- 投稿日:2020-11-27T23:09:19+09:00
Thymeleafの?(クエスチョンマーク)ってなんぞや
Thymeleafを業務で使っていて、\${user?.name}とか${object?.id}みたいな記法を見かけて
使い方が分からなかったのでメモ※誤りがありましたらご指摘ください。
結論
Safe Navigation operatorと呼ばれるいわゆるNullチェックをしてくれる
Spring Expression Language (SpEL)の記法の一種です。ちゃんとSpringのドキュメントにものっていますね。
訳してみると、以下のとおりです。
セーフナビゲーション演算子は、NullPointerExceptionを回避するために使用され、Groovy言語に由来する。通常、オブジェクトへの参照がある場合は、オブジェクトのメソッドまたはプロパティにアクセスする前に、それがnullでないことを確認する必要があります。これを回避するために、安全なナビゲーションオペレーターは、例外をスローする代わりに単にnullを返します。
使い方
hoge.html<tr th:each="o: ${object}"> <td th:text="${o.id}"></td> <td th:text="${o.user?.name?}"></td> <td th:if="${o.address?.contains('Tokyo')" th:text=""></td> <td th:if="${o.salary? gt 10000}" th:text=""></td> </tr>例えば、objectエンティティにuserエンティティやaddressエンティティを埋め込んで、
埋め込んだエンティティのフィールドを取得するときにこのように使います。このように参照したいオブジェクトの後ろに?をつけることで、本来nullであればNullPointerExceptionが帰ってくるところを、nullの場合は空を返してくれます。
上記のように連続でつけることもできますし、必要であれば?のあとにJavaのメソッドを使うこともできます。
(Thymeleaf内でJavaメソッドが使えるのは、ThymeleafがはOGNLというJavaの値にアクセスするための式言語で書かれているため)注意点
値や配列を扱うフィールドでセーフナビゲーション演算子を使うときは注意が必要です。
この演算子はnullだけでなく、0もfalseと判断するようです。ちなみに
似たような演算子にエルビス演算子という演算子があるみたいです。
https://ja.wikipedia.org/wiki/%E3%82%A8%E3%83%AB%E3%83%93%E3%82%B9%E6%BC%94%E7%AE%97%E5%AD%90
PHPやKotlinでサポートされているそうですが、そういう言語だと普通に使う演算子なのかしら。
以上です。
- 投稿日:2020-11-27T18:14:52+09:00
Javaのラムダ式やStream APIの可読性を向上させるテクニック
Advent Calendarの3日目です
2日目は @exotic-toybox さんによる「Java8の日時APIにおける期間の重複判定」でした。
はじめに
Java 8 でラムダ式や Stream API が導入されてから随分経ちましたが、いまだに読みづらいコードに出会うことがあります。
本稿では可読性を向上させるためのテクニックをいくつかご紹介します。
以降のサンプルコードの動作確認は AdoptOpenJDK 14.0.2 で行いました。ロジックを抽出してストリームをすっきりさせる
filterやmapなどのメソッドに渡すラムダ式が長くなると、ストリーム処理の全体の見通しが悪くなります。// かさばる本の一覧 List<String> bookTitles = null; // BEFORE bookTitles = ownedBooks.stream() .filter(b -> { // 500ページ以上または800グラム以上の紙の本 if (b instanceof EBook) { return false; } if (b.getPages() > 500) { return true; } if (b.getWeight() > 800) { return true; } return false; }).map(Book::getTitle) .collect(Collectors.toList());このような場合、 Extract Method リファクタリングパターンを用いて処理をメソッドに抽出するのが定石です。
private boolean isBulky(Book b) { // 500ページ以上または800グラム以上の紙の本 if (b instanceof EBook) { return false; } if (b.getPages() > 500) { return true; } if (b.getWeight() > 800) { return true; } return false; }抽出したメソッドをメソッド参照で指定するように置き換えます。
// AFTER bookTitles = ownedBooks.stream() .filter(this::isBulky) .map(Book::getTitle) .collect(Collectors.toList());
メソッドとして抽出せずとも、事前にラムダ式を定義して的確な名前を与えることでも可読性が向上します。// AFTER(2) Predicate<Book> byBulkiness = b -> { // 500ページ以上または800グラム以上の紙の本 if (b instanceof EBook) { return false; } if (b.getPages() > 500) { return true; } if (b.getWeight() > 800) { return true; } return false; }; bookTitles = ownedBooks.stream() .filter(byBulkiness) .map(Book::getTitle) .collect(Collectors.toList());static import を活用する
ComparatorやCollectorsはストリーム処理の中で繰り返し利用されがちです。map<String, List<Book>> books = null; // BEFORE books = ownedBooks.stream() .sorted(Comparator.comparing(Book::getPages).reversed()) .collect(Collectors.groupingBy(Book::getAuthor, Collectors.toList()));
タイプするが面倒なだけでなく、コードを読むときもノイズとなって邪魔なので、 static import しましょう。import static java.util.stream.Collectors.*; import static java.util.Comparator.*;
クラス名の指定が不要となります。// AFTER books = ownedBooks.stream() .sorted(comparing(Book::getPages).reversed()) .collect(groupingBy(Book::getAuthor, toList()));
現場によってはコーディング規約で static import を禁止し、Checkstyle等で警告を出すようになっているかもしれません。
その場合は、CollectorsやComparatorを除外指定できないか相談してみましょう。 (筆者の個人的意見ですが、クラスを小さく保っていれば名前衝突の可能性やメソッドの所属の曖昧性は十分回避可能なので、 static import は禁止せずに可読性を優先すべきだと思います。)独自の関数インタフェースを作成する
以下のレポート出力クラスを考えます。
static class BookReport { private List<Book> books; // 行のフォーマットを行う関数 private Function<Book, String> rowFormatter; // フッターのフォーマットを行う関数 private Function<Integer, String> footerFormatter; BookReport(List<Book> books, Function<Book, String> rowFormatter, Function<Integer, String> footerFormatter) { this.books = books; this.rowFormatter = rowFormatter; this.footerFormatter = footerFormatter; } String create() { String rows = books.stream().map(rowFormatter).collect(joining("\r\n")); int numOfBooks = books.size(); String footer = footerFormatter.apply(numOfBooks); return rows + "\r\n" + footer; } }行のフォーマットやフッタのフォーマットという責務をを標準APIの関数型インタフェース
java.util.functions.Function型で定義することで、利用側では以下のようにラムダ式を使った簡潔な記述が可能です。// BEFORE Function<Book, String> rowFormatter = b -> "著者:" + b.getAuthor() + " タイトル:" + b.getTitle(); Function<Integer, String> footerFormatter = num -> "合計:" + num + "冊"; var report = new BookReport(ownedBooks, rowFormatter, footerFormatter); var output = report.create();上記コードはまったく問題ないのですが、あえて独自の関数型インタフェースを定義した方がプログラムの意図が明確になる場合もあります。
static class BookReport2 { private List<Book> books; private RowFormatter rowFormatter; private FooterFormatter footerFormatter; BookReport2(List<Book> books, RowFormatter rowFormatter, FooterFormatter footerFormatter) { this.books = books; this.rowFormatter = rowFormatter; this.footerFormatter = footerFormatter; } @FunctionalInterface interface RowFormatter { String format(Book book); } @FunctionalInterface interface FooterFormatter { String format(int numOfBooks); } String create() { String rows = books.stream().map(rowFormatter::format).collect(joining("\r\n")); int numOfBooks = books.size(); String footer = footerFormatter.format(numOfBooks); return rows + "\r\n" + footer; } }呼び出し側は以下のようになります。ジェネリック型ではない独自型を使用しているので、変数の宣言時に型引数も不要となります。
// AFTER BookReport2.RowFormatter rowFormatter2 = b -> "著者:" + b.getAuthor() + " タイトル:" + b.getTitle(); BookReport2.FooterFormatter footerFormatter2 = num -> "合計:" + num + "冊"; var report2 = new BookReport2(ownedBooks, rowFormatter2, footerFormatter2); var output2 = report2.create();また、プログラムの利用側に対して、振る舞いを実装するために(ラムダ式ではなく)専用の型を用意するという選択肢も与えられます。
static class TaggingRowFormatter implements BookReport2.RowFormatter { @Override public String format(Book book) { return "<著者>" + book.getAuthor() + "</著者><タイトル>" + book.getTitle() + "</タイトル>"; } } static class TaggingFooterFormatter implements BookReport2.FooterFormatter { @Override public String format(int numOfBooks) { return "<合計>" + numOfBooks + "</合計>"; } }
// AFTER(2) BookReport2.RowFormatter rowFormatter3 = new TaggingRowFormatter(); BookReport2.FooterFormatter footerFormatter3 = new TaggingFooterFormatter(); var report3 = new BookReport2(ownedBooks, rowFormatter3, footerFormatter3); var output3 = report3.create();まとめ
ラムダ式や Stream API の登場によって、以前の Java のいわゆるボイラープレート的な冗長なコードをすっきりさせることが可能となりました。ラムダ式や Stream API を使った処理自体が冗長な記述とならないように気をつけたいところです。
- 投稿日:2020-11-27T15:30:54+09:00
Java 繰り返しの処理
はじめに
学習用のメモになります。
while文
// whileによるループ処理 public class Main { public static void main(String[] args) { // カウンタ変数の初期化 while (条件式) { // 繰り返し処理 // カウンタ変数の更新 } } }
- 括弧の中に入るのは条件式のみ
iが5以下の場合の繰り返す処理
// whileによるループ処理 public class Main { public static void main(String[] args) { int i = 0; // カウンタ変数の初期化 while (i <= 5) { // 0 -> 1 -> 2 -> 3 ・・・ 5 -> 6 System.out.println("hello world " + i); // 繰り返し処理 i = i + 1; // カウンタ変数の更新 } System.out.println("last " + i); } }出力結果
hello world 0 hello world 1 hello world 2 hello world 3 hello world 4 hello world 5for文
// forによるループ処理 public class Main { public static void main(String[] args) { for(カウンタ変数の初期化; 条件式; カウンタ変数の更新) { // 繰り返し処理 } } }
- 括弧の中には初期化式、条件式、変化式
- i のスコープは for 文の中だけ
- i をスコープ外にまたがって使用する場合、
- スコープの外で宣言しておく必要がある
- 実は処理が一行だけなら中括弧はなくても動く
- 変化式が実行されるのは処理が行われたあと
- list 等の中身を全て参照する場合などには for-each 文が使える
*スコープとは
プログラム中で定義された変数や定数、関数などを参照・利用できる有効範囲を表します
iが4以下だったら処理を繰り返す処理
// forによるループ処理 public class Main { public static void main(String[] args) { for(int i=0; i<=4; i++) { System.out.println(i); } } }配列の繰り返し処理
// ループで配列を操作する public class Main { public static void main(String[] args) { String[] team = {"勇者", "戦士", "魔法使い"}; System.out.println(team.length); for(int i=0;i<team.length; i++){ System.out.println(team[i]); } } }出力結果
3 勇者 戦士 魔法使い拡張for文の繰り返し処理
String[] team = {"勇者", "戦士", "魔法使い", "忍者"}; for (String member : team) { System.out.println(member); }出力結果
勇者 戦士 魔法使いfor文とwhile文の使い分け
- 単純な前処理、単純な後処理が必要な反復処理においては for 文
- 例えば: 繰り返す回数が分かっている処理など
- 複雑な前処理や後処理が必要な反復処理が必要な場合は while 文を使う
- 投稿日:2020-11-27T15:23:55+09:00
Java 標準入力
はじめに
学習用のメモになります。
標準入力とは?
もともとはLINUXなどのUnix系OSで用意されていた仕組みです。
標準入力に対応するようにプログラムを作っておけば、プログラム実行時に、ファイルを読み込んだり、キーボードからデータを読み込んだり、パラメータを指定したりというように、入力先を切り替えることができます。標準入力から文字列の読み込み
// 標準入力 import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); String line = sc.next(); System.out.println(line); } }Scanner sc = new Scanner(System.in);標準入力を読み込むために必要
String line = sc.next();標準入力された値をline変数に代入している
標準入力から数値の読み込み
// 標準入力 import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int line = sc.nextInt(); //データ型をintで数値に変換 System.out.println(line); } }複数データを読み込む
入力値
3 Java Ruby HTML// 標準入力とループ処理 import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int count = sc.nextInt(); System.out.println("データ個数 "+count); String data; for(int i =0;i<count;i++){ data = sc.next(); System.out.println("hello " + data); } } }出力値
データ個数 3 hello Java hello Ruby hello HTML
- 投稿日:2020-11-27T14:57:19+09:00
TomcatのJavaアプリ(VM環境)をTransformation Advisorを使ってモダナイズする
1. はじめに
今回は Tomcat環境でTransformation Advisorを実行する内容が日本語・英語ともにネットを検索しても見つからなかったので、実際に試して、Qiitaに投稿することにしました。
この投稿をきっかけに、Tomcatを分析・移行対象としたTransformation Advisorの流れの雰囲気がつかんでもらえればと思います。
2. Transformation Advisorとは
Transformation Advisorはオンプレミス環境で動作しているJavaのミドルウェア・アプリケーションを分析し、生成されたマイグレーションバンドルを使って、 OpenShiftの Libertyコンテナ上にJavaアプリをデプロイすることができるJavaアプリケーションのモダナイズするための移行支援ツールです。
分析結果では、コンテナ化(Liberty)するために必要な項目が、「移行の複雑さ、コスト、および推奨事項など」という観点で出力されます。
また、コンテナ化に必要なDockerfile、OpenShiftにデプロイするために必要なYaml、 Liberty化に必要な設定が自動生成されます。3. Transformation Advisorを使用する流れ
Transformation Advisorを使って既存のJavaアプリをコンテナ化するには以下の3つのステップを行います。
- Transformation Advisorを実行して既存のJavaアプリのコンテナ化の難易度や工数など視覚化するために分析結果を出力
- 分析結果を元に、既存のJavaアプリを改修する
- マイグレーションバンドルで生成されたコンテナ化に必要なファイル(yamlやDockerfileなど)を使って、OpenShiftに Javaアプリをデプロイする
4. Transformation Advisorの分析対象
Transformation Advisorで分析できる対象は、下記のJavaアプリケーション、メッセージングになります。
- ソース(分析対象)ホストのミドルウェア種類とバージョン:
- IBM WebSphere v7 以上
- Oracle ™ WebLogic v6.x 以上
- Red Hat ™ JBoss v4.x 以上
- Apache Tomcat® v6.x 以上
- メッセージング:
- IBM MQ v7 以上
また、分析できるJavaのバージョンは以下の一覧になります。
- ソース(分析対象)ホストのJavaのバージョン
- ibm5 - IBM Java 5
- ibm6 - IBM Java 6
- ibm7 - IBM Java 7
- ibm8 - IBM Java 8
- java11 - Java 11 (LTS)
- java14 - Java 14 (非 LTS)
- oracle5 - Oracle Java 5
- oracle6 - Oracle Java 6
- oracle7 - Oracle Java 7
- oracle8 - Oracle Java 8
注) CentOS6のyumで導入されるopenjdkは上記のリストに含まれないため、Transformation Advisorは実行されませんでした。そのような環境では、アプリケーションをwar/earファイルに固めて、アプリケーションのみTransformationAdvisor実行するか、別の環境で対応するJavaのバージョンに変えて実行で回避できると思います。
5. Tomcatの環境にTransformation Advisorを実行してみる
今回は、前述のとおり、TomcatにTransformation Advisorを実行する手順を確認します。
前提
- Transformation Advisorが導入されていること
- Transformation Advisor Local
- Transformation Advisor Operator ( OpenShift / OpenShift on IBM Cloud)
Transformation Advisorの解説・ダウンロードページ :
https://www.ibm.com/garage/method/practices/learn/ibm-transformation-advisor
- 分析対象の環境
- OS: CentOS6(x86_64)
- JDK: IBM Java 7 (java-x86_64-71) ダウンロード先 https://www.ibm.com/support/pages/java-sdk-downloads-version-71
- Tomcatのバージョン: 6.0.53
- Javaアプリケーション: Tomcatのexample、自作したHelloWorldが出力されるServlet・jsp
手順
これからの手順はTransformation Advisor Local を使って検証しました。
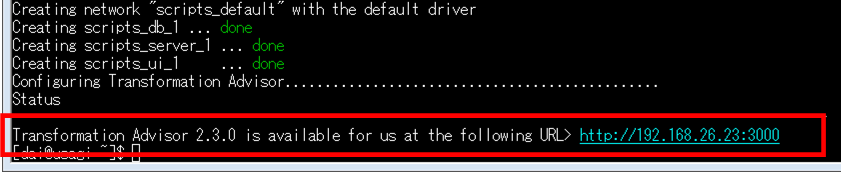
Transformation Advisorを起動する
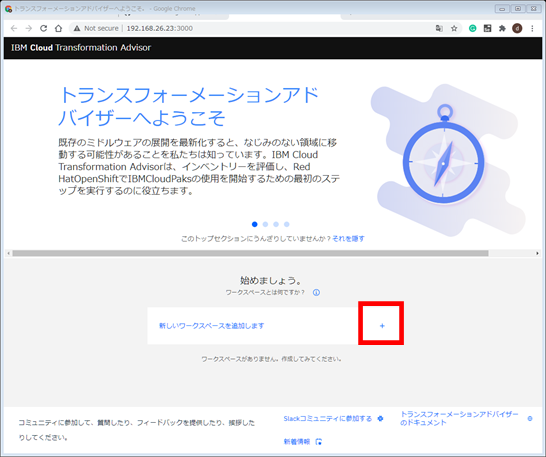
Transformation Advisor Localの起動時に出力されるURL (例: http://192.168.26.23:3000 )を使って、ブラウザでTransformation Advisorを起動します。
「新しいワークスペースを追加します」の右側の「 + 」ボタンをクリックしてワークスーペースを作成します。
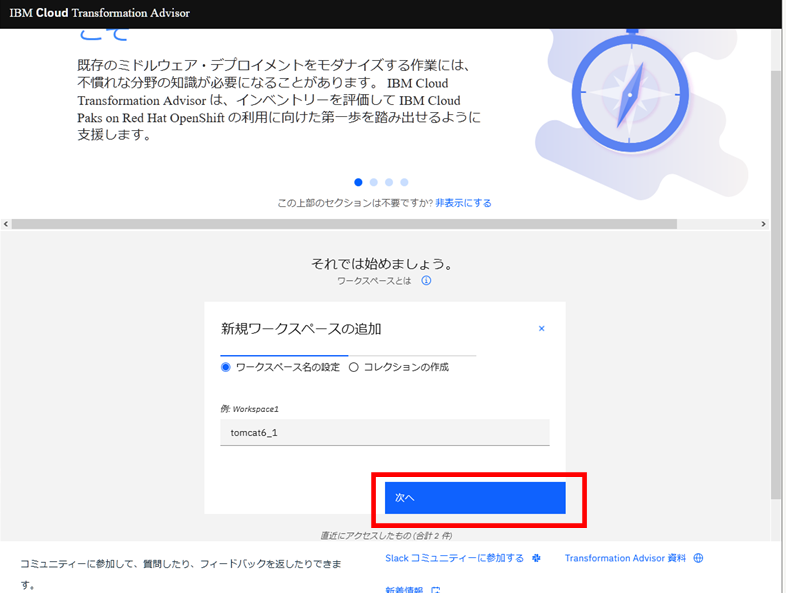
ワークスペース名に、今回は「tomcat6_1」を入力し、「次へ」ボタンをクリックします。
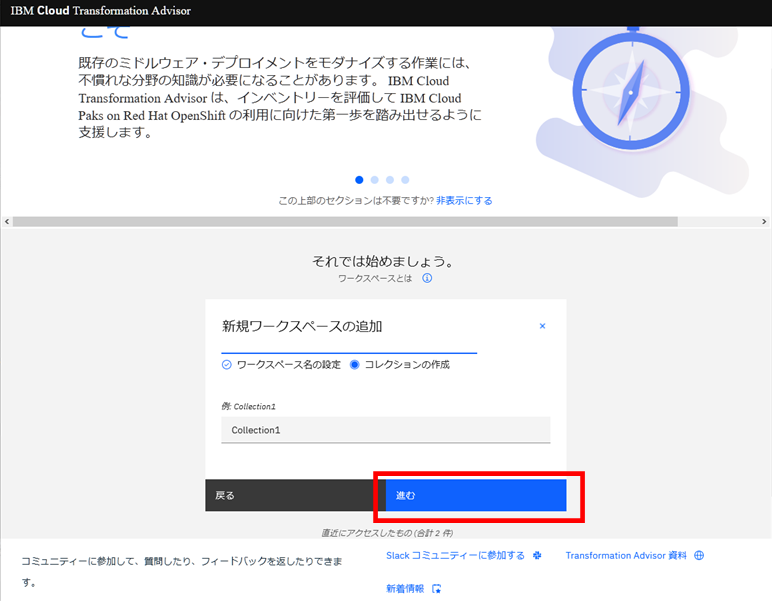
コレクションは、分析(Data Collector)を実行する単位で作成します。今回は「Collection1」と入力し、「進む」ボタンをクリックします。
分析(データコレクター)を実行する
データコレクターのダウンロード
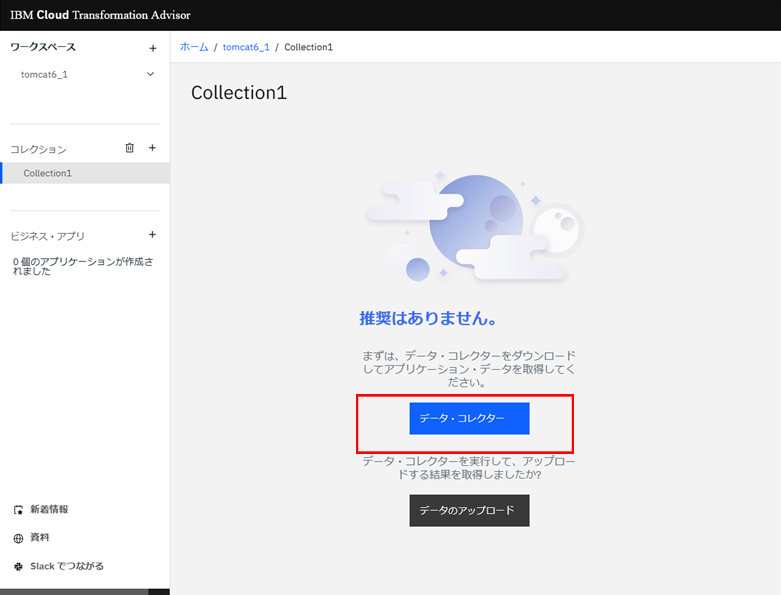
コレクションを作成した後に、下記画面が表示されます。 分析(データーコレクター)を実行する為に「データ・コレクター」ボタンをクリックします。
ソース(分析対象)ホストのOSを、今回は「Linux」を選択して、「Linux用のダウンロード」ボタンをクリックしてデータコレクターをダウンロードします。 そして、ソース(分析対象)ホストに、ダウンロードしたファイルをアップロードします。
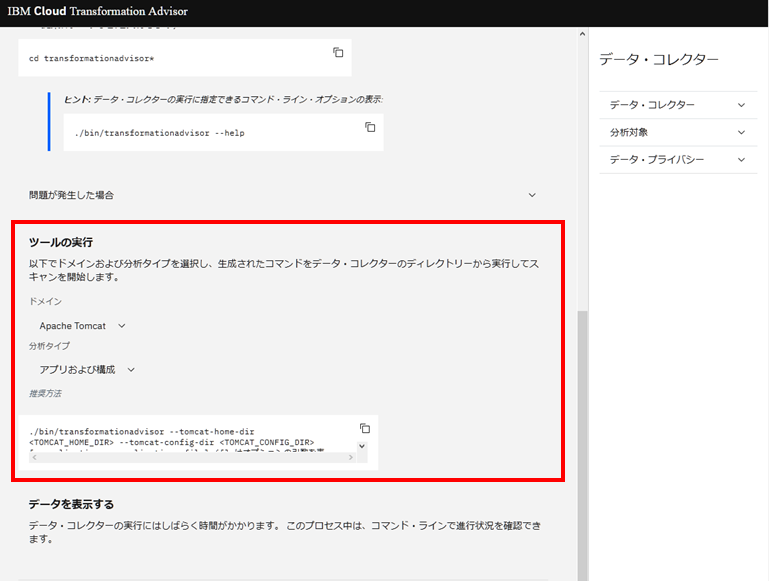
この画面の下部ではツールを実行するためのコマンドを確認することができます。
今回は、ドメイン:「Apache Tomcat」、 分析タイプ:「アプリおよび構成」を選択しました。
なお、ドメインは、WebSphere、JBoss、Weblogic、Tomcatとミドルウェア、分析タイプは、アプリおよび構成(ミドルウェア) と .warファイル(アプリのみ)が選択できます。
(参考)Apache Tomcatを選択して出力される実行用のコマンド
# .warファイルを分析 ./bin/transformationadvisor --tomcat-apps-location <.war ファイルの Tomcat アプリの外部ロケーション> #アプリおよび構成を分析 ./bin/transformationadvisor --tomcat-home-dir <TOMCAT_HOME_DIR> --tomcat-config-dir <TOMCAT_CONFIG_DIR> [--applications --applications-file] ([] はオプションの引数を表します) ([] はオプションの引数を表します)データコレクターの解凍
- 作業ホスト: ソース(分析対象)ホスト
ソース(分析対象)ホストにアップロードしたデータコレクターを解凍します。
そして解凍したフォルダに、特に「transformationadvisor-2.3.0/bin」フォルダの実行ファイルに、
実行権限が付与されていないとツールが実行できませんでしたので、実行前に確認してください。# tar xvfz transformationadvisor-Linux_tomcat6_1_Collection1.tgz # cd transformationadvisor-2.3.0/ #ls bin conf docs jre lib LICENCEデータコレクターのテスト実行
まず、ツール(transformationadvisorコマンド)が実行できるか、helpオプションを使って実行します。
# ./bin/transformationadvisor --help特に問題がなければ helpオプションの内容が出力されますが、私の実行した CentOS6(x86_64)の環境ではライブラリなど足りなくてエラーが出力されたので、記録しておきます。
- ld-linux.so.2 が入っていなくて、エラー
#エラー内容 In the case of duplicated or conflicting options, basically the order above shows precedence: JAVA_OPTS lowest, command line options highest except --. /root/transformationadvisor-2.3.0/bin/scan: /root/transformationadvisor-2.3.0/bin/../jre/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory /root/transformationadvisor-2.3.0/bin/scan: line 159: /root/transformationadvisor-2.3.0/bin/../jre/bin/java: Success # 対応内容 yum install ld-linux.so.2 -y
- compat-libstdc++ が入ってなくてエラー
#エラー内容 In the case of duplicated or conflicting options, basically the order above shows precedence: JAVA_OPTS lowest, command line options highest except --. libgcc_s.so.1 must be installed for pthread_cancel to work JVMDUMP039I Processing dump event "abort", detail "" at 2020/11/27 18:55:24 - please wait. JVMDUMP032I JVM requested System dump using '/root/transformationadvisor-2.3.0/core.20201127.185524.3779.0001.dmp' in response to an event JVMDUMP010I System dump written to /root/transformationadvisor-2.3.0/core.20201127.185524.3779.0001.dmp JVMDUMP032I JVM requested Java dump using '/root/transformationadvisor-2.3.0/javacore.20201127.185524.3779.0002.txt' in response to an event JVMDUMP010I Java dump written to /root/transformationadvisor-2.3.0/javacore.20201127.185524.3779.0002.txt JVMDUMP032I JVM requested Snap dump using '/root/transformationadvisor-2.3.0/Snap.20201127.185524.3779.0003.trc' in response to an event libgcc_s.so.1 must be installed for pthread_cancel to work ./bin/transformationadvisor: line 90: 3779 Aborted (core dumped) bash $currentDir/scan $args #対応内容 yum install compat-libstdc++*データコレクターのテスト実行
「# ./bin/transformationadvisor --help」 コマンドが正常実行が確認出来たら、データコレクターを実行します。
事前に把握しておく内容としては、Tomcatのホームディレクトリ(CATALINA_HOME)とJAVA_HOMEです。
今回の環境では、以下の構成になっています。
CATALINA_HOME: /usr/local/apache-tomcat-6.0.53 JAVA_HOME: /opt/ibm/java-x86_64-71下記コマンドでデータコレクターを実行します、
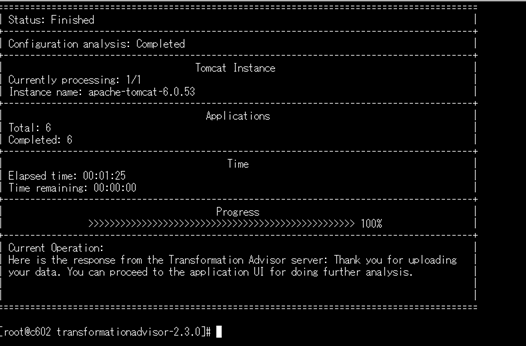
#実行するコマンド(アプリおよび構成を分析) ./bin/transformationadvisor --tomcat-home-dir /usr/local/apache-tomcat-6.0.53 --tomcat-config-dir /usr/local/apache-tomcat-6.0.53 #./bin/transformationadvisor --tomcat-home-dir <TOMCAT_HOME_DIR> --tomcat-config-dir <TOMCAT_CONFIG_DIR> [--applications --applications-file] ([] はオプションの引数を表します) ([] はオプションの引数を表します)下記画面のように、データーコレクターの実行が終了すると正常終了すると、結果は、自動的にTransformation Advisorにアップロードされます。 (注) ソース(分析対象)ホストとTransformationAdvisor間の通信が切断されている場合は、アップロードできません。
分析結果を確認する
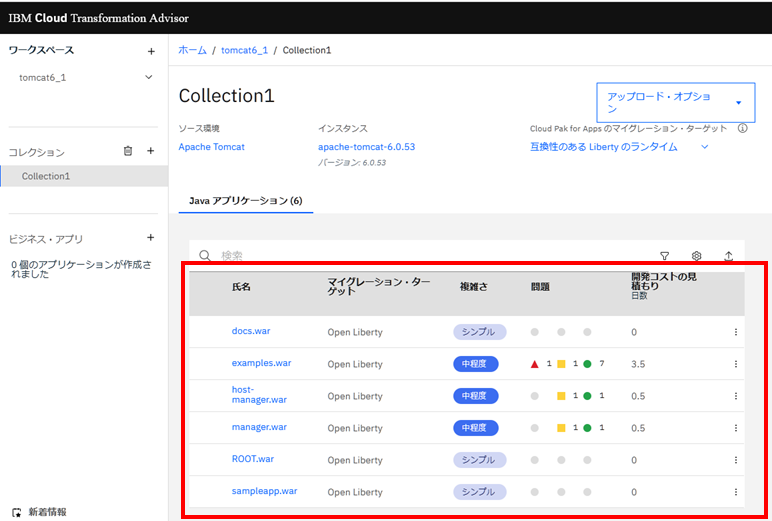
ブラウザでTransformationAdvisorで、コレクションの画面を開くと、今回は「Collection1」、データーコレクターの実行結果が出力されます。
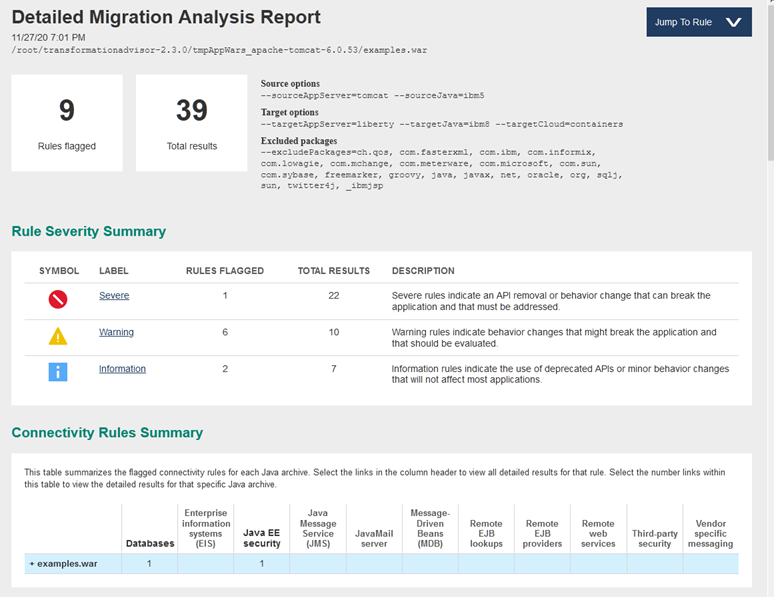
赤枠の中では、Tomcatで動作していたJavaのアプリケーションのEAR/WARファイル単位で、
- クラウドに移行する際のTransformationAdvisorが判断した難易度
- アプリケーションの移行に関する潜在的な問題の数と重大度
- 移行を実行するための開発作業の日数での見積もリ
が出力されます。 アプリケーション名など各項目をクリックすると詳細を確認することができます。
分析レポート
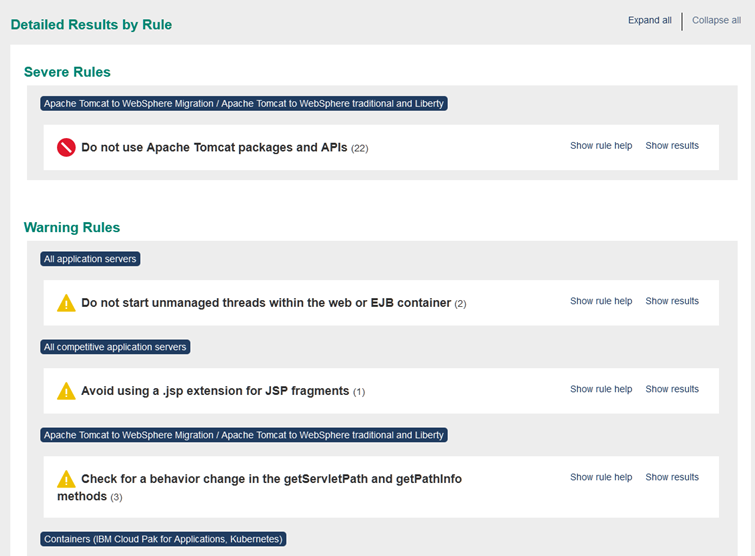
分析レポートでは、 アプリケーションの移行に関する潜在的な問題の数と重大度の詳細を確認する事ができます。また、分析の観点の一例として、非推奨または削除されたAPI、Java SEバージョンの違い、JavaEEの動作の違いをTransformation Advisorが分析し出力します。
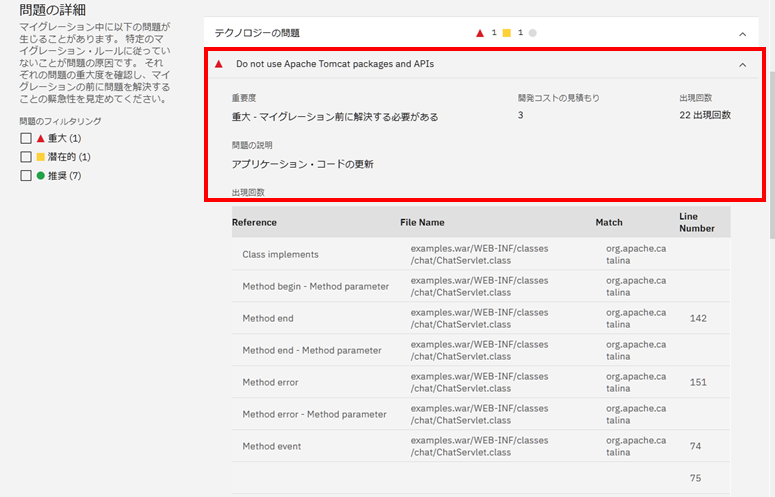
例えば、下図の様に、Tomcatのサンプルアプリ「examples.war」では、 TomcatのPackageやAPIを利用しているため、 移行先のWebSphere LibertyやOpen Libertyでは、使えないためCritical表示になってます。
テクノロジーレポート
テクノロジーレポートでは、同様に Tomcatのパッケージを使ってるClassが移行できないため、一覧表示されています。
実際にみなさんが試す際は、テクノロジーレポートで出力された内容を、1つ1つ解決していく作業が必要になります。
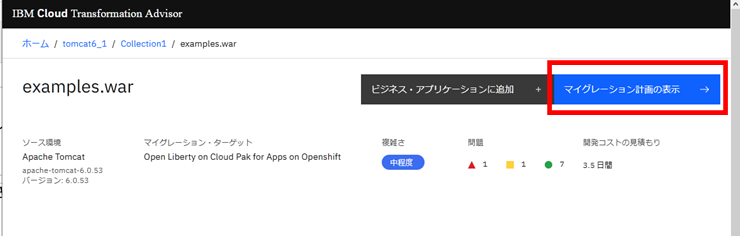
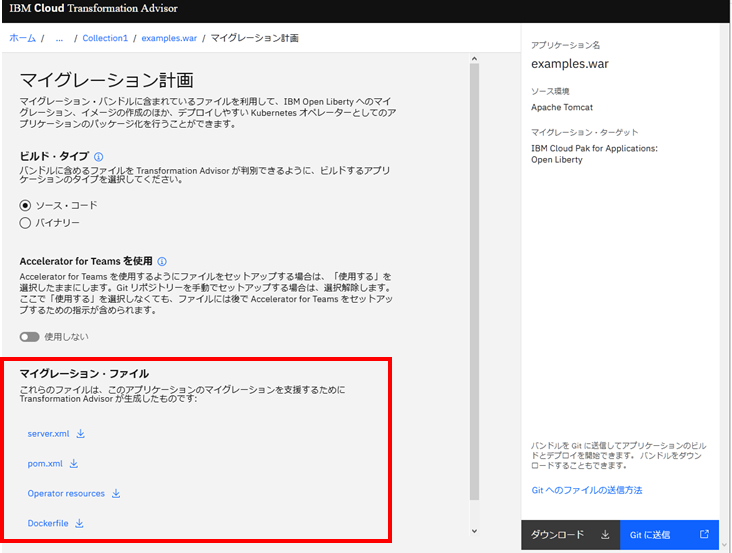
マイグレーション計画
各アプリケーション(WAR/EAR単位)の詳細で「マイグレーション計画の表示」ボタンをクリックすると
マイグレーション計画画面が表示されます。ここは、ソース(分析対象)ホストのデータコレクターの実行結果を元に、OpenShift 上に移行するために必要なファイルが出力されます。
赤枠の箇所がOpenShift環境へデプロイするためのOperator(Yaml)
Tomcatで動かしていたJavaアプリケーションをOpen Libertyで動かすための設定ファイルや
コンテナ化するためのDockerfileが Transformation Advisorを使って自動生成されます。ですので、データコレクターの実行結果、問題がないJavaアプリケーションは、Open Libertyを使って
コンテナ化し、OpenShift にデプロイすることができます。6. まとめ
今回は Tomcatに Transformation Advisorを実行してみた という内容がネットを検索しても見つからなかったので試してみようと思ったのがきっかけで、実際に試して、Tomcatでも、動作することが確認できました。
Tomcatを使っている方はたくさんいらっしゃると思います。 Open LibertyはOSSですので、
Transformation Advisorを使って、コンテナ化・モダナイゼーションを試す価値はあると思います。また、今回試した中では最初、CentOS6の環境でライブラリが不足していてTransformationAdvisorのコマンドが実行できなかった等、みなさんも試される時は、各環境で差異があるので、詰まりどころは違うかもしれません。
ですので、試行錯誤が発生しますし、データーコレクター実行時は負荷があがるので、実際に利用する際は、検証用の環境を用意して、実行するのが現実的だと思います。
ぜひ、この投稿を参考にTomcatでTransformation Advisorを使ってみてください。

- 投稿日:2020-11-27T13:52:04+09:00
【Java】コレクションフレームワーク ( List )
コレクションフレームワーク
この記事では、java.utilをして利用できる便利なクラスを学んで行きます。
コレクションフレームワークとは
そもそも、フレームワークとは概念的な意味で、
- 「何かの枠組み」
- 「システム開発を楽に行えるように用意された、プログラムとかのひな形」のことです。つまり、
コレクションフレームワーク = 便利な機能をまとめたものみたいな考え方でいいと思います。これらの 用意された便利な機能を、柔軟に扱うことを考えられているのがコレクション・フレームワークです。
java.utilパッケージとは
java.utilは Javaのフレームワークの一種で、Javaで使われる 、以下のような データを表現するのに必要なデータ構造が一通り揃っています。
- [配列操作]
- イベント
- モデル
- 日付および時間...
その中でも代表的な「[配列操作]」をするために3つの便利なクラスがあります。それが、「List」, 「Set」, 「Map」です。
- リスト(List) 値が順番に並んで格納したもの
- セット(Set) 順序があるとは限らず格納され、同じ値のものが1つだけのもの
- マップ(Map)ペアで対応づけて格納し、キーごとに値が対応したもの
【List】順序を持ったコレクション
Listとは
リストは配列によく似た性質を持つ「
0から始まるインデックスごとにデータが入ったもの」です。
インデックスによって要素を挿入したり要素にアクセスしたりする位置を自由に変更することができます。List と 配列 の違い
Listは、持っている特長が [配列] に非常によく似ているものの、Javaの「 通常の[配列操作]とは少々異なります。 」
- 【配列】
- 最初にサイズを決めるため、「後からサイズを拡張することができない」
- 【Listクラス】
- 要素を追加した分だけ「自動的にサイズが拡張される動的な配列」を作ることができる。
- Listクラスのメソッドを使うことで「値を追加したり途中に挿入したり、削除することができる。」
Listの定義の仕方
Listの基本的な定義の仕方はこちらになります。
リストインターフェース名<型> インスタンス名 = new コンストラクタ名<型>();ちなみに、Java 1.4以降 ダイヤモンド演算子"<>"を用いて以下のように書くことが可能ですので、基本この型で書いていいと思います。
// ArrayListに<型>を指定しない List<String> sampleList = new ArrayList<>();ArrayList(可変長配列)
ArrayList とは
Listインタフェースを実装したコレクションクラスです。
「Array」 という名にあるように 「配列のような感覚」で扱うことができる。
JavaのArrayListは大きさが決まっていない配列のようなものとイメージしてください。ArrayListは、複数の値を管理する時に使います。ArrayListの特徴
メリットはこちら
- ArrayListクラス は配列でリストを実装しており、「添え字による要素へのアクセス」が高速です。
- 要素の「追加」が、新たな要素を末尾へ加えるだけなので楽
短所はこちら
- 配列の途中の位置への要素の「挿入」や「削除」に関しては、 挿入・削除した位置以降の全ての要素の位置を移動させるという処理を行う必要があるため低速になる。
ArrayList の宣言・初期化
書き方はこちらです。
// 基本の定義の仕方 ArrayList<型> 変数名 = new ArrayList<型>(); // サンプルコード List<String> sampleList = new ArrayList<String>(); ## ArrayListクラスの使用例 2パターンありますので、見ていただきます。 やってることは同じですから実行結果は変わりませんのでお好みで。 ```java package practiceListClass; //utilパッケージのArrayListクラスをimport import java.util.ArrayList; //utilパッケージのListクラスをimport import java.util.List; public class ArrayAboutMain { public static void main(String args[]) { // ここから ===================================== List<String> sampleList = new ArrayList<String>(); sampleList.add("1回目のリストに格納"); sampleList.add("2回目のリストに格納"); // ここまで ===================================== // リストに格納した全要素を順番に出力 for (int i = 0; i < sampleList.size(); i++) { System.out.println(sampleList.get(i)); } } }2パターン目。addの書き方が少し違うバージョン。
// ここから ===================================== List<String> sampleList = new ArrayList<String>(); sampleList = new ArrayList<String>() { { add("1回目のリストに格納"); add("2回目のリストに格納"); } }; // ここまで =====================================実行結果はこちら
1回目のリストに格納 2回目のリストに格納上記のコードを解説すると
生成したArrayListクラスのインスタンスを、Listインタフェース型の変数sampleListに保持しています。Listインタフェースでは、
- 要素の追加: addメソッド
- 値を取り出すとき: getメソッド
を使用してください。
LinkedList(連結リスト)
LinkedListとは
LinkedListは、要素同士を前後双方向のリンクで参照するリンクリストを表します。
LinkedListの特徴
- 要素の挿入/削除はリンクの付け替えで済むため、ArrayListに較べても高速
- インデックス値によるランダムなアクセスは苦手
LinkedListクラス はリスト構造を使用して実装しています。
このため、「添え字による要素へのアクセス」は、毎回先頭から順番に要素をたどっていきながら
目的の位置を探す(添え字の番号まで移動していく)必要があるため、低速です。LinkedList の宣言・初期化
// 基本の定義の仕方 LinkedList<型> 変数名 = new LinkedList<型>(); // サンプルコード List<String> sampleList = new LinkedList<String>();LinkedList の使用例
ArrayListとやってることは変わりませんが、コピペ用でこちらも載せておきます。
こちらも2パターンありますので、見ていただきます。
やってることは同じですから実行結果は変わりませんのでお好みで。package practiceListClass; //utilパッケージのArrayListクラスをimport import java.util.ArrayList; //utilパッケージのListクラスをimport import java.util.List; public class ArrayAboutMain { public static void main(String args[]) { // ここから ===================================== List<String> sampleList = new LinkedList<String>(); sampleList.add("1回目のリストに格納"); sampleList.add("2回目のリストに格納"); // ここまで ===================================== // リストに格納した全要素を順番に出力 for (int i = 0; i < sampleList.size(); i++) { System.out.println(sampleList.get(i)); } } }2パターン目。addの書き方が少し違うバージョン。
// ここから ===================================== List<String> sampleList = new LinkedList<String>(); sampleList = new LinkedList<String>() { { add("1回目のリストに格納"); add("2回目のリストに格納"); } }; // ここまで =====================================実行結果はこちら
1回目のリストに格納 2回目のリストに格納上記のコードを解説すると
生成したArrayListクラスのインスタンスを、Listインタフェース型の変数sampleListに保持しています。Listインタフェースでは、
- 要素の追加: addメソッド
- 値を取り出すとき: getメソッド
を使用してください。
List系クラス チートシート
各クラスの特徴を踏まえて、用途に応じてクラスを選択することが Listインタフェースを使いこなす
ポイントとなります。
以下のように、
- 挿入/削除操作が多い状況ではLinkedList
- それ以外の場合はArrayList
という使い分けになると思います。
クラス 概要 長所 短所 使う場面 ArrayList 複数の値を管理する時に使う、「大きさの決まっていない配列のようなもの」 添え字による要素へのアクセス」が高速
要素の「追加」が、新たな要素を末尾へ加えるだけなので楽要素を追加するスピードが遅い 配列内の要素に対してランダムなアクセスを必要とし、配列内の要素に対して挿入/削除の操作があまり必要ない場合 LinkedList 要素同士を前後双方向のリンクで参照するリンクリストを表します。 要素の挿入/削除はリンクの付け替えで済むため高速 ・特定の要素にアクセスするスピードが遅い
・インデックス値によるランダムなアクセスは苦手要素数が多くて、且つ要素の挿入・削除を頻繁に行うことが予想 でき、配列内の要素に対してランダムなアクセスを必要としない場面
- 投稿日:2020-11-27T13:21:40+09:00
オブジェクト指向は、こう設計しよう
はじめに
はい、何番煎じか分からないオブジェクト指向によるクラス設計の話です。
オブジェクト指向の設計のはなしは、ネット上ググるといくらでも出てくるし、私もいくつかは見たのですが、正直私はあまり理解できませんでした。理由ははっきりしていて、話が抽象的で具体的な手順については何も書かれていないからです(いくらオブジェクト指向の中心は抽象化だったとしても、説明まで抽象化しなくていいんですよ)。さらに言うと、自分の考え方とかなり違うなぁ、とも思いました。
そんなわけで、クラス設計のはなしでも書こうと思ったわけです。ただし注意点として、ここに書いた方法は完全に私の自己流です。そのため、この方法はおかしい、この方法は合わない、こんなの見たことない(自己流だから当たり前です)から意味不明、という人が少なくない数でいると思います。なので、はなし半分、ポエム要素半分で読んでもらえればと思います。ちなみに、私は人並みにUMLの本とかも読んだのですが、理解できなくて投げ捨てましたw。そのため、この記事にはクラス図などという高等技術はでてきません(書くほどのクラス構成ではないですが)。
また、具体的に手順を書いていくため、プログラム言語も特定のものを使います。Javaにしました。型付けの強いオブジェクト指向言語ですので、手順もこれに即したものになります。C# も型付けの強いオブジェクト指向言語なので、大体同じように設計できます。しかし型付けの弱い Ruby や Python は少し設計方法が異なるので、この記事と同じようにはできないかもしれません(特にポリモーフィズムの表現方法が違っていたり、リフレクションをどの程度積極的に利用するか、など)。
問題
ネット上に公開されている問題は、(オブジェクト指向の問題、と書きつつ)アルゴリズムの問題だったり、単に~のクラスを作れだったり、ただの文法問題だったりと、なかなか良い問題が見つからなったので、オブジェクト指向の問題としてはあまり良問ではないですが、情報処理技術試験の午後問題を使うことにしました。
転載可能なのかが分からないので、リンクだけ張ることにします。過去問は、商用利用でなければ特に許諾無く転載可能みたいなので、問題を載せておきます。問3の問題をやりますが、読むべき問題文は[食券購入時の要件]だけでいいです。状態遷移やイベントコードは使わないので。これをコンソールアプリケーションで作ります。なお、超長文になりそうなので、UnitTestとエラー処理については何も書きません。また、アルゴリズムの説明も割愛させていただきます(たいしたアルゴリズムは出てきませんが)。
作成アプリケーション
先ほど書いたように、コンソールアプリケーションで作ります。内容は、メニューの表示 → メニューの入力 → 合計金額の表示、です。メニューの入力はコンソールアプリケーションなので、番号で指定するようにします。
設計する
まず、クラスを抽出しよう
最初にやることは、クラスを抽出することです。JavaやC#のようなオブジェクト指向言語はクラスがすべてなので、クラス抽出から始めないと何も始められません。
では、何をクラスにするか? 目に入ったものは片っ端からクラスにします。名詞はクラスで動詞はメソッドで… と書いてある本やサイトもあるっぽいですが、GoFのデザインパターンで言う Command パターンは、処理をクラスにしているわけだから、多分そういう考え方は間違っているのでしょう。
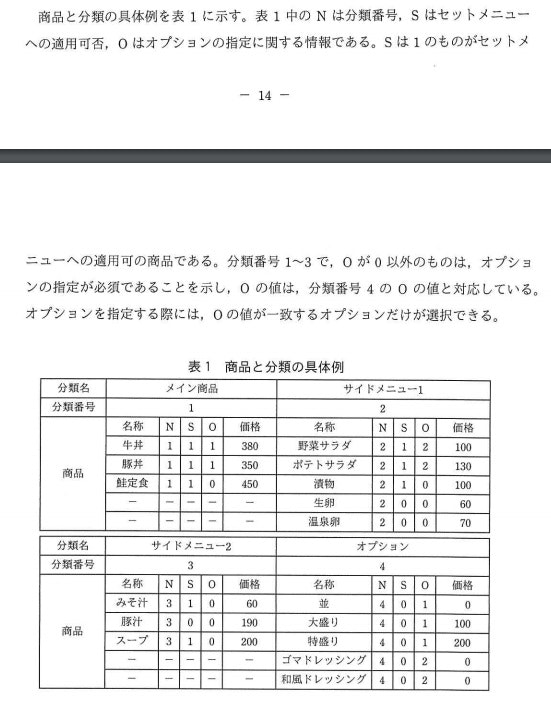
問題文を読んで、手当たり次第クラスを抽出していきます… と言っても、おそらく設計の中心になりそうなのは「表1」の部分に見えるので、ここからクラスを抽出していこう。クラスになりそうなのは、メイン商品とかオプションとか書かれている「カテゴリー(
Category)」とそのカテゴリーが持っている「メニュー(Menu)」があるので、これはクラスにします。それと図1の長い日本語をナナメ読みすると、なんか「利用者(User)」と「券売機(TicketMachine)」が出てくるので、この辺がクラスになりそうです。とりあえずこの4つをクラスにします。おそらくこの時点で疑問に思うことは、この段階で 100% クラスを抽出しなければならないのか、だと思います。結論を言うと、全く不要です。もし後でクラスが足りないと気づいたら… そのとき足せば良いです。もし不要なクラスだったら… そのとき消せば良いのです。重要なことは、この段階で 100% クラス抽出するぞ、と頑張らないことです。というか、この段階で 100% クラス抽出は絶対不可能です。それは、仕様や問題文にない、クラスとクラスをつなぐようなユーティリティークラスが必ず発生するからです。こういったクラスはいわゆる非機能にあたるので、仕様や問題文をいくら読んでも機能に当たるクラスしか抽出できません。オブジェクト指向の設計は、70%~80%できたら先に進む、後で間違っていたらその都度修正する、としたほうがいいでしょう。
作ったクラスのインスタンス変数とメソッドを決めよう
次は、作ると決めたクラスに対して、インスタンス変数とメソッドを決めていきます。ここも 100% 決める必要はありません。さらに言うと、メソッドの引数や戻り値型も厳密に決めておく必要はありません。ぱっと分かる部分だけ決めればいいです。これも必要ならあとから追加したり変更したりすればいいです。
まず
Categoryクラスから始めます。表1を眺めていると、分類番号とメニューというデータを持っているので、この辺がインスタンス変数として必要そうです。そしてこのインスタンス変数の値の設定をどこでやるか、ですが、一般的には、仕様で与えられているものはコンストラクタ(あるいはファクトリーメソッド)にしたほうがいいです。その理由は、こういった値は大抵不変だからです。ただ、CategoryクラスでのMenuは、メニューの数が多くコンストラクタがごたつきそうなので、しぶしぶメソッドにしておきます。Category.javapublic class Category { private final int no; private List<Menu> menus = new ArrayList<>(); public Category(int no) { this.no = no; } public void addMenu(Menu menu) { menus.add(menu); } ... }「分類番号」は不変であることを表すために、
finalを付けるべきです。menusのほうも付けていいですが、Javaの文法ではあまり意味がないのでそのままにします。ここで1つ気になるのは、
Categoryはinterface/abstract classにして、メイン商品やサイドメニューなどはサブクラスにしたほうがいいのでは、ということです。私の基準では次のようにしています。
- 処理が変わりそうなら、サブクラスを作る(継承を使う)。
- データ部分(=インスタンス変数の値)しか変わりそうにないなら、サブクラスは作らない(継承は使わない)
今回は、表1を見た限りでは、「分類番号」と「メニュー」というデータ部分しか差がなさそうなので、継承は使わないでおきます。ここも、もし後で継承が必要になったら、そのとき
interface/abstract classにすればいいのです。話を戻して、
Categoryクラスと同様の方法でMenuクラスも作っていきます。インスタンス変数は「名称」「N」「S」「O」「価格」あたりでしょうか。ここで気になるのが、「N」「S」「O」とは何なのか、です。「N」「S」「O」という名前だけ見ても意味不明だし、この値は数値ですが1や2という値に(数量のような)意味があるのか、何かのコード値なのか、単に ON/OFF を表しているのかが良く分からないことです(正直、この仕様は良くないと思う)。こういう場合は、とりあえずありのままにしておくのが無難です。Menu.javapublic class Menu { private final String name; private final int n; private final int s; private final int o; private final int price; public Menu(String name, int n, int s, int o, int price) { this.name = name; this.n = n; this.s = s; this.o = o; this.price = price; } ... }変数名に
sとかoとか使いたくないのですが、今の時点では意味が分からないのでこうしておきます。次に券売機(
TicketMachine)クラスですが、Categoryを4つ持っているので、これがインスタンス変数(categories)になりそうです。ここで、categoriesをjava.util.Listにするのがいいのか、配列にするのがいいのか、という問題があります。私の基準では次のようにしています。
- 基本的には
java.util.Listを使う。- サイズが固定であり、変更の可能性がなさそうな場合のみ、配列を使う。
今回は、
Categoryが4つと固定なので、配列にします。ここで、将来仕様変更でサイドメニュー3が追加されたときのことを考えて、Listのほうがいいのでは? と思う人がいるがいるかもしれません。個人的には、あるかどうか分からない仕様変更については実装しない、という方針にしています。その理由は、大抵予想しない方向に仕様変更が起こるからです。例えば、サイドメニュー3が追加されると思っていたら、期間限定割引メニューを追加する、といった感じです。そして経験上、予想通りに仕様変更が起きたことはありませんでした。現実は予想よりずっと複雑だということでしょう。こういう予想できない仕様変更があるとき、あまり凝った実装をするより、極小の実装にしておいたほうが修正しやすいです。オブジェクト指向の設計について書かれたサイト/本では、やたらと抽象化したがるのですが、なんでも(不要な)抽象化をすることがオブジェクト指向の設計ではありません。仕様を満たすように使う道具がオブジェクト指向です。(オブジェクト指向は目的ではなく手段、ということね)TicketMachine.javapublic class TicketMachine { /** カテゴリー */ private Category[] categories = new Category[4]; /** 選択されたメニュー */ private List<Menu> selectedMenus = new ArrayList<>(); public void setMainMenu(Category category) { categories[0] = category; } public void setSide1(Category category) { categories[1] = category; } public void setSide2(Category category) { categories[2] = category; } public void setOption(Category category) { categories[3] = category; } }
setXxx()というメソッドがダサいですが、今は思い付きでどんどん実装していきます。最後に利用者(
User)クラスですが、実装すべきものが思い当たらないので、箱だけ用意しておきます。User.javapublic class User { // なにも実装するものがない }道具がそろったら、処理の順番にならべよう
必要な道具(クラス)がそろったら、処理順にプログラムを書いていきます。今回はコンソールアプリケーションなので、mainメソッドに処理を書きます。
Main.javapublic class Main { public static void main(String[] args) throws Exception { // 初期化 TicketMachine machine = new TicketMachine(); Category mainMenu = new Category(1); mainMenu.addMenu(new Menu("牛丼", 1, 1, 1, 380)); mainMenu.addMenu(new Menu("豚丼", 1, 1, 1, 350)); mainMenu.addMenu(new Menu("鮭定食", 1, 1, 0, 450)); machine.addCategory(mainMenu); (...以下、長いので省略...) // メニューを注文する (ここには何を書けばいいのだろうか?) // 合計金額を算出する (ここには何を書けばいいのだろうか?) } }もちろん、これで完成するわけないですよね。不足している部分を追加していきます。
足りないものを追加していこう
合計金額を算出する
足りない部分はどこから始めてもいいのですが、まずは合計金額を求めるメソッド(
getTotal())を追加します。このメソッドはどのクラスに追加すればいいでしょうか?オブジェクト指向の分析(?)だと、(特に理由が書かれることもなく)券売機クラスに実装する、となりそうだし、そのように設計してもいいのですが、どのクラスに実装すべきかはっきりしない場合はどうすればいいでしょうか? この場合ちょっと視点を変えて、どのクラスに実装すべきか、ではなく、どのクラスで実装できるか、で考えてみます。具体的にやりましょう。合計金額を求めるには、注文したメニュー一覧が必要です。そして注文したメニュー一覧を知っているクラスは券売機クラスだけです。つまり、そもそも券売機クラスにしか実装できない、ということになります。このやり方であれば、分析どうこうとか考えなくても、必然から実装箇所が分かるでしょう。なお、記事中ではアルゴリズムの説明までする余裕がないので、合計金額算出はこうなるんだ、くらいに思ってくれればいいです。
TicketMachine.javapublic class TicketMachine { ... public int getTotal() { // メニューの合計 int total = orderedMenus.stream().map(m -> m.getPrice()).sum(); // 割引処理 boolean c1 = orderedMenus.stream().anyMatch(m -> m.getN() == 1); boolean c2 = orderedMenus.stream().anyMatch(m -> m.getN() == 2); boolean c3 = orderedMenus.stream().anyMatch(m -> m.getN() == 3); if (c1 && c2 && c3) total -= 50; return total; } }
MenuクラスにgetPrice(),getN()も追加して、合計金額算出の呼び出し部分はこうなります。Main.java... // 合計金額を算出する int total = machine.getTotal(); System.out.printf("合計金額: %d 円\n", total); } }メニューの表示
次に、処理の本体となるメニュー注文部分です。入力をどうするかに先に頭が向いてしまいがちですが、画面に表示しないと何を入力してよいか分からないので、先に表示から考えます。メニューは
Categoryが持っているので、表示するメソッド(onDraw())はここに定義します。引数は出力先オブジェクトにします。標準出力に表示するなら引数なしでもいいのでは、と思うかもしれませんが、経験上出力先は抽象化しておいたほうが良いことが多いです。これは、「出力内容を生成する処理」と「実際に出力する処理」は分離したほうが良い場合が多いからです。この記事では、きちんと分離できていないのですが。話を戻して表示処理ですが、ここで、オプションは選択したメイン商品やサイドによって変わる、と書かれていることに気づきます。先に言ってくれ…(※問題文をちゃんと読んでないだけです)。つまり、表示方法がオプションとそれ以外で異なる=処理が異なるので、継承を使う必要がありそうです。
Categaoryクラスは、abstract classにし、MainCategory,Side1Category,Side2Category,OptionCategoryクラスを作ります。なお、interfaceではなくabstract classにしたのは、おそらく各サブクラスで共通で保持する変数「分類番号」がありそうだからです(あと「メニュー」も)。Category.javapublic abstract class Category { protected final int no; protected List<Menu> menus = new ArrayList<>(); public Category (int no) { this.no = no; } public final void addMenu(Menu menu) { menus.add(menu); } public abstract void onDraw(PrintStream out) throws IOException; }MainCategory.javapublic class MainCategory extends Category { public MainCategory(int no) { super(no); } @Override public void onDraw(PrintStream out) throws IOException { out.println("*** メイン商品 ***"); menus.stream().forEach(m -> out.printf("%d: %s (%d 円)\n", m.getNo(), m.getName(), m.getPrice()) } }(サイドメニュー1、サイドメニュー2も同様なので省略)
OptionCategory.javapublic class OptionCategory extends Category { public OptionCategory(int no) { super(no); } @Override public void onDraw(PrintStream out) throws IOException { out.println("*** オプション ***"); // メイン商品、サイド1、サイド2で選択されたメニューに応じて、出力を変えたい } }ここで、オプションのメニュー表示には、選択されたメニュー情報が必要だということに気づきます。選択されたメニューは、
TicketMachineが持っているため、その値がもらえるように引数に追加します(当然、Categoryクラスなどにも追加します)。OptionCategory.javapublic class OptionCategory extends Category { ... @Override public void onDraw(PrintStream out, List<Menu> selectedMenus) throws IOException { out.println("*** オプション ***"); // 表示するメニューの取得 List<Menu> shownMenus = menus.stream() .filter(m -> selectedMenus.stream().anyMatch(m2-> m.getO() == m2.getO())) .collect(Collectors.toList()); // 取得したメニューの表示 shownMenus.stream().forEach(m -> out.printf("%d: %s (%d 円)\n", m.getNo(), m.getName(), m.getPrice())); } }呼び出し元も修正します。
TickerMachine.javapublic TickerMachine { ... public void onDraw(PrintWriter writer) throws IOException { for (int i = 0; i<menus.length, ++i) { categories[i].onDraw(writer, selectedMenu); } }メニューの入力
表示ができたので、ようやく入力処理に移れます。メニューの入力処理の場所ですが、ぱっと思いつくのは、入力用のメソッド
waitFor()を実装する、出力処理onDraw()の中に一緒にしてしまう、の2通りが考えられます。ポイントは(メニューの出力 → メニューの入力)という一連の処理を各カテゴリーで行うのですが、そのループ終了条件をどこに書くか、になります。waitFor()にするとmain側、onDraw()に入れるとTicketMachineの中に書くことになります。どのカテゴリーの処理を行っているかは、TicketMachineが知っているので(TicketMachineがカテゴリーを持っているから)、今回はonDraw()の中で処理することにします。
onDraw()に、出力と同様、入力用のオブジェクトを引数に追加します。TickerMachine.javapublic TickerMachine { ... public void onDraw(PrintWriter writer, BufferedReader reader) throws IOException { for (int i = 0; i<menus.length; ++i) { categories[i].onDraw(writer); writer.print("> "); int selected = Integer.parseInt(reader.readLine()); selectedMenus.add(categories[i].getMenu(selected)); } } }
Categoryには、メニューを取得するメソッドを追加しておきます。メニューの取り出し方はすべてのCategoryで同じであるため、スーパークラスで実装すればいいでしょう。また、メニューの取り出し方がCategoryによって変わる可能性が低いので、オーバーライドを防ぐfinalをつけておきます。finalを付けるかどうかは賛否両論あると思いますが、Category.javapublic abstract class Category { ... public final Menu getMenu(int no) { menus.stream().filter(m -> m.getNo() == no).findFirst().orElseThrow(); } }細かい処理を
TicketMachineに実装したので、main は呼び出すだけで済みます。Main.java... // メニューを注文する machine.onDraw(System.in, new BufferedReader(new InputStreamReader(System.in))); ...これでいったん動くものが一通り実装できました。しかし実際動かしてみると、何か足りないような…
足りないものを追加していこう(2周目)
問題文をよく読むと、サイドメニューは複数選択可能と書いてあることに気づきます(問題はよく読もう)。実際の発券機では「次へ」みたいなボタンがあって、次のカテゴリーのメニューを選択する画面に行くのでしょうが、CLIなので、「9」を入力したら次のカテゴリーへ進む、という仕様にします。メニューが9個以上になったらどうするんだ、という心配性な人は、別に
AでもNにしても構いません。ただし、複数メニューが選べるのはサイド1とサイド2だけなので、サイド1とサイド2だけ「9」を表示するようにします。
Side1Category.javapublic class Side1Category extends Category { ... @Override public void onDraw(PrintWriter out) { out.println("*** サイドメニュー1 ***"); menus.stream().forEach(m -> out.printf("%d: %s (%d 円)\n", m.getNo(), m.getName(), m.getPrice()); out.println("9: 次のメニューへ進む"); } }
Side2Categoryも同様です。
TicketMachine#onDraw()はこんな風になるのですが…TickerMachine.javapublic TickerMachine { ... public void onDraw(PrintWriter writer, BufferedReader reader) throws IOException { for (int i = 0; i<menus.length; ) { // メニューの出力 categories[i].onDraw(writer); // メニュー入力 writer.print("> "); // 選択されたメニューを追加 int selected = Integer.parseInt(reader.readLine()); if (selected != 9) { selectedMenus.add(categories[i].getMenu(selected)); } (...次のカテゴリーへ進む判定をしたい...) } } }ここで、「次のカテゴリーへ進む判定をしたい」の部分をどうするか、が問題になります。メイン商品とオプションのときは常に次のカテゴリーへ進み、サイド1とサイド2は「9」が選択されたら次のカテゴリーへ進む処理になります。ここでやってはいけないことは、面倒だからメイン商品とオプションにも「9」を実装することや、
categories[i]がサイド1かサイド2であるかをinstanceofなどifで判定しようとすることです。「9」を実装してしまうと、メイン商品とオプションが複数のメニューが選択できてしまいます。複数のメニューが選択されたらエラーにすればいいのでは、と考える人もいるかもしれませんが、それは「複数メニューが選択できない」のではなく、「複数メニューを選択しようとしたらエラーになる」実装です。複数メニューが選択できない仕様なら、複数メニューが選択できないように実装すべきです。
また、
instanceofなどによる判定が悪いのは、あまり説明はいらないでしょう。何のために継承を使ったのか、というそもそも論になってしまいます。type check による分岐は最終手段とすべきです。ではどうすればいいのか? もう一度やろうとしている処理を見ると、「メイン商品とオプションのときは常に次のカテゴリーへ進進み、サイド1とサイド2は「9」が選択されたら次のカテゴリーへ進む」です。つまり、サイド1、2とメイン商品、オプションのときと動作が異なっています。だから、ポリモーフィズムを使うところです。
つまり、次のカテゴリーへ進むかどうかを判定するメソッドを追加すればよい、ということになります(Javaでポリモーフィズムの実現方法はメソッドしかないから)。各
Categoryにnext()を実装しましょう。MainCategoryとOptionCategoryは常に次のカテゴリーへ進むので、trueを返すだけです。MainCategory.javapublic class MainCategroy extends Category { ... @Override public boolean next(int no) { return true; }サイドは「9」が選択されたら次のカテゴリーへ進みます。
Side1Category.javapublic class Side1Category extends Category { ... @Override public boolean next(int no) { return no == 9; } }これで、呼び出し元はこうできます。
TickerMachine.javapublic TickerMachine { ... public void onDraw(PrintWriter writer, BufferedReader reader) throws IOException { for (int i = 0; i<menus.length; ) { // メニューの出力 categories[i].onDraw(writer); // メニュー入力 writer.print("> "); int selected = Integer.parseInt(reader.readLine()); // 選択されたメニューを追加 if (selected != 9) { selectedMenus.add(categories[i].getMenu(selected)); } // 次のカテゴリーへ進む if (categories[i].next()) { ++i; } } } }ちなみに、サイド1、2で同じ商品を何度も注文できてしますが、特に問題文には「同じ商品を注文できない」とは書かれていないので、許容することにします。2つ注文したい人がいるかもしれないしね。
完成? その前にプログラムの掃除をしよう
これで一通り問題文の仕様を実装した(はず)です。動くプログラムもできました。完成でしょうか? いえ、ここで終わりにしてはいけません。最後にプログラムをきれいにします。ボトムアップで設計すると、その場の思い付きでの実装になり、全体から見ると命名などに一貫性が無かったりすることが多いです。そのため、動いたら終わり、ではなく、最後にプログラムを掃除するフェーズを入れたほうがいいです。
やり方は、一般的なリファクタリングと変わりません。基本的に動作が変わらないので、リファクタリングの手法が使えます。汚そうな箇所を見つけたら、リファクタリングのマニュアル通りに進めます(今回はユニットテストを作っていませんが)。今回の記事で気になるところをピックアップして修正していきます。ちなみに、どの部分を汚く感じるかは、完全に主観です。つまり、汚いと思った箇所を修正していけばいいです。ちなみに私は、このフェーズでJavadocコメントを付けていきます。
汚い箇所をきれいにする
個人的に一番気にくわないのは、
TicketMachineの生成です。カテゴリーはすでにTichektMachineの内部にしかなく、main側が知る必要もないので、このクラスの構築をmainでやりたくないです。TicketMachineのコンストラクタに移してしまいましょう。TicketMachine.javapublic class TicketMachine { ... public TicketMachine() { catogories[0] = new MainCategory(); catogories[0].addMenu(new Menu("牛丼", 1, 1, 1, 380)); catogories[0].addMenu(new Menu("豚丼", 1, 1, 1, 350)); catogories[0].addMenu(new Menu("鮭定食", 1, 1, 0, 450)); catogories[1] = new Side1Category(); (...以下、長いので省略...) } ...これにより、
TicketMachineからsetXXXメソッドがすべて削除できます。また呼び出し元のmain全体はこうなります。Main.javapublic class Main { public static void main(String[] args) throws Exception { // 初期化 TicketMachine machine = new TicketMachine(); // メニューを注文する machine.onDraw(System.out, new BufferedReader(new InputStreamReader(System.in)); // 合計金額を算出する int total = machine.getTotal(); System.out.printf("合計金額: %d 円\n", total); } }使用していないクラス、メソッド、インスタンス変数を削除する
- メソッド名の変更
メニューの入力と出力は、メソッドを分ける可能性もあったため、出力を
onDraw()としましたが、入力も行うことにしたため、このメソッド名はどこか浮いています。show()くらいのメソッド名にしておきましょう。
Userの削除存在自体覚えてないかもしれませんが、一回も出てこなかったので、削除してしまいましょう。このクラスが不要だった理由ですが、後付けですが、
MainがUserの役割になりましたが。
Categoryクラスはこのまま
Side1CategoryとSide2Categoryは全く同じことをしているので、AbstractSideCategoryを作って共通化したほうがいいのでは、と考えた人もいるかもしれません。作れば「サイド3を追加」という仕様変更にも対応できますし。正直悩ましいところなのですが、私は作らないと思います。私の共通化の指針は次のようにしているからです。
- 同じ処理が2回までなら、コピペを許す(共通化する場合もあり)
- 同じ処理が3回以上出てきたら、共通化する
今回は、サイド1とサイド2の2回なので、自分の指針としては許容範囲であり、なおかつ
Side1Category自体が大した規模のクラスではないので、メンテ可能、という判断です。もちろん、AbstractSideCategoryを作るのが間違いということはありません。まとめ
自己流オブジェクト指向の設計方法をまとめておきます。
- 1. まずはトップダウンでクラスの抽出とメソッドやインスタンス変数を決めていく
- 分かる範囲で抽出する。足りないものは後で追加すればいい、くらいの気持ちで気軽にやる
- 2. 足りないクラスやメソッドなどをボトムアップで追加、不要なものは削除していく
- クラスやメソッドがごっそり削除、ということもある。もったいないから、とか考えない。使えない実装はあるだけで害悪、という意識を持とう。
- 3. 2. を繰り返す。
- 普通は1回では終わらない。この記事では2回で完走したが、通常は3回以上かかる。
- 4. 完成、終了、ではない。最後にプログラムの掃除を。
- 一般的なリファクタリングの手法で行う。単体テストを作ってない? じゃあ、ここで作ってしまおう!
また、記事中に出てきた、自己流設計指針も整理しておきます。
java.util.Listか配列か?
- 固定長だとはっきりしている場合は配列
- それ以外では
Listを使う- 継承を使う? 使わない?
- 処理(メソッド)が変わるときはポリモーフィズムで表現するので継承を使う。
- データ(インスタンス変数/プロパティ)だけしか変わらない場合は、継承は使わない。
interface?abstract class?
- 実はクラス設計上はどちらも差がない。(だからどちらでもいいし、文法上の制約でしかない)
- インスタンス変数を持たせたいなら、(文法上の制約で)
abstract classにする。- そうでないなら
interfaceにする。- コンストラクタで設定したインスタンス変数も値が変わらないなら、
finalを付ける。
- このクラスが不変(immutable)であることを明示する。primary type ではないと効果半減だが、明示するため primary type ではなくても付けておく。
- いつ共通化する?
- 2回まではコピペを許容
- 3回以上は必ず共通化
おわりに
オブジェクト指向の初心者がこの記事を読んでいたら、クラス設計は難しい、と感じたかもしれません。はい、難しいです。なので、最初は1つずつゆっくり丁寧にやり、慣れてきたら少しずつ速くしていくといいと思います。特に 1. は何%くらいまでやればいいのか、疑問があるかもしれませんが、最初は 70% ~ 80% くらいを目標にしておくといいと思います。慣れてくると 60% 程度でも 2. で修正が効くのでなんとかなります。もし、仕事でプログラムをする人ならば、こんなことを数年続けていれば、息をするようにできるようになります。私もこの規模の設計ならば、直感と感覚で(考えてない、とも言う)設計しています。というか、実際私はあまりクラス設計を考えてしていません。今回記事にするにあたり、がんばって言語化したのですが、文字として書き出してみるまで、どう考えているか自分でも分かってなかった…
なお、元の問題には、掲載した部分の後に状態を表す3桁コードや状態遷移図を使って… と続くのですが、この記事を読んでいただいた通り、こんなものは一度も出てきません。その理由は、状態の管理は各クラス(
TicketMachineや各Categoryクラス)に分散したからです。各クラスが自分の責任/役割を果たしてくれている限り、状態遷移を考慮してプログラムする必要はないでしょう(テストでケースを起こすときには、ああいった2次元の表は必要になるでしょうが)。個人的に複雑な要素を一か所にまとめて管理するやり方は好きではないです、特に多次元配列をつ使うやり方は。読み解くのが大変だし、大抵「1列見ているところ間違った」とかなりますし(メニューが増えました、からの1列ずれていました、までテンプレ)。本当は、この後に作ったクラスの分類や、OOP(Object Oriented Principals/オブジェクト指向原理)の話もしたかったのですが、さすがに記事長すぎなので、別の機会があったら、にしたいと思います。長文おつきあいありがとうございました。

- 投稿日:2020-11-27T11:16:33+09:00
今日からできるスマートな条件分岐(if,switch)【初級編】
はじめに
コードを読む際にわかりにくいコードがあると思います。それはなぜでしょうか?
大方長過ぎるコードであったり、実装方法がスマートではなかったりします。変数が長い間生きていたり、何してるのかそもそもわからなかったり…。
そんな中でもよく書くif文、switch文に関していい感じの実装方法を紹介したいと思います。
チートシートの類ではないですがいい例と悪い例を載せつついい条件分岐の書き方を紹介しようと思います。
実務未経験から実務半年程度の人向けです。コードはJavaですが他の言語にも使えるはずです。単純な分岐
プログラム内容:boolがtrueならば「1」をfalseならば「2」を設定する。
悪い例
Test.javapublic class Test { public static void main(String[] args) { boolean bool = true; int num = 0; //if文の判定がくどい。これは古い書き方 if(bool == true) { //trueの場合の処理 num = 1; }else { //falseの場合の処理 num =2; } } }いい例1
Test.javapackage Test; public class Test { public static void main(String[] args) { boolean bool = true; int num = 0; //booleanにTrue,Falseが入っていればちゃんと動きます if(bool) { //trueの場合の処理 num = 1; }else { //falseの場合の処理 num =2; } } }いい例2
Test.javapackage Test; public class Test { public static void main(String[] args) { boolean bool = true; int num = 0; //TrueとFalseで同じような処理をする場合は三項演算子を使用するといいかも //ただし三項演算子のネストは可読性が著しく下がるのでNG num = bool ? 1 : 2 ; } }単純な分岐2
プログラム内容:変数numの値が
1~3ならば「春」
4~6ならば「夏」
7~9ならば「秋」
10~12ならば「冬」
を標準出力する。悪い例
Test.javapublic class Test { public static void main(String[] args) { int num = 5; //条件分岐を12個書くのは正気の沙汰ではない if(num == 1) { System.out.println("春"); }else if(num == 2) { System.out.println("春"); } //3~11は省略 else if(num == 12){ System.out.println("冬"); } } }いい例1
Test.javapublic class Test { public static void main(String[] args) { int num = 5; //人間が視認しやすいようにプログラムを作る //条件分岐の数も減りわかりやすい if(1 <= num && num <= 3) { System.out.println("春"); }else if(4 <= num && num <= 6) { System.out.println("夏"); }else if(7 <= num && num <= 9){ System.out.println("秋"); }else if(10 <= num && num <= 12){ System.out.println("冬"); } } }いい例2
Test.javapublic class Test { public static void main(String[] args) { int num = 5; //switch文の特性を生かして条件分岐をする switch (num) { case 1: case 2: case 3: System.out.println("春"); break; case 4: case 5: case 6: System.out.println("夏"); break; case 7: case 8: case 9: System.out.println("秋"); break; case 10: case 11: case 12: System.out.println("冬"); break; } } }何もしない処理が来た場合
プログラム内容:boolがtrueならば色々するけどをfalseならば何もしない。
悪い例
Test.javapublic class Test { public static void main(String[] args) { boolean bool = false; //「う~んfalseの場合はどうなるんやろう…」 //と脳裏の片隅に置きながらコードを読まないと行けないため読みづらい if(bool) { System.out.println("それは一瞬の出来事だった"); System.out.println("高くそびえた断崖から"); System.out.println("僅かな体温感覚さえ失う"); System.out.println("果てしない心の恐怖"); //以下数百行 }else { return; } } }いい例
Test.javapublic class Test { public static void main(String[] args) { boolean bool = false; //「falseの場合は何もしないんやな!」 //と安心してコードを読み進められるため非常に読みやすい if(!bool) { return; }else { System.out.println("それは一瞬の出来事だった"); System.out.println("高くそびえた断崖から"); System.out.println("僅かな体温感覚さえ失う"); System.out.println("果てしない心の恐怖"); //以下数百行 } } }終わりに
以上となります。これらを使えばネストしたときも最初はなんとかできると思います。あまりにもネストした際はクラスなどに切り分けして運用したほうがいいと思いますがここでは割愛。(Qiitaランキング入ったらやる)
今回はただの標準出力でしたが、「レコードが存在していた場合は何もしない」「数値が100以上の場合のみ特定の処理をする」などに読み替えてお使いください。
- 投稿日:2020-11-27T09:10:01+09:00
【Java・SpringBoot】Spring JDBC(SpringBootアプリケーション実践編9)
ホーム画面からユーザー一覧画面に遷移し、ユーザーの詳細を表示するアプリケーションを作成して
Spring JDBCの使い方について学びます⭐️
今回はまずJDBC Templateを実装するための画面作成を行います構成はこれまでの記事を参考にしてください
【Java・SpringBoot・Thymeleaf】ブラウザ言語設定でエラーメッセージの言語を変更(SpringBootアプリケーション実践編8)
【Java・SpringBoot】Spring AOP実践Spring JDBCとは
- JDBCはJavaでDBにアクセスするためのライブラリ
- SpringJDBCは、JDBCを使ってデータベースにアクセス
- 通常のJDBCでは、DBへの接続やクローズ処理などを毎回書かないといけない。。。
- →?SpringJDBCを使えば、DBの接続やクローズなどの処理を書かなくてOK^^
- ?DB製品固有のエラーコードを解釈して、適切な例外を投げてくれる
- 一意制約違反(他の行の値と重複禁止)が発生した場合、SQLServerでは
2627、OracleではORA0001- 一意制約違反が発生した場合は、
DuplicateKeyExceptionという例外クラスでキャッチ- →製品ごとに実装を分ける必要がない!
DataAccessExceptionクラス:すべての例外クラスのスーパークラス
- データベース関連のエラーをすべてキャッチできる
SpringJDBC実践!
- 以下の画面を作成しながら、SpringJDBCを使います
- それぞれの画面は、テンプレート部分とコンテンツ部分に分かれている
- テンプレート部分:共通部分のhtml(ヘッダー、サイドバーなど)
- レイアウトを変更する場合、テンプレート用のファイルを修正するだけでOK!
ホーム画面
- ログインボタンを押した後に表示される * ログイン画面については過去の記事のコードを参考にしてください
- ログアウトやユーザー一覧画面に飛ぶことができる<> 【Java・SpringBoot・Thymeleaf】ログイン・新規登録画面作成(SpringBootアプリケーション実践編1)
ユーザー一覧画面
- DBから全ユーザーの情報を取得して、画面に表示
詳細ボタンを押すと、各ユーザーの詳細画面に移る- ユーザー一覧をCSV出力できる
ユーザー詳細画面
- ユーザーの詳細を表示
- ユーザーの更新、削除をする
- 更新・削除した後はユーザー一覧画面に移る
画面作成
- 先に画面を作成して、タイムリーフでテンプレート画面を作る方法について学びます
- 構成は以下のようになってます
Project Root └─src └─ main └─ java └─ com.example.demo └─ login └─ aspect ...AOP用パッケージ └─ controller ...コントローラクラス用パッケージ └─ HomeController.java └─ domain ...ビジネスロジック用パッケージ └─ model ...Model(DTO)用パッケージ └─ User.java └─ repository ...リポジトリクラス用パッケージ └─ UserDao.java └─ jdbc └─ UserDaoJdbcImpl.java └─ service ...サービスクラス用パッケージ └─ UserService.java └─ resouces └─ static ...css,js用フォルダ └─ cs └─ home.css └─ templates └─ login └─ home.html └─ homeLayout.htmlホーム画面のテンプレート用htmlを作成
th:include属性
- タグ内に別ファイルのコンテンツ部分のhtmlが追加される
th:includeの値th:include="<ファイルパス>::<th:fragment属性の値>"
- ファイルパス:コンテンツ部分のhtmlファイルのファイルパスです。
- th:fragment属性:コンテンツ部分のhtmlで使う属性
- ex: loginフォルダー内にあるhome.htmlというコンテンツ用のhtml内に、
th:fragment="home_contents"と書き、
th:includeには、th:include="login/home::home_contents"と記述- コンテンツ部分を動的に変更する場合は、
th:includeの値はModelに登録された値を参照するようにする
- Modelに
login/home::home_contentsという文字列を登録- ※動的にコンテンツ部分のhtmlを変える場合、プリプロセッシングを使う必要がある
プリプロセッシング
- 通常の式よりも先に評価させる仕組み
- プリプロセッシングでは変数(${変数名})に__(アンダースコア2つ)を前後に付ける
th:include="__${contents}__"の部分がth:include="login/home::home_contents"と先に評価され、その後でhtmlが作成される- →コンテンツ部分のhtmlを表示させることができる!
homeLayout.html<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"> <head> <meta charset="UTF-8"></meta> <!-- Bootstrap --> <link th:href="@{/webjars/bootstrap/3.3.7-1/css/bootstrap.min.css}" rel="stylesheet"></link> <script th:src="@{/webjars/jquery/1.11.1/jquery.min.js}"></script> <script th:src="@{/webjars/bootstrap/3.3.7-1/js/bootstrap.min.js}"></script> <!-- CSS読込 --> <link th:href="@{/css/home.css}" rel="stylesheet"></link> <title>Home</title> </head> <body> <!-- ヘッダー --> <nav class="navbar navbar-inverse navbar-fixed-top"> <div class="container-fluid"> <div class="navbar-header"> <a class="navbar-brand" href="#">SpringBoot</a> </div> <form method="post" th:action="@{/logout}"> <button class="btn btn-link pull-right navbar-brand" type="submit"> ログアウト </button> </form> </div> </nav> <!-- サイドバー --> <div class="container-fluid"> <div class="row"> <div class="col-sm-2 sidebar"> <ul class="nav nav-pills nav-stacked"> <li role="presentation"> <a th:href="@{'/userList'}">ユーザ管理</a> </li> </ul> </div> </div> </div> <!-- コンテンツ --> <div class="container-fluid"> <div class="row"> <div class="col-sm-10 col-sm-offset-2 main"> <div th:include="__${contents}__"></div> </div> </div> </div> </body> </html>ホーム画面のhtmlを作成
th:fragment
- th:fragment属性が付いているタグ内のhtmlが、テンプレート用のhtml内に追加される
home.html<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"> <head> <meta charset="UTF-8"></meta> </head> <body> <!-- ポイント:th:fragment --> <div th:fragment="home_contents"> <div class="page-header"> <h1>ホーム</h1> </div> </div> </body> </html>ホーム画面用のコントローラークラスを作成
ホーム画面にGETリクエスト
- /homeにGETリクエストが来たときに、Modelクラスの"contents"というキーに
"login/home::home_contents"という値をセット- この値がth:include属性に入る
th:include="login/home::home_contents"- ログアウトボタンが押されたら、ログイン画面にリダイレクトする
HomeController.javapackage com.example.demo.login.controller; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PostMapping; import com.example.demo.login.domain.service.UserService; @Controller public class HomeController { @Autowired UserService userService; @GetMapping("/home") public String getHome(Model model) { //コンテンツ部分にユーザー詳細を表示するための文字列を登録 model.addAttribute("contents", "login/home :: home_contents"); return "login/homeLayout"; } @PostMapping("/logout") public String postLogout() { return "redirect:/login"; } }ホーム画面のcssを作成
home.cssbody { padding-top: 50px; } .sidebar { position: fixed; display: block; top: 50px; bottom: 0; background-color: #F4F5F7; } .main { padding-top: 50px; padding-left: 20px; position: fixed; display: block; top: 0px; bottom: 0; } .page-header { margin-top: 0px; }ユーザーテーブルのカラムをフィールドに保持
- データベースから取得した値を、コントローラークラスやサービスクラスなどの間でやり取りするためのクラスを用意
- @Dataアノテーション:Lombokでgetterやsetterを自動で作る
User.javapackage com.example.demo.login.domain.model; import java.util.Date; import lombok.Data; @Data public class User { private String userId; //ユーザーID private String password; //パスワード private String userName; //ユーザー名 private Date birthday; //誕生日 private int age; //年齢 private boolean marriage; //結婚ステータス private String role; //ロール }リポジトリークラスのインターフェース
- インターフェースを作る理由は、後で中身の実装クラスを簡単に切替えられるようにするため
- DataAccessException
- Springでは、データベース操作で例外が発生した場合、Springが提供しているDataAccessExceptionを投げる
- SpringJDBCだけでなく、Spring+MyBatisを使った時にも投げられる
UserDao.javapackage com.example.demo.login.domain.repository; import java.util.List; import org.springframework.dao.DataAccessException; import com.example.demo.login.domain.model.User; public interface UserDao { // Userテーブルの件数を取得. public int count() throws DataAccessException; // Userテーブルにデータを1件insert. public int insertOne(User user) throws DataAccessException; // Userテーブルのデータを1件取得 public User selectOne(String userId) throws DataAccessException; // Userテーブルの全データを取得. public List<User> selectMany() throws DataAccessException; // Userテーブルを1件更新. public int updateOne(User user) throws DataAccessException; // Userテーブルを1件削除. public int deleteOne(String userId) throws DataAccessException; //SQL取得結果をサーバーにCSVで保存する public void userCsvOut() throws DataAccessException; }インターフェース実装クラスを作成
- 各メソッドの中身は、まだ空の状態
- JdbcTemplateはSpringが用意しているため、既にBean定義がされている
- →@AutowiredするだけでOK
- このクラスのメソッドでSQLを実行
UserDaoJdbcImpl.javapackage com.example.demo.login.domain.repository.jdbc; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.dao.DataAccessException; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.stereotype.Repository; import com.example.demo.login.domain.model.User; import com.example.demo.login.domain.repository.UserDao; @Repository("UserDaoJdbcImpl") public class UserDaoJdbcImpl implements UserDao { @Autowired JdbcTemplate jdbc; // Userテーブルの件数を取得. @Override public int count() throws DataAccessException { return 0; } // Userテーブルにデータを1件insert. @Override public int insertOne(User user) throws DataAccessException { return 0; } // Userテーブルのデータを1件取得 @Override public User selectOne(String userId) throws DataAccessException { return null; } // Userテーブルの全データを取得. @Override public List<User> selectMany() throws DataAccessException { return null; } // Userテーブルを1件更新. @Override public int updateOne(User user) throws DataAccessException { return 0; } // Userテーブルを1件削除. @Override public int deleteOne(String userId) throws DataAccessException { return 0; } //SQL取得結果をサーバーにCSVで保存する @Override public void userCsvOut() throws DataAccessException { } }サービス用のクラスを作成
- クラスを用意するだけ
UserService.javapackage com.example.demo.login.domain.service; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import com.example.demo.login.domain.repository.UserDao; @Service public class UserService { @Autowired UserDao dao; }ログ出力用のアスペクトクラス
- ユーザーDaoクラスのメソッドが呼び出されたときに、どのクラスのどのメソッドが呼ばれたのかをログ出力できるようにする
LogAspct.javapackage com.example.demo.login.aspect; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.springframework.stereotype.Component; @Aspect @Component public class LogAspct { @Around("execution(* *..*.*Controller.*(..))") public Object startLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { //メソッド実行 Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } } /** * Daoクラスのログ出力用アスペクトを追加 */ @Around("execution(* *..*.*UserDao*.*(..))") public Object daoLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } } }テーブルを作成します
ユーザーテーブル作成
schema.sql/* 従業員テーブル */ CREATE TABLE IF NOT EXISTS employee ( employee_id INT PRIMARY KEY, employee_name VARCHAR(50), age INT ); /* ユーザーマスタ */ CREATE TABLE IF NOT EXISTS m_user ( user_id VARCHAR(50) PRIMARY KEY, password VARCHAR(100), user_name VARCHAR(50), birthday DATE, age INT, marriage BOOLEAN, role VARCHAR(50) );ユーザーテーブルの初期化データを作成
data.sql/* 従業員テーブルのデータ */ INSERT INTO employee (employee_id, employee_name, age) VALUES(1, 'Teshita Neko', 3); /* ユーザーマスタのデータ(ADMIN) */ INSERT INTO m_user (user_id, password, user_name, birthday, age, marriage, role) VALUES('nekomofu@xxx.co.jp', 'password', 'Oyakata Neko', '2020-01-01', 3, false, 'ROLE_ADMIN');ログイン画面からホーム画面に遷移
- ログインボタンを押すとホーム画面に遷移
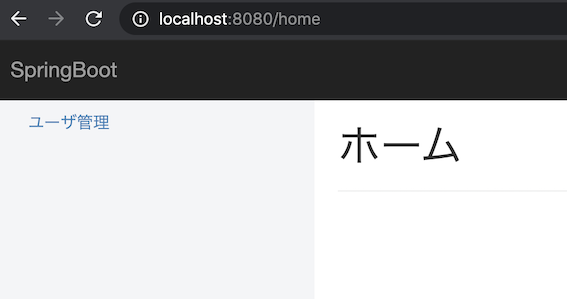
return "redirect:/home";LoginController.javapackage com.example.demo.login.controller; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PostMapping; @Controller public class LoginController { @GetMapping("/login") public String getLogin(Model model) { //login.htmlに画面遷移 return "login/login"; } @PostMapping("/login") public String postLogin(Model model) { //ホーム画面に遷移 return "redirect:/home"; } }SpringBootを起動して画面を確認!
- http://localhost:8080/home
- ホーム画面を作成できました〜〜^^
- 次回はJDBC Templateを実装します?
- 投稿日:2020-11-27T08:37:31+09:00
【Java・SpringBoot】Spring AOP実践
AOP(AspectOrientedProgramming)とは?
- AOPとは、アスペクト指向プログラミング
- 各クラスで共通する処理を抜き出して、まとめて管理すること
- 例えば、各クラスのメソッドでいちいち開始ログと終了ログを書くのは面倒。。。。
- 書き忘れる、コードの修正量がとても多くなることも。。。
- AOPを使えば、共通の処理をまとめて一ヶ所に書いておき、共通処理をどのクラスの、どのメソッドに適用するかを選択することができる!!嬉しい!
- 共通処理の例:ログ出力、セキュリティ、トランザクション、例外処理、キャッシュリトライなどなど。
- そうすることで、各クラスでは本来書くべきコードに集中でき、コードの可読性もUP?
AOPの用語
- Advice:AOPで実行する処理
- Pointcut:処理を実行する場所(クラスやメソッド)
- JoinPoint:処理を実行するタイミング
JoinPoint Advice実行タイミング Before メソッドが実行される前に、Advice実行 After メソッドが実行された後に、Advice実行 AfterReturning メソッドが正常終了した場合だけ、Advice実行 Around メソッド実行の前後に、Advice実行 AfterThrowing メソッドが異常終了した場合のみ、Advice実行 AOPの内部の仕組み
- AOPの仕組みはとっても簡単?
- 例えばBeanとして
LoginControllerが登録されていてLoginControllerクラスのメソッドを呼び出す場合、
- 1.DIコンテナに登録されているBeanのメソッドを呼び出す
- 2.Proxyが自動生成され、Proxy経由でBeanのメソッドを呼ぶ(Beanのメソッドを直接呼び出さない!)
- 3.Beanのメソッドを呼び出す前後に、Advice(AOPの処理)を実行する
AOP実装の準備
- 各コントローラークラスのメソッドが呼び出されるたびに、開始ログと終了ログを出力する
- AOPを使うためには、pom.xmlのdependenciesタグ内に以下のコードを追加
pom.xml<!-- Spring AOP --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aop</artifactId> </dependency> <!-- AspectJ --> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency>Pointcutの指定方法
- PointcutでどのクラスにAOPを適用するかを指定する方法
Pointcut 対象 execution 正規表現を使って任意のクラス、メソッドなどをAOPの対象に指定 bean DIコンテナに登録されているBean名でAOPの対象に指定 @annotation 指定したアノテーションが付いているメソッドがAOPの対象 @within 指定したアノテーションが付いているクラスの全てのメソッドがAOPの対象 Before・Afterの実装
コントローラークラスのログ出力用アスペクトを作成
@Aspectアノテーション
- AOPのクラスには、@Aspectアノテーションを付ける
- 同時にDIコンテナへBean定義をするので@Componentアノテーションも付ける
AOPの実装
- AOP実行するメソッドには@Beforeや@Afterアノテーションを付ける
- executionでどのクラスのどのメソッドが実行されたときに、このメソッドが呼び出されるかを指定
- executionの指定方法
"execution(<戻り値><パッケージ名>.<クラス名>.<メソッド名>(<引数>)”- 正規表現の使い方
- *:任意の文字列
- ..:任意(0以上)のパッケージ、メソッドの引数では、任意(0以上)の引数
- +:クラス名の後に指定すると、指定クラスのサブクラス/実装クラスが含まれる
@Before("execution(*com.example.demo.login.controller.LoginController.getLogin(..))")
- 上の例では、LoginControllerクラスのgetLoginメソッドをPointcutに指定
LogAspct.javapackage com.example.demo.login.aspect; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.After; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.springframework.stereotype.Component; @Aspect @Component public class LogAspct { //AOP実装 @Before("execution(* com.example.demo.login.controller.LoginController.getLogin(..))") public void startLog(JoinPoint jp){ System.out.println("メソッド開始: " + jp.getSignature()); } //AOP実装 @After("execution(* com.example.demo.login.controller.LoginController.getLogin(..))") public void endLog(JoinPoint jp) { System.out.println("メソッド終了: " + jp.getSignature()); } }ログイン画面にアクセスしてコンソールログを確認
- http://localhost:8080/login
- ログインコントローラーのgetLoginメソッドが呼ばれるたびに、コンソールにログをだすことができました〜〜^^
//コンソール画面 メソッド開始: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド終了: String com.example.demo.login.controller.LoginController.getLogin(Model)@Before・@Afterの引数を変更
- コントローラークラスのすべてのメソッドの開始・終了ログが出るように変更します
executionの指定方法
"execution(<戻り値><パッケージ名>.<クラス名>.<メソッド名>(<引数>)”//クラス名の最後に"Controller"が付くクラスの全てのメソッドをAOPの対象にする @Before("execution(* *..*.*Controller.*(..))") @After("execution(* *..*.*Controller.*(..))")
- 戻り値
*:全ての戻り値を指定- パッケー名
∗..∗:全てのパッケージが対象- クラス名
∗Controller:末尾にControllerと付くクラスが対象- メソッド名
*:全ての戻り値を指定- 引数
..:全ての引数が対象SpringBootを起動、ログイン画面とユーザー登録画面にアクセス
- コントローラークラスのすべてのメソッドの開始・終了ログがコンソールに出ました^^
//コンソール画面 メソッド開始: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド終了: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド開始: String com.example.demo.login.controller.SignupController.getSignUp(SignupForm,Model) メソッド終了: String com.example.demo.login.controller.SignupController.getSignUp(SignupForm,Model) メソッド開始: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model) メソッド終了: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model)Aroundの実装
- LogAspectクラスを以下のように修正します
- Aroundを使う場合、アノテーションをを付けたメソッドの中で、AOP対象クラスのメソッドを直接proceedメソッドで実行する
- →Aroundを使うと、メソッド実行の前後で任意の処理をすることができる!
- メソッドを直接実行しているため、returnには実行結果の戻り値を指定
- Around内でメソッドの実行を忘れないようにしよう
LogAspct.javapackage com.example.demo.login.aspect; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.springframework.stereotype.Component; @Aspect @Component public class LogAspct { //AOP実装 @Around("execution(* *..*.*Controller.*(..))") public Object startLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { //メソッド実行 Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } } }ログイン画面にアクセスしてコンソールログを確認
- http://localhost:8080/login
- ユーザー登録画面にアクセス
- ログインコントローラーのコントローラークラスのすべてのメソッドの開始・終了ログをコンソールに出すことができました〜〜^^
//コンソール画面 メソッド開始: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド終了: String com.example.demo.login.controller.LoginController.getLogin(Model) メソッド開始: String com.example.demo.login.controller.LoginController.postLogin(Model) メソッド終了: String com.example.demo.login.controller.LoginController.postLogin(Model) メソッド開始: String com.example.demo.login.controller.SignupController.getSignUp(SignupForm,Model) メソッド終了: String com.example.demo.login.controller.SignupController.getSignUp(SignupForm,Model) メソッド開始: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model) メソッド終了: String com.example.demo.login.controller.SignupController.postSignUp(SignupForm,BindingResult,Model)Pointcutその他の指定方法
- 1.Bean名で指定
- 2.アノテーションが付いているメソッドを指定
- 3.アノテーションが付いているクラスの全メソッドを指定
1. Bean名でAOPの対象を指定する
- bean:DIに登録されているBean名でAOPの対象を指定
bean(<Bean名>)でbeanを指定
@Around("bean(*Controller)")- 上記では、名前の最後に"Controller"と付くBeanを対象にする
LogAspct.java//中略 @Around("bean(*Controller)") public Object startLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { //メソッド実行 Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } }2. 任意のアノテーションが付いているメソッドを指定する
- @annotation:指定したアノテーションが付いているメソッド全てを対象とする
- パッケージ名を含めたクラス名を指定
LogAspct.java//中略 @Around("@annotation(org.springframework.web.bind.annotation.GetMapping)") public Object startLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } }3. アノテーションが付いているクラスの全メソッドを指定する
- @within:指定したアノテーションが付いているクラスの全てのメソッドが対象
LogAspct.java//中略 @Around("@within(org.springframework.stereotype.Controller)") public Object startLog(ProceedingJoinPoint jp) throws Throwable { System.out.println("メソッド開始: " + jp.getSignature()); try { Object result = jp.proceed(); System.out.println("メソッド終了: " + jp.getSignature()); return result; } catch (Exception e) { System.out.println("メソッド異常終了: " + jp.getSignature()); e.printStackTrace(); throw e; } }
- 投稿日:2020-11-27T08:08:20+09:00
【Java・SpringBoot・Thymeleaf】ブラウザ言語設定でエラーメッセージの言語を変更(SpringBootアプリケーション実践編8)
おさらい
ログインをして、ユーザー一覧を表示するアプリケーションを作成し、
Springでの開発について勉強していきます?
前回はユーザー登録画面で、まずは必須入力チェックを行い、次に中身のチェックを行うという、エラーメッセージを順番に実行する実装をしました〜
今回はWebブラウザの言語設定に応じて、メッセージプロパティファイルを切り替え、表示メッセージを英語に切り替えられるようにします前回の記事?
【Java・SpringBoot・Thymeleaf】バリデーションチェックの順番を設定(SpringBootアプリケーション実践編7)構成は以下のようになっています
Project Root └─src └─ main └─ java └─ com.example.demo └─ login └─ controller ...コントローラクラス用パッケージ └─ domain ...ビジネスロジック用パッケージ └─ model ...Modelクラス用パッケージ └─ LoginForm.java └─ SignupForm.java └─ ValidGroup1.java └─ ValidGroup2.java └─ ValidGroup3.java └─ GroupOrder.java └─ resouces └─ static ...css,js用フォルダ └─ templates └─ login └─ login.html └─ signup.html └─ messages.properties └─ messages_en.properties英語用のメッセージファイルを作成
- messages_en.propertiesを作成します
src/main/resources/messages_en.properties# ======================================= # データバインドエラーメッセージ # ======================================= #typeMismatch.[ModelAttribute名].[プロパティ名] typeMismatch.signupForm.age=Please enter a numeric value typeMismatch.signupForm.birthday=Please enter in yyyy / MM / dd format # ================================================= # バリデーションエラーメッセージ # ================================================= #ユーザーID signupForm.userId=UserID NotBlank.signupForm.userId={0} is required Email.signupForm.userId=Please enter {0} in e-mail address format #パスワード signupForm.password=Password NotBlank.signupForm.password={0} is required Length.signupForm.password=Please input {0} with more than {2} digits, {1} digits or fewer digits Pattern.signupForm.password=Please enter {0} with half-width alphanumeric characters #ユーザー名 signupForm.userName=UserName NotBlank.signupForm.userName={0} is required #誕生日 signupForm.birthday=Birthday NotNull.signupForm.birthday={0} is required #年齢 signupForm.age=Age Min.signupForm.age={0} must be at least {1} Max.signupForm.age={0} must be less than {1} #結婚 AssertFalse.signupForm.marriage=You can only register if falseブラウザの言語設定を変更
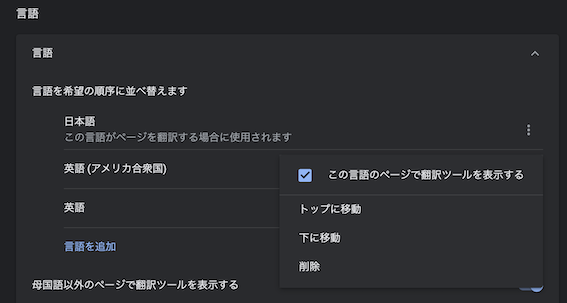
- ブラウザの言語設定で英語の優先順位を一番にする
- Googleの設定から、
- 詳細設定>言語>英語(アメリカ合衆国)
- その他の操作>トップに移動
ユーザー登録画面を確認!
- ブラウザを再起動
- http://localhost:8080/signup
- ユーザー登録画面で何も入力せずにユーザー登録ボタンをクリック
- エラーメッセージが英語になりました〜〜^^
- これでブラウザの言語設定に応じて、メッセージ用プロパティファイルが切り替えられましたo(^_^)o
バインド・バリデーションのまとめ
- ?データバインド
- @ModelAttribute:コントローラークラスと画面の間でフォームクラスを受け取る
- th:object属性やth:field属性:画面とフォームクラスのマッピングを行う
- @DateTimeFormat:Date型フィールドへのバインドを行う
- エラーメッセージは
src/main/resources/messages.propertiesに設定- ?バリデーション
- バリデーションをするには、フォームクラスに@NotBlankなどを付け、
コントローラークラスに@Validatedを付ける- @GroupSequence:バリデーションの順番を制御する
- 言語毎のメッセージプロパティファイルを用意すれば、多言語対応可能!
- 投稿日:2020-11-27T02:38:00+09:00
SpringBoot+MyBatis+DBUnitでCRUDのテストを書いてみた(後編)
はじめに
前回の記事ではDB操作を行うService層以降のクラスの実装を行いました。
今回はいよいよServiceを使ったDBのCRUD操作を検証するJUnitテストケースを実装していきます。開発環境
OS : macOS Catalina
IDE : IntelliJ Ultimate
Java : 11
Gradle : 6.6.1
SpringBoot : 2.3.41. 単体テスト用のデータベースの準備
前回の記事でローカル開発用にDockerの
MySQLをセットアップしました。
今回は単体テスト用にH2データベースを使います。Java製でアプリに組み込んで使えて、外部接続の必要がないため単体テストを行うには最適のDBです。
MySQL固有の機能や関数はH2では使えませんが、CRUDが主なWebアプリ開発ではほとんど困ることはないと思います。実際、アジャイルの開発現場では自動テストや継続的インテグレーションと非常に相性のいい
H2を利用するケースが多いです。1-1. 依存関係の追加
前回作成したSpringBootのプロジェクトに、単体テストで使う
H2とDBUnit、spring-test-dbunitをdependenciesに追加します。
spring-test-dbunitはSpringでDBUnitを使うなら必須といっても過言ではない便利なライブラリです。
簡単なアノテーションの記述で事前データの読み込みや事後検証などのDBUnitの機能が使えるようになります。build.gradledependencies { implementation 'org.springframework.boot:spring-boot-starter-validation' implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.1.3' compile group: 'mysql', name: 'mysql-connector-java', version: '8.0.22' compileOnly 'org.projectlombok:lombok' annotationProcessor 'org.projectlombok:lombok' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } testCompileOnly 'org.projectlombok:lombok' testAnnotationProcessor 'org.projectlombok:lombok' testRuntimeOnly 'com.h2database:h2' // 追加 testCompile group: 'org.dbunit', name: 'dbunit', version: '2.7.0' // 追加 testCompile group: 'com.github.springtestdbunit', name: 'spring-test-dbunit', version: '1.3.0' // 追加 }1-2. JUnitテスト用のデータソースのを設定
JUnitテスト用に
H2への接続設定を、test/resources/application.ymlとしてファイルを作成します。
*main/resouces/...の方ではないことに注意してください。src/test/resouces/application.ymlspring: datasource: driver-class-name: org.h2.Driver url: jdbc:h2:mem:testdb;MODE=MySQL;DATABASE_TO_LOWER=TRUE # H2DBをインメモリ、MySQL互換モードで利用 username: sa password: initialization-mode: always # 常に以下のschema,dataのSQLを使って初期化 schema: classpath:schema.sql # test/resources/schema.sql data: classpath:data.sql # test/resources/data.sql sql-script-encoding: utf-8補足:データベースURLについて
url: jdbc:h2:mem:testdb;MODE=MySQL;DATABASE_TO_LOWER=TRUE # H2DBをインメモリ、MySQL互換モードで利用単体テストではデータの永続化をしないため、インメモリモード(=DBシャットダウン時にデータも破棄)を利用するようURLで指定します。
url指定 モード 概要 jdbc:h2:mem:(DB名) インメモリ DBのデータはメモリ上で保持するためシャットダウン時にデータが破棄される。この性質がJUnitと相性が良い。 jdbc:h2:(dbファイルのパス)[:(DB名)] ファイル保存 パスの (ファイル名).mv.dbに永続化したデータが保存される。例)jdbc:h2:./demodbまた、本番では
MySQLを使うのでH2をMySQL互換モードにするため、
urlに;MODE=MySQL;DATABASE_TO_LOWER=TRUEを追記します。
互換モードについてはこちら補足:起動時にDDL、DMLを読み込み初期化する
initialization-mode: always # 常に以下のschema,dataのSQLを使って初期化 schema: classpath:schema.sql # test/resources/schema.sql data: classpath:data.sql # test/resources/data.sqlインメモリモードのDBは起動直後はテーブルも何もありません。
そのためschema.sqlでDDLを、data.sqlでDMLを指定し、initialization-modeにalwaysを指定することで、起動時に毎回DDLとDMLを読み込みセットアップするようにします。
(DDLとDMLは前回の記事で作成したものを指定しています)以上でJUnitテスト用の
H2の接続設定は完了です。最終的に、ローカル環境用とテスト用に作成した
application.ymlは以下のように配置します。├── build.gradle └── src ├── main | ├── java | └── resources | └── application.yml // 前回作ったローカル環境用のMySQLの設定 └── test ├── java └── resources └── application.yml // *今回作ったJUnitテスト用のH2DBの設定*2. Serviceのテスト
DBを絡めたService層のテストケースでは、主に以下の観点のテストを実施します。
- Serviceの各メソッドで期待通りのDBのデータを操作できること
- Serviceのメソッド単位でトランザクション制御(commit/rollback)ができていること
これらを確認するために、各テストメソッドの実行前にDBにテストデータの準備を行い、実行後にはデータが期待値通りの状態であるかを検証します。
2-1. DBUnitを使ったテストケースのサンプル
CRUD処理のテストケースのサンプルは以下の通りです。
DBUnitへ投入するテストデータや検証データにCSVファイルを扱えるようにしている点もポイントです。
デフォルトのXML形式よりCSV形式の方が圧倒的にデータ加工がし易いはずです。package com.example.dbunitdemo.domain.service; import com.example.dbunitdemo.domain.model.Customer; import com.example.dbunitdemo.dataset.CsvDataSetLoader; import com.github.springtestdbunit.TransactionDbUnitTestExecutionListener; import com.github.springtestdbunit.annotation.DatabaseSetup; import com.github.springtestdbunit.annotation.DbUnitConfiguration; import com.github.springtestdbunit.annotation.ExpectedDatabase; import com.github.springtestdbunit.assertion.DatabaseAssertionMode; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.Assertions; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.TestExecutionListeners; import org.springframework.test.context.support.DependencyInjectionTestExecutionListener; import org.springframework.transaction.annotation.Transactional; import java.util.List; @Slf4j @SpringBootTest @DbUnitConfiguration(dataSetLoader = CsvDataSetLoader.class) // DBUnitでCSVファイルを使えるよう指定。*CsvDataSetLoaderクラスは自作します(後述) @TestExecutionListeners({ DependencyInjectionTestExecutionListener.class, // このテストクラスでDIを使えるように指定 TransactionDbUnitTestExecutionListener.class // @DatabaseSetupや@ExpectedDatabaseなどを使えるように指定 }) @Transactional // @DatabaseSetupで投入するデータをテスト処理と同じトランザクション制御とする。(テスト後に投入データもロールバックできるように) class CustomerServiceTest { @Autowired private CustomerService customerService; @Test @DatabaseSetup("/testdata/CustomerServiceTest/init-data") // テスト実行前に初期データを投入 @ExpectedDatabase(value = "/testdata/CustomerServiceTest/init-data", assertionMode = DatabaseAssertionMode.NON_STRICT_UNORDERED) // テスト実行後のデータ検証(初期データのままであること) void findByPk() { // id=3のデータの期待値 Customer expect = Customer.builder() .id(3L) .name("ハン・ソロ") .age(32) .address("コレリア") .build(); // id=3の検索結果 Customer actual = customerService.findByPk(3L); // 検証:期待値と一致していること Assertions.assertEquals(expect, actual); } @Test @DatabaseSetup("/testdata/CustomerServiceTest/init-data") @ExpectedDatabase(value = "/testdata/CustomerServiceTest/init-data", assertionMode = DatabaseAssertionMode.NON_STRICT_UNORDERED) void findAll() { // 検索結果 List<Customer> customers = customerService.findAll(); log.info("actual customers = {}", customers); // 検証:全4件であること(本当なら各レコードの中身も検証した方がよい) Assertions.assertEquals(4, customers.size()); } @Test @DatabaseSetup("/testdata/CustomerServiceTest/init-data") @ExpectedDatabase(value = "/testdata/CustomerServiceTest/after-create-data", assertionMode = DatabaseAssertionMode.NON_STRICT_UNORDERED) // テスト実行後に1件データが追加されていること void create() { // 登録するデータを準備 Customer newCustomer = Customer.builder() .name("ボバ・フェット") .age(32) .address("カミーノ") .build(); // 登録実行 int createdCount = customerService.create(newCustomer); // 検証:1件の追加に成功していること Assertions.assertEquals(1, createdCount); // 検証:登録に使ったオブジェクトに採番されたid=5が設定されていること Assertions.assertEquals(5, newCustomer.getId()); } @Test @DatabaseSetup("/testdata/CustomerServiceTest/init-data") @ExpectedDatabase(value = "/testdata/CustomerServiceTest/after-update-data", assertionMode = DatabaseAssertionMode.NON_STRICT_UNORDERED) // テスト実行後に1件データが更新されていること void update() { // 更新するデータを準備 Customer updateCustomer = Customer.builder() .id(4L) .name("アナキン・スカイウォーカー") .age(41) .address("タトゥイーン") .build(); // 更新実行 int updatedCount = customerService.update(updateCustomer); // 検証:1件の更新に成功していること Assertions.assertEquals(1, updatedCount); } @Test @DatabaseSetup("/testdata/CustomerServiceTest/init-data") @ExpectedDatabase(value = "/testdata/CustomerServiceTest/after-delete-data", assertionMode = DatabaseAssertionMode.NON_STRICT_UNORDERED) // テスト実行後に1件データが削除されていること void delete() { // id=1のレコードを削除 int deletedCount = customerService.delete(1L); // 検証:1件の削除に成功していること Assertions.assertEquals(1, deletedCount); } }クラスに指定されているアノテーションはSpringBootで
JUnit5+DBUnit+spring-test-dbunitを使う場合のお決まりの記述として覚えてしまいましょう。(@SpringBootTest、@DbUnitConfiguration、@TestExecutionListeners、@Transactional)その中の
@DbUnitConfiguration(dataSetLoader = CsvDataSetLoader.java)でCSVファイルを読み込めるようにしていますが、CsvDataSetLoader.javaは自前で実装する必要があるため、次の2-2で説明します。そして各テストメソッドに指定されている
@DatabaseSetupと@ExpectedDatabaseが、事前データの投入と事後データの検証を行うデータ定義ファイル(今回はCSVファイル)を指定するアノテーションです。2-2. CSVファイルを利用するため
CsvDataSetLoaderを作成するデフォルトではXMLファイル形式で事前データや事後検証用のデータを記述しますが、CSVファイル形式の方がデータを加工しやすいはずです。
そこで@DbUnitConfigurationにCsvDataSetLoader.javaを指定してCSVファイルを利用できるようにします。
CsvDataSetLoader.javaは以下のクラスを自前で作る必要があります。(最初から用意されていればいいのに)CsvDataSetLoader.javapackage com.example.dbunitdemo.dataset; import com.github.springtestdbunit.dataset.AbstractDataSetLoader; import lombok.extern.slf4j.Slf4j; import org.dbunit.dataset.IDataSet; import org.dbunit.dataset.csv.CsvDataSet; import org.springframework.core.io.Resource; @Slf4j public class CsvDataSetLoader extends AbstractDataSetLoader { @Override protected IDataSet createDataSet(Resource resource) throws Exception { return new CsvDataSet(resource.getFile()); } }2-3. CSVファイルを作成する
各テストメソッドの初期データや事後の検証用に読み込むCSVファイルを準備します。
例えば、以下のパス指定の場合@DatabaseSetup("/testdata/CustomerServiceTest/init-data")
src/test/resources配下の/testdata/CustomerServiceTest/init-dataディレクトリ内に
- table-ordering.txt
- [テーブル名].csv (複数配置可)
を配置して読み込ませます。
src └── test ├── java └── resources └── testdata └── CustomerServiceTest └── init-data ├── table-ordering.txt // テーブルの読み込み順 └── customer.csv // customerテーブルに読み込むデータtable-ordering.txtcustomercustomer.csvid,name,age,address 1,ルーク・スカイウォーカー,19,タトゥイーン 2,レイア・オーガナ,19,オルデラン 3,ハン・ソロ,32,コレリア 4,ダース・ベイダー,41,タトゥイーン
table-ordering.txtには読み込むテーブルの順序を記述しますが、今回はテスト対象のテーブルがcustomer1つしかないので冗長に見えるかもしれません。
しかし複数のテーブルに初期データを準備する場合、特に外部キー(FOREIGN KEY)制約のあるテーブルが対象の場合は、子テーブルより先に親テーブルにデータを投入しないとエラーになります。そのためテーブルのデータ投入の順番を
table-ordering.txtで指定する必要があります。
まぁ、CSVファイルが1件なら要らないじゃん、というのはありますが・・CRUDテストの検証用CSVファイルを作成
CSVファイルの読み込み方がわかったところで、今回のCRUDテストに必要なCSVデータをみてみます。
初期データ(init-data)
初期データは4件。どのテストメソッドも初期データはこれを読み込む想定。
customer.csvid,name,age,address 1,ルーク・スカイウォーカー,19,タトゥイーン 2,レイア・オーガナ,19,オルデラン 3,ハン・ソロ,32,コレリア 4,ダース・ベイダー,41,タトゥイーン登録後検証データ(after-create-data)
1件登録した後の検証用データ。5.ボバ・フェットが追加されている想定。
customer.csvid,name,age,address 1,ルーク・スカイウォーカー,19,タトゥイーン 2,レイア・オーガナ,19,オルデラン 3,ハン・ソロ,32,コレリア 4,ダース・ベイダー,41,タトゥイーン 5,ボバ・フェット,32,カミーノ更新後検証データ(after-update-data)
1件更新した後の検証用データ。4.ダース・ベイダーがアナキン・スカイウォーカーに更新されている想定。
customer.csvid,name,age,address 1,ルーク・スカイウォーカー,19,タトゥイーン 2,レイア・オーガナ,19,オルデラン 3,ハン・ソロ,32,コレリア 4,アナキン・スカイウォーカー,41,タトゥイーン削除後検証データ(after-delete-data)
1件削除した後の検証用データ。1.ルーク・スカイウォーカーが削除されている想定。
customer.csvid,name,age,address 2,レイア・オーガナ,19,オルデラン 3,ハン・ソロ,32,コレリア 4,ダース・ベイダー,41,タトゥイーン以上でテストデータの作成が完了です。
3. テストの実行
いよいよテストを実行してみます。
プロジェクトルートで以下のコマンドを実行するか、IDEからCustomerServiceTestクラスのテストを実行します。$ gradle testタスクが完了したら
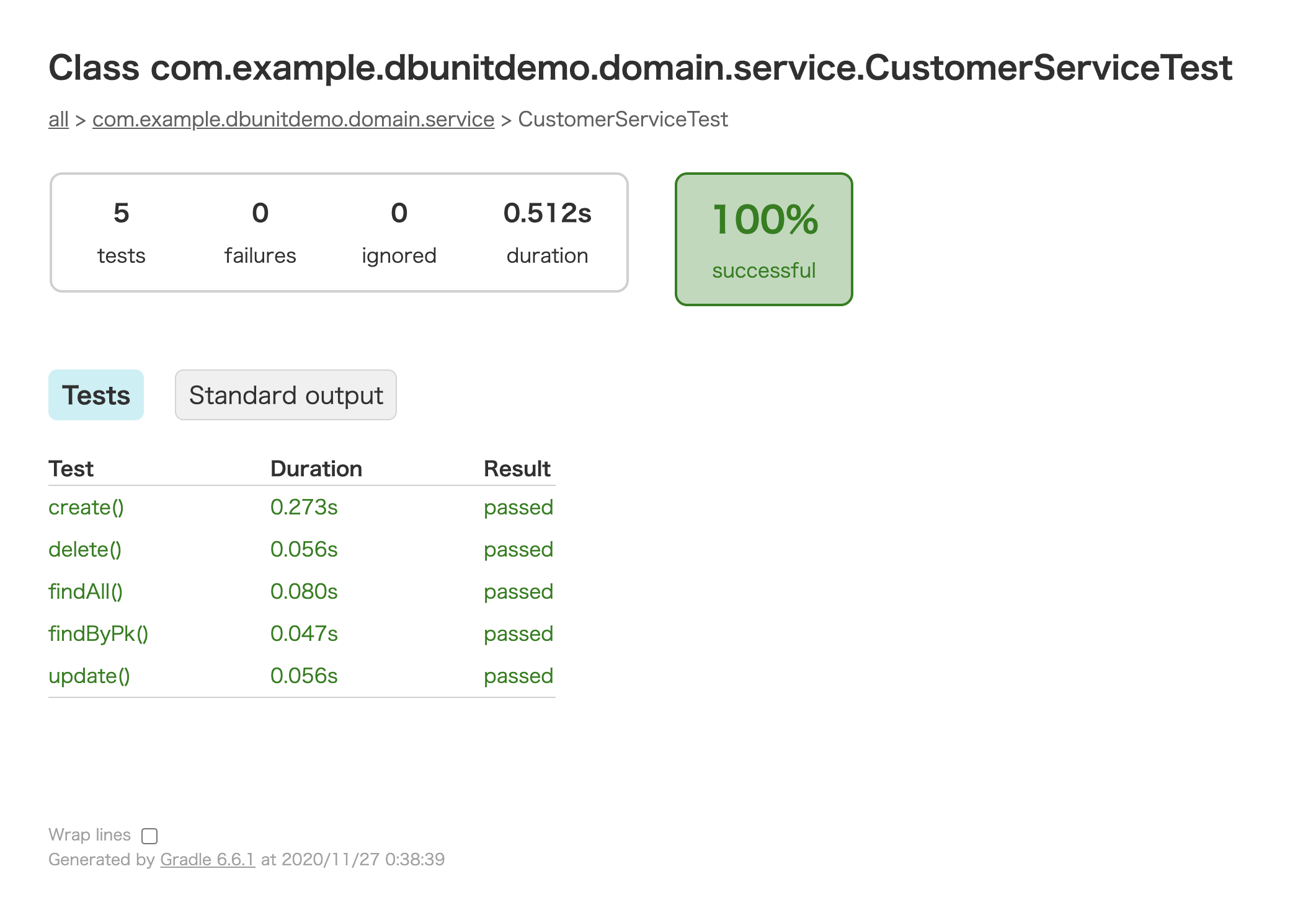
build/reports/tests/test/classes/...htmlとして出力されているので確認してみます。
見事にオールグリーンのテスト結果となっています!!
最終的なファイル構成
参考までに今回作成したファイル群は以下の通りです。
CSVファイルのの読み込みにうまくいかないなどの場合は、以下の構成になっているか確認してみてください。src ├── main // 前回作成 └── test ├── java │ └── com │ └── example │ └── dbunitdemo │ ├── DbunitDemoApplicationTests.java │ ├── dataset │ │ └── CsvDataSetLoader.java │ └── domain │ └── service │ └── CustomerServiceTest.java └── resources └── testdata └── CustomerServiceTest ├── after-create-data // 登録後検証データ │ ├── table-ordering.txt │ └── customer.csv ├── after-delete-data // 削除後検証データ │ ├── table-ordering.txt │ └── customer.csv ├── after-update-data // 更新後検証データ │ ├── table-ordering.txt │ └── customer.csv └── init-data // 初期データ ├── table-ordering.txt └── customer.csvあとがき
以前の記事から合わせると、ようやくJUnit5でController、Service(Repository)の実装サンプルができました。
特にDBUnitとspring-test-dbunitの組み合わせは手軽にDBUnitの強力な機能が使えるので是非使いこなしたいところです。
- 投稿日:2020-11-27T01:15:02+09:00
【Eclipse】Javaのパッケージの作成方法
Eclipse上でパッケージを作成する方法
パッケージの基本的な作り方
パッケージ の直下に パッケージをつくる
- 先程と同様にパッケージ作成にすすむ
- パッケージ名を入力する際に
先程の親パッケージ名.子パッケージ名にして命名する例えば、 最初に作った パッケージ名が、「package」だったとしたら、
package.child_1
みたいな感じで、ドットで繋いであげましょう。パッケージはカテゴリーみたいな考え方でいいと思います。
パッケージの階層も、「 大分類 > 中分類 > 小分類 」のようなイメージですね。料理で例えるなら、
「 料理 > イタリアン > 前菜 」みたいな感じでしょうか?
プロジェクトのファイルは、基本的にはパッケージ直下に作成してグルーピングすることにより、 作業効率とメンテナンス性の向上 図ることが出来ます。
- 投稿日:2020-11-27T00:36:27+09:00
Maven の mvn exec:java で datadog agent によりお手軽に Profile する方法
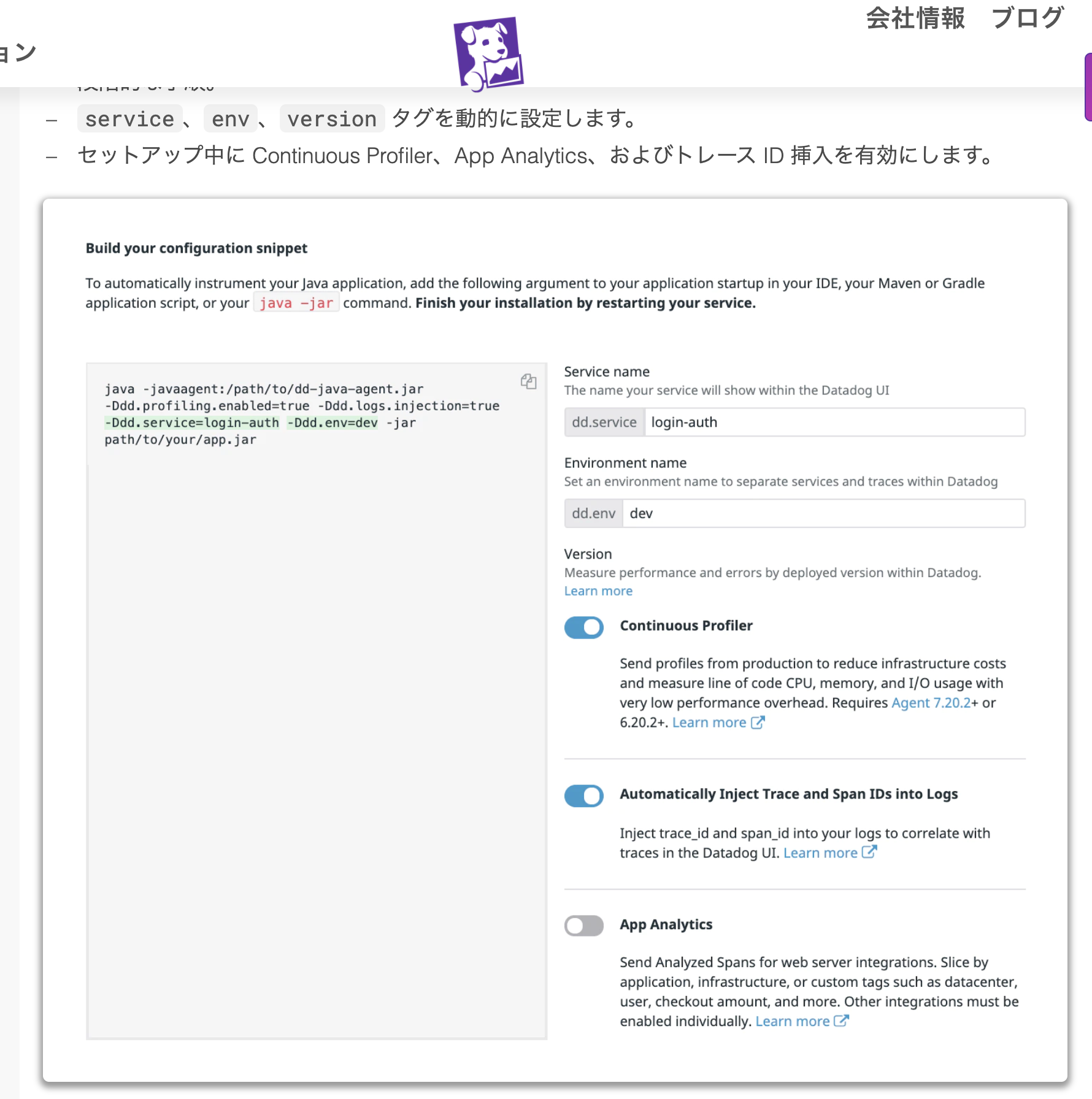
MAVEN_OPTS に、
https://docs.datadoghq.com/ja/tracing/setup/java/?tab=springboot
の、
で作った -javaagent の snipet を指定する。
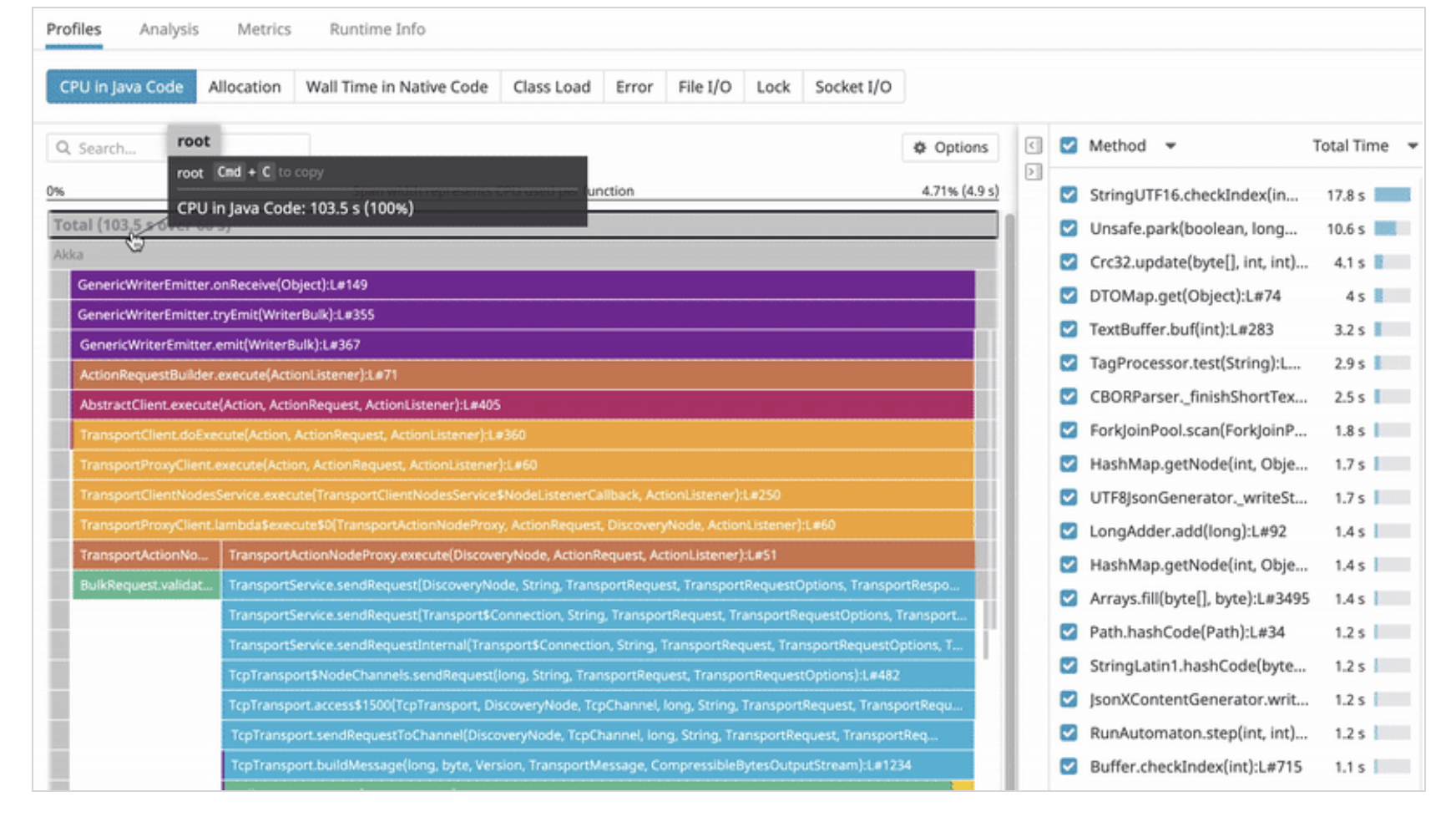
export MAVEN_OPTS="-javaagent:/path/to/dd-java-agent.jar -Ddd.profiling.enabled=true -Ddd.logs.injection=true -Ddd.trace.sample.rate=1 -Ddd.service=YOURAPPNAME -Ddd.env=dev" mvn install; mvn compile; mvn exec:java -Dexec.mainClass=YOURAPPCLASS -Dexec.args="arg1 arg2"その後 Datadog の Web 画面から APM -> Profile にて、
のような画面が確認できる。
- 投稿日:2020-11-27T00:36:27+09:00
Maven の mvn exec:java で実行した java のプログラムを datadog agent によりお手軽に Profile する方法
MAVEN_OPTS に、
https://docs.datadoghq.com/ja/tracing/setup/java/?tab=springboot
の、
で作った -javaagent の snipet を指定する。
export MAVEN_OPTS="-javaagent:/path/to/dd-java-agent.jar -Ddd.profiling.enabled=true -Ddd.logs.injection=true -Ddd.trace.sample.rate=1 -Ddd.service=YOURAPPNAME -Ddd.env=dev" mvn install; mvn compile; mvn exec:java -Dexec.mainClass=YOURAPPCLASS -Dexec.args="arg1 arg2"その後 Datadog の Web 画面から APM -> Profile にて、
のような画面が確認できる。
- 投稿日:2020-11-27T00:32:29+09:00
【Java】インポート( 他のパッケージのクラスやメソッドを使う )
インポート
他のパッケージやクラスを呼び出して使う、インポートに関するメモです。
インポートとは
インポートとは、「 他のパッケージに記入されているクラスや関数を実行するための記述 」です。
「 他の クラス を利用して クラス の インスタンス を生成することができ、また「外部ライブラリを自分のプログラムで使えるようにする時** 」も、インポートを用います。
インポートの使い方
インポートは基本的にソースコードの先頭にある、パッケージの下に記述する。
import の後ろに、 パッケージとクラスもしくはインターフェイス名を指定して読み込むみます。
import パッケージ名.クラス名; import パッケージ名.インターフェイス名;サンプルコード
// javaパッケージの中のlangパッケージの中のMathクラスをimport import java.lang.Math; public class StaticClass { public static void staticMethod(){ int num1 = 10; int num2 = 20; // importしたMathクラスのmaxメソッドを使用 int nmax = Math.max(num1, num2); System.out.println("nmax : " + nmax); } }【出力結果】
nmax : 20import不要のクラス
- インポート宣言することで、パッケージ名を省略してクラス名だけで記述することができる
- java.langパッケージは基本的な クラス がまとめられた パッケージ であり、頻繁に利用するためインポート宣言を省略することができる
- アスタリスク「 * 」を使って、その パッケージ に属する クラス すべて利用することがインポートできる
//java.utilパッケージに属する全クラスのインポート宣言 import java.util.*;※ ただし、指定したパッケージに属するクラスに限定されるので、サブパッケージに属するクラスがインポートされることはない
staticインポート
本来、static修飾子のつくフィールドやメソッドは、
クラス名.フィールド{名やクラス名.メソッド名の書式で、どのクラスに定義されているものか明示しなければいけません。これを 「フィールド名や メソッド名だけで省略表記できる」ようにするための宣言が staticインポートです。
staticメソッドをインポート宣言するとき
- メソッドだけを記述し、"()" や引数などは記述しない
- オーバーロードされた同名のメソッドが複数あった場合はオーバーロードのルールが適用されるので、メソッドの数だけインポート宣言したり、引数を指定したりする必要はない
- インポートしたクラスに、インポートされたメソッドやフィールドと同名のものがあった場合、そのインポートは無視される
- staticインポートは、import staticに続けて、省略表記したいフィールドやメソッドの完全修飾クラス名を記述する
staticメソッドのインポート宣言
import static jp.co.xxx.Sample.num //Sampleクラスのstaticなフィールドをインポート import static jp.co.xxx.Sample.print //Sampleクラスのstaticなメソッドをインポート