- 投稿日:2020-11-27T23:21:56+09:00
Tensorflow インストールでWARNING, numpy, metadata,...なんとかかんとかを解決。
pip install tensorflowでインストールしようとすると、
こういうエラーが出ました。FileNotFoundError: [Errno 2] No such file or directory: '/Users/-/anaconda3/lib/python3.6/site-packages/numpy-1.19.4.dist-info/RECORD'とか、
No metadata found in ./anaconda3/lib/python3.6/site-packagesとか、
WARNING: Error parsing requirements for numpy: [Errno 2] No such file or directory: '/Users/-/anaconda3/lib/python3.6/site-packages/numpy-1.19.4.dist-info/METADATA'解決策
外国に解決された方がいました。
Installation problem :Could not install packages due to an EnvironmentError: [Errno 2] No such file or directory: #6647
翻訳...
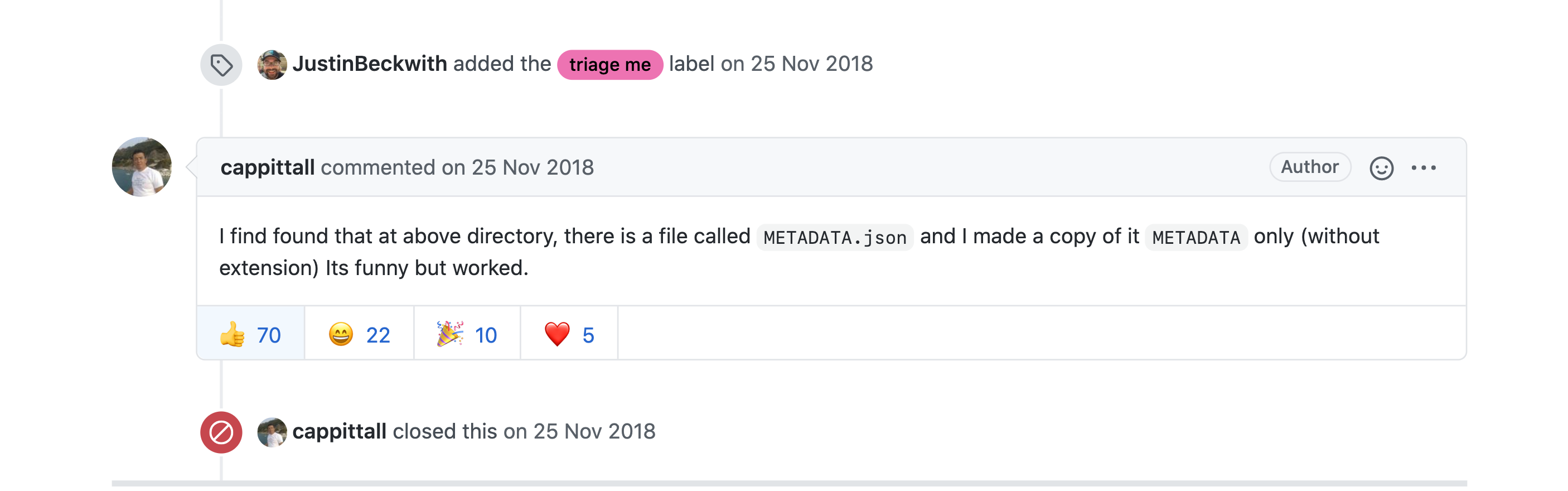
つまり、/Users/-/anaconda3/lib/python3.6/site-packages/ に存在する他のライブラリのフォルダーにあった、METADATA、metadata.json、RECORDを持ってきて入れました。そしたらなんか解決します。
なんじゃこりゃ。

- 投稿日:2020-11-27T22:30:29+09:00
pythonによるスクレイピング&機械学習をtensorflow2で動かしてみた
前提条件
対象
この記事は、Webエンジニア向けです。
私自身Webプログラマでして、機械学習を仕事に活かせないかと考えるために勉強しつつ書いたものになります。
それと、「pythonによるスクレイピング&機械学習」に沿って書くので、本の補足のつもりでみてください。環境
・PC : Macbook pro
・OS : Catalina(10.15.7)
・言語 : python2.7.16
・エディタ : jupyter(せっかくなので使いましょう、便利です)
pythonやライブラリのインストールは、つまづいた記憶もないのでここでは省きます。お願い
あなたに感想や要望を書いて頂けると主が喜びます。ぜひ気軽にコメントしていってください。
もっとシンプルな方法があれば教えてください。レッツ機械学習
tensorflow2(以下、tf2)の便利技
基本的にtf2は、無印の動作もできます
sess = tf.compat.v1.Session() sess.run(tf.global_variables_initializer())本をよみながら、うまくtf2の書き方にできない時は、これで誤魔化しましょう
5-4をtf2でやってみる
src/ch5/placeholder1.pyをtf2化
著作権上元コードは乗せてませんimport tensorflow as tf #メソッドで制御 #noneを指定してあげると、配列が可変となる @tf.function(input_signature=[tf.TensorSpec([None], tf.int32)]) def hoge(a): b = tf.constant(2) return a * b #.numpy()で数字の部分だけとれる print( hoge(tf.constant([1,2,3])).numpy() ) print( hoge(tf.constant([10,20,30])) )結果
[2 4 6] tf.Tensor([20 40 60], shape=(3,), dtype=int32)簡単な解説
このメソッド自体は
元のコードでは、メソッドではなくsession.runで動作してます。
tf2ではsessionは使わなくてよくなったので、シンプルに作れます。まず、元のコードではrun時に値を代入していますが、私はメソッドに引数を渡して、動作させてます。
@tf.function(input_signature=[tf.TensorSpec([None], tf.int32)])
この定義により引数の型を決めています。もちろん複数定義もできます。その後は、元コードと同じように配列の掛け算を行って表示してます。
まとめ
短いですが、tf2のさわりはこんな感じです。
1.sessionは必要ない
2.メソッドを作りやすくなった
それ以外にももちろん機械学習において便利になった点もあるので、
この本を元に今後アップしていけたらと思います。ありがとうございました。
- 投稿日:2020-11-27T21:25:18+09:00
UbuntuにTensorFlow 2系のGPU環境を作ろう !
実行環境
ubuntu 20.04.1 LTS (日本語Ubuntu最新版)
Condaは使わない。
確実性を重視。
バージョン管理はpyenv
機体要件
CPU Ryzen7 5800X
GPU RTX3070
詳しくは
https://qiita.com/YU_GENE/items/09d7ffa85ad8e37dc063インストールするものを考える
TensorFlowのGPU環境を作るのは大変らしい。
Python,cuDNN,CUDAのバージョンが違うと動かない可能性があるからだ。
まず、Tensorflowのページに行って、ubuntuのTensorFlowのGPUバージョンの動作確認がされている最新版を確認しにいく。
2020/11/27現在、Ubuntu版TensorFlowは上のものが一番確実らしい。Pythonのバージョンを自在に操る
ubuntuインストール段階でのpythonのバージョンは3.8系だったが、pythonバージョンは3.7までが確認済みのようだから、pyenvというものを使って、自由自在にpythonのバージョンを管理できるようにする。
pyenvのインストール
pyenvのインストール$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ brew install pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profileUbuntuの場合、以下のコードを実行しないとpythonをインストールしてこれないので注意
Ubuntuの場合は以下も実行$sudo apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl git $sudo apt install libedit-dpythonの設定
今回は3.7系まで保証されているということなので、python3.7.9を入れる。
インストールできるもののリストは$pyenv install --list | lessで確認できる。
インストールの手順$pyenv install 3.7.9 $pyenv versions $pyenv shell 3.7.9でインストール完了。試しにpythonを起動すると、きっとpython3.7.9が起動するはず。
インストール、確認、起動設定の順である。これでバージョン問題に悩まされることは一生ない。
アツいぜ。python仮想環境の構築
PC環境を破壊しないために、venvというものを使って仮想環境を作る。
ここでいう仮想環境とはVirtualBoxとかがPC自体の仮想環境だとすれば、Python言語だけの仮想環境みたいなものである。今回はtfという適当なディレクトリ下に仮想環境設定をする。pyenvでpythonを3.7.1にした状態で$mkdir tf $cd tf $python -m venv .venvこれで設定は完了。仮想環境に入るにはこの状態で、
$source ~/tf/.venv/bin/activateこれで仮想環境に入れる。
左側に.venvと出れば成功。このコードは適当にエイリアスに保存しておくと楽。NVIDIAドライバのインストール
ちゃちゃっとインストール
他の方も記事にされているので、詳細は省略。
デフォルトグラフィックドライバを停止して、オートインストールするだけ!(やり方は下リンク)
https://qiita.com/sho8e69/items/66c1662c49ac89a024besudo ubuntu-drivers autoinstall
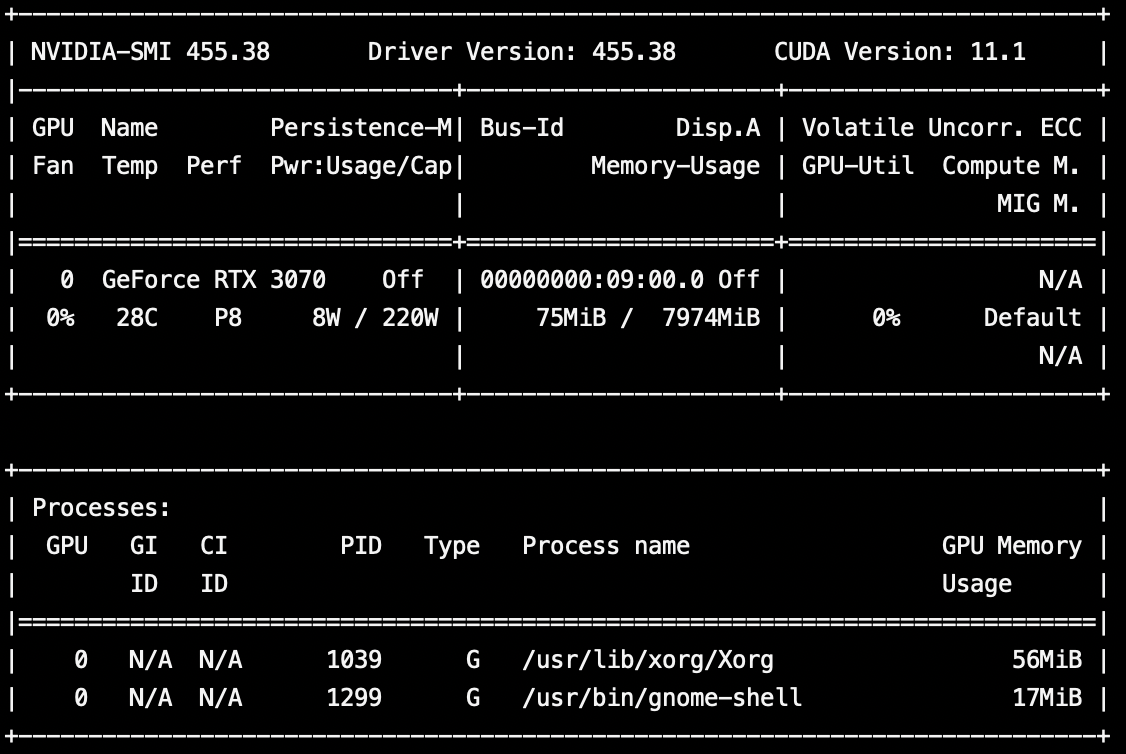
nvidia-smiを実行するとRTX3070の文字が。美しい。
CUDAのインストール
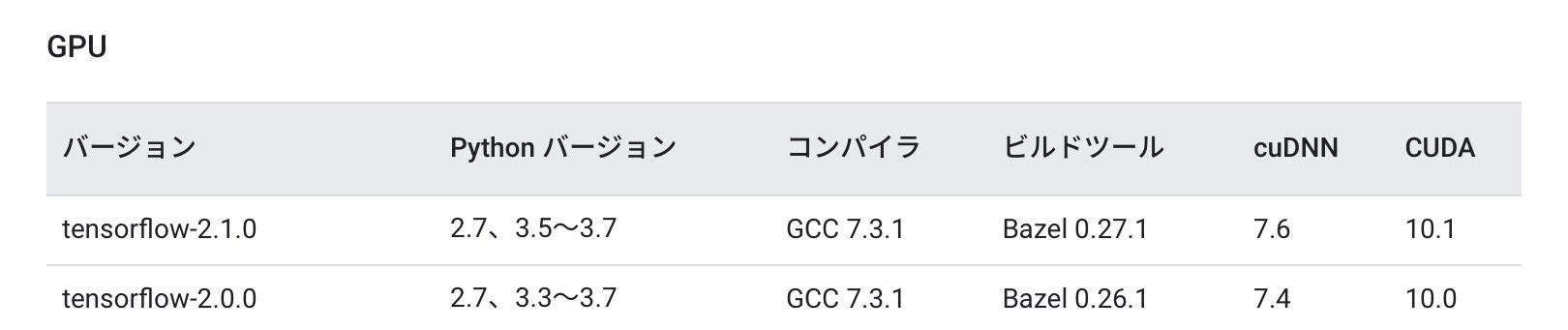
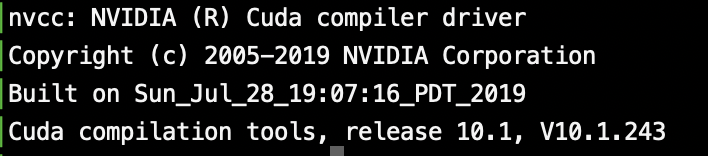
さて、CUDAの確認済みバージョンは10.1だったな。
CUDA10.1はaptからそのまま入手できる。簡単。最新版が欲しかったらnvidiaのサイトに行くべきだが、今回は丁度10.1が欲しかったのでそのまま以下を実行。$sudo apt install nvidia-cuda-toolkitnvcc -Vコマンドで確認できる。
TensorFlowのインストール
さて、TensorFlowの確認済みバージョンはTensorFlow2.1.0だったな。
仮想環境に入っている状態で、(pipは更新しといてね)(.venv)$pip install tensorflow==2.1.0で仮想環境のみにtensorflow2.1.0が入る。
pip listコマンドで入っているのが確認できる。
いいねぇ。cuDNNのインストール
CUDAと名前似てるけど、一応別物。
めんどいけど、以下で会員登録して
https://developer.nvidia.com/rdp/cudnn-archive
「CUDA10.1に対応したCuDNN7.6系」を探そう。
cuDNN Runtime Library for Ubuntu18.04 (Deb)
cuDNN Developer Library for Ubuntu18.04 (Deb)
をダウンロードして、
それぞれdpkg iコマンドで展開するだけ。簡単。sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.debできたかな?
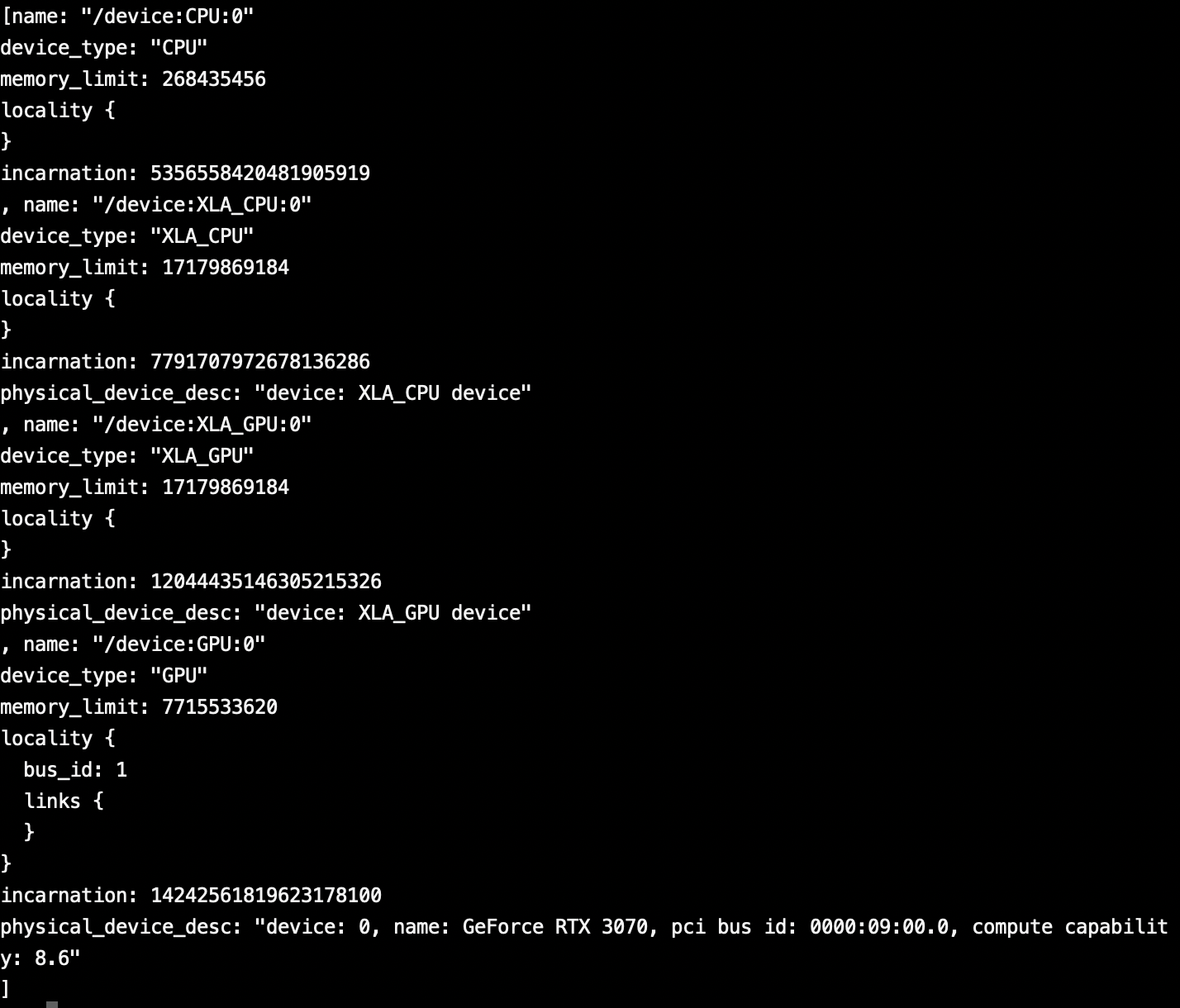
pythonで以下を実行してみよう。
from tensorflow.python.client import device_lib device_lib.list_local_devices()
GPUの文言がちらほら。
一番下にはRTX3070の文字があるので正常にできたっぽい。まとめ
これで機械学習のために自作PCしたとか自慢できるね。
決して流行りのオンラインゲームがしたかったとかじゃないよ。
ほんとにね。(嘘)
- 投稿日:2020-11-27T21:25:18+09:00
UbuntuにTensorFlow 2.X 系のGPU環境を作ろう
実行環境
ubuntu 20.04.1 LTS (日本語Ubuntu最新版)
Condaは使わない。
確実性を重視。
バージョン管理はpyenv
機体要件
CPU Ryzen7 5800X
GPU RTX3070
詳しくは
https://qiita.com/YU_GENE/items/09d7ffa85ad8e37dc063インストールするものを考える
TensorFlowのGPU環境を作るのは大変らしい。
Python,cuDNN,CUDAのバージョンが違うと動かない可能性があるからだ。
まず、Tensorflowのページに行って、ubuntuのTensorFlowのGPUバージョンの動作確認がされている最新版を確認しにいく。
2020/11/27現在、Ubuntu版TensorFlowは上のものが一番確実らしい。Pythonのバージョンを自在に操る
ubuntuインストール段階でのpythonのバージョンは3.8系だったが、pythonバージョンは3.7までが確認済みのようだから、pyenvというものを使って、自由自在にpythonのバージョンを管理できるようにする。
pyenvのインストール
pyenvのインストール$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ brew install pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profileUbuntuの場合、以下のコードを実行しないとpythonをインストールしてこれないので注意
Ubuntuの場合は以下も実行$sudo apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl git $sudo apt install libedit-dpythonの設定
今回は3.7系まで保証されているということなので、python3.7.9を入れる。
インストールできるもののリストは$pyenv install --list | lessで確認できる。
インストールの手順$pyenv install 3.7.9 $pyenv versions $pyenv shell 3.7.9でインストール完了。試しにpythonを起動すると、きっとpython3.7.9が起動するはず。
インストール、確認、起動設定の順である。これでバージョン問題に悩まされることは一生ない。
アツいぜ。python仮想環境の構築
PC環境を破壊しないために、venvというものを使って仮想環境を作る。
ここでいう仮想環境とはVirtualBoxとかがPC自体の仮想環境だとすれば、Python言語だけの仮想環境みたいなものである。今回はtfという適当なディレクトリ下に仮想環境設定をする。pyenvでpythonを3.7.1にした状態で$mkdir tf $cd tf $python -m venv .venvこれで設定は完了。仮想環境に入るにはこの状態で、
$source ~/tf/.venv/bin/activateこれで仮想環境に入れる。
左側に.venvと出れば成功。このコードは適当にエイリアスに保存しておくと楽。NVIDIAドライバのインストール
ちゃちゃっとインストール
他の方も記事にされているので、詳細は省略。
デフォルトグラフィックドライバを停止して、オートインストールするだけ!(やり方は下リンク)
https://qiita.com/sho8e69/items/66c1662c49ac89a024besudo ubuntu-drivers autoinstall
nvidia-smiを実行するとRTX3070の文字が。美しい。
CUDAのインストール
さて、CUDAの確認済みバージョンは10.1だったな。
CUDA10.1はaptからそのまま入手できる。簡単。最新版が欲しかったらnvidiaのサイトに行くべきだが、今回は丁度10.1が欲しかったのでそのまま以下を実行。$sudo apt install nvidia-cuda-toolkitnvcc -Vコマンドで確認できる。
TensorFlowのインストール
さて、TensorFlowの確認済みバージョンはTensorFlow2.1.0だったな。
仮想環境に入っている状態で、(pipは更新しといてね)(.venv)$pip install tensorflow==2.1.0で仮想環境のみにtensorflow2.1.0が入る。
pip listコマンドで入っているのが確認できる。
いいねぇ。cuDNNのインストール
CUDAと名前似てるけど、一応別物。
めんどいけど、以下で会員登録して
https://developer.nvidia.com/rdp/cudnn-archive
「CUDA10.1に対応したCuDNN7.6系」を探そう。
cuDNN Runtime Library for Ubuntu18.04 (Deb)
cuDNN Developer Library for Ubuntu18.04 (Deb)
をダウンロードして、
それぞれdpkg iコマンドで展開するだけ。簡単。sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.debできたかな?
pythonで以下を実行してみよう。
from tensorflow.python.client import device_lib device_lib.list_local_devices()
GPUの文言がちらほら。
一番下にはRTX3070の文字があるので正常にできたっぽい。まとめ
これで機械学習のために自作PCしたとか自慢できるね。
決して流行りのオンラインゲームがしたかったとかじゃないよ。
ほんとにね。(嘘)
- 投稿日:2020-11-27T18:53:16+09:00
RTX3070+Ryzen7 5800Xで機械学習PCを組ーむぞっ(組み立て編)
※本記事は自作PCの組み立て講座ではなく、次回の最新GPUでの機械学習環境構築の布石記事です
組み立てについて知りたい方はブラウザバック推奨です。今は時期がいい。
今は時期がいい。
最近RTX3000番台のGPUとZen3アーキテクチャの新型Ryzenが発売された。
CPUとGPUが同時期に発売された今、自作PCを一つも持たない僕にとってはいい機会であった。秋葉で3万ちょいで買ったlet's noteに入れたubuntuで機械学習の勉強をしている僕だったが、ニューラルネットワークに手をつけ始めてからというものの、かなり前のPCの為、計算時間がとてつもなくなって待っている間何も手がつけられなくなってしまったため、デスクトップの自作PCを作るのは好都合だ。
(あとApexとかもしたいよね、折角だし。)
御祝儀価格とか、ストレージが時期が悪いとかはいい。買いたい時が、買い時。
機械学習PCに求める要件
機械学習をするぞ!っていうPCを作る場合、いくつか制限されることがあるので、初めに「どんなPCを組みたいかな」っていう要件を書き出しておく。同志の方は、是非次のセットアップ編も参考にして欲しい。
1.NvidiaのGPUを使うこと。
最近RadeonのGPUが出たけど、TensorFlowのGPU版を使う場合、NvidiaのCUDAというソフトを使わなければいけない。故にNvidiaのGeForceが一般学生には適当なGPUだろう。
RadeonはopenGLのサポートが強いイメージがあるので、映像編集、Unityとかを使って機械学習はしないよって人には丁度いいのではないだろうか。2.Windows/Linuxを共存させること。
自作PCを作ったのにゲームをしないのももったいない。故にWindowsが必要。機械学習をするならlinuxがいい。故にLinuxが必要。そんな状況を解決するのがデュアルブートとか仮想環境とかという技術だろう。
けど仮想環境は処理が遅くなりそうで怖い。
ということで物理的にSSDを二つ用意して、それぞれWindowsとLinuxをインストールする。
Bios起動の後に使うディスクを選べば簡単に使い分けができる。3.インテリア性
美しいPCを組みたいのは自明の理。
見た目が美しければモチベも上がる。ってわけで
どーん
構成
CPU: Ryzen7 5800X
GPU: Zotac RTX3070 OC model
マザー: ASROCK X570 pro4
メモリ: GSKILL Trident Z Neo 16GB×2 3200
クーラー: COOLER MASTER HYPER 212 with edition
電源: Apex Gaming AG-750M
ストレージ: Western Digital black/500GB
Crucial P1/500GB
PCケース: NZXT H510
約20万円の構成。組む。
CPUくっつけて
(ピン折れめちゃ怖かった)
GPUくっつけて
(美しい)
その他適当にぶっさして
(大体説明書とか見ればわかる。吉田製作所さんとかとモヤシさんとかコジコジさんとかしみおじさんとかのyoutube見れば手順も丁寧に解説してるのでおすすめ。)
こうじゃぁぁあ
Bios起動。お疲れ様。
説明書が読めないチンパンジーじゃない限り普通に組めるから安心して欲しい。
組み方とかパーツの選び方とか、それを自分で調べるのが自作PCの醍醐味だから、特にこれを選べとかはないよね。選んでる時、迷ってる時が一番楽しいって言われるしね。まとめ
今回はただの自作PC回だったので次回は本題のLinuxとWindowsのディスクデュアルブートについてと、TensorflowのGPUインストールについて書いていくので、是非ストックして欲しい。
最後にはベンチマークも取りたいな。
それではまた。





- 投稿日:2020-11-27T14:57:51+09:00
CIFAR-10の精度9%から73%に上げる手法を探索
はじめに
ひとまずCIFAR-10は画像認識作業用のデータセットです。
画像はサイトにより (https://www.cs.toronto.edu/~kriz/cifar.html)CIFAR-10は手書き数字のつぎ一番簡単なデータセットだと言われます。手書き数字は逆に簡単すぎて変数を調整しても効果が見づらいです。
今回はTensorflowを使って、いろんな変数を調整し、たくさんの手法を導入して精度を9%から73%に上げて、手法を探索しつつディープラーニングを学びます。ちなみに画像はOpenCVで処理して、one-hotラベルでエンコードします。
この記事は8月にGithubに投稿した記事に基づいて作成します。
https://github.com/leolui2004/cifar_compareやり方
最初はCNNを使わずDense層だけ使うモデルコードを書きます。これは当然画像認識タスクにとって悪いモデルだけど、ここから徐々に他の手法を導入します。
学習率:0.0005
バッチサイズ:128
訓練回数:10回
ネットワーク:Dense層 x3
最適化:Adamimport tensorflow as tf tf.device('/cpu:0') tf.keras.backend.set_floatx('float32') tf.compat.v1.disable_eager_execution() import pickle import numpy as np c_InputNumber = 3072, c_OutputNumber = 10 c_Lr = 0.0005 # 学習率 c_Batchsize = 128 # バッチサイズ c_Epochs = 10 # 訓練回数 c_FolderPath = 'cifar10/' c_Filepath_Train = f'{c_FolderPath}/dataset/data_batch_1' c_Filepath_Test = f'{c_FolderPath}/dataset/test_batch' class DenseModel: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.model = self.CreateModel() self.opt = tf.keras.optimizers.Adam(Lr) # ネットワークを構築 def CreateModel(self): input = tf.keras.layers.Input(self.InputNumber) layer1 = tf.keras.layers.Dense(1024, activation='relu')(input) layer2 = tf.keras.layers.Dense(256, activation='relu')(layer1) layer3 = tf.keras.layers.Dense(64, activation='relu')(layer2) labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax')(layer3) return tf.keras.Model(inputs=[input], outputs=[labels]) # ネットワークを作成 def CompileModel(self): self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy']) # ネットワークを訓練 def TrainModel(self, x_train, y_train, batch_size, epochs): self.model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs) # テストデータで評価 def EvaluateModel(self, x_test, y_test): score = self.model.evaluate(x_test, y_test) return score[1] def Unpickle(file): with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='bytes') return dict # One-hotエンコード def Onehot(value): onehot = np.zeros((10)) onehot[value] = 1 return onehot dict_train = Unpickle(c_Filepath_Train) dict_test = Unpickle(c_Filepath_Test) dense = DenseModel(c_InputNumber, c_OutputNumber, c_Lr) x_train = dict_train[b'data'] y_train = np.zeros((10000,10)) x_test = dict_test[b'data'] y_test = np.zeros((10000,10)) for i in range(10000): y_train[i][:] = Onehot(dict_train[b'labels'][i]) y_test[i][:] = Onehot(dict_test[b'labels'][i]) dense.CompileModel() dense.TrainModel(x_train, y_train, c_Batchsize, c_Epochs) print('Epoch Test') accuracy = dense.EvaluateModel(x_test, y_test) print('Accuracy: ', accuracy)結果はこちらになります。テストデータの精度は9.26%です。
Train on 10000 samples Epoch 1/10 10000/10000 - 1s 111us/sample - loss: 121.0524 - accuracy: 0.1384 Epoch 2/10 10000/10000 - 1s 110us/sample - loss: 21.6848 - accuracy: 0.1899 Epoch 3/10 10000/10000 - 1s 110us/sample - loss: 19.7853 - accuracy: 0.1953 Epoch 4/10 10000/10000 - 1s 110us/sample - loss: 12.3984 - accuracy: 0.2081 Epoch 5/10 10000/10000 - 1s 112us/sample - loss: 7.9875 - accuracy: 0.1667 Epoch 6/10 10000/10000 - 1s 117us/sample - loss: 2.3029 - accuracy: 0.0989 Epoch 7/10 10000/10000 - 1s 114us/sample - loss: 2.3013 - accuracy: 0.0985 Epoch 8/10 10000/10000 - 1s 114us/sample - loss: 2.2992 - accuracy: 0.0992 Epoch 9/10 10000/10000 - 1s 114us/sample - loss: 2.2978 - accuracy: 0.1002 Epoch 10/10 10000/10000 - 1s 114us/sample - loss: 2.2962 - accuracy: 0.0988 Epoch Test Accuracy: 0.0926
そしていろんな中間テストをしました。全部コード出したら長すぎるので結果だけ載せます。
Dense層からCNN(Conv2D)層に
- カラー - 46.63%
- グレースケール - 47.12%
訓練回数50回に、5バッチから1バッチに結合、検証用データ10%に
- CNN(Conv2D)層、カラー - 49.46%
- Resnet層、カラー - 62.89%
- CNN(Conv2D)層、グレースケール - 58.11%
- Resnet層、グレースケール - 60.74%
訓練回数100回に、1バッチに結合、検証用データ10%に、学習率指数関数的減衰
- CNN(Conv2D)層、カラー - 70.81%
- Resnet層、グレースケール - 64.32%
全部乗せ - 73.69%
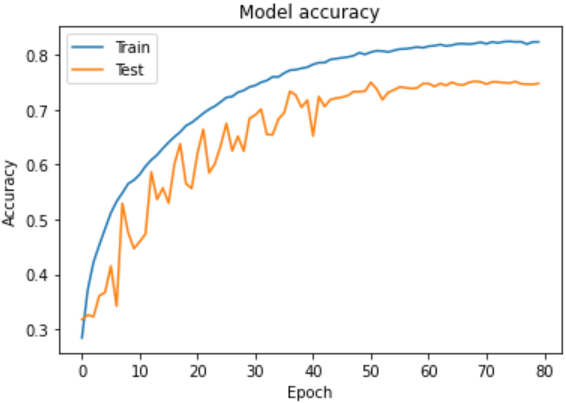
最後に73.69%に上がった手法はこちらです。
- バッチサイズ:32
- 訓練回数:80回
- ネットワーク:Resnet-56
- 最適化:Amsgrad
- 5バッチから1バッチに結合
- 検証用データ10%に
- 学習率指数関数的減衰 (Exponential Decresing)
- データ拡張 (Data Augmentation)
import tensorflow as tf from tensorflow import keras from keras.preprocessing.image import ImageDataGenerator # データ拡張用 from sklearn.model_selection import train_test_split tf.keras.backend.set_floatx('float32') tf.compat.v1.disable_eager_execution() import pickle import numpy as np import matplotlib.pyplot as plt c_InputNumber = 32,32,3 c_OutputNumber = 10 c_Lr = 0.0005 c_Batchsize = 32 c_Epochs = 80 c_Filepath_Train = 'data_batch_' c_Filepath_Test = 'test_batch' class DenseModel: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.model = self.CreateModel() self.opt = tf.keras.optimizers.Adam(Lr, amsgrad=True) # Amsgradを適用 # 学習率指数関数的減衰 def Scheduler(self, epoch): # 最初の10回は0.005、その後徐々に下げる if epoch < 10: return 0.005 else: return 0.005 * tf.math.exp(0.1 * (10 - epoch)) # Resnet-56 def CreateModel(self): channels = [16, 32, 64] input = tf.keras.layers.Input(self.InputNumber) x = tf.keras.layers.Conv2D(channels[0], kernel_size=(3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(input) x = tf.keras.layers.BatchNormalization()(x) x = tf.keras.layers.Activation(tf.nn.relu)(x) for c in channels: for i in range(9): subsampling = i == 0 and c > 16 strides = (2, 2) if subsampling else (1, 1) y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same', strides=strides, kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x) y = tf.keras.layers.BatchNormalization()(y) y = tf.keras.layers.Activation(tf.nn.relu)(y) y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(y) y = tf.keras.layers.BatchNormalization()(y) if subsampling: x = tf.keras.layers.Conv2D(c, kernel_size=(1, 1), strides=(2, 2), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x) x = tf.keras.layers.Add()([x, y]) x = tf.keras.layers.Activation(tf.nn.relu)(x) x = tf.keras.layers.GlobalAveragePooling2D()(x) x = tf.keras.layers.Flatten()(x) labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax', kernel_initializer='he_normal')(x) return tf.keras.Model(inputs=[input], outputs=[labels]) def CompileModel(self): self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy']) def TrainModel(self, x_train, x_valid, y_train, y_valid, batch_size, epochs): # データ拡張を適用 (回転、フリップ、シフト) igen = ImageDataGenerator(rotation_range=10, horizontal_flip=True, width_shift_range=0.1, height_shift_range=0.1) igen.fit(x_train) callback = [tf.keras.callbacks.LearningRateScheduler(self.Scheduler)] history = self.model.fit_generator(igen.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=len(x_train)/batch_size, validation_data=(x_valid, y_valid), epochs=epochs, callbacks=callback, verbose=2) return history def EvaluateModel(self, x_test, y_test): score = self.model.evaluate(x_test, y_test) return score[1] class Agent: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.Lr = Lr self.dense = DenseModel(self.InputNumber, self.OutputNumber, self.Lr) def Unpickle(self, file): with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='bytes') return dict def Pixelize(self, flat): return np.reshape(flat, (32,32,3)) def Onehot(self, value): onehot = np.zeros((10)) onehot[value] = 1 return onehot def Encode(self, dict): x = np.zeros((10000,32,32,3)) y = np.zeros((10000,10)) for i in range(10000): x[i][:][:][:] = self.Pixelize(dict[b'data'][i]) y[i][:] = self.Onehot(dict[b'labels'][i]) return x, y def Run(self, Filepath_Test, Filepath_Train, Batchsize, Epochs): self.dense.CompileModel() dict_test = self.Unpickle(Filepath_Test) x_test, y_test = self.Encode(dict_test) # 5バッチから1バッチに結合 for i in range(1, 6): dict_train = self.Unpickle(Filepath_Train + str(i)) if i == 1: x_train, y_train = self.Encode(dict_train) else: x, y = self.Encode(dict_train) x_train = np.vstack((x_train,x)) y_train = np.vstack((y_train,y)) # 検証用データに分ける x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, shuffle=True) history = self.dense.TrainModel(x_train, x_valid, y_train, y_valid, Batchsize, Epochs) print('Epoch Test') accuracy = self.dense.EvaluateModel(x_test, y_test) print('Accuracy: ', accuracy) plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show() agent = Agent(c_InputNumber, c_OutputNumber, c_Lr) agent.Run(c_Filepath_Test, c_Filepath_Train, c_Batchsize, c_Epochs)もっと上に目指すなら
実は現在SOTAのモデルは既に95%に達しました。しかしそれほとんどは簡単に導入できるモデルではないです。今回はあくまで手法を探索しながら勉強するために書きますので必ずSOTA並みの結果を得る必要がないと思います。
CIFAR-10のリーダーボード
https://paperswithcode.com/sota/image-classification-on-cifar-10もう一つ
ネットで調べると精度90%以上のサンプルコードがたくさんあります。しかもコードがすごく簡単です。しかし先話した通り、何十行だけのコードならSOTA並みの結果が出る可能性が低いです。そしてなぜか90%以上という結果が出ますか。コードを見るとほぼ100%損失関数の設定が間違いました。
それを再現するために、上記nのプログラムの損失関数をbinary_crossentropyに変わってみます。
Epoch 1/10 45000/45000 - 13s - loss: 2.7665 - accuracy: 0.8200 - val_loss: 2.7680 - val_accuracy: 0.8195その結果は1回目の訓練にも82%の精度に達しました。明らかに問題がありますね。詳しい説明はこのリンク (https://stackoverflow.com/questions/41327601/why-is-binary-crossentropy-more-accurate-than-categorical-crossentropy-for-multi) に参考してもいいですけど、簡単に言うとbinary_crossentropyは元々2分類作業用の損失関数です。なのでCIFAR-10のような10種類がある画像認識作業で使うと当然正しい結果を表現できないです。