- 投稿日:2020-11-28T23:51:48+09:00
RSpecを実行すると、 Lock wait timeout exceeded; try restarting transaction mysqlというエラーがでる
ある日、RSpecのテストの実行中に、Ctrl+Cでキャンセルし、再びテストを走らせた。すると、いつまでたっても処理が止まったままだったのでそのまま放置していたら以下のようなエラーが出ました。
Lock wait timeout exceeded; try restarting transaction mysqlなぜこうなったのか
おそらく、MySQLのトランザクション(システムスペックは自動でテストデータのトランザクション処理をしてくれる)がコミットされる前にCtrl+Cでキャンセルしてしまったからだと思いますが、はっきりした原因は不明です(超ピンポイントでCtrl+Cを押してしまったため発生した?)
解決策
①mysqlに
mysql -u root -pでログインする。
②SHOW ENGINE INNODB STATUSを実行し、TRANSACTIONSの部分を確認する。TRANSACTIONS ------------ Trx id counter 60949 Purge done for trx's n:o < 60941 undo n:o < 0 state: running but idle History list length 4 LIST OF TRANSACTIONS FOR EACH SESSION: ---TRANSACTION 421573119466232, not started 0 lock struct(s), heap size 1136, 0 row lock(s) ---TRANSACTION 60934, ACTIVE 151 sec 7 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 6 MySQL thread id 3, OS thread handle 140097739974400, query id 78 172.20.0.3 kiyo Trx read view will not see trx with id >= 60934, sees < 60934③すると、151秒コミットされないままのトランザクションがありました!
thread id 3 とあるのでこのプロセスを kill 3 で削除します。④再度実行したら、RSpecが無事実行されるようになりました。
おそらくそう起こるエラーではないですが、同じ状況になった方の手助けになれば幸いです!
参考
トランザクションを強制的に終了させる
rakeタスクでDBのレコードが更新出来なかった時の解決法最後まで読んでいただきありがとうございます!
何かご指摘などございましたら、コメントいただけると嬉しいです!
- 投稿日:2020-11-28T23:37:00+09:00
Railsで、現在時刻・日時を表示させる方法
はじめに
Rubyでは標準ライブラリなど、様々なものがあるが、その中で、日付についてのものがあり、現在制作中のアプリに日付を表示させようと思い、ここにいたる。
Rubyでは…
require 'date'を記述することで、そのライブラリを使用できる。
Railsでは…
調べが足りないので、定かではないが、デフォルトで使用できるみたい。私は、上記の記述を書いた覚えがないが、日時を表示できた。
現在の時刻
Time.now #=>2020-11-28 23:33:32 +0900今日の日付
Date.today #=>2020-11-28最後に
どこの記述されているのか、わからないが使える機能がたくさん出てきた。Railsは便利だが、ブラックボックスな部分が私にはまだまだあり、難しい。開いたことのないファイルがたくさんある…
表示方法を変えたいなぁ…ja.ymlあたりをいじればいいのかなぁ…
- 投稿日:2020-11-28T20:13:23+09:00
【Rails】form_withの使い分け
はじめに
はじめまして。元ものづくりエンジニアのまついです。独学でRailsを勉強している初学者です。
私と同じようなRails初学者の方でもわかりやすいように、そして私自身の備忘録として記事をアウトプットしていきたいと思います。もくじ
- form_withとは? form_tag, form_forとの違いは?
- form_withの使い方
- URL指定の場合
- モデル指定の場合
- まとめ
1. form_withとは? form_tag, form_forとの違いは?
まずform_with、form_tag、form_forヘルパーとはRailsで使用されるフォームを生成するヘルパーのことです。ヘルパーとはRails内であらかじめ用意されたメソッドのことです。特にform_withはRailsアプリのviewを作成するときに必ずと言っていいほどでてきます。
ではこれら3つのヘルパーの違いは?というと、
- form_tagはモデルと関係しないフォームの生成。
- form_forはモデルのオブジェクトなどに送信したりするフォームの生成。
- form_withは上記2つの機能を統合したもの。
となります。form_tag、form_forはRails5.1以降非推奨となっており、form_withが推奨となっています。
なのでここではform_withについて書いていこうと思います。2. form_withの使い方
form_withの使い方は
<%= form_with(モデル or スコープ or URL [, オプション]) do |f| %> <%= f.label :name, '名前' %> <%= f.text_field :name %> <%= f.submit "送信" %> <% end %>となります。
3. URL指定の場合
URLを指定したい場合は、pathを指定してあげます。
<%= form_with url: users_path do |form| %> <%= form.label :email %> <%= form.text_field :email %> <%= form.submit %> <% end %>デフォルトではPOSTメソッドで入力された値が送られます。GETメソッドを使用したい場合はオプションでmethod:を:getに指定すればできます。特に検索フォームを生成する場合にGETメソッドを使用します。
4. モデル指定の場合
モデルを指定したい場合は
<%= form_with model: @user do |form| %> <%= form.label :email %> <%= form.text_field :email %> <%= form.submit %> <% end %>のように受け渡したいインスタンスを指定します。
例えば、newアクションでsubmit(登録のボタンをクリック)されるとcreateアクションが呼び出されます。editアクションでsubmitされるとupdateアクションが呼び出されます。5. まとめ
form_withの代表的な使い方についてまとめました。
- form_withはフォーム要素を生成するヘルパー。
- URLを指定したい場合はpathを指定することで、デフォルトではPOSTメソッドが実行される。
- モデルを指定したい場合はコントローラーで生成したインスタンスを指定する。
以上になります。お役に立てれば幸いです。
- 投稿日:2020-11-28T20:05:34+09:00
[rails]突然自動デプロイが反映されなくなった
何が起きたのか
よくわかりませんが、調べたところEC2に問題があった
自動デプロイしてたら突然変更が反映されなくなった解決方法
よくわかりませんが突如起こった出来事ですので
とりあえずAWSのマネジメントコンソールにログインしてEC2インスタンスを再起動
再起動後は以下のコマンドでNginxとdbを起動。$ sudo service nginx start $ sudo systemctl restart mariadbその後 自動デプロイする 完 (勝手にunicornは起動されるであろう )
bundle exec cap production deploy補足
EC2に問題がある場合の確認すべきところ
基本的に以下のどれかがどうにかこうにかなっていることが多い説
( unicorn,db,nginx...)なのでエラーログみてもよくわからなかったらコマンドでいろいろ確認してみよう
データーベースの状態を確認 sudo systemctl status mariadbデーターベースの起動 sudo systemctl restart mariadbnginxの再起動 sudo systemctl restart nginxunicornの状態確認 ps aux | grep unicornunicornの起動 RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D
- 投稿日:2020-11-28T19:18:36+09:00
タグ振り分け機能の実装
はじめに
今回は、zipang(漢字、ひらがな、カタカナをローマ字に変換するもの)というgemを用いてタグを頭文字ごとに0~9、A~Zに振り分けて索引のようなものになるよう実装いたしました。その際、予め ancestry を用いて親カテゴリーとして0~9、A~Zをデータに保存するseedを作成しております。
機能の実行順序
大まかな流れといたしましては、
① タグを入力する
② 入力されたタグをzipangでローマ字に変換
③ 変換した文字の頭文字を取得し、その頭文字を親としてタグをその子要素に保存する。(タグのテーブルにはancestryを用いているので、知らない方は検索してみてください)
②③の流れをメソッドでまとめると以下の通りになります。(このメソッドはbefore_saveにて実行しております。)
def find_or_create_tag self.tags = self.tags.map do |tag| word = Zipang.to_slug tag[:name] parent = Tag.find_by( ancestry: nil, name: word[0].upcase ) parent.children.find_or_create_by(name: tag.name) end end④ 表示する際は、頭文字の子要素として出力する。
以上のことを応用すると、あいうえお順に振り分けることもできるかと思います。

- 投稿日:2020-11-28T19:17:19+09:00
ECSコンテナに接続する方法
意外と忘れるコンテナ接続
本番環境のコンテナに入ってDB操作したりデバッグしたり...
久しぶりにやろうとしたらど忘れしていたのでこの記事を書くに至りました。
接続までの手順
- セキュリティーグループのインバウンドルール変更
- EC2インスタンスのPublic IP / Public DNSを確認
ssh -i /path/to/my-key-pair.pem ec2-user@ec2-198-51-100-1.compute-1.amazonaws.comコマンドでECSコンテナにssh接続それでは始めます
インバウンドルールの変更
EC2>セキュリティーグループ>該当のセキュリティーグループ>インバウンドルールを編集
sshタイプのソースを「 マイIP 」に変更するこの変更をしていないと後でssh接続したとき以下のエラーが出るため必要な手順です
ssh: connect to host [自分のPublic IP] port 22: Connection refusedPublic IP / Public DNSを確認
Elastic Container Service>クラスター>ECSインスタンス
コンテナインスタンス> 該当のインスタンスを選択
詳細> 「 Public DNS 」をコピーするECSコンテナにssh接続
以下のコマンドを使用します
$ ssh -i /path/to/my-key-pair.pem ec2-user@ec2-198-51-100-1.compute-1.amazonaws.comキーペアはパスを指定する必要があります。
例えば私は~/.ssh下に配置しているので下記のように指定します$ ssh -i ~/.ssh/my-key-pair.pem次に前の手順でコピーしていたPublic DNSをその後に書いてあげましょう
接続するとき
以下のような表示が出ますが落ち着いて読みましょう
Are you sure you want to continue connecting (yes/no/[fingerprint])?「 yes 」で大丈夫です。
その後はこのような表示が出ましたでしょうか。
__| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/お疲れさまでした
ここまで読んでいただきありがとうございました。
簡単な手順ではありますが、久しぶりにやると忘れているものです。
参考
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/instance-connect.html
- 投稿日:2020-11-28T17:12:04+09:00
SIerエンジニアからWeb系フロントエンドエンジニアに転身するために今やっていること
こんにちは!SIerでJavaプログラマをしているゆうきデザイン(@yuki_design_gr)と言います。
Qiita初投稿として、自己紹介も兼ねて
"SIerエンジニアからWeb系フロントエンドエンジニアに転身するために今やっていること"
というテーマで書いてみようと思います。同じような境遇にいる人の道しるべの1つになりますように!
目次
1. 自己紹介
2. なぜWeb系を目指すのか
3. SIerエンジニアからWeb系フロントエンドエンジニアに転身するために今やっていること1. 自己紹介
東京在住の20代半ば。
学歴
東京外大韓国語専攻卒業
職歴
新卒で大手SIerに入社し、アカウント営業を担当(10ヶ月)
→SE(現職。Java・.NET・Oracleのコーディング実務1年半)
→Web系企業への転職準備中モットー
技術とデザインのことをポジティブに共有すること
目標
・世の中をポジティブにするWebサービスを作ること
・ビジネスを始めたい・サービスを作りたい友だちをIT・デザイン面でサポートすること趣味など
韓国語と英語は日常会話レベル
持久系のスポーツが好き(陸上・水泳。社会人になってからもたまにやってる)
実写の動画編集
映画・音楽・コーヒー
ミスチルが生まれた時から好きで、人生ピンチの時に助けてくれる存在(←いま)さあ、本題に入ります!
2. なぜWeb系を目指すのか
①新しいものを追いかけるのが好きだから
音楽や映画などのエンタメや好きで、
SI業界よりもトレンドの移り変わりが激しいWeb業界が楽しそうに見えるため。②Webサービスを作りたいという目標があるから
自己紹介でも書いたように
世の中をポジティブにするWebサービスを作る
という目標があり、
SI業界に身を置くよりも目標実現への近道だと思っています。③システムの裏側の処理よりも見た目に魅かれるから
Javaエンジニアをしていてプログラミングは基本的に全般楽しいですが、
JSPやCSS等のシステムの見た目の開発が楽しく、
また他のメンバーが気にかけないレイアウトのズレなどに何度も気づくことができました。そのため、まずはWebデザイナーやUI・UXデザイナーに興味を持ち、
デザイナーのための勉強会などに参加してきました。しかし、自分のプログラマとしての経験を活かす×システムの見た目に寄与できる
というフロントエンドの技術が一番しっくりくるなあと今は思っています。3. SIerエンジニアからWeb系フロントエンドエンジニアに転身するために今やっていること
①フロントエンド技術に触れること
結局はどの言語がベスト!とかはなさそうなので
今は色々触ってみてます。フロント: react, vue, rails
バックエンドやインフラ等: node, ruby, docker, laravel
その他: TypeScript, Sass, Bootstrap色々触れる今の時期が一番楽しいですね。
何かを極めた方が勉強になる気もしますが。個人的にはnode + react(またはvue・angular) + TypeScriptがアツい気がします!
全部jsで書けるなんて!②フロントエンド技術を用いたWebアプリを作ってみること
上記のそれぞれの言語を使って
簡単なSNSやTodoリストをチュートリアルを見ながら作成中です。
ネット上に公開するところまでやりたいです。③SNSやGitHub、Qiita等でのアウトプット
個人的に苦手であまりできていないアウトプット。
でも見てる人との交流が生まれたり、自分の特性や技術力を客観視できる機会と思って、
定期的に取り組んでいきたいです。
この投稿の内容は以上です。
ここまで読んでいただきありがとうございます。
これからも有益な情報をポジティブに発信していきたいです。ぜひ、Twitter(@yuki_design_gr)のフォローもよろしくお願いします。
- 投稿日:2020-11-28T16:58:03+09:00
【CircleCI】Rails × PostgreSQL環境作ってHerokuにデプロイする最低限のCIとその解説
最近、CIの勉強をするにあたって「CircleCI実践入門──CI/CDがもたらす開発速度と品質の両立」という本を読んでCIの勉強をし直しました。
その整理でRailsでテストやデプロイをするCIを作りました。
その中で学んだ知識とか書いていきます。環境
- Ruby On Rails6系
- Ruby 2.6.5
- PostgreSQL 11.5
- Bundler 1.17.3
- CircleCI 2.1
準備
- https://circleci.com/ から CircleCIに登録
- .circleciディレクトリ配下にconfig.ymlを置く
$ mkdir .circleci $ touch .circleci/config.yml3.config/database.ymlに環境変数を使う設定を書く
test: <<: *default database: <%= ENV['DATABASE_NAME'] || 'test_app_db' %> host: <%= ENV['DATABASE_HOST'] || 'localhost' %> port: <%= ENV['DATABASE_PORT'] || 5432 %> username: <%= ENV['DATABASE_USER'] || '' %> password: <%= ENV['DATABASE_PASSWORD'] || '' %>用語の説明
ここからCIの説明を書いていきます。
ステップ
- ジョブの設定の最小単位
- CircleCIで実行されるコマンドのリストをステップと呼ぶ
- 大別するとRunステップとビルトインステップの2種類に分別できる
- runステップ:CircleCI上で実行したいシェルコマンドはユーザー自身がrunステップとして定義する
- ビルトインステップ:リポジトリからのソースコードのチェックアウトやキャッシュなど、CircleCIが用意した特殊なステップをビルトインステップと呼ぶ
▼たとえば▼
steps: # ビルトインステップ - checkout # checkoutする。working_directoryにGitリポジトリをコピーする # runステップ - run: # runしているコマンドの名前をつけられる name: pg gem の依存関係のインストール # 実際に動かすコマンド command: sudo apt-get update; sudo apt-get install libpq-devrun
- コマンドライン プログラムの呼び出しのために使用する
commandは必須▼たとえば▼
# ステップの1つ。ステップのうちのRunステップに該当する - run: # runの名前。なんでもいい。 name: pg gem の依存関係のインストール # 実行するコマンド command: sudo apt-get update; sudo apt-get install libpq-devジョブ
- ステップの1つ以上のまとまり
- 他のCI/CD ツールではビルドとも呼ばれる
- 実行を開始するたびに実行環境をゼロから構築する(終了すると破棄する)
▼たとえば▼
jobs: # jobの名前 build_and_test: # 動かすマシンを定義 docker: - image: cimg/ruby:2.6.5-node # ↓動かすStep steps: - checkout - run: name: pg gem の依存関係のインストール command: sudo apt-get update; sudo apt-get install libpq-devExecutor
- Executorではどのようなマシン環境でジョブ中のステップを実行するのかを定義する
▼docker executor▼
jobs: build_and_test: docker: - image: cimg/ruby:2.6.5-nodeワークフロー
- ワークフローはいくつかのジョブの塊とそれらのジョブの実行順序を定めたルール
▼たとえば▼
# ワークフロー # ジョブの実行順序を定める workflows: version: 2 # ワークフローの名前 main: # ↓Jobの実行順序を書いていく jobs: # Jobの名前。上で書いた名前を実行したい順番に書く - build_and_test # Jobの名前 - deploy-production: # ↓Jobを実行する条件も書ける requires: # build_and_testって「Jobが成功したら」実行する - build_and_test filters: # masterブランチでのみ実行する branches: only: masterworking_directory
ステップを実行するディレクトリを明示
▼たとえば▼
# ステップを実行するディレクトリ working_directory: ~/reposave_cache
- save_cacheはキャッシュを生成する
- pathとkeyが必要
▼たとえば▼
# キャッシュを生成する - save_cache: # キャッシュに追加するディレクトリのリスト paths: - ./vendor/bundle # キャッシュのキー。識別子 # checksumによって、Gemfile.lockのファイルの中身が変わると新しいキーになる key: rails-bundle-v1-{{ checksum "Gemfile.lock" }}restore_cache
- キーを元にキャッシュを復元する
- keysで書かれたキャッシュキーのうち最初にヒットしたキャシュを復元する
▼たとえば▼
# 以前に保存したキャッシュを key に基づいて復元する # 保存は save_cache によって行われる - restore_cache: # 復元するキャッシュを検索するためのキャッシュ キーのリスト # 最初に一致したキーのみが復元される keys: # checksumは、指定したファイルの中身の SHA256 ハッシュを Base64 エンコードした値が入る - rails-bundle-v1-{{ checksum "Gemfile.lock" }} - rails-bundle-v1-
他にも色々出来ることはありますが、最低限CIでテストしてデプロイするまでがここで出来ました。
最後にまとめて書いたCIのコードを記載します。書いたCI
# CircleCIの実行バージョン version: 2.1 # ジョブはステップの集まり jobs: # jobの名前 build_and_test: # Docker Executor(動かすマシンの設定) docker: # cimg/はCircleICがあらかじめ用意しているDockerイメージの新板 - image: cimg/ruby:2.6.5-node # circleci/はCircleICがあらかじめ用意しているDockerイメージの旧板 - image: circleci/postgres:11.5-alpine # 環境変数の設定 environment: RAILS_ENV: test BUNDLE_PATH: ./vendor/bundle DATABASE_NAME: connpass_tube_api_test DATABASE_USER: postgres DATABASE_PASSWORD: "" DATABASE_HOST: 127.0.0.1 DATABASE_PORT: 5432 TZ: Asia/Tokyo # ステップを実行するディレクトリ working_directory: ~/repo # ジョブの設定の最小単位 # CircleCIで実行されるコマンドのリスト steps: # checkoutする。working_directoryにGitリポジトリをコピーする - checkout # 以前に保存したキャッシュを key に基づいて復元する # 保存は save_cache によって行われる - restore_cache: # 復元するキャッシュを検索するためのキャッシュ キーのリスト # 最初に一致したキーのみが復元される keys: # checksumは、指定したファイルの中身の SHA256 ハッシュを Base64 エンコードした値が入る - rails-bundle-v1-{{ checksum "Gemfile.lock" }} - rails-bundle-v1- # ステップの1つ。ステップのうちのRunステップに該当する - run: # ステップの名前。なんでもいい。 name: pg gem の依存関係のインストール # ステップで実行するコマンド command: sudo apt-get update; sudo apt-get install libpq-dev - run: name: Bundler のインストール # gemfile.lockの一番下くらいに書かれているbundlerのバージョンを書く command: gem install bundler -v 1.17.3 - run: name: gem の依存関係のインストール command: bundle check || bundle install # キャッシュを生成する - save_cache: # キャッシュに追加するディレクトリのリスト paths: - ./vendor/bundle # キャッシュのキー。識別子。 key: rails-bundle-v1-{{ checksum "Gemfile.lock" }} # キャッシュを復元 - restore_cache: keys: - rails-yarn-v1-{{ checksum "yarn.lock" }} - rails-yarn-v1- - run: name: node_modules の依存関係のインストール command: yarn install - save_cache: paths: - ~/.cache/yarn key: rails-yarn-v1-{{ checksum "yarn.lock" }} - run: name: データベースの起動を待機 command: dockerize -wait tcp://localhost:5432 -timeout 1m - run: name: データベースのセットアップ command: bundle exec rails db:create db:schema:load --trace # RSpecでテスト - run: name: run tests command: | bundle exec rspec --format documentation --backtrace # 2つめのJob deploy-production: # Docker Executor(動かすマシンの設定) docker: - image: cimg/ruby:2.6.5-node environment: RAILS_ENV: production working_directory: ~/repo steps: - checkout - run: name: Deploy to Heroku Production # HEROKU_API_KEYとHEROKU_APP_NAMEはCiecleCI上で設定している環境変数 # HerokuでAPI_KEYやアプリケーションの名前を調べてCiecleCIに設定してあげてください command: | git push https://heroku:$HEROKU_API_KEY@git.heroku.com/$HEROKU_APP_NAME.git master # ワークフロー # ジョブの実行順序を定める workflows: # ここのバージョンは2である必要がある version: 2 # ワークフローの名前 main: # Jobの実行順序を書いていく jobs: # Jobの名前。上で書いた名前を実行したい順番に書く(が、requiresなどの設定をしないと同時にJobは実行される) - build_and_test - deploy-production: # build_and_testのJobが成功したらdeploy-productのJobを実行する制御 requires: - build_and_test # Jobを実行したいブランチやコミットタグを書く filters: # BranchがMasterのときだけ動かしたい branches: only: master「CircleCI を設定する」このCircleCIのドキュメントもとってもわかりやすいです。
- 投稿日:2020-11-28T16:08:06+09:00
Railsの機能をcronから実行する
この記事は、Railsの機能をcronから実行する方法について解説しています。
Railsの機能をcronから実行する方法はいくつかありますが、単純に実装してしまうと、サーバーのリソースを無駄に消費し、実行完了までとても時間のかかるものになってしまいます。
ある程度アクセスのあるサービスを運営している場合は、上記のリソースの無駄使いを防ぐために、Railsの機能をcronから実行するときに少し工夫が必要になります。
最終的な完成形は、「バックグラウンドジョブとして実装し、起動しているRailsサーバーからジョブをキューイングする」というものになります。順を追って解説していきます。
既存の方法の何が問題なのか
既存のよくある方法は、cronからRailsサーバーを起動するものがほとんどです。この方法だと、Railsサーバーの起動に10秒ほど時間がかかります。時間だけでなく、100MBほどのメモリが消費されます。規模が大きい場合はもっとたくさんの時間とメモリが必要になります。
cronから毎分実行する場合は、このリソースの無駄使いを避けたいところです。cronから呼び出したい機能をバックグラウンドジョブとして実装し、ジョブのキューイングをRailsサーバーから行うことで、このリソースの無駄使いを避けることができます。
バックグラウンドジョブとして実装する
まずは、cronから呼び出したいRailsの機能をバックグラウンドジョブとして実装します。ジョブキューシステムにはSidekiqを利用している想定です。
このジョブは、
UpdateSomethingWorker.perform_async(user_id)というコードで実行することができます。app/workers/update_something_worker.rbclass UpdateSomethingWorker include Sidekiq::Worker sidekiq_options queue: 'misc', retry: 0, backtrace: false def perform(user_id, options = {}) user = User.find(user_id) # 数秒よりも長い時間がかかると想定 user.update_something end end実装したジョブの動作テスト用として、Rakeタスクもついでに用意します。ここは必須ではありません。
このRakeタスクは、
rails users:update_somethingというコードで実行することができます。lib/tasks/users.rakenamespace :users do desc 'Update something' task update_something: :environment do user_id = ENV['USER_ID'] UpdateSomethingWorker.perform_async(user_id) end end起動しているRailsサーバーからジョブをキューイングする
Railsでアプリケーションを実装している場合、ほとんどの場合はWebサーバーが起動している思います。このWebサーバーに、ジョブをキューイングするためのエンドポイントを用意します。
必ず、リクエストの正当性チェックをする必要があります。そうしないと、第三者に意図しないタイミングでジョブをキューイングされてしまう脆弱性が残ってしまいます。
app/controllers/users_controller.rbclass UsersController < ApplicationController before_action do # !!! リクエストの正当性を必ずチェックすること !!! end def update_something user_id = params[:user_id] UpdateSomethingWorker.perform_async(user_id) render json: {status: 'ok'} end endこのルーティングを追加することで、コントローラーで実装したコードが有効になります。
ビューの中では、
users_update_something_pathというコードでこのルーティングに対応するパスを取得できます。config/routes.rbpost 'users/update_something', to: 'users#update_something'ここがポイントです。実装したコントローラーにアクセスするためのRubyコードを書きます。RailsではなくRuby単体で動くようにしている点が重要です。こうすることで、cronからRailsの機能を実行するときの不要なオーバーヘッドを減らすことができます。
このRubyスクリプトは、
ruby bin/users_update_something.rbというコードで実行することができます。bin/users_update_something.rb#!/usr/bin/env ruby require 'net/http' require 'uri' if __FILE__ == $0 # users_update_something_url url = 'https://yourweb.com/users/update_something' puts Net::HTTP.post_form(URI.parse(url), {}).body endさらに、現実的にはcronから実行したときのログも記録したくなると思います。そのためのシェルスクリプトを用意します。
このシェルスクリプトは、
sh bin/cron_ruby.sh [実行したいRubyファイル]というコードで実行することができます。bin/cron_ruby.sh#!/usr/bin/env bash exec >>/var/yourapp/log/cron.log 2>&1 cmd="/usr/local/bin/ruby $1" SECONDS=0 echo -e "$(date) $cmd started" cd /var/yourapp && $cmd echo -e "$(date) $cmd finished elapsed=${SECONDS}"crontabを更新する
後は、上記のシェルスクリプトをcronから実行するようにすればOKです。こうすることで、Rais起動時のオーバーヘッドを避けつつ、cronからRailsの機能を呼び出すことができます。
crontab* * * * * /bin/sh -c "/var/yourapp/bin/cron_ruby.sh /var/yourapp/bin/users_update_something.rb"Railsの機能をcronから実行する他の方法
毎分ではなくもっと長いスパンでの実行であったり、サーバーのスペックに余裕があるのなら、今回のような複雑な仕組みは不要かもしれません。そういう場合は、下記の方法を使うことができます。
両方とも、crontabに直接書くことでcronから実行できます。
# Rubyのコードをコマンドラインから実行する方法 rails runner "実行したいRubyコード" # Rakeタスクをコマンドラインから実行する方法 rails "実行したいRakeタスク"質問の連絡先
質問や分からない点はお気軽に @ts_3156 までご連絡ください。
- 投稿日:2020-11-28T15:49:45+09:00
Rails ページネーション
はじめに
今回はrailsでのページネーションを実装していきます。
kaminariというページネーション用のgemを使って実装していきます。
簡単に実装できるので一緒にやっていきましょう!kaminariのインストール
Gemfileに
gem 'kaminari'を追加し、$ bundle installでインストールします。# 最後の行に追加 gem 'kaminari'
$ bundle installこれでkaminariをインストールすることができました。
ページネーションを表示させる
controllerで、ページネーションを表示させたいデータに
.page(params[:page])を追加します。app/controllers/notes_controller.rbdef index @q = Note.all.ransack(params[:q]) # ページネーションをつけたいデータに.page(params[:page])を追加 @notes = @q.result(distinct: true).page(params[:page]) end次に、viewでページネーションを表示させたいところに
<%= paginate @notes %>を追加します。app/views/notes/index.html.erb<%= render 'shared/flash_messages' %> <div class='container'> <div class='row'> <div class= serch.id> <%= search_form_for @q, class:'form-inline' ,url: notes_path do |f| %> <%= f.search_field :title_cont, class: 'form-control input-lg', placeholder: "IT用語やカテゴリー名を入力" ,data: {"turbolinks" => false}%> <%= f.submit "検索", class: "btn btn-success btn-lg" %> <% end %> </div> <h1>メモ一覧</h1> <div class='col-md-3 col-xs-12'> <%= render 'categories/serch', categorys: @categorys %> </div> <div class='col-md-9 col-xs-12'> <h2><%= @title %>一覧</h2> <p>(全<%= @notes.count %>件)</p> <%= render 'notes/notes_index', notes: @notes %> </div> <div class='child-center'> <%= paginate @notes %> #追加 </div> </div> </div>これでページネーションが実装できました!
ページネーションが1ページに表示するレコード数はデフォルトで25件です。ページネーションを表示させるために、レコード数が26件以上になるようデータを作りましょう。
レコード数が26件以上あれば、ページネーションが表示されます。
ページに表示するレコード数の変更
1ページに表示するレコード数はデフォルトで25件です。このレコード数を変更したい場合は、controllerで
.per(表示したいレコード数)を追加します。例えば、.per(10)を追加すると1ページに10件のみレコードを表示します。
app/controllers/notes_controller.rbdef index @q = Note.all.ransack(params[:q]) # .page(params[:page])の後に.per(10)を追加 @notes = @q.result(distinct: true).page(params[:page]).per(10) endこれで1ページに表示するレコード数を10件にすることができます。
ページネーションのデザイン変更
ページネーションが実装できたら、デザインを変更して見た目を分かりやすくしましょう。
1.bootstrapで見た目を整える
kaminariにbootstrapを適用させて、整ったページネーションにします。
まずはじめにbootstrapを読み込みます。
app/views/layouts/application.html.erbに以下のコードを追加して、アプリ全体にbootstrapを適用します。app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title>ItT</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <!-- bootstrap --> <!-- コード追加 Bootstrap CSS読み込みコード--> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css" integrity="sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u" crossorigin="anonymous"> <!-- Optional theme --> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap-theme.min.css" integrity="sha384-rHyoN1iRsVXV4nD0JutlnGaslCJuC7uwjduW9SVrLvRYooPp2bWYgmgJQIXwl/Sp" crossorigin="anonymous"> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> </html>これでアプリにbootstrapが適用されます。
次に、kaminariにbootstrapを適用させます。
以下のコマンドを実行しましょう。$ rails g kaminari:views bootstrap3このコマンドにより
app/viewsにkaminariフォルダが自動生成され、ページネーションにbootstrapデザインが適用されます。2.ラベルを日本語に変更する
ラベルはi18nに対応しています。
config/application.rbのmoduleにconfig.i18n.default_locale = :jaを追加し、デフォルト言語を日本語に設定しましょう。config/application.rb#最後 module Testapp(自分のアプリ名) class Application < Rails::Application # Settings in config/environments/* take precedence over those specified here. # Application configuration should go into files in config/initializers # -- all .rb files in that directory are automatically loaded. config.i18n.default_locale = :ja #追加 end endサーバを再起動して設定を反映させます。
ラベルの変更
config/localesに日本語変換用のymlファイルja.ymlを作成し、以下のコードを追加します。config/locales/ja.ymja: views: pagination: first: "« 最初" last: "最後 »" previous: "‹ 前" next: "次 ›" truncate: "..."これでページネーションのラベルを日本語に変更できました!
最後に
これで最低限度の実装ができました。
あとはお好みで見た目を整えてみてください。
間違っているところがあればご指摘いただければ幸いです。
最後までありがとうございました。

- 投稿日:2020-11-28T14:23:52+09:00
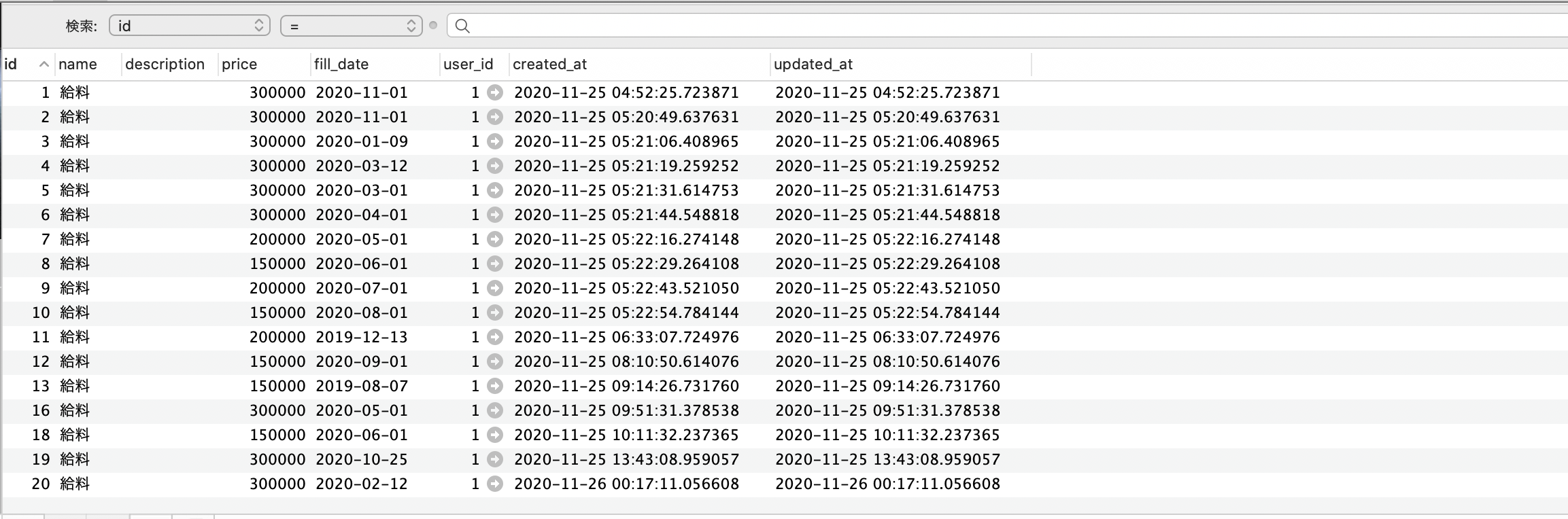
ActiveRecordでデータを月毎に集計
[ActiveRecord]でデータを月毎に集計する方法
今回は入力した数値を月毎に集計して合計値を出力させる方法を投稿します。
ネットで検索しても、なかなか良い方法がなかったので、参考になればと思います。使用テーブル(incomesテーブル)↓↓↓
このテーブルから2019年-月分・・・2020年-月分としたいと思います。
実行コード↓↓↓Income.group("YEAR(fill_date)").group("MONTH(fill_date)").sum(:price)YEAR(fill_date)で年毎にグルーピングして、さらにMONTH(fill_date)で月毎にグルーピングした後、sum(:カラム名)でpriceを合計しています。
このときのターミナルのログ↓↓↓
結果、年と月を区別して合計値を出力させることができました。今回の記事が誰かの役に立てればと思います。またもっと良い方法があればコメントしてもらえると助かります!!

- 投稿日:2020-11-28T13:15:04+09:00
【Rails】parent_idとchild_idを持つ中間テーブルを作って親子関係を実装する
はじめに
階層構造を持つモデルを実装することがあったのでその時のメモ書きです。
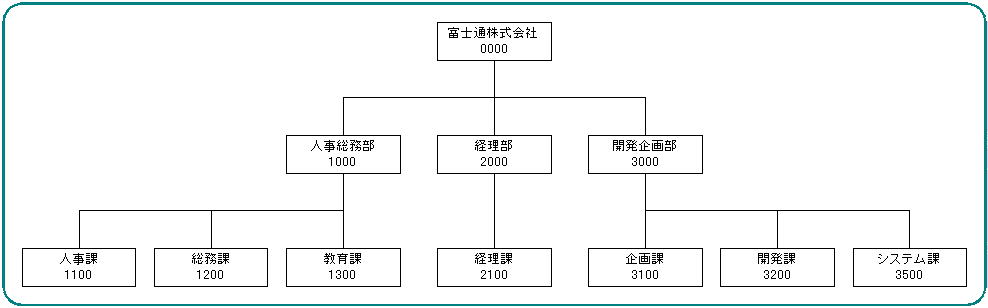
例として部署を考えます、以下の画像のようなイメージですね。
( ※ 適当に拾ってきました。)
テーブルは departments と department_pathsの二つを用意します。
departments id integer name string
department_paths id integer parent_id string child_id string association の実装
まず assciation の実装です。
- department.parent で自分の親部署を取得
- department.children で自分の子部署を取得
ができることを目指します。
まずは DepartmentPath の parent_id から親部署を, child_id から子部署を取得できるように association を実装していきます。
app/models/department_path.rbbelongs_to :parent, class_name: 'Department' belongs_to :child, class_name: 'Department'次に Dpartment です。
DepartmentPath を throughして親部署・子部署を取得できるように association を実装します。
ちなみに子部署は複数持ち得るので has_many ですね。app/models/department.rb# 親との association has_one :parent_path, class_name: 'DepartmentPath', foreign_key: :child_id, has_one :parent, class_name: 'Department',through: :parent_path, source: :parent # 子との association has_many :child_paths, class_name: 'DepartmentPath', foreign_key: :parent_id, dependent: :destroy has_many :children, class_name: 'Department', through: :child_paths, source: :child以上で association は実装完了です!
先祖や子孫を階層構造で取得する
association は 実装できましたが、これだけだと自身の直近の親と子しか取得できないの自分の子孫の末端までを取得したり、親を遡って部署の頂点から自身までを取得することはできませんね。
ここでは以下の二つができることを目指します。
- 部署の頂点から順に自身までの name を配列で取得
- 自身から子孫までの末端を Hash で取得
前者は画像中の「経理課」でいうと以下のような感じですね。
( ※ 説明しやすいように「富士通株式会社」も部署の一つとさせてください。)['富士通株式会社', '経理部', '経理課']後者は画像の中の「富士通株式会社」でいうと以下のような感じですね。
{ '富士通株式会社' => [ '人事総務部' => [ '人事課', '総務課', '教育課' ], '経理部' => [ '経理課' ], '開発企画部' => [ '企画課', '開発課', 'システム課' ], ] }まずは部署の頂点から順に自身までの name を配列で取得できるように実装していきます
再帰関数を使えば簡単ですね。app/models/department.rbdef ancestors(array = [self]) if parent.present? # 親が存在すれば instanceを配列の先頭に挿入 array.unshift(parent) parent.ancestors(array) else # 親が存在しなければ配列の instance をそれぞれ name に変換して返す array.map do |department| department.name end end end次にできるように実装していきます。
これも再帰関数を使えば簡単ですね。app/models/department.rb# まず子孫の Hash を取得するメソッドを定義し、 # そのメソッドを使って { 自身 => 子孫のHash } を返せるように実装します def get_nested_children_hash return if children.blank? children.map do |child| child.children.present? ? { child.name => child.get_nested_children_hash } : child.name end end def descendants children.present? ? { name => get_nested_children_hash) } : name endまとめ
以上の実装で以下のように部署構造が取得できるようになりました。
department.parent #親 department.children #子 department.ancestors # 先祖 department.descendants # 子孫
- 投稿日:2020-11-28T11:54:49+09:00
【Rails】mark_for_destruction を 使って特定の条件のレコードを削除する。
使用ケース
「特定のカラムが空である場合にはそのレコードを削除したい」みたいなときに便利です。
そのレコードに削除マークをつけておくと削除されるイメージで実装できます。サンプルコード
前提として users は name カラムを持つとします。
name の値が nil か 空文字であればそのレコードを削除したいみたいな時は、以下のように実装できると思います。
今回はインスタンスメソッドを定義し、before_validationのコールバックで実行しました。
app/models/user.rbbefore_validation :delete_user_if_name_blank def delete_user_if_name_blank self.mark_for_destruction if name.blank? endif 文を使えば色んな条件で適用できますし、アソシエーションしているレコードも削除できたりするので色々と応用が効きそうですね。
- 投稿日:2020-11-28T05:23:15+09:00
新規投稿機能を作成した際にNoMethodError【Ruby on Rails】
Railsで一般的な新規投稿機能を作成した際にNoMethodErrorが発生した。
原因
一口にノーメソッドエラーと言っても原因は色々考えられる。
私の場合は、UserモデルとPostモデルの間で1対多の関連付けをしていたのだが、app/model/User.rbに
has many :posts
を記述していない事が原因だった。
教訓
判明してみると、なんでこんなミスをしたのだろうと思ってしまうような凡ミスではあるが、
ノーメソッドエラー
→メソッドが定義されていない
→メソッドを一生懸命確認するという安易な発想で、原因にたどり着くまでに30分くらい費やしてしまった。
エラー画面の情報はあてにならない(この言い方は大いに語弊があるかもしれないが)場合が多々あるため、周辺情報も含めて行うべき設定は正しく行っているか確認するように心がけたい。
- 投稿日:2020-11-28T04:11:24+09:00
rails db:migrateでalready existsというエラーの対処方法
rails g modelでモデルを作った後、rails db:migrateしたらエラーが出たのでその時の対処法をメモしておきます。
エラー内容
-------------------------------------------------------------------------- rails aborted! StandardError: An error has occurred, all later migrations canceled: Mysql2::Error: Table 'notifications' already exists: CREATE TABLE `notifications` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `visiter_id` int NOT NULL, `visited_id` int NOT NULL, `post_id` int, `comment_id` int, `action` varchar(255) DEFAULT '' NOT NULL, `checked` tinyint(1) DEFAULT FALSE NOT NULL, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL) --------------------------------------------------------------------------もうすでにこのファイルは存在していると言われているみたいです。
1回モデルを消したときにテーブルが残っていたのかも?対処方法
最初にモデルを削除します
$ rails destroy model Notification次にテーブル削除のために削除用のmigrationファイルを作成します(ファイル名はなんでも良いです)
$ docker-compose run web rails generate migration drop_table_notifications作成したmigrationファイルにテーブル削除を記述する
class DropTableNotifications < ActiveRecord::Migration[5.2] def change drop_table :notifications end end最後にマイグレーションを実行します
$ rails db:migrateこれでちゃんとテーブルも削除できて、無事モデル作成後、rails db:migrateも通りました!
参考にした記事
https://note.com/oreno/n/n45f8208ade29
とても分かりやすかったです!ありがとうございました!
- 投稿日:2020-11-28T00:51:57+09:00
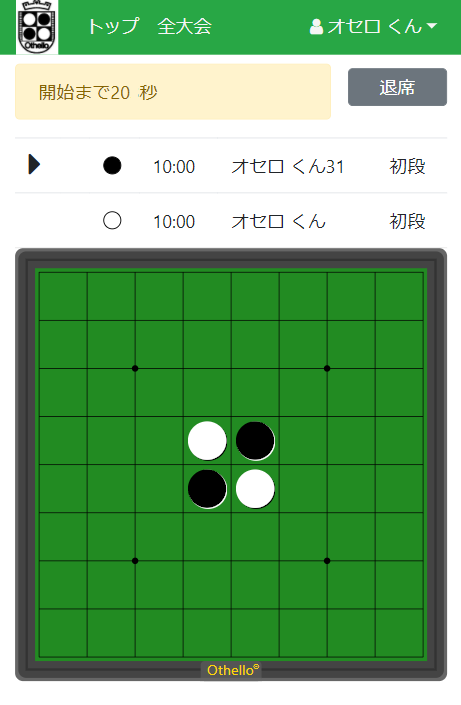
Websocket通信で作るリアルタイムオセロ対局 - GORO解体真書Chapter1
皆さんおひさし!!
エンジニアオセラーのはじぽんです!
さて、今年のアドベントカレンダー1番乗りをGETしちゃいましたので、
今年は割と技術的にも真面目にやっていこうかなって思います。と!いうのも!
今年はコロナでオセロ大会が開けないなんてことがあったので、なんとなんと!
日本オセロ連盟公式でオンライン対局できるものを作っちゃったのです!!はい、テンションも上げ上げなのはこれのおかげで技術ネタが豊富で記事がスラスラ書けちゃうからなのですわ。
というわけでこのシリーズを『GORO解体真書』と名付けて書いていこうと思います。第一弾 Websocket通信で作るリアルタイムオセロ対局
Websocketとは
サーバ、クライアント間を双方向通信するプロトコル。
httpと比較すると、リクエスト送ってレスポンス返ってくるという1セットに対して、1回コネクション繋いだら後はどっちからでも通信を自由に送り合うやつ。どう使うの?
オセロの盤面の通信に使っていきます。
F5に打つ → クライアントからサーバに着手座標の送信
盤面の更新 ← サーバからクライアントに最新盤面の送信
これは対局してる人にとっての流れだけど、観戦してる人には、盤面の更新だけ受信し続ければよい。でも(ハードルが)お高いんでしょ?
世の中のWebアプリなんて、めんどくさいことは全部フレームワークがやってくれるんですわ()
GOROはRuby on Railsで作成しているので、フレームワークに標準で入っているWebSocketライブラリのActionCableを使って簡単実装しちゃうよ!!
※Ruby on RailsとかActionCableの基本編みたいなことはやらないよ!着手送信
まぁ座標を送るだけです。クライアントでは一切判定処理とか入れずに全部サーバでやらせちゃいます。
盤面の絵をhtmlのSVGタグだけで簡単にお絵描きして、(Viewテンプレートにslimを使って動的に書いてますが、これがHTMLになる)
show.html.slimsvg width="#{outer_board}px" height="#{outer_board}px" viewBox="0 0 #{outer_board} #{outer_board}" class="board img-fluid" defs filter id="white_shadow" feDropShadow dx="1" dy="1" stdDeviation="0" flood-color="white" filter id="black_shadow" feDropShadow dx="1" dy="1" stdDeviation="0" flood-color="black" rect x="0" y="0" width="#{outer_board}" height="#{outer_board}" fill="#666" rx=10 ry=10 rect x="4" y="4" width="#{outer_board - 8}" height="#{outer_board - 8}" fill="#444" rx=10 ry=10 rect x="13" y="13" width="#{outer_board - 26}" height="#{outer_board - 26}" fill="#333" rect x="16" y="16" width="#{outer_board - 32}" height="#{outer_board - 32}" fill="#444" rect x="#{outer}" y="#{outer}" width="#{inner_board}" height="#{inner_board}" fill="forestgreen" rect x="#{outer_board / 2 - cell / 2 - 8}" y="#{outer_board - 25}" width="#{cell + 16}" height="25" fill="#555" rx=5 ry=5 rect x="#{outer_board / 2 - cell / 2 - 8}" y="#{outer_board - 4}" width="#{cell + 16}" height="4" fill="#666" text x="#{outer_board / 2 - cell / 2}" y="#{outer_board - 8}" font-size="18" stroke="none" fill="gold" Othello text x="#{outer_board / 2 - cell / 2 + cell - 4}" y="#{outer_board - 14}" font-size="11" stroke="none" fill="gold" R circle cx="#{point(2)}" cy="#{point(2)}" r="#{4}" fill="#000" circle cx="#{point(2)}" cy="#{point(6)}" r="#{4}" fill="#000" circle cx="#{point(6)}" cy="#{point(2)}" r="#{4}" fill="#000" circle cx="#{point(6)}" cy="#{point(6)}" r="#{4}" fill="#000" - (0..8).each do |i| line x1="#{point(i)}" y1="#{from}" x2="#{point(i)}" y2="#{to}" fill="none" stroke="#000" stroke-linejoin="round" stroke-width="1" line x1="#{from}" y1="#{point(i)}" x2="#{to}" y2="#{point(i)}" fill="none" stroke="#000" stroke-linejoin="round" stroke-width="1"
クリック(タップ)した場所をオセロの座標に変換して
app/assets/javascripts/board.jslet board = document.getElementsByClassName('board'); $(board).on('click', function (event) { let offset =$(this).offset(); let x = Math.floor((event.pageX - offset.left - border) / cell_px_absolute()); let y = Math.floor((event.pageY - offset.top - border) / cell_px_absolute()); let point = String.fromCharCode(x + 'A'.charCodeAt(0)) + String(y + 1); // マス以外も無理やり座標文字列できちゃうけどサーバ側ではじくようにしてる。 App.game.put_stone(point); });ActionCableの通信として送るだけ。
app/assets/javascripts/channels/game.js$(function() { // ActionCable送受信をしてくれるインスタンス生成 App.game = App.cable.subscriptions.create({channel: 'GameChannel', room: 'room'}, { connected: function() { }, disconnected: function() { }, received: function(data) { }, // 送信用メソッドは好きなようにいくつでも作れる。preformを呼び出すことで実際の送信。 put_stone: function(point) { return this.perform('put_stone', {point: point, game_table_id: 1}); } }); });着手受信
サーバ側で座標を受信して盤面判定処理とかかませる。
盤面ロジックはビットボードのアルゴリズムを採用してるけど、Ruby版の実装として別エントリーにしようかな。着手送信の受け取り口とリアルタイムに盤面見てる人に送信(ブロードキャスト)
app/channels/game_channel.rbclass GameChannel < ApplicationCable::Channel def subscribed stream_from params['room'] end def unsubscribed; end def put_stone(data) game = GameLoader.load(data['game_table_id']) # 着手処理&置けたかどうかの戻り値 return unless GameService.put_stone(current_user, game, data) # コネクション繋がってる人に対してブロードキャスト ActionCable.server.broadcast "game_channel_#{data['game_table_id']}", game: game.to_h end end盤面情報の中身
ビットボードで持ってる値をあんまり加工せずそのまんま渡してます。つまり黒と白でそれぞれ配置情報をビットで持つと。
しかしruby側は64ビットの変数に対応できるけどクライアント側のJavaScriptはそういうわけにもいかないので、
盤をパキッと割って32ビット変数2つな感じでやり取りしてるという歪さは残ってしまった…!
rubyで使うデータ(64bit)
{ black_stones: 0x0000000810000000, white_stones: 0x0000001008000000 }
javascriptで使うデータ(32bit)
{ black_stones: [0x00000008, 0x10000000], white_stones: [0x00000010, 0x08000000] }最新の盤面情報を受信
さっき送信の時に作ったActionCable専用クラスに受信時の処理を書く。
app/assets/javascripts/channels/game.js$(function() { App.game = App.cable.subscriptions.create({channel: 'GameChannel', room: 'room'}, { connected: function() { }, disconnected: function() { }, // このメソッドが受け取り口 received: function(data) { receive_game(data); }, put_stone: function(point) { return this.perform('put_stone', {point: point, game_table_id: 1}); } }); });受信した盤面情報で画面を書き換える
黒と白の配置のビットをそれぞれ描画していきます。32ビット二つなのでちょっとだけかっこ悪い
app/assets/javascripts/board.jsfunction receive_game(data) { black_stones = change_32bits(data['game']['black_stones']); white_stones = change_32bits(data['game']['white_stones']); update_board(); } function change_32bits(bit_stones) { let bit_32 = bit_stones.match(/.{8}/g); return [parseInt(bit_32[0], 16), parseInt(bit_32[1], 16)]; } function update_board() { clear_board(); let board = document.createDocumentFragment(); for (let i = 0; i < 32; i++) { let point_bit = (base_point_bit >>> i); if ((point_bit & black_stones[0]) !== 0) { board.appendChild(stone(i, color_num.black)); } if ((point_bit & black_stones[1]) !== 0) { board.appendChild(stone(i + 32, color_num.black)); } if ((point_bit & white_stones[0]) !== 0) { board.appendChild(stone(i, color_num.white)); } if ((point_bit & white_stones[1]) !== 0) { board.appendChild(stone(i + 32, color_num.white)); } } document.querySelector('#view_board > .board').appendChild(board); }基本はこんなもん
これでリアルタイム対局のコア部分は出来上がり。割とあっさりできちゃうもんだけど、素のWebSocketを触ってないから楽なだけっていうのもありそう。チャットとかなんて30分で作れちゃうからねぇ。
次回はビットボードをクローズアップしていきます!
ではまた!