- 投稿日:2020-11-20T23:59:41+09:00
フィボナッチ数列にお世話になりました。
こんにちは。
自分なりに書き方を色々検討してみました。参考にして頂ければ幸いです。
以下の記述はよく見る奴です。fib_1.pydef fib(n): if n == 1: return 0 if n == 2: return 1 else: return fib(n-1) +fib(n-2)こんな書き方もあると思います。
fib_2.pydef fib(n): if n == 1 or n == 2: return n-1 return fib(n-1) +fib(n-2)シンプルな記述に最適化が出来て、手を叩いて喜びましたが、
重複する計算が多いので、何とか最適化したいです。
有識者のアドバイスを参考にするとメモを用意し、
該当するものから取り出すことで計算を削減できるそうです。fib_3.pyclass fib: def __init__(self): self.table ={} def cal(self,n): if n <= 2: return n-1 if n in self.table: return self.table[n] self.table[n] = self.cal(n-2)+self.cal(n-1) return self.table[n] fib_sequence = fib()再帰処理 + メモ、なるほど。
こんなことも出来るんですね。
ちょっといじりました。fib_4.pydef fib(n): if n <= 2: return n-1 if n in memo: return memo[n] memo[n] = fib(n-2)+fib(n-1) return memo[n] memo = {}メモで簡略化する以外にも貪欲法というアプローチがあるようですが、
それはまた今度にします。やりたいことをイメージし、
アプローチを色々試してみる事は楽しいです。ココには for 文を使った方法もありました。素晴らしい!!
イメージが付かなくて困っている方は、ワンランクレベルを下げて、
こちら の記事で準備運動をすると良いと思います。
参考になります、これも素晴らしい記事でした。
- 投稿日:2020-11-20T23:53:42+09:00
yukicoder contest 275 参戦記
yukicoder contest 275 参戦記
A 1291 小手調べ
答えは0以上の整数なので、1桁にトラップがあるので注意. di≦100 なので、素直に整数で答えを計算すると int64 の範囲を超えますね. Python だから何も考えずに計算できるけど.
N, *d = map(int, open(0).read().split()) for i in range(N): if d[i] == 1: print(10) else: print(9 * 10 ** (d[i] - 1))まあ、文字列で計算しても難しくはないですが.
N, *d = map(int, open(0).read().split()) for i in range(N): if d[i] == 1: print(10) else: print('9' + '0' * (d[i] - 1))C 1293 2種類の道路
都市 i から行けるところを考える. 自動車専用道路を通って、都市 i から行ける都市の集合S(都市 i 自身も含む)に含まれる都市を j とすると、都市 j から歩行者専用道路通っていける都市(都市 j 自身も含む)の集合の和集合が、都市 i から行ける都市の集合となる. また当然ながら同じ集合Sに含まれる都市から行ける都市は全て同じである. つまり各集合S毎に、集合Sに含まれる都市の数だけ処理をするので O(N) となり解ける.
from sys import setrecursionlimit, stdin def find(parent, i): t = parent[i] if t < 0: return i t = find(parent, t) parent[i] = t return t def unite(parent, i, j): i = find(parent, i) j = find(parent, j) if i == j: return parent[j] += parent[i] parent[i] = j readline = stdin.readline setrecursionlimit(10 ** 6) N, D, W = map(int, readline().split()) car = [-1] * N for _ in range(D): a, b = map(lambda x: int(x) - 1, readline().split()) unite(car, a, b) walking = [-1] * N for _ in range(W): c, d = map(lambda x: int(x) - 1, readline().split()) unite(walking, c, d) xs = [i for i in range(N) if car[i] < 0] cs = {} ss = {} for x in xs: cs[x] = 0 ss[x] = set() for i in range(N): a = find(car, i) b = find(walking, i) if b in ss[a]: continue ss[a].add(b) cs[a] -= walking[b] result = 0 for x in xs: result -= car[x] * (cs[x] - 1) print(result)
- 投稿日:2020-11-20T22:16:27+09:00
Python学習 基礎編 ~文字列を出力(表示)するには?~
こちらではPython学習の備忘録と、Ruby、JavaScriptとの比較も含め記載していきたいと思います。
プログラミング初心者や他の言語にも興味、関心をお持ちの方の参考になれば幸いです。文字を出力(表示)するには?
共通部分
文字列は、必ず半角の「''」シングルクォーテーション、または「""」ダブルクォーテーションのどちらかで囲む必要がある。
記述がない場合はエラーになるので注意!Python
script.pyprint('Hello World')Ruby
index.rbputs 'Hello World'JavaScript
script.jsconsole.log('Hello World');文の最後は「;」セミコロンで終わりにする。
Pythonにてクォーテーションの記述がなかった場合
SyntaxError: invalid syntax「構文エラー:無効な構文」というエラーが発生します。
そして、 今後、記述が多くなると上記エラーが発生する確率も高くなるのでその際は下記をチェックしてみましょう。
- Pythonのコマンドや関数の名前を打ち間違えていないか?
- カッコを閉じ忘れていないか?
- 半角スペースのところが全角になっていないか?
- for文, if文, 関数などの「:」を書き忘れていないか?
- 「''」シングルクォーテーション、または「""」ダブルクォーテーションを忘れていないか?
おわりに
私自身「Python」の学習を始めたばかりなので、これからよろしくお願い致します!
また間違いがあれば遠慮なくご指摘願います!!
- 投稿日:2020-11-20T21:46:19+09:00
量子情報理論の基本:表面符号によるユニバーサル量子計算(1)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前回の記事では、平面格子上に敷き詰められた面演算子と頂点演算子に欠陥(演算子がない領域)をつくることで論理量子ビットと論理$X$および論理$Z$演算子を定義できて、さらに欠陥を互いに巻きつけるように移動させることでCNOT演算が実現できるということを見てきました。ところが、このCNOT演算はユニバーサル量子計算の要素とするには、実は不完全なものです。理由はこのあと説明します。今回の記事では、じゃあ完全なCNOTはどうやったら実現できるのか、そのあたりを勉強してみます。ユニバーサル量子計算を実現するには、さらに1量子ビットの任意のユニタリ演算が用意できれば良いのですが、それは次回にします。一通り理解できたところで、量子計算シミュレータqlazyを使って、その動作を確認します。
参考にさせていただいたのは、以下の文献です。
- 小柴、森前、藤井「観測に基づく量子計算」コロナ社(2017年)
- K.Fujii,"Quantum Computation with Topological Codes - from qubit to topological fault-tolerance",arXiv:1504.01444v1 [quant-ph] 7 Apr 2015
- 藤井「量子計算超入門」(2012年)
- ニールセン・チャン「量子コンピュータと量子通信Ⅱ」(2005年)
理論説明
Braiding操作のトポロジカルな表現
本題に入る前にひとつ押さえておきたい話題があります。前回の記事でBraidingによって2量子ビットの論理演算を表現できることがわかりましたが、平面上の欠陥をぐるっと移動させる説明図では欠陥をどのように時間変化させるとどんなトポロジー的な巻きつけが実現されて、それがどんな論理演算に対応しているのか極めてわかりにくいです。そこで3次元時空間上でのトポロジー的な特徴をわかりやすくするための模式図を導入します。
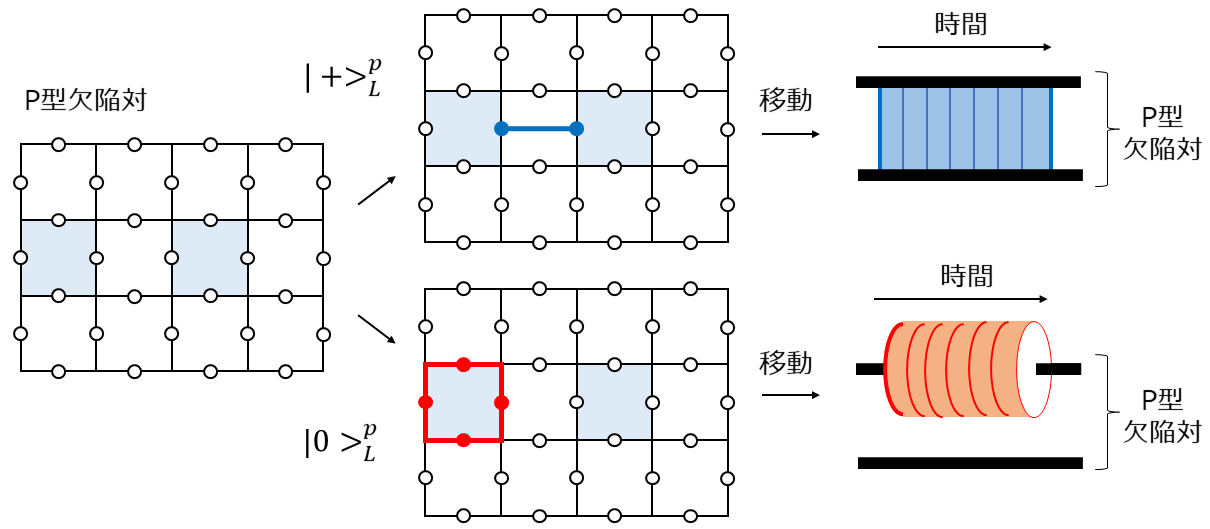
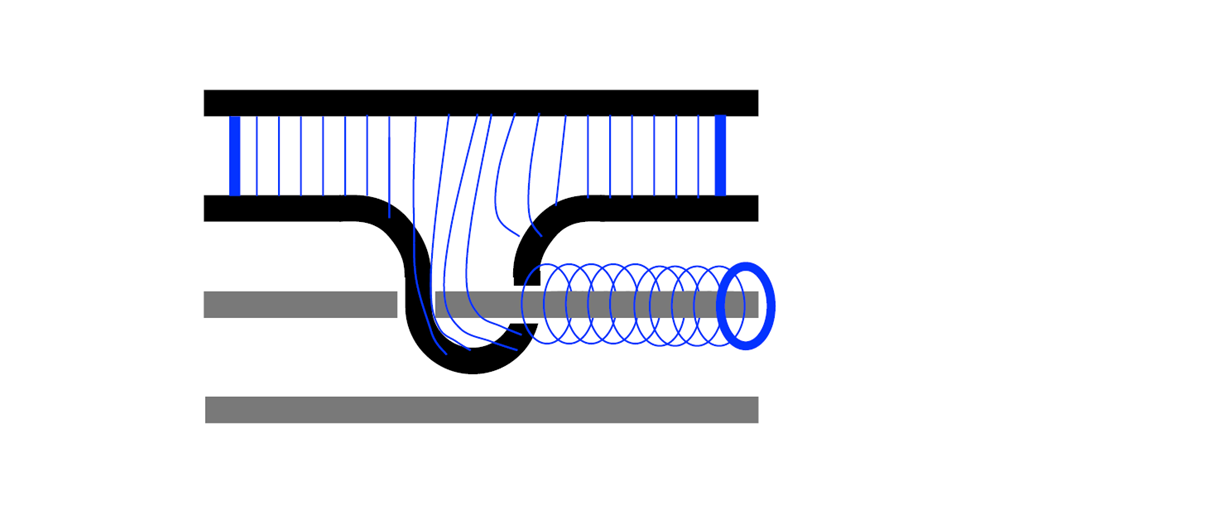
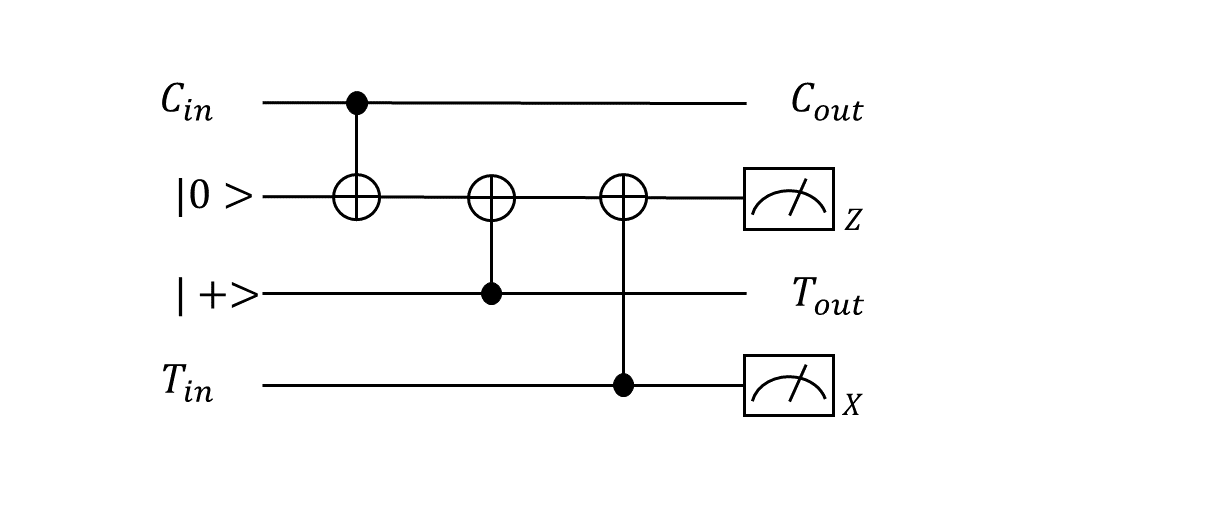
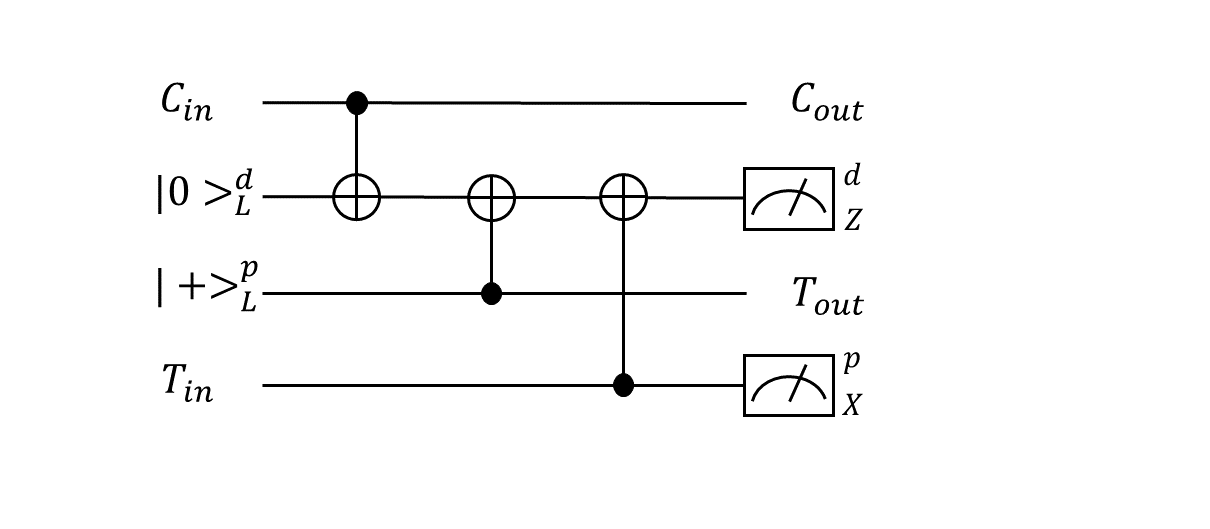
まず、p型欠陥の移動について考えます。下図左に示すようなp型欠陥対があったとします。この欠陥をつなぐ$X$演算子のチェーンを生成元に追加することで論理$X$の固有状態である論理$\ket{+}$を表現することができました(下図中上)。p型欠陥で作った論理$\ket{+}$という意味で$\ket{+}^{p}$という記号でこの状態を表すことにします(図に示したように下付きの添字Lをケットの右に書きたいのですが、、なぜかうまくレンダリングしてくれません、すみません、Lがあるものと思ってください、以下同様)。これを模式的に表したのが下図右上です。ここで縦方向が空間位置を表しており(2次元平面を1次元にマッピングしていると思ってください)、横方向が時間軸を表しています。こうすると$X$チェーンの時間変化はこの時空間における曲面によって表されることになります。欠陥をつなぐ紐が時間軸に沿って移動しながら時空間中をリボンのような軌跡を描いていくというようにイメージしていただければ良いです。一方、欠陥対のどちらかの欠陥を囲む$Z$演算子のループを生成元に追加することで$\ket{0}^{p}$を表現することができます(下図中下)。これを模式的に表したのが下図右下です。この$Z$演算子のループの時間変化もこの時空間上の曲面によって表されます。が、先程と違って欠陥を囲むループ(輪ゴムのようなもの)が時間軸に沿って移動していくのでその軌跡はチューブのような曲面になります。
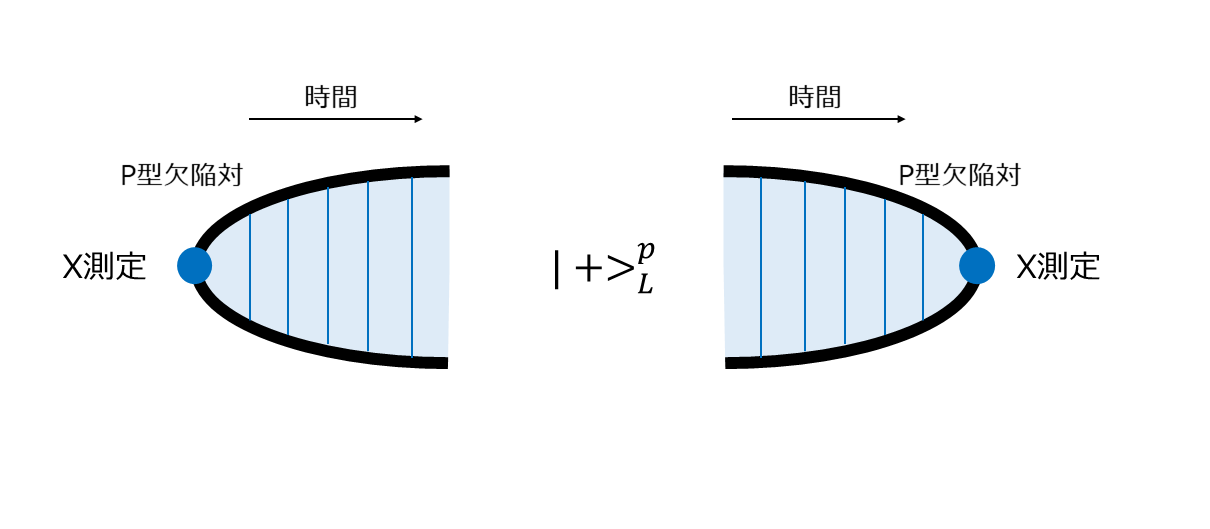
この模式図で欠陥対の生成と測定も表現することができます。p型欠陥対は真空状態のどこか1点(量子ビット)を$X$測定することによって生成させることができました。これは何もない真空からある時どこかで測定が行われ欠陥対が対生成されるような形で模式的に表せます。このように生成された状態は2つの欠陥をつなぐ$X$チェーンの固有状態になっています。そして、この$X$チェーンを測定することで論理ビットとしての値を確定することができますが、その操作を欠陥が対消滅するような図で表現することにします1(下図)。
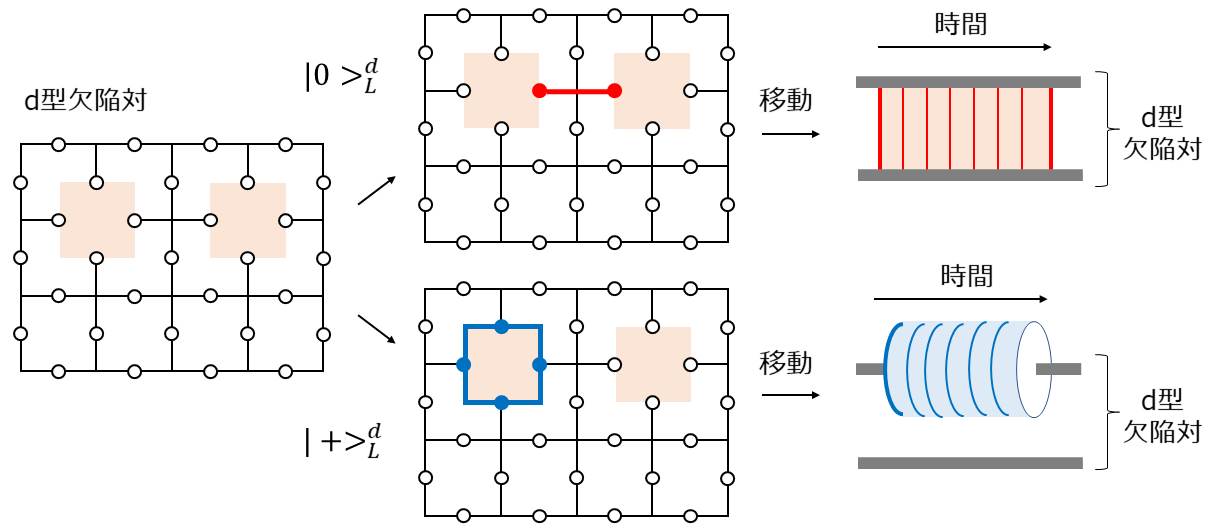
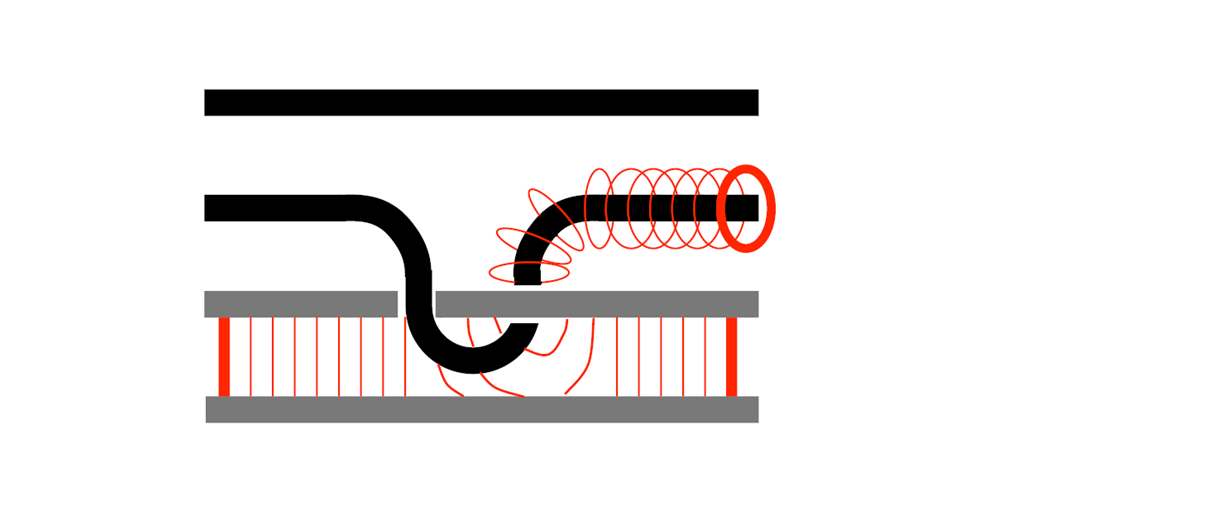
次に、d型欠陥について考えます。$X$演算子と$Z$演算子の立場が逆になるだけでp型とまったく同じイメージなのでサラッといきます。下図左に示すようなd型欠陥対があったとします。この欠陥をつなぐ$Z$演算子のチェーンを生成元に追加することで$\ket{0}^{d}$を表すことができ(下図中上)、この時間変化は模式的に下図右上のような曲面(リボン)で表されます。また、この欠陥対のどちらか一方を囲む$X$演算子のループで$\ket{+}^{d}$を表すことができ(下図中下)、この時間変化は模式的に下図右下のような曲面(チューブ)で表されます。
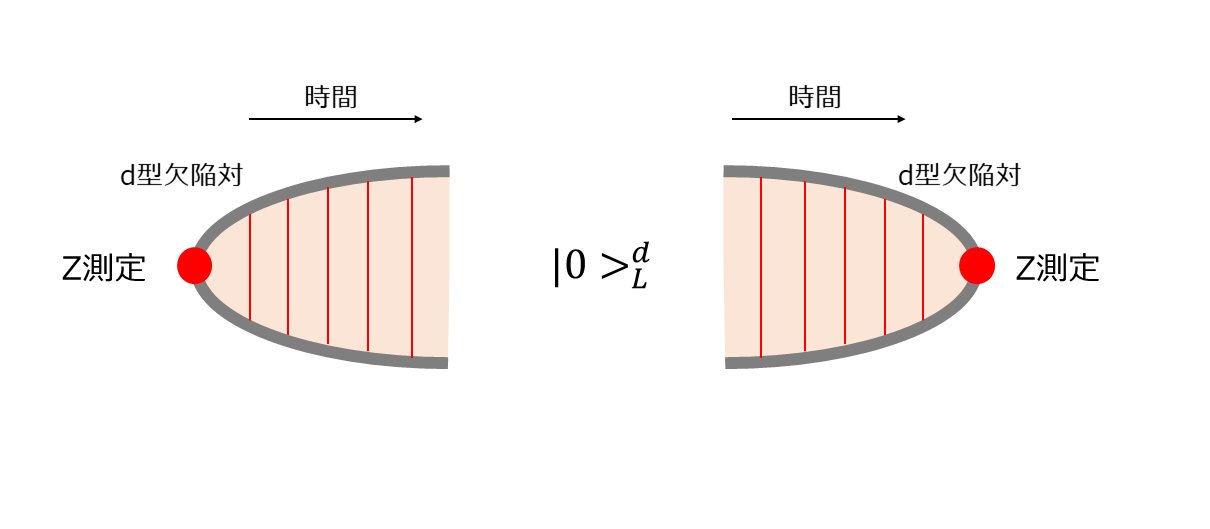
d型欠陥対の生成は、$Z$測定によって真空から対生成されて論理$Z$の固有状態$\ket{0}^{d}$となることで表現できます。最後に$Z$チェーンを測定することで論理ビットとしての値を得ることができますが、この操作を欠陥対が消滅するような図で表現することにします(下図)。
前回のCNOT
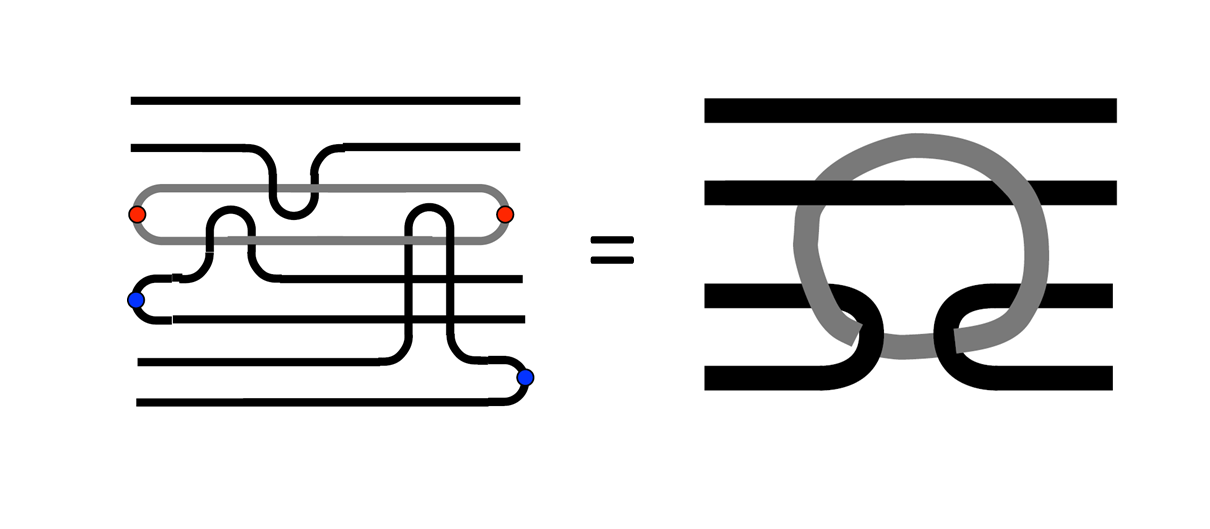
それでは、前回の記事で実現したCNOT演算を、前節で導入した模式図を使って表してみます。下図は、p型欠陥対で論理$X$の固有状態$\ket{+}^{p}$を作成して、その欠陥の片方をd型欠陥に巻きつけた様子を表しています2。p型欠陥をつなぐチェーンがd型欠陥に巻き付いてd型欠陥に新たにチューブ(論理$X$演算子)が現れ、元のp型のリボンはそのままの形を保っています。これは、
X_1 \otimes I_2 \rightarrow X_1 \otimes X_2 \tag{1}という論理演算に対応しています。どうでしょう、わかりますでしょうか。下のd型欠陥を2本の棒だと思ってください。その上にp型欠陥を表すチェーンがあって、それが左から右に移動しながらチェーンの下端が下の棒にぐるっと巻きつくのです。そうするとひとつのチェーンから一つの輪っかが新たに生まれることがイメージできると思います3。
同じ操作を初期状態を変えてやってみたものが下図です。ここではd型欠陥対で論理$Z$演算子の固有状態$\ket{0}^{d}$を作成して、p型欠陥の片方をd型欠陥に巻きつけた様子を表しています。d型欠陥をつなぐチェーンがp型欠陥に巻き取られてp型欠陥に新たにチューブ(論理$Z$演算子)が現れることがわかると思います。元のd型の面はそのままの形を保っています。これは、
I_1 \otimes Z_2 \rightarrow Z_1 \otimes Z_2 \tag{2}という論理演算に対応しています。先程と同じ操作ですが、今度はd型欠陥を表す2本棒の間に薄い膜があって、上のp型欠陥の片方がぐるっとd型の棒に巻き付いてp型欠陥の片方の周りに新たな輪っかが生まれるイメージです。
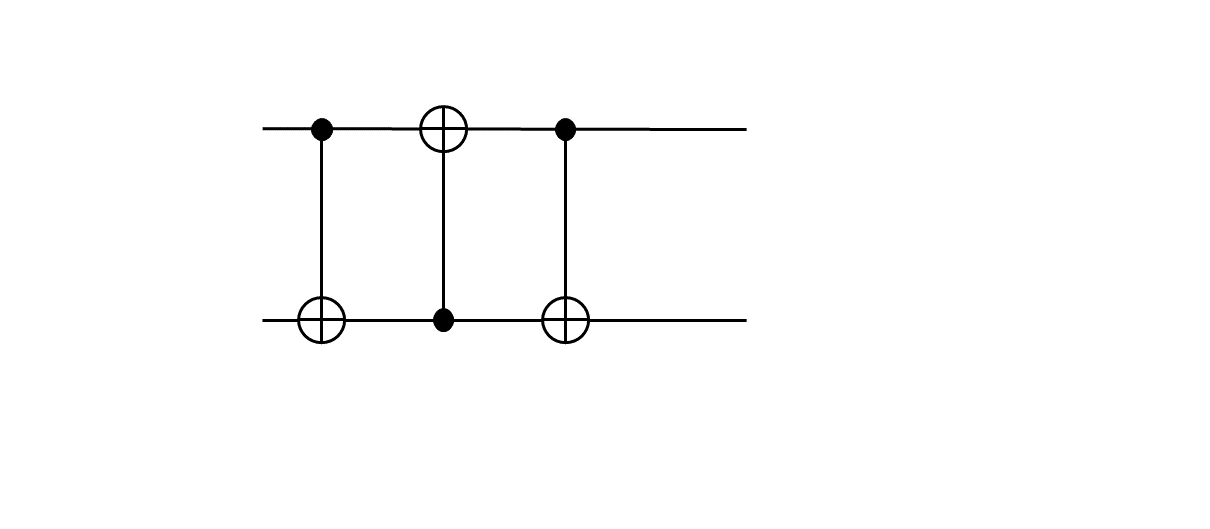
前回の記事では、これでCNOTが実現できた、と言っていました。ところが、これ、よく見ると制御側がp型欠陥で、標的側がd型欠陥になっています。この組み合わせでないとCNOTができません。それで何がマズイの?と言われそうですが、とてもよろしくないです。例えば、
のようなCNOTの組み合わせしかできません。SWAPゲートは代表的な2量子に対するユニタリ演算ですが、
のように書いてみればわかるように、p型欠陥がCNOT演算の制御側にしか使えないのだとすると実現不可能です。一般に任意のN量子ビット状態に対するユニタリ演算は1量子ビットのユニタリ演算と2量子ビットのCNOT演算の積に分解することができます(参考文献4参照)が、特定の量子ビットしか制御ビットにできない(あるいは特定の量子ビットしか標的ビットにできない)という制約があるのだとすると、そのような分解は不可能になります。つまり、欠陥対による表面符号を用いてユニバーサル量子計算を実現するためには、少なくとも制御ビットも標的ビットもp型欠陥であるようなCNOT演算が実現できないといけないということです。
今回のCNOT
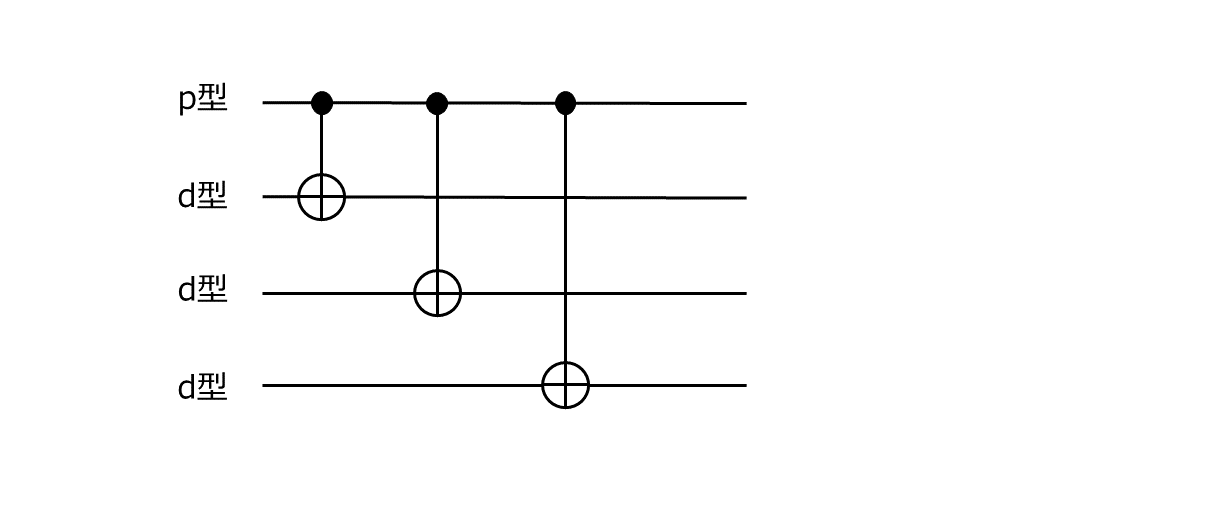
それではそのような制御側も標的側もp型欠陥であるようなCNOT演算はどうやれば実現できるのでしょうか?ともったいぶっても、どうやって導き出したのか正直よくわからないので、参考文献に書いてあった答えをそのまま言います。答えは、以下のようなCNOT演算の等価回路を考えればよろし、です4。
これ自体は表面符号ではない普通の量子回路ですが、上から1番目と3番目と4番目の量子ビットが制御ビットとして使われていて、2番目の量子ビットが標的ビットとして使われているという形になっています。ということなので、これをそのまま表面符号に焼き直して、以下のように1番目と3番目と4番目をp型欠陥として、2番目をd型欠陥とすれば、p型欠陥だけを使ったCNOTが実現できます。
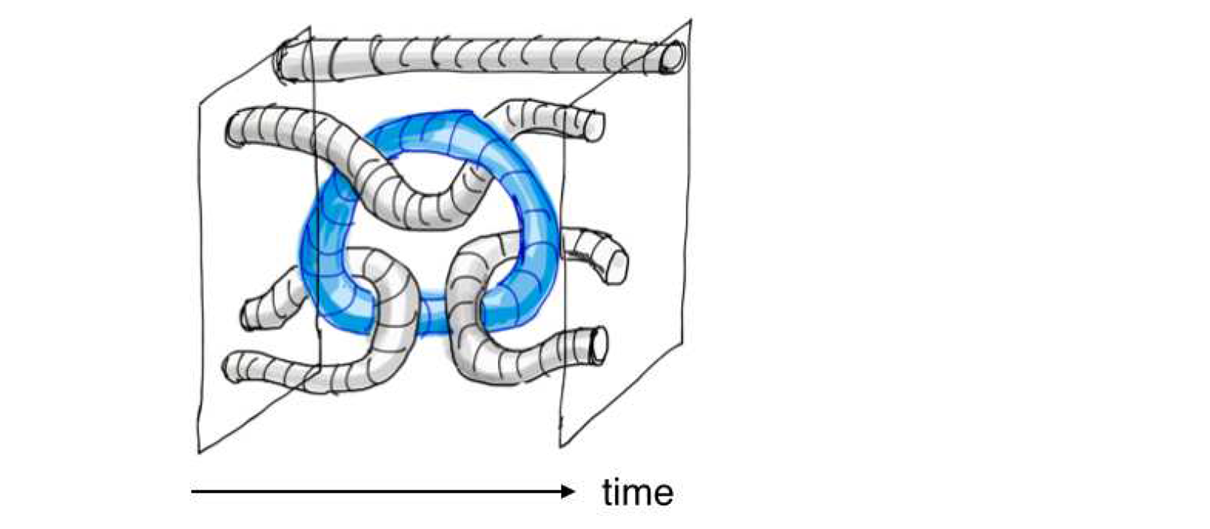
先程説明した模式図で書くと下図左のような形になります。巻きつき方の構造を不変に保ちながらトポロジー的に同値になるように簡単に表現し直すと下図右のようになります。
さらに空間次元は本来2次元だったので、正確に3次元時空間上でトポロジーを表現すると、
となります。どうでしょう。何やら不思議な現代アートのオブジェ風の物体が現れましたが、これが欠陥を用いた表面符号におけるCNOT演算を表しています。
動作確認
それでは量子計算シミュレータqlazyを使って、これで本当にCNOT演算が実現できるのかを確認してみます。前回以上に複雑なBraidingが必要になるのでその分用意すべき平面格子のサイズが大きくなるのですが、クリフォード演算と測定だけで済むのでスタビライザー形式を使えば問題ないです。
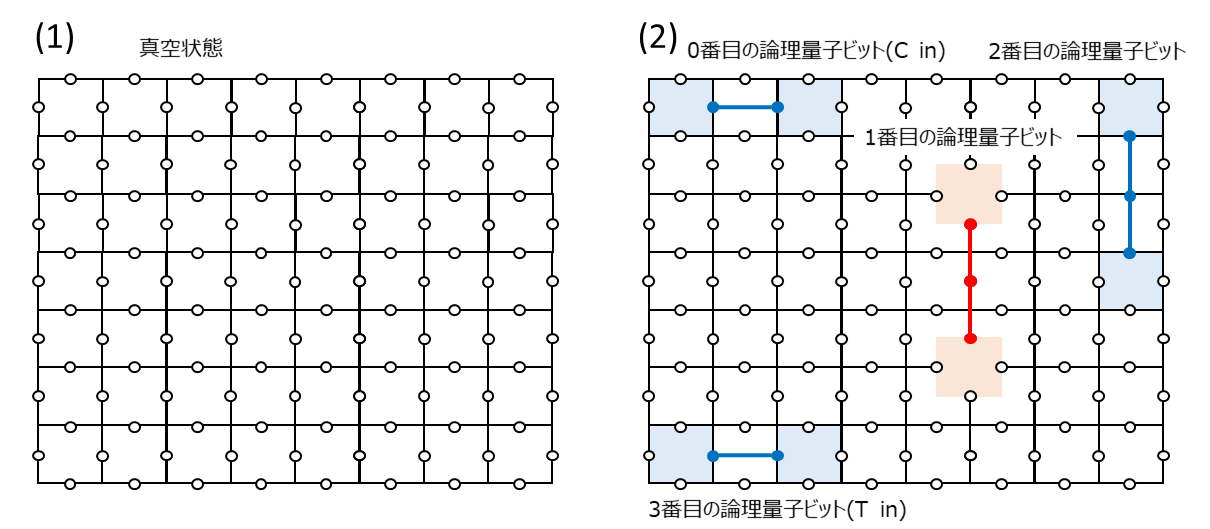
具体的にどういうBraidingを実行するか最初に設計しておきます。欠陥とその動き方が上で説明したトポロジーになっていればどう決めても良いはずなので、とりあえず下図に示すような動き方にしてみました。
まず(1)で真空状態を作成します(面演算子と頂点演算子を格子全体に敷き詰めます)。
(2)で欠陥対を4つ生成します(適当な場所を測定して欠陥を移動させます)。先程示したCNOTの回路図の一番上から量子ビット番号を0番目、1番目、2番目、3番目と名付けて5、それを(2)のように配置します。0番目、2番目、3番目はp型欠陥対で論理$X$の固有状態、1番目はd型欠陥対で論理$Z$の固有状態となります。測定値に応じて論理$Z$または論理$X$演算子を適用することで$+1$の固有状態を用意することができます。
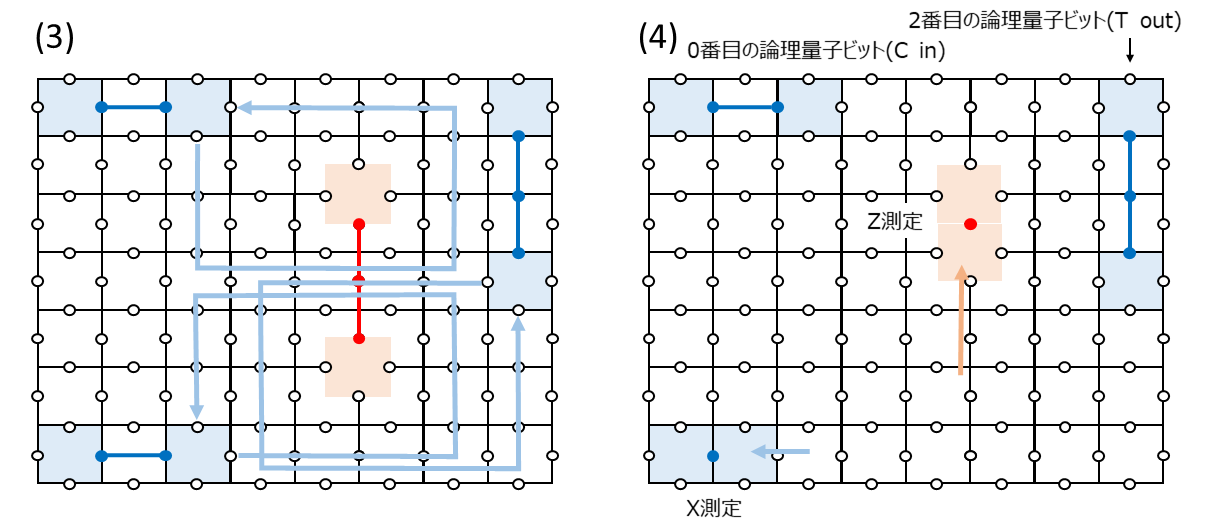
(3)で欠陥をBraidさせます。0番目の欠陥対の片方を1番目の欠陥対の片方に巻きつけて、2番目の欠陥対と3番目の欠陥対の片方を1番目の欠陥対のもう片方に巻きつけます。
(4)で1番目の欠陥対を$Z$測定し、3番目の欠陥対を$X$測定します。
これでCNOTが実現されるはずです。$X$基底で入出力関係を表すなら、
入力側の制御と標的 出力側の制御と標的 $\ket{++}$ $\ket{++}$ $\ket{+-}$ $\ket{-+}$ $\ket{+-}$ $\ket{--}$ $\ket{--}$ $\ket{+-}$ となります6。上の(2)で入力側の制御ビット(0番目の量子ビット)として$\ket{+}$、入力側の標的ビット(3番目の量子ビット)として$\ket{+}$を用意したとすると、この表の1行目から、出力側の制御ビット(0番目の量子ビット)は$\ket{+}$、出力側の標的ビット(2番目の量子ビット)は$\ket{+}$になります。つまり、0番目と2番目の量子ビットを$X$測定すると$100\%$の確率で$(+1,+1)$が観測されるはずです。また、入力側の制御ビットとして$\ket{+}$を用意し、入力側の標的ビット$\ket{+}$に論理$Z$演算子を適用して$\ket{-}$を用意したとすると、この表の2行目から、出力側の制御および標的ビットは$\ket{-}$および$\ket{+}$になります。つまり、0番目と2番目の量子ビットを$X$測定すると$100\%$の確率で$(-1,+1)$が観測されるはずです。同様にこの表の3行目、4行目の入出力関係も確認することができます。
実装
全体のPythonコードを示します。
from collections import Counter from qlazypy import Stabilizer XBASE = {'0':'+', '1':'-'} OBJECT = {'p':'face', 'd':'vertex'} def get_common_qid(obj_A, obj_B): return list(set(obj_A['dat']) & set(obj_B['dat'])) def get_path(pos_A, pos_B): path = [] if pos_A[1] < pos_B[1]: h_list = list(range(pos_A[1], pos_B[1] + 1)) else: h_list = list(reversed(range(pos_B[1], pos_A[1] + 1))) for j in h_list: path.append([pos_A[0], j]) if pos_A[0] < pos_B[0]: v_list = list(range(pos_A[0] + 1, pos_B[0] + 1)) else: v_list = list(reversed(range(pos_B[0], pos_A[0]))) for i in v_list: path.append([i, pos_B[1]]) return path def create_lattice(row, col): face = [[None]*col for _ in range(row)] vertex = [[None]*(col+1) for _ in range(row+1)] q_row = 2 * row + 1 q_col = 2 * col + 1 q_id = 0 for i in range(q_row): for j in range(q_col): if i%2 == 1 and j%2 == 1: # face dat = [] dat.append((i - 1) * q_col + j) # up dat.append((i + 1) * q_col + j) # down dat.append(i * q_col + (j - 1)) # left dat.append(i * q_col + (j + 1)) # right face[i//2][j//2] = {'anc': q_id, 'dat': dat} elif i%2 == 0 and j%2 == 0: # vertex dat = [] if i > 0: dat.append((i - 1) * q_col + j) # up if i < q_row - 1: dat.append((i + 1) * q_col + j) # down if j > 0: dat.append(i * q_col + (j - 1)) # left if j < q_col - 1: dat.append(i * q_col + (j + 1)) # right vertex[i//2][j//2] = {'anc': q_id, 'dat': dat} q_id += 1 return {'face': face, 'vertex': vertex} def initialize(sb, lattice): i = 0 # generator id for face_list in lattice['face']: for face in face_list: [sb.set_pauli_op(i, q, 'Z') for q in face['dat']] i += 1 sb.set_pauli_op(i, face['anc'], 'Z') i += 1 for vertex_list in lattice['vertex']: for vertex in vertex_list: [sb.set_pauli_op(i, q, 'X') for q in vertex['dat']] i += 1 sb.set_pauli_op(i, vertex['anc'], 'Z') i += 1 def get_chain(pos_list, dtype, lattice): chain = [] for i in range(1,len(pos_list)): pos_A = pos_list[i-1] pos_B = pos_list[i] chain.append(get_common_qid(lattice[OBJECT[dtype]][pos_A[0]][pos_A[1]], lattice[OBJECT[dtype]][pos_B[0]][pos_B[1]])[0]) return chain def move_defect(sb, pos_A, pos_B, path, dtype, lattice, create=False, annihilate=False): obj = OBJECT[dtype] if create == True: obj_A = lattice[obj][pos_A[0]][pos_A[1]] obj_B = lattice[obj][pos_B[0]][pos_B[1]] q = get_common_qid(obj_A, obj_B)[0] if dtype == 'p': md = sb.mx(qid=[q]) if md.last == '1': [sb.z(i) for i in obj_B['dat']] elif dtype == 'd': md = sb.m(qid=[q]) if md.last == '1': [sb.x(i) for i in obj_B['dat']] chain = get_chain(get_path(pos_A, pos_B), dtype, lattice) for i in range(1,len(path)): # extend defect obj_A = lattice[obj][path[i-1][0]][path[i-1][1]] obj_B = lattice[obj][path[i][0]][path[i][1]] q = get_common_qid(obj_A, obj_B)[0] if dtype == 'p': md = sb.mx(qid=[q]) if md.last == '1': [sb.z(i) for i in obj_B['dat']] elif dtype == 'd': md = sb.m(qid=[q]) if md.last == '1': [sb.x(i) for i in obj_B['dat']] # remove defect sb.h(obj_A['anc']) if dtype == 'p': [sb.cz(obj_A['anc'], target) for target in obj_A['dat']] elif dtype == 'd': [sb.cx(obj_A['anc'], target) for target in obj_A['dat']] sb.h(obj_A['anc']) md = sb.m(qid=[obj_A['anc']]) if md.last == '1': if dtype == 'p': [sb.x(i) for i in chain] elif dtype == 'd': [sb.z(i) for i in chain] sb.x(obj_A['anc']) chain.append(q) if annihilate == True: obj_A = lattice[obj][pos_A[0]][pos_A[1]] obj_B = lattice[obj][path[-1][0]][path[-1][1]] q = get_common_qid(obj_A, obj_B)[0] if dtype == 'p': md = sb.mx(qid=[q]) elif dtype == 'd': md = sb.m(qid=[q]) return md.last return None def measure_logical_X(sb, chain_A, chain_B, shots=1): mval_list = [] for _ in range(shots): sb_tmp = sb.clone() mval_A = sb_tmp.mx(qid=chain_A).last mval_B = sb_tmp.mx(qid=chain_B).last mval_A_bin = str(sum([int(s) for s in list(mval_A)])%2) mval_B_bin = str(sum([int(s) for s in list(mval_B)])%2) mval = (XBASE[mval_A_bin] + XBASE[mval_B_bin]) mval_list.append(mval) sb_tmp.free() return Counter(mval_list) def operate_logical_Z(sb, lq, lattice): if lq == 0: face = lattice['face'][0][0] elif lq == 2: face = lattice['face'][0][7] elif lq == 3: face = lattice['face'][6][0] [sb.z(q) for q in face['dat']] def operate_logical_cnot(lq, shots=5): # set lattice lattice_row, lattice_col = 7, 8 lattice = create_lattice(lattice_row, lattice_col) # make vacuum state qubit_num = (2 * lattice_row + 1) * (2 * lattice_col + 1) sb = Stabilizer(qubit_num=qubit_num, gene_num=qubit_num+1) initialize(sb, lattice) # set logical qubit #0 p0_pos_A, p0_pos_B = [0,0], [0,1] p0_path = [[0,1],[0,2]] move_defect(sb, p0_pos_A, p0_pos_B, p0_path, 'p', lattice, create=True) if lq[0] == '-': operate_logical_Z(sb, 0, lattice) # set logical qubit #1 d1_pos_A, d1_pos_B = [2,5], [3,5] d1_path = [[3,5],[4,5],[5,5]] move_defect(sb, d1_pos_A, d1_pos_B, d1_path, 'd', lattice, create=True) # set logical qubit #2 p2_pos_A, p2_pos_B = [0,7], [1,7] p2_path = [[1,7],[2,7],[3,7]] move_defect(sb, p2_pos_A, p2_pos_B, p2_path, 'p', lattice, create=True) # set logical qubit #3 p3_pos_A, p3_pos_B = [6,0], [6,1] p3_path = [[6,1],[6,2]] move_defect(sb, p3_pos_A, p3_pos_B, p3_path, 'p', lattice, create=True) if lq[1] == '-': operate_logical_Z(sb, 3, lattice) # braid logical qubit #0 p0_pos_A, p0_pos_B = [0,0], [0,2] p0_path = [[0,2],[1,2],[2,2],[3,2],[3,3],[3,4],[3,5],[3,6], [2,6],[1,6],[0,6],[0,5],[0,4],[0,3],[0,2]] move_defect(sb, p0_pos_A, p0_pos_B, p0_path, 'p', lattice) # braid logical qubit #2 p2_pos_A, p2_pos_B = [0,7], [3,7] p2_path = [[3,7],[3,6],[3,5],[3,4],[3,3],[4,3],[5,3], [6,3],[6,4],[6,5],[6,6],[6,7],[5,7],[4,7],[3,7]] move_defect(sb, p2_pos_A, p2_pos_B, p2_path, 'p', lattice) # braid and annihilate logical qubit #3 p3_pos_A, p3_pos_B = [6,0], [6,2] p3_path = [[6,2],[6,3],[6,4],[6,5],[6,6],[5,6],[4,6],[3,6], [3,5],[3,4],[3,3],[3,2],[4,2],[5,2],[6,2],[6,1]] mval_p = move_defect(sb, p3_pos_A, p3_pos_B, p3_path, 'p', lattice, annihilate=True) # braid and annihilate logical qubit #1 d1_pos_A, d1_pos_B = [2,5], [5,5] d1_path = [[5,5],[4,5],[3,5]] mval_d = move_defect(sb, d1_pos_A, d1_pos_B, d1_path, 'd', lattice, annihilate=True) if mval_p == '1': operate_logical_Z(sb, 0, lattice) operate_logical_Z(sb, 2, lattice) # measure logical qubits: #0 and #2 chain_0 = get_chain(get_path([0,0],[0,2]), 'p', lattice) chain_2 = get_chain(get_path([0,7],[3,7]), 'p', lattice) freq = measure_logical_X(sb, chain_0, chain_2, shots=shots) print("Input('{0:}') == [CNOT] ==> {1:}".format(lq, freq)) sb.free() if __name__ == '__main__': operate_logical_cnot('++', shots=10) # --> '++' operate_logical_cnot('+-', shots=10) # --> '--' operate_logical_cnot('-+', shots=10) # --> '-+' operate_logical_cnot('--', shots=10) # --> '+-'結構長くなってしまったので、ざっくり説明します。operate_logical_cnot関数が今回のメイン部分になります。第1引数として入力状態を文字列(’++’, '+-', '-+', '--')で与え、第2引数に測定回数を整数値で与えることで、測定結果を表示します。
operation_logical_cnot関数の中身を見てください。
# set lattice lattice_row, lattice_col = 7, 8 lattice = create_lattice(lattice_row, lattice_col)で、格子の縦横のサイズを上図で説明したように$7 \times 8$に設定して格子データをcreate_lattice関数で作成します。これは前回の記事と同じなので説明省略します。
# make vacuum state qubit_num = (2 * lattice_row + 1) * (2 * lattice_col + 1) sb = Stabilizer(qubit_num=qubit_num, gene_num=qubit_num+1) initialize(sb, lattice)で、作成した格子に対応した量子ビット数と生成元数をスタビライザーのコンストラクタStabilizerに与えてインスタンスsbを作成します。そしてinitialize関数でそれを真空状態にします。つまり、面演算子と頂点演算子を格子全体に敷き詰めます。詳細は上の関数定義を見てください。sbのset_pauli_opメソッドを使って$X$または$Z$演算子を各量子ビットにセットしているだけです。
# set logical qubit #0 p0_pos_A, p0_pos_B = [0,0], [0,1] p0_path = [[0,1],[0,2]] move_defect(sb, p0_pos_A, p0_pos_B, p0_path, 'p', lattice, create=True) if lq[0] == '-': operate_logical_Z(sb, 0, lattice)で、0番目の論理量子ビットを生成します。move_defect関数で、面演算子の座標[0,0],[0,1]の境界にある量子ビットを$X$測定してp型欠陥を対生成して、[0,1]の欠陥を座標[0,2]に移動する処理を行っています。move_defect関数のcreateオプションをTrueにすると生成とその後の移動を実行します。False(デフォルト)の場合、生成しないで(すでに生成されていると見なして)移動だけを実行します。また、後で出てきますがannihilateオプションというのもあってこれにTrueを指定すると、移動した後(欠陥対が隣接しているものと見なして)測定を行います。make_defect関数の詳細については関数定義を見てください。これで論理的な$\ket{+}$が実現されます。最後のif lq[0] == '-'というのはoperate_logical_cnot関数に与えられた0番目の入力状態が'-'だった場合、論理$Z$演算子をかけて反転させる操作です。operate_logical_Z関数の詳細についても関数定義を見てください。
# set logical qubit #1 d1_pos_A, d1_pos_B = [2,5], [3,5] d1_path = [[3,5],[4,5],[5,5]] move_defect(sb, d1_pos_A, d1_pos_B, d1_path, 'd', lattice, create=True) # set logical qubit #2 p2_pos_A, p2_pos_B = [0,7], [1,7] p2_path = [[1,7],[2,7],[3,7]] move_defect(sb, p2_pos_A, p2_pos_B, p2_path, 'p', lattice, create=True) # set logical qubit #3 p3_pos_A, p3_pos_B = [6,0], [6,1] p3_path = [[6,1],[6,2]] move_defect(sb, p3_pos_A, p3_pos_B, p3_path, 'p', lattice, create=True) if lq[1] == '-': operate_logical_Z(sb, 3, lattice)で。1番目、2番目、3番目の論理量子ビットを生成します。これで初期状態が出来上がりました。
# braid logical qubit #0 p0_pos_A, p0_pos_B = [0,0], [0,2] p0_path = [[0,2],[1,2],[2,2],[3,2],[3,3],[3,4],[3,5],[3,6], [2,6],[1,6],[0,6],[0,5],[0,4],[0,3],[0,2]] move_defect(sb, p0_pos_A, p0_pos_B, p0_path, 'p', lattice)で、0番目の論理量子ビット(p型欠陥)を1番目の論理量子ビット(d型欠陥)に巻きつけます。
# braid logical qubit #2 p2_pos_A, p2_pos_B = [0,7], [3,7] p2_path = [[3,7],[3,6],[3,5],[3,4],[3,3],[4,3],[5,3], [6,3],[6,4],[6,5],[6,6],[6,7],[5,7],[4,7],[3,7]] move_defect(sb, p2_pos_A, p2_pos_B, p2_path, 'p', lattice)で、2番目の論理量子ビット(p型欠陥)を1番目の論理量子ビット(d型欠陥)に巻きつけます。
# braid and annihilate logical qubit #3 p3_pos_A, p3_pos_B = [6,0], [6,2] p3_path = [[6,2],[6,3],[6,4],[6,5],[6,6],[5,6],[4,6],[3,6], [3,5],[3,4],[3,3],[3,2],[4,2],[5,2],[6,2],[6,1]] mval_p = move_defect(sb, p3_pos_A, p3_pos_B, p3_path, 'p', lattice, annihilate=True)で、3番目の論理量子ビット(p型欠陥)を1番目の論理量子ビット(d型欠陥)に巻きつけて、最後に消滅させます。move_defect関数は消滅時の測定値をリターンするようになっているのでそれをmval_pとして保持しておきます(後で使います)。
# braid and annihilate logical qubit #1 d1_pos_A, d1_pos_B = [2,5], [5,5] d1_path = [[5,5],[4,5],[3,5]] mval_d = move_defect(sb, d1_pos_A, d1_pos_B, d1_path, 'd', lattice, annihilate=True)で、1番目の論理量子ビット(d型欠陥)を測定します。測定値をmval_dとしておきます。
if mval_p == '1': operate_logical_Z(sb, 0, lattice) operate_logical_Z(sb, 2, lattice)で、mval_p(3番目の論理量子ビットの消滅時の測定値)の値が-1だった場合(測定指標としては1)だった場合、最後の0番目と2番目の論理量子ビットを反転させます。
# measure logical qubits: #0 and #2 chain_0 = get_chain(get_path([0,0],[0,2]), 'p', lattice) chain_2 = get_chain(get_path([0,7],[3,7]), 'p', lattice) freq = measure_logical_X(sb, chain_0, chain_2, shots=shots) print("Input('{0:}') == [CNOT] ==> {1:}".format(lq, freq))で、CNOT演算になっているか確認するため、0番目の論理量子ビットと2番目の論理量子ビットを$X$測定します。両方p型欠陥なので欠陥をつなぐ$X$演算子のチェーンを測定すれば良いです。measure_logical_X演算子でそれを実行しています。測定結果はCounter形式でfreqに格納されるので、最後に表示します。以上です。
結果
実行結果は以下の通りです。
Input('++') == [CNOT] ==> Counter({'++': 10}) Input('+-') == [CNOT] ==> Counter({'--': 10}) Input('-+') == [CNOT] ==> Counter({'-+': 10}) Input('--') == [CNOT] ==> Counter({'+-': 10})4つの入力パターンのすべてについて、$100\%$の確率で正しいCNOT演算の結果が得られました。
おわりに
こんなBraidingで論理演算ができるのはとても面白いのですが、実際のハードウェア上で実装しようとすると結構大変です。大量な欠陥が格子平面上にあってそれら欠陥同士を巻きつける演算を実施しないといけないのですが、初期配置や巻きつけ方は一通りではないですし、そもそも大量の欠陥を前にして下手な実装をすると回路=プログラムがスパゲッティ状態になりかねません(というか、スパゲッティ状態にすることで論理演算ができるのでした、うーむ)。おそらくこのあたり、コンパイラの役割なので一般人は気にすることはないのかもしれませんが、これからコンパイラを作ろうっていう人にとっては大問題ですね。やはりBraidingよりもLattice Surgeryの方がスッキリしていて見通しが良いのでしょうか(未勉強ですが)。
ということを本記事の下書きを書きながらツラツラ考えていたら、以下のような発表がありました。
- 量子コンピュータの小型化・高速化を実現する回路圧縮手法を開発−ソフトウエア新技術で大規模量子コンピュータ開発を加速化−
- Effective Compression of Quantum Braided Circuits Aided by ZX-Calculus
Lattice SurgeryではなくBraidingをベースにしてZX calculusというものを使うことで効率的に回路圧縮ができるそうです(なんと)。要チェックかもしれません!(が、その前にやることが、、)
以上
ここで欠陥対が消滅してしまう印象をもってしまうかもしれませんが、論理量子ビットの固有値が+1か-1に確定するだけで、真空状態に戻るのではないと思います(多分)。真空状態に戻すためには、2つの欠陥を隣接させておいてどちらかの面演算子($Z$演算子のループ)を測定しないといけないと思います(間違っていたらご指摘ください)。p型欠陥対の片方の周囲に置かれた$Z$演算子で論理$Z$演算子の固有状態を表すことができますが、このときもこれを測定しても欠陥が消滅するわけではありません(と思います)。 ↩
参考文献3にあった図の引用です。本記事の他の箇所でもいくつか引用させていただきました。藤井先生のこのスライドはトポロジカルな図がたくさん掲載されていてわかりやすいです。おすすめです! ↩
この様子を動画で説明できればよりわかりやすいと思うのですが、すみません、当方動画制作の素養がありません。頑張って頭の中で動画作成してみてください。 ↩
これ、確かにCNOTになっているのですが、大丈夫でしょうか。スタビライザー形式で入出力を考えてみればわかりやすいと思います。つまり、入力が$X \otimes I$のときに出力が$X \otimes X$になっているとか、入力が$I \otimes Z$のときに出力が$Z \otimes Z$になっている等々を確認すれば確かにCNOTだね、ということがわかります。ただし、注意すべき点が一つあります。4番目のp型欠陥を消滅させたときの測定値が-1だった場合、1番目と3番目の論理量子ビットを反転($\ket{+}$を$\ket{-}$に$\ket{-}$を$\ket{+}$に反転)させる必要があります。スタビライザー形式の計算を注意深くやるとわかります。 ↩
プログラム実装の都合により量子ビット番号は0番目からはじめることにします。理論説明の際には1番目から始めた方が説明しやすいので本ブログでもほぼそうしていますが、大抵のプログラミング言語では配列のインデックスは0番目から始まります(FORTRANは確か配列のインデックスは1番目からだったと思いますが)。ときどき混乱しますが慣れるしかないですね。 ↩
これは大丈夫でしょうか。スタビライザー形式で考えてみればすぐにわかると思います。表の1行目は$<XI,IX> \rightarrow <XX, IX> = <XI,IX>$、2行目は$<XI,-IX> \rightarrow <-XX, IX> = <-XI, IX>$等々、を表しています。 ↩
- 投稿日:2020-11-20T19:27:48+09:00
【Python】スクレイピングでデータを取得し、リストに入れる時の注意点
スクレイピングをするときの注意点
自分が沼にはまった時の対応です。test.pyfor s in name: name_list=[] name_list.append(s.string)このコードの問題点はname_listの位置です。
この位置だと毎回name_listの中身が更新されます。
つまりforで回しているが、結局nameの一番最後の要素しか
name_listにappendされません。ということで、name_listの位置を変えましょう。
test.pyname_list=[] for s in name: name_list.append(s.string)name_listをforの外に出すことで、nameの要素を順番に取得して、
appendするというコードになります。特に私はまず1P、1要素スクレイピングできるか試してから、全体のスクレイピングを
行うので、そもそもテスト段階ではforをほとんど使いません。その為、いざ全体のスクレイピングを行う際に空のリストの位置を間違えると
このようなことになります。
- 投稿日:2020-11-20T17:40:06+09:00
kerasのConv2D(2次元畳み込み層)について調べてみた
やりたいこと
- kerasのConv2Dを理解したい
- それにより下記のようなコードを理解したい(それぞれの関数が何をやっているのか?や引数の意味を説明できるようになりたい)。
from keras import layers, models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
- そして画像分類モデルをpythonで実装したい(犬の写真と猫の写真を判別できるなど)
この記事を読んで理解できること
- 「畳み込みって何ですか?」がざっくりわかる。
- 「kerasのConv2D関数に渡す引数の値はどうやって決めればいいですか?」がざっくり分かる。
- 「カーネル」「フィルタ」「ストライド」の意味が理解できる。
Conv2Dとは?
「keras Conv2D」で検索すると「2次元畳み込み層」と出てくる。
では「2次元畳み込み層」とは何なのか?
なお「1次元畳み込みニューラルネットワーク」という言葉もある。
よって「1次元と2次元はどう違うのか?」を理解する前提として、
「畳み込みニューラルネットワーク」や「畳み込み」を理解する必要がある。CNNとは?
Convolutional Neural Network のこと。
Convolutional : 畳み込み
Neural Network : ニューラルネットワークなので、CNNは「畳み込みニューラルネットワーク」である。
CNNについて理解を深める参考情報
https://www.atmarkit.co.jp/ait/articles/1804/23/news138.html
によると下記の通り。
- 「画像の深層学習」と言えばCNNというくらいメジャーな手法である。CNNはConvolutional Neural Networkの頭文字を取ったもので、ニューラルネットワークに「畳み込み」という操作を導入したものである。
- 畳み込み(convolution)とは、カーネル(またはフィルタ)と呼ばれる格子状の数値データと、カーネルと同サイズの部分画像(ウィンドウと呼ぶ)の数値データについて、要素ごとの積の和を計算することで、1つの数値に変換する処理のことである。この変換処理を、ウィンドウを少しずつずらして処理を行うことで、小さい格子状の数値データ(すなわちテンソル)に変換する。
基本的な考え方
そもそも「画像」とは何か?
jpgなどの画像ファイルは、横(width)と縦(height)、それぞれピクセル数が決まっている。
たとえば、width:300px で height:200px の写真があるとする。
1個のピクセルを■(正方形)で表現するならば
その写真は、300 x 200 = 60000個の■を並べたものである。
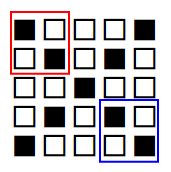
なので、width:5px かつ height:5px で、計25個の■が存在する場合は、下図のようになる。
さらに白黒写真の場合、
- それぞれの■がブラックまたはホワイトのいずれかである
- ブラックを■(黒塗り)で表現し、ホワイトを□(白抜き)で表現する
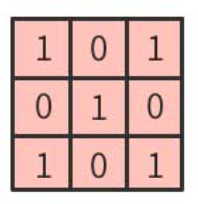
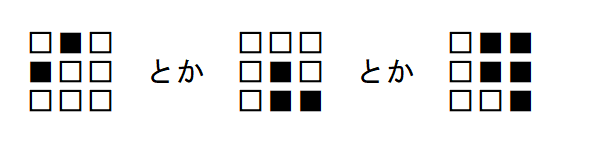
ならば「白背景に黒文字で×(バツ)を描く」場合、下図のようになる。
同様に、プラス記号(+)なら、
であり、マイナス記号(―)なら、
であり、イコール記号(=)なら、
である。
「小さな区分に着目して特徴を調べる」という考え方
白背景に黒文字でバツ
という画像データに対して「小さな区分に着目して特徴を調べる」とどうなるか?
たとえば赤枠および青枠で囲った部分に着目してみる。
この領域は、いずれも
である。つまり「赤枠部分と青枠部分は特徴が同じである」ということが分かる。
ここで、
のような「特徴を示すデータ(特徴検出器)」のことを
カーネル
と呼ぶ(フィルタと呼んだりもする。意味は同じである)。
言い換えると「5 x 5」の元画像の特徴を把握したければ、
元画像を細かく分割して、それぞれを「2 x 2」のカーネルと比較していけばよい、ということである。
これが「画像を判定する」とか「画像の特徴や他画像との違いを識別する」という考え方になる。「畳み込み」とは何か?
Conv2Dを理解するためには「2次元畳み込み層」を理解する必要がある。
そのためには、まず「畳み込み層」を理解する必要がある。
では「畳み込み」とは何なのか?ざっくり言うと、下記のとおり。
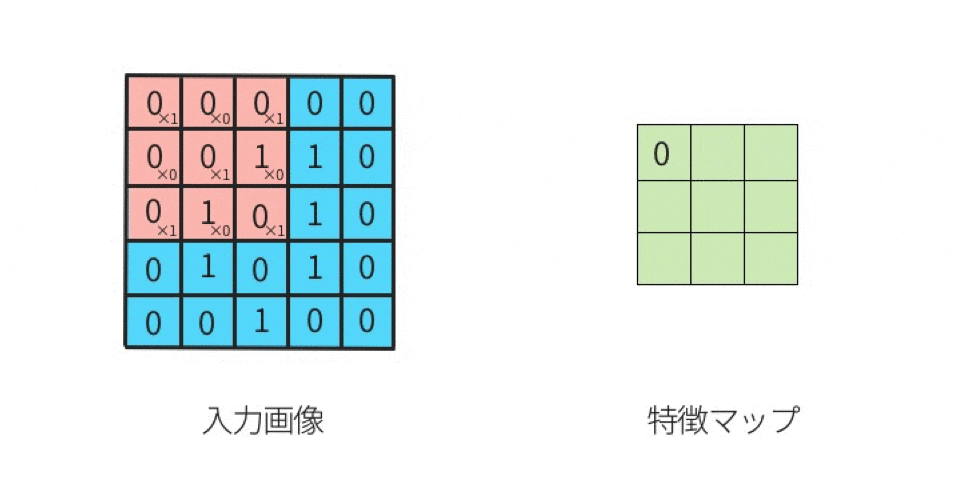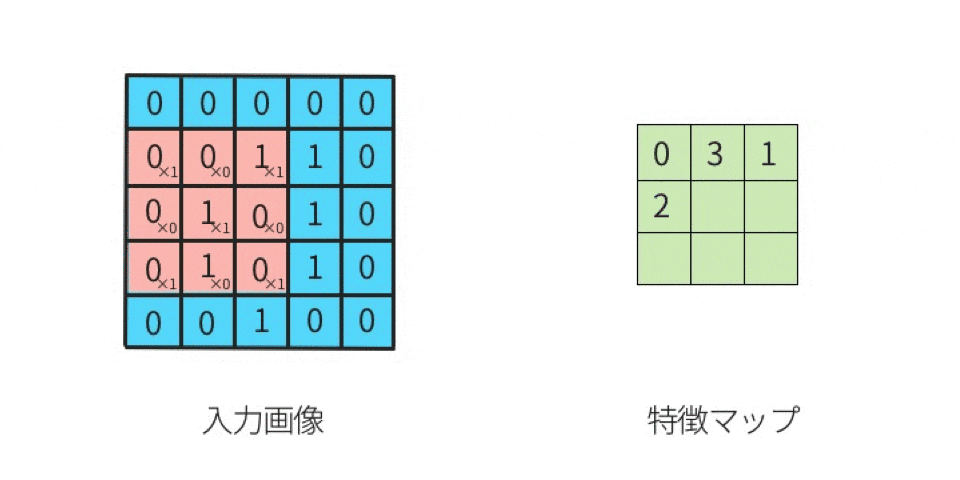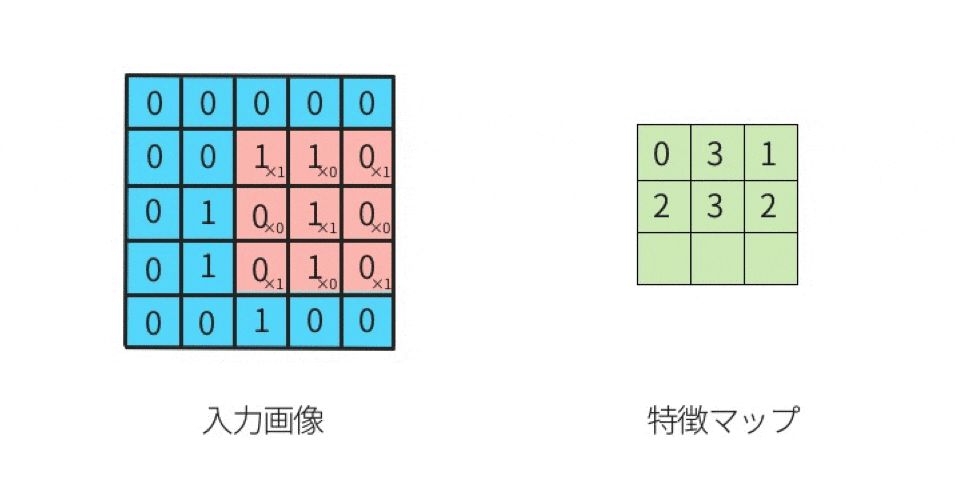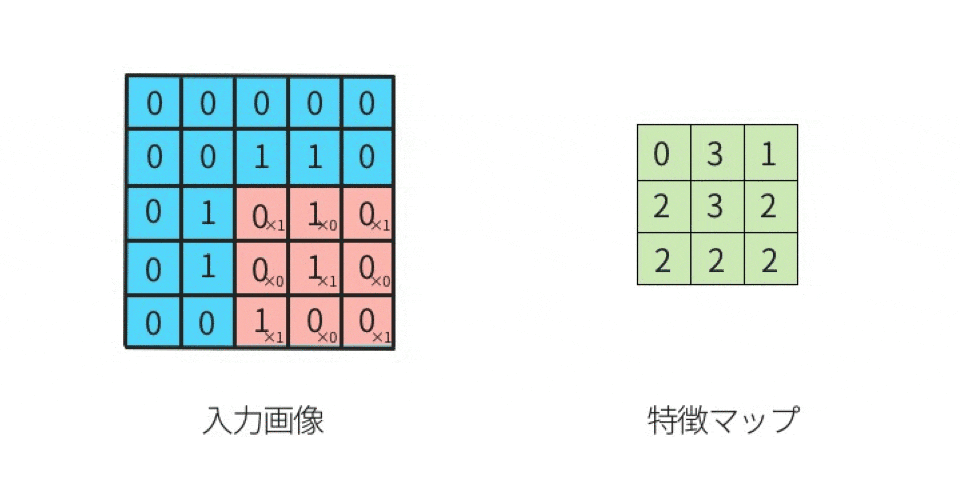
- 元画像とカーネル(フィルタ)を比較して計算し、その計算(行列演算)結果を出力して並べていく処理のことを「畳み込み」という。
- 畳み込んだ出力結果を「特徴マップ」と呼ぶことがある。
- 畳み込みによって出力されたデータは、元画像のデータよりも小さくなる。
5 x 5 の元画像と 3 x 3 のカーネル(フィルタ)で「畳み込み」をした出力結果(特徴マップ)は 9マス(3 x 3) になる
5 x 5 の元画像に対して、3 x 3 のカーネルで畳み込みを実行する場合、
1マスずつズラしていく(このことを「ストライド(ズラすピクセル数)が1である」という)
なら、合計9回の行列計算を実施することになる。
そのため、計算結果を出力して並べたら、9回分つまり「特徴マップは9マス」となる。
赤枠はカーネルと比較する対象、つまり「着目する領域(ウインドウ、と呼んだりする)」である。
元画像の左上から右下へ向かって1マス(1ピクセル)ずつズラして行列演算を繰り返していく。
この場合、9回の演算を実施するので、特徴マップは9マス(3 x 3)になる。
1ピクセルずつズラして計算することを「ストライドが1である」という。
2ピクセルずつズラして計算するならを「ストライドが2である」という。具体的な計算例
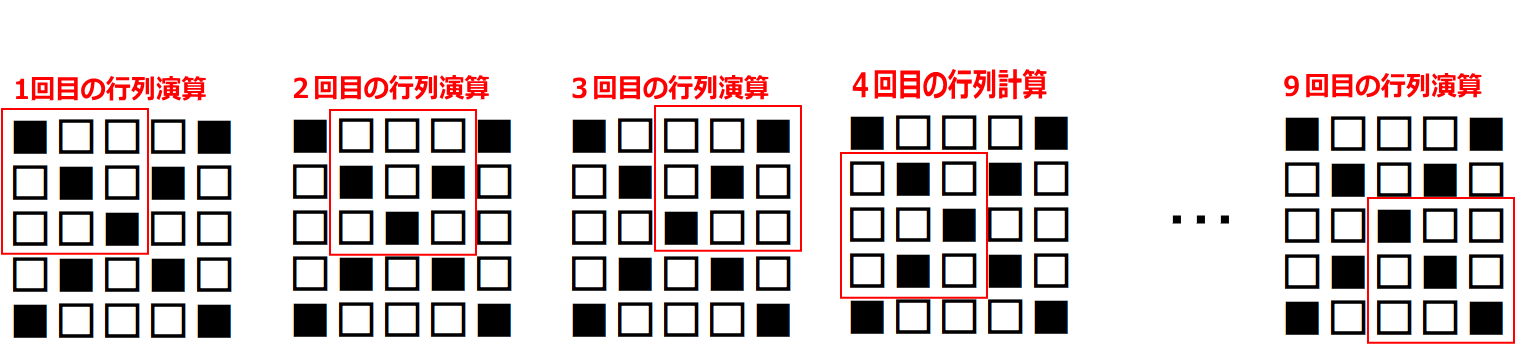
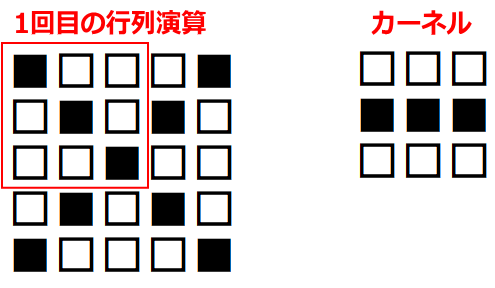
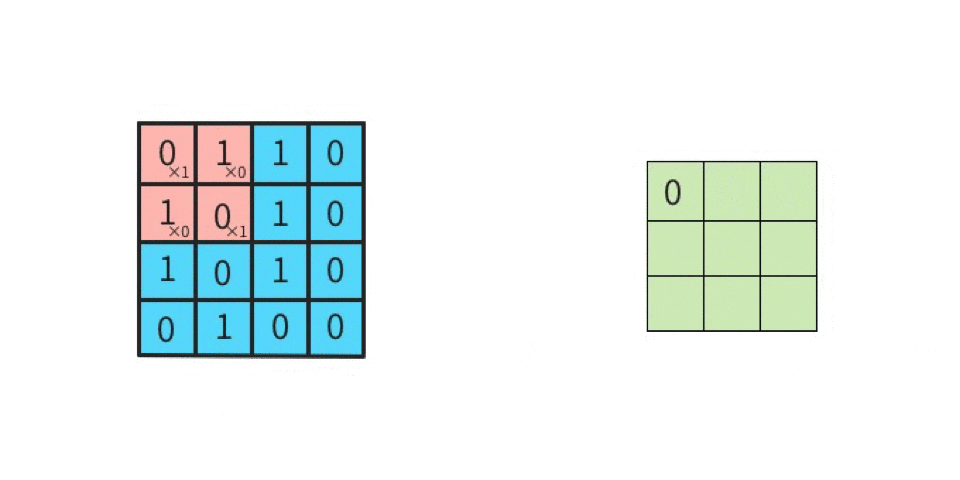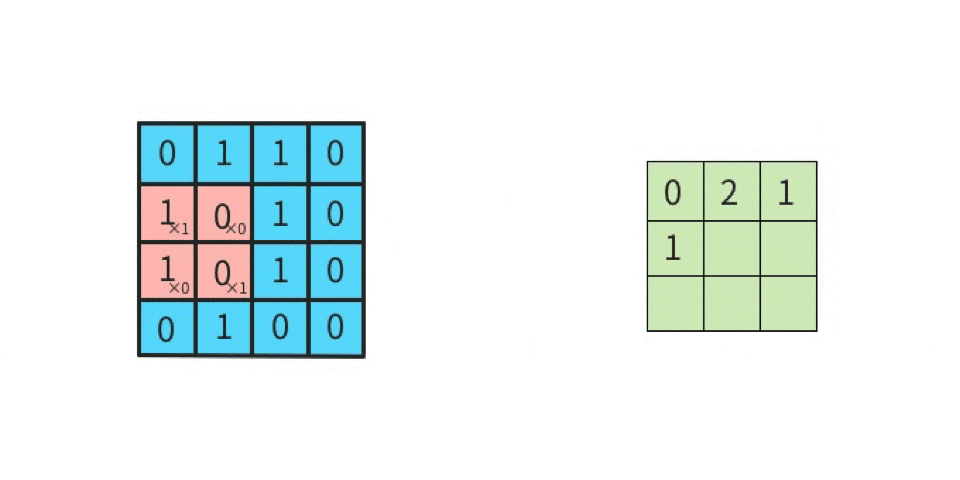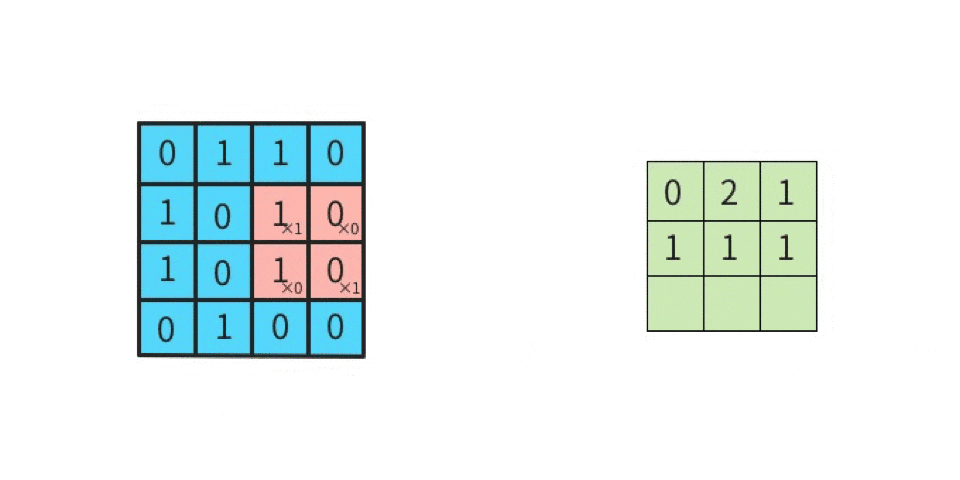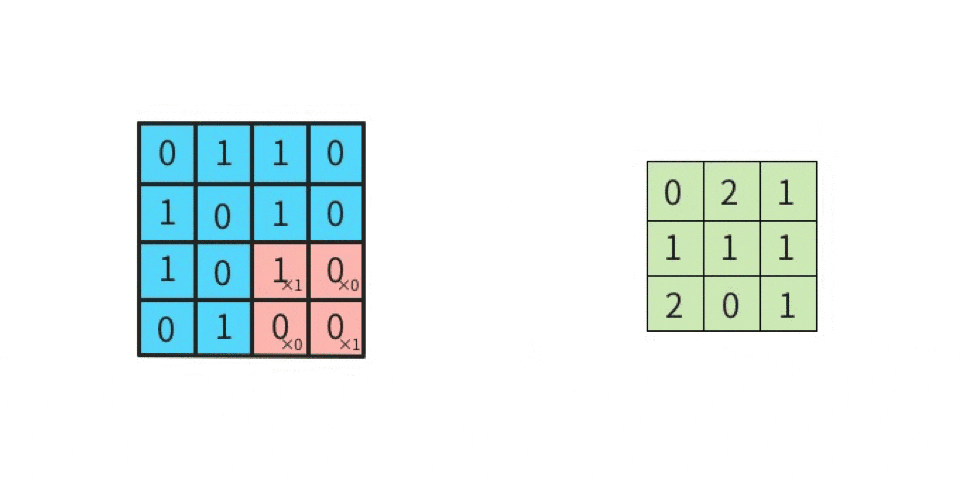
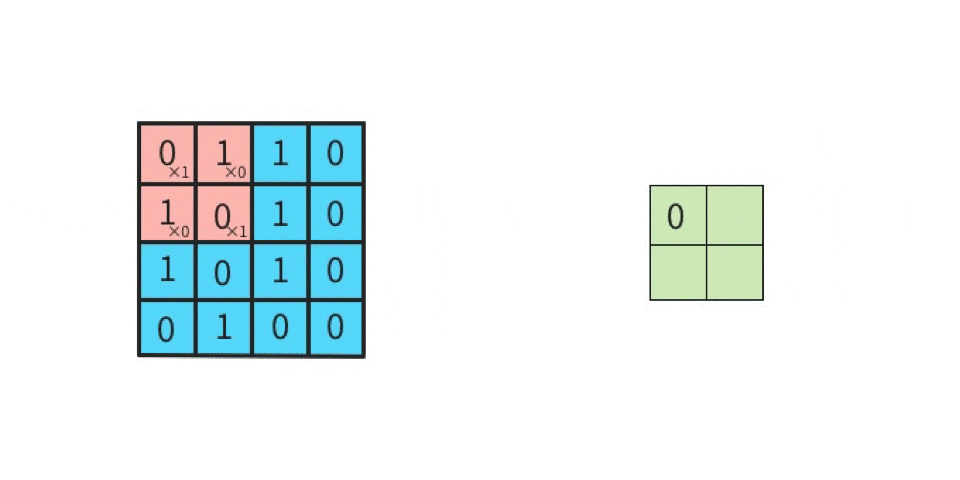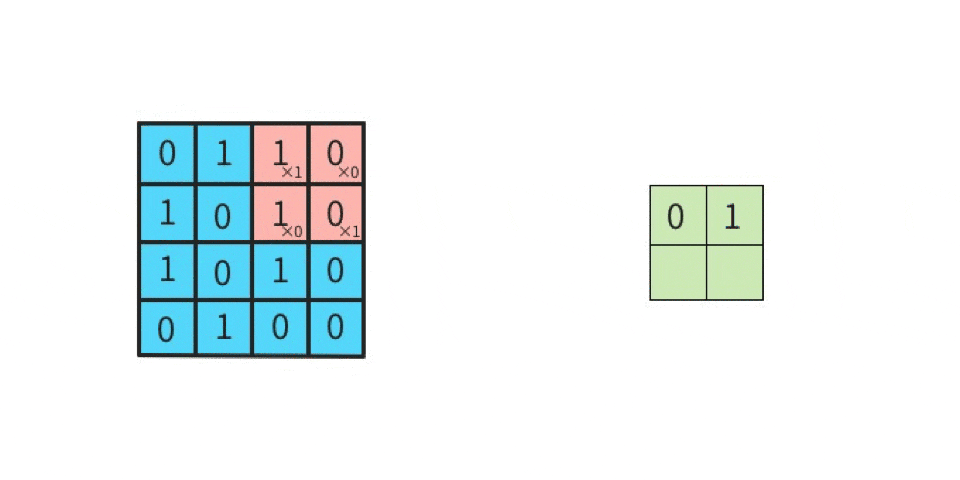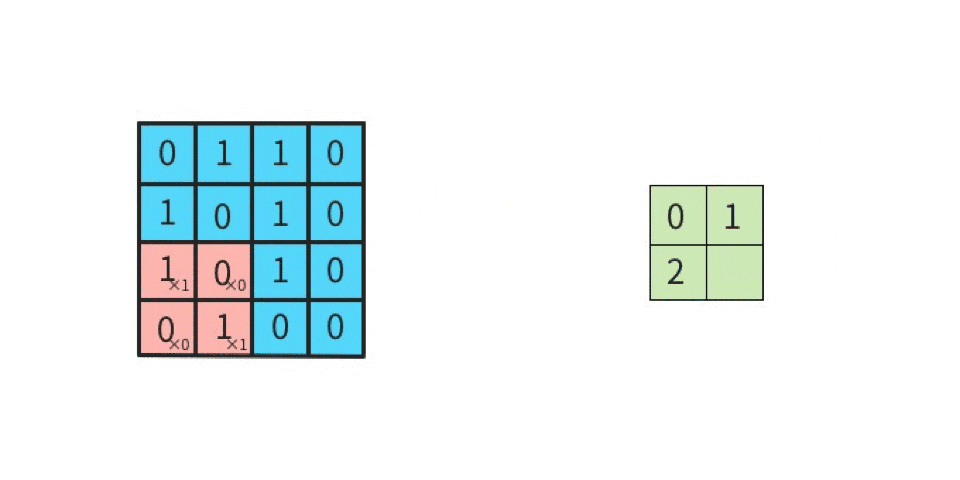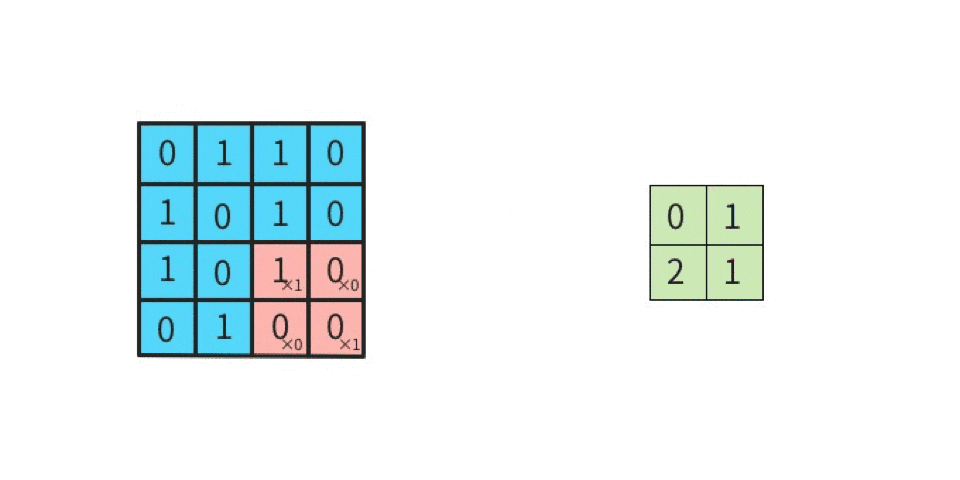
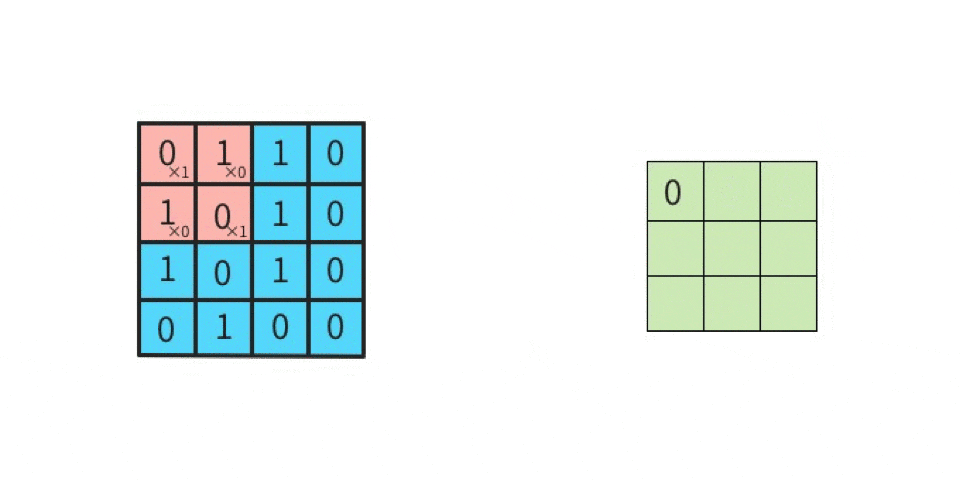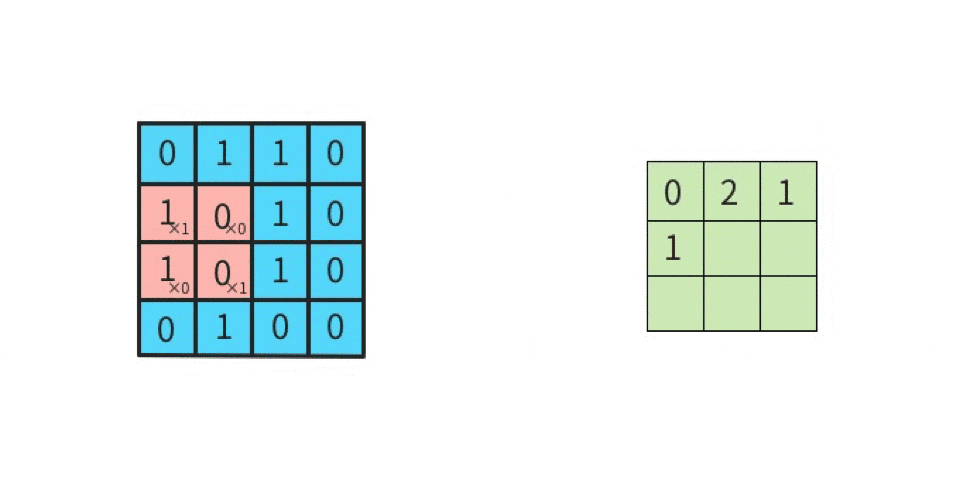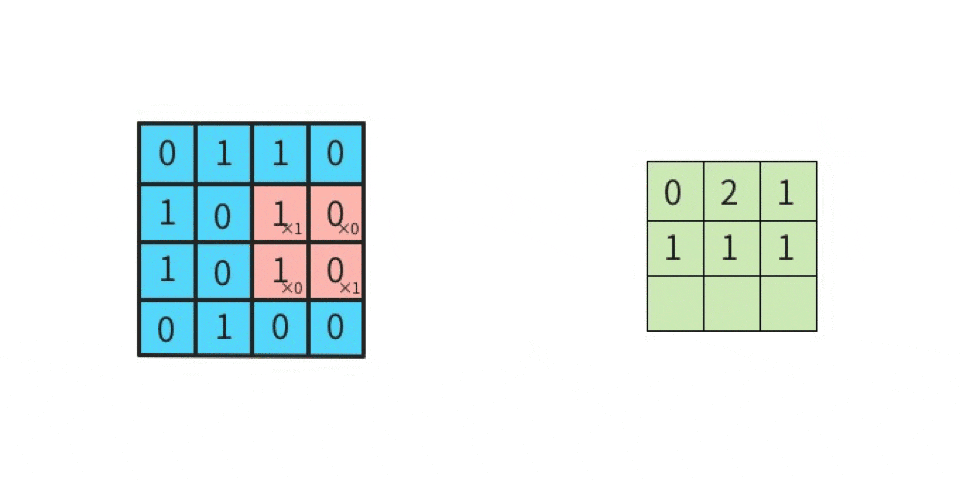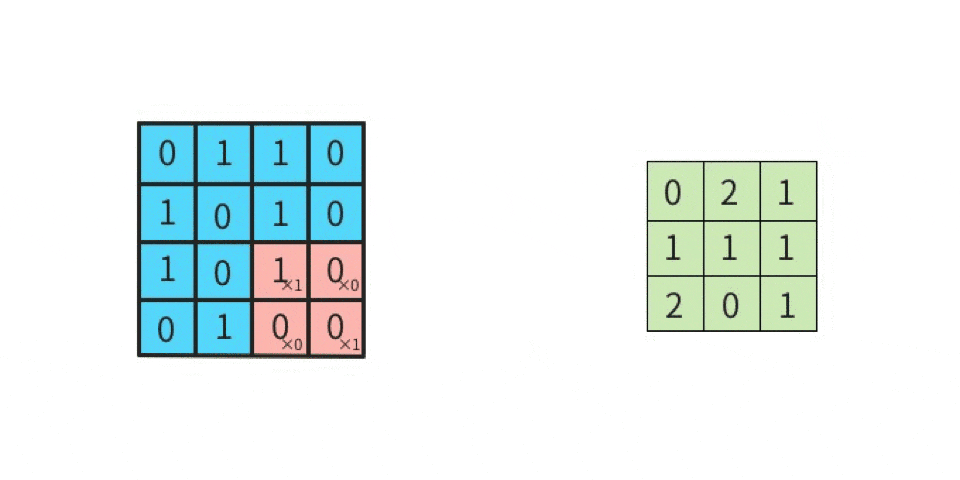
上図の「1回目の行列演算」を、実際にやってみる。
行列計算の手順は下記。左図の赤枠部分(ウインドウ)と、右図(カーネル)とを行列演算する。
ちなみに、ここで挙げたカーネルは一例であり、
実際の畳み込みでは「カーネルの縦横サイズは3x3以外にも、任意に指定できる」
かつ「カーネルは一種類だけではなく、複数種類使って畳み込む」という点に注意する(詳細は後述)。さて、行列演算は
- 元画像の一部(ウインドウ)とカーネルを比べて、同じ位置にある要素同士を掛け算する
- その掛け算で求めた各値を全部足す
ことにより、出力結果が求まる。
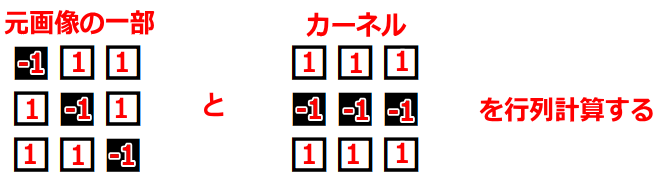
分かりやすくするために、数値を入れてみる。
ここでは、
黒を -1
白を 1
とする。
左上のマスから右下のマスに向かって、順番に(全部で9回)計算していくと、下記のようになる。
-1 x 1 = -1(上段の左同士を掛け算する) 1 x 1 = 1(上段のセンター同士を掛け算する) 1 x 1 = 1(上段の右同士を掛け算する) 1 x -1 = -1(中段の左同士を掛け算する) -1 x -1 = 1(中段のセンター同士を掛け算する) 1 x -1 = -1(中段の右同士を掛け算する) 1 x 1 = 1(下段の左同士を掛け算する) 1 x 1 = 1(下段のセンター同士を掛け算する) -1 x 1 = -1(下段の右同士を掛け算する)左辺が「元画像の一部における一つのマスの値」であり、
右辺が「カーネルにおける一つのマスの値」である。
そして、答えを「全部足す」と、SUM(-1, 1, 1, -1, 1, -1, 1, 1, -1)であるから、結果は 1 である。
この 1 は「特徴マップの左上」に並べるので、
特徴マップは下記になる。
このように計算を続けていけば、特徴マップの残り8マスにも数値が入る。
このような計算を実施することが「畳み込む」ことである。
別の言い方をすれば「畳み込みとは、元画像とカーネルを行列計算して、その結果を特徴マップに出力していく作業」である。しかし、このような畳み込み(行列計算)を手動でやるのは大変である。
よって、kerasのConv2Dのような関数を使って計算する。kerasの関数である Conv2D() に渡す引数の意味
冒頭のサンプルコードについて。
from keras import layers, models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))この中で使われている Conv2D()
Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3))の引数が何を意味するのか調査する。
4つの引数を渡している。Conv2D( 32, (3,3), activation="relu", input_shape=(150,150,3) )kerasの公式ドキュメント
https://keras.io/ja/layers/convolutional/#conv2d
の記載は以下の通り。keras.layers.Conv2D( filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None )まずは第一引数から見ていく。
公式ドキュメントの記載は下記の通り。filters : 整数で、出力空間の次元(つまり畳み込みにおける出力フィルタの数)。このコードでは、32 を渡している。
つまり「出力フィルタ数は32」を指定している。
では「出力フィルタ」とは何なのか?そもそも「フィルタ」とは何か?
畳み込みにおける「カーネルとは何か?」については前述した。
ここで「カーネル」のことを「フィルタ」と呼ぶ場合もあることを知っておく必要がある。
つまり、第一引数の filters は「フィルタ」であり「カーネル」であるから、
カーネルに関する設定値であることが分かる。https://qastack.jp/stats/154798/difference-between-kernel-and-filter-in-cnn
では、下記のような質疑応答がなされている。
質問:畳み込みニューラルネットワークの「カーネル」と「フィルタ」の違いは何ですか?
回答:同じ意味です。カーネルのことをフィルタと呼んだりします。
よって、結論としては
- カーネルは「フィルタ」であり「特徴検出器」である。すべて同じ意味である。
となる。
であれば「出力フィルタ数が32」は「出力カーネル数が32」という意味である。
畳み込みのおさらい
5x5の入力画像
に対して、3x3のフィルタ(カーネルとも呼ぶ)
にて畳み込みをする場合。
下図のように1マスずつズラして計算するなら、合計9回の計算を実施するので、答え(特徴マップ)は9マス(3x3)になる。(ちなみに、このような1マスずつスライドする畳み込みのことを「ストライドが1である」と表現する。
ストライドの値が大きくなるほど、計算の回数は少なくなる)
ストライドとは?
何マスずつズラして計算するか?の、ズラす値。
ストライドが1なら
となる。
ストライドが2なら
となる。
では、下記条件における畳み込みで、特徴マップの縦横は何x何になるか?
- 入力画像は 25 x 25 である。
- フィルタ(カーネル)は 5 x 5 である。
- ストライドは 2 である。
答えは 11 x 11 となる。
スプレッドシートなどで方眼を書いて実際に手でズラしながら数えてみると理解できる。
25 x 25 の方眼がある。これを入力画像とする。
重なっているピンク枠(5x5)がフィルタ(カーネル)である。
ストライドが 2 なので、2マスずつズラして計算していく。
11回目の計算で右端にたどり着く。
縦も同様なので、特徴マップは 11 x 11 となる。
Conv2D関数に渡す引数をどうやって決めればいいのか
以上の知識を前提として、畳み込みの実行に必要なパラメータを考える。
具体的には、下記の問いに答える必要がある。
- 質問(1): 畳み込みで利用したいカーネル(フィルタ)の縦横ピクセル数は、何x何ですか?
- 質問(2): 畳み込みで識別したい画像(つまり入力画像)の縦横ピクセル数は、何x何ですか?
- 質問(3): ストライドの値はいくつですか?(何ピクセルですか?)
他にも問いはあるだろうが、このような問いに答えることが、すなわち「関数に渡す引数の値を決めること」である。
フィルタ(カーネル)の縦横サイズの決め方について
https://child-programmer.com/ai/keras/conv2d/
の記載を抜粋する。Conv2D(16, (3, 3)の解説 :「3×3」の大きさのフィルタを16枚使うという意味です(16種類の「3×3」のフィルタ)。 「5×5」「7×7」などと、中心を決められる奇数が使いやすいようです。 フィルタ数は、「16・32・64・128・256・512枚」などが使われる傾向にあるようですが、 複雑そうな問題ならフィルタ数を多めに、簡単そうな問題ならフィルタ数を少なめで試してみるようです。ここで、フィルタに関する値は
- 1つのフィルタの縦横サイズは、何x何ピクセルか?(ピクセル値)
と
- その縦横サイズのフィルタを、何枚使うのか?(枚数)
があるので混同しないように注意する。
縦横サイズについては、これまで解説したとおり。
下記の例では、フィルタの縦横サイズは「5 x 5」である(ピンク塗の領域は5x5=25ピクセルの正方形である)。
では「フィルタ数(何枚使うのか?その枚数)」は、どういう意味か?
畳み込みを実施するにあたり、フィルタの種類は1種類ではない。
「1種類」では「1つの特徴」を示すに過ぎない。
たとえば、3x3のフィルタがあった場合、フィルタの種類としては、たとえば
など、いろいろ存在しうる。これが「フィルタの種類」であり「フィルタの枚数」つまり「フィルタ数」である。
まとめると、
Conv2D(16, (3, 3)は「縦横ピクセル3x3のフィルタを、16枚(16種類)使って畳み込みをしなさい」
という命令である。「フィルタ数」に関する補足
「複数のフィルタ、たとえば16種類(16枚)のフィルタを使って畳み込む」ことの意味について深く知りたい場合は
https://products.sint.co.jp/aisia/blog/vol1-16
に記載の「畳み込み層(Convolutional layer)」を参照のこと。
抜粋すると下記。
- フィルタは自動作成され、学習により変わってゆく(誤差逆伝搬)。
- フィルタの数だけ特徴マップが出力される。
「フィルタの数だけ特徴マップが出力される」ということは、
16種類(16枚)のフィルタで畳み込みを実施したら、
16個の「特徴マップ」が出力される、という意味である。ここでは説明を簡単にするために
「3枚のフィルタで畳み込みを実施する」ケースを考える。たとえば下図は、フィルタ(ピンク塗り領域)が2x2であり、
特徴マップ(グリーン塗り領域)は3x3である。
フィルタ(ピンク塗り領域)の種類が1つだけなら、
特徴マップ(グリーン塗り領域)も1つしか出力されない。しかし、フィルタを3種類準備したら、
それぞれの種類で行列計算を行うため、
特徴マップもそれぞれ異なる結果になるゆえに、3つの特徴マップが出力される。
冒頭のサンプルコードを見てみる
冒頭のサンプルコード
from keras import layers, models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))では、
Conv2D(32,(3,3)と書かれている。
これは「3x3のフィルタ(カーネル)を、32種類(32枚)用いて、畳み込みをしなさい」という命令である。以上で、
- 質問(1): 畳み込みで利用したいカーネル(フィルタ)の縦横ピクセル数は、何x何ですか?
に対する答えの決め方(引数の渡し方)は理解できた。
引き続き、
- 質問(2): 畳み込みで識別したい画像(つまり入力画像)の縦横ピクセル数は、何x何ですか?
を考察する。
input_shape とは何か?
https://child-programmer.com/ai/keras/conv2d/
から抜粋すると下記。input_shape=(28, 28, 1)の解説 :縦28・横28ピクセルのグレースケール(白黒画像)を入力しています。つまり、冒頭サンプルコードの
input_shape=(150,150,3)なら
「入力画像の縦横ピクセルは 150 x 150 である」
となる。では 3 は何を意味するのか?公式ドキュメント
https://keras.io/ja/layers/convolutional/#conv2d
にはRGB画像ではinput_shape=(128, 128, 3)となります.とある。
白黒画像なら1
RGBなら3であるため、色の数(RGBならレッド、グリーン、ブルーの3種類)と考えられる。
普通の写真(.jpg)ならRGBなので、3を設定しておけば問題ないだろう。activation とは何か?
サンプルコード
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))に書かれている
activation="relu"
はどういう意味か?
https://child-programmer.com/ai/keras/conv2d/
での説明は下記。activation=relu の解説 :活性化関数「ReLU(Rectified Linear Unit)- ランプ関数」。 フィルタ後の画像に実施。入力が0以下の時は出力0。入力が0より大きい場合はそのまま出力する。https://keras.io/ja/layers/convolutional/#conv2d
での説明は下記。activation: 使用する活性化関数の名前(activationsを参照) 何も指定しなければ,活性化は一切適用されませんつまり、
activation="relu"
は「活性化関数としてReLUを使いなさい」という命令になる。活性化とは?
活性化するための関数が「活性化関数」である。では「活性化」とは?
活性化を理解するための文脈を集めたら下記の通り。
- 活性化関数は、ニューラルネットワークに欠かせないものである。 https://qiita.com/omiita/items/bfbba775597624056987
- 活性化関数のデファクトスタンダートは「ReLU」である。 https://qiita.com/omiita/items/bfbba775597624056987
- 活性化関数を用いるのは、モデルの表現力を増すためである。 https://ai-trend.jp/basic-study/neural-network/activation_function/
- 代表的な活性化関数として「ステップ関数」「シグモイド関数」「ReLU関数」などがある。 https://ai-trend.jp/basic-study/neural-network/activation_function/
まとめると、
「活性化関数を指定すればモデルの表現力が増す(賢いAIが作れる)から活性化関数を指定しましょう」そして「標準的に使われるのはReLUですよね」といった感じ。ストライドの指定について
- 質問(3): ストライドの値はいくつですか?(何ピクセルですか?)
だが、これは
strides = 1のように指定する。詳細は
https://keras.io/ja/layers/convolutional/#conv2d
を参照。まとめ
以上のとおり、
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))が何をやっているのか? それぞれの引数は何を意味するのか?
がざっくり理解できた。
この章の目的は「kerasのConv2D(2次元畳み込み層)を理解すること」なので、
いったんここまでにする。
Sequential() や MaxPooling2D() については別の章で調査していく。






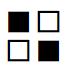



- 投稿日:2020-11-20T17:39:54+09:00
千葉県Go To EAT向けに店舗検索BOT(AI LINE BOT)を作った話(1)
こんにちは。初めて記事を作成しております。
「不適切な記事」のボーダーラインが分かっていないので至らない所あればご指摘ください。現在、私は千葉県のGo To EATキャンペーンを使っています。
プレミアム付き食事クーポンを10000円で買うと12500円分の食事券として使えるのでとてもお得です。【千葉県Go To EAT事業公式サイト】
https://www.chiba-gte.jp/ただ一つ、微妙だなぁと思ったのがクーポンが使えるお店が検索しづらいこと。
提供されているUIは、駅名等の地域情報から近くにあるお店が分かるのですが、
「今日はこれが食べたい!」といった目的が決まっている場合には検索しづらいと感じました(個人的意見)。
地域情報の他に料理のジャンルや店名でも検索出来たらいいのに。
そこでLINEのAPIを利用して、利用者が入れたキーワードを元にお店をサジェストしてくれるAI LINE BOTを作ろうと思い立ちました。
やってみたら意外とサクサク手が進み、作りたいものが出来たのでやったことを共有します。
この記事では、以下の方々を対象にやったことをご紹介していきたいと思います。
・LINE BOT(messagingAPI)を作ってみたい。
・簡単な機械学習モデルを作ってみたい。
・システム構築にお金をかけたくない(AWS無償トライアルやOSSを利用して費用ゼロで構築)。(自分のスキルを世の中に発信することで最終的に転職活動に有利になればと思っています 笑)
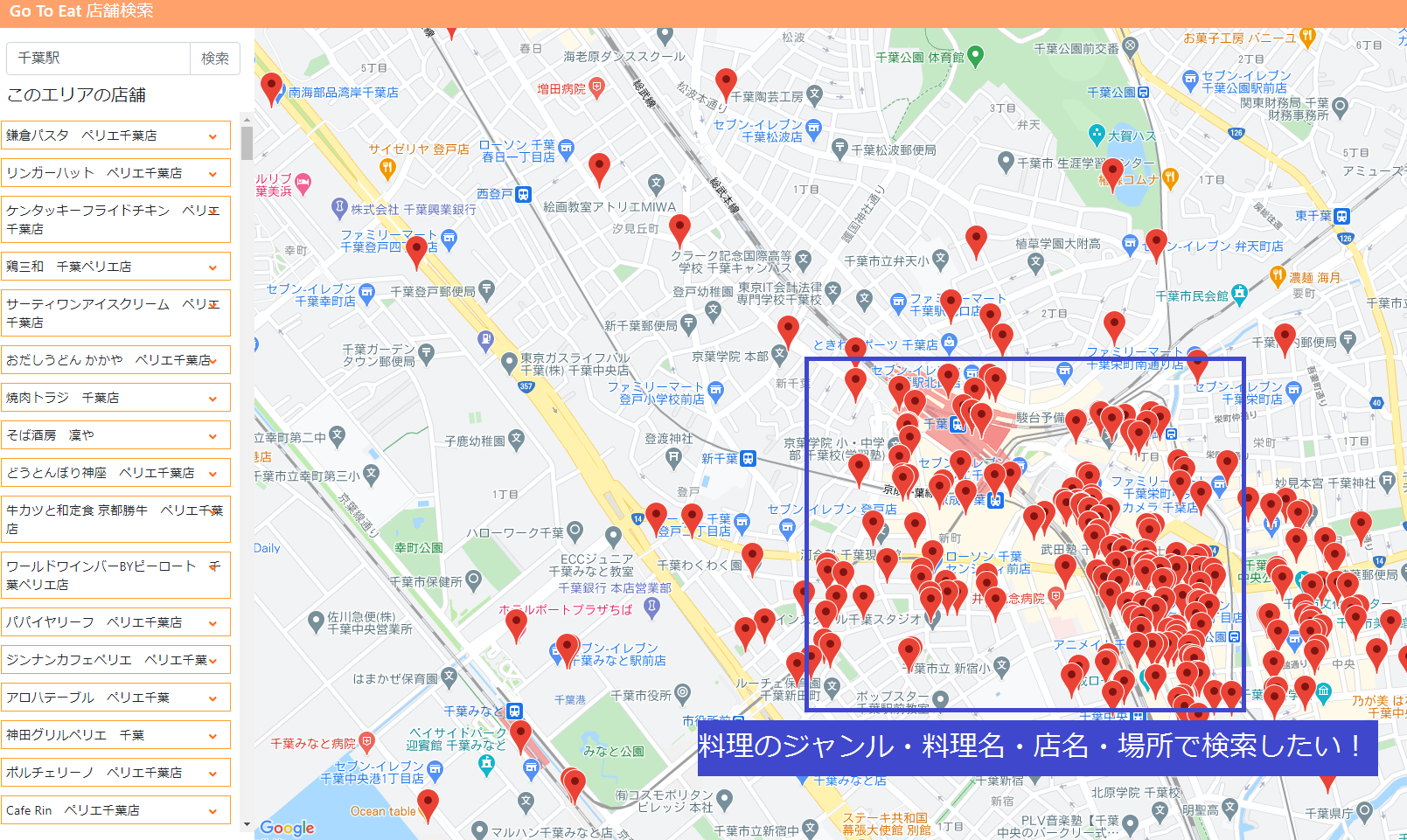
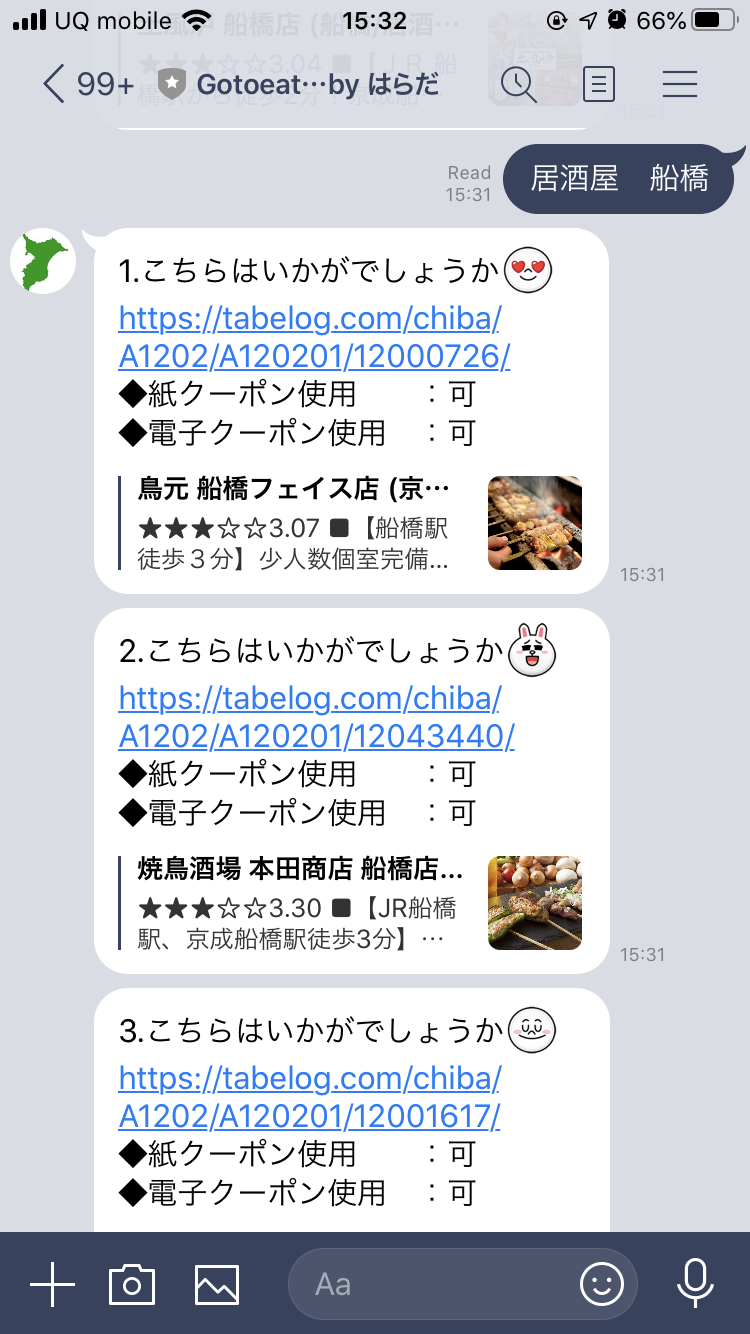
- 投稿日:2020-11-20T17:02:22+09:00
matplotlibインストール時のpolyfitエラー
matplotlibインストール時にエラーが出た
OSはMacOS BigSur。
python versionは3.6.10。
何も考えずに「numpy, pandas, matplotlib」をインストールしようとしたら、下記エラーが出た。pip install matplotlib RuntimeError: Polyfit sanity test emitted a warning, most likely due to using a buggy Accelerate backend. If you compiled yourself, see site.cfg.example for information. Otherwise report this to the vendor that provided NumPy. RankWarning: Polyfit may be poorly conditioned ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.対処法
インストールされたnumpyのバージョンが新しすぎる。らしい。
1.18を入れると動く。pip install numpy==1.18 pip install matplotlib
- 投稿日:2020-11-20T16:56:21+09:00
Pythonを使って東京都家賃についての研究 (3の2)
結果抜粋
統計の手法1
データ収集
- データ元:https://suumo.jp
- 使ったライブラリ:requests, BeautifulSoup, re, time, sqlite3
- 収集の部分がただrequestしてデータベースに入れるだけなのでコードを割愛します
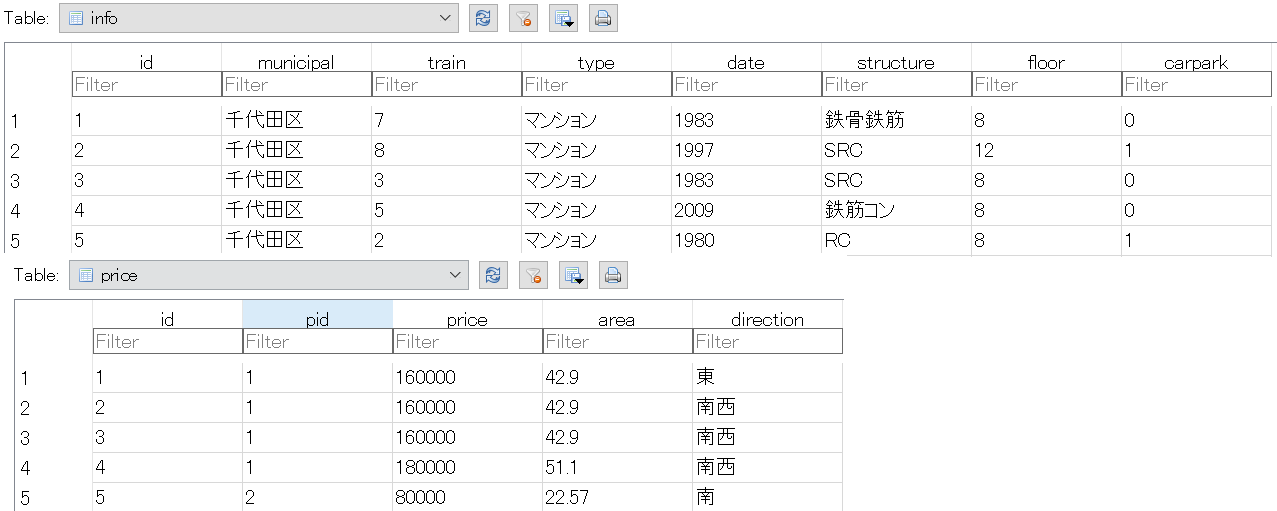
データベース
データベースの構造
info id 1 (PRIMARY KEY) municipal 千代田区 train 7 (駅まで徒歩) type マンション date 1983 structure 鉄骨鉄筋 floor 8 carpark 0 (0は無・1は有)
price id 1 (PRIMARY KEY) pid 160000 (円) 1 (= infoのid) 7 (駅まで徒歩) area 42.9 (平米) date 東 テーブル毎に最初の5行目
プログラムと結果
まず必要なライブラリーを導入
import sqlite3 import pandas as pd import plotly.express as px import plotly.graph_objects as go from plotly.offline import plot from sklearn.decomposition import PCA
データベースを接続する
# 結果を出力だけの場合 conn = sqlite3.connect(‘info.db’) c = conn.cursor() cursor = c.execute(“SQLコード”) for row in cursor: print(結果) conn.close() # 結果を保存して処理の場合 conn = sqlite3.connect(‘info.db’) df = pd.read_sql_query(“SQLコード”, conn) conn.close()
最初はデータの分布を見る
# infoの行数 SELECT COUNT(id) FROM info # 結果:82,812 # priceの行数 SELECT COUNT(id) FROM price # 結果:624,499 # 「アパート」と「マンション」の数 SELECT type,COUNT(type) FROM info GROUP BY type # 結果:アパート 33,110 / マンション 49,702
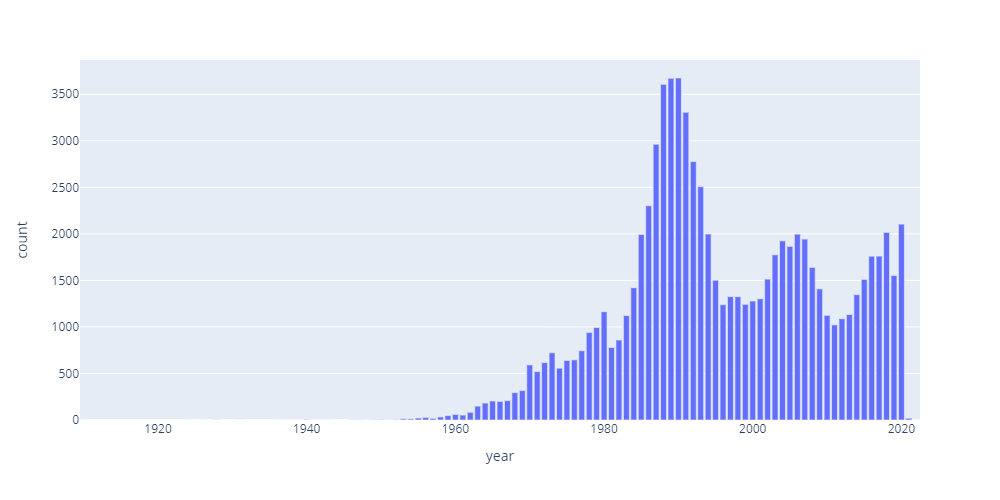
完成日の分布
# SQL SELECT date AS year,COUNT(date) AS count FROM info WHERE date > 0 GROUP BY date # グラフ fig = px.bar(df, x=’year’, y=’count’, height=500, width=1000)
建物構造の分布
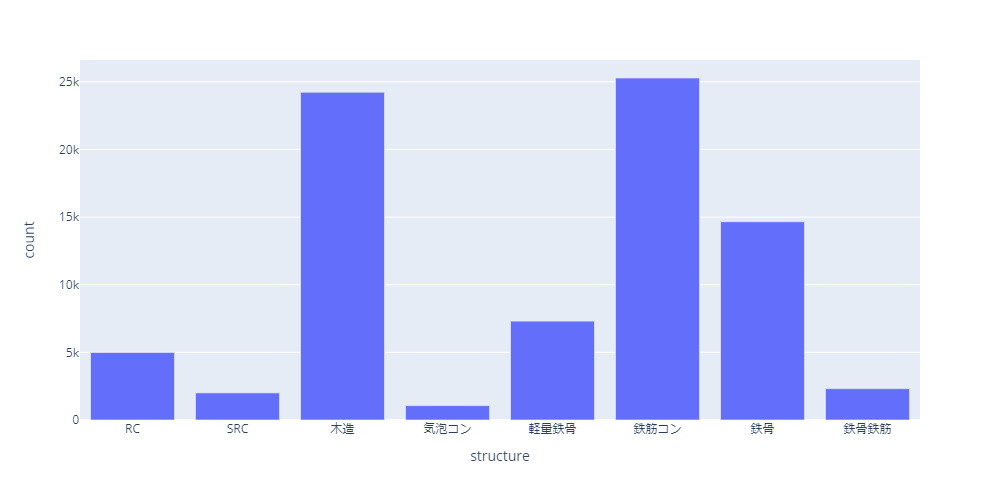
# SQL SELECT structure,COUNT(structure) AS count FROM info WHERE structure != 0 GROUP BY structure # グラフ fig = px.bar(df, x=structure, y=’count’, height=500, width=1000)
階数の分布
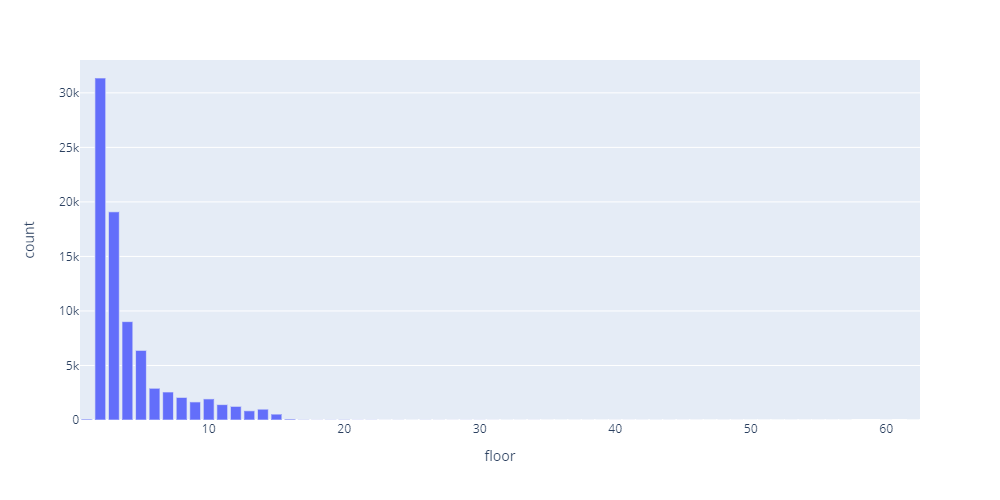
# SQL SELECT floor,COUNT(floor) AS count FROM info WHERE floor != 0 GROUP BY floor # グラフ fig = px.bar(df, x=floor, y=’count’, height=500, width=1000)
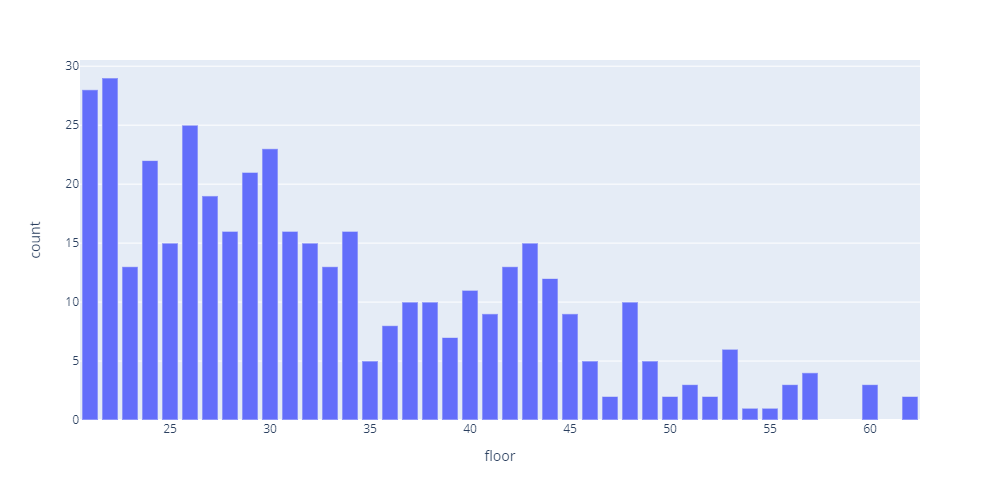
上の表で20階以上の分布が全く見えないのでこちらで細かく見ていきます。
# SQL SELECT floor,COUNT(floor) AS count FROM info WHERE floor > 20 GROUP BY floor # グラフ fig = px.bar(df, x=floor, y=’count’, height=500, width=1000)
連続型変数 (e.g. 価格) を分析する前にグループに分ける必要があります。
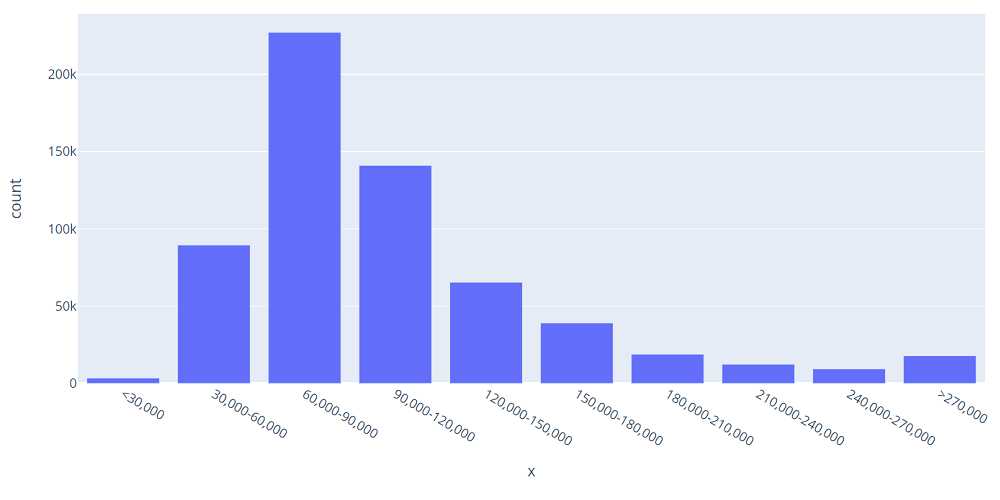
def pricegroup(df): if df[‘price’] < 30000: return ‘<30,000’ elif df[‘price’] < 60000: return ‘30,000-60,000’ …… else: return ‘>270,000’ pricegroup_list = [‘<30,000’, ‘30,000-60,000’, ‘60,000-90,000’, …… ‘240,000-270,000’, ‘>270,000’]価格の分布
# SQL SELECT price FROM price # Dataframeの処理df[‘pricegroup’] = df.apply(pricegroup, axis=1) dfcount = df.groupby([‘pricegroup’]).count() #グラフ fig = px.bar(dfcount, x=dfcount.index, y=’price’, height=500, width=1000) fig.update_layout(xaxis={‘categoryorder’:’array’, ‘categoryarray’:pricegroup_list}, yaxis_title=’count’)
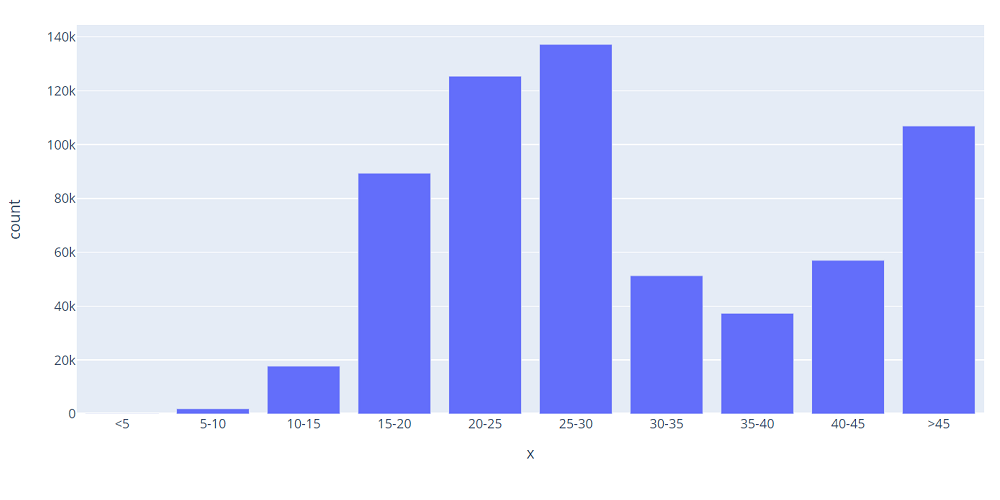
面積の分布も同じくように
def pricegroup(df): if df[‘area’] < 5: return ‘<5’ elif df[‘area’] < 10: return ‘5-10’ …… else: return ‘>45’ pricegroup_list = [‘<5′, ’5-10′, ’10-15′, ’15-20′, ’20-25′, ’25-30′, ’30-35′, ’35-40′, ’40-45′,’>45′] # SQL SELECT area FROM price # Dataframeの処理 df[‘areagroup’] = df.apply(areagroup, axis=1) dfcount = df.groupby([‘areagroup’]).count() # グラフ fig = px.bar(dfcount, x=dfcount.index, y=’area’, height=500, width=1000) fig.update_layout(xaxis={‘categoryorder’:’array’, ‘categoryarray’:areagroup_list}, yaxis_title=’count’)
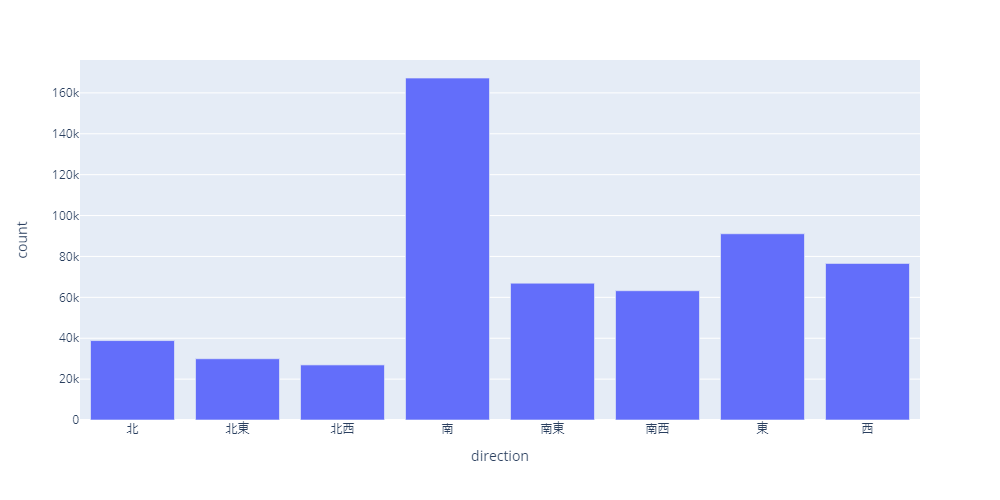
方向の分布
# SQL SELECT direction,COUNT(direction) AS count FROM price WHERE direction != ‘-‘ GROUP BY direction # グラフ fig = px.bar(df, x=direction, y=’count’, height=500, width=1000)
区市町村の分析をする前に23区と市部に分けます。
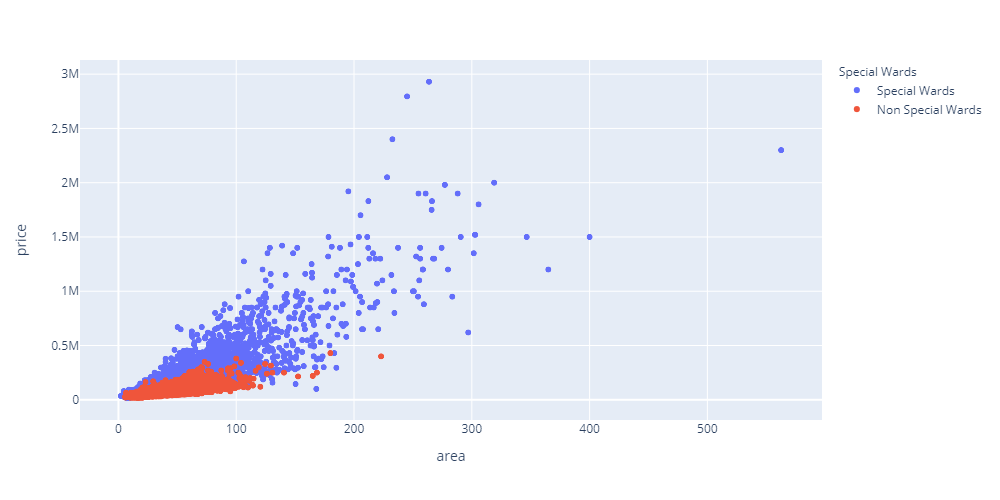
m23_list = [‘千代田区’,’中央区’,’港区’,’新宿区’,’文京区’,’台東区’,’墨田区’, ‘江東区’,’品川区’,’目黒区’,’大田区’,’世田谷区’,’渋谷区’,’中野区’, ‘杉並区’,’豊島区’,’北区’,’荒川区’,’板橋区’,’練馬区’,’足立区’, ‘葛飾区’,’江戸川区’] municipal_dict = {} conn = sqlite3.connect(‘info.db’) c = conn.cursor() cursor = c.execute(“SELECT id,municipal FROM info”) for row in cursor: municipal_dict.update({row[0]:row[1]}) conn.close() def municipal(df): return municipal_dict[df[‘pid’]] def municipal23(df): if df[‘municipal’] in m23_list: return ‘Special Wards’ else: return ‘Non Special Wards’価格と面積の関係(23区と市部に分ける)
# SQL SELECT pid,price,area FROM price # Dataframeの処理 df[‘municipal’] = df.apply(municipal, axis=1) df[‘municipal23’] = df.apply(municipal23, axis=1) dfmedian = df.groupby([‘pid’, ‘municipal23’])[‘price’, ‘area’].median() dfmedian_reset = dfmedian.reset_index(level=’municipal23′) # グラフ fig = px.scatter(dfmedian_reset, x=’area’, y=’price’, color=’municipal23′, labels={‘municipal23’: ‘Special Wards’}, height=500, width=1000)
- 投稿日:2020-11-20T16:56:08+09:00
pythonでbar chart race
pythonでbar chart race
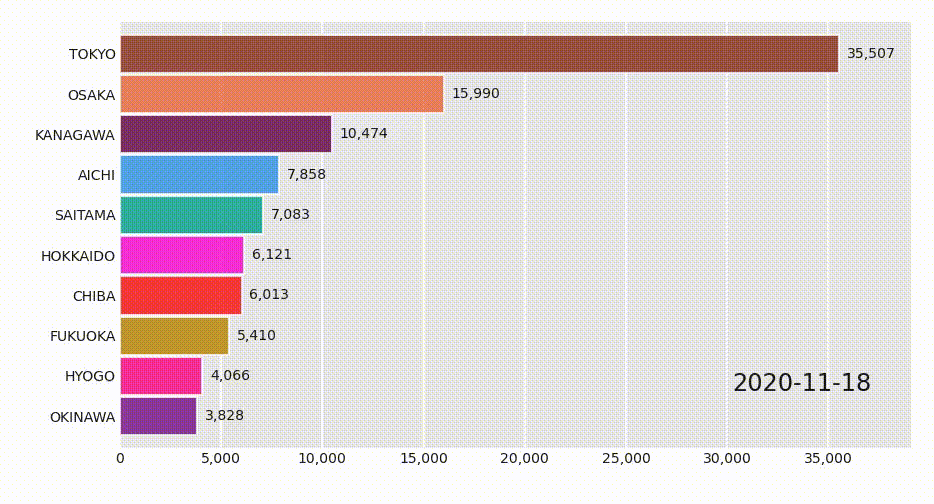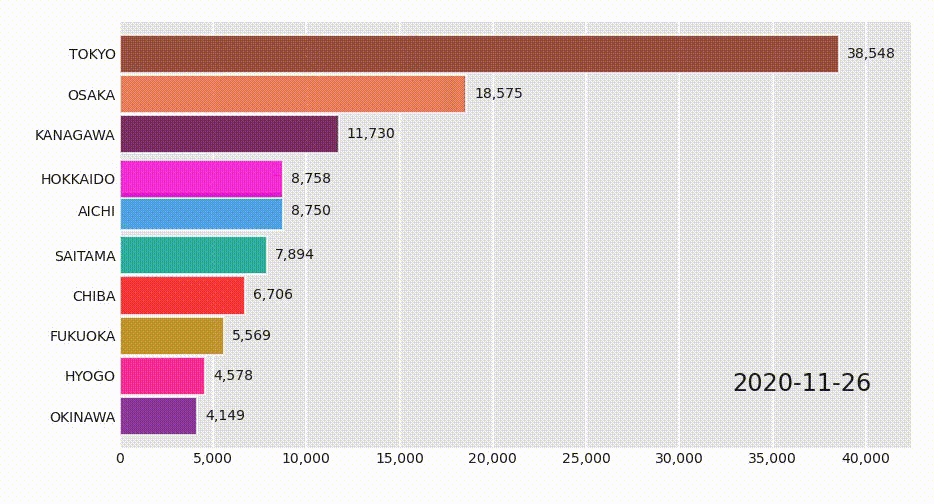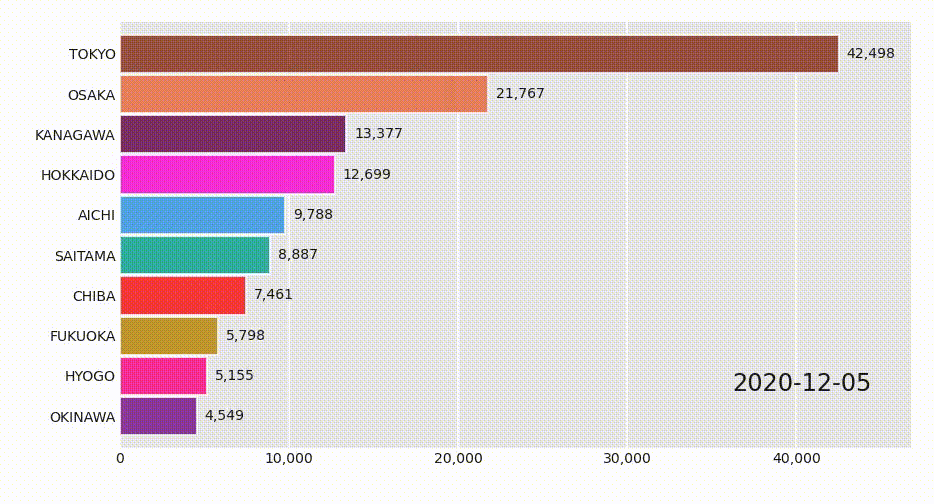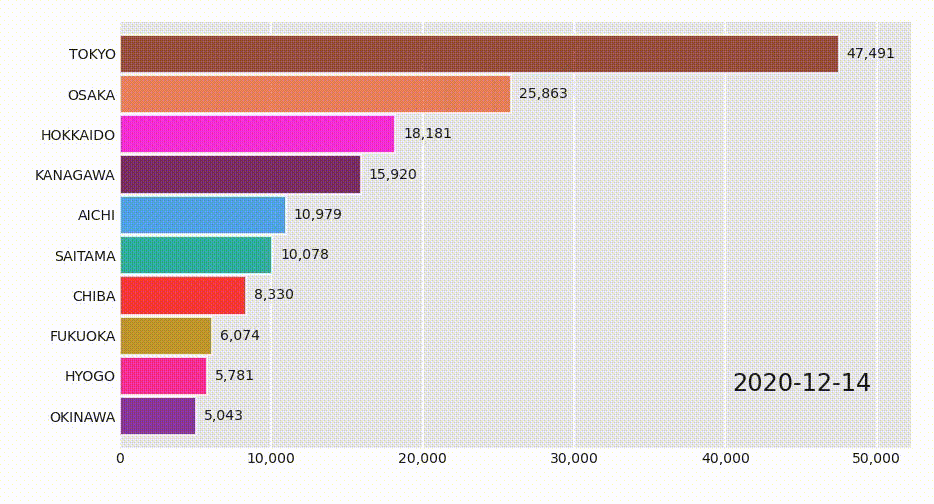
Youtubeなどでよく見かける棒グラフレースはflourishで作成されることが多いようですが、pythonで作成するライブラリがあるので紹介します。インストールや使用方法やDependencyなどは以下を参照のこと。
https://www.dexplo.org/bar_chart_race/
使い方は超簡単で、各データ名をコラムに持つ、日付ごとレコードをpandasのDataFrameに格納し、関数を呼び出すだけです。具体的にはこんなデータを用意します。
これを関数に与えるだけなのですが、GoogleがCovid-19の向こう28日間予測を公表しているのでそれをサンプルデータとして使用してみます。以下サンプルコードです。import pandas as pd import bar_chart_race as bcr df = pd.read_csv('https://storage.googleapis.com/covid-external/forecast_JAPAN_PREFECTURE_28.csv') df = df.pivot_table(index='target_prediction_date', columns='prefecture_name', values='cumulative_confirmed') bcr.bar_chart_race(df=df, n_bars=10)Jupyter上で実行し、しばらくするとアニメーションが表示されるはずです。
4行目でピボットしているのは、GoogleのレコードがPrefectureごとにレコードになっているので、ここでは累積陽性者数(cumulative_confirmed)に着目して、県ごとの数字をコラムに配置しています。変換後のDataFrameが上記の画像というわけです。Googleは他にもいろんな予測値を発表しているので、valuesの引数を色々変えて試してみるとよいです。
https://storage.googleapis.com/covid-external/COVID-19ForecastUserGuideJapan_Japanese.pdfオプションなど
n_bars=10はTop 10を表示するオプションで、省略すると全部棒グラフになります。filenameオプションで、mpeg動画やgifアニメを作成することができますが、別途ffmpegやImageMagickのインストールが必要です。その他グラフを縦にしたりタイトルを入れるオプションなど、上記の作者さんのサイトにものすごく詳しく書いてあるので見たほうが早いです。参考にした記事
FFmpegで動画をGIFに変換(トップの圧縮GIF画像を作成するのに)
Pythonで二次元ランダムウォーク+matplotlib.animationのgif保存(ImageMagickのインストール)
Create a Bar Chart Race Animation in Python with Matplotlib

- 投稿日:2020-11-20T16:19:25+09:00
raise ValueError, "unsupported hash type"となった時の対応方法
事象 : hmacをインストールしようとして失敗した
- 環境 : Cloud9
$ pip install hmac Defaulting to user installation because normal site-packages is not writeable Collecting hmac Downloading hmac-20101005.tar.gz (4.5 kB) Requirement already satisfied: setuptools in /usr/lib/python3.6/dist-packages (from hmac) (36.2.7) Collecting hashlib Downloading hashlib-20081119.zip (42 kB) |████████████████████████████████| 42 kB 1.1 MB/s ERROR: Command errored out with exit status 1: command: /usr/bin/python3.6 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-5jes0rhx/hashlib/setup.py'"'"'; __file__='"'"'/tmp/pip-install-5jes0rhx/hashlib/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-uvx1s968 cwd: /tmp/pip-install-5jes0rhx/hashlib/ Complete output (22 lines): Traceback (most recent call last): File "<string>", line 1, in <module> File "/usr/lib/python3.6/dist-packages/setuptools/__init__.py", line 10, in <module> from setuptools.extern.six.moves import filter, map File "/usr/lib/python3.6/dist-packages/setuptools/extern/__init__.py", line 1, in <module> from pkg_resources.extern import VendorImporter File "/usr/lib/python3.6/dist-packages/pkg_resources/__init__.py", line 36, in <module> import email.parser File "/usr/lib64/python3.6/email/parser.py", line 12, in <module> from email.feedparser import FeedParser, BytesFeedParser File "/usr/lib64/python3.6/email/feedparser.py", line 27, in <module> from email._policybase import compat32 File "/usr/lib64/python3.6/email/_policybase.py", line 9, in <module> from email.utils import _has_surrogates File "/usr/lib64/python3.6/email/utils.py", line 28, in <module> import random File "/usr/lib64/python3.6/random.py", line 46, in <module> from hashlib import sha512 as _sha512 File "/tmp/pip-install-5jes0rhx/hashlib/hashlib.py", line 80 raise ValueError, "unsupported hash type" ^ SyntaxError: invalid syntax ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.原因 : そもそもインストールする必要がないから
インストールしなくてもhmac, hashlibはあるようだ・・・おちついてメッセージを見ると
Requirement already satisfied: setuptools in /usr/lib/python3.6/dist-packages (from hmac) (36.2.7)
と書いてある。
結果がわかると何故とりあえずインストールしようとしたのかがわからない。参考 : python - Unsupported hash type error while installing hashlib using pip3 - Stack Overflow
はじめてのHMACとCloud9で混乱を極めてPythonのバージョンアップなどもしてしまった・・・
# Pythonが3じゃない! $ python --version Python 2.7.18 # pipは・・・なぜかPython3.6のもの? $ pip --version pip 20.2.4 from /home/ec2-user/.local/lib/python3.6/site-packages/pip (python 3.6) # Python3はあるようだ・・・ $ python3 --version Python 3.6.12 # Cloud9のPythonを3にすればよいのか?いやもうなっている・・・ $ sudo update-alternatives --config python There are 3 programs which provide 'python'. Selection Command ----------------------------------------------- * 1 /usr/bin/python2.7 + 2 /usr/bin/python3.6 3 /usr/bin/python2.6 Enter to keep the current selection[+], or type selection number: 2 # Python3にならない・・・ $ python -V Python 2.7.18 # 自分のアカウントのPythonが2になっている・・・ $ alias | grep python alias python='python27' # aliasでPython2.7が設定されている・・・ $ cat ~/.bashrc | grep python alias python=python27 # viで開いてaliasでPython3.6を指定して $ vi ~/.bashrc $ cat ~/.bashrc | grep python alias python=python36 # 反映すると $ source ~/.bashrc function # Python3.6になった・・・ $ python --version Python 3.6.12 # しかし状況は変わらない・・・ $ pip install hmac #...省略... File "/tmp/pip-install-tea_8pms/hashlib/hashlib.py", line 80 raise ValueError, "unsupported hash type" ^ SyntaxError: invalid syntax ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.対応 : インストールしないでただ使う
import hmac, hashlibを書いて使えばOK
- 投稿日:2020-11-20T15:06:00+09:00
【Pythonの超基本】基礎の基礎を勉強したので簡単にまとめてみた
概要
Pythonをちょっとだけ勉強したので、簡単にまとめておきます。
自分用のメモなのであしからず。
目次
example.pyprint('Hello World') # 出力結果 -> Hello World出力したい文字を
()の中に記述します。文字列の出力
文字列とは、上の部分で言う
Hello Worldという文字のことです。文字列は
'、"で囲む必要があります。
どちらを用いた場合でも出力に差は生じません。example.py#シングルクォーテーションで囲んだ場合 print('Hello World') # 出力結果 -> Hello World #ダブルクォーテーションで囲んだ場合 print("Hello World") # 出力結果 -> Hello World数値の出力
文字列と同様に数値も扱うことができます。
数値を出力する場合は、クォーテーションで囲む必要がありません。
クォーテーションで囲んだ場合は、文字列として出力されます。
example.py#数字を数値として出力 print(14) # 出力結果 -> 14 (数値) #数字を文字列として出力 print('7') # 出力結果 -> 7 (文字列)追記
ご指摘いただいたので、訂正いたします。print関数は、与えられた引数をstr関数を呼び出して文字列化し、クォートを外した結果を出力します。
引用 : この記事のコメント欄参照つまり、printによって出力された値は全て文字列型であるということなんですね。全然知りませんでした。
数値の計算
数値は、
+、-を用いて、足し算や引き算が可能です。
注意点としては、数値や記号はすべて半角で記述しなければいけません。計算記号について抑えておきましょう。
記号 処理 + 足し算 - 引き算 * かけ算 / 割り算 % 割り算の余りを表示 example.py#足し算 print(5 + 3) # 出力結果 -> 8 #引き算 print(10 - 8) # 出力結果 -> 2 #かけ算 print(2 * 5) # 出力結果 -> 10 #割り算 print(6 / 2) # 出力結果 -> 3 #余りの計算 print(10 % 3) # 出力結果 -> 1文字列と数値
計算結果を出力する際は、クォーテーションの有無に気をつけなければいけません。
example.pyprint(2 + 4) # 出力結果 -> 6 print('2 + 4') # 出力結果 -> 2 + 4クォーテーションで囲まない場合は、計算結果が出力されます。
一方、クォーテーションで囲んだ場合は、2 + 4は文字列として解釈されそのまま出力されます。変数
変数には、データを代入することができます。
変数は
変数名 = 値で定義します。変数名は'や"で囲む必要はありません。Pythonにおいて
=は、右辺を左辺に代入するという意味になります。変数の名前の付け方には、いくつか注意点があります。
- 変数名は数字から始めることはできない
- 2語以上の変数名を使う場合には、
_で区切ぎるexample.py#文字列の代入 name = 'ふくもとたいち' #数値の代入 age = 22 #変数名が2語以上の場合 first_name = 'たいち'上の例では、
nameにたいちが、ageに`22を代入しています。では、上の例で定義した変数を取り出してみましょう。
変数名を使って値を出力するときは、
print(変数名)とします。変数名は'で囲む必要はありません。example.pyname = 'ふくもとたいち' #変数の出力 print(name) # 出力結果 -> ふくもとたいちこのように、変数に代入した値が出力されました。
変数を使うことで、扱っているデータの中身が何を表しているのかはっきりします。そのため、コードが読みやすくなります。
また、同じデータを繰り返し使えたり、数値などの修正をする場合に修正箇所が少なくったりというメリットもあります。変数の値は更新することができます。
変数名 = 新しい値をすることで変数の値を上書きできます。example.pyage = 22 print(age) # 出力結果 -> 22 #ageの値を更新 age = 30 print(age) # 出力結果 -> 30すでに定義された数値を足したり、引いたりすることで値を更新することもできます。
example.pyage = 22 print(age) # 出力結果 -> 22 age = age + 8 print(age) # 出力結果 -> 30数値を更新する際には、省略形が存在します。以下に省略形をまとめます。
標準 省略形 x = x + 1 x += 1 x = x – 1 x -= 1 x = x * 1 x *= 1 x = x / 1 x /= 1 x = x %1 x %= 1 データ型
扱うデータには種類が存在します。
ここでは「文字列型」と「数値型」を学びます。
今まで
'で囲んで表示していたものが文字列型です。一方、
2や14といった数字を数値型といいます。example.pyprint(100) # 出力結果 -> 100 print('100') # 出力結果 -> 100出力の結果は目ではわかりませんが、一つ目は数値型、二つ目は文字列型として出力されています。
文字列の連結
ここからは文字列の連結について学んでいきます。
+を用いることで、文字列を連結することができます。example.pyfirst_name = 'たいち' last_name = 'ふくもと' #文字列を連結して出力する print('私のフルネームは' + last_name + first_name + 'です') # 出力結果 -> 私のフルネームはふくもとたいちです上の例のように書くことで、文字列同士、文字列と変数、あるいは変数同士といった組み合わせで連結することができます。
ここで注意が必要なのは、変数は文字列型でなければいけない点です。
つまり、同じデータ型でしか連結することができないということです。
次の例を見てみましょう。
example.pyprint(3 + 7) # 出力結果 -> 10 print('3' + '7') # 出力結果 -> 37 print('3' + 7) # 出力結果 -> Type Error1行目のコードは数値型で書かれているため、計算式の結果が出力されます。
2行目のコードは文字列型で書かれているため、3という文字列と7という文字列が連結された37が出力されます
3行目のコードは文字列型と数値列型を用いているため、エラーが発生していまいます。連結は文字列型同士でしか行えないことを学びました。
型変換
数値型 → 文字列型
では、数値型を代入してある変数を文字列として連結するにはどうすればいいのでしょうか。
example.pyname = 'たいち' age = 22これらの変数を用いて、
たいちは22歳ですと出力する方法学びます。数値型の変数を文字列として連結するときには型変換を行います。
数値型を文字列型に変換するには
strを用います。
str(数値型)とすることで数値型に変換することができます。example.pyname = 'たいち' age = 22 print(name + 'は' + str(age) + '歳です。') # 出力結果 -> たいちは22歳です
strによって変数ageが文字列型に変換されたため、エラーが起きることなく出力が行われました。文字列型 → 数値型
先ほどの例とは反対に文字列型を数値型に変換するには、
intを用います。
strと同じように、int(文字列型)とすることで数値型に変換することができます。例をみていきましょう。
example.pycount = '5' price = 200 total_price = price * int(count) print(total_price) # 出力結果 -> 1000
countには5が文字列型で代入されていますので、数値型に変換して計算することでエラーを起こすことなく処理が実行されます。条件分岐
ある条件に当てはまる場合だけに処理を行う条件分岐について学んでいきます。
条件分岐の構文を学ぶ前に、「真偽値」と「比較演算子」について学びましょう。
真偽値
まず、真偽値というものについて学んでいきます。
以下のようなコードを実行します。
example.pyage = 20 print(age == 20) # 出力結果 -> True
==は両辺が等しいかどうかを比較する比較演算子になります。比較演算子については、まとめて説明します。では、このとき出力された
Trueとは一体なんなのでしょうか。この
Trueが真偽値と呼ばれるものになります。
真偽値を扱うデータ型は「真偽値型」に分類され、TrueとFalseの2種類が存在します。
比較演算子を用いた条件式の部分が成り立つときはTrue、成り立たないときはFalseとなります。比較演算子
ここで先ほど出てきた「比較演算子」についてみていきます。
比較演算子とは、値の等しさや大小を比較するときに用いる記号のことです。
比較演算子には以下のものが存在します。
演算子 意味 a == b aがbと等しいときTrue a != b aがbと等しくないときTrue a > b aがbより大きいときTrue a < b aがbより小さいときTrue a >= b aがb以上のときTrue a <= b aがb以下のときTrue この比較演算子は、条件分岐の際の条件文で出てきますので、しっかり抑えておきましょう。
if文
それでは、条件分岐のコードについてみていきます。
ifを用いると、ある条件の場合にだけ処理を行うことが可能になります。構文をみてみましょう。
if 条件式: 処理
ifのあとに条件式を指定し、その条件が成り立つときに実行する処理を次の行に書きます。
処理はインデントにより字下げを行わなければいけない点に注意してください。例をみていきましょう。
example.pyage = 22 if age >= 20: print('お酒が飲めます') # 出力結果 -> お酒が飲めます上の例では、
age >= 20の部分が条件式になります。上の条件式では、「ageの値が20以上だった場合」に
Trueとなります。
ageには22が代入されていて条件式はTrueになるので、その後の処理であるprint(‘お酒が飲めます’)が実行されます。
次の例をみてみましょう。example.pyage = 19 if age >= 20: print('お酒が飲めます') # 出力結果 -> お酒が飲めます上の例では処理の部分にインデントがありません。
その結果、本来実行されないはずの処理が行われてしまっています。インデントには気をつけましょう。
else
if文に
elseを組み合わせることで「if文の条件に当てはまらなかった場合に別の処理を実行する」ことができます。構文は以下の通りです。
if 条件式: 処理 else: 処理
ifの処理の後に、else:と書いて、次の行に処理を書きます。
elseのあとには:が必要なので忘れないようにしましょう。また、if文と同様にインデントにも注意しましょう。具体例をみてみます。
example.pyage = 19 if age >= 20: print('お酒が飲めます') else: print('お酒は二十歳になってから') # 出力結果 -> お酒は二十歳になってから具体例では、
ageに19が代入されているためifブロックの条件を満たしていません。よって
elseの中に書かれている処理が実行されます。elif
if文で成り立たなかった場合の条件式を複数定義したい場合は、
elifを用います。
構文は以下の通りです。if 条件式: 処理 elif 条件式: 処理 else: 処理
ifとelseの間に、elifブロックを追加します。
書き方は、ifの場合と同じで、elif'の後ろに条件式:`を書いて、次の行に処理を書きます。
elifはいくつでも書くことができます。
しかし、上から順に条件が成り立つか判断され、最初に条件を満たしている部分の処理だけが行われます。
elifを用いて条件を書いていく場合には条件の順番にも注意が必要です。具体例を見てみましょう。
example.pynumber = 0 if number > 0: print('正です') elif number == 0: print('0です') else: print('負です') # 出力結果 -> 0です
numberには0が代入されているため、elifの条件分であるnumber == 0を満たします。よって、
elifの中に書かれている処理が実行されます。
elifの処理が実行されたので、ここで処理は終了となります。条件の組み合わせ
and
andを使い複数の条件式を組み合わせることで、「条件1も条件2も成り立つ」場合に処理を実行させることができます。if 条件式1 and 条件式2: 処理
andを用いた場合は、すべての条件式がTrueのとき全体がTrueとなり、処理が実行されます。or
orを使い複数の条件式を組み合わせると、「条件1と条件2のどちらかが成り立つ」場合に処理を実行させることができます。if 条件式1 or 条件式2: 処理
orを用いた場合は、複数の条件式のうち一つでもTrueであれば全体がTrueとなり処理が実行されます。not
notを用いると、条件の否定をすることができます。条件式が
Trueじゃない時に処理が実行されます。
つまり、not 条件式のようにすると、条件式がTrueであれば全体がFalseになります。if not 条件式: 処理リスト
複数のデータを扱うには「リスト」を用います。
リストは、
[〇〇, △△, … ]のように[]を用いて作ります。リストに入っているそれぞれの値を「要素」といいます。また、リストも1つの値なので、変数に代入することができます。
example.pynames = ['山田', '田中', '鈴木'] print(names) # 出力結果 -> ['山田', '田中', '鈴木']出力すると、リストがそのまま出力されます。
また、変数には複数形を使うことが一般的です。リストの要素には、前から順に「0, 1, 2, …」と番号が割り振られています。これを「インデックス番号」といいます。
上の例でいうと、
’山田’がインデックス番号0の要素です。リストの各要素はリスト
リスト名[インデックス番号]とすることで取得することができます。example.pynames = ['山田', '田中', '鈴木'] print('彼は' + names[0] + 'さんです。') # 出力結果 -> 彼は山田さんです。
names[0]では、要素のインデックス番号0の要素を取り出しているので、山田が入ります。リストの要素の更新
リストの要素の更新は、
リスト[インデックス番号] = 値とすることで行うことができます。更新したい場所を指定して、代入をやり直すという感じですね。
具体例をみてみます。
example.pynames = ['山田', '田中', '鈴木'] names[2] = '佐藤' print(names) # 出力結果 -> ['山田', '田中', '佐藤']インデックス番号2の要素を更新しています。出力したリストは、値が更新されていることがわかります。
リストの要素の追加
次に、リストに値を追加してみましょう。
リスト.append(値)とすることで、すでに定義されているリストに新たな要素を追加することが可能です。具体例をみてみましょう。
example.pynames = ['山田', '田中', '鈴木'] names.append('佐藤') print(names) # 出力結果 -> ['山田', '田中', '鈴木', '佐藤']要素は、リストの末尾に追加されます。
具体例でもリストの末尾に
佐藤が追加されたリストが出力されていることがわかります。辞書
「辞書」も、複数のデータをまとめて管理するのに使われます。
辞書はリストと違い、インデックス番号をではなく「キー」と呼ばれる名前をつけて管理します。
辞書は
{キー1: 値1, キー2: 値2, …}のように定義します。一般にキーには文字列が使われます。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} print(names) # 出力結果 -> {'山田': 22, '田中': 40, '鈴木': 33}辞書の要素には順序がないため、出力すると要素の順番が定義したときと変わっていることがあります。
辞書の要素は、取り出したいキーを用いて、
辞書名['キー']とすることで取り出すことができます。example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} print('彼は' + str(names['田中']) + '歳です。') # 出力結果 -> 彼は40歳です。辞書の要素の更新
基本的にはリストの更新と同じです。
インデックス番号の代わりにキーを用います。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} #値を更新 names['田中'] = 50 print('彼は' + str(names['田中']) + '歳です。') # 出力結果 -> 彼は50歳です。値が更新されていることが確認できました。
辞書の要素の追加
辞書に要素を追加するときは、
辞書名['新しいキー'] = 値のように新しいキーを設定してそこに値を代入します。example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} names['佐藤'] = 15 #辞書を出力 print(names) # 出力結果 -> {'山田': 22, '田中': 40, '鈴木': 33, '佐藤': 15} #新しく追加した要素を出力 print('彼は' + str(names['佐藤']) + '歳です。') # 出力結果 -> 彼は15歳です。要素が追加され、指定して取り出すこともできています。
繰り返し処理
Pythonの繰り返し処理である「for文」と「while文」について学んでいきます。
for文
リストのすべての要素を一つひとつ取り出したい場合、1つずつインデックス番号を指定するのは非常に面倒です。
「for文」を使うことで、「繰り返し処理」を行うことができます。
for文は、
for 変数名 in リスト名:のように記述します。変数名にリストの要素が先頭から順に1つずつ入っていき、その上でfor文の中の処理が実行されます。
具体例をみてみましょう。
example.pynames = ['山田', '田中', '鈴木'] for name in names: print('彼は' + name + 'さんです。') # 出力結果 -> 彼は山田さんです。 彼は田中さんです。 彼は鈴木さんです。このように、for文中の出力の処理がリストの先頭から順に行われていきます。
また、変数名は一般的にリスト名の単数形にします。同じように、辞書もfor文を用いることで、要素を1つずつ取り出し、繰り返し処理を実行することができます。
辞書の場合、for文は、
for 〇〇_key in 辞書名:のように記述します。具体例をみてみましょう。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} for name_key in names: print(name_key + 'さんは' + str(names[name_key]) + '歳です。') # 出力結果 -> 山田さんは22歳です。 田中さんは40歳です。 鈴木さんは33歳です。このように辞書の要素もfor文で取り出すことができました。
while文
もう一つの繰り返し処理が、「while文」です。
while文を用いると「ある条件に当てはまる間、処理を繰り返す」ことができます。
構文を見てみましょう。
example.pywhile 条件式: 値の更新を含む処理
while 条件式:のように書き、その後にインデントして処理を書きます。
処理の部分には、必ず値を更新する処理を含めます。具体例をみてみましょう。
example.pyx = 1 while x <= 5: print(x) x += 1 # 出力結果 -> 1 2 3 4 5例を見てみると、条件式の部分は「
xが5以下のとき」となってます。while文の中の処理は、まず「xの値を出力」し、そのあと「xに1を足す」というものになってます。
5が出力された後、1が足され、xの値は6になり条件を満たさなくなるので処理は終了します。よって、
xが5になるまで処理は繰り返されます。無限ループ
while文では、処理の最後に変数の値を更新し忘れたり、インデントが間違っていたりすると条件式が常に
Trueとなってしまい、無限に繰り返し処理が行われてしまいます。気をつけましょう。
breakとcontinue
break
breakを用いることで、繰り返し処理を「強制的に終了」させることができます。
breakはif文などの条件分岐を組み合わせて使います。具体例をみてみましょう。
example.pynumbers = [1, 2, 3, 4, 5] for number in numbers: print(number) if number == 4: break # 出力結果 -> 1 2 3 4コードを見てみましょう。
if文の条件式が「4になったとき」となっています。
ifブロックの中には、breakが書いてあり条件を満たした場合に実行されます。よって、
5の出力は行われることなく処理が終了しています。continue
continueを用いると、条件を満たしている場合の処理をスキップすることができます。
breakと同様に条件分岐と組み合わせて使います。example.pynumbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] for number in numbers: if number % 2 == 0: continue print(number) # 出力結果 -> 1 3 5 7 9
ifの条件式の部分は、「numberが2で割り切れるとき」となっているため、偶数の処理はスキップされ、奇数だけが出力されています。まとめ
一気にまとめてみました。
Pythonはコードがシンプルで読みやすいですね。最後まで読んでいただきありがとうございました。
- 投稿日:2020-11-20T15:06:00+09:00
Pythonをちょっとだけ勉強したので簡単にまとめてみた ~出力, 文字列, 数値, 変数, データ型, 配列, 条件分岐, 繰り返し処理~
概要
Pythonをちょっとだけ勉強したので、簡単にまとめておきます。
自分用のメモなのであしからず。
目次
example.pyprint('Hello World') # 出力結果 -> Hello World出力したい文字を
()の中に記述します。文字列の出力
文字列とは、上の部分で言う
Hello Worldという文字のことです。文字列は
'、"で囲む必要があります。
どちらを用いた場合でも出力に差は生じません。example.py#シングルクォーテーションで囲んだ場合 print('Hello World') # 出力結果 -> Hello World #ダブルクォーテーションで囲んだ場合 print("Hello World") # 出力結果 -> Hello World数値の出力
文字列と同様に数値も扱うことができます。
数値を出力する場合は、クォーテーションで囲む必要がありません。
クォーテーションで囲んだ場合は、文字列として出力されます。
example.py#数字を数値として出力 print(14) # 出力結果 -> 14 (数値) #数字を文字列として出力 print('7') # 出力結果 -> 7 (文字列)追記
ご指摘いただいたので、訂正いたします。print関数は、与えられた引数をstr関数を呼び出して文字列化し、クォートを外した結果を出力します。
引用 : この記事のコメント欄参照つまり、printによって出力された値は全て文字列型であるということなんですね。全然知りませんでした。
数値の計算
数値は、
+、-を用いて、足し算や引き算が可能です。
注意点としては、数値や記号はすべて半角で記述しなければいけません。計算記号について抑えておきましょう。
記号 処理 + 足し算 - 引き算 * かけ算 / 割り算 % 割り算の余りを表示 example.py#足し算 print(5 + 3) # 出力結果 -> 8 #引き算 print(10 - 8) # 出力結果 -> 2 #かけ算 print(2 * 5) # 出力結果 -> 10 #割り算 print(6 / 2) # 出力結果 -> 3 #余りの計算 print(10 % 3) # 出力結果 -> 1文字列と数値
計算結果を出力する際は、クォーテーションの有無に気をつけなければいけません。
example.pyprint(2 + 4) # 出力結果 -> 6 print('2 + 4') # 出力結果 -> 2 + 4クォーテーションで囲まない場合は、計算結果が出力されます。
一方、クォーテーションで囲んだ場合は、2 + 4は文字列として解釈されそのまま出力されます。変数
変数には、データを代入することができます。
変数は
変数名 = 値で定義します。変数名は'や"で囲む必要はありません。Pythonにおいて
=は、右辺を左辺に代入するという意味になります。変数の名前の付け方には、いくつか注意点があります。
- 変数名は数字から始めることはできない
- 2語以上の変数名を使う場合には、
_で区切ぎるexample.py#文字列の代入 name = 'ふくもとたいち' #数値の代入 age = 22 #変数名が2語以上の場合 first_name = 'たいち'上の例では、
nameにたいちが、ageに`22を代入しています。では、上の例で定義した変数を取り出してみましょう。
変数名を使って値を出力するときは、
print(変数名)とします。変数名は'で囲む必要はありません。example.pyname = 'ふくもとたいち' #変数の出力 print(name) # 出力結果 -> ふくもとたいちこのように、変数に代入した値が出力されました。
変数を使うことで、扱っているデータの中身が何を表しているのかはっきりします。そのため、コードが読みやすくなります。
また、同じデータを繰り返し使えたり、数値などの修正をする場合に修正箇所が少なくったりというメリットもあります。変数の値は更新することができます。
変数名 = 新しい値をすることで変数の値を上書きできます。example.pyage = 22 print(age) # 出力結果 -> 22 #ageの値を更新 age = 30 print(age) # 出力結果 -> 30すでに定義された数値を足したり、引いたりすることで値を更新することもできます。
example.pyage = 22 print(age) # 出力結果 -> 22 age = age + 8 print(age) # 出力結果 -> 30数値を更新する際には、省略形が存在します。以下に省略形をまとめます。
標準 省略形 1だけ変化させる場合の省略形 x = x + 1 x += 1 x++ x = x – 1 x -= 1 x-- x = x * 1 x *= 1 - x = x / 1 x /= 1 - x = x %1 x %= 1 - データ型
扱うデータには種類が存在します。
ここでは「文字列型」と「数値型」を学びます。
今まで
'で囲んで表示していたものが文字列型です。一方、
2や14といった数字を数値型といいます。example.pyprint(100) # 出力結果 -> 100 print('100') # 出力結果 -> 100出力の結果は目ではわかりませんが、一つ目は数値型、二つ目は文字列型として出力されています。
文字列の連結
ここからは文字列の連結について学んでいきます。
+を用いることで、文字列を連結することができます。example.pyfirst_name = 'たいち' last_name = 'ふくもと' #文字列を連結して出力する print('私のフルネームは' + last_name + first_name + 'です') # 出力結果 -> 私のフルネームはふくもとたいちです上の例のように書くことで、文字列同士、文字列と変数、あるいは変数同士といった組み合わせで連結することができます。
ここで注意が必要なのは、変数は文字列型でなければいけない点です。
つまり、同じデータ型でしか連結することができないということです。
次の例を見てみましょう。
example.pyprint(3 + 7) # 出力結果 -> 10 print('3' + '7') # 出力結果 -> 37 print('3' + 7) # 出力結果 -> Type Error1行目のコードは数値型で書かれているため、計算式の結果が出力されます。
2行目のコードは文字列型で書かれているため、3という文字列と7という文字列が連結された37が出力されます
3行目のコードは文字列型と数値列型を用いているため、エラーが発生していまいます。連結は文字列型同士でしか行えないことを学びました。
型変換
数値型 → 文字列型
では、数値型を代入してある変数を文字列として連結するにはどうすればいいのでしょうか。
example.pyname = 'たいち' age = 22これらの変数を用いて、
たいちは22歳ですと出力する方法学びます。数値型の変数を文字列として連結するときには型変換を行います。
数値型を文字列型に変換するには
strを用います。
str(数値型)とすることで数値型に変換することができます。example.pyname = 'たいち' age = 22 print(name + 'は' + str(age) + '歳です。') # 出力結果 -> たいちは22歳です
strによって変数ageが文字列型に変換されたため、エラーが起きることなく出力が行われました。文字列型 → 数値型
先ほどの例とは反対に文字列型を数値型に変換するには、
intを用います。
strと同じように、int(文字列型)とすることで数値型に変換することができます。例をみていきましょう。
example.pycount = '5' price = 200 total_price = price * int(count) print(total_price) # 出力結果 -> 1000
countには5が文字列型で代入されていますので、数値型に変換して計算することでエラーを起こすことなく処理が実行されます。条件分岐
ある条件に当てはまる場合だけに処理を行う条件分岐について学んでいきます。
条件分岐の構文を学ぶ前に、「真偽値」と「比較演算子」について学びましょう。
真偽値
まず、真偽値というものについて学んでいきます。
以下のようなコードを実行します。
example.pyage = 20 print(age == 20) # 出力結果 -> True
==は両辺が等しいかどうかを比較する比較演算子になります。比較演算子については、まとめて説明します。では、このとき出力された
Trueとは一体なんなのでしょうか。この
Trueが真偽値と呼ばれるものになります。
真偽値を扱うデータ型は「真偽値型」に分類され、TrueとFalseの2種類が存在します。
比較演算子を用いた条件式の部分が成り立つときはTrue、成り立たないときはFalseとなります。比較演算子
ここで先ほど出てきた「比較演算子」についてみていきます。
比較演算子とは、値の等しさや大小を比較するときに用いる記号のことです。
比較演算子には以下のものが存在します。
演算子 意味 a == b aがbと等しいときTrue a != b aがbと等しくないときTrue a > b aがbより大きいときTrue a < b aがbより小さいときTrue a >= b aがb以上のときTrue a <= b aがb以下のときTrue この比較演算子は、条件分岐の際の条件文で出てきますので、しっかり抑えておきましょう。
if文
それでは、条件分岐のコードについてみていきます。
ifを用いると、ある条件の場合にだけ処理を行うことが可能になります。構文をみてみましょう。
if 条件式: 処理
ifのあとに条件式を指定し、その条件が成り立つときに実行する処理を次の行に書きます。
処理はインデントにより字下げを行わなければいけない点に注意してください。例をみていきましょう。
example.pyage = 22 if age >= 20: print('お酒が飲めます') # 出力結果 -> お酒が飲めます上の例では、
age >= 20の部分が条件式になります。上の条件式では、「ageの値が20以上だった場合」に
Trueとなります。
ageには22が代入されていて条件式はTrueになるので、その後の処理であるprint(‘お酒が飲めます’)が実行されます。
次の例をみてみましょう。example.pyage = 19 if age >= 20: print('お酒が飲めます') # 出力結果 -> お酒が飲めます上の例では処理の部分にインデントがありません。
その結果、本来実行されないはずの処理が行われてしまっています。インデントには気をつけましょう。
else
if文に
elseを組み合わせることで「if文の条件に当てはまらなかった場合に別の処理を実行する」ことができます。構文は以下の通りです。
if 条件式: 処理 else: 処理
ifの処理の後に、else:と書いて、次の行に処理を書きます。
elseのあとには:が必要なので忘れないようにしましょう。また、if文と同様にインデントにも注意しましょう。具体例をみてみます。
example.pyage = 19 if age >= 20: print('お酒が飲めます') else: print('お酒は二十歳になってから') # 出力結果 -> お酒は二十歳になってから具体例では、
ageに19が代入されているためifブロックの条件を満たしていません。よって
elseの中に書かれている処理が実行されます。elif
if文で成り立たなかった場合の条件式を複数定義したい場合は、
elifを用います。
構文は以下の通りです。if 条件式: 処理 elif 条件式: 処理 else: 処理
ifとelseの間に、elifブロックを追加します。
書き方は、ifの場合と同じで、elif'の後ろに条件式:`を書いて、次の行に処理を書きます。
elifはいくつでも書くことができます。
しかし、上から順に条件が成り立つか判断され、最初に条件を満たしている部分の処理だけが行われます。
elifを用いて条件を書いていく場合には条件の順番にも注意が必要です。具体例を見てみましょう。
example.pynumber = 0 if number > 0: print('正です') elif number == 0: print('0です') else: print('負です') # 出力結果 -> 0です
numberには0が代入されているため、elifの条件分であるnumber == 0を満たします。よって、
elifの中に書かれている処理が実行されます。
elifの処理が実行されたので、ここで処理は終了となります。条件の組み合わせ
and
andを使い複数の条件式を組み合わせることで、「条件1も条件2も成り立つ」場合に処理を実行させることができます。if 条件式1 and 条件式2: 処理
andを用いた場合は、すべての条件式がTrueのとき全体がTrueとなり、処理が実行されます。or
orを使い複数の条件式を組み合わせると、「条件1と条件2のどちらかが成り立つ」場合に処理を実行させることができます。if 条件式1 or 条件式2: 処理
orを用いた場合は、複数の条件式のうち一つでもTrueであれば全体がTrueとなり処理が実行されます。not
notを用いると、条件の否定をすることができます。条件式が
Trueじゃない時に処理が実行されます。
つまり、not 条件式のようにすると、条件式がTrueであれば全体がFalseになります。if not 条件式: 処理リスト
複数のデータを扱うには「リスト」を用います。
リストは、
[〇〇, △△, … ]のように[]を用いて作ります。リストに入っているそれぞれの値を「要素」といいます。また、リストも1つの値なので、変数に代入することができます。
example.pynames = ['山田', '田中', '鈴木'] print(names) # 出力結果 -> ['山田', '田中', '鈴木']出力すると、リストがそのまま出力されます。
また、変数には複数形を使うことが一般的です。リストの要素には、前から順に「0, 1, 2, …」と番号が割り振られています。これを「インデックス番号」といいます。
上の例でいうと、
’山田’がインデックス番号0の要素です。リストの各要素はリスト
リスト名[インデックス番号]とすることで取得することができます。example.pynames = ['山田', '田中', '鈴木'] print('彼は' + names[0] + 'さんです。') # 出力結果 -> 彼は山田さんです。
names[0]では、要素のインデックス番号0の要素を取り出しているので、山田が入ります。リストの要素の更新
リストの要素の更新は、
リスト[インデックス番号] = 値とすることで行うことができます。更新したい場所を指定して、代入をやり直すという感じですね。
具体例をみてみます。
example.pynames = ['山田', '田中', '鈴木'] names[2] = '佐藤' print(names) # 出力結果 -> ['山田', '田中', '佐藤']インデックス番号2の要素を更新しています。出力したリストは、値が更新されていることがわかります。
リストの要素の追加
次に、リストに値を追加してみましょう。
リスト.append(値)とすることで、すでに定義されているリストに新たな要素を追加することが可能です。具体例をみてみましょう。
example.pynames = ['山田', '田中', '鈴木'] names.append('佐藤') print(names) # 出力結果 -> ['山田', '田中', '鈴木', '佐藤']要素は、リストの末尾に追加されます。
具体例でもリストの末尾に
佐藤が追加されたリストが出力されていることがわかります。辞書
「辞書」も、複数のデータをまとめて管理するのに使われます。
辞書はリストと違い、インデックス番号をではなく「キー」と呼ばれる名前をつけて管理します。
辞書は
{キー1: 値1, キー2: 値2, …}のように定義します。一般にキーには文字列が使われます。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} print(names) # 出力結果 -> {'山田': 22, '田中': 40, '鈴木': 33}辞書の要素には順序がないため、出力すると要素の順番が定義したときと変わっていることがあります。
辞書の要素は、取り出したいキーを用いて、
辞書名['キー']とすることで取り出すことができます。example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} print('彼は' + str(names['田中']) + '歳です。') # 出力結果 -> 彼は40歳です。辞書の要素の更新
基本的にはリストの更新と同じです。
インデックス番号の代わりにキーを用います。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} #値を更新 names['田中'] = 50 print('彼は' + str(names['田中']) + '歳です。') # 出力結果 -> 彼は50歳です。値が更新されていることが確認できました。
辞書の要素の追加
辞書に要素を追加するときは、
辞書名['新しいキー'] = 値のように新しいキーを設定してそこに値を代入します。example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} names['佐藤'] = 15 #辞書を出力 print(names) # 出力結果 -> {'山田': 22, '田中': 40, '鈴木': 33, '佐藤': 15} #新しく追加した要素を出力 print('彼は' + str(names['佐藤']) + '歳です。') # 出力結果 -> 彼は15歳です。要素が追加され、指定して取り出すこともできています。
繰り返し処理
Pythonの繰り返し処理である「for文」と「while文」について学んでいきます。
for文
リストのすべての要素を一つひとつ取り出したい場合、1つずつインデックス番号を指定するのは非常に面倒です。
「for文」を使うことで、「繰り返し処理」を行うことができます。
for文は、
for 変数名 in リスト名:のように記述します。変数名にリストの要素が先頭から順に1つずつ入っていき、その上でfor文の中の処理が実行されます。
具体例をみてみましょう。
example.pynames = ['山田', '田中', '鈴木'] for name in names: print('彼は' + name + 'さんです。') # 出力結果 -> 彼は山田さんです。 彼は田中さんです。 彼は鈴木さんです。このように、for文中の出力の処理がリストの先頭から順に行われていきます。
また、変数名は一般的にリスト名の単数形にします。同じように、辞書もfor文を用いることで、要素を1つずつ取り出し、繰り返し処理を実行することができます。
辞書の場合、for文は、
for 〇〇_key in 辞書名:のように記述します。具体例をみてみましょう。
example.pynames = {'山田': 22, '田中': 40, '鈴木': 33} for name_key in names: print(name_key + 'さんは' + str(names[name_key]) + '歳です。') # 出力結果 -> 山田さんは22歳です。 田中さんは40歳です。 鈴木さんは33歳です。このように辞書の要素もfor文で取り出すことができました。
while文
もう一つの繰り返し処理が、「while文」です。
while文を用いると「ある条件に当てはまる間、処理を繰り返す」ことができます。
構文を見てみましょう。
example.pywhile 条件式: 値の更新を含む処理
while 条件式:のように書き、その後にインデントして処理を書きます。
処理の部分には、必ず値を更新する処理を含めます。具体例をみてみましょう。
example.pyx = 1 while x <= 5: print(x) x++ # 出力結果 -> 1 2 3 4 5例を見てみると、条件式の部分は「
xが5以下のとき」となってます。while文の中の処理は、まず「xの値を出力」し、そのあと「xに1を足す」というものになってます。
5が出力された後、1が足され、xの値は6になり条件を満たさなくなるので処理は終了します。よって、
xが5になるまで処理は繰り返されます。無限ループ
while文では、処理の最後に変数の値を更新し忘れたり、インデントが間違っていたりすると条件式が常に
Trueとなってしまい、無限に繰り返し処理が行われてしまいます。気をつけましょう。
breakとcontinue
break
breakを用いることで、繰り返し処理を「強制的に終了」させることができます。
breakはif文などの条件分岐を組み合わせて使います。具体例をみてみましょう。
example.pynumbers = [1, 2, 3, 4, 5] for number in numbers: print(number) if number == 4: break # 出力結果 -> 1 2 3 4コードを見てみましょう。
if文の条件式が「4になったとき」となっています。
ifブロックの中には、breakが書いてあり条件を満たした場合に実行されます。よって、
5の出力は行われることなく処理が終了しています。continue
continueを用いると、条件を満たしている場合の処理をスキップすることができます。
breakと同様に条件分岐と組み合わせて使います。example.pynumbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] for number in numbers: if number % 2 == 0: continue print(number) # 出力結果 -> 1 3 5 7 9
ifの条件式の部分は、「numberが2で割り切れるとき」となっているため、偶数の処理はスキップされ、奇数だけが出力されています。まとめ
一気にまとめてみました。
Pythonはコードがシンプルで読みやすいですね。最後まで読んでいただきありがとうございました。
- 投稿日:2020-11-20T14:33:19+09:00
Pythonのクラスの変数に潜む地雷
https://docs.python.org/3/tutorial/classes.html#class-and-instance-variables
Class variables Python are strange.
If they are mutable, they act like STATIC PROPERTY in PHP;
If they are immutable, when they reassigned, the act like DYNAMIC PROPERTY in PHP.
It seems to do with reference.class X: array: list = [] immutable_array: tuple = () static_v: str = 'ori' def __init__(self, name: str): self.name = name def init_ext(self): self.array = [] # or even use [self.name], just let it be another id def work(self): self.array.append(self.name) self.immutable_array = (len(self.array),) self.static_v = f"[{self.name}]" if __name__ == '__main__': x1 = X("A") x2 = X("B") for i in range(3): print("x1 array: ", x1.array, 'tuple: ', x1.immutable_array, "v: ", x1.static_v), print("x1[id] array: ", id(x1.array), 'tuple: ', id(x1.immutable_array), "v: ", id(x1.static_v)) print("x2 array: ", x2.array, 'tuple: ', x2.immutable_array, "v: ", x2.static_v) print("x2[id] array: ", id(x2.array), 'tuple: ', id(x2.immutable_array), "v: ", id(x2.static_v)) x1.work() x2.work() print("finally") print("x1 array: ", x1.array, 'tuple: ', x1.immutable_array, "v: ", x1.static_v), print("x1[id] array: ", id(x1.array), 'tuple: ', id(x1.immutable_array), "v: ", id(x1.static_v)) print("x2 array: ", x2.array, 'tuple: ', x2.immutable_array, "v: ", x2.static_v) print("x2[id] array: ", id(x2.array), 'tuple: ', id(x2.immutable_array), "v: ", id(x2.static_v))Output:
x1 array: [] tuple: () v: ori x1[id] array: 4477451776 tuple: 4475306048 v: 4477483952 x2 array: [] tuple: () v: ori x2[id] array: 4477451776 tuple: 4475306048 v: 4477483952 x1 array: ['A', 'B'] tuple: (1,) v: [A] x1[id] array: 4477451776 tuple: 4476906464 v: 4477621936 x2 array: ['A', 'B'] tuple: (2,) v: [B] x2[id] array: 4477451776 tuple: 4476375872 v: 4477622000 x1 array: ['A', 'B', 'A', 'B'] tuple: (3,) v: [A] x1[id] array: 4477451776 tuple: 4476751488 v: 4477622064 x2 array: ['A', 'B', 'A', 'B'] tuple: (4,) v: [B] x2[id] array: 4477451776 tuple: 4476906464 v: 4477621936 finally x1 array: ['A', 'B', 'A', 'B', 'A', 'B'] tuple: (5,) v: [A] x1[id] array: 4477451776 tuple: 4476375872 v: 4477622128 x2 array: ['A', 'B', 'A', 'B', 'A', 'B'] tuple: (6,) v: [B] x2[id] array: 4477451776 tuple: 4476751488 v: 4477622064If you execute
init_extafter initialization, the result changed.x1 = X("A") x2 = X("B") x1.init_ext() x2.init_ext() # the same test codes as aboveThe output would be :
x1 array: [] tuple: () v: ori x1[id] array: 4327900992 tuple: 4325756992 v: 4327930800 x2 array: [] tuple: () v: ori x2[id] array: 4327899904 tuple: 4325756992 v: 4327930800 x1 array: ['A'] tuple: (1,) v: [A] x1[id] array: 4327900992 tuple: 4327849648 v: 4328077168 x2 array: ['B'] tuple: (1,) v: [B] x2[id] array: 4327899904 tuple: 4327372112 v: 4328077232 x1 array: ['A', 'A'] tuple: (2,) v: [A] x1[id] array: 4327900992 tuple: 4326822720 v: 4328077296 x2 array: ['B', 'B'] tuple: (2,) v: [B] x2[id] array: 4327899904 tuple: 4327849648 v: 4328077168 finally x1 array: ['A', 'A', 'A'] tuple: (3,) v: [A] x1[id] array: 4327900992 tuple: 4327372112 v: 4328077232 x2 array: ['B', 'B', 'B'] tuple: (3,) v: [B] x2[id] array: 4327899904 tuple: 4326822720 v: 4328077296
- 投稿日:2020-11-20T14:24:11+09:00
Pythonでシーザー暗号のプログラムを書く
はじめに
CTFを始めたらシーザー暗号と言うものが出てきたので復号処理が必要になった。
手作業でも出来るけどここはプログラムでしょ!リハビリにもなるし!と言う事で早速書いてみた。
私のマシンにはPythonの開発環境しか無かったのでPythonでGo!シーザー暗号とは
復号するためにはどんなアルゴリズムで生成された暗号なのかを知らなければいけない。
シーザー暗号は文字を3文字ずつシフトして生成する。ほうほうシンプル!
※特に3文字じゃなくても良いそう。
参考サイト:https://ja.wikipedia.org/wiki/シーザー暗号暗号化と復号化のプログラム
まずは暗号化を。
平文を1文字ごとに指定のキー(数)でシフトする。
大文字小文字は別なので今回は英小文字のみで組む。
英文字は25個なのでぐるっと回るように注意。
適当な文字列「wjrslairznb」を暗号化!def crypt(plainStr, shiftInt): resultStr = "" for char in plainStr: if ord(char) + shiftInt > ord('z'): resultStr = resultStr + chr(ord(char) + shiftInt - 26) else: resultStr = resultStr + chr(ord(char) + shiftInt) print('crypt:' + resultStr)実行結果
復号化は単純に逆に計算しただけです…
def decrypt(cryptoStr, shiftInt): resultStr = "" for char in cryptoStr: if ord(char) - shiftInt < ord('a'): resultStr = resultStr + chr(ord(char) - shiftInt + 26) else: resultStr = resultStr + chr(ord(char) - shiftInt) print('decrypt:' + resultStr)実行結果
もっとサラッとシンプルに出来そう…余談:シーザー暗号って暗号としては簡単過ぎるけど使えるの?
使えない。脆弱ぅ!!
古代ローマに作られた暗号なので、昔は有効だったのでしょうと言う事。
暗号に歴史あり。おわりに
実はプログラムは久しぶりでしかもPython環境はあるのにほとんど触った事ないしでとても楽しかった。
この手のプログラムはググれば山程出てくるけどまずは自分で書いてみて、後で天才的なコードを見て答え合わせをするのが好きです。


- 投稿日:2020-11-20T14:15:39+09:00
AWS lambda layer で仮想環境を構築したった
Background
Python3.6 以降で
venvを使ってpipしたパッケージを保存していたのですが、AWS上で出来ないかと調べているとlayerという手頃な機能があったので使ってみた。venv
作業PC上ではこれでOK
python -m venv [仮想環境名] ./[仮想環境名]/bin/activate ([仮想環境名]) pip install [パッケージ名]パッケージ用のzip作成
AWS lambda を使ってWebスクレイピングしたった-Development (Webスクレイピング)と同様にAWS上にuploadするためにzipファイルを作ります。
mkdir packages cd packages pip install [パッケージ] -t ./ pip install [パッケージ] -t ./ ...... zip -r ./myDeploymentPackage.zip ./packagesLayer
pip環境を作成するにはLayerを作成します。
Development (error)
ここでAWS lambda を使ってWebスクレイピングしたった-Development (Webスクレイピング)でbeautifulsoupを使ったコードを書いてみます。
import json import requests from bs4 import BeautifulSoup def lambda_handler(event, context): # TODO implement response = requests.get('https://mainichi.jp/editorial/') soup = BeautifulSoup(response.text) pages = soup.find("ul", class_="list-typeD") articles = pages.find_all("article") links = [ "https:" + a.a.get("href") for a in articles] return { 'statusCode': 200, 'links' : links }とすると、
{ "errorMessage": "Unable to import module 'lambda_function'" }importエラーが出てしまいます。
Lambda@Pythonのレイヤーを使う際の基本的な注意点(レイヤーに上げたファイルがimport出来ない人向け)-注意点
を見ると、zipファイルは/opt/配下に解凍されるみたいです。この場合だと、
/opt/packages/に作業用PCにpipでインストールしたパッケージがあるので、import sys sys.path.append('/opt/packages')にして事前にパスを通しておく必要があります。
Development (modified)
import sys sys.path.append('/opt/packages') import json import requests from bs4 import BeautifulSoup def lambda_handler(event, context): # TODO implement response = requests.get('https://mainichi.jp/editorial/') soup = BeautifulSoup(response.text) pages = soup.find("ul", class_="list-typeD") articles = pages.find_all("article") links = [ "https:" + a.a.get("href") for a in articles] return { 'statusCode': 200, 'links' : links }{ "statusCode": 200, "links": [ "https://mainichi.jp/articles/20201120/ddm/005/070/067000c", "https://mainichi.jp/articles/20201120/ddm/005/070/065000c", "https://mainichi.jp/articles/20201119/ddm/005/070/119000c", "https://mainichi.jp/articles/20201119/ddm/005/070/118000c", "https://mainichi.jp/articles/20201118/ddm/005/070/115000c", "https://mainichi.jp/articles/20201118/ddm/005/070/114000c", "https://mainichi.jp/articles/20201117/ddm/005/070/114000c", "https://mainichi.jp/articles/20201117/ddm/005/070/113000c", "https://mainichi.jp/articles/20201116/ddm/005/070/043000c" ] }Post Scripting
zipで圧縮するときに"/packages/"なしでできればいいんすけどね
- 投稿日:2020-11-20T14:14:26+09:00
Human In The Loop実装してみた ― Part① ダッシュボード ―
はじめに
Human in the loop(HITL)とはAIの判断や制御に人間のオペレーションなどを介在させることであり、品質管理が難しいAIの社会実装の手段の一つとして考えられています。[参考1]
この記事では、HITLのイメージが掴めるように、機械学習モデル、モニタリング用ダッシュボード、検証ツールを簡単なWEBアプリで実装したいと思います。(全3回予定)
HITLにおいて、実際のデータとAIの挙動を同時に確認できるダッシュボードはモニタリングに効果的なため、Part①の今回は、目標設定、使用データ紹介、モニタリング用ダッシュボードの実装を行います。<HITL実装目次>
Part① ダッシュボード ← 今回
Part② 検証ツール
Part③ HITL(①と②+モデル再学習の仕組み)■ 実装結果
■ 環境Python 3.7.7
dash 1.16.1
dash-bootstrap-components 0.10.7
dash-core-components 1.12.1
dash-html-components 1.1.1
dash-renderer 1.8.1
dash-table 4.10.1
plotly 4.10.0
Flask 1.1.2
lightgbm 3.0.0目標設定
HITLはタスクによって様々な構築が想定されますが、このシリーズでは異常検知をベースとしたものを採用します。
■ WEBアプリで以下を実装
- モニタリング
- ダッシュボード(Chart)
- 機械学習モデル
- 教師有モデルで既知異常検知
- 検知モデル
- 教師無モデルで未知検知(正常か異常かは検証しないと不明)
- 有識者検証
- アノテーションツールを意識し実装
- 未知検知部分を検証者が正常か異常か確認する
- シナリオ
- 検知モデルが未知検知(機械学習モデルは異常と判定)
- 検証者が未知検知部分を検証、正常と判定
- 判定を受け、該当部分をモデルが正常と判定するよう再学習を実行
利用データ
実装ではKaggleのCredit Card Fraud Detectionのデータを利用しました。[参考2]
このデータはクレジットカードの不正利用を目的変数とした不均衡データのため、異常検知モデルの試行によく使用されます。
元データはPCAされたV1からV28のデータが含まれるのですが、
今回はイメージを掴むデモを目的としているので、可視化した際分かりやすいように入力特徴量は2変数(V4,V14)※とします。※ V4とV14のみでもいくつかの不正利用は検知できることを事前に確認しています
デモでは、上記データに人為的に未知正常データを加えたものをモニタリング、検証、再学習します。人為的に作成する未知正常データはシナリオ上、以下を満たす必要があります。
① 教師有モデルが誤検知(誤って異常と判定)する
② 検知モデルが検知可能(つまり人為データが本来の学習データと明確に異なる)
③ 再学習しても、教師有モデルが既存の異常判定を保ち得る以上を踏まえ、デモ用のデータを作成しました。(以下)
(1〜8s:既知(3s時異常)、9〜11s:未知、を二回繰り返す)

利用技術
実装するにあたって利用したフレームワークやモデルについて記載します。
■ 可視化部分
- flask
- 軽量なwebアプリケーションフレームワーク
- ルーティング関数によりWEBアプリとサーバー間をやり取り
- Dash
- 可視化に特化したwebアプリケーションフレームワーク[参考5]
- flaskを拡張したものでコーディング感覚が似ている
- plotly
- インタラクティブな可視化フレームワーク[参考6]
- Pythonの同様のフレームワークの中ではBokehと並び人気
■ 機械学習モデル、検知モデル
- 機械学習モデル
- LightGBM
- 二値分類のスコアを表示(正常:0、不正:1)
- はじめは事前学習したものを使用
- 検知モデル
- KNN
- 近傍距離を異常度とし、閾値を切り二値化(正常:0、未知:-1)
- はじめは事前学習したものを使用
実装
以下に分けて実装していきます。
1. ダッシュボード ← 今回
2. 検証ツール
3. HITL(①と②+モデル再学習の仕組み)1. ダッシュボード
■ 実装内容
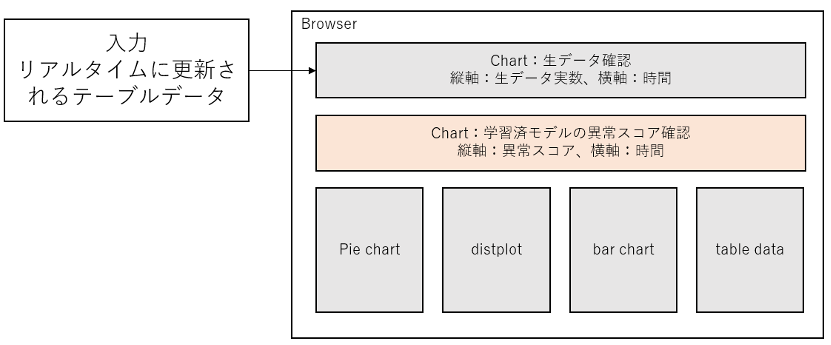
- 目標:簡単なダッシュボード(Chart+α)
- 入力:テーブルデータ(csvファイル)
- 出力:異常スコアが高い(と観察された)検証用データ
- 異常判定:実データと並べてモデルの異常スコアを表示
- その他:リアルタイム更新
- +α:ここではチャートの他に円グラフ、distplot、棒グラフ、テーブルを実装
■ 実装イメージ
■ 実装結果
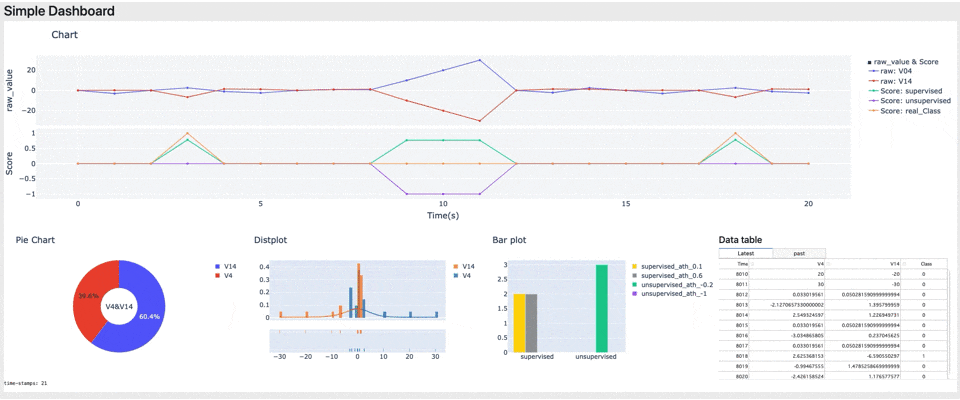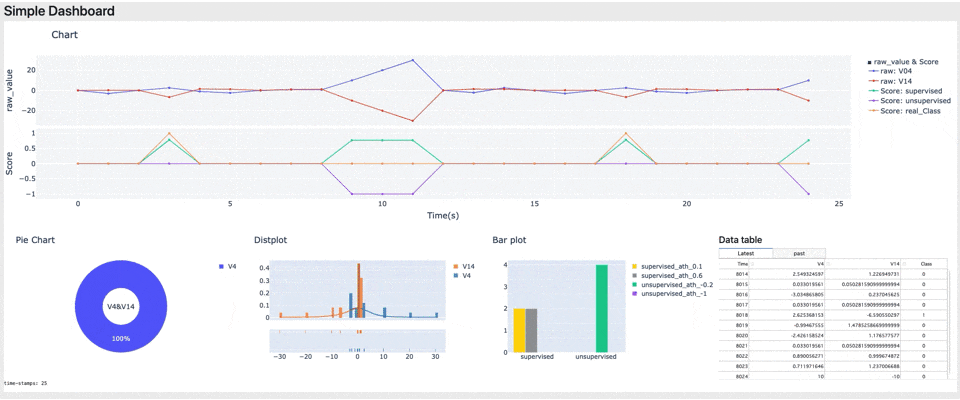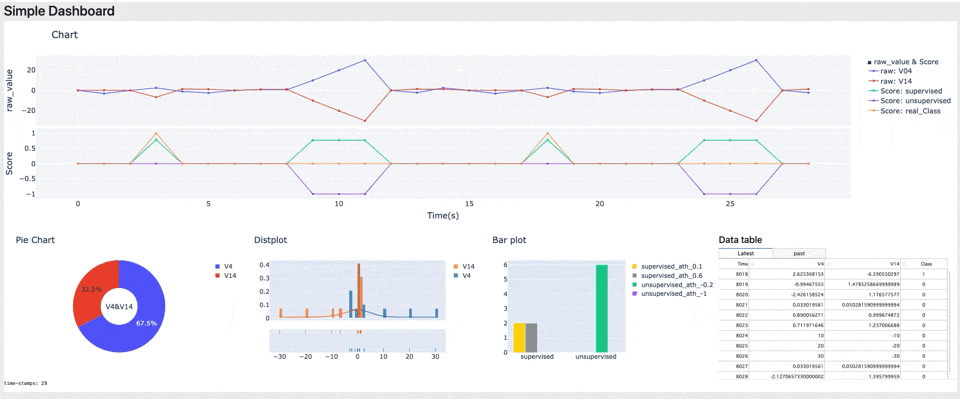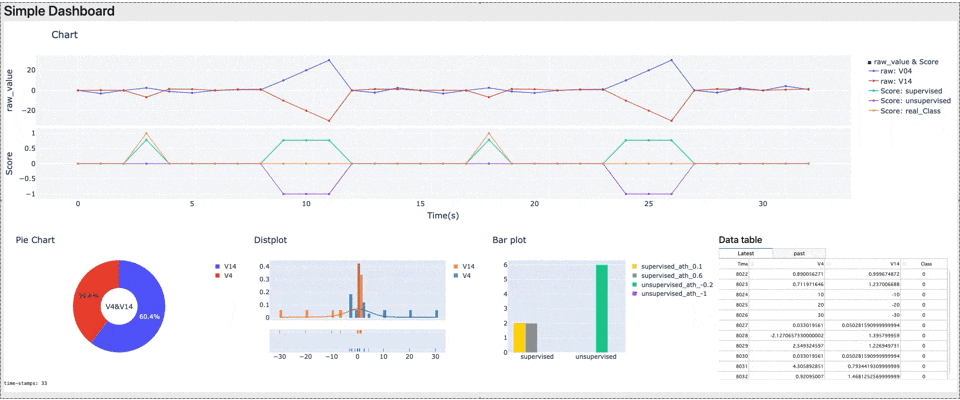
まとめ
今回はHuman In The Loopにおけるモニタリング時に使用する、ダッシュボードを実装しました。ダッシュボードにより実データの情報とAIのスコアがリアルタイムに可視化され、AIが実データのどこに着目して判定しているかが分かりやすくなりました。(今回のデータではAIはV4が正でV14が負のとき不正と判定しているようです)
Dashとplotlyを使用することで、HTMLやCSS部分のコーディングが比較的楽になっていると感じました。何より、こうしたリアルタイムに動くWEBアプリが簡単に実装できる感覚は、是非体験いただきたいと思います。改善点やご質問などあれば、コメントいただければ幸いです。
参考
よりよいビジネス、社会、未来を作る人間参加型(Human-in-the-loop)AI
https://note.com/masayamori/n/n2764e3cecc05Kaggle - Credit Card Fraud Detection
https://www.kaggle.com/mlg-ulb/creditcardfraudDashで機械学習ができるWebアプリを作る [Step1]
https://wimper-1996.hatenablog.com/entry/2019/10/28/dash_machine_learning1
※ Dashのテーブルデータ処理などで参考にさせていただきましたコード公開済み
http://github.com/utmotoplotly
https://plotly.com/
- 投稿日:2020-11-20T13:47:21+09:00
Pandasでto_csvしたら一行ずつになった件
- 投稿日:2020-11-20T13:42:58+09:00
matplotで凡例を手動で作りたい
はじめに
matplotの凡例はほとんどの場合自動作成で事足りると思いますが、イレギュラーが発生したので手動で設定する方法をメモしておきます。
普通のプロット
おそらくほとんどの場合これで十分で、これができるようにデータをまとめればいいと思います。
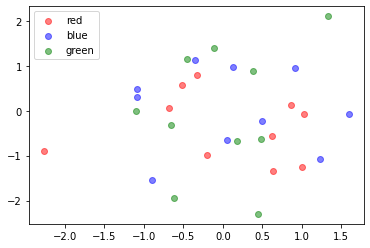
import numpy as np from matplotlib import pyplot as plt red_x, red_y = np.random.randn(10), np.random.randn(10) blue_x, blue_y = np.random.randn(10), np.random.randn(10) green_x, green_y = np.random.randn(10), np.random.randn(10) plt.scatter(red_x, red_y, c="r", alpha=0.5, label="red") plt.scatter(blue_x, blue_y, c="b", alpha=0.5, label="blue") plt.scatter(green_x, green_y, c="g", alpha=0.5, label="green") plt.legend() plt.show()
手動で設定する
特殊な状況、特殊なデータを扱っていて上のコードにできない、もしくはコードが汚くなってしまうときは以下のようにして手動で設定できます。
import numpy as np from matplotlib import pyplot as plt red_x, red_y = np.random.randn(10), np.random.randn(10) blue_x, blue_y = np.random.randn(10), np.random.randn(10) green_x, green_y = np.random.randn(10), np.random.randn(10) # データの部分からlabelを取っ払う plt.scatter(red_x, red_y, c="r", alpha=0.5) plt.scatter(blue_x, blue_y, c="b", alpha=0.5) plt.scatter(green_x, green_y, c="g", alpha=0.5) # 凡例用に空のデータをlabel付でプロットする(実際はなにもプロットしてない) plt.scatter([], [], c="r", alpha=0.5, label="red") plt.scatter([], [], c="b", alpha=0.5, label="blue") plt.scatter([], [], c="g", alpha=0.5, label="green") plt.legend() plt.show()
おわりに
凡例の部分だけ透明度や点の大きさを変えるなどのときにも使用できそうな感じです。
- 投稿日:2020-11-20T13:05:09+09:00
【pandas_flavor】Pandas DataFrameのメソッドを追加する
TL;DR
BEFOREdataframe_ = dataframe.loc[(dataframe.time == 'pre') & \ (dataframe.group == 'exp') & \ (dataframe.cond == 'a'), :] sns.regplot(x='mood', y='score', data=dataframe_)↓↓↓
AFTERdataframe.by(time='pre', cond='exp', group='a').regplot(x='trait', y='score')pandas_flavorを使うことで、好きなメソッドをpandas DataFrame(およびSeries)に追加することができます。
モチベーション
Long形式のデータから条件に合う箇所を抽出するのはめんどい!
例えばこんなデータがあったとします。
被験者50人をふたつの群(group: exp, ctrl)に分け、それぞれになにやら介入を行ったという設定です。
介入の前後(time: pre, post)で課題を行わせ、課題中のふたつの条件(cond: a, b)における成績(score)を測定しました。
同時に、課題をやっているときの気分(mood)も、条件(cond: a, b)ごとに測定しました。1測定データは、上の画像のようにlong形式でまとめるとその後の解析がやりやすくなりますね。
さて、いろいろな解析をやる前にひとまず、
preにおけるexp群の課題条件aのときのscoreとmoodとの相関関係をプロットすることにしましょう。以上の条件に合う行を抽出してくるので、↓こんなコードになりますね。
dataframe_ = dataframe.loc[(dataframe.time == 'pre') & \ (dataframe.group == 'exp') & \ (dataframe.cond == 'a'), :] sns.regplot(x='mood', y='score', data=dataframe_)条件を表したbool型のSeriesを作り、
.locに入れてやってます。
うーん、なんか汚い。
.query()メソッドを使えば、↓こんなふうにも書けます。dataframe_ = dataframe.query('time == "pre" & group == "exp" & cond == "a"') sns.regplot(x='mood', y='score', data=dataframe_)こっちのほうがだいぶスッキリしていますが、もうちょっといい感じにならんかなぁ。
.query()使う方法はboolのSeriesを使う方法に比べて遅いそうですし。
やっぱり、Long形式のデータから条件に合う箇所を抽出するのはめんどい!Pandas DataFrameのメソッドを追加する
ならメソッドを作ればいいじゃない
そこで、DataFrameから条件に合うような行を抽出してくるような新しいメソッドを作ってやりましょう。
↓こんなふうに使える.by()メソッドをDataFrameに新しく追加します。dataframe.by(time='pre', cond='exp', group='a')pandas_flavorというパッケージを使うと、簡単にこれを達成することができます。
インストール方法
pipか、
pip install pandas_flavorcondaで一発です。
conda install -c conda-forge pandas_flavor使用例
import pandas_flavor as pf @pf.register_dataframe_method def by(self, **args): for key in args.keys(): self = self.loc[self.loc[:, key] == args[key], :] return self関数を書いて、デコレータとして
@pf.register_dataframe_methodを付けてやるだけです。
こちらの例では、**argsとやることで引数を辞書型で受け取ります。
これによって、各引数で指定した行を抽出しています。さらに、seabornの各種関数をメソッド化させるのもいいですね。
@pf.register_dataframe_method def regplot(self, **args): return sns.regplot(data=self, **args)
と、こんな感じです。
pandas.Seriesにメソッドを追加してやりたければ、@pf.register_series_methodで同じことができるようです。今回の例は…、まぁ
.query()使えばいいような気もしますが、色々と応用ができそうです。
言うまでもありませんが、すべてでっち上げの心理学実験です。数値はrandomモジュールで生成しています。 ↩
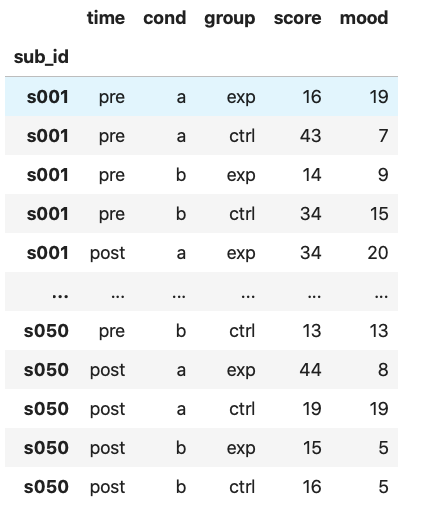
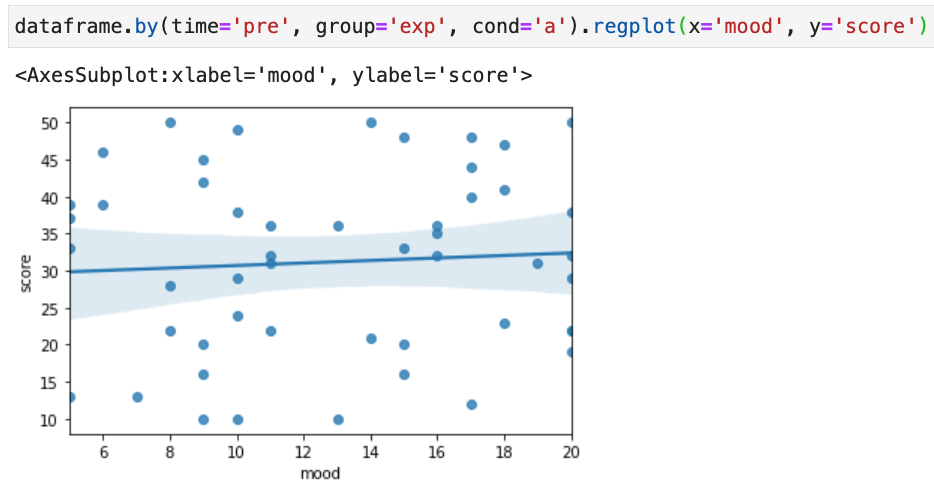
- 投稿日:2020-11-20T12:51:23+09:00
キャッチコピー自動生成のWEBアプリケーションを開発した話【MeCab】
サービスサイト
MakeLike
https://melikeke.sakura.ne.jp/malike/intro概要
PythonのMecabを使用して、様々な教師データから「っぽい文章」を生成します
・カテゴリから生成
・ファイルから生成
・直接入力から生成
の3パターンから教師データを指定できます。機能
キャッチコピー自動生成
・カテゴリから生成
・ファイルから生成
・直接入力から生成ログイン機能
会員登録
ログイン
会員登録通知
パスワード再設定お気に入り機能
実装
環境
さくらサーバー
フロントエンド
Laravel
基本部分
テンプレートの活用
LaravelのBladeテンプレートでレイアウト部分を共通にする
http://cly7796.net/wp/php/to-a-common-layout-in-blade-template-of-laravel/
ログイン認証系
Laravelでサクッとログイン機能を実装する方法
https://php-junkie.net/framework/laravel/login/「Command "make:auth" is not defined.」が出たら
https://qiita.com/daisu_yamazaki/items/a914a16ca1640334d7a5【Laravel7でユーザー認証_8】メールアドレス変更時にメール認証を行う
https://qiita.com/crosawassant/items/018b29ab770c0a373bc9Laravelの標準Authentication(Auth)の動きを調べてみる
https://qiita.com/zaburo/items/9fcf0f4c771e011a4d35
会員登録時の自動通知
下記のどちらかの方法で、メール通知やSlack通知が可能
Laravel
これを読めばLaravelのイベントとリスナーが設定できる
https://reffect.co.jp/laravel/laravel-event-listener#i-8Google Analytics
Google アナリティクスからのアラートを受信しよう
https://www.ad-market.jp/column/2020/04/20200420.html
メール機能
パスワードリセットメールを送信するため、Laravelのメール機能を設定します。
ローカル開発時には「mailTrap」
本番環境では「さくらサーバ」のSMTPを設定し、疎通確認をしました。Laravel mailTrapでメール送信テスト 備忘録
https://qiita.com/ryomaDsakamoto/items/e9d3a2c258dbfc66c524LaravelのSMTPサーバにさくらサーバのSMTPを設定
https://laraweb.net/tutorial/1265/洗練された『Laravel』のメール送信機能を使ってみる
https://liginc.co.jp/369690Laravel5.7: 日本語のパスワードリセット用のメールを送信する
https://qiita.com/sutara79/items/0ea48847f5565aacceea
日本語設定
Laravelで日本語設定をする場合は、
ja.jsonへ記述することで設定を適応することができます。/resources/lang/ja.json{ "Click link below and reset password.": "下記のURLにアクセスして、パスワードを再設定してください。", "If you did not request a password reset, no further action is required.": "このメールに心当たりがない場合は、このまま削除してください。", }blade.php<p> {{ __('Click link below and reset password.') }}<br> {{ __('If you did not request a password reset, no further action is required.') }} </p>実際の表示
生成部分
「カテゴリから生成」表示部分の実装
カテゴリプルダウンは「カテゴリ1」に紐づいて「カテゴリ2」の選択肢が変動するようにします。
・カテゴリ1が「歌詞」の場合
・カテゴリ1が「小説」の場合
リレーション
category1.id = category2.parent_id
categori1
categori2
参考
laravel5.1で、カテゴリー・サブカテゴリーのような親子セレクトボックスを作る方法
https://www.messiahworks.com/archives/12202
「カテゴリから生成」処理部分の実装
カテゴリで指定した値を元にStorageで読み込む教師データのパスを設定します。
contoloer.php$input = $request->input(); $category1 = Arr::get($input, 'category1'); $category2 = Arr::get($input, 'category2'); $path = 'public/constText/'; $path .= $category1 . '/'; $path .= $category2 . '.txt';constTextの構成
「ファイルから生成」部分の実装
LaravelのStorage機能を使用し、アップロード処理を実装します。
今回はテキストデータのみに制限するため拡張子を以下のように設定します。
・txt
・csv
・xls
・xlsx参考
Laravelでファイルをアップロードする方法を詳細解説
https://reffect.co.jp/laravel/how_to_upload_file_in_laravelLaravelでStorageを使ったファイルおよびディレクトリの操作をまとめてみた
https://qiita.com/t1k2a/items/50081988363cf2fa1bca
「直接入力から生成」部分の実装
「ファイルから生成」は上記のようなフローで実行していますが、
「直接入力から生成」もStorage機能を活用して実行しています。直接入力から生成フロー
textareaの値をテキストファイルでStorage保存
以下、「ファイルから生成」と同様の処理サーバエンド
Python
MeCabによる自動生成部分については以下の記事にまとめています。
参考
自動生成キャッチコピー【Python】
https://qiita.com/SyogoSuganoya/items/ba542f686104811e2d6b
PHPからPython実行
Laravelで実装したinput button等の発火イベントで
Pythonを実装できるようにします。PHPのexec関数を使用し、Pythonを実行します。
参考
ゼロから作るPHPとPythonの連携 on Laravel
https://qiita.com/SwitchBlade/items/96ed4ea425ef2d758f71PHP - exec()のエラーハンドリングと標準エラー出力の関係をまとめる
https://qiita.com/smd8122/items/65b552f1d53bfb7fad9a
Ajax
基本
Laravel、Ajaxを用いて動的なコメント閲覧画面の作成
https://www.merges.co.jp/archives/1980LaravelでAjax(jQuery)を使用する
https://pointsandlines.jp/server-side/php/laravel-ajaxLaravel と Ajax で値の受け渡して非同期処理。
https://niwacan.com/1619-laravel-ajax/
生成文章の表示
生成ボタン押下後の「生成文章」エリアの表示にはAjaxを使用します。
PHPのexec関数の「\$outputs」を生成文章に表示します。
$outputsにはPython実行中のprintした文字列が格納されていますcontroller.phpexec($command , $outputs, $return_var); $data = [ 'outputs' => $outputs, 'return_var' => $return_var, ]; return response()->json($data);pythonCall.jsvar params = { headers: { 'X-CSRF-TOKEN': $('meta[name="csrf-token"]').attr('content') }, url: url, method: 'post', dataType: 'json', data: paramData, //リクエストが完了するまで実行される beforeSend: function(){ $('h3').text('読み込み中'); $("input").attr("disabled","true"); $('.wrapper .button').addClass('pushed'); $('.heart-check').prop('checked', false); //アイテムを全部checkedはずす } }; $.ajax( params ).done(function( data ) { // 生成文章の初期化 $('input.sentence').val(''); // 生成文章の入力 for(var i = 0; i < data.outputs.length && i < 5; i++){ $('input.sentence').eq(i).val(data.outputs[i]); } }
お気に入り機能
生成文章のお気に入り登録および
マイページのお気に入り文章の管理
お気に入り機能はAjaxを使用し、非同期で処理します。
controller.php// 一覧画面の表示 public function index(Request $request) { $posts = Favorite_sentence::where('user_id', $request->user()->id) //$userによる投稿を取得 ->orderBy('created_at', 'desc') // 投稿作成日が新しい順に並べる ->paginate(10); // ページネーション; return view('user.mypage', [ 'posts' => $posts, // $userの書いた記事をviewへ渡す ]); } // ハートマークのクリック(登録 or 削除) public function ajaxlike(Request $request) { // $user_id = $request->user()->id; $user_id = Auth::user()->id; $post_id = $request->post_id; $sentence = $request->sentence; $like = new Favorite_sentence; $exist = Favorite_sentence::where('id', $post_id)->get(); $isExist = $exist->isEmpty(); if ($isExist) { // 空(まだ「いいね」していない)ならlikesテーブルに新しいレコードを作成する $like = new Favorite_sentence; $like->user_id = $user_id; $like->sentence = $sentence; $like->save(); $post_id = $like->id; $command = 'insert'; } else { // お気に入りフレーズの存在確認 Favorite_sentence::findOrFail($post_id); // likesテーブルのレコードを削除 $like = Favorite_sentence::where('id', $post_id) ->delete(); $command = 'delete'; } $data = [ 'user_id' => $user_id, 'post_id' => $post_id, 'sentence' => $sentence, 'command' => $command, ]; //下記の記述でajaxに引数の値を返す return response()->json($data); }likeSentence.jsvar like = $('.heart-label'); var likePostId; var sentence; like.on('click', function () { var $this = $(this); // お気に入り文章ID likePostId = $this.parent().parent().find(".sentence").attr('data-postid'); // お気に入り文章 sentence = $this.parent().parent().find(".sentence").val(); // お気に入り文章が空白 if (!sentence) { return; } $.ajax({ headers: { 'X-CSRF-TOKEN': $('meta[name="csrf-token"]').attr('content') }, url: '/ajaxlike', type: 'POST', data: { 'post_id': likePostId , 'sentence': sentence , }, }).done(function (data) { if(data.command = 'insert') { $this.parent().parent().find(".sentence").attr('data-postid', data.post_id); } });リリース
本番環境では「さくらサーバー」を使用
Python/MeCab環境構築
さくらサーバ・UTF-8に対応したWEBブラウザにMecabで形態素解析した結果を出力する
https://qiita.com/Jshirius/items/ac3ca66a2d5262b98b58さくら共有サーバーにmecabをインストールしてpythonから呼び出してみる
https://qiita.com/Jshirius/items/3a067486e2a693544c32
MeCabがターミナルからは実行できるが、PHP呼び出しから使えない時…
まずはPythonをフルパスで呼び出してみる
エックスサーバーでphpからexec関数でpythonを呼び出そうとして苦労した話
https://hazukei.com/1259/
site-packagesを追加指定
それでもうまくいかない時は、「site-packages」をターミナル実行とPHP実行で比較
import site site.USER_SITE差分を追加し、インストール済みパッケージを実行可能な状態にする
import sys sys.path.append('vendor\Lib\site-packages')参考
さくらのレンタルサーバに Python モジュールをインストール
https://emptypage.jp/notes/sakura-python.htmlPythonモジュールのインストール先の確認方法や設定方法を現役エンジニアが解説【初心者向け】
https://techacademy.jp/magazine/46510Laravel
[0001]さくらのレンタルサーバーにSSHで入りLaravelをインストール
https://www.failibere.com/development_memo/lalavel/0001さくらサーバでstorageへのシンボリックリンクを張る
https://blog.hiroyuki90.com/articles/laravelで作成したwebアプリをレンタルサーバに公開する/

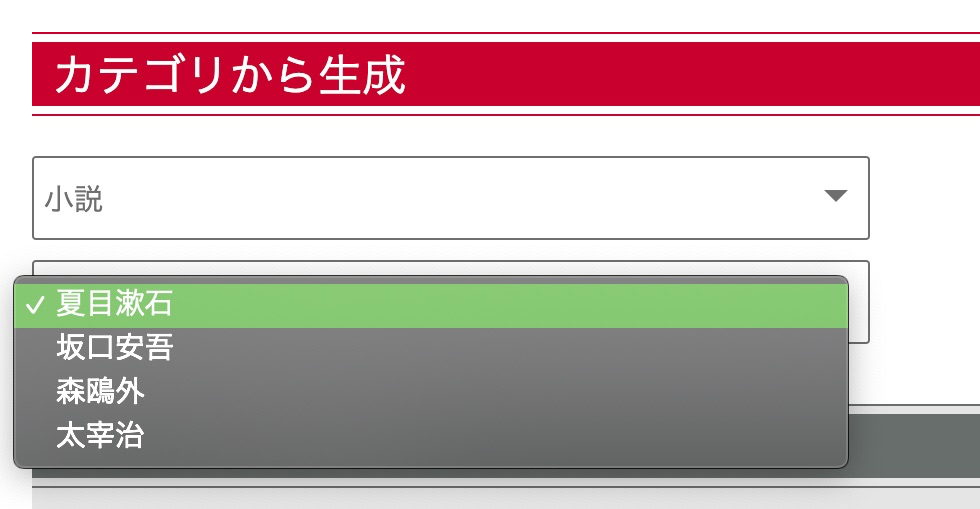

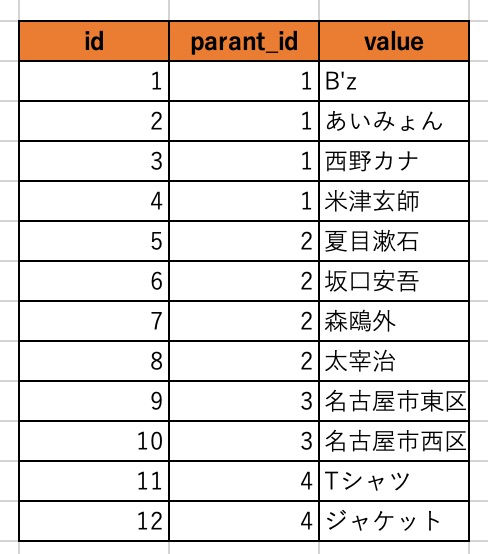

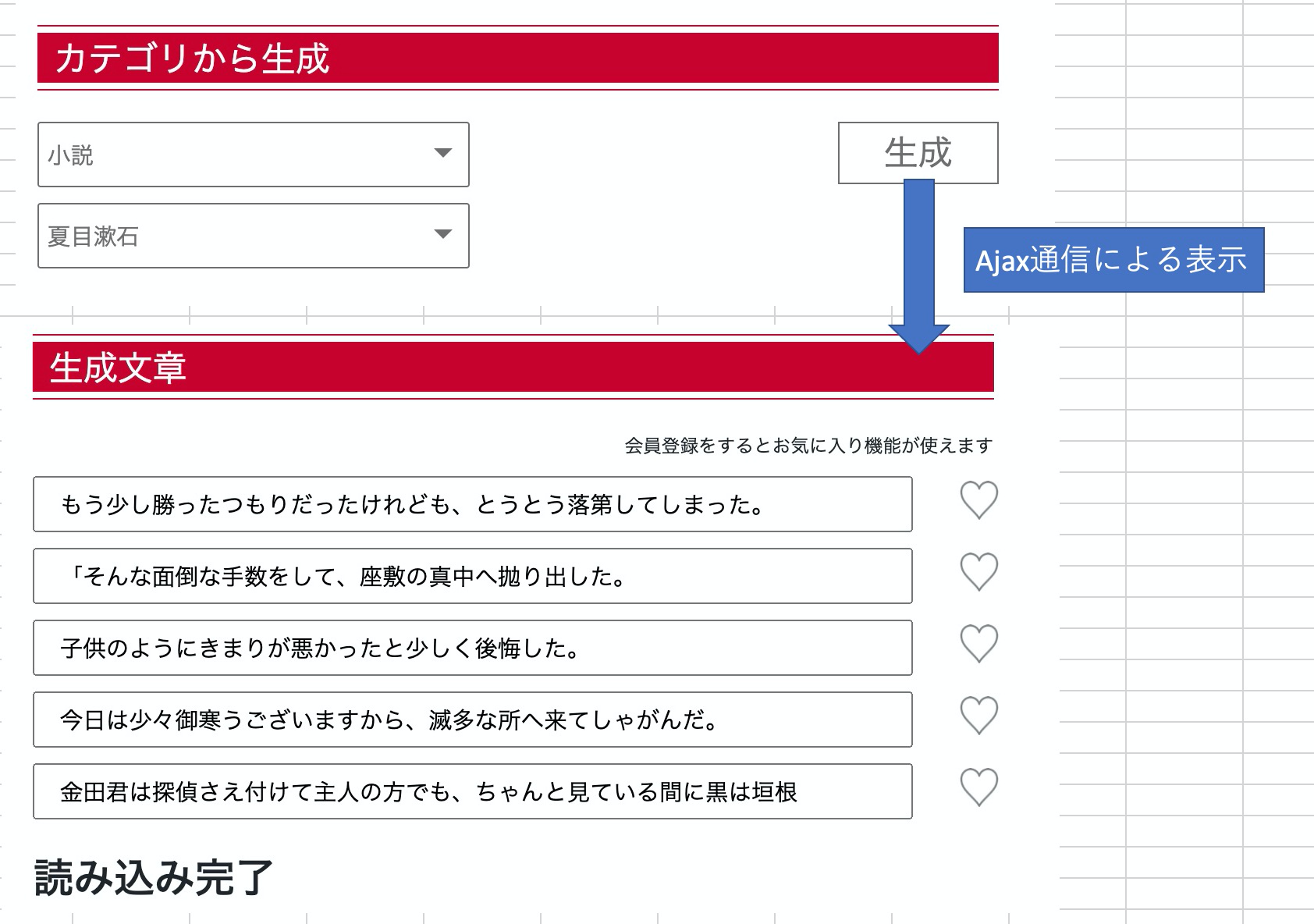
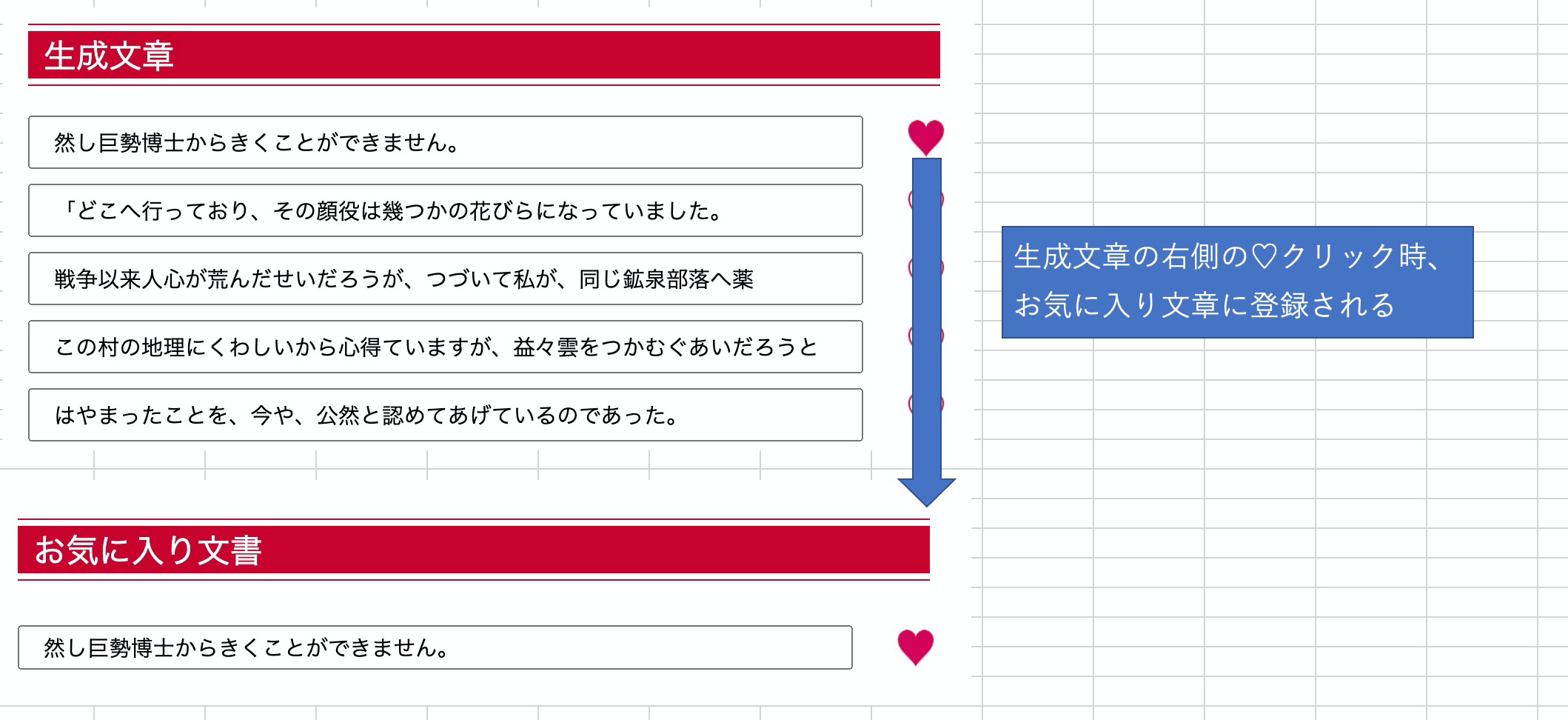
- 投稿日:2020-11-20T12:29:21+09:00
Dockerでgccエラーが出た時の対処方法
概要
google-cloud-bigqueryの最新バージョンをpython*alpineの最新版に入れようとしたら下記のようなエラーが出てインストールに失敗しました最終的に修正後のDockerfileのようにしたところ無事インストールできました。修正前のDockerfile
DockerfileFROM python:3.9.0-alpine3.12 RUN apk --update add \ curl \ bash RUN apk --update add tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime COPY ./requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt RUN curl -sSL https://sdk.cloud.google.com | bash ENV PATH $PATH:/root/google-cloud-sdk/bin RUN mkdir -p /src FROM python:3.9.0-alpine3.12 RUN apk --update add \ curl \ gcc \ musl-dev \ linux-headers \ build-base \ libffi-dev \ bash RUN apk --update add tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime COPY ./requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt RUN curl -sSL https://sdk.cloud.google.com | bash ENV PATH $PATH:/root/google-cloud-sdk/bin
- エラー1
error: command 'gcc' failed: No such file or directory
- エラー2
fatal error: limits.h: No such file or directory
- エラー3
fatal error: ffi.h: No such file or directoryrequirements.txtgoogle-cloud-bigquery==2.4.0修正後のDockerfile
DockerfileFROM python:3.9.0-alpine3.12 RUN apk --update add \ curl \ gcc \ musl-dev \ linux-headers \ build-base \ libffi-dev \ bash RUN apk --update add tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime COPY ./requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt RUN curl -sSL https://sdk.cloud.google.com | bash ENV PATH $PATH:/root/google-cloud-sdk/bin RUN mkdir -p /src FROM python:3.9.0-alpine3.12 RUN apk --update add \ curl \ gcc \ musl-dev \ linux-headers \ build-base \ libffi-dev \ bash RUN apk --update add tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime COPY ./requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt RUN curl -sSL https://sdk.cloud.google.com | bash ENV PATH $PATH:/root/google-cloud-sdk/bin
- 投稿日:2020-11-20T10:34:49+09:00
Pythonで文字が似ているか確認する
タイトル通り
スパム対策のため作ろうとした
指定した文字の数かぶっている場合はTrueを返す関数
スパゲッティソースコード許して
あんま使えないかもしれんw
パワーアップしたら編集で新しくするコード
一文字づつ取り出してそれを比較するやつに追加してそれがあるか確認してって感じ
自分が最初に作ったやつ
def similer(b,a,m): al = list(a) cc = "" cu = 0 co = 0 cuo = 0 for c in al: co += 1 for ck in al: cuo += 1 if cuo-1 < co-1: continue cc = cc + ck cu += 1 if cu == m: break if cu == m: if cc in b: return True cc = "" cuo = 0 cu = 0 return False # スパゲッティソースコードw # 多分もっとコンパクトにできるけどまあ許してくれ # 面倒だったんだコメント欄で他の人が作ったやつ (追記)
こっちの方が圧倒的わかりやすくコンパクト
勉強になった
ありがとうございますdef similer(b,a,m): return any(a[i:i+m] in b for i in range(len(a) - m)) # スライスで取って確認とanyでreturn # すごく勉強になる使用例
similer(チェックされる文字,チェックする文字,かぶってるか確認する言葉の長さ)
で使える。スパム
とあるチャットであったランダムな文字とメッセージを送るスパムメッセージ。
Trueが帰ってきます。b = """こんにちは。フラゲチャットのきょーたです 嘮""" a = """こんにちは。フラゲチャットのきょーたです 蕻""" print(similer(b,a,5)) # True普通のメッセージ
スパムじゃないからFalseが帰ってきます。
b = """i-FILTER 誤検出w""" a = """昔入れられてた""" print(similer(b,a,5)) # False使用しようとしている場合見て
注意!
チャットアプリなどで使う場合、数回か繰り返し確認を行いましょう。
人の名前を入れて送信している場合スパムに誤判定されるため。
あと短い文を検出できないことがあるります。
関数の最後の引数を順に増やすなどで繰り返し行いましょう。誤検出例
このようなものを比較するとtasurenという人の名前でTrueになってしまいます。
b = """tasurenがやったんだろ?""" a = """だってtassurenがhugahugaやったからなったんじゃん""" print(similer(b,a,5)) # Trueなので
五回メッセージ送った時に五回連続でスパムとしてTrueが帰ってきた場合
スパムだよ!と知らせるのような感じにしたほうがいいです。終わり
おわりだよ!
- 投稿日:2020-11-20T09:02:07+09:00
【初学者向け】カーネルSVM(make_circles)
■ はじめに
今回は、簡単なカーネルSVMの実装をまとめていきます。
【対象とする読者の方】
・カーネルSVMの簡単なコードを学びたい方
・理論は分からないが、実装を見てイメージをつけたい方 など
■ カーネルSVMの手順
次の7つのSTEPで進めます。
- モジュールの用意
- データの準備
- データの可視化
- モデルの作成
- モデルのプロット
- 予測値の出力
- モデルの評価
1. モジュールの用意
最初に、必要なモジュールをインポートしておきます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import make_circles from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.metrics import roc_curve, roc_auc_score from sklearn.metrics import accuracy_score, f1_score from sklearn.metrics import confusion_matrix, classification_report
2. データの準備
今回はsklearnに用意されている、make_circlesというデータセットを使用します。
最初にデータの取得をし、標準化を行ってから分割します。
X , y = make_circles(n_samples=100, factor = 0.5, noise = 0.05) std = StandardScaler() X = std.fit_transform(X)標準化は、例えば2桁と4桁の特徴量(説明変数)があった際に、後者の影響が大きくなってしまうため
全ての特徴量に対して平均が0・分散は1になるように調整して、スケールを揃えています。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=123) print(X.shape) print(y.shape) # (100, 2) # (100,) print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) # (70, 2) # (70,) # (30, 2) # (30,)
3. データの可視化
カーネルSVMで、二値分類をする前のデータプロットを見ておきます。
fig, ax = plt.subplots() ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c = "red", label = 'class 0' ) ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c = "blue", label = 'class 1') ax.set_xlabel('X0') ax.set_ylabel('X1') ax.legend(loc = 'best') plt.show()class 0 (y_train ==0) に対応する特徴量(X0 を横軸, X1 を縦軸):赤
class 1 (y_train ==1) に対応する特徴量(X0 を横軸, X1 を縦軸):青
上記は少し冗長なコードとなっていますが、簡潔に短く書くことも可能です。plt.scatter(X_train[:, 0], X_train[:, 1], c = y_train) plt.show()
4. モデルの作成
カーネルSVMのインスタンスを作成し、学習させます。
svc = SVC(kernel = 'rbf', C = 1e3, probability=True) svc.fit(X_train, y_train)今回はすでに線形分離(1本の直線で分ける)が不可能なため、引数に kernel = 'rbf' を設定しています。
また C はハイパーパラメータで、出力数値やプロットを見ながら自身で調整していくものです。
5. モデルのプロット
カーネルSVMのモデルが作成できたので、プロットして確認します。
前半は、先ほどの散布図コードと全く同じです。
それ以降は少し難しいですが、そのままペーストするだけで、他データでもプロットできます。
(多少の微調整は必要となります)fig, ax = plt.subplots() ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c='red', marker='o', label='class 0') ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c='blue', marker='x', label='class 1') xmin = -2.0 xmax = 2.0 ymin = -2.0 ymax = 2.0 xx, yy = np.meshgrid(np.linspace(xmin, xmax, 100), np.linspace(ymin, ymax, 100)) xy = np.vstack([xx.ravel(), yy.ravel()]).T p = svc.decision_function(xy).reshape(100, 100) ax.contour(xx, yy, p, colors='k', levels=[-1, 0, 1], alpha=1, linestyles=['--', '-', '--']) ax.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s=250, facecolors='none', edgecolors='black') ax.set_xlabel('X0') ax.set_ylabel('X1') ax.legend(loc = 'best') plt.show()
6. 予測値の出力
作成したモデルで、分類の予測値を出していきます。
y_proba = svc.predict_proba(X_test)[: , 1] y_pred = svc.predict(X_test) print(y_proba[:5]) print(y_pred[:5]) print(y_test[:5]) # [0.99998279 0.01680679 0.98267058 0.02400808 0.82879465] # [1 0 1 0 1] # [1 0 1 0 1]
7. 性能評価
ROC曲線を用いて、AUCの値を求めます。
fpr, tpr, thresholds = roc_curve(y_test, y_proba) auc_score = roc_auc_score(y_test, y_proba) plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score)) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) print('accuracy:',accuracy_score(y_test, y_pred)) print('f1_score:',f1_score(y_test, y_pred)) # accuracy: 1.0 # f1_score: 1.0
classes = [1, 0] cm = confusion_matrix(y_test, y_pred, labels=classes) cmdf = pd.DataFrame(cm, index=classes, columns=classes) sns.heatmap(cmdf, annot=True) print(classification_report(y_test, y_pred)) ''' precision recall f1-score support 0 1.00 1.00 1.00 17 1 1.00 1.00 1.00 13 accuracy 1.00 30 macro avg 1.00 1.00 1.00 30 weighted avg 1.00 1.00 1.00 30 '''
■ 最後に
上記1~7の手順をもとに、カーネルSVMのモデル作成・性能評価ができました。
初学者の方にとって、少しでもお役に立てたようでしたら幸いです。
■ 参考文献
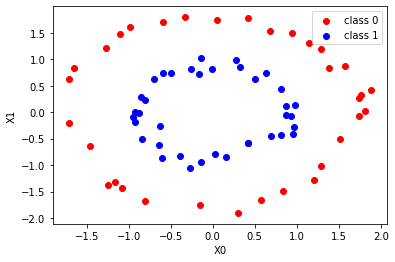
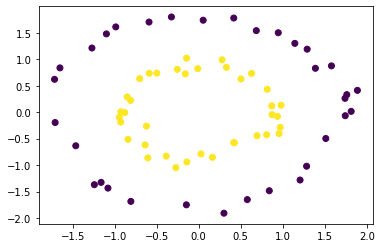
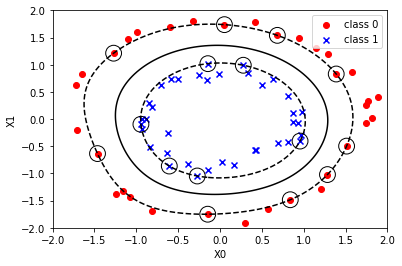
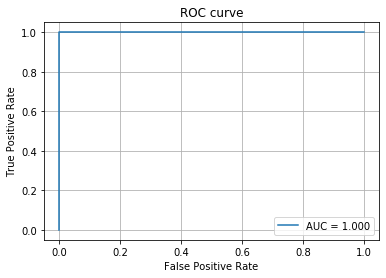

- 投稿日:2020-11-20T09:02:07+09:00
【初学者向け】カーネルSVM(make_circles)の実装
■ はじめに
今回は、簡単なカーネルSVMの実装をまとめていきます。
【対象とする読者の方】
・カーネルSVMの簡単なコードを学びたい方
・理論は分からないが、実装を見てイメージをつけたい方 など
■ カーネルSVMの手順
次の7つのSTEPで進めます。
- モジュールの用意
- データの準備
- データの可視化
- モデルの作成
- モデルのプロット
- 予測値の出力
- モデルの評価
1. モジュールの用意
最初に、必要なモジュールをインポートしておきます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import make_circles from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.metrics import roc_curve, roc_auc_score from sklearn.metrics import accuracy_score, f1_score from sklearn.metrics import confusion_matrix, classification_report
2. データの準備
今回はsklearnに用意されている、make_circlesというデータセットを使用します。
最初にデータの取得をし、標準化を行ってから分割します。
X , y = make_circles(n_samples=100, factor = 0.5, noise = 0.05) std = StandardScaler() X = std.fit_transform(X)標準化は、例えば2桁と4桁の特徴量(説明変数)があった際に、後者の影響が大きくなってしまうため
全ての特徴量に対して平均が0・分散は1になるように調整して、スケールを揃えています。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=123) print(X.shape) print(y.shape) # (100, 2) # (100,) print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) # (70, 2) # (70,) # (30, 2) # (30,)
3. データの可視化
カーネルSVMで、二値分類をする前のデータプロットを見ておきます。
fig, ax = plt.subplots() ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c = "red", label = 'class 0' ) ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c = "blue", label = 'class 1') ax.set_xlabel('X0') ax.set_ylabel('X1') ax.legend(loc = 'best') plt.show()class 0 (y_train ==0) に対応する特徴量(X0 を横軸, X1 を縦軸):赤
class 1 (y_train ==1) に対応する特徴量(X0 を横軸, X1 を縦軸):青
上記は少し冗長なコードとなっていますが、簡潔に短く書くことも可能です。plt.scatter(X_train[:, 0], X_train[:, 1], c = y_train) plt.show()
4. モデルの作成
カーネルSVMのインスタンスを作成し、学習させます。
svc = SVC(kernel = 'rbf', C = 1e3, probability=True) svc.fit(X_train, y_train)今回はすでに線形分離(1本の直線で分ける)が不可能なため、引数に kernel = 'rbf' を設定しています。
また C はハイパーパラメータで、出力数値やプロットを見ながら自身で調整していくものです。
5. モデルのプロット
カーネルSVMのモデルが作成できたので、プロットして確認します。
前半は、先ほどの散布図コードと全く同じです。
それ以降は少し難しいですが、そのままペーストするだけで、他データでもプロットできます。
(多少の微調整は必要となります)fig, ax = plt.subplots() ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c='red', marker='o', label='class 0') ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c='blue', marker='x', label='class 1') xmin = -2.0 xmax = 2.0 ymin = -2.0 ymax = 2.0 xx, yy = np.meshgrid(np.linspace(xmin, xmax, 100), np.linspace(ymin, ymax, 100)) xy = np.vstack([xx.ravel(), yy.ravel()]).T p = svc.decision_function(xy).reshape(100, 100) ax.contour(xx, yy, p, colors='k', levels=[-1, 0, 1], alpha=1, linestyles=['--', '-', '--']) ax.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s=250, facecolors='none', edgecolors='black') ax.set_xlabel('X0') ax.set_ylabel('X1') ax.legend(loc = 'best') plt.show()
6. 予測値の出力
作成したモデルで、分類の予測値を出していきます。
y_proba = svc.predict_proba(X_test)[: , 1] y_pred = svc.predict(X_test) print(y_proba[:5]) print(y_pred[:5]) print(y_test[:5]) # [0.99998279 0.01680679 0.98267058 0.02400808 0.82879465] # [1 0 1 0 1] # [1 0 1 0 1]
7. 性能評価
ROC曲線を用いて、AUCの値を求めます。
fpr, tpr, thresholds = roc_curve(y_test, y_proba) auc_score = roc_auc_score(y_test, y_proba) plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score)) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) print('accuracy:',accuracy_score(y_test, y_pred)) print('f1_score:',f1_score(y_test, y_pred)) # accuracy: 1.0 # f1_score: 1.0
classes = [1, 0] cm = confusion_matrix(y_test, y_pred, labels=classes) cmdf = pd.DataFrame(cm, index=classes, columns=classes) sns.heatmap(cmdf, annot=True) print(classification_report(y_test, y_pred)) ''' precision recall f1-score support 0 1.00 1.00 1.00 17 1 1.00 1.00 1.00 13 accuracy 1.00 30 macro avg 1.00 1.00 1.00 30 weighted avg 1.00 1.00 1.00 30 '''
■ 最後に
上記1~7の手順をもとに、カーネルSVMのモデル作成・性能評価ができました。
初学者の方にとって、少しでもお役に立てたようでしたら幸いです。
■ 参考文献
- 投稿日:2020-11-20T08:43:07+09:00
【実践編/解説動画?あり】集計からダッシュボードの作成まで一本化!PythonとDashによるデータ可視化アプリ開発
本記事は、2020年10月23日に作成されました。
はじめに
マーケティングリサーチプラットフォームを提供している株式会社マーケティングアプリケーションズの今井です。
弊社では、Dashに関した内容を、基礎編、Tips編、実践編の3つに分けてQiitaで投稿していきます。
実践編(本記事)
本麒麟のヒット分析を行うにあたり、Dashを用いてどのようにダッシュボードを作成したか、Tips編の内容を組み合わせた実践的な手法を紹介します。
サンプルを動かしている動画はこちらです。
読んで良かった、参考になったという方は、ぜひLGTMボタンを押してください。???
解説動画もあります!(むしろ動画がメインです)
この記事はYouTubeにアップした解説動画?との連動記事です。
動画がメインになっており、私が伝えたい内容を動画内で説明しています。?
こちらの記事は動画の中で話している内容を、箇条書きしたものとなっております。内容をしっかり理解するためにも、ぜひ動画と合わせてQiitaの記事もご参照ください。
今回の例
今回は、バブルチャートの作成方法を例に説明していきます
Jupyter Notebookで集計をする、関数を作る
動画はこちら?
- 関数とは?モジュールとは?
- Anaconda Navigatorを立ち上げる
- Anaconda Navigatorで仮想環境「dash」を立ち上げる
- Jupyter Notebookを立ち上げる
- 必要なデータとノートブックを用意する
- ノートブックのセル内に集計用の関数を1つ1つ用意する (今回の場合、バブルチャートのX軸、Y軸、バブルサイズ、ラベル用のテキスト、それらの関数をまとめる関数を作成)
関数の作り方にも礼儀あり?良くない例を見てみよう
【コメント】
※動画内では、関数化した状態で説明をしています。集計を行った後に関数を作るようにしてください。
また集計を行う際は、違うツールで同じ集計方法を使って値の確認を行って、同じ値になることまで確認した方が良いでしょう。例)バブルチャートだとクロス集計を行ったが、エクセルでも同じようにクロス集計を行って値を確認する
モジュールを作る
動画はこちら?
- ディレクトリを用意する
- 必要なデータを用意する
- アプリを表示させるためのファイル「app.py」と関数をまとめたファイル(モジュール)「data_processing.py」を用意する
- data_processing.pyを開いて、中身を見てみよう
【コメント】
「app.py」ではまず最初に必要とするグラフのコードを入れておいて準備をしておきます。
次に「data_processing.py」のファイルを作成します。
「data_processing.py」にJupyter Notebookで値の確認が終わって正常に動くことが確認できた関数をコピペします。モジュールを読み込ませて使う
動画はこちら?
- 「app.py」を開く
- importで「data_processing.py」を読み込み
- 作成した関数から、それぞれ値を呼び出してそれぞれの変数に代入する
- 作成した変数を、今後はグラフを作成するために使用する
go.Scatterは散布図を作成する
go.ScatterのxはX軸を作成するので、X軸の値が入った変数x_axis_listを代入、yはY軸を作成するので、Y軸の値が入った変数y_axis_listを代入app.pyx_axis_list = dp.gender_age_bubble_chart()['x_axis_list'] y_axis_list = dp.gender_age_bubble_chart()['y_axis_list'] bubble_size_list = dp.gender_age_bubble_chart()['bubble_size_list'] text_list = dp.gender_age_bubble_chart()['text_list'] gender_and_age_distribution = go.Figure() gender_and_age_distribution_data = go.Scatter( x=x_axis_list, y=y_axis_list, )
- ローカルサーバーを起動して、アプリを表示する
アプリを表示して、グラフを見てみよう
- 全ての工程が終わり、表示されていることを確認する
- 動画内でバブルチャートの説明を行っています
解説動画の紹介(再掲)
いかがだったでしょうか?
ここで再度、解説動画の紹介です。
冒頭でもお伝えしましたが、動画がメインで、この記事はオマケです!
内容をしっかり理解するためにも、ぜひ動画と本記事をご活用ください
ソースコードはこちら
まとめ
弊社でDashの解説をシリーズ化してお送りしましたが、いかがでしたでしょうか?
自作ダッシュボードをPythonで作る際の助けとなる情報になりましたら、幸いです!


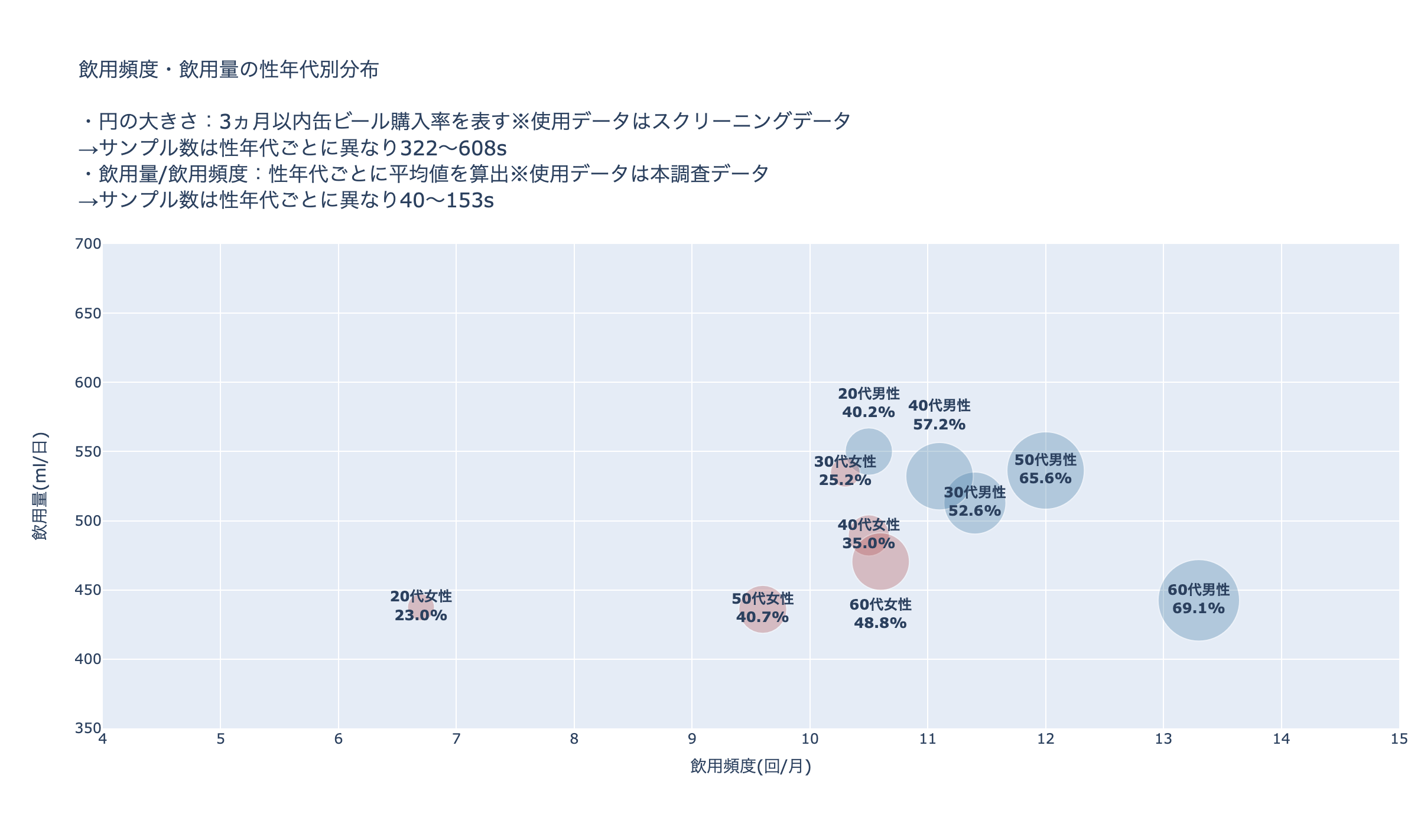
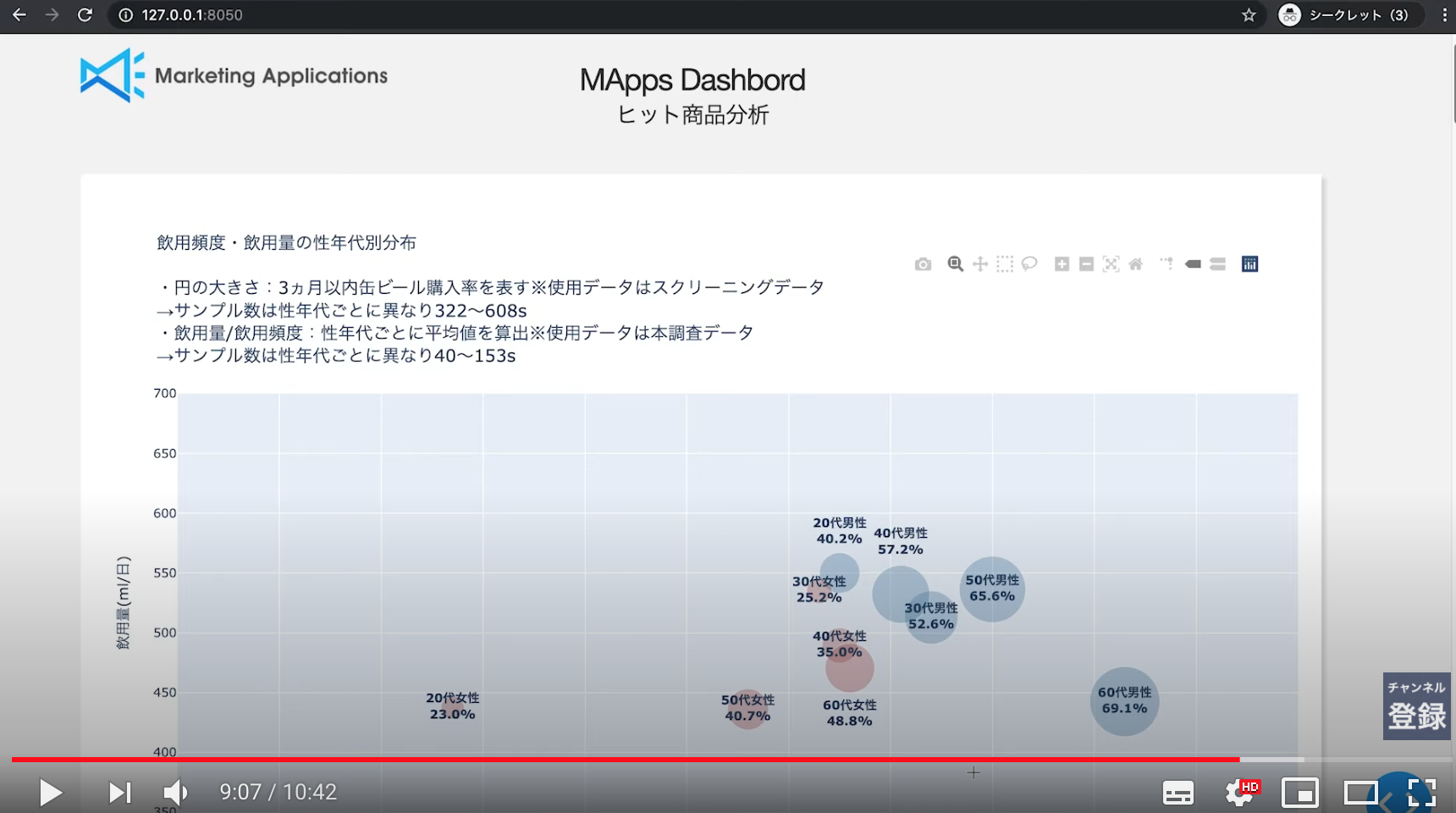
- 投稿日:2020-11-20T01:12:19+09:00
数字を3桁ごとに区切る(python)
'{:,}'.format()を使って98765の数字を98,765にする。
数値(int)じゃないと区切れない。文字列(str)だとValueErrorになる。# python >>> l=['12345',98765] # 12345は文字列、98765は数値なリストを作る >>> >>> l ['12345', 98765] >>> >>> print(type(l[0])) # 型の確認 <type 'str'> >>> print(type(l[1])) # 型の確認 <type 'int'> >>> >>> l[0] = '{:,}'.format(l[0]) # str型を区切ろうとしてもエラーになる Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: Cannot specify ',' with 's'. >>> >>> l[1] = '{:,}'.format(l[1]) # int型だと問題ない >>> >>> l ['12345', '98,765'] >>> >>> type(l[1]) # ただし、区切ったあとはintじゃなくてstrになる。 <type 'str'>
- 投稿日:2020-11-20T00:34:12+09:00
pyenvが有効にならない場合の対処法(zsh)
前提
- macOS 10.15.7(Catalina)
- zsh
- pyenvはインストール済み
- ここを参考に
.zshenvに環境変数を記述pyenvが使用されていないことの発見
pyenvで3.8.6に指定されていることを確認。
% pyenv versions system * 3.8.6 (set by /Users/user/.pyenv/version)ところが実際pythonのバージョンを確認したところ、3.8.6になってない!!
% python3 -V Python 3.9.0 % python -V Python 2.7.16そもそもPATHを確認すると
% echo $PATH /usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/user/.pyenv/bin最初に
/user/local/binが来ている!% which python /usr/bin/python % which python3 /usr/local/bin/python3なるほど、pyenvが使われていないわけだ。
~/.zshenvはこうなっている% cat ~/.zshenv export PYENV_ROOT=$HOME/.pyenv export PATH=$PYENV_ROOT/bin:$PATH if command -v pyenv 1>/dev/null 2>&1; then eval "$(pyenv init -)" fi内容的には問題なさそう。
PATHの順番を書き換えるとなると、/etc/zprofileあたりか。% cat /etc/zprofile # System-wide profile for interactive zsh(1) login shells. # Setup user specific overrides for this in ~/.zprofile. See zshbuiltins(1) # and zshoptions(1) for more details. if [ -x /usr/libexec/path_helper ]; then eval `/usr/libexec/path_helper -s` fiこんなところ書き換える必要があるのか疑わしいので、pyenvの公式サイトを確認。
すると、~/.zshrcに~/.zshrcif command -v pyenv 1>/dev/null 2>&1; then eval "$(pyenv init -)" fiとするよう書いてある、早速
~/.zshenvに記載していた部分を~/.zshrcに移動して、ターミナル再起動!すると、
% echo $PATH /Users/user/.pyenv/shims:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/user/.pyenv/bin % python -V Python 3.8.6 % which python /Users/ham/.pyenv/shims/python結論
- zshの場合は環境変数は全て
~/.zshenvに記載すればよいというわけではなく、~/.zshrcも使用する。- 公式ドキュメントを確認する。