- 投稿日:2021-01-09T22:23:46+09:00
Wikipediaの記事をランダムに取得して1日1回ツイートするbotを作ってみた
ネット中心で生活していると、どうしても自分の興味があることに情報閲覧が偏ってしまって、興味のない事柄に触れる機会が減ってしまいます。なので、1日1回、強制的に知らない言葉を自分にインプットするためにWikipediaの記事をランダムに1件取得してツイートするTwitterのbotを作りました。
開発したTwitter bot
個人的には、朝一で脳みそのちょっとした刺激になることがあります。
環境
- AWS Lambda
- python3.7
ポイント
- Wikipediaの記事をランダムに1件取得するのに、MediaWiki APIを利用しました。
- 1日1回の起動は、AWS Lambdaの関数をAmazon CloudWatch Eventsのcron式で定期的に実行することで実現しました。(AWS Lambdaでの関数の作り方はたくさんの解説があるのでここでの説明は割愛します。)
- Twitterのbotを開発するためには、アカウント取得に加えてTwitter Appへの登録が必要です。(Twitter Appについてもたくさんの解説があるのでここでの説明は割愛します。)
Wikipediaの記事の取得について
Wikipediaの記事をランダムに1件取得するのに、MediaWiki APIを利用しました。
記事のタイトルを取得するだけでは味気ないので、最初にランダムに記事を1件取得し、その記事のID(pageid)を使って内容を取り出すということをしています。
TwitterのTweetは140文字以内という制限があるので、Tweetするメッセージは、
記事の内容(冒頭部分) + Wikipediaの記事へのリンク
という形式で140文字に収まるように作っています。「収まるようにする」あたりに少々工夫があるので、時間を作って改めて解説してみたいと思っています。wiki_random.pyimport json import sys import urllib.parse import urllib.request import os # Wikipedia API WIKI_URL = "https://ja.wikipedia.org/w/api.php?" # 記事を1件、ランダムに取得するクエリのパラメータを生成する def set_url_random(): params = { 'action': 'query', 'format': 'json', 'list': 'random', #ランダムに取得 'rnnamespace': 0, #標準名前空間を指定する 'rnlimit': 1 #結果数の上限を1にする(Default: 1) } return params # 指定された記事の内容を取得するクエリのパラメータを生成する def set_url_extract(pageid): params = { 'action': 'query', 'format': 'json', 'prop': 'extracts', #記事の文章を取得 'exsentences': 5, #5行分取り出す 'explaintext': '', 'pageids': pageid #記事のID } return params #ランダムな記事IDを取得 def get_random_wordid(): try: request_url = WIKI_URL + urllib.parse.urlencode(set_url_random()) html = urllib.request.urlopen(request_url) html_json = json.loads(html.read().decode('utf-8')) pageid = (html_json['query']['random'][0])['id'] except Exception as e: print ("get_random_word: Exception Error: ", e) sys.exit(1) return pageid #記事IDの内容を取得して、140文字以内のTweetの文章を作成 def get_word_content(pageid): request_url = WIKI_URL + urllib.parse.urlencode(set_url_extract(pageid)) html = urllib.request.urlopen(request_url) html_json = json.loads(html.read().decode('utf-8')) explaintext = html_json['query']['pages'][str(pageid)]['extract'] explaintext = explaintext.splitlines()[0] #改行が含まれる場合に最初の要素のみを取得 if len(explaintext) > 128: explaintext = explaintext[0:124] + "..." explaintext += "\nhttps://ja.wikipedia.org/?curid=" + str(pageid) #twitterはurlを11.5文字とカウントする仕様 return explaintext if __name__ == '__main__': pageid = get_random_wordid() extract = get_word_content(pageid) print(extract)Twitterでのツイートについて
twitterライブラリを使っています。
tweet.pyimport os from twitter import Twitter, OAuth #環境変数に設定したTwitter Appで取得したキー情報を取得 API_KEY = os.environ.get("TWITTER_API_KEY") API_SECRET_KEY = os.environ.get("TWITTER_API_SECRET_KEY") ACCESS_TOKEN = os.environ.get("TWITTER_ACCESS_TOKEN") ACCESS_TOKEN_SECRET = os.environ.get("TWITTER_ACCESS_TOKEN_SECRET") #TwitterのTweetを生成 def TweetMessage(msg): t = Twitter(auth = OAuth(ACCESS_TOKEN, ACCESS_TOKEN_SECRET, API_KEY, API_SECRET_KEY)) statusUpdate = t.statuses.update(status=msg)AWSのlambda_functionについて
一応、書いておきます。
lambda_function.pyimport wiki_random import tweet def lambda_handler(event, context): pageid = wiki_random.get_random_wordid() msg = wiki_random.get_word_content(pageid) tweet.TweetMessage(msg)実行結果がどのようになるかは、こちらを見てみてください。
AWS LambdaのLayerについて
requests、requests-oauthlib、twitterの3つのPythonのライブラリはAWS Lambdaに標準で組み込まれていないのでLayer機能を使って組み込みました。(Layer機能についてもたくさんの解説があるのでここでの説明は割愛します。)
- 投稿日:2021-01-09T21:00:07+09:00
戦略的設計を実現するためデータ駆動設計-ネットワーク設計-コマンドアンドコントロール設計の統合アプローチ
今回の記事では、以下の記事に記載されているInformation(情報)、Cyber(サイバー)、Synergy(相乗)アプローチに基づいた戦略的設計を実現するためのデータ駆動設計、ネットワーク設計、コマンドアンドコントロール設計の統合アプローチについて紹介したいと思います。
前回の記事:ICSアプローチに基づくドメイン駆動設計の戦略的設計
URL:https://qiita.com/aLtrh3IpQEnXKN7/items/64596260d786b22112db前回の記事のおさらい
ICSアプローチとは
ICSアプローチとはInformation(情報)、Cyber(サイバー)、Synergy(相乗)の3つの概念を統括したロシア式ドメイン駆動設計による戦略的設計です。
ICSアプローチでは以下の3つの機能に焦点を当てています。
・目標に基づくシステムの監視によるエラー検知
・検知したエラーの報告
・メディアへ情報を投射する反射環境の構築ICSアプローチの機能
・通信に使用する情報モデルの作成
・情報モデルを合成し、情報モデルを組み合わせた情報構造体モデルの作成
・情報構造体モデルのプロパティに設定された値の意味を解釈する解釈機能
・異なるコンテキスト間で通信を行うために接続先URL、ユーザー、パスワードを設定する通信先設定インターフェース機能
・SNS、動画サイトなどへイベント情報を投射するための通知機能分散システムに必要な情報保護
分散システムは情報化によって業務の縦割りを一つのシステムに統合します。
情報が人間の体内の血液のように循環することによって、全てのシステムが正常に稼働します。
そのため、分散システムにおいて情報の保護が最優先に置かれます。
情報の保護を優先するために以下のような設計手法に焦点になります。
・情報の暗号化通信
・情報の共通データ構造の設定
・設定されたデータの書式チェック
ICSアプローチではREST-API-暗号通信-メッセージ駆動が実現されます。データ駆動設計、ネットワーク設計、コマンドアンドコントロール設計の統合アプローチ
ICSアプローチを設計するにはデータ駆動設計、ネットワーク設計、コマンドアンドコントロール設計の3つの要素を統合する必要があります。
設計の順番として、データ駆動設計=>ネットワーク設計=>コマンドアンドコントロール設計の順番になります。データ駆動設計
ICSアプローチでは境界づけられたコンテキストを跨いでアプリ間の連携を行うため、全アプリのデータを格納する共通したフォーマットを設計する必要があります。
そのため、まず初めにデータ駆動設計を実施します。
データ駆動設計にはData-DrivenとData-Informedの2種類のアプローチが存在します。Data-Driven
Data-Drivenはデータの収集=>分析=>意識決定の順番で処理を実施するアプローチです。
Data-Drivenは収集したデータの内容に応じて意識決定を実施します。
そのため、訪問するユーザー数や店舗の売上など具体的な数値から意識決定を行う際に有効なアプローチです。Data-Informed
Data-Informedは課題設定=>分析=>仮説=>意識決定=>データの収集の順番で処理を実施するアプローチです。
Data-Informedは因果律に基づいて発生している事象の原因について仮説を立て、データ収集を実行します。
複雑な事象を取り扱う際に有効なアプローチです。ネットワーク設計
ネットワーク設計は以下の4つのレベルに分類することができます。
戦略レベル・・・データ駆動に基づく意識決定、戦略的目標の達成状況の確認、アプリ連結によるエラー状況の確認、政府が施行する法律の適応など
戦域レベル・・・スマートシティ戦略、スマートファクトリーなど
作戦レベル・・・フロントエンド + バックエンド
戦術レベル・・・認証システム、決済システム今回の記事では戦略レベルのネットワーク設計を実施します。
戦略レベルのネットワーク設計では境界づけられたコンテキストを跨いでアプリ間の連携を行うためIPアドレス、OSI参照モデル、ノード、エンドポイント、トポロジーの5つの要素を決定する必要があります。IPアドレス
IPアドレスはネットワーク内での位置座標を表します。
戦略レベルのネットワーク設計ではIPアドレスの数が膨大になるため、IPアドレス単位の管理は困難です。
そこで、network-context(ネットワークコンテキスト)と呼ばれる文脈単位でIPアドレスを管理する手法がおすすめです。OSI参照モデル
OSI参照モデルは1980年代に国際標準化機構(ISO)によって策定されたネットワーク設計モデルです。
以下の7層によって構成されています 。
Wikipediaから引用第7層 - アプリケーション層
具体的な通信サービス(例えばファイル・メールの転送、遠隔データベースアクセスなど)を提供。HTTPやFTP等の通信サービス。
第6層 - プレゼンテーション層
データの表現方法(例えばEBCDICコードのテキストファイルをASCIIコードのファイルへ変換する)。
第5層 - セッション層
通信プログラム間の通信の開始から終了までの手順(接続が途切れた場合、接続の回復を試みる)。
第4層 - トランスポート層
ネットワークの端から端までの通信管理(エラー訂正、再送制御等)。
第3層 - ネットワーク層
ネットワークにおける通信経路の選択(ルーティング)。データ中継。
第2層 - データリンク層
直接的(隣接的)に接続されている通信機器間の信号の受け渡し。
第1層 - 物理層
物理的な接続。コネクタのピンの数、コネクタ形状の規定等。銅線-光ファイバ間の電気信号の変換等。
ネットワーク設計では第1層 - 物理層~第4層 - トランスポート層までの範囲が対象となります。ノード
ノードとは、結び目・節・集合点・中心点といった意味で使用されるネットワークの結び目を指します。
ノードの機能はOSI参照モデルのレイヤーごとに異なります。
IPアドレスによる位置座標を設定後、OSI参照モデルのレイヤーを設定することで、ノードの機能を確定することができます。エンドポイント
エンドポイントとは情報が集約する場所、情報の最終地点を表します。
エンドポイントではアプリが稼働しており、エンドポイントを介して情報のフローが流れます。
ネットワーク設計ではICSアプローチに基づく中央管理システムとエンドポイントのIPアドレスを確定したうえで各ノードのIPアドレスを設定します。
「エンドツーエンドの原則」に基づきエラー検知など高度な処理はなるべくエンドポイントで行い、ネットワーク経路上のノードはなるべく単純な処理のみを行います。トポロジー
トポロジーとは、ノードの接続形態を指します。
トポロジーには以下のような種類が存在します。以下Wikipediから引用。
環形(リング型)・・・1つの区間の障害時には逆向きの接続で伝送できるネットワークもある。ただし、2箇所で断絶した場合、それ以上に通信が不可能になるため、ネットワーク・トポロジー単体の障害耐性は高くない。信号の伝送を1方向に限定し、多重化したネットワークもある。メッシュ形・・・それぞれのノードは1つ以上の他のノードとポイントツーポイントで接続している。そのため、ノードごとに通信のコストが異なる。
星型・車輪型(スター型)交換設備(ハブ)から放射状に接続されるトポロジー。バス形に比べ、ハブ接続されているそれぞれの線は独立しているため障害耐性が高いが、ハブが故障した場合、全ての通信が途絶するため、ネットワークの障害耐性はハブに依存する。
フルコネクト型・・・1つ1つのノードが全ての他のノードと接続しているトポロジー。1つのノードが故障しても他のノードとの通信には関係なく、自由に接続できるため、障害耐性はネットワーク中でもっとも高い。反面、設置にはコストがかかり、管理も煩雑になる。
バス型・・・CSMA/CD (Carrier Sence Multiple Access with Collision Detection) で用いられるトポロジーで、送信した信号が全ての端末で受信される。また信号の衝突による干渉が発生しないような工夫が必要になる。
木型(ツリー型)・・・ただ1つの根(ルートノード)から枝分かれする様に伸びていくトポロジー。USBのような、1対多通信が主になるネットワークで使われる
経路パス、負荷分散、冗長化などの設定を吟味したうえで最適なトポロジーを選択することが重要です。
コマンドアンドコントロール設計
コマンドアンドコントロール設計とは指揮統制センターより出力される指令と指令によって実施されるビジネスロジックの設計ことを指します。
ICSアプローチでは指揮統制センターより出力される指令はREST-API-暗号通信-メッセージ駆動で実現されます。コマンドアンドコントロールとは
指揮(Command)は、統制(Control)と合わせて指揮統制(Command and Control, C2)と呼ばれています。「指揮は芸術(art)であり、統制は科学(science)である」と言及されるとおり、指揮は手動の性格が強いのに対し、統制は自動の性格が強いものとなっています。
コマンドアンドコントロール規制(Command and control regulation)の文脈において「何が許可され、何が違法であるかを規定する法律による業界または活動の直接規制」と定義されており、指揮(Command)とは遵守しなければならない政府からの品質基準/目標の提示、統制(Control)の部分は、法律違反による制裁となっています。
上記2つのコマンドアンドコントロールの定義から以下の結論が導き出せます。
・指揮(Command)とは、データ収集=>分析=>仮説=>検証=>評価=>結論によって決定される組織全体の具体的目標を設定するための意識決定プロセス。
・統制(Control)とは、指揮(Command)によって決定された意識決定プロセスを組織全体へ施行するための具体的手法RESTとは
REST(Representational State Transfer)とは分散システムにおいて複数のソフトウェアを連携させるのに適した設計原則の一つです。
サービスのURIにHTTPメソッドでアクセスすることでデータの送受信を行います。
REST(Representational State Transfer)には以下の原則が存在します。以下Wikipediから引用。
・ステートレスなクライアント/サーバプロトコル
HTTPメッセージの一つ一つが、そのリクエスト(メッセージ)を理解するために必要な全ての情報を含む。そのため、クライアントもサーバも、メッセージ間におけるセッションの状態を記憶しておく必要がない。ただし実際には、多くのHTTPベースのアプリケーションはクッキーやその他の仕掛けを使ってセッションの状態を管理している(URLリライティングのような一部のセッション管理手法を使うシステムは、RESTfulではない)。・すべての情報(リソース)に適用できる「よく定義された操作」のセット
HTTP では操作(メソッド)の小さなセットが定義されている。最も重要なのは "GET"、"POST"、"PUT"、"DELETE" である。これらはデータ永続化に要求されるCRUDと比較されることがある。もっとも "POST" に関してはCRUDにはぴったり対応していない。・リソースを一意に識別する「汎用的な構文」
RESTfulなシステムでは、すべてのリソースはUniform Resource Identifier (URI) で表される一意的な(ユニークな)アドレスを持つ。・アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
RESTシステムでは、多くの場合、HTML文書またはXML文書を使う。こうした文書に情報およびその他のリソースへのリンクを含める。こうすることにより、あるRESTリソースから他のRESTリソースを参照したい場合は単にリンクを辿るだけでよい。レジストリなどの他の基盤的な機能を使う必要はない。REST(Representational State Transfer)を設計するには以下の要素を決定する必要があります。
・HTTPメソッド
HTTPメソッドは、クライアントが行いたい処理をサーバに伝えるという役割があります。
以下の8種類のメソッドが存在しています
GET・・・リソースの取得
POST・・・子リソースの作成、リソースへのデータ追加、その他処理
PUT・・・リソースの更新、リソースの作成
DELETE・・・リソースの削除
HEAD・・・リソースのヘッダ (メタデータの取得)
OPTIONS・・・リソースがサポートしているメソッドの取得
TRACE・・・プロキシ動作の確認
CONNECT・・・プロキシ動作のトンネル接続への変更・HTTPステータスコード
HTTPステータスコードは、HTTPにおいてWebサーバからのレスポンスの意味を表現する3桁の数字からなるコードです。
クライアントはサーバーへ送信したレスポンスの結果をHTTPステータスコードで確認します。
頭文字から以下の5つの種類に分類することができます。1xx Informational 情報・・・リクエストは受け取られ、処理は継続されます。
2xx Success 成功・・・リクエスト成功
3xx Redirection リダイレクション・・・リクエストを完了させるために、追加的な処理が必要。
4xx Client Error クライアントエラー・・・クライアントからのリクエストに誤りが発生
5xx Server Error サーバエラー・・・サーバがリクエストの処理に失敗。・RESTのリクエストの引数とレスポンスの戻り値について
RESTのリクエストの引数とレスポンスの戻り値にはデータ駆動設計で設計したデータフォーマットを使用します。
戻り値の結果は基本的にJSON形式で取得します。具体的なロジックの流れ
1.ICSアプローチに基づく指揮統制センターから実行される指揮(Command).によってメソッドが実行
2.REST(Representational State Transfer)のURIのリクエストにデータ駆動設計**で設計したデータフォーマットを使用しレスポンスを受け取る
3.レスポンスの結果を使用して以下のような処理を実行する。
<例>
・レスポンスの結果を画面に表示する。
・レスポンスの結果をテキストファイルにして保存し、結果を分析する。
・レスポンスの結果をSNS、動画サイトなどにアップするまとめ
データ駆動設計、ネットワーク設計、コマンドアンドコントロール設計を統合することで、ドメイン駆動設計の戦略的設計を実現するためのプロセスを策定することができました。
データ駆動設計、ネットワーク設計、コマンドアンドコントロール設計はドメイン駆動設計の戦略的設計において密接に関係しており、切り離して考えることはできません。
データ駆動設計、ネットワーク設計、コマンドアンドコントロール設計の統合アプローチはドメイン駆動設計の戦略的設計を実現する際の統合アプローチとして定着していくと思われます。
- 投稿日:2021-01-09T20:07:33+09:00
Rails AWS 本番環境でテータベースリセットしてseedデータ投入方法
Railsで本番環境でテータベースリセットしてseedデータ投入方法
[ec2-user@******* current]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop [ec2-user@******* current]$ bundle exec rails db:create RAILS_ENV=production [ec2-user@******* current]$ bundle exec rails db:migrate RAILS_ENV=production [ec2-user@******* current]$ bundle exec rails db:seed RAILS_ENV=production上から順番に実行で終わりです。
最後に
bundle execをつけないとエラーになりました。
- 投稿日:2021-01-09T19:30:18+09:00
AWS Cloud9における「Oops VFS connection does not exist」というエラーと解決策について
はじめに
Railsチュートリアル第4版の第1章の開発中に発生した「Oops VFS connection does not exist」というエラー発生状況とその解決策についてです。
開発環境
- MacOS Catalina 10.15.7
- Safari 13.1.3
- AWS Cloud9
- Rails 5.1.6
- ruby 2.6.3
エラー内容
Cloud9上にてRailsサーバを起動し、プレビューよりデフォルトページを
表示しようとしたところ、以下の画像が表示される。
エラーメッセージ:「Oops VFS connection does not exist」
原因
Could9IDE起動自体にはCookieは不要だが、アプリやファイルのプレビュー機能を利用するにはCookieを有効化する必要があるらしい。
(実は「Third-party cookies disabled」というエラーメッセージが一番最初にプレビュー実行した際に出ていた。エラーメッセージはよく見ないといけないですね。)[参考]
AWSユーザガイド アプリケーションプレビューまたはファイルプレビュー通知: 「サードパーティーの Cookie を無効にしました」
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/troubleshooting.html#troubleshooting-preview (2021年1月2日)解決策
Safariの[環境設定]>[プライバシー]タブにて「サイト越えトラッキングを防ぐ」のチェックをオフにする。デフォルトでは「オン(有効)」になっている。
ちなみに、Safariの「サイト越えトラッキングを防ぐ」のデフォルト設定はバージョン11.0から。
まとめ
「Oops VFS connection does not exist」というエラーメッセージから今回の原因にたどりつきにくかったと感じたので記事にしました。クラウドベースでの開発の際には、ブラウザ設定にも注意を払ってやる必要がありますね。


- 投稿日:2021-01-09T18:02:12+09:00
AWSからメールがauのezweb.ne.jpに送れない
現象
- AWSのCognitoを使って、ログインメールをau携帯のezweb.ne.jpあてに送信したところ、 いつまでたっても確認メールが来ないという事象が起きました。
- また、以前も、Billingの請求アラートや、SESでau携帯メールアドレスを指定しても届かない、受信できないということが発生していました。
原因
- auの迷惑メールフィルター トップのおススメ設定が、なりすまし規制 レベル「高」になっており、レベル「高」だと受信できないようです。

対策
- なりすまし規制は、レベル「低」にする。
以上
- 投稿日:2021-01-09T17:57:29+09:00
「AWS Well-Architected フレームワーク」の「レビュープロセス」資料がとても良かったので紹介したい
はじめに
仕事の品質を高める上で、知見のある方にレビューをしてもらうプロセスは欠かせません。
ただこのレビュー、やり方や意見の伝え方によっては、期待した効果が得られなかったり、ネガティブな効果を生み出しかねません。そうした結果、レビューという行為自体が開催されにくくなることは、チームにとって非常にマイナスです。
全員のレビューへの期待を整えておくために、レビューの心構えや望ましい運営方法などを、レビューに関わる全ての人が共通認識化しておくことは、非常に重要だと考えています。今回、このレビューを効果的に進めるポイントをまとめた、とても良い資料を見つけたのでご紹介します。
レビュープロセス - AWS Well-Architected フレームワーク
この資料をおすすめしたい方
エンジニアに限らず、仕事で他者の成果物をレビューをする人、および他者からレビューを受ける人(そう考えると、仕事をする人はすべて、なのかもしれません。)
「AWS Well-Architected フレームワーク」とは?
引用元:AWS Well-Architected フレームワーク - AWS Well-Architected フレームワークAWS のソリューションアーキテクトが、10 年以上に渡り、様々な業種業界、数多くのお客様のアーキテクチャ設計および検証をお手伝いしてきた経験から作成した“クラウド設計・運用のベストプラクティス集”です。(下記Youtube概要欄より抜粋)
「AWS Well-Architected フレームワーク」について詳しくは、こちらの動画またはスライド資料をご覧ください。
【AWS Black Belt Online Seminar】AWS Well-Architected Framework - YouTube
AWS Black Belt Online Seminar 2018 AWS Well-Architected FrameworkWell-Architectedフレームワーク自体は、言わずと知れた素晴らしいノウハウの塊なのですが、それ自体の説明は趣旨と異なるので、ここでは割愛します。
この中の一節に「レビュープロセス」という章があり、それが今回ご紹介したい内容なんです。実は上記の動画/資料の中でも紹介されております。
引用元:AWS Well-Architected フレームワーク - AWS Well-Architected フレームワークこのレビュープロセスの一節、私も拝見したところ、実はAWSのみならず他のあらゆるレビューに応用できる普遍的な内容でした。しかも重要なことが端的に言語化されていることに感動し、今回この紹介記事を書いた次第です。
「レビュープロセス」のエッセンス
コンテンツ自体は5分ぐらいで読めます。是非読んでみてください。
ところどころ翻訳がやさしくないかなと思われる箇所もあるので、気になる方は英語版をご覧頂けるとよいかと思います。ちなみに本文に出てくる「ワークロード」という言葉、AWSになじみの薄い方は少し違和感があるかもしれません。AWS文脈ではAWSのコンポーネントで作られたひとまとまりの「システム」というような意味で使われます。詳しくはこちらをご覧ください。本文の内容を、活用機会をより広げるために私の方で少し意訳しつつ、構造化してシンプルに整理してみました。
レビューに臨む基本スタンス
- 非難しない
- 深く掘り下げることを奨励する
- 監査ではなく話し合い
- 全体の整合性や品質に対して全員が責任を持つ(自分のところだけ良ければOKではない)
レビューの目的と成果
- 目的
- 対策を必要とする重大な問題の発見
- 改善できる領域の特定
- 成果
- 回答に別途調査が必要な質問のリスト
- 課題リスト(ビジネス文脈に応じて優先順位を設定する)
レビューの運営方法
- 一貫した方法で行う
- レビューに必要な人が全員含まれているかを確認する
- 共通のフレームワーク/ガイドライン/チェックリストを元にする
- 過去発生した問題の根本原因が含まれているもの
- 会議を進行するために次のアイテムを用意しておく
- ホワイトボードのある会議室 又はオンラインホワイドボードツール
- 構成図や設計ノート
- 他チームの人がレビューする場合は、その時初めて中身を理解することがほとんど
- 正式なレビュー会議よりも、継続的な話し合いが望ましい
レビューの開催タイミング
- 一度決めたら変更が難しかったり、後戻りが難しい場合は必ず着手前にレビューを設定する
- 後で変更できるものの場合はできるだけ軽量にする
- ローンチしたら終わりではなく、アーキテクチャが劣化しないように、変更が入る場合は継続的にレビューを行っていく
レビュープロセスの改善
- プロダクトに重要な問題が発生した場合は、都度レビュープロセスを見直す
レビューの組織的価値
- 同一組織内の複数チームで継続的にレビューを行い、その結果を分析することで、組織共通の課題が発見でき可能性がある
- 発見した共通課題は、仕組み改善やトレーニングなどで適切に対策する
レビューへの反発対策
- 「忙しい!」
- 忙しい時こそミスが許されない。見過ごしている問題を発見できるかもしれない
- 「指摘を受けても対策をする時間も余裕もない!」
- 指摘事項全てに対策しなくてもよい。リスクがわかれば、問題が起こった時の対策を事前に備えておくこともできる
- 「秘匿事項があるからできない!」
- 秘匿事項をオープンにしなくても、質問への回答はできる
最後に
こうしたチームで仕事をするためのベースとなる考え方は、自分一人だけ理解していても効果は限定的です。是非一緒に働く仲間の皆さんに共有し、これをたたき台に、自分達のチームのレビューの在り方を是非会話してみて頂けるとよいかと思います。
ストレスなく、効果的なレビューを日々運営できるチームが増えると最高です。あわせて読みたい
レビュープロセスと同様に、エンジニアの汎用的なスキル向上をテーマに何本か記事を書いています。よろしければあわせてご覧ください。
ドキュメント作成スキル向上を目指す人向けおすすめ記事まとめ - Qiita
Google社のテクニカルライティングの基礎教育資料がとても良かったので紹介したい - Qiita
政府CIOの「デジタル・ガバメント推進標準ガイドライン実践ガイドブック」が とても良かったので紹介したい - Qiita


- 投稿日:2021-01-09T17:47:22+09:00
【AWS】EBS
EBS-backedインスタンスに障害が発生した場合
→EBSbackedインスタンスを停止して再起動関連する全てのボリュームのスナップショットを自動的に作成し、新しいAMIを作成
以下の手順に従って、ボリュームを新しいインスタンスにアタッチする
1)ルートボリュームのスナップショットを作成
2)作成したスナップショットを使用して新しいAMIを登録
3)新しいAMIから新しいインスタンスを起動
4)残りのAmazon EBSボリュームを古いインスタンスからデタッチ
5)Amazon EBSボリュームを新しいインスタンスに再アップ
- 投稿日:2021-01-09T17:15:18+09:00
Amazon CloudFront ディストリビューション作成方法メモ
- AWS CLIを用いたAmazon CloudFront ディストリビューション作成方法をメモする。
概念・用語
ディストリビューション
- ドメインごとのCloudFront設定。
オリジンアクセスアイデンティティ(Origin Access Identity,OAI)
- オリジンへのアクセス制限に利用する特別なCloudFrontユーザー。
- オリジンコンテンツにCloudFront以外からアクセスさせたくない場合に利用する。
- ディストリビューションに関連付ける。
- S3のバケットポリシーとして設定を加える。
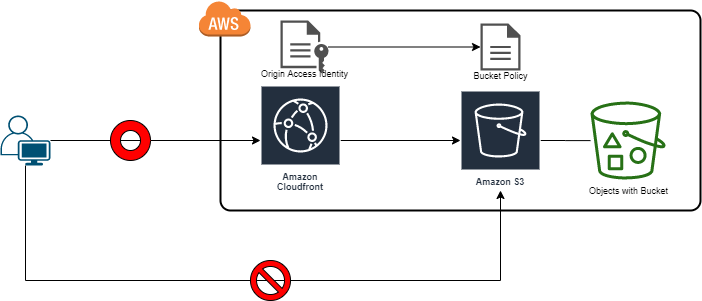
ディストリビューション作成方法
- シェルスクリプトからAWS CLIを実行して作成する。
- 以下のようなケースのCloudFrontディストリビューションを作成する。
- Amazon S3をオリジンサーバー(静的コンテンツ配置)とする。
- バケット:
testbucket(作成済みとする)- 配信元としてCloudFrontを利用する。
- ディストリビューションに対してOAIを作成し、S3バケットポリシーとしてそのOAIからのリクエストのみを受け付けるよう設定する。
1. OAI 作成
- OAI
CF_OAIを作成する。※jq使用RESPONSE=$(aws cloudfront create-cloudfront-origin-access-identity --cloudfront-origin-access-identity-config CallerReference=2020010801,Comment=test-oai) export CF_OAI=$(echo ${RESPONSE} | jq -r ".CloudFrontOriginAccessIdentity.Id")2. バケットへのバケットポリシー設定
- OAI
CF_OAIからバケットtestbucketへのアクセス権を設定する。tempfile=$(mktemp) cat ${tempfile} << EOS { "Version": "2012-10-17", "Id": "PolicyForCFPrivateContent", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${CF_OAI}" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::testbucket/*" } ] } EOS aws s3api put-bucket-policy --bucket testbucket --policy file://${tempfile} rm -f ${tempfile}3. OAIを設定したディストリビューションを作成
- 1で作成したOAIを設定してCloudFrontディストリビューションを作成する。
distibution_json_path=$(dirname $0)/json/TestDistribution.json distibution_json=$(cat ${distibution_json_path}) tempfile=$(mktemp) echo ${distibution_json} | envsubst > ${tempfile} aws cloudfront create-distribution --cli-input-json file://${tempfile} rm -f ${tempfile}
ディストリビューション用JSON
TestDistribution.json
- OAIを設定する箇所だけ抽出。その他は要件に応じて設定。
{ // ... "Origins": { "Quantity": 1, "Items": [ { "Id": "testbucket.s3.amazonaws.com", "DomainName": "testbucket.s3.amazonaws.com", "OriginPath": "", "CustomHeaders": { "Quantity": 0 }, "S3OriginConfig": { "OriginAccessIdentity": "${CF_OAI}" } } ] } // ... }参考情報
- 投稿日:2021-01-09T15:45:04+09:00
【AWS】Route53
Route53とは
・権威DNSサービス
– AWSの提供する権威DNSサービス
– DNSはドメイン名をIPアドレスに変換するインターネット上の「電話帳」
・AWS上で高可用性、低レイテンシなアーキテクチャを実現するツール
– ポリシーベースの柔軟なトラフィックルーティング、フェイルオーバー、
トラフィックフローなどの機能により、様々な条件に基づくルーティングが可能
・高い可用性を提供
– DNSはインターネットの根幹のサービス
– Route 53 は 100%のAvailabilityのSLAを提供
・マネージドサービスとして提供
– DNSサーバーの設計・構築・維持管理が不要
– 冗長性・性能・セキュリティ等は全てAWSにて管理されるホストゾーン
・ホストゾーンとは
– ドメイン、サブドメイン内のDNSリソースレコードを管理するコンテナ
• ホストゾーンの中に、DNSリソースレコードを登録
– ホストゾーンには、ゾーンを管理する複数のDNSサーバーが割り当てられる (Delegation Set)
• 1つのホストゾーンに対して、4台のDNSサーバーが割り当て
• DNSサーバーは、全て異なるエッジロケーションに配置されている
• 4つのトップレベルドメイン (*.com, *.org, *.net, *.co.uk) にまたがる
– パブリックホストゾーン、プライベートホストゾーンを作成可能
・ホストゾーンの制限
– AWSアカウント毎に500ゾーンまで (上限緩和可能)
– レコードはホストゾーンあたり10,000個まで (上限緩和可能)ALIASレコード
・ALIASレコードとは
– Route 53固有の仮想リソースレコード
– DNSクエリに対して、以下のAWSサービスのエンドポイントのIPアドレス
を直接返す(通常はCNAMEを利用)
• 静的ウェブサイトとして設定されたS3バケット
• CloudFront ディストリビューション
• ELB
• ホストゾーン内のリソースレコードセット (複雑なポリシーの作成で使用)
・ALIASレコードを使うメリット
– DNSクエリに対するレスポンスが高速
– Zone Apexが利用可能
– ALIASレコードに対するクエリが無料(S3, CloudFront, ELB)ALIASレコードによるDNS名前解決の高速化
・Route 53と連携したDNS Lookupの高速化
• CloudFrontのAlternative Domain NameをRoute53を利用して名前解決する際は、
レコードセットTypeをCNAMEではなくAレコードのAlias設定することでクエリの回数が削減トラフィックルーティング
・トラフィックルーティングとは
– クライアントからのトラフィックを、要件に応じて適切な宛先へ転送すること
– ここでは、DNS名前解決によるトラフィックの転送を対象とする
– DNSクエリに対して適切な転送先を応答するために、ルーティングポリシーを活用する
– トラフィックルーティングを適切に設計することにより、
可用性が高くレイテンシの少ないアーキテクチャを構築することができる
・従来のDNSでのルーティング
– DNSで事前に定義された、静的なリソースレコードにのみに基づいてDNSクエリに応答
(例)
• www.example.com へのリクエストは IPアドレス 1.1.1.1 に転送
• ポリシーベースのルーティング
– DNSクエリに対して、ポリシーで定義されたルールに基づいて、
動的に状況に応じた転送先を応答
(例)
• www.example.com へは、送信元が日本の場合、東京リージョンへ転送
• 送信元が日本以外の場合、送信元からのレイテンシーが最も小さいリージョンへ転送ルーティングポリシー
Route 53では、複数のルーティングポリシーにより柔軟なルールを作成可能
• シンプルルーティング (Simple)
– レコードセットで事前に設定された値のみに基づいてDNSクエリに応答する
– 従来のDNSと同様に、静的なマッピングによりルーティングが決定される
• 加重ルーティング (Weighted)
– 複数エンドポイント毎に設定された重みづけに基づいて、DNSクエリに応答する
– より重み付けの高いエンドポイントのリソースに、より多くルーティングされる
– A/Bテスト、段階的な移行、サーバー毎に性能に偏りがある場合
• レイテンシールーティング (Latency)
– AWSリージョンとの遅延によって、DNSクエリに応答する
– リージョン間の遅延が少ない方のリソースへルーティングされる
– エンドユーザーのレイテンシーを低減したい
動的なサイトでレスポンスを早くしたい
(静的:CloudFrontでキャッシュを活用、動的:キャッシュの制約がある)
• フェイルオーバールーティング (Failover)
– ヘルスチェックの結果に基づいて、利用可能なリソースをDNSクエリに応答する
– 利用可能なリソースにのみルーティングされる
– 複数のリージョンにまたがるシステムで冗長化構成、
災害発生時にリージョン間でフェイルオーバー、
サイト障害時にS3静的WebサイトホスティングのSorryPageを表示
• 位置情報ルーティング (Geolocation)
– クライアントの位置情報に基づいて、DNSクエリに応答する
– 特定の地域・国からのDNSクエリに対して、特定のアドレスを応答する
– ローカライズ:クライアントの地域により適切な言語でコンテンツを提供
コンプライアンス:コンテンツディストリビューションを
ライセンス許可した市場のみに制限
パフォーマンス:特定の地域からエンドエンドポイント間の
安定したルーティングを必要とするケースDNSフェイルオーバとは
ヘルスチェックによりエンドポイントのリソースの正常性をチェックし、正常な場合のみルーティングされるようにDNSクエリに応答
ヘルスチェック
異常と判断した対象のIPアドレスをクエリ結果として返さない。全て以上の場合はIPアドレスを返す仕様
- 投稿日:2021-01-09T14:37:18+09:00
【AWS】ロードバランサー
複数AZに分散
・二段階での負荷分散
1)DNSラウンドロビンで各AZ内のELBに振り分け
2)負荷が均等になるようにバックエンドのEC2にそれぞれのルーティングアルゴリズムで振り分け
ALB:ラウンドロビンルーティング
NLB:フローハッシュアルゴリズムルーティング・クロスゾーン負荷分散
ALB:デフォルトで有効
NLB:デフォルトで無効
CLB:デフォルトで有効・同一のインスタンスで複数ポートに負荷分散可能
異なるポートに対して負荷分散・IPアドレスをターゲットに設定
ALB \NLB・ELB自体のスケーリング
ALB,CLBにおいては接続が習慣的に急増した場合、HTTP503を返す
→Pre-Warming(暖機運転)の申請をサポートケースにて行う
→自前で付加を段階的にかけてスケーリングさせておく
・NLBは暖機不要で突発的な数百万リクエスト1/秒のトラフィックも捌けるモニタリング
・ヘルスチェック
1)HTTP及びHTTPSリスナーを使用する場合には、EC2インスタンスでキーアライブのオプションを有効化することでロードバランサーがバックエンドインスタンスへの接続を再利用できるようになり、CPU使用率が削減される
2)異常と判断したインスタンスにはトラフィックは流さない
・アクセスログ
ELBのアクセスログを取得可能
S3バケットに簡単にログを自動保管スティッキーセッション
・一時ファイルなどをEC2インスタンスが保持するな場合に必要
・デフォルトで無効
・HTTP/HTTPのみ利用可能SL/TLS Termination
・ELB側でSSL/TLS認証ができる
1)ELBでSSLTerminationし、バックエンドとはSSLなし ←通常これが多い
2)ELBでSSLTerminationし、バックエンドとは別途SSL
3)SSLをバイパスしてバックエンドにTCPで送信ACMを利用すれば証明書を利用可能
ALB
・L7ロードバランサー
・HPPP \HTTPSのみ対応
・コンテンツベースのルーティング(高度なリクエストルーティング)
・ユーザー認証機能
Cognitoによる認証
OIDC IdPによる認証(Google、Amazonなど)
・暖機申請は必要
・その他
・ネイティブHTTP/2対応
・ターゲットとしてのLambda関数
・クライアントのIPアドレス取得について(ALB \NLBの違い)
・AWS WAFとに連携について
ALBのみ可能
・Websocketに対応NLB
・TCP(L4)のバランサとして機能
・固定IPアドレス:AZごとに1つ、既に持っているEIPも利用可能
・送信元にIPアドレスの保持:X−Forwarded−ForやProxy Protocolが不要
・暖機なしに急激なスパイクにも対応
・Vpcエンドポイントサービス(AWS PrivateLink)のサポート
・NLBnihaセキュリティグループの設定がない→以下、特に重要
1)高可用性、高スループット、低レイテンシー
2)Source IP/Portがターゲットまで保持される
3)固定IPGlocal Acceleratorとの連携
ALBとNLBを指定できる
ユーザは近いエッジjロケーションからGlobal Networkを経由して最も近いリージョンにアクセス可能
- 投稿日:2021-01-09T01:29:43+09:00
IPSec VPN(ネイティブサービスのみ) で Oracle Cloud と AWS つないじゃった
はじめに
この記事は「Oracle Cloud Infrastructure(その2) Advent Calendar 2020」の12月25日の記事の追加情報としての投稿になります。
あけましておめでとうございます!
今年もよろしくお願いいたします。年も明けたので、昨年の Advent Calendar で「静的ルーティングならできたよ
」という話で締めてしまいましたけど、実のところ、どちらでも構築できました
新しい気持ちで取り組んだら構築できる。これぞ 謹賀新年パワー!です。
と、冗談はこの辺にしておいて、なぜできなかったのか。という点は最後の方に記載しますけど、ここでは実際どうやって設定したらいいの?というのを、改めて、まとめておきます。
こちらで Qiita 始めにします※使っている画像や内容は一部、過去の記事(オレのブログを安く運用したい。(aws から Oracle Cloud へ移行(最終回))※IPSec VPN で AWS と OCI をつないでマルチクラウド化しようよ)から引っ張ってきてたりします。そのため、一部IDとかは異なったりしますが構築方法には問題ないので、記事作成簡潔化を優先してしまいました
その点を理解して、参考にしてください
用意するもの(2021/1/8現在)
- OCI(Oracle Cloud)
- ネットワーキング
- 動的ルーティング・ゲートウェイ
- 顧客構内機器
- VPN接続
- AWS(Amazon Web Service)
- 仮想プライベートネットワーク (VPN)
- カスタマーゲートウェイ
- 仮想プライベートゲートウェイ
- サイト間のVPN接続
そのほかにも、VPNで接続する先のネットワーク(VPC(AWS)、VCN(OCI))が必要になりますが、こちらは割愛します。「なんぞや!VPC、VCN」という方は、別途、AWSとOCIのネットワークについて調べてください
構築手順
所要時間 30分
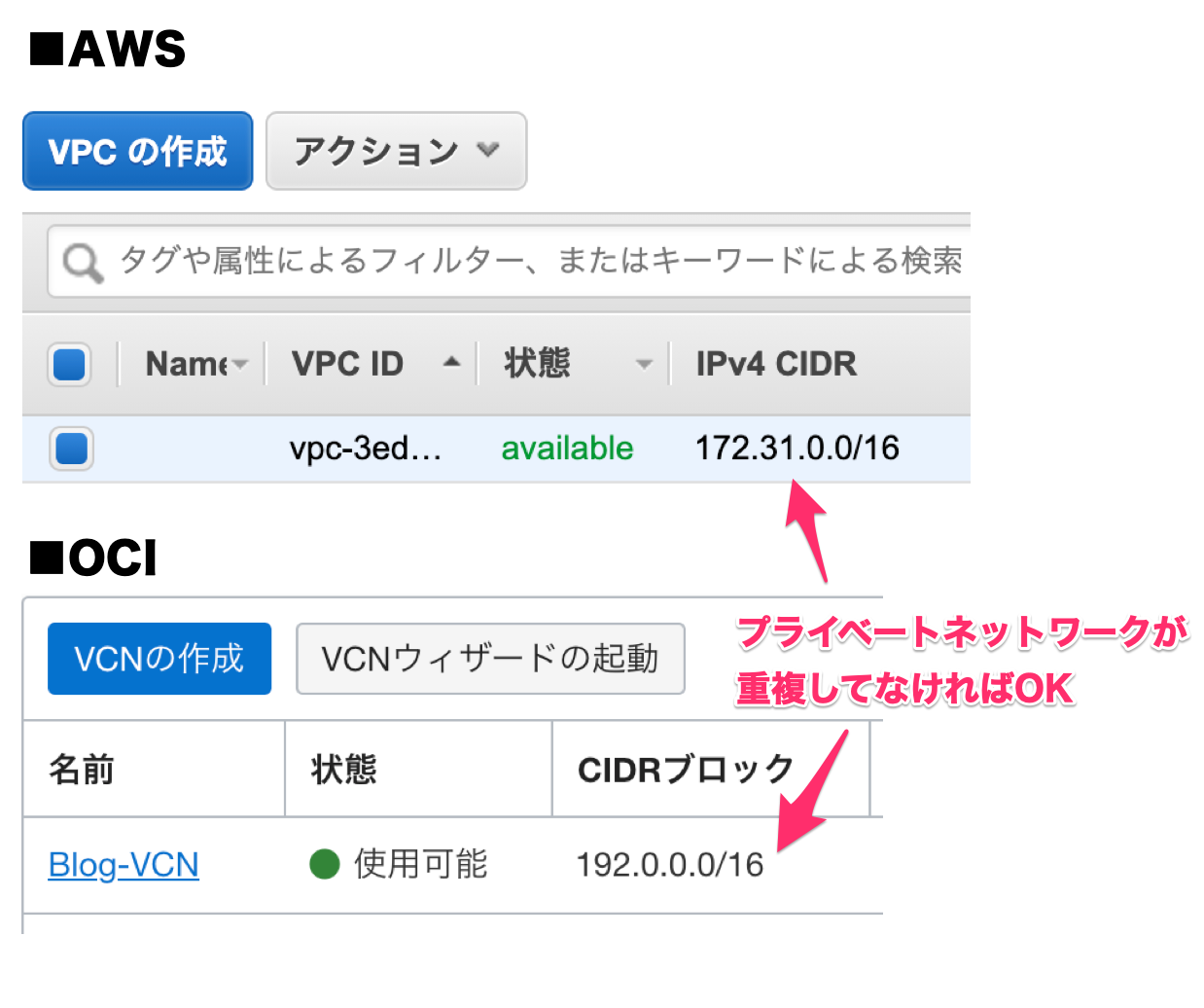
※IPSec VPNで接続する先のVPC(AWS)、VCN(OCI)は用意されている前提になります。1.ネットワーク条件の確認
VPCとVCNのネットワークセグメントは異なる範囲を指定しておくこと。
重複していなければOK。2.AWS側にIPSecトンネルを作成する
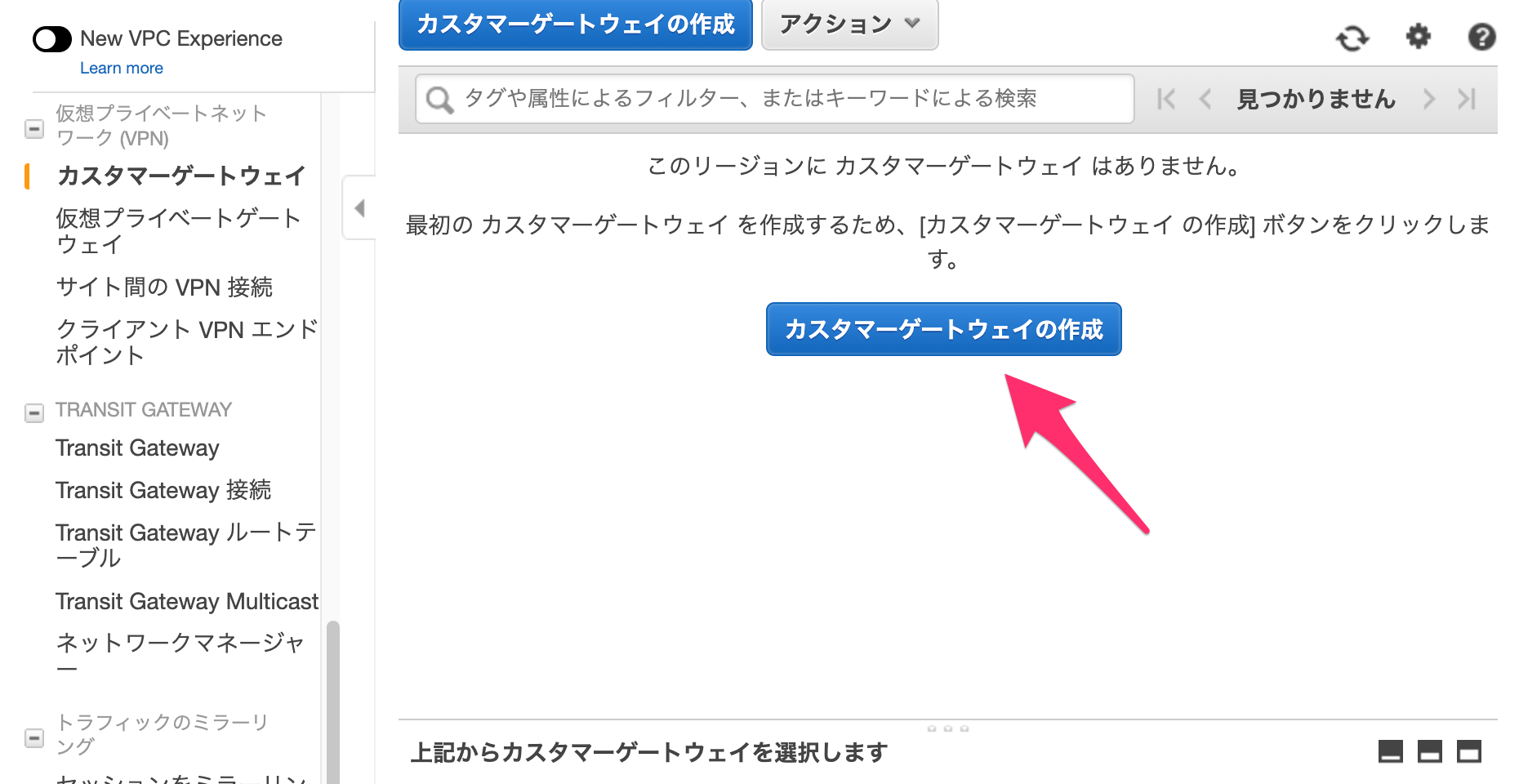
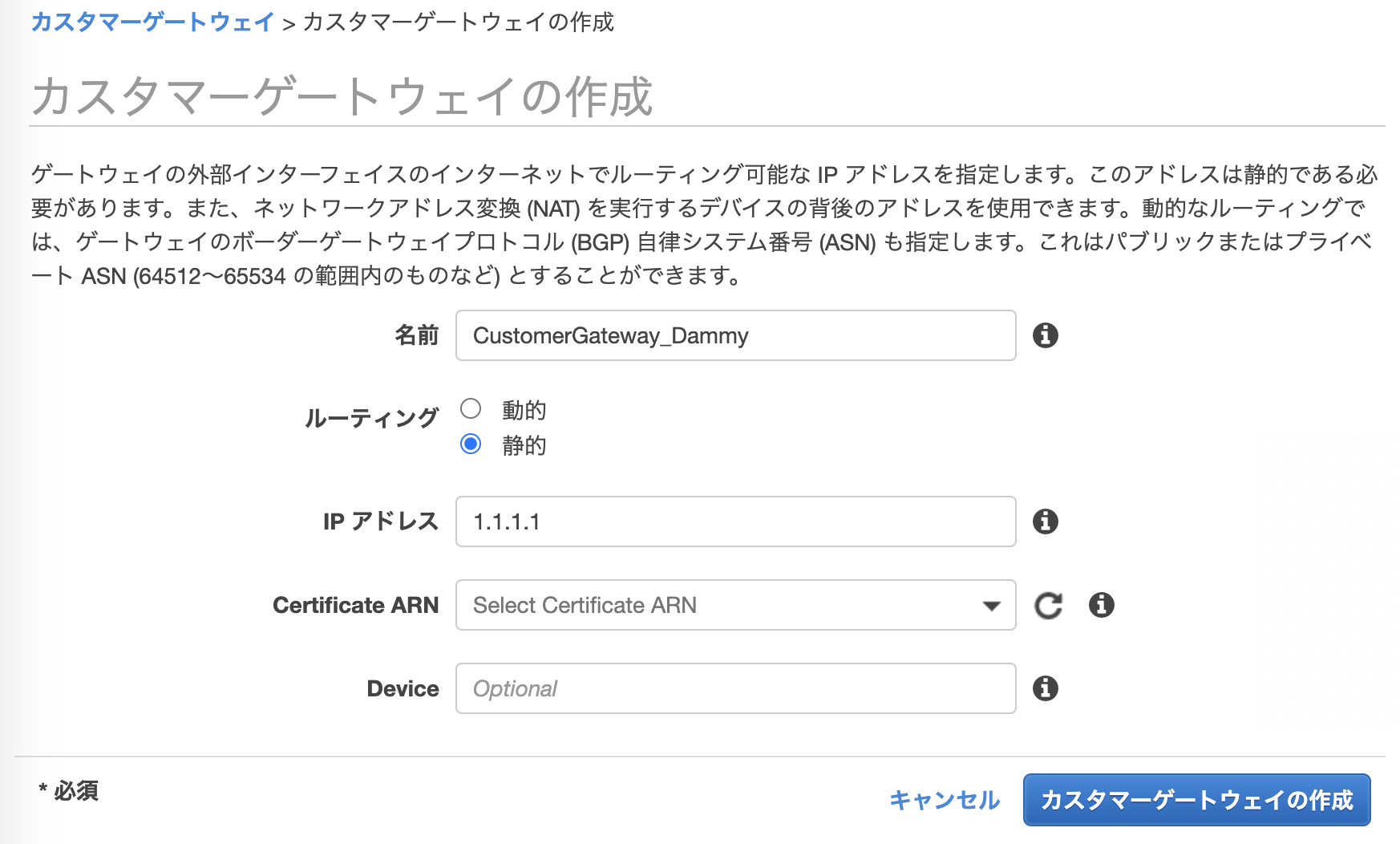
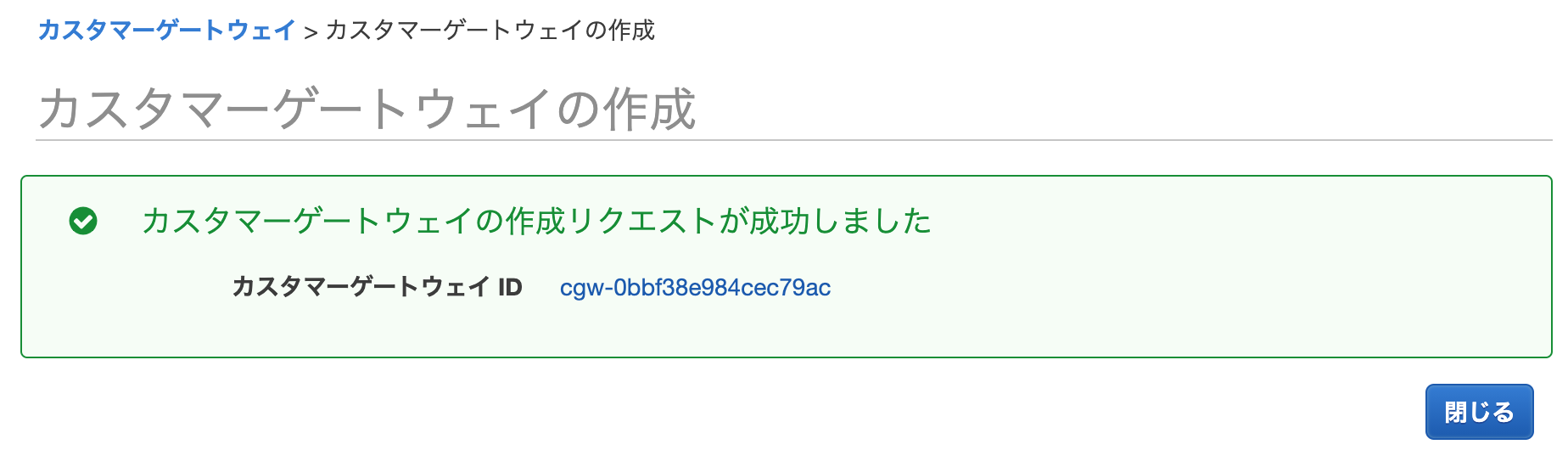
2-1.カスタマーゲートウェイの用意(AWS)
AWS側にVPN接続設定を用意するため、カスタマーゲートウェイ(仮)を用意します。
※仮であるのは、OCI側の設定値が分からないので仮に作成します。この情報がないとAWS側で作るサービスが用意できないため。
設定する情報としては、「名前とルーティング」設定ぐらい。あとは、デフォルトで良いです。IPアドレスは適当なもの(1.1.1.1とか)を入れて[カスタマーゲートウェイの作成]をポチッとする。
※こちらは「静的ルーティング」例になります。動的ルーティングは、2020年のAdvent Calendar記事をみてください
問題なく作成できれば、こんな画面が表示されます。
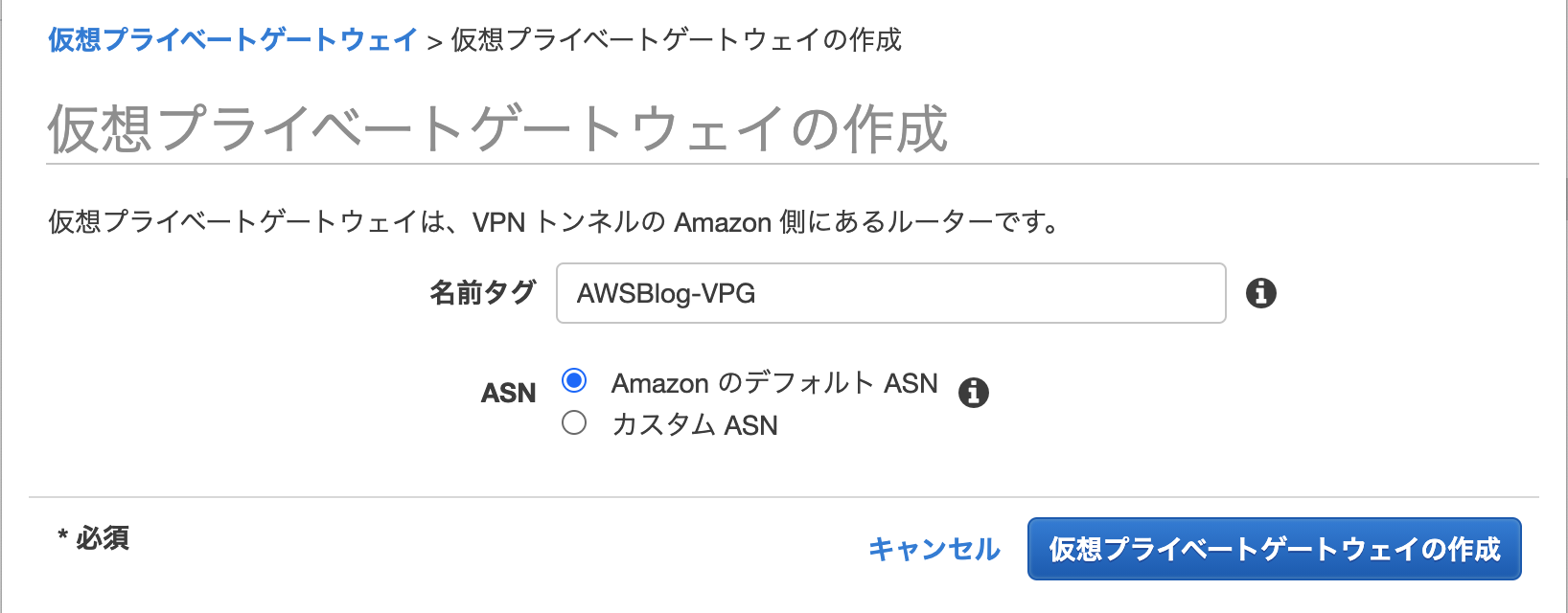
2-2.仮想プライベート・ゲートウェイ(VPG)の用意(AWS)
AWS側のルーティングサービス。OCIでいうDRGにあたるものの準備になります。
[仮想プライベートネットワーク(VPN)]-[仮想プライベートゲートウェイ]をポチッとする。
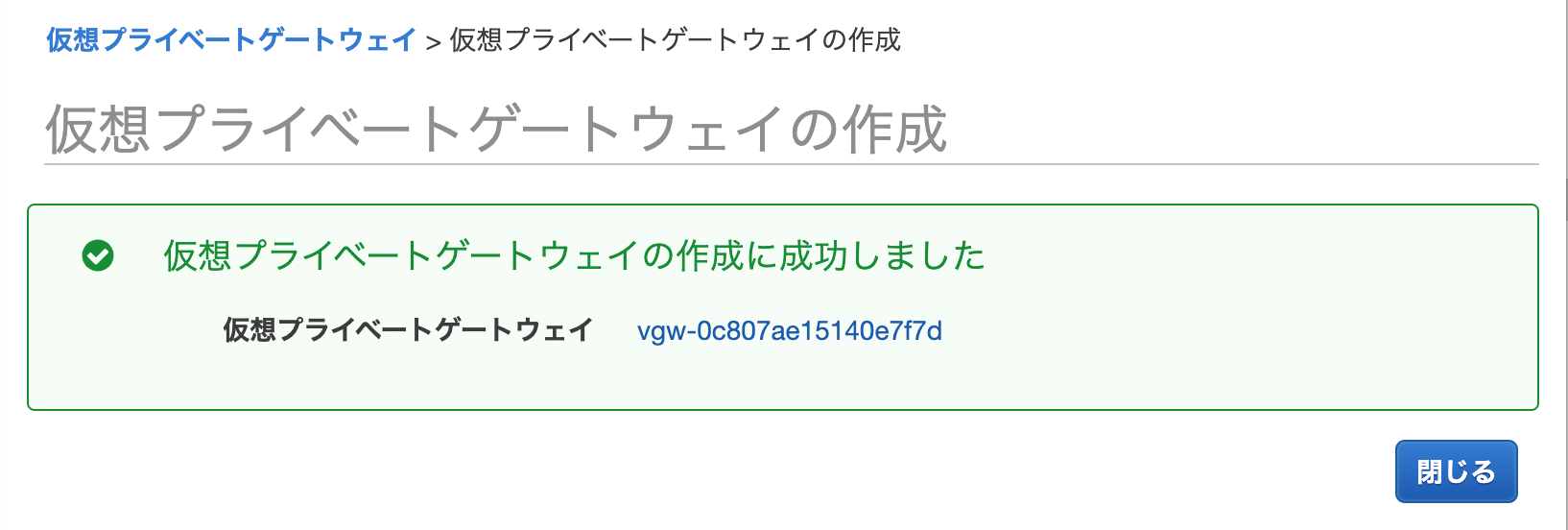
最初のVPG作成に必要な情報は、名前ぐらいです。
サクッと作成できます。
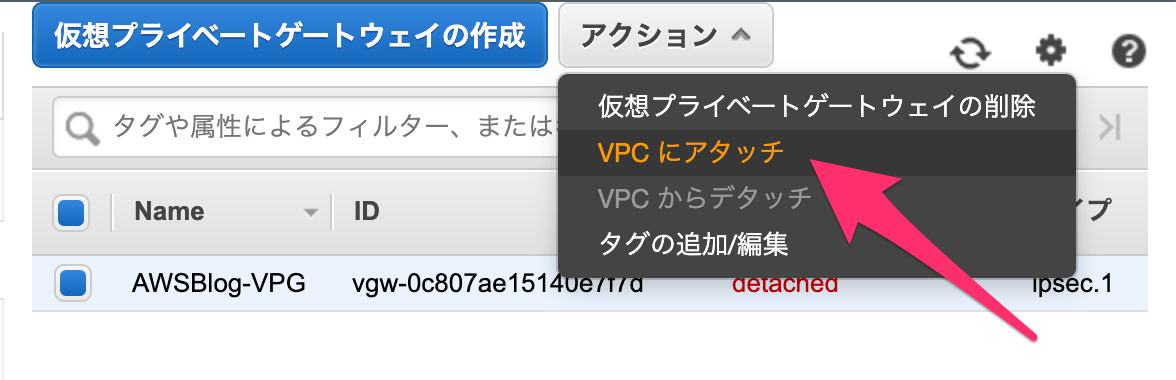
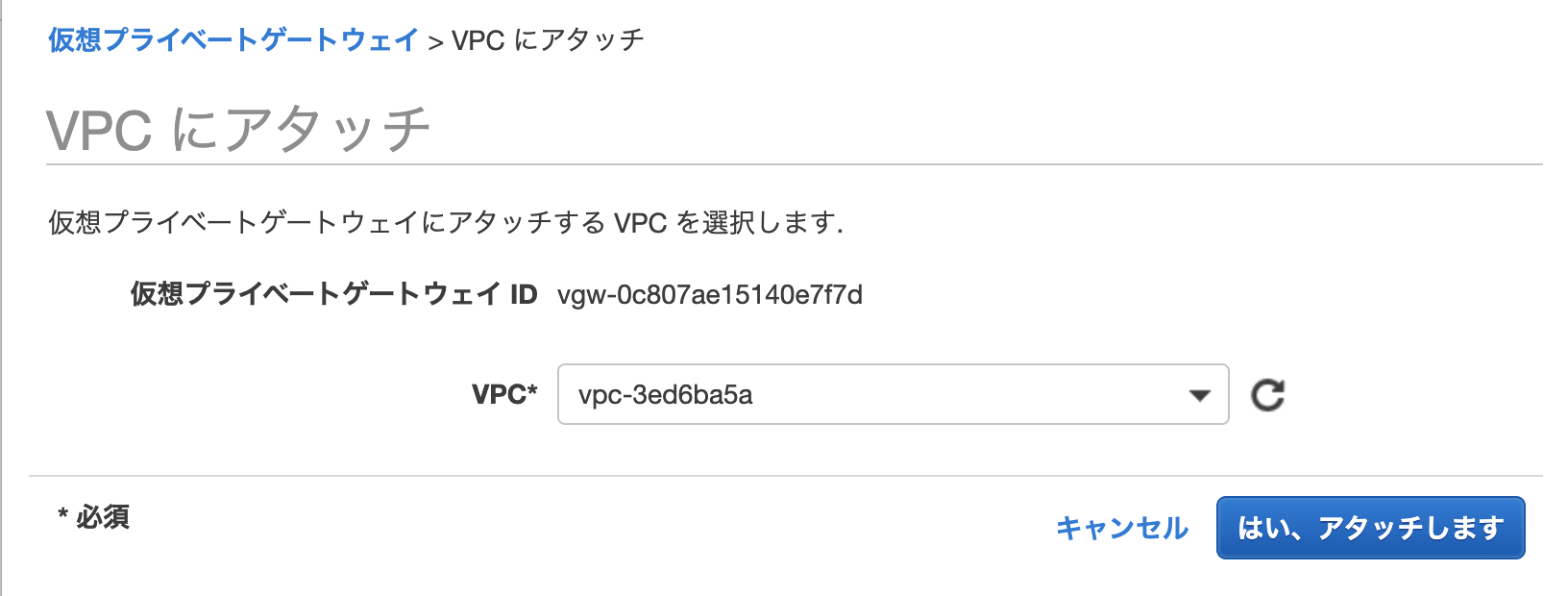
あとは、この VPG を VPC にアタッチします。[アクション]-[VPCにアタッチ]をポチッとします。
現在用意してあるVPCを選択できるので、該当するVPCを選択します。(今回はAWS上で稼働しているブログのVPCを選択しています。)
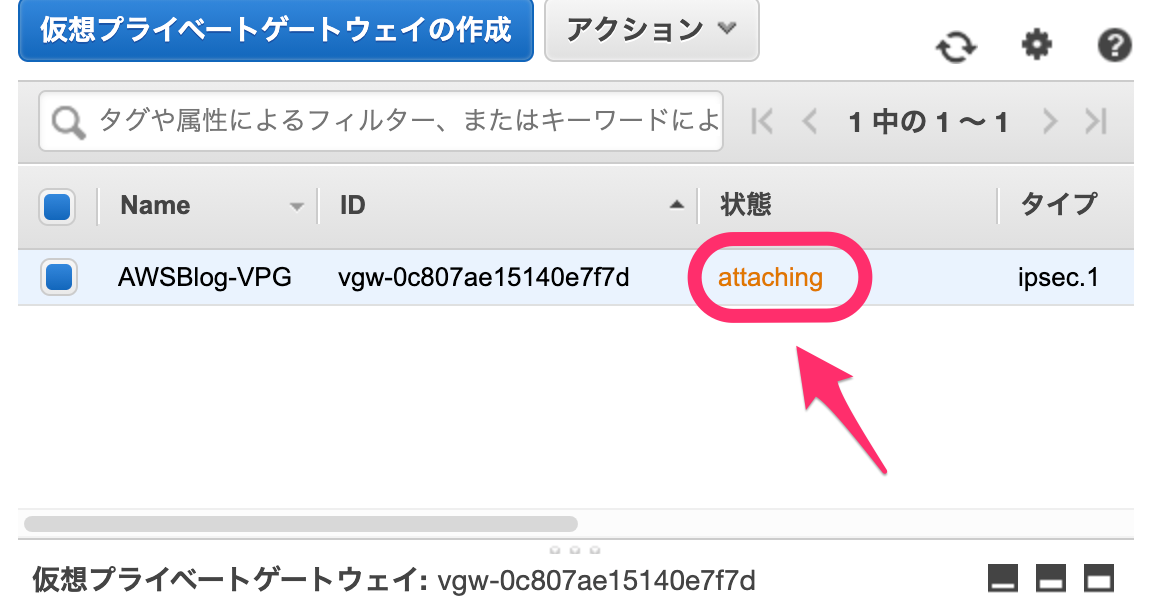
特に問題なければ、「状態」が attaching になります。
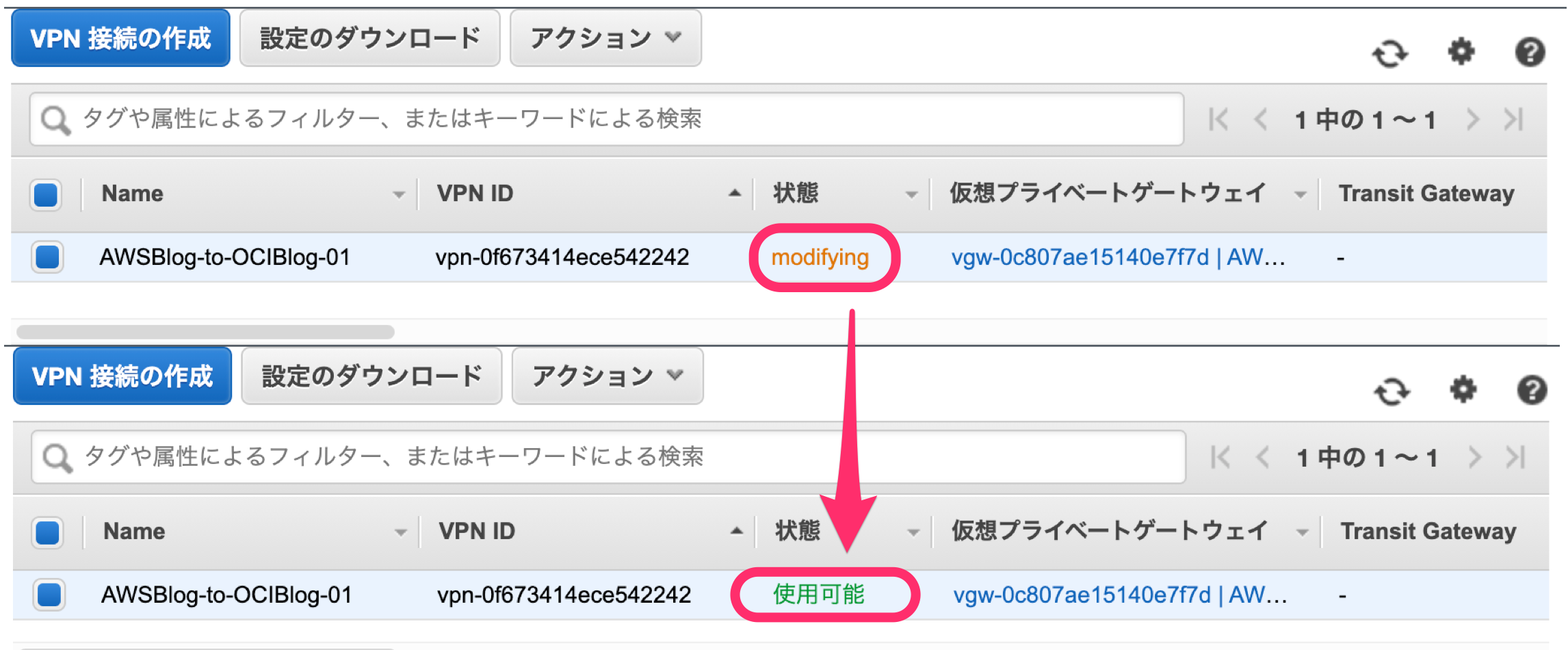
2-3.VPN接続の作成(トンネルの作成)(AWS)
AWS 側に IPSec トンネルを作成します。
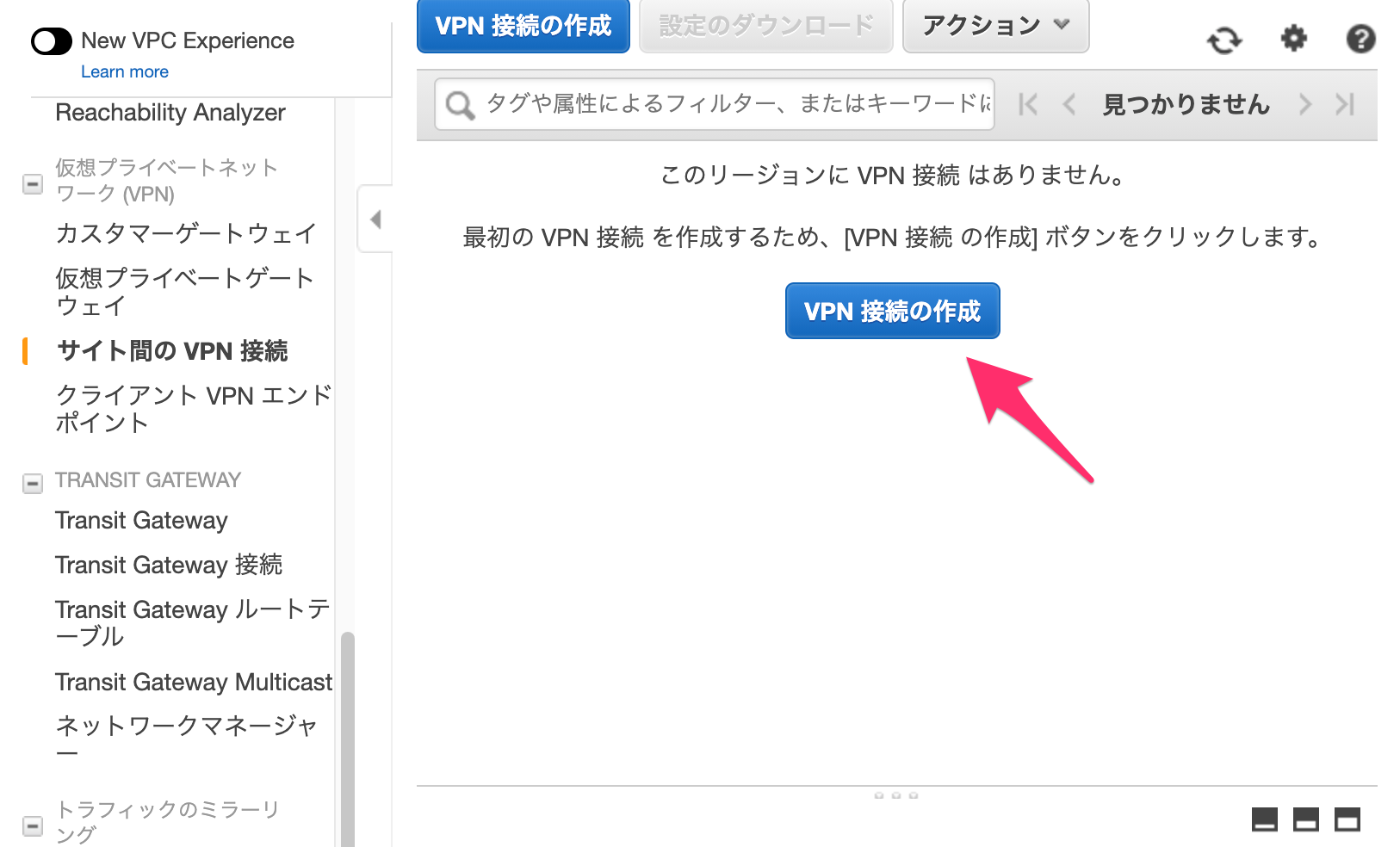
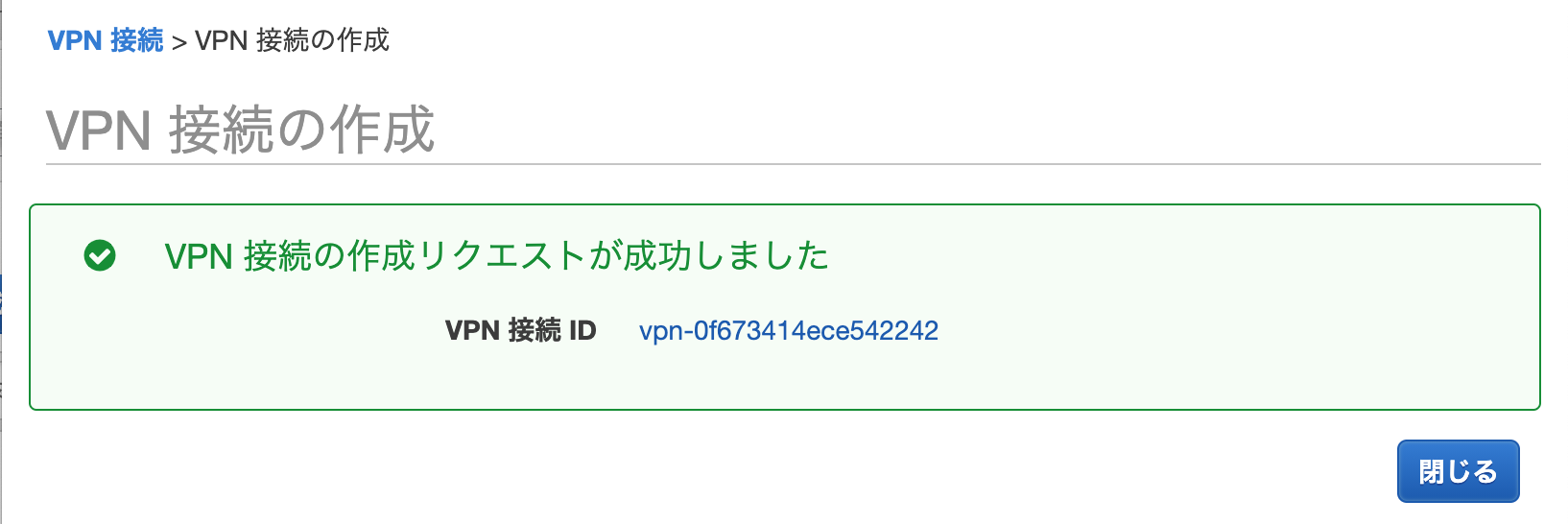
[仮想プライベートネットワーク(VPN)]-[サイト間のVPN接続]から[VPN接続の作成]をポチッとする。
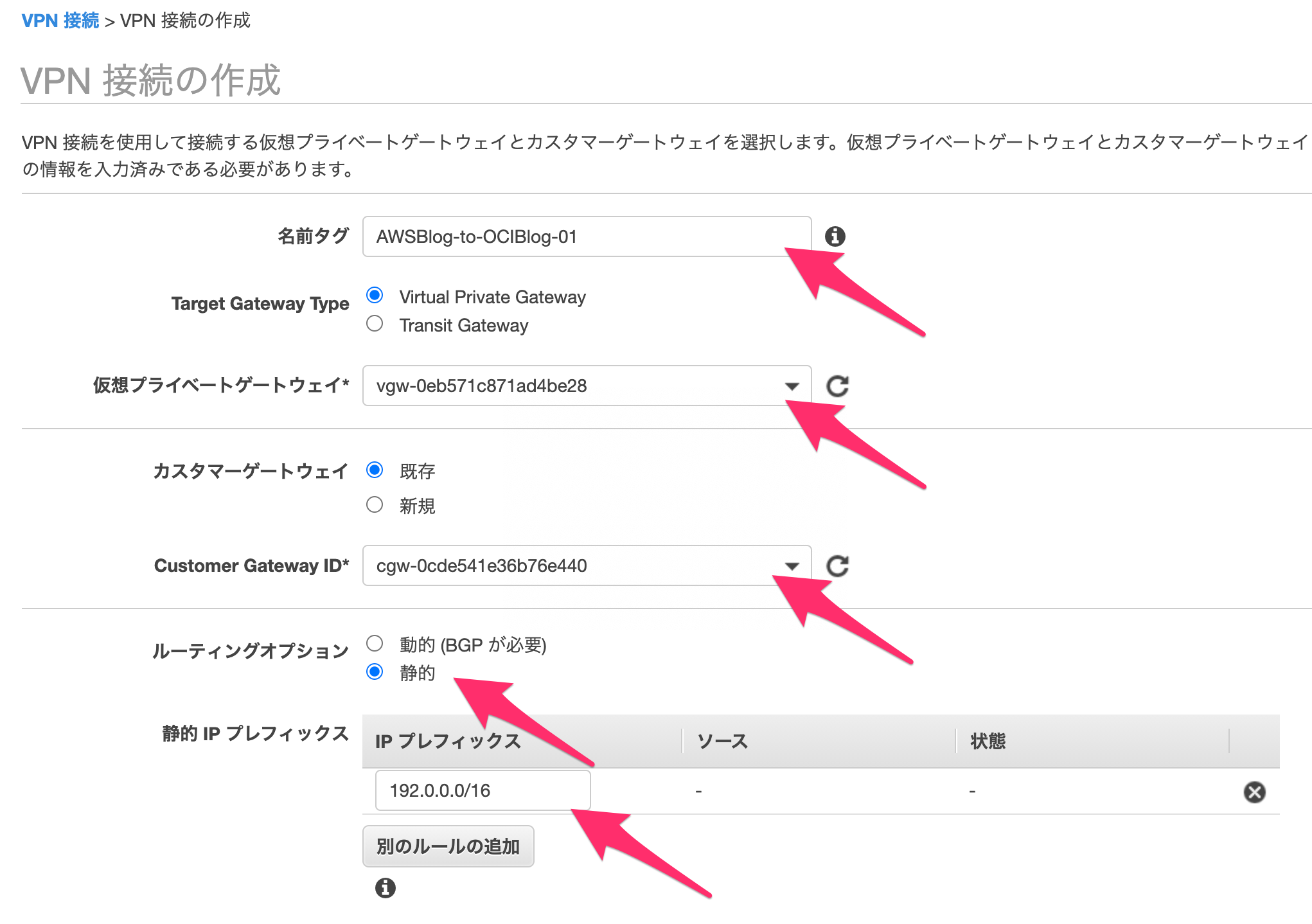
設定する項目は、矢印で示したところです。コンボボックスから選択できるものは、事前に用意した仮想プライベートゲートウェイ(VPG)とカスタマーゲートウェイを設定します。なお、こちらのIPSecトンネルは複数構築(冗長構成)することもできます。今回は1本だけ用意します。
※しつこいですけど、こちらは「静的ルーティング」例になります。動的ルーティングは、2020年のAdvent Calendar記事をみてください
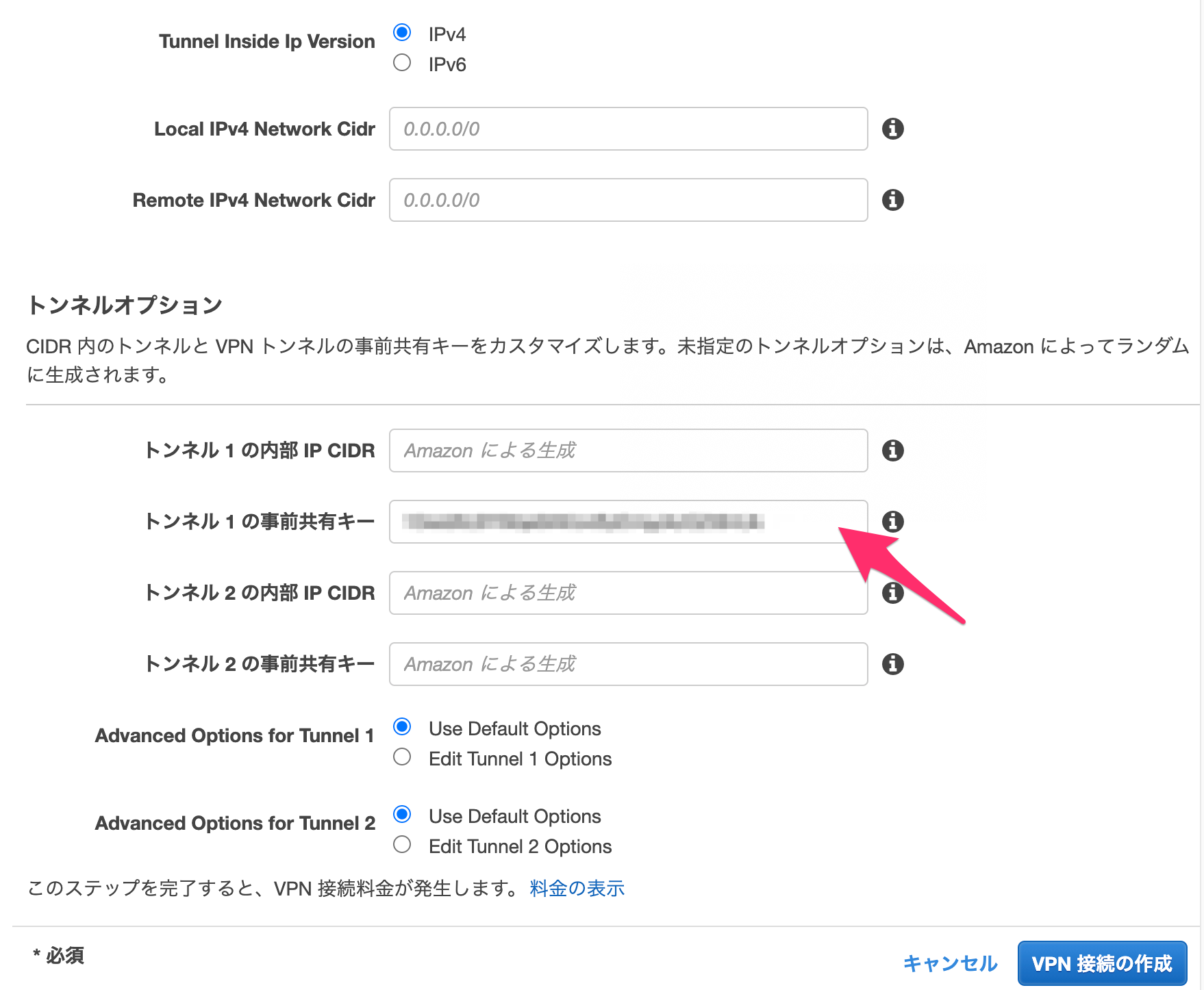
ルーティングオプション「静的」を選択すると「静的IPプレフィックス」情報が表示されますが、こちらは相手先(OCI(VPN))側のセグメントを登録します。
「トンネル1の事前共有キー」は、OCI側で認められる文字列(数字、文字およびスペースのみ許可)で事前に用意してください。作成自体は、問題なくできます。
IPSec(AWS)の準備ができたら、OCIでIPSecトンネルを用意するため、AWS側のVPN構成情報を取得します。
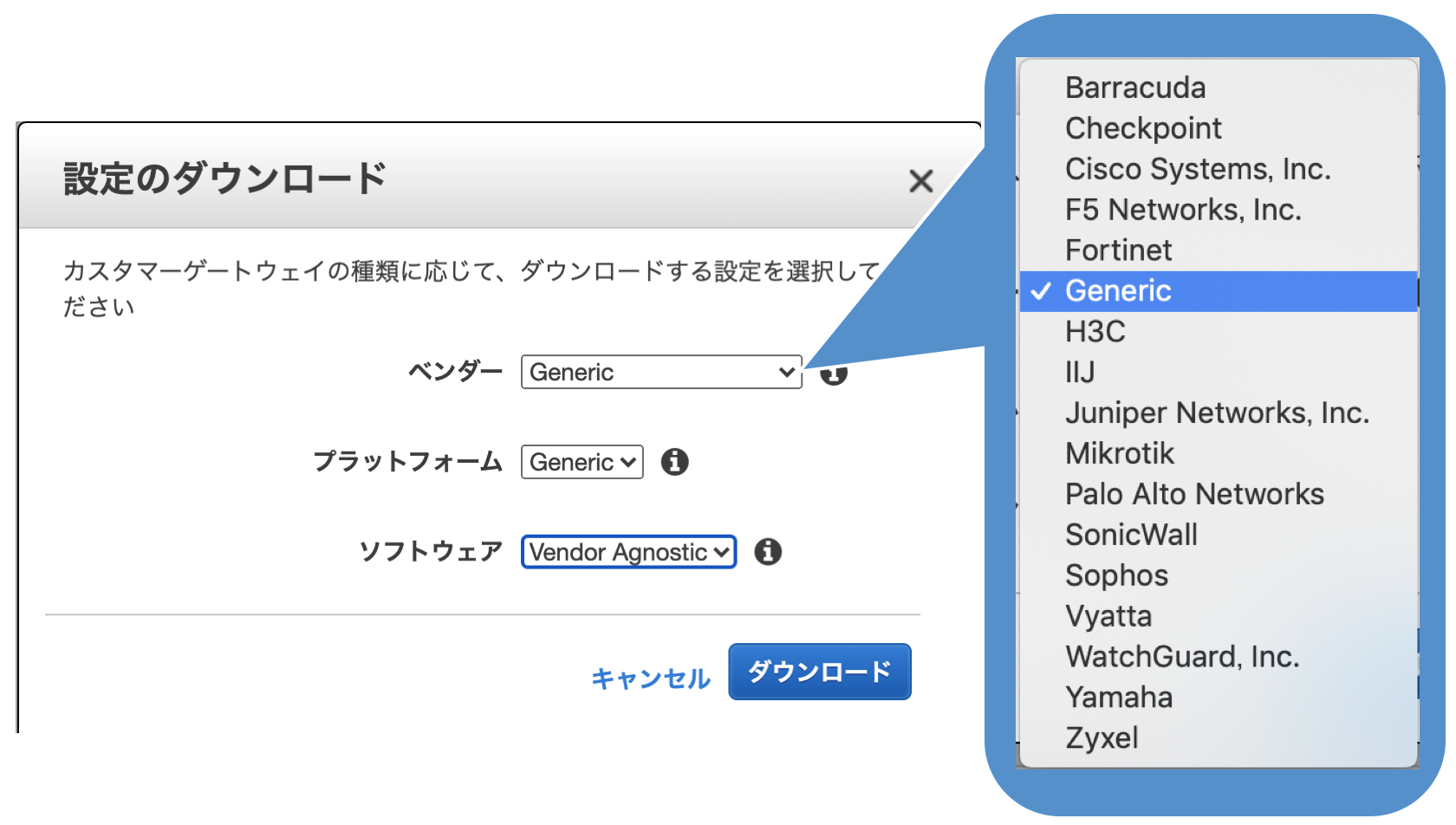
設定については、各ベンダー用の定義情報がダウンロードできますが、ここでは(Vendor)Generic、(Platform)Generic に設定してダウンロードします。
設定をダウンロードすると、こんな感じのテキストファイルを入手できます。
こちらの情報をもってOCI側のIPSecトンネルを作成します。3.OCI側にIPSecトンネルを作成する
3-1.顧客宅内機器(CPE)の作成(OCI)
先ほど用意したAWS側のVPN接続の情報を「顧客宅内機器」として登録します。
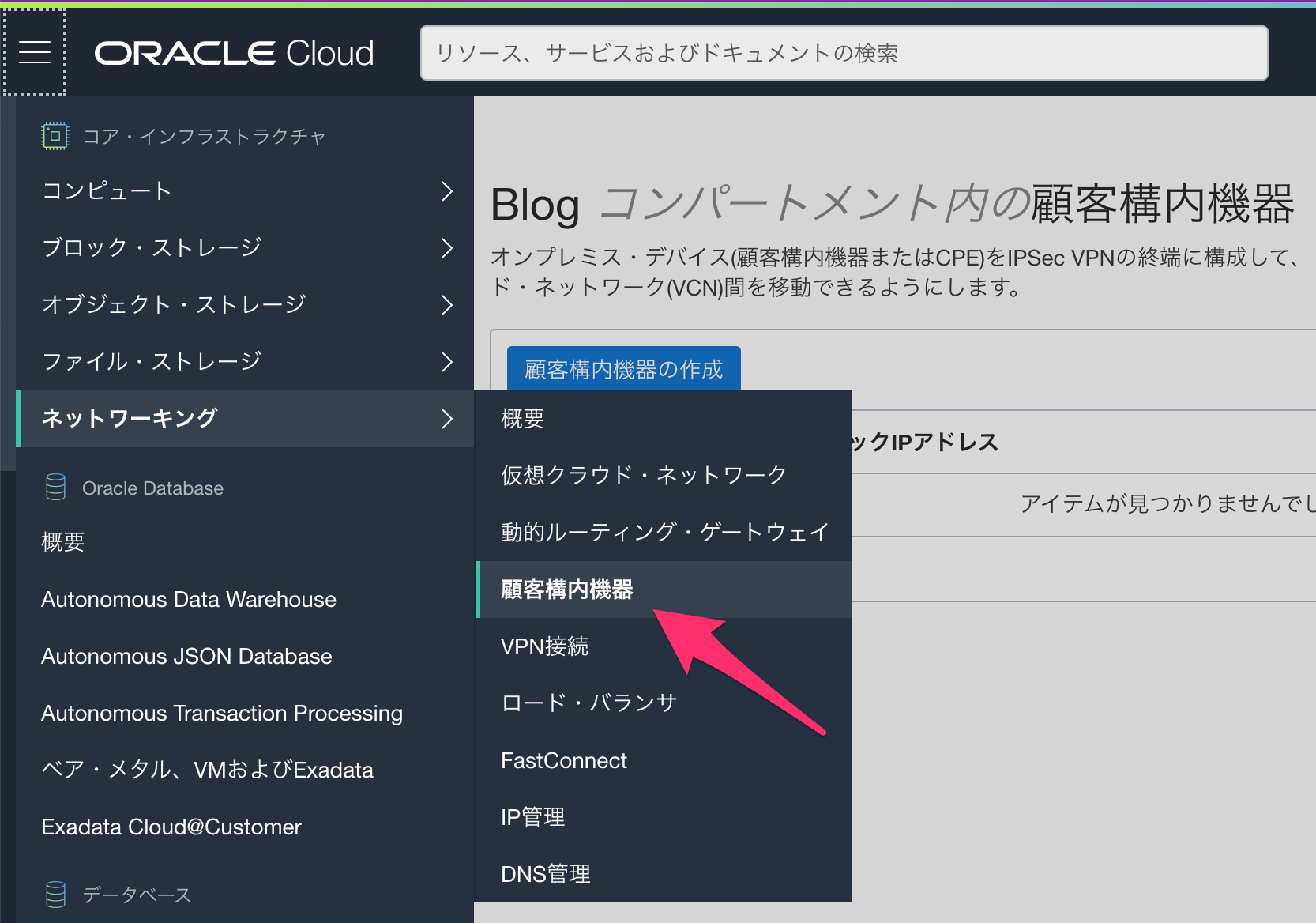
[ネットワーキング]-[顧客宅内機器]をポチッとします。
こちらでAWS側のVPN接続を設定します。
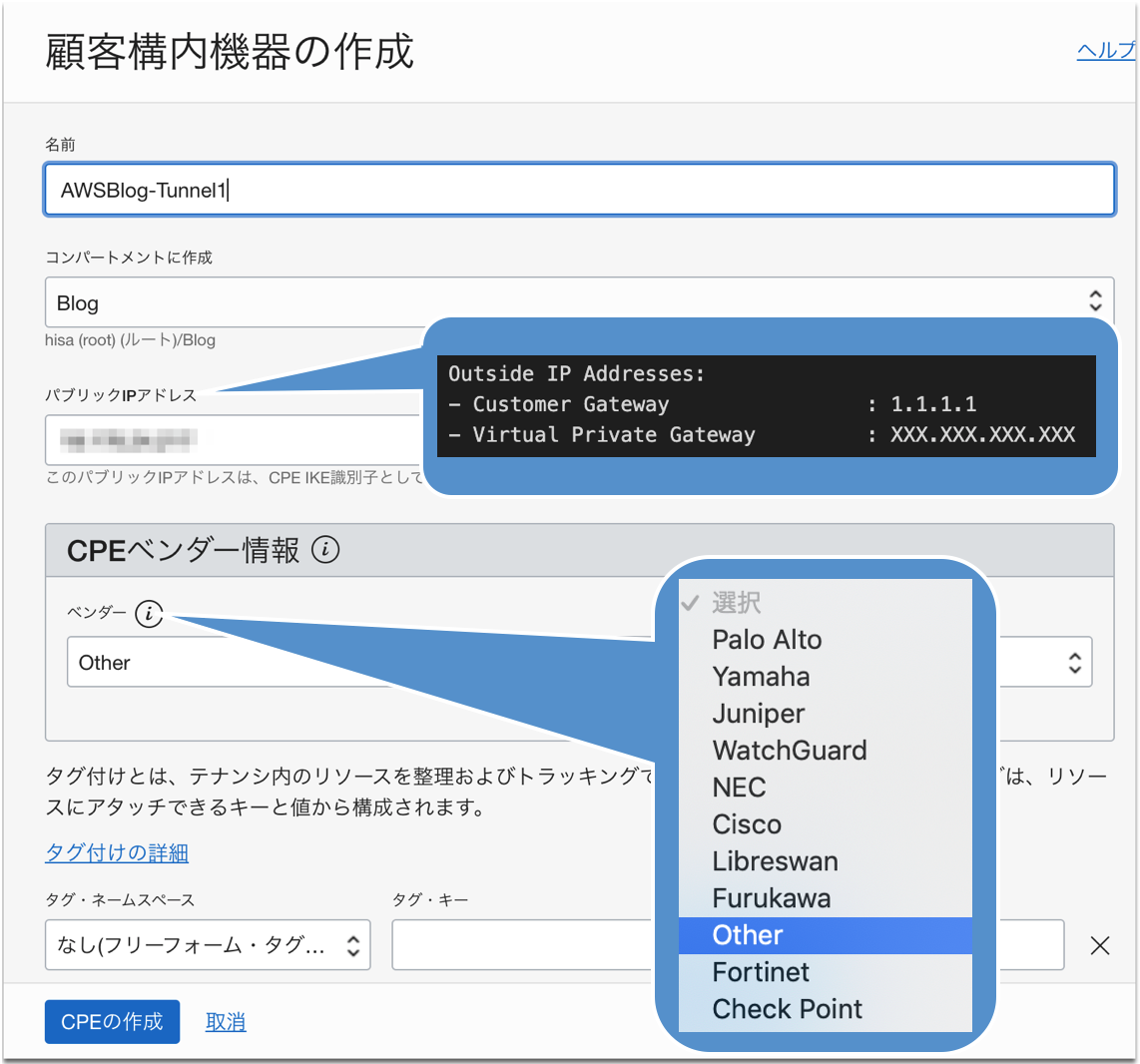
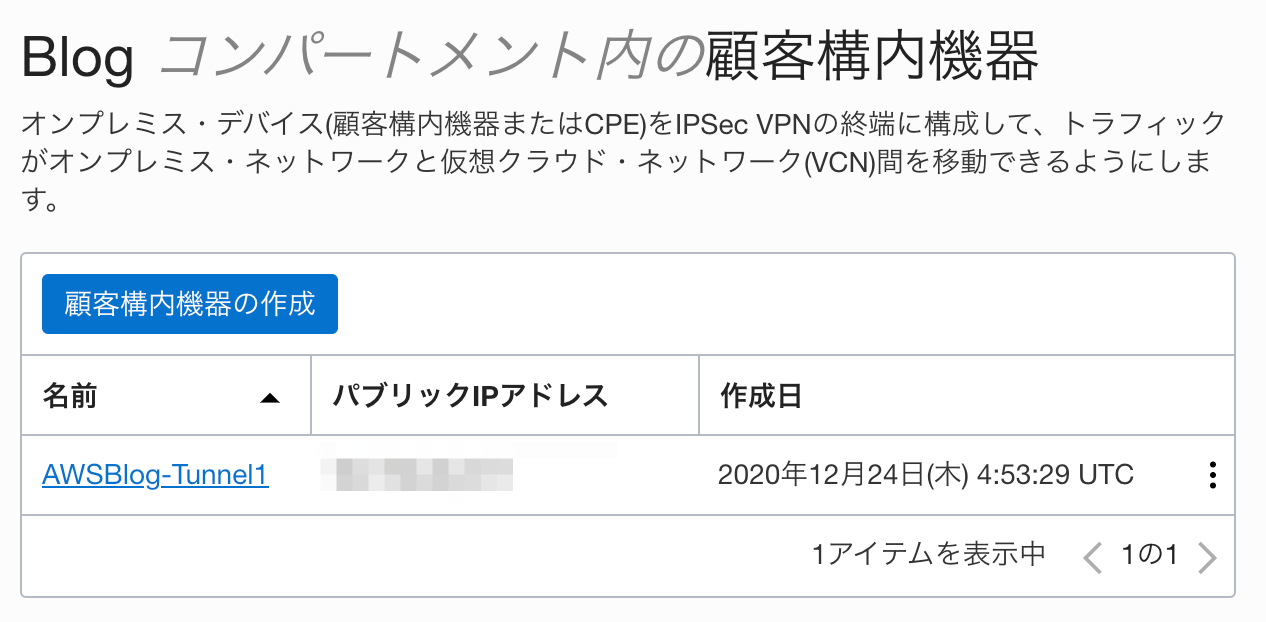
パブリックIPは、先ほどの構成情報にある[Outside IP Addresses]の[Virtual Private Gateway]のIPアドレスを登録します。CPEベンダー情報としては、もちろん AWS なんてあるわけがないので、Otherを選択して作成します。作成すると、こんな感じになります。
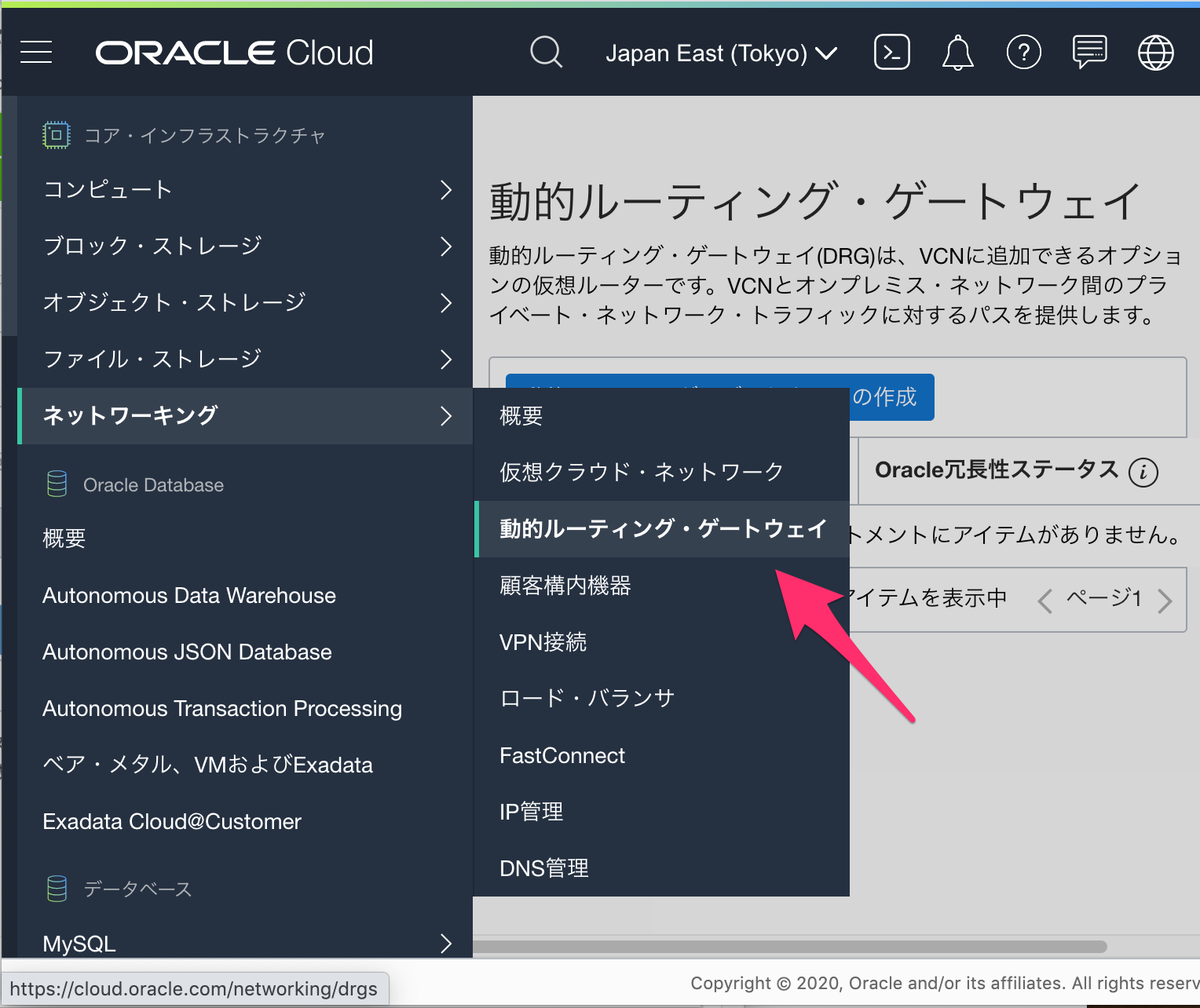
3-2.動的ルーティング・ゲートウェイ(DRG)の作成(OCI)
AWSでもVPGを作成しましたが、OCI側も同様にゲートウェイを作成する必要があります。
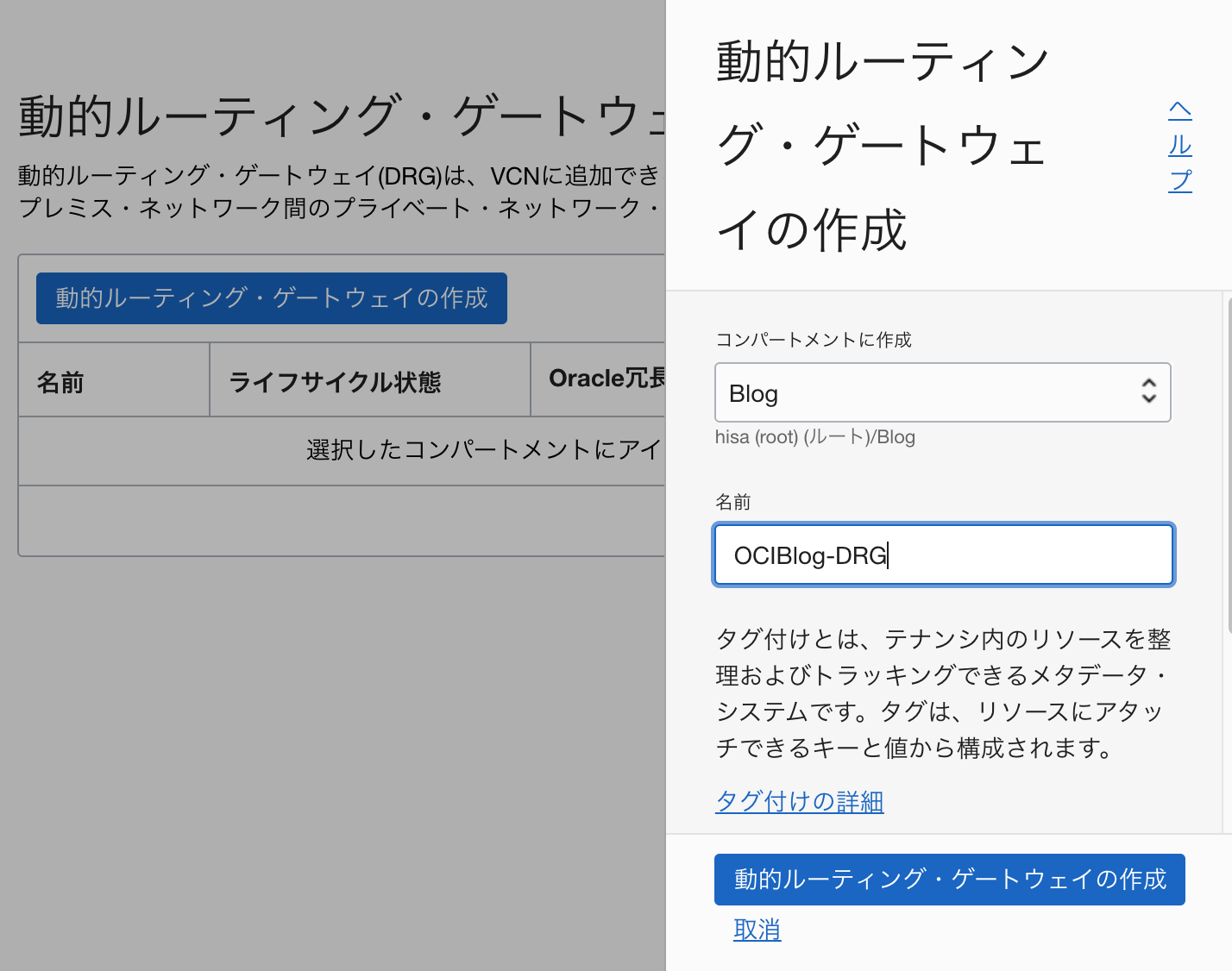
[ネットワーキング]-[動的ルーティング・ゲートウェイ]をポチッとします。
こちらも、まずは名前を設定して作成。
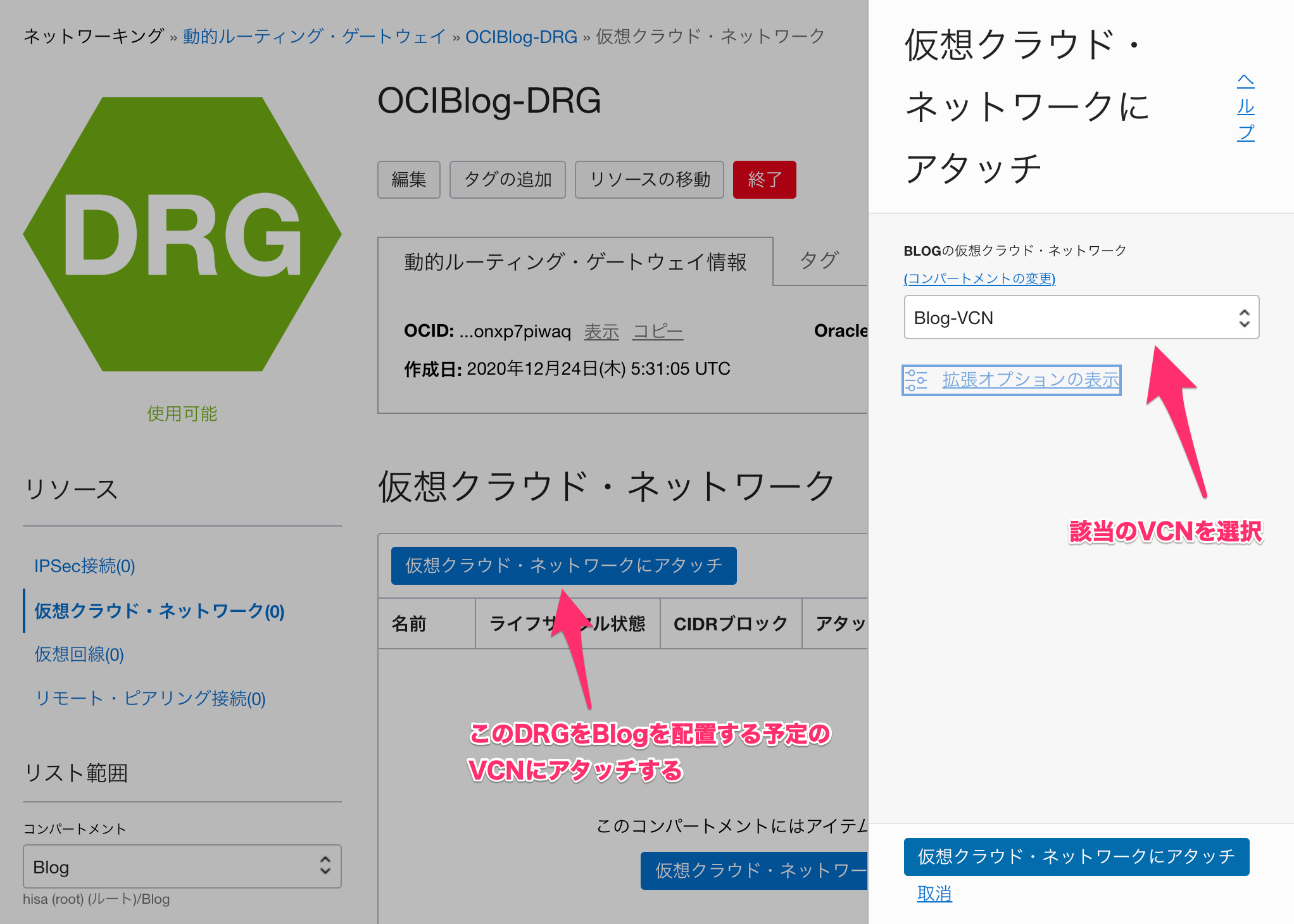
DRGを用意したら、このDRGに、Blog用として用意したVCNをアタッチします。
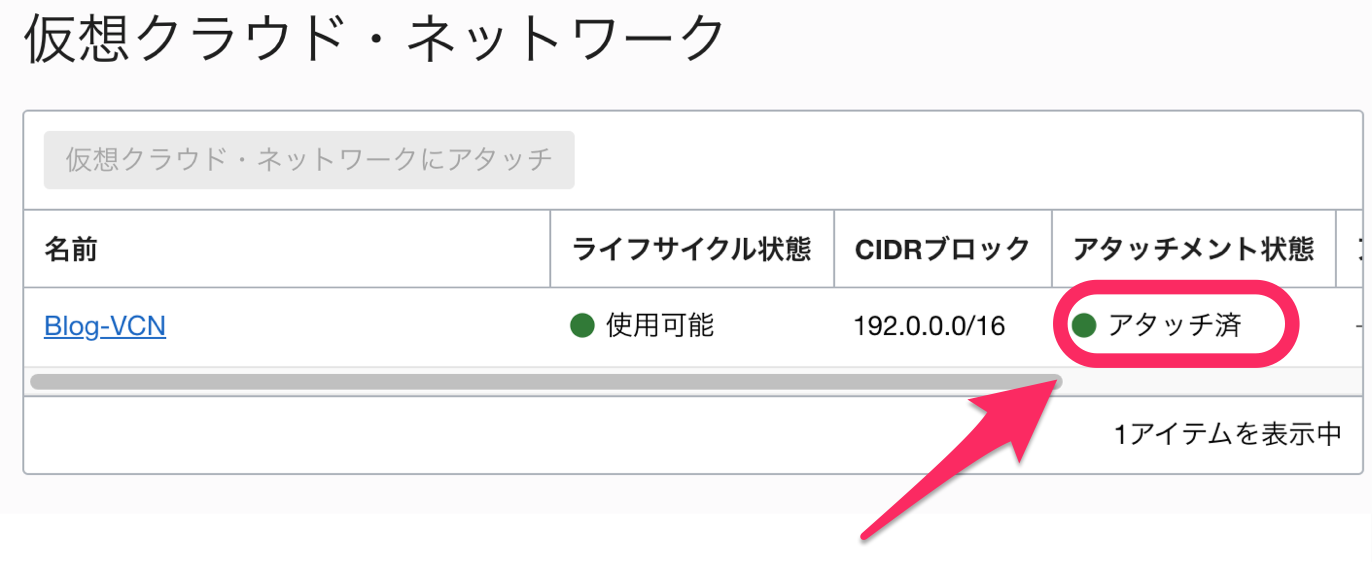
アタッチまでは少し時間がかかりますが、無事に完了すると「アタッチ済」になります。
3-3.VPN接続の作成(OCI)
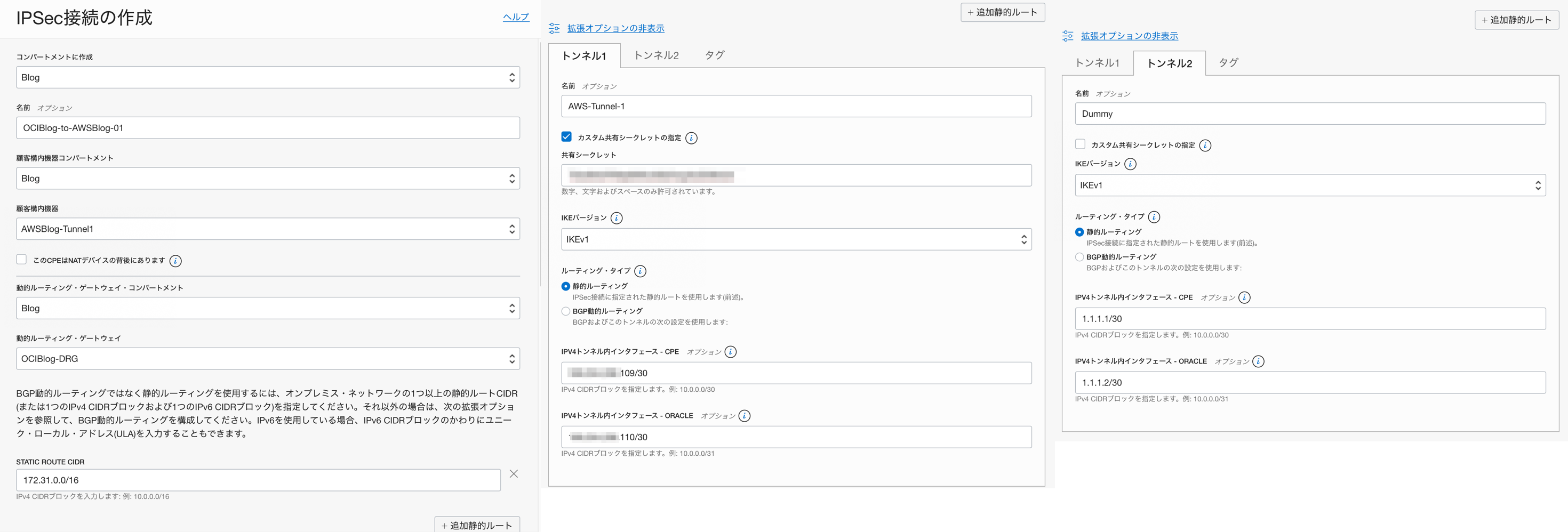
VPN接続の作成(OCI)
OCI側にIPSecトンネルを作成します。
[ネットワーキング]-[VPN接続]をポチッとします。
[IPSec接続の作成]をポチッとします。このとき、先ほどAWSにて定義情報をダウンロードしたテキストを利用します。
登録する情報は、こんな感じ。
拡張オプションの設定以外については、そんなに難しいところはないと思いますが、今回、静的ルーティングを選択しているので、相手側(AWS)の[STATIC ROUTE CIDR]を設定する必要があります。今回は、AWS側のVPCで設定しているCIDRを設定しています。トンネル設定は少しややこしいので、こちらをフォーカスして記載します。
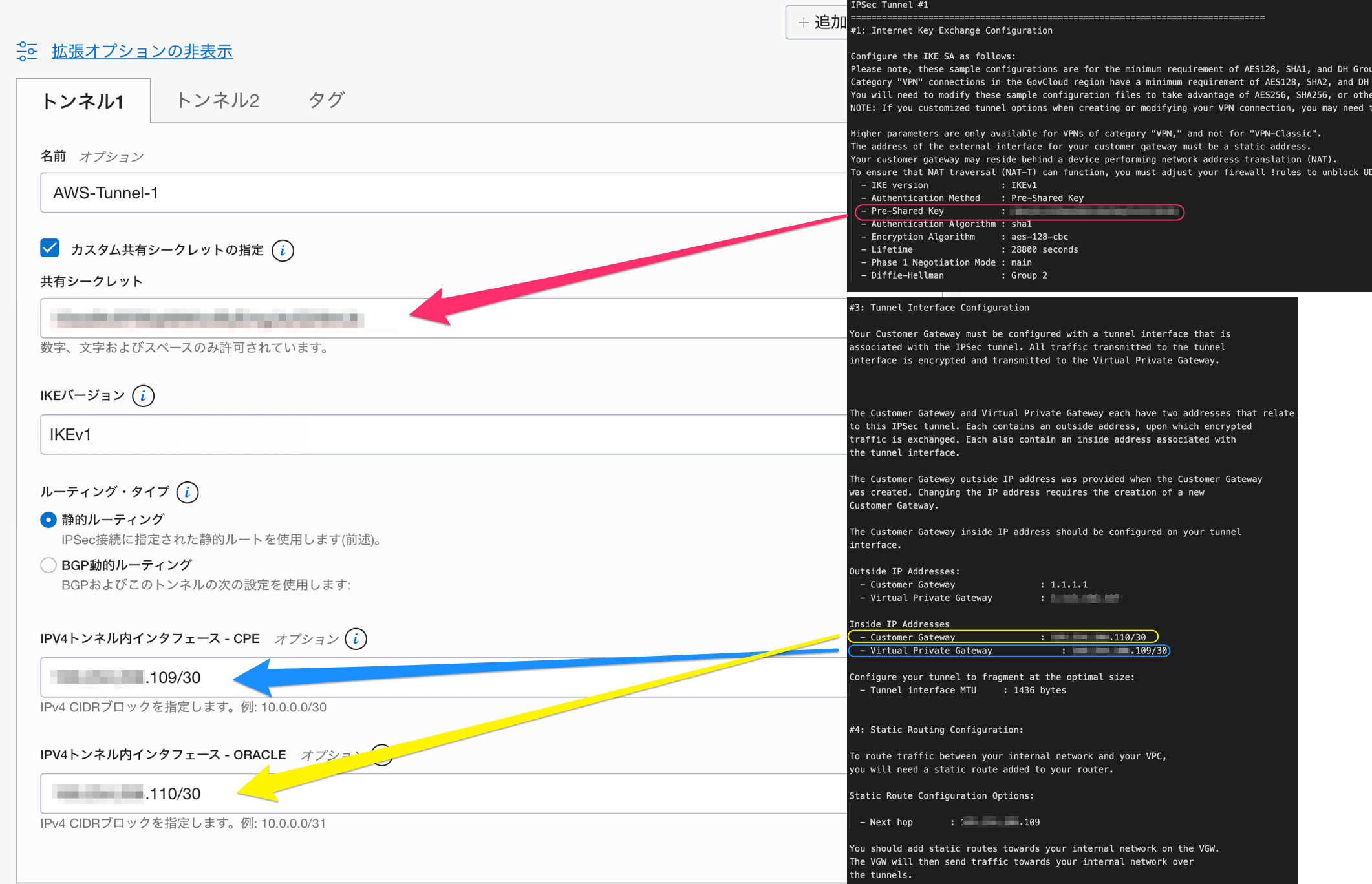
トンネル設定(OCI)
AWS上で作成した「VPN接続」について定義情報を確認しながら、下記の通り設定します。
※誤って欲しくないので、しつこいぐらいに・・・。こちらは「静的ルーティング」例になります。動的ルーティングは、2020年のAdvent Calendar記事をみてください
■共有シークレット
[カスタム共有シークレットの指定]にチェックをつけて共有シークレットを登録します。こちらは、「#1: Internet Key Exchange Configuration」にある[Pre-Shared Key]の値を貼り付けます。
※注意:AWSのVPN接続でも補足しましたが、AWS上で共有シークレットキーにOCI側で認められない文字を利用している際は、AWS上の共有シークレットキーをOCIで認められている文字列で更新してください。■IPV4トンネル内のインタフェース - CPE
こちらは「#3: Tunnel Interface Configuration」の[Inside IP Addresses]-[Virtual Private Gateway]の値を貼り付けます。
※「静的ルーティング」の場合はオプションになります。■IPV4トンネル内のインタフェース - ORACLE
こちらは「#3: Tunnel Interface Configuration」の[Inside IP Addresses]-[Customer Gateway]の値を貼り付けます。
※「静的ルーティング」の場合はオプションになります。間違えやすい気がしますので、よく確認して設定してください
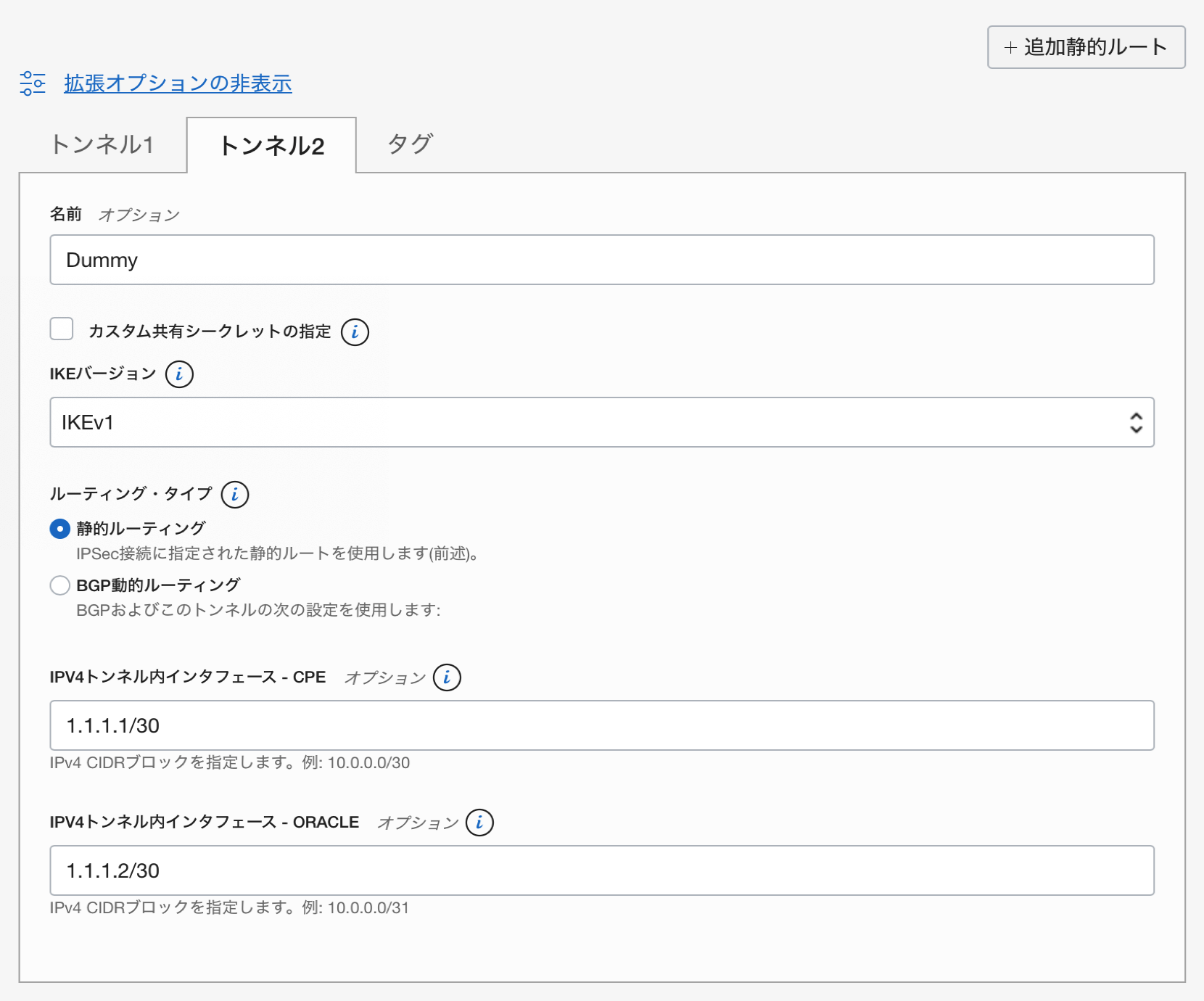
。
あと「トンネル2」の設定ですが、今回は1本だけ用意したいので使わないのですが、VPN接続の設定としては必須情報になりますので、ダミーとして登録しています。
VPN接続情報の登録完了
使えるようになるまで少し時間がかかりますが、OCI側のIPSecトンネルを準備できました。
今度は、OCIで用意したIPSec情報を元にAWS側のカスタマーゲートウェイに登録します。
4.AWS側にIPSecトンネルを作成する(続)
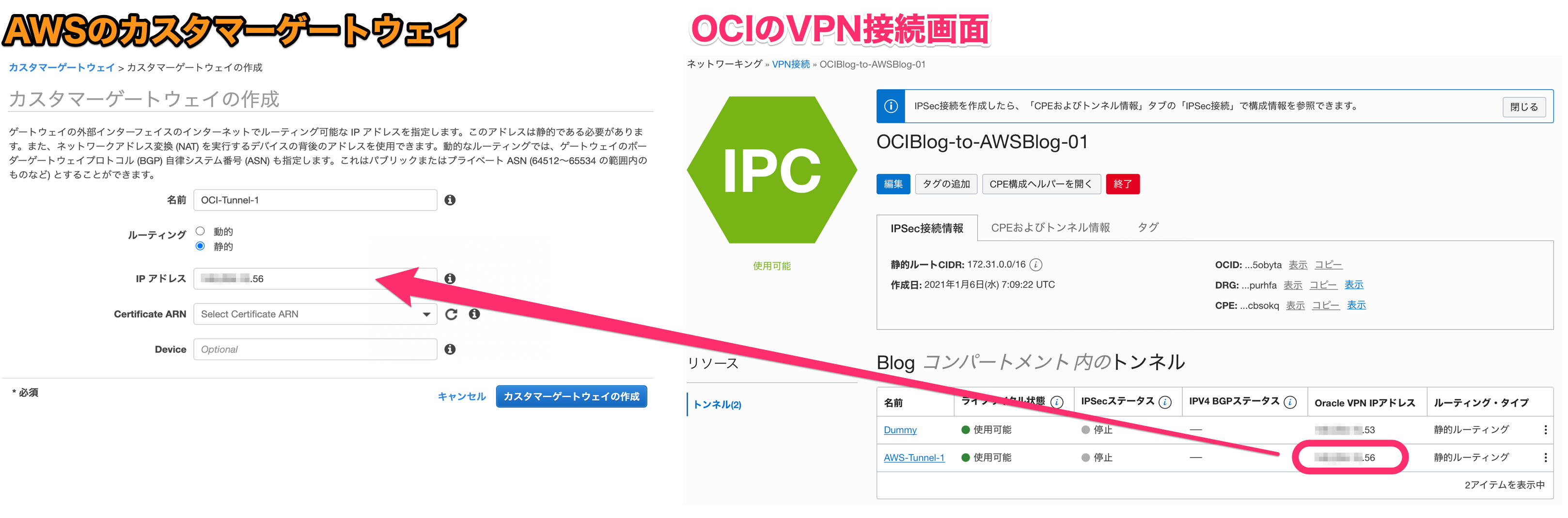
4-1.カスタマーゲートウェイの用意。(前に仮で登録したところを正しく設定する)(AWS)
先ほどは仮で登録しましたが、今回はOCI側のIPSec接続情報があるので、こちらを元に作成します。
先ほど作ったOCIの[VPN接続]の情報(接続先のIP)を確認しながら、カスタマーゲートウェイを作成します。
- ルーティング設定を「静的」にする
- IPアドレスは、Oracle VPN IPアドレス(AWS-Tunnel-1 の Oracle VPN IPアドレス)を設定する。
こちらでカスタマーゲートウェイとしては完成です。
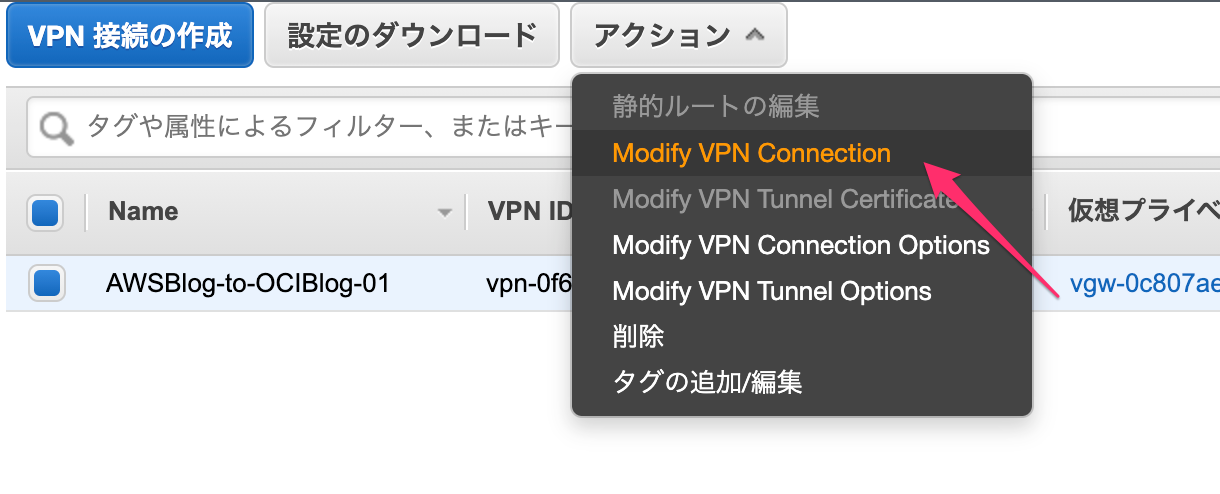
4-2.VPN接続の更新(トンネル情報の更新)(AWS)
先ほどサイト間VPN接続で仮のカスタマーゲートウェイを設定していた情報を、上記で作成したカスタマーゲートウェイに差し替えます。
先ほど用意した[VPN接続情報]を選択して、[アクション]から[Modify VPN Connection]をポチッとします。
VPN接続情報のカスタマーゲートウェイを、先ほど、作成した本番用のものに変更します。
ここで[Save]すれば、AWSとOCI間のIPSec接続に関する設定は終了です。
設定反映に少し時間がかかりますが、設定が正しければAWS(VPC)とOCI(VPN)がIPSecでつながります。
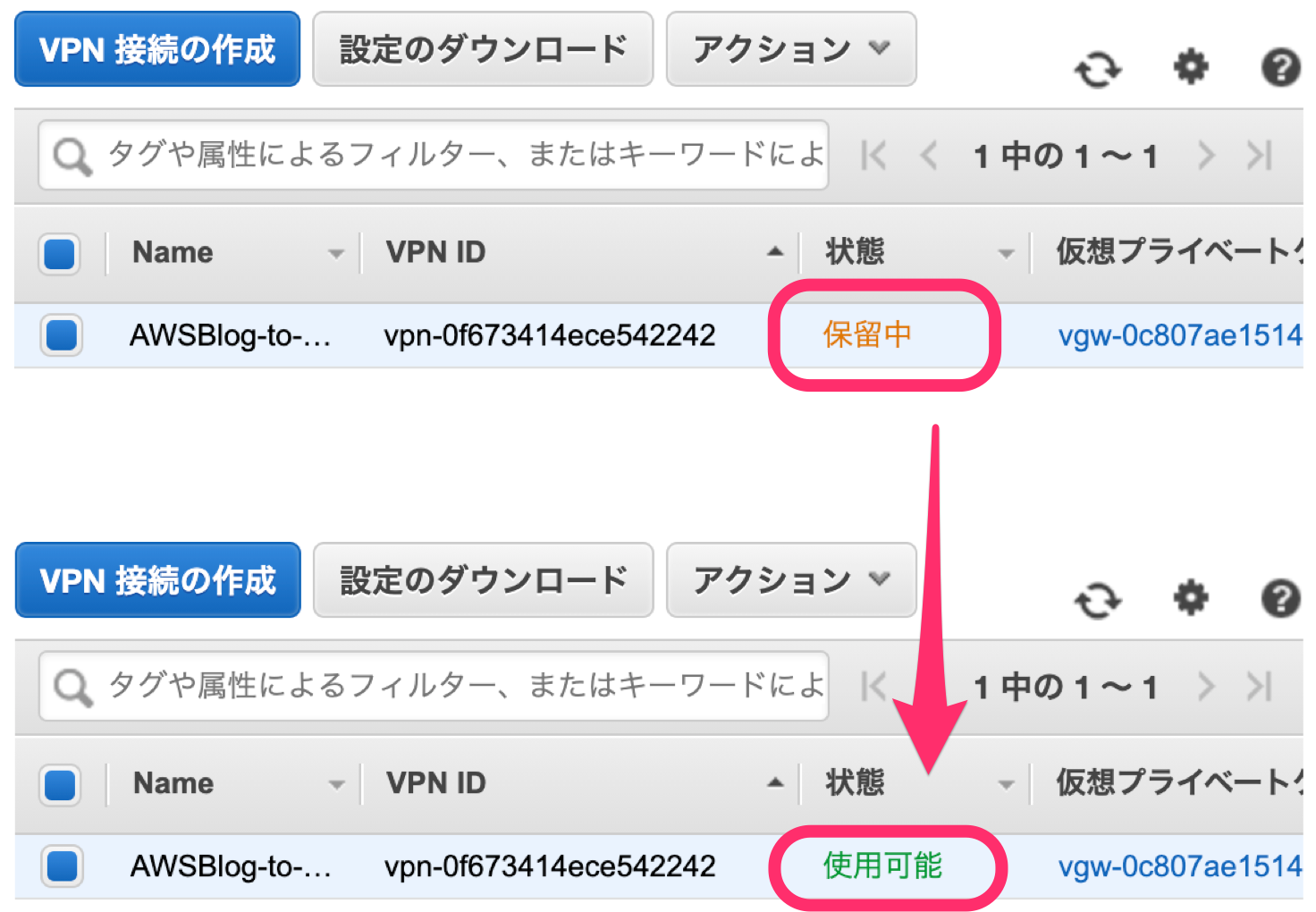
4-3.接続ステータスの確認
AWS側のVPN接続の状態が「使用可能」になると、トンネルのステータスが変更されます。
AWS側のトンネルステータスは、こんな感じ。
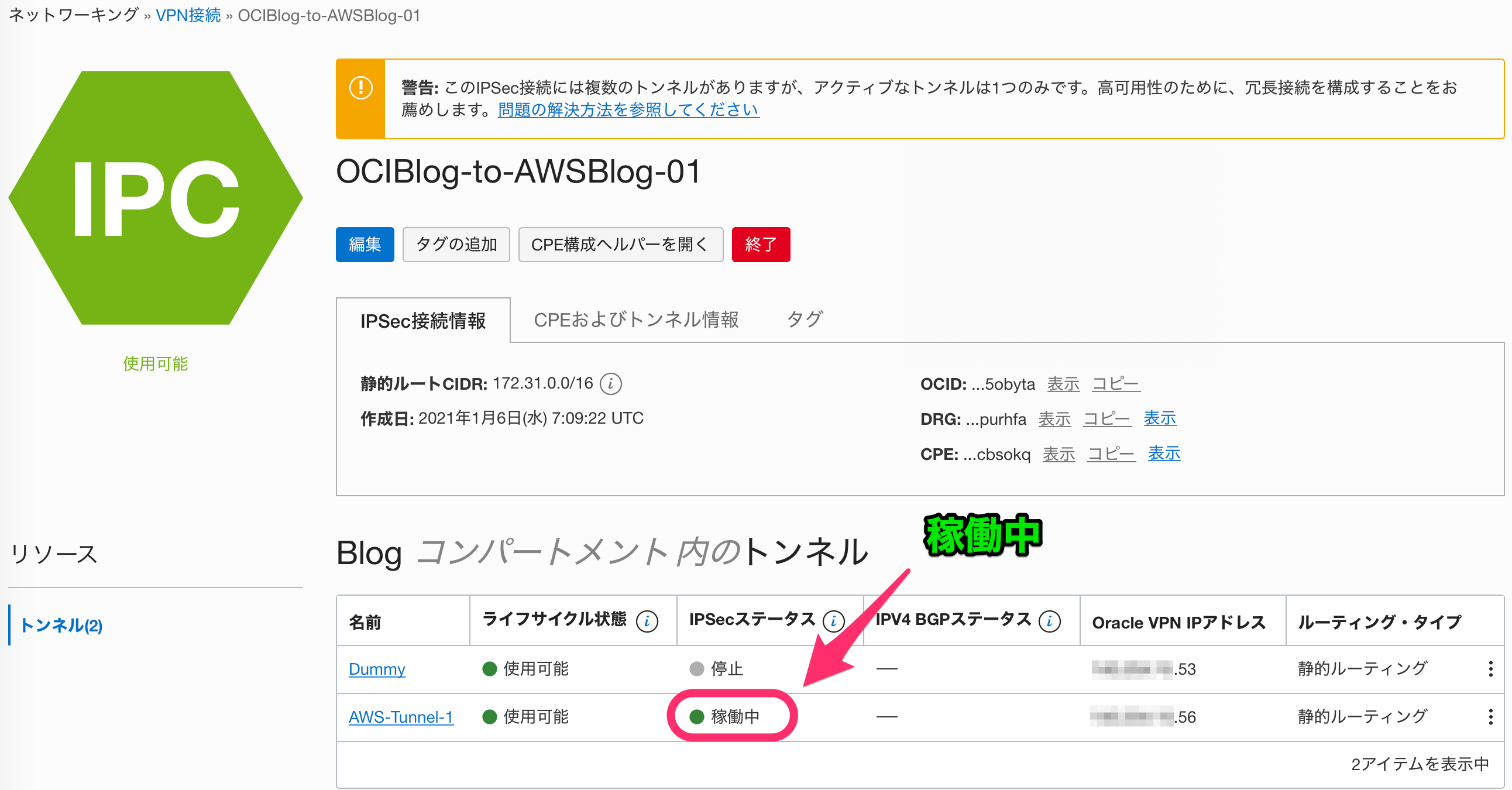
※前回の使い回しにしようと思ったのですけど「ちゃんと検証していないだろう!」という方は居ないと思いますがこちらを確認してOCI側のステータスは、こちらで確認します。
※こちらも、前回の使い回しにしようと思ったのですけど「ちゃんと検証していないだろう!」という方は居ないと思いますが少しでも誰かの役に立てるといいなあ
設定が正しければ、両トンネルのステータスは稼働状態(アップ)になります。
5.ルーティング設定
さて、ここからは去年のAdvent Calendarでも記載していなかったので、参考にしてください。
AWSとOCIでトンネルが張られたら、後は、このトンネルを使ってAWS(VPC)とOCI(VCN)間のルーティング設定をしてあげます。これをしないとお互いのネットワークに所属するマシンから相手先が分かりません。
5-1.AWS側のルーティング設定
VPC(Virtual Private Cloud)-ルートテーブルを選択し、該当するルートテーブルを選択しルートのタブを選択します。
ルートタブのすぐそばにある「ルートの編集」をクリックすると、こんな画面になります。
「ルートの追加」をポチッとして、送信先(ココではOCI側のネットワーク)を設定して、ターゲットを Virtual Private Cloud から該当のVPG(VPNをターゲットゲートウェイとしたVPG)を選択します。その後は、ルートの保存をポチッて終了です。
5-2.OCI側のルーティング設定
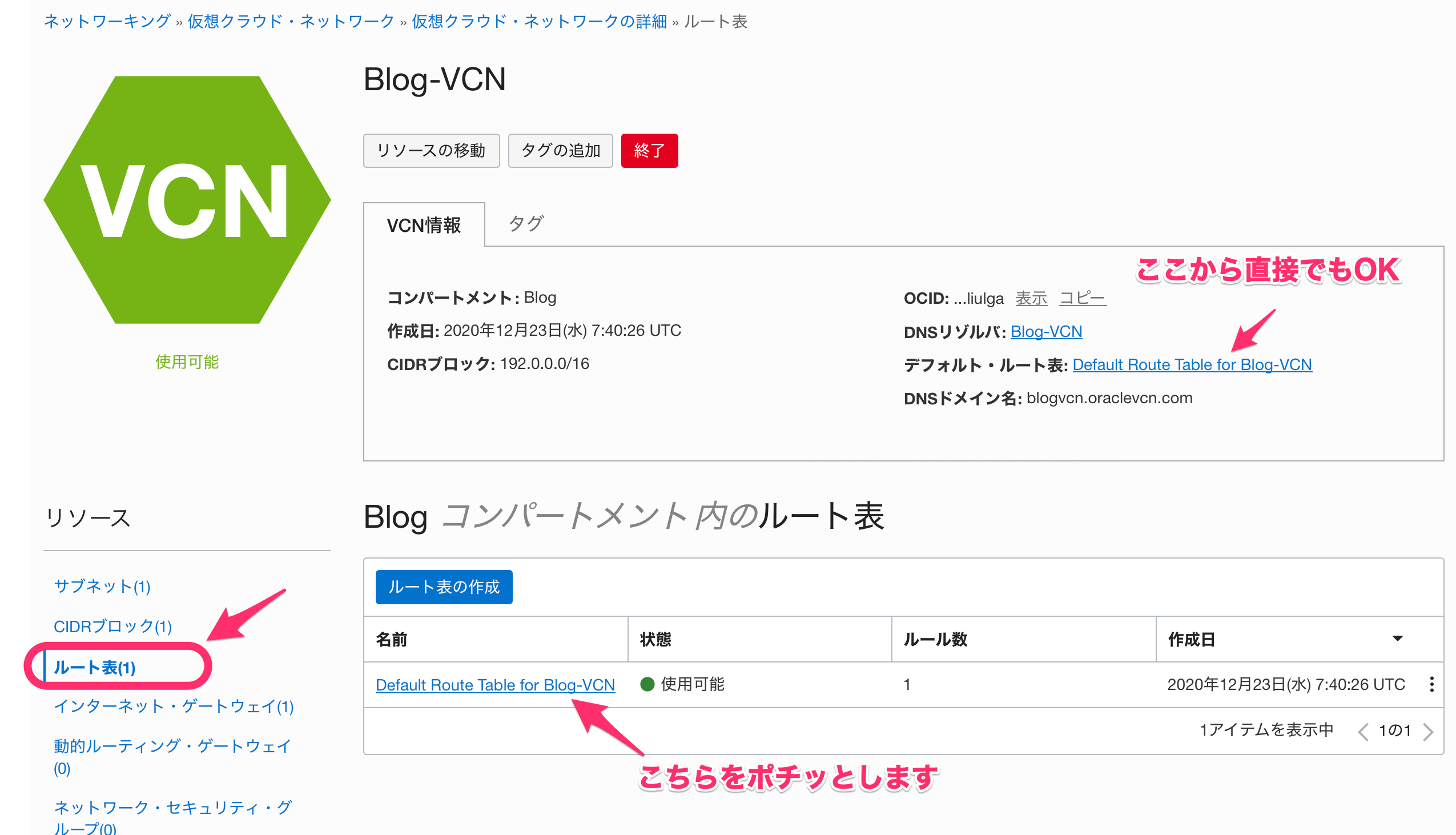
ネットワーキング-仮想クラウド・ネットワークから該当のVCNを選択して、「ルート表」を選択します。
※今回はデフォルト・ルートを変更しますので、VCN情報から設定されているデフォルト・ルート表から直接でもOKです。
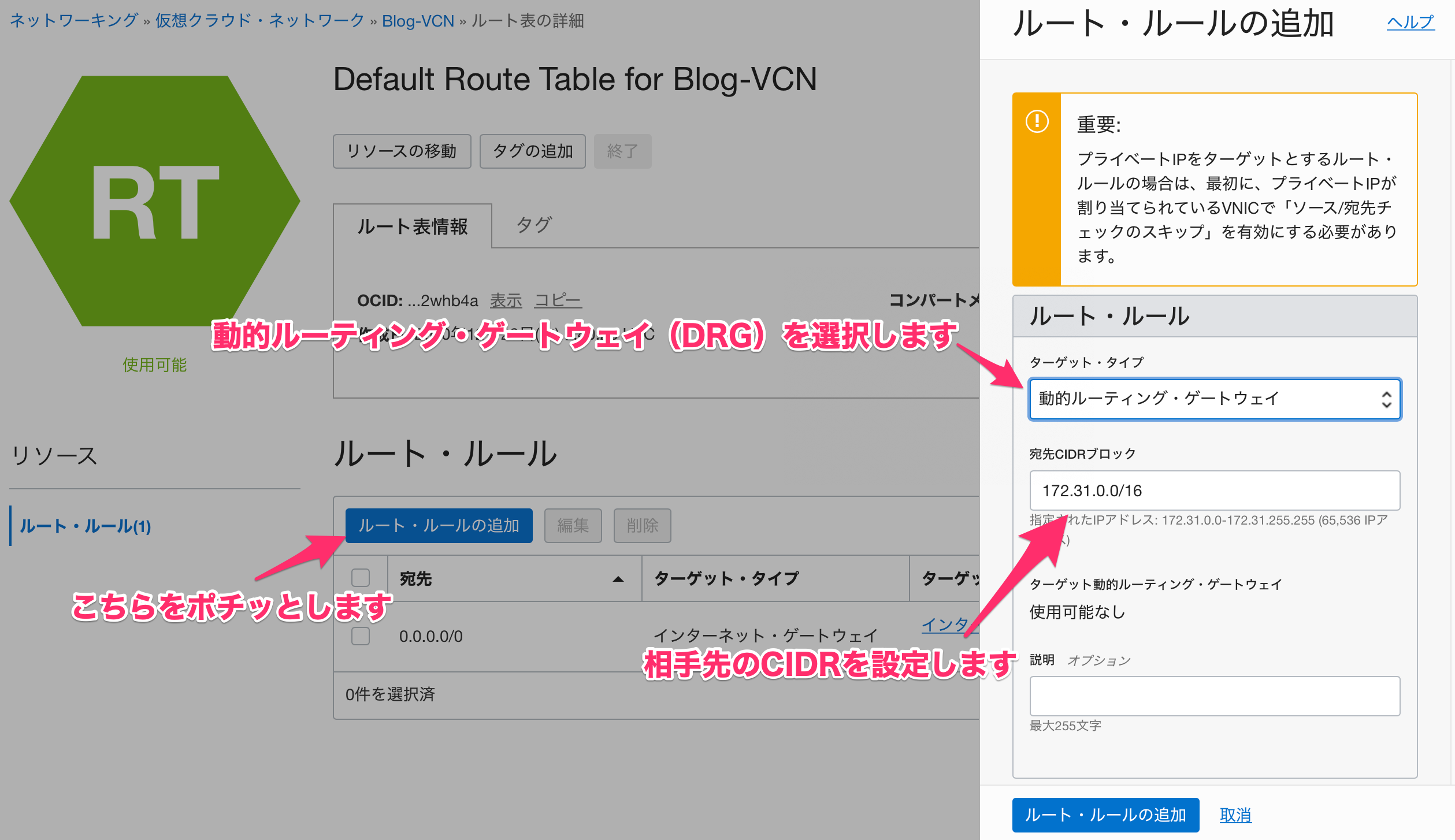
ルート表の詳細画面に遷移したら「ルート・ルールの追加」を行います。
こんな感じ。補足
これで、AWS(VPC)に設定されているルート表とOCI(VCN)に設定されているルート表それぞれに、相手先のIPをOCI(192.0.0.0/16)であれば、AWS(VPG)。AWS(172.31.0.0/16)であれば、OCI(DRG)に問い合わせるようになった感じです。
6.セキュリティ設定
ここまでで、トンネル設定(AWSとOCI間)、ルーティング設定も完了。となると、もう通信経路は完成しています。あとは、クラウドで考慮しなくてはならないセキュリティ設定です。
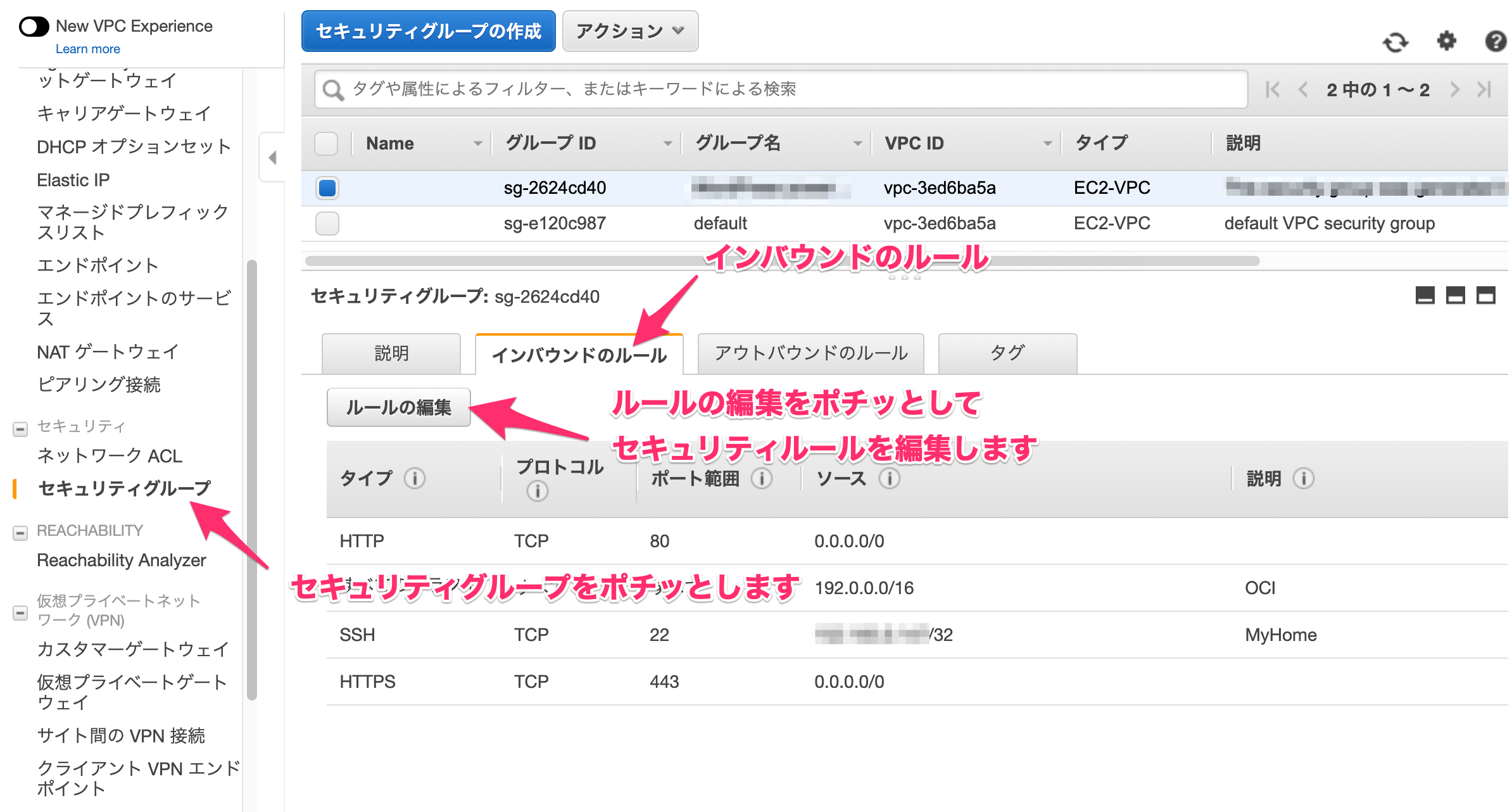
今は、お互いのネットワークセグメントからの通信を許可していないので、こちらを許可してあげなくては通信はできません。今回は、すべてのトラフィックを開ける例です。(※デフォルト設定での例になります)6-1.セキュリティグループの設定(AWS)
VPC(Virtual Private Cloud)-セキュリティ-セキュリティグループを選択し、該当する(OCIと通信したいEC2にマッピングしているセキュリティグループ)セキュリティグループを選択し、「インバウンドのルール」タブを選択します。
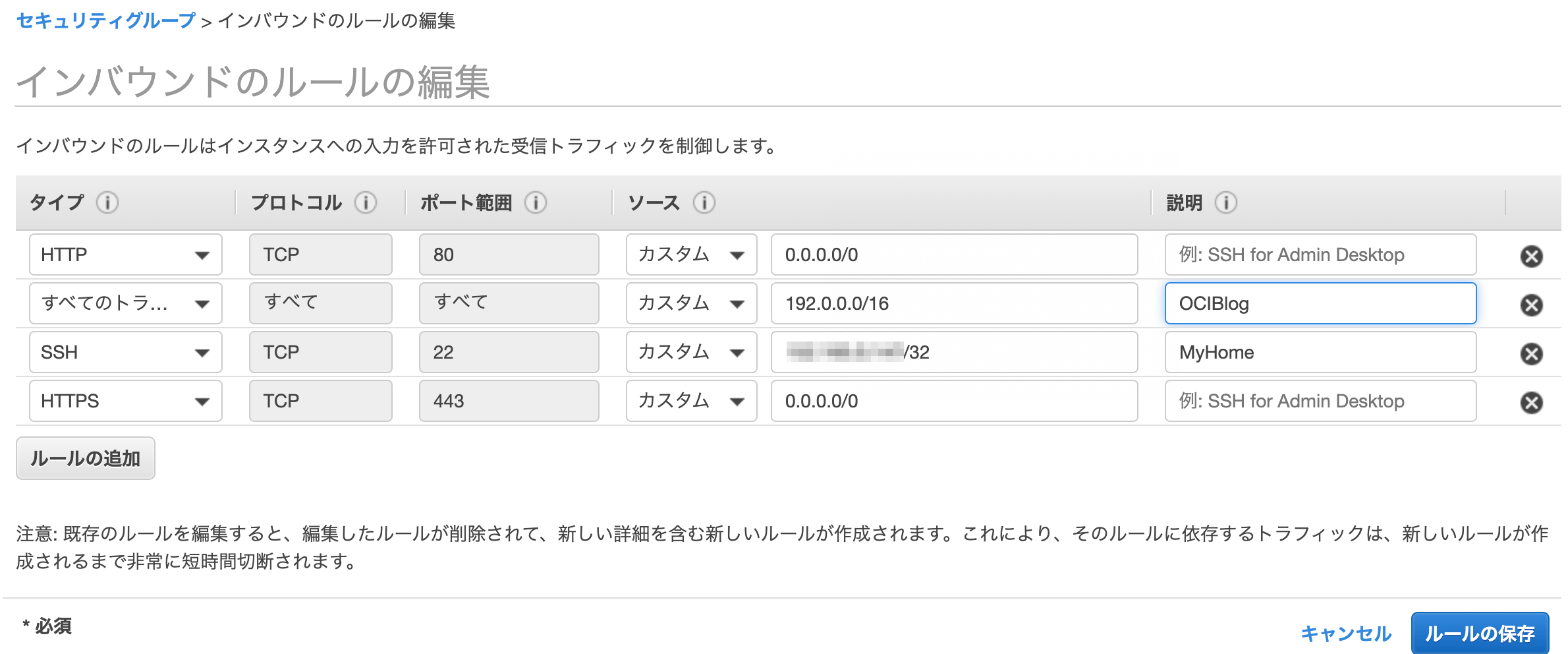
「ルールの編集」を選択すると、こんな感じ。
今回はOCIからの通信はすべて許可するので、タイプを「すべてのトラフィック」を選択して、ソース先をOCIのCIDR(今回の例だと192.0.0.0/16)を設定します。こちらで、ルールの保存をポチって終了です。
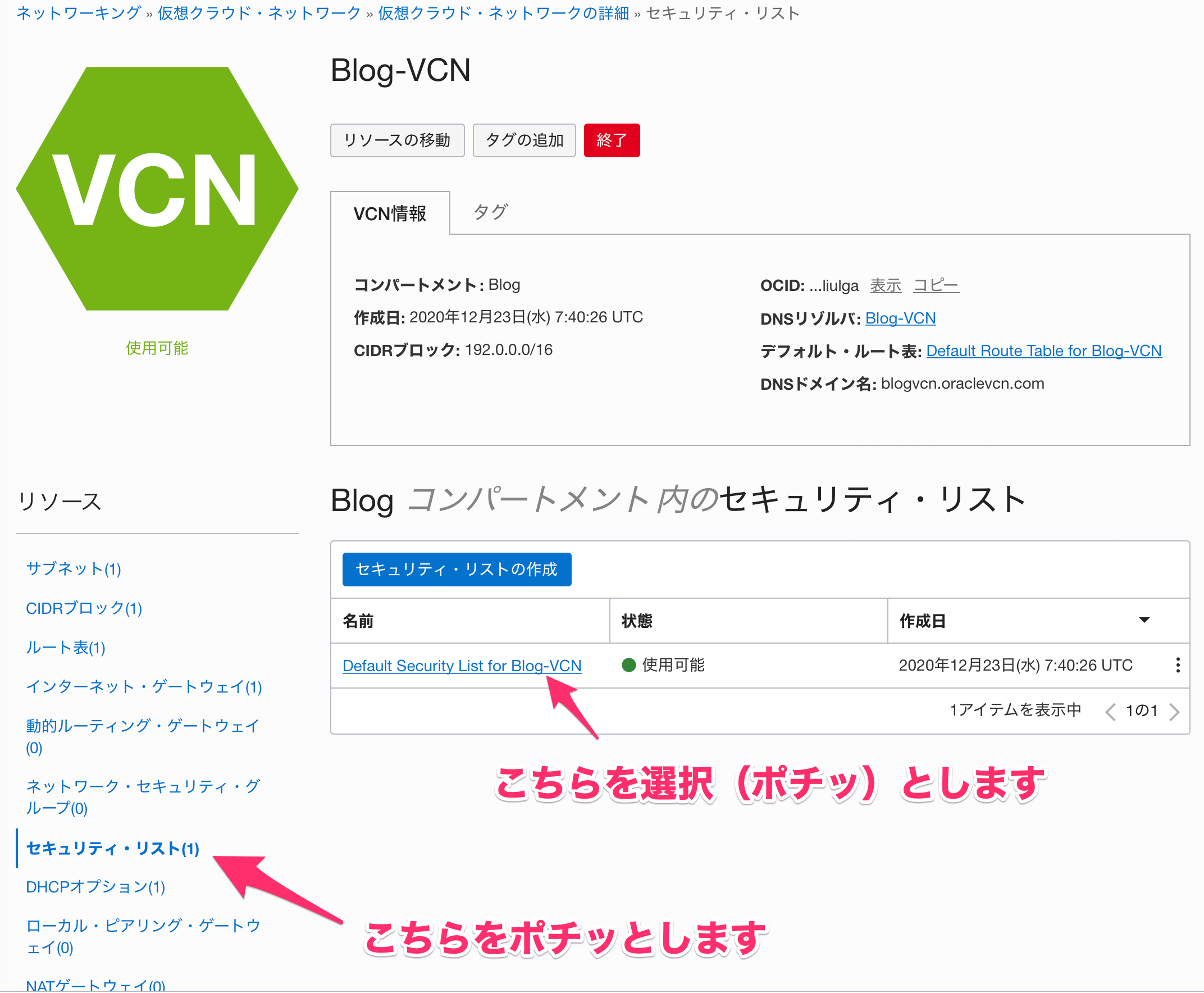
6-2.セキュリティ・リストの設定(OCI)
ネットワーキング-仮想クラウド・ネットワークから該当のVCNを選択して、「セキュリティ・リスト」を選択します。
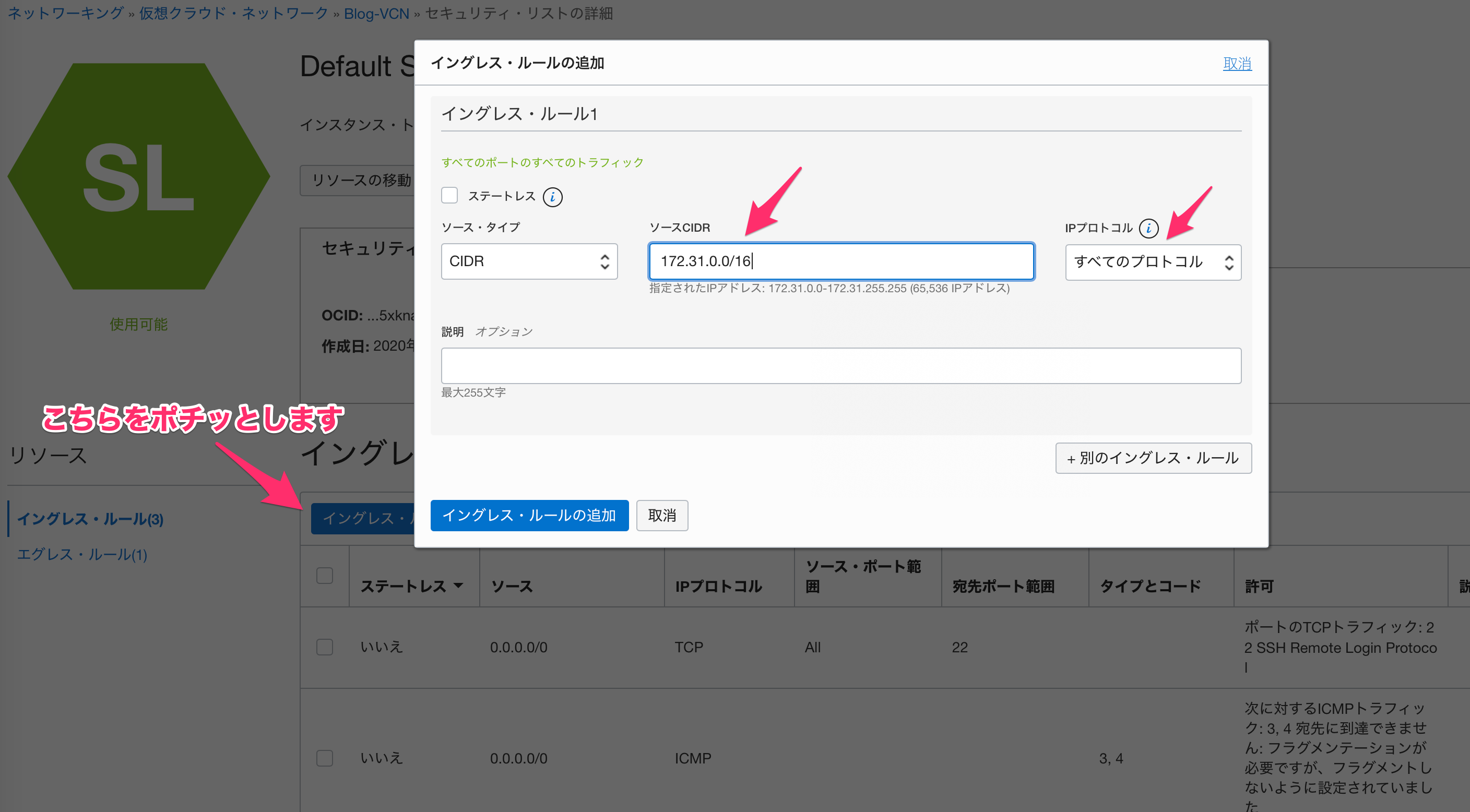
セキュリティ・リストの詳細から「イングレス・ルールの追加」をポチッとします。
今回はAWSからの通信はすべて許可するので、IPプロトコルを「すべてのプロトコル」を選択して、ソースCIDRをAWSのCIDR(今回の例だと172.31.0.0/16)を設定します。こちらで、イングレス・ルールの追加をポチって終了です。
補足
これで、AWS(VPC)に設定されているセキュリティグループとOCI(VCN)に設定されているセキュリティ・リストそれぞれに、通信許可を加えたので通信ができるようになりました。
設定が正しければ、これでAWS(VPC)とOCI(VCN)がVPN経由でつながっています
おわりに
こちら2020年Advent Calendar(12/25)の回収ネタでした。両社のVPNサービスのみを利用してIPSec VPNの構築例になります。念のため、改めて記載しますが、この構成はAWSさん、Oracleさん共にサポートしている構成ではないと思うので利用する際は注意してください
こちらで今年のQiita始めを終えようと思います。今年もよろしくお願いいたします!
また何か検証したら投稿したいのですけど、なかなか検証する時間ないのですよねぇ。2021年のAdvent Calendarまで空いちゃうかなあ。。。あとがき
こちらは2020年のAdvent Calendar(12/25)に投稿したときに構築できなかった理由の推測です。根本的な原因は、すでに構築した設定を削除したので追えないため…。
昨年、構築できなかった理由
始めは「サポートされている構成ではない」ため、そもそも動的ルーティングの構築ができないのかな?と思いましたが、そうではありませんでした。
冒頭では「謹賀新年パワー!」と始めましたが、ある意味正しいかも(笑)理由を調べてみたのですけど、おそらく、OCI側で変な情報が残っていたかな?というのが推測です。
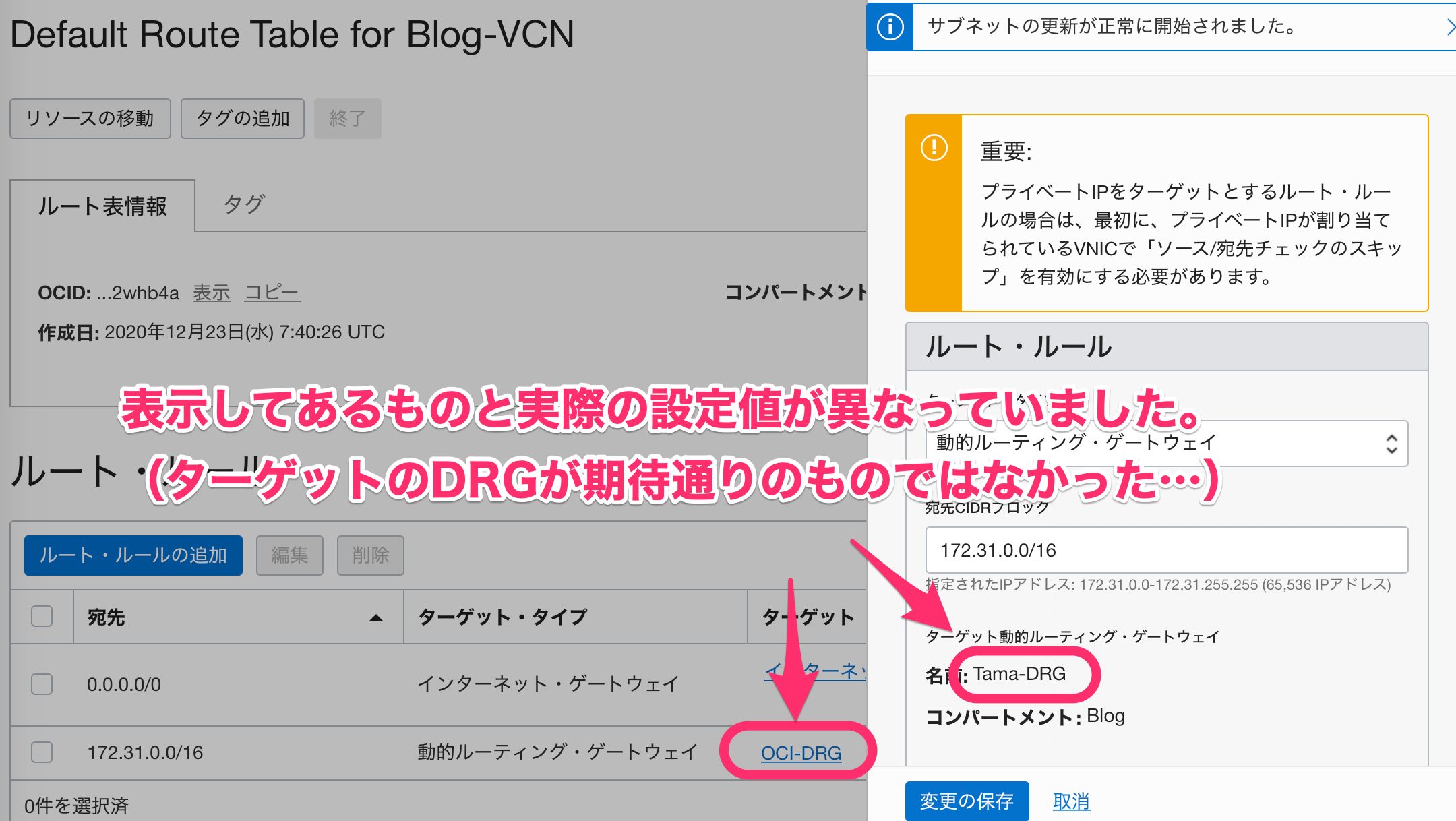
ちなみに、今回も検証中VPN経由で通信ができない状態が発生しました。このとき調べてみると、ルーティング設定が期待通りではない状態になっていました。
上記の画面をみると、ターゲットに指定しているDRGが表示している情報(OCI-DRG)と内部での設定(Tama-DRG)が異なっています。私がチェックしていたのは、表示上の情報だったので「設定されている」と思っていたけど、実際には設定されていなかったものがあったかもしれません「おい!コレBugじゃねーのか!」と思う方もいらっしゃるかもしれませんが、今回のケースはサポート対象の構成ではなく、色々と試している中だったので自己責任範囲と思ってやり過ごしてしまいました
ですが、他にも色々と期待したとおり動作しないケースがあるかもしれません。マニュアル通り進めて期待通りにならなかった場合は「サポートまで問い合わせるのが吉です!」もちろん、動作としておかしくない?もサポートです。私もサポートへ問い合わせても良かったのですが、すぐに回避方法を探しちゃうタイプなので、復旧させてしまいましたという感じで、先ほども記載したとおりサポートされていない構成や手順については自己責任でお願いします。(けど、技術検証は好きなので、こういうのを見つけるとワクワクする自分がいたりします
)
ちなみに、理由がわかるとなんのこともないです。キチンと設定値が反映されているか確認するようにして、今回は構築することができました
教訓
「思い込み(表示だけで信じず)はせず、自分を信じて、本当に設定されているか疑うべし」
かな?最後まで、読んでいただきありがとうございました!!
ではでは、今年もよろしくお願いいたします








- 投稿日:2021-01-09T01:14:10+09:00
AWS ストレージ関連サービスについて
AWS Summitの公演を聞いて、再度まとめてみたものです。
分類
- ブロックストレージ(EBS)
ある一定の容量で区切られた記憶領域
- ファイルストレージ(EFS)
ファイルストレージをファイル装置に搭載しているもの
ブロックストレージの上にファイルストレージが乗っている
- オブジェクトストレージ(s3)
ファイルに対してkeyを発行して1対1で管理を行う
サービス
Amazon Elastic Bloc Store(EBS)
EC2と合わせて使用するブロックストレージ
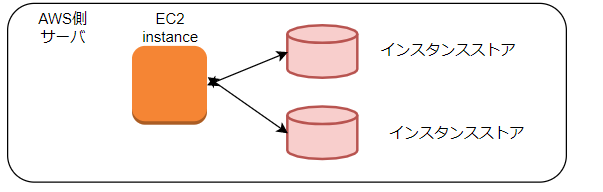
EBSには以下の2つのストレージがあるインスタンスストア
ホストの内蔵デバイスを使用する
EC2インスタンスは起動ごとにホストが変わるので、終了・起動を行うとデータは消えてしまう
内蔵デバイスなので、レイテンシーが優れている
一時的にデータを確保することに優れています
EBS
物理筐体が分かれていて、ネットワークでアタッチ・デタッチができる
ホストに依存しないので終了・起動を行ってもデータは消えない
ネットワーク経由でのデータのやり取りなので、インスタンスストアよりはレイテンシーが優れていない
EBSの選択肢
- SSD
- 汎用SSD : 標準的によく使われれる
- プロビジョンドIOPS SSD : 高頻度でアクセスされる場合
- HDD
- スループット最適化 HDD : ストリーミングやログ処理で使われる
- Cold HDD : アーカイブなど低頻度のアクセスの場合
Amazon Simple Storage Service(s3)
格納容量無制限の安価なストレージサービス
また、リージョン内で複数箇所に自動で保存するので耐久性も高い
s3のオブジェクト(データ)はバケット内でフラットに格納される
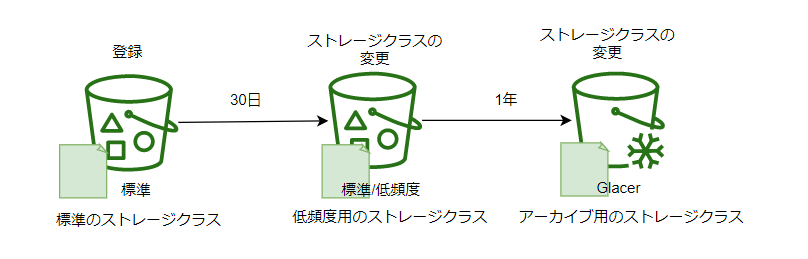
コンソール画面の表示上はパス指定ができ、ディレクトリ構造にも見えるようになっているライフサイクルルール
使用頻度によって低価格なストレージクラスに格納させることが出来ます
さらに、Glacierというサービスと組み合わせてアーカイブ用のストレージクラスに格納することで費用を抑えることが出来ます
Glacierは実体はs3とは別サービスでアーカイブ用のストレージサービス。
なのでGlacierに格納された後、復元する際は一時的にGlacierからs3にデータがコピーされデータを取り出すことができる
復元にかかる時間も選択できる
- Expedited : 緊急のデータの取得が必要な場合・少量のファイル
- Standard : 3-5時間程度でデータを取得できる
- Bulk : 5-12時間でデータを取得できる・大量データ
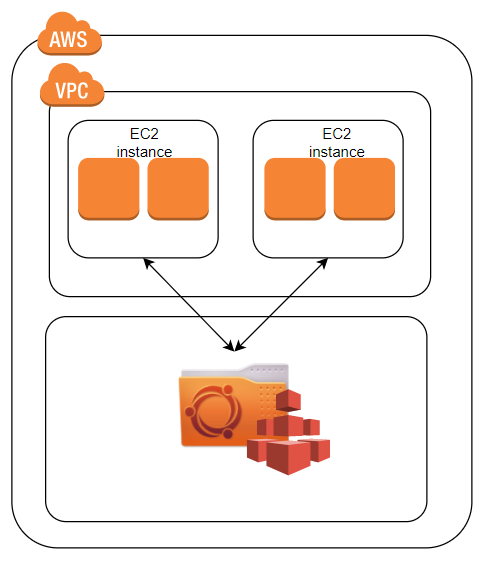
Amazon Elastic File System (EFS)
EC2インスタンスと組み合わせて使用する、NFS(Network File System)ファイルストレージサービスです
マルチAZに対応していたり、容量を自動で拡張出来たりなど使用用途が多くあります
参考