- 投稿日:2020-11-21T23:44:38+09:00
ナップサックの制限は重さじゃなくて体積だと思うよw
こんばんは(*´ω`)
いつも応援有難うございます m(_ _)m有名なナップサックに挑戦しました。
有識者のコードを斜め見しながら、
何がしたいのかを考察した次第です。KnapSack.pyclass Item: def __init__(self,w=0,p=0): self.weight=w self.price=p items = [ Item(300,400), Item(500,250), Item(200,980), Item(600,340), Item(900,670), Item(1360,780), Item(800,570), Item(250,800) ] def knapsack(i, w): if i==len(items): return 0 if w - items[i].weight < 0.0: return knapsack(i+1, w) Val_sum0 = knapsack(i+1, w) Val_sum1 = knapsack(i+1, w - items[i].weight) + items[i].price return max(Val_sum0,Val_sum1) p = knapsack(0, 1200) print("MAXIMUM TOTAL PRICE is",p)荷物を入れようが、入れまいが、
トライした回数(試行回数)を i として考えます。
並べられた items は幸いにも制限があり、
与えられた条件内で最大値を求める問題です。最後まで試行した時に knapsack は 0 を返すことにします。
再帰処理のお約束、ベースケースにこれを定義します。KnapSack.pydef knapsack(i, w): if i==len(items): return 0しかし、これでは話がまとまらないので、
その過程の中で item の値段を加算していきます。勿論、無限に加算するわけではありません。
定義した重量以内で最大値を求めなければなりません。
よって、item を追加するたびに、定義された最大重量からitemの重量を引いていき、
w - items[i].weigh < 0 になったら、
重量制限を超えるので、items[i] の追加は諦めて
i をインクリメントして次の item の追加を試みます。KnapSack.pyif w - items[i].weight < 0.0: return knapsack(i+1, w)めでたく、前述にあるように、
1. 試行(トライ)回数 i が items 個数以下
2. 重さ制限をオーバーすることがない
条件をクリアして初めて、items を追加するか、しないかを
検討することが出来ます。KnapSack.pyVal_sum0 = knapsack(i+1, w)# 追加しない Val_sum1 = knapsack(i+1, w - items[i].weight) + items[i].price # 追加する return max(Val_sum0,Val_sum1)#どっちがデカい?前述の記述で、自分がハマったのは、
Val_sum1 = knapsack(i+1, w - items[i].weight) + items[i].price です。
knapsack に items.price を足す?は?( ゚Д゚)
でした。でも、考えてみると、knapsack は再帰処理なので、最終的には base case に落ちます。
そうです、0 になるのです。そのため、items.price を積み重ねた結果だけが帰ってくるのです。ではでは、前述の記述は全探索なので、
重複計算が含まれていました。
それを削減していこうと思います。ただ、出来たけど微妙かもしれません(笑)
knapsack.pyclass Item: def __init__(self,w=0,p=0): self.weight=w self.price=p items = [ Item(300,400), Item(500,250), Item(200,980), Item(600,340), Item(900,670), Item(1360,780), Item(800,570), Item(250,800) ] def knapsack(i, w): if memo[i][w]:#メモの該当セルに何か入っているか確認。 return memo[i][w]#入ってたら値を返す、計算削減!! if i==len(items): return 0 if w - items[i].weight < 0.0: return knapsack(i+1, w) Val_sum0 = knapsack(i+1, w) Val_sum1 = knapsack(i+1, w - items[i].weight) + items[i].price memo[i][w] = max(Val_sum0,Val_sum1) # メモる!! return memo[i][w]# メモした値を返す wgoal = 700 memo = [[[]for k in range(wgoal + 1)] for l in range(len(items)+1)] # 広大なメモ帳を作った(笑) p = knapsack(0,wgoal) print("MAXIMUM TOTAL PRICE is",p)今まで学んできたのはメモを用意して、
過去に計算したものを呼び出すことで計算を削減するチャレンジです。ただ、今回は用意したメモが広大過ぎる(笑)。
今メモしているのは、
特定の試行回数の時の重さにおける最大価格をメモしています。
重さが、数百である以上は、用意するメモの規模が大きくなってしまいます。
問題の設定ミス!! (*ノωノ)因みに、再帰を用いない方法もあります。
knap_dp.pyN = 8 #number of backs w =[300, 500, 200, 600, 900, 1360, 800, 250] v =[400, 250, 980, 340, 670, 780, 570, 800] wgoal = 700 memo = [[0]*(wgoal+1)for l in range(N+1)] for i in range(N): for j in range(wgoal+1): if j < w[i]: memo[i+1][j] = memo[i][j] else: memo[i+1][j] = max(memo[i][j],memo[i][j-w[i]]+v[i]) print("MAXIMUM TOTAL PRICE is",memo[N][wgoal])とても装いがスッキリしました。
再帰処理で重さを色々試していましたが、
for 文に切り替えて i 回目の試行時の
重さを全部書き出しています(DP って言うらしいです)。読んだり書いたり、何となく動かしている感は否めません。
もうちょっとローカールでイメージづくりをしてしてみます( *´艸`)。
- 投稿日:2020-11-21T22:49:20+09:00
深層強化学習1 強化学習概論
Aidemy 2020/11/21
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、深層強化学習の一つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・(復習)強化学習について
・強化学習の手法
・DQN(復習)強化学習について
・強化学習は機械学習の一手法である。
・強化学習の構成要素としては次のようなものがある。行動する主体であるエージェント、行動の対象である環境、環境に対する働きかけを行動、それにより変化する環境の各要素が状態である。また、行動により即時に得られる評価のことを報酬、最終的に合計でどれぐらいの報酬を得られたのかを示すのが収益である。
・強化学習の目的は、この収益の総和を最大化することである。
・強化学習のモデルとしては、エージェントの行動選択の方策について、「現在の環境の状態を入力」、「行動を出力」として表現する。そしてこの行動は、より高い報酬が得られるようなものを選択する。
・この「より高い報酬」について、報酬の内容が全て既知だったら、その中から最も報酬が高いものを選べば良いが、実際にはこれが事前に与えられているケースは少ない。このような時は「探索」を行うことで選択したことのない行動も行って情報を収集することが必要である。これにより情報を集めたら、その中から最も報酬が高いと推測した行動を選択すると良い。これを「利用」という。強化学習の方策
(復習)greedy手法
・上記で示した探索と利用をどのように行っていくかという方策について、その問題に即した方策をとることが重要になってくる。
・例えば報酬の期待値が全て既知である場合は、期待値の最も大きい行動のみを選択するという「greedy手法」を選択するのが最も良い方策となる。
・しかし先述の通り、一般的には報酬が全て既知であるケースは少ないため、このような時は、得られる報酬が少ないと分かっていても別の行動を選択する必要がある。この方策の一つに「ε-greedy手法」がある。これは確率εで探索を行い、1-εで利用を行うというものである。試行回数に基づいてεの値を小さくすることで、利用の割合が増えていくため、効率よく探索できるようになる。ボルツマン選択
・ε-greedy手法はある程度確率的に行動を選択する方策であった。これと同じようなものとして「ボルツマン選択」という方策がある。
・ボルツマン選択は選択確率が以下のボルツマン分布に従うためこのように呼ばれる。
・この式のうち「T」は温度関数と呼ばれるもので、「時間経過とともに0に収束する関数」のことである。この時、T→無限の極限で全ての行動を同じ確率で選択し、T→0の極限で報酬の期待値が最大のものを選びやすくなるというものである。
・つまり、初めのうちはTが大きいため行動選択がランダムであるが、時間経過によりTが0に近づくとgreedy手法のように選択するようになる。DQN
・DQNとは、Q学習のQ関数を深層学習で表したものである。Q関数とは「行動価値関数」のことであり、Q学習はこれを推定する強化学習のアルゴリズムである。
・行動価値関数は「状態sと行動a」を入力として、最適方策を行った時の報酬の期待値を計算する関数である。行われることとしては、試しにある行動を行って得られた行動価値と、一つ先の状態で可能な行動を行って得られた行動価値を合算して、今の行動価値との差をとって、少しだけ(学習率を調整して)関数を更新する、ということ行われる。
・実際には状態sと行動aは全ての組み合わせについてテーブル関数で表されるが、問題によってはこの組み合わせの量が膨大になるという恐れがある。
・このような場合に、DQNで、このQ関数を深層学習によって関数近似することで解決できる。・DQNの特徴としては、以下のようなものがある。詳しくは次のChapterでみる。
・Experience Replay:データの時系列をシャッフルして時系列の相関に対処する
・Target Network:正解との誤差を計算し、モデルが正解に近くなるように調整する。データからランダムにバッチを作成し、バッチ学習を行う。
・CNN:畳み込みによって画像にフィルタをかけ変換する。
・clipping:報酬について、負なら-1、正なら+1、なしなら0とする。Experience Replay
・例えばゲームをプレイしているエージェントが得られる入力には、時系列の性質がある。時系列の入力には強い相関があるため、学習に時系列の入力をそのまま使うと、学習結果に偏りが生じ、収束性が悪くなる。これを解決するのが、Experience Replayと呼ばれるものである。これは、状態や行動、報酬を入力として、全て、あるいは一定個数記録しておき、そこからランダムに呼び出して学習させる手法である。
まとめ
・強化学習では収益の総和を最大化するために、探索と利用が行われる。これをどのように行なっていくか、というのが方策である。
・この方策について、報酬の期待値がわかっている状態の時に有効なのが「greedy手法」である。これは、最も期待値の高い行動のみを選択するというものである。
・報酬の期待値が全て既知でない場合にも対応したものが「ε-greedy手法」である。この方策は確率εで探索を、1-εで利用を行うというものである。
・同様の方策として、ボルツマン選択というものがある。時間経過で値が0に収束していく温度関数Tを使ったボルツマン分布に従って選択されるため、最初はランダムに行動が選ばれるが、時間経過につれて最も期待値の高い行動を選択するようになる。
・DQNはQ関数(行動価値関数)を深層学習で表したものである。行動価値関数は状態sと行動aを入力として報酬の期待値を算出するのであるが、sとaは全ての組み合わせをテーブル関数で表すと量が膨大になってしまうため、この手法が使われる。
・DQNの特徴の一つに「Experience Replay」というものがある。これは、入力データの時系列の性質を除去するために、状態、行動、報酬について、ランダムに取り出すということを行う。今回は異常です。ここまで読んでいただきありがとうございました。


- 投稿日:2020-11-21T22:22:03+09:00
Pythonを使って東京都家賃についての研究 (3の3)
結果抜粋
統計の手法2
プログラムと結果
建物ごとに中央値を計算する
理由としては、建物の物件数が違います。例えば1ビル50物件があれば、分布を計算する時、その重みが1ビル1物件より50倍になります。均等に計算するように、建物ごとに中央値を取ります。
conn = sqlite3.connect(‘info.db’) df = pd.read_sql_query(“SELECT pid,price,area FROM price”, conn) conn.close() df[‘municipal’] = df.apply(municipal, axis=1) dfmedian = df.groupby([‘pid’, ‘municipal’])[‘price’, ‘area’, ‘average’].median() dfmedian_reset = dfmedian.reset_index(level=’municipal’)
区ごとに価格の分布(23区)
# グラフ fig = go.Figure() for i in m23_list: dfgroup = dfmedian_reset[dfmedian_reset[‘municipal’] == i] fig.add_trace(go.Box(x=dfgroup[‘price’], y=dfgroup[‘municipal’], boxpoints=False)) fig.update_traces(orientation=’h’, showlegend=False) fig.update_xaxes(range=[0, 500000])
区ごとに面積の分布(23区)
# グラフ fig = go.Figure() for i in m23_list: dfgroup = dfmedian_reset[dfmedian_reset[‘municipal’] == i] fig.add_trace(go.Box(x=dfgroup[‘area’], y=dfgroup[‘municipal’], boxpoints=False)) fig.update_traces(orientation=’h’, showlegend=False) fig.update_xaxes(range=[0, 100])
平均価格(価格 / 面積)を計算する
def average(df): return int(df[‘price’] / df[‘area’]) df[‘average’] = df.apply(average, axis=1)
区ごとに平均価格の分布(23区)
# グラフ fig = go.Figure() for i in m23_list: dfgroup = dfmedian_reset[dfmedian_reset[‘municipal’] == i] fig.add_trace(go.Box(x=dfgroup[‘average’], y=dfgroup[‘municipal’], boxpoints=False)) fig.update_traces(orientation=’h’, showlegend=False)
平均価格と駅まで徒歩の時間の関係
# Dataframeの処理 dfmedian_reset = dfmedian.reset_index(level=’pid’) dfmedian_reset[‘train’] = dfmedian_reset.apply(trainminute, axis=1) # グラフ fig = px.scatter(dfmedian_reset, x=’train’, y=’average’, height=500, width=1000)
平均価格と建物のタイプの関係
dfmedian_reset = dfmedian.reset_index(level=’pid’) dfmedian_reset[‘type’] = dfmedian_reset.apply(buildtype, axis=1) fig = go.Figure() for i in ([‘マンション’, ‘アパート’]): dfgroup = dfmedian_reset[dfmedian_reset[‘type’] == i] fig.add_trace(go.Box(x=dfgroup[‘price’], y=dfgroup[‘type’], boxpoints=False)) fig.update_traces(orientation=’h’, showlegend=False) fig.update_xaxes(range=[0, 500000]) fig.update_layout(height=500, width=1000)
その他の結果
平均価格と建物のタイプの関係
平均価格と建物構造の関係
平均価格と駐車場の関係
平均価格と駐車場の関係
完成日の分布(23区と市部に分ける)
方向と区市町村の価格ヒートマップ











- 投稿日:2020-11-21T21:19:01+09:00
画像処理100本ノック!!(011 - 020)序盤戦
1. はじめに
画像の前処理の技術力向上のためにこちらを実践 画像処理100本ノック!!
とっかかりやすいようにColaboratoryでやります。
目標は2週間で完了できるようにやっていきます。丁寧に解説します。質問バシバシください!
001 - 010 は右のリンクから画像処理100本ノック!!(001 - 010)丁寧にじっくりと2. 前準備
ライブラリ等々を以下のように導入。
# ライブラリをインポート from google.colab import drive import numpy as np import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow # 画像の読み込み img = cv2.imread('画像のパス/imori.jpg') img_noise = cv2.imread('画像のパス/imori_noise.jpg') # 画像保存用 OUT_DIR = '出力先のパス/OUTPUT/'3.解説
Q.11. 平滑化フィルタ
平滑化フィルタ(3x3)を実装せよ。
平滑化フィルタはフィルタ内の画素の平均値を出力するフィルタである。A11""" 平滑化フィルタ cv2.filter2D(src, -1, kernel) src 入力画像 kernel フィルタのカーネル(※NumPy配列で与える) """ # フィルタのカーネル kernel = np.ones((3,3),np.float32)/9 # 平滑化フィルタ img11 = cv2.filter2D(img, -1, kernel) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans11.jpg', img11) # 画像を表示する cv2_imshow(img11) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】空間フィルタリングで平滑化・輪郭検出
参考: 脱初心者を目指すQ.12. モーションフィルタ
モーションフィルタ(3x3)を実装せよ。
A12def motion_filter(img, k_size=3): """ モーションフィルタ(対角方向の平均値を取るフィルタ) parameters ------------------------- param1: numpy.ndarray形式のimage param2: カーネルサイズ returns ------------------------- (130x130)のnumpy.ndarray形式のimage """ # 画像の高さ、幅、色を取得 H, W, C = img.shape # カーネル(numpy.diag()で対角成分を抽出) K = np.diag([1] * k_size).astype(np.float) # array([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]]) K /= k_size # array([[0.33333333, 0., 0.],[0., 0.33333333, 0.],[0., 0., 0.33333333]]) # ゼロパディング pad = k_size // 2 out = np.zeros((H + pad * 2, W + pad * 2, C), dtype=np.float) #out.shape >>> (130, 130, 3) out[pad:pad+H, pad:pad+W] = img.copy().astype(np.float) tmp = out.copy() # フィルタリング for y in range(H): for x in range(W): for c in range(C): out[pad + y, pad + x, c] = np.sum(K * tmp[y:y+k_size, x:x+k_size, c]) out = out[pad: pad + H, pad: pad + W].astype(np.uint8) return out # モーションフィルタ img12 = motion_filter(img, k_size=3) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans12.jpg', img12) # 画像を表示する cv2_imshow(img12) cv2.waitKey(0) cv2.destroyAllWindows()
Q.13. MAX-MINフィルタ
MAX-MINフィルタ(3x3)を実装せよ。
MAX-MINフィルタとはフィルタ内の画素の最大値と最小値の差を出力するフィルタであり、エッジ検出のフィルタの一つである。 エッジ検出とは画像内の線を検出るすることであり、このような画像内の情報を抜き出す操作を特徴抽出と呼ぶ。 エッジ検出では多くの場合、グレースケール画像に対してフィルタリングを行う。A13def max_min_filter(img, k_size=3): """ Max-Minフィルタ(対角方向の平均値を取るフィルタ) グレースケールの処理となるのでカラー画像の場合と場合分けする parameters ------------------------- param1: numpy.ndarray形式のimage param2: カーネルサイズ returns ------------------------- (130x130)のnumpy.ndarray形式のimage """ # 入力画像がカラーの場合 if len(img.shape) == 3: # H(高さ), W(幅), C(色) H, W, C = img.shape # ゼロパディング pad = k_size // 2 out = np.zeros((H + pad * 2, W + pad * 2, C), dtype=np.float) #out.shape >>> (130, 130, 3) out[pad:pad+H, pad:pad+W] = img.copy().astype(np.float) tmp = out.copy() # フィルタリング for y in range(H): for x in range(W): for c in range(C): # 3x3のカーネル内の最大から最小を引く out[pad + y, pad + x, c] = np.max(tmp[y:y+k_size, x:x+k_size, c]) - np.min(tmp[y:y+k_size, x:x+k_size, c]) out = out[pad: pad + H, pad: pad + W].astype(np.uint8) # 入力画像がグレースケールの場合 else: H, W = img.shape # ゼロパディング pad = k_size // 2 out = np.zeros((H + pad * 2, W + pad * 2), dtype=np.float) out[pad:pad+H, pad:pad+W] = img.copy().astype(np.float) tmp = out.copy() # フィルタリング for y in range(H): for x in range(W): # 3x3のカーネル内の最大から最小を引く out[pad + y, pad + x] = np.max(tmp[y:y+k_size, x:x+k_size]) - np.min(tmp[y:y+k_size, x:x+k_size]) out = out[pad: pad + H, pad: pad + W].astype(np.uint8) return out # Max-Minフィルタ img13 = max_min_filter(img, k_size=3) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans13.jpg', img13) # 画像を表示する cv2_imshow(img13) cv2.waitKey(0) cv2.destroyAllWindows()
Q.14. 微分フィルタ
微分フィルタ(3x3)を実装せよ。
微分フィルタは輝度の急激な変化が起こっている部分のエッジを取り出すフィルタであり、隣り合う画素同士の差を取る。
画像でエxジになるのは輝度変化が激しい部分である。赤部分は殆ど色が変化しないが、青枠は色の変化が激しい。この変化がエッジとなる。A14""" cv2.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]]) src: 入力画像 ddepth: 出力の色深度 dx: x方向の微分の次数 dy: y方向の微分の次数 ksize: カーネルサイズ、1, 3, 5, 7のどれかを指定 """ # 横方向 dx = cv2.Sobel(gray, cv2.CV_64F, 1, 0, ksize=3) # 縦方向 dy = cv2.Sobel(gray, cv2.CV_64F, 0, 1, ksize=3) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans14_v.jpg', dy) cv2.imwrite(OUT_DIR + 'ans14_h.jpg', dx) # 画像を表示する cv2_imshow(dy) cv2_imshow(dx) cv2.waitKey(0) cv2.destroyAllWindows()

模範解答の画像より白部分がくっきりした印象
参考: python+OpenCVでエッジ抽出(Sobelフィルタ、ラプラシアンフィルタ)
Q.15. Prewittフィルタ
Prewittフィルタ(3x3)を実装せよ。
Prewitt(プレウィット)フィルタはエッジ抽出フィルタの一種であり、次式で定義される。 これは微分フィルタを3x3に拡大したものである。A15""" Prewitt(プレヴィット)は、画像から輪郭を抽出する空間フィルタの1つ cv2.filter2D(src, -1, kernel) src 入力画像 cv2.CV_64F float64 kernel フィルタのカーネル(※NumPy配列で与える) """ # カーネル(水平、垂直方向の輪郭検出用) kernel_x = np.array([[1, 0, -1], [1, 0, -1], [1, 0, -1]]) kernel_y = np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]]) dx = cv2.filter2D(gray, cv2.CV_64F, kernel_x) dy = cv2.filter2D(gray, cv2.CV_64F, kernel_y) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans15_v.jpg', dy) cv2.imwrite(OUT_DIR + 'ans15_h.jpg', dx) # 画像を表示する cv2_imshow(dy) cv2_imshow(dx) cv2.waitKey(0) cv2.destroyAllWindows()

参考: 1次微分フィルタ Prewitt(プレヴィット)フィルタ - 画像のエッジ抽出
参考: 【Python/OpenCV】Prewittフィルタで輪郭検出Q.16. Sobelフィルタ
Sobelフィルタ(3x3)を実装せよ。
Sobel(ソーベル)フィルタもエッジを抽出するフィルタであり、次式でそれぞれ定義される。 これはprewittフィルタの中心部分に重みをつけたフィルタである。A16""" ソーベルフィルタは輝度差のが少ないエッジも非常に強調 cv2.filter2D(src, -1, kernel) src 入力画像 cv2.CV_64F float64 kernel フィルタのカーネル(※NumPy配列で与える) """ # カーネル(水平、垂直方向の輪郭検出用) kernel_x = np.array([[1, 0, -1], [2, 0, -2], [1, 0, -1]]) kernel_y = np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]]) dx = cv2.filter2D(gray, cv2.CV_64F, kernel_x) dy = cv2.filter2D(gray, cv2.CV_64F, kernel_y) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans16_v.jpg', dy) cv2.imwrite(OUT_DIR + 'ans16_h.jpg', dx) # 画像を表示する cv2_imshow(dy) cv2_imshow(dx) cv2.waitKey(0) cv2.destroyAllWindows()

参考: 1次微分フィルタ Sobel(ソーベル)フィルタ - 画像のエッジ抽出
参考: 【Python/OpenCV】Prewittフィルタで輪郭検出Q.17. Laplacianフィルタ
Laplacianフィルタを実装せよ。
Laplacian(ラプラシアン)フィルタとは輝度の二次微分をとることでエッジ検出を行うフィルタである。
デジタル画像は離散データであるので、x方向・y方向の一次微分は、それぞれ次式で表される。(微分フィルタと同じ)A17""" ラプラシアンフィルタ(Laplacian Filter)は、二次微分を利用して画像から輪郭を抽出する空間フィルタ cv2.filter2D(src, -1, kernel) src 入力画像 cv2.CV_64F float64 kernel フィルタのカーネル(※NumPy配列で与える) """ # カーネル kernel = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]) # ラプラシアンフィルタ img17 = cv2.filter2D(gray, cv2.CV_64F, kernel) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans17.jpg', img17) # 画像を表示する cv2_imshow(img17) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】ラプラシアンフィルタで輪郭検出(エッジ抽出)
Q.18. Embossフィルタ
Embossフィルタを実装せよ。
Embossフィルタとは輪郭部分を浮き出しにするフィルタで、次式で定義される。A18""" エンボスフィルタ(Emboss Filter)は、輪郭部分を浮き出しする空間フィル cv2.filter2D(src, -1, kernel) src 入力画像 cv2.CV_64F float64 kernel フィルタのカーネル(※NumPy配列で与える) """ # カーネル kernel = np.array([[-2, -1, 0], [-1, 1, 1], [0, 1, 2]]) # ラプラシアンフィルタ img18 = cv2.filter2D(gray, cv2.CV_64F, kernel) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans18.jpg', img18) # 画像を表示する cv2_imshow(img18) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】エンボスフィルタで加工
Q.19. LoGフィルタ
LoGフィルタ(sigma=3、カーネルサイズ=5)を実装し、imori_noise.jpgのエッジを検出せよ。
LoGフィルタとはLaplacian of Gaussianであり、ガウシアンフィルタで画像を平滑化した後にラプラシアンフィルタで輪郭を取り出すフィルタである。
Laplcianフィルタは二次微分をとるのでノイズが強調されるのを防ぐために、予めGaussianフィルタでノイズを抑える。LoGフィルタは次式で定義される。A19""" LoGフィルタ(Laplacian Of Gaussian Filter)とは、ガウシアンフィルタとラプラシアンフィルタを組み合わせたフィルタ ガウシアンフィルタで画像を平滑化してノイズを低減した後、ラプラシアンフィルタで輪郭を取り出します。 ガウシアンフィルタ cv2.GaussianBlur(src, ksize, sigmaX) src: 入力画像, ksize: カーネルサイズ, sigmaX: ガウス分布のsigma_x ラプラシアンフィルタ cv2.filter2D(src, -1, kernel) src 入力画像 cv2.CV_64F float64 kernel フィルタのカーネル(※NumPy配列で与える) """ # ガウシアンフィルタ gauss_img = cv2.GaussianBlur(gray_noise, ksize=(3, 3), sigmaX=1.3) # カーネル kernel = np.array([[0, 0, 1, 0, 0], [0, 1, 2, 1, 0], [1, 2, -16, 2, 1], [0, 1, 2, 1, 0], [0, 0, 1, 0, 0]]) # ラプラシアンフィルタ img19 = cv2.filter2D(gauss_img, cv2.CV_64F, kernel) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans19.jpg', img19) # 画像を表示する cv2_imshow(img19) cv2.waitKey(0) cv2.destroyAllWindows()
回答と違う画像。でもラプラシアンフィルタにするとこんな感じな気がする。間違っていたら教えてください。
Q.20. ヒストグラム表示
matplotlibを用いてimori_dark.jpgのヒストグラムを表示せよ。
ヒストグラムとは画素の出現回数をグラフにしたものである。 matplotlibではhist()という関数がすでにあるので、それを利用する。A# ヒストグラム """ matplotlib.pyplot.hist(x, bins=10, range=None, normed=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, hold=None, data=None, **kwargs) x (必須) ヒストグラムを作成するための生データの配列。 bins ビン (表示する棒) の数。階級数。(デフォルト値: 10) range ビンの最小値と最大値を指定。(デフォルト値: (x.min(), x.max())) rwidth 各棒の幅を数値または、配列で指定。 """ # ravel: 多次元のリストを1次元のリスト, ビン数:255, 範囲0~255 plt.hist(img_dark.ravel(), bins=255, rwidth=0.8, range=(0, 255)) plt.savefig("out.png") plt.show()参考: Python でデータサイエンス
感想
公式版ではnumpyを用いて、原理通りやっているがOpenCVを可能な限り用いて、簡単に実装できるようにする。









- 投稿日:2020-11-21T21:15:45+09:00
pipでの依存性管理を少しだけラクにしてみる
はじめに
PythonBytes ポッドキャストの最新エピソード(第208回)を聴いていて面白そうなツールの紹介をしていたので試してみました。pipでの依存性管理が少しだけラクになると思います。
pipでの依存性管理とその課題
まずpipでの依存性管理について基本的なおさらいを。必要なパッケージをインストールするには
pip installで行います。例えば、requestsとpandasという2つのパッケージをインストールすると以下のようになります。$ pip install requests Collecting requests Downloading requests-2.25.0-py2.py3-none-any.whl (61 kB) |████████████████████████████████| 61 kB 7.2 MB/s Collecting urllib3<1.27,>=1.21.1 Downloading urllib3-1.26.2-py2.py3-none-any.whl (136 kB) |████████████████████████████████| 136 kB 10.5 MB/s Collecting certifi>=2017.4.17 Downloading certifi-2020.11.8-py2.py3-none-any.whl (155 kB) |████████████████████████████████| 155 kB 12.9 MB/s Collecting chardet<4,>=3.0.2 Using cached chardet-3.0.4-py2.py3-none-any.whl (133 kB) Collecting idna<3,>=2.5 Using cached idna-2.10-py2.py3-none-any.whl (58 kB) Installing collected packages: urllib3, certifi, chardet, idna, requests Successfully installed certifi-2020.11.8 chardet-3.0.4 idna-2.10 requests-2.25.0 urllib3-1.26.2$ pip install pandas Collecting pandas Downloading pandas-1.1.4-cp39-cp39-macosx_10_9_x86_64.whl (10.3 MB) |████████████████████████████████| 10.3 MB 5.9 MB/s Collecting numpy>=1.15.4 Using cached numpy-1.19.4-cp39-cp39-macosx_10_9_x86_64.whl (15.4 MB) Collecting pytz>=2017.2 Downloading pytz-2020.4-py2.py3-none-any.whl (509 kB) |████████████████████████████████| 509 kB 31.7 MB/s Collecting python-dateutil>=2.7.3 Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB) |████████████████████████████████| 227 kB 33.8 MB/s Collecting six>=1.5 Using cached six-1.15.0-py2.py3-none-any.whl (10 kB) Installing collected packages: numpy, pytz, six, python-dateutil, pandas Successfully installed numpy-1.19.4 pandas-1.1.4 python-dateutil-2.8.1 pytz-2020.4 six-1.15.0これを見ると指定したパッケージだけでなくそれが依存しているパッケージも自動的に引っ張ってきてくれます。インストールされているパッケージのリストが見たければ
pip freezeを使います。$ pip freeze certifi==2020.11.8 chardet==3.0.4 idna==2.10 numpy==1.19.4 pandas==1.1.4 python-dateutil==2.8.1 pytz==2020.4 requests==2.25.0 six==1.15.0 urllib3==1.26.2これは別にPythonで決められていることではないですが、多くの人がこの結果を
requirements.txtというファイルに書き出しておいて、あとから再度インストールする時や他の人が使うときに一括でインストール出来るようにしています。$ pip freeze > requirements.txt $ pip install -r requirements.txt
pip freezeの結果はpip installしたパッケージだけでなく、依存したパッケージも同じようにリストされています。さらに各パッケージのバージョンも入っていて、pip install -rするとインストールした時と同じ全く同じ環境を作り出すことができます。他のツールだとlockファイルと称するものも多いと思いますが、pipの場合は「freeze (凍らせる)」という言い方をしているわけですね。同じ環境を再現するという意味で全てのパッケージが羅列されているのは良いのですが、これだけ見るとどれが自分がインストールしたもので、どれが依存関係で引っ張られてきたのかがわかりません。パッケージをアンインストールする際に自分が
package installしたものは消せてもそれが引っ張ってきたパッケージがどれだったかがわからないと消すのが難しい。また、依存するパッケージにバグ修正があったとしても古いバージョンを使い続けてしまうという問題もあります。そこで、次の章でご紹介するツールです。pip-chill
pip freezeの不便さを補うツールとして pip-chillというツールがあります。これはpip freezeとは違ってpipには組み込まれていないので単独でインストールする必要があります。$ pip install pip-chillこれで pip-chillが使えるようになります。引数無しで実行するとこうなります。
$ pip-chill pandas==1.1.4 pip-chill==1.0.0 requests==2.25.0
pip freezeと似ていますが、自分でインストールしたパッケージのみが表示されています。「何をインストールしていたっけ?」というときにひと目で分かるので便利ですね。
pip-chillがこのリストに入ってしまっているのが玉に瑕で、ポッドキャストでもブライアンさんが「リストからpip-chill自身を隠すオプションあったら良かったのに」って言っていましたが、pip-chill | grep -v pip-chillすればとりあえず回避できます。pip-chillにはオプションがいくつかあり、例えば
--no-versionを使うとパッケージ名だけを表示してくれます。$ pip-chill --no-version pandas pip-chill requests例えば開発中の段階ではあまり細かくバージョン指定とかする必要ないと思うのでこれを
requirements.txtに入れておくというのはあると思うんですよね。途中で不要になって抜いたり、同じような機能のパッケージを複数試してみたりの時に簡単にできるように。それで、テストも終えてコレでよし!となったらpip freeze > requirements.txtして依存パッケージも含めて固定すると。もう一つ有用なオプションがあって、それを使うとこんな出力になります。
$ pip-chill -v pandas==1.1.4 pip-chill==1.0.0 requests==2.25.0 # certifi==2020.11.8 # Installed as dependency for requests # chardet==3.0.4 # Installed as dependency for requests # idna==2.10 # Installed as dependency for requests # numpy==1.19.4 # Installed as dependency for pandas # python-dateutil==2.8.1 # Installed as dependency for pandas # pytz==2020.4 # Installed as dependency for pandas # six==1.15.0 # Installed as dependency for python-dateutil # urllib3==1.26.2 # Installed as dependency for requests通常の出力の後に依存関係でインストールされたパッケージのリストがコメントアウトの形で並んでいて、そこに「どのパッケージから依存されているか」という情報を出してくれています。いや、こういうのが欲しかったです。
さらに
-aすると全てのパッケージを表示してくれます(つまりpip freezeと同じ)。なお、pip-chillは
pip installした履歴を覚えていて処理しているわけではなく「誰からも依存関係が張られていないもの(つまりは手動でインストールしたであろうもの)」を表示しているだけです。単純な仕組みでやりたいことを実現していて良いですね。ただそんな仕組みなので、例えば上の状態からpandasをアンインストールするとこうなります。$ pip uninstall pandas $ pip-chill numpy==1.19.4 pip-chill==1.0.0 python-dateutil==2.8.1 pytz==2020.4 requests==2.25.0当たり前ですが、pandasがいなくなったのでそこから依存関係を張られていたnumpy, python-dateutil, pytz が上に出てきちゃってます。pandasを消した時にこれらも一緒に消せるとさらに便利になるんですけどね。
なお、"Chill" というのは「冷たくする」という意味があります。日本語だと冷蔵庫に「チルド」という機能がありますが、それの語源(?)ですね。Freeze(凍らせる)までは行かないけど、その手前まで冷やすという感じで、上手いネーミングかと思います。
まとめ
pip-chillというツールを使ってみました。
pip freezeにこんな機能ないのかなと思っていたことをやってくれます。いずれpipに取り込まれないかな…。
- 投稿日:2020-11-21T20:50:44+09:00
FastAPIでformから複数画像をアップロードできない
概要
jsを使ってではなく、普通のhtmlの
<input type="file" ...>タグからfastapiのバックエンドサーバーに複数画像をアップロードしようとした時にはまった備忘録です。問題コード
index.html<html> <head> <title>Face Swap App</title> </head> <body> <h1>Look ma! HTML!</h1> <form enctype="multipart/form-data" method="post" action="swap"> <input type="file" id="source" name="file"></input> <input type="file" id="target" name="file"></input> <input type="submit" value="Face Swap"> </form> </body> </html>main.py@app.post("/swap", response_class=HTMLResponse) async def create_swapped_image(files: List[UploadFile] = File(...)): print(files) return """ <html> <head> <title>Face Swap App</title> </head> <body> <h1>Success!</h1> </body> </html> """解決法
結論から言えば
inputタグのnameをfastapiのエンドポイントの関数の引数と同じにする必要があるようです!つまりindex.htmlのinputをindex.html<input type="file" id="source" name="files"> <input type="file" id="target" name="files">に変えることで解決しました。
全部読んだわけではないですが、こんなこと公式docに書いていた記憶がないのでわかりづらいなあと思いました。書いていたらごめんなさい、、
- 投稿日:2020-11-21T20:50:12+09:00
PythonでPDFにされた表をCSVに戻したい
表のデータベースがそのまま欲しかったのに
PDFという形式は人にデータを渡すときや、報告書などに他の資料とまとめて配布するには便利な形式ですが、FIXされてしまっているのでデータの再利用性という意味ではやっかいなことが多々あります。私自身も報告書に何千行という表をA4フォーマットで落とし込んで提出したのはいいが、後日それを利用したいタイミングで元データがなく、PDFから取り出さなければならない事態になったためこちらを書きました。
作り方
下のコードを書いてください。また別途tabulaというJavaのライブラリをインストールしておく必要があります。Pyhonのモジュールはあくまでもそのラッパです。
import tabula import PyPDF2 import pandas as pd FILE_PATH = "./test.pdf" with open(FILE_PATH, mode='rb') as f: pages = PyPDF2.PdfFileReader(f).getNumPages() for i in range(pages+1): tmp = tabula.read_pdf(FILE_PATH, pages = i, encoding = "utf-8_sig", spreadsheet=True) df = pd.concat([df, tmp], ignore_index=True) df = tabula.read_pdf(FILE_PATH, lattice=True, pages = '1' ) df[0].to_csv("./test.csv", encoding="shift_jis")使い方
上の.pyファイルを実行するだけです。
よいPDFライフを。
- 投稿日:2020-11-21T19:35:10+09:00
エラーや実行完了をLINEで通知する【Python】
はじめに
機械学習などをやっていると1つのプログラムの実行に数日かかるなんてことは珍しくありません.
プログラムの実行状況が気になり,数時間おきに端末を開く.
そんな日々を送っていませんか?
そんな人のために,今回はPythonプログラムのエラーや実行完了をLINEで通知する方法を紹介します.
LINEアカウントを持っている人なら10分程度でできるので是非!LINE Notifyの準備
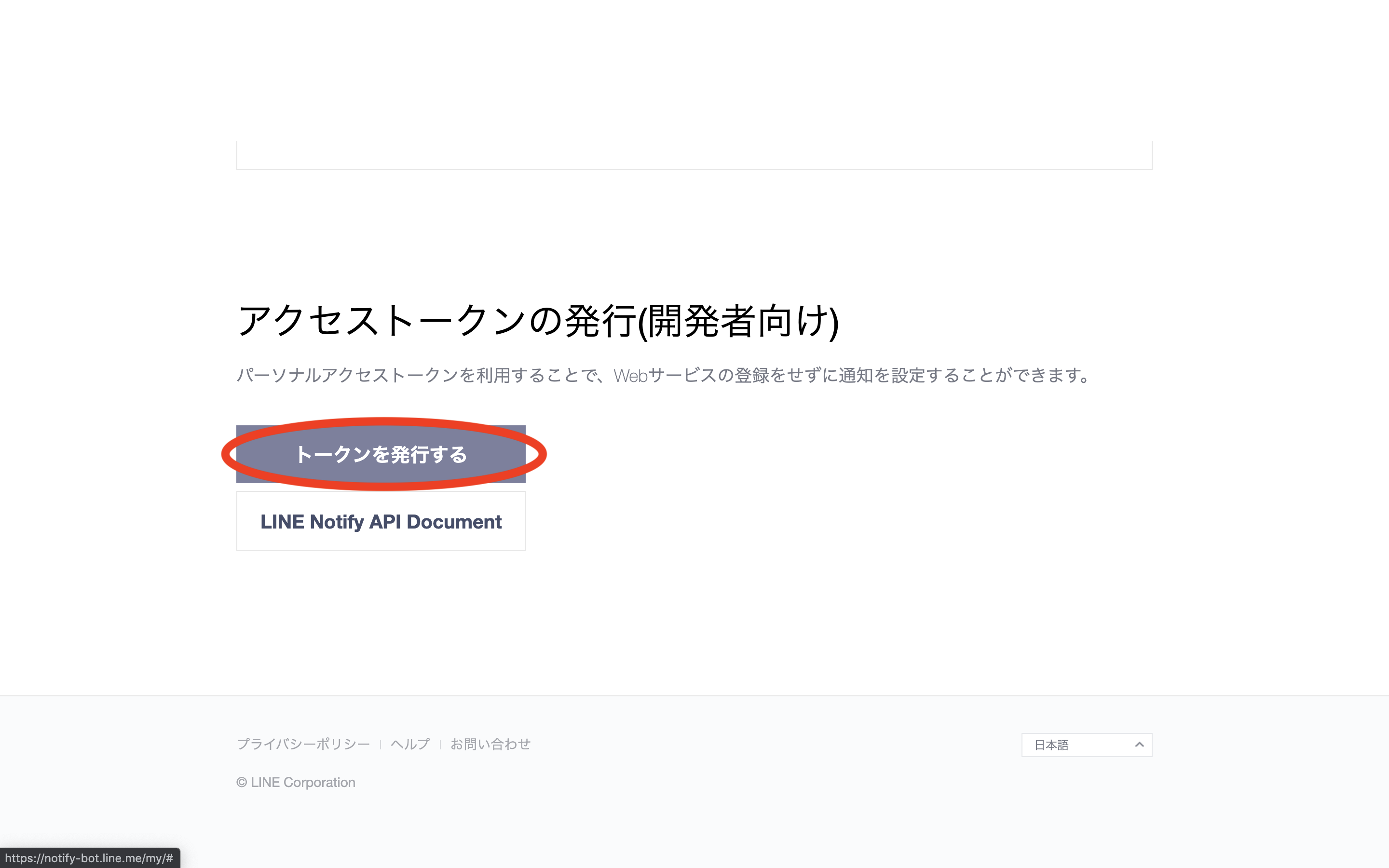
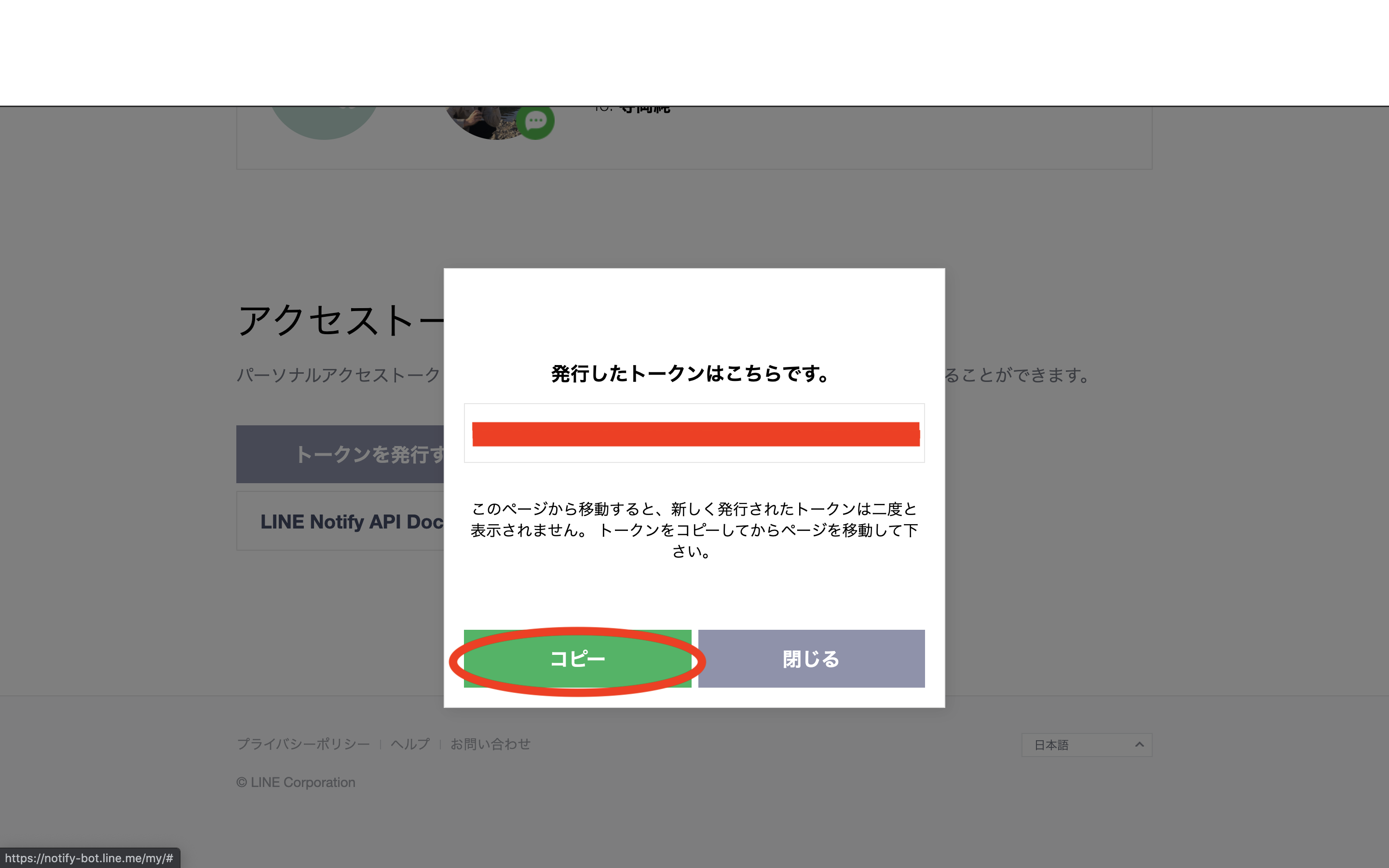
通知を送るためにLINEが提供するLINE Notifyというサービスを使います.
まずは,ここからトークンを発行します.
https://notify-bot.line.me/my/右上のログインボタンからLINEアカウントにログイン後,以下のような手順でトークンを発行&コピーします.
トークン名は好きに設定してください.今回は「実行結果通知」としています.
ここで必ずコピーしてください.
これでLINE Notifyの準備は完了です.
LINE通知用のPythonプログラム
以下のプログラムをコピペし,トークンの部分を変更するだけでOKです.
(pip install requestsが必要かも)line_notify.pyimport requests # LINEに通知する関数 def line_notify(message): line_notify_token = 'ここにトークンをペーストしてください' line_notify_api = 'https://notify-api.line.me/api/notify' payload = {'message': message} headers = {'Authorization': 'Bearer ' + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) if __name__ == '__main__': message = "Hello world!" line_notify(message)
python line_notify.pyを実行すると,LINEに"Hello world!"とメッセージが届くはずです.エラーや実行完了を通知
あとは,例外処理などと組み合わせて通知するだけです.
試しに以下のプログラムを実行してみます.hoge.pyimport requests # LINEに通知する関数 def line_notify(message): line_notify_token = 'ここにトークンをペーストしてください' line_notify_api = 'https://notify-api.line.me/api/notify' payload = {'message': message} headers = {'Authorization': 'Bearer ' + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) # a/bを計算する関数 def foo(a, b): return a / b if __name__ == '__main__': try: ans = foo(1, 0) except Exception as e: line_notify(e) else: line_notify("finished")
foo(1, 0) を foo(1, 1) と変更して実行してみます.
正しく通知できていますね.参考




- 投稿日:2020-11-21T19:15:10+09:00
TensorFlow Object Detection API のつかいかた(推論。Colabサンプル付き)
記事を読めば、TensorFlow Object Detection API (推論部分)のつかいかたがわかります。
Colabでできます。
Colabサンプル
サンプルのセルを実行していくと、TensorFlowObjectDetectionAPIが試せます。
最後のセルのImage_Pathを自前の画像のものに変えると、自前の画像で物体検出できます。
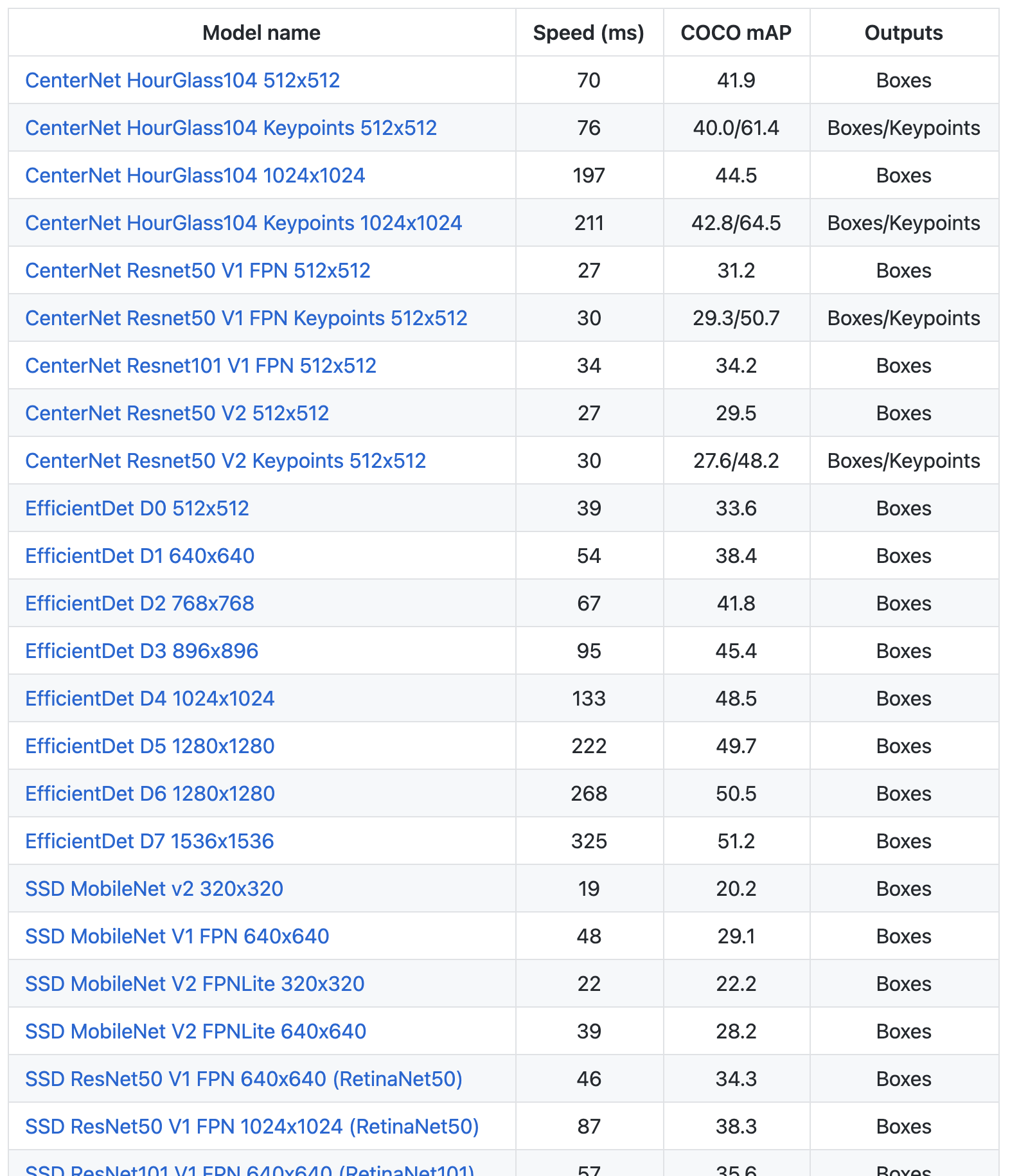
TensorFlow公式 Model Zooにはいろんな種類のモデルがあります!
手順
0.TensorFlow2をインストール
!pip install -U --pre tensorflow=="2.2.0"1.TensorFlow 公式 Models をGitHubからClone
import os import pathlib # 現在のディレクトリパスにmodelsが含まれていれば、そこに移動する。なければクローンする。 if "models" in pathlib.Path.cwd().parts: while "models" in pathlib.Path.cwd().parts: os.chdir('..') elif not pathlib.Path('models').exists(): !git clone --depth 1 https://github.com/tensorflow/models2.Object Detection API、必要なモジュールをインストール
%%bash #bashコマンドを有効に cd models/research/ protoc object_detection/protos/*.proto --python_out=. cp object_detection/packages/tf2/setup.py . python -m pip install .3.モジュールのインポート
import matplotlib import matplotlib.pyplot as plt import io import scipy.misc import numpy as np from six import BytesIO from PIL import Image, ImageDraw, ImageFont import tensorflow as tf from object_detection.utils import label_map_util from object_detection.utils import config_util from object_detection.utils import visualization_utils as viz_utils from object_detection.builders import model_builder %matplotlib inline4.画像読み込み関数
def load_image_into_numpy_array(path): """画像を読み込んでNumpy Arrayにする Puts image into numpy array to feed into tensorflow graph. Note that by convention we put it into a numpy array with shape (height, width, channels), where channels=3 for RGB. Args: path: the file path to the image Returns: uint8 numpy array with shape (img_height, img_width, 3) """ img_data = tf.io.gfile.GFile(path, 'rb').read() image = Image.open(BytesIO(img_data)) (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8)5.モデルをダウンロード
!wget http://download.tensorflow.org/models/object_detection/tf2/20200713/centernet_hg104_512x512_coco17_tpu-8.tar.gz !tar -xf centernet_hg104_512x512_coco17_tpu-8.tar.gz公式 Model Zoo から好きなモデルをダウンロードします。
ダウンロードURLは上記リンクのモデル名にカーソルを合わせると表示されます。
性能比較を見てるだけでたのしいですね。
ダウンロード・解凍が完了すると、checkpoint、saved_model、pipline.configを含むフォルダが展開されます。
6.pipeline config(モデルの構成情報)を読み込んで、モデルをビルドする
#構成情報ファイルのパス。リポジトリにConfigファイルの揃ったフォルダがあるけど、微妙にモデル名が省略されていたりするので、ダウンロードしたものの方が確実? pipeline_config = "./centernet_hg104_512x512_coco17_tpu-8/pipeline.config" #チェックポイントのパス model_dir = "./centernet_hg104_512x512_coco17_tpu-8/checkpoint" #モデル構成情報読み込み configs = config_util.get_configs_from_pipeline_file(pipeline_config) model_config = configs['model'] #読み込んだ構成情報でモデルをビルド detection_model = model_builder.build( model_config=model_config, is_training=False) #チェックポイントから重みを復元 ckpt = tf.compat.v2.train.Checkpoint(model=detection_model) ckpt.restore(os.path.join(model_dir, 'ckpt-0')).expect_partial()7.モデルによる推論関数を準備
def get_model_detection_function(model): """Get a tf.function for detection.""" @tf.function def detect_fn(image): """Detect objects in image.""" image, shapes = model.preprocess(image) prediction_dict = model.predict(image, shapes) detections = model.postprocess(prediction_dict, shapes) return detections, prediction_dict, tf.reshape(shapes, [-1]) return detect_fn detect_fn = get_model_detection_function(detection_model)8.ラベルを準備
物体検出の推論ではモデルをトレーニングをした物体ラベルが必要です。
ラベルは公式リポジトリの models/research/object_detection/data/ にあります。今回のモデルはCocoデータセットでトレーニングされているので、 mscoco_label_map.pbtxt を使います。label_map_path = './models/research/object_detection/data/mscoco_label_map.pbtxt' label_map = label_map_util.load_labelmap(label_map_path) categories = label_map_util.convert_label_map_to_categories( label_map, max_num_classes=label_map_util.get_max_label_map_index(label_map), use_display_name=True) category_index = label_map_util.create_category_index(categories) label_map_dict = label_map_util.get_label_map_dict(label_map, use_display_name=True)9.用意した画像で物体検出の実行
Colabに好きな画像をアップロードして、image_pathにそのパスを指定します。
ちなみに、アルファチャネル付きの画像は3チャネルに直してから実行する必要があるっぽいです。image_dir = 'models/research/object_detection/test_images/' image_path = os.path.join(image_dir, 'image2.jpg') image_np = load_image_into_numpy_array(image_path) # Things to try: # Flip horizontally # image_np = np.fliplr(image_np).copy() # Convert image to grayscale # image_np = np.tile( # np.mean(image_np, 2, keepdims=True), (1, 1, 3)).astype(np.uint8) input_tensor = tf.convert_to_tensor( np.expand_dims(image_np, 0), dtype=tf.float32) detections, predictions_dict, shapes = detect_fn(input_tensor) label_id_offset = 1 image_np_with_detections = image_np.copy() # Use keypoints if available in detections keypoints, keypoint_scores = None, None if 'detection_keypoints' in detections: keypoints = detections['detection_keypoints'][0].numpy() keypoint_scores = detections['detection_keypoint_scores'][0].numpy() viz_utils.visualize_boxes_and_labels_on_image_array( image_np_with_detections, detections['detection_boxes'][0].numpy(), (detections['detection_classes'][0].numpy() + label_id_offset).astype(int), detections['detection_scores'][0].numpy(), category_index, use_normalized_coordinates=True, max_boxes_to_draw=200, min_score_thresh=.30, agnostic_mode=False, keypoints=keypoints, keypoint_scores=keypoint_scores, keypoint_edges=get_keypoint_tuples(configs['eval_config'])) plt.figure(figsize=(12,16)) plt.imshow(image_np_with_detections) plt.show()
ボックス、ラベル、信頼度が表示されます。
?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。


- 投稿日:2020-11-21T19:15:10+09:00
TensorFlow Object Detection API のつかいかた(事前学習済みモデルで推論)
記事を読めば、TensorFlow Object Detection API (推論部分)のつかいかたがわかります。
Colabでできます。
TensorFlow公式 Model Zooにはいろんな種類のモデルがあります!
手順
0.TensorFlow2をインストール
!pip install -U --pre tensorflow=="2.2.0"1.TensorFlow 公式 Models をGitHubからClone
import os import pathlib # 現在のディレクトリパスにmodelsが含まれていれば、そこに移動する。なければクローンする。 if "models" in pathlib.Path.cwd().parts: while "models" in pathlib.Path.cwd().parts: os.chdir('..') elif not pathlib.Path('models').exists(): !git clone --depth 1 https://github.com/tensorflow/models2.Object Detection API、必要なモジュールをインストール
%%bash #bashコマンドを有効に cd models/research/ protoc object_detection/protos/*.proto --python_out=. cp object_detection/packages/tf2/setup.py . python -m pip install .3.モジュールのインポート
import matplotlib import matplotlib.pyplot as plt import io import scipy.misc import numpy as np from six import BytesIO from PIL import Image, ImageDraw, ImageFont import tensorflow as tf from object_detection.utils import label_map_util from object_detection.utils import config_util from object_detection.utils import visualization_utils as viz_utils from object_detection.builders import model_builder %matplotlib inline4.画像読み込み関数
def load_image_into_numpy_array(path): """画像を読み込んでNumpy Arrayにする Puts image into numpy array to feed into tensorflow graph. Note that by convention we put it into a numpy array with shape (height, width, channels), where channels=3 for RGB. Args: path: the file path to the image Returns: uint8 numpy array with shape (img_height, img_width, 3) """ img_data = tf.io.gfile.GFile(path, 'rb').read() image = Image.open(BytesIO(img_data)) (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8)5.モデルをダウンロード
!wget http://download.tensorflow.org/models/object_detection/tf2/20200713/centernet_hg104_512x512_coco17_tpu-8.tar.gz !tar -xf centernet_hg104_512x512_coco17_tpu-8.tar.gz公式 Model Zoo から好きなモデルをダウンロードします。
ダウンロードURLは上記リンクのモデル名にカーソルを合わせると表示されます。
性能比較を見てるだけでたのしいですね。
ダウンロード・解凍が完了すると、checkpoint、saved_model、pipline.configを含むフォルダが展開されます。
6.pipeline config(モデルの構成情報)を読み込んで、モデルをビルドする
#構成情報ファイルのパス。リポジトリにConfigファイルの揃ったフォルダがあるけど、微妙にモデル名が省略されていたりするので、ダウンロードしたものの方が確実? pipeline_config = "./centernet_hg104_512x512_coco17_tpu-8/pipeline.config" #チェックポイントのパス model_dir = "./centernet_hg104_512x512_coco17_tpu-8/checkpoint" #モデル構成情報読み込み configs = config_util.get_configs_from_pipeline_file(pipeline_config) model_config = configs['model'] #読み込んだ構成情報でモデルをビルド detection_model = model_builder.build( model_config=model_config, is_training=False) #チェックポイントから重みを復元 ckpt = tf.compat.v2.train.Checkpoint(model=detection_model) ckpt.restore(os.path.join(model_dir, 'ckpt-0')).expect_partial()7.モデルによる推論関数を準備
def get_model_detection_function(model): """Get a tf.function for detection.""" @tf.function def detect_fn(image): """Detect objects in image.""" image, shapes = model.preprocess(image) prediction_dict = model.predict(image, shapes) detections = model.postprocess(prediction_dict, shapes) return detections, prediction_dict, tf.reshape(shapes, [-1]) return detect_fn detect_fn = get_model_detection_function(detection_model)8.ラベルを準備
物体検出の推論ではモデルをトレーニングをした物体ラベルが必要です。
ラベルは公式リポジトリの models/research/object_detection/data/ にあります。今回のモデルはCocoデータセットでトレーニングされているので、 mscoco_label_map.pbtxt を使います。label_map_path = './models/research/object_detection/data/mscoco_label_map.pbtxt' label_map = label_map_util.load_labelmap(label_map_path) categories = label_map_util.convert_label_map_to_categories( label_map, max_num_classes=label_map_util.get_max_label_map_index(label_map), use_display_name=True) category_index = label_map_util.create_category_index(categories) label_map_dict = label_map_util.get_label_map_dict(label_map, use_display_name=True)9.用意した画像で物体検出の実行
Colabに好きな画像をアップロードして、image_pathにそのパスを指定します。
ちなみに、アルファチャネル付きの画像は3チャネルに直してから実行する必要があるっぽいです。image_dir = 'models/research/object_detection/test_images/' image_path = os.path.join(image_dir, 'image2.jpg') image_np = load_image_into_numpy_array(image_path) # Things to try: # Flip horizontally # image_np = np.fliplr(image_np).copy() # Convert image to grayscale # image_np = np.tile( # np.mean(image_np, 2, keepdims=True), (1, 1, 3)).astype(np.uint8) input_tensor = tf.convert_to_tensor( np.expand_dims(image_np, 0), dtype=tf.float32) detections, predictions_dict, shapes = detect_fn(input_tensor) label_id_offset = 1 image_np_with_detections = image_np.copy() # Use keypoints if available in detections keypoints, keypoint_scores = None, None if 'detection_keypoints' in detections: keypoints = detections['detection_keypoints'][0].numpy() keypoint_scores = detections['detection_keypoint_scores'][0].numpy() viz_utils.visualize_boxes_and_labels_on_image_array( image_np_with_detections, detections['detection_boxes'][0].numpy(), (detections['detection_classes'][0].numpy() + label_id_offset).astype(int), detections['detection_scores'][0].numpy(), category_index, use_normalized_coordinates=True, max_boxes_to_draw=200, min_score_thresh=.30, agnostic_mode=False, keypoints=keypoints, keypoint_scores=keypoint_scores, keypoint_edges=get_keypoint_tuples(configs['eval_config'])) plt.figure(figsize=(12,16)) plt.imshow(image_np_with_detections) plt.show()
ボックス、ラベル、信頼度が表示されます。
?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2020-11-21T18:40:33+09:00
VS codeで、Ubuntuからスクリプトファイルを開く方法
スクリプトファイルがあるディレクトリに行って、下記を実行せよ。
但し、「」『←<ファイル(英語)>って書きたいのに、消えてしまう』は実行したいスクリプトファイルである。例えば、xx.py などのpythonスクリプトファイル。cmd.exe /C code <file>健闘を祈る。
- 投稿日:2020-11-21T18:01:51+09:00
C++ の学習サイトを作りました
はじめに
C++ って他の言語に比べると勉強しづらくないですか?
書籍や学習サイトの内容が古い、または少ないんですよね。ただでさえ言語仕様が複雑なのに、それを手助けする情報も少ないと初学者には辛いんじゃないかと思います。というか僕がそうでした。
そんなわけで、もう少し今風な学習サイトを作ろうと思って作成しました。
ゼロから学ぶ C++
https://rinatz.github.io/cpp-book/
ちゃんとスマホでも読めるようになっています。
C++11 をベースに作っているので、このサイトももはや古い方に入るかも知れませんが、C++20 が浸透してきたらアップデートしようと思います。
よかったらご活用下さい。
ゼロから学ぶ Python(姉妹サイト)
『ゼロから学ぶ Python』というサイトも作成しています。あわせてご活用下さい。
https://rinatz.github.io/python-book/
さいごに
上記のサイトはどちらも GitHub でソースコードを管理しています。
スターを付けてもらうと励みになります

- 投稿日:2020-11-21T17:40:17+09:00
「伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門」を更新しました
オンラインブックを更新しました
チャプター「POSTパラメータを扱えるようにする」 を更新しました。
続きを読みたい方は、ぜひBookの「いいね」か「筆者フォロー」をお願いします ;-)
以下、書籍の内容の抜粋です。
リクエストボディを扱う
前章の最後に、Chromeで
/show_requestsへアクセスした結果を見てみるとリクエストボディが空になっていたことが分かりました。しかし、仮にボディが空でなかったとして、私達のWebアプリケーションはリクエストボディを変換したり解釈したりする処理はまだないのでした。
せっかくなので、ここいらでリクエストボディを扱えるようにしておきましょう。リクエストボディはクライアントからサーバーへ付加的な情報(パラメータとも言う)を送るのに用いられ、一例として
POSTメソッドのリクエスト(以下、POSTリクエスト)などで使われます。本章では、
POSTメソッドのパラメータに関する処理を実装することで、リクエストボディの取り扱いについて学びましょう。POSTリクエストを送信し、ボディを観察してみる。
アレコレと説明する前に、まずはリクエストボディが実際にどのように使われているのか観察するところから始めましょう。
POSTリクエストを送信する
POSTリクエストをブラウザがどのようなときに送るかというと、代表的なのは
<form>タグを用いて作られたフォームのsubmitボタンが押された時です。実際にフォームを含むHTMLを作成し、実験してみましょう。
下記のHTMLを
study/static内に作成してください。内容は初歩的なHTMLで、詳しく説明する必要はないでしょう。
1つの<form>タグの中に、テキストボックスやプルダウン、セレクトボックスなど、色々な種類の入力フォームが入っているだけです。
study/static/form.html
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter15/static/form.htmlまた、今回からレスポンスヘッダーを少し変更します。
Content-Typeヘッダーには文字列のエンコーディングを指定することができ、ブラウザで日本語を表示させるためには日本語に対応したエンコーディングの指定が必要になります。エンコーディングについては話が込み入ってしまいますので、ピンと来ない方はおなじないだと思って追記しておいてください。
study/workerthread.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter15/workerthread.py#L169このファイルは
staticディレクトリの中に入っており静的ファイル配信の対象となります ので、サーバーを起動した状態でChromeからhttp://localhsot:8080/form.htmlへアクセスすると表示することができます。
ブラウザは、
type="submit"の要素(以下、submitボタンと呼びます)がクリックされると、<form>タグのaction属性で指定されたURLへPOSTリクエストを送信します。
action属性で指定するURLについて、ホストやポートを省略すると、現在開いているページと同じホスト/ポートへ送信されます。
つまり、今回のように
- 現在開いているページが
http://localhost:8080/form.htmlである<form action="/show_requests">であるという場合では、POSTリクエストは
http://localhost:8080/show_requestsへ送信されます。
では、下図のようにフォームに値を入力して、送信ボタンを押してみましょう。
先程説明した通り、このフォームの入力内容は、POSTリクエスト
/show_requestsへ送られます。
/show_requestsは前章でHTTPリクエストの内容が表示されるようにしておいたはずですので、これでPOSTリクエストの内容が見れるだろう、という算段です。実際、送信ボタンを押すと、次の画面で下記のように表示されるはずです。
単にURLバーに
/show_requestsと入力してページ遷移した場合と違って、リクエストボディに値が含まれていることが分かります。また、
Content-Type: application/x-www-form-urlencodedというヘッダーも新たに追加されていることにも注目しておいてください。
後ほど、このヘッダーが大きな意味を持つことを説明します。POSTリクエストのボディを観察する
さて、POSTリクエストのボディの具体的な中身が見れたことですので、観察してお勉強していきましょう。
リクエストボディを見てみると、テキストボックスやパスワードなどの個々の入力フォームの値が決まったフォーマットで連結されて渡されてきているのが分かります。そのフォーマットとは、1つの入力フォームに対して
[HTML要素のname属性の値]=[フォームに入力された値]
というペアがあり、別々のフォームの値同士は&で連結されているようなフォーマットです。また、
半角スペースは+という記号に置き換えられ、改行コードや日本語は%で始まる謎の文字列に変換されていることが分かります。
(日本語の入力値は、hidden_valueの値を見てください)また、
<select>要素のように複数選択を許可する入力フォームでは、同じnameで複数の値が送られてきているようです。
例)check_name=check2&check_name=check3また、アップロードしたファイルを見てみるとファイル名だけしか送られておらず、ファイルの内容は送信されていません。
POSTパラメータのフォーマットについて
POSTリクエストで送りたいデータ(以下、POSTパラメータ)をリクエストボディを使ってサーバーへ送る際、どのようなフォーマットで送るかは重要です。
ここでフォーマットと言っているのは、リクエストボディの中でパラメータのnameとvalueを表すのになんの記号を使うのか、複数のデータを分けるのになんの記号を使うのか、マルチバイト文字をどのように表現するのか、画像ファイルのようなバイナリデータをどのように表現するのか、などです。フォーマットは様々な種類が考えられますが、このフォーマット方式の認識がクライアント側とサーバー側で違うと、送ったパラメータをサーバ側で正しく認識できません。
(クライアント側は=という記号は「nameとvalueを分ける記号」だと思って使っているのに、サーバー側ではこれを「改行コード」だと思って解釈してしまうと、訳の分からない事になってしまうわけです。)そこで、POSTリクエストを送る時は、必ずリクエストボディのフォーマットを示す
Content-Typeというヘッダーをつけてフォーマットを明示してあげる必要があります。今回でいうと、
http
Content-Type: application/x-www-form-urlencoded
がそれに当たるというわけです。以下では、よく使われるフォーマット(
Content-Type)について3つ紹介しておきます。
application/x-www-form-urlencodedこちらは、ブラウザが
<form>タグでenctype属性を指定しなかった場合に使われるデフォルトのフォーマットです。
別名「URLエンコーディング」や「パーセントエンコーディング」とも呼ばれ、URLとして利用可能な文字のみを使って様々なデータを表せるようにフォーマットが決められています。既にさきほど見た通り、
- 項目の
nameとvalueは=で連結する- 複数の項目を送る際は
&で連結する- 半角スペースは
+を使う- その他のURLに使えない文字は、
UTF-8で符号化した上で、そのバイト列を%XXで表す- UTF-8で符号化できないバイナリデータは扱えない(ファイルアップロージ時、ファイルの中身は送信しない)
などが特徴です。
multipart/form-dataこちらは、
<form enctype="multipart/form-data">のように、enctype属性で明示的に指定することで利用できます。
説明する前に実際に中身を見てみましょう。さきほど作成した
form.htmlの<form>要素に、enctypeを指定して、フォームを送信してみてください。注意
ファイルアップロードした時の表示を確認したい場合は、
ChromeではなくFirefoxというブラウザを使い、小さいデータ(数KBの画像など)を送るようにしてください。ChromeやSafariは、ファイルデータを送る際にkeep-aliveを使って複数回に分けてリクエストを送信する挙動となっていますが、私たちのWebサーバーはkeep-aliveに対応しておらずデータを正常に受け取れないためです。
Firefoxは小さいデータであれば1リクエストで送ってきますので、正常にデータを受け取ることができます。
下記ではFirefoxで挙動確認した画面を掲載しますが、Firefoxをインストールするのが面倒な方は、Chromeでファイルはアップロードせずに動作確認してみてください。
テキストフォームなど、ファイル以外のフォームであればデータが受け取れるはずです。
まず最初に注目するのは、フォームデータの各項目が特殊なセパレータによって分割されている点です。
(今回でいうとセパレータは---------------------------10847194838586372301567045317)
続きはBookで!





- 投稿日:2020-11-21T17:28:23+09:00
PythonでCoinMetricsが提供するBitcoinに関する簡単なデータ分析
【本文】
今回は少し趣向を変えて、Pythonを利用した簡単なデータ分析(可視化)の事例を紹介。
CoinMetricsが各暗号通貨(ステーブルコイン等も含む)のデータをcsv形式で提供しているので、そちらを利用して、Bitcoinのトランザクション量と価格(USD)について可視化してみた。Pythonはデータ分析用のライブラリが豊富な為、簡単な可視化であれば、数行~数十行程度で済むのが嬉しい。
(今回の事例では、pandasとmatplotlibを利用するだけでごく簡単なコードで、何となくそれなりの可視化が可能。同じことをMS-Excelで実現しようとすると。。。)<備考>
CoinMetricsが提供するデータは以下からダウンロード可能
(主要な暗号通貨のデータを活用できる)
https://coinmetrics.io/community-network-data/【Pythonコード】
getCoinMetrics%matplotlib inline import matplotlib.pyplot as plt import pandas as pd data = pd.read_csv('xxx\\btc.csv') data['date'] = pd.to_datetime(data['date']) data.set_index('date', inplace=True)
- これでdate(日付)をベースにデータ分析が可能となる。
<トランザクション量の遷移を年別で可視化>
plt.plot(data.TxCnt)
<価格(USD)の遷移を年別で可視化>
plt.plot(data.PriceUSD)
<トランザクション量と価格(USD)の年別遷移状況を複合グラフで表現>
fig, ax1 = plt.subplots() plt.plot(data.TxCnt, color='darkblue', label='TxCnt') ax2 = ax1.twinx() plt.plot(data.PriceUSD, color='darkorange', label='PriceUSD') h1, l1 = ax1.get_legend_handles_labels() h2, l2 = ax2.get_legend_handles_labels() ax1.legend(h1+h2, l1+l2, loc='upper left') ax1.set_xlabel('date') ax1.set_ylabel('TxCnt') ax2.set_ylabel('PriceUSD')
<因みに、特定の年度に絞ることも出来る(例:2014年)>
変更箇所のみ抜粋~ plt.plot(df_data['2014'].TxCnt, color='darkblue', label='TxCnt') ~ plt.plot(df_data['2014'].PriceUSD, color='darkorange', label='PriceUSD') ~
- トランザクション量と価格(USD)とで負の相関が見れて興味深い。この後、トランザクション量の増加傾向が続く。
<散布図で見てみる>
plt.scatter(data.TxCnt,data.PriceUSD)
- トランザクションが一定量(200,000-)に達すると、価格への影響はあまり見受けられなくなる。(と、言えそう)
以上





- 投稿日:2020-11-21T17:27:17+09:00
Pythonのtkinterで簡易タイピングゲームを作ってみた
はじめに
本記事ではPythonを使ったアプリケーションを開発していきます。
GUIライブラリには標準ライブラリのtkinterを採用しています。
本記事を読むことである程度pythonを理解している方であれば、ある程度tkinterの使い方を覚えることができます。Tkinterとは
Pythonの標準ライブラリの1つです。
GUIアプリケーションを構築するためのライブラリです。
シンプルな文法と起動の速さが特徴のGUIライブラリです。ウィンドウの作成
まずは基礎となるウィンドウを作っていきましょう。
import tkinter as tk if __name__ == "__main__": root = tk.Tk() root.mainloop()
画面の作成
次にオブジェクト指向を意識して書くためにFrameクラスを継承したクラスを作成していきます。
create_widgets()内で必要な部品(ウィジェット)を生成し、配置して画面を作っていきます。import tkinter as tk class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x200") master.title("タイピングゲーム!") self.create_widgets() # ウィジェットの生成と配置 def create_widgets(self): self.q_label = tk.Label(self, text="お題:", font=("",20)) self.q_label.grid(row=0, column=0) self.q_label2 = tk.Label(self, text="tkinter", width=5, anchor="w", font=("",20)) self.q_label2.grid(row=0, column=1) self.ans_label = tk.Label(self, text="解答:", font=("",20)) self.ans_label.grid(row=1, column=0) self.ans_label2 = tk.Label(self, text="tkinter", width=5, anchor="w", font=("",20)) self.ans_label2.grid(row=1, column=1) self.result_label = tk.Label(self, text="正否ラベル", font=("",20)) self.result_label.grid(row=2, column=0, columnspan=2) if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()
キー入力のイベント処理の設定
次にキー入力処理の部分を作成していきます。
まずは文字が入力された際に解答欄に値を追加していく処理を実装します。まずは、先ほどの解答欄の値の初期値は空文字にしておきます。
self.ans_label2 = tk.Label(self, text="", width=5, anchor="w", font=("",20))次にキー入力時のイベント処理用のメソッドを作ります。
入力されたキーの情報はevent.keysymに格納されています。
例えばAキーを押すと「a」という情報が格納されています。# キー入力時のイベント処理 def type_event(self, event): self.ans_label2["text"] += event.keysym最後に作成したイベント処理をTkクラスのインスタンスにbind()を使って紐づけます。
# Tkインスタンスに対してキーイベント処理を実装 self.master.bind("<KeyPress>", self.click_event)ここまでをまとめると下記の通りになります。
import tkinter as tk class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x200") master.title("タイピングゲーム!") self.create_widgets() # Tkインスタンスに対してキーイベント処理を実装 self.master.bind("<KeyPress>", self.type_event) # ウィジェットの生成と配置 def create_widgets(self): self.q_label = tk.Label(self, text="お題:", font=("",20)) self.q_label.grid(row=0, column=0) self.q_label2 = tk.Label(self, text="tkinter", width=5, anchor="w", font=("",20)) self.q_label2.grid(row=0, column=1) self.ans_label = tk.Label(self, text="解答:", font=("",20)) self.ans_label.grid(row=1, column=0) self.ans_label2 = tk.Label(self, text="", width=5, anchor="w", font=("",20)) self.ans_label2.grid(row=1, column=1) self.result_label = tk.Label(self, text="正否ラベル", font=("",20)) self.result_label.grid(row=2, column=0, columnspan=2) # キー入力時のイベント処理 def type_event(self, event): self.ans_label2["text"] += event.keysym if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()
答え合わせ処理の実装
今回は「Enterキー」を押したら正解判定をするという仕様で作成していきます。
入力されたキーの判定はevent.keysymの値を使って判定していきます。
「Enterキー」を押すとevent.keysymには"Return"が格納されるのでそれをifで判定していきます。
ちなみに「keysym」は「キーシンボル」の略です。# キー入力時のイベント処理 def type_event(self, event): # 入力値がEnterの場合は答え合わせ if event.keysym == "Return": if self.q_label2["text"] == self.ans_label2["text"]: self.result_label.configure(text="正解!", fg="red") else: self.result_label.configure(text="残念!", fg="blue") # 解答欄をクリア self.ans_label2.configure(text="") else: # 入力値がEnter以外の場合は文字入力としてラベルに追記する self.ans_label2["text"] += event.keysym
連続出題機能の実装
正否判定後に次の問題へ進む機能を実装します。
まずは問題のリストを作成します。
QUESTION = ["tkinter", "geometry", "widgets", "messagebox", "configure", "label", "column", "rowspan", "grid", "init"]次に、コンストラクタ内で問題数を管理するindex用の変数を用意します。
# 問題数インデックス self.index = 0最後に、イベント処理内で次の問題にラベルの値を書き換える処理を追記します。
# 次の問題を出題 self.index += 1 self.q_label2.configure(text=QUESTION[self.index])ここまでをまとめると下記の通りです。
import tkinter as tk QUESTION = ["tkinter", "geometry", "widgets", "messagebox", "configure", "label", "column", "rowspan", "grid", "init"] class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x200") master.title("タイピングゲーム!") # 問題数インデックス self.index = 0 self.create_widgets() # Tkインスタンスに対してキーイベント処理を実装 self.master.bind("<KeyPress>", self.type_event) # ウィジェットの生成と配置 def create_widgets(self): self.q_label = tk.Label(self, text="お題:", font=("",20)) self.q_label.grid(row=0, column=0) self.q_label2 = tk.Label(self, text=QUESTION[self.index], width=10, anchor="w", font=("",20)) self.q_label2.grid(row=0, column=1) self.ans_label = tk.Label(self, text="解答:", font=("",20)) self.ans_label.grid(row=1, column=0) self.ans_label2 = tk.Label(self, text="", width=10, anchor="w", font=("",20)) self.ans_label2.grid(row=1, column=1) self.result_label = tk.Label(self, text="正否ラベル", font=("",20)) self.result_label.grid(row=2, column=0, columnspan=2) # キー入力時のイベント処理 def type_event(self, event): # 入力値がEnterの場合は答え合わせ if event.keysym == "Return": if self.q_label2["text"] == self.ans_label2["text"]: self.result_label.configure(text="正解!", fg="red") else: self.result_label.configure(text="残念!", fg="blue") # 解答欄をクリア self.ans_label2.configure(text="") # 次の問題を出題 self.index += 1 self.q_label2.configure(text=QUESTION[self.index]) else: # 入力値がEnter以外の場合は文字入力としてラベルに追記する self.ans_label2["text"] += event.keysym if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()
バックスペース機能の実装
次にバックスペース機能を実装していきます。
event.keysymが「BackSpace」の場合の分岐を追加して実装します。# キー入力時のイベント処理 def type_event(self, event): # 入力値がEnterの場合は答え合わせ if event.keysym == "Return": if self.q_label2["text"] == self.ans_label2["text"]: self.result_label.configure(text="正解!", fg="red") else: self.result_label.configure(text="残念!", fg="blue") # 解答欄をクリア self.ans_label2.configure(text="") # 次の問題を出題 self.index += 1 self.q_label2.configure(text=QUESTION[self.index]) elif event.keysym == "BackSpace": text = self.ans_label2["text"] self.ans_label2["text"] = text[:-1] else: # 入力値がEnter以外の場合は文字入力としてラベルに追記する self.ans_label2["text"] += event.keysym
結果表示機能の実装
最後まで解答した後にリザルトを表示する機能を実装します。
リザルトはポップアップウィンドウを使って表示します。
また、今回はポップアップを閉じると同時にアプリも強制終了するような仕様にします。上記処理を実装するために、まずは2つのライブラリをインポートします。
from tkinter import messagebox import sysまた、正解数をカウントしておく変数を用意します。
こちらはコンストラクタ内で初期化するようにしましょう。# 正解数カウント用 self.correct_cnt = 0最後にイベント処理内の次の問題に進むで問題の最後まで到達しているかを判定し、リザルトのポップアップ(messagebox)を表示する処理を呼び出します。
sys.exit(0)はプログラムを強制終了するメソッドです。# 次の問題を出題 self.index += 1 if self.index == len(QUESTION): self.q_label2.configure(text="終了!") messagebox.showinfo("リザルト", f"あなたのスコアは{self.correct_cnt}/{self.index}問正解です。") sys.exit(0) self.q_label2.configure(text=QUESTION[self.index])ここまでをまとめると下記の通りです。
import tkinter as tk from tkinter import messagebox import sys QUESTION = ["tkinter", "geometry", "widgets", "messagebox", "configure", "label", "column", "rowspan", "grid", "init"] class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x200") master.title("タイピングゲーム!") # 問題数インデックス self.index = 0 # 正解数カウント用 self.correct_cnt = 0 self.create_widgets() # Tkインスタンスに対してキーイベント処理を実装 self.master.bind("<KeyPress>", self.type_event) # ウィジェットの生成と配置 def create_widgets(self): self.q_label = tk.Label(self, text="お題:", font=("",20)) self.q_label.grid(row=0, column=0) self.q_label2 = tk.Label(self, text=QUESTION[self.index], width=10, anchor="w", font=("",20)) self.q_label2.grid(row=0, column=1) self.ans_label = tk.Label(self, text="解答:", font=("",20)) self.ans_label.grid(row=1, column=0) self.ans_label2 = tk.Label(self, text="", width=10, anchor="w", font=("",20)) self.ans_label2.grid(row=1, column=1) self.result_label = tk.Label(self, text="", font=("",20)) self.result_label.grid(row=2, column=0, columnspan=2) # キー入力時のイベント処理 def type_event(self, event): # 入力値がEnterの場合は答え合わせ if event.keysym == "Return": if self.q_label2["text"] == self.ans_label2["text"]: self.result_label.configure(text="正解!", fg="red") self.correct_cnt += 1 else: self.result_label.configure(text="残念!", fg="blue") # 解答欄をクリア self.ans_label2.configure(text="") # 次の問題を出題 self.index += 1 if self.index == len(QUESTION): self.q_label2.configure(text="終了!") messagebox.showinfo("リザルト", f"あなたのスコアは{self.correct_cnt}/{self.index}問正解です。") sys.exit(0) self.q_label2.configure(text=QUESTION[self.index]) elif event.keysym == "BackSpace": text = self.ans_label2["text"] self.ans_label2["text"] = text[:-1] else: # 入力値がEnter以外の場合は文字入力としてラベルに追記する self.ans_label2["text"] += event.keysym if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()これで基本的な機能は大体実装できたと思います。
実行結果は下記の通りです。
おまけ(マルチスレッド処理を使って時間の計測処理を追加)
おまけとしてマルチスレッド処理を使ってリアルタイムで時間も計測できるようにすると下記の通りになります。
ソースコードは下記通りです。
import tkinter as tk from tkinter import messagebox import sys import time import threading QUESTION = ["tkinter", "geometry", "widgets", "messagebox", "configure", "label", "column", "rowspan", "grid", "init"] class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() master.geometry("300x200") master.title("タイピングゲーム!") # 問題数インデックス self.index = 0 # 正解数カウント用 self.correct_cnt = 0 self.create_widgets() # 経過時間スレッドの開始 t = threading.Thread(target=self.timer) t.start() # Tkインスタンスに対してキーイベント処理を実装 self.master.bind("<KeyPress>", self.type_event) # ウィジェットの生成と配置 def create_widgets(self): self.q_label = tk.Label(self, text="お題:", font=("",20)) self.q_label.grid(row=0, column=0) self.q_label2 = tk.Label(self, text=QUESTION[self.index], width=10, anchor="w", font=("",20)) self.q_label2.grid(row=0, column=1) self.ans_label = tk.Label(self, text="解答:", font=("",20)) self.ans_label.grid(row=1, column=0) self.ans_label2 = tk.Label(self, text="", width=10, anchor="w", font=("",20)) self.ans_label2.grid(row=1, column=1) self.result_label = tk.Label(self, text="", font=("",20)) self.result_label.grid(row=2, column=0, columnspan=2) # # 時間計測用のラベル self.time_label = tk.Label(self, text="", font=("",20)) self.time_label.grid(row=3, column=0, columnspan=2) self.flg2 = True # キー入力時のイベント処理 def type_event(self, event): # 入力値がEnterの場合は答え合わせ if event.keysym == "Return": if self.q_label2["text"] == self.ans_label2["text"]: self.result_label.configure(text="正解!", fg="red") self.correct_cnt += 1 else: self.result_label.configure(text="残念!", fg="blue") # 解答欄をクリア self.ans_label2.configure(text="") # 次の問題を出題 self.index += 1 if self.index == len(QUESTION): self.flg = False self.q_label2.configure(text="終了!") messagebox.showinfo("リザルト", f"あなたのスコアは{self.correct_cnt}/{self.index}問正解です。\nクリアタイムは{self.second}秒です。") sys.exit(0) self.q_label2.configure(text=QUESTION[self.index]) elif event.keysym == "BackSpace": text = self.ans_label2["text"] self.ans_label2["text"] = text[:-1] else: # 入力値がEnter以外の場合は文字入力としてラベルに追記する self.ans_label2["text"] += event.keysym def timer(self): self.second = 0 self.flg = True while self.flg: self.second += 1 self.time_label.configure(text=f"経過時間:{self.second}秒") time.sleep(1) if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()







- 投稿日:2020-11-21T17:18:33+09:00
edgetpu上で動く温度予測モデル
はじめに
Raspberry pi4につなげたedgetpu上で動く、tensorflowliteの温度予測モデルを作成しました。Tensorflowのバージョンは2.3.1です。
主な流れ
1.GoogleColab上でTensorflowのKerasを用いて1次元CNNベースのモデルを作成・学習
2.学習後にモデルを量子化してtensorflowliteのモデルに変換
3.edgetpuで動くようにedgetpu compilerでコンパイル
4.Raspberry pi4上でテストデータを用いて予測 & Raspberry pi4のCPU温度を予測
1.モデルの作成・学習
データセットの準備
過去の気象データを検索できる気象庁のサイトを利用して、ある場所1箇所の1日の平均気温のデータを20年分ほど集めました。
モデルの作成
30日間の平均気温を入力とし、次の日の平均気温を予測する、1次元CNNベースのモデルをKerasのfunctional apiを用いて作成しました。
inputs = tf.keras.Input(shape=(30,1)) cnn1 = tf.keras.layers.Conv1D(filters=1,kernel_size=10,strides=1,activation='relu',input_shape=(30,1)) cnn2 = tf.keras.layers.Conv1D(filters=1,kernel_size=5,strides=1,activation='relu') cnn3 = tf.keras.layers.Conv1D(filters=1,kernel_size=3,strides=1,activation='relu') dense1 = tf.keras.layers.Dense(units=8,activation='relu') dense2 = tf.keras.layers.Dense(units=1) x = cnn1(inputs) x = cnn2(x) x = cnn3(x) x = tf.keras.layers.Flatten()(x) x = dense1(x) outputs = dense2(x) model = tf.keras.Model(inputs=inputs,outputs=outputs) model.compile(optimizer="Adam",loss="mean_squared_error", metrics="binary_accuracy")_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_14 (InputLayer) [(None, 30, 1)] 0 _________________________________________________________________ conv1d_31 (Conv1D) (None, 21, 1) 11 _________________________________________________________________ conv1d_32 (Conv1D) (None, 17, 1) 6 _________________________________________________________________ conv1d_33 (Conv1D) (None, 15, 1) 4 _________________________________________________________________ flatten_5 (Flatten) (None, 15) 0 _________________________________________________________________ dense_24 (Dense) (None, 8) 128 _________________________________________________________________ dense_25 (Dense) (None, 1) 9 ================================================================= Total params: 158 Trainable params: 158 Non-trainable params: 0 _________________________________________________________________ """モデルの学習
バッチサイズ50,エポック数30で学習させました。
model.fit(x=in_temp,y=out_temp,batch_size=50,epochs=30)2.モデルの量子化
edgetpu上で動かすには8bit整数に量子化する必要があります。量子化には入力サイズを固定する必要があるので、
siganturesを指定して一旦モデルを保存します。ここでは入力サイズを1×30×1にしました。opt = tf.function(lambda x:model(x)) BACTH_SIZE = 1 STEPS = 30 INPUT_SIZE = 1 concrete_func = opt.get_concrete_function(tf.TensorSpec([BACTH_SIZE,STEPS,INPUT_SIZE], model.inputs[0].dtype,name="inputs") ) model.save('/content/weather',save_format="tf",signatures=concrete_func)その後、モデルを量子化させます。詳細はTensorflowのドキュメントを参照してください。
in_tempはモデルの学習時に入力したnumpy ndarrayです。conv_data = in_temp[0] conv_data = conv_data.reshape(1,30,1) def representative_dataset_gen(): for i in range(len(conv_data)): yield [conv_data[i]] converter_edgetpu = tf.lite.TFLiteConverter.from_saved_model("/content/weather") converter_edgetpu.optimizations = [tf.lite.Optimize.DEFAULT] converter_edgetpu.representative_dataset = representative_dataset_gen converter_edgetpu.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter_edgetpu.inference_input_type = tf.uint8 converter_edgetpu.inference_output_type = tf.uint8 converter_edgetpu.experimental_new_converter = True tflite = converter_edgetpu.convert()最後にモデルを保存します。
open("cnn_weather_lite_quantized.tflite","wb").write(tflite)edgetpu compilerでコンパイル
edgetpu compilerをインストール
Google Colab上にedgetpu compilerをインストールします。
インストール方法の詳細はドキュメントを参照してください。ドキュメントにあるようにCPUアーキテクチャにx86-64が必要であり、Raspberry pi4BのCPUアーキテクチャはARMv8であるため、直接Raspberry pi4上にインストールすることはできないと思われます。(Raspberry piのCPUアーキテクチャ:https://nw-electric.way-nifty.com/blog/2020/02/post-6c09ad.html)
!curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - !echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list !sudo apt -y update !sudo apt-get install edgetpu-compileredgetpu compilerでコンパイル
参考:https://coral.ai/docs/edgetpu/compiler/#usage
!edgetpu_compiler /content/cnn_weather_lite_quantized.tflite予測
テストデータで予測
気象庁のサイトから再び1日の平均気温のデータを30日分用意しました。
そして以下のコード(edgetpu使用時)をRaspberry pi上で実行して次の日の気温を予測しました。また、実行時間を計測して、CPU使用時と時間を比較しました。
推論のコードはTensorflowのサイトの「Pythonでモデルをロードして実行する」という部分を参考にしました。自動で日本語翻訳されるので、翻訳がおかしければ英語で読むことを勧めます。import numpy as np import pandas as pd import tflite_runtime.interpreter as tflite import time def main(args): interpreter = tflite.Interpreter('/home/pi/cnn_weather/cnn_weather_lite_quantized_edgetpu.tflite', experimental_delegates=[tflite.load_delegate('libedgetpu.so.1')]) data = pd.read_csv('/home/pi/cnn_weather/test.csv') test_data = np.asarray(data.loc[:len(data),"平均気温"],dtype=np.uint8) test_data = test_data.reshape(1,30,1) start = time.perf_counter() interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() input_shape = input_details[0]['shape'] interpreter.set_tensor(input_details[0]['index'],test_data) interpreter.invoke() output_data = interpreter.get_tensor(output_details[0]['index']) end = time.perf_counter() print("The next day's temperature is " + str(output_data[0,0]) + " degrees Celsius.") print("It took " + str((end-start)*1000) + " ms.") return 0 if __name__ == '__main__': import sys sys.exit(main(sys.argv))結果を示します。
一番上がedgetpuで実行した結果、真ん中が量子化してないモデルをCPUで実行した結果、一番下が量子化したモデルをCPUで実行した結果です。
量子化すると速くなりますが、edgetpuを使うとむしろ遅くなるという結果になってしまいました、、、
実行時間が2msとかなので、edgetpuを使ったほうがedgetpuの呼び出し等で時間がかかっているのかもしれません。
ちなみに、量子化するとかなり精度が落ちていることがわかります。(テストデータは9月下旬から10月下旬までのデータで、だいたい22℃くらいから始まって18℃くらいで終わっているので、24℃や26℃はだいぶ的外れな気がします。)pi@raspberrypi:~$ python3 /home/pi/cnn_weather/edgetpu_time.py The next day's temperature is 24 degrees Celsius. It took 2.218683000137389 ms. pi@raspberrypi:~$ python3 /home/pi/cnn_weather/cpu_time.py The next day's temperature is 17.671713 degrees Celsius. It took 3.6856149999948684 ms. pi@raspberrypi:~$ python3 /home/pi/cnn_weather/cpu_quantized_time.py The next day's temperature is 26 degrees Celsius. It took 1.4244879994294024 ms.CPU温度の予測
Raspberry piという小型デバイスで動かしているので、せっかくならリアルタイム予測のようなものに挑戦してみたくなりました。外気温で予測したかったのですが、センサーがなく自作するのも大変そうなので、CPU温度でとりあえず予測してみました。
1秒ごとに$cat /sys/class/thermal/thermal_zone0/tempでCPU温度を取り、30秒分集まったところで1秒後の温度を予測しました。
なお、$cat /sys/class/thermal/thermal_zone0/tempでは1000倍されたCPU温度の値が返ってくるので、出力結果を1000で割って使いました。以下がRaspberry piで実行したコードです。(edgetpu使用時のコードのみ示します)
import numpy as np import tflite_runtime.interpreter as tflite import time import subprocess def main(args): start = time.perf_counter() interpreter = tflite.Interpreter('/home/pi/cnn_weather/cnn_weather_lite_quantized_edgetpu.tflite', experimental_delegates=[tflite.load_delegate('libedgetpu.so.1')]) data = list() for i in range(30): res = subprocess.run(['cat', '/sys/class/thermal/thermal_zone0/temp'], stdout=subprocess.PIPE) get_start = time.perf_counter() result = res.stdout.decode('utf-8') result = int(result)/1000 data.append(result) print(result,end='℃ ') if (i+1)%10 == 0: print() get_end = time.perf_counter() get_time = get_end-get_start if get_time < 1: time.sleep(1-get_time) else: print("Took " + str(get_time) + " s to get " + str(i) + "'s temp.") pre_start = time.perf_counter() np_data = np.asarray(data,dtype=np.uint8).reshape(1,30,1) interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() input_shape = input_details[0]['shape'] interpreter.set_tensor(input_details[0]['index'],np_data) interpreter.invoke() pred = interpreter.get_tensor(output_details[0]['index']) pre_end = time.perf_counter() pre_time = pre_end - pre_start if pre_time < 1: print("The cpu's temp will be " + str(pred[0,0]) + "℃ in " + str(1-pre_time) + " s.") time.sleep(1-pre_time) res = subprocess.run(['cat', '/sys/class/thermal/thermal_zone0/temp'], stdout=subprocess.PIPE) result = res.stdout.decode('utf-8') result = int(result)/1000 print("The cpu's temp is " + str(result) + "℃.") else: print("The cpu's temp must have been " + str(pred[0,0]) + "℃ " + str(1-pre_time) + " s ago.") end = time.perf_counter() print("Took " + str(end-start) + " s to run this code.") return 0 if __name__ == '__main__': import sys sys.exit(main(sys.argv))結果を示します。
一番上がedgetpu使用時、真ん中が量子化されていないモデル使用時、一番下が量子化したモデル使用時です。
羅列されている温度は予測につかったCPU温度のデータです。やはり量子化したモデルでは100℃を超える的外れな出力をしてしまっています。
また、先程のようにedgetpu使用時のが時間がかかる結果となってしまっています。今回は推論だけでなくtf.lite.Interpreterを呼び出すところも含めて時間を測っていたので、その部分もedgetpuを使用することで時間がかかっているのかもしれません。pi@raspberrypi:~$ python3 /home/pi/cnn_weather/predict_edgetpu.py 63.783℃ 64.757℃ 63.783℃ 63.783℃ 63.296℃ 62.809℃ 63.296℃ 63.296℃ 62.809℃ 62.809℃ 62.809℃ 63.296℃ 62.322℃ 62.809℃ 63.783℃ 62.809℃ 63.783℃ 63.783℃ 62.322℃ 62.809℃ 62.322℃ 63.783℃ 62.809℃ 62.322℃ 62.322℃ 62.322℃ 62.322℃ 62.322℃ 62.322℃ 63.296℃ The cpu's temp will be 105℃ in 0.9969898569997895 s. The cpu's temp is 61.835℃. Took 34.21252226499928 s to run this code. pi@raspberrypi:~$ python3 /home/pi/cnn_weather/predict_cpu.py 63.783℃ 63.783℃ 63.296℃ 62.809℃ 63.783℃ 63.296℃ 62.809℃ 63.296℃ 62.809℃ 62.322℃ 62.322℃ 62.322℃ 62.809℃ 62.322℃ 61.835℃ 62.322℃ 62.322℃ 61.348℃ 62.322℃ 62.322℃ 63.296℃ 61.835℃ 62.322℃ 61.835℃ 61.348℃ 61.348℃ 61.835℃ 62.322℃ 62.809℃ 62.322℃ The cpu's temp will be 62.17556℃ in 0.9969654129999981 s. The cpu's temp is 62.322℃. Took 31.404364756001087 s to run this code. pi@raspberrypi:~$ python3 /home/pi/cnn_weather/predict_cpu_quantized.py 63.296℃ 63.296℃ 62.809℃ 62.322℃ 62.322℃ 61.835℃ 61.835℃ 62.322℃ 61.835℃ 62.322℃ 62.809℃ 62.322℃ 62.809℃ 62.322℃ 60.861℃ 62.322℃ 61.835℃ 61.835℃ 62.322℃ 61.835℃ 61.835℃ 61.835℃ 61.348℃ 62.322℃ 60.861℃ 61.348℃ 62.322℃ 61.348℃ 61.835℃ 61.348℃ The cpu's temp will be 101℃ in 0.9984136980001495 s. The cpu's temp is 61.835℃. Took 31.43542323499969 s to run this code.最後に
Raspberry pi4につなげたedgetpu上で動く、tensorflowliteの温度予測モデルを作成して実行しました。
量子化することで精度がかなり落ち(というよりほとんど意味のないモデルになってしまいました)、実行時間もCPU使用時よりedgetpu使用時のが多いという結果になってしまいました。
今回は精度のいいモデルを作るというよりもedgetpuを使って推論するモデルを作成すること自体がひとまずの目標であったので、とりあえずここで終わりにしようと思います。
今回使用したデータやコード、tensorflowliteのモデルのすべては、githubに置いてあります。ここまで見てくださってありがとうございました。
はじめての記事ですので、気になること、指摘等ございましたら気軽にコメントお願いします。余談
1次元CNNを使用する前にLSTMを使って同じことをしようとしていたのですが、ここにあるようなエラーが出てつまったので、1次元CNNを使うことにしました。そのリンク先のissueを見ると、LSTMなどRNN系のモデルを量子化させることは現在できなさそうです。(リンク先のTensorflowのバージョンは2.2.0、今回ここで使ったのは2.3.1)
同じエラー文ではないですが、関連していると思われるエラーでもLSTMなどRNN系は量子化に対応していないのではないかと言われていました。
なお、量子化していない状態でtensorflowliteのモデルにconvertさせてRaspberry piで動かすことはできました。
- 投稿日:2020-11-21T16:58:55+09:00
プログラミング学習を目的とした、ブロックを操作してスコアを競うゲームをpythonで作成する試み
この辺りの先人のコードをベースにしています。
https://github.com/LoveDaisy/tetris_game
http://zetcode.com/gui/pyqt5/tetris/違いは、pythonでブロック操作できるよう改造してる点です。
将来的にはAIでブロック操作できるようにしたいです。(現在プレイヤーは私のみ。。)実行環境準備
Mac環境
Finder→Application→Utility→Terminalから、ターミナルを起動して以下コマンドを実行する。
# install pyqt5 and NumPy brew install python3 pip3 install pyqt5 pip3 install numpy # install other packages brew install git実行方法
リポジトリを取得
git clone https://github.com/seigot/tetris_gameゲーム開始用スクリプトを実行
cd tetris_game bash start.shデフォルトはランダム操作にしてあります。
ファイル構成
こちらからファイル一覧を抜粋
ファイル一覧game_manager/game_manager.py : ゲーム管理用プログラム game_manager/board_model.py : ボード管理用プログラム board_controller.py : ボード制御用プログラム(ブロックの操作は、このファイルを編集して下さい。) start.sh : ゲーム開始用スクリプト以下のような構成になっています。
ボード制御用プログラムは、管理プログラムから定期的に呼び出されるので、ボード情報から次の動作を決定するようにしています。
各プログラムの詳細はこちら
サンプルコード
実行時、以下のようにオプションを与えることで、サンプルコードの実行が可能です。
サンプルコードはこちらを参照下さい。bash start.sh -s yHow to play manually
実行時、以下のようにオプションを与えることで、手動操作が可能です。
bash start.sh -m y
操作キー 動作 up key 回転 left key 左に移動 right key 右に移動 m key 下に移動 space key 落下 P key Pause Play rules
制限時間内の獲得スコアを評価します。
Score
加点
項目 得点 備考 1ライン消し + 100点 - 2ライン消し + 300点 - 3ライン消し + 700点 - 4ライン消し + 1300点 - 落下ボーナス + 落下したブロック数を得点に加算 - 減点
項目 得点 備考 gameover - 500点 ブロック出現時にフィールドが埋まっていたらgameover game level
実行時、オプションを与えることで、難易度(レベル)を指定できます。
level0 level1 level2 level3 実行方法 bash start.sh bash start.sh -l1 bash start.sh -l2 bash start.sh -l3 制限時間 なし 300秒 300秒 300秒 次のブロック 固定 固定 ランダム ランダム フィールドの初期ブロック なし なし なし あり フレーム更新頻度 約1秒 約1秒 約1秒 約1秒 備考 練習用 - - - 次のブロックのランダム性
次のブロックは、現在はランダム関数を使ってランダムに選択しています。
しかし、こちらの記事によると選択方式が色々ありそうです。
有識者の方からアドバイス頂けると嬉しいです。
- 参考:次のブロック選択処理 game_manager.py
nextShapeIndex = np_randomShape.random.randint(1, 7)その他
今後、AIを実装しやすいようにルール等、変更していくかもしれません。
何か感想やアドバイス等あれば教えて頂けると幸いです。参考
https://github.com/LoveDaisy/tetris_game
http://zetcode.com/gui/pyqt5/tetris/
テトリスの歴史を「ブロックが落ちるルール」の進化から学ぶ
https://github.com/seigot/tetris_game


- 投稿日:2020-11-21T16:42:34+09:00
HEICとか何なのかは知りません。でも、とりあえずはPNGにしよう!
前置き
たまに「このファイル形式は対応していません」と言われることがありません?
僕はありました。
なので、pythonで変換プログラムを作成しました。
誰かの助けになれば幸いでーす。環境
- Mac
- python 3.7.1
- jupyter lab
使用するライブラリ
- pyheif
- pillow
コード
from PIL import Image import pyheif heif_file = pyheif.read(image_path) # 1 data = Image.frombytes( # 2 heif_file.mode, heif_file.size, heif_file.data, "raw", heif_file.mode, heif_file.stride, ) image = data.resize(size) # 3 image.save(save_path, "PNG") # 4何をやっているか
- HEIC画像を読みます。この時に「HeifFile object」ができます。
- それらをImage.frombytesモジュールに必要な物を打ち込みます。この時に「Image object」ができます。
- あとはresizeして
- saveで完了
最後に
- 簡単なので、大量のHEICデータがある場合は、上記のコードを関数化して、globなどで一括で読み込むと良いです!
参考
- 投稿日:2020-11-21T16:12:43+09:00
FlaskのAPIサーバをforeverで永続化する
環境情報
環境Raspi 3B+ OS rasbian (stretch) pip 20.2.4 python 3.5 npm 6.14.9 forever v3.0.2 flask 0.12.1各種インストール
$ pip install Flask $ npm install -g foreverFlaskでサーバを立てる
(参考)https://qiita.com/tomboyboy/items/122dfdb41188176e45b5
hoge.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'Hello world' if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=5000)実行(テスト)$ python hoge.py ^Cトラブルシュート
- 80番ポートを使用しようとすると
Permittion Denyで弾かれるので他を利用するといい。
(参考)https://stackoverflow.com/questions/550032/what-causes-python-socket-error- ファイアウォール設定変更(ラズパイ内から
curl 192.168.x.x:5000が通るが外からアクセスできない場合)
$ sudo ufw allow 5000実施。永続化
このままだとsshを抜ける際にプロセスが終了するのでforeverで永続化する。foreverはコマンドがデフォルトでnodeなだけで
-cオプションを利用することで任意のコマンドを指定でき、Pythonコードも永続化できる。永続化を実行$ forever start -c python hoge.pyforeverのコマンドやオプションについては以下参考
https://qiita.com/disc99/items/57490f5eef3e2eb685ba再起動時にforeverを実行する
上記のままでもラズパイ自体をrebootすると起動時にforeverが実行されないためサーバは死んでしまっている。
/etc/rc.localに以下を記述
(参考)https://584homes.com/it/raspberry-pi/rasberrypi-startup1803.html%20=rc.localsudo forever start -a --uid Hoge -c python /home/pi/hoge.py exit 0
- 投稿日:2020-11-21T14:41:07+09:00
Pythonで画像を収集する方法
はじめに
Deep Learning用に画像収集しようと思い、この記事に行きついたのですが、
webページの中身が変わったのか、うまくいかなかったので、書き換えてみました。コード
image_download.pyimport requests import urllib.request import time import json def scraping(url, max_page_num): # ページネーション実装 page_list = get_page_list(url, max_page_num) # 画像URLリスト取得 all_img_src_list = [] for page in page_list: try: img_src_list = get_img_src_list(page) all_img_src_list.extend(img_src_list) except:pass return all_img_src_list def get_img_src_list(url): # 検索結果ページにアクセス response = requests.get(url) webtext = response.text # 元の記事ではBeatifulsoupを使っていたのですが、画像が取れなかったので、変更しています。 start_word='<script>__NEXT_DATA__ = ' start_num = webtext.find(start_word) webtext_start = webtext[start_num + len(start_word):] end_word = ';__NEXT_LOADED_PAGES__=' end_num = webtext_start.find(end_word) webtext_all = webtext_start[:end_num] web_dic = json.loads(webtext_all) img_src_list = [img['imageSrc'] for img in web_dic["props"]["initialProps"]["pageProps"]["algos"]] return img_src_list def get_page_list(url, max_page_num): img_num_per_page = 20 #ここを変えるとダウンロード数が変わります。 page_list = [f'{url}{i*img_num_per_page+1}' for i in range(max_page_num)] return page_list def download_img(src, dist_path): time.sleep(1) try: with urllib.request.urlopen(src) as data: img = data.read() with open(dist_path, 'wb') as f: f.write(img) except: pass def main(): search_words = ["橋本環奈"] #検索したいワードをリストで渡します。 for num, search_word in enumerate(search_words): url = f"https://search.yahoo.co.jp/image/search?p={search_word}&ei=UTF-8&b=" max_page_num = 20 all_img_src_list = scraping(url, max_page_num) # 画像ダウンロード for i, src in enumerate(all_img_src_list): download_img(src, f'./img/image_{num}_{i}.jpg') #保存先は適当に変えてください if __name__ == '__main__': main()imgフォルダを作って、上記をpythonで実行するとimgフォルダ内に画像が保存されます。
こんなイメージです。
スクレイピングは相手のサーバーに負荷がかかるため気を付けましょう!
参考

- 投稿日:2020-11-21T14:27:54+09:00
Pythonの基礎を学ぶ①初歩の初歩
はじめに
独学でプログラミングを始めました。
30歳から未経験でエンジニアへ。
人工知能に興味があるので、少しずつ学んでいきたい。学習手順と環境
・Aidemyなどの学習ツール、インフルエンサーを参考にして学ぶ。
・iMacが良いらしいが、予算の都合でWindows10のデスクトップパソコンでプログラミングする。やったこと
(1)Aidemyでプログラミングの勉強
・pythonの用途
・pythonで文字出力(2)pythonの環境構築
・Windows10にpythonの環境を構築する
Microsoft storeより「python3.8」をインストール
Aidemyで勉強した「print関数」を試してみた
感想や課題
・Qittaの投稿には、HTMLの知識が必要なので勉強する。
今回、『文字のサイズ変更の#』『画像を張り付け、大きさを変更するコード』を使ってみた。
能力不足を痛感し、もっと読みやすい記事にしていくためにも「HTML」を勉強します。。。・人工知能の開発の初歩のPythonの勉強は、とにかく地道にやる。
ゴールがもの凄く遠く感じる。
でも、10代や20代でもできることを挫折するのは、ダサいと思うので、
努力を楽しみつつ継続していきたい。


- 投稿日:2020-11-21T13:33:27+09:00
AtCoderBeginnerContest183復習&まとめ
AtCoder ABC183
2020-11-15(日)に行われたAtCoderBeginnerContest183の問題をA問題から順に考察も踏まえてまとめたものとなります.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説A問題 ReLU
問題文
ReLU関数は以下のように定義されます。
整数$x$が与えられるので$ReLU(x)$を求めてください。活性化関数で馴染みのReLU関数.
abc183a.pyx = int(input()) if x >= 0: print(x) else: print(0)B問題 Billiards
問題文
高橋君は$2$次元平面上でビリヤードをしています。$x$軸は壁になっており、球をぶつけると入射角と反射角が等しくなるように球が跳ね返されます。
いま高橋君の球が$(S_x,S_y)$にあります。ある座標を狙って球を撞くと、球はその座標へ向かって直線的に転がっていきます。
$x$軸で球をちょうど$1$回反射させたのち、$(G_x,G_y)$を通過させるためには、$x$軸のどこを狙えば良いでしょうか?制約が$0 < S_y, G_y \leq 10^6$だったので,解説同様に$G_y$を負にして,直線の式と$x$軸の交点として解きました.
$x = S_x - S_y × (G_x - S_x) ÷ (G_y - S_y)$
abc183b.pys_x, s_y, g_x, g_y = map(int, input().split()) g_y = -g_y print(s_x - s_y * (g_x - s_x) / (g_y - s_y))C問題 Travel
問題文
$N$個の都市があります。都市$i$から都市$j$へ移動するには$T_{i,j}$の時間がかかります。
都市$1$を出発し、全ての都市をちょうど$1$度ずつ訪問してから都市$1$に戻るような経路のうち、移動時間の合計がちょうど$K$になるようなものはいくつありますか?制約が$2\leq N \leq 8$と小さいので,全探索しても実行時間制限内に解くことができましたが,最初問題見たときには,$1\to 2\to 3\to 4\to 1$の経路と$1\to 4\to 3\to 2\to 1$の経路は,$T_{i,j}=T_{j,i}$の制約から移動時間の合計が一緒になるから,計算量減らせるとか,再帰関数とか使ったら,計算量減らせるかもとか考えていたので,けっこう解き始めるのに時間とられてしまいました.
abc183c.pyimport itertools import numpy as np n, k = map(int, input().split()) matrix = np.zeros((n, n), dtype=int) for i in range(n): x_list = list(map(int, input().split())) for j in range(n): matrix[i, j] = x_list[j] no_list = range(1, n) count = 0 for temp_list in itertools.permutations(no_list): no = 0 total = 0 for next_no in temp_list: total += matrix[no, next_no] no = next_no total += matrix[no, 0] if total == k: count += 1 print(count)D問題 Water Heater
問題文
給湯器が$1$つあり、毎分$W$リットルのお湯を供給することができます。
$N$人の人がいます。$i$番目の人は時刻$S_i$から$T_i$までの間 (時刻$T_i$ちょうどを除く)、この湯沸かし器で沸かしたお湯を毎分$P_i$リットル使おうと計画しています。お湯はすぐ冷めてしまうので、溜めておくことはできません。
すべての人に計画通りにお湯を供給することはできますか?なぜかコンテスト中はdictで解いていますが,listでも同じように解けます.
そもそも,増やすと減らすで別々に管理する必要もないので,無駄が多く反省.abc183d.pyn, w = map(int, input().split()) start_dict = {} end_dict = {} for i in range(n): s, t, p = map(int, input().split()) if s in start_dict: start_dict[s] += p else: start_dict[s] = p if t in end_dict: end_dict[t] += p else: end_dict[t] = p now = 0 flag = 1 for i in range(2 * 100000): if i in start_dict: now += start_dict[i] if i in end_dict: now -= end_dict[i] if now > w: flag = 0 break if flag == 1: print("Yes") else: print("No")解説を参考に手直ししたコード.
abc183d.pyn, w = map(int, input().split()) a_list = [0] * 200001 for i in range(n): s, t, p = map(int, input().split()) a_list[s] += p a_list[t] -= p for i in range(1, 200001): a_list[i] += a_list[i - 1] if max(a_list) > w: print("No") else: print("Yes")E問題は,'TLE'から抜け出せず終わってしまいました.
時間があるときに追記できたらと思います.最後まで読んでいただきありがとうございました.

- 投稿日:2020-11-21T13:31:22+09:00
Pythonでパスワードツールを作成してみました。
はじめに
pythonを勉強し始めて、約1ヶ月が経った筆者が初めて作成した
パスワードツールが完成したので記事にしました。
まだまだ、改善の余地はたくさんありますのでより良いものにしていきます!利用環境
・windows 10
・VS code 1.51.1目的
テキストファイルにパスワードを三種類ランダムで生成する。
コード
長文のため、閲覧注意願います。
コード
password.pyimport random , string password = [random.choice(string.hexdigits) for i in range(10)] password1 = [random.choice(string.hexdigits) for i in range(10)] password2 = [random.choice(string.hexdigits) for i in range(10)] passwordlist = ''.join(password) passwordlist1 = ''.join(password1) passwordlist2 = ''.join(password2) passwordlist = str(passwordlist) passwordlist1 = str(passwordlist1) passwordlist2 = str(passwordlist2) passname = 'pass' passname1 = 'pass1' passname2 = 'pass2' import pathlib pathlib.Path("パスワード.txt").write_text('{}\n{}\n{}\n{}\n{}\n{}\n'.format(passname,passwordlist,passname1,passwordlist1,passname2,passwordlist2))
結果
パスワード.txtpass Q2n8d7favk pass1 PRpnbOuTuj pass2 0Y1hpyMkea解説
それでは、解説していきます。
import random , stringこちらは、pythonにrandom関数とstring関数をimportしています。
random:乱数を生成する関数。
string:文字列操作の関数。
stringは、実は今回初めて知ったのですが、私はpython標準ライブラリから確認を行いました。
python標準ライブラリ
次に、
password = [random.choice(string.hexdigits) for i in range(10)]こちらは、変数名:passwordにランダムな英数字10文字を代入するコードです。
random.choice():()内のものをランダムに生成する。
string.hexdigits:英数字で大文字、小文字混在のものです。
for i in range(10):10回同じ処理を繰り返す。
次は少しまとめますが、
passwordlist = ''.join(password) passwordlist = str(passwordlist) passname = 'pass'passwordlist = ''.join(password):変数名passwordを結合し、passwordlistへ代入
passwordlist = str(passwordlist):変数名passwordlistを文字列へ変換
passname = 'pass':変数名passnameに文字列passを代入
最後です。
import pathlib pathlib.Path("パスワード.txt").write_text('{}\n{}\n{}\n{}\n{}\n{}\n'.format(passname,passwordlist,passname1,passwordlist1,passname2,passwordlist2))ここに関しては、以下リンクに記載されている内容をそのまま踏襲しました。
ファイルに書き込む文字列の変数が複数ある場合
以上です。
やっぱり、一つのプログラム作るのも大変です。
今後の改訂としては、毎月更新したいので更新のタイミングを設定
自動で更新。
前月のパスワードを念のため保管する。ここまで作ってみたいなと思います!
他にもアイデアあったり、コードもっと短く出来る方法あれば
是非教えていただけると嬉しいです!閲覧ありがとうございました!!
- 投稿日:2020-11-21T12:17:41+09:00
画像処理100本ノック!!(001 - 010)丁寧にじっくりと
1. はじめに
画像の前処理の技術力向上のためにこちらを実践 画像処理100本ノック!!
とっかかりやすいようにColaboratoryでやります。
目標は2週間で完了できるようにやっていきます。丁寧に解説します。質問バシバシください!2. 前準備
ライブラリ等々を以下のように導入。
# ライブラリをインポート from google.colab import drive import numpy as np import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow # 画像の読み込み img = cv2.imread('画像のパス/imori.jpg') img_noise = cv2.imread('画像のパス/imori_noise.jpg') # 画像保存用 OUT_DIR = '出力先のパス/OUTPUT/'3.解説
Q.1. チャネル入れ替え
画像を読み込み、RGBをBGRの順に入れ替えよ。
画像の赤成分を取り出すには、以下のコードで可能。 cv2.imread()関数ではチャネルがBGRの順になることに注意! これで変数redにimori.jpgの赤成分のみが入る。A1# OpenCVの関数cvtColor()でBGRとRGBを変換 img1 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans1_a.jpg', img1) # 画像を表示する cv2_imshow(img1) cv2.waitKey(0) cv2.destroyAllWindows()
参考: Python, OpenCVでBGRとRGBを変換するcvtColor
Q.2. グレースケール化
画像をグレースケールにせよ。 グレースケールとは、画像の輝度表現方法の一種であり下式で計算される。
Y = 0.2126 R + 0.7152 G + 0.0722 BA2# OpenCVの関数cv2.cvtColor(), cv2.COLOR_BGR2GRAYで変換 img2 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans2_.jpg', img2) # 画像を表示する cv2_imshow(img2) cv2.waitKey(0) cv2.destroyAllWindows()
参考: Python, OpenCV, NumPyでカラー画像を白黒(グレースケール)に変換
Q.3. 二値化
画像を二値化せよ。 二値化とは、画像を黒と白の二値で表現する方法である。 ここでは、グレースケールにおいて閾値を128に設定し、下式で二値化する。
A3# 画像(グレースケール)のコピー img3 = img2.copy() # 閾値の設定 threshold = 128 # 二値化(閾値128を超えた画素を255にする。) ret, img3 = cv2.threshold(img3, threshold, 255, cv2.THRESH_BINARY) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans3_.jpg', img3) # 画像を表示する cv2_imshow(img3) cv2.waitKey(0) cv2.destroyAllWindows()
参考: OpenCV 画像の二値化
参考: 画像のしきい値処理Q.4. 大津の二値化
大津の二値化を実装せよ。 大津の二値化とは判別分析法と呼ばれ、二値化における分離の閾値を自動決定する手法である。 これはクラス内分散とクラス間分散の比から計算される。
A4# OpenCVで実装 # 画像(グレースケール)のコピー gray = img2.copy() # 大津の2値化処理 ret, image4 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans4.jpg', img4) # 画像を表示する cv2_imshow(img4) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】大津の手法で二値化処理
Q.5. HSV変換
HSV変換を実装して、色相Hを反転せよ。
HSV変換とは、Hue(色相)、Saturation(彩度)、Value(明度) で色を表現する手法である。
Hue ... 色合いを0~360度で表現し、赤や青など色の種類を示す。 ( 0 <= H < 360) 色相は次の色に対応する。
赤 黄色 緑 水色 青 紫 赤
0 60 120 180 240 300 360
Saturation ... 色の鮮やかさ。Saturationが低いと灰色さが顕著になり、くすんだ色となる。 ( 0<= S < 1)
Value ... 色の明るさ。Valueが高いほど白に近く、Valueが低いほど黒に近くなる。 ( 0 <= V < 1)A5# 画像をコピーする img5 = img.copy() # RGB -> HSVに変換 hsv = cv2.cvtColor(img5, cv2.COLOR_BGR2HSV) # Hueに180を足す hsv[..., 0] = (hsv[..., 0] + 180) % 360 # HSV -> RGBに変換 img5 = cv2.cvtColor(hsv, cv2.COLOR_HSV2RGB) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans5.jpg', img5) # 画像を表示する cv2_imshow(img5) cv2.waitKey(0) cv2.destroyAllWindows()
なぜか微妙に解答の画像と異なる。間違ってたら教えてください
参考: Python/OpenCV】RGBからHSVに変換(cv2.cvtColor)
Q.6. 減色処理
ここでは画像の値を256^3から4^3、すなわちR,G,B in {32, 96, 160, 224}の各4値に減色せよ。 これは量子化操作である。 各値に関して、以下の様に定義する。
A6def decrease_color(img): """ R,G,Bをそれぞれ256ある値を4にする [0, 64), [64, 128), [128, 192), (192, 256)に4等分する ※[] :閉区間(以上や以下), ():開区間(大きいや小さい) [0, 64)->32, [64, 128)->96, [128, 192)->160, (192, 256) -> 2224 へ各範囲変換 parameters ------------------------- param: numpy.ndarray形式のimage returns ------------------------- numpy.ndarray形式 右のように変換[132 80 67] >>> [160 96 96] """ # イメージをコピー out = img.copy() print(out) # 256/4 = 64であるため64でわり、 +32 することで32, 96, 160, 224へ変換 out = out // 64 * 64 + 32 return out img6 = img.copy() img6 = decrease_color(img6) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans6.jpg', img6) # 画像を表示する cv2_imshow(img6) cv2.waitKey(0) cv2.destroyAllWindows()
参考: なんとなくのブログ
Q.7. 平均プーリング
ここでは画像をグリッド分割(ある固定長の領域に分ける)し、かく領域内(セル)の平均値でその領域内の値を埋める。 このようにグリッド分割し、その領域内の代表値を求める操作はPooling(プーリング) と呼ばれる。 これらプーリング操作はCNN(Convolutional Neural Network) において重要な役割を持つ。
A7def average_pooling(img, G=8): """ 平均プーリング parameters ------------------------- param1: numpy.ndarray形式のimage param2: 8x8にグリッド分割 returns ------------------------- 平均プーリングされたnumpy.ndarray形式のimage """ # 画像をコピー out = img.copy() # H(画像高さ), W(画像幅), C(色)を取得 H, W, C = img.shape # グリッド分割 Nh = int(H / G) Nw = int(W / G) # 8分割された範囲ごとに平均プーリング for y in range(Nh): for x in range(Nw): for c in range(C): out[G*y:G*(y+1), G*x:G*(x+1), c] = np.mean(out[G*y:G*(y+1), G*x:G*(x+1), c]).astype(np.int) return out # 平均プーリング img7 = average_pooling(img) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans7.jpg', img7) # 画像を表示する cv2_imshow(img7) cv2.waitKey(0) cv2.destroyAllWindows()
Q.8. Maxプーリング
ここでは平均値でなく最大値でプーリングせよ。
A8def max_pooling(img, G=8): """ 最大プーリング parameters ------------------------- param1: numpy.ndarray形式のimage param2: 8x8にグリッド分割 returns ------------------------- 最大プーリングされたnumpy.ndarray形式のimage """ # 画像をコピー out = img.copy() # H(画像高さ), W(画像幅), C(色)を取得 H, W, C = img.shape # グリッド分割 Nh = int(H / G) Nw = int(W / G) # 8分割された範囲ごとに平均プーリング for y in range(Nh): for x in range(Nw): for c in range(C): out[G*y:G*(y+1), G*x:G*(x+1), c] = np.max(out[G*y:G*(y+1), G*x:G*(x+1), c]).astype(np.int) return out # 最大プーリング img8 = average_pooling(img) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans8.jpg', img8) # 画像を表示する cv2_imshow(img8) cv2.waitKey(0) cv2.destroyAllWindows()
Q.9. ガウシアンフィルタ
ガウシアンフィルタ(3x3、標準偏差1.3)を実装し、imori_noise.jpgのノイズを除去せよ。
ガウシアンフィルタとは画像の平滑化(滑らかにする)を行うフィルタの一種であり、ノイズ除去にも使われる。
ノイズ除去には他にも、メディアンフィルタ(Q.10)、平滑化フィルタ(Q.11)、LoGフィルタ(Q.19)などがある。
ガウシアンフィルタは注目画素の周辺画素を、ガウス分布による重み付けで平滑化し、次式で定義される。 このような重みはカーネルやフィルタと呼ばれる。
ただし、画像の端はこのままではフィルタリングできないため、画素が足りない部分は0で埋める。これを0パディングと呼ぶ。 かつ、重みは正規化する。(sum g = 1)A9# OpenCVで処理 # cv2.GaussianBlur(src, ksize, sigmaX) # src: 入力画像, ksize: カーネルサイズ, sigmaX: ガウス分布のsigma_x img9 = cv2.GaussianBlur(img_noise, ksize=(3, 3), sigmaX=1.3) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans9.jpg', img9) # 画像を表示する cv2_imshow(img9) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】ガウシアンフィルタでぼかし・平滑化
Q.10 メディアンフィルタ
メディアンフィルタ(3x3)を実装し、imori_noise.jpgのノイズを除去せよ。
メディアンフィルタとは画像の平滑化を行うフィルタの一種である。
これは注目画素の3x3の領域内の、メディアン値(中央値)を出力するフィルタである。 これもゼロパディングせよ。A10# OpenCVで処理 """ cv2.medianBlur(src, ksize) src 入力画像 kernel フィルタのカーネルサイズ(3なら8近傍) """ # メディアンフィルタ img10 = cv2.medianBlur(img_noise, ksize=3) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans10.jpg', img10) # 画像を表示する cv2_imshow(img10) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】メディアンフィルタでぼかし・平滑化・ノイズ除去
感想
機械学習において前処理は重要である。手法を知らなければアイデアも出ないので取り組む価値は十分にある。
ノック形式なので取り組みやすい










- 投稿日:2020-11-21T09:33:31+09:00
2つのディレクトリの内容を比較するPythonスクリプト
動機
デジタルカメラやアクションカムなどの記録メディアを(USBメモリ,SDカードなど)のデータを別の大容量の外付けSSDにコピーして蓄積していたが、外付けSSDの残量が少なくなってきた。外付けSSDの中には重複したデータがあるようなので削除したい。重複したファイルが発生したのは、
- 外付けSSDにコピーしたあとに、記録メディアのコピー元のファイルを消去する前に追記したのちに、再度バックアップしてしまった。
- バックアップ作業を行ったOS環境の違いによりファイル名の大文字/小文字が変わってしまったことがあり、その際バックアップ作業済みなのかか未作業なのか誤解して2回バックアップしてしまった
といったことが原因のようだ。大文字小文字を区別せず、2つのディレクトリの内容の過不足をチェックするのは手間なので、スクリプトを書くことにした。
ファイル置き場
実行例
比較したい2つのディレクトリを引数にして実行すると、サブディレクトリごとに、ファイル、ディレクトリ、シンボリックリンク毎に
タイムスタンプとファイルサイズを比較する。同じサイズのファイルには、filecmp.cmp(..., shallow=False)関数で比較する。
比較の結果を示す下記の記号をファイル名の前につけて表示する。
- 比較対象に同名のファイルがある場合には、タイムスタンプ(mtime)を表す記号(
>,=,<)と内容の比較結果の記号(++,--,!=,==,,!!)を結合した3バイトたとえば、
===は「タイムスタンプも内容も同じ」、>++は「比較対象のディレクトリにある同名ファイルよりも新しくサイズも大きい」、=!=は、「比較対象のディレクトリにある同名ファイルとタイムスタンプもファイルサイズも同じだが、中身(データ)は違う」という意味となる。シンボリックリンクの場合には、'=(空白2文字)'は「タイムスタンプもリンク先のパスも同じ」、'=!!'は「タイムスタンプは同じだがリンク先のパスが違う」という記号になる。実行例% ./cmp_dirtree ./data0 ./data1 ### ======================================== 1: ./data0 2: ./data1 ### ======================================== ###-----------------< M4ROOT >-------------------- 1: ./data0/M4ROOT 2: ./data1/M4ROOT ### Sub directories: --- 1: =++ : 2019/02/09 12:43:35 : 952 : CLIP 2: =-- : 2019/02/09 12:43:35 : 476 : CLIP 1: === : 2019/02/09 12:43:35 : 68 : GENERAL 2: === : 2019/02/09 12:43:35 : 68 : GENERAL (途中略) ### File lists: --- 1: >== : 2019/11/05 03:47:45 : 6148 : .DS_Store 2: <== : 2019/11/05 01:10:13 : 6148 : .DS_Store 1: >++ : 2019/11/02 19:09:34 : 5122 : MEDIAPRO.XML 2: <-- : 2019/07/01 19:07:35 : 2595 : MEDIAPRO.XML 1: >== : 2019/11/02 19:09:34 : 7 : STATUS.BIN 2: <== : 2019/07/01 19:07:35 : 7 : STATUS.BIN ###-----------------< M4ROOT/CLIP >-------------------- 1: ./data0/M4ROOT/CLIP 2: ./data1/M4ROOT/CLIP ### File lists: --- 1: === : 2019/02/09 14:53:23 : 1878686635 : C0001.MP4 2: === : 2019/02/09 14:53:23 : 1878686635 : C0001.MP4 1: === : 2019/02/09 14:53:23 : 2008 : C0001M01.XML 2: === : 2019/02/09 14:53:23 : 2008 : C0001M01.XML (途中略) 1: === : 2019/07/01 19:07:35 : 7627022896 : C0006.MP4 2: === : 2019/07/01 19:07:35 : 7627022896 : C0006.MP4 1: === : 2019/07/01 19:07:35 : 2009 : C0006M01.XML 2: === : 2019/07/01 19:07:35 : 2009 : C0006M01.XML 1: : 2019/07/28 14:15:53 : 15709053750 : C0007.MP4 2: ! : ~~ 1: : 2019/07/28 14:15:53 : 2008 : C0007M01.XML 2: ! : ~~ (以下略)比較するディレクトリ、ファイル数が多い場合には、
./cmp_dirtree ./data0 ./data1 | grep -e ' .== 'といった方法でフィルタすると、容易に重複するファイルを見つけられるようになった。
- 投稿日:2020-11-21T08:43:46+09:00
Python Jupyter Lab (Notebook) でメモリリーク?
環境
- Kaggle Docker Python v86
https://console.cloud.google.com/gcr/images/kaggle-images/GLOBAL/python問題
Jupyter Labを使っていて、変数を定義したのちdelしてgc.collect()してもメモリが解放されない。
調査・直接原因
pandas.DataFrame の問題かと思ったが、そうではない。
「セル」の最後にJupyter Labの機能による出力表示を行うと、それ以後他のセルでdelしても解放されないようだ。再現手順
1つのセルの中に以下のようなコードを書いて実行する。
import numpy as np import pandas as pd import psutil print(psutil.Process().memory_info().rss / 1024**2) df = pd.DataFrame(np.arange(50000000).reshape(-1,5)) df.head()
最後にdf.head() としていることに注意。
次のセルで
print(psutil.Process().memory_info().rss / 1024**2) del df print(psutil.Process().memory_info().rss / 1024**2)
メモリの状況はすぐに表示されないので念のためさらに次のセルでも確認
print(psutil.Process().memory_info().rss / 1024**2)
※ちなみに引き続いてgc.collect()しても同じ。
解決策
セルの最後でdf.head()しない。表示したければprintする。
コメント
- 地味に不安要素になる部分・挙動だけれど、きちんとJupyter 入門すると注意されていることなのだろうか(知らない)。
- 手元で調査して確認できたが、gc対象とならない理由はjupyterの画面表示機能に参照が保持されるか何かだろうか。IPythonに原因があるらしい。検索語をJupyter memory leakとすれば https://github.com/jupyter/notebook/issues/3713 が出てきて、この先に説明があるらしい(見てない)。
- 検索語をpandas memory leak とすると https://stackoverflow.com/questions/14224068/memory-leak-using-pandas-dataframe などが出てきて、迷い続ける(迷った)。





- 投稿日:2020-11-21T08:31:46+09:00
Flaskで簡易的なドット絵ジェネレータを作る
完成形
以下のような感じ。
https://flaskandheroku.herokuapp.com/仕様
- トップ画面にはランダム生成されたドット絵が表示されている
- 「ランダム生成」ボタンを押下するとランダムでドット絵が表示される
- ドット絵は画像ではなく文字の「■(四角)」で構成されている
- 文字を画像へ変換する技術は実装していない
- Twitterシェアボタンを配置
作ろうと思った経緯
- Flaskを勉強中なので、簡単な成果物を作ってみたくなった
- 以下のようなドット絵を描くのが趣味なので、自動で生成できるようなツールを作ってみたくなった
https://akihanari.github.io/gif-amabie/
使用言語やフレームワークなど
- HTML5
- CSS3
- Bootstrap
- Python
- Flask
- Heroku
ファイル構成
- templates
- layout.html
- index.hrml
- app.py
- Procfile
- requirements.txt
仕組み(コード)
シンプルです。
# app.py @app.route('/') def dot_gene(): numbers = [[random.randrange(4) for i in range(8)] for j in range(8)] return render_template("index.html", numbers = numbers)まずは@app.route('/')に、二重ループの関数を作成します。
今回は8×8のドットを作るのですが、各ドットの色が白か黒かを決めるため、
0〜3のランダムな数値を生成します。
例えばこんな感じになっています11230032 31231000 30023111 12213303 01202010 32111320 01322031 00011203次に、index.htmlの中で処理を行います。
# index.html {% extends "layout.html" %} {% block content %} <h1>Pixel art generator</h1> <div class="spaces"> {% for number in numbers %} {% for num in number %} {% if num == 0 %} <font color="#000000">■</font> {% elif num == 1%} <font color="#ededed">■</font> {% elif num == 2%} <font color="#ededed">■</font> {% else %} <font color="#ededed">■</font> {% endif %} {% endfor %} <br> {% endfor %} </div> . . . {% endblock %}
コードが非常に汚くて大変申し訳ないのですが
作成した二重ループの数字と「■」、白か黒かを関連付けます。
今回は数字が0の時のみ黒に、それ以外の数字の場合は白(っぽい)色に変換します。
そうするとこのようなドット絵が表示される訳です。改善点
- スマートフォン表示だとドット絵が若干崩れてしまう
- 生成されたドット絵を画像に変換して保存できるようにしたい
- もっとドット絵らしいドット絵を生成されるようにしたい

参考


- 投稿日:2020-11-21T06:42:27+09:00
辞書の値を属性参照するメモ(車輪の再開発)
AttrDictの方が便利だけど、ちょっと使いたいのにインストールしたくない人向け
定義
class Dict(dict): pass Dict.__getattr__ = lambda s, k: s.get(k)使うとき
a = Dict(a=0, b=Dict(c=1, d=2)) (a.a, a.b.c, a["a"], a["b"]["c"])もう少ししっかり定義したい
class Dict(dict): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def __getattr__(self, key): return self.get(key) def __getstate__(self): return self.__dict__ def __setstate__(self, dict_): self.__dict__ = dict_a = Dict(a=0, b=Dict(c=1, d=2)) (a.a, a.b.c, a["a"], a["b"]["c"], pickle.loads(pickle.dumps(a)))
__getstate__, __setstate__はpickle対策。pickle使わなければいらない。番外編
OneLinerでも書いたけど。カケタダケ
globals().update({"D": type("D", (dict,), {"__getattr__": lambda s, k: s.get(k)})}); D(a=1, b=D(c=2, d=3)).b.c
- 投稿日:2020-11-21T03:17:53+09:00
[TensorFlow]"ValueError: tf.function-decorated function tried to create variables on non-first call"を解決する
OptimizerやModelを入力とするtf.functionが"tried to create variables on non-first call"で死ぬ
最初のモデルコール(build)以外で変数を宣言したつもりなんてなかったとおもっていたら思わぬトラップにかかったので備忘録
前提
TensorFlow2(筆者は2.5 nightlyで確認)
tf.function内でのtf.Variableの作成は禁止
- tf.functionは基本的に一度確保したら同じメモリ領域で動作する。
- tf.Variableは新しいメモリ領域を確保して変数を生成する。
- したがって毎回新しいVariableを生成すると毎回新しいメモリを食ってしまうのでエラーがおきる。
@tf.function def f(x): v = tf.Variable(1.0) v.assign_add(x) return v with assert_raises(ValueError): f(1.0)Caught expected exception <class 'ValueError'>: in user code: <ipython-input-17-73e410646579>:3 f * v = tf.Variable(1.0) /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/ops/variables.py:262 __call__ ** return cls._variable_v2_call(*args, **kwargs) /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/ops/variables.py:256 _variable_v2_call shape=shape) /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/eager/def_function.py:702 invalid_creator_scope "tf.function-decorated function tried to create "単なるpython変数の宣言ならよい。関数を呼び出すたびに同じメモリ領域をリサイクルして使われるので。
@tf.function def f(x): v = tf.ones((5, 5), dtype=tf.float32) return v # raises no error!本題
tf.keras.models.Modelを入力としたtf.functionは思わぬエラーを引き起こす。
@tf.function def call(model1: tf.keras.models.Model, inputs: tf.Tensor): return model1(inputs) if __name__ == '__main__': model1 = tf.keras.Sequential([ tf.keras.layers.Dense(16), tf.keras.layers.Dense(4) ]) model2 = tf.keras.Sequential([ tf.keras.layers.Dense(16), tf.keras.layers.Dense(4) ]) inputs = tf.ones((10, 10), dtype=tf.float32) call(model1, inputs) # raises no error! call(model2, inputs) # raises an error! "tf.function-decorated function tried to create variables on non-first call"ポイントはkerasのモデルは一番最初にコールされたときに重み行列などのVariableをbuildすること。
よってこのcall関数にビルドされていない2つのモデルを引数として渡すと2度めの呼び出し時に2つめのモデルの重みをビルドしようとして事故る!!解決策
# @tf.functionは直接つけない def call(model1: tf.keras.models.Model, inputs: tf.Tensor): return model1(inputs) if __name__ == '__main__': model1 = tf.keras.Sequential([ tf.keras.layers.Dense(16), tf.keras.layers.Dense(4) ]) model2 = tf.keras.Sequential([ tf.keras.layers.Dense(16), tf.keras.layers.Dense(4) ]) inputs = tf.ones((10, 10), dtype=tf.float32) # pythonでは関数もオブジェクト。それぞれのモデル専用の関数を生成する。 model1_call = tf.function(call) model2_call = tf.function(call) model1_call(model1, inputs) model2_call(model2, inputs)tf.functionは関数の定義に直接書くのをやめて各モデル専用の関数オブジェクトを生成する。デコレータとか高階関数とかってメタプログラミング的な概念はpython初心者には難しいので理由を深追いしないのが大事。
これでいける理由を知りたい人はpython デコレータ 高階関数などでぐぐるとよいとおもわれる。
まとめ
Eager ExecutionはGPU上で複雑かつstep数の多いアルゴリズムを書く場合はおそすぎて話にならないので計算効率を追求するためにtf.functionを使いたいところだがまだTF2がリリースされて間もないことやtf.functionがブラックボックスすぎることが原因で意味不明なバグに躓きがち。
今後もtf2まわりやdeeplearningまわりの知見をたくさん蓄積していくのでLGTMとフォローをお願いします!
- 投稿日:2020-11-21T01:44:17+09:00
有名な7つのソートアルゴリズムをPythonで実装しよう
前書き
基本情報技術者試験の対策でソートアルゴリズムを学習したのでまとめておきます。ここに記載してあるプログラムの関数はいずれも昇順(小さい順)でソートを行うものです。
ソートとは
データを整列させることです。ソートを行うアルゴリズムのことをソートアルゴリズムといいます。
ソートの性能を評価するには
ソートの性能を評価するには計算量(オーダ)という指標を用います。ソートの場合、計算量には最良時間計算量、平均時間計算量、最悪時間計算量の3つがありますが、性能を比較する場合には基本的に平均時間計算量が用いられます。時間計算量が少ないアルゴリズムほど、より素早くソートを行えるので良いアルゴリズムであると言えます。
バブルソート
リスト(配列)の隣り合う値の大小関係を比較して必要に応じて並べ替えることを繰り返し、全体を整列させる方法です。
平均時間計算量は$O(n^2)$で、比較的遅いソート方法です。
Pythonでの実装例
bubble_sort.pydef bubble_sort(l): for i in range(len(l)): for j in reversed(range(i + 1, len(l))): if l[j - 1] > l[j]: # 値を入れ替える l[j - 1], l[j] = l[j], l[j - 1] return l選択ソート(セレクションソート)
リスト(配列)の整列されていない部分から最小値、または最大値を探し、その値をリスト(配列)の整列されていない部分の先頭の要素と入れ替えることを繰り返して全体を整列させる方法です。
平均時間計算量は$O(n^2)$で、比較的遅いソート方法です。
Pythonでの実装例
selection_sort.pydef selection_sort(l): # その範囲における最小値を探し、リストの左側から値を順番に選んで最小値と入れ替える for i in range(len(l) - 1): min_index = i for j in range(i + 1, len(l)): if l[min_index] > l[j]: min_index = j l[i], l[min_index] = l[min_index], l[i] return l挿入ソート(インサーションソート)
リスト(配列)の整列済みの部分に対して適切な位置に値を挿入することを繰り返し、全体を整列させる方法です。
平均時間計算量は$O(n^2)$で、比較的遅いソート方法です。
Pythonでの実装例
insertion_sort.pydef insertion_sort(l): for i in range(1, len(l)): # tmpは挿入する位置を考えている値を指す # リストの左の値から順に挿入する位置を考える tmp = l[i] if tmp < l[i - 1]: while True: # 値を右にずらして挿入する場所を確保する l[i] = l[i - 1] i -= 1 # 挿入する位置が決まったら if i == 0 or tmp >= l[i - 1]: break # そこに値を挿入する l[i] = tmp return lヒープソート
ヒープ木を構成してルートノードにある最小値、あるいは最大値を取得することをヒープ木の構成に用いる要素の範囲を狭めながら繰り返し、全体を整列させる方法です。
アップヒープではリストのすべての要素を用いたヒープ木を構成しています。また、ダウンヒープではルートノードの値が置き換わったヒープ木を用いて、それまでに取得した最大値をヒープ木の構成要素から除外したヒープ木を構成しています。平均時間計算量は$O(nlogn)$で、比較的速いソート方法です。
Pythonでの実装例
heap_sort.pydef heap_sort(l): i = 0 # ヒープ木を構成する while i < len(l): # リストの左から順番に値を取得して、その値を一つずつヒープ木の末尾からヒープ木に組み込む upheap(l, i) i += 1 while i > 1: # ヒープ木のルートノードにあたる、リストの先頭にその範囲における最大値があるので、 # リストの右から順にその値をリストの先頭の値(その範囲における最大値)と交換する i -= 1 l[0], l[i] = l[i], l[0] # ヒープ木を再構成する downheap(l, i - 1) return l def upheap(l, child): # 確認する要素がルートノードでない場合は、ソートを続ける # その要素がルートノードの場合は、全ての親子関係の確認が済んだ(すなわち正しい位置に値を配置できた)のでソートを終了する while child != 0: parent = int((child - 1) / 2) # 子要素の値が親要素の値よりも大きかったら、親要素の値の方が大きくなるように両者を入れ替える if l[child] > l[parent]: l[child], l[parent] = l[parent], l[child] # 対象とする親子関係の確認が済んだので次は一つ上の親子関係を見ていく child = parent # それ以外の場合は正しい位置に値を配置できたのでソートを終了する else: break def downheap(l, j): parent = 0 while True: child = 2 * parent + 1 # 範囲外の要素まで考えようとした場合はソートが完了したということなのでソートを終了する if child > j: break # 二つの子要素のうち、値の大きい方を選んで if child < j and l[child] < l[child + 1]: child += 1 # 親要素と比較する # 子要素の値が親要素の値よりも大きかったら、親要素の値の方が大きくなるように両者を入れ替える if l[parent] < l[child]: l[child], l[parent] = l[parent], l[child] # 対象とする親子関係の確認が済んだので次は一つ下の親子関係を見ていく parent = child # それ以外の場合は正しい位置に値を配置できたということなのでソートを終了する else: breakマージソート
それぞれのリスト(配列)を2つに分割する操作をすべてのリスト(配列)の要素数が1になるまで繰り返し、続いてなるべくお互いの要素数が等しくなるように2つのリストを選んでマージ(結合)するということを繰り返すことで全体を整列させる方法です。
平均時間計算量は$O(nlogn)$で、比較的速いソート方法です。
Pythonでの実装例
merge_sort.pydef merge_sort(l): if len(l) < 2: return l # 真ん中辺りの要素のインデックスを基準として左のグループと右のグループに分割することを、 # すべてのリストの要素数が1になるまで行う pivot = len(l) // 2 l_left = merge_sort(l[:pivot]) l_right = merge_sort(l[pivot:]) # なるべくそれぞれの要素数が等しくなるように2つのリストを選んで結合することを繰り返す return merge(l_left, l_right) def merge(l_left, l_right): sorted_l = [] while len(l_left) > 0 and len(l_right) > 0: if l_left[0] < l_right[0]: sorted_l.append(l_left.pop(0)) else: sorted_l.append(l_right.pop(0)) if len(l_left) > 0: sorted_l.extend(l_left) else: sorted_l.extend(l_right) return sorted_lクイックソート
ある決まりに基づいて基準値を決め、その基準値よりも小さいグループと基準値以上のグループ、あるいはその基準値よりも大きいグループと基準値以下のグループのどちらかに分割することを繰り返すことで全体を整列させる方法です。
平均時間計算量は$O(nlogn)$で、比較的速いソート方法です。
Pythonでの実装例
quick_sort.pydef quick_sort(l): if len(l) < 2: return l pivot = l[0] l_rest = l[1:] smaller = [x for x in l_rest if x < pivot] larger = [x for x in l_rest if x >= pivot] return quick_sort(smaller) + [pivot] + quick_sort(larger)シェルソート
挿入ソートを改良したものです。
まず、最大の間隔を空けて要素の組を作りそれに対してソートを行い、続いて徐々に比較する要素間の間隔を小さくしながらソートを繰り返すことで全体を整列させる方法です。平均時間計算量はデータの並び方や間隔 $h$ の取り方によって変化します。
Pythonでの実装例
shell_sort.pydef shell_sort(l): h = 1 # ソートを行う2つの要素の最大の間隔を求める while h < len(l) / 9: h = h * 3 + 1 while h > 0: for i in range(h, len(l)): # その要素の左側に、指定された間隔の値以上の要素数があり、 # かつその要素の値よりも左の要素の値の方が大きい間、2つの値を入れ替える while i >= h and l[i - h] > l[i]: l[i], l[i - h] = l[i - h], l[i] i -= h # 2つの要素を指定するときの間隔を狭める h = int(h / 3) return l