- 投稿日:2021-01-06T16:33:01+09:00
Federated Learning Demo アプリを動かしてみよう
はじめに
最近Fedarated Learningという考え方が提唱されています。学習そのものは、分散したノードで行い、学習済みモデルは、すべての学習データを反映した全体的なものにするという考え方です。
IBMでは、その考え方に基づいたAPIをライブラリとして実装し、すでにデモプログラムが動くようになっています。
これからご紹介するのは、そのデモプログラムで、コメントを日本語化したものです。
Fedarated Learningがどんなものか、試してみたい方は、是非、このコードを実行してみて下さい。Federated Learningとは
Federated Learningは、当事者がデータを共有せずにデータを活用したい場合に適しています。
例えば、航空会社連合が、世界的なパンデミックが航空会社の遅延にどのように影響するかをモデル化したいとします。
フェデレーションに参加している各パーティは、データを移動したり共有したりすることなく、データを使用して共通のモデルを学習することができます。
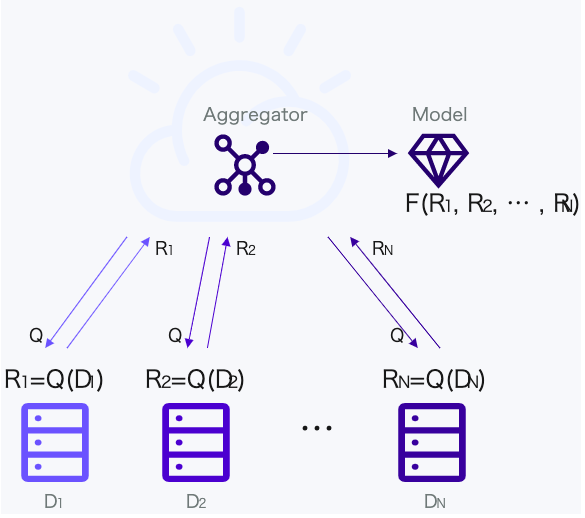
結果として得られたモデルは、スコアリングデータに対してより正確な予測を提供するために展開することができ、連合の各メンバーにより良い結果と洞察力を与えることができます。この図は、連合した当事者が、データを互いに共有することなく、共通のモデルを訓練するためにデータを送信する方法を示しています。アグリゲータはモデルの更新を管理します。
中央のアグリゲーターは、各パーティに対して、問い合わせ(Q)を行います。各パーティは、自分のローカルのデータで作成したモデルに基づき、問い合わせに対する回答を返します。(R1からRNまで)
アグリゲーターは、問い合わせ結果を総合して、中央のモデルを学習させます。より詳細な説明については、以下を参照して下さい。
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fed-lea.html?audience=wdp
動作確認済み環境
動作は、Watson Studio上のJupyter Notebookで確認しています。
IBM Cloud上で必要なサービスはCloud Object Storage、Watson Studio、Watson Machine Learningのみです。すべて、クレジットカード登録なしのライトアカウントで利用できますので、このデモも、ライトアカウントで試してみることが可能です。サンプルnotebook
サンプルNotebookは以下の2つになります。
概要紹介
NotebookはPart1とPart2に分かれています。
Part1では、Federation Learningのための枠組みを作ります。
Part2では、アグリゲーターが各パーティと通信して、実際の学習を行います。
Federated Learning実施時には、IBM社が提供しているライブラリである、ibmflが用いられています。実習ステップ1
それでは、実習をはじめましょう。
Notebookの読み込み
最初にWatson Studioのプロジェクト管理画面から「Projectに追加」->「Notebook」を選択します。
Notebook名入力画面になったら、下のように各項目を入力します。① 「URLから」タブを選択
② 名前に「FL Part1」を入力
③ URL欄に以下のURLをコピペして入力
https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/Federeted%20Learning%20%E3%83%87%E3%83%A2%20Part1.ipynb
④ 「作成」ボタンをクリック
正しく読み込めると下のような画面になります。
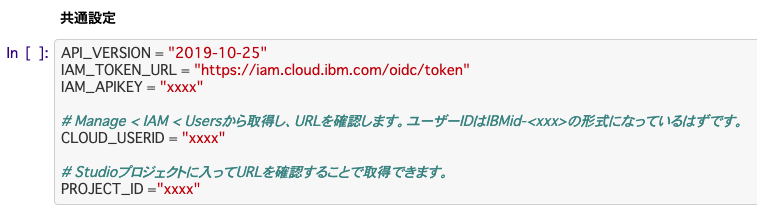
共通設定
IAM_APIKEY、CLOUD_USERID、PROJECT_IDの3つのパラメータを設定します。
IAM_APIKEY
IAM_APIKEYは、下のリンクから「IBM Cloud APIキーの作成」ボタンをクリックして作成します。
https://cloud.ibm.com/iam/apikeys
CLOUD_USERID
CLOUD_USERIDは、下のリンクから、アカウントオーナーのリンクをクリックします。
https://cloud.ibm.com/iam/users
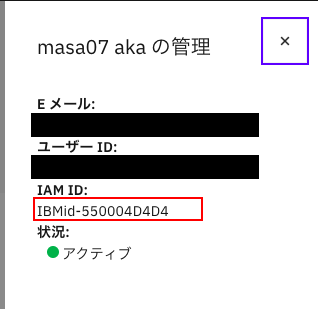
下の管理画面で、右上の「詳細」ボタンをクリックします。
すると、下のようにIAM IDが表示されるので、この値を用います。
PROJECT_ID
NotebookのURLをテキストエディタに貼り付けます。このとき、赤枠で囲んだ部分がProject_IDになるので、このテキストをコピペします。
WML設定
Watson Machine Learningのサイトをダラスにしている場合、修正は不要です。
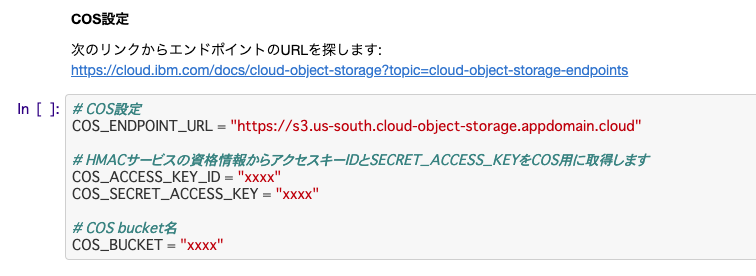
COS設定
COSに関しては、資格情報取得の前に、COSにバケットを作るところから始める必要があります。
目的は違うのですが、ちょうど下記手順の1章がそのまま該当するので、この手順に従って下さい。https://qiita.com/makaishi2/items/d2f5fa23cbc2255ab476#1-cos%E5%81%B4%E3%81%AE%E4%BD%9C%E6%A5%AD
これで、Notebook設定に必要な「バケット名(COS_BUCKET)」「資格情報(COS_ACCESS_KEY_IDとCOS_SECRET_ACCESS_KEY)」「エンドポイントURL(COS_ENDPOINT_URL)」のすべての情報が入手できるはずです。
Notebookの実行
これでNotebook実行に際して必要な事前準備はすべて完了です。
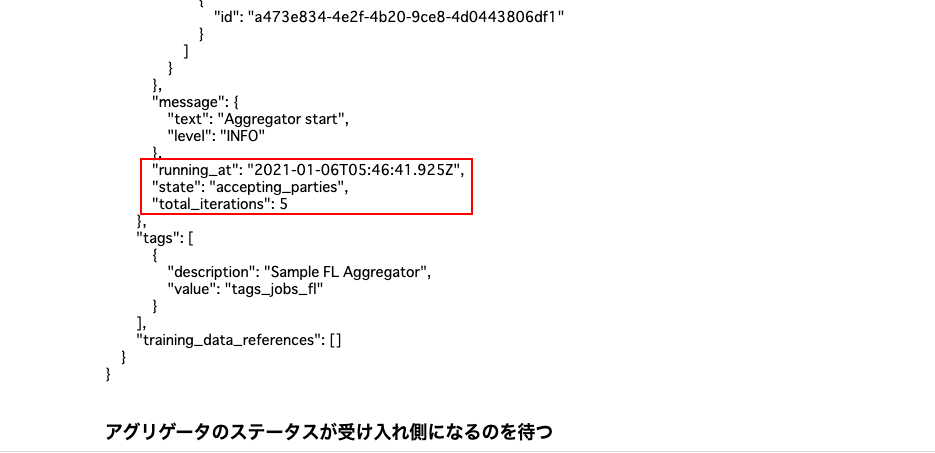
あとは、Notebook内の指示に従って、上から順にセルを実行して下さい。一番下の方に「4.1 トレーニングジョブのステータス取得」というセルがあります。
このセルは1分おきに繰り返し実行して、 最後、Statusがaccepting_partiesとなるのを待ちます。
このセルが実行エラーになった場合は、上の設定のどこかに誤りがありますので、記事を参考に一つ一つ見直すようにして下さい。
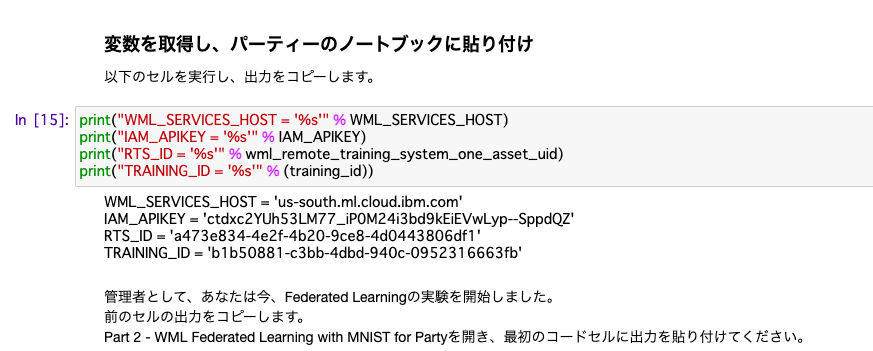
COSのエンドポイントURLが間違えやすい箇所のようです。(回復力によってURLが別になる)ステータスが正しく変わったら、下記の一番下のセルを実行し、出力結果をコピーしてテキストエディタなどに保存します。
この結果は、Part 2でそのまま利用することになります。
実習ステップ2
Notebookの読み込み
Notebook読み込み手順はPart1とほぼ同じです。
Notebook名入力画面になったら、下のように各項目を入力します。① 「URLから」タブを選択
② 名前に「FL Part2」を入力
③ URL欄に以下のURLをコピペして入力
https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/Federeted%20Learning%20%E3%83%87%E3%83%A2%20Part2.ipynb
④ 「作成」ボタンをクリック正しく読み込まれると、下のような画面になります。
セルの設定
Notebook上部の下記のセルを、Part1で取得した情報にまるごと置き換えます。
Part2は、これで設定作業は終わりです。
Notebookの実行
あとは、上から順にNotebookを実行して下さい。
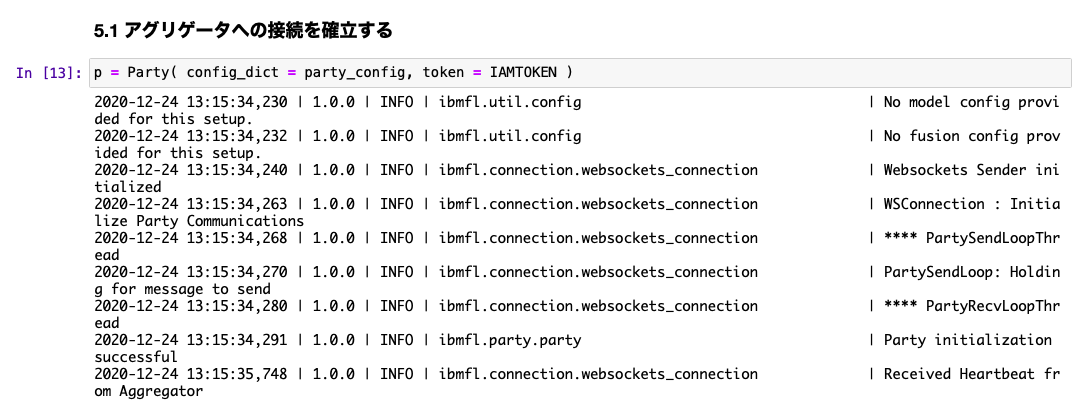
うまくいくと、次のような結果が得られるはずです。5.1の実行結果
5.2の実行結果
(途中略)
一番下の結果例








- 投稿日:2021-01-06T09:50:37+09:00
tensorflow-gpuを動くようにするためにすること
初めに
パソコンを初期化したらtensorflowをgpuで動かすために色々入れなおさなきゃいけなかった。
そしたらいろいろ躓いたので、今後また入れなおすようにメモ環境
windows10
RTX2070
Ryzen 3700x
Anaconda道筋
Anacondaのダウンロード
環境の作成
tensorflowの依存環境の把握
cudaのダウンロード
cuDNNのダウンロード
パスバージョン
2019年にtensorflowが1.xから2.xになって書き方が結構変わったみたい
よってネット上に結構あるプログラムが動かないのでないっぽい
よって環境を二つ作って、一つは2.xの最新版、もう一つは1.xの最新版を入れる2.x
Python3.7
tensorflow-gpu==2.4.0
cudnn8.0.5
cuda11.0
keras-2.4.3環境作成
https://qiita.com/ozaki_physics/items/985188feb92570e5b82d
に環境の作り方がある。Conda create -n 37tens24 python=3.7 anacondaversionの把握
次に、tensorflowの依存環境を把握
https://www.tensorflow.org/install/source_windows?hl=ja
最新版はなかったため、また時々間違っているためhttps://www.kkaneko.jp/tools/win/keras.html
こちらで確認した
また、基本的にこのサイトに沿えば良い
最新版はkerasは依存間関係なさそうpip install tensorflow-gpu==2.4.0 pip install kerascuda toolkit
https://developer.nvidia.com/cuda-toolkit-archive
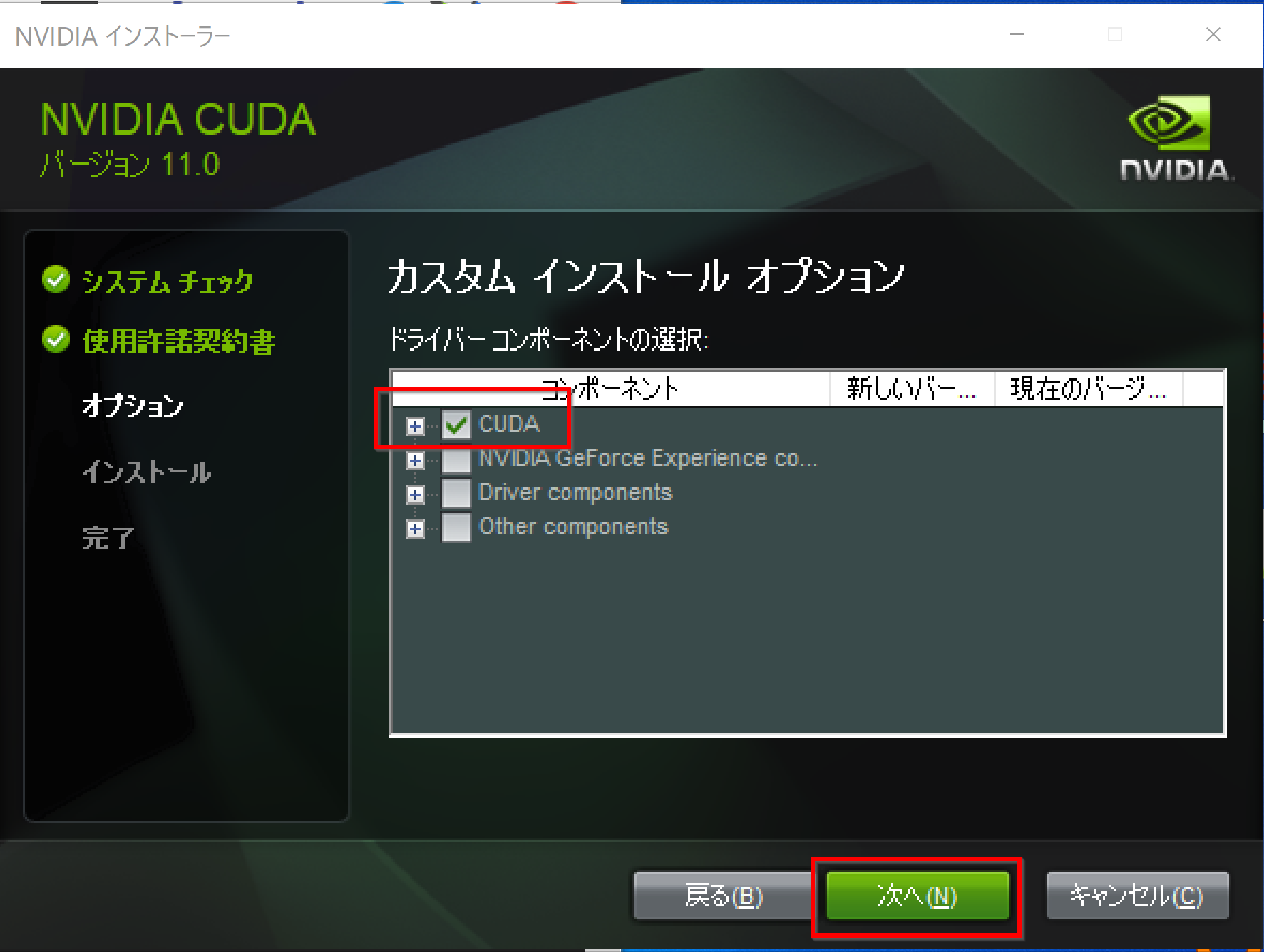
ここからダウンロード11.0をダウンロード
やり直すことを考えてlocalの方をダウンロードしたほうがいい(500MBぐらい)実行
最初はすべてダウンロードhttps://www.kkaneko.jp/tools/win/cuda.html
ここが詳しいcudnn
詳しい解説
https://www.kkaneko.jp/tools/win/cudnn805.htmlhttps://developer.nvidia.com/cudnn
ここからダウンロード
そして解凍C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
やり直すこと考えてこれをバックアップしてから解凍内容をコピペpathの追加
システム の環境変数の名前
CUDNN_PATH
値
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
のように設定(管理者から)なお、システムの環境変数の変更には管理者で開く必要がある。
https://www.lisz-works.com/entry/sys-env-admin
Windowsマーク右クリックからの管理者powershell
Start C:\Windows\system32\rundll32.exe sysdm.cpl, EditEnvironmentVariablesこれで全て使えるようになる。
1.x
37tens115
tensorflow_gpu-1.15.0
Cudnn7.4.2では動かないので7.6.5
Cuda10.0
Keras2.3.1
最新版の Keras は TensorFlow 1.15 では動かない. Keras のバージョン 2.3.1 をインストールする二つ目かつ古いバージョンの場合、cudaは
これだけでいいこのサイトが詳しい
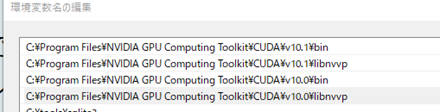
https://www.kkaneko.jp/tools/win/cuda.html※ 複数の版の CUDA ツールキットをインストールする場合には, 複数のパスが設定される このとき・古い版の方が先に来ている場合には、後になるように調整する
Cudnn_pathは11のままで動いた
まとめ
意外とすんなりいかず、大変なので頑張ってください。