- 投稿日:2021-01-06T23:15:51+09:00
Python数学シリーズ③ 行列式(置換)
このシリーズについて
数学の理解を深めるためにpythonで実装しながら、理解を進めてます。当分は線形代数やろうと思います。数学はそんなに好きではありませんでしたが、最近好きになってきたかもしれません。シリーズの目次はこちら。間違いやもっといい方法など、ご意見あれば気軽にコメントください。
行列式と置換
行列式は以下の式で定義されます。参照元
いきなり、行列式を実装しようとしても色々と知識が足りなかったので、とりあえず置換をまずやっていこうと思います。
置換は以下のように定義されます。参照元
(1, 2, 3)とかだと(3, 1, 2)とかが置換されたものの例になります。n文字の置換は全部でn!通りあることになります。今回は置換の積を実装していこうと思います。
置換の積は以下のように表されます。参照元
こちらの記事いわく、2つの置換の対応関係(「A→B」と「B→C」)を3段論法的な感じで1つにギュッとまとめる(「A→C」)感じだそうです。詳しく突き詰めると、自分の場合沼にはまりそうなのでこのイメージでとどめておきます。今回はこの置換の積を実装していこうと思います。置換の積
置換の積ができるpythonのライブラリが見つからなかったので、自分の実装が合っているか不安です。もしライブラリがあれば教えてください。下のような感じで実装してみました。シンプルに定義どおりにやってみました。
def permutation(list1, list2): list_len = len(list2[1]) final_list = [] first_list = [] ans_list = [] for i in range(list_len): a = list2[1][i] ans = list1[1][a - 1] if list1[0][i] != ans: first_list.append(list1[0][i]) ans_list.append(ans) final_list.append(first_list) final_list.append(ans_list) return final_list def main(): print("~~permutation_test~~") pm1 = [[1, 2, 3], [2, 3, 1]] pm2 = [[1, 2, 3], [3, 2, 1]] print("my_answer:", permutation(pm1, pm2)) # 出力結果 # ~~permutation_test~~ # my_answer: [[2, 3], [3, 2]]これは改善の余地が大いにありそうですが、とりあえずこんな感じで今回はやってみました。
まとめ
大学の数学の授業、予備のりたくみの動画でいい説。
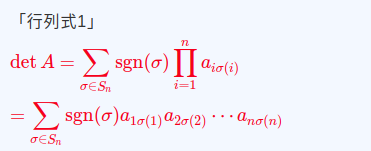


- 投稿日:2021-01-06T23:12:30+09:00
Effective Python 学習備忘録 5日目 【5/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- Effective Python
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:48-55ページ
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
動的なデフォルト引数を指定するときにはNoneとドキュメンテーション文字列を使う
デフォルト引数は一度しか評価されない
キーワード引数のデフォルト値に、現在時刻を使うプログラムを考える。
from datetime import datetime from time import sleep def log(message, when=datetime.now()): print('%s: %s' % (when, message)) log('Hi there!') sleep(0.1) log('Hi again!')出力結果
2021-01-06 14:52:16.518219: Hi there! 2021-01-06 14:52:16.518219: Hi again!キーワード引数はモジュールロード時の関数定義の時だけなので、時刻は変化しない。デフォルト値をNoneにして、ドキュメンテーション文字列に実際の振る舞いを文書化することで、可読性を担保しつつ、正しい動作を得ることができる。
def log(message, when=None): """Log a message with a timestamp. Args: message: Message to print. when: datetime of when the message occurred. Defaults to the present time. """ when = datetime.now() print('%s: %s' % (when, message)) log('Hi there!') sleep(0.1) log('Hi again!')出力結果
2021-01-06 15:20:07.665323: Hi there! 2021-01-06 15:20:12.870457: Hi again!キーワード専用引数で明確さを高める
関数の引数が多くなった際に、位置引数を用いると可読性が落ちる。
例として、4つの引数を持ち、初めの2つはint型、最後の二つはboolian型を受け取る、関数を考える。def sample(int_a, int_b, bool_c, bool_d): # ... sample(1, 2, True, False)この場合、bool_c, bool_dを容易に位置を取り違える可能性がある。
キーワード引数であれば、そのような心配は無くなる。Pythonでは、位置で引数を指定できなくする、キーワード専用引数が用意されている。
引数リストの中の*記号が、位置引数の終わりと、キーワード専用引数の始まりを示す。def sample(int_a, int_b, *, bool_c, bool_d) # ... sample(1, 2, True, False) # Error になる sample(1, 2, bool_c=True, bool_d=False) # 動作する
- 投稿日:2021-01-06T22:55:01+09:00
Pythonで環境変数にアクセスする方法
環境変数にアクセスする方法
モジュールのインポート
import os環境変数にアクセスする
Pythonでは、osモジュールの
environに環境変数が格納されている。
型は、マップ型です。user_name = os.environ['USERNAME'] print(user_name)また、
os.getenv(key, default=None)を使用することでも取得できます。user_name = os.getenv('USERNAME', 'dummy') print(user_name)
os.getenv()は第1引数で環境変数のキーを指定します。
指定されたキーが存在していない場合は、第2引数の値を返却します。まとめ
環境変数にアクセスする方法は2つある。
- 1つ目は、
os.environを使用する方法- 2つ目は、
os.getenv()を使用する方法場合によると思いますが、単純にアクセスするだけなら、環境変数が存在していない場合に任意の値を返却してもらえる
os.getenv()を使用するのが良いと思います。
- 投稿日:2021-01-06T22:40:34+09:00
【SIGNATE】【lightgbm】コンペ アメリカの都市エイムズの住宅価格予測 参加記録 (1/2)
はじめに
SIGNATEで開催されているBegginer向けコンペ
【第5回_Beginner限定コンペ】アメリカの都市エイムズの住宅価格予測 に参加したため、参加記録を書きます。コンペについて
- 目的: 都市エイムズの住居や周辺環境に関する情報を元に
住宅の価格 'Sale Price' を予測します。 (よくあるやつ)- 期間: 2020/12/01 ~ 2021/01/10
以降で順位等を記載してますが、コンペ開催中のため未確定です。- SIGNATEの称号Begginerのみ参加可能 (初心者向け)
現在のスキル
- 機械学習初心者
- コンペ経験はKaggleの タイタニック号の生存者予測 のみ
方針
- アルゴリズムはLightGBM を採用します。
コンペでよく使われるとのことなので一回やってみようという考えです。
XGBoostとかとのアンサンブルまでは頑張らない。- 本来はデータを理解してから作業を進めるべきですが、
最初にLightGBMでモデルを一発作成し、それを基準に改めてデータを理解する流れで書いてます。- 解法は調べるといくらでも出てくると思うので、調べず頑張る。
環境とか
Windows10のWSL2にUbuntuをインストールし、主に以下のライブラリを入れて試しました。
ライブラリ バージョン 備考 Python 3.8.5 - lightgbm 3.1.1 - notebook 6.0.3 jupyter-notebook scikit-learn 0.24.0 - matplotlib 3.3.3 - seaborn 0.11.1 - やったこと1
1-1. データ読み込み
train_data = pd.read_csv('./train.csv')データ数: 3000
カラム数: 47 (目的変数 'Sale Price' 含む)1-2. カテゴリカルデータへの変換
このまま学習を行うと、object型(文字列)でエラーが起こるのでpandasのcategory型に変換しました。
category_columns = ['MS Zoning', 'Lot Shape', 省略] # object->categoryにしたいlist for col in category_columns: train_data[col] = train_data[col].astype('category') print(train_data.dtypes) index int64 Order int64 MS SubClass int64 MS Zoning category ... 略以前、勉強した時のカテゴリカルデータは
One Hot エンコーディング/ラベルエンコーディングが必要だったのが一発で変換できて少し感動。
lightgbmのバージョンが古いと対応していない(?)らしく、
検索して出るURLによってはラベルエンコーダ等を使ってるページもありました。1-3. データの分割/データセット作成
ホールドアウト法で 7:3に分割して学習用、検証用にします。
その流れでLightGBM用データセットを作成。train, test = train_test_split(train_data, test_size=0.3, shuffle=True, random_state=0) Y_train = train.loc[:, 'SalePrice'] X_train = train.drop(['index', 'SalePrice'], axis=1) Y_eval = test.loc[:, 'SalePrice'] X_eval = test.drop(['index', 'SalePrice'], axis=1) lgb_train = lgb.Dataset(X_train, Y_train) lgb_eval = lgb.Dataset(X_eval, Y_eval, reference=lgb_train)indexをなんとなく消しましたけどLightGBMだし不要だったかも。
1-4. 学習
お試しなので最小限の設定のみ。
lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'max_depth' : 10 } evals_results = {} model = lgb.train(lgbm_params, lgb_train, num_boost_round=1000, valid_sets=[lgb_eval, lgb_train], valid_names=['eval', 'train'], early_stopping_rounds=50, evals_result=evals_results, verbose_eval=50)結果1
学習曲線
lightgbmのplot_metric() で学習曲線を表示
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.plot_metric.htmllgb.plot_metric(evals_results, metric='rmse', figsize=(8, 8))
27回の学習でピークに達し、その後は過学習気味に性能が微減。
パラメータチューニングでもう少し過学習を抑えられそう。メモ: plot_metric()の第一引数は
Dictionary returned from lightgbm.train()
と公式Documentにあったため train()の戻り値 modelを入れたけど 駄目だった、、、
train()のevals_resultパラメータにDictを設定した場合
学習結果を出力してくれるので、それを設定する必要があるみたい。importance
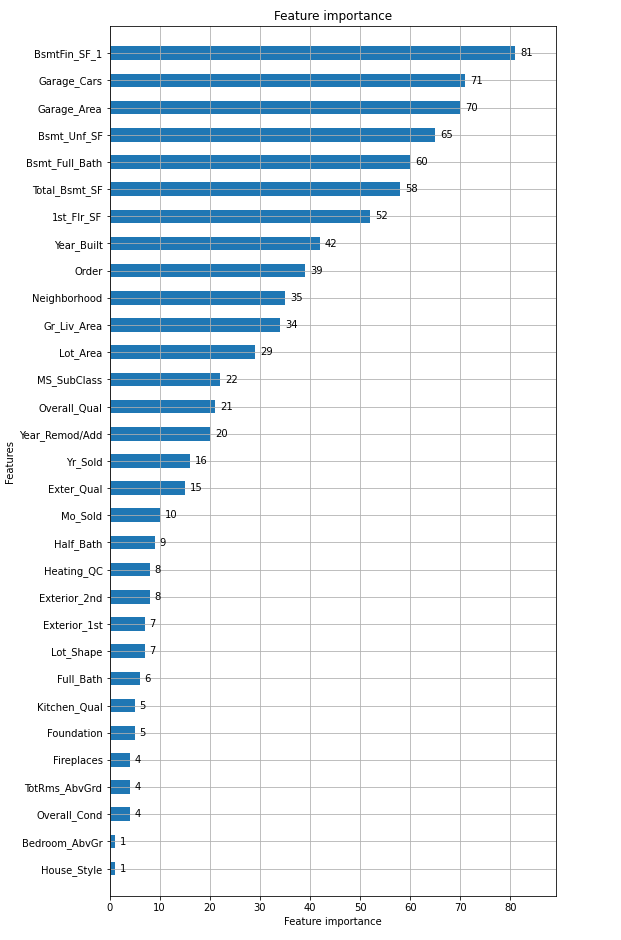
lightgbmのplot_importance()で特徴量の重要度を表示
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.plot_importance.htmllgb.plot_importance(model, height=0.5, figsize=(8, 16))
BsmtFin SF 1(地下の広さ)、Garage xxx (車の収納)が重要とのこと。
データの本質がわかった気持ちになった。現時点の順位
RMSE: 26818.0705594
順位: 132/542 のため上位25%程度やったこと2
もう少し汎用的にしたいため クロスバリデーションに置き換えました。
LightGBM には cv()関数があるので train()関数をほぼ置き換えれば可能でした。
検索して出るURLによっては StratifiedKFold()で自分で実装する方法もあり混乱したが、
以下のページで良い感じに解説してくれてました。
https://blog.amedama.jp/entry/lightgbm-cv-implementationlgb_train = lgb.Dataset(X_train, Y_train) # lgb_eval = lgb.Dataset(X_eval, Y_eval, reference=lgb_train) lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'max_depth' : 10 } model = lgb.cv(lgbm_params, lgb_train, num_boost_round=1000, early_stopping_rounds=50, verbose_eval=50, nfold=7, shuffle=True, stratified=False, seed=42, return_cvbooster=True, )メモ: return_cvboosterパラメータにTrueを設定すると model['cvbooster'] が学習モデルのlistになるので
それを使ってpredict()が可能。古いLightGBMはreturn_cvboosterが未対応らしく、検索して出るURLだと使ってない場合有。結果2
クロスバリデーションによる現時点の順位
RMSE: 26552.7208586
順位: 86/543 のため上位16%程度RMSEは250程度改善。train_test_split()の分割は良くなかった模様。
順位は 約10%向上。まとめ1
初心者のみのコンペですが、LightGBMを使うだけで上位16%程度には入れる模様。
ここからデータ理解・パラメータ調整を試します。

- 投稿日:2021-01-06T22:11:26+09:00
リストワイズ除去のツリーを簡単に計算する関数(Python)
本記事について
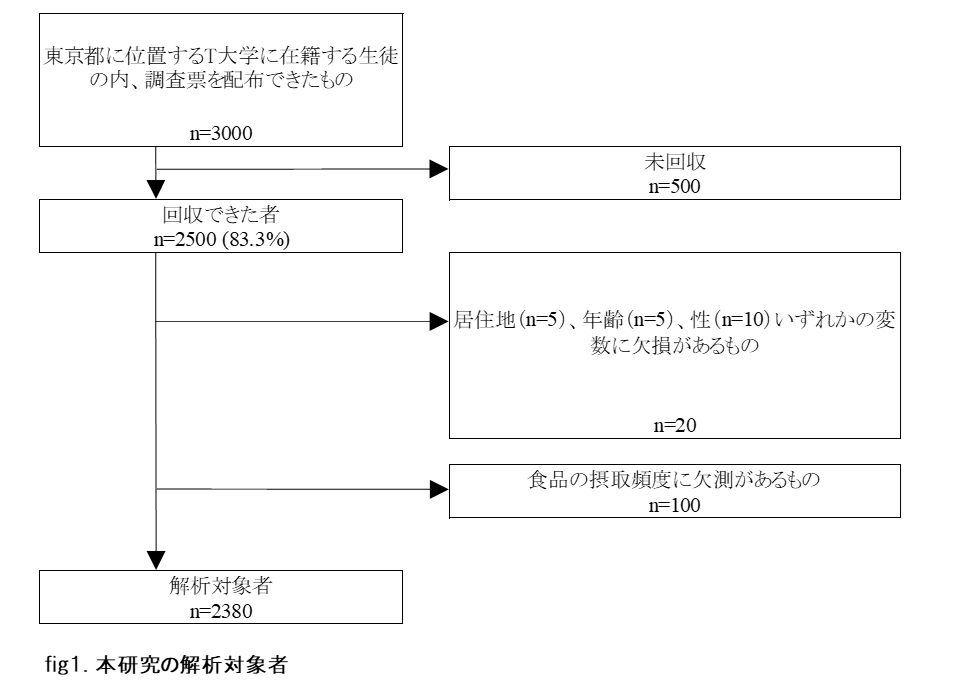
- 疫学研究等で目にする、Fig1.本研究の解析対象者 のツリーを素早く計算する関数を書いた。
- リストワイズ除去を行った際のツリーを想定する。
- コードはPythonであるが、記事内にてRより呼び出す方法も追記した。
そもそもリストワイズ除去のツリーって?
こんなヤツ↓ エクセルでシコシコ関数組んでると平気で半時間とかかかったり。(目や腰もいたくなるね)
(この図に正式名称があればご教示ください)
何が面倒くさいの?
単にそれぞれの変数の欠測数を乗せるだけならdf.isnull.sum()で終了ですが、、
- x1の欠測は●人でした。
- x1の欠測を除いたデータにおいて、x2の欠測は▲人でした。
- x1と、x2の欠測を除いたデータにおいてx3の欠測は■人でした。
- ・・・
どんどんネスト(?)していくんですね。
あぁ面倒くさい。
では、本題へ
import pandas as pd import numpy as np def caluculate_missing_tree(df): d ={} d[0]= df.loc[df[df.columns[0]].isnull() != True] for i in range(len(df.columns)-1): d[1+i]= d[i].loc[d[i][d[i].columns[1+i]].isnull() != True] le = [] colnames = [] missing_tree = pd.DataFrame() for i in range(len(df.columns)): le.append(len(d[i])) for i in range(len(df.columns)): colnames.append(df.columns[i]) missing_tree['col_name'] = colnames missing_tree['Size'] = le return missing_treecaluculate_missing_tree() の引数に、ツリーを描きたい順番に変数が入っているデータフレームをぶち込むだけです。
たとえば、titanicのデータで試してみる。
import pandas as pd import numpy as np import os df = pd.read_csv("train.csv") df.shape #(891, 12) df.isnull().sum() # それぞれの変数の欠測数 -------------------------------- PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64こいつを今回の関数に食わせると・・
caluculate_missing_tree(df) -------------------------------------- col_name Size 0 PassengerId 891 1 Survived 891 2 Pclass 891 3 Name 891 4 Sex 891 5 Age 714 6 SibSp 714 7 Parch 714 8 Ticket 714 9 Fare 714 10 Cabin 185 11 Embarked 183一瞬で計算できた。嬉しい。
中身の説明
.loc を使用して、条件に合う(欠測していない)データセットをどんどん作っていけば良いのではという発想。
df <- 元のデータ df1 = df.loc[df['x1'].isnull() != True]] <- x1 の欠測が除かれたデータ df2 = df1.loc[df1['x2'].isnull() != True]] <- x1, x2の欠測が除かれたデータ df3 = df2.loc[df2['x3'].isnull() != True]] <- x1, x2, x3の欠測が除かれたデータ ... ...こんな感じ。
さらに、for文書くことまで考えてみるとこんな感じ。
d[0]= df.loc[df[df.columns[0]].isnull() != True] <- ここはfor文の外 --- こっからfor のイメージ --- d[1]= d[0].loc[d[0][d[0].columns[1]].isnull() != True] d[2]= d[2-1].loc[d[2-1][d[2-1].columns[2]].isnull() != True] d[3]= d[3-1].loc[d[3-1][d[3-1].columns[3]].isnull() != True]しかし、for文でdfの作成を自動化するのが少々難儀だった。
複数のデータフレームを格納するリストを作成。そこに、それぞれの変数に対応するデータフレームを格納していくという手法を使用した。
d ={} d[0]= df.loc[df[df.columns[0]].isnull() != True] for i in range(len(df.columns)-1): d[1+i]= d[i].loc[d[i][d[i].columns[1+i]].isnull() != True]こんな感じ。例えばtitanicのデータでは、
・d[0]はPassengerID
・d[1]はPassengerID, Survived
・d[2]はpassengerID, Survived, Pclass の欠測に対応している。その後、確認を容易にするために、変数名とサンプルサイズを列名に持つデータフレームを作ろうという発想になるのは必然であろう。
le = [] colnames = [] missing_tree = pd.DataFrame() for i in range(len(df.columns)): le.append(len(d[i])) for i in range(len(df.columns)): colnames.append(df.columns[i]) missing_tree['col_name'] = colnames missing_tree['Size'] = le return missing_treeleにそれぞれの変数の欠測値を消去したデータフレームのlen(df.columns)を格納していった。同様に、colnamesにそれぞれのデータフレームに対応する変数名を格納し、可視化した。
caluculate_missing_tree(df) -------------------------------------- col_name Size 0 PassengerId 891 1 Survived 891 2 Pclass 891 3 Name 891 4 Sex 891 5 Age 714 6 SibSp 714 7 Parch 714 8 Ticket 714 9 Fare 714 10 Cabin 185 11 Embarked 183ジャジャーン(2度目)
Rでの実装方法
- Rnotebookと reticulateライブラリ を使用する。(追記するかも)
- 投稿日:2021-01-06T21:46:11+09:00
privateでないAPIがscikit-learn v0.24で削除されたために、unpickleできない経験をしました
scikit-learn v0.22 より前に作った
MultiLabelBinarizerが、scikit-learn v0.24以降の入った環境でunpickleできないことを示します。
ちょっとハマった身から言えること:pickleする環境とunpickleする環境のバージョン違いにはご注意ください環境
macOS
Python 3.7.3手順
scikit-learn0.22より前scikit-learn-0.21.3
ドキュメントのExamplesを用います
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MultiLabelBinarizer.html#sklearn.preprocessing.MultiLabelBinarizerexperiment.py
import pickle from sklearn.preprocessing import MultiLabelBinarizer mlb = MultiLabelBinarizer() mlb.fit_transform([{'sci-fi', 'thriller'}, {'comedy'}]) print(list(mlb.classes_)) with open("mlb_021.pkl", "wb") as fout: pickle.dump(mlb, fout)$ python experiment.py ['comedy', 'sci-fi', 'thriller'] $ python -q対話モードでunpickleします。
>>> import pickle >>> with open("mlb_021.pkl", "rb") as fin: ... mlb = pickle.load(fin) ... >>> list(mlb.classes_) ['comedy', 'sci-fi', 'thriller'] >>> mlb.transform([['sci-fi', 'comedy']]) array([[1, 1, 0]]) >>> type(mlb) <class 'sklearn.preprocessing.label.MultiLabelBinarizer'>
scikit-learn0.24以降
pip install -U scikit-learnで0.24.0が入りました。対話モードでunpickleを試みます(エラーになります)。
>>> import pickle >>> with open("mlb_021.pkl", "rb") as fin: ... mlb = pickle.load(fin) ... Traceback (most recent call last): File "<stdin>", line 2, in <module> ModuleNotFoundError: No module named 'sklearn.preprocessing.label'原因
以下のIssueへの対応でモジュールをprivateにしています。
https://github.com/scikit-learn/scikit-learn/issues/9250rename file.py into _file.py
それにより、sklearn/preprocessing/label.py(
sklearn.preprocessing.label)はsklearn/preprocessing/_label.py(sklearn.preprocessing._label)とrenameされました。
https://github.com/scikit-learn/scikit-learn/commit/15d5ef04df21f1d8db6583c74d1869c3fad36970#diff-e4f17cabd1bed4babf2fbfb7a31a3d955563e0267e8c310fa61629e722a64488対処法
0.24まで上げなければunpickleはできます(後述するように自己責任でお願いします)。
pip install -U 'scikit-learn<0.24'で0.23.2をインストール。>>> import pickle >>> with open("mlb_021.pkl", "rb") as fin: ... mlb = pickle.load(fin) ...このとき、バージョン0.24でremoveされるとwarningも出ています。
/.../env/lib/python3.7/site-packages/sklearn/utils/deprecation.py:143: FutureWarning: The sklearn.preprocessing.label module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.preprocessing. Anything that cannot be imported from sklearn.preprocessing is now part of the private API.
warnings.warn(message, FutureWarning)ドキュメントでも通知されていました!
https://scikit-learn.org/dev/whats_new/v0.22.html#clear-definition-of-the-public-api実際、
MultiLabelBinarizerのtypeを確認すると、renameされた_label.pyを使っています(0.23.2で確認)。>>> from sklearn.preprocessing import MultiLabelBinarizer >>> mlb = MultiLabelBinarizer() >>> type(mlb) <class 'sklearn.preprocessing._label.MultiLabelBinarizer'>なお、scikit-learnのバージョンが違うことのWarningも出ますので、文面にあるように自己責任でお願いします。
/.../env/lib/python3.7/site-packages/sklearn/base.py:334: UserWarning: Trying to unpickle estimator MultiLabelBinarizer from version 0.21.3 when using version 0.23.2. This might lead to breaking code or invalid results. Use at your own risk.
UserWarning)メモ
pip install -U(docs)にバージョン込みで指定すると、パッケージのバージョンを自由に変えられます(--upgradeオプションですが、ダウングレードもできます)。
?バージョン指定の仕方について
https://pip.pypa.io/en/stable/user_guide/#understanding-your-error-messageTODO:pickleの仕組みを今よりももう少し理解したいです
- 投稿日:2021-01-06T21:38:42+09:00
Google画像検索を保存するPythonライブラリの使い方。【最新版】
あけましておめでとうございます。
結構知ってる人が多いとは思いますが私が何度も迷うので書き留めておきます。
機械学習の際の学習データにご利用ください。2020年8月ごろ?に検索結果の提供方法が大きく変わったらしく、Windows用ソフトの「ImageSpider」が使えなくなりました。(結構便利だったんですけどね...)
そこでこれからはPython用ライブラリの「google_images_download」を使うことにしました。インストール
【注意】pipではインストールしないでください!
pip3 install google_images_downloadPIPにあるバージョンではGoogle側の変更に対応できていないため、インストールしても使えません。
なので直接インストールします。git clone https://github.com/Joeclinton1/google-images-download.git cd google-images-download && sudo python setup.py installこれでインストールは終わりです。
使い方
ここでは代表的な使い方としてコマンドライン上での利用方法を載せておきます。
googleimagesdownload --keywords "apple" --limit 20上記の例だと「apple」の検索結果を20件、カレントディレクトリに保存します。
Python上での使い方やその他の条件設定等は公式ドキュメント*を見てください。100件以上を取得する場合
取得したい画像が100件を超える場合はchromedriverをインストールする必要があります。
※Ubuntu20.04 LTSでの操作方法です。Windowsの場合は各自お調べくださいm(_ _)mまずドライバの最新バージョンを確認
以下のサイトに行って最新版の「chromedriver_linux64.zip」のURlをコピーしてください。
*https://sites.google.com/a/chromium.org/chromedriver/downloads
因みに2021年1月6日現在はhttps://chromedriver.storage.googleapis.com/88.0.4324.27/chromedriver_linux64.zipでした。次に以下のコマンドを続けて入力してください。(こちらの記事を参考にさせていただきました。)
sudo apt install unzip cd /tmp/ curl -O <<<<<ここにさっき確認したURLを入れる>>>>> unzip chromedriver_linux64.zip mv chromedriver /usr/local/bin/ rm chromedriver_linux64.zipこれでインストールは以上です。
100件以上取得する際のコマンド
googleimagesdownload --keywords "apple" --limit 120 --chromedriver /usr/local/bin/chromedriverさっき紹介したやつに --chromedriver オプションでインストール先を選択するだけです。
↓取得結果
ちゃんと取得できていますね。
- 投稿日:2021-01-06T21:38:42+09:00
【最新】Google画像検索を保存するPythonライブラリの使い方&ChromeDriverをubuntuで使う
あけましておめでとうございます。
結構知ってる人が多いとは思いますが私が何度も迷うので書き留めておきます。
機械学習の際の学習データにご利用ください。2020年8月ごろ?に検索結果の提供方法が大きく変わったらしく、Windows用ソフトの「ImageSpider」が使えなくなりました。(結構便利だったんですけどね...)
そこでこれからはPython用ライブラリの「google_images_download」を使うことにしました。インストール
【注意】pipではインストールしないでください!
pip3 install google_images_downloadPIPにあるバージョンではGoogle側の変更に対応できていないため、インストールしても使えません。
なので直接インストールします。git clone https://github.com/Joeclinton1/google-images-download.git cd google-images-download && sudo python setup.py installこれでインストールは終わりです。
使い方
ここでは代表的な使い方としてコマンドライン上での利用方法を載せておきます。
googleimagesdownload --keywords "apple" --limit 20上記の例だと「apple」の検索結果を20件、カレントディレクトリに保存します。
Python上での使い方やその他の条件設定等は公式ドキュメント*を見てください。100件以上を取得する場合
取得したい画像が100件を超える場合はchromedriverをインストールする必要があります。
※Ubuntu20.04 LTSでの操作方法です。Windowsの場合は各自お調べくださいm(_ _)mまずドライバの最新バージョンを確認
以下のサイトに行って最新版の「chromedriver_linux64.zip」のURlをコピーしてください。
*https://sites.google.com/a/chromium.org/chromedriver/downloads
因みに2021年1月6日現在はhttps://chromedriver.storage.googleapis.com/88.0.4324.27/chromedriver_linux64.zipでした。次に以下のコマンドを続けて入力してください。(こちらの記事を参考にさせていただきました。)
sudo apt install unzip cd /tmp/ curl -O <<<<<ここにさっき確認したURLを入れる>>>>> unzip chromedriver_linux64.zip mv chromedriver /usr/local/bin/ rm chromedriver_linux64.zipこれでインストールは以上です。
100件以上取得する際のコマンド
googleimagesdownload --keywords "apple" --limit 120 --chromedriver /usr/local/bin/chromedriverさっき紹介したやつに --chromedriver オプションでインストール先を選択するだけです。
↓取得結果
ちゃんと取得できていますね。
- 投稿日:2021-01-06T21:32:39+09:00
Pythonのhttp.serverはRange Requestに対応してなかった
発生した問題
ローカルPCにサーバーを立てて、iOS Safariから動画を開いて再生しようとしたら何故か再生できない...
PCのFirefoxからは再生できるのに...Googleで検索したらこのような記事を発見
【HTML5】iOSのSafariでvideoタグ埋め込みのmp4が再生できないのはインターレースだから
つまり動画方式が悪いんじゃねーのってこと。
ところが、インターレース方式ではなくプログレス方式なっていた。
FFmpegで再エンコードしてみたりしたが変わらず。
記事の最後の方に追記でほかの原因かもと書いてあり、この記事にたどり着く。
【MP4】SafariでMP4動画が再生できない問題を解決
一番目はそもそもvideo要素すら使ってないのでありえない。
2番目、別の記事のリンクが張ってあり、タイトルが「Safariで動画を表示する際、サーバーのHTTP Range Request対応が必須になっている」となっていてRange Requestに対応してないなんてそんなわけないだろと確認したら...
あれ?対応してなくね?
そんなわけあった。
まあそもそもhttp.serverはスクレイピングとかのテスト用だろうしRange Requestとかに対応しなくても問題無かったのだろう。対処法
やっぱりApache最強
- 投稿日:2021-01-06T20:59:41+09:00
macOS Big Sur で poetry を使って numpy をインストールできなかったので無理やり回避した
環境
- OS: macOS Big Sur
- Python : 3.8.7 (from Homebrew)
- pip : 20.2.3
- shell : zsh
発生した事象
pyproject.tomlに次のような記述が含まれている状態で、poetry installを行ったところ[tool.poetry.dependencies] python = "3.8.*" pip = "^20.3.3" gcsfs = "^0.7.1" lightgbm = "^3.1.1" pandas = "^1.2.0" matplotlib = "^3.3.3" seaborn = "^0.11.1"% poetry install Python 2.7 will no longer be supported in the next feature release of Poetry (1.2). You should consider updating your Python version to a supported one. Note that you will still be able to manage Python 2.7 projects by using the env command. See https://python-poetry.org/docs/managing-environments/ for more information. Installing dependencies from lock file Package operations: 80 installs, 0 updates, 0 removals • Installing lazy-object-proxy (1.4.3) • Installing six (1.15.0) • Installing wrapt (1.12.1) • Installing certifi (2020.12.5) • Installing astroid (2.4.1) • Installing chardet (3.0.4) • Installing idna (2.10) • Installing isort (4.3.21) • Installing mccabe (0.6.1) • Installing pyasn1 (0.4.8) • Installing pycodestyle (2.6.0) • Installing pyflakes (2.2.0) • Installing toml (0.10.2) • Installing urllib3 (1.26.2) • Installing cachetools (4.2.0) • Installing flake8 (3.8.4) • Installing multidict (5.1.0) • Installing numpy (1.19.5): Failed EnvCommandError回避策
poetry を使わずに pip 20.3.3 を使うとインストールできる (python 3.9 を用いているものの、python 3.8 でも同様)
% python3.9 -m venv --upgrade-deps venv Collecting pip Downloading pip-20.3.3-py2.py3-none-any.whl (1.5 MB) |████████████████████████████████| 1.5 MB 4.9 MB/s Collecting setuptools Using cached setuptools-51.1.1-py3-none-any.whl (2.0 MB) Installing collected packages: pip, setuptools Attempting uninstall: pip Found existing installation: pip 20.2.3 Uninstalling pip-20.2.3: Successfully uninstalled pip-20.2.3 Attempting uninstall: setuptools Found existing installation: setuptools 49.2.1 Uninstalling setuptools-49.2.1: Successfully uninstalled setuptools-49.2.1 Successfully installed pip-20.3.3 setuptools-51.1.1 % source venv/bin/activate (venv) % pip install numpy Collecting numpy Downloading numpy-1.19.5-cp39-cp39-macosx_10_9_x86_64.whl (15.6 MB) |████████████████████████████████| 15.6 MB 411 kB/s Installing collected packages: numpy Successfully installed numpy-1.19.5ので、pip を使えば解決は一応できます。が、おすすめしません。poetry で
requirements.txtを出力するようにすればまあなんとか…。% poetry config virtualenvs.create false % python3.8 -m venv .venv && source .venv/bin/activate && pip install -U pip && (poetry export --without-hashes > requirements.txt) && pip install -r requirements.txt && deactivateこのあと
poetry installすると通りますし、poetry shellも通りますが、なんかコレジャナイ感がすごいです。よりよく解決したいですね。関連
- 投稿日:2021-01-06T20:58:44+09:00
1byteデータに含まれる任意のbit位置にある値を取得する方法
やりたいこと
1byteデータから任意のbit位置にある値を取得する方法をいろいろ考えたので記事に残したいと思います。
例えば
0b10100000という1byteのデータがあったとき(以下図)、4bit目から2bit分の値である0b10)を取得する方法です。
今回思いついた方法が以下の2点です。
- 文字列に変換
- bit演算を利用
ソースコードはpythonです。
文字列に変換
目的のbit値を文字列に変換し、bit位置=文字列の位置と考えて目的のbit値を抽出するやり方です。
この方法の注意点は文字列の位置とbit位置は方向が逆である点です。以下の例では、文字列を反転(
[::-1])させてから目的の値を抽出し、抽出後に再反転させて、正しいbit値に変換しています。bit_pos = 4 bit_len = 2 value = 0xA0 # 0b10100000 # bit値として文字列に変換 bit_str = "{:08b}".format(value) # bit_str = '10100000' # 文字列を反転し、bit位置(`bit_pos`)とbit長(`bit_len`)で目的の値を抽出。抽出値はbit値としては反転しているので、再反転して値を戻す value = bit_str[::-1][bit_pos:bit_pos+bit_len][::-1] result = int(value, 2) # result: 2 (='0b10')
bit_pos,bit_lenをうまく文字列位置に変換できれば、文字列反転をさせずに目的の値が抽出できそうですね。bit演算を使う
次は、bit演算を使う方法です。具体的にはbitシフト演算と論理積を利用します。
まず、対象データの取得したいbit位置が0bitになるよう右シフトします。
これに対して、00000011という値と論理積を計算してあげれば、目的のbit値を取得することができます。
なので11111111=0xFFを右シフトして、論理積の対象データである00000011を作ります。以上の処理を図でまとめると、以下のようになります。
実際のコードは以下の通りです。
bit_pos = 4 bit_len = 2 value = 0xA0 # 0b10100000 result = (value >> bit_pos) & (0xFF >> (8 - bit_len)) # result: 2 (='0b10')終わりに
もっとシンプルでスマートに計算できそうな気がするのですが、これ以上の案は思いつきませんでした。
ただ、目的の値はこれで取得できそうです。もっとbit操作をうまく使えるように、日々精進していきたいです。


- 投稿日:2021-01-06T19:43:04+09:00
pythonの配列をjsonデータに加えるだけ
pythonの配列をjsonデータに加えるだけです
コード
test.py#!/env/python import json def addJson(list): # state data to json json = { "parameter": list, } return json l = list(range(0)) for i in range(25): l.append(i) data = addJson(l) print(data)実行結果
$ python test.py {'parameter': [0]} {'parameter': [0, 1]} {'parameter': [0, 1, 2]} {'parameter': [0, 1, 2, 3]} {'parameter': [0, 1, 2, 3, 4]} {'parameter': [0, 1, 2, 3, 4, 5]} {'parameter': [0, 1, 2, 3, 4, 5, 6]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]} {'parameter': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]}以上です
- 投稿日:2021-01-06T19:27:02+09:00
manimの作法 その11
概要
manimの作法、調べてみた。
Animation、使ってみた。サンプルコード
from manimlib.imports import * class FuncRotater(Animation): CONFIG = { "rev_func" : lambda x : x, } def interpolate_submobject(self, submobject, starting_submobject, alpha): submobject.points = np.array(starting_submobject.points) def interpolate_mobject(self, alpha): Animation.interpolate_mobject(self, alpha) angle_revs = self.rev_func(alpha) self.mobject.rotate(angle_revs * TAU, about_point = ORIGIN) class test(Scene): def construct(self): circle = Circle() dot = Dot() dot2 = dot.copy().shift(RIGHT) self.play(GrowFromCenter(dot)) self.wait() self.play(Transform(dot, dot2)) self.wait() self.play(MoveAlongPath(dot, circle), run_time = 1, rate_func = linear) self.wait() self.play(Rotating(dot, about_point = [2, 0, 0]), run_time = 1) self.wait() self.play(FuncRotater(dot, rev_func = lambda x : x % 0.25, run_time = 2)) self.wait() self.play(ApplyMethod(dot.scale, 2)) self.wait() self.play(FadeOut(dot)) self.wait()生成した動画
https://www.youtube.com/watch?v=0aBAezBXB-w
以上。
- 投稿日:2021-01-06T19:21:07+09:00
Pythonで関数とグローバル変数の応用練習
はじめに
閲覧していただきありがとうございます。
英語の文法は許してください。
有識者の方へ、もっとなんとかなるとかあったら優しく教えてください。概要
・AかBに投票をする。
・投票数の確認と投票数の初期化をする。
・終了処理をする。完成例
def voteA (): global vote1 vote1 = vote1 + 1 def voteB (): global vote2 vote2 = vote2 + 1 def count (): global vote1 global vote2 print("[The number of votes for A is",vote1,".]") print("[The number of votes for B is",vote2,".]") def Initialize (): global vote1 global vote2 vote1 = 0 vote2 = 0 op = 0 while op != 9: if op == 1: voteA () print("[Vote for A.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 2: voteB () print("[Vote for B.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 3: print("[Check the vote count.]") count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 0: print("[Initialize the vote count.]") Initialize () count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) else: while op != 1 and op != 2 and op != 3 and op != 9 and op != 0: print("[Vote for A.>1]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) print("[Good bye.]")実行例
[Initialize the vote count.] [The number of votes for A is 0 .] [The number of votes for B is 0 .] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:1 [Vote for A.] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:1 [Vote for A.] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:2 [Vote for B.] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:3 [Check the vote count.] [The number of votes for A is 2 .] [The number of votes for B is 1 .] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:0 [Initialize the vote count.] [The number of votes for A is 0 .] [The number of votes for B is 0 .] [Vote for A.>1] [Vote for B.>2] [Check the vote count.>3] [End.>9] [Initialize the vote count.>0] '[Chose 1 or 2 or 3 or 9 or 0.]:9 [Good bye.]AとBに投票する関数の作成
今回は複数の関数で同じ変数を使用するため、グローバル変数を使います。
def voteA (): global vote1 vote1 = vote1 + 1 def voteB (): global vote2 vote2 = vote2 + 1投票数を確認する関数の作成
シンプルにグローバル変数であるvote1とvote2を表示させる。
def count (): global vote1 global vote2 print("[The number of votes for A is",vote1,".]") print("[The number of votes for B is",vote2,".]")投票数を初期化する関数の作成
グローバル変数のため複数の関数で同じ変数を使える。
こちらもシンプルにvote1とvote2を0にしている。def Initialize (): global vote1 global vote2 vote1 = 0 vote2 = 0ABそれぞれに投票する文の作成
Bに投票する文はAとほとんど変わらないので割愛。
opは後にwhileでループするときに使う。voteA () print("[Vote for A.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:"))投票数を確認する文を作成
シンプルに関数を呼び出すだけ。
print("[Check the vote count.]") count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:"))投票数を初期化する文を作成
こちらも、シンプルに関数を呼び出すだけ。
正しく初期化されているかを確認するために、投票数を確認する関数も呼び出しておく。print("[Initialize the vote count.]") Initialize () count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:"))A,Bを投票するか、投票数を確認するか、投票数を初期化するか、終了するかを選択する文を作成
whileにそれぞれ挿入していく。
最初にopを0に宣言しておくことで、投票の初期化と確認をしてから開始できる。
できるだけ強制終了であるbrakeを使用したくないため、終了の9を入力したらwhileのループが終了するようになっている。
最後のifでは誤った選択肢を選択された場合に正しい選択肢が選択されるまでwhileでループさせている。op = 0 while op != 9: if op == 1: voteA () print("[Vote for A.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 2: voteB () print("[Vote for B.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 3: print("[Check the vote count.]") count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 0: print("[Initialize the vote count.]") Initialize () count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) else: while op != 1 and op != 2 and op != 3 and op != 9 and op != 0: print("[Vote for A.>1]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:"))完成
全部組み合わせて完成。
def voteA (): global vote1 vote1 = vote1 + 1 def voteB (): global vote2 vote2 = vote2 + 1 def count (): global vote1 global vote2 print("[The number of votes for A is",vote1,".]") print("[The number of votes for B is",vote2,".]") def Initialize (): global vote1 global vote2 vote1 = 0 vote2 = 0 op = 0 while op != 9: if op == 1: voteA () print("[Vote for A.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 2: voteB () print("[Vote for B.]") print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 3: print("[Check the vote count.]") count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) elif op == 0: print("[Initialize the vote count.]") Initialize () count () print("[Vote for A.>1]","\n","[Vote for B.>2]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) else: while op != 1 and op != 2 and op != 3 and op != 9 and op != 0: print("[Vote for A.>1]","\n","[Check the vote count.>3]","\n","[End.>9]","\n","[Initialize the vote count.>0]") op = int(input("[Chose 1 or 2 or 3 or 9 or 0.]:")) print("[Good bye.]")おわりに
グローバル変数はとっても便利でおもしろい。
終了するときGood Bye.てでるのすごいかっこいい。もっと関数の勉強をしたい。
- 投稿日:2021-01-06T18:17:03+09:00
【Python】エラー発生時に関数内の変数を知りたい!
はじめに
皆さんはデバッグをどのように行っていますか?
デバッガとか使ってするのが一般的でしょうか、Pdbとか?それはさておき、エラー発生時ってとりあえず関数内のローカル変数を見たくなりますよね。
でも”ローカルな”変数ですので、関数外からは見られず結局今回は、せめてエラー発生時の変数だけでもまとめて出力できたら…と思いデコレータを作成しました。
つくったもの
def raise_locals(f): import sys, traceback def wrapper(*args, **kwargs): try: f(*args, **kwargs) except Exception: exc_type, exc_value, exc_traceback = sys.exc_info() ext = traceback.StackSummary.extract(traceback.walk_tb(exc_traceback), capture_locals=True) locals_ = ext[-1].locals if locals_: print('{' + ', '.join([f"'{k}': {v}" for k, v in locals_.items()]) + '}') raise return wrapper構造としては、実行してみてエラーが発生したらtracebackを通じてローカル変数を拾ってくるって感じです。
では使ってみましょう。@raise_locals def f(x): a = x b = 1 / a a = 1 f(0)out{'x': 0, 'a': 0} --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-137-16e1baa342f5> in <module> 5 a = 1 6 ----> 7 f(0) <ipython-input-136-f595b8b52afb> in wrapper(*args, **kwargs) 3 def wrapper(*args, **kwargs): 4 try: ----> 5 f(*args, **kwargs) 6 except Exception as e: 7 exc_type, exc_value, exc_traceback = sys.exc_info() <ipython-input-137-16e1baa342f5> in f(x) 2 def f(x): 3 a = x ----> 4 b = 1 / a 5 a = 1 6 ZeroDivisionError: division by zeroいつものエラー文の前にエラー発生時のローカル変数が表示されていますね。
def f(x): a = x b = 1 / a @raise_locals def main(): f(x=0) if __name__=='__main__': main()一番親となる関数につけておけば、どこでエラーが発生してもそのエラーが発生した関数のローカル変数を見ることができます。
- 投稿日:2021-01-06T17:54:34+09:00
Slack - APIGateway - Lambda(Python) - RedShift インタラクティブアプリの作り方
概要
表題のとおりのSlackアプリケーションを作成する。
まともに書くと長文になるので、以下の要点ポイントのみを重点的に記載する。
- Slackアプリケーションの留意点
- Slack側のアプリケーション設定(権限周り)
- SlackのHomeView(Homeタブ)やattachmentに関して
- Lambda(python)周りの実装とライブラリ利用
- APIGateWay設定
なお、シンプルに試すだけならWebHookURLを設定してLambdaとかをスケジュール実行してPOSTすれば終わるが、SlackClientライブラリを利用したインタラクティブなリクエストに対するメッセージ通知ができるようなシーンを想定している。
手順通りにやれば動くものが作れるというよりは、
調べるのが面倒だったり、案外ハマったポイントを断片的に紹介する点はご承知おきください。Slackアプリケーションを作成するにあたっての留意点
レスポンスは3秒以内に一旦返す
ボタンをクリックし、レスポンスを返す場合などは3秒を超えるとエラーになる。
これは、処理でひとまずHTTPコード200を返して、
その後非同期で処理を行い、改めて結果をチャンネルに通知することで簡単に回避できる。なお、本記事では深く触れないが
実際はリクエストパラメータのresponse_urlは3秒経過しても数分以上有効なので
タイムアウト覚悟のまま、response_urlに直接POSTすることもできなくはない。UI(ホームタブ、フォーム)やメッセージの装飾にはBlock Kitと呼ばれるJSONの組み立てが必要
Block Kit Builderで試せるのだが、非常に面倒。
最低限、チャンネルIDとユーザIDを理解する
ユーザIDはrequestBodyのPayLoadに入ってる。ユーザ名ではないので注意。
チャンネルIDもrequestBodyのPayLoadにあるが、特定のパターンでは入ってこないこともあるし
別チャンネルへの通知を行いたい場合もあると思うので、対象のIDを、定数で埋め込んでおくのが良いだろう。なお、チャンネルIDはブラウザで対象チャンネルを開くとアドレスから簡単に判別できる。
/app.slack.com/client/<ここは組織ID>/<ここがチャンネルID>/details/top
メッセージ装飾のマークアップが、テーブル(表)をサポートしていない
できないものは仕方ないですね。
私はdividerと引用マークアップとスペース埋めを駆使して強引に整形。。Slack側のアプリケーション設定(権限周り)
これだけセットしときゃ大丈夫ってところだけ。意外に限られてる。
今回はWebHookURLは使わないが、一応設定入れる。設定後は
[Settings] -> [Installed App Settings] -> [(Re)Install to WorkSpace]
での反映を忘れずに。表示情報
[Settings] -> [Basic Infomation] -> [Display Information]
アプリ名とか説明とか、ロゴとか。適当に。WebHookURL
[Features] -> [Incoming Webhooks]
- [Activate Incoming Webhooks]をオンにする
- [Webhook URLs for Your Workspace]で[Add New Webhook to Workspace]で追加
認証と許可
[Settings] -> [OAuth & Permissions]
[Bot User OAuth Access Token]
ここの値はlambdaからメッセージなどを送るのに必要になるので控えておく
[Scope] -> [Bot Token Scopes]
必須なのは
chat:write, chat:write.customize, channels:history くらいだと思う。
WebHook使うなら、incoming-webhookも。
私は他にapp_mentions:read, commands, reactions:read とか入れてる。イベントの活性化とリクエストURLの設定
[Features] -> [Event Subscriptions]
APIを作成して、GateWayを設定し終わったら(方法は後述)
最後にここの[Enable Events]をオンにして、各種設定を入れる。ここに作成したAPIのURL等を設定することで
実際に特定のアクションを実施した時にリクエストが飛ぶようにしておく。リクエスト(API)URLの設定
現段階ではできないので、後で設定したら。暫定で適当なURLを入れても認証でNGになる。
最低限、API側の処理でチャレンジレスポンスが実装されていないと認証が通らないので。最後にAPIのURLを入れておく場所と認識しておいてください。
どのイベントをHookするかの設定
[Subscribe to bot events]で設定する。
とりあえず、ホームタブのUI表示用に app_home_opened と
メッセージからのボタンイベントをとるために message.channels を追加しておけば大体OK。SlackアプリケーションのUIやメッセージ装飾に関して
以下に簡単な例とイメージを記載。
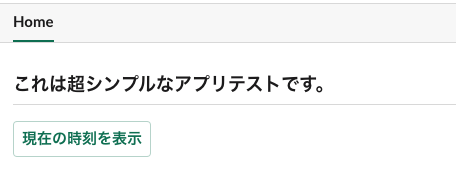
コードでの実装イメージはSlackClientAPIの利用サンプルとともに後述する。ホームタブ
HomeTabSample.json{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }ボタン付きメッセージ
MessageSample.json{ "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "こんにちは、サンプルアプリケーションです!" } }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "emoji": true, "text": "現在時刻を教えて" }, "style": "primary", "value": "click_from_message_button" } ] } ] }実際のAPIをlambdaで構築 (Python)
ポイントだけ紹介。
ちなみにログ関係はAPIGatewayのログで十分なので、lambda側では特に設定してない。必要な構成(非同期実装のため)
Slackアプリケーション(前述)
↓↑
AWS APIGateway(後述)
↓↑
lambda slack-request.py API(ここで説明)
> 3秒ルールがあるため、処理を非同期lambdaに委譲し一旦レスポンスを返す
> payloadの解析などはここでほぼ行う
↓↑
lambda async-notice.py API(ここで説明)
> 依頼内容や属性情報を全てもらった状態で処理を行い結果をSlackへ通知
> 今回はスケジュール実行の例もここで必要なライブラリの準備(Layer設定)
地味にてこずる部分。ハマると数時間たったりするという。
毎回忘れた頃にlambdaを作るので、
pythonフォルダで包むの忘れてアップロードして動かなくて戸惑うという。まあ、これをアップロードして、両方のlambdaのlayerに追加する。
必要なのはslack-clientだけのような気もする(作り方は別でググってください)。あとは今回はいらないけど、いろいろやるならついでにdjangoやpandasの最新版も入れておくといい感じ。
お試し版では上記のslackレイヤーだけあれば大丈夫。
実装のポイント : リクエスト処理のlambda
チャレンジ・レスポンスの実装
リクエストURLは最低でも、以下の実装をど先頭に入れる。
これがないと、アプリケーション設定で認証されない。slack-request.pyif "challenge" in event: return event["challenge"]通知はSlackClientAPIで行う
SlackClientの生成# アプリケーション設定のBot User OAuth Access Tokenの値 import slack client = slack.WebClient(token="xoxb-XXXXXXXXXX....")ホームタブのUI描画
JSONで指定するホームタブの描画を行う""" HomeTabメニューの表示 """ if ('event' in event): slack_event = event['event'] if (slack_event['type'] == 'app_home_opened') : if ('tab' in slack_event) and (slack_event['tab'] == 'home'): user = slack_event['user'] channel = slack_event['channel'] blocks = <ここがJSON> views = {"type": "home", "blocks": blocks} client.views_publish(user_id=user, view=views) return {'statusCode': 200}
ホームタブのJSON(再掲)
ホームタブのJSON{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }イベントハンドル(ホームボタンやインタラクティブメッセージボタンの処理)
厳密には振り分けもう少し整理した方が良いが、これでも動く。最大のポイントは、
リクエストは非同期で別のlambdaに依頼して先にリクエストを受け付けましたレスポンスを返すこと。また、通知の度に他のSlackユーザに応答を返したくない場合もあるのでサンプルでは
メッセージ通知を「あなただけに表示されます」のEphemeralにしている。slack-request.py""" ActionをHookして処理を振り分け、SlackへのResponseを返す ChannelIdは固定不変なのでリクエストからではなく定数を利用する """ if ('body-json' in event): # payloadの内容を抽出 action_message = urllib.parse.unquote(event['body-json'].split('=')[1]) action_message = json.loads(action_message) # 通知先となるユーザIDを取得 user_id = action_message['user']['id'] # Message Button == Interactive Messageか否かを判定 isInteractiveMessage = False if('type' in action_message ) and (action_message['type'] == 'interactive_message'): isInteractiveMessage = True # actionがあればイベントをHook if ('actions' in action_message): """ 値の取得と通知依頼は別のlambdaに非同期で依頼する 非同期依頼は複数あって良いが、依頼は主にPrimaryModeのみで判定する """ delegateLambda_primaryMode = [] # payloadからaction message部分のみを抽出する action_message = action_message['actions'][0] # 非同期送信なので同期レスポンスメッセージのDefaultを先に設定しておく send_message = "リクエストを受け付けました。少しお待ちください。" if (action_message['type'] == 'button') : if (action_message['value'] == 'click_from_home_tab'): """ ホームタブのボタンがクリックされた """ delegateLambda_primaryMode.append('click_from_home_tab') elif (action_message['value'] == 'click_from_message_button'): """ ホームタブのボタンがクリックされた """ delegateLambda_primaryMode.append('click_from_message_button') """ 設定した非同期依頼をかける PrimaryとSecondaryのほか、user_idを渡す仕様にした 非同期処理は後述する """ for p in delegateLambda_primaryMode: input_event = { "primaryMode": p, "secondaryMode": "now no mean", "user_id": user_id } lambdaMediator.callNortifyAsync(json.dumps(input_event)) """ 一旦、応答メッセージを返却する """ if isSendEphemeral == True: response = client.chat_postEphemeral( channel=notice_channel_id, text=send_message, user=user_id ) else: response = client.chat_postMessage( channel=notice_channel_id, text=send_message ) if isInteractiveMessage == True: pass else: return {'statusCode': 200}lambdaMediator.pyimport boto3 def callNortifyAsync(payload): """ 非同期で委譲先のlambda(async-notice.py固定)を呼ぶ Parameters ---------- event : 委譲先lambdaのevent json PrimaryMode: 依頼内容を表す第一Key文字列 SecondaryMode: 依頼内容を表す第二Key文字列 UserId: 依頼者のSlackユーザID Returns ---------- response """ response = boto3.client('lambda').invoke( FunctionName='async-notice', InvocationType='Event', Payload=payload ) return response実装のポイント : 非同期処理のlambda
attachmentは利用しなくてもいいが、凝ったことをやりたい場合は
メッセージではなくattachmentでやるので、サンプルはそうしている。今回は両方のlambdaの実行RoleにAWSLambda_FullAccessを付与している。
また、サンプルなのでPrimaryModeをslack-request.pyからもらっているが分岐は入れていない。attachmentを利用してメッセージを送信
async-notice.pyimport json import datetime import time import boto3 import slack from libs import mylib from libs import slack_info def lambda_handler(event, context): """ このlambdaはslack-requestからのdelegate処理(非同期)、およびスケジューラからのみKickされる Parameters ---------- event : PrimaryMode: 依頼内容を表す第一Key文字列 SecondaryMode: 依頼内容を表す第二Key文字列(未利用:拡張用) UserId: 依頼者のSlackユーザID Returns ---------- httpResponseBody : statusCode:200 , body -> SlackClientからの送信を行うため200を返すだけ ToDo ---------- """ # ユーザIDの取得 user_id = "" if 'user_id' in event: user_id = event['user_id'] """ パラメータなしはスケジューラからの起動なので全体通知 パラメータありは非同期依頼なのでEphemeral(あなただけに見えてます)通知 """ isEphemeral = True if ('primaryMode' in event) == False: isEphemeral = False """ メッセージ通知を行う attachmentsはメッセージJSON """ postDataMessage(attachments, False, isEphemeral, user_id, "ここに本文メッセージを入れる。") return { 'statusCode': 200, 'body': json.dumps('OK') } def postDataMessage(attachment_data, isSendMultiple=False, isEphemeral=True, userId="", textMessage=""): """ メッセージを送信する Parameters ---------- attachment : アタッチメントデータ isSendMultiple : アタッチメントデータが複数あるか否か isEphemeral : リクエストユーザのみ見えるように送信するか否か userId : リクエストユーザのID textMessage : テキストメッセージ Returns ---------- ToDo ---------- """ client = slack.WebClient(token="xoxb-XXXXXXXXX.....") # 複数送信対応のため、単一送信であってもリストで包み直す if isSendMultiple == False: attachment_data = [attachment_data] # TARGET_CHANNEL_IDは通知先のチャネルIDを別途設定しておくこと for attachment in attachment_data: if isEphemeral == True: response = client.chat_postEphemeral( channel=TARGET_CHANNEL_ID, attachments = attachment, user=userId ) else: response = client.chat_postMessage( text=textMessage, channel=TARGET_CHANNEL_ID, attachments = attachment )
ボタン付きメッセージのJSON(再掲)
attachmentのjson例{ "type": "home", "blocks": [ { "type": "header", "text": { "type": "plain_text", "text": "これは超シンプルなアプリテストです。" } }, { "type": "divider" }, { "type": "actions", "elements": [ { "type": "button", "text": { "type": "plain_text", "text": "現在の時刻を表示" }, "style": "primary", "value": "click_from_home_tab" } ] } ] }おまけ : スケジュール実行したい場合
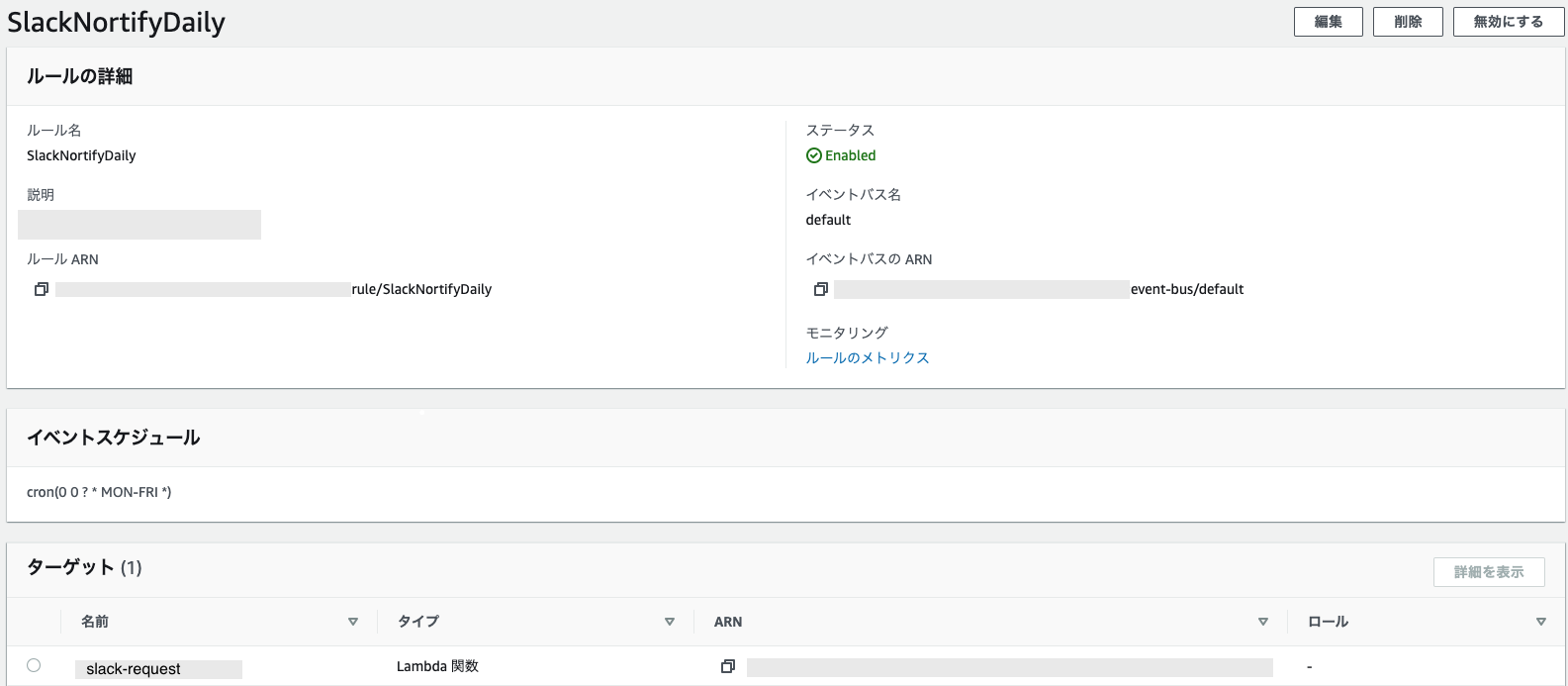
Amazon EventBridgeのルール作成で対象をasync-noticeのlambdaとcron設定をブラウザから入れるだけ。
月曜から金曜の9時に実行(GMT時間なので-9時間で設定)cron(0 0 ? * MON-FRI *)
おまけ : RedShiftへの接続
boto3でredshift-dataを指定するだけで
データアクセスはクエリ実行時に指定したRedshiftアカウント内でのロール権限で実施されるため非常に楽。
サンプルコード
RedShift接続import json import time import boto3 # Redshift接続情報 CLUSTER_NAME='cluster名を入れる' DATABASE_NAME='データベース名を入れる' DB_USER='ユーザ名を入れる' def getDateTimeSample(): """ 時刻の取得 """ sql = ''' select getdate(); ''' return _getData(sql) def _getData(sql): """ RedShiftへクエリを発行して結果をそのまま返す Parameters ---------- String : sql文 Returns ---------- statement : boto3の取得結果そのまま """ # Redshiftにクエリを投げる。非同期なのですぐ返ってくる data_client = boto3.client('redshift-data') result = data_client.execute_statement( ClusterIdentifier=CLUSTER_NAME, Database=DATABASE_NAME, DbUser=DB_USER, Sql=sql, ) # 実行IDを取得 id = result['Id'] # クエリが終わるのを待つ statement = '' status = '' while status != 'FINISHED' and status != 'FAILED' and status != 'ABORTED': statement = data_client.describe_statement(Id=id) #print(statement) status = statement['Status'] time.sleep(1) # 結果の表示 if status == 'FINISHED': if int(statement['ResultSize']) > 0: # select文等なら戻り値を表示 statement = data_client.get_statement_result(Id=id) else: # 戻り値がないものはFINISHだけ出力して終わり print('QUERY FINSHED') elif status == 'FAILED': # 失敗時 print('QUERY FAILED\n{}'.format(statement)) elif status == 'ABORTED': # ユーザによる停止時 print('QUERY ABORTED: The query run was stopped by the user.') return statementAPIGateWayの設定
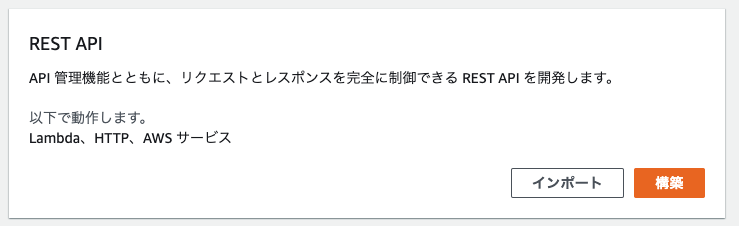
作成したlambda APIにURLを与えてアクセスできるようにする。
大まかな手順
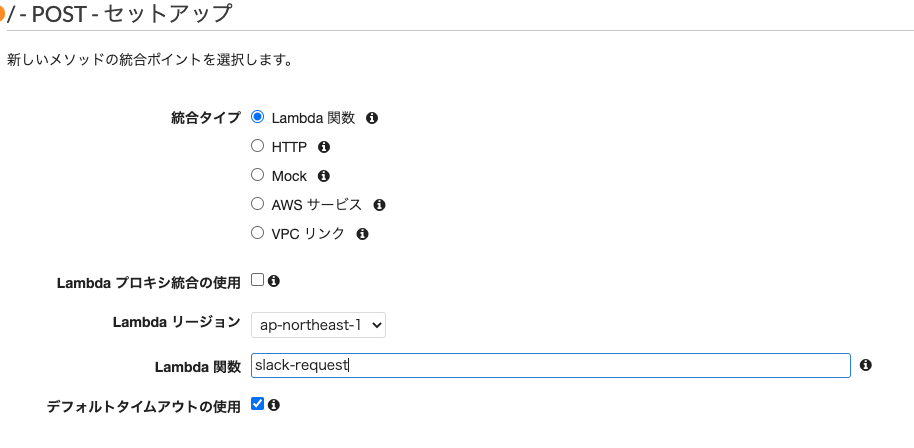
REST APIで作成
lambdaを統合
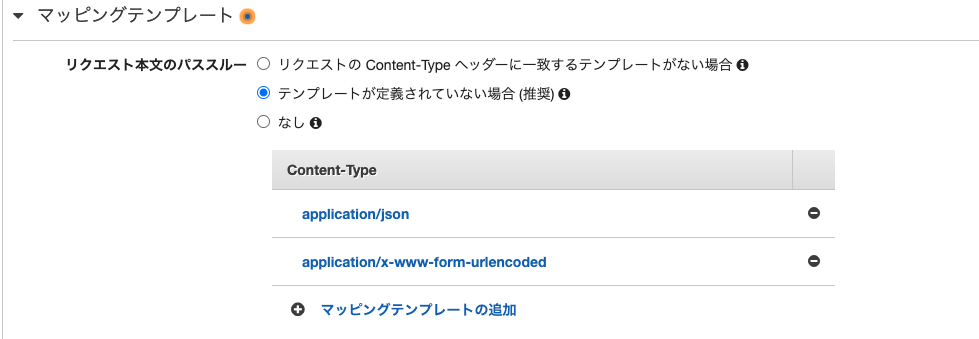
マッピングテンプレートでapplication/x-www-form-urlencodedの追加
一番重要。ホームタブのオープンイベントではこのフォーマットで来るので、ここいれないと動作しない。
また、他のリクエストはapplication/jsonで来るものがあるので、合わせて追記するのもポイント。
あとはステージをデプロイするだけ
ログ設定
この設定で十分デバッグできる。
ログはCloudWatchにステージ名のロググループで出力される。
その他のポイント・気付き
3秒ルールはしんどい
Slackの性質を考えればまあ、そうなるのは理解できるが凝ったこともしたくなる場合もある。
非同期でデータベースアクセス含めた処理を行って
単純にレスポンス200を返すだけでも、lambdaのコールドスタートなどを考えるとギリギリ間に合わない場合も稀にある。lambdaにはProvisioned Concurrencyもあり、料金はかかるが場合によってはこれも活用できる。
マークアップにテーブルが欲しい
結構需要はあると思うが。
引用を使うと引用内では半角スペースを忠実に再現するのでこれと、division線を使うと表っぽくはなる。
ただ、無理やり感は拭えない。

- 投稿日:2021-01-06T17:32:26+09:00
Azure Machine Learning SDK for Python をアップグレードする
はじめに
Azure Machine Learning SDK for Python は多数のライブラリから構成されていて、一つだけアップグレードしてしまうとライブラリ間でバージョンが異なってしまいます..。
そのため、依存関係も含めて一気にアップグレードする必要があります。方法
pip install --upgrade --upgrade-strategy eager azureml-sdk参考
https://docs.microsoft.com/ja-jp/python/api/overview/azure/ml/install?view=azure-ml-py
- 投稿日:2021-01-06T17:27:49+09:00
pythonで作る戦車ゲーム 戦車の挙動について
pythonを勉強していて、戦車の挙動をとてもうまく作ることができたので紹介します。挙動といっても戦車の移動をどうやってコードに書き起こすかという感じです。僕はpythonを利用しましたが、他の言語でも応用はとても簡単だと思います。
環境
・Python3.9.0
・pygame(ライブラリ)を使っています。使う知識
・ちょっぴりのプログラミング知識
・高校物理(力学)高校物理と言ってもとても簡単なものなのでご安心ください。
今回は戦車の動きを作るのにあたって、二つのステップを作りました。それは速度と方向です。それとこのゲームはwキーで上、aキーで左、dキーで右、sキーで下に動くようにしています。
速度(位置)編
速度とは何か、と聞かれたらおそらくほとんどの人が「単位時間あたりに進む距離」と考えると思います。そうです。これをコードに起こしてしまうのです。物理で習う式は
x=a*t^2+b*t+x_0
という感じですよね。tは時間、x_0は最初の位置、そしてa,bは定数です。
これをプログラミングで表すにはどうすればよいのか。大前提として、このプログラムではwhileループごとに戦車の位置差を計算してます。それを速度と呼ぶこととします。話を戻して、プログラミングでこの式を表すには、tを方向キーを押している時間と捉えることで上手く解決します。この式を利用するとゆっくりと発進する動作は書けるようになります。でもここまで来たらゆっくり慣性があるように止まってほしいので、この式をさらに少しいじります。
x=a*t^2+b*t+x_0-c*t_stop^2
後ろに新しい項を追加しました。t_stopとは、キーが押されていないかつ、速度が0でないときにカウントしていく変数です。これを追加することで現実のようにゆっくり滑らかに進み始めてゆっくり滑らかに止まるようになります。pressed_key=pygame.key.get_pressed() if speed == 0: if pressed_key[K_a]: power_left = 1 if pressed_key[K_d]: power_right = 1 if pressed_key[K_w]: power_up = 1 if pressed_key[K_s]: power_down = 1 if(pressed_key[K_a] or pressed_key[K_s] or pressed_key[K_d] or pressed_key[K_w]): # キーを押したとき t += 0.1 # 時間の計測を始める t_stop = 0 else: # 戦車が動いていてかつ速度があるときに慣性を使うためにt_stopの計測を始める。 if speed > 0: t_stop += 0.01 else: # 速度が0でキーも押されてないときに初期化 t = 0 speed = 0 speed = 20*t*t+1*t-18*t_stop*t_stop # 移動速度の計算 if(speed > 7): # 最高速度の設定 speed = 7方向編
速度編でスピードは計算できたので次にそのスピードをどの方向に割り振るかを考えていきます。この処理を考えることで曲がるときの慣性を表現しました。でもこの式は物理法則に則ったわけでは無いのでもっといい方法があるとは思います。しかし、かなり高精度にカーブの慣性を表せていると思うので参考にしてみてください。まず、
power_left = 1 power_right = 1 power_up = 1 power_down = 1と四つの変数を用意します。そして、
# 速度がどの横行に向いているのかを計算して、なめらかな方向転換を実現 # 処理開始 if pressed_key[K_a]: power_left += 0.1 last_key = 2 elif(power_left > 1): power_left -= 0.1 if pressed_key[K_d]: power_right += 0.1 last_key = 3 elif(power_right > 1): power_right -= 0.1 if pressed_key[K_w]: power_up += 0.1 last_key = 0 elif(power_up > 1): power_up -= 0.1 if pressed_key[K_s]: power_down += 0.1 last_key = 1 elif(power_down > 1): power_down -= 0.1 # 処理終了このようにして方向キーが押されている間、四つの変数の値を増やしていきます。そして最後に、
x -= speed*hit[0]*power_left / \ (power_left+power_right+power_up+power_down) # 実際の位置の計算 x += speed*hit[1]*power_right / \ (power_left+power_right+power_up+power_down) y -= speed*hit[2]*power_up/ \ (power_left+power_right+power_up+power_down) y += speed*hit[3]*power_down / \ (power_left+power_right+power_up+power_down) # 戦車の移動処理の終了x,yというのは戦車(プレイヤー)の座標です。また、ここのhitという配列は当たり判定の返り値で、障害物に当たっているとこの値が0になり移動できなくなります。こうすることで滑らかなカーブを実現することができました。まっすぐ進んでいて急に曲がろうとしても曲がれないあの慣性をコードに書き起こすことができました。
まとめ
かなりこだわって作ったので、ぜひ参考になればうれしいです。
- 投稿日:2021-01-06T15:49:14+09:00
1株1千円以下の価格変動が大きい銘柄に投資してパフォーマンスをあげる
はじめに
昨年は新型コロナウイルス拡大により,相場(株価)の上げ下げが激しい1年となりました.
昨年11月18日のファイザーがワクチン開発に成功したことを発端に,2020年末までに日経平均株価は約30年ぶりとなる高値を更新し続けました.
足元では業績拡大期待が先行して株価と足元の利益が乖離しつつあります.
イギリスではコロナ変異種が感染拡大によりロンドンで3回目都市封鎖が実行されました.さらに,日本でも緊急事態宣言が再び検討されるなど,現在でも国内および世界でも感染拡大が広がっている状況です.
したがって,新型コロナウイルスの影響により,今後も激しい株価の上げ下げが予想されます.
本記事では,今後も激しい株価の上げ下げが予想されることを踏まえて,
激しい価格変動を利用して,どの銘柄が短期的に稼げるかについて調査しました.株価値動きの大きさの指標
株価の1日の値動きの幅の大きさを表した指標としてボラティリティがあります.この指標は主に個別株の短期トレードをするときに使用します.
ボラティリティ$(\%)$は,
\frac{当日のトゥルー・レンジ{\rm TR}}{当日のティピカル・プライス{\rm TP}} \times 100 \ (\%)で計算することができます.
分母のティピカル・プライスTPは高値,安値,終値の3つの平均値です.
分子のトゥルー・レンジTRは次の3つのうち値が最大のものを使用します(${\rm TR}=\max(t_1, t_2, t_3)$).
t_1 = 当日の高値-当日の安値t_2 = 当日の高値-前日の終値t_3 = 前日の終値-当日の安値ボラティリティが5%以上であれば比較的ボラティリティが高いといえます.株価が低い銘柄では値幅が小さくてもボラティリティーが高くなってしまうことがあります.また,株価の変動幅を表していると同時に,リスクを示しています.あくまでも値動きの変動幅が分かるだけなので,実際に売買をするときは,他の指標も同時にみて判断する必要があります.
分析結果
※ 詳しい分析の方法は記事下の付録(Pythonプログラム)を参照してください.データを取得方法,分析方法もすべて説明してあります.
1株1千円以下の価格変動が大きい銘柄を選定していきます.
そのために,まず以下の条件に合致する銘柄を選別します.選定する際,株価の時系列データ,出来高データは,2020年1月5日から過去90日分を使用しました.
【銘柄選定基準】
・東京証券取引所に上場している
・1日の平均出来高50万株以上
・1日の平均終値50円以上1千円以下「1日の平均出来高50万株以上」という条件は,出来高が少ない銘柄だと取引が成立しにくいので,ある程度出来高が多い銘柄を選別するためのものです.「1日の平均終値50円以上1千円以下」の「50円以上」は,株価が低い銘柄では値幅が小さくてもボラティリティーが高くなってしまうことがあるので,「50円以上」と設定しました.
この条件で銘柄を選定した結果,242件の該当する銘柄がありました.その中で,ボラティリティが高い10銘柄を下の表にまとめてみました.
順位 証券コード 銘柄名 平均ボラティリティ(%) 平均終値(円) 平均出来高(株) 1 9878 セキド 10.8 700.6 573921 2 5337 ダントーホールディングス 9.9 502.7 2699480 3 6400 不二精機 9.2 529.5 2886709 4 1757 クレアホールディングス 8.9 70.6 5968157 5 5952 アマテイ 8.7 172.6 3114188 6 6659 メディアリンクス 8.3 487.0 1453528 7 3645 メディカルネット 8.2 747.3 798739 8 2586 フルッタフルッタ 7.9 191.5 1508418 9 2191 テラ 7.6 769.2 2084927 10 3071 ストリーム 7.6 140.0 1470286
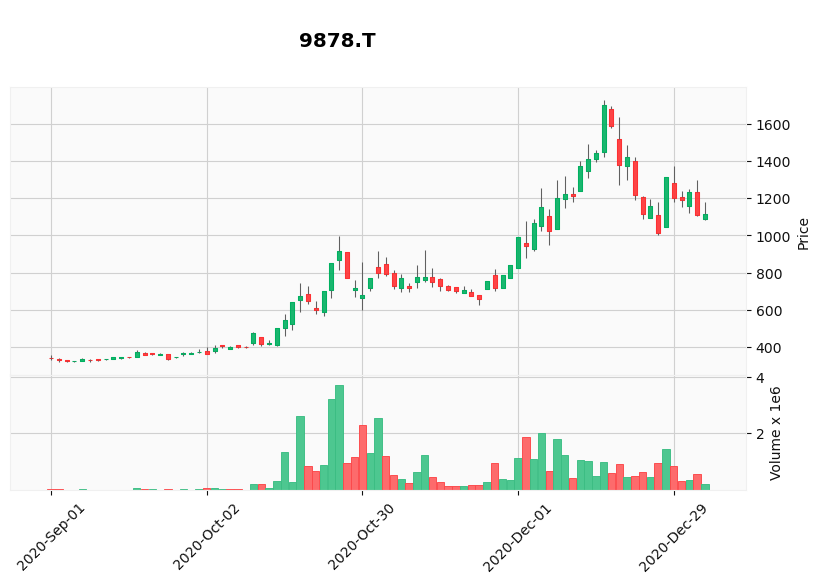
- 1位.セキド(9878)の4か月間のチャート
ワクチン開発以降,株価は徐々に上昇し,ワクチン開発以前と比べて,一時2倍以上になっていますね.
特色:祖業の家電店から撤退しファッションが柱。オークファンと提携、ECや催事、卸の育成に軸足 Yahoo!JAPANファイナンス
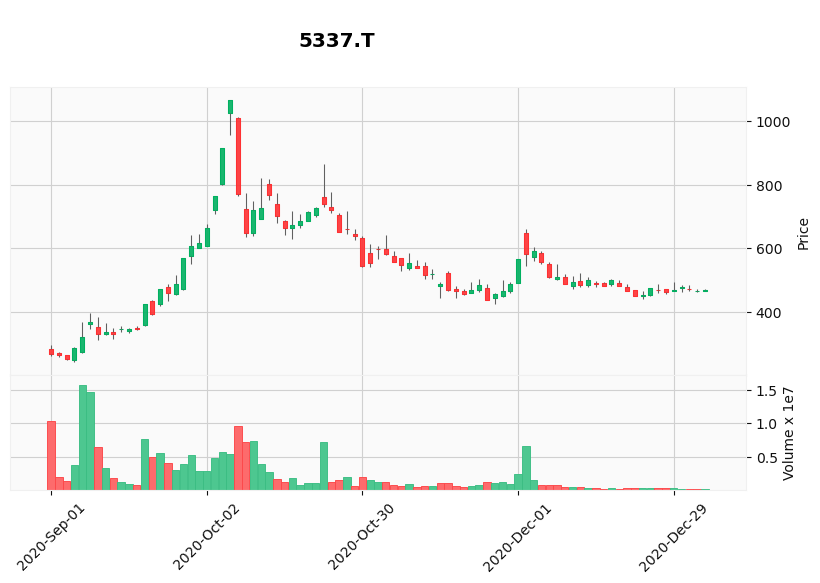
- 2位.ダントーホールディングス(5337)の4か月間のチャート
最近では出来高が小さいので,活発な取引は行われていないようですね...
特色:内外装タイル老舗。16年に販売、製造、投資3事業統合、本業再建中。不動産マネジメント事業も Yahoo!JAPANファイナンス
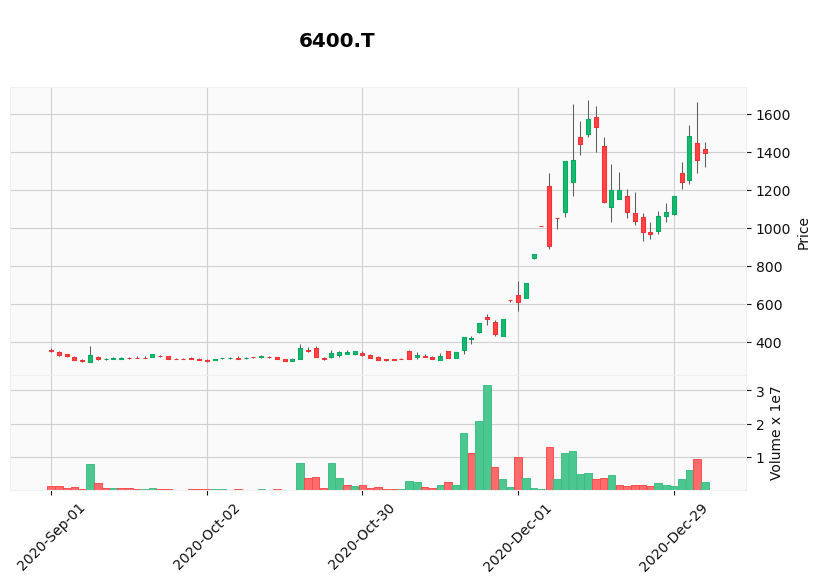
- 3位.不二精機(6400)の4か月間のチャート
取引が活発に行われるようになってから,4倍以上の株価となっています.
特色:精密金型から出発、成形品受託が主体。2輪・4輪車部品中心に幅広く展開。中国、東南アに工場 Yahoo!JAPANファイナンス
おわりに
新型コロナウイルスの影響で,今後も激しい株価の上げ下げが予想されます.
このとき,投資資金の一部をボラティリティが高い銘柄に短期的に投資することで,投資のパフォーマンスを上げられる可能性があります.
それを踏まえて,1株1千円以下つまり10万円以内ぐらいで買える銘柄のうちで,どの銘柄が短期的に稼げるかについて調べてみました.
1位から10位までを上のリストにまとめましたが,ひょっとすると上のリストの中に2倍以上になる銘柄がふくまれているかもしれません.
ボラティリティをうまく使いこなせば,より良い投資パフォーマンス出すための助けになります.ただ,その分損をする可能性もあるので,ほかの指標も用いて銘柄を見極めていきましょう.
以下は今回までに株式や暗号資産について検証した記事の一覧です.もし興味ある方は見て頂けると嬉しく思います.
<過去記事>
・日経225全銘柄の投資効率を検証
・日経平均株価の30%は5銘柄で決まることを投資先選びに生かせるか?
・日経平均株価が上がった次の日に上がる銘柄を見つけたい
・散投資でリスク回避の仕方【2銘柄編】
・【時間アノマリー】1日の中で最も株価が上がる/下がる時間帯
・投資商品を分散しリスクを最小化する【3銘柄編】
・日経平均株価が上がった5分後に上がる銘柄を見つけたい
・どの暗号資産が効率よく稼げるか
付録(分析方法:Pythonプログラム)
- 株銘柄リストを作成する
まずは,「東証上場銘柄一覧」を参考にして,株銘柄のリストを作成します.
東証上場銘柄一覧 - 東京証券取引所で,「東証上場銘柄一覧(2020年11月末)」のエクセルファイルをダウンロードします(2021/01/05現在).
ダウンロードしたファイル名は
data_j.xlsになっていると思います.これをエクセルで開いて,「名前を付けて保存」で,CSV形式で新しく保存します.このときファイル名は
data_j.csvとしてください.ファイルはプログラムを保存する予定のフォルダの中にいれてください.data_j.csv日付,コード,銘柄名,市場・商品区分,33業種コード,33業種区分,17業種コード,17業種区分,規模コード,規模区分 20201130,1301,極洋,市場第一部(内国株),50,水産・農林業,1,食品 ,7,TOPIX Small 2 20201130,1305,ダイワ上場投信-トピックス,ETF・ETN,-,-,-,-,-,- 20201130,1306,NEXT FUNDS TOPIX連動型上場投信,ETF・ETN,-,-,-,-,-,- ... 20201130,9996,サトー商会,JASDAQ(スタンダード・内国株),6050,卸売業,13,商社・卸売 ,-,- 20201130,9997,ベルーナ,市場第一部(内国株),6100,小売業,14,小売 ,6,TOPIX Small 1この操作は以下で紹介するPythonプログラムがファイルをCSV形式で読み込むようになっているからです.
Pythonのpandasモジュールでも,エクセルファイル
.xlsは読み込めるので,この操作が煩わしい方は,直接エクセルファイルを読み込めるようにプログラムを変更してみてください.
- フォルダを作成する
プログラムを保存する予定のフォルダの中に,「data」という名前のフォルダを作成してください.このフォルダの中に各銘柄の株価データなどを保存していきます.
- 株価データを取得する
銘柄リスト
data_j.csvを基にして,Yahoo!ファイナンスから株価データを取得していきます.株価データは「data」フォルダの中に保存されます.以下のプログラムを実行すると各銘柄の株価が取得できます.全部で4千銘柄以上あり,2015年から現在までの株価を取得するので,かなり時間がかかります.取得に時間がかかる場合は,取得期間を変更してみるとよいかもしれません.
タイムエラーなどで一部の銘柄のデータ取得に失敗ことがあるので,数回実行してみてください.すでにデータ取得している銘柄は,スキップして実行されるようになっています.
get_stock_data.pyimport glob import pandas_datareader.data as web import pandas as pd # 東証全銘柄取得 def get_tokyo(): tokyo = pd.read_csv("data_j.csv", engine="python", names=("date","code", "name","market", "CodeIndustry33", "ClassificationIndustry33", "CodeIndustry17", "ClassificationIndustry17", "CodeScale", "ClassificationScale"), skiprows=1, usecols=[1,2], encoding="utf-8") return tokyo # 株価取得 def get_price_csv(stock_name,start=None,end=None): data = web.DataReader(stock_name,"yahoo",start,end) data.to_csv("./data/"+stock_name+".csv") list_tokyo = get_tokyo() list_file_exist = glob.glob("./data/*") for code in list_tokyo.code: filename = './data\\'+str(code)+'.T.csv' if filename in list_file_exist: pass else: print(code, 'GET... ', end='') try: get_price_csv(str(code)+'.T', start='2015-1-1') print('SUCCESS') except Exception as e: print('FAIL:', e)実行結果
1432 GET... FAIL: No data fetched for symbol 1432.T using YahooDailyReader 1440 GET... FAIL: No data fetched for symbol 1440.T using YahooDailyReader 25935 GET... FAIL: No data fetched for symbol 25935.T using YahooDailyReader 3456 GET... FAIL: No data fetched for symbol 3456.T using YahooDailyReader 3483 GET... FAIL: No data fetched for symbol 3483.T using YahooDailyReader 6695 GET... FAIL: No data fetched for symbol 6695.T using YahooDailyReader 6945 GET... FAIL: No data fetched for symbol 6945.T using YahooDailyReader 7693 GET... FAIL: No data fetched for symbol 7693.T using YahooDailyReader 7790 GET... FAIL: No data fetched for symbol 7790.T using YahooDailyReader 9388 GET... FAIL: No data fetched for symbol 9388.T using YahooDailyReader 9437 GET... FAIL: No data fetched for symbol 9437.T using YahooDailyReader以上のような表示が出ればYahoo! ファイナンスから取得できる時系列データはすべて取得することができています.
data_j.csvに上場廃止した銘柄などが含まれているので,No data fetched for symbol 9437.T using YahooDailyReaderというエラーが起きます.9437はNTTドコモの証券コードですが,2020年12月25日に上場廃止したので,Yahoo! ファイナンスからも取得できなくなっています.data_j.csvは2020年11月末時点のリストを使用したのでこのようなことが起きています.
- 各銘柄のボラティリティを計算する 全銘柄のボラティリティの平均や出来高の平均などを計算します.
その後,【銘柄選定基準】を満たす銘柄を選びます.
【銘柄選定基準】
・東京証券取引所に上場している
・1日の平均出来高50万株以上
・1日の平均終値50円以上1千円以下最後に,【銘柄選定基準】を満たした銘柄をボラティリティが高い順に並べ替え,その結果を
result.csvというCSVファイルに保存します.analysis_volatility.pyimport pandas as pd import glob from tarade_module import trade_module # 各銘柄のファイル名をリストに保存 list_file_exist = glob.glob("./data/*.csv") # データフレーム作成 df_result = pd.DataFrame(columns=['Name','AveVolatility','StdVolatility','AveClose','AveVol']) # 東証上場企業のコード,銘柄名 list_tokyo = trade_module.get_tokyo() # 各銘柄のボラティリティを計算 for filename in list_file_exist: # csvファイル読み込み,最新90日分 df = pd.read_csv(filename, usecols=[0,1,2,3,4,5])[-91:-1] # トゥルー・レンジ,ティピカル・プライス df_TR = pd.concat([df['High']-df['Low'],df['High']-df['Close'],df['Close']-df['Low']], axis=1).max(axis=1) df_TP = pd.concat([df['High'],df['Low'],df['Close']], axis=1).mean(axis=1) # ボラティリティを計算 df_volatility = df_TR/df_TP*100 # 結果を表示 #print(pd.concat([df,df_TR,df_TP,df_volatility], axis=1)) # ボラティリティの平均,標準偏差,終値の平均,出来高平均 df_var_volatility = df_volatility.describe()['std'] df_ave_volatility = df_volatility.describe()['mean'] df_ave_close = df['Close'].describe()['mean'] df_ave_vol = df['Volume'].describe()['mean'] # 結果をデータフレームに追加 df_result.loc[filename[7:-6]] \ = [list(list_tokyo[list_tokyo.code==int(filename[7:-6])].name)[0].replace('\uff0d', '-'),df_ave_volatility, df_var_volatility, df_ave_close, df_ave_vol] # 平均出来高10万株以上の銘柄に限定 df_result_vol100000 = df_result[(df_result['AveVol']>=500000)&(df_result['AveClose']<=1000)&(df_result['AveClose']>=50)] print(df_result_vol100000.sort_values('AveVolatility', ascending=False)) # 結果を出力, エクセルなどで開くにはshift_jis保存 df_result_vol100000.sort_values('AveVolatility', ascending=False).to_csv('result.csv', encoding="shift-jis")以下は
analysis_volatility.pyを実行すると出力される結果のファイルです.result.csv,Name,AveVolatility,StdVolatility,AveClose,AveVol 9878,セキド,10.809049789076301,7.314944329411106,700.6222222222223,573921.1111111111 5337,ダントーホールディングス,9.92851091994063,5.829129218840265,502.6666666666667,2699480.0 6400,不二精機,9.232563647851181,7.672251177037584,529.4888888888889,2886708.888888889 1757,クレアホールディングス,8.889975863776952,7.016323356057786,70.56666666666666,5968156.666666667 5952,アマテイ,8.686544778591992,7.34355369522554,172.5888888888889,3114187.777777778 6659,メディアリンクス,8.254688076596251,5.6874328079605885,486.9555555555556,1453527.7777777778 3645,メディカルネット,8.223274540256988,4.850665328679253,747.3,798738.8888888889 2586,フルッタフルッタ,7.912068446987964,7.29850462904478,191.46666666666667,1508417.7777777778 2191,テラ,7.6447258931396584,4.669643170906718,769.2333333333333,2084926.6666666667 3071,ストリーム,7.585819866804538,4.527170396284742,140.04444444444445,1470285.5555555555 5950,日本パワーファスニング,7.446253747895412,7.0779071007236425,130.16666666666666,1637843.3333333333 4772,ストリームメディアコーポレーション,7.40040609365142,4.485065376345073,319.1,869971.1111111111 7625,グローバルダイニング,7.314423734014114,7.072805004359223,190.6888888888889,1005386.6666666666 2459,アウンコンサルティング,7.278918564082975,6.233558919862727,233.4111111111111,652956.6666666666 3909,ショーケース,7.070315411038762,4.199331323446159,894.6888888888889,626668.8888888889 7608,エスケイジャパン,6.917702918007265,6.282340278985323,418.74444444444447,666320.0 3776,ブロードバンドタワー,6.822772043330271,4.151829727326367,383.7111111111111,6908035.555555556 3264,アスコット,6.757181195267253,4.057884357817521,219.27777777777777,1141836.6666666667 6181,タメニー,6.682391492378576,4.773359432557025,187.17777777777778,1400831.111111111 7448,ジーンズメイト,6.599137804949079,6.763328689586605,274.74444444444447,780083.3333333334 3556,リネットジャパングループ,6.574738312165315,4.017277288743839,576.7111111111111,550920.0 6779,日本電波工業,6.535959574856966,4.692920736222049,457.7888888888889,655442.2222222222 ... 2768,双日,1.7286240106385853,0.6413982014908903,237.5222222222222,5425306.666666667 9508,九州電力,1.7224171026624042,0.6751134425152434,922.9555555555555,1161698.888888889 8601,大和証券グループ本社,1.6910960304616955,0.8788866774373107,462.2066667344835,4492950.0 6178,日本郵政,1.6550971289374474,0.6455812899662257,766.626666937934,5703288.888888889 8355,静岡銀行,1.6505290019625318,0.792098756434268,746.7666666666667,1464793.3333333333 7182,ゆうちょ銀行,1.612183745456123,0.6859743481317608,848.5888888888888,2572678.888888889 5020,ENEOSホールディングス,1.5173205855293537,0.6202105245263454,379.30999959309895,16662358.888888888 8628,松井証券,1.5071163588276981,0.6693067820926953,890.8111111111111,673733.3333333334 8306,三菱UFJフィナンシャル・グループ,1.499832308077275,0.6679667878012966,440.46333279079863,55239340.0 1671,WTI原油価格連動型上場投信,1.1440880131986952,0.7287071846639852,864.4333333333333,2514501.388888889
- 投稿日:2021-01-06T15:00:54+09:00
[python] 16進数表記のRGB値を暗くするメソッド
def darken(rgb, rate=0.5): rgb = rgb.replace('#', '') s = '#' for i in [0,2,4]: c = rgb[i:i+2] c = int(c, 16) c = int(c * rate) c = format(c, '02x') s += c return s # 使用例 import numpy as np import pandas as pd import matplotlib.pyplot as plt color_orig = [ '#C5DAEE', '#ABCFE5', '#8DC0DD', '#6AADD5', '#4F9BCB', '#3787C0', '#2070B4', '#0F5BA3', '#08458B', '#08306B', ] color = [ [darken(c) for c in color_orig], color_orig, ] df = pd.DataFrame([np.ones(10), np.ones(10)], columns=[x[1] + '\n' + x[0] for x in np.array(color).T]) df.T.plot.bar(color=color, stacked=True) plt.legend().remove() plt.yticks([]) plt.xticks(rotation=0) plt.show()out:
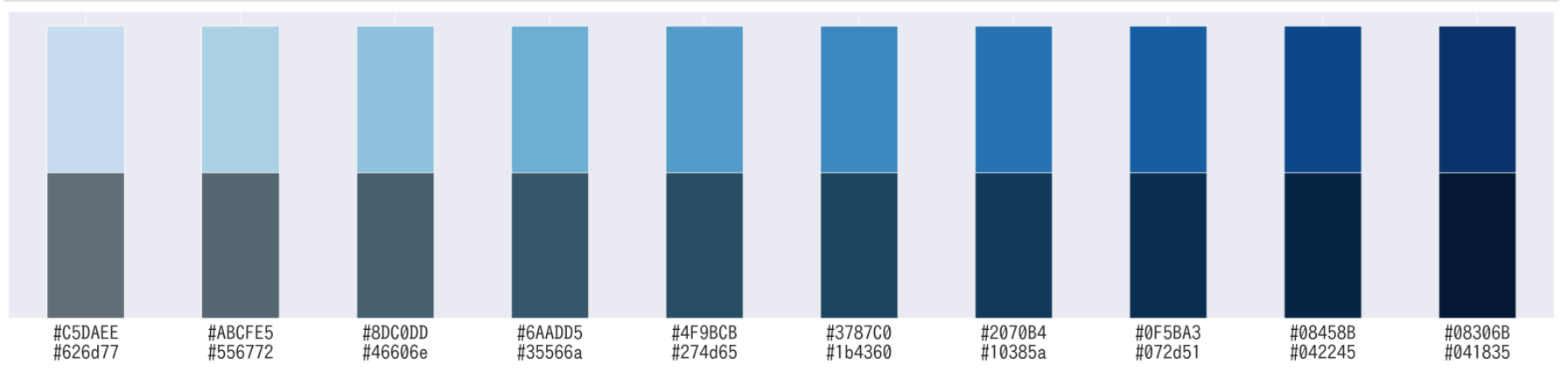
- 投稿日:2021-01-06T12:20:53+09:00
多目的最適化問題のNSGA-Ⅲを実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は多目的最適化手法の中で、NSGA-Ⅲを実装(サンプルコード使用)しました。
はじめに
先日、ご紹介した多目的最適化(NSGA-Ⅲ)を実装したのでご紹介します。
NSGA-Ⅲとは何か?と言うことについては上記の記事に書いておりますので、そちらをご参照ください。使用するライブラリー(deap)
今回も遺伝的アルゴリズムライブラリdeapを使って実装したいと思います。
NSGA-Ⅲの実装
今回はdeapのチュートリアルにNSGA-Ⅲのサンプルがありましたので、そちらを活用しました。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート from math import factorial import random import matplotlib.pyplot as plt import numpy import pymop.factory from deap import algorithms from deap import base from deap.benchmarks.tools import igd from deap import creator from deap import tools import matplotlib.pyplot as plt import mpl_toolkits.mplot3d as Axes3d最初に遺伝的アルゴリズムの設計を行っていきます。
# 問題設定 PROBLEM = "dtlz2" NOBJ = 3 K = 10 NDIM = NOBJ + K - 1 P = 12 H = factorial(NOBJ + P - 1) / (factorial(P) * factorial(NOBJ - 1)) BOUND_LOW, BOUND_UP = 0.0, 1.0 problem = pymop.factory.get_problem(PROBLEM, n_var=NDIM, n_obj=NOBJ) # アルゴリズムのパラメータ MU = int(H + (4 - H % 4)) NGEN = 400 CXPB = 1.0 MUTPB = 1.0 # reference point ref_points = tools.uniform_reference_points(NOBJ, P) # 適合度を最小化することで最適化されるような適合度クラスの作成 creator.create("FitnessMin", base.Fitness, weights=(-1.0,) * NOBJ) # 個体クラスIndividualを作成 creator.create("Individual", list, fitness=creator.FitnessMin) # 遺伝子生成の関数 def uniform(low, up, size=None): try: return [random.uniform(a, b) for a, b in zip(low, up)] except TypeError: return [random.uniform(a, b) for a, b in zip([low] * size, [up] * size)] # Toolboxの作成 toolbox = base.Toolbox() # 遺伝子を生成する関数"attr_gene"を登録 toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM) # 個体を生成する関数”individual"を登録 toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float) # 個体集団を生成する関数"population"を登録 toolbox.register("population", tools.initRepeat, list, toolbox.individual) # 評価関数"evaluate"を登録 toolbox.register("evaluate", problem.evaluate, return_values_of=["F"]) # 交叉を行う関数"mate"を登録 toolbox.register("mate", tools.cxSimulatedBinaryBounded, low=BOUND_LOW, up=BOUND_UP, eta=30.0) # 変異を行う関数"mutate"を登録 toolbox.register("mutate", tools.mutPolynomialBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0, indpb=1.0/NDIM) # 個体選択法"select"を登録 toolbox.register("select", tools.selNSGA3, ref_points=ref_points)各コードで何を実施しているのかはコメント文で分かるように記載しているため、コード全体が見にくくなっている部分はご容赦願います。
今回は、DTLZ2問題(ベンチマーク関数)を使用しています。
次に実際の進化計算部分になります。
def main(seed=None): random.seed(1) # 世代ループ中のログに何を出力するかの設定 stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", numpy.mean, axis=0) stats.register("std", numpy.std, axis=0) stats.register("min", numpy.min, axis=0) stats.register("max", numpy.max, axis=0) logbook = tools.Logbook() logbook.header = "gen", "evals", "std", "min", "avg", "max" # 第一世代の生成 pop = toolbox.population(n=MU) pop_init = pop[:] invalid_ind = [ind for ind in pop if not ind.fitness.valid] fitnesses = toolbox.map(toolbox.evaluate, invalid_ind) for ind, fit in zip(invalid_ind, fitnesses): ind.fitness.values = fit record = stats.compile(pop) logbook.record(gen=0, evals=len(invalid_ind), **record) print(logbook.stream) # 最適計算の実行 for gen in range(1, NGEN): # 子母集団生成 offspring = algorithms.varAnd(pop, toolbox, CXPB, MUTPB) invalid_ind = [ind for ind in offspring if not ind.fitness.valid] # 適合度計算 fitnesses = toolbox.map(toolbox.evaluate, invalid_ind) for ind, fit in zip(invalid_ind, fitnesses): ind.fitness.values = fit # 次世代選択 pop = toolbox.select(pop + offspring, MU) record = stats.compile(pop) logbook.record(gen=gen, evals=len(invalid_ind), **record) print(logbook.stream) return pop, pop_init, logbookあとは、このmain関数を呼び出します。
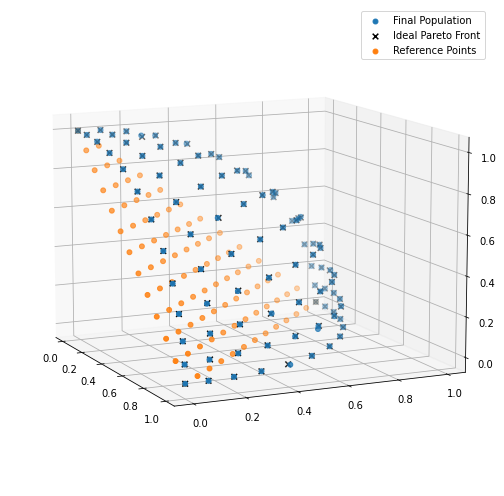
if __name__ == "__main__": pop, pop_init, stats = main() pop_fit = numpy.array([ind.fitness.values for ind in pop]) pf = problem.pareto_front(ref_points)今回は、Reference Pointsと最終世代の結果を可視化してみたいと思います。
fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, projection="3d") p = numpy.array([ind.fitness.values for ind in pop]) ax.scatter(p[:, 0], p[:, 1], p[:, 2], marker="o", s=24, label="Final Population") ax.scatter(pf[:, 0], pf[:, 1], pf[:, 2], marker="x", c="k", s=32, label="Ideal Pareto Front") ref_points = tools.uniform_reference_points(NOBJ, P) ax.scatter(ref_points[:, 0], ref_points[:, 1], ref_points[:, 2], marker="o", s=24, label="Reference Points") ax.view_init(elev=11, azim=-25) ax.autoscale(tight=True) plt.legend() plt.tight_layout()
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、多目的最適化のNSGA-Ⅲについてサンプルコードを確認しました。実際の業務で使う際は、NSGA-Ⅱ、NSGA-Ⅲともに制約条件を業務実態に合わせた形で細かく整理する部分が大変になるのかなと思います。
また、目的変数が4つ以上でパレート解を求めようと思うと可視化できないため、その部分も工夫する必要がありそうです。訂正要望がありましたら、ご連絡頂けますと幸いです。
- 投稿日:2021-01-06T12:14:53+09:00
pandasでの棒グラフ表示(基礎編)
やりたいこと
- pandasでCSVデータを読み込んで棒グラフを表示したい。
- グラフの色やサイズも自由にカスタムしたい。
- 基本操作の習得が目的であるため、データセットは自作したシンプルな内容を扱う。
- ここでは、データの「集計」ではなく「可視化」が目的なので、groupbyなどは使わない。
前提
- jupyterの環境が構築済みであること。
- 必要なpythonライブラリをインストール済みであること。
公式ドキュメント
pandas公式ドキュメント。plot.barの仕様。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.bar.html
CSVデータセット
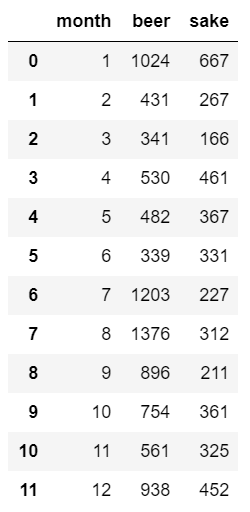
sample.csv
自作した架空データ。
酒類を販売する会社の売り上げを示す。
ビールと日本酒の月別売り上げ金額(億円)。
たとえば2月は、ビール(beer)を431億円、日本酒(sake)を267億円、売り上げた。month,beer,sake 1,1024,667 2,431,267 3,341,166 4,530,461 5,482,367 6,339,331 7,1203,227 8,1376,312 9,896,211 10,754,361 11,561,325 12,938,452以下、pythonでの実装。
ライブラリをインポートする
import pandas as pd import matplotlib as mpl import matplotlib.pyplot as pltCSVを読み込む
df = pd.read_csv('csv/sample.csv')dfの中身は下記。
月別のビールの売り上げを表示する
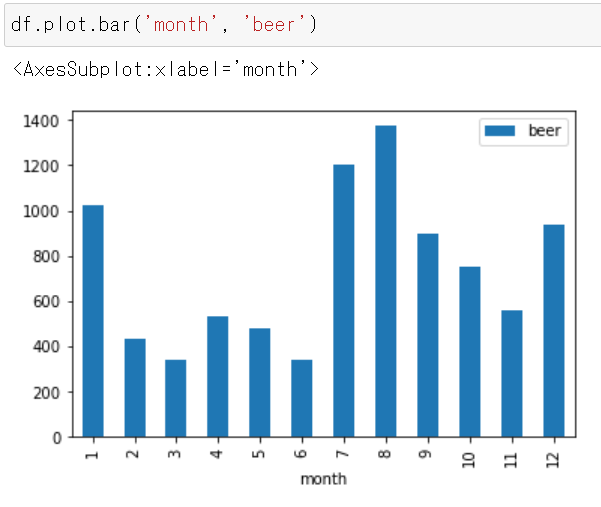
df.plot.bar('month', 'beer')横軸が「月」で、縦軸が「ビールの売り上げ金額(億円)」となる。
- 8月の売り上げが最も多い(1376億円である)ことが分かる。
月別の日本酒の売り上げを表示する
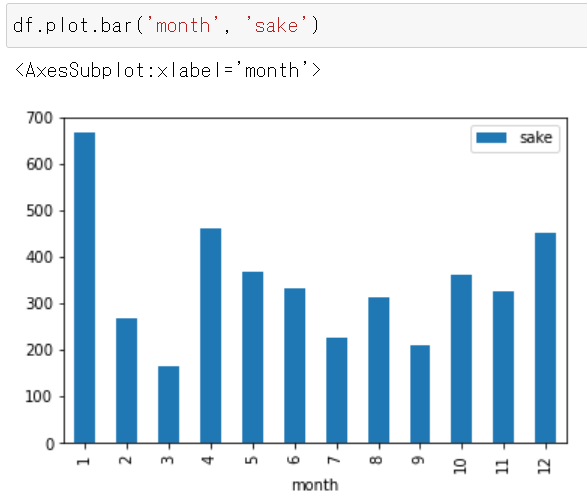
df.plot.bar('month', 'sake')横軸が「月」で、縦軸が「日本酒の売り上げ金額(億円)」となる。
- 1月の売り上げが最も多い(667億円である)ことが分かる。
月別の「ビールと日本酒の売り上げ」を表示する
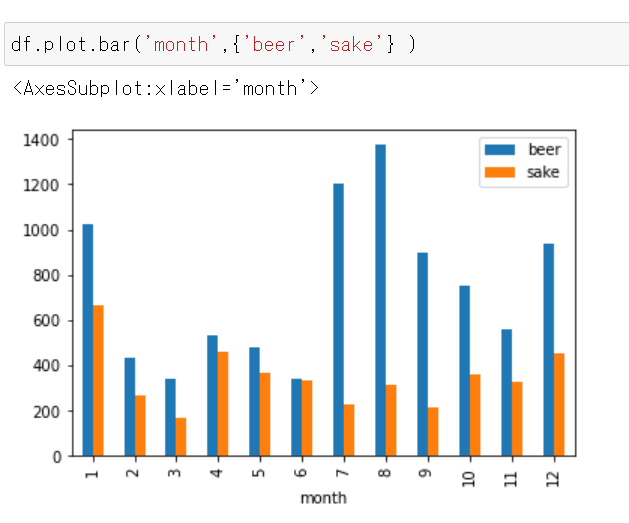
df.plot.bar('month',{'beer','sake'} )横軸が「月」で、縦軸が「ビール(青)と日本酒(オレンジ)の売り上げ金額(億円)」となる。
下記が分かる。
- ビールの売り上げ最多は8月だが、日本酒の売り上げ最多は1月である。
- 日本酒よりもビールのほうが売り上げ金額が大きい。
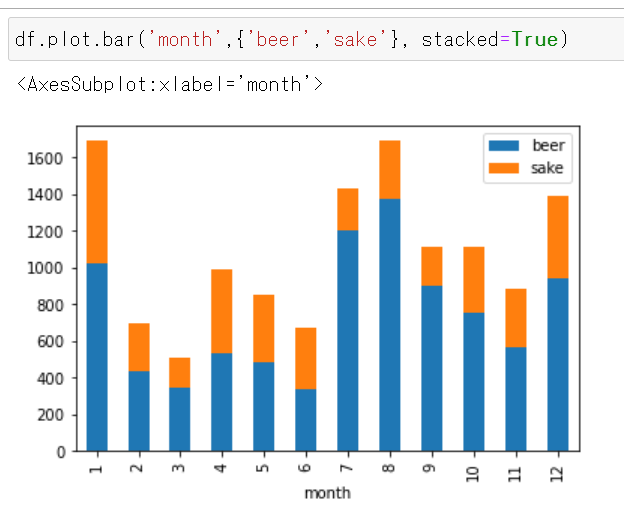
月別の「ビールと日本酒の売り上げ」を表示する(積み上げ)
stacked=Trueを付けると積み上げグラフになる。df.plot.bar('month',{'beer','sake'}, stacked=True)横軸が「月」で、縦軸が「ビール(青)と日本酒(オレンジ)の売り上げ金額(億円)」(積み上げ)となる。
下記が分かる。
- ビールと日本酒を合計して、もっとも売れるのは1月と8月である。
- 日本酒よりもビールのほうが総売り上げに対する比率が高い。
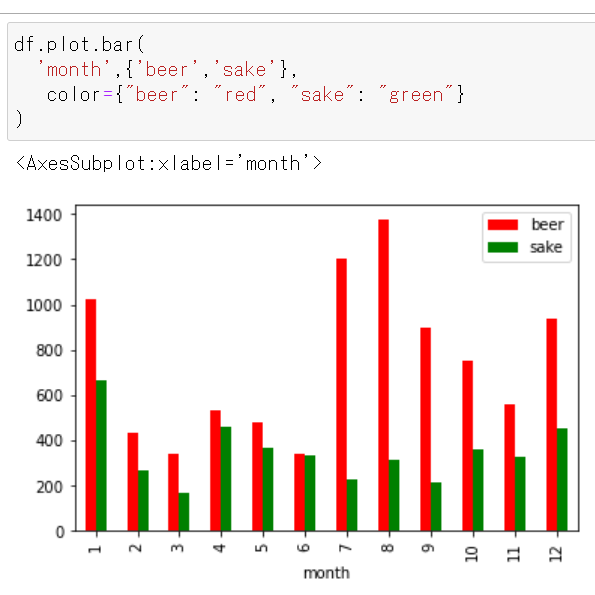
棒の色を変更する
- ビールは赤色、日本酒は緑色、にしたい場合。
df.plot.bar( 'month',{'beer','sake'}, color={"beer": "red", "sake": "green"} )
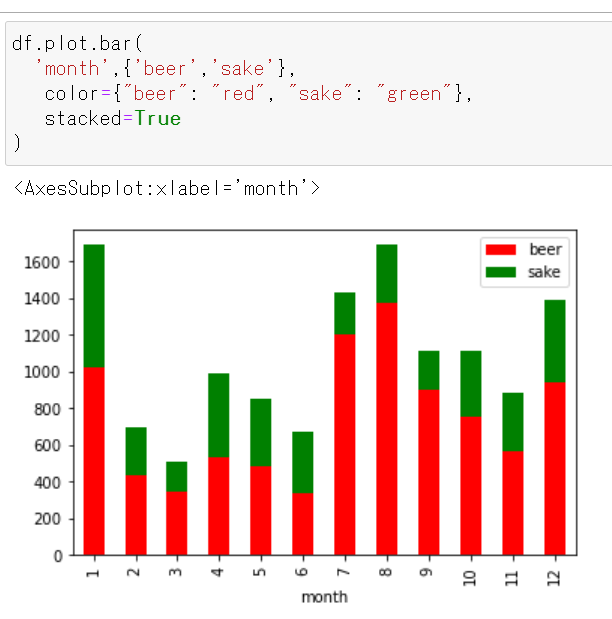
積み上げ
df.plot.bar( 'month',{'beer','sake'}, color={"beer": "red", "sake": "green"}, stacked=True )
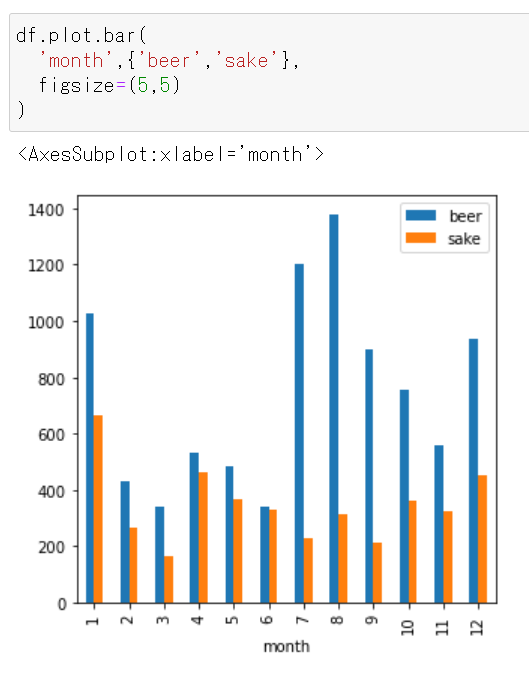
グラフ表示領域のサイズを拡大縮小する
figsizeで指定する。figsize=(5,5)
df.plot.bar( 'month',{'beer','sake'}, figsize=(5,5) )
figsize=(8,5)
figsize=(5,10)
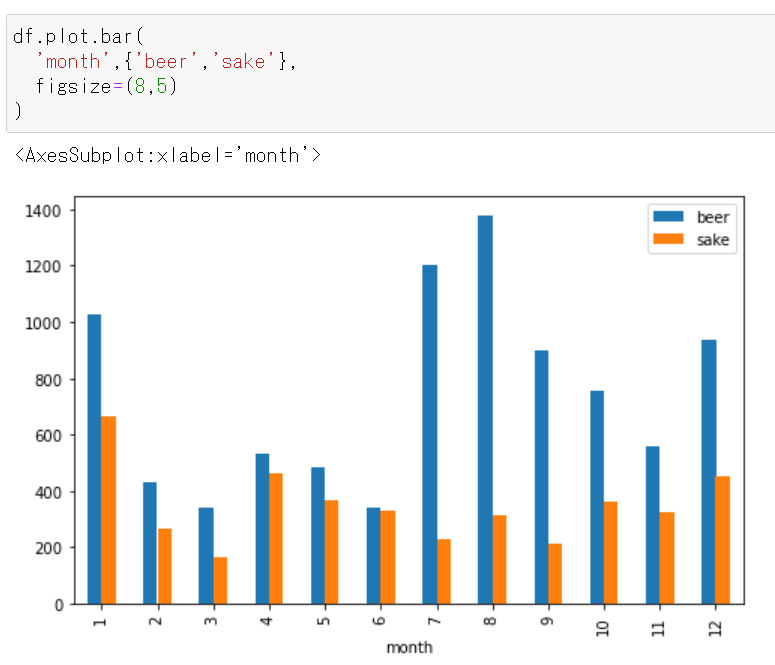
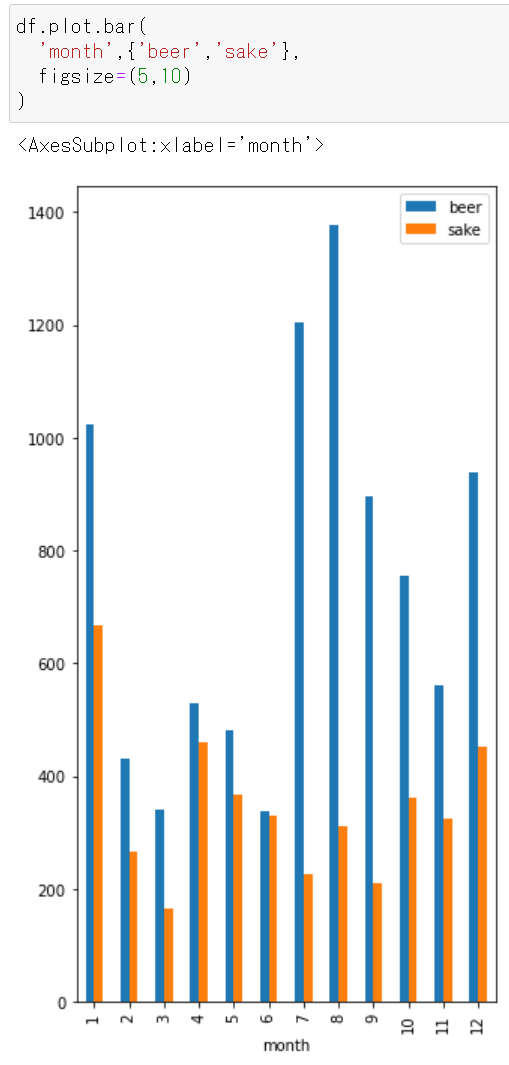
- 投稿日:2021-01-06T11:55:36+09:00
Pythonでボードゲーム「バンカース」の家の止まりやすさを計算した
年末年始にボードゲーム「バンカース」をプレイして、明らかに止まりやすい家があるなと興味を持ち、シミュレーションして、止まりやすさを計算することにした。
環境はiPhoneのPythonistaで行った。シミュレーションの方針
シミュレーションを行い、家に止まった回数をカウントし、それを十分大きな数だけ繰り返すことで収束した値を比較する。
盤の実装
盤には40マスあり、40番目の次は1番目に戻る。
したがって、総移動数をカウントし、剰余演算でどこのマスにいるかを判定する。実装しないマス
止まりやすさ(移動の仕方)に影響しないマスについては特に細かいところは実装せず、何も起こらないマスとして扱う(実際にはお金を取られたりもらったりする)。
止まったことの判定の仕方
止まったと判定するのは1ターンの最後に止まったマスとしている。なぜなら、家に泊まった場合は必ずそこでターンが終了するため。また、このシミュレーションの目的は家の止まりやすさを計算し、比較することにある。
マスの評価の仕方
マスを移動する関数を作成し、それを介して移動することで、マスの評価を行う。
マスの評価関数def stepEval(steps, count, card): if (count + steps) % len(BOARD) == 18: if steps == 7: return steps if steps == 0: return 0 else: count += steps next_steps = BOARD[where_board(count)].getMove(card, where_board(count)) return steps + stepEval(next_steps, count, card)実行結果例
ソースコード
GitHub: https://github.com/huwns/bankers/blob/main/analyze_bankers.py
- 投稿日:2021-01-06T11:29:36+09:00
機械学習における競馬予測
はじめに
みなさんは競馬をしたことがありますか?
私は機械学習を勉強して初めて、競馬に触れました。
プログラミングを勉強する上で「手を動かしながら学ぶ」というのがあります。私は、勉強するなら楽しく、ビジネスに貢献できる題材がいいと思いました。
そこで色々調べた結果、特徴量(予測する際に使う要素)が多く、ビジネスに関係のある競馬を選びました。
最初は「馬が速いか遅いかなんて馬にしか分からないでしょ。」と思っていましたが、機械学習を使うことである程度は予測できるということを知って、今回の記事を書きました。
初めての記事なので、分かりにくい部分が多々あるかと思いますが、その際はご指摘いただけると幸いです。行ったこと
競馬データを分析し、予測精度(AUC)を出すところまで行いました。本当は実際に予測した後に、回収率などを出せるともっと面白そうですが、そこまでの技術はないので「データの取得→前処理→学習→AUCの算出→考察」まで行いました。
環境
Google Colab(初めはローカルのJupyter labで行っていましたが、私のPCでは学習時にkernelが落ちてしまうため、Google colabを使用しました。)
手順
1 https://www.netkeiba.com/よりスクレイピング
2 前処理
3 lightGBMで学習、予測1 netkeiba.comよりスクレイピング
この工程は https://qiita.com/penguinz222/items/6a30d026ede2e822e245 を参考にさせていただきました。
2 前処理
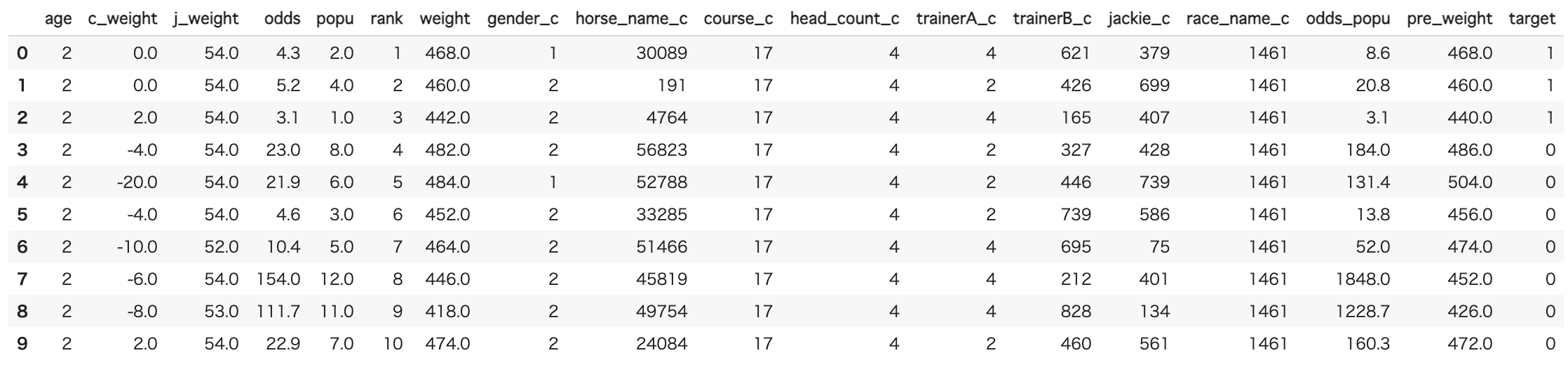
スクレイピングしてきたCSVファイルはこんな感じです。
データの大きさは約50万行×20列です。
これらに対して前処理を行っていきます。先に、一般には馴染みのない列名があるので解説します。
・c_weight...前回のレースからの体重差
・j_weight...ジョッキーの体重
・popu...人気(運営側が事前情報によって馬それぞれに人気をつけます)
・odds...払い戻し額÷掛け金(人気な馬ほどoddsは低いです。)
・trainerA,trainerB...調教師2-1 データを扱いやすくする
一番左の列がUnnamed:0となっています。この列は開催された日付、レース番号、馬番が連なっていますので、これは2列に分解します。
# データの読み込み # Unnamed0のカラムは日付、レース番号、馬番号なのでrenameして分割。 keiba_data = pd.read_csv('/content/drive/MyDrive/競馬.csv', encoding = "shift-jis") keiba_data.rename(columns={"Unnamed: 0":"date_num"},inplace=True) keiba_data["date_num"]=keiba_data["date_num"].astype(str) keiba_data["race_num"]=keiba_data["date_num"].str[0:12].astype(int) keiba_data["horse_num"]=keiba_data["date_num"].str[12:14].astype(int) keiba_data.drop(columns=["date_num"],inplace=True) # 扱いやすいようにrace_numとhorse_numは一番左に配置。 keiba_data=keiba_data.reindex(columns=['race_num','horse_num','age', 'c_weight', 'course', 'date', 'field', 'gender', 'head_count', 'horse_name', 'j_weight', 'jackie', 'odds', 'popu', 'race', 'race_name', 'rank', 'trainerA', 'trainerB', 'weight', 'year'])2-2 欠損値処理
データに欠損値があるか確認します。
keiba_data.isnull().sum()
いくつか欠損値があります。今回、学習に使うモデルはlightGBMという欠損値の処理をしなくていいモデルなのですが、どこかでlightGBMも欠損値処理をした方が精度があがるという記事をみたので(すいません、どの記事かは忘れてしまいました。)欠損値処理を行います。
intのカラムは0や平均値で埋めていき、objectのカラムなどはdropしていきます。
popuとoddsはかなり重要な要素となることが予想されるので、欠損値は平均値や中央値では埋めずdropしました。#欠損値処理 keiba_data["c_weight"].fillna(0,inplace=True) keiba_data["j_weight"].fillna(keiba_data["j_weight"].mean(),inplace=True) keiba_data["weight"].fillna(keiba_data["weight"].mean(),inplace=True) keiba_data.dropna(subset=["race_name"],inplace=True) keiba_data.dropna(subset=["odds"],inplace=True) keiba_data.dropna(subset=["popu"],inplace=True)2-3 データ型の確認
keiba_data.dtypes
object型は全てLabel Encoderによってint型に変換します。
その後、yearなどの不要な列を削除します。#labelencoderを使って、カテゴリ変数を変換。 le=LabelEncoder() keiba_categorical = keiba_data[["gender","field","horse_name","course","head_count","trainerA","trainerB","race","jackie","race_name"]].apply(le.fit_transform) keiba_categorical = keiba_categorical.rename(columns={"race_name":"race_name_c","filed":"field_c","gender":"gender_c","horse_name":"horse_name_c","course":"course_c","head_count":"head_count_c","trainerA":"trainerA_c","trainerB":"trainerB_c","jackie":"jackie_c"}) keiba_data = pd.concat([keiba_data,keiba_categorical],axis=1) # 変換前と不要な列を削除 keiba_data.drop(columns=["race_num","horse_num","date","year","race_name","race","trainerA","trainerB","course","field","gender","jackie","head_count","horse_name"],inplace=True)2-4 特徴量生成
oddsとpopuはかなり重要な特徴量と考え、それらの積をとった特徴量とc_weightから前回の体重が分かるので前回の体重を新たに特徴量として追加しました。
# 特徴量生成 # 1つ目はoddsとpopuの積 # 2つ目は前回の体重 keiba_data["odds_popu"]=keiba_data["odds"]*keiba_data["popu"] keiba_data["pre_weight"]=keiba_data["weight"]-keiba_data["c_weight"]2-5 目的変数の処理
ここから目的変数であるrankの処理を行います。
# rankの確認 keiba_data["rank"].unique()
すると順位以外に中止、失格の行があります。rankが分からなければ、学習もできないのでこの行は全てdropします。count()で数えると約2000と数も少ないのでdropしても大丈夫そうです。
#中止、失格の行は全て削除する。 delete_index = keiba_data.index[((keiba_data["rank"]=="中止") | (keiba_data["rank"]=="失格")] keiba_data.drop(delete_index,inplace=True)さて、順位を予測したいところですが、競馬は基本的には3着以内に入るかが賞金に関わってきます。逆に言えば、7位や8位の馬をドンピシャで当てる必要はありません。
ということで、3着以内かそれより下位かの二値分類問題にしようと思います。要は勝つか負けるかですね。
他の方の記事では上位、中位、下位と3つに分けて多値分類問題にしてる方もいらっしゃいました。# 1,2,3着かそれ以外かに分割して、二値分類問題にする。 keiba_data["rank"]=keiba_data["rank"].astype(int) keiba_data = keiba_data.assign(target = (keiba_data['rank'] <= 3).astype(int))3着以内であれば1,それより下位であれば0を与えたtargetという列を作りました。
ここまでが前処理になります。次はlightGBMを使って、学習→予測まで行います。
ここまで処理したデータはこんな感じです。
3 学習、予測
特徴量と目的変数をXとyに分割して、さらに学習用データと評価用データに分割します。
またそれらのデータをlgb.DatasetでlightGBMで読めるデータに変換します。# trainデータおよびtestデータの分割と特徴量および目的変数の分割 import lightgbm as lgb X = keiba_data.drop(['rank','target'], axis=1) y = keiba_data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) # データの変換 lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test)パラメータチューニングに関してはoptunaというフレームワークを使って、自動で決めます。
# ハイパーパラメータをoptunaで自動設定 %%time !pip install optuna from optuna.integration import lightgbm as lgb params = { 'objective': 'binary', 'metric': 'auc' } best_params, history = {}, [] model = lgb.train(params, lgb_train, valid_sets=[lgb_train,lgb_eval], verbose_eval=False, num_boost_round=10, early_stopping_rounds=10) best_params_ = model.params # モデルの作成 import lightgbm as lgb_orig model = lgb_orig.train(best_params_, lgb_train, valid_sets=lgb_eval, num_boost_round=100, early_stopping_rounds=10)最終的なAUCは
でした。AUCなので82%当てているということではないですが、思ったよりいい数値が出てくれました。
(AUCについてはこちらのサイトが分かりやすかったです。
https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/)最後に特徴量の重要度をみてみます。
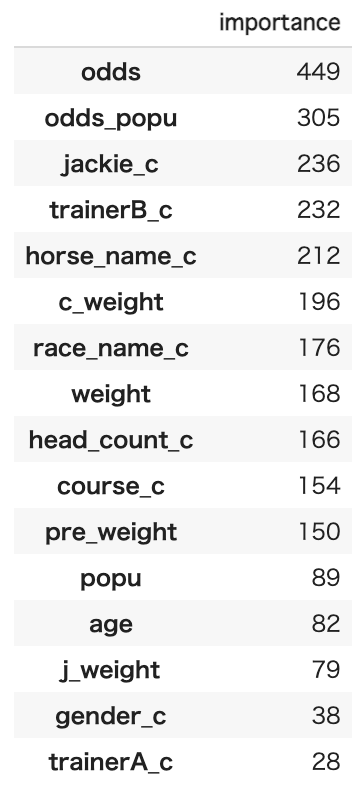
#特徴量の重要度を表示。 keiba_data.drop(columns = ["rank","target"],inplace=True) importance = pd.DataFrame(model.feature_importance(), index=keiba_data.columns,columns=['importance']) importance=importance.sort_values(by="importance",ascending=False) display(importance)
やはりoddsはかなり重要な特徴量であるようです。また馬に乗るジョッキー(jackie_c)も重要なようです。
意外だったのはpopuやtrainerAの重要度が低いという点です。しかしtrainerBは重要度が高いです。この辺りは競馬に詳しい人に聞いた方が良いかもしれないです。筆者は競馬を数回しかやったことがないので、この辺りはまだまだ勉強が必要です。おわりに
今回、前処理について基礎的なことしか行っていませんが、AUCは0.816736という割と良い数値がでました。
結構当てくれるので、これを使えば儲かるかと言われるとまたそれは別の問題になってきます。モデルは3着以内に入るか否かだけを判定してくれてるので、いくら賭けていくら戻ってくるなどの回収率は一切考慮していません。
人気な馬に賭けておけば的中しやすくなりますが、その分oddsは低いので払い戻し金額も少なくなってしまいます。
要するに「当たるけど、戻ってくるお金は少ない」ということです。
理想は穴馬(oddsが高い不人気な馬)にもかけつつ、人気な馬で安定的に稼ぐみたいな感じがいいのかなと思います。
最終的にできたモデルはDjangoなどで実装して日付とレース番号を入れると、予測を返してくれるようなものを作りたいと思っています。これを作ってて思いましたが、好きな題材でプログラミングの勉強ができるのは良いですね。プログラミングを勉強する上で、実際に何かを作りながら勉強するのが大事だなと改めて実感しました。
最後までご覧いただきありがとうございました。参考にさせていただいた記事
・https://qiita.com/Mshimia/items/6c54d82b3792925b8199
・https://qiita.com/km_takao/items/0a448543961a97fc9c94
・https://qiita.com/km_takao/items/70f7a7c3c9c533d7bee4
・https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/




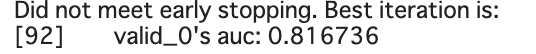
- 投稿日:2021-01-06T11:24:09+09:00
PythonでKubernetesPodのCPU使用量を表示させる方法
PythonによるPodのCPU使用量を表示させるプログラム
from kubernetes import client, config import json config.load_kube_config() api = client.CustomObjectsApi() resource = api.list_namespaced_custom_object(group="metrics.k8s.io",version="v1beta1", namespace="c0118220", plural="pods") #print(json.dumps(resource,ensure_ascii=False, indent=4, sort_keys=True, separators=(',', ': '))) for pod in resource["items"]: print(pod["metadata"]["name"],pod['containers']) ~ ~
- 投稿日:2021-01-06T11:17:46+09:00
【注意】mecabでシステム辞書やユーザー辞書を指定する【Windows】
MeCabをpythonで利用していて辞書指定で引っかかったことがあったので備忘録として残しておく。
1つの処理の間でユーザ辞書を切り替える必要があったことが背景になっている。mecabの公式ページは以下。
https://taku910.github.io/mecab/
大体のことはここに書いてあるが、懇切丁寧に書いてあるわけではないので別途調べる必要がある。
mecabはWindowsを前提に作られているわけではなく、調べて出てくるドキュメントもWindows向けのものが少なかった印象。結論
パスは
¥や\で区切らずにせずに/で区切れ
辞書へのパス指定時にスペースを入れるな解説
ここではpythonコードから辞書指定をするときについて解説する。
ちなみにコマンドラインから実行する場合はスペースがあっても問題ない。
ただ、スペースで区切りとみなされるためパス全体を""で覆うこと# システム辞書指定 mecab -d "C:\Program Files (x86)\MeCab\dic\ipadic" # ユーザ辞書指定 mecab -u "C:\Program Files (x86)\MeCab\dic\ipadic\user.dic"※ユーザ辞書は自分が作成して置いたパスを指定する(作成方法は別途調べてください。)
pythonコードから辞書指定
辞書指定するときにはTagger作成時に引数に渡す必要がある
import MeCab tagger = MeCab.Tagger("-d [システム辞書へのパス]") tagger = MeCab.Tagger("-u [ユーザ辞書へのパス]")Windowsの場合、多分
C:\Program Files (x86)\MeCab\dic\ipadicに辞書があるはず。(x86じゃない方の可能性も)それを上記の[辞書へのパス]に書くのだが2つ注意点がある。
- パスは
/で区切らなくてはならない- スペースを入れてはならない
どちらもMeCabの仕様ではなくpythonの仕様によるもの。
パスは
/で区切らなくてはならない文字列のダブルクォーテーション
""の中で¥や\を使うとエスケープ文字とみなされてしまう。import MeCab tagger = MeCab.Tagger("-d C:\Program Files (x86)\MeCab\dic\ipadic") tagger = MeCab.Tagger("-u C:\Program Files (x86)\MeCab\dic\ipadic\user.dic") ではなく tagger = MeCab.Tagger("-d C:/Program Files (x86)/MeCab/dic/ipadic") tagger = MeCab.Tagger("-u C:/Program Files (x86)/MeCab/dic/ipadic/user.dic")※ユーザ辞書は自分が作成して置いたパスを指定する(作成方法は別途調べてください。)
これはVSCodeなどのエディタを使っていればエラーとして表示してくれるためすぐに気付ける。
※追記※
他の解決策として
r"-d C:\Program Files (x86)\MeCab\dic\ipadic"
のように文字列の前にrをつけることで¥や\のままでも問題なく動作します。
@palm23さん教えていただきありがとうございました。スペースを入れてはならない
デフォルトだと
C:\Program Files (x86)\MeCab\dic\ipadicに辞書があると思うが、Program Files (x86)にスペースが入っているとエラーになる。辞書指定したいのならば、パスにスペースを含まない別の場所に辞書をコピーし、その辞書を指定する必要がある。
例えばC直下にmecabというフォルダを作成して辞書を配置し、以下のように指定する。import MeCab tagger = MeCab.Tagger("-d C:/mecab/ipadic") tagger = MeCab.Tagger("-u C:/mecab/ipadic/user.dic")※スペースがあるのがだめならクォーテーションで囲んでやればいいのでは?
tagger = MeCab.Tagger("-d 'C:/Program Files (x86)/MeCab/dic/ipadic'")
残念ながらこれでもエラーになる。※追記※
mecab-python3の場合はスペースがあってもクォーテーションで囲えば正常に動作します。
pip install mecab-python3
@palm23さん教えていただきありがとうございました。まとめ
mecabに限らず、pythonでパスを指定するときは、
- パスは
¥や\で区切らずにせずに/で区切れ(もしくはr"")- 辞書へのパス指定時にスペースを入れるな(もしくはmecab-python3を使う)
- 投稿日:2021-01-06T10:51:58+09:00
Opencvについて③
Opencv3系についてのメモ
基本的には公式ドキュメントを確認しながらの物。
メモについて
Opencvについて①
Opencvについて②環境・使用画像は前回と同様。
①リサイズ
cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]])
cv2.resize(第1引数、第2引数、第3引数)のイメージ自分が使用している画像の通常時
opencv.py#通常画像 img = cv2,imread(cap_dir) img.shape >>>(340,255,3)Opencvチュートリアルとしては
opencv公式.pyimport cv2 import numpy as np img = cv2.imread(cap_dir) res = cv2.resize(img,None,fx=1, fy=1, interpolation = cv2.INTER_CUBIC)img:表示画像
None:未使用
fx=2:元画像に対してxを何倍にするか
fy=2:元画像に対してyを何倍にするか
interpolation=cv2.INTER_CUBIC:画像拡大時の補間メソッド又は
opencv公式.pyimport cv2 import numpy as np img = cv2.imread(cap_dir) height, width = img.shape[:2] res = cv2.resize(img,(2*width, 2*height), interpolation = cv2.INTER_CUBIC)
img.shape[:2]で画像のxとyの数値を取り込んで
(2*width, 2*height)で元の大きさに対して何倍かを決定している。どちらも同じ事を実施しています。
元画像を元に変化させていくならこちらかと。(縦横比率は変わらない)アスペクト比を気にせずに拡大・縮小をするのであれば
opencv.pysize = (300,200) img_resize = cv2.resize(img,size) #or img_resize = cv2.resize(img,(300,200))これだけでも可能です。
縦横比に関しては超適当です。
画像のアスペクト比を確認してからごちゃごちゃやるよりは
.shape[:2]で取り込んだ方がスマートかと
第3引数と記載している部分に関してのメソッド
interpolation = method
INTER_NEAREST
INTER_LINEAR(デフォルト設定)
INTER_AREA
INTER_CUBIC
INTER_LANCZOS4
と結構ありました拡大時には
interpolation=cv2.INTER_LINEAR(処理速い)orcv2.INTER_CUBIC(処理遅い)
縮小時にはinterpolation=cv2.INTER_AREA
との認識でよいかと…
英語表記なので細かいニュアンスが読み取れません…
②画像平行移動
opencv.pyimg = cv2.imread(cap_dir) h, w = img.shape[:2] dx, dy = 30, 30 M = np.float32([[1,0,dx],[0,1,dy]]) img_afn = cv2.warpAffine(img,M,(w,h))物体の位置を移動させる処理です.(x,y)方向への移動量が $(t_x,t_y)$ だとすると,この並進を表す変換行列 $\textbf{M}$ は以下のようになります:
M = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \end{bmatrix}by公式
opencv.pyimg.shape >>>(340, 255, 3) afn_mat = np.float32([[1,0,dx],[0,1,dy]]) print(afn_mat) [[ 1. 0. 30.] [ 0. 1. 30.]]
np.float32([[1,0,dx],[0,1,dy]])numpy配列で移動量を設定。cv2.warpAffine(第1引数、第2引数、第3引数)
第1引数:画像
第2引数:移動量
第3引数:出力画像のサイズ ← 公式にはサイズを指定しないとエラー吐くって表記ありこれで画像が移動します。(現時点で使い道は思いつかず)
③画像回転
opencv.pyimg = cv2.imread(cap_dir,0) h, w = img.shape M = cv2.getRotationMatrix2D((w/2,h/2),45,1) img_afn2 = cv2.warpAffine(img,M,(w,h))cv2.getRotationMatrix2D((w/2,h/2),45,1)
(w/2,h/2):回転中心位置。数値を変更すると中心位置がずれます。
45:回転角度。
1:倍率。2に設定したら表示枠はそのままで画像が2倍になりました。
カラー表示も問題なく出来ますが
カラーにすると(縦、横、色)と情報が増えるので
img.shapeの格納数を増やせばカラー画像の取り扱いの出来ます。
h, w, c = img.shapeって事です。公式さん曰く
画像を回転角 $\theta$ 回転させるための変換行列は以下のようになります.
M = \begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta \end{bmatrix}OpenCVが提供する回転はスケーリングも同時に行い,回転の中心位置を変更できます.この変換を表す変換行列は以下のようになります.
\begin{bmatrix} \alpha & \beta & (1- \alpha ) \cdot center.x - \beta \cdot center.y \\ - \beta & \alpha & \beta \cdot center.x + (1- \alpha ) \cdot center.y \end{bmatrix}ここで:
\begin{array}{l} \alpha = scale \cdot \cos \theta , \\ \beta = scale \cdot \sin \theta \end{array}
この変換行列を計算するための cv2.getRotationMatrix2D という関数があります.以下の例はスケーリングをせずに画像中心に対して90度回転する変換を試しています.
cv2.getRotationMatrix2D((w/2,h/2),45,1)は上記の計算式を用いて画像回転している様です。
公式には上記の様に記載されていますが式に関しては正直理解していませn。
どこの数値を触ると画像がどう変化するかを試してみた結果ですので
試してみて画像で理解するしかないかと思っています。
④まとめ
使う・使わない別としてのまとめ
画像処理に関してはかなり多いので多分使うであろう物を
別途まとめます。




- 投稿日:2021-01-06T10:35:25+09:00
クラスター分析手法のひとつ k-means を scikit-learn で実行したり scikit-learn を使わず実装したりする
クラスターを生成する代表的手法としてk-meansがあります。これについては過去にも記事を書きましたが、今回は皆さんの勉強用に、 scikit-learnを使う方法と、使わない方法を併記したいと思います。
- K-meansクラスタリング(過去記事)
データの取得
機械学習の勉強用データとしてよく使われるあやめのデータを用います。
import urllib.request url = "https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/iris.txt" filename = url.split("/")[-1] urllib.request.urlretrieve(url, filename)('iris.txt', <http.client.HTTPMessage at 0x7fac1779a470>)import pandas as pd df = pd.read_csv(filename, delimiter="\t", index_col=0) df
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 0 2 4.9 3.0 1.4 0.2 0 3 4.7 3.2 1.3 0.2 0 4 4.6 3.1 1.5 0.2 0 5 5.0 3.6 1.4 0.2 0 ... ... ... ... ... ... 146 6.7 3.0 5.2 2.3 2 147 6.3 2.5 5.0 1.9 2 148 6.5 3.0 5.2 2.0 2 149 6.2 3.4 5.4 2.3 2 150 5.9 3.0 5.1 1.8 2 150 rows × 5 columns
この中の左2列のデータだけを使ってみましょう。
%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], s=50) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
scikit-learn で k-means
機械学習用ライブラリとして有名なscikit-learnの中で、k-meansを行うモジュールはこちらになります。
k-meansでは、クラスターの数
n_clustersをあらかじめ指定しておく必要があります。from sklearn.cluster import KMeans kmeans_model = KMeans(n_clusters = 3).fit(df.iloc[:, :2])たったこれだけで学習完了です。クラスタリング結果は次のようにして確認できます。
kmeans_model.labels_array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 2, 1, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 2], dtype=int32)同じクラスターに属するサンプルは同じ色にして描画してみましょう。
%matplotlib inline import matplotlib.pyplot as plt plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=kmeans_model.labels_, s=50) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
scikit-lean を使わず k-means
さて、意味が分からなくても使えるscikit-learnは大変便利なのですが、意味が分からずに使っていると、もしも何か間違った使い方をしてしまってもそれに気づかなかったり、結果の解釈を誤ってしまったりする恐れがあります。ですので、何が行われているか基礎を確認してみましょう。おおよそ次のような手順で計算が行われます。
ランダムにラベルを与える
最終目標は、ラベルがクラスターを表すようにしたいのですが、最初はランダムから開始します。
import random n_clusters = 3 df['labels'] = [random.randint(0, n_clusters) for x in range(len(df))] df
Sepal.Length Sepal.Width Petal.Length Petal.Width Species labels 1 5.1 3.5 1.4 0.2 0 2 2 4.9 3.0 1.4 0.2 0 3 3 4.7 3.2 1.3 0.2 0 2 4 4.6 3.1 1.5 0.2 0 1 5 5.0 3.6 1.4 0.2 0 2 ... ... ... ... ... ... ... 146 6.7 3.0 5.2 2.3 2 3 147 6.3 2.5 5.0 1.9 2 0 148 6.5 3.0 5.2 2.0 2 2 149 6.2 3.4 5.4 2.3 2 2 150 5.9 3.0 5.1 1.8 2 2 150 rows × 6 columns
%matplotlib inline import matplotlib.pyplot as plt plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
重心を求める
ラベルが与えられた集団ごとに、重心を求めます。
centroids = [] for i in range(n_clusters): df_mean = df[df['labels'] == i].mean() centroids.append([df_mean[0], df_mean[1]]) centroids[[5.7, 2.9851851851851845], [5.765789473684211, 3.189473684210527], [5.968749999999999, 3.014583333333333]]重心を星印で描画してみましょう。
%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
ラベルを再配分する
各サンプルごとに、最も近い重心を選び、その重心のラベルに基づいてラベルを再配分します。
def nearest_centroid(centroids, x, y): min_dist = False min_id = False for i, xy in enumerate(centroids): dist = (xy[0] - x)**2 + (xy[1] - y)**2 if i == 0 or min_dist > dist: min_dist = dist min_id = i return min_iddf['labels'] = [ nearest_centroid( centroids, df[df.columns[0]][x + 1], df[df.columns[1]][x + 1] ) for x in range(len(df)) ]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
重心を求める
再配分されたラベルに基づいて、ラベルごとに重心を求めます。
centroids = [] for i in range(n_clusters): df_mean = df[df['labels'] == i].mean() centroids.append([df_mean[0], df_mean[1]]) centroids[[5.20204081632653, 2.808163265306123], [5.239393939393939, 3.6272727272727274], [6.598529411764702, 2.9602941176470594]]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
ラベルを再配分する
再計算された重心に基づいて、ラベルを再配分します。
df['labels'] = [ nearest_centroid( centroids, df[df.columns[0]][x + 1], df[df.columns[1]][x + 1] ) for x in range(len(df)) ]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
重心を求める
再配分されたラベルに基づいて、重心を再計算します。
centroids = [] for i in range(n_clusters): df_mean = df[df['labels'] == i].mean() centroids.append([df_mean[0], df_mean[1]]) centroids[[5.219148936170212, 2.7851063829787237], [5.16969696969697, 3.6303030303030304], [6.579999999999997, 2.9700000000000006]]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
ラベルを再配分する
再計算された重心に基づいて、ラベルを再配分します。
df['labels'] = [ nearest_centroid( centroids, df[df.columns[0]][x + 1], df[df.columns[1]][x + 1] ) for x in range(len(df)) ]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
重心を求める
再配分されたラベルに基づいて、重心を再計算します。
centroids = [] for i in range(n_clusters): df_mean = df[df['labels'] == i].mean() centroids.append([df_mean[0], df_mean[1]]) centroids[[5.283333333333333, 2.7357142857142853], [5.105263157894737, 3.573684210526316], [6.579999999999997, 2.9700000000000006]]%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(6,6)) plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['labels'], s=50) plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], c=range(n_clusters), marker='*', s=500) plt.xlabel(df.columns[0]) plt.ylabel(df.columns[1]) plt.show()
以上のように、計算が落ち着くまで繰り返します。
課題
上記の「scikit-learnを使わないコード」について、以下の課題に取り組んでください。
- 計算が落ち着くまで繰り返し計算ができるように、上記のコードを改良してください。
- クラスターの数を増やして、挙動を確認してください。
- 左2列だけでなく左4列を用いて実行してください。
- 上記のアルゴリズムでは、たとえば
n_clusters = 10にしても、最終的に得られるクラスターの数が10にならないときがあります。それはなぜか説明し、それを避けるためにはアルゴリズムをどう改変すれば良いか提案してください。
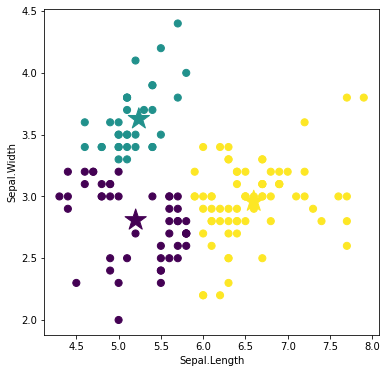
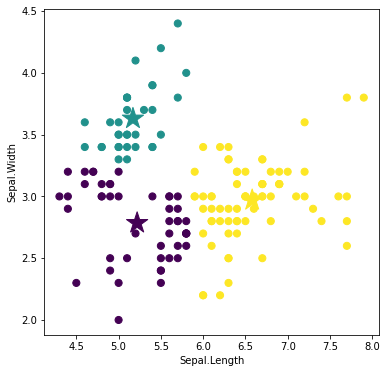
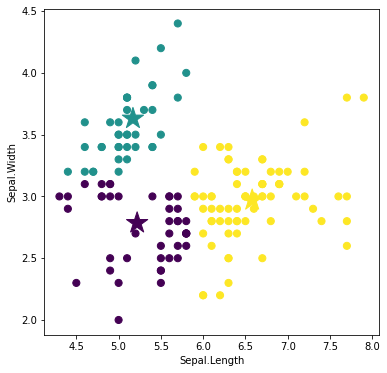
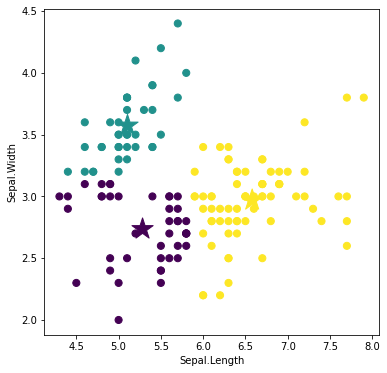
- 投稿日:2021-01-06T09:50:37+09:00
tensorflow-gpuを動くようにするためにすること
初めに
パソコンを初期化したらtensorflowをgpuで動かすために色々入れなおさなきゃいけなかった。
そしたらいろいろ躓いたので、今後また入れなおすようにメモ環境
windows10
RTX2070
Ryzen 3700x
Anaconda道筋
Anacondaのダウンロード
環境の作成
tensorflowの依存環境の把握
cudaのダウンロード
cuDNNのダウンロード
パスバージョン
2019年にtensorflowが1.xから2.xになって書き方が結構変わったみたい
よってネット上に結構あるプログラムが動かないのでないっぽい
よって環境を二つ作って、一つは2.xの最新版、もう一つは1.xの最新版を入れる2.x
Python3.7
tensorflow-gpu==2.4.0
cudnn8.0.5
cuda11.0
keras-2.4.3環境作成
https://qiita.com/ozaki_physics/items/985188feb92570e5b82d
に環境の作り方がある。Conda create -n 37tens24 python=3.7 anacondaversionの把握
次に、tensorflowの依存環境を把握
https://www.tensorflow.org/install/source_windows?hl=ja
最新版はなかったため、また時々間違っているためhttps://www.kkaneko.jp/tools/win/keras.html
こちらで確認した
また、基本的にこのサイトに沿えば良い
最新版はkerasは依存間関係なさそうpip install tensorflow-gpu==2.4.0 pip install kerascuda toolkit
https://developer.nvidia.com/cuda-toolkit-archive
ここからダウンロード11.0をダウンロード
やり直すことを考えてlocalの方をダウンロードしたほうがいい(500MBぐらい)実行
最初はすべてダウンロードhttps://www.kkaneko.jp/tools/win/cuda.html
ここが詳しいcudnn
詳しい解説
https://www.kkaneko.jp/tools/win/cudnn805.htmlhttps://developer.nvidia.com/cudnn
ここからダウンロード
そして解凍C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
やり直すこと考えてこれをバックアップしてから解凍内容をコピペpathの追加
システム の環境変数の名前
CUDNN_PATH
値
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
のように設定(管理者から)なお、システムの環境変数の変更には管理者で開く必要がある。
https://www.lisz-works.com/entry/sys-env-admin
Windowsマーク右クリックからの管理者powershell
Start C:\Windows\system32\rundll32.exe sysdm.cpl, EditEnvironmentVariablesこれで全て使えるようになる。
1.x
37tens115
tensorflow_gpu-1.15.0
Cudnn7.4.2では動かないので7.6.5
Cuda10.0
Keras2.3.1
最新版の Keras は TensorFlow 1.15 では動かない. Keras のバージョン 2.3.1 をインストールする二つ目かつ古いバージョンの場合、cudaは
これだけでいいこのサイトが詳しい
https://www.kkaneko.jp/tools/win/cuda.html※ 複数の版の CUDA ツールキットをインストールする場合には, 複数のパスが設定される このとき・古い版の方が先に来ている場合には、後になるように調整する
Cudnn_pathは11のままで動いた
まとめ
意外とすんなりいかず、大変なので頑張ってください。
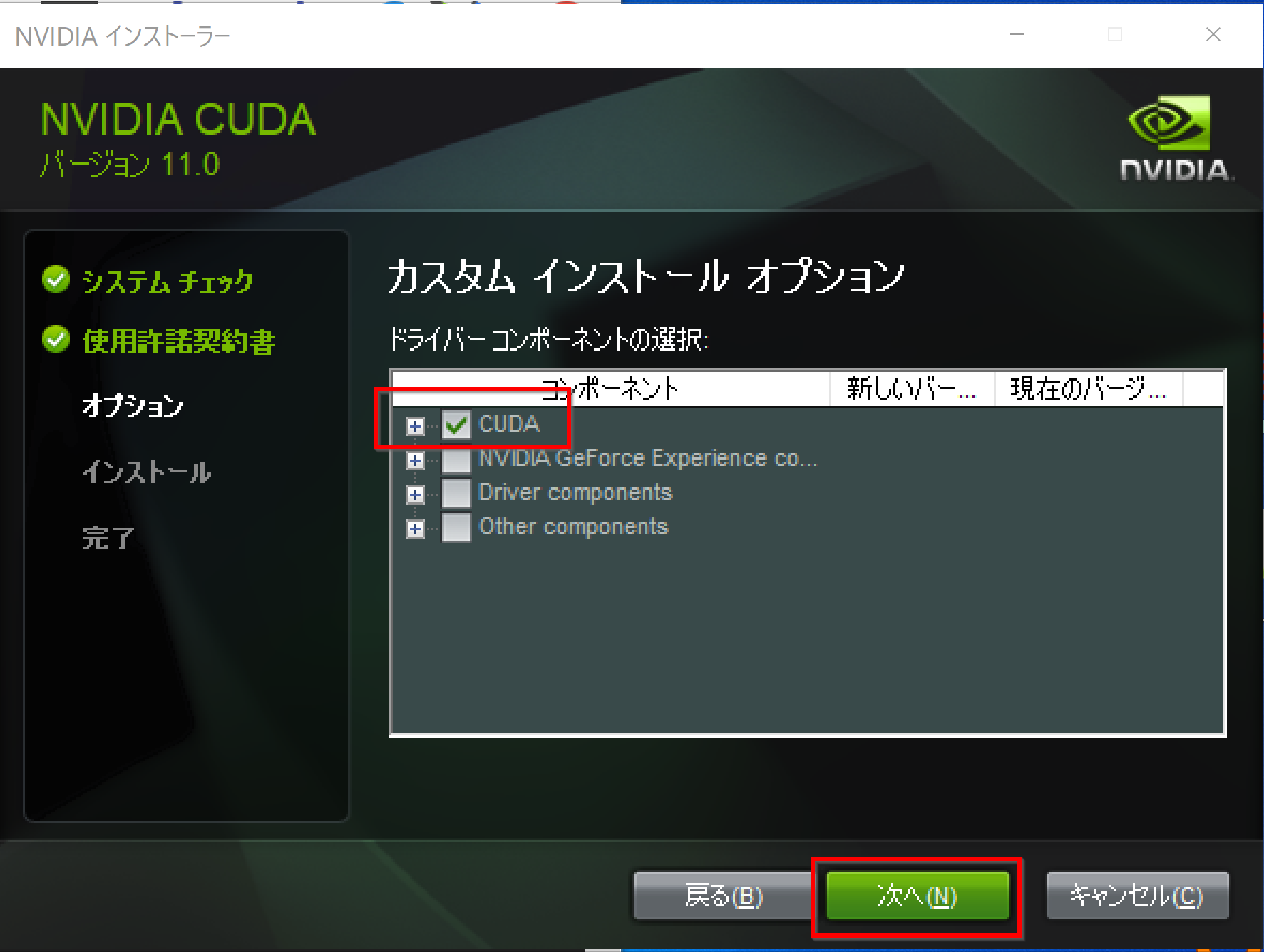
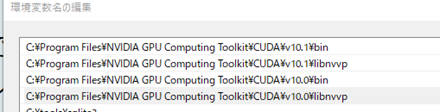
- 投稿日:2021-01-06T09:43:29+09:00
Jupyter notebook の結果を Qiita に上げるために markdown にする
Google colaboratory を使っていて、できあがった Jupyter notebook のファイル(.ipynb) を Qiita にアップしたいとき markdown に変換するのですが、これをコマンドラインで行ないたいと思ってもすぐには思い出せない。かといってググってもすぐには見つからないのでメモします。
jupyter nbconvert --to markdown Untitled.ipynb以上ッ!