- 投稿日:2021-01-10T19:09:58+09:00
Tensorflowで自作のデータセットで学習する
Keras公式のデータセットの構造を確認
testfashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()ダウンロードすると実体は下記に保存される
~/.keras/datasets/fashion-mnist/自作データセット用の画像を準備する
Jpegで手頃な大きさのものを用意
用意した画像を読み込んで、学習できる配列にする
4枚の画像を読み込んでみる。
np.arrayで変換しなきゃいけないのはみんなハマるようなので要注意!エラーの例ValueError: Failed to find data adapter that can handle input: <class 'numpy.ndarray'>, (<class 'list'> containing values of types {"<class 'int'>"})#ラベル train_labels = [0, 0, 1, 1] train_labels = np.array(train_labels) #np.array形式にしないと読み込めないので #画像を読み込む train_images = [] for i in range(4): print("/img/img"+str(i+1)+".jpeg") img_path = "/img/img"+str(i+1)+".jpeg" img_raw = tf.io.read_file(img_path) img_tensor = tf.image.decode_image(img_raw) img_final = tf.image.resize(img_tensor, [28, 28]) img_gray = tf.image.rgb_to_grayscale(img_final) img_squeeze = tf.squeeze(img_gray) train_images.append(img_squeeze) #配列に追加していく train_images = np.array(train_images) #np.array形式にしないと読み込めないので train_images = train_images / 255.0あれ、、あんまり正しく判定できてない。学習データがよくないかも。。
画像処理で二値化とか、境界線くっきりとかした方がよいか。出力層が2だと判定ミス、10だと正解。ただ差が明確についてない。
- 投稿日:2021-01-10T18:09:41+09:00
TensorFlowとCameraXでリアルタイム物体検知Androidアプリ
今回やること
CameraXとTensorflow liteを使ってリアルタイムに物体検知するアプリをcameraXの画像解析ユースケースを使ってサクッと作っていきます。
(注: CameraXの実装は1.0.0-rc01のものです。)
GitHubリポジトリを今記事最下部に載せてますので適宜参照してください。
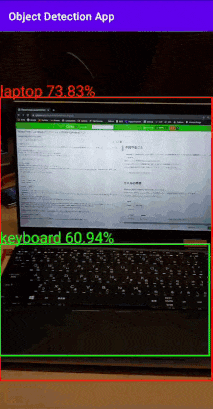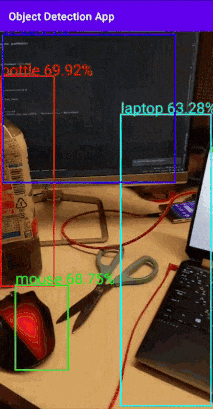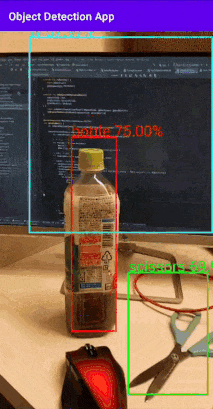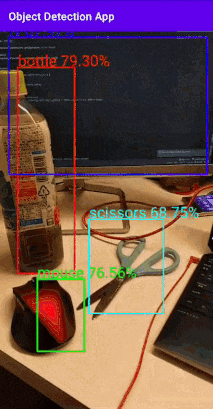
ちょっと長めなのでとりあえず試したい方はリポジトリを見てください。こんな感じのもの作っていきます↓
バウンディングボックスとスコアを表示するものです
モデルの用意
物体検知に使用する訓練済みモデルを探してとってきます。
今回はTensorFlow Hub のssd_mobileNet_v1を使用します。tfliteモデルをダウンロードします。
ssd_mobileNet_v1はこんな感じのモデルです。
input shape 300 x 300 color channel 3
output sahpe location [1, 10, 4] バウンディングボックス category [1, 10] カテゴリラベルのインデックス (91クラスのcoco_datasetで学習したモデルです) score [1, 10] 検出結果のスコア number of detection [1] 検出した物体の数(今回のモデルは10で一定) TensorFlow Hubにはほかにも色々訓練済みモデルがあるので好きなものを選んでください。
ただ、input sizeが大きいものはパラメータ数が多くAndroidだと推論に時間がかかるので注意が必要です。
また、場合によってはtfliteモデルを自分でエクスポートする必要がある場合もあります。今回はそのままモデルを使いますが、
Tensorflow APIとか使って転移学習させるのも面白そうですね。Android Studio で実装
gradle
Tensorflow lite APIとCameraX、カメラ権限用にpermission dispatcherの依存関係を追加します。
build.gradle// permissionDispatcher implementation "org.permissionsdispatcher:permissionsdispatcher:4.7.0" kapt "org.permissionsdispatcher:permissionsdispatcher-processor:4.7.0" // cameraX def camerax_version = "1.0.0-rc01" implementation "androidx.camera:camera-core:${camerax_version}" implementation "androidx.camera:camera-camera2:$camerax_version" implementation "androidx.camera:camera-lifecycle:$camerax_version" implementation "androidx.camera:camera-view:1.0.0-alpha20" // tensorflow lite implementation 'org.tensorflow:tensorflow-lite:2.2.0' implementation 'org.tensorflow:tensorflow-lite-support:0.0.0-nightly'assetsフォルダの用意
先ほどダウンロードした
.tfliteモデルをAndroid Studioのassetsフォルダに入れます。(assetsはプロジェクト右クリック「New -> Folder -> Assets Folder」で作れます)
検出結果のインデックスをラベルにマッピングするために正解ラベルも用意しておきます。
自分のリポですがこちらからcoco_datasetのラベルをDLして同様にassetsフォルダにtxtファイルを入れてください。これでAndroid Studioのassetsフォルダには
ssd_mobile_net_v1.tfliteとcoco_dataset_labels.txtの2つが入っている状態になったと思います。
CameraXの実装
(注: CameraXの実装は
1.0.0-rc01のものです。)
基本的にはこちらの公式チュートリアルのままやっていくだけです。マニフェストにカメラ権限を追加
AndroidManifest.xml<uses-permission android:name="android.permission.CAMERA" />レイアウトファイルの定義
カメラビューとsurfaceViewを定義します。
バウンディングボックスなどリアルタイムに描写するのでViewではなくsurfaceViewを使用してビューに検出結果を反映させます。activity_main.xml<androidx.constraintlayout.widget.ConstraintLayout //省略// > <androidx.camera.view.PreviewView android:id="@+id/cameraView" android:layout_width="0dp" android:layout_height="0dp" //省略// /> <SurfaceView android:id="@+id/resultView" android:layout_width="0dp" android:layout_height="0dp" //省略// /> </androidx.constraintlayout.widget.ConstraintLayout>MainActivityにcameraXの実装。後からpermissionDispatcherを追加します。
この辺はチュートリアルと一緒なので最新のチュートリアルを参考にしたほうがいいかもしれません。MainActivity.ktprivate lateinit var cameraExecutor: ExecutorService override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) cameraExecutor = Executors.newSingleThreadExecutor() setupCamera() } fun setupCamera() { val cameraProviderFuture = ProcessCameraProvider.getInstance(this) cameraProviderFuture.addListener({ val cameraProvider: ProcessCameraProvider = cameraProviderFuture.get() // プレビューユースケース val preview = Preview.Builder() .build() .also { it.setSurfaceProvider(cameraView.surfaceProvider) } // 背面カメラを使用 val cameraSelector = CameraSelector.DEFAULT_BACK_CAMERA // 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() // TODO ここに物体検知 画像解析ユースケースのImageAnalyzerを実装 try { cameraProvider.unbindAll() // 各ユースケースをcameraXにバインドする cameraProvider.bindToLifecycle(this, cameraSelector, preview, imageAnalyzer) } catch (exc: Exception) { Log.e("ERROR: Camera", "Use case binding failed", exc) } }, ContextCompat.getMainExecutor(this)) } override fun onDestroy() { super.onDestroy() cameraExecutor.shutdown() }とりあえずここまで来たら設定から手動でカメラ権限を許可すればカメラプレビューが見れるはずです。ただ、
surfaceViewはデフォルトでは黒なので画面が黒くなっている場合はいったんsurfaceViewをコメントアウトして確認してください。permission dispatcherの実装
カメラ権限リクエスト用にpermission disptcherを実装します。(手動で権限許可するから別にいいというかたは飛ばしてください)
MainActivity.kt@RuntimePermissions class MainActivity : AppCompatActivity() { // 略 @NeedsPermission(Manifest.permission.CAMERA) fun setupCamera() {...} }各アノテーションを対象クラスとメソッドに追加していったんビルドします。
パーミッションリクエスト用の関数が自動生成されます。先ほどの
setupCameraメソッドを以下のように変更し、権限リクエスト結果からコールされるようにします。
なお、今回は拒否された時などの処理に関しては実装しません。MainActivity.ktoverride fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) cameraExecutor = Executors.newSingleThreadExecutor() //setupCamera() 削除 // permissionDispatcherでsetUpCamera()メソッドをコール setupCameraWithPermissionCheck() } override fun onRequestPermissionsResult( requestCode: Int, permissions: Array<String>, grantResults: IntArray ) { super.onRequestPermissionsResult(requestCode, permissions, grantResults) onRequestPermissionsResult(requestCode, grantResults) }これでカメラのプレビュー関連については実装完了です。
続いて、画像解析ユースケースやモデル読み込み、結果の表示などを実装します。モデル読み込み関数の実装
tfliteモデルの読み込みや正解ラベルをassetsから読み込む関数をMainActivityに実装します。
特に難しいこともしていないのでコピペでokです。MainActivity.ktcompanion object { private const val MODEL_FILE_NAME = "ssd_mobilenet_v1.tflite" private const val LABEL_FILE_NAME = "coco_dataset_labels.txt" } // tfliteモデルを扱うためのラッパーを含んだinterpreter private val interpreter: Interpreter by lazy { Interpreter(loadModel()) } // モデルの正解ラベルリスト private val labels: List<String> by lazy { loadLabels() } // tfliteモデルをassetsから読み込む private fun loadModel(fileName: String = MainActivity.MODEL_FILE_NAME): ByteBuffer { lateinit var modelBuffer: ByteBuffer var file: AssetFileDescriptor? = null try { file = assets.openFd(fileName) val inputStream = FileInputStream(file.fileDescriptor) val fileChannel = inputStream.channel modelBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, file.startOffset, file.declaredLength) } catch (e: Exception) { Toast.makeText(this, "モデルファイル読み込みエラー", Toast.LENGTH_SHORT).show() finish() } finally { file?.close() } return modelBuffer } // モデルの正解ラベルデータをassetsから取得 private fun loadLabels(fileName: String = MainActivity.LABEL_FILE_NAME): List<String> { var labels = listOf<String>() var inputStream: InputStream? = null try { inputStream = assets.open(fileName) val reader = BufferedReader(InputStreamReader(inputStream)) labels = reader.readLines() } catch (e: Exception) { Toast.makeText(this, "txtファイル読み込みエラー", Toast.LENGTH_SHORT).show() finish() } finally { inputStream?.close() } return labels }画像解析ユースケースの実装
メインの物体検知の推論パイプラインを実装していきます。
CameraXの画像解析ユースケースを利用することでより手軽に実装できるようになりました。(数行で実装できるというわけではないですが。。。)
チュートリアルでは画素値の平均をとったりしています。cameraXで用意されている
ImageAnalysis.Analyzerを実装しカメラのプレビューを受け取り、解析結果を返すようなObjectDetectorクラスを作ります。
typealiasでコールバックとして解析結果を受け取れるように定義します。ObjectDetector.kttypealias ObjectDetectorCallback = (image: List<DetectionObject>) -> Unit /** * CameraXの物体検知の画像解析ユースケース * @param yuvToRgbConverter カメラ画像のImageバッファYUV_420_888からRGB形式に変換する * @param interpreter tfliteモデルを操作するライブラリ * @param labels 正解ラベルのリスト * @param resultViewSize 結果を表示するsurfaceViewのサイズ * @param listener コールバックで解析結果のリストを受け取る */ class ObjectDetector( private val yuvToRgbConverter: YuvToRgbConverter, private val interpreter: Interpreter, private val labels: List<String>, private val resultViewSize: Size, private val listener: ObjectDetectorCallback ) : ImageAnalysis.Analyzer { override fun analyze(image: ImageProxy) { //TODO 推論コードの実装 } } /** * 検出結果を入れるクラス */ data class DetectionObject( val score: Float, val label: String, val boundingBox: RectF )MainActivityの「TODO ここに物体検知 画像解析ユースケースのImageAnalyzerを実装」の部分を以下のように書き換えます。
MainActivity.kt// 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() .also { it.setAnalyzer( cameraExecutor, ObjectDetector( yuvToRgbConverter, interpreter, labels, Size(resultView.width, resultView.height) ) { detectedObjectList -> // TODO 検出結果の表示 } ) }各コンストラクタ変数についてはコメントを参照してください。
ここでYuvToRgbConverterがエラーになっていると思いますが今から説明しますので大丈夫です。
ImageAnalysis.Analyzerインターフェースのanalyzeメソッドを実装していくのですが、ここでanalyzeメソッドの引数にImageProxyという型でカメラのプレビュー画像が流れてきます。
このImageProxyをbitmapやtensorに変換しないと推論とかができないのですが、これがちょっと面倒なんです。。。
ImageProxyの中にはandroid.Media.Imageが入っており画像ピクセルデータを一つもしくは複数のPlaneとしてグルーピングして保存しています。アンドロイドのカメラではYUV_420_888という形式でImageが生成されるのでこれをRGB bitmapに変換するコンバーターを作る必要があります。確か、pytorch mobileにはコンバーターが用意されていた気がしますが、tensorflowにはありませんでした。リポジトリあさってたらcameraXのサンプルにソースがあったので今回はそれを使用します。(自分で実装するのもありですが)
ということで
この公式サンプルのコンバータをコピーしてYuvToRgbConverterクラスを作って、MainActivityにそのインスタンスを以下のように追加してください。MainActivity.kt// カメラのYUV画像をRGBに変換するコンバータ private val yuvToRgbConverter: YuvToRgbConverter by lazy { YuvToRgbConverter(this) }モデル関連の変数定義
モデルのinput画像サイズや結果を受け取るための変数を先ほどの
ObjectDetectorクラスに定義します。使用するモデルのshapeに合わせる必要があります。ObjectDetector.ktcompanion object { // モデルのinputとoutputサイズ private const val IMG_SIZE_X = 300 private const val IMG_SIZE_Y = 300 private const val MAX_DETECTION_NUM = 10 // 今回使うtfliteモデルは量子化済みなのでnormalize関連は127.5fではなく以下の通り private const val NORMALIZE_MEAN = 0f private const val NORMALIZE_STD = 1f // 検出結果のスコアしきい値 private const val SCORE_THRESHOLD = 0.5f } private var imageRotationDegrees: Int = 0 private val tfImageProcessor by lazy { ImageProcessor.Builder() .add(ResizeOp(IMG_SIZE_X, IMG_SIZE_Y, ResizeOp.ResizeMethod.BILINEAR)) // モデルのinputに合うように画像のリサイズ .add(Rot90Op(-imageRotationDegrees / 90)) // 流れてくるImageProxyは90度回転しているのでその補正 .add(NormalizeOp(NORMALIZE_MEAN, NORMALIZE_STD)) // normalization関連 .build() } private val tfImageBuffer = TensorImage(DataType.UINT8) // 検出結果のバウンディングボックス [1:10:4] // バウンディングボックスは [top, left, bottom, right] の形 private val outputBoundingBoxes: Array<Array<FloatArray>> = arrayOf( Array(MAX_DETECTION_NUM) { FloatArray(4) } ) // 検出結果のクラスラベルインデックス [1:10] private val outputLabels: Array<FloatArray> = arrayOf( FloatArray(MAX_DETECTION_NUM) ) // 検出結果の各スコア [1:10] private val outputScores: Array<FloatArray> = arrayOf( FloatArray(MAX_DETECTION_NUM) ) // 検出した物体の数(今回はtflite変換時に設定されているので 10 (一定)) private val outputDetectionNum: FloatArray = FloatArray(1) // 検出結果を受け取るためにmapにまとめる private val outputMap = mapOf( 0 to outputBoundingBoxes, 1 to outputLabels, 2 to outputScores, 3 to outputDetectionNum )なんだか変数ばっかりで見づらいですが全部必要です。
画像の前処理はtensorflow lite ライブラリのImageProcessorを使用して行います。
各変数の説明はコメントを参照してください。基本的にここで示したモデルinfoをkotlinで定義しています。推論コードの実装
続いてinterpreterを使ってモデルで推論します。
ObjectDetector.kt// 画像をYUV -> RGB bitmap -> tensorflowImage -> tensorflowBufferに変換して推論し結果をリストとして出力 private fun detect(targetImage: Image): List<DetectionObject> { val targetBitmap = Bitmap.createBitmap(targetImage.width, targetImage.height, Bitmap.Config.ARGB_8888) yuvToRgbConverter.yuvToRgb(targetImage, targetBitmap) // rgbに変換 tfImageBuffer.load(targetBitmap) val tensorImage = tfImageProcessor.process(tfImageBuffer) //tfliteモデルで推論の実行 interpreter.runForMultipleInputsOutputs(arrayOf(tensorImage.buffer), outputMap) // 推論結果を整形してリストにして返す val detectedObjectList = arrayListOf<DetectionObject>() loop@ for (i in 0 until outputDetectionNum[0].toInt()) { val score = outputScores[0][i] val label = labels[outputLabels[0][i].toInt()] val boundingBox = RectF( outputBoundingBoxes[0][i][1] * resultViewSize.width, outputBoundingBoxes[0][i][0] * resultViewSize.height, outputBoundingBoxes[0][i][3] * resultViewSize.width, outputBoundingBoxes[0][i][2] * resultViewSize.height ) // しきい値よりも大きいもののみ追加 if (score >= ObjectDetector.SCORE_THRESHOLD) { detectedObjectList.add( DetectionObject( score = score, label = label, boundingBox = boundingBox ) ) } else { // 検出結果はスコアの高い順にソートされたものが入っているので、しきい値を下回ったらループ終了 break@loop } } return detectedObjectList.take(4) }まずcameraXの画像をYUV -> RGB bitmap -> tensorflowImage -> tensorflowBufferと変換していき
interpreterを使って推論します。引数に入れたoutputMapに推論結果が格納されるので定義した各output変数から結果を整形してリストとして返すようなdetect関数を作成します。続いて
analyze関数からこのdetect関数をコールするようにしてObjectDetectorクラスは完成です。ObjectDetector.kt// cameraXから流れてくるプレビューのimageを物体検知モデルに入れて推論する @SuppressLint("UnsafeExperimentalUsageError") override fun analyze(image: ImageProxy) { if (image.image == null) return imageRotationDegrees = image.imageInfo.rotationDegrees val detectedObjectList = detect(image.image!!) listener(detectedObjectList) //コールバックで検出結果を受け取る image.close() }
image.close()は必ず呼ぶ必要があるので注意してください。android.Media.Imageはシステムリソースを食うので開放する必要があります。ここまで実装出来たらが推論パイプラインの実装は完了です。
最後に検出結果の表示を実装します。検出結果の表示を実装
viewの描画がリアルタイムに行われるので
ViewではなくsurfaceViewを使ってバウンディングボックスなどの表示を実装します。
初期化処理をOverlaySurfaceViewクラスを作って適当に書いていきます。
コールバックやsurfaceViewとは?みたいなのはほかの方の記事でたくさん書かれているので割愛します。OverlaySurfaceView.ktclass OverlaySurfaceView(surfaceView: SurfaceView) : SurfaceView(surfaceView.context), SurfaceHolder.Callback { init { surfaceView.holder.addCallback(this) surfaceView.setZOrderOnTop(true) } private var surfaceHolder = surfaceView.holder private val paint = Paint() private val pathColorList = listOf(Color.RED, Color.GREEN, Color.CYAN, Color.BLUE) override fun surfaceCreated(holder: SurfaceHolder) { // surfaceViewを透過させる surfaceHolder.setFormat(PixelFormat.TRANSPARENT) } override fun surfaceChanged(holder: SurfaceHolder, format: Int, width: Int, height: Int) { } override fun surfaceDestroyed(holder: SurfaceHolder) { } }これにバウンディングボックスを表示する
draw関数を作っていきます。OverlaySurfaceView.ktfun draw(detectedObjectList: List<DetectionObject>) { // surfaceHolder経由でキャンバス取得(画面がactiveでない時にもdrawされてしまいexception発生の可能性があるのでnullableにして以下扱ってます) val canvas: Canvas? = surfaceHolder.lockCanvas() // 前に描画していたものをクリア canvas?.drawColor(0, PorterDuff.Mode.CLEAR) detectedObjectList.mapIndexed { i, detectionObject -> // バウンディングボックスの表示 paint.apply { color = pathColorList[i] style = Paint.Style.STROKE strokeWidth = 7f isAntiAlias = false } canvas?.drawRect(detectionObject.boundingBox, paint) // ラベルとスコアの表示 paint.apply { style = Paint.Style.FILL isAntiAlias = true textSize = 77f } canvas?.drawText( detectionObject.label + " " + "%,.2f".format(detectionObject.score * 100) + "%", detectionObject.boundingBox.left, detectionObject.boundingBox.top - 5f, paint ) } surfaceHolder.unlockCanvasAndPost(canvas ?: return) }surfaceHolder経由で取得するcanvasですが、viewがリークする可能性があるのでnullableで扱ってます。
canvasを使ってバウンディングボックス(Rect)と文字を表示しているだけです。あとは、SurfaceViewのコールバックなどをセットするだけです。
MainActity.ktprivate lateinit var overlaySurfaceView: OverlaySurfaceView override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) overlaySurfaceView = OverlaySurfaceView(resultView) // 略 }MainActivityの画像解析ユースケースのコールバック「TODO 検出結果の表示」の部分を以下のように変更します。
MainActivity.kt// 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() .also { it.setAnalyzer( cameraExecutor, ObjectDetector( yuvToRgbConverter, interpreter, labels, Size(resultView.width, resultView.height) ) { detectedObjectList -> // 解析結果の表示 overlaySurfaceView.draw(detectedObjectList) } ) }これで完成です!
いい感じに実装出来ましたか?おわり
cameraXもrcになってもうそろそろかっってみんな思ってるんじゃないでしょうか。ユースケースが色々用意されていてそれに則って実装するとやりやすくて拡張性があるのが魅力ですね。個人的にはもうプロダクトにバンバン投入していってもいいんじゃないかって思ってたり。。