- 投稿日:2020-11-28T21:56:08+09:00
【Tips】TerraformでAPI Gatewayを構築しているときに出る ConflictException の回避手段
はじめに
Terraform で API Gateway を構築していて、メソッドや統合を多用していると、たまに
Error: error deleting API Gateway Integration Response (xxxx-xxxxxxxxxx-xxxxxx-PUT-500): ConflictException: Unable to complete operation due to concurrent modification. Please try again later.みたいな感じでエラーが出て悩まされることがある。
これはおそらく、API Gateway を更新する API(Terraform が裏で叩いていると思われるもの)が、並列処理に対応していない(処理を排他している)と考えられる。
Terraform はお利口なので、依存関係のないリソースについてはなるべく並列で処理をして高速化をしてくれる。この仕様が仇になって、排他処理しているところに並列でAPIを叩きんでエラーになっているようだ。対処策
その1: もう一度
terraform applyする一番原始的な方法。別に HCL が悪いわけではないので、ConflictException が出ている限りは何度も apply すれば良い。でもこれ、他のエラーとか見落としてしまうとかありそうだよね……。
その2: Terraform の実行並列度を下げる
こんな感じ。
$ terraform destroy --parallelism=1別に 1 多重まで落とす必要はないのかもしれないけど、冪等性を考えるなら絶対に処理が並列にならない 1 を指定すべき。リソースがいっぱいあるとめちゃくちゃ遅くなるので選択したくない案。
その3: 排他される処理については
depends_onで順序性を持たせる仕方がないので、
aws_api_gateway_integration_responseのように排他されるリソースについては、全部depends_onで他のaws_api_gateway_integration_responseの名前を書いて順序を持たせる。resource "aws_api_gateway_integration_response" "example1" { depends_on = [] (中略) } resource "aws_api_gateway_integration_response" "example2" { depends_on = [aws_api_gateway_integration_response.example1] (中略) } resource "aws_api_gateway_integration_response" "example3" { depends_on = [aws_api_gateway_integration_response.example2] (中略) }分かりにくい!
これ、後になって知らない人が見たら「なぜ関係のないリソースに依存関係を持たせるんだろう……」と思ってしまうよね。
結論
どの案もイマイチだったので、作っている人の好みに合わせれば良いのではないかと思う。
ただ、いずれも初めてこの問題にあたる人は悩むことになるだろうから、ちゃんとドキュメンテーションはしておいてあげよう(めちゃくちゃ悩んだ)。
- 投稿日:2020-11-28T21:19:26+09:00
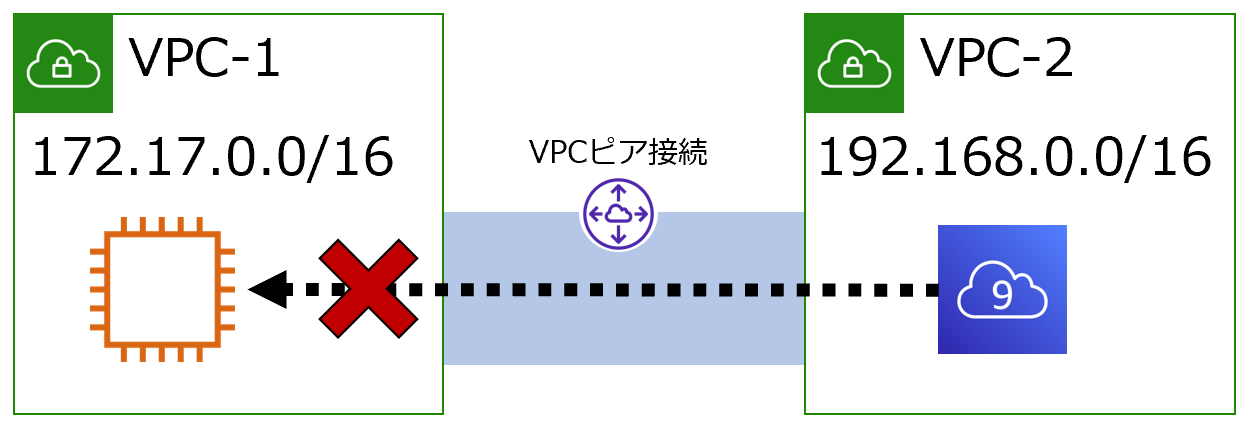
Cloud9は172.17.0.0/16に気を付けろ!
言いたいこと
- Cloud9を使うときはVPCのCIDRに172.17.0.0/16は禁物
- VPCピア接続でも影響あるからね
Cloud9トラブルシュートから抜粋
10月29日にAWS Cloud9 のトラブルシューティングに以下が追記されました。(英語版はもっと前に追記されてました)
VPC の IP アドレスが Docker で使用されているEC2 環境ため、 に接続できない
問題: EC2 環境の場合、Amazon VPCクラスレスドメイン間ルーティング IPv4 (CIDR) ブロックを使用する (仮想プライベートクラウド) 172.17.0.0/16 で EC2 インスタンスを起動すると、その環境を開いたときに接続が停止することがあります。
原因: Docker では、同じブリッジネットワークに接続されたコンテナが通信できるようにするブリッジネットワークと呼ばれるリンクレイヤーデバイスを使用します。 AWS Cloud9は、コンテナ通信用のデフォルトブリッジを使用するコンテナを作成します。通常、デフォルトのブリッジはコンテナネットワーキングに172.17.0.0/16サブネットを使用します。
Cloud9のネットワークみてみた
Cloud9でブリッジネットワークみてみるとサブネット172.17.0.0/16でした。
$ docker network inspect bridge [ { "Name": "bridge", "Id": "xxx", "Created": "2020-11-28T11:05:59.364729174Z", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.17.0.0/16", "Gateway": "172.17.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": {}, "Options": { "com.docker.network.bridge.default_bridge": "true", "com.docker.network.bridge.enable_icc": "true", "com.docker.network.bridge.enable_ip_masquerade": "true", "com.docker.network.bridge.host_binding_ipv4": "0.0.0.0", "com.docker.network.bridge.name": "docker0", "com.docker.network.driver.mtu": "1500" }, "Labels": {} } ]VPC(172.17.0.0/16)でCloud9作ってみた
禁断の構成VPC(172.17.0.0/16)で、Cloud9を作ると何が起こるか試してみました。
作成したところ、以下の画面からなかなか進みません。
しばらくするとエラーが発生しました。(画面のオレンジ色のところ)
(オレンジ色の)エラーメッセージの内容
This is taking longer than expected. The delay may be caused by high CPU usage in your environment, or your T2 or T3 instance is running out of burstable CPU capacity credits, or there are VPC configuration issues. Please check documentation.
Google翻訳
これには予想よりも時間がかかっています。 遅延は、環境内のCPU使用率が高いか、T2またはT3インスタンスでバースト可能なCPU容量クレジットが不足しているか、VPC構成に問題があることが原因である可能性があります。 ドキュメントを確認してください。
エラー内容から
172.17.0.0/16が問題と気が付くのは困難ですね。エラー発生後の状態も確認しました。
AWSコンソールのCloud9を確認すると問題なく作れたみたいに見えます。
Cloud9のEC2は起動状態でこれまた問題無いように見えます。
Cloud9はCloudFormationスタックで構築されます。そのスタックも
CREATE_COMPLETEとなっていて、これも問題無いように見えます。
という感じで、エラーメッセージからCIDR
172.17.0.0/16が問題ってことはわかりにくいことがわかりました。VPCピア接続時も要注意
Dockerネットワークを理解している方には当然の話ですが、以下の構成でも問題が発生します。
VPC-2(192.168.0.0/16)にCluod9を作ることはできますが、Cloud9から、ピア接続したVPC-1(172.17.0.0/16)のEC2への接続は通信不具合が発生します。
さいごに
Cloud9が好きでよく使うのですが、
172.17.0.0/16の制限を知らず苦労しました。



- 投稿日:2020-11-28T20:05:34+09:00
[rails]突然自動デプロイが反映されなくなった
何が起きたのか
よくわかりませんが、調べたところEC2に問題があった
自動デプロイしてたら突然変更が反映されなくなった解決方法
よくわかりませんが突如起こった出来事ですので
とりあえずAWSのマネジメントコンソールにログインしてEC2インスタンスを再起動
再起動後は以下のコマンドでNginxとdbを起動。$ sudo service nginx start $ sudo systemctl restart mariadbその後 自動デプロイする 完 (勝手にunicornは起動されるであろう )
bundle exec cap production deploy補足
EC2に問題がある場合の確認すべきところ
基本的に以下のどれかがどうにかこうにかなっていることが多い説
( unicorn,db,nginx...)なのでエラーログみてもよくわからなかったらコマンドでいろいろ確認してみよう
データーベースの状態を確認 sudo systemctl status mariadbデーターベースの起動 sudo systemctl restart mariadbnginxの再起動 sudo systemctl restart nginxunicornの状態確認 ps aux | grep unicornunicornの起動 RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D
- 投稿日:2020-11-28T19:18:31+09:00
[AWS][goofys][Docker] バックアップを考える
AWS EC2 上でのバックアップの仕組みを作ったので覚え書き。
バックアップとしては、特定のディレクトリを tar ball にアーカイブできればよいという単純な要件だけど、ちゃんと定時の仕組みにしようとすると面倒くさいものだったりします。
- 固めた tar ball はどこに置くのか?
- バックアップのサイクルは?(日次など)
- 世代管理も必要ですよね?
他に、個人的な要望として、以下のようなものもありました。
- OS へのセットアップはしたくない
- できるだけ docker コンテナで~
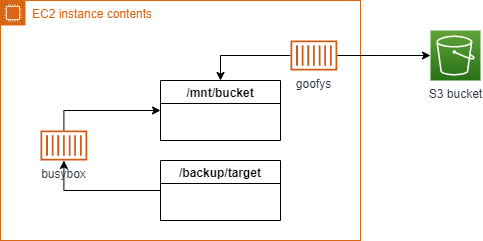
ということで、以下の形で構成。
- 格納先は S3 バケットへ
- S3 へのアクセスは goofys マウントで
- goofys マウントを docker コンテナ上で
- バックアップのシェルスクリプトの実行を busybox コンテナ上で
- 世代管理は自前のスクリプトで
すべてコンテナ上で実現したので、いくらかの設定ファイルとスクリプトだけ用意するだけで済みました。
世代管理のスクリプトは自前で面倒ですが、一度作っておくと再利用できて便利です。通常、OS の設定が必要になる goofys マウントや世代管理の logrotate など使わなくてよい構成です。
こうしておけば、Kubernetes な環境になったときにも流用しやすいかなというのもあります。
全体のシーケンス
全体の流れは以下のステップとなりました。
- S3 バケットをマウント
- バックアップ実行
- S3 バケットのマウント解除
全体を一発で流せるようにとも考えたのですが、バックアップ完了後にマウント解除を連動するのがうまくいかなかったのと、リストア処理の連動などマウントだけを利用したいケースもあるのでこの形で。
S3 バケットをマウント
S3 バケットをファイルシステムとしてマウントする goofys を利用します。
以下のコンテナが用意されています。https://github.com/cloudposse/goofys
これを使って docker-compose.yml を用意するだけで簡単に S3 バケットのマウントができます。
docker-compose.ymlversion: '3.8' services: goofys: image: cloudposse/goofys privileged: true environment: - REGION=ap-northeast-1 - BUCKET=my-backup-backet - UID=1000 - GID=1000 volumes: - /backup_store:/mnt/s3:shared$ docker-compose up -d # S3 バケットをマウント $ ls /backup_store/ # バケットを参照できるようになる : $ docker-compose down # S3 バケットのマウント解除 $ sudo umount /backup_store # ホスト上でのマウントが解除されないのでアンマウントgoofys コンテナ内で /mnt/s3 へ S3 バケットがマウントされます。
このポイントをホストへの外部ボリュームにしておくことで、ホスト側で S3 バケットへのファイルシステム参照ができるようになります。バックアップスクリプト実行
バックアップ処理自体はシェルスクリプトを作成し、スクリプトの実行を busybox コンテナで動かします。
これも docker-compose.yml を用意しておくと簡単。環境変数設定、コマンド名はスクリプトの内容による
docker-compose.command.ymlversion: '3.8' services: backup-base: &base image: busybox environment: - ENV_BACKUP_TARGET_DIR=/backup_target # バックアップ対象 - ENV_BACKUP_STORE_DIR=/backup_store/ # バックアップ先 (S3 マウント先) - ENV_BACKUP_DAYS=5 # 世代指定 volumes: - /backup_store:/backup_store:slave - /data:/backup_target # バックアップ対象(ホスト上のディレクトリ) - ./backup.sh:/backup.sh # バックアップ用のスクリプト - ./restore.sh:/restore.sh # リストア用のスクリプト backup-store: <<: *base command: - "sh" - "/backup.sh" backup-restore: <<: *base command: - "sh" - "/restore.sh"$ docker-compose -f docker-compose.command.yml run backup-store # バックアップを実行 $ docker-compose -f docker-compose.command.yml run backup-restore # リストアを実行これらの docker-compose のコマンドイメージを Makefile などにまとめておくと便利です。
なお、busybox には bash ではなく ash という組み込み用のコンパクトなシェルが入っているので、シェルスクリプトを書く際には注意が必要です。
おまけ: 世代管理処理のサンプル
対象ファイルと保存する世代数を指定して実行する形です。(日次実行)
function rotate() { _tgd=$1 _tgf=$2 _days=$3 _now=$( date +%Y/%m/%d ) _nod=$( date +%Y%m%d ) _thd=$( date +%Y%m%d -d "1970.01.01-00:00:$(( $( date +%s ) - $(( ${_days} * 24*60*60 )) ))" ) if test -f ${_tgd}/${_tgf} ; then _mod=$( stat -c%y ${_tgd}/${_tgf} | cut -d " " -f1 | sed -e 's/[-:]//g' ) mv ${_tgd}/${_tgf} ${_tgd}/${_tgf}-${_mod} fi _a="" ( cd ${_tgd} ; ls -1 ${_tgf}-* 2>&1 > /dev/null ) if test $? -eq 0 ; then _a=$( cd ${_tgd} ; ls -1 ${_tgf}-* | sort -r ) fi _t=${_tgf}-${_thd} for _i in ${_a} do if test ${_i} \< ${_t} || test ${_i} = ${_t} ; then rm -f ${_tgd}/${_i} fi done }以下のように実行すると、ファイルの作成日別のファイルにリネームし、指定した世代分だけ残して他を削除します。
rotate /backup_store aaa.tar.gz 3 ---- /backup_store/aaa.tar.gz-20201128 /backup_store/aaa.tar.gz-20201127 /backup_store/aaa.tar.gz-20201126なお、ash 用に考慮が必要だったのは以下の点。
# -d に "- 5 day" のような形式が使えない date -d "2020/11/28 - 5 day"# 配列が使えない array=()# if [[ ]] が使えない if [[ $i < $t >]] ; then : fi
- 投稿日:2020-11-28T19:17:19+09:00
ECSコンテナに接続する方法
意外と忘れるコンテナ接続
本番環境のコンテナに入ってDB操作したりデバッグしたり...
久しぶりにやろうとしたらど忘れしていたのでこの記事を書くに至りました。
接続までの手順
- セキュリティーグループのインバウンドルール変更
- EC2インスタンスのPublic IP / Public DNSを確認
ssh -i /path/to/my-key-pair.pem ec2-user@ec2-198-51-100-1.compute-1.amazonaws.comコマンドでECSコンテナにssh接続それでは始めます
インバウンドルールの変更
EC2>セキュリティーグループ>該当のセキュリティーグループ>インバウンドルールを編集
sshタイプのソースを「 マイIP 」に変更するこの変更をしていないと後でssh接続したとき以下のエラーが出るため必要な手順です
ssh: connect to host [自分のPublic IP] port 22: Connection refusedPublic IP / Public DNSを確認
Elastic Container Service>クラスター>ECSインスタンス
コンテナインスタンス> 該当のインスタンスを選択
詳細> 「 Public DNS 」をコピーするECSコンテナにssh接続
以下のコマンドを使用します
$ ssh -i /path/to/my-key-pair.pem ec2-user@ec2-198-51-100-1.compute-1.amazonaws.comキーペアはパスを指定する必要があります。
例えば私は~/.ssh下に配置しているので下記のように指定します$ ssh -i ~/.ssh/my-key-pair.pem次に前の手順でコピーしていたPublic DNSをその後に書いてあげましょう
接続するとき
以下のような表示が出ますが落ち着いて読みましょう
Are you sure you want to continue connecting (yes/no/[fingerprint])?「 yes 」で大丈夫です。
その後はこのような表示が出ましたでしょうか。
__| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/お疲れさまでした
ここまで読んでいただきありがとうございました。
簡単な手順ではありますが、久しぶりにやると忘れているものです。
参考
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/instance-connect.html
- 投稿日:2020-11-28T19:09:40+09:00
AWS CDK で AWS アカウントのユーザーを一気に100個作る
はじめに
- AWS CDK を使って一気にAWSアカウントのユーザーを100個 (+adminアカウント3つ) 作るソースを公開1
- TypeScript によるパスワード生成器を実装し、生成器で得られた文字列を 作成したAWS アカウントの初期パスワードとして設定
- 使い道は謎・・・というより自己満足
ソース
前提条件
- CDK のセットアップが完了していること2
動作環境
- 下記の環境で動作することを確認
OS
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.7 BuildVersion: 19H15AWS CDK
$ cdk --version 1.74.0 (build e86602f)AWS CLI
$ aws --version aws-cli/2.1.1 Python/3.9.0 Darwin/19.6.0 source/x86_64Node.js
$ node -v v12.19.1npm
$ npm --version 6.14.8AWS CDK による AWS アカウントのユーザー生成
概要は以下の通り
- 管理者アカウント3つ
- グループ名は
admins, グループに適用するポリシーはAdministratorAccess3- ユーザー名は
admin_01,admin_02,admin_03
- 開発者パワーユーザーアカウント3つ
- グループ名は
developers, グループに適用するポリシーはPowerUserAccess3- ユーザー名は
user_xxx(0番から99番の連番)
- グループを作成→ポリシー適用→グループに所属するユーザーを作成と追加
- 管理者アカウント用のパスワード、開発者パワーユーザー用のパスワードをそれぞれ TypeScriptで実装したパスワード生成器で作成し初期パスワードとして設定
cdk deploy実行後、出力されたパスワードでログインsimple_iam_user_management.tsimport * as cdk from '@aws-cdk/core'; import { Group, ManagedPolicy, User } from '@aws-cdk/aws-iam'; import * as password from './password_generator'; const admins = 'AdminGroup'; const adminUsers = [ 'admin_01', 'admin_02', 'admin_03' ]; const developers = 'DevGroup'; export class SimpleIamUserManagementStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // AWS managed policy const adminPolicy = ManagedPolicy.fromAwsManagedPolicyName('AdministratorAccess'); const powerUserPolicy = ManagedPolicy.fromAwsManagedPolicyName('PowerUserAccess'); // Admin group const adminGroup = new Group(this, admins, { groupName: admins }); adminGroup.addManagedPolicy(adminPolicy); let adminPassword = ""; // For Admin { const c = new password.composite_password_generator(); c.add(new password.digit_generator(4)); c.add(new password.lower_letter_generator(3)); c.add(new password.symbol_generator(3)); c.add(new password.upper_letter_generator(3)); adminPassword = c.generate(); } // Admin User adminUsers.forEach(admin => { new User(this, admin, { userName: admin, groups: [adminGroup], password: cdk.SecretValue.plainText(adminPassword), //passwordResetRequired: true // 初期パスワードでログインしたあとパスワードの再設定を促す。個人のアカウントで使う範囲であれば不要 }) }) // Developer group const devGroup = new Group(this, developers, { groupName: developers }); devGroup.addManagedPolicy(powerUserPolicy); let devPassword: string = ""; // For Developer's Password { const c = new password.composite_password_generator(); c.add(new password.digit_generator(3)); c.add(new password.lower_letter_generator(3)); c.add(new password.symbol_generator(3)); c.add(new password.upper_letter_generator(3)); devPassword = c.generate(); } const numOfUser = 100; for (let n = 0; n < numOfUser; n++) { const user = "user_" + ('000' + n).slice(-3); new User(this, user, { userName: user, groups: [devGroup], password: cdk.SecretValue.plainText(devPassword), //passwordResetRequired: true // 初期パスワードでログインしたあとパスワードの再設定を促す。個人のアカウントで使う範囲であれば不要 }); } // Output Admin Password new cdk.CfnOutput(this, "adminPassword", { value: adminPassword }); // Output Developer Password new cdk.CfnOutput(this, "devPassword", { value: devPassword }); } }パスワード生成器
概要
- Modern C++チャレンジ――C++17プログラミング力を鍛える100問に Composite パターンを用いたパスワード生成器の例4があり、TypeScriptで再実装
- digit_...は数字、lower_...は小文字、upper_...は大文字、symbol_...は記号を管理
- composite_..に追加された上記の4つの生成器を用いてパスワードの文字列を生成する5
クラス図
ソース
password_generator.tsabstract class password_generator { public abstract allowed_chars(): string; public abstract length(): number; public abstract add(generator: password_generator): void; } class basic_password_generator extends password_generator { private readonly _length: number; constructor(len: number) { super(); this._length = len; } public allowed_chars(): string { throw new Error("Method not implemented."); } public add(generator: password_generator) { throw new Error("Method not implemented."); } public length(): number { return this._length; } } export class digit_generator extends basic_password_generator { constructor(length: number) { super(length); } allowed_chars(): string { return "0123456789"; } } export class symbol_generator extends basic_password_generator { constructor(length: number) { super(length); } allowed_chars(): string { return "!@^#$%&()[]{}?"; } } export class upper_letter_generator extends basic_password_generator { constructor(length: number) { super(length); } allowed_chars(): string { return "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; } } export class lower_letter_generator extends basic_password_generator { constructor(length: number) { super(length); } allowed_chars(): string { return "abcdefghijklmnopqrstuvwxyz"; } } function shuffle(str: string): string { let buffer = []; for (let i = 0; i < str.length; i++) { buffer.push(str[i]); } let currentIndex = str.length, temporaryValue, randomIndex; while (0 !== currentIndex) { randomIndex = Math.floor(Math.random() * currentIndex); currentIndex -= 1; temporaryValue = buffer[currentIndex]; buffer[currentIndex] = buffer[randomIndex]; buffer[randomIndex] = temporaryValue; } let shuffle_string = ""; for (let i = 0; i < buffer.length; i++) { shuffle_string += buffer[i]; } return shuffle_string; } export class composite_password_generator extends password_generator { public allowed_chars(): string { throw new Error("Method not implemented."); } public length(): number { throw new Error("Method not implemented."); } private generator: password_generator[]; constructor() { super(); this.generator = []; } generate(): string { let password = ""; this.generator.forEach(g => { for (let i = 0; i < g.length(); i++) { const randomIndex = Math.floor(Math.random() * g.allowed_chars().length); password += g.allowed_chars()[randomIndex]; } }); return shuffle(password); } add(generator: password_generator): void { this.generator.push(generator); } }実行結果
デプロイ
cdk deployのコマンドを実行- デプロイ成功時、管理者アカウント用と開発者パワーユーザー用のパスワードを表示
- ユーザー名とパスワードでログインできることを確認
作成したユーザーの存在を確認
管理者アカウントの確認
admin_0xユーザーの存在の確認
aws iam list-users --query "Users[].[UserName]" --output text | grep "admin_*"
admin_01所属グループの確認
aws iam list-groups-for-user --user-name admin_01 --query 'Groups[].GroupName'
- グループのポリシーを確認
aws iam list-attached-group-policies --group-name AdminGroup --query 'AttachedPolicies[].PolicyArn'
開発者パワーユーザーアカウントの確認
user_xxxユーザーの存在の確認
aws iam list-users --query "Users[].[UserName]" --output text | grep "user_*"
user_001所属グループの確認
aws iam list-groups-for-user --user-name user_001 --query 'Groups[].GroupName'
- グループのポリシーを確認
aws iam list-attached-group-policies --group-name DevGroup --query 'AttachedPolicies[].PolicyArn'
おわりに
- AWS アカウントのユーザーを 100+α 個をCDKで作成
- パスワード生成器を使いたかっただけという感じは否定できないが、ちょっとした実験用途にはなった







- 投稿日:2020-11-28T16:50:21+09:00
EC2でSambaを構築し、ファイル共有を確認する
はじめに
AWS初心者が、練習目的でEC2を使ってSambaを勉強・構築した際の情報・手順をまとめた物です。
SambaでWindows用ファイルサーバとして構築し、Windowsのクライアントからファイル共有をしてみます。
同じような情報は既にあるので、解説を細かくしすぎず、かつ少し余談を交えた記事にしています。目的
- Sambaを構築して、構築・ファイル共有の流れと感覚を掴む。
- さらっとやってみる。
- WindowsServerをリモートで操作してみる。
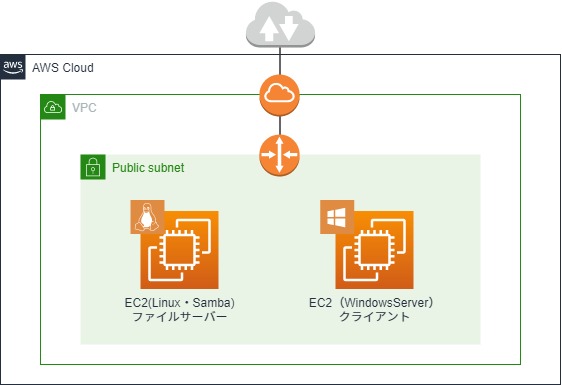
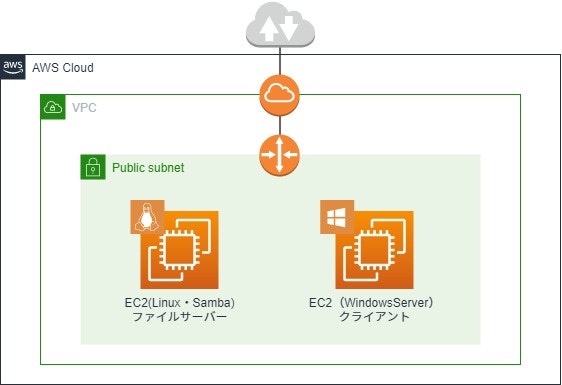
構成図
EC2 OS:AmazonLinux2 (ファイルサーバー用) ポート:22(SSH)・445(TCP)
※ファイル共有用に445だけ開けていますが、その他の機能を使う場合は対応した他のポートも開ける必要があります。EC2 OS:WindowsServer2019 (クライアント用) ポート:3389(RDP)
同一パブリックサブネット内にAmazonLinux2とWindowsServerのEC2を用意していて下さい。
EBSの無料枠の30GBを超えるはずなので、課金が発生しますが数時間で消す予定なので「超」低額だと思います。
その辺りが気になる方は公式でお調べ下さい。
終わったらささっと消しましょう。パブリックにファイル共有サーバを置くのは実運用としては駄目でしょうが、練習・検証用ですので続行します。
全体の流れ
- Sambaとは
- Sambaをインストール、Samba用ユーザーの作成
- クライアントからSambaにアクセス、共有ファイルの作成
- Samba側から共有ファイルを確認
1. Sambaとは
今回使っている「Samba」はLinuxをWindowsのファイルサーバにするだけの物ではありません。
Windowsで使われているネットワークプロトコル(SMB・CIFS)を使うことで、LinuxでWindowsのネットワークシステムに参加する事が出来るようにするフリーソフトウェアです。
ファイル共有・プリンタ共有・ドメインコントローラー等のWindowsネットワークの諸機能を有しています。
よって、LinuxからWindowsのネットワークにアクセスできるようにさせるクライアント機能もある訳です。そんな認識の上で、今回は単にファイル共有サーバの機能を利用させて頂きます。
2.Sambaをインストール、Samba用ユーザーの作成
Sambaのインストール
LinuxのEC2にSSHして、rootに切り替えます。
sudo su -そしてSambaをインストールします。
yum -y install sambaSamba用ユーザーの作成
Sambaを利用するためにLinuxユーザーを作成します。
useradd samba-test passwd samba-test Changing password for user samba-test. New password: Retype new password: passwd: all authentication tokens updated successfully.Sambaにユーザーを登録
先程のユーザーをSambaに登録し、Windowsと接続できるようにします。
Samba上にWindows形式のユーザー情報を登録するイメージです。pdbedit -a samba-test new password: retype new password:追加された事を確認してみましょう。
pdbedit -L samba-test:1001:コマンドについて余談
今回はpdbeditコマンドを使っていますが、smbpasswdというコマンドも使えます
「smbpasswd」はSamba2.2系で使われた旧来のユーザ管理コマンドです。
これは、rootでなくても使えますが先程の「ユーザーの一覧」を表示する機能は持っていません。
またデータベース形式が固定です。「pdbedit」はSamba3.0以降で使われている新しいユーザ管理コマンドで、root権限がないと使えませんが、
先程の「ユーザーの一覧」や別の種類のデータベースを使用する事が出来るため、出来ることが多く汎用的なようです。情報によって使っている管理コマンドが違いますが、今回の用途だとどちらを使っても問題ないと思います。
ただ、私は利用されることが多いだろう新しい方のコマンドを使うことにしました。設定について
「/etc/samba/smb.conf 」にて、ワークグループやプリンタ共有の有無・パスワードの暗号化等々の設定。
そして共有ファイルの場所・名前の指定も行えますが、今回はサクっと作るため特に設定しません。
よって、ファイルの共有先は登録したLinuxユーザーのホームディレクトリになります。余談
Sambaの設定に関することはLPICレベル2の参考書(記事下部に記載)がとても参考になりました。
ただ、manに詳しく書いてあるのでそれを読むほうが速いです。(ただし当然ながら英語です)Sambaの起動、自動起動設定
設定は終わったので、Sambaを起動して自動起動もするようにします。
systemctl start smb systemctl enable smb3.クライアントからSambaにアクセス、共有ファイルの作成
WindowsのクライアントからSambaに接続する
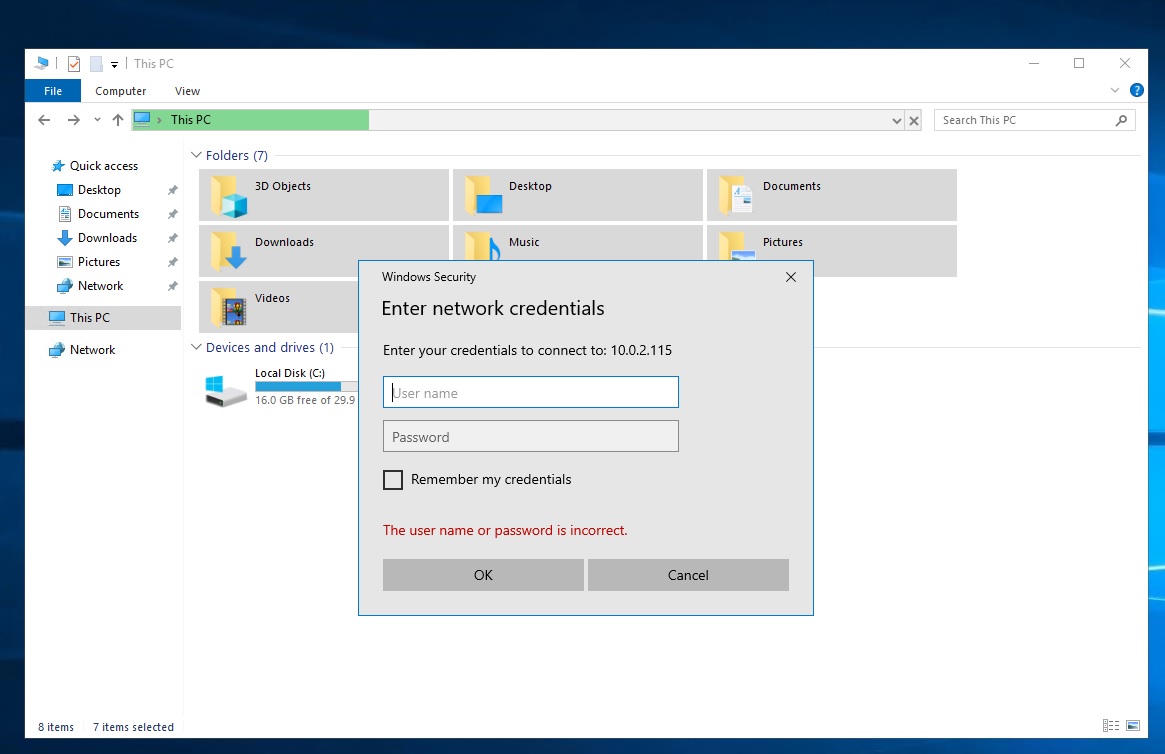
エクスプローラーのアドレスバーに「\(sambaのIPアドレス:今回だと10.0.2.115)」と入力すると、
下記のようにユーザーとパスワードを求められるので、Sambaに登録した物を入力。
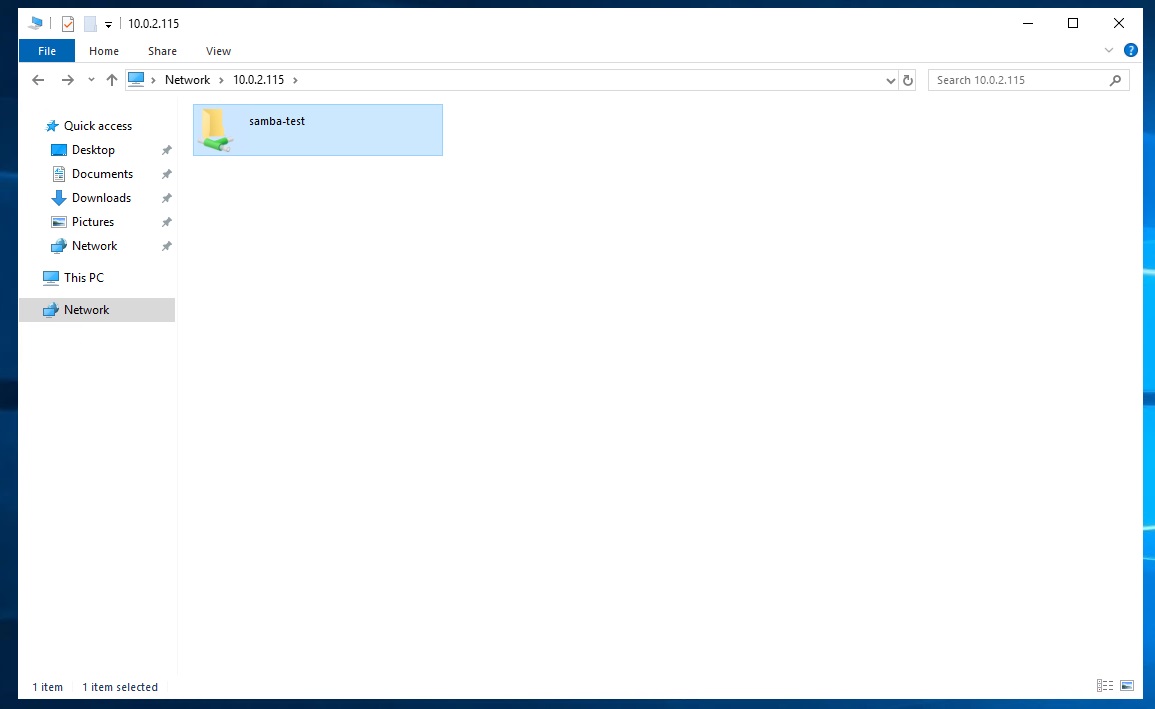
「samba-test」に接続します。
共有ファイルの作成
何でも良いのですが、簡単にテキストファイルを作ります。
4.Samba側から共有ファイルを確認
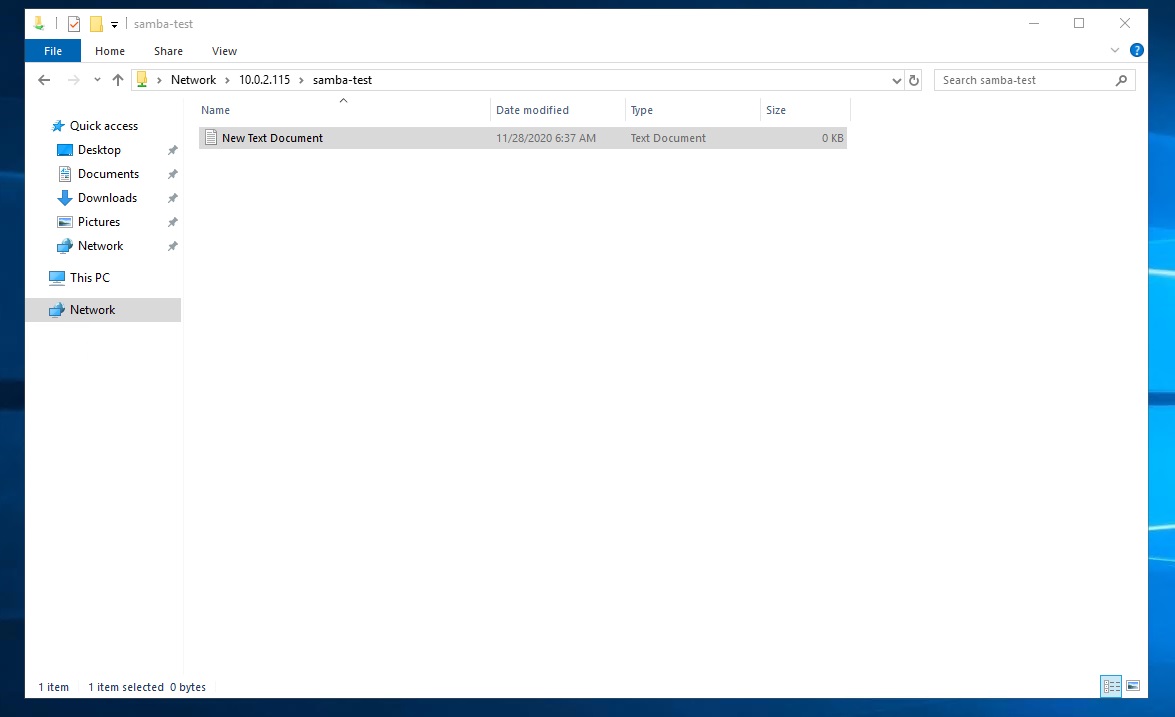
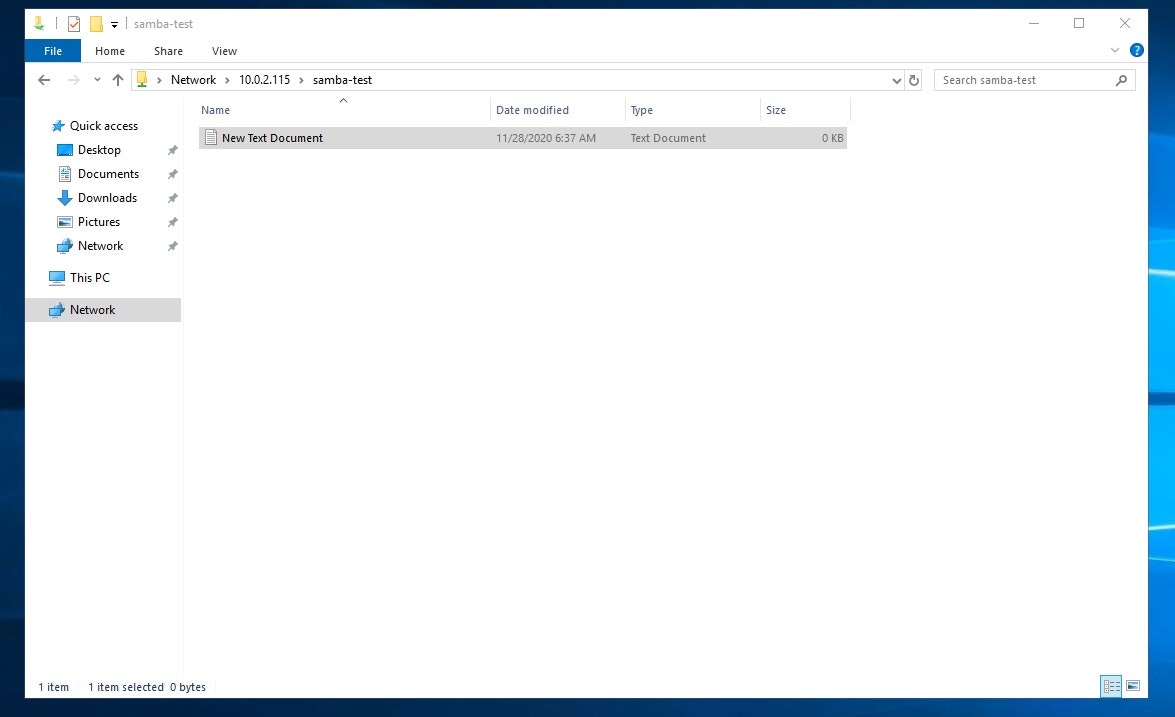
最後に共有先である「Samba-test」のディレクトリに先程作成したテキストがあるか確認します。
cd /home/samba-test ls -l -rwxr--r-- 1 samba-test samba-test 0 11月 28 06:37 New Text Document.txtテキストが無事反映されているので、ファイル共有が出来ていることが確認出来ました。
参考URL
- EC2にSambaを構築してWindowsからファイル共有してみた
- Sambaの基本を知っておこう
- オープンソースのドキュメント管理/Sambaとは
- Amazon Linux 2でSambaを構築する
参考文献
- Linux教科書 LPICレベル2 Version4.5対応
- 投稿日:2020-11-28T16:50:21+09:00
EC2でSambaを構築してファイル共有を確認する
はじめに
AWS初心者が、練習目的でEC2を使ってSambaを勉強・構築した際の情報・手順をまとめた物です。
SambaでWindows用ファイルサーバとして構築し、Windowsのクライアントからファイル共有をしてみます。
同じような情報は既にあるので、解説を細かくしすぎず、かつ少し余談を交えた記事にしています。目的
- Sambaを構築して、構築・ファイル共有の流れと感覚を掴む。
- さらっとやってみる。
- WindowsServerをリモートで操作してみる。
構成図
EC2 OS:AmazonLinux2 (ファイルサーバー用) ポート:22(SSH)・445(TCP)
※ファイル共有用に445だけ開けていますが、その他の機能を使う場合は対応した他のポートも開ける必要があります。EC2 OS:WindowsServer2019 (クライアント用) ポート:3389(RDP)
同一パブリックサブネット内にAmazonLinux2とWindowsServerのEC2を用意していて下さい。
EBSの無料枠の30GBを超えるはずなので、課金が発生しますが数時間で消す予定なので「超」低額だと思います。
その辺りが気になる方は公式でお調べ下さい。
終わったらささっと消しましょう。パブリックにファイル共有サーバを置くのは実運用としては駄目でしょうが、練習・検証用ですので続行します。
全体の流れ
- Sambaとは
- Sambaをインストール、Samba用ユーザーの作成
- クライアントからSambaにアクセス、共有ファイルの作成
- Samba側から共有ファイルを確認
1. Sambaとは
今回使っている「Samba」はLinuxをWindowsのファイルサーバにするだけの物ではありません。
Windowsで使われているネットワークプロトコル(SMB・CIFS)を使うことで、LinuxでWindowsのネットワークシステムに参加する事が出来るようにするフリーソフトウェアです。
ファイル共有・プリンタ共有・ドメインコントローラー等のWindowsネットワークの諸機能を有しています。
よって、LinuxからWindowsのネットワークにアクセスできるようにさせるクライアント機能もある訳です。そんな認識の上で、今回は単にファイル共有サーバの機能を利用させて頂きます。
2.Sambaをインストール、Samba用ユーザーの作成
Sambaのインストール
LinuxのEC2にSSHして、rootに切り替えます。
sudo su -そしてSambaをインストールします。
yum -y install sambaSamba用ユーザーの作成
Sambaを利用するためにLinuxユーザーを作成します。
useradd samba-test passwd samba-test Changing password for user samba-test. New password: Retype new password: passwd: all authentication tokens updated successfully.Sambaにユーザーを登録
先程のユーザーをSambaに登録し、Windowsと接続できるようにします。
Samba上にWindows形式のユーザー情報を登録するイメージです。pdbedit -a samba-test new password: retype new password:追加された事を確認してみましょう。
pdbedit -L samba-test:1001:コマンドについて余談
今回はpdbeditコマンドを使っていますが、smbpasswdというコマンドも使えます
「smbpasswd」はSamba2.2系で使われた旧来のユーザ管理コマンドです。
これは、rootでなくても使えますが先程の「ユーザーの一覧」を表示する機能は持っていません。
またデータベース形式が固定です。「pdbedit」はSamba3.0以降で使われている新しいユーザ管理コマンドで、root権限がないと使えませんが、
先程の「ユーザーの一覧」や別の種類のデータベースを使用する事が出来るため、出来ることが多く汎用的なようです。情報によって使っている管理コマンドが違いますが、今回の用途だとどちらを使っても問題ないと思います。
ただ、私は利用されることが多いだろう新しい方のコマンドを使うことにしました。設定について
「/etc/samba/smb.conf 」にて、ワークグループやプリンタ共有の有無・パスワードの暗号化等々の設定。
そして共有ファイルの場所・名前の指定も行えますが、今回はサクっと作るため特に設定しません。
よって、ファイルの共有先は登録したLinuxユーザーのホームディレクトリになります。余談
Sambaの設定に関することはLPICレベル2の参考書(記事下部に記載)がとても参考になりました。
ただ、manに詳しく書いてあるのでそれを読むほうが速いです。(ただし当然ながら英語です)Sambaの起動、自動起動設定
設定は終わったので、Sambaを起動して自動起動もするようにします。
systemctl start smb systemctl enable smb3.クライアントからSambaにアクセス、共有ファイルの作成
WindowsのクライアントからSambaに接続する
エクスプローラーのアドレスバーに「\(sambaのIPアドレス:今回だと10.0.2.115)」と入力すると、
下記のようにユーザーとパスワードを求められるので、Sambaに登録した物を入力。
「samba-test」に接続します。
共有ファイルの作成
何でも良いのですが、簡単にテキストファイルを作ります。
4.Samba側から共有ファイルを確認
最後に共有先である「Samba-test」のディレクトリに先程作成したテキストがあるか確認します。
cd /home/samba-test ls -l -rwxr--r-- 1 samba-test samba-test 0 11月 28 06:37 New Text Document.txtテキストが無事反映されているので、ファイル共有が出来ていることが確認出来ました。
※今回の筆者の環境では言語設定を日本語化していました。
参考URL
- EC2にSambaを構築してWindowsからファイル共有してみた
- Sambaの基本を知っておこう
- オープンソースのドキュメント管理/Sambaとは
- Amazon Linux 2でSambaを構築する
参考文献
- Linux教科書 LPICレベル2 Version4.5対応
- 投稿日:2020-11-28T16:49:23+09:00
AWS LambdaからPythonを実行してみた
やったこと
AWSの勉強がてら、「QiitaマイページからLGTM / View / ストック数の一覧を確認できるようにしてみた」で作ったpythonファイルをAWS Lambdaから定期実行できるようにしてみました。
(過去記事ではHerokuで定期実行させていました)ちょうど同じ時期にAWS Lambdaでpythonプログラムの定期実行という記事が上がっていたので、全体の流れはこちらを参考にさせていただきました。
ところどころ追加で調べた箇所があるので、この記事はそちらをメインにした内容になります。
また例によって、AWSアカウントは作成済みとします。ちなみに料金の方は
AWS Lambda の無料利用枠には、1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間が、それぞれ含まれます。
とあるので今回のように1日1回程度のリクエストであれば問題ないだろうと一安心。
(今のところ基本無料でやりたいので、一応8$を超えたらアラートが飛ぶようにしています)作成したLambda関数の内容
- ランタイム:python 3.8
- トリガー:毎朝7時に実行
- 外部モジュール(pytz, requests)を使用
- タイムアウト時間:30秒
- その他:初期値のまま
ソースコード
おおむね同じですが、前回と比較して以下を変更しています。
- Qiitaのアクセストークンや記事IDをべた書き⇒環境変数から読み込む
if __name__ == "__main__":
⇒def lambda_handler(event, context):
※lambda_handler:Lambda関数から最初に呼ばれる関数名
ソースコード
lambda_function.pyimport os import http.client import json import requests import datetime import pytz TOKEN = os.environ['TOKEN'] # Read&Write用 HEADERS = {'content-type': 'application/json', 'Authorization': 'Bearer ' + TOKEN} URL_BASE = 'https://qiita.com/api/v2' ARTICLE_ID = os.environ['ARTICLE_ID'] # 記事一覧のLGTM, View, ストック数を取得する def get_info(): url_authenticate = URL_BASE + '/authenticated_user/items' # 記事一覧を取得 res = requests.get(url_authenticate, headers=HEADERS) list = res.json() # 不要な記事を除外 list_item = [] for item in list: # 限定記事は対象外 if item['private']: continue # 投稿先の記事は対象外 if item['id'] == ARTICLE_ID: continue list_item.append(item) num = 0 list_iteminfo = [[0 for i in range(5)] for j in range(len(list_item))] for item in list_item: # 各種項目を取得 id = item['id'] title = item['title'] url = item['url'] likes_count = item['likes_count'] # 記事の情報を取得 url_item = URL_BASE + '/items/' + id res = requests.get(url_item, headers=HEADERS) json = res.json() # タイトル別のview数のセット page_views_count = json['page_views_count'] i = 1 # stock数の取得(最大1000件) while i < 10: url_stock = url_item + '/stockers?page=' + str(i) + '&per_page=100' res_stock = requests.get(url_stock, headers=HEADERS) json_stock = res_stock.json() stock_num = len(json_stock) if stock_num != 100: stock_count = (i * 100) - 100 + stock_num break else: i += 1 list_iteminfo[num] = [title, url, likes_count, page_views_count, stock_num] num += 1 return list_iteminfo # 記事を更新する def update_article(list_iteminfo): item = { 'body': '', 'coediting': False, 'private': False, 'tags': [{'name': 'qiita'}], 'title': '投稿記事のLGTM, View, ストック数一覧' } # 本文の作成([記事タイトル](URL), LGTM数, View数, ストック数) now = datetime.datetime.now(pytz.timezone('Asia/Tokyo')) setdate = now.strftime('%Y/%m/%d %H:%M:%S') body = 'この記事は [' + setdate + '] に更新されました。\r\n' for info in list_iteminfo: body += '\r\n[' + str(info[0]) + '](' + str(info[1]) + ')' body += '\r\nLGTM:' + str(info[2]) + '件, View:' + str(info[3]) + '件, ストック:' + str(info[4]) + '件\r\n' item["body"] += body url = URL_BASE + '/items/' + ARTICLE_ID # 記事の更新 res = requests.patch(url, headers=HEADERS, json=item) return res def lambda_handler(event, context): list_iteminfo = get_info() res = update_article(list_iteminfo) print(res)追加で調べたこと
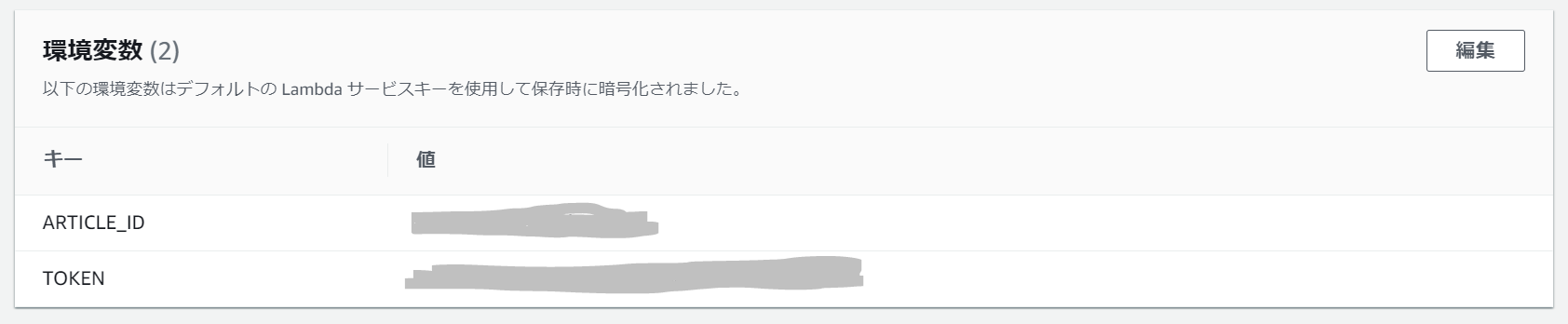
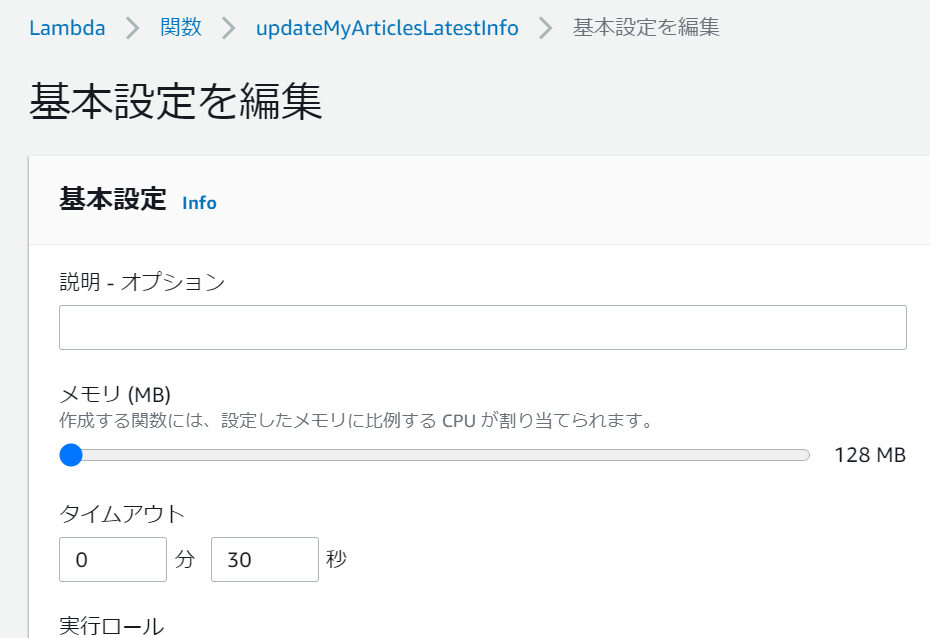
環境変数の設定
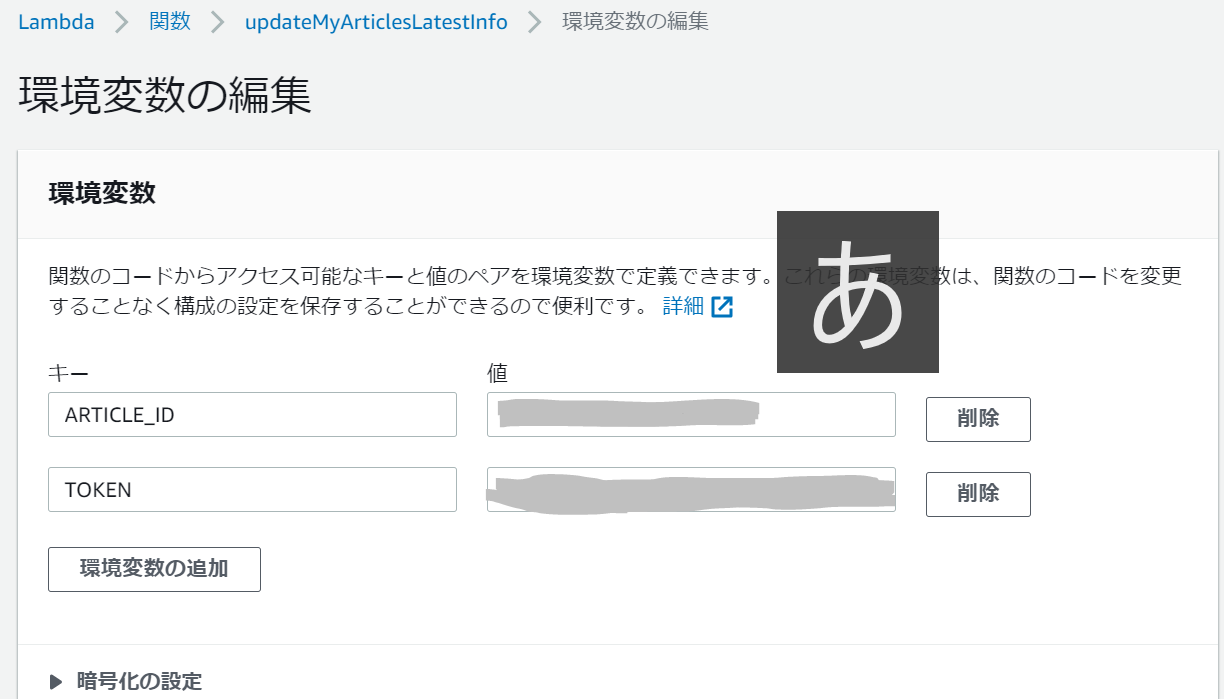
Qiitaのアクセストークンなどを環境変数に設定したかったのですが、コードやデザイナと同じページの「環境変数」欄の編集ボタンから簡単に編集ページへ遷移できました。
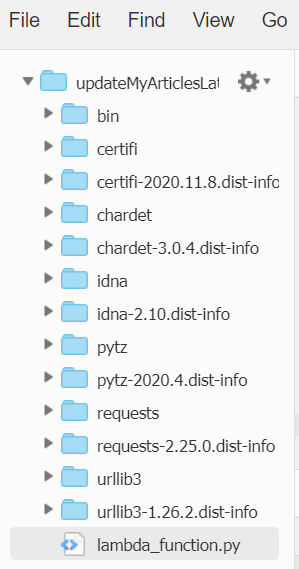
外部モジュールの配置方法
初めは単純に実行対象となる
lambda_function.pyのみを配置しましたが、
"errorMessage": "Unable to import module 'lambda_function': No module named 'requests'"
とエラーになってしまいました。どうやら外部モジュールがある場合、自分で読み込ませる必要がある様子。
こちらを参考に、ローカル環境でlambda_function.pyと同階層に対象のモジュール(pytz, requests)をpipでインストールし、zip化してアップロードしました。
アップロード後は下記のようにモジュールが展開されました。
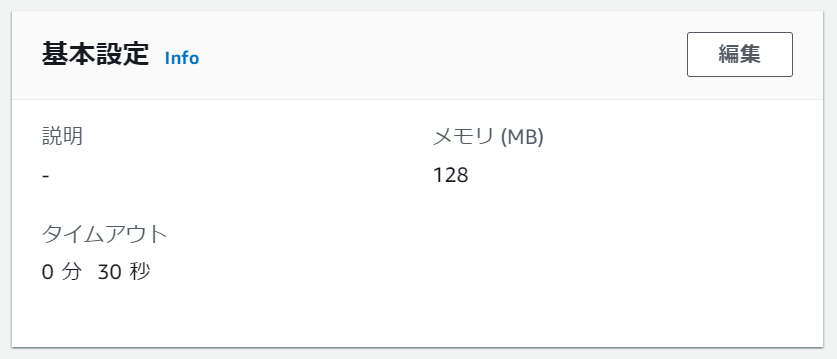
タイムアウト時間の変更
外部モジュールも無事読み込め、これで実行成功!と思いきや、今度は
Task timed out after 3.00 seconds
というエラーが発生しました。
初期設定だと実行時間が3秒を超えるとタイムアウトしてしまうので、こちらの設定を変更します。
環境変数の設定同様、今度は「基本設定」欄の編集ボタンから編集ページへ遷移し、設定値を30秒に変更しました。
最後に
Lambda、思ってたより簡単。
次はサーバー立てたり、いろいろ試したくなりました。参考
AWS Lambdaでpythonプログラムの定期実行
AWS Lambda 環境変数の使用
AWS_Cron式のワイルドカード
AWS Lambdaで「No module named 'pytz'」エラーが発生したときの対処方法
【AWS】Lambdaでtime out after 3.00 secondsが出たときの対処法
- 投稿日:2020-11-28T16:05:03+09:00
【初心者向け】転職にも活用できるAWSの基礎知識を解説
「AWSって何するの?」
結論、インフラ構築です。
今回はIT業界で多く利用されているAWSについて、初心者向けにわかりやすく解説していこうと思います。
最後まで読んでみて、もし良いなと思ったら、記事を書く励みになるので、ぜひLGTMをお願いします!
AWSについて
冒頭でもお伝えした通り、AWSとはインフラ構築をクラウド上で行う、非常に便利なツールの一つです。
「インフラ構築って?」
「クラウドって?」これらを解説していきます。
インフラ構築について
まずIT業界で言うインフラとは、物理的なコンピュータやサーバー、データベースなどの事を指します。そしてインフラ構築とは、これらの物理的な機器をインターネットに接続し、Webやアプリケーション上での利用ができるような環境を、構築をする事を意味します。
厳密に言えば、もっといろいろあるのですが、ここではAWSについての説明がメインなので割愛します。
オンプレミスとクラウド
次にクラウドについてですが、その前にオンプレミスと言う言葉を紹介します。
オンプレミス
オンプレミスとは、上記の説明と同じように、実際に企業が物理的なコンピュータやサーバーなどを購入し、独立したインフラ構築を行うことです。
主に社内の情報や、顧客の個人情報など、機密性の高いシステムを開発する際などに、採用されることの多い手法です。
クラウド
これに対しクラウドとは、ある企業が構築した大規模なインフラを、インターネット上で利用する事ができると言うサービスです。
例えばAWSは、Amazonが世界中に整えたインフラ施設(リージョン)を利用して、各企業にその一部を貸し出している、と言うのがわかりやすいかと。
主流はクラウドへ
このオンプレミスとクラウドに関しては、それぞれメリットとデメリットがあるのですが、現時点で日本でも主流になりつつあるのは、クラウドサービスの方になります。
理由は、オンプレミスと比較した際に、導入コストが抑えられたり、インフラを稼働させるのに時間がほとんど掛からない、と言うメリットがあるためです。
特に時間が掛からないと言うメリットは、スピード感を求められるスタートアップやベンチャーにとって、かなり強力な利点になります。そのため、モダンな開発をしている企業のほとんどが、AWSなどのインフラ系クラウドサービスを利用しています。
クラウドサービスのシェア
ちなみにインフラ構築が可能なクラウドサービスは、他にも有名所がいくつか存在し、代表的なものは以下の3つになります。
- AWS - Amazonの提供
- GCP - Googleの提供
- Azure - Microsoftの提供
この3つは主要3大クラウドサービスとも言われており、世界のインフラ系クラウドサービスシェアの、約7割を担っています。
さらにその中でも、GCPやAzureに倍以上のシェアを持ち、圧倒的に利用されているのが、このAWSになります。
AWSを学習するメリット
世界的にみても、圧倒的なシェアを持つAWSですが、国内でもその風潮は顕在です。つまり転職や仕事に生かすと言う意味で、AWSを学習することは、かなり需要が高い人材になれる。といった具合です。
実際、未経験からエンジニアに転職をする際に、面接でポートフォリオの話はほとんどせず、AWSの話をするだけで内定が決まった、と言う事例も多数聞きます。
またこのようなインフラ系クラウドサービスが主要になりつつあると言うことは、今までソフト側だったバックエンドエンジニアと、ハード側だったインフラエンジニアの垣根は無くなっていくと、容易に想像がつきます。
そういった意味でも、エンジニアになるのであれば、バックエンドだろうがインフラだろうが(もっと言えばフロントだろうが)、AWSを学ぶことにより、転職の可能性や仕事領域の拡大は、充分見込めるものとなるでしょう。
まとめ
少し長くなりましたが、これらの知識は知っておくだけでも、転職や仕事で大いに活用できるものになります。さらに深くAWSについて知りたい方は、
AWS EC2
AWS RDS
AWs S3このあたりを検索してみるのがオススメです。
最後まで読んでいただき、ありがとうございました!
筆者:yuki|学習10日目で初案件獲得→現在はフルスタックエンジニア転職に向けて学習中
Qiita:https://qiita.com/yuki4839
Twitter:https://twitter.com/yuki35522891
- 投稿日:2020-11-28T16:05:03+09:00
【初心者向け】転職にも活用できるAWSの前提知識を解説
「AWSって何するの?」
結論、インフラ構築です。
今回はIT業界で多く利用されているAWSについて、初心者向けにわかりやすく解説していこうと思います。
最後まで読んでみて、もし良いなと思ったら、記事を書く励みになるので、ぜひLGTMをお願いします!
AWSについて
冒頭でもお伝えした通り、AWSとはインフラ構築をクラウド上で行う、非常に便利なツールの一つです。
「インフラ構築って?」
「クラウドって?」これらを解説していきます。
インフラ構築について
まずIT業界で言うインフラとは、物理的なコンピュータやサーバー、データベースなどの事を指します。そしてインフラ構築とは、これらの物理的な機器をインターネットに接続し、Webやアプリケーション上での利用ができるような環境を、構築をする事を意味します。
厳密に言えば、もっといろいろあるのですが、ここではAWSについての説明がメインなので割愛します。
オンプレミスとクラウド
次にクラウドについてですが、その前にオンプレミスと言う言葉を紹介します。
オンプレミス
オンプレミスとは、上記の説明と同じように、実際に企業が物理的なコンピュータやサーバーなどを購入し、独立したインフラ構築を行うことです。
主に社内の情報や、顧客の個人情報など、機密性の高いシステムを開発する際などに、採用されることの多い手法です。
クラウド
これに対しクラウドとは、ある企業が構築した大規模なインフラを、インターネット上で利用する事ができると言うサービスです。
例えばAWSは、Amazonが世界中に整えたインフラ施設(リージョン)を利用して、各企業にその一部を貸し出している、と言うのがわかりやすいかと。
主流はクラウドへ
このオンプレミスとクラウドに関しては、それぞれメリットとデメリットがあるのですが、現時点で日本でも主流になりつつあるのは、クラウドサービスの方になります。
理由は、オンプレミスと比較した際に、導入コストが抑えられたり、インフラを稼働させるのに時間がほとんど掛からない、と言うメリットがあるためです。
特に時間が掛からないと言うメリットは、スピード感を求められるスタートアップやベンチャーにとって、かなり強力な利点になります。そのため、モダンな開発をしている企業のほとんどが、AWSなどのインフラ系クラウドサービスを利用しています。
クラウドサービスのシェア
ちなみにインフラ構築が可能なクラウドサービスは、他にも有名所がいくつか存在し、代表的なものは以下の3つになります。
- AWS - Amazonの提供
- GCP - Googleの提供
- Azure - Microsoftの提供
この3つは主要3大クラウドサービスとも言われており、世界のインフラ系クラウドサービスシェアの、約7割を担っています。
さらにその中でも、GCPやAzureに倍以上のシェアを持ち、圧倒的に利用されているのが、このAWSになります。
AWSを学習するメリット
世界的にみても、圧倒的なシェアを持つAWSですが、国内でもその風潮は顕在です。つまり転職や仕事に生かすと言う意味で、AWSを学習することは、かなり需要が高い人材になれる。といった具合です。
実際、未経験からエンジニアに転職をする際に、面接でポートフォリオの話はほとんどせず、AWSの話をするだけで内定が決まった、と言う事例も多数聞きます。
またこのようなインフラ系クラウドサービスが主要になりつつあると言うことは、今までソフト側だったバックエンドエンジニアと、ハード側だったインフラエンジニアの垣根は無くなっていくと、容易に想像がつきます。
そういった意味でも、エンジニアになるのであれば、バックエンドだろうがインフラだろうが(もっと言えばフロントだろうが)、AWSを学ぶことにより、転職の可能性や仕事領域の拡大は、充分見込めるものとなるでしょう。
まとめ
少し長くなりましたが、これらの知識は知っておくだけでも、転職や仕事で大いに活用できるものになります。さらに深くAWSについて知りたい方は、
AWS EC2
AWS RDS
AWs S3このあたりを検索してみるのがオススメです。
最後まで読んでいただき、ありがとうございました!
筆者:yuki|学習10日目で初案件獲得→現在はフルスタックエンジニア転職に向けて学習中
Qiita:https://qiita.com/yuki4839
Twitter:https://twitter.com/yuki35522891
- 投稿日:2020-11-28T15:47:11+09:00
EC2でyum install時に「Another app is currently holding the yum lock;」で実行できない
背景
yum update -y実行時に以下文言が出て、実行できなかった。$yum update -y Another app is currently holding the yum lock;原因
yum実行中に以下ロックファイルが作成され、残っているため
/var/run/yum.pid対処法
以下コマンドでロックファイルを削除すればOKです。
rm /var/run/yum.pid参考
https://onoredekaiketsu.com/yum-sleeps-and-cant-be-executed/
- 投稿日:2020-11-28T12:12:36+09:00
AWS SAM CLIをmacOSにインストールする
AWS SAM CLI
準備
※参考:Installing the AWS SAM CLI on macOS
※参考:AWS CLIをmacOSにインストールする
- AWSアカウントを用意する。
- Administrator権限を持つIAMユーザーを用意する。
- IAMユーザーのアクセスキー、シークレットアクセスキーを払い出す。
- credentialsファイル、configファイルを作成する。
- Dockerをインストールする。
- Homebrewをインストールする。
- SAM CLIをインストールする。
macOSにインストール
次のコマンドを実行する。
% brew tap aws/tap % brew install aws-sam-cliインストールされたことを確認する。
% sam --versionSAM CLI, version 0.47.0
- 投稿日:2020-11-28T12:12:36+09:00
AWS SAM CLIをLinux、macOSにインストールする
AWS SAM CLI
準備
※参考:Installing the AWS SAM CLI on macOS
※参考:AWS CLIをmacOSにインストールする
- AWSアカウントを用意する。
- Administrator権限を持つIAMユーザーを用意する。
- IAMユーザーのアクセスキー、シークレットアクセスキーを払い出す。
- credentialsファイル、configファイルを作成する。
- Dockerをインストールする。
- Homebrewをインストールする。
- SAM CLIをインストールする。
共通
Linux、WSL2、macOSで次のコマンドを実行し、
brewをインストールする。/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"Linux、WSL2にインストール
Ubuntu on WSL2`では、4行目のechoコマンドを実行すれば良い。
test -d ~/.linuxbrew && eval $(~/.linuxbrew/bin/brew shellenv) test -d /home/linuxbrew/.linuxbrew && eval $(/home/linuxbrew/.linuxbrew/bin/brew shellenv) test -r ~/.bash_profile && echo "eval \$($(brew --prefix)/bin/brew shellenv)" >>~/.bash_profile echo "eval \$($(brew --prefix)/bin/brew shellenv)" >>~/.profile共通
brewコマンドがインストールされていることを確認する。brew --version次のコマンドを実行する。
% brew tap aws/tap % brew install aws-sam-cliインストールされたことを確認する。
% sam --versionSAM CLI, version 0.47.0
- 投稿日:2020-11-28T11:01:12+09:00
【AWS】用語を整理しながら学ぶAWS - part3
はじめに
この記事では
AWSのあんなことやこんなことについてまとめた記事です。
ベストプラクティスや間違いがあれば、書き直していく予定です。
今回は
NATゲートウェイの設定
サーバの設定
他、重要な用語について整理してみました。参考図書:さわって学ぶクラウドインフラAmazon Web Services 基礎からのネットワーク&サーバー構築
NATゲートウェイとは
NetworkAddressTranslation
要はアドレスの読み替えです。グローバルアドレスからローカルアドレスへの読み替え
AWSで例えるとパブリックIPからプライベートIPへの変換
Ciscoなどでは静的か動的かというところまで分かれるのでここでは割愛よく、インフラエンジニアのお姉さんに
NAPTのことをNATだと注意されましたが
実際のところ、近年ではどちらでも構わないということただし、参考図書にもあるように
ポート変換も含めてアドレスを変換する場合は
NAPT(IPマスカレード)と呼んだほうが正確です。私と同じようなツッコミを受ける人には使える受け答えかもしれませんね。
ちなみにAWSではNATをする方法として
本記事で紹介しているNATゲートウェイの他にNATインスタンスというモノがあります。
お手軽に済ませたいので本稿では割愛
NATの良いところ
内部のIPアドレスを外向けに公開しないようにできること
NATされたネットワーク機器のアドレスを隠すことができること参考図書では
DBサーバを内部ネットワークに配置するとき
DBサーバをインターネットに接続する方法の解説でNATゲートウェイを用いています。ただし、内部のDBサーバと接続されたサーバが乗っ取られてしまうと
NATの意味がなくなってしまうので
適切なファイアウォールの設定が必要である。また、今回ではAWSをベースにNATの説明をしているので
あまり関係ないですが、オンプレ環境の装置でNATをかけている場合は
隣接されているL3スイッチやルータのコンフィグレーションが流出しないように気を付けましょう。
ファイアウォール(FW)とは
NATのところで名前が出ましたので解説
要するに装置を攻撃者から守る防御壁
いろんなタイプが存在する防御壁いろんな会社が生産している
ネットワークアプライアンスに必ずと言って良いほど存在する機能Ciscoで言えば CiscoASA
Juniperで言えば SRX
パロアルトで言えば Palo Alto Networks PA シリーズ
Check Pointで言えば..なんだったか
とりあえず、いろんなところが開発してます。AWSではセキュリティグループという考え方で
FWを構築できます。
NATとFW
アドレス変換したらFWの設定はどうなるのって思いますよね。
ここが重要なポイント
基本的にFWがブロックするのは隣接装置からの
IPアドレスまたはIPアドレスとサービスを組み合わせた接続をブロックします。つまり、NATで変換した通信がFWから見えているのであれば
NAT後のアドレスでFWのセキュリティポリシーを設計しなければなりません。
変換前のアドレスで設計しないように気を付けましょう。
サーバの設定
NAT、FWの設定ができたらいよいよサーバの設定
サーバの設定をするときに重要なコマンド
(Amazon Linux 2 ベースで)sudo ~
systemctl enable
systemctl start
yum install
wget [URL]
tar xzvf [tarファイル名]
chownsudo : スーパーユーザードゥー、つまりWindowsでいうところの管理者として実行
systemctl : システムコントロール、利用するアプリケーションを動かす動かさないはこれを使う
yum : パッケージマネージャと呼ばれるモノ
wget : ウェブゲット、指定されたURLからファイルを取得する。
tar : 圧縮ファイル形式 tarを作成・解凍するコマンド
chown : チェンジオーナー、ファイルの所有者/グループを変更するコマンド具体例
sudo amazon-linux-extras install php7.3
訳:管理者権限を用いてamazon-linux-extrasを実行し、php7.3をインストールする。sudo yum -y install mariadb-server
訳:管理者権限を用いてMariaDBを強制的にインストールする。sudo systemctl start mariadb
訳:管理者権限を用いてMariaDBを起動する。sudo systemctl enable mariadb
訳:管理者権限を用いてMariaDBをサーバー立ち上げ時に自動起動するよう設定する。Windowsで言うところのスタートアップsystemctl start 後に変更した設定を反映させる場合は
sudo systemctl restart ~
と打ってください。でないと反映されません。
※ちなみにここで結構ハマりました。sudo yum -y install php php-mbstring
訳:管理者権限を用いてphpとphpのマルバイト文字列対応ライブラリをインストールする。wget https://ja.wordpress.org/latest-ja.tar.gz
訳:wordpressをダウンロードする。tar xzvf latest-ja.tar.gz
訳:latest-ja.tar.gzを解凍する。sudo cp -r * /var/www/html/
訳:カレントディレクトリにあるフォルダとファイルを全て/var/www/html/に移動する。sudo chown apache:apache /var/www/html/ -R
訳:カレントディレクトリにあるフォルダとファイルを全て、所有者をapacheに変更する。
まとめ
- IPアドレスを公開したくない場合はNATゲートウェイかNATインスタンスを使う。
- FWにはいろんな種類が存在するがAWSではセキュリティグループという単位でセキュリティを管理する。
- 一般的にはNATを構築した際は隣接しているFWの設定も見直さなければならない。
- システムの変更をする場合はスーパーユーザー権限を使う。
おわり
- 投稿日:2020-11-28T02:54:35+09:00
AWS LambdaでAPI開発するときのパターン集
結論
AWS LambdaでAPI開発をする場合は以下の4パターンが考えられます。それぞれにメリットデメリットがあるので、要件やメンバーのスキルセットなどをもとに選択することになると思います。
① Functions(別ソース)パターン
② Functions(同一ソース)パターン
③ WebFrameworkパターン
④ GraphQLパターン
各パターンのメリット/デメリットを表にまとめました。
こちらは開発するAPIの規模や開発フェーズによって異なることから参考程度に捉えてください。
影響範囲を考慮しなくていい 細かなポリシー管理 共通ロジックの利用 導入容易 サーバへの移行 学習コストの低さ 開発のしやすさ エラーログの追いやすさ デプロイ容易度 functionsパターン(ソースコード分離) ◎ ○ △ ◎ × △ × ○ △ functionsパターン(ソースコード共通) △ ○ ○ ◎ △ △ △ ○ △ WebFrameworkパターン △ × ○ △ ◎ ○ ○ △ ○ GraphQLパターン △ △ ○ ○ ◎ × ○ △ ○ 背景
AWS LambdaでAPI開発をする
AWS LambdaとAPI Gatewayを組み合わせることでサーバレスのAPIを開発することが可能です。サーバレスで構築することで手間をかけずにスケーラビリティやコストの最適化を手に入れることができ、さらに死活監視等が不要のため運用のコストを大幅に下げることができます。
開発パターンがまとまっていない
サーバレスによるAPI開発は非常にメリットが多いのですが、開発パターンが様々あり一貫した方法があるわけではありません。例えば、Lambdaのデプロイは手動でzipをアップロードする方法や、SAM/ServerlesssFrameworkなどのデプロイ支援ツールを利用する方法、さらにオンラインエディタのCloud9を利用することもあります。関数ごとにディレクトリを分離する場合もあるし、ソースコードを共有してエントリーポイントだけ切り替える場合もあります。さらに言うとRESTだけでなくGraphQLで作成することができます。これらのパターンはきちんと体系立ってまとめられているドキュメントが見つけられなかったので、今回まとめてみようと思いました。
Lambda API開発パターン
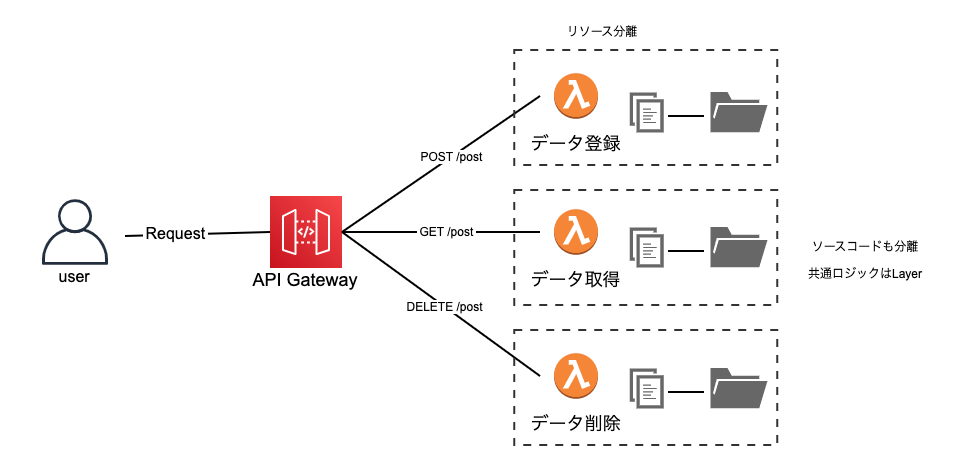
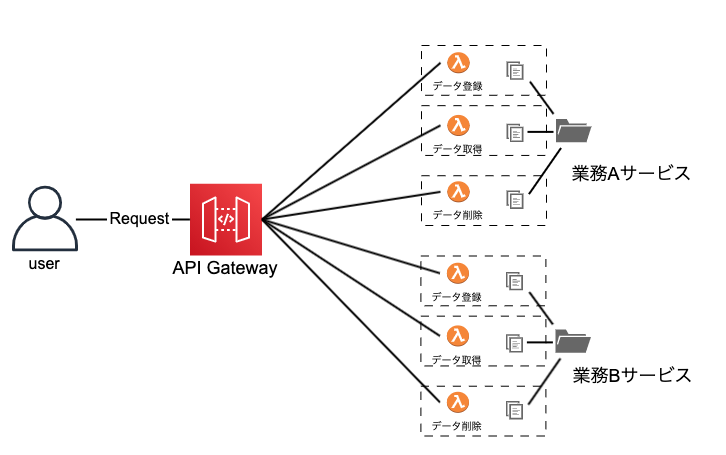
① Functions(別ソース)パターン
特徴
- Lambda間でリソースもソースファイルもが共有されません
- APIのパスの数だけLambda関数のリソースが作成されます
- 共通ロジックがある場合はLayerにおきます
- Cloud9で開発するとこのパターンになります
メリット
- Lambda間の依存関係がないため非常に疎結合になります。このためAPIの追加や修正が気軽に行えます。
- リソースが分離されるので、Cloudwatchのログが関数ごとに出力され、エラーログがとても追いやすくなります。
- 関数ごとにリソースが分離されるので、細かくポリシーを設定できるためセキュアな構成を作ることができます。
デメリット
- 共通ロジックをLayerに置いといたとしても、Layerのバージョン管理に悩まされます。Layerを更新しても、すでにデプロイ済みのLambda関数は古いLayerを参照しているため、一度全てのLambda関数をデプロイしなおさないといけません。
- Layerに配置したロジックはエディタの補完が効かないため、開発効率が下がります。
- SAM/ServerlessFrameworkのようなデプロイ支援ツールを使う場合、その設定ファイル(template.yaml/serverless.yaml)が煩雑になりがちです。環境変数を全てのリソースに渡す必要があると、それだけで設定ファイルの行数が増えてしまいます。
- 関数ごとに細かくポリシーを設定することはメリットである一方で、管理が難しくなります。
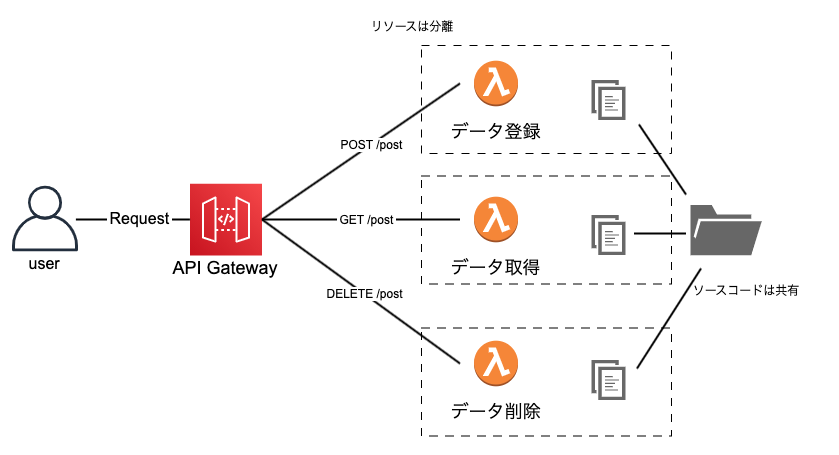
② Functions(同一ソース)パターン
特徴
- ソースファイルは同じものを利用しますが、各Lambdaのエントリーポイント(ファイル名/関数名)を切り替えることでLambda関数を作成するため、リソースは分離されます。
- APIのパスの数だけLambda関数のリソースが作成されます
メリット
- Layerを使わずに共通ロジックを再利用することができます
- リソースが分離されるので、Cloudwatchのログが関数ごとに出力され、エラーログがとても追いやすくなります。
- 関数ごとにリソースが分離されるので、細かくポリシーを調整できるためセキュアな構成を作ることができます。
デメリット
- ソースファイルが各Lambdaで共有されるためAPIの追加や修正時に影響範囲を考慮する必要があります。
- SAM/ServerlessFrameworkのようなデプロイ支援ツールを使う場合、その設定ファイル(template.yaml/serverless.yaml)が煩雑になりがちです。環境変数を全てのリソースに渡す必要があると、それだけで設定ファイルの行数が増えてしまいます。
- 関数ごとに細かくポリシーを設定することはメリットである一方で、管理が難しくなります。
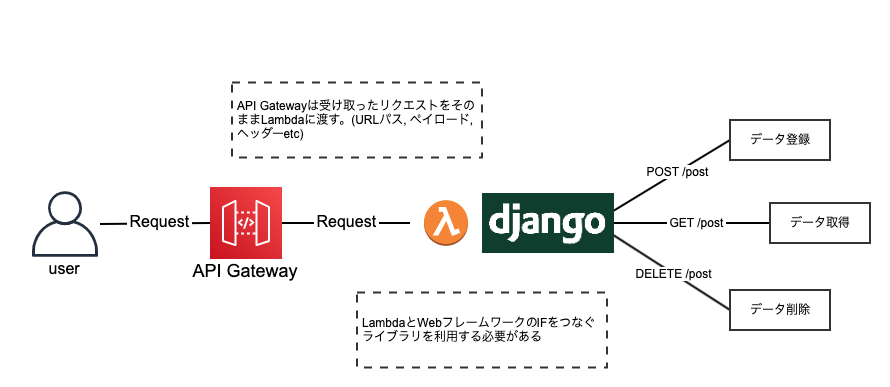
③ WebFrameworkパターン
特徴
- API Gatewayは受け取ったリクエストをそのままLambdaにパススルーし、Lambdaに載っているWebフレームワークがルーティング等を行います
- API Gatewayはプロキシリソースとの統合となります。(パス変数が/{proxy+}のようになります)
- LambdaとWebFrameworkの間のインターフェイスをつなぐライブラリを利用する必要があります(例: aws-serverless-express, challice, Serverless Framework Pluginなど)
メリット
- WebFrameworkの知識があればLambdaの知識がなくても開発が可能です
- WebFrameworkをライブラリでラップしているだけなので、サーバレスからEC2やオンプレへ移行する必要があったときにそれがとても容易にできます
デメリット
- ライブラリに対応しているWebフレームワーク以外では使用できません
- モノリスになりがちな構成になります
- デプロイパッケージのサイズが大きくなってしまいます。しかしこれはLayerに依存パッケージを載せることで解決可能です。
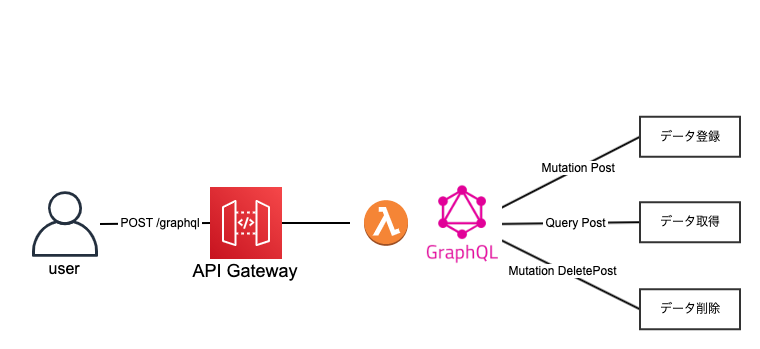
④ GraphQLパターン
特徴
- Apollo Server on Lambdaを利用してGraphQLサーバをLambdaに載せます。
- GraphQLサーバがリクエストのbodyを見てクエリを捌く形になります
- API Gatewayは/graphqlの単一エンドポイントになります
メリット
- GraphQLの恩恵を得ることができます(クエリの柔軟性、アジリティ、パフォーマンス向上、PlayGround、型情報の自動生成 etc...)
- API Gatewayにエンドポイントを追加できる余地があるため、RESTと共生することが可能です。
デメリット
- RESTに比べて知識が浸透していないため学習コストがかかります。教育コストや引継ぎコストに繋がるため慎重に選ぶ必要があると思っています。
- GraphQLのデメリットを受けます(クライアント側でライブラリの利用がほぼ必須になるetc)
まとめ
影響範囲を考慮しなくていい 細かなポリシー管理 共通ロジックの利用 導入容易 サーバへの移行 学習コストの低さ 開発のしやすさ エラーログの追いやすさ デプロイ容易度 functionsパターン(ソースコード分離) ◎ ○ △ ◎ × △ × ○ △ functionsパターン(ソースコード共通) △ ○ ○ ◎ △ △ △ ○ △ WebFrameworkパターン △ × ○ △ ◎ ○ ○ △ ○ GraphQLパターン △ △ ○ ○ ◎ × ○ △ ○ 最後に各パターンを項目別に比較してまとめたいと思います。
影響範囲を考慮しなくていい
functionsパターン(ソースコード分離)はリソースとソースが両方とも分離されるため一切の依存関係がなく、影響範囲を考慮せずに機能の追加や修正を行うことができます。複数のメンバーで開発する場合などに大きなメリットがあると思います。その他のパターンはソースコードを共有するため、一定程度の影響範囲を考慮する必要があります。
細かなポリシー管理
Lambda関数ごとにポリシーを設定したいニーズがある場合は、functionsパターンを選択する必要があります。これはセキュリティ的にはメリットと言えますが、管理が大変になるデメリットでもあります。
GraphQLパターンの場合は必要に応じてREST APIを追加できるので、どうしてもこのニーズがあったときはそこだけ切り出してLambdaを作成しポリシーを設定することが可能です。共通ロジックの利用
ソースコードを共有できる場合は共通ロジックを利用できますが、functionsパターン(ソースコード分離)ではできません。Layerを使えば共通ロジックを利用することができますが、補完が効かないことやバージョン管理が面倒なことを考えるとあまり良い選択肢とは言えないと思っています。
導入容易性
functionsパターンはSAM/ServerlessFrameworkを利用することですぐに始められますが、他パターンはライブラリやプラグインの設定が必要な分、少しだけ導入容易性が低いと言えます。
サーバへの移行
パフォーマンスの観点からサーバレスからEC2/オンプレへ移行する可能性がある場合は、すぐにリソースを剥がせる構成であることが望ましいでしょう。WebFrameworkパターンとGraphQLパターンはラップしているライブラリを引き剥がすことですぐにオンプレに移行することができます。
学習コストの低さ
Lambdaを意識せずに開発できるWebFrameworkパターンが学習コストの面では軍配が上がります。現在はGraphQLが最も学習コストが高い選択肢であると言えるでしょう。
開発のしやすさ
functionsパターン(ソースコード分離)は共通ロジックが利用しにくいため開発がしにくいです。WebFrameworkパターンとGraphQLパターンはフレームワークの恩恵が受けられるため問題なく開発を行うことができます。
エラーログの追いやすさ
デプロイした後のエラーログを追いたいときはリソースごとにCloudWatchが分かれているfunctionsパターンがエラーログが追いやすいです。
デプロイ容易度
functionsパターンはどうしてもSAM/ServerlessFrameworkの設定ファイルが煩雑になりやすいことがネックになります。WebFrameworkパターンはプロクシパスに、GraphQLパターンは単一エンドポイントにまとまるため、設定ファイルをシンプルに保つことが可能です。
最後に
いかがだったでしょうか?
今回の記事の内容は基本的に経験ベースでの記述になっているため網羅性が低いかもしれません。
是非とも皆さんのご意見をいただいて内容に反映していければと思います。
「このパターンで開発したけど、ここが良かったよ、ここが不便だったよ」みたいな話をコメントでいただけると大変嬉しいです。追記 マイクロサービスパターン
書き終わって思いついたことであるが、Functionsパターン(ソース別/ソース共有)をハイブリッドさせることで上の図のようなマイクロサービスパターンを構築できるかもしれません。サービス間は疎結合でサービス内で共通ロジックを使いまわせるのでFunctionsパターンのいいところ取りができそうです。実際にこのパターンで開発をしたことがないので、もし似たようなことをやったことがある人は是非感想聞かせてください!