- 投稿日:2021-01-10T23:29:30+09:00
AtCoder Beginner Contest 188 参戦記
AtCoder Beginner Contest 188 参戦記
ABC188A - Three-Point Shot
2分で突破. 書くだけ.
X, Y = map(int, input().split()) if Y < X: X, Y = Y, X if X + 3 > Y: print('Yes') else: print('No')ABC188B - Orthogonality
2分で突破. 書くだけ.
N = int(input()) A = list(map(int, input().split())) B = list(map(int, input().split())) if sum(a * b for a, b in zip(A, B)) == 0: print('Yes') else: print('No')ABC188C - ABC Tournament
7分で突破. N≤16 なので、素直にトーナメントを実行しても O(217) で TLE しないので、素直にやって AC.
N, *A = map(int, open(0).read().split()) a = range(2 ** N) while len(a) != 2: t = [] for i in range(0, len(a), 2): if A[a[i]] > A[a[i + 1]]: t.append(a[i]) else: t.append(a[i + 1]) a = t if A[a[0]] > A[a[1]]: print(a[1] + 1) else: print(a[0] + 1)コンテスト後に、山を真ん中で2つに分けて、一番強いやつがいない側の一番強いやつが準優勝だから、サクッと解けるなと気づいた.
N, *A = map(int, open(0).read().split()) i = A.index(max(A)) if i < 2 ** (N - 1): print(A.index(max(A[:2 ** (N - 1)]) + 1) else: print(A.index(max(A[2 ** (N - 1):]) + 1)ABC188D - Snuke Prime
13分で突破. 問題文を見た瞬間に imos 法一発じゃんラッキーと思ったが bi≤109 を見て憤死した. 辞書で imos 法をするのを脳内シミュレーションしたら全然問題ないことに気づいて驚きつつ AC. 座圧でも良かったらしい. 後で座圧でも解こう.
from sys import stdin readline = stdin .readline N, C = map(int, readline().split()) d = {} for _ in range(N): a, b, c = map(int, readline().split()) d.setdefault(a, 0) d[a] += c d.setdefault(b + 1, 0) d[b + 1] -= c skeys = sorted(d) for i in range(1, len(skeys)): d[skeys[i]] += d[skeys[i - 1]] for k in d: if d[k] > C: d[k] = C result = 0 for i in range(len(skeys) - 1): result += d[skeys[i]] * (skeys[i + 1] - skeys[i]) print(result)追記: 座標圧縮+imos法で解いてみた.
from sys import stdin from itertools import accumulate readline = stdin .readline N, C = map(int, readline().split()) abc = [tuple(map(int, readline().split())) for _ in range(N)] p = set() for a, b, _ in abc: p.add(a) p.add(b) p.add(b + 1) inv = sorted(p) fwd = {} for i in range(len(inv)): fwd[inv[i]] = i t = [0] * len(inv) for a, b, c in abc: t[fwd[a]] += c t[fwd[b + 1]] -= c t = list(accumulate(t)) result = 0 for i in range(len(t) - 1): result += min(t[i], C) * (inv[i + 1] - inv[i]) print(result)追々記: 解説に書かれている方法で解いてみた. うーん、スマート.
from sys import stdin readline = stdin .readline N, C = map(int, readline().split()) q = [] for _ in range(N): a, b, c = map(int, readline().split()) q.append((a, c)) q.append((b + 1, -c)) result = 0 p = 0 ac = 0 for x, y in sorted(q): result += min(C, ac) * (x - p) p = x ac += y print(result)ABC188E - Peddler
67分で突破. WA2. 問題文を読んだ瞬間に後ろからやっていけばいいと分かったけど、何故か行けるところ管理に Union Find を使って自爆.
from sys import stdin readline = stdin.readline N, M = map(int, readline().split()) A = list(map(int, readline().split())) links = [[] for _ in range(N)] for _ in range(M): X, Y = map(lambda x: int(x) - 1, readline().split()) links[X].append(Y) maxvs = [None] * N result = -(10 ** 18) for i in range(N - 1, -1, -1): if len(links[i]) == 0: maxvs[i] = A[i] continue maxv = max(maxvs[j] for j in links[i]) result = max(result, maxv - A[i]) maxvs[i] = max(maxv, A[i]) print(result)ABC188F - +1-1x2
WA2 まで行ったものの突破できず. Greedy じゃなくてメモ化再帰でやればよかったのか. (Y-1)÷2 を優先していたが、(Y+1)÷2 のほうが良かったことがあったようだ. Xを変化させるのではなく、Yを変化させたほうがいいというのはどこかで似たような問題をやって知ってた.
from functools import lru_cache X, Y = map(int, input().split()) @lru_cache(maxsize=None) def f(y): if X >= y: return abs(X - y) if y % 2 == 0: return min(abs(y - X), f(y // 2) + 1) else: return min(abs(y - X), f((y - 1) // 2) + 2, f((y + 1) // 2) + 2) print(f(Y))
- 投稿日:2021-01-10T23:24:18+09:00
pyenv + conda の環境構築メモ
はじめに
anacondaを直接インストールすると,Homebrewと衝突してしまうらしいので,pyenv + condaでanaconda環境を構築しました.
インストール方法(pyenvインストール済みの状態)
インストール可能なanacondaの検索
pyenv install -l | grep anacondaインストール
pyenv install anaconda3-2020.07condaによる仮想環境の作り方
anacondaをglobalに切り替え
pyenv global anaconda3-2020.07仮想環境の作成
conda create -n [仮想環境名] python=[pythonのバージョン] [installしたいライブラリ] [installしたいライブラリ] ...作業用のディレクトリでのみ作成した仮想環境を有効化
mkdir test_conda cd test_conda pyenv local [仮想環境名] # ディレクトリ内に.python-versionというファイルが生成される. # ディレクトリを抜けると, globalで有効化された環境に戻る作成した仮想環境をactivateで起動(フルパス指定)
conda activate [仮想環境名] # sourceで直接ファイルを実行してもおけ source $PYENV_ROOT/versions/anaconda3-2020.07/bin/activate [仮想環境名]起動中の仮想環境の停止
conda deactivateその他のコマンド
ライブラリのインストール
conda install [ライブラリ名]インストール済みのライブラリの表示
conda list仮想環境の削除
conda remove -n [仮想環境名] --all参考
- 投稿日:2021-01-10T23:21:58+09:00
Effective Python 学習備忘録 9日目 【9/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- Effective Python
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:69-73ページ
- 第3章:クラスと継承
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
親クラスをsuperを使って初期化する
子クラスから親クラスを初期化する方法
__init__メソッドを用いた初期化
- 問題点
- superを用いた初期化
__init__メソッドを用いた初期化# 親クラス class MyBaseClass(object): def __init__(self, value): self.value = value # 子クラス class MyChildClass(MyBaseClass): def __init__(self): MyBaseClass.__init__(self, 5) # 親クラスの__init__メソッドを呼びだし初期化
__init__メソッドを用いた初期化の問題点この方式は、単純な階層では問題なく動作しますが、多重継承によって、影響を受けている状態でスーパークラスの
__init__メソッドを直接呼び出すと、おかしな振る舞いを起こす場合があります。特に、ダイヤモンド継承の際に、予期せぬ振る舞いを起こします。
ダイヤモンド継承とは、サブクラスが2つの別々のクラスから継承し、かつその2つが継承改装で同じスーパークラスを持っていることを指します。例えば、MyBaseClassを継承する2つの子クラスとそれらを継承する子クラスを次のように定義します。# 親クラス class MyBaseClass(object): def __init__(self, value): self.value = value # 親クラスを継承する子クラス1 class TimesFive(MyBaseClass): def __init__(self, value): MyBaseClass.__init__(self, value) self.value *= 5 # 親クラスを継承する子クラス2 class PlusTwo(MyBaseClass): def __init__(self, value): MyBaseClass.__init__(self, value) self.value += 2 # 2つのクラスを継承する子クラス定義し、MyBaseClassをダイヤモンドの頂点に class ThisWay(TimesFive, PlusTwo): def __init__(self, value): TimesFive.__init__(self, value) PlusTwo.__init__(self, value) foo = ThisWay(5) print('Should be ( 5 * 5) + 2 = 27 but is', foo.value)出力結果
Should be ( 5 * 5) + 2 = 27 but is 7出力は、ThisWayの引数5がTimesFiveで5倍され、PlusTwoで2を加算し、27になるはずですが、7になっています。この原因は、PlusTwo.initの呼び出しで、MyBaseClass.initが2回目に呼び出されたところで5にリセットされるためです。Python3ではsuperを使うことでこの問題を解決することができます。また、Python3では常にsuperを使うべきです。
superを用いた初期化
class Explicit(MyBaseClass): def __init__(self, value): super(__class__, self).__init__(value * 2) class Implicit(MyBaseClass): def __init__(self, value): super().__init__(value * 2) print('Explicit', Explicit(10).value) print('Implicit', Implicit(10).value)出力結果
Explicit 20 Implicit 20まとめ
- Pythonの標準メソッド解決順序は、スーパークラスの初期化順序とダイヤモンド継承の問題を解決する
- 親クラスを初期化するには、常に組み込み関数superを使う
- 投稿日:2021-01-10T22:46:59+09:00
Pythonで学ぶアルゴリズム 第17弾:並べ替え(バブルソート)
#Pythonで学ぶアルゴリズム< バブルソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第17弾として挿入ソートを扱う.バブルソート
一般に交換ソートいうとバブルソートを指す.
リストの隣り合ったデータを比較して,大小の順序が違っているときは並べていく.そのイメージ図を次に示す.
実装
先ほどの手順に従ったプログラムのコードとそのときの出力を以下に示す.
コード
bubble_sort.py""" 2021/01/10 @Yuya Shimizu バブルソート """ def bubble_sort(data): """バブルソート:前から2つずつデータを比較し並べ替える.""" for i in range(len(data)): for j in range(len(data) - i -1): if data[j] > data[j+1]: #左の方が大きい場合 data[j], data[j+1] = data[j+1], data[j] #前後入れ替え return data if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sorted_data = bubble_sort(DATA.copy()) print(f"{DATA} → {sorted_data}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]うまく入れ替えられているが,これでは比較入れ替えが途中で必要なくなったとしてもデータの数だけ必ず繰り返すことになる.その部分を省くために,一巡して入れ替えが行われなくなった場合,繰り返しを抜ける操作を付け加えた.そのコードと出力を以下に示す.
コード
bubble_sort_improved.py""" 2021/01/10 @Yuya Shimizu バブルソート(改良版) """ def bubble_sort(data): """バブルソート:前から2つずつデータを比較し並べ替える.ただし,交換がもう必要ない所は省略する""" change = True #交換の余地ありと仮定 for i in range(len(data)): if not change: #交換の余地無しで繰り返し脱出 break change = False #交換の余地無しと仮定 for j in range(len(data) - i -1): if data[j] > data[j+1]: #左の方が大きい場合 data[j], data[j+1] = data[j+1], data[j] #前後入れ替え change = True #交換の余地ありかも return data if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sorted_data = bubble_sort(DATA.copy()) print(f"{DATA} → {sorted_data}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]ちゃんと昇順に並べ替えられていることが分かる.
今回は並べ替える前後での比較をしたいがために,あえてsorted_dataという変数に結果を格納し,さらに関数への引数はDATA.copy()というようにcopy関数により,引数に影響が出ないようにしている.並べ替えるだけなら,そのような操作は必要でなく,bubble_sort(DATA)とすればよい.バブルソートの計算量
最後に計算量について触れる.
基本的に選択ソートと同様,計算量はオーダー記法で表すと,$O(n^2)$となる.
ただし,一度も交換が発生しない場合は,比較のみ(入れ替えなし)で済むため$O(n)$となる.
最悪時間計算量が$O(n^2)$であることに変わりはない.感想
前回に引き続き,そこまで複雑ではなかった.リスト内で一度に入れ替えを行うとき,一時的に値を保存する必要はなく,次のようにカンマで代入するだけでよいことを知った.これは大きなものを得られたと思う.
data[j+1], data[j] = data[j], data[j+1]次回以降の並べ替えアルゴリズムも楽しみである.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2021-01-10T22:34:25+09:00
[Python] Foliumのコロプレス図(Choropleth)でデータがないと黒くなる箇所を白くする
How to make black colored area in Folium Choropleth white where data is missing; simply set the nan_fill_color
この記事について
現在、Foliumのコロプレス図(Choropleth)を勉強中ですが、ネットに掲載されているものはきちんと動かないものが多く、苦労しています。そんな中、こちらのサイトのものはきちんと動作して、非常に参考になりました。
Pythonでビックマック指数のヒートマップ世界地図を作ってみる
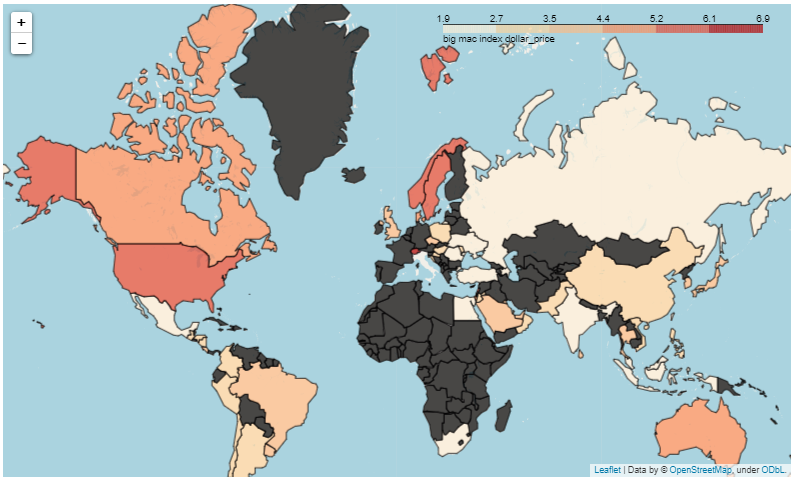
https://techray.hatenablog.com/entry/2019/12/16/200248しかし、表示される地図で、ビックマック指数がないところ(マクドナルドの店舗がないところ?!)は黒くなり、ちょっと見ずらいです。(厳密にはダークグレーですが、黒として進めます)
(こんな感じ)
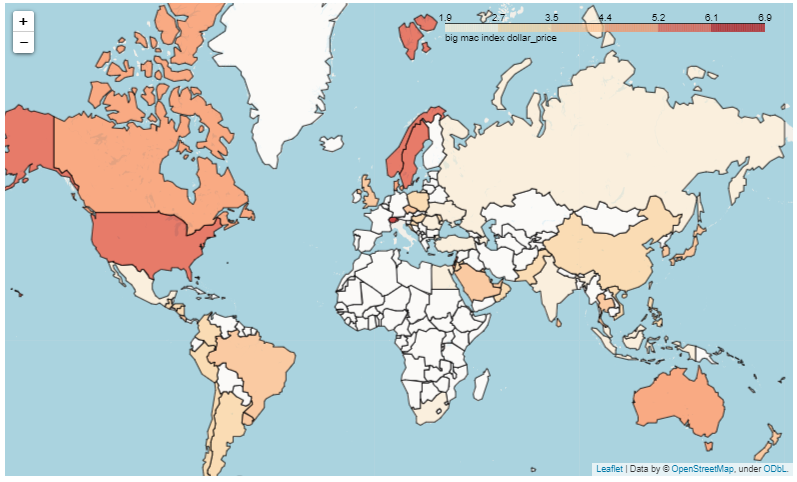
ちょっと、黒を白くしてみました!
こうしてみると、一番、ビッグマックが高いのはスイスであることが分かりやすかと思います。
何を変えたか
元のサイトに掲載されるデータはそちらで見ていただきたいのですが、以下、nan_fill_colorという箇所を1行追加しました。
# 地図に色を塗る folium.Choropleth( geo_data=geojson, name='choropleth', data=df,# 描画データ columns=['iso_a3', 'dollar_price'], # ["国コード", "値の列"] key_on='feature.id', fill_color='OrRd',# 色指定 fill_opacity=0.7, # 色の透明度 line_opacity=1,#国境線の透明度 nan_fill_color="white", #### ここでdfにない国は白にする!!! ##### legend_name='big mac index dollar_price' #凡例 ).add_to(m)これはFoliumのdocumentationに記載されていましたが、あまり知られていないようです。
https://python-visualization.github.io/folium/modules.htmlnan_fill_color (string, default 'black') – Area fill color for nan or missing values. Can pass a hex code, color name.
値のないものはNaN扱いとなり、その色を指定できるようです。
色を指示する他にも透明度を変えることもできるそうです。その他
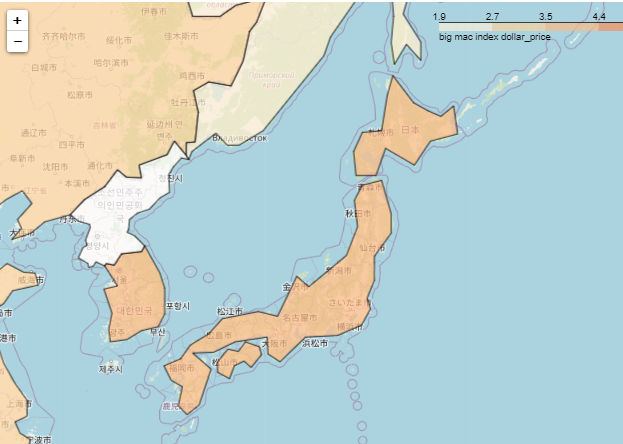
こちらのコロプレス図のデータは、けっこう粗かった。日本はこんな感じ。。
でも、結局、境界線をポイントでつないで表現していることが分かる。
- 投稿日:2021-01-10T21:34:43+09:00
python初心者が犯罪者数を予測してみた
はじめに
まずは簡単に自己紹介させてください。
私は大学で工学(化学系)を学び、一般企業で研究員として働いて5年目になります。
今回会社から半年間の育休をもらえたので、育児の合間をぬってプログラミングを勉強することにしました。
はじめるに至った動機ですが、YouTubeで「最近は簡単にプログラミングを学べる」といった動画を多く目にし、
大学時代に少し触ったことがあったのも相まって、思い切って3か月間オンラインスクールに通うことにしました。本記事の概要
- どんな人向けの記事か
完全に初心者向けです。今からプログラミングを始めてみようという人に読んでもらいたいです。
どうやってオンラインスクールを選び、何を学んだのかということから書いています。
- この記事で挑戦したこと
3か月の受講期間で学んだ技術の中で、面白いなと思ったコードを、自分で題材を決めて動かしてみました。
具体的には、月別の犯罪者数を予測してみました。
はじめはLSTMモデルで予測してみたのですが、精度がいまいちだったため、機械学習を用いて予測してみました。オンライン学習の振り返り
- なぜAidemyを選んだのか
オンラインスクールを選ぶにあたり、たくさんの選択肢がありました。
それぞれHPを見に行ったのですが、転職成功率等のビジネスよりの広告が最も少なかったAidemyに決めました。
今回は転職のためのスキルを磨くというよりは、純粋に流行の機会学習やデフィープラーニングってどんなの?
という感情が大きかったので、結果的にこの選択は良かったです。
また、代表の方がホリエモンチャンネルに出演していたり、ヨビノリのたくみ先生が推していたのも大きかったですね。
- Aidemyで学んだこと
私はデータ分析コースだったのですが、
Premium Planというものを選択したので、他コースの教材も+αで学ぶことができました。
幅広く勉強できて、大変満足できるものでした。私が学習したことを簡単に書いておきますね。
(1)Numpy、Pandas、Matplotlib、データクレンジング、データハンドリング
(2)教師あり学習、教師なし学習
(3)時系列分析、株価予測、kaggleのコンペ(タイタニック号、住宅価格予測)
(4)自然言語処理、トピック抽出、感情分析
(5)深層学習画像認識
【本題】犯罪者数の予測
●犯罪者数
さて本題です。 今回は月別の犯罪者数を予測してみることにしました。まずは、LSTMモデルでの予測を行います。
使用するデータはe-Statという政府の統計を管理しているページから引っ張ってきました。
この中の「罪名別被疑事件の処理人員(2007年1月~2018年1月)」の数字を扱います。※「犯罪認知件数」という言葉の方が一般的かもしれませんが、
犯罪を件数単位ではなく、人数単位でカウントしたかったのでこの統計を選びました。●データの読み込みとindex,columnsの除去
使用するデータは先頭Sheetの先頭列です。
また、取り出したデータの値はLSTMでの分析に適合させるため、float型に変換して読み込みます。#データの読み込み dataframe = pd.read_excel('./blog_data/criminal_prediction.xlsx', sheet_name=0, usecols=[0]) #index,columns除去 dataset = dataframe.values #float型に変換 dataset = dataset.astype('float32')●トレーニングデータ・テストデータの作成
前半の2/3をトレーニング用、残りの1/3をテスト用に分ける操作を行います。
トレインデータが89個、テストデータが44個です。# トレーニングデータにするデータ件数を算出 train_size = int(len(dataset) * 0.67) # トレーニングデータ、テストデータに分割 train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] print(len(dataset), len(train), len(test)) #出力結果:133 89 44●データのスケーリング
前処理でスケーリングを行います。
ここでは正規化(MinMaxScaler)を用いて、トレーニングデータを基準としたスケーリングを行いました。from sklearn.preprocessing import MinMaxScaler # 最小値が0, 最大値が1となるようにスケーリング方法を定義 scaler = MinMaxScaler(feature_range=(0, 1)) # `train`のデータを基準にスケーリングするようパラメータを定義 scaler_train = scaler.fit(train) # パラメータを用いて`train`データをスケーリング train = scaler_train.transform(train) # パラメータを用いて`test`データをスケーリング test = scaler_train.transform(test)●入力データ・正解ラベルの作成
LSTMの予測では、基準となる時点からいくつか前のデータを用いて次の時点のデータの予測を行います。
ここでは入力データと正解ラベルを次の要件で作成しました。・入力データ:基準点を含め、3か月前の時点までのデータ
・正解ラベル:基準点の次の時点のデータimport numpy as np # 入力データ・正解ラベルを作成する関数を定義 # data_X:入力データ。n月分のデータを1セットとする # data_Y:正解ラベル。Xの翌月を正解とする def create_dataset(dataset, look_back): data_X, data_Y = [], [] for i in range(look_back, len(dataset)): data_X.append(dataset[i-look_back:i, 0]) data_Y.append(dataset[i, 0]) return np.array(data_X), np.array(data_Y) # 3つ前のデータを1セットとする入力データと正解ラベルを作成 look_back = 3 # 作成した関数`create_dataset`を用いて、入力データ・正解ラベルを作成 train_X, train_Y = create_dataset(train, look_back) test_X, test_Y = create_dataset(test, look_back)●データの整形
作成したデータはLSTMで分析できるデータ形式ではないので、入力データの整形を行います。
入力データを行数×変数数×カラム数の3次元の行列に変換し、LSTMで分析できるデータ形式に整形します。・行数:データの総数
・変数数:1セットのデータに含まれる要素数 = look_back
・カラム数:扱うデータの種別数 = 1(犯罪者数の1種類だけ)# データの整形 # 3次元のnumpy.ndarrayに変換 train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)●LSTMネットワークの構築と訓練
次に、LSTMネットワークを構築し、用意したデータを用いてモデルの訓練を行います。from sklearn.metrics import mean_squared_error import keras from keras.models import Sequential from keras.layers.core import Dense, Activation from keras.layers.recurrent import LSTM from keras.callbacks import EarlyStopping # LSTMモデルを作成 model = Sequential() model.add(LSTM(64, input_shape=(look_back, 1), return_sequences=True)) model.add(LSTM(32)) model.add(Dense(1)) # モデルをコンパイル model.compile(loss='mean_squared_error', optimizer='adam') # 訓練 model.fit(train_X, train_Y, epochs=50, batch_size=1, verbose=1)●データの予測・評価
モデルの構築と訓練が終了したので、データの予測と評価を行います。
出力されたデータの予測結果を正しく評価するには、スケーリングしたデータを元に戻す必要があります。
元に戻すには、transform()メソッドの逆変換を行う、inverse_transform()メソッドを用います。
データが少ないせいか、誤差が大きくなっていますね。import math # 予測データを作成 train_predict = model.predict(train_X) test_predict = model.predict(test_X) # スケールしたデータを元に戻す train_predict = scaler_train.inverse_transform(train_predict) train_Y = scaler_train.inverse_transform([train_Y]) test_predict = scaler_train.inverse_transform(test_predict) test_Y = scaler_train.inverse_transform([test_Y]) # 予測精度の計算 train_score = math.sqrt(mean_squared_error(train_Y[0], train_predict[:, 0])) print('Train Score: %.2f RMSE' % (train_score)) #出力結果:Train Score: 13596.52 RMSE test_score = math.sqrt(mean_squared_error(test_Y[0], test_predict[:, 0])) print('Test Score: %.2f RMSE' % (test_score)) #出力結果:Test Score: 14855.30 RMSE●予測結果の可視化
次の3つを1つのグラフにプロットします。
・読み込んだままのデータ(dataset)
・トレーニングデータから予測した値(train_predict)
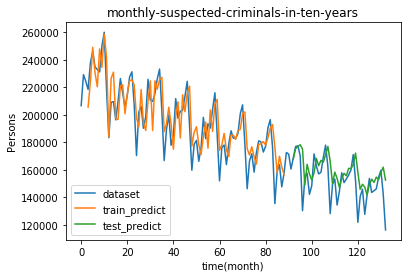
・テストデータから予測した値(test_predict)import matplotlib.pyplot as plt # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict # データのプロット plt.title("monthly-suspected-criminals-in-ten-years") plt.xlabel("time(month)") plt.ylabel("Persons") # 読み込んだままのデータをプロット plt.plot(dataset, label='dataset') # トレーニングデータから予測した値をプロット plt.plot(train_predict_plot, label='train_predict') # テストデータから予測した値をプロット plt.plot(test_predict_plot, label='test_predict') plt.legend(loc='lower left') plt.show()
X軸の0のところが2007年1月です。意外にも犯罪者数は減少していますね。
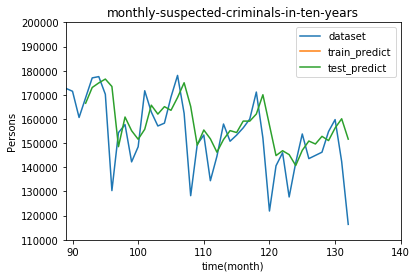
テストデータの部分を拡大してみます。import matplotlib.pyplot as plt import numpy as np # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict # データのプロット plt.title("monthly-suspected-criminals-in-ten-years") plt.xlabel("time(month)") plt.ylabel("Persons") #範囲設定 plt.xlim(89,140) plt.ylim(110000,200000) # 読み込んだままのデータをプロット plt.plot(dataset, label='dataset') # トレーニングデータから予測した値をプロット plt.plot(train_predict_plot, label='train_predict') # テストデータから予測した値をプロット plt.plot(test_predict_plot, label='test_predict') plt.legend(loc='upper right') plt.show()
うーん、やはりデータが少ないせいか、ところどころ誤差が目立ちますね。
機械学習で予測してみた
少し不完全燃焼な気分だったので、視点を変えてもう少し工夫してみました。
何か犯罪者数とは全く異なる説明変数で、犯罪者数を予測できないかと考え、次のようなデータを用意しました。
これらを使って以下のように重回帰分析を行いました。import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression #データの読み込み、日付の削除 df = pd.read_excel('./blog_data/criminal_prediction.xlsx', sheet_name=0) df = df.drop(df.columns[0], axis=1) X = df.drop('被疑事件の受理人員', axis=1) y = df['被疑事件の受理人員'] #データの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) #訓練、評価 model = LinearRegression() model.fit(X_train, y_train) R2 = model.score(X_test, y_test) print("{:.5f}".format(R2)) #出力結果:0.79810まずまずの結果ですね。とりあえず満足です。
おわりに
受講期間は終わってしまいましたが、これからも時間を見つけて少しずつ勉強していこうと思います。
卒業までに実際にコードを実行しながら、幅広く触れることができて良かったです。

- 投稿日:2021-01-10T20:06:56+09:00
[pyqtgraph] SignalProxyを理解してグラフ上にカーソルを追従する十字線を作成する
やりたいこと
pyqtgraph.exsamples.run()のCrosshair / Mouse interactionにあるカーソルに合わせて動く十字線を作成したい。
サンプルコードの中に初めてみるスクリプトがあった。
proxy = pg.SignalProxy(p1.scene().sigMouseMoved, rateLimit=60, slot=mouseMoved)SignalProxyは何をしているのか理解しながら十字線を作成していく。
環境
Mac OS
Python 3.8.5PyQt5 5.15.2
PyQt5-sip 12.8.1
pyqtgraph 0.11.1
pip install PyQt5 PyQt5-sip pyqtgraphpyqtgraph.exsamples
import pyqtgraph.examples as ex ex.run()で色々なサンプルグラフが見れます。今回参考にしたのはCrosshair / Mouse interactionです。
SignalProxy
SignalProxyのアノテーションの内容
Object which collects rapid-fire signals and condenses them
into a single signal or a rate-limited stream of signals.
Used, for example, to prevent a SpinBox from generating multiple
signals when the mouse wheel is rolled over it.Emits sigDelayed after input signals have stopped for a certain period of
time.Initialization arguments:
signal - a bound Signal or pyqtSignal instance
delay - Time (in seconds) to wait for signals to stop before emitting (default 0.3s)
slot - Optional function to connect sigDelayed to.
rateLimit - (signals/sec) if greater than 0, this allows signals to stream out at a
steady rate while they are being received.短時間で同じシグナルが大量に発生する場合使用するオブジェクト。
発生したシグナルを全て発光するのではなく、一定間隔ごとに一つだけ発光する。引数
- signal : 処理したいシグナルを指定
- delay : シグナルを受信してから発光するまでの待ち時間。デフォルトは0.3秒。指定する時は秒単位で入力。
- slot : シグナルが発光した時に実行されるスロット
- rateLimit : シグナルが発光する間隔を正確に設定したい時に使う。単位は[Hz]。デフォルトは0。
どうやって間隔を指定している?
SignalProxyのコンストラクタとシグナルを受信している部分
self.timerがtimeoutした時スロットが実行される。sigDelayed = QtCore.Signal(object) def __init__(self, signal, delay=0.3, rateLimit=0, slot=None): """Initialization arguments: signal - a bound Signal or pyqtSignal instance delay - Time (in seconds) to wait for signals to stop before emitting (default 0.3s) slot - Optional function to connect sigDelayed to. rateLimit - (signals/sec) if greater than 0, this allows signals to stream out at a steady rate while they are being received. """ QtCore.QObject.__init__(self) self.delay = delay self.rateLimit = rateLimit self.args = None self.timer = ThreadsafeTimer.ThreadsafeTimer() self.timer.timeout.connect(self.flush) self.lastFlushTime = None self.signal = signal self.signal.connect(self.signalReceived) if slot is not None: self.blockSignal = False self.sigDelayed.connect(slot) self.slot = weakref.ref(slot) else: self.blockSignal = True self.slot = None def signalReceived(self, *args): """Received signal. Cancel previous timer and store args to be forwarded later.""" if self.blockSignal: return self.args = args if self.rateLimit == 0: self.timer.stop() self.timer.start(int(self.delay * 1000) + 1) else: now = time() if self.lastFlushTime is None: leakTime = 0 else: lastFlush = self.lastFlushTime leakTime = max(0, (lastFlush + (1.0 / self.rateLimit)) - now) self.timer.stop() self.timer.start(int(min(leakTime, self.delay) * 1000) + 1)rateLimitを指定していない時
rateLimitのデフォルトは0
if self.rateLimit == 0: self.timer.stop() self.timer.start(int(self.delay * 1000) + 1)シグナルが最後に受信されてから
self.delay秒後に発光するようにタイマーを再設定している。
timer.start()はミリ秒で指定する為 *1000している。rateLimitを指定している時
else: now = time() if self.lastFlushTime is None: leakTime = 0 else: lastFlush = self.lastFlushTime leakTime = max(0, (lastFlush + (1.0 / self.rateLimit)) - now) self.timer.stop() self.timer.start(int(min(leakTime, self.delay) * 1000) + 1)
self.lastFlushTimeはシグナルが最後に発行した時のunix時刻。シグナルが最後に発光してから十分に時間が経過している時
例
-self.rateLimit= 5
-self.lastFlushTime= 100
-now= 102
leakTime = max(0, (lastFlush + (1.0 / self.rateLimit)) - now)
= max(0, -1.8) でleakTime= 0
その後のself.timer.start(int(min(leakTime, self.delay) * 1000) + 1)でself.delayの方が大きい為delay秒後に発光する。シグナルが(1 / rateLimit)秒未満に発生した時
例
-self.rateLimit= 5
-self.lastFlushTime= 100
-now= 100.01
leakTime = max(0, (lastFlush + (1.0 / self.rateLimit)) - now)
= max(0, 0.19) でleakTime= 0.19その後の
self.timer.start(int(min(leakTime, self.delay) * 1000) + 1)でself.delayより大きければleaktime秒後に発光する。最後に発行してからnowまでは0.01秒経過している為、0.01 + 0,19 = 0.2 = 5[Hz]
要するに
最初のこれは
proxy = pg.SignalProxy(p1.scene().sigMouseMoved, rateLimit=60, slot=mouseMoved)マウスが動いたら(
p1.scene().sigMouseMoved)を60 HzごとにmouseMovedを実行してという意味。コード
SignalProxyが何をしているか分かったので使ってみる。
プロット用にnumpyを使用。pip install numpy
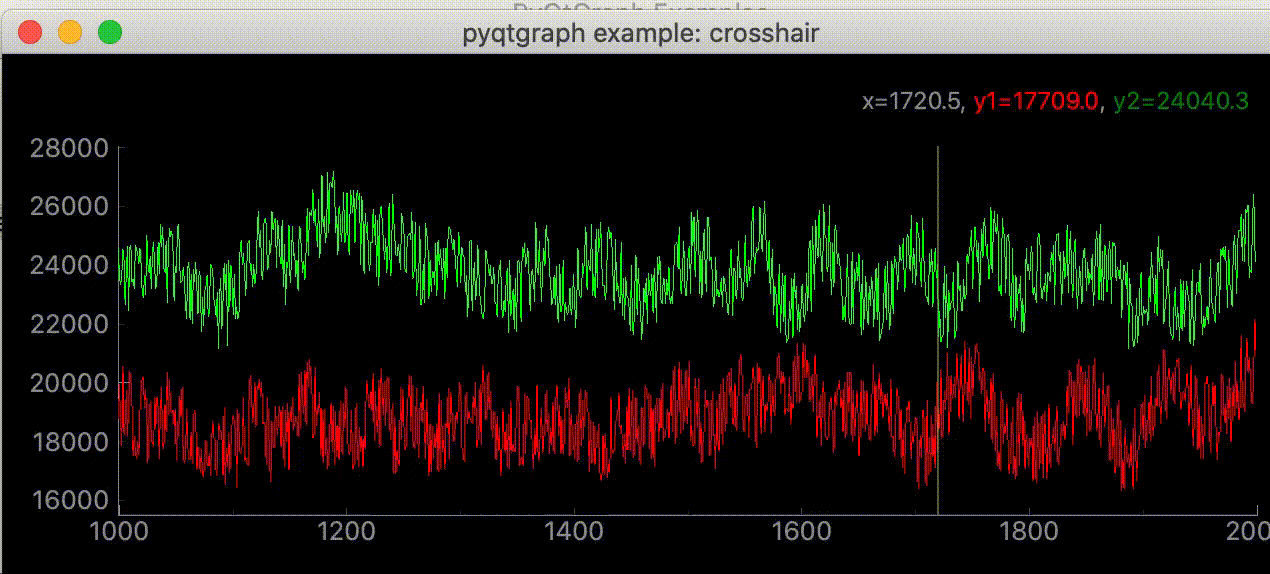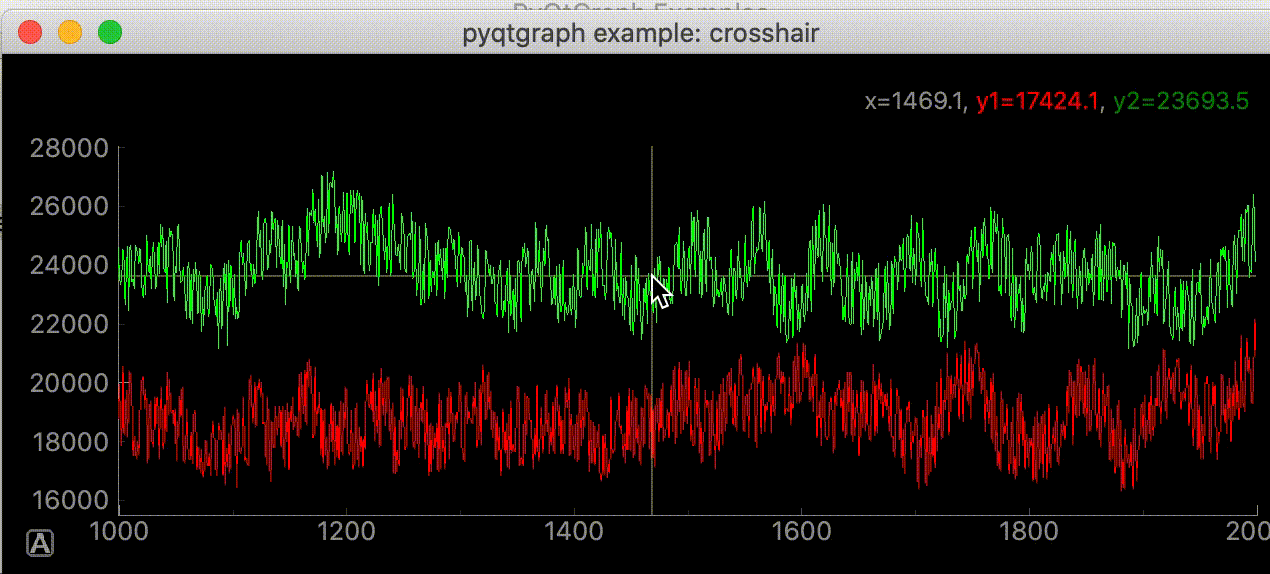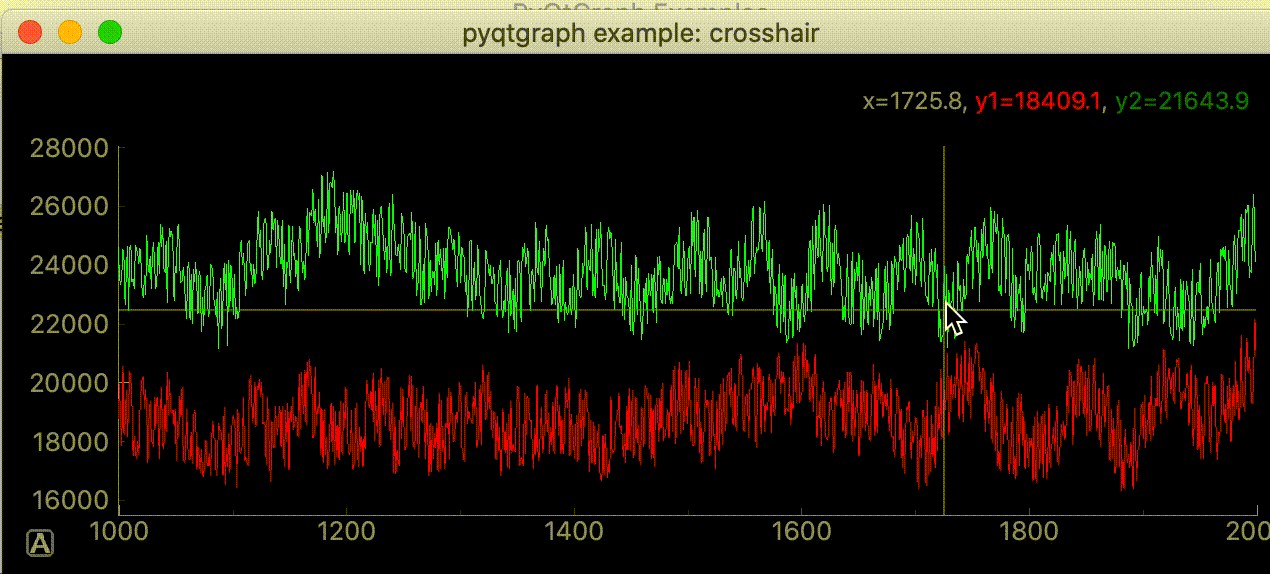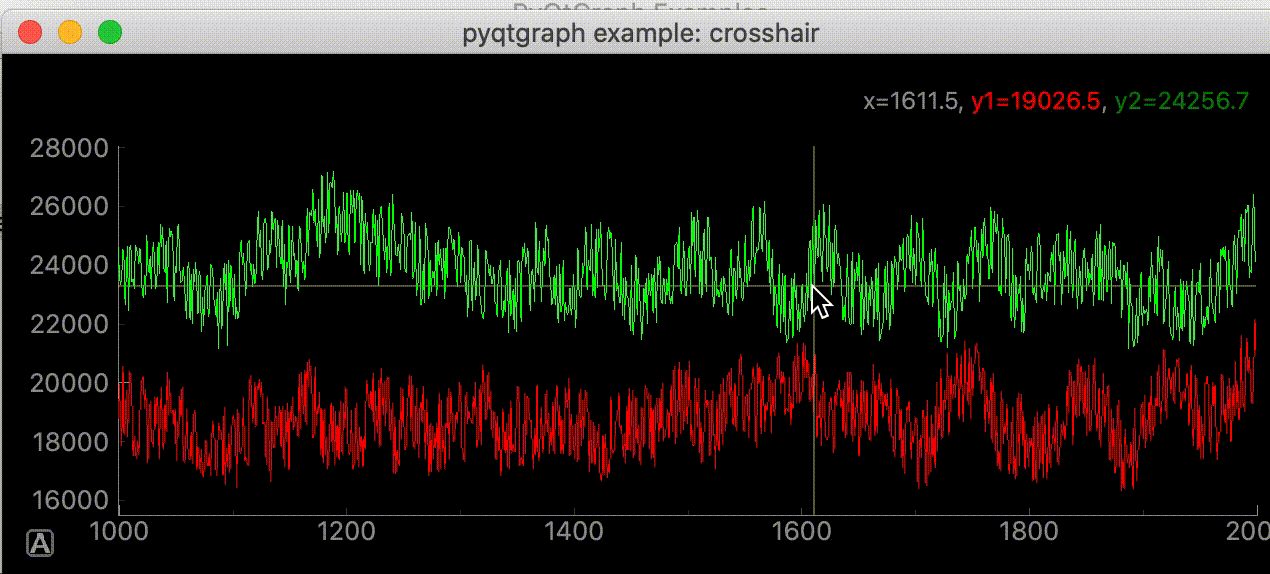
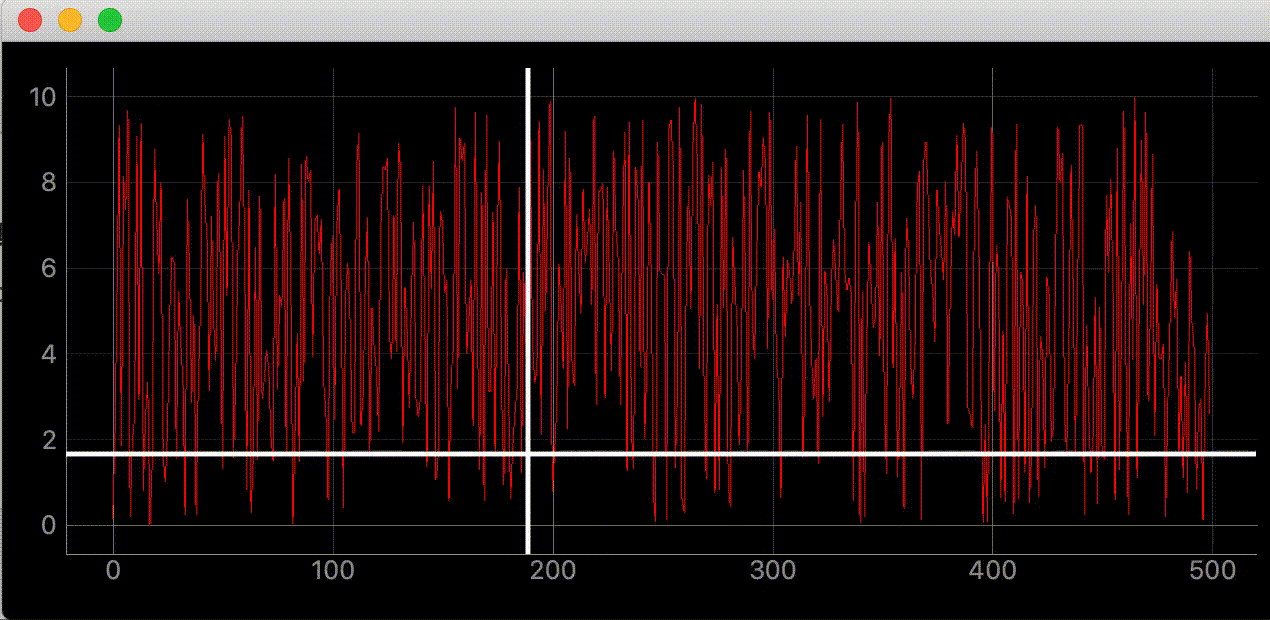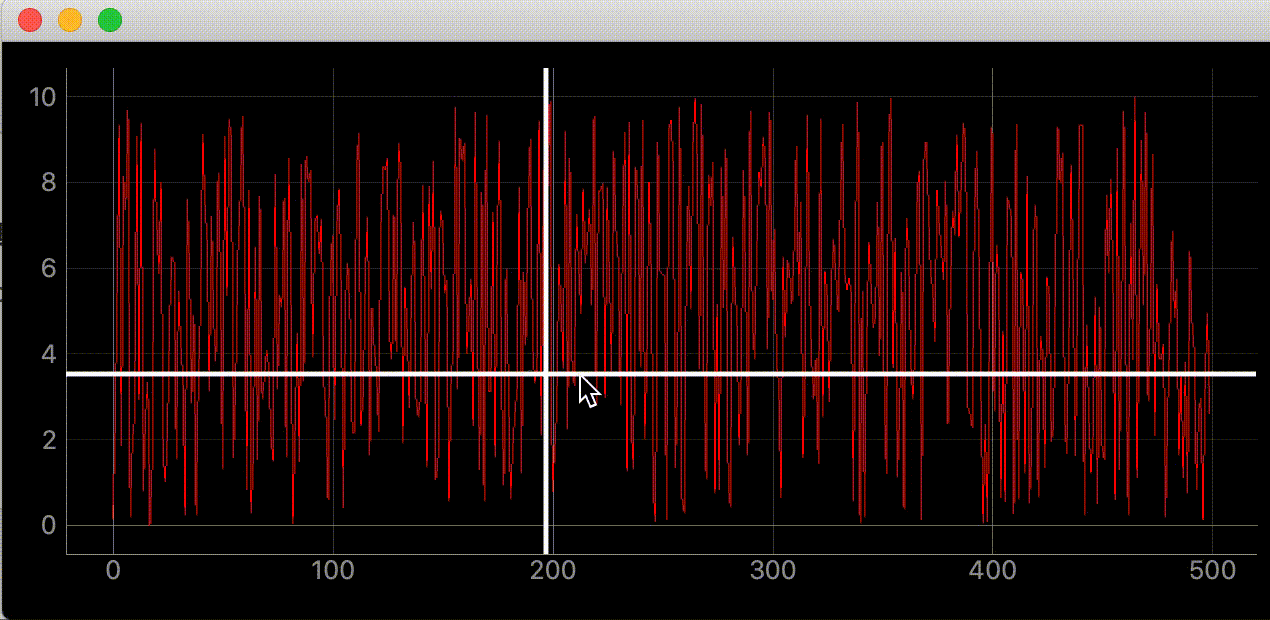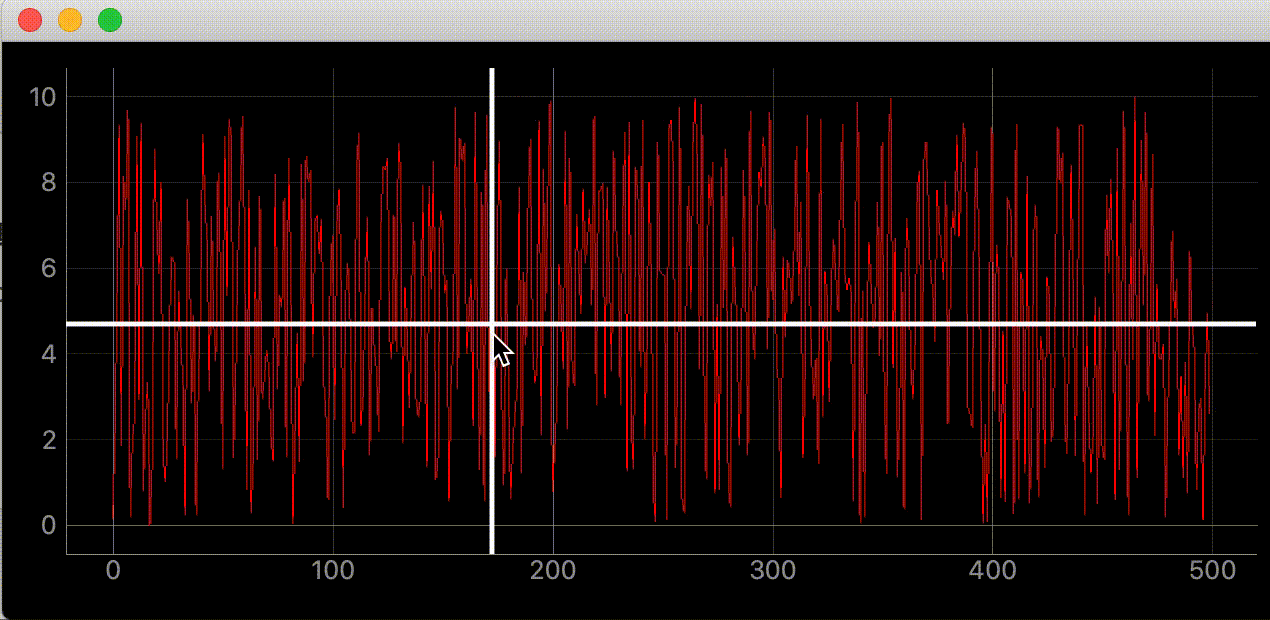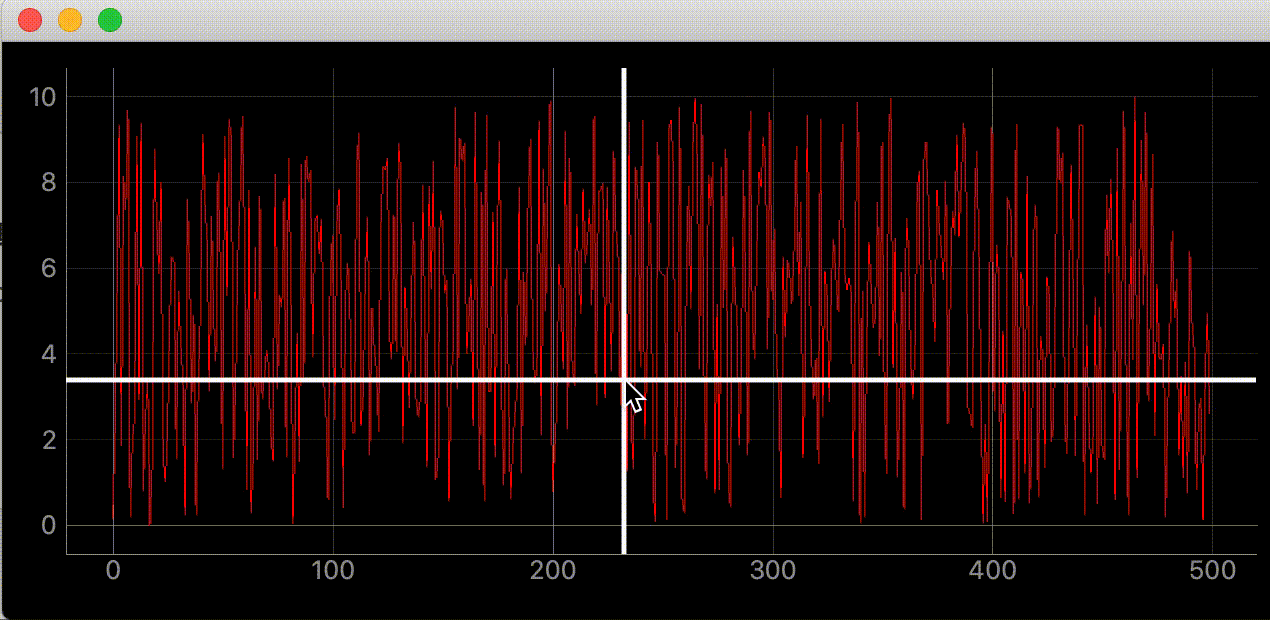
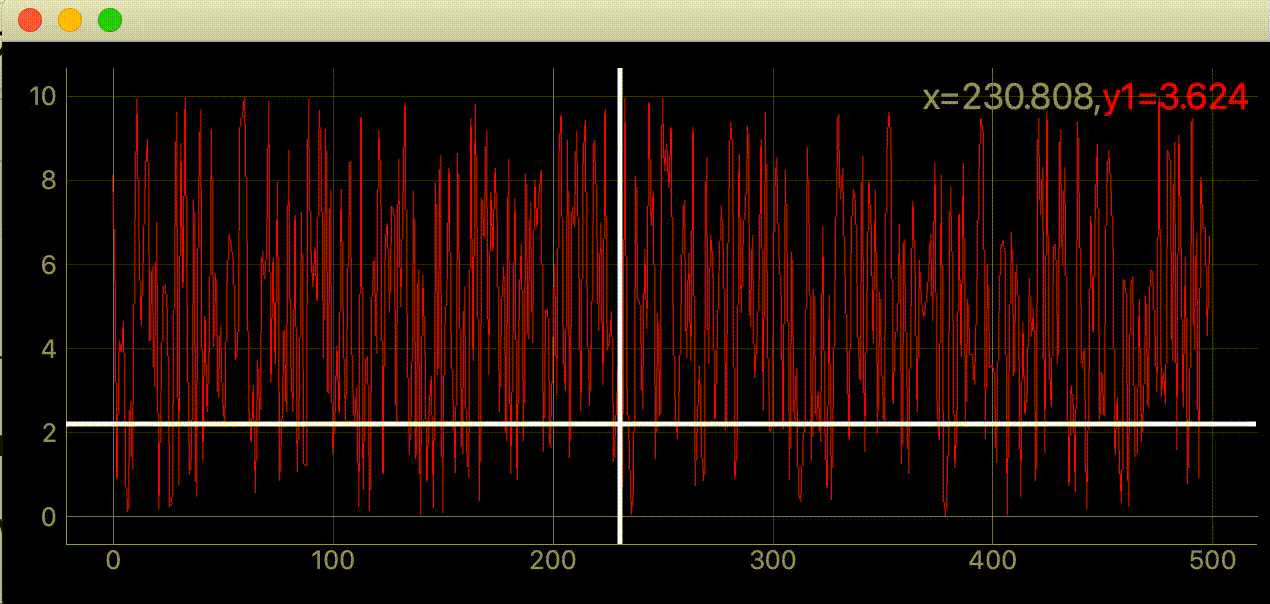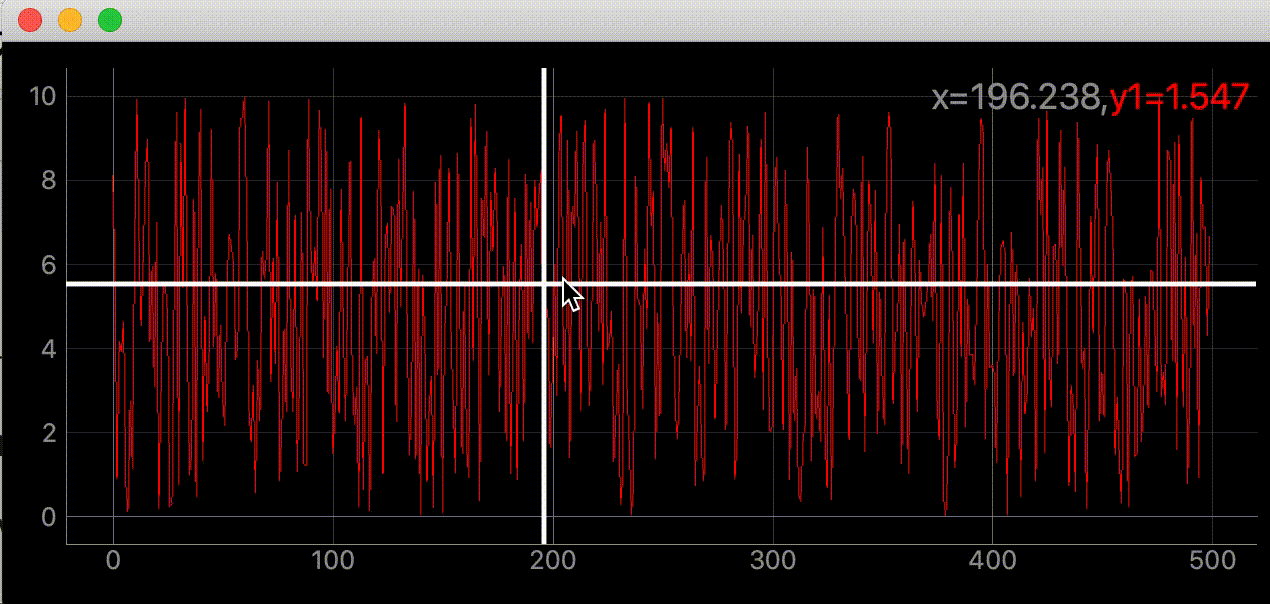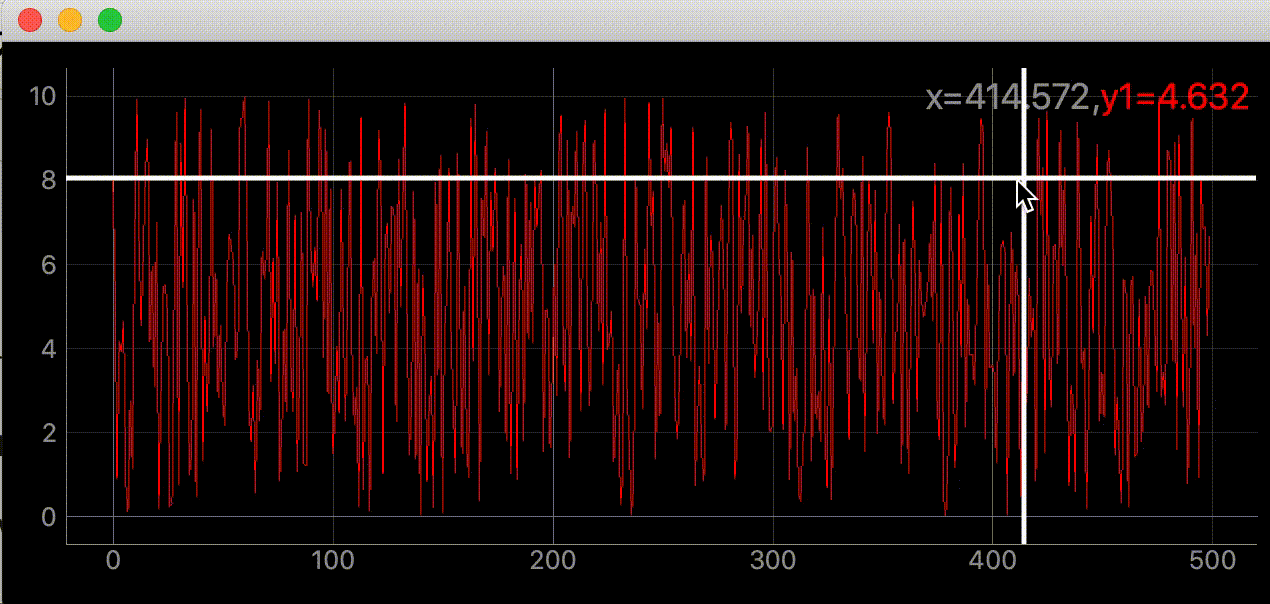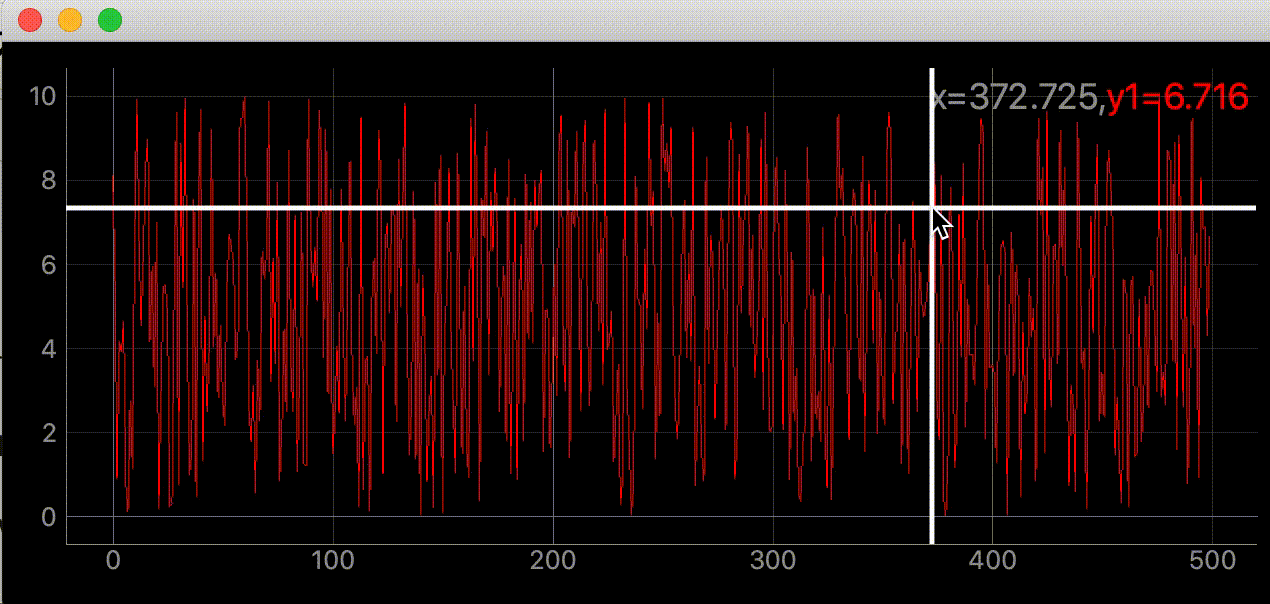
"""グラフにマウスカーソルを追いかける十字線を追加する""" import dataclasses from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets, QtCore import pyqtgraph as pg SAMPLE_DATA = np.random.rand(500) * 10 @dataclasses.dataclass class AddLineWidget(pg.GraphicsLayoutWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 plotter: pyqtgraph.graphicsItems.PlotItem.PlotItem.PlotItem メイングラフ view_box: pyqtgraph.graphicsItems.ViewBox.ViewBox.ViewBox メイングラフのViewBox vertical_line: pyqtgraph.graphicsItems.InfiniteLine.InfiniteLine マウスカーソルを追いかける縦線 horizontal_line: pyqtgraph.graphicsItems.InfiniteLine.InfiniteLine マウスカーソルを追いかける横線 proxy: pyqtgraph.SignalProxy.SignalProxy マウスカーソルが動いた時に発生するシグナルの発光を制御する """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとplot, line追加""" super(AddLineWidget, self).__init__(parent=self.parent) self.add_plot_and_viewbox() self.add_line() self.set_proxy() def add_plot_and_viewbox(self) -> None: """plotとviewboxを追加する""" self.plotter = self.addPlot(row=0, col=0) self.plotter.showGrid(x=True, y=True, alpha=0.8) self.plotter.plot(SAMPLE_DATA, pen=pg.mkPen('#f00')) # self.plotterのViewBox self.view_box = self.plotter.vb def add_line(self): """カーソルに合わせて動くラインの追加""" # デフォルトでは見えにくいので色、幅指定 self.vertical_line = pg.InfiniteLine(angle=90, movable=False, pen=pg.mkPen('#fff', width=5)) self.horizontal_line = pg.InfiniteLine(angle=0, movable=False, pen=pg.mkPen('#fff', width=5)) self.plotter.addItem(self.vertical_line, ignoreBounds=True) self.plotter.addItem(self.horizontal_line, ignoreBounds=True) def set_proxy(self) -> None: """SignalProxyを設定""" self.proxy = pg.SignalProxy(self.plotter.scene().sigMouseMoved, rateLimit=60, slot=self.mouse_moved) @QtCore.pyqtSlot(tuple) def mouse_moved(self, evt) -> None: """マウスが動いた時に60FPSごとに実行される関数 PlotItem.scene().sigMouseMovedはグラフの座標ではなく画面のピクセル単位の座標を返す Parameters ---------- evt: tuple 画面のピクセル単位の座標 ex) (PyQt5.QtCore.QPointF(2.0, 44.0),) """ # 画面のピクセル座標取得 # ex) pos=PyQt5.QtCore.QPointF(2.0, 44.0) pos = evt[0] # posがグラフ内の座標だったら if self.plotter.sceneBoundingRect().contains(pos): # グラフの座標取得 # ex) mousePoint=PyQt5.QtCore.QPointF(141.6549821809388, 4.725564511858496) mouse_point = self.view_box.mapSceneToView(pos) # 線をmouse_pointの座標に移動 # ex) mouse_point.x()=46.13389087421787 self.vertical_line.setPos(mouse_point.x()) # ex) mouse_point.y()=9.535145662930628 self.horizontal_line.setPos(mouse_point.y()) def main() -> None: app = QtWidgets.QApplication(sys.argv) window = AddLineWidget(parent=None) window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()右上に座標を表示する
"""グラフにマウスカーソルを追いかける十字線を追加する""" import dataclasses from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets, QtCore import pyqtgraph as pg SAMPLE_DATA = np.random.rand(500) * 10 @dataclasses.dataclass class AddLineWidget(pg.GraphicsLayoutWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 plotter: pyqtgraph.graphicsItems.PlotItem.PlotItem.PlotItem メイングラフ view_box: pyqtgraph.graphicsItems.ViewBox.ViewBox.ViewBox メイングラフのViewBox vertical_line: pyqtgraph.graphicsItems.InfiniteLine.InfiniteLine マウスカーソルを追いかける縦線 horizontal_line: pyqtgraph.graphicsItems.InfiniteLine.InfiniteLine マウスカーソルを追いかける横線 proxy: pyqtgraph.SignalProxy.SignalProxy マウスカーソルが動いた時に発生するシグナルの発光を制御する """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとlabel, plot, line追加""" super(AddLineWidget, self).__init__(parent=self.parent) self.add_label() self.add_plot_and_viewbox() self.add_line() self.set_proxy() def add_plot_and_viewbox(self) -> None: """plotとviewboxを追加する""" self.plotter = self.addPlot(row=0, col=0) self.plotter.showGrid(x=True, y=True, alpha=0.8) self.plotter.plot(SAMPLE_DATA, pen=pg.mkPen('#f00')) # self.plotterのViewBox self.view_box = self.plotter.vb def add_label(self) -> None: """座標を表示するラベルを追加""" self.label = pg.LabelItem(justify='right') self.addItem(self.label) def add_line(self): """カーソルに合わせて動くラインの追加""" # デフォルトでは見えにくいので色、幅指定 self.vertical_line = pg.InfiniteLine(angle=90, movable=False, pen=pg.mkPen('#fff', width=5)) self.horizontal_line = pg.InfiniteLine(angle=0, movable=False, pen=pg.mkPen('#fff', width=5)) self.plotter.addItem(self.vertical_line, ignoreBounds=True) self.plotter.addItem(self.horizontal_line, ignoreBounds=True) def set_proxy(self) -> None: """SignalProxyを設定""" self.proxy = pg.SignalProxy(self.plotter.scene().sigMouseMoved, rateLimit=60, slot=self.mouse_moved) @QtCore.pyqtSlot(tuple) def mouse_moved(self, evt) -> None: """マウスが動いた時に60FPSごとに実行される関数 PlotItem.scene().sigMouseMovedはグラフの座標ではなく画面のピクセル単位の座標を返す Parameters ---------- evt: tuple 画面のピクセル単位の座標 ex) (PyQt5.QtCore.QPointF(2.0, 44.0),) """ # 画面のピクセル座標取得 # ex) pos=PyQt5.QtCore.QPointF(2.0, 44.0) pos = evt[0] # posがグラフ内の座標だったら if self.plotter.sceneBoundingRect().contains(pos): # グラフの座標取得 # ex) mousePoint=PyQt5.QtCore.QPointF(141.6549821809388, 4.725564511858496) mouse_point = self.view_box.mapSceneToView(pos) # SAMPLE_DATA内の座標であればx, y値を表示する index = int(mouse_point.x()) if 0 < index < len(SAMPLE_DATA): self.label.setText( f"<span style='font-size: 18pt'>x={mouse_point.x():.3f}," f"<span style='color: red'>y1={SAMPLE_DATA[index]:.3f}</span>") # 線をmouse_pointの座標に移動 # ex) mouse_point.x()=46.13389087421787 self.vertical_line.setPos(mouse_point.x()) # ex) mouse_point.y()=9.535145662930628 self.horizontal_line.setPos(mouse_point.y()) def main() -> None: app = QtWidgets.QApplication(sys.argv) window = AddLineWidget(parent=None) window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()参考
SignalProxy
Python pyqtgraph package v0.10.0, pyqtgraph.SignalProxy module source code :: PyDoc.netViewBox
ViewBox — pyqtgraph 0.11.1.dev0 documentationSignalProxy
Python pyqtgraph package v0.10.0, pyqtgraph.SignalProxy module source code :: PyDoc.net
- 投稿日:2021-01-10T20:04:14+09:00
Google Colaboratoryの90分セッション切れ対策 --- Pythonをつかう!---
やること
Google Colab はプログラム実行中でも、何もさわらないと90分経過でプログラムが止まってしまいます。
このセッション切れ対策として、Google Chromeのアドオンを使う方法やスクリプトを実行する方法が紹介されていましたが、アドオンがうまくいかなかったので、Pythonプログラムで画面を定期的にクリックするという原始的な方法のシンプルプログラムを書きましたので、その紹介です。やりかた
1. pyautoguiモジュールをインストールする
画面をクリックするのにpyautoguiモジュールを使用します。pipを使って普通にインストールします。
pip install pyautogui
2. Google Colaboratoryを動かす
いつもどおりにColabでプログラムをはしらせます。ブラウザはなんでもOKです。
3. Pythonプログラムを動かす
ターミナルかエディタから、以下のプログラムを動かします。一応、for_colab.pyと名付けてますが、自由に名前をつけて保存、実行してください。
for_colab.py#! python3 # -*- coding: utf-8 -*- # colabを継続して使う import time import pyautogui print() print('''10分ごとにマウスカーソルを左右に少し動かし、クリックします。 12時間後に終了します。途中で停止するときは、Ctrl + c を押してください。 ''') try: dir = -10 counter = 0 while counter < 72: time.sleep(600) pyautogui.moveRel(dir, 0) dir = - dir pyautogui.click() counter += 1 # print('カウンター:', counter) # クリックしたときに出力したい場合はコメントアウト print('停止:12時間経過') except KeyboardInterrupt: print('停止:Ctrl + c による終了')
プログラムはとてもシンプルで、time sleepで10分待ったあと、ポインタを右(または左)に少し動かしクリックします。
それを72回(=12時間)実施したら終了します。4. google colabに戻る
先ほどプログラムをはしらせたcolabに戻って、プログラムが動いているのを確認します。
colabのプログラムの最後の方に空欄のセルをいくつか作っておき、その場所にポインタをおいておきます。以上です。
注意事項
- 「for_colab.py」は定期的にクリックしますので、ポインターをどこに置いておくかが重要です。左右の動きを繰り返すので、全然違う方に動いていくことはありませんが、colabの方がスクロールしていて思いもかけないところをクリックしないように、最後にポインターを置く位置に気をつけてください。
- colabとは別のプログラムですので、colabの計算が終わっても当然「for_colab.py」は止まりません。colabの計算が終了したら、ctrl-Cで「for_colab.py」を停止させてください。私は止め忘れていて、なんかパソコンの動きが変になった、と思ったらバックで「for_colab.py」が動いてました...
- 10分間隔でクリックしますが、その前にパソコンがスリープしないように、スリープまでの時間は10分超に設定してください。
- 単純に時間がきたらクリックするだけの機能ですので、動作中は別の作業はできません。睡眠学習用として使用ください。
プログラム「for_colab.py」は10分間隔でクリックするようにしていますが、colabのルール的には90分以内にクリックすればよいので、time sleepの値を各自の好みで変更してください。
また、クリック時にクリックしたことを確認したければ、コメントアウトしているPRINT文を有効にしてください。
単純なプログラムですので、使いやすいように変更して使ってみてください。Google Colaboratoryは無料でGPUが使用できるので、機械学習の訓練にとても便利ですよね。
寝ている間にGoogle先生に訓練してもらいましょう。'--------------------おしまい--------------------'
- 投稿日:2021-01-10T19:50:23+09:00
指定したURLのリンクが有効かどうかをチェックするpythonスクリプトを作成2
以下の更新版
コード
こちらにあるものと同じ
チェック対象のURLリスト作成
カレントディレクトリ以下の
https://...と続く文字列をなるべくgrepする。input.txtという名前で保存。grep -r "https://" * > test.txt cat test.txt | sed -e 's/.*https//' | sed "s/^/http/g" > test.txt cat test2.txt | sed 's/>//g' | sed 's/"//g' | sed 's/)//g' | sed 's/;//g' | sed 's/]//g' | cut -d' ' -f 1 > input.txtチェック
input.txtのURLにアクセスできるかどうかを確認する。$ python3 check_url.py # 出力結果 # アクセスできる→OK # アクセスできない→NotFound # ※ ただし、grep結果が意図通りでない場合もあるので確認する。 NotFound:http://www.kernel.org/pub/linux/kernel/v5.x/linux-${PV}.tar.xz OK:http://facebook.github.io/watchman/ ...check_url.py#-*- using:utf-8 -*- import urllib.request, urllib.error with open('out.txt', 'w') as txt: txt.write("chdck result\n") def checkURL(url): try: f = urllib.request.urlopen(url) f.close() return True except: return False if __name__ == '__main__': with open("./input.txt") as f: for url in f: # print(url, end='') ret = checkURL(url) if ret == True: result = "OK:" else: result = "NotFound:" ret_text = result + url #ret_text = ret_text.replace('\n', '') print(ret_text) if ret != True: with open('out.txt', 'a') as txt: txt.write(ret_text)結果
結果OK/NGを以下に出力する
cat out.txt参考
指定したURLのリンクが有効かどうかをチェックするpythonスクリプトを作成
入力した文字列から、指定した文字列より右の文字列をとりだす
- 投稿日:2021-01-10T19:32:05+09:00
AGL(Automotive Grade Linux)の公開ブランチに、ソースコードをcommitするまで2
目的
AGL(Automotive Grade Linux)の公開ブランチに、ソースコードをcommitするまでの備忘録です。
AGLについてはこちらやAutomotive Linux Wikiをご参照本記事は以下の更新版です
準備
AGLの公開コードに対しては、誰でも更新リクエストを送ることが可能になっています。
Contributing to the AGL Distro
The AGL community appreciates feedback, ideas, suggestion, bugs and documentation just as much as code.リクエストしたコードは
gerritを通じてtrackおよびreviewが行われます。Contributing Code
We use Gerrit to track and review changes to AGL software (i.e. projects at gerrit.automotivelinux.org).以下の開発向けドキュメントに詳細が記載されているのでご参考ください。
Welcome to the Automotive Grade Linux (AGL) documentation.
5_How_To_Contributeソースコード取得
以下を参考にソースコード取得します。
1.Define Your Top-Level Directoryexport AGL_TOP=$HOME/AGL echo 'export AGL_TOP=$HOME/AGL' >> $HOME/.bashrc mkdir -p $AGL_TOP
2.Download the repo Tool and Set Permissionsmkdir -p $HOME/bin export PATH=$HOME/bin:$PATH echo 'export PATH=$HOME/bin:$PATH' >> $HOME/.bashrc curl https://storage.googleapis.com/git-repo-downloads/repo > $HOME/bin/repo chmod a+x $HOME/bin/repo以下は
stableブランチではなく、masterブランチを取得する場合
3.Cutting-Edge Files: Using the "cutting-edge" AGL files gives you a snapshot of the "master" branch.cd $AGL_TOP mkdir master cd master repo init -u https://gerrit.automotivelinux.org/gerrit/AGL/AGL-repo repo synccommit用コード作成
元記事同様に、以下のような観点でcommit用コードを作成してみます。
commit用コード作成
いきなりの機能追加は大変なので、期限切れリンクの修正や、ビルドワーニング修正で何か貢献できないか、という観点で確認します。commitのための前準備
元記事記を参考に、前準備をします
AGLのコードリリースの際、
CIATという継続的インテグレーションの評価システムにcommitすることになります。
CIATについては以下が詳しいです。
Building and testing an automotive platform
How to Write Tests for the AGL HW Test Infra
20161210_第8回jenkins勉強会Gerrit Serverは以下URLからアクセスすることが可能です。
gerrit.automotivelinux.org
Building AGL with the Yocto Project - A Crashcourse -
Gerritはレビューシステムであり、commitは最終的にExpert Memberの承認を受けてMergeされます。
また、自動評価も実行されます。Gerrit上は以下の通り記載されています。CR : Code review V : Verified CIB : ci-image-build CIBT : ci-image-boot-testcommit手順
アカウント作成
以下を参考にLinuxFoundationのアカウント作成します。
Creating Linux Foundation ID
Go to the Linux Foundation ID website.上記Documentの通り作成し、Gerritにsign inできればOK
Access Gerrit by selecting Sign In, and use your new Linux Foundation account ID to sign in.
gerritのconfiguring
次に、gerritとssh通信できるようにします。commitのために必要です。
SSH key生成
こちらを参考に、
ssh-keygenします。
生成したprivate key,public keyのうち、public keyをgerrit側に登録します。public keyをgerritに登録
元記事同様に、こちらを参考に、gerritに生成した
public keyを登録します。(private keyではない)Finally, add the public key of the generated key pair to the Gerrit server, with the following steps:
1.Go to Gerrit.
2.Click on your account name in the upper right corner.
3.From the pop-up menu, select Settings.
4.On the left side menu, click on SSH Public Keys.
5.Paste the contents of your public key ~/.ssh/id_rsa.pub and click Add key.gerritとssh通信する際に正しい鍵ペアが使われるように、
~/.ssh/configに以下のように記載しておく。you need to create a ~/.ssh/config file modeled after the one below.
host gerrit.automotivelinux.org
HostName gerrit.automotivelinux.org
IdentityFile ~/.ssh/id_rsa_automotivelinux_gerrit
User
is your Linux Foundation ID and the value of IdentityFile is the name of the public key file you generated.いざ、commit
上記が完了し、修正ファイルも準備できたら、以下記事を参考にcommitを進めます。
コマンドは以下を参考
修正対象のリポジトリに移動し、remote branchが意図通りか確認する
(以下はmeta-aglにcommitする場合の例)cd meta-agl git remote -v agl https://gerrit.automotivelinux.org/gerrit/AGL/meta-agl (fetch) agl ssh://gerrit.automotivelinux.org:29418/AGL/meta-agl (push)修正対象ファイルを
git add,git commit --signoffする。git add (修正対象ファイル) git commit --signoff > Please sign you commit before you submit the change (otherwise it will not be accepted by gerrit): git commit --signoffremoteのレビューリクエスト用ブランチにpushする。
以下はmasterブランチにpushする場合。git push agl HEAD:refs/for/master # git push <remote> HEAD:refs/for/<targetbranch>以下記事のように、commitした内容がgerrit上から確認できればOK
Commit message記載の注意点
Commit messageはしっかり書く必要があります。(更新内容,JIRA番号,を記述する必要がある)
相手にどんな変更点かを伝える手段であるCommit メッセージを分かりやすく書く事は重要です。
特に、リモートで直接対話したことがない相手に対して意図を伝えるために尚更重要となります。
How to Write a Git Commit Message例えばbugを見つけた場合は、JIRAに類似bugがないかチェックの上、新規JIRAを発行して番号をcommit messageに書く必要がある。
Reporting bugs
If you are a user and you have found a bug, please submit an issue using JIRA. Before you create a new JIRA issue, please try to search the existing items to be sure no one else has previously reported it.commit messageのフォーマットは以下の記述を参考
4_Submitting_Changes
For example: One commit fixes whitespace issues, another renames a function and a third one changes the code's functionality. An example commit file is illustrated below in detail:
無事にmerge頂けました
簡単なtypo修正をcommitさせて頂いたところ、
無事にレビューを終え、Merged Statusになりました。
感想
何か至らぬ点がありましたら、アドバイス頂けると幸いです。
参考
Automotive Linux Wiki
Contributing to the AGL Distro
Welcome to the Automotive Grade Linux (AGL) documentation.


- 投稿日:2021-01-10T19:17:56+09:00
機械学習環境構築 macbook 2021
この記事は
macbook にML用の環境作る際の備忘録
随時更新されます
環境構築手順
Finder
新規Finderウィンドウで次を表示:の表示項目をドライブに変更しておく.
Notionのインストールについて。マルチユーザの場合は、ユーザディレクトリ配下の
Applicationディレクトリに配置する権限設定
基本的にマルチユーザで使うので権限与えておく.
(これを忘れてよくトラブル)
$ sudo chown -R $(whoami):admin /usr/local/* $ sudo chmod -R g+w /usr/local/*Mac を買ったら必ずやっておきたい初期設定 - Qiita
zshを使う
これからのデフォルトはzshになった。
もしまだbashの場合はzshにしておく。chsh -s /bin/zsh echo $SHELL cat /etc/shellszsh-autosuggestions/INSTALL.md at master · zsh-users/zsh-autosuggestions
git clone https://github.com/zsh-users/zsh-autosuggestions ~/.zsh/zsh-autosuggestions # .zshrcに追加 source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zshターミナル環境
補完に
fishと、テーマにstarshipを使います
ただしデフォルトシェルには設定しません.# terminal brew install fish brew install startship echo 'starship init fish | source' >> ~/.config/fish/config.fish echo 'alias c="clear"' >> ~/.config/fish/config.fishその他
# いけてるcat brew install batPython
# 以下fish環境です fish # shellはzsh echo $SHELL # /bin/zsh # pyenv brew install pyenv # pyenvの初期設定をfish設定ファイルに追加 echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.zshrc # fishをリロード exec fish pyenv install 3.7.9 pyenv global 3.7.9 pyenv rehash pyenv version which python3 python3 -V which pip3 # pipenv pip3 install --upgrade pip pip3 install pipenv pipenv install pandas numpy sklearn tqdm seaborn matplotlib japanize-matplotlib pipenv install --dev autopep8 yapf isort pipenv install --dev jupyter pipenv install --dev jupyter_contrib_nbextensions pipenv install --dev autopep8 yapf isort pipenv run jupyter contrib nbextension install --user pipenv run jupyter nbextension enable code_prettify/autopep8 pipenv run jupyter nbextension enable codefolding/main pipenv run jupyter nbextension enable hide_input_all/main pipenv run jupyter nbextension enable highlight_selected_word/main pipenv run jupyter nbextension enable code_prettify/isort pipenv run jupyter nbextension enable scratchpad/main pipenv run jupyter nbextension enable table_beautifier/main pipenv run jupyter nbextension enable zenmode/main pipenv run jupyter notebook --generate-config -y echo 'c.NotebookApp.password="sha1:ef7a7482cc53:6ad03768dd7e9ca09cf0e98c1c7238ee923f5917"' > ~/.jupyter/jupyter_notebook_config.pyshellについて
fishをデフォルトシェルにすると色々と面倒がありそう.
デフォルトはzshにしておいて、都度fishを呼び出す方法でやってみる。zsh
zshの設定ファイルの読み込み順序と使い方Tipsまとめ - Qiita
zshenv > zprofile > zshrc > zloginの順で読まれる
.zshenv
順序からもわかるようにどんな場合でも必ず最初に読み込まれる。
.zprofile
ログインシェルの場合に1度だけ読み込まれる。
.zshrc
ログインシェルとインタラクティブシェルの場合だけ読み込まれる。とりあえず. zshrcに書いておけば良さそうか.
- 投稿日:2021-01-10T19:11:44+09:00
面倒なので自動化するよ!~画像自動読み込み失敗編~
こんにちは!
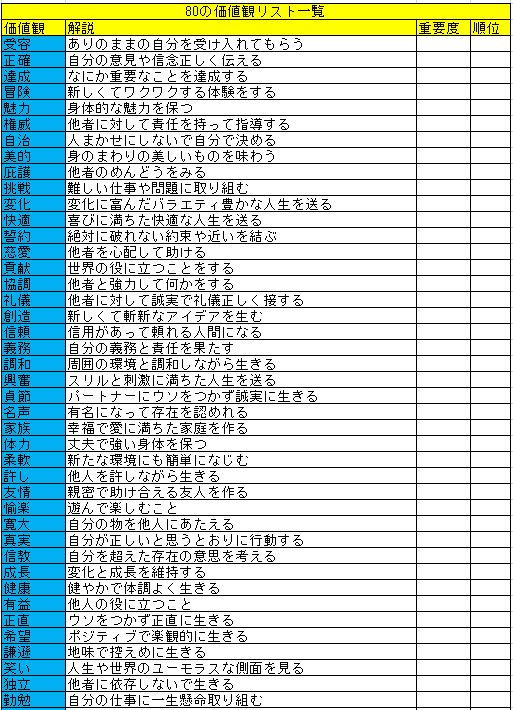
今回、年始の目標立案のために価値観リストを活用したいが、質問項目が画像のばかりみつかり打ち込むのが吐くほど面倒...
なので、文字の抽出を自動で行たいとおもいます。実行環境
mac
python3
環境anaconda画像を読み込む方法
・PIL(pillow)
・OpenCV
・scikit-image一番使われるのがPLIらしい。
pillowはpythonで代表的な画像処理ライブラリで、画像のリサイズや描画を容易に行うことができます。form PIL import Image,ImageFilter im = Image.open('画像ファイル名')テキストに変換する方法
・画像をテキストに変換する技術をOCR(Optical Character Recoding)という。
・OCRはOCRエンジンというソフトを使い、画像データからテキストを抽出する。
・今回はオープンソースのTesseract OCRを使用・また、PythonからOCRエンジンを使えるようにする代表的なライブラリがPyOCRです。
txt = tool.iamge_to_string( Image.open('画像ファイル名') lang=言語名, builder=pyocr.builders.TextBuilder() )実際にpng画像をテキストに変換してみる
brew install tesseractpyocrの日本語学習モデル取得のためにwgetもインストール
brew install wgetjpn.traineddataを取得
wget https://github.com/tesseract-ocr/tessdata/raw/4.00/jpn.traineddata mv jpn.traineddata /usr/local/Cellar/tesseract/4.1.1/share/tessdata※Pathが存在しない場合、以下コマンドでtesseractのpathとバージョン確認
which tessaract tessaract -v・コード実行
from PIL import Image import sys import pyocr import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = 'jpn' print("Will use lang '%s'" % (lang)) # Ex: Will use lang 'fra' # Note that languages are NOT sorted in any way. Please refer # to the system locale settings for the default language # to use. txt = tool.image_to_string( Image.open('target.png'), lang=lang, builder=pyocr.builders.TextBuilder() ) # txt is a Python string print(txt)変換元
変換結果
python3 Image-To-Text.py Will use tool 'Tesseract (sh)' Available languages: eng, jpn, osd, snum Will use lang 'jpn' あ ⑤ り の ま ま の ⑧② を る け れ て も ぅ う ⑧② の ⑧ 見 や ① ま ょ し く な ぇ る な に が 恒 美 な こ と そ ま a す る I し く て ワ ク ワ ク ⑨ る M を す る ⑯BAMN カ を ほ っ H ま に ガ し て き せ る 街 っ て fW す る ま セ に し Au で ⑧② で Aea ⑧ の ま わ り の 美 し D も の を 味 ち う HR&⑦⑥④ と ぅ そ a る iams aaliitcdiits ‥ た ロ ラ ェ テ ィ ま か ④ 入 $ を ま る EROEREfaiR ezRtd ⑤ @ れ な い B ま や igu を ほ o 医 ま そ i し て Ma ①⑧f の ① に ⑤ っ こ と を す る 医 ま と ③ カ し て M② を す る GEiESimEreiirimeikid IR し く て W な ァ イ テ ァ を ま ど 匣 が ⑤ っ て 種 れ aREe ⑧② の 製 阿 と 口 せ る 木 た す IIN の 現 M と 00 し ④ か ぅ ょ aa ス リ ル と BA に 迦 ぅ た ん キ を き ゃ ー に ド ク ッ そ っ 0 ず i き k 牡 き る な っ て な な を 品 h る ERte itha taiii Reaeimtiisaci R た ④ 琴 0 も mmWk な じ て N 入 そ f し な か ら ま き る IR⑧ て Mi+S ぇ る ぁ そ る 国 ん で ま し と こ と ⑧②0⑨ を ①A に ぁ た ぇ る ⑧② が ょ し い と ⑧ ぅ と ち り に B あ ず る ⑧② を 合 え た な な の 思 ⑧ そ き ぇ る R と R ま る M す や が で IM ょ く ま き る HA の ① に z っ こ と ② ソ を っ か ず E に ま き る ポ ッ テ ィ フ で ま W に よ き る ① 林 で R ス め に $ き る ム 生 M が の ユ ー ェ ュ ス な m を 見 る H&lcmtg し A い て で $ き る ⑧②0 せ 荷 に ー ま り 0 りきびしいですね...
画像の画質もあるのでしょうか、それともライブラリの問題でしょうか、どちらにせよ読めません...(追記)Cloud Vision APIの方が断然精度がよいです...
GoogleのAPI、さすが精度がよいですね。
時間を見つけて実装し直していきたいです。参考
https://aitanu.com/kachikan-list/
https://qiita.com/seigot/items/7d424000c8d35e5146e4
https://punhundon-lifeshift.com/tesseract_ocr
https://webkaru.net/dev/mac-wget-command-install/
https://cloud.google.com/vision/?hl=ja
- 投稿日:2021-01-10T19:09:05+09:00
Heapqを使ってみた
はじめに
pythonのheapqというライブラリを使って,ソートを行う方法を学んだのでメモしました.
heapqとは
- heapq: ヒープキューアルゴリズムを利用できるライブラリ.ヒープキューは優先度キューの一種.全ての親の値が,その全ての子の値以下であるようなツリー構造を持ち,その構造を利用して効率的に要素を取り出す.
- キュー:複数要素の並び
- 優先度キュー:ある優先度に従って要素を取り出す仕組みを持つキュー.
ヒープキューは,主にソートに用いられる(ヒープソート).
実行時間については,
全ての値の大小を比較するバブルソートの場合,$O(N^2)$.
対して,ヒープソートの場合,$O(NlogN)$.heapqを使って,leetcodeの問題を解いてみた
import heapq class KthLargest: def __init__(self, k: int, nums: List[int]): self.heap = [] self.k = k for num in nums: self.add(num) def add(self, val: int) -> int: heapq.heappush(self.heap, val) if len(self.heap) > self.k: heapq.heappop(self.heap) return self.heap[0]
- 投稿日:2021-01-10T18:33:33+09:00
【環境構築】JDLA認定のE資格対策口座であるラビットチャレンジのPython環境をDatabricksで実施する手順
概要
日本ディープラーニング協会のDeep Learning資格試験(E資格)の対策講座であるラビットチャレンジの学習環境を、無償でブラウザにより利用可能なDatabricks Community Editionで実施したので、共有します。
ラビットチャレンジとは
Study-AI株式会社が提供している自己学習を主体的に進めることが前提で提供されている、月額3000円で提供されている格安の対策口座です。
引用元:ラビット★チャレンジ Deep Learning (ai999.careers)Databricks Community Edition
Sparkによるビッグデータ処理やPythonやRによるデータ分析を実施可能なデータ統合データプラットフォーム(レイクハウス)のサービスであるDatabricksの無償環境です。
引用元:Databricks - 統合データ分析なぜDatabricksを利用するのか
Databricksで学習しておくことで、実際の業務で利用可能するためです。
Databricksは、AWSやAzureなどのマルチクラウドで提供されており、仮想ネットワーク上にデプロイできることからエンタープライズレベルのセキュリティ要件を満たすことができます。Anacondaは有償化されてしまい利用は難しいですし、Google Colabはセキュリティという観点で業務では利用できませんでした。
必要そうな環境
下記の環境が必要であり、最新版のDatabricks RuntimeだとKearas(スタンドアロン)がインストールされていないため、Databricks Runtime 6.4 MLを利用するのがよさそうです
- Python
- Pandas
- Numbpy
- tensolflow
- Kerasa(スタンドアロン)
Databricks Runtime 6.4 MLにインストールされているライブラリは、下記のドキュメントを参考にしてください
Databricks環境構築
Databricks Community Editonの申し込みます。
Try Databricksから申し込みを実施します。
引用元:Try Databricks下記にて、"COMMUNITY EDITION"を選択します。
引用元:Try Databricks届いたメールのリンクを設定します。
パスワードを設定します。
Databricksに接続できることを確認します。
講座を学習する際の手順
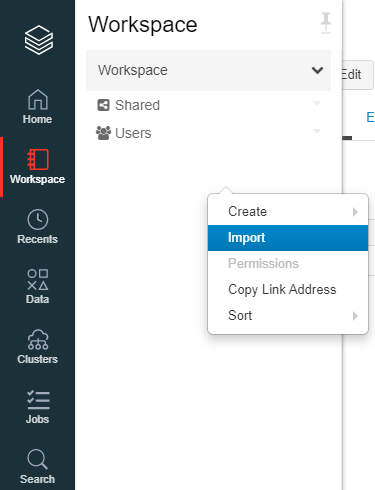
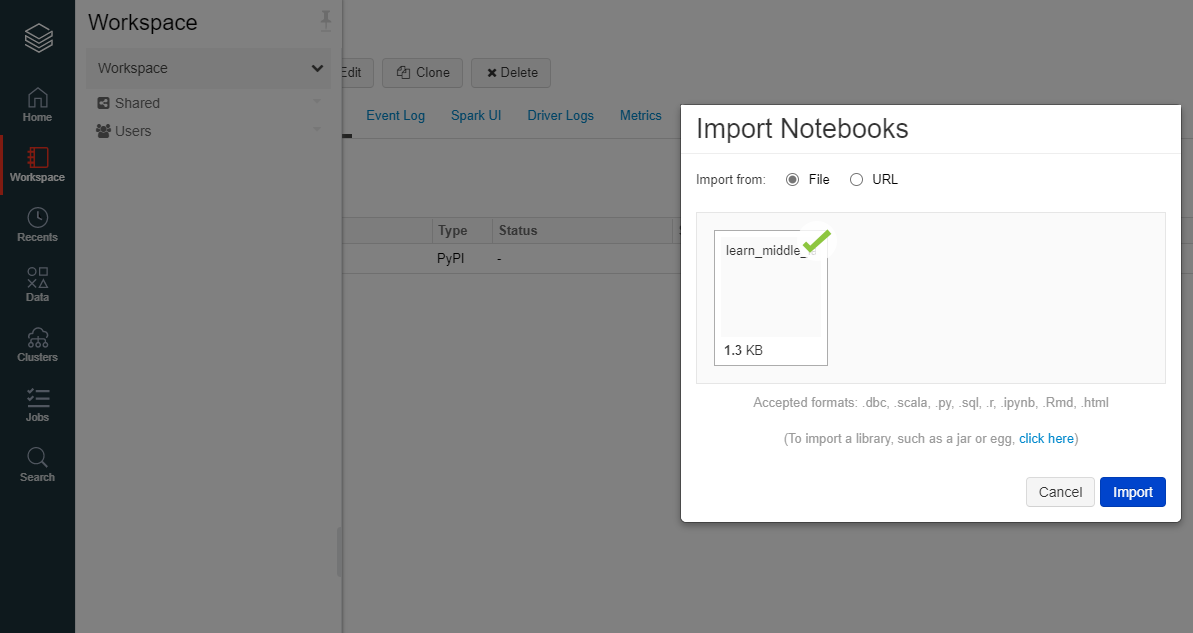
インポートするファイルをインポートします。フォルダーで取り込めないため、コマンドラインで一括で取り込んだほうが楽かもしれません。
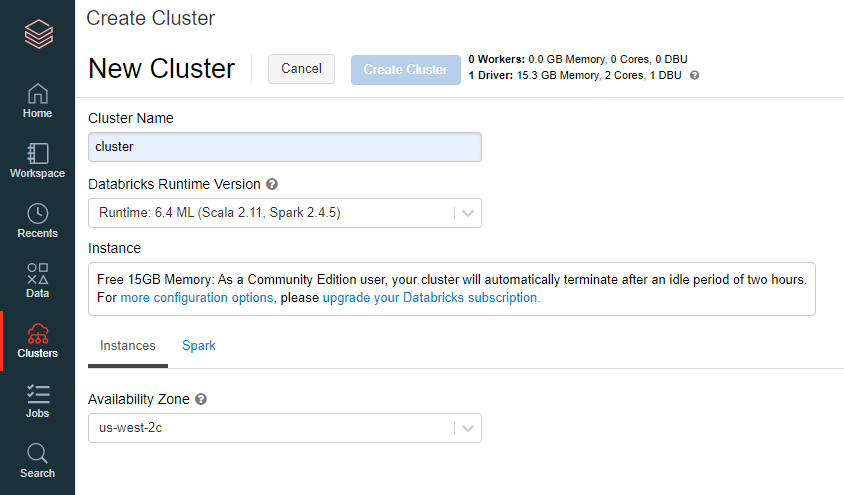
"Clustres"を右クリック後、"Cluster Name"に適当な名前を、"Databricks Runtime Version"を"Databricks Runtime 6.4 ML(Scala 2.11 Spark 2.4.5)"を入力し、"Create Cluster"を選択。
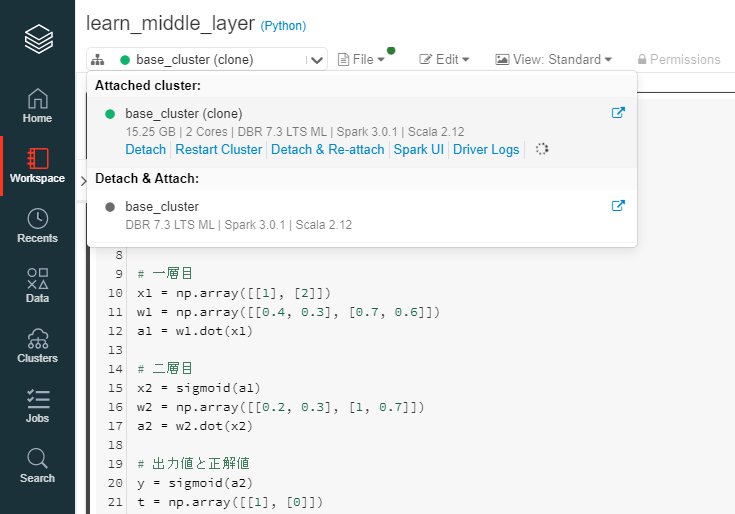
ノートブックを開き、クラスターをアタッチして、ノートブックを実行します。
本手順で学習する場合の注意事項
- Community Editionでは、GPUを利用することはできないこと
- 学習前に毎回クラスターをクローンにより作成する必要があること
- 学習コードのインポートをGUIで実施する場合にフォルダー単位で実施する必要があること



- 投稿日:2021-01-10T18:26:11+09:00
[翻訳] SLY (Sly Lex Yacc)
Python用の字句解析器と構文解析器の生成用ライブラリである、SLYのドキュメントを和訳しました。
原文はこちらです:https://sly.readthedocs.io/en/latest/sly.html訳語の選択に、サイエンス社のコンパイラ 原理・技法・ツール I & II(初版)とbison、flexの日本語訳を参考にしました。
ありがとうございます。SLY (Sly Lex Yacc)
本ドキュメントはSLYによる字句解析処理と構文解析処理の概要を紹介する。構文解析処理は本質的に複雑なため、SLYで大規模開発に当たる前に、本ドキュメント全体を(さわりだけでも)読むことを強く推奨する。
SLYはPython 3.6以上を必要とする。より古いバージョンを使っている場合、運が悪いと諦めること。すまんね。
前置き
SLYは構文解析器やコンパイラを記述するためのライブラリである。伝統あるコンパイラ生成ツールであるlexとyaccを手本とし、それらが用いるのと同様にLALR(1)構文解析アルゴリズムを実装している。lexとyaccで使える機能の大部分はSLYにも備わっている。SLYは付加機能(たとえば抽象構文木の自動生成機能や深さ優先巡回)を十分に提供していないことに注意せよ。また、これを構文解析フレームワークと捉えるべきでない。その代わり、Pythonによる構文解析器を記述用ライブラリとして十分な骨組みであることが分るだろう。
本ドキュメントの残りの部分は、読者が構文解析器の定石、構文主導翻訳、他言語向けのlexやyacc風コンパイラ生成ツールの用法に十分慣れ親しんでいることを想定している。これらの題目に不慣れなら、たとえばAho、 Sethi、Ullmanらによる"Compilers: Principles, Techniques, and Tools(コンパイラ―原理・技法・ツール)"などの入門書に当たるべきだろう。O'Reillyから出ているJohn Levineの"Lex and Yacc"も手頃だろう。実際、SLYの参考に実質的に同じ概念のものを扱うO'Reilly本が使用できる。
SLYの概要
SLYは2つの独立したクラス
LexerとParserを提供する。Lexerクラスは入力テキストを正規表現規則によって特定されるトークン列への分割処理に使用される。Parserクラスは文脈自由文法の形式で記述される言語構文の認識処理に使用される。構文解析器の作成には、通常、この2つのクラスが併用される。もちろん、これはそうした制限ではなく、柔軟に変更する余地がある。基本的な事項を次の2つのパートで説明する。字句解析器の記述
あるプログラミング言語の記述に際し、以下の文字列を構文解析したいと仮定しよう。
x = 3 + 42 * (s - t)構文解析の第一歩は、テキストをトークンに分割する処理である。トークンはそれぞれ型と値を持つ。上記のテキストは、以下のトークンタプルのリストとして記述することができる。
[ ('ID','x'), ('EQUALS','='), ('NUMBER','3'), ('PLUS','+'), ('NUMBER','42'), ('TIMES','*'), ('LPAREN','('), ('ID','s'), ('MINUS','-'), ('ID','t'), ('RPAREN',')') ]SLYの
Lexerクラスが、これを実行する。上記のテキストをトークン分割する、単純な字句解析器のサンプルがこちら。# calclex.py from sly import Lexer class CalcLexer(Lexer): # Set of token names. This is always required tokens = { ID, NUMBER, PLUS, MINUS, TIMES, DIVIDE, ASSIGN, LPAREN, RPAREN } # String containing ignored characters between tokens ignore = ' \t' # Regular expression rules for tokens ID = r'[a-zA-Z_][a-zA-Z0-9_]*' NUMBER = r'\d+' PLUS = r'\+' MINUS = r'-' TIMES = r'\*' DIVIDE = r'/' ASSIGN = r'=' LPAREN = r'\(' RPAREN = r'\)' if __name__ == '__main__': data = 'x = 3 + 42 * (s - t)' lexer = CalcLexer() for tok in lexer.tokenize(data): print('type=%r, value=%r' % (tok.type, tok.value))これを実行すると、以下の出力が生成される。
type='ID', value='x' type='ASSIGN', value='=' type='NUMBER', value='3' type='PLUS', value='+' type='NUMBER', value='42' type='TIMES', value='*' type='LPAREN', value='(' type='ID', value='s' type='MINUS', value='-' type='ID', value='t' type='RPAREN', value=')'字句解析器は公開メソッド
tokenize()を一つだけ備えている。これは、Tokenインスタンスのストリームを生成するジェネレータ函数となっている。Tokenのtype属性とvalue属性は、それぞれトークン型名と値を保持している。tokensのセット
字句解析器は、自身によって生成される可能性のあるあらゆるトークン型名を
tokensセットで規定しておく必要がある。これは常に必須で、様々な検証処理で使用される。トークン名を規定するコードの例。
class CalcLexer(Lexer): ... # Set of token names. This is always required tokens = { ID, NUMBER, PLUS, MINUS, TIMES, DIVIDE, ASSIGN, LPAREN, RPAREN } ...トークン名はすべて大文字で指定することが推奨される。
トークン照合パターンの仕様
トークンの指定は、
reモジュールと互換性のある正規表現規則の記述で行なう。規則の名称は、tokensセットで示したトークン名のいずれか一つに対応させる必要がある。例)PLUS = r'\+' MINUS = r'-'可読性を向上させるため、正規表現パターンは
re.VERBOSEフラグをつけてコンパイルされる。このモードでは、エスケープされていない空白文字は無視され、コメントの記述も許可される。パターンに空白文字を含める場合、\sを使用する。#文字の照合には、[#]か\#を使う。
Lexerクラスにリストされたパターンの順序が、トークンの照合順序となる。長めのトークンは、短めのトークンより常に先に指定しておかれなければならない。たとえば、=と==のトークンを区別したい場合、==を先に指定する必要がある。例)class MyLexer(Lexer): tokens = { ASSIGN, EQ, ...} ... EQ = r'==' # MUST APPEAR FIRST! (LONGER) ASSIGN = r'='破棄テキスト
入力ストリーム中で無視すべき単一文字の集まりを指定するために、
ignore特殊指定が用意されている。通常、これは、空白文字やその他不要な文字の読み飛ばし処理で使用される。ignoreに文字が指定されていても、正規表現パターンの一部として含まれているその文字は無視されない。たとえば、引用符で括られたテキストの規則があるとき、そのパターンにignore指定された文字が含まれていてもおかしくない。ignoreは主として、構文解析処理の対象となるトークンの隙間にある空白文字やその他のパディングを無視するために使われる。また、名称に接頭子
ignore_付けた正規表現ルールを記述することで、それ以外のテキストパターンを破棄することができる。例えば、次の構文解析器はコメントと改行を無視する規則を備えている。# calclex.py from sly import Lexer class CalcLexer(Lexer): ... # String containing ignored characters (between tokens) ignore = ' \t' # Other ignored patterns ignore_comment = r'\#.*' ignore_newline = r'\n+' ... if __name__ == '__main__': data = '''x = 3 + 42 * (s # This is a comment - t)''' lexer = CalcLexer() for tok in lexer.tokenize(data): print('type=%r, value=%r' % (tok.type, tok.value))照合動作の追加
特定トークンの照合時に、照合に加えて何らかの追加動作を実行したい場合がある。例えば、数値の変換処理や言語の予約語の検索処理などがある。これを実施する一つの手法として、その動作をメソッドとして記述し、それを紐付ける正規表現を
@_()デコレータで付与する。@_(r'\d+') def NUMBER(self, t): t.value = int(t.value) # Convert to a numeric value return tこのメソッドは単一引数を持ち、
Token型のインスタンスを受け取る。規定動作では、t.typeにトークンの名称('NUMBER'など)が格納されている。必要に応じ、函数内でトークン型やトークン値を変更して良い。最後に、戻り値として処理後のトークンが返される必要がある。函数が戻り値を返さない場合、そのトークンは破棄され、次のトークンが読み込まれる。
@_()デコレータはLexerクラス内に自動的に定義される。このため、importなどは不要である。正規表現規則を複数持たせても良い。例:@_(r'0x[0-9a-fA-F]+', r'\d+') def NUMBER(self, t): if t.value.startswith('0x'): t.value = int(t.value[2:], 16) else: t.value = int(t.value) return t
@_()デコレータを使用する代わりに、文字列で指定したトークンと同名のメソッドを直後に記述してもよい。例:NUMBER = r'\d+' ... def NUMBER(self, t): t.value = int(t.value) return tこの手法は字句解析器のデバッグで役立つ可能性がある。メソッドをトークンに一時的に紐付け、トークン出現時にそれを実行させることができる。用が済んだらそのメソッドを取り除き、字句解析器の挙動を元に戻すことができる。
トークンの再割り当て
特定条件の下でトークンの再割り当てが必要になる場合がある。"abc"、"python"、"guido"などの識別子を照合する場合を考えてみよう。"if"、"else"、"while"など特定の識別子は、特殊キーワードとして扱われるべきである。字句解析器の記述にトークン再割り当て規則を含めることで、これを実現できる。
# calclex.py from sly import Lexer class CalcLexer(Lexer): tokens = { ID, IF, ELSE, WHILE } # String containing ignored characters (between tokens) ignore = ' \t' # Base ID rule ID = r'[a-zA-Z_][a-zA-Z0-9_]*' # Special cases ID['if'] = IF ID['else'] = ELSE ID['while'] = WHILE識別子の解析時に、この特例が特定トークンの照合値を新しいトークン型で置き換える。上の例では、識別子の値が"if"の場合に
IFトークンが生成される。行番号と位置の追跡
規定動作では、字句解析器は行番号について何も関知しない。字句解析器に入力の"行"に関する定義(たとえば改行文字や、そもそも入力がテキストデータかどうかなど)が与えられていない、というのがその理由である。そうした情報を与えるために、改行に関する特例指定を追加してもい。
ignore_newline特例でこれを実施してみよう。# Define a rule so we can track line numbers @_(r'\n+') def ignore_newline(self, t): self.lineno += len(t.value)特例により、字句解析器のlineno属性が更新されるようになった。行番号が更新された後、何も返していないためそのトークンは破棄される。
字句解析器は桁位置追跡に類することを自動で行なわない。その代わり、トークンの
index属性に個々のトークンの位置情報を記録する。これを使用することで。桁位置を算出できる可能性がある。たとえば、直前の改行が見つかるまで後方検索を行なっても良い。# Compute column. # input is the input text string # token is a token instance def find_column(text, token): last_cr = text.rfind('\n', 0, token.index) if last_cr < 0: last_cr = 0 column = (token.index - last_cr) + 1 return column桁位置情報はエラー処理の文脈でのみ必要とされる。このため桁位置の計算処理は各トークンに対してではなく、必要に応じて実施できるようになっている。
文字定数
文字定数をクラスの
literalsセットで定義することができる。例)class MyLexer(Lexer): ... literals = { '+','-','*','/' } ...文字定数は、字句解析器から遭遇した"まま"の状態で返される、単なる単一文字である。文字定数は、定義済み正規表現規則すべての後に確認される。そのため、文字定数のいずれか一文字を先頭に持つルールは、文字定数より優先される。
文字定数は、その返却時に
type属性とvalue属性にその文字自身が格納される。 例)'+'定数が照合された時に実行される追加動作として、トークンメソッドを記述することができる。ただし、そのトークンメソッドは適切なトークン型を設定するように実装されなければならない。例:
class MyLexer(Lexer): literals = { '{', '}' } def __init__(self): self.nesting_level = 0 @_(r'\{') def lbrace(self, t): t.type = '{' # Set token type to the expected literal self.nesting_level += 1 return t @_(r'\}') def rbrace(t): t.type = '}' # Set token type to the expected literal self.nesting_level -=1 return tエラー処理
字句解析中に不正な文字が検出されると、字句解析処理は停止する。これに対し、字句解析エラーを処理する
error()メソッドを追加することができる。エラー処理メソッドはTokenを一つ受け取る。このトークンのvalue属性には、トークン化される前のテキスト全体が格納されている。典型的なハンドラーは、このテキストを見て、何らかの方法で読み飛ばし処理を行なう。例:class MyLexer(Lexer): ... # Error handling rule def error(self, t): print("Illegal character '%s'" % t.value[0]) self.index += 1このケースでは、そこで問題となっている文字を印字し、字句解析の位置情報を更新することで1文字の読み飛ばし処理を実施する。解析器のエラー処理は、多くの場合、難しい問題を引き起こす。エラー処理では、セミコロン、空行や、それに類する記号といった、論理的に判断できる同期箇所までの読み飛ばし処理が必要になるだろう。
error()メソッドが未処理のトークンを返すと、ストリームにERRORトークンが出現する。これは、構文解析器がエラートークンを確認したい場合、たとえば、エラーメッセージの改良やその他エラー処理を行なうのに役立つ。より完全な例
参考用に、これらの多くの概念を実践するより完全な例を示す。
# calclex.py from sly import Lexer class CalcLexer(Lexer): # Set of token names. This is always required tokens = { NUMBER, ID, WHILE, IF, ELSE, PRINT, PLUS, MINUS, TIMES, DIVIDE, ASSIGN, EQ, LT, LE, GT, GE, NE } literals = { '(', ')', '{', '}', ';' } # String containing ignored characters ignore = ' \t' # Regular expression rules for tokens PLUS = r'\+' MINUS = r'-' TIMES = r'\*' DIVIDE = r'/' EQ = r'==' ASSIGN = r'=' LE = r'<=' LT = r'<' GE = r'>=' GT = r'>' NE = r'!=' @_(r'\d+') def NUMBER(self, t): t.value = int(t.value) return t # Identifiers and keywords ID = r'[a-zA-Z_][a-zA-Z0-9_]*' ID['if'] = IF ID['else'] = ELSE ID['while'] = WHILE ID['print'] = PRINT ignore_comment = r'\#.*' # Line number tracking @_(r'\n+') def ignore_newline(self, t): self.lineno += t.value.count('\n') def error(self, t): print('Line %d: Bad character %r' % (self.lineno, t.value[0])) self.index += 1 if __name__ == '__main__': data = ''' # Counting x = 0; while (x < 10) { print x: x = x + 1; } ''' lexer = CalcLexer() for tok in lexer.tokenize(data): print(tok)このコードを実行すると、次のような出力が得られる。
Token(type='ID', value='x', lineno=3, index=20) Token(type='ASSIGN', value='=', lineno=3, index=22) Token(type='NUMBER', value=0, lineno=3, index=24) Token(type=';', value=';', lineno=3, index=25) Token(type='WHILE', value='while', lineno=4, index=31) Token(type='(', value='(', lineno=4, index=37) Token(type='ID', value='x', lineno=4, index=38) Token(type='LT', value='<', lineno=4, index=40) Token(type='NUMBER', value=10, lineno=4, index=42) Token(type=')', value=')', lineno=4, index=44) Token(type='{', value='{', lineno=4, index=46) Token(type='PRINT', value='print', lineno=5, index=56) Token(type='ID', value='x', lineno=5, index=62) Line 5: Bad character ':' Token(type='ID', value='x', lineno=6, index=73) Token(type='ASSIGN', value='=', lineno=6, index=75) Token(type='ID', value='x', lineno=6, index=77) Token(type='PLUS', value='+', lineno=6, index=79) Token(type='NUMBER', value=1, lineno=6, index=81) Token(type=';', value=';', lineno=6, index=82) Token(type='}', value='}', lineno=7, index=88)この例をもう少し掘り下げてみよう。解釈に時間がかかるかもしれないが、字句解析器の記述の要点が、すべてここに示されている。トークンは正規表現ルールで指定されなければならない。一定のパターンが検出された場合に実行される動作を付随させることができる。文字定数などのいくつかの機能により、正規表現ルールを個別に作成する手間を省ける。また、エラー処理を追加することもできる。
構文解析器の記述
Parserクラスは言語構文の構文解析に使用される。例を示す前に、押さえておくべき背景知識がいくつか存在する。構文解析の背景知識
構文解析器の記述を行う際、通常、構文はBNF記法で定義される。たとえば単純な数式を構文解析する場合、最初に、曖昧さを排除した次のような文法仕様を記述する。
expr : expr + term | expr - term | term term : term * factor | term / factor | factor factor : NUMBER | ( expr )文法の中にある
NUMBER、+、-、*、/などの記号は終端記号と呼ばれ、生の入力トークンに対応している。term、factorなどの識別子は、終端記号の集合とその他規則で構成される文法規則を参照する。これらの識別子は 非終端記号として知られている。文法を複数の階層(expr、termなど)に分割することで、扱いが異なる演算子の優先順位規則を組み込むことができる。この例では、乗算と除算の方が加算と減算よりも優先される。構文解析の中で生じる意味(semantics)は、多くの場合、構文主導翻訳として知られる手法で定義される。構文主導翻訳において、文法の中にある記号は一つの対象物として扱われる。各種文法規則が認識されると、値が記号に割り当てられ、それらの値に対する操作が実行される。先に取り上げた数式の文法が与えられたとき、以下のようにして、単純な計算機の計算処理を以下のように記述できる。
Grammar Action ------------------------ -------------------------------- expr0 : expr1 + term expr0.val = expr1.val + term.val | expr1 - term expr0.val = expr1.val - term.val | term expr0.val = term.val term0 : term1 * factor term0.val = term1.val * factor.val | term1 / factor term0.val = term1.val / factor.val | factor term0.val = factor.val factor : NUMBER factor.val = int(NUMBER.val) | ( expr ) factor.val = expr.valこの文法において、新しい値は
NUMBERトークンを通して導入される。これらの値は上で示した動作によって伝搬される。例えば、factor.val = int(NUMBER.val)がNUMBERの値をfactorへ伝搬する。term0.val = factor.valがfactorの値をtermに伝搬する。expr0.val = expr1.val + term1.valのような規則が値の結合を実施し、更にその先へと値を伝搬する。数式2 + 3 * 4のなかで値がどのように伝搬されていくかを以下に示す。NUMBER.val=2 + NUMBER.val=3 * NUMBER.val=4 # NUMBER -> factor factor.val=2 + NUMBER.val=3 * NUMBER.val=4 # factor -> term term.val=2 + NUMBER.val=3 * NUMBER.val=4 # term -> expr expr.val=2 + NUMBER.val=3 * NUMBER.val=4 # NUMBER -> factor expr.val=2 + factor.val=3 * NUMBER.val=4 # factor -> term expr.val=2 + term.val=3 * NUMBER.val=4 # NUMBER -> factor expr.val=2 + term.val=3 * factor.val=4 # term * factor -> term expr.val=2 + term.val=12 # expr + term -> expr expr.val=14SLYは、LR構文解析、または、移動還元構文解析(shift-reduce parsing)として知られる構文解析技法を使用する。LR構文解析法は、様々な文法規則の右辺の認識を試行する、ボトムアップ手法である。入力されたものの中に(文法定義の)右辺に適合するものが見つかると、それに沿った動作メソッドが実行され、右辺に相当する文法記号群が左辺の文法記号で置換される。
LR構文解析は、一般的に、文法記号をスタックに移動(shift)する処理と、スタックと次の入力が文法規則の型にはまるかどうかを試行する処理で実装されている。アルゴリズムの詳細はコンパイラの教科書を見れば分るだろう。次の例は数式
3 + 5 * (10 - 20)を上で定義した文法で構文解析する過程を示す。この例のなかで、特殊記号$は入力の終端を示す。---- --------------------- --------------------- ------------------------------- 1 3 + 5 * ( 10 - 20 )$ Shift 3 2 3 + 5 * ( 10 - 20 )$ Reduce factor : NUMBER 3 factor + 5 * ( 10 - 20 )$ Reduce term : factor 4 term + 5 * ( 10 - 20 )$ Reduce expr : term 5 expr + 5 * ( 10 - 20 )$ Shift + 6 expr + 5 * ( 10 - 20 )$ Shift 5 7 expr + 5 * ( 10 - 20 )$ Reduce factor : NUMBER 8 expr + factor * ( 10 - 20 )$ Reduce term : factor 9 expr + term * ( 10 - 20 )$ Shift * 10 expr + term * ( 10 - 20 )$ Shift ( 11 expr + term * ( 10 - 20 )$ Shift 10 12 expr + term * ( 10 - 20 )$ Reduce factor : NUMBER 13 expr + term * ( factor - 20 )$ Reduce term : factor 14 expr + term * ( term - 20 )$ Reduce expr : term 15 expr + term * ( expr - 20 )$ Shift - 16 expr + term * ( expr - 20 )$ Shift 20 17 expr + term * ( expr - 20 )$ Reduce factor : NUMBER 18 expr + term * ( expr - factor )$ Reduce term : factor 19 expr + term * ( expr - term )$ Reduce expr : expr - term 20 expr + term * ( expr )$ Shift ) 21 expr + term * ( expr ) $ Reduce factor : (expr) 22 expr + term * factor $ Reduce term : term * factor 23 expr + term $ Reduce expr : expr + term 24 expr $ Reduce expr 25 $ Success!数式の構文解析を行なう時、背後にある状態機械と手元の入力トークンによって次の動作が決定される。次のトークンが(スタック上の要素と併せて)有効な文法規則の一部として見なされると、そのトークンはスタック上に移動される(積まれる)。スタックの先頭部分が文法ルールの右辺に適合すると、それが"還元(reduce)"され、それらの記号群が左辺のシンボルに置き換えられる。この還元が発生したときに、それに対応する動作が(あれば)実行される。入力トークンが移動されず、スタックの先頭がいずれの文法規則にも適合しない場合、構文エラーが発生し、構文解析器は復旧手順をとるか救済処置を行なう必要がある。構文解析スタックが空でかつ入力トークンがなくなったとき、唯一、構文解析が成功したものとみなされる。
裏側にある巨大な有限状態機械が、巨大な表の集まりで実装されていることに留意しなければならない。これらの表の構成法は単純ではなく、説明の範囲を超えている。この上の例9段階目で構文解析器が
expr : expr + termを還元する代わりにトークンをスタックに移動するその理由は、手順の詳細を見ることで解き明かされる。構文解析の例
先に紹介したような単純な算術計算式を評価する構文解析器を作成したいと仮定する。SLYでそれを実現するにはこのようにする。
from sly import Parser from calclex import CalcLexer class CalcParser(Parser): # Get the token list from the lexer (required) tokens = CalcLexer.tokens # Grammar rules and actions @_('expr PLUS term') def expr(self, p): return p.expr + p.term @_('expr MINUS term') def expr(self, p): return p.expr - p.term @_('term') def expr(self, p): return p.term @_('term TIMES factor') def term(self, p): return p.term * p.factor @_('term DIVIDE factor') def term(self, p): return p.term / p.factor @_('factor') def term(self, p): return p.factor @_('NUMBER') def factor(self, p): return p.NUMBER @_('LPAREN expr RPAREN') def factor(self, p): return p.expr if __name__ == '__main__': lexer = CalcLexer() parser = CalcParser() while True: try: text = input('calc > ') result = parser.parse(lexer.tokenize(text)) print(result) except EOFError: breakこの例では、各文法規則は
@_(rule)によってデコレートされたメソッドとして記述されている。一番最初の文法規則(BNF記法の中で最初の規則)は、構文解析の最上位を定義する。各メソッドの名称は、構文解析対象となる文法ルールの名称と一致している必要がある。@_()デコレータの引数には、文法の右辺を記述する文字列文字列となっている。以下のような文法規則は、expr : expr PLUS termこのようなメソッドになる。
Python
@_('expr PLUS term')
def expr(self, p):
...
入力の中で文法規則が認識されると、そのメソッドが起動される。メソッドは文法記号値のシーケンスを引数
pで受け取る。これらのシンボルを参照する方法が二つある。一つ目は、以下のようにシンボル名を使用する。@_('expr PLUS term') def expr(self, p): return p.expr + p.term他にも、配列と同じようにpのインデックスを扱える。
@_('expr PLUS term') def expr(self, p): return p[0] + p[2]トークンの
p.symbolやp[i]には、構文解析器がトークンに割り当てるp.value属性と同じ値が割り当てられている。非終端記号では、規則の中でメソッドに返された値になっている。文法規則に同じ記号名が複数含まれている場合、記号名を明確に区別するために数字を末尾に追加する必要がある。例:
@_('expr PLUS expr') def expr(self, p): return p.expr0 + p.expr1最後に、各規則内で値を返却し、文法記号に対応させる必要がある。このようにして、文法内で値が伝搬される。
文法の中で、これとは違う種類の動作をしても良い。たとえば、文法定義で構文木の一部を生成しても良い。
@_('expr PLUS term') def expr(self, p): return ('+', p.expr, p.term)また、抽象構文木に関連したインスタンスを作成しても良い。
class BinOp(object): def __init__(self, op, left, right): self.op = op self.left = left self.right = right @_('expr PLUS term') def expr(self, p): return BinOp('+', p.expr, p.term)記号(ここでは"expr")に関連付けする値をメソッドが返すことが大切である。これは前節で示した値の伝搬である。
文法規則函数の組み合わせ
文法規則が似ている場合、単一のメソッドに統合しても良い。たとえば、1つの構文木を生成する規則が2つ存在するとしよう。
Python
```
@_('expr PLUS term')
def expr(self, p):
return ('+', p.expr, p.term)@_('expr MINUS term')
def expr(self, p):
return ('-', p.expr, p.term)
```2つの函数の代わりに、単一の函数を以下のように記述しても良い。
@_('expr PLUS term', 'expr MINUS term') def expr(self, p): return (p[1], p.expr, p.term)この例では、演算子は
PLUSかMINUSのどちらかになる。シンボル名を値として使用することはできないので、代わりにp[1]のように配列操作を行なうとよい。一般的に、 あるメソッドの
@_()デコレータに複数の文法規則を与えることが許される。単一函数に複数の文法ルールを組み込む場合、すべての規則が同じ構造をとっている(例えば、項とシンボル名の数が一致している)必要がある。さもないと、それを対処するアクションコードが必要以上に複雑になる可能性がある。文字リテラル
必要に応じ、文法に単一文字からなるトークンを含めることができる。例:
@_('expr "+" term') def expr(self, p): return p.expr + p.term @_('expr "-" term') def expr(self, p): return p.expr - p.term文字リテラルは、必ず
"+"のように引用服で括る必要がある。加えて、対応する字句解析器クラスのliteralsでそれらを宣言しておく必要がある。class CalcLexer(Lexer): ... literals = { '+','-','*','/' } ...文字定数は、単一文字に限られる。つまり、
<=、==のような定数の指定は合法ではない。こうした定数は、通常の字句解析規則に従う必要がある(たとえば、LE = r'<='のような規則を定義する)。空の生成規則
何も生成したくない場合、以下のような規則を定義する。
@_('') def empty(self, p): pass空の生成規則を使用する場合、"empty" という名前をシンボルとして使用するとよい。省略可能な要素を規則に組み込む必要がある場合、以下のようにする。
spam : optitem grok optitem : item | emptySLYでは以下のように組み込む。
@_('optitem grok') def spam(self, p): ... @_('item') def optitem(self, p): ... @_('empty') def optitem(self, p): ...注:空の文字列を指定することで、どこにでも空のルールを記述できる。一方、"empty"規則を記述し、それが何も生成しない"空"であることを明記することで、可読性が上がり、意図がより明確に示される。
曖昧な文法の対処法
先に示した数式の文法は、曖昧さを排除するため特別な書式で記述されている。しかし、多くの場合、この書式で文法を記述するのはとても困難かつ厄介なものになる。より自然な文法の記法は、以下のようなコンパクトな記法である。
expr : expr PLUS expr | expr MINUS expr | expr TIMES expr | expr DIVIDE expr | LPAREN expr RPAREN | NUMBER残念なことに、この文法仕様には曖昧さがある。例えば、文字列"3 * 4 + 5"を構文解析するとき、演算子がどのようにグループ化されるかを判断する方法がない。この式は"(3 * 4) + 5"だろうか、さもなくば"3 * (4+5)"だろうか?
曖昧な文法が与えられると、"shift/reduce conflicts"や"reduce/reduce conflicts"といったメッセージが表示される。shift/reduce conflict(シフト/還元衝突)は、構文解析器生成器が規則を還元するか、解析スタック上のシンボルをシフトするかを判断できない場合に発生する。例えば、文字列"3 * 4 + 5"の構文解析の内部スタックを考えてみよう。
Step Symbol Stack Input Tokens Action ---- ------------- ---------------- ------------------------------- 1 $ 3 * 4 + 5$ Shift 3 2 $ 3 * 4 + 5$ Reduce : expr : NUMBER 3 $ expr * 4 + 5$ Shift * 4 $ expr * 4 + 5$ Shift 4 5 $ expr * 4 + 5$ Reduce: expr : NUMBER 6 $ expr * expr + 5$ SHIFT/REDUCE CONFLICT ????この例の構文解析器は、6番目の段階に到達したとき、2つの選択肢がある。一つは、規則
expr : expr * exprをスタック上で還元することである。もう一つの選択肢は、トークン+をスタックに移動することである。両選択肢とも、文脈自由文法の規則上完全に合法である。通常、すべての移動/還元衝突は移動の選択によって解決される。それ故に、上記の例の構文解析器は、+を還元せずに移動する。この戦略は多くの場合上手く働く(たとえば"if-then"と"if-then-else")が、算術計算式ではそうならない。実際、上記の例において、+の移動は完全に誤りである。乗算は加算より算術の優先順位が高く、
expr * exprの還元を選択するべきである。特に計算式の文法において、曖昧さを解決するために、SLYはトークンに対し優先順位と結合規則の割り当てを許している。これを実現するには、構文解析器クラスに変数
precedenceを追加すれば良い。class CalcParser(Parser): ... precedence = ( ('left', PLUS, MINUS), ('left', TIMES, DIVIDE), ) # Rules where precedence is applied @_('expr PLUS expr') def expr(self, p): return p.expr0 + p.expr1 @_('expr MINUS expr') def expr(self, p): return p.expr0 - p.expr1 @_('expr TIMES expr') def expr(self, p): return p.expr0 * p.expr1 @_('expr DIVIDE expr') def expr(self, p): return p.expr0 / p.expr1 ...この
precedence指定はPLUS/MINUSが同じ優先順位で左結合、TIMES/DIVIDEが同じ優先順位で左結合であることを指定している。precedence指定の中で、トークンは底優先度から高い優先度の順に並べられる。従って、この指定は、優先度指定の後部にあるTIMES/DIVIDEがPLUS/MINUSより高い優先度を持つことを指定している。優先順位指定は、優先順位レベル値や結合方向をトークンに関連付けることによって機能する。たとえば、上記の例では以下が得られる。
PLUS : level = 1, assoc = 'left' MINUS : level = 1, assoc = 'left' TIMES : level = 2, assoc = 'left' DIVIDE : level = 2, assoc = 'left'次に、これらの数値は、優先順位レベル値や結合方向を個々の分布規則に付与するために使用される。_常にこれらは右端の終端記号の値によって決定される。例:
expr : expr PLUS expr # level = 1, left | expr MINUS expr # level = 1, left | expr TIMES expr # level = 2, left | expr DIVIDE expr # level = 2, left | LPAREN expr RPAREN # level = None (not specified) | NUMBER # level = None (not specified)移動/還元衝突が発生すると、構文解析器生成器は優先順位規則や結合の指定を用いて衝突の解決を行なう。
- 現在のトークンがスタック上の規則より高い優先順位を持つ場合、それは移動される。
- スタック上の文法規則が高い優先順位を持つ場合、それは還元される。
- 現在のトークンと文法規則が同じ優先順位を持つ場合、左結合であれば規則が還元され、右結合であればトークンは移動される。
- 優先順位についての情報が存在しない場合、移動/還元衝突は規定動作の移動によって解決される。
たとえば、
expr PLUS exprが構文解析された次のトークンとしてTIMESが来たとする。TIMESの優先順位レベルはPLUSより高いため、移動が行なわれる。逆に、expr TIMES exprが構文解析され次のトークンとしてPLUSが来たとする。PLUSの優先順位はTIMESより低いため、還元が行なわれる。優先順位規則があっても三番目の手法で移動/還元衝突が解決されたときSLYはエラーや衝突を報告しない。
優先順位指定の手法には一つ問題がある。特定の文脈で優先順位を変えたくなる場合がある。たとえば、
3 + 4 * -5にある単項マイナス演算子を考えよう。数学的には、単項マイナスは通常非常に高く、優先順位–乗算の前に評価される。しかしながら、我々の優先順位指定では、MINUSはTIMESより低い優先順位を持っている。これに対処するため、"架空のトークン"と呼ばれる優先順位規則を与えることができる。class CalcParser(Parser): ... precedence = ( ('left', PLUS, MINUS), ('left', TIMES, DIVIDE), ('right', UMINUS), # Unary minus operator )ここで、文法ファイルに単項マイナスの規則を記述する。
@_('MINUS expr %prec UMINUS') def expr(p): return -p.exprこの例では、
%prec UMINUSが規定規則による優先順位設定を、UMINUSの優先順位で上書きする。初見だと、この例にある
UMINUSの用法が、非常に紛らわしく見えるかもしれない。UMINUSは入力トークンでも文法規則でもない。これは、優先順位表の中の特殊マーカーに付けた名称と考えると良い。%prec修飾子を使用するとき、SLYに対し、その式の優先順位を通常の優先順位ではなく、特殊マーカーの優先順位と同様とするよう伝えていることになる。また、優先順位表の中で、結合なしを指定することもできる。このやり方は、演算子同士を連続して使いたくないときに使われる。たとえば、
<と>の比較演算子をサポートしたいが、a < b < cのような組み合わせは求めていないと仮定する。このために、優先順位を以下のように指定する。... precedence = ( ('nonassoc', LESSTHAN, GREATERTHAN), # Nonassociative operators ('left', PLUS, MINUS), ('left', TIMES, DIVIDE), ('right', UMINUS), # Unary minus operator )こうすることで、
a < b < cのような入力テキストに対し、構文エラーが生成される。もちろん、a < bのような単純な式に対してはうまくいく。還元/還元衝突は、与えられた記号のセットに対し、複数の文法規則が適用可能なときに引き起こされる。この類いの衝突はほぼ必ず間違いである。この衝突は文法ファイルの中で最初に現れた規則によって解決される。異なる文法規則の集合が、何らかの形で同じ記号のセットを生成しようとする場合に、還元/還元衝突が発生する。例:
assignment : ID EQUALS NUMBER | ID EQUALS expr expr : expr PLUS expr | expr MINUS expr | expr TIMES expr | expr DIVIDE expr | LPAREN expr RPAREN | NUMBERこの例では、2つの規則の間で還元/還元衝突が存在する。
assignment : ID EQUALS NUMBER expr : NUMBERたとえば、
a = 5を構文解析しているとき、構文解析器はassignment : ID EQUALS NUMBERを還元するべきか、または5をexpressionとして還元してさらにassignment : ID EQUALS expr規則を還元するべきかを特定できない。文法から還元/還元衝突を見つけ出すのが難しい、ということは周知の事実である。還元/還元衝突が発生すると、SLYは以下のような警告文を出して、助けを求める。
WARNING: 1 reduce/reduce conflict WARNING: reduce/reduce conflict in state 15 resolved using rule (assignment -> ID EQUALS NUMBER) WARNING: rejected rule (expression -> NUMBER)このメッセージは、衝突状態にある規則が2つ存在することを特定している。しかし、なぜ構文解析器がそのような結論を出したかについて、このメッセージはなにも伝えてくれない。これを特定するためには、適度に高濃度なカフェイン添加を以て、文法と、構文解析器のデバッグファイルの内容を調べる必要があるだろう。
構文解析器のデバッグ
LR構文解析アルゴリズムの使用の中でも、移動/還元衝突と還元/還元衝突の掘り下げは歓喜の一言に尽きる。デバッグ処理を支援するため、SLYの構文解析表の作成時にデバッグファイルを出力させることができる。これには、クラスに
debugfile属性を追加する。class CalcParser(Parser): debugfile = 'parser.out' ...このようにすると、指定したファイルに文法全体と、構文解析の状態が出力される。構文解析器の状態は以下のような形式で出力される。
state 2 (7) factor -> LPAREN . expr RPAREN (1) expr -> . term (2) expr -> . expr MINUS term (3) expr -> . expr PLUS term (4) term -> . factor (5) term -> . term DIVIDE factor (6) term -> . term TIMES factor (7) factor -> . LPAREN expr RPAREN (8) factor -> . NUMBER LPAREN shift and go to state 2 NUMBER shift and go to state 3 factor shift and go to state 1 term shift and go to state 4 expr shift and go to state 6状態は、その時点で照合過程の一部となり得る文法規則の追跡をする。各規則の中で、その規則の構文解析における現在位置が文字"."で示される。他にも、有効な入力トークンに対応する動作が一覧化されている。(若干の練習が必要だが、)これら規則を調査することで、構文解析における衝突を追跡することができるようになる。すべての移動/還元衝突が間違いとは限らないことを、強調しておこう。それらが正しく解決されることを確認する方法は、デバッグファイルの調査しかない。
構文エラー処理
業務用途の構文解析器を作成する場合、構文エラー処理を疎かにしてはならない。誰も、問題の兆候が出ただけでお手上げ状態になるような構文解析器を求めていない。そうす代わりに、入力に含まれる複数のエラーが利用者にまとめて報告される方が望ましい。そのためには、エラーを報告し、可能なら回復し、構文解析処理を継続させる必要がある。これは、C、C++、Javaなどの言語のコンパイラで見られる、ありふれた振る舞いである。
SLYでは、構文解析中に構文エラーが発生すると、そのエラーは即座に検出される(つまり、構文解析器はエラーの原因となる箇所を超えてトークンを読み取ることをしない)。その時点で構文解析器が復旧モードに入るため、そこで構文解析を継続するための試みが可能である。一般的に、LR構文解析器内でのエラー回復処理は古代の技術と黒魔術を含む繊細なトピックである。SLYによって提供される復旧の仕組みはUnix yaccに匹敵しており、その詳細はO'Reillyの"Lex and Yacc"を参照すると良い。
構文エラーが発生すると、SLYは以下の手順を実施する。
- エラーが発生したとき、最初に
error()メソッドが問題のトークンを引数にとって呼び出される。end-of-fileの到達による構文エラーでは、代わりにNoneが渡される。そして構文解析器は"エラー回復"モードに入り、少なくとも3つのトークンが構文解析スタック上で移動に成功するまでerror()メソッドの呼び出しは行なわれなくなる。error()で回復動作が行なわれない場合、問題となっている先読トークンは特殊なerrorトークンに置き換えられる。- 問題のある先読みトークンが既に
errorトークンに設定されると、構文解析スタックの先頭要素が削除される。- 構文解析スタックが巻き戻されると、構文解析器は再起動状態に入り、初期状態からの構文解析の開始を試みる。
- 文法規則が
errorをトークンとして受容する場合、構文解析スタックにそれが移動される。- 構文解析スタックの先頭が
errorとなった場合、構文解析器によって新しい記号が移動されるかerrorに巻き込まれた規則が還元されるまで、先読みトークンが破棄されていく。エラー規則による回復処理と再同期
格調高い構文エラー処理を試みるには、文法規則内に
errorトークンを組み込むことである。print文の文法規則を持つとある言語を考えてみよう。@_('PRINT expr SEMI') def statement(self, p): ...記述に問題がある可能性を考慮し、以下のような文法規則を追加しても良い。
@_('PRINT error SEMI') def statement(self, p): print("Syntax error in print statement. Bad expression")この例の
errorトークンは、セミコロンが出現するまでの何らかのトークン列を照合する。セミコロンに到達するとその規則が呼び出され、errorトークンは消失する。この種の回復処理は、構文解析の再同期処理と呼ばれることもある。
errorトークンは不正な入力テキストに対するワイルドカードとして機能し、errorトークンの直後にあるトークンが同期トークンとして動作する。
errorがエラー規則の最右端トークンとしておかれることは、通常あり得ないことに留意しよう。例:@_('PRINT error') def statement(self, p): print("Syntax error in print statement. Bad expression")不正なトークンの先頭要素が規則を発動し移動の対象となるため、不正なトークンが連続していると復旧をより難しいものにしてしまう、というのがその理由である。セミコロン、閉じ括弧、その他同期点として使用できる境界の区切りをいくつか用意しておくとよい。
パニックモ-ド回復処理
別のエラー回復策として、それなりの手段で構文解析器が回復できる箇所までトークンを破棄する、パニックモード回復処理がある。
パニックモード回復処理は、そのすべてが
error()函数として実装される。たとえば、次の函数は閉じ括弧'}'に達するまでトークンを捨てる。その後、構文解析器は初期状態から再開する。def error(self, p): print("Whoa. You are seriously hosed.") if not p: print("End of File!") return # Read ahead looking for a closing '}' while True: tok = next(self.tokens, None) if not tok or tok.type == 'RBRACE': break self.restart()この函数は不正なトークンを破棄し、構文解析器にエラーから回復したことを伝える。
def error(self, p): if p: print("Syntax error at token", p.type) # Just discard the token and tell the parser it's okay. self.errok() else: print("Syntax error at EOF")使用されている属性とメソッドについての詳細を示す。
self.errok()これは構文解析器をリセットし、すでにエラー回復モードではないことを示す。これによりerrorトークン生成の抑止と内部カウンターリセットを実施し、別の構文エラーが見つかったときに再度error()を呼び出せるようにする。self.tokensこれは構文解析対象の列挙可能なシーケンスとなっている。next(self.tokens)を呼ぶことで、一つ先のトークンへと進ませる。self.restart()構文解析スタックをすべて破棄し、構文解析器を初期状態へリセットする。
error()はトークンを一つ返すことにより、構文解析器に次の先読みトークンを渡すことができる。これは、特定文字での同期を試みる際に役立つ。例:def error(self, tok): # Read ahead looking for a terminating ";" while True: tok = next(self.tokens, None) # Get the next token if not tok or tok.type == 'SEMI': break self.errok() # Return SEMI to the parser as the next lookahead token return tok構文エラーの報告タイミング
入力中に不正なトークンが見つかると、多くの場合、SLYは即座にエラーを処理する。このとき、SLYがエラー処理を、一つ以上の文法規則が還元されるまでの間、遅延させようとすることに注意せよ。"既定の状態"として知られる背後の構文解析表上の特殊な状態によって、この動作が予期しない結果を引き起こす可能性がある。既定の状態とは、次の入力にかかわらず同じ文法規則が還元される構文解析器の状態である。そのような状態下のSLYは、次の入力トークンを読まずに先に進むことを選択し、文法規則を還元する。継続するトークンが不正であれば、SLYはそれを読み込もうとし、構文エラーを報告する。こうした文法エラーに先立って文法規則が実行される動作仕様は、変わったものに見えるかもしれない。
エラー処理についての一般論
通常の言語において、エラー規則と再同期文字によるエラーからの復旧は、最も信頼性の高い手法である。文法でエラーを拾えるようになり、比較的容易に復旧し、構文解析処理を継続できる。パニックモード回復処理は、入力テキストからごっそり内容をそぎ落とし、再開のための道を歩ませたい、といったある種特別なアプリケーションでのみ役立つ。
行番号と位置情報の追跡
位置情報の追跡は、コンパイラーの作成時にしばしば厄介な問題となる。規定動作では、SLYはどのあらゆるトークンの行番号や位置情報を追跡する。生成規則内で、以下の属性が役に立つ。
p.lineno生成規則中の左端にある終端記号の行番号。p.index生成規則の左端にある終端記号の字句解析インデックス。例)
@_('expr PLUS expr') def expr(self, p): line = p.lineno # line number of the PLUS token index = p.index # Index of the PLUS token in input textSLYは、非終端記号に対して行番号を伝搬しない。これを行なう必要がある場合、自身で行番号を格納し、ASTノード内で他のデータ構造にそれを伝搬させる必要がある。
AST(抽象構文木)の生成
SLYは抽象構文木の生成に関する特殊函数を提供しない。とはいえ、そうした構築処理は自前で簡単に実施できる。
木構造生成の簡易手法として、個々の文法規則函数でタプルやリストを生成し、伝搬させる方法がある。様々な実現方法があるが、そのうちの一つを示す。
@_('expr PLUS expr', 'expr MINUS expr', 'expr TIMES expr', 'expr DIVIDE expr') def expr(self, p): return ('binary-expression', p[1], p.expr0, p.expr1) @_('LPAREN expr RPAREN') def expr(self, p): return ('group-expression',p.expr]) @_('NUMBER') def expr(self, p): return ('number-expression', p.NUMBER)他にも、抽象構文木ノードの種類に応じたデータ構造を作り、規則の中で対応するノード型を生成する方法がある。
class Expr: pass class BinOp(Expr): def __init__(self, op, left, right) self.op = op self.left = left self.right = right class Number(Expr): def __init__(self, value): self.value = value @_('expr PLUS expr', 'expr MINUS expr', 'expr TIMES expr', 'expr DIVIDE expr') def expr(self, p): return BinOp(p[1], p.expr0, p.expr1) @_('LPAREN expr RPAREN') def expr(self, p): return p.expr @_('NUMBER') def expr(self, p): return Number(p.NUMBER)この手法の利点は、より複雑な意味情報や型チェック、コード生成機能、ノードクラスのためのその他機能を付与できることにある。
開始記号の変更
通常、構文解析クラスに最初に現れる規則が、文法規則の開始規則(最上位規則)となる。これを変更するには、クラスに
start指定を追加する。例:class CalcParser(Parser): start = 'foo' @_('A B') def bar(self, p): ... @_('bar X') def foo(self, p): # Parsing starts here (start symbol above) ...
start指定は、巨大な文法の一部分のデバッグ処理で役に立つ。埋め込み動作
SLYが使用する構文解析手法は、動作は規則の終了時に実行される。以下のような規則があると仮定する。
@_('A B C D') def foo(self, p): print("Parsed a foo", p.A, p.B, p.C, p.D)この例では、提供された動作コードは、記号
A、B、C、Dのすべてが構文解析がされた後に実行される。ときおり、ではあるが、構文解析の最中にで小さなコードの断片を実行させることが有効な場合がある。たとえば、Aが構文解析された直後に、いくつかの動作を実行させたい場合があるとする。このためには、空規則を作成する。@_('A seen_A B C D') def foo(self, p): print("Parsed a foo", p.A, p.B, p.C, p.D) print("seen_A returned", p.seen_A]) @_('') def seen_A(self, p): print("Saw an A = ", p[-1]) # Access grammar symbol to the left return 'some_value' # Assign value to seen_Aこの例では
Aが構文解析スタックに移動された直後に空のseen_A規則が実行される。この規則の中でp[-1]は、スタック上にあるseen_A記号のすぐ左隣の記号を参照する。 上記のfoo規則では、Aの値となる。他の規則と同様に、埋め込み動作が値を返すことで、値が返却される。埋め込み動作の使用は、希に余計な移動/還元衝突を引き起こす。たとえば、衝突を起こさない文法があるとする。
@_('abcd', 'abcx') def foo(self, p): pass @_('A B C D') def abcd(self, p): pass @_('A B C X') def abcx(self, p): passここで、規則の一つに埋め込み動作を挿入したとする。
@_('abcd', 'abcx') def foo(self, p): pass @_('A B C D') def abcd(self, p): pass @_('A B seen_AB C X') def abcx(self, p): pass @_('') def seen_AB(self, p): passこれにより余計な移動/還元衝突が差し込まれる。この衝突は、
abcd規則とabcx規則の双方で同じ記号Cが隣に出現する、という事実によって引き起こされる。構文解析器は記号の移動(abcd規則)と、規則seen_AB(abcx規則)の還元のどちらを実行しても良い。埋め込み規則の一般的な使用法は、ローカル変数のスコープなど、構文解析の別の側面から制御を行なうことである。たとえばCのコードの構文解析をするなら、以下のようなコードを記述する。
@_('LBRACE new_scope statements RBRACE') def statements(self, p): # Action code ... pop_scope() # Return to previous scope @_('') def new_scope(self, p): # Create a new scope for local variables create_scope() ...この例の
new_scopeはLBRACE({)記号が構文解析された直後に実行される。これが、内部の記号表と構文解析器とは別の側面の挙動を修正する。規則statementsが完了すると、コードが埋め込み動作で行なわれた操作(pop_scope()など)を元に戻す。
- 投稿日:2021-01-10T18:18:42+09:00
機械学習の定番「サポートベクターマシン(SVM)」を高校生でもわかるよう解説
はじめに
機械学習の定番アルゴリズムの1つである「サポートベクターマシン(SVM)」ですが、
実用的、かつ比較的シンプルなアルゴリズムから、入門書等でも取り上げられることが多いです。ただし、解説の抜け漏れや、難解すぎる書籍や記事が多いと感じたので、備忘録も兼ねて
・網羅的
・平易な説明
・実データでの実装例あり(Pythonのライブラリscikit-learnを使用)を心がけ、高校生でも「理解した!」と言えるような記事を目指したいと思います。
注意
その1
・高校生でもわかると銘打ってしまったのに申し訳ありませんが、
高校で勉強しない(理系の大学1~2年で学習)偏微分の知識が出てきます。大変分かりやすいYouTube動画があるので、こちらを見れば「理解した!」と言えるのではと思います。
偏微分
ラグランジュの未定乗数法
不等式条件のラグランジュの未定乗数法(KKT条件)その2
・本文中の数式に
$${W^T}X$$
のように"T"という記号が出てきますが、これは行列の縦横を交換する「転置」です。
一見難解に見えますが、ベクトルの内積を行列の積で表現するための慣用的な表現で、
上式の場合ベクトルWとXの内積と読み替えれば問題ありません。その3
・アルゴリズムの最後に出てくる2次計画問題に関しては、私もソルバー頼みで解法を理解しているわけではないので、説明を省略することをご了承いただければと思います。
機械学習におけるサポートベクターマシンの位置づけ
機械学習のアルゴリズムは、大きく下図のように分けられます。
サポートベクターマシンは、主に「分類」に使用されるアルゴリズムとなります。
・分類の例
ケース1:体温、せきの回数から、病気の有無を推定する
ケース2:長さ、重さ、色から果物の種類(リンゴ、ミカン、ブドウ)を推定するケース1は「有り」か「無し」の2種類の分類しか存在しないので、2値分類と呼び、
ケース2は3種類以上の分類が存在するので、多値分類(多クラス分類)と呼びます多値分類とサポートベクターマシン
本記事では2値分類のアルゴリズムを解説していますが、2値分類のアルゴリズムを複数並べることで、他値分類にも対応できます。
詳細はこちらが参考になります回帰とサポートベクターマシン
本手法を回帰に応用した「サポートベクター回帰」と呼ばれる手法もありますが、分類と比べると利用頻度が低いため、本記事では割愛します。
サポートベクターマシンの基本概念
例えば下図のような2つの説明変数(例:体温、せきの回数)を使って、
クラス1(例:病気あり)とクラス2(例:病気なし)を分類したいとします。
機械学習の分類問題においては、これらのクラス間に境目となる直線や曲線(3次元以上では面)を引くことで、分類を実現します。
この境目となる直線や曲線を、決定境界と言います。上の例において直線で決定境界を引いた場合を考えます。
下図の決定境界Aと決定境界Bではどちらが分類性能が高く見えるでしょうか?
多くの人が、決定境界Aの方が高性能だと感じるかと思います。
そして決定境界Bが良くないと思う根拠として、
「赤く塗りつぶした点までの距離が近すぎて、誤判定しそう」
が、感覚的に違和感のない説明になるかと思います。この感覚を下図のようにアルゴリズム化し、
「最も近い点(サポートベクター)までの距離が遠くなるよう決定境界を決める」分類手法を、
サポートベクターマシンと呼びます。例えば、2次元において直線の方程式は
ax + by + c = 0となります。
このとき、点(xi, yi)と直線の距離は\frac{|ax_i+by_i+c|}{\sqrt{a^2+b^2}}となるので、全ての学習データ(i=1,2,‥n)に対して
min_{i=1,2‥n}\frac{|ax_i+by_i+c|}{\sqrt{a^2+b^2}}を最大化するa, bの組合せを探す(cは規格化して消去される)ことが、2次元におけるサポートベクターマシンの学習となります。
アルゴリズム詳細は次節で解説するので、まずは実データで実装してみましょう!
バスケットボール(NBA)選手とアメリカンフットボール(NFL)選手を身長体重で識別できるかを試してみますnba_nfl_1.csvname,league,position,height,weight Wilt Chambelain,NBA,C,215.9,113.4 Bill Russel,NBA,C,208.3,97.5 Kareem Abdul-Jabbar,NBA,C,218.4,102.1 Elvin Hayes,NBA,PF,205.7,106.6 Moses Malone,NBA,C,208.3,97.5 Tim Duncan,NBA,PF,210.8,113.4 Karl Malone,NBA,PF,205.7,117.5 Robert Parish,NBA,C,215.9,110.7 Kevin Garnett,NBA,PF,210.8,108.9 Nate Thurmond,NBA,C,210.8,102.1 Walt Bellamy,NBA,C,208.3,102.1 Wes Unseld,NBA,C,200.7,111.1 Hakeem Olajuwon,NBA,C,213.4,115.7 Dwight Howard,NBA,C,208.3,120.2 Shaquille O'Neal,NBA,C,215.9,147.4 John Stockton,NBA,PG,185.4,79.4 Jason Kidd,NBA,PG,193,95.3 Steve Nash,NBA,PG,190.5,80.7 Mark Jackson,NBA,PG,190.5,88.5 Magic Johnson,NBA,PG,205.7,99.8 Oscar Robertson,NBA,PG,195.6,93 Chris Paul,NBA,PG,185.4,79.4 LeBron James,NBA,SF,205.7,113.4 Isiah Thomas,NBA,PG,185.4,81.6 Gary Payton,NBA,PG,193,86.2 Andre Miller,NBA,PG,190.5,90.7 Rod Strickland,NBA,PG,190.5,83.9 Maurice Cheeks,NBA,PG,185.4,81.6 Russel Westbrook,NBA,PG,190.5,90.7 Rajon Rondo,NBA,PG,185.4,81.6 Ray Lewis,NFL,LB,185.4,108.9 London Fletcher,NFL,LB,177.8,109.8 Derrick Brooks,NFL,LB,182.9,106.6 Donnie Edwards,NFL,LB,188,100.7 Zack thomas,NFL,LB,180.3,103.4 Keith Brooking,NFL,LB,188,108.9 Karlos Dansby,NFL,LB,193,113.4 Junior Seau,NFL,LB,190.5,113.4 Brian Urlacher,NFL,LB,193,117 Ronde Barber,NFL,DB,177.8,83.5 Lawyer Milloy,NFL,DB,182.9,95.7 Takeo Spikes,NFL,LB,188,109.8 James Farrior,NFL,LB,188,110.2 Charles Woodson,NFL,DB,185.4,95.3 Antoine Bethea,NFL,DB,180.3,93.4 Derrick Johnson,NFL,LB,190.5,109.8 Lance Briggs,NFL,LB,185.4,110.7 Antoine Winfield,NFL,DB,175.3,81.6 Rodney Harrison,NFL,DB,185.4,99.8 Brian Dawkins,NFL,DB,182.9,95.3※NBA選手はポジションがばらけるようAssistsとReboundsの歴代15位までを、
NFL選手はTacklesの歴代20位まで(ディフェンスの選手)をデータベース化しています。縦軸を体重、横軸を身長としてプロットすると
ml_param_instruction.py(の一部)import matplotlib.pyplot as plt import pandas as pd import numpy as np import seaborn as sns df_athelete = pd.read_csv(f'./nba_nfl_1.csv') # データ読込 sns.scatterplot(x='height', y='weight', data=df_athelete, hue='league') # 説明変数と目的変数のデータ点の散布図をプロット plt.xlabel('height [cm]') # X軸のラベル(身長) plt.ylabel('weight [kg]') # Y軸のラベル(体重)
のようになります。
きれいに直線で分かれそうですね!このデータをscikit-learnを使ってサポートベクターマシンで分類し、
mlxtend(参考)で決定境界を可視化します。ml_param_instruction.py(の一部)from sklearn.svm import SVC from mlxtend.plotting import plot_decision_regions def label_str_to_int(y): # 目的変数をstr型→int型に変換(plot_decision_regions用) label_names = list(dict.fromkeys(y[:, 0])) label_dict = dict(zip(label_names, range(len(label_names)))) y_int=np.vectorize(lambda x: label_dict[x])(y) return y_int def legend_int_to_str(ax, y): # 凡例をint型→str型に変更(plot_decision_regions用) hans, labs = ax.get_legend_handles_labels() ax.legend(handles=hans, labels=list(dict.fromkeys(y[:, 0]))) X = df_athelete[['height','weight']].values # 説明変数(身長、体重) y = df_athelete[['league']].values # 目的変数(種目) y_int = label_str_to_int(y) # 目的変数をint型に変換 model = SVC(kernel='linear') # 線形SVMを定義 model.fit(X, y_int) # SVM学習を実行 ax = plot_decision_regions(X, y_int[:, 0], clf=model) #決定境界を可視化 plt.xlabel('height [cm]') # x軸のラベル plt.ylabel('weight [kg]') # y軸のラベル legend_int_to_str(ax, y) # 凡例をint型→str型に変更※なお、label_str_to_int()およびlegend_int_to_str()メソッドですが、mlxtendでの決定境界表示はクラスラベルをint型に変更しないとエラーが出る
謎仕様特殊な仕様となっているため、一度int型に変換してモデルを作成したのち、凡例のみstr型に表示を戻すための処理です。
直線で決定境界が引かれ、かつマージンが最大化されていることが分かります。
サポートベクターマシンの性能向上
こちらの記事で触れましたが、機械学習は推定性能を向上させるため、次のような機能に対応していることが一般的です。
A. 多次元説明変数:任意のn次元の説明変数に対応
B. 非線形:決定境界を直線(超平面)以外の柔軟な形状に変化させる
C. 汎化性能向上:学習データへの過剰適合を防ぎ、未知データに対する推定能力を向上させるSVMにおいても、A~Cに対応するアルゴリズムが付加されているので、以下で詳説します。
A. 多次元説明変数
以下の式では、大文字はベクトルを表します(参考)
前述の2次元の例では直線で引いた決定境界ですが、3次元以上で一般化すると、超平面で境界を引くこととなります。
超平面の方程式は、{W^T}X_i+w_0=0で表されます。
この超平面と点Xiとの距離は、d = \frac{|w_1x_1 + w_2x_2... + w_nx_n + w_0|}{\sqrt{w_1^2+w_2^2...+w_n^2}} = \frac{|W^TX_i + w_0|}{||W||}となります。
この距離の最小値をマージンmとした上で、y_i= \left\{ \begin{array}{ll} 1 & (X_iがクラス1のとき) \\ -1 & (X_iがクラス2のとき) \end{array} \right.となるyiを定義すると、
マージンmは下式のように表わされます\frac{y_i(W^TX_i + w_0)}{||W||} \geq m \quad (i = 1, 2, ...N)両辺をmで割って変形すると
y_i\biggl(\biggl(\frac{W}{m||W||}\biggl)^TX_i + \frac{w_0}{m||W||}\biggl) - 1 \geq 0ここで
新たなW = \frac{W}{m||W||}\\新たなw_0 = \frac{w_0}{m||W||}となるよう標準化すると、
(最初の式のように、Wは平面を張るベクトルの方向が同じであれば大きさは問わないので、計算しやすいよう||W||=1/mとなるよう標準化)y_i({W^T}X_i+w_0)-1 \geq 0となります。
この条件下で、マージンm=\frac{1}{||W||}を最大化すれば良いのですが、
この後の計算をしやすくするため、\frac{1}{2}{||W||}^2を最小化する問題に置き換えます。
するとマージン最大化の条件式は、
g_i(W,w_0)=y_i({W^T}X_i+w_0)-1 \geq 0(※等号が成り立つときが、決定境界に最も近い点=サポートベクター)
の制約条件下で、f(W)=\frac{1}{2}{||W||}^2を最小化する問題となります。
不等号条件化での最小化問題なので、ラグランジュの未定乗数法に基づきL(W,w_0,\alpha)=f(W)-\sum_{i=1}^{n}\alpha_i g_i(W,w_0)\\ =\frac{1}{2}{||W||}^2-\sum_{i=1}^{n}\alpha_i(y_i({W^T}X_i+w_0)-1)の極値を求めます。
極値を求めるためにW, w0で偏微分し、
\frac{\partial L}{\partial W}=0 \quad \Rightarrow \quad W=\sum_{i=1}^{n}\alpha_i y_i X_i\\ \frac{\partial L}{\partial w_0}=0 \quad \Rightarrow \quad \sum_{i=1}^{n}\alpha_i y_i=0となるので、これらをLの式に代入し、KKT条件の式(αi≧0)も追加すると、
\sum_{i=1}^{n}\alpha_i y_i=0\\\alpha_i \geq 0の制約条件下で
L(\alpha)=\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i \alpha_j y_i y_j X_i^T X_j - \sum_{i=1}^{n}\alpha_iを最小化する問題となります。
以降はαに関する2次計画問題に帰結するので省略しますが、興味がある方はこちらのサイトが分かりやすいです上記手法により、多次元説明変数においてもマージンを最大化する超平面(の係数W)を求めることができます。
B. 非線形
先ほどのNBA選手とNFL選手の識別の例において、NFL選手のデータを、より体重の軽い傾向にあるオフェンス(ライン以外)の選手に置き換えます
name,event,position,height,weight Wilt Chambelain,NBA,C,215.9,113.4 Bill Russel,NBA,C,208.3,97.5 Kareem Abdul-Jabbar,NBA,C,218.4,102.1 Elvin Hayes,NBA,PF,205.7,106.6 Moses Malone,NBA,C,208.3,97.5 Tim Duncan,NBA,PF,210.8,113.4 Karl Malone,NBA,PF,205.7,117.5 Robert Parish,NBA,C,215.9,110.7 Kevin Garnett,NBA,PF,210.8,108.9 Nate Thurmond,NBA,C,210.8,102.1 Walt Bellamy,NBA,C,208.3,102.1 Wes Unseld,NBA,C,200.7,111.1 Hakeem Olajuwon,NBA,C,213.4,115.7 Dwight Howard,NBA,C,208.3,120.2 Shaquille O'Neal,NBA,C,215.9,147.4 John Stockton,NBA,PG,185.4,79.4 Jason Kidd,NBA,PG,193,95.3 Steve Nash,NBA,PG,190.5,80.7 Mark Jackson,NBA,PG,190.5,88.5 Magic Johnson,NBA,PG,205.7,99.8 Oscar Robertson,NBA,PG,195.6,93 Chris Paul,NBA,PG,185.4,79.4 LeBron James,NBA,SF,205.7,113.4 Isiah Thomas,NBA,PG,185.4,81.6 Gary Payton,NBA,PG,193,86.2 Andre Miller,NBA,PG,190.5,90.7 Rod Strickland,NBA,PG,190.5,83.9 Maurice Cheeks,NBA,PG,185.4,81.6 Russel Westbrook,NBA,PG,190.5,90.7 Rajon Rondo,NBA,PG,185.4,81.6 Drew Brees,NFL,QB,182.9,94.8 Tom Brady,NFL,QB,193,102.1 Payton Manning,NFL,QB,195.6,104.3 Brett Favre,NFL,QB,188,100.7 Philip Rivers,NFL,QB,195.6,103.4 Dan Marino,NFL,QB,193,101.6 Ben Roethlisberger,NFL,QB,195.6,108.9 Eli Manning,NFL,QB,195.6,99.8 Matt Ryan,NFL,QB,193,98.4 John Elway,NFL,QB,190.5,97.5 Emmitt Smith,NFL,RB,175.3,100.2 Walter Payton,NFL,RB,177.8,90.7 Frank Gore,NFL,RB,175.3,96.2 Barry Sanders,NFL,RB,172.7,92.1 Adrian Peterson,NFL,RB,185.4,99.8 Curtis Martin,NFL,RB,180.3,95.3 LaDainian Tomlinson,NFL,RB,177.8,97.5 Jerome Bettis,NFL,RB,180.3,114.3 Eric Dickerson,NFL,RB,190.5,99.8 Tony Dorsett,NFL,RB,180.3,87.1 Jerry Rice,NFL,WR,188,90.7 Larry Fitzgerald,NFL,WR,190.5,98.9 Terrell Owens,NFL,WR,190.5,101.6 Randy Moss,NFL,WR,193,95.3 Isaac Bruce,NFL,WR,182.9,85.3 Tony Gonzalez,NFL,TE,195.6,112 Tim Brown,NFL,WR,182.9,88.5 Steve Smith,NFL,WR,175.3,88.5 Marvin Harrison,NFL,WR,182.9,83.9 Reggie Wayne,NFL,WR,182.9,92.1※NFL選手は、Passing(主にQB), Rushing(主にRB), Receiving(主にWR)の各ヤード数歴代10位までをデータベース化しています
ml_param_instruction.py(の一部)df_athelete = pd.read_csv(f'./nba_nfl_2.csv') sns.scatterplot(x='height', y='weight', data=df_athelete, hue='league') # 説明変数と目的変数のデータ点の散布図をプロット plt.xlabel('height [cm]') # x軸のラベル plt.ylabel('weight [kg]') # y軸のラベル
残念ながら直線(線形)の決定境界では分けられないようです。
前述のSVMは線形分離可能な場合のみを想定したアルゴリズムのため、線形分離不可のときは、
① カーネルトリックによる非線形決定境界 → 「B.非線形」に対応する工夫
② ソフトマージン → 「C.汎化性能」に対応する工夫
という2種類の対処法いずれか(あるいは両方)を実施する必要があります。
本節では①に関して解説します。カーネルトリックとは?
例えば、下図の青い点と赤い点とを分類したい場合を考えます。
見ての通り、xy座標系では線形(直線)での分離は困難です。
ではz=x^2+y^2として、z軸を追加した座標系でプロットしてみるとどうなるでしょう?
上図のように、z軸を追加することで線形分離可能となり、
この分離面を元のxy座標系に逆変換すると、円形(=非線形)の決定境界を引くことに相当します。このように、元の座標軸(特徴量)を組み合わせた高次元の座標系への変換Φを行うことで、
線形分離不可能な場合でも、非線形な決定境界による分類を実現できます。このとき、xを射影してΦ(x)に変換するため、前述のラグランジュの未定乗数法で最小化する関数
L(\alpha)=\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i \alpha_j y_i y_j X_i^T X_j - \sum_{i=1}^{n}\alpha_iは、
L(\alpha)=\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i \alpha_j y_i y_j \phi(X_i)^T \phi(X_j) - \sum_{i=1}^{n}\alpha_iへと置き換えられます。
ただし、\phi(X_i)^T \phi(X_j)の部分が計算コストが大きいため、
一般的には写像Φは直接定義せず、カーネル関数
K(X_i,X_j)=\phi(X_i)^T \phi(X_j)を定義して計算することが多いです。このカーネル関数による変換法をカーネルトリックと呼びます。
カーネル関数の中でも特によく使われるのがK(X_i,X_j)=exp\biggl(-\frac{||X_i-X_j||^2}{2\sigma^2}\biggl)\\ =exp \Bigl(-\gamma||X_i-X_j||^2 \Bigl)で定義されるRBFカーネル(Radial Basis Function kernel)です。
この式中に含まれるγが、ハイパーパラメータの1つとなりますscikit-learn公式の説明を見ると、γは「1点の学習データが、識別面に影響を与える距離」を表すパラメータと記載されており、数式で分散σ2の逆数となっていることからも、何となくイメージが付くかと思います。
γが大きくなるほど、1点の影響範囲が小さい = 曲率が大きな識別面となる
というようなイメージです。先ほどのNBA選手とNFL選手での分類を、γ(scikit-learnでは"gamma")を変えてRBFカーネルで学習してみます。
ml_param_instruction.py(の一部)X = df_athelete[['height','weight']].values # 説明変数(身長、体重) y = df_athelete[['league']].values # 目的変数(種目) y_int = label_str_to_int(y) for gamma in [0.1, 0.01, 0.001, 0.0001]: # gammaを変えてループ model = SVC(kernel='rbf', gamma=gamma) # RBFカーネルのSVMをgammaを変えて定義 model.fit(X, y_int) # SVM学習を実行 ax = plot_decision_regions(X, y_int[:, 0], clf=model) plt.xlabel('height [cm]') plt.ylabel('weight [kg]') legend_int_to_str(ax, y) plt.text(175, 140, f'gamma={model.gamma}, C={model.C}') # gammaとCを表示 plt.show()※scikit-learnのSVMはソフトマージンのため、後述のCも含まれていることにご注意ください
gamma(γ)が小さくなるほど曲率が小さくなって線形に近づき、gammaが大きくなるほど曲率が大きくなることが分かります。
ここからも、gammaが「どれくらい非線形か」を調整するパラメータであることが分かるでしょうC. 汎化性能
前述のように、SVMには線形分離不可能な場合に対応するために「ソフトマージン」という手法が適用できます(詳細はこちらが詳しいです)
Aで登場したマージン最大化の制約条件
y_i({W^T}X_i+w_0)-1 \geq 0ですが、これは「誤分類は1個も許さない」(ハードマージン)という意味合いの式となっています。
これでは線形分離不可能な場合、この制約条件を満たせず学習ができなくなってしまうため、
下式で表すスラック変数ξiを導入し、\xi_i = max\bigl\{0, 1 - y_i(W^TX_i + w_0)\bigr\}制約条件を下式のように書き換え、ある程度の誤分類を許容するようにします(ソフトマージン)
y_i({W^T}X_i+w_0)-1+\xi_i \geq 0上式から読みとれるスラック変数ξiの性質として
・ξi = 0のとき、本来の定義でのマージン範囲内(線形分離可)
・0 < ξi < 1のとき、本来の定義でのマージンを超えて決定境界に近づく(誤分類ではない)
・ξi > 1のとき、決定境界を飛び越えて誤分類が発生する
・ξiが大きくなるほど、誤分類の度合いが大きくなる
があり、誤分類を防ぐ観点では、スラック変数は小さくしたい変数であることがわかります。そこで、マージン最大化の式において最小化すべき関数
f(W)=\frac{1}{2}{||W||}^2に、スラック変数の総和に係数Cを掛けて足し合わせた
f(W)=\frac{1}{2}{||W||}^2+C\sum_{i=1}^{n}\xi_iを新たに最小化すべき関数として定義することで、
「マージン最大化」と「誤分類許容」のバランスを取って学習することができます。この誤分類許容のバランスを決める係数Cが、ハイパーパラメータの1つとなります
基本的にはCが大きいほど誤分類の最小化関数に対する影響が大きくなるため、
Cが大:誤分類を許容しない傾向(過学習寄り)
Cが小:誤分類を許容する傾向(未学習=汎化寄り)
となります先ほどのNBA選手とNFL選手の分類を、Cを変えてRBFカーネルで学習してみます。
(gammaは0.01で固定)ml_param_instruction.py(の一部)for C in [10, 1, 0.1]: # Cを変えてループ model = SVC(kernel='rbf', gamma=0.01, C=C) # RBFカーネルのSVMをCを変えて定義 model.fit(X, y_int) # SVM学習を実行 ax = plot_decision_regions(X, y_int[:, 0], clf=model) plt.xlabel('height [cm]') plt.ylabel('weight [kg]') legend_int_to_str(ax, y) plt.text(175, 140, f'gamma={model.gamma}, C={model.C}') # gammaとCを表示 plt.show()
Cが大きいほど、誤分類は少ないがいびつな決定境界(過学習寄り)
Cが小さいほど、誤分類は多いが滑らかな決定境界(未学習=汎化寄り)
となっていることが分かります。まとめ
・サポートベクターマシンは、決定境界から最近点までの距離(マージン)を最大化するアルゴリズム
・カーネルトリックで、非線形の決定境界に対応
・カーネルトリックでは、RBFカーネルがよく使われる
・RBFカーネルに対応するハイパーパラメータは"gamma"、小さいほど線形に近づく・ソフトマージンで、一定の誤分類を許容して汎化性を向上
・ソフトマージンに対応するハイパーパラメータは"C"、小さいほど汎化(未学習)寄りとなるおわりに
コードはこちらにアップロードしております
(VSCodeでの動作推奨。101行目以降が本記事のコードに該当しますが、1行目から順番に実行してください)パラメータCとgammaをどの値に設定すれば良いのか?が気になる方も多いと思うので、
パラメータチューニングについても別途記事を作成中です。乞うご期待いただければと思います。

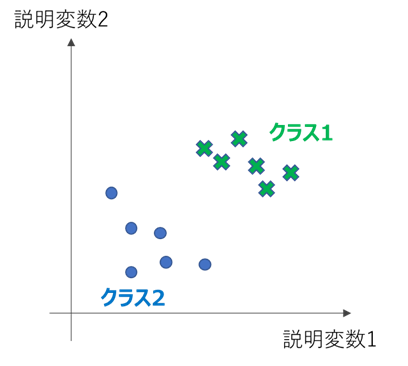
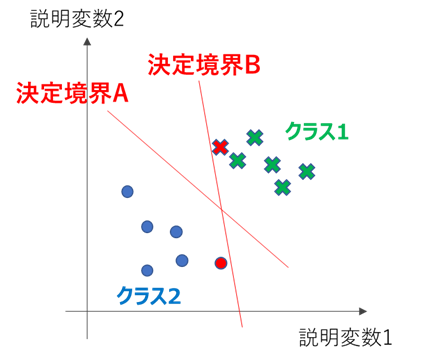
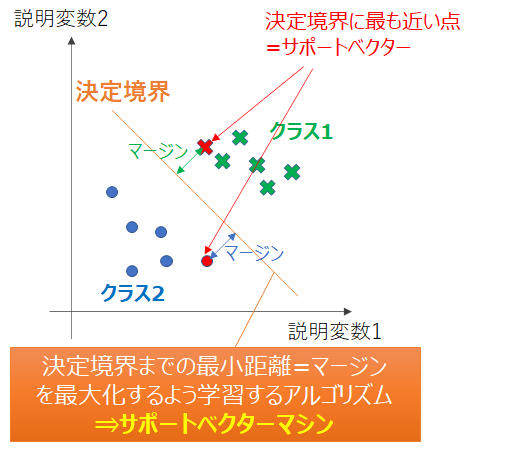

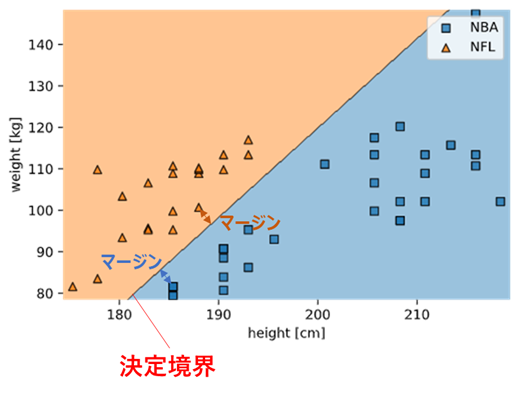
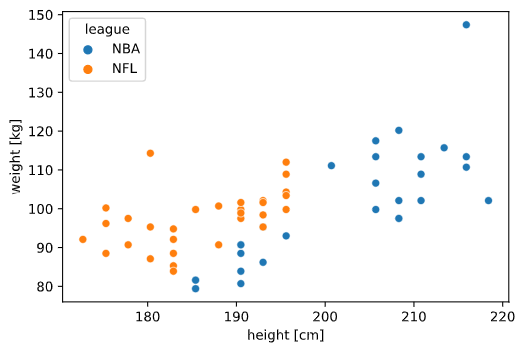
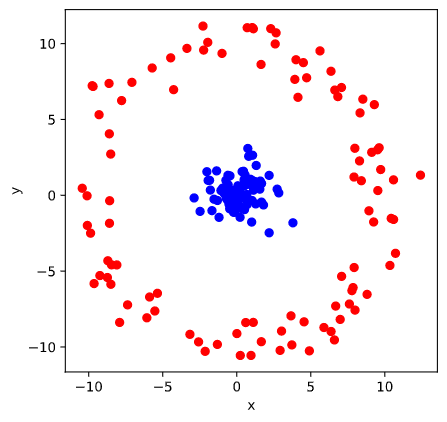
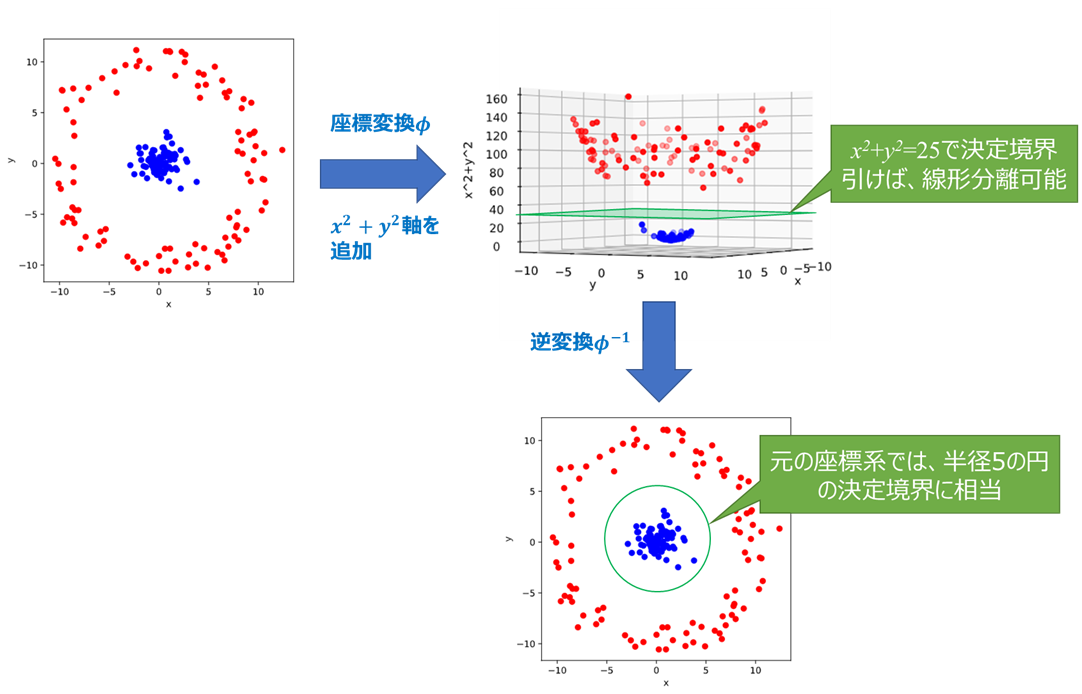
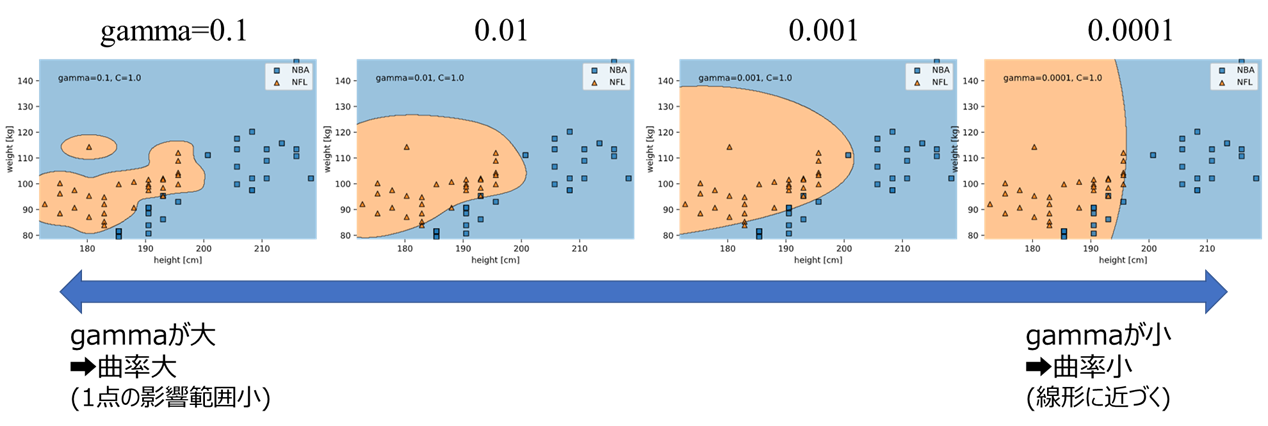
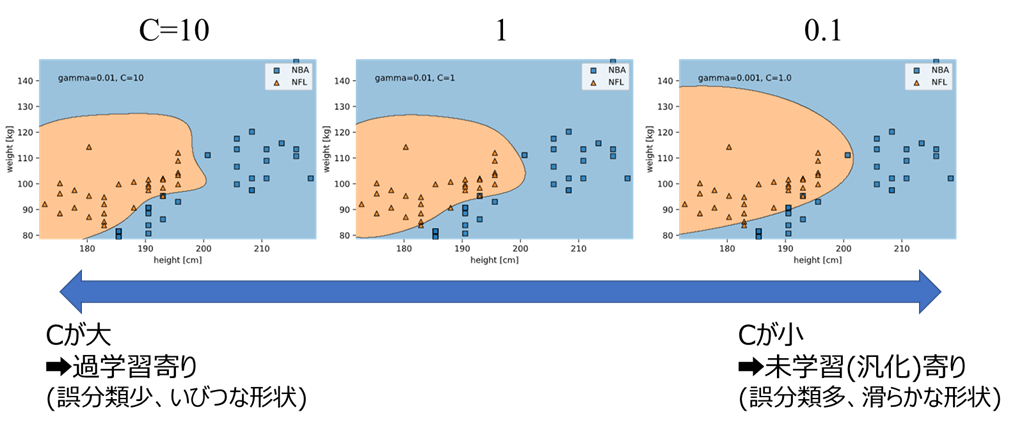
- 投稿日:2021-01-10T18:09:41+09:00
TensorFlowとCameraXでリアルタイム物体検知Androidアプリ
今回やること
CameraXとTensorflow liteを使ってリアルタイムに物体検知するアプリをcameraXの画像解析ユースケースを使ってサクッと作っていきます。
(注: CameraXの実装は1.0.0-rc01のものです。)
GitHubリポジトリを今記事最下部に載せてますので適宜参照してください。
ちょっと長めなのでとりあえず試したい方はリポジトリを見てください。こんな感じのもの作っていきます↓
バウンディングボックスとスコアを表示するものです
モデルの用意
物体検知に使用する訓練済みモデルを探してとってきます。
今回はTensorFlow Hub のssd_mobileNet_v1を使用します。tfliteモデルをダウンロードします。
ssd_mobileNet_v1はこんな感じのモデルです。
input shape 300 x 300 color channel 3
output sahpe location [1, 10, 4] バウンディングボックス category [1, 10] カテゴリラベルのインデックス (91クラスのcoco_datasetで学習したモデルです) score [1, 10] 検出結果のスコア number of detection [1] 検出した物体の数(今回のモデルは10で一定) TensorFlow Hubにはほかにも色々訓練済みモデルがあるので好きなものを選んでください。
ただ、input sizeが大きいものはパラメータ数が多くAndroidだと推論に時間がかかるので注意が必要です。
また、場合によってはtfliteモデルを自分でエクスポートする必要がある場合もあります。今回はそのままモデルを使いますが、
Tensorflow APIとか使って転移学習させるのも面白そうですね。Android Studio で実装
gradle
Tensorflow lite APIとCameraX、カメラ権限用にpermission dispatcherの依存関係を追加します。
build.gradle// permissionDispatcher implementation "org.permissionsdispatcher:permissionsdispatcher:4.7.0" kapt "org.permissionsdispatcher:permissionsdispatcher-processor:4.7.0" // cameraX def camerax_version = "1.0.0-rc01" implementation "androidx.camera:camera-core:${camerax_version}" implementation "androidx.camera:camera-camera2:$camerax_version" implementation "androidx.camera:camera-lifecycle:$camerax_version" implementation "androidx.camera:camera-view:1.0.0-alpha20" // tensorflow lite implementation 'org.tensorflow:tensorflow-lite:2.2.0' implementation 'org.tensorflow:tensorflow-lite-support:0.0.0-nightly'assetsフォルダの用意
先ほどダウンロードした
.tfliteモデルをAndroid Studioのassetsフォルダに入れます。(assetsはプロジェクト右クリック「New -> Folder -> Assets Folder」で作れます)
検出結果のインデックスをラベルにマッピングするために正解ラベルも用意しておきます。
自分のリポですがこちらからcoco_datasetのラベルをDLして同様にassetsフォルダにtxtファイルを入れてください。これでAndroid Studioのassetsフォルダには
ssd_mobile_net_v1.tfliteとcoco_dataset_labels.txtの2つが入っている状態になったと思います。
CameraXの実装
(注: CameraXの実装は
1.0.0-rc01のものです。)
基本的にはこちらの公式チュートリアルのままやっていくだけです。マニフェストにカメラ権限を追加
AndroidManifest.xml<uses-permission android:name="android.permission.CAMERA" />レイアウトファイルの定義
カメラビューとsurfaceViewを定義します。
バウンディングボックスなどリアルタイムに描写するのでViewではなくsurfaceViewを使用してビューに検出結果を反映させます。activity_main.xml<androidx.constraintlayout.widget.ConstraintLayout //省略// > <androidx.camera.view.PreviewView android:id="@+id/cameraView" android:layout_width="0dp" android:layout_height="0dp" //省略// /> <SurfaceView android:id="@+id/resultView" android:layout_width="0dp" android:layout_height="0dp" //省略// /> </androidx.constraintlayout.widget.ConstraintLayout>MainActivityにcameraXの実装。後からpermissionDispatcherを追加します。
この辺はチュートリアルと一緒なので最新のチュートリアルを参考にしたほうがいいかもしれません。MainActivity.ktprivate lateinit var cameraExecutor: ExecutorService override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) cameraExecutor = Executors.newSingleThreadExecutor() setupCamera() } fun setupCamera() { val cameraProviderFuture = ProcessCameraProvider.getInstance(this) cameraProviderFuture.addListener({ val cameraProvider: ProcessCameraProvider = cameraProviderFuture.get() // プレビューユースケース val preview = Preview.Builder() .build() .also { it.setSurfaceProvider(cameraView.surfaceProvider) } // 背面カメラを使用 val cameraSelector = CameraSelector.DEFAULT_BACK_CAMERA // 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() // TODO ここに物体検知 画像解析ユースケースのImageAnalyzerを実装 try { cameraProvider.unbindAll() // 各ユースケースをcameraXにバインドする cameraProvider.bindToLifecycle(this, cameraSelector, preview, imageAnalyzer) } catch (exc: Exception) { Log.e("ERROR: Camera", "Use case binding failed", exc) } }, ContextCompat.getMainExecutor(this)) } override fun onDestroy() { super.onDestroy() cameraExecutor.shutdown() }とりあえずここまで来たら設定から手動でカメラ権限を許可すればカメラプレビューが見れるはずです。ただ、
surfaceViewはデフォルトでは黒なので画面が黒くなっている場合はいったんsurfaceViewをコメントアウトして確認してください。permission dispatcherの実装
カメラ権限リクエスト用にpermission disptcherを実装します。(手動で権限許可するから別にいいというかたは飛ばしてください)
MainActivity.kt@RuntimePermissions class MainActivity : AppCompatActivity() { // 略 @NeedsPermission(Manifest.permission.CAMERA) fun setupCamera() {...} }各アノテーションを対象クラスとメソッドに追加していったんビルドします。
パーミッションリクエスト用の関数が自動生成されます。先ほどの
setupCameraメソッドを以下のように変更し、権限リクエスト結果からコールされるようにします。
なお、今回は拒否された時などの処理に関しては実装しません。MainActivity.ktoverride fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) cameraExecutor = Executors.newSingleThreadExecutor() //setupCamera() 削除 // permissionDispatcherでsetUpCamera()メソッドをコール setupCameraWithPermissionCheck() } override fun onRequestPermissionsResult( requestCode: Int, permissions: Array<String>, grantResults: IntArray ) { super.onRequestPermissionsResult(requestCode, permissions, grantResults) onRequestPermissionsResult(requestCode, grantResults) }これでカメラのプレビュー関連については実装完了です。
続いて、画像解析ユースケースやモデル読み込み、結果の表示などを実装します。モデル読み込み関数の実装
tfliteモデルの読み込みや正解ラベルをassetsから読み込む関数をMainActivityに実装します。
特に難しいこともしていないのでコピペでokです。MainActivity.ktcompanion object { private const val MODEL_FILE_NAME = "ssd_mobilenet_v1.tflite" private const val LABEL_FILE_NAME = "coco_dataset_labels.txt" } // tfliteモデルを扱うためのラッパーを含んだinterpreter private val interpreter: Interpreter by lazy { Interpreter(loadModel()) } // モデルの正解ラベルリスト private val labels: List<String> by lazy { loadLabels() } // tfliteモデルをassetsから読み込む private fun loadModel(fileName: String = MainActivity.MODEL_FILE_NAME): ByteBuffer { lateinit var modelBuffer: ByteBuffer var file: AssetFileDescriptor? = null try { file = assets.openFd(fileName) val inputStream = FileInputStream(file.fileDescriptor) val fileChannel = inputStream.channel modelBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, file.startOffset, file.declaredLength) } catch (e: Exception) { Toast.makeText(this, "モデルファイル読み込みエラー", Toast.LENGTH_SHORT).show() finish() } finally { file?.close() } return modelBuffer } // モデルの正解ラベルデータをassetsから取得 private fun loadLabels(fileName: String = MainActivity.LABEL_FILE_NAME): List<String> { var labels = listOf<String>() var inputStream: InputStream? = null try { inputStream = assets.open(fileName) val reader = BufferedReader(InputStreamReader(inputStream)) labels = reader.readLines() } catch (e: Exception) { Toast.makeText(this, "txtファイル読み込みエラー", Toast.LENGTH_SHORT).show() finish() } finally { inputStream?.close() } return labels }画像解析ユースケースの実装
メインの物体検知の推論パイプラインを実装していきます。
CameraXの画像解析ユースケースを利用することでより手軽に実装できるようになりました。(数行で実装できるというわけではないですが。。。)
チュートリアルでは画素値の平均をとったりしています。cameraXで用意されている
ImageAnalysis.Analyzerを実装しカメラのプレビューを受け取り、解析結果を返すようなObjectDetectorクラスを作ります。
typealiasでコールバックとして解析結果を受け取れるように定義します。ObjectDetector.kttypealias ObjectDetectorCallback = (image: List<DetectionObject>) -> Unit /** * CameraXの物体検知の画像解析ユースケース * @param yuvToRgbConverter カメラ画像のImageバッファYUV_420_888からRGB形式に変換する * @param interpreter tfliteモデルを操作するライブラリ * @param labels 正解ラベルのリスト * @param resultViewSize 結果を表示するsurfaceViewのサイズ * @param listener コールバックで解析結果のリストを受け取る */ class ObjectDetector( private val yuvToRgbConverter: YuvToRgbConverter, private val interpreter: Interpreter, private val labels: List<String>, private val resultViewSize: Size, private val listener: ObjectDetectorCallback ) : ImageAnalysis.Analyzer { override fun analyze(image: ImageProxy) { //TODO 推論コードの実装 } } /** * 検出結果を入れるクラス */ data class DetectionObject( val score: Float, val label: String, val boundingBox: RectF )MainActivityの「TODO ここに物体検知 画像解析ユースケースのImageAnalyzerを実装」の部分を以下のように書き換えます。
MainActivity.kt// 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() .also { it.setAnalyzer( cameraExecutor, ObjectDetector( yuvToRgbConverter, interpreter, labels, Size(resultView.width, resultView.height) ) { detectedObjectList -> // TODO 検出結果の表示 } ) }各コンストラクタ変数についてはコメントを参照してください。
ここでYuvToRgbConverterがエラーになっていると思いますが今から説明しますので大丈夫です。
ImageAnalysis.Analyzerインターフェースのanalyzeメソッドを実装していくのですが、ここでanalyzeメソッドの引数にImageProxyという型でカメラのプレビュー画像が流れてきます。
このImageProxyをbitmapやtensorに変換しないと推論とかができないのですが、これがちょっと面倒なんです。。。
ImageProxyの中にはandroid.Media.Imageが入っており画像ピクセルデータを一つもしくは複数のPlaneとしてグルーピングして保存しています。アンドロイドのカメラではYUV_420_888という形式でImageが生成されるのでこれをRGB bitmapに変換するコンバーターを作る必要があります。確か、pytorch mobileにはコンバーターが用意されていた気がしますが、tensorflowにはありませんでした。リポジトリあさってたらcameraXのサンプルにソースがあったので今回はそれを使用します。(自分で実装するのもありですが)
ということで
この公式サンプルのコンバータをコピーしてYuvToRgbConverterクラスを作って、MainActivityにそのインスタンスを以下のように追加してください。MainActivity.kt// カメラのYUV画像をRGBに変換するコンバータ private val yuvToRgbConverter: YuvToRgbConverter by lazy { YuvToRgbConverter(this) }モデル関連の変数定義
モデルのinput画像サイズや結果を受け取るための変数を先ほどの
ObjectDetectorクラスに定義します。使用するモデルのshapeに合わせる必要があります。ObjectDetector.ktcompanion object { // モデルのinputとoutputサイズ private const val IMG_SIZE_X = 300 private const val IMG_SIZE_Y = 300 private const val MAX_DETECTION_NUM = 10 // 今回使うtfliteモデルは量子化済みなのでnormalize関連は127.5fではなく以下の通り private const val NORMALIZE_MEAN = 0f private const val NORMALIZE_STD = 1f // 検出結果のスコアしきい値 private const val SCORE_THRESHOLD = 0.5f } private var imageRotationDegrees: Int = 0 private val tfImageProcessor by lazy { ImageProcessor.Builder() .add(ResizeOp(IMG_SIZE_X, IMG_SIZE_Y, ResizeOp.ResizeMethod.BILINEAR)) // モデルのinputに合うように画像のリサイズ .add(Rot90Op(-imageRotationDegrees / 90)) // 流れてくるImageProxyは90度回転しているのでその補正 .add(NormalizeOp(NORMALIZE_MEAN, NORMALIZE_STD)) // normalization関連 .build() } private val tfImageBuffer = TensorImage(DataType.UINT8) // 検出結果のバウンディングボックス [1:10:4] // バウンディングボックスは [top, left, bottom, right] の形 private val outputBoundingBoxes: Array<Array<FloatArray>> = arrayOf( Array(MAX_DETECTION_NUM) { FloatArray(4) } ) // 検出結果のクラスラベルインデックス [1:10] private val outputLabels: Array<FloatArray> = arrayOf( FloatArray(MAX_DETECTION_NUM) ) // 検出結果の各スコア [1:10] private val outputScores: Array<FloatArray> = arrayOf( FloatArray(MAX_DETECTION_NUM) ) // 検出した物体の数(今回はtflite変換時に設定されているので 10 (一定)) private val outputDetectionNum: FloatArray = FloatArray(1) // 検出結果を受け取るためにmapにまとめる private val outputMap = mapOf( 0 to outputBoundingBoxes, 1 to outputLabels, 2 to outputScores, 3 to outputDetectionNum )なんだか変数ばっかりで見づらいですが全部必要です。
画像の前処理はtensorflow lite ライブラリのImageProcessorを使用して行います。
各変数の説明はコメントを参照してください。基本的にここで示したモデルinfoをkotlinで定義しています。推論コードの実装
続いてinterpreterを使ってモデルで推論します。
ObjectDetector.kt// 画像をYUV -> RGB bitmap -> tensorflowImage -> tensorflowBufferに変換して推論し結果をリストとして出力 private fun detect(targetImage: Image): List<DetectionObject> { val targetBitmap = Bitmap.createBitmap(targetImage.width, targetImage.height, Bitmap.Config.ARGB_8888) yuvToRgbConverter.yuvToRgb(targetImage, targetBitmap) // rgbに変換 tfImageBuffer.load(targetBitmap) val tensorImage = tfImageProcessor.process(tfImageBuffer) //tfliteモデルで推論の実行 interpreter.runForMultipleInputsOutputs(arrayOf(tensorImage.buffer), outputMap) // 推論結果を整形してリストにして返す val detectedObjectList = arrayListOf<DetectionObject>() loop@ for (i in 0 until outputDetectionNum[0].toInt()) { val score = outputScores[0][i] val label = labels[outputLabels[0][i].toInt()] val boundingBox = RectF( outputBoundingBoxes[0][i][1] * resultViewSize.width, outputBoundingBoxes[0][i][0] * resultViewSize.height, outputBoundingBoxes[0][i][3] * resultViewSize.width, outputBoundingBoxes[0][i][2] * resultViewSize.height ) // しきい値よりも大きいもののみ追加 if (score >= ObjectDetector.SCORE_THRESHOLD) { detectedObjectList.add( DetectionObject( score = score, label = label, boundingBox = boundingBox ) ) } else { // 検出結果はスコアの高い順にソートされたものが入っているので、しきい値を下回ったらループ終了 break@loop } } return detectedObjectList.take(4) }まずcameraXの画像をYUV -> RGB bitmap -> tensorflowImage -> tensorflowBufferと変換していき
interpreterを使って推論します。引数に入れたoutputMapに推論結果が格納されるので定義した各output変数から結果を整形してリストとして返すようなdetect関数を作成します。続いて
analyze関数からこのdetect関数をコールするようにしてObjectDetectorクラスは完成です。ObjectDetector.kt// cameraXから流れてくるプレビューのimageを物体検知モデルに入れて推論する @SuppressLint("UnsafeExperimentalUsageError") override fun analyze(image: ImageProxy) { if (image.image == null) return imageRotationDegrees = image.imageInfo.rotationDegrees val detectedObjectList = detect(image.image!!) listener(detectedObjectList) //コールバックで検出結果を受け取る image.close() }
image.close()は必ず呼ぶ必要があるので注意してください。android.Media.Imageはシステムリソースを食うので開放する必要があります。ここまで実装出来たらが推論パイプラインの実装は完了です。
最後に検出結果の表示を実装します。検出結果の表示を実装
viewの描画がリアルタイムに行われるので
ViewではなくsurfaceViewを使ってバウンディングボックスなどの表示を実装します。
初期化処理をOverlaySurfaceViewクラスを作って適当に書いていきます。
コールバックやsurfaceViewとは?みたいなのはほかの方の記事でたくさん書かれているので割愛します。OverlaySurfaceView.ktclass OverlaySurfaceView(surfaceView: SurfaceView) : SurfaceView(surfaceView.context), SurfaceHolder.Callback { init { surfaceView.holder.addCallback(this) surfaceView.setZOrderOnTop(true) } private var surfaceHolder = surfaceView.holder private val paint = Paint() private val pathColorList = listOf(Color.RED, Color.GREEN, Color.CYAN, Color.BLUE) override fun surfaceCreated(holder: SurfaceHolder) { // surfaceViewを透過させる surfaceHolder.setFormat(PixelFormat.TRANSPARENT) } override fun surfaceChanged(holder: SurfaceHolder, format: Int, width: Int, height: Int) { } override fun surfaceDestroyed(holder: SurfaceHolder) { } }これにバウンディングボックスを表示する
draw関数を作っていきます。OverlaySurfaceView.ktfun draw(detectedObjectList: List<DetectionObject>) { // surfaceHolder経由でキャンバス取得(画面がactiveでない時にもdrawされてしまいexception発生の可能性があるのでnullableにして以下扱ってます) val canvas: Canvas? = surfaceHolder.lockCanvas() // 前に描画していたものをクリア canvas?.drawColor(0, PorterDuff.Mode.CLEAR) detectedObjectList.mapIndexed { i, detectionObject -> // バウンディングボックスの表示 paint.apply { color = pathColorList[i] style = Paint.Style.STROKE strokeWidth = 7f isAntiAlias = false } canvas?.drawRect(detectionObject.boundingBox, paint) // ラベルとスコアの表示 paint.apply { style = Paint.Style.FILL isAntiAlias = true textSize = 77f } canvas?.drawText( detectionObject.label + " " + "%,.2f".format(detectionObject.score * 100) + "%", detectionObject.boundingBox.left, detectionObject.boundingBox.top - 5f, paint ) } surfaceHolder.unlockCanvasAndPost(canvas ?: return) }surfaceHolder経由で取得するcanvasですが、viewがリークする可能性があるのでnullableで扱ってます。
canvasを使ってバウンディングボックス(Rect)と文字を表示しているだけです。あとは、SurfaceViewのコールバックなどをセットするだけです。
MainActity.ktprivate lateinit var overlaySurfaceView: OverlaySurfaceView override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) overlaySurfaceView = OverlaySurfaceView(resultView) // 略 }MainActivityの画像解析ユースケースのコールバック「TODO 検出結果の表示」の部分を以下のように変更します。
MainActivity.kt// 画像解析(今回は物体検知)のユースケース val imageAnalyzer = ImageAnalysis.Builder() .setTargetRotation(cameraView.display.rotation) .setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) // 最新のcameraのプレビュー画像だけをを流す .build() .also { it.setAnalyzer( cameraExecutor, ObjectDetector( yuvToRgbConverter, interpreter, labels, Size(resultView.width, resultView.height) ) { detectedObjectList -> // 解析結果の表示 overlaySurfaceView.draw(detectedObjectList) } ) }これで完成です!
いい感じに実装出来ましたか?おわり
cameraXもrcになってもうそろそろかっってみんな思ってるんじゃないでしょうか。ユースケースが色々用意されていてそれに則って実装するとやりやすくて拡張性があるのが魅力ですね。個人的にはもうプロダクトにバンバン投入していってもいいんじゃないかって思ってたり。。
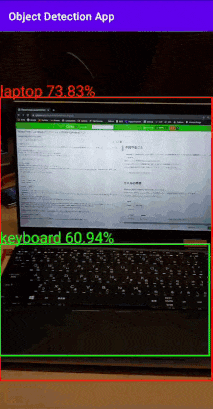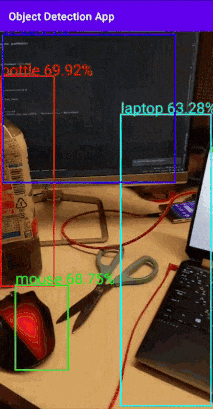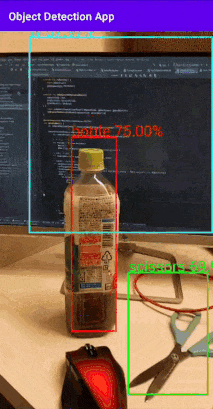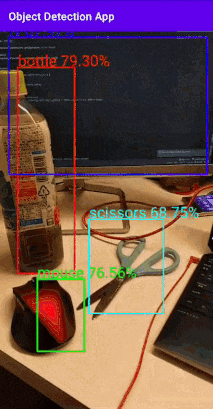
- 投稿日:2021-01-10T17:20:47+09:00
PyQt5アプリに対してPylintを使う方法
PyQt5を使っているコードに対してPylintを使うと
E0611: No name 'QWidget' in module 'foo.bar' (no-name-in-module)のようなエラーが出る。このようなエラーを防ぐには、
pylintrcファイルに下記の設定を入れる。[MASTER] extension-pkg-whitelist=PyQt5
- 投稿日:2021-01-10T17:06:35+09:00
Flat Field画像処理
はじめに
顕微鏡写真から粒子などを自動カウントさせる際に、元の画像の明度にばらつきがあると閾値の設定が難しくなります。
そこで、あらかじめ背景の明度のばらつきを落とす処理が必要になります。その処理にはFlat Field補正が用いられれます。
PyhtonとOpenCVを用いて背景の画像処理について覚えとして記載します。Flat Field補正
天体写真撮影(撮影時の補正)
Flat Field補正は、天体の撮影の際に用いられます。
参考1
Starry Urban Sky
参考2
フラット補正処理とは?
参考3
フラットフレームの撮影方法参考にあるように、
ライトフレーム(LF):一切何の処理も行わず、撮ったそのままの画像
ダークフレーム(DF):ライトフレームと同じ撮影条件でカメラにキャップをして外からの光が入らないようにした撮影画像
フラットフレーム(FF):ライトフレームと同じ撮影条件で、何も写っておらず、光の分布だけが記録された画像
これらの画像から補正画像を以下の様に画像処理します
補正画像:(LF-DF)/(FF-DF)ちなみに分光測定での反射率測定でも同じ処理を行っています。
反射率 =(測定サンプルの反射強度 - ダークフレーム)/(リファレンスの反射強度(例えばAlとか)- ダークフレーム)すでに得られている画像(撮影後)での処理
参考4
背景除去について
大体の場合、すでに画像があってこの画像から粒子の数を自動的にカウントしてほしいと頼まれるので、上記に説明したような処理はできません。
今ある画像から背景処理を行う必要があります。そこで、元画像からフラットフレームを作り出します。
フラットフレームは、元画像(ライトフレーム)にMeanフィルター処理を行い、元画像の平均輝度をかけます。(Meanフィルターは画素範囲を少し大きめにして細かい構造がなくなるようにします。)補正画像:ライトフレーム(元画像)/ フラットフレーム(Meanフィルタ後の画像 × 平均輝度)
試した環境
Windows 10 Pro
anaconda
Python = 3.7
conda = 4.9
numpy = 1.18.5
opencv = 4.2.0 (conda-forgeからインストール)実際
参考4に掲載されている画像データを利用してPythonでFlat Fieldを実装してみました。
import cv2 import numpy as np import matplotlib.pyplot as plt # 処理前と処理後の比較のPlot def bef_aft_img_show(img1,img2): print(f'average brightness:{img1.mean():.1f}, {img2.mean():.1f} ') plt.figure(figsize=(10,10)) plt.subplot(121),plt.imshow(img1),plt.title('Original') plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(img2),plt.title('After') plt.xticks([]), plt.yticks([]) plt.show() # ImageとHistgramのPlot def image_hist_show(img): print(f'Shape:{img.shape},type:{img.dtype}') print(f'Average Brightness:{img.mean():.1f}') hist = cv2.calcHist([img],[0],None,[256],[0,256]) plt.figure(figsize=(10,5)) plt.subplot(121),plt.imshow(img),plt.title('Image') plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.plot(hist),plt.title('Histgram') plt.show()# 画像読み込み(OpenCVを利用しています) file_path = './data/samp_Gradation1.bmp' # 適宜変更してください。 img = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE) image_hist_show(img)Shape:(256, 256),type:uint8 Average Brightness:111.5
# Flat Frameの作成 # Meanフィルタリングを行う。 # 参考:画像の平滑化 # http://whitewell.sakura.ne.jp/OpenCV/py_tutorials/py_imgproc/py_filtering/py_filtering.html dst = cv2.blur(img, (50, 50)) # 通常引数として(3,3)とか(5,5)を入力しますが、全体的な明暗を取り除くために大きい値にしている # 適当に値を調整してください。 image_hist_show(dst)Shape:(256, 256),type:uint8 Average Brightness:111.7
# 元画像 / Mean フィルタ後の画像 × 平均輝度 avg_hist = img.mean() ffc = (img/dst)*avg_hist print(ffc.dtype) # >>> float64 # float64になっているので、この後OpenCVの関数を利用するためにunit8にしています。 cast_ffc = ffc.astype('uint8') image_hist_show(cast_ffc) # この画像を保存する場合 # cv2.imwrite('case1_ffc.png', ffc)float64 Shape:(256, 256),type:uint8 Average Brightness:110.3
#処理前処理後の比較 bef_aft_img_show(img,cast_ffc)average brightness:111.5, 110.3
# 参考資料4にあった、 # 元画像 - Mean フィルタ後の画像 + 平均輝度 # の処理である程度背景処理ができるならばそれでも良いと思います。 l_ffc = img - dst + avg_hist cast_l_ffc = l_ffc.astype('uint8') image_hist_show(cast_l_ffc)Shape:(256, 256),type:uint8 Average Brightness:110.8
ImgeJに実装されているrolling ball algorithmというものがあります
これについては、下記のサイトにPythonのパッケージがあります。https://github.com/mbalatsko/opencv-rolling-ball
pipでしかインストールできません。
また、場合によっては、opencv-pythonもインストールされるので、このパッケージを試すならば、新しく仮想環境を作って試されたほうが良いと思います。実際に使ってみましたが、計算に少し時間がかかります。from cv2_rolling_ball import subtract_background_rolling_ball img_rg, background = subtract_background_rolling_ball(img, 30, light_background=True, use_paraboloid=False, do_presmooth=True) image_hist_show(img_rg)Shape:(256, 256),type:uint8 Average Brightness:246.0
まとめ
既にある画像から平均化処理を行いフラット画像を作成し、Flat Field処理を行いました。

- 投稿日:2021-01-10T16:39:45+09:00
NNCとPython+Flaskで簡単なディープラーニングWebアプリ
Flaskを少しかじって、ごく簡単なWebアプリを作れるようになったので、さっそくディープラーニングを組み込んで遊んでみました。ディープラーニングの部分はNeural Network Console(NNC)を使用します。
利用環境
- Windows 10 Home 20H2
- Neural Network Console Windows版 2.0.0
- Neural Network Libraries 1.15.0
- Anaconda3-2020.11-Windows-x86_64
- Flask 1.1.2
環境構築
環境を構築します。試行錯誤しながらやっているので、いくつか手順が抜けてるかもしれませんが、だいたいこんな感じだったと思います。
Neural Network Consoleのインストール
こちらからダウンロードしてインストールしてください。
https://dl.sony.com/ja/app/Anacondaのインストールと仮想環境構築
Anacondaをインストールし、仮想環境を構築します。具体的な方法は
こちらの記事【初心者向け】AnacondaでPythonの仮想環境を作成・切り替える(多分)最も簡単な方法を参照してください。
Neural Network LibrariesはPython 3.6~3.8に対応しているとのことなので、仮想環境構築時にPythonのバージョンを指定するようにします。仮想環境にNeural Network Librariesをインストール
Neural Network Librariesのインストール方法は下記ページに記載されています。
https://nnabla.org/ja/install/
といっても難しいものはなく、> pip install -U nnablaとするだけです。(GPUを利用するときは設定が異なります)
ただし、これ以外にもモジュールが必要なようです。
https://nnabla.readthedocs.io/en/latest/python/installation.html
によるとscipy等も必要らしいので、あわせてインストールしておきます。> conda install scipy scikit-image ipython仮想環境にFlaskをインストール
Flaskもインストールしておきます。
> conda install flaskNeural Network Librariesで推論実行できるようにする
今回は下記のチュートリアルの「2. Python APIを用いて推論を実行する方法」をそのまま利用してみました。使用したプロジェクトは
02_binary_cnnという、手書き数字の4と9を識別するCNN(Convolutional Neural Network,畳み込みニューラルネットワーク)です。
チュートリアル:Neural Network Consoleによる学習済みニューラルネットワークのNeural Network Librariesを用いた利用方法2種チュートリアル通りに作業して、Anacondaの仮想環境でエラーなく実行できれば準備完了です。
Webアプリの作成
準備ができたら、Webアプリを作成していきます。
NNCの推論実行処理
こちらはほぼ上記のチュートリアル通りです。今回画像を扱うので、画像の読み込みと正規化の処理を入れています。
今回は、画像は28×28ピクセルのグレースケールを想定しています。必要に応じて画像のリサイズや減色処理を入れてもいいと思います。app.py前半import nnabla as nn import nnabla.functions as F import nnabla.parametric_functions as PF import os import sys from PIL import Image import numpy as np #----------NNCの処理---------- def network(x, test=False): # Input:x -> 1,28,28 # Convolution -> 16,24,24 h = PF.convolution(x, 16, (5,5), (0,0), name='Convolution') # MaxPooling -> 16,12,12 h = F.max_pooling(h, (2,2), (2,2)) # Tanh h = F.tanh(h) # Convolution_2 -> 8,8,8 h = PF.convolution(h, 8, (5,5), (0,0), name='Convolution_2') # MaxPooling_2 -> 8,4,4 h = F.max_pooling(h, (2,2), (2,2)) # Tanh_2 h = F.tanh(h) # Affine -> 10 h = PF.affine(h, (10,), name='Affine') # Tanh_3 h = F.tanh(h) # Affine_2 -> 1 h = PF.affine(h, (1,), name='Affine_2') # Sigmoid h = F.sigmoid(h) return h #画像の読み込みと正規化 def normalize_image(save_filepath): im_gray = np.array(Image.open(save_filepath)) / 255.0 return im_gray def predict(im_gray): # load parameters nn.load_parameters('./results.nnp') # Prepare input variable x=nn.Variable((1,1,28,28)) # Let input data to x.d x.d = im_gray #x.data.zero() # Build network for inference y = network(x, test=True) # Execute inference y.forward() print(y.d) return y.dPython+FlaskでWebアプリ作成
FlaskでWebアプリを作ります。
digitsPred.htmlに作成したフォーム(後述)から画像を指定してSubmitすると、裏でNNCの推論処理が走って得られた結果をsuccess.htmlで表示します。app.py後半from flask import Flask, render_template, request, redirect, url_for from werkzeug.utils import secure_filename import os app = Flask(__name__) @app.route('/digitsPred', methods=['GET', 'POST']) def upload(): # GETの場合 if request.method == 'GET': return render_template('digitsPred.html') # POSTの場合 elif request.method == 'POST': #submitされたファイルを取得 file = request.files['file'] #安全なファイル名に変換 save_filename = secure_filename(file.filename) #ファイル保存 save_filepath = os.path.join('./static/image', save_filename) file.save(save_filepath) #画像ファイルを正規化しndarrayに変換 im_gray = normalize_image(save_filepath) #NNCで推論実行 pred = predict(im_gray) #結果処理 if pred < 0.5: res = 4 #数字の4と判定 else: res = 9 #数字の9と判定 #結果表示 return render_template('success.html', save_filename=save_filename, res=res, pred=pred[0][0]) if __name__ == '__main__': app.run(debug=True)この2つのコードを、
app.pyという単一のPythonファイルで保存します。
なお、上記の処理で描かれているように、./static/imageフォルダに画像を保管するようになっているので、フォルダを作成しておきます。HTMLファイルの準備
Pythonファイルがある場所に
templatesというフォルダを作成し、その中に以下の3つのHTMLファイルを作成します。
- base.html
- digitsPred.html
- success.htmlbase.html
base.htmlで各HTMLファイルで共通となる部分を作っておき、継承するようにします。
base.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>Form Sample</title> </head> <body> {% block content %} {% endblock %} </body> </html>digitsPred.html
このページにフォームを作成し、ファイルをSubmitできるようにします。
digitsPred.html{% extends "base.html" %} {% block content %} <title>深層学習で数字判定</title> <h1>数字の画像をアップロード</h1> <p>画像はモノクロで28x28ピクセルにしてください。</p> <p>現在のところ"4"と"9"の分類のみに対応しています。</p> <form action="{{url_for('upload')}}" method="POST" enctype="multipart/form-data"> <input type="file" name="file"> <input type="submit" value="アップロード"> </form> {% endblock %}success.html
success.html{% extends "base.html" %} {% block content %} <title>推論結果</title> <h1>推論が完了しました</h1> <p>アップロードされたファイルは {{save_filename}} です。</p> <h2>画像に書かれている数字は{{res}}です。</h2> <p>NNCの推論結果は{{pred}}でした。</p> {% endblock %}実行結果
app.pyファイルを実行します。たとえばhttp://127.0.0.1:5000/digitsPredにアクセスすると、フォームが表示されます。
画像を指定して[アップロード]ボタンをクリックすると、こんな感じで結果を表示してくれます。
※画像ファイルは、NNCのサンプルデータセットに入っているものを使うと簡単です。
neural_network_console_200\neural_network_console\samples\sample_dataset\MNIST\validation参考資料

- 投稿日:2021-01-10T16:19:10+09:00
ファッションサイト、WEARのスナップ写真の姿勢をクラスタリング
ファッションサイトWEARでは、ファッションコーディネイトサイトで様々な人のスナップ写真がアップロードされています。見てみると、モデルの方々は正面に直立不動でただ立っているというよりは、少し横に向いたり、服が見えやすいように少し片足上げるなど、立ち方に工夫があります。今回はそのスナップ写真のモデルの姿勢推定を行い、その推定結果をクラスタリングしてみました。
姿勢推定モデル
https://github.com/ildoonet/tf-pose-estimation
こちらのモデルを利用させていただきました。以下の関数にて、画像のパスを与えると身体の各点(
body_parts)のx座標とy座標を結合したリストを返します。すべての画像においてすぺての点の推定できるわけではないので、目や耳を除いた骨格の部分をすべて(max_n_body_parts)推定できたものについてのみ結果を返しています。from tf_pose import common import cv2 import numpy as np from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh # 先にモデルをロードしておく model = 'mobilenet_thin' resize = '432x368' w, h = model_wh(resize) if w == 0 or h == 0: e = TfPoseEstimator(get_graph_path(model), target_size=(432, 368)) else: e = TfPoseEstimator(get_graph_path(model), target_size=(w, h)) def img2vec(estimator, w, h, img_path, resize=resize, local_file=True): max_n_body_parts = 14 # 目や耳を省く resize_out_ratio = 4.0 if local_file: image = common.read_imgfile(img_path, None, None) if image is None: image = requests.get(img_path).text else: res = requests.get(img_path) image = np.array(Image.open(BytesIO(res.content)).convert('RGB')) humans = estimator.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=resize_out_ratio) image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False) image_h, image_w = image.shape[:2] dfs = pd.DataFrame(index=[]) columns = ['human', 'point', 'x', 'y'] xx = 0 if len(humans) != 1: return for human in humans: # 実際は一人しかいない xx = xx + 1 for m in human.body_parts: body_part = human.body_parts[m] center = (int(body_part.x * image_w + 0.5), int(body_part.y * image_h + 0.5)) list = [[xx, m, center[0],center[1]]] df = pd.DataFrame(data=list, columns=columns) dfs = pd.concat([dfs, df]) dfs = dfs[dfs['point'] < max_n_body_parts] if len(dfs) != max_n_body_parts: return return np.array(dfs.x).tolist() + np.array(dfs.y).tolist()また、画像中の身体の位置を補正するために、x座標とy座標それぞれでmin-maxの正規化をかけるので、実際はベクトル化の部分の処理は以下のようになりました。
def min_max_norm(l): max_ = max(l) return [l_ / max_ for l_ in l] vec = img2vec(e, w, h, f"{file_path}", resize="432x368", local_file=False) min_max_norm(vec[:14]) + min_max_norm(vec[14:]) # このベクトルが一つの画像に対するベクトル(リスト型)スナップ写真をベクトル化
今回は、メンズのスナップ写真とレディースのスナップ写真に分けてデータを作りました。また、冬服はコートやロングスカートやマフラーなどで姿勢推定の難易度が少し上がる気がしたので、夏の期間に絞って画像を集めました。
- https://wear.jp/men-coordinate/?from_month=6&to_month=8&pageno=hoge
- https://wear.jp/women-coordinate/?from_month=6&to_month=8&pageno=hoge
それぞれ、
men_vecsとwomen_vecsという変数名のリストに先程の関数で作られるベクトルをappendしていったところ、それぞれ708個と374個のベクトルが集まりました。クラスタリング(K-means)
メンズとレディースそれぞれのベクトルの集合をクラスタリングしていきます。姿勢の座標特有のベクトル化やクラスタリングの手法がよく分からなかったこともあり、x座標とy座標を結合したベクトルをその空間上のk-meansによるクラスタリングを行いました。
クラスタ数の決定
まずは、クラスタ数(
k)を決めるために、クラスタ数ごとの損失のようなものを計算します。sklearnのKMeansによると、
inertia_ : float
Sum of squared distances of samples to their closest cluster center.とのことなので、この値(各点の最寄りの重心からの距離の総和)をその損失のようなものとして、各クラスタ数ごとにプロットします。
from sklearn.cluster import KMeans # kを変えて距離の総和を計算 errors = [] for k in range(1, 14): kmeans_model = KMeans(n_clusters=k, random_state=0).fit(np.array(men_vecs)) # もしくはwomen_vecs errors.append(kmeans_model.inertia_) plt.plot(errors)
メンズ画像のクラスタリング レディース画像のクラスタリング これ以降は
men_vecsもしくはwomen_vecsをvecsに置き換えたものとします。vecs = men_vecs # vecs = women_vecsクラスタリングのプロット(PCA)
先程のプロットから、今回は
k = 3とすることにしました。クラスタごとのデータの散らばりを主成分分析を用いた2次元のプロットで確認します。k = 3 kmeans_model = KMeans(n_clusters=k, random_state=0).fit(np.array(vecs)) labels = kmeans_model.labels_クラスタごとに色を塗り分ける設定をしています。重心はすべて黒にしました。
from sklearn.decomposition import PCA pca = PCA() pca.fit(np.array(vecs)) feature = pca.transform(np.array(vecs)) centroids_pca = pca.transform(kmeans_model.cluster_centers_) # NOTE: クラスタの重心を別の色に割り当てる color_codes = list(sns.color_palette(n_colors=k).as_hex()) colors = [color_codes[label] for label in labels] colors += ['#000000' for i in range(k)] plt.figure(figsize=(6, 6)) for x, y in zip(feature[:, 0], feature[:, 1]): plt.text(x, y, '', alpha=0.8, size=10) features = np.append(feature, centroids_pca, axis=0) plt.scatter(features[:, 0], features[:, 1], alpha=0.8, color=colors) plt.show()
メンズ画像のクラスタリングごとのPCAのプロット レディース画像のクラスタリングごとのPCAのプロット クラスタの重心を姿勢にプロット
ここまでで、姿勢推定のクラスタリングが完了したので、それらのクラスタの重心をベクトルからx座標とy座標の姿勢のプロットに変換したいと思います。各body_partを散布図の点で表して、実際の骨格になるように棒グラフの棒で結んでいます
def show_poses(vecs_list, m=50): n_poses = len(vecs_list) fig, axes = plt.subplots(n_poses, 1, figsize=(276/m, 368/m*n_poses)) for i, vecs in enumerate(vecs_list): x, y = vecs[:14], vecs[14:] links = [[0, 1], [1, 2], [2, 3], [3, 4], [1, 5], [5, 6], [6, 7], [1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13]] axes[i].scatter(x, [-y_ for y_ in y]) if n_poses > 1 else plt.scatter(x, [-y_ for y_ in y]) for l in links: axes[i].plot([x[l[0]], x[l[1]]], [-y[l[0]], -y[l[1]]]) if n_poses > 1 else plt.plot([x[l[0]], x[l[1]]], [-y[l[0]], -y[l[1]]])試しにレディースの最初の画像の推定結果を表示してみると次のようになりました。おしゃれな立ち姿が想像できます
show_poses([women_vecs[0]])
以下が、クラスタの重心を姿勢のプロットに変換した結果になります
show_poses([v.tolist() for v in kmeans_model.cluster_centers_])
カテゴリ クラスタ1 クラスタ2 クラスタ3 メンズ レディース メンズの3つ目なんかは斜めに立って片足伸ばしてるんだろうなぁとわかるんですが、全体的にはっきりしない結果になりました
おわりに
手法の改善点として考えられるのは、
- ベクトル化:単純なx座標とy座標の結合ベクトルは単純すぎたかもしれない
- 正規化:x座標とy座標を両方0から1に押し込めたが、実際はそれらの比率が異なる(人間なので縦長になる)
後者の話は記事後半の姿勢のプロットでも、実際の画像より横長になっているようなので、何か良い方法があればいいなと考えております


- 投稿日:2021-01-10T15:57:57+09:00
python 仮想環境の構築と有効化など(venv)
概要
pythonで仮想環境の作り方、仮想環境へ入る方法(有効化)、出る方法などをメモります。
pythonでWebアプリケーションを作成して、デプロイする時なんかにreqirements.txtでライブラリを書きますが、アプリで使用しないライブラリが入ってると重くなる原因の1つになります。
こんな時は仮想環境を使います。有効化の方法はWindowsとMacで若干異なります。
準備
仮想環境を作るフォルダを用意します。
今回はDesktopにtestというフォルダがあるとして、ここに仮想環境を作成します。仮想環境作成
Windowsの場合はAnaconda Promptを、Macならターミナルを開き、testフォルダをカレントディレクトリにします。
この状態でpython -m venv venvと入力し、Enterを押します。するとvenvという名前のフォルダが作成されると思います。このフォルダが仮想環境です。必要がなくなった仮想環境は、このフォルダを削除することで破棄できます。
仮想環境の有効化
Windowsでは
venv¥Scripts¥activate.batMacでは
source venv/bin/activateで有効化できます。
このコマンドを実行すると、(base)が(venv)になります。こうなれば、仮想環境に入れたことになります。必要なライブラリは(venv)の状態でインストールします(pip, conda等)
※仮想環境に名前をtestとかにしたら、venvのところが、testに変わります。
仮想環境から抜ける
deactiveを打つだけです。
以上です。
- 投稿日:2021-01-10T15:56:26+09:00
【SAM】Lambda(Python)でRDS Proxyを使ってみる【user/pass, IAM認証】
2020年の7月に発表され大きな話題を読んだRDS Proxyですが、意外とIAM認証やCloudFormationを使った設定方法などの情報が多くなかったので記事にしました。
今回はPython(pymysql)を使用してuser/passでの認証とIAM認証の両方をAWS SAMを用いたCloudFormationで構築しました。
全てを説明すると長くなってしまうので、記事内で省略している部分は以下のリポジトリを参照してください。
https://github.com/yumemi-dendo/sample-aws-rds-proxy環境
SAM CLI:1.15.0
Python:3.8user/passでの認証
user/passでの認証は主にIAM認証での要件に合わない場合に使用される接続方法です。
秒間20~200以上の新規コネクション生成が想定される場合はこちらにするべきでしょう。また通常のRDSへの接続方法と同じなので探せば割と情報がある方法でもあります。
シンプルにSecrets ManagerからDBの認証情報を取得し、それを用いてRDSへ接続します。RDS Proxyのセットアップ
ネットワークやRDSのセットアップはサンプルのリポジトリを参照してください。
RDS ProxyがDBの認証情報を保存しているSecrets Managerにアクセスできるようにする必要があります。
なのでAWS::RDS::DBProxyの他にIAMロールを作成し、RDS Proxyにアクセスを許可するMySQLユーザーの認証情報が保存されているSecretsManagerの読み取り権限を付与します。
今回はrootユーザーとlambdaユーザーの二種類を許可しています。最後に定義したRDS Proxyを
AWS::RDS::DBProxyTargetGroupでRDSに紐付けたら完了です。この記事では割愛していますがRDS Proxy->RDS間のSecurityGroupのパスを通すのを忘れないようにしましょう。
template.yamlRDSProxyRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: rds.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: AllowGetSecretValue PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - secretsmanager:GetSecretValue - secretsmanager:DescribeSecret Resource: - !Ref RDSSecretAttachment - !Ref RDSLambdaUserPassword RDSProxy: Type: AWS::RDS::DBProxy Properties: DBProxyName: sample-rds-proxy-for-mysql EngineFamily: MYSQL RoleArn: !GetAtt RDSProxyRole.Arn Auth: - AuthScheme: SECRETS SecretArn: !Ref RDSSecretAttachment IAMAuth: DISABLED - AuthScheme: SECRETS SecretArn: !Ref RDSLambdaUserPassword IAMAuth: DISABLED VpcSecurityGroupIds: - !Ref RDSProxySecurityGroup VpcSubnetIds: - !Ref PrivateSubnet1 - !Ref PrivateSubnet2 RDSProxyTargetGroup: Type: AWS::RDS::DBProxyTargetGroup DependsOn: - RDSInstance Properties: DBProxyName: !Ref RDSProxy DBInstanceIdentifiers: - !Ref RDSInstance TargetGroupName: default ConnectionPoolConfigurationInfo: ConnectionBorrowTimeout: 120 MaxConnectionsPercent: 90 MaxIdleConnectionsPercent: 10Lambdaのセットアップ
Secrets ManagerからDBの認証情報を取得し、それを使用してRDS ProxyにアクセスできるLambdaの設定をしていきます。
まずはLambdaをVPC上で実行するように
VpcConfigとAWSLambdaVPCAccessExecutionRoleを設定し、PoliciesにSecrets Managerの読み取り権限を付与します。また今回はVPC上でLambdaを実行するため、VPCからSecrets ManagerへアクセスするためにVPCエンドポイントを用意してSecrityGroupなどのネットワークの設定を行う必要があります。
(こちらも割愛しているのでリポジトリを参照してください。)あとはRDS ProxyのSecurityGroupにLambdaのSecurityGroupを追加すれば完了です。
template.yamlRDSProxySecurityGroup: Type: AWS::EC2::SecurityGroup Properties: VpcId: !Ref VPC GroupDescription: "Security Group for RDS Proxy" SecurityGroupIngress: - IpProtocol: "tcp" FromPort: !Ref RDSDBPort ToPort: !Ref RDSDBPort SourceSecurityGroupId: !Ref EC2SecurityGroup - IpProtocol: "tcp" FromPort: !Ref RDSDBPort ToPort: !Ref RDSDBPort SourceSecurityGroupId: !Ref FunctionSecurityGroup # # Lambda # FunctionSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: "Lambda Function Security Group" VpcId: !Ref VPC GetUserWithDBPassFunction: Type: AWS::Serverless::Function Properties: CodeUri: functions/get_user_with_db_pass/ VpcConfig: SecurityGroupIds: - !Ref FunctionSecurityGroup SubnetIds: - !Ref PrivateSubnet1 - !Ref PrivateSubnet2 Environment: Variables: RDS_PROXY_ENDPOINT: !GetAtt RDSProxy.Endpoint RDS_SECRET_NAME: "sample-rds-lambda-user" DB_NAME: "sample_rds_proxy" Policies: - Version: 2012-10-17 Statement: - Effect: Allow Action: secretsmanager:GetSecretValue Resource: !Ref RDSLambdaUserPassword - AWSLambdaVPCAccessExecutionRoleLambdaのコード実装
Secrets ManagerからDBの認証情報を取得し、それを使用してRDS Proxy経由でRDSにアクセスするLambdaを実装します。
user/passを使用する場合は普通にRDSにアクセスする場合と同じようにusernameとpasswordを設定するだけです。
hostの向き先をRDS Proxyのエンドポイントにすることを忘れないようにしましょう。
(今回はpymysqlを使用していますが、mysql.connectorでも同様です。)app.pyimport sys import os import boto3 from botocore.client import Config import json import pymysql import logging logger = logging.getLogger(__name__) RDS_SECRET_NAME = os.environ['RDS_SECRET_NAME'] RDS_PROXY_ENDPOINT = os.environ['RDS_PROXY_ENDPOINT'] DB_NAME = os.environ['DB_NAME'] def lambda_handler(event, context): """ SecretsManagerに保存されたDBの認証情報を使用してRDSからデータを取得する。 """ try: config = Config(connect_timeout=5, retries={'max_attempts': 0}) client = boto3.client(service_name='secretsmanager', config=config) get_secret_value_response = client.get_secret_value(SecretId=RDS_SECRET_NAME) except Exception: logger.error("不明なエラーが発生しました。") raise rds_secret = json.loads(get_secret_value_response['SecretString']) try: conn = pymysql.connect( host=RDS_PROXY_ENDPOINT, user=rds_secret['username'], passwd=rds_secret['password'], db=DB_NAME, connect_timeout=5, cursorclass=pymysql.cursors.DictCursor ) except Exception as e: logger.error("不明なエラーが発生しました。") logger.error(e) sys.exit() with conn.cursor() as cur: cur.execute('SELECT id, name FROM users;') results = cur.fetchall() return resultsIAM認証
IAM認証ではLambda側でSecrets Managerにアクセスする必要がなくなるので、権限的にもコスト的にも優れています。
しかしIAM認証では秒間あたりの新規コネクション生成数に制限があるので注意する必要があります。
(具体的な制限数に関してはドキュメントに記載がありませんでした。)RDS Proxyのセットアップ
RDS ProxyでIAM認証を行う場合、TLS/SSLを有効にして紐付けられているSecrets ManagerのIAM認証を有効にする必要があります。
なのでRequireTLSをTrueにし、AuthのIAMAuthをREQUIREDにします。それ以外の設定はuser/passの方と同じです。
template.yamlRDSProxyWithIam: Type: AWS::RDS::DBProxy Properties: DBProxyName: sample-rds-proxy-for-mysql-with-iam EngineFamily: MYSQL RequireTLS: True RoleArn: !GetAtt RDSProxyRole.Arn Auth: - AuthScheme: SECRETS SecretArn: !Ref RDSLambdaUserPassword IAMAuth: REQUIRED VpcSecurityGroupIds: - !Ref RDSProxySecurityGroup VpcSubnetIds: - !Ref PrivateSubnet1 - !Ref PrivateSubnet2Lambdaのセットアップ
基本的にはuser/passと同じですが、Secrets Managerの代わりにデータベース用のIAMポリシーを付与します。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/UsingWithRDS.IAMDBAuth.IAMPolicy.htmlActionは
rds-db:connectを許可し、リソースにはデータベースのユーザーを指定します。命名規則は以下のようになっています。
arn:aws:rds-db:{region}:{account-id}:dbuser:{DbiResourceId}/{db-user-name}
account-idはDBインスタンスのAWSアカウント番号です。コンソールやRDS, RDS ProxyのArnから確認することができます。DbiResourceIdはDBインスタンスの識別子です。今回はRDS Proxyの値を挿入します。db-user-nameはアクセスを許可するMySQLユーザー名です。複数指定したり*で指定することも可能です。実際に値を入れると以下のようになります。
arn:aws:rds-db:eu-west-1:414867676510:dbuser:prx-07af81c332474cf27/lambdatemplate.yamlGetUserWithIamFunction: Type: AWS::Serverless::Function Properties: CodeUri: functions/get_user_with_iam/ VpcConfig: SecurityGroupIds: - !Ref FunctionSecurityGroup SubnetIds: - !Ref PrivateSubnet1 - !Ref PrivateSubnet2 Environment: Variables: RDS_PROXY_ENDPOINT: !GetAtt RDSProxyWithIam.Endpoint RDS_PROXY_PORT: !Ref RDSDBPort RDS_USER: "lambda" DB_NAME: "sample_rds_proxy" Policies: - Version: 2012-10-17 Statement: - Effect: Allow Action: rds-db:connect Resource: "arn:aws:rds-db:eu-west-1:414867676510:dbuser:prx-07af81c332474cf27/lambda" - AWSLambdaVPCAccessExecutionRoleLambdaのコード実装
Secrets Managerから認証情報を取得する代わりに
generate_db_auth_tokenを使用します。
generate_db_auth_tokenIAM認証情報を使用してデータベースに接続するために使用する認証トークンを生成します。またIAM認証をする場合はTLS/SSL接続が必要なので証明書を
app.pyから参照できる場所に保存します。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/rds-proxy.html#rds-proxy-security.tlsRDS Proxyを使用する場合は
Amazon root CA 1 trust storeが必要となるので以下のURLから取得します。
https://www.amazontrust.com/repository/AmazonRootCA1.pem最後にpymysqlでの接続時に認証トークンと証明書を読み込ませれば完了です。
app.pyimport sys import os import boto3 import pymysql import logging logger = logging.getLogger(__name__) RDS_PROXY_ENDPOINT = os.environ['RDS_PROXY_ENDPOINT'] RDS_PROXY_PORT = os.environ['RDS_PROXY_PORT'] RDS_USER = os.environ['RDS_USER'] REGION = os.environ['AWS_REGION'] DB_NAME = os.environ['DB_NAME'] rds = boto3.client('rds') def lambda_handler(event, context): """ IAM認証でRDS Proxy経由でRDSからデータを取得する。 https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/UsingWithRDS.IAMDBAuth.Connecting.Python.html TLS/SSLに関しては以下のURLを参照 https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/rds-proxy.html#rds-proxy-security.tls """ password = rds.generate_db_auth_token( DBHostname=RDS_PROXY_ENDPOINT, Port=RDS_PROXY_PORT, DBUsername=RDS_USER, Region=REGION ) try: conn = pymysql.connect( host=RDS_PROXY_ENDPOINT, user=RDS_USER, passwd=password, db=DB_NAME, connect_timeout=5, cursorclass=pymysql.cursors.DictCursor, ssl={'ca': 'AmazonRootCA1.pem'} ) except Exception as e: logger.error("不明なエラーが発生しました。") logger.error(e) sys.exit() with conn.cursor() as cur: cur.execute('SELECT id, name FROM users;') results = cur.fetchall() return resultsちなみに
mysql.connectorを使用する場合は証明書は不要でそのまま接続することができます。
(なぜかまでは調べきれてないのですが、たぶんライブラリ内に証明書も含まれているのかな…?)
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/UsingWithRDS.IAMDBAuth.Connecting.Python.html最後に
IAM認証やCloudFormation周りの情報が全然なくて探すのがめちゃくちゃ大変でした。
最終的に公式ドキュメントを隅々まで読んでなんとか動かすことができました。RDSに直接繋ぐのと比べ多少性能は落ちるものの今まで問題だったLambdaでのコネクションの問題を解決し、料金的にも超大規模なRDSインスタンスタイプを使わない限りはお手軽なので、API Gatewayなど以外にもイベント実行や5~10分間隔といった短いバッチ処理などでも十分使えるレベルにあるのではないかと思います。
ただ実務で使うにはRDS Proxy周りのクォータに関する情報がほとんどないのでAWSのサポートにあれこれ問い合わせる必要がありそうです。
参考資料
AWS LambdaでAmazon RDS Proxyを使用する
Amazon RDS Proxy による接続の管理
AM 認証および AWS SDK for Python (Boto3) を使用した DB インスタンスへの接続
IAM データベースアクセス用の IAM ポリシーの作成と使用
サーバーレスアプリケーションから Amazon Aurora への IAM ロールベース認証
IAM 認証情報を使用して Amazon RDS MySQL DB インスタンスに対する認証をユーザーに許可する方法を教えてください。
【全世界待望】Public AccessのRDSへIAM認証(+ SSL)で安全にLambda Pythonから接続する
- 投稿日:2021-01-10T15:41:50+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python 高速化編
MH ソフトウェア&サービスでの画像処理として、OpenCV使用しています。
Raspberry Piでの最高速な処理方法を検討すべく、OpenCVとnumpyの処理速度の比較をしています。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
ベンチマーク結果
各処理を50万回処理させて、どちらが速いか調査し、速い方を採用してTiD サーモ AI デバイス TiDの処理の高速化を図りました。
import cv2 import numpy as np # ファイル名は適宜決定してください file_name = "test.jpg" img = None org = cv2.imread(file_name) for i in range(500000): # Resize: OpenCV is fast. #img = cv2.resize(org, (300,300), cv2.INTER_CUBIC) #img = cv2.resize(org, dsize=(300,300)) #img = org.repeat(2, axis=0).repeat(2, axis=1) # Frip: OpenCV is fast. #img = cv2.flip(org, 1) #img = np.fliplr(org) # BGR to RGB: Numpy is fast. #img = org #img = cv2.cvtColor(org, cv2.COLOR_BGR2RGB) #img = org[:, :, ::-1] # Grayslace: OpenCV is fast. #img = cv2.cvtColor(org, cv2.COLOR_BGR2GRAY) #img = 0.299 * org[:, :, 0] + 0.587 * org[:, :, 1] + 0.114 * org[:, :, 2] # Rotate: OpenCV is fast. #img = np.rot90(org) #img = cv2.rotate(org, cv2.ROTATE_90_CLOCKWISE) #2.99[sec]
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python 高速化編 (URLは変更される場合があります。)
- 投稿日:2021-01-10T15:41:13+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python OpenCV編
Raspberry Pi上のPythonでOpenCVを使用して、人検出を行います。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
OpenCVの準備
OpenCVモジュールがインストールされていない場合、下記コマンドでインストールしてください。
sudo apt update sudo apt upgrade -y sudo apt install python3-pip -y sudo pip3 --default-timeout=1000 install opencv-contrib-python sudo apt-get install libhdf5-dev libhdf5-serial-dev libatlas-base-dev libjasper-dev libqtgui4 libqt4-test libgstreamer1.0-0 libwebp-dev libilmbase-dev libopenexr-dev libavcodec-dev libavformat-dev libswscale-dev libharfbuzz-devimport時にエラーが出たら4.1.1.26から4.1.0.25へバージョンダウン
sudo pip3 install opencv-python==4.1.0.25 sudo pip3 install opencv-contrib-python==4.1.0.25Pillowの準備
Pillowモジュールがインストールされていない場合、下記コマンドでインストールしてください。
sudo apt-get update sudo apt-get install libjpeg-dev -y sudo apt-get install zlib1g-dev -y sudo apt-get install libfreetype6-dev -y sudo apt-get install liblcms1-dev -y sudo apt-get install libopenjp2-7 -y sudo apt-get install libtiff5 -y sudo pip install Pillow下記のエラーが出たら
from PIL import Image, ImageTk ImportError: cannot import name 'ImageTk' from 'PIL' (/usr/lib/python3/dist-packages/PIL/__init__.py)sudo apt-get install python3-pil.imaget顔検出
顔を検出してみます。
detect.py と haarcascade_frontalface_default.xml(ZIPで圧縮済)import os import cv2 os.chdir(os.path.dirname(os.path.abspath(__file__))) face_cascade_path = 'haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) cap = cv2.VideoCapture(0) while True: ret, img = cap.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5) for x, y, w, h in faces: cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2) face = img[y: y + h, x: x + w] face_gray = gray[y: y + h, x: x + w] cv2.imshow('video image', img) key = cv2.waitKey(10) if key == 27: break cap.release() cv2.destroyAllWindows()
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python OpenCV編 (URLは変更される場合があります。)

- 投稿日:2021-01-10T15:40:38+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python スイッチ編
Raspberry Piのシャットダウンと、再起動が出来るスイッチを制御します。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
再起動スイッチ配線
再起動スイッチ(a接点)をGPIO3とGNDに接続します。
Raspberry Piをシャットダウンし、電源が入っている状態で再起動スイッチを押すと、 Raspberry Piが再起動します。シャットダウンスイッチ配線
シャットダウンスイッチ(a接点)をGPIO14とGNDに接続しますpigpioの準備
最近のOSではraspi-configを用いて、「9 Advanced Options」から入り、「AB GPIO Server」を選択すれば、pigpioが利用できます。
有効にできない場合は、下記コマンドでインストールしてください。sudo apt-get update sudo apt-get install pigpiopigpioをサービスで動かしておくと便利です。
- サービスの確認
sudo nano /lib/systemd/system/pigpiod.service
- サービスの有効化
sudo systemctl enable pigpiod sudo systemctl start pigpiod sudo systemctl status pigpiodシャットダウンプログラム
shutdown.pyをRaspberry Piのフォルダにコピーします。/home/pi直下で良いと思います。
shutdown.py (ZIPで圧縮済)#!/usr/bin/python # coding:utf-8 """ Raspberry Pi Shutdown script. ============================= """ import os rp_mode = False try: import pigpio rp_mode = True except ModuleNotFoundError: rp_mode = False import sys import time def main(): if rp_mode == False: return gpionumber = 14 shutdown_time = 3 wait_time = 0.5 args = sys.argv if len(args) > 1: shutdown_time = float(args[1]) pi = pigpio.pi() pi.set_mode(gpionumber, pigpio.INPUT) while True: counter = 0 while True: if pi.read(gpionumber) == 0: counter = counter + 1 if counter >= (shutdown_time / wait_time): os.system('sudo shutdown -h now') #print('sudo shutdown -h now') break time.sleep(wait_time) if __name__ == '__main__': main()シャットダウンプログラムのサービス化
shutdownbuttond.serviceファイルを作成します。
sudo nano /usr/lib/systemd/system/shutdownbuttond.serviceshutdownbuttond.serviceファイルの内容は下記です。
python3、shutdown.pyの場所は適宜変更してください。[Unit] Description=Shutdown Daemon [Service] ExecStart=/usr/bin/python3 /home/pi/pyhome/shutdownd.py Restart=always Type=simple [Install] WantedBy=multi-user.targetサービスに登録します。
sudo systemctl enable shutdownbuttond.service sudo systemctl daemon-reloadサービスが登録されているか確認します。
sudo systemctl status shutdownbuttond.serviceActiveと言う文字があれば、正常に起動しています。
* shutdownbuttond.service - Shutdown Daemon Loaded: loaded (/usr/lib/systemd/system/shutdownbuttond.service; enabled; ven Active: active (running) since Sun 2020-11-01 13:45:21 JST; 2h 10min ago Main PID: 354 (python3) Tasks: 2 (limit: 4915) CGroup: /system.slice/shutdownbuttond.service -- 354 /usr/bin/python3 /home/pi/shutdown.py **月 ** 13:45:21 user systemd[1]: Started Shutdown Daemon.再起動して、シャットダウンできるか確認します。
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python スイッチ編 (URLは変更される場合があります。)
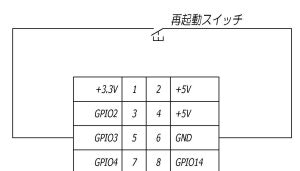
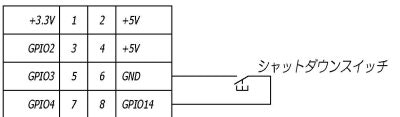
- 投稿日:2021-01-10T15:40:01+09:00
NameError(Importの記入ミス)とImportError(_init_.pyが無い)
flagcheckerのフローチャート:
***/ ├ flagchecker/ │ ├ flagchecker/ │ │ ├ __init__.py │ │ ├ main.py │ │ └ dict.json │ └ test/ │ └ test_main.py ├ pipfile └ pipfile.locktest_main.py:
import json from flagchecker.flagchecker import main def test_get_base_date(): myurl = "C:/Users/***/flagchecker/flagchecker/dict.json" dict_json = json.load(open(myurl,"r")) dict_json["config"]["candle_bar"] = "1day" base_date, pre_date = BaseDate(dict_json).get_base_date() assert base_date == "2021" and pre_date == "2020"pytestを実行したところエラーが発生・・・。
NameError:’BaseDate'is not defined
main.pyにあるクラス”BaseData”が見つかりません。ということらしい
エラーの内容は以下の通り、======================= test session starts ======================== platform win32 -- Python 3.8.5, pytest-6.2.1, py-1.10.0, pluggy-0.13.1 rootdir: C:\Users\***\flagchecker\test collected 1 item test_main.py F [100%] ============================= FAILURES ============================= ________________________ test_get_base_date ________________________ def test_get_base_date(): myurl = "C:/Users/***/flagchecker/flagchecker/dict.json" dict_json = json.load(open(myurl,"r")) dict_json["config"]["candle_bar"] = "1day" base_date, pre_date = BaseDate(dict_json).get_base_date() NameError: name 'BaseDate' is not defined ←ここ test_main.py:8: NameError ===================== short test summary info ====================== FAILED test_main.py::test_get_base_date - NameError: name 'BaseDat... ======================== 1 failed in 2.83s =========================いろいろ試しているとimportの仕方がいけなかったようで
以下のように修正import json from flagchecker import main ←ここ def test_get_base_date(): myurl = "C:/Users/***/flagchecker/flagchecker/dict.json" dict_json = json.load(open(myurl,"r")) dict_json["config"]["candle_bar"] = "1day" base_date, pre_date = main.BaseDate(dict_json).get_base_date() assert base_date == "2021" and pre_date == "2020"これで、NameErrorは解消されたものの、
今度はImportErrorが発生・・・。======================= test session starts ======================== platform win32 -- Python 3.8.5, pytest-6.2.1, py-1.10.0, pluggy-0.13.1 rootdir: C:\Users\***\flagchecker\test collected 0 items / 1 error ============================== ERRORS ============================== __________________ ERROR collecting test_main.py ___________________ ImportError while importing test module 'C:\Users\***\flagchecker\test\test_main.py'. Hint: make sure your test modules/packages have valid Python names. Traceback: ..\..\appdata\local\programs\python\python38\lib\importlib\__init__.py:127: in import_module return _bootstrap._gcd_import(name[level:], package, level) test_main.py:2: in <module> from flagchecker import main E ImportError: cannot import name 'main' from 'flagchecker' (c:\users\***\appdata\local\programs\python\python38\lib\site- packages\flagchecker\__init__.py) ===================== short test summary info ====================== ERROR test_main.py !!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!! ========================= 1 error in 0.43s =========================どうやら_init_.pyがいるよ!って事の様なので
テストフォルダに_init_.pyを下記の通り追加しました。
flagcheckerのフローチャート:***/ ├ flagchecker/ │ ├ flagchecker/ │ │ ├ __init__.py │ │ ├ main.py │ │ └ dict.json │ └ test/ │ ├ __init__.py ←ここ │ └ test_main.py ├ pipfile └ pipfile.lockでは再度pytestを実行!
======================== test session starts ======================== platform win32 -- Python 3.8.5, pytest-6.2.1, py-1.10.0, pluggy-0.13.1 rootdir: C:\Users\***\flagchecker\test collected 1 item test_main.py . [100%] ========================= 1 passed in 0.09s =========================無事pytest完了しました。
- 投稿日:2021-01-10T15:40:00+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python BME280編
BOSCH 温湿度気圧センサ BME280の温湿度・気圧データを、I2C通信で取得します。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
Raspberry Pi上のPythonでI2Cを制御する為に、smbusモジュールを使用します。
smbusモジュールがインストールされていない場合、下記コマンドでインストールしてください。pip install smbusbme280.pyはパッケージとしてimportして使用しますが、テスト用に単体で温湿度・気圧データを取得できます。
bme280.py (ZIPで圧縮済)#!/usr/bin/env python # -*- coding:utf-8 -*- """ BM280 script. ============= Temperature: -40 to +85 [degC] Dumidity: 0 ot 100[%] barometer: 300 to 1100[hPa] """ i2c_enable = False try: import smbus i2c_enable = True except: i2c_enable = False import random import time class BME280(): def __init__(self): self.bus_number = 1 self.i2c_address = 0x76 self.i2c_enable = i2c_enable if self.i2c_enable: self.bus = smbus.SMBus(self.bus_number) else: self.bus = self.SMBus(self.bus_number) return self.digT = [] self.digP = [] self.digH = [] self.t_fine = 0.0 self.setup() self.get_calib_param() @property def barometer(self): result = float(f'{random.uniform(1020.0, 1040.0):.2f}') if self.i2c_enable == False: return result # For I2C error at pushed power switch. try: pres_raw = self._read_bus_data('barometer') except: return result pressure = 0.0 v1 = (self.t_fine / 2.0) - 64000.0 v2 = (((v1 / 4.0) * (v1 / 4.0)) / 2048) * self.digP[5] v2 = v2 + ((v1 * self.digP[4]) * 2.0) v2 = (v2 / 4.0) + (self.digP[3] * 65536.0) v1 = (((self.digP[2] * (((v1 / 4.0) * (v1 / 4.0)) / 8192)) / 8) + ((self.digP[1] * v1) / 2.0)) / 262144 v1 = ((32768 + v1) * self.digP[0]) / 32768 if v1 == 0: return 0 pressure = ((1048576 - pres_raw) - (v2 / 4096)) * 3125 if pressure < 0x80000000: pressure = (pressure * 2.0) / v1 else: pressure = (pressure / v1) * 2 v1 = (self.digP[8] * (((pressure / 8.0) * (pressure / 8.0)) / 8192.0)) / 4096 v2 = ((pressure / 4.0) * self.digP[7]) / 8192.0 pressure = pressure + ((v1 + v2 + self.digP[6]) / 16.0) #print('pressure : %7.2f hPa' % (pressure/100)) result = float(f'{pressure/100:7.2f}') return result def get_calib_param(self): if self.i2c_enable == False: return calib = [] for i in range (0x88,0x88+24): calib.append(self.bus.read_byte_data(self.i2c_address,i)) calib.append(self.bus.read_byte_data(self.i2c_address,0xA1)) for i in range (0xE1,0xE1+7): calib.append(self.bus.read_byte_data(self.i2c_address,i)) self.digT.append((calib[1] << 8) | calib[0]) self.digT.append((calib[3] << 8) | calib[2]) self.digT.append((calib[5] << 8) | calib[4]) self.digP.append((calib[7] << 8) | calib[6]) self.digP.append((calib[9] << 8) | calib[8]) self.digP.append((calib[11]<< 8) | calib[10]) self.digP.append((calib[13]<< 8) | calib[12]) self.digP.append((calib[15]<< 8) | calib[14]) self.digP.append((calib[17]<< 8) | calib[16]) self.digP.append((calib[19]<< 8) | calib[18]) self.digP.append((calib[21]<< 8) | calib[20]) self.digP.append((calib[23]<< 8) | calib[22]) self.digH.append( calib[24] ) self.digH.append((calib[26]<< 8) | calib[25]) self.digH.append( calib[27] ) self.digH.append((calib[28]<< 4) | (0x0F & calib[29])) self.digH.append((calib[30]<< 4) | ((calib[29] >> 4) & 0x0F)) self.digH.append( calib[31] ) for i in range(1,2): if self.digT[i] & 0x8000: self.digT[i] = (-self.digT[i] ^ 0xFFFF) + 1 for i in range(1,8): if self.digP[i] & 0x8000: self.digP[i] = (-self.digP[i] ^ 0xFFFF) + 1 for i in range(0,6): if self.digH[i] & 0x8000: self.digH[i] = (-self.digH[i] ^ 0xFFFF) + 1 @property def humidity(self): result = float(f'{random.uniform(10.0, 60.0):.2f}') if self.i2c_enable == False: return result # For I2C error at pushed power switch. try: hum_raw = self._read_bus_data('humidity') except: return result var_h = self.t_fine - 76800.0 if var_h != 0: var_h = (hum_raw - (self.digH[3] * 64.0 + self.digH[4]/16384.0 * var_h))\ * (self.digH[1] / 65536.0\ * (1.0 + self.digH[5] / 67108864.0 * var_h \ * (1.0 + self.digH[2] / 67108864.0 * var_h))) else: return 0 var_h = var_h * (1.0 - self.digH[0] * var_h / 524288.0) if var_h > 100.0: var_h = 100.0 elif var_h < 0.0: var_h = 0.0 #print('hum : %6.2f %' % (var_h)) result = float(f'{var_h:.2f}') return result def _read_bus_data(self, data_type): """ data_tpye: 'temperature' or 'hidumity' or 'barometer' """ data = [] for i in range (0xF7, 0xF7+8): data.append(self.bus.read_byte_data(self.i2c_address,i)) if data_type == 'barometer': return (data[0] << 12) | (data[1] << 4) | (data[2] >> 4) elif data_type == 'humidity': return (data[6] << 8) | data[7] elif data_type == 'temperature': return (data[3] << 12) | (data[4] << 4) | (data[5] >> 4) else: return [0] def read_data(self): t = self.temperature h = self.humidity p = self.barometer return [t, h, p] def setup(self, ): osrs_t = 1 #Temperature oversampling x 1 osrs_p = 1 #Pressure oversampling x 1 osrs_h = 1 #Humidity oversampling x 1 mode = 3 #Normal mode t_sb = 5 #Tstandby 1000ms filter = 0 #Filter off spi3w_en = 0 #3-wire SPI Disable ctrl_meas_reg = (osrs_t << 5) | (osrs_p << 2) | mode config_reg = (t_sb << 5) | (filter << 2) | spi3w_en ctrl_hum_reg = osrs_h self.write_reg(0xF2,ctrl_hum_reg) self.write_reg(0xF4,ctrl_meas_reg) self.write_reg(0xF5,config_reg) # Dummy SMBus. class SMBus(): def __init__(self, *args, **kwargs): pass @property def temperature(self): result = float(f'{random.uniform(20.0, 40.0):.2f}') if self.i2c_enable == False: return result # For I2C error at pushed power switch. try: temp_raw = self._read_bus_data('temperature') except: return result v1 = (temp_raw / 16384.0 - self.digT[0] / 1024.0) * self.digT[1] v2 = (temp_raw / 131072.0 - self.digT[0] / 8192.0) * (temp_raw / 131072.0 - self.digT[0] / 8192.0) * self.digT[2] self.t_fine = v1 + v2 temperature = self.t_fine / 5120.0 result = float(f'{temperature:.2f}') return result def write_reg(self, reg_address, data): if self.i2c_enable == False: return try: self.bus.write_byte_data(self.i2c_address, reg_address, data) except: self.i2c_enable = False self.bus = self.SMBus(self.bus_number) if __name__ == '__main__': em = BME280() while True: print(em.read_data()) #print(em.barometer) #print(em.humidity) #print(em.temperature) time.sleep(0.5)
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python BME280編 (URLは変更される場合があります。)

- 投稿日:2021-01-10T15:39:21+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python VL53L0X編
Pololu Time-of-Flight 距離センサモジュール VL53L0Xの距離データを、I2C通信で取得します。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
Raspberry Pi上のPythonでVL53L0Xからデータを取得する為に、adafruit-circuitpython-vl53l0xモジュールを使用します。
adafruit-circuitpython-vl53l0xモジュールがインストールされていない場合、下記コマンドでインストールしてください。sudo pip3 install adafruit-circuitpython-vl53l0xvl53l0x.pyはパッケージとしてimportして使用しますが、テスト用に単体で距離データを取得できます。
vl53l0x.py (ZIPで圧縮済)#!/usr/bin/env python # -*- coding:utf-8 -*- """ MH VL53L0X script. ================== """ import threading import time i2c_enable = False try: import adafruit_vl53l0x import board import busio i2c_enable = True except: i2c_enable = False import numpy as np import random class VL53L0X(): def __init__(self, *args, **kwargs): """ mesure length: 30 - 2000[mm] Optionally adjust the measurement timing budget to change speed and accuracy. See the example here for more details: https://github.com/pololu/vl53l0x-arduino/blob/master/examples/Single/Single.ino For example a higher speed but less accurate timing budget of 20ms: vl53.measurement_timing_budget = 20000 Or a slower but more accurate timing budget of 200ms: vl53.measurement_timing_budget = 200000 The default timing budget is 33ms, a good compromise of speed and accuracy. *** avg: Average counts. range: Default is (30, 2000). in_range: If distance is inth range then True. """ self.i2c_enable = i2c_enable self._distance = 0 self._history = [] self._shutdowning = False self._in_range = False self._avg = 1 self.avg = kwargs.get('avg', self._avg) self._range = (30, 2000) self.range = kwargs.get('range', self._range) self.vl53 = None if self.i2c_enable: i2c = busio.I2C(board.SCL, board.SDA) try: self.vl53 = adafruit_vl53l0x.VL53L0X(i2c) except: self.i2c_enable = False self._processing() def __call__(self, *args, **kwargs): return self.distance @property def avg(self): return self._avg @avg.setter def avg(self, value): self._avg = value self._history = [0] for _ in range(self.avg - 1): self._history.append(0) def __del__(self): self._shutdowning = True @property def distance(self): return self._distance @property def in_range(self): return self._in_range def _processing(self): if self._shutdowning: return tmp = 0 if self.i2c_enable: # For I2C error at pushed power switch. try: tmp = self.vl53.range except: pass else: # This value is for D6T-44L-06. tmp = random.randint(500, 550) if tmp <= 2000: self._history[1: self.avg] = self._history[0: self.avg - 1] self._history[0] = tmp self._distance = np.average(self._history) if (self._distance >= self._range[0]) \ & (self._distance <= self._range[1]): self._in_range = True else: self._in_range = False time.sleep(0.1) thread = threading.Thread( name='VL53L0X_Measuring', target=self._processing, ) thread.daeom = True thread.start() @property def range(self): return self._range @range.setter def range(self, value): self._range = value def stop(self): self._shutdowning = True if __name__ == '__main__': vl = VL53L0X(avg=10) while True: print(f'Range: {vl()}[mm] {vl.in_range}') time.sleep(0.1) pass
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python D6T編 (URLは変更される場合があります。)

- 投稿日:2021-01-10T15:38:34+09:00
サーマルカメラ(サーモ AI デバイス TiD) Python D6T-44L-06編
オムロン MEMS非接触温度センサ D6T-44L-06の温度データを、I2C通信で取得します。
- 紹介編
- センサ編
- センサケース編
- Raspberry Pi編
- Python編
5.1 Form編
5.2 オムロン 非接触温度センサ D6T-44L-06編
5.3 Pololu 測距センサ VL53L0X編
5.4 BOSCH 温湿度・気圧センサ BME280
5.5 シャットダウン・再起動スイッチ編
5.6 OpenCV編
5.7 高速化編
Raspberry Pi上のPythonでI2Cを制御する為に、smbusモジュールを使用します。
smbusモジュールがインストールされていない場合、下記コマンドでインストールしてください。pip install smbusd6t_44l_06.pyはパッケージとしてimportして使用しますが、テスト用に単体で温度データを取得できます。
d6t_44l_06.py (ZIPで圧縮済)#!/usr/bin/env python # -*- coding:utf-8 -*- """ D6T-44L-06 script. ================== Temperature measure 5 times/second. Human-detectable distance: MAX 7[m] 5.0[V] I2C(0Ah) 4x4 array 5~45[deg] *** 2020/9/7 * Remake def pixels(). * Previous def result[0] is device temperature. * Sometime temperature is 41degC over. * Max temperature set 40degC. """ import threading import time import numpy as np i2c_enable = False try: import smbus i2c_enable = True except: i2c_enable = False ADDRESS = 0x0a REGISTER = 0x4c class Sensor(): def __init__(self, *args, **kwargs): self.avg_count = 10 self.enable = False self._previous_result = None self._shutdowning = False self.temperature = 0.0 self.i2c_enable = i2c_enable self._pixels_data = None if self.i2c_enable: self.enable = True self._i2c = smbus.SMBus(1) thread = threading.Thread( name='D6T-44L-06_Measuring', target=self.thread, ) thread.daeom = True thread.start() @property def array(self): return (self.x, self.y) def avg(self, pixels): if self._pixels_data is None: self._pixels_data = [pixels] elif len(self._pixels_data) < self.avg_count: self._pixels_data = np.append( self._pixels_data, [pixels], axis=0) elif len(self._pixels_data) == self.avg_count: self._pixels_data = np.delete( self._pixels_data, 0, axis=0) self._pixels_data = np.append( self._pixels_data, [pixels], axis=0) def __del__(self): self._shutdowning = True @property def high(self): return 45.0 @property def low(self): return 5.0 @property def name(self): return 'D6T-44L-06' @property def pixels(self): result = None if self._pixels_data is not None: result = np.average(self._pixels_data, axis=0) return result def stop(self): self._shutdowning = True def thread(self): if self._shutdowning: return # for parent Thermo class. result = None if self.enable: result = [] try: data = self._i2c.read_i2c_block_data( ADDRESS, REGISTER, 32) except: self.i2c_enable = False self.enable = False return self.temperature = (data[1]*256 + data[0]) / 10.0 data.pop(0) data.pop(0) if data[1] < 250 : for i in range(4): for j in range(4): temperature \ = int((data[i*2*j+1])*256 + data[i*2*j]) / 10.0 if temperature > 41.0: break result.append(temperature) if len(result) != 16: result = self._previous_result else: self._previous_result = result self.avg(result) time.sleep(0.2) thread = threading.Thread( name='D6T-44L-06_Measuring', target=self.thread, ) thread.daeom = True thread.start() @property def x(self): return 4 @property def y(self): return 4 if __name__ == '__main__': import time sensor = Sensor() while True: tmp = sensor.pixels if tmp is not None: print(tmp) #print(max(tmp), min(tmp)) time.sleep(1) pass
YouTube: サーマルカメラ(サーモ AI デバイス TiD) Python編
web: サーモ AI デバイス TiD Python D6T編 (URLは変更される場合があります。)
