- 投稿日:2020-11-27T23:56:35+09:00
Google Cloud FunctionsからNature Remo APIを叩いて部屋の温度や湿度を記録する。
はじめに
Nature Remoは赤外線を利用して普通の家電をスマート家電にするスマートリモコンです。
テレビ、照明、エアコンなどをスケジュールや条件でオン、オフできたりする製品ですが、
温度、湿度、照度、人感センサーなどが搭載されており、
公式のAPIが公開されているので、APIを叩いて取得してみることにします。
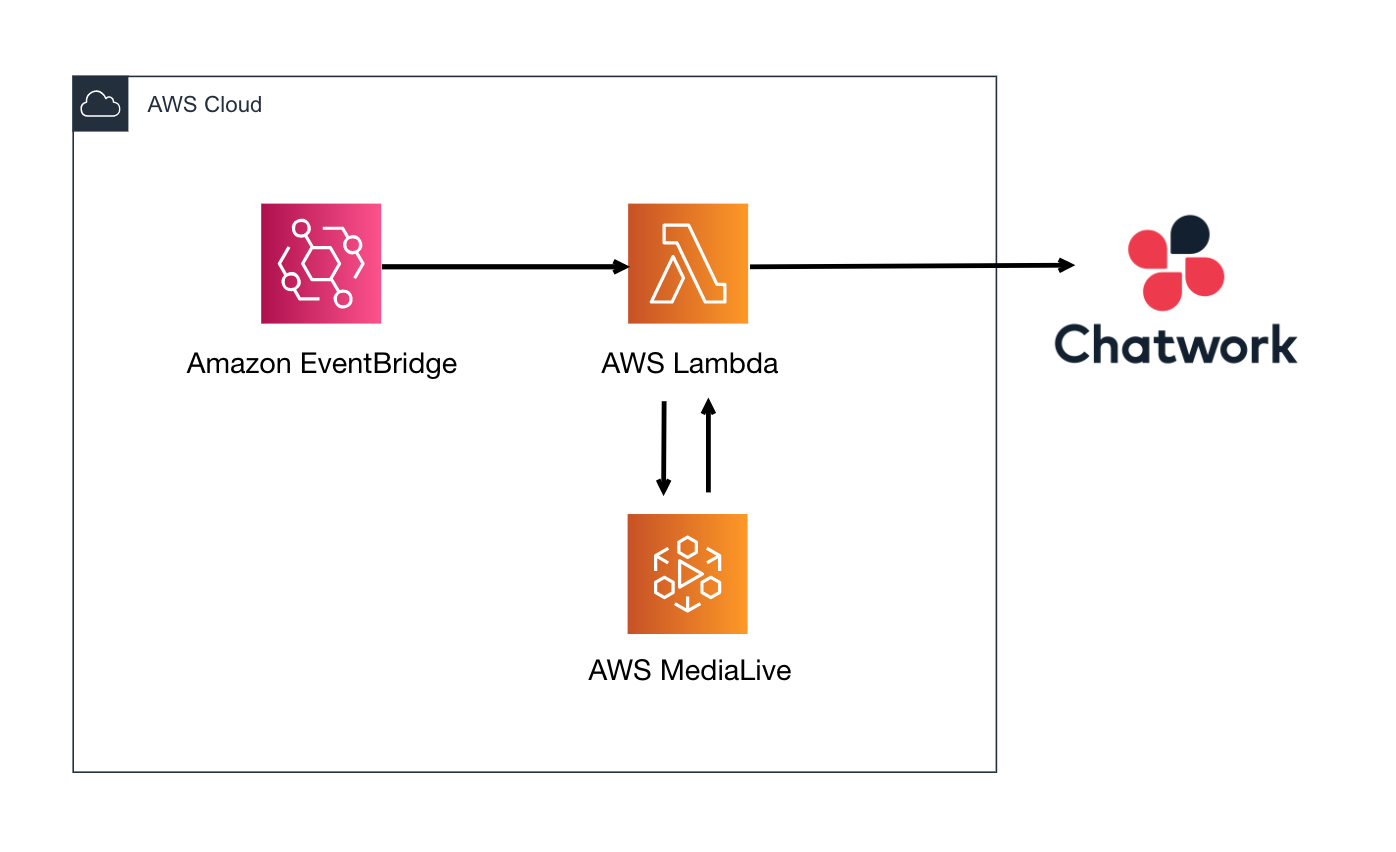
また取得した情報を、継続的に記録していくための仕組みも構築してみます。構成
- Google Cloud Functions (Python 3.7)
- Nature Remo API
- Google BigQuery
構成は単純ですが、APIを叩いて情報を取得しDBに書き込むプログラムを
GoogleCloudFunctionで定期的に動かす、というつくりです。Pythonは使い慣れているからという理由ですが、JavaやNode.jsなども対応しています。
データベースは、APIで取得したJSON形式のままFirestoreに保存する方法もありますが、
実際やってみたところ、後々のデータ可視化で面倒ということがわかったので、
表形式のBigQueryを使うことにしました。(各種BIツールも多く対応しています。)また、他のPaaS系のDBと違ってインスタンスを立ち上げるという概念がなく、
フルマネージドのため、発行したクエリに対してのみの課金となります。
このような個人のデータ蓄積程度であれば、ほぼ無料に近い料金で済みます。準備
以下について事前に準備しておきます。
他にたくさん記事があるため、手順は説明しません。・Nature Remo APIのアクセストークン取得
(公式サイト https://home.nature.global/ にログインして発行)
・Google Cloud Platformを使うための利用開始登録
・Google Cloud Platformで新規プロジェクトを作成手順
以下の順番で進めていきます。
① Cloud Functionsに関数をデプロイ
② BigQueryの準備
③ Cloud Scheduler でスケジュール実行の設定GCP上の設定画面は度々変更があるため、
本記事で掲載している表示とは異なる場合がありますのでご了承ください。① Cloud Functionsに関数をデプロイ
GCP上で新しいプロジェクトを作成したら、
左のメニューからコンピューティング>Google Cloud Functionsを選択します。
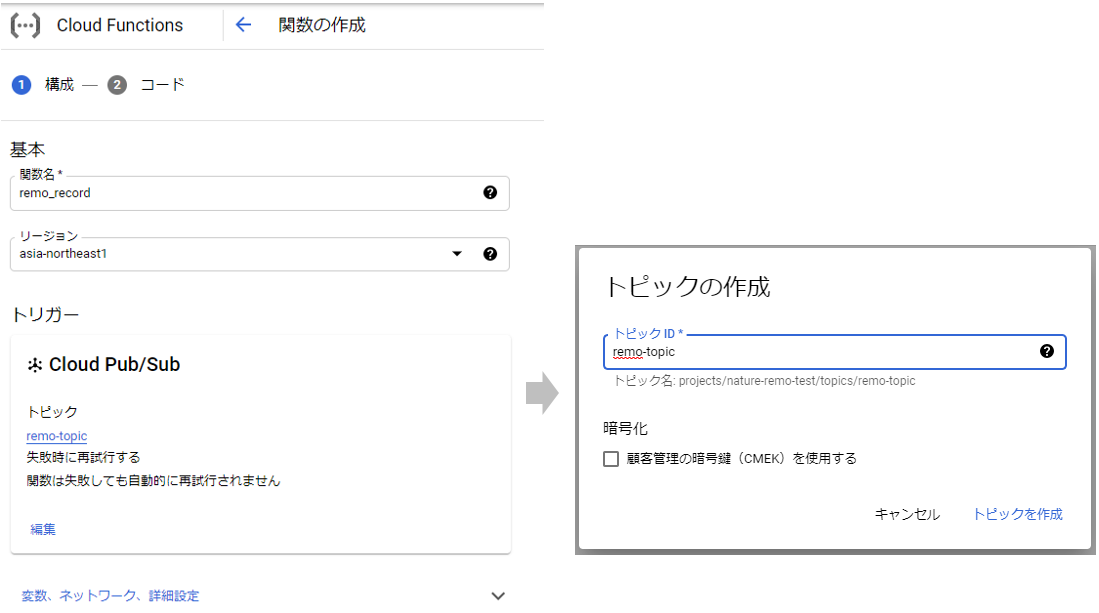
「関数を作成」をクリック
基本
関数名を入力し、リージョンを選択します。
トリガー
スケジュール実行は「Cloud Scheduler」を使用しますが、
「Pub/Sub」という非同期メッセージングのサービスを介して、関数をトリガーします。トリガーのタイプで「Cloud Pub/Sub」を選択し、
「トピックを作成する」を選択して、適当なトピックIDを入力して作成しておきます。
スケジュール自体は後でCloud Scheduler側で設定するので、ここはトピック作成までです。
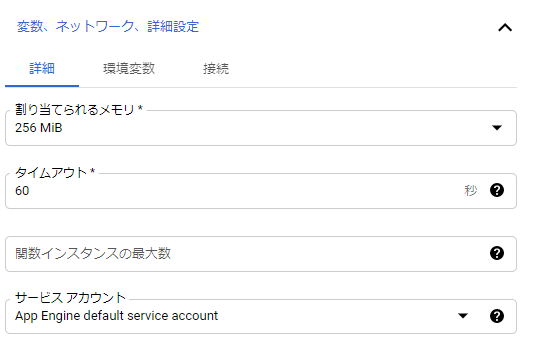
変数、ネットワーク、詳細設定
割り当てメモリやタイムアウトを設定できます。
今回のような軽い処理はデフォルトで大丈夫ですが、必要に応じて変更します。
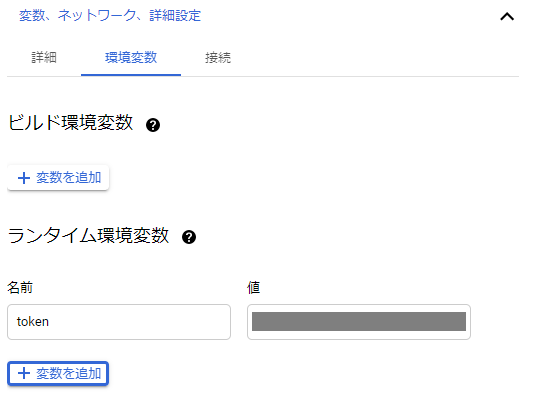
環境変数のタブで、
事前に入手したNature Remo APIのトークンを、ランタイム環境変数に設定しておきます。
トークンは機密情報なので、ソース内には書かず環境変数に指定します。
万が一、ソースに書いたのをGitHubなどの公開リポジトリにあげたりして漏れてしまうと、
世界中の誰でも、あなたの家の電気を点けたり消したりできるようになります。
コード
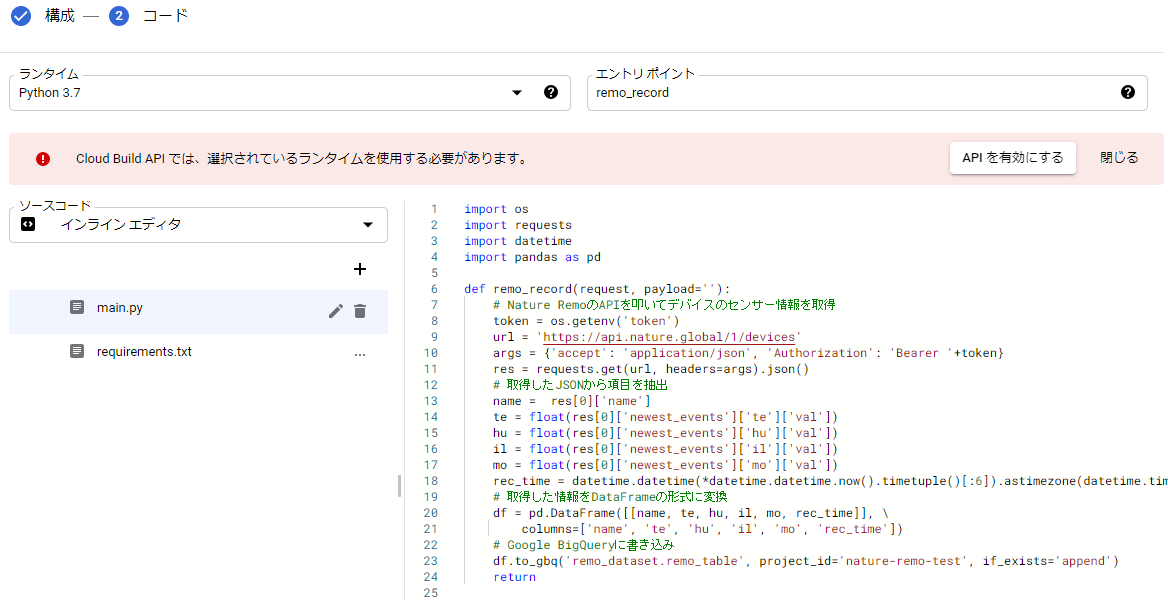
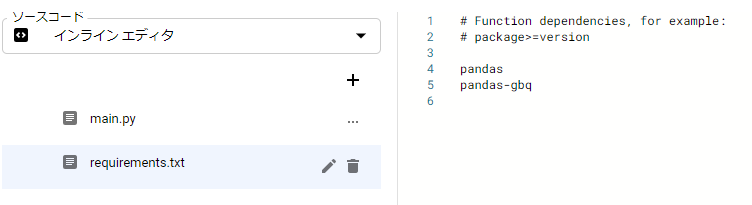
次の画面で実際に動かすコードを入力します。
- ランタイムで「Python 3.7」を選択
- エントリポイントには、ソースコード中の呼び出す関数名を入力
- main.py にメインのソースコード
- requirements.txt に必要なライブラリを記載
- Cloud Build APIを有効にするようアラートが出ているので有効にしておきます
継続的に開発する場合は、インラインエディタよりリポジトリからのデプロイがお勧めです。
Googleのリポジトリが利用でき、各種Gitクライアントからプッシュすることができます。ソースコードは以下の通り
main.pyimport os import requests import datetime import pandas as pd def remo_record(request, payload=''): # Nature RemoのAPIを叩いてデバイスのセンサー情報を取得 token = os.getenv('token') url = 'https://api.nature.global/1/devices' args = {'accept': 'application/json', 'Authorization': 'Bearer '+token} res = requests.get(url, headers=args).json() # 取得したJSONから項目を抽出 name = res[0]['name'] te = float(res[0]['newest_events']['te']['val']) hu = float(res[0]['newest_events']['hu']['val']) il = float(res[0]['newest_events']['il']['val']) mo = float(res[0]['newest_events']['mo']['val']) rec_time = datetime.datetime(*datetime.datetime.now().timetuple()[:6]).astimezone(datetime.timezone(datetime.timedelta(hours=+9))) # 取得した情報をDataFrameの形式に変換 df = pd.DataFrame([[name, te, hu, il, mo, rec_time]], \ columns=['name', 'te', 'hu', 'il', 'mo', 'rec_time']) # Google BigQueryに書き込み df.to_gbq('remo_dataset.remo_table', project_id='nature-remo-test', if_exists='append') returnAPIを叩いて取得したJSONから各項目の値を抽出し、
pandasのDataFrame形式に変換し、DBに書き込むという単純なものです。
pandasのto_gbqでBigQueryに一発で書き込みができます。(pandas-gbqのインストールが必要)
引数は、データセット名.テーブル名、プロジェクトID、書き込み方式を指定します。
GoogleCloudFunctionと同じアカウント内で行うので、認証などの記述は必要ありません。家にNature Remoが1台だけある前提でのソースコードです。
複数台のデバイスがある場合は識別するロジックが必要かも知れません。
詳細は公式のAPI仕様を確認してください。
https://developer.nature.global/requirements.txtに記載したライブラリが、デプロイ時にインストールされます。
pandas の他、Google BigQueryに接続するためのpandas-gbqを入れておきます。
ここまでできたら、「デプロイ」をクリックして関数をデプロイします。
しばらくして、関数の左に緑色のチェックマークが付いたら無事デプロイ完了です。
② BigQueryの準備
メニューからビッグデータ>BigQueryを選択します。
初めての場合でBigQueryを有効にするような画面が出る場合は、有効にします。
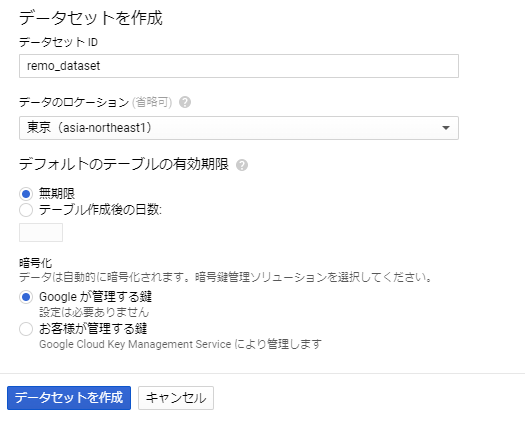
BigQueryが有効になったら、まずは「データセット」を作成します。
BigQueryでは、プロジェクト > データセット > テーブル のような関係になっています。
データセットのID等を入力します。
データセットIDはCloudFunctionsのソース中のデータセット名と一致させてください。
データセットの作成だけで、準備はとりあえず完了です。
テーブルは関数を実行した際に、無ければ作成されます。スキーマを決めてテーブルを作成しておくこともできます。
その場合は、スキーマと挿入しようとしたデータで型などが違う場合にエラーとなります。③ Cloud Scheduler でスケジュール実行の設定
メニューからツール>Cloud Schedulerを選択します。
「ジョブを作成」を選択
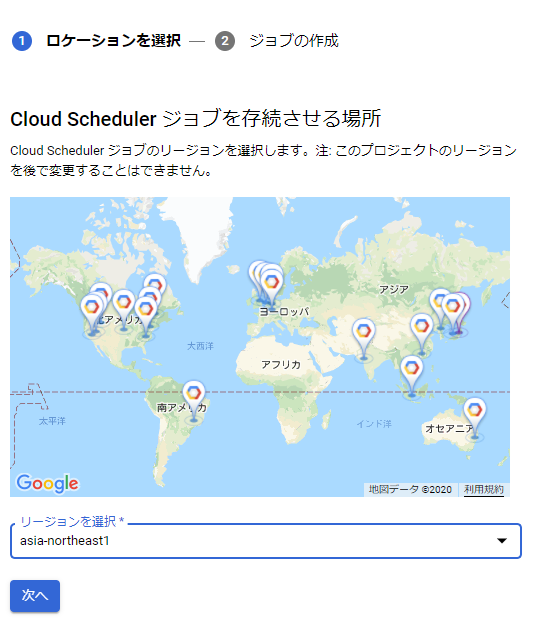
リージョンを選択します。
(なぜかSchedulerの時だけ世界地図が出てきます)
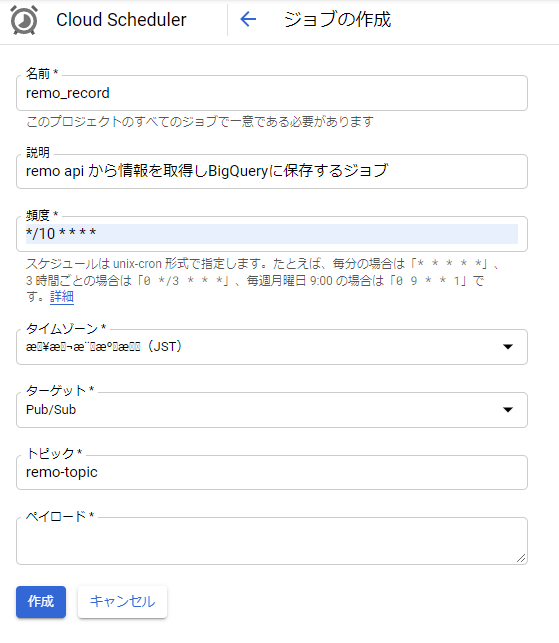
名前: ジョブ名を入力します。(関数名と同じにしましたが何でも構いません)
説明: ジョブの説明を分かりやすく記載します。
頻度: cron形式で入力します。 10分間隔で実行されるように記載しています。
タイムゾーン: JSTを選択(なぜかこの時文字化けしていますが、日本で検索できます)
ターゲット: Pub/Subを選択
トピック: 関数作成時に作成したトピックIDを入力
ペイロード: 関数に引数を渡すことができるようです。必須入力ですがスペースでOKです。
作成するとすでに有効になっているので、次の10分間隔からジョブが実行されます。
ちなみにここでログの表示とありますが、
Schedulerでジョブが起動したか(Pub/Subにメッセージを発行できたか)のみの内容です。
このログでOKでも、関数の処理が正常終了したかどうかは別なので、注意してください。
CloudFunctions側で関数を開いてログを確認すると正常終了していることが確認できました。
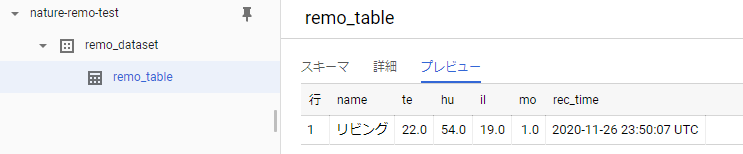
実行後にBigQueryを確認すると、データセットの下にテーブルが作成されています。
プレビューを開くと1行レコードが追加されていることが確認できました。
気温22℃、湿度54%、照度19(単位はよくわかりませんが・・・)とのことです。
moは人感センサーとのことですが、記録を見る限りは不在時でも常に1となってたので、
機能していないように思えます。
終わりに
Google Cloud Platform の各種サービスを使って、
クラウド上でNatureRemoのデータを蓄積する仕組みを作ることができました。
貯めたデータがどうだったかについても、可視化して後日記載してみたいと思います。


- 投稿日:2020-11-27T23:51:52+09:00
Pythonでエクセルを操作する
記事を書く経緯
Pythonを相変わらず学習しています。Pythonはよく「自動化ができる」、「Excel操作ができる」という話しを聞くので他の言語でもExcel操作はできますが、私が一番親しい言語のPythonでExcel操作をしていきたいと考えました。
また、学習は楽しくするのが大事だと思うので今後の展開も考え、自分が好きなアイドルグループ「日向坂46」のメンバーの情報を利用します。
1. 準備
まずは準備です。PythonでExcel操作をするためにはopenpyxlというライブラリが必要なので「pip」コマンドでライブラリをインストールしていきます。
pip install openpyxlその後 「pip list」コマンドを打って openpyxlがあれば成功です。
2.使ってみる
Excelファイルはこのようになっています
名前 誕生日 星座 身長 出身 血液型 何期生 情報は1期生から50音順に入力しています。(情報ソースは公式ホームページです。)
*最終的なセルの様子は割愛させていただきます。また、ファイル名は "hinata.xlsl" シート名は "member"になっています。この部分は任意で変えることが可能です。
はじめはExcelファイルの読み込みと操作に使うシート名を変数に格納します。
Excelファイルの読み込みは openpyxl.load_workbookで行い、シートは読み込んだ変数を利用して指定します。import openpyxl #Excelファイル読み込み wb = openpyxl.load_workbook('hinata.xlsx') #シート名指定 ws = wb['member']次に実際にセルを指定しましょう。セルは「タプル」になっていて値の出力に少し工夫を加える必要があります。
#セルの行数を指定することでその行の要素を変数へ格納できる(1行目は1でOK) fact = ws[1] for i in fact: #.valueを追加することでセルの値を出力可能 print(i.value,end=" ") #endオプションは出力あとのに追加で出力できる(改行を防げる) """ 出力↓ 名前 誕生日 星座 身長 出身 血液型 何期生 """次はメンバー全員の情報を一気に出力してみましょう
最後の行を 「指定したシートを格納した変数.max_row」で取得できます。import openpyxl wb = openpyxl.load_workbook('hinata.xlsx') ws = wb['member'] #最後の行を取得 max = ws.max_row #range(最初,最後)を指定できる #rangeは(最後-1)になるのでmaxは+1することで解決できる # ↓ for i in range(2,max+1): for j in ws[i]: print(j.value, end=" ") print() """出力 潮 紗理奈 1997-12-26 00:00:00 やぎ座 157cm 神奈川県 O型 1期 影山 優佳 2001-05-08 00:00:00 おうし座 155.5cm 東京都 O型 1期 加藤 史帆 1998-02-02 00:00:00 みずがめ座 160cm 東京都 A型 1期 斉藤 京子 1997-09-05 00:00:00 おとめ座 155cm 東京都 A型 1期 佐々木 久美 1996-01-22 00:00:00 みずがめ座 167.5cm 千葉県 O型 1期 佐々木 美鈴 1999-12-17 00:00:00 いて座 165cm 兵庫県 O型 1期 高瀬 愛奈 1998-09-20 00:00:00 おとめ座 157cm 大阪府 A型 1期 高本彩花 1998-11-02 00:00:00 さそり座 162.5cm 神奈川県 B型 1期 東村 芽衣 1998-08-23 00:00:00 おとめ座 154cm 奈良県 O型 1期 金村 美玖 2002-09-10 00:00:00 おとめ座 163cm 埼玉県 O型 2期 河田 陽菜 2001-07-23 00:00:00 しし座 154cm 山口県 B型 2期 小坂 菜緒 2002-09-07 00:00:00 おとめ座 161.5cm 大阪府 O型 2期 富田 鈴花 2001-01-18 00:00:00 やぎ座 165cm 神奈川県 A型 2期 丹生 明里 2001-02-15 00:00:00 みずがめ座 156.5cm 埼玉県 AB型 2期 濱岸 ひより 2002-09-28 00:00:00 てんびん座 167cm 福岡県 A型 2期 松田 好花 1999-04-27 00:00:00 おうし座 157.2cm 京都府 A型 2期 宮田 愛萌 1998-04-28 00:00:00 おうし座 157.5cm 東京都 A型 2期 渡邊 美穂 2000-02-24 00:00:00 うお座 158.6cm 埼玉県 A型 2期 上村 ひなの 2004-04-12 00:00:00 おひつじ座 162cm 東京都 AB型 3期 高橋 未来虹 2003-09-27 00:00:00 てんびん座 168.5cm 東京都 B型 3期 森本 茉莉 2004-02-23 00:00:00 うお座 159.6cm 東京都 A型 3期 山口 陽世 2004-02-23 00:00:00 うお座 151cm 鳥取県 O型 3期 """できました。
3.セルを表示する
今後のことを考え、セル番号を取得する方法も学ぶ
セル番号表示指定した行.coordinate
試しに1行目のセル番号を表示するimport openpyxl wb = openpyxl.load_workbook('hinata.xlsx') ws = wb['member'] fact = ws[1] for i in fact: print(i.coordinate) """ #出力 A1 B1 C1 D1 E1 F1 G1 """これを応用して全セル番号を出力します。
import openpyxl wb = openpyxl.load_workbook('hinata.xlsx') ws = wb['member'] fact = ws[1] max = ws.max_row for i in range(2,max+1): for j in ws[i]: print(j.coordinate ,end=" ") print() """ 出力 A2 B2 C2 D2 E2 F2 G2 A3 B3 C3 D3 E3 F3 G3 A4 B4 C4 D4 E4 F4 G4 A5 B5 C5 D5 E5 F5 G5 A6 B6 C6 D6 E6 F6 G6 A7 B7 C7 D7 E7 F7 G7 A8 B8 C8 D8 E8 F8 G8 A9 B9 C9 D9 E9 F9 G9 A10 B10 C10 D10 E10 F10 G10 A11 B11 C11 D11 E11 F11 G11 A12 B12 C12 D12 E12 F12 G12 A13 B13 C13 D13 E13 F13 G13 A14 B14 C14 D14 E14 F14 G14 A15 B15 C15 D15 E15 F15 G15 A16 B16 C16 D16 E16 F16 G16 A17 B17 C17 D17 E17 F17 G17 A18 B18 C18 D18 E18 F18 G18 A19 B19 C19 D19 E19 F19 G19 A20 B20 C20 D20 E20 F20 G20 A21 B21 C21 D21 E21 F21 G21 A22 B22 C22 D22 E22 F22 G22 A23 B23 C23 D23 E23 F23 G23 """4.最後に
今回はPythonでExcel操作をする方法(基礎の基礎)を学びました。
これをきっかけにもう少しExcel操作を学び、Excelの情報を加工、変更、Excelデータから情報解析ができたら良いなと思います。最後までお読みいただきありがとうございました。
- 投稿日:2020-11-27T23:34:42+09:00
MatplotLibでループして図を書き、あとからX軸を変更する
目的
MatplotLibにてループでfigureを描く場合に、あとから軸を修正する方法を記述
動作環境
Python 3.7 (Anaconda) Spyder
方法
axesを保存しておいて、あとからaxes.set_xlim(start,end) で変更すれば、軸をあとから修正
できるらしい。
ウインドウが別枠で出ない場合は、コンソール上で %matplotlib qt と打つ実行コード
import matplotlib.pyplot as plt import numpy as np plt.close('all') #Make Data Time =np.arange(0,1,0.001); Data = np.sin(2*np.pi*10*Time); #3回のループで3つのFigureを描画 fig = {} ax ={} for idx in range(1,4): fig[idx] = plt.figure() ax[idx] = plt.subplot(311) plt.plot(Time, Data) #2番目のfigureの軸を変更 ax[2].set_xlim(0,0.5) plt.show()
- 投稿日:2020-11-27T23:34:13+09:00
PDF・Word・PowerPoint・Excelファイルからテキスト部分を一括抽出するメソッド
1. 実行時に走らせるコード
from text_from_string_files import * from pprint import pprint pprint(func_dict) # 実行結果 {'docx': <function get_text_from_word at 0x11783ff70>, 'pdf': <function get_text_from_pdf at 0x11783fe50>, 'pptx': <function get_text_from_powerpoint at 0x11783fee0>, 'xlsx': <function get_text_from_excel at 0x11783d040>} result = get_filename_text_dict(func_dict) print(result.keys()) pprint(result['あるKeyの文字列']) pprint(result)返り値は、以下を要素に持つ辞書(dict)型オブジェクトです。
返り値の辞書の要素{ファイル名 : そのファイルのテキスト部分を文字列結合した文}( 事前にインストールしておくべき資源 )
pip install python-docx pip install openpyxl2. スクリプトファイル
以下、PowerPointファイルとExcelファイルからテキストデータを読み込むメソッド以外は、以下のWebページ所収のコードを踏襲させていただきました(一部改変)。
・ [Python] Word/Excel/PowerPoint/PDFからテキスト抽出するライブラリ・サンプルコード」
なお、上記のサイトのコードは、List[str]オブジェクトを返します。
今回は、配列の中身のstrオブジェクトを文字列結合して、単一のstrオブジェクトを返すように、手を加えました。元のメソッドのlayout = device.get_result()の次の行に、以下を追記。
Pythontext = str(get_text_list_recursively(layout)) text = text.replace("\\n", "").replace("\n", "") results.append(text) output = "".join(results)Excelファイルからテキスト部分を取得するメソッドは、以下を参考に作成しました。
・ 「Python Excelのシート名をすべて取得するsheetnames」
・ 「Python Excelのデータをすべて取得する方法」また、PowerPointファイルからテキストを取得するコードは、以下を参考にしました(一部改変)。
「[Python] Word/Excel/PowerPoint/PDFからテキスト抽出するライブラリ・サンプルコード」所収のコードは、PowerPointファイルのうち、表紙スライドに含まれるテキストしか、取得できなかったためです。
実装コード
text_from_string_files.pyimport docx, openpyxl, pptx, os.path from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LAParams, LTContainer, LTTextBox from pdfminer.pdfinterp import PDFPageInterpreter, PDFResourceManager from pdfminer.pdfpage import PDFPage ####指定したディレクトリから、テキストファイルを抽出できるファイルを検索するメソッド def get_text_matching_file_names(ext_pattern_list, search_directory_path) -> list: file_names_list = os.listdir(search_directory_path) # 上記のいずれかの拡張子を持つファイルのファイル名を格納する配列を用意 available_filename_list = [] # 上記のいずれかの拡張子を持つファイルのファイル名を配列に格納する for file_name in file_names_list: ext_check_result = [] for ext in ext_pattern_list: boolean = ext in file_name ext_check_result.append(boolean) if True in ext_check_result: available_filename_list.append(file_name) return available_filename_list ####PDFファイル(拡張子:.pdf)からテキスト抽出するメソッド def get_text_list_recursively(layout) -> list: if isinstance(layout, LTTextBox): return [layout.get_text()] if isinstance(layout, LTContainer): text_list = [] for child in layout: text_list.extend(get_text_list_recursively(child)) return text_list def get_text_from_pdf(filepath: str) -> str: laparams = LAParams(detect_vertical=True) resource_manager = PDFResourceManager() device = PDFPageAggregator(resource_manager, laparams=laparams) interpreter = PDFPageInterpreter(resource_manager, device) results = [] with open(filepath, "rb") as file: for page in PDFPage.get_pages(file): interpreter.process_page(page) layout = device.get_result() text = str(get_text_list_recursively(layout)) text = text.replace("\\n", "").replace("\n", "").replace(" ", "").replace(" ", "") results.append(text) output = "".join(results) return output ####PowerPointファイル(拡張子:.pptx)からテキスト抽出するメソッド def get_text_from_powerpoint(filepath: str) -> str: prs = pptx.Presentation(filepath) output = "" for i, sld in enumerate(prs.slides, start=1): for shp in sld.shapes: if shp.has_text_frame: text = shp.text output += text.replace("\n", "").replace("\n", "").replace(" ", "").replace(" ", "") return output ####Wordファイル(拡張子:.pptx)からテキスト抽出するメソッド def get_text_from_word(filepath: str) -> str: document = docx.Document(filepath) text_list = list(map(lambda par: par.text, document.paragraphs)) text = "".join(text_list) output = text.replace(" ", "").replace(" ", "") return output ####Excelファイル(拡張子:.xlsx)からテキスト抽出するメソッド def get_text_from_excel(filepath: str) -> str: output_text = "" book = openpyxl.load_workbook(filepath) sheet_list = book.sheetnames for sheet_name in sheet_list: sheet = book[sheet_name] for cells in tuple(sheet.rows): for cell in cells: data = cell.value if data is None: continue else: output_text += str(data).replace(" ", "").replace(" ", "") return output_text ####Key: ファイルの拡張子に応じて、Value: 適切なメソッドを選択する際に用いる辞書 func_dict = { 'pdf' : get_text_from_pdf, 'docx' : get_text_from_word, 'xlsx' : get_text_from_excel, 'pptx' : get_text_from_powerpoint } ####mainメソッド def get_filename_text_dict(func_dict): func_dict = func_dict # カレントディレクトリの絶対パスを取得 current_directory_path = os.getcwd() available_ext_list = list(func_dict.keys()) # カレントディレクトリにあるテキストデータを抽出可能なファイルのファイル名を全件取得 file_list = get_text_matching_file_names(available_ext_list, current_directory_path) # ファイルの拡張子に応じた適切なテキストデータ抽出メソッドを実行 output_dict = {} for filename in file_list: for ext in available_ext_list: if ext in filename: text = func_dict[ext](filename) output_dict[filename] = text return output_dict #if __name__ == '__main__': # main()
- 投稿日:2020-11-27T23:32:55+09:00
python でKMPの前処理テーブルを書く[備忘録]
イントロ
競プロの問題でKMPを書いたので備忘録
今まで書いたことがなかった割にはアルゴリズムは単純で、一方で少し混乱するところもあったのでそこに関しても記述する
KMPalgorithmとは
クヌース–モリス–プラット法(Knuth–Morris–Pratt algorithm、KMP法と略記)とは、文字列検索アルゴリズムの一種。テキスト(文字列)Sから単語Wを探すにあたり、不一致となった位置と単語自身の情報から次に照合を試すべき位置を決定することで検索を効率化するアルゴリズムである。
wikipediaの説明より文字列から単語(モチーフ)を検索する際にだいたいBrute-forthの次に説明されるアルゴリズムな気がします。
そこからBM法、Z-algorithm, SA-ISとかにつながって線形や対数時間(SA-IS、ただし前処理には線形)と計算量が改善していきます。(この辺はあまり中身理解できていない)今回はKMPについて説明していきます
問題の定式化
検索対象の文字列をref,探したい文字列をmotifとします。
説明のためそれぞれの長さをS,Tとおきます。問題としてはrefの中でmotifに一致した部分文字列の位置
つまりref[i:i+T]=motifとなるi をすべて出力することが目標です。naiveな(愚直な)解法 Brute-Forth
まず文字列から単語を計算する際に一番愚直な方法を考えます。
refからmotifの長さと一致するすべての部分文字列を先頭からとって比較すれば良いです。brute_forth.pyS = len(ref) T = len(motif) motif_count = 0 # brute force for i in range(S - T): if ref[i:i+T] == motif: print(i+1,end=" ")#1_idxでのpositionを出力する文字列の比較を丁寧に書くと以下のようになります
brute_forth_2.pyS = len(ref) T = len(motif) motif_count = 0 # brute force for i in range(S - T): for j in range(T): if ref[i+j] != motif[j]: break elif j == T-1: print(i+1)この計算量は部分文字列とmotifの比較にO(T),motifの長さと一致する部分文字列がS-T個あるため、O(ST)になります。
KMPアルゴリズムイメージ
Brute Forthの処理の中で改善できそうな箇所を考えます。
Brute Forthではrefの文字列の同一のpositionをループのたびに(開始位置i が変わるたびに)何度も比較していることがわかります
一度比較しているならばどの文字がその場所にあるかはわかっているはずなので、開始位置が変わった次のループではその箇所の比較はうまくやればskipできそうです。
例えばref="bakanabanana",motif="banana"というケースを考えると
i=0(先頭から始まる部分文字列の比較)ではbakana とbananaを比較することになりますが3文字目でref[i+j]="k",motif[j]="n"となり一致しないことがわかります。
ここでbrute forthなら開始位置を一つずらしますが、先程の比較でrefの先頭に文字がb,aであることはわかっています。
そして、今回のmotif"banana"は先頭が"b"なので、開始位置を1つずらしても絶対にそこからの部分文字列は一致しないことが比較する前からわかります。
以上のことからmotifとの3文字目の比較でmismatchが起こったならば、次の文字列の比較では先頭位置を先程より2文字ずらせばいいいことがわかります。
このように前回のmotifとの比較際のmismatch(match) の場所から次にどれだけずらす(開始位置をskipする)ことができるかを予め前計算して高速化したものがKMP法となります
計算量としては前処理テーブル作成(今回の記事)でO(T),実際にrefの探索でO(S)となります
実装イメージ
尺取法のようなイメージでどれだけskipできるかを考えていきます。
前処理テーブルにおいて、長さ2以上のmatchを作るためにはそのpositionの1つ前が1以上のmatchであることを利用します。
実装
motifの文字列からテーブルをつくる所の実装です。
make_kmp_table.pydef make_kmp_table(motif): """return kmp failure table params : motif return : kmp table(1 dimensional-array) """ match_len = [0] table = [0] * len(motif) for i in range(1, len(motif)): next_match_len = [] for current_match_len in match_len: if motif[i] == motif[current_match_len]: current_match_len += 1 next_match_len.append(current_match_len) match_len = next_match_len match_len.append(0) table[i] = match_len[0] return table参考
いかたこのたこつぼ(ブログ)
文字列アルゴリズムについて簡単な説明とpythonでの実装が記載されています
Wikipedia
- 投稿日:2020-11-27T23:29:58+09:00
位相空間の数え上げをbit演算で行う
位相空間の定義
位相空間(≒開集合)は以下のように定義される。
$$
1. \varnothing,X \subseteq \mathcal{O} \\
2. \forall O_1,O_2 \in A : O_1 \cap O_2 \in \mathcal{O} \\
3. \forall [O_\lambda]_{\lambda \in \Lambda} : \bigcup _ {\lambda \in \Lambda} O _\lambda \in \mathcal{O}
$$要は、集合の集合(ややこしいので集合族と呼ぶ)において、お互いの和集合または積集合がまた同じ集合族に属するようなもののことである。
例えば$a,b,c$が全要素である場合、
$$
(\varnothing),(b),(a,b),(b,c),(a,b,c)
$$は位相空間である(※$\varnothing$は空集合)。$(a,b)$と$(b,c)$の積集合$(a)$は同じグループに属するからである。他の任意の集合の組み合わせについても同様である。
ちなみに大学数学の書籍にしては珍しく、「はじめよう 位相空間」には位相空間の素朴な数え上げの例題(と、嫌々ながらも解答が)がある。
いかにもbit演算で行えそうな計算である。プログラムしてみる。
考え方
$N=3$ の時を考える。
ありえる集合としては、
$$(\varnothing),(a),(b),(c),(a,b),(b,c),(c,a),(a,b,c)$$
の8通りである。これは$2^3 = 8$通りなので 3bit で表現できる。列挙すると以下の通り。0 = 000 () 1 = 001 (a) 2 = 010 (b) 3 = 011 (a,b) 4 = 100 (c) 5 = 101 (a,c) 6 = 110 (b,c) 7 = 111 (a,b,c)では、これらの集合を含むか含まないかは、それを更にbit演算すればいい。$2^{2^3} = 65536$ 通りである。上のグループ $0\thicksim7$ を便宜的に $G0\thicksim G7$ と名付ける。
0 = 00000000 () 1 = 00000001 (G0) 2 = 00000010 (G1) 3 = 00000011 (G0,G1) . . . 65531 = 11111100 (G2,G3,G4,G5,G6,G7) 65532 = 11111101 (G0,G2,G3,G4,G5,G6,G7) 65534 = 11111110 (G1,G2,G3,G4,G5,G6,G7) 65535 = 11111111 (G0,G1,G2,G3,G4,G5,G6,G7)さて、それぞれのグループの積集合・和集合はそのままお互いの数の
and演算とor演算で実装できる。$(a,b)$と$(b,c)$の積集合は$(b)$,和集合は$(a,b,c)$であるが、これはbit演算でいうと3&6=2と3|6=7に対応する。コード
コードに落とし込む。
条件1
これは簡単だ。状態数のbitの左端と右端が立っているかを調べればよい。
def O1(i): if i&1 == 0:#∅を含むか return False bitlim = (1<<3)-1 if i>>bitlim&1 == 0:#全体集合を含むか return False return True条件2
状態数に含まれるbitをカウントした上で、それぞれの積集合がbitに集合族に含まれるかを調べる。
def O2(i): num = 0 sets = [] #bitを数えておくリスト for j in range(1<<3): if i>>j&1: num += 1 sets.append(j) for j in range(1<<num): if j == 0: continue tmp = 0 #含まれるbitの全和集合 for k in range(num): tmp |= sets[k] for k in range(num): if j>>k&1: tmp &= sets[k] #積集合をとっていく if tmp not in sets: return False #bitリストに含まれていなかったらアウト return True条件3
基本的には条件2の演算子を変えただけのものになる。
def O3(i,points): num = 0 sets = [] for j in range(1<<points): if i>>j&1: num += 1 sets.append(j) for j in range(1<<num): if j == 0: continue tmp = 0 for k in range(num): if j>>k&1: tmp |= sets[k] if tmp not in sets: return False return True以上の関数を定義した上で、
def setstext(i): chars = 'abc' ans = [] for j in range(1<<3): if i>>j&1: tmp = [] for k in range(3): if (j>>k)&1: tmp.append(chars[k]) if len(tmp) == 0: tmp.append('∅') elif len(tmp) == points: tmp = ['S'] ans.append(tmp) return ans def isOpen(i): if not O1(i): return 0 if not O2(i): return 0 if not O3(i): return 0 print(setstext(i)) return 1 def main(): count = 0 max_range = 1<<(1<<3) for i in range(max_range): count += isOpen(i) print(count) main()と実行すれば以下の解答が得られる。
[['∅'], ['S']] [['∅'], ['a'], ['S']] [['∅'], ['b'], ['S']] [['∅'], ['a', 'b'], ['S']] [['∅'], ['a'], ['a', 'b'], ['S']] [['∅'], ['b'], ['a', 'b'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['S']] [['∅'], ['c'], ['S']] [['∅'], ['a', 'b'], ['c'], ['S']] [['∅'], ['a', 'c'], ['S']] [['∅'], ['a'], ['a', 'c'], ['S']] [['∅'], ['b'], ['a', 'c'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['S']] [['∅'], ['c'], ['a', 'c'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['S']] [['∅'], ['b', 'c'], ['S']] [['∅'], ['a'], ['b', 'c'], ['S']] [['∅'], ['b'], ['b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['S']] [['∅'], ['c'], ['b', 'c'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['S']] 29これは教科書の答えと一致する。
一般化
せっかくなので一般化する。集合の要素の数を
pointsとする。def O1(i,points): if i&1 == 0:#∅を含むか return False bitlim = (1<<points)-1 if i>>bitlim&1 == 0:#全体集合を含むか return False return True def O2(i,points): num = 0 sets = [] for j in range(1<<points): if i>>j&1: num += 1 sets.append(j) for j in range(1<<num): if j == 0: continue tmp = 0 for k in range(num): tmp |= sets[k] for k in range(num): if j>>k&1: tmp &= sets[k] if tmp not in sets: return False return True def O3(i,points): num = 0 sets = [] for j in range(1<<points): if i>>j&1: num += 1 sets.append(j) for j in range(1<<num): if j == 0: continue tmp = 0 for k in range(num): if j>>k&1: tmp |= sets[k] if tmp not in sets: return False return True def setstext(i,points): chars = 'abcdefghijklmnopqrstuvxyz' #zまでやったら計算時間で地球が爆発する ans = [] for j in range(1<<points): if i>>j&1: tmp = [] for k in range(points): if (j>>k)&1: tmp.append(chars[k]) if len(tmp) == 0: tmp.append('∅') elif len(tmp) == points: tmp = ['S'] ans.append(tmp) return ans def isOpen(i,points): if not O1(i,points): return 0 if not O2(i,points): return 0 if not O3(i,points): return 0 print(setstext(i,points)) return 1 def main(points): count = 0 max_range = 1<<(1<<points) for i in range(max_range): count += isOpen(i,points) print(count) points = 4 main(points)実行結果
points = 1 ... [['∅'], ['S']] 1points = 2 ... [['∅'], ['S']] [['∅'], ['a'], ['S']] [['∅'], ['b'], ['S']] [['∅'], ['a'], ['b'], ['S']] 4points = 3 (略) 29points = 4 ... [['∅'], ['S']] [['∅'], ['a'], ['S']] [['∅'], ['b'], ['S']] [['∅'], ['a', 'b'], ['S']] [['∅'], ['a'], ['a', 'b'], ['S']] [['∅'], ['b'], ['a', 'b'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['S']] [['∅'], ['c'], ['S']] [['∅'], ['a', 'c'], ['S']] [['∅'], ['a'], ['a', 'c'], ['S']] [['∅'], ['c'], ['a', 'c'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['S']] [['∅'], ['b', 'c'], ['S']] [['∅'], ['b'], ['b', 'c'], ['S']] [['∅'], ['c'], ['b', 'c'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['S']] [['∅'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b', 'c'], ['S']] [['∅'], ['a', 'b'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['S']] [['∅'], ['c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a', 'b'], ['c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['S']] [['∅'], ['d'], ['S']] [['∅'], ['a', 'b', 'c'], ['d'], ['S']] [['∅'], ['a', 'd'], ['S']] [['∅'], ['a'], ['a', 'd'], ['S']] [['∅'], ['b', 'c'], ['a', 'd'], ['S']] [['∅'], ['a'], ['a', 'b', 'c'], ['a', 'd'], ['S']] [['∅'], ['a'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['S']] [['∅'], ['a'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['S']] [['∅'], ['b', 'd'], ['S']] [['∅'], ['b'], ['b', 'd'], ['S']] [['∅'], ['a', 'c'], ['b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b', 'c'], ['b', 'd'], ['S']] [['∅'], ['b'], ['a', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['S']] [['∅'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'b'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'd'], ['S']] [['∅'], ['c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'b'], ['c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'd'], ['S']] [['∅'], ['d'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'b'], ['d'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'b'], ['a', 'b', 'c'], ['d'], ['a', 'b', 'd'], ['S']] [['∅'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['S']] [['∅'], ['c', 'd'], ['S']] [['∅'], ['a', 'b'], ['c', 'd'], ['S']] [['∅'], ['c'], ['c', 'd'], ['S']] [['∅'], ['c'], ['a', 'b', 'c'], ['c', 'd'], ['S']] [['∅'], ['a', 'b'], ['c'], ['a', 'b', 'c'], ['c', 'd'], ['S']] [['∅'], ['d'], ['c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['c', 'd'], ['S']] [['∅'], ['c'], ['a', 'b', 'c'], ['d'], ['c', 'd'], ['S']] [['∅'], ['d'], ['a', 'b', 'd'], ['c', 'd'], ['S']] [['∅'], ['a', 'b'], ['d'], ['a', 'b', 'd'], ['c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['a', 'b', 'd'], ['c', 'd'], ['S']] [['∅'], ['a', 'b'], ['c'], ['a', 'b', 'c'], ['d'], ['a', 'b', 'd'], ['c', 'd'], ['S']] [['∅'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'c'], ['d'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['d'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'c'], ['d'], ['b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['a'], ['a', 'b'], ['c'], ['a', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['S']] [['∅'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'c'], ['d'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'c'], ['d'], ['a', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['d'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['d'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['d'], ['b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['a', 'b'], ['c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['b', 'c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['a', 'c'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['c'], ['a', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['b'], ['c'], ['b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] [['∅'], ['a'], ['b'], ['a', 'b'], ['c'], ['a', 'c'], ['b', 'c'], ['a', 'b', 'c'], ['d'], ['a', 'd'], ['b', 'd'], ['a', 'b', 'd'], ['c', 'd'], ['a', 'c', 'd'], ['b', 'c', 'd'], ['S']] 355
n=4ですごい数である。この答えがあっているかについては、奈良教育大学学術リポジトリの紀要論文(40年近く前!)でも同様の計算が行われているが、合ってそうである。ちなみにnを5以上にするとすごい時間がかかる。計算量オーダーを見積もったところ、
$$
O(2^{2^n+2n})
$$とすごいことになったので、アルゴリズムを洗練させないとこれ以上は無理だと思われる。

- 投稿日:2020-11-27T23:21:19+09:00
yukicoder contest 276 参戦記
yukicoder contest 276 参戦記
A 1298 OR XOR
C = N とすると、求める A, B の条件は A or B = N, A xor B = 0 となる. つまり、N を2進数で考えた時に立っているビットが A と B のどちら片方で立っていれば条件を満たせる. そのようなものの一つとして、N の MSB だけ落とした整数と、N の MSB だけが立った整数がある. ただし、前者は N が MSB だけが立っている場合には 0 となってしまうので、答えとならない.
N = int(input()) c = -1 t = N while t != 0: c += 1 t >>= 1 B = 1 << c A = N ^ B C = N if A == 0: print(-1, -1, -1) else: print(A, B, C)B 1299 Random Array Score
ある Ai が選ばれる可能性は 1 / N で、選ばれたときは A の要素の総和は Ai×N 増える. これを積算すると結局1回の操作で A の要素の総和が増える期待値は A の要素の総和そのものである. つまり1回の操作毎に倍になるので、最終的に求める解は A の要素の総和×2Kとなる.
N, K, *A = map(int, open(0).read().split()) m = 998244353 print(sum(A) * pow(2, K, m) % m)
- 投稿日:2020-11-27T23:18:09+09:00
matplotlibを使ったpythonジョブでsshサーバーを抜けたあとでもエラーが出ないようにbackendをうまく切り替える
エラーになる条件
以下のmatplotlibで図を保存するpythonコードを考える。
check.pyimport time import matplotlib import matplotlib.pyplot as plt # あとでsshサーバーを抜けるための猶予 time.sleep(10) print(matplotlib.get_backend()) fig = plt.figure(figsize=(3.0, 3.0)) plt.plot([0, 1, 2, 3], [0, 1, 2, 3]) plt.savefig("hoge.png")このコードを
$ python3 check.py $ python3 check.py $のように普通にフォアグラウンド、バックグラウンドで実行しても問題なく図は保存される。
しかしながら、sshサーバー上で次のようにバックグラウンドジョブで投げたあとにサーバーを抜けるとtkinterのdisplay周りのエラーで落ちる(sshの-Xや-Yオプション関係なく)。$ nohup python3 check.py > log 2>&1 & # sleepで止まっている間にサーバを抜けるlogTkAgg Traceback (most recent call last): File "check.py", line 9, in <module> fig = plt.figure(figsize=(3.0, 3.0)) ... window = tk.Tk(className="matplotlib") File "$path/lib/python3.7/tkinter/__init__.py", line 2023, in __init__ self.tk = _tkinter.create(screenName, baseName, className, interactive, wantobjects, useTk, sync, use) _tkinter.TclError: couldn't connect to display "localhost:10.0"これは今のbackendにTkAggのようなGUIを使うbackendを指定していることが原因なので、コード内で明示的に
matplotlib.use('Agg')を指定するか、$ python3 -c "import matplotlib ;print(matplotlib.get_configdir())"で確認できる場所にある
matplotlibrcのbackendをAggにするか、plt.ioff()を使いインタラクティブモードをoffにするかなどをして回避する必要がある。いずれにしてもサーバーを抜けるようなバックグラウンドジョブを実行するときだけbackendを書き換える方法では反映し忘れたり、戻し忘れたりするので
nohupを使いバックグラウンドジョブを実行するときだけbackendをAggに切り替えられるようにしたい。解決策
nohupを指定したバックグラウンドジョブを実行しても特に新たな環境変数は作成されないので自分で環境変数を適当に指定する。
このときにexportコマンドで指定してしまうとログアウトするまで環境変数が残ってしまうので上記のように実行時にのみ反映されるようにする。$ BG=1 nohup python3 check2.py & or $ alias nohup=`BG=1 nohup` # bashrcやzshrcに追加 $ nohup python3 check2.py &pythonコードは次のように環境変数
BGの有無によってbackendをAggに変更する処理を入れる。check2.pyimport os import time import matplotlib # 環境変数BGがある場合のみ実行される if os.getenv('BG') != None: matplotlib.use('Agg') # backendを明示的に指定する場合は import matplotlib.pyplot より前に書く import matplotlib.pyplot as plt time.sleep(10) print(matplotlib.get_backend()) fig = plt.figure(figsize=(3.0, 3.0)) plt.plot([0, 1, 2, 3], [0, 1, 2, 3]) plt.savefig("hoge.png")
BGという環境変数が存在しなければos.getenv('BG')でNoneが返るので、存在するときだけ上記のmatplotlib.use('Agg')が実行され、サーバーを抜けたあとでも正常に図が保存できる。なお、plt.show()があるようなコードではbackendがAggの場合はエラーになるので上記の環境変数かmatplotlib.get_backend()結果を使い実行させないようにする必要がある。
- 投稿日:2020-11-27T22:30:29+09:00
pythonによるスクレイピング&機械学習をtensorflow2で動かしてみた
前提条件
対象
この記事は、Webエンジニア向けです。
私自身Webプログラマでして、機械学習を仕事に活かせないかと考えるために勉強しつつ書いたものになります。
それと、「pythonによるスクレイピング&機械学習」に沿って書くので、本の補足のつもりでみてください。環境
・PC : Macbook pro
・OS : Catalina(10.15.7)
・言語 : python2.7.16
・エディタ : jupyter(せっかくなので使いましょう、便利です)
pythonやライブラリのインストールは、つまづいた記憶もないのでここでは省きます。お願い
あなたに感想や要望を書いて頂けると主が喜びます。ぜひ気軽にコメントしていってください。
もっとシンプルな方法があれば教えてください。レッツ機械学習
tensorflow2(以下、tf2)の便利技
基本的にtf2は、無印の動作もできます
sess = tf.compat.v1.Session() sess.run(tf.global_variables_initializer())本をよみながら、うまくtf2の書き方にできない時は、これで誤魔化しましょう
5-4をtf2でやってみる
src/ch5/placeholder1.pyをtf2化
著作権上元コードは乗せてませんimport tensorflow as tf #メソッドで制御 #noneを指定してあげると、配列が可変となる @tf.function(input_signature=[tf.TensorSpec([None], tf.int32)]) def hoge(a): b = tf.constant(2) return a * b #.numpy()で数字の部分だけとれる print( hoge(tf.constant([1,2,3])).numpy() ) print( hoge(tf.constant([10,20,30])) )結果
[2 4 6] tf.Tensor([20 40 60], shape=(3,), dtype=int32)簡単な解説
このメソッド自体は
元のコードでは、メソッドではなくsession.runで動作してます。
tf2ではsessionは使わなくてよくなったので、シンプルに作れます。まず、元のコードではrun時に値を代入していますが、私はメソッドに引数を渡して、動作させてます。
@tf.function(input_signature=[tf.TensorSpec([None], tf.int32)])
この定義により引数の型を決めています。もちろん複数定義もできます。その後は、元コードと同じように配列の掛け算を行って表示してます。
まとめ
短いですが、tf2のさわりはこんな感じです。
1.sessionは必要ない
2.メソッドを作りやすくなった
それ以外にももちろん機械学習において便利になった点もあるので、
この本を元に今後アップしていけたらと思います。ありがとうございました。
- 投稿日:2020-11-27T22:17:32+09:00
今日の積み上げ
初めて投稿します。
本日の勉強内容はudemyにて小山内さんの絶対に挫折させないPython入門講座を視聴+写経しました。
今日でほぼ見終えましたが最後のほうはあまり頭に入らず写経ばかりでした。
課金はしてないからいいもののPyQ、paizaと続き意味はわかるが頭に入ってこない状況が発生し今回の小山内さんの動画も同じ感じでした。
初めてprogateの無料版したときは簡単だと感じたので明日からprogateを課金してみようかと思います。
あと気になったのが講師のみなさん( [ { の切り替えがめちゃ早いのですが何かコツとかあるのでしょうか?僕は ( 以外は毎回全角モード?に切り替えて戻してを繰り返してますが正直面倒です(笑)
何か良い方法知っている人いたら教えてください!!
- 投稿日:2020-11-27T21:55:05+09:00
PyTorchベースの計算科学用ディープラーニングライブラリOpenChem
はじめに
化合物でディープラーニングといえば、DeepChem (https://deepchem.io/) や Chainer Chemistory(https://chainer-chemistry.readthedocs.io/en/latest/) が有名だが、今回OpenChemというライブラリを紹介したい。
OpenChemとは
計算化学およびドラッグデザイン研究のためのディープラーニングツールキットである。PyTorchをバックエンドに使用しており、ライセンスはMITライセンスである。
どんな特徴があるの?
その特徴として以下があげられる
- モジュラー設計により、設定ファイルのみでモジュールを簡単に組み合わせて構築することができる。
- マルチGPUをサポートしており、高速に学習することができる。
- データ前処理のためのユーティリティ等も備えている。
- テンソルボードという可視化ツールにも対応している。
モジュラー設計について簡単に説明すると、DeepChemで新しいモデルを作成する場合、入力から出力までほぼ1から開発する必要があるのに対し、OpenChemではエンコーダー、デコーダー、埋め込みレイヤーなどの標準的なディープニューラルネットワークのブロックが用意されており、これらを組み合わせることとで既存のものを再利用しながら新しいモデルを比較的容易に開発することができるのである。
どんなタイプのモデルが作れるの?
- 分類(2クラス、多クラス)
- 回帰
- マルチタスク
- 生成モデル
どんなデータを扱えるの?
- SMILES文字列やアミノ酸配列などの文字の配列。
- 分子グラフ(SMILES文字列から生成)
どんなモジュールが用意されているの?
- トークンの埋め込み
- リカレントニューラルネットワークエンコーダー
- グラフ畳み込みニューラルネットワークエンコーダー
- 多層パーセプトロン
インストール
以下の環境でインストールしてみる。
環境
- Windows 10
- python 3.7
- rdkit-2020.09.1
- pytorch 1.7.0
- scikit-learn 0.23.2
- tensorboard 2.4.0
手順
以下のコマンドを順に実行すればよい。
ちなみに、tqdm以降はドキュメントに書かれていなかったが、試行錯誤しているうちに必要だと分かったため追加している。$ conda create -n openchem python=3.7 $ conda activate openchem $ git clone https://github.com/Mariewelt/OpenChem.git $ cd OpenChem $ conda install --yes --file requirements.txt $ conda install -c rdkit rdkit nox cairo $ conda install pytorch torchvision -c pytorch $ conda install tqdm $ conda install tensorboard $ conda install networkxモデルの定義と学習はどうやるの?
OpenChemのモデルは、設定ファイル(Pythonのディクショナリ形式でパラメータを指定)によって定義することができる。
設定ファイルには、以下を含める必要がある。
- モデルの実行/トレーニング/評価の方法を定義するパラメータ
- モデルアーキテクチャを定義するパラメータ
また、モデルの作成と分散プロセスの起動を処理する2つのPythonファイルである「run.py」と「launch.py」も必要となる。
runc.pyの引数
項目 説明 nproc_per_node ノードあたりのプロセス数。 ノード上のGPUの数と同じである必要がある。 lanch.pyの引数
項目 説明 config_file モデルが定義されているPython設定ファイルへのパス。 mode train、train_evalまたはeval。 continue_learning この引数が指定されている場合、トレーニングは最新のチェックポイントから再開される 設定ファイル
設定ファイルにはモデルが含まれている必要がある。
モデルは、OpenChemModelおよびディクショナリmodel_paramsから派生したクラスである必要がある。
以下は、モデルアーキテクチャに関連しないすべてのモデルに共通のパラメータの説明である。
項目 説明 task モデルによって解決されるタスクを指定する。 classification, regression , multitaskのいずれか train_data_layer トレーニングデータ用のpytorchデータセット。 --mode = evalの場合、Noneになる。 OpenChemは現在、SMILES、Graph、およびMoleculeProteinデータセットを作成するためのユーティリティを提供していている。 val_data_layer 検証データ用のpytorchデータセット。 --mode = trainの場合、Noneになる。 print_every ログ出力の頻度 save_every モデルがチェックポイントに保存される頻度。 logdir モデルチェックポイントとテンソルボードログが保存されるフォルダーへのパス。 use_clip_grad 勾配クリッピングを使用するかどうか。 max_grad_norm 勾配クリッピングが使用されている場合のパラメーターの最大ノルム。 batch_size バッチサイズ num_epochs エポック数。 --mode = evalの場合、Noneになる eval_metrics 評価のためのユーザー定義関数、指標。 --mode = trainの場合、Noneになる。 criterion pytorchの損失、モデルの損失 optimizer pytorchオプティマイザー、モデルをトレーニングするためのオプティマイザー。 --mode = evalの場合、Noneになる。 その他のパラメータは、モデルアーキテクチャに固有のものとなるので、APIドキュメントやその他のチュートリアルを確認してほしい。
ジョブの起動
以下4つのGPUを備えたノードで実行されるジョブの例である。1つのGPUで単一のプロセスを実行することもできる。
python launch.py --nproc_per_node=4 run.py --config_file="./my_config.py" --mode="train"チュートリアルをやってみよう
分子フィンガープリントからlogP値を予測するための単純な多層パーセプトロンニューラルネットワークを構築することにより、OpenChemでのモデル構築の基本について試してみる。
データのロード
まず、ファイルからデータを読み取る必要がある。
サンンプルのデータは、PyTorchのリポジトリの ./benchmark_datasets/logp_dataset/logP_labels.csv にあるものを使う。OpenChemは、複数の列を持つテキストファイルを処理することができる。
read_smiles_property_file では読み取る列、区切り文字を指定することができる。
読み取る列(cols_to_read)では、最初にSMILESの列、次の列にはラベルを指定する。import numpy as np from openchem.data.utils import read_smiles_property_file data = read_smiles_property_file('./benchmark_datasets/logp_dataset/logP_labels.csv', delimiter=",", cols_to_read=[1, 2], keep_header=False)read_smiles_property_fileの戻り値は、ファイルから読み取られた列と同じ数のオブジェクトを含むリストであり、上の例では、data[0]にはSMILESが含まれ、残りはすべてラベルとなっている。
smiles = data[0] labels = np.array(data[1:]) labels = labels.Tデータを読み取った後、scikit-learnの関数を使用してトレーニングセットとテストセットに分割し、新規にファイルに保存する。
from sklearn.model_selection import train_test_split from openchem.data.utils import save_smiles_property_file X_train, X_test, y_train, y_test = train_test_split(smiles, labels, test_size=0.2, random_state=42) save_smiles_property_file('./benchmark_datasets/logp_dataset/train.smi', X_train, y_train) save_smiles_property_file('./benchmark_datasets/logp_dataset/test.smi', X_test, y_test)PyTorchデータセットの作成
続いてPyTorchで処理するためのデータセットを作成する。OpenChemには、データ型に基づいてPyTorchデータセットを作成するための複数のユーティリティがある。
今回、SMILES文字列をユーザー定義関数を使用して特徴のベクトルに変換するFeatureDatasetを使用する。from openchem.data.feature_data_layer import FeatureDataset from openchem.data.utils import get_fp train_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/train.smi', delimiter=',', cols_to_read=[0, 1], get_features=get_fp, get_features_args={"n_bits": 2048}) test_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/test.smi', delimiter=',', cols_to_read=[0, 1], get_features=get_fp, get_features_args={"n_bits": 2048}) predict_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/test.smi', delimiter=',', cols_to_read=[0], get_features=get_fp, get_features_args={"n_bits": 2048}, return_smiles=True)ユーザー定義関数は、FeatureDatasetの引数get_featuresに渡され、さらにユーザー定義関数の引数はget_features_argsにディクショナリとして渡すことができる。
この例では、ユーザー定義関数として、RDKitフィンガープリントを生成するopenchem.data.utils.get_fp を利用している。
この関数はn_bitsにフィンガープリントのビット数を指定することができる。read_smiles_property_finction と同様、Datasetには cols_to_read およびdelimiter引数を指定する。
最終的に、train_dataset、test_dataset、predict_dataset の3つのデータセットを作成している。train_datasetとtest_datasetは、それぞれトレーニングと評価に使用する。
これらのデータセットでは、cols_to_read にSMILES文字列だけでなく、ラベルを持つ列のインデックスも含める必要がある。トレーニングが完了した後、predict_datasets を使用して、新しいサンプルの予測結果を取得する。
predict_datasets ではラベルは必要ないため、cols_to_read引数には、SMILES文字列に対する列のインデックスのみ指定すればよい。また、predict_datasetには、引数return_smiles = True を指定する。OpenChemモデルの作成とパラメータの定義
続いて、モデルタイプとモデルパラメータを指定する。ここでは多層パーセプトロンモデルであるMLP2Labelモデルを使用しており、特徴ベクトルからラベルを予測する。
from openchem.models.MLP2Label import MLP2Label model = MLP2Label model_params = { 'task': 'regression', 'random_seed': 42, 'batch_size': 256, 'num_epochs': 101, 'logdir': 'logs/logp_mlp_logs', 'print_every': 20, 'save_every': 5, 'train_data_layer': train_dataset, 'val_data_layer': test_dataset, 'predict_data_layer': predict_dataset, 'eval_metrics': r2_score, 'criterion': nn.MSELoss(), 'optimizer': Adam, 'optimizer_params': { 'lr': 0.001, }, 'lr_scheduler': StepLR, 'lr_scheduler_params': { 'step_size': 15, 'gamma': 0.9 }, 'mlp': OpenChemMLP, 'mlp_params': { 'input_size': 2048, 'n_layers': 4, 'hidden_size': [1024, 512, 128, 1], 'dropout': 0.5, 'activation': [F.relu, F.relu, F.relu, identity] }モデルの学習
上記で記載した「データのロード」から「OpenChemモデルの作成とパラメータの定義」までに記載したPythonのコードをファイルに保存する。ここではexample_configsフォルダーにあるlogp_mlp_config.pyファイルに同じものが保存されているので、それをそのまま使うことにする。
そして、コマンドラインから次のコマンドを実行して学習を開始することができる。
python launch.py --nproc_per_node=1 run.py --config_file=example_configs/getting_started.py --mode="train_eval"うまくいけば、モデル構成、全体的なトレーニングの進行状況、トレーニングの損失、検証の損失、およびR^2スコアである検証メトリックが出力される。
トレーニング済みモデルを予測モードでさらに実行して、新しいサンプルの予測結果を得るには、コマンドラインから次のコマンドを実行する必要がある。
python launch.py --nproc_per_node=1 run.py --config_file=example_configs/getting_started.py --mode="predict"予測結果
こんな感じで得られる。
less logs/logp_mlp_logs/predictions.txt CCCCCCN(C)N=Nc1ccc(C(N)=O)cc1,4.7723255 NC1C2CCC1c1ccccc12,2.6808066 Nc1nccc2ccccc12,1.7958283 CC(C)(O)CCS(=O)(=O)c1ccc(S(N)(=O)=O)cc1,0.10045385 CCCNC(=O)c1ccc[nH]1,0.9938375 O=C(Nc1ccc(Cl)cc1)c1cccc([N+](=O)[O-])c1O,4.165857 COC(=O)C(C#N)=NNc1ccc2c(c1)OC(F)(F)C(F)(F)O2,4.892629おわりに
この後は、Tox21のデータを使ったチュートリアル等でさらに理解を深めるとよい。また、プログラミング力は必要になるが、試行錯誤しながら論文のモデルを実装してみると面白い。DeepChemに比べるとカスタマイズできる感じが半端なくあるし、バックエンドもPyTorchなのでソースも理解しやすい。まさに、化合物によるDeepLearningの入門にうってつけのライブラリといえるだろう。
URL
- 投稿日:2020-11-27T21:55:05+09:00
PyTorchベースの計算化学用ディープラーニングライブラリOpenChem
はじめに
化合物でディープラーニングといえば、DeepChem (https://deepchem.io/) や Chainer Chemistory(https://chainer-chemistry.readthedocs.io/en/latest/) が有名だが、今回OpenChemというライブラリを紹介したい。
OpenChemとは
計算化学およびドラッグデザイン研究のためのディープラーニングツールキットである。PyTorchをバックエンドに使用しており、ライセンスはMITライセンスである。
どんな特徴があるの?
その特徴として以下があげられる
- モジュラー設計により、設定ファイルのみでモジュールを簡単に組み合わせて構築することができる。
- マルチGPUをサポートしており、高速に学習することができる。
- データ前処理のためのユーティリティ等も備えている。
- テンソルボードという可視化ツールにも対応している。
モジュラー設計について簡単に説明すると、DeepChemで新しいモデルを作成する場合、入力から出力までほぼ1から開発する必要があるのに対し、OpenChemではエンコーダー、デコーダー、埋め込みレイヤーなどの標準的なディープニューラルネットワークのブロックが用意されており、これらを組み合わせることとで既存のものを再利用しながら新しいモデルを比較的容易に開発することができるのである。
どんなタイプのモデルが作れるの?
- 分類(2クラス、多クラス)
- 回帰
- マルチタスク
- 生成モデル
どんなデータを扱えるの?
- SMILES文字列やアミノ酸配列などの文字の配列。
- 分子グラフ(SMILES文字列から生成)
どんなモジュールが用意されているの?
- トークンの埋め込み
- リカレントニューラルネットワークエンコーダー
- グラフ畳み込みニューラルネットワークエンコーダー
- 多層パーセプトロン
インストール
以下の環境でインストールしてみる。
環境
- Windows 10
- python 3.7
- rdkit-2020.09.1
- pytorch 1.7.0
- scikit-learn 0.23.2
- tensorboard 2.4.0
手順
以下のコマンドを順に実行すればよい。
ちなみに、tqdm以降はドキュメントに書かれていなかったが、試行錯誤しているうちに必要だと分かったため追加している。$ conda create -n openchem python=3.7 $ conda activate openchem $ git clone https://github.com/Mariewelt/OpenChem.git $ cd OpenChem $ conda install --yes --file requirements.txt $ conda install -c rdkit rdkit nox cairo $ conda install pytorch torchvision -c pytorch $ conda install tqdm $ conda install tensorboard $ conda install networkxモデルの定義と学習はどうやるの?
OpenChemのモデルは、設定ファイル(Pythonのディクショナリ形式でパラメータを指定)によって定義することができる。
設定ファイルには、以下を含める必要がある。
- モデルの実行/トレーニング/評価の方法を定義するパラメータ
- モデルアーキテクチャを定義するパラメータ
また、モデルの作成と分散プロセスの起動を処理する2つのPythonファイルである「run.py」と「launch.py」も必要となる。
runc.pyの引数
項目 説明 nproc_per_node ノードあたりのプロセス数。 ノード上のGPUの数と同じである必要がある。 lanch.pyの引数
項目 説明 config_file モデルが定義されているPython設定ファイルへのパス。 mode train、train_evalまたはeval。 continue_learning この引数が指定されている場合、トレーニングは最新のチェックポイントから再開される 設定ファイル
設定ファイルにはモデルが含まれている必要がある。
モデルは、OpenChemModelおよびディクショナリmodel_paramsから派生したクラスである必要がある。
以下は、モデルアーキテクチャに関連しないすべてのモデルに共通のパラメータの説明である。
項目 説明 task モデルによって解決されるタスクを指定する。 classification, regression , multitaskのいずれか train_data_layer トレーニングデータ用のpytorchデータセット。 --mode = evalの場合、Noneになる。 OpenChemは現在、SMILES、Graph、およびMoleculeProteinデータセットを作成するためのユーティリティを提供していている。 val_data_layer 検証データ用のpytorchデータセット。 --mode = trainの場合、Noneになる。 print_every ログ出力の頻度 save_every モデルがチェックポイントに保存される頻度。 logdir モデルチェックポイントとテンソルボードログが保存されるフォルダーへのパス。 use_clip_grad 勾配クリッピングを使用するかどうか。 max_grad_norm 勾配クリッピングが使用されている場合のパラメーターの最大ノルム。 batch_size バッチサイズ num_epochs エポック数。 --mode = evalの場合、Noneになる eval_metrics 評価のためのユーザー定義関数、指標。 --mode = trainの場合、Noneになる。 criterion pytorchの損失、モデルの損失 optimizer pytorchオプティマイザー、モデルをトレーニングするためのオプティマイザー。 --mode = evalの場合、Noneになる。 その他のパラメータは、モデルアーキテクチャに固有のものとなるので、APIドキュメントやその他のチュートリアルを確認してほしい。
ジョブの起動
以下4つのGPUを備えたノードで実行されるジョブの例である。1つのGPUで単一のプロセスを実行することもできる。
python launch.py --nproc_per_node=4 run.py --config_file="./my_config.py" --mode="train"チュートリアルをやってみよう
分子フィンガープリントからlogP値を予測するための単純な多層パーセプトロンニューラルネットワークを構築することにより、OpenChemでのモデル構築の基本について試してみる。
データのロード
まず、ファイルからデータを読み取る必要がある。
サンンプルのデータは、PyTorchのリポジトリの ./benchmark_datasets/logp_dataset/logP_labels.csv にあるものを使う。OpenChemは、複数の列を持つテキストファイルを処理することができる。
read_smiles_property_file では読み取る列、区切り文字を指定することができる。
読み取る列(cols_to_read)では、最初にSMILESの列、次の列にはラベルを指定する。import numpy as np from openchem.data.utils import read_smiles_property_file data = read_smiles_property_file('./benchmark_datasets/logp_dataset/logP_labels.csv', delimiter=",", cols_to_read=[1, 2], keep_header=False)read_smiles_property_fileの戻り値は、ファイルから読み取られた列と同じ数のオブジェクトを含むリストであり、上の例では、data[0]にはSMILESが含まれ、残りはすべてラベルとなっている。
smiles = data[0] labels = np.array(data[1:]) labels = labels.Tデータを読み取った後、scikit-learnの関数を使用してトレーニングセットとテストセットに分割し、新規にファイルに保存する。
from sklearn.model_selection import train_test_split from openchem.data.utils import save_smiles_property_file X_train, X_test, y_train, y_test = train_test_split(smiles, labels, test_size=0.2, random_state=42) save_smiles_property_file('./benchmark_datasets/logp_dataset/train.smi', X_train, y_train) save_smiles_property_file('./benchmark_datasets/logp_dataset/test.smi', X_test, y_test)PyTorchデータセットの作成
続いてPyTorchで処理するためのデータセットを作成する。OpenChemには、データ型に基づいてPyTorchデータセットを作成するための複数のユーティリティがある。
今回、SMILES文字列をユーザー定義関数を使用して特徴のベクトルに変換するFeatureDatasetを使用する。from openchem.data.feature_data_layer import FeatureDataset from openchem.data.utils import get_fp train_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/train.smi', delimiter=',', cols_to_read=[0, 1], get_features=get_fp, get_features_args={"n_bits": 2048}) test_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/test.smi', delimiter=',', cols_to_read=[0, 1], get_features=get_fp, get_features_args={"n_bits": 2048}) predict_dataset = FeatureDataset(filename='./benchmark_datasets/logp_dataset/test.smi', delimiter=',', cols_to_read=[0], get_features=get_fp, get_features_args={"n_bits": 2048}, return_smiles=True)ユーザー定義関数は、FeatureDatasetの引数get_featuresに渡され、さらにユーザー定義関数の引数はget_features_argsにディクショナリとして渡すことができる。
この例では、ユーザー定義関数として、RDKitフィンガープリントを生成するopenchem.data.utils.get_fp を利用している。
この関数はn_bitsにフィンガープリントのビット数を指定することができる。read_smiles_property_finction と同様、Datasetには cols_to_read およびdelimiter引数を指定する。
最終的に、train_dataset、test_dataset、predict_dataset の3つのデータセットを作成している。train_datasetとtest_datasetは、それぞれトレーニングと評価に使用する。
これらのデータセットでは、cols_to_read にSMILES文字列だけでなく、ラベルを持つ列のインデックスも含める必要がある。トレーニングが完了した後、predict_datasets を使用して、新しいサンプルの予測結果を取得する。
predict_datasets ではラベルは必要ないため、cols_to_read引数には、SMILES文字列に対する列のインデックスのみ指定すればよい。また、predict_datasetには、引数return_smiles = True を指定する。OpenChemモデルの作成とパラメータの定義
続いて、モデルタイプとモデルパラメータを指定する。ここでは多層パーセプトロンモデルであるMLP2Labelモデルを使用しており、特徴ベクトルからラベルを予測する。
from openchem.models.MLP2Label import MLP2Label model = MLP2Label model_params = { 'task': 'regression', 'random_seed': 42, 'batch_size': 256, 'num_epochs': 101, 'logdir': 'logs/logp_mlp_logs', 'print_every': 20, 'save_every': 5, 'train_data_layer': train_dataset, 'val_data_layer': test_dataset, 'predict_data_layer': predict_dataset, 'eval_metrics': r2_score, 'criterion': nn.MSELoss(), 'optimizer': Adam, 'optimizer_params': { 'lr': 0.001, }, 'lr_scheduler': StepLR, 'lr_scheduler_params': { 'step_size': 15, 'gamma': 0.9 }, 'mlp': OpenChemMLP, 'mlp_params': { 'input_size': 2048, 'n_layers': 4, 'hidden_size': [1024, 512, 128, 1], 'dropout': 0.5, 'activation': [F.relu, F.relu, F.relu, identity] }モデルの学習
上記で記載した「データのロード」から「OpenChemモデルの作成とパラメータの定義」までに記載したPythonのコードをファイルに保存する。ここではexample_configsフォルダーにあるlogp_mlp_config.pyファイルに同じものが保存されているので、それをそのまま使うことにする。
そして、コマンドラインから次のコマンドを実行して学習を開始することができる。
python launch.py --nproc_per_node=1 run.py --config_file=example_configs/getting_started.py --mode="train_eval"うまくいけば、モデル構成、全体的なトレーニングの進行状況、トレーニングの損失、検証の損失、およびR^2スコアである検証メトリックが出力される。
トレーニング済みモデルを予測モードでさらに実行して、新しいサンプルの予測結果を得るには、コマンドラインから次のコマンドを実行する必要がある。
python launch.py --nproc_per_node=1 run.py --config_file=example_configs/getting_started.py --mode="predict"予測結果
こんな感じで得られる。
less logs/logp_mlp_logs/predictions.txt CCCCCCN(C)N=Nc1ccc(C(N)=O)cc1,4.7723255 NC1C2CCC1c1ccccc12,2.6808066 Nc1nccc2ccccc12,1.7958283 CC(C)(O)CCS(=O)(=O)c1ccc(S(N)(=O)=O)cc1,0.10045385 CCCNC(=O)c1ccc[nH]1,0.9938375 O=C(Nc1ccc(Cl)cc1)c1cccc([N+](=O)[O-])c1O,4.165857 COC(=O)C(C#N)=NNc1ccc2c(c1)OC(F)(F)C(F)(F)O2,4.892629おわりに
この後は、Tox21のデータを使ったチュートリアル等でさらに理解を深めるとよい。また、プログラミング力は必要になるが、試行錯誤しながら論文のモデルを実装してみると面白い。DeepChemに比べるとカスタマイズできる感じが半端なくあるし、バックエンドもPyTorchなのでソースも理解しやすい。まさに、化合物によるDeepLearningの入門にうってつけのライブラリといえるだろう。
URL
- 投稿日:2020-11-27T21:46:19+09:00
Python 基本文法
1. 基本構文
1.1.print関数
文字列を画面に出力したいときに、print関数を使用する。
print関数print("Hello World!")1.2.コメント
Pythonでは「#」がコメントとして表記される。
複数行をコメントしたい場合はダブルクォーテーションで囲むか、シングルクォーテーション3つで囲む。コメント# 行コメント " 複数行コメント1 " ''' 複数行コメント2 '''1.3.変数
宣言や代入は以下のように記述する。
変数名 = 値
Javaのように変数の前に型を宣言せず、値の形によって変数の型が決まる。
変数#int var_int = 10 #float var_float = 1.234 #str:""もしくは'' var_str = "piyo" #bool:True,False var_bool = True1.4.演算子
演算子に関しては以下のものを使用できる。
加算:x + y
減算:x - y
乗算:x * y
除算:x / y
割った余り:x % y
べき乗:x ** y
切り捨て除算:x // y
論理演算子(AND):x and y
論理演算子(OR):x or y
論理演算子(NOT):not x(xは条件式で、条件式がTrueの場合のみFalseを返す。)1.5.if文
条件式がTrueの場合のみ後続の処理が実行される。
Pythonでは同じインデントが1つのブロックとなる。
コロン(:)で始まる行が複合分の始まりと判定されるため、複合文中に含まれる同じインデントは1つのブロックとなる。if文if 条件式: #行いたい処理 elif 条件式: #行いたい処理 #行いたい処理 else: #どの条件にも当てはまらなかった時の処理1.6.for文
for文の繰り返し処理の構文は以下のようになる。
for 変数 in range([始まりの数値=0,]最後の数値[,増加する量=1]):
#ループ処理for文for x in range(3): print(x) #結果 #0 #1 #2 for x in range(4,10,2): print(x) #結果 #4 #6 #81.7.while文
条件が正しい時だけ、whileブロック中の繰り返し処理を行う。
while文var = 1 while var < 3: print(var) var += 1 #加算1.8.条件分岐内、ループ内の処理
1.8.1.break
for,whileを途中で終了したい場合、break文を使用する。
break文for number in range(10): if number == 5: break print(number)1.8.2.continue
for,whileの中にある特定の処理をスキップしたい場合、continue文を使用する。
continue文for number in range (10): if number == 5: continue print(number)1.9.配列
1.9.1.リスト構造
単純な要素をいくつか持っている集合。
リスト# 単純なリスト list_1 = [1, 2, 3, 4] # 異なる型のリスト list_2 = [1, "Hello", True] # リストにリスト list_3 = [1, ["hoge", "piyo"], 2, 3] # 空のリスト list_4 = [] # 要素を指定した個数繰り返すリスト list_5 = [1, 2, 3] * 3 # [1, 2, 3, 1, 2, 3, 1, 2, 3] # 要素の取得 # 要素のインデックスは0から始まる print(list_1[0])1.9.2.辞書構造
keyとvalueの組み合わせが含まれている構造。
keyの重複は許されない、同じkeyは値が上書きされる。dict = { key1:value1, key2:value2, key3:value3 }>
dictionarydict = { 1:"hoge", 2:"piyo" } # piyo dict[2] # [1, 2] dict.keys() # [”hoge”, "piyo"] dict.values() # [(1, "hoge"), (2, "piyo")] dict.items()1.9.3.変更を許可しない配列
リストと同じ構造だが、編集が不可能。
tupletuple = (1, 2, 3)1.9.4.集合演算等に使用する配列
リストと同じ構造だが、要素が重複できないのと順序の保証がない。
setset = set([ 1, 2, 3 ]) # 要素を追加:add set.add(4) # 要素を削除:remove set.remove(3)
- 投稿日:2020-11-27T21:25:18+09:00
UbuntuにTensorFlow 2系のGPU環境を作ろう !
実行環境
ubuntu 20.04.1 LTS (日本語Ubuntu最新版)
Condaは使わない。
確実性を重視。
バージョン管理はpyenv
機体要件
CPU Ryzen7 5800X
GPU RTX3070
詳しくは
https://qiita.com/YU_GENE/items/09d7ffa85ad8e37dc063インストールするものを考える
TensorFlowのGPU環境を作るのは大変らしい。
Python,cuDNN,CUDAのバージョンが違うと動かない可能性があるからだ。
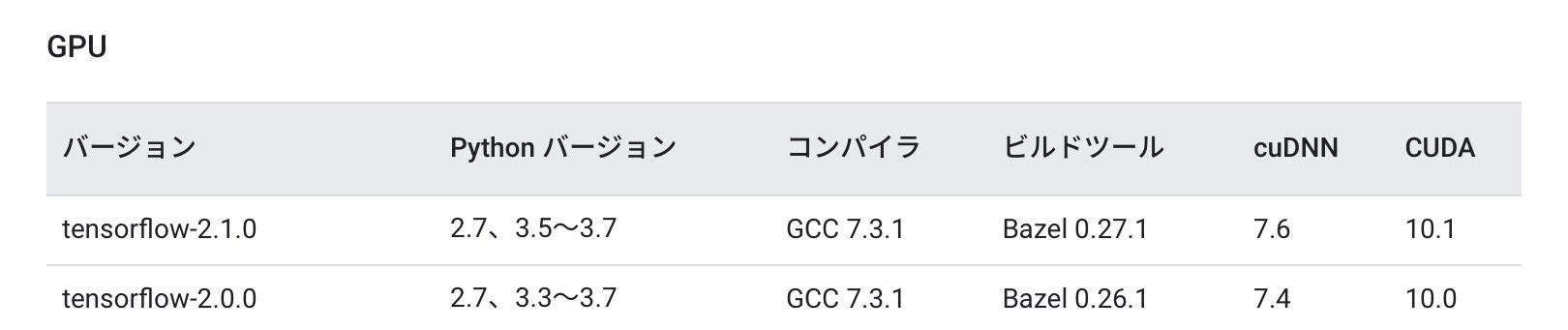
まず、Tensorflowのページに行って、ubuntuのTensorFlowのGPUバージョンの動作確認がされている最新版を確認しにいく。
2020/11/27現在、Ubuntu版TensorFlowは上のものが一番確実らしい。Pythonのバージョンを自在に操る
ubuntuインストール段階でのpythonのバージョンは3.8系だったが、pythonバージョンは3.7までが確認済みのようだから、pyenvというものを使って、自由自在にpythonのバージョンを管理できるようにする。
pyenvのインストール
pyenvのインストール$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ brew install pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profileUbuntuの場合、以下のコードを実行しないとpythonをインストールしてこれないので注意
Ubuntuの場合は以下も実行$sudo apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl git $sudo apt install libedit-dpythonの設定
今回は3.7系まで保証されているということなので、python3.7.9を入れる。
インストールできるもののリストは$pyenv install --list | lessで確認できる。
インストールの手順$pyenv install 3.7.9 $pyenv versions $pyenv shell 3.7.9でインストール完了。試しにpythonを起動すると、きっとpython3.7.9が起動するはず。
インストール、確認、起動設定の順である。これでバージョン問題に悩まされることは一生ない。
アツいぜ。python仮想環境の構築
PC環境を破壊しないために、venvというものを使って仮想環境を作る。
ここでいう仮想環境とはVirtualBoxとかがPC自体の仮想環境だとすれば、Python言語だけの仮想環境みたいなものである。今回はtfという適当なディレクトリ下に仮想環境設定をする。pyenvでpythonを3.7.1にした状態で$mkdir tf $cd tf $python -m venv .venvこれで設定は完了。仮想環境に入るにはこの状態で、
$source ~/tf/.venv/bin/activateこれで仮想環境に入れる。
左側に.venvと出れば成功。このコードは適当にエイリアスに保存しておくと楽。NVIDIAドライバのインストール
ちゃちゃっとインストール
他の方も記事にされているので、詳細は省略。
デフォルトグラフィックドライバを停止して、オートインストールするだけ!(やり方は下リンク)
https://qiita.com/sho8e69/items/66c1662c49ac89a024besudo ubuntu-drivers autoinstall
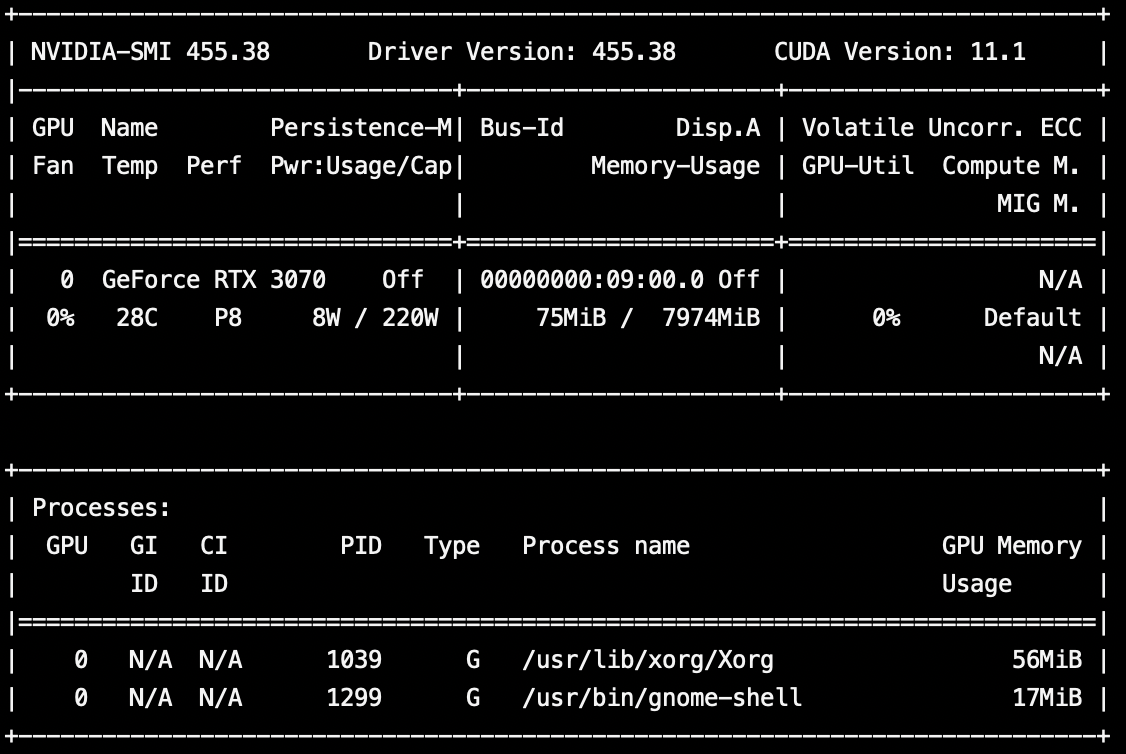
nvidia-smiを実行するとRTX3070の文字が。美しい。
CUDAのインストール
さて、CUDAの確認済みバージョンは10.1だったな。
CUDA10.1はaptからそのまま入手できる。簡単。最新版が欲しかったらnvidiaのサイトに行くべきだが、今回は丁度10.1が欲しかったのでそのまま以下を実行。$sudo apt install nvidia-cuda-toolkitnvcc -Vコマンドで確認できる。
TensorFlowのインストール
さて、TensorFlowの確認済みバージョンはTensorFlow2.1.0だったな。
仮想環境に入っている状態で、(pipは更新しといてね)(.venv)$pip install tensorflow==2.1.0で仮想環境のみにtensorflow2.1.0が入る。
pip listコマンドで入っているのが確認できる。
いいねぇ。cuDNNのインストール
CUDAと名前似てるけど、一応別物。
めんどいけど、以下で会員登録して
https://developer.nvidia.com/rdp/cudnn-archive
「CUDA10.1に対応したCuDNN7.6系」を探そう。
cuDNN Runtime Library for Ubuntu18.04 (Deb)
cuDNN Developer Library for Ubuntu18.04 (Deb)
をダウンロードして、
それぞれdpkg iコマンドで展開するだけ。簡単。sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.debできたかな?
pythonで以下を実行してみよう。
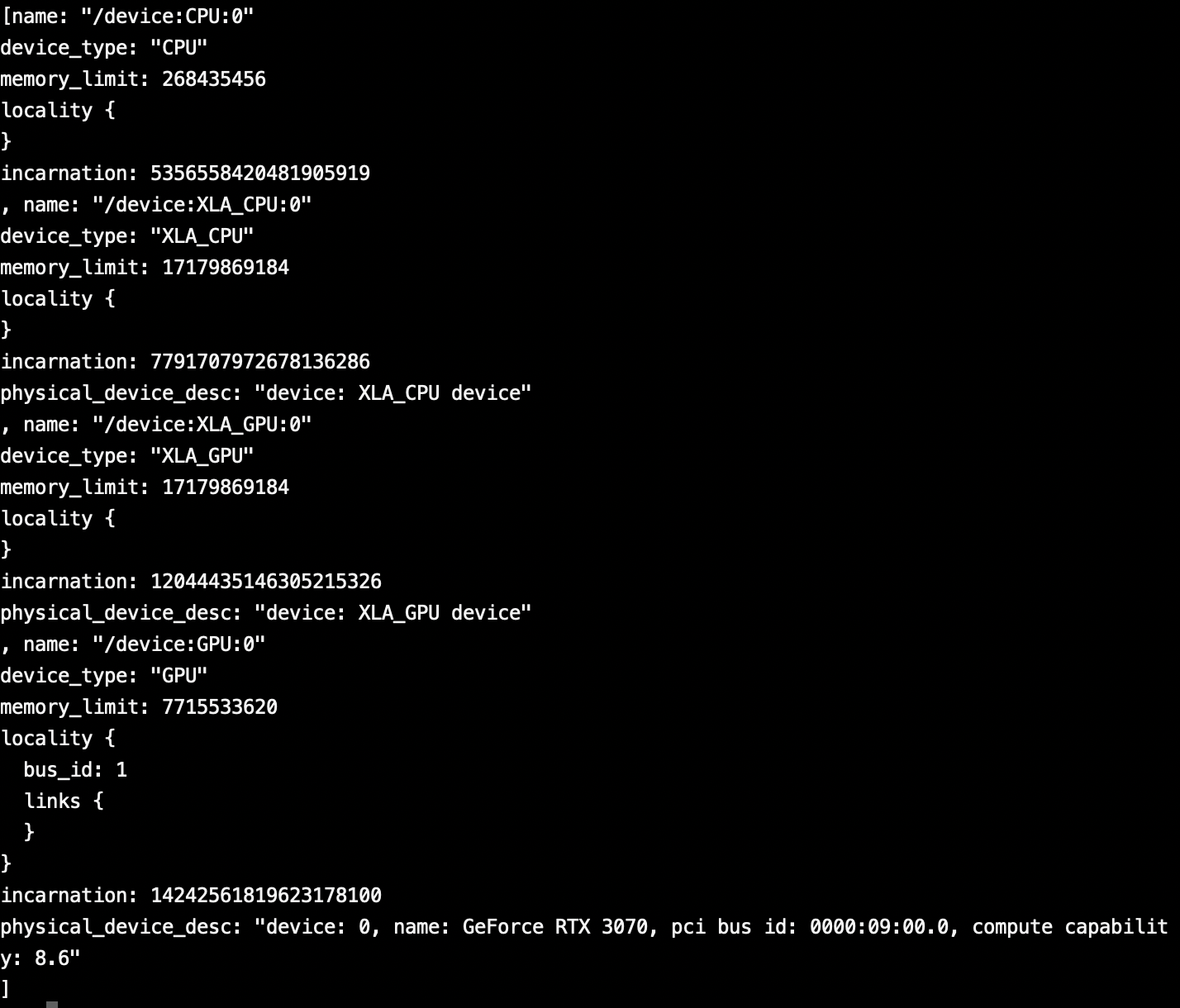
from tensorflow.python.client import device_lib device_lib.list_local_devices()
GPUの文言がちらほら。
一番下にはRTX3070の文字があるので正常にできたっぽい。まとめ
これで機械学習のために自作PCしたとか自慢できるね。
決して流行りのオンラインゲームがしたかったとかじゃないよ。
ほんとにね。(嘘)
- 投稿日:2020-11-27T21:25:18+09:00
UbuntuにTensorFlow 2.X 系のGPU環境を作ろう
実行環境
ubuntu 20.04.1 LTS (日本語Ubuntu最新版)
Condaは使わない。
確実性を重視。
バージョン管理はpyenv
機体要件
CPU Ryzen7 5800X
GPU RTX3070
詳しくは
https://qiita.com/YU_GENE/items/09d7ffa85ad8e37dc063インストールするものを考える
TensorFlowのGPU環境を作るのは大変らしい。
Python,cuDNN,CUDAのバージョンが違うと動かない可能性があるからだ。
まず、Tensorflowのページに行って、ubuntuのTensorFlowのGPUバージョンの動作確認がされている最新版を確認しにいく。
2020/11/27現在、Ubuntu版TensorFlowは上のものが一番確実らしい。Pythonのバージョンを自在に操る
ubuntuインストール段階でのpythonのバージョンは3.8系だったが、pythonバージョンは3.7までが確認済みのようだから、pyenvというものを使って、自由自在にpythonのバージョンを管理できるようにする。
pyenvのインストール
pyenvのインストール$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ brew install pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profileUbuntuの場合、以下のコードを実行しないとpythonをインストールしてこれないので注意
Ubuntuの場合は以下も実行$sudo apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl git $sudo apt install libedit-dpythonの設定
今回は3.7系まで保証されているということなので、python3.7.9を入れる。
インストールできるもののリストは$pyenv install --list | lessで確認できる。
インストールの手順$pyenv install 3.7.9 $pyenv versions $pyenv shell 3.7.9でインストール完了。試しにpythonを起動すると、きっとpython3.7.9が起動するはず。
インストール、確認、起動設定の順である。これでバージョン問題に悩まされることは一生ない。
アツいぜ。python仮想環境の構築
PC環境を破壊しないために、venvというものを使って仮想環境を作る。
ここでいう仮想環境とはVirtualBoxとかがPC自体の仮想環境だとすれば、Python言語だけの仮想環境みたいなものである。今回はtfという適当なディレクトリ下に仮想環境設定をする。pyenvでpythonを3.7.1にした状態で$mkdir tf $cd tf $python -m venv .venvこれで設定は完了。仮想環境に入るにはこの状態で、
$source ~/tf/.venv/bin/activateこれで仮想環境に入れる。
左側に.venvと出れば成功。このコードは適当にエイリアスに保存しておくと楽。NVIDIAドライバのインストール
ちゃちゃっとインストール
他の方も記事にされているので、詳細は省略。
デフォルトグラフィックドライバを停止して、オートインストールするだけ!(やり方は下リンク)
https://qiita.com/sho8e69/items/66c1662c49ac89a024besudo ubuntu-drivers autoinstall
nvidia-smiを実行するとRTX3070の文字が。美しい。
CUDAのインストール
さて、CUDAの確認済みバージョンは10.1だったな。
CUDA10.1はaptからそのまま入手できる。簡単。最新版が欲しかったらnvidiaのサイトに行くべきだが、今回は丁度10.1が欲しかったのでそのまま以下を実行。$sudo apt install nvidia-cuda-toolkitnvcc -Vコマンドで確認できる。
TensorFlowのインストール
さて、TensorFlowの確認済みバージョンはTensorFlow2.1.0だったな。
仮想環境に入っている状態で、(pipは更新しといてね)(.venv)$pip install tensorflow==2.1.0で仮想環境のみにtensorflow2.1.0が入る。
pip listコマンドで入っているのが確認できる。
いいねぇ。cuDNNのインストール
CUDAと名前似てるけど、一応別物。
めんどいけど、以下で会員登録して
https://developer.nvidia.com/rdp/cudnn-archive
「CUDA10.1に対応したCuDNN7.6系」を探そう。
cuDNN Runtime Library for Ubuntu18.04 (Deb)
cuDNN Developer Library for Ubuntu18.04 (Deb)
をダウンロードして、
それぞれdpkg iコマンドで展開するだけ。簡単。sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.debできたかな?
pythonで以下を実行してみよう。
from tensorflow.python.client import device_lib device_lib.list_local_devices()
GPUの文言がちらほら。
一番下にはRTX3070の文字があるので正常にできたっぽい。まとめ
これで機械学習のために自作PCしたとか自慢できるね。
決して流行りのオンラインゲームがしたかったとかじゃないよ。
ほんとにね。(嘘)
- 投稿日:2020-11-27T21:03:19+09:00
Python学習 基礎編 ~数値と計算~
こちらではPython学習の備忘録と、Ruby、JavaScriptとの比較も含め記載していきたいと思います。
プログラミング初心者や他の言語にも興味、関心をお持ちの方の参考になれば幸いです。数値とは?
プログラミングでは、数値を扱うこともでき、文字列とは違いクォーテーションで囲む必要がない。
クォーテーションをつけると、文字列と解釈されるため、文字列と数値は明確に違うものであることを意識しよう。計算について
数値は、足し算「+」、引き算「-」、掛け算「*」(アスタリスク)、割り算「/」(スラッシュ)、余剰(割り算の余り)「%」の計算が可能です。
また数値や記号はすべて半角で記述する。※記号の前後の半角スペースはなくても構わないですが、入れた方がコードが見やすいと思います。
以上は、Python、Ruby、JavaScriptで共通となります。
各言語の記述を下記に記載します。Python
script.pyprint(3) # 数値のみ print(3 + 5) # 対し算 print(6 - 5) # 引き算 print(3 * 5) # 掛け算 print(20 / 5) # 割り算 print(8 % 5) # 余剰(割り算の余り) # コンソール 3 8 1 15 4 3 # 8割る5は、1余り3Ruby
index.rbputs 3 puts 3 + 5 puts 6 - 5 puts 3 * 5 puts 20 / 5 puts 8 % 5JavaScript
script.jsconsole.log(3); console.log(3 + 5); console.log(6 - 5); console.log(3 * 5); console.log(20 / 5); console.log(8 % 5);
おわりに
数値に関しては、各言語ともに共通する部分が多いので覚えやすいですね。次回は文字列の連結などをやろうかな...では!
- 投稿日:2020-11-27T19:46:43+09:00
Towards Streaming Perception の解説
こんにちは、高校生の kamikawaです。
機械学習に興味があって勉強中です。特にCV分野に興味があります。今回はECCV2020でBest paperに選ばれた「Towards Streaming Perception」という論文について解説します。
自動運転やVR、ARなど、リアルタイムでのperceptionに興味がある方、ぜひご覧ください。
間違い等あればご指摘お願いします。概要
モチベーション:リアルタイムで認識から再行動までを行うための高速で正確なperceptionの実現
- オフラインの評価と実世界への応用との間に矛盾を指摘
- レイテンシと精度を一貫して評価できる指標を提案
- ストリーミング環境下の様々なタスクへ応用できるメタベンチマークを提案
- ストリーミング環境下のタスクで、性能を向上させるための手法を提案
提案されたベンチマーク
streaming accuracy
- レイテンシと精度を一度に評価できる
- 評価指標を確立
pseudo ground truth
- 高フレームレートかつ高アノテーションレートのデータセットを人の手を使わずに作れる
- データセット不足を解消
infinite GPUsシミュレーション
- モデルの性能を最大化するために必要なGPU数が分かる
- 実用化に向けた計算資源に関する知見が得られる
提案手法
ストリーミング環境でperceptionの性能を向上させるための汎用的な手法を提案している
- 動的スケジューリング
- 処理すべきフレームを決定する
- レイテンシの累積を防ぐ
- 状態予測
- 物体の将来の位置を予測する
- レイテンシを補う
- トラッキング
- 検出器より高速に動作する
- レイテンシを減らす
背景
ストリーミング環境下でのperception(YOLOやSSDなど)は難しい
- レイテンシの問題
- 処理を行っている間に物体が移動してしまう
- 精度とレイテンシを間にトレードオフがある
- 良い評価指標がない
- レイテンシと精度のトレードオフの良さを測りたい
- データセットが少ない
- 高フレームレートかつ高アノテーションレートのデータセットが欲しい
従来のCV分野(リアルタイム)の研究
自動運転やVR、ARなどストリーミング環境で高度なperceptionの需要は高まっている
多くの研究:オフライン環境で精度とレイテンシを評価し、トレードオフを指摘
高速な検出器 ・・・ 精度が低い
高精度な検出器・・・ 遅いオフライン環境で測定された精度とruntime
この研究
オフライン環境での評価と実世界での応用との間に矛盾
- オフライン環境 (従来の研究)
- 一枚のフレームの処理が終わった段階で次のフレームが与えられる
- レイテンシが累積しない
- ストリーミング環境 (実世界での応用)
- 処理が終了したかどうかに関わらず、次々とフレームが与えられる
- レイテンシが累積する
従来の研究のようなオフライン環境での実験や評価には問題がある
高度なperceptionを実現するために
実世界の応用:人間の反応時間(200ms)に匹敵する速さのperceptionが求められる
ストリーミング環境特有の課題 : アルゴリズムが処理を終えるまでに周囲の環境が遷移してしまう
そのため、周囲の環境を認識・行動するためには、将来の状態を予測することが必要
提案ベンチマークの詳細
streaming accuracy
- 適切な評価指標を確立
- 精度とレイテンシのトレードオフの良さを評価できる
従来の評価 : ( y , y^t)
今回の評価 : ( yt , y^φ(t) )t : 連続的な時間(i = 1 ~ T)
φ(ti) : アルゴリズが最後に予測を出した時間 φ(ti) = argmaxj sj < ti
sj : 特定の予測(y^)が生成された時間 ( j = 1 ~ N < T)
y : ground truth
t : 連続的な時間( i = 1 ~ T)
y^ : 予測
φ(ti) = argmaxj sj < ti
sj : 特定の予測(y^)が生成された時間 ( j = 1 ~ N < T)
様々な評価指標(AP,IoUなど)を拡張し、レイテンシと精度を同時評価できるpseudo ground truth
- 高フレームレートかつ高アノテーションレートのデータセットを人の手を使わずに作れる
- 擬似的なground truth を作成する
- 高精度の評価器(HTC)がオフライン環境で物体検出を行なった結果を用いる
- pseudo ground truth によるAPと実際のground truthを用いたAPは相関が高い
- 相関係数 : 0.9925(正規化済み)
- 性能評価に用いることができる (今回の性能評価には用いられていない)
infinite GPUsシミュレーション
- モデルの性能を最大化するために必要なGPU数が分かる
- 仮想的にGPU資源が無限である状態でシミュレーション
- 各GPUタスクを別々のデバイス割り振る
- タスクのパフォーマンスを最大化するために必要なGPUの数が分かる
- ハードウェア設計に役立つ可能性がある
左は単一のGPUでの処理:一つのデバイスが複数のGPUタスク(例 : 物体検出、状態予測、トラッキングなど)を行う
右はinfinite GPUsでの処理:一つのデバイスは一つのGPUタスクを行う提案手法の詳細
提案手法
動的スケジューリング
- 処理すべきフレームを決定する
- レイテンシの累積を防ぐ
状態予測
- 物体の将来の状態を予測することで、レイテンシを補う
- バウンディングボックスの状態遷移をもとに予測
- 入力 : BBの左上の座標(x,y)、高さ(h)、幅(w)
- カルマンフィルターによる予測が最も高性能
- 4~80%の性能上昇を確認(平均で33%上昇)
- 軽量
トラッキング
- 検出器より高速に動作する
- レイテンシを減らすために高速化
- 以前検出されたオブジェクトのみを追跡
- 最新の物体の位置を入力とし、領域提案を省略
領域提案(RPNのhead)を省略することで24%ランタイムを削減できる
実験
データセットはArgoverse-HDを用いた (詳細は後述)
* フレームレート : 30FPS
* * アノテーション レート : 30FPS
* 人、自転車、自動車、バイク、バス、トラック、交通信号、止まれの標識の8クラスストリーミング環境とオフライン環境の比較
物体検出のみを行う
HTCやMask R-CNN、RetinaNet などのモデルを用いて実験した結果
- ストリーミング環境ではAPが大幅に低下する
(AP₅₀ , AP₇₅ とは、IOU が 0.5 , 0.7 を閾値としたAP
@の後の数字は入力のスケール
*は前処理にGPUを使用したもの)
- ランタイムのベースライン : 33ms = 30FPSのフレーム間隔(1000/30)
- しかし、高速なモデル(3),(4)は性能が低い
- 入力スケール0.5のMask R-CNN R 50が最高性能
- ストリーミング環境ではHTCより性能が高い
infinite GPUsでの検証結果
- infinite GPUsにおいて、複雑な検出器の方が性能が良い
- 入力スケールを0.5から0.75、ランタイム約2倍
- 4つのGPUでstreaming accuracy を最大化できる
動的スケジューリングの有効性の検証
物体検出のみを行う
Mask R-CNN R50で動的スケジューリングの有無による性能差を評価する結果
- 動的スケジューリングを取り入れたアルゴリズムは性能が向上
- AP , APւ において1.0 / 2.3 性能が向上
状態予測の有効性の検証
- 状態予測を取り入れたモデルの性能評価
- 物体検出 + アソシエーション + 状態予測
- アソシエーション : IOUベースのgreedy matchingを使用
- 状態予測 : カルマンフィルターを使用
結果
- 状態予測によって性能が向上
- AP比 13.0 : 16.7
- 複雑なアルゴリズムの方が性能が高い
- Mask R-CNN(ResNet 50)が最高性能
- 入力スケール、ランタイムが共に大きい方が高性能
トラッキングの有効性の検証
トラッキングを取り入れたモデルの性能評価
- Mask R-CNN (ResNet 50)を使用
- VOT2019 Challenge で2位になったモデルTracktorを使用
- 物体検出にはFPNを使用
- 2,5,15,30 の固定ストライドで実験
- (30固定ストライド→検出器を1回実行してからトラッカーを29回実行)
通常速度のモデルの性能評価
- 通常速度のトラッキングモデルは、アソシエーションに比べて性能が劣る
- トラッキングのみ AP比 12.0 < 16.7
- +状態予測 AP比 13.7 < 16.7
高速化したモデルの性能評価
高速化したトラッキングモデル
- 以前検出されたオブジェクトのみを追跡
- 最新の物体の位置を入力とし、領域提案(RPN)を実行しない
結果
- 同精度で2倍に高速化したモデルは、アソシエーションに比べて性能が良い
- トラッキング+ 状態予測 AP比 19.8 > 16.7
分析と課題
- ストリーミング環境はオフライン環境より遥かに難しい
- 性能差はAP比 20.3 : 38.0
- 汎用的な内部表現によってstreaming accuracyが向上
- 動的スケジューリング、トラッキング、状態予測など
- 精度とレイテンシの最適なトレードオフが存在
- streaming accuracyの最大化する点が最適なトレードオフ
- 動的スケジューリングの有効性
- 場合によっては「処理をしない」ことでレイテンシを最小化できる
追加情報
データセットの詳細
Argoverse-HD
- Argoverse 1.1 をストリーミング評価用に拡張したもの
- 米国の2つの都市からの多様な走行シーンを収録
- RGB画像(1920 × 1200)
- 15~30秒の動画が30本
- 総フレーム数 : 15k
- フレームレート : 30FPS
- アノテーションはMSCOCOに従って行なった
- 人、自転車、自動車、バイク、バス、トラック、交通信号、止まれの標識
- アノテーション レート : 30FPS
End-to-Endに向けた実験
- 本編の実験では、様々なモジュールに分けてを検証した
- 物体検出、状態予測、トラッキングなど
- 今回の実験では、F2Fを使用する
- 直接、検出結果を出力するモデル
結果
- F2Fはカルマンフィルターより性能が低い
レイテンシを減らすテクニック
画像の前処理
モチベーション : 画像の前処理におけるレイテンシを減らしたい
- 前処理にCPUを用いるのではなくGPUを用いる
- *は前処理にGPUを使用したもの
最後に
図は論文、プロジェクトページ、Git Hub、YouTubeから引用しています。(一部編集を加えた箇所もあります)
記事をご覧いただきありがとうございました。
今後も機械学習の論文について解説していきたいと思いますのでよろしくお願いします。
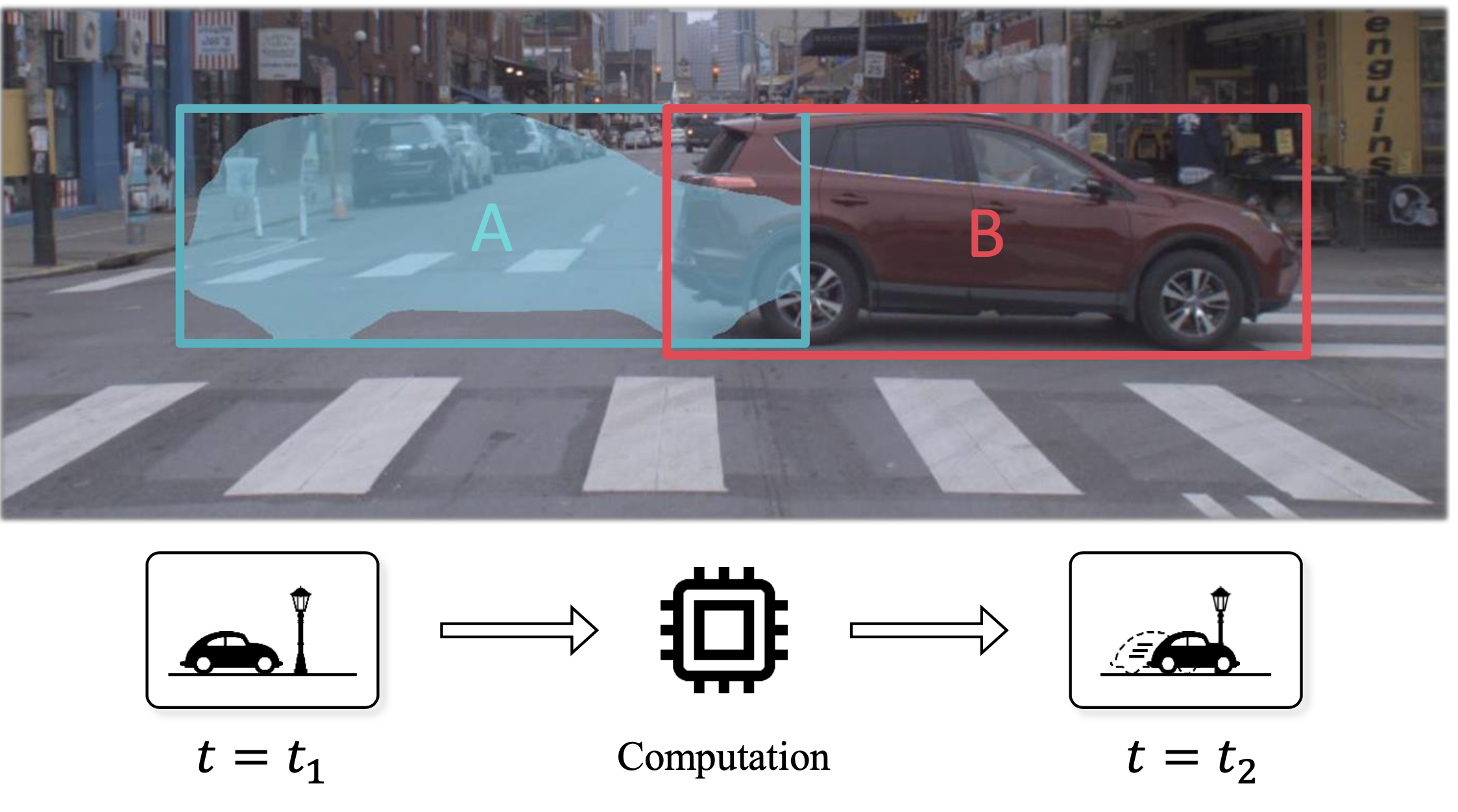
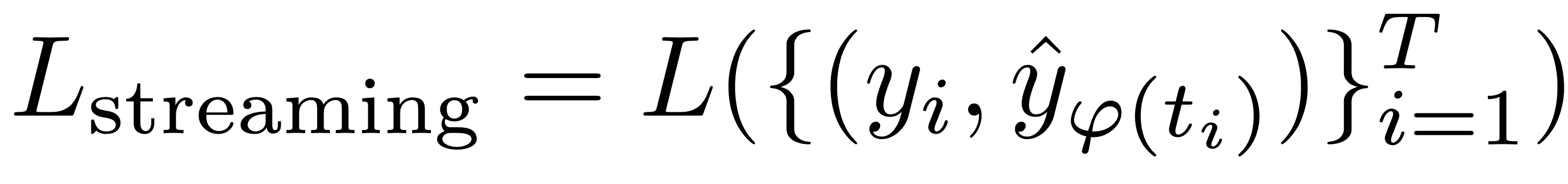
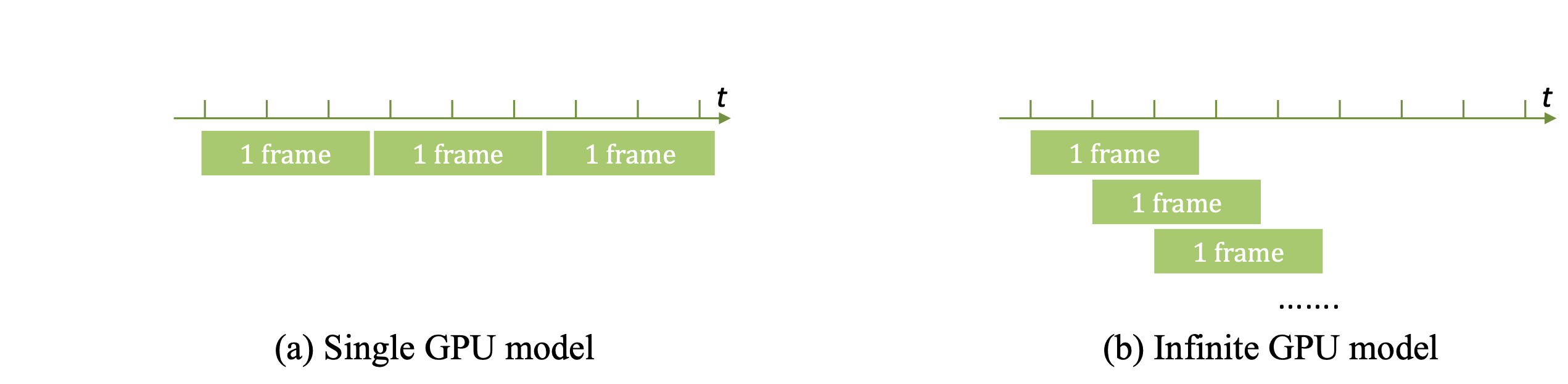

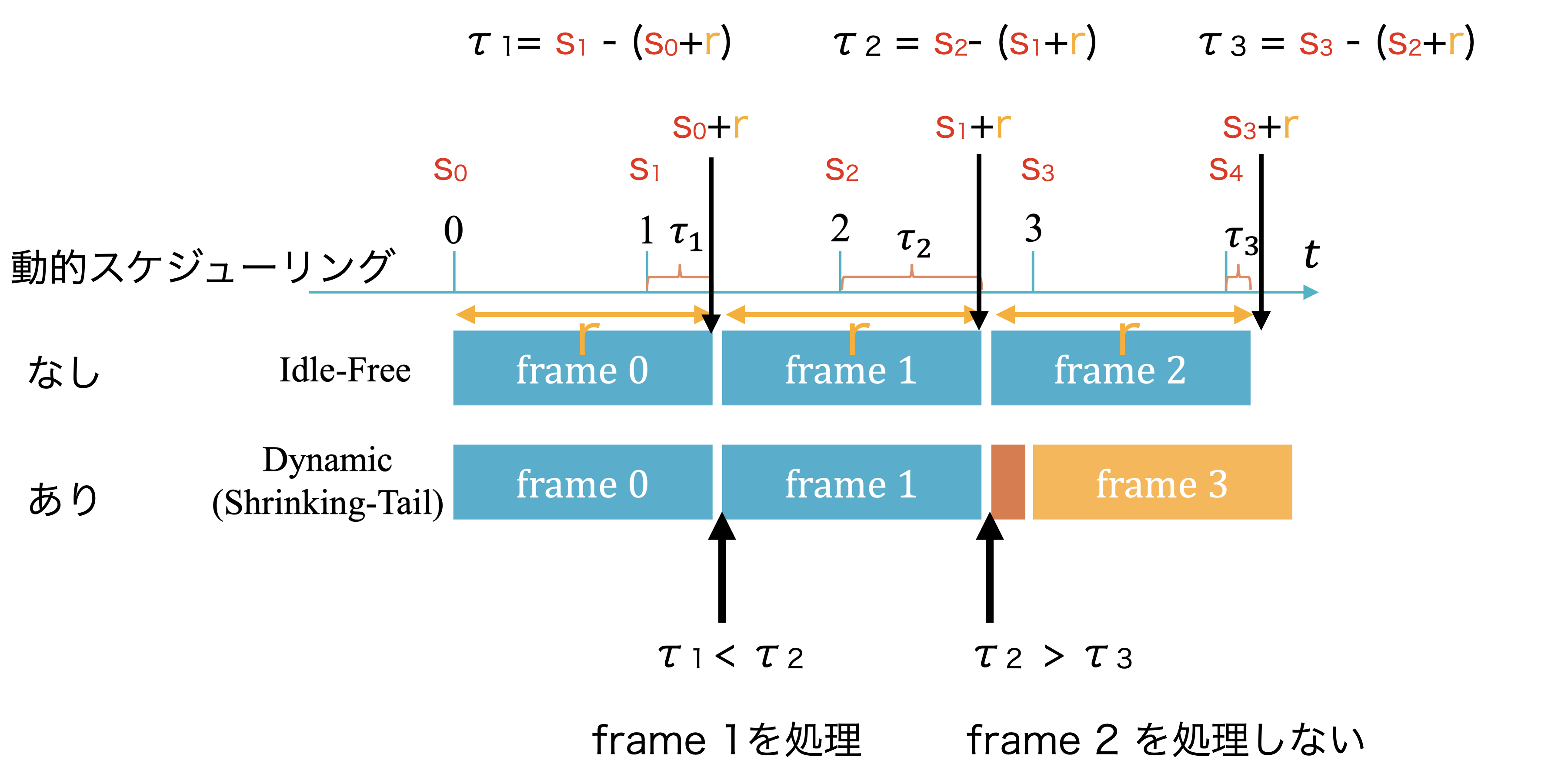

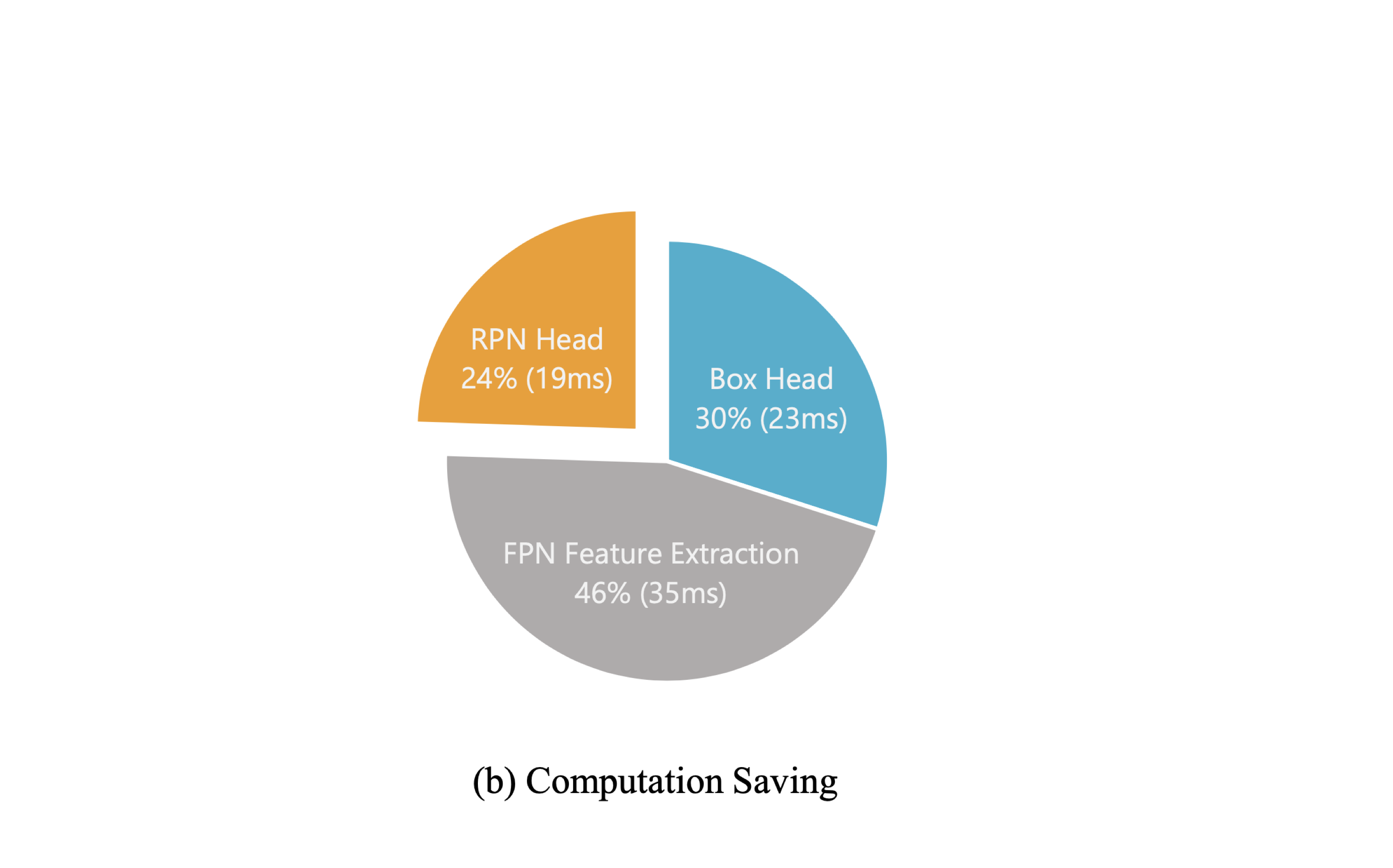

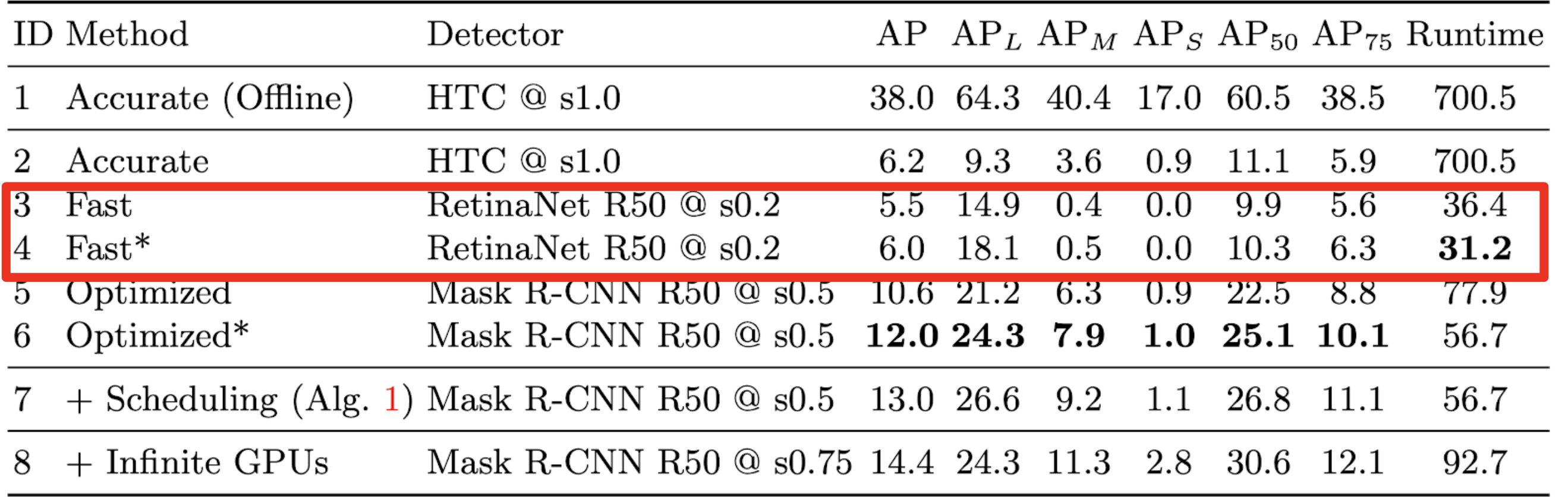

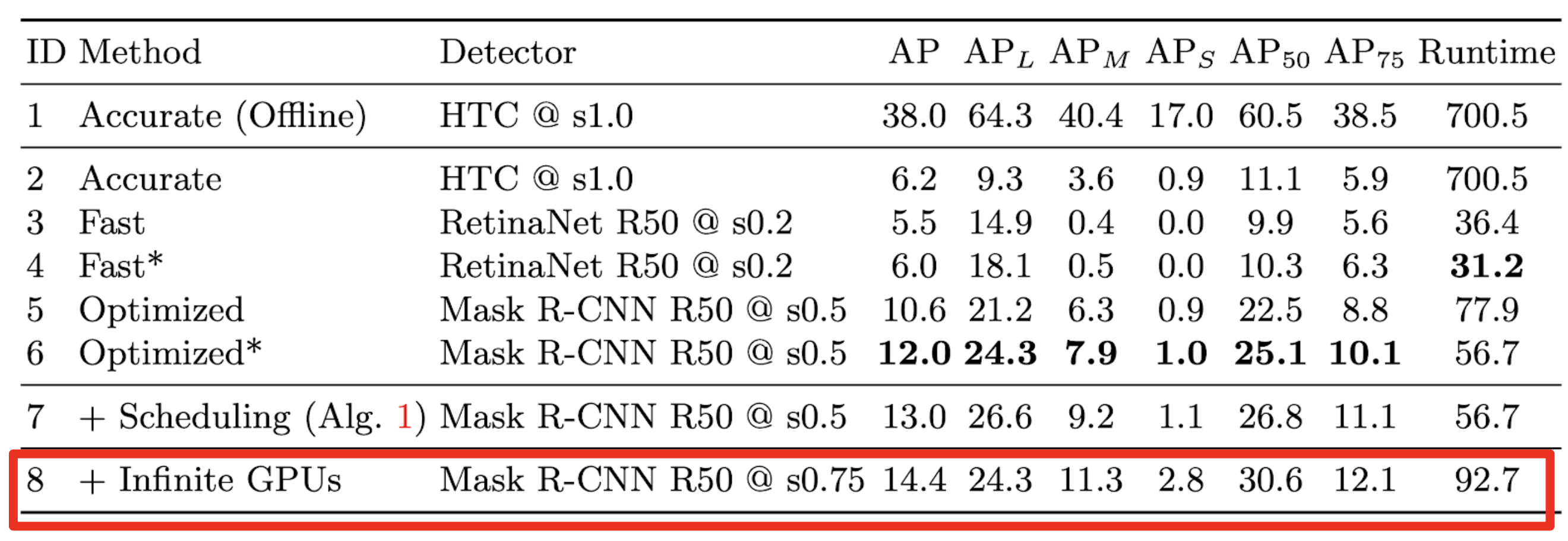
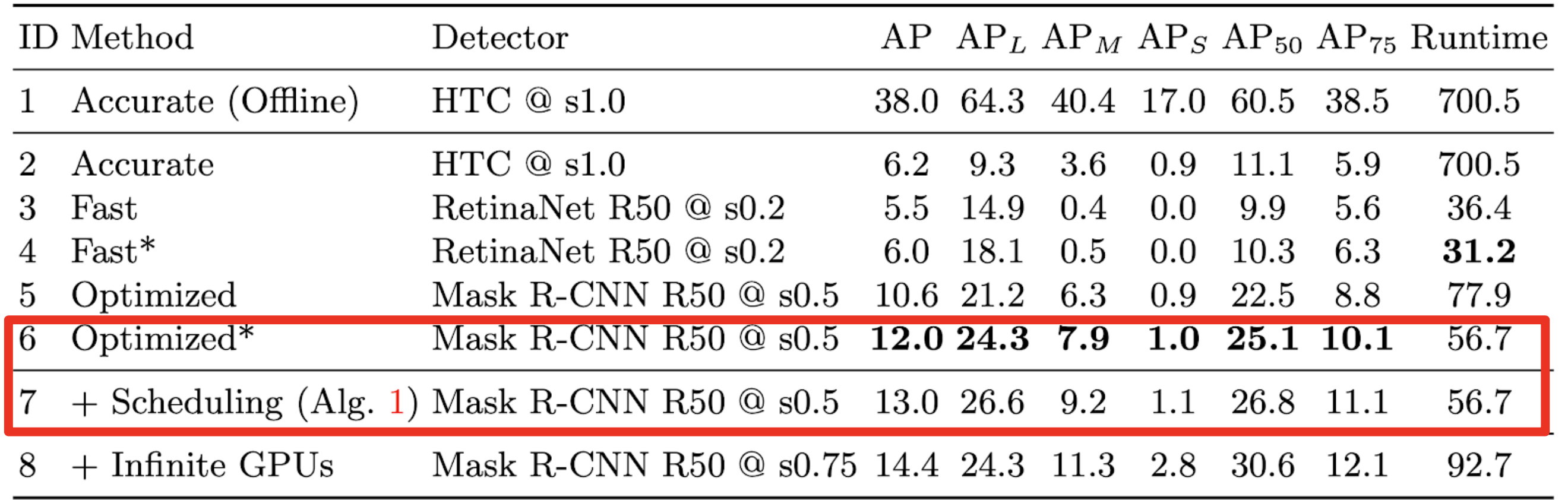
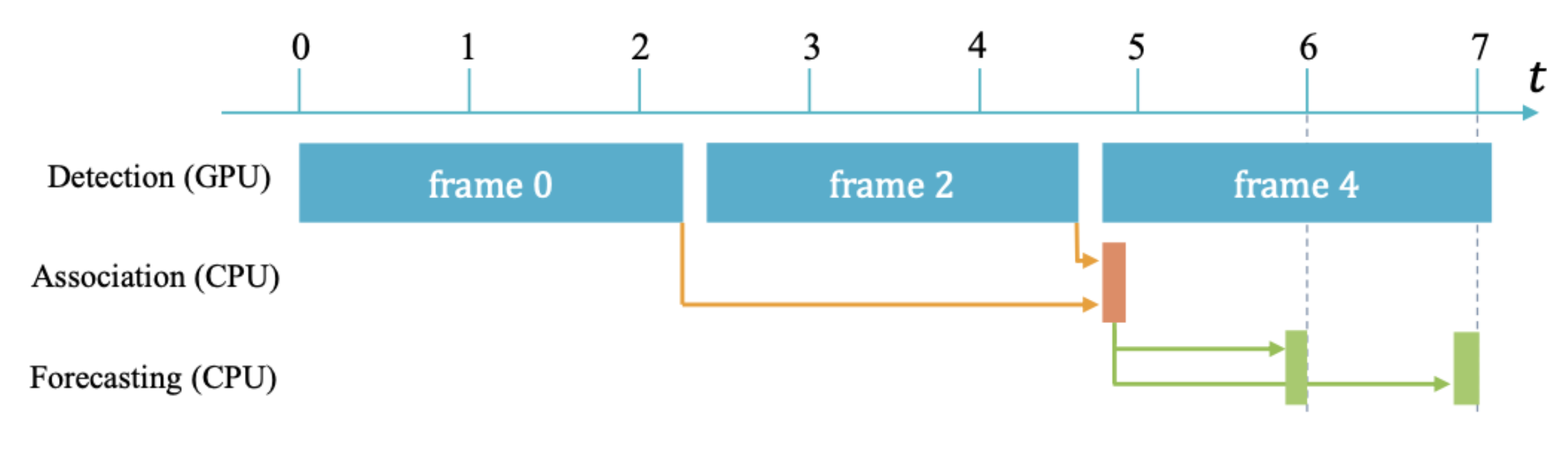
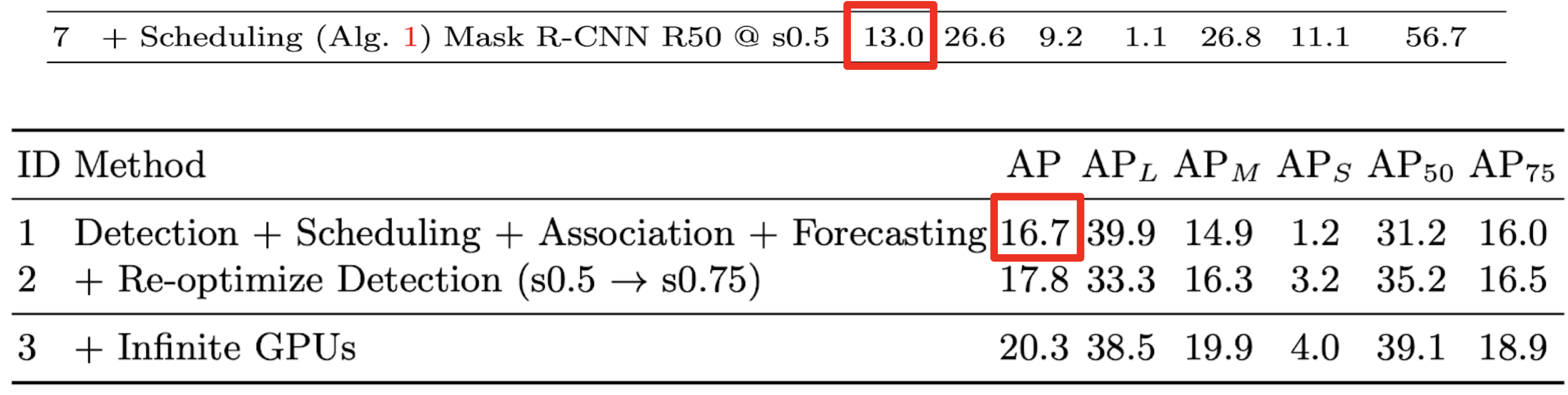
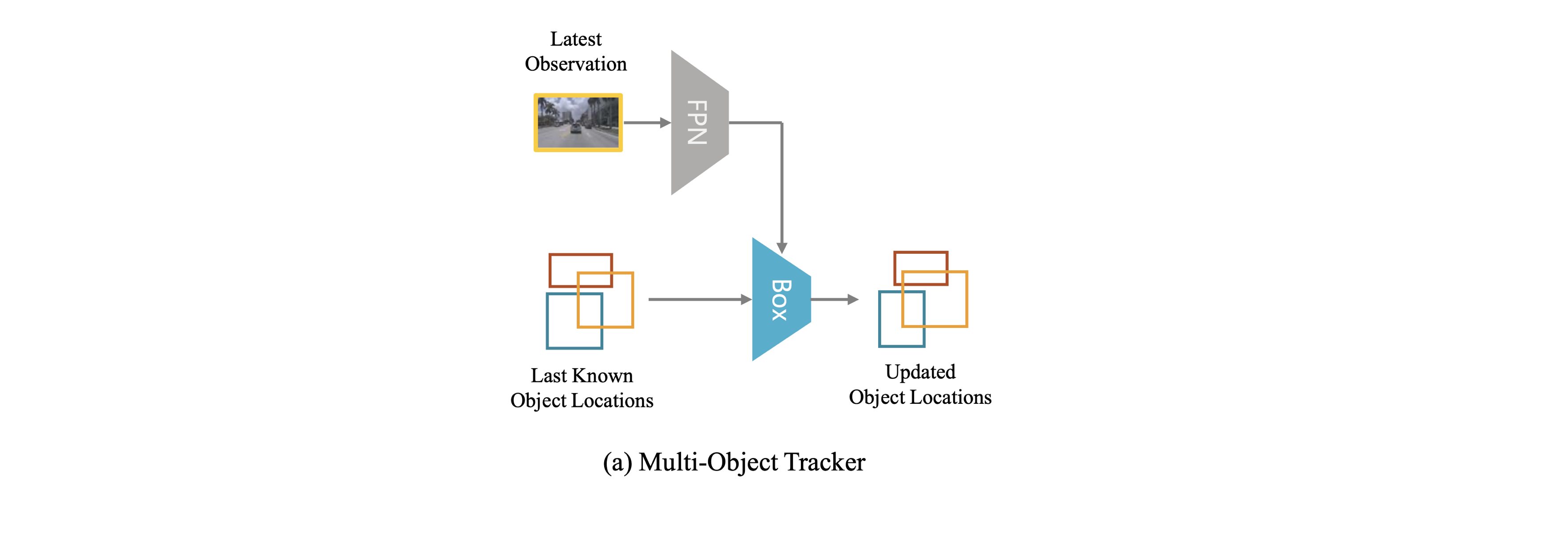


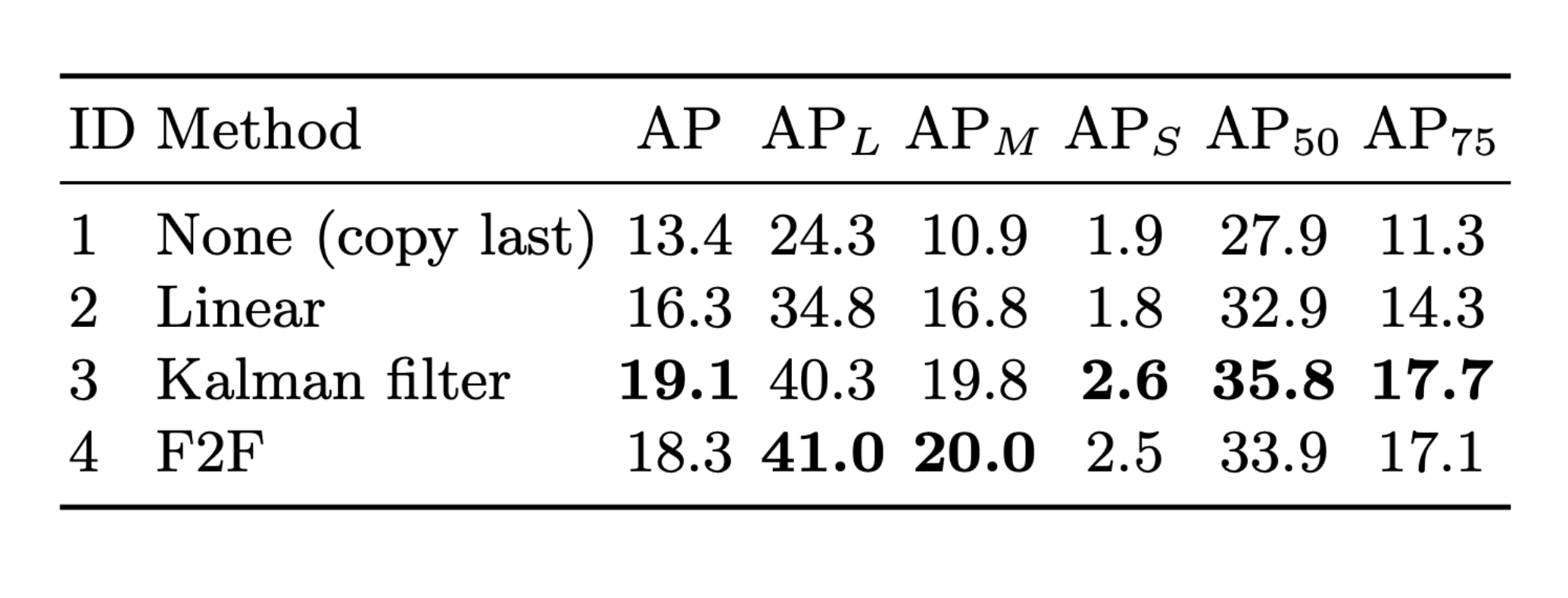
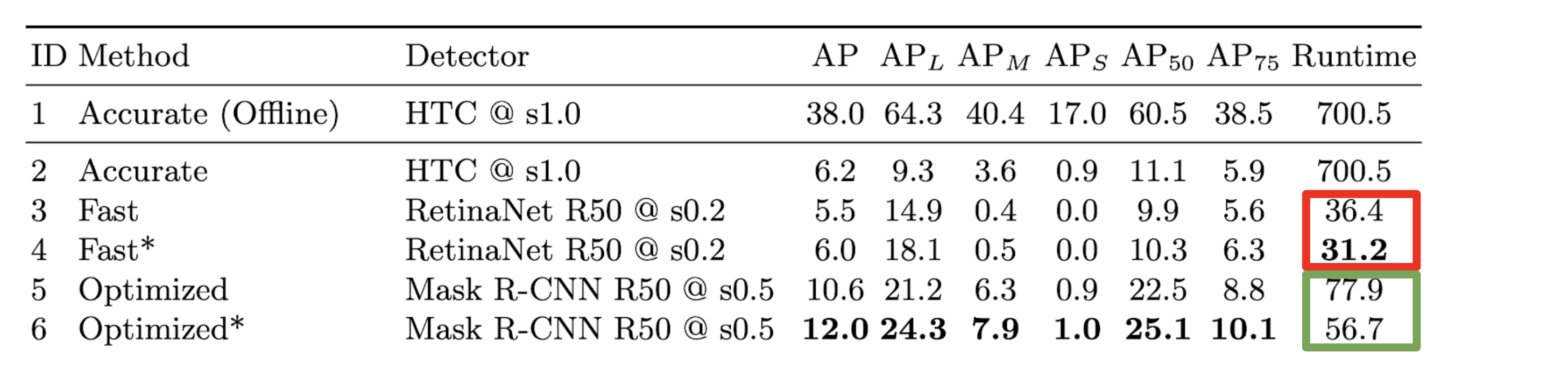
- 投稿日:2020-11-27T19:45:19+09:00
SIGNATE【SOTA】アップル引っ越し需要予測の解法
はじめに
SIGNATEで過去に終了したコンペに参加できるSOTA Challengeをしてみました。
今回の記事は引っ越し需要予測がテーマです。
コンペに参加してコードを書いてsubmitしても、忘れがちなので復習として記事にします。
凝ったことはしてないので、自分のような機械学習初学者の参考になれば幸いです。SOTA Challenge機能の特徴
SIGNATE【SOTA】アップル引っ越し需要予測SIGNATEのフォーラムで、こちらの記事を公開したことを記載しています。
実行環境
GoogleColaboratory
コンペ概要
引越しに関する要因(休業日や料金区分)をもとに、引越し数を時系列予測する。
学習用データは2101
評価用データは365
評価はMAE前準備
import pandas as pd import numpy as np import lightgbm as lgb from sklearn.metrics import mean_absolute_error as MAEdef reduce_mem_usage(df, verbose=True): numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64'] start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns: col_type = df[col].dtypes if col_type in numerics: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else: if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum() / 1024**2 if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem)) return df#上限表示数を拡張 pd.set_option('display.max_columns', 50) pd.set_option('display.max_rows', 50)train = pd.read_csv('../sota/train.csv') test = pd.read_csv('../sota/test.csv') sample = pd.read_csv('../sota/sample_submit.csv')train = reduce_mem_usage(train) test = reduce_mem_usage(test) sample = reduce_mem_usage(sample)特徴量生成
#四則演算 train['am*pm'] = train['price_am']*train['price_pm'] train['cli*clo'] = train['client']*train['close'] train['cli*am'] = train['client']*train['price_am'] train['cli*pm'] = train['client']*train['price_pm'] train['clo*am'] = train['close']*train['price_am'] train['clo*pm'] = train['close']*train['price_pm'] train['am+pm'] = train['price_am']+train['price_pm'] train['cli+clo'] = train['client']+train['close'] train['cli+am'] = train['client']+train['price_am'] train['cli+pm'] = train['client']+train['price_pm'] train['clo+am'] = train['close']+train['price_am'] train['clo+pm'] = train['close']+train['price_pm'] train['am-pm'] = train['price_am']-train['price_pm'] train['cli-clo'] = train['client']-train['close'] train['cli-am'] = train['client']-train['price_am'] train['cli-pm'] = train['client']-train['price_pm'] train['clo-am'] = train['close']-train['price_am'] train['clo-pm'] = train['close']-train['price_pm']#ラグ特徴量、移動平均、日付 train['oneday_before_am'] = train['price_am'].shift(1) train['oneday_before_pm'] = train['price_pm'].shift(1) train['rel_3am'] = train['price_am'].rolling(7).sum() train['rel_3pm'] = train['price_pm'].rolling(7).sum() train['rel_3cli'] = train['client'].rolling(7).sum() train['rel_3clo'] = train['close'].rolling(7).sum() train['datetime'] = pd.to_datetime(train['datetime']) train['year'] = train['datetime'].dt.year train['month'] = train['datetime'].dt.month train['day'] = train['datetime'].dt.day train['dayofweek'] = train['datetime'].dt.dayofweek同様の処理をtestにも行う
test['am*pm'] = test['price_am']*test['price_pm'] test['cli*clo'] = test['client']*test['close'] test['cli*am'] = test['client']*test['price_am'] test['cli*pm'] = test['client']*test['price_pm'] test['clo*am'] = test['close']*test['price_am'] test['clo*pm'] = test['close']*test['price_pm'] test['am+pm'] = test['price_am']+test['price_pm'] test['cli+clo'] = test['client']+test['close'] test['cli+am'] = test['client']+test['price_am'] test['cli+pm'] = test['client']+test['price_pm'] test['clo+am'] = test['close']+test['price_am'] test['clo+pm'] = test['close']+test['price_pm'] test['am-pm'] = test['price_am']-test['price_pm'] test['cli-clo'] = test['client']-test['close'] test['cli-am'] = test['client']-test['price_am'] test['cli-pm'] = test['client']-test['price_pm'] test['clo-am'] = test['close']-test['price_am'] test['clo-pm'] = test['close']-test['price_pm']test['oneday_before_am'] = test['price_am'].shift(1) test['oneday_before_pm'] = test['price_pm'].shift(1) test['rel_3am'] = test['price_am'].rolling(7).sum() test['rel_3pm'] = test['price_pm'].rolling(7).sum() test['rel_3cli'] = test['client'].rolling(7).sum() test['rel_3clo'] = test['close'].rolling(7).sum() test['datetime'] = pd.to_datetime(test['datetime']) # dtype を datetime64 に変換 test['year'] = test['datetime'].dt.year test['month'] = test['datetime'].dt.month test['day'] = test['datetime'].dt.day test['dayofweek'] = test['datetime'].dt.dayofweekモデル実装
X_train = train.drop(['y','datetime'], axis=1) y_train = train['y'] X_test = test.drop(['datetime'], axis=1) model = lgb.LGBMRegressor(random_state=42,n_estimators=500) model.fit(X_train,y_train) y_pred_train = model.predict(X_train) MAE(y_train,y_pred_train)1.8381673365676439
y_pred_test = model.predict(X_test)※sample_submit.csvのヘッダーがなかったので、csv側で予めカラム名を入れる
#日付の区切りを'/'から'-'へ sample['datetime'] = pd.to_datetime(sample['datetime'])sample.to_csv('submit.csv', index=False, header = False)これでsubmitしたところ、81位でした。(2020/11/27時点)
単純な特徴量生成とモデルなので、改善余地は多いと思います。
おわりに
今回はじめてSOTA Challengeをやってみました。
SOTA Challengeは過去のコンペに参加し、精度向上を極限まで挑戦し、知見を共有することを目的とした終わりのないコンペということなので、今後も少しずつ参加してみたいと思います。
最後まで記事を読んで頂き、ありがとうございました。
- 投稿日:2020-11-27T19:07:47+09:00
指定した拡張子を持つファイルを調べて、ファイル名の配列を返すメソッド
1. 定義したメソッド
Pythondef get_ext_matching_file_names(ext_pattern_list, search_directory_path) : file_names_list = os.listdir(search_directory_path) # 上記のいずれかの拡張子を持つファイルのファイル名を格納する配列を用意 available_filename_list = [] # 上記のいずれかの拡張子を持つファイルのファイル名を配列に格納する for file_name in file_names_list: ext_check_result = [] for ext in ext_pattern_list: boolean = ext in file_name ext_check_result.append(boolean) if True in ext_check_result: available_filename_list.append(file_name) return available_filename_list2. 使い方
カレントディレクトリに格納されているファイルを対象に、実行する場合は、以下のコードで実行します。
Pythonimport os.path # カレントディレクトリの絶対パスを取得 current_directory_path = os.getcwd() # abstract_path = os.path.abspath() # 探したいファイルの拡張子 available_ext_list = ['pdf', 'docx', 'xlsx', 'pptx'] file_list = get_ext_matching_file_names(available_ext_list, current_directory_path) print(file_list) # 出力例 ['sample.xlsx', 'siryou1.pptx', 'sample.docx']
- 投稿日:2020-11-27T18:53:16+09:00
RTX3070+Ryzen7 5800Xで機械学習PCを組ーむぞっ(組み立て編)
※本記事は自作PCの組み立て講座ではなく、次回の最新GPUでの機械学習環境構築の布石記事です
組み立てについて知りたい方はブラウザバック推奨です。今は時期がいい。
今は時期がいい。
最近RTX3000番台のGPUとZen3アーキテクチャの新型Ryzenが発売された。
CPUとGPUが同時期に発売された今、自作PCを一つも持たない僕にとってはいい機会であった。秋葉で3万ちょいで買ったlet's noteに入れたubuntuで機械学習の勉強をしている僕だったが、ニューラルネットワークに手をつけ始めてからというものの、かなり前のPCの為、計算時間がとてつもなくなって待っている間何も手がつけられなくなってしまったため、デスクトップの自作PCを作るのは好都合だ。
(あとApexとかもしたいよね、折角だし。)
御祝儀価格とか、ストレージが時期が悪いとかはいい。買いたい時が、買い時。
機械学習PCに求める要件
機械学習をするぞ!っていうPCを作る場合、いくつか制限されることがあるので、初めに「どんなPCを組みたいかな」っていう要件を書き出しておく。同志の方は、是非次のセットアップ編も参考にして欲しい。
1.NvidiaのGPUを使うこと。
最近RadeonのGPUが出たけど、TensorFlowのGPU版を使う場合、NvidiaのCUDAというソフトを使わなければいけない。故にNvidiaのGeForceが一般学生には適当なGPUだろう。
RadeonはopenGLのサポートが強いイメージがあるので、映像編集、Unityとかを使って機械学習はしないよって人には丁度いいのではないだろうか。2.Windows/Linuxを共存させること。
自作PCを作ったのにゲームをしないのももったいない。故にWindowsが必要。機械学習をするならlinuxがいい。故にLinuxが必要。そんな状況を解決するのがデュアルブートとか仮想環境とかという技術だろう。
けど仮想環境は処理が遅くなりそうで怖い。
ということで物理的にSSDを二つ用意して、それぞれWindowsとLinuxをインストールする。
Bios起動の後に使うディスクを選べば簡単に使い分けができる。3.インテリア性
美しいPCを組みたいのは自明の理。
見た目が美しければモチベも上がる。ってわけで
どーん
構成
CPU: Ryzen7 5800X
GPU: Zotac RTX3070 OC model
マザー: ASROCK X570 pro4
メモリ: GSKILL Trident Z Neo 16GB×2 3200
クーラー: COOLER MASTER HYPER 212 with edition
電源: Apex Gaming AG-750M
ストレージ: Western Digital black/500GB
Crucial P1/500GB
PCケース: NZXT H510
約20万円の構成。組む。
CPUくっつけて
(ピン折れめちゃ怖かった)
GPUくっつけて
(美しい)
その他適当にぶっさして
(大体説明書とか見ればわかる。吉田製作所さんとかとモヤシさんとかコジコジさんとかしみおじさんとかのyoutube見れば手順も丁寧に解説してるのでおすすめ。)
こうじゃぁぁあ
Bios起動。お疲れ様。
説明書が読めないチンパンジーじゃない限り普通に組めるから安心して欲しい。
組み方とかパーツの選び方とか、それを自分で調べるのが自作PCの醍醐味だから、特にこれを選べとかはないよね。選んでる時、迷ってる時が一番楽しいって言われるしね。まとめ
今回はただの自作PC回だったので次回は本題のLinuxとWindowsのディスクデュアルブートについてと、TensorflowのGPUインストールについて書いていくので、是非ストックして欲しい。
最後にはベンチマークも取りたいな。
それではまた。





- 投稿日:2020-11-27T18:50:22+09:00
Dockerで始めるDjango生活(2日目)
初めに
2日目です。
1日目はこちら
今回はdjangoの設定などを見ながら日本語化してアプリケーションを作成するのがゴールになります。目次
- 前回の復習
- settings.pyについて
- アプリについて
- アプリを作成する
- アプリの中身について
- 最後に
1. 前回の復習
まずはコンテナを起動しましょう!
# docker exec -it c9b27b34be02 /bin/sh開発ディレクトリに遷移します。
# cd /root/projects/myproject/myprojectサーバーを起動します。
# python3 manage.py runserverhttp://127.0.0.1:8000/
に遷移して以下の画面が出れば大丈夫です!
2. settings.pyについて
まずは、settings.pyの中身を見ていきます。
さすがに全部を見ると長いのでいくつかを紹介します。DEBUG
DEBUGはブール値になっています。
デフォルトではTrueになっています。
Djangoのデバッグモードのオンオフの切り替えを行います。True
アプリケーションによってキャッチできないエクセプションが起こるとエクセプションの詳細ページを表示します。
False
Trueで表示されていた詳細ページを表示しないようにします。
本番環境では必ずFalseにしてください。機密データが漏れたりするので!!!ALLOWED_HOSTS
デバッグモードがオンの時、テストの実行中には適用されません。
ドメインやホストはここに追加します。INSTALLED_APPS
Djangoにインストールされているアプリを追加します。
アプリを新たにインストールした場合はここに追加する必要があります。
以下ではデフォルトでインストールされているアプリを書いておきます。django.contrib.admin
管理サイト
django.contrib.auth
認証のためのアプリ
django.contrib.contenttypes
コンテンツタイプを処理するためのアプリ
django.contrib.sessions
セッションのためのアプリ
django.contrib.messages
メッセージのためのアプリ
django.contrib.staticfiles
静的ファイルを管理するためのアプリ
DATABASES
djangoで使用するデータベースの情報を書きます。
デフォルトではSQLite3が設定されています。LANGUAGE_CODE
djangoで使用する言語を書きます。
デフォルトではen-usになっているのでjaに変更しておきます。TIME_ZONE
djangoで使用するタイムゾーンを書きます。
デフォルトではUTCになっているのでAsia/Tokyoに変更しておきます。ここまでくると以下のようにdjangoの起動画面が日本語化されたと思います。
3. アプリについて
djangoにはプロジェクトとアプリと言う概念があります。
イメージとしてはプロジェクトが親でアプリが子になります。
1つのプロジェクトに対して同じ設定を持つアプリを複数作成する事が可能です。1. アプリを作成する
これからブログアプリを作成してみようと思います。
# ls db.sqlite3 manage.py myproject # python3 manage.py startapp blog # ls blog db.sqlite3 manage.py myproject # tree blog blog |-- __init__.py |-- admin.py |-- apps.py |-- migrations | `-- __init__.py |-- models.py |-- tests.py `-- views.py 1 directory, 7 files #新たにblogディレクトリが作成されました。
2. アプリの中身について
上で作成したblogディレクトリの中身を紹介していきます。
admin.py
ここでモデルを登録します。
apps.py
blogアプリケーションの構成が書かれています。
migrations
blogアプリケーションのモデルの変更を追跡してデータベースを同期します。
models.py
blogアプリケーションのデータモデルです。
tests.py
blogアプリケーションのテストを追加することができます。
views.py
blogアプリケーションのビューです。
4. 最後に
今回はファイルやファイルの中身についての紹介がメインになりました。
次回は実際にモデルを作成していこうと思います。
お疲れ様でした!
- 投稿日:2020-11-27T17:23:04+09:00
irisデータセットでデータサイエンス超絶初歩入門する
動機
自然言語処理の文書分類の前に普通の分類やってみたい
設定
かの有名なirisデータセット使います
適当にsklearnで訓練用、検証用、テスト用にわけて精度測ります
モデルはおなじみlightgbmですコード
import numpy as np from pandas import DataFrame import pandas as pd import lightgbm as lgb from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report, confusion_matrix iris = load_iris() #irisdatasetの読み込み data = iris["data"] target = iris["target"].reshape(150,1) dataset = np.concatenate([data, target], axis=1) features = iris['feature_names'] features.append("target") df = DataFrame(dataset, columns=features) #中身の確認 print(df) #訓練とテストにデータを分ける train_set, test_set = train_test_split(df, test_size = 0.3, random_state = 123) eval_set, test_set = train_test_split(test_set, test_size = 0.5, random_state = 123) #目的変数と説明変数に分ける x_train, y_train = train_set.drop("target", axis=1), train_set["target"] x_eval, y_eval = eval_set.drop("target", axis=1), eval_set["target"] x_test, y_test = test_set.drop("target", axis=1), test_set["target"] #lightgbmのパラメータを設定 params = { 'task': 'train', #訓練する 'num_class': 3, #irisデータは目的変数が3種類であるため 'boosting_type': 'gbdt', 'objective': 'multiclass', #多クラス分類 'metric': {'multi_logloss'}, #多クラス分類の損失 'verbose': -1 } #入力データの統合 lgb_train = lgb.Dataset(x_train, label=y_train) lgb_eval = lgb.Dataset(x_eval, label=y_eval) #訓練 model = lgb.train(params=params, #パラメータ train_set=lgb_train, #訓練データ num_boost_round=100, #計算回数 valid_sets=lgb_eval, #検証データ early_stopping_rounds=10) #アーリーストッピング #テストデータで予測&精度確認 y_pred = model.predict(x_test, num_iteration=model.best_iteration) y_pred = DataFrame(np.argmax(y_pred, axis=1).reshape(len(y_pred),1)) #単純な精度 print(accuracy_score(y_test, y_pred)) #Recall Precsionなど print(classification_report(y_test, y_pred)) #混同行列 print(confusion_matrix(y_test, y_pred))参考
- 投稿日:2020-11-27T17:17:12+09:00
文字列が○○で始まってるか、終わってるかを調べる
文字列.startswith(文字列)で初めの一致を
文字列.endswith(文字列)で終わりの一致をTrue, Falseで返すqiita.pyletters = 'abcdefg' #abで始まっているか if letters.startswith('ab'): print('Yes') else: print('No') #出力>>Yes #fgで終わっているか if letters.endswith('fg'): print('Yes') else: print('No') #出力>>Yes
- 投稿日:2020-11-27T14:58:24+09:00
Python 3 エンジニア認定データ分析試験 受験体験記
受験した資格
- Python 3 エンジニア認定データ分析試験 (一般社団法人Pythonエンジニア育成推進協会)
- 費用: 11,000円(税込)(後述するキャンペーンで書籍と受験チケットのセットを購入)
内容
出題範囲 にありますが、翔泳社「Pythonによるあたらしいデータ分析の教科書」の内容から出題されて、データ分析に必要となる数学の知識やnumpy、pandas、matplotlib、scikit-learn等のライブラリについて出題される。
受験方法
事前に日時を予約してテストセンターで受験する方式です(CBT)。
60分。
(詳細はこちら)受験のきっかけ・目的
【1万人達成キャンペーン】Python試験 受験チケット+対策教材セット割引のキャンペーン(現在は終了しています)を見て、興味を持った。試しに基礎試験の模擬試験を受験したが、基礎試験のほうは簡単に感じられたことと、自分自身が機械学習やディープラーニングに興味があったため、データ分析試験を受験することにした。
また、エンジニアの採用を行なう時に、資格試験の内容を把握しておくことが役に立つと考えたためである。学習方法
翔泳社「Pythonによるあたらしいデータ分析の教科書」を一通り読み、ダウンロードできるJupyter Notebook形式のファイルも一通り実行して確認した。期間としては2週間程度。特に理解するのに苦労するようなものはなかった。模擬試験もオンラインで受験した(90%以上正答できるレベル)。
結果
合格
(975点。1000満点、700点以上が合格。)所感
私はPythonを使用している某オープンソースソフトウェアのContributorとして何年も活動してきているので、Pythonの文法などに不安はなく、numpy、pandas、matplotlib、scikit-learn等のライブラリの使用方法を学習するだけで合格できた。比較的易しい部類の資格試験だと思う。そういう意味で(Pythonを使用してデータ分析を行なう)初心者向けの資格だと思う。ただ、易しいからといって存在価値がないわけではなく、データ分析に用いるライブラリなどの使用方法の基本などの基礎ができているかを確認するには有用だと思う。一般的に言われることだが、基礎がしっかりしていないと応用はできないと思う。
また、オープンソースのContributorの中には他の人に書いてもらったコードをSubmitしている人もいるので、それらのソースコードを見ても本人が書いているのか分からないケースもあるが、受験時に本人証明書(運転免許等)での本人確認があり、本人の知識・スキルが確認できているので、採用などでの時間の節約になると思う。※ 2020年11月現在の情報に基づいて記載しております。受験の際は必ず公式サイトで最新の情報をご確認ください。
- 投稿日:2020-11-27T14:57:51+09:00
CIFAR-10の精度9%から73%に上げる手法を探索
はじめに
ひとまずCIFAR-10は画像認識作業用のデータセットです。
画像はサイトにより (https://www.cs.toronto.edu/~kriz/cifar.html)CIFAR-10は手書き数字のつぎ一番簡単なデータセットだと言われます。手書き数字は逆に簡単すぎて変数を調整しても効果が見づらいです。
今回はTensorflowを使って、いろんな変数を調整し、たくさんの手法を導入して精度を9%から73%に上げて、手法を探索しつつディープラーニングを学びます。ちなみに画像はOpenCVで処理して、one-hotラベルでエンコードします。
この記事は8月にGithubに投稿した記事に基づいて作成します。
https://github.com/leolui2004/cifar_compareやり方
最初はCNNを使わずDense層だけ使うモデルコードを書きます。これは当然画像認識タスクにとって悪いモデルだけど、ここから徐々に他の手法を導入します。
学習率:0.0005
バッチサイズ:128
訓練回数:10回
ネットワーク:Dense層 x3
最適化:Adamimport tensorflow as tf tf.device('/cpu:0') tf.keras.backend.set_floatx('float32') tf.compat.v1.disable_eager_execution() import pickle import numpy as np c_InputNumber = 3072, c_OutputNumber = 10 c_Lr = 0.0005 # 学習率 c_Batchsize = 128 # バッチサイズ c_Epochs = 10 # 訓練回数 c_FolderPath = 'cifar10/' c_Filepath_Train = f'{c_FolderPath}/dataset/data_batch_1' c_Filepath_Test = f'{c_FolderPath}/dataset/test_batch' class DenseModel: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.model = self.CreateModel() self.opt = tf.keras.optimizers.Adam(Lr) # ネットワークを構築 def CreateModel(self): input = tf.keras.layers.Input(self.InputNumber) layer1 = tf.keras.layers.Dense(1024, activation='relu')(input) layer2 = tf.keras.layers.Dense(256, activation='relu')(layer1) layer3 = tf.keras.layers.Dense(64, activation='relu')(layer2) labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax')(layer3) return tf.keras.Model(inputs=[input], outputs=[labels]) # ネットワークを作成 def CompileModel(self): self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy']) # ネットワークを訓練 def TrainModel(self, x_train, y_train, batch_size, epochs): self.model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs) # テストデータで評価 def EvaluateModel(self, x_test, y_test): score = self.model.evaluate(x_test, y_test) return score[1] def Unpickle(file): with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='bytes') return dict # One-hotエンコード def Onehot(value): onehot = np.zeros((10)) onehot[value] = 1 return onehot dict_train = Unpickle(c_Filepath_Train) dict_test = Unpickle(c_Filepath_Test) dense = DenseModel(c_InputNumber, c_OutputNumber, c_Lr) x_train = dict_train[b'data'] y_train = np.zeros((10000,10)) x_test = dict_test[b'data'] y_test = np.zeros((10000,10)) for i in range(10000): y_train[i][:] = Onehot(dict_train[b'labels'][i]) y_test[i][:] = Onehot(dict_test[b'labels'][i]) dense.CompileModel() dense.TrainModel(x_train, y_train, c_Batchsize, c_Epochs) print('Epoch Test') accuracy = dense.EvaluateModel(x_test, y_test) print('Accuracy: ', accuracy)結果はこちらになります。テストデータの精度は9.26%です。
Train on 10000 samples Epoch 1/10 10000/10000 - 1s 111us/sample - loss: 121.0524 - accuracy: 0.1384 Epoch 2/10 10000/10000 - 1s 110us/sample - loss: 21.6848 - accuracy: 0.1899 Epoch 3/10 10000/10000 - 1s 110us/sample - loss: 19.7853 - accuracy: 0.1953 Epoch 4/10 10000/10000 - 1s 110us/sample - loss: 12.3984 - accuracy: 0.2081 Epoch 5/10 10000/10000 - 1s 112us/sample - loss: 7.9875 - accuracy: 0.1667 Epoch 6/10 10000/10000 - 1s 117us/sample - loss: 2.3029 - accuracy: 0.0989 Epoch 7/10 10000/10000 - 1s 114us/sample - loss: 2.3013 - accuracy: 0.0985 Epoch 8/10 10000/10000 - 1s 114us/sample - loss: 2.2992 - accuracy: 0.0992 Epoch 9/10 10000/10000 - 1s 114us/sample - loss: 2.2978 - accuracy: 0.1002 Epoch 10/10 10000/10000 - 1s 114us/sample - loss: 2.2962 - accuracy: 0.0988 Epoch Test Accuracy: 0.0926
そしていろんな中間テストをしました。全部コード出したら長すぎるので結果だけ載せます。
Dense層からCNN(Conv2D)層に
- カラー - 46.63%
- グレースケール - 47.12%
訓練回数50回に、5バッチから1バッチに結合、検証用データ10%に
- CNN(Conv2D)層、カラー - 49.46%
- Resnet層、カラー - 62.89%
- CNN(Conv2D)層、グレースケール - 58.11%
- Resnet層、グレースケール - 60.74%
訓練回数100回に、1バッチに結合、検証用データ10%に、学習率指数関数的減衰
- CNN(Conv2D)層、カラー - 70.81%
- Resnet層、グレースケール - 64.32%
全部乗せ - 73.69%
最後に73.69%に上がった手法はこちらです。
- バッチサイズ:32
- 訓練回数:80回
- ネットワーク:Resnet-56
- 最適化:Amsgrad
- 5バッチから1バッチに結合
- 検証用データ10%に
- 学習率指数関数的減衰 (Exponential Decresing)
- データ拡張 (Data Augmentation)
import tensorflow as tf from tensorflow import keras from keras.preprocessing.image import ImageDataGenerator # データ拡張用 from sklearn.model_selection import train_test_split tf.keras.backend.set_floatx('float32') tf.compat.v1.disable_eager_execution() import pickle import numpy as np import matplotlib.pyplot as plt c_InputNumber = 32,32,3 c_OutputNumber = 10 c_Lr = 0.0005 c_Batchsize = 32 c_Epochs = 80 c_Filepath_Train = 'data_batch_' c_Filepath_Test = 'test_batch' class DenseModel: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.model = self.CreateModel() self.opt = tf.keras.optimizers.Adam(Lr, amsgrad=True) # Amsgradを適用 # 学習率指数関数的減衰 def Scheduler(self, epoch): # 最初の10回は0.005、その後徐々に下げる if epoch < 10: return 0.005 else: return 0.005 * tf.math.exp(0.1 * (10 - epoch)) # Resnet-56 def CreateModel(self): channels = [16, 32, 64] input = tf.keras.layers.Input(self.InputNumber) x = tf.keras.layers.Conv2D(channels[0], kernel_size=(3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(input) x = tf.keras.layers.BatchNormalization()(x) x = tf.keras.layers.Activation(tf.nn.relu)(x) for c in channels: for i in range(9): subsampling = i == 0 and c > 16 strides = (2, 2) if subsampling else (1, 1) y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same', strides=strides, kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x) y = tf.keras.layers.BatchNormalization()(y) y = tf.keras.layers.Activation(tf.nn.relu)(y) y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(y) y = tf.keras.layers.BatchNormalization()(y) if subsampling: x = tf.keras.layers.Conv2D(c, kernel_size=(1, 1), strides=(2, 2), padding='same', kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x) x = tf.keras.layers.Add()([x, y]) x = tf.keras.layers.Activation(tf.nn.relu)(x) x = tf.keras.layers.GlobalAveragePooling2D()(x) x = tf.keras.layers.Flatten()(x) labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax', kernel_initializer='he_normal')(x) return tf.keras.Model(inputs=[input], outputs=[labels]) def CompileModel(self): self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy']) def TrainModel(self, x_train, x_valid, y_train, y_valid, batch_size, epochs): # データ拡張を適用 (回転、フリップ、シフト) igen = ImageDataGenerator(rotation_range=10, horizontal_flip=True, width_shift_range=0.1, height_shift_range=0.1) igen.fit(x_train) callback = [tf.keras.callbacks.LearningRateScheduler(self.Scheduler)] history = self.model.fit_generator(igen.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=len(x_train)/batch_size, validation_data=(x_valid, y_valid), epochs=epochs, callbacks=callback, verbose=2) return history def EvaluateModel(self, x_test, y_test): score = self.model.evaluate(x_test, y_test) return score[1] class Agent: def __init__(self, InputNumber, OutputNumber, Lr): self.InputNumber = InputNumber self.OutputNumber = OutputNumber self.Lr = Lr self.dense = DenseModel(self.InputNumber, self.OutputNumber, self.Lr) def Unpickle(self, file): with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='bytes') return dict def Pixelize(self, flat): return np.reshape(flat, (32,32,3)) def Onehot(self, value): onehot = np.zeros((10)) onehot[value] = 1 return onehot def Encode(self, dict): x = np.zeros((10000,32,32,3)) y = np.zeros((10000,10)) for i in range(10000): x[i][:][:][:] = self.Pixelize(dict[b'data'][i]) y[i][:] = self.Onehot(dict[b'labels'][i]) return x, y def Run(self, Filepath_Test, Filepath_Train, Batchsize, Epochs): self.dense.CompileModel() dict_test = self.Unpickle(Filepath_Test) x_test, y_test = self.Encode(dict_test) # 5バッチから1バッチに結合 for i in range(1, 6): dict_train = self.Unpickle(Filepath_Train + str(i)) if i == 1: x_train, y_train = self.Encode(dict_train) else: x, y = self.Encode(dict_train) x_train = np.vstack((x_train,x)) y_train = np.vstack((y_train,y)) # 検証用データに分ける x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, shuffle=True) history = self.dense.TrainModel(x_train, x_valid, y_train, y_valid, Batchsize, Epochs) print('Epoch Test') accuracy = self.dense.EvaluateModel(x_test, y_test) print('Accuracy: ', accuracy) plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show() agent = Agent(c_InputNumber, c_OutputNumber, c_Lr) agent.Run(c_Filepath_Test, c_Filepath_Train, c_Batchsize, c_Epochs)もっと上に目指すなら
実は現在SOTAのモデルは既に95%に達しました。しかしそれほとんどは簡単に導入できるモデルではないです。今回はあくまで手法を探索しながら勉強するために書きますので必ずSOTA並みの結果を得る必要がないと思います。
CIFAR-10のリーダーボード
https://paperswithcode.com/sota/image-classification-on-cifar-10もう一つ
ネットで調べると精度90%以上のサンプルコードがたくさんあります。しかもコードがすごく簡単です。しかし先話した通り、何十行だけのコードならSOTA並みの結果が出る可能性が低いです。そしてなぜか90%以上という結果が出ますか。コードを見るとほぼ100%損失関数の設定が間違いました。
それを再現するために、上記nのプログラムの損失関数をbinary_crossentropyに変わってみます。
Epoch 1/10 45000/45000 - 13s - loss: 2.7665 - accuracy: 0.8200 - val_loss: 2.7680 - val_accuracy: 0.8195その結果は1回目の訓練にも82%の精度に達しました。明らかに問題がありますね。詳しい説明はこのリンク (https://stackoverflow.com/questions/41327601/why-is-binary-crossentropy-more-accurate-than-categorical-crossentropy-for-multi) に参考してもいいですけど、簡単に言うとbinary_crossentropyは元々2分類作業用の損失関数です。なのでCIFAR-10のような10種類がある画像認識作業で使うと当然正しい結果を表現できないです。

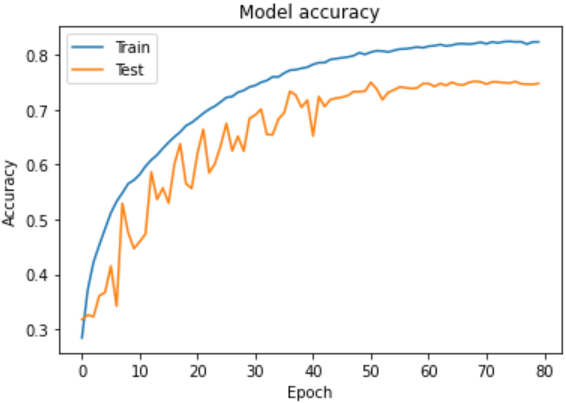
- 投稿日:2020-11-27T13:59:50+09:00
AWS Lambda boto3でCognitoのユーザーを削除する
はじめに
AWS LambdaでCognitoのユーザーを削除します。
ランタイムはpythonです。
環境変数COGNITO_MAX_RESULTSには、50を指定します。
ユーザープールの数が50以下である事を想定しています。
Cognitoからユーザーを削除する場合、ループ処理となり、たまにコケることがあるため、リトライ処理を追加しています。Lambdaのスクリプト
Lambdaimport os import boto3 cognito = boto3.client('cognito-idp', region_name='ap-northeast-1') def handler(event, context): user_pool_name = 'ユーザープール名' user_ids = ['ユーザーID'] # Cognitoからユーザーを削除する response = delCognitoUser(user_pool_name, user_ids) return response def getUserPoolId(user_pool_name): """[サービスに紐づくCognitoのユーザープールIDを取得する] Args: user_pool_name ([str]): [Cognitoユーザープール名] Returns: [str]: [CognitoユーザープールID] """ # COGNITO_MAX_RESULTSの数だけ、ユーザープールの情報を取得する userPools = cognito.list_user_pools( MaxResults=int(os.environ['COGNITO_MAX_RESULTS']) ) # サービス識別名に紐づくユーザープールIDを探索する for userPool in userPools['UserPools']: if userPool['Name'] == user_pool_name: return userPool['Id'] def delCognitoUser(user_pool_name, user_ids): """[Cognitoからユーザーを削除する] Args: user_pool_name ([str]): [Cognitoユーザープール名] user_ids ([list]): [ユーザーID] Returns: [list]: [Cognitoの結果] """ # サービスに紐づくCognitoのユーザープールIDを取得する user_pool_id = getUserPoolId(user_pool_name) for user_id in user_ids: # Cognitoのユーザープールからユーザーを削除する while True: try: response = cognito.admin_delete_user( UserPoolId=user_pool_id, Username=user_id ) print(user_id) print(response) except cognito.exceptions.TooManyRequestsException: print('time wait 5 seconds') time.sleep(5) # 必要であれば失敗時の処理 except cognito.exceptions.UserNotFoundException: print('UserNotFoundException: ' + user_id) break else: break # 失敗しなかった時はループを抜ける else: print('Do not delete: ' + user_id) continue # リトライが全部失敗した時の処理 return True
- 投稿日:2020-11-27T13:44:07+09:00
AWS Lambda boto3でWAFのIP setsを更新する
はじめに
AWS LambdaでWAFのIP setsを更新します。
ランタイムはpythonです。
WAFはCLOUDFRONTのものとなるため、AWSリージョンはバージニア北部のus-east-1となります。
WAFのIP Setsの更新は、渡したIPアドレスのリストで上書きされるので、登録・更新・削除が同じメソッドとなります。
リストip_adressesは重複していても問題なく、WAFに登録されます。Lambdaのスクリプト
Lambdaimport boto3 waf = boto3.client('wafv2',region_name='us-east-1') def handler(event, context): ip_set_name = 'IP Sets名' ip_adresses = ['IPアドレス'] response = update_ip_addresses(ip_set_name, ip_adresses) return response def update_ip_addresses(ip_set_name, ip_adresses, scope='CLOUDFRONT'): """[指定したIPアドレスでWAFを更新する] Args: ip_set_name ([str]): [IP sets名] ip_adresses ([list]): [IPアドレス] scope ([str], optional): [スコープ]. Defaults to CLOUDFRONT. Returns: [dict]: [] """ try: # IP setsの更新情報を取得する ip_set_info = get_ip_set_info(ip_set_name) response = waf.update_ip_set( Name=ip_set_name, Scope=scope, Id=ip_set_info['IPSet']['Id'], Addresses=ip_adresses, LockToken=ip_set_info['LockToken'] ) except waf.exceptions.WAFOptimisticLockException: update_ip_addresses(ip_set_name, ip_adresses) return response def get_ip_set_info(ip_set_name, scope='CLOUDFRONT'): """[指定したIP setsの詳細情報を取得する] Args: ip_set_name ([str]): [IP sets名] scope ([str], optional): [スコープ]. Defaults to CLOUDFRONT. Returns: [dict]: [指定したIP setsの詳細情報] """ response = waf.get_ip_set( Name=ip_set_name, Scope=scope, Id=get_filtering_ip_sets()[ip_set_name]['id'] ) return response def get_filtering_ip_sets(): """[取得したIP setsの情報をフィルタリングする] Returns: [dict]: [フィルタリングしたIP setsの情報] """ ip_sets_dict= {} for ip_set in get_all_ip_sets(): ip_sets_dict[ip_set['Name']] = dict( id=ip_set['Id'], lock_token=ip_set['LockToken'] ) return ip_sets_dict def get_all_ip_sets(scope='CLOUDFRONT', limit=100, next_marker=None): """[全てのIP setsの情報を取得する] Args: scope ([str], optional): [スコープ]. Defaults to CLOUDFRONT. limit ([int]): [取得上限値] next_marker ([list]): [次の取得マーカー]. Defaults to None. Returns: [list]: [IP setsの情報] """ all_ip_sets = [] # 初回実行の場合 if next_marker is None: ret = waf.list_ip_sets(Scope=scope, Limit=limit) # 次のデータが存在する場合 else: ret = waf.list_ip_sets(Scope=scope, Limit=limit, NextMarker=next_marker) if 'NextMarker' in ret: all_ip_sets = ret['IPSets'] + get_all_ip_sets(next_marker=ret['NextMarker']) else: all_ip_sets = ret['IPSets'] return all_ip_sets
- 投稿日:2020-11-27T13:19:30+09:00
SmallTrainを使って簡単な転移学習を実行
今回は先日オープンソース化したGeek Guild社が提供しているSmallTrainを使って
簡単な転移学習を実行したレビューをします。
(本記事はGeekGuild様より依頼を受けて書いています)記事作成にあたり公式HPに記載されているチュートリアルを参考にしています。
作成するモデルの概要
SmallTrainの学習デモを応用して自作の熊の画像認識を行うモデル、熊: 0 , 哺乳類(猫,鹿,犬,馬): 1 , 乗り物(飛行機,車,船,トラック): 2 として認識するモデルを作成します。
環境構築
今回はAWSのGPUインスタンス上で実行しています。
方法については以下を参照してください。
- AWSでGPUインスタンスを使う準備
- AWSのGPUインスタンスを使う
- SmallTrainをAWSのGPUインスタンスで動かす(※「SmallTrain用のDocker bridge networkを作成します。」まで)
1つ目のリンクについてはGPUインスタンス使用のための制限緩和のリクエストについての説明のため必要がなければ2つ目のリンクのみ参照してください。
リンク先にも記載がありますがGPUインスタンスの利用額はCPUのものより高額のため利用の際は注意が必要です。データの準備
学習のための画像を準備します。熊以外の画像についてはデモで使用されているCIFAR10の画像を流用しています。
SmallTrainのソースに含まれるconvert_cifar_data_set.pyを参考に作成しました。
CIFAR-10とCIFAR100ではフォルダ構成が異なっており多少工夫が必要ですが画像ファイルの仕様は同一のため比較的簡単にデータを準備することができます。
こちらで今回の記事で利用した修正後のソースを公開しておりますのでご自身で差し替えて頂く(/var/smalltrain/tutorials/image_recognition/convert_cifar_data_set.py)か公開しているブランチをクローンして頂ければと思います。
※注意:今回はあえて上書きしているため以前のチュートリアルが実行できなくなります。以前の状態に戻すには再度オリジナルのSmallTrainをcloneしてください熊の画像
CIFAR-100を利用しています。
CIFAR-100では熊の画像はClassは3に分類されており、このクラスの画像のみ取得しています。
再定義後のクラスは0としています。データセット作成
チュートリアルのこちらのページを参考に作成します。
データセット定義ファイル(/var/data/cifar-10-image/data_set_def/train_cifar10_classification.csv)に以下の行が作成されるようにします。data_set_id,label,sub_label,test,group /var/data/cifar-10-image/data_batch_1/data_batch_1_i90000_c0.png,0,0,0,TRAIN ... /var/data/cifar-10-image/data_batch_5/data_batch_5_i90099_c0.png,0,0,0,TRAIN /var/data/cifar-10-image/test_batch/test_batch_i90000_c0.png,0,0,1,TRAIN ... /var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png,0,0,1,TRAINCIFAR100のデータはバッチに分けられていないのでdata_batch_1からdata_batch_5まで均等に分けるようにします。
番号を90000から振っているのはdata_batch_1とtest_batchの9から始まるデータのみを使った同時実行されるスモールデータ学習利用のためです。熊以外の画像
CIFAR-10を利用しています。
10個のClassを2種類に分けて再定義しています。
元のClass 今回のClass 3,4,5,7 (猫,鹿,犬,馬) 1 (哺乳類) 0,1,8,9 (飛行機,車,船,トラック) 2 (乗り物) Class1と2でデータ数を揃えるため2(鳥),6(カエル)は除外しています。
データセット定義ファイル(/var/data/cifar-10-image/data_set_def/train_cifar10_classification.csv)に以下の行が作成されるようにします。data_set_id,label,sub_label,test,group /var/data/cifar-10-image/data_batch_1/data_batch_1_i0_c2.png,2,2,0,TRAIN ... /var/data/cifar-10-image/data_batch_5/data_batch_5_i90099_c0.png,0,0,0,TRAIN /var/data/cifar-10-image/test_batch/test_batch_i0_c1.png,1,1,1,TRAIN ... /var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png,0,0,1,TRAIN画像ファイル自体はデータセット定義ファイルに記載されているパスに格納します。
元のClassの画像はbatchあたり1000個あるためClass0:Class1:Class2のデータ比率は100:4000:4000となります。
Class0の画像だけ少ないデータセットとなっています。学習の実行
SmallTrainをAWSのGPUインスタンスで動かすページの
「dockerイメージを実行します。」以降を実施します。実行結果の確認
チュートリアルにあるように学習後の予測結果を確認します。(less /var/data/smalltrain/results/report/IR_2D_CNN_V2_l49-c64_TUTORIAL-DEBUG-WITH-SMALLDATASET-20200708-TRAIN/prediction_e35999_all.csv)
DateTime,Estimated,MaskedEstimated,True /var/data/cifar-10-image/test_batch/test_batch_i0_c1.png_0,1,0.0,1 /var/data/cifar-10-image/test_batch/test_batch_i1_c2.png_0,2,0.0,2 /var/data/cifar-10-image/test_batch/test_batch_i2_c2.png_0,2,0.0,2 /var/data/cifar-10-image/test_batch/test_batch_i3_c2.png_0,2,0.0,2 /var/data/cifar-10-image/test_batch/test_batch_i4_c2.png_0,2,0.0,2 ... /var/data/cifar-10-image/test_batch/test_batch_i90095_c0.png_0,0,0.0,0 /var/data/cifar-10-image/test_batch/test_batch_i90096_c0.png_0,0,0.0,0 /var/data/cifar-10-image/test_batch/test_batch_i90097_c0.png_0,0,0.0,0 /var/data/cifar-10-image/test_batch/test_batch_i90098_c0.png_0,0,0.0,0 /var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png_0,0,0.0,0上記の例では分類が正しく行われていることが確認できます。もちろん
以下の表はtest accuracyと個別の画像の精度をまとめており、画像はTensorBoardのtest accuracyのグラフとなっています。
今回の検証は5時間程度の計算の結果となっています。気軽に画像認識モデル作成が体験できます。
epoch 15999 35999 test accuracy 0.9762 0.973 熊画像以外の精度 0.9826 0.9723 熊画像のみの精度 0.46 0.73
熊画像以外のデータ数が非常に多いため熊画像以外の精度が高く、test accuracyに大きく寄与しています。
test accuracyが最大なのはepoch15999ですが熊画像のみの精度が0.46と低くなっています。
epoch35999はtest accuracyは少し低いですが熊画像のみの精度が0.73と大きく向上していることが分かります。今回はデモの設定をそのまま流用しているためチューニングすれば精度は上がるはずです。
画像とデータセット定義ファイルを準備するだけで簡単に画像認識モデル作成がきるのでぜひ試してみてください。
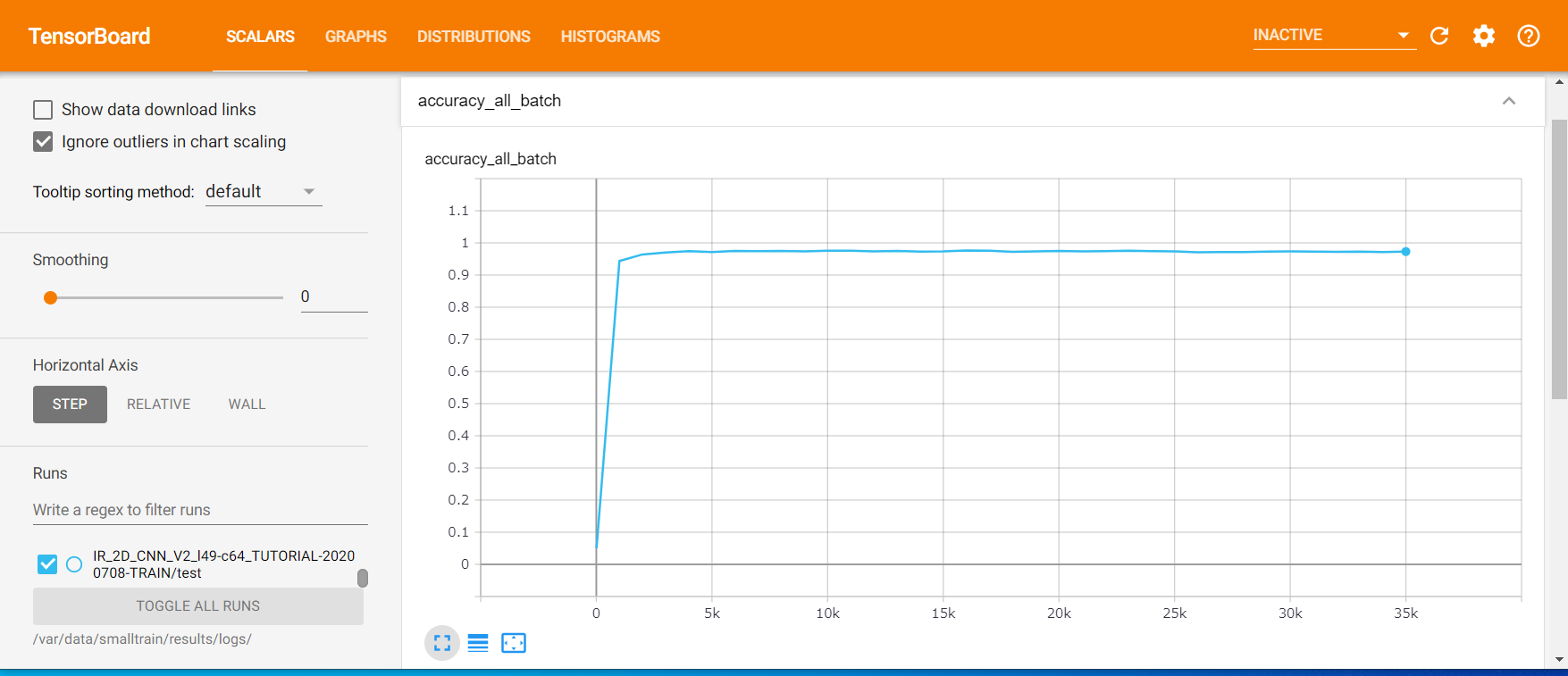
- 投稿日:2020-11-27T13:08:41+09:00
Python、LINEbot【番外編】~もしも赤ちゃん服のお店をしていたら~
経緯
前回Python、Herokuを用いたLINEbot(オウム返し)を作成してみた!
よろしければそちらの記事も読んでいただければ幸いです!
PythonとHerokuでLINEBOTを作ってみたそこで更に調べてみるとLINEdevelopersを調べていくとたくさん遊べると感じたので少しだけアレンジしたものを作ってみました。テーマは何でもよかったのですが、今年赤ちゃんが生まれたので「赤ちゃん服のお店」だったらにしました(笑)
※今回はホームページありきの内容を想定しております。
LINEの編集
基本設定
LINEdevelopersの基本設定からLINEbotのアイコンや挨拶メッセージを編集します。
※アイコンは間もなくクリスマスなのでサンタにしてますあいさつメッセージ設定
友達登録された際のあいさつ文を編集します
指定したメッセージを送ってもらうように同線を作ります。
※なお、指定されたメッセージ以外は前回同様にオウム返しされます。あとはソースコードをいじるだけ
main.py# 必要モジュールの読み込み from flask import Flask, request, abort import os from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) # 変数appにFlaskを代入。インスタンス化 app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) # Herokuログイン接続確認のためのメソッド # Herokuにログインすると「hello world」とブラウザに表示される @app.route("/") def hello_world(): return "hello world!" # ユーザーからメッセージが送信された際、LINE Message APIからこちらのメソッドが呼び出される。 @app.route("/callback", methods=['POST']) def callback(): # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['X-Line-Signature'] # リクエストボディを取得 body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # 署名を検証し、問題なければhandleに定義されている関数を呼び出す。 try: handler.handle(body, signature) # 署名検証で失敗した場合、例外を出す。 except InvalidSignatureError: abort(400) # handleの処理を終えればOK return 'OK' # LINEでMessageEvent(普通のメッセージを送信された場合)が起こった場合に、 # def以下の関数を実行します。 # 変更ポイント # 指定されたメッセージにあわせてURLを送る。 # reply_messageの第一引数のevent.reply_tokenは、イベントの応答に用いるトークンです。 # 第二引数にホームページなどのURLを指定する("http://~"の部分)。 @handler.add(MessageEvent, message=TextMessage) def handle_message(event): if event.message.text == "赤ちゃん": line_bot_api.reply_message( event.reply_token, TextSendMessage(text="https://~")) elif event.message.text == "ママ": line_bot_api.reply_message( event.reply_token, TextSendMessage(text="https://~")) else: line_bot_api.reply_message( event.reply_token, TextSendMessage(text="https://~")) line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) # ポート番号の設定 if __name__ == "__main__": # app.run() port = int(os.getenv("PORT")) app.run(host="0.0.0.0", port=port)前回作成したオウム返しの部分にif文で送られてきたメッセージに応じてサイトの各ページに飛べるようにURLを返すように修正しました。
※ここに画像や文を乗せてもOKcd linebot git init git add . git commit -am "make it better" git push heroku master前回作成したHerokuに設置します
友達登録してみる
友達登録をすると挨拶文が表示されるため、それらに応じたメッセージを送信すると、、、
各ページへのリンクを返信することができました!バージョンアップ
これらの機能以外にも一斉送信で新商品の宣伝も出来ると思ったので試してみたいと思います!
作ってみた感想
ただ実際に作ってみての感想としては赤ちゃん用品の場合、こういったBotによる宣伝よりも友人や知人による口コミなどの方が影響力があるのかな思いつつ、お店の人があいさつ代わりに友達登録してもらうドブ板営業をしていけば、、、なんて思いました(笑)
お付き合いいただきありがとうございました!
- 投稿日:2020-11-27T12:51:42+09:00
Lambda(Python)からChatworkに通知を送る
はじめに
特に真新しい内容ではないですが、備忘録として記載しておきます。
この記事の続編です。
・AWS MediaLiveチャンネルの停止忘れを防ぐための自動通知設定
https://qiita.com/ktsuchi/items/fe74125df4ee79c97d5d以前作成したLambdaの通知先としてChatworkを追加しました。
SNSは使わずにLambdaから直接メッセージをチャットワークに飛ばします。構成図
手順
Chatworkに通知する手軽な方法を探していたところ、
requestsモジュールのPOSTメソッドを利用する方法に行き着いたので、その方法を採用することにしました。Lambdaの設定箇所のみ記載します。
requestsモジュールのインストール
まずは下記のドキュメントに従って、requestsモジュールをインストールします。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package.html#python-package-dependenciesChatwork API
Chatworkにメッセージを送るには下記2つの情報が必要になります。
取得方法のリンク先を貼っておきます。・ルームID
https://help.chatwork.com/hc/ja/articles/360000142942・APIトークン
https://help.chatwork.com/hc/ja/articles/115000172402Lambdaコード
今回追記した内容は、後半部分になります。
lambda_function.pyimport boto3 import requests medialive = boto3.client('medialive') sns = boto3.client('sns') def lambda_handler(event, context): channels = medialive.list_channels() channel_list = [] for Channels in channels['Channels'] : if Channels['State'] == 'RUNNING': name = Channels['Name'] id = Channels['Id'] state = Channels['State'] channel_list.append("| " + name + " | " + id + " | " + state + " |") print('\n'.join(channel_list)) if channel_list == []: pass else: #to_SNS request = { 'TopicArn': "<SNSトピックのARN>", 'Message': ('\n'.join(channel_list)), 'Subject': "Running MediaLive Channels" } sns.publish(**request) #to_Chatwork apiurl = 'https://api.chatwork.com/v2' roomid = 'xxxxxxxx' message = ('\n'.join(channel_list)) apikey = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' post_message_url = '{}/rooms/{}/messages'.format(apiurl, roomid) headers = { 'X-ChatWorkToken': apikey } params = { 'body': message } r = requests.post(post_message_url,headers=headers,params=params) print(r)実行結果
参考
https://tonari-it.com/python-chatwork/
https://hacknote.jp/archives/48083/