- 投稿日:2020-11-28T23:57:29+09:00
【OpenCV】りんごを青りんごにしてみた
結果の画像は以下です。
(元画像(左)はPixabayのフリー画像を使用しました)
コードは以下です。
言語はPython、環境はGoogle Colaboratoryを使用しました。import cv2 import numpy as np from google.colab.patches import cv2_imshow img_path = "/path/to/image_file" img = cv2.imread(img_path) hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) hsv[:, :, 0] += 40 img_new = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) imgs = cv2.hconcat([img, img_new]) cv2_imshow(imgs)参考

- 投稿日:2020-11-28T23:57:29+09:00
【OpenCV】りんご?を青りんご?にしてみた
画像処理で遊んでみました☺️
結果の画像は以下です。
(元画像(左)はPixabayのフリー画像を使用しました)
コードは以下です。
言語はPython、環境はGoogle Colaboratoryを使用しました。import cv2 import numpy as np from google.colab.patches import cv2_imshow img_path = "/path/to/image_file" img = cv2.imread(img_path) hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) hsv[:, :, 0] += 40 img_new = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) imgs = cv2.hconcat([img, img_new]) cv2_imshow(imgs)参考
- 投稿日:2020-11-28T23:54:02+09:00
[Python]演算誤差 ARC109B
ARC109B
長さ n+1 の丸太を買って、短い方から丸太を作れるだけ作った後、残りの丸太を買うのが最適です。この「作れるだけ作った」ときにいくつの丸太が作れるかを求めるためには、$1 + \dots + k \leq n+1$ を満たす最大の整数 k を求めれば良いです。
私は、$1 + \dots + k = k(1+k)/2$ であることを使って、 $k(1+k)/2 \leq n+1$ を満たす最大の $k = \frac{-1+\sqrt{8n+9}}{2}$ を実装し提出しましたが、ルート演算誤差のために1ケースWAでした。本問の内容であれば、10進数の小数型Decimalを用いることで対応可能だと思われます。
サンプルコードfrom decimal import Decimal n = int(input()) k = int((-1 + Decimal(8*n+9)**Decimal(0.5))/2) print(n-k+1)誤差を確実に回避するために、二分探索をすることで求めることができます。
- 投稿日:2020-11-28T23:41:51+09:00
OpenChemでCan't pickleエラーが発生した時の対応メモ
はじめに
OpenChemで掲題のエラーが発生した時の対応メモ
環境
- PyTorch 1.7(GPU)
エラー内容
PyTorchのGCNNのチュートリアルであるlogP_gcnn_config.pyを実行すると以下のエラーが。
$ python launch.py --nproc_per_node=1 run.py --config_file="./example_configs/logP_gcnn _config.py" --mode="train_eval" --batch_size=256 --num_epochs=100 11339 unsanitized smiles (10.8%) warnings.warn('{:d}/{:d} unsanitized smiles ({:.1f}%)'.format(num_bad, len(smiles), 10 0 * invalid_rate)) C:\kimisyo\work\SoftwareDevelop\OpenChem\openchem\data\utils.py:187: UserWarning: 300/2 835 unsanitized smiles (10.6%) warnings.warn('{:d}/{:d} unsanitized smiles ({:.1f}%)'.format(num_bad, len(smiles), 10 0 * invalid_rate)) 2020-11-28 14:29:53,054 openchem INFO: Running on 1 GPUs 2020-11-28 14:29:53,055 openchem INFO: Logging directory is set to logs/logp_gcnn_logs 2020-11-28 14:29:53,055 openchem INFO: Running with config: batch_size: 256 encoder_params/encoder_dim: 128 encoder_params/input_size: 33 encoder_params/n_layers: 3 logdir: logs/logp_gcnn_logs lr_scheduler_params/gamma: 0.8 lr_scheduler_params/step_size: 15 mlp_params/input_size: 128 mlp_params/n_layers: 2 num_epochs: 100 optimizer_params/lr: 0.0005 print_every: 10 random_seed: 42 save_every: 5 task: regression use_clip_grad: False use_cuda: True 2020-11-28 14:29:54,342 openchem INFO: Starting training from scratch 2020-11-28 14:29:54,342 openchem INFO: Training is set up from epoch 0 0%| | 0/100 [00:00<?, ?it/s]2 020-11-28 14:30:14,451 openchem.fit INFO: TRAINING: [Time: 0m 20s, Epoch: 0, Progress: 0 %, Loss: 3.7441] 0%| | 0/100 [00:20<?, ?it/s] Traceback (most recent call last): File "run.py", line 327, in <module> main() File "run.py", line 257, in main model_config, eval=True, val_loader=val_loader, cur_epoch=cur_epoch) File "C:\kimisyo\work\SoftwareDevelop\OpenChem\openchem\models\openchem_model.py", li ne 174, in fit val_loss, metrics = evaluate(model, val_loader, criterion, epoch=epoch) File "C:\kimisyo\work\SoftwareDevelop\OpenChem\openchem\models\openchem_model.py", li ne 238, in evaluate for i_batch, sample_batched in enumerate(data_loader): File "C:\Users\kimisyo\.conda\envs\openchem\lib\site-packages\torch\utils\data\dataloade r.py", line 352, in __iter__ return self._get_iterator() File "C:\Users\kimisyo\.conda\envs\openchem\lib\site-packages\torch\utils\data\dataloade r.py", line 294, in _get_iterator return _MultiProcessingDataLoaderIter(self) File "C:\Users\kimisyo\.conda\envs\openchem\lib\site-packages\torch\utils\data\dataloade r.py", line 801, in __init__ w.start() File "C:\Users\kimisyo\.conda\envs\openchem\lib\multiprocessing\process.py", line 112, i n start self._popen = self._Popen(self) File "C:\Users\kimisyo\.conda\envs\openchem\lib\multiprocessing\context.py", line 223, i n _Popen return _default_context.get_context().Process._Popen(process_obj) File "C:\Users\kimisyo\.conda\envs\openchem\lib\multiprocessing\context.py", line 322, i n _Popen return Popen(process_obj) File "C:\Users\kimisyo\.conda\envs\openchem\lib\multiprocessing\popen_spawn_win32.py", l ine 89, in __init__ reduction.dump(process_obj, to_child) File "C:\Users\kimisyo\.conda\envs\openchem\lib\multiprocessing\reduction.py", line 60, in dump ForkingPickler(file, protocol).dump(obj) _pickle.PicklingError: Can't pickle <function get_atomic_attributes at 0x000002169C40D55 8>: import of module '<run_path>' failed対応
原因不明。
PyTorchのデータローダでmultiprocess処理をしているときに発生しているようなので、singleprocessになるよう、応急処置としてopenchemのrun.pyのcreate_loaderの引数 num_workerを1から0に変更する。
run.pyval_loader = create_loader(val_dataset, batch_size=model_config['batch_size'], shuffle=False, #num_workers=1, num_workers=0, pin_memory=Trueこれでとりあえず、問題なく動作するようになった。
- 投稿日:2020-11-28T23:36:17+09:00
SwaggerでREST APIを生成する
SwaggerでREST APIを生成する
はじめに
macOS環境の記事ですが、Windows環境も同じ手順になります。環境依存の部分は読み替えてお試しください。目的
この記事を最後まで読むと、次のことができるようになります。
No. 概要 備考 1 Swaggerを理解する 2 Swagger EditorでAPIを設計する 3 Swagger CodegenでAPIを生成する python-flask 4 Swagger UIで仕様/定義を可視化する 5 Generated APIを検証する 実行環境
環境 Ver. macOS Catalina 10.15.6 Swagger 3.0.3 Docker 19.03.13 関連する記事
Swaggerを理解する
特徴
- REST APIを構築するためのオープンソースフレームワーク
- YAML/JSONでAPIを設計
- 設計をもとにAPIドキュメントの生成が可能
- 設計をもとに20以上の言語からスタブの生成が可能
API Tools
No. 概要 備考 Swagger Editor APIを設計するためのツール Swagger Codegen 設計からサーバ向けスタブ/クライアント向けSDKを生成するためのツール Generate Server, Generate Client Swagger UI 設計から仕様/定義を可視化(ドキュメント化)するためのツール Generate Server Swagger EditorでAPIを設計する
Case1: Swagger Editor (Web)
1. Swagger Editor表示
Case2: Swagger Editor (Docker)
1. Swagger Editor起動
command.shdocker stop $(docker ps -q) docker rm $(docker ps -q -a) docker rmi $(docker images -q) -f docker pull swaggerapi/swagger-editor docker run -d -p 80:8080 swaggerapi/swagger-editor*今回は
PORT:80に割り当てる2. Swagger Editor表示
YAML - Hello World
hello_world.yamlopenapi: 3.0.3 info: title: Hello World description: Sample API for trying out Swagger termsOfService: http://localhost/termsOfService contact: email: na010210dv@gmail.com license: name: nsuhara url: http://localhost/license version: 0.0.1 externalDocs: description: Find out more about Swagger url: http://swagger.io servers: - url: http://localhost:8080 - url: http://localhost:80 tags: - name: hello description: Greeting API externalDocs: description: Find out more about hello url: http://localhost/hello - name: xxx description: xxx externalDocs: description: xxx url: http://localhost/xxx paths: /hello: get: tags: - hello summary: Return 'Hello, {your_name}' description: Return 'Hello, {your_name}' operationId: get_hello parameters: - name: your_name in: query description: The name displayed with Hello required: true schema: type: string responses: 200: description: Successful operation content: application/json: schema: $ref: '#/components/schemas/Hello' application/xml: schema: $ref: '#/components/schemas/Hello' 400: description: Invalid parameters content: {} 404: description: Not found content: {} /xxx: post: tags: - xxx summary: xxx operationId: post_xxx requestBody: description: xxx content: '*/*': schema: type: array items: $ref: '#/components/schemas/Xxx' required: true responses: default: description: Successful operation content: {} x-codegen-request-body-name: body get: tags: - xxx summary: xxx description: xxx operationId: get_xxx parameters: - name: xxx in: query description: xxx required: true schema: type: string responses: 200: description: Successful operation content: {} 400: description: Invalid parameters content: {} 404: description: Not found content: {} components: schemas: Hello: type: object properties: result: type: string example: Hello, {your_name} xml: name: Hello Xxx: type: object properties: id: type: integer format: int64 xxx: type: string xml: name: Xxx securitySchemes: petstore_auth: type: oauth2 flows: implicit: authorizationUrl: http://petstore.swagger.io/oauth/dialog scopes: write:pets: modify pets in your account read:pets: read your pets api_key: type: apiKey name: api_key in: headerSwagger CodegenでAPIを生成する
Swagger Editor > Generate Server > python-flask
*今回は
python-flask環境を生成するSwagger UIで仕様/定義を可視化する
1. zip解凍
- python-flask-server-generated.zip
2. requirements編集 (connexion問題)
- python-flask-server-generated/requirements.txt
requirements.txt- connexion + connexion[swagger-ui] python_dateutil == 2.6.0 setuptools >= 21.0.03. Swagger UI起動
- python-flask-server-generated/README.md
command.shdocker build -t swagger_server . docker run -p 8080:8080 swagger_server*今回は
PORT:8080に割り当てる4. Swagger UI表示
Generated APIを検証する
1. ビジネスロジック追加
- python-flask-server-generated/swagger_server/controllers/hello_controller.py
hello_controller.py+ import json import connexion import six from swagger_server.models.hello import Hello # noqa: E501 from swagger_server import util def get_hello(your_name): # noqa: E501 """Return 'Hello, {your_name}' Return 'Hello, {your_name}' # noqa: E501 :param your_name: The name displayed with Hello :type your_name: str :rtype: Hello """ - return 'do some magic!' + return json.dumps({ + 'result': 'Hello, {}'.format(your_name) + })2. ビジネスロジック検証 (Web browser)
command.shopen "http://localhost:8080/hello?your_name=nsuhara"result.sh"{\"result\": \"Hello, nsuhara\"}"3. ビジネスロジックを検証 (Curl)
command.shcurl -X GET "http://localhost:8080/hello?your_name=nsuhara" -H "accept: application/json"result.sh"{\"result\": \"Hello, nsuhara\"}"
- 投稿日:2020-11-28T23:12:28+09:00
Pythonのreportlabの使い方まとめ
はじめに
この記事ではPythonから帳票等でPDFファイルを出力する際に必要になりそうな書き方をまとめた記事です。
開発環境
Windows10
Python3.7ライブラリのインストール
まずはreportlabをインストールしましょう。
pip install reportlab空のPDFファイル作成
まずは空のPDFファイルをユーザのデスクトップに作成してみましょう。
下記のプログラムを実行すると空のPDFファイルがデスクトップに作成されます。from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import A4, portrait import os # ユーザのデスクトップのディレクトリを取得 file = "sample.pdf" file_path = os.path.expanduser("~") + "/Desktop/" + file # A4の新規PDFファイルを作成 page = canvas.Canvas(file_path, pagesize=portrait(A4)) # PDFファイルとして保存 page.save()フォントの読み込み
文字を書き込むための準備としてフォントファイルの読み込みを行います。
必要なライブラリをインポートしてフォント読み込みのメソッドを呼び出します。
第1引数は読み込み名(任意の名前)、第2引数が対象フォントファイルへのパスです。
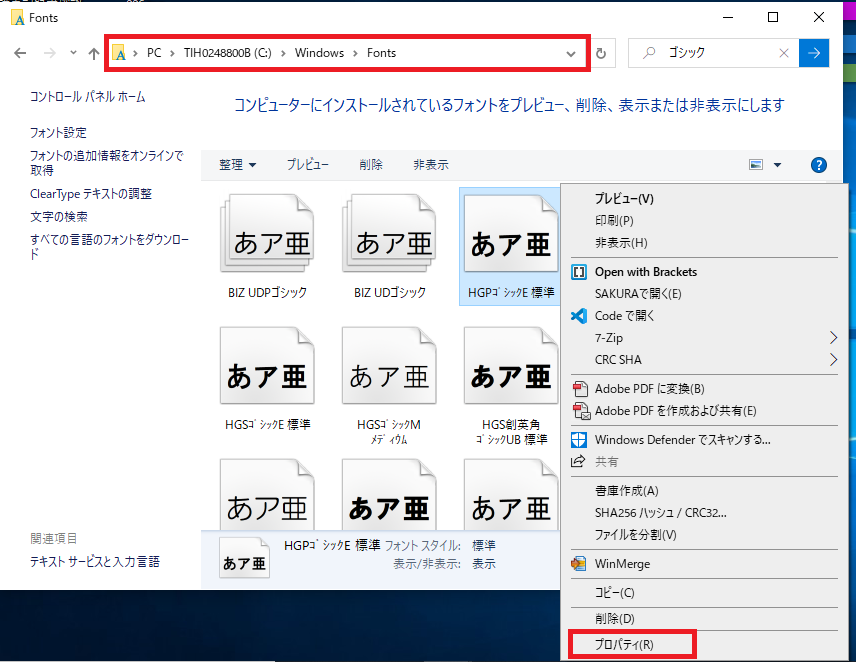
下記はWindowsに標準で入っているゴシックと明朝のフォントを読み込むコードです。from reportlab.pdfbase import pdfmetrics from reportlab.pdfbase.ttfonts import TTFont # フォントの読み込み pdfmetrics.registerFont(TTFont("HGRGE", "C:/Windows/Fonts/HGRGE.TTC")) pdfmetrics.registerFont(TTFont("HGRME", "C:/Windows/Fonts/HGRME.TTC"))インストールされているフォントは下記ディレクトリに格納されています。
C:\Windows\Fontsフォントファイル名を参照する場合は右クリックしてプロパティから参照しましょう。
文字の書き込み
次に文字を書き込んだPDFを作成していきましょう。
使用するフォントと文字サイズを指定して書き込みます。
文字書き込みのメソッドは3種類あります。
それぞれ第1,2引数がx,y座標、第3引数が書き込み文字列となります。
なお、PDFの場合は左下が原点(0,0)となりますので、指定する際は注意してください。# フォントの設定(第1引数:フォント、第2引数:サイズ) page.setFont("HGRGE", 20) # 指定座標が左端となるように文字を挿入 page.drawString(200, 300, "Hello World!") # 指定座標が中心となるように文字を挿入 page.drawCentredString(200, 200, "Hello World!") # 指定座標が右端となるように文字を挿入 page.drawRightString(200, 100, "Hello World!")実行結果は下記通りです。
ここまでのソースコードをまとめると下記通りです。
from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import A4, portrait from reportlab.pdfbase import pdfmetrics from reportlab.pdfbase.ttfonts import TTFont import os # ユーザのデスクトップのディレクトリを取得 file = "sample.pdf" file_path = os.path.expanduser("~") + "/Desktop/" + file # A4の新規PDFファイルを作成 page = canvas.Canvas(file_path, pagesize=portrait(A4)) # フォントの読み込み pdfmetrics.registerFont(TTFont("HGRGE", "C:/Windows/Fonts/HGRGE.TTC")) pdfmetrics.registerFont(TTFont("HGRME", "C:/Windows/Fonts/HGRME.TTC")) # フォントの設定(第1引数:フォント、第2引数:サイズ) page.setFont("HGRGE", 20) # 指定座標が左端となるように文字を挿入 page.drawString(200, 300, "Hello World!") # 指定座標が中心となるように文字を挿入 page.drawCentredString(200, 200, "Hello World!") # 指定座標が右端となるように文字を挿入 page.drawRightString(200, 100, "Hello World!") # PDFファイルとして保存 page.save()画像の挿入
画像を挿入する場合はdrawImage()を使います。
第1引数が画像へのパス、第2,3引数がx,y座標です。# 挿入したいファイルのパス img_path = os.path.expanduser("~") + "/Pictures/dog.png" # 画像ファイルの挿入 page.drawImage(img_path, 200, 500)改ページ
1ページ目を書き終えて、2ページ目に移る場合はshowPage()を使用します。
それまでに記述していたページの内容を確定し、メソッド呼び出し以降は次のページの文字等を出力するようになります。
例えば下記のように実行すると1ページ目に「Hello World」と表示し、
2ページ目に「reportlab」と表示します。page.drawString(200, 300, "Hello World!") # 改ページ page.showPage() page.drawString(200, 300, "reportlab")線の描画
線を描画したい場合はline()を使用します。
第1,2引数が始点の座標、第3,4引数が終点の座標です。
始点と終点間を結ぶ線を描画します。# 線の色の変更(RBGを0~1の少数で指定) page.setStrokeColorRGB(1.0, 0.0, 1.0) # 線の太さを変更 page.setLineWidth(3) # 線の描画 page.line(100, 100, 200, 200)四角形の描画
四角形の図形を描画したい場合はrect()を使用します。
第1,2引数が四角形の左下の座標、第3,4引数は幅と高さです。# 四角形の描画 page.rect(200, 200, 100, 50) # 塗りつぶした四角形の描画 page.setFillColorRGB(1.0, 0.5, 0.3) page.rect(300, 300, 100, 50, fill=True)最後に
このぐらい使えれば思い通りのPDFが生成できるようになります。


- 投稿日:2020-11-28T23:05:28+09:00
concurrent.futuresのThreadPoolExecutor/ProcessPoolExecutorを試す
本記事でやること
100000個のファイルコピーをThreadPoolExecutor/ProcessExecutorで検証.
検証環境
- MacBook Pro 2017
- 2.3 GHz デュアルコアIntel Core i5
- 8 GB 2133 MHz LPDDR3
- Python 3.7.3
とりあえず100000個のファイルを作る
ランダムなファイル名を持つファイルを./data1配下に作成.
create_random_file.pyimport os import random import string CREATE_FILES_NUM = 100000 FILE_NAME_NUM = 10 SAVE_DIR = 'data1/' def random_file_name(n, extension='.txt'): random_strs = [random.choice(string.ascii_letters + string.digits) for i in range(n)] return ''.join(random_strs) + extension def _create_file(): for _ in range(CREATE_FILES_NUM): file_name = random_file_name(FILE_NAME_NUM) with open(os.path.join(SAVE_DIR, file_name), 'w') as f: f.write('') if __name__ == '__main__': _create_file()並列処理を行わないコピーの場合
data1配下に作った1000個のファイルをdata2配下にコピー.
以下のコードの実行に約16.1秒かかった.naive_copy.pyimport os import time import shutil def print_time(func): def wrapper(*args, **kwargs): t1 = time.time() func(*args, **kwargs) t2 = time.time() print(f'{func.__name__}: {t2-t1}') return wrapper def _get_file_list(dir_name): file_list = [os.path.join(dir_name, f) for f in os.listdir(dir_name) if \ os.path.isfile(os.path.join(dir_name, f))] return file_list def _copy_file(file_list, copy_to): for f in file_list: f_copy = copy_to + f.split('/')[-1] shutil.copyfile(f, f_copy) def main(): file_list = _get_file_list(dir_name='data1') os.mkdir('data2/') _copy_file(file_list, 'data2/') shutil.rmtree('data2/') os.mkdir('data2/') if __name__ == '__main__': main()ThreadPoolExecutorを利用した場合
上記同様にコピーを実施. 以下コードを実行. 約15.1秒かかった.
thread_copy.pyimport os import time import shutil import numpy as np from concurrent.futures import ThreadPoolExecutor MAX_WORKERS = os.cpu_count() print('MAX WORKERS:', MAX_WORKERS) def print_time(func): def wrapper(*args, **kwargs): t1 = time.time() func(*args, **kwargs) t2 = time.time() print(f'{func.__name__}: {t2-t1}') return wrapper def _get_file_list(dir_name): file_list = [os.path.join(dir_name, f) for f in os.listdir(dir_name) if \ os.path.isfile(os.path.join(dir_name, f))] return file_list def _copy_file(file_list, copy_to): for f in file_list: f_copy = copy_to + f.split('/')[-1] shutil.copyfile(f, f_copy) @print_time def _copy_file_concurrent_thread(file_list, copy_to): with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: split_file_list = np.array_split(np.array(file_list), MAX_WORKERS) copy_to_list = [copy_to for _ in range(MAX_WORKERS)] results = executor.map(_copy_file, split_file_list, copy_to_list) def main(): file_list = _get_file_list(dir_name='data1') _copy_file_concurrent_thread(file_list, 'data2/') shutil.rmtree('data2/') os.mkdir('data2/') if __name__ == '__main__': main()ProcessPoolExecutorを利用した場合
以下コードを実行. 約9.9秒かかった.
process_copy.pyimport os import time import shutil import numpy as np from concurrent.futures import ProcessPoolExecutor MAX_WORKERS = os.cpu_count() print('MAX WORKERS:', MAX_WORKERS) def print_time(func): def wrapper(*args, **kwargs): t1 = time.time() func(*args, **kwargs) t2 = time.time() print(f'{func.__name__}: {t2-t1}') return wrapper def _get_file_list(dir_name): file_list = [os.path.join(dir_name, f) for f in os.listdir(dir_name) if \ os.path.isfile(os.path.join(dir_name, f))] return file_list def _copy_file(file_list, copy_to): for f in file_list: f_copy = copy_to + f.split('/')[-1] shutil.copyfile(f, f_copy) @print_time def _copy_file_concurrent_process(file_list, copy_to): with ProcessPoolExecutor(max_workers=MAX_WORKERS) as executor: split_file_list = np.array_split(np.array(file_list), MAX_WORKERS) copy_to_list = [copy_to for _ in range(MAX_WORKERS)] results = executor.map(_copy_file, split_file_list, copy_to_list) def main(): file_list = _get_file_list(dir_name='data1') _copy_file_concurrent_process(file_list, 'data2/') shutil.rmtree('data2/') os.mkdir('data2/') if __name__ == '__main__': main()結論
ローカルの大量ファイルコピーにはProcessPoolExecutorがはやいよ.
- 投稿日:2020-11-28T22:57:22+09:00
(xlwing使用)空白があるテキストファイル(数行)を読み込んで、excelに貼り付ける
xlwing 使用
テキストファイルの中身
test.txtテスト test t3 USD 44 te 55 99 gbe 99pythonファイル
hello.pydef import_txt_split(): # ブックの読み込み wb = xw.Book.caller() # シートの読み込み sht = wb.sheets['Sheet1'] # テキストファイルの読み込み f = open('test.txt', 'r',encoding='UTF-8') # 各行をリストで取得 datalist = f.readlines() # 空白を取り除く s = [i.split() for i in datalist] # 1行ずつ、リストをペッと貼り付ける for num,i in enumerate(s): sht.cells(num+1,1).value = i # テキストファイルを閉じる f.close()VBA側
Sub import_text() RunPython ("import hello; hello.import_txt_split()") End SubこのVBAをボタンにマクロ登録。クリック
結果
上記の方法以外に、pandasのdataframeに貼り付けて、A1セルにぺっと貼り付ける方法でも出来た

- 投稿日:2020-11-28T22:53:18+09:00
MacでDjango(Python3)環境を構築してみた
はじめに
今回は、Python/DjangoでWebアプリを作る目的で、
Macにて環境構築をしていく過程を確認していきます。参考記事
https://qiita.com/M-Yamashii/items/bfc45596c2913a7571dc目標
『Macにインストール済みのエディタ「VSCode」にて、
Python3/Djangoプロジェクトを実行できる仮想環境を構築』1.Djangoをインストール
早速Djangoをインストールしていくのですが、
その前に、以下2点を確認します。1.homebrewがインストールされているか
していなければ、以下を先に確認のうえ実施していきます。『MacでHomebrewをインストールしてみた』
https://qiita.com/kosments/items/bf8edd9743596c2366e42."1"が完了していたら、pipenvがインストールされているか
していなければ、ターミナルを開き、以下のコマンドを実行$ brew install pipenvインストールが開始するのでしばらく待機。。。
完了したらDjangoをインストールしていきます。
以下のコマンドを実行します。$ pipenv install django Installing django... Adding django to Pipfile's [packages]... ✔ Installation Succeeded2.Python3の仮想環境を作成する
①Documents等の任意のフォルダに新規フォルダを作成します。
例:/Users/Documents/django_test
フォルダ名:django_test②cdコマンドで作成したディレクトリに移動します。
$ cd /Users/Documents/django_test③以下のコマンドを実行し、仮想環境を作成します。
$ python3 -m venv env3.VSCodeにて
①VSCodeを立ち上げて、「開く」から作成したフォルダを開きます。
②F1(またはfn+F1)を押して、"Python Select Interpreter"を検索して選択。
③ディレクトリを選択する画面が出るので、作成した仮想環境(今回の場合「./env/bin/python」)を選択。
※青くなっているところは無視します
④VSCode画面左下部(青いバー)に指定した環境が表示されているか確認。
(今回の場合「Python 3.8.3 64-bit('env')」)⑤VSCodeにてターミナルを開き、以下のコマンドを実行し、仮想環境を利用できるようにします。
$ source env/bin/activateこれで、VSCode上で、作成しておいた仮想環境にて、Djangoを利用できるようになります。
「4」にて、プロジェクトを作成し、ブラウザ上でアクセスするところまで、確認しておきます。4.VSCode上でプロジェクトを作成
①引き続き、VSCodeのターミナルにて以下のコマンドを実行。
$ django-admin startproject test_project※django-adminが「command not found」となる場合は、以下のどちらかもしくは両方を確認した後、上記のコマンドを再度、実行します。
1.「$ pip install django」を実行
2.「$ python -m」コマンドを利用し、django-admin.pyがあるフォルダを探す。
該当ファイルが仮想環境に保管されていることを確認します。仮想環境に「test_project」フォルダが作成されていることを確認します。
②ブラウザでアクセスを試します。
まずは以下のコマンドで作成したフォルダに移動します。$ cd ./test_project次に、以下のコマンドを実行します。
$ python manage.py runserver次に、ブラウザ上で、以下のURLにアクセスします。
以下の画面になることを確認します。
今回は、これで以上です。
まとめ
今回は、MacにてDjango環境の構築過程を確認しました。
参考にさせて頂いた記事の作成者様ありがとうございました。引き続きPython/Djangoを触っていきたいと思います。
ありがとうございました。


- 投稿日:2020-11-28T22:30:45+09:00
【Pandas】基礎1(DataFrame, Series)
はじめに
機械学習や深層学習が人気の昨今、
データを加工し、前処理を行う機会が非常に多くなってきた。データ処理方法は様々存在するが、そのデータ処理ツールの一つとしてpythonのpandasが存在する。
そこで、今回は公式のpandasのintro記事を参考に
pandasの基礎にDaraFrame、Seriesについて記していく。そもそもPandasはどのようなデータを扱うのに適しているのか?
表形式のデータを扱うのに非常に適している。
例えば、エクセルやSQLといったデータだ。pandasを利用することでデータの検索やデータの処理などを行うことができる。
DataFrame
pandasが使えるデータテーブルのことである。
下の図のように、行(rows)列(columns)で構成されている。
pythonでの記述方法
手動でdataframeを作成するには、pythonのdictonaryを使用する。
dictonaryのキーがDataFrameの列のheadとして、 dictonaryのリストがDataFrameの行となる。
df = pd.DataFrame({ "Name": ["Braund, Mr. Owen Harris", "Allen, Mr. William Henry", "Bonnell, Miss. Elizabeth"], "Age": [22, 35, 58], "Sex": ["male", "male", "female"]} )出力結果
Series
SeriesとはDataFrameの各列のことを言う。
イメージは以下の通り
pythonでの記述方法
例として、上記のDataFrameから'Name'を取得してみる。
series = df['Name']もしくは、手動で作成することもできる。
series2 = pd.Series(["Braund, Mr. Owen Harris", "Allen, Mr. William Henry", "Bonnell, Miss. Elizabeth"], name = 'Name' )出力結果
まとめ
- DataFrame
- pandasで扱うデータのテーブル
- Series
- DataFrameの各列のこと
参考





- 投稿日:2020-11-28T22:28:14+09:00
Windows10で CUDA10.2をインストール
はじめに
Windows10にCUDAドライバを以前入れていたものの、TensorflowやPyTorchでうまく動作しなくなり、しばらくGPUなしで動かしていたが、いい加減バージョンアップしてみた。
きっかけ
ある日PyTorchでこんなエラーが。よし、上げよう。
RuntimeError: The NVIDIA driver on your system is too old (found version 10010). Please updat e your GPU driver by downloading and installing a new version from the URL: http://www.nvidia .com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch versi on that has been compiled with your version of the CUDA driver.現状調査
そもそもインストールされているPyTorchのバージョンはというと、
pytorch 1.7.0 py3.7_cuda110_cudnn8_0 pytorch torchvision 0.8.1 py37_cu110 pytorchなんかしらんが11用が入っている。
現状インストールされてCUDAは?
$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2017 NVIDIA Corporation Built on Fri_Sep__1_21:08:32_Central_Daylight_Time_2017 Cuda compilation tools, release 9.0, V9.0.1769.0だ。
WindowsでPyTorchを使うための最適なCUDAのバージョンは?
PyTorchのホームページを見てみる。これによると、
PyTorch1.7, CUDA 10.2の組み合わせがよさそう。よって10.2をインストールすることにする。
インストール
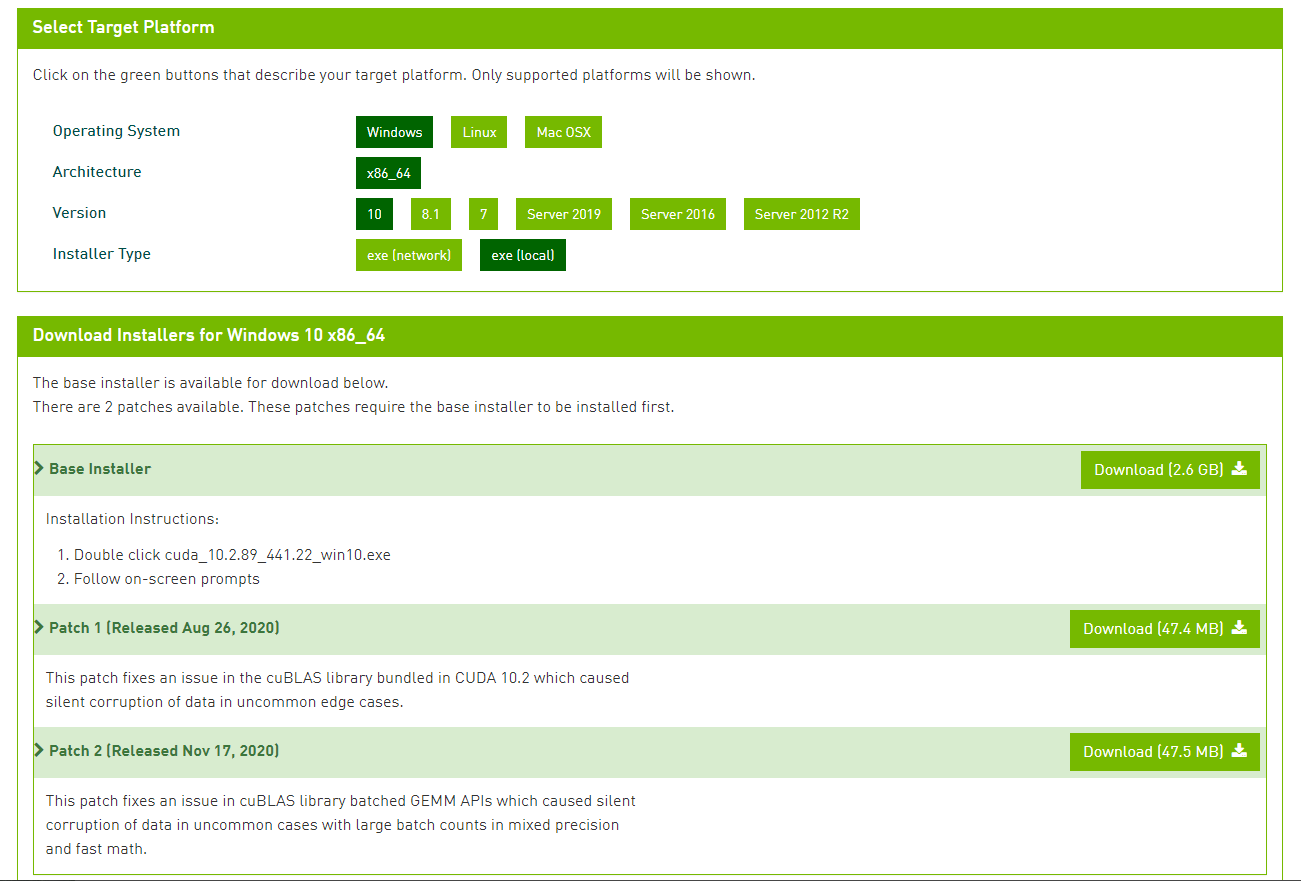
NVIDIAのホームページより、Windows10用の10.2のドライバをダウンロードしインストールする。
上記よりBase Insataller、Patch1, Patch2を順にダウンロード、インストールしていくだけ。
インストール後の確認
$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019 Cuda compilation tools, release 10.2, V10.2.8910.2がインストールされている。
環境変数も以下の通り、10.2がCUDA PATHに設定されている。
CUDA_PATH='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2' CUDA_PATH_V10_2='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2' CUDA_PATH_V8_0='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0' CUDA_PATH_V9_0='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0' CUDA_PATH_V9_1='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1'PyTorchのインストール
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch無事CUDA 10.2用のものがインストールされていることを確認。
$ conda list |grep torch pytorch 1.7.0 py3.7_cuda102_cudnn7_0 pytorch torchaudio 0.7.0 py37 pytorch torchvision 0.8.1 py37_cu102 pytorchこの後はPyTorchのモデルを実行するなりして、実際に動作することを確認すればよい。

- 投稿日:2020-11-28T22:06:28+09:00
【Google Colab】OpenCVでBounding Box 検出
はじめに
OpenCVで物体のBounding Boxを検出してみました。
機械学習で物体検出のモデルを作成する際には、画像にBounding Boxとラベルを付けた情報が必要となります。このアノテーション作業の効率化に役立てばと思います。
画像はPixabayのフリー画像を使用しました。
また、以下を前提としてしています。
- 対象とする物体は1つ(複数存在する場合、以下のコードでは最大のものを取得)
- 背景は白色(異なる色の場合、hsvで指定する値の範囲を変更する必要あり)
環境
言語はPython、環境はGoogle Colaboratoryを使用します。
コード
コード全体は以下です。
import cv2 import numpy as np from google.colab.patches import cv2_imshow img_path = "/path/to/image_file" img = cv2.imread(img_path) img2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) lower = np.array([0, 0, 0], dtype = "uint8") upper = np.array([255, 50, 255], dtype = "uint8") img2 = cv2.inRange(img2, lower, upper) img2 = cv2.blur(img2, (2, 2)) ret, img2 = cv2.threshold(img2, 0, 255, cv2.THRESH_BINARY) img2 = cv2.bitwise_not(img2) contours, hierarchy = cv2.findContours(img2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) contours = max(contours, key=lambda x: cv2.contourArea(x)) x, y, w, h = cv2.boundingRect(contours) img = cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3) cv2_imshow(img)結果は以下です。
説明
以下、コードの内容を説明します。
まず、必要なライブラリをインストールします。
import cv2 import numpy as np from google.colab.patches import cv2_imshow次に、画像を読み込みます。
元画像を表示すると以下になります。img_path = "/path/to/image_file" img = cv2.imread(img_path) cv2_imshow(img)
次に、以下の操作を行います。
- 画像をRGBからHSVに変換(RGBとHSVの関係についてはこちら)
- H,S,Vの値が指定した範囲内の色の部分のみ取り出す
- ノイズ除去のため、blur(ぼかし)処理を行う(「ぼかし、平滑化」についてはこちら )
- 二値化する(「二値化」についてはこちら)
- 白黒反転する
この画像を表示すると以下になります。
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) lower = np.array([0, 0, 0], dtype = "uint8") upper = np.array([255, 50, 255], dtype = "uint8") img2 = cv2.inRange(img2, lower, upper) img2 = cv2.blur(img2, (2, 2)) ret, img2 = cv2.threshold(img2, 0, 255, cv2.THRESH_BINARY) img2 = cv2.bitwise_not(img2) cv2_imshow(img2)
最後に、以下の操作を行います。
- findContoursで輪郭を検出
- 検出した輪郭のうち、最大のものを取得
- 輪郭の外接矩形(Bounding Box)を取得
- Bounding Boxを描画
最終的に、Bounding Boxを描画した図を得ます。
contours, hierarchy = cv2.findContours(img2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) contours = max(contours, key=lambda x: cv2.contourArea(x)) x, y, w, h = cv2.boundingRect(contours) img = cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3) cv2_imshow(img)
参考




- 投稿日:2020-11-28T22:06:28+09:00
【Google Colab】OpenCVでBounding Box検出
はじめに
OpenCVで物体のBounding Boxを検出してみました。
機械学習で物体検出のモデルを作成する際には、画像にBounding Boxとラベルを付けた情報が必要となります。このアノテーション作業の効率化に役立てばと思います。
画像はPixabayのフリー画像を使用しました。
また、以下を前提としてしています。
- 対象とする物体は1つ(複数存在する場合、以下のコードでは最大のものを取得)
- 背景は白色やそれに類する色(異なる場合、hsvで指定する値の範囲を変更する)
環境
言語はPython、環境はGoogle Colaboratoryを使用します。
コード
コード全体は以下です。
import cv2 import numpy as np from google.colab.patches import cv2_imshow img_path = "/path/to/image_file" img = cv2.imread(img_path) img2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) lower = np.array([0, 0, 0], dtype = "uint8") upper = np.array([255, 50, 255], dtype = "uint8") img2 = cv2.inRange(img2, lower, upper) img2 = cv2.blur(img2, (2, 2)) ret, img2 = cv2.threshold(img2, 0, 255, cv2.THRESH_BINARY) img2 = cv2.bitwise_not(img2) contours, hierarchy = cv2.findContours(img2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) contours = max(contours, key=lambda x: cv2.contourArea(x)) x, y, w, h = cv2.boundingRect(contours) img = cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3) cv2_imshow(img)結果は以下です。
説明
以下、コードの内容を説明します。
まず、必要なライブラリをインストールします。
import cv2 import numpy as np from google.colab.patches import cv2_imshow次に、画像を読み込みます。
元画像を表示すると以下になります。img_path = "/path/to/image_file" img = cv2.imread(img_path) cv2_imshow(img)
次に、以下の操作を行います。
- 画像をRGBからHSVに変換(RGBとHSVの関係についてはこちら)
- H,S,Vの値が指定した範囲内の色の部分のみ取り出す
- ノイズ除去のため、blur(ぼかし)処理を行う(「ぼかし、平滑化」についてはこちら )
- 二値化する(「二値化」についてはこちら)
- 白黒反転する
この画像を表示すると以下になります。
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) lower = np.array([0, 0, 0], dtype = "uint8") upper = np.array([255, 50, 255], dtype = "uint8") img2 = cv2.inRange(img2, lower, upper) img2 = cv2.blur(img2, (2, 2)) ret, img2 = cv2.threshold(img2, 0, 255, cv2.THRESH_BINARY) img2 = cv2.bitwise_not(img2) cv2_imshow(img2)
最後に、以下の操作を行います。
- findContoursで輪郭を検出
- 検出した輪郭のうち、最大のものを取得
- 輪郭の外接矩形(Bounding Box)を取得
- Bounding Boxを描画
最終的に、Bounding Boxを描画した図を得ます。
contours, hierarchy = cv2.findContours(img2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) contours = max(contours, key=lambda x: cv2.contourArea(x)) x, y, w, h = cv2.boundingRect(contours) img = cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3) cv2_imshow(img)
参考
- 投稿日:2020-11-28T21:15:33+09:00
PySide2でWebブラウザをウィジェットとして使う
この記事はTakumi Akashiro ひとり Advent Calendar 2020の1日目の記事になります。Yeh!
前置き
どうも!皆さんは最近、PySide2を触ってますか?
私は……まあボチボチですね!HoudiniでもMayaでも標準で入っているPySide2。
PySide2で標準で使えるウィジェットにWebブラウザがあるのは御存知でしょうか?
ご存じですよね?既にタイトルを見てクリックしてるはずですからね!と茶番はさておいて。
PySide2のラップ元であるQtにはQt WebEngineと呼ばれるモジュールが存在します。Qt WebEngineはWebコンテンツをレンダリングするための機能を提供します。
Qt WebEngine 5.15.2 - PySide2公式ドキュメントよりQt WebEngine とは
Qt WebEngineはChromiumをベースとしたウェブブラウザを扱えるモジュールであり、
PySide2でも標準で組み込まれています。つまり、PySide2でウェブブラウザを使えるということです!
ちなみに過去にはWebKitベースのQt WebKitもあったようですが、
こちらはQt 5.5以降非推奨になっており、
現在、PySide2ではビルドしなおさない限りは使えないようです。1では試しに使ってみましょう!
試してみた
#!python3 # encoding:utf-8 from PySide2 import QtCore from PySide2 import QtWidgets from PySide2 import QtWebEngineWidgets class WebDemo(QtWidgets.QWidget): URL = "https://google.com/" def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.setGeometry(500, 300, 250, 110) self.setWindowTitle('Web Demo') hbox = QtWidgets.QHBoxLayout() webview = QtWebEngineWidgets.QWebEngineView() webview.setUrl(self.URL) hbox.addWidget(webview) self.setLayout(hbox) if __name__ == "__main__": app = QtWidgets.QApplication() webdemo = WebDemo() webdemo.show() exit(app.exec_())Google.com
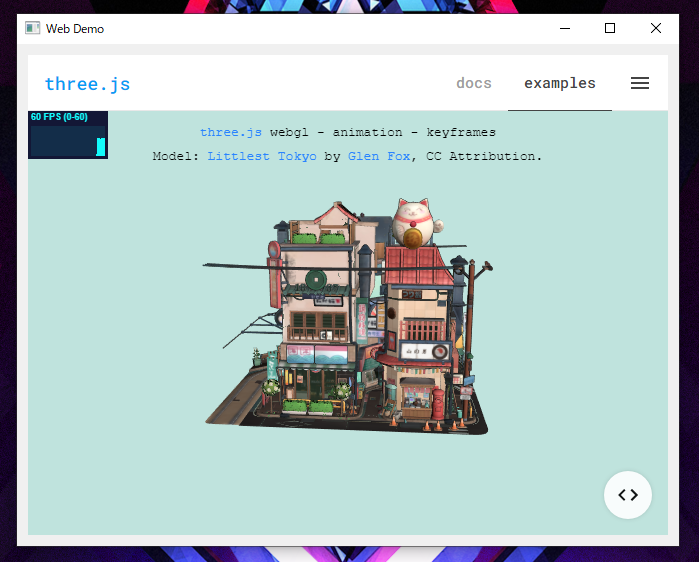
three.js examples
three.jsも問題なく表示できてますね!
RedmineやShotgunを開いたり2、
ツールのマニュアルを載せたりするときには便利なんじゃないですかね?締め
というわけで、今回紹介した技術の評価としては以下の通りですね。
評価ラベル ランク(5段階) おすすめ度 ★★ 難易度 ★★ ニッチ ★★★ 汎用性 ★★★★ キュート度 ★★★★★ 個人的にはツールに依存していない部分は、分離して実装しておくと、
DCCツールを移行したり、新フローを構築する際に、
簡単に流用できたりするので、ウェブ技術を組み込むのは結構アリな気がしますね!
「あー、このWebブラウザ、表示するだけかぁ……
WEBでUI作って、DCCツールの関数を実行出来るようになれば楽なのになー……」とお考えの貴方。3出来ます! 詳細は明日の記事で!!!
それでは、シーユーアゲイン!!!!!!
- 投稿日:2020-11-28T21:07:43+09:00
Angular(Ionic)で非同期通信を実装する
フロントエンドアプリケーションフレームワークであるAngular(Ionic)で非同期通信を実装する方法をサンプルアプリとして紹介します。動作確認用にPythonで作成したバックエンドコード付きです。
Angularの場合、非同期通信を実装するにはHttpClientModuleをapp.module.tsに追加して、tsファイルで呼び出して使うだけです。AngularはReactと異なりフルスタックなので、この辺の安心感はReactにはるかに勝ると思います。
ソースコードの素性
ソースコードの素性ですが、Ionic(Aunglar)のblankアプリから実装しました。なお、バックエンドのサンプルコードも作成しましたが、こちらはPythonのFlaskを使っています。Flaskでホスティングした http;//127.0.0.1:5000 のURLを叩いてデータを取ってくるアプリです。
GitHubにコードあげたのでそのまま動作確認できると思います。環境
フロントエンド
Angular CLI: 10.0.5
Ionic CLI : 6.10.0
Node: 12.18.0バックエンド
Python 3.7.3
Flask 1.1.2
Flask-Cors 3.0.9コード
app.module.ts
app.module.tsに
import { HttpClientModule } from '@angular/common/http';
を追加します。app.module.tsimport { NgModule } from '@angular/core'; import { BrowserModule } from '@angular/platform-browser'; import { RouteReuseStrategy } from '@angular/router'; //下記の行を追加 import { HttpClientModule } from '@angular/common/http'; import { IonicModule, IonicRouteStrategy } from '@ionic/angular'; import { SplashScreen } from '@ionic-native/splash-screen/ngx'; import { StatusBar } from '@ionic-native/status-bar/ngx'; import { AppComponent } from './app.component'; import { AppRoutingModule } from './app-routing.module'; @NgModule({ declarations: [AppComponent], entryComponents: [], imports: [BrowserModule,HttpClientModule, IonicModule.forRoot(), AppRoutingModule], providers: [ StatusBar, SplashScreen, { provide: RouteReuseStrategy, useClass: IonicRouteStrategy } ], bootstrap: [AppComponent] }) export class AppModule {}注意点は特になし。Ionicの場合、moduleファイルが複数あるけど、app.module.tsにだけ書いておけば問題ないです。
home.page.ts
あとは使いたい場所で呼び出せばいいです。
home.page.tsimport { Component } from '@angular/core'; import { HttpClient } from '@angular/common/http'; @Component({ selector: 'app-home', templateUrl: 'home.page.html', styleUrls: ['home.page.scss'], }) export class HomePage { constructor(private http: HttpClient) { this.hello(); } hello(){ this.http.get('http://127.0.0.1:5000') .subscribe( (res) => { console.log(res); }) } }これでOK.この辺の安心感はフルスタックのAngularのいいところだと思います。
バックエンド
バックエンドはこちら
main.py# -*- coding: utf-8 -*- from flask import Flask from flask_cors import CORS import json app = Flask(__name__) CORS(app) @app.route('/',methods=["GET","POST"]) def hello(): name = "Hello World" return json.dumps({'name':name}) if __name__ == "__main__": app.run(host='127.0.0.1',debug=True)
- 投稿日:2020-11-28T20:58:48+09:00
SHAP値を用いて機械学習(予測モデル)の予測結果を解釈してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はscikit-learnを活用して様々な予測モデルを実装し整理しました。
はじめに
前回、機械学習の予測モデルをscikit-learnを活用して実装してみました。また、構築したモデルは評価指標を用いてモデルを評価します。
しかし、評価指標だけでモデルの良し悪しを判断するのは危険であり、構築したモデルが実態と乖離している場合があります。つまり、汎化能力が低いモデルである可能性があるということです。汎化能力を高める方法は多々ありますが、製造現場では構築したモデルの解釈性を求められることが多いです。実際は、回帰モデル系であれば各説明変数の回帰係数の正負や標準偏回帰係数で変数間の影響度を見て固有技術と合致しているかを見極めたりします。また、決定木系のモデルであれば変数重要度を見て判断をします。
しかし、決定木系のモデル(RandomForest、GBDT、等)は各変数が目的変数へ与える影響の正負を判断することができません。また、SVRではカーネルをlinear以外を選択すると回帰係数も変数重要度も算出することができません(※scikit-learnのライブラリーに限った話です)。
そこで、今回は上記のような課題を解決する手段の一つとして、SHAP値を用いて、予測した値に対して、「各変数がどのような影響を与えたのか?」を可視化する技術を整理しました。
SHAPとは
理論的な詳細は今回は省略します。
SHAPの実装
今回はUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
項目 概要 データセット ・boston house-price サンプル数 ・506個 カラム数 ・14個 pythonのコードは下記の通りです。
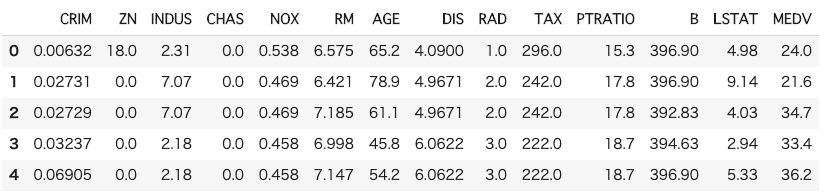
# 必要なライブラリーのインポート import pandas as pd import numpy as np import shap from sklearn.datasets import load_boston # データセットの読込み boston = load_boston() # データフレームの作成 # 説明変数の格納 df = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 df['MEDV'] = boston.target # データの中身を確認 df.head()
各カラム名の説明は省略します。
・説明変数:13個
・目的変数:1個(MEDV)次に、予測モデルを構築します。今回は、RandomForest回帰を活用します。
# ライブラリーのインポート from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor # 学習データと評価データを作成 x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13], test_size=0.2, random_state=1) # モデルの学習 RF = RandomForestRegressor() RF.fit(x_train, y_train)SHAPで結果を解釈する
最初に、SHAPの説明木の作成とSHAP値を算出します。
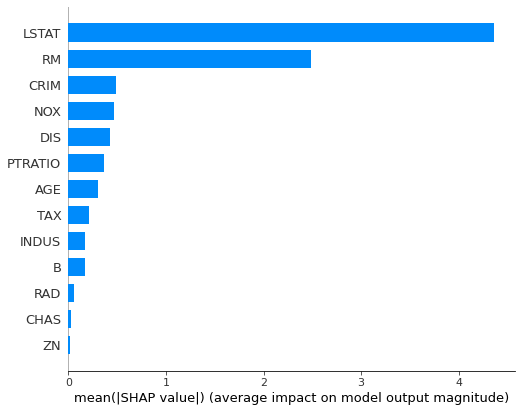
explainer = shap.TreeExplainer(RF) shap_values = explainer.shap_values(X=x_train)次に変数重要度を算出してみます。
shap.summary_plot(shap_values, x_train, plot_type="bar")
ここで、RandonForestであれば、scikit-learnでも変数重要度を算出することができるので、算出してみようと思います。
import matplotlib.pyplot as plt %matplotlib inline features = df.columns importances = RF.feature_importances_ indices = np.argsort(importances) plt.figure(figsize=(6,6)) plt.barh(range(len(indices)), importances[indices], color='b', align='center') plt.yticks(range(len(indices)), features[indices]) plt.show()
結果は全く一緒ではないですが、LSTAT、RMが重要な部分は似ておりますね。算出式が異なるので結果が異なるのは当たり前ですが。
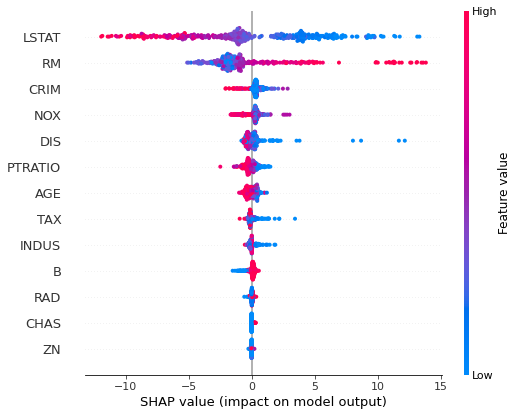
次に、説明変数と目的変数の相関関係を確認します。
shap.summary_plot(shap_values, x_train)
結果の見方は、横軸がSHAP値を表しており、縦軸が変数重要度を表しております。赤が正の値、青が負の値を示しております。
次に一つの入力結果に対する予測結果の解釈を確認します。
shap.initjs() shap.force_plot(explainer.expected_value, shap_values[0,:], x_train.iloc[0,:])
この図はRandomForest回帰の予測結果24.98を計算する際の各変数の寄与を表しております。目的変数の結果を正の方向へ動かすのに寄与した変数が赤で示しており、負の方向へ動かすのに寄与したの変数が青で示されております。
最後に全てのデータを用いて可視化してみます。
shap.force_plot(base_value=explainer.expected_value, shap_values=shap_values, features=x_train)
上記の結果を見るとLSTAT(給与の低い職業に従事する人口の割合)が高くなるほど、住宅価格が低くなることが読み取れます。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は予測モデルの結果を解釈する手法としてSHAPを実装してみました。
製造業では上司、現場へ説明する際に解釈が求められます。ブラックボックスモデルでなぜか良い結果が出ましたでは、納得してもらえないことが多いかと思います。しかし、SHAPを活用することでその問題も解決することができます。訂正要望がありましたら、ご連絡頂けますと幸いです。
参考文献



- 投稿日:2020-11-28T20:17:48+09:00
【Python】csv・txtファイルの行データを読み込み、リストに格納する
読み込んだ行データをリストに格納する作業がよくあったので、関数化して実装していきたいと思います。
実装
Python 3.7.6
- txtファイル
txtApple Grape Orange Melon Peach
- CSVファイル
引数にtxtかcsvのfileパスを指定すると、読み込んだデータをリストとして返します。
import csv import itertools # 2次元配列=>1次元配列にするため TEXT_FILE = 'sample.txt' CSV_FILE = 'sample.csv' def read_txtfile_as_list(filePath=None): """ テキストファイルを読み込み、リストとして返します。 Parameters ---------- filePath : str Returns ------- item_list : list of str """ with open(filePath, 'r') as f: text_data = [line.strip() for line in f] return text_data def read_csvfie_as_list(filePath=None): """ CSVファイルを読み込み、リストとして返します。 Parameters ---------- filePath : str Returns ------- item_list : list of str """ with open(filePath, 'r') as f: csv_data = [line for line in csv.reader(f)] # return sum(csv_data, []) 簡易的な書き方 こっちだと処理が遅い return list(itertools.chain.from_iterable(csv_data)) def read_file_as_list(filePath=None): """ テキストファイルかCSVファイルを読み込み、リストとして返します。 Parameters ---------- filePath : str Returns ------- item_list : list of str """ if filePath[-4:] == '.txt': with open(filePath, 'r') as f: text_data = [line.strip() for line in f] return text_data elif filePath[-4:] == '.csv': with open(filePath, 'r') as f: csv_data = [line for line in csv.reader(f)] return list(itertools.chain.from_iterable(csv_data)) else: return None # テキストファイルの中身を表示 text_samp1 = read_txtfile_as_list(TEXT_FILE) print(text_samp1) # OUTPUT: ['Apple', 'Grape', 'Orange', 'Melon', 'Peach'] # CSVファイルの中身を表示 csv_samp1 = read_csvfie_as_list(CSV_FILE) print(csv_samp1) # OUTPUT: ['dog', 'cat', 'cow', 'fox', 'monkey'] # テキスト・CSVファイルの中身を表示 text_samp2 = read_file_as_list(TEXT_FILE) csv_samp2 = read_file_as_list(CSV_FILE) print(text_samp2) print(csv_samp2) # OUTPUT: ['Apple', 'Grape', 'Orange', 'Melon', 'Peach'] # OUTPUT: ['dog', 'cat', 'cow', 'fox', 'monkey']書いている途中で行データだけを読み込むのであれば、標準の
readlinesメソッドで読み込めるので、csvライブラリをインポートする必要性はなかったなーと思ったのですが、今後、csvファイルの中身をリストにする機会があるかもしれないと思ったので、一応、残しておきます。


- 投稿日:2020-11-28T18:05:23+09:00
【Python】要素がないだと… それ、iframeではありませんか?
背景
Pythonでスクレイピングをやってみようと思い、
取り合えず地図画像でも集めてみようかな…ということで、
中部電力が公開している地図画像をスクレイピング。しかし、何度やっても要素を取得してくれない。
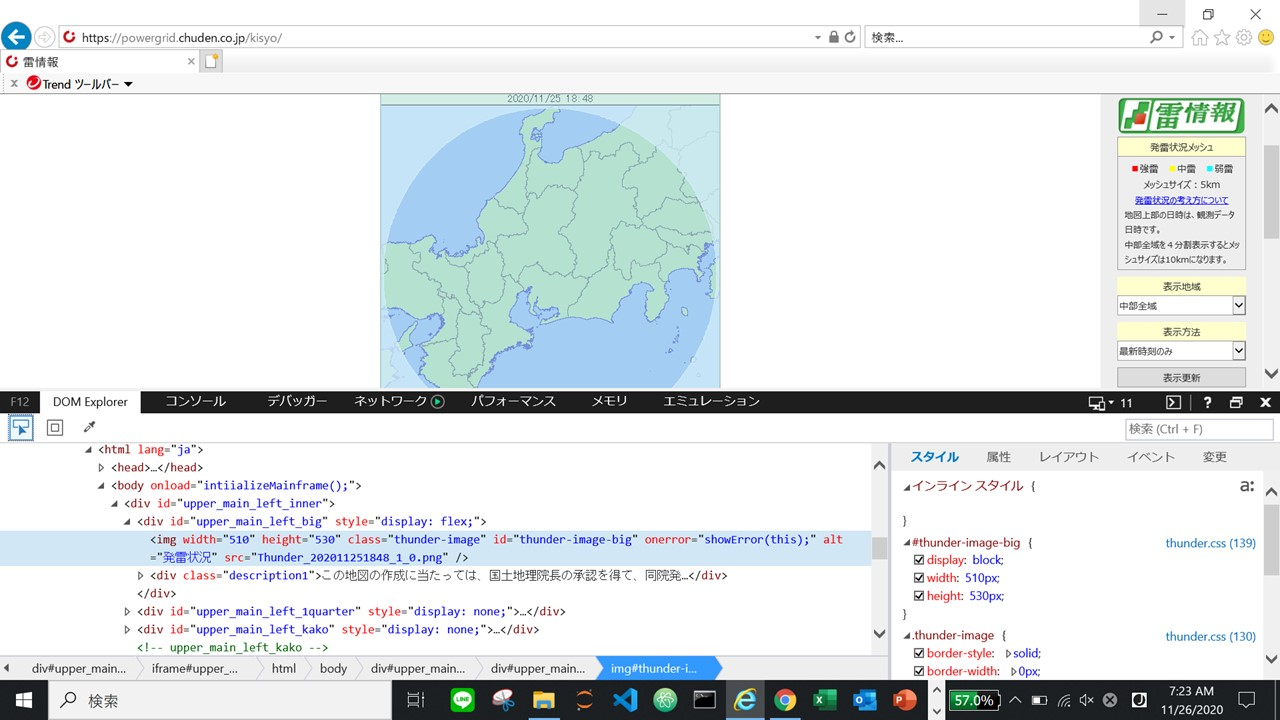
import time from selenium import webdriver #IEを起動 #ドライバーの保管ディレクトリを記述 driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe") #パワーグリッドにアクセス driver.get("https://powergrid.chuden.co.jp/kisyo/") time.sleep(5) element = driver.find_element_by_css_selector("#thunder-image-big") print(element) >>>NoSuchElementException: Message: Unable to find element with css selector == #thunder-image-big検証ツールを開いて地図画像の要素にあるclassやidなど該当しそうな属性を
指定して取得を試みるが、「そんなものはねぇよ」と突っぱねられます。
本当に何が原因なのかわからなかったので、teratailで質問をしたら
解決したので備忘としてこの記事を書きました。環境
使用ブラウザ:IE11
OS:Microsoft Windows 10 Home
エディタ:Jupyter notebookこうやったらできた(結論)
import time from selenium import webdriver import urllib.request from datetime import datetime #IEを起動 #ドライバーの保管ディレクトリを記述 driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe") #パワーグリッドにアクセス driver.get("https://powergrid.chuden.co.jp/kisyo/") iframe = driver.find_element_by_id('upper_main_left_cont') driver.switch_to.frame(iframe) time.sleep(5) element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src") #ファイル名を日付で保存 now = datetime.now() urllib.request.urlretrieve(element, now.strftime('%Y%m%d_%H%M%S') + '.png')解説
自分もまだまだ、よちよちPythonマンなので復習用に書いておきます。
モジュールをインポート
import time #時刻に関するさまざまな関数を提供 from selenium import webdriver #Webの自動テストのためのライブラリ import urllib.request #URL を開いて読むためのモジュール from datetime import datetime #日付や時刻を操作するためのクラスを提供Pythonでライブラリの中のモジュールに含まれる
関数、クラスを利用するには、次のようにimportを記述し、
読み込んでから利用します。import ライブラリ名/モジュール名準備
Seleniumでは、PythonのコードからWEBブラウザを操作します。
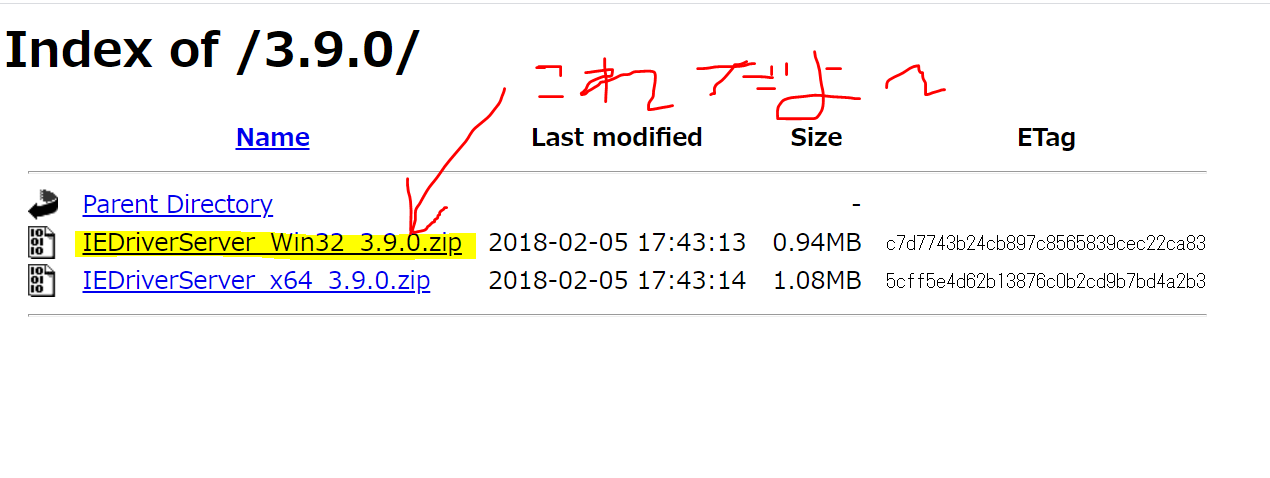
操作するためには、WebDriverというものが必要になります。下記のリンクからドライバーをインストールします。
http://selenium-release.storage.googleapis.com/index.html?path=3.9.0/
あとは、ブラウザやレジストリの設定がありますので、
こちらを参考に進めていきました。
SeleniumでInternet Explorer11を動かす方法
ブラウザの指定
driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe")このようにwebdriverのIEインスタンスを作成することによって
ブラウザを操作することが可能になります。
webdriverはPATHが通ったディレクトリに配置されていないと
実行に失敗してしまうので注意してください。例として、デスクトップの"Python"というフォルダ内に置いているので
上記のようにPATHを指定しています。ページを開く
Seleniumのget関数を使用して、指定したページのFullPATHを記述します。
driver.get("https://powergrid.chuden.co.jp/kisyo/")要素の指定
通常なら、find_element_by_~という関数で、適した属性
(xpath, id, cssSelecter, classNameなど)から要素を取得します。参考記事: Selenium Python Bindings
.しかし今回、取得したい地図画像は"iframe"という形で扱われていました。
iframeとは
別のWebページや画像などをあたかもページの要素の一つのように埋め込んで
一体的に表示することができるものです。
表示する内容はsrc属性でURLの形で指定されます。
よくある公式サイトにYouTubeの動画を表示させているあれも
iframeで構成されています。
なので、スクレイピングで画像取得できていなかったのは、
今まで要素を取得しようとしていた属性は、iframeを入れるための器であって
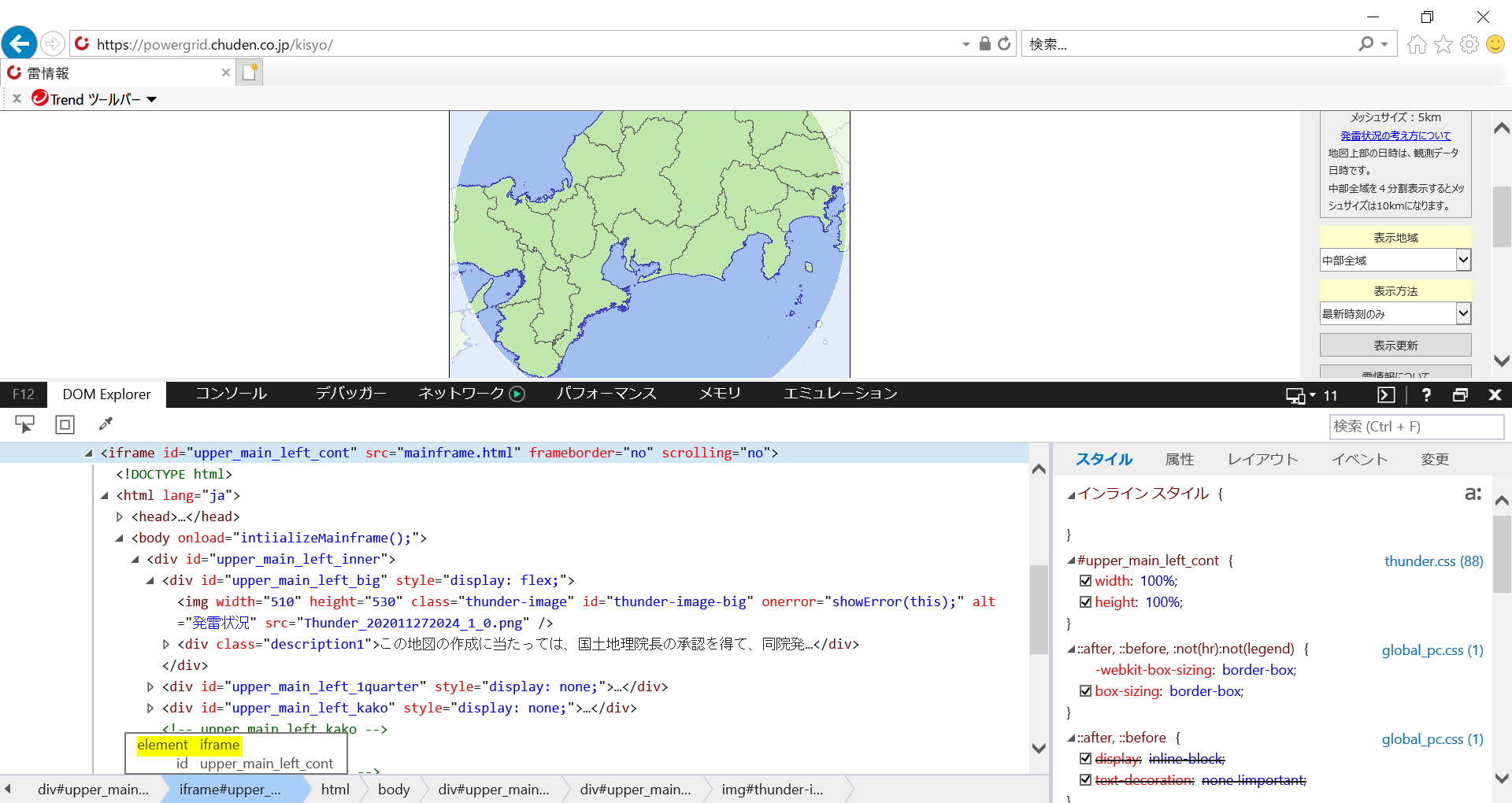
中身は空っぽだったからです。(間違っていたらご指摘願います)iframeを操作できるようにする
iframeは別ウィンドウとして扱われるので、
switch_to.frameを使ってiframe側に切り替える操作をします。iframe = driver.find_element_by_id('upper_main_left_cont') #対象のインラインフレームIDを取得 driver.switch_to.frame(iframe) #取得したインラインフレームにスイッチ要素を取得
前の操作で、iframeを切り替えて要素の取得が出来ます。
element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src")例として、cssセレクタを指定することで要素を取得しています。
他にもname属性やid属性などで指定が可能です。保存
保存するファイルのファイル名が被らないように、
要素を取得した時の日付をファイル名にして保存します。now = datetime.now() #現在時刻を取得 urllib.request.urlretrieve(element, now.strftime('%Y%m%d_%H%M%S') + '.png').
urlretrieveは、ファイルをダウンロードし保存する際に使用します。
urllib.request.urlretrieve(URL, 保存先のファイル名).
例として、URLにあたる場所にelementという変数を置いていますが、
前述でelementの中にはdriver.find_element…で取得してきたimgURLが既に入っています。element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src") print(element) >>>https://powergrid.chuden.co.jp/kisyo/Thunder_202011281715_1_0.png.
now.strftimeは現在時刻を字列への変換するメソッドです。
('%Y%m%d_%H%M%S')という記述は、書式化コードで
"西暦""何月""何日""何時""何分""何秒"と表示させます。さらに、拡張子を'.png'に指定して保存します。
上手に保存ができました。
参考記事



- 投稿日:2020-11-28T17:53:15+09:00
グーグルドライブAPIを使ってスプレッドシートをxlsxでダウンロード、pythonで
グーグルドライブAPIというものがありこれを使えばブラウザにアクセスしなくてもダウンロードできるぞと書いてあったが思いの外手こずったのでメモ
APIキーやOAuthを手に入れる方法は他にあるので割愛
また、コードはpythonで書く。
調べてみたところやれることはスコープによって変わるようだ# これでダウンロードや書き込み、読み込み、その他諸々が自由になる。 SCOPES = ['https://www.googleapis.com/auth/drive', 'https://www.googleapis.com/auth/drive.metadata.readonly']from googleapiclient.discovery import build from googleapiclient.http import MediaIoBaseDownload from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request def getfile(): """ ファイルをダウンロードするだけの簡単な関数。 """ with open('token.pickle', 'rb') as token: creds = pickle.load(token) service = build('drive', 'v3', credentials=creds) file_id = '1lllnzSFApok_umno0gsXotykBSjOOBgCr85F6gM1ed4' file_name = 'chatwork_test.xlsx' request = service.files().export_media(fileId=file_id, mimeType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet') fh = io.BytesIO() downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print("Download %d%%." % int(status.progress() * 100)) fh.seek(0) with open(os.path.join('./resultFile', file_name), 'wb') as f: f.write(fh.read()) f.close() if __name__ == '__main__': getfile()コードを見るとわかるように
request = service.files().export_media(fileId=file_id, mimeType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')ここの
mimeType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'でspreadsheetをexcelファイルに変換し、file_name = 'chatwork_test.xlsx' fh = io.BytesIO() # ファイルをバイナリで開く、エクセルファイルはバイナリだから downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print("Download %d%%." % int(status.progress() * 100))ここで実際にダウンロードを行うわけだがここの処理をよく理解していなかった。
このあたりの処理はいわゆるf.open('hoge', 'rb')しただけと大体一緒なのでその後に書き込む処理をしなければならなかったのだ。
つまり「ダウンロードしました(ダウンロードしたとはいってない)」と同じ状態なのである。したがって。fh.seek(0) with open(os.path.join('./resultFile', file_name), 'wb') as f: f.write(fh.read()) f.close()これらの処理が必要になる。
正直このfh.seek(0)の意味がよくわかっていない、参考になった動画
- 投稿日:2020-11-28T17:14:42+09:00
Djangoアプリにタグ機能を実装したメモ
はじめに
Django-girlsチュートリアル終了後のblogアプリに多対多のリレーションをもつタグモデルをつくる。postモデルは複数のタグを持ち、タグも複数のpostモデルを持っている状態を目指す。
前提
Django-girlsチュートリアルでpostモデルがすでに作成済み。
タグの登録等は管理画面上のみでおこなうので、テンプレートなどは作成しない手順
といっても2ステップしかない。
まず、タグモデルを作成する。TagモデルをPostモデルより上に定義。blog/models.pyclass Tag(models.Model): #tagモデルを新しく定義する name = models.CharField(max_length=200) def __str__(self): return self.name class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = MarkdownxField() created_date = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) tags = models.ManyToManyField(Tag) #この行を追加するマイグレーションを作成、適応させる
ターミナルMacBook djangoblog % python manage.py makemigrations blog Migrations for 'blog': blog/migrations/0005_auto_20201128_1608.py - Create model Tag - Add field tags to post MacBook djangoblog % python manage.py migrate blog Operations to perform: Apply all migrations: blog Running migrations: Applying blog.0005_auto_20201128_1608... OK管理画面にコメントモデルを登録する
admin.pyfrom django.contrib import admin from .models import Post, Comment, Tag #追加部分 from markdownx.admin import MarkdownxModelAdmin # 管理画面にpostモデルを登録 admin.site.register(Post, MarkdownxModelAdmin) # 管理画面にコメントモデルを登録 admin.site.register(Comment) # 管理画面にtagモデルを登録 #追加部分 admin.site.register(Tag)これで管理画面でtagの登録、削除などができるようになりました。
Postオブジェクトを選択すると、tagが選べるようにもなっているはずです。参考文献
https://docs.djangoproject.com/ja/3.1/topics/db/examples/many_to_many/
https://tutorial-extensions.djangogirls.org/ja/homework_create_more_models
- 投稿日:2020-11-28T17:14:42+09:00
Djangogirlsで作成したDjangoアプリにタグ機能を追加したメモ
はじめに
Django-girlsチュートリアル終了後のblogアプリに多対多の関係をもつTagモデルをつくる。
postモデルは複数のtagモデルを持ち、tagモデルも複数のpostモデルを持っている状態を目指す。前提
Django-girlsチュートリアルでpostモデルがすでに作成済み。
タグの登録等は管理画面上のみでおこなうので、テンプレートなどは説明しない手順
といっても2ステップしかない。
まず、タグモデルを作成する。TagモデルをPostモデルより上に定義。blog/models.pyclass Tag(models.Model): #tagモデルを新しく定義する name = models.CharField(max_length=200) def __str__(self): return self.name class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = MarkdownxField() created_date = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) tags = models.ManyToManyField(Tag) #この行を追加するマイグレーションを作成、適応させる
ターミナルMacBook djangoblog % python manage.py makemigrations blog Migrations for 'blog': blog/migrations/0005_auto_20201128_1608.py - Create model Tag - Add field tags to post MacBook djangoblog % python manage.py migrate blog Operations to perform: Apply all migrations: blog Running migrations: Applying blog.0005_auto_20201128_1608... OK管理画面にコメントモデルを登録する
admin.pyfrom django.contrib import admin from .models import Post, Comment, Tag #追加部分 from markdownx.admin import MarkdownxModelAdmin # 管理画面にpostモデルを登録 admin.site.register(Post, MarkdownxModelAdmin) # 管理画面にコメントモデルを登録 admin.site.register(Comment) # 管理画面にtagモデルを登録 #追加部分 admin.site.register(Tag)これで管理画面でtagの登録、削除などができるようになりました。
Postオブジェクトを選択すると、tagが選べるようにもなっているはずです。参考文献
https://docs.djangoproject.com/ja/3.1/topics/db/examples/many_to_many/
https://tutorial-extensions.djangogirls.org/ja/homework_create_more_models
- 投稿日:2020-11-28T16:58:17+09:00
pythonでメールを送信してみる
pythonでメールを送信してみる
参考元:https://kinsta.com/jp/blog/smtp-port/#what
pythonには、メールの送受信を扱うモジュールが用意されている
emailとsmtplibモジュールを使用してメール送信を試してみる。SMTPポートとは
(簡易メール転送プロトコル)の略で、インターネット上のメールを転送するための標準的なプロトコル。メールサーバーがインターネット上で送受信をするのにこれを使用する。
例えば、あなたがメールを送る時、あなたの利用しているメールクライアントは送信用のメールサーバーにメールをアップロードする手段が必要となります。その後、そのメールサーバーはメールの受取人の受信用のメールサーバーへメールを転送する手段が必要となります。メールサーバーは、表面上はユーザーに分かりやすいドメイン名が表示されつつ、実際のコミュニケーションは222.501.285.45といったIPアドレスで行われるという点では、ウェブサイトのサーバーとよく似ています(さらに詳しい仕組みが知りたいという方はDNS(ドメイン・ネーム・システム)の基本に関する記事をご覧ください)。
「ポート」はコンピューター同士(メールサーバー同士)が互いにコミュニケーションを取るためのもう一つの手段です。
* IPアドレスはコンピューターを識別します。
* ポートはSMTPなど、そのコンピューター上で動作している特定のアプリケーション/サービスを識別します。
もう少し分かりやすいように例を用いてご説明します。
IPアドレスはオフィスビルが位置する通りの名前を示します。ポートはそのオフィスビルの中の特定の会社を示す数字です。
その会社に何かを配送したい場合、そのオフィスビルの住所だけではなく、オフィスビルの中の正しい場所に届くよう、会社名まで指定する必要があります。
IPアドレスの割り当てなどを担う組織であるIANA(インターネット割当番号公社)は、SMTPを含め、一般的なインターネットサービスのポート番号の登録も担当しています。SMTPが重要な理由
SMTPサーバーに接続したい時、IPアドレスとポート番号の両方を入力する必要がある。しかし、一般的なSMTPポートは複数存在しその全てがどんな状況でも使用できるとは限らない。
例えば、メールサーバー間でメッセージのやり取りをするための標準的なSMTPポートである25番ポートは、しばしばISPやクラウドプロバイダー(Kinstaでも使用しているGoogle Cloud Platformを含む)にブロックされてしまいます。
このように、多くのサービスが25番ポートをブロックしているため、このポートを使用してSMTPサーバーに接続しようとすると問題が発生することが多いのです。目的に応じたポート
上記を別としても、それぞれのSMTPポートには異なる目的が存在する。
SMTPの伝達には2つの段階がある。サブミッション- 送信する側のメールサーバーにメールのメッセージを送るプロセス。例えばAplle Mailでメールを送る時、メッセージは送信側のメールサーバーに送られる必要がある。
- リレー– 2つのサーバー間でメッセージを転送するプロセスです。送信側のメールサーバーにメールが送られた後、そのメールサーバーは受取人のメールサーバーにメッセージを転送します。 メールクライアントもしくはWordPressサイトの設定をする場合、上記のうち主に「サブミッション」のプロセスについて気になるところでしょう。 「リレー」のプロセスがSMTPの重要な部分であることは間違いありませんが、多くの場合、自分のメールサーバーでの設定は不要です。
SMTPで使用されるポート
現代のインターネット上に存在するSMTPポートは1つではありません。一般的なSMTPポートは4つあります。
* 25
* 587
* 465
* 2525
それぞれ見ていきましょう。25番ポートの用途
25番ポートは1982年に作られたポートでSMTPポートの中で一番古いものです。
25番ポートは今でも標準的なSMTPポートとして知られていて、主にSMTPリレーに使用されます。
しかし、多くのISPやクラウドホスティングプロバイダーが25番ポートをブロックしていることから、WordPressサイトやメールクライアントのSMTPを設定する際は25番ポートを使わない方が良いでしょう。
これは、25番ポートは感染したコンピューターからスパムメールを送信するのに悪用されることが多いからです。
まとめ:SMTPのサブミッションとリレーのプロセスには違いがあります。25番ポートはリレーには適していますが、サブミッションには使用しない方が良いでしょう。587番ポートの用途
587番ポートは現代のインターネット上ではSMTPサブミッションに用いるデフォルトのポートとなっています。他のポートを使用することもできますが(詳しくは後ほどご紹介します)、まずは587番ポートをデフォルトで設定し、ほかのポートはやむを得ない場合(使用しているホスティングサービスがなんらかの理由で587番ポートをブロックしている場合など)のみ使用するようにしましょう。
587番ポートはTLSもサポートしているため、安心してメールを送信できます。465番ポートの用途
465番ポートはもともとSMTPS(SSL over SSL)に割り当てられていました。その後しばらくして、別の用途に割り当てられた後、非推奨となりました。
しかし、多くのISPやクラウドホスティングプロバイダーは今でもSMTPサブミッションに465番ポートをサポートしています。2525番ポートの用途
2525番ポートは(IETFやIANAに認証された)正式なSMTPポートではありません。しかし、587番ポートの代替手段としてSMTPサブミッションによく利用されるポートで、多くのISPやクラウドホスティングプロバイダーもこのポートをサポートしています。
587番ポートがブロックされている場合、2525番ポートを代わりに使うと良いでしょう。どのSMTPポートを使用すべきか
この問いへの答えについては既に触れてきましたが、非常に重要な点なので改めて正しいSMTPポートの選び方を確認しましょう。
SMTPでメールを送信するためにWordPressサイトやメールクライアントを設定する場合、まずは587番ポートを選択しましょう。これはサブミッション用のデフォルトのSMTPポートであり、TLSを用いた安全な伝達に対応しています。
何らかの理由により587番ポートがブロックされている場合は2525番ポートを代わりに使用するのが一般的です。このポートは正式に認証されたSMTPポートではありませんが、一般的に使われているポートで、多くのプロバイダーがサポートしています。
多くのプロバイダーが今でも465番ポートをサポートしていますが、今では推奨されていないスタンダードなので、465番ポートを使用する前にまずは587番ポート、もしくは2525番ポートを使用しましょう。
最後に25番ポートはSMTPリレーには一般的に使用されますが、多くのISPやクラウドホスティングプロバイダーはこのポートをブロックしているため、メールクライアントやWordPressサイトの設定を行う際には使用してはいけません。まとめ
SMTPはインターネット上のメールの送受信において重要な役割を果たします。
WordPressサイトのトランザクションメールが正しく配信されるようにするためには、SMTPでメールを送信できるような設定をWordPressで行うことができます。また、Apple MailやOutlookなどのメールクライアントを使用する場合、送信メールをメールサーバーへ送信するのにSMTPが使用されます。
WordPressサイトやメールクライアントをSMTPサーバーに接続するにはSMTPポートの入力が必要となります。
一般的なSMTPポートは4つあります。
* 25
* 587
* 465
* 2525
25番ポートはSMTPリレーに一般的に使用されますが、多くのプロバイダーはこのポートをブロックしているので、SMTPサブミッションには使用してはいけません。
WordPressサイトやメールクライアントでSMTPの設定を行う場合は、まずはSMTPサブミッションの標準的なポートである587番ポートを選びましょう。
587番ポートで接続できない場合は、2525番ポートを試してみましょう。公式なSMTPポートではありませんが、広くサポートされているポートであり、安全な伝達のためにTLSが使用されています。
- 投稿日:2020-11-28T16:52:16+09:00
今日の積み上げ python 学習記録#2 + {}[]キーの位置知らんかった人向け(笑)
本日の学習15:00~16:30
15:30からprogate有料版のpython編を引き続きやってましたが僕にとっては重大なことを発見しましたのでメモ代わりに記事を上げときます。
プログラミングしている方やパソコンスキルがある方や無い方でも僕以外の人間であればもしかしたら当たり前すぎな事だと失笑されるかもしれません(失笑)
excelVBAは多少経験があって() 丸括弧というのでしょうか?これはVBAの時でもrange("A1")のようによく使用していたのでpythonでも何も問題は無かったのですが問題はこれ➡[[[[[]]]]]]]{{{{{{{}}}}}}}}
角括弧、波括弧というのでしょうか?リストや辞書を作るときに使用するあれです!今までこの二つを使用するときは全角モードにして一々shift+8を押して候補から選んでました(笑)
知らないって恐ろしいですね、pythonの勉強を初めておそらく合計30時間くらい経ちましたが今までエンターの左側にあるのを気付かずに上記の方法でずっとやってました。youtubeやUdemyで講師の方達がこの括弧をうつのが早すぎて僕はセンスが無いわ~って思ったりこれがめんどくさくてめんどくさくていつか挫折する時はこれが原因一位やなって思ってました。
いや、ぐぐれよって話でしょうけど常識的すぎて記事がみつからなかったんです~(笑)
万が一僕と同じような人いたらいけないのと、僕が忘れたらいけないので記事上げときます。引き続き学習頑張ります!!
- 投稿日:2020-11-28T16:49:23+09:00
AWS LambdaからPythonを実行してみた
やったこと
AWSの勉強がてら、「QiitaマイページからLGTM / View / ストック数の一覧を確認できるようにしてみた」で作ったpythonファイルをAWS Lambdaから定期実行できるようにしてみました。
(過去記事ではHerokuで定期実行させていました)ちょうど同じ時期にAWS Lambdaでpythonプログラムの定期実行という記事が上がっていたので、全体の流れはこちらを参考にさせていただきました。
ところどころ追加で調べた箇所があるので、この記事はそちらをメインにした内容になります。
また例によって、AWSアカウントは作成済みとします。ちなみに料金の方は
AWS Lambda の無料利用枠には、1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間が、それぞれ含まれます。
とあるので今回のように1日1回程度のリクエストであれば問題ないだろうと一安心。
(今のところ基本無料でやりたいので、一応8$を超えたらアラートが飛ぶようにしています)作成したLambda関数の内容
- ランタイム:python 3.8
- トリガー:毎朝7時に実行
- 外部モジュール(pytz, requests)を使用
- タイムアウト時間:30秒
- その他:初期値のまま
ソースコード
おおむね同じですが、前回と比較して以下を変更しています。
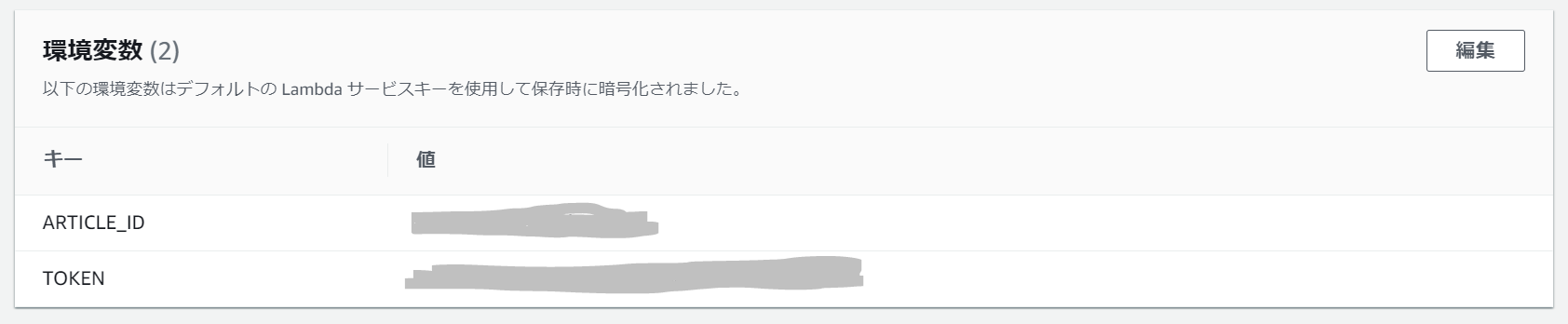
- Qiitaのアクセストークンや記事IDをべた書き⇒環境変数から読み込む
if __name__ == "__main__":
⇒def lambda_handler(event, context):
※lambda_handler:Lambda関数から最初に呼ばれる関数名
ソースコード
lambda_function.pyimport os import http.client import json import requests import datetime import pytz TOKEN = os.environ['TOKEN'] # Read&Write用 HEADERS = {'content-type': 'application/json', 'Authorization': 'Bearer ' + TOKEN} URL_BASE = 'https://qiita.com/api/v2' ARTICLE_ID = os.environ['ARTICLE_ID'] # 記事一覧のLGTM, View, ストック数を取得する def get_info(): url_authenticate = URL_BASE + '/authenticated_user/items' # 記事一覧を取得 res = requests.get(url_authenticate, headers=HEADERS) list = res.json() # 不要な記事を除外 list_item = [] for item in list: # 限定記事は対象外 if item['private']: continue # 投稿先の記事は対象外 if item['id'] == ARTICLE_ID: continue list_item.append(item) num = 0 list_iteminfo = [[0 for i in range(5)] for j in range(len(list_item))] for item in list_item: # 各種項目を取得 id = item['id'] title = item['title'] url = item['url'] likes_count = item['likes_count'] # 記事の情報を取得 url_item = URL_BASE + '/items/' + id res = requests.get(url_item, headers=HEADERS) json = res.json() # タイトル別のview数のセット page_views_count = json['page_views_count'] i = 1 # stock数の取得(最大1000件) while i < 10: url_stock = url_item + '/stockers?page=' + str(i) + '&per_page=100' res_stock = requests.get(url_stock, headers=HEADERS) json_stock = res_stock.json() stock_num = len(json_stock) if stock_num != 100: stock_count = (i * 100) - 100 + stock_num break else: i += 1 list_iteminfo[num] = [title, url, likes_count, page_views_count, stock_num] num += 1 return list_iteminfo # 記事を更新する def update_article(list_iteminfo): item = { 'body': '', 'coediting': False, 'private': False, 'tags': [{'name': 'qiita'}], 'title': '投稿記事のLGTM, View, ストック数一覧' } # 本文の作成([記事タイトル](URL), LGTM数, View数, ストック数) now = datetime.datetime.now(pytz.timezone('Asia/Tokyo')) setdate = now.strftime('%Y/%m/%d %H:%M:%S') body = 'この記事は [' + setdate + '] に更新されました。\r\n' for info in list_iteminfo: body += '\r\n[' + str(info[0]) + '](' + str(info[1]) + ')' body += '\r\nLGTM:' + str(info[2]) + '件, View:' + str(info[3]) + '件, ストック:' + str(info[4]) + '件\r\n' item["body"] += body url = URL_BASE + '/items/' + ARTICLE_ID # 記事の更新 res = requests.patch(url, headers=HEADERS, json=item) return res def lambda_handler(event, context): list_iteminfo = get_info() res = update_article(list_iteminfo) print(res)追加で調べたこと
環境変数の設定
Qiitaのアクセストークンなどを環境変数に設定したかったのですが、コードやデザイナと同じページの「環境変数」欄の編集ボタンから簡単に編集ページへ遷移できました。
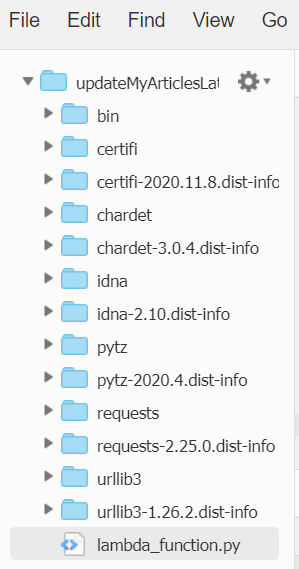
外部モジュールの配置方法
初めは単純に実行対象となる
lambda_function.pyのみを配置しましたが、
"errorMessage": "Unable to import module 'lambda_function': No module named 'requests'"
とエラーになってしまいました。どうやら外部モジュールがある場合、自分で読み込ませる必要がある様子。
こちらを参考に、ローカル環境でlambda_function.pyと同階層に対象のモジュール(pytz, requests)をpipでインストールし、zip化してアップロードしました。
アップロード後は下記のようにモジュールが展開されました。
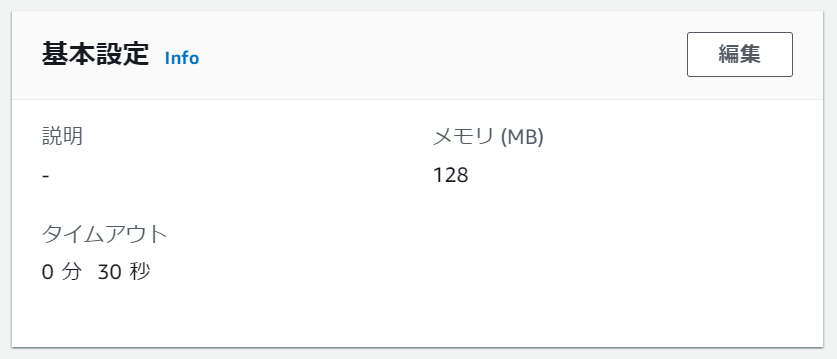
タイムアウト時間の変更
外部モジュールも無事読み込め、これで実行成功!と思いきや、今度は
Task timed out after 3.00 seconds
というエラーが発生しました。
初期設定だと実行時間が3秒を超えるとタイムアウトしてしまうので、こちらの設定を変更します。
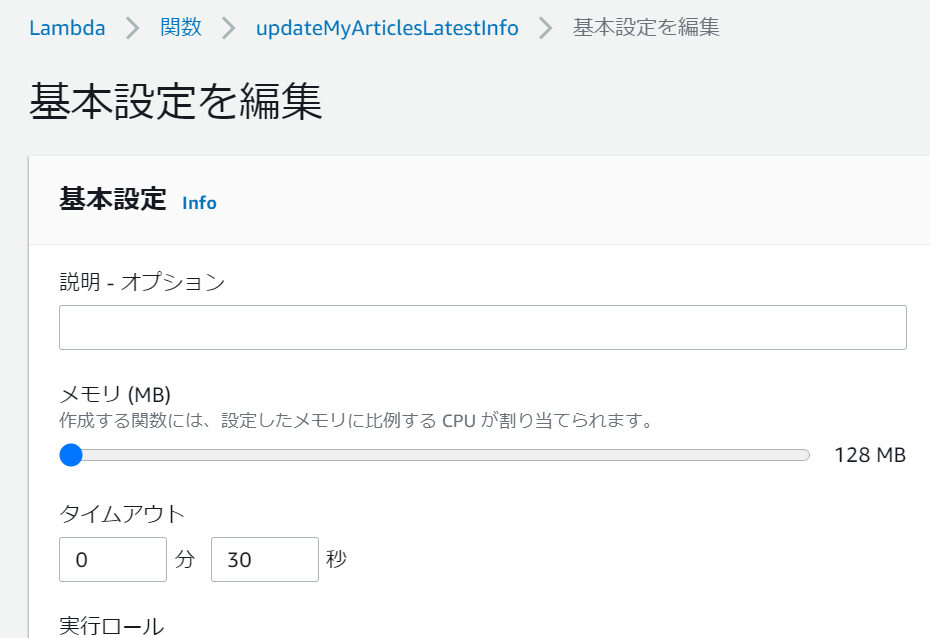
環境変数の設定同様、今度は「基本設定」欄の編集ボタンから編集ページへ遷移し、設定値を30秒に変更しました。
最後に
Lambda、思ってたより簡単。
次はサーバー立てたり、いろいろ試したくなりました。参考
AWS Lambdaでpythonプログラムの定期実行
AWS Lambda 環境変数の使用
AWS_Cron式のワイルドカード
AWS Lambdaで「No module named 'pytz'」エラーが発生したときの対処方法
【AWS】Lambdaでtime out after 3.00 secondsが出たときの対処法
- 投稿日:2020-11-28T16:45:32+09:00
除外リスト
- 投稿日:2020-11-28T16:30:31+09:00
python from import*使い方を解説
python from import*使い方を解説
importとは、別のファイル(モジュール)に記載されたpythonコードを取り込む機能のこと。
以下のようなファイルamod.pyがあるとする
def a_method():
pass
a_var = None別のファイルbprog.pyでは、以下のようにamod.pyのメソッドや変数を参照できる。
pythonには、公式、サードパティ製のモジュールが多数存在し、多様な機能を提供している。
プログラムの冒頭でモジュールをインポートすることでそれらモジュールを活用できる。「from import 」の意味は?
上述のように、 ., . のような記法で、モジュールのメソッドや変数を参照できます。
さらに、 from import , from import という記法を用いると、モジュール名を省略できるようになります。
from amod import a_method
from amod import a_var
a_method()
a_var
加えて 「」(ワイルドカード)を用いると、モジュール内で定義されているメソッドや変数をまとめてインポートできます。
from amod import *
a_method()
a_var
- 投稿日:2020-11-28T16:08:47+09:00
[Python] クラス メモ
単語帳=毎回検索するのが面倒なので転載多め.元URLあり.
主に自作クラス関連.クラスの定義
抽象クラス
テンプレート
from abc import ABCMeta, abstractmethod # 抽象クラス class AbstClass(metaclass=ABCMeta): @abstractmethod def my_abstract_method(self): pass @property @abstractmethod def my_abstract_property(self): passQiita@kaneshin: PythonのABC - 抽象クラスとダック・タイピング
stackoverflow: How to create abstract properties in python abstract classes※親クラス (含抽象クラス) ではメソッドの引数の個数などを拘束できない
(オーバーライドすると,サブクラスでの定義が優先される)from abc import ABCMeta, abstractmethod class AbstClass(metaclass=ABCMeta): @abstractmethod def mymethod(self, arg1, arg2): pass class SuperClass: def mymethod(self, arg1, arg2): pass class MyClass(AbstClass): #class MyClass(SuperClass): 同じく拘束できない def __init__(self): pass def mymethod(self, arg1): print(arg1) obj = MyClass() obj.mymethod(1) obj.mymethod(1, 2) # TypeError: mymethod() takes 2 positional arguments but 3 were givenstackoverflow: Abstract classes with varying amounts of parameters
class MyClass(object):の(object)は省略可能 (Python3のみ)元々クラスには2種類 (Python2.1以前と以降) の2種類があり,
Python2だと(object)を
- 明記: 新スタイル
- 省略: 旧スタイル,
@propertyのsetterが動かなかったりとして区別される.Python3では新スタイルに統一されている.
Qiita@alt-core: Python2.7で class C: と class C(object): の違いに大ハマりした話
クラスのキャスト
メソッド
特殊メソッド
公式: 3. Data model > 3.3. Special method names
__contains(self, item)__:item in selfstackoverflow: Override Python's 'in' operator?
文字列による動的なメソッドの呼び出し
getattr(オブジェクト, 'メソッド名')(引数)でOK.adict = {'a': 1} getattr(adict, 'get')('a', None)クラス/インスタンスに後からメソッドを追加する
def fooFighters(self): print "fooFighters" A.fooFighters = fooFighters # クラス自体にfooFightersメソッドを追加 a.barFighters = types.MethodType(barFighters, a) # インスタンスだけにbarFightersメソッドを追加 a.barFighters = barFighters # これではselfが使えない (単なるプロパティとして追加されてしまう→メソッドだとは思われない)stackoverflow: Adding a Method to an Existing Object Instance
Ian Lewis: Pythonでメソッドをクラスまたはインスタンスに動的に追加するインスタンスへの追加に
setattrを使う時methods = [method0, method1] for method in methods: setattr(obj, method.__name__, types.MethodType(method, obj))※これらの方法は特殊メソッドには適用不可
e.g.__add__をあるobjに追加すると,obj.__add__(item)はできてもobj + itemは不可
上記はインスタンスにメソッドを追加するが,特殊メソッドを追加・上書きするにはクラスでの定義自体を変更する必要がある.
stackoverflow: Setting special methods using setattr()
stackoverflow: Overriding special methods on an instanceイテレータの実装
Qiita@tchnkmr: [Python] イテレータを実装する
デコレータ
classmethod, staticmethod
DjangoBrothers: 【Python】インスタンスメソッド、staticmethod、classmethodの違いと使い方
property
Effective Pythonに
その他
getattr(obj, attr_name, default_value)attributeが存在しないときにはデフォルト値を返す
import datetime as dt a = dt.date(2000, 1, 1) print(a.year) print(getattr(a, 'years', 'not found'))あるオブジェクトがiterableか確認
from collections.abc import Iterable # drop `.abc` with Python 2.7 or lower isinstance(obj, Iterable)stackoverflow: In Python, how do I determine if an object is iterable?
時々紹介されている
hasattr(obj, '__iter__')は必ずしも正しくない.
イテレータは__iter__ではなく__getitem__でも動作するからである.
(但し,__getitem__はint以外でも動作するため,__getitem__があるからiterableだ,というのは誤り.)
- 投稿日:2020-11-28T15:22:51+09:00
【備忘録】Jupyter notebookで複数カーネルを設定する方法
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は自分の備忘録として記事に残しておきます。
はじめに
複数人で開発する際にMinicondaによる仮想環境を作成して開発することがあります。その中で、Jupyter notebookでなぜかカーネルを上手く設定できないことがありましたので、自分でカーネルを簡単に変更できる方法を備忘録として残しておきます。
手順
仮想環境の作成
condaを使って仮想環境を作成します。下記コードで簡単に設定できます。
# conda create -n 環境名 $ conda create -n env $ conda info -e下記のように仮想環境(env)が簡単に作れます。
base * /Users/opt/anaconda3 env /Users/opt/anaconda3/envs/envJupyter notebookへカーネルを設定する方法
先ほど構築した仮想環境をカーネルに追加します。仮想環境をactivateにして、下記コードで簡単に設定できます。
# conda activate 仮想環境名 $ conda activate env # jupyter notebookへカーネルを追加 $ ipython kernel install --user --name=env --display-name=env下記にオプションを整理しておきます。
オプション 内容 --user ・現在ログイン中のユーザーにインストール --name NAME ・カーネルスペックの名前を指定 --display-name NAME ・表示されるカーネルの名前を指定
- 投稿日:2020-11-28T13:10:29+09:00
AWS LambdaでPython3.8のOpenCVをする
https://qiita.com/clerk67/items/33c5eee07834b947cbb1
上記のリンクを参考にopenCVをLambdaに乗っけようとしました。
普通のpip install -tじゃダメだったのでDockerでopencvのビルドからやったらうまくいきました。手順
まずはDockerfileを作る
DockerfileFROM lambci/lambda:build-python3.8 ENV OPENCV_VERSION 4.5.0 RUN git clone https://github.com/opencv/opencv.git RUN git clone https://github.com/opencv/opencv_contrib.git RUN mkdir opencv/cache/xfeatures2d/boostdesc -p RUN mkdir opencv/cache/xfeatures2d/vgg -p WORKDIR opencv/cache/xfeatures2d/boostdesc RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_lbgm.i > boostdesc_lbgm.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_binboost_256.i > boostdesc_binboost_256.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_binboost_128.i > boostdesc_binboost_128.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_binboost_064.i > boostdesc_binboost_064.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_bgm_hd.i > boostdesc_bgm_hd.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_bgm_bi.i > boostdesc_bgm_bi.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_bgm.i > boostdesc_bgm.i WORKDIR ../vgg RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/fccf7cd6a4b12079f73bbfb21745f9babcd4eb1d/vgg_generated_120.i > vgg_generated_120.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/fccf7cd6a4b12079f73bbfb21745f9babcd4eb1d/vgg_generated_64.i > vgg_generated_64.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/fccf7cd6a4b12079f73bbfb21745f9babcd4eb1d/vgg_generated_48.i > vgg_generated_48.i RUN curl https://raw.githubusercontent.com/opencv/opencv_3rdparty/fccf7cd6a4b12079f73bbfb21745f9babcd4eb1d/vgg_generated_80.i > vgg_generated_80.i WORKDIR ../../../ RUN cp ./cache/xfeatures2d/boostdesc/* ../opencv_contrib/modules/xfeatures2d/src/ RUN cp ./cache/xfeatures2d/vgg/* ../opencv_contrib/modules/xfeatures2d/src/ RUN ls -l /var/task/opencv_contrib/modules/xfeatures2d/src/ RUN yum install -y cmake3 RUN pip install --upgrade pip&& pip install numpy RUN mkdir build RUN cp -r modules/features2d build WORKDIR build RUN cmake3 \ -DBUILD_SHARED_LIBS=NO \ -DCMAKE_BUILD_TYPE=RELEASE \ -DCMAKE_INSTALL_PREFIX=../../python \ -DOPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules \ -DPYTHON3_EXECUTABLE=/var/lang/bin/python .. \ && make install RUN find ../../python/lib/python3.8 -name *.so | xargs -n 1 strip -s RUN mkdir /var/task/dist RUN cp ../../python/lib/python3.8/site-packages/cv2/python-3.8/* /var/task/dist WORKDIR /var/task/dist RUN pip install numpy -t . RUN mkdir /var/task/output CMD cp -r /var/task/dist/ /var/task/output/そしてそのDockerfileのある場所で
docker build . -t LambdaCVContainer docker run --rm -v "{PWD}":/var/task/output LambdaCVContainerでうまくいくはずでする。
おまけ
dockerでのビルドめっちゃ時間かかったのですぐ使いたい人ようにビルド済みのパッケージ置いておきます。
git clone https://github.com/misogihagi/lambda-opencv.git cd lambda-opencvあとはdistいかにあるlambda_function.pyをいじればopencvは使えるようになるはず
- 投稿日:2020-11-28T11:52:59+09:00
LeetCodeに毎日挑戦してみた 35. Search Insert Position(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
10問目(問題35)
35. Search Insert Position
- 問題内容
Given a sorted array of distinct integers and a target value, return the index if the target is found. If not, return the index where it would be if it were inserted in order.
(日本語訳)
個別の整数のソートされた配列とターゲット値が与えられた場合、ターゲットが見つかった場合はインデックスを返します。そうでない場合は、順番に挿入された場合のインデックスを返します。
**
Example 1:
Input: nums = [1,3,5,6], target = 5 Output: 2Example 2:
Input: nums = [1,3,5,6], target = 2 Output: 1Example 3:
Input: nums = [1,3,5,6], target = 7 Output: 4Example 4:
Input: nums = [1,3,5,6], target = 0 Output: 0Example 5:
Input: nums = [1], target = 0 Output: 0考え方
バイナリーサーチを使って実装しました
midとターゲットを比較して二分探索していきます
範囲を絞っていき、見つかったらreturnします
- 解答コード
def searchInsert(self, nums, target): # works even if there are duplicates. l , r = 0, len(nums)-1 while l <= r: mid=(l+r)/2 if nums[mid] < target: l = mid+1 else: if nums[mid]== target and nums[mid-1]!=target: return mid else: r = mid-1 return l
- Goでも書いてみます!
func searchInsert(nums []int, target int) int { l := 0 r := len(nums) - 1 for (r >= l) { mid := l + (r - l) / 2 if (nums[mid] == target) { return mid } else if (nums[mid] > target) { r = mid - 1; } else { l = mid + 1; } } return l }