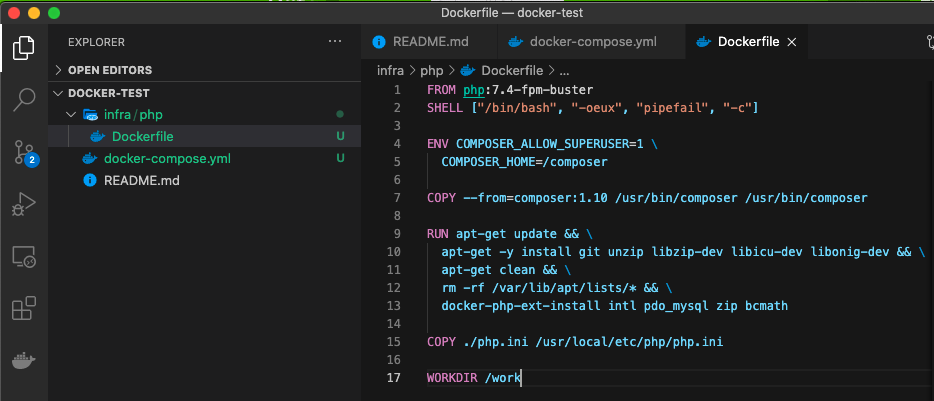
作りたい環境をここで設定してこれに合わせてDockerにインストールしていく!!!②./docker/php/Dockerfile を作成する
MacBook-Pro docker-test % mkdir -p infra/php MacBook-Pro docker-test % touch infra/php/Dockerfile下記のコードを Dockerfile へ。
FROM php:7.4-fpm-buster SHELL ["/bin/bash", "-oeux", "pipefail", "-c"] ENV COMPOSER_ALLOW_SUPERUSER=1 \ COMPOSER_HOME=/composer COPY --from=composer:1.10 /usr/bin/composer /usr/bin/composer RUN apt-get update && \ apt-get -y install git unzip libzip-dev libicu-dev libonig-dev && \ apt-get clean && \ rm -rf /var/lib/apt/lists/* && \ docker-php-ext-install intl pdo_mysql zip bcmath COPY ./php.ini /usr/local/etc/php/php.ini WORKDIR /workここで行っていること
Composerコマンドのインストール
Laravelで必要な
bcmath, pdo_mysql が不足しているのでインストール③./docker/php/Dockerfile を作成する
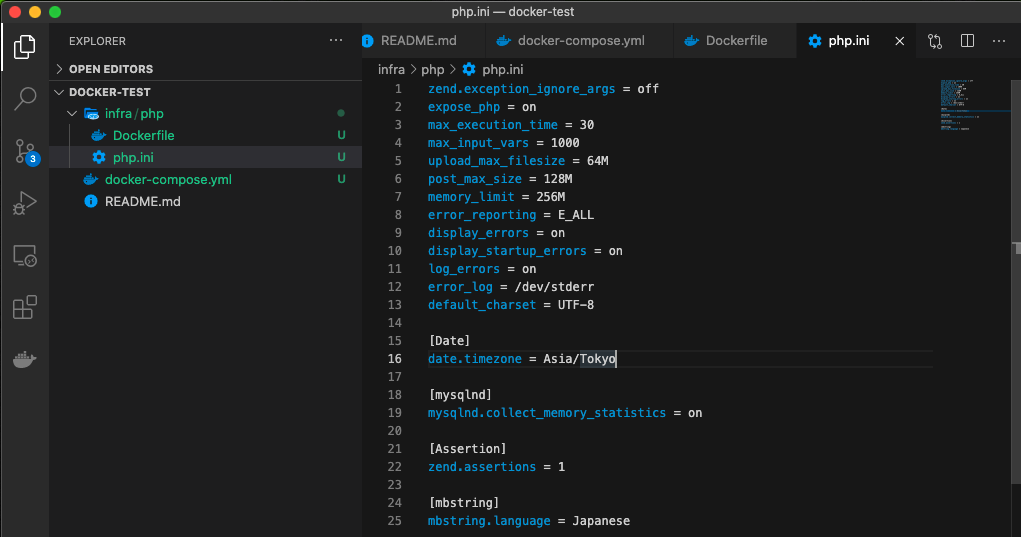
MacBook-Pro docker-test % touch infra/php/php.ini
以下のコードをphp.iniへ
zend.exception_ignore_args = off expose_php = on max_execution_time = 30 max_input_vars = 1000 upload_max_filesize = 64M post_max_size = 128M memory_limit = 256M error_reporting = E_ALL display_errors = on display_startup_errors = on log_errors = on error_log = /dev/stderr default_charset = UTF-8 [Date] date.timezone = Asia/Tokyo [mysqlnd] mysqlnd.collect_memory_statistics = on [Assertion] zend.assertions = 1 [mbstring] mbstring.language = Japanese3-4.ウェブサーバー(web)を作る(入れる)
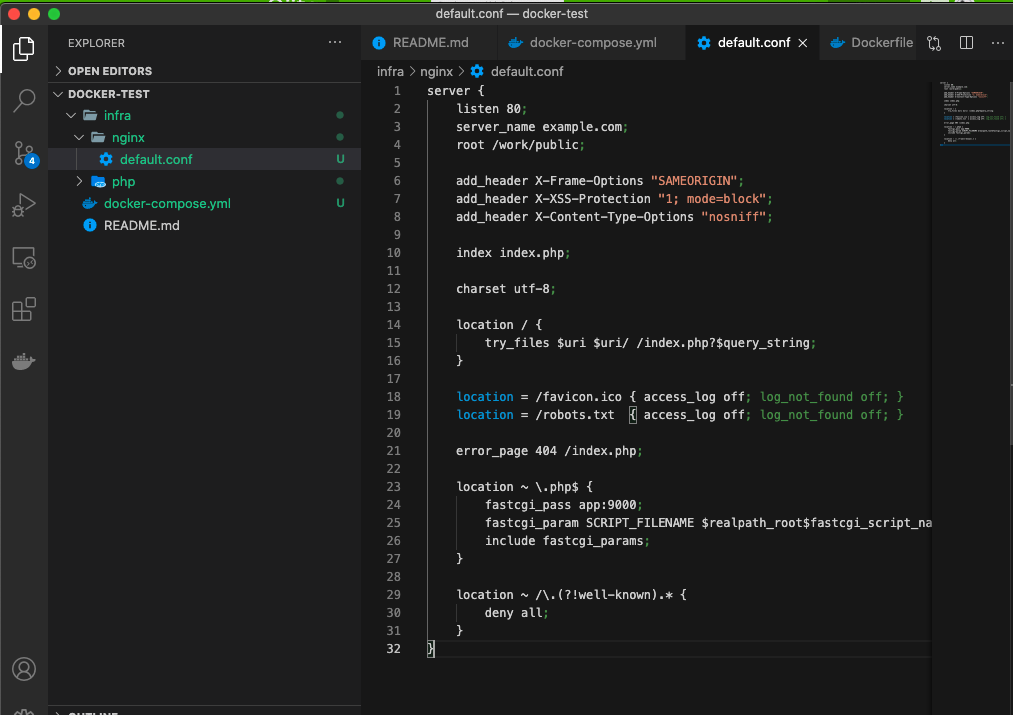
①docker/nginx/default.conf を作成する
MacBook-Pro docker-test % mkdir infra/nginx MacBook-Pro docker-test % touch infra/nginx/default.conf
以下のコードを貼り付ける!!server { listen 80; server_name example.com; root /work/public; add_header X-Frame-Options "SAMEORIGIN"; add_header X-XSS-Protection "1; mode=block"; add_header X-Content-Type-Options "nosniff"; index index.php; charset utf-8; location / { try_files $uri $uri/ /index.php?$query_string; } location = /favicon.ico { access_log off; log_not_found off; } location = /robots.txt { access_log off; log_not_found off; } error_page 404 /index.php; location ~ \.php$ { fastcgi_pass app:9000; fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name; include fastcgi_params; } location ~ /\.(?!well-known).* { deny all; } }3-5.データベース(db)サーバーを作る(入れる)
①./docker/mysql/Dockerfile を作成する
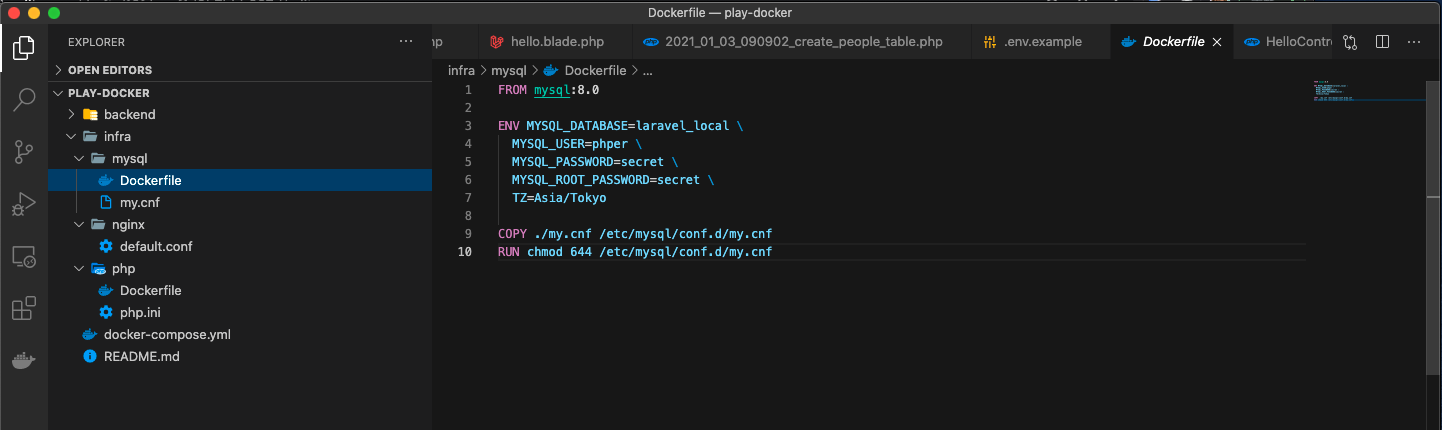
MacBook-Pro docker-test % mkdir infra/mysql MacBook-Pro docker-test % touch infra/mysql/Dockerfile
以下のコードを貼り付ける!
FROM mysql:8.0 ENV MYSQL_DATABASE=sg_db \ MYSQL_USER=sg \ MYSQL_PASSWORD=sg \ MYSQL_ROOT_PASSWORD=sg \ TZ=Asia/Tokyo COPY ./my.cnf /etc/mysql/conf.d/my.cnf RUN chmod 644 /etc/mysql/conf.d/my.cnfここは任意なので好きにしてもらって結構!
データベースを接続するときの名前とパスワードだから
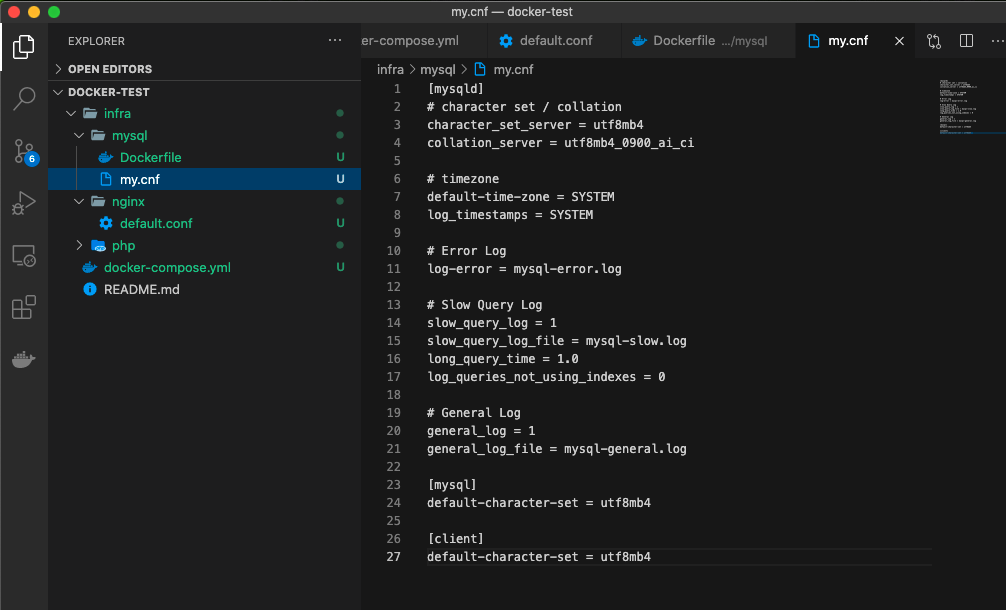
忘れないようにおぼえておこう!MYSQL_USER=sg \ MYSQL_PASSWORD=sg \ MYSQL_ROOT_PASSWORD=sg \②docker/mysql/my.cnf を作成する
MacBook-Pro docker-test % touch infra/mysql/my.cnf
以下のコードを貼り付ける
[mysqld] # character set / collation character_set_server = utf8mb4 collation_server = utf8mb4_0900_ai_ci # timezone default-time-zone = SYSTEM log_timestamps = SYSTEM # Error Log log-error = mysql-error.log # Slow Query Log slow_query_log = 1 slow_query_log_file = mysql-slow.log long_query_time = 1.0 log_queries_not_using_indexes = 0 # General Log general_log = 1 general_log_file = mysql-general.log [mysql] default-character-set = utf8mb4 [client] default-character-set = utf8mb4これで3つのコンテナが完成!!!!しっかり最終的なディレクトリ構成になりましたか???
3-6.Docker起動!(中身の確認)
①dockerを動かしたいときに使うよ!
MacBook-Pro docker-test % docker-compose up -d --build ・・・・ Successfully built 9813d5181de8 Successfully tagged docker-test_db:latest Creating docker-test_app_1 ... done Creating docker-test_db_1 ... done Creating docker-test_web_1 ... done MacBook-Pro docker-test %上の感じにdoneとでたらそれらはOKということ!
・動かした状態でどう動いてるのか確認!MacBook-Pro docker-test % docker-compose ps Name Command State Ports ---------------------------------------------------------------------------------- docker-test_app_1 docker-php-entrypoint php-fpm Up 9000/tcp docker-test_db_1 docker-entrypoint.sh mysqld Up 3306/tcp, 33060/tcp docker-test_web_1 /docker-entrypoint.sh ngin ... Up 0.0.0.0:10080->80/tcpちなみにリスタートしたりしたかったら、一度止めたかったらdown!
MacBook-Pro docker-test % docker-compose down //一度止めたらまた起動しよう MacBook-Pro docker-test % docker-compose up -d --buildDockerに入れたそれぞれサーバー(コンテナ)内に入れたのバージョン確認する方法
・appサーバー
MacBook-Pro docker-test % docker-compose exec app bash //PHPのバージョン確認 root@5ce9c9fa1435:/work# php -V //composerのバージョン確認 root@5ce9c9fa1435:/work# composer -v //インストール済みの拡張機能一覧の確認 root@5ce9c9fa1435:/work# php -m //dockerから出る root@5ce9c9fa1435:/work# exit・webサーバー
MacBook-Pro docker-test % docker-compose exec web nginx -v・DBサーバー
MacBook-Pro docker-test % docker-compose exec db bash //mysqlのバージョン確認 root@6bcf6de7e31e:/# mysql -V //dockerから出る root@6bcf6de7e31e:/work# exitこれでDocker環境構築終了だ!!!さあLaravelを入れてプログラミングしていきます!!!
定期的にGitコミットはしていったほうがよいですよ!
MacBook-Pro docker-test % git add . MacBook-Pro docker-test % git commit -m "laravel commit" MacBook-Pro docker-test % git push3-7.Laravelをインストールする(appサーバー上でやります)
①appに入って、Laravelをインストール
MacBook-Pro docker-test % docker-compose exec app bash root@5ce9c9fa1435:/work# composer create-project --prefer-dist "laravel/laravel=8.*" . //laravelバージョン確認 root@5ce9c9fa1435:/work# php artisan -V Laravel Framework 8.21.0 root@5ce9c9fa1435:/work# exit②Laravel ウェルカム画面の表示
http://127.0.0.1:10080
にアクセス!!!
・VScode確認するとbackendこんな感じになっているはず!
3-8.プログラミングしてみる!!(html,blade.phpファイルを作って表示できるか確認!)
HTML(.blade.php)を表示してみよう!!MVCモデルで進めていきます!
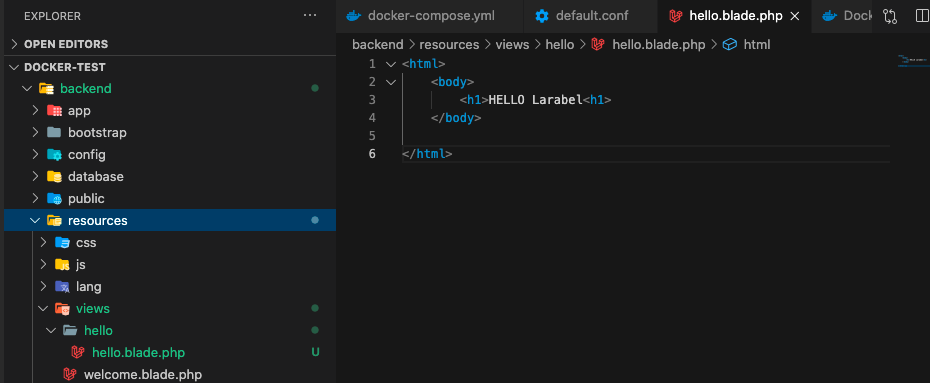
①backend/resources/viewsのなかに
helloディレクトリを作成
helloディレクトリの中にhello.blade.phpを作成
中身はこれとする。貼り付けてOKです!<html> <body> <h1>HELLO Larabel<h1> </body> </html>②URLから呼び出すコントローラーを設定!
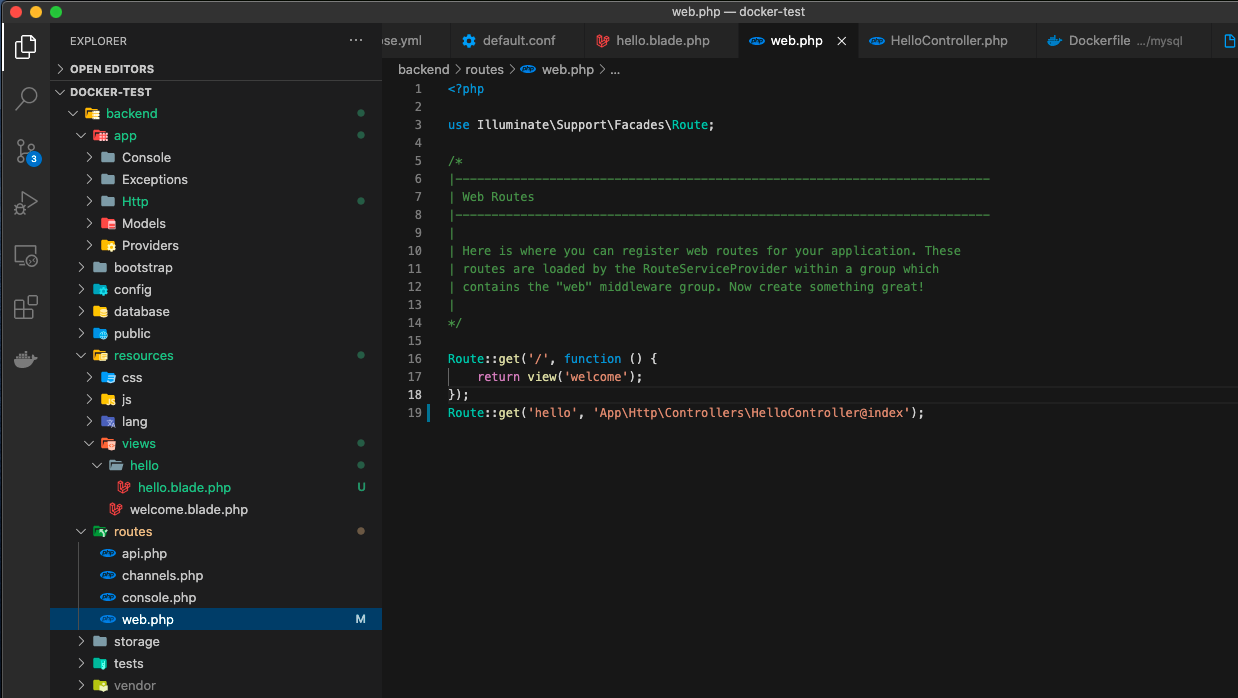
・backend/routes/web.phpを修正
以下のコードをbackend/routes/web.phpに追加する!/// URL/helloのとき「HelloController」を呼び出す Route::get('hello', 'App\Http\Controllers\HelloController@index');③backend/app/http/Controllers/の中に
HelloController.phpを作成する
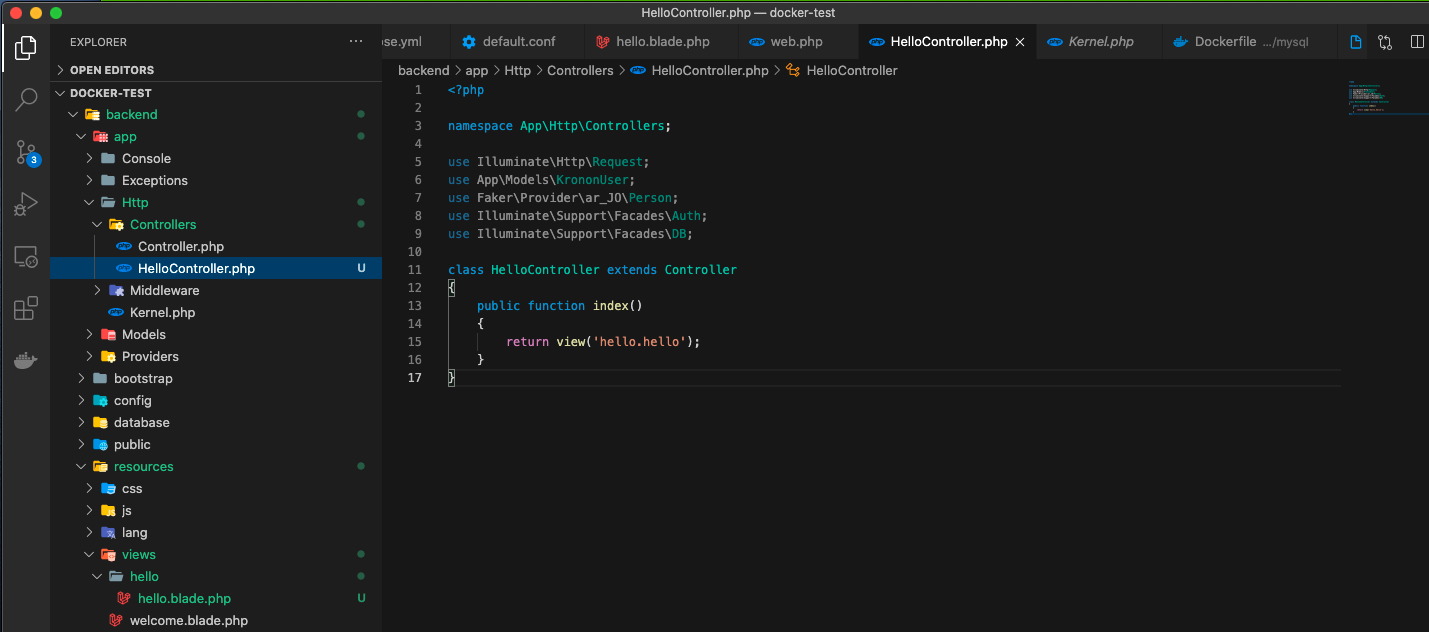
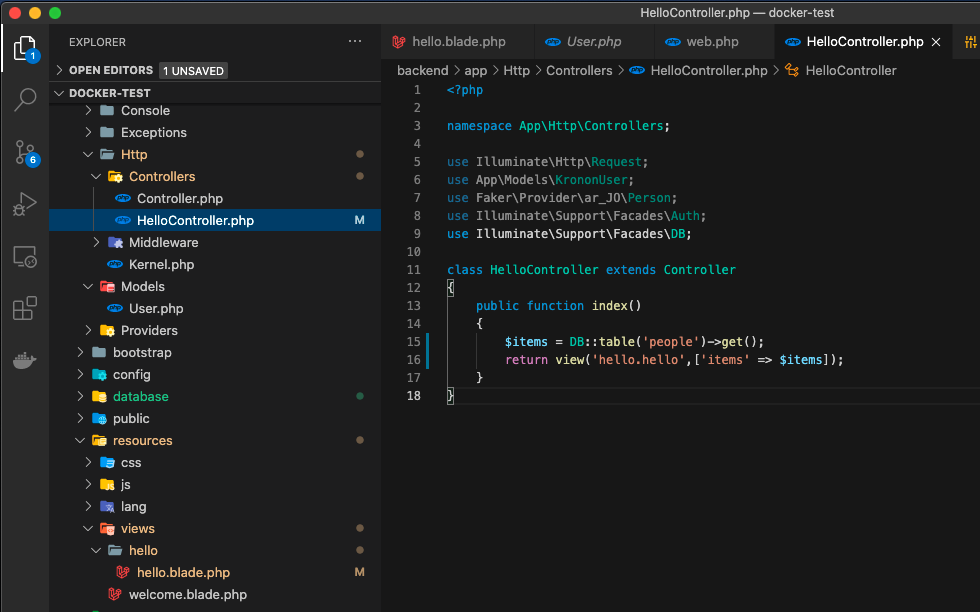
以下のコードをbackend/app/http/Controllers/の中に
HelloController.phpに追加する!<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use App\Models\KrononUser; use Faker\Provider\ar_JO\Person; use Illuminate\Support\Facades\Auth; use Illuminate\Support\Facades\DB; class HelloController extends Controller { public function index() { return view('hello.hello'); } }④URLにアクセスして表示!!!
http://127.0.0.1:10080/hello
3-9.データベースに接続してみる!!!!
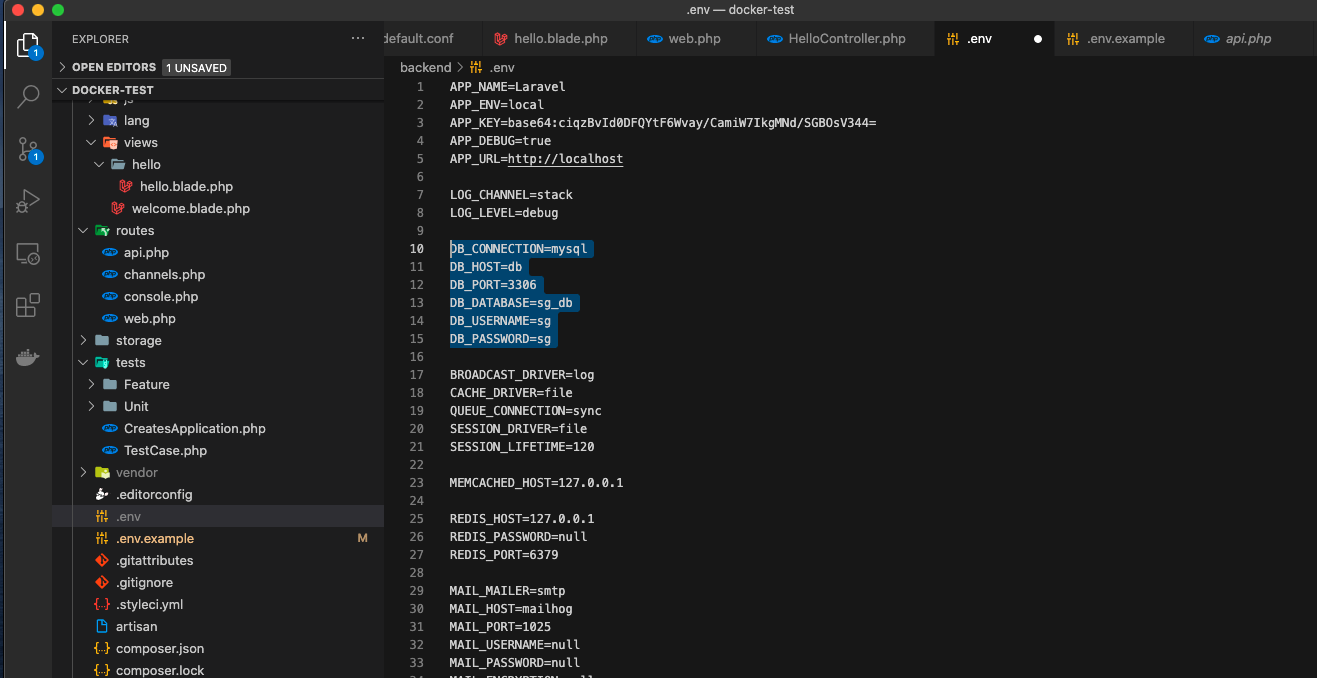
ソースコード上で backend/.env のDB接続設定を修正する。
①以下のコードに変更!!DBサーバー作った時のに合わせながら!DB_CONNECTION=mysql DB_HOST=db DB_PORT=3306 DB_DATABASE=sg_db DB_USERNAME=sg DB_PASSWORD=sg
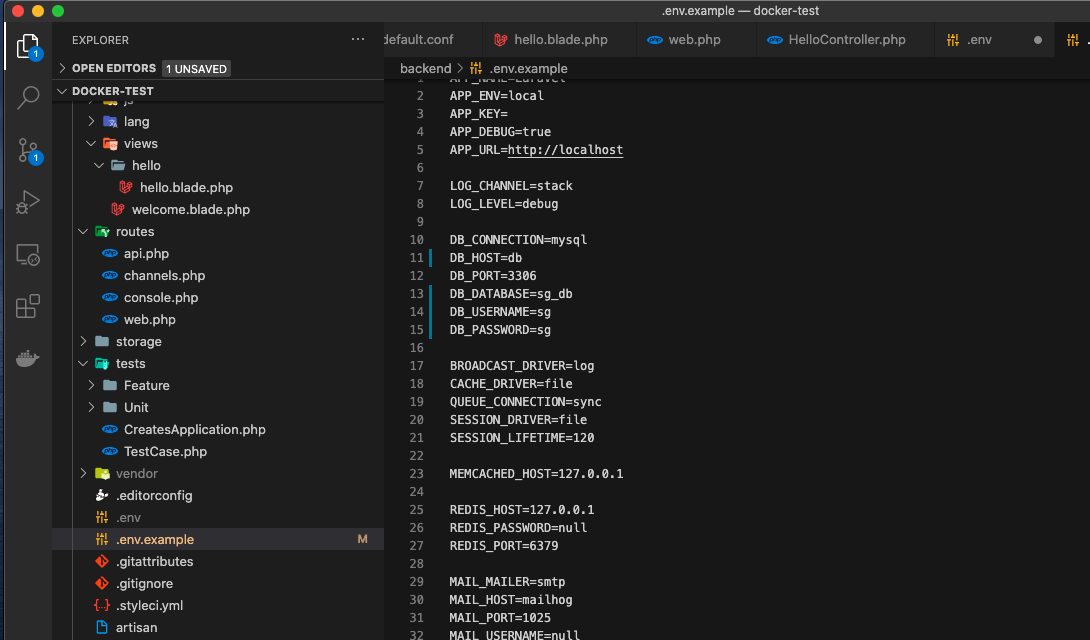
②backend/.env.example も同様に変更するDB_CONNECTION=mysql DB_HOST=db DB_PORT=3306 DB_DATABASE=sg_db DB_USERNAME=sg DB_PASSWORD=sgちなみにgitcloneした際はここからやれば動きます
③Laravelインストール
app コンテナにはいってからいろいろ
MacBook-Pro docker-test % docker-compose exec app bash //コンポーザーをインストールする root@36ffabe3ffc9:/work# composer install //.env.exampleを.envファイルにコピーする root@36ffabe3ffc9:/work# cp .env.example .env //このコマンドでアプリケーションキーを生成できます。 root@36ffabe3ffc9:/work# php artisan key:generate Application key set successfully. //デフォルトで入っているマイグレーションを実行!!デフォルトのテーブルがDBに反映される root@36ffabe3ffc9:/work# php artisan migrate Migration table created successfully. Migration table created successfully. Migrating: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_000000_create_users_table (40.88ms) Migrating: 2014_10_12_100000_create_password_resets_table Migrated: 2014_10_12_100000_create_password_resets_table (37.06ms) Migrating: 2019_08_19_000000_create_failed_jobs_table Migrated: 2019_08_19_000000_create_failed_jobs_table (35.00ms)これでデフォルトですが、DBにテーブルなどが入りました!!
④データベースの確認(デフォルト)
MacBook-Pro docker-test % docker-compose exec db bash //設定したUSERでmysqlにログイン root@d94d20dd2212:/# mysql -u sg -p //設定したPASSWORDを入力.envに書いた!! Enter password: mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | sg_db | +--------------------+ 2 rows in set (0.01 sec) mysql> use sg_db Database changed mysql> show tables; +-----------------+ | Tables_in_sg_db | +-----------------+ | failed_jobs | | migrations | | password_resets | | users | +-----------------+⑤migrationをつくってアプリに反映する!!
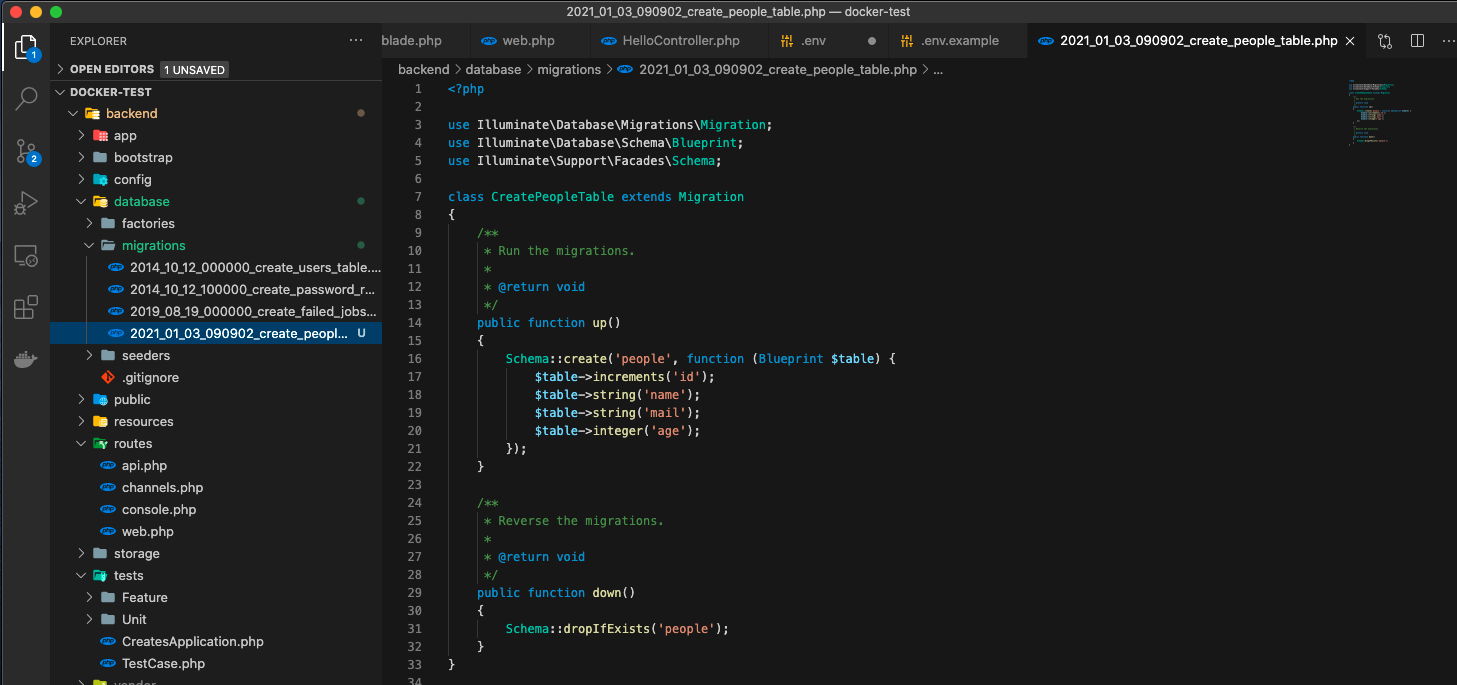
/backend/database/migration/2021_01_03_090902_create_people_table.php
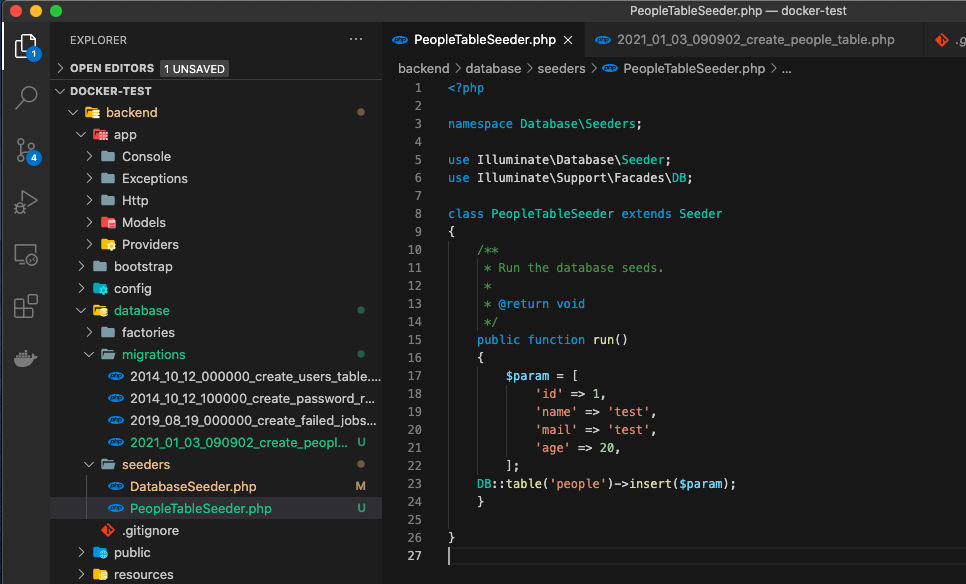
を作成
※/backend/database/migration/の中にデフォルトでいろいろ入っているからそれをコピーすればいいかも!!
以下のコードを貼り付け!<?php use Illuminate\Database\Migrations\Migration; use Illuminate\Database\Schema\Blueprint; use Illuminate\Support\Facades\Schema; class CreatePeopleTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('people', function (Blueprint $table) { $table->increments('id'); $table->string('name'); $table->string('mail'); $table->integer('age'); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('people'); } }⑥migrationを実行(appコンテナ)の中に入って実行!
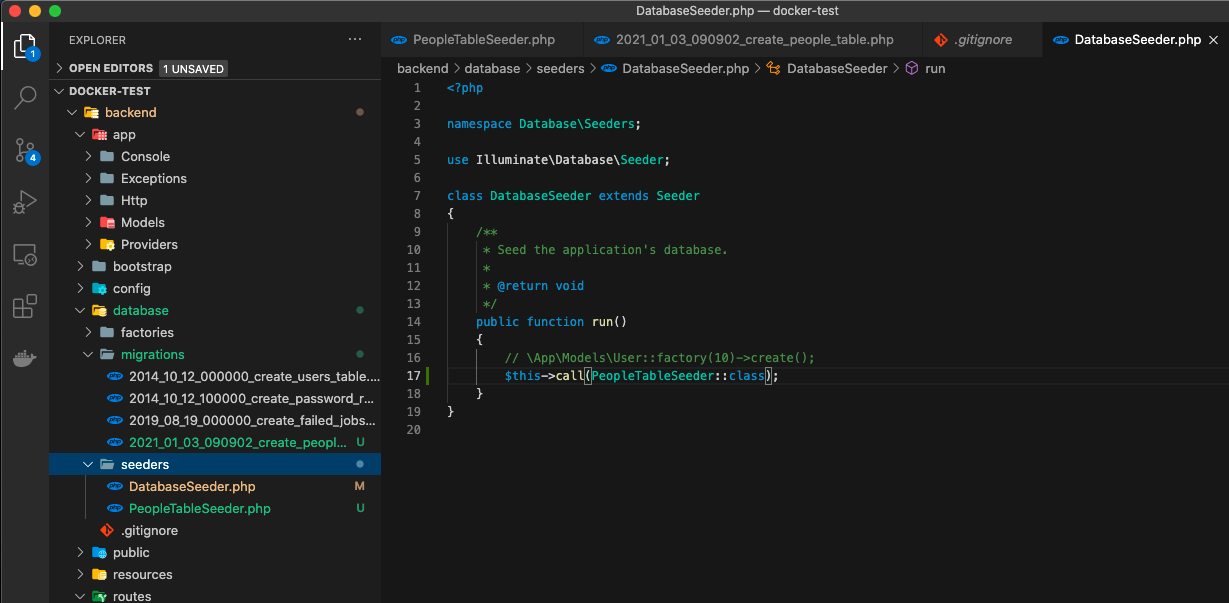
appのなかじゃないとdockerにあるDBコンテナに届かないMacBook-Pro docker-test % docker-compose exec app bash root@36ffabe3ffc9:/work# php artisan migrate Migrating: 2021_01_03_090902_create_people_table Migrated: 2021_01_03_090902_create_people_table (49.03ms)⑦Seederを作成する!!まずはデフォルトにあるDatabaseSeeder.phpから
"Seederとは??"
ダミーデータ。データベースにコマンドを実行するだけでデータを入れられる!!
DatabaseSeeder.phpに以下のソースを貼り付け$this->call(PeopleTableSeeder::class);呼び出される側のPeopleTableSeeder.phpを作成
PeopleTableSeeder.phpに以下のソースを貼り付け<?php namespace Database\Seeders; use Illuminate\Database\Seeder; use Illuminate\Support\Facades\DB; class PeopleTableSeeder extends Seeder { /** * Run the database seeds. * * @return void */ public function run() { $param = [ 'id' => 1, 'name' => 'test', 'mail' => 'test', 'age' => 20, ]; DB::table('people')->insert($param); } }⑧Seederを実行する!
MacBook-Pro docker-test % docker-compose exec app bash root@36ffabe3ffc9:/work# php artisan db:seed Seeding: Database\Seeders\PeopleTableSeeder Seeded: Database\Seeders\PeopleTableSeeder (29.08ms) Database seeding completed successfully.これでテーブルはできたし、ダミーデータもできました!あとはweb上で表示すれば完璧ですね!!
データベースに登録されているデータを表示する
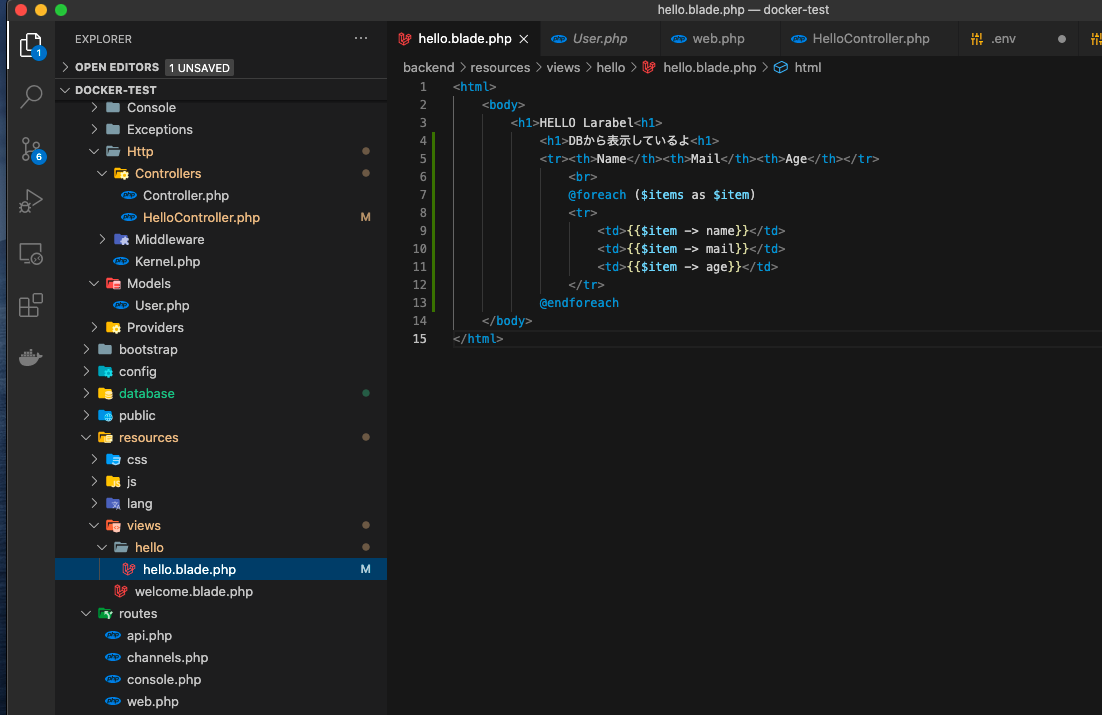
①views/hello.blade.phpを作成
以下のソースhello.blade.phpを変更<html> <body> <h1>HELLO Larabel<h1> <h1>DBから表示しているよ<h1> <tr><th>Name</th><th>Mail</th><th>Age</th></tr> <br> @foreach ($items as $item) <tr> <td>{{$item -> name}}</td> <td>{{$item -> mail}}</td> <td>{{$item -> age}}</td> </tr> @endforeach </body> </html>②Controllers/HelloController.phpを変更
以下のソースに変更する<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use App\Models\KrononUser; use Faker\Provider\ar_JO\Person; use Illuminate\Support\Facades\Auth; use Illuminate\Support\Facades\DB; class HelloController extends Controller { public function index() { $items = DB::table('people')->get(); return view('hello.hello',['items' => $items]); } }③作成したアプリにアクセス!!
http://127.0.0.1:10080/hello
これでDBさきほどSeederでいれたダミーデータが表示されていたら完璧ですね!!!
最後にcommmitして終了!!!MacBook-Pro docker-test % git add . MacBook-Pro docker-test % git commit -m "db complete" MacBook-Pro docker-test % git pushあとはこれを世の中に出すためAWSを使えればOK!!!
次回にご期待!!お疲れ様でした
こういった環境構築かなり疲れますよねーもうへとへとです
全体像を確認したければこちら
【ギリ初心者向け】Laravel Docker AWS(EC2) Webアプリ(PHP)を0から簡単にデプロイする方法(無料)① ー全体像編ー
https://qiita.com/SG_Sg/items/6b8ce48567b6b6602805
次回は③
【ギリ初心者向け】Laravel Docker AWS(EC2) Webアプリ(PHP)を0から簡単にデプロイする方法(無料)③ ーEC2にデプロイ編ー
を予定してます。参考文献
【超入門】20分でLaravel開発環境を爆速構築するDockerハンズオン
https://qiita.com/ucan-lab/items/56c9dc3cf2e6762672f4
↑の方の記事めちゃくちゃわかりやすいし、細かく書いてあるのでこちらも参考にしていただければ
特に最初の初期設定の情報のまとまりがすばらしいです。この記事の上位互換。

- 投稿日:2021-01-11T14:42:04+09:00
【AWS】VPC
インターネットゲートウェイ
サブネット内の他のインスタンスはインターネットに接続できるため、ネットワークACLの設定に問題はない
通信は行きと戻りが必要。インターネットゲートウェイでの通信いおいて、戻りの通信はインスタンスのプライベートIPアドレスではなくパブリックIPv4アドレスまたはElasticIPアドレスが必要セキュリティグループ
・インスタンスの仮想ファイアウォールとして機能し、インバウンドトラフィックとアウトバウンドトラフィックをコントロールする
メモ
◆VPCのサブネットのインスタンスでインターネットアクセスを有効にするには以下を実行する必要がある
・VPCにインターネットゲートウェイをアタッチする
・サブネットのルートテーブルがインターネットゲートウェイにつながっていることの確認
・サブネットのインスタンスに、グローバルに一意なIPアドレス(パブリックIPv4アドレス、ElasticIPアドレス、IPV6アドレス)が割り振られてることの確認
・ネットワークアクセスコントロールとセキュリティグループルールがインスタンス間で関連するトラフィックを許可していることの確認◆インターネットへ接続する手順
1)サブネット作成
2)インターネットゲートウェイをアタッチ
3)カスタムルートテーブルを作成
4)セキュリティグループルール更新
デフォルト設定ではインターネットへのアウトバウンドトラフィックは全て許可しているが、インバウンドトラフィックは全て許可していないため許可する必要がある
5)ElasticIPアドレスを追加◆クラスタープライスメントグループ
・単一のAZ内のインスタンスを論理的にグループ化したもの。
同じリージョン内のピアVPCにまたがることが可能
クラスタープライスメントグループの主な利点は、10Gbpsのフロー制限に加えて、非ブロッキング、非オーバサブスクライブの完全に2分割されている接続であること
つまり、プレイスメントグループ内の全てのノードは、他の全てのノードと対話可能
オーバーサブスクリプションによる遅れなしに10Gbpsフローと25アグリゲートのフルラインレートで行われる
→多数のインスタンスを起動し並列処理を行う際にレイテンシーを低く抑えることが可能
- 投稿日:2021-01-11T14:28:54+09:00
AWS CLIでAWSアカウント間のドメインの移管をする時のパスワードについて
AWS CLIを使うと、あるAWSアカウントから別のAWSアカウントにドメインを移管できます。作業の中で、あるAWSアカウントでまず
transfer-domain-to-another-aws-accountを使って移管準備を行うのですが、このコマンドが出力するpasswordに"|"が含まれていると、次のaccept-domain-transfer-from-another-aws-accountによるコマンドが、正しいパスワードを入れてもpassword is incorrectとなって失敗してしまいます。この時は、いったん
cancel-domain-transfer-to-another-aws-accountを使って移管処理を中止した後に、もう一度transfer-domain-to-another-aws-accountを実行して"|"がpasswordに含まれていないことを確認してから、作業を続けると良いです。
- 投稿日:2021-01-11T13:49:51+09:00
Let's Encrypt SSL化(apache) がQiitaで検索した手順通りで進めても一時ファイル作成するコマンドで落ちる
Apacheサーバーをssl化
Apacheサーバーをssl化したくてググってたらまぁいっぱい記事が出てきてたから、
あーこれ余裕ー ( ´_ゝ`)フーン
とかって思ってたら割と時間溶かしたのでメモ。
問題点
certbotの導入は色々な記事に載ってるので、調べれば素晴らしい記事がいっぱい出てくると思います。自分はこちらを参考にさせていただきました。感謝
記事通り進めたけど。。。
Type: unauthorizedエラーが出る。。。色々な記事で紹介されている通り、こんな感じのコマンドをうつ。
そうすると指定されたドキュメントルート(アプリのメインルート)に一時ファイルが作成されてそのファイルに80番ポートからアクセスできるかを確認してアクセスできたらOKということで認証完了するみたいだけれどもここがなぜかできない。$ certbot certonly –webroot -w [ドキュメントルート] -d [SSLをかけたいドメイン・URL] –email [メールアドレス]しかし!
Type: unauthorizedが出て先に進めない。Domain: mydomain.com Type: unauthorized Detail: Invalid response from http://mydomain.com/.well-known/acme-challenge/rwH-dBrZhXrgii7uiGmccp8GFMOdv1RRRHrBSVfkWuU To fix these errors, please make sure that your domain name was entered correctly and the DNS A/AAAA record(s) for that domain contain(s) the right IP address.解決方法
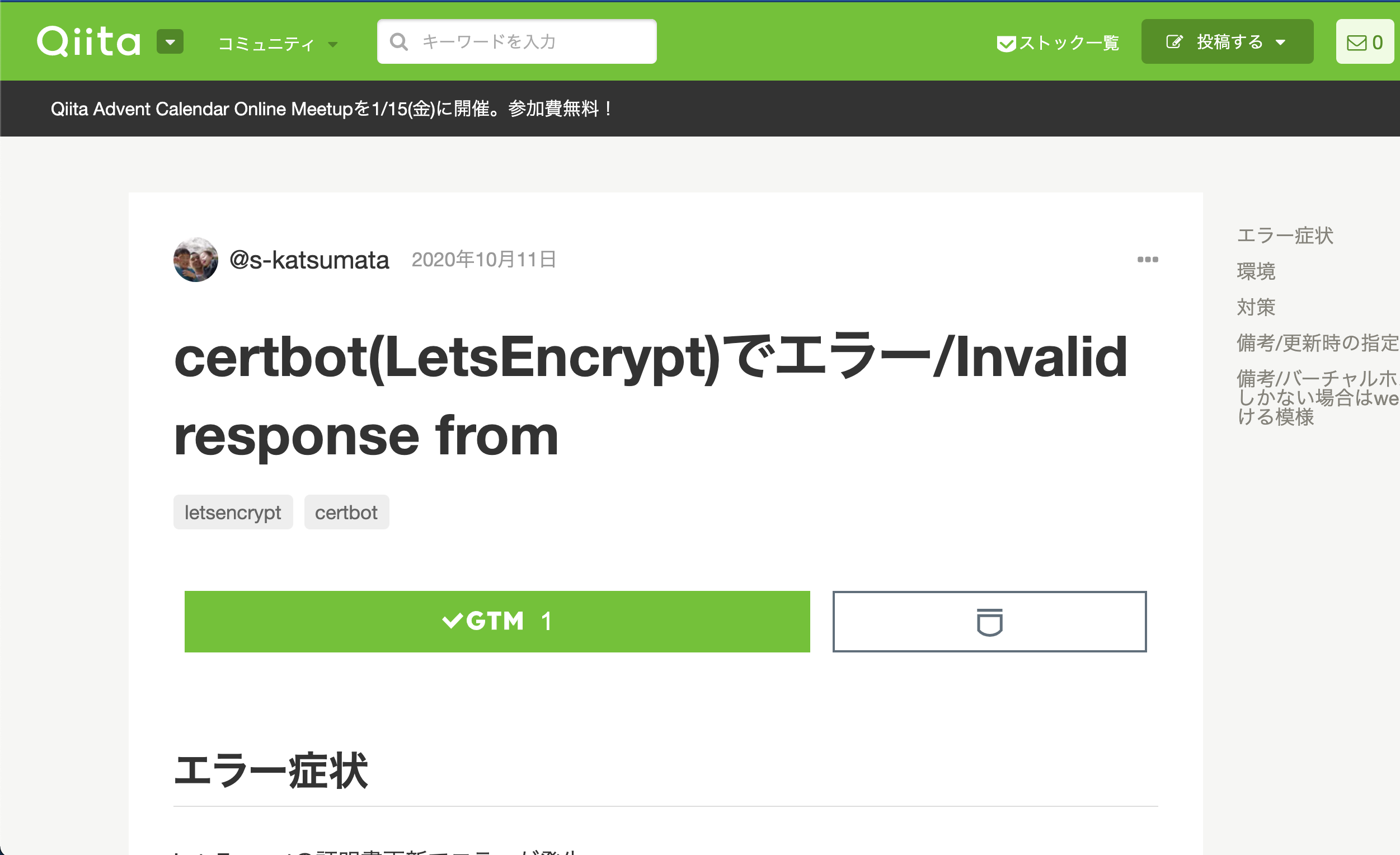
@s-katsumataさんの記事に書いてあったもので解消できました。ありがとうございます。mm
certbot(LetsEncrypt)でエラー/Invalid response from
--webrootでなく--apacheオプションを付与して証明書を再取得するだけ。これだけで本当にいけた!$ certbot certonly --agree-tos --non-interactive -d [ドメイン名] --webroot -w [ドキュメントルートのパス] --email [管理者のメールアドレス]を
certbot certonly --agree-tos --non-interactive -d [ドメイン名] --apache -w [ドキュメントルートのパス] --email [管理者のメールアドレス]に変えたらできました。
LGTM第一号、わーい
個人的にはLGTMってちょっと上から目線なのであまり好きではありませんが、まぁこれしかないので許してください。mm
LGTMをTYFUGQ(Thank You for Your Great Qiita)とかにして欲しい。
なげえかw
じゃあ、THXで(Thank you!/Thanks!!)がいいかな
はてなブログ
こっちでもなんか書いてるよー
勉強したことについてまとめるサイト
- 勉強したことをまとめるだけのサイト、数学、プログラミング、機械学習とか -
https://learn-programing.hatenablog.jp/
- 投稿日:2021-01-11T13:18:54+09:00
Cloud9 環境を用意する
はじめに
AWS Cloud9 は複数の言語をサポートし、AWS SDK、Docker、Git などのツール ( 詳細は こちら ) があらかじめインストールされてる開発環境です。コードサンプルの実行や、ちょっとしたコードを書く環境としてつかったり、開発が終わって運用に入りコードの更新がすくなくなったプロジェクトの環境を構築しておいたりするのもいいかもしれません。
ここでは、VPC を用意し、Systems Manager オプションを使った Cloud9 環境を用意します。
VPC を用意する
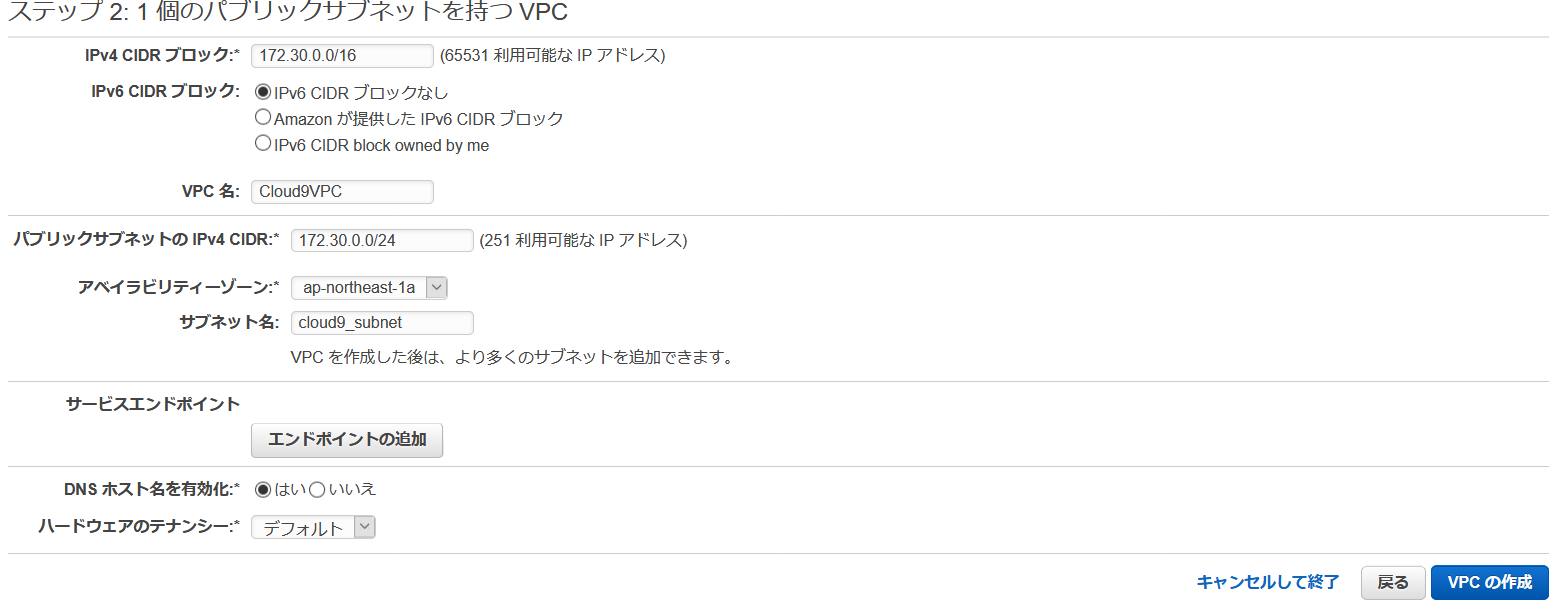
- VPC ダッシュボードを開き、"VPC ウィザードの起動" を選択します。
- "1個のパブリックサブネットを持つ VPC" を選び、"選択" を押します。
- 次のプロパティを入力し、"VPC の作成" を押します。
- IPv4 CIDR ブロック - 172.30.0.0/16
- IPv6 CIDR ブロック - IPv6 CIDR ブロックなし
- VPC 名 - Cloud9VPC
- パブリックサブネットの IPv4 CIDR - 172.30.0.0/24
- アベイラビリティーゾーン - ap-northeast-1a
- サブネット名 - cloud9_subnet
- VPC が正常に作成されました という画面がでるので、"OK" を押してください。
Cloud9 環境を用意する
- Cloud9 コンソールを開き、"Create environment" を選択します。
- Name に
SampleCloud9と入力して "Next Step" を押します。- Configure settings 画面で以下のプロパティを入力して "Next Step" を押します。
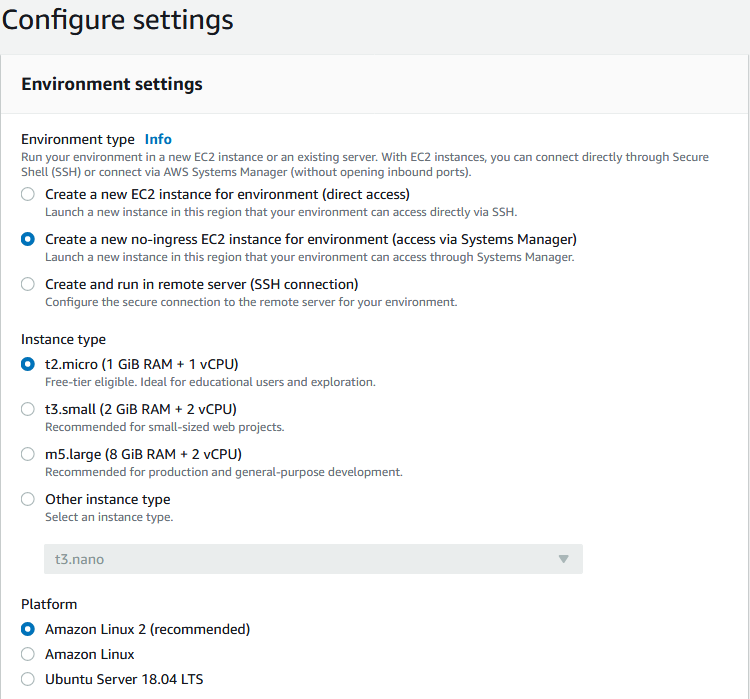
- Environment type -
Create a new no-ingress EC2 instance for environment (access via Systems Manager)- Instance type -
t2.micro (1 GiB RAM + 1 vCPU)- Platform -
Amazon Linux 2 (recommended)- Cost-saving setting -
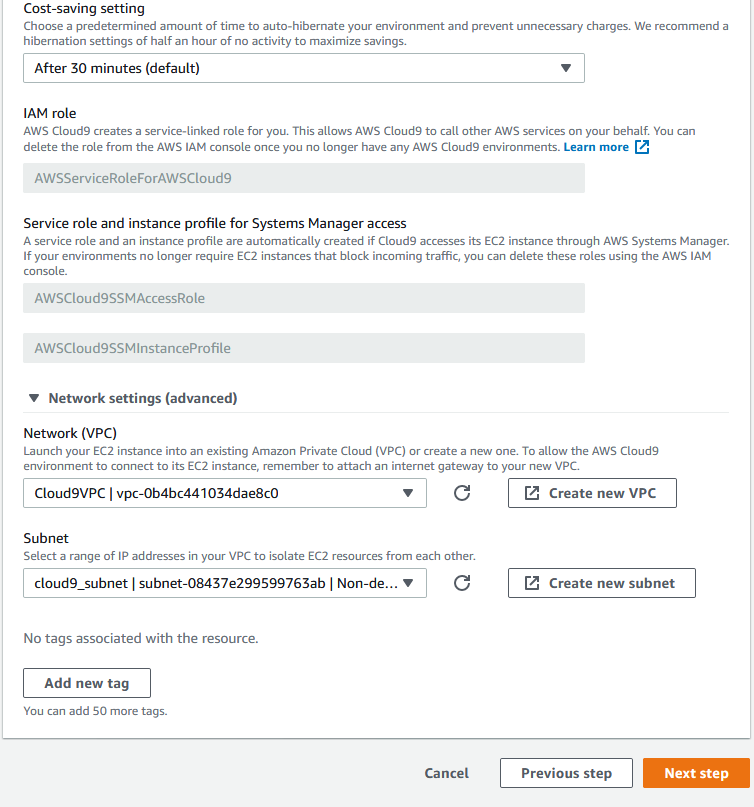
After 30 minutes (default)- Network settings - VPC 、Subnet にさきほど作成した
Cloud9VPC、cloud9_subnetを選択します。
- Review 画面に変わります。
Create environmentを押してください。Cloud9 環境の構築がはじまり、しばらくした後に Cloud9 が立ち上がります。
補足
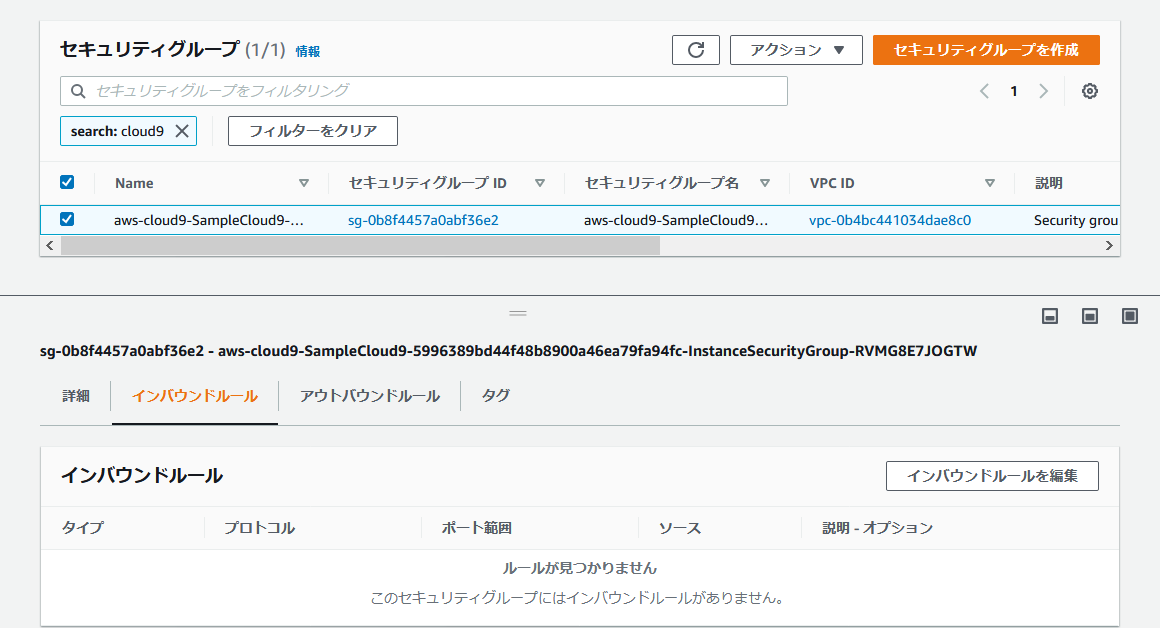
今回、Cloud9 の環境をパブリックサブネットに作成しましたが、作成した EC2 インスタンスのセキュリティグループを確認するとインバウンドが閉じられているので、Configure settings で Environment type を
access via Systems Managerオプションを使った時の方がdirect accessオプションを使った時よりもセキュリティが安全なことが分かります。
Cloud9 の環境をプライベートサブネットでも作成できますが、その場合 Cloud9 IDE から AWS CLI の実行に制約が生じるようです。
参考

- 投稿日:2021-01-11T10:29:04+09:00
【ruby on rails + Mysql】herokuからAWSに切り替える際のデータ移行手順メモ
内容
ruby on railsで作成したアプリケーションの本番環境をherokuからAWSに移行する際のデータ移行について備忘録として書き残す。
実際には本番稼働後にサーバー環境を移すというのはリスクと手間ばかりかかって悪手だとは思うのですが、個人開発なのでお許しを・・。
環境
・ruby 2.7.1
・Rails 6.0.3.2
・mysql 5.7以下のような形でAWSインフラを構築していることを想定
heroku側:clearDB(Mysql)からデータのエクスポート
※本番環境の場合は、タイムラグによるデータ欠落等を防ぐため、一時的にサーバーを停止する等の措置が必要かと。詳しくはチームの方針に従ってください。ここではタイトル通りデータ移行の手順についてのみ記載します。
データベースURL取得
$heroku config --app アプリ名 | grep DATABASE_URL CLEARDB_DATABASE_URL: mysql://<USER_NAME>:<PASSWORD>@< HOST >/<DB_NAME>?reconnect=trueデータのエクスポート
データのエクスポートをします。おそらくしばらく時間がかかるため気長に待ちましょう。
カレントディレクトリにdump.sqlが出力されていれば成功です。
mysqldump -uUSER_NAME -pPASSWORD -h HOST -r dump.sql --single-transaction DB_NAME --skip-column-statisticsオプションの内容を軽く説明しておくと、
--single-transaction・・・ダンプ処理をトランザクションで囲む。データの整合性を保つのに有効。MyISAMテーブルが含まれるDBでは別オプションが必要らしい。
--skip-column-statistics・・・mysqldump 8以降でそれ以前 (5.7とか) のMySQLサーバに対してダンプをする際に起こるエラーを回避。詳しくは筆者もよくわからない。。
以下記事参考
https://blog.pinkumohikan.com/entry/mysqldump-disable-column-statisticsmysqldumpのよく使うオプションを書いてくれている記事もあったため、リンクを貼っておきます。
よく使うmysqldumpのオプションと使用例
https://qiita.com/ryounagaoka/items/7be0479a36c97618907fAWS側:EC2へsqlを転送
前提
・ssh接続ができている
・クライアントのssh/configは以下の場合Host myapp HostName IPAddress Port 22 IdentityFile ~/.ssh/myapp_rsa User hoge以下コマンドを叩く
scp 転送元ファイル myapp:/転送先ディレクトリ転送できない場合以下サイト等を参照
http://gallardolp570.hatenablog.com/entry/2014/11/17/205325AWS側:RDSにsqlをインポート
事前に接続先のエンドポイント、ユーザー名、パスワードを確認しておく。
mysql -h エンドポイント -u ユーザー名 -p DB名> dump.sql進捗状況を確認したい場合はパイプで繋ぎpvコマンドをつけると良き
https://qiita.com/hiroq/items/efd8c3580c9c9457c869反映されていればインポート成功です。お疲れ様でした。
見よう見まねの部分も多いため、何か誤り等あればご指摘いただけますと幸いです。参考サイト
http://kayakuguri.github.io/blog/2015/09/10/mysql-postgres-import-export/
https://photo-tea.com/p/aws-ec2-to-rds-csv/
http://gallardolp570.hatenablog.com/entry/2014/11/17/205325
https://qiita.com/hiroq/items/efd8c3580c9c9457c869
https://blog.pinkumohikan.com/entry/mysqldump-disable-column-statistics
- 投稿日:2021-01-11T03:10:58+09:00
[2021Jan] AWS の Windows Server 2016 は専用コンフィグかもしれない
はじめに
AWS で Windows Server 2016 (Datacenter Edition) を使ってみたら .NET Framework アプリでハマりました。起動しません。
結論としては .NET Framework を追いインストールしたら普通に動きました。あ、結論。諸元
AMI
ami-0532b5a8a610e78e0Azure の場合
比較のため Azure でも同じことをしてみましたが、特に何も問題なく同じアプリが動きました。
ポリシーの違いでしょうかね。おわりに
AWS は何らかフットプリント削減してるんじゃないかと思います。そういうの、どっかに書いてありますかね? 制限事項は誰の目にも触れるところに書かないとダメですよねぇ。
というか、クラウドイメージ類も、開発用と実行用とで分けたらいいんじゃないでしょうかね。
- 投稿日:2021-01-11T02:24:38+09:00
Amazon Athenaに入門してみた(Terraformで構築)
概要
Amazon Athena を利用する機会があったので、入門した際に学んだことを記載したいと思います。
また、AthenaはTerraformで構築しました。サンプルコードもあります。試したことは下記の通りです。
- TerraformでAthenaを構築
- JSONのデータにSQLを実行できる設定
- Partition Projectionの設定
- クエリの実行
- Nested JSONにクエリを実行する
- パーティションの指定
想定読者
- Amazon Athenaに入門したい人
- Amazon AthenaをTerraformで構築したい人
ソースコード
Terraformで構築したサンプルコードです。
https://github.com/kobayashi-m42/terraform-aws-athena-sampleAmazon Athenaとは
AthenaはS3にあるデータ(およびさまざまなデータソース)に対して標準SQLを利用して簡単に分析可能とするインタラクティブなクエリサービスです。
AthenaはS3のデータに直接SQLを実行できるサーバレスな分析サービスであるため、インフラ管理が不要であり簡単に導入することができます。
簡単にログの分析などユースケースで利用できるかと思います。
Athenaの構築
S3バケットに保存されたJSON形式のログに対して、Athenaを利用してSQLを実行できる環境を構築します。
ログのサンプルは下記の通りです。sample-log{"level":"info","msg":"message0","name":{"first":"first0","last":"last0"},"time":"2021-01-10T18:08:40+09:00"} {"level":"info","msg":"message1","name":{"first":"first1","last":"last1"},"time":"2021-01-10T18:08:41+09:00"} {"level":"info","msg":"message2","name":{"first":"first2","last":"last2"},"time":"2021-01-10T18:08:42+09:00"} {"level":"info","msg":"message3","name":{"first":"first3","last":"last3"},"time":"2021-01-10T18:08:43+09:00"} {"level":"info","msg":"message4","name":{"first":"first4","last":"last4"},"time":"2021-01-10T18:08:44+09:00"} {"level":"info","msg":"message5","name":{"first":"first5","last":"last5"},"time":"2021-01-10T18:08:45+09:00"} {"level":"info","msg":"message6","name":{"first":"first6","last":"last6"},"time":"2021-01-10T18:08:46+09:00"} {"level":"info","msg":"message7","name":{"first":"first7","last":"last7"},"time":"2021-01-10T18:08:47+09:00"} {"level":"info","msg":"message8","name":{"first":"first8","last":"last8"},"time":"2021-01-10T18:08:48+09:00"} {"level":"info","msg":"message9","name":{"first":"first9","last":"last9"},"time":"2021-01-10T18:08:49+09:00"}今回は、Partition Projectionも試したいので、下記の構成でS3バケットに保存します。
それぞれ同じファイルを置いています。日付を指定してSQLを実行できるようにすることを想定しています。s3://<bucket_name>/logs/2020/01/10/sample-log s3://<bucket_name>/logs/2020/01/11/sample-logPartition Projection については公式のドキュメントや下記の記事がわかりやすかったので参考にしてください。
[新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説 | Developers.IOS3 Bucket
事前にS3バケットを2つ作成します。
- ログを保存するためのS3バケット
- Athenaの実行結果を保存するS3バケット
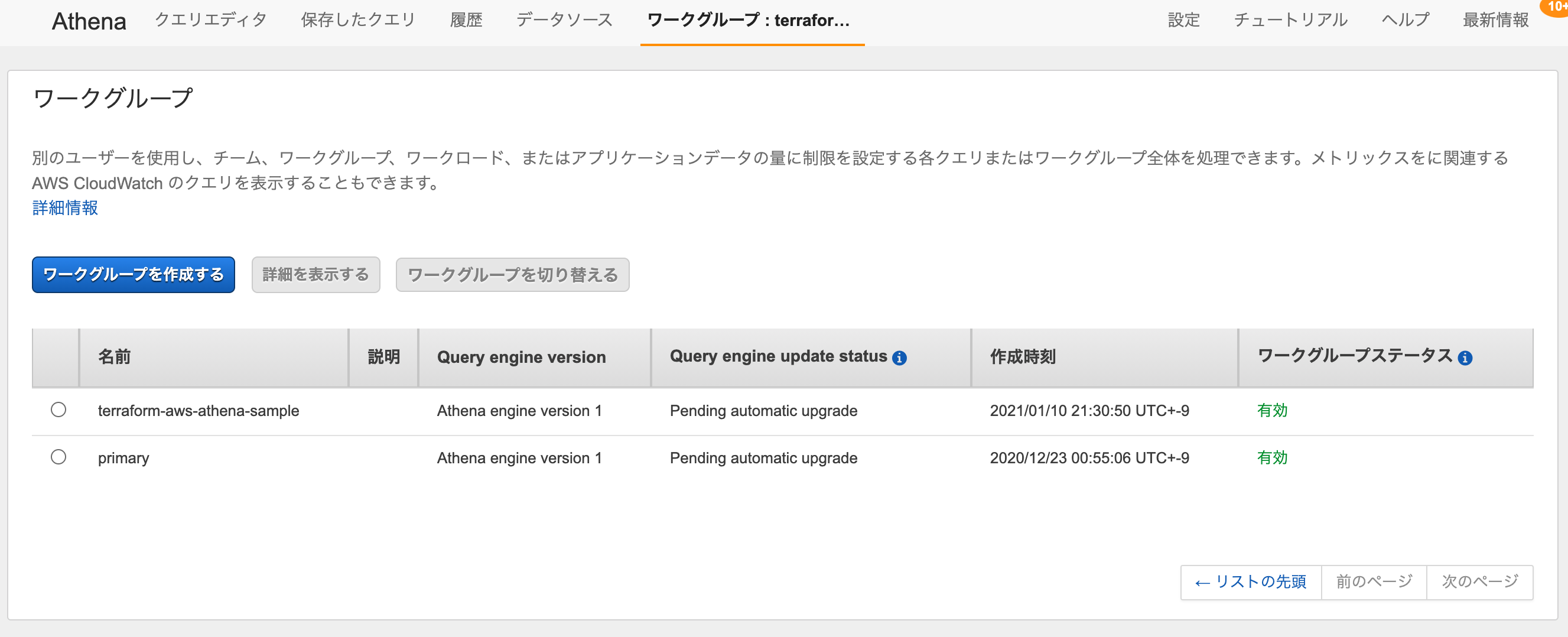
Athena Workgroup
resource "aws_athena_workgroup" "this" { name = var.athena_workgroup_name configuration { enforce_workgroup_configuration = true publish_cloudwatch_metrics_enabled = false result_configuration { output_location = "s3://${var.athena_result_bucket_name}/athena-result/" } } } variable "athena_result_bucket_name" { description = "Athenaの結果を出力するためのS3バケット名" }AWSコンソールから確認すると、Workgroupが作成されています。
Workgroupを利用するためのIAMポリシーを設定することで、特定のWorkgroupの実行権限のみIAMユーザに付与することも可能です。詳細は、下記のドキュメントを参照してください。
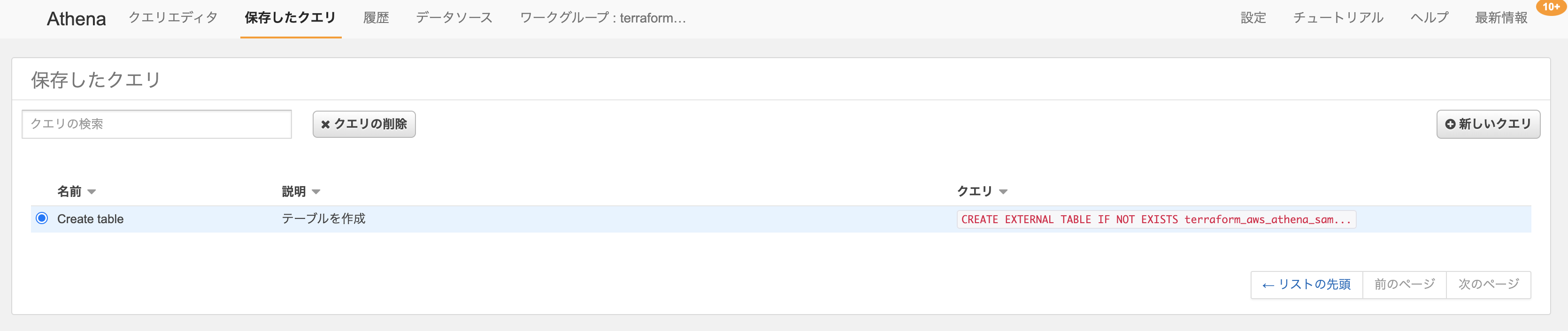
Workgroup Example Policies - Amazon AthenaAthena Database と Athena Named Query
Athennaのデータベースとテーブルを構築します。
Athena Database
resource "aws_athena_database" "this" { name = var.athena_database_name bucket = var.log_bucket_name } variable "log_bucket_name" { description = "ログが保存されているS3バケット名" } variable "athena_database_name" { description = "任意のデータベース名" }Athena Named Query
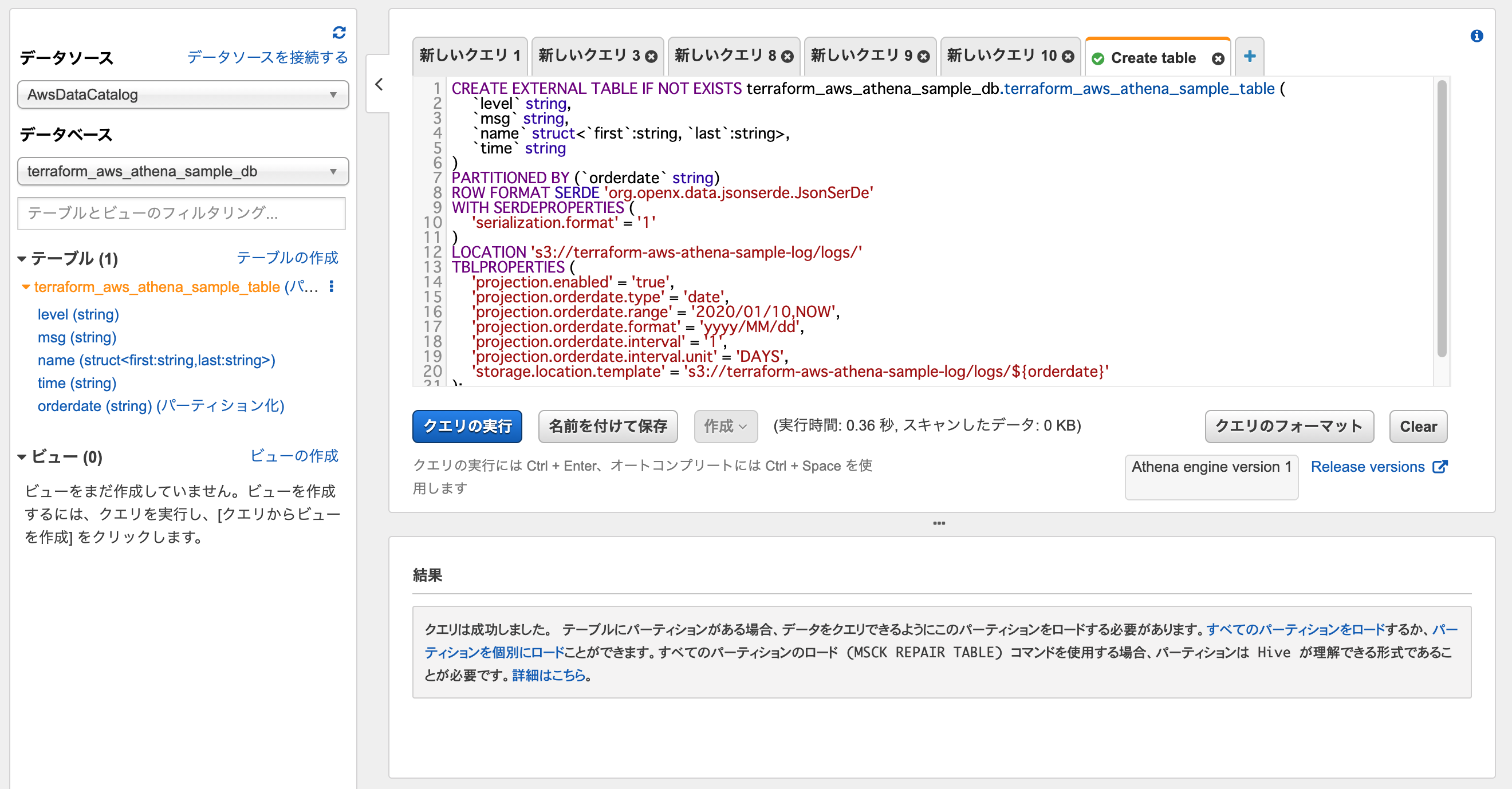
// SQLは別のファイルで定義 data "template_file" "create_table_sql" { template = file("${path.module}/sql/create-table.sql.tpl") vars = { athena_database_name = var.athena_database_name athena_table_name = var.athena_table_name log_bucket_name = var.log_bucket_name } } resource "aws_athena_named_query" "create_table" { name = "Create table" description = "テーブルを作成" workgroup = var.athena_workgroup_name database = var.athena_database_name query = data.template_file.create_table_sql.rendered } variable "athena_workgroup_name" { description = "Athena Workgroup名" } variable "athena_database_name" { description = "任意のデータベース名" } variable "athena_table_name" { description = "任意のテーブル名" }create-table.sql.tplCREATE EXTERNAL TABLE IF NOT EXISTS ${athena_database_name}.${athena_table_name} ( `level` string, `msg` string, `name` struct<`first`:string, `last`:string>, `time` string ) PARTITIONED BY (`orderdate` string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1' ) LOCATION 's3://${log_bucket_name}/logs/' TBLPROPERTIES ( 'projection.enabled' = 'true', 'projection.orderdate.type' = 'date', 'projection.orderdate.range' = '2020/01/10,NOW', 'projection.orderdate.format' = 'yyyy/MM/dd', 'projection.orderdate.interval' = '1', 'projection.orderdate.interval.unit' = 'DAYS', 'storage.location.template' = 's3://${log_bucket_name}/logs/$${orderdate}' );
- Nested JSON形式のログを想定しているため、
name struct<first:string, last:string>のように定義。TBLPROPERTIESでPartition Projectionの設定を追加
- S3には
s3://<bucket_name>/logs/yyyy/MM/ddの形式でログが保存される- 年月日(
yyyy/MM/dd)でパーティションを設定するAWSコンソールから確認すると、クエリが作成されています。
クエリを選択し実行すると、テーブルが作成されます。
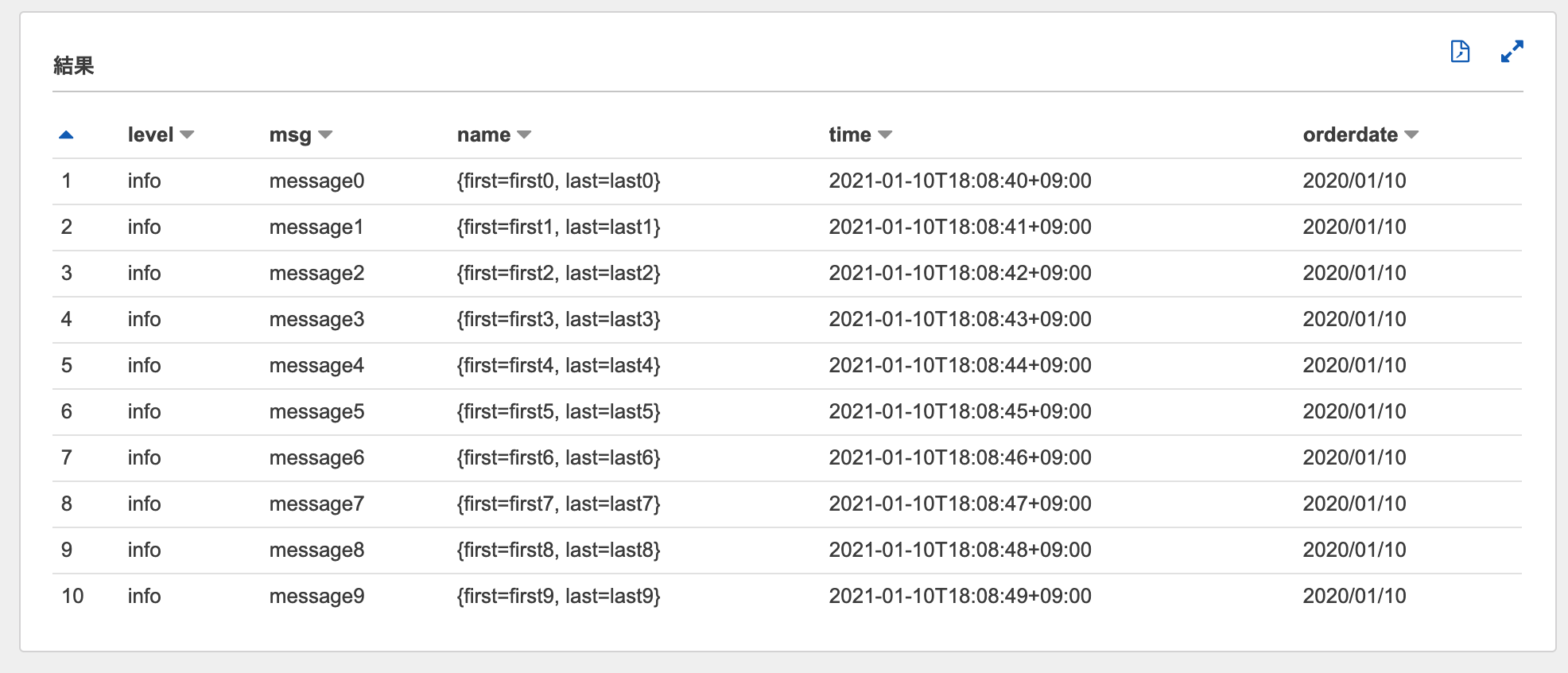
テーブルプレビューを実行すると、クエリの結果が表示されます。
クエリエディタSELECT * FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" limit 10;実行結果
ここで、AWSコンソールからGlueを見てみると、Athenaで構築されたDatabaseとテーブルを確認することができます。
データベース
テーブル
当初、AthenaとGlueの関係性がわからなかったのですが、Black Beltの資料にこのように記載がありました。
Athenaではクエリのために、テーブル定義が必要。デフォルトでは、AWS Glue Data Catalog上のテーブル定義を使用。
AWS Glue Data Catalogは、Apache Hive MetastoreというOSSと互換性のある、メタデータを管理するためのリポジトリ。AWS Glue Data Catalogにテーブル定義を作成する方法は、次の3つ
・ Athena DDL
・ AWS Glue Catalog API
・ AWS Glue Crawler参考:20200617 AWS Black Belt Online Seminar Amazon Athena
上記は「Athena DDL」を利用して、テーブル定義を利用した例でした。
ここからは、「AWS Glue Catalog API」の方法(TerraformのGlueのリソースを利用して)でデータベースとテーブルを作成してみます。Glue Catalog Database と Glue Catalog Table
Glue Catalog Database
resource "aws_glue_catalog_database" "this" { name = var.glue_catalog_database_name } variable "glue_catalog_database_name" { description = "任意のデータベース名" }Glue Catalog Table
resource "aws_glue_catalog_database" "this" { name = var.glue_catalog_database_name } resource "aws_glue_catalog_table" "this" { database_name = aws_glue_catalog_database.this.name name = var.glue_catalog_table_name table_type = "EXTERNAL_TABLE" parameters = { "projection.enabled" = "true" "projection.orderdate.format" = "yyyy/MM/dd" "projection.orderdate.type" = "date" "projection.orderdate.interval" = "1" "projection.orderdate.interval.unit" = "DAYS" "projection.orderdate.range" = "${var.date_range_start},NOW" "storage.location.template" = "s3://${var.log_bucket_name}/logs/$${orderdate}" } storage_descriptor { location = "s3://${var.log_bucket_name}/logs" input_format = "org.apache.hadoop.mapred.TextInputFormat" output_format = "org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat" ser_de_info { serialization_library = "org.openx.data.jsonserde.JsonSerDe" parameters = { "serialization.format" = "1" } } columns { name = "level" type = "string" } columns { name = "msg" type = "string" } columns { name = "name" type = "struct<first:string,last:string>" } columns { name = "time" type = "string" } } partition_keys { name = "orderdate" type = "string" } } variable "glue_catalog_database_name" { description = "任意のデータベース名" } variable "glue_catalog_table_name" { description = "任意のテーブル名" } variable "date_range_start" {}Terraformを実行すると、Athenaのデータベースとテーブルが作成されていることを確認できました。
AWSコンソールでテーブルのプレビューを実行してみると、Athenaリソースで定義したもの同様の結果が表示されています。クエリエディタSELECT * FROM "terraform_aws_athena_sample_glue_db"."terraform_aws_athena_sample_glue_teble" limit 10;実行結果
SQLの実行方法
Nested-JSON の例
ログの一部がNested-JSONになっています。要素名nameの下に、
firstとlastが入れ子になっています。{"level":"info","msg":"message0","name":{"first":"first0","last":"last0"},"time":"2021-01-10T18:08:40+09:00"}
name."last"のようにカラムを指定することができます。またfirstやlastのような予約語はダブルクォートで囲む必要があります。クエリエディタSELECT name."first", name."last" FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" limit 1;実行結果(CSV)"first","last" "first0","last0"絞り込むことも可能です。
クエリエディタSELECT * FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" WHERE name."first" = 'first0' limit 1;実行結果(CSV)"level","msg","name","time","orderdate" "info","message0","{first=first0, last=last0}","2021-01-10T18:08:40+09:00","2020/01/11"パーティションの指定
パーティションを設定しているので、年月日で対象を絞り込むことが可能です。
クエリエディタSELECT * FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" WHERE msg = 'message0' and orderdate = '2020/01/11';
orderdateを指定しなかった場合、結果は2件になります。実行結果(CSV)"info","message0","{first=first0, last=last0}","2021-01-10T18:08:40+09:00","2020/01/11"参考
公式ドキュメント: What is Amazon Athena? - Amazon Athena
[新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説 | Developers.IO
Amazon Athena Nested-JSONのSESログファイルを検索する | Developers.IO



- 投稿日:2021-01-11T00:40:32+09:00
EBSについて
SAAに向けて学習中に間違えた内容について調べまとめる記事①。
個人的備忘録。EBS
ブロックストレージサービス。EC2にアタッチして利用する。
ストレージの違い
ブロックストレージ
EC2にアタッチして使用。ブロック形式でデータを保存。
高速、広帯域幅。
例:EBS、インスタンスストアオブジェクトストレージ
安価かつ、高い耐久性をもつオンラインストレージ。
オブジェクト形式でデータを保存。
デフォルトで複数AZに冗長化されている。
例:S3、Glacierファイルストレージ
複数のEC2インスタンスから同時にアタッチ可能な共有ストレージサービス。
ファイル形式でデータを保存。
例:EFSインスタンスストアとEBSの違い
インスタンスストア
ホストコンピュータに内蔵されたディスクでEC2と不可分のブロックレベルの物理ストレージ。
EC2の一時的なデータが保持され、EC2の停止・終了とともにデータがクリアされる。
無料。EBS
ネットワークで接続されたブロックレベルのストレージでEC2とは独立管理。
EC2を終了してもEBSデータは保持可能。→デフォルトでは削除される設定
snapshotをS3に保持可能。
別途EBS料金が必要。EBSの特徴
- OSやアプリケーションで、データの置き場所など様々な用途で利用される。
- 実態はネットワーク接続型ストレージ
- 99.999%の可用性
- サイズは1GB~16TB
- サイズと利用期間で課金
- ボリュームデータは単一のAZ内で複数HWにデフォルトでレプリケートされており、冗長化不要
- セキュリティグループによる通信制限対象外であり、全てのポートを閉じてもEBS利用可能
- データは永続的に保存
- ひとつのEBSをEC2インスタンスで共有することはできない(プロビジョンドIOPSのみできる)
- 同じAZ内の付け替えは可能
EBSのボリュームタイプ
ユースケース サイズ SSD 汎用SSD 仮想デスクトップ。低レイテンシーを要求するアプリ。中小規模のデータベース。開発環境 1GB~16TB プロビジョンドIOPS 高いI/O性能に依存するNOSQLアプリ。10000IOPSや160MB/sのワークロード大規模DB。EBS最適化インスタンスタイプで高速化 4GB~16TB HDD スループット最適化HDD ビックデータ処理。DWH。大規模なETL処理やログ分析。ルート(ブート)ボリュームには利用不可 500GB~16TB コールドHDD ログデータなどのアクセス頻度が低いデータ。バックアップやアーカイブ。ルート(ブート)ボリュームには利用不可 500GB~16TB マグネティック 旧世代ボリュームタイプで利用しない。データアクセス頻度が低いワークロード 1GB~1TB ミラーリングとは
同じデータを複数のディスクに書き込む(ミラーリング)。信頼性は上がるが、台数を増やしても1台分の容量となるため、効率は悪くなる。
RAIDとは
コンピューターの5大機能のうちの記憶の一部を司る、外部記憶装置「ディスク」のこと。(AWSではEBS等のサービスを指す)
主記憶装置に比べるとアクセス速度が遅い。
そのためディスクアクセスを早くすること、また冗長化し、対障害性を高めることを目的とした技術のことをいいます。
レベルがいくつかあり、
RAID0はディスクアクセスを高速化するための技術(ストライピング)であり、
残りの1〜6は対障害性を高めるためのミラーリングを中心とした技術です。
レベル 概要 0 データをブロック単位で複数のディスクに分散して記録(ストライピング)する。1台が故障すると全体の故障となるので、信頼性が低下する 1 同じデータを複数のディスクに書き込む(ミラーリング)。信頼性は上がるが、台数を増やしても1台分の容量となるため、効率は悪くなる。 3 データをバイト単位でストライピングし、1台をエラー訂正用のパリティ情報記録用として固定する。パリティ情報からデータを復旧することができる 5 RAID3からパリティ情報に関してもブロック単位に分散して記録する スナップショットの特徴
EBSはスナップショットでバックアップする。
スナップショットからEBSを復元する。別AZにも可能。
スナップショットの二世代目以降は増分バックアップ。
スナップショット作成時に圧縮され保管される。その容量に応じて課金される。
スナップショットの作成時は静止点を設けて作成することを推奨している。
世代管理はAWSCLIやAPI等で自動化する
DLMを利用してスナップしょっ値取得をスケジューリングできる。
別リージョンを跨いで利用することもできる(別リージョンにコピーして使用)
別アカウントにも権限を以上することによることでスナップショットを利用可能。AMIとスナップショットの違い
- AMI ECインスタンスのOS設定などをイメージとして保持して、新規インスタンス設定に転用するもの
- スナップショット ストレージ・EBSのその時点の断面バックアップとして保持するもの。復元、複製に使用。
参考
https://qiita.com/tomiyama0119/items/d70861b4634378d763fb
https://www.udemy.com/course/aws-associate/