- 投稿日:2021-01-09T23:56:00+09:00
Effective Python 学習備忘録 8日目 【8/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- Effective Python
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:64-69ページ
- 第3章:クラスと継承
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
@classmethodポリモルフィズムを使ってオブジェクトをジェネリックに構築する
- ポリモルフィズムとは、ある階層の複数のクラスが、あるメソッドのそれぞれのバージョンを実装する方式の一つ
例えば、MapReduceの実装を書いていて、入力データを表す共通クラスが欲しいとします。サブクラスで定義する必要のあるreadメソッドを持つ共通クラスを次のように定義します。
ここで、MapReduceとは「分割された大量のデータをクラスタで分散処理するためのプログラムのことです。class InputData(object): def read(self): raise NotImplementedErrorInputDataクラスを継承してサブクラスを定義
class PathInputData(InputData): def __init__(self, path): super().__init__() # はInputDataの__init__()を実行するはずですが、InputDataに__init__は無いのですが、必要なのでしょうか...? self.path = path def read(self): return open(self.path).read()続いて、入力データを利用するMapReduceのWorkerも定義します。
class Worker(object): def __init_(self, input_data): self.input_data = input_data self.result = None def map(self): raise NotImplementedError def reduce(self, other): raise NotImplementedError続いて、Workerクラスを継承して改行のカウンタを定義します。
class LineCountWorker(Worker): def map(self): data = self.input_data.read() self.result = data.count('\n') def reduce(self, other): self.result += other.resultこれまで定義してきたクラスを統合する方法を考えます。1つ目は、ヘルパー関数を使ってオブジェクトを構築し、連携する作業を手作業で行うことです。
import os from threading import Thread # ディレクトリの内容をリストして、そこに含まれる各ファイルに対するPathInputDataインスタンスを生成 def generate_inputs(data_dir): for name in os.listdir(data_dir): yield PathInputData(os.path.join(data_dir, name)) # generate_inputsで返されたinputDataインスタンスを用いてLineCountWorkerインスタンスを生成 def create_workers(input_list): workers = [] for input_data in input_list: workers.append(LineCountWorker(input_data)) return workers def execute(workers): threads = [Thread(target=w.map) for w in workers] for thread in threads: thread.start() for thread in threads: thread.join() first, rest = workers[0], workers[1:] for worker in rest: first.reduce(worker) return first.result # 最後に、これらをまとめて、各ステップを実行する関数に def mapreduce(data_dir): inputs = generate_inputs(data_dir) workers = create_workers(inputs) return execute(workers)この統合方法の問題は、他のInputDataやWorkerといったサブクラスを書いたら、generate_inputsやcreate_workersを書き直して、mapreduce関数がを対応させなければいけないという点です。
この問題を解決する方法は@classmethodを使うことです。これは、高知宇されたオブジェクトにではなく、クラス全体に適用されます。
この方式をMapReduceクラスに適用したコードが以下になります。import os from threading import Thread class InputData(object): def read(self): raise NotImplementedError class PathInputData(InputData): def __init__(self, path): super().__init__() self.path = path def read(self): return open(self.path).read() class Worker(object): def __init_(self, input_data): self.input_data = input_data self.result = None def map(self): raise NotImplementedError def reduce(self, other): raise NotImplementedError class LineCountWorker(Worker): def map(self): data = self.input_data.read() self.result = data.count('\n') def reduce(self, other): self.result += other.result def generate_inputs(data_dir): for name in os.listdir(data_dir): yield PathInputData(os.path.join(data_dir, name)) def create_workers(input_list): workers = [] for input_data in input_list: workers.append(LineCountWorker(input_data)) return workers def execute(workers): threads = [Thread(target=w.map) for w in workers] for thread in threads: thread.start() for thread in threads: thread.join() first, rest = workers[0], workers[1:] for worker in rest: first.reduce(worker) return first.result class GenericInputData(object): def rad(self): raise NotImplementedError @classmethod def generate_inputs(cls, config): raise NotImplementedError class PathInputData(GenericInputData): def __init__(self, path): super().__init__() self.path = path def read(self): with open(self.path) as f: return f.read() @classmethod def generate_inputs(cls, config): data_dir = config['data_dir'] for name in os.listdir(data_dir): yield cls(os.path.join(data_dir, name)) class GenericWorker: def __init__(self, input_data): self.input_data = input_data self.result = None def map(self): raise NotImplementedError def reduce(self, other): raise NotImplementedError @classmethod def create_workers(cls, input_class, config): workers = [] for input_data in input_class.generate_inputs(config): workers.append(cls(input_data)) return workers class LineCountWorker(GenericWorker): def map(self): data = self.input_data.read() self.result = data.count('\n') def reduce(self, other): self.result += other.result def mapreduce(worker_class, input_class, config): workers = worker_class.create_workers(input_class, config) return execute(workers)こちらのコードは前の実装と同じ結果を出力します。こちらの書き方であれば、GenericInputDataやGenericWorkerサブクラスを変更した際に、関係するコードを書き直す必要が無くなります。
- 投稿日:2021-01-09T23:46:13+09:00
[pyqtgraph] グラフのサイズ比率を設定する
やりたいこと
複数グラフを並べている時のサイズ比率を設定したい環境
Mac OS
Python 3.8.5PyQt5 5.15.2
PyQt5-sip 12.8.1
pyqtgraph 0.11.1
pip install PyQt5 PyQt5-sip pyqtgraphコード
プロット用にnumpyを使用しています。
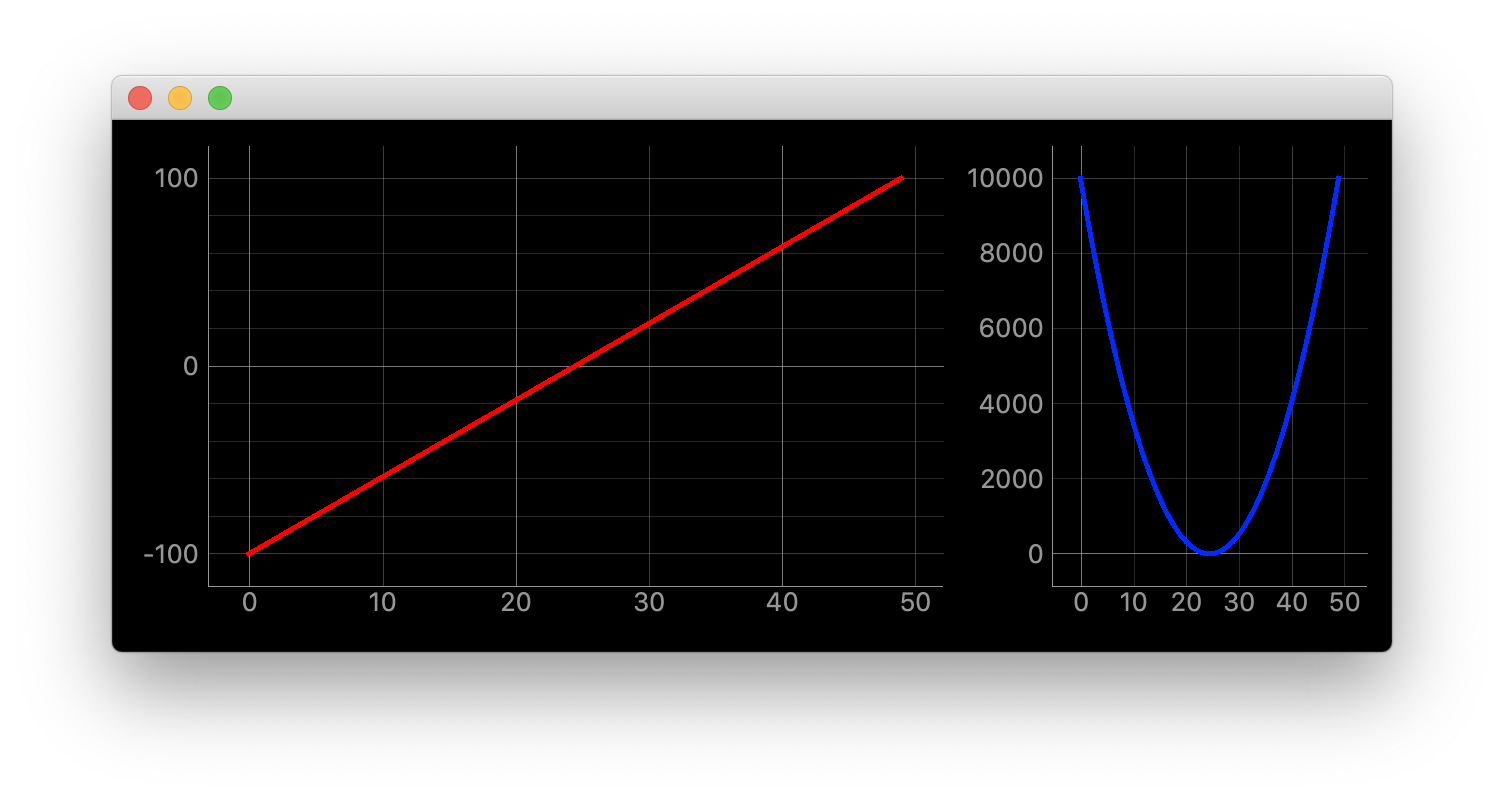
pip install numpy"""グラフのサイズ比率を設定する""" import dataclasses import itertools from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets # ほぼ使わない import pyqtgraph as pg SAMPLE_DATA1 = np.linspace(-100, 100) ** 1 SAMPLE_DATA2 = np.linspace(-100, 100) ** 2 SAMPLE_DATA3 = np.linspace(-100, 100) ** 3 @dataclasses.dataclass class ChangeSizeRatioWidget(pg.GraphicsLayoutWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとプロット追加""" super(ChangeSizeRatioWidget, self).__init__(parent=self.parent) self.plotter1 = self.addPlot(row=0, col=0) self.plotter1.showGrid(x=True, y=True, alpha=0.8) self.plotter1_curve = self.plotter1.plot(pen=pg.mkPen('#f00', width=5)) self.plotter1_curve.setData(SAMPLE_DATA1) self.plotter2 = self.addPlot(row=0, col=1) self.plotter2.showGrid(x=True, y=True, alpha=0.8) self.plotter2_curve = self.plotter2.plot(pen=pg.mkPen('#00f', width=5)) self.plotter2_curve.setData(SAMPLE_DATA2) self.ci.layout.setColumnStretchFactor(0, 8) self.ci.layout.setColumnStretchFactor(1, 5) def main(): app = QtWidgets.QApplication(sys.argv) window = ChangeSizeRatioWidget(parent=None) window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()詳細
self.ci.layout.setColumnStretchFactor(0, 8) self.ci.layout.setColumnStretchFactor(1, 5)pg.GraphicsLayoutWidget.ci.layout.setColumnStretchFactor(col, size)
col -> カラムのインデックス
size -> 比率行に対して変える時は
self.ci.layout.setRowStretchFactor(0, 8) self.ci.layout.setRowStretchFactor(1, 5)です
その他
複数のカラムを跨がる
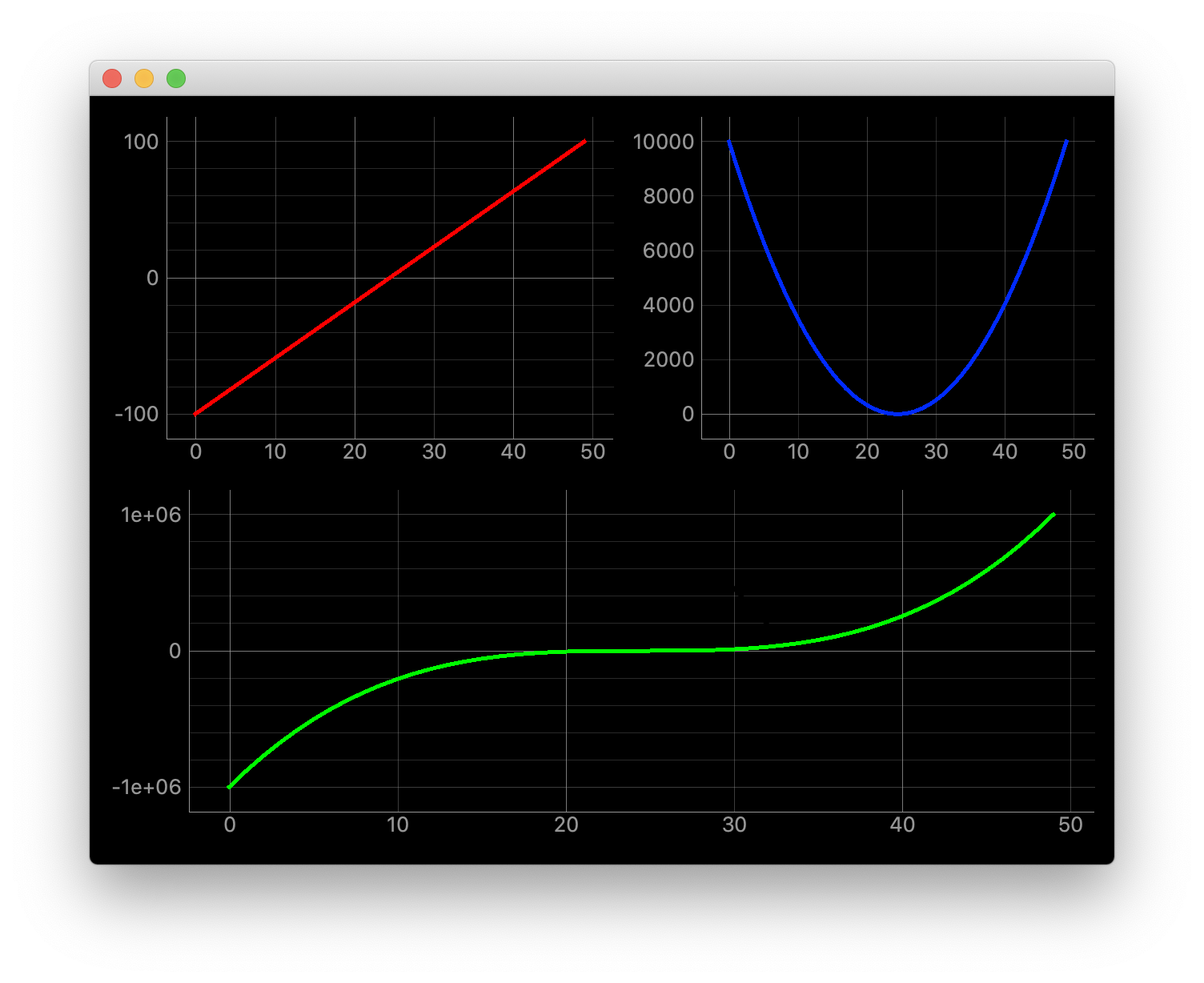
"""複数のカラムを跨がる""" import dataclasses import itertools from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets # ほぼ使わない import pyqtgraph as pg SAMPLE_DATA1 = np.linspace(-100, 100) ** 1 SAMPLE_DATA2 = np.linspace(-100, 100) ** 2 SAMPLE_DATA3 = np.linspace(-100, 100) ** 3 @dataclasses.dataclass class ChangeSizeRatioWidget(pg.GraphicsLayoutWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとプロット追加""" super(ChangeSizeRatioWidget, self).__init__(parent=self.parent) self.plotter1 = self.addPlot(row=0, col=0) self.plotter1.showGrid(x=True, y=True, alpha=0.8) self.plotter1_curve = self.plotter1.plot(pen=pg.mkPen('#f00', width=5)) self.plotter1_curve.setData(SAMPLE_DATA1) self.plotter2 = self.addPlot(row=0, col=1) self.plotter2.showGrid(x=True, y=True, alpha=0.8) self.plotter2_curve = self.plotter2.plot(pen=pg.mkPen('#00f', width=5)) self.plotter2_curve.setData(SAMPLE_DATA2) self.plotter3 = self.addPlot(row=1, col=0, colspan=2) self.plotter3.showGrid(x=True, y=True, alpha=0.8) self.plotter3_curve = self.plotter3.plot(pen=pg.mkPen('#0f0', width=5)) self.plotter3_curve.setData(SAMPLE_DATA3) def main(): app = QtWidgets.QApplication(sys.argv) window = ChangeSizeRatioWidget(parent=None) window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()
self.plotter3 = self.addPlot(row=1, col=0, colspan=2)
colspanで設定参考
忘れてしまった、、
- 投稿日:2021-01-09T23:37:28+09:00
doctestの使い方メモ
doctestとは
簡易なテストを実行する為のpython標準ライブラリです
使い方
1. テストを書く
docstringに実行内容と正しい返り値をセットで書くだけです
def add(a, b): ''' >>> add(1, 2) 3 >>> add(-8, -2) -10 ''' pass if __name__ == '__main__': import doctest doctest.testmod()2. テストを実行する
terminalpython hoge.py3. 結果
出力********************************************************************** File "__main__", line 3, in __main__.add Failed example: add(1, 2) Expected: 3 Got nothing ********************************************************************** File "__main__", line 5, in __main__.add Failed example: add(-8, -2) Expected: -10 Got nothing ********************************************************************** 1 items had failures: 2 of 2 in __main__.add ***Test Failed*** 2 failures. TestResults(failed=2, attempted=2)4. 修正する
正しく返すように修正します
hoge.pydef add(a, b): ''' >>> add(1, 2) 3 >>> add(-8, -2) -10 ''' return a + b if __name__ == '__main__': import doctest doctest.testmod()5. 再度テストする
terminalpython hoge.py6. 結果
テストがすべて成功すれば出力は出ません
出力特定の関数を指定してテストする
doctest.testmod()を使うとすべての関数をテストしてくれますが、特定の関数だけをテストする場合はdoctest.run_docstring_examples()を使います。以下のように書けばadd()だけテストします。
hoge.pyimport doctest doctest.run_docstring_examples(add, globals())jupyter notebookで使う場合
doctest.testmod()すると定義したすべての関数をテストするのは同じなので、セル内で普通に実行するだけです。
jupyter_notebookdef add(a, b): ''' >>> add(1, 2) 3 >>> add(-8, -2) -10 ''' pass import doctest doctest.testmod()
- 投稿日:2021-01-09T23:27:04+09:00
numpy.zeros()でndarrayを初期化した際はメモリが確保されない
題の通り、ndarrayをnumpy.zeros([行数,列数])で初期化した際、[行数,列数]サイズのndarrayのデータを入れるためのメモリ領域は確保されない。内部的には0以外のデータに対してだけ実際にメモリを割り当てている模様。
このため、例えば100万×100万のような巨大なndarrayであっても、numpy.zeros()で初期化した場合は、メモリ32GBや64GBのPCでも軽快に扱うことが出来る。スパースな行列をメモリに制限のある環境で扱う際に利用できるかもしれない。(素直にscipy.sparseを使えば良い気もするが)import numpy as np import sys # 100万×100万,型はfloat64のndarrayを生成 zero_array = np.zeros([1000000,1000000]) # メモリサイズを確認 sys.getsizeof(zero_array) # 8000000000112(約8TB) # メモリ32GBのPCでも軽快に動作する print(zero_array) #[[0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # ... # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.]] zero_array[0,0] = 1 print(zero_array) #[[1. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # ... # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.] # [0. 0. 0. ... 0. 0. 0.]]numpy.ones()で初期化しようとすると、メモリが足りずプロセスが落ちる。
one_array = np.ones([1000000,1000000]) # プロセス異常終了
- 投稿日:2021-01-09T23:20:59+09:00
PyTorchのSoftmax関数で軸を指定してみる
はじめに
掲題の件、調べたときのメモ。
環境
- pytorch 1.7.0
軸の指定方法
nn.Softmax クラスのインスタンスを作成する際、引数dimで軸を指定すればよい。
やってみよう
今回は以下の配列を例にやってみる。
input = torch.randn(2, 3) print(input)tensor([[-0.2562, -1.2630, -0.1973], [ 0.8285, -0.9981, 0.3171]])dimを指定しない場合
m = nn.Softmax() print(m(input))こんな風に怒られる。
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.dim=0を指定した場合
m = nn.Softmax(dim=0) print(m(input))列単位でSoftmaxをかけてくれる。
tensor([[0.2526, 0.4342, 0.3742], [0.7474, 0.5658, 0.6258]])念のため列単位で集計をすると、各列合計が1になる。
torch.sum(m(input), axis=0) tensor([1., 1., 1.])dim=1を指定した場合
m = nn.Softmax(dim=1) print(m(input))行単位でSoftmaxをかけてくれる。
tensor([[0.4122, 0.1506, 0.4372], [0.5680, 0.0914, 0.3406]])念のため行単位で集計すると、各行合計が1になる。
torch.sum(m(input), axis=1) tensor([1.0000, 1.0000])
- 投稿日:2021-01-09T22:45:13+09:00
[pyqtgraph] Plot Options -> Transformsの表示をリンクさせる
やりたいこと
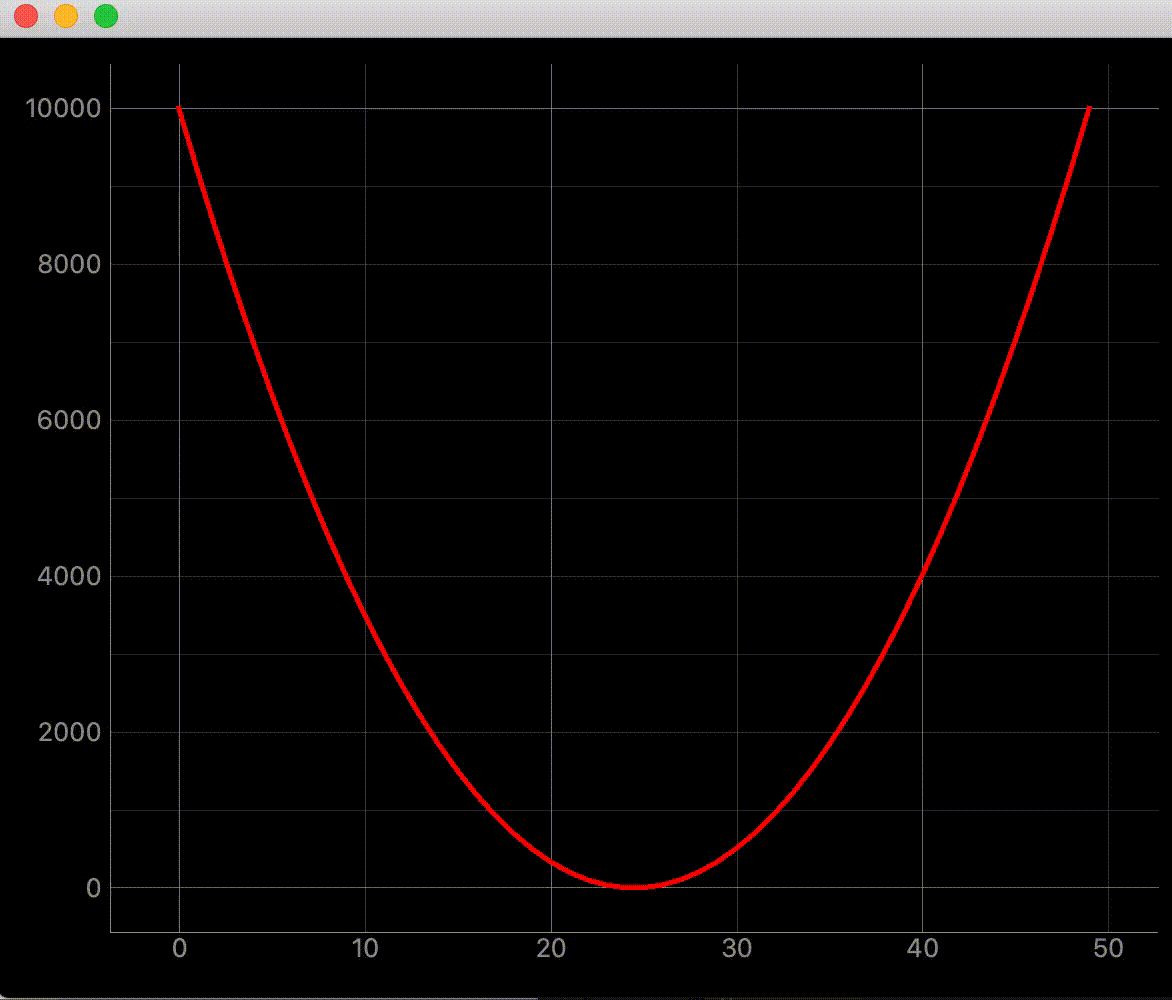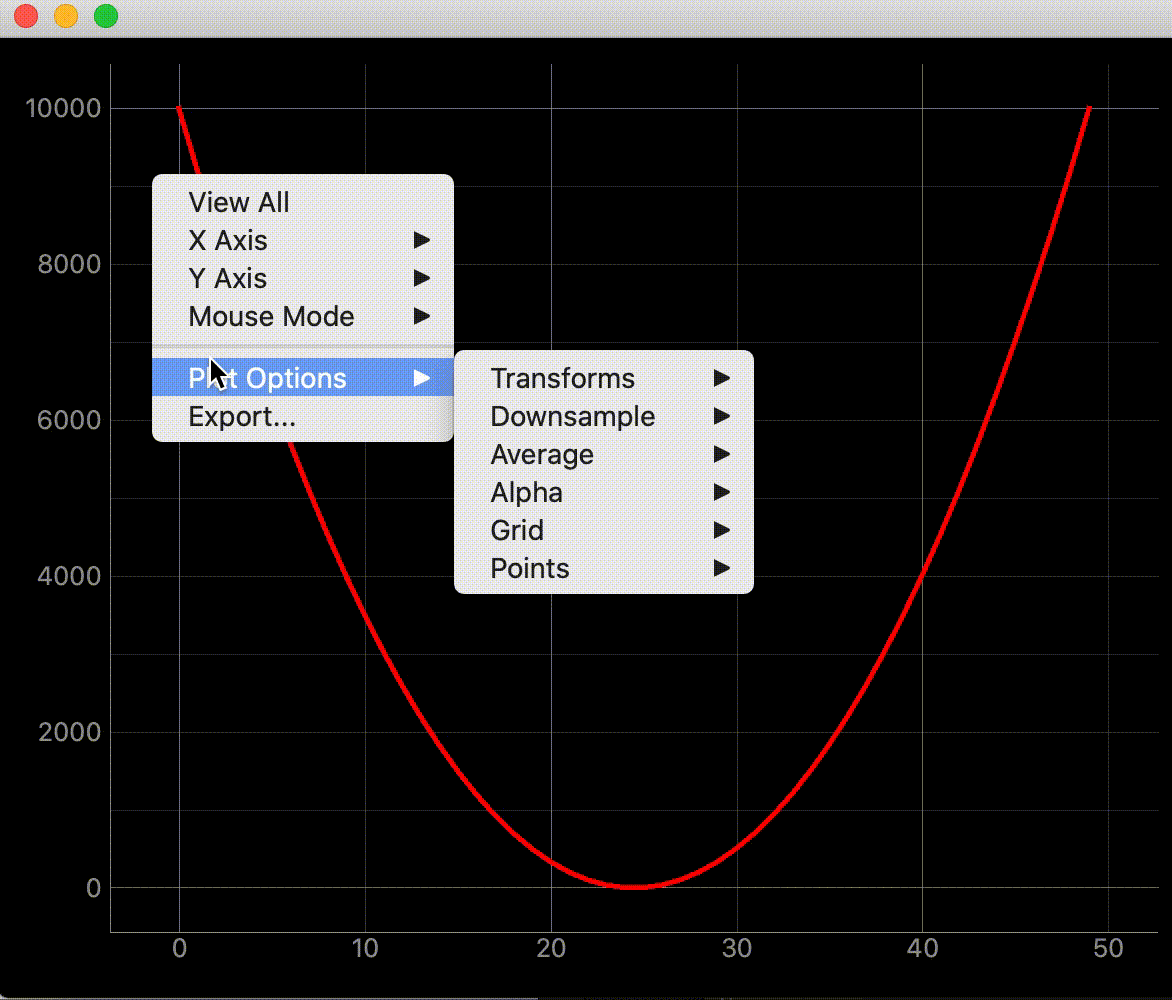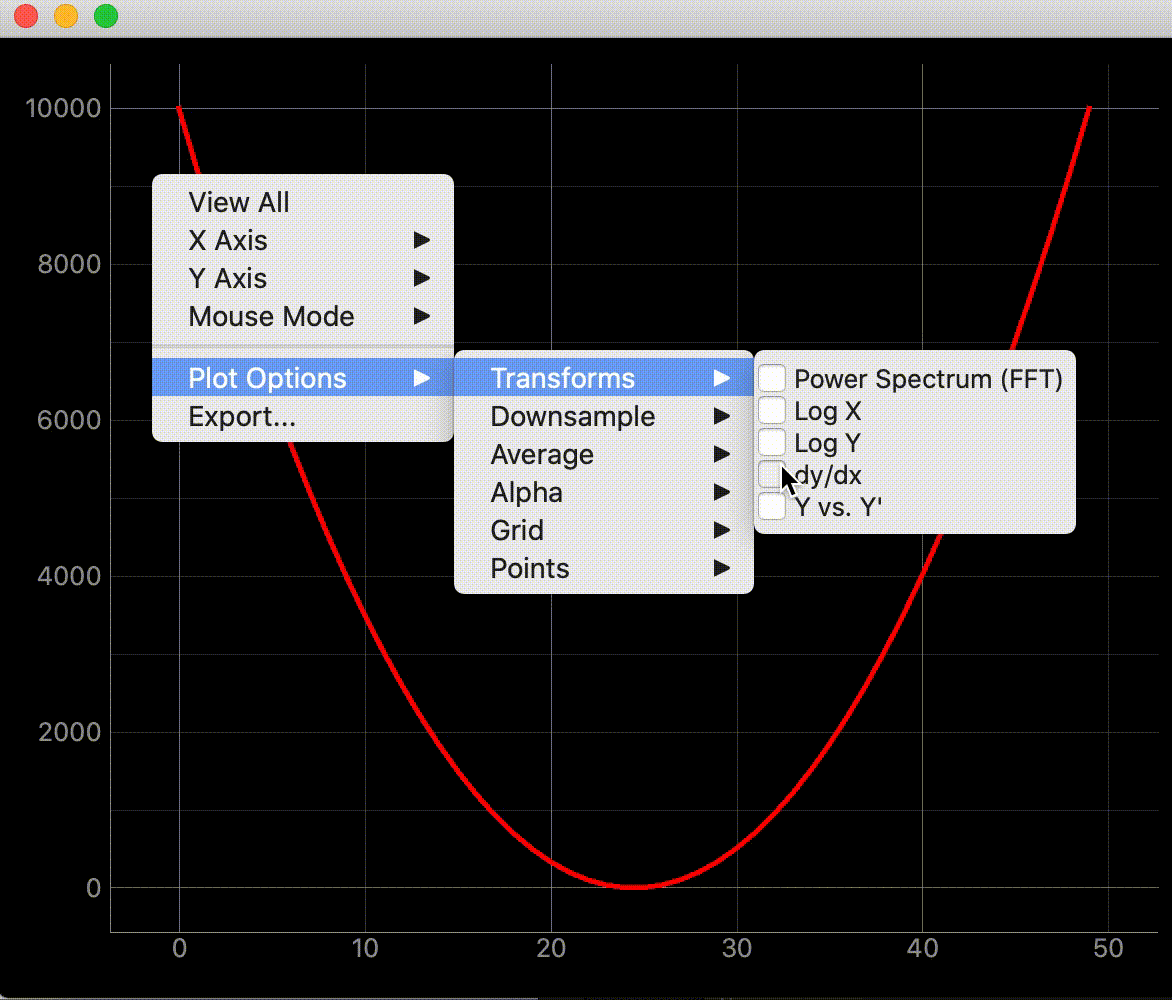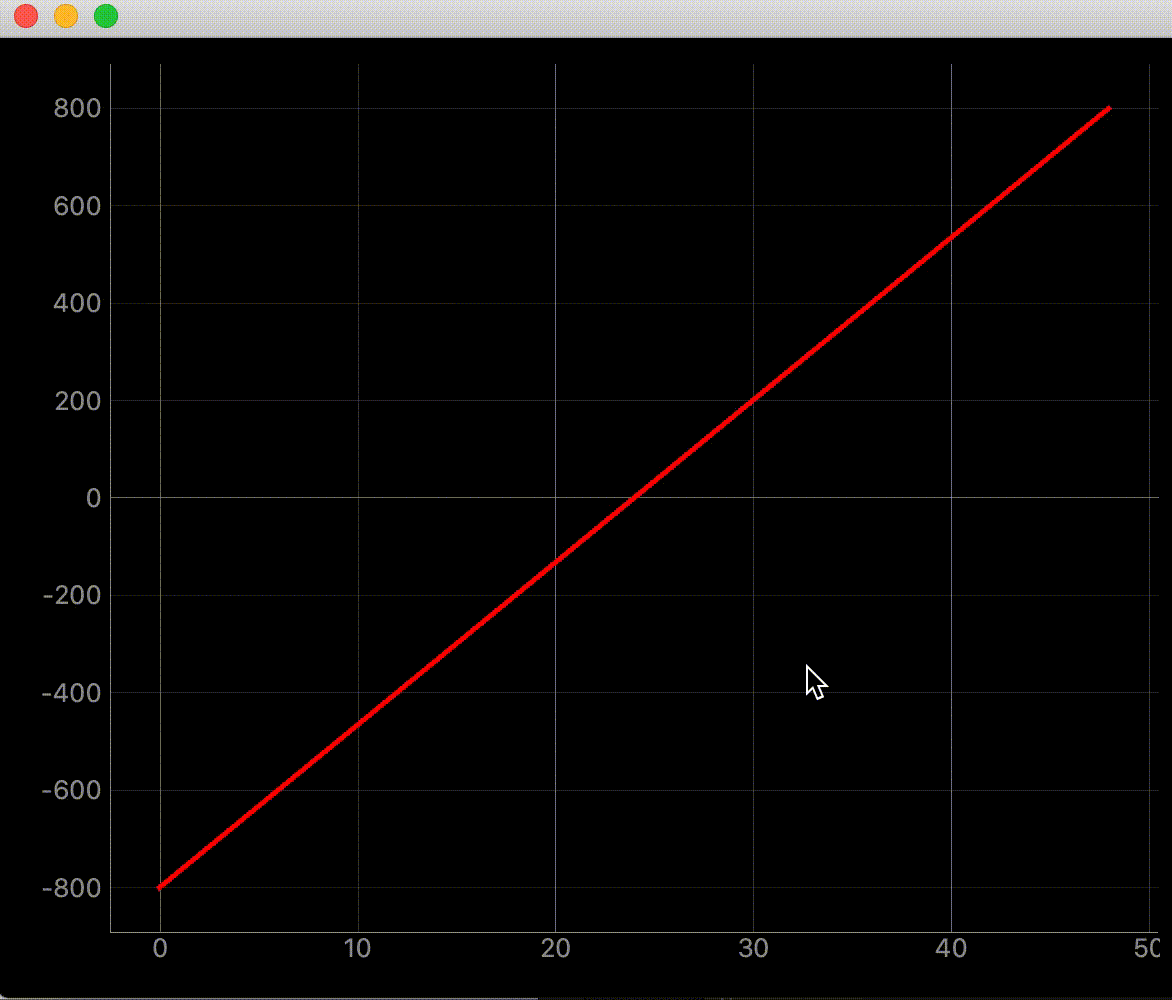
pyqtgraph内で右クリックしてPlot Options -> Transformsと進むとグラフの表示形式を変更してくれます。
表示変更の種類
この変更を複数のグラフでリンクさせるのが目的です。
環境
Mac OS
Python 3.8.5PyQt5 5.15.2
PyQt5-sip 12.8.1
pyqtgraph 0.11.1
pip install PyQt5 PyQt5-sip pyqtgraphコード
プロット用にnumpyを使用しています。
pip install numpy"""pyqtgraphのPlot Options -> Transformsをリンクさせる""" import dataclasses import itertools from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets # ほぼ使わない import pyqtgraph as pg SAMPLE_DATA1 = np.linspace(-100, 100) ** 2 SAMPLE_DATA2 = np.linspace(-100, 100) ** 3 @dataclasses.dataclass class GraphLinkWidget(pg.GraphicsLayoutWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとプロット追加""" super(GraphLinkWidget, self).__init__(parent=self.parent) self.plotter1 = self.addPlot(row=0, col=0) self.plotter1.showGrid(x=True, y=True, alpha=0.8) self.plotter1_curve = self.plotter1.plot(pen=pg.mkPen('#f00', width=5)) # 線色:赤, 幅:5 self.plotter1_curve.setData(SAMPLE_DATA1) self.plotter2 = self.addPlot(row=0, col=1) self.plotter2.showGrid(x=True, y=True, alpha=0.8) self.plotter2_curve = self.plotter2.plot(pen=pg.mkPen('#00f', width=5)) self.plotter2_curve.setData(SAMPLE_DATA2) self.connect_slot() def connect_slot(self) -> None: """スロット接続 itertools.permutationsは順列を作成してくれる関数 ex) list(itertools.permutations([1, 2, 3])) >> [(0, 1, 2), (0, 2, 1), (1, 0, 2), (1, 2, 0), (2, 0, 1), (2, 1, 0)] """ for plot1, plot2 in itertools.permutations([self.plotter1, self.plotter2]): plot1.ctrl.fftCheck.toggled.connect(plot2.ctrl.fftCheck.setChecked) plot1.ctrl.logXCheck.toggled.connect(plot2.ctrl.logXCheck.setChecked) plot1.ctrl.logYCheck.toggled.connect(plot2.ctrl.logYCheck.setChecked) plot1.ctrl.derivativeCheck.toggled.connect(plot2.ctrl.derivativeCheck.setChecked) plot1.ctrl.phasemapCheck.toggled.connect(plot2.ctrl.phasemapCheck.setChecked) def main(): app = QtWidgets.QApplication(sys.argv) window = GraphLinkWidget(parent=None) window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()詳細
以下でリンクさせています
def connect_slot(self) -> None: """スロット接続 itertools.permutationsは順列を作成してくれる関数 ex) list(itertools.permutations([1, 2, 3])) >> [(0, 1, 2), (0, 2, 1), (1, 0, 2), (1, 2, 0), (2, 0, 1), (2, 1, 0)] """ for plot1, plot2 in itertools.permutations([self.plotter1, self.plotter2]): plot1.ctrl.fftCheck.toggled.connect(plot2.ctrl.fftCheck.setChecked) plot1.ctrl.logXCheck.toggled.connect(plot2.ctrl.logXCheck.setChecked) plot1.ctrl.logYCheck.toggled.connect(plot2.ctrl.logYCheck.setChecked) plot1.ctrl.derivativeCheck.toggled.connect(plot2.ctrl.derivativeCheck.setChecked) plot1.ctrl.phasemapCheck.toggled.connect(plot2.ctrl.phasemapCheck.setChecked)
plot1.ctrl.logXCheck.toggled.connect(plot2.ctrl.logXCheck.setChecked)
例えば上記の場合、片方のグラフ(plot1)のlogXチェクボックスが押されたらもう片方(plot2)のlogXチェックボックスにもチェックをいれてリンクさせています。self,plotter1, self.plotter2はPlotItemという型です。pg.PlotWidgetでグラフを作成した場合は
getPlotItem()で取得できます。class 'pyqtgraph.graphicsItems.PlotItem.PlotItem.PlotItem'
PlotWidgetの場合
plotter = pg.PlotWidget()
plotitem = plotter1.getPlotItem()応用
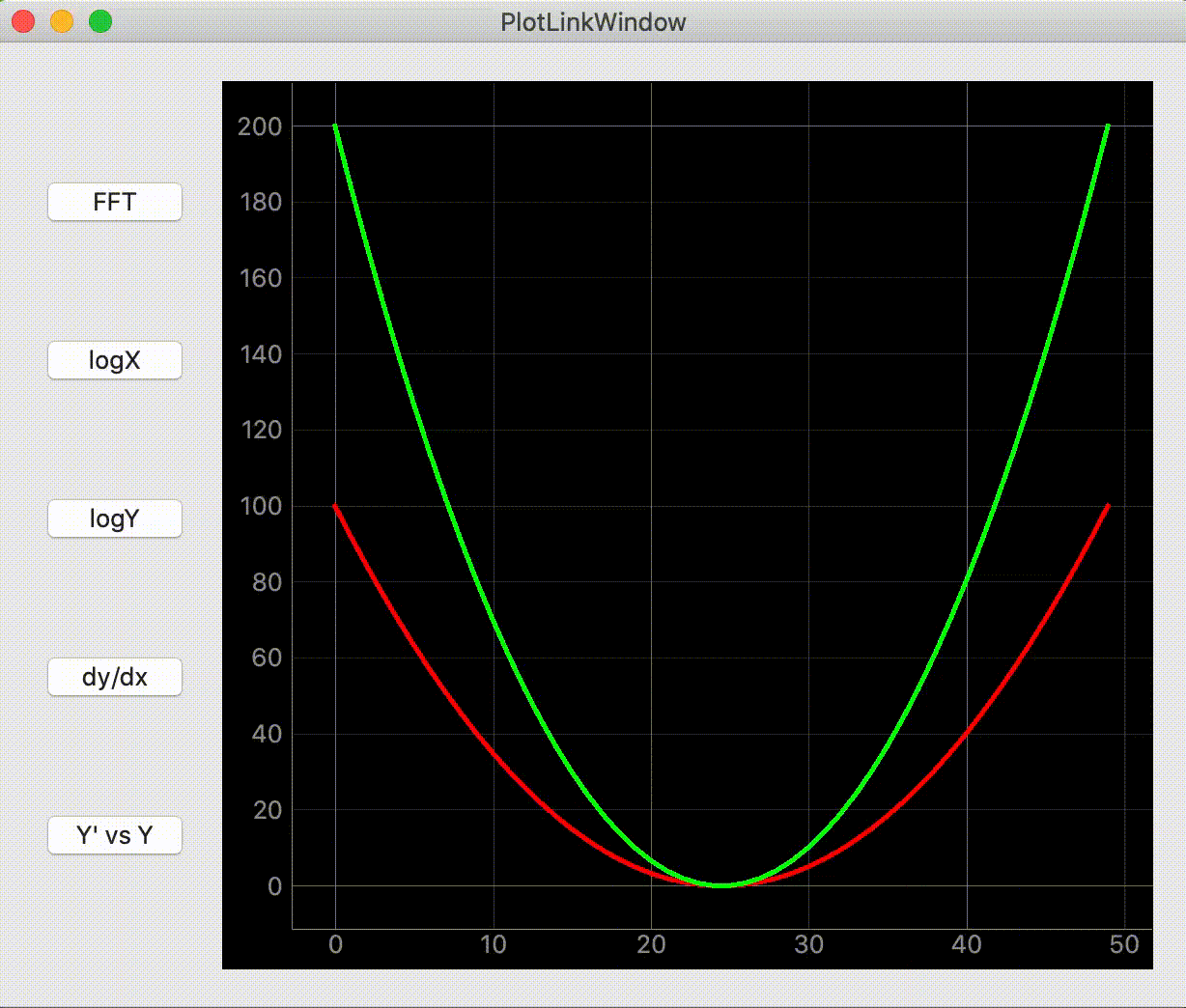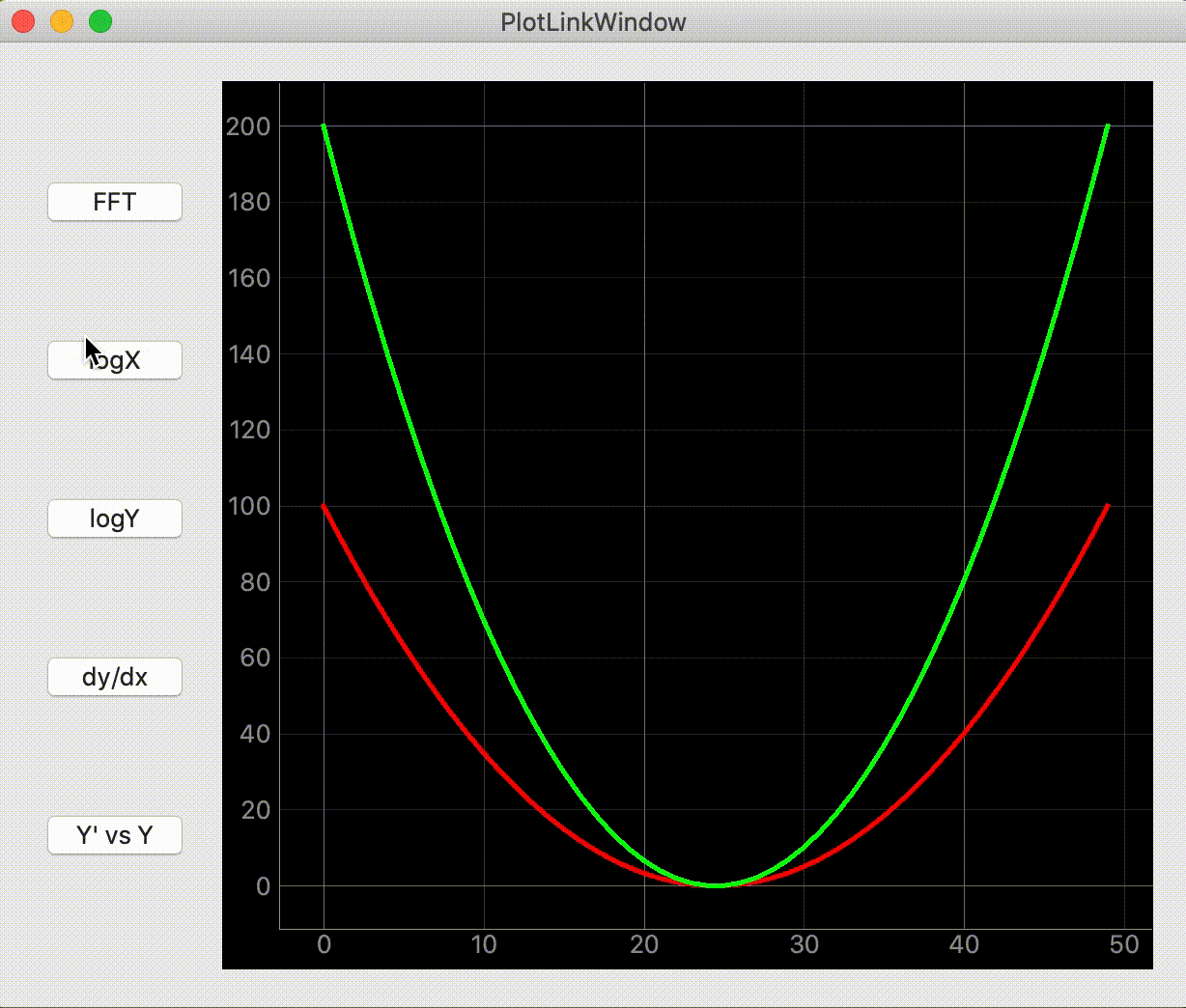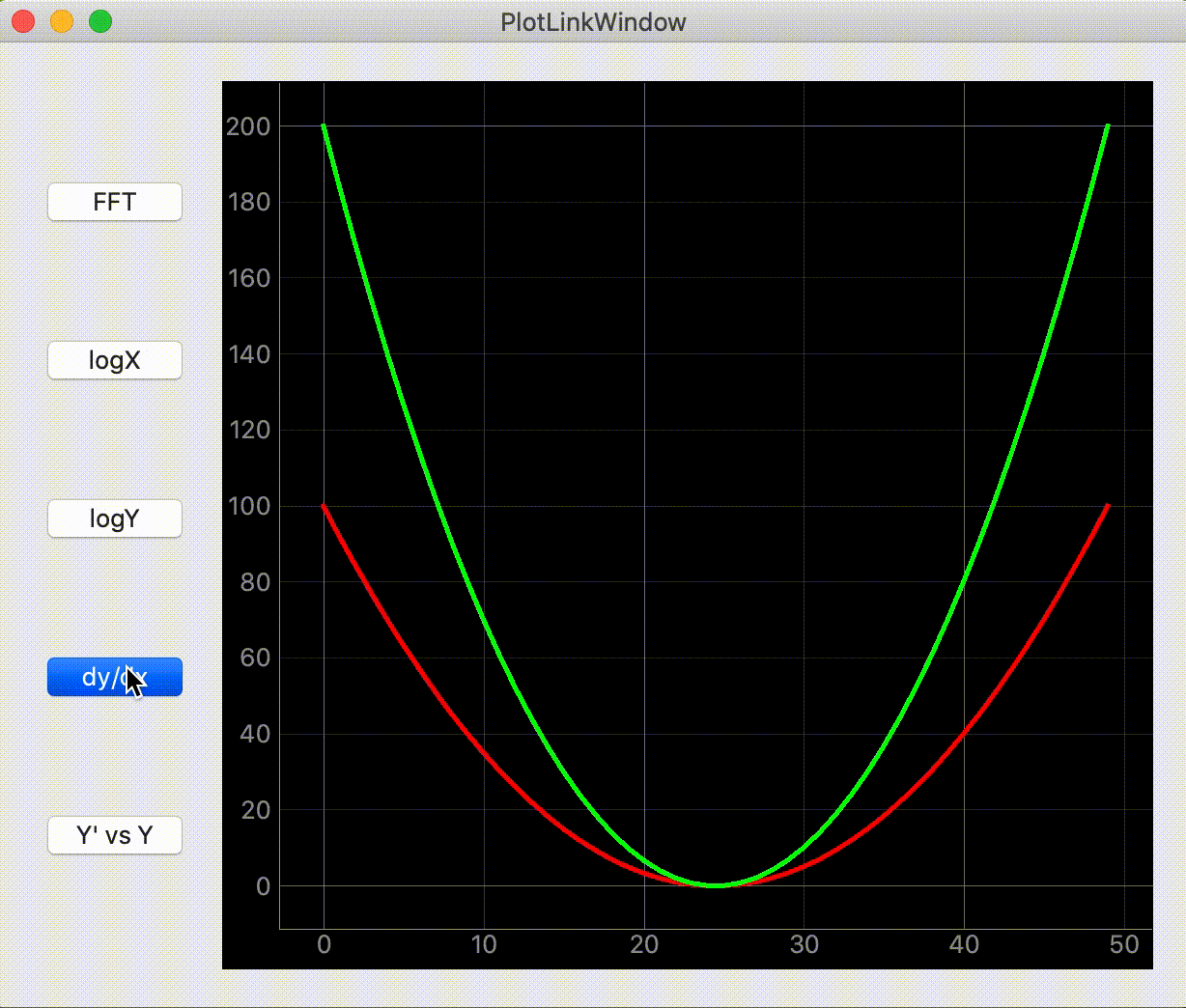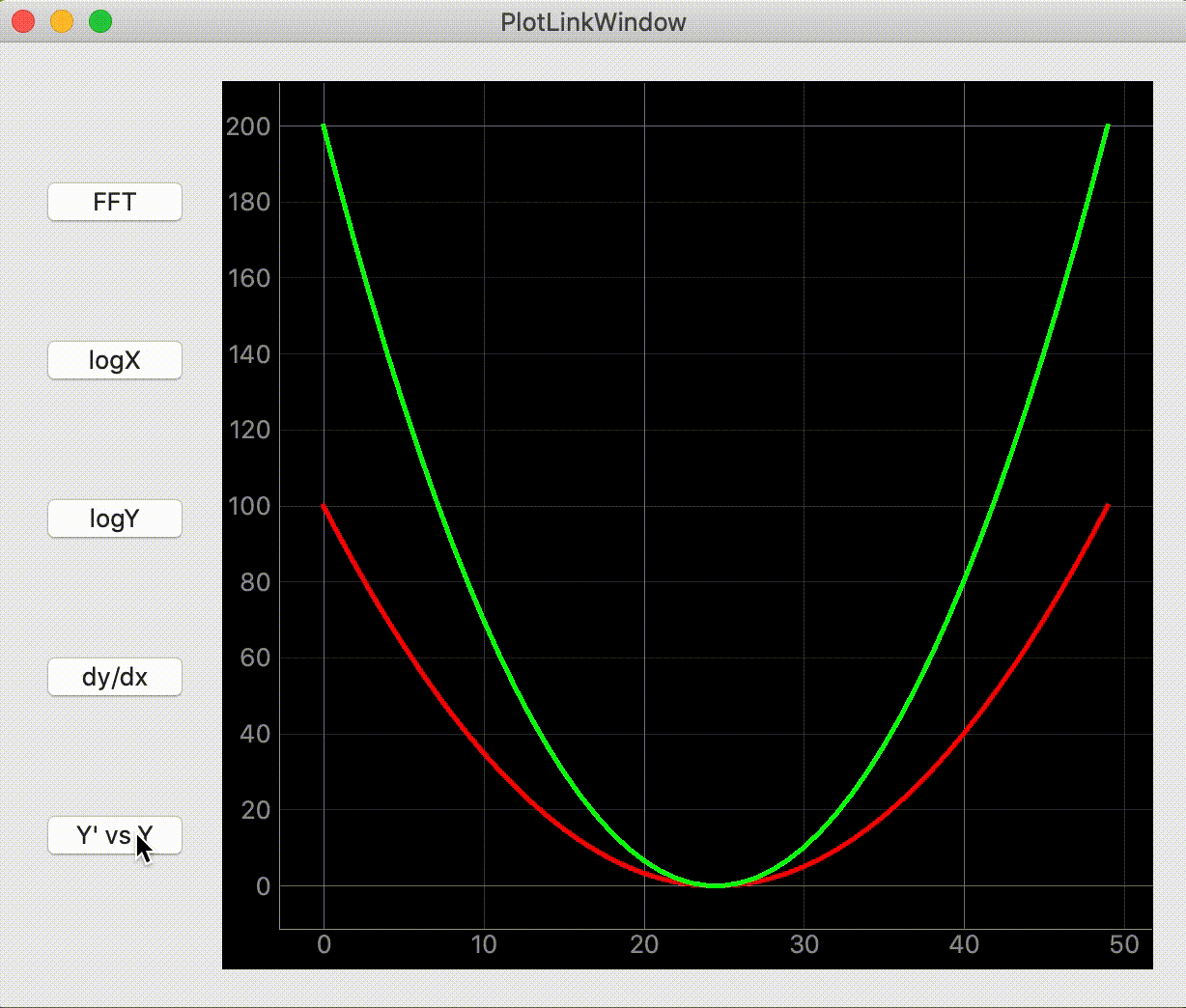
GUIのボタンからグラフ表示を変更する
"""GUIのボタンからグラフ表示を変更する""" import dataclasses from typing import Optional import sys import numpy as np from PyQt5 import QtWidgets import pyqtgraph as pg SAMPLE_DATA1 = np.linspace(-10, 10) ** 2 SAMPLE_DATA2 = 2 * np.linspace(-10, 10) ** 2 @dataclasses.dataclass class PlotLinkWindow(QtWidgets.QWidget): """メイン画面 Attributes # ---------- parent: Optional[QtWidgets.QWidget] default=None 親画面 """ parent: Optional[QtWidgets.QWidget] = None def __post_init__(self) -> None: """スーパークラス読み込みとウィジット作成""" super(PlotLinkWindow, self).__init__(parent=self.parent) self.setGeometry(100, 100, 800, 500) self.setWindowTitle('PlotLinkWindow') self.create_widgets() self.create_layouts() self.set_layouts() self.connect_slot() def create_widgets(self) -> None: """ウィジット作成""" # toggle buttons self.fft_btn = QtWidgets.QPushButton('FFT') self.fft_btn.setCheckable(True) self.logX_btn = QtWidgets.QPushButton('logX') self.logX_btn.setCheckable(True) self.logY_btn = QtWidgets.QPushButton('logY') self.logY_btn.setCheckable(True) self.derivative_btn = QtWidgets.QPushButton('dy/dx') self.derivative_btn.setCheckable(True) self.phasemap_btn = QtWidgets.QPushButton("Y' vs Y") self.phasemap_btn.setCheckable(True) # graph self.plotter1 = pg.PlotWidget() self.plotter1.showGrid(x=True, y=True, alpha=0.8) self.plotter1_curve1 = self.plotter1.plot(pen=pg.mkPen('#f00', width=5)) self.plotter1_curve2 = self.plotter1.plot(pen=pg.mkPen('#0f0', width=5)) self.plotter1_curve1.setData(SAMPLE_DATA1) self.plotter1_curve2.setData(SAMPLE_DATA2) self.plotitem = self.plotter1.getPlotItem() def create_layouts(self) -> None: """レイアウト作成""" self.main_layout = QtWidgets.QHBoxLayout() self.button_layout = QtWidgets.QVBoxLayout() def set_layouts(self) -> None: """ウィジットをレイアウトにセット""" self.main_layout.addLayout(self.button_layout) self.main_layout.addWidget(self.plotter1) self.button_layout.addWidget(self.fft_btn) self.button_layout.addWidget(self.logX_btn) self.button_layout.addWidget(self.logY_btn) self.button_layout.addWidget(self.derivative_btn) self.button_layout.addWidget(self.phasemap_btn) self.setLayout(self.main_layout) def connect_slot(self) -> None: """スロット接続""" self.fft_btn.clicked.connect(lambda: self.plotitem.ctrl.fftCheck.setChecked(self.fft_btn.isChecked())) self.logX_btn.clicked.connect(lambda: self.plotitem.ctrl.logXCheck.setChecked(self.logX_btn.isChecked())) self.logY_btn.clicked.connect(lambda: self.plotitem.ctrl.logYCheck.setChecked(self.logY_btn.isChecked())) self.derivative_btn.clicked.connect( lambda: self.plotitem.ctrl.derivativeCheck.setChecked(self.derivative_btn.isChecked())) self.phasemap_btn.clicked.connect( lambda: self.plotitem.ctrl.phasemapCheck.setChecked(self.phasemap_btn.isChecked())) def main(): app = QtWidgets.QApplication(sys.argv) window = PlotLinkWindow() window.show() sys.exit(app.exec_()) if __name__ == "__main__": main()参考
pyqtgraph、リンク軸間のトラックログ/リニア軸変換の違い
pyqtgraph.graphicsItems.PlotItem.PlotItem — pyqtgraph 0.11.1.dev0 documentation
この辺りself.ctrl = c = Ui_Form()
...
c.fftCheck.toggled.connect(self.updateSpectrumMode)
c.logXCheck.toggled.connect(self.updateLogMode)
c.logYCheck.toggled.connect(self.updateLogMode)
c.derivativeCheck.toggled.connect(self.updateDerivativeMode)
c.phasemapCheck.toggled.connect(self.updatePhasemapMode)itertools
すごいぞitertoolsくん - Qiita


- 投稿日:2021-01-09T22:31:31+09:00
FizzBuzz問題ができないプログラマーがいるとは?
FizzBuzz問題を書くことができないプログラマーがいると聞いて学生の身でも「本当にそんな事あるの?」と考えてしまいました。
そりゃきれいなコードにするのは難しいかもしれないけど出力するだけならできるでしょと考えるのは自然ではないでしょうか。
そう考えて作ったコードが以下のようになります。(言語はpythonです)
for i in range(1,101): if i%15==0: print('FizzBuzz') elif i%3==0: print('Fizz') elif i%5==0: print('Buzz') else: print(i)出力としては正しいのですがなんとも技のないコードですよね‥
。(あくまで経験街著しく少ないド素人が考え出したコードです)多分できないと言っている方もこのレベルのコードは論外と考えてきれいに書く方法がわからないということなんでしょうか。
でも本当にまったくもって書くことができないとしたら‥
あくまで職業として使えるプログラムとこれは別ということなんでしょうか。なんとも不思議です
- 投稿日:2021-01-09T22:26:21+09:00
Python + paramiko でSFTP転送
環境
macOS 10.14.6
Python 3.8.5
paramiko 2.7.2目次
背景
SFTP通信を行うフリーソフトは色々ありますが、
- 特定のファイルだけ送りたい
- 日次バッチで自動連携したい
のようなニーズがでできたのでPythonとparamikoというライブラリを使ってSFTPによるファイル転送を実装してみました。
実装方法
まずはライブラリのインストール
pip install paramikoSFTP転送コードは以下の通り。
SFTP通信はSSHで暗号化された通路を使ってFTP通信を行いファイルデータのやりとりを行います。
そのためSSH接続をしてから通信を開始する実装手順となっています。import paramiko # SFTP接続設定 sftp_config = { 'host' : 'example.com', 'port' : '22', 'user' : 'user', 'pass' : 'pass' } #SSH接続の準備 client = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy) client.connect(sftp_config['host'], port=sftp_config['port'], username=sftp_config('user'), password=sftp_config['pass']) # SFTPセッション開始 sftp_connection = client.open_sftp() ### 相手先サーバにファイルを転送する場合 CONNECT_PATH = 'XXX' # 相手先サーバのフォルダパス for f in files: #転送対象ファイルリストがfilesに入っていると仮定 sftp_connection.put(f, CONNECT_PATH + f) sftp_connection.close() ### 相手先サーバからファイルをダウンロードする場合 #第1引数が相手先サーバのファイル名、第2引数がダウンロードしてくるときのファイル名 sftp_connection.get(CONNECT_PATH + 'test.csv', 'download_test.csv') client.close()参考文献
- 投稿日:2021-01-09T22:23:46+09:00
Wikipediaの記事をランダムに取得して1日1回ツイートするbotを作ってみた
ネット中心で生活していると、どうしても自分の興味があることに情報閲覧が偏ってしまって、興味のない事柄に触れる機会が減ってしまいます。なので、1日1回、強制的に知らない言葉を自分にインプットするためにWikipediaの記事をランダムに1件取得してツイートするTwitterのbotを作りました。
開発したTwitter bot
個人的には、朝一で脳みそのちょっとした刺激になることがあります。
環境
- AWS Lambda
- python3.7
ポイント
- Wikipediaの記事をランダムに1件取得するのに、MediaWiki APIを利用しました。
- 1日1回の起動は、AWS Lambdaの関数をAmazon CloudWatch Eventsのcron式で定期的に実行することで実現しました。(AWS Lambdaでの関数の作り方はたくさんの解説があるのでここでの説明は割愛します。)
- Twitterのbotを開発するためには、アカウント取得に加えてTwitter Appへの登録が必要です。(Twitter Appについてもたくさんの解説があるのでここでの説明は割愛します。)
Wikipediaの記事の取得について
Wikipediaの記事をランダムに1件取得するのに、MediaWiki APIを利用しました。
記事のタイトルを取得するだけでは味気ないので、最初にランダムに記事を1件取得し、その記事のID(pageid)を使って内容を取り出すということをしています。
TwitterのTweetは140文字以内という制限があるので、Tweetするメッセージは、
記事の内容(冒頭部分) + Wikipediaの記事へのリンク
という形式で140文字に収まるように作っています。「収まるようにする」あたりに少々工夫があるので、時間を作って改めて解説してみたいと思っています。wiki_random.pyimport json import sys import urllib.parse import urllib.request import os # Wikipedia API WIKI_URL = "https://ja.wikipedia.org/w/api.php?" # 記事を1件、ランダムに取得するクエリのパラメータを生成する def set_url_random(): params = { 'action': 'query', 'format': 'json', 'list': 'random', #ランダムに取得 'rnnamespace': 0, #標準名前空間を指定する 'rnlimit': 1 #結果数の上限を1にする(Default: 1) } return params # 指定された記事の内容を取得するクエリのパラメータを生成する def set_url_extract(pageid): params = { 'action': 'query', 'format': 'json', 'prop': 'extracts', #記事の文章を取得 'exsentences': 5, #5行分取り出す 'explaintext': '', 'pageids': pageid #記事のID } return params #ランダムな記事IDを取得 def get_random_wordid(): try: request_url = WIKI_URL + urllib.parse.urlencode(set_url_random()) html = urllib.request.urlopen(request_url) html_json = json.loads(html.read().decode('utf-8')) pageid = (html_json['query']['random'][0])['id'] except Exception as e: print ("get_random_word: Exception Error: ", e) sys.exit(1) return pageid #記事IDの内容を取得して、140文字以内のTweetの文章を作成 def get_word_content(pageid): request_url = WIKI_URL + urllib.parse.urlencode(set_url_extract(pageid)) html = urllib.request.urlopen(request_url) html_json = json.loads(html.read().decode('utf-8')) explaintext = html_json['query']['pages'][str(pageid)]['extract'] explaintext = explaintext.splitlines()[0] #改行が含まれる場合に最初の要素のみを取得 if len(explaintext) > 128: explaintext = explaintext[0:124] + "..." explaintext += "\nhttps://ja.wikipedia.org/?curid=" + str(pageid) #twitterはurlを11.5文字とカウントする仕様 return explaintext if __name__ == '__main__': pageid = get_random_wordid() extract = get_word_content(pageid) print(extract)Twitterでのツイートについて
twitterライブラリを使っています。
tweet.pyimport os from twitter import Twitter, OAuth #環境変数に設定したTwitter Appで取得したキー情報を取得 API_KEY = os.environ.get("TWITTER_API_KEY") API_SECRET_KEY = os.environ.get("TWITTER_API_SECRET_KEY") ACCESS_TOKEN = os.environ.get("TWITTER_ACCESS_TOKEN") ACCESS_TOKEN_SECRET = os.environ.get("TWITTER_ACCESS_TOKEN_SECRET") #TwitterのTweetを生成 def TweetMessage(msg): t = Twitter(auth = OAuth(ACCESS_TOKEN, ACCESS_TOKEN_SECRET, API_KEY, API_SECRET_KEY)) statusUpdate = t.statuses.update(status=msg)AWSのlambda_functionについて
一応、書いておきます。
lambda_function.pyimport wiki_random import tweet def lambda_handler(event, context): pageid = wiki_random.get_random_wordid() msg = wiki_random.get_word_content(pageid) tweet.TweetMessage(msg)実行結果がどのようになるかは、こちらを見てみてください。
AWS LambdaのLayerについて
requests、requests-oauthlib、twitterの3つのPythonのライブラリはAWS Lambdaに標準で組み込まれていないのでLayer機能を使って組み込みました。(Layer機能についてもたくさんの解説があるのでここでの説明は割愛します。)
- 投稿日:2021-01-09T22:21:27+09:00
Anacondaの仮想環境でJupyter Notebookを動かすときにエラー
Jupyter NotebookをAnacondaの仮想環境で動かそうとしてトラブルに見舞われたので、自分の施した対処法を書いておきます。
環境
- Windows10 64bit Home バージョン20H2
- Anaconda3-2020.11-Windows-x86_64
仮想環境の作成~Jupyter Notebookのインストールまで
Web上には様々な情報がありますが、自分が試した中ではこれが一番簡単だと思いました。
まずは仮想環境を作成します。
$ conda create -n 環境名 python=バージョン ライブラリ名作成した仮想環境に入ります。
$ conda activate 環境名仮想環境でJupyter Notebookをインストールします。
(仮想環境作成時にライブラリ名で「jupyter」を指定して一緒にインストールしていた場合は不要)$ conda install jupyterJupyter Notebookのカーネルに作成した仮想環境を表示するように設定します。
$ ipython kernel install --user --name=環境名エラー発生
この状態で仮想環境で以下のコマンドでJupyter Notebookを起動できます。
$ jupyter notebookが、Pythonコードを書いても実行されず。Jupyterはカーネルに何回も接続をトライした挙句エラーが発生。以下のようなメッセージが出てきたのでDLLの読み込みに失敗しているようです。
File "C:\Users\ユーザ名\anaconda3\envs\環境名\lib\site-packages\zmq\backend\cython\__init__.py", line 6, in <module> from . import (constants, error, message, context, ImportError: DLL load failed while importing error: 指定されたモジュールが見 つかりません。エラー対処策
解決策がないか探し回ったところ、以下の情報にたどり着きました。
Anacondaの仮想環境がjupyterに認識されないorエラー出るときの対処
コマンドをそのまま引用させていただきますが、自分の環境でもこのコマンドを仮想環境で実行することで解決できました!
$conda uninstall pyzmq $conda install pyzmq $conda install jupyter補足:カーネルの削除
Jupyterに追加した仮想環境のカーネルを削除する方法は以下の通りです。
$ jupyter kernelspec uninstall 環境名
- 投稿日:2021-01-09T22:10:00+09:00
Pythonで学ぶアルゴリズム 第16弾:並べ替え(挿入ソート)
#Pythonで学ぶアルゴリズム< 挿入ソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第16弾として挿入ソートを扱う.挿入ソート
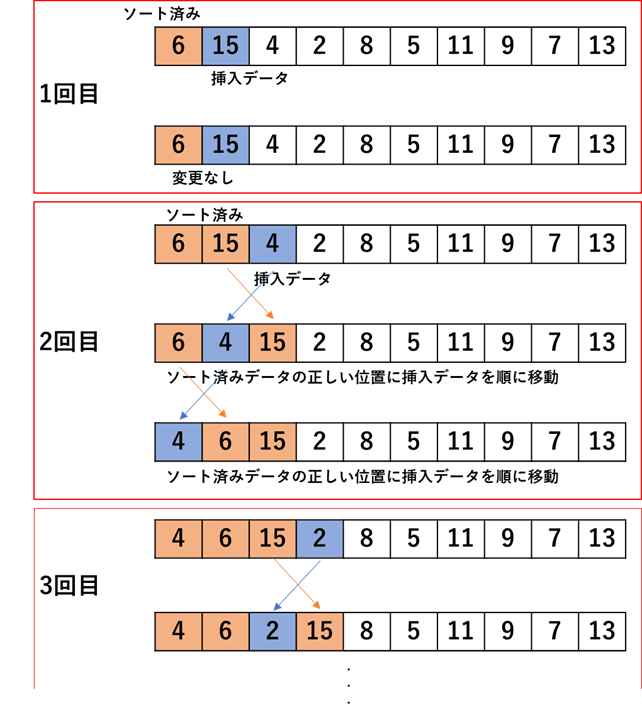
リストの先頭から順にソート済みとして,その隣のデータを挿入データとする.それから挿入データがソート済みのデータの中のどこに位置するのかというのをソート済みデータの末尾から順に比較し必要があれば入れ替えを行い,所望の位置に移動させる.そのイメージ図を次に示す.
上図のように,ソート済みデータを拡張していくような形で徐々に昇順に並べ替えられていく様子が分かる.
実装
先ほどの手順に従ったプログラムのコードとそのときの出力を以下に示す.
コード
insert_sort.py""" 2021/01/09 @Yuya Shimizu 挿入ソート """ def insert_sort(data): """挿入ソート:少しずつソート済み箇所を広げ,昇順に並べ替える""" #1つずつ挿入データを吟味する for i in range(1, len(data)): temporary = data[i] #挿入データを一時的に記録 j = i - 1 while (j >= 0) and (data[j] > temporary): #挿入データがソート済みデータ内のデータよりも小さく右にあれば繰り返し入れ替え data[j + 1] = data[j] #右へ1つデータを移す j -= 1 data[j + 1] = temporary #上の操作で移動を終えた所に一時的に記録していた挿入データを代入 return data if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sorted_data = insert_sort(DATA.copy()) print(f"{DATA} → {sorted_data}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]ちゃんと昇順に並べ替えられていることが分かる.
今回は並べ替える前後での比較をしたいがために,あえてsorted_dataという変数に結果を格納し,さらに関数への引数はDATA.copy()というようにcopy関数により,引数に影響が出ないようにしている.並べ替えるだけなら,そのような操作は必要でなく,insert_sort(DATA)とすればよい.挿入ソートの計算量
最後に計算量について触れる.
基本的に選択ソートと同様,計算量はオーダー記法で表すと,$O(n^2)$となる.
ただし,一度も交換が発生しない場合は,比較のみ(入れ替えなし)で済むため$O(n)$となる.感想
前回に引き続き,そこまで複雑ではなかった.後ろから並べ替えることにはなるほどと学べた.次回以降の並べ替えアルゴリズムも楽しみである.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2021-01-09T22:04:21+09:00
遺伝的アルゴリズム(GA)を用いたニューラルネットワークの学習
はじめに
f(x,y)=\frac{(\frac{\sin x^2}{cos y}+x^2-5y+30)}{80}の関数を遺伝的アルゴリズムを用いてニューラルネットワークを学習させる.
(学部のときの課題で,できなかったのでリベンジしてみた)遺伝的アルゴリズム(GA:Genetic Algorithms)とは
GAはHollandによって開発された,生物の進化のメカニズムを模倣した最適解探索のプログラムである.有性生殖をする生物の進化の課程の中で,環境に適応できる個体ほど次世代に自分の遺伝子を残すことができ,2個体の交叉により子をつくる,また稀に突然変異がおこるという特徴に着目をしている.決定的な優れた厳密解法が発見されておらず,全探索が不可能と考えられるほど広大な解空間をもつ問題に有効とされており,様々な最適化問題に応用可能であり,今後もさらなる発展が期待される.
GAのアルゴリズム
GAのアルゴリズムを以下に示す.
1. 個体の初期生成:
初期の個体をランダムに生成する.
2. 適合度(評価値)の算出
各個体の適合度(評価値)決定する.
3. 再生
各個体の適合度に依存した個体の再生を行う.適合度の高い個体は増殖し,低い個体は淘汰される.
4. 交叉
Step3で選択された個体群からランダムに選択された個体のペアから,新しい個体を生成する.これを既定回数繰り返す.
5. 突然変異
突然変異確率に基づいて,各個体の遺伝子の一部をランダムに書き換える.
6. 終了条件判定
終了条件を満たせば終了,そうでなければStep2に戻る.GAアルゴリズムの性質
GAでは再生により評価値の高い粒子を重点的に探索すると同時に,交叉と突然変異により広範囲に解を探索するため,これらの遺伝的操作が有効に動作すれば良好な解が発見されることが期待される.しかし,遺伝的操作により,最良解の情報を失い,局所解に陥ってしまうことがあり最適解をうまく発見できない場合がしばしばある.特に,制御パラメータの解空間は多数の局所解が存在しているため,交叉の操作は不向きであるといえる.また,GAは決定変数が離散な値であることを前提とした解探索手法であるが,制御パラメータの最適化のための解情報は連続値であることから解の探索に最適ではないことも考えられる.
実装
遺伝子はニューラルネットワークの重みと閾値から構成されるものとして,1つのニューラルネットワークが1つの個体に対応するように設計を行い,上記のGAの手法を用いて更新を行った.
コードはこちらパラメータなどを設定
# 世代 GEN = 100 # NNの個数 In = 2 Hidden = 2 Out = 1 # NNの個体数 Number = 1000 # 教師信号の数 Num = 1000 # 交叉確率 kousa = 0.8 # 突然変異確率 change = 0.05 # 学習する関数 def kansu(x): return((math.sin(x[0])*math.sin(x[0])/math.cos(x[1]))+x[0]*x[0]-5*x[1]+30)/80 # シグモイド関数 def sigmoid(x): return 1/(1+np.exp(-x)) # プロット def plot(data,name): fig = plt.figure() plt.plot(data) fig.show() fig.savefig(str(name)+'.pdf')教師信号作成
class Kyoshi: def __init__(self): self.input = np.random.rand(Num, In)*10-5 self.output = np.zeros(Num) def make_teacher(self): for count in range(Num): self.output[count]=kansu(self.input[count])ニューラルネット(NN)を作成
class NN: def __init__(self): self.u = np.random.rand(In, Hidden)*2-1 #入力層-隠れ層の重み self.v = np.random.rand(Hidden, Out)*2-1 #隠れ層-出力層の重み self.bias_h = np.random.rand(Hidden)*2-1 #隠れ層のバイアス self.bias_o = np.random.rand(Out)*2-1 #出力層のバイアス self.Output = 0 #出力 ## GA用 self.gosa = 0 #教師データとの誤差 self.F = 0 #適合度 # 入力が与えられたときの出力を計算 def calOutput(self, x): # xは入力 hidden_node = np.zeros(Hidden) for j in range(Hidden): for i in range(In): hidden_node[j]+=self.u[i][j]*x[i] hidden_node[j]-=self.bias_h[j] self.Output+=sigmoid(self.v[j]*hidden_node[j]) self.Output-=self.bias_oGAを用いてNNを最適化する
class NNGA: def __init__(self): self.nn = [NN()]*Number self.aveE = 0 #全体誤差平均 # 誤差と適合度計算 def error(self, x,y): #xが教師入力,yが教師出力 self.aveE = 0 for count in range(Number): self.nn[count].gosa = 0 #入力を入れて各NNに出力させる self.nn[count].calOutput(x[count]) # 誤差を計算 self.nn[count].gosa = abs(self.nn[count].Output - y[count]) ################################# # for i in range(Num): # # 入力を入れて各NNに出力させる # self.nn[count].calOutput(x[i]) # # 誤差を計算 # self.nn[count].gosa = abs(self.nn[count].Output - y[i])/Num ################################# self.aveE += self.nn[count].gosa/Num # 適合度計算 for count in range(Number): self.nn[count].F= 1/ self.nn[count].gosa # 遺伝的アルゴリズム(GA) def GA(self): # 個体数/2 回行う for _ in range(int(Number/2)): F_sum=0 #各個体の適合度の合計 for count in range(Number): F_sum+=self.nn[count].F # 選択 p = [0,0] #選択されるインデックスを記録する # ルーレット選択 for i in range(2): F_temp=0 j = -1 for count in range(Number): j +=1 F_temp+=self.nn[count].F if F_temp > random.random()*F_sum: break p[i]=j # 子ども候補を作成 child = [NN()]*2 # 一様交叉 if random.random() < kousa: if random.random() < 0.5: child[0].u = self.nn[p[0]].u child[1].u = self.nn[p[1]].u else: child[0].u = self.nn[p[1]].u child[1].u = self.nn[p[0]].u if random.random() < 0.5: child[0].v = self.nn[p[0]].v child[1].v = self.nn[p[1]].v else: child[0].v = self.nn[p[1]].v child[1].v = self.nn[p[0]].v if random.random() < 0.5: child[0].bias_h = self.nn[p[0]].bias_h child[1].bias_h = self.nn[p[1]].bias_h else: child[0].bias_h = self.nn[p[1]].bias_h child[1].bias_h = self.nn[p[0]].bias_h if random.random() < 0.5: child[0].bias_o = self.nn[p[0]].bias_o child[1].bias_o = self.nn[p[1]].bias_o else: child[0].bias_o = self.nn[p[1]].bias_o child[1].bias_o = self.nn[p[0]].bias_o else: child[0] = self.nn[p[0]] child[1] = self.nn[p[1]] #親の平均適合度を受け継ぐ child[0].F = (self.nn[p[0]].F+self.nn[p[1]].F)/2 child[1].F = (self.nn[p[0]].F+self.nn[p[1]].F)/2 # 突然変異 for count in range(2): for j in range(Hidden): for i in range(In): if random.random() < change: child[count].u[i][j] = random.random()*2-1 if random.random() < change: child[count].bias_h[j] = random.random()*2-1 if random.random() < change: child[count].v[j] = random.random()*2-1 if random.random() < change: child[count].bias_o = random.random()*2-1 #個体群に子どもを追加 rm1=0 rm2=0 min_F=100000 # 最小適合度の個体と入れ替え rm1 = np.argmin(self.nn[count].F) self.nn[rm1]=child[0] # 2番目に低い適合度の個体と入れ替え for count in range(Number): if count==rm1: pass elif min_F > self.nn[count].F: min_F = self.nn[count].F rm2 = count self.nn[rm2]=child[1]main関数
def main(): # 世代数のカウント generation=0 # 初期の個体を生成する nnga = NNGA() # 教師信号の入出力を決定 teacher = Kyoshi() teacher.make_teacher() # テストデータ testTeacher = Kyoshi() testTeacher.make_teacher() # 適合度計算 nnga.error(teacher.input, teacher.output) # 記録用関数 kiroku = [] eliteKiroku = [] minEKiroku = [] # 学習開始 while(True): generation += 1 # GAによる最適化 nnga.GA() # 適合度を計算 nnga.error(teacher.input,teacher.output) # 最小誤差のエリートを見つける min_E = 100000 elite = 0 for count in range(Number): if min_E > nnga.nn[count].gosa: min_E = nnga.nn[count].gosa elite = count # エリートをテストデータで確認 sumE = 0 for i in range(Num): nnga.nn[elite].calOutput(testTeacher.input[i]) sumE += abs(nnga.nn[elite].Output - testTeacher.output[i])/Num # 教師データをシャッフル # np.random.shuffle(teacher.input) # teacher.make_teacher() # 記録 kiroku.append(nnga.aveE) eliteKiroku.append(sumE) minEKiroku.append(min_E) print("世代:",generation,"平均",nnga.aveE, "エリート",min_E,"テスト", sumE) # if min_E < 0.06: # break if generation==GEN: break # plot plot(kiroku,"平均誤差") plot(minEKiroku,"エリート個体の誤差") plot(eliteKiroku,"エリート個体の誤差(テストデータ)") if __name__ == '__main__': main()実験結果
各世代のエリート個体とテストデータの誤差の平均が以下のグラフとなった.横軸が世代数,縦軸が誤差.
最初の5世代までで一気に誤差が小さくなった.しかし,それ以降はほとんど変化がなかった.
いろいろパラメータの条件変えたり,設計を変えたりして試したが,性能が上がらなかった.うーーん.また知識が増えたら更新したい.(もし,アドバイスくださる方がいれば,ぜひお願いします.)


- 投稿日:2021-01-09T21:59:26+09:00
taichiのトリセツ② ~初期化~
このシリーズについて
taichiというpythonで使えるグラフィックのライブラリに最近ハマっているので、使い方をまとめてます。シリーズの目次はこちら。
初期化について
今回はtaichiを使ったプログラムで、必ず実行する初期化の処理のやり方についてまとめてみました。具体的には計算に使うアーキテクチャとデザインを描写するフィールドを初期化します。
手順
今回も前回と同じくfractal.pyという公式が用意してくれているデモプログラムを使って説明してきます。まずは計算に使うアーキテクチャの初期化です。下のコードのti.init(arch=ti.gpu)のところですね。CPUを使う場合は、ti.cpuとすれば大丈夫みたいです。
fractal.pyimport taichi as ti ti.init(arch=ti.gpu) n = 320 pixels = ti.field(dtype=float, shape=(n * 2, n)) # 以下省略gpuのバックエンドをcudaなどに指定もできるみたいです。ti.gpuとしておけば、バックエンドは自動的に見つけてくれるみたいですが。以下の様な感じです。
もう1つの初期化としては、fieldの初期化をします。taichiでは作成したデザインが描写される場所をfieldと呼ぶそうです。このfieldの大きさはshapeに代入する値で変更することが出来ます。ti.field()で初期化すると上のコード(fractal.py)のpixelsにはfloat型の0がfieldの大きさに合わせて入れられます。出来たフィールドに、その後の処理による数値を入れていくという流れになります。まとめ
次はfunctionとkernelについてまとめようと思います。

- 投稿日:2021-01-09T19:32:58+09:00
(深層学習で大切な内積。)内積、外積、ドット積、numpyのdot関数の関係について。
概要
深層学習で内積は、かなり重要。
内積、外積、ドット積、numpyのdot関数の関係について、若干、ややこしいので記事にする。内積、外積、ドット積、numpyのdot関数
ここで示したい結論は、
numpyのdot関数は、ドット積という意味では少し、ずれた内容のものが含まれている。
あえて、狭い範囲で考えて、dot関数、ドット積、内積は、同じものを指すことができる。
(numpyのdot関数は、別の意味、機能もあるので、ご注意。)外積は、なんというか、別途、広がりのあるものなので、、、、深層学習には直接は影響なし、
だと思う。深層学習において、内積がどう重要かは、この記事の対象外。
とりあえず、Wikiの記載で、内積、外積、ドット積の関係を示す。
内積(wikiより)
以下から引用。
https://ja.wikipedia.org/wiki/%E5%86%85%E7%A9%8D線型代数学における内積(ないせき、英: inner product)は、(実または複素)ベクトル空間上で定義される非退化かつ正定値のエルミート半双線型形式(実係数の場合には対称双線型形式)のことである。二つのベクトルに対してある数(スカラー)を定める二項演算であるためスカラー積(スカラーせき、英: scalar product)ともいう。
「内積」(inner) という語は「外積」(outer) の反対という意味での名称だが、外積は(きっちり反対というよりは)もう少し広い状況で考えることができる。
外積(wikiより)
以下から引用。
https://ja.wikipedia.org/wiki/%E3%82%AF%E3%83%AD%E3%82%B9%E7%A9%8Dベクトル積(英語: vector product)とは、ベクトル解析において、3次元の向き付けられた内積空間において定義される、2つのベクトルから新たなベクトルを与える二項演算である。2つのベクトル a, b (以下、ベクトルは太字で表記)のベクトル積は a×b や [a,b] で表される。演算の記号からクロス積(cross product)と呼ばれることもある。2つのベクトルからスカラーを与える二項演算である内積に対して外積(がいせき)とも呼ばれるが、英語でouter productは直積を意味するので注意を要する。
ドット積(wikiより)
以下から引用。
https://ja.wikipedia.org/wiki/%E3%83%89%E3%83%83%E3%83%88%E7%A9%8D数学あるいは物理学においてドット積(ドットせき、英: dot product)あるいは点乗積(てんじょうせき)とは、ベクトル演算の一種で、2つの同じ長さの数列から一つの数値を返す演算。代数的および幾何的に定義されている。幾何的定義では、(デカルト座標の入った)ユークリッド空間 Rn において標準的に定義される内積のことである。
上記より、「標準内積」を意味する。
dot関数
numpyのhelpより
dot(...) dot(a, b, out=None) Dot product of two arrays. Specifically, - If both `a` and `b` are 1-D arrays, it is inner product of vectors (without complex conjugation). - If both `a` and `b` are 2-D arrays, it is matrix multiplication, but using :func:`matmul` or ``a @ b`` is preferred. - If either `a` or `b` is 0-D (scalar), it is equivalent to :func:`multiply` and using ``numpy.multiply(a, b)`` or ``a * b`` is preferred. - If `a` is an N-D array and `b` is a 1-D array, it is a sum product over the last axis of `a` and `b`. - If `a` is an N-D array and `b` is an M-D array (where ``M>=2``), it is a sum product over the last axis of `a` and the second-to-last axis of `b`:: dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m])Google翻訳
-
aとbの両方が2次元配列の場合、それは行列の乗算です。
ただし、:func:matmulまたはa @ bを使用することをお勧めします。-
aまたはbのいずれかが0-D(スカラー)の場合、:func:multiplyと同等です。
numpy.multiply(a、b)またはa * bを使用することをお勧めします。まとめ
深層学習では内積が重要であることを別途記事にしたいと思います。
コメントなどあれば、お願いします。
- 投稿日:2021-01-09T19:14:47+09:00
【エラー対処】peeweeでpeewee.IntegrityError 1451が発生する
はじめに
pythonのORMマッパーであるpeeweeでUserテーブルの行を削除するAPIを書いたところ以下のようなエラーが発生しました.
peewee.IntegrityError: (1451, 'Cannot delete or update a parent row: a foreign key constraint fails (`atnow_database`.`task`, CONSTRAINT `task_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`))')原因
今回使用したpeeweeのORMモデルは以下のようになっていました.
import peewee from code.models.base import Base class User(Base): username = peewee.CharField(unique=True, index=True) is_active = peewee.BooleanField(default=True) hashed_user_token = peewee.CharField()from code.models.base import Base from code.models.user import User class Task(Base): name = peewee.CharField(max_length=30, index=True) description = peewee.CharField(max_length=300, default='') # 外部キー user = peewee.ForeignKeyField(User, backref='tasks')このようなモデル設計において,Userの行を削除しようとしていました.
ここで,Task側のテーブルは外部キーとしてUserを持っています.
また,それをUser側も知っており外部参照されていることを知っています.よって,何も指定しないまま書くと自動的に外部キー制約がSQLのテーブルのスキーマに追加されます.
そのため,Userの行だけを削除しようとすると,関連ついているTaskたちが取り残されてしまうので,それを防ぐために削除を許さず1451エラーが出ていました.
Task側に立って考えてみると,参照先のUserが勝手に消えていたら困ってしまいますね..
対応策
削除されたときのアクションを文字列で指定できます.
CASCADEを用いると,Userを消すときに関連づいているTaskも自動で消せるため,エラーは起こりません.class Task(Base): name = peewee.CharField(max_length=30, index=True) description = peewee.CharField(max_length=300, default='') # 外部キー user = peewee.ForeignKeyField(User, backref='tasks', on_delete='CASCADE')
- 投稿日:2021-01-09T18:48:05+09:00
NVD公開のREST APIを用いて脆弱性情報を取得する
背景
NVD (National Vulnerability Database) は、NISTが管理している脆弱性情報のデータベースであり、ソフトウェアやハードウェアの脆弱性情報を確認する際、NVDにお世話になることは非常に多いです。
そんなNVDですが、各CVEの脆弱性の情報が取得できればいいなあと思っていたところ、
NVDがREST APIを2019年9月に公開しているのを見つけました。
https://nvd.nist.gov/General/News/New-NVD-CVE-CPE-API-and-SOAP-Retirement結構簡単に情報を取得できたので、情報共有も兼ねてプログラムを公開します。
実行環境
- Ubuntu 18.04 LTS
- Python 3.9.1
ざっくりセキュリティ用語
厳密な意味はググれば出てくると思うので、ここではざっくりレベルで。
- CVE (Common Vulnerabilities and Exposures) : 特定の脆弱性に割り当てられる識別子
- CWE (Common Weakness Enumeration) : 脆弱性のカテゴリ。例えばCWE-89はSQLインジェクションを指す。
- CPE (Common Platform Enumeration) : ハードウェア、ソフトウェアを識別するための仕様。CPEを使うことで、例えばどのOSSのどのバージョンで脆弱性の影響が出るか分かる。
- CVSS (Common Vulnerability Scoring System) : 脆弱性の深刻度を表す指標。深刻度のスコアや攻撃難度とか。NVDではCVSS v3とCVSS v2が公開されている
REST API
あるCVEの情報を取得したい場合は下記のリクエストを実行します。
https://services.nvd.nist.gov/rest/json/cve/1.0/<cveId>条件に合致するCVEの情報を取得したい場合は、下記のリクエストを実行します。
先程のリクエストは"cve"であることに対し、こちらは"cves"であることに注意。https://services.nvd.nist.gov/rest/json/cves/1.0例えば、CPEに合致するCVE情報を取得したい場合は下記のようなリクエストを送信すれば良いです。
例:OpenSSL1.1.1cのCVE情報を取得したい場合https://services.nvd.nist.gov/rest/json/cves/1.0?cpeMatchString=cpe:2.3:a:openssl:openssl:1.1.1c:*:*:*:*:*:*:*レスポンスはJSON形式で返ってきます。
Current Descriptionを取得する
NVDに記載されている脆弱性の説明(Current Description)を取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['cve']['description']['description_data'][0]['value']※ x はCVEリストのインデックス
CWEを取得する
CWEを取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['cve']['problemtype']['problemtype_data'][0]['description'][0]['value']※ x はCVEリストのインデックス
CVSSv3 情報を取得する
BaseScoreを取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['impact']['baseMetricV3']['cvssV3']['baseScore']※ x はCVEリストのインデックス
VectorString(例:AV:N/AC:M/Au:N/C:P/I:P/A:P)を取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['impact']['baseMetricV3']['cvssV3']['vectorString']※ x はCVEリストのインデックス
CVSSv2 情報を取得する
BaseScoreを取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['impact']['baseMetricV2']['cvssV2']['baseScore']※ x はCVEリストのインデックス
VectorStringを取得したい場合は、レスポンスのJSONデータに下記のようにアクセスします。
json_data['result']['CVE_Items'][x]['impact']['baseMetricV2']['cvssV2']['vectorString']※ x はCVEリストのインデックス
CPEの条件を満たすCVEの情報を取得
上記を踏まえて、CPEに合致するCVEの情報を取得し、出力するプログラムを実装しました。
get_software_vuln.py#!/usr/bin/env python import requests import json import argparse import textwrap def main(): # コマンドライン引数Parse parser = argparse.ArgumentParser() parser.add_argument('cpe_name', help='CPE Name') args = parser.parse_args() # CPEに対応した脆弱性情報をNVDからJSON形式で取得 cpe_name = args.cpe_name api = 'https://services.nvd.nist.gov/rest/json/cves/1.0?cpeMatchString={cpe_name}' uri = api.format(cpe_name=cpe_name) response = requests.get(uri) json_data = json.loads(response.text) vulnerabilities = json_data['result']['CVE_Items'] for vuln in vulnerabilities: cve_id = vuln['cve']['CVE_data_meta']['ID'] # CVE-IDを取得 current_description = vuln['cve']['description']['description_data'][0]['value'] # Current Descriptionを取得 cwe_id = vuln['cve']['problemtype']['problemtype_data'][0]['description'][0]['value'] # CWE-IDを取得 # CVSS v3の情報があればBaseScoreとVectorStringを取得 if 'baseMetricV3' in vuln['impact']: cvssv3_base_score = vuln['impact']['baseMetricV3']['cvssV3']['baseScore'] cvssv3_vector_string = vuln['impact']['baseMetricV3']['cvssV3']['vectorString'] else: cvssv3_base_score = None cvssv3_vector_string = None # CVSS v2のBaseScoreとVectorStringを取得 cvssv2_base_score = vuln['impact']['baseMetricV2']['cvssV2']['baseScore'] cvssv2_vector_string = vuln['impact']['baseMetricV2']['cvssV2']['vectorString'] # 出力 print('---------') text = textwrap.dedent(''' CVE-ID:{cve_id} CWE-ID:{cwe_id} CVSSv3 BaseScore:{cvssv3_base_score} CVSSv3 VectorString:{cvssv3_vector_string} CVSSv2 BaseScore:{cvssv2_base_score} CVSSv2 VectorString: {cvssv2_vector_string} Current Description: {current_description} ''') print(text.format(cve_id=cve_id, cwe_id=cwe_id, cvssv3_base_score=cvssv3_base_score, cvssv3_vector_string=cvssv3_vector_string, cvssv2_base_score=cvssv2_base_score, cvssv2_vector_string=cvssv2_vector_string, current_description=current_description)) print('---------') main()下記のように実行できます。
python get_software_vulns.py <CPE>例:openssl 1.1.1cについて実行する場合
python get_software_vulns.py cpe:2.3:a:openssl:openssl:1.1.1c:*:*:*:*:*:*:*GitHub
https://github.com/riikunn1004/NVDAPI
にてコードを公開しています。参考まで。下記のPythonプログラムを公開しています。
get_software_vuln.py:上記のプログラム
get_cve_info.py : 指定したCVEの情報を取得するプログラムまとめ
REST APIを用いて脆弱性情報を取得する方法について述べました。
今回記載した内容は一部なので、詳しくはNVDが公開しているドキュメントをご覧ください。
脆弱性情報を管理するためのツールはいろいろとありますが、
このREST APIを活用して自身のニーズにあったツールを自分で開発するのも有りですね。
- 投稿日:2021-01-09T17:55:33+09:00
明日のビットコイン価格を予知する
概要
乗るしかないビッグウェーブなのかを判断する。
Prophet
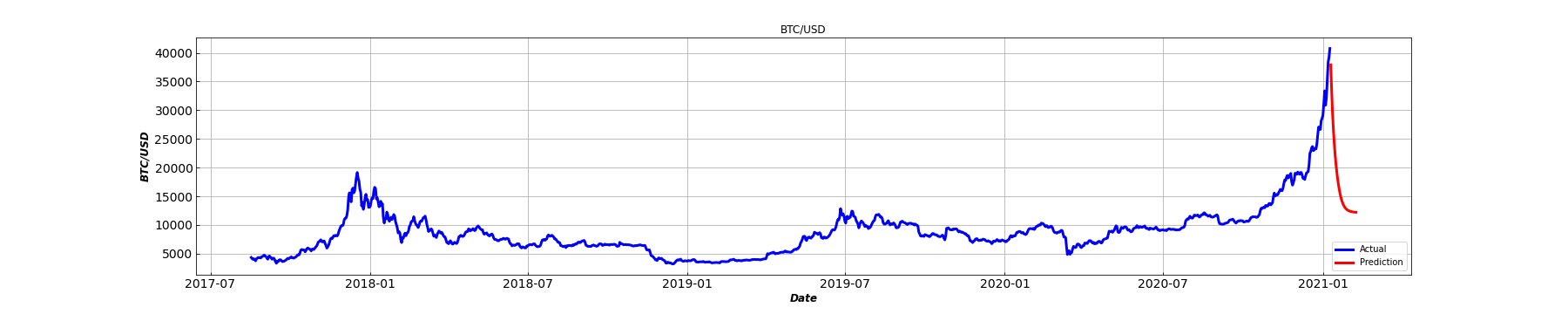
とても簡単でそれっぽいことができるProphetに、Binanceのデータを入れてみる。
df = pd.read_csv('http://www.cryptodatadownload.com/cdd/Binance_BTCUSDT_d.csv', skiprows=[0]) df['y'] = df[['high', 'low']].mean(axis = 1)(中略)
?結果
Time-series forecasting of Bitcoin prices using Prophet$BTC #Bitcoin pic.twitter.com/7y1qoDb0xn
— 今川哲矢 (@TetsuyaImagawa) January 8, 2021乗るしかないこのビッグウェーブに。
LSTM
適当()なパラメータを入れます。
scaler = MinMaxScaler() n_input = 30 n_features = 1 generator = TimeseriesGenerator(train, train, length=n_input, batch_size=7) model = Sequential() model.add(LSTM(200, activation='relu', input_shape=(n_input, n_features))) model.add(Dropout(0.15)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse') model.fit_generator(generator,epochs=90)?結果
乗るべきではないこのビッグウェーブに。
- 投稿日:2021-01-09T17:51:53+09:00
【discord.py】リアクションをついたら役職を付けたり消したりする方法【python】
ちょっとばかしハマったのでメモしておきます。
特定のメッセージに特定のリアクションをつけたら役職(role)をつける
@client.event async def on_raw_reaction_add(payload): if payload.message_id == リアクションを付けてほしいメッセージID: checked_emoji = payload.emoji.id guild_id = payload.guild_id guild = discord.utils.find(lambda g: g.id == guild_id, client.guilds) if checked_emoji == リアクションのID: role = guild.get_role(役職のID) await payload.member.add_roles(role)リアクションを消したらその役職(role)が消える
@client.event async def on_raw_reaction_remove(payload): if payload.message_id == リアクションを付けてほしいメッセージID: checked_emoji = payload.emoji.id guild_id = payload.guild_id guild = discord.utils.find(lambda g: g.id == guild_id, client.guilds) if checked_emoji == リアクションのID: role = guild.get_role(役職のID) member = guild.get_member(payload.user_id) await member.remove_roles(role)ハマったところ
役職をつける方は、
await payload.member.add_roles(role)でいけるのですが、消すほうは、
member = guild.get_member(payload.user_id) await member.remove_roles(role)という感じでいったん
memberを取得する必要があります。リアクションが付けられた場合は
payloadの中にmemberが入ってくるのですが、リアクションが消されたときはmemberが存在しないためです。await payload.member.remove_roles(role)と書いたりして、
AttributeError: 'NoneType' object has no attribute 'remove_roles'と怒られまくったりしてる人がこの記事を見て解決に至ってくれれば幸いです。
- 投稿日:2021-01-09T17:43:38+09:00
イラストを解析(めも)
test.pyimport cv2 import glob import os import numpy as np def ToneExtract(path_input,path_output): img = cv2.imread(path_input) hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #https://design-spice.com/2012/07/09/photoshop-color-sheme/ #https://www.google.com/url?sa=i&url=http%3A%2F%2Fxn--rms9i4ix79n.jp.net%2F%25E5%25A4%2596%25E5%25A3%2581%25E5%25A1%2597%25E8%25A3%2585%25E3%2581%25AE%25E5%25BD%25A9%25E3%2582%258A%25E3%2582%25B3%25E3%2583%25A9%25E3%2583%25A0%2F%25E3%2583%2588%25E3%2583%25BC%25E3%2583%25B3%25E3%2581%25AB%25E5%259F%25BA%25E3%2581%25A5%25E3%2581%2584%25E3%2581%259F%25E9%2585%258D%25E8%2589%25B2%25E6%2596%25B9%25E6%25B3%2595%25E3%2580%2581%25E9%25A1%259E%25E4%25BC%25BC%25E3%2583%2588%25E3%2583%25BC%25E3%2583%25B3%25E9%2585%258D%25E8%2589%25B2%2F&psig=AOvVaw0UClXlbAjJqXYI4tm9esR2&ust=1610260671526000&source=images&cd=vfe&ved=0CA0QjhxqFwoTCPic_cueju4CFQAAAAAdAAAAABAE #彩度ごとの4グループ 0-100 arr_Saido_High = list(range(90,100)) arr_Saido_Middle= list(range(70,90)) arr_Saido_Low = list(range(40,70)) arr_Saido_Buttom = list(range(0,40)) # 白いHSVデータ作成 white = np.array([0,0,255],dtype="uint8") white_color = np.tile(white, (hsv.shape[0],hsv.shape[1],1)) white_color.reshape(hsv.shape) # 各トーン list_tone = [] list_tone.append({"S": arr_Saido_High, "V": list(range(10, 95)), "Name": "vivid", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Middle, "V": list(range(60, 95)), "Name": "blight", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Middle, "V": list(range(40, 60)), "Name": "strong", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Middle, "V": list(range(30, 40)), "Name": "deep", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Low, "V": list(range(70, 100)), "Name": "light", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Low, "V": list(range(60, 70)), "Name": "soft", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Low, "V": list(range(40, 60)), "Name": "dull", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Low, "V": list(range(20, 40)), "Name": "dark", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Buttom, "V": list(range(80, 100)), "Name": "pale", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Buttom, "V": list(range(60, 80)), "Name": "light_grayish", "cnt": 0,"data": white_color.copy()}) list_tone.append({"S": arr_Saido_Buttom, "V": list(range(40, 60)), "Name": "grayish", "cnt": 0, "data": white_color.copy()}) list_tone.append({"S": arr_Saido_Buttom, "V": list(range(20, 40)), "Name": "dark_grayish", "cnt": 0,"data": white_color.copy()}) cnt_no_tone = 0 none_data = white_color.copy() # トーンごとにピクセルを分類 arr = hsv[:, :, (1)] for height in range(arr.shape[0]): for width in range(arr.shape[1]): Saido = hsv[:, :, (1)][height][width] Value = hsv[:, :, (2)][height][width] if Saido == 0: none_data[height][width] =hsv[height][width] cnt_no_tone = cnt_no_tone + 1 continue #https://axa.biopapyrus.jp/ia/color-space/opencv-hsv.html #opencvだと彩度明度ともに0-255。0-100の範囲に変換する。 Saido = int(100 * Saido/255) Value = int(100 * Value/255) notExistflg = False for idx in range(len(list_tone)): if Saido in list_tone[idx]["S"]: if Value in list_tone[idx]["V"]: #該当のピクセル抽出 list_tone[idx]["data"][height][width] =hsv[height][width] notExistflg = True break if notExistflg == False: cnt_no_tone = cnt_no_tone + 1 none_data[height][width] =hsv[height][width] # 色空間変換 for idx in range(len(list_tone)): img_gs = cv2.cvtColor(list_tone[idx]["data"], cv2.COLOR_HSV2BGR) list_tone[idx]["img"] = img_gs # 抽出回数カウント for idx in range(len(list_tone)): img = list_tone[idx]["img"] img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) list_tone[idx]["cnt"] = np.sum(img_gray != 255) #抽出順でソート change = True while change: change = False for i in range(len(list_tone) - 1): if list_tone[i]["cnt"] < list_tone[i + 1]["cnt"]: list_tone[i], list_tone[i + 1] = list_tone[i + 1], list_tone[i] change = True #保存 allpixel = arr.shape[0]*arr.shape[1] - cnt_no_tone cnt = 0 for tone in list_tone: cnt+=1 # 上位5個のみ出力 if cnt >= 5: break print(tone["Name"],tone["cnt"]) ratio = str(int(100*(tone["cnt"]/allpixel)).zfill(2)) + "%" cv2.imwrite(path_output + ratio + "_" + tone["Name"] + ".png", tone["img"], [int(cv2.IMWRITE_JPEG_QUALITY), 0]) # 分類されないデータ # img_gs = cv2.cvtColor(none_data, cv2.COLOR_HSV2BGR) # cv2.imwrite(path_output + "NonCategory.png", img_gs, [int(cv2.IMWRITE_JPEG_QUALITY), 0]) return def Grayscale(path_input,path_output): img = cv2.imread(path_input) img_gs = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imwrite(path_output + ".png", img_gs, [int(cv2.IMWRITE_JPEG_QUALITY), 0]) return def SaidoGrayscale(path_input,path_output): img = cv2.imread(path_input) # 彩度のグレースケール化 hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) hsv[:, :, (2)] = hsv[:, :, (1)] img_gs = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) img_gs = cv2.cvtColor(img_gs, cv2.COLOR_BGR2GRAY) cv2.imwrite(path_output + ".png", img_gs, [int(cv2.IMWRITE_JPEG_QUALITY), 0]) return def SaidoExtarct(path_input, path_output): img = cv2.imread(path_input) hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) arr = hsv[:, :, (1)] for height in range(arr.shape[0]): for width in range(arr.shape[1]): saido = arr[height][width] if saido < 10: #彩度ゼロはスキップ continue # 0(red) - 100(blue) で正規化 blue_saido = 100 norm_saido = int(abs(blue_saido -blue_saido * saido/255)) hsv[:, :, (0)][height][width] = norm_saido hsv[:, :, (1)][height][width] = 255 hsv[:, :, (2)][height][width] = 255 img_gs = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) cv2.imwrite(path_output + ".png", img_gs, [int(cv2.IMWRITE_JPEG_QUALITY), 0]) return def SimpleHue(path_input,path_output): img = cv2.imread(path_input) # 色相の単純化 cnt = 0 h_max = 360 h_sep = 10 h_unit = h_max / h_sep hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) arr = hsv[:, :, (0)] for height in range(arr.shape[0]): for width in range(arr.shape[1]): if 240 < hsv[:, :, (2)][height][width]: # 白色はスキップ continue cnt += 1 hue = arr[height][width] group = hue // h_unit output = group * h_sep # hsv[:, :, (0)][height][width] = output hsv[:, :, (1)][height][width] = 100 hsv[:, :, (2)][height][width] = 255 img_gs = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) cv2.imwrite(path_output + ".png", img_gs, [int(cv2.IMWRITE_JPEG_QUALITY), 0]) return if __name__ == '__main__': output_path = 'output/' try: os.makedirs(output_path) except FileExistsError: pass imglist = [] files = glob.glob("*.png") for file in files: imglist.append(file) files = glob.glob("*.jpg") for file in files: imglist.append(file) files = glob.glob("*.jpeg") for file in files: imglist.append(file) for fileNm in imglist: # イラストをトーンごとに分類 ToneExtract(fileNm, output_path + fileNm + '_tone') # グレースケール Grayscale(fileNm, output_path + fileNm + '_grayscale') # 彩度の強さを抽出(赤->緑->青の順で弱い) SaidoExtarct(fileNm, output_path + fileNm + '_saido_extract') # 360パターンある色相を単純化 SimpleHue(fileNm, output_path + fileNm + '_saido_gray') SaidoGrayscale(fileNm, output_path + fileNm + '_shikiso_simple')
- 投稿日:2021-01-09T17:32:50+09:00
サーモ AI デバイス TiD 紹介
開発情報
はじめに
MH ソフトウェア & サービスでは非接触温度センサなどを用いて、サーモ AI デバイス TiD を設計開発いたしました。
市販のサーマルカメラは、まだまだ高価なものが多いです。
一般的に入手しやすい部品を利用して、温度を測定しコロナ感染防止対策が取れないかと試行錯誤しました。
そこで、興味のある方にサーモ AI デバイス TiD で使用しているセンサやRaspberry Piの配線、Pythonによる処理を公開する事で、コロナ感染防止対策の一環を担えればよいと考えております。
使用部品
紹介するサーモ AI デバイス TiDの使用部品一覧表です。名称とメーカ/型式/購入先(参考)です。
別部品を使用する場合は、同等の配線をお願いします。RaspberryPi 4
Raspberry財団 / Raspberry Pi 4 Bodel B (8GB) / Amazon
RaspberryPi ケース
Physical Computing Lab / Raspberry Pi4 Model B DIYメタルケース / Amazon
非接触温度センサ
{d6t} / chip1stop
*D6T-HARNESS-02が必要です。
I2Cレベル変換
ELEFINE / I2Cレベル変換器 / ELEFINE
*{d6ts}は5[V]で動作しますので、Raspberry PiのI2Cに接続する為に、3.3[V]へレベル変換する必要があります。
測距センサ
KOOKYE / KK-VL53L0X-JP / Amazon
温湿度・気圧センサ
KeeYees / KYES503 / Amazon
3個入っています。
- 投稿日:2021-01-09T17:25:46+09:00
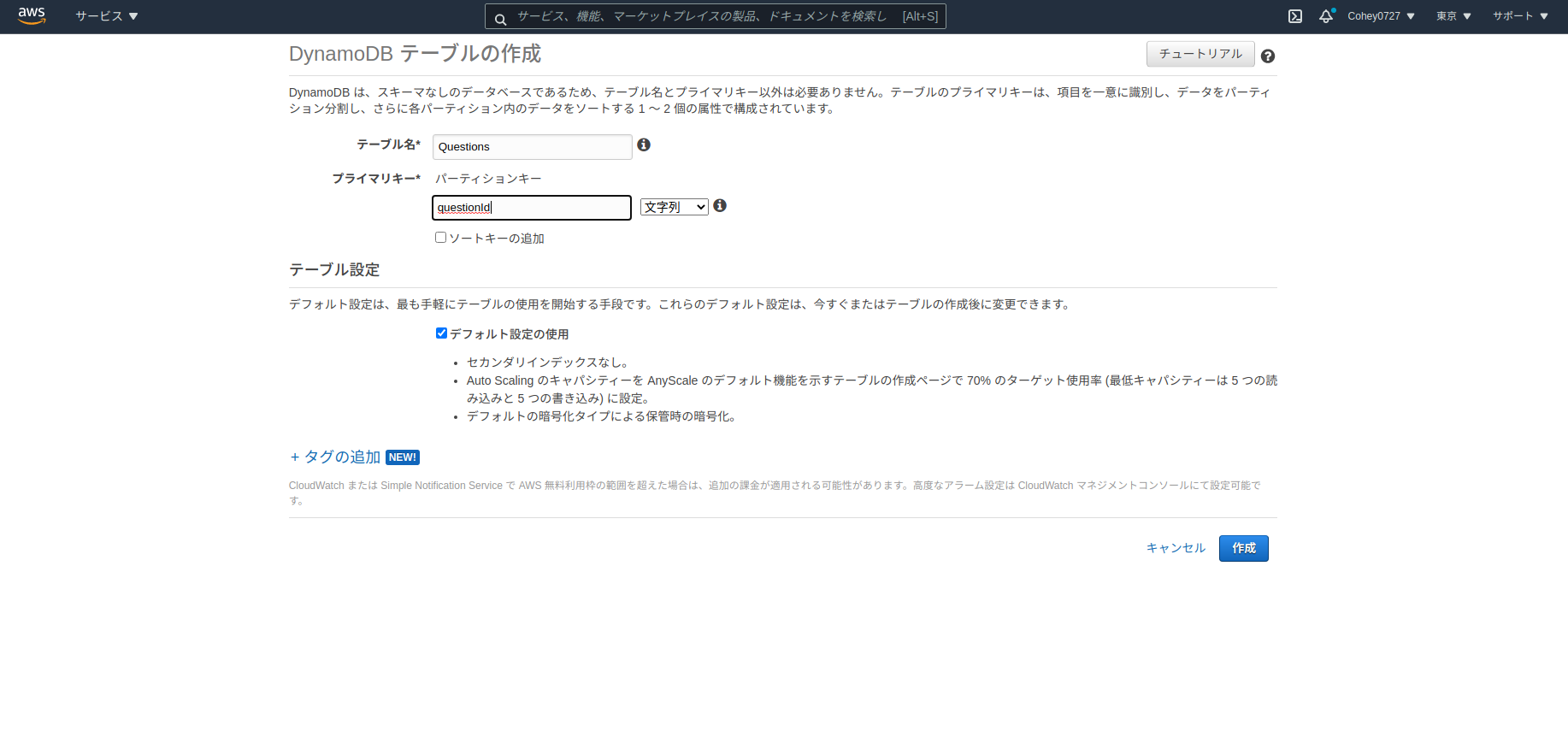
boto3経由でDynamodbにPartiQLを実行
boto3経由でDynamodbにPartiQLを実行
はじめに
昨年11月にDynamoDBにSQL互換のクエリ言語PartiQLが実行できるようになりました。
https://aws.amazon.com/jp/about-aws/whats-new/2020/11/you-now-can-use-a-sql-compatible-query-language-to-query-insert-update-and-delete-table-data-in-amazon-dynamodb/私はcliではなく、boto3で実行する際のメモです。
環境
項目 version Python 3.8.5 boto3 1.16.51 botocore 1.19.51 実行
boto3経由でCREATE TABLE時のIndexの仕方がよくわからないのでとりあえず、CREATE TABLEだけを実行するとUnsupportedがでました。
import boto3 clinet = boto3.client('dynamodb') clinet = clinet.execute_statement(Statement='CREATE TABLE Questions') botocore.exceptions.ClientError: An error occurred (ValidationException) when calling the ExecuteStatement operation: Unsupported operation: CreateTableなのでAWSコンソールでテーブルを作成します。
とりあえずデータをINSERTしてみます。
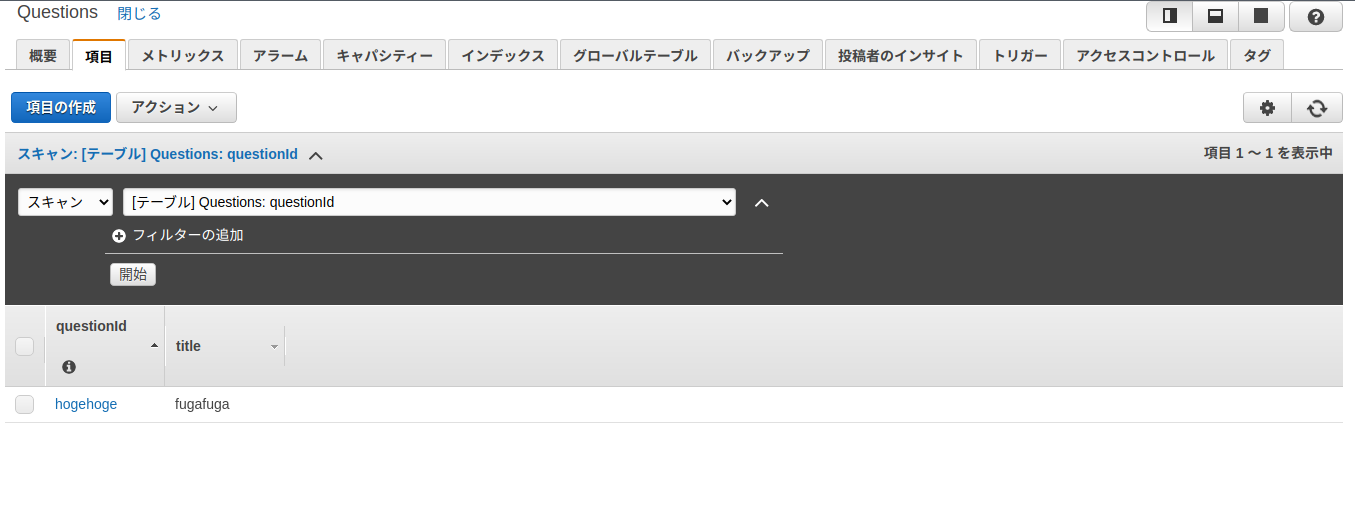
>>> import boto3 >>> clinet = boto3.client('dynamodb') >>> clinet.execute_statement(Statement="INSERT INTO Questions VALUE {'questionId': 'hogehoge', 'title':'fugafuga'}") {'Items': [], 'ResponseMetadata': {'RequestId': 'STSLJF4VO9CA61MU1SKCOVLGMRVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:13:13 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '12', 'connection': 'keep-alive', 'x-amzn-requestid': 'STSLJF4VO9CA61MU1SKCOVLGMRVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2770214093'}, 'RetryAttempts': 0}}コンソールを確認するとデータが作成されていることがわかります。
boto3経由でも確認できます。
>>> clinet.execute_statement(Statement="SELECT * FROM Questions") {'Items': [{'questionId': {'S': 'hogehoge'}, 'title': {'S': 'fugafuga'}}], 'ResponseMetadata': {'RequestId': 'I6S1NDUU93R9O4SE8T9657AH77VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:15:12 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '68', 'connection': 'keep-alive', 'x-amzn-requestid': 'I6S1NDUU93R9O4SE8T9657AH77VV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2555902000'}, 'RetryAttempts': 0}}UPDATEして確認してみます。
>>> clinet.execute_statement(Statement="UPDATE Questions SET title='foofoo' WHERE questionId='hogehoge'") {'Items': [], 'ResponseMetadata': {'RequestId': 'C5TMDKMTT9NM2RPTVVK0GBOTKFVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:18:58 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '12', 'connection': 'keep-alive', 'x-amzn-requestid': 'C5TMDKMTT9NM2RPTVVK0GBOTKFVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2770214093'}, 'RetryAttempts': 0}} >>> clinet.execute_statement(Statement="SELECT * FROM Questions") {'Items': [{'questionId': {'S': 'hogehoge'}, 'title': {'S': 'foofoo'}}], 'ResponseMetadata': {'RequestId': '898QE0R431PLKG3QJRGH26EUN7VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:19:15 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '66', 'connection': 'keep-alive', 'x-amzn-requestid': '898QE0R431PLKG3QJRGH26EUN7VV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '379791711'}, 'RetryAttempts': 0}}更新できました。
ただしKeyを指定せずにUPDATEするとエラーになります。>>> clinet.execute_statement(Statement="UPDATE Questions SET title='foofoo'") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/kohei/.local/lib/python3.8/site-packages/botocore/client.py", line 357, in _api_call return self._make_api_call(operation_name, kwargs) File "/home/kohei/.local/lib/python3.8/site-packages/botocore/client.py", line 676, in _make_api_call raise error_class(parsed_response, operation_name) botocore.exceptions.ClientError: An error occurred (ValidationException) when calling the ExecuteStatement operation: Where clause does not contain a mandatory equality on all key attributesDELETEもできました。
>>> clinet.execute_statement(Statement="DELETE FROM Questions WHERE questionId='hogehoge'") {'Items': [], 'ResponseMetadata': {'RequestId': 'AQOONAN30T0NHC0OAPS1QLFH3RVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:21:54 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '12', 'connection': 'keep-alive', 'x-amzn-requestid': 'AQOONAN30T0NHC0OAPS1QLFH3RVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2770214093'}, 'RetryAttempts': 0}} >>> clinet.execute_statement(Statement="SELECT * FROM Questions") {'Items': [], 'ResponseMetadata': {'RequestId': 'AV8FBJ2FU4KUDEI3J0R184RJ47VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Sat, 09 Jan 2021 08:21:57 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '12', 'connection': 'keep-alive', 'x-amzn-requestid': 'AV8FBJ2FU4KUDEI3J0R184RJ47VV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2770214093'}, 'RetryAttempts': 0}}まとめ
Indexを意識せずQueryを実行することができてしまうので少し不安ですが、これまでのSQLインターフェースが用意されているのはいいですね。
参考
- 投稿日:2021-01-09T16:53:58+09:00
最適化アルゴリズムを実装していくぞ(粒子群最適化)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
粒子群最適化
概要
粒子群最適化(Particle Swarm Optimization:PSO)とは、スズメやイワシといった小さい個体が大きな群れを作って効率よく餌を探す行動に着目して作られたアルゴリズムです。
群れに属する個体は以下のような行動モデルに基づいているといわれています。
- 近くにいる個体に影響されて行動する
- 他の個体の近くにとどまろうとするが、一定以上は近づかない
- 他の個体の速度に合わせて移動する
参考
・粒子群最適化法(PSO)を救いたい
・進化計算アルゴリズム入門 生物の行動科学から導く最適解(amazonリンク)アルゴリズム
各個体を粒子と呼びます。
全粒子の中で今までに一番良かった位置をグローバルベスト、自分自身がこれまでに見つけた位置の中で一番良かった位置をパーソナルベストとして覚えておきます。
これら2つの情報を元に次の自分の位置を更新していく探索が粒子群最適化となります。
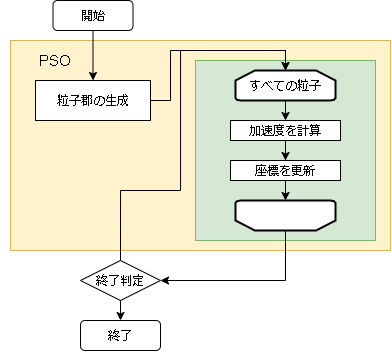
- アルゴリズムのフロー
- 問題との対応
問題 粒子群最適化 入力値の配列 粒子 入力値 粒子の座標 評価値 粒子の評価値
- コード内で使う変数の意味
変数名 数式 意味 所感 problem 任意の問題のクラス(問題編を参照) particle_max 粒子の数 inertia $I$ 慣性係数 加速度の減少率 global_acceleration $A_g$ 加速係数(グローバルベスト) グローバルベストに近づく割合 personal_acceleration $A_p$ 加速係数(パーソナルベスト) パーソナルベストに近づく割合 particles 粒子の配列 particles[i]["personal"] i番目の粒子のパーソナルベスト particles[i]["v"] i番目の粒子の速度 粒子の位置と加速度の更新
加速度と座標の初期値は空間内の範囲でランダムに初期化します。
位置を求めるにあたりまずは加速度が更新されます。
時刻(t)から時刻(t+1)への速度はグローバルベストとパーソナルベストを用いて以下の式となります。$$
\vec{v_i}(t+1) = I \vec{v_i}(t)
+ A_g ( \vec{g}(t) - \vec{x_i}(t) ) \times rand[0,1]
+ A_p ( \vec{p}(t) - \vec{x_i}(t) ) \times rand[0,1]
$$$I$ は慣性係数、$A_g$と$A_p$は加速係数で3つとも1より小さい値を指定します。
また、$\vec{g}$はグローバルベストの位置を表し、$\vec{p}$はその粒子が持っているパーソナルベストの位置を表します。
$rand[0,1]$ は0~1の乱数です。コード全体
コード全体です。
import math import random import numpy as np class PSO(): def __init__(self, particle_max, inertia=0.9, global_acceleration=0.9, personal_acceleration=0.9, ): self.particle_max = particle_max self.inertia = inertia self.global_acceleration = global_acceleration self.personal_acceleration = personal_acceleration def init(self, problem): self.problem = problem # 初期粒子群を生成 self.global_best = None self.particles = [] for _ in range(self.particle_max): o = problem.create() # ランダムな位置に粒子を作成 # 初期加速度 v = [(problem.MAX_VAL - problem.MIN_VAL) * random.uniform(-1, 1) for _ in range(problem.size)] # パーソナルベストと速度の情報を付与する d = { "particle": o, "personal": None, "v": np.asarray(v), } self.particles.append(d) # パーソナルベストとグローバルベストの更新 self._updateBest(d) def step(self): # 各粒子に対して for particle in self.particles: # 各座標を出力(numpy化してベクトル計算をしやすくしています) pos = np.asarray(particle["particle"].getArray()) g_pos = np.asarray(self.global_best.getArray()) p_pos = np.asarray(particle["personal"].getArray()) # 加速度を計算 v = particle["v"] v = self.inertia * v v += self.global_acceleration * (g_pos - pos) * random.random() v += self.personal_acceleration * (p_pos - pos) * random.random() particle["v"] = v # 座標を更新 particle["particle"].setArray(pos + v) # パーソナルベストとグローバルベストの更新 self._updateBest(particle) def _updateBest(self, particle): # パーソナルベストの更新 if particle["personal"] is None or particle["personal"]["particle"].getScore() < particle["particle"].getScore(): # パーソナルベストとしてコピーして保存する particle["personal"] = particle["particle"].copy() # グローバルベストの更新 if self.global_best is None or self.global_best.getScore() < particle["particle"].getScore(): # グローバルベストとしてコピーして保存する self.global_best = particle["particle"].copy()ハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を2秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
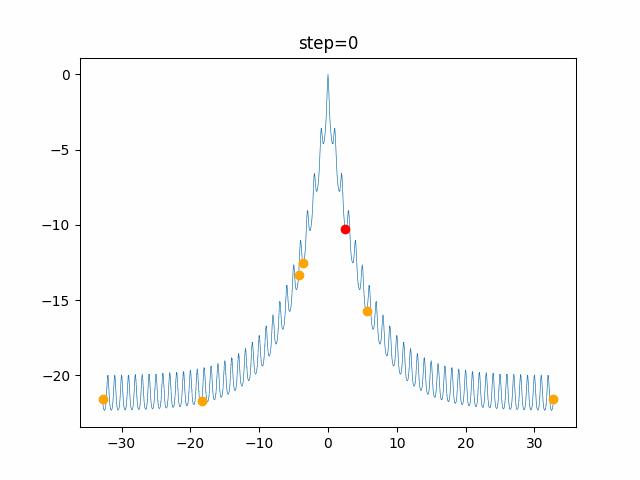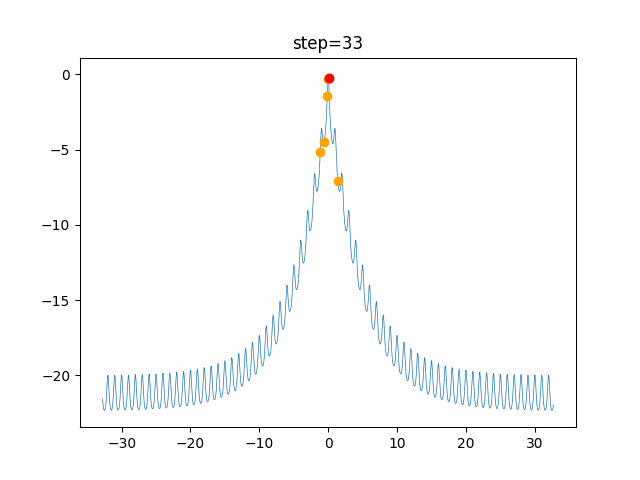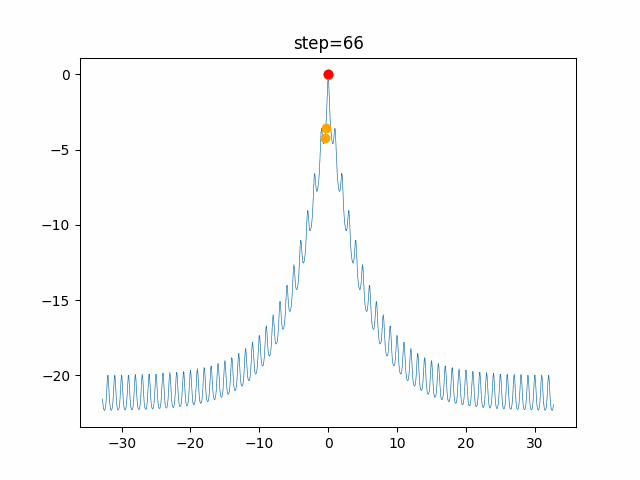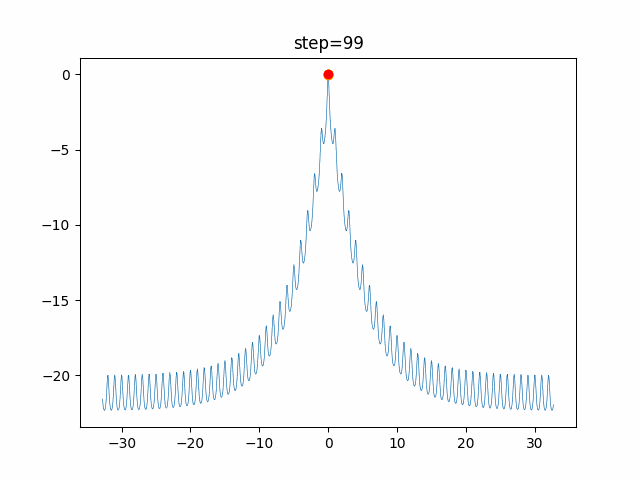
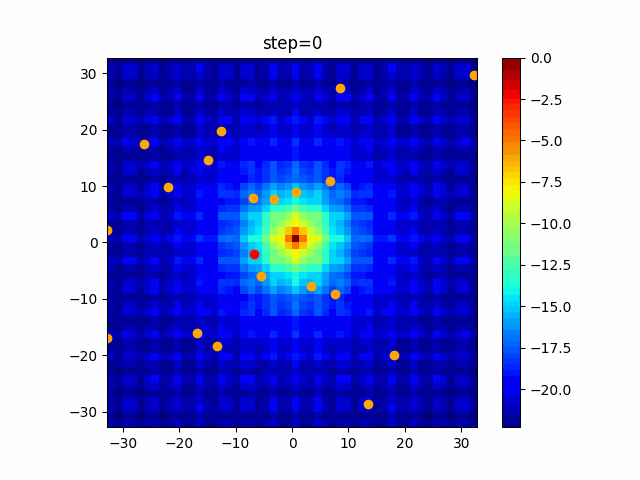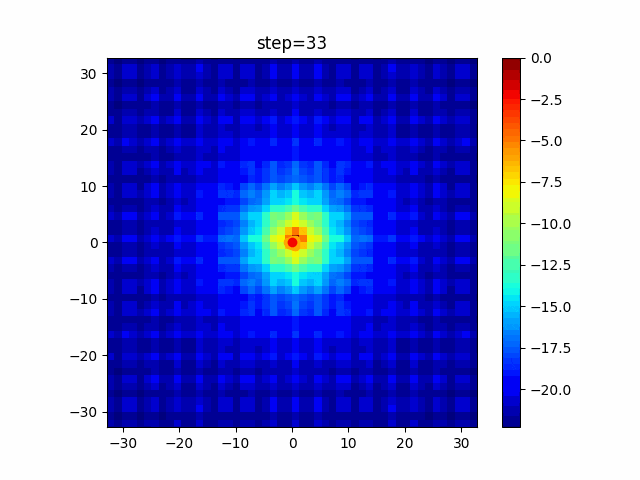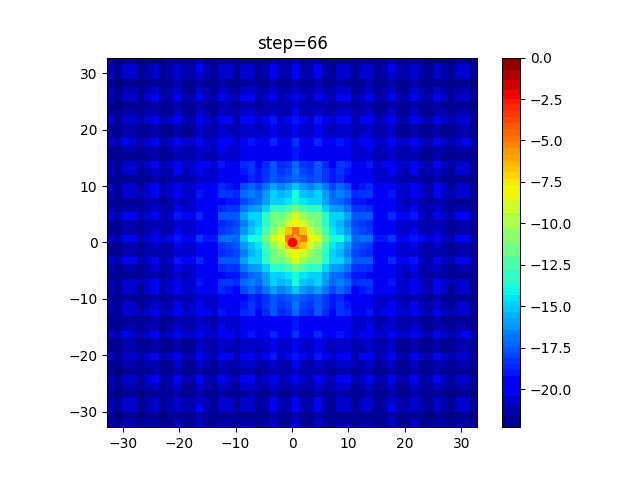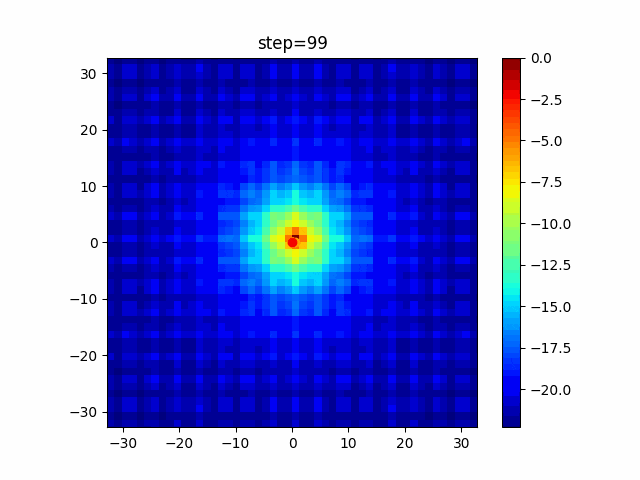
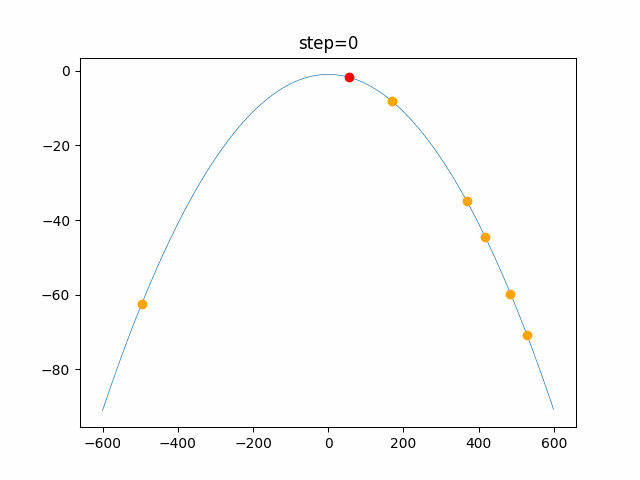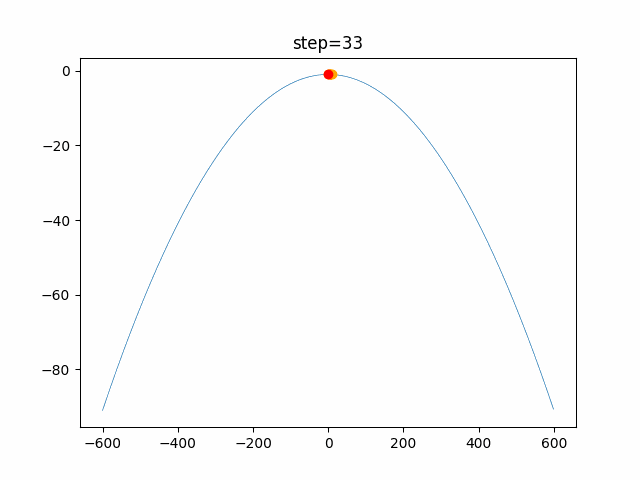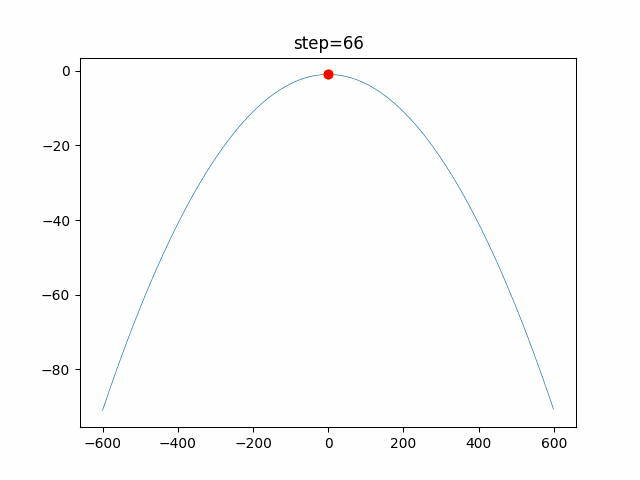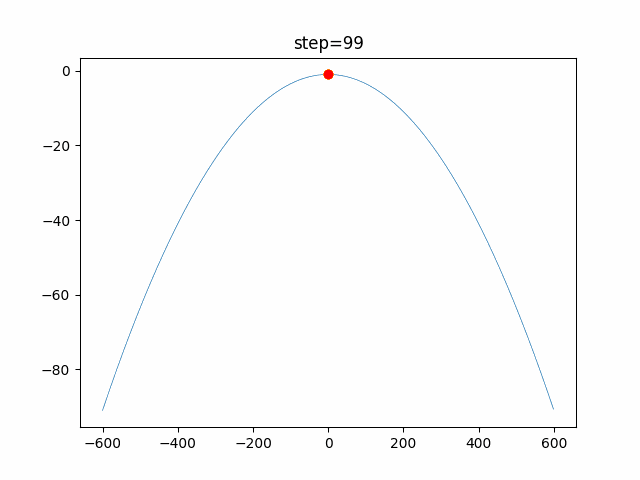
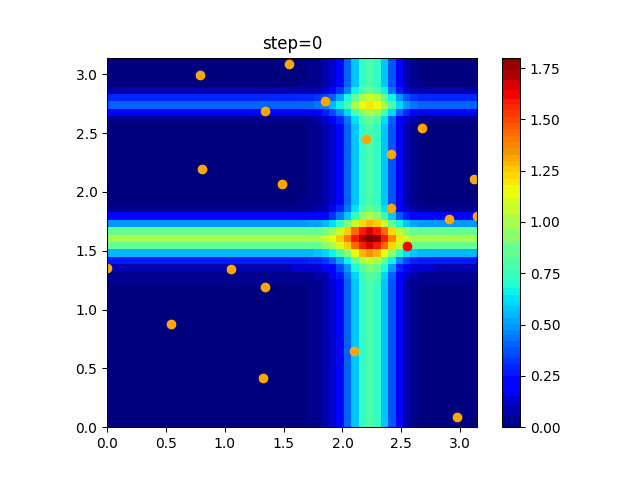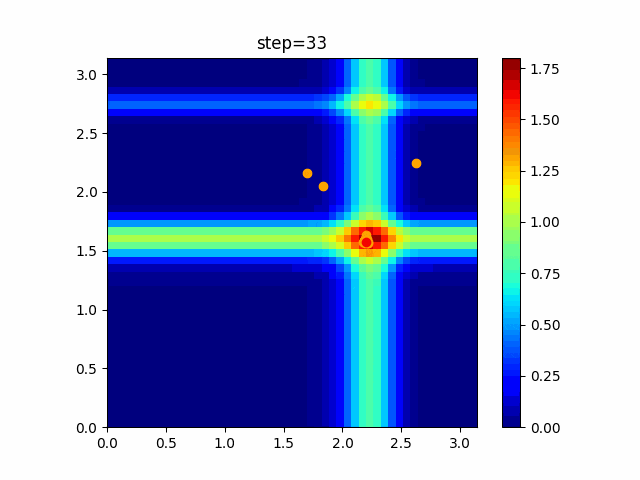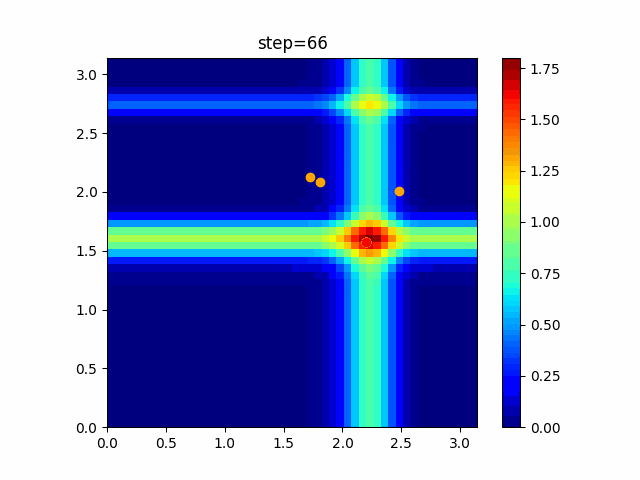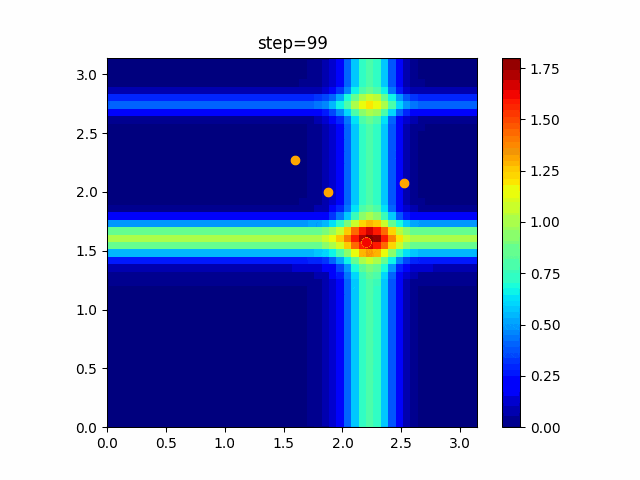
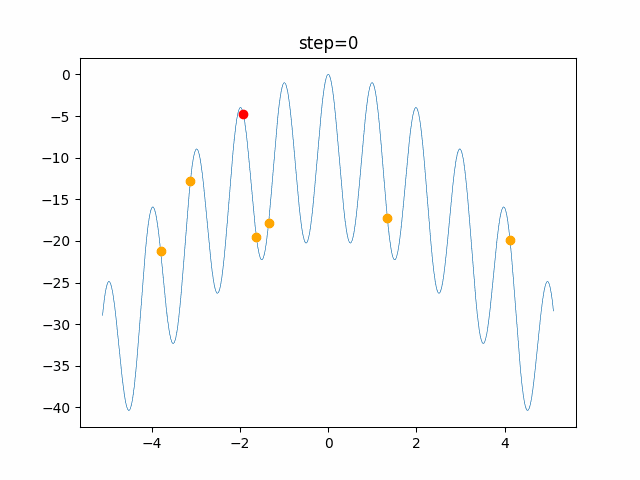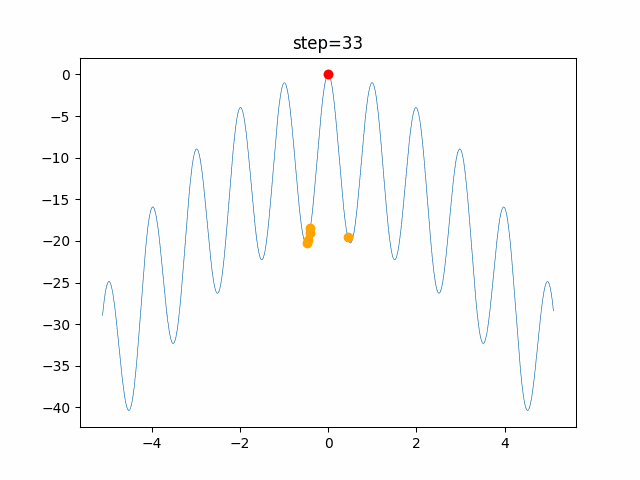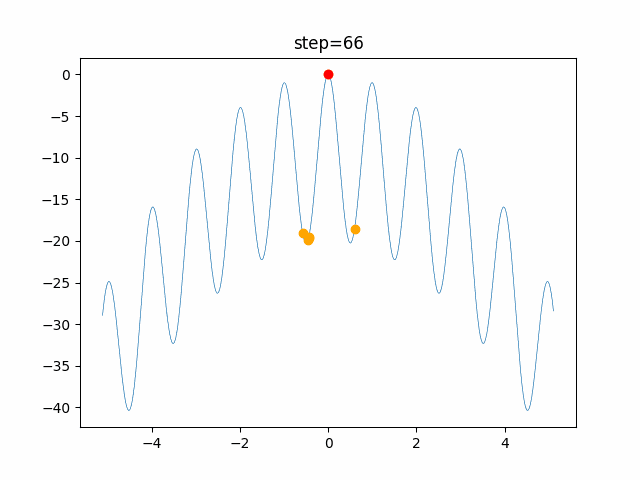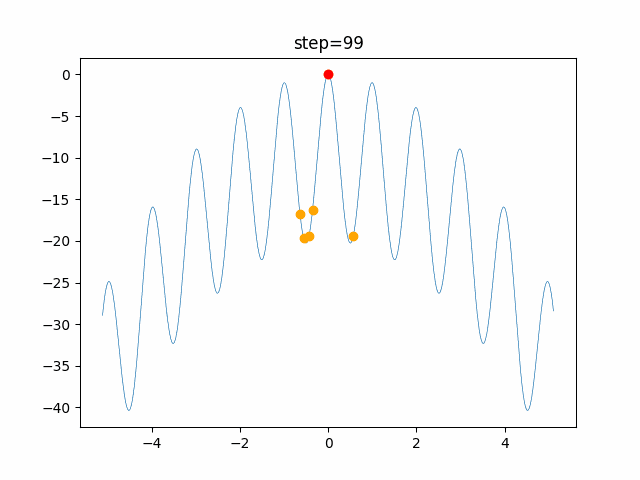
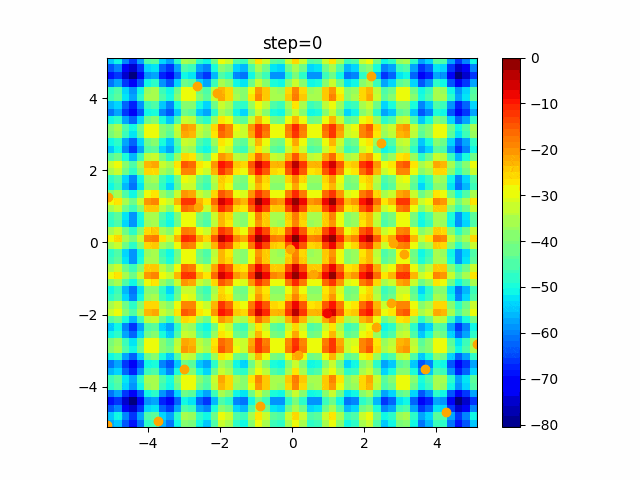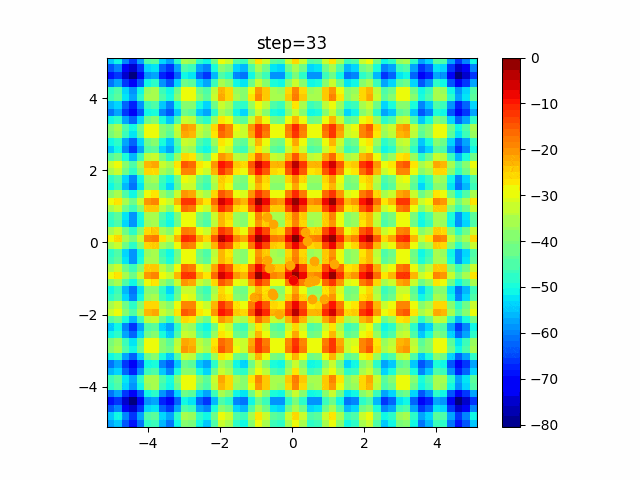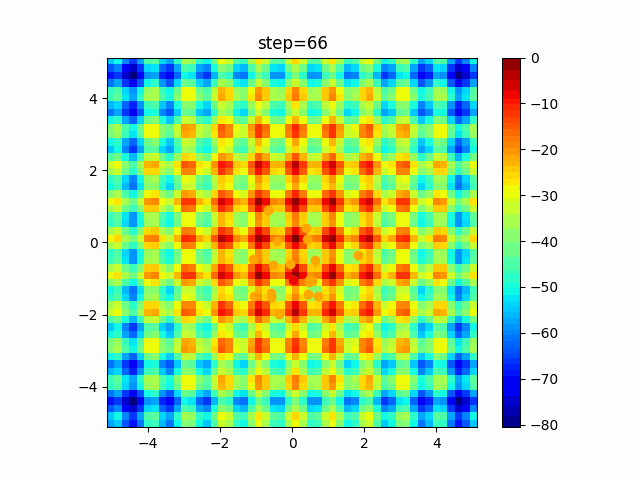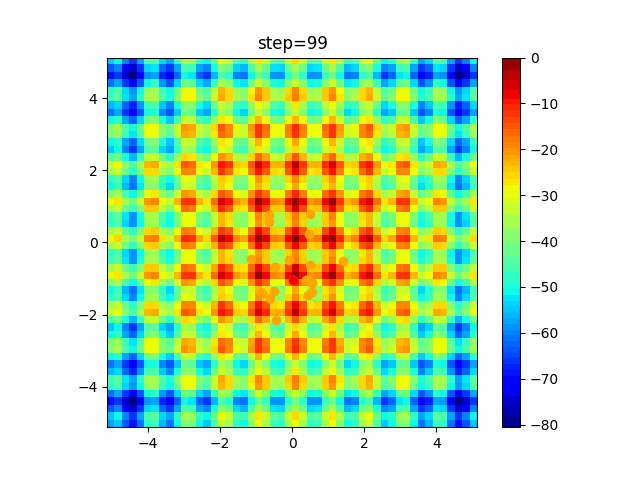
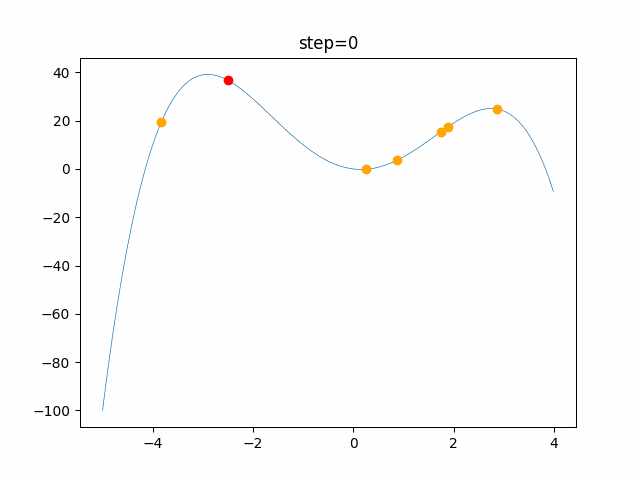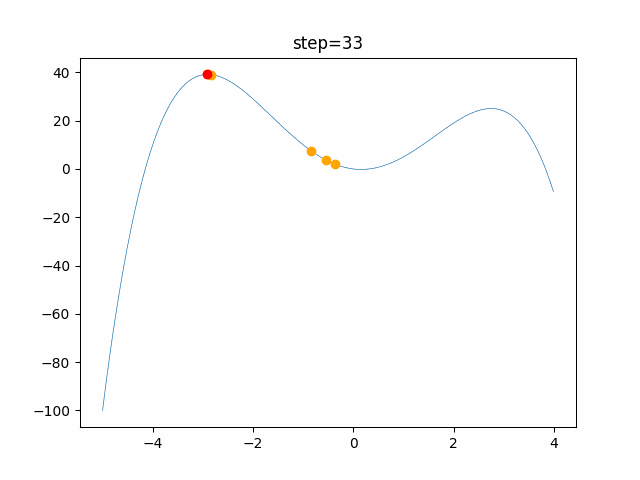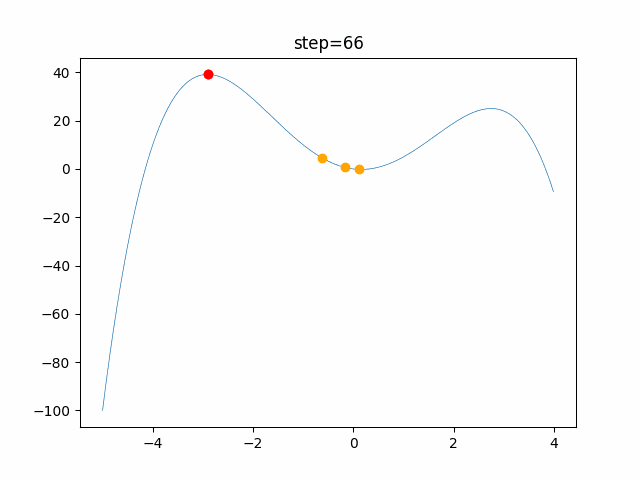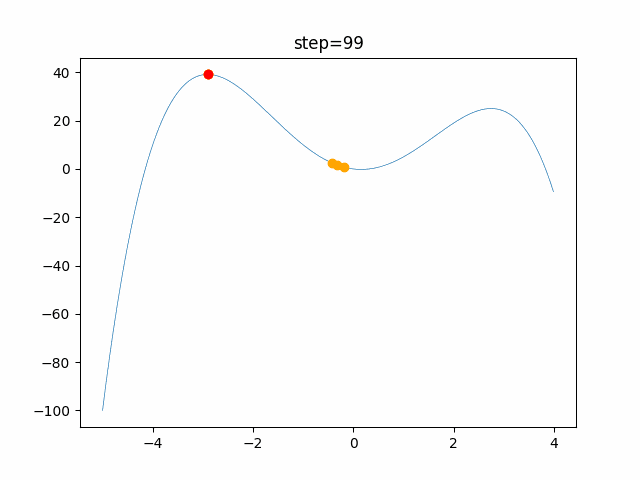
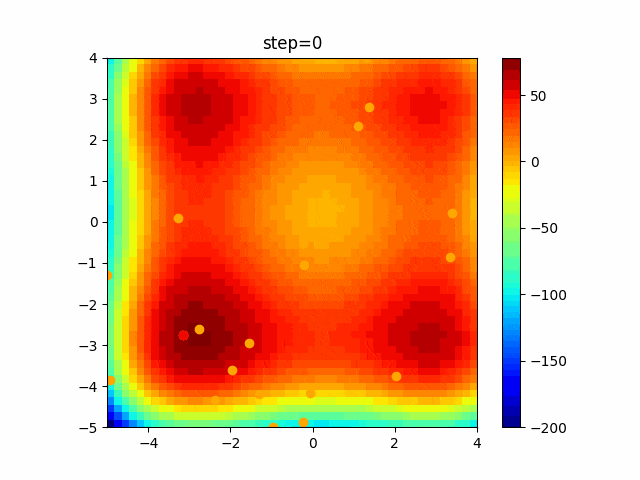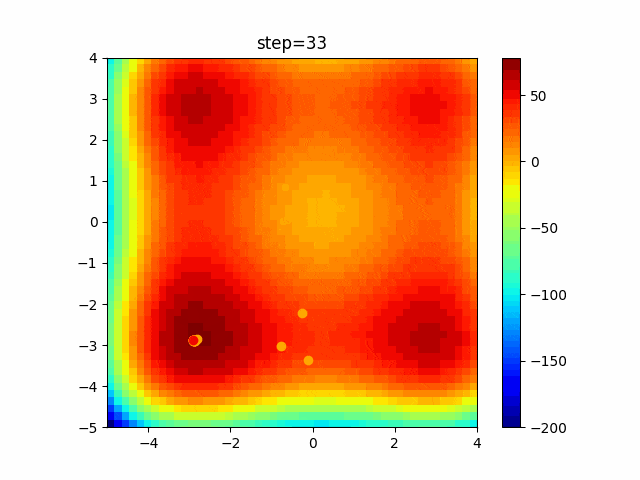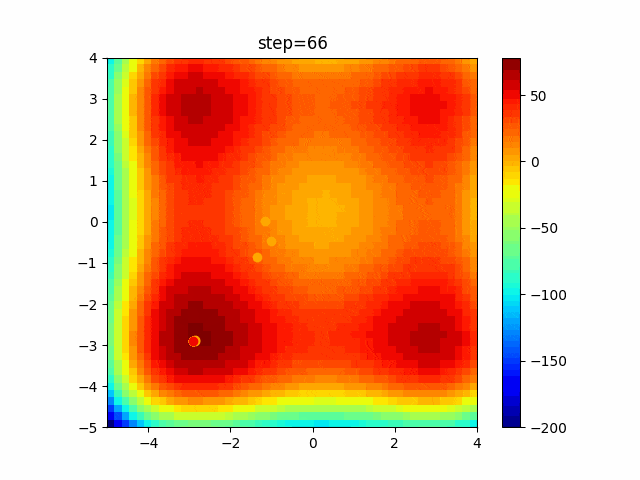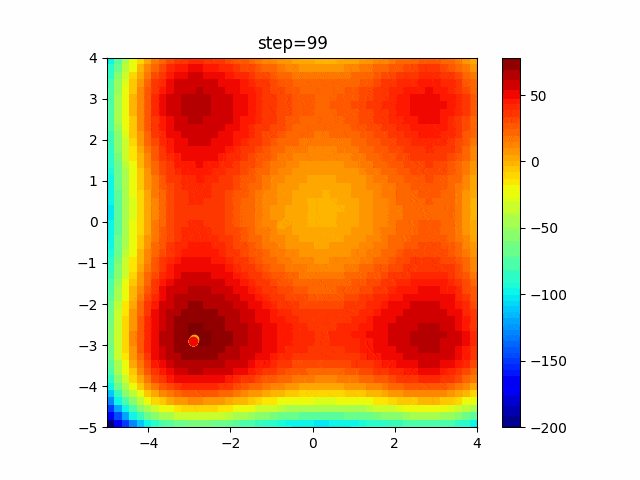
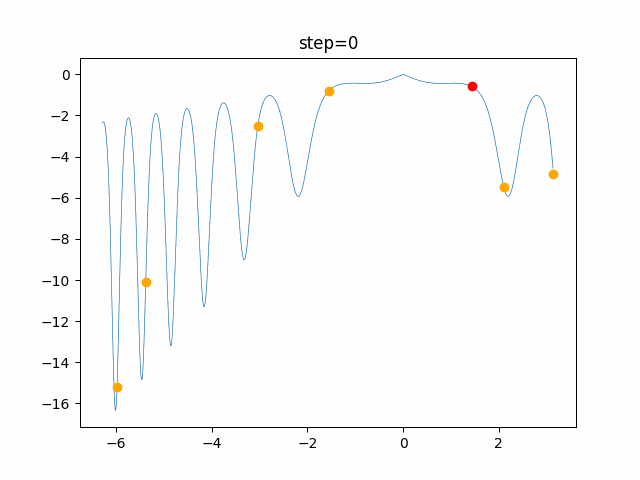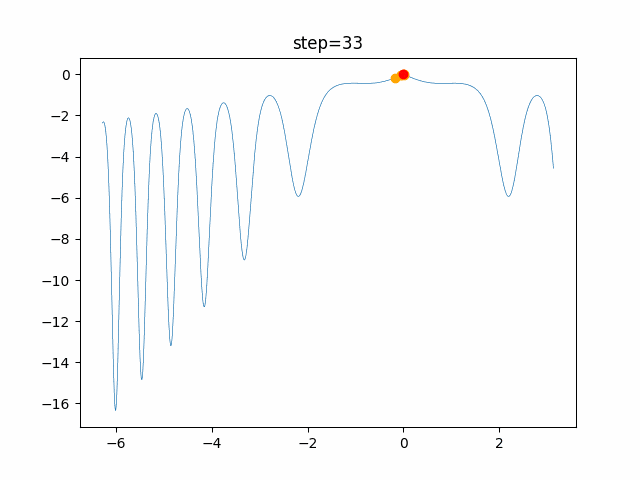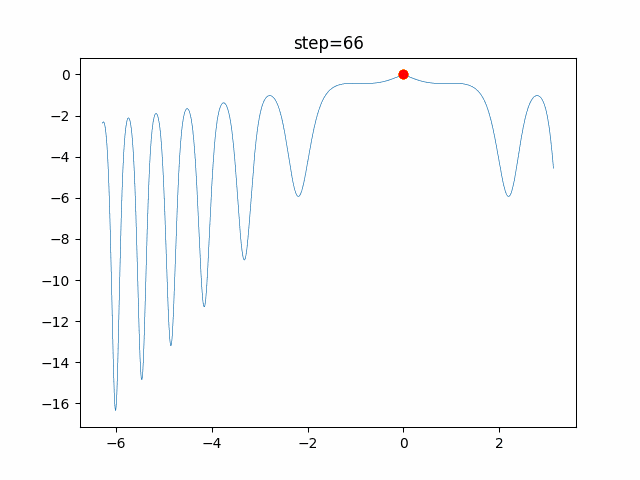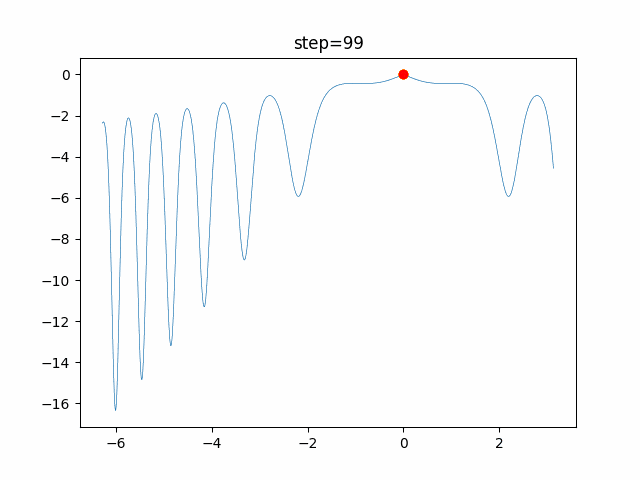
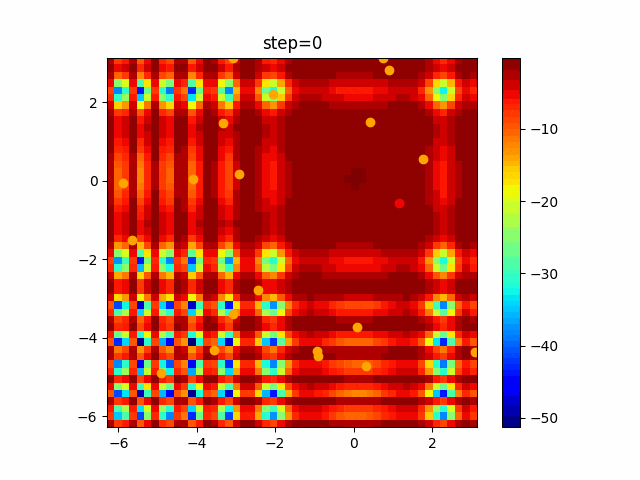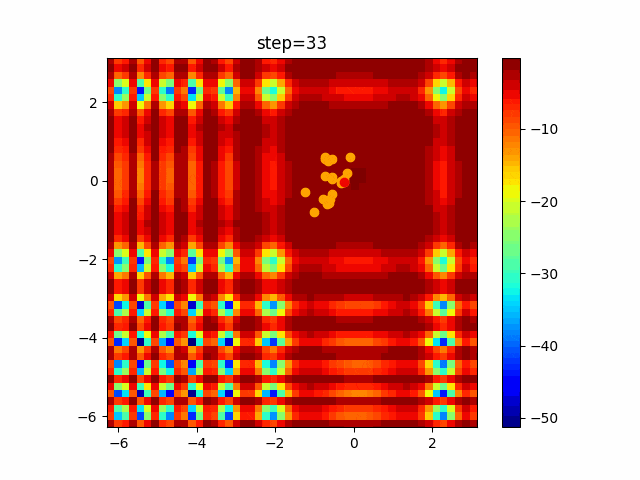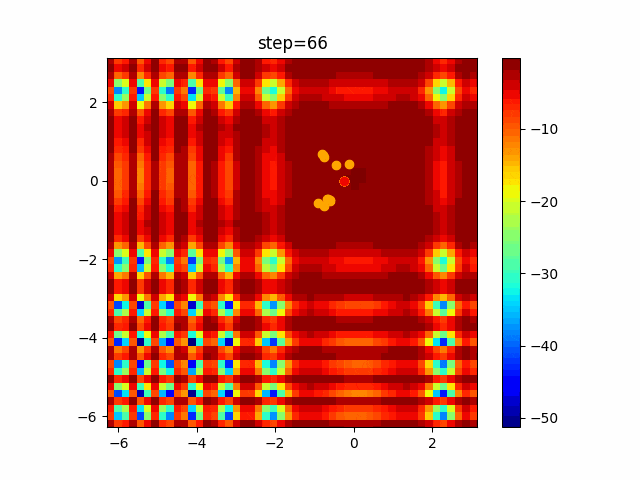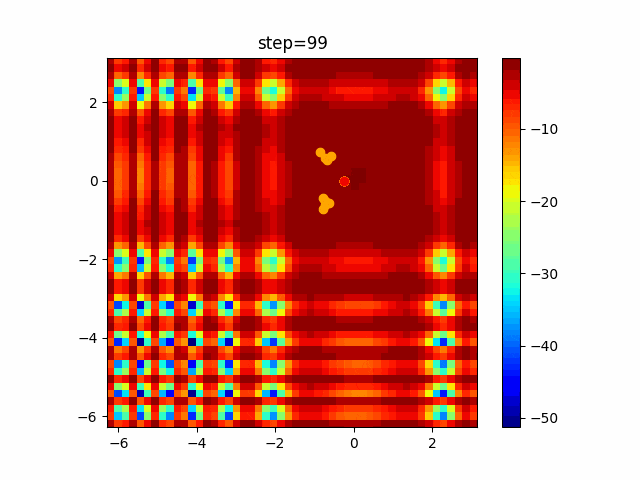
問題 global_acceleration inertia particle_max personal_acceleration EightQueen 0.7839287773369192 0.8235075101639827 28 0.9467161852490191 function_Ackley 0.11778673996028691 0.062427889313103786 47 0.6739352477292235 function_Griewank 0.1939265329859151 0.9886894890970368 21 0.9870275206300417 function_Michalewicz 0.5004800811479669 0.7828732926170527 23 0.5089894615381799 function_Rastrigin 0.7067489271622391 0.8580154745241855 31 0.2988574441297245 function_Schwefel 0.6251927739536115 0.9030347446658787 42 0.2540225969044799 function_StyblinskiTang 0.970834173658411 0.9365843106326938 31 0.9298455482443944 LifeGame 0.539526858214075 0.08845815509172461 14 0.4249882950339423 OneMax 0.5056801912085691 0.6273453999411102 42 0.29656995228071314 TSP 0.7018381808726923 0.888427895281042 48 0.6464768696714887 実際の動きの可視化
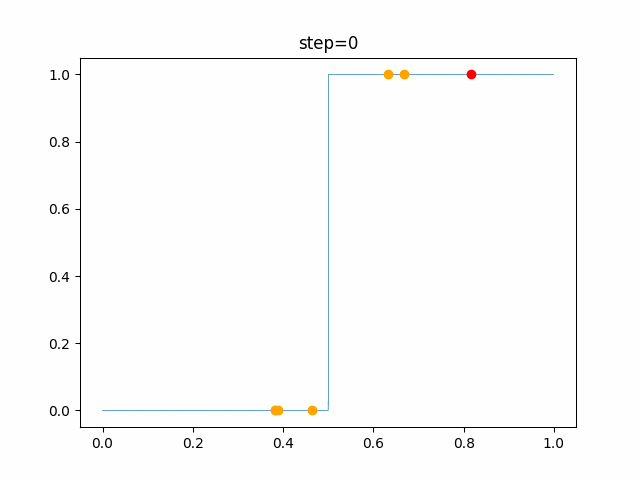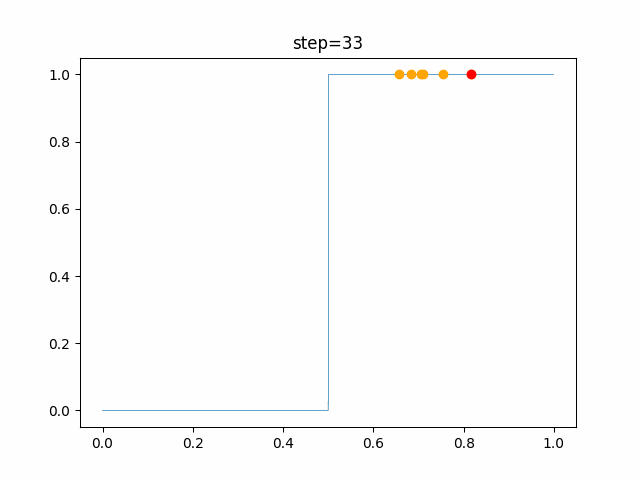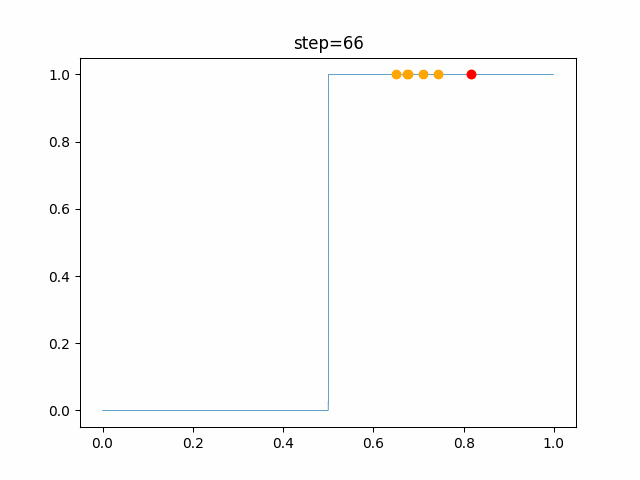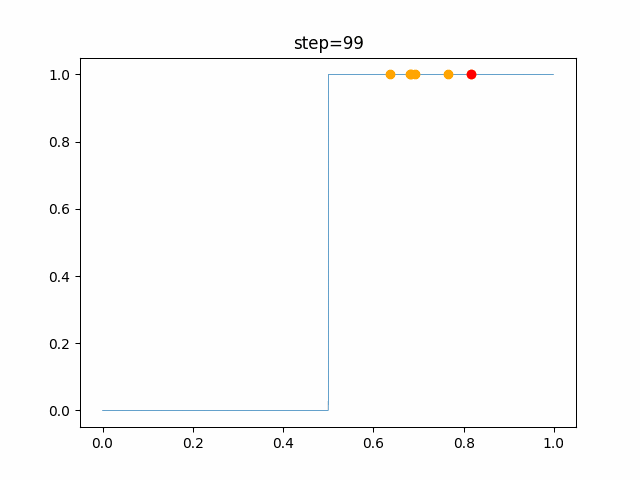
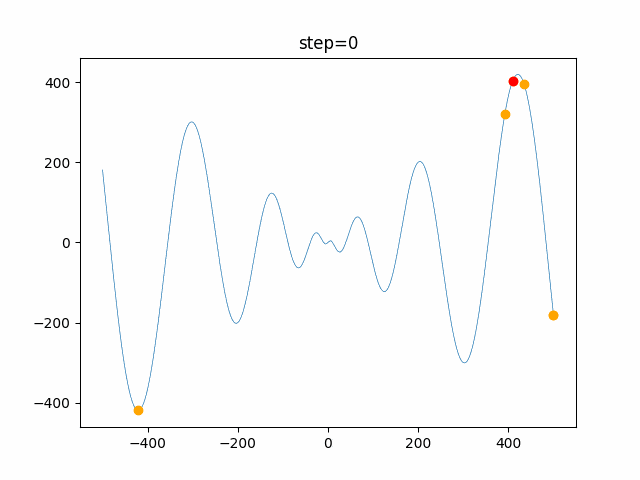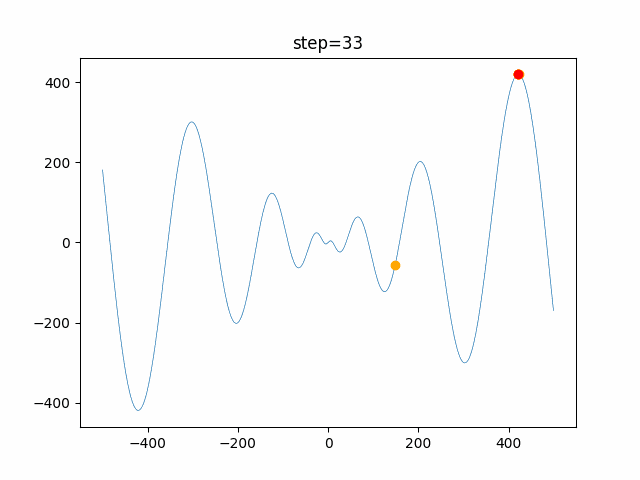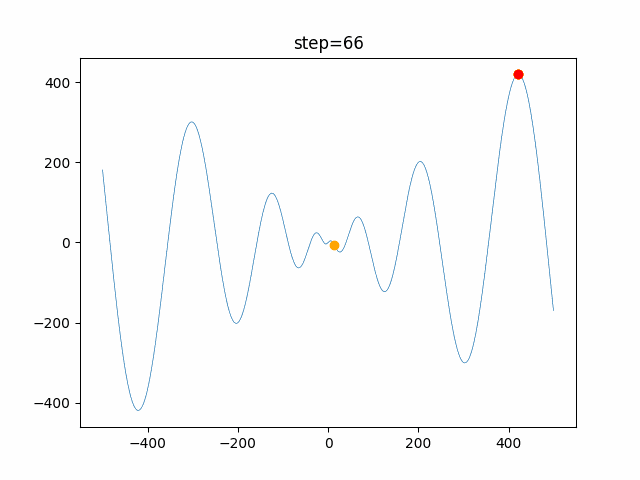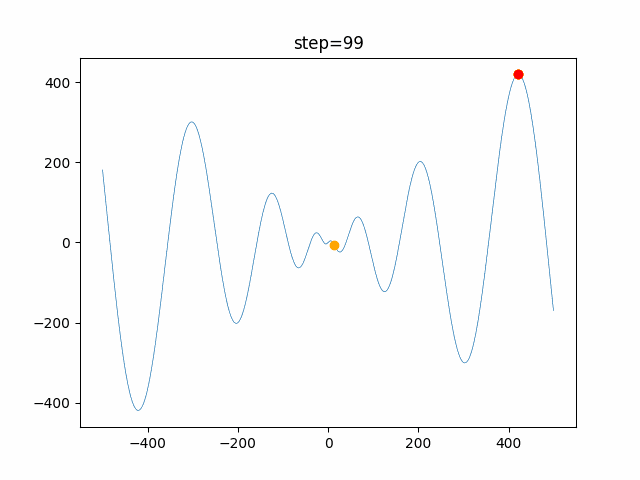
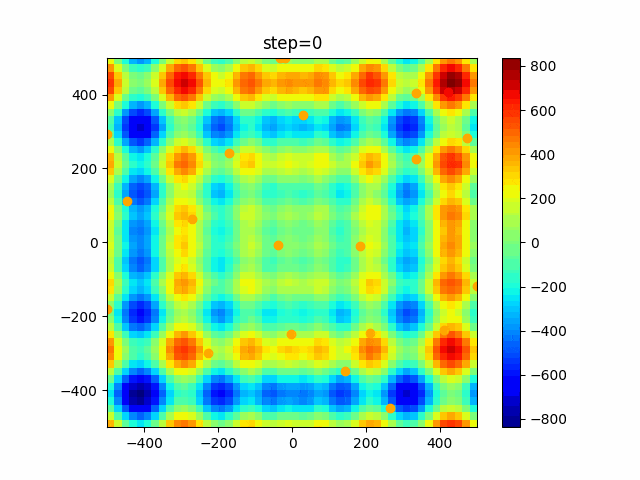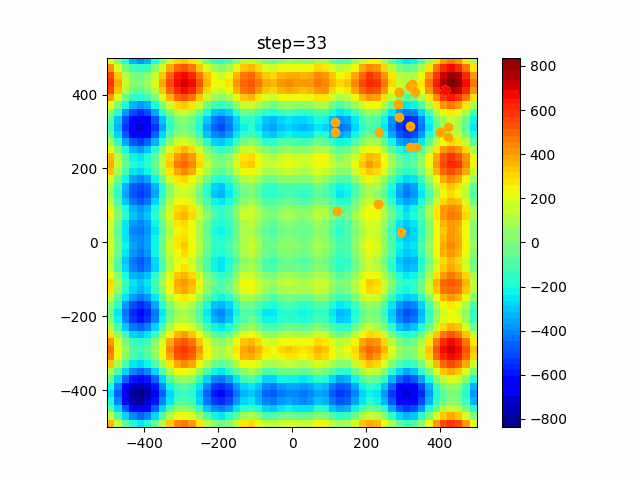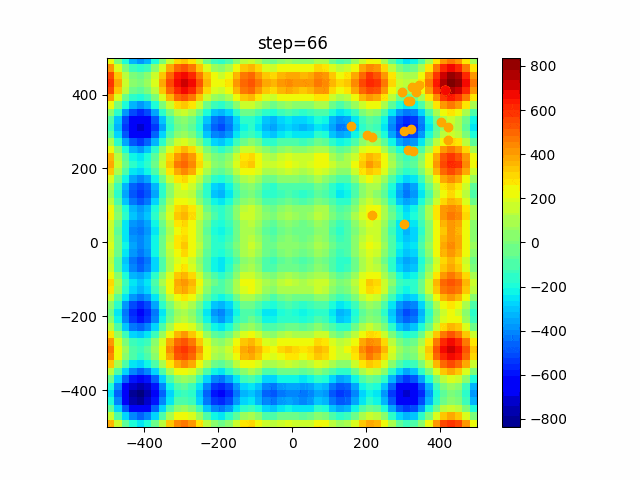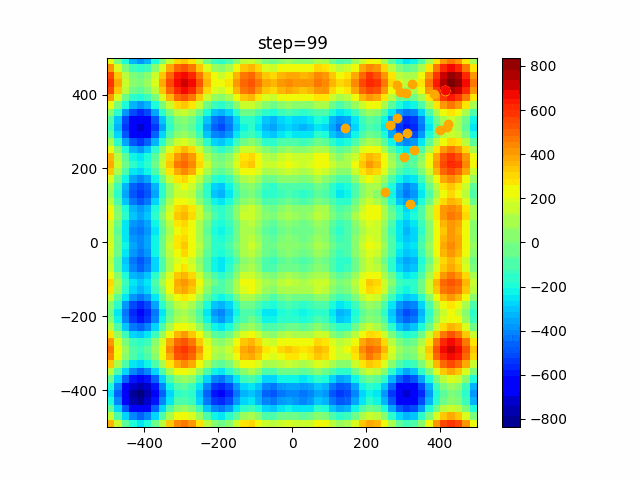
1次元は6個体、2次元は20個体で100step実行した結果です。
赤い丸がそのstepでの最高スコアを持っている個体です。パラメータは以下で実行しました。
PSO(N, inertia=0.2, global_acceleration=0.2, personal_acceleration=0.2)OneMax
- 1次元
- 2次元
function_Ackley
- 1次元
2次元
function_Griewank
- 1次元
- 2次元
function_Michalewicz
- 1次元
- 2次元
function_Rastrigin
1次元
2次元
function_Schwefel
- 1次元
- 2次元
function_StyblinskiTang
- 1次元
- 2次元
function_XinSheYang
- 1次元
- 2次元
あとがき
現状の最適解にみんなが集まってくる様子が粒子群っぽくていいですね。
アルゴリズム的には、一度局所解に入ってしまうとみんなそこに集まってしまうので抜け出せなさそうなイメージです。
また現状の最適解周辺でうろうろしている個体はパーソナルベストとグローバルベストの両方に引っ張られて釣り合っている個体ですね。今回実装した内容は一番シンプルなPSOなので、改良されたPSOならこれらの問題点が解決されているかもしれません。
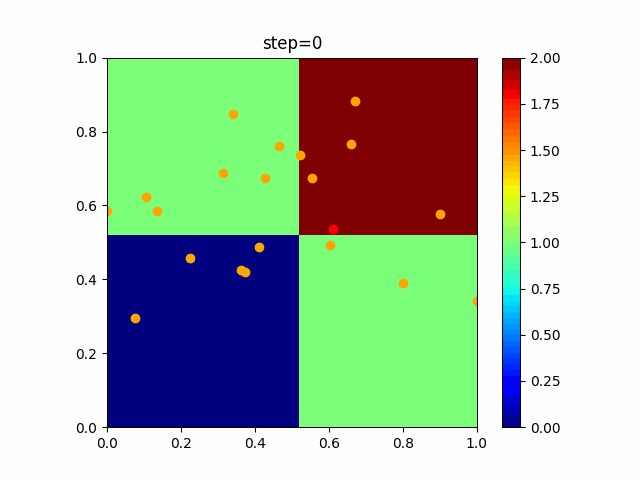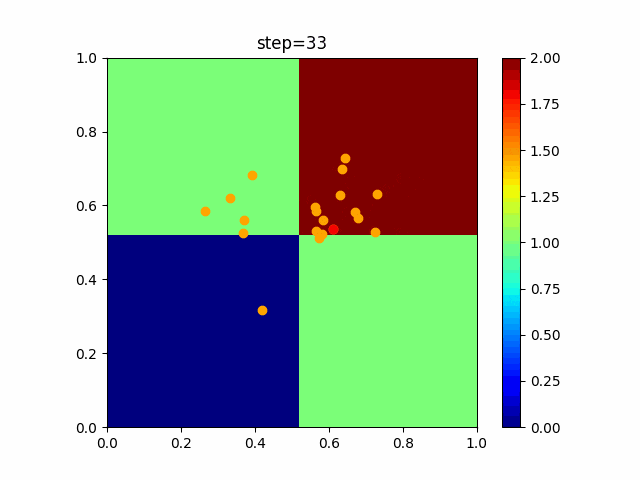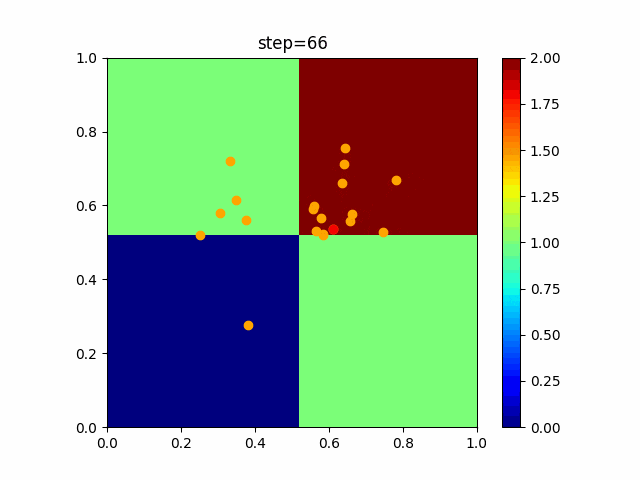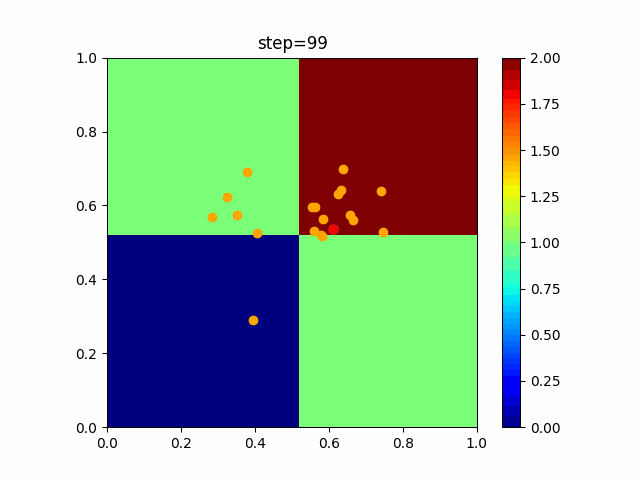
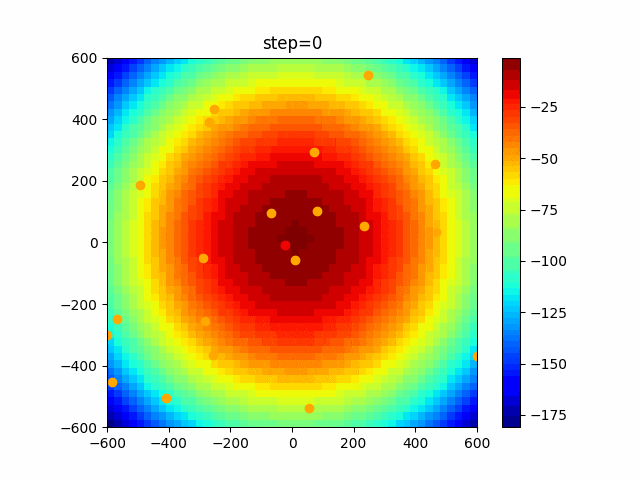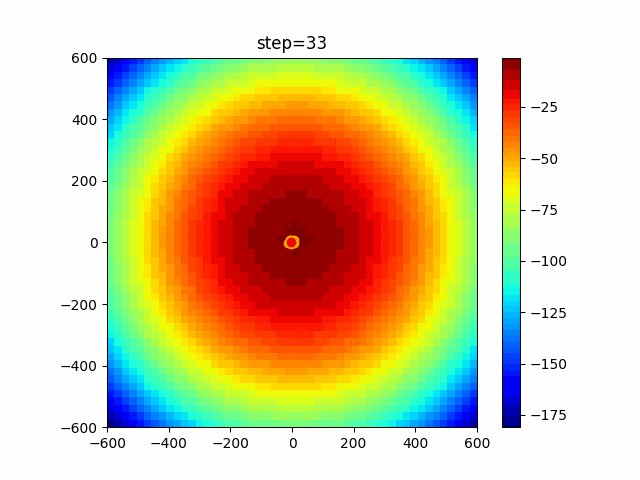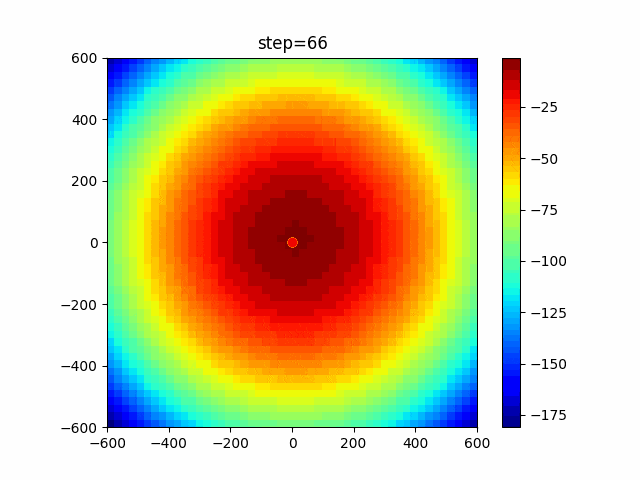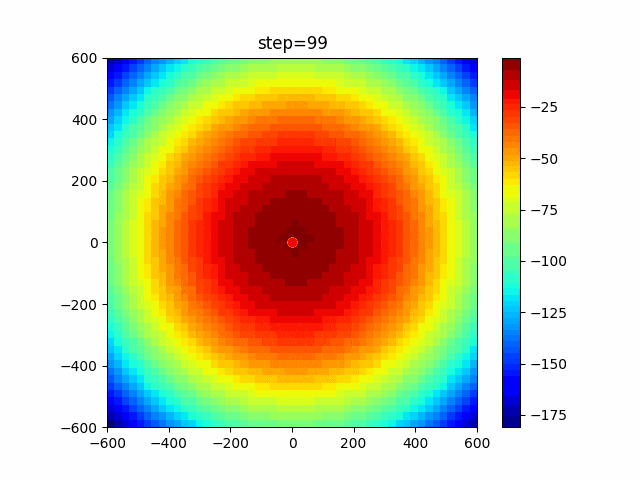
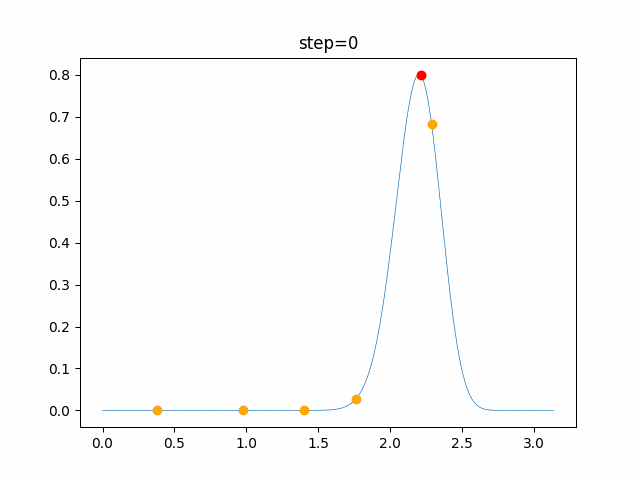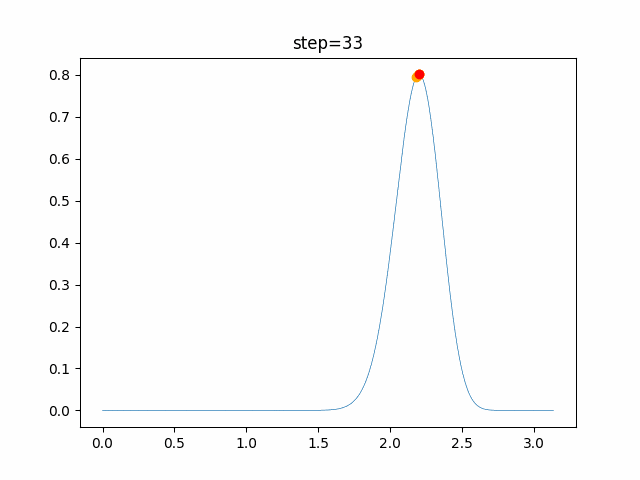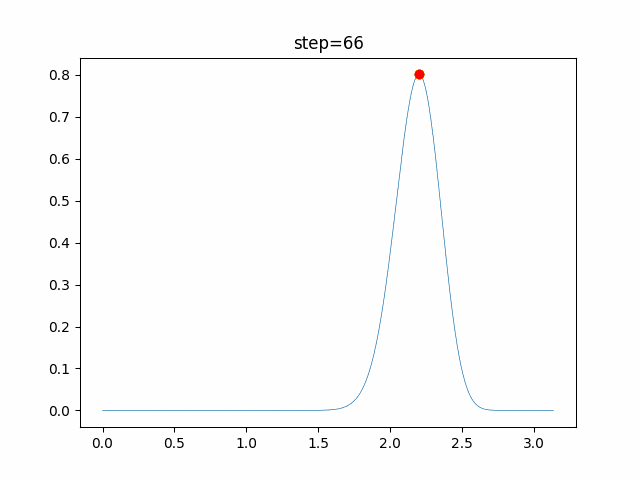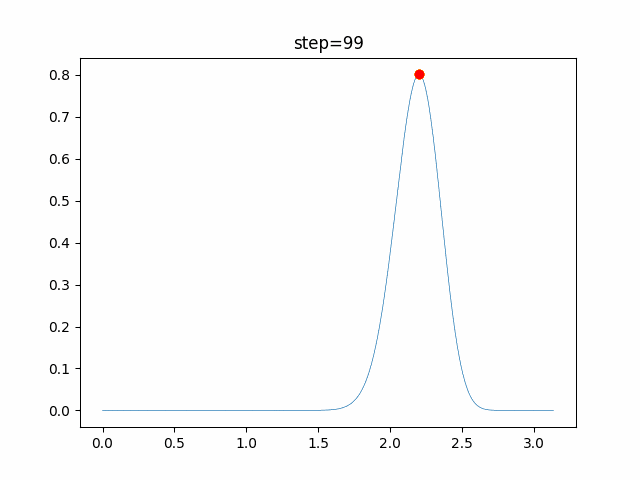
- 投稿日:2021-01-09T16:43:27+09:00
Pythonで正規表現を使う
regex.spl| makeresults | eval text="THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now." | rex field=text "(?ix)((?P<big_japan>(?P<japan>Japan).*?(?P=japan))) #Japanからjapanまで"とSplunkでもグループマッチ使えたんだ〜というのは別なところに転記するとして、
reがあまりにもできなすぎたので練習reオフィシャルはとてもわかりやすい。
re
sample.txt"THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now. The content of education is reduced and students come to have free time more. Furthermore, 'total education time' is taken in all Japanese junior high school. I think this change is bad and Japanese government must change it to original form rapidly for the following reasons. Firstly, many young people this time cannot read or write basic words (Japanese 'kanji.') And, they cannot calculate, too. These things are need in daily life, even if they don't go to college or university. Originally, Japanese student got better score in reading and calculation than any other country's student few decades ago. For, reading, writing, and calculation were very important in Japanese society. Now, however, this good value in old Japan is being reduced. This is very large problem in Japan. Secondly, there is deep gap between the level of high school education and university education. Many students who don't learn the content of high school education cannot catch up with the class in universities. Furthermore, for example, I am medical student, but I don't learn biology in high school. And there are many students like me. In addition, the care of university to us is nearly nothing. So, the level of the study in technology, medicine and so is going down. This is very large problem in Japan, too. Thirdly, as the content of school education is reduced, at the same time, the curiosity of students seems reduced. The new idea and new device are coming from the curiosity, I think. So, the reduction of it means the down of possibility that the evolutional change in various field will happen. This is very large problem in Japan. In conclusion, there are problems like these in Japan, because of the reduction of basic education. Luckily, the Japanese government is planning to change the education system. I hope this change will be going back to old Japanese school education system. \n"https://www.f.waseda.jp/yusukekondo/TALL19/TALL_Spring03.html
から引用search
matchが頭から(^キーワード)しか一致しないのでsearchを使う。search.pyimport re m=re.compile(r""" \b(?P<sentence>.*?[.]) # 文章で抽出してみる """,re.X) result=m.search(text) print(result)英文なので
.区切ってみる。結果
<_sre.SRE_Match object; span=(0, 78), match='THE JAPANESE SCHOOL EDUCATION In Japan, education>
len('"THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now.')が79なので、一致Match objectの説明がPython3で出てこないのは何故なんだろう

SRE_Match object
getattr.pyimport re m=re.compile(r""" \b(?P<sentence>.*?[.]) # 文章で抽出してみる """,re.X) result=m.search(text) for i in dir(result): if not i.startswith('__'): print(f'{i}: {getattr(result,i)}')Match Objectがなんなのかよくわからないので、メソッドを確認してみる。
結果
結果end: <built-in method end of _sre.SRE_Match object at 0x7fe65d3ba198> endpos: 1969 expand: <built-in method expand of _sre.SRE_Match object at 0x7fe65d3ba198> group: <built-in method group of _sre.SRE_Match object at 0x7fe65d3ba198> groupdict: <built-in method groupdict of _sre.SRE_Match object at 0x7fe65d3ba198> groups: <built-in method groups of _sre.SRE_Match object at 0x7fe65d3ba198> lastgroup: sentence lastindex: 1 pos: 0 re: re.compile('\n\\b(?P<sentence>.*?[.]) # 文章で抽出してみる\n', re.VERBOSE) regs: ((0, 78), (0, 78)) span: <built-in method span of _sre.SRE_Match object at 0x7fe65d3ba198> start: <built-in method start of _sre.SRE_Match object at 0x7fe65d3ba198> string: THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now. The (...省略)Python2.7 MatchObjectの通り。Python3のやつはどこにあるんだろ
findall
findall.pym=re.compile(r""" \b(?P<sentence>.*?[.]) # 文章で抽出してみる """,re.X) result=m.findall(text) # search は一つだけだけど、findallは全部 print(type(result)) print('-'*10) for i in dir(result): if not i.startswith('__'): print(f'{i}: {getattr(result,i)}') print('-'*10) for i in result: print(i) #結果がリストなので、一つずつ展開一致した全てを出したいときは
findall結果
結果<class 'list'> ---------- append: <built-in method append of list object at 0x7fe65d2dca48> clear: <built-in method clear of list object at 0x7fe65d2dca48> copy: <built-in method copy of list object at 0x7fe65d2dca48> count: <built-in method count of list object at 0x7fe65d2dca48> extend: <built-in method extend of list object at 0x7fe65d2dca48> index: <built-in method index of list object at 0x7fe65d2dca48> insert: <built-in method insert of list object at 0x7fe65d2dca48> pop: <built-in method pop of list object at 0x7fe65d2dca48> remove: <built-in method remove of list object at 0x7fe65d2dca48> reverse: <built-in method reverse of list object at 0x7fe65d2dca48> sort: <built-in method sort of list object at 0x7fe65d2dca48> ---------- THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now. The content of education is reduced and students come to have free time more. Furthermore, 'total education time' is taken in all Japanese junior high school. I think this change is bad and Japanese government must change it to original form rapidly for the following reasons. Firstly, many young people this time cannot read or write basic words (Japanese 'kanji. And, they cannot calculate, too. These things are need in daily life, even if they don't go to college or university. Originally, Japanese student got better score in reading and calculation than any other country's student few decades ago. For, reading, writing, and calculation were very important in Japanese society. Now, however, this good value in old Japan is being reduced. This is very large problem in Japan. Secondly, there is deep gap between the level of high school education and university education. Many students who don't learn the content of high school education cannot catch up with the class in universities. Furthermore, for example, I am medical student, but I don't learn biology in high school. And there are many students like me. In addition, the care of university to us is nearly nothing. So, the level of the study in technology, medicine and so is going down. This is very large problem in Japan, too. Thirdly, as the content of school education is reduced, at the same time, the curiosity of students seems reduced. The new idea and new device are coming from the curiosity, I think. So, the reduction of it means the down of possibility that the evolutional change in various field will happen. This is very large problem in Japan. In conclusion, there are problems like these in Japan, because of the reduction of basic education. Luckily, the Japanese government is planning to change the education system. I hope this change will be going back to old Japanese school education system.結果はリスト
split
split.pyresult1=re.split('(?<=\.)\s',text) # splitで区切り文字を含めてみた。 print(type(result1)) print('-'*10) m2=re.compile(r""" (?P<japan_txt>japan.*?)\b #test """,re.VERBOSE|re.IGNORECASE) {i:[v,re.search(m2,v).group()] for i,v in enumerate(result1) if re.search(m2,v)}文を区切るだけなら
split()で十分と思ってやってみた。
区切りを.としつつ残したかったので、そのあとの(スペース)で区切っている。結果
結果<class 'list'> ---------- {0: ['THE JAPANESE SCHOOL EDUCATION In Japan, education system is changing fast now.', 'JAPANESE'], 2: ["Furthermore, 'total education time' is taken in all Japanese junior high school.", 'Japanese'], 3: ['I think this change is bad and Japanese government must change it to original form rapidly for the following reasons.', 'Japanese'], 4: ["Firstly, many young people this time cannot read or write basic words (Japanese 'kanji.') And, they cannot calculate, too.", 'Japanese'], 6: ["Originally, Japanese student got better score in reading and calculation than any other country's student few decades ago.", 'Japanese'], 7: ['For, reading, writing, and calculation were very important in Japanese society.', 'Japanese'], 8: ['Now, however, this good value in old Japan is being reduced.', 'Japan'], 9: ['This is very large problem in Japan.', 'Japan'], 16: ['This is very large problem in Japan, too.', 'Japan'], 20: ['This is very large problem in Japan.', 'Japan'], 21: ['In conclusion, there are problems like these in Japan, because of the reduction of basic education.', 'Japan'], 22: ['Luckily, the Japanese government is planning to change the education system.', 'Japanese'], 23: ['I hope this change will be going back to old Japanese school education system.', 'Japanese']}結果はリスト
そのあとjapanを大文字小文字関係なく(
re.IGNORECASE)で検索して、その文字が含まれている行をインデックス:[当該行,検索文字]の辞書型で出力している。finditer
m2=re.compile(r""" (?P<japan_txt>japan.*?)\b #test """,re.VERBOSE|re.IGNORECASE) result=re.finditer(m2,text) print(result) print('-'*10) for i in result: print(i)イテレータ型で結果を返す
finditer結果
結果<callable_iterator object at 0x7fe65d2e5ba8> ---------- <_sre.SRE_Match object; span=(4, 12), match='JAPANESE'> <_sre.SRE_Match object; span=(33, 38), match='Japan'> <_sre.SRE_Match object; span=(209, 217), match='Japanese'> <_sre.SRE_Match object; span=(269, 277), match='Japanese'> <_sre.SRE_Match object; span=(427, 435), match='Japanese'> <_sre.SRE_Match object; span=(576, 584), match='Japanese'> <_sre.SRE_Match object; span=(749, 757), match='Japanese'> <_sre.SRE_Match object; span=(804, 809), match='Japan'> <_sre.SRE_Match object; span=(858, 863), match='Japan'> <_sre.SRE_Match object; span=(1368, 1373), match='Japan'> <_sre.SRE_Match object; span=(1705, 1710), match='Japan'> <_sre.SRE_Match object; span=(1760, 1765), match='Japan'> <_sre.SRE_Match object; span=(1825, 1833), match='Japanese'> <_sre.SRE_Match object; span=(1934, 1942), match='Japanese'>場所と一致箇所が返ってくる。
groupdict
groupdict.pym2=re.compile(r""" (?P<japan_txt>japan.*?)\b #test """,re.VERBOSE|re.IGNORECASE) result=re.finditer(m2,text) [i.groupdict() for i in result]結果
結果[{'japan_txt': 'JAPANESE'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japan'}, {'japan_txt': 'Japanese'}, {'japan_txt': 'Japanese'}]一致した文字とキャプチャーの文字が返ってくる
まとめ
とりあえずはいろいろと試してみたけど、まだ不十分
いったん終了とします。
- 投稿日:2021-01-09T15:37:29+09:00
[CpawCTF]Q14.[PPC]並べ替えろ!をPythonで書いてみる
https://ctf.cpaw.site/questions.php?qnum=14
CpawCTFのQ14をPython解いてみるメモです配列を降順に並び替えるらしい
せっかくなのでやってみたいなPythonで記述したい
結果を先に書くとこんな感じlist = [15,1,93,52,66,31,87,0,42,77,46,24,99,10,19,36,27,4,58,76,2,81,50,102,33,94,20,14,80,82,49,41,12,143,121,7,111,100,60,55,108,34,150,103,109,130,25,54,57,159,136,110,3,167,119,72,18,151,105,171,160,144,85,201,193,188,190,146,210,211,63,207] sort_list = sorted(list, reverse=True) answer = ''.join(map(str,sort_list)) print(answer)※参考させていただいたURL
https://note.nkmk.me/python-list-sort-sorted/
https://note.nkmk.me/python-string-concat/最初にjoinのところを
answer = ''.join(sort_list)と記述したところ下記のようなエラーが出た
TypeError: sequence item 0: expected str instance, int foundどうもjoinはstr型じゃないといけないらしく、下記の通りmap()で型を変換できるらしいのでやってみたらエラーを吐かなくなった
answer = ''.join(map(str,sort_list))調べればもっと簡単なのがありそうな気もするけどとりあえず解けたのでメモとして残しておく(´・ω・`)
- 投稿日:2021-01-09T14:42:14+09:00
最適化アルゴリズムを実装していくぞ(問題編)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。全体コードはgithubにあります。
問題
実装した問題は以下です。
- OneMax問題
- 巡回セールスマン問題(Traveling Salesman Problem: TSP)
- エイト・クイーン(Eight Queens)
- ライフゲーム
- 最適化アルゴリズムを評価するベンチマーク関数まとめよりいくつか抜粋
OneMax問題
値が0か1のN次元の配列において、合計が最大となるようにする問題です。
最高値はすべてが1の場合です。4次元の場合の例:[0, 1, 1, 0] → 2
入力のサイズ $N \geqq 1$ 入力値の範囲 $0 \leqq x_i \leqq 1$ 評価値 入力値を四捨五入した値の合計 評価値の最大値(最適解) $Prob(1 , \cdots , 1)=N$
- 入力が1次元の場合のグラフ
- 入力が2次元の場合のグラフ
プログラムコード
class OneMax(): def __init__(self, size): self.size = size self.MIN_VAL = 0 self.MAX_VAL = 1 self.SCORE_MIN = 0 self.SCORE_MAX = size def init(self): pass def eval(self, arr): t = [int(x+0.5) for x in arr] # 四捨五入 return sum(t)巡回セールスマン問題
複数の都市を巡回する場合、どの順番でまわれば一番移動距離が少なるなるかという問題です。
本記事では以下のように定義しました。
都市の場所 2次元(x,y)の座標で、0~1の間に乱数で配置 入力のサイズ $N \geqq 2$ 入力値の範囲 $0 \leqq x_i \leqq 1$ 評価値 移動した距離のマイナス値(最小値を求めたいので符号を反転) 評価値の最大値(最適解) 不明(0に近いほうが良い) ※最初のスタート地点は(0,0)からとしています
入力ですが、配列のindexと都市のindexが対応しており、入力値が小さい都市から順番に回るようにしています。
例えば都市が3つ(A,B,C)で入力が[0.3, 0.1, 0.2]の場合、回る順番は (0,0)→B→C→A となります。
- 描画例
プログラムコード
import math class TSP(): def __init__(self, size): self.size = size self.MIN_VAL = 0 self.MAX_VAL = 1 self.SCORE_MIN = -(math.sqrt(1+1) * size) self.SCORE_MAX = 0 def init(self): # 都市の位置をランダムに作成 self.towns = [ { "x": random.random(), "y": random.random() } for _ in range(self.size) ] def eval(self, arr): score = 0 # 入力値にソートした入力のindexを取得 tmp = [(i, x) for i, x in enumerate(arr)] tmp = sorted(tmp, key=lambda x: x[1]) for i in range(len(tmp)): if i == 0: # 最初は 0,0 から始める town = {"x":0, "y":0} else: town = self.towns[tmp[i-1][0]] next_town = self.towns[tmp[i][0]] # 移動距離がスコア d = abs(town["x"] - next_town["x"]) d += abs(town["y"] - next_town["y"]) score += d # 最小を求めたいので符号反転させる return -scoreエイト・クイーン
8×8のチェス盤に8個のクイーンを置く問題です。
ただし、クイーン同士は縦横斜めでかぶってはいけません。
8としていますがN個の場合に拡張できます。4クイーンの場合の解は以下です。
□□■□
■□□□
□□□■
□■□□
盤のサイズ $M \geqq 4$ 入力のサイズ $N=M×2$((x,y)の2次元配列を1次元に並べる) 入力値の範囲 $0 \leqq x_i \leqq M$ (マス内の座標) 評価値 他と被らないクイーンの数 評価値の最大値(最適解) M 入力ですが、各クイーンのxとy座標を並べた1次元配列としています。
たとえば[0, 0, 1, 2, 2, 1] とあった場合、(0,0)(1,2)(2,1) に3個のクイーンが置かれていることになります。プログラムコード
class EightQueen(): def __init__(self, size): self.size = size self.MIN_VAL = 0 self.MAX_VAL = size self.SCORE_MIN = 0 self.SCORE_MAX = size def init(self): pass def eval(self, arr): arr = [int(x+0.5) for x in arr] # 四捨五入 # 座標に変換 koma_list = [] for i in range(0, len(arr), 2): koma_list.append((arr[i], arr[i+1])) score = 0 for i in range(len(koma_list)): f = True for j in range(len(koma_list)): if i==j: continue # x if koma_list[i][0] == koma_list[j][0]: f = False break # y if koma_list[i][1] == koma_list[j][1]: f = False break # 斜め ax = abs(koma_list[i][0] - koma_list[j][0]) ay = abs(koma_list[i][1] - koma_list[j][1]) if ax == ay: f = False break if f: score += 1 return scoreライフゲーム
ライフゲームです。細胞の生き死にを模倣したゲームですね。
ルールはN×Nの盤があり、それぞれのマス(セル)は1(生)、0(死)の状態を持っています。
これらのセルは時間が進むごとに以下条件で生死を繰り返します。
- 誕生:死んでいるセルに隣接する生きたセルがちょうど3つあれば、次の世代が誕生する。
- 生存:生きているセルに隣接する生きたセルが2つか3つならば、次の世代でも生存する。
- 過疎:生きているセルに隣接する生きたセルが1つ以下ならば、過疎により死滅する。
- 過密:生きているセルに隣接する生きたセルが4つ以上ならば、過密により死滅する。
盤のサイズ $M \geqq 2$ 入力のサイズ $N=M×M$(2次元の盤のマスを1次元に並べる) 入力値の範囲 $0 \leqq x_i \leqq 1$ 評価値 生存しているセルの合計 評価値の最大値(最適解) 不明(M×Mに近い値) 評価ではXターン(max_turn)経過した後、生存しているセルの数を評価値としています。
プログラムコード
class LifeGame(): def __init__(self, size, max_turn): self.field_size = size self.max_turn = max_turn self.MIN_VAL = 0 self.MAX_VAL = 1 self.SCORE_MIN = 0 self.SCORE_MAX = size*size def init(self): pass def eval(self, arr): arr = [int(x+0.5) for x in arr] # 四捨五入 # 1次元→2次元に cells = [] for y in range(self.field_size): d = [] for x in range(self.field_size): d.append(arr[y*self.field_size + x]) cells.append(d) # 更新 for _ in range(self.max_turn): cells = self._step(cells) # 合計を出す n = 0 for y in range(self.field_size): for x in range(self.field_size): n += cells[y][x] return n def _step(self, cells): # 0でいったん初期化 next_cells = [[ 0 for _ in range(field_size)] for _ in range(self.field_size)] for y in range(self.field_size): for x in range(self.field_size): n = 0 n += self._get(cells, x-1, y-1) n += self._get(cells, x , y-1) n += self._get(cells, x+1, y-1) n += self._get(cells, x+1, y) n += self._get(cells, x-1, y) n += self._get(cells, x-1, y+1) n += self._get(cells, x , y+1) n += self._get(cells, x+1, y+1) if self._get(cells, x, y) == 0: if n == 3: next_cells[y][x] = 1 else: if n == 2 or n == 3: next_cells[y][x] = 1 else: next_cells[y][x] = 0 return next_cells def _get(self, cells, x, y): if x < 0: return 0 if y < 0: return 0 if x >= self.field_size: return 0 if y >= self.field_size: return 0 return cells[y][x]ベンチマーク関数
例として Ackley function を紹介します。
それ以外は、最適化アルゴリズムを評価するベンチマーク関数まとめ を見てください。
- 数式
$$
f(x_{1} \cdots x_{n})=20-20\exp \biggl( -0.2\sqrt{\frac{1}{n}\sum_{i=1}^{n}x_{i}^2} \biggr) +e-\exp \biggl(\frac{1}{n}\sum_{i=1}^{n}\cos(2\pi x_{i}) \biggr)
$$※最大値にするために数式に-1を掛けています。
- 1次元のグラフ
- 2次元のグラフ
- 探索範囲と最適解
次元数 $N \geqq 1$ 入力値の範囲 $-32.768 \leqq x_i \leqq −32.768$ 評価値の最大値 0 (すべて0の時0の値をとります) プログラムコード
import math class function_Ackley(): def __init__(self, size): self.size = size self.MIN_VAL = -32.768 self.MAX_VAL = 32.768 self.SCORE_MIN = -float('inf') self.SCORE_MAX = 0 def init(self): pass def eval(self, arr): sum1 = sum([x**2 for x in arr]) sum2 = sum([math.cos(2*math.pi*x) for x in arr]) n = len(arr) score = 20 - 20 * math.exp(-0.2 * math.sqrt(sum1/n)) + math.e - math.exp(sum2/n) return -score
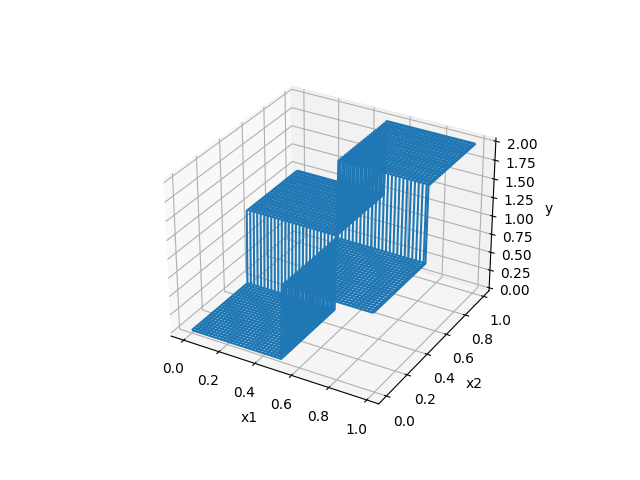
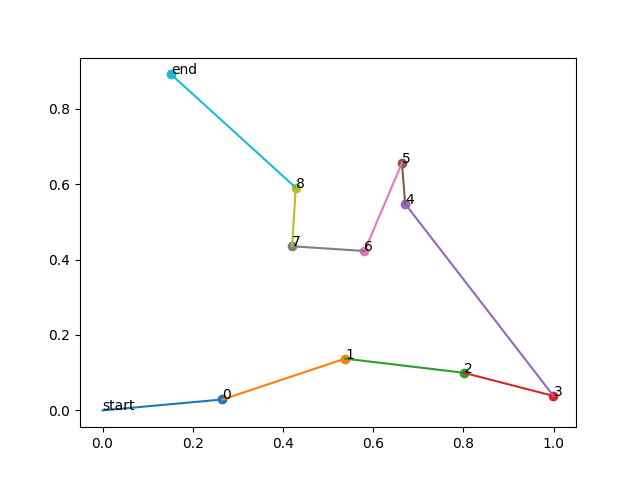
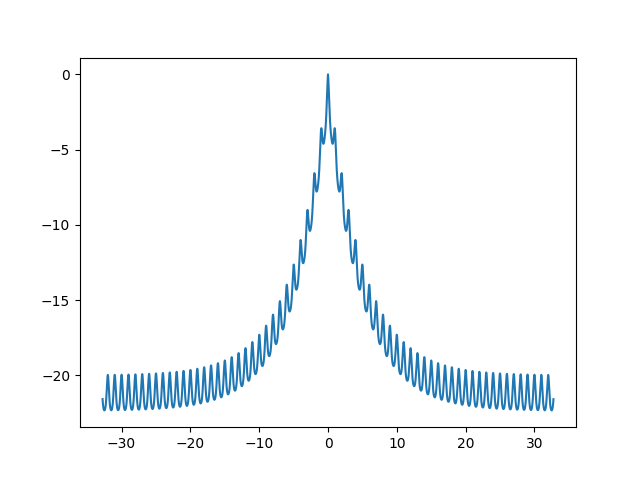
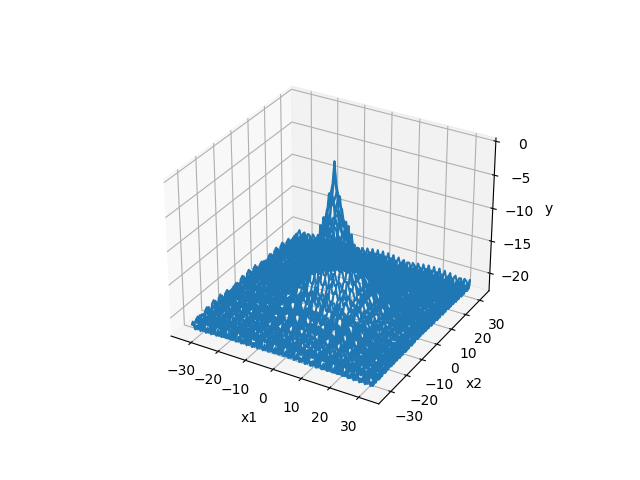
- 投稿日:2021-01-09T14:17:37+09:00
最適化アルゴリズムを実装していくぞ(概要)
はじめに
最適化アルゴリズムにおけるメタヒューリスティクスアルゴリズムを主に実装していきます。
メタヒューリスティクスは、問題に依存しないで解を得られることが最大の利点ですが、
実際の問題に対してどうアプローチしていいかがいまいち分かりにくかったのでまとめてみました。やりたいことは、
- できる限りわかりやすく一般化して、問題に対する共通のインターフェースをつくる
- 各アルゴリズムを比較
です。
また、各アルゴリズムについては別記事にして少しずつ上げていく予定です。
(記事を上げたらリンクをつけていきます)
コードはgithubにあります。対象アルゴリズム
- 遺伝的アルゴリズム(Genetic Algorithm: GA)
- 人口蜂コロニーアルゴリズム(Artificial Bee Colony: ABC)
- 粒子群最適化(Particle Swarm Optimization: PSO)
- ホタルアルゴリズム(Firefly Algorithm)
- コウモリアルゴリズム(Bat Algorithm)
- カッコウ探索(Cucko Search)
- ハーモニーサーチ(Harmony Search)
- くじらさんアルゴリズム(The Whale Optimization Algorithm: WOA)
- 差分進化(Differential Evolution: DE)
※気になるアルゴリズムがあれば追加するかもしれません
対象の問題
問題の詳細は問題編にまとめてあります。
実装した問題は以下です。
- OneMax問題
- 巡回セールスマン問題(Traveling Salesman Problem: TSP)
- エイト・クイーン(Eight Queens)
- ライフゲーム
- 最適化アルゴリズムを評価するベンチマーク関数まとめよりいくつか抜粋
比較結果
最適化アルゴリズムを比較してみた(仮)(todo)
問題について
組み合わせ最適化問題とは、ある目的関数(問題)が与えられたとき目的関数の結果が最大(または最小)となる関数への入力(組み合わせ)を見つける事が目的となります。
本記事で想定する目的関数は、一番難しい不連続なもの(図でいうと(e))を想定しています。
(図は最適化アルゴリズムを評価するベンチマーク関数まとめより引用)
(e)のような関数を解く手法の1つにメタヒューリスティクスアルゴリズムがあります。
問題の一般化
一般化の目的は、ある問題を今回紹介するアルゴリズムに適用したい場合、問題側はどういうインターフェース(入力形式だったり出力形式だったり)を用意すればいいかを表現することです。
そしてアルゴリズム側の責務は、そのインターフェースのみを使って結果を出すことになります。
(もちろん各アルゴリズムの特性を理解してそれに合ったチューニングをしたほうが性能は上がります)本記事では問題側の入力と出力を以下のように定義しました。
問題への入力のサイズ $N$ 問題への入力 $\vec{x}=(x_1,x_2,...,x_N)$ 問題への入力の1要素(入力値) $x_i (i=1...N)$ 1要素の範囲 $Prob_{min}\leqq x_i \leqq Prob_{max}$ 入力値の配列を問題へ渡した結果(評価値) $Score = Prob(\vec{x})$ $Prob$ は問題毎に変化する要素です。
入力はn次元の配列 $(x_1,x_2,...,x_N)$ で各$x$は問題側で指定した範囲の値を持ちます。
問題側はこの配列を受け取ったら評価し、評価値を返します。
この評価値を最大にすることがアルゴリズム側の責務です。※入力値は汎用性を持たせるために実数値としています。ので、問題によっては評価するときに離散値にする必要があります。
※最大値を対象にしています。最小にしたい場合は問題側でマイナスする事としています。プログラムコードでのインターフェースの表現
問題を表すクラスと入力を表すクラスを分離しています。
- 問題クラス
問題を表すクラスの責務は入力の作成及び、入力を受け取ったときの評価です。
各問題で共通に実装しなければいけない内容のみ記載しています。import random class Problem(): def __init__(self, size): self.size = size # 目的関数への入力サイズ(N) self.MIN_VAL = 0 # 要素の最低値(問題毎に指定)(Prob_min) self.MAX_VAL = 1 # 要素の最大値(問題毎に指定)(Prob_max) def create(self, arr=None): """ 入力の値を生成します。 引数が None の場合はランダムな入力を作成し、 値が指定されている場合はその値で入力を作成します。 ProblemDataについては後述 """ o = ProblemData(self, self.size) if arr is None: arr = [ self.randomVal() for _ in self.size] o.setArray(arr) return o def randomVal(self): """ 1要素のランダムな値を返す関数です """ return self.MIN_VAL + random.random() * (self.MAX_VAL - self.domain.MIN_VAL) def init(self): """ 問題の初期化、任意で作成 """ raise NotImplementedError() def eval(self, arr): """ 入力に対して評価をし、結果を返します ここが目的関数部分に相当します """ raise NotImplementedError()
- 問題への入力クラス
入力クラスの責務は入力の操作及び、評価値をキャッシュして返すことです。
問題によっては評価値を出すことが一番時間がかかるので、入力クラス側でキャッシュさせます。
これにより問題クラス側でキャッシュを考える必要がなくなるようにしています。class ProblemData(): def __init__(self, domain, size): self.domain = domain # 問題クラスです self.size = size # 目的関数への入力サイズ self.arr = [ 0 for _ in range(self.size)] # 入力値 self.score = None # 評価値(キャッシュ用) def copy(self): """ 自身のcopyを返します """ o = ProblemData(self.domain, self.size) o.arr = [ x for x in self.arr] # deepcopy o.score = self.score return o def getArray(self): """ 入力値を返します。 安全のため、複製して返します。 """ return [ x for x in self.arr] def setArray(self, arr): """ 入力値を設定します。 """ # 下限と上限でまるめます for i in range(len(arr)): if arr[i] < self.domain.MIN_VAL: arr[i] = self.domain.MIN_VAL if arr[i] > self.domain.MAX_VAL: arr[i] = self.domain.MAX_VAL self.arr = arr self.score = None # キャッシュクリア def getScore(self): """ 評価値を返します """ if self.score is not None: return self.score self.score = self.domain.eval(self.arr) return self.scoreアルゴリズムの一般化
アルゴリズムでは問題を $M$ 個持ちます。
(必ず持つ必要はないのですが、複数問題を持つアルゴリズムしか今のところありません)各問題への入力を更新することで、評価値が最大となる問題を探すことが目的となります。
※実装では評価値を最大にする場合のみを想定しています。
- アルゴリズムクラス
class IAlgorithm(): def init(self, problem): """ 初期化関数です 引数で問題を関連付けし、アルゴリズム側の初期化も行います """ raise NotImplementedError() def step(self): """ アルゴリズム側の1回の更新です """ raise NotImplementedError() def getMaxElement(self): """ アルゴリズム内の最大評価値の問題を返します """ raise NotImplementedError() def getElements(self): """ アルゴリズム内で使っている全問題を返します """ raise NotImplementedError() def getScores(self): """ アルゴリズム内で使っている全問題の評価値を返します """ return [x.getScore() for x in self.getElements()] def getMaxScore(self): """ アルゴリズム内の最大評価値を返します """ return self.getMaxElement().getScore()main関数
上記の問題クラスとアルゴリズムクラスは、以下のように動かすことを想定しています。
prob = Problem(N) # N次元の入力をもった問題を作成 alg = IAlgorithm() # アルゴリズムを指定 # 初期化 prob.init() alg.init(prob) # アルゴリズムと問題を紐づけ # 任意の回数loop for i in range(100): alg.step() # 結果 result = alg.getMaxElement() print("max score : {}".foramat(result.getScore()) print("max values: {}".format(result.getArray()))
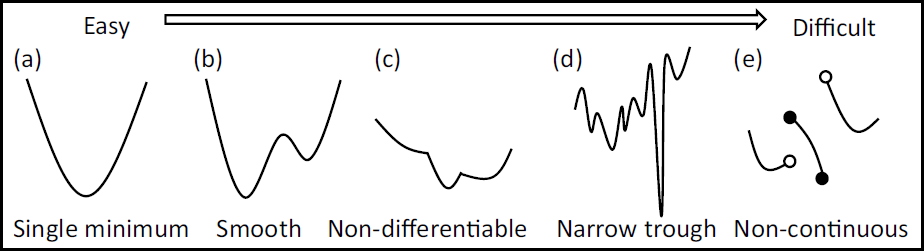
- 投稿日:2021-01-09T13:15:29+09:00
【DeepFake】ついにうちのワンコが喋り始めました
①はじめに
なにかアウトプットがあるとAIをやった気になって楽しいですよね。今回はちまたで話題のDeepFakeをやってみたいと思います。
②DeepFakeとは
DeepFakeとは、深層学習と偽物を組み合わせた造語で、人工知能にもとづく人物画像合成技術のことです。サンプルを見ると楽しさが分かると思いますが、今回は「
first-order-model」を利用して、静止画のワンコを喋らせてみたいと思います。

③TRY
では、早速やってみましょう!
環境は、プログラムを動作させるのはGPUが使えるのでGoogle Colab、データの格納はGoogle Driveでやります。■事前準備
Google Driveで実施してください。
事前準備として、各種データ(チェックポイント、動画、静止画)をGoogle Driveへ格納します。➊データ格納フォルダ作成
Google Driveのマイドライブ直下に「
first-order-motion-model」のフォルダを作ってください。➋チェックポイントのDL
共有されている「トレーニングされたチェックポイント」を自分のGoogle Driveに格納してください。チェックポイントのリンクを開いて、先程作った「
first-order-motion-model」へドラッグ・アンド・ドロップすれば良いです。この方法だと実際はショートカットが作成されますが、これでも大丈夫です。ダウンロードはこちら ▶ Google Drive or Yandex Disk
ショートカットで実施している場合、チェックポイント読み込みでエラーとなる場合がありますが、これは共有フォルダからのダウンロード制限がかかってしまっていることが原因です。その場合は、1日くらい待ってから再度実施してください。こういうのが嫌な場合はローカルPCへ一旦ダウンロードし、Google Driveへ実態ファイルをアップロードしてください。実態ファイルは700MBくらいのサイズです。
➌動画データ、静止画データの格納
撮影やトリミングは、携帯電話などで簡単にできます。
- 喋らせたいワンコの静止画を撮影します。
- 人が喋っている動画を撮影します。(目をパチクリさせたり首を縦横に振ると、より面白くなります)
正方形にトリミングした動画と静止画を「
first-order-motion-model」フォルダに置いてください。ファイル名は以下の様にしてください。
- 動画 :movie001.mp4
- 静止画:pic001.png
■DeepFake処理
Google Colabで実施してください。
Google Driveに格納したデータを利用して、DeepFake処理を行います。➊git clone
まずは、「
first-order-model」をgit cloneします。!git clone https://github.com/AliaksandrSiarohin/first-order-model➋カレントディレクトリ移動
「
first-order-model」配下へ移動します。%cd first-order-model➌リサイズ
静止画と動画を256x256へリサイズするために以下を実行します。
import imageio import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import warnings warnings.filterwarnings("ignore") source_image = imageio.imread('/content/drive/My Drive/first-order-motion-model/pic001.png') reader = imageio.get_reader('/content/drive/My Drive/first-order-motion-model/movie001.mp4') #Resize image and video to 256x256 source_image = resize(source_image, (256, 256))[..., :3] fps = reader.get_meta_data()['fps'] driving_video = [] try: for im in reader: driving_video.append(im) except RuntimeError: pass reader.close() driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video] def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani HTML(display(source_image, driving_video).to_html5_video())➍チェックポイント読み込み
事前にトレーニングしたチェックポイントを読み込みます。
from demo import load_checkpoints generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml', checkpoint_path='/content/drive/My Drive/first-order-motion-model/vox-cpk.pth.tar')➎DeepFake作成
DeepFakeを作成します。作成した動画は「../generated.mp4」となります。
from demo import make_animation from skimage import img_as_ubyte predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True) #save resulting video imageio.mimsave('../generated.mp4', [img_as_ubyte(frame) for frame in predictions], fps=fps) #video can be downloaded from /content folder HTML(display(source_image, driving_video, predictions).to_html5_video())④以上
お疲れ様でした。
なんかアウトプットがあると出来た感があって超楽しいですね。こんなにも簡単にDeepFakeができるなんてびっくりです。全ては「first-order-model」さまのお力なんですけどね。

- 投稿日:2021-01-09T12:56:14+09:00
Raspberry PIでBITCOINのLTP情報取得
概要
最近BITCOINの売買価格が高くなっていたので、BITCOINの売買情報をデータ化するため、BitflyerのAPIを通して情報を収集しようと思って今回のコードを作成ました。
事前環境構築
・Python
・MySql
※バージョンによって大きい影響はないと思います。
下記のコマンドでインストールしました。■基本設定 sudo apt-get install python2.7-dev python3-dev sudo apt-get install mariadb-server-10.0 sudo apt-get install python-mysqldb ■その他設定 sudo apt-get install python-pandas sudo apt-get install jq ※ネットのサンプルを試すため、インストールしていたパッケージです。テーブル作成
各項目のデータ型は仮で下記のように設定しましたので、各自変更してみてください。これでテーブルが作成できます。
create table coindata( product_code varchar(50), state varchar(50), timestamp varchar(50), tick_id varchar(50), best_bid varchar(50), best_ask varchar(50), best_bid_size varchar(50), best_ask_size varchar(50), total_bid_depth varchar(50), total_ask_depth varchar(50), market_bid_size varchar(50), market_ask_size varchar(50), ltp varchar(50), volume varchar(50), volume_by_product varchar(50) );テーブル作成結果
下記の操作で正しくテーブルが作成されます。
pi@RPI4-DEV:~/work/python $ sudo mysql -uroot -A Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 58 Server version: 10.0.28-MariaDB-2+b1 Raspbian testing-staging Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> create database bitcoin; Query OK, 1 row affected (0.00 sec) MariaDB [bitcoin]> use bitcoin; Database changed MariaDB [bitcoin]> create table coindata( -> product_code varchar(50), -> state varchar(50), -> timestamp varchar(50), -> tick_id varchar(50), -> best_bid varchar(50), -> best_ask varchar(50), -> best_bid_size varchar(50), -> best_ask_size varchar(50), -> total_bid_depth varchar(50), -> total_ask_depth varchar(50), -> market_bid_size varchar(50), -> market_ask_size varchar(50), -> ltp varchar(50), -> volume varchar(50), -> volume_by_product varchar(50) -> ); Query OK, 0 rows affected (0.06 sec) MariaDB [bitcoin]>ソースコード
次のコードをコピーしてファイルを作成します。
#!/usr/bin/python # -*- coding: utf-8 -*- import requests import sys import MySQLdb ############### #### const #### ############### host="localhost" user="bitcoin" passwd="bitcoin" db="bitcoin" ############### def insertDB(data): try: database = MySQLdb.connect (host=host, user=user, passwd=passwd, db=db, charset="utf8") cursor = database.cursor() query = """INSERT INTO coindata (product_code, state, timestamp, tick_id, best_bid, best_ask, best_bid_size, best_ask_size, total_bid_depth, total_ask_depth, market_bid_size, market_ask_size, ltp, volume,volume_by_product) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""" values = (str(data['product_code']),str(data['state']),str(data['timestamp']),str(data['tick_id']),str(data['best_bid']),str(data['best_ask']),str(data['best_bid_size']),str(data['best_ask_size']),str(data['total_bid_depth']),str(data['total_ask_depth']),str(data['market_bid_size']),str(data['market_ask_size']),str(data['ltp']),str(data['volume']),str(data['volume_by_product'])) cursor.execute(query, values) cursor.close() database.commit() database.close() except Exception as e: print("#######################") print("# data process error. #") print("#######################") print("# Error >>>>>>>>>>>>>>>") print(e) print("#######################") sys.exit(1) def main(): headers = { 'Accept': 'application/json', } response = requests.get('https://api.bitflyer.com/v1/ticker?product_code=BTC_JPY', headers=headers, data={}) #print(response.text) data = response.json() if response is not None: print("#######################") print("# Api response data. #") print("#######################") print('product_code='+ str(data['product_code'])) print('state='+ str(data['state'])) print('timestamp='+ str(data['timestamp'])) print('tick_id='+ str(data['tick_id'])) print('best_bid='+ str(data['best_bid'])) print('best_ask='+ str(data['best_ask'])) print('best_bid_size='+ str(data['best_bid_size'])) print('best_ask_size='+ str(data['best_ask_size'])) print('total_bid_depth='+ str(data['total_bid_depth'])) print('total_ask_depth='+ str(data['total_ask_depth'])) print('market_bid_size='+ str(data['market_bid_size'])) print('market_ask_size='+ str(data['market_ask_size'])) print('ltp='+ str(data['ltp'])) print('volume='+ str(data['volume'])) print('volume_by_product='+ str(data['volume_by_product'])) insertDB(data); else: print("reponse is null") if __name__ == '__main__': main() pi@RPI4-DEV:~/work/python $実行結果
コマンドを実行すると下記のように現在の売買情報が表示されます。
表示されている各項目はDBへ登録されます。pi@RPI4-DEV:~/work/python $ python pybitflyer1.py ####################### # Api response data. # ####################### product_code=BTC_JPY state=RUNNING timestamp=2021-01-09T01:36:12.597 tick_id=7241936 best_bid=4154675.0 best_ask=4156000.0 best_bid_size=0.38445428 best_ask_size=0.03 total_bid_depth=1206.39330272 total_ask_depth=603.2624046 market_bid_size=0.0 market_ask_size=0.0 ltp=4154675.0 volume=190283.400721 volume_by_product=17158.1161835 pi@RPI4-DEV:~/work/python $DBにてテーブル情報確認
次のコマンド操作で登録されている情報の確認ができます。
pi@RPI4-DEV:~/work/python $ sudo mysql -uroot -A Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 62 Server version: 10.0.28-MariaDB-2+b1 Raspbian testing-staging Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> use bitcoin Database changed MariaDB [bitcoin]> select * from coindata; +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ | product_code | state | timestamp | tick_id | best_bid | best_ask | best_bid_size | best_ask_size | total_bid_depth | total_ask_depth | market_bid_size | market_ask_size | ltp | volume | volume_by_product | +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ | BTC_JPY | RUNNING | 2021-01-09T01:36:12.597 | 7241936 | 4154675.0 | 4156000.0 | 0.38445428 | 0.03 | 1206.39330272 | 603.2624046 | 0.0 | 0.0 | 4154675.0 | 190283.400721 | 17158.1161835 | +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ 1 rows in set (0.00 sec) MariaDB [bitcoin]>CRON設定
次は上記の売買情報を1分間隔で実行してDBへ登録するようにCRONに設定します。
設定するコマンドは以下の通りです。crontab -eまずはプログラムの絶対パスを確認します。
※CRONの設定について詳しい情報は各自で検索してみてください。pi@RPI4-DEV:~/work/python $ pwd /home/pi/work/python pi@RPI4-DEV:~/work/python $ crontab -e pi@RPI4-DEV:~/work/python $ crontab -e no crontab for pi - using an empty one Select an editor. To change later, run 'select-editor'. 1. /bin/nano <---- easiest 2. /usr/bin/vim.tiny 3. /bin/ed Choose 1-3 [1]: 2 ※初めて実行する場合は、この画面が表示されます。好きなエディタを選びます。 ※エディタ画面が表示されたら一番下に次の行を追加します。 # m h dom mon dow command */1 * * * * /usr/bin/python /home/pi/work/python/pybitflyer.py登録データを確認
次のコマンドで1分間隔で登録されているデータが確認できます。
pi@RPI4-DEV:~/work/python $ sudo mysql -uroot bitcoin -A Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 67 Server version: 10.0.28-MariaDB-2+b1 Raspbian testing-staging Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [bitcoin]> select * from coindata; +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ | product_code | state | timestamp | tick_id | best_bid | best_ask | best_bid_size | best_ask_size | total_bid_depth | total_ask_depth | market_bid_size | market_ask_size | ltp | volume | volume_by_product | +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ | BTC_JPY | RUNNING | 2021-01-09T01:36:12.597 | 7241936 | 4154675.0 | 4156000.0 | 0.38445428 | 0.03 | 1206.39330272 | 603.2624046 | 0.0 | 0.0 | 4154675.0 | 190283.400721 | 17158.1161835 | | BTC_JPY | RUNNING | 2021-01-09T02:00:01.737 | 7277223 | 4181830.0 | 4183521.0 | 0.1782 | 0.05 | 1209.05388127 | 607.47497788 | 0.0 | 0.0 | 4182870.0 | 188553.381385 | 16853.8598802 | | BTC_JPY | RUNNING | 2021-01-09T02:01:01.477 | 7278952 | 4185354.0 | 4189102.0 | 0.204 | 0.05 | 1202.80743073 | 609.78078502 | 0.0 | 0.0 | 4186504.0 | 188608.251493 | 16866.3219666 | | BTC_JPY | RUNNING | 2021-01-09T02:02:01.51 | 7280690 | 4184065.0 | 4186520.0 | 0.1 | 0.03 | 1201.72775047 | 610.64902502 | 0.0 | 0.0 | 4184065.0 | 188603.676283 | 16867.4278812 | | BTC_JPY | RUNNING | 2021-01-09T02:03:00.583 | 7282149 | 4182182.0 | 4185000.0 | 0.05 | 0.2 | 1203.15019458 | 605.12780202 | 0.0 | 0.0 | 4183657.0 | 188626.810728 | 16863.1595472 | | BTC_JPY | RUNNING | 2021-01-09T02:04:01.443 | 7283487 | 4186501.0 | 4188169.0 | 0.107 | 0.1762 | 1203.22910919 | 606.56515624 | 0.0 | 0.0 | 4188169.0 | 188611.955945 | 16854.4726057 | | BTC_JPY | RUNNING | 2021-01-09T02:05:01.99 | 7284970 | 4183318.0 | 4185000.0 | 0.03 | 0.02994 | 1203.19692324 | 612.95260845 | 0.0 | 0.0 | 4184364.0 | 188625.722582 | 16854.5922007 | | BTC_JPY | RUNNING | 2021-01-09T02:06:01.467 | 7286247 | 4182683.0 | 4184961.0 | 0.074 | 0.01 | 1205.67149056 | 618.09582191 | 0.0 | 0.0 | 4184961.0 | 188616.57201 | 16850.0963765 | | BTC_JPY | RUNNING | 2021-01-09T02:07:01.627 | 7287530 | 4186482.0 | 4188998.0 | 0.03 | 0.6 | 1199.76322728 | 614.5609498 | 0.0 | 0.0 | 4186483.0 | 188612.761309 | 16855.8516827 | | BTC_JPY | RUNNING | 2021-01-09T02:08:02.017 | 7289554 | 4208196.0 | 4210176.0 | 0.0296 | 0.02896875 | 1199.07365715 | 584.77633435 | 0.0 | 0.0 | 4210000.0 | 188746.858826 | 16885.9375454 | | BTC_JPY | RUNNING | 2021-01-09T02:09:01.2 | 7291398 | 4218089.0 | 4220000.0 | 0.202 | 0.5989905 | 1203.38397034 | 578.56932313 | 0.0 | 0.0 | 4220000.0 | 188808.063154 | 16888.2721248 | +--------------+---------+-------------------------+---------+-----------+-----------+---------------+---------------+-----------------+-----------------+-----------------+-----------------+-----------+---------------+-------------------+ 13 rows in set (0.00 sec) MariaDB [bitcoin]>終わりに
今日はこれで1分間隔でBITCOINの売買情報を取得することができましたので、このデータを基に自動売買及び仮想シミュレーションを作ってみたいですね。
今日はここまでです。ありがとうございます。^^
- 投稿日:2021-01-09T12:15:36+09:00
stackの問題:「20. Valid Parentheses」を解いてみる
はじめに
stackの問題を解いたので,メモしました.
「20. Valid Parentheses」を解いてみる
問題へのリンク:
https://leetcode.com/problems/valid-parentheses/解答:
class Solution: def isValid(self, s: str) -> bool: if len(s)%2 != 0: return False dic = {'(':')','{':'}','[':']'} stack = list() for i, c in enumerate(s): if s[i] in dic: # verify only left-bracket stack.append(s[i]) # add only left-bracket else: if len(stack) != 0 and dic[stack[-1]] == s[i]: stack.pop() # remove a last element else: return False if len(stack) == 0: return Trueこの処理の流れについて説明します.
まず,左・右かっこをそれぞれペアとした辞書,stackというリストを作成します.
そして,入力の文字列を前から順に見ていき,左かっこの場合はstackに追加.(stackに追加されるのは左かっこのみ)
右かっこの場合はstackの最後の要素がペアとなる左かっこであればその左かっこをstackから除去.(そうでない場合はFalseを返し終了)最終的に,stackの中身が空となればTrueを返します.
- 投稿日:2021-01-09T12:09:45+09:00
Ubuntu18.04でログイン後自動でpythonスクリプト(GUI付き)とsudo権限のコマンドを実行する方法
はじめに
Ubuntu18.04でGUIの出るpythonスクリプトをログイン後に自動実行する方法と、
sudo権限でいつも行っていたchmodコマンドを同様にログイン後に自動実行する方法を探していまして、
上手くいく方法が見つかったので備忘録がてら記事にしました。
GUIが出るというところが肝だったように思います。この記事を読んでわかること
Ubuntu18.04
・GUIを生ずるpythonスクリプトをログイン後に自動実行する方法
・sudo権限のコマンドをログイン後に自動実行する方法実行環境
Ubuntu18.04
python3.8
anaconda環境使用
起動後あるユーザーに自動ログインする設定済み実施内容
Pythonスクリプトの自動実行方法について
sessionにpythonスクリプトを実行するシェルスクリプトを登録する
・アプリケーション一覧の検索窓で「session」と検索
・「アプリの自動実行」みたいな名前のアプリケーションを起動
・「追加」を押して、コマンド欄に実行したいシェルスクリプトを選択して設定…以上
essionはfirefoxなどGUIアプリケーションを自動起動させるときにも使います。
OS側でGUIを立ち上げる準備が出来てから実行されることが保証できるので、
GUIを生ずる今回のpythonスクリプトはここで実行することにしました。※crontabで実行することも試しましたが、GUIの立ち上がりでエラーしました。
sessionに登録すると、実行するまでの時間がかかる印象ですが、
それだけOS側では準備が必要なのでしょう。ちなみに.shの内容
/hoge/hoge/foo.shcd /home/user名/hoge/hoge /home/user名/anaconda3/bin/python /home/user名/hoge/hoge/foo.py私は実行するpythonスクリプトの中に相対パスが含まれていたので、
foo.shも実行するスクリプトと同じ場所に作成しましたが、
なぜかfile not found errorになってしまったので、
シェルスクリプトの中でもcdして実行ファイルの場所まで移動することで解決しました。pythonコマンドやスクリプトのパスは念のため絶対パスで書きました。
あとpythonはanaconda環境を使用しています。
sudo権限でコマンドを実行する方法について
rc.localにコマンドを記載
/etc/rc.local#!/bin/sh sudo chmod 666 /hoge/hogeポイント
rc.localがなければsudo権限で作成します
sudo vi /etc/rc.localrc.localを実行可能ファイルにしておきます
sudo chmod u+x /etc/rc.local説明
rc.localは今回の環境では/etc/rc.localでした。
18.04からは起動時の自動実行にsystemdが使われるようになりましたが、
互換性のためrc.localも使用可能です。rc.localはroot権限で実行されるので記述が簡単です。
(試してないけど、sudoって記述要らない気がする)
crontabはroot権限ではないのでsudoコマンド書こうとすると少しめんどくさいです。以前systemdを使おうとしてややこしい印象を持ったのと、
あまりうまくいかなかったので(笑)、今回はsystemdは使用しません。
ただ、18.04でrc.localを使うには結局systemdから動かしてもらうことになります。参考
Ubuntu 18.04 rc.localsystemd設定
rc.localを動かすために必要な準備
rc-local.serviceというファイルに追記が必要です。
通常/bin/systemd/system下に存在しますが、
systemdに実行してもらうには/etc/systemd/system下にないといけませんので、
ポイントを見て方法を選んでください。ポイント
rc-local.serviceが/etcに無ければ作成するか、
touch /etc/systemd/system/rc-local.serviceもしくは本来/lib/systemd/system/rc-local.serviceなのでそこからリンクを貼ってください
ln -fs /lib/systemd/system/rc-local.service /etc/systemd/system/rc-local.serviceもし/etcに新規作成をした場合は、下記コマンドを実行して有効にしてください
systemctl enable rc-local.service※systemdは/etc下を実行するようです。でもrc-local.serviceは/libにあります。
なのでリンクを貼るか、作成するかということになります。rc-local.serviceへの追記内容
/bin/systemd/system/rc-local.service# SPDX-License-Identifier: LGPL-2.1+ # # This file is part of systemd. # # systemd is free software; you can redistribute it and/or modify it # under the terms of the GNU Lesser General Public License as published by # the Free Software Foundation; either version 2.1 of the License, or # (at your option) any later version. # This unit gets pulled automatically into multi-user.target by # systemd-rc-local-generator if /etc/rc.local is executable. [Unit] Description=/etc/rc.local Compatibility Documentation=man:systemd-rc-local-generator(8) ConditionFileIsExecutable=/etc/rc.local After=network.target [Service] Type=forking ExecStart=/etc/rc.local start TimeoutSec=0 RemainAfterExit=yes GuessMainPID=no [Install] WantedBy=multi-user.target Alias=rc-local.service参考
Documentation Ubuntu 18.04 rc.localsystemd設定
rc.localを使えない環境でマシン起動時にコマンドを実行する
ubuntu 18.04 で rc.local を使うおわりに
GUIが出るときはsessionに登録することがポイントでした。
また、crontabとrc.localでは実行権限が異なることもポイントです。
rc.localで作ったファイルには鍵マークがつきます。
色々なやり方がありますが、似たような状況で困っている方の参考になれば幸いです。