- 投稿日:2020-11-19T23:58:09+09:00
herokuにデプロイする際にpackage installation failed出た時の対処
発生したエラー
- pipenv install django-herokuを実行した際に、以下のエラーが発生した。
$ pipenv install django-heroku ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) error: command 'clang' failed with exit status 1 ERROR: package installation failedエラーの原因
postgresqlはインストール済み。
色々調べてみた結果「opensslがないよ!」と言われているということが分かったのでその辺りを調べてみると下記の方法で解決できました。
解決方法
- 以下のコマンドで自分の場合は解決することができた。
$ xcode-select --install $ env LDFLAGS="-I/usr/local/opt/openssl/include -L/usr/local/opt/openssl/lib" pipenv install psycopg2参考サイト
Package installation failed - psycopg2 in OsX
Can't install psycopg2 package through pip install… Is this because of Sierra?Herokuでよくあるエラーまとめリンク
- 今回のエラーの副産物として参考になりそうなサイトがあったので、一応貼り付けておきます。
公式ドキュメント(Git周り)
Pyhton Heroku でpushできなくてあきらめる前に見るページ
DjangoをHerokuにデプロイしてもアプリケーションエラーになる時に見直すべきこと最後に
Herokuでのデプロイに関しては、様々なエラーがあるようで中々上手くいかない場合もあるようです。
例えば諸々の設定終わってPushしようと思ったら出来ないとか…。
海外のサイトなどで調べつつなんとか自己解決できたので良かったです。
- 投稿日:2020-11-19T23:43:27+09:00
【 Python】よくあるエラーと過去の自分の経験から回避法も
ImportError: No module named
そのようなモジュールはない
error.pyImportError: No module named pandaas単純にスペル違いがほとんどです。
list index out of range
リストの参照先が範囲外
error.pyIndexError: list index out of range例えばfor文で回してるときに、n番目が存在しないのに、処理してしまっているときは範囲外のエラーが出ることが多い。
個人的にはforで回して削除するときに多い印象です。NameError: name 'XXX' is not defined
XXXという変数は定義されていません
error.pyNameError: name 'XXX' is not defined個人的によくあるのが、例えばtestという変数作って、試して、いざ本番で処理してみようとしたときにこのエラーが出ることが多いです。
ただ基本的に変数が定義されてないだけなので、スペル間違いなどを疑えばすぐに回避できます。TypeError: 'XXX' object is not iterable
XXXという型は繰り返しできません。
error.pyTypeError: 'int' object is not iterableこれはfor構文で発生するエラーです。
本来、繰り返しできない型をfor構文で回すことで発生します。例えば、整数型・少数型はfor構文では繰り返し処理できません。
一度文字型(str)に変換して繰り返し処理する必要があります。随時書き足していきます。
- 投稿日:2020-11-19T23:16:24+09:00
dictやlistの値を文字列で取り出す
dict や list の値を
a.bやc.d.2.eのようなピリオド区切りの文字列を使って値を取り出したいことがあったので書いてみた。def get_item(src, path): now = src for i in path.split('.'): if type(now) is list: now = now[int(i)] else: now = now[i] return nownowは現在の値を入れるための変数。初期値は引数の dict or list。
pathをピリオドで分割してforで回す。
nowの値をforが終わるまで入れ替えていって最後にリターン。ちなみに、Key名にピリオドが入っている場合は想定してないです。
my_dict = { 'a': { 'b': 'hello' }, 'c': { 'd':[ {'e': 3}, {'e': 4}, {'e': 5}, {'e': 6}, ] } } print(get_item(my_dict, 'a.b')) print(get_item(my_dict, 'c.d.3.e')) print(get_item(my_dict, 'c.d')) # hello # 6 # [{'e': 3}, {'e': 4}, {'e': 5}, {'e': 6}]
- 投稿日:2020-11-19T22:57:54+09:00
Researchmap APIをPythonでパースして業績リストのWordファイルを自動作成する
研究者のみなさま、今日も書類作成お疲れ様です。
researchmapに入力した業績をコピペするのが地味にめんどくさかったので、APIをパースしてみました。
PythonからWordファイルを作成するところまでやってみます。環境
- MacOS Mojave 10.14.5
- Anaconda 2020.02
- Python 3.7.6
- Jupyter Notebook 6.0.3
python-docxのインストール
こちらをご覧ください。といっても1行です:
bashpip install python-docxJSONのパース
JSON弱者なので、
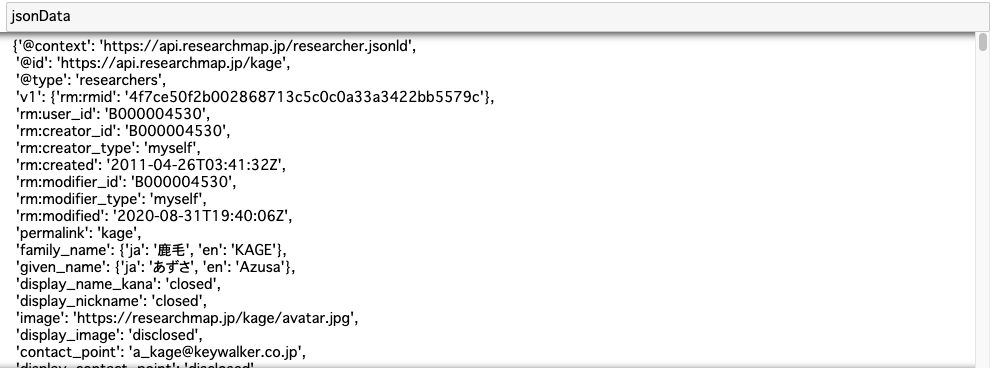
@idとか@typeって何?!?!と涙目になりながらやりました。
もっと効率の良い方法があったら教えてください。
(ちなみに、「パースする」という言葉の指す範囲がいまひとつよくわかっていません。JSONを取得して必要な情報を取り出すところまでを指しているのかなと思っていますが、間違っていたら教えてください)JSONの取得
ここを参考にしました。
pythonimport requests import json url = "https://api.researchmap.jp/kage" response = requests.get(url) jsonData = response.json()こんな感じのデータがとれてきます。(print文を使うと改行なしでびっしり書かれたので、使っていません。)
JSONから必要なデータを取り出す
業績データの位置の特定
JSON弱者なので、表示したJSONをスクロールして構造をじっと見ます。
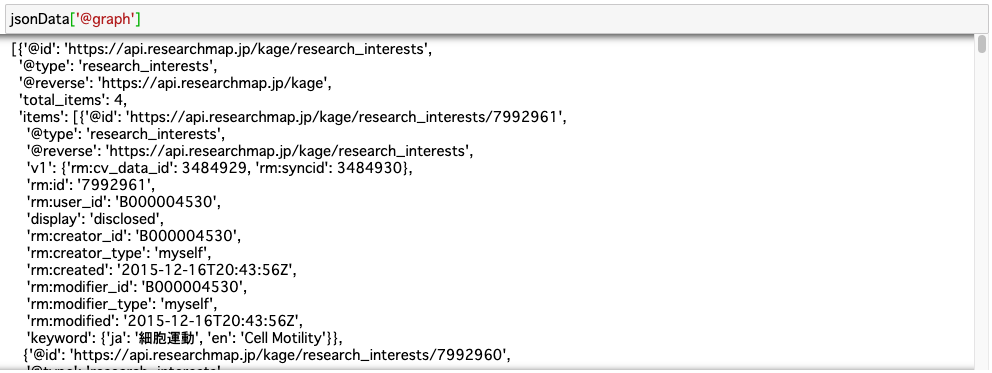
@graphという部分に業績データが格納されているようです。
@graphの要素の一部を表示してみます。pythonfor i in range(len(jsonData['@graph'])): print(i) print(jsonData['@graph'][i]['@type'])出力結果0 research_interests 1 research_areas 2 research_experience 3 published_papers 4 books_etc 5 misc 6 presentations 7 awards 8 research_projects 9 education 10 teaching_experience 11 committee_membershipsこの中に業績データが入っています。
要素3のpublished_papersを抽出してみます。published_papersを業績リストっぽく表示する
下記のスクリプトでそれっぽい表示ができました。
pythonfor i in range(len(jsonData['@graph'][3]['items'])): author_list = [] authors = jsonData['@graph'][3]['items'][i]['authors']['en'] title = jsonData['@graph'][3]['items'][i]['paper_title']['en'] journal = jsonData['@graph'][3]['items'][i]['publication_name']['en'] date = jsonData['@graph'][3]['items'][i]['publication_date'] vol = jsonData['@graph'][3]['items'][i]['volume'] doi = jsonData['@graph'][3]['items'][i]['identifiers']['doi'][0] # authorの体裁を整える for j in range(len(authors)): author = ''.join(authors[j].values()) author_list.append(author) print(', '.join(author_list)) print(title) print(journal, vol, date) print('doi:', doi) print('')
これをWordファイルにコピペしてもいいですが、せっかくなのでもう一歩頑張りましょう。Wordファイルへの書き込み
python-docxで数字付きリスト
業績を数字付きのリストにしたいです。
まずはリスト書き込みのテストをしてみます。
ここを参考にしました。pythonfrom docx import Document doc = Document() docx_file = 'test.docx' p0 = doc.add_paragraph('Item 1', style='List Number') p1 = doc.add_paragraph('Item 2', style='List Number') doc.save(docx_file)Wordファイルが作成され、リストが書き込めました。
書き込み用に業績データを整形する
上のprint文からちょっとだけ変えます。
python# 全論文データ格納用リスト papers = [] for i in range(len(jsonData['@graph'][3]['items'])): author_list = [] authors = jsonData['@graph'][3]['items'][i]['authors']['en'] title = jsonData['@graph'][3]['items'][i]['paper_title']['en'] journal = jsonData['@graph'][3]['items'][i]['publication_name']['en'] date = jsonData['@graph'][3]['items'][i]['publication_date'] vol = jsonData['@graph'][3]['items'][i]['volume'] doi = jsonData['@graph'][3]['items'][i]['identifiers']['doi'][0] # authorの体裁を整える for j in range(len(authors)): author = ''.join(authors[j].values()) author_list.append(author) # 論文の体裁を整えてリストに格納 paper = [', '.join(author_list), title, ', '.join([journal, vol, date]), ' '.join(['doi:', doi])] papers.append('\n'.join(paper))
リストpapersをWordに書き込んでいきます。Wordファイルへのデータ書き込み
見出しの追加はここを参考にしました。
pythondoc = Document() docx_file = 'publication.docx' # タイトル heading = doc.add_heading('研究業績', level=1) subheading = doc.add_heading('原著論文', level=2) # 論文リスト for paper in papers: p = doc.add_paragraph(paper, style='List Number') doc.save(docx_file)
Wordファイルにデータが書き込めました! あとは細かい体裁を整えるだけですね。
ここを見ながら、とりあえずフォントの色を全部黒くしましょう。pythonfrom docx.shared import RGBColor doc = Document() docx_file = 'publication.docx' # タイトル heading = doc.add_heading('研究業績', level=1) heading.runs[0].font.color.rgb = RGBColor(0, 0, 0) subheading = doc.add_heading('原著論文', level=2) subheading.runs[0].font.color.rgb = RGBColor(0, 0, 0) # 論文リスト for paper in papers: p = doc.add_paragraph(paper, style='List Number') doc.save(docx_file)
手作業でのコピペなしでresearchmapから業績リストのWordファイルが作成できました!参考





- 投稿日:2020-11-19T22:02:32+09:00
Point and Figure Data Modeling
In the meantime, I found a source for PYTHON, and I decided to use it as a reference.
Reference Source
https://medium.com/veltra-engineering/python-nikkei-quandl-api-2-2ae2002e361c
I decided to use the market data from the source I referred to before.
https://www.alphavantage.co/Testing
We obtained the original sequence of P&Fs from the daily data of EURUSD.
The reference number of blocks (cell height) was set to (MAX-MIN)/200 for the entire range.
The data length was 5000 rows before compression, but the P&F sequence was 531.eurusd_daily date,1. open,2. high,3. low,4. close,5. volume 2001-09-20,0.9299,0.9308,0.9224,0.9257,0.0 2001-09-21,0.9258,0.9281,0.9088,0.913,0.0 .... 2020-11-18,1.1862,1.1891,1.1847,1.1852,0.0 2020-11-19,1.1851,1.1852,1.1821,1.1823,0.0(Pdb) len(histories) 531 [3, -11, 6, -6, 6, -11, 5, -4, 6, -4, 12, -4, 24, -5, 11, -8, 4, -9, 5, -4, 7, -7, 5, -5, 11, -6, 16, -4, 12, -3, 4, -4, 7, -11, 8, -6, 21, -4, 12, -5, 5, -5, 6, -10, 4, -10, 9, -17, 13, -3, 15, -4, 4, -10, 13, -4, 23, -10, 8, -6, 4, -6, 11, -8, 4, -12, 5, -4, 4, -8, 7, -10, 4, -9, 9, -10, 12, -7, 11, -11, 9, -10, 10, -5, 28, -5, 4, -4, 9, -16, 6, -14, 13, -4, 9, -17, 7, -26, 7, -7, 4, -7, 9, -5, 4, -4, 11, -8, 10, -14, 6, -5, 5, -11, 4, -4, 7, -5, 8, -3, 7, -11, 4, -4, 7, -6, 8, -5, 21, -5, 5, -9, 6, -6, 8, -4, 4, -8, 19, -6, 4, -9, 9, -4, 15, -9, 11, -4, 4, -8, 20, -4, 6, -3, 12, -4, 8, -6, 4, -11, 13, -9, 9, -10, 32, -7, 10, -6, 9, -15, 9, -9, 9, -10, 13, -4, 6, -29, 4, -23, 9, -5, 18, -33, 4, -6, 5, -20, 4, -10, 10, -8, 8, -10, 6, -8, 15, -10, 45, -12, 4, -13, 4, -15, 4, -9, 8, -10, 6, -6, 6, -12, 8, -7, 30, -12, 8, -8, 6, -11, 8, -6, 16, -4, 13, -4, 12, -11, 5, -3, 4, -8, 8, -4, 6, -7, 9, -5, 10, -8, 17, -5, 12, -7, 4, -4, 8, -4, 8, -22, 7, -22, 4, -4, 4, -6, 6, -11, 5, -5, 9, -13, 4, -17, 4, -15, 9, -10, 6, -11, 10, -5, 19, -5, 14, -14, 4, -6, 6, -5, 35, -9, 6, -4, 11, -18, 5, -17, 10, -4, 4, -7, 7, -13, 21, -3, 5, -8, 12, -5, 10, -3, 10, -6, 14, -18, 5, -7, 17, -13, 6, -6, 9, -15, 7, -3, 11, -9, 5, -8, 6, -4, 6, -6, 8, -3, 5, -21, 5, -11, 4, -11, 17, -4, 11, -16, 4, -12, 6, -19, 12, -4, 5, -5, 9, -9, 4, -6, 9, -8, 4, -21, 6, -3, 6, -6, 5, -14, 5, -3, 24, -7, 4, -4, 6, -9, 9, -4, 7, -5, 14, -15, 4, -6, 4, -6, 10, -4, 4, -7, 13, -14, 15, -3, 4, -7, 17, -9, 9, -5, 4, -6, 11, -5, 5, -9, 4, -29, 7, -9, 4, -5, 6, -31, 6, -4, 4, -22, 6, -4, 8, -6, 6, -10, 18, -4, 7, -13, 9, -4, 7, -15, 7, -5, 7, -3, 15, -13, 7, -6, 7, -23, 11, -8, 5, -3, 13, -10, 11, -4, 5, -3, 7, -10, 7, -9, 4, -5, 7, -4, 6, -10, 7, -13, 5, -10, 9, -3, 4, -7, 8, -7, 11, -3, 11, -3, 16, -3, 7, -10, 8, -5, 9, -3, 14, -7, 7, -9, 6, -4, 5, -20, 6, -5, 4, -10, 9, -4, 6, -14, 5, -3, 4, -4, 6, -6, 4, -5, 4, -6, 5, -5, 4, -3, 5, -8, 4, -8, 7, -4, 5, -11, 17, -20, 13, -8, 5, -5, 5, -5, 5, -3, 12, -5, 17, -3, 5, -6, 5, -5, 6]Block Reference Number and Data Compression
If we now consider the characteristics of P&F charts carefully, we realize that this is a way to compress the data.
If you increase the number of reference feet in that case, the data length will probably be smaller.
In general, the granularity of data in a currency chart changes depending on the length of the reference foot, such as daily, weekly or monthly. However, the P&F chart is based on the concept of updating to the next leg only when the trend has turned, so the leg is not updated uniformly with the time update.Multi-Time Frame Analysis
In addition, for general technical indicators, it is common to use multiple time scales for a reference foot to comprehensively determine the market's phase, and a technique called multi-time frame analysis exists.
Since varying the reference number of blocks has the characteristic of changing the data length, multi-block analysis, which is based on multiple reference number of blocks, is considered to be effective for the concept of multi-frame in P&F.AI Algorithm
In addition, recurrent learning (recurrent networks), which takes into account the influence of past data, is used as a general theory for AI learning on general time series data, and it is considered effective for cyclical fluctuations such as market ranges. However, in the case of exchange rate fluctuations, it is considered to be most important to capture the trend changes by key technical signs (breakout as the starting point), and thus requires conditional judgments based on a combination of patterns rather than recurrent learning. We think it makes sense. (To begin with, we can assume that the RNN is computationally expensive compared to normal AI analysis.
In this article, I will try to tune the parameters by adding multiple block reference numbers to the factors that make up the various hyperparameters.
The model
Looking at the characteristics of PF, we can see the following
×The x's and z's are always repeated
×→In the change from x to 0, starting from one step down
In the change from 0 to x, starting from one step upThis feature can be completely ignored.
For now, the following P&F chart will show
×If you replace the number of x's with positive numbers and the number of z's with negative numbersThis chart equals the following sequence of numbers.
12 , -7 , 7 , -5 , -5 , 5 , -3 , 12 , -5 , 5 , -5 , -5 , 6 , -6 , 3 , -6 , 2
Furthermore, taking the sum of the front and back
5 , 0 , 2 , 0 , 2 , 2 , 9 , 7 , 0 , 0 , 0 , 1 , 0 , -3 , -3 , -4 max = 9 , min = -4 , Range = 13The dynamic range can be reduced, as in
In AI, this is the direction of increasing the sensitivity of the learning machine.By the way, it appears that doing it again is a no-no
5 , 2 , 2 , 2 , 11 , 16 , 7 , 0 , 1 , 1 , -3 , -6 , -7 max = 16 , min = -7 , Range = 23
And AI-wise, if you can predict the following numbers
You can know the turning points of a trade position.The best thing about P&F charts is that they
In this way, every possible price movement in a string of numbers
It's an interwoven point.So, now that we've finished defining the model first, let's go to
From the above sequence of numbers from the exchange data
Coding shall be done.

- 投稿日:2020-11-19T21:34:25+09:00
LeetCodeに毎日挑戦してみた 9. Palindrome Number (Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。Go言語入門+アルゴリズム脳の強化のためにGolangとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
3問目(問題09)
Palindrome Number
- 問題内容(日本語訳)
整数が回文であるかどうかを判別します。整数は、前方と後方で同じように読み取られる場合、回文です。
フォローアップ:整数を文字列に変換せずに解決できますか?
Example 1:
Input: x = 121 Output: trueExample 2:
Input: x = -121 Output: false Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome.Example 3:
Input: x = 10 Output: false Explanation: Reads 01 from right to left. Therefore it is not a palindrome.Example 4:
Input: x = -101 Output: false考え方
- 正負判定をして正のみ処理を行う。
- 文字列にして逆順にして判定
説明
- 負の場合は回文になりません。
- str関数を使うとintをstrにできます。そしてスライスを使って逆順に。。。(問題で推奨されていません)
- 解答コード
class Solution(object): def isPalindrome(self, x): return str(x) == str(x)[::-1]スライスを使って文字列を逆順にして判定です!
こちら@shiracamus様よりアドバイスをいただきました。
比較式は値が真偽値になるため条件式が省略できます。
以前のコード↓def isPalindrome(self, x): if x >= 0: if str(x) == str(x)[::-1]: return True return False
- Goでも書いてみます!
import "strconv" func isPalindrome(x int) bool { s := strconv.Itoa(x) r := []rune(s) for i, j := 0, len(r)-1; i < j; i, j = i+1, j-1 { if r[i] != r[j] { return false } } return true }解き方は同じですが、Goの場合は文字列はイミュータブル(不変)のためにこの書き方になります。
また、strconvパッケージをインポートしてItoaを使いました。Integer To a です。
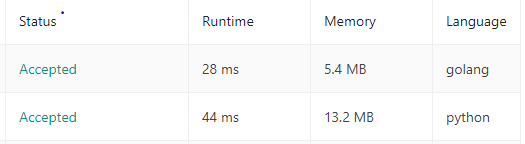
GoとPythonの実行時間
左から、RunTime, Memory, 言語です。
別解
前日に解いた 9.Reverse Integer の仕組みを使って数字のまま解きました。(こちらが推奨です。)
func isPalindrome(x int) bool { if x<0{ return false } new_var := x rev := 0 for x!=0{ pop := x%10 x = x/10 rev = rev *10 + pop } if rev==new_var{ return true }else{ return false } }
- 自分メモ(Go)
文字列を文字単位で扱うには rune 型を使う
Stringは[]runeと[]byteにキャストできる。
runeの実態はint32になっていて、unicodeの4byte分を表現するのに十分なサイズ
string と rune 配列は相互変換できるので,文字列を切り取る場合は
package main import "fmt" func main() { nihongo := "日本語" fmt.Printf("nihongo = %s\n", nihongo) fmt.Printf("nippon = %s\n", string([]rune(nihongo)[:2])) }のように
string→[]rune→stringと変換していけば安全に処理できる。実行結果
nihongo = 日本語 nippon = 日本参考にした記事
- 投稿日:2020-11-19T20:12:52+09:00
pythonで超簡単な分子動力学プログラムを書く
3原子の分子動力学計算
3つの原子だけを扱う分子動力学(MD)コードを書いてみる。
ステップバイステップでMDっぽくしていく。1. キャンバスに原子を配置する
原子3つの初期配置と速度をファイルに書いておく。
initial.d15 10 0 0 20 10 0 0 20 15 0 0initial. d の各行は 原子のx座標、y座標、速度のx成分、y成分 の4つの項目からなり、スペースで区切られている必要がある。
物体を描画できるようにキャンバスを開き、ファイル(initial.d)から原子配置(と速度)情報を読み取って原子を初期位置に配置するプログラム例を下に示す。
後々のため、ダミーのボタンも用意している(ここではボタンが押されても特に何もしない)。
ここではinitial.dが3行なので原子数は3つとなるが、行数を増やすことで原子数が増やせる。プログラム中では各行を読み込む度に配列サイズを増やしている。
座標の単位はÅ、速度の単位はÅ/sとしている。
プログラム例を示す。
crudemd0.pyimport tkinter as tk def dummy(event): print('button is pressed') def drawatom(x,y): scl=10 rad=5 x1=x0+x*scl y1=y0+l-y*scl canvas.create_oval(x1-rad,y1-rad,x1+rad,y1+rad, fill='blue') # creation of main window and canvas win = tk.Tk() win.title("Crude MD") win.geometry("520x540") x0=10 y0=10 l=500 canvas = tk.Canvas(win,width=l+x0*2,height=l+y0*2) canvas.place(x=0, y=20) canvas.create_rectangle(x0,y0,l+x0,l+y0) # declaration of arrays rx = [] ry = [] vx = [] vy = [] fx = [] fy = [] # button sample (dummy) button_dummy = tk.Button(win,text="dummy",width=15) button_dummy.bind("<Button-1>",dummy) button_dummy.place(x=0,y=0) # read initial position and velocity f = open('initial.d', 'r') i = 0 for line in f: xy = line.split(' ') rx = rx + [float(xy[0])] ry = ry + [float(xy[1])] vx = vx + [float(xy[2])] vy = vy + [float(xy[3])] print(rx) drawatom(rx[i],ry[i]) i = i + 1 win.mainloop()2. ボタンイベントを取得して原子を移動
上記のプログラムを元に機能を追加。
ボタンが押されたイベントを検出して、原子を斜め上方向にただ連続的に動かすようにしたもの。crudemd1.pyimport tkinter as tk def dummy(event): global imd # to substitute value into variable if (imd == 0 ): imd = 1 else: imd = 0 def drawatom(x,y): x1=x0+x*scl y1=y0+l-y*scl return canvas.create_oval(x1-rad,y1-rad,x1+rad,y1+rad, fill='blue') def moveatom(obj,x,y): x1=x0+x*scl y1=y0+l-y*scl canvas.coords(obj,x1-rad,y1-rad,x1+rad,y1+rad) # creation of main window and canvas win = tk.Tk() win.title("Crude MD") win.geometry("520x540") x0=10 # Origin y0=10 # Origin l=500 # Size of canvas scl=10 # Scaling (magnification) factor rad=5 # Radius of sphere canvas = tk.Canvas(win,width=l+x0*2,height=l+y0*2) canvas.place(x=0, y=20) canvas.create_rectangle(x0,y0,l+x0,l+y0) imd = 0 # MD on/off # declaration of arrays rx = [] ry = [] vx = [] vy = [] fx = [] fy = [] obj = [] # button sample (dummy) button_dummy = tk.Button(win,text="dummy",width=15) button_dummy.bind("<Button-1>",dummy) button_dummy.place(x=0,y=0) # Entry box (MD step) entry_step = tk.Entry(width=10) entry_step.place(x=150,y=5) # read initial position and velocity f = open('initial.d', 'r') n = 0 for line in f: xy = line.split(' ') rx = rx + [float(xy[0])] ry = ry + [float(xy[1])] vx = vx + [float(xy[2])] vy = vy + [float(xy[3])] print(rx) obj = obj + [drawatom(rx[n],ry[n])] # obj[] holds pointer to object n = n + 1 # number of total atoms print("number of atoms = ",n) step = 0 stepend = 1000 while step < stepend: if imd == 1: for i in range(n): rx[i] = rx[i] + 0.01 ry[i] = ry[i] + 0.01 moveatom(obj[i],rx[i],ry[i]) step = step + 1 entry_step.delete(0,tk.END) entry_step.insert(tk.END,step) win.update() win.mainloop()3. ボタンが押されたらMDをオン・オフする
上記をさらに改変。
ボタンが押されたらMDのon/offを切り替えるようにした。
原子同士の相互作用をMorseポテンシャルで計算し、Verlet法で原子を動かすようになっている。crudemd2.pyimport tkinter as tk import math def dummy(event): global imd # to substitute value into variable if (imd == 0 ): imd = 1 else: imd = 0 def drawatom(x,y): x1=x0+x*scl y1=y0+l-y*scl return canvas.create_oval(x1-rad,y1-rad,x1+rad,y1+rad, fill='blue') def moveatom(obj,x,y): x1=x0+x*scl y1=y0+l-y*scl canvas.coords(obj,x1-rad,y1-rad,x1+rad,y1+rad) def v(rang): ep = 0.2703 al = 1.1646 ro = 3.253 ev = 1.6021892e-19 return ep*(math.exp(-2.0*al*(rang-ro))-2.0*math.exp(-al*(rang-ro))) *ev def vp(rang): ep = 0.2703 al = 1.1646 ro = 3.253 ev = 1.6021892e-19 return -2.0*al*ep*(math.exp(-2.0*al*(rang-ro))-math.exp(-al*(rang-ro))) *ev*1.0e10 # creation of main window and canvas win = tk.Tk() win.title("Crude MD") win.geometry("520x540") x0=10 # Origin y0=10 # Origin l=500 # Size of canvas scl=10 # Scaling (magnification) factor rad=5 # Radius of sphere canvas = tk.Canvas(win,width=l+x0*2,height=l+y0*2) canvas.place(x=0, y=20) canvas.create_rectangle(x0,y0,l+x0,l+y0) imd = 0 # MD on/off # declaration of arrays rx = [] # ang ry = [] vx = [] # ang/s vy = [] fx = [] # N fy = [] epot = [] obj = [] dt = 1.0e-16 # s wm = 1.67e-37 # 1e-10 kg # button sample (dummy) button_dummy = tk.Button(win,text="MD on/off",width=15) button_dummy.bind("<Button-1>",dummy) button_dummy.place(x=0,y=0) # Entry box (MD step) entry_step = tk.Entry(width=10) entry_step.place(x=150,y=5) # read initial position and velocity f = open('initial.d', 'r') n = 0 for line in f: xy = line.split(' ') rx = rx + [float(xy[0])] ry = ry + [float(xy[1])] vx = vx + [float(xy[2])] vy = vy + [float(xy[3])] fx = fx + [0] fy = fy + [0] epot = epot + [0] obj = obj + [drawatom(rx[n],ry[n])] # obj[] holds pointer to object n = n + 1 # number of total atoms print("number of atoms = ",n) step = 0 stepend = 100000 while step < stepend: if imd == 1: # Verlet(1) for i in range(n): rx[i] = rx[i] + dt * vx[i] + (dt*dt/2.0) * fx[i] / wm ry[i] = ry[i] + dt * vy[i] + (dt*dt/2.0) * fy[i] / wm vx[i] = vx[i] + dt/2.0 * fx[i] / wm vy[i] = vy[i] + dt/2.0 * fy[i] / wm # Force and energy for i in range(n): fx[i] = 0 fy[i] = 0 epot[i] = 0 for i in range(n): for j in range(n): if (i != j): rr = math.sqrt((rx[i]-rx[j])**2 + (ry[i]-ry[j])**2) drx = rx[i] - rx[j] dry = ry[i] - ry[j] fx[i] = fx[i]-vp(rr)/rr*drx fy[i] = fy[i]-vp(rr)/rr*dry epot[i] = epot[i]+v(rr)/2.0 # Verlet(2) for i in range(n): vx[i] = vx[i] + dt/2.0 * fx[i] / wm vy[i] = vy[i] + dt/2.0 * fy[i] / wm moveatom(obj[i],rx[i],ry[i]) step = step + 1 entry_step.delete(0,tk.END) entry_step.insert(tk.END,step) win.update() win.mainloop()
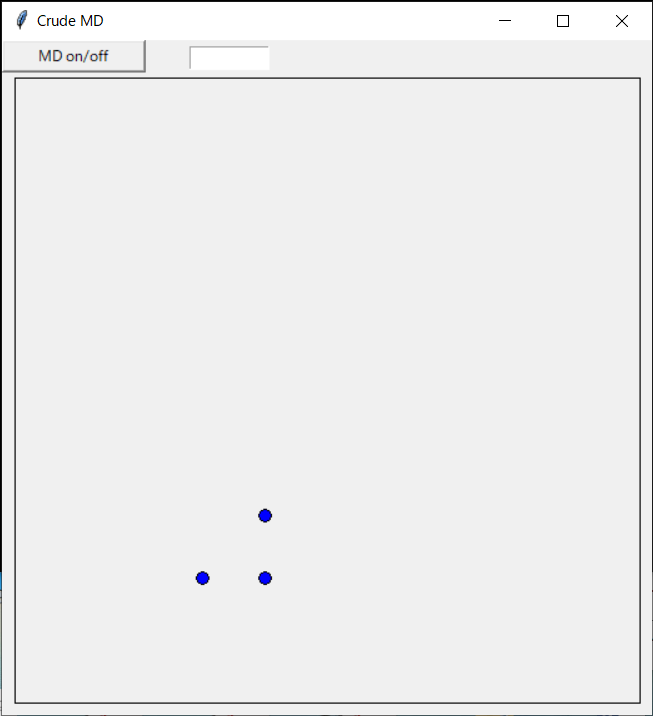
- 投稿日:2020-11-19T19:08:48+09:00
Django template formで渡されるパラメータを項目ごとに手動で装飾したいメモ
Python 3.8.5
Django version 3.1.2備忘録
/formtest/formman$ tree . ├── admin.py ├── apps.py ├── forms.py ★つくりました。 ├── __init__.py ├── migrations │ ├── 0001_initial.py │ ├── 0002_auto_20201119_1155.py │ └── __init__.py ├── models.py ★書きました ├── templates ★作りました │ ├── base.html │ └── formman │ └── form.html ├── tests.py └── views.py ★書きました 3 directories, 12 filesDjangoのチュートリアルやリファレンスを読んでると
以下の用に記載するとDjangoのViewはTemplateにformの項目を表示してくれると書いてあります。{{ form.as_p }}こんな感じで書くんですよね。
実際にrunserverして、HTMLソースをみるとこんな感じ。
ということは、form.as_pに該当するのは以下の部分。<p><label for="id_id">ID:</label> <input type="number" name="id" required id="id_id"></p> <p><label for="id_name">名:</label> <input type="text" name="name" maxlength="100" required id="id_name"></p> <p><label for="id_number">値:</label> <input type="number" name="number" required id="id_number"></p>
form.as_pを以下のように書き換えると…。{{ form.id.label }} {{ form.name.label }} {{ form.number.label }} {{ form.id }} {{ form.name }} {{ form.number }}おお。うまく行った。
これで項目ごとに装飾できそうです。


- 投稿日:2020-11-19T18:48:21+09:00
k本のハノイの塔の動かし方(Python版)
お題
「ハノイの塔」で塔の本数をk本に拡張せよ
塔の数が3本のとき
ディスクの枚数を
nとします。
塔が3本のときの最小手数は、$2^n - 1$であることがよく知られています。
また、そのときの動かし方は1通りに決まります。
この動かし方のコードは再起関数で次のように書けます。def hanoi(n, pos): if n == 1: yield pos[0], pos[-1] return yield from hanoi(n - 1, pos[:1] + pos[2:] + pos[1:2]) yield from hanoi(1, pos[:1] + pos[2:-1] + pos[-1:]) yield from hanoi(n - 1, pos[1:-1] + [pos[0], pos[-1]])コードの解説
hanoi(n, pos)は、「どの塔からどの塔に移動するか」を返すジェネレーター(forで使える関数)です。引数は以下の通りです。
-n:ディスクの枚数。
-pos:利用可能な塔のインデックスのリスト。このリストの先頭の塔のn枚のディスクを最後の塔に移動します。4枚のディスクを塔0から塔2へ動かす方法は、下記のように書きます。
for i, j in hanoi(4, [0, 1, 2]): print(f'{i} -> {j}')出力は以下のようになります(改行を変えてます)。
0 -> 1 0 -> 2 1 -> 2 0 -> 1 2 -> 0 2 -> 1 0 -> 1 0 -> 2 1 -> 2 1 -> 0 2 -> 0 1 -> 2 0 -> 1 0 -> 2 1 -> 2ディスクが1枚のときは、「移動元、移動先」を返して終了します。
ディスクが2枚以上のときは、以下を実行します。
yield from hanoi(n - 1, pos[:1] + pos[2:] + pos[1:2]) yield from hanoi(1, pos[:1] + pos[2:-1] + pos[-1:]) yield from hanoi(n - 1, pos[1:-1] + [pos[0], pos[-1]])上記は、わかりにくいですが下記の処理です。
- ステップ1)
pos[0]からpos[1]にn - 1枚移動- ステップ2)
pos[0]からpos[-1]に1枚移動- ステップ3)
pos[1]からpos[-1]にn - 1枚移動簡単に説明します。
pos[0]にある最下段のディスクは、その上にあるn - 1枚のディスクをどかさないと移動できません。
そこで、ステップ1でn - 1枚どけます。ステップ2で最下段のディスクを動かし、ステップ3で残ったディスクを動かします。塔の数がk本のときの方針
しばらく考えましたが、どうすればよいかわかりませんでした。
仕方がないので、考えやすいように下記を仮定することにしました。命題
n枚をk本で動かしたいとき、以下の3ステップで最短手数で動かせる
-m枚を別の塔にどかす
- 下に残ったn - m枚を移動先に動かす
- 残りm枚を移動先に動かすこの命題は証明できていませんが、結果はうまくいっているようです。
mは、後で求めます。最短手数
n枚をk本で動かすときの最短手数の数式はわかりませんでした。
しかし、動的最適化で以下のように計算できます。from functools import lru_cache @lru_cache(maxsize=1024) def nmove(n, k): k = min(n + 1, k) if k == 2: return 1 if n == 1 else float("inf") elif k == 3: return 2 ** n - 1 elif k == n + 1: return 2 * n - 1 return min(nmove(i, k) * 2 + nmove(n - i, k - 1) for i in range(1, n))解説
- 塔の本数が
n + 1を超えていても使わない塔がでてきます。そこで、塔の数は無駄がないようにk = min(n + 1, k)とします。これで無駄な計算が減ります。k == 2のとき
- ディスクが1枚なら1回で移動できます。
- ディスクが2枚以上なら移動できません。移動回数として∞(
float("inf"))を返します。k == 3のときは、2 ** n - 1です。この処理はなくても動きますが、高速になります。k == n + 1のときは、2 * n - 1です。これは各ディスクを空いている塔に退避すれば良いからです。- それ以外のときは、先ほどの命題を使ってしらみつぶしに調べます。
塔の数がk本のとき
命題を使えば以下のようになります。
def hanoi(n, pos): if n == 1: yield pos[0], pos[-1] return k = len(pos) m = min((nmove(i, k) * 2 + nmove(n - i, k - 1), i) for i in range(1, n))[1] yield from hanoi(m, pos[:1] + pos[2:] + pos[1:2]) yield from hanoi(n - m, pos[:1] + pos[2:-1] + pos[-1:]) yield from hanoi(m, pos[1:-1] + [pos[0], pos[-1]])塔が3本のときにステップ1で
n - 1本移動していたのが、m本の移動に変わっただけで、ほぼ同じコードになっています。
最短手数になるmも、nmoveを使えばしらみつぶしで求められます。全コード
4枚のディスクを4本の塔で動かすコードは以下のようになります。
from functools import lru_cache @lru_cache(maxsize=1024) def nmove(n, k): k = min(n + 1, k) if k == 2: return 1 if n == 1 else float("inf") elif k == 3: return 2 ** n - 1 elif k == n + 1: return 2 * n - 1 return min(nmove(i, k) * 2 + nmove(n - i, k - 1) for i in range(1, n)) def hanoi(n, pos): if n == 1: yield pos[0], pos[-1] return k = len(pos) m = min((nmove(i, k) * 2 + nmove(n - i, k - 1), i) for i in range(1, n))[1] yield from hanoi(m, pos[:1] + pos[2:] + pos[1:2]) yield from hanoi(n - m, pos[:1] + pos[2:-1] + pos[-1:]) yield from hanoi(m, pos[1:-1] + [pos[0], pos[-1]]) for i, j in hanoi(4, [0, 1, 2, 3]): print(f'{i} -> {j}')出力は以下のようになります(改行を変えてます)。
0 -> 1 0 -> 3 0 -> 2 3 -> 2 0 -> 3 2 -> 0 2 -> 3 0 -> 3 1 -> 3可視化
塔の番号だけだとあっているかわかりにくいですね。
可視化しました。$ pip install k-peg-hanoi $ hanoi 4 4= === ===== ======= 0------------------------------ === ===== ======= = 1------------------------------ ===== ======= = === 2------------------------------ ======= = ===== === 3------------------------------ === ======= = ===== 4------------------------------ === = ===== ======= 5------------------------------ === = ===== ======= 6------------------------------ ===== === = ======= 7------------------------------ === ===== = ======= 8------------------------------ = === ===== ======= 9------------------------------最短手数の表
k\n 6 7 8 9 10 3 63 127 255 511 1023 4 17 25 33 41 49 5 15 19 23 27 31 6 13 17 21 25 29 7 11 15 19 23 27 8 11 13 17 21 25 以下で作成しました。
print("k\\n|6|7|8|9|10") print(":--|:--|:--|:--|:--|:--|") for k in range(3, 9): print(k, end='|') for n in range(6, 11): print(nmove(n, k), end='|') print()
- 投稿日:2020-11-19T18:30:19+09:00
Pythonを使って東京都家賃についての研究 (3の1)
結果抜粋
研究の目標、手法
目標
- 東京都の家賃やそれに関連する属性の関連性を研究したい
その関連性についての結果をグラフにして可視化にする
手法
2020年8月でネットで載せていた家賃データをプログラムで自動収集(データ元:https://suumo.jp)
82,812建物、624,499部屋のデータを基に分析
研究結果の抜粋
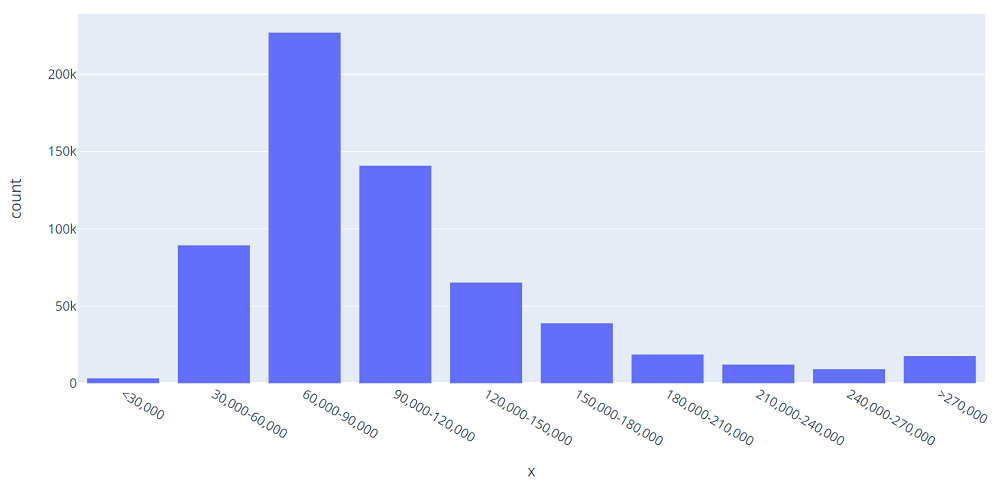
東京の家賃価格の分布
Xはグループに分ける家賃(円)、Yは数(kは1,000)
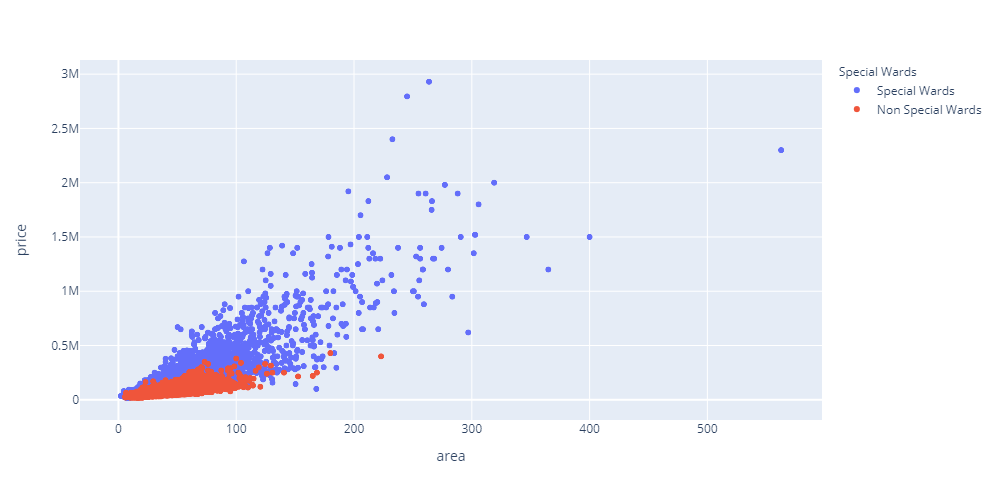
価格と面積の関係(23区と市部に分ける)
青い点が23区、赤い点が市部、Xは面積(平方メートル)、Yは家賃(Mは百万円)
区ごとに平均価格の分布(23区)
- Xは数(kは1,000)
- Yは23区
- 箱ひげ図の見方:
- 一番左側の線は最小値
- 箱の左側は第1四分位点
- 箱の中の線は中央値
- 箱の左側は第3四分位点
- 一番右側の線は最大値
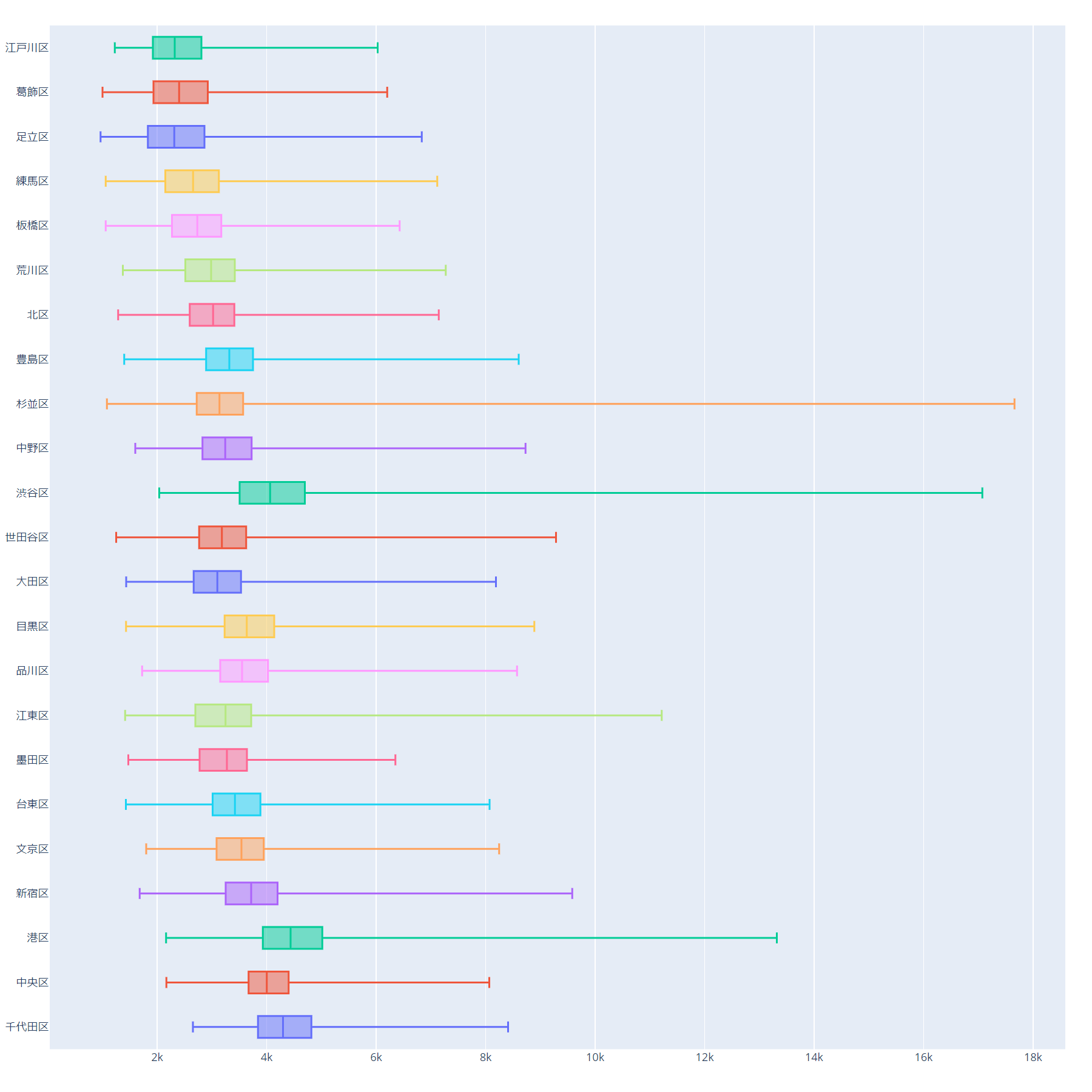
方向と区市町村の価格ヒートマップ
- Xは8方向
- Yは23区
- 色が明るいほど価格が高い
- 色が暗い(青い)ほど価格が低い
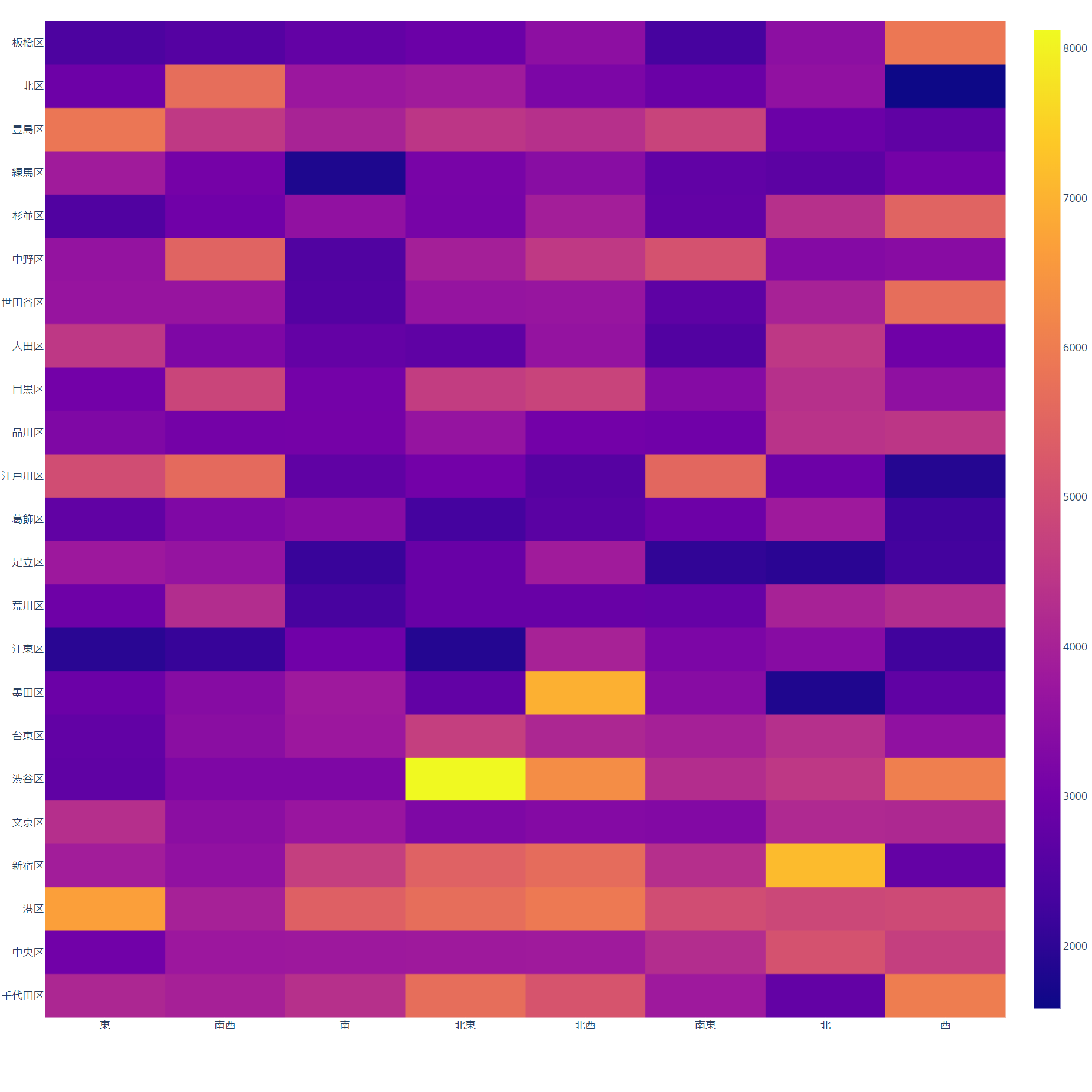
- 投稿日:2020-11-19T18:05:00+09:00
駆け出しエンジニアがG検定に合格したので学習内容をメモ
概要
G検定受験にあたり、振り返りのために学習メモをまとめました。
どなたかの参考になれば幸いです。G検定概要
ディープラーニングの基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているかを検定する。
受験資格 制限なし
実施概要 試験時間:120分
知識問題(多肢選択式・220問程度)
オンライン実施(自宅受験)
出題範囲 シラバスより出題
受験費用 一般:12,000円(税抜)
学生:5,000円(税抜)学習方法
平日の21:00~2300にZoomにて集まり学習を開始
1. 動画 or 書籍での個人学習(40分)
2. DIVE INTO EXAMの模擬試験を受講(10分)
※どなたでも受講可能です。
3. チーム内で学習内容を共有(10分)
※4人くらいがちょうど良かったです。※1~3を2週して1日2時間ほど学習する感じです。
個人的に1番理解が遅かったので終わった後、
復習を1時間ほど取っていたため1日3時間ほど学習しておりました。書籍
これ1冊で最短合格 ディープラーニングG検定ジェネラリスト 要点整理テキスト&問題集
最短突破 ディープラーニングG検定(ジェネラリスト) 問題集動画
しろ玄IT
AIcia Solid Project
JDLA G検定模試をひたすら解説する!
予備校のノリで学ぶ「大学の数学・物理」
一緒に学べるAIドル
Neural Network Console振り返ってみて
機械学習に関して何も知らない状態からのスタートだったこともあり書籍はとても難しく感じました。
ある程度、機械学習に関して理解がある方は書籍のみで良いと思います。しかし、私のように事前知識がない状態なのであれば初めは解説動画をざっとみて概要を把握した後に
書籍の内容と解説動画の内容を照らし合わせながら学んでいくと効率よく学べると思います。また必須ではないのですが、時間の確保が可能であれば数学を学び直したり、
Pythonを使用して実装したりすると楽しく学べると思います。ここまで読んでいただきありがとうございました。
参考URL
しろ玄IT
AIcia Solid Project
JDLA G検定模試をひたすら解説する!
予備校のノリで学ぶ「大学の数学・物理」
一緒に学べるAIドル
Neural Network Consoleこれ1冊で最短合格 ディープラーニングG検定ジェネラリスト 要点整理テキスト&問題集
最短突破 ディープラーニングG検定(ジェネラリスト) 問題集
- 投稿日:2020-11-19T17:58:17+09:00
DynamoDBで前方一致検索を実施する
はじめに
便利で何より安いけど何かと検索についてはあんまり使い勝手の良くないDynamoDBちゃん。今日はそれで前方一致検索をする方法を考えたのでまとめておきたいと思います。事前に言っておきますがScanを使うので使いすぎにはご注意。
最初に実際にLambdaにぶち込んだソースコードを
lambda_function.pyimport json import boto3 from boto3.dynamodb.conditions import Attr def lambda_handler(event, context): dynamoDB = boto3.resource("dynamodb") table = dynamoDB.Table(event["type"]) title = event["title"] fin = title[0]+chr(ord(title[1])+2) queryData = table.scan( FilterExpression = Attr("Title").between(title,fin) ) return queryDataなにをしてるのか?
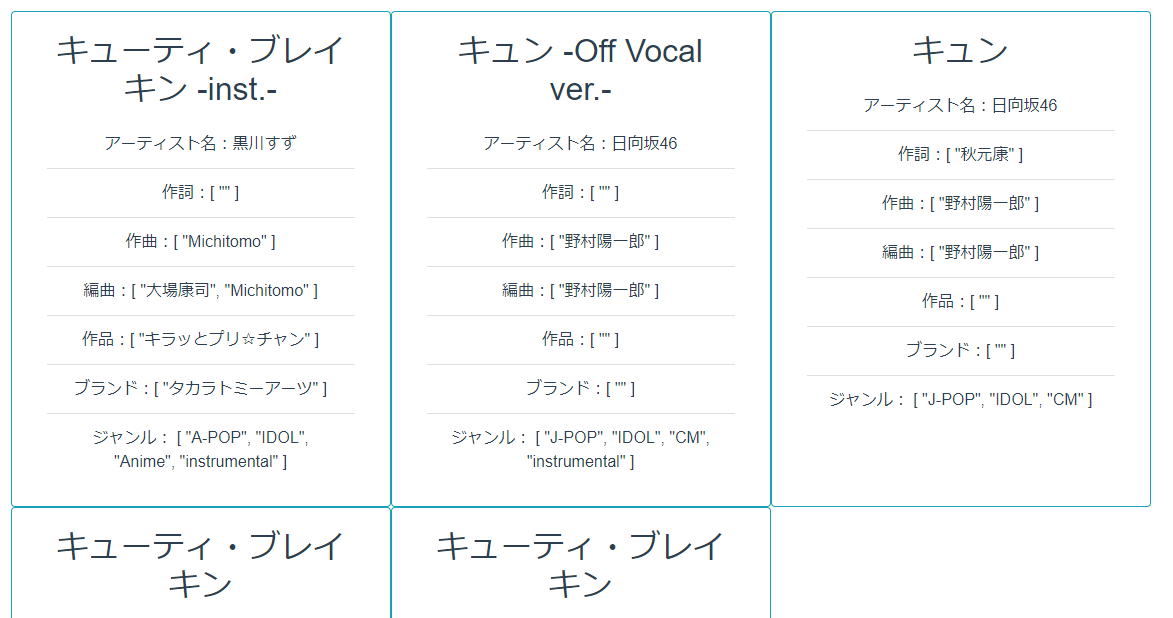
これはようするに入力された文字列と入力された文字列の2文字目を2つずらした文字列を用意してその間を取得しています。
今回、テストに使った日向坂46の「キュン」という曲の場合はまず「キュン」という文字列から「キョ」という文字列を作ります。
それが次の部分となります。
fin = title[0]+chr(ord(title[1])+2)
あとは普通にscanで差分を取るだけです。ちなみに「キュン」の場合は次のようになります。
「キュン」から「キョ」の間なので「キュー」で始まる曲が混じってますがそれはご愛敬という事でお願いします。最後に
DynamoDBのscanは全件取得してから目当てのデータを絞り込むため、滅茶苦茶苦重いです。特に頻繁に叩かれる事が想定できる場合は素直にRDSを契約しましょう。ぼくはピンチケ開発者なのでまだしばらくDynamoDBで頑張ろうと思います。
- 投稿日:2020-11-19T17:15:50+09:00
Pandas の groupby で処理してグラフを描く
はじめに
Kaggle の Titanic で遊び始めているが, 欠損値の補完やハイパーパラメータの見直しの前に, まずデータをしっかり見ようと思い, データを眺めている. 読み込んだデータを, 例えば
Survivedの値でグルーピングしてグラフを描くということをササッとやりたいのだが, なかなかうまくいかない. Pandas の "GroupBy" の理解が不十分だからだ.ネットには, 先人たちのグラフ描画の例がたくさんあるが, 私の理解の道筋を記すことで, 初心者の役に立てるのではないか? と思って, この記事を書く.
目指すゴール
下記のようなグラフを描くこと.
このグラフは, 横軸が
Ticketの記号, 縦軸が生存 (s), 死亡 (d), 不明 (na) の人数を積み上げたもので, 合計人数で降順にソートしている. 例えば, 一番左端のCA. 2343のチケット記号は, 合計 11 人, 不明が 4 名, 残りの 7 名が死亡となっている.こんなグラフをササッと描きたい.
データを読み込む
データを読み込んで,
Ticketのデータで, 同じ記号ごとの数を調べる.import numpy as np import pandas as pd import matplotlib.pyplot as plt train_data = pd.read_csv("../train.csv") test_data = pd.read_csv("../test.csv") total_data = pd.concat([train_data, test_data]) # train_data と test_data を連結 ticket_freq = total_data["Ticket"].value_counts()CA. 2343 11 CA 2144 8 1601 8 S.O.C. 14879 7 3101295 7 .. 350404 1 248706 1 367655 1 W./C. 14260 1 350047 1 Name: Ticket, Length: 929, dtype: int64
CA. 2343が 11 人,CA 2144が 8 人, などが分かる.グラフ用のデータを作る
groupby でグループ化
まず,
total_dataをチケット記号でグルーピングする.total_data_ticket = total_data.groupby("Ticket")# 出力 <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F5A14327C8>
groupbyの欠点は, データの中身を表示してくれないことだ. ここは, グループ化された と頭の中で理解して, 次へ行く.生存情報だけ取り出す
次に, 生存情報 (
Survived) を取り出す.total_data_ticket = total_data.groupby("Ticket")["Survived"] total_data_ticket# 出力 <pandas.core.groupby.generic.SeriesGroupBy object at 0x000001F5A1437B48>ここでもデータは表示してくれない.
生存, 死亡, 不明ごとに数を数える
引き続き,
value_counts()を使って,Survivedの値ごとの数を数える.dropna=Falseとすることで, N/A もカウントする.total_data_ticket = total_data.groupby("Ticket")["Survived"].value_counts(dropna=False) total_data_ticket# 出力 Ticket Survived 110152 1.0 3 110413 1.0 2 0.0 1 110465 0.0 2 110469 NaN 1 .. W.E.P. 5734 NaN 1 0.0 1 W/C 14208 0.0 1 WE/P 5735 0.0 1 1.0 1 Name: Survived, Length: 1093, dtype: int64データの形を変える
グラフを描くために, 生存, 死亡, 不明のデータが列方向に並ぶようなデータに変える. 使うのは
unstack().total_data_ticket = total_data.groupby("Ticket")["Survived"].value_counts(dropna=False).unstack() total_data_ticket# 出力 Survived NaN 0.0 1.0 Ticket 110152 NaN NaN 3.0 110413 NaN 1.0 2.0 110465 NaN 2.0 NaN 110469 1.0 NaN NaN 110489 1.0 NaN NaN ... ... ... ... W./C. 6608 1.0 4.0 NaN W./C. 6609 NaN 1.0 NaN W.E.P. 5734 1.0 1.0 NaN W/C 14208 NaN 1.0 NaN WE/P 5735 NaN 1.0 1.0 929 rows × 3 columnsグラフを描く
N/A を数字に変える
上の出力を見ると, 値に
NaNがまだ残っている. そこでNaNを 0 にする.total_data_ticket.fillna(0, inplace=True) total_data_ticket# 出力 Survived NaN 0.0 1.0 Ticket 110152 0.0 0.0 3.0 110413 0.0 1.0 2.0 110465 0.0 2.0 0.0 110469 1.0 0.0 0.0 110489 1.0 0.0 0.0 ... ... ... ... W./C. 6608 1.0 4.0 0.0 W./C. 6609 0.0 1.0 0.0 W.E.P. 5734 1.0 1.0 0.0 W/C 14208 0.0 1.0 0.0 WE/P 5735 0.0 1.0 1.0 929 rows × 3 columns列名を変える
列名が
NaN,0.0,1.0となっているが, これでは扱いにくいので, 列名を変える.total_data_ticket.columns = ["nan", "d", "s"] total_data_ticket# 出力 nan d s Ticket 110152 0.0 0.0 3.0 110413 0.0 1.0 2.0 110465 0.0 2.0 0.0 110469 1.0 0.0 0.0 110489 1.0 0.0 0.0 ... ... ... ... W./C. 6608 1.0 4.0 0.0 W./C. 6609 0.0 1.0 0.0 W.E.P. 5734 1.0 1.0 0.0 W/C 14208 0.0 1.0 0.0 WE/P 5735 0.0 1.0 1.0 929 rows × 3 columns行ごとの合計人数を計算する
合計人数で降順にソートしたいので, 合計人数を計算して, 新しい列に保存する. 合計を計算するには
sum()を使うが, 列方向に計算するのでsum(axis=1)としている.total_data_ticket["count"] = total_data_ticket.sum(axis=1) total_data_ticket#出力 nan d s count Ticket 110152 0.0 0.0 3.0 3.0 110413 0.0 1.0 2.0 3.0 110465 0.0 2.0 0.0 2.0 110469 1.0 0.0 0.0 1.0 110489 1.0 0.0 0.0 1.0 ... ... ... ... ... W./C. 6608 1.0 4.0 0.0 5.0 W./C. 6609 0.0 1.0 0.0 1.0 W.E.P. 5734 1.0 1.0 0.0 2.0 W/C 14208 0.0 1.0 0.0 1.0 WE/P 5735 0.0 1.0 1.0 2.0 929 rows × 4 columnsこれで, グラフを描く準備は整った.
グラフを描く
人数の領域を決めて, 降順にソートする
まずコードを示して, 順番に説明する.
total_data_ticket[total_data_ticket["count"] > 3].sort_values("count", ascending=False)[["nan", "d", "s"]].plot.bar(figsize=(15,10),stacked=True)
コード 内容 total_data_ticket[total_data_ticket["count"] > 3]"count"が 3 より大きいデータ.sort_values("count", ascending=False)"count"で降順にソート[["nan", "d", "s"]]左記の 3 つの列だけ取り出す ( "count"はお役御免).plot.bar(figsize=(15,10),stacked=True)棒グラフを描く. サイズを指定し, 積み上げ方式にした これで, 冒頭に示したグラフが書ける.
これを見ると,
CA. 2343やCA 2144の人はSurvived = 0かな…とか想像できる.全体のコード
最後に全体のコードを示す.
import numpy as np import pandas as pd import matplotlib.pyplot as plt train_data = pd.read_csv("../train.csv") test_data = pd.read_csv("../test.csv") total_data = pd.concat([train_data, test_data]) ticket_freq = total_data["Ticket"].value_counts() ticket_freq total_data_ticket = total_data.groupby("Ticket")["Survived"].value_counts(dropna=False).unstack() total_data_ticket.fillna(0, inplace=True) total_data_ticket.columns = ["nan", "d", "s"] total_data_ticket["count"] = total_data_ticket.sum(axis=1) total_data_ticket[total_data_ticket["count"] > 3].sort_values("count", ascending=False)[["nan", "d", "s"]].plot.bar(figsize=(15,10),stacked=True)おわりに
この手法を使って,
EmbarkedやCabin,Nameの苗字や敬称など, 他の非数値データも確認していく.参考

- 投稿日:2020-11-19T17:10:18+09:00
AWS lambda を使ってWebスクレイピングしたった
Background
AWS Lambda を使ってFizzBuzzしたったの続き。
今回はスクレイピングで外部のWebページからデータを取得してみた。AWS Architecture
- S3(データ保存)
- AWS Lambda(データ処理)
- Amazon EventBridge(定期実行)
の3つのサービスを使っています。
Setting
S3
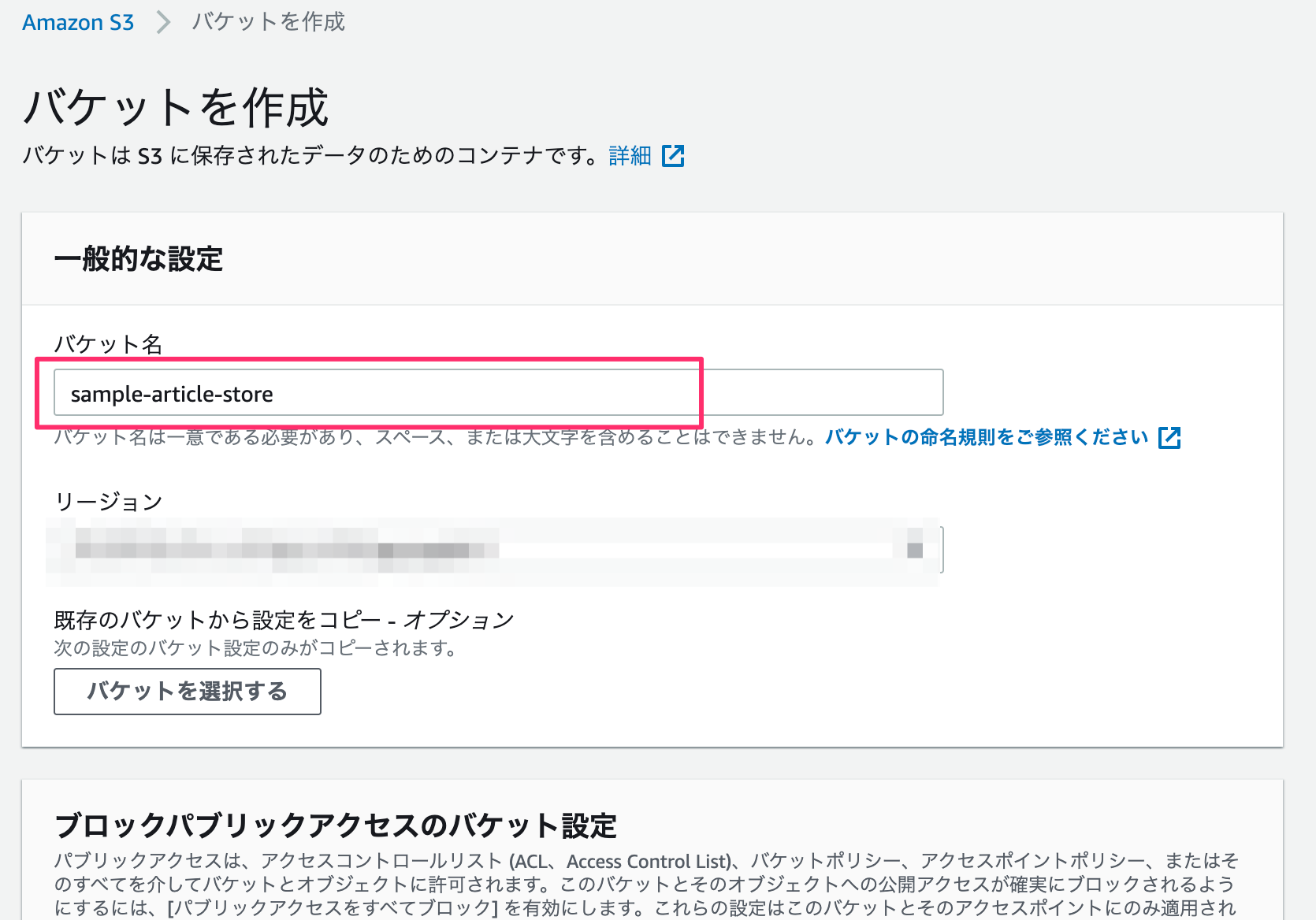
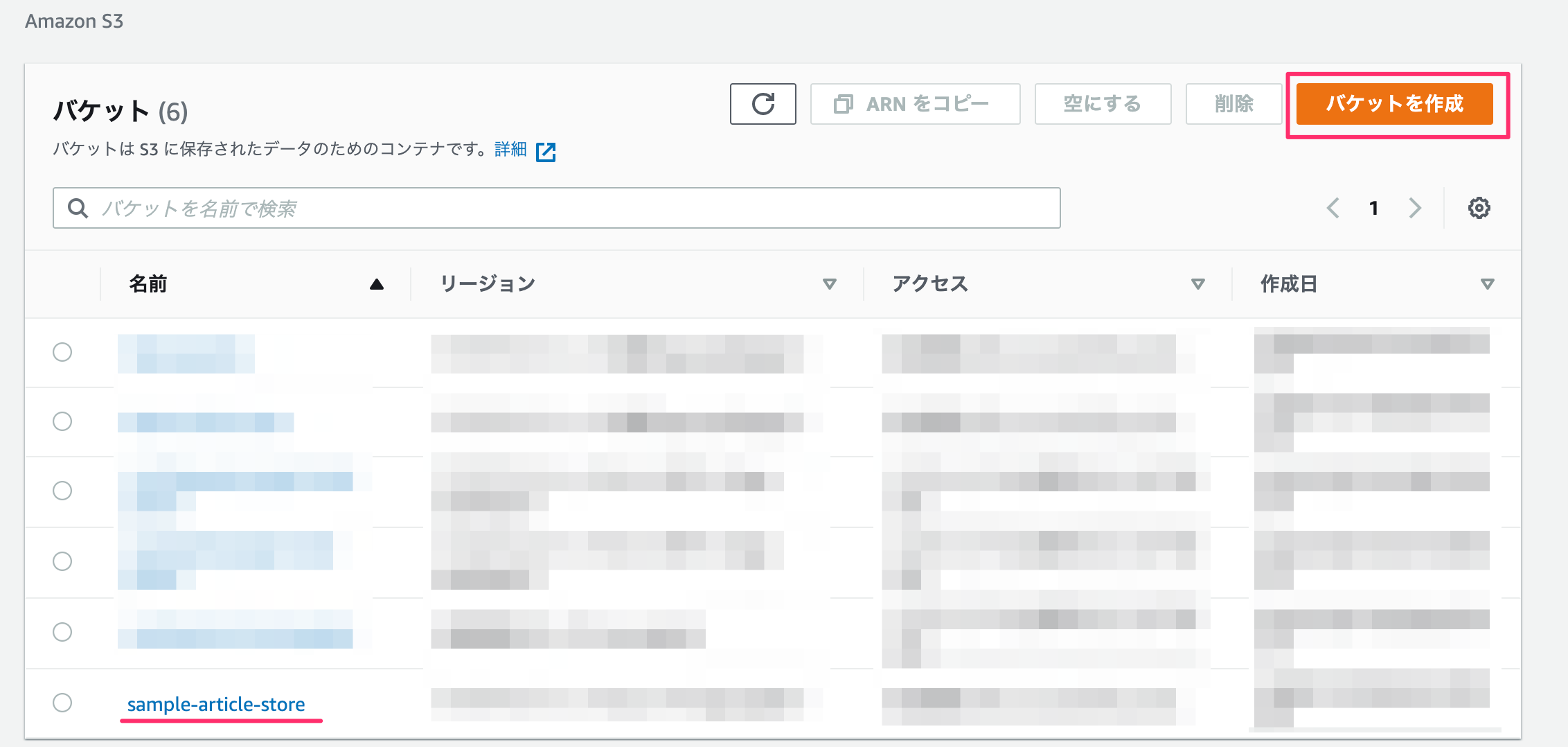
データ保存用のバケットを作成します。
バケット名のみ入力して、その他の設定はデフォルトのままにします。(リージョンは適宜選択する。)
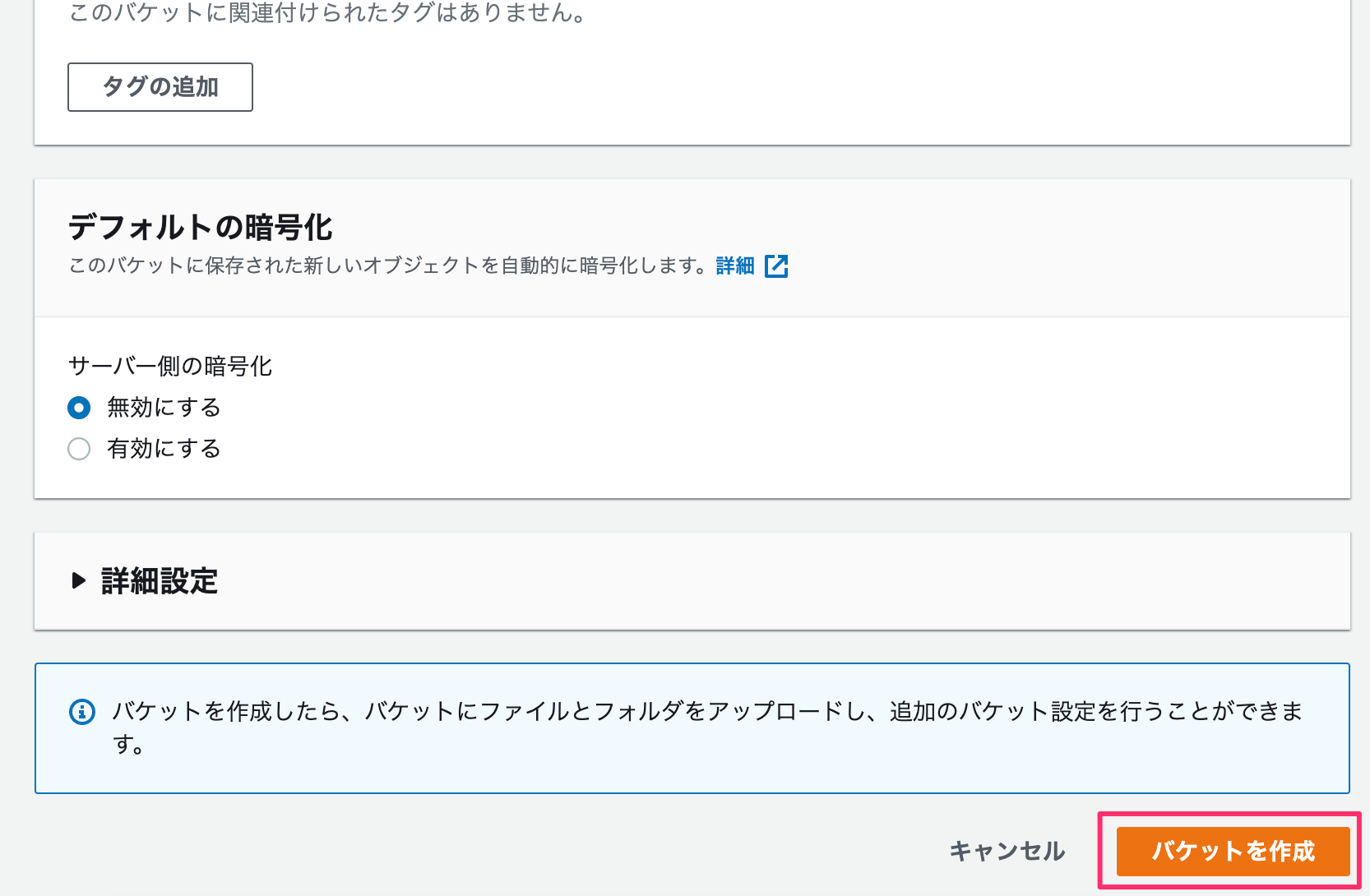
バケットの作成は完了。
Lambda
データ処理用のlambdaを作成します。
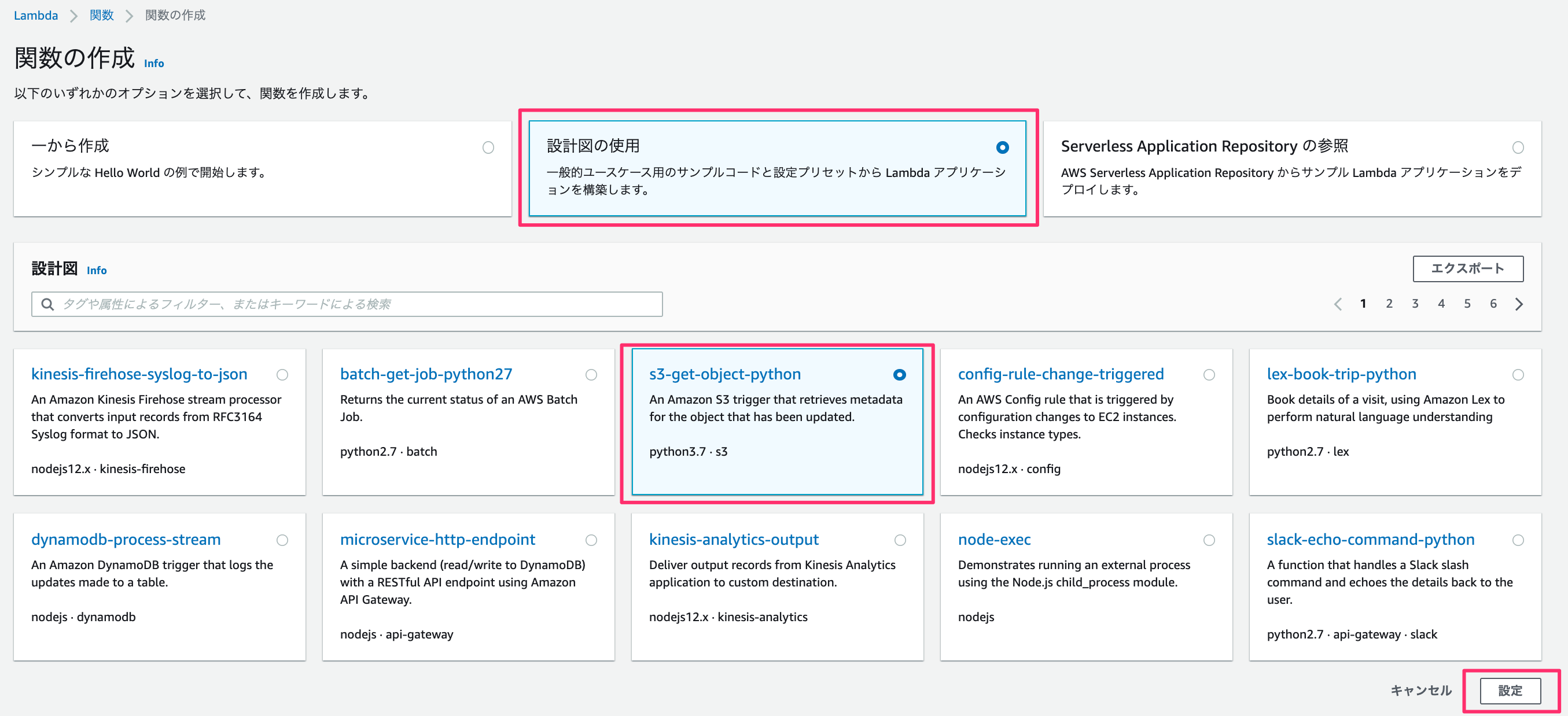
一から作成、、、ではなく、
ここでは「設計図の使用」のなかの「s3-get-object-python」を使います。
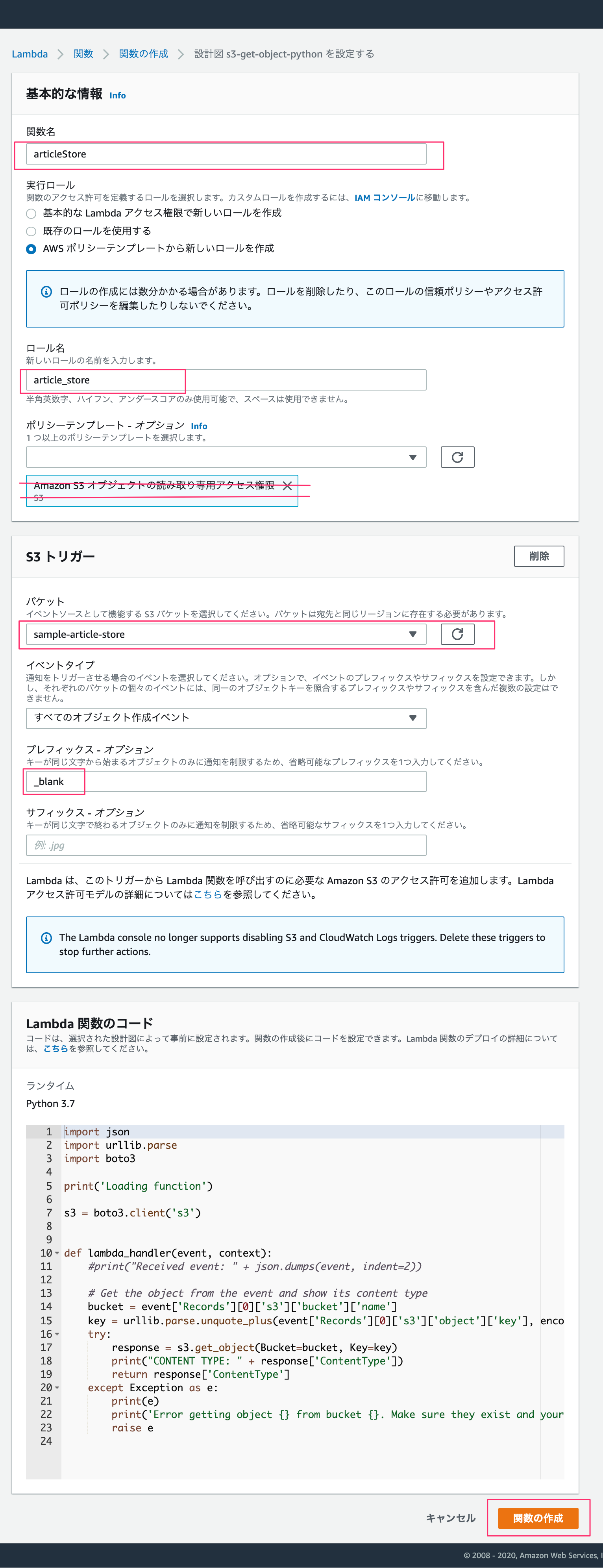
関数名・ロール名を入力。
今回はS3にファイルをuploadするので「読み取り専用のアクセス」のポリシーテンプレートを削除します。
S3トリガーですが、バケット名には先ほど作成したバケットを入力します。あとは、プレフィックス - オプションには任意の文字を入力してください。
ここで言っている任意の文字とは、lambdaにてファイルを作成するのですがファイル名の先頭と重複しない文字です。
もし、未入力や重複する文字を入力した場合は lambdaへ無限ループにトリガーを作動させ、多額の料金が発生することになるので重要です。
他の対処法としては、イベントタイプをコピーのみにするなどの制限を加えるのもいいと思います。
全ての入力が終わったあとは、「関数の作成」を押します。
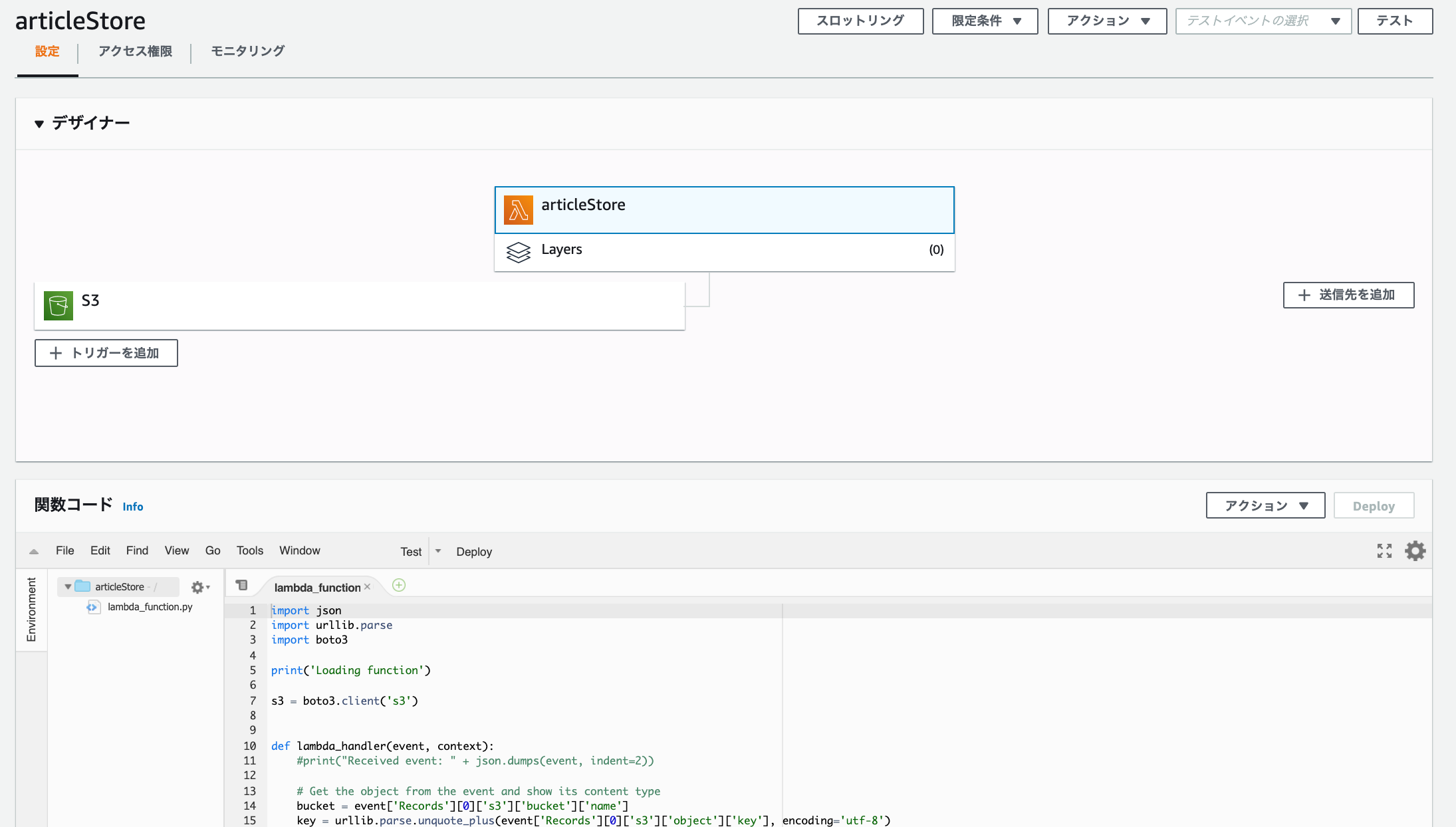
テンプレートが作成されますが、このまま開発を進めてデプロイ、テストしても権限エラーが発生します。
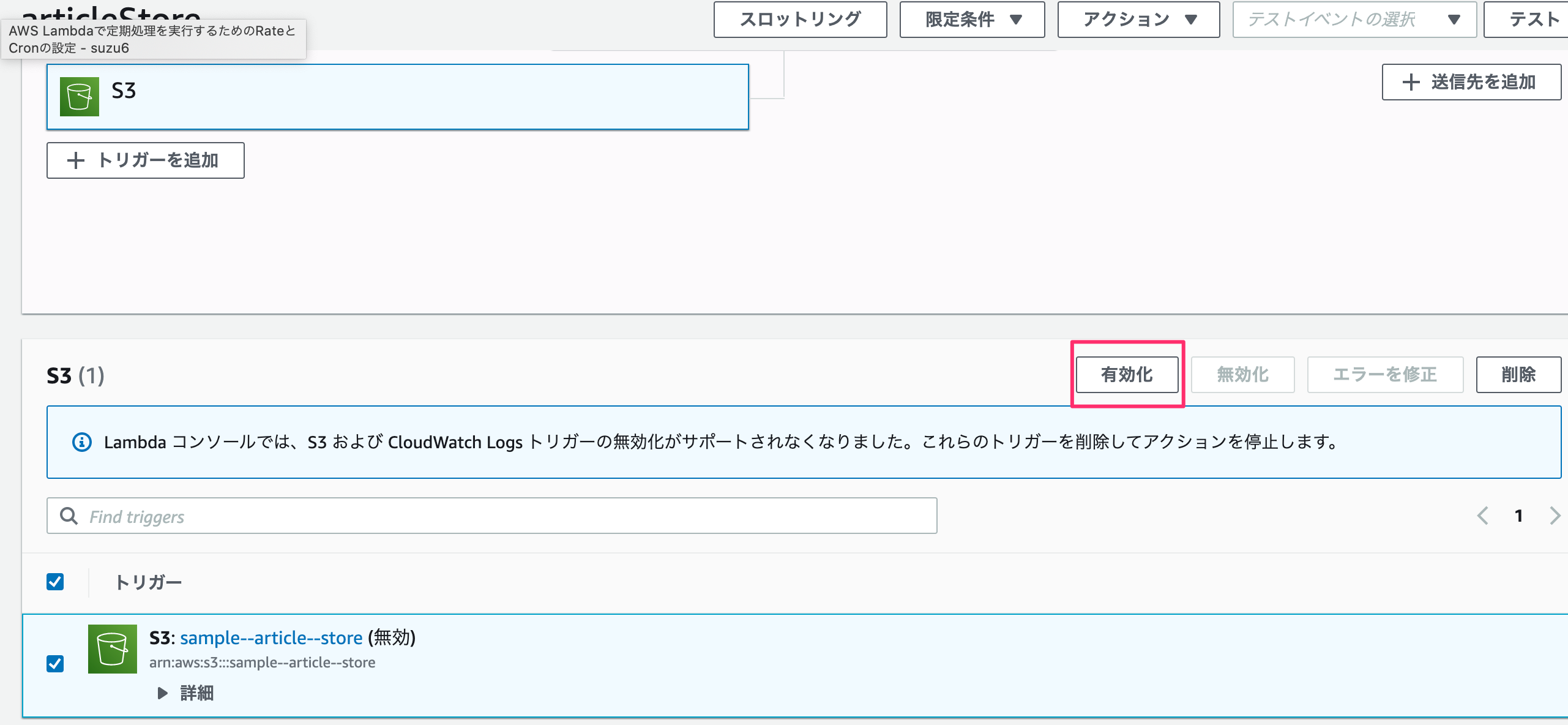
S3の設定
まずS3を有効化させます。
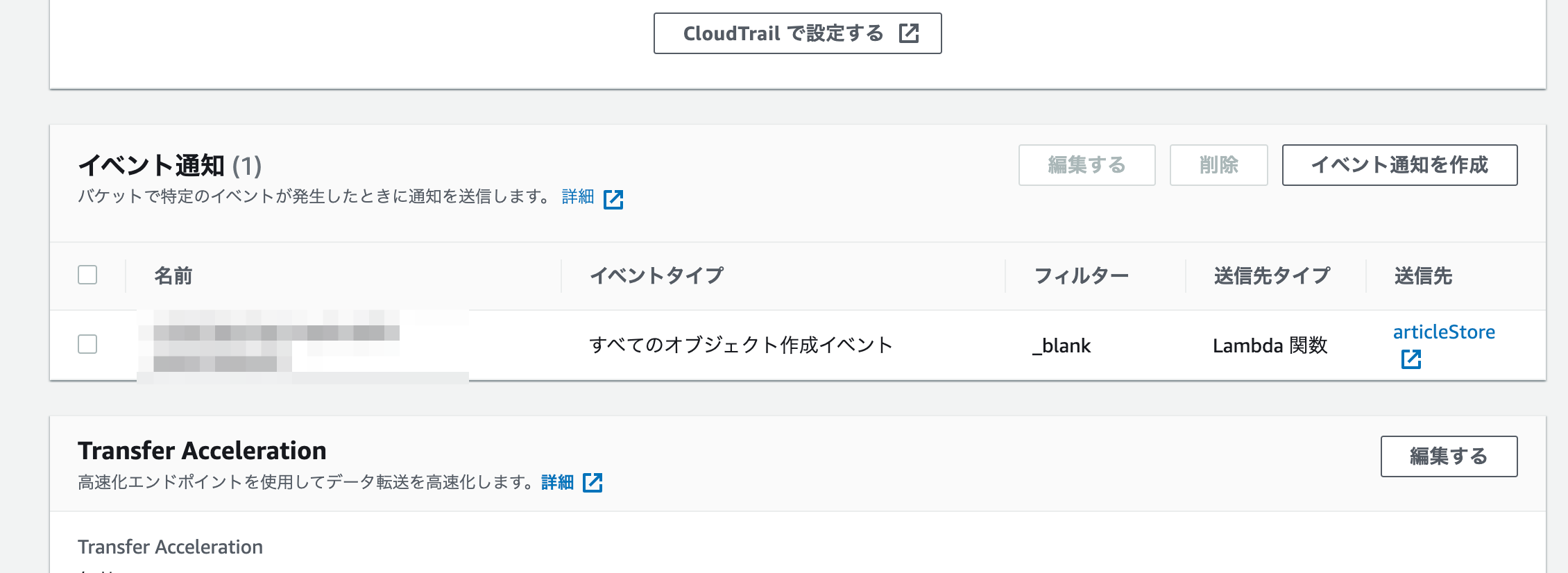
S3でバケットのプロパティ内にあるイベント通知を見ると追加されているのが分かります。
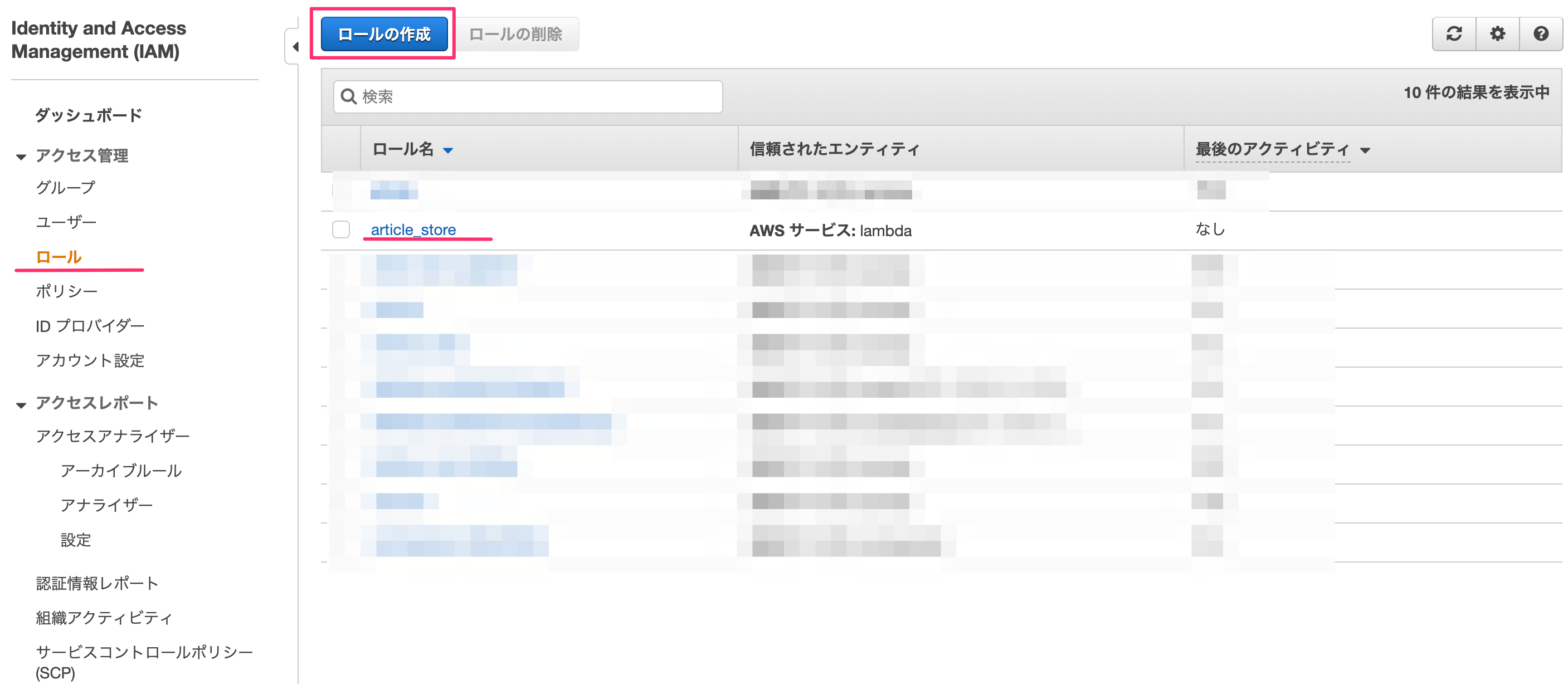
ロールに権限の追加
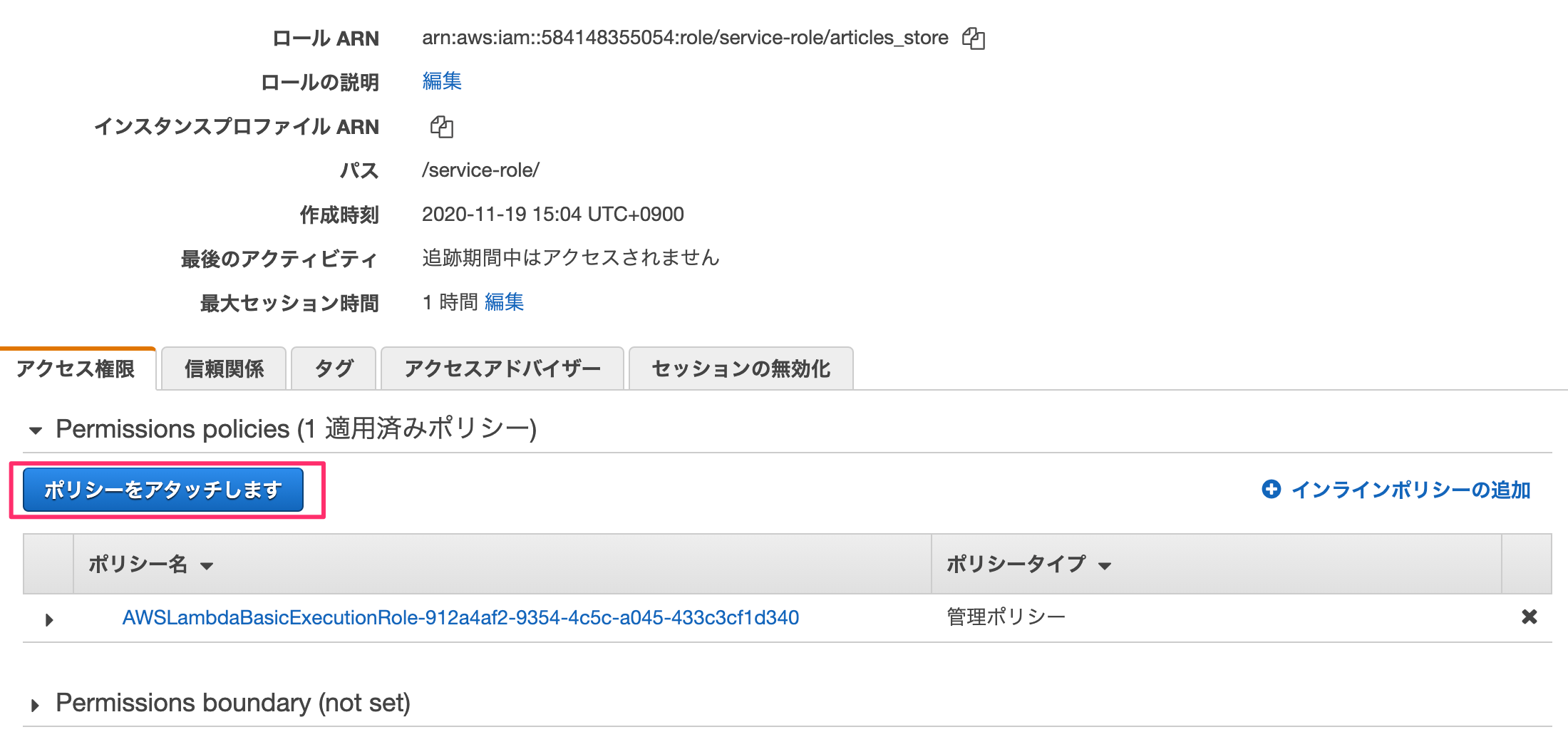
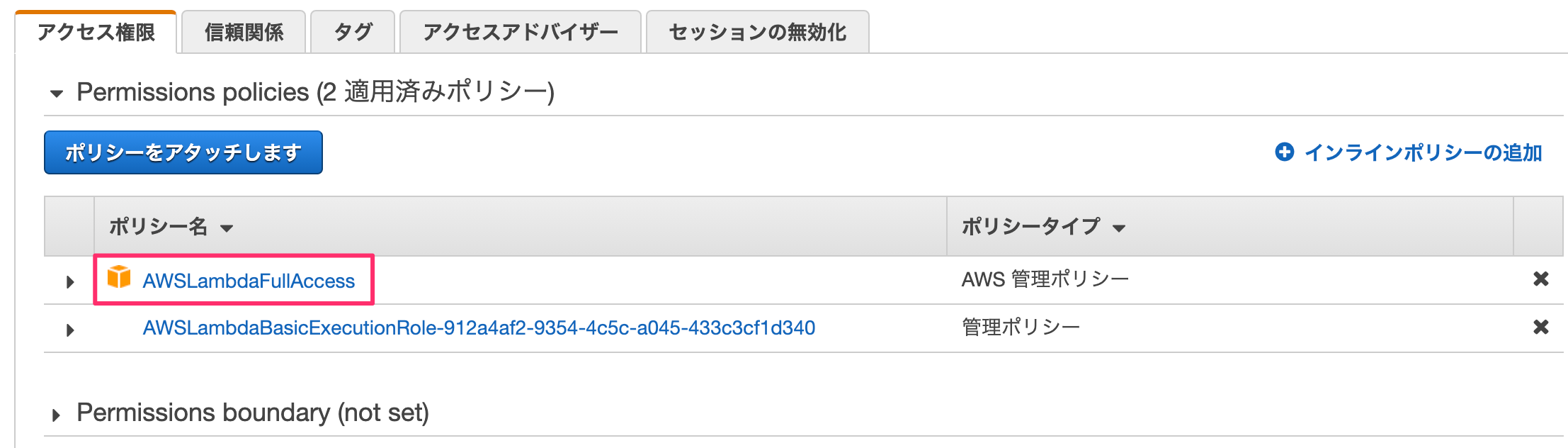
IAM→ロールを選ぶとロールリストが表示されます。ここで先ほどlambda作成時に記載したロール名を選択します。
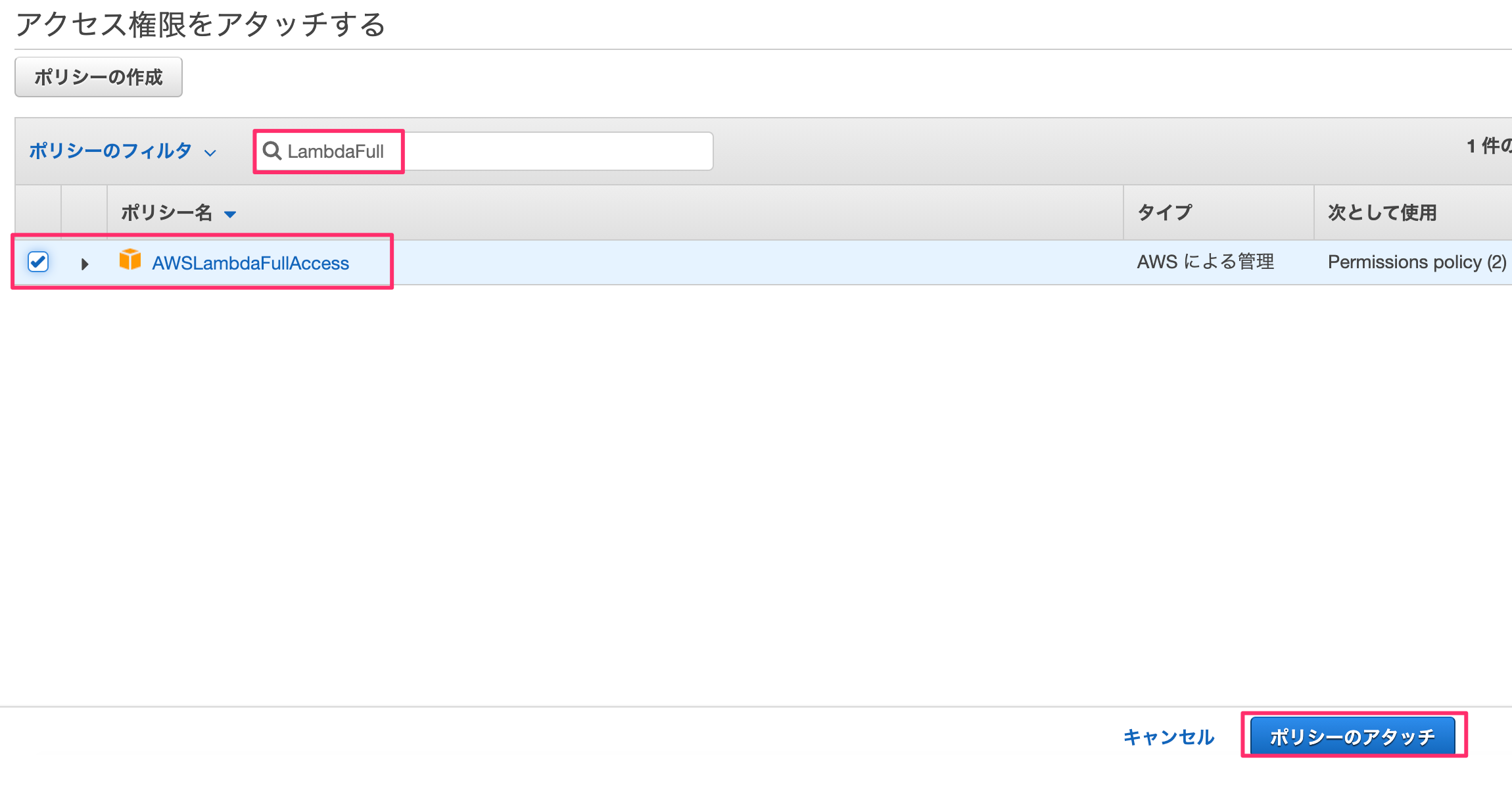
何も考えずに「ポリシーをアタッチします」を押す。
"LambdaFull"でフィルタをかけ、「AWSLambdaFullAccess」を選んで「ポリシーのアタッチ」を押します。
これで権限の追加が完了しました。
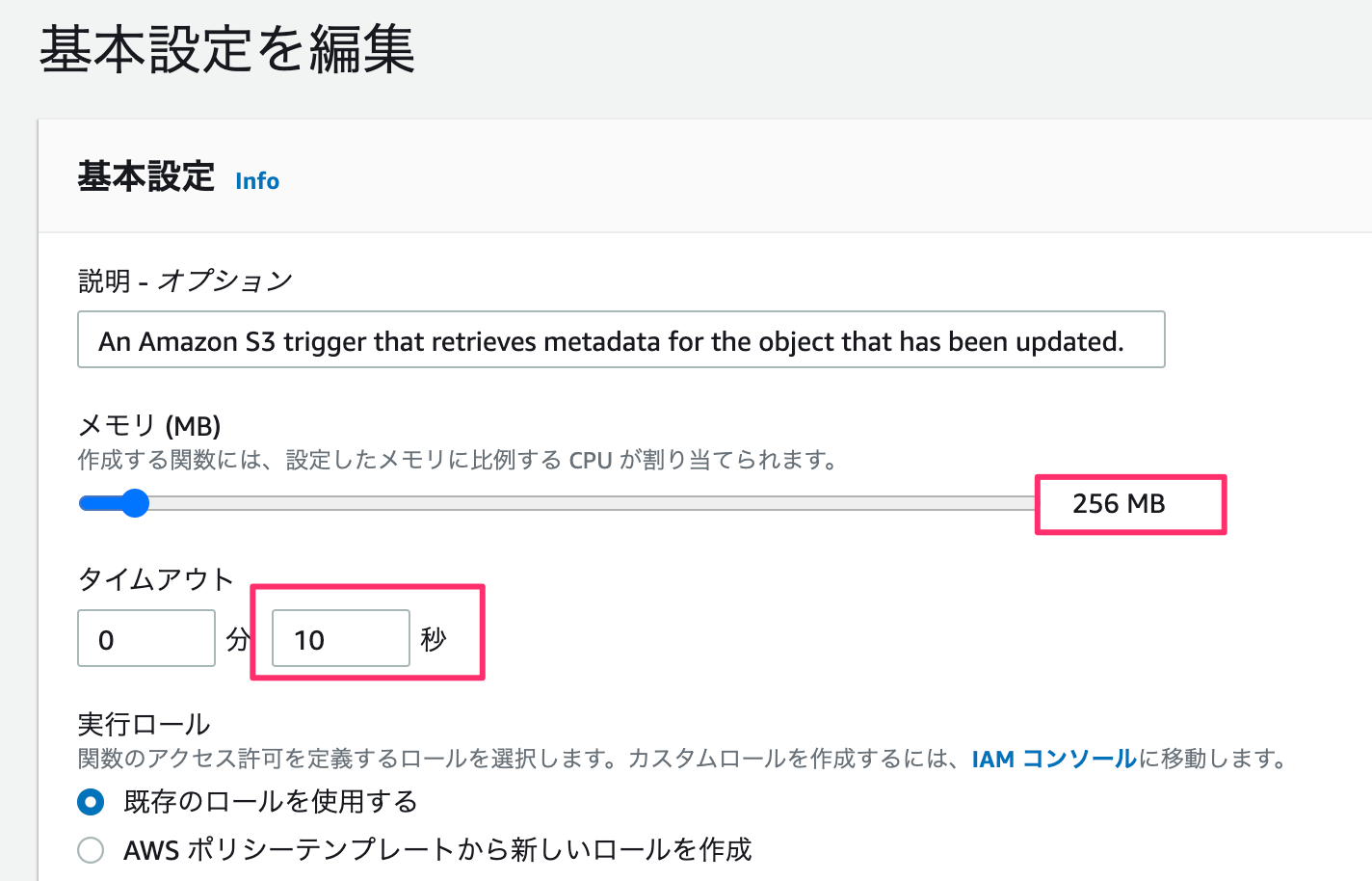
基本設定
メモリが小さいと処理落ちしました。
てことでメモリ:256MB、タイムアウトを10秒にセットします。
これで完了。
Development (ファイル送信)
S3バケットの送受信にはbote3パッケージを使います。 lambda作成時に
s3-get-object-pythonを選ぶと付属でついてきます。最初からパッケージをuploadするとbote3自体の容量が大きく10MB以上になるので既存のものを使った方が良さげです。import json import urllib.parse import boto3 import datetime def lambda_handler(event, context): try: # Get the object from the event and show its content type s3 = boto3.resource('s3') bucket = '[バケット名]' key = 'test_{}.txt'.format(datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')) file_contents = 'Lambda test' obj = s3.Object(bucket,key) obj.put( Body=file_contents ) except Exception as e: print(e) raise eあとはデプロイして、テストするとバケットにファイルがuploadされます。
あと、テストイベントの設定ですが空のjsonでも起動します。Development (Webスクレイピング)
スクレイピングするには、
requestsbeautifulsoupがいるのですがpipでインストールしているパッケージをlambdaにuploadする必要があります。方法はフォルダにpipでパッケージをインストールし、zipでフォルダを圧縮化します。
ここで実行ファイルを作成し、lambdaで書いたコードをコピーします。mkdir packages cd packages pip install requests -t ./ pip install beautifulsoup -t ./ touch lambda_function.py
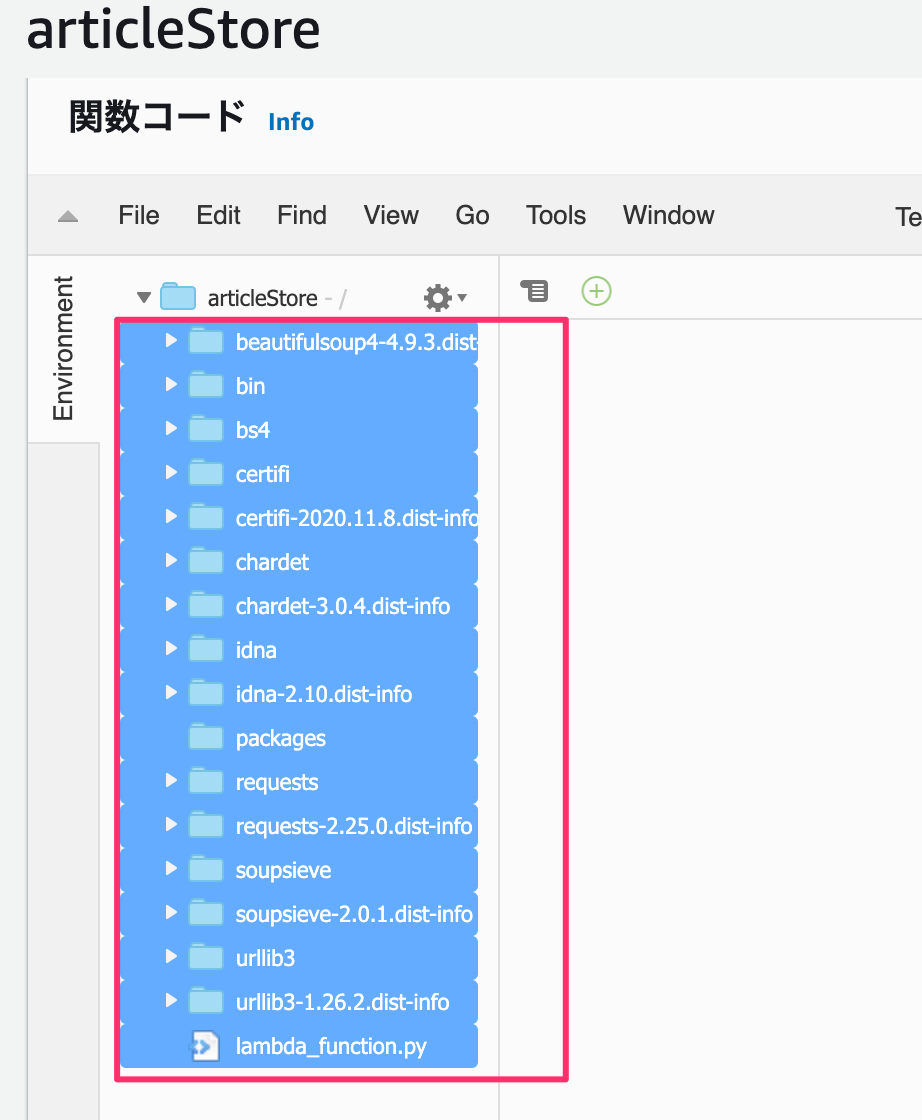
プロジェクト内にパッケージが置かれます。
で、packages配下のフォルダ・ファイルをひとつ上の階層のarticleStoreに移動させます。
その後で、デプロイしてテストするとS3にファイルが追加されます。
あとは、webスクレイピングするだけです。
ここでは今日付の毎日新聞の社説を取得してみます。import json import urllib.parse import boto3 import datetime from datetime import timedelta, timezone import random import os import requests from bs4 import BeautifulSoup print('Loading function') s3 = boto3.resource('s3') def lambda_handler(event, context): # Get the object from the event and show its content type JST = timezone(timedelta(hours=+9), 'JST') dt_now = datetime.datetime.now(JST) date_str = dt_now.strftime('%Y年%m月%d日') response = requests.get('https://mainichi.jp/editorial/') soup = BeautifulSoup(response.text) pages = soup.find("ul", class_="list-typeD") articles = pages.find_all("article") links = [ "https:" + a.a.get("href") for a in articles if date_str in a.time.text ] for i, link in enumerate(links): bucket_name = "[バケット名]" folder_path = "/tmp/" filename = 'article_{0}_{1}.txt'.format(dt_now.strftime('%Y-%m-%d'), i + 1) try: bucket = s3.Bucket(bucket_name) with open(folder_path + filename, 'w') as fout: fout.write(extract_article(link)) bucket.upload_file(folder_path + filename, filename) os.remove(folder_path + filename) except Exception as e: print(e) raise e return { "date" : dt_now.strftime('%Y-%m-%d %H:%M:%S') } #社説を抽出 def extract_article(src): response = requests.get(src) soup = BeautifulSoup(response.text) text_area = soup.find(class_="main-text") title = soup.h1.text.strip() sentence = "".join([txt.text.strip() for txt in text_area.find_all(class_="txt")]) return title + "\n" + sentenceこれで、「デプロイ」→「テスト」でS3バケットに抽出した記事が書かれた2つのテキストファイルが追加されます。
とても、長くなりましたがLambdaの設定は完了です。
Amazon EventBridge
処理はできたのですが、毎朝「テスト」ボタンを押すのはマジだるです。
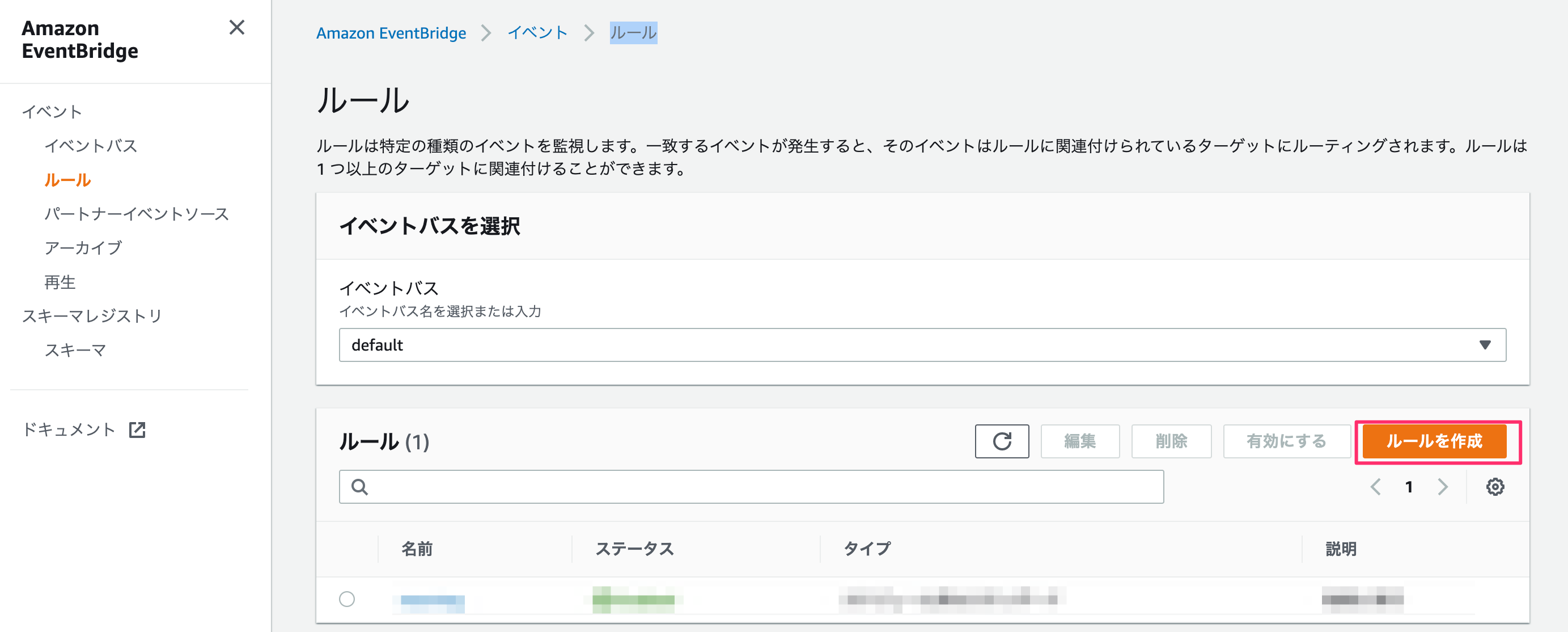
そのため、Amazon EventBridgeを使って定期実行を設定します。Amazon EventBridge → イベント → ルール を選んで、
「ルールの作成」を押します。
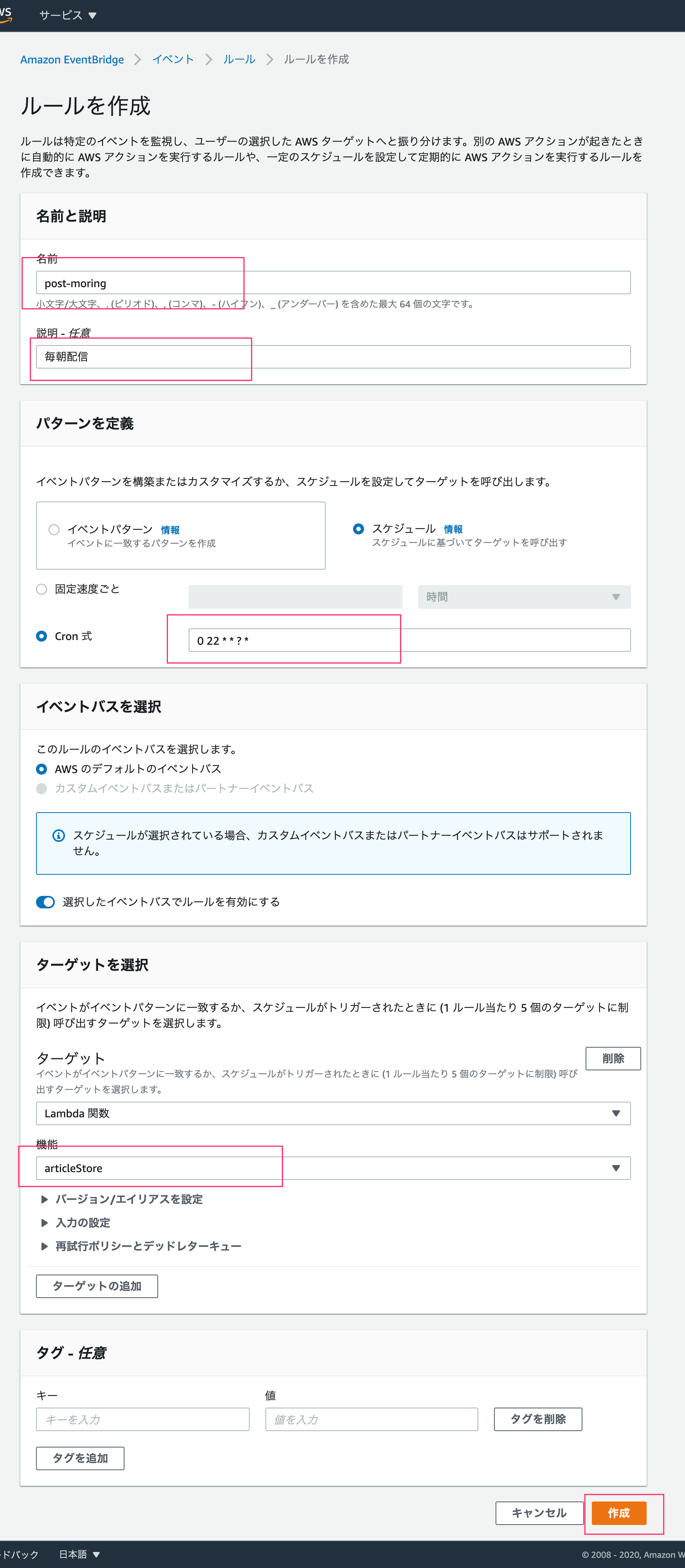
ルール名・説明を書き、cron式は標準時間で実行されるので
0 22 * * ? *として日本時間午前7時に実行するようにします。
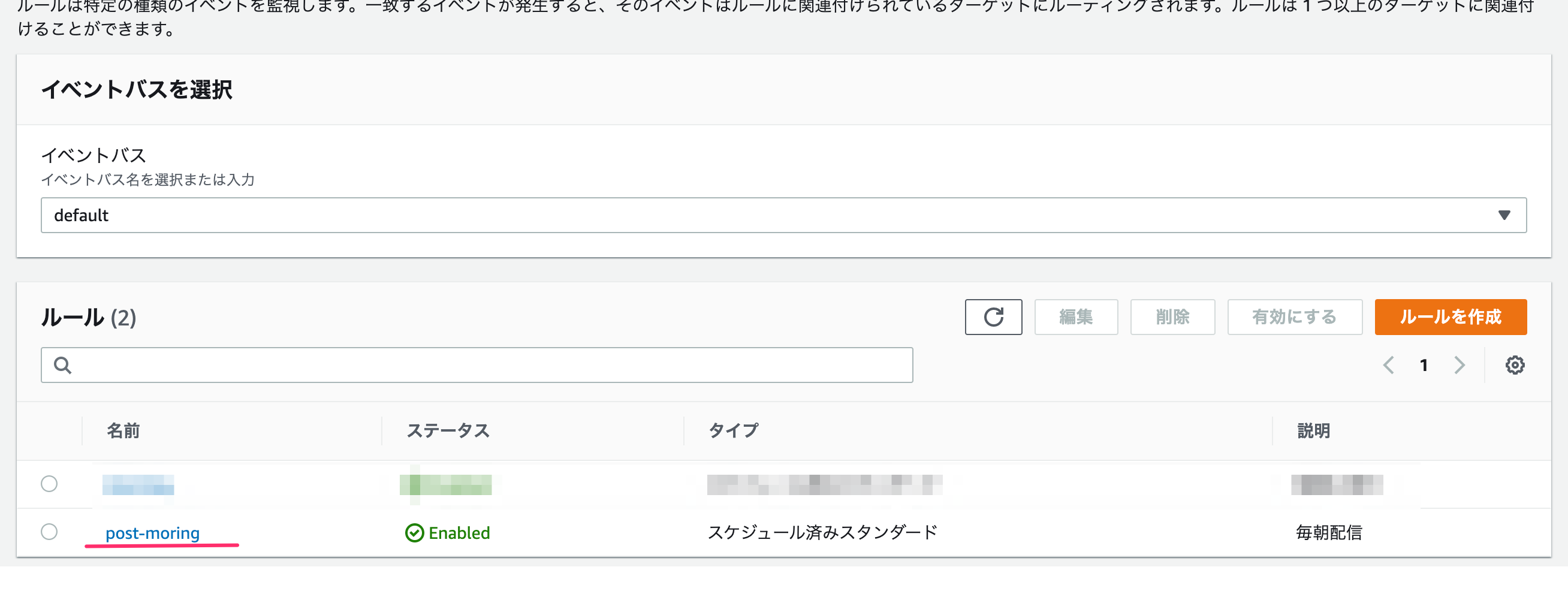
ターゲットで対象のlambda名を選び、作成します。
これで完了。
Post-Scripting
この後の予定として、いくつかの新聞社の社説を1年分ストックして機械学習してみようと思っています。
requestsで全てのページを取得できる場合はいいのですが、ページロード時にさらにロードして一覧表示しているサイト(例えば、朝日新聞)がある場合はseleniumでブラウザをコントロールする必要があります。


- 投稿日:2020-11-19T16:39:20+09:00
どこでもスマホでプログラミング!(C言語 / Pythonにオススメ)
いつでもどこでもプログラミングしたい
そんな時もありますよね?
今回はスマホでプログラミングができるアプリを紹介したいと思います。アプリの紹介(※随時更新していきます)
・【モバイルC】(iOS / Android両対応)
※スクリーンショットはAndroidで進めていきます※無料版は広告あり、有料版は広告なし
日本語がとてもチャーミングですね!対応言語(公式サイトより)
• C
• C++ 11
• Python 3
• Javascript ( Duktape )
• Lua
• LLVM Assembly
• OpenGL ES 2 GLSLモバイルCとはありますが、Pythonなんかも使えます!
操作方法(iOS / Androidほぼ同じ)
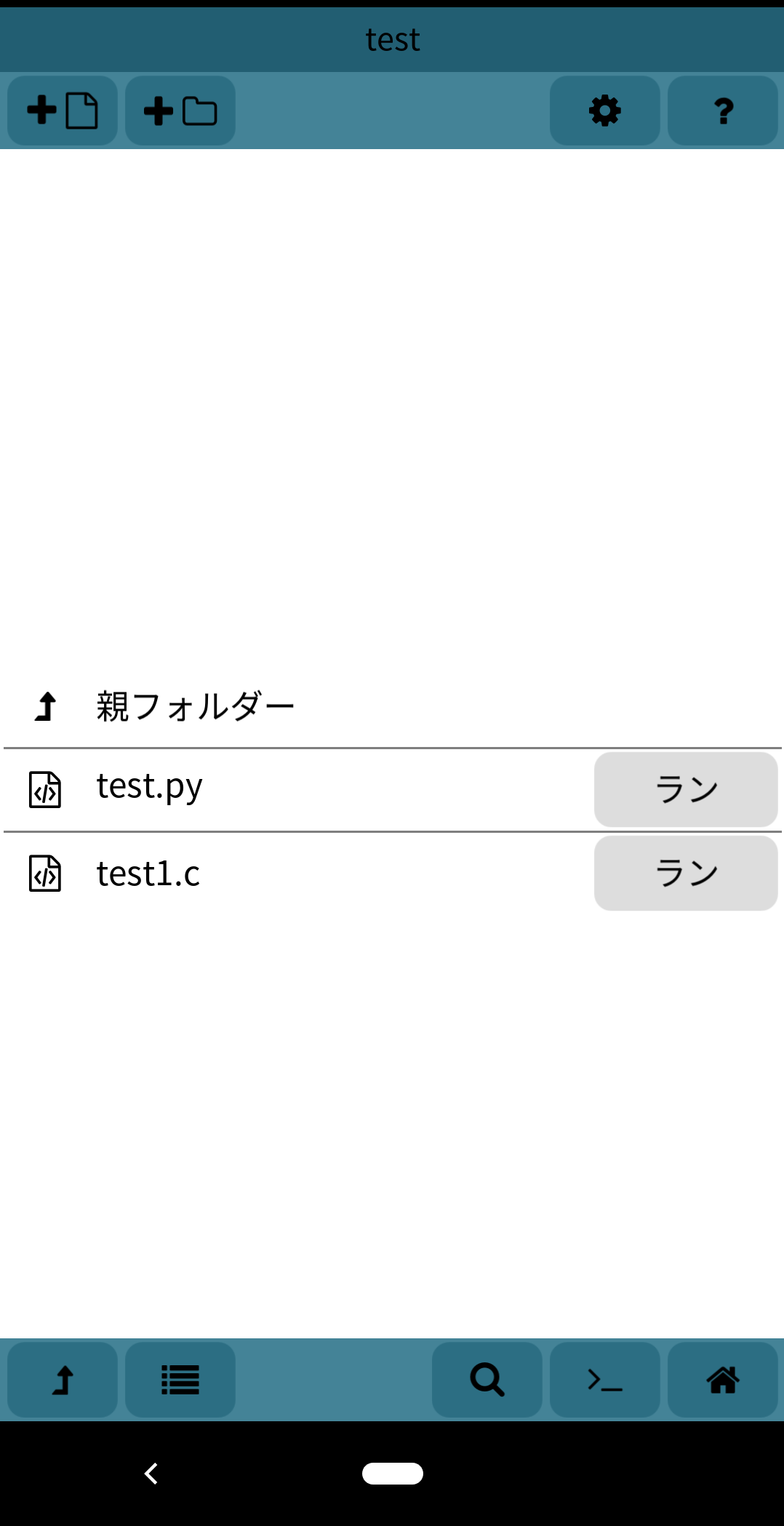
画面上部のアイコンで各フォルダ、ファイルを作成できます。
今回はC言語とPythonで試してみます。
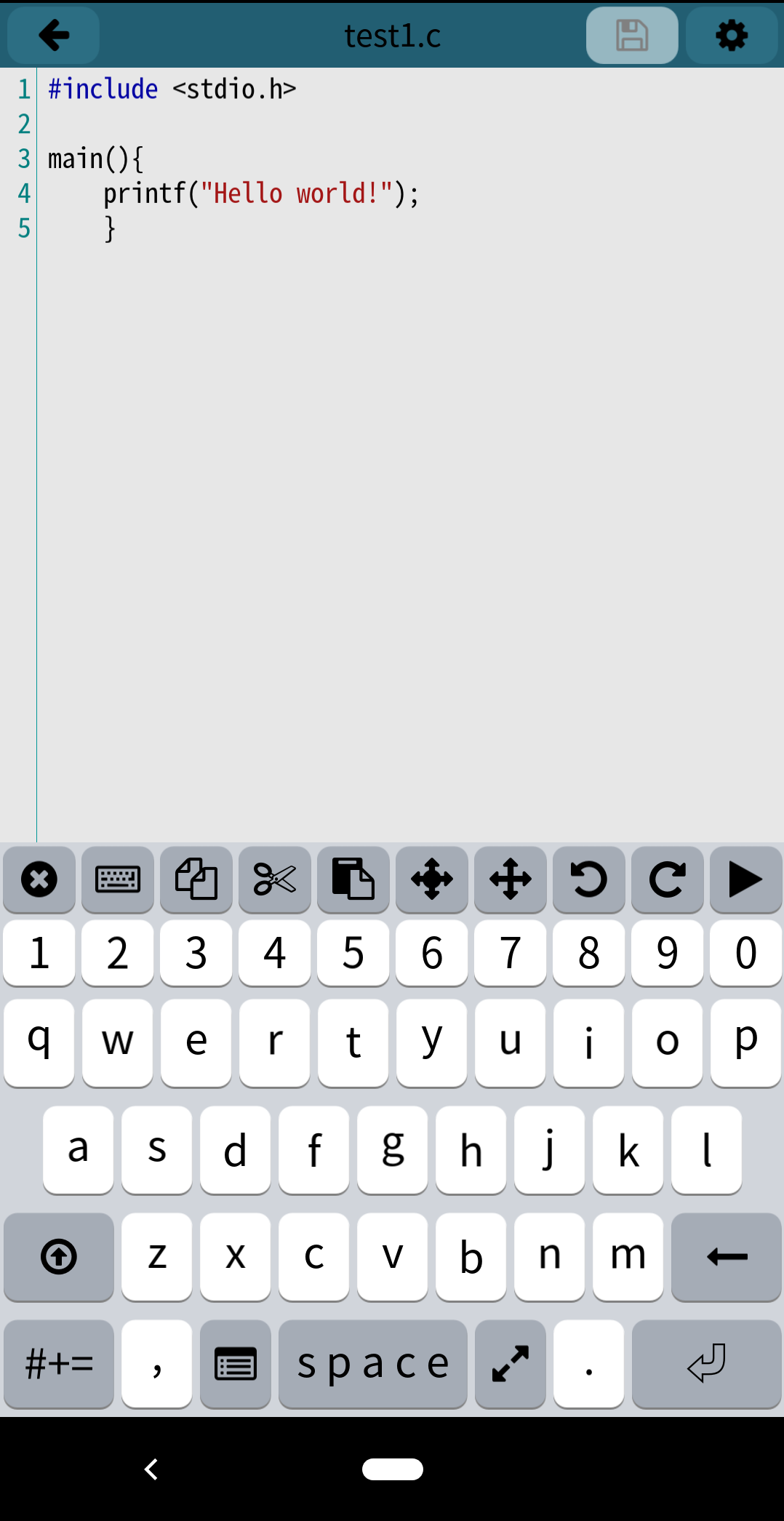
C言語でHello world!してみます。
キーボード上部のショートカットの ▶︎ を押すと実行できます。
無事出力できました!
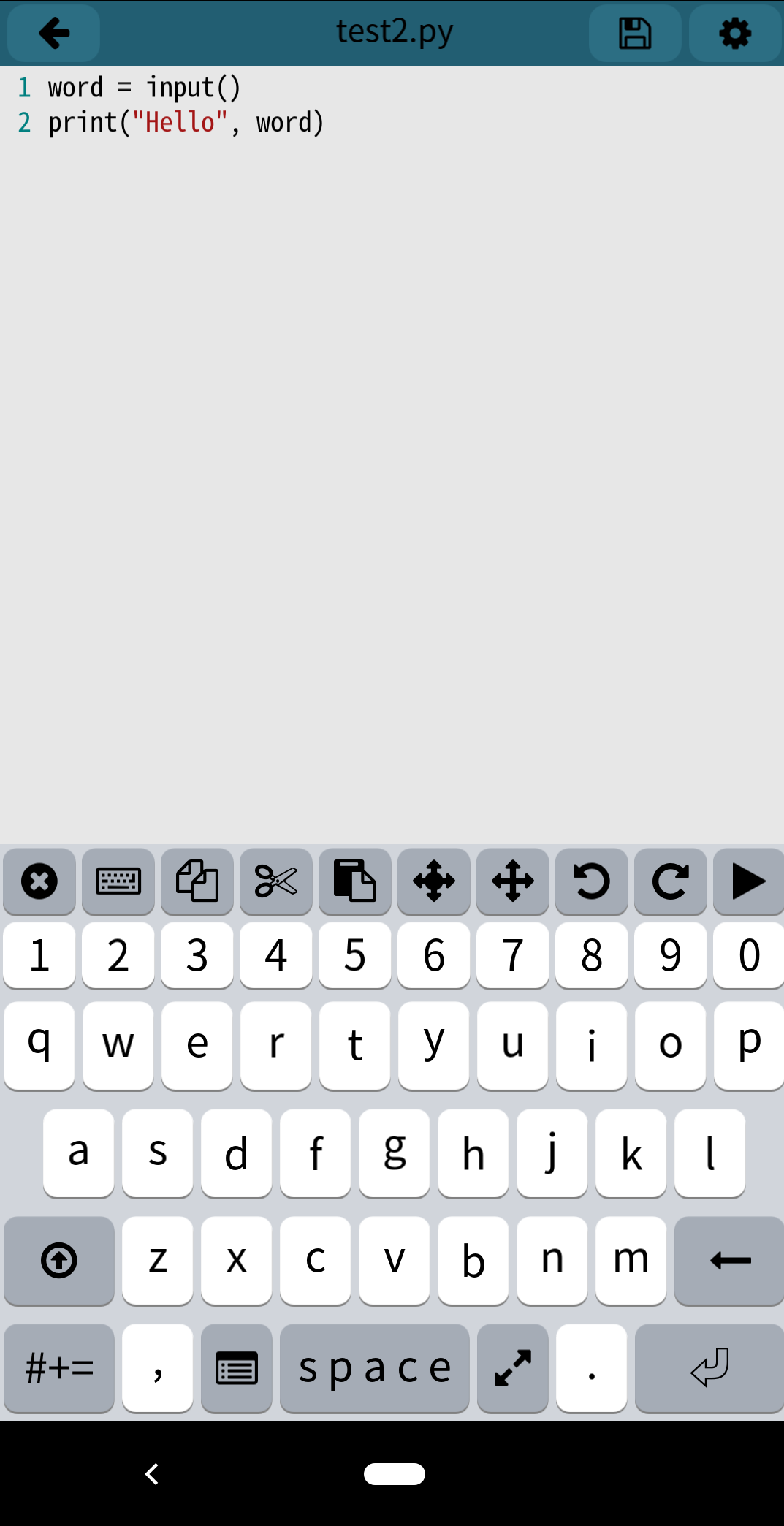
今度はPythonで標準入力を試してみましょう。
実行すると真っ白な画面になるので、キーボードで適当な言葉(ここではPython)と入力し、Enterを押します。
無事うまく実行できました!まとめ
これで電車の中でも公園でも気軽にプログラミングができちゃいますね!
ぜひ皆さんも使ってみてはいかがでしょうか(このアプリの回し者でないです笑)




- 投稿日:2020-11-19T13:56:09+09:00
MNISTデータをランダムにサンプリングしてデータセットを作成する
概要
MNISTデータセット全てではなく、MNISTの一部を使って学習をさせる必要が出てきました。そこでMNISTのTrainingデータ60000枚からランダムにn枚抽出して、クラス毎にフォルダ分けをして画像を保存するプログラムを作成しました。
実行環境
Google Colaboratory
PyTorch 1.6.0実装
MNISTを画像形式で保存
Trainデータセットからランダムに抽出できるようにMNISTデータセットをダウンロードし、画像形式で保存します。
こちらのサイトを参考にさせていただきました。
PyTorchでImageFolderを使ってみるまずは必要なモジュールのimportから
import os from PIL import Image from torchvision.datasets import MNIST import shutil import glob from pprint import pprint import random from pathlib import Path from tqdm import tqdm必要なモジュールがない場合は適宜pipやcondaでインストールしてください。
続いてMNISTをダウンロードします。
mnist_data = MNIST(root='./', train=True, transform=None, download=True)mnistをダウンロードした際にUserWarningが出るかもしれませんが、今回はダウンロードしたmnistを使って学習を行うわけでは無いので気にしないでください。
ダウンロードしたMNISTのバイナリファイルからPNG形式でMNIST画像を保存します。
def makeMnistPng(image_dsets): for idx in tqdm(range(10)): print("Making image file for index {}".format(idx)) num_img = 0 dir_path = './mnist_all/' if not os.path.exists(dir_path): os.makedirs(dir_path) for image, label in image_dsets: if label == idx: filename = dir_path +'/mnist_'+ str(idx) + '-' + str(num_img) + '.png' if not os.path.exists(filename): image.save(filename) num_img += 1 print('Success to make MNIST PNG image files. index={}'.format(idx))関数を実行します。
makeMnistPng(mnist_data)これで
mnist_all下にmnistの画像60000万枚全てが保存されました。クラス毎に画像を保存したい場合は以下のようにしてください。def makeMnistPng(image_dsets): for idx in tqdm(range(10)): print("Making image file for index {}".format(idx)) num_img = 0 dir_path = './MNIST_PNG/' + str(idx) if not os.path.exists(dir_path): os.makedirs(dir_path) for image, label in image_dsets: if label == idx: filename = dir_path +'/' + 'mnist_'+ str(idx) + '_' + str(num_img) + '.png' if not os.path.exists(filename): image.save(filename) num_img += 1 print('Success to make MNIST PNG image files. index={}'.format(idx))ディレクトリ内のファイルからランダムにサンプリングする
mnistの全てのデータを1つのディレクトリに落とし込むことができたのでそこからランダムにn枚の画像をサンプリングし、別ディレクトリにコピーしていきます。
参考にさせていただいた(ほぼそのまま使用した)記事はこちらクラスの定義
class FileControler(object): def get_file_path(self, input_dir, pattern): #ファイルパスの取得 #ディレクトリを指定しパスオブジェクトを生成 path_obj = Path(input_dir) #glob形式でファイルをマッチ files_path = path_obj.glob(pattern) #文字列として扱うためposix変換 files_path_posix = [file_path.as_posix() for file_path in files_path] return files_path_posix def random_sampling(self, files_path, sample_num, output_dir, fix_seed=True) -> None: #ランダムサンプリング #毎回同じファイルをサンプリングするにはSeedを固定する if fix_seed is True: random.seed(0) #ファイル群のパスとサンプル数を指定 files_path_sampled = random.sample(files_path, sample_num) #出力先ディレクトリがなければ作成 os.makedirs(output_dir, exist_ok=True) #コピー for file_path in files_path_sampled: shutil.copy(file_path, output_dir)インスタンス作成
file_controler =FileControler()ディレクトリの設定
サンプリング元のディレクトリとサンプリングしたファイルをコピーするディレクトリを設定します。
all_file_dir = './mnist_all/' sampled_dir = './mnist_sampled/'全てのファイルのパスを取得
pattern = '*.png' files_path = file_controler.get_file_path(all_file_dir, pattern) print(len(files_path)) # 60000n枚サンプリング
sample_num = 100 file_controler.random_sampling(files_path, sample_num, sampled_dir) sampled_files_path = file_controler.get_file_path(sampled_dir, pattern) print(len(sampled_files_path)) # 100これでmnist60000枚の中からランダムにn枚(今回は100枚)サンプリングされました。
クラス分け
機械学習のデータセットとして使用できるよう、サンプリングされた画像たちをクラス毎に分けていきます。
まずサンプリングしたディレクトリ内のファイル名をリスト形式で全て取得します。
files = glob.glob("./mnist_sampled/*")ファイル名のリストに対してin演算子を用いて部分文字列の判定を行いクラス毎にフォルダわけしていきます。
for i in range(10): os.makedirs(sampled_dir+str(i), exist_ok=True) for x in files: if '_' + str(i) in x: shutil.move(x, sampled_dir + str(i))サンプリングしたディレクトリはこのようなディレクトリ構成になります。
./mnist_sampled ├── 0 ├── 1 ├── 2 ├── 3 ├── 4 ├── 5 ├── 6 ├── 7 ├── 8 └── 9これでmnistの画像をランダムにサンプリングし、それらをクラス分けをしてデータセットを作成することができました。
- 投稿日:2020-11-19T12:52:33+09:00
Tensorflow-GPUってTF2.0以降なら一緒になってるらしい?
ここもhtmlとか使って書くものなのか?無知なのでよくわかりませんが
Autokerasを走らせてるときに、もしやGPU使われてないのでは?
と思っていたら、本当に使われていなかった。今までGPUなんて勝手に使ってくれるもんだと思ってたんですねえ。でも、
CPU性能はそこまで低くないから、別に遅くは無くて何とも思ってなかった。
いや、何と比べてやねんって話やが。で、Tensorflow-gpuというのがいるんだ!と思って頑張って入れてみて、
CUDAやらCuDNNのバージョンもぴったし合わせないといけない、みたいで
一応動いたけど、どうやらAutokerasは余裕でTF2.3とか要求してくるから
なんやねんって思った。それで結局Autokerasは動かせんかったけど、よくよく調べてみたら
TF2.0以降なら一緒になっているらしい。確かにTF1.15以下は個別になっている
とかいうのを見たが、ちょっと意味が分からんくて無視してた。アホ。tensorflow-gpuを入れたらtensorflowが上書きされるとかいうのを見たけど、
それはその当時の話なんだなと。まだ試してないけど、とりあえずTF2.3が動くように環境構築してみる。
あと、自分が使うバージョンの記事かどうかは確認します。
めちゃくちゃ時間無駄にしたけど勉強になりました。完
- 投稿日:2020-11-19T12:10:29+09:00
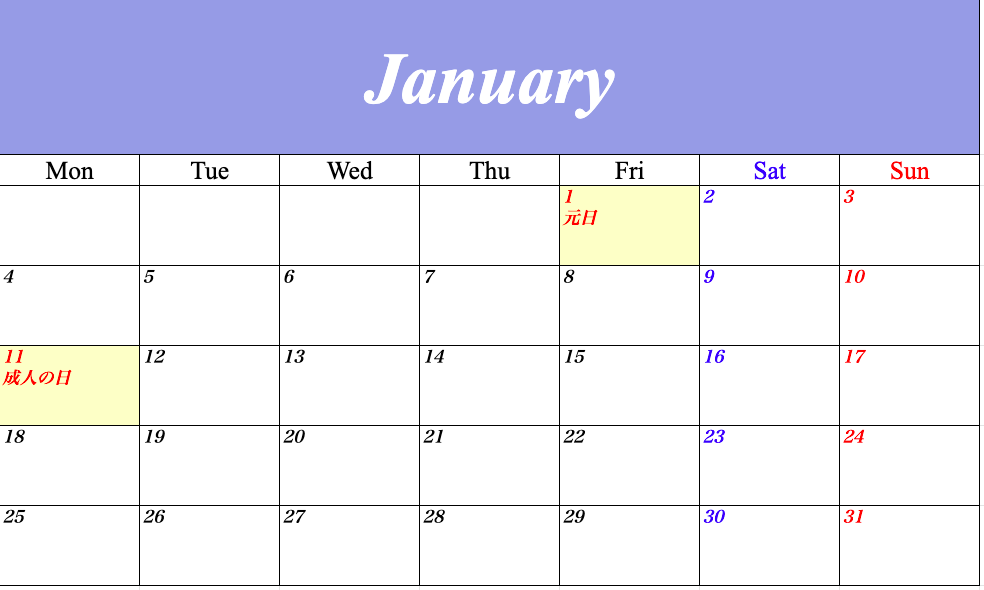
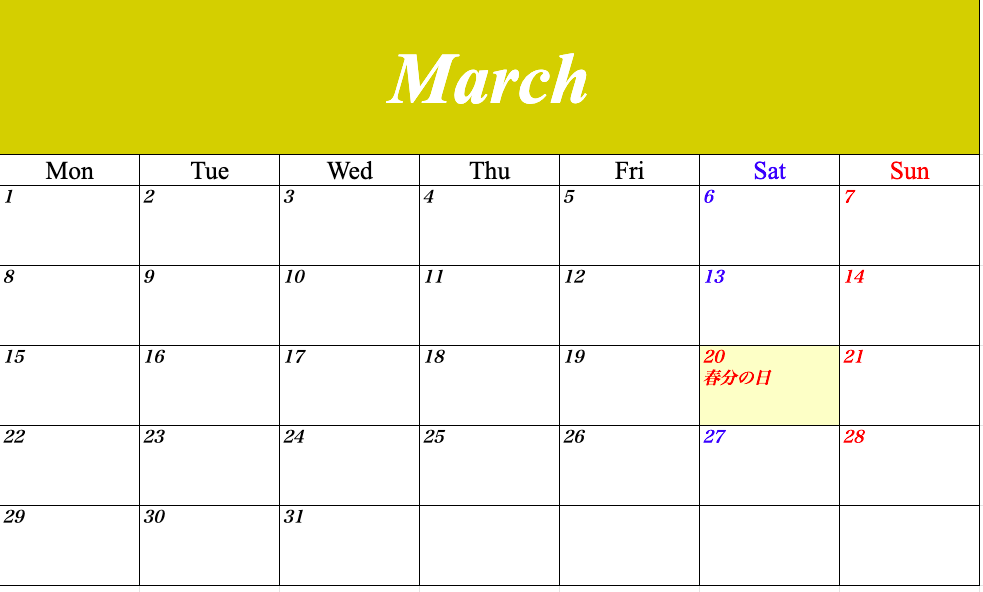
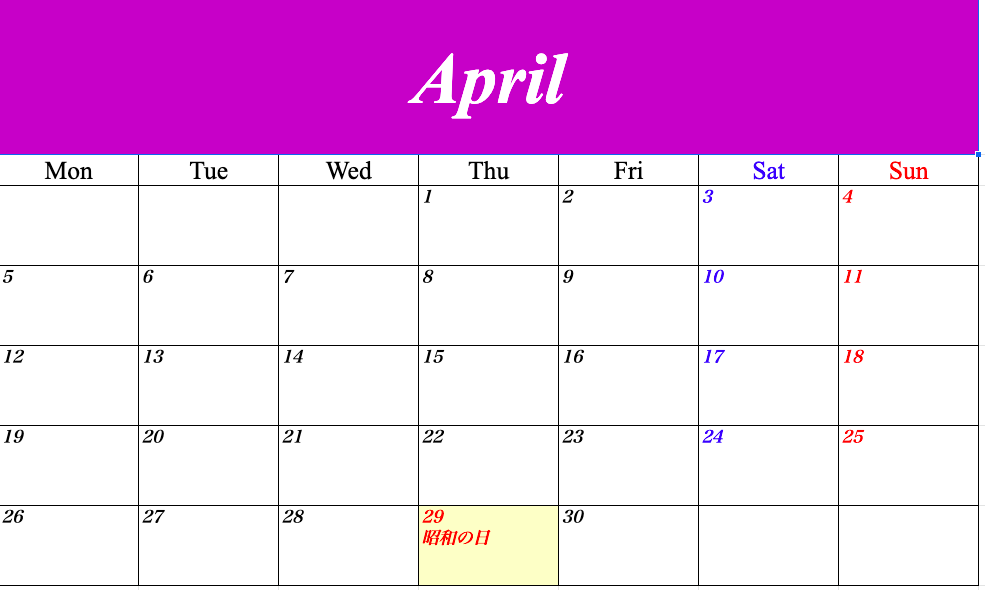
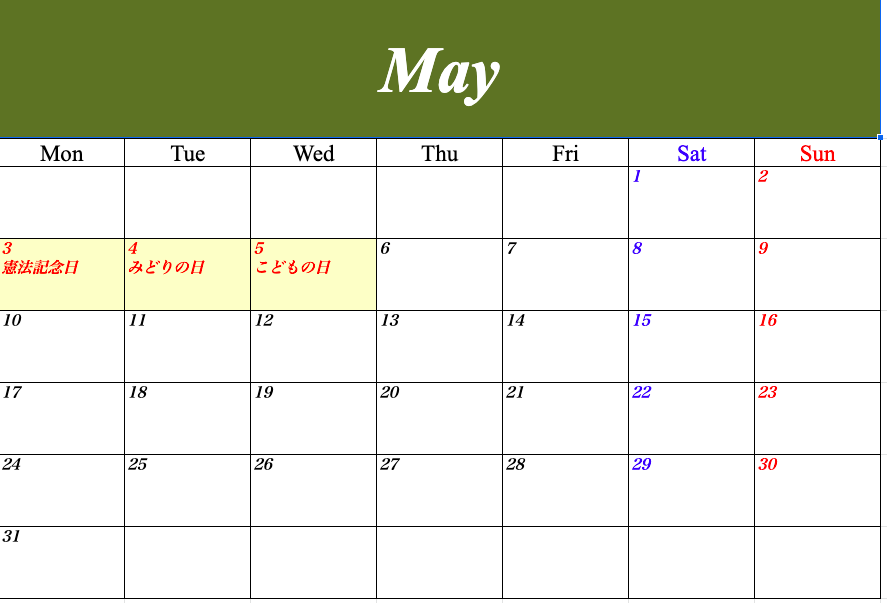
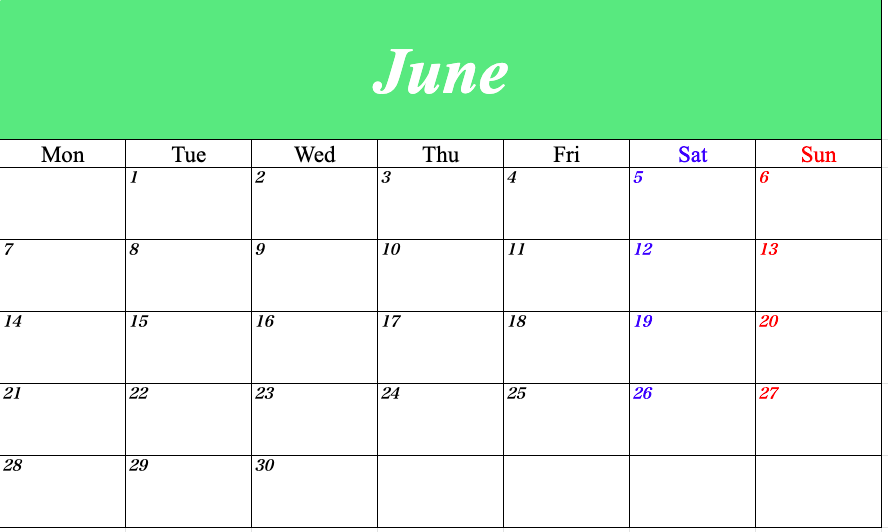
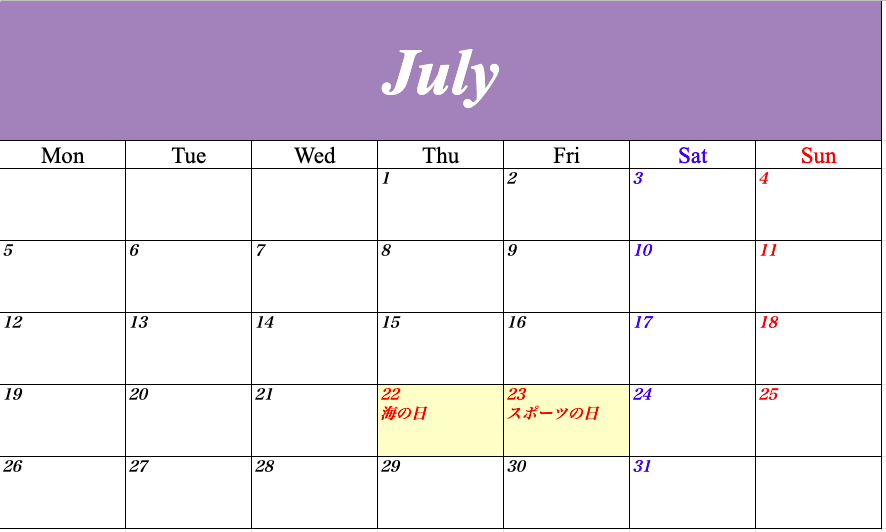
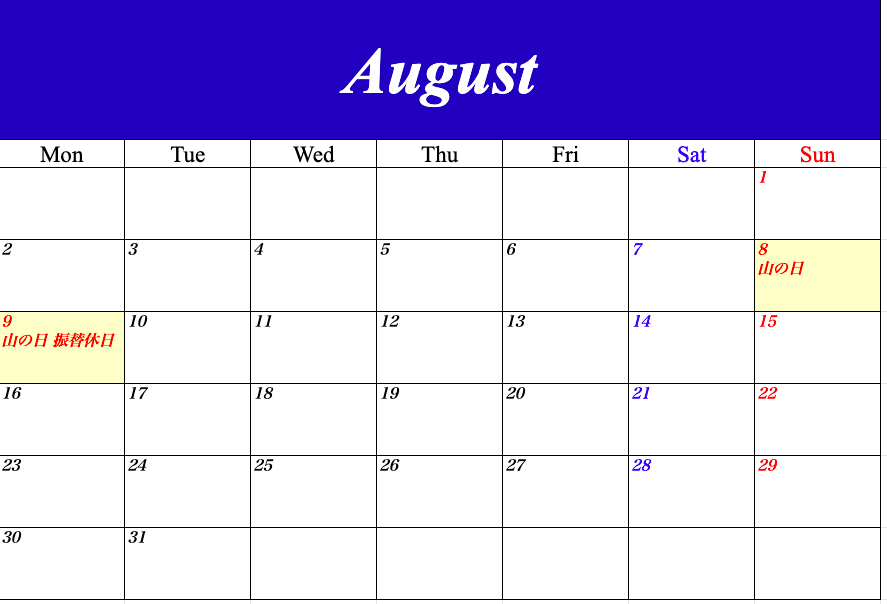
【Python】2021年のカレンダーをつくってみた【openpyxl】
はじめに
早いもので今年もあとわずか
ということで、Pythonを使ってExcelで2021年のカレンダーをつくってみました!
環境
言語はPython、環境はGoogle Colaboratoryを使用しました。
ライブラリのインストール
日本の祝日を扱うライブラリをインストールします。
!pip install jpholidayコード全体
※かなり汚いです。気が向いたら修正します。
import pandas as pd import datetime import random import calendar import jpholiday import openpyxl from openpyxl.styles import Font from openpyxl.styles import PatternFill from openpyxl.styles.alignment import Alignment from openpyxl.styles.borders import Border, Side from openpyxl.utils import get_column_letter def get_font_type(category): if category == 'month': font_type = Font(name='Times New Roman', size=70, color='ffffff', bold=True, italic=True) # 曜日 elif category == 'day': font_type = Font(name='Times New Roman', size=25, color='000000') elif category == 'sat': font_type = Font(name='Times New Roman', size=25, color='0000ff') elif category == 'sun': font_type = Font(name='Times New Roman', size=25, color='ff0000') # 日付 elif category == 'date': font_type = Font(name='ヒラギノ明朝 Pro', size=16, color='000000', bold=True, italic=True) elif category == 'date_hol': font_type = Font(name='ヒラギノ明朝 Pro', size=16, color='ff0000', bold=True, italic=True) elif category == 'date_sat': font_type = Font(name='ヒラギノ明朝 Pro', size=16, color='0000ff', bold=True, italic=True) elif category == 'date_sun': font_type = Font(name='ヒラギノ明朝 Pro', size=16, color='ff0000', bold=True, italic=True) return font_type def get_font_position(category): if category == 'month': font_position = Alignment(vertical='center', horizontal='center') # 曜日 elif category == 'day': font_position = Alignment(vertical='center', horizontal='center') elif category == 'sat': font_position = Alignment(vertical='center', horizontal='center') elif category == 'sun': font_position = Alignment(vertical='center', horizontal='center') # 日付 elif category == 'date': font_position = Alignment(vertical='top', horizontal='left') elif category == 'date_hol': font_position = Alignment(vertical='top', horizontal='left') elif category == 'date_sat': font_position = Alignment(vertical='top', horizontal='left') elif category == 'date_sun': font_position = Alignment(vertical='top', horizontal='left') return font_position def create_cell(category, row, col, val): # 罫線を引く side = Side(style='thin', color='000000') border = Border(top=side, bottom=side, left=side, right=side) ws.cell(row, col).border = border # フォントの種類、文字の位置を指定してセルに書き込み ws.cell(row, col).font = get_font_type(category) ws.cell(row, col).alignment = get_font_position(category) ws.cell(row, col).value = val # 必要に応じて、セルの行や列の幅調整、セルの結合、セルの色塗りつぶしをする if category == 'month': ws.row_dimensions[row].height = 146 ws.merge_cells('A1:G1') random_color = format(random.randrange(255), '02x') + format(random.randrange(255), '02x') + format(random.randrange(255), '02x') ws.cell(row, col).fill = PatternFill(patternType='solid', fgColor=random_color) elif category == 'date': ws.column_dimensions[get_column_letter(col)].width = 25 ws.row_dimensions[row].height = 75 elif category == 'date_sat': ws.column_dimensions[get_column_letter(col)].width = 25 ws.row_dimensions[row].height = 75 elif category == 'date_sun': ws.column_dimensions[get_column_letter(col)].width = 25 ws.row_dimensions[row].height = 75 elif category == 'date_hol': ws.column_dimensions[get_column_letter(col)].width = 25 ws.row_dimensions[row].height = 75 ws.cell(row, col).fill = PatternFill(patternType='solid', fgColor='ffffcc') ## main year = int(input('作成したいカレンダーの西暦を、数字4ケタで入力して下さい (例 2021)\n')) dir_path = '/path/to/file' file_name = dir_path + 'calendar_{}.xlsx'.format(year) # 新規ファイル作成 wb = openpyxl.Workbook() wb.save(file_name) # カレンダーの作成 c = calendar.Calendar(firstweekday=0) for month_number in range(1, 13): # シートの作成 month_name = calendar.month_name[month_number] ws = wb.create_sheet(title=month_name) ws = wb[month_name] # セルに記載 category = 'month' val = month_name row = 1 col = 1 create_cell(category, row, col, val) # 日の部分 # セルに記載 row += 1 for col in range(0, 7): category = 'sat' if col == 5 else 'sun' if col == 6 else 'day' val = calendar.day_abbr[col] # 曜日の略称(Sun, Satなど)を取得 col += 1 create_cell(category, row, col, val) for week in c.monthdays2calendar(year, month_number): row += 1 for col, date_day in enumerate(week): col += 1 date, day = date_day if date == 0: val = '' category = 'date' elif jpholiday.is_holiday_name(datetime.date(year, month_number, date)): val = str(date) + '\n' + jpholiday.is_holiday_name(datetime.date(year, month_number, date)) category = 'date_hol' else: val = str(date) category = 'date_sat' if day == 5 else 'date_sun' if day == 6 else 'date' create_cell(category, row, col, val) wb.save(file_name) # ファイルを保存実行
作成したいカレンダーの西暦を、数字4ケタで入力して下さい (例 2021)と表示されるので、好きな西暦4ケタを入力して下さい。
以下のようなカレンダーができるはずです!
各月ごとにシートが分かれています。
最後に
それでは皆さん、良いお年を〜





- 投稿日:2020-11-19T11:55:28+09:00
Redashのダッシュボード変更権限を付与
Redashのダッシュボードやクエリは、adminや所有者以外に変更することができません。
これは、同じグループに所属していようが変わりません。個別のユーザに変更権限を付与することはできるので、その方法を記載します。
環境
Redash 8.0.0+b32245 (a16f551e)
仕組み
Redash の
access_permissionsテーブルにレコードを追加することで実現できます。
PostgreSQLを直接触るのは嫌なので、AccessPermission.grantを使うことでレコードを追加します。ここでやること
あるユーザ(old_user)が保持するダッシュボードの変更権限を別のユーザ(new_user)へ付与する。
やりかた
Redash で shell を開く。
/opt/redashdocker-compose exec server ./manage.py shell以下をコピペする。
# # ./manage.py shell # from redash.models.users import AccessPermission, User from redash.models.base import db from redash.models import Dashboard from redash import permissions from contextlib import contextmanager old_user = User.get_by_id(5) new_user = User.get_by_id(2) def grant_dashboards(): all_dashboards = Dashboard.all( old_user.org, old_user.group_ids, old_user.id, ) not_exists_dashboards = not_exists_obj(all_dashboards) grant(not_exists_dashboards) def not_exists_obj(objects): return [ obj for obj in objects if not AccessPermission.exists(obj, permissions.ACCESS_TYPE_MODIFY, new_user) ] @contextmanager def grant(objects): try: for obj in objects: # !!! grantee == grantor AccessPermission.grant(obj, permissions.ACCESS_TYPE_MODIFY, new_user, new_user) db.session.commit() except Exception: db.session.rollback() raise grant_dashboards()grantorをnew_userにしているが深い意味はない。
https://github.com/getredash/redash/blob/004bc7a2ac0de041907ab0b9b560151ea7057332/redash/models/users.py#L332ちなみに
クエリも前述したものと同等のことで実現することができる。
また、設定(/settings/organization)よりEnable experimental multiple owners supportを有効にすることで、クエリの編集画面よりユーザに権限付与することができる。
- 投稿日:2020-11-19T11:05:39+09:00
法令における「等」の登場回数とそのパターンを検証してみた
noteで書いた記事がそれなりに好評だったので、こちらにも転載させていただきます。
先日の日経記事で話題になった件について、金商法を素材にプログラム書いて検証してみました。結果は予想どおりという感じですが、よければご笑覧ください。しかし定義の抽出・識別はやっぱり難しい。。
— カルアパ (@lawyer_alpaca) November 17, 2020
法令における「等」の登場回数とそのパターンを検証してみた #note https://t.co/HRbQ99bNtf
11月11日の日経新聞に以下の記事(本件記事)が掲載されました。読めない方のために一言で雑に要約させていただくと、「法令には『等』が多用されており、それがルールを不明確にしている面がある」という内容です。
法律から「等」追放を 不明確でデジタル化阻む|日本経済新聞
https://www.nikkei.com/article/DGXMZO66041390Q0A111C2000000/本件記事に対してはいろいろツッコミたい点はあるのですが、私も含め多くの法律実務家が違和感を覚えるのは、「法令中で『等』が用いられるのは定義語や略称としてのケースが大半で、キャッチオール的な意味で用いられているケースはほとんどないのでは」という点かと思います。
といっても、これは肌感覚にすぎませんので、実際どうなのか検証してみたいと思います。ここしばらく法令データを解析に取り組んでいることもあり、個人的には興味のあるトピックです。
【目次】
検証の目的と手法
A: 前文・標題・目的規定の中に出現するパターン
B: 熟語の中に出現するパターン
C: 参照法令の法令名の中に出現するパターン
D: 下位規則への委任文言の中に出現するパターン
E: 定義語・略称の中に出現するパターン
最終的に残ったもの
まとめ検証の目的と手法
本件記事では金融商品取引法における「等」の出現回数(4,407回)に言及がありますので、本記事でも金融商品取引法を対象に検証します。
まず、本件記事の記者さんがどうやって「等」の出現回数・出現割合を調査したかですが、「租税特別措置法を文書作成ソフトに落とすとA4判で2650ページにもなる」というくだりから推測するに、おそらく、e-Govで表示した金商法の文字列データ(目次部分を除く)をWord等にコピペして「等」で検索したのでしょう(Wordなら総文字数も表示されるので出現割合も算出できますね)。実際にやってみると確かに4,407回になります。
とはいえ、上記手法ではこれ以上の処理はできませんので、金商法のXMLデータをプログラムで解析して検証することにします。言語はPythonを使用します。XMLデータはe-Govで入手できます(※)。
※ 11月18日12:00から11月24日9:00までメンテナンスのためサービス停止中のようです。
検証の対象は次のとおりです。
法令で用いられる「等」のうち、文字どおりの用法、つまり「キャッチオール的な意味で用いられているもの」がどのくらいあるか?
したがって、総出現回数の4,407回から「そうでない用法のもの」を除けばよいわけですが、この「そうでない用法のもの」にはいくつかの類型があります。詳細は後述しますが、先に列挙すると次のとおりです。
A : 前文・標題・目的規定の中に出現するパターン
B : 熟語の中に出現するパターン
C : 参照法令の法令名の中に出現するパターン
D : 下位規則への委任文言の中に出現するパターン
E : 定義語・略称の中に出現するパターンこれらを順に処理していき、それぞれの処理によりどのくらい「等」の出現回数が減っていくか、そして最終的にどういうものが残るか、を見ていくことにします。
A: 前文・標題・目的規定の中に出現するパターン
本件記事は、金商法第1条の目的規定には6回も「等」が出現すると述べています。しかし、一般に目的規定は実体的なルールを定めたものではなく、ここに「等」が出てきてもルールが不明確になるということはないはずです。というわけで、目的規定に出てくる「等」はカウントしないことにします。
同じ理由で、制定文や前文に出てくる「等」もカウントしません(そもそも金商法に制定文や前文はないですが)。
また、以下のようないわゆる標題も実体的ルールとは無関係ですので、この中に出てくる「等」もカウントしないことにします。
(組織再編成等)
第二条の三 この章において「組織再編成」とは、・・・この条件で実行すると、以下の結果になりました。
金融商品取引法 全文字数(目次除く): 774629 「等」の出現回数: 3935 全文字数に対する割合: 0.50799 %標題に含まれる「等」がそれなりにあるようで、最初の4,407個から500個近く減りました。でも、まだまだ先は長そうです。
B: 熟語の中に出現するパターン
本件記事でも言及されているとおり、「平等」「親等」といった熟語として「等」が出現するケースがあります。これは当然ノーカウントです。
「等」が用いられる熟語としては、とりあえずこのあたりを押さえておけば十分な気がします(およそ法令で使われそうにないものもありますが)。
この条件で実行すると、以下の結果になりました。
金融商品取引法 全文字数(目次除く): 774629 「等」の出現回数: 3870 全文字数に対する割合: 0.49959 %減ったような減ってないような。。熟語としての用例はそれほどない気がするので、まあこんなもんかなと思います。
C: 参照法令の法令名の中に出現するパターン
法令内で別の法令が参照されている場合に、参照先の法令名として「等」が含まれていることがあります。
(信託業務を営む場合等の特例等)
第三十三条の八 銀行、協同組織金融機関その他政令で定める金融機関が金融機関の信託業務の兼営等に関する法律第一条第一項の認可を受けた金融機関である場合における
上記のケースでは「金融機関の信託業務の兼営等に関する法律」でひとかたまりの固有名詞(参照先の法令名)になっているので、この中の「等」はカウントすべきではありません。この条件で実行すると、以下の結果になりました。
金融商品取引法 全文字数(目次除く): 774629 「等」の出現回数: 3772 全文字数に対する割合: 0.48694 %100個くらい減りましたね。金商法は他法令の参照箇所が多いので、さもありなんという感じです。しかし、まだ3,772個もありますね。
D: 下位規則への委任文言の中に出現するパターン
金商法をはじめとする専門的・技術的な色彩が強い法律では、法律レベルではルールの大枠のみを定め、詳細を「政令」や「内閣府令」といった下位規則に委ねている箇所(委任文言)が多数登場します。
こうした委任文言として、例えば、以下のような言い回し・表現が用いられることがあります。
(外国証券情報の提供又は公表)
第二十七条の三十二の二
2 ・・・ただし、当該有価証券に関する情報の取得の容易性、当該有価証券の保有の状況等に照らして公益又は投資者保護に欠けることがないものと認められる場合として内閣府令で定める場合は、この限りでない。(金融商品取引清算機関等による取引情報の保存及び報告)
第百五十六条の六十三 金融商品取引清算機関等・・・は、・・・清算集中等取引情報(前条各号に掲げる取引その他取引の状況等を勘案して内閣府令で定める取引に関する情報のうち、当該金融商品取引清算機関等が当該取引に基づく債務を負担した取引に係るものをいう。・・・)について・・・ここでの「等」は一見するとキャッチオール的な意味で使われているようにも見えます。しかし、これは委任先の省庁が具体的・詳細なルールを定める際は「●●等」を勘案・考慮して検討せよという意味にとどまり、その結果が政令・内閣府令という形で明確化されることになります。したがって、ここでの「等」は実体的ルールとしての意味を持つものではありません。
実際、上記例の「内閣府令で定める場合」は証券情報等の提供又は公表に関する内閣府令第13条で、「内閣府令で定める取引」は店頭デリバティブ取引等の規制に関する内閣府令第3条で、それぞれ明確化されています。
よって、委任文言の中に出てくる「等」はノーカウントとします。委任文言の書き方には種々のバリエーションがありそうですが、正規表現で対応できそうです。
この条件で実行すると、以下の結果になりました。
金融商品取引法 全文字数(目次除く): 774629 「等」の出現回数: 3502 全文字数に対する割合: 0.45209 %思ったよりは減った感じですが、やはりまだ3,500個もあります。
E: 定義語・略称の中に出現するパターン
最後の処理です。これはまさに冒頭で述べた問題意識そのものです。
定義語や略称の中で「等」が用いられる場合は、定義規定の中でその意味するところは明確になっているので、固有名詞に準じてノーカウントでよいでしょう。
コーディングの観点からは、法令中の定義・略称を漏れなく正確に抽出・識別するにはそれなりに複雑・緻密なロジックが必要になります。とりあえず金商法に限ればほぼ100%カバーできるものが書けた気がしますが、他の法令もカバーするにはさらなるブラッシュアップが必要になりそうです。
さて、この条件で実行すると・・・
金融商品取引法 全文字数(目次除く): 774629 「等」の出現回数: 8 全文字数に対する割合: 0.00103 %キタ―――(゚∀゚)―――― !!
一気に激減しました。「法令中で『等』が用いられるのは定義語や略称としてのケースが大半である」という肌感覚は客観的にも正しかったようです。
※ 各ステップにおける出現回数は処理の順番・組み合わせ等によって若干異なる可能性がありますが、金商法については、最終的にはこの8個に行き着くのではないかと思います。
最終的に残ったもの
最後に残った8箇所がどのようなものか見てみましょう。
第二条第八項
十七 社債、株式等の振替に関する法律・・・第二条第一項に規定する社債等の振替を行うために口座の開設を受けて社債等の振替を行うこと。第三十五条第二項
一 商品先物取引法第二条第二十一項に規定する商品市場における取引等に係る業務第七十九条の三十四第1項
四 会員に関する事項(業務の種類に関する特別の事由等により会員の加入を制限する場合は、当該特別の事由等を含む。)附則(昭和五八年一二月二日法律第七八号)第二項
この法律の施行の日の前日において法律の規定により置かれている機関等・・・に関し必要となる・・・経過措置は、政令で定めることができる。附則(平成四年六月五日法律第七三号)第九条
・・・証券取引所の施行日前にした・・・会員又は発行者が施行日前に旧証券取引法第百五十五条第一項第一号の定款等に違反した場合における当該証券取引所の同号の怠る行為については、なお従前の例による。附則(平成一三年六月二七日法律第七五号)第一条
この法律は、平成十四年四月一日(以下「施行日」という。)から施行し、施行日以後に発行される短期社債等について適用する。この中の「等」が含まれる用語には、定義こそされていないものの、「●●に規定する」「●●条の」といった**外延を画する文言*が付されたものが見られます。したがって、純粋にキャッチオール的な意味で「等」を用いているケースは、8個よりもさらに少ないと言えそうです。
まとめ
以上により、「法令中で『等』が用いられるのは定義語や略称としてのケースが大半で、キャッチオール的な意味で用いられているケースはほとんどない」という肌感覚は(少なくとも金商法に関しては)客観的にも正しかったといえそうです。
では、本件記事の問題提起がまったく的外れだったかというと、私自身はそうは思いません。「●●等」という定義の仕方は、複雑・長大な法概念を変数に格納し、他の条文からの参照を容易にするという点で便利な立法技術ですが、その定義語がどこでどう定義されているのかが容易に分からなければ、全体を仔細に読めば明確なルールになっていても、パッとみてルールの内容が分かりにくいという点は変わらないように思われるからです。林修三先生の本にも次のような一節がありました。
なるほど「等」の字がついていることによって、何か他のものが含まれていることはわかるが、その「等」の示すものが何であるかは、結局法令の内容をよく見ない限りはわからないわけで、親切さは、ある意味では中途半端に終わっているともいえるのである。(林修三著『法令用語の常識〔第3版〕』(日本評論社・1975年)174頁)
こうした課題感をプログラム(本記事で使用したような解析技術)で解決できないかというのが個人的な関心ごとですが、それについてはまた別の機会に書くかもしれません。
なお、今回改めて、金商法は複雑・難解ではあるけれども、極めて精緻に作られた法律であるとの印象を強くしました。こういう法律は人間が読むのはしんどいですが、少なくともプログラムでは処理しやすいですね。
- 投稿日:2020-11-19T10:33:16+09:00
Elasticsearchのsnapshot取得してリストア(復元)するまで
Amazon Elasticsearch Service(以後esと記載)のsnapshotを取得する際、権限まわりで詰まったので、まとめてみる。
利用環境はMacです。【背景】
- esのsnapshotを手動で取得するのってどんな方法でできるんだろう。
- なんかちょっと権限まわりややこしそうだから一回触ってみよう
- 取得と復元でどれぐらい時間がかかるかもできたら測ってみよう
こんな課題感で手を動かし始めました。
【実際にやったこと】
- 公式ドキュメントを参考にする
- 【Amazon Elasticsearch Service】 手動スナップショットからリストアする方法を参考にする(この記事を本当に参考にさせていただきました)
- Kibanaでアクセス許可を与える
このような手順で実現させて行きました!!!
手動でS3にsnapshotを取得していく
手動でsnapshotを作成するためには、前提として、以下の対応が必要になります。
- s3のバケットの作成
- IAMロール、ポリシーを整理する(←ここで苦労しました)
- Kibanaでの認証
- 手動snapshotのリポジトリを登録する
- 手動snapshotを取得する
- snapshotを取得したリポジトリを確認する
- snapshotの取得状況を確認する
- スナップショットのリストア
- 一度インデックスを削除する
- 指定したインデックスをリストアする
今回記述しているscriptはpythonで書いていますが、他にもJava, Ruby, Node, Goでも記述できます。こちらの公式ドキュメントを参考にしてください
それでは順番に説明していきたいと思います。
S3バケットの作成
手動でsnapshotを保存するためのバケットを作成する。
今回はS3コンソールでarn:aws:s3:::test-es-snapshotを作成した。これは以下の二つの箇所で必要になる
- IAMロールにアタッチされたIAMポリシーのResource Statement内
- snapshotリポジトリ登録に使用するpythonのpayload内
IAMロール、ポリシーを整理する
今回確認すべき箇所は三箇所
1.ESのサービスロール(arn:aws:iam::ユーザ名:role/es_s3_role)を作成する。
信頼関係を以下のように編集する
principalで指定するのは"誰がこのロールを引き受けるか”ということ
以下のServiceはesを示しており、「作成したサービスロールはesを引き受ける」という意味(だと思う。)サービスロールの信頼関係に記載{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" }] }2.S3に対してアクセスし、データを取得するためのポリシーをサービスロールに対してアタッチする
create-es-backup-policyという管理ポリシーを以下の内容で作成し、上で作成したサービスロールに対してアタッチする
create-es-backup-policy(作成したサービスロールに対してアタッチする){ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot/*" ] } ] }3.Kibana側でIAMロールのアクセスを許可する
Kibana で、[Security (セキュリティ)]、[Role Mappings (ロールのマッピング)]、[Add (追加)] の順に選択します。[Role (ロール)]で、[manage_snapshots] を選択します。次に、IAM ユーザーまたは IAM ロールの ARN を該当するフィールドに指定します。ユーザーの ARN は、[Users (ユーザー)]セクションに入力します。ロールの ARN は、[Backend roles (バックエンドロール)] セクションに入力します。(※これで、スナップショットを使用するためのロール情報のアクセス許可を付与する)
今回はKibanaのRole MappingsというページのBackend Rolesというところに、作成したサービスロールのARN情報を入力した。
(IAMのポリシーの操作でも認証情報は設定できるはずだが、エラーで詰まったのでこの手法で回避した)以上で、IAMロール周りの整理は終わりです。
手動snapshotのリポジトリを登録する
以下のpythonスクリプトを実行する(参考資料では認証をアクセスキーで行っていたが、現在公式からアクセスキーでの認証は、推奨されていない)
register-repositry.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # Register repository path = '_snapshot/test-es-snapshot' # the Elasticsearch API endpoint url = host + path payload = { "type": "s3", "settings": { "bucket": "バケット名", "region": "リージョン名", "role_arn": "作成したサービスロール名" } } headers = {"Content-Type": "application/json"} r = requests.put(url, auth=awsauth, json=payload, headers=headers) print(r.status_code) print(r.text)responseが以下のようになっていることを確認する
200 {"acknowledged":true}手動snapshotを取得する
snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1' # the Elasticsearch API endpoint url = host + path r = requests.put(url, auth=awsauth) print(r.text)実行例-> % python snapshot.py Enter MFA code for : {"accepted":true}snapshotを取得したリポジトリを確認する
check_repository.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_repository.py Enter MFA code for : { "cs-automated-enc" : { "type" : "s3" }, "test-es-snapshot" : { "type" : "s3", "settings" : { "bucket" : "test-es-snapshot", "region" : "リージョン名", "role_arn" : "作成したサービスロール名" } } }snapshotの取得状況を確認する
check_snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/_all?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_snapshot.py Enter MFA code for : { "snapshots" : [ { "snapshot" : "my-snapshot-1", "uuid" : "*************", "version_id" : ******, "version" : "7.8.0", "indices" : [ "index名①", "index名②", ・・・・・・ ], "include_global_state" : true, "state" : "SUCCESS", "start_time" : "2020-11-17T07:20:17.265Z", "start_time_in_millis" : 1605597617265, "end_time" : "2020-11-17T07:21:21.901Z", "end_time_in_millis" : 1605597681901, "duration_in_millis" : 64636, "failures" : [ ], "shards" : { "total" : 38, "failed" : 0, "successful" : 38 } } ] }スナップショットのリストア
リストアの際に同じ名前のインデックスがある場合、リストアできないので、リストアしたいインデックスを一度削除する必要があります。
指定のインデックスを一度削除して、リストアするまでの手順を示します。一度インデックスを削除する
delete_index.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # DELETE INDEX path = 'インデックス名' url = host + path r = requests.delete(url, auth=awsauth) print(r.text)実行例-> % python delete_index.py Enter MFA code for : {"acknowledged":true}esのコンソールで、ドメインを選択し、インデックスタブに行くと、インデックスが削除できていることを確認できます。
また、ダッシュボードで、検索可能なドキュメントが少なくなっていることも確認できます。指定したインデックスをリストアする
restore_one.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1/_restore' url = host + path payload = {"indices": "インデックス名"} headers = {"Content-Type": "application/json"} r = requests.post(url, auth=awsauth, json=payload, headers=headers) print(r.text)実行例-> % python restore_one.py Enter MFA code for : {"accepted":true}まとめ
snapshotの取得やリストアは参考資料がとても役に立ちました。(ほとんど同じです。)
IAMのロールやポリシーの整理をするときに、結構苦労しました。。。
どのロールにどのポリシーをアタッチしたとかをしっかり整理できてないと厳しかったです。。どなたかの参考になれば幸いです。。
- 投稿日:2020-11-19T10:33:16+09:00
Amazon Elasticsearch serviceのsnapshot取得してリストア(復元)するまで
Amazon Elasticsearch Service(以後esと記載)のsnapshotを取得する際、権限まわりで詰まったので、まとめてみる。
利用環境はMacです。【背景】
- esのsnapshotを手動で取得するのってどんな方法でできるんだろう。
- なんかちょっと権限まわりややこしそうだから一回触ってみよう
- 取得と復元でどれぐらい時間がかかるかもできたら測ってみよう
こんな課題感で手を動かし始めました。
【実際にやったこと】
- 公式ドキュメントを参考にする
- 【Amazon Elasticsearch Service】 手動スナップショットからリストアする方法を参考にする(この記事を本当に参考にさせていただきました)
- Kibanaでアクセス許可を与える
このような手順で実現させて行きました!!!
手動でS3にsnapshotを取得していく
手動でsnapshotを作成するためには、前提として、以下の対応が必要になります。
- s3のバケットの作成
- IAMロール、ポリシーを整理する(←ここで苦労しました)
- Kibanaでの認証
- 手動snapshotのリポジトリを登録する
- 手動snapshotを取得する
- snapshotを取得したリポジトリを確認する
- snapshotの取得状況を確認する
- スナップショットのリストア
- 一度インデックスを削除する
- 指定したインデックスをリストアする
今回記述しているscriptはpythonで書いていますが、他にもJava, Ruby, Node, Goでも記述できます。こちらの公式ドキュメントを参考にしてください
それでは順番に説明していきたいと思います。
S3バケットの作成
手動でsnapshotを保存するためのバケットを作成する。
今回はS3コンソールでarn:aws:s3:::test-es-snapshotを作成した。これは以下の二つの箇所で必要になる
- IAMロールにアタッチされたIAMポリシーのResource Statement内
- snapshotリポジトリ登録に使用するpythonのpayload内
IAMロール、ポリシーを整理する
今回確認すべき箇所は三箇所
1.ESのサービスロール(arn:aws:iam::ユーザ名:role/es_s3_role)を作成する。
信頼関係を以下のように編集する
principalで指定するのは"誰がこのロールを引き受けるか”ということ
以下のServiceはesを示しており、「作成したサービスロールはesを引き受ける」という意味(だと思う。)サービスロールの信頼関係に記載{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" }] }2.S3に対してアクセスし、データを取得するためのポリシーをサービスロールに対してアタッチする
create-es-backup-policyという管理ポリシーを以下の内容で作成し、上で作成したサービスロールに対してアタッチする
create-es-backup-policy(作成したサービスロールに対してアタッチする){ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot/*" ] } ] }3.Kibana側でIAMロールのアクセスを許可する
Kibana で、[Security (セキュリティ)]、[Role Mappings (ロールのマッピング)]、[Add (追加)] の順に選択します。[Role (ロール)]で、[manage_snapshots] を選択します。次に、IAM ユーザーまたは IAM ロールの ARN を該当するフィールドに指定します。ユーザーの ARN は、[Users (ユーザー)]セクションに入力します。ロールの ARN は、[Backend roles (バックエンドロール)] セクションに入力します。(※これで、スナップショットを使用するためのロール情報のアクセス許可を付与する)
今回はKibanaのRole MappingsというページのBackend Rolesというところに、作成したサービスロールのARN情報を入力した。
(IAMのポリシーの操作でも認証情報は設定できるはずだが、エラーで詰まったのでこの手法で回避した)以上で、IAMロール周りの整理は終わりです。
手動snapshotのリポジトリを登録する
以下のpythonスクリプトを実行する(参考資料では認証をアクセスキーで行っていたが、現在公式からアクセスキーでの認証は、推奨されていない)
register-repositry.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # Register repository path = '_snapshot/test-es-snapshot' # the Elasticsearch API endpoint url = host + path payload = { "type": "s3", "settings": { "bucket": "バケット名", "region": "リージョン名", "role_arn": "作成したサービスロール名" } } headers = {"Content-Type": "application/json"} r = requests.put(url, auth=awsauth, json=payload, headers=headers) print(r.status_code) print(r.text)responseが以下のようになっていることを確認する
200 {"acknowledged":true}手動snapshotを取得する
snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1' # the Elasticsearch API endpoint url = host + path r = requests.put(url, auth=awsauth) print(r.text)実行例-> % python snapshot.py Enter MFA code for : {"accepted":true}snapshotを取得したリポジトリを確認する
check_repository.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_repository.py Enter MFA code for : { "cs-automated-enc" : { "type" : "s3" }, "test-es-snapshot" : { "type" : "s3", "settings" : { "bucket" : "test-es-snapshot", "region" : "リージョン名", "role_arn" : "作成したサービスロール名" } } }snapshotの取得状況を確認する
check_snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/_all?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_snapshot.py Enter MFA code for : { "snapshots" : [ { "snapshot" : "my-snapshot-1", "uuid" : "*************", "version_id" : ******, "version" : "7.8.0", "indices" : [ "index名①", "index名②", ・・・・・・ ], "include_global_state" : true, "state" : "SUCCESS", "start_time" : "2020-11-17T07:20:17.265Z", "start_time_in_millis" : 1605597617265, "end_time" : "2020-11-17T07:21:21.901Z", "end_time_in_millis" : 1605597681901, "duration_in_millis" : 64636, "failures" : [ ], "shards" : { "total" : 38, "failed" : 0, "successful" : 38 } } ] }スナップショットのリストア
リストアの際に同じ名前のインデックスがある場合、リストアできないので、リストアしたいインデックスを一度削除する必要があります。
指定のインデックスを一度削除して、リストアするまでの手順を示します。一度インデックスを削除する
delete_index.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # DELETE INDEX path = 'インデックス名' url = host + path r = requests.delete(url, auth=awsauth) print(r.text)実行例-> % python delete_index.py Enter MFA code for : {"acknowledged":true}esのコンソールで、ドメインを選択し、インデックスタブに行くと、インデックスが削除できていることを確認できます。
また、ダッシュボードで、検索可能なドキュメントが少なくなっていることも確認できます。指定したインデックスをリストアする
restore_one.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1/_restore' url = host + path payload = {"indices": "インデックス名"} headers = {"Content-Type": "application/json"} r = requests.post(url, auth=awsauth, json=payload, headers=headers) print(r.text)実行例-> % python restore_one.py Enter MFA code for : {"accepted":true}まとめ
snapshotの取得やリストアは参考資料がとても役に立ちました。(ほとんど同じです。)
IAMのロールやポリシーの整理をするときに、結構苦労しました。。。
どのロールにどのポリシーをアタッチしたとかをしっかり整理できてないと厳しかったです。。どなたかの参考になれば幸いです。。
- 投稿日:2020-11-19T10:22:43+09:00
Apple Silicon で psycopg2 (python3用pgsqlライブラリ) をインストール
Apple Silicon psycopg2 インストール作業メモ 2020/11/19
1, python3,pip3はos(Big Sur 11.1beta)バンドルのものを使う
$ which python3
/usr/bin/python3$ python3 -V
Python 3.8.2pip3は直接呼び出すとwarning出るので回避
alias pip3='/usr/bin/python3 -m pip'$ pip3 -V
pip 20.2.4 from /Users/myname/Library/Python/3.8/lib/python/site-packages/pip (python 3.8)2, Postgresqlをインストール
$ cd ~
$ wget https://ftp.postgresql.org/pub/source/v12.5/postgresql-12.5.tar.bz2
$ tar xvfz <上のファイル>
$ cd pgsql
$ ./configure
$ make
$ sudo make install
$ vi ~/.zshrc
export PATH=/usr/local/pgsql/bin:$PATHライブラリを使いたいだけなのでユーザなどは作らない
3, Opensslをインストール
$ cd ~
$ git clone git://git.openssl.org/openssl.git
$ cd openssl
$ vi Configurations/10-main.conf1618 "darwin64-arm64-cc" => { inherit_from => [ "darwin64-arm64" ] }, # "His toric" alias
1619 "darwin64-arm64" => {
1620 inherit_from => [ "darwin-common" ],
1621 CFLAGS => add("-Wall"),
1622 cflags => add("-arch arm64"),
1623 lib_cppflags => add("-DL_ENDIAN"),
1624 bn_ops => "SIXTY_FOUR_BIT_LONG",
1625 asm_arch => 'aarch64_asm',
1626 perlasm_scheme => "macosx", <----- ここを ios から macosxに書き換える
1627 },$ ./Configure darwin64-x86_64-cc --prefix="/usr/local/openssl-arm"
$ make
$ make test
$ sudo make install$ vi ~/.zshrc
export LIBRARY_PATH=/usr/local/openssl-arm/lib:$LIBRARY_PATH
$ source ~/.zshrc4, psycopg2をインストール
$ pip3 install psycopg2以上
- 投稿日:2020-11-19T10:19:32+09:00
DjangoでREST APIを作成する場合に使えるライブラリ
はじめに
DjangoでREST APIを作成する際に必要,便利なフレームワークまたはライブラリに関する記事です。
Djangoで各ライブラリを使用するには、インストールをしてsettings.pyを編集する必要があります。
※settings.pyとはDjangoプロジェクト作成時に自動生成されるファイルでミドルウェアやライブラリなどの設定を行うものです。
今回は各ライブラリの紹介と環境構築方法をまとめました。
間違いなどありましたら容赦無くご指摘ください。それでは見ていきましょう!!
必要、便利なフレームワーク(ライブラリ)
Django
Webフレームワーク。
Webアプリケーションに必要なありとあらゆるモジュールが用意されています。
例えばディレクトリのパスやデータベースを楽に扱うなどなど。
これがないと始まらない。インストール方法
terminal$ pip install djangoDjango Rest framework
REST APIに必要なモジュールの集まり。
DBのデータをJSON形式に変換する機能などなど。
挙げ出したらキリないです。
これも必須。インストール方法
terminal$ pip install djangorestframeworksettings.py
settings.pyINSTALLED_APPS = [ 'rest_framework', ]以上のようにINSTALLED_APPSに1行追加する。
INSTALLED_APPS
アプリケーションを定義することで、djangoに認識させることができます。
マイグレーションファイル作成時などに利用されるパラメータ。以降INSTALLED_APPSの説明は省略します。
SimpleJwt
JWT(Json Web Token)はデータの改ざんを検知できます。
主に認証トークンで使われる。
セキュリティの範疇なので地味ですが、ポートフォリオでもちゃんと使った方がいいと思います。インストール方法
$ pip install djangorestframework-simplejwtsettings.py
settings.pyfrom datetime import timedelta REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': [ 'rest_framework.permissions.IsAuthenticated', ], 'DEFAULT_AUTHENTICATION_CLASSES':[ 'rest_framework_simplejwt.authentication.JWTAuthentication', ], } SIMPLE_JWT = { 'AUTH_HEADER_TYPES':('JWT'), 'ACCESS_TOKEN_LIFETIME':timedelta(minutes=30), }REST_FRAMEWORK
API用のライブラリを定義することでdjangorestframeworkに認識させる。
DEFAULT_PERMISSION_CLASSES
アクセス許可を判断するクラスを指定する。
DEFAULT_AUTHENTICATION_CLASSES
認証に使うクラスを指定する。
rest_framework.permissions.IsAuthenticated
全てのリクエストに対してリクエストが必要。
rest_framework_simplejwt.authentication.JWTAuthentication
SIMPLEJWTを定義。
SIMPLE_JWT
SIMPLE JWTに関する設定を行うことができる。
AUTH_HEADER_TYPES
トークンを指定できる。今回はJWTを指定。
ACCESS_TOKEN_LIFETIME
トークンの持続時間を設定。timedeltaオブジェクトは日時の加算減算を行う。djoser
djangoのサードパーティーモジュール。
登録、ログイン、ログアウト、パスワードリセットなど認証周りをサポートしてくれるモジュール。
名前の雰囲気の通り、django専用なのでdjangoのRESTAPIでしか動きません。インストール方法
$ pip install djosersettings.py
settings.pyINSTALLED_APPS = [ 'djoser', ]pillow
画像処理ライブラリ。画像を扱うときに使います。
リサイズや回転など簡単な処理を楽に行える。
顔認証など高度な処理はできませんので注意。インストール方法
$ pip install pillowCORS
フロント側からのアクセス制御を行うライブラリ。
例えばリクエスト元を制限する機能など。
日本語にするとオリジン間リソース共有。インストール方法
$ pip install django-cors-headerssettings.py
settings.pyINSTALLED_APPS = [ 'corsheaders', ] MIDDLEWARE = [ #django.middleware.common.CommonMiddlewareより上に書く。 'corsheaders.middleware.CorsMiddleware', ] CORS_ORIGIN_WHITELIST=[ #許可するオリジン "http://localhost:3000" ]MIDDLEWARE
ミドルウェアの一覧を定義することで、HTTP処理後にdjangoが順次実行する。順次なので書く順番は大事です。
CORS_ORIGIN_WHITELIST
許可するオリジンを定義することで、他のリクエストは弾いてくれます。最後に
これらを使えば汎用的にRESTAPIを実装できると思います。
他に必要,便利なライブラリがありましたらご指摘のほどよろしくお願い致します。
また、これらの開発環境の構築は仮想環境を想定しています。
仮想環境の構築方法が気になる方は以下の記事からさくっと構築してみてください。
Anacondaで仮想環境を作り、PyCharmと連携する。
最後まで読んでいただきありがとうございました。参考文献
- 投稿日:2020-11-19T10:19:32+09:00
REST APIの必須,便利ライブラリまとめ(Django)
はじめに
DjangoでREST APIを作成する際に必要,便利なフレームワークまたはライブラリに関する記事です。
Djangoで各ライブラリを使用するには、インストールをしてsettings.pyを編集する必要があります。
※settings.pyとはDjangoプロジェクト作成時に自動生成されるファイルでミドルウェアやライブラリなどの設定を行うものです。
今回は各ライブラリの紹介と環境構築方法をまとめました。
間違いなどありましたら容赦無くご指摘ください。それでは見ていきましょう!!
必要、便利なフレームワーク(ライブラリ)
Django
Webフレームワーク。
Webアプリケーションに必要なありとあらゆるモジュールが用意されています。
例えばディレクトリのパスやデータベースを楽に扱うなどなど。
これがないと始まらない。インストール方法
terminal$ pip install djangoDjango Rest framework
REST APIに必要なモジュールの集まり。
DBのデータをJSON形式に変換する機能などなど。
挙げ出したらキリないです。
これも必須。インストール方法
terminal$ pip install djangorestframeworksettings.py
settings.pyINSTALLED_APPS = [ 'rest_framework', ]以上のようにINSTALLED_APPSに1行追加する。
INSTALLED_APPS
アプリケーションを定義することで、djangoに認識させることができます。
マイグレーションファイル作成時などに利用されるパラメータ。以降INSTALLED_APPSの説明は省略します。
SimpleJwt
JWT(Json Web Token)はデータの改ざんを検知できます。
主に認証トークンで使われる。
セキュリティの範疇なので地味ですが、ポートフォリオでもちゃんと使った方がいいと思います。インストール方法
$ pip install djangorestframework-simplejwtsettings.py
settings.pyfrom datetime import timedelta REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': [ 'rest_framework.permissions.IsAuthenticated', ], 'DEFAULT_AUTHENTICATION_CLASSES':[ 'rest_framework_simplejwt.authentication.JWTAuthentication', ], } SIMPLE_JWT = { 'AUTH_HEADER_TYPES':('JWT'), 'ACCESS_TOKEN_LIFETIME':timedelta(minutes=30), }REST_FRAMEWORK
API用のライブラリを定義することでdjangorestframeworkに認識させる。
DEFAULT_PERMISSION_CLASSES
アクセス許可を判断するクラスを指定する。
DEFAULT_AUTHENTICATION_CLASSES
認証に使うクラスを指定する。
rest_framework.permissions.IsAuthenticated
全てのリクエストに対してリクエストが必要。
rest_framework_simplejwt.authentication.JWTAuthentication
SIMPLEJWTを定義。
SIMPLE_JWT
SIMPLE JWTに関する設定を行うことができる。
AUTH_HEADER_TYPES
トークンを指定できる。今回はJWTを指定。
ACCESS_TOKEN_LIFETIME
トークンの持続時間を設定。timedeltaオブジェクトは日時の加算減算を行う。djoser
djangoのサードパーティーモジュール。
登録、ログイン、ログアウト、パスワードリセットなど認証周りをサポートしてくれるモジュール。
名前の雰囲気の通り、django専用なのでdjangoのRESTAPIでしか動きません。インストール方法
$ pip install djosersettings.py
settings.pyINSTALLED_APPS = [ 'djoser', ]pillow
画像処理ライブラリ。画像を扱うときに使います。
リサイズや回転など簡単な処理を楽に行える。
顔認証など高度な処理はできませんので注意。インストール方法
$ pip install pillowCORS
フロント側からのアクセス制御を行うライブラリ。
例えばリクエスト元を制限する機能など。
日本語にするとオリジン間リソース共有。インストール方法
$ pip install django-cors-headerssettings.py
settings.pyINSTALLED_APPS = [ 'corsheaders', ] MIDDLEWARE = [ #django.middleware.common.CommonMiddlewareより上に書く。 'corsheaders.middleware.CorsMiddleware', ] CORS_ORIGIN_WHITELIST=[ #許可するオリジン "http://localhost:3000" ]MIDDLEWARE
ミドルウェアの一覧を定義することで、HTTP処理後にdjangoが順次実行する。順次なので書く順番は大事です。
CORS_ORIGIN_WHITELIST
許可するオリジンを定義することで、他のリクエストは弾いてくれます。最後に
これらを使えば汎用的にRESTAPIを実装できると思います。
他に必要,便利なライブラリがありましたらご指摘のほどよろしくお願い致します。
また、これらの開発環境の構築は仮想環境を想定しています。
仮想環境の構築方法が気になる方は以下の記事からさくっと構築してみてください。
Anacondaで仮想環境を作り、PyCharmと連携する。
最後まで読んでいただきありがとうございました。参考文献
- 投稿日:2020-11-19T10:19:32+09:00
【Python】REST APIの必須,便利ライブラリまとめ
はじめに
PythonでREST APIを作成する際に必要,便利なフレームワークまたはライブラリに関する記事です。
この記事ではPythonのwebフレームワークのDjangoを使います。
Flaskは別で出そうかなと考えています。
またDjangoで各ライブラリ,フレームワークを使用するには、インストールをしてsettings.pyを編集する必要があります。
※settings.pyとはDjangoプロジェクト作成時に自動生成されるファイルでミドルウェアやライブラリなどの設定を行うものです。
なので今回は各ライブラリの紹介と環境構築方法をまとめました。
間違いなどありましたら容赦無くご指摘ください。それでは見ていきましょう!!
Django
Webフレームワーク。
Webアプリケーションに必要なありとあらゆるモジュールが用意されています。
例えばディレクトリのパスやデータベースを楽に扱うなどなど。
これがないと始まらない。インストール方法
terminal$ pip install djangoDjango Rest framework
REST APIに必要なモジュールの集まり。
DBのデータをJSON形式に変換する機能などなど。
挙げ出したらキリないです。
これも必須。インストール方法
terminal$ pip install djangorestframeworksettings.py
settings.pyINSTALLED_APPS = [ 'rest_framework', ]以上のようにINSTALLED_APPSに1行追加する。
INSTALLED_APPS
アプリケーションを定義することで、djangoに認識させることができます。
マイグレーションファイル作成時などに利用されるパラメータ。以降INSTALLED_APPSの説明は省略します。
SimpleJwt
JWT(Json Web Token)はデータの改ざんを検知できます。
主に認証トークンで使われる。
セキュリティの範疇なので地味ですが、ポートフォリオでもちゃんと使った方がいいと思います。インストール方法
$ pip install djangorestframework-simplejwtsettings.py
settings.pyfrom datetime import timedelta REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': [ 'rest_framework.permissions.IsAuthenticated', ], 'DEFAULT_AUTHENTICATION_CLASSES':[ 'rest_framework_simplejwt.authentication.JWTAuthentication', ], } SIMPLE_JWT = { 'AUTH_HEADER_TYPES':('JWT'), 'ACCESS_TOKEN_LIFETIME':timedelta(minutes=30), }REST_FRAMEWORK
API用のライブラリを定義することでdjangorestframeworkに認識させる。
DEFAULT_PERMISSION_CLASSES
アクセス許可を判断するクラスを指定する。
DEFAULT_AUTHENTICATION_CLASSES
認証に使うクラスを指定する。
rest_framework.permissions.IsAuthenticated
全てのリクエストに対してリクエストが必要。
rest_framework_simplejwt.authentication.JWTAuthentication
SIMPLEJWTを定義。
SIMPLE_JWT
SIMPLE JWTに関する設定を行うことができる。
AUTH_HEADER_TYPES
トークンを指定できる。今回はJWTを指定。
ACCESS_TOKEN_LIFETIME
トークンの持続時間を設定。timedeltaオブジェクトは日時の加算減算を行う。djoser
djangoのサードパーティーモジュール。
登録、ログイン、ログアウト、パスワードリセットなど認証周りをサポートしてくれるモジュール。
名前の雰囲気の通り、django専用なのでdjangoのRESTAPIでしか動きません。インストール方法
$ pip install djosersettings.py
settings.pyINSTALLED_APPS = [ 'djoser', ]pillow
画像処理ライブラリ。画像を扱うときに使います。
リサイズや回転など簡単な処理を楽に行える。
顔認証など高度な処理はできませんので注意。インストール方法
$ pip install pillowCORS
フロント側からのアクセス制御を行うライブラリ。
例えばリクエスト元を制限する機能など。
日本語にするとオリジン間リソース共有。インストール方法
$ pip install django-cors-headerssettings.py
settings.pyINSTALLED_APPS = [ 'corsheaders', ] MIDDLEWARE = [ #django.middleware.common.CommonMiddlewareより上に書く。 'corsheaders.middleware.CorsMiddleware', ] CORS_ORIGIN_WHITELIST=[ #許可するオリジン "http://localhost:3000" ]MIDDLEWARE
ミドルウェアの一覧を定義することで、HTTP処理後にdjangoが順次実行する。順次なので書く順番は大事です。
CORS_ORIGIN_WHITELIST
許可するオリジンを定義することで、他のリクエストは弾いてくれます。最後に
これらを使えば汎用的にRESTAPIを実装できると思います。
他に必要,便利なライブラリがありましたらご指摘のほどよろしくお願い致します。
また、これらの開発環境の構築は仮想環境を想定しています。
仮想環境の構築方法が気になる方は以下の記事からさくっと構築してみてください。
Anacondaで仮想環境を作り、PyCharmと連携する。
最後まで読んでいただきありがとうございました。参考文献
- 投稿日:2020-11-19T09:41:47+09:00
mnistの数字たちをkerasで教師なし学習で分類する【オートエンコーダ編】
はじめに
教師なし学習は一般的に教師あり学習と比較すると精度が落ちますが、その代わりに様々なメリットがあります。具体的に教師なし学習が役に立つシーンとして
- パターンがあまりわかっていないデータ
- 時間的に変動するデータ
- 十分にラベルがついていないデータなどが挙げられます。
教師なし学習ではデータそのものから、データの背後にある構造を学習します。これによってラベルのついていないデータをより多く活用できるので、新たなアプリケーションへの道が開けるかもしれません。
前回、PCAとt-SNEを用いて教師なし学習で分類しました。
https://qiita.com/nakanakana12/items/af08b9f605a48cad3e4eでもやっぱ流行りのディープラーニング使いたいですよね、ってことで今回の記事では
オートエンコーダを使った教師なし学習
を行います。
オートエンコーダ自体の詳しい説明は省略します。参考文献をご参照ください。ライブラリのインポート
import keras import random import matplotlib.pyplot as plt from matplotlib import cm import seaborn as sns import pandas as pd import numpy as np import plotly.express as px import os from sklearn.decomposition import PCA from sklearn.cluster import KMeans from sklearn.metrics import confusion_matrix from sklearn.manifold import TSNE from keras import backend as K from keras.models import Sequential, Model, clone_model from keras.layers import Activation, Dense, Dropout, Conv2D,MaxPooling2D,UpSampling2D from keras import callbacks from keras.layers import BatchNormalization, Input, Lambda from keras import regularizers from keras.losses import mse, binary_crossentropy sns.set("talk")データの準備
mnistのデータをダウンロードして前処理を行います。
前処理では正規化とチャネル位置の調整をしています。fashion_mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() #正規化 train_images = (train_images - train_images.min()) / (train_images.max() - train_images.min()) test_images = (test_images - test_images.min()) / (test_images.max() - test_images.min()) print(train_images.shape,test_images.shape) #チャネル位置の調整 image_height, image_width = 28,28 train_images = train_images.reshape(train_images.shape[0],28*28) test_images = test_images.reshape(test_images.shape[0],28*28) print(train_images.shape, test_images.shape)オートエンコーダの作成
オートエンコーダのモデルを作成します。
コード数がめちゃくちゃ少なくて感動しました。ここでは36次元に圧縮するオートエンコーダを作成します。
全結合層を2つ繋げているのみで、一層目で36次元に圧縮、二層目でもとの大きさに戻す、という操作をしています。
つまり一層目がエンコーダ、二層目がデコーダになっています。ここは書き方なども普通の教師あり学習と同じですね。
model = Sequential() #エンコーダ model.add(Dense(36, activation="relu", input_shape=(28*28,))) #デコーダ model.add(Dense(28*28,activation="sigmoid")) model.compile(optimizer="adam",loss="binary_crossentropy") model.summary()オートエンコーダの学習
次にオートエンコーダを学習させます。
ここでのポイントとして、正解データはラベルではなく、画像データを用いているところです。
自分の環境では156epochで学習が完了しました。fit_callbacks = [ callbacks.EarlyStopping(monitor='val_loss', patience=5, mode='min') ] # モデルを学習させる # 正解データにtrain_imagesを用いる model.fit(train_images, train_images, epochs=200, batch_size=2024, shuffle=True, validation_data=(test_images, test_images), callbacks=fit_callbacks, )学習結果を確認してみます。損失が一定の値に収束しているのがわかりますね。
# テストデータの損失を確認 score = model.evaluate(test_images, test_images, verbose=0) print('test xentropy:', score) # テストデータの損失を可視化 score = model.evaluate(test_images, test_images, verbose=0) print('test xentropy:', score)
オートエンコーダのモデル作成
次に先程のモデルからエンコーダ部分のみを取り出してモデルを作ります。
#次元圧縮するモデル encoder = clone_model(model) encoder.compile(optimizer="adam", loss="binary_crossentropy") encoder.set_weights(model.get_weights()) #最後のレイヤーを削除 encoder.pop()取り出したオートエンコーダを使って、36次元のデータを可視化します。
中間層では36次元の画像となっていますが、出力層では元のデータが復元されているのがわかります。
なんだか不思議ですね。# テストデータから10点選んで可視化 p = np.random.randint(0, len(test_images), 10) x_test_sampled = test_images[p] # 選びだしたサンプルを AutoEncoder にかける x_test_sampled_pred = model.predict(x_test_sampled,verbose=0) # encoderのみにかける x_test_sampled_enc = encoder.predict(x_test_sampled,verbose=0) # 処理結果を可視化する fig, ax = plt.subplots(3, 10,figsize=[20,10]) for i, label in enumerate(test_labels[p]): # 元画像 img = x_test_sampled[i].reshape(image_height, image_width) ax[0][i].imshow(img, cmap=cm.gray_r) ax[0][i].axis('off') # AutoEncoder で次元圧縮した画像 enc_img = x_test_sampled_enc[i].reshape(6, 6) ax[1][i].imshow(enc_img, cmap=cm.gray_r) ax[1][i].axis('off') # AutoEncoder で復元した画像 pred_img = x_test_sampled_pred[i].reshape(image_height, image_width) ax[2][i].imshow(pred_img, cmap=cm.gray_r) ax[2][i].axis('off')
k-meansによる画像の分類
最後に36次元のデータを使ってk-meansによる分類を行います。
10個のクラスタに分類して、クラスタごとに最も多い数字を予測ラベルとしています。#次元削減したデータの作成 x_test_enc = encoder.predict(train_images) print(x_test_enc.shape) #k-menasによる分類 KM = KMeans(n_clusters = 10) result = KM.fit(x_test_enc) #混同行列による評価 df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) df_eval.columns = df_eval.idxmax() df_eval = df_eval.sort_index(axis=1) df_eval
混同行列を確認すると、上手に10個には分類できなかったようです。
ここで、各クラスターの画像を可視化してみます。
#クラスターから5つずつ画像を表示する fig, ax = plt.subplots(5,10,figsize=[15,8]) for col_i in range(10): idx_list = random.sample(set(np.where(result.labels_ == col_i)[0]), 5) ax[0][col_i].set_title("cluster:" + str(col_i), fontsize=12) for row_i, idx_i in enumerate(idx_list): ax[row_i][col_i].imshow((train_images[idx_i].reshape(image_height, image_width)), cmap=cm.gray_r) ax[row_i][col_i].axis('off')
各クラスターをみると、数字が異なっていても画像的に似たような特徴があることがわかります。
例えばcluster 0は太くて、cluster 4は細いなどの特徴がありますね。
このことからラベルだけで表されるデータではなく、画像そのものから上手に特徴をとってこれていることがわかります。ラベル外の情報で分類できるっていうのは面白いですね。新たなラベル付けなどができるということですもんね。
終わりに
今回はオートエンコーダを用いてmnistの数字を教師なし分類しました。
ラベルのデータ通りの分類はできなかったですが、クラスタを可視化するとラベル外の情報が浮き彫りになってきました。ラベル外の情報を手に入れることができるというのが教師なし学習のすごいところですね。
参考になりましたらLGTMなどしていただけると励みになります。
参考文献
オートエンコーダとは?事前学習の仕組み・現在の活用方法を解説!!
https://it-trend.jp/development_tools/article/32-0024KerasでAutoEncoder
https://qiita.com/fukuit/items/2f8bdbd36979fff96b07Python: Keras で AutoEncoder を書いてみる
https://blog.amedama.jp/entry/keras-auto-encoder
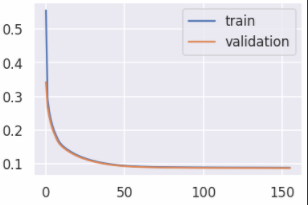
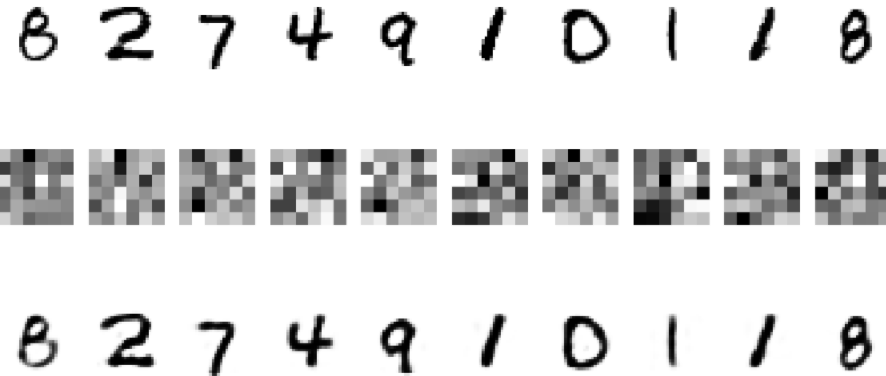


- 投稿日:2020-11-19T09:32:07+09:00
CycloneVSoCにOpenCVを組み込んでUSBカメラの映像をLinux Desktopに表示する
CycloneVSoCにOpenCVを組み込んでUSBカメラの映像をLinux Desktopに表示する
はじめに
Cyclone V SoCをつかった基板でAIの開発をする際、カメラ映像の取り込みはベースとなるので、自分への忘却録としても手順を記載したいと思います。
開発環境(Linux)
- クロスコンパイル環境: VirtualBox グラフィカルユーザーインターフェースバージョン 6.1.14 r140239 (Qt5.6.2)
- ゲストOS:Ubuntu18.04lts
- FPGAコンパイル環境:Quartus Prime Version 18.1.1 build 646
Linux Desktopの構築
こちらのサイトの7.6.2項までを参考に、Cyclone V SoCにLinux Desktopのインストールをします。
https://rocketboards.org/foswiki/Projects/OpenVINOForSoCFPGA手順は上記サイトを参考に、下記の変更を加えています。
- ツールチェーン:gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar.xz
- Linuxカーネル: socfpga-5.4.45-lts
- rootfs:linaro-stretch-developer-20170706-43.tar.gz
OpenCVのインストール
下記公式サイトを参考にインストールを進めていきます。
https://docs.opencv.org/4.4.0/d7/d9f/tutorial_linux_install.htmlツールのインストール
$ sudo apt-get install build-essential $ sudo sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev $ sudo apt-get install python-dev python-numpy libtbb2 libtbb5-dev libjpeg-dev libpng-dev libtiff-dev libdc1394-22-dev公式には、libtbb-devが指定してありましたが、パッケージが見つからなかったので代わりにlibtbb5-devを、libjasper-devは見つからなかったので省略します。
GitからOpenCVをチェックアウト
$ git clone https://github.com/opencv/opencv.git $ git clone https://github.com/opencv/opencv_contrib.gitOpenCVのビルド
$ cd ~/opencv $ mkdir build $ cd build $ cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local .. $ make -j2OpenCVのインストール
$ sudo make install正常にインストールされているか確認します。Pythonのインタラクティブコンソールを使えば確認できると思います。
$ Python3 >>> import cv2 >>>エラーが出ずにプロンプト>>>が返ってくれば正常にインストールされていると思います。
Pythonプログラム
previe.py#!/usr/bin/env python3 import cv2 cap = cv2.VideoCapture(0) while(True): ret, frame = cap.read() if not ret: break cv2.imshow(`preview`, frame) key = cv2.waitKey(1) if key == 27: # ESC break cap.release() cv2.destroyAllWindows()実行
下記でプログラムを実行すれば、カメラの映像がWindowに表示されます。
$ python3 previe.py
- 投稿日:2020-11-19T00:59:48+09:00
機械学習を用いてリアルタイムにギター のコードを分類してみた
目的
趣味でギターを引いていて,ギター音をAIが正しく識別できるか気になった
今回は通常のNeural Networkと簡単なCNNを用いてリアルタイムに9種類のコードを分類してみる環境
Pythonを使用する.以下のライブラリをインストールする.
・Pyaudio
・Chainer
・keras
・sklearn
・pandasアジェンダ
- 音波形の取得,フーリエ変換
- Neural Network
- CNN
- 今後の課題
1. 音波形の取得,フーリエ変換
リアルタイムで音声波形を取得し,フーリエ変換し正規化,結果をcsvファイルに書き込むプログラム
申し訳ないが,フーリエ変換に関しては専門外のためあまり詳しくない
プログラムも他の記事を参考にしたため勉強して使用した方が良いが,numpyで簡単にできるみたいですね
全てのコードの波形をcsvファイルに記録したら,ラベルをつけて1つのファイルに結合しておく
今回はC,D,G,A,Am,F,Fm,B,Bm, 無音状態 の10種類のスペクトルを分類するdata-kakikomi.pyimport pyaudio import numpy as np import matplotlib.pyplot as plt import math import csv CHUNK = 1024 RATE = 44100 #サンプリング周波数 P = pyaudio.PyAudio() stream = P.open(format=pyaudio.paInt16, channels=1, rate=RATE, frames_per_buffer=CHUNK, input=True, output=False) x = np.arange(1,1025,1) freq = np.linspace(0, RATE, CHUNK) #正規化 def min_max(x, axis=None): min = x.min(axis=axis, keepdims=True) max = x.max(axis=axis, keepdims=True) result = (x-min)/(max-min) return result o = open('fmcode.csv','a') #コードごとにファイルを変更する writer = csv.writer(o, lineterminator=',\n') while stream.is_active(): try: input = stream.read(CHUNK, exception_on_overflow=False) # bufferからndarrayに変換 ndarray = np.frombuffer(input, dtype='int16') #フーリエ変換 f = np.fft.fft(ndarray) #周波数 freq = np.fft.fftfreq(CHUNK, d=44100/CHUNK) Amp = np.abs(f/(CHUNK/2))**2 Amp = min_max(Amp) writer.writerow(Amp) print(Amp) #フーリエ変換後のスペクトルを表示 line, = plt.plot(freq[1:int(CHUNK/2)], Amp[1:int(CHUNK/2)], color='blue') plt.pause(0.01) plt.ylim(0,1) ax = plt.gca() ax.set_xscale('log') line.remove() except KeyboardInterrupt: break stream.stop_stream() stream.close() P.terminate() f.close() print('Stop Streaming')下の図のようにフーリエ変換後の波形が表示される
2. Neural Network
次にChainer(NN)を用いて学習モデルを作成する
chainer_NN.pyimport chainer from chainer import Chain, optimizers, iterators, training, datasets, Variable from chainer.training import extensions import chainer.functions as F import chainer.links as L import numpy as np import pandas as pd from chainer import serializers from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt #chainerによるニューラルネトワークのクラス class NN(Chain): def __init__(self, in_size, hidden_size, out_size): super(NN, self).__init__( xh = L.Linear(in_size, hidden_size), hh = L.Linear(hidden_size, hidden_size), hy = L.Linear(hidden_size, out_size) ) def __call__(self, x): h1 = F.sigmoid(self.xh(x)) #h1 = F.dropout(F.relu(self.xh(x)), train=train) h2 = F.sigmoid(self.hh(h1)) y = F.softmax(self.hy(h2)) return y #データ読み込み data1 = pd.read_csv("data.csv") X = data1.iloc[:, 0:1024] #140 #no_outline:106 Y = data1.iloc[:, 1025] #↑+2 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.1, random_state = 0) X_train = X_train.values Y_train = Y_train.values X_test = X_test.values Y_test = Y_test.values #chainerでデータを読み込む時に必要な部分 X_train = np.array(X_train.astype(np.float32)) Y_train = np.ndarray.flatten(np.array(Y_train.astype(np.int32))) X_test = np.array(X_test.astype(np.float32)) Y_test = np.ndarray.flatten(np.array(Y_test.astype(np.int32))) #各層のユニット数,エポック数 n_in_units = 1024 n_out_units = 10 n_hidden_units = 100 n_epoch = 3000 #決めたユニット数をニューラルネットワークに反映, model = L.Classifier(NN(in_size = n_in_units, hidden_size = n_hidden_units, out_size = n_out_units)) optimizer = optimizers.Adam() optimizer.setup(model) #訓練部分 print("Train") train, test = datasets.split_dataset_random(datasets.TupleDataset(X_train, Y_train), int(len(Y_train)*0.9)) train_iter = iterators.SerialIterator(train, int(len(Y_train)*0.9)) test_iter = iterators.SerialIterator(test, int(len(Y_train)*0.1), False, False) updater = training.StandardUpdater(train_iter, optimizer, device=-1) trainer = training.Trainer(updater, (n_epoch, "epoch"), out="result") trainer.extend(extensions.Evaluator(test_iter, model, device=-1)) trainer.extend(extensions.LogReport(trigger=(10, "epoch"))) # 10エポックごとにログ出力 trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy"])) #エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間 trainer.extend(extensions.ProgressBar()) # プログレスバー出力 trainer.run() #訓練部分で作成した学習済みモデルを保存 serializers.save_npz("model.npz", model) #テスト部分,結果出力 C_list1 = [] print("Test") print("y\tpredict") for i in range(len(X_test)): x = Variable(X_test[i]) y_ = np.argmax(model.predictor(x=x.reshape(1,len(x))).data, axis=1) y = Y_test[i] print(y+2, "\t", y_+2) C = y_ - y C_list1 = np.append(C_list1,C) A = np.count_nonzero(C_list1 == 0) p = A / (len(C_list1)) print(p)学習した結果を以下に示す.
0.6749311294765841通常のNNではあまり精度がよくない.
3. CNN
次にkeras(CNN)を用いて学習モデルを作成する
CNN.pyimport numpy as np #データの読み込みと前処理 from keras.utils import np_utils #kerasでCNN構築 from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras.optimizers import Adam from sklearn.model_selection import train_test_split import pandas as pd import time f_model = './model' #時間計測 import time correct = 10 data = pd.read_csv("data.csv") X = data.iloc[:, 0:1024] Y = data.iloc[:, 1025] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.1, random_state = 0) X_train = X_train.to_numpy() X_train = X_train.reshape(3264,32,32,1) X_train = X_train.astype('float32') Y_train = Y_train.to_numpy() Y_train = np_utils.to_categorical(Y_train, correct) X_test = X_test.to_numpy() X_test = X_test.reshape(363,32,32,1) X_test = X_test.astype('float32') Y_test = Y_test.to_numpy() Y_test = np_utils.to_categorical(Y_test, correct) model = Sequential() model.add(Conv2D(filters=10, kernel_size=(3,3),padding='same', input_shape=(32,32,1), activation='relu')) model.add(Conv2D(32,1,activation='relu')) model.add(Conv2D(64,1,activation='relu')) model.add(Flatten()) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy']) startTime = time.time() history = model.fit(X_train, Y_train, epochs=200, batch_size=100, verbose=1, validation_data=(X_test, Y_test)) score = model.evaluate(X_test, Y_test, verbose=0) print('Test Loss:{0:.3f}'.format(score[0])) print('Test accuracy:{0:.3}'.format(score[1])) #処理時間 print("time:{0:.3f}sec".format(time.time() - startTime)) json_string = model.to_json() model.save('model_CNN.h5')学習結果を以下に示す
Test Loss:0.389 Test accuracy:0.948 time:327.122sec正解率94.8%であり,だいぶよくなった
最後にCNNでリアルタイムにコードを分類してみる
code_detector.pyfrom keras.models import load_model import pyaudio import numpy as np import matplotlib.pyplot as plt import math CHUNK = 1024 RATE = 44100 #サンプリング周波数 P = pyaudio.PyAudio() stream = P.open(format=pyaudio.paInt16, channels=1, rate=RATE, frames_per_buffer=CHUNK, input=True, output=False) def min_max(x, axis=None): min = x.min(axis=axis, keepdims=True) max = x.max(axis=axis, keepdims=True) result = (x-min)/(max-min) return result model = load_model('model_CNN.h5') def detect(pred): a = ["C","D","G","Bm","B","","A","Am","F","Fm"] pred_label = a[np.argmax(pred[0])] score = np.max(pred) if pred_label != "": print(pred_label,score) while stream.is_active(): try: input = stream.read(CHUNK, exception_on_overflow=False) # bufferからndarrayに変換 ndarray = np.frombuffer(input, dtype='int16') line, = plt.plot(ndarray, color='blue') plt.pause(0.01) f = np.fft.fft(ndarray) Amp = np.abs(f/(CHUNK/2))**2 Amp = min_max(Amp) Amp = Amp.reshape(1,32,32,1) Amp = Amp.astype('float32') pred = model.predict(Amp) detect(pred) plt.ylim(-200,200) line.remove() except KeyboardInterrupt: break stream.stop_stream() stream.close() P.terminate() print('Stop Streaming')Cコードを弾いた時
C 1.0 C 1.0 C 1.0 C 1.0 C 1.0 C 1.0 C 1.0 C 1.0 C 1.0 C 0.99999833 C 1.0 C 0.9999988 C 1.0 C 1.0 C 1.0 G 0.98923177Dコードを弾いた時
D 0.9921374 D 1.0 D 1.0 D 1.0 D 1.0 D 1.0 D 0.99915206 Bm 0.9782265 D 1.0 D 0.967693 Bm 0.43872046 D 0.5228199 D 0.9998678 D 0.99264586Amコードを弾いた時
A 0.7428425 Am 0.98781455 Am 1.0 Am 1.0 Am 1.0 Am 1.0 Am 0.99081403 Am 0.9998661 Am 0.98926556 Am 0.9721039 Am 0.9999999 Am 0.99899584 A 0.7681879 Am 0.59727216 Am 0.77573067Fコードを弾いた時
Fm 0.54534096 F 1.0 F 0.4746885 F 0.99983275 F 0.9708171 F 1.0 F 0.9999441 F 0.99999964 C 0.50546944 F 0.9999746 F 1.0 F 1.0 F 0.9999999 F 0.966004 C 0.79529727 F 1.0 F 0.99999976Fmコードを弾いた時
Fm 0.9999492 Fm 1.0 Fm 1.0 Fm 0.99058926 Fm 1.0 Fm 0.99991775 Fm 0.9677996 F 0.96835506 Fm 1.0 Fm 0.9965939 Am 0.63923794 C 0.8398564 Fm 0.91774964 Am 0.9995415今後の課題
個人的にはFとFmが識別できていることに驚いたw
現状,音声データを主のギター でしか取得していため,他のギター や弾き手によって精度が落ちてしまう
さらにデータ数を増やしてモデルを作成することが今後の課題かなあ?
- 投稿日:2020-11-19T00:36:42+09:00
Blender でキーフレームごとに出力解像度を設定する方法
漫画の下書きに、 Blender のレンダー画像を使うことになりました。「1コマ=1キーフレーム」と対応させ、キーフレームごとのレンダー画像を漫画作成ソフトに貼り付けて使う想定です。
通常、漫画のコマは、1コマごとに縦横比が異なります。しかし、Blender ではキーフレームごとに解像度を設定することができません。すべてのキーフレームで同じ解像度にするか、1フレームずつ手動で切り替えるしかありません。どちらも不便です。
そこで、キーフレームごとに解像度を設定する方法を考えました。 Blender にはキーフレームに マーカー という文字列を設定できるので、そこに解像度の縦横比を記録することにしました。
なお、一般的な横読み漫画ではコマの縦横のサイズは不定ですが、今回は縦読み漫画であり、コマの横幅が常に 2480px で一定という想定です。縦横を同時に指定する方法は、末尾で補足しておきます。
実行環境
- Blender 2.90.1
やりたいこと
- "Scene > Dimensions > Resolution X&Y" を、キーフレームごとに設定・保持できるようにしたい
- X は 2480px 固定で、Y はキーフレームに設定された解像度比の値に応じて変更したい
- 例えば上の画像では、キーフレーム 47 に設定された縦横比は 1.5 なので、
Y = 2480 * 1.5 = 3720 pxになる実現方針
- 「キーフレームごとに設定された解像度比の値を参照し、自動で Resolution X&Y を変更する」 という Python スクリプトを作成する
- 解像度比はマーカーに数値で記録する
設定手順
マーカーに縦横比を入力する
Timeline パネルで、[M] キーでキーフレームにマーカーを追加し、[Ctrl+M] でマーカー名として縦横比を入力します。
今回は
Y/Xの数値を入力してください。例えば X:Y = 4:3 なら0.75, 1:1 なら1, 1:2 なら2です。ちなみに1フレームに複数のマーカーが設定できますが、今回のプログラムでは最初に見つかった数値を縦横比として採用します。
Python スクリプトを書く
次に Text Editor パネルを開き、以下のコードを入力してください。
set_resolution_from_marker.pyimport bpy RESOLUTION_X = 2480 DEFAULT_RATIO = 1.0 def find_ratio_from_current_keyframe(): # 全マーカーの中から、現在のキーフレームに設定されているマーカーを探す marker_items = bpy.context.scene.timeline_markers.items() current = bpy.data.scenes["Scene"].frame_current markers = [item[0] for item in marker_items if item[1].frame == current] # マーカーが存在しなければデフォルト比率を返す if len(markers) < 1: print(f"No marker is set to current keyframe. Now ratio is {DEFAULT_RATIO}.") return DEFAULT_RATIO print("Found marker(s): ", markers) # マーカーの文字列を数値に変換して返す for m in markers: try: ratio = float(m) print("Ratio is set to ", ratio) return ratio except ValueError as e: print(e) continue # 数値に変換できるマーカーが無かった場合、デフォルト比率を返す print(f"Marker is set to current keyframe but not valid number. Now ratio is {DEFAULT_RATIO}.") return DEFAULT_RATIO def update_resolution(scene): scene.render.resolution_x = RESOLUTION_X scene.render.resolution_y = RESOLUTION_X * find_ratio_from_current_keyframe() # キーフレーム変更時に解像度を更新するよう、コールバックを設定 bpy.app.handlers.frame_change_pre.append(update_resolution)ℹ️ 簡単な解説
- 「現在のキーフレームにあるマーカーだけを取得する」というAPIがなかったので、タイムライン全体のマーカーを一度全部取得し、その中から現在のキーフレームのマーカーだけを抽出しています。
- 現在のキーフレームにマーカーが設定されてない、または有効な数値が入力されてない場合、
DEFAULT_RATIOという定数を返すようにしています。今回は1(=縦横比 1:1)です。- 最後の行では、キーフレームが変更されるたびに
update_resolution()を呼び出して解像度を変更するよう、コールバックを設定しています。スクリプトを実行する
Text Editor パネルで "Run Script (Alt+P)" を実行してください。
あとは、キーフレームを切り替えるたび、Resolution X&Y が自動的に設定されます。
補足
Resolution X&Y どちらも設定可能にしたい場合は?
今回は「X=2480px 固定」というやや特殊なケースでしたが、X,Y を同時に設定したければ、マーカーの表記と Python スクリプトを変更すれば簡単に対応できます。
たとえばマーカーに
1280,720と書くようにし、Python スクリプトでカンマ区切りで文字列を分割して、1つ目の値を X, 2つ目の値を Y に代入するなど。ドライバーで実現できないの?
できませんでした。Resolution を含め、Scene プロパティー配下の値にはどれもドライバーが設定できないためです。
マーカーを入力・変更した時に解像度が更新されないんだけど?
そのタイミングで呼び出せるコールバックが見当たりませんでした
お手数ですが、矢印キーでキーフレームを1つ進めて戻してください。参考リンク
- Add driver to render resolution - Support / Animation and Rigging - Blender Artists Community
- Application Handlers (bpy.app.handlers) --- Blender 2.61.4 - API documentation
- TimelineMarker(bpy_struct) --- Blender Python API
- TimelineMarkers(bpy_struct) --- Blender Python API
- https://docs.blender.org/api/current/bpy.types.Scene.html#bpy.types.Scene.frame_current