- 投稿日:2020-11-28T23:30:21+09:00
Java ArrayListクラス 使い方
はじめに
学習用のメモになります。
ArrayListとは?
ArrayListは複数の要素を入れるための入れ物ようなもの
ArrayListと配列の違い
配列には格納できる要素の大きさが決まっています。その為、あらかじめ決めた大きさを超える要素を格納すると、IndexOutOfBoundsExceptionエラーが発生します。ArrayListは要素数の大きさが決まっていません。要素数の上限値を気にせず、どんどん値を追加できます。ArrayListを使う
import java.util.*; public class Main { public static void main(String[] args) { ArrayList<String> team = new ArrayList<String>(); team.add("勇者"); team.add("魔法使い"); for (String member : team) { System.out.println(member); } } }ArrayListを作成
import java.util.*; ArrayList<String> team = new ArrayList<String>();ArrayListの要素を追加
team.add("勇者"); team.add("魔法使い");
addで要素を追加ArrayListの要素をループする
for (String member : team) { System.out.println(member); }ArrayListの要素を出力
System.out.println(team.get(0));
getで要素を出力ArrayListのサイズを出力
System.out.println(team.size());
sizeで要素の長さを出力ArrayListの要素の更新
team.set(1, "忍者");
setで追加ArrayListの要素の削除
team.remove(1);
removeで削除
- 投稿日:2020-11-28T20:13:58+09:00
[Java]StringBuilder、StringBuffer、プラス演算子、concat、joinによる文字列結合の処理速度比較
文字列を結合する方法は色々あるけど「StringBuilder」か「StringBuffer」が推奨されているみたいなので、「StringBuilder」と「StringBuffer」とそれ以外でどのくらい処理速度が違うのか比較してみた。
比較したのは「StringBuilder」「StringBuffer」「プラス演算子」「concat」「join」で、"1"から"10000"までを文字列結合したときの処理速度を比較してみた。結果から見てみると、
StringBuilder StringBuffer プラス演算子 concat join 2ms 3ms 208ms 102ms 8ms となり、ほぼ予想通りでStringBuilderとStringBufferがダントツで早くプラス演算子とconcatが遅かったが、Listに詰める処理とか入ってるjoinが思いのほか早かった。
また、測定した各結合処理のコードは以下の通り。StringBuilder.javapublic static void main(String[] args) { String st = ""; long startTime = System.currentTimeMillis(); StringBuilder sbi = new StringBuilder(); for(int i = 0; i < 10000; i++) { sbi.append(String.valueOf(i+1)); } st = sbi.toString(); long endTime = System.currentTimeMillis(); System.out.println("文字列長さ:" + st.length()); System.out.println("処理時間:" + (endTime - startTime) + "ms"); }StringBuffer.javapublic static void main(String[] args) { String st = ""; long startTime = System.currentTimeMillis(); StringBuffer sbf = new StringBuffer(); for(int i = 0; i < 10000; i++) { sbf.append(String.valueOf(i+1)); } st = sbf.toString(); long endTime = System.currentTimeMillis(); System.out.println("文字列長さ:" + st.length()); System.out.println("処理時間:" + (endTime - startTime) + "ms"); }StringPlus.javapublic static void main(String[] args) { String st = ""; long startTime = System.currentTimeMillis(); for(int i = 0; i < 10000; i++) { st = st + String.valueOf(i+1); } long endTime = System.currentTimeMillis(); System.out.println("文字列長さ:" + st.length()); System.out.println("処理時間:" + (endTime - startTime) + "ms"); }StringConcat.javapublic static void main(String[] args) { String st = ""; long startTime = System.currentTimeMillis(); for(int i = 0; i < 10000; i++) { st = st.concat(String.valueOf(i+1)) ; } long endTime = System.currentTimeMillis(); System.out.println("文字列長さ:" + st.length()); System.out.println("処理時間:" + (endTime - startTime) + "ms"); }StringJoin.javapublic static void main(String[] args) { String st = ""; long startTime = System.currentTimeMillis(); List<String> list = new ArrayList<String>(); for(int i = 0; i < 10000; i++) { list.add(String.valueOf(i+1)); } st = String.join("", list); long endTime = System.currentTimeMillis(); System.out.println("文字列長さ:" + st.length()); System.out.println("処理時間:" + (endTime - startTime) + "ms"); }
- 投稿日:2020-11-28T19:03:32+09:00
続・Servlet + Apache FOP で動的に PDF を作成して Web サイトに表示してみるサンプル (+Lombok)
前回の投稿 は Apache FOP を用いて、JSP/Servlet サイトで PDF を動的に生成して表示するまでを試しました。日本語の表示がちょっと厄介でしたね。
Qiita 上でイイネ!(LGTM)はゼロなのですが、知り合いからは反応があったので、もうちょっと進めてみます。コードは apache-fop-jp-sample リポジトリ にあります。
今回のネタ
さて、具体的には以下のような感じの拡張を試してみます。
- 入力値からデータ用 xml をダイレクトに生成してるけど、DB から取ってこれますか
- フォーマット指定がファイル読み込みだけど、これも DB から取ってこれますか
- サンプルがシンプルすぎるけど、説明レターとか請求書的なやつもちゃんと作れそうですか
- 説明レターなどたまに更新されるのですが、版管理とかできますかね
なかなか具体的で、すごく業務寄りの拡張でありまして。これ全部実装したら、お金貰っても良いんじゃね?レベルかもしれない。まあ、気楽に趣味の範囲で対応してみますー。
DB アクセス
Java での DB アクセスって、結局は以下の2つを設計・実装することだと思います。
- データ構造を表現する DTO (Data Transfer Object) クラスの定義
- データを提供する DAO (Data Access Object) クラスの定義
DTO を設計するということは、RDB のテーブルを定義すること、DDL を用意するのと同じレイヤです。また DAO を設計・実装するということは、そのテーブルへのアクセスを定義すること、SQL を用意するのと同じレイヤです。
そして今回は DTO 作成を主に試します。DAO は実際に DB アクセスせず、それをエミューレートするだけに。いわゆるスタブ、モック的な実装ですね。というのも、DB アクセス部分は古典的で、今更試すことは少ないからです。
DTO 定義に Lombok を使ってみる
DTO クラスは setter/getter ばかり並ぶコードになります。せっかくなので、前から気になっていた Lombok を使ってみましょう。アノテーション付けると setter/getter を自動的に生成してくれるやつ。
興味ない人、ここはスキップしてもokです。そのかわり setter/getter は自分で実装してください。まあ Eclipse なら自動生成できますので、そんなに大変ではないハズ。
この解説ページ を参考に最新版の Version 1.18.16 をダウンロードしたのですが、残念ながらインストールに失敗します。
Fail to install lombok-1.18.14.jar in Eclipse Version: 2020-09 (4.17.0) とか読むと、Version 1.18.12 以前を推奨しているみたいですね。なので素直に 1.18.12 を使います。
あとはプロジェクトの CLASS PATH に lombok-1.18.12.jar を追加して、念のためリビルドすればokなハズ。【追記】後で読み返してみたら、1.18.16 でもインストール成功している!問題あるのは 1.18.14 だけみたいですね… 早とちりでしたw
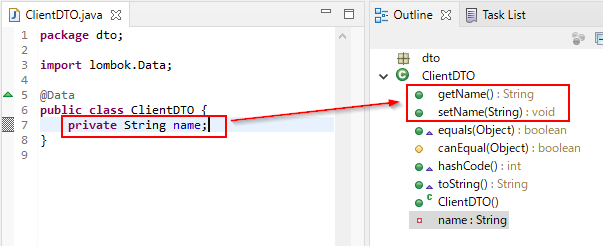
以下がインストール後の様子。name というインスタンス変数を定義しただけで、対応する setName/getName メソッドが自動生成されるのがわかります。これは便利!
これ、アノテーションプロセッサで AST 変換して実現しているハズです。コンパイル時にこれら setName/getName メソッドが追加されており、生成された Java Class は通常と変わらないと思われます。つまり、Lambok は開発環境だけにあれば良くて、生成された実行クラスは Lambok には依存しない。配布時に lambok*.jar が無くても大丈夫、なハズ。
DTO クラスを定義
さて、それっぽい DTO クラスを定義しておきましょう。まずはシンプルな顧客データ。
dto/ClientDTO.javapackage dto; import lombok.Data; @Data public class ClientDTO { public ClientDTO(long id, String name, int age) { super(); this.id = id; this.name = name; this.age = age; } private long id; private String name; private int age; }そしてシンプルな表示用フォーマット用の DTO です。最初の定義部分と、コンストラクターは省略しました。
dto/DocumentDTO.javapublic class DocumentDTO { private Date start; private String name; private String format; }DAO クラスを定義
えーっと、まずは顧客用の DAO なのですが、DB アクセスどころか… めっちゃ手抜きして、とりあえずは以下のように定義しますw
dao/ClientDAO.javapackage dao; import dto.ClientDTO; public class ClientDAO { public static ClientDTO getClient(long id) { return new ClientDTO(id, "name of " + id, 10 + (int)id); } }そして表示用フォーマット用の DAO です。3つのフォーマットを用意します。それぞれのフォーマット用の文字列(前回の変換設定に該当する) は後で実装します。
dao/DocumentDAO.javapackage dao; import java.util.Date; import dto.DocumentDTO; public class DocumentDAO { private static DocumentDTO[] documents = { new DocumentDTO(new Date(0), "sample1", "<ここは後で>"), // フォーマットその1 new DocumentDTO(new Date(0), "sample2", "<ここは後で>"), // フォーマットその2 new DocumentDTO(new Date(), "sample2", "<ここは後で>"), // フォーマットその2の新しい版 }; public static DocumentDTO getDocument(Date start, String name) { DocumentDTO ret = null; for (int l=0; l < documents.length; l++) { DocumentDTO doc = documents[l]; if (doc.getName().equals(name) && (start == null || start.compareTo(doc.getStart()) >= 0)) { if (ret == null || ret.getStart().compareTo(doc.getStart()) < 0) { ret = doc; } } } return ret; } }ここで重要なのが start 日付で、これを 版管理 に用います。表示用フォーマットを入手する際に「name が同じで start 日付が指定より後」を探すことで、その日時用の版のフォーマットが得られるわけです。条件に合うものが複数あった場合は、最も新しい版を使用します。
はじめの2つで
new Date(0)としているものは 1970年1月1日、つまりだいぶ昔を指定しています。それに対して最後のnew Date()は新しい日付、実行時の日時を指定しています。上記の Java のコードで for ループで探している部分、実際に SQL で用意すると例えば以下のような感じですかね。
SELECT format FROM Documet_table WHERE name = ? AND start >= ?;前回のサンプルを更新しよう
まずは少し改善
前回は時間がなくて sample.xsl に無駄があったので、まずは必要そうな要素だけに整理してみます。以下のような感じでしょうか。
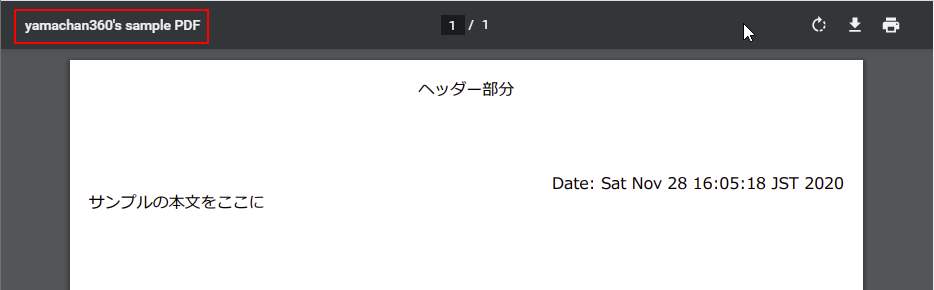
sample.xsl<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format" version="1.0"> <xsl:output encoding="UTF-8" indent="yes" method="xml" standalone="no" omit-xml-declaration="no" /> <xsl:template match="users-data"> <fo:root language="ja"> <fo:layout-master-set> <fo:simple-page-master master-name="simpleA4" page-height="29.7cm" page-width="21cm" margin-top="2cm" margin-bottom="2cm" margin-left="2cm" margin-right="2cm"> <fo:region-body /> </fo:simple-page-master> </fo:layout-master-set> <fo:page-sequence master-reference="simpleA4" font-family="Meiryo,Hiragino"> <fo:flow flow-name="xsl-region-body"> <fo:block text-align="center" margin-bottom="20mm"> ヘッダー部分 </fo:block> <fo:block text-align="right"> Date: <xsl:value-of select="date" /> </fo:block> <fo:block> <xsl:value-of select="body" /> </fo:block> </fo:flow> </fo:page-sequence> </fo:root> </xsl:template> </xsl:stylesheet>生成される PDF は以下のようになります。
また Servlet コードも PDF の属性をセットできるよう修正します。pdfServlet.javaFOUserAgent userAgent = fopFactory.newFOUserAgent(); userAgent.setTitle("yamachan360's sample PDF"); //Fop fop = fopFactory.newFop(MimeConstants.MIME_PDF, out); Fop fop = fopFactory.newFop(MimeConstants.MIME_PDF, userAgent, out);これで以下のように PDF のタイトルが指定できました。
他にもuserAgentを用いて PDF の作成日や作成者などを指定可能です。詳しくは英語ですが マニュアル を参照してください。入力画面の修正
入力画面の項目を増やします。文書フォーマット、日付、顧客コードを追加しました。ボディテキスト入力も残してあります。
細かな修正としては、フォーム送信 method を GET から POST に変更しました。URL にデータ残すのも宜しくないですし。
これら変更は本質的ではないため、説明は省きますね。GitHub: index.html の html コードを参照すれば中身は理解いただけるとおもいます。
ClientDAO を利用するよう Servlet を修正
入力画面から顧客コードを得られるようになったので、Servlet 側でそれを利用するよう修正します。また作成するデータ用 xml に得られた値を埋め込みます。
pdfServlet.javalong i_ccode = Long.parseLong(request.getParameter("i_ccode")); ClientDTO client = ClientDAO.getClient(i_ccode); String xmlData = "<?xml version=\"1.0\" encoding=\"UTF-8\"?><?xml-stylesheet type=\"application/xml\"?>" + "<users-data>" + "<date>" + (new Date()).toString() + "</date>" + "<cname>" + client.getName() + "</cname>" + "<cage>" + client.getAge() + "</cage>" + "<body>" + i_body + "</body>" + "</users-data>";DocumentDAO と Servlet の修正
これまで sample.xsl ファイルを読み込んでいた部分を、DocumentDTO 経由で得られるよう、DocumentDAO の中にフォーマット用のテキストを埋め込みます。これもコードが長いので、GitHub: DocumentDAO.java で直接参照してください。
そして Servlet 側でも、sample.xsl ファイルのかわりに DocumentDTO から得られるフォーマット用のテキストを利用するように修正します。
pdfServlet.java//Source xsl = new StreamSource(this.getServletContext().getRealPath("/WEB-INF/sample.xsl")); DocumentDTO document = DocumentDAO.getDocument(i_fdate, i_fname); Source xsl = new StreamSource(new StringReader(document.getFormat())); Transformer transformer = tFactory.newTransformer(xsl);以上、Servlet 変更点もけっこう多いので、GitHub: pdfServlet.java でコード全体を参照してください。
実行してみる
さて、これで修正も一段落しました。
DB を模した DAO クラスがあり、そこから得られた DTO クラスを用いて PDF を自動生成することができます。フォーマットは sample1 と sample2 が用意され、更に sample2 は実行日を境に版が更新されています。
まずは sample1 フォーマットを試してみましょう。
「Submit」ボタンをクリックすると、以下の PDF が生成され表示されます。
次に sample2 フォーマットを試してみましょう。
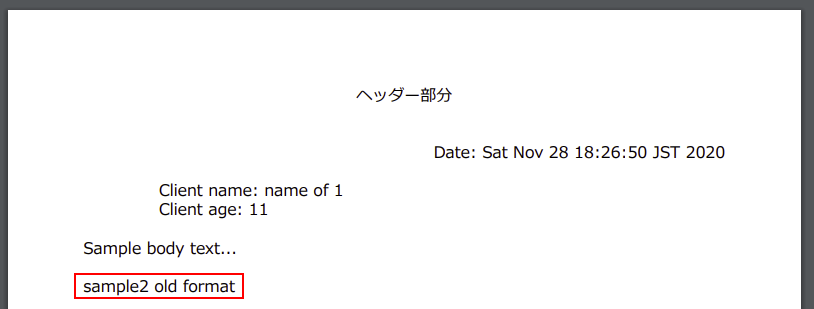
「Submit」ボタンをクリックすると、以下の PDF が生成され表示されます。sample1 との違いは最後に追加されたテキストです。
次に sample2 フォーマットの新しい版を試してみましょう。新しい版は start が現在時刻になっているので、いまより未来を指定してみてください。
「Submit」ボタンをクリックすると、以下の PDF が生成され表示されます。旧版との違いは最後に追加されたテキストの new の部分です。
以上、用意した3つの変換フォーマットの違いが小さいので、判り辛くて済みません。ただ、フォーマットを名前と版(日付)で使い分けることができること、これで最低限試すことができたとおもいます。生成された PDF について
今回のサンプルプログラムで生成した PDF ファイルを以下の URL に置きました。
いまのところ、以下の環境で表示の確認をしています。もし文字化けとかしちゃう環境などありましたら、コメントいただけると助かります!
- Google Chrome on Windows 10
- Edge on Windows 10 (IEで開いてもこちら起動する)
- Safari on Mac
- Safari on iPhone
- Kindle Fire HD (いったんダウンロードしてKindleアプリで表示)
今回のコードについて
コード量が多くなったので、GitHub の apache-fop-jp-sample リポジトリ にまとめました。参考にしていただければ幸いです。
ライセンス
この投稿に含まれる私の作成した全てのコードは Creative Commons Zero ライセンスとします。権利は一切主張しませんので、商用でもなんでも、自由にお使いください。
Enjoy!
以上、Servlet を用いて Web サイトで、PDF の動的生成を試してみました。これをベースに、いろいろ機能を追加して遊んでみてください。
ではまた!




- 投稿日:2020-11-28T12:19:41+09:00
Oracle Code One 2020について
この記事はSRA Advent Calendar 2020の1日目の記事です。
こんにちは! 関西事業部の佐々木です。
今年のOracle Code One
1996年から20年以上続いてきたJavaOneは2018年からOracle Code Oneになりました。
去年のOracle Code One 2019まではずっとサンフランシスコで行われていたのですが、今年のOracle Code One 2020はラスベガスで開催する予定でした。
しかし今年は新型コロナウイルスの影響によりオンライン実施となりました。セッションを視聴したい方へ
Oracle Code One 2020のオンラインセッションはここから見ることができます。
Oracle Code Oneに興味はあるけど参加する機会がなかった方はぜひご視聴ください。オンラインで良かったこと
Oracle Code Oneがオンラインで実施されたことによって良かったことがいくつかあります。
参加費がタダ
まずは何と言っても参加費が無料だということです。
Oracle Code Oneは参加料が10万円以上するのですが、今年は参加料はかかりませんでした。経費がタダ
去年まではアメリカで開催されていたので日本から参加するには旅費・宿泊費などがかかります。しかもサンフランシスコのホテル代はかなり高額です。
旅費・宿泊費だけでも毎年だいたい20万ほどはかかってたのでかなり節約できます。
(私の場合費用はすべて会社持ちでしたが)自宅でゆっくり視聴できる
会場まで足を運んでセッション開始前に列に並んだり、(人気のセッションの場合)空いてる席をさがしたりする必要が無く、家のPCでゆっくり視ることができます。
字幕付きでセッションを聴ける
オンラインはYouTubeで配信されたので、YouTubeの機能を使って字幕を表示したりできます。自動翻訳で日本語字幕にもできますが、私は英語の勉強も兼ねて英語字幕で視聴してました。
オンラインで残念だったこと
逆にオンラインで開催されたために残念だったこともあります。
セッションの数が少ない
これはオンラインそのものが原因ではないんですが、例年4~5日間で数百のセッションがあったのが今年は1日間だけで10程度セッションがあっただけでした。
現地の雰囲気や観光を味わえない
セッション会場でのスピーカーを生で観たり、オーディエンスのリアルタイムの反応なんかはオフライン開催ならではだと思います。
また、「蟹One」という日本からのメンバーが集まって蟹を食べたりするのが恒例なのですが、普段関西にいる身としては東京のJava技術者と直接会える貴重な機会でもあり、そういった場がないのはとても残念です。
さらに普段海外旅行を全くしない私にとって、Oracle Code Oneは海外の雰囲気を味わえる機会でもあります。
毎年Chipotleというメキシコ料理のファストフードの店に行くのですが、今年は食べることができず何を血迷ったのかChipotleのロゴのスマホケースを作ってしまいました。
来年はどうなる?
アメリカは今も新型コロナウイルスが猛威をふるっています。
正直来年の現地開催も厳しいのではないでしょうか。世界中の多くの人も同じかもしれませんが、早く新型コロナウイルスの脅威が落ち着いて平和な日が訪れることを願いたいと思います。
I wish you a Merry Christmas.

- 投稿日:2020-11-28T12:04:36+09:00
Note Book : OpenCV v4.5.0-openvino Mask CNN by With Spring Boot
Mask RCNN
Final Result
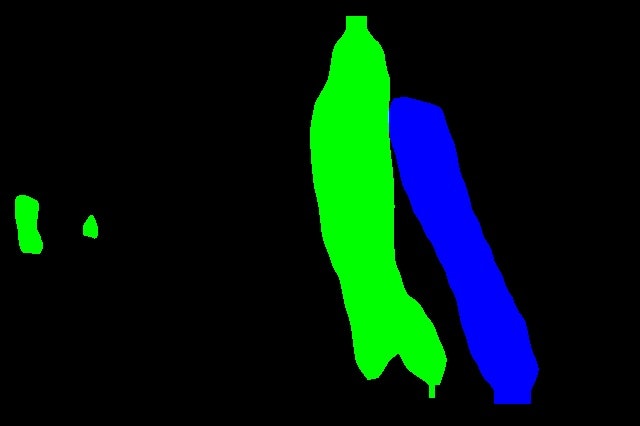
Mask
Rectangle Mask
log
2020-11-28 12:30:59.341 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Running 24 / 29
2020-11-28 12:30:59.341 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Iinput file /usr/local/src/Mask_RCNN/images/8829708882_48f263491e_z.jpg
2020-11-28 12:30:59.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : file rows 427 file cols 640 threshold 0.5
2020-11-28 12:30:59.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : bus:1.0
2020-11-28 12:30:59.539 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Output file ./output/mask_rcnn_inception_v2_coco_2018_01_28/8829708882_48f263491e_z.jpg
2020-11-28 12:30:59.539 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Running 25 / 29
2020-11-28 12:30:59.539 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Iinput file /usr/local/src/Mask_RCNN/images/8734543718_37f6b8bd45_z.jpg
2020-11-28 12:30:59.740 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : file rows 394 file cols 640 threshold 0.5
2020-11-28 12:30:59.740 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : donut:0.83
2020-11-28 12:30:59.741 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : donut:0.77
2020-11-28 12:30:59.741 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : donut:0.58
2020-11-28 12:30:59.741 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : donut:0.53
2020-11-28 12:30:59.744 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Output file ./output/mask_rcnn_inception_v2_coco_2018_01_28/8734543718_37f6b8bd45_z.jpgFinal Result
Mask
Rectangle Mask
log
2020-11-28 12:30:58.340 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Running 19 / 29
2020-11-28 12:30:58.340 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Iinput file /usr/local/src/Mask_RCNN/images/7933423348_c30bd9bd4e_z.jpg
2020-11-28 12:30:58.535 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : file rows 480 file cols 640 threshold 0.5
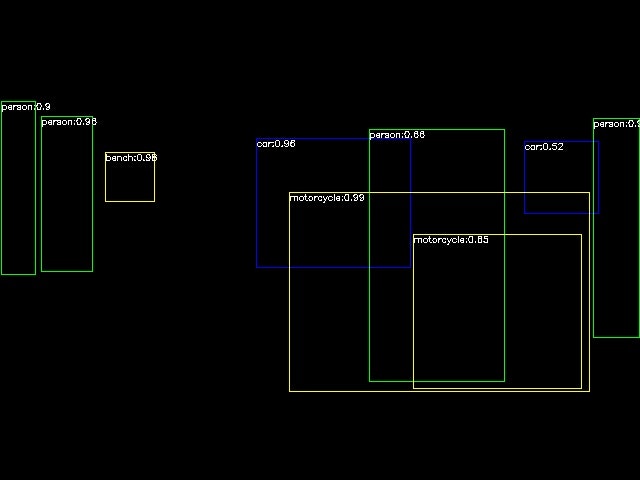
2020-11-28 12:30:58.535 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : motorcycle:0.99
2020-11-28 12:30:58.535 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : bench:0.98
2020-11-28 12:30:58.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.96
2020-11-28 12:30:58.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : car:0.96
2020-11-28 12:30:58.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.95
2020-11-28 12:30:58.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.9
2020-11-28 12:30:58.536 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.66
2020-11-28 12:30:58.537 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : motorcycle:0.65
2020-11-28 12:30:58.537 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : car:0.52
2020-11-28 12:30:58.541 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Output file ./output/mask_rcnn_inception_v2_coco_2018_01_28/7933423348_c30bd9bd4e_z.jpgFinal Result
Mask
Rectangle Mask
log
2020-11-28 12:30:59.942 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Running 27 / 29
2020-11-28 12:30:59.942 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Iinput file /usr/local/src/Mask_RCNN/images/4410436637_7b0ca36ee7_z.jpg
2020-11-28 12:31:00.137 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : file rows 426 file cols 640 threshold 0.5
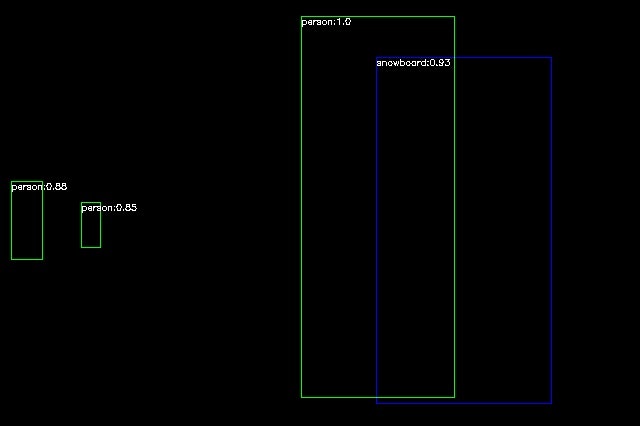
2020-11-28 12:31:00.138 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:1.0
2020-11-28 12:31:00.138 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : snowboard:0.93
2020-11-28 12:31:00.139 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.88
2020-11-28 12:31:00.139 INFO 6778 --- [ main] deepl.dnn.impl.SimpleRCnn : person:0.85
2020-11-28 12:31:00.141 INFO 6778 --- [ main] deepl.dnn.impl.MaskRCnn : Output file ./output/mask_rcnn_inception_v2_coco_2018_01_28/4410436637_7b0ca36ee7_z.jpgRCnn.java/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package deepl.dnn; import org.opencv.core.Mat; /** * @author jashika.t.e * @since 0.1 */ public interface RCnn<T> { Mat run(T targetObject); }Source Code
SimpleRCnn.java/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package deepl.dnn.impl; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.stream.IntStream; import org.opencv.core.Core; import org.opencv.core.CvType; import org.opencv.core.Mat; import org.opencv.core.MatOfPoint; import org.opencv.core.Point; import org.opencv.core.Rect; import org.opencv.core.Scalar; import org.opencv.core.Size; import org.opencv.dnn.Dnn; import org.opencv.dnn.Net; import org.opencv.imgcodecs.Imgcodecs; import org.opencv.imgproc.Imgproc; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import deepl.dnn.RCnn; /** * @author jashika.t.e * @since 0.1 */ public class SimpleRCnn implements RCnn<Mat> { /** * logger. */ protected static final Logger log = LoggerFactory.getLogger(SimpleRCnn.class); /** * properties. */ protected RCnnProperties properties; /** * network. */ protected Net net; /** * constractor. * * @param properties */ public SimpleRCnn(RCnnProperties properties, Net net) { this.properties = properties; this.net = net; } public Mat run(Mat orgImage) { Mat dstImage = orgImage.clone(); List<Mat> outputBlobs = getOutputBlobs(dstImage); Mat detectionOutFinal = outputBlobs.get(0); Mat detectionMasks = outputBlobs.get(1); // Output size of masks is NxCxHxW where // N - number of detected boxes // C - number of classes (excluding background) // HxW - segmentation shape Mat detection = detectionOutFinal.reshape(1, (int) detectionOutFinal.total() / detectionOutFinal.size(3)); Mat reshapeMask = detectionMasks.reshape(1, (int) detectionMasks.total() / (detectionMasks.size(2) * detectionMasks.size(3))); log.debug("detectionOutFinal.reshape(1, " + (int) (detectionOutFinal.total() / detectionOutFinal.size(3)) + ")"); log.debug("detectionOutFinal.size(2) == " + detectionOutFinal.size(2)); log.debug("detectionMasks.reshape(1, " + (int) detectionMasks.total() / (detectionMasks.size(2) * detectionMasks.size(3)) + ")"); int cols = dstImage.cols(); int rows = dstImage.rows(); List<Mat> masks = new ArrayList<Mat>(); List<Mat> ractangleMasks = new ArrayList<Mat>(); List<double[]> colors = properties.getColors(); List<String> names = properties.getNames(); double threshold = properties.getThreshold(); log.info("file rows " + rows + " file cols " + cols + " threshold " + threshold); IntStream.range(0, detectionOutFinal.size(2)).filter(i -> detection.get(i, 2)[0] > threshold).forEach(i -> { int classId = (int) detection.get(i, 1)[0]; // color from txt Scalar color = new Scalar(colors.get(classId % colors.size())); color.val[3] = 255d; // axis Rect box = createRect(detection, i, cols, rows); // for rectangle txt String label = createLabel(detection, i, cols, rows, names); // create and collect ractangle mask ractangleMasks.add(createRectangleMask(dstImage.size(), label, color, box)); // 1 x 255 Mat objectMask = reshapeMask.row(i * detectionMasks.size(0) + classId); // 15 x 15 objectMask = objectMask.reshape(1, detectionMasks.size(2)); // create and collect mask masks.add(createMask(objectMask, dstImage.size(), color, box)); log.info("result " + label); }); return createFinalDst(dstImage, masks, ractangleMasks); } protected Mat createFinalDst(Mat targetMat, List<Mat> masks, List<Mat> ractangleMasks) { Mat mask = new Mat(); masks.stream().forEach(m -> m.copyTo(mask, m)); Imgcodecs.imwrite("/tmp/mask.png", mask); Mat ractangleMask = new Mat(); ractangleMasks.stream().forEach(m -> m.copyTo(ractangleMask, m)); Imgcodecs.imwrite("/tmp/mask.png", ractangleMask); ractangleMask.copyTo(targetMat, ractangleMask); // mask.copyTo(targetMat, mask); Core.addWeighted(targetMat, properties.getMask().getAlpha(), mask, properties.getMask().getBeta(), properties.getMask().getGannma(), targetMat); Imgcodecs.imwrite("/tmp/mask.png", targetMat); return targetMat; } protected List<Mat> getOutputBlobs(Mat orgImage) { net.setInput(Dnn.blobFromImage(orgImage)); List<Mat> outputBlobs = new ArrayList<>(); // outputNames = detection_out_final, detection_masks List<String> outputNames = Arrays.asList(properties.getDetection().getNames()); net.forward(outputBlobs, outputNames); log.debug("output blob size " + outputBlobs.size()); return outputBlobs; } protected Mat createRectangleMask(Size maskSize, String label, Scalar color, Rect box) { int thickness = properties.getRectangle().getThickness(); double fontScale = properties.getRectangle().getFontScale(); Mat dstMask = Mat.zeros(maskSize, CvType.CV_8UC3); // non alpha Imgproc.rectangle(dstMask, new Point(box.x, box.y), new Point(box.x + box.width, box.y + box.height), color, thickness); // text box size Size size = Imgproc.getTextSize(label, Imgproc.FONT_HERSHEY_SIMPLEX, fontScale, thickness, null); Imgproc.putText(dstMask, label, new Point(box.x, box.y + size.height - 1), Imgproc.FONT_HERSHEY_SIMPLEX, fontScale - 0.1, new Scalar(255, 255, 255, 255), thickness); return dstMask; } protected Mat createMask(Mat objectMask, Size maskSize, Scalar color, Rect box) { Imgproc.resize(objectMask, objectMask, new Size(box.width + 1, box.height + 1)); Mat mask = new Mat(); objectMask.convertTo(mask, CvType.CV_8U); Mat dstMask = Mat.zeros(maskSize, CvType.CV_8UC3); List<MatOfPoint> contours = new ArrayList<>(); Mat hierarchy = new Mat(); Imgproc.findContours(mask, contours, hierarchy, Imgproc.RETR_CCOMP, Imgproc.CHAIN_APPROX_SIMPLE); Imgproc.drawContours(dstMask, contours, -1, color, Imgproc.FILLED, Imgproc.LINE_8, hierarchy, 500, new Point(box.x, box.y)); return dstMask; } protected String createLabel(Mat detection, int detectionNumber, int cols, int rows, List<String> names) { return names.get((int) detection.get(detectionNumber, 1)[0]) + ":" + (double) Math.round(detection.get(detectionNumber, 2)[0] * 100) / 100; } protected Rect createRect(Mat detection, int detectionNumber, int cols, int rows) { double left = detection.get(detectionNumber, 3)[0] * cols; double top = detection.get(detectionNumber, 4)[0] * rows; double right = detection.get(detectionNumber, 5)[0] * cols; double bottom = detection.get(detectionNumber, 6)[0] * rows; left = Math.max(0, Math.min(left, cols - 1)); top = Math.max(0, Math.min(top, rows - 1)); right = Math.max(0, Math.min(right, cols - 1)); bottom = Math.max(0, Math.min(bottom, rows - 1)); log.debug("rect data left " + left + " top " + top + " right " + right + " bottom " + bottom); return new Rect(new double[] { left, top, right - left + 1, bottom - top + 1 }); } }MaskRCnnRunner/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package deepl.controller.dnn; import java.nio.file.FileSystems; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.util.List; import java.util.stream.Collectors; import java.util.stream.IntStream; import org.opencv.core.Mat; import org.opencv.core.Size; import org.opencv.imgcodecs.Imgcodecs; import org.opencv.imgproc.Imgproc; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.CommandLineRunner; import deepl.dnn.impl.MaskRCnn; import deepl.dnn.impl.RCnnProperties; import deepl.support.io.MediaFormat; /** * @author jashika.t.e * @since 0.1 */ public class MaskRCnnRunner implements CommandLineRunner { /** * logger. */ private Logger log = LoggerFactory.getLogger(MaskRCnn.class); /** * @see MaskRCnn */ private MaskRCnn maskRCnn; /** * settings. */ private RCnnProperties properties; /** * constructor. * * @param maskRCnn * @param properties */ public MaskRCnnRunner(MaskRCnn maskRCnn, RCnnProperties properties) { this.maskRCnn = maskRCnn; this.properties = properties; } @Override public void run(String... args) throws Exception { List<Path> files = properties.getInputFileExtension() == MediaFormat.NONE ? Files.walk(Files.createDirectories(Paths.get(properties.getInputDir()))) .filter(p -> p.toFile().isFile()).collect(Collectors.toList()) : Files.walk(Files.createDirectories(Paths.get(properties.getInputDir()))) .filter(FileSystems.getDefault() .getPathMatcher("regex:.+" + properties.getInputFileExtension())::matches) .collect(Collectors.toList()); int size = files.size(); Paths.get(properties.getOutputDir()).toFile().mkdirs(); IntStream.range(0, files.size()).forEach(i -> { log.info("Running " + (i + 1) + " / " + size); Path targetFile = files.get(i); String inputFile = targetFile.toString(); String outputFile = properties.getOutputDir() + "/" + targetFile.getFileName().toString(); log.info("Iinput file " + targetFile); Mat input = Imgcodecs.imread(inputFile); Imgproc.resize(input, input, new Size(input.width() * 1.5, input.height() * 1.5)); Mat dstImage = maskRCnn.run(input); Imgcodecs.imwrite(outputFile, dstImage); log.info("Output file " + outputFile); }); } }DnnConfiguration/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package deepl.configre.dnn; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.Arrays; import org.opencv.dnn.Dnn; import org.opencv.dnn.Net; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; /** * @author jashika.t.e * @since 0.1 */ import org.springframework.context.annotation.Configuration; import deepl.controller.dnn.MaskRCnnRunner; import deepl.dnn.impl.MaskRCnn; import deepl.dnn.impl.RCnnProperties; @Configuration public class DnnConfiguration { @Bean public MaskRCnnRunner dnnRunner(MaskRCnn maskRCnn, RCnnProperties maskRCnnProperties) { return new MaskRCnnRunner(maskRCnn, maskRCnnProperties); } @Bean @ConfigurationProperties(prefix = "mask.rcnn") public RCnnProperties maskRCnnProperties() { RCnnProperties properties = new RCnnProperties(); return properties; } @Bean public MaskRCnn maskRCnn(RCnnProperties maskRCnnProperties) throws IOException { maskRCnnProperties.setNames(Files.readAllLines(Paths.get(maskRCnnProperties.getLabelNamesTextPath()))); for (String line : Files.readAllLines(Paths.get(maskRCnnProperties.getColorsTextPath()))) { maskRCnnProperties.getColors() .add(Arrays.stream(line.split(" ")).mapToDouble(Double::parseDouble).toArray()); } Net net = Dnn.readNetFromTensorflow(maskRCnnProperties.getModelPath(), maskRCnnProperties.getConfigPath()); net.setPreferableBackend(Dnn.DNN_BACKEND_CUDA); net.setPreferableTarget(Dnn.DNN_TARGET_CUDA); return new MaskRCnn(maskRCnnProperties, net); } }RCnnProperties.java/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package deepl.dnn.impl; import java.util.ArrayList; import java.util.List; import deepl.support.io.MediaFormat; /** * @author jashika.t.e * @since 0.1 */ public class RCnnProperties { /** * default input directory. */ private String DEFAULT_INPUT_DIR = "./data/input"; /** * default output directory. */ private String DEFAULT_OUTPUT_DIR = "./data/output"; /** * TensorFlowModel:frozen_inference_graph.pb file path string. */ private String modelPath = DEFAULT_INPUT_DIR + "/metadata/frozen_inference_graph.pb"; /** * TensorFlowModel:pbtxt file path string. */ private String configPath = DEFAULT_INPUT_DIR + "/metadata/mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"; /** * Coco:mscoco_labels.names text file path strein. */ private String labelNamesTextPath = DEFAULT_INPUT_DIR + "/metadata/mscoco_labels.names"; /** * Coco:mscoco_labels.color text file path strein. */ private String colorsTextPath = DEFAULT_INPUT_DIR + "/metadata/colors.txt"; /** * input data dir. */ private String inputDir = DEFAULT_INPUT_DIR + "/images"; /** * output data dir. */ private String outputDir = DEFAULT_OUTPUT_DIR + "/images"; /** * input file extension. */ private MediaFormat inputFileExtension = MediaFormat.NONE; /** * output file extension. */ private MediaFormat outputFileExtension = MediaFormat.NONE; /** * labelNames. */ private List<String> names; /** * colors. */ private List<double[]> colors = new ArrayList<>(); private Rectangle rectangle = new Rectangle(); private Mask mask = new Mask(); private Detection detection = new Detection(); /** * threshold */ private double threshold = 0.5; /** * @return the modelPath */ public String getModelPath() { return modelPath; } /** * @param modelPath the modelPath to set */ public void setModelPath(String modelPath) { this.modelPath = modelPath; } /** * @return the configPath */ public String getConfigPath() { return configPath; } /** * @param configPath the configPath to set */ public void setConfigPath(String configPath) { this.configPath = configPath; } /** * @return the labelNamesTextPath */ public String getLabelNamesTextPath() { return labelNamesTextPath; } /** * @param labelNamesTextPath the labelNamesTextPath to set */ public void setLabelNamesTextPath(String labelNamesTextPath) { this.labelNamesTextPath = labelNamesTextPath; } /** * @return the colorsTextPath */ public String getColorsTextPath() { return colorsTextPath; } /** * @param colorsTextPath the colorsTextPath to set */ public void setColorsTextPath(String colorsTextPath) { this.colorsTextPath = colorsTextPath; } /** * @return the names */ public List<String> getNames() { return names; } /** * @param names the names to set */ public void setNames(List<String> names) { this.names = names; } /** * @return the colors */ public List<double[]> getColors() { return colors; } /** * @param colors the colors to set */ public void setColors(List<double[]> colors) { this.colors = colors; } /** * @return the threshold */ public double getThreshold() { return threshold; } /** * @param threshold the threshold to set */ public void setThreshold(double threshold) { this.threshold = threshold; } /** * @return the inputDir */ public String getInputDir() { return inputDir; } /** * @param inputDir the inputDir to set */ public void setInputDir(String inputDir) { this.inputDir = inputDir; } /** * @return the outputDir */ public String getOutputDir() { return outputDir; } /** * @param outputDir the outputDir to set */ public void setOutputDir(String outputDir) { this.outputDir = outputDir; } /** * @return the inputFileExtension */ public MediaFormat getInputFileExtension() { return inputFileExtension; } /** * @return the outputFileExtension */ public MediaFormat getOutputFileExtension() { return outputFileExtension; } /** * @param outputFileExtension the outputFileExtension to set */ public void setOutputFileExtension(MediaFormat outputFileExtension) { this.outputFileExtension = outputFileExtension; } /** * @param inputFileExtension the inputFileExtension to set */ public void setInputFileExtension(MediaFormat inputFileExtension) { this.inputFileExtension = inputFileExtension; } /** * @return the rectangle */ public Rectangle getRectangle() { return rectangle; } /** * @param rectangle the rectangle to set */ public void setRectangle(Rectangle rectangle) { this.rectangle = rectangle; } public Mask getMask() { return mask; } public void setMask(Mask mask) { this.mask = mask; } static class Detection { private String[] names = { "detection_out_final", "detection_masks" }; /** * @return the names */ public String[] getNames() { return names; } /** * @param names the names to set */ public void setNames(String[] names) { this.names = names; } } static class Rectangle { /** * thickness. */ private int thickness = 1; /** * fontScale. */ private double fontScale = 0.4d; /** * @return the fontScale */ public double getFontScale() { return fontScale; } /** * @param fontScale the fontScale to set */ public void setFontScale(double fontScale) { this.fontScale = fontScale; } /** * @return the thickness */ public int getThickness() { return thickness; } /** * @param thickness the thickness to set */ public void setThickness(int thickness) { this.thickness = thickness; } } static class Mask { private double alpha = 1.0; private double beta = 0.5; private double gannma = 0; /** * @return the alpha */ public double getAlpha() { return alpha; } /** * @param alpha the alpha to set */ public void setAlpha(double alpha) { this.alpha = alpha; } /** * @return the beta */ public double getBeta() { return beta; } /** * @param beta the beta to set */ public void setBeta(double beta) { this.beta = beta; } /** * @return the gannma */ public double getGannma() { return gannma; } /** * @param gannma the gannma to set */ public void setGannma(double gannma) { this.gannma = gannma; } } /** * @return the detection */ public Detection getDetection() { return detection; } /** * @param detection the detection to set */ public void setDetection(Detection detection) { this.detection = detection; } }application.ymlspring: main: banner-mode: off management: endpoint: shutdown: enabled: true logging: level: org.springframework.aop.interceptor.PerformanceMonitorInterceptor: trace model: rcnn: name: mask_rcnn_inception_v2_coco_2018_01_28 mask: rcnn: model-path: ./data/${model.rcnn.name}/frozen_inference_graph.pb config-path: ./data/${model.rcnn.name}/mask_rcnn_inception_v2_coco_2018_01_28.pbtxt colors-text-path: ./data/${model.rcnn.name}/colors.txt label-names-text-path: ./data/${model.rcnn.name}/mscoco_labels.names input-dir: /usr/local/src/Mask_RCNN/images output-dir: ./output/${model.rcnn.name}If there is demand, put it in git.






- 投稿日:2020-11-28T11:30:27+09:00
【Java】コレクションフレームワーク( set )
【Set】 重複要素のないコレクション
Setとは
Setは、Listのと同様に 「データをまとめたもの」になります。
ですが、双方にはこのような違いがあります。
- Mapのようなキーと値の関連付けをしない
- インデックスが存在しない
- 同じ値のものは2つ以上持てない
SQL にある 「DISTINCT」や、「ORDER BY」 のようなイメージだと思います。
Setの使い所
以上に書いた「 同じ値のものは2つ以上持てない 」などの特性をいかし、このような使い所が考えられます。
- 商品を安い順に並べる
- 会社の部署はいくつあるのか調べる
- ポケモンのタイプは何種類あるか調べる
- この学校の生徒はどこの出身者がいるかみる。
といったとき Set が役立つのではないかと思います。
Setの種類
Setインタフェースを実装するものには、
HashSetクラス,TreeSetクラス,LinkedHashSetクラスなどがあります。
それぞれの配列の並べ方は以下にです。
クラス 概要 要素の並び ( 1 ~ 5 の値が格納されている場合) HashSet ランダム 2, 4, 3, 5, 1 TreeSet 昇順 1, 2, 3, 4, 5 LinkedHashSet 追加した順 1, 3, 4, 5, 2 Setの定義
Set の基本の型
Setも List、Map 等と同様の書き方ができます。
基本的な書き方は以下です。セットインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();HashSet、TreeSet、LinkedHashSet はそれぞれ次のように定義します。
HashSet の定義
※Setの代わりに左辺を同じHashSetにしてもOK
Set<String> hashSet = new HashSet<String>();TreeSet の定義
※Setの代わりに、左辺を同じTreeSetにしてOK
Set<String> treeSet = new TreeSet<String>();LinkedHashSet の定義
※Set の代わりに、左辺を同じLinkedHashSet にしてもOK
Setサンプルコード
以下のコードは、各種setを用いて出力結果を比べたものです。
import java.util.HashSet; import java.util.LinkedHashSet; import java.util.TreeSet; public class Main { public static void main(String[] args) { HashSet<String> vegetableSet = new HashSet<String>(); //適当に値を入れていく vegetableSet.add("大根"); vegetableSet.add("人参"); vegetableSet.add("ブロッコリー"); vegetableSet.add("すいか"); vegetableSet.add("かぼちゃ"); System.out.println("HashSetはランダムで表示"する"); //拡張for文 で変数vs を vegetableSet から一つづつ取り出す for (String vs : vegetableSet) { System.out.println(vs); } TreeSet<String> fruitsSet = new TreeSet<String>(); //適当に値を入れていく fruitsSet.add("もも"); fruitsSet.add("ミカン"); fruitsSet.add("りんご"); fruitsSet.add("梨"); System.out.println("TreeSet は昇降順に表示する"); for (String fs : fruitsSet) { System.out.println(fs); } LinkedHashSet<String> fishSet = new LinkedHashSet<String>(); fishSet.add("カツオ"); fishSet.add("カンパチ"); fishSet.add("鯵"); fishSet.add("ブリ"); System.out.println("LinkedHashSet は追加した順に表示する"); for (String fs : fishSet) { System.out.println(fs); } TreeSet<String> meetSet = new TreeSet<String>(); //適当に値を入れていく meetSet.add("牛"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("豚"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("豚"); meetSet.add("豚"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("羊"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("羊"); System.out.println("set には同じ値が入らないので重複分は出力されない"); for (String ms : meetSet) { System.out.println(ms); } } }出力結果
HashSetはランダムで表示 人参 大根 すいか かぼちゃ ブロッコリー TreeSet は昇降順に表示する もも りんご ミカン 梨 LinkedHashSet は追加した順に表示する カツオ カンパチ 鯵 ブリ set には同じ値が入らないので重複分は出力されない 牛 羊 豚 鹿これらをうまく利用することで、システムのいろいろな表現ができそうです。
実際に手を動かしながら覚えていきたいと思います。参考文献・記事
- 投稿日:2020-11-28T11:21:26+09:00
【Java】 java.util コレクションフレームワーク (List, Set, Map )
コレクションフレームワーク
この記事では、java.utilをして利用できる便利なクラスを学んで行きます。
コレクションフレームワークとは
そもそも、フレームワークとは概念的な意味で、
- 「何かの枠組み」
- 「システム開発を楽に行えるように用意された、プログラムとかのひな形」のことです。つまり、
コレクションフレームワーク = 便利な機能をまとめたものみたいな考え方でいいと思います。これらの 用意された便利な機能を、柔軟に扱うことを考えられているのがコレクション・フレームワークです。
Javaのコレクションフレームワーク
(他にも両端からしか値を出し入れできないDequeというのもあるんですが、用途が限られるので今回は割愛)。
java.utilパッケージとは
java.utilは Javaのフレームワークの一種で、Javaで使われる 、以下のような データを表現するのに必要なデータ構造が一通り揃っています。
- 配列操作
- イベント
- モデル
- 日付および時間...
その中でも代表的な「配列操作」をするために3つの便利なクラスがあります。それが、「List」, 「Set」, 「Map」です。
- リスト(List) 値が順番に並んで格納したもの
- セット(Set) 順序があるとは限らず格納され、同じ値のものが1つだけのもの
- マップ(Map)ペアで対応づけて格納し、キーごとに値が対応したもの
【List】順序を持ったコレクション
Listとは
リストは配列によく似た性質を持つ「
0から始まるインデックスごとにデータが入ったもの」です。
インデックスによって要素を挿入したり要素にアクセスしたりする位置を自由に変更することができます。List と 配列 の違い
Listは、持っている特長が 配列 に非常によく似ているものの、Javaの「 通常の配列操作とは少々異なります。 」
- 【配列】
- 最初にサイズを決めるため、「後からサイズを拡張することができない」
- 【Listクラス】
- 要素を追加した分だけ「自動的にサイズが拡張される動的な配列」を作ることができる。
- Listクラスのメソッドを使うことで「値を追加したり途中に挿入したり、削除することができる。」
Listの定義の仕方
Listの基本的な定義の仕方はこちらになります。
リストインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();ちなみに、Java 1.4以降 ダイヤモンド演算子"<>"を用いて以下のように書くことが可能ですので、基本この型で書いていいと思います。
// ArrayListに<型>を指定しない List<String> sampleList = new ArrayList<>();ArrayList(可変長配列)
ArrayList とは
Listインタフェースを実装したコレクションクラスです。
「Array」 という名にあるように 「配列のような感覚」で扱うことができる。
JavaのArrayListは大きさが決まっていない配列のようなものとイメージしてください。ArrayListは、複数の値を管理する時に使います。ArrayListの特徴
メリットはこちら
- ArrayListクラス は配列でリストを実装しており、「添え字による要素へのアクセス」が高速です。
- 要素の「追加」が、新たな要素を末尾へ加えるだけなので楽
短所はこちら
- 配列の途中の位置への要素の「挿入」や「削除」に関しては、 挿入・削除した位置以降の全ての要素の位置を移動させるという処理を行う必要があるため低速になる。
ArrayList の宣言・初期化
書き方はこちらです。
// 基本の定義の仕方 ArrayList<型> 変数名 = new ArrayList<型>(); // サンプルコード List<String> sampleList = new ArrayList<String>(); ## ArrayListクラスの使用例 2パターンありますので、見ていただきます。 やってることは同じですから実行結果は変わりませんのでお好みで。 ```java package practiceListClass; //utilパッケージのArrayListクラスをimport import java.util.ArrayList; //utilパッケージのListクラスをimport import java.util.List; public class ArrayAboutMain { public static void main(String args[]) { // ここから ===================================== List<String> sampleList = new ArrayList<String>(); sampleList.add("1回目のリストに格納"); sampleList.add("2回目のリストに格納"); // ここまで ===================================== // リストに格納した全要素を順番に出力 for (int i = 0; i < sampleList.size(); i++) { System.out.println(sampleList.get(i)); } } }2パターン目。addの書き方が少し違うバージョン。
// ここから ===================================== List<String> sampleList = new ArrayList<String>(); sampleList = new ArrayList<String>() { { add("1回目のリストに格納"); add("2回目のリストに格納"); } }; // ここまで =====================================実行結果はこちら
1回目のリストに格納 2回目のリストに格納上記のコードを解説すると
生成したArrayListクラスのインスタンスを、Listインタフェース型の変数sampleListに保持しています。Listインタフェースでは、
- 要素の追加: addメソッド
- 値を取り出すとき: getメソッド
を使用してください。
LinkedList(連結リスト)
LinkedListとは
LinkedListは、要素同士を前後双方向のリンクで参照するリンクリストを表します。
LinkedListの特徴
- 要素の挿入/削除はリンクの付け替えで済むため、ArrayListに較べても高速
- インデックス値によるランダムなアクセスは苦手
LinkedListクラス はリスト構造を使用して実装しています。
このため、「添え字による要素へのアクセス」は、毎回先頭から順番に要素をたどっていきながら
目的の位置を探す(添え字の番号まで移動していく)必要があるため、低速です。LinkedList の宣言・初期化
// 基本の定義の仕方 LinkedList<型> 変数名 = new LinkedList<型>(); // サンプルコード List<String> sampleList = new LinkedList<String>();LinkedList の使用例
ArrayListとやってることは変わりませんが、コピペ用でこちらも載せておきます。
こちらも2パターンありますので、見ていただきます。
やってることは同じですから実行結果は変わりませんのでお好みで。package practiceListClass; //utilパッケージのArrayListクラスをimport import java.util.ArrayList; //utilパッケージのListクラスをimport import java.util.List; public class ArrayAboutMain { public static void main(String args[]) { // ここから ===================================== List<String> sampleList = new LinkedList<String>(); sampleList.add("1回目のリストに格納"); sampleList.add("2回目のリストに格納"); // ここまで ===================================== // リストに格納した全要素を順番に出力 for (int i = 0; i < sampleList.size(); i++) { System.out.println(sampleList.get(i)); } } }2パターン目。addの書き方が少し違うバージョン。
// ここから ===================================== List<String> sampleList = new LinkedList<String>(); sampleList = new LinkedList<String>() { { add("1回目のリストに格納"); add("2回目のリストに格納"); } }; // ここまで =====================================実行結果はこちら
1回目のリストに格納 2回目のリストに格納上記のコードを解説すると
生成したArrayListクラスのインスタンスを、Listインタフェース型の変数sampleListに保持しています。Listインタフェースでは、
- 要素の追加: addメソッド
- 値を取り出すとき: getメソッド
を使用してください。
List系クラス チートシート
各クラスの特徴を踏まえて、用途に応じてクラスを選択することが Listインタフェースを使いこなす
ポイントとなります。
以下のように、
- 挿入/削除操作が多い状況ではLinkedList
- それ以外の場合はArrayList
という使い分けになると思います。
クラス 概要 長所 短所 使う場面 ArrayList 複数の値を管理する時に使う、「大きさの決まっていない配列のようなもの」 添え字による要素へのアクセス」が高速
要素の「追加」が、新たな要素を末尾へ加えるだけなので楽要素を追加するスピードが遅い 配列内の要素に対してランダムなアクセスを必要とし、配列内の要素に対して挿入/削除の操作があまり必要ない場合 LinkedList 要素同士を前後双方向のリンクで参照するリンクリストを表します。 要素の挿入/削除はリンクの付け替えで済むため高速 ・特定の要素にアクセスするスピードが遅い
・インデックス値によるランダムなアクセスは苦手要素数が多くて、且つ要素の挿入・削除を頻繁に行うことが予想 でき、配列内の要素に対してランダムなアクセスを必要としない場面 【Map】キーと値とのマッピングを保持する
連想配列を取り扱うものに Map というコレクションがあります。
Mapとは
Mapは「キー」と「値」の二つの要素から成り立っています。
「 キー は値につける名前のようなもの 」で、値ひとつひとつに「キー」が存在しており、「キー」と「値」がペアになっているのがMapの特徴です。
キーは一意(同じものが複数存在しない)ですが、値は同じものが複数あってもいいです。
Map系クラスの特徴
マップはMapインターフェースを元に実装されていて、*HashMap、TreMap、LinkedHashMap *の3つがよく使われます。
Mapクラス 概要 HashMap ハッシュを使ったMapのデフォルト。 要素数によらない高速な検索ができます。
順序が保持されていないので目的の要素のキーを指定してそれに紐づく値を取得するのが早いTreeMap 順序がキーの順番になっている。キーが数値の場合は小さい順に要素が保持されます。
キーが文字列の場合は、文字コードの順(辞書順、アルファベット順)に要素が保持される。LinkedHashMap キーの挿入順を保持する。 コンストラクタの引数の指定によって、
挿入順ではなくアクセス順を保持することもできます。デフォルトは挿入順です。
要素を追加(put)した順番に、そのままの順番で要素が保持されます。
または、コンストラクタの引数に順序付けモードを指定して、アクセス順(getした順番)に保持されるようにすることもできます。Mapの定義方法
Mapの初期化は以下のようにして行います。
ArrayList等と同様の記述のしかたで書くことが出来、ダイヤモンド演算子を用いての記述も可能です。基本の定義の仕方がこちらです。
マップインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();HashMap の定義
// HashMap(Mapの代わりに左辺を同じHashMapにしても可) Map<String, Integer> hashMap = new HashMap<String, Integer>();TreeMap の定義
// TreeMap(Mapの代わりに左辺を同じTreeMapにしても可) Map<String, Integer> treeMap = new TreeMap<String, Integer>();LinkedHashMap の定義
// LinkedHashMap(Mapの代わりに左辺を同じLinkedHashMapにしても可) Map<String, Integer> treeMap = new LinkedHashMap<String, Integer>();Map の使用例
まずはこちらのコードを御覧ください、説明はコメントアウトで記述してありますので、詳し異解説は下記に書きます。
package about_map; // Mapのインポート import java.util.HashMap; import java.util.Map; public class MainAboutMap { public static void main(String[] args) { // ここから ===================================== // 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>(); // 2「put」を使用して値を追加する sampleHashMap.put("ニビジム", "タケシ"); sampleHashMap.put("ハナダジム", "カスミ"); sampleHashMap.put("クチバジム", "マチス"); // ここまで ===================================== // 3 「get」でキー値を指定して出力 System.out.println(sampleHashMap.get("ニビジム")); System.out.println(sampleHashMap.get("ハナダジム")); System.out.println(sampleHashMap.get("クチバジム")); System.out.println(sampleHashMap.get("タマムシジム")); //null になる } }出力結果
タケシ カスミ マチス null解説
こちらのコードの手順は、、
- Mapをインポートする
- newの時にキーと値の両方を型として指定
- 「put」を使用して値を追加する
- 「get」でキー値を指定して出力
といった記述をしています。
① newの時にキーと値の両方を型として指定
生成したHashMapクラスのインスタンスをMap[インタフェース]型の変数sampleHashMapに保持。
// 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>();② 「 put 」を使用して値を追加する
Map[インタフェース]では値の追加は「 add 」ではなく、
「 put 」という名前のメソッドで要素の追加を行います。putメソッドには引数を2つ指定します。
第1引数がキー、第2引数がキーに紐づく値です。// 2「put」を使用して値を追加する sampleHashMap.put("ニビジム", "タケシ"); sampleHashMap.put("ハナダジム", "カスミ"); sampleHashMap.put("クチバジム", "マチス");③ 「get」でキー値を指定して出力
値を取り出すときは、 getメソッド を使用します。
Map.getを使うと、Mapにputされているキー・値の対応付けの中から、キーに対応する値を取り出せます。キーがputされていない場合はnullが戻ります。
// 3 「get」でキー値を指定して出力 System.out.println(sampleHashMap.get("ニビジム")); System.out.println(sampleHashMap.get("ハナダジム")); System.out.println(sampleHashMap.get("クチバジム")); System.out.println(sampleHashMap.get("タマムシジム")); //null になる【補足】 put の別パターン
putする時の別パターンでこちらの方法でも値の追加が可能です。
コメントアウト部分を上記のコードの部分を境に入れ替えて使用してください。
やっていることは上記のコードと同じなので、出力結果も同じです。// ここから ===================================== // 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>(); // 2「put」を使用して値を追加する sampleHashMap = new HashMap<String, String>() { { put("ニビジム", "タケシ"); put("ハナダジム", "カスミ"); put("クチバジム", "マチス"); } }; // ここまで =====================================【Set】 重複要素のないコレクション
Setとは
Setは、Listのと同様に 「データをまとめたもの」になります。
ですが、双方にはこのような違いがあります。
- Mapのようなキーと値の関連付けをしない
- インデックスが存在しない
- 同じ値のものは2つ以上持てない
SQL にある 「DISTINCT」や、「ORDER BY」 のようなイメージだと思います。
Setの使い所
以上に書いた「 同じ値のものは2つ以上持てない 」などの特性をいかし、このような使い所が考えられます。
- 商品を安い順に並べる
- 会社の部署はいくつあるのか調べる
- ポケモンのタイプは何種類あるか調べる
- この学校の生徒はどこの出身者がいるかみる。
といったとき Set が役立つのではないかと思います。
Setの種類
Setインタフェースを実装するものには、
HashSetクラス,TreeSetクラス,LinkedHashSetクラスなどがあります。
それぞれの配列の並べ方は以下にです。
クラス 概要 要素の並び ( 1 ~ 5 の値が格納されている場合) HashSet ランダム 2, 4, 3, 5, 1 TreeSet 昇順 1, 2, 3, 4, 5 LinkedHashSet 追加した順 1, 3, 4, 5, 2 Setの定義
Set の基本の型
Setも List、Map 等と同様の書き方ができます。
基本的な書き方は以下です。セットインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();HashSet、TreeSet、LinkedHashSet はそれぞれ次のように定義します。
HashSet の定義
※Setの代わりに左辺を同じHashSetにしてもOK
Set<String> hashSet = new HashSet<String>();TreeSet の定義
※Setの代わりに、左辺を同じTreeSetにしてOK
Set<String> treeSet = new TreeSet<String>();LinkedHashSet の定義
※Set の代わりに、左辺を同じLinkedHashSet にしてもOK
Setサンプルコード
以下のコードは、各種setを用いて出力結果を比べたものです。
import java.util.HashSet; import java.util.LinkedHashSet; import java.util.TreeSet; public class Main { public static void main(String[] args) { HashSet<String> vegetableSet = new HashSet<String>(); //適当に値を入れていく vegetableSet.add("大根"); vegetableSet.add("人参"); vegetableSet.add("ブロッコリー"); vegetableSet.add("すいか"); vegetableSet.add("かぼちゃ"); System.out.println("HashSetはランダムで表示"する"); //拡張for文 で変数vs を vegetableSet から一つづつ取り出す for (String vs : vegetableSet) { System.out.println(vs); } TreeSet<String> fruitsSet = new TreeSet<String>(); //適当に値を入れていく fruitsSet.add("もも"); fruitsSet.add("ミカン"); fruitsSet.add("りんご"); fruitsSet.add("梨"); System.out.println("TreeSet は昇降順に表示する"); for (String fs : fruitsSet) { System.out.println(fs); } LinkedHashSet<String> fishSet = new LinkedHashSet<String>(); fishSet.add("カツオ"); fishSet.add("カンパチ"); fishSet.add("鯵"); fishSet.add("ブリ"); System.out.println("LinkedHashSet は追加した順に表示する"); for (String fs : fishSet) { System.out.println(fs); } TreeSet<String> meetSet = new TreeSet<String>(); //適当に値を入れていく meetSet.add("牛"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("豚"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("牛"); meetSet.add("豚"); meetSet.add("豚"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("羊"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("羊"); meetSet.add("豚"); meetSet.add("鹿"); meetSet.add("羊"); System.out.println("set には同じ値が入らないので重複分は出力されない"); for (String ms : meetSet) { System.out.println(ms); } } }出力結果
HashSetはランダムで表示 人参 大根 すいか かぼちゃ ブロッコリー TreeSet は昇降順に表示する もも りんご ミカン 梨 LinkedHashSet は追加した順に表示する カツオ カンパチ 鯵 ブリ set には同じ値が入らないので重複分は出力されない 牛 羊 豚 鹿これらをうまく利用することで、システムのいろいろな表現ができそうです。
実際に手を動かしながら覚えていきたいと思います。参考文献・記事
- 投稿日:2020-11-28T10:38:36+09:00
【Java】拡張 for文
拡張for文
拡張for文とは
配列やコレクションといった複数の要素を持っているものからすべての要素に含まれる値を順番に取り出して処理するために使われます。
拡張for文は、「要素の指定ができない」という通常のfor文との違いがあります。
## 拡張for文の記述の仕方
拡張for文の基本的な書き方はこちらです。for (型 変数名: 配列名もしくはコレクション名){ 実行する処理 }値を順番に取り出したい配列やコレクションと、取り出した値を格納する変数を:(コロン)で区切って記述します。
繰り返される回数は配列やコレクションに含まれている値の数なので条件式と変化式は必要ありません。
for文との使い分け
結論、拡張for文をつかったほうが「 記述内容がシンプルでコーディングもしやすく、可読性も優れている」ので記述ミスが軽減される点で現場では重宝されます。
こちらが通常のfor文です。
for(初期化式; 条件式; 変化式){ 実行する処理 }for文 の使い所
- 指定した条件で繰り返し処理を実行するときに使う
- 繰り返す処理の内容を指定できる。
拡張for文 の使い所
- コレクションのすべての要素に対して繰り返し処理をするとき
- 「 リストの 何番目が必要 」という要件がないとき
for文をより簡単に書けるメリットはとても大きいので、「拡張for文でかけるかどうかを検討」し、難しそうだったらfor文を使うといいかと思います。
拡張for文のサンプルコード
こちらは配列内の値を全部足すループと、全部引き算をかけるループのコードになります。
public class Main { public static void main(String[] args) { int plusTotal = 0; int minusTotal = 0; int number[] = { 1, 2, 3, 4, 5 }; for (int score : number) { // 配列内で足し算するループ plusTotal += score; // 配列内で引き算するループ minusTotal -= score; } System.out.println("配列内を全部プラスすると" + plusTotal); System.out.println("配列内を全部マイナスすると" + minusTotal); } }実行結果
配列内を全部プラスすると15 配列内を全部マイナスすると-15参考文献・記事
- 投稿日:2020-11-28T09:53:29+09:00
Javaでの文字列結合について
Javaでの文字列結合
業務でJavaを触っている中で何気なく、文字列結合って使ってるが、先日コードレビューを受けた時に、文字列結合をする時は
+ではなく、StringBuilderを使ったほうが処理速度が早いとの指摘を受けた。
正直経験も浅く、言語の仕様までを把握していないのでいい機会だと思い調べてみました。「+」 を使用した文字列結合
StrgingBuilderのインスタンスを生成しappend()で文字列を結合した後に、Stringのインスタンスを作成するらしい。メモリ上の領域が広がるわけではないらしいです。つまりループ処理の中などで
+演算子を使って文字列を結合すると、メモリを無駄に消費してしまう。そのため
StringBuilderを使用するほうが性能的には良いらしい。ただし以下のようなケースの場合は、
+演算子を使うほうがよい。
・1行で複数の文字列リテラルを結合する場合
・1行で複数の文字列リテラルとString変数を結合する場合public class Main { public static void main(String[] args) { public static final String COMMA = "," String subject1 = "国語"; String subject2 = "数学"; String timeTable = subject1 + COMMA subject1 + COMMA subject2 } }StringBuilder を使用した文字列結合
先程も説明したようにループ処理等で文字列を結合する場合には適している。
public class Main { public static void main(String[] args) { String languageAry[] = {"Java", "Ruby", "PHP", "JavaScript"}; StringBuilder sb = new StringBuilder(); for(language : languageAry){ sb.append(language) } String sb = sb.toString(); System.out.println(fuga); } }ちなみに
append()は引数にString以外の型の変数を受け取ることが出来る。
今まで、それを知らずにint型の値をその都度ToString()でパースしていたので、コードも減るし、便利なので積極的に使って行こうと思います。public class Main { public static void main(String[] args) { StringBuilder sb = new StringBuilder(); sb.append("hoge"); sb.append(10); // 問題なく処理が通る String fuga = sb.toString(); System.out.println(fuga); } }実行結果
hoge10参考
[Java]文字列連結で、+演算子 or StringBuilder どちらを使うべき?
StringBuilderクラスについて
Java(tm) Platform, Standard Edition 8
- 投稿日:2020-11-28T09:00:03+09:00
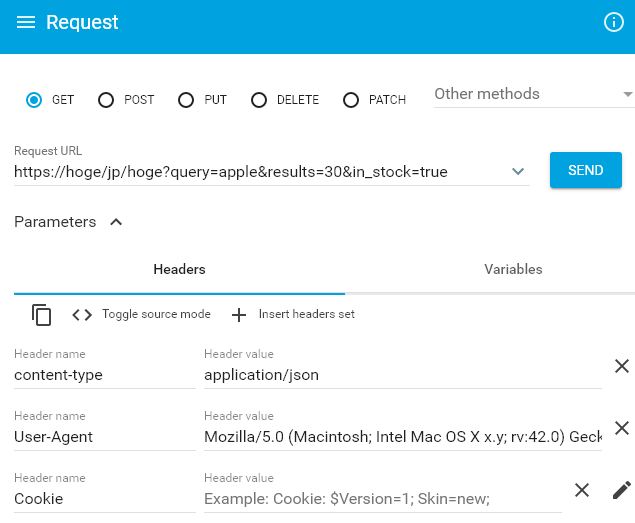
リクエストパラメータに情報を含めず ヘッダーに設定する方法
結論:実装は以下
@GetMapping(path = "/hoge", produces = "application/json") public Response getSproItems(@Validated Request request, @RequestHeader (value="User-Agent", required=false) String agent, @RequestHeader("Cookie") String cookie) return service.getResponse(request,agent,cookie) }リクエストURL
https://hoge.jp/hoge?query=apple&results=30&in_stock=true
クエリ:apple
件数:30
在庫有無:有ARCで送るとこんな感じ。
するとリクエストパラメータ(query=apple&results=30&in_stock=true)は
格納用のクラスに格納され、
リクエストヘッダーの情報は、string型として別で保管されます。情報をリクエストURLに
含めたくないときは便利かもしれません。
- 投稿日:2020-11-28T08:08:23+09:00
【Java】 java.util コレクションフレームワーク ( Map )
【Map】キーと値とのマッピングを保持する
連想配列を取り扱うものに Map というコレクションがあります。
Mapとは
Mapは 「キー」と「値」 の二つの要素から成り立っています。
「 キー は値につける名前のようなもの 」で、値ひとつひとつに「 キー 」が存在しており、「 キー 」と「 値 」がペアになっているのが Map の特徴です。
キー は一意(同じものが複数存在しない)ですが、値は同じものが複数あってもいいです。
Map系クラスの特徴
マップはMapインターフェースを元に実装されていて、 HashMap、TreMap、LinkedHashMap の3つがよく使われます。
Mapクラス 概要 HashMap ハッシュを使ったMapのデフォルト。 要素数によらない高速な検索ができます。
順序が保持されていないので目的の要素のキーを指定してそれに紐づく値を取得するのが早いTreeMap 順序がキーの順番になっている。キーが数値の場合は小さい順に要素が保持されます。
キーが文字列の場合は、文字コードの順(辞書順、アルファベット順)に要素が保持される。LinkedHashMap キーの挿入順を保持する。 コンストラクタの引数の指定によって、
挿入順ではなくアクセス順を保持することもできます。デフォルトは挿入順です。
要素を追加(put)した順番に、そのままの順番で要素が保持されます。
または、コンストラクタの引数に順序付けモードを指定して、アクセス順(getした順番)に保持されるようにすることもできます。Map の定義方法
Mapの初期化は以下のようにして行います。
ArrayList 等と同様の記述のしかたで書くことが出来、ダイヤモンド演算子を用いての記述も可能です。基本の定義の仕方がこちらです。
マップインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();HashMap の定義
// HashMap(Mapの代わりに左辺を同じHashMapにしても可) Map<String, Integer> hashMap = new HashMap<String, Integer>();TreeMap の定義
// TreeMap(Mapの代わりに左辺を同じTreeMapにしても可) Map<String, Integer> treeMap = new TreeMap<String, Integer>();LinkedHashMap の定義
// LinkedHashMap(Mapの代わりに左辺を同じLinkedHashMapにしても可) Map<String, Integer> treeMap = new LinkedHashMap<String, Integer>();Map の使用例
まずはこちらのコードを御覧ください、説明はコメントアウトで記述してありますので、詳し異解説は下記に書きます。
package about_map; // Mapのインポート import java.util.HashMap; import java.util.Map; public class MainAboutMap { public static void main(String[] args) { // ここから ===================================== // 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>(); // 2「put」を使用して値を追加する sampleHashMap.put("ニビジム", "タケシ"); sampleHashMap.put("ハナダジム", "カスミ"); sampleHashMap.put("クチバジム", "マチス"); // ここまで ===================================== // 3 「get」でキー値を指定して出力 System.out.println(sampleHashMap.get("ニビジム")); System.out.println(sampleHashMap.get("ハナダジム")); System.out.println(sampleHashMap.get("クチバジム")); System.out.println(sampleHashMap.get("タマムシジム")); //null になる } }出力結果
タケシ カスミ マチス null解説
こちらのコードの手順は、、
といった記述をしています。
① newの時にキーと値の両方を型として指定
生成したHashMapクラスのインスタンスをMap[インタフェース]型の変数sampleHashMapに保持。
// 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>();② 「 put 」を使用して値を追加する
Map[インタフェース]では値の追加は「 add 」ではなく、
「 put 」という名前のメソッドで要素の追加を行います。putメソッドには引数を2つ指定します。
第1引数がキー、第2引数がキーに紐づく値です。// 2「put」を使用して値を追加する sampleHashMap.put("ニビジム", "タケシ"); sampleHashMap.put("ハナダジム", "カスミ"); sampleHashMap.put("クチバジム", "マチス");③ 「get」でキー値を指定して出力
値を取り出すときは、 getメソッド を使用します。
Map.getを使うと、Mapにputされているキー・値の対応付けの中から、キーに対応する値を取り出せます。キーがputされていない場合はnullが戻ります。
// 3 「get」でキー値を指定して出力 System.out.println(sampleHashMap.get("ニビジム")); System.out.println(sampleHashMap.get("ハナダジム")); System.out.println(sampleHashMap.get("クチバジム")); System.out.println(sampleHashMap.get("タマムシジム")); //null になる【補足】 put の別パターン
putする時の別パターンでこちらの方法でも値の追加が可能です。
コメントアウト部分を上記のコードの部分を境に入れ替えて使用してください。
やっていることは上記のコードと同じなので、出力結果も同じです。// ここから ===================================== // 1 newの時にキーと値の両方を型として指定 Map<String, String> sampleHashMap = new HashMap<String, String>(); // 2「put」を使用して値を追加する sampleHashMap = new HashMap<String, String>() { { put("ニビジム", "タケシ"); put("ハナダジム", "カスミ"); put("クチバジム", "マチス"); } }; // ここまで =====================================参考文献・記事
- 投稿日:2020-11-28T07:59:54+09:00
【Java・SpringBoot】Spring JDBC でユーザー登録(SpringBootアプリケーション実践編10)
ホーム画面からユーザー一覧画面に遷移し、ユーザーの詳細を表示するアプリケーションを作成して
Spring JDBCの使い方について学びます⭐️
今回は前回作った画面に引き続き、JDBC Templateを実装して、データを登録(insert)する方法について学んでいきます^^
構成は前回の記事を参考にしてください⭐️前回の記事
【Java・SpringBoot】Spring JDBC(SpringBootアプリケーション実践編9)データの登録(insert)
updateメソッド
- リポジトリー用クラスのinsert用メソッドを作成
- JdbcTemplateクラスを使って登録・更新・削除する
//例 int rowNumber = jdbc.update("INSERT INTO m_user(user_id," + " password," + " user_name," + " role)" + " VALUES(?, ?, ?, ?, ?, ?, ?)", user.getUserId(), user.getPassword(), user.getUserName(), user.getBirthday(), user.getAge(), user.isMarriage(), user.getRole());
- 第1引数:SQL文を入れます
- 第2引数以降:PreparedStatement
- PreparedStatementには、SQL文の?の部分に入れる変数を引数にセット
VALUES(?, ?, ?, ?, ?, ?, ?)- 引数にセットした順番にSQL文に代入される
- 戻り値には、登録したレコード数が返る
UserDaoJdbcImpl.javapackage com.example.demo.login.domain.repository.jdbc; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.dao.DataAccessException; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.stereotype.Repository; import com.example.demo.login.domain.model.User; import com.example.demo.login.domain.repository.UserDao; @Repository("UserDaoJdbcImpl") public class UserDaoJdbcImpl implements UserDao { @Autowired JdbcTemplate jdbc; // Userテーブルの件数を取得. @Override public int count() throws DataAccessException { return 0; } /** Userテーブルにデータを1件insert. */ @Override public int insertOne(User user) throws DataAccessException { int rowNumber = jdbc.update("INSERT INTO m_user(user_id," + " password," + " user_name," + " birthday," + " age," + " marriage," + " role)" + " VALUES(?, ?, ?, ?, ?, ?, ?)", user.getUserId(), user.getPassword(), user.getUserName(), user.getBirthday(), user.getAge(), user.isMarriage(), user.getRole()); return rowNumber; } // Userテーブルのデータを1件取得 @Override public User selectOne(String userId) throws DataAccessException { return null; } // Userテーブルの全データを取得. @Override public List<User> selectMany() throws DataAccessException { return null; } // Userテーブルを1件更新. @Override public int updateOne(User user) throws DataAccessException { return 0; } // Userテーブルを1件削除. @Override public int deleteOne(String userId) throws DataAccessException { return 0; } //SQL取得結果をサーバーにCSVで保存する @Override public void userCsvOut() throws DataAccessException { } }サービスクラスにinsert用のメソッド追加
- insertメソッドでリポジトリークラスのinsertOneメソッドを呼び出す
- 戻り値が0より大きければ、"insert成功"の判定結果をリターン
UserService.javapackage com.example.demo.login.domain.service; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import com.example.demo.login.domain.model.User; import com.example.demo.login.domain.repository.UserDao; @Service public class UserService { @Autowired UserDao dao; public boolean insert(User user) { // insert実行 int rowNumber = dao.insertOne(user); // 判定用変数 boolean result = false; if (rowNumber > 0) { // insert成功 result = true; } return result; } }ユーザー登録画面のコントローラークラス
サービスクラスのinsertメソッドを呼び出す
- サービスクラスのメソッドに渡すUserクラスをnewする
- Userクラスには、画面から入力された値をセット
- サービスクラスのinsertメソッドを呼び出す
boolean result = userService.insert(user);- コンソールにinsert結果出力
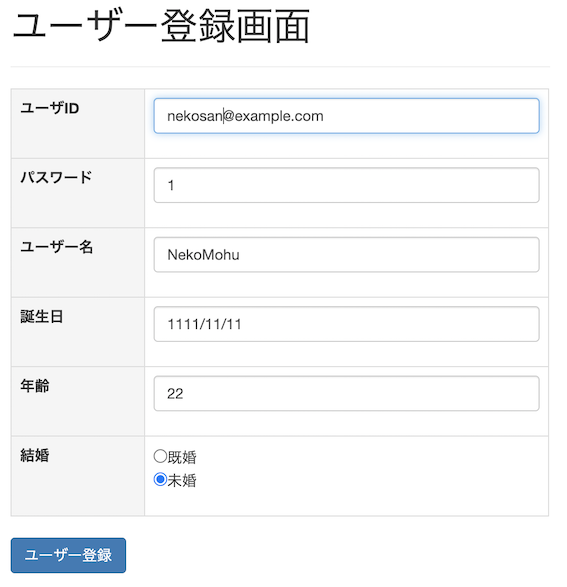
SignupController.javapackage com.example.demo.login.controller; import java.util.LinkedHashMap; import java.util.Map; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.validation.BindingResult; import org.springframework.validation.annotation.Validated; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.ModelAttribute; import org.springframework.web.bind.annotation.PostMapping; import com.example.demo.login.domain.model.GroupOrder; import com.example.demo.login.domain.model.SignupForm; import com.example.demo.login.domain.model.User; import com.example.demo.login.domain.service.UserService; @Controller public class SignupController { @Autowired private UserService userService; //ラジオボタン用変数 private Map<String, String> radioMarriage; private Map<String, String> initRadioMarrige() { Map<String, String> radio = new LinkedHashMap<>(); // 既婚、未婚をMapに格納 radio.put("既婚", "true"); radio.put("未婚", "false"); return radio; } @GetMapping("/signup") public String getSignUp(@ModelAttribute SignupForm form, Model model) { // ラジオボタンの初期化メソッド呼び出し radioMarriage = initRadioMarrige(); // ラジオボタン用のMapをModelに登録 model.addAttribute("radioMarriage", radioMarriage); // signup.htmlに画面遷移 return "login/signup"; } @PostMapping("/signup") public String postSignUp(@ModelAttribute @Validated(GroupOrder.class) SignupForm form, BindingResult bindingResult, Model model) { // 入力チェックに引っかかった場合、ユーザー登録画面に戻る if (bindingResult.hasErrors()) { // GETリクエスト用のメソッドを呼び出して、ユーザー登録画面に戻ります return getSignUp(form, model); } // formの中身をコンソールに出して確認します System.out.println(form); // insert用変数 User user = new User(); user.setUserId(form.getUserId()); //ユーザーID user.setPassword(form.getPassword()); //パスワード user.setUserName(form.getUserName()); //ユーザー名 user.setBirthday(form.getBirthday()); //誕生日 user.setAge(form.getAge()); //年齢 user.setMarriage(form.isMarriage()); //結婚ステータス user.setRole("ROLE_GENERAL"); //ロール(一般) // ユーザー登録処理 boolean result = userService.insert(user); // ユーザー登録結果の判定 if (result == true) { System.out.println("insert成功"); } else { System.out.println("insert失敗"); } // login.htmlにリダイレクト return "redirect:/login"; } }SpringBootで新規登録画面を確認!
- http://localhost:8080/signup
- ユーザー登録画面からフォーム入力し、ユーザーを登録
- 成功すれば、コンソールに
insert成功と出ました〜〜〜^o^- 次回は、insert結果を確認できるように、複数件のselectとカウントを実装します!
//コンソール画面 メソッド開始: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model) SignupForm(userId=nekosan@example.com, password=1, userName=NekoMohu, birthday=Sat Nov 11 00:00:00 JST 1111, age=22, marriage=false) メソッド開始: int com.example.demo.login.domain.repository.jdbc.UserDaoJdbcImpl.insertOne(User) メソッド終了: int com.example.demo.login.domain.repository.jdbc.UserDaoJdbcImpl.insertOne(User) insert成功 メソッド終了: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model) メソッド開始: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド終了: String com.example.demo.login.controller.LoginController.getLogin(Model)
- 投稿日:2020-11-28T03:06:14+09:00
新卒1年目が荒れ果てた開発環境に1年間でCIを導入し単体テストを布教した話
この記事は 「Develop fun!」を体現する Works Human Intelligence Advent Calendar 2020 21日目の記事です。
昨日の記事は@sparklingbabyさんのStream API がもっとわかる記事でした。
あらすじ
私は2019年にWorks Human Intelligence(正確には分社前の会社)に新卒入社し、
19年10月からプロダクト開発部門に配属され、SETエンジニアとしてとある製品のJava開発環境の改善に取り組んでいます。ざっくりとプロダクト開発を紹介するとこんな感じです。
- 3万クラス程度ある大規模Java Webアプリケーション
- 開発環境はEclipseを使用
- 開発者のOSはWindowsのみ
Before
私が開発チームに参加した時点では
部門として新規開発に注力しており、足下の環境改善をやる担当者がおらず、
いろいろな汚れが少しずつ蓄積していた結果、
工数的にも、技術的にも誰も手がつけられない状況になっていました。具体的にあげると
- 新人が開発環境のセットアップするのに2日かかる
- セットアップを正しく行えていない開発者が多く、LinterやFormatterの設定がバラバラ
- 推奨設定でセットアップするとIDEのエラー表示タブが1000件を超えるLintエラーで溢れてコンパイルエラーも埋もれてしまう
- ユニットテストは存在していたが、メンテが一切されておらず、コンパイルすら通らない。開発者はテストコードのビルドエラーを無視してローカルでテストを実行する必要がある
- 依存ライブラリの管理を手動で行なっているため、安全なライブラリ更新が実質不可能
- プレマージの自動チェックは一切なく、レビュワーの目視のみが頼り。結果、ビルドが頻繁に落ちる。
- 大半の開発者はユニットテストを利用していない
と言った感じです。なかなかにワイルドな開発者体験だと思いませんか?
そこで、部署に配属された私は、
この環境で開発やりたくないこの状況をなんとかしたかったため、
上長と相談して専任で開発環境改善を担当することになりました。After
私が1年間改善に取り組んだ結果、以下のようなモダンな開発環境になりました。
- 開発環境のセットアップは大半が自動化され、2時間以内で終わるように
- セットアップ自動化により、全員が推奨設定で開発環境を利用するように
- フォーマット違反、Lintエラーを0件に削減。
- ユニットテストをメンテし、コンパイルエラーを修正し、動くテスト約2000件を抽出。(動かないテストは隔離)
- 依存ライブラリ管理をGradleに任せることで、安全なライブラリ更新が可能に。
- プレマージでビルド、フォーマッタ、Linter、ユニットテストが自動チェックされるCIを導入。ビルドエラー、Lintエラー、ユニットテスト失敗の0件維持をCI導入から半年以上達成。
- 開発者がユニットテストをコンスタントに書くように
この記事ではどのように改善を進めていったのかを紹介します。
ステップ1: 開発環境セットアップ工数の削減
退屈なことはPowerShellにやらせよう
まず、手始めに開発環境セットアップ手順を見直しました。
当時の開発環境構築は十数ステップに渡る手順から構成されており、
- 新人がセットアップを完了するのに2日かかる
- 間違いなくセットアップを完了させられる人はほぼいない
と言う状況でした。
セットアップが複雑な理由
このような長い設定手順になっている原因は大きく2点ありました。
1. デフォルト設定のEclipseに設定を入れていた。
2. 開発に必要なソフトウェアを各自が手動インストールしていた。解決策
1つ目の原因に対しては、ローカル環境に依存しない設定をプリセット1したEclipseを作成し、配布することにしました。
2つ目に対しては、また、開発に必要なソフトウェア一式をサイレントインストールするPowerShellスクリプト2を作成し、自動化しました。
荒れ果てたソースコード
これで、開発環境のセットアップ工数が大幅に削減され、全員が推奨設定で開発できるようになりました。
しかし、前述の通り、「推奨設定でセットアップするとIDEのエラー表示タブが1000件を超えるLintエラーで溢れてコンパイルエラーも埋もれてしまう」という問題があったため、
新しい開発環境への移行前に既存のLintエラーを直す必要がありました。
(なお、ここでいうLintエラーとはEclipseのError/Warning設定で指定するUnused Imports等のエラーのことです)開墾
既存のLintエラーですが、間違った直し方をしてしまうと、大量のデグレードを発生させてしまう恐れがありました。
デグレードは言うまでもなくダメですが、
特に私は新卒1年目で、社内での信頼度はまだ低く、最初のプロジェクトで悪評が立つことは避けなければなりません。エラーの内容を精査し、
- QuickFixで一意に直せるもの(Unused Imports, Missing Annotation等)
- 単純なコードの削除で直せるもの(Unused local variable等)
- 手動修正が必要なもの
に分類し、1は一括で自動修正し、2についてはコードレビューを実施して削除して問題ないコードかを確認して慎重に修正を行いました。
3については@SuppressWarningsアノテーションを付与することで、コードは修正せずにエラーを抑制する対応を取りました。効果
このようにして新しい開発環境への移行を行いました。
結果として以下のような効果が出ました。
- セットアップにかかる工数を2日から2時間に短縮
- 全員が同じ設定で開発できるように
- EclipseのProblems Viewに表示されるLintエラーが0件になり、自分が新たに発生させたコンパイルエラー、Lintエラーに気づくことができるように
開発環境自動化を作成したことで現場からも「セットアップが楽になった」 「開発環境を壊してもすぐ直せるので便利」と言った評判をいただきました。
ステップ2: プレマージ導入
このビルドを落としたのは誰ですか?
開発環境セットアップ自動化により、全員が推奨設定でIDEを使えるようになったのですが、
以下のような場合にフォーマッタ違反、Lintエラーが混入する可能性がありました。
- 何かの弾みで設定を変えてしまった場合
- 推奨IDEを使わずにコードを修正している場合
このままでは、徐々にエラーが蓄積し、せっかく綺麗にしたソースがまた荒れてしまいます。
それを防ぐためにプレマージでの自動チェックを導入することにしました。目標
プレマージを導入するにあたって、以下の3点に注意して要件を設定しました。
1. 待ち時間が妥当でありジョブの待ち行列が詰まらないこと
CIにかけられるマシンリソースはオンプレのメモリ16GBのマシン2台でした。
対象プロダクトのビルドは8GBのメモリが必要で、クリーンビルドすると3分程度かかります。繁忙期にジョブキューが詰まると、MRの承認に待ち時間がかかり、
場合によってはプレマージを無視してマージするようになってしまいます。そのようなことを避けるために一回のチェックは5分以内に終了することを目標にしました。
2. エラーがあったときには迅速かつわかりやすく通知され、エラーがないときにはウザくないこと。
プレマージがエラーを検出したとき、最も実装が簡単な通知方法は
「MRのコミットステータスを失敗させ、開発者にジョブのログを確認させる」
というものになるでしょう。しかし、小規模開発やCIの仕様を開発者全員が知っている場合はこれでも良いですが、
この方法は大規模開発において迅速かつわかりやすくとは言えません。MRの失敗通知はメールで送られてきますが、メールを常時チェックしている人は少ないでしょう。
また、開発者がジョブのログを確認するのも無視できない手間がかかります。
また、ログを読み慣れていない開発者はエラー原因が分からず、CI担当者(私)に問い合わせてくることでしょう。
そうなってしまうと、コミュニケーションコストがかかってくるため、双方が幸せになれません。今回はエラーの通知方法として
エラーの箇所をMRのコメントで指摘し、同時にエラーがあったことをSlackに通知するようにしました。
また、多数のコミットをpushしたときにMRのコメント欄が読みにくくなるのを防ぐために、コメントをつけるのはエラーを検出したときのみとして、正常終了した場合はコミットステータスの更新のみを行うようにしました。3. 誤検知が少ないこと
プレマージの信頼性は非常に重要です。なぜなら信頼性が低いプレマージはそのうちに無視されるようになるからです。
プレマージのエラー誤検知のパターンは2種類あります。
- チェック時に実行環境に障害が生じてジョブが失敗する場合
- 元々存在していて、MR起因ではないエラーを検出した場合
一つ目のパターンはなかなか難しい問題でCIインフラ担当者が頑張る必要がありますが、
大抵は再実行してもらうことでなんとかなります。二つ目のパターンをなくすために
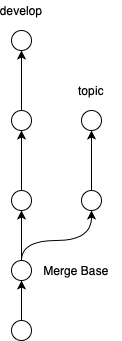
「topicブランチのHEADとMerge Baseコミットをそれぞれチェックしてエラーの増分を検出する」
と言う方法を取ることにしました。34※ここでMerge Baseコミットは以下の図のようなものです。
大規模プロジェクトにおける課題
上記要件を達成するにあたって幾つかの技術的な課題がありました。
- ビルドスクリプトはAntで書かれており、長らく変更されておらずメンテナがいない状態だった。
- フォーマッタおよびLinterはEclipseの付属のもの利用しており、コマンドラインから簡単に実行できない。
- 全クラス(3万程度)をコンパイルするのに3分程度かかる。一方でエラーは変更したソース起因のものだけ表示するためには2回ビルドしなければならず、5分に間に合わせるためには差分ビルドを行う必要がある。
解決策
フォーマッタやLinterがEclipseに強く依存していたため、切り出してビルドスクリプトに組み込むのは困難でした。
そこでEclipseをCLIから操作できるようにしようと考え、Eclipse RCP として以下の機能を実装しました。
- ビルドしてビルドエラーとLintエラーをCSVに出力する
- 指定したファイルにフォーマッタを適用する
実はEclipse JDTは優秀なのでうまくキャッシュをすると5差分ビルドもしてくれるので結構6高速です。
効果
プレマージチェックを導入したことで以下のような効果がでました。
- developブランチにコンパイルエラー、Lintエラーが混入することがほぼなくなった
- 以下のようなエラーをコードレビュー前に開発者が自主的に気づいて直せるようになった
- ファイルのコミット漏れ
- 不要になったメソッド、変数の削除漏れ
- サブクラスで既に定義されているメソッドと同名のメソッド、フィールドを親クラスに追加してしまうミス
また、プレマージチェックに失敗するとSlackのチャンネルに
レビュワーと開発者の名前が晒されるレビュワーと開発者に通知が飛ぶようにしたため、CIに怒られないようにしようという意識が開発者全体に浸透しました。その結果、懸念であった、エラーが放置されたり、修正前にマージされたりということは起こりませんでした。
ステップ3: Gradle化
とあるライブラリの身元特定(バージョニング)
プレマージを導入した後、今後SpotBugs等のLinterやJUnitを整備していきたいと考えていました。
しかし、それらのツールをビルドツールの助けなしで整備するのは骨が折れるため、
先にビルドスクリプトをAntからGradleに移行することにしました。また、外部ライブラリの管理を温かみのあるベタ書きシェルスクリプトで行っていたため、
ライブラリ更新時の変更箇所が多く、工数がかかると言う問題も解決することにしました。目標
- Antで書かれたビルドスクリプトをGradleに移行する
- シェルスクリプトで管理されていた外部ライブラリをGradleのdependencyで管理する
課題
- 既存のAntのビルドスクリプトのメンテナはいない。あるのはAntのXMLのみ。
- 外部ライブラリは社内のmavenレポジトリに再ホストされており、それらバージョン情報や依存ライブラリの情報が失われているため、各ライブラリがMaven Centralのどのバージョンに対応するものか特定する必要がある
古代技術の再現
メンテナ不在のなか、絶対にデグレードを起こしたくなかったので、
ビルド結果に意図しない変更が起こらないようにテスト駆動開発でGradleスクリプトを作成しました。つまり、Antでのビルド結果と比較して
- 生成されるクラスファイルがバイナリ一致すること
- 生成される各Jarに含まれるファイル名に意図しない変更がないこと
- 生成されるWarに含まれるファイル名に意図しない変更がないこと
をテストするスクリプトを書き、
テストに通るようにGradleスクリプトを書いていきました。ご注文はライブラリですか?
外部ライブラリの依存関係解決をGradleに任せるためには、失われた各ライブラリの依存情報を再構築する必要がありました。
そのため、社内ホストされた外部ライブラリを一つ一つ展開し、バージョンの特定を行いました。特定は簡単なものもあれば難しいものもありました。難易度順で並べると以下のようでした。
- Easy: ファイル名にバージョンが書いてあるもの
- Medium: Jarの中にpomファイルがあるもの
- Hard: Jarの中の
META-INF/MANIFEST.MFにそれっぽい情報があるもの- Extreme: No hints (WEB上で存在する同名Jarを虱潰しで特定できることも)
バージョンがわかったからと言って安易に差し替えてはいけません。
もしかしたらホストする際に別のバージョンをアップロードしている可能性や、Jarの一部のファイルを差し替えている可能性もあります。バージョンのずれによるデグレードを避けるために、
二つのJarが同じバージョンかどうかを以下の基準で判定するスクリプトを書き、
確認をしながら特定を進めていきました。
- 二つのJarのハッシュ値が等しい場合は同じバージョン
- そうでない場合、二つのJarに含まれるファイルがMETA-INF以下をのぞいて全て等しい場合は同じバージョン
- そうでない場合、差分のあるファイルを確認し、同じバージョンか人間が判断する。
このようにした結果、主要な外部ライブラリについては安全にバージョンを特定することができました。
一方、特定できなかったものについてはそのまま残すこととしました。効果
Gradleに移行したことで外部ライブラリ周りの更新が非常に楽になりました。
- これまで外部ライブラリに更新があったときに各開発者がローカルで更新スクリプトを手動実行する作業がなくなった
- ライブラリのバージョンを安全に更新できるようになった。
ステップ4: JUnit復活
俺、このテストが動いたら退勤するんだ
ようやくGradleに移行できたので次はJUnitの整備です。
JUnitテストは昔に書かれたテストがそれなりに存在していたのですが、
開発者がローカルのEclipseで動かしてテストするという運用になっており、
- 全JUnitの定期的な実行
- プレマージチェックでのJUnitの実行 は行われていませんでした。
また、既存のJUnitテストを動かすにもライブラリが足りておらず、
必要なライブラリを各開発者がクラスパスに手動で追加する必要がありました。目標
gradle testで全テストが実行できるようにする- Eclipse上で特に追加設定なしにJUnitを実行できるようにする
- プレマージチェックで変更のあったクラスに対応するJUnitテストがあれば実行する
- 例:
SomeService.javaを修正したら、SomeServiceTest.javaを実行。- 実行結果とカバレッジをGitLab上から簡単に確認できるように
- テストが失敗したらビルドエラーと同様にパイプラインを失敗させ開発者に通知する
- 日次で全JUnitを実行し、結果サマリをSlackに投稿する
動かないテスト
まず、既存のJUnitを動かせるように
build.gradleにテスト用のライブラリを足して、gradle testを実行してみました。> gradlew test .... .... ....いくつもの問題のあるテストがあり、全てを動かすの一筋縄ではいきませんでした。
例をあげると
- 無限ループするテスト
System.exit(0)を呼び出すテスト(←マジでEvil)- 開発DBに接続しにいくテスト
等がありました。テストがハングしている雰囲気を察して、
問題のあるテストを特定し、除外していくことを繰り返すと
ようやく全テスト実行が終了するようになりました。遅すぎるテスト
しかし、全テストを実行するのに20分程度かかっていました。
テストケース数から鑑みても遅すぎるので
遅い原因を調査していくと以下の二つが主な原因でした。
- 同じテストが複数回実行されている
- DBに接続しようとしてタイムアウトしている
テストの重複
テストの重複は、TestSuiteクラスが原因でした。すなわち、
HogeSuite.java - FugaTest.java - PiyoTest.java - FooSuite.java - BarTest.java - BazTest.javaのように階層化されたTestクラスとTestSuiteクラスがあった場合、
素朴に全クラスを実行すると、Suiteクラスからの実行とTestクラスの単体実行が重複してしまうのです。- FugaTest - PiyoTest - BarTest - BazTest - FooSuite:BarTest - FooSuite:BazTest - HogeSuite:FugaTest - HogeSuite:PiyoTest - HogeSuite:FooSuite:BarTest - HogeSuite:FooSuite:BazTest今回の場合Suiteクラスである必要は特になかったのでSuiteクラスはテストの対象から除外することにしました。
DBにつなぐテスト
残るはDBに接続する必要のあるテストでした。
DBにつなぐ必要のあるテストは遅くて不安定であるため、
プレマージでの実行対象からは除外することにしました。DBアクセスするテストの多くは古い時代に書かれたJUnit3のテストでした。
ご存知の通りJUnit3ではTestCaseクラスのサブクラスとしてテストを書きます。
そして、本プロダクトでは独自のTestCaseのサブクラスをテストの
基底クラスとしていたのですが、その基底クラスがDBに接続する仕様になっていました。そのため、テスト自体はDBアクセスを必要としないが、独自の基底クラスを継承している故にDBアクセスをしているテストが相当数あることが予想されました。
そのようなテストまで除外してしまうのはもったいないので、以下のやり方で修正することにしました。
- 継承の親クラスを
TestCaseクラスに変更する- そのクラスのビルドが通り、実行した際に1つ以上のテストケースが成功する場合、プレマージでの実行対象とする。
- そうでない場合(コンパイルが通らない場合または全てのテストケースが失敗する場合)、修正を元に戻し、プレマージでの実行対象から外す。
これで動くテストを抽出することができ、20分かかっていたテストも2分程度で終わるようになりました。
失敗するテスト
最後に導入時点で失敗しているテストをIgnoreする修正を行いました。
- JUnit4テストの場合、
@Ignoreアノテーションをつける- JUnit3テストの場合、テストメソッド名に
_をつける(testHoge->_testHoge)これでめでたく
gradle testで全テストが実行でき、かつ失敗件数を0件にすることができました。CIの整備
最後にプレマージでのテスト実行を整備しました。
gradle testでは全てのテストを実行するので、
現時点では2分とはいえ、今後テスト件数が増えていくことを考えると、プレマージでの全件実行はできません。
したがって、修正したファイルに対応するテスト(末尾にTestがつくもの)のみを実行する仕様にしました。また、gradleタスクでテストを実行する場合、普通にやるとgradleでのビルドが実行され、
5分ほど時間がかかってしまいます。
Lintエラーを出力する関係で、ビルドはgradleではなくEclipseを用いたいため、
Eclipseがコンパイルした結果を用いてテストを実行するgradleタスクを作成しました。結果として、プレマージでのテストを30秒程度で実行することができるようになりました。
効果
JUnitのCIを整備したことで、テストを定期的に実行し、テストの失敗がメンテされる仕組みを作ることができました。
一方でテストを新規に書く人は残念ながらほとんど増えませんでした。
ステップ5: JUnit道場
やってみせ、言って聞かせて、させてみせ、ほめてやらねば、人は動かじ
上記の通り、プレマージでJUnitを動かすようにしたのですが、ユニットテストを書く開発者はほとんど増えませんでした。
ユニットテストには以下のようなメリットがあります。
- サーバを起動しなくて良いため確認が速く、繰り返し実行できる
- プレマージで自動実行されるため、評価時の手動テスト実行が一部7不要に
- 日次実行されるため、多くのテストを整備することで長期的にデグレードの早期発見が可能になる
目標
JUnitをコンスタントに書く文化を開発者に根付かせることを目標にしました。
現状の可視化
しかし、上の目標はまだ曖昧です。
まず、具体的な目標数値を設定するために現状の可視化を行いました。
テストの日次実行の結果を集計用DBに突っ込み、
Metabaseを使ってダッシュボードを作成し、どの部署がどのくらいテストを書いているのかを可視化しました。8
ダッシュボードを観察していてわかったことは
- テストの追加件数は10件/月程度である
- テストを追加しているのは特定のごく少数の開発者に限られる
ということでした。したがってテストを増やしていくためにはテストを書く開発者を増やす必要がありました。
目標数値
テストの追加件数を10件/月から100件/月にする。
テストを書かない理由
テストを書いていない理由を考察してみたところ以下のような要因がありそうでした。
- そもそもJUnitの使い方を知らない
- (E2Eテストではなく)ユニットテストを書くメリットを理解していない
- プロダクトのコードのテスト容易性が低くテストを書きたくてもかけない
JUnit道場
テストを書く文化を根付かせるために、JUnitの書き方を教える研修(JUnit道場)を企画しました。
現場の開発者のテスト技術にもレベルがあることを考慮して以下のようなコンテンツを作成しました。
- 基礎編
- 対象者: JUnitの書き方を知らない人向け
- 参加者: 開発者40名程度
- 形式: developer dojo (30 min x 4)
- 内容: JUnit4 + hamcrest + Mockitoの基礎的な書き方をハンズオンでやってみる
- マインド編
- 対象者: ユニットテストを書くメリットを知らない人向け
- 参加者: 開発者40名程度
- 形式: オンラインYouTube鑑賞会
- 内容: t_wadaさんのTDDライブコーディング動画を鑑賞
- 実践編
- 対象者: 基本的なJUnitは使えるがプロダクト開発でどうテストを書いたら良いかわからない人向け
- 参加者: 各開発チームから2-3人(計十数名)
- 形式: ライブコーディング(60min) + ハンズオン(60 min x 3)
- 内容: レガシーコード改善ガイドからいくつかのテクニックを抜粋して練習用のレガシーコード上でリファクタリングしながらテストを書いてみる。
効果
JUnit道場を実施した結果
- これまでユニットテストを書いていたチームは「息をするように」テストを書くように
- これまでユニットテストをを書いていなかったチームも所々テストを書くように
なりました。
定量的にも、JUnit道場前後でテスト追加件数が10件/月から100件/月に増えました。
今後もユニットテストをかける開発者が啓蒙活動を行なっていくことででテスト追加件数はさらに加速していくことが期待できます。
まとめ
まだまだ道半ばなところはありますが、レガシーコードであっても粘り強く改善していった結果、
モダンな開発環境、開発手法を取り入れることができました。1年間改善を続けて来て以下のような教訓を得ました。
- 改善は片手間ではできない。専任者を建て、十分な裁量を与えるべし。
- 環境をきれいにすることに集中する。コードによくないところがあっても直そうとすると泥沼。
- 施策を導入する前に、何を改善・削減するのかを明確にしておく。
- 訳のわからない仕様であっても必ずそうなった原因がある。可能な限りその仕様になった理由を探るべし。
- 使われていないコード、動かないテストは潔く切り捨てる。
- 文化を根付かせるためには技術や仕組みだけでは不十分。地道な啓蒙活動あるのみ。
Works Human Intelligenceではレガシーコードに立ち向かうエンジニアを募集しています!
長い記事に最後までお付き合いいただきありがとうございました。
明日の記事は@_53aさんの テレワークをより快適にするソフトウェア n 選です。
Eclipse Pleiadesプラグインを使うとそのようなことができます。 ↩
Chocolatey等のパッケージマネージャを利用することも検討しましたが、一部の開発者はインターネットアクセスに制限があることから断念しました ↩
ちなみに「修正されたソースコード上のエラーを検出する」という方法もありそうですが、検出すべきエラーを見逃すケースがあるため採用しませんでした。 ↩
「エラーは0件維持されているんだからMerge Baseコミットにエラーはないんじゃないの」と思った方もいるかもしれませんが、開発イテレーション末で0件になっていますが、開発イテレーション中にエラーが混入することは想定する必要があります。また0件維持されていないWarningも同じ仕組みで検出しているためこのようになっています。 ↩
なかなかキャッシュが言うことを聞いてくれないのでJDTの判定ロジックをHackする必要がありましたが ↩
のちにGradleでの差分ビルドも試しましたが、いまのところEclipseの方が高速です ↩
もちろんE2Eテストじゃないと評価できないものもあります。 ↩
ダッシュボードは毎日眺めているだけで仕事した気になるのでとても良いですね。 ↩
- 投稿日:2020-11-28T02:22:05+09:00
Mockitoの使い方
Mockitoとは
Mockitoは、Javaのユニットテストのために開発されたモックフレームワーク(mocking framework)です。テストでモックオブジェクトを直感的に操作できるのを目的として開発されています。
キレイでシンプルなAPIでモックを扱うテストコードを記述できること、また記述されたテストコードの可読性が高くわかりやすい検証エラーを生成することがMockitoの特徴です。
なぜモック化が必要なのか。
ユニットテストにおいてサービス単位に切り離してテストを行いたいにもかかわらず、処理内にサービスの呼び出しがあり、
サービス区切りにテストをすることが行えない場合があります。
そこで必要となるのがモック化です。
ユニットテスト時に依存関係ができているものをモック化することにより、正常にユニットテストを行うことができます。モック化が想定されるのは以下のようなケースです。
・依存する部品で任意の内容をテスト対象に返すのが困難な場合
※たとえばHDDの容量不足というエラーを出力する必要がある試験の場合
・依存する部品を利用すると別の試験で副作用が発生する場合
※たとえばデーターベースの特定のテーブルを全て削除するような試験を行う場合
・依存する部品がまだ完成していない場合
※たとえばテスト対象のプログラムと依存する部品が並行で開発されている場合。
etc...このような依存する処理やクラスをモックに置き換えることにより、単体テストを容易にします。
モックオブジェクトの種類
モックオブジェクトには、スタブやモックなどのオブジェクトが備わっています(厳密に言えば、モックの中にスタブが備わっている)。スタブやモックはオブジェクトですが、Mockitoではモックオブジェクトを介してスタブやモックの操作を行うためそれらを機能として捉えたほうがわかりやすいかもしれません。
テストを目的として本物のオブジェクトの動作を真似ているスタブやモックなどのオブジェクトの総称をテストダブルと呼びます。
テストダブルは5つの代役として、ダミー、フェイク、スタブ、モック、スパイを定義しています。
今回はスタブ、モック、スパイについて解説します。
- スタブ
メソッドの実行に対して、事前に定義された振る舞い(引数、返り値)を提供するオブジェクト。外部の依存性を排除し、テストがオブジェクトの実装の正しさだけに注目する目的で使われている。- モック
メソッドの実行に対して、実行回数やパラメータの呼び出しを記録するオブジェクト。テスト対象から呼び出されたスタブの動作を記録し、その記録からメソッドの実行回数などを検証します。- スパイ メソッドの実行に対して、実行回数やパラメータの呼び出しを記録するオブジェクトです。モックと同様の役割ですが、基本的な定義として、モックはメソッドの実行中に検証するのに対して、スパイはメソッドの実行後に検証するという違いがあります。
Mockitoで扱う検証メソッドではメソッドの実行後に検証するので両者の違いはありませんが、Mockitoにおけるスパイはオブジェクトを部分的にモックする用途で使用されています。インストール方法
mavenプロジェクトであればpom.xmlに以下の記載をします。
<dependency> <groupId>org.mockito</groupId> <artifactId>mockito-core</artifactId> <version>1.10.19</version> </dependency>どのようにmockオブジェクトを作成するのか?
// mockオブジェクトの作り方 // すでにモックオブジェクトが定義されている場合利用できる private Service service = mock(Service.class); @Mock private Service service; // テスト対象への注入 @InjectMocks private Controller controller;mockオブジェクトの作成には二つの方法があります。
①mock()メソッドを利用←初期化、インジェクトがいらない
②@Mockを利用してモック化したのち、初期化上記に適宜されているように@Mockを利用してmock化をしたのちテスト対象にInjectします。
しかし、これだけでは利用できません。
利用するにはmockオブジェクトの初期化をしなければいけません。
Mockitoで言う初期化とは、モックオブジェクトを生成することなのです。
初期化処理はJUnitの@Beforeを利用してテスト前に行うように記述します。@Before private void initMocks() { // @Beforeが付与されているメソッドのなかにinitMocksメソッドを書くことで、各テストメソッドを実行する前に毎回実行できる MockitoAnnotations.initMocks(this); }振る舞いの定義方法
mockitoのオブジェクトのmockオブジェクトの作成方法はわかりました。
次はどのようにmockオブジェクトの振る舞いを定義するかを説明します。
モックオブジェクトのスタブメソッドの振る舞いを定義するのにthenメソッド系(thenReturnメソッドやthenThrowメソッドなど)とdoメソッド系(doReturnメソッドやdoThrowメソッド)があります。
whenメソッドとthenReturnメソッドもしくはdoReturnメソッドを合わせてスタブメソッドの振る舞いを定義します。それぞれのメソッド系で構文が異なります。戻り値ありの場合Mockito.when(モックインスタンス).メソッド(任意の引数).thenReturn(任意の戻り値); // モックされたクラスのメソッドが呼ばれた時、この戻り値を返すよ Mockito.doReturn(任意の戻り値).when(モックインスタンス).メソッド(任意の引数); // この戻り値を返すよ、モックされたクラスのメソッドが呼ばれた時どちらもできることに大差はありませんが、doメソッド系にしかできないことが2つあります。
- voidメソッドをスタブ化する場合
- @Spy、spyメソッドで生成したモックオブジェクトの場合
戻り値のないメソッドの場合Mockito.doNothing().when(モックインスタンス).メソッド(任意の引数); // 何も返さないよ、モッククラスのメソッドが呼ばれた時このように戻り値がない場合もmock化することができます。
ちなみに、頭のMockito.は、あってもなくてもどちらでも大丈夫です。
PowerMockでも同じような書き方をするため、同時に使用する場合は使い分ける必要があるため、頭につけたほうが分かりやすくなると思います。モック化したメソッドの呼び出し回数を検証する
メソッドをmockオブジェクトとした場合、何度実行されているのか確認したい場合があります。
その時に利用するのがverify()メソッドです。Mockito.verify(モックインスタンス, times(index)).モックメソッド(引数);verify()メソッドは第一引数にモックオブジェクト、第二引数にtimes()で引数に回数を持たせることにより想定の回数実行されているか確認を行うことができます。
よって戻り値が必要ないメソッドはverify()メソッドのみで実行確認ができ、戻り値の比較を行う必要がありません。spyオブジェクトの使用法
spyオブジェクトは下記の二つの方法にて利用することができる。
//① SampleController sampleController = spy(new SampleController()); //② @Spy @InjectMocks SampleController sampleController = new SampleController();spyオブジェクトはmockオブジェクトと異なり、内部の処理を残した状態でmock化することができる。
これによるメリットは、内部メソッドを一部mockオブジェクトとして利用できることにある。
privateメソッドとして切り分けたメソッドの処理が肥大化している場合、まだ一部処理要件が決まっていないなどといった場合においても問題なくテストが進められる点にある。簡単な使用例
今回mockitを使用したテストコードを書くために下記ようなサービスとコントローラを用意しました。
MessgeService@Component public class MessageService { public String getMessage(int a) { if (1 < a) { return "getMessageメソッドを呼び出しました。"; } return "引数が小さいです"; } public String margeMessage(String a, String b) { return a + b; } }SampleController@Controller public class SampleController { @Autowired private MessageService messageService; public String sample1(int i) { return messageService.getMessage(i); } public String sample2(int i, String margeMessage) { String message = messageService.getMessage(i); message = messageService.margeMessage(message, margeMessage); return messageTrim(message); } public String messageTrim(String message) { if (2 < message.length()) { return message.substring(0, 3); } return "文字数が小さいよ"; } }テストクラスは以下のように記述します。
import static org.hamcrest.MatcherAssert.*; import static org.hamcrest.Matchers.*; import static org.mockito.Matchers.*; import static org.mockito.Mockito.*; import org.junit.Before; import org.junit.Test; import org.junit.jupiter.api.extension.ExtendWith; import org.mockito.InjectMocks; import org.mockito.Mock; import org.mockito.MockitoAnnotations; import org.mockito.Spy; import org.mockito.junit.jupiter.MockitoExtension; import com.example.mocktest.controller.SampleController; import com.example.mocktest.service.MessageService; @ExtendWith(MockitoExtension.class) public class SampleTest { @Mock MessageService messageService; @Spy @InjectMocks SampleController sampleController = new SampleController(); @Mock private final int i = 1; @Mock private final String margeMessage = "marge"; @Before public void initMocks() { // @Beforeが付与されているメソッドのなかにinitMocksメソッドを書くことで、各テストメソッドを実行する前に毎回実行できる MockitoAnnotations.initMocks(this); } @Test public void testcase001() { // ServiceのgetMessageメソッドをモック化 doReturn("モック化できたよ").when(messageService).getMessage(i); // 期待している返り値 String expected = "モック化できたよ"; // 実際の返り値 String actual = sampleController.sample1(i); // 呼び出し回数確認 verify(messageService, times(1)).getMessage(i); // 期待している返り値と実際の返り値を比較検証 assertThat(actual, is(expected)); } @Test public void testcase002() throws Exception { // SampleController spy = PowerMockito.spy(sampleController); // ServiceのgetMessageメソッドをモック化 doReturn("モック化できたよ").when(messageService).getMessage(i); // ServiceのmargeMessageメソッドをモック化 doReturn("モック化できたよ").when(messageService).margeMessage("モック化できたよ", margeMessage); // messageTrimモック化 doReturn("spyオブジェクトモック化").when(sampleController).messageTrim(anyString()); // 期待している返り値 String expected = "spyオブジェクトモック化"; // 実際の返り値 String actual = sampleController.sample2(i, margeMessage); // 呼び出し回数確認 verify(messageService, times(1)).getMessage(anyInt()); verify(messageService, times(1)).margeMessage(anyString(), anyString()); verify(sampleController, times(1)).messageTrim(anyString()); // 期待している返り値と実際の返り値を比較検証 assertThat(actual, is(expected)); } }testcase001はSampleController.sample1のテストを行っている。MessageServiceをmockオブジェクトとして生成しテストを実行している。
これにより、Serviceの実装を考慮せず、Controllerの処理のみ確認するためのメソッドを作成できる。testcase002はSampleController.sample2のテストを行っている。
このテストメソッドではSampleControllerをspyオブジェクトとして生成して、内部メソッドであるmessageTrimメソッドをmock化している。
これによりmessageTrimの内部処理を気にすることなくテストを実行できている。
anyInt()、anyString()は引数がIntまたはStringであれば良い(指定しない)場合に利用する。
voidメソッドの試験の場合利用すると紹介したdoNothing()も同様である。また、privateメソッドをmock化する場合はPowerMockを利用する必要がある。
今回の記事では紹介することができなかったが、参考記事を参照に実践してみると勉強になると思います。参考
jmockit 1.48を使ってみる
JMockit と共に生きる者ためのメモ
Mockitoの最低限な使い方
【Java】Mockitoの飲み方(入門)
Mockitoを使ってみる。
MockitoとPowerMockの使い分け