- 投稿日:2021-01-06T23:18:04+09:00
EC2(AmazonLinux2)でnode.jsを起動するまでの過程記録(nodemonを使う)
前提として行ったこと
①AWSへの登録
②EC2サーバーの新規立ち上げ
③RDBの新規構築
④ローカル環境で制作したフォルダの、EC2へのアップロード今回はnodemon を使いました。
これによってシステムの内容に変更があった時、再起動しなくても適応される(はず)。以下、EC2サーバー上で正しく動作させるために行ったことを記録する。
目次
・行ったこと
→パーミッション設定
→「npm start で起動するようにする」
→必要なもののインストール
→DB情報の書き換え
→エラー「Permission denied」
→nodemonのインストール
・おまけ(永久実行)
・参考文献行ったこと(失敗も含む)
パーミッション設定
編集したいファイルは、フォルダごと権限を777にした。
$sudo chmod 777 フォルダ名orファイル名
権限を変えるのは危ないので「ローカルで書き換えてアップロード」を繰りかえす方がいいかも。
(今回は個人製作でいじられても重大事件になるようなシステムではないので気軽に変えた)「npm start」で起動するようにする
package.jsonに以下を追加
"scripts": { "start": "nodemon ./bin/www" }これは絶対に必要ではない。
直接nodemon ./bon/wwwと打ち込んでも実行できる。必要なもののインストール
npm install
$curl --silent --location https://rpm.nodesource.com/setup_10.x | sudo bash -
$sudo yum -y install npmnode.js install
$sudo yum -y install nodejsnodemon install
$sudo npm install -g nodemonpostgresql install
ここを見ましたexpress install
$npm -g install expressDB情報の書き換え
ローカル環境で開発した際、index.jsのソースコードの中に書いた接続情報は、ローカル環境でしか動作しない。
EC2サーバー上で正常に動作させるために、host: 'localhost' → host: '[AWSで作成したDBのエンドポイント]' ←変更 port: 5432 ←追加と書き換えた。
ここで
$npm start (もしくは$nodemon ./bin/www)
を実行したが、Permission denied(権限エラー)で実行できず。エラー「Permission denied」
/node_modules/.bin/nodemon: Permission denied npm ERR! code ELIFECYCLE npm ERR! errno 126 npm ERR! ths-web-page@1.0.0 start: `nodemon ./bin/www` npm ERR! Exit status 126 npm ERR! npm ERR! Failed at the ths-web-page@1.0.0 start script. npm ERR! This is probably not a problem with npm. There is likely additional logging output above.wwwがあるフォルダまでのすべてのフォルダの権限をゆるくしてみる
権限エラーが出ていたので権限制限ゆるくしてみた。
※当たり前ですが会社のシステムとかで勝手に権限ゆるくするのは絶対にダメ!→まだ同じエラーが出ます。多分この操作は意味がなかった
nodemonをインストールする
$sudo npm install -g nodemon
このコマンドを打ったらインストールされ、
正常に$npm start (もしくは$nodemon ./bin/www)を実行できた!!それにしてもなぜ権限エラーに??
おまけ(永久実行)
node.jsを、AmazonLinuxからログアウトした後もそのまま起動しておくには、
$sudo npm install -g forever
でインストールして
$sudo forever start ./bin/www
というコマンドを叩く。参考文献URL
Amazon EC2でnode.js,Expressアプリケーションを立ち上げる
Amazon Linux 2 に PostgreSQL 11 をインストールする
npm start の使い方
node.js バージョンアップコマンド
AWS EC2 AmazonLinux2 Node.jsをインストールしてnpmコマンドを使用できる様にする
- 投稿日:2021-01-06T22:43:39+09:00
インスタンスの自動起動停止をする Instance Scheduler を触ってみた
Instance Scheduler とは
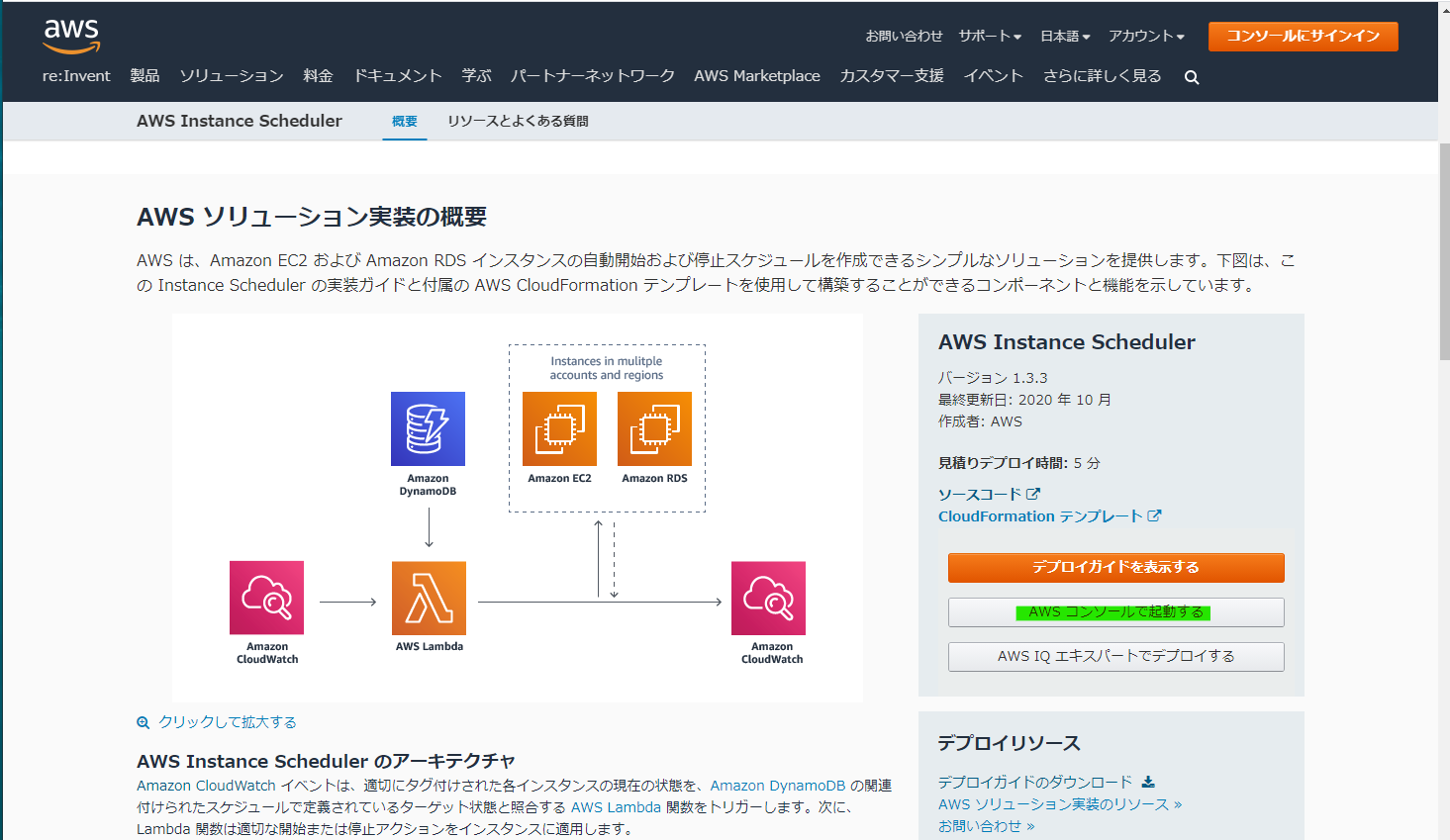
AWS を使っていると、コストを削減するために、定期的に EC2 インスタンスや RDS インスタンスを停止したいときがあります。CloudWatch Event + Lambda を使って独自にプログラムを作っても良いですが、実装するのがめんどくさいです。そういったときに、AWS が提供している Instance Scheduler が便利に使えます。AWS 公式で提供されているソリューションになっていて、多機能で安心感があります。
Instance Scheduler は、AWS のマネージドサービスではなく、いくつかのマネージドサービスを組み合わせて提供されているソリューションです。CloudFormation のテンプレートが提供されており、簡単に Deploy が出来て、自動的に起動停止をしてくれます。
こちらのURL で公開されています。
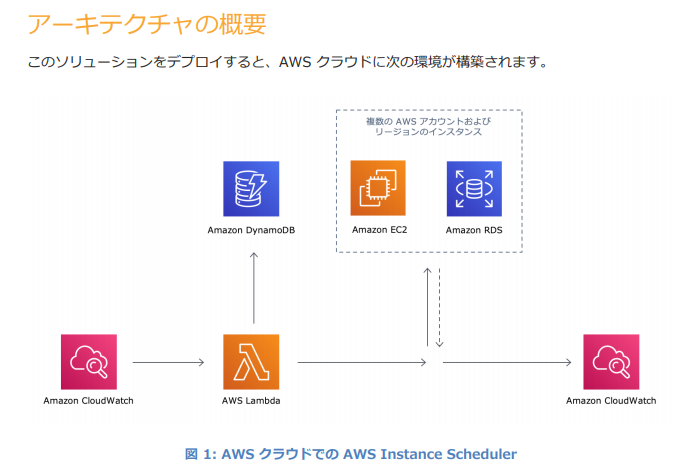
https://aws.amazon.com/jp/solutions/implementations/instance-scheduler/アーキテクチャの概要はこんなかんじです。 (引用)
EventBridge (画像では CloudWatch) が定期的に Lambda を起動して、その Lambda が DynamoDB に格納されている情報を読み込んで、EC2 インスタンスと RDS インスタンスの自動停止・起動を行う構成です。対象のインスタンスは、特定の Tag を付与して起動停止の対象と判断しています。
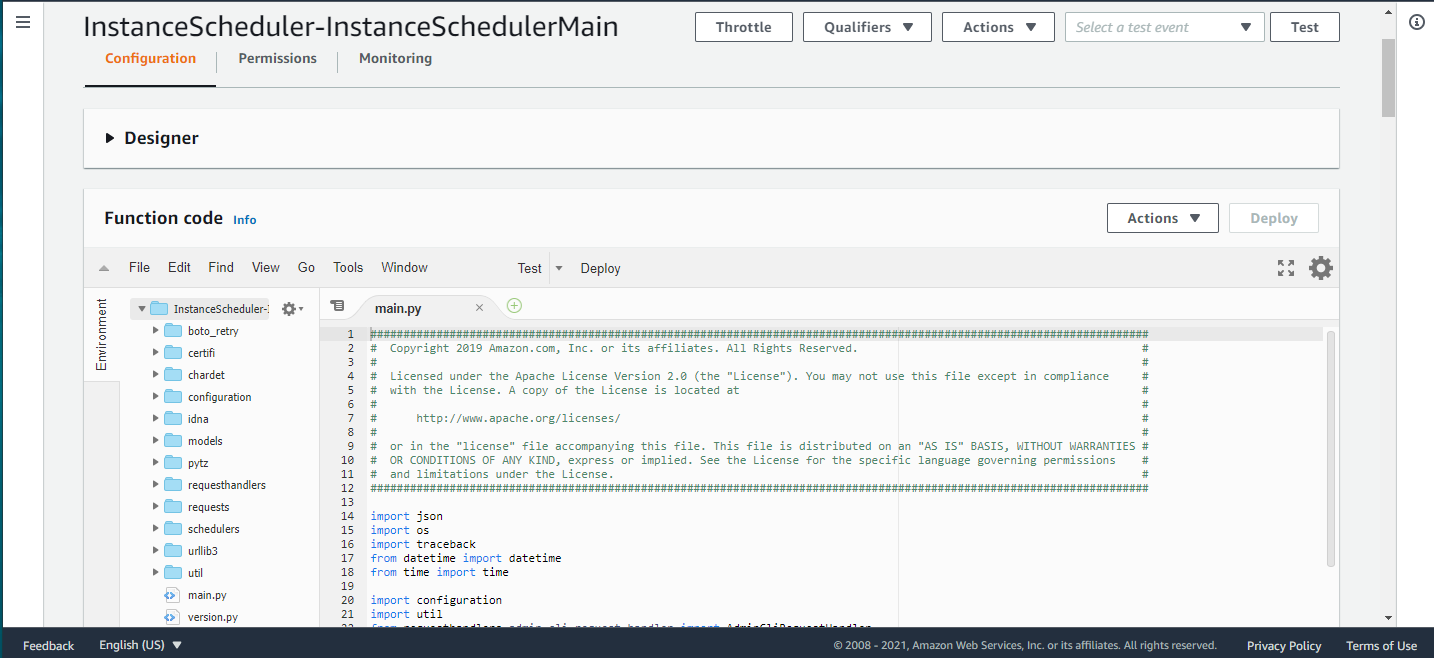
それでは、Instance Scheduler の Deploy 方法を備忘録としてメモしておきます。
Instance Scheduler Stack の起動
次の URL にアクセスします。
https://aws.amazon.com/jp/solutions/implementations/instance-scheduler/画面の中から、AWS コンソールで起動する を選択します。
すると、AWS のマネージドコンソールで、Instance Scheduler を CloudFormation で Deploy する画面に移ります。対象の Region を確認したあとで、Next を押します。
ちなみに、ここで View in Designer を押すと視覚的にわかりやすく CloudFormation で出来上がるリソースが確認できます。
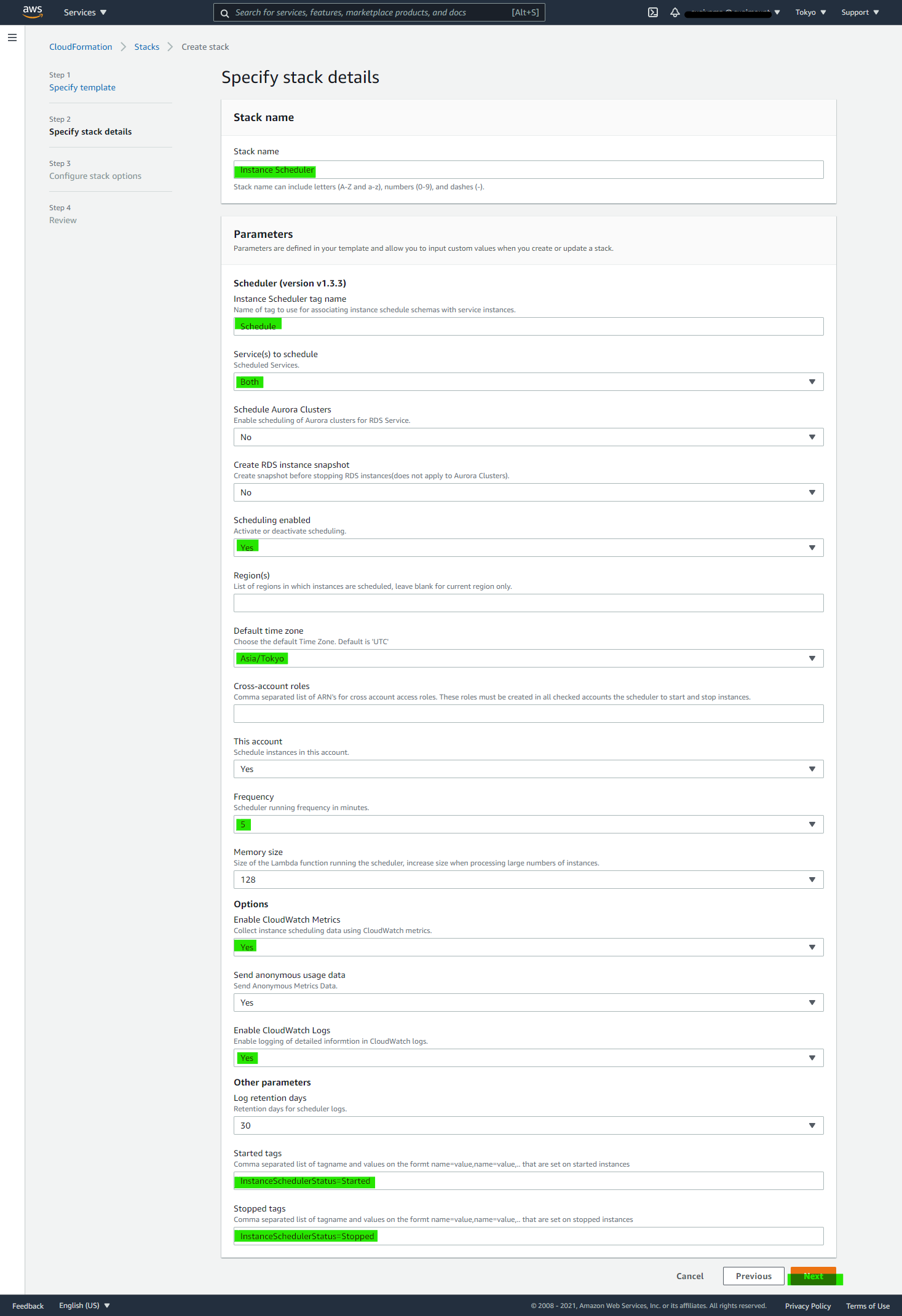
各種パラメータを入れて Next を入れます。パラメータの詳細はこちら のドキュメントに乗っています。
この記事の場合は、5分おきに Lambda を起動するパラメータをいれています。
確認画面で IAM リソースの作成を許すチェックを入れて Create stack を押します。
作成中になります。約5分ほど待つと作成完了になりました。
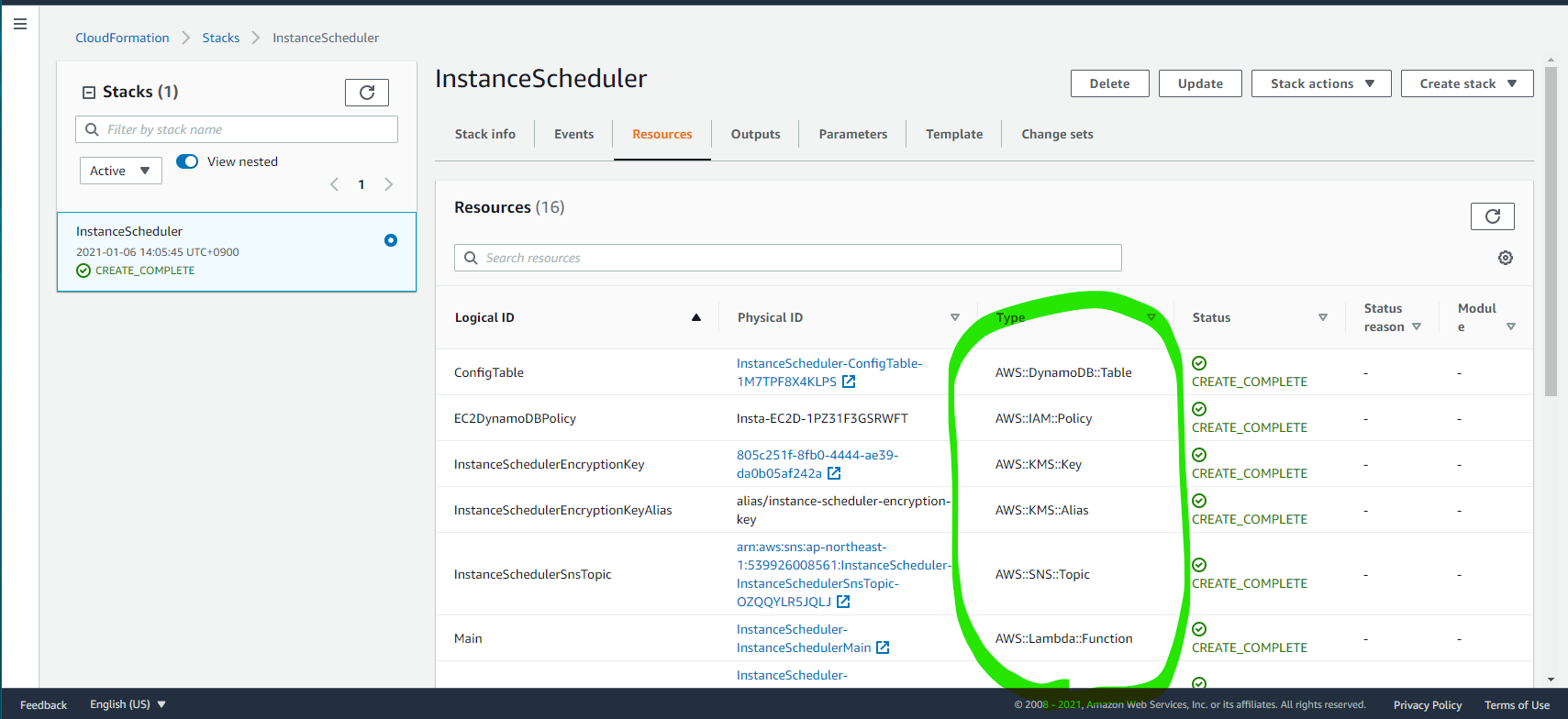
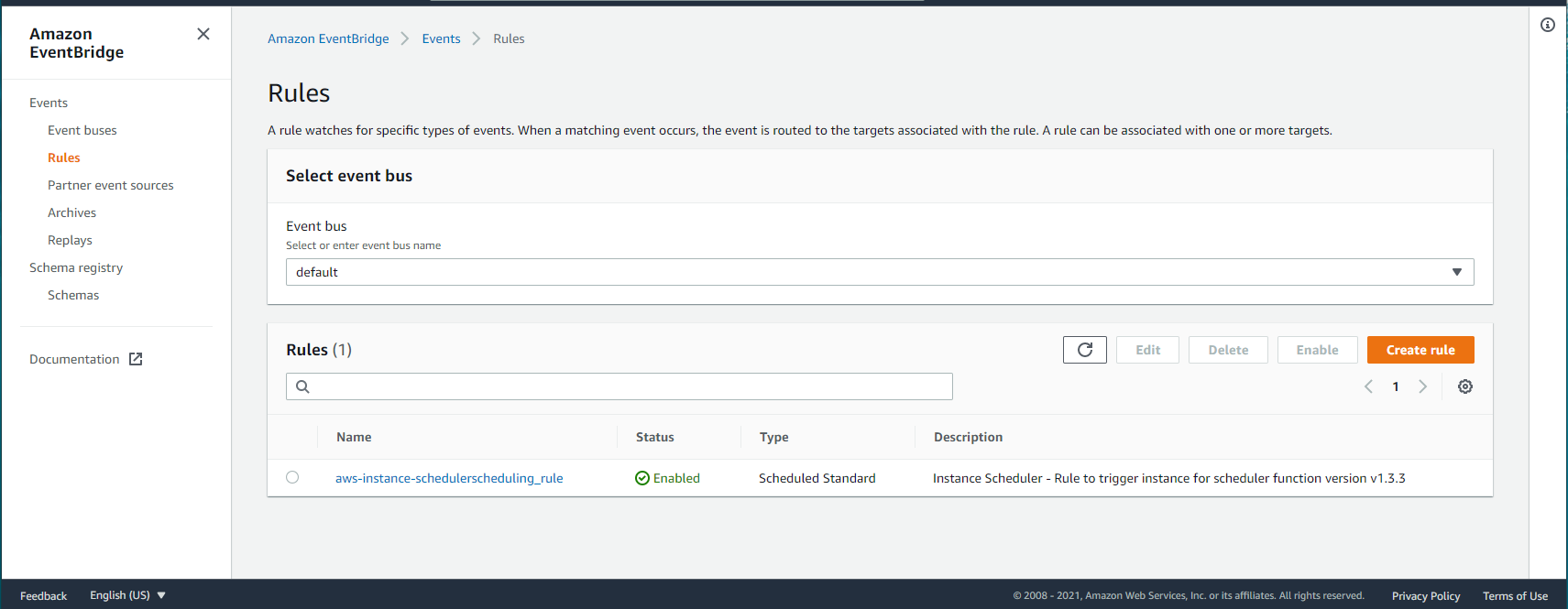
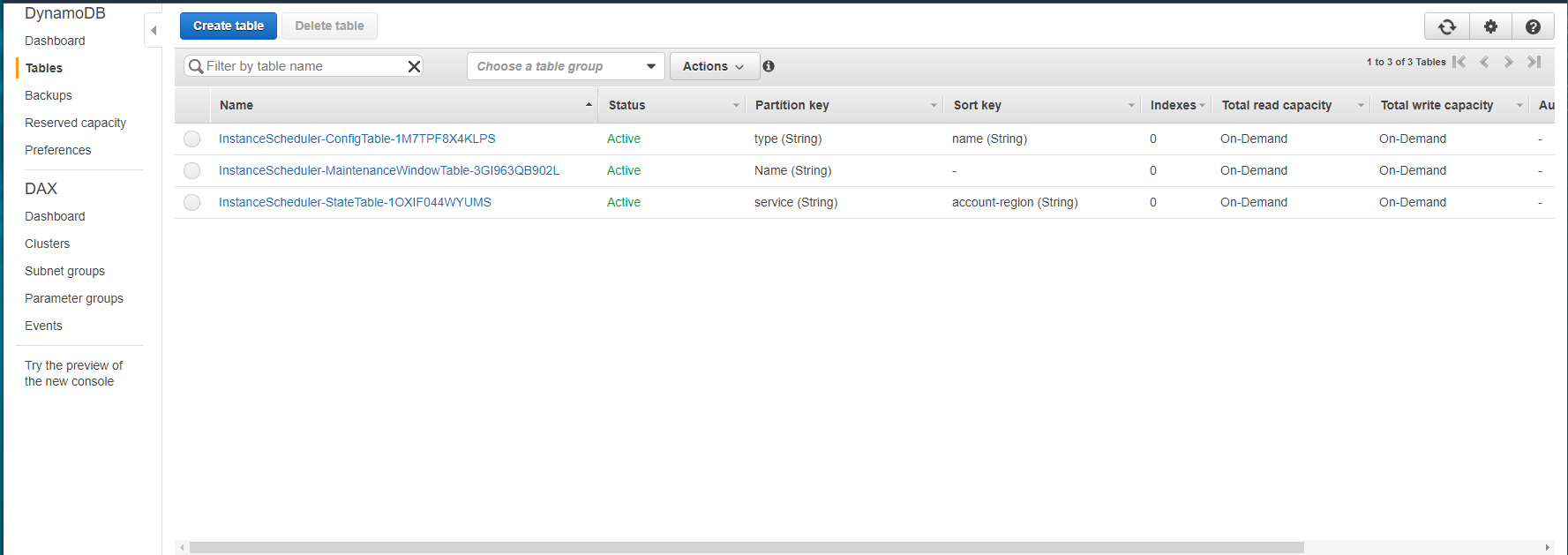
CloudFormation によって、作成された Resources はこれらです
- Lambda Function
- DynamoDB Table
- IAM Policy
- KMS Key
- KMS Alias
- SNS Topic
- EventBridge Rule
Scheduler CLI Install
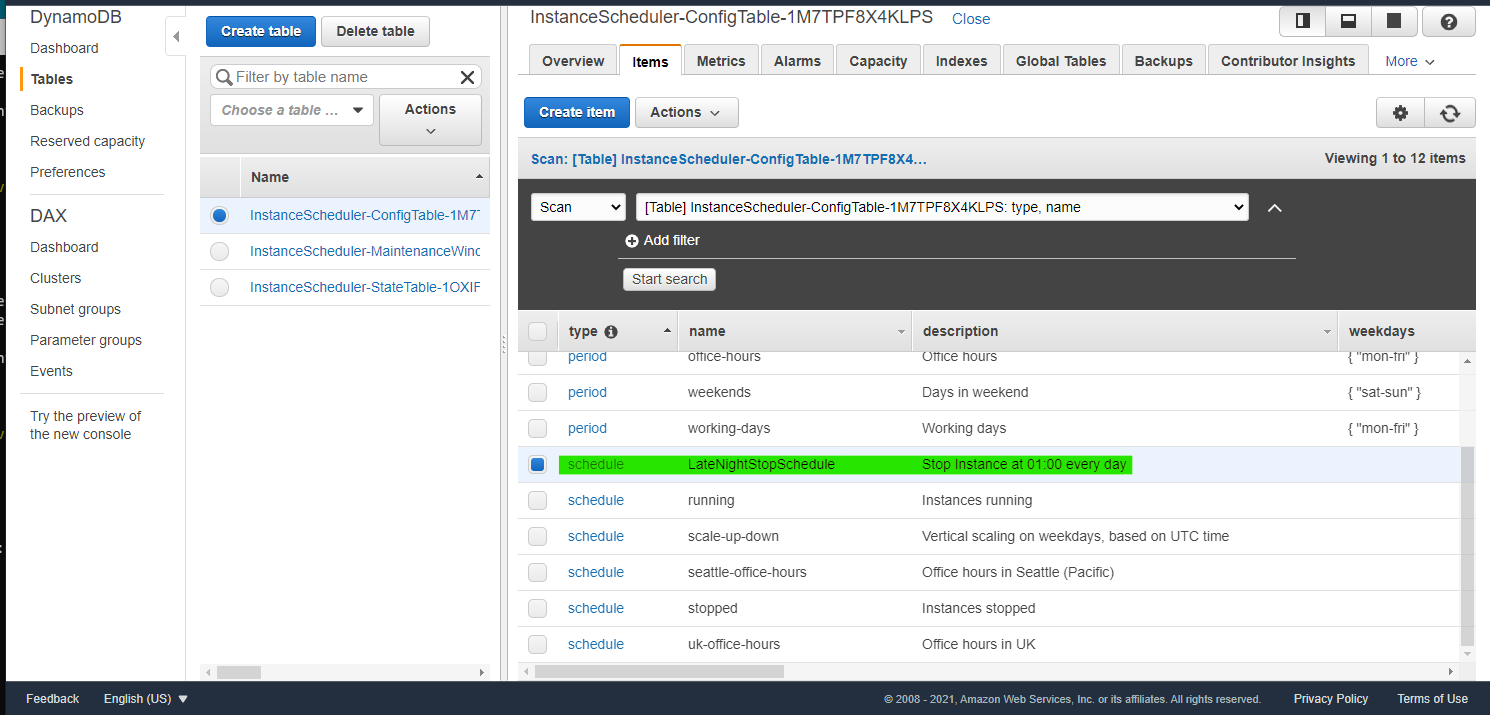
Instance Scheduler では、いつどのようにインスタンスを起動停止するかを Dynamo DB でデータを格納しています。DynamoDB データに紐づくインスタンスを、自動的に起動・停止をしてくれます。
DynamoDB には、次の2つの重要なデータが格納されています
- スケジュール(Schedule) : インスタンス起動停止に関係するスケジュールを指定。1つ以上の期間(Period)が含まれている。
- 期間(Period) : いつからいつまでを起動するのか期間を定義
紐づくインスタンスとの関係性はこんな感じです。
インスタンス → Schedule → Period
インスタンスは、Schedule と1対1で紐づき、Schedule は Period と、1対多で紐づきます。詳細はこちらに書かれています。
https://d1.awsstatic.com/Solutions/ja_JP/instance-scheduler.pdfSchedule と Period は独自にカスタマイズが出来ます。DynamoDB のデータを直接編集することもできますが、Scheduler CLI を使うのが便利です。次のコマンドで Scheduler CLI をダウンロードします。
wget https://s3.amazonaws.com/solutions-reference/aws-instance-scheduler/latest/scheduler-cli.zip unzip scheduler-cli.zipScheduler CLI を Install
sudo python3 setup.py install実行例
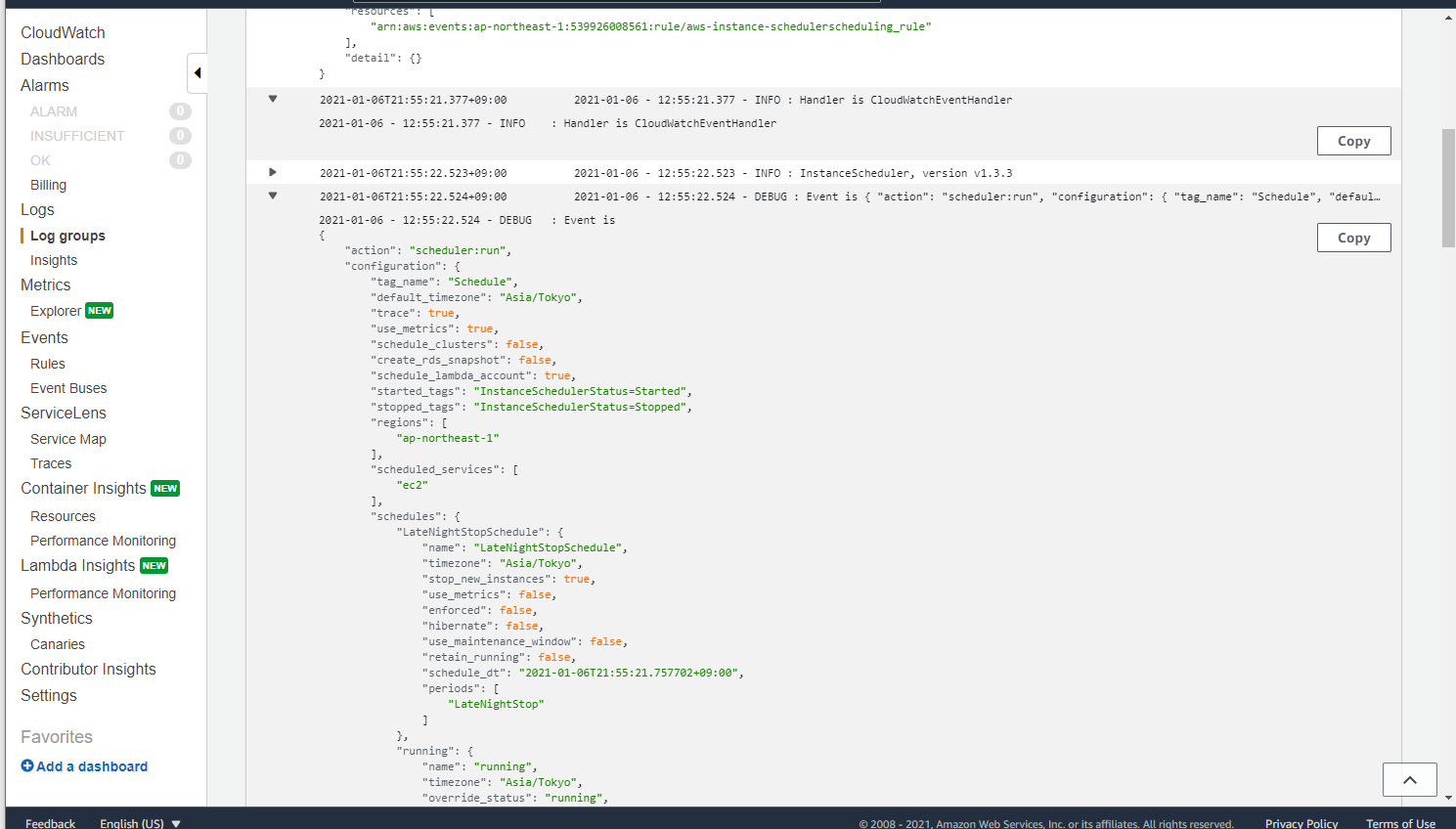
> sudo python3 setup.py install /usr/lib/python3/dist-packages/setuptools/dist.py:473: UserWarning: Normalizing 'v1.2.0' to '1.2.0' warnings.warn( running install running bdist_egg running egg_info creating scheduler_cli.egg-info 省略 Using /usr/lib/python3/dist-packages Finished processing dependencies for scheduler-cli==1.2.0 >Scheduler CLI の 動作検証 をしていきます。
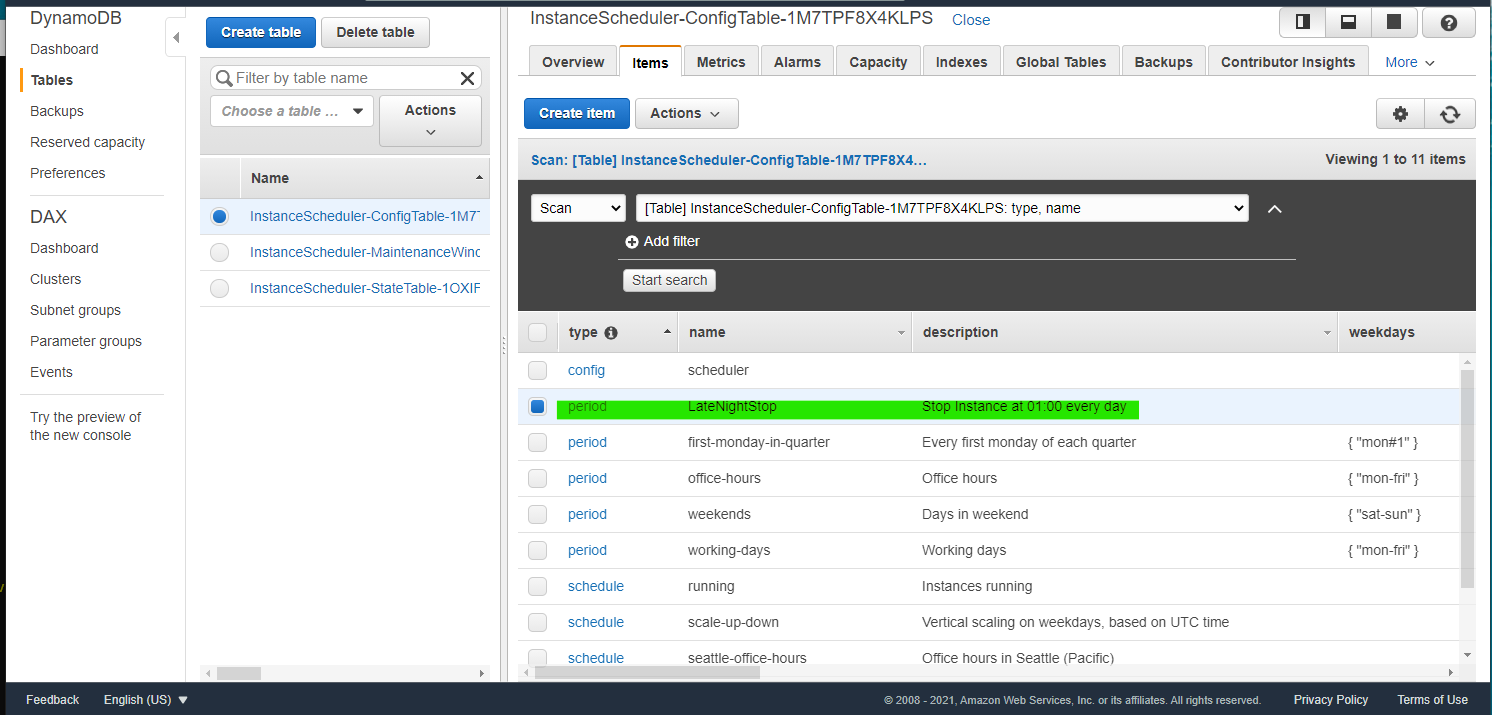
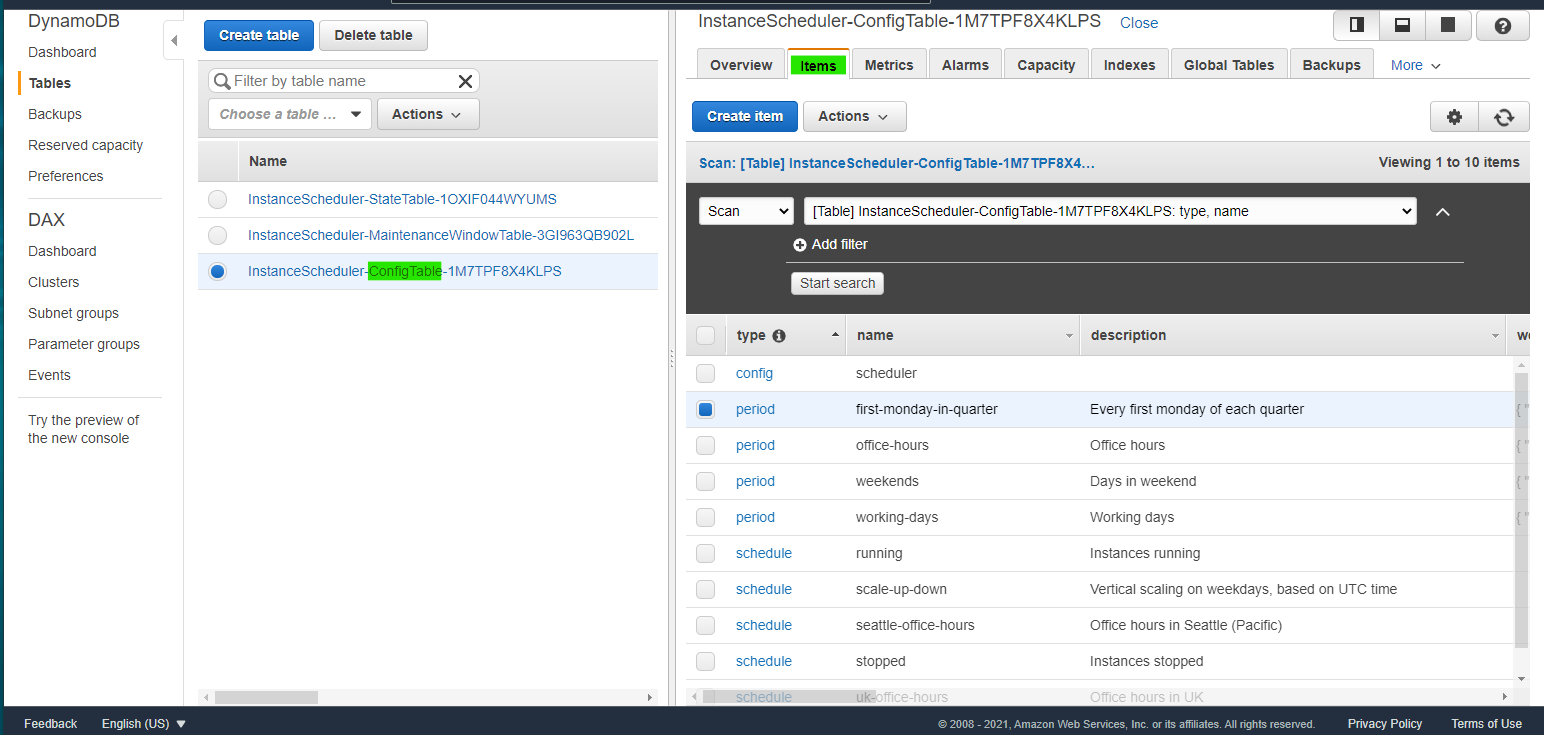
DynamoDB の ConfigTable に保存されている Period 一覧を取得するコマンドです。scheduler-cli describe-periods --stack InstanceSchedulerデフォルトで格納されている Period を JSON で取得できます。
> scheduler-cli describe-periods --stack InstanceScheduler { "Periods": [ { "Months": [ "jan/3" ], "Description": "Every first monday of each quarter", "Weekdays": [ "mon#1" ], "Name": "first-monday-in-quarter", "Type": "period" }, { "Begintime": "09:00", "Description": "Office hours", "Endtime": "17:00", "Weekdays": [ "mon-fri" ], "Name": "office-hours", "Type": "period" }, { "Description": "Days in weekend", "Weekdays": [ "sat-sun" ], "Name": "weekends", "Type": "period" }, { "Description": "Working days", "Weekdays": [ "mon-fri" ], "Name": "working-days", "Type": "period" } ] }同様に、Schedule の一覧を取得します
scheduler-cli describe-schedules --stack InstanceScheduler実行例
> scheduler-cli describe-schedules --stack InstanceScheduler { "Schedules": [ { "Description": "Instances running", "Name": "running", "UseMetrics": false, "Type": "schedule", "OverrideStatus": "running" }, { "Timezone": "UTC", "Description": "Vertical scaling on weekdays, based on UTC time", "Periods": [ "weekends@t2.nano", "working-days@t2.micro" ], "Name": "scale-up-down", "Type": "schedule" }, { "Timezone": "US/Pacific", "Description": "Office hours in Seattle (Pacific)", "Periods": [ "office-hours" ], "Name": "seattle-office-hours", "Type": "schedule" }, { "Description": "Instances stopped", "Name": "stopped", "UseMetrics": false, "Type": "schedule", "OverrideStatus": "stopped" }, { "Timezone": "Europe/London", "Description": "Office hours in UK", "Periods": [ "office-hours" ], "Name": "uk-office-hours", "Type": "schedule" } ] }Period の設定
Scheduler CLI が正常に動作したので、Period を独自に設定していきます。今回は、深夜1時に起動しているインスタンスを自動的に停止したいので、次のコマンドで
LateNightStopという名前の Period を作成します。scheduler-cli create-period \ --name "LateNightStop" \ --description "Stop Instance at 01:00 every day" \ --endtime "01:00" \ --stack InstanceScheduler実行例
> scheduler-cli create-period \ --name "LateNightStop" \ --description "Stop Instance at 01:00 every day" \ --endtime "01:00" \ --stack InstanceScheduler { "Period": { "Description": "Stop Instance at 01:00 every day", "Endtime": "01:00", "Name": "LateNightStop", "Type": "period" } }DynamoDB Table に、作成した
LateNightStopItem が生成されています。
Schedule の設定
次に、作成した Period を使った
LateNightStopScheduleという名前の Schedule を作成します。scheduler-cli create-schedule \ --name "LateNightStopSchedule" \ --description "Stop Instance at 01:00 every day" \ --periods "LateNightStop" \ --timezone "Asia/Tokyo" \ --stack InstanceScheduler実行例
> scheduler-cli create-schedule \ --name "LateNightStopSchedule" \ --description "Stop Instance at 01:00 every day" \ --periods "LateNightStop" \ --timezone "Asia/Tokyo" \ --stack InstanceScheduler { "Schedule": { "Description": "Stop Instance at 01:00 every day", "Timezone": "Asia/Tokyo", "Name": "LateNightStopSchedule", "Periods": [ "LateNightStop" ], "StopNewInstances": true, "UseMaintenanceWindow": false, "RetainRunning": false, "Enforced": false, "Hibernate": false, "UseMetrics": false, "Type": "schedule" } }DynamoDB Table に、作成した
LateNightStopScheduleItem が生成されています。
インスタンスにタグ付け
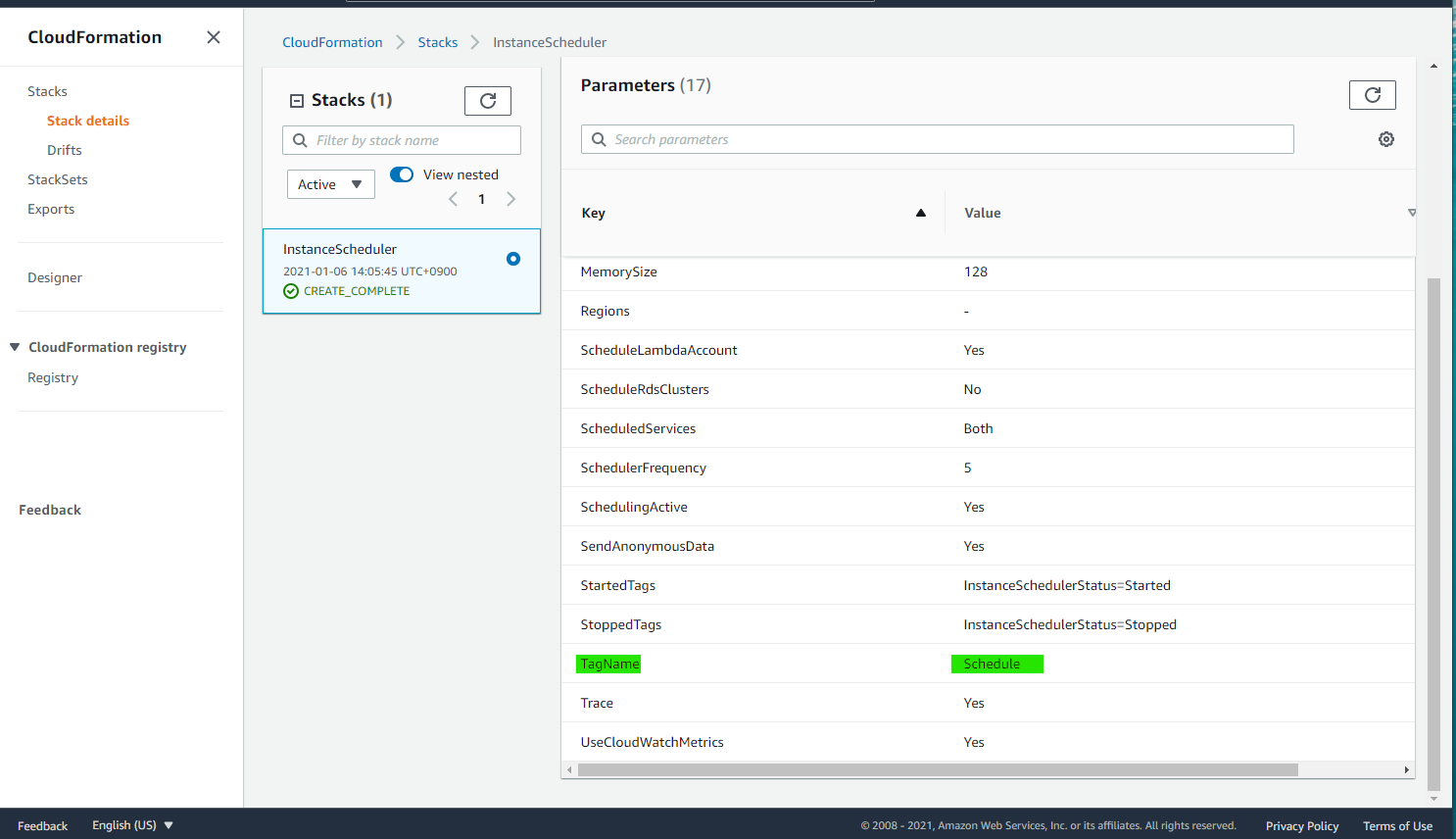
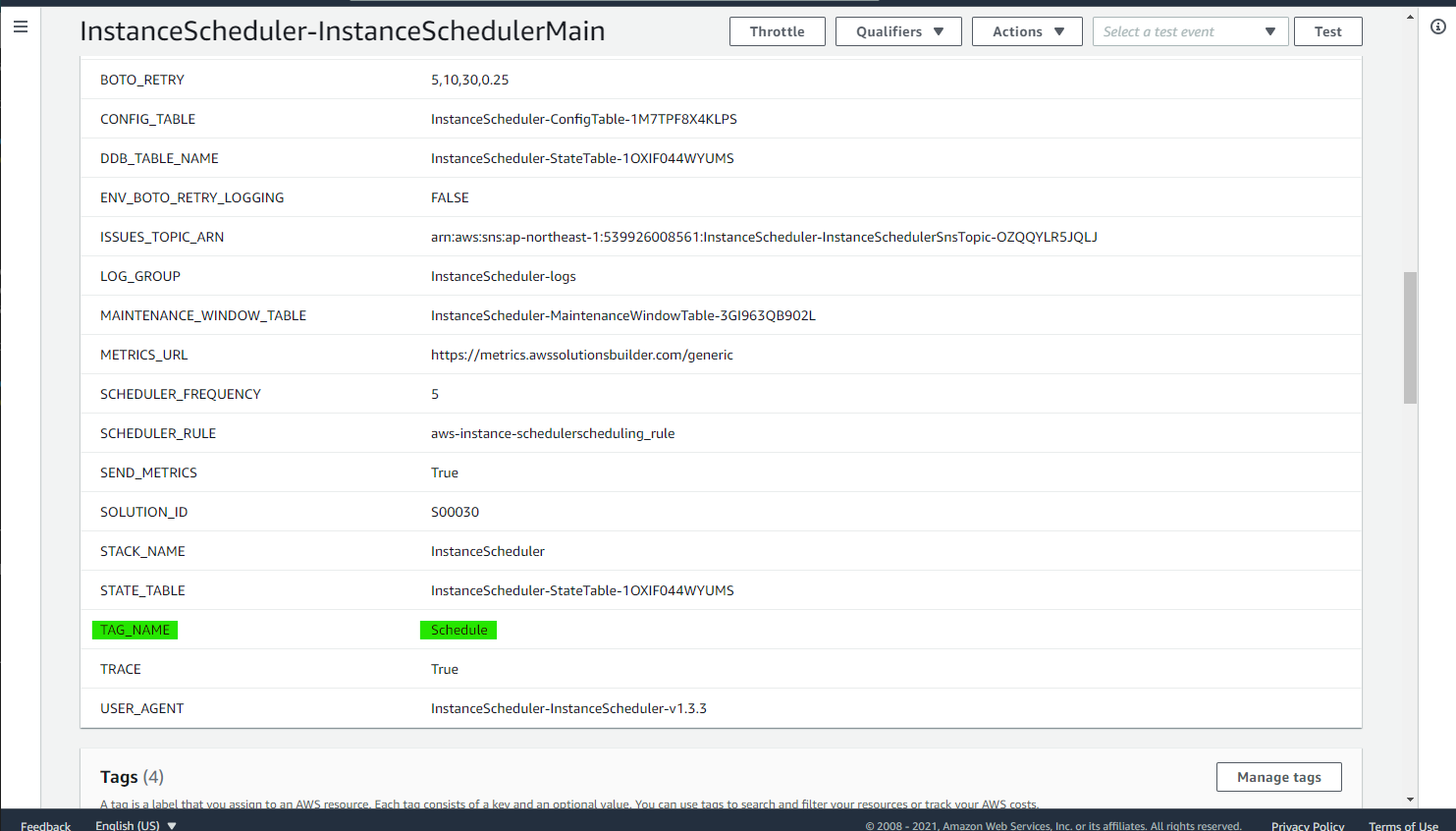
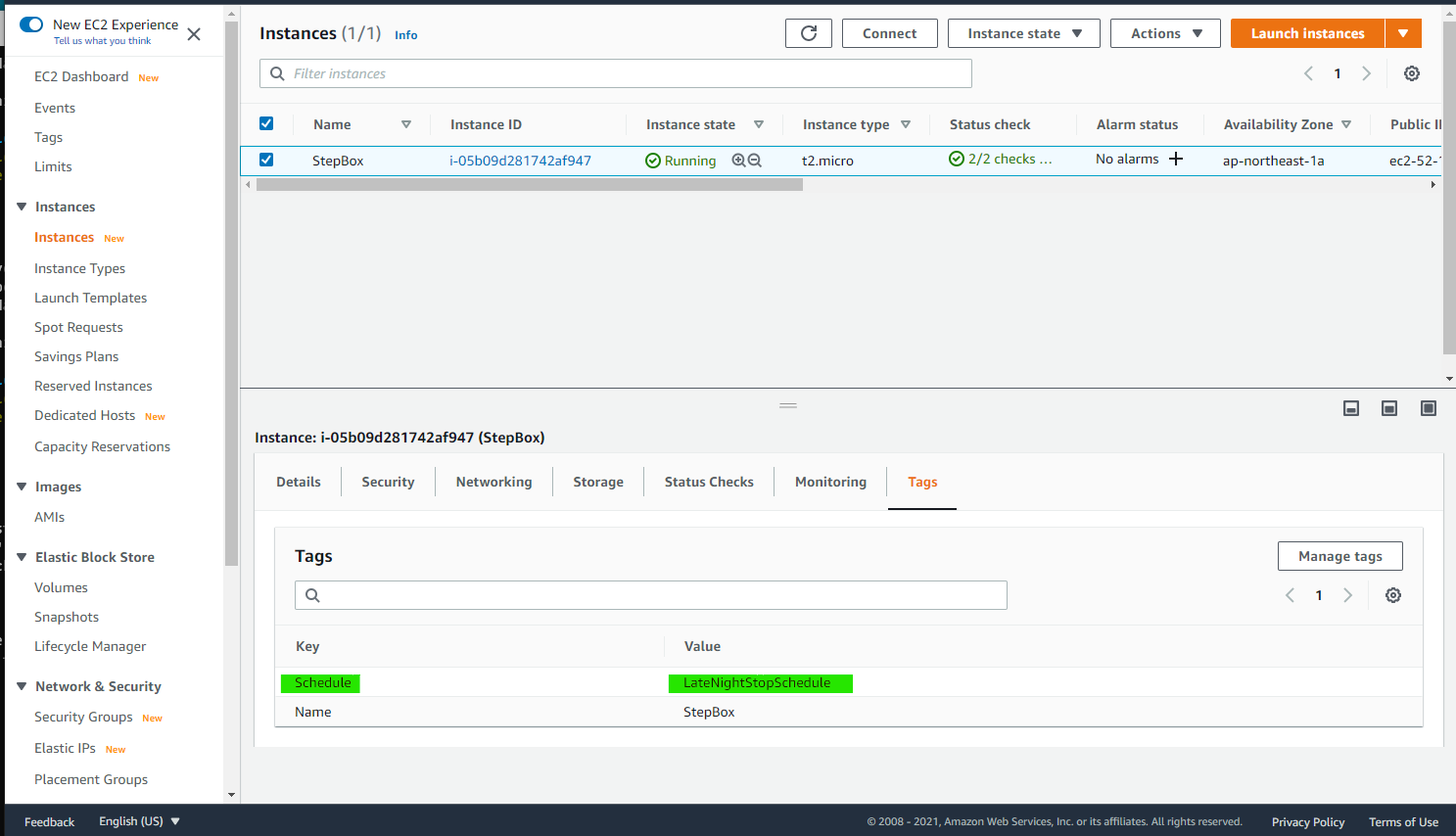
EC2 インスタンスに 特定の Tag をつけると自動起動・停止が動作します。TagName=Shedule名の書式で Tag を設定すればよいです。
この記事の場合は、TagName をScheduleとしているので、Schedule=LateNightStopScheduleという形式で Tag を生成します。TagName は Stack の Parameters を表示すれば確認できます。
ちなみに、この指定は Lambda Function の Environment で使われています。
それでは、EC2 Instance に Tag を付与しました。これで自動的に停止されます。
CloudWatch Logs
Instance Scheduler 配下の Lambda の Log は、CloudWatch Logs に出力されています。
また、エラーが発生した際には、自動生成された SNS にサブスクライブ先を追加することで、エラーメッセージを受けることも出来ます。必要そうな場合は手動で追加をしておくのもよいです。
付録 : CloudFormation で作成されたリソースの確認
Event Bridge
Rule
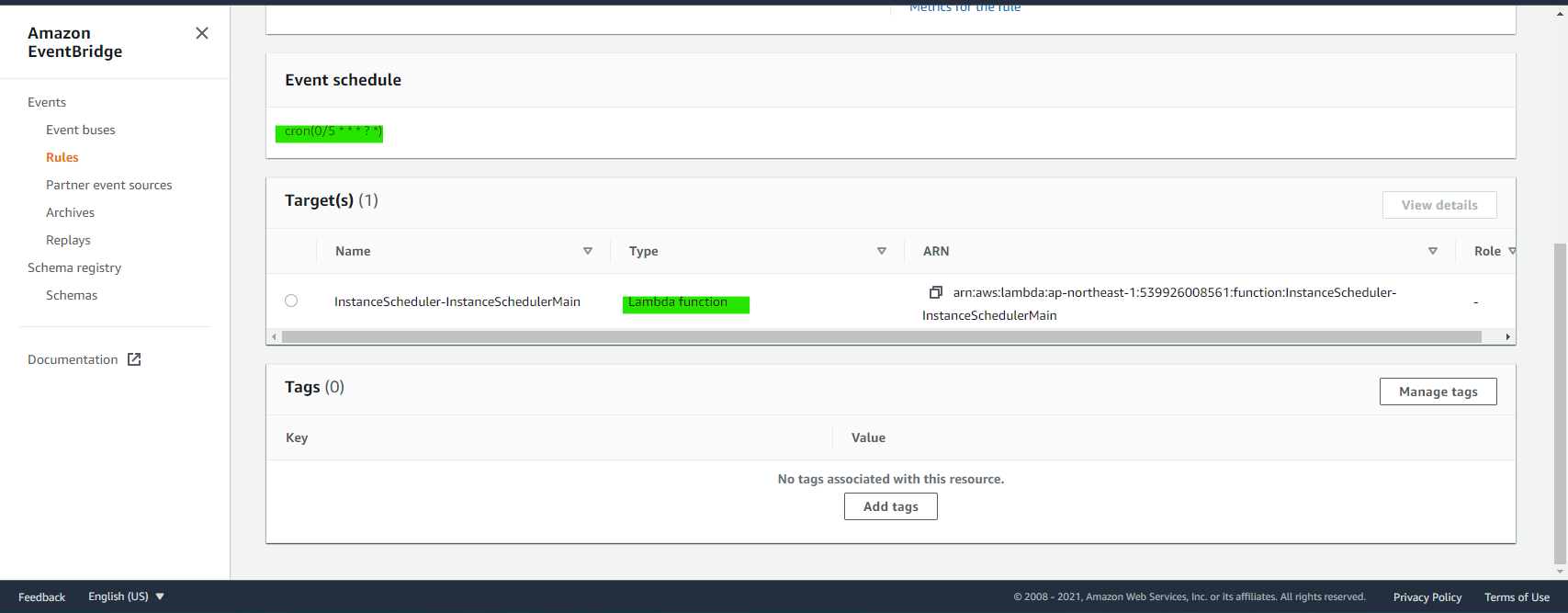
5分おきに、Lambda を Trigger している
Lambda
Function が作成されている
実際のソースコードや環境変数などが確認可能
DynamoDB
DynamoDB Table が3つ作成されている
ConfigTable には、スケジュールや期間のテンプレート設定が初めから入っている
StateTable や MantenainceWindowTable の中身は空っぽ
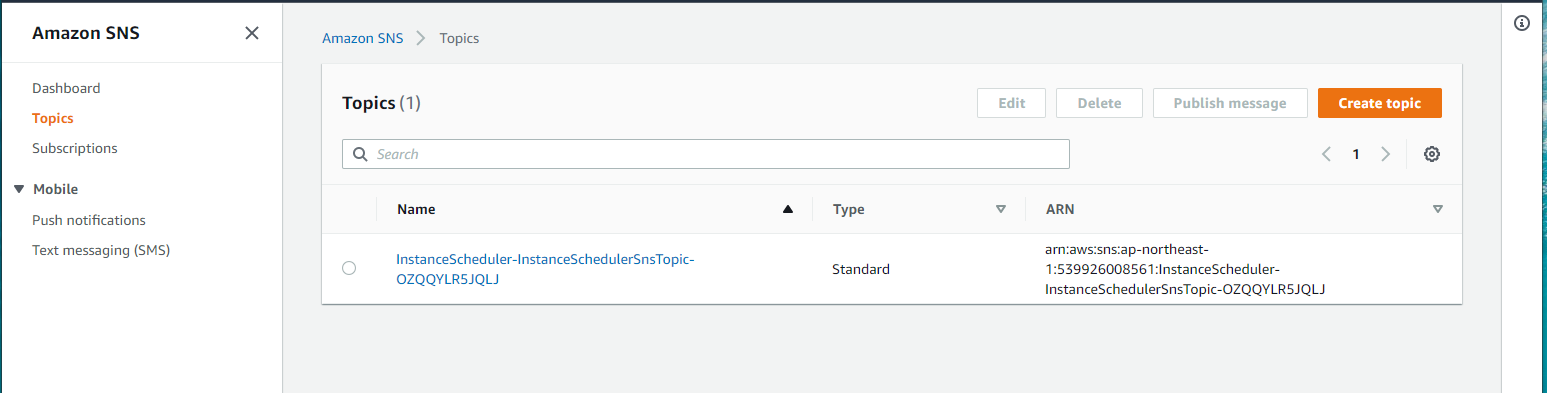
SNS
Topic が1個作成されている
Subscription は空なので、手動でメール通知したいアドレスを入れる
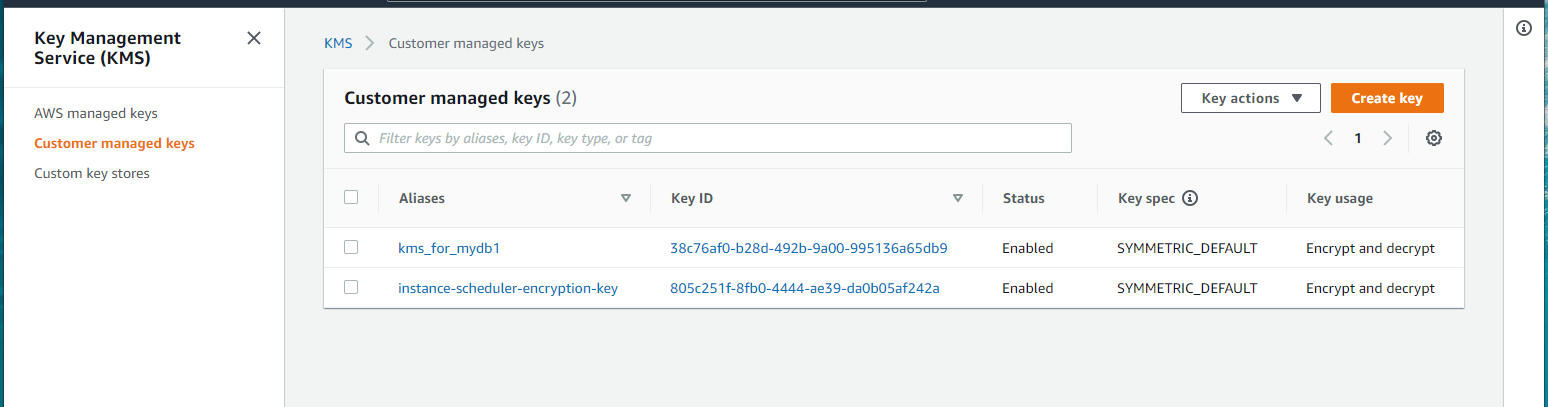
KMS
Customer managed key が作成されている
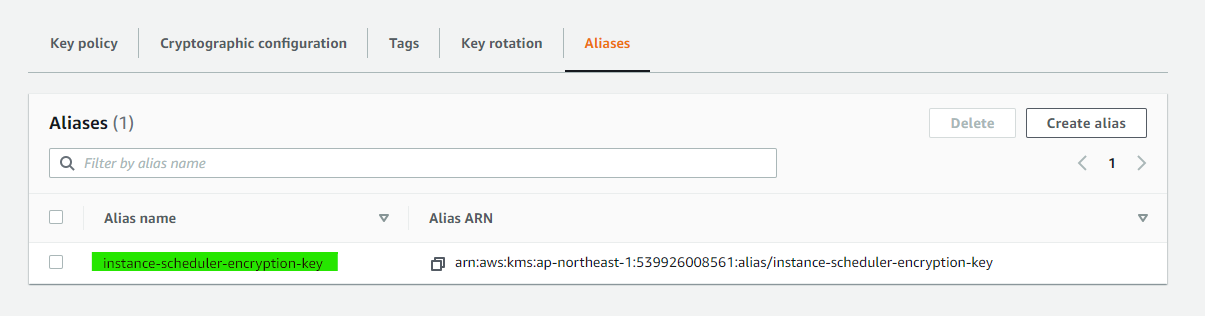
Alias name もこんなかんじ
参考URL
AWS Instance Scheduler
https://aws.amazon.com/jp/solutions/implementations/instance-scheduler/AWS 実装ガイド
https://d1.awsstatic.com/Solutions/ja_JP/instance-scheduler.pdfhttps://aws.amazon.com/jp/premiumsupport/knowledge-center/stop-start-instance-scheduler/
- 投稿日:2021-01-06T22:33:11+09:00
AWS 認定 Alexa スキルビルダー 専門知識 サンプル問題を解説します
こんにちは。
今回は、 AWS 認定 Alexa スキルビルダー 専門知識のサンプル問題解説です。
Amazon Alexa のスキル開発者の方向けの認定試験です。
AWS 認定とは
AWS 認定は、クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
AWS 認定は領域やレベルごとに分けられ、本校執筆時点(2021/1)では12の認定資格が存在しています。
- レベル
- 基礎
- アソシエイト(中級ととらえてください)
- プロフェッショナル(上級ととらえてください)
- 専門知識(対象分野に特化した高度な認定)
- 領域
- 全般
- ソリューション
- 開発
- 運用
- DBや機械学習といった専門分野
表にまとめると以下の通りです。
# レベル 認定名 1 基礎 クラウドプラクティショナー 2 アソシエイト ソリューションアーキテクト アソシエイト 3 アソシエイト デベロッパー アソシエイト 4 アソシエイト SysOps アドミニストレーター アソシエイト 5 プロフェッショナル ソシューションアーキテクト プロフェッショナル 6 プロフェッショナル DevOps エンジニア プロフェッショナル 7 専門知識 高度なネットワーク 8 専門知識 Alexa スキルビルダー 9 専門知識 セキュリティ 10 専門知識 機械学習 11 専門知識 データ分析 12 専門知識 データベース AWS 認定 Alexa スキルビルダー 専門知識
試験の概要や出題割合などは、以下の試験ガイドをご確認ください。
https://d1.awsstatic.com/ja_JP/training-and-certification/docs-alexa-skill-builder-specialty/AWS-Certified-Alexa-Skill-Builder-Specialty_Exam-Guide.pdfサンプル問題を解いてみよう
それでは、サンプル問題を確認していきましょう。
※以降、Markdown 記法に合わせて、サンプル問題の ABCD を 1234 と置き換えています。
第1問
問題文
Alexa スキル開発者が、SSML の audio タグを使用して、短い MP3 ファイルの再生をするスキルを作成しています。
MP3 ファイルをホストする、可用性と拡張性が最も高いソリューションを開発するには、どうすればよいですか。
- ファイルを Amazon S3 バケットに格納する。
- ファイルを Amazon EC2 インスタンスに格納する。
- ファイルを Amazon DynamoDB テーブルに格納する。
- ファイルを Amazon ElastiCache に格納する。
回答
1
解説
MP3 ファイルを格納する場所として最適なものはどれか?という問題です。MP3 ファイルは HTTPS アクセスができる場所に格納できる必要があります。
https://developer.amazon.com/ja-JP/docs/alexa/custom-skills/speech-synthesis-markup-language-ssml-reference.html#hosting-the-audio-files-for-your-skill
- 適当であると考えます。 Amazon S3 は可用性と耐久性が高いストレージであること、容量無制限のため拡張性も選択肢の中では最も高いです。
- 不適当です。HTTPS アクセスは可能ですが、Amazon EC2 にアタッチした Amazon EBS に MP3 ファイルを格納し、 AMI 化して AutoScaling を使えば可用性は得られますが、拡張性に関しては難しいところです。例えば、新しいファイルを導入するたびに AMI を作る必要が出てきますし、容量上限もあります。
- 不適当です。Amazon DynamoDB には MP3 ファイルをそのまま格納することができません。
- 不適当です。Amazon ElastiCache はデータベースなどのデータをキャッシュするサービスで、データを永続的に格納するには適していません。またメモリ容量にも限界があります。
第2問
問題文
Login with Amazon を使用して Amazon Alexa スキル用のアカウントリンクをのコンフィギュレーションを行う際、個人情報 (PII) へのアクセス権の取得を避けるには、どのスコープを使用すればよいですか。
- profile:email
- profile:user_id
- profile
- profile:name
回答
2
解説
選択肢の中から、個人情報(PII:Personally Identifiable Information)へのアクセス権を取得することなく、ユーザーを一意に識別できるスコープはどれか?という問題です。
https://developer.amazon.com/ja/docs/login-with-amazon/customer-profile.html
- 不適当です。このスコープは存在しません。
- 適当であると考えます。 ユーザーを一意に識別できる情報を取得しつつ、メールアドレスや名前といった個人を特定する情報が含まれません。
- 不適当です。メールアドレスや名前にアクセスするため、個人情報へのアクセス権の取得を行ってしまいます。
- 不適当です。このスコープは存在しません。
第3問
問題文
Alexa スキル開発者が、リクエスト処理中の値を検査するために、console.log() ステートメントを使用して AWS Lambda 関数をデバッグしています。
log ステートメントの出力結果は、どこで確認できますか。
- ログファイルが Amazon CloudWatch Logs に格納される。
- 出力結果を表示するカードが Amazon Alexa アプリに作成される。
- ask simulate --debug コマンドの使用時に、メッセージがコンソールに表示される。
- メッセージが Amazon Alexa の音声出力として再生される。
回答
1
解説
AWS Lambda のログはどこに出力される?という問題です。
- 適当であると考えます。 CloudWatch Logs 内の対象の AWS Lambda 関数のロググループに格納されます。
- 不適当です。console.log() の内容はカードとして作成されません。 Amazon Alexa アプリにカードとして登録するには、JSON 応答に card プロパティを追加します。
- 不適当です。ask simulate --debug (ask v2 では ask smapi simulate-skill --debug )コマンド で、 console.log() の内容は表示されません。
- 不適当です。console.log() は Amazon Alexa の音声出力にはなりません。
第4問
問題文
地元企業を検索するスキルが、次の出力を応答として返しました。
<speak>I’ve found <emphasis level=”strong”>Bananas & Bears</emphasis></speak>Alexa スキル開発者はテスト中、スキルの処理が何回も失敗ていることに気付きました。Amazon CloudWatch のログを確認したところ、次のエラーが見つかりました。
"error":{ "type":"INVALID_RESPONSE" , "message":"Invalid SSML Output Speech for requestId amzn1.echoapi.request.afb31745-05ad-400e-8703-3a.Error:Fatal error occurred when processing SSML content.This usually happens when the SSML is not well formed.Error:Unexpected character ' ' (code 32) (missing name?)¥n at [row,col {unknown-source}]:[1,101]" }<speak> タグ内の応答テキストで、誤っている点は何ですか。
- <emphasis> の代わりに <say-as> を使用する必要がある。
- 文字列全体を引用符で囲む必要がある。
- 「I've」内のアポストロフィを削除する必要がある。
- テキスト内にアンパサンド (&) がある。
回答
4
解説
音声合成マークアップ言語(SSML:Speech Synthesis-Markup Language)の構成で誤っている箇所を見つけ出すという問題です。
- 不適当です。内容を見る限り Bananas & Bears を強く発話せよと読み取れるので emphasis タグは正しいです。 say-as タグはテキスト内容の解釈の仕方を指定するタグです。そのため、エラー内容と異なります。
- 不適当です。speak タグ内の文字列全体を引用符で囲んでしまうと、その中の emphasis タグも発話対象文字列として扱われてしまいます。
- 不適当です。Alexa スキルの発話ルールとして、アポストロフィは所有格や短縮形を示す際に使うとあるので問題ありません。
- 適当であると考えます。 アンパサンド(&)はそのまま使ってしまうと、 XML の制御文字として認識されてしまい、誤動作を起こします。そのため、エラーメッセージの内容と合致します。
第5問
問題文
スキルでマルチターンの対話をサポートするには、どうすればよいですか。
- スキルに、プロンプトのテキストを含んだ「必須」とマークされたスロットがある必要がある。
- スキルがフォローアップの質問をして、ユーザーに応答する必要がある。
- スキルで、質問と応答を格納するためのセッションアトリビュートを定義する必要がある。
- スキルは、応答で shouldEndSession=false を返す必要がある。
回答
4
解説
ワンショットではなく、Alexa と対話して利用するスキルを作るにはどうしたらよいか?という問題です。
- 不適当です。必須とマークされたスロットがあっても、マルチターンの対話にはなりません。
- 不適当です。reprompt メソッドを指していると思いますが、それだけでは、マルチターンの対話にはなりません。
- 不適当です。セッションアトリビュート自体は、セッションが維持されている間、記憶できる領域です。セッションを継続するために使われるものではありません。
- 適当であると考えます。 shouldEndSession=false を返すことでユーザーからの応答待ち状態になります。
第6問
問題文
Alexa スキル開発者が、ASK SDK と AWS Lambda を使用してポッドキャストスキルを作成しています。開発者は、ユーザーがポッドキャストのどのタイミングにいるか (途中、最後、最初) に応じて、スキルをそれぞれ異なる方法で起動させたいと考えています。
スキル呼び出しの再開タイミングを格納するには、どのアトリビュートを使用すればよいですか。
- 永続アトリビュート
- ユーザーアトリビュート
- セッションアトリビュート
- デバイスアトリビュート
回答
1
解説
スキル呼び出しの再開タイミングとあるので、セッションが終了した後、改めて起動した際に参照できるアトリビュートはどれか?という問題です。
https://developer.amazon.com/ja-JP/docs/alexa/alexa-skills-kit-sdk-for-nodejs/manage-attributes.html
- 適当であると考えます。 現在のセッションのライフサイクルが終了しても存続するアトリビュートなので要件を満たせます。
- 不適当です。ユーザーアトリビュートは存在しません。
- 不適当です。現在のスキルセッションが継続している間存続するアトリビュートなので、再開時には破棄されているため要件を満たせません。
- 不適当です。デバイスアトリビュートは存在しません。
第7問
問題文
outputSpeech オブジェクトを返すことができる Amazon Alexa リクエストは、次のうちどれですか(2 つ選択してください)。
- IntentRequest
- SessionEndedRequest
- Display.ElementSelected
- PlaybackController.NextCommandIssued
- AudioPlayer.PlaybackStarted
回答
1,3
解説
文字通り、選択肢の各種リクエストを実行後、応答として outputSopeech オブジェクトを返すことが可能なものはどれかという問題です。
https://developer.amazon.com/ja-JP/docs/alexa/custom-skills/request-and-response-json-reference.html#outputspeech-object
- 適当であると考えます。 IntentRequest リクエストに対する応答時に outputSpeech オブジェクトを返すことができます。
- 不適当です。SessionEndedRequest リクエストに対する応答時に outputSpeech オブジェクトを返すことができません。
- 適当であると考えます。 Display.ElementSelected リクエストに対する応答時に outputSpeech オブジェクトを返すことができます。
- 不適当です。PlaybackController.NextCommandIssued リクエストに対する応答時に outputSpeech オブジェクトを返すことができません。
- 不適当です。AudioPlayer.PlaybackStarted リクエストに対する応答時に outputSpeech オブジェクトを返すことができません。
第8問
問題文
Alexa スキル開発者が、「cat and dog facts」というスキル呼び出し名を選択しました。
このスキル呼び出し名は無効です。それはなぜですか。
- 文字数が多すぎる。
- 音節が 4 個以上ある。
- 「and」という接続語が含まれている。
- 文法的に誤っている。
回答
3
解説
スキル呼び出し名のつけ方を理解しているか?という問題です。
https://developer.amazon.com/ja-JP/docs/alexa/custom-skills/choose-the-invocation-name-for-a-custom-skill.html#cert-invocation-name-req
- 不適当です。文字数には特に規定はありません。
- 不適当です。特別な場合を除き、1語の呼び出し名は認められませんが、1語より多い分には規定はありません。
- 適当であると考えます。 and は特定のリクエスト(インテント)でスキルを呼び出す際に用いられる語句(つなぎ語/接続語)であるため、呼び出し名としては無効です。
- 不適当です。文法的に誤っていても「呼び出し名」の要件を満たしていれば問題ありません。
第9問
問題文
Alexa スキル開発者が、2 都市間での電車の接続情報を取得するスキルを作成しています。このスキルの呼び出し名は「train finder」です。また、接続を検索するためのメインインテントで、次のサンプル発話を指定しています。
- trains between {cityA} and {cityB}
- connections between {cityA} and {cityB}
- how do I go from {cityA} to {cityB}
- when is the next train from {cityA} to {cityB}
認定プロセスで合格するサンプルフレーズはどれですか(2 つ選択してください)。
- 「Alexa, how can I go from Manchester to London」
- 「Alexa, ask train finder for connections from Manchester to London」
- 「Alexa, ask train finder when is the next train from London to Manchester」
- 「How do I go from Manchester to London」
- 「Alexa, ask train finder what are the trains between London and Manchester」
回答
3、4
解説
認定プロセスでは、サンプルフレーズの中に指定したサンプル発話が完全に含まれていないと合格できません。よって、選択肢の中から、指定したサンプル発話と合致するものはどれか?という問題です。
ちなみに、 Alexa, ... はウェイクワード込みでの発話です。
- 不適当です。how do I ~ のサンプル発話はありますが、 how can I ~ のサンプル発話が存在しません。
- 不適当です。connections between ~のサンプル発話はありますが、 connections from ~ のサンプル発話が存在しません。
- 適当であると考えます。 上から4つ目のサンプル発話と合致します。
- 適当であると考えます。 上から3つ目のサンプル発話と合致します。
- 不適当です。上から1つ目のサンプル発話に合致しているように見えますが、what are the という疑問詞がありません。疑問詞は上から5番目のサンプル発話(when is the)のように含まれている必要があります。
第10問
問題文
次の JSON コードでは、MEDIA_TYPE という名前のカスタムスロットタイプを指定しています。このスロットには値が 2 つあります。
{ "types":[ { "name":"MEDIA_TYPE", "values":[ { "id":"SONG", "name":{ "value":"song", "synonyms":["tune","single","track"] } }, { "id":"ALBUMS", "name":{ "value":"album", "synonyms":["record","lp","cd"] } } ] } ] }ユーザーが「change the record」と言ったときに、あるインテントが一致し、MEDIA_TYPE スロットの値が格納されるとします。標準スロット値として返されるものはどれですか。
- ALBUMS
- album
- record
- song
回答
2
解説
発話した内容からどの値が格納されるかを判断する問題です。JSON 内で synonyms が定義されているので同義語が存在していますので、発話の内容と同義語が一致するものの値(value)が回答です。
- 不適当です。ALBUMS は id で定義されている内容です。値の ID として返されるものです。
- 適当であると考えます。 synonyms に record が存在するので、その value で定義されている album が標準スロット値として返されます。
- 不適当です。record は synonyms で定義されている内容であり、標準スロット値としては album が返されるので record は正しくありません。
- 不適当です。「change the record」と発話しているので、value: song やその synonyms と合致しません。
サンプル問題以外の学習リソース
様々な学習リソースが用意されています。
以下はその一例です。
- AWS 公式の模擬問題
- AWS 認定サイトから受験可能です。
- AWS 公式のトレーニング教材
まとめ
Alexa スキルビルダー 専門知識試験は、Alexa スキルの開発時に必要となるお作法に加えて、AWS のサービスとどう組み合わせていくとよいのかを理解しているか問うものです。そのため、可能であれば、 Alexa スキルを開発して、リリースするまでの一連の流れを体験すると試験対策としても実りのあるものになると考えます。
記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。
- 投稿日:2021-01-06T22:01:45+09:00
[RDSとElasticache]のマルチAZとレプリカの違い
背景
RDSとElasticacheのコストを削減をしてます。
RDSインスタンスのマルチAZを無効にすることでコストを半減した。考えずにElasticacheのインスタンスで同じことをやってみたら、全然効果がなかったです。ちゃんと両者のマルチAZの違いを理解してなかったのでまとめた。
前提
ここのElasticacheはRedisを指してます。
違い
RDS
- マルチAZ
- 有効すると、スタンバイインスタンスを自動的に立ち上げられる
- コストはマルチAZ無効の2倍
- レプリカ
- 別で手動で作成する必要
- インスタンスタイプはプライマリと異なっても大丈夫
Elasticache
- マルチAZ
- レプリカの存在はマルチAZ有効の前提条件なので、レプリカがないと、マルチAZを有効することができない
- マルチAZ自体は無料
- 故障のとき
- 有効
- 一番遅延が短いレプリカへの自動フェイルオーバーを行われる
- 無効
- 新しいリソースを自動的にリクエストする
- レプリカ
- Redisクラスターを作成するときか、その後追加することができる
- インスタンスタイプはプライマリと一緒
コスト削減例
例 効果 説明 RDSインスタンスのマルチAZを無効にする O 自動的にスタンバイを削減されるため、コスト半額 RDSのレプリカを消す O インスタンス数が減ったから ElasticacheクラスターのマルチAZを無効にする X マルチAZは無料;無効にすると、プライマリが故障するときに、レプリカへの自動フェイルオーバーが行われないだけ、レプリカのコストはかかるまま Elasticacheクラスターのレプリカを減らす O インスタンス数が減ったから 参照
- 投稿日:2021-01-06T21:45:52+09:00
docker-compose環境でRuby on Jetsの構築からデプロイまで<後編>
概要
以前の記事でRuby on Jetsのローカル環境を作成するところまで書きました。
docker-compose環境でRuby on Jetsの構築からデプロイまで<前編>
今回は実際にデプロイするところまでまとめてみたいと思います。
ユーザを準備
コンソールからIAMユーザを作成し、credentialを取得してください。
https://console.aws.amazon.com/iam/home#/users
今回デプロイするためだけのユーザということで「プログラムによるアクセス」にチェックを入れます。
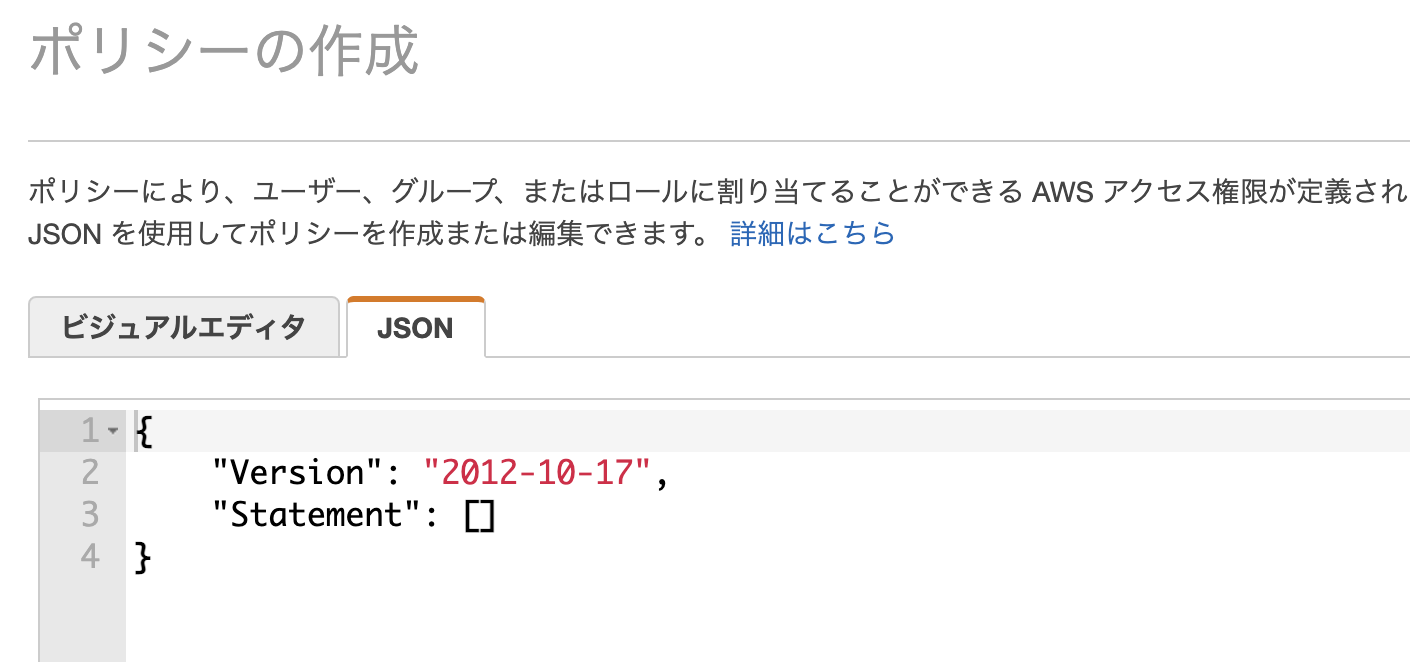
ポリシーの作成では「JSON」というタブを押して以下に記述したjsonを貼り付けてください。
ポリシー設定用json
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "apigateway:*", "cloudformation:*", "dynamodb:*", "events:*", "iam:*", "lambda:*", "logs:*", "route53:*", "s3:*" ], "Resource": [ "*" ] } ] }便宜上フルでアクションを許可しました。
もしセキュリティ視点でIAMポリシーを最小限にしたい場合は
以下のページを参考にデプロイ用IAMユーザにポリシーを設定してください。
(自分は最小限で設定しました。)
https://rubyonjets.com/docs/extras/minimal-deploy-iam/
公式ドキュメントには現時点では載っていなかったのですがVPCを設定するためには以下のような記述を追加する必要があると思います(というより記述しないとapplication.rbに書いたVPCの設定でデプロイが落ちました。。)
# Statementに追加 { "Version": "2012-10-17", "Statement": [ 中略 }, { "Effect": "Allow", "Action": [ "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs" ], "Resource": [ "*" ] } ] }ここでは説明を省きますが、注意点としてはこのIAMポリシーは関数ロールに設定するIAMポリシーとは異なるという点です。config/application.rbの方で関数ロールへIAMポリシーをアタッチできます。気が向いたらそちらも書く予定です。
好みの名前を入力してポリシーを作成します。
この後はお好みの設定でユーザを作成してください。
credentialをローカルに設定
IAMコンソールで作成したIAMユーザの画面へ行き、「認証情報」タブからアクセスキーとシークレットキーを作成してください。
取得した2つのキーを、以下を参考に~/.aws/credentialsと~/.aws/configに設定します。
https://rubyonjets.com/docs/deploy/
~/.aws/credentials:
[default] aws_access_key_id=<アクセスキー> aws_secret_access_key=<シークレットキー>~/.aws/config:
[default] region=<リージョン> output=jsonデプロイ実行
デプロイにはjets deployというコマンドを使います。ちなみに裏ではcloud formationが動いています。
dockerコンテナからそのままデプロイします。
ちなみに①で記述したDockerfileでaws-cliがコンテナに入っている状態になっています。
(①の方でDockerfileやdocker-compose.ymlの設定を載せています)
.env.containerでコンテナの環境変数を管理しているのでここにENVを記述します。
# .env.container JETS_ENV = production次に.env.production.remoteにDB情報などの、関数で使うための環境変数を記述します
(.env.developmentはローカル用、.env.development.remoteはリモート用でstagingとprodも同様)
# .env.production.remote # DB情報などを記述後はdeployするだけです!
$ docker-compose run --rm app bundle exec jets deploylambdaコンソールからアプリケーションがデプロイされているのを確認できれば完了です!
https://ap-northeast-1.console.aws.amazon.com/lambda/home?region=ap-northeast-1#/applications
staging環境を作成する
jetsでは先ほど記述したJETS_ENVという環境変数によって別の環境を簡単に作れます
以下のように.envなどに設定してみます
# .env.container JETS_ENV=staging先程と同様にdeployします
この時関数の環境変数は.env.staging.remoteに記述しましょう
$ docker-compose run --rm app bundle exec jets deploy環境を入れ替えたいときはJETS_ENVの値を変えるだけでいいのでCI/CDの構築も
環境変数を切り替えてあげるだけで大丈夫です!
アプリケーションの削除
以下のコマンドでアプリケーションに依存しているリソース全てを消すことができます
扱いには注意が必要です
$ docker-compose run --rm app bundle exec jets deletehttps://rubyonjets.com/reference/jets-delete/
まとめ
まだまだ書きたいことがたくさんあるのですが、とりあえずデプロイするところまで
行けました!!
引き続き気づいたことや詰まったことは発信していきたいと思います。
- 投稿日:2021-01-06T21:28:02+09:00
SageMakerのエンドポイントを呼び出すAPIをFastAPIを使って非同期処理させる
はじめに
- AWSのSageMakerに設置した推論エンドポイントを呼び出すAPIを実装するにあたって、推論処理に時間が掛かるため、API側を非同期処理させたいという要件がありました。
- 上記の要件を満たすためにFastAPIを使って非同期処理をするように対応したので、その際のメモ書きになります。
- ちなみにこちらにあるようにSageMakerのエンドポイントは60秒以内にレスポンスを返す必要があるので、注意しましょう。
準備
- はじめにSageMaker上に推論処理を行うエンドポイントの設定を行います。
- 今回はサンプルとして以下のようなコードを推論処理のエンドポイントとして設定します。
- リクエストを受けると5秒間スリープしてメッセージを返却する単純な処理になります。
- スリープする部分で時間のかかる推論処理を行うイメージです。
from fastapi import FastAPI from time import sleep import uvicorn app = FastAPI() @app.get('/ping') async def ping(): return {"message": "ok"} @app.post('/invocations') async def invocations(): sleep(5) return {"message": "finish"} if __name__ == '__main__': uvicorn.run('sagemaker_endpoint:app', host='0.0.0.0', port=8080, log_level='info')
- また、エンドポイントは同時に2つ処理が行えるようにインスタンスを2個起動するように設定させておきます。
通常の呼び出し
- はじめに、設置した推論エンドポイントを同期的に呼び出すAPIを作成して試してみます。
- boto3を利用してsagemakerのクライアントオブジェクトに対してinvoke_endpointする感じになります。
import os from fastapi import FastAPI, HTTPException import uvicorn import boto3 import json import aiobotocore from datetime import datetime app = FastAPI() ENDPOINT_NAME = os.environ['ENDPOINT_NAME'] @app.get('/') async def index(): try: sagemaker = boto3.client('sagemaker-runtime') sagemaker_response = sagemaker.invoke_endpoint( EndpointName='sagemaker-endpoint-test', Accept='application/json', ContentType='application/json', Body=json.dumps({'message': 'test'})) except Exception as e: raise HTTPException(status_code=500, detail='Sagemaker invoke endpoint exception') response_body = sagemaker_response['Body'] return json.load(response_body) if __name__ == '__main__': uvicorn.run('main:app', host='0.0.0.0', port=3000, log_level='info')
- こちらのAPIを同時に4回呼び出してみます。
- asyncio.gatherを利用して非同期に呼び出してみます。
import aiohttp import asyncio from datetime import datetime URL = 'http://localhost:3000' async def main(id): async with aiohttp.ClientSession() as session: async with session.get(URL) as response: res_text = await response.text() return f"response:{res_text} id:{id}" if __name__ == '__main__': print(f"{datetime.now():%H:%M:%S} start") loop = asyncio.get_event_loop() gather = asyncio.gather(main(1), main(2), main(3), main(4)) results = loop.run_until_complete(gather) for r in results: print(f"result: {r}") print(f"{datetime.now():%H:%M:%S} end")
- インスタンスは2つ起動していますが、呼び出しがシーケンシャルに処理されるので、20秒かかります(5秒✕4回)。
11:47:11 start result: response:{"message":"finish"} id:1 result: response:{"message":"finish"} id:2 result: response:{"message":"finish"} id:3 result: response:{"message":"finish"} id:4 11:47:31 end非同期の呼び出し
- 次に非同期に推論エンドポイントを呼び出すAPIを作成して試してみます。
- 非同期の呼び出しにはaiobotocoreを利用して実装します。
- boto3よりも低レベルの処理を行うことが出来るbotocoreをラップしているライブラリで、READMEにはs3のapiのみサポートしているとありますが、他のサービスでも利用できるでしょうとのことなので、試してみます。
- 先程のAPIと大体おなじような感じですが、async / awaitを利用して実装してあります。
import os from fastapi import FastAPI, HTTPException import uvicorn import boto3 import json import aiobotocore from datetime import datetime app = FastAPI() ENDPOINT_NAME = os.environ['ENDPOINT_NAME'] @app.get('/async') async def index_async(): print('receive requests') try: session = aiobotocore.get_session() async with session.create_client('sagemaker-runtime') as client: sagemaker_response = await client.invoke_endpoint( EndpointName=ENDPOINT_NAME, Accept='application/json', ContentType='application/json', Body=json.dumps({'message': 'test'})) response_body = sagemaker_response['Body'] async with response_body as stream: data = await stream.read() return json.loads(data.decode()) except Exception as e: print(e) raise HTTPException(status_code=500, detail='Sagemaker invoke endpoint exception') if __name__ == '__main__': uvicorn.run('main:app', host='0.0.0.0', port=3000, log_level='info')
- では、同じようにAPIを同時に4回呼び出してみます。
- レスポンスを待たずに推論エンドポイントの呼び出しが行われ、インスタンスが2つ起動しているので半分の10秒で処理が完了しています。
11:46:40 start result: response:{"message":"finish"} id:1 result: response:{"message":"finish"} id:2 result: response:{"message":"finish"} id:3 result: response:{"message":"finish"} id:4 11:46:50 endまとめ
- aiobotocoreを利用することで、非同期にSageMakerに設置した推論エンドポイントを呼び出すことが出来ました。
- fastapi + uvicornという構成で非同期に処理できるAPIを実装しても、AWSのリソースを呼び出す処理でI/O待ちが発生してしまっては意味がないので、他のAWSリソースを呼び出す際にも利用すると良さそうです。
- 上記に記載したコードはこちらにアップしてありますので、ご参考まで。
- 投稿日:2021-01-06T21:26:57+09:00
AWS Organizationsの専門用語とその概念をわかりやすく日本語訳しました。
この記事とは?
以下の記事の日本語訳になります。AWSが出している翻訳がわかりにくかったので、学習も兼ねて私なりに翻訳してみました。誤訳等ありましたらご指摘いただけると嬉しいです。
AWS Organizations terminology and concepts
以下翻訳です。
AWS Organizations の専門用語とその概念
このトピックではAWS Organizationsの学習に役立つ、重要な概念について解説します。
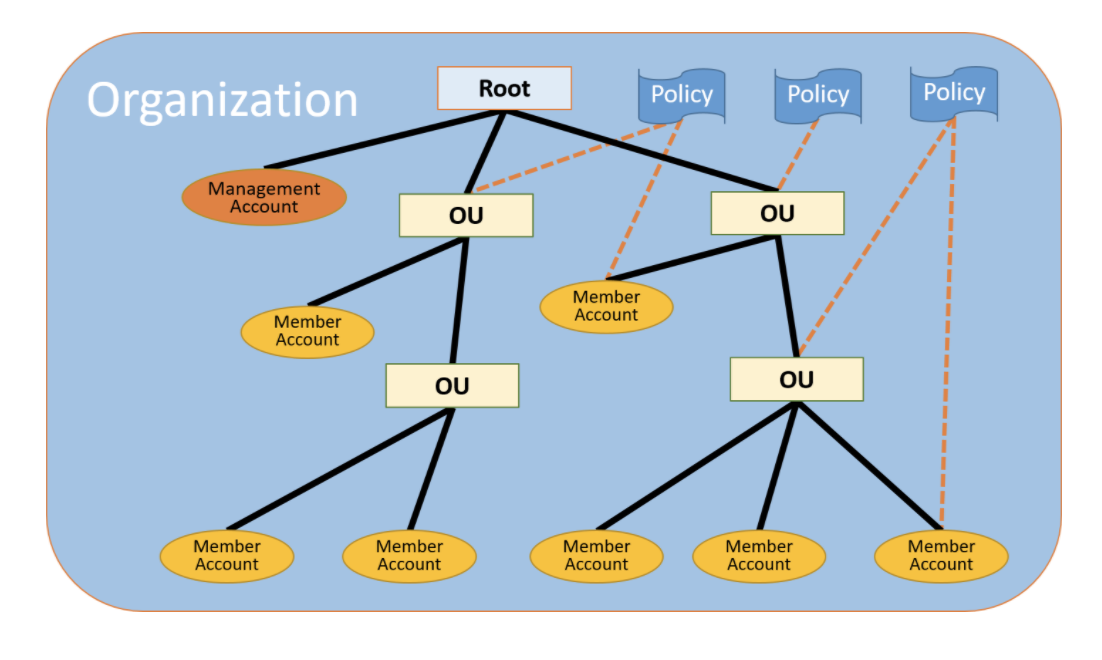
次の図は、基本的な組織を示しています。この組織は、7 つのメンバーアカウントで構成され、そのアカウントは、ルートアカウントを親として、4つの組織単位 (OU) に分類されています。
一部の組織単位(OU)やアカウントに複数のポリシーがアタッチされています。これらの各項目の詳細については、以下に記述するこのトピックの定義を参照してください。
※注意
AWS Organizationsは、「マスターアカウント」の名前を「管理アカウント」に変更しています。これは名前の変更のみであり、機能に変更はありません。組織 / Organization
AWSアカウントを一つの単位として管理できるように統合されたもの。
AWS Organizations consoleを使うと、組織(Organization)配下に存在する複数のアカウントを一元管理することができます。
組織(Organization)は一つのマネジメントアカウントを持ち、それらは0個以上のメンバーアカウントで構成されます。
ルートアカウントを頂点として複数のアカウントを階層構造で管理することができます。
各アカウントは、ルートアカウントに直接含めるか、組織単位(OU)内の のいずれかに配置することができます。
ルートアカウント / Root
全てのアカウントの親となるアカウント。もしルートにポリシーをアタッチすると、配下の組織単位(OU)やアカウントにそのポリシーが適応される。
※注意
現在、ひとつのルートアカウントしか作れません。ルートアカウントは組織を作成時に自動的に作成されます。組織単位 (OU) / Organization Unit(OU)
ルートアカウント配下のアカウントを統合する単位。
組織単位 (OU) は他の組織単位 (OU) を含めることができます。ルートアカウントを木の頂点として、組織単位 (OU)は下に向かって伸びる枝、メンバーアカウントが葉を表すような、上下反転したツリー構造で管理することができます。
ポリシーをアタッチすると、下の階層の組織単位 (OU)やアカウントに同じく適応されます。
組織単位 (OU)は必ずルートアカウントをもち、メンバーアカウントは組織単位 (OU)を必ずひとつもつ構造になります。
アカウント / Account
AWSリソースを含む標準のAWSアカウントのこと。1つのアカウントにポリシーをアタッチすると、そのアカウントのみに適応されることになります。
アカウントは2種類あります。マネジメントアカウントとメンバーアカウントです。
マネジメントアカウント / Management Account
マネジメントアカウントは組織を作成できるアカウントです。以下のことができます。
- 組織内にアカウントを作成する
- 組織に他のアカウントを招待する
- 組織からアカウントを削除する
- 招待を管理する
- 組織内に存在するルートアカウント、組織単位(OU)、アカウントに対してポリシーをアタッチする
マネジメントアカウントは支払いの責務を持つアカウントであり、またメンバーアカウントによって発生したすべての料金を支払う責任があります。組織のマネジメントアカウントを変更することはできません。
メンバーアカウント / Member Accounts
残りのアカウントはメンバーアカウントと呼ばれます。
アカウントが組織のメンバーになることができるのは、一度に 1つのみです。招待 / Invitation
別のアカウントを自分の組織に招待するプロセスのことです。
招待は、組織のマスターアカウントでのみ発行できます。
招待はアカウントIDまたは招待されるアカウントに登録されたEメールアドレスに送られます。
招待されたアカウントが招待を承認すると、そのアカウントが、組織内のメンバーアカウントになります。招待は組織が全てのメンバーに対して、一括請求機能のみのサポートから、組織の持つすべての機能のサポートへの変更をする必要が出てきた時に、現在のすべてのメンバーアカウントに対して招待を送信することもできます。
AWS Organizations コンソールで作業している場合は、ハンドシェイクが表示されないことがあります。ただし、AWS CLI 、またはAWS Organizations API を使用する場合は、ハンドシェイクを直接操作する必要があります。
ハンドシェイク / Handshake
情報を2者間で交換する複数ステップを持つプロセスのことです。
AWS Organizationsの主な用途の1つは、招待の基盤実装です。
ハンドシェイクメッセージは、ハンドシェイクの開始者と受信者の間で受け渡しと応答が行われます。
メッセージは、両者が確実に現在のステータスを把握できる方法で渡されます。
また、ハンドシェイクは、組織を一括請求機能のみのサポートから、AWS Organizationsで提供される組織の持つすべての機能のサポートへ変更する際にも使用されます。
通常ハンドシェイクは、AWS Organizations APIまたはAWS CLI などのコマンドラインツールを使用する場合にのみ、直接交換する必要があります。利用可能な機能セット / Available feature sets
すべての機能
AWS Organizations で利用できるデフォルトの機能セットです。
一括請求の機能だけでなく、高度な機能を使用して、組織のアカウントを詳細に制御できます。
たとえば、すべての機能が有効になっている場合、マネジメントアカウントは、メンバーアカウントができることを全て制御できます。
マネジメントアカウントはIAMユーザーやIAMロールが利用可能なサービスやアクションをコントロールするためにサービスコントロールポリシー(SCP)を適応できます。
マネジメントアカウントは、メンバーアカウントが組織から削除されるのを防ぐこともできます。
組織を作成する際に、すべての機能を有効にするか、一括請求のみのサポートにするのか選ぶことができます。変更も可能です。
すべての機能を有効にするには、すべての招待されたメンバーアカウントが、マネジメントアカウントから送信される招待を承諾して、変更を承認する必要があります。
一括請求
この機能を利用すると、請求機能を共有できますが、AWS Organizationsの高度な機能は利用できません。
たとえば、ポリシーを使用して、異なるアカウントのIAMユーザーとIAMロールの実行範囲を制限することはできません。
高度なAWS Organizations機能を使用するには、組織のすべての機能を有効にする必要があります。
サービスコントロールポリシー / Service control policy (SCP)
SCPを適応されたアカウントにおいて、IAMユーザーやIAMロールが使用できるサービスやアクションを指定するポリシーです。
SCPは、アクセス許可を付与しない点を除き、IAMポリシーと似ています。
代わりに、組織、組織単位 (OU) またはアカウントの最大アクセス許可を指定します。SCPを組織のルートアカウントあるいは組織単位(OU)にアタッチすると、SCPはメンバーアカウント内のアクセス権限を制限します。
許可リスト vs 拒否リスト / Allow lists vs. deny lists
許可リストと拒否リストは、アカウントがSCPを利用して、使用可能なアクセス許可をフィルタリングするために使える戦略です。
許可リスト
許可されるアクセスを明示的に指定します。その他のアクセス権限はすべて暗黙的にブロックされます。
デフォルトでは、AWS OrganizationsはFullAWSAccessと呼ばれるポリシーを、組織単位(OU)、そしてアカウントに付与しています。
これにより、新たな組織を作成した際には、設定しない限りアクセスは一切ブロックされません。つまり、デフォルトではすべてのアクセスが許可されます。
アクセスを制限する場合は、FullAWSAccessポリシーを、一連の権限のみ使用できるポリシーに変更します。
アカウントのIAMユーザーやIAMロールは、ポリシーですべてのアクションを実行できる権限を付与されていたとしてもに、SCPで制限された対象アクセスレベルしか実行できません。
ルートアカウントのポリシーを変更する場合、組織内のアカウントはすべて、制限が適用されます。
SCPはアクセス許可を付与することができないため、下の階層でアクセス権限を追加するできません。フィルタ処理のみを行うのです。
拒否リスト
許可されないアクセスを明示的に指定します。その他のアクセス権限はすべて有効になります。
この場合、明示的にブロックしない限り、すべてのアクセス権限が有効です。これがAWS Organizationsのデフォルトの動作です。
デフォルトでは、AWS OrganizationsはFullAWSAccessと呼ばれるポリシーを、組織単位(OU)、そしてアカウントに付与しています。
そのため、どのアカウントでも、AWS Organizationsの制限が適用されることなく、サービスやオペレーションにアクセスできます。
上記の許可リスト手法とは異なり、拒否リストを使用する場合は、デフォルトの FullAWSAccessポリシーをそのまま使用します。
ただし、その際は不要なサービスやアクションへのアクセスを明示的に拒否する追加のポリシーをアタッチします。
IAMポリシーを使用するのと同様に、SCPで特定のサービスやアクションを明示的に拒否すると、許可されているアクションも上書きされ使用できなくなります。
Artificial intelligence (AI) services opt-out policy
組織内のすべてのアカウント間で AWS AIサービスのオプトアウト設定を標準化するのに役立つポリシー。
特定の AWS AIサービスは、Amazon AIサービスおよびテクノロジーの開発と継続的な改善する目的のために、それらのサービスによって処理されたお客様の情報を保存および使用します。
AWSのお客様は、AI サービスのオプトアウトポリシーを使用することで、AWSがコンテンツの保存やサービスの改善のための使用を拒否することができます。
Backup policy
組織内のすべてのアカウント全体でリソースのバックアップ戦略を標準化し、実装するために役立つポリシーのタイプ。バックアップポリシーでは、リソースのバックアップ設定を調整し、デプロイできます。
Tag policy
組織内のすべてのアカウント間でリソース間でタグを標準化するのに役立つポリシー。タグポリシーでは、特定のリソースのタグ付けルールを指定できます。
あとがき
AWSソリューションアーキテクトプロフェッショナルの資格勉強でこの辺を覚えるのが難しかったので、こつこつ訳しながら理解していきました。
AWS Organizationsの理解にはBlack Beltの資料も役に立ちますのでみてみるといいかと思います!
20180214 AWS Black Belt Online Seminar AWS Organizations
- 投稿日:2021-01-06T21:26:57+09:00
AWS Organizationsの用語とその概念をわかりやすく日本語訳しました。
この記事とは?
以下の記事の日本語訳になります。AWSが出している翻訳がわかりにくかったので、学習も兼ねて私なりに翻訳してみました。誤訳等ありましたらご指摘いただけると嬉しいです。
AWS Organizations terminology and concepts
以下翻訳です。
AWS Organizations の専門用語とその概念
このトピックではAWS Organizationsの学習に役立つ、重要な概念について解説します。
次の図は、基本的な組織を示しています。この組織は、7 つのメンバーアカウントで構成され、そのアカウントは、ルートアカウントを親として、4つの組織単位 (OU) に分類されています。
一部の組織単位(OU)やアカウントに複数のポリシーがアタッチされています。
これらの各項目の詳細については、以下に記述するこのトピックの定義を参照してください。
※注意
AWS Organizationsは、「マスターアカウント」の名前を「管理アカウント」に変更しています。これは名前の変更のみであり、機能に変更はありません。組織 / Organization
AWSアカウントを一つの単位として管理できるように統合されたもの。
AWS Organizations consoleを使うと、組織(Organization)配下に存在する複数のアカウントを一元管理することができます。
組織(Organization)は一つのマネジメントアカウントを持ち、それらは0個以上のメンバーアカウントで構成されます。
ルートアカウントを頂点として複数のアカウントを階層構造で管理することができます。
各アカウントは、ルートアカウントに直接含めるか、組織単位(OU)内の のいずれかに配置することができます。
ルートアカウント / Root
全てのアカウントの親となるアカウント。もしルートにポリシーをアタッチすると、配下の組織単位(OU)やアカウントにそのポリシーが適応される。
※注意
現在、ひとつのルートアカウントしか作れません。ルートアカウントは組織を作成時に自動的に作成されます。組織単位 (OU) / Organization Unit(OU)
ルートアカウント配下のアカウントを統合する単位。
組織単位 (OU) は他の組織単位 (OU) を含めることができます。ルートアカウントを木の頂点として、組織単位 (OU)は下に向かって伸びる枝、メンバーアカウントが葉を表すような、上下反転したツリー構造で管理することができます。
ポリシーをアタッチすると、下の階層の組織単位 (OU)やアカウントに同じく適応されます。
組織単位 (OU)は必ずルートアカウントをもち、メンバーアカウントは組織単位 (OU)を必ずひとつもつ構造になります。
アカウント / Account
AWSリソースを含む標準のAWSアカウントのこと。1つのアカウントにポリシーをアタッチすると、そのアカウントのみに適応されることになります。
アカウントは2種類あります。マネジメントアカウントとメンバーアカウントです。
マネジメントアカウント / Management Account
マネジメントアカウントは組織を作成できるアカウントです。以下のことができます。
- 組織内にアカウントを作成する
- 組織に他のアカウントを招待する
- 組織からアカウントを削除する
- 招待を管理する
- 組織内に存在するルートアカウント、組織単位(OU)、アカウントに対してポリシーをアタッチする
マネジメントアカウントは支払いの責務を持つアカウントであり、またメンバーアカウントによって発生したすべての料金を支払う責任があります。
組織のマネジメントアカウントを変更することはできません。
メンバーアカウント / Member Accounts
残りのアカウントはメンバーアカウントと呼ばれます。
アカウントが組織のメンバーになることができるのは、一度に 1つのみです。招待 / Invitation
別のアカウントを自分の組織に招待するプロセスのことです。
招待は、組織のマスターアカウントでのみ発行できます。
招待はアカウントIDまたは招待されるアカウントに登録されたEメールアドレスに送られます。
招待されたアカウントが招待を承認すると、そのアカウントが、組織内のメンバーアカウントになります。
招待は組織が全てのメンバーに対して、一括請求機能のみのサポートから、組織の持つすべての機能のサポートへの変更をする必要が出てきた時に、現在のすべてのメンバーアカウントに対して招待を送信することもできます。
AWS Organizations コンソールで作業している場合は、ハンドシェイクが表示されないことがあります。
ただし、AWS CLI 、またはAWS Organizations API を使用する場合は、ハンドシェイクを直接操作する必要があります。
ハンドシェイク / Handshake
情報を2者間で交換する複数ステップを持つプロセスのことです。
AWS Organizationsの主な用途の1つは、招待の基盤実装です。
ハンドシェイクメッセージは、ハンドシェイクの開始者と受信者の間で受け渡しと応答が行われます。
メッセージは、両者が確実に現在のステータスを把握できる方法で渡されます。
また、ハンドシェイクは、組織を一括請求機能のみのサポートから、AWS Organizationsで提供される組織の持つすべての機能のサポートへ変更する際にも使用されます。
通常ハンドシェイクは、AWS Organizations APIまたはAWS CLI などのコマンドラインツールを使用する場合にのみ、直接交換する必要があります。
利用可能な機能セット / Available feature sets
すべての機能
AWS Organizations で利用できるデフォルトの機能セットです。
一括請求の機能だけでなく、高度な機能を使用して、組織のアカウントを詳細に制御できます。
たとえば、すべての機能が有効になっている場合、マネジメントアカウントは、メンバーアカウントができることを全て制御できます。
マネジメントアカウントはIAMユーザーやIAMロールが利用可能なサービスやアクションをコントロールするためにサービスコントロールポリシー(SCP)を適応できます。
マネジメントアカウントは、メンバーアカウントが組織から削除されるのを防ぐこともできます。
組織を作成する際に、すべての機能を有効にするか、一括請求のみのサポートにするのか選ぶことができます。変更も可能です。
すべての機能を有効にするには、すべての招待されたメンバーアカウントが、マネジメントアカウントから送信される招待を承諾して、変更を承認する必要があります。
一括請求
この機能を利用すると、請求機能を共有できますが、AWS Organizationsの高度な機能は利用できません。
たとえば、ポリシーを使用して、異なるアカウントのIAMユーザーとIAMロールの実行範囲を制限することはできません。
高度なAWS Organizations機能を使用するには、組織のすべての機能を有効にする必要があります。
サービスコントロールポリシー / Service control policy (SCP)
SCPを適応されたアカウントにおいて、IAMユーザーやIAMロールが使用できるサービスやアクションを指定するポリシーです。
SCPは、アクセス許可を付与しない点を除き、IAMポリシーと似ています。
代わりに、組織、組織単位 (OU) またはアカウントの最大アクセス許可を指定します。SCPを組織のルートアカウントあるいは組織単位(OU)にアタッチすると、SCPはメンバーアカウント内のアクセス権限を制限します。
許可リスト vs 拒否リスト / Allow lists vs. deny lists
許可リストと拒否リストは、アカウントがSCPを利用して、使用可能なアクセス許可をフィルタリングするために使える戦略です。
許可リスト
許可されるアクセスを明示的に指定します。その他のアクセス権限はすべて暗黙的にブロックされます。
デフォルトでは、AWS OrganizationsはFullAWSAccessと呼ばれるポリシーを、組織単位(OU)、そしてアカウントに付与しています。
これにより、新たな組織を作成した際には、設定しない限りアクセスは一切ブロックされません。つまり、デフォルトではすべてのアクセスが許可されます。
アクセスを制限する場合は、FullAWSAccessポリシーを、一連の権限のみ使用できるポリシーに変更します。
アカウントのIAMユーザーやIAMロールは、ポリシーですべてのアクションを実行できる権限を付与されていたとしてもに、SCPで制限された対象アクセスレベルしか実行できません。
ルートアカウントのポリシーを変更する場合、組織内のアカウントはすべて、制限が適用されます。
SCPはアクセス許可を付与することができないため、下の階層でアクセス権限を追加するできません。フィルタ処理のみを行うのです。
拒否リスト
許可されないアクセスを明示的に指定します。その他のアクセス権限はすべて有効になります。
この場合、明示的にブロックしない限り、すべてのアクセス権限が有効です。これがAWS Organizationsのデフォルトの動作です。
デフォルトでは、AWS OrganizationsはFullAWSAccessと呼ばれるポリシーを、組織単位(OU)、そしてアカウントに付与しています。
そのため、どのアカウントでも、AWS Organizationsの制限が適用されることなく、サービスやオペレーションにアクセスできます。
上記の許可リスト手法とは異なり、拒否リストを使用する場合は、デフォルトの FullAWSAccessポリシーをそのまま使用します。
ただし、その際は不要なサービスやアクションへのアクセスを明示的に拒否する追加のポリシーをアタッチします。
IAMポリシーを使用するのと同様に、SCPで特定のサービスやアクションを明示的に拒否すると、許可されているアクションも上書きされ使用できなくなります。
Artificial intelligence (AI) services opt-out policy
組織内のすべてのアカウント間で AWS AIサービスのオプトアウト設定を標準化するのに役立つポリシー。
特定の AWS AIサービスは、Amazon AIサービスおよびテクノロジーの開発と継続的な改善する目的のために、それらのサービスによって処理されたお客様の情報を保存および使用します。
AWSのお客様は、AI サービスのオプトアウトポリシーを使用することで、AWSがコンテンツの保存やサービスの改善のための使用を拒否することができます。
Backup policy
組織内のすべてのアカウント全体でリソースのバックアップ戦略を標準化し、実装するために役立つポリシーのタイプ。バックアップポリシーでは、リソースのバックアップ設定を調整し、デプロイできます。
Tag policy
組織内のすべてのアカウント間でリソース間でタグを標準化するのに役立つポリシー。タグポリシーでは、特定のリソースのタグ付けルールを指定できます。
あとがき
AWSソリューションアーキテクトプロフェッショナルの資格勉強でこの辺を覚えるのが難しかったので、こつこつ訳しながら理解していきました。
AWS Organizationsの理解にはBlack Beltの資料も役に立ちますのでみてみるといいかと思います!
20180214 AWS Black Belt Online Seminar AWS Organizations
- 投稿日:2021-01-06T18:01:22+09:00
Salesforce と直接連携する AWS サービス一覧 (随時更新)
初投稿です。
2021年1月時点でのSalesforce と直接連携する AWS サービスの一覧を作成しました。(Heroku や S3 経由など間接的なものは対象としておりません)
随時更新したいと思っているので、過不足ありましたら、コメントでお知らせ頂けると嬉しいです。カスタマーエンゲージメント
Amazon Connect
Salesforce 内でWebRTCブラウザベースの問い合わせコントロールパネル (CCP) を提供し、IVR から 顧客 DB として、Salesforce への問い合わせの連携なども可能です。
IoT
IoT Core
ルールをトリガーした MQTT メッセージから Salesforce IoT 入力ストリームにデータを送信します。
分析
Amazon QuickSight
QuickSight のデータソースとして、Salesforceに接続することが可能です。
アプリケーション統合
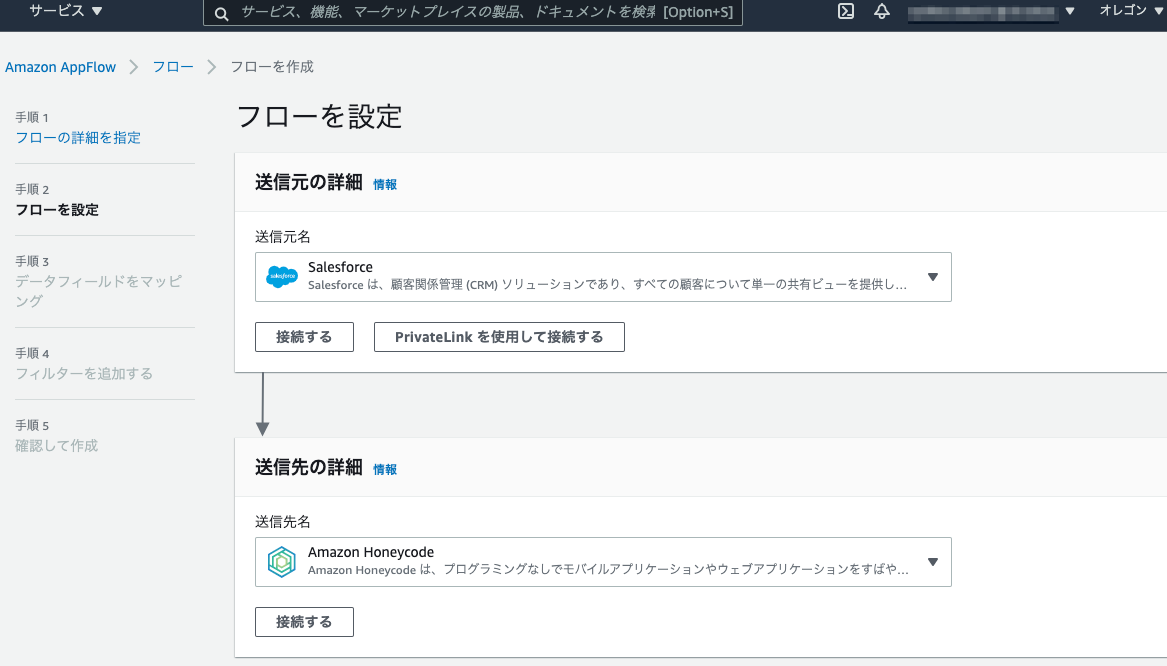
Amazon AppFlow
ノーコードで、Salesforce のレコードデータを Amazon S3 や Amazon Redshift に出力できます。
Amazon EventBridge
Amazon AppFlowを経由して、Salesforce や Pardot の変更が発生したときに AWS のサービスを自動的に動作させることができます。(例えば、Lambda 関数を呼び出すなど)
管理とガバナンス
AWS Single Sign-On
AWS Single Sign-On (SSO) には、Salesforce 多くのビジネスアプリケーションに対する事前構成型の SAML 統合が用意されています。
AWS SSO マネジメントコンソールで数回クリックするだけで、AWS SSO を既存のアイデンティティソースに接続し、ユーザーに割り当てられた AWS Organizations アカウント、および事前統合された数百ものクラウドアプリケーションへのアクセス権をユーザーに付与するアクセス許可を設定することが可能で、これらはすべて、単一のユーザーポータルから実行できます。ネットワーキングとコンテンツ配信
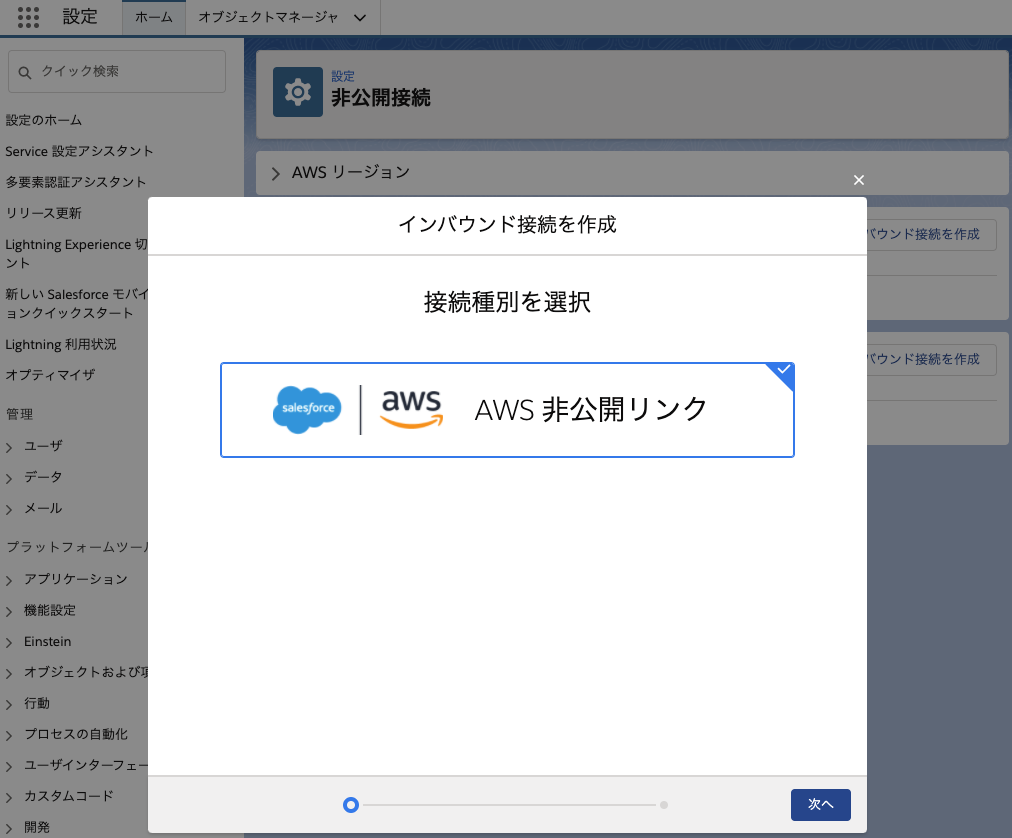
Amazon VPC
非公開接続では、Salesforce 組織と AWS Virtual Private Cloud (VPC) の間に完全に管理された安全な接続を設定することにより、Amazon Web Services (AWS) インテグレーションでのセキュリティを強化できます。その後、クロスクラウドトラフィックを公開インターネットの代わりにこの接続を介して転送できるため、部外者のセキュリティ脅威にさらされるリスクが減少します。
ビジネスアプリケーション
Amazon Honeycode
Amazon AppFlow を経由して、Salesforce など SaaS アプリケーションからAmazonHoneycodeワークブックへのデータ連携フローを作成できます。
番外編 - Salesforce 側からの分析
Salesforce Einstein Analytics
Salesforce Einstein Analytics のデータソースとして、Amazon Redshift / Amazon RDS / Amazon S3 に接続することが可能です。
参考URL


- 投稿日:2021-01-06T17:54:34+09:00
Slack - APIGateway - Lambda(Python) - RedShift インタラクティブアプリの作り方
概要
表題のとおりのSlackアプリケーションを作成する。
まともに書くと長文になるので、以下の要点ポイントのみを重点的に記載する。
- Slackアプリケーションの留意点
- Slack側のアプリケーション設定(権限周り)
- SlackのHomeView(Homeタブ)やattachmentに関して
- Lambda(python)周りの実装とライブラリ利用
- APIGateWay設定
なお、シンプルに試すだけならWebHookURLを設定してLambdaとかをスケジュール実行してPOSTすれば終わるが、SlackClientライブラリを利用したインタラクティブなリクエストに対するメッセージ通知ができるようなシーンを想定している。
手順通りにやれば動くものが作れるというよりは、
調べるのが面倒だったり、案外ハマったポイントを断片的に紹介する点はご承知おきください。Slackアプリケーションを作成するにあたっての留意点
レスポンスは3秒以内に一旦返す
ボタンをクリックし、レスポンスを返す場合などは3秒を超えるとエラーになる。
これは、処理でひとまずHTTPコード200を返して、
その後非同期で処理を行い、改めて結果をチャンネルに通知することで簡単に回避できる。なお、本記事では深く触れないが
実際はリクエストパラメータのresponse_urlは3秒経過しても数分以上有効なので
タイムアウト覚悟のまま、response_urlに直接POSTすることもできなくはない。UI(ホームタブ、フォーム)やメッセージの装飾にはBlock Kitと呼ばれるJSONの組み立てが必要
Block Kit Builderで試せるのだが、非常に面倒。
最低限、チャンネルIDとユーザIDを理解する
ユーザIDはrequestBodyのPayLoadに入ってる。ユーザ名ではないので注意。
チャンネルIDもrequestBodyのPayLoadにあるが、特定のパターンでは入ってこないこともあるし
別チャンネルへの通知を行いたい場合もあると思うので、対象のIDを、定数で埋め込んでおくのが良いだろう。なお、チャンネルIDはブラウザで対象チャンネルを開くとアドレスから簡単に判別できる。
/app.slack.com/client/<ここは組織ID>/<ここがチャンネルID>/details/top
メッセージ装飾のマークアップが、テーブル(表)をサポートしていない
できないものは仕方ないですね。
私はdividerと引用マークアップとスペース埋めを駆使して強引に整形。。Slack側のアプリケーション設定(権限周り)
これだけセットしときゃ大丈夫ってところだけ。意外に限られてる。
今回はWebHookURLは使わないが、一応設定入れる。設定後は
[Settings] -> [Installed App Settings] -> [(Re)Install to WorkSpace]
での反映を忘れずに。表示情報
[Settings] -> [Basic Infomation] -> [Display Information]
アプリ名とか説明とか、ロゴとか。適当に。WebHookURL
[Features] -> [Incoming Webhooks]
- [Activate Incoming Webhooks]をオンにする
- [Webhook URLs for Your Workspace]で[Add New Webhook to Workspace]で追加
認証と許可
[Settings] -> [OAuth & Permissions]
[Bot User OAuth Access Token]
ここの値はlambdaからメッセージなどを送るのに必要になるので控えておく
[Scope] -> [Bot Token Scopes]
必須なのは
chat:write, chat:write.customize, channels:history くらいだと思う。
WebHook使うなら、incoming-webhookも。
私は他にapp_mentions:read, commands, reactions:read とか入れてる。イベントの活性化とリクエストURLの設定
[Features] -> [Event Subscriptions]
APIを作成して、GateWayを設定し終わったら(方法は後述)
最後にここの[Enable Events]をオンにして、各種設定を入れる。ここに作成したAPIのURL等を設定することで
実際に特定のアクションを実施した時にリクエストが飛ぶようにしておく。リクエスト(API)URLの設定
現段階ではできないので、後で設定したら。暫定で適当なURLを入れても認証でNGになる。
最低限、API側の処理でチャレンジレスポンスが実装されていないと認証が通らないので。最後にAPIのURLを入れておく場所と認識しておいてください。
どのイベントをHookするかの設定
[Subscribe to bot events]で設定する。
とりあえず、ホームタブのUI表示用に app_home_opened と
メッセージからのボタンイベントをとるために message.channels を追加しておけば大体OK。SlackアプリケーションのUIやメッセージ装飾に関して
以下に簡単な例とイメージを記載。
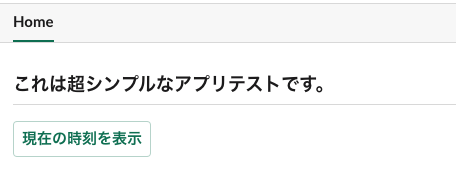
コードでの実装イメージはSlackClientAPIの利用サンプルとともに後述する。ホームタブ
HomeTabSample.json{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }ボタン付きメッセージ
MessageSample.json{ "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "こんにちは、サンプルアプリケーションです!" } }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "emoji": true, "text": "現在時刻を教えて" }, "style": "primary", "value": "click_from_message_button" } ] } ] }実際のAPIをlambdaで構築 (Python)
ポイントだけ紹介。
ちなみにログ関係はAPIGatewayのログで十分なので、lambda側では特に設定してない。必要な構成(非同期実装のため)
Slackアプリケーション(前述)
↓↑
AWS APIGateway(後述)
↓↑
lambda slack-request.py API(ここで説明)
> 3秒ルールがあるため、処理を非同期lambdaに委譲し一旦レスポンスを返す
> payloadの解析などはここでほぼ行う
↓↑
lambda async-notice.py API(ここで説明)
> 依頼内容や属性情報を全てもらった状態で処理を行い結果をSlackへ通知
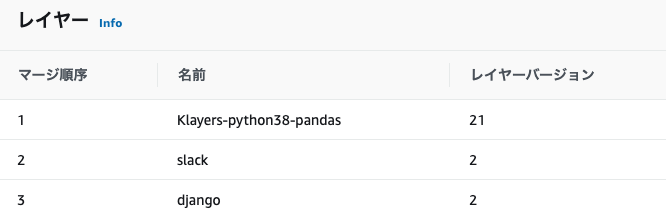
> 今回はスケジュール実行の例もここで必要なライブラリの準備(Layer設定)
地味にてこずる部分。ハマると数時間たったりするという。
毎回忘れた頃にlambdaを作るので、
pythonフォルダで包むの忘れてアップロードして動かなくて戸惑うという。まあ、これをアップロードして、両方のlambdaのlayerに追加する。
必要なのはslack-clientだけのような気もする(作り方は別でググってください)。あとは今回はいらないけど、いろいろやるならついでにdjangoやpandasの最新版も入れておくといい感じ。
お試し版では上記のslackレイヤーだけあれば大丈夫。
実装のポイント : リクエスト処理のlambda
チャレンジ・レスポンスの実装
リクエストURLは最低でも、以下の実装をど先頭に入れる。
これがないと、アプリケーション設定で認証されない。slack-request.pyif "challenge" in event: return event["challenge"]通知はSlackClientAPIで行う
SlackClientの生成# アプリケーション設定のBot User OAuth Access Tokenの値 import slack client = slack.WebClient(token="xoxb-XXXXXXXXXX....")ホームタブのUI描画
JSONで指定するホームタブの描画を行う""" HomeTabメニューの表示 """ if ('event' in event): slack_event = event['event'] if (slack_event['type'] == 'app_home_opened') : if ('tab' in slack_event) and (slack_event['tab'] == 'home'): user = slack_event['user'] channel = slack_event['channel'] blocks = <ここがJSON> views = {"type": "home", "blocks": blocks} client.views_publish(user_id=user, view=views) return {'statusCode': 200}
ホームタブのJSON(再掲)
ホームタブのJSON{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }イベントハンドル(ホームボタンやインタラクティブメッセージボタンの処理)
厳密には振り分けもう少し整理した方が良いが、これでも動く。最大のポイントは、
リクエストは非同期で別のlambdaに依頼して先にリクエストを受け付けましたレスポンスを返すこと。また、通知の度に他のSlackユーザに応答を返したくない場合もあるのでサンプルでは
メッセージ通知を「あなただけに表示されます」のEphemeralにしている。slack-request.py""" ActionをHookして処理を振り分け、SlackへのResponseを返す ChannelIdは固定不変なのでリクエストからではなく定数を利用する """ if ('body-json' in event): # payloadの内容を抽出 action_message = urllib.parse.unquote(event['body-json'].split('=')[1]) action_message = json.loads(action_message) # 通知先となるユーザIDを取得 user_id = action_message['user']['id'] # Message Button == Interactive Messageか否かを判定 isInteractiveMessage = False if('type' in action_message ) and (action_message['type'] == 'interactive_message'): isInteractiveMessage = True # actionがあればイベントをHook if ('actions' in action_message): """ 値の取得と通知依頼は別のlambdaに非同期で依頼する 非同期依頼は複数あって良いが、依頼は主にPrimaryModeのみで判定する """ delegateLambda_primaryMode = [] # payloadからaction message部分のみを抽出する action_message = action_message['actions'][0] # 非同期送信なので同期レスポンスメッセージのDefaultを先に設定しておく send_message = "リクエストを受け付けました。少しお待ちください。" if (action_message['type'] == 'button') : if (action_message['value'] == 'click_from_home_tab'): """ ホームタブのボタンがクリックされた """ delegateLambda_primaryMode.append('click_from_home_tab') elif (action_message['value'] == 'click_from_message_button'): """ ホームタブのボタンがクリックされた """ delegateLambda_primaryMode.append('click_from_message_button') """ 設定した非同期依頼をかける PrimaryとSecondaryのほか、user_idを渡す仕様にした 非同期処理は後述する """ for p in delegateLambda_primaryMode: input_event = { "primaryMode": p, "secondaryMode": "now no mean", "user_id": user_id } lambdaMediator.callNortifyAsync(json.dumps(input_event)) """ 一旦、応答メッセージを返却する """ if isSendEphemeral == True: response = client.chat_postEphemeral( channel=notice_channel_id, text=send_message, user=user_id ) else: response = client.chat_postMessage( channel=notice_channel_id, text=send_message ) if isInteractiveMessage == True: pass else: return {'statusCode': 200}lambdaMediator.pyimport boto3 def callNortifyAsync(payload): """ 非同期で委譲先のlambda(async-notice.py固定)を呼ぶ Parameters ---------- event : 委譲先lambdaのevent json PrimaryMode: 依頼内容を表す第一Key文字列 SecondaryMode: 依頼内容を表す第二Key文字列 UserId: 依頼者のSlackユーザID Returns ---------- response """ response = boto3.client('lambda').invoke( FunctionName='async-notice', InvocationType='Event', Payload=payload ) return response実装のポイント : 非同期処理のlambda
attachmentは利用しなくてもいいが、凝ったことをやりたい場合は
メッセージではなくattachmentでやるので、サンプルはそうしている。今回は両方のlambdaの実行RoleにAWSLambda_FullAccessを付与している。
また、サンプルなのでPrimaryModeをslack-request.pyからもらっているが分岐は入れていない。attachmentを利用してメッセージを送信
async-notice.pyimport json import datetime import time import boto3 import slack from libs import mylib from libs import slack_info def lambda_handler(event, context): """ このlambdaはslack-requestからのdelegate処理(非同期)、およびスケジューラからのみKickされる Parameters ---------- event : PrimaryMode: 依頼内容を表す第一Key文字列 SecondaryMode: 依頼内容を表す第二Key文字列(未利用:拡張用) UserId: 依頼者のSlackユーザID Returns ---------- httpResponseBody : statusCode:200 , body -> SlackClientからの送信を行うため200を返すだけ ToDo ---------- """ # ユーザIDの取得 user_id = "" if 'user_id' in event: user_id = event['user_id'] """ パラメータなしはスケジューラからの起動なので全体通知 パラメータありは非同期依頼なのでEphemeral(あなただけに見えてます)通知 """ isEphemeral = True if ('primaryMode' in event) == False: isEphemeral = False """ メッセージ通知を行う attachmentsはメッセージJSON """ postDataMessage(attachments, False, isEphemeral, user_id, "ここに本文メッセージを入れる。") return { 'statusCode': 200, 'body': json.dumps('OK') } def postDataMessage(attachment_data, isSendMultiple=False, isEphemeral=True, userId="", textMessage=""): """ メッセージを送信する Parameters ---------- attachment : アタッチメントデータ isSendMultiple : アタッチメントデータが複数あるか否か isEphemeral : リクエストユーザのみ見えるように送信するか否か userId : リクエストユーザのID textMessage : テキストメッセージ Returns ---------- ToDo ---------- """ client = slack.WebClient(token="xoxb-XXXXXXXXX.....") # 複数送信対応のため、単一送信であってもリストで包み直す if isSendMultiple == False: attachment_data = [attachment_data] # TARGET_CHANNEL_IDは通知先のチャネルIDを別途設定しておくこと for attachment in attachment_data: if isEphemeral == True: response = client.chat_postEphemeral( channel=TARGET_CHANNEL_ID, attachments = attachment, user=userId ) else: response = client.chat_postMessage( text=textMessage, channel=TARGET_CHANNEL_ID, attachments = attachment )
ボタン付きメッセージのJSON(再掲)
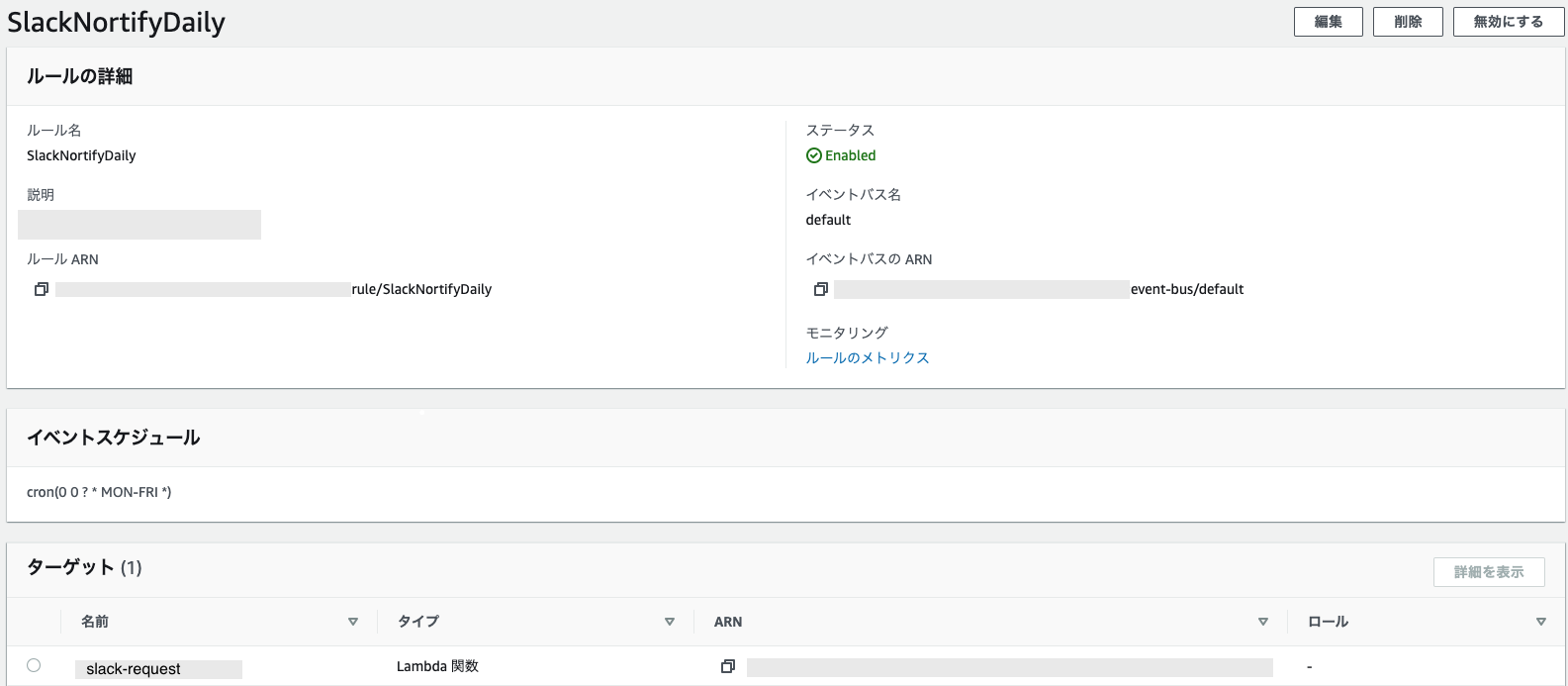
attachmentのjson例{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }おまけ : スケジュール実行したい場合
Amazon EventBridgeのルール作成で対象をasync-noticeのlambdaとcron設定をブラウザから入れるだけ。
月曜から金曜の9時に実行(GMT時間なので-9時間で設定)cron(0 0 ? * MON-FRI *)
おまけ : RedShiftへの接続
boto3でredshift-dataを指定するだけで
データアクセスはクエリ実行時に指定したRedshiftアカウント内でのロール権限で実施されるため非常に楽。
サンプルコード
RedShift接続import json import time import boto3 # Redshift接続情報 CLUSTER_NAME='cluster名を入れる' DATABASE_NAME='データベース名を入れる' DB_USER='ユーザ名を入れる' def getDateTimeSample(): """ 時刻の取得 """ sql = ''' select getdate(); ''' return _getData(sql) def _getData(sql): """ RedShiftへクエリを発行して結果をそのまま返す Parameters ---------- String : sql文 Returns ---------- statement : boto3の取得結果そのまま """ # Redshiftにクエリを投げる。非同期なのですぐ返ってくる data_client = boto3.client('redshift-data') result = data_client.execute_statement( ClusterIdentifier=CLUSTER_NAME, Database=DATABASE_NAME, DbUser=DB_USER, Sql=sql, ) # 実行IDを取得 id = result['Id'] # クエリが終わるのを待つ statement = '' status = '' while status != 'FINISHED' and status != 'FAILED' and status != 'ABORTED': statement = data_client.describe_statement(Id=id) #print(statement) status = statement['Status'] time.sleep(1) # 結果の表示 if status == 'FINISHED': if int(statement['ResultSize']) > 0: # select文等なら戻り値を表示 statement = data_client.get_statement_result(Id=id) else: # 戻り値がないものはFINISHだけ出力して終わり print('QUERY FINSHED') elif status == 'FAILED': # 失敗時 print('QUERY FAILED\n{}'.format(statement)) elif status == 'ABORTED': # ユーザによる停止時 print('QUERY ABORTED: The query run was stopped by the user.') return statementAPIGateWayの設定
作成したlambda APIにURLを与えてアクセスできるようにする。
大まかな手順
REST APIで作成
lambdaを統合
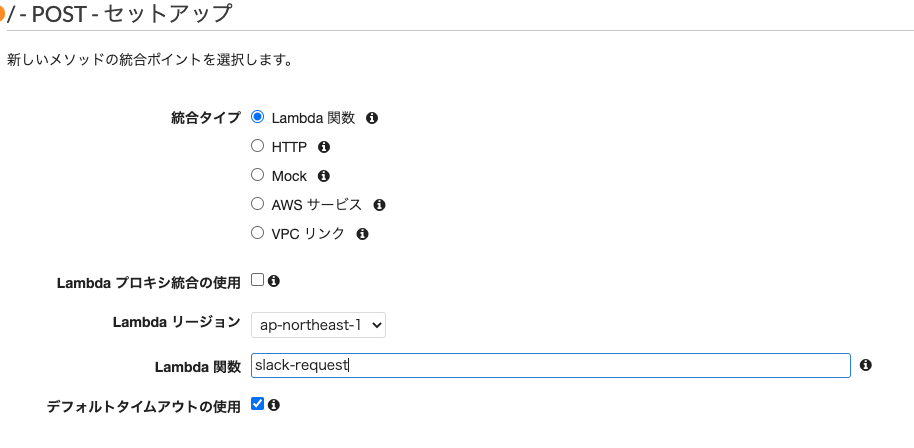
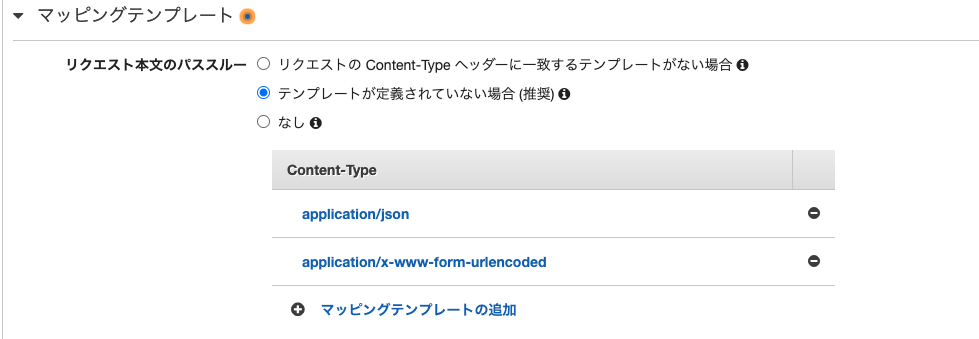
マッピングテンプレートでapplication/x-www-form-urlencodedの追加
一番重要。ホームタブのオープンイベントではこのフォーマットで来るので、ここいれないと動作しない。
また、他のリクエストはapplication/jsonで来るものがあるので、合わせて追記するのもポイント。
あとはステージをデプロイするだけ
ログ設定
この設定で十分デバッグできる。
ログはCloudWatchにステージ名のロググループで出力される。
その他のポイント・気付き
3秒ルールはしんどい
Slackの性質を考えればまあ、そうなるのは理解できるが凝ったこともしたくなる場合もある。
非同期でデータベースアクセス含めた処理を行って
単純にレスポンス200を返すだけでも、lambdaのコールドスタートなどを考えるとギリギリ間に合わない場合も稀にある。lambdaにはProvisioned Concurrencyもあり、料金はかかるが場合によってはこれも活用できる。
マークアップにテーブルが欲しい
結構需要はあると思うが。
引用を使うと引用内では半角スペースを忠実に再現するのでこれと、division線を使うと表っぽくはなる。
ただ、無理やり感は拭えない。

- 投稿日:2021-01-06T17:18:10+09:00
AWSサービス用ロール/ポリシー作成方法メモ
- AWSサービス用のIAMロール/ポリシーの作成方法についてメモする。
- シェルスクリプトからAWS CLIコマンドを叩いて作成ケースを想定。
- 基本的な流れ
- ロール作成→ポリシー作成→ロールにポリシーをアタッチ
サービスロールの作成
- EC2用ロール(
RoleForEC2)を作成する場合。trust_policy_path=$(dirname $0)/json/TrustPolicyForEC2.json trust_policy=$(cat ${trust_policy_path}) tempfile=$(mktemp) echo ${trust_policy} | envsubst > {tempfile} aws iam create-role --role-name RoleForEC2 --asume-role-policy-document file://${tempfile} rm -f ${tempfile}
- 信頼ポリシー (
TrustPolicyForEC2.json)例
- EC2サービスに本ロールを割り当てるためのポリシー。
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": {"Service": "ec2.amazonaws.com"}, "Action": "sts:AssumeRole" } }アクセス許可ポリシーの作成
- 前述のEC2ロール(
RoleForEC2)に設定するアクセス許可ポリシー(PermissionsPolicyForEC2)を作成する場合。permission_policy_path=$(dirname $0)/json/PermissionsPolicyForEC2.json permission_policy=$(cat ${permission_policy_path}) tempfile=$(mktemp) echo ${permission_policy} | envsubst > {tempfile} aws iam create-policy --policy-name PermissionsPolicyForEC2 --policy-document file://${tempfile} rm -f ${tempfile}
- アクセス許可ポリシー(
PermissionsPolicyForEC2)例
- Amazon S3 バケット
test_bucketに対してListBucketアクションのみを実行することを許可するポリシー。{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::test_bucket" } }サービスロールへのアクセス許可ポリシーのアタッチ
- 作成したサービスロール
RoleForEC2にポリシーPermissionsPolicyForEC2をアタッチする。aws iam attach-role-policy --role-name RoleForEC2 --policy-arn arn:aws:iam::${YOUR_AWS_ACCOUNT_ID}:policy/PermissionsPolicyForEC2参考情報
- 投稿日:2021-01-06T17:12:16+09:00
EKSのノードのKubeletが突然Unauthorizedでクラスタ接続不可となった時の調査メモ
ある日開発環境のEKSのマネージドノードが突然クラスタに参加不可の状態になりました。
単純に自分の理解が足りてなかっただけなのですが、調査方法等のTipsを残しておきたいと思います。
事象
開発環境で開発をしていたら、ノードが全てNot Readyになっていました。
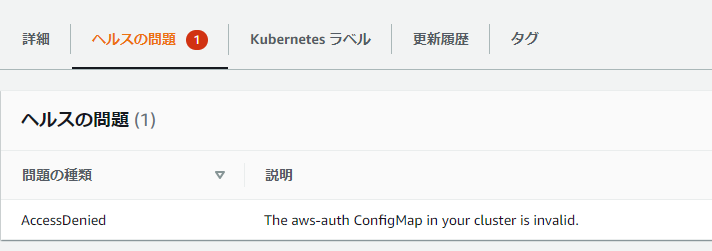
kubelet[14180]: E0106 06:58:01.678158 14180 reflector.go:178] k8s.io/kubernetes/pkg/kubelet/config/apiserver.go:46: Failed to list *v1.Pod: Unauthorized kubelet[14180]: E0106 06:58:02.269813 14180 controller.go:136] failed to ensure node lease exists, will retry in 7s, error: Unauthorized kubelet[14180]: E0106 07:00:31.476224 14180 kubelet_node_status.go:92] Unable to register node "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" with API server: Unauthorized kubelet[14180]: E0106 07:11:24.484369 14180 reflector.go:178] k8s.io/client-go/informers/factory.go:135: Failed to list *v1.CSIDriver: Unauthorized原因
今回の原因は画面にもメッセージに出ている通り、aws-authのConfigMapの不備でした。
以下のURLにもあるような、マネージドノードのロールマッピングが手違いで消えてしまったのが原因でした。
https://amazon-eks.s3.us-west-2.amazonaws.com/cloudformation/2020-08-12/aws-auth-cm.yaml
apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: <ARN of instance role (not instance profile)> username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes調査メモ
調査や調整に使えるTipsができたので、書いておきます。
Unauthorisedということで権限が問題なのですが、どこで権限を取得しているかをまず確認します。
kubeletは以下の設定ファイルを見ています。
ここを見るとわかるのですがaws-iam-authenticatorを使ってトークンを取得して、そのトークンを
clusters.cluster.serverで定義されているサーバーに投げて認証しています。$ cat /var/lib/kubelet/kubeconfig apiVersion: v1 kind: Config clusters: - cluster: certificate-authority: /etc/kubernetes/pki/ca.crt server: https://xxxxxxxxxxxx.yyy.ap-northeast-1.eks.amazonaws.com name: kubernetes contexts: - context: cluster: kubernetes user: kubelet name: kubelet current-context: kubelet users: - name: kubelet user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 command: /usr/bin/aws-iam-authenticator args: - "token" - "-i" - "YourClusterName" - --region - "ap-northeast-1"この動きをコマンドで追っていきます。これができるとチェックの手間が省けます。
# END_POINT= </var/lib/kubelet/kubeconfigのclusters.cluster.serverを設定> # 以下で取得も可能 CLUSTER_NAME=YourClusterName REGION=ap-northeast-1 END_POINT=$(aws eks describe-cluster --region ${REGION} --name ${CLUSTER_NAME} | jq -r '.cluster.endpoint') # Kubeletが認証に使っているトークンを取得 # aws-iam-authenticatorは引数のクラスタ名やRegionが間違っていてもトークン取得できるので注意してください USER_TOKEN=$(/usr/bin/aws-iam-authenticator token -i ${CLUSTER_NAME}--region ${REGION} --token-only) # 認証処理を投げてみる curl -XPOST --insecure ${END_POINT}/apis/authentication.k8s.io/v1/tokenreviews \ -H "Authorization: Bearer ${USER_TOKEN}" \ -H "Content-Type: application/json" \ -d "{\"apiVersion\": \"authentication.k8s.io/v1\",\"kind\": \"TokenReview\",\"spec\": {\"token\": \"${USER_TOKEN}\"}}"認証失敗すると以下のようにUnauthorizedのエラーが出ます。
{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "Unauthorized", "reason": "Unauthorized", "code": 401 }成功すると以下のようなメッセージが返ります。
{ "kind": "TokenReview", "apiVersion": "authentication.k8s.io/v1", "metadata": { "creationTimestamp": null, "managedFields": [ { "manager": "curl", "operation": "Update", "apiVersion": "authentication.k8s.io/v1", "time": "2021-01-06T07:29:12Z", "fieldsType": "FieldsV1", "fieldsV1": {"f:spec":{"f:token":{}}} } ] }, "spec": { "token": "k8s-aws-v1.xxxxx" }, "status": { "authenticated": true, "user": { "username": "system:node:ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal", "uid": "heptio-authenticator-aws:123456789012:Axxxxxxxxxx", "groups": [ "system:bootstrappers", "system:nodes", "system:authenticated" ], "extra": { "accessKeyId": ["Axxxxxx"] } }, "audiences": [ "https://kubernetes.default.svc" ] } }
- 投稿日:2021-01-06T16:00:17+09:00
個人的によく利用するシェルコマンド備忘録
- シェルスクリプト内でAWS CLIコマンドを実行し、AWSリソースを作成することがあり、その際に利用したシェルコマンドを備忘録としてまとめる。
ファイルの一括読み込み
ユースケース
- 変数ファイル(.env)を一括で読み込み、環境変数に埋め込みたい場合。
set -a; for f in ./env/*.env; do . ${f}; done; set +a;ディレクトリパスを取得する
ユースケース
- 実行スクリプト内でスクリプトのディレクトリパスを取得したい場合。
dir=$(dirname $0)
/home/bin/create_aws_resource.shのように実行した場合、/home/binが取得される。一時的なJSONデータを作成する
- ユースケース
- AWS CLIコマンドに渡す一時的なJSONデータを作成したい場合。
外部のJSONファイルをベースに作成したい場合
- JSON構造が複雑で、スクリプト内部にJSONを定義したくない場合。
test_json_path=$(dirname $0)/json/test.json test_json=$(cat ${test_json_path}) tempfile=$(mktemp) echo ${test_json} | envsubst > ${tempfile}※
envsubst利用スクリプト内部で定義したJSONデータをベースに作成したい場合
- JSON構造が簡潔で、スクリプト内部にJSONを定義したい場合。
tempfile=$(mktemp) cat > ${tempfile} << EOS { # JSON } EOS※ヒアドキュメント利用
※スクリプト実行後には、
tempfileを削除することを忘れない。JSONから任意の値を取得する。
ユースケース
- AWS CLIの実行結果として出力されたJSONから任意の値を取得したい場合。
response=$(AWS CLIコマンド) target_value=$(echo ${response} | jq -r ".HogeId")※
jqコマンド利用
※ダブルクォートなしで取得参考情報
- 投稿日:2021-01-06T12:16:33+09:00
ポート開放
ポートを解放
立ち上げたばかりのEC2インスタンスはsshでアクセスすることはできますが、HTTPなどの他の通信方法では一切つながらないようになっています。そのため、サーバーとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
さきほど、config/unicorn.rb内に「listen 3000」と記述しましたが、これは「Railsのサーバを3000番ポートで起動する」ということを意味するのでした。ポートの設定をするためには、EC2の「セキュリティグループ」という設定を変更する必要があります。
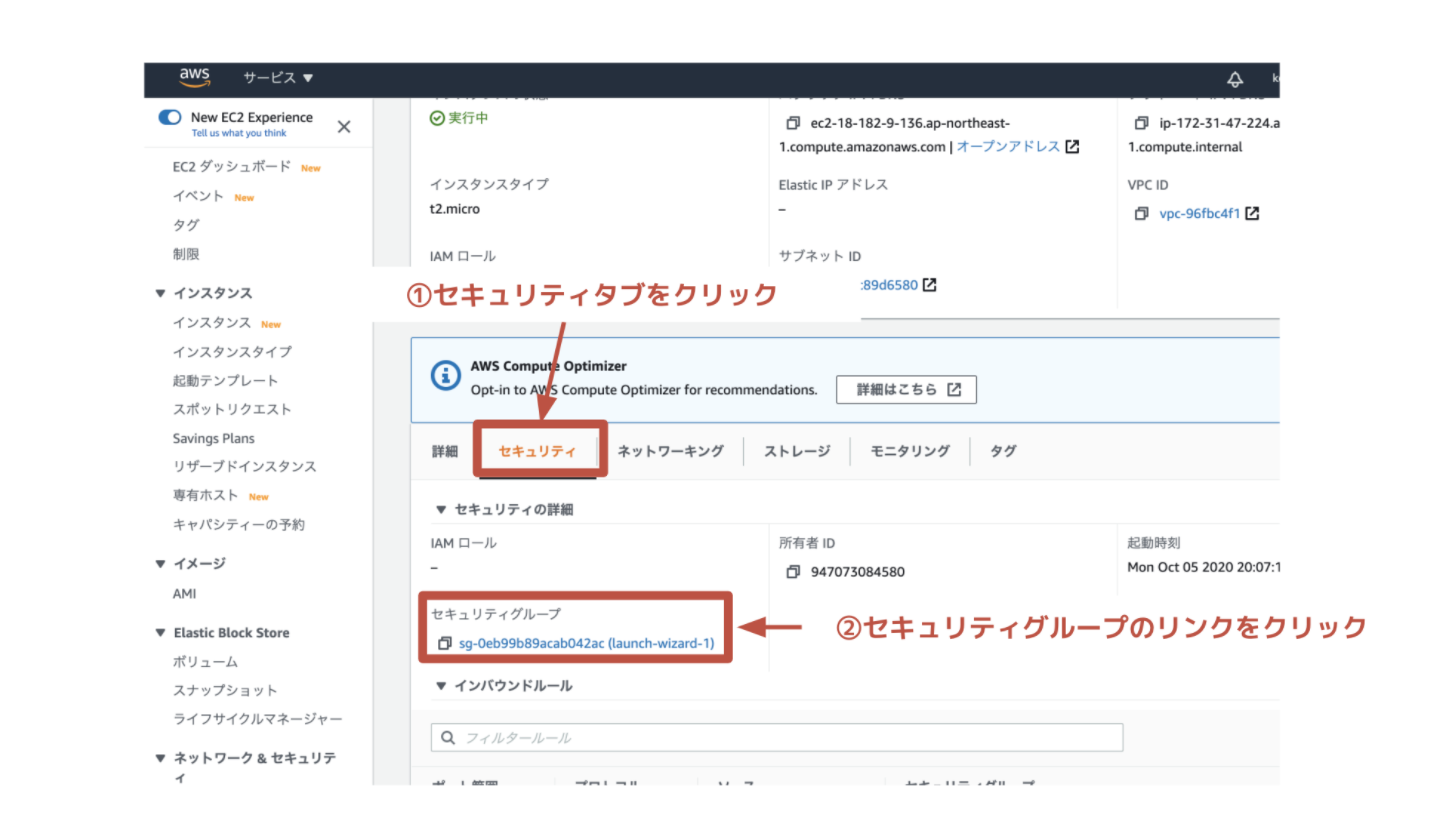
「セキュリティグループ」とは、EC2サーバが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものです。まず、EC2インスタンス一覧画面から、対象のインスタンスを選択し、「セキュリティ」のタブを開きます。次に、「セキュリティグループ」のリンク(図中では「launch-wizard-1」)をクリックしましょう。
すると、インスタンスの属するセキュリティグループの設定画面に移動するので、「インバウンド」タブの中の「編集」をクリックします。
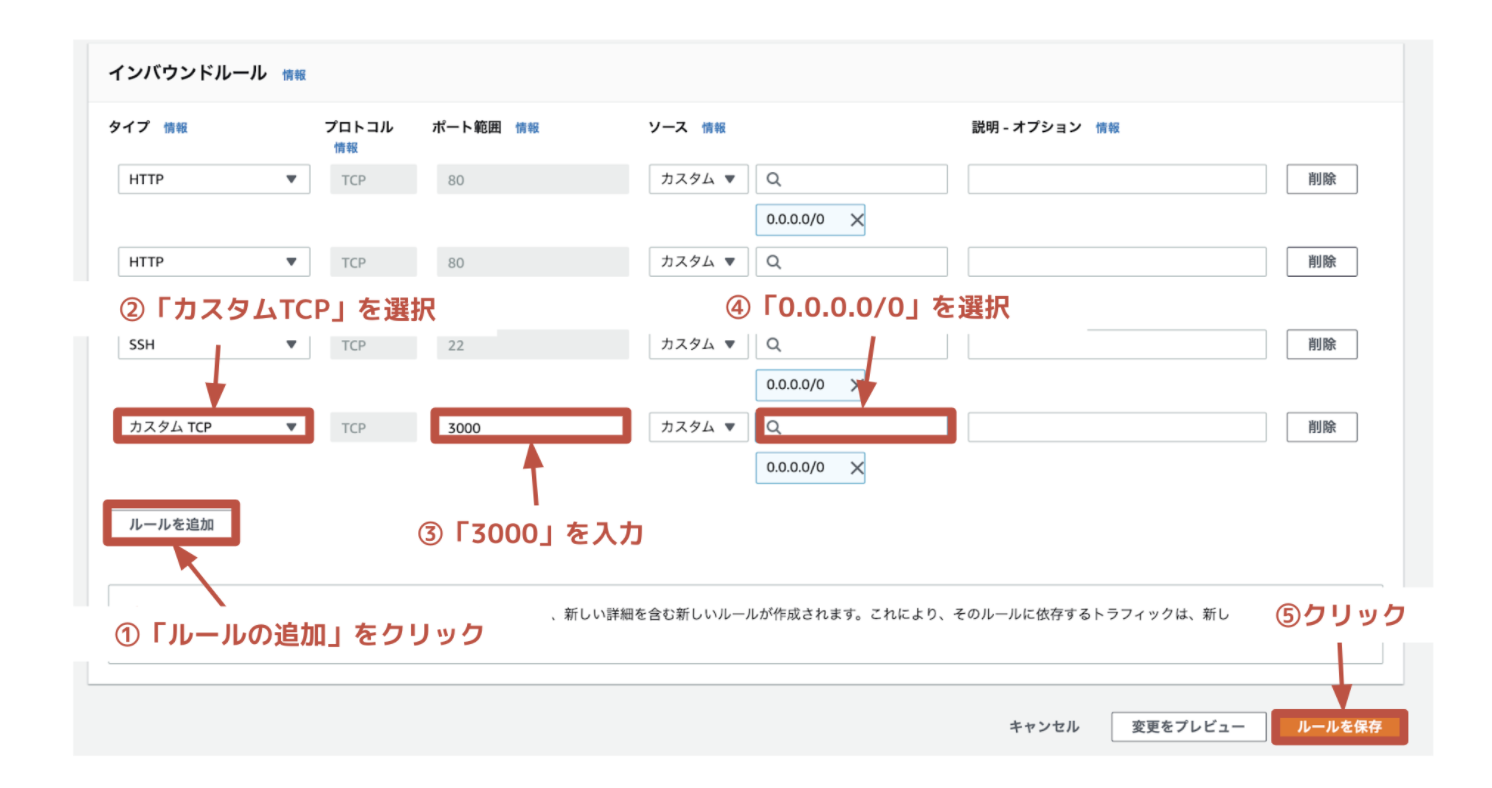
ページ遷移後、「ルールを追加」をクリックして下記に編集しましょう。
設定後、「ルールを保存」をクリックしましょう。ポートの開放は以上です。
本番環境でRailsを起動
本番環境でRailsを起動するには「unicorn_railsコマンド」を使います。
本番環境のmysqlの設定に合わせるため、ローカルのdatabase.ymlを以下のように編集してください。config/database.yml(ローカル)production: <<: *default database:(※こちらは編集しないでください) username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock次に、編集を「commit→push」しましょう。
リモートリポジトリが更新されたため、サーバ上のアプリケーションにも反映させましょう。
次は、GitHubの内容をEC2に反映させる作業です。[ec2-user@ip-172-31-23-189 <リポジトリ名>] git pull origin master次は、EC2内でデータベースを作成するのですが、「RAILS_ENV=production」というオプションがつきます。
「RAILS_ENV=production」とは、本番環境でコマンド実行する時につくオプションです。
実行しようとしているコマンドは、「RAILSのENV(環境)がproduction(本番環境)ですよ」という意味です。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>' [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:migrate RAILS_ENV=production「sudo systemctl start mariadb」というコマンドをターミナルから打ち込み、mysqlの起動を試してみましょう。
ここまでできたら、Railsを起動しましょう。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dアセットファイルをコンパイルしましょう
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails assets:precompile RAILS_ENV=productionここまで終えたら再度Railsを起動させたいのですが、すでにサーバーは立ち上がっています。
そこで、「Railsを再起動する方法」を学びましょう。
まず、「Unicornのプロセス」を確認します。
ターミナルからプロセスを確認するには「psコマンド」を利用します。
「psコマンド」とは、現在動いているプロセスを確認するためのコマンドです。それでは「psコマンド」を実行し、Unicornのプロセスを確認しましょう
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicornすると、以下のようにプロセスが表示されるはずです。
ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn大事なのは左から2番目の列です。ここに表示されるのがプロセスのid(PIDと言う)になります。
「unicorn_rails master」と表示されているプロセスがUnicornのプロセス本体です。この時のプロセスidは「17877」となっています。
プロセスidは、プロセスを識別するための一意の数字です。PIDがあることで、あるプログラムから別のプロセスを指定して操作したり、プロセスからプログラムを停止したりできます。
killコマンドは、現在動いているプロセスを停止させるためのコマンドです。それでは、以下のコマンドを実行してUnicornのプロセスをKillしましょう。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのプロセスid>実行したプロセスを再度表示させ、終了できていることを確認しましょう。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ... ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn最後に、Railsを再起動するコマンドを実行しましょう。
今回はコマンドの先頭に「RAILS_SERVE_STATIC_FILES=1」というオプションをつけます。
「RAILS_SERVE_STATIC_FILES=1」は、Railsがコンパイルされたアセットを見つけられるように指定する役割があります。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dブラウザで http://<Elastic IP>:3000/ にアクセスして、サイトが正常に表示されているか確認してみましょう。
接続時、<Elastic IP>の<>は不要です。Railsの起動がうまくできなかった時
「Railsが起動しない」「ブラウザで確認するとエラーが表示されている」などの問題がある場合、まずは「エラーログ」を確認する必要があります。
ターミナルで「unicorn_rails」が起動しない時の対処法を学びましょう[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D master failed to start, check stderr log for detailsこのように、unicorn_railsを実行した際に「master failed to start, check stderr log for details」と出た場合、unicornのエラーログを確認する必要があります。
「check stderr log for details」というのは、「詳細(detail)はstderr logを確認(check)しましょう」という意味です。
「lessコマンド」を使うと、ファイルの中身を確認できます。「catコマンド」も同様の役割をします。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/unicorn.stderr.log I, [2016-12-21T04:01:19.135154 #18813] INFO -- : Refreshing Gem list I, [2016-12-21T04:01:20.732521 #18813] INFO -- : listening on addr=0.0.0.0:3000 fd=10 E, [2016-12-21T04:01:20.734067 #18813] Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2) /var/www/furima/shared/bundle/ruby/2.6.0/gems/mysql2-0.5.3/lib/mysql2/client.rb:90:in `connect' /var/www/furima/shared/bundle/ruby/2.6.0/gems/mysql2-0.5.3/lib/mysql2/client.rb:90:in `initialize' /var/www/furima/shared/bundle/ruby/2.6.0/gems/activerecord-6.0.2.1/lib/active_record/connection_adapters/mysql2_adapter.rb:24:in `new' /var/www/furima/shared/bundle/ruby/2.6.0/gems/activerecord-6.0.2.1/lib/active_record/connection_adapters/mysql2_adapter.rb:24:in `mysql2_connection' /var/www/furima/shared/bundle/ruby/2.6.0/gems/activerecord-6.0.2.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:889:in `new_connection'ログファイルは「一番下から最新のログ」が表示されます。”「shiftキー」+「G」”を実行すると、一番下まで一瞬で移動できます。
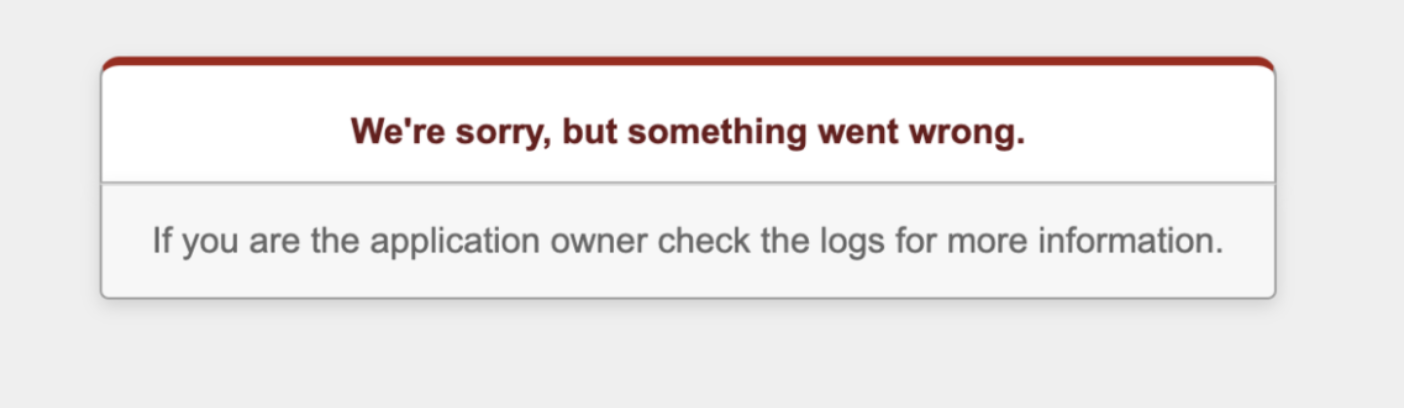
ブラウザに「We’re sorry, but 〜」と表示されている時の対処法を学びましょう
このような表示が出ている場合、まずは「production.log」を確認する必要があります。
「production.log」とは、サーバーログを記録する場所で、いわば「EC2内での出来事を記録している場所」です。ローカルにおいてrails sコマンドでアプリケーションを実行したときも、さまざまなログが表示されます。それと同様の役割です。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/production.log (production.logの表示)この中からエラー文を探しましょう。
また、もう少しログを見やすく確認できるツールとして「tail -fコマンド」というものもあります。
「tail -fコマンド」とは、最新のログを10行分だけ表示してくれるコマンドです。
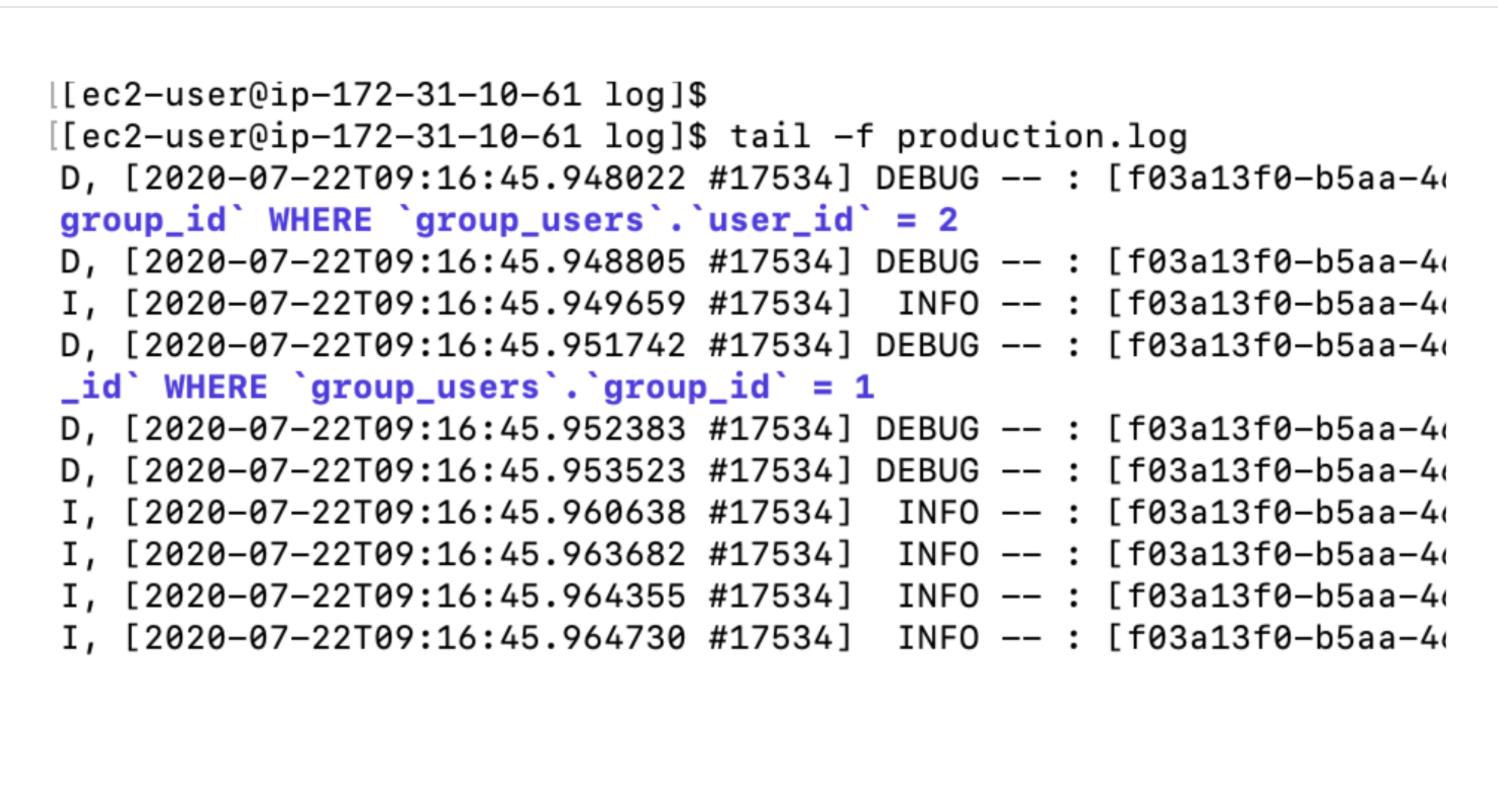
次回は、Webサーバーの設定を投稿します。
- 投稿日:2021-01-06T12:02:11+09:00
EC2 on MacでiOSビルド環境の夢を見た
※個人の感想です
※2021-01-06時点での情報と調査結果をもとに書いているので今後変わる可能性たかし君ですやろうと思ったこと
2020年12月頭くらいに発表された、EC2でmacが起動できるって話で、
ついにiosビルド環境をクラウドで完結できる日が来たかと思いいわゆるCI/CD環境を構築しようかと思った。=> 断念
苦しい
mac1.metalインスタンスは専有ホストでしか利用できない。これが運用面・料金にダイレクトに響く。
起動が結構長い
us-west2でやりましたが、30分近くかかった。
1度起動すると24H解放されない
物理マシンを借りてるみたいなもんらしいから致し方なしとは思いますが…
専有ホストはインスタンスが起動しているかによらず課金される(多分)
これもし認識違ったらそっと教えて欲しい…けど
専有ホスト作成しようとしたときのコンソールの
インスタンスごとではなく、割り当てられた専有ホストごとに請求
って文言や、そもそも物理マシンを借りるって性質である以上、使ってない時間は課金されないなんて虫の良い話があると思えないので…断念理由まとめ
上記3つがジェットストリームアタックのように襲い掛かってくるので、
・1回起動すると必ずおよそ3000円かかる(us-west2)
・使う時だけ起動して終わったら即解放って運用もかなり苦しそうというわけでクラウドでのios CI/CD環境として利用するのは現在のところ厳しいかなあという印象でした。
2-3か月フル稼働でまっくぶっくが買えてしまう…
月に1-2日だけピンポイントで使いたい日がある、みたいな特殊な要件でならあるのかなあ?
- 投稿日:2021-01-06T11:43:50+09:00
Cloud9でLaravelの環境構築の方法
手順
PHPをインストール
$ sudo yum -y update $ sudo yum -y install php72 php72-mbstring php72-pdo php72-intl php72-pdo_mysql php72-pdo_pgsql php72-xdebug php72-opcache php72-apcu $ sudo unlink /usr/bin/php $ sudo ln -s /etc/alternatives/php7 /usr/bin/php $ php -vcomposerをインストール
$ curl -sS https://getcomposer.org/installer | php $ sudo mv composer.phar /usr/bin/composerLaravelをインストール
$ composer global require "laravel/installer" $ composer create-project laravel/laravel アプリ名 6.* --prefer-dist
- 投稿日:2021-01-06T11:40:02+09:00
strongSwanでIPv4 over IPv6のVPNトンネルを構成する
strongSwanを利用してIPv4 over IPv6のVPNトンネルを構築します。最終目標はYAMAHAルーターとの拠点間接続ですが、今回は検証のためにAWSにインスタンスを立てて検証します。
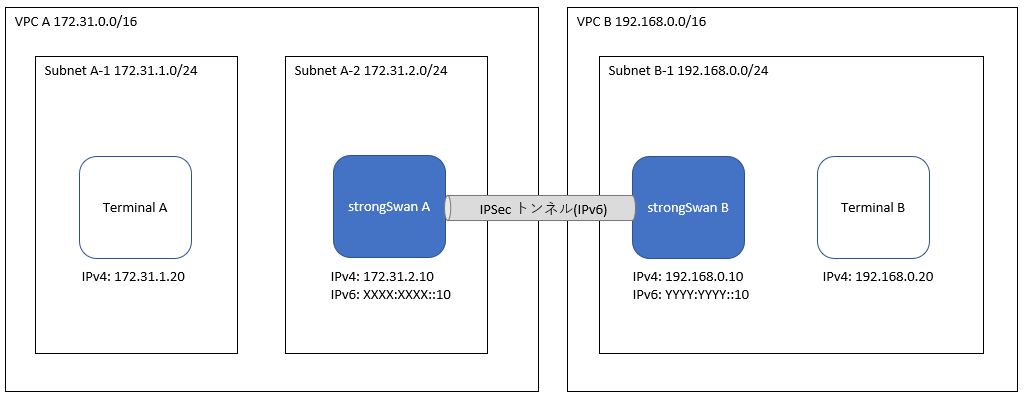
構成図
Terminal AとTerminal Bを通信させるため、strongSwan AとstrongSwan Bの2台のマシンでIPSecトンネルを張ります。今回の構成例では、VPC A(172.31.0.0/16)とSubnet B-1(192.168.0.0/24)に属する端末相互間で自由に接続ができるようにします。
- strongSwan A,Bのスペック
- AMI : Ubuntu Server 20.04 LTS (ami-0d1f7bec0e294ef80)
- インスタンスタイプ : t4g.nano
- strongSwan 5.8.2
構築手順
初期設定
# OSの初期アップデート sudo apt update sudo apt upgrade -y # strongSwanとswanctlのインストール sudo apt install strongswan strongswan-swanctl -y # インターフェース間のパケット転送を許可 echo "net.ipv4.ip_forward = 1" | sudo tee -a /etc/sysctl.conf sudo sysctl -pswanctl を利用するため、charon.confのstart-scriptsに以下の内容を追記します。
/etc/strongswan.d/charon.confcharon { (省略) start-scripts { swanctl = /usr/sbin/swanctl -q } (省略) }また、strongSwanをSystemctlで起動できるようにするため、構成ファイルを作成します。
/etc/systemd/system/strongswan.service[Unit] Description=strongSwan [Service] Type=forking ExecStart=/usr/sbin/ipsec start ExecStop=/usr/sbin/ipsec stop [Install] WantedBy=multi-user.targetsudo systemctl start strongswan sudo systemctl enable strongswan接続設定
以下はstrongSwanAの設定です。strongSwanBの設定をする場合は、自身と接続先の表記を入れ替える必要があります。
/etc/swanctl/conf.d/connection.confconnections { net-net { local_addrs = XXXX:XXXX::10 #自身(strongSwanA)のIPv6アドレス remote_addrs = YYYY:YYYY::10 #接続先(strongSwanB)のIPv6アドレス local { auth = psk id = XXXX:XXXX::10 #自身(strongSwanA)のIPv6アドレス } remote { auth = psk id = YYYY:YYYY::10 #接続先(strongSwanB)のIPv6アドレス } children { net-net { local_ts = 172.31.0.0/16 #自身(strongSwanA)側のCIDR remote_ts = 192.168.0.0/24 #接続先(strongSwanB)側のCIDR esp_proposals = aes128-sha256-x25519 } } version = 2 mobike = no proposals = aes128-sha256-x25519 } } secrets { ike-1 { id = XXXX:XXXX::10 #自身(strongSwanA)のIPv6アドレス secret = "pre-shared-key-password" } }参考:https://www.strongswan.org/testing/testresults/ipv6/net2net-ip4-in-ip6-ikev2/
VPNセッションを張る
今回は、strongSwanAからstrongSwanBへセッションを張ります。まず、strongSwanB側で設定を読み込むためstrongSwanを再起動します。その後、ログを確認するために
sudo swanctl --logを実行します。このコマンドを実行することで、ログをリアルタイムで確認できます。strongSwanBsudo systemctl restart strongswan sudo swanctl --log次に、strongSwanA側で設定を読み込み、VPNセッションを張ります。
strongSwanAsudo systemctl restart strongswan sudo swanctl -i -c net-netAWS側の設定
ここまでの設定で、strongSwanAとstrongSwanB間でpingが通るようになっているはずです。Terminal AとTerminal B間で接続できるようにするためには、AWS側で宛先チェックの無効化と、ルートテーブルの設定が必要です。
未解決事象
OS再起動時に以下のログが表示され、strongSwanが立ち上がりません。
systemctl restart strongswanで治るため、とりあえず放置しています。systemd[1]: Starting strongSwan... ipsec[529]: Starting strongSwan 5.8.2 IPsec [starter]... ipsec_starter[529]: Starting strongSwan 5.8.2 IPsec [starter]... ipsec[529]: starter is already running (/var/run/starter.charon.pid exists) -- no fork done ipsec_starter[529]: starter is already running (/var/run/starter.charon.pid exists) -- no fork done ipsec[545]: Stopping strongSwan IPsec... systemd[1]: strongswan.service: Succeeded. systemd[1]: Started strongSwan.参考にしたサイト
IPv6 Configuration Examples - strongSwan
swanctl - strongSwan
- 投稿日:2021-01-06T10:50:34+09:00
AWS管理コンソールにIP制限をかける
AWS管理のセキュリティの向上
AWSの管理コンソールに対して社内IPからの制限をかけることにした。これによりAccessKey/SecretKeyが万が一漏れても社内IPからしか接続できないためセキュリティの向上を行うことができる。
ただし、デメリットもあり会社が入っている建物が定期点検のためにルータを落としたりする場合は一切接続ができなくなってしまうのでいくつかのアカウントはIP制限をしないようにする必要がある。グループに適用する
一つ一つのユーザに対してポリシーをアタッチするのはナンセンスなためグループを作成してそのグループに所属したメンバーはIP制限が適用されるようにする。
ポリシーの作成
以下のポリシーを作成する。
aws:SourceIpで許可するIPを記載する。{ "Version": "2012-10-17", "Statement": [ { "Sid": "AdministratorAccess", "Effect": "Allow", "Action": "*", "Resource": "*" }, { "Sid": "SourceIPRestriction", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "NotIpAddress": { "aws:SourceIp": [ "111.222.333.444/32", "1.111.222.333", "2.111.222.333" ] } } } ] }ロールの作成
適用なロールを作って上記で作成したポリシーを適用する。
グループの作成
グループを作成してロールを適用する。
メンバーを参加
メンバーをグループに参加させる。
確認してみる
AWSの管理コンソールに対してかけたIP以外からログインしてみるとログイン後、以下のようなAPIエラーが出る。
次にAWS CLIでS3コマンドを叩いてみる
# aws s3 ls An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied次に社内からアクセスすると上記のようなエラーが出ないことを確認できた。

- 投稿日:2021-01-06T08:15:31+09:00
Serverless FrameworkとAWS Lambda with Pythonの環境にpipインストール
pipインストールが必要なAWS LambdaのPythonスクリプトをServerless Frameworkでデプロイする方法です。
gemインストールが必要なAWS LambdaのRubyスクリプトについては前回の記事で書きました。
手順概要
プラグインを入れれば簡単にできます。
serverless plugin install -n serverless-python-requirementsrequirements.txt作成- あとは普通にデプロイすると勝手にいろいろやってくれる
手順詳細
Serverless Frameworkのサービス作成
$ serverless create --template aws-python3 Serverless: Generating boilerplate... _______ __ | _ .-----.----.--.--.-----.----| .-----.-----.-----. | |___| -__| _| | | -__| _| | -__|__ --|__ --| |____ |_____|__| \___/|_____|__| |__|_____|_____|_____| | | | The Serverless Application Framework | | serverless.com, v2.16.1 -------' Serverless: Successfully generated boilerplate for template: "aws-python3" Serverless: NOTE: Please update the "service" property in serverless.yml with your service nameファイルが3つ生成されます。
.gitignore handler.py serverless.ymlプラグインインストール
serverless-python-requirementsというプラグインをインストールします。$ serverless plugin install -n serverless-python-requirements以下のファイルやディレクトリが増えます。
node_modules package.json package-lock.jsonServerless FrameworkがNode.jsで実装されているので、Pythonのプロジェクトなのに
node_modulesやpackage.jsonが存在することになるようです。ソースコード
serverless.yml
serverless.ymlは以下の内容にします。pluginsのところの記述はプラグインをインストールすると勝手に追記されています。
serverless.ymlservice: sample frameworkVersion: '2' provider: name: aws runtime: python3.8 region: ap-northeast-1 functions: hello: handler: handler.hello plugins: - serverless-python-requirementsrequirements.txt
サンプルのライブラリとして
jpholidayというライブラリを使ってみます。日本の祝日を判定するライブラリです。
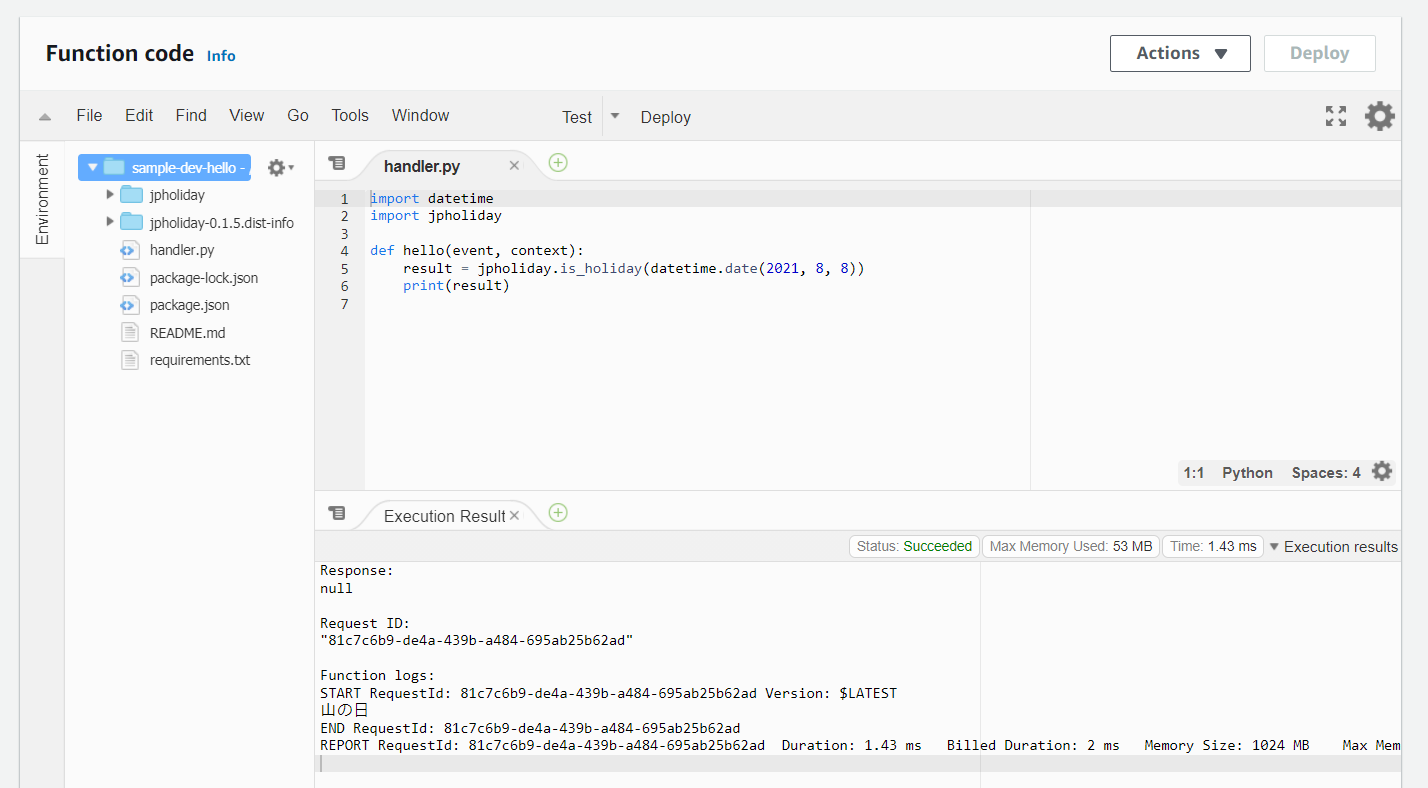
requirements.txtを作成し、以下の内容にします。ライブラリ名1行のみのファイルです。jpholidayサンプルとして
jpholidayというライブラリを使ってみます。日本の祝日を判定するライブラリです。Pythonソースコード
handler.pyimport datetime import jpholiday def hello(event, context): holidayName = jpholiday.is_holiday_name(datetime.date(2021, 8, 8)) print(holidayName) # CloudWatch に "山の日" と書き出されるデプロイ
ここまで作成してから
serverlessコマンドでデプロイすると、Lambda本体だけでなく、serverlessコマンドが自動でライブラリをインストールしたイメージを作成し、AWS LambdaのLayerとしてアップロードしてくれます。$ serverless deploy -v実行
デプロイ後にAWSマネジメントコンソールでLambdaを見ると次のように見えます。
Rubyと違ってLayerではなくLambdaに直接ライブラリが保管されるようです。
リンク