- 投稿日:2020-11-19T23:55:38+09:00
【初心者向け】Rails6で作られたWebアプリをCircleCIを使いAWS ECR・ECSへ自動デプロイする方法②-2 インフラ構築編【コンテナデプロイ】
さて、前回RDSまで作成できたので、今回はALBの作成をしていこうと思います!
この記事ではALBを作成するだけなので、今までの記事を比べるとこの記事は短めです!
タイトル ① 下準備編 ②-1 インフラ構築編 ②-2 インフラ構築編 ←今ここ! 自動デプロイ編(執筆中) ALBとは?
ここで、ALBについて説明させていただきます。
ALBとは「Application Load Balancer」の略称で、Webからのアクセスを分散してくれるものです。
一つのWebサイトにアクセスが集中してしまうと、サーバーがアクセスを処理しきれなくなり、ページが表示できなるくなるといったトラブルが起こります。ALBを導入することで複数のサーバーに負荷を振り分けることができるので、安定したサービスをユーザーに提供することができるというわけです。
これは余談ですが、ALBの他にも、CLB(Classic Load Balancer)、NLB(Network Load Balancer)というものがあり、これらのロードバランシングサービスを総称してELBと呼びます。
ALBを作成する
それではさっそく、ALBを作成していきましょう!
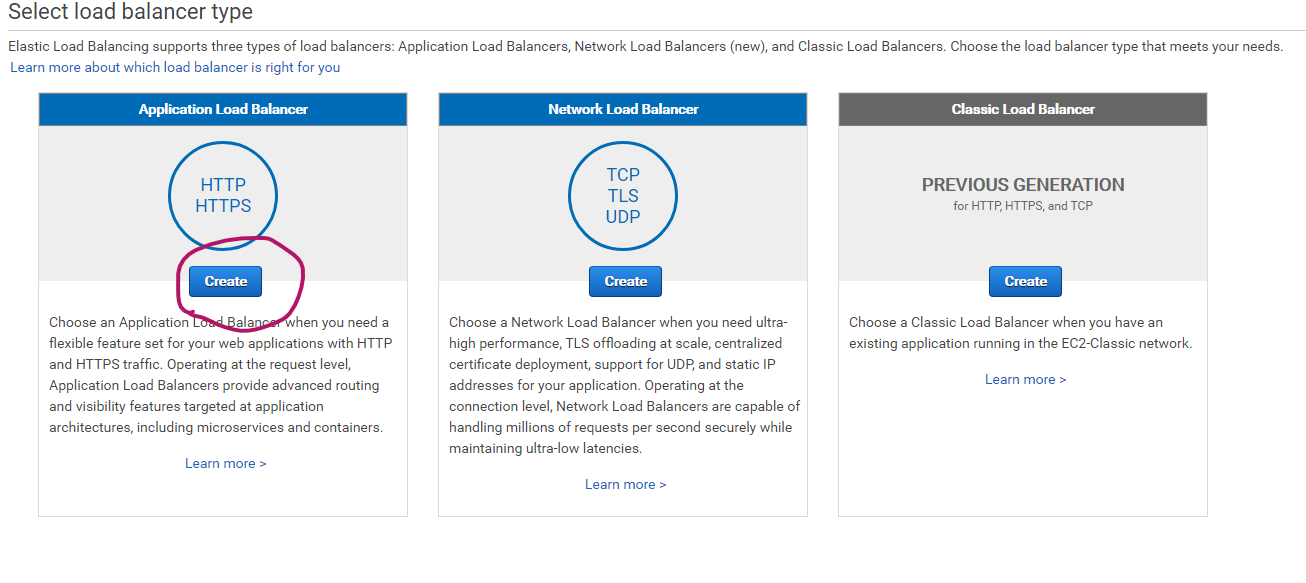
サービスからEC2のコンソールへ行き、Load Balancers→Create Load Balancerとクリックし、 Application Load Balancersを選択する。
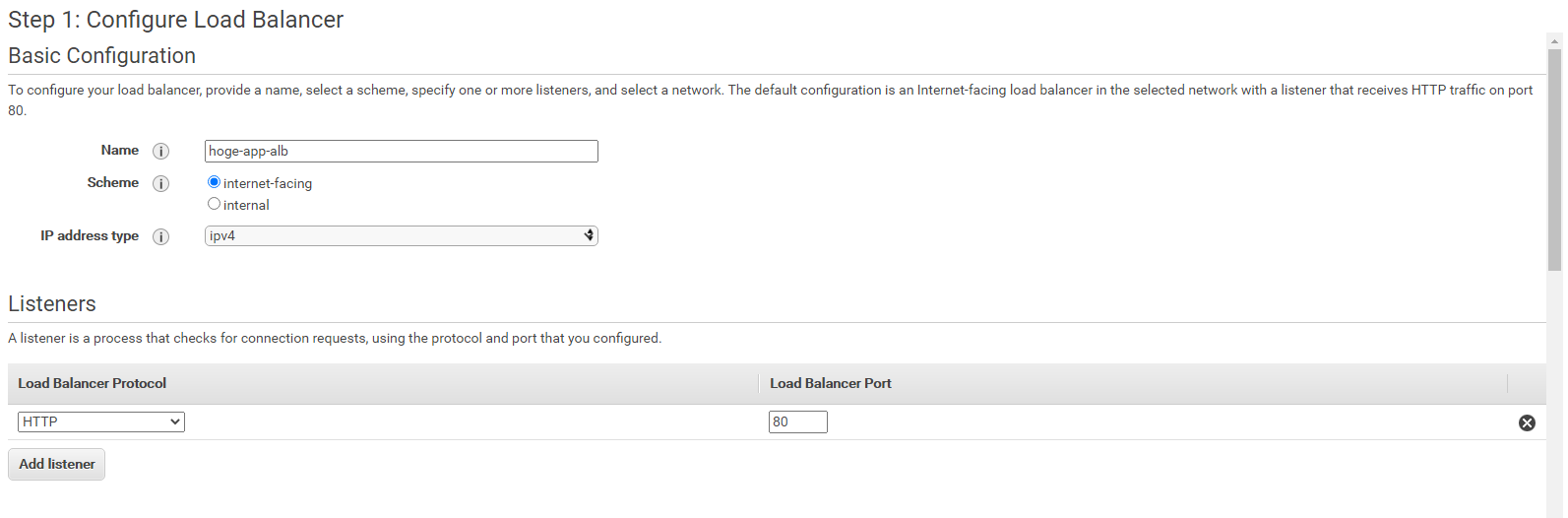
任意のALBの名前を入力します。
Listenerは一旦デフォルトのままでいいです。
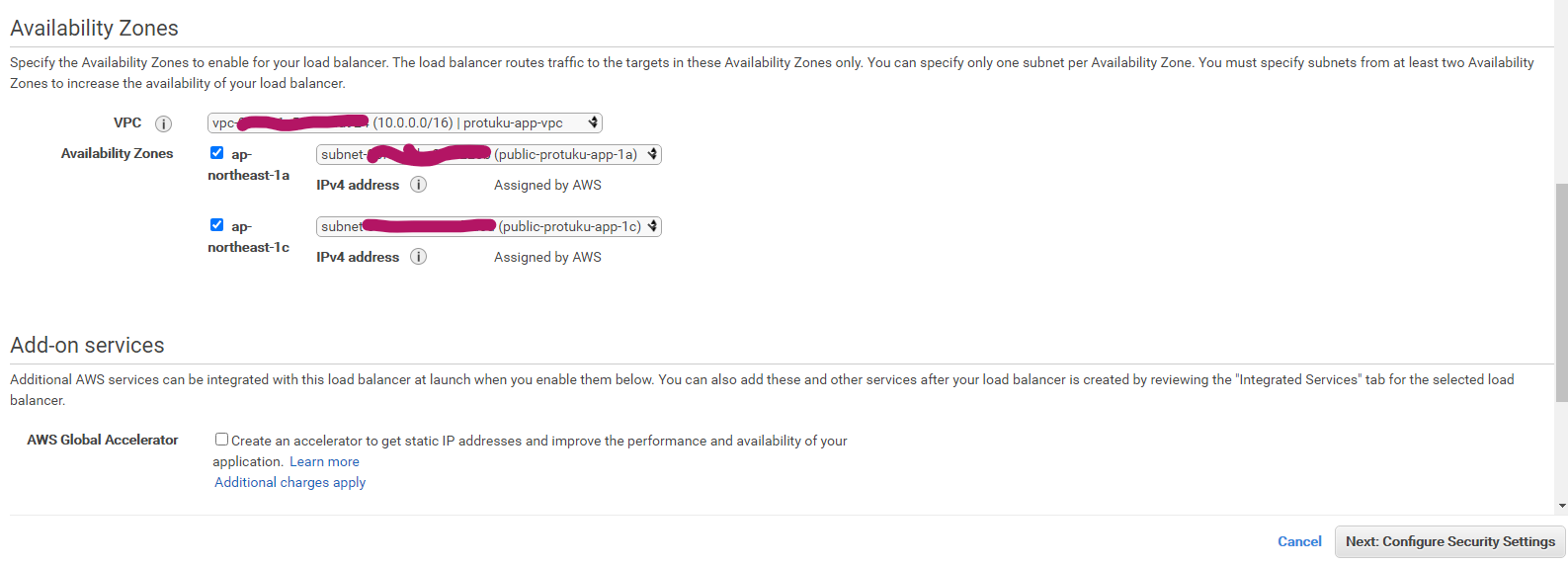
その後、自動作成されたVPC、サブネットを選択し、Nextをクリック。
警告が出てきますが、かまわずNextをクリックします。
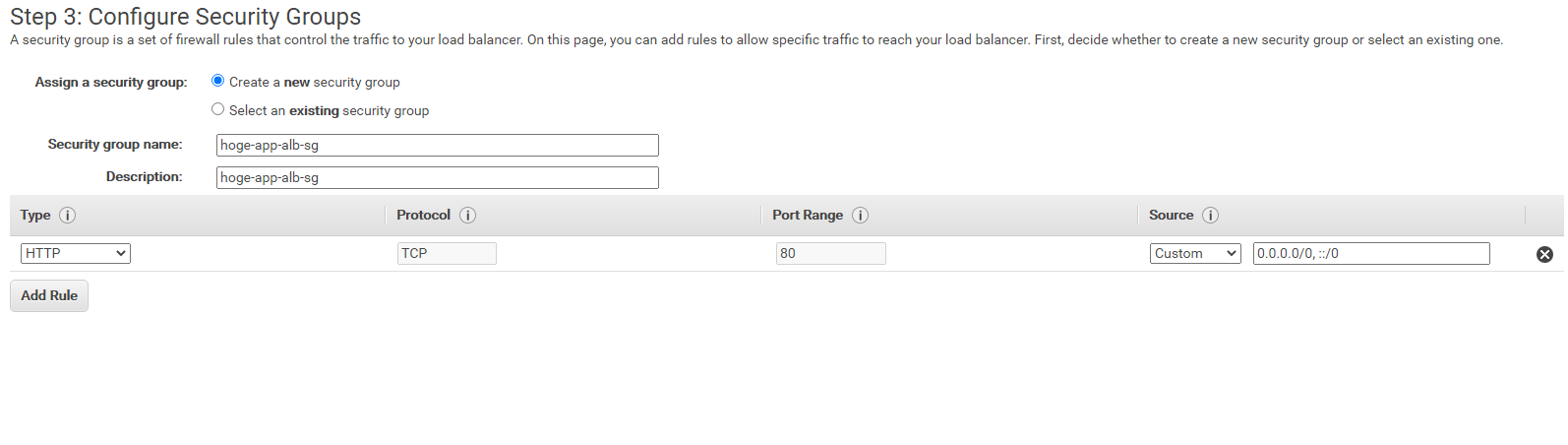
次にALBのセキュリティグループを新に作成します。任意の名前と説明を入力します。
インバウンドルールはHTTPプロトコルで、すべてのソースを許可します。(画像参照)
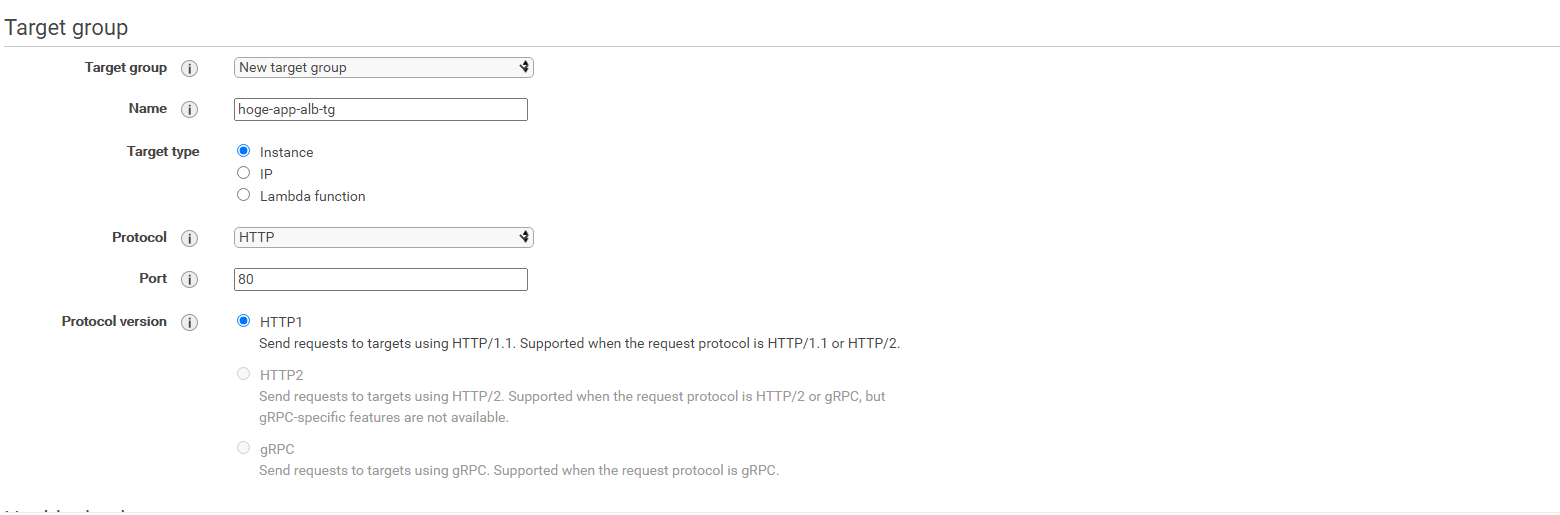
次にターゲットグループ(ALBに来たアクセスのリダイレクト先)を新しく作成します。
ターゲットグループにはEC2インスタンスを指定していきます。New Target groupを選択し任意のターゲットグループの名前を入力します。
後はデフォルトでOKです。
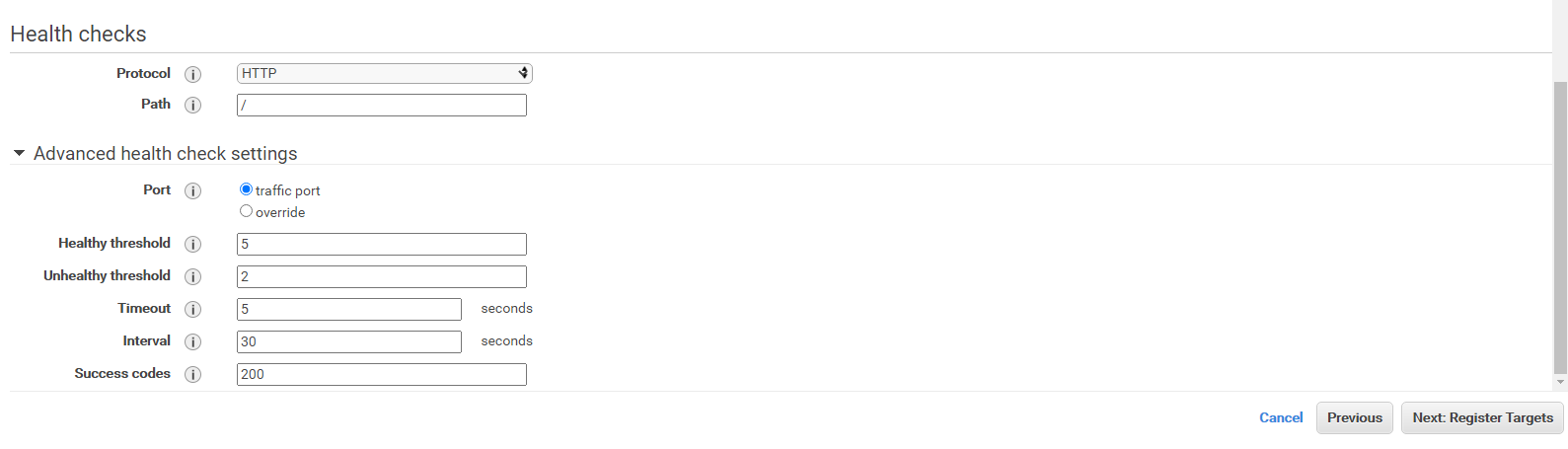
ヘルスチェック(ALBからサーバーが正常に動いているかどうかチェックする機構)もデフォルトでOK
デフォルトだとヘルスチェックのパスはルートパスになってます。
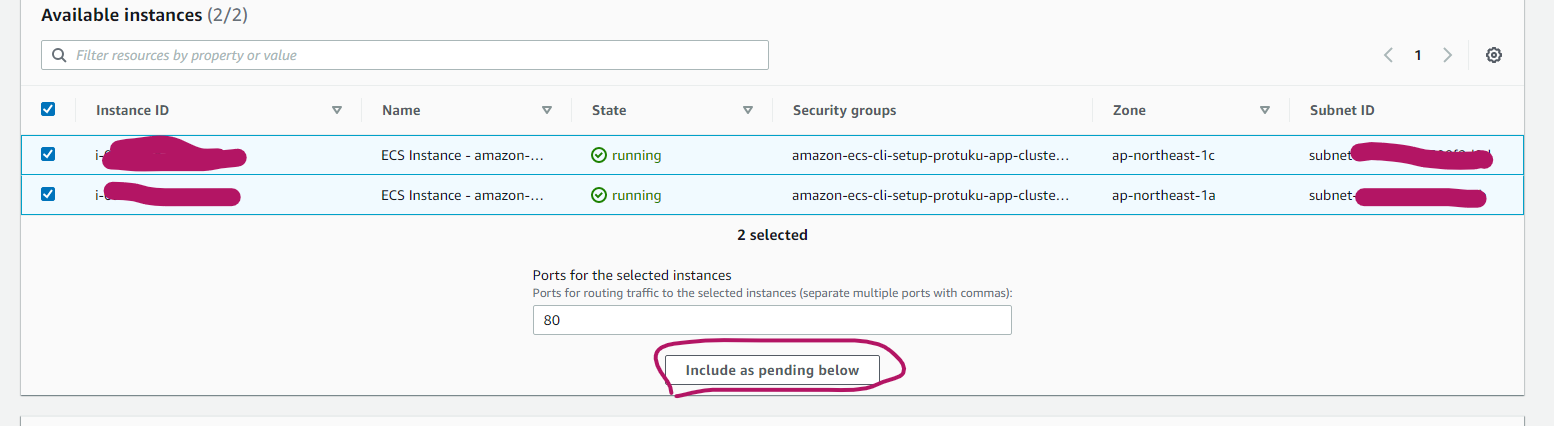
次にターゲットグループのインスタンスを登録します。
自動生成されたEC2インスタンスが二つあるはずなのでチェックマークをいれ、赤丸のinclude as pending below をクリックします。
その後、Register pending targetsをクリックします!
最後に、確認画面が出るので、設定があっているか確認出来たらCreateをクリックして作成完了です!
お疲れ様でした!最後まで読んでいただきありがとうございます!
今回はALB作成編をやっていきました!次回はいよいよDockerイメージをECRへpushしていきます!
今週中にはすべての記事を完成させていくつもりですので、よろしくお願い致します!!何かご指摘やご質問などあればコメントいただけますと嬉しいです。
- 投稿日:2020-11-19T22:28:29+09:00
AWS〜EC2にRailsアプリのデータベースを作成・セットアップする〜
この記事を読んでできるようになること
EC2にSSHログインし、Railsアプリのデータベースを作成・セットアップすることができる。
今回は、MariaDBをインストールしていきます(Amazon Linux 2には、デフォルトでMariaDBがインストールされているため)。ローカル環境のデータベースがMySQLの場合でも、問題なく動作します。
また、AWS上にデータベースを設置する方法は、EC2に設置する方法と、RDSを利用する方法がありますが、この記事では、前者のEC2にデータベースを設置する手順となります。記事を読むにあたってのお願い
私はAWSの初学者で、アウトプットをすることで知識を定着させるためにこの記事を書いています。内容に誤りがある場合は、コメントをいただけますと幸いです。
MariaDBとは
MySQLから派生したRDBMS(リレーショナルデータベースマネジメントシステム)です。MySQLと高い互換性があり、MySQLと比べて、パフォーマンスや堅牢性が高いという特徴があります。
データベースの作成手順
※Railsの環境構築まで完了している前提です。
※MACでの操作手順となります。ご了承ください。① sshログインする
# pemファイルのあるディレクトリへ移動 % cd 〇〇〇〇 # 秘密鍵(pemファイル)を使用して、EC2インスタンスにSSHログイン % ssh -i 〇〇.pem ec2-user@Elastic IP② MariaDBをインストールする
# yumコマンドでインストール(yum: Linuxシステムにおけるソフトウェアパッケージの管理システム) ~ % sudo yum -y install mysql56-server mysql56-devel mysql56 mariadb-server mysql-devel③ MariaDBの起動と起動確認する
# MariaDBの起動 ~ % sudo systemctl start mariadb # MariaDBの起動確認 ~ % sudo systemctl status mariadb # 以下のように、Active:が「active (running)」になっていればOK ● mariadb.service - MariaDB database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disabled) Active: active (running)④ データベースのrootユーザーのパスワードを設定する
※ 本番環境のデータベースのセキュリティを高めるため
# 以下コマンドを入力 ~ % sudo /usr/bin/mysql_secure_installation # 現在のrootのパスワードを入力する(ない場合はEnterを押す)を言われるので、「Enter」を押す Enter current password for root (enter for none): Enter # rootパスワードを設定するか聞かれるので、「Y」を入力 Set root password? [Y/n] Y # 新しいパスワードの入力を求められるので、自分が覚えやすいパスワードを入力しEnter New password: ******** # 再度入力を求められるので、もう一度パスワードを入力しEnter Re-enter new password: ******** # 「Success」と表示されれば設定完了 ... Success! # その後、何点か問われるので、全て Y を入力する。 [Y/n] Y⑤ データベースにrootユーザーで接続する
# 以下コマンドを入力(rootユーザーで接続、-pはパスワードオプション) ~ % mysql -u root -p # パスワードの入力を求められるので、先ほど設定したパスワードを入力後、Enter Enter password: ******** # MariaDBへようこそと表示されれば接続成功 Welcome to the MariaDB ... (省略) # 「exit」で接続解除 > exitこれで、データベースの設置まで完了しました。
次回は手動でデプロイを行っていこうと思います。
- 投稿日:2020-11-19T21:01:03+09:00
kusanagiのAMI ID を AWS CLI で調べる
Kusanagiの最新のAMI IDをCLIで確認してCLIからEC2を起動したい( 2020/11 時点 )
※ AWSマーケットプレイスの ProductCodeId の運用については、オフィシャルがアナウンスしている訳ではないので注意が必要だと思います。将来的に変わる可能性もあるかと。
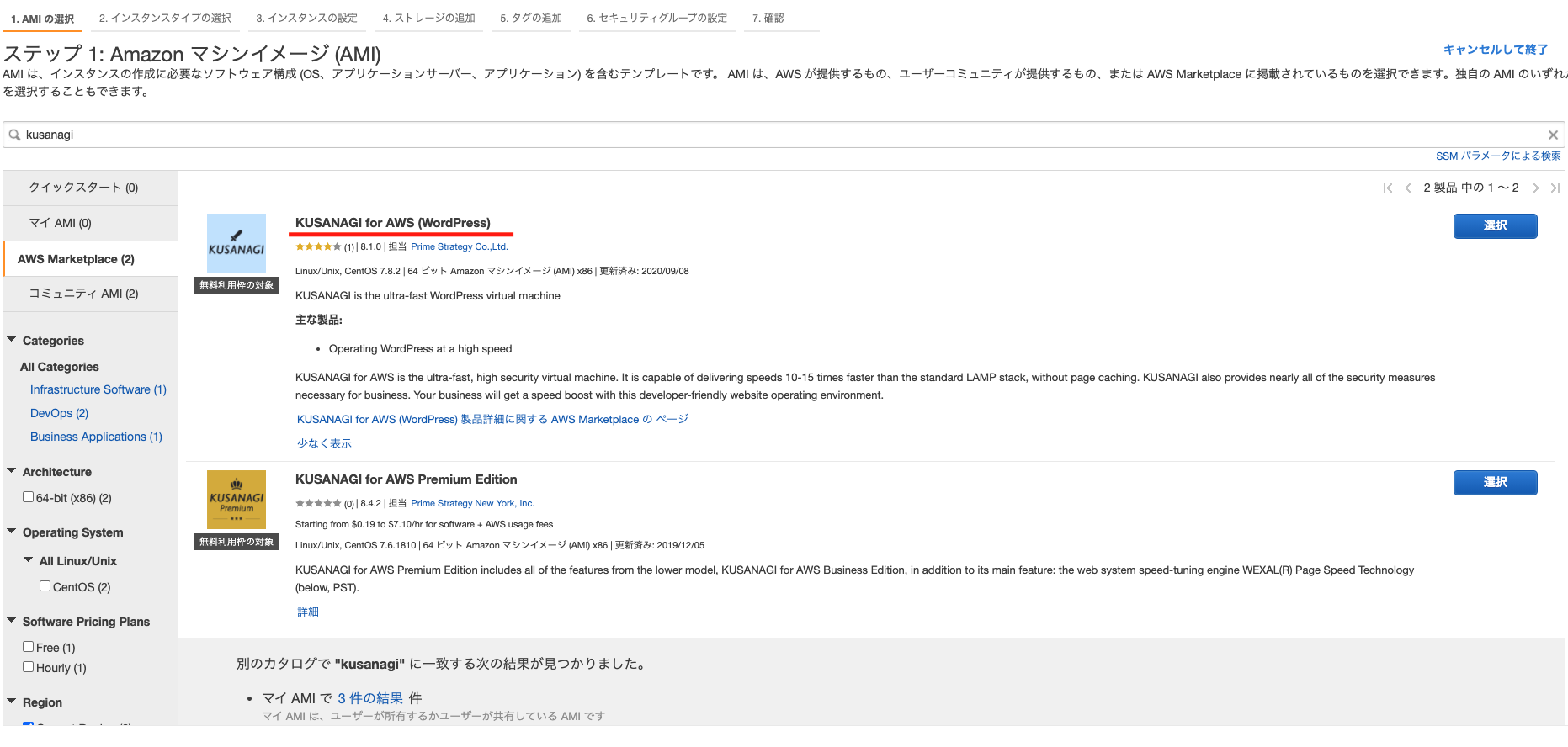
AWSマーケットプレイス内を『KUSANAGI』で検索
aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=name,Values=*KUSANAGI*' | jq .出力内容をみると...
ProductCodeId は
* 239igp26xilrqtgegz3yqea8h
* f18wc0igqjhsxwoxouogwqb8m
の2つあり...
f18wc0igqjhsxwoxouogwqb8mの方が起動したいKUSANAGI for AWS (WordPress)を含んでいました。
「最新のイメージ」かつ「無償のマシンイメージ」のAMI IDを取得したい
aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=product-code,Values=f18wc0igqjhsxwoxouogwqb8m' --query 'sort_by(Images, &CreationDate)[-1].[ImageId]' --output 'text'CentOSの例ですが、ここを参考にしました
( CentOSの場合は、こんな感じでプロダクトコードを公開してくれてるんですよね )--query で日付ごとにソートし、
--output 'text' でシンプルなテキストのみを取得しています。また --filters で使えるオプションはここが参考になりそうです
AWS CLI で一発起動
aws ec2 run-instances --profile AWSプロファイル名 \ --count 1 \ --subnet-id サブネットID \ --security-group-ids セキュリティグループID \ --instance-type t2.medium \ --image-id $(aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=product-code,Values=f18wc0igqjhsxwoxouogwqb8m' --query 'sort_by(Images, &CreationDate)[-1].[ImageId]' --output 'text')
- 投稿日:2020-11-19T21:01:03+09:00
kusanagiのAMI ID を AWS CLI で調べて、一撃で起動したい
Kusanagiの最新のAMI IDをCLIで確認してCLIからEC2を起動したい( 2020/11 時点 )
※ AWSマーケットプレイスの ProductCodeId の運用については、オフィシャルがアナウンスしている訳ではないので注意が必要だと思います。将来的に変わる可能性もあるかと。
AWSマーケットプレイス内を『KUSANAGI』で検索
aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=name,Values=*KUSANAGI*' | jq .出力内容をみると...
ProductCodeId は
* 239igp26xilrqtgegz3yqea8h
* f18wc0igqjhsxwoxouogwqb8m
の2つあり...
f18wc0igqjhsxwoxouogwqb8mの方が起動したいKUSANAGI for AWS (WordPress)を含んでいました。
「最新のイメージ」かつ「無償のマシンイメージ」のAMI IDを取得したい
aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=product-code,Values=f18wc0igqjhsxwoxouogwqb8m' --query 'sort_by(Images, &CreationDate)[-1].[ImageId]' --output 'text'CentOSの例ですが、ここを参考にしました
( CentOSの場合は、こんな感じでプロダクトコードを公開してくれてるんですよね )--query で日付ごとにソートし、
--output 'text' でシンプルなテキストのみを取得しています。また --filters で使えるオプションはここが参考になりそうです
AWS CLI で一発起動
最後にjqでパースしてIPアドレスを返します( sshでログインする設定を作るので欲しい )
aws ec2 run-instances --profile AWSプロファイル名 \ --count 1 \ --subnet-id サブネットID \ --security-group-ids セキュリティグループID \ --instance-type t2.medium \ --image-id $(aws ec2 describe-images --region ap-northeast-1 --owners 'aws-marketplace' --filters --filters 'Name=product-code,Values=f18wc0igqjhsxwoxouogwqb8m' --query 'sort_by(Images, &CreationDate)[-1].[ImageId]' --output 'text') \ | jq --raw-output '.Instances[0].NetworkInterfaces[0].PrivateIpAddress'
- 投稿日:2020-11-19T20:15:24+09:00
別のAWSアカウントのorganizations,CostExplorerの情報をLambda(python)で取得する方法
結論
下記ドキュメントを参照。。。。。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-function-assume-iam-role/読んでも全然わからん状態なので、
取得したい情報があるアカウント(アカウントA)と
それを渡したいアカウント(アカウントB)がある状態でやってみたアカウントA側の処理
1.アカウントAでlambda用のロールを作成する
2.ロールに情報を取得するための必要なポリシーをアタッチ
CostExplorerFullAccess、AWSOrganizationsFullAccessなど
3.ロールの概要の信頼関係タブの信頼関係の編集を押す。
4.下記ポリシーを張り付け、更新する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::アカウントBのアカウント番号:role/service-role/アカウントBのロールの名前" ], "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }アカウントB側の処理(IAM)
1.アカウントBのロール作成、必要な権限を与える。
とりあえずAdministratorAccessを与えておく
2.ロールの概要のアクセス権限タブから、インラインポリシーの追加を押す
3.Jsonタブをクリック、インラインポリシーとして下記を張り付けポリシーの確認を押し適応する
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::アカウントAのアカウント番号:role/アカウントAのロールの名前" } }アカウントB側の処理(lambda)
boto3のドキュメントに取得方法が詳しく書いてある。
詳しくは下記を参照。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sts.html
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/organizations.html
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/ce.html#CostExplorer.Client.get_cost_forecast
https://docs.aws.amazon.com/aws-cost-management/latest/APIReference/API_GetCostAndUsage.htmlimport boto3 def lambda_handler(event, context): #他アカウントAWSリソースへのアクセスに使用するセキュリティ認証情報のセットを取得 sts_connection = boto3.client('sts') acct_b = sts_connection.assume_role( RoleArn="arn:aws:iam::アカウントAのアカウント番号:role/アカウントAのロールの名前", RoleSessionName="cross_acct_lambda" ) ACCESS_KEY = acct_b['Credentials']['AccessKeyId'] SECRET_KEY = acct_b['Credentials']['SecretAccessKey'] SESSION_TOKEN = acct_b['Credentials']['SessionToken'] #アカウントAのorganizations の情報取得 organizations = boto3.client( 'organizations', aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY, aws_session_token=SESSION_TOKEN, ) responses = [] res = {} while True: if 'NextToken' in res: res = organizations.list_accounts(NextToken = res['NextToken']) else: res = organizations.list_accounts() responses += res['Accounts'] if 'NextToken' not in res: break print(responses) #アカウントAのCostExplorer の情報取得 ce = boto3.client( 'ce', region_name='us-east-1', aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY, aws_session_token=SESSION_TOKEN, ) response = ce.get_cost_and_usage( TimePeriod = {"Start": "2020-10-01", "End": "2020-11-01"}, Granularity = 'MONTHLY', Metrics = ["UnblendedCost"], GroupBy=[{'Type': 'DIMENSION','Key': 'LINKED_ACCOUNT'}] ) print(response)

- 投稿日:2020-11-19T17:58:17+09:00
DynamoDBで前方一致検索を実施する
はじめに
便利で何より安いけど何かと検索についてはあんまり使い勝手の良くないDynamoDBちゃん。今日はそれで前方一致検索をする方法を考えたのでまとめておきたいと思います。事前に言っておきますがScanを使うので使いすぎにはご注意。
最初に実際にLambdaにぶち込んだソースコードを
lambda_function.pyimport json import boto3 from boto3.dynamodb.conditions import Attr def lambda_handler(event, context): dynamoDB = boto3.resource("dynamodb") table = dynamoDB.Table(event["type"]) title = event["title"] fin = title[0]+chr(ord(title[1])+2) queryData = table.scan( FilterExpression = Attr("Title").between(title,fin) ) return queryDataなにをしてるのか?
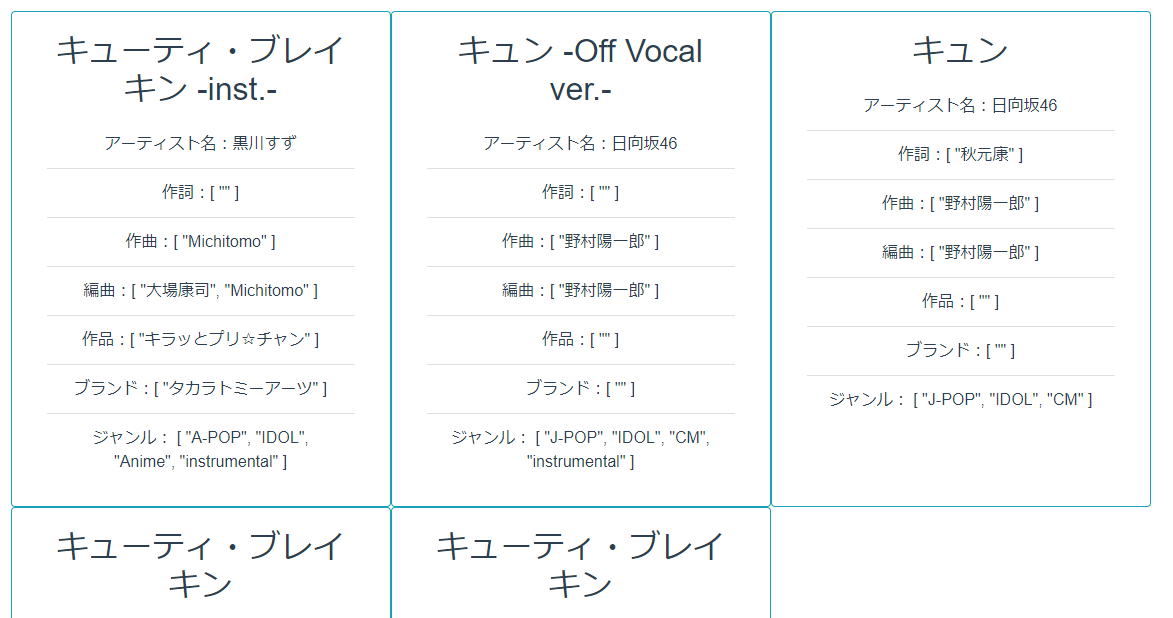
これはようするに入力された文字列と入力された文字列の2文字目を2つずらした文字列を用意してその間を取得しています。
今回、テストに使った日向坂46の「キュン」という曲の場合はまず「キュン」という文字列から「キョ」という文字列を作ります。
それが次の部分となります。
fin = title[0]+chr(ord(title[1])+2)
あとは普通にscanで差分を取るだけです。ちなみに「キュン」の場合は次のようになります。
「キュン」から「キョ」の間なので「キュー」で始まる曲が混じってますがそれはご愛敬という事でお願いします。最後に
DynamoDBのscanは全件取得してから目当てのデータを絞り込むため、滅茶苦茶苦重いです。特に頻繁に叩かれる事が想定できる場合は素直にRDSを契約しましょう。ぼくはピンチケ開発者なのでまだしばらくDynamoDBで頑張ろうと思います。
- 投稿日:2020-11-19T17:10:18+09:00
AWS lambda を使ってWebスクレイピングしたった
Background
AWS Lambda を使ってFizzBuzzしたったの続き。
今回はスクレイピングで外部のWebページからデータを取得してみた。AWS Architecture
- S3(データ保存)
- AWS Lambda(データ処理)
- Amazon EventBridge(定期実行)
の3つのサービスを使っています。
Setting
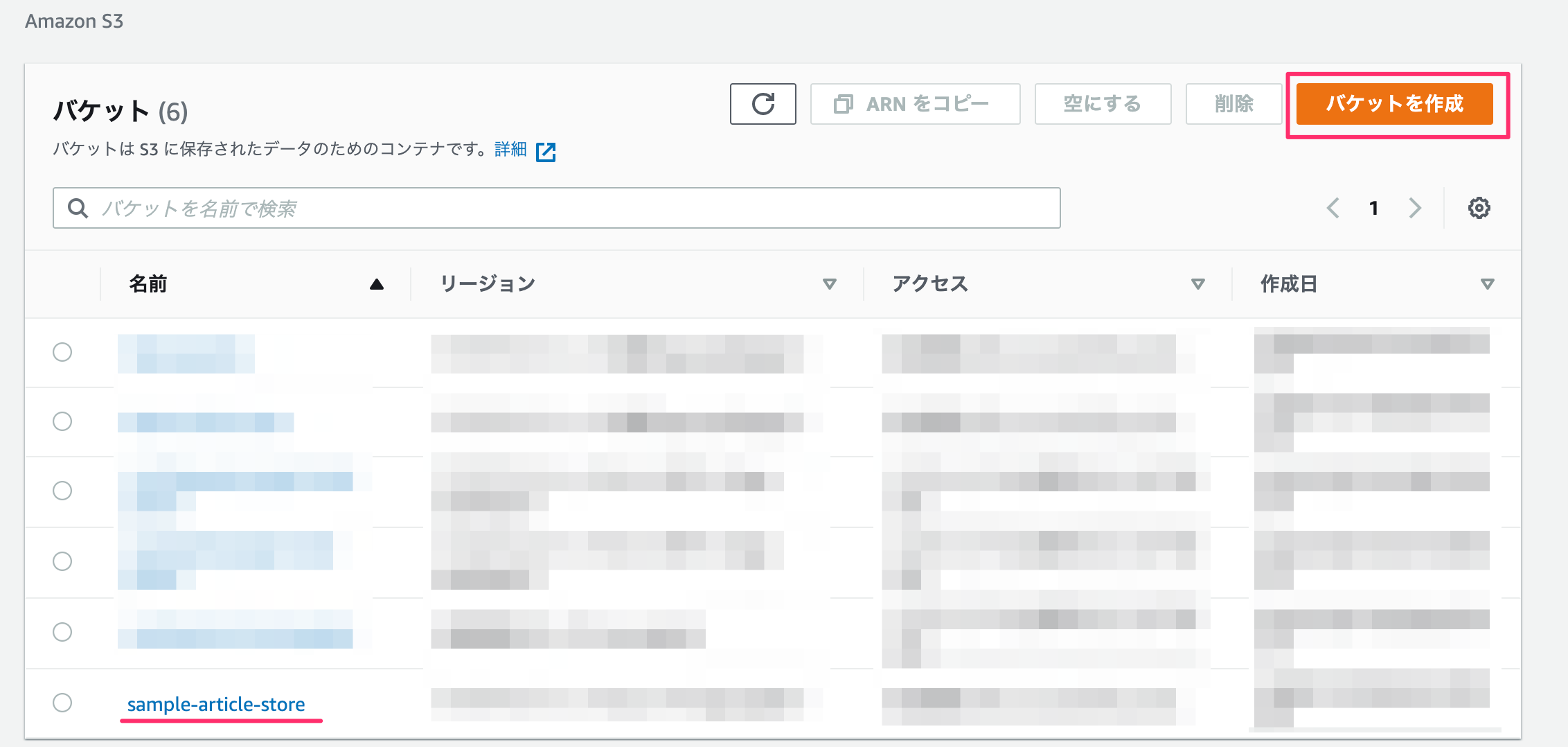
S3
データ保存用のバケットを作成します。
バケット名のみ入力して、その他の設定はデフォルトのままにします。(リージョンは適宜選択する。)
バケットの作成は完了。
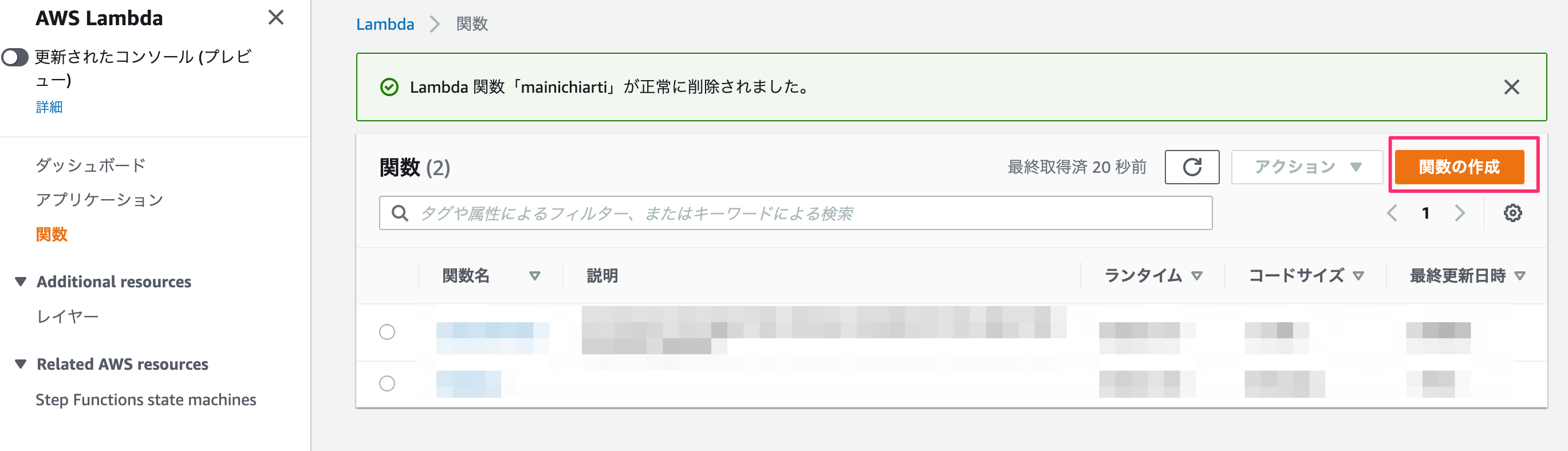
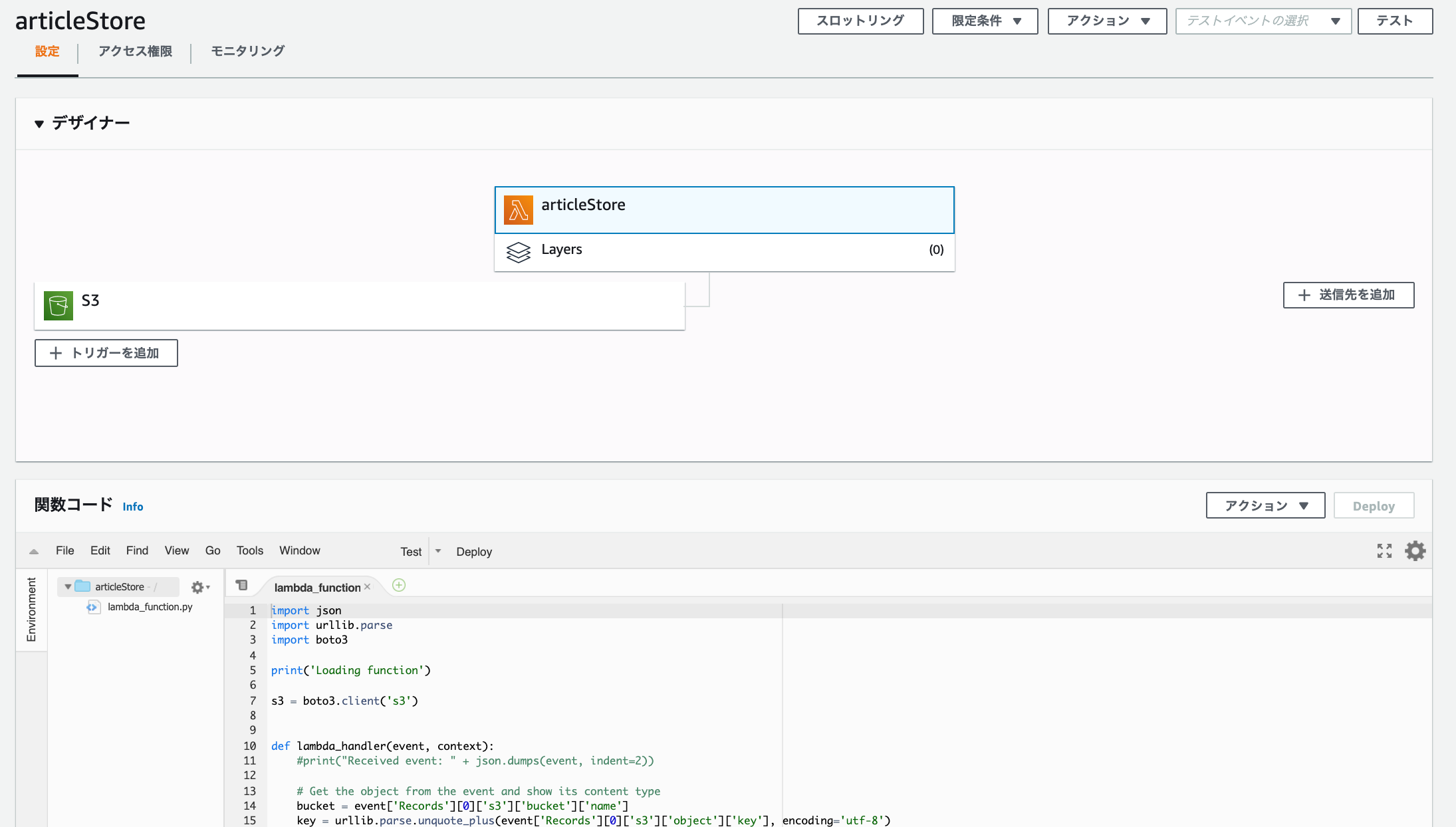
Lambda
データ処理用のlambdaを作成します。
一から作成、、、ではなく、
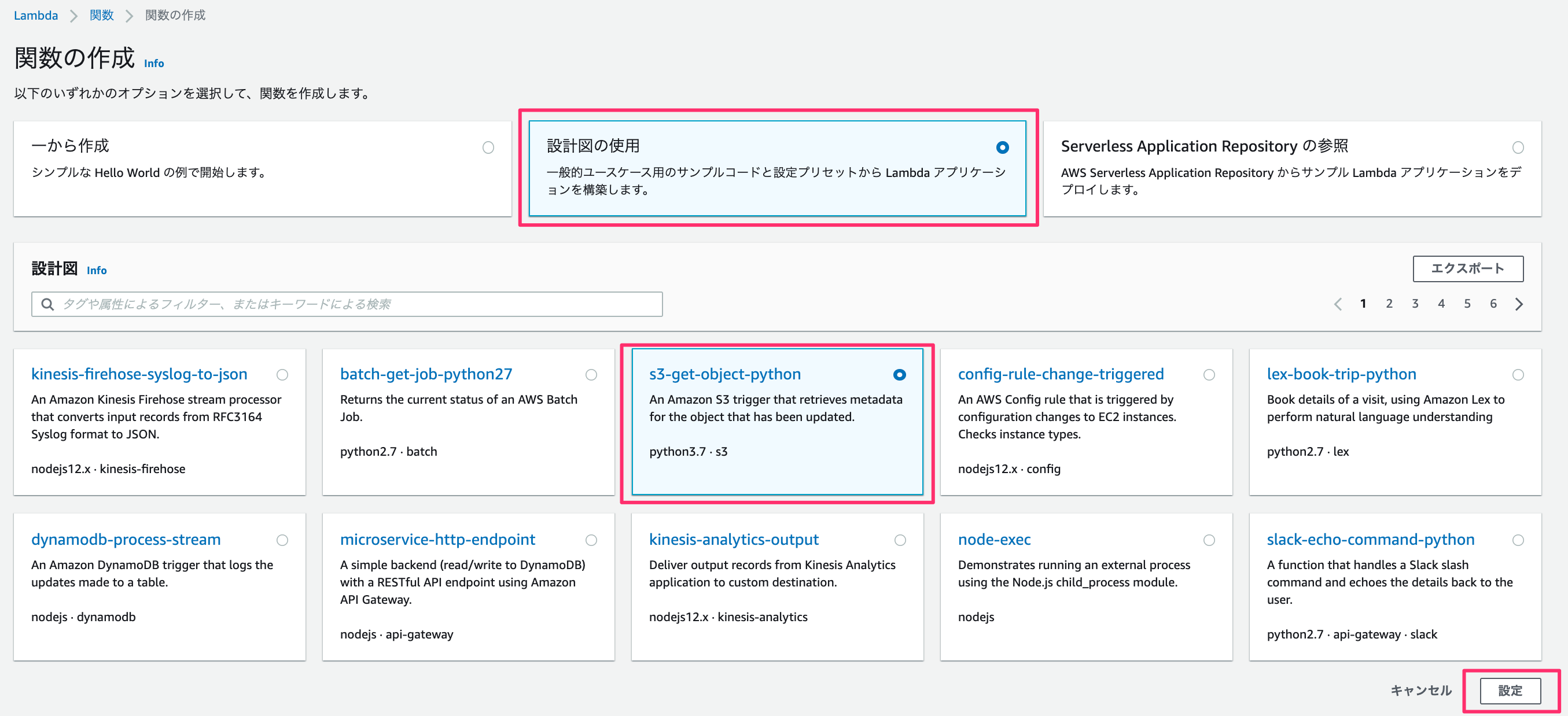
ここでは「設計図の使用」のなかの「s3-get-object-python」を使います。
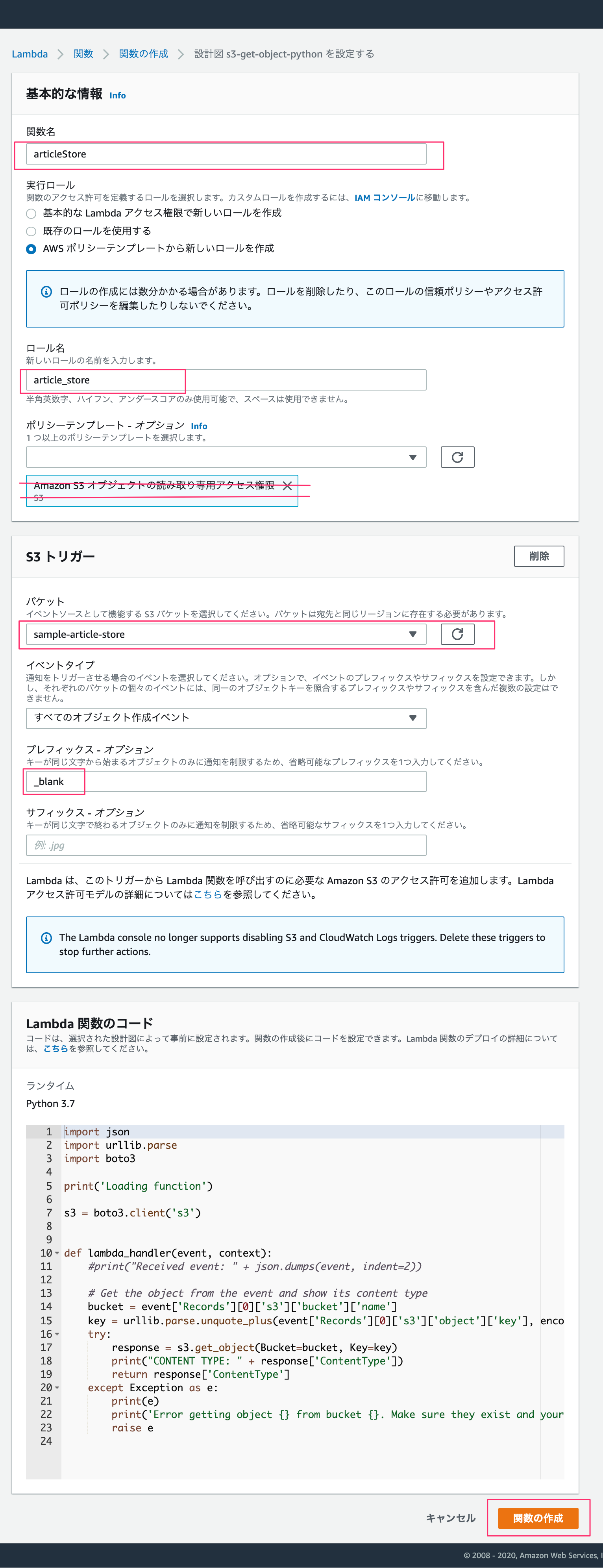
関数名・ロール名を入力。
今回はS3にファイルをuploadするので「読み取り専用のアクセス」のポリシーテンプレートを削除します。
S3トリガーですが、バケット名には先ほど作成したバケットを入力します。あとは、プレフィックス - オプションには任意の文字を入力してください。
ここで言っている任意の文字とは、lambdaにてファイルを作成するのですがファイル名の先頭と重複しない文字です。
もし、未入力や重複する文字を入力した場合は lambdaへ無限ループにトリガーを作動させ、多額の料金が発生することになるので重要です。
他の対処法としては、イベントタイプをコピーのみにするなどの制限を加えるのもいいと思います。
全ての入力が終わったあとは、「関数の作成」を押します。
テンプレートが作成されますが、このまま開発を進めてデプロイ、テストしても権限エラーが発生します。
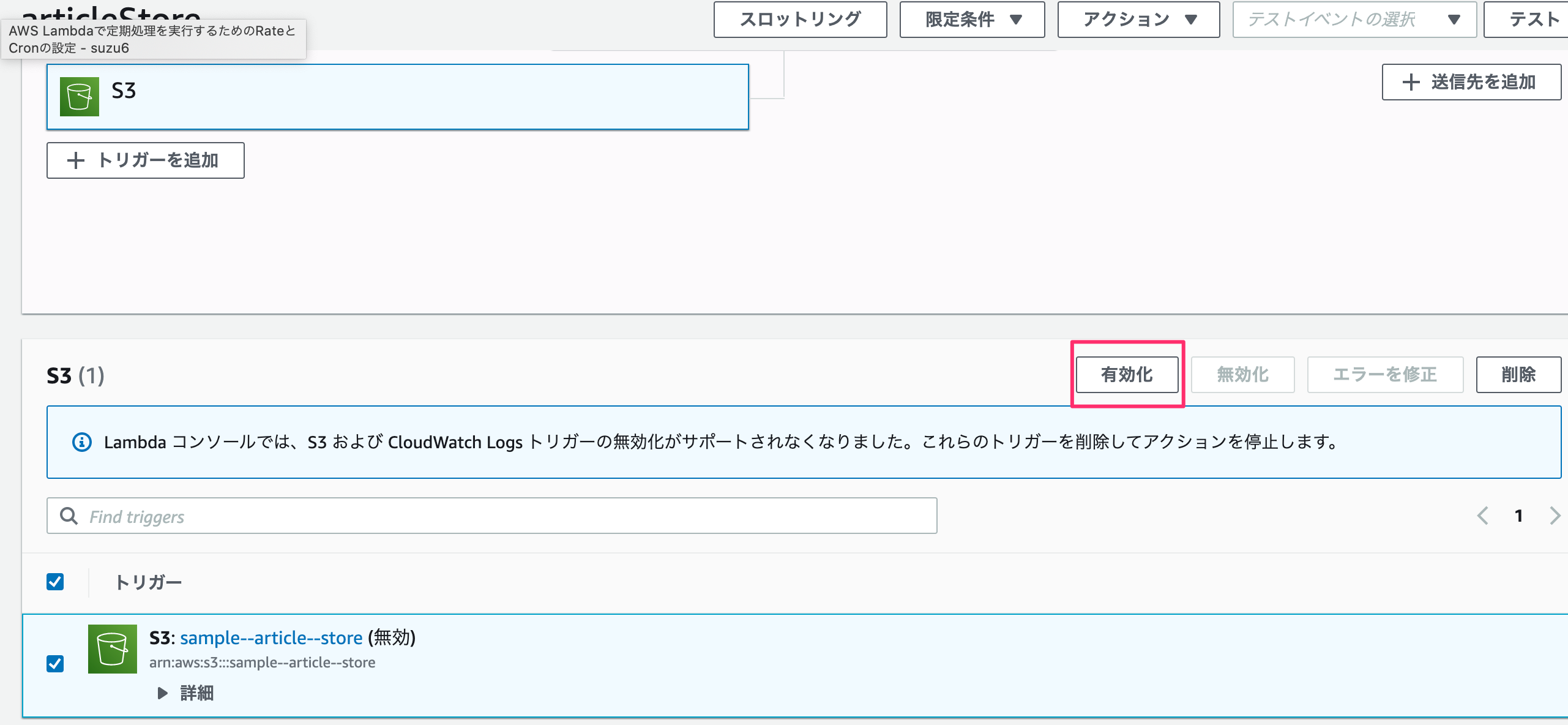
S3の設定
まずS3を有効化させます。
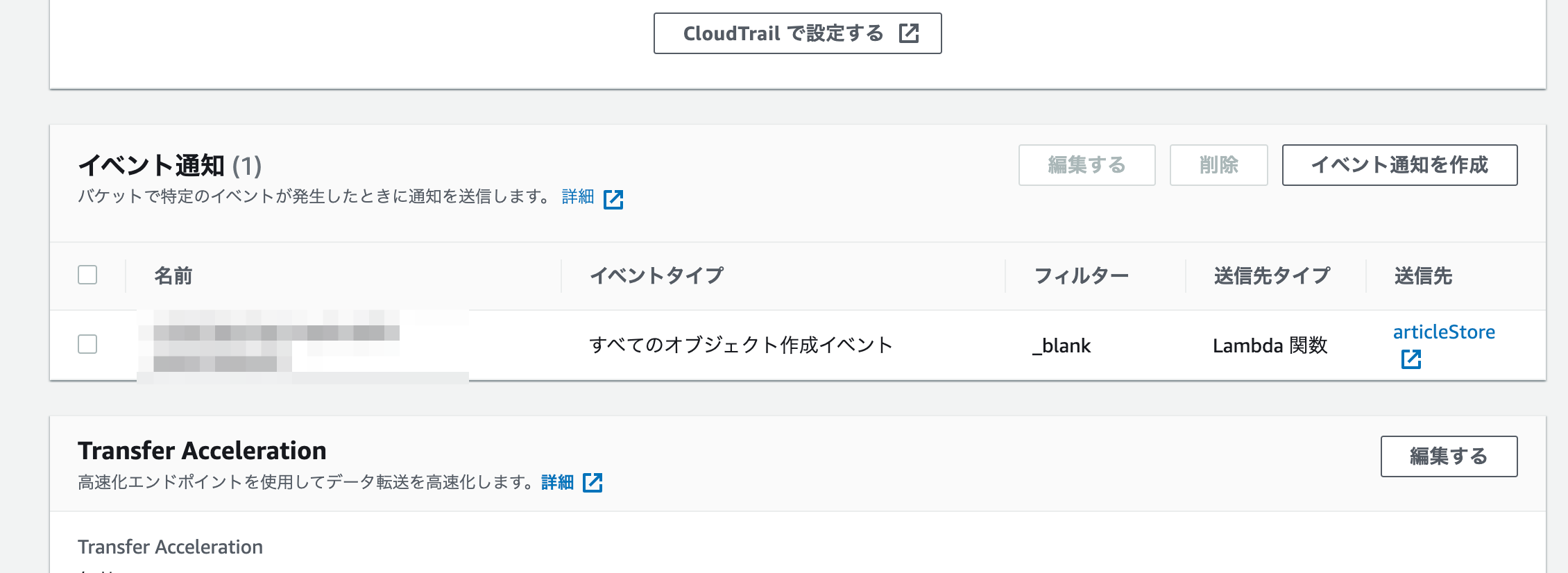
S3でバケットのプロパティ内にあるイベント通知を見ると追加されているのが分かります。
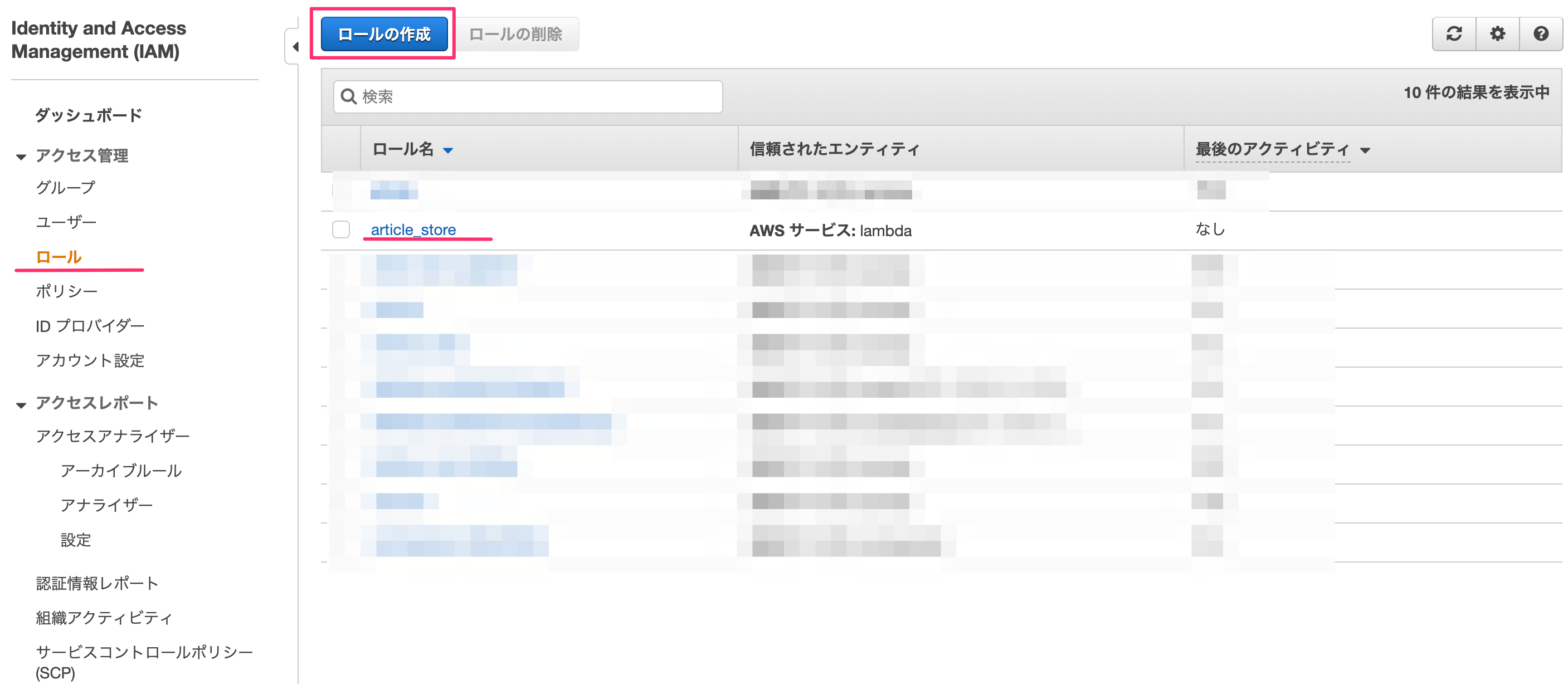
ロールに権限の追加
IAM→ロールを選ぶとロールリストが表示されます。ここで先ほどlambda作成時に記載したロール名を選択します。
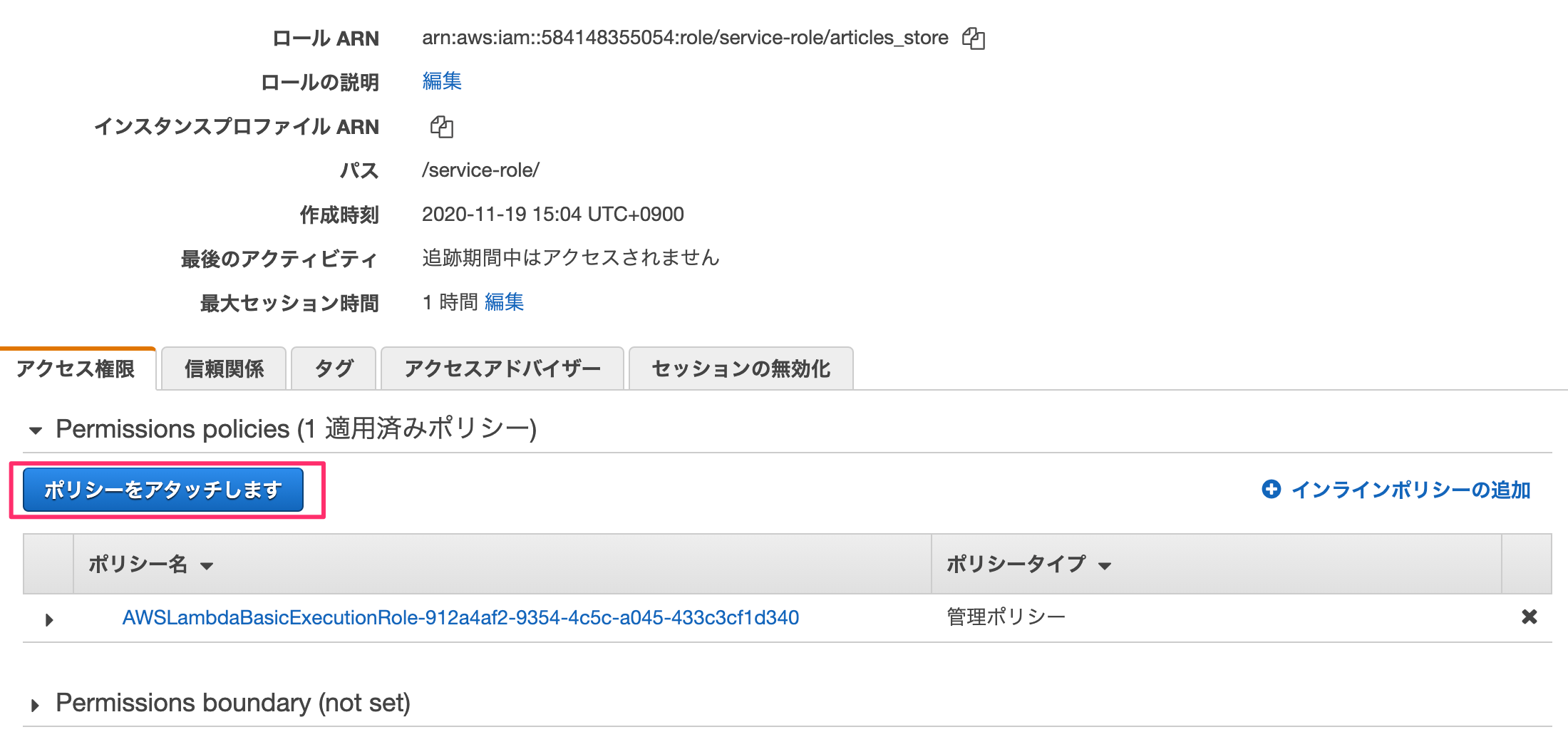
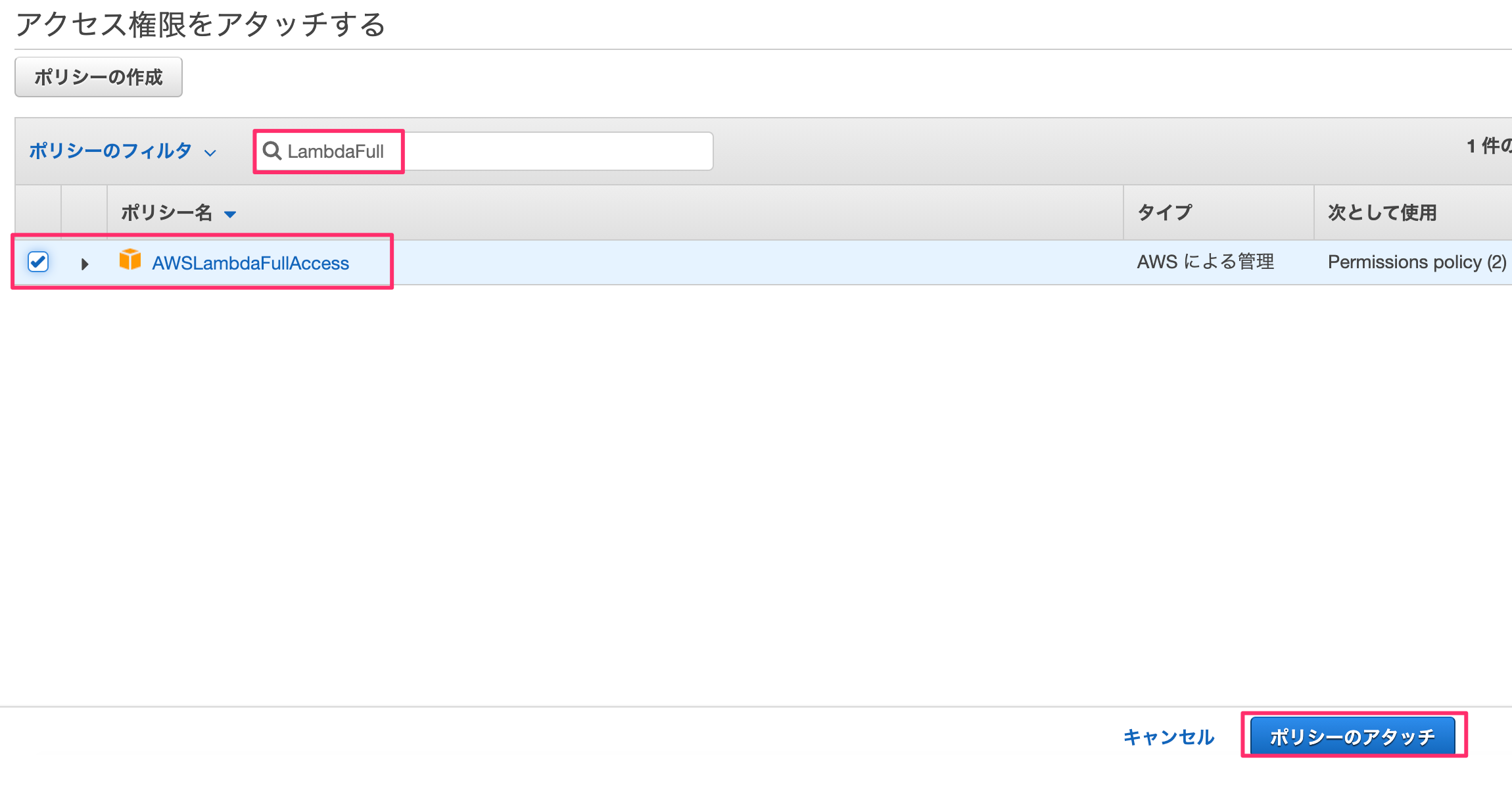
何も考えずに「ポリシーをアタッチします」を押す。
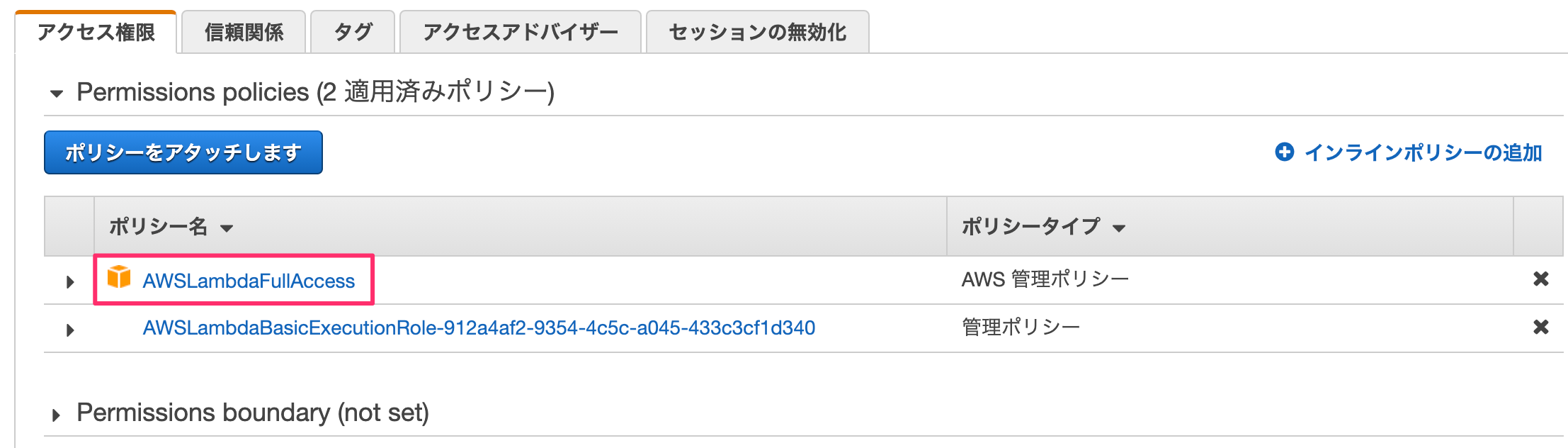
"LambdaFull"でフィルタをかけ、「AWSLambdaFullAccess」を選んで「ポリシーのアタッチ」を押します。
これで権限の追加が完了しました。
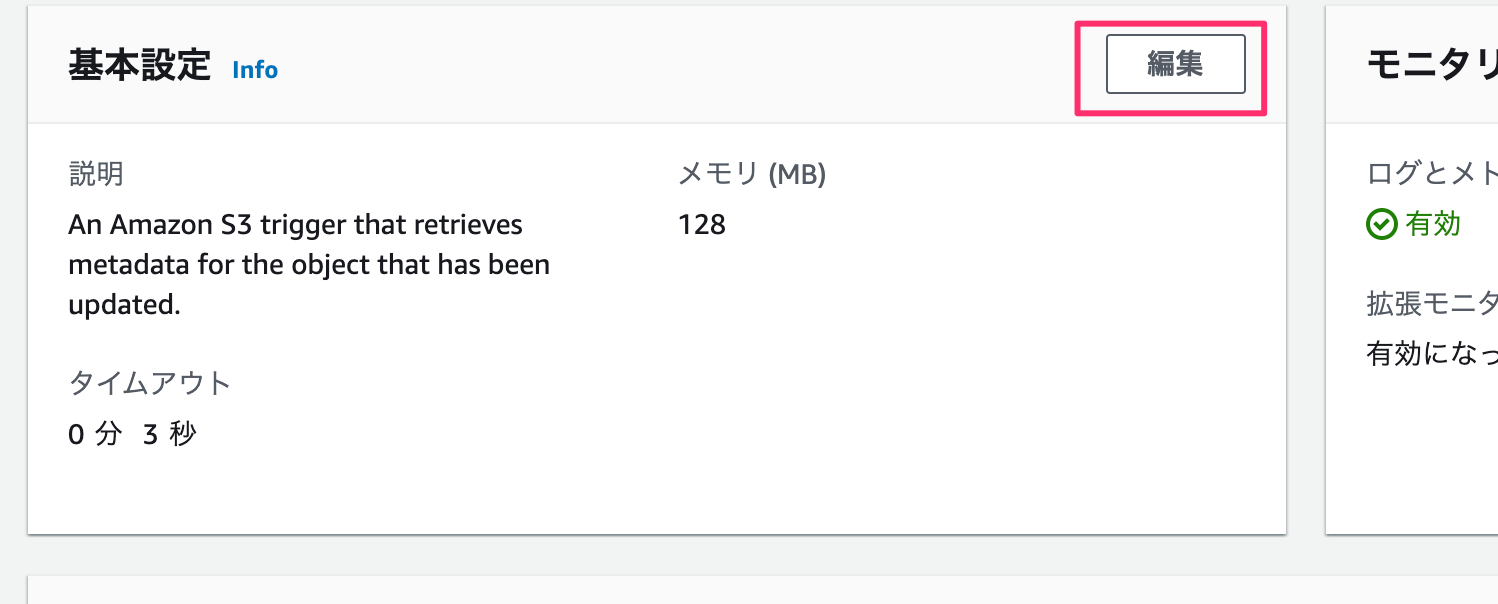
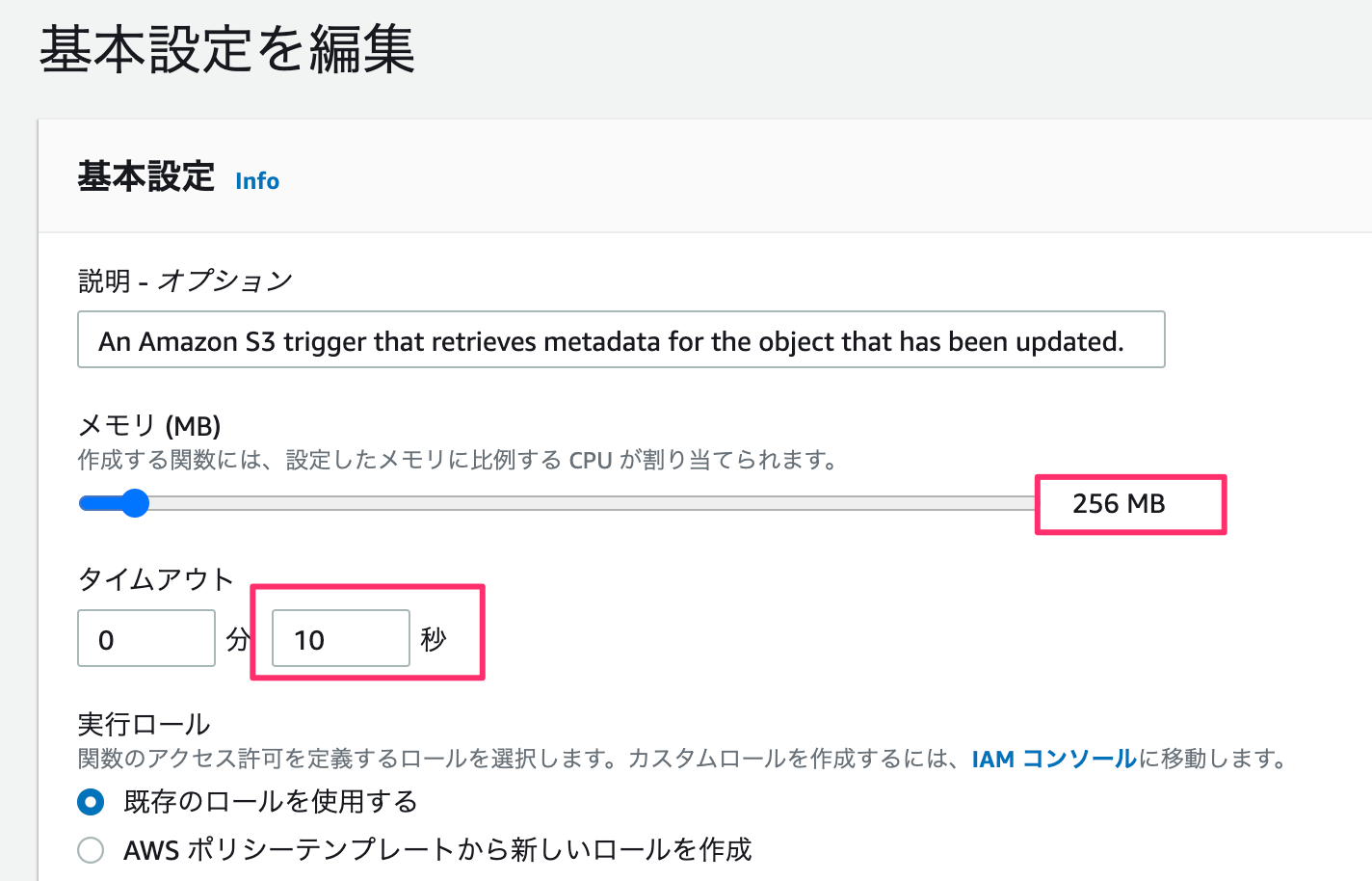
基本設定
メモリが小さいと処理落ちしました。
てことでメモリ:256MB、タイムアウトを10秒にセットします。
これで完了。
Development (ファイル送信)
S3バケットの送受信にはbote3パッケージを使います。 lambda作成時に
s3-get-object-pythonを選ぶと付属でついてきます。最初からパッケージをuploadするとbote3自体の容量が大きく10MB以上になるので既存のものを使った方が良さげです。import json import urllib.parse import boto3 import datetime def lambda_handler(event, context): try: # Get the object from the event and show its content type s3 = boto3.resource('s3') bucket = '[バケット名]' key = 'test_{}.txt'.format(datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')) file_contents = 'Lambda test' obj = s3.Object(bucket,key) obj.put( Body=file_contents ) except Exception as e: print(e) raise eあとはデプロイして、テストするとバケットにファイルがuploadされます。
あと、テストイベントの設定ですが空のjsonでも起動します。Development (Webスクレイピング)
スクレイピングするには、
requestsbeautifulsoupがいるのですがpipでインストールしているパッケージをlambdaにuploadする必要があります。方法はフォルダにpipでパッケージをインストールし、zipでフォルダを圧縮化します。
ここで実行ファイルを作成し、lambdaで書いたコードをコピーします。mkdir packages cd packages pip install requests -t ./ pip install beautifulsoup -t ./ touch lambda_function.py
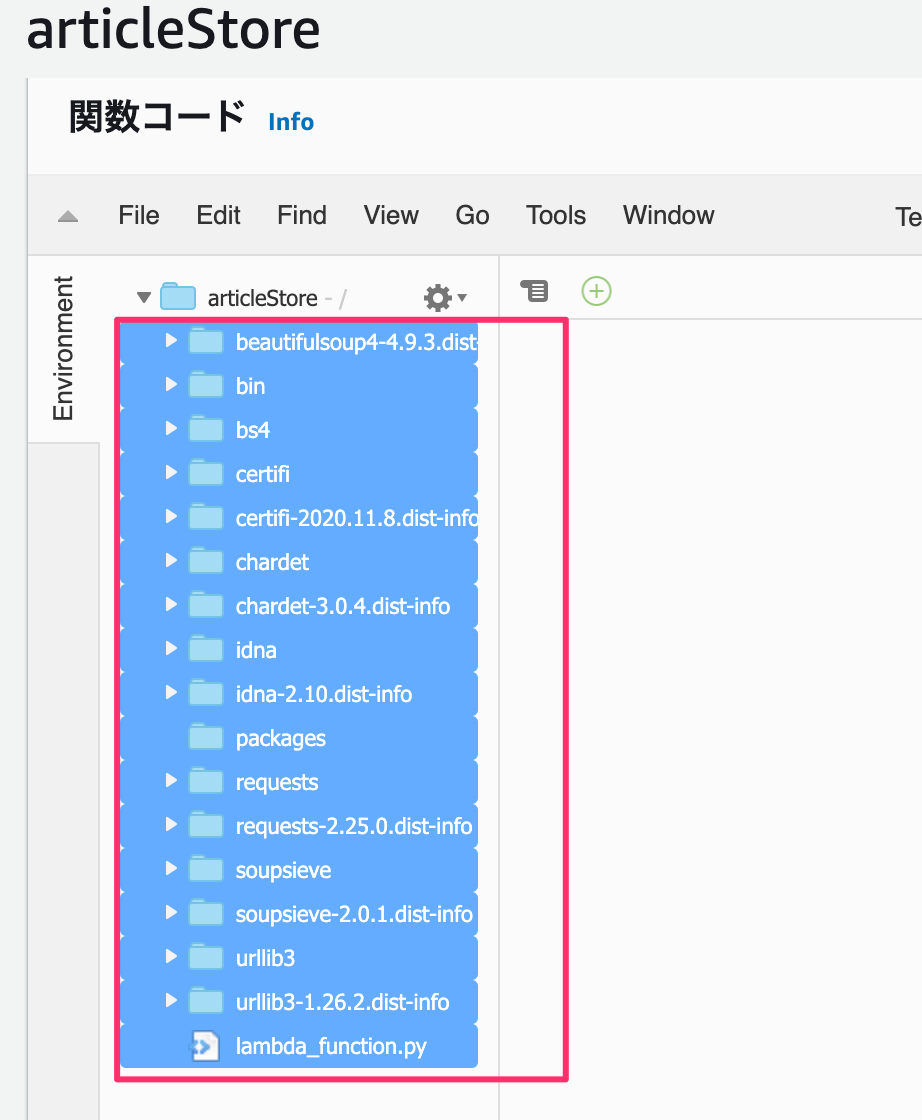
プロジェクト内にパッケージが置かれます。
で、packages配下のフォルダ・ファイルをひとつ上の階層のarticleStoreに移動させます。
その後で、デプロイしてテストするとS3にファイルが追加されます。
あとは、webスクレイピングするだけです。
ここでは今日付の毎日新聞の社説を取得してみます。import json import urllib.parse import boto3 import datetime from datetime import timedelta, timezone import random import os import requests from bs4 import BeautifulSoup print('Loading function') s3 = boto3.resource('s3') def lambda_handler(event, context): # Get the object from the event and show its content type JST = timezone(timedelta(hours=+9), 'JST') dt_now = datetime.datetime.now(JST) date_str = dt_now.strftime('%Y年%m月%d日') response = requests.get('https://mainichi.jp/editorial/') soup = BeautifulSoup(response.text) pages = soup.find("ul", class_="list-typeD") articles = pages.find_all("article") links = [ "https:" + a.a.get("href") for a in articles if date_str in a.time.text ] for i, link in enumerate(links): bucket_name = "[バケット名]" folder_path = "/tmp/" filename = 'article_{0}_{1}.txt'.format(dt_now.strftime('%Y-%m-%d'), i + 1) try: bucket = s3.Bucket(bucket_name) with open(folder_path + filename, 'w') as fout: fout.write(extract_article(link)) bucket.upload_file(folder_path + filename, filename) os.remove(folder_path + filename) except Exception as e: print(e) raise e return { "date" : dt_now.strftime('%Y-%m-%d %H:%M:%S') } #社説を抽出 def extract_article(src): response = requests.get(src) soup = BeautifulSoup(response.text) text_area = soup.find(class_="main-text") title = soup.h1.text.strip() sentence = "".join([txt.text.strip() for txt in text_area.find_all(class_="txt")]) return title + "\n" + sentenceこれで、「デプロイ」→「テスト」でS3バケットに抽出した記事が書かれた2つのテキストファイルが追加されます。
とても、長くなりましたがLambdaの設定は完了です。
Amazon EventBridge
処理はできたのですが、毎朝「テスト」ボタンを押すのはマジだるです。
そのため、Amazon EventBridgeを使って定期実行を設定します。Amazon EventBridge → イベント → ルール を選んで、
「ルールの作成」を押します。
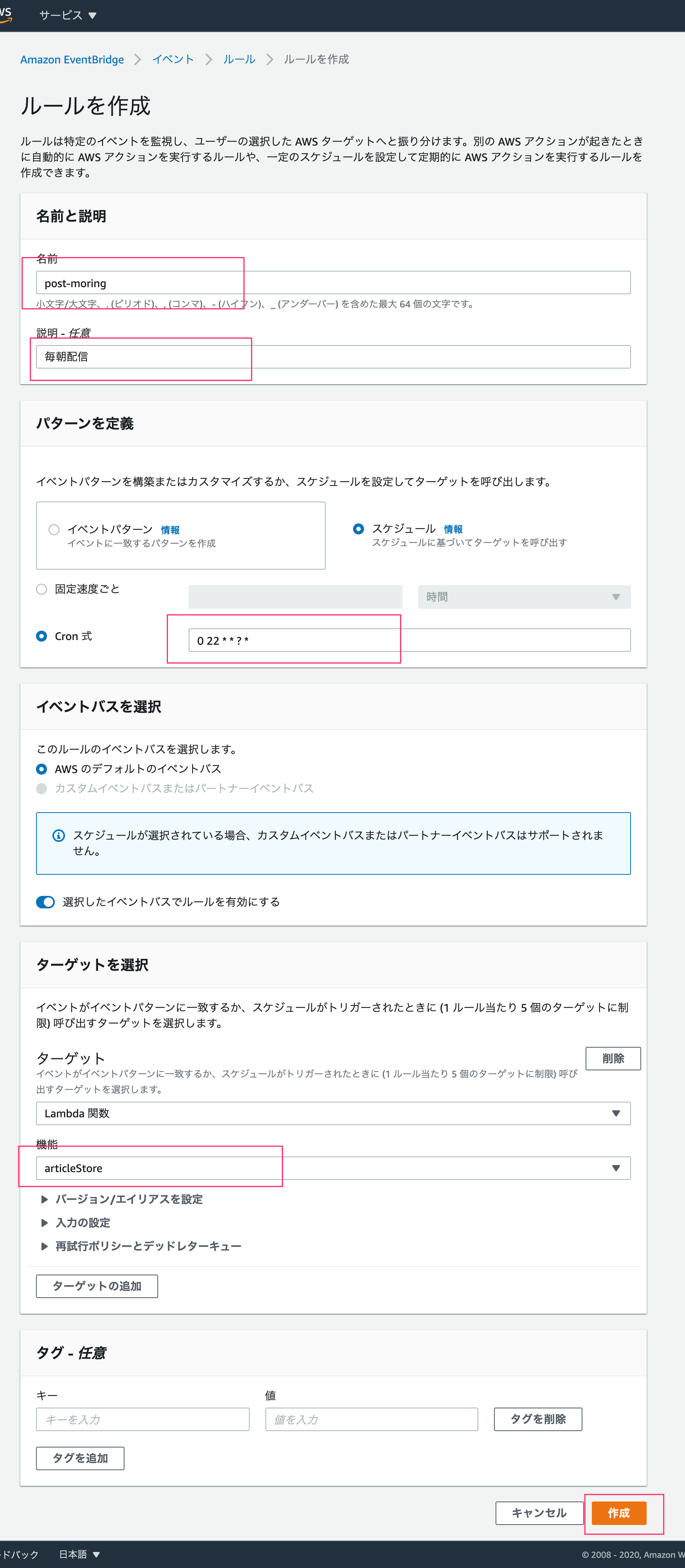
ルール名・説明を書き、cron式は標準時間で実行されるので
0 22 * * ? *として日本時間午前7時に実行するようにします。
ターゲットで対象のlambda名を選び、作成します。
これで完了。
Post-Scripting
この後の予定として、いくつかの新聞社の社説を1年分ストックして機械学習してみようと思っています。
requestsで全てのページを取得できる場合はいいのですが、ページロード時にさらにロードして一覧表示しているサイト(例えば、朝日新聞)がある場合はseleniumでブラウザをコントロールする必要があります。


- 投稿日:2020-11-19T14:54:06+09:00
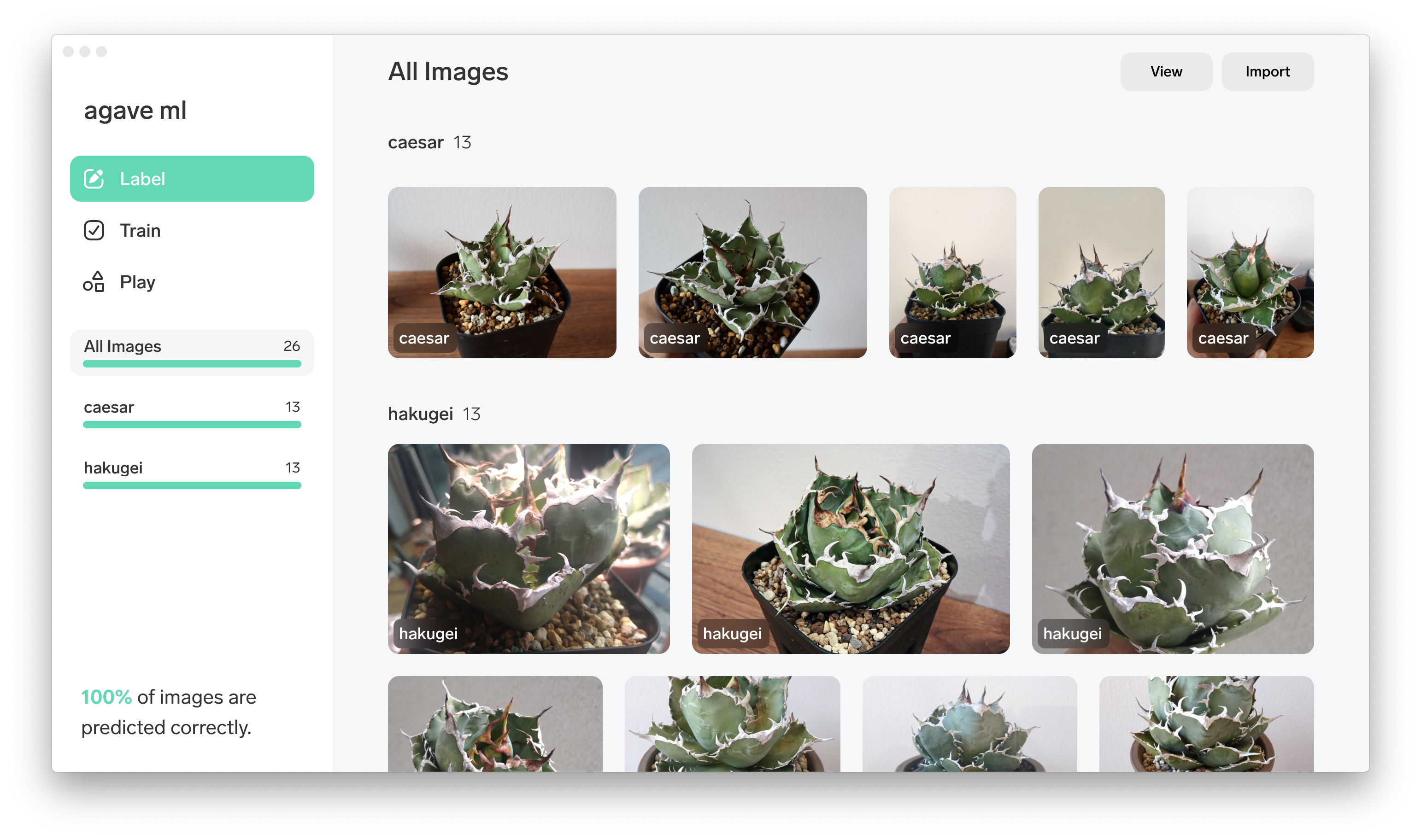
機械学習でアガベを判定してみた。ノーコードで。
はじめに
皆さん植物は好きですか?僕は大好きです。
特にアガベという多肉植物が好きで、好きが講じて海外からアガベを小口輸入してオリジナル鉢と合わせて販売しています。D2Cによりinstagramさえあれば誰だってブランドを立ち上げられるいい時代になりました。
足元に転がった大量のアガベの写真を整理したい
さて本業の傍らで運営している中で困っていることの一つがストックしているアガベの管理です。中でも売れ筋なのがコンパクトで型が良い台湾アガベ。ただ台湾のチタノタ系は独自の名称がついた株が多数存在していてしかも形がよく似ているんです。例えば下の写真
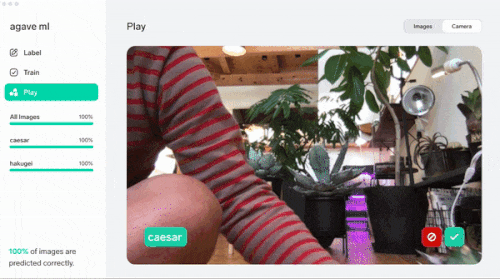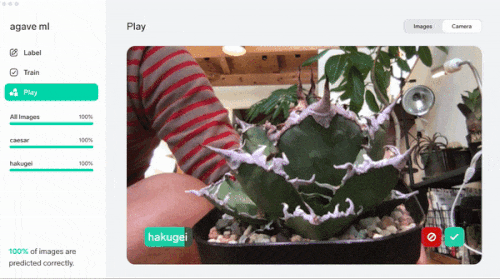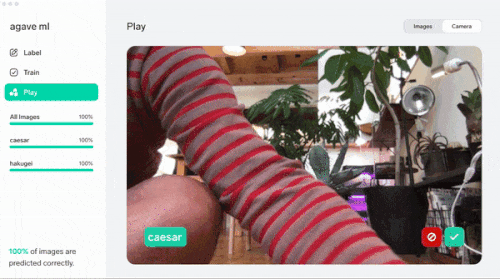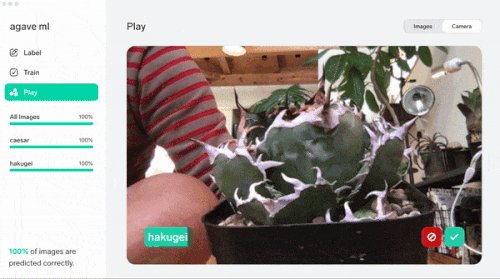
左はみんな大好き『agave titanota "白鯨(はくげい)"』。右がみんなの憧れ『agave titanota "Caesar(シーザー)"』。見分けられますか? うちの家族に見せたところ全然違いが分からないとのこと
見た目が似ていてややこしいアガベの写真を機械学習で種別を判定させて、ゆくゆくは個体も判定できたら各チャネル用の多量な写真の管理が捗りそう、、、でも機械学習についての専門的な知識は持ち合わせていない、、、
そんな自分にぴったりなサービスが各クラウドプラットフォームから出ているので、今回は2つピックアップして検証してみました。
試してみたサービス
今回使ってみたサービスは以下の2つ。
AWS Recognition Image Custom Label
AWSが提供する画像認識、画像分析サービスであるAWS Recognition。基本的にはすでに用意された学習済みモデルしか利用できませんが、Custom Labelを使うことで用途に合わせた独自のモデルの作成とオブジェクトの検出が可能。
Microsoft Lobe
Microsoftが10月26日にプレビューを公開した、ローカルで簡単に機械学習モデルを用意できるツール。ラベルあたり5枚あれば推論ができて、用意したモデルデータは各種フォーマットにエクスポート可能。
いずれも無料(Recognitionは条件あり)でノーコードでラベリング〜学習〜検証までできます。素敵。
検証の内容
上記2つの画像識別サービスを使って以下の内容を検証してみます。
検証方法
- 学習で用意するラベルは二種類。それぞれ10枚ずつ計20枚の学習用の画像を使って学習モデルを用意。
- 学習用とは別の画像40枚を用意してそれぞれのモデルで検証。
検証項目
- 推論結果の精度
- 学習プロセス
【おことわり】
今回の検証は、少ない学習データでかつアガベという特定の植物の種類の判定という条件のもとでの検証なので、この内容が各サービスの品質評価に繋がるものではないということを先にお断りしておきますAWS Recognitionによる機械学習モデルの作成
まずはAWS Recognitionのカスタムラベルから触っていきます。
プロジェクトを作成しカスタムラベルを作成していきます。カスタムラベルは現在us-north-1のリージョンでのみ利用可能なのでその点は忘れずに。
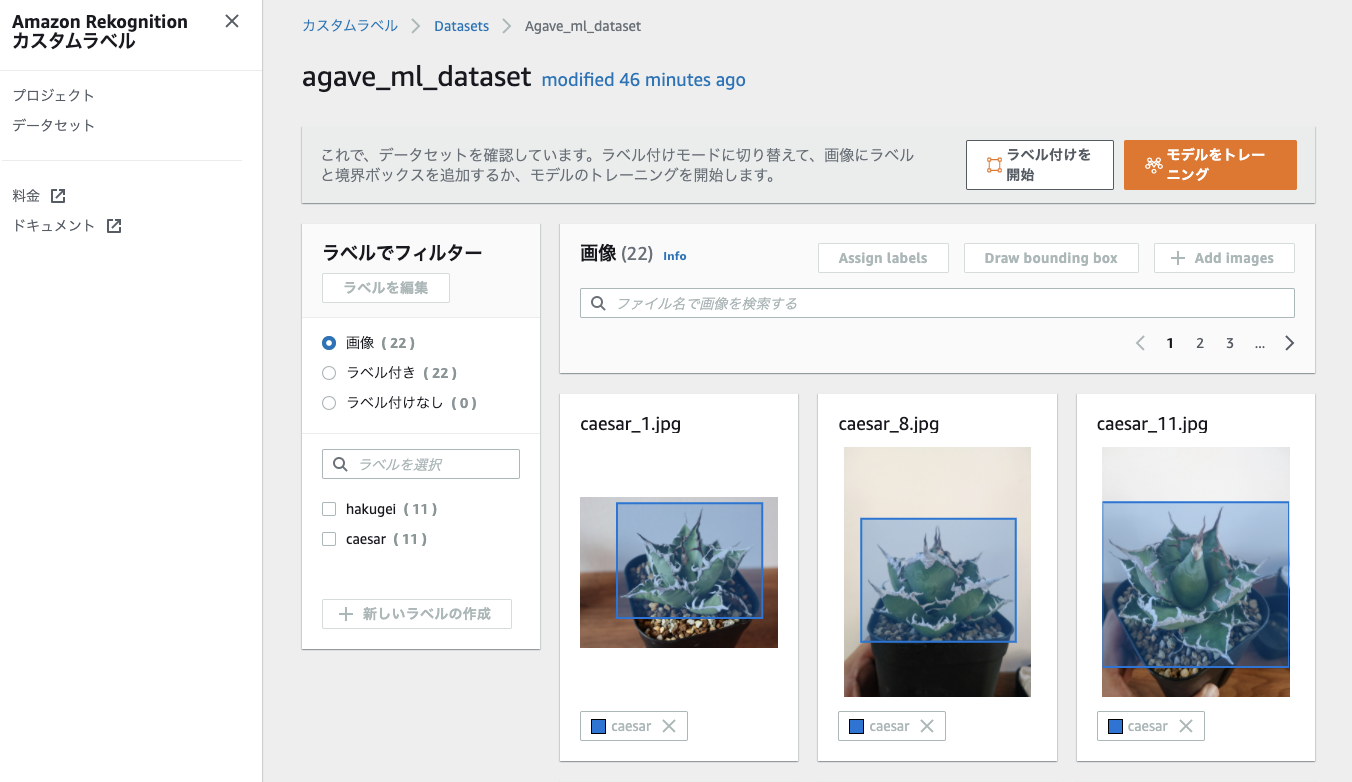
※AWS Recognitionカスタムラベルのプロジェクトやデータセットの詳細な作成方法はここでは割愛します。画像データをアップロードし(一度にできるのは30枚まで)、それぞれにバウンディングボックスとラベルを設定したら、モデルのトレーニングを開始します。
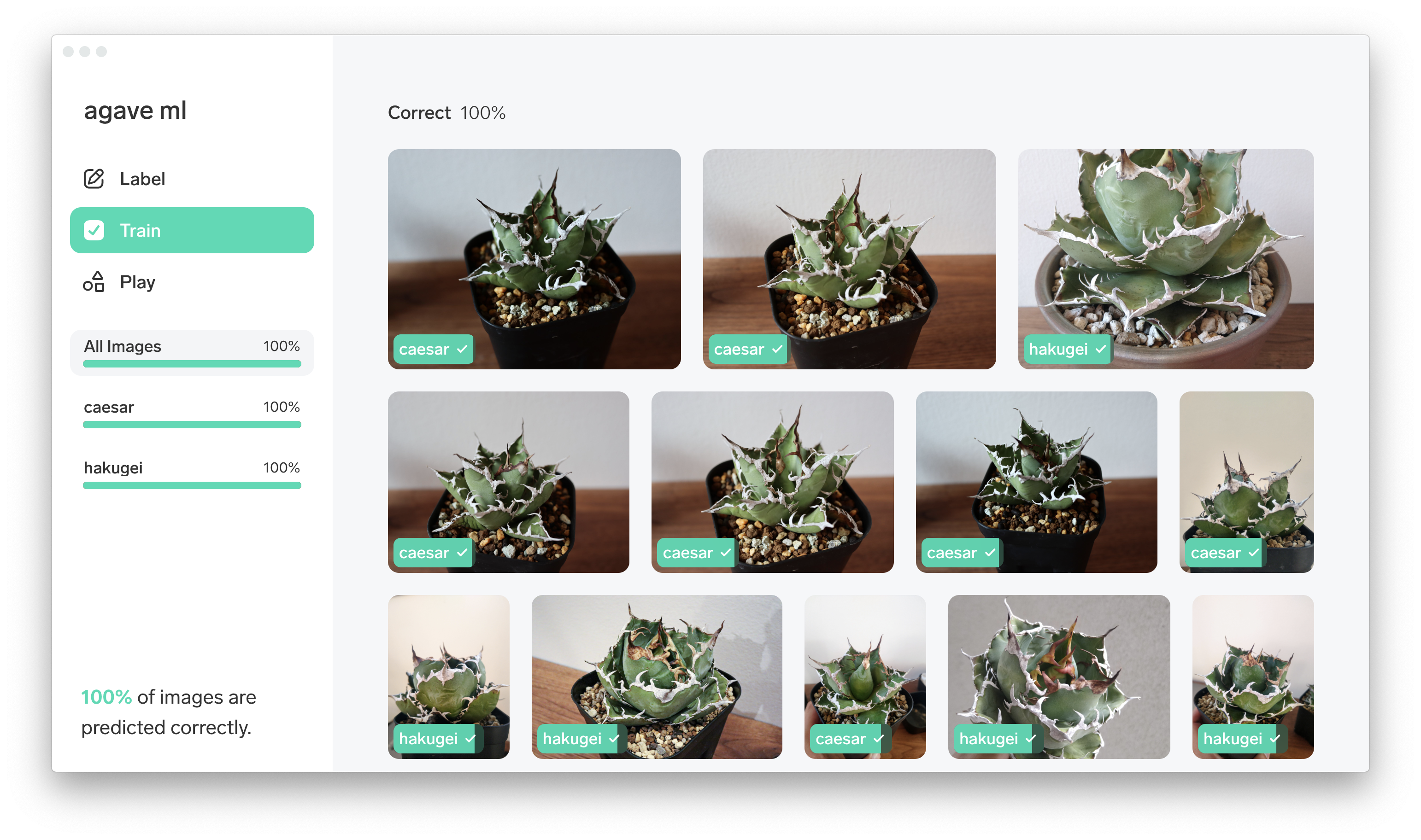
学習
モデルのトレーニングは22枚の画像だと約1時間ほどかかりました。
終わるとモデルの詳細画面にてトレーニングの結果を確認できます。
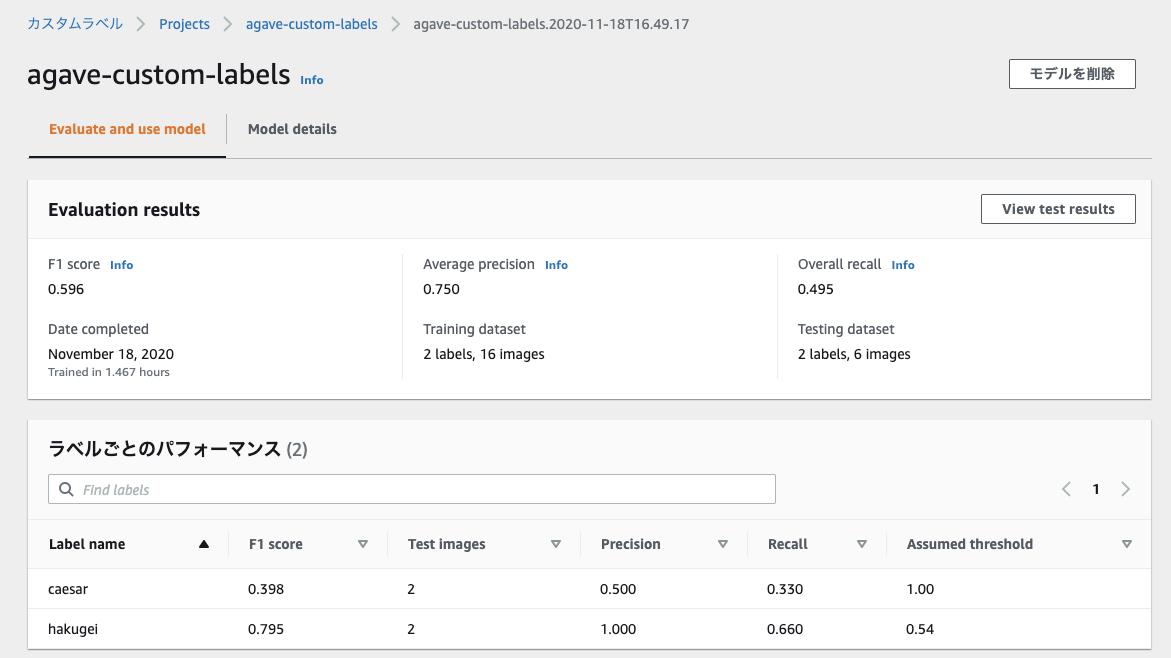
F1 Score(精度と検出率をバランス良く持ち合わせているか示す指標)がめっちゃ低い。。
どうやら内訳を見ると白鯨は0.79とまあ好成績な一方でシーザーが0.39と低く足を引っ張る形に。
今回は数が少ない上に角度もばらばらの画像を使った事で精度が出なかったのかもしれない。推論
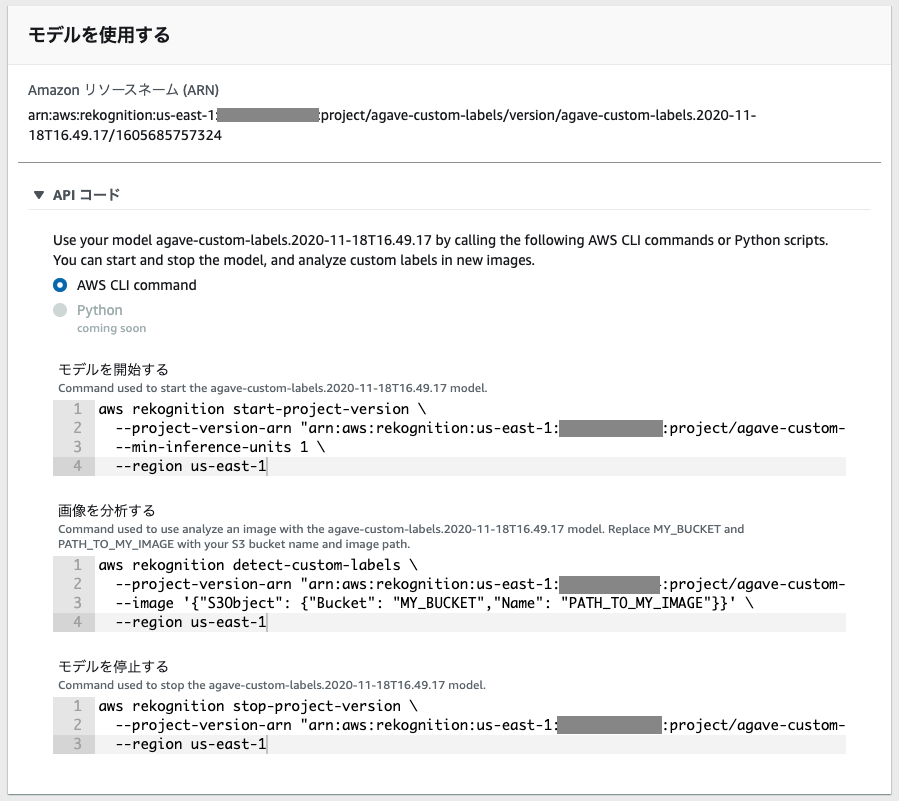
とはいえ一応モデルは出来上がったのでモデルを起動してみます。
AWSの管理コンソール画面上で起動、推論、停止用のAWS CLIコマンドが記載してあるので動作確認がとても楽。
StartAPIを実行。ただなかなかモデルが立ち上がらない。。結局ステータスが"RUNNING"になったのは約30分後。
ようやくRUNNINGになったので早速推論してみます。
推論用のサンプルコードはs3のオブジェクトを参照するようになっているので、適当にS3のバケットを作って画像を上げて実行。"CustomLabels": [ { "Name": "hakugei", "Confidence": 100.0, "Geometry": { "BoundingBox": { "Width": 0.7819100022315979, "Height": 0.9035300016403198, "Left": 0.15939000248908997, "Top": 0.05576999858021736 } } } ]こんな感じのresponceが帰ってきます。テストした画像は白鯨(hakugei)。Confidece(確信度)が100て。めっちゃ心強いやん。ただこのあといくつかテストしてみましたがやはりCaesar(シーザー)はほとんど判定できませんでした。
AWS Recognition Custom Labelによるアガベ画像の自動振り分け
推論の検証をする上でいちいちAPI叩くのが面倒なので、s3に上げた画像をLambdaでAWS Recognition Custom Labelの推論APIを使って判定し、その結果で保存先を自動で振り分けるようにしてみます。
フォルダの振り分けは推論の信頼度が70よりも低い場合は直下に。判別できたものはラベル名のフォルダに振り分けます。今回はPyton製のサーバーレスフレームワークChaliceを使ってLambdaを構築しました。Chaliceめっちゃ便利。用意したコードはこんな感じです。
app.pyimport uuid import boto3 from chalice import Chalice from chalice.app import S3Event app = Chalice(app_name='detect-agave') # S3へのPutをトリガーに設定 @app.on_s3_event(bucket='detect-agave', events=['s3:ObjectCreated:Put'], prefix='', suffix='jpg', name='detect-image') def lambda_handler(event: S3Event): s3 = boto3.client('s3') rekognition = boto3.client('rekognition') bucket = event.bucket key = event.key tmp_key = key.replace('/', '') image_path = '/tmp/{}{}'.format(uuid.uuid4(), tmp_key) # データダウンロード s3.download_file(bucket, key, image_path) # カスタムラベル推論API呼び出し response = rekognition.detect_custom_labels( ProjectVersionArn = 'YOUR_PROJECT_VERSION_ARN', #用意したモデルのリソースネームを設定 Image={'S3Object': {'Bucket': bucket, 'Name': key}}, MinConfidence=70) # 推論結果による振り分け update_bucket = '{}-detected'.format(bucket) for labelDetail in response['CustomLabels']: s3.upload_file(image_path, update_bucket, '{}/{}'.format(labelDetail['Name'],key) else: s3.upload_file(image_path, update_bucket, key)このようにAPIを呼び出すだけで簡単に機械学習モデルによる判定を実装することができました。
Lobeによる機械学習モデルの作成
続いてLobeを試します。
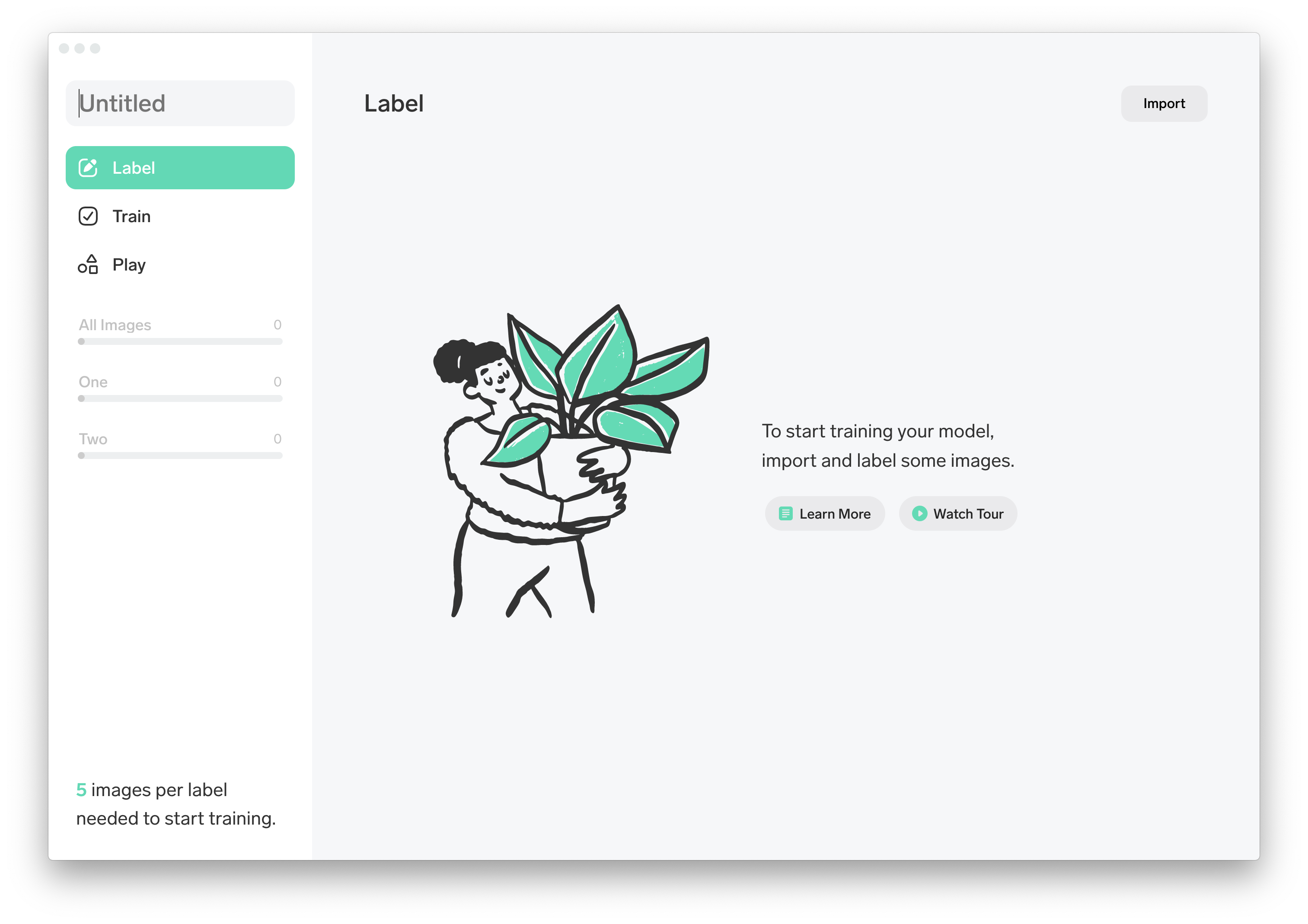
Lobeはローカルで動作します。Windows、Macそれぞれのプログラムが用意されているのでダウンロードします。ダウンロードしたZipファイルを展開して起動すると、以下のような画面が表示されました。
シンプルなメニュー。そして"5 images per label needed to start training."とのこと。今回は10枚ですがそれで一定の精度を出せるのであればすごい。
学習用データのアップロード&ラベル付け
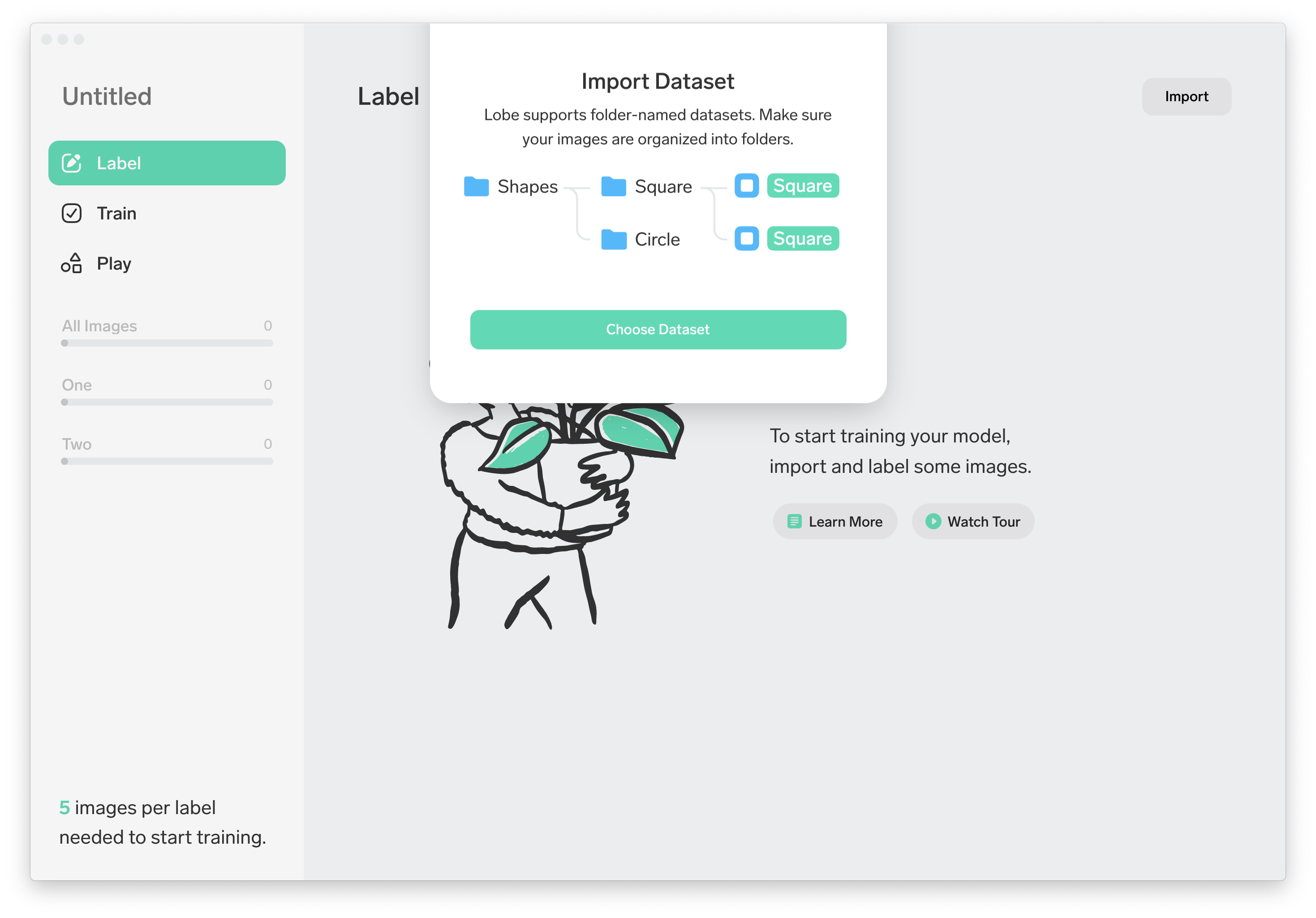
Importは(Image, Camera, Dataset)の3種類の方法から選べます。今回は『Dataset』を選択します。
構造化したフォルダを用意することで自動でラベル付けをしてくれる。これはめちゃ便利でした。
ただ一方でバウンディングボックスによるアノテーションには対応していないということかな。
学習
あっという間にアップロード完了。そしてアップロードすると自動で学習してくれます。これがとにかく速い!気がついたら終わっています。『Train』メニューで結果を確認できます。
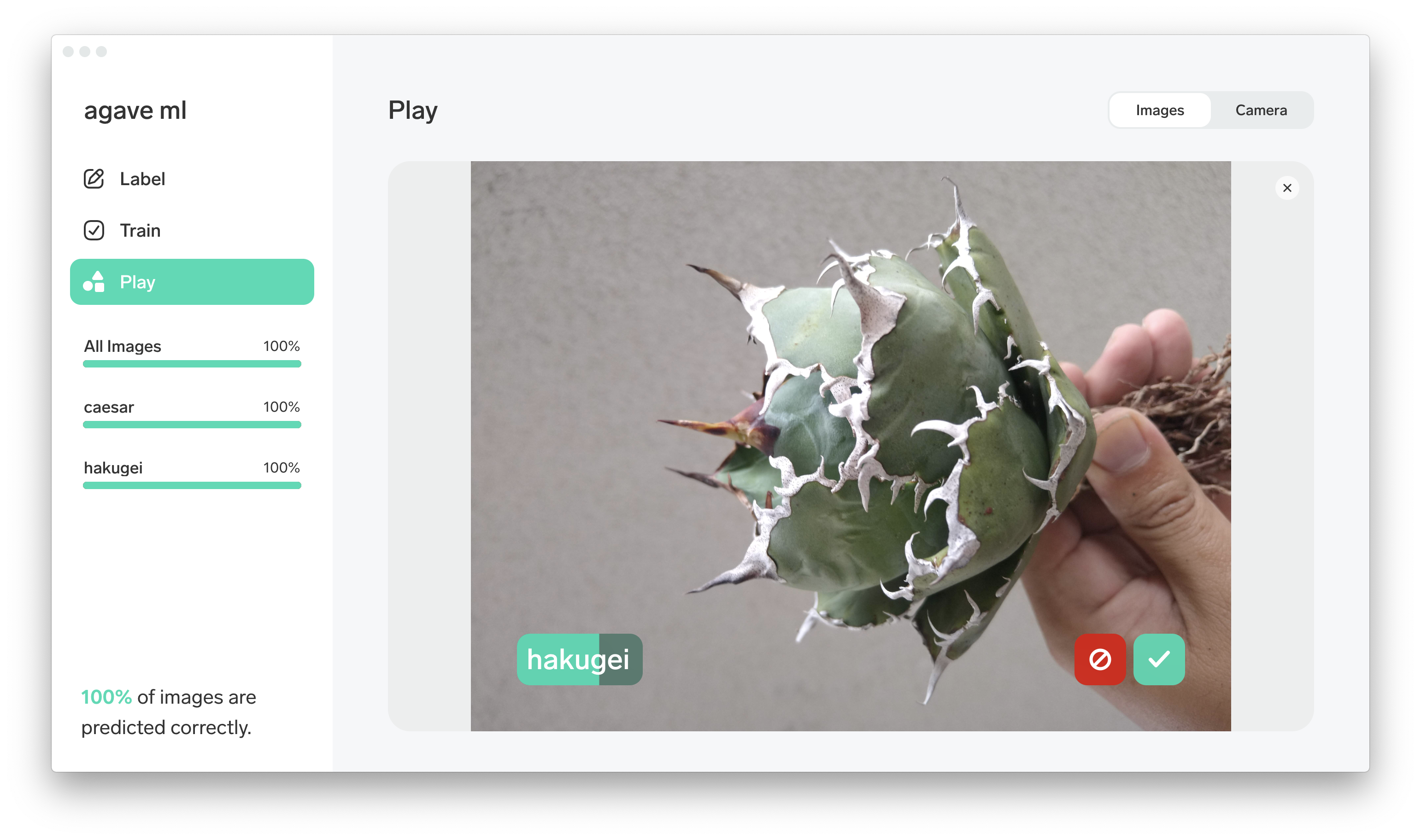
なんと精度100%! ほんと? 早速『Play』で推論してみます。
推論
学習データ以外の画像ファイルをドラッグ&ドロップすることで正しく推論してくれました
さらに『Camera』を使うことでカメラに写ったオブジェクトに対してリアルタイムに推論と修正を進めてくれます。これは捗る。
とにかくデータの用意とトレーニングがサクサク進んで終始ストレスなく進められました。
作成したモデルは汎用的なフォーマットでエキスポートも可能。
本当に簡単なのでこういったツールを使ってたくさんの実用的なモデルが生み出されていくと素敵ですね。検証結果
サービス AWS Recognition - Custom Label Microsoft Lobe 推論の精度 45% 74.5% 学習プロセス 学習データのアップロード、ラベル付の際にUI上の数制限あり。少ないデータでもモデル作成までに時間を要する。バウディングボックスによる単一画像からの複数ラベル抽出が可能。 アップロードしたら即学習開始。モデルの作成時間が非常に短くテンポよく学習が進められる。バウンディングボックスによるラベル付けはできない 上記結果はあくまで各ラベル10枚程度というごく少数でかつアガベという植物の写真を使った検証結果です。
もちろん対象やデータセットの数と画像の処理によってはまた結果は異なるかと思いますが、今回の条件ではLobeの学習プロセスの容易さと少ないデータセットでの精度の高さが目立つ結果となりました。まとめ
簡単に機械学習を使えるいい時代になりました。
個人的に普段はAWSを利用しているので扱いやすいのはAWS Recognitionですが、Lobeの手軽さと精度の高さに感動しました。Lobeは作成したモデルをTensorFlow等様々なフォーマットでエクスポートできるので、分業化して効率を上げながら精度の高いモデルを使ったサービスを手軽に作ることができそうです。皆さんも機械学習で快適なアガベライフを!

- 投稿日:2020-11-19T14:40:57+09:00
インフラ未経験のWEB屋がAWS認定SAA-C02を取得するまでのお話
前書き
実務としてインフラ領域に触れたことなかった僕ですが、
AWS認定ソリューションアーキテクトアソシエイト(SAA-C02)に一発で合格することができたので、勉強開始からの感想を記してみました。
インフラ何もわからなくても興味とやる気があれば受かるってことが伝わればいいなあ受験動機
・インフラに興味あったのでAWS通じて学びたかった
・肩書きがないので資格が欲しかったマイスペック(勉強開始日時点)
・社会人2年目、WEB屋始めて1年目くらい
・バックエンドやフロントエンドのコーディングはなんとなくできる(いわゆるローカル上だけ、ローカルとかその概念すらわかってなかったですよ当時)
・インフラやネットワークの知識0(サーバとかIPとかDNSとか概念からよくわからん、ほんとにほんとに)
・AWSの存在を知って3ヶ月目くらい勉強期間
トータル4ヶ月くらい
勉強開始から受験までは約9ヶ月(有効期間3年と聞いて途中やる気なくした)勉強の流れ
書籍①(後述記載)を1周読み進める。
↓
書式②を読み進める。
↓
Udemy①をちょっと進めてやる気を無くす
↓(数ヶ月後)
Udemy①再開
↓
Udemy②を解きまくる
↓
公式模擬試験を受けてみて正答率50%だったので絶望する
↓
とはいえ勉強飽きてきたので試験日を2週間後に決めてUdemy②を再び解きまくる
↓
試験日1週間前にBlackBeltを初めて読んで感動する(わかりやすくて)
↓
試験実施
↓
合格!!!!!!!試験の感想
正直、Udemyの問題の方が難しく感じた。
でもやっぱり回答中は震えましたね。(受験料高いし・・)
問題について詳しくは書けませんが、勉強した内容がほぼほぼ出題されたので自信ありで回答できました。
一部よくわからないのもあったので怖かったけど。点数
※まだ正確な点数は出ていないので届いたら載せようかなと思います。(よろしければご参考に)2020/11/20追記
点数届いたので追記しました。
結果: 747/1000 点
めちゃくちゃギリギリで震えた。。。自信あったのにしんど。↓こんな感じで届きます
※余談
↓約2千円の公式模擬試験の結果
一瞬投げ出しましたが諦めずに続けて良かった。
(個人的)合格に向けてのポイント
- サービス名を見て、どんなサービスなのか、どんな役割があるかがすぐに浮かぶレベルはマスト
- 類似サービスの比較、適切なユースケースは理解しておく(特にストレージ類)
- 各サービスを使った基本的なアーキテクチャは把握しておく
- 練習問題をとにかく解いて要件ごとのポイントを体感で覚える(Udemyオススメ)
- 各種教材を通して出たサービスのBlackBeltの資料は見ておく
- 各種サービスは絶対に動かしてみる!!(ホント大事)
勉強に使用したモノ
書籍
①AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
- 主要サービスの役割をなんとなく知れる
- 1周読んで、後は不明点出た時に都度振り返りに
- ざっくり辞書って感じ、体系的には学べないのが難点
- 多分もう古い
②一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト
- 上記読んだ後に1周
- ポイントに沿って各サービスのユースケースが知れて良い
- 各サービスへの理解が薄いうちに読むと効率悪いかも
Udemy
①これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
- 最初にこれから見とけば良かったと思うくらい良いハンズオン教材
- ただこれだけじゃダメです(さすがに)
https://www.udemy.com/share/101WKkAEIceV5bRHkH/
②【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
- 作者様考案の模擬試験
- ひたすら解いてた
https://www.udemy.com/share/101rfMAEIceV5bRHkH/
AWS公式資料
BlackBelt資料
- 絶対見るべきモノ、とても分かりやすい
- ある程度理解が深まった後に見ると尚良いかも
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/#compute-services
公式模擬試験
- 理解度確認と受験システムへの慣れのために受けてみた
- 約2000円する・・・
- 本試験より簡単という意見が多いですが、自分は難しく感じました。操作しないとわからないことや抜けてた知識が丁度でまくったせいかも。
以上
他の方の合格体験記を見ると、他にも色々なサービスで勉強されていますが、自分は上記のみでした。
試験を終えて
ネットワークに関する知識は勉強前に比べてかなり付いたと思います。
AWSというサービスに特化した試験とはいえ、WEB技術者にとっては例えAWSを使わなくても取得を目指してみる価値はあるのかなーと思います。こんな人に受けてみて欲しい
- 何か資格が欲しい → 肩書きあると気持ち変わりますよ(体験談)
転職、昇進の武器にしたい → IT市場ではとても有名かつ有用な資格みたいなので(まだ実感ないけど)
インフラ、ネットワーク領域について学びたい → ほんと理解が深まりました。アプリケーションの公開をしてみたい人とか良い足掛かりになると思う。
最後に
以上僕の合格体験記でした。
結構月日をかけてしまったので、数週間で合格された方など見るとすごいな〜と思います。
インフラの知識なくても受かるんだーって少しでも勇気を与えられたら幸いです。




- 投稿日:2020-11-19T13:56:02+09:00
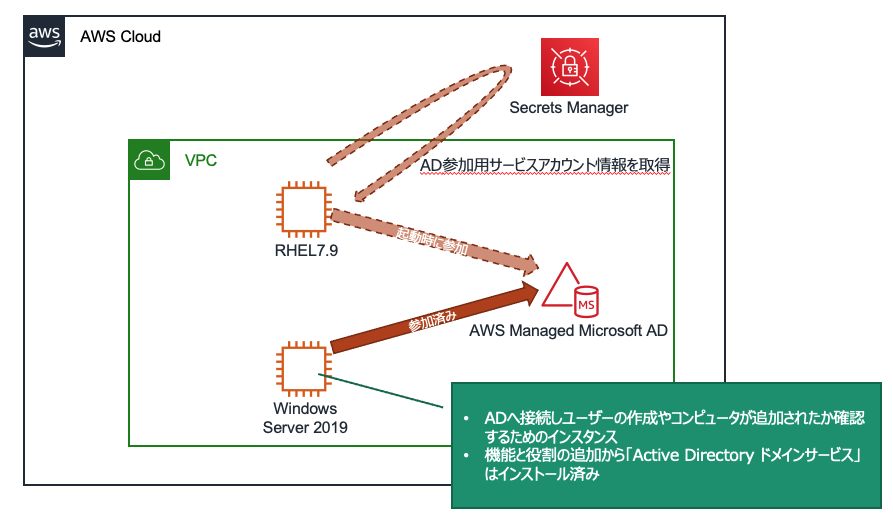
Linux EC2インスタンスをAWS Managed Microsoft ADへシームレスに参加させる
Linux EC2インスタンスをAWS Managed Microsoft ADに参加させてIDの統合管理をしている環境があるのですが、今までインスタンスが増える度に手動でAD参加コマンド実行、パスワード入力という手順を実施してインスタンスのデプロイに非常に時間がかかっていました。加えてEC2 AutoScalingの検討しておりこのパスワード入力の壁越えなきゃなーと調べていたら、今年に入りシームレスなAD参加がサポートされていました!
Amazon EC2 for Linux インスタンスを AWS Directory Service にシームレスに参加させる
ということでLinuxインスタンスデプロイ時にAD参加させる方法を検証してみました。
ちなみに、冒頭で触れた今までのAD参加方法はこちら↓↓
Linux インスタンスを手動で結合する今回検証した手順はこちら↓↓
Linux EC2インスタンスをシームレスに参加 AWS Managed Microsoft AD ディレクトリ前提条件
まず2020/11/17時点でサポートされているディストリビューション、バージョンは以下となります。
- Amazon Linux AMI 2018.03.0
- Amazon Linux 2 (64 ビット x86)
- Red Hat Enterprise Linux 8 (HVM) (64 ビット x86)
- Ubuntu Server 18.04 LTS & Ubuntu Server 16.04 LTS
- CentOS 7 x86-64
- SUSE Linux Enterprise Server 15 SP1
Noteに
"Distributions prior to Ubuntu 14 and Red Hat Enterprise Linux 7 do not support the seamless domain join feature."
とありましたので、RHEL7はOKと判断しRHEL7で検証しました。また、対象インスタンスにはAWS Systems Manager (SSM Agent) バージョン 2.3.1644.0 以上が必要となっています。
ということで、
検証環境
- Region: Tokyo
- DirectoryService: AWS Managed Microsoft AD Standard ※作成済み
- AD参加するインスタンス: RedHat Enterprise Linux 7.9
- ADに接続して操作するインスタンス: WindowsServer 2019 ※作成済み
では、検証
AWS Managed Microsoft ADへRHEL7.9インスタンスを起動時に参加させます。
まずはドメインユーザーの作成から。AD参加用ドメインユーザーの作成
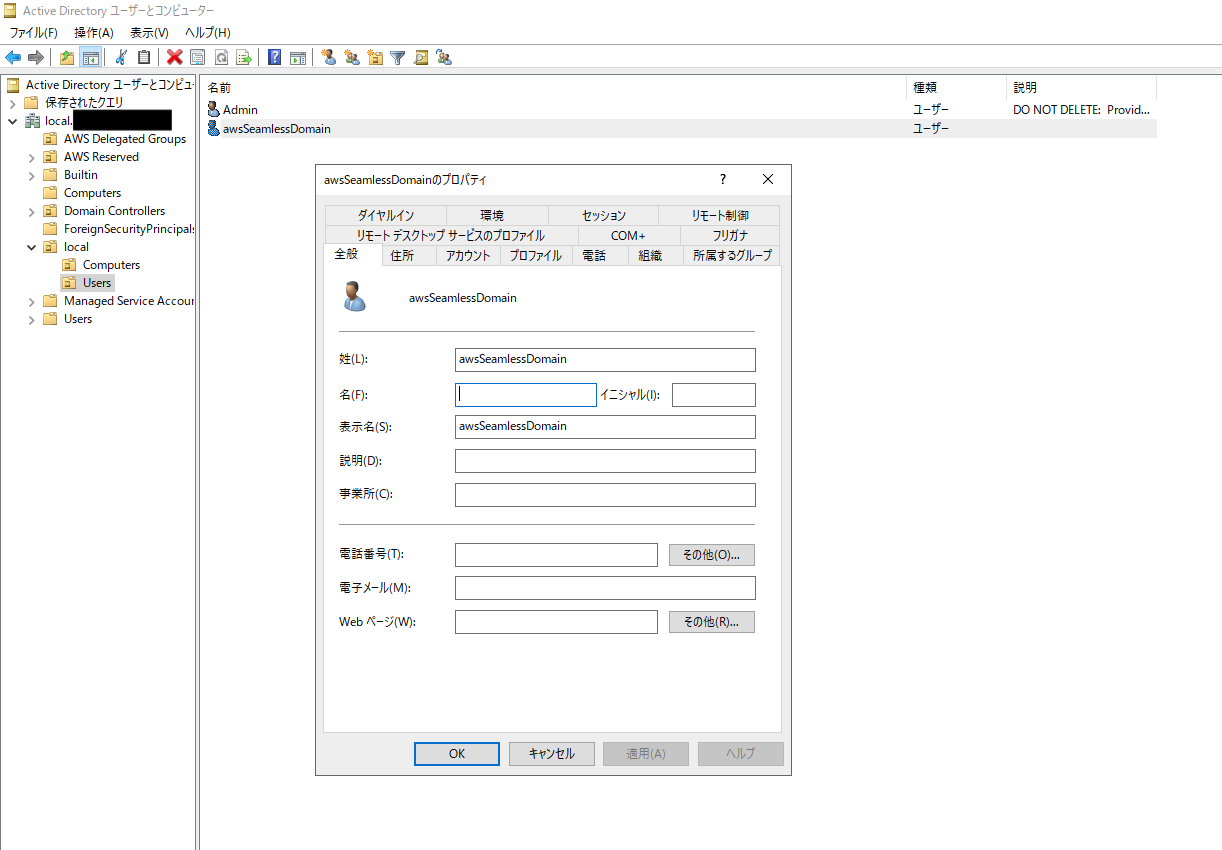
LinuxインスタンスをAD参加させるため、コンピュータアカウントの作成権限をもつドメインユーザーをサービスアカウントとして設定します。
今回の構成で言うと、AD参加済みのWindowsServer 2019にて、"Active Directory ドメインサービス"を開いて(別のユーザーとして実行からMicrosoft ADのAdminユーザーで接続)ユーザを新規作成しておきました。
次に作成したドメインユーザーに対し権限を付与します。AD参加させるためだけに使用するものとなりますので、できる限り最小限の権限をもたせる形にしたい、ということで下記の通りPowerShellコマンドが用意されていました。1行目の
$AccountNameには先程作成したドメインユーザー名を入力します。$AccountName = 'awsSeamlessDomain' # DO NOT modify anything below this comment. # Getting Active Directory information. Import-Module 'ActiveDirectory' $Domain = Get-ADDomain -ErrorAction Stop $BaseDn = $Domain.DistinguishedName $ComputersContainer = $Domain.ComputersContainer $SchemaNamingContext = Get-ADRootDSE | Select-Object -ExpandProperty 'schemaNamingContext' [System.GUID]$ServicePrincipalNameGuid = (Get-ADObject -SearchBase $SchemaNamingContext -Filter { lDAPDisplayName -eq 'Computer' } -Properties 'schemaIDGUID').schemaIDGUID # Getting Service account Information. $AccountProperties = Get-ADUser -Identity $AccountName $AccountSid = New-Object -TypeName 'System.Security.Principal.SecurityIdentifier' $AccountProperties.SID.Value # Getting ACL settings for the Computers container. $ObjectAcl = Get-ACL -Path "AD:\$ComputersContainer" # Setting ACL allowing the service account the ability to create child computer objects in the Computers container. $AddAccessRule = New-Object -TypeName 'System.DirectoryServices.ActiveDirectoryAccessRule' $AccountSid, 'CreateChild', 'Allow', $ServicePrincipalNameGUID, 'All' $ObjectAcl.AddAccessRule($AddAccessRule) Set-ACL -AclObject $ObjectAcl -Path "AD:\$ComputersContainer"上記コマンドをWindowsServer 2019で実行し、awsSeamlessDomainを必要最小限の権限を持ったサービスアカウントとして設定しました。
Secrets Managerにサービスアカウント情報を保存
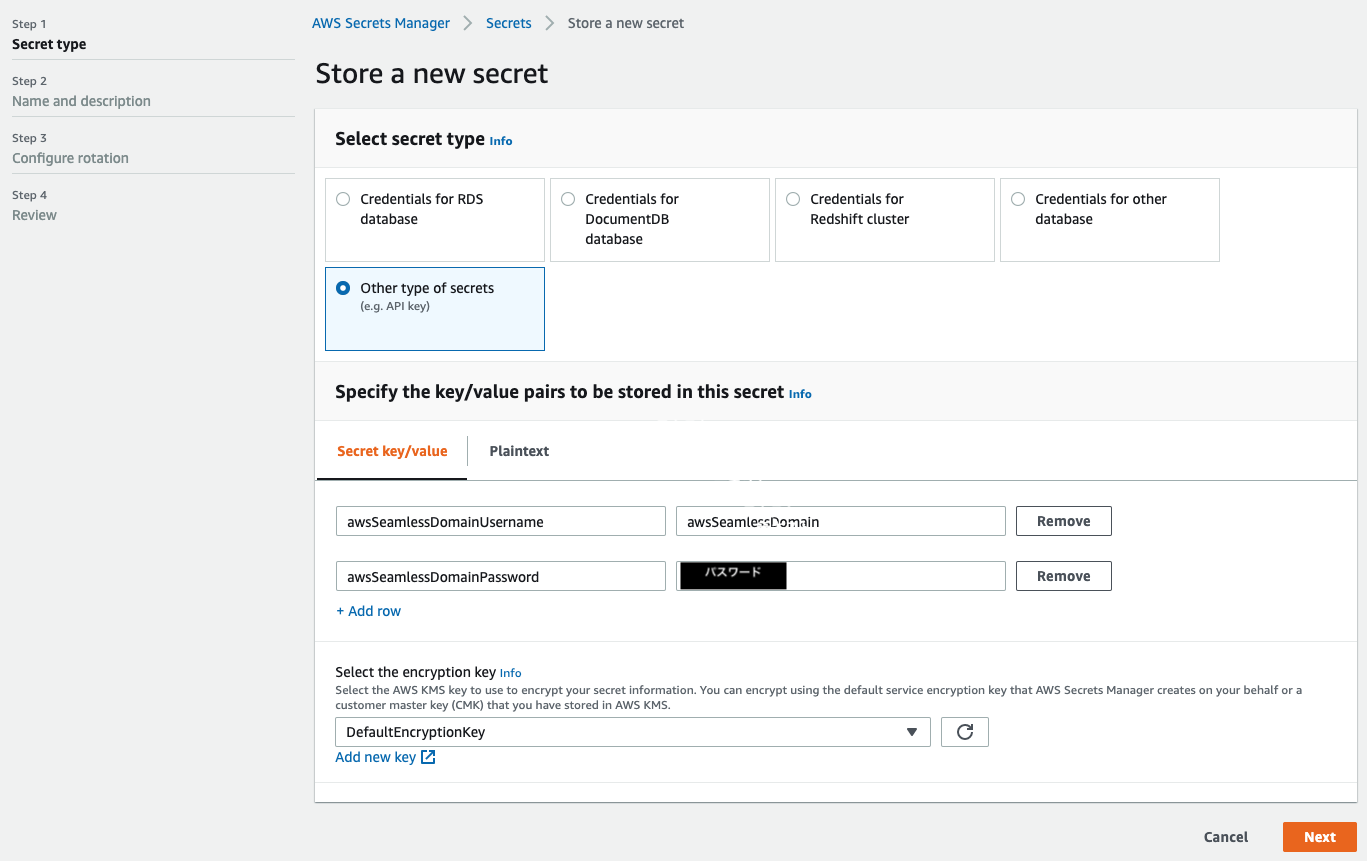
インスタンス起動時のドメイン参加において、先程作成したサービスアカウントを利用するため、Secrets Managerに情報を保存しておきます。
Secrets Managerのサービスコンソールに遷移後、Store a new secretをクリックし、下図の通り設定しました。
Other type of secretsを選択し、key/valueにサービスアカウント名とパスワードを指定します。
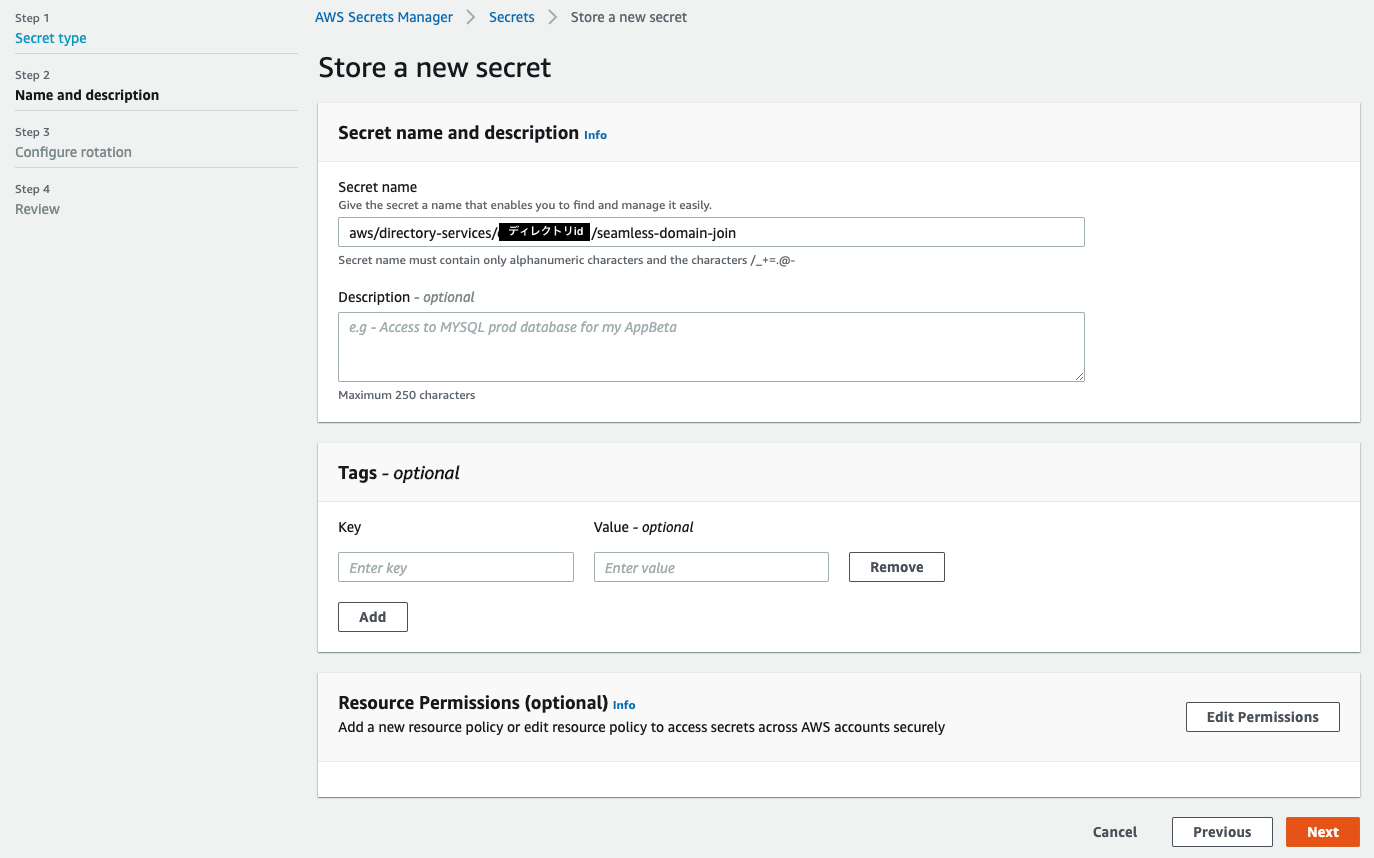
Secret nameを指定します。
Configure rotationではDisable automatic rotationを指定します。
設定を確認して保存すると、新しいシークレットが追加されます。Secret ARNはIAMポリシー設定時に使いますので、控えておきます。
IAMロールの作成
AD参加するインスタンスに付与するIAMロールを作成します。
対象IAMロールにはAWS管理ポリシー×2、カスタマー管理ポリシー×1をアタッチしますので、先にカスタマー管理ポリシーを作成しておきます。
手順は省略しますが、ポリシー名をSM-Secret-Linux-DJ-<ディレクトリid>-Readとし、以下のポリシードキュメントで作成しました。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret" ], "Resource": [ "<作成したSecretのARN>" ] } ] }続いてIAMロールはSelect type of trusted entityでEC2を選択し、ポリシーの選択で下記3つの管理ポリシーにチェックを入れます。
- AmazonSSMManagedInstanceCore
- AmazonSSMDirectoryServiceAccess
- SM-Secret-Linux-DJ-<ディレクトリid>-Read ※先程作成したカスタマー管理ポリシー
ロール名はLinuxEC2DomainJoinとし、IAMロールを作成します。
Linux EC2インスタンスをADに参加させる
ここまででLinux EC2インスタンスを新規起動時にAD参加させるための準備が整いました!
インスタンスを起動し、AD参加できていることを実際に確認してみます。
- EC2コンソールからLaunch Instancesをクリックします。
- Step 1: Choose an Amazon Machine Image (AMI)では、起動するLinuxインスタンスAMIをします。今回はCommunity AMIsからRHEL7.9を選択しました。
- Step 2: Choose an Instance Typeで任意のインスタンスタイプを選択します。
- Step 3: Configure Instance Detailsはポイントとなるステップです。VPCなどは各環境に合わせて指定しますが、本ステップでは参加するAD、IAMロール、およびSSM AgentをインストールするためのUserDataを指定します。
- Domain join directory: 作成済みのAWS Managed Microsoft AD Standardドメイン
- IAM role: LinuxEC2DomainJoin
- User data: 以下のスクリプトを指定
#!/bin/bash -xe exec > >(tee /var/log/user-data.log|logger -t user-data -s 2>/dev/console) 2>&1 yum install -y https://s3.ap-northeast-1.amazonaws.com/amazon-ssm-ap-northeast-1/latest/linux_amd64/amazon-ssm-agent.rpm systemctl enable amazon-ssm-agent systemctl start amazon-ssm-agent systemctl status amazon-ssm-agent
- Step 4〜6については環境に合わせて設定します。
- Step 7: Review Instance Launchで設定内容を確認し、Launchをクリックします。
新規Linux EC2インスタンスの起動が開始されました。
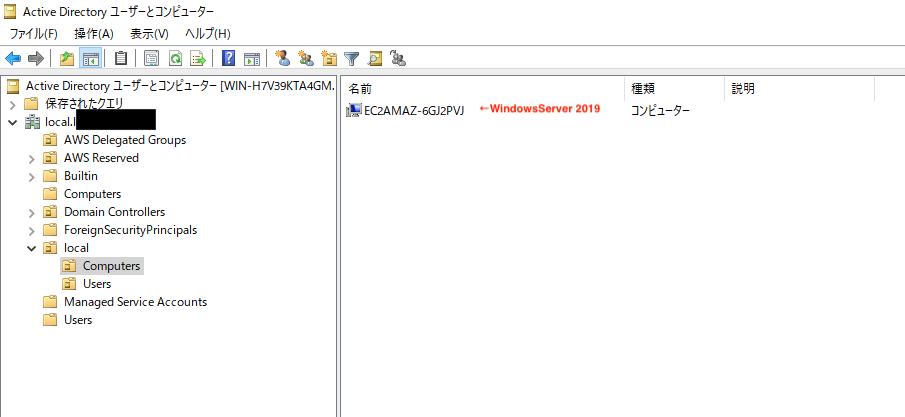
ここで再度WindowsServerにログインし、ADのコンピュータアカウントを確認してみます。起動前は既にAD参加済みのWindowsのみ表示されていました。
Linux EC2インスタンスの起動完了後、画面を更新すると、コンピュータアカウントが追加されています。
ドメインユーザーでLinux EC2インスタンスにSSHログインできるか確認してみると、
無事ログインできました!まとめ
Linux EC2インスタンス起動時にシームレスにAD参加する方法を検証しました。
以前は手動でコマンド実行していた関係でドメイン参加が漏れていた、なんてこともありましたが
起動時に自動で参加してくれるのであれば作業漏れありませんね。
これでEC2 AutoScaling時にも活用できそうです。(2020/11/19追記)
AutoScalingグループで指定するLaunch Templatesでは、参加するドメインの指定ができなさそう。。なので結局はUserDataでゴリゴリやるしかないかなぁ。。
- 投稿日:2020-11-19T12:10:05+09:00
AWSを勉強する - ELB
ELB(Elastic Load Balancing)
リリースしたサービスが人気で、負荷がかかって来た時、単純にスケールアップすることでも対応できるが、インスタンスタイプには限界がある。
また、単一のインスタンスで運用していると、そのインスタンスが停止したときにサービス全体が停止してしまう。(単一障害点)
そのため、ロードバランサーを使って負荷を分散させ、高負荷にも対応するスケールアウトを行う必要がある。
ELBは、ロードバランサーのマネージドサービス。ELBのタイプ
- CLB(Classic Load Balancer):L4/L7レイヤーでの負荷分散を行う
- ALB(Application Load Balancer):L7レイヤーでの負荷分散を行う
WebSocketやHTTP/2に対応している。
ALBはパスルーティングによりCLBより容易にバランシング構成が可能。
ALBは一つのバランサーでより複雑な構成に対応できる。
- NLB(Network Load Balancer):L4レイヤーでの負荷分散を行う。HTTP(S)以外のプロトコル通信の負荷分散をしたいときに利用する。
ロードバランサー自体が固定のIPアドレスを持っている。
超低遅延で高スループットを維持しながら秒間何百万リクエストを捌くように設計された新しいロードバランサー。ELBの特徴
ヘルスチェック
設定された間隔で配下にあるEC2にリクエストを送り、各インスタンスが正常に動作しているかを確認する機能
もし異常なインスタンスが見つかった時は自動的に切り離し、その後正常になったタイミングで改めてインスタンスをELBに紐付ける。ヘルスチェックの設定値
- 対象のファイル
- ヘルスチェックの間隔
- 何回連続でリスエストが失敗したらインスタンスを切り離すか
- 何回連続でリクエストが成功したらインスタンスを紐付けるか
Auto Scaling
システムの利用状況に応じて自動的にELBに紐づくインスタンスの台数を増減させる機能。
Auto Scaling設定項目
- 最小のインスタンス数
- 最大のインスタンス数
- インスタンスの数を増やす条件と増やす数
- インスタンスの数を減らす条件と減らす数
Auto Scalingを利用することで、繁忙期やピーク時間はインスタンス数を増やし、閑散期や夜間のリクエストが少ない時は、インスタンス数を減らすといったことができる。
EC2の利用状況に応じて自動的にインスタンスの台数を増減させることて、リソースの最適化、耐障害性の向上を図れる。ターミネーションポリシー
需要減に基づくスケールインの際にどのインスタンスから終了するかを設定。
- OldestInstance / NewesInstance:最も古いインスタンスや新しい起動時刻のインスタンスなどの順から終了
- OldestLaunch Configuration:最も古い起動設定により起動しているインスタンスから終了
- ClosestToNextInstanceHoure:次の課金が始まるタイミングが最も近いインスタンスから終了
- デフォルト設定:OldestLaunch Configuration、ClosestToNextInstanceHoureの順に適用する。その後、複数インスタンスが残った場合はランダムに終了する。
Auto Scalingの設定プロセス
- ALBの作成
- ターゲットグループの作成
- 起動するインスタンス設定
- Auto Scalingグループ作成
- Auto Scalingポリシー作成 or スケジュール設定
ELBとAuto Scalingの設計ポイント
サーバーをステートレスに、つまり状態を保持しないように設計すること。
AZをまたがってインスタンスを配置する設計にすべき。以下に単一障害点をなくすか、部分の障害は起こり得ることを前提として設計する。
用語まとめ
スケールアップ
インスタンスタイプを上げる。垂直にスペックを上げる。メモリやCPUの追加・増強
スケールダウン
インスタンスタイプを下げる。垂直にスペックを下げる。メモリやCPUの削減・低性能化
単一障害点(Single Point Of Failure、SPOF)
ある特定の部分が止まると全体が止まってしまう箇所のこと。
スケールアウト
EC2インスタンスを水平に並べる。EC2インスタンスを複数並べ、その前段にロードバランサーを配置してリクエストを各インスタンスに分散させる。
処理する機器・サーバー台数を増加する。スケールイン
処理する機器・サーバー台数を低減する。
スパイク
急激な負担増。
参考
- 投稿日:2020-11-19T10:33:16+09:00
Elasticsearchのsnapshot取得してリストア(復元)するまで
Amazon Elasticsearch Service(以後esと記載)のsnapshotを取得する際、権限まわりで詰まったので、まとめてみる。
利用環境はMacです。【背景】
- esのsnapshotを手動で取得するのってどんな方法でできるんだろう。
- なんかちょっと権限まわりややこしそうだから一回触ってみよう
- 取得と復元でどれぐらい時間がかかるかもできたら測ってみよう
こんな課題感で手を動かし始めました。
【実際にやったこと】
- 公式ドキュメントを参考にする
- 【Amazon Elasticsearch Service】 手動スナップショットからリストアする方法を参考にする(この記事を本当に参考にさせていただきました)
- Kibanaでアクセス許可を与える
このような手順で実現させて行きました!!!
手動でS3にsnapshotを取得していく
手動でsnapshotを作成するためには、前提として、以下の対応が必要になります。
- s3のバケットの作成
- IAMロール、ポリシーを整理する(←ここで苦労しました)
- Kibanaでの認証
- 手動snapshotのリポジトリを登録する
- 手動snapshotを取得する
- snapshotを取得したリポジトリを確認する
- snapshotの取得状況を確認する
- スナップショットのリストア
- 一度インデックスを削除する
- 指定したインデックスをリストアする
今回記述しているscriptはpythonで書いていますが、他にもJava, Ruby, Node, Goでも記述できます。こちらの公式ドキュメントを参考にしてください
それでは順番に説明していきたいと思います。
S3バケットの作成
手動でsnapshotを保存するためのバケットを作成する。
今回はS3コンソールでarn:aws:s3:::test-es-snapshotを作成した。これは以下の二つの箇所で必要になる
- IAMロールにアタッチされたIAMポリシーのResource Statement内
- snapshotリポジトリ登録に使用するpythonのpayload内
IAMロール、ポリシーを整理する
今回確認すべき箇所は三箇所
1.ESのサービスロール(arn:aws:iam::ユーザ名:role/es_s3_role)を作成する。
信頼関係を以下のように編集する
principalで指定するのは"誰がこのロールを引き受けるか”ということ
以下のServiceはesを示しており、「作成したサービスロールはesを引き受ける」という意味(だと思う。)サービスロールの信頼関係に記載{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" }] }2.S3に対してアクセスし、データを取得するためのポリシーをサービスロールに対してアタッチする
create-es-backup-policyという管理ポリシーを以下の内容で作成し、上で作成したサービスロールに対してアタッチする
create-es-backup-policy(作成したサービスロールに対してアタッチする){ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot/*" ] } ] }3.Kibana側でIAMロールのアクセスを許可する
Kibana で、[Security (セキュリティ)]、[Role Mappings (ロールのマッピング)]、[Add (追加)] の順に選択します。[Role (ロール)]で、[manage_snapshots] を選択します。次に、IAM ユーザーまたは IAM ロールの ARN を該当するフィールドに指定します。ユーザーの ARN は、[Users (ユーザー)]セクションに入力します。ロールの ARN は、[Backend roles (バックエンドロール)] セクションに入力します。(※これで、スナップショットを使用するためのロール情報のアクセス許可を付与する)
今回はKibanaのRole MappingsというページのBackend Rolesというところに、作成したサービスロールのARN情報を入力した。
(IAMのポリシーの操作でも認証情報は設定できるはずだが、エラーで詰まったのでこの手法で回避した)以上で、IAMロール周りの整理は終わりです。
手動snapshotのリポジトリを登録する
以下のpythonスクリプトを実行する(参考資料では認証をアクセスキーで行っていたが、現在公式からアクセスキーでの認証は、推奨されていない)
register-repositry.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # Register repository path = '_snapshot/test-es-snapshot' # the Elasticsearch API endpoint url = host + path payload = { "type": "s3", "settings": { "bucket": "バケット名", "region": "リージョン名", "role_arn": "作成したサービスロール名" } } headers = {"Content-Type": "application/json"} r = requests.put(url, auth=awsauth, json=payload, headers=headers) print(r.status_code) print(r.text)responseが以下のようになっていることを確認する
200 {"acknowledged":true}手動snapshotを取得する
snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1' # the Elasticsearch API endpoint url = host + path r = requests.put(url, auth=awsauth) print(r.text)実行例-> % python snapshot.py Enter MFA code for : {"accepted":true}snapshotを取得したリポジトリを確認する
check_repository.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_repository.py Enter MFA code for : { "cs-automated-enc" : { "type" : "s3" }, "test-es-snapshot" : { "type" : "s3", "settings" : { "bucket" : "test-es-snapshot", "region" : "リージョン名", "role_arn" : "作成したサービスロール名" } } }snapshotの取得状況を確認する
check_snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/_all?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_snapshot.py Enter MFA code for : { "snapshots" : [ { "snapshot" : "my-snapshot-1", "uuid" : "*************", "version_id" : ******, "version" : "7.8.0", "indices" : [ "index名①", "index名②", ・・・・・・ ], "include_global_state" : true, "state" : "SUCCESS", "start_time" : "2020-11-17T07:20:17.265Z", "start_time_in_millis" : 1605597617265, "end_time" : "2020-11-17T07:21:21.901Z", "end_time_in_millis" : 1605597681901, "duration_in_millis" : 64636, "failures" : [ ], "shards" : { "total" : 38, "failed" : 0, "successful" : 38 } } ] }スナップショットのリストア
リストアの際に同じ名前のインデックスがある場合、リストアできないので、リストアしたいインデックスを一度削除する必要があります。
指定のインデックスを一度削除して、リストアするまでの手順を示します。一度インデックスを削除する
delete_index.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # DELETE INDEX path = 'インデックス名' url = host + path r = requests.delete(url, auth=awsauth) print(r.text)実行例-> % python delete_index.py Enter MFA code for : {"acknowledged":true}esのコンソールで、ドメインを選択し、インデックスタブに行くと、インデックスが削除できていることを確認できます。
また、ダッシュボードで、検索可能なドキュメントが少なくなっていることも確認できます。指定したインデックスをリストアする
restore_one.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1/_restore' url = host + path payload = {"indices": "インデックス名"} headers = {"Content-Type": "application/json"} r = requests.post(url, auth=awsauth, json=payload, headers=headers) print(r.text)実行例-> % python restore_one.py Enter MFA code for : {"accepted":true}まとめ
snapshotの取得やリストアは参考資料がとても役に立ちました。(ほとんど同じです。)
IAMのロールやポリシーの整理をするときに、結構苦労しました。。。
どのロールにどのポリシーをアタッチしたとかをしっかり整理できてないと厳しかったです。。どなたかの参考になれば幸いです。。
- 投稿日:2020-11-19T10:33:16+09:00
Amazon Elasticsearch serviceのsnapshot取得してリストア(復元)するまで
Amazon Elasticsearch Service(以後esと記載)のsnapshotを取得する際、権限まわりで詰まったので、まとめてみる。
利用環境はMacです。【背景】
- esのsnapshotを手動で取得するのってどんな方法でできるんだろう。
- なんかちょっと権限まわりややこしそうだから一回触ってみよう
- 取得と復元でどれぐらい時間がかかるかもできたら測ってみよう
こんな課題感で手を動かし始めました。
【実際にやったこと】
- 公式ドキュメントを参考にする
- 【Amazon Elasticsearch Service】 手動スナップショットからリストアする方法を参考にする(この記事を本当に参考にさせていただきました)
- Kibanaでアクセス許可を与える
このような手順で実現させて行きました!!!
手動でS3にsnapshotを取得していく
手動でsnapshotを作成するためには、前提として、以下の対応が必要になります。
- s3のバケットの作成
- IAMロール、ポリシーを整理する(←ここで苦労しました)
- Kibanaでの認証
- 手動snapshotのリポジトリを登録する
- 手動snapshotを取得する
- snapshotを取得したリポジトリを確認する
- snapshotの取得状況を確認する
- スナップショットのリストア
- 一度インデックスを削除する
- 指定したインデックスをリストアする
今回記述しているscriptはpythonで書いていますが、他にもJava, Ruby, Node, Goでも記述できます。こちらの公式ドキュメントを参考にしてください
それでは順番に説明していきたいと思います。
S3バケットの作成
手動でsnapshotを保存するためのバケットを作成する。
今回はS3コンソールでarn:aws:s3:::test-es-snapshotを作成した。これは以下の二つの箇所で必要になる
- IAMロールにアタッチされたIAMポリシーのResource Statement内
- snapshotリポジトリ登録に使用するpythonのpayload内
IAMロール、ポリシーを整理する
今回確認すべき箇所は三箇所
1.ESのサービスロール(arn:aws:iam::ユーザ名:role/es_s3_role)を作成する。
信頼関係を以下のように編集する
principalで指定するのは"誰がこのロールを引き受けるか”ということ
以下のServiceはesを示しており、「作成したサービスロールはesを引き受ける」という意味(だと思う。)サービスロールの信頼関係に記載{ "Version": "2012-10-17", "Statement": [{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" }] }2.S3に対してアクセスし、データを取得するためのポリシーをサービスロールに対してアタッチする
create-es-backup-policyという管理ポリシーを以下の内容で作成し、上で作成したサービスロールに対してアタッチする
create-es-backup-policy(作成したサービスロールに対してアタッチする){ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::test-es-snapshot/*" ] } ] }3.Kibana側でIAMロールのアクセスを許可する
Kibana で、[Security (セキュリティ)]、[Role Mappings (ロールのマッピング)]、[Add (追加)] の順に選択します。[Role (ロール)]で、[manage_snapshots] を選択します。次に、IAM ユーザーまたは IAM ロールの ARN を該当するフィールドに指定します。ユーザーの ARN は、[Users (ユーザー)]セクションに入力します。ロールの ARN は、[Backend roles (バックエンドロール)] セクションに入力します。(※これで、スナップショットを使用するためのロール情報のアクセス許可を付与する)
今回はKibanaのRole MappingsというページのBackend Rolesというところに、作成したサービスロールのARN情報を入力した。
(IAMのポリシーの操作でも認証情報は設定できるはずだが、エラーで詰まったのでこの手法で回避した)以上で、IAMロール周りの整理は終わりです。
手動snapshotのリポジトリを登録する
以下のpythonスクリプトを実行する(参考資料では認証をアクセスキーで行っていたが、現在公式からアクセスキーでの認証は、推奨されていない)
register-repositry.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # Register repository path = '_snapshot/test-es-snapshot' # the Elasticsearch API endpoint url = host + path payload = { "type": "s3", "settings": { "bucket": "バケット名", "region": "リージョン名", "role_arn": "作成したサービスロール名" } } headers = {"Content-Type": "application/json"} r = requests.put(url, auth=awsauth, json=payload, headers=headers) print(r.status_code) print(r.text)responseが以下のようになっていることを確認する
200 {"acknowledged":true}手動snapshotを取得する
snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1' # the Elasticsearch API endpoint url = host + path r = requests.put(url, auth=awsauth) print(r.text)実行例-> % python snapshot.py Enter MFA code for : {"accepted":true}snapshotを取得したリポジトリを確認する
check_repository.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_repository.py Enter MFA code for : { "cs-automated-enc" : { "type" : "s3" }, "test-es-snapshot" : { "type" : "s3", "settings" : { "bucket" : "test-es-snapshot", "region" : "リージョン名", "role_arn" : "作成したサービスロール名" } } }snapshotの取得状況を確認する
check_snapshot.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/_all?pretty' url = host + path r = requests.get(url, auth=awsauth) print(r.text)実行例-> % python check_snapshot.py Enter MFA code for : { "snapshots" : [ { "snapshot" : "my-snapshot-1", "uuid" : "*************", "version_id" : ******, "version" : "7.8.0", "indices" : [ "index名①", "index名②", ・・・・・・ ], "include_global_state" : true, "state" : "SUCCESS", "start_time" : "2020-11-17T07:20:17.265Z", "start_time_in_millis" : 1605597617265, "end_time" : "2020-11-17T07:21:21.901Z", "end_time_in_millis" : 1605597681901, "duration_in_millis" : 64636, "failures" : [ ], "shards" : { "total" : 38, "failed" : 0, "successful" : 38 } } ] }スナップショットのリストア
リストアの際に同じ名前のインデックスがある場合、リストアできないので、リストアしたいインデックスを一度削除する必要があります。
指定のインデックスを一度削除して、リストアするまでの手順を示します。一度インデックスを削除する
delete_index.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように # DELETE INDEX path = 'インデックス名' url = host + path r = requests.delete(url, auth=awsauth) print(r.text)実行例-> % python delete_index.py Enter MFA code for : {"acknowledged":true}esのコンソールで、ドメインを選択し、インデックスタブに行くと、インデックスが削除できていることを確認できます。
また、ダッシュボードで、検索可能なドキュメントが少なくなっていることも確認できます。指定したインデックスをリストアする
restore_one.pyimport boto3 import requests from requests_aws4auth import AWS4Auth region = 'リージョン名' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) host = 'esドメインのエンドポイント /' # /を忘れないように path = '_snapshot/test-es-snapshot/my-snapshot-1/_restore' url = host + path payload = {"indices": "インデックス名"} headers = {"Content-Type": "application/json"} r = requests.post(url, auth=awsauth, json=payload, headers=headers) print(r.text)実行例-> % python restore_one.py Enter MFA code for : {"accepted":true}まとめ
snapshotの取得やリストアは参考資料がとても役に立ちました。(ほとんど同じです。)
IAMのロールやポリシーの整理をするときに、結構苦労しました。。。
どのロールにどのポリシーをアタッチしたとかをしっかり整理できてないと厳しかったです。。どなたかの参考になれば幸いです。。
- 投稿日:2020-11-19T00:58:19+09:00
AWSの新サービス「AWS Network Firewall」を早速使ってみた
はじめに
2020/11/17のアップデートで「AWS Network Firewall」という新しいサービスが登場しました。
本記事ではこのサービスの特徴について調べ、使い所を検討してみます。これまでのサービスとは
これまで、AWSで外部からのアクセス制御・保護と言えば以下のサービスがありました。
- Amazon Elastic Compute Cloud (EC2) インスタンスレベルでアクセス制御するSecurity Group
- Amazon Virtual Private Cloud (VPC) のサブネットレベルでアクセス制御するNetwork ACL
- Amazon CloudFront、Application Load Balancer (ALB)、Amazon API Gatewayで実行されているWebアプリケーションを保護するAWS Web Application Firewall (WAF)
- 分散サービス拒否(DDoS)攻撃から保護するAWS Shield
AWS Network Firewallとは
新たに登場した「AWS Network Firewall」では、AWS上の仮想ネットワークを保護するために、ステートフルインスペクション、侵入防止・検知、Webフィルタリングを簡単に導入・管理できます。
また「AWS Network Firewall」は、トラフィック量に応じて自動的にスケーリングし、高可用性のあるアクセス制御・保護機能となります。特に、新たにできること
「AWS Network Firewall」では、以下の事が可能となります。
- VPCが不正なドメインにアクセスしないようにカスタマイズしたルールを実装
- 数千もの既知の悪意のあるIPアドレスをブロックしたり、シグネチャベースの検出機能を使って悪意のあるアクティビティを特定
- CloudWatchのメトリクスを介してファイアウォールのアクティビティをリアルタイムで可視化し、ログをS3、CloudWatch、Kinesis Firehoseに送信することでネットワークトラフィックの可視性を向上
- AWS Firewall Managerと統合されているため、AWS Organizationsを利用していれば、すべてのVPCとAWSアカウントのファイアウォールアクティビティを単一の場所で有効化し、監視
- Network Firewallは、CrowdStrike、Palo Alto Networks、Splunkなどの既存のサードパーティ製セキュリティ製品との相互運用が可能
- コミュニティで管理されているSuricataのルールセットから既存のルールをインポート可能
基本的な考え方
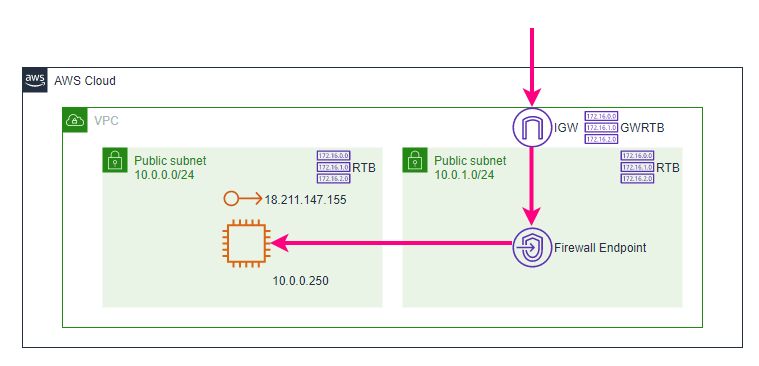
VPCで、AZごとにFirewallを使用し、各AZでトラフィックをフィルタリングするためのFirewall Endpointを起動するサブネットを選択します。
AZ内のFirewall Endpointは、そのサブネットを除く、AZ内のすべてのサブネットを保護できます。AWS Network Firewallは以下の3つの要素で成り立っています。
Firewall
- 保護したいVPCをFirewall Policyで定義された動作にアタッチします。
- 保護したい各AZに対して、Firewall Endpoint専用のパブリックサブネットをNetwork Firewall用に構築します。
- Firewallを使用するには、Route Tableを更新して、Firewall Endpoint経由でInboundとOutboundトラフィックを送信するようにします。
Firewall Policy
- ステートレスとステートフルのRule Groupやその他の設定の集合体
- Firewallの動作を定義
- 各Firewallを1つのFirewall Policyにアタッチしたり、1つのFirewall Policyを複数のFirewallにアタッチすることが可能
Rule Group
- ネットワークトラフィックの検査と処理方法を定義するステートレスまたはステートフルなルールの集合
- ルール設定には、5-tuple (送信元IP、送信元ポート番号、宛先IP、宛先ポート番号、プロトコル番号)とドメイン名によるフィルタリングを含む
- Suricataのオープンソースのルールセットを使用することによるステートフルルールも定義可能
AWS Network Firewall経由で外部から接続できるように構成変更する
記事執筆(2020/11/18)時点では東京リージョンには登場していません。
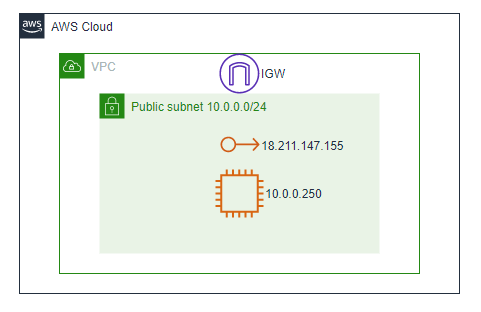
バージニア北部リージョンで試していきます。前提1: 前提環境の用意
まずはインターネット経由でElastic IPを宛先にして、直接SSHとHTTPで接続できるEC2を用意します。
ここから検証のスタートです。
※記事を公開した時点で、Elastic IPをリリースしております。
クライアントから、Elastic IP宛にHTTPで接続します。
この時のVPC Flow Logsは以下の通りで、クライアントのGlobal IPから、EC2のPrivate IPに80番ポートで接続され、戻りの通信が発生しています。
この接続を、AWS Network Firewallを経由してもパスすることを目指してみます。前提2: 目指す構成
目指す構成は、クライアントとWebサーバの間にAWS Network Firewallが挟まったとしても接続を維持できる状態とします。
手順1: Firewall用サブネットの作成
作るだけなので割愛します。
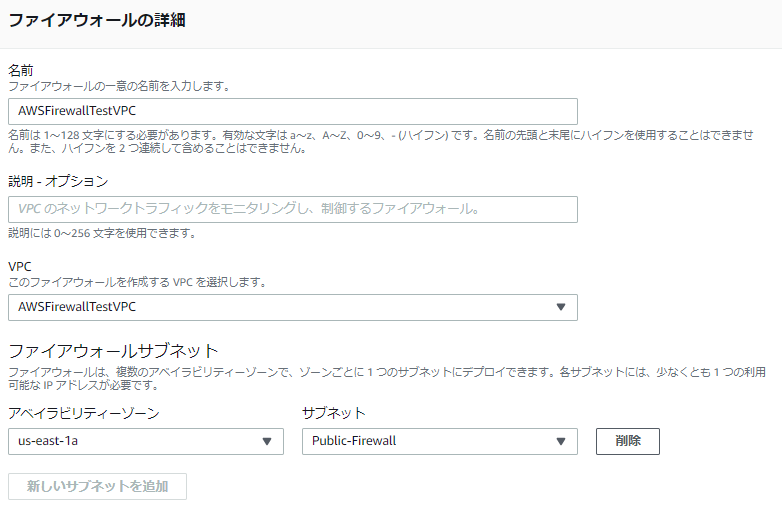
手順2: Firewallの作成
手順1で作ったサブネット上に、まずFirewallを作成します。
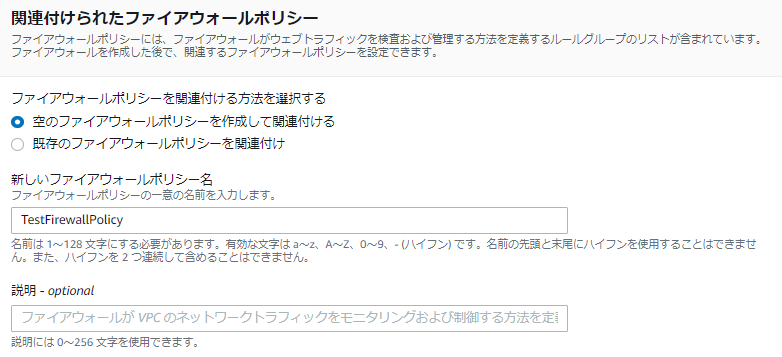
一緒に空のFirewall Policyを作っておきます。
ここまで入力して「ファイアウォールの作成」を押します。
ここまでで、FirewallとFirewall Policyのプロビジョニングが開始されます。
プロビジョニングには少々の時間がかかります。
完了すると以下のように表示されます。
Firewallがプロビジョニングされると、Firewallに接続するためのFirewall Endpointが作成されます。
手順3: Firewall PolicyのRule Groupを設定
判定順はステートレスルール→ステートフルルールの順番です。
今回はステートレスルールだけを設定します。
まずはInboundのHTTP通信をパスします。
パスさせたいので、アクションには「パス」を選びます。
戻りのOutboundも同じようにパスします。
ルールの登録が以下の状態になったところで「作成と追加」を押します。
また、ステートレスルールに合致しなかったアクションの取り扱いを決めておきます。
今回は「ドロップする」にします。
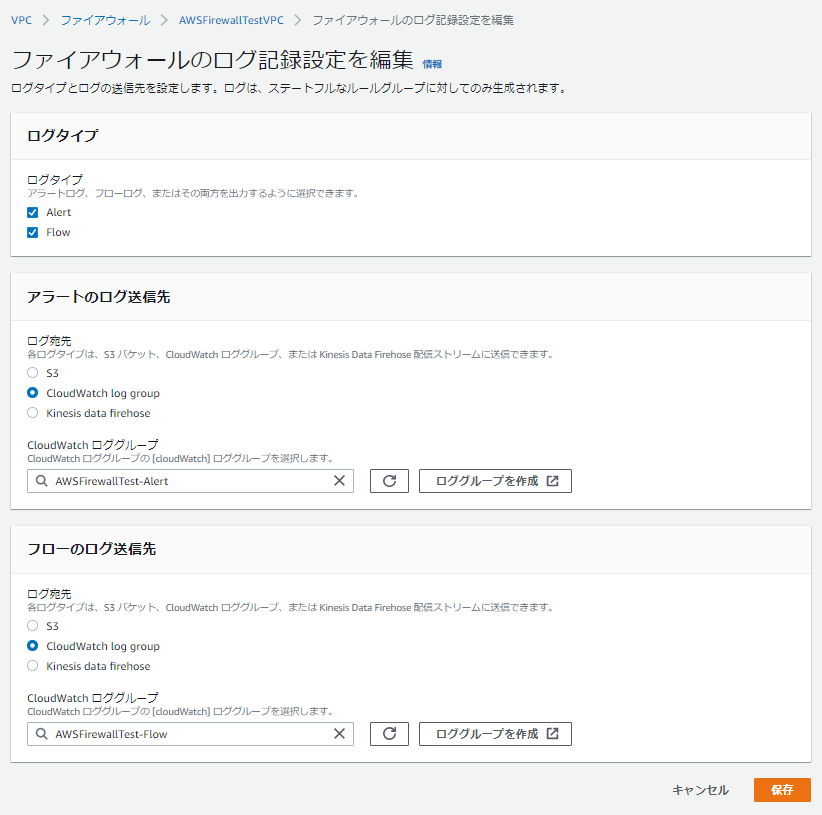
手順4: Firewallのログ記録を有効化する
Firewallで「ログ記録」を有効化しておきます。
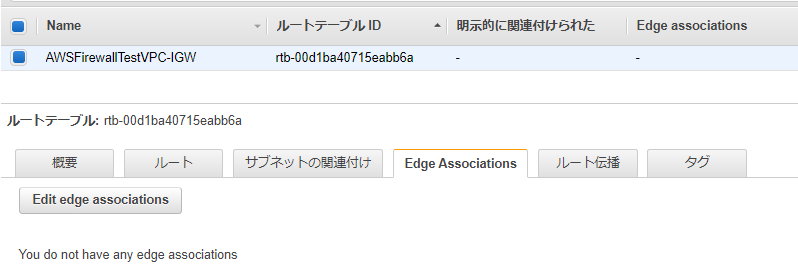
手順5: Gateway Route Tableの作成とInternet Gatewayへのアタッチ
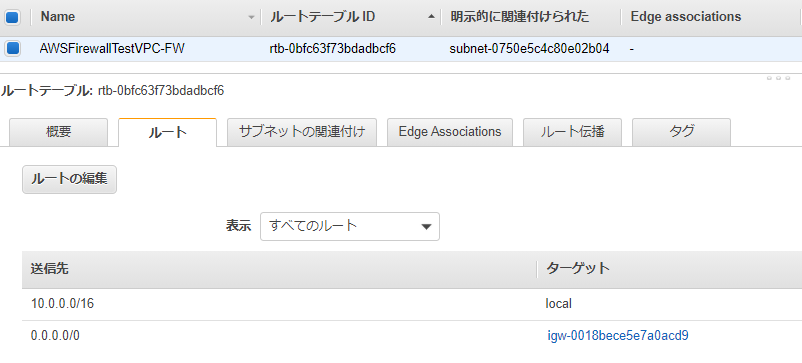
トラフィックがInternet Gatewayを通過する時に、Firewall Endpointを経由させるために、Internet GatewayにRoute Tableをアタッチします。
以下の画面の「Edge Associations」を編集します。
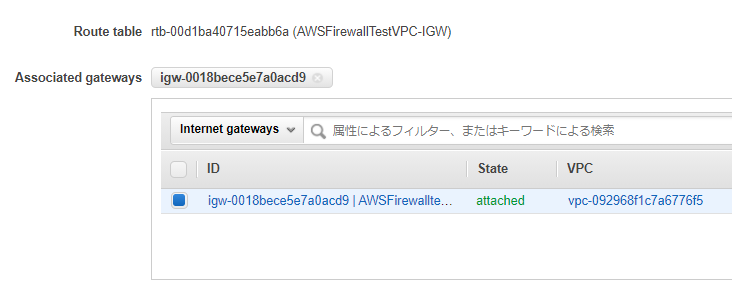
既に作られているIGWに、Route Tableを関連付けます。
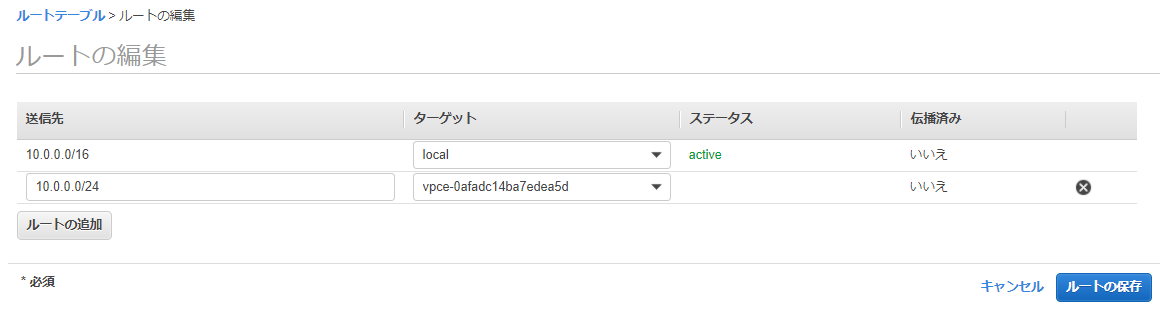
ルートには、今回の例でWebサーバが存在する10.0.0.0/24宛のアクセスがFirewall経由になるように設定します。
手順6: Subnet Route Tableの変更
サブネットにアタッチされているRoute Tableの設定を変更し、通信経路を変えます。
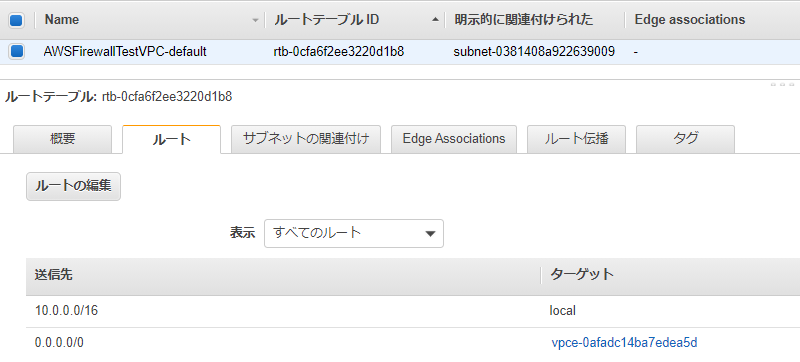
Firewallが存在する10.0.1.0/24のサブネットにアタッチされているRoute Tableは以下となります。
Webサーバが存在する10.0.0.0/24のサブネットにアタッチされているRoute Tableは以下となります。
デフォルトゲートウェイが、IGWからFirewall Endpointに変わりました。
ここまでの作業で「序章2: 目指す構成」の通りとなりました。
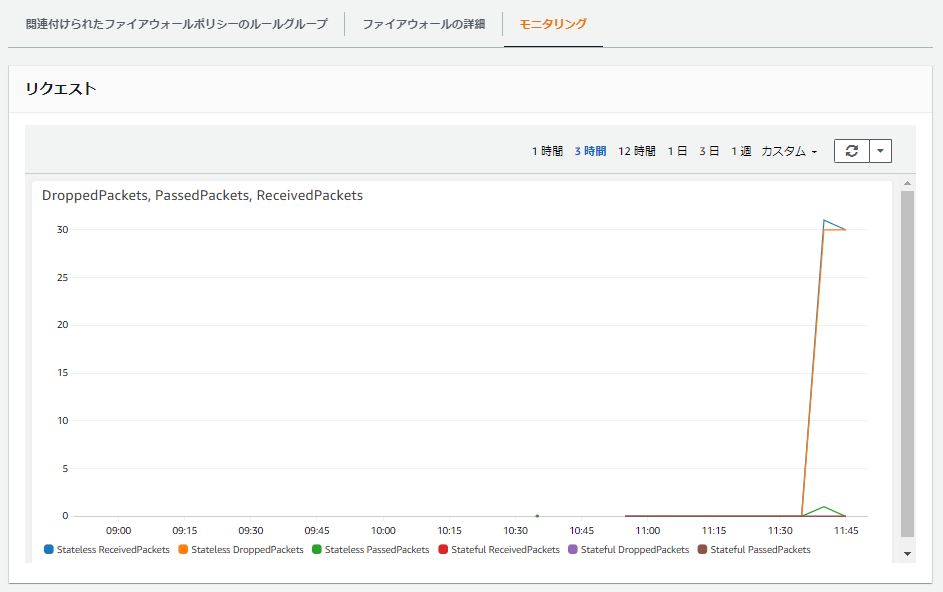
検証1: HTTP接続前のモニタリング
既にFirewall経由の通信が通る状況となっているため、このタイミングでモニタリングしてみると、許可されているHTTP以外の通信は軒並みドロップされていることが分かります。
検証2: クライアントからの接続確認
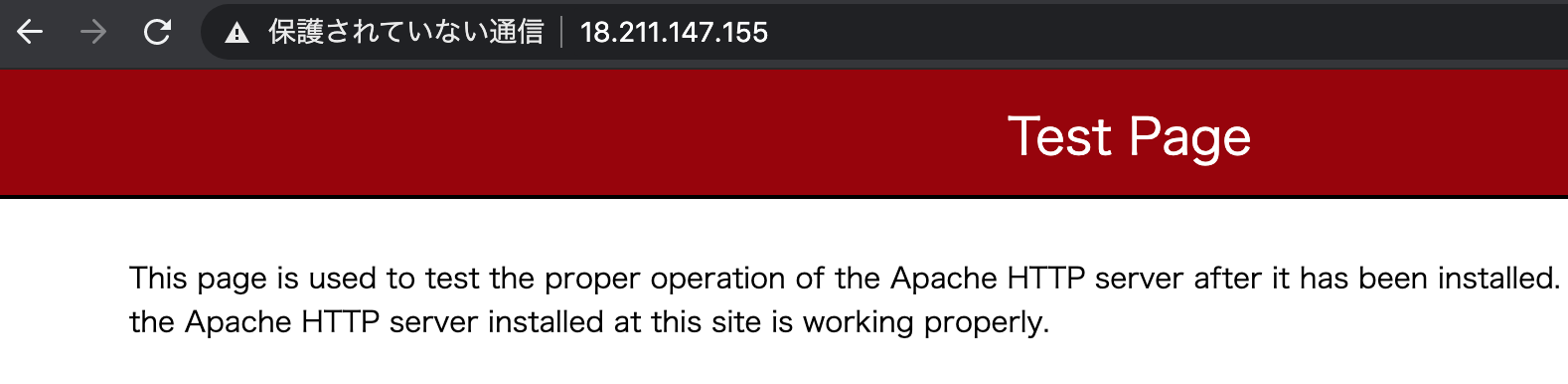
この状態で、Firewall Policyで許可したHTTP接続が通ることが確認できました。
次に、許可していないSSH接続を試みると、接続できません。$ ssh -i web.pem ec2-user@18.211.147.155 ssh: connect to host 18.211.147.155 port 22: Operation timed out以上の検証により、AWS Network Firewallを挟んでWebサーバ用EC2にHTTP接続でき、許可していない通信が期待通りドロップされていることが分かりました。
ルール評価の検証
検証2の状態から設定を変更して、ルール評価について検証してみました。
検証3: 検証2の状態でステートレスルールを片方向だけ消すとどうなるか
ステートレスルールからInboundまたはOutboundのいずれか片方向のルールを消したところ、接続できなくなりました。
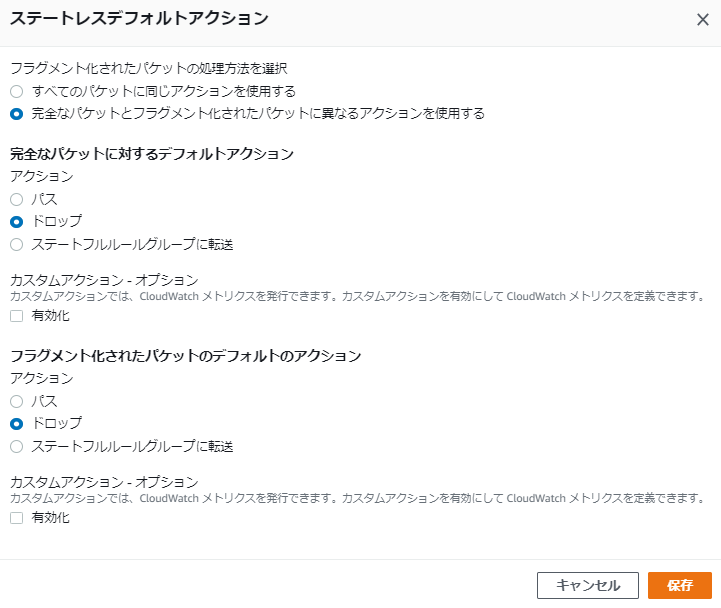
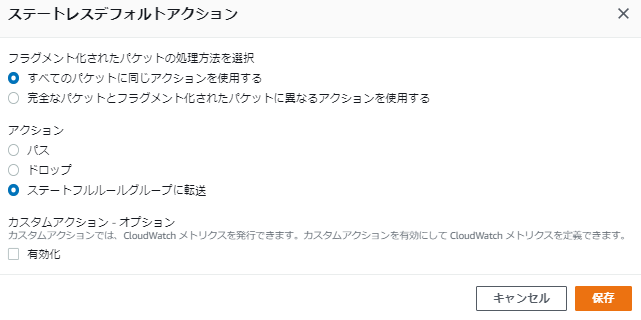
ステートレスだけに、Network ACLと同じく戻りの通信を許可する必要があると言えます。検証4: 検証2の状態でステートレスデフォルトアクションを「ステートフルルールグループに転送」と変更するとどうなるか
検証2の状態では、許可されている通信はHTTPのみであり、その他の通信、例えばSSHは許可されていません。
この状態で、手順3で「ドロップ」としていたステートレスデフォルトアクションを「ステートフルルールグループに転送」と変更するとどうなるのか試してみました。以下のように変更します。
転送先のステートフルルールグループはまだ設定されていません。
変更後、SSHで接続してみると、接続できてしまいました。ルール評価の検証まとめ
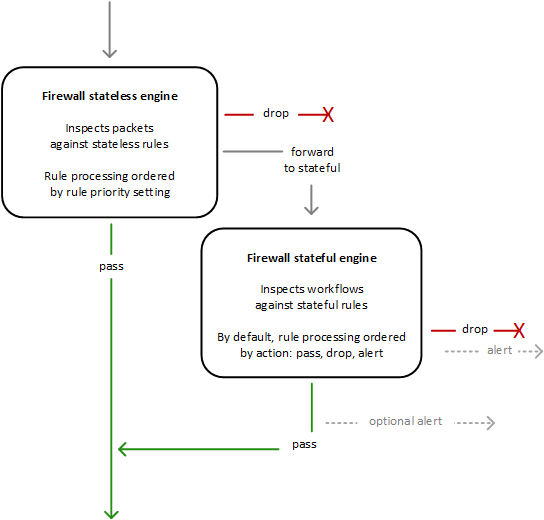
これまでの検証から分かることとしては、以下となります。
- ステートレスルールに合致するかどうかが、まず優先度順で評価される
- ステートレスルールは戻りの通信の許可も必要
- 行きの通信と戻りの通信それぞれの評価時点で、条件に一致した場合の「ステートフルルールグループに転送」ができ、複合的に評価可能
- いずれのステートレスルールにも合致しない場合 (1つもルールが設定されていない場合を含む) のアクションが3種類設定可能
- 「パス」とした場合、アクセス許可して終了
- 「ドロップ」とした場合、アクセス拒否して終了 ※検証2のSSH
- 「ステートフルルールグループに転送」とした場合、ステートフルルールグループの評価に移る
- ステートフルルールグループは、デフォルトが許可となっている
- ステートフルルールグループが空の状態では、転送されてきた場合に「パス」と同じ動きとなる ※検証4
- ステートフルルールグループにDenyルールを追加することで、不要なアクセスを拒否することが可能
- ただし、いずれのステートフルルールにも合致しない場合は「パス」される
引用: https://docs.aws.amazon.com/network-firewall/latest/developerguide/firewall-rules-engines.htmlまとめ
「AWS Network Firewall」では、これまでのNetwork ACLやSecurity Groupに比べ、さらに細かい制御が可能となっています。
また、ステートフルルールでドメイン名でのアクセス拒否が可能となるため、ブラックリスト型のプロキシとしての用途も考えられます。
マネージド型プロキシと考えれば、ありがたい存在となりそうです。
ただし、ステートレスルールとステートフルルールを併用して使う際は、前述の通りルール評価には注意が必要となります。
片方だけ使うという手もあるでしょうから、まずは少しずつ検証してみるのが良さそうです。参考文献


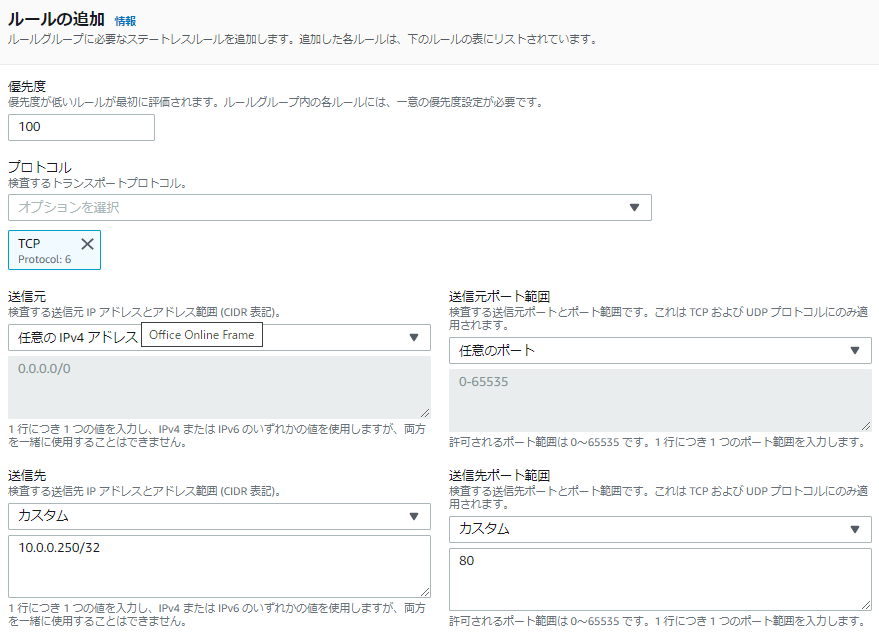

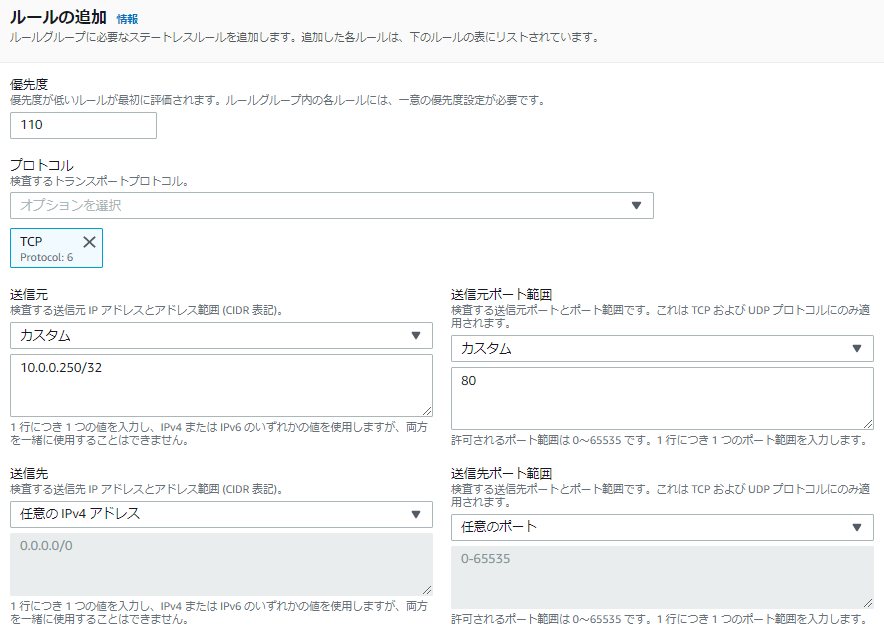
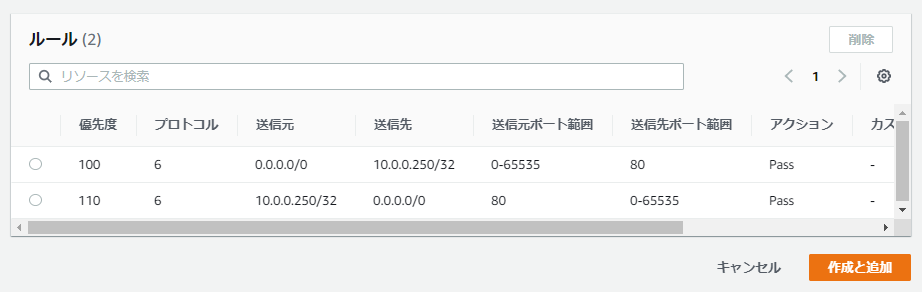

- 投稿日:2020-11-19T00:26:01+09:00
AWSの新サービス「AWS Network Firewall」を早速使ってみた
はじめに
2020/11/17のアップデートで「AWS Network Firewall」という新しいサービスが登場しました。
本記事ではこのサービスの特徴について調べ、使い所を検討してみます。これまでのサービスとは
これまで、AWSで外部からのアクセス制御・保護と言えば以下のサービスがありました。
- Amazon Elastic Compute Cloud (EC2) インスタンスレベルでアクセス制御するSecurity Group
- Amazon Virtual Private Cloud (VPC) のサブネットレベルでアクセス制御するNetwork ACL
- Amazon CloudFront、Application Load Balancer (ALB)、Amazon API Gatewayで実行されているWebアプリケーションを保護するAWS Web Application Firewall (WAF)
- 分散サービス拒否(DDoS)攻撃から保護するAWS Shield
AWS Network Firewallとは
新たに登場した「AWS Network Firewall」では、AWS上の仮想ネットワークを保護するために、ステートフルインスペクション、侵入防止・検知、Webフィルタリングを簡単に導入・管理できます。
また「AWS Network Firewall」は、トラフィック量に応じて自動的にスケーリングし、高可用性のあるアクセス制御・保護機能となります。特に、新たにできること
「AWS Network Firewall」では、以下の事が可能となります。
- VPCが不正なドメインにアクセスしないようにカスタマイズしたルールを実装
- 数千もの既知の悪意のあるIPアドレスをブロックしたり、シグネチャベースの検出機能を使って悪意のあるアクティビティを特定
- CloudWatchのメトリクスを介してファイアウォールのアクティビティをリアルタイムで可視化し、ログをS3、CloudWatch、Kinesis Firehoseに送信することでネットワークトラフィックの可視性を向上
- AWS Firewall Managerと統合されているため、AWS Organizationsを利用していれば、すべてのVPCとAWSアカウントのファイアウォールアクティビティを単一の場所で有効化し、監視
- Network Firewallは、CrowdStrike、Palo Alto Networks、Splunkなどの既存のサードパーティ製セキュリティ製品との相互運用が可能
- コミュニティで管理されているSuricataのルールセットから既存のルールをインポート可能
基本的な考え方
VPCで、AZごとにFirewallを使用し、各AZでトラフィックをフィルタリングするためのFirewall Endpointを起動するサブネットを選択します。
AZ内のファイアウォールエンドポイントは、そのサブネットを除く、AZ内のすべてのサブネットを保護できます。AWS Network Firewallは以下の3つの要素で成り立っています。
Firewall
- 保護したいVPCをFirewall Policyで定義された動作にアタッチします。
- 保護したい各AZに対して、ファイアウォールエンドポイント専用のパブリックサブネットをNetwork Firewall用に構築します。
- Firewallを使用するには、Route Tableを更新して、Firewall Endpoint経由でInboundとOutboundトラフィックを送信するようにします。
Firewall Policy
- ステートレスとステートフルのRule Groupやその他の設定の集合体
- Firewallの動作を定義
- 各Firewallを1つのFirewall Policyにアタッチしたり、1つのFirewall Policyを複数のFirewallにアタッチすることが可能
Rule Group
- ネットワークトラフィックの検査と処理方法を定義するステートレスまたはステートフルなルールの集合
- ルール設定には、5-tuple (送信元IP、送信元ポート番号、宛先IP、宛先ポート番号、プロトコル番号)とドメイン名によるフィルタリングを含む
- Suricataのオープンソースのルールセットを使用することによるステートフルルールも定義可能
AWS Network Firewall経由で外部から接続できるように構成変更する
記事執筆(2020/11/18)時点では東京リージョンには登場していません。
バージニア北部リージョンで試していきます。前提1: 前提環境の用意
まずはインターネット経由でElastic IPを宛先にして、直接SSHとHTTPで接続できるEC2を用意します。
ここから検証のスタートです。
※記事を公開した時点で、Elastic IPをリリースしております。
クライアントから、Elastic IP宛にHTTPで接続します。
この時のVPC Flow Logsは以下の通りで、クライアントのGlobal IPから、EC2のPrivate IPに80番ポートで接続され、戻りの通信が発生しています。
この接続を、AWS Network Firewallを経由してもパスすることを目指してみます。前提2: 目指す構成
目指す構成は、クライアントとWebサーバの間にAWS Network Firewallが挟まったとしても接続を維持できる状態とします。
手順1: Firewall用サブネットの作成
作るだけなので割愛します。
手順2: Firewallの作成
手順1で作ったサブネット上に、まずFirewallを作成します。
一緒に空のFirewall Policyを作っておきます。
ここまで入力して「ファイアウォールの作成」を押します。
ここまでで、FirewallとFirewall Policyのプロビジョニングが開始されます。
プロビジョニングには少々の時間がかかります。
完了すると以下のように表示されます。
Firewallがプロビジョニングされると、Firewallに接続するためのFirewall Endpointが作成されます。
手順3: Firewall PolicyのRule Groupを設定
判定順はステートレスルール→ステートフルルールの順番です。
今回はステートレスルールだけを設定します。
まずはInboundのHTTP通信をパスします。
パスさせたいので、アクションには「パス」を選びます。
戻りのOutboundも同じようにパスします。
ルールの登録が以下の状態になったところで「作成と追加」を押します。
また、ステートレスルールに合致しなかったアクションの取り扱いを決めておきます。
今回は「ドロップする」にします。
手順4: Firewallのログ記録を有効化する
Firewallで「ログ記録」を有効化しておきます。
手順5: Gateway Route Tableの作成とInternet Gatewayへのアタッチ
トラフィックがInternet Gatewayを通過する時に、Firewall Endpointを経由させるために、Internet GatewayにRoute Tableをアタッチします。
以下の画面の「Edge Associations」を編集します。
既に作られているIGWに、Route Tableを関連付けます。
ルートには、今回の例でWebサーバが存在する10.0.0.0/24宛のアクセスがFirewall経由になるように設定します。
手順6: Subnet Route Tableの変更
サブネットにアタッチされているRoute Tableの設定を変更し、通信経路を変えます。
Firewallが存在する10.0.1.0/24のサブネットにアタッチされているRoute Tableは以下となります。
Webサーバが存在する10.0.0.0/24のサブネットにアタッチされているRoute Tableは以下となります。
デフォルトゲートウェイが、IGWからFirewall Endpointに変わりました。
ここまでの作業で「序章2: 目指す構成」の通りとなりました。
検証1: HTTP接続前のモニタリング
既にFirewall経由の通信が通る状況となっているため、このタイミングでモニタリングしてみると、許可されているHTTP以外の通信は軒並みドロップされていることが分かります。
検証2: クライアントからの接続確認
この状態で、Firewall Policyで許可したHTTP接続が通ることが確認できました。
次に、許可していないSSH接続を試みると、接続できません。$ ssh -i web.pem ec2-user@18.211.147.155 ssh: connect to host 18.211.147.155 port 22: Operation timed out以上の検証により、AWS Network Firewallを挟んでWebサーバ用EC2にHTTP接続でき、許可していない通信が期待通りドロップされていることが分かりました。
ルール評価の検証
検証2の状態から設定を変更して、ルール評価について検証してみました。
検証3: 検証2の状態でステートレスルールを片方向だけ消すとどうなるか
ステートレスルールからInboundまたはOutboundのいずれか片方向のルールを消したところ、接続できなくなりました。
ステートレスだけに、Network ACLと同じく戻りの通信を許可する必要があると言えます。検証4: 検証2の状態でステートレスデフォルトアクションを「ステートフルルールグループに転送」と変更するとどうなるか
検証2の状態では、許可されている通信はHTTPのみであり、その他の通信、例えばSSHは許可されていません。
この状態で、手順3で「ドロップ」としていたステートレスデフォルトアクションを「ステートフルルールグループに転送」と変更するとどうなるのか試してみました。以下のように変更します。
転送先のステートフルルールグループはまだ設定されていません。
変更後、SSHで接続してみると、接続できてしまいました。ルール評価の検証まとめ
これまでの検証から分かることとしては、以下となります。
- ステートレスルールに合致するかどうかが、まず優先度順で評価される
- ステートレスルールは戻りの通信の許可も必要
- いずれのステートレスルールにも合致しない場合 (1つもルールが設定されていない場合を含む) のアクションが3種類設定可能
- 「パス」とした場合、アクセス許可して終了
- 「ドロップ」とした場合、アクセス拒否して終了 ※検証2のSSH
- 「ステートフルルールグループに転送」とした場合、ステートフルルールグループの評価に移る
- ステートフルルールグループは、デフォルトが許可となっている
- ステートフルルールグループが空の状態では、転送されてきた場合に「パス」と同じ動きとなる ※検証4
- ステートフルルールグループにDenyルールを追加することで、不要なアクセスを拒否することが可能
- ただし、いずれのステートフルルールにも合致しない場合は「パス」される
引用: https://docs.aws.amazon.com/network-firewall/latest/developerguide/firewall-rules-engines.htmlまとめ
「AWS Network Firewall」では、これまでのNetwork ACLやSecurity Groupに比べ、さらに細かい制御が可能となっています。
また、ステートフルルールでドメイン名でのアクセス拒否が可能となるため、ブラックリスト型のプロキシとしての用途も考えられます。
マネージド型プロキシと考えれば、ありがたい存在となりそうです。
ただし、ステートレスルールとステートフルルールを併用して使う際は、前述の通りルール評価には注意が必要となります。
片方だけ使うという手もあるでしょうから、まずは少しずつ検証してみるのが良さそうです。参考文献
- 投稿日:2020-11-19T00:24:54+09:00
AWSのリザーブドインスタンスについての学び
この記事で書くこと
AWSのリザーブドインスタンスについて学んだことをきちんと残す
体系的なものではなく、断片的な情報になります。
リザーブドインスタンスとは?
利用するインスタンスの枠を注文することによって、個別で使用するよりも割引を利用できるのでお得になる、という仕組みです。
何を学んだ?
リザーブドインスタンスを途中で変更したくなった時にどうしたらいいのか?の答え
「え、枠で割引を受けてるんだから、途中で変えられないでしょ。」と思っていました。
が、変えられます。ただ、何でも好きなように変更可能というわけではないです。
自分の今回学んだケースは、インスタンスサイズの変更が可能かどうかというユースケースについてです。
ここで登場する概念が「インスタンスファミリー」と「フットプリント」です。
インスタンスファミリー
例えば以下のようなインスタンスのことをいいます。
- t2.small
- t2.medium
これらはインスタンスファミリーにあたります。例えば、 t2.smallから、t2.mediumにインスタンスサイズを変更したい、という時はできます、ただし、
「フットプリント」が元のリザーブドインスタンスのものを超えない限り、です。フットプリント
フットプリントとは、インスタンスサイズごとに決まっている正規化係数を全て合計したものです。
例えば、リザーブドインスタンスを設定時に、
- t2.medium
- t2.small
の2台を設定した場合、フットプリントは、
- t2.medium 2
- t2.small 1
2+1で3ということになります。それを途中で
- t2.large
にしたい!というのはインスタンスファミリーが同じであってもできません。
4で3という元々のフットプリントを超えてしまっているからです。以下のケースへは変更が可能です。
- t2.micro
- t2.micro
- t2.micro
- t2.micro
- t2.small
の5台にしたい。というものですが、
- t2.micro 0.5
- t2.micro 0.5
- t2.micro 0.5
- t2.micro 0.5
- t2.small 1
(0.5 * 4) + 1 で3、元々のフットプリントと一致しますので、変更が可能です。なかなかリザーブドインスタンスを扱う機会が無かったので勉強になりました。