- 投稿日:2020-11-16T23:32:49+09:00
googleapiclientを使うプログラムでPyInstallerするとエラーがでた話
問題
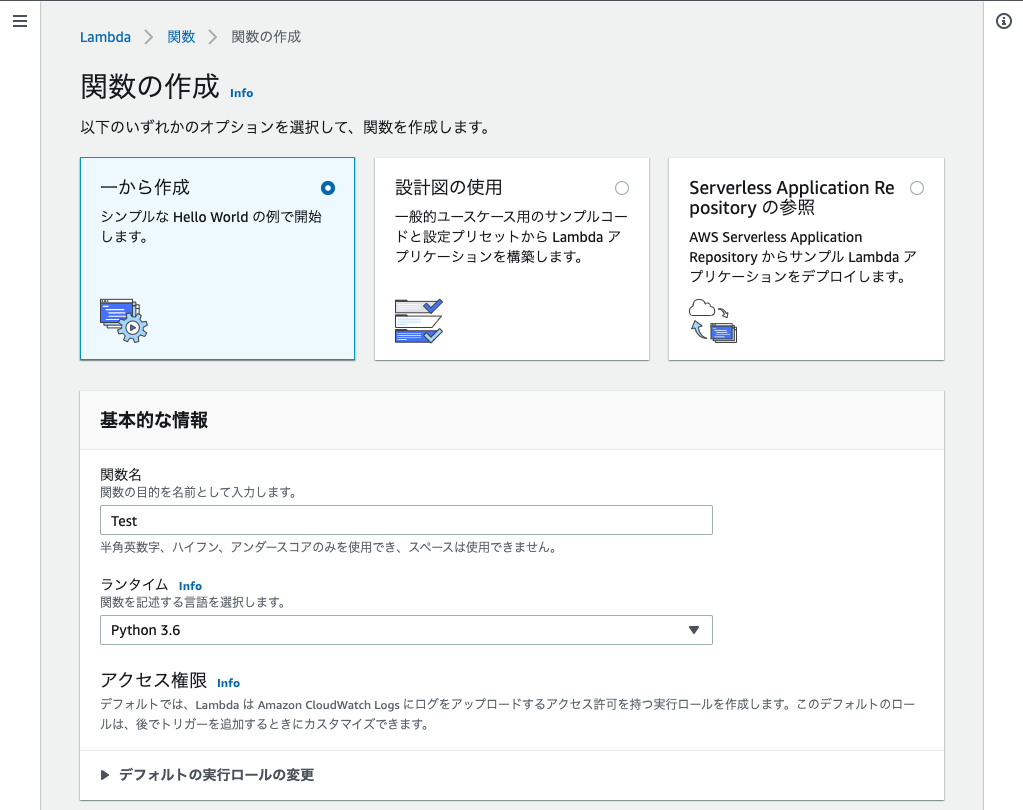
Google Api(スプレッドシート)を使うプログラムをPyInstallerで実行ファイル化しようとしたら,コンパイルはできたが実行時にエラーが発生.
コンパイルしたプログラムは以下のようなものmain.pyfrom googleapiclient.discovery import build # 以下略ここで,
pyinstaller --onefile main.py ./dist/main # コンパイルに成功し,実行ファイルができるさて,実行ファイルを実行すると,
pkg_resources.DistributionNotFound: The 'google-api-python-client' distribution was not found and is required by the application
解決方法
google-api-clientのバージョンを1.8.0にする.
要は以下を実行すれば良い.pip install google-api-python-client==1.8.0なんと画期的な解決方法でしょう!!!!
詳細
参考程度ですが,実行環境は
- OS: Raspbian GNU/Linux 10 (buster)
- Python: Python 3.7.3
おわりに
google-could-visionやFirestoreを使う場合類似したエラーについて書かれた記事を見かけたがあまり参考にならなかった.いずれの例でも
pkg_resources.DistributionNotFoundに遭遇しているため同様の解決方法で行けるかと思ったが全然できずに時間が溶けました.
結局,google-api-clientのgithubのissueの議論で解決した.
PyInstallerの代替としてcx_Freezeなどでも試してみたが結局できなかった.
この問題がいつまで発生(PyInstaller/Googleが対応するまで?)するか分かりませんし,いつまでこの方法で解決するかもわからないので参考程度にしてください.
PythonもGolangのように公式で(クロスプラットフォームな)実行ファイル化するような方法を確立してほしいと思いました.
- 投稿日:2020-11-16T22:24:27+09:00
総務省APIを使ってデータを取得する
総務省APIを使用してデータを取得
計量経済学のパネルデータを作成するためにPythonでデータをとってみました。(備忘録です)
準備
Python実行環境
総務省APIの取得
こちらからユーザ登録して取得できます。コード
def_TakeDataimport requests,urllib import pandas as pd import numpy as np import json def get_json(base_url,params): params_str=urllib.parse.urlencode(params) url=base_url+params_str json=requests.get(url).json() return json def take_data(dataid): appID="appIDを入れます" base_url="http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?" params={ "appId":appID, "lang":"J", "statsDataId":dataid, "metaGetFlg":"Y", "cntGetFlg":"N", "sectionHeaderFlg":"1" } data=get_json(base_url,params) return datatakedata=take_data(XXXXX)json形式のデータが変換されます
urlは
http://api.e-stat.go.jp/rest/2.1/app/getStatsData?appId=&lang=J&statsDataId=(ここにデータIDを入れる)&metaGetFlg=Y&cntGetFlg=N§ionHeaderFlg=1
上記の形式です。
総務省サイトから簡単にAPIリクエストURLを参照できます。json->DataFrame
例df=pd.DataFrame(data['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) #jsonデータをpandasDataFrameに変換(例)欲しいデータをDataFrameに格納します。
-`data['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']`上記のコードでjsonにどのようなデータが入っているの確認できます。
これで操作しやすいDataFrameになりました
最後に
TwitterAPIとかよりは使いやすかったのでもっと詳しくかけるように頑張ります
Python初学者ですので間違いあれば指摘お願いいたします
- 投稿日:2020-11-16T21:59:33+09:00
pandas DataFrame で任意の値を含む行を削除
- 投稿日:2020-11-16T21:54:28+09:00
円周率の近似分数について
円周率
円周率。ただの定数であるがただの定数でない魅力と謎が詰まっている偉大な数です。
証明は簡単でないが一番馴染み深い無理数であり超越数なのではないのでしょうか?円周率の値
様々な方法で求められてきた歴史があります。今回の記事とはそこまで関係がないので具体的な方法を述べたりしませんが, 普通のノートpcでも現代のスペックであれば100桁くらいは簡単に(秒で)求めることができます。なぜそれで求められるか?の理論は普通に難しかったりしますが計算方法さえ認めてしまえば簡単です。
一応値を述べておきますが
π=3.141592653589 793238462643 383279502884 197169399375 105820974944 592307816406 286208998628 034825342117 067982148086 513282306647...と続いていきます。円周率の近似分数
今回の本題の近似分数とはなんぞや。という話です。厳密にやろうとすれば大学数学で勉強する実数の(有理数, 無理数の)稠密性なんかを考える必要がありますが直感的な説明だけで済ませますね。
まず円周率は無理数です。これも認めます。 完全にランダムかどうかはわかっていません。n桁目の数はランダムであるといわれています.
一方有理数は必ずどこがでループが出てきます. 1÷6=0.666...と6のループが出てきますし, 123÷999=0.123123123...と123のループが出てきます。
6÷2なんかも6÷2=3=2.999...と書くこともできるので割り切れたとしてもループが出てくるんですね.
ループの有り無しは有理数と無理数の大きな違いの一つです。
このように有理数無理数とは全然違う数なのですが, 円周率という無理数にいくらでも近い有理数を作ることはできます。 稠密なんて難しい言葉で言ったりするんですが, 雑に説明すると有理数の数列AnをA_1=3, \quad A_2=3.1, \quad A_3=3.14,\quad ...と定めればこの数列の極限は円周率と一致するんですね. 有理数しか現れないのに極限は無理数と同じといわれると変な感じが一瞬しますが, まあ直感的には納得できるのかなあと思います.
つまるところ, 円周率にいくらでも近い分数をつくれる. というわけです.
面白い事実
ここで以下のような問題を考えましょう
\text{集合$F_n$を以下のように定める.}\\ F_n:=\{\frac{a}{b}\mid 1 \leq a,b \leq 10^n-1,\quad a,b\in \mathbb{Z} \}とする.
このとき,F_n\text{の元で最も}\pi\text{に近いのは何だろう?}つまり
F_1\text{とは1÷1から9÷9までで作れる数の集合で} F_2\text{とは1÷1から99÷99までで作れる集合.}でありこのように分母分子の桁数に制限を与える中で最も円周率に近い分数とは何なのだろう?という問題です.
それをp(n)とでもしておきましょう.そして以下のような事実が知れれています。
\begin{align*} p(1)&=3/1\\ p(2)&=22/7\\ p(3)&=355/113\\ p(4)&=355/113=p(3) \end{align*}つまり355/113とはものすごく精度がよい近似値である!!というわけです!!
これは個人的にとても面白い事実です. だって分母分子4桁まで使ってもよいのに3桁÷3桁が精度の良い分数なんですから。
しかし, これは事実として知っているだけで「ほんまに?」と思ったわけですよ.ならプログラムの出番ですね.プログラムで総当たりで調べましょうプログラムを作る前の考察
今回は4桁/4桁までを調べるので総当たりの計算量は10000*10000=10^8程度
このくらいなら総当たりでも調べられますが今後p(8)なんかも求めたくなるかもしれないので多少計算を省ける工夫をしてみましょう.工夫1:分子を分母*3から探索を始める
工夫2.途中で打ち切る動作を入れる
以上!多分これだけでも相当計算量減ると思うのでこれで実装していきます!プログラム
プログラムの実力が圧倒的に足りないので愚直に書いていきます.
pi=3.141592653589793#このくらいあれば十分かなあ n=int(input()) check=((10**n)-1)//3 ans=100 ans_list=[100,1] for i in range(1,check+1):#こっちが分母 for j in range(3*i,(10**n)): frac=j/i if abs(frac-pi)<abs(pi-ans): ans=frac ans_list=[j,i] else: if frac>ans: break print(ans) print(ans_list)実行結果
1 >>>3.0 >>>[3, 1] 2 >>>3.142857142857143 >>>[22, 7] 3 >>>3.1415929203539825 >>>[355, 113] 4 >>>3.1415929203539825 >>>[355, 113] 5 >>>3.1415926415926414 >>>[99733, 31746]本当に4桁÷4桁でも355/113が最強なんですね
ふざけたまとめ
355/113はすごい数字ですね. ちなみに僕のiPhoneの暗証番号昔355113でした.
まじめなまとめ
n=5あたりで相当遅いので改良してくださる方がいれば教えてもらえると幸いです.
追記
mathにmath.piなんてのあるんですね. ならこれでよろしいとおもいます.
import time import math n=int(input()) start=time.time() pi=math.pi check=((10**n)-1)//3 ans=100 ans_list=[100,1] for i in range(1,check+1):#こっちが分母 for j in range(int((pi)*i),(10**n)): frac=j/i if abs(frac-pi)<abs(pi-ans): ans=frac ans_list=[j,i] else: if frac>ans: break print(ans) print(ans_list) end=time.time() print(end-start)めちゃくちゃ早くなったのでp(8)まで求めてしましました
6 >>>3.141592653581078 >>>[833719, 265381] 7 >>>3.1415926535898153 >>>[5419351, 1725033] 8 >>>3.1415926535897927 >>>[80143857, 25510582]長年の謎が解けた気がして気持ちいです.
- 投稿日:2020-11-16T21:52:27+09:00
Ubuntu 20.04でSSL接続エラー(ssl.SSLError: [SSL: DH_KEY_TOO_SMALL])が発生する際の対処法
Ubuntu 20.04でPythonのサードパーティAPIを用いてSSL通信しようとしたところ以下のエラーが発生。Ubuntu 20.04で起こるらしい。
(Caused by SSLError(SSLError(1, '[SSL: DH_KEY_TOO_SMALL] dh key too small (_ssl.c:1123)')
下記のQAを参考に解決した方法をまとめます。
https://askubuntu.com/questions/1233186/ubuntu-20-04-how-to-set-lower-ssl-security-levelこのエラーが発生する背景
Debine系のOpenSSLのデフォルト設定がよりセキュアになったことが原因らしい。
セキュアになった背景はこれです。(英文です)
https://weakdh.org/簡単に概要を訳すとSSLで使用する鍵交換のアルゴリズムに脆弱性が見つかったため。
脆弱性に該当するSSL通信をしようとするとDH_KEY_TOO_SMALLのエラーが発生する。根本解決としてはサーバー側のセキュリティが改善されることだが、今回はサードパーティAPIを用いており不可能。
そのため暫定対処ではあるが、セキュリティレベルを変更する方法を採用した。openssl.cnfの編集してセキュリティレベルを変更
以下コマンドでopensslコンフィグファイルの配置ディレクトリを確認。
% openssl version -d
ちなみに一般的には"/usr/lib/ssl"配下にある。
ファイル冒頭に以下の1行を追記して保存。
openssl_conf = default_conf
次にファイル末尾に以下を追記する。
[ default_conf ]
ssl_conf = ssl_sect
[ssl_sect]
system_default = system_default_sect
[system_default_sect]
MinProtocol = TLSv1.2
CipherString = DEFAULT:@SECLEVEL=1これは何をしているかというとOpenSSLの暗号化のセキュリティレベルを下げている。
これだけでSSL通信できるようになるはず。openssl.cnfのローカル化
/usr/lib/ssl配下のコンフィグファイルを直接編集するとLinuxシステム全体に影響を与える。
影響を特定ユーザーでのログイン時等に局所化したい場合は以下を環境変数を.bashrcに追記する。export OPENSSL_CONF=/path/to/my/openssl.cnf
- 投稿日:2020-11-16T21:50:02+09:00
【検証】pytorchの最適化関数で点群の位置合わせをしてみる その1
はじめに
最近pytorchを覚えたので遊んでみます。
やることとしては、点群の位置合わせです。
目的としては、icpは局所解に陥りがちなイメージが個人的にはありますが、
pytorchの最先端な最適化関数なら結構いい線行くんじゃね?
というふわっとした期待の元やってみます。流れは以下の通りです。
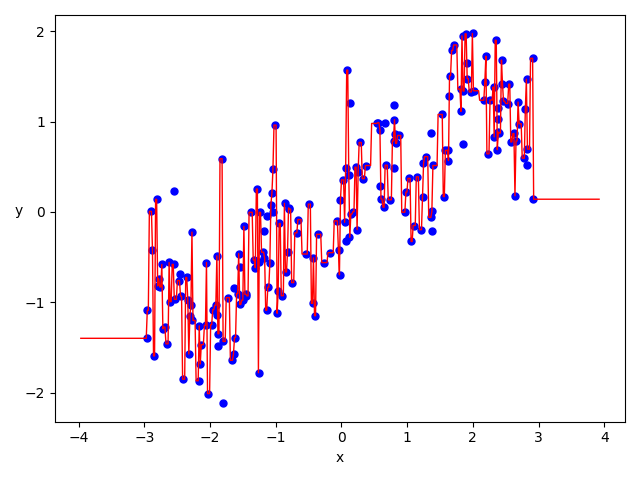
for 点群Bの各ポイント 1.変換行列$P = [R|t]$を定義する。 このパラメータの最適化を行うことで位置合わせをする。 2.点群の最近傍を計算し、最も近いポイントの組を取得する。 3.変換行列$P$を適用した点群Bのポイントと、 点群Aの最近傍のポイント、この2つを損失関数で評価する。 4.最適化処理 最適化された変換行列$P$を適用してもう一度1から実行以下の流れで検証します。
1.同じ点群を2つ用意して、移動だけ行う(3次元のパラメータの調整) 2.同じ点群を2つ用意して、回転だけ行う(9次元のパラメータの調整) 3.同じ点群を2つ用意して、回転・移動行う(12次元のパラメータの調整) 3.異なる2つの点群を用意して、回転・移動行う(12次元のパラメータの調整) 3.他方にノイズを付与して異なる2つの点群を用意して、回転・移動行う(12次元のパラメータの調整)結果
・・・と、書きましたが1の段階で失敗しました。
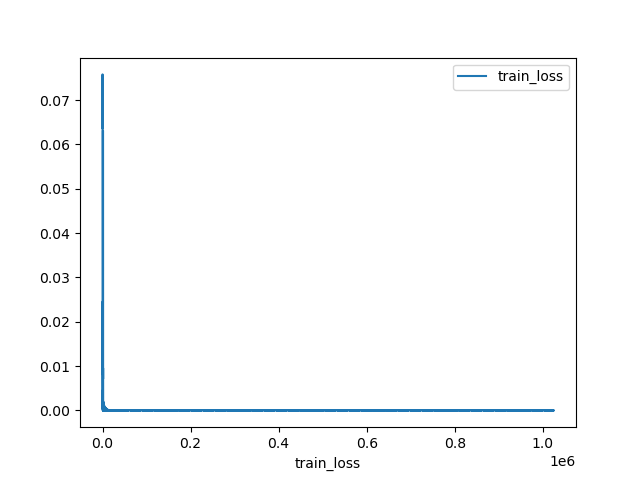
pytorchは未だ使い慣れていないので、何かが足りてないのかもしれません。tetst.pyimport copy import numpy as np import open3d as o3d import random import math import torch.nn as nn import torch.nn.functional as F import torch import torch.optim as optim import matplotlib.pyplot as plt epoch = 1000 def getPLYfromNumpy(nplist): pcd = o3d.geometry.PointCloud() pcd.points = o3d.utility.Vector3dVector(nplist) return pcd def write_point_cloud(path, pcl): assert o3d.io.write_point_cloud(path, pcl), "write pcl error : " + path def read_point_cloud(path): pcl = o3d.io.read_point_cloud(path) if len(pcl.points) == 0: assert False, "load pcl error : " + path return pcl def Register_EachPoint_RT(pclA, pclB,testP,criterion,optimizer): history = { 'train_loss': [], 'test_acc': [], } transP = torch.tensor( [[1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0], [0.0, 0.0, 0.0, 1.0]], requires_grad=True) params = [transP] optimizer = optimizer(params) kd_tree_A = o3d.geometry.KDTreeFlann(pclA) cnt = 0 # ポイント単位でやってみる for j in range(epoch): for didx in range(len(pclB.points)): cnt += 1 optimizer.zero_grad() # 最近傍の計算 [_, Aidx1, _] = kd_tree_A.search_knn_vector_3d(pclB.points[didx], 1) ptA_sample = pclA.points[Aidx1[0]] ptB_sample = pclB.points[didx] # 同次座標 ptA_sample = np.array([ptA_sample[0], ptA_sample[1], ptA_sample[2], 1]) ptB_sample = np.array([ptB_sample[0], ptB_sample[1], ptB_sample[2], 1]) ptA_sample = ptA_sample.reshape(4, 1) ptB_sample = ptB_sample.reshape(4, 1) A_tor = torch.tensor(ptA_sample.tolist(), requires_grad=False) B_tor = torch.tensor(ptB_sample.tolist(), requires_grad=False) answer = A_tor output = torch.mm(transP, B_tor) loss = criterion(answer, output) loss.backward() optimizer.step() # print( j, cnt, " : 誤差 = ", loss.item(),"\n",transP) ls = np.linalg.norm(testP - transP.to('cpu').detach().numpy().copy()) history['train_loss'].append(loss) history['test_acc'].append(ls) print(" : 誤差 = ", loss.item(),"\t 正解の変換行列との誤差 = ",ls) plt.figure() plt.plot(range(1, cnt + 1), history['train_loss'], label='train_loss') plt.xlabel('train_loss') plt.legend() plt.savefig('train_loss.png') plt.figure() plt.plot(range(1, cnt + 1), history['test_acc'], label='test_acc') plt.xlabel('test_acc') plt.legend() plt.savefig('test_acc.png') return transP def Register_EachPoint_T(pclA, pclB,testP,criterion,optimizer): history = { 'train_loss': [], 'test_acc': [], } transP = torch.tensor([[0.0], [0.0], [0.0]],requires_grad=True) params = [transP] optimizer = optimizer(params) kd_tree_A = o3d.geometry.KDTreeFlann(pclA) cnt = 0 # ポイント単位でやってみる for j in range(epoch): for didx in range(len(pclB.points)): cnt += 1 optimizer.zero_grad() # 点群Bの各ポイントに対して最も近い点群Aのポイントを取得 [_, Aidx1, _] = kd_tree_A.search_knn_vector_3d(pclB.points[didx], 1) ptA_sample = pclA.points[Aidx1[0]] ptB_sample = pclB.points[didx] # 同次座標 ptA_sample = np.array([ptA_sample[0], ptA_sample[1], ptA_sample[2]]) ptB_sample = np.array([ptB_sample[0], ptB_sample[1], ptB_sample[2]]) ptA_sample = ptA_sample.reshape(3, 1) ptB_sample = ptB_sample.reshape(3, 1) # 各ポイントをTensor化 A_tor = torch.tensor(ptA_sample.tolist(), requires_grad=False) B_tor = torch.tensor(ptB_sample.tolist(), requires_grad=False) # 点群Bを調整して、点群Aに合わせていく。 answer = A_tor output = (B_tor + transP) # 損失計算 -> 最適化 loss = criterion(answer, output) loss.backward() optimizer.step() # 正解の変換行列との比較。(0が望ましい) ls = np.linalg.norm(testP - transP.to('cpu').detach().numpy().copy()) history['train_loss'].append(loss) history['test_acc'].append(ls) print(" : 誤差 = ", loss.item(), "\t 正解の変換行列との誤差 = ", ls) # 調整結果を反映 -> 次のループで再び最近傍計算 nptransP = transP.to('cpu').detach().numpy().copy().reshape(1,3) pclB = getPLYfromNumpy(pclB.points + nptransP) plt.figure() plt.plot(range(1, cnt + 1), history['train_loss'], label='train_loss') plt.xlabel('train_loss') plt.legend() plt.savefig('train_loss.png') plt.figure() plt.plot(range(1, cnt + 1), history['test_acc'], label='test_acc') plt.xlabel('test_acc') plt.legend() plt.savefig('test_acc.png') return transP POINT_NUM = 1024 # http://graphics.stanford.edu/data/3Dscanrep/ pclA = read_point_cloud("bun000.ply") A = np.array(pclA.points) A = np.array(random.sample(A.tolist(), POINT_NUM)) # 難易度が少し上の点群。たぶんこれはまだできない・・・ # pclB = read_point_cloud("bun045.ply") # B = np.array(pclB.points) # B = np.array(random.sample(B.tolist(), POINT_NUM)) # # ノイズ付与 # B += np.random.randn(POINT_NUM, 3) * 0.005 # # 点群のUnorder性(順番バラバラ)付与 # np.random.shuffle(B) # pclB_sample = getPLYfromNumpy(B) pclA_sample = getPLYfromNumpy(A) T_Projection = np.array([[1, 0, 0, 0.5], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]]) T_translation = np.array([[T_Projection[0][3]], [T_Projection[1][3]], [T_Projection[2][3]]]) pclA_trans_sample = getPLYfromNumpy(A).transform(T_Projection) write_point_cloud("A_before.ply", pclA_sample) write_point_cloud("A_rot_before.ply", pclA_trans_sample) def testEstimateT(pclA_sample,pclA_trans_sample,T_translation): optimizer = optim.Adam # MSELoss transP = Register_EachPoint_T(pclA_sample, pclA_trans_sample, T_translation, nn.MSELoss(),optimizer) T_res = np.array([[1, 0, 0, transP[0]], [0, 1, 0, transP[1]], [0, 0, 1, transP[2]], [0, 0, 0, 1]]) pclA_res = copy.copy(pclA_trans_sample) pclA_res = pclA_res.transform(T_res) write_point_cloud("TOnlytest_A_rot_after_MSELoss.ply", pclA_res) # # L1Loss # transP = Register_EachPoint_T(pclA_sample, pclA_trans_sample, T_translation, nn.L1Loss(),optimizer) # T_res = np.array([[1, 0, 0, transP[0]], # [0, 1, 0, transP[1]], # [0, 0, 1, transP[2]], # [0, 0, 0, 1]]) # pclA_res = copy.copy(pclA_trans_sample) # pclA_res = pclA_res.transform(T_res) # write_point_cloud("TOnlytest_A_rot_after_L1Loss.ply", pclA_res) def testEstimateRT(pclA_sample,pclA_trans_sample,T_Projection): optimizer = optim.Adam # MSELoss transP = Register_EachPoint_RT(pclA_sample, pclA_trans_sample, T_Projection, nn.MSELoss(),optimizer) transP = transP.to('cpu').detach().numpy().copy() pclA_res = copy.copy(pclA_trans_sample) pclA_res = pclA_res.transform(transP) write_point_cloud("RTtest_A_rot_after_MSELoss.ply", pclA_res) testEstimateT(pclA_sample, pclA_trans_sample, T_translation) # testEstimateRT(pclA_sample, pclA_trans_sample, T_Projection) exit()損失関数の出力結果を見てみます。
これだけ見ると、あっという間に0に収束してるように見えます。
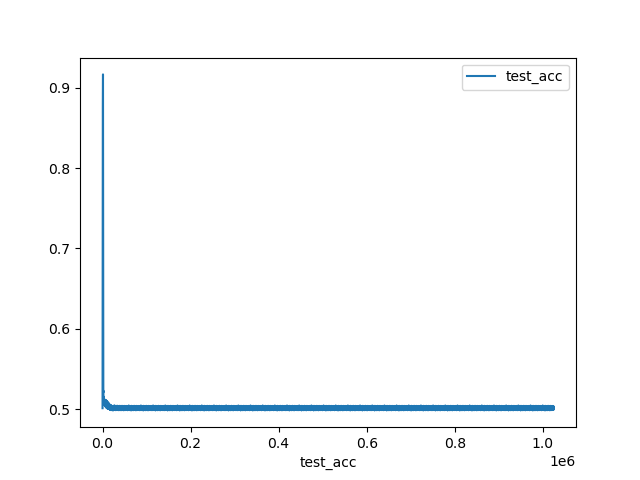
そして最適化により出力された変換行列と、正解の変換行列を比較したものがこれ。
・・・最初ちょっとだけ下がったかと思えば、あとはずっと腹ばいです。0.5と大きめの誤差です。
点群も出力しましたがわずかーーーーに近寄っただけだったので割愛します。まとめ
外れ値もなく3次元しかないのにどうしてぇ・・・という感じです。
pytorchの使い方を単純に間違えている気もします。
分かる方いたらぜひご連絡を。次はPointNetのT-netを拡張させたもの、PointNetLKについて勉強します。
https://github.com/wentaoyuan/it-net
https://www.slideshare.net/naoyachiba18/pointnetlk-robust-efficient-point-cloud-registration-using-pointnet-167874587
- 投稿日:2020-11-16T19:31:09+09:00
RXTE衛星PCA検出器でAGNの時間変動解析をgoogle Colabで簡単に行う方法
背景
RXTE衛星のPCAという検出器によって取得された 2-10 keV のフラックスのデータを用いてプロットする方法を紹介する。
RXTEはASMという全天モニターの検出器もあるが、AGNのような暗い天体の場合(mCrabレベル)は、PCAのポインティング観測で得られたデータを使わないとまともなデータ解析ができない。
このような長期のデータは、サンプル時間が非一様で疎らであるが、その場合にえいやっと内挿してパワースペクトルを生成する方法も紹介する。スパースなデータの扱いはこれでは不十分であるが、quickにトレンドや傾向をみたい場合には知っておいてたら得するテクニックではある。
コードを読めばわかる人は、私の google Colab を参考ください。
3C273とは?
3C273 は、1959年に出版されたケンブリッジ電波源カタログ第3版の273番目に掲載された天体で、赤方偏移 z = 0.158 にあるクエーサーである。中心には太陽質量の8億倍ものブラックホールが存在しており、そこから強力なジェットが噴出していることが観測から確認されている。
ここでは、https://cass.ucsd.edu/~rxteagn/ の中から、
3C273という有名なブレーザーの長期の時間変動解析をgoogle Colab でやる方法を紹介する。にライトカーブのデータはある。
サンプルコード
データの取得とライトカーブのプロット
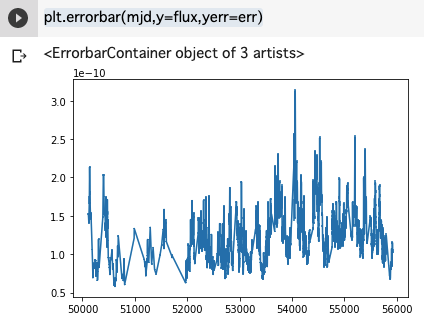
plot_3C273import urllib.request url="https://cass.ucsd.edu/~rxteagn/3C273/F0210_3C273" urllib.request.urlretrieve(url, '3C273.txt') import numpy as np mjd, flux, err, exp = np.loadtxt("3C273.txt", comments='#', unpack=True) import matplotlib.pyplot as plt plt.errorbar(mjd,y=flux,yerr=err)
データの内挿
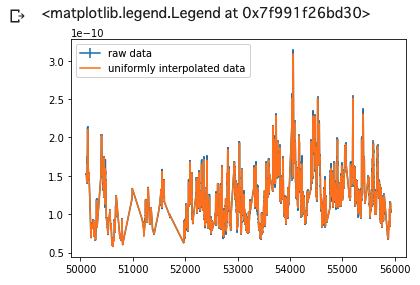
mjd_uniform=np.linspace(np.amin(mjd), np.amax(mjd), 6000) # 最初から最後までを6000等分する.6000という数字は適当だけど,1dayが一ビンになるくらい. interpolated_y = np.interp(mjd_uniform,mjd,flux) # スプライン補間をして,等間隔のデータを作る. plt.errorbar(mjd,y=flux,yerr=err, label="raw data") plt.errorbar(mjd_uniform,y=interpolated_y, label="uniformly interpolated data") plt.legend()numpyのinterpという関数で、スプライン補完して、等時間間隔のデータを生成する。
パワースペクトルの計算
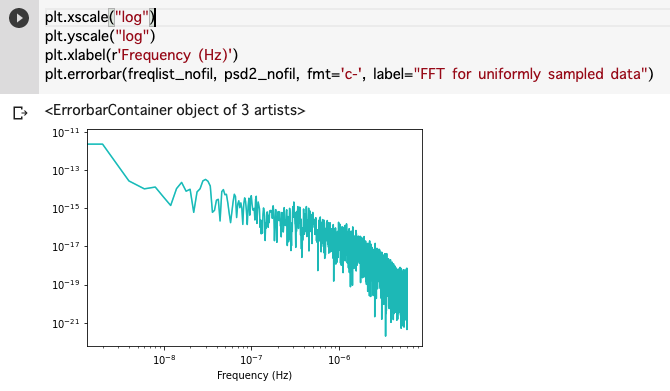
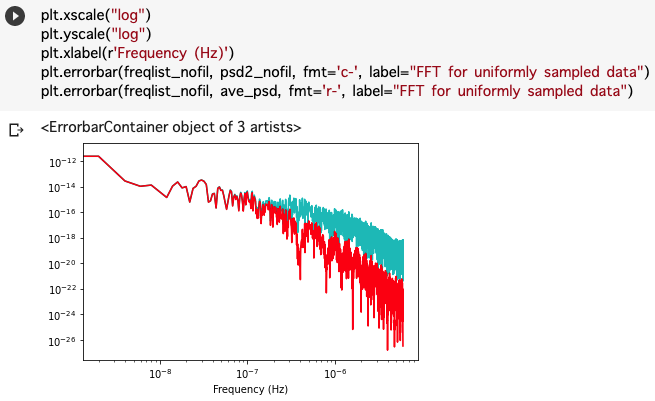
import matplotlib.mlab as mlab fNum=len(mjd_uniform) timebin=(mjd_uniform[1] - mjd_uniform[0]) * 24*60*60 # day to sec print("timebin = ", timebin, " fNum = ", fNum) psd2_nofil, freqlist_nofil = mlab.psd(interpolated_y,fNum,1./timebin, sides='onesided', scale_by_freq=True) plt.xscale("log") plt.yscale("log") plt.xlabel(r'Frequency (Hz)') plt.errorbar(freqlist_nofil, psd2_nofil, fmt='c-', label="FFT for uniformly sampled data")
これでかなり強引であるが、低周波数までのパワースペクトルがかける。
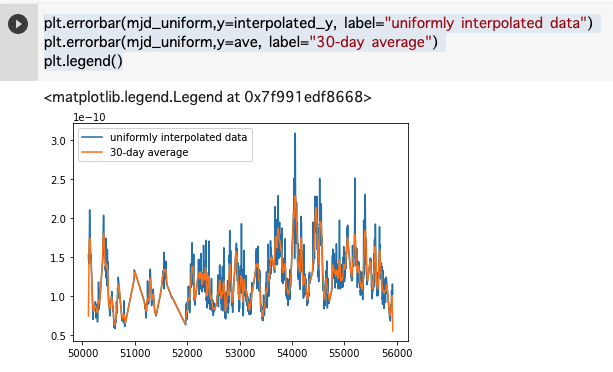
移動平均を取る方法
# 30日の移動平均 # https://qiita.com/yamadasuzaku/items/fb744a207e7694d1598d ave = np.convolve(interpolated_y, np.ones(30)/float(30), 'same') plt.errorbar(mjd_uniform,y=interpolated_y, label="uniformly interpolated data") plt.errorbar(mjd_uniform,y=ave, label="30-day average") plt.legend()移動平均で高周波数成分を落とすには、numpyのconvolveを使うのがもっとも簡単にできる。
移動平均と取る前後でのパワースペクトルの比較
ave_psd, freq = mlab.psd(ave,fNum,1./timebin, sides='onesided', scale_by_freq=True) plt.xscale("log") plt.yscale("log") plt.xlabel(r'Frequency (Hz)') plt.errorbar(freqlist_nofil, psd2_nofil, fmt='c-', label="FFT for uniformly sampled data") plt.errorbar(freqlist_nofil, ave_psd, fmt='r-', label="FFT for uniformly sampled data")
移動平均を取ることで高い周波数の成分が落ちていることが確認できる。
おまけ
これを利用すると、3C273の多波長の時系列データの相関なども簡単にとることができる。
データは手っ取り早くは、などに公開されている。
ただし、ここ紹介した補完は、台形補完で内挿して等間隔なデータを生成しているので、その近似が妥当かどうかはよく考えて使う必要がある。(とりあえずざっくりと相関をみる、というレベルでは問題ないので、実験データなどデータを手にしたらこれくらいはサッとやってみるのは大事かとは思う。)
- 投稿日:2020-11-16T19:06:32+09:00
[Blender×Python] ランダムをマスターしよう!!
今回は、オブジェクトを大量に、かつランダムに配置する仕組みを紹介していきます。
目次
0.ランダムな数値を取得する方法
1.ランダムな位置に立方体を出現させる
2.関数をつくって処理をまとめる
3.サンプルコード
4.英単語
参考資料
0.ランダムな数値を取得する方法
今回は、numpyというライブラリ(便利なコードの集まり)の中の
rand()関数を使っていきます。rand()関数は、0から1までのランダムな値を返します。
引数(パラメータ)には、幾つのランダムな数値を返すかを指定します。
rand(3)ならば、ランダムな数値を3つ返します。import numpy as np #np.randomは右向きの矢印と考え無視して構いません。 np.random.rand(3)Point:import numpy as np
numpyというライブラリをコード中でnpという略称で表記するということ。array([0.90681482, 0.04813658, 0.47969033])↑
0から1の範囲のランダムな値が3つ出力されます。※arrayは配列という意味ですが、今回は気にしなくて大丈夫です。
数字が順番に入っている入れ物みたいなものです。1.ランダムな位置に立方体を出現させる
1-0.立方体をランダムな位置に出現させよう!!
数値計算のためのライブラリ
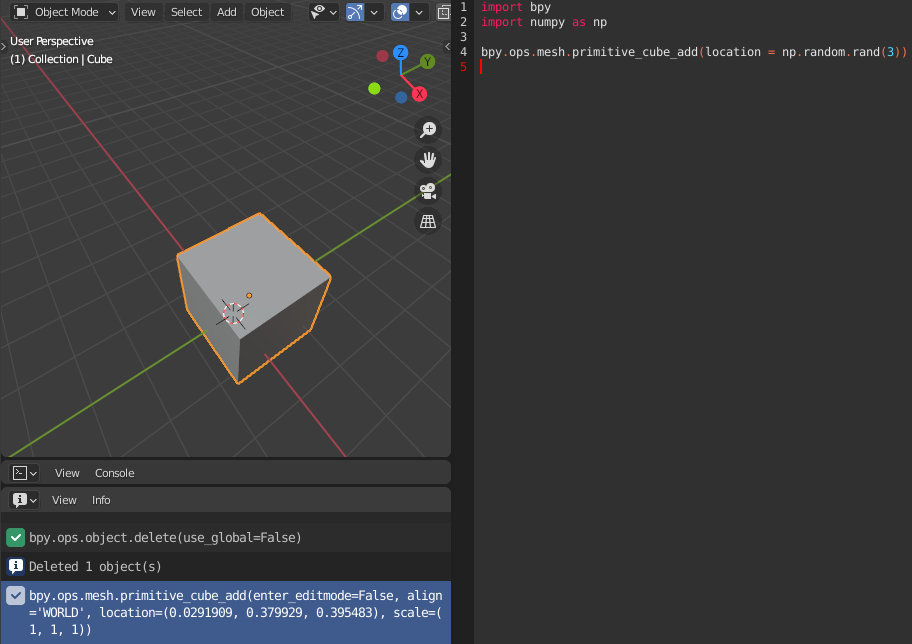
numpyを利用するimport bpy import numpy as np bpy.ops.mesh.primitive_cube_add(location = np.random.rand(3))Point:rand( )
0から1までのランダムな値を生成する。
引数で、値を何個返すのか決定する。rand(3)なら、ランダムな値を3つ返す。
※写真では、変数locationに、3つのランダムな値→(0.0291909, 0.379929, 0.395483)が代入された。
1-1.立方体が出現する範囲を指定できるようにしよう
○-10以上10未満の範囲のランダムな数値を取得します。
コードは以下のような構造になっています。変数□にデータ(情報)を代入して、そのデータを使って処理を実行する。
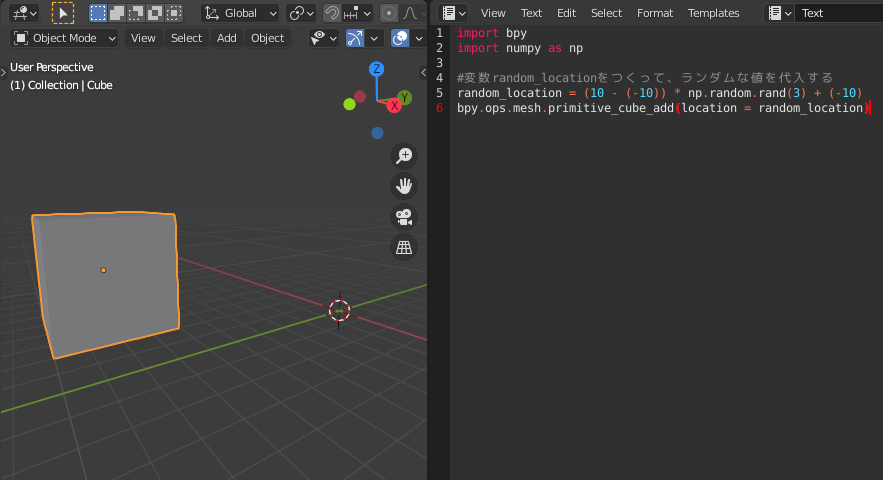
そして、ドットは右向き矢印と考えてOK(ほぼ無視して良い).□ ← ランダムな数値データ ===> 関数( □ )import bpy import numpy as np #変数random_locationをつくって、ランダムな値を代入する random_location = (10 - (-10)) * np.random.rand(3) + (-10) bpy.ops.mesh.primitive_cube_add(location = random_location)
Point:ある範囲内の数値
min以上max未満の範囲のランダムな値を取得する式は、
(max-min) * np.random.rand() + min
です。つまり、
数値が変動する範囲 * 0から1までのランダムな値 + 範囲のはじまり
ということです。今回の例で言うと、-10から、+20の範囲内の(ランダムな)数値を取得する。
範囲→(-10,..-9,..0,..9,..10)2.関数をつくって処理をまとめる
2-0.ランダムな数値を返す関数と、それを使って立方体を出現させる関数をつくる
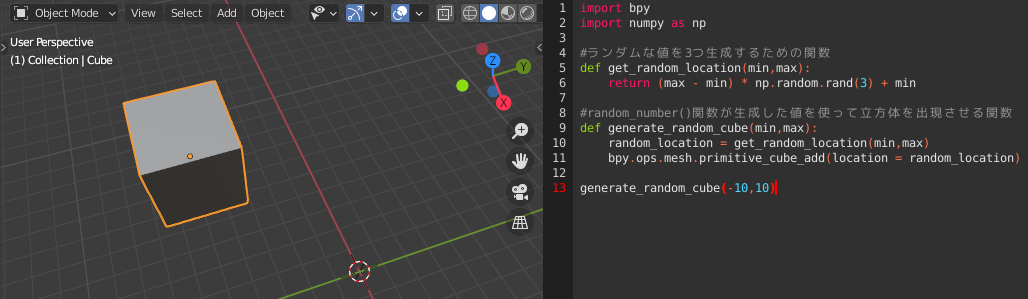
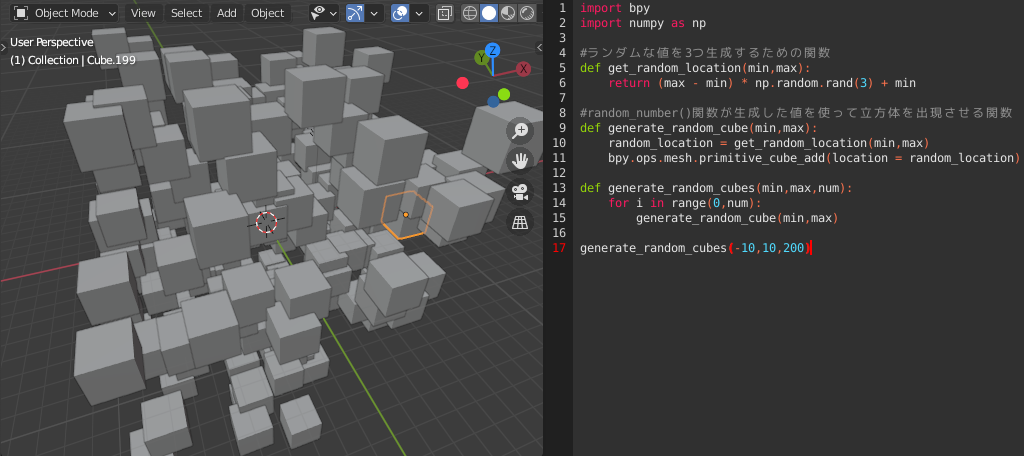
import bpy import numpy as np #ランダムな値を3つ生成するための関数の定義 def get_random_location(min,max): return (max - min) * np.random.rand(3) + min #get_random_location()関数が生成した値を使って立方体を出現させる関数の定義 def generate_random_cube(min,max): random_location = get_random_location(min,max) bpy.ops.mesh.primitive_cube_add(location = random_location) generate_random_cube(-10,10)Point:Return
関数が何らかの情報を出力する時にreturn 情報という形で使います。
2-1.複数の立方体をランダムな位置に出現させる関数をつくる
import bpy import numpy as np #ランダムな値を3つ生成するための関数の定義 def get_random_location(min,max): return (max - min) * np.random.rand(3) + min #get_random_location()関数が生成した値を使って立方体を出現させる関数の定義 def generate_random_cube(min,max): random_location = get_random_location(min,max) bpy.ops.mesh.primitive_cube_add(location = random_location) #複数の立方体をランダムな位置に出現させる関数の定義 def generate_random_cubes(min,max,num): for i in range(0,num): generate_random_cube(min,max) generate_random_cubes(-10,10,200)
2-2.ランダムな位置にランダムな角度の立方体を複数出現させる
import bpy import math import numpy as np #ランダムな値を3つ生成するための関数の定義 def get_random_location(min,max): return (max - min) * np.random.rand(3) + min #random_number()関数が生成した値を使って立方体を回転、出現させる関数の定義 def generate_random_rotate_cube(min,max): random_location = get_random_location(min,max) bpy.ops.mesh.primitive_cube_add(location = random_location,rotation = math.pi * np.random.rand(3)) #複数の立方体をランダムな位置に回転、出現させる関数の定義 def generate_random_rotate_cubes(min,max,num): for i in range(0,num): generate_random_rotate_cube(min,max) generate_random_rotate_cubes(-10,10,200)
3.サンプルコード
色をランダムに決める関数をつくる
○カラフルな立方体をランダムな位置にランダムな角度で配置します。
import bpy import math import numpy as np #マテリアルを決める関数の定義 def material(name = 'material'): material_glass = bpy.data.materials.new(name) #ノードを使えるようにする material_glass.use_nodes = True p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/7→roughness(=粗さ)/15→transmission(=伝播) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = np.random.rand(4) p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass) #ランダムな値を3つ生成するための関数の定義 def get_random_location(min,max): return (max - min) * np.random.rand(3) + min #random_number()関数が生成した値を使って立方体を回転、出現させる関数の定義 def generate_random_rotate_cube(min,max): random_location = get_random_location(min,max) bpy.ops.mesh.primitive_cube_add(location = random_location,rotation = math.pi * np.random.rand(3)) #複数の立方体をランダムな位置に回転、出現させる関数の定義 def generate_random_rotate_colorful_cubes(min,max,num): for i in range(0,num): generate_random_rotate_cube(min,max) material('Random') generate_random_rotate_colorful_cubes(-10,10,200)
立方体を回転させながら並べる関数をつくる
import bpy import math import numpy as np #マテリアルを決める関数の定義 def material(name = 'material'): material_glass = bpy.data.materials.new(name) #ノードを使えるようにする material_glass.use_nodes = True p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/7→roughness(=粗さ)/15→transmission(=伝播) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = np.random.rand(4) p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass) #カラフルな立方体を回転させながら並べる関数の定義 def spiral_colorful_cubes(): #100回反復処理をする for i in range(0,100): bpy.ops.mesh.primitive_cube_add( #少しずつ上にずらす location=(0, 0, i/50), scale=(1, 1, 0.05), #180 * i * 36(度)ずつずらしていく rotation = (0, 0, math.pi*i*10/360) ) #オブジェクトにマテリアルの要素を追加する material('Random') #処理を実行する spiral_colorful_cubes()
トーラスを変形させて回転し、並べていく関数をつくる
import bpy import math import numpy as np #マテリアルを決める関数の定義 def material(name = 'material'): material_glass = bpy.data.materials.new(name) #ノードを使えるようにする material_glass.use_nodes = True p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/7→roughness(=粗さ)/15→transmission(=伝播) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = np.random.rand(4) p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass) #トーラスを変形してずらしながら並べ、それぞれに色をつける関数の定義 def colorful_torus_spiral(): for i in range(0,36): bpy.ops.mesh.primitive_torus_add( location=(0, 0, 0), major_radius=1.0, minor_radius=0.01, ) #Y軸方向に縮める bpy.ops.transform.resize(value=(1, 0.3, 1)) #Z軸を中心に回転する bpy.ops.transform.rotate(value=math.pi*i*10/360,orient_axis='Z') #オブジェクトにマテリアルの要素を追加する material('Random') colorful_torus_spiral()
4.英単語
英単語 訳 spiral 螺旋 material 素材、材質 principled 原理、原則の primitive 原始的な math 数学 add 追加する context 文脈、環境 value 値 default 既定の append 追加する generate 生み出す inputs 取得する 参考資料



- 投稿日:2020-11-16T18:06:03+09:00
ツイッタートレンド解析のためのプログラム(個人的メモ)
こんにちは。自分は現在駒澤大学GMS学部の2年生でタイトルにあるようにツイッターのトレンドについて研究しています。この記事では研究やコードや参考になりそうなものを紹介します。
元々、ツイッタートレンドに興味があり、1年生の頃から、PythonとTwitterAPIとMeCabを使っていましたが、形態素解析して単語ごとに集計するという原始的なものでした。他に言語と位置情報や出現する漢字などで遊んでいました()
↓
そしてN-gramの要領で例えば2-12単語節ごとに記録し、全てを集計する簡易的なトレンド解析ができました。補足として、単語節にはツイッターのトレンドにあるように助詞がどこにこないとか助動詞がどうとか、だいぶ手作業で規則を作りました。これが2年生最初の頃です
↓
その後、何を研究するかとなった時に、一日の中で変動する定常トレンドを定義してモデル化というアイデアもありましたが、それをして何になるのかとか自分でも思っていて、某大学の先生からもその点と規則に人の手が入っていることを指摘されました。2年生夏頃です
↓
少し彷徨っていましたが、https://pj.ninjal.ac.jp/corpus_center/goihyo.html
国立国語研究所のUnidic,分類語彙表,意味分類に辿り着き、単語の意味的正規化、クラスタリング?をしようとしました。なかなか良くできましたが、複数の辞書の対応表?逆引きの際に同音異義語のはずなのに意味が極端な方で参照されるだとかで、若干の人の手が入りましたが問題ではない程度だと思います。あと、Unidicには未知語もあり、そのトレンドが考慮されないという問題も。2年生の10月くらいですか
↓
意味の正規化ができたところで、係り受けを用いて意味の係り受けでトレンドを出したいというのは、前段の頃から思っていたため、CaboChaを使いました。これが面倒でゼミのサーバでもAWSでもできなかったので、苦労しながら自分のWindowsにインストールして、subprocessでバインディング?しました(Pythonは32bitしかないため)。UnidicとCabochaで(Cabochaも辞書指定できる?)区切る位置が違っていたので、最小公倍数的な要領で共通部分で合わせました
↓
結果、意味の係り受けに基づいた意味トレンド?は出せました。しかし、『同音異義語のはずなのに意味が極端な方で参照される』というので修正を加えたり、それこそ『キャンペーンで当たる!フォローしてツイート』とかいうのがあり、『簡易的なトレンド解析』では、表出トレンド?の重複を用いて削除する方法がありましたが、やはりそれを用いることにしました
↓
ここまで、『意味の係り受けに基づいた意味トレンド』と『簡易的表出トレンド』の解析ができていて、今思っているのは、意味トレンドというのは表出と違って分けるのが難しいというか深層心理とか大局的なものであって、この研究では具体的なものにすることが大事だと思っていて、
独立した?表出トレンドに付随する意味トレンドごとに集計するとか、意味トレンドから表出トレンドを推定するとか、どの程度両者を使い分けられるか、どう組み合わせるかというところが今後の課題で、今が2年生の11月で卒業研究に向けてまあ頑張っているところです。
一段落したので書きました。(もっと早くから書いておけばよかったかも)今更ですが表出トレンドというのは文字の羅列で、意味トレンドというのは文字を意味に置き換えた意味の羅列といった具合です。
もし使いたいとかなったら一言ツイッターでも、教えてくれるとありがたいです。そこが心配でした。著作権は自分にあるということにしてください。
バックアップ的な意味でも書きたいと思いました。
環境はWindows10-64bit Python3です(雑)
https://twitter.com/kenkensz9まず、表出トレンドを推定するためのプログラムです。
custam_freq_sentece.txtは解析のために取得した全テキスト
custam_freq_tue.txtはトレンド候補。
custam_freq.txtはトレンド。
custam_freq_new.txtはトレンドから重複したものを除いて最長トレンドを出したプログラムです。
また、トレンドは時間ごとに入れ替えています。
freshtime=int(time.time()*1000)-200000の部分。これはツイート取得の速度によって変えると良いです。
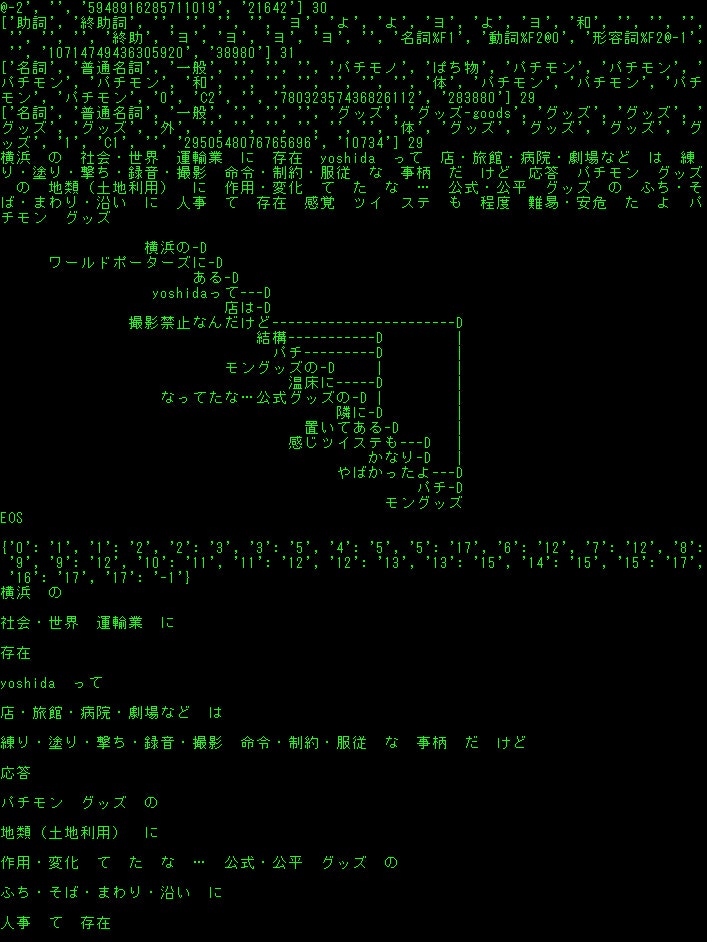
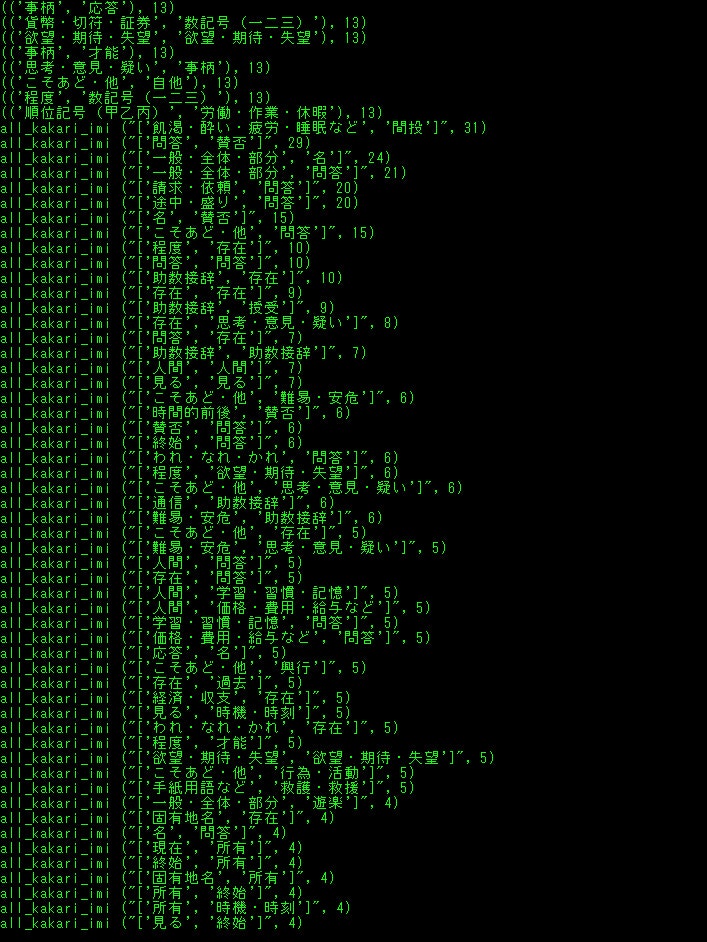
あと、そもそもツイートにこのワードが含まれていたら処理しない単語リストbadwordもあって、これはプログラムのバージョンで無いのもありますが管理がヘタなので、、お好みでどうぞ。hyousyutu_trend.py# coding: utf-8 import tweepy import datetime import re import itertools import collections from pytz import timezone import time import MeCab #import threading #from multiprocessing import Pool import os #import multiprocessing import concurrent.futures import urllib.parse #インポート import pdb; pdb.set_trace() import gc import sys import emoji consumer_key = "" consumer_secret = "" access_token = "" access_token_secret = "" auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) authapp = tweepy.AppAuthHandler(consumer_key,consumer_secret) apiapp = tweepy.API(authapp) #認証 m_owaka = MeCab.Tagger("-Owakati") m_ocha = MeCab.Tagger("-Ochasen") #mecab形態素分解定義 lang_dict="{'en': '英語', 'und': '不明', 'is': 'アイスランド語', 'ay': 'アイマラ語', 'ga': 'アイルランド語', 'az': 'アゼルバイジェン語', 'as': 'アッサム語', 'aa': 'アファル語', 'ab': 'アプハジア語', 'af': 'アフリカーンス語', 'am': 'アムハラ語', 'ar': 'アラビア語', 'sq': 'アルバニア語', 'hy': 'アルメニア語', 'it': 'イタリア語', 'yi': 'イディッシュ語', 'iu': 'イヌクティトット語', 'ik': 'イヌピア語', 'ia': 'インターリングア', 'ie': 'インターリング語', 'in': 'インドネシア語', 'ug': 'ウイグル語', 'cy': 'ウェールズ語', 'vo': 'ヴォラピュック語', 'wo': 'ウォロフ語', 'uk': 'ウクライナ語', 'uz': 'ウズベク語', 'ur': 'ウルドゥー語', 'et': 'エストニア語', 'eo': 'エスペラント語', 'or': 'オーリア語', 'oc': 'オキタン語', 'nl': 'オランダ語', 'om': 'オロモ語', 'kk': 'カザフ語', 'ks': 'カシミール語', 'ca': 'カタラン語', 'gl': 'ガリシア語', 'ko': '韓国語', 'kn': 'カンナダ語', 'km': 'カンボジア語', 'rw': 'キヤーワンダ語', 'el': 'ギリシャ語', 'ky': 'キルギス語', 'rn': 'キルンディ語', 'gn': 'グアラニー語', 'qu': 'クエチュア語', 'gu': 'グジャラト語', 'kl': 'グリーンランド語', 'ku': 'クルド語', 'ckb': '中央クルド語', 'hr': 'クロアチア語', 'gd': 'ゲーリック語', 'gv': 'ゲーリック語', 'xh': 'コーサ語', 'co': 'コルシカ語', 'sm': 'サモア語', 'sg': 'サングホ語', 'sa': 'サンスクリット語', 'ss': 'シスワティ語', 'jv': 'ジャワ語', 'ka': 'ジョージア語', 'sn': 'ショナ語', 'sd': 'シンド語', 'si': 'シンハラ語', 'sv': 'スウェーデン語', 'su': 'スーダン語', 'zu': 'ズールー語', 'es': 'スペイン語', 'sk': 'スロヴァキア語', 'sl': 'スロヴェニア語', 'sw': 'スワヒリ語', 'tn': 'セツワナ語', 'st': 'セト語', 'sr': 'セルビア語', 'sh': 'セルボクロアチア語', 'so': 'ソマリ語', 'th': 'タイ語', 'tl': 'タガログ語', 'tg': 'タジク語', 'tt': 'タタール語', 'ta': 'タミル語', 'cs': 'チェコ語', 'ti': 'チグリニャ語', 'bo': 'チベット語', 'zh': '中国語', 'ts': 'ヅォンガ語', 'te': 'テルグ語', 'da': 'デンマーク 語', 'de': 'ドイツ語', 'tw': 'トウィ語', 'tk': 'トルクメン語', 'tr': 'トルコ語', 'to': 'トンガ語', 'na': 'ナウル語', 'ja': '日本語', 'ne': 'ネパール語', 'no': 'ノルウェー語', 'ht': 'ハイチ語', 'ha': 'ハウサ語', 'be': '白ロシア語', 'ba': 'バシキール語', 'ps': 'パシト語', 'eu': 'バスク語', 'hu': 'ハンガリー語', 'pa': 'パンジャビ語', 'bi': 'ビスラマ語', 'bh': 'ビハール語', 'my': 'ビルマ語', 'hi': 'ヒンディー語', 'fj': 'フィジー語', 'fi': 'フィンランド語', 'dz': 'ブータン語', 'fo': 'フェロー語', 'fr': 'フランス語', 'fy': 'フリジア語', 'bg': 'ブルガリア語', 'br': 'ブルターニュ語', 'vi': 'ベトナム語', 'iw': 'ヘブライ語', 'fa': 'ペルシャ語', 'bn': 'ベンガル語', 'pl': 'ポーランド語', 'pt': 'ポルトガル語', 'mi': 'マオリ語', 'mk': 'マカドニア語', 'mg': 'マダガスカル語', 'mr': 'マラッタ語', 'ml': 'マラヤーラム語', 'mt': 'マルタ語', 'ms': 'マレー語', 'mo': 'モルダビア語', 'mn': 'モンゴル語', 'yo': 'ヨルバ語', 'lo': 'ラオタ語', 'la': 'ラテン語', 'lv': 'ラトビア語', 'lt': 'リトアニア語', 'ln': 'リンガラ語', 'li': 'リンブルク語', 'ro': 'ルーマニア語', 'rm': 'レートロマンス語', 'ru': 'ロシア語'}" lang_dict=eval(lang_dict) lang_dict_inv = {v:k for k, v in lang_dict.items()} #言語辞書 all=[] #リスト初期化 if os.path.exists('custam_freq_tue.txt'): alll=open("custam_freq_tue.txt","r",encoding="utf-8-sig") alll=alll.read() all=eval(alll) del alll #all=[] #書き出し用意 #freq_write=open("custam_freq.txt","w",encoding="utf-8-sig") sent_write=open("custam_freq_sentece.txt","a",encoding="utf-8-sig", errors='ignore') #書き出し用意 use_lang=["日本語"] use_type=["tweet"] #config uselang="" for k in use_lang: k_key=lang_dict_inv[k] uselang=uselang+" lang:"+k_key #config準備 def inita(f,k): suball=[] small=[] for s in k: if not int(f)==int(s[1]): #print("------",f) suball.append(small) small=[] #print(s[0],s[1]) small.append(s) f=s[1] suball.append(small) #2を含むなら return suball def notwo(al): micro=[] final=[] kaburilist=[] for fg in al: kaburilist=[] if len(fg)>1: for v in itertools.combinations(fg, 2): micro=[] for s in v: micro.append(s[0]) micro=sorted(micro,key=len,reverse=False) kaburi=len(set(micro[0]) & set(micro[1])) per=kaburi*100//len(micro[1]) #print(s[1],per,kaburi,len(micro[0]),len(micro[1]),"m",micro) if per>50: kaburilist.append(micro[0]) kaburilist.append(micro[1]) else: final.append([micro[0],s[1]]) #print("fin1",micro[0],s[1]) if micro[0] in micro[1]: pass #print(micro[0],micro[1]) #print("含まれます"*5) #if micro[0] in kaburilist: # kaburilist.remove(micro[0]) else: pass #print(fg[0][1],fg[0][0]) final.append([fg[0][0],fg[0][1]]) #print("fin3",fg[0][0],fg[0][1]) #if kaburilist: #longword=max(kaburilist,key=len) #final.append([longword,s[1]]) ##print("fin2",longword,s[1]) #kaburilist.remove(longword) #kaburilist=list(set(kaburilist)) #for k in kaburilist: # if k in final: # final.remove(k) # #print("finremove1",k) return final def siage(fin): fin=list(map(list, set(map(tuple, fin)))) finallen = sorted(fin, key=lambda x: len(x[0])) finallendic=dict(finallen) finalword=[] for f in finallen: finalword.append(f[0]) #print("f1",finalword) notwo=[] for v in itertools.combinations(finalword, 2): #print(v) if v[0] in v[1]: #print("in") if v[0] in finalword: finalword.remove(v[0]) #print("f2",finalword) finall=[] for f in finalword: finall.append([f,finallendic[f]]) finall = sorted(finall, key=lambda x: int(x[1]), reverse=True) #print("final",finall) kk=open("custam_freq_new.txt", 'w', errors='ignore') kk.write(str(finall)) kk.close() def eval_pattern(use_t): tw=0 rp=0 rt=0 if "tweet" in use_t: tw=1 if "retweet" in use_t: rt=1 if "reply" in use_t: rp=1 sword="" if tw==1: sword="filter:safe OR -filter:safe" if rp==0: sword=sword+" exclude:replies" if rt==0: sword=sword+" exclude:retweets" elif tw==0: if rp==1 and rt ==1: sword="filter:reply OR filter:retweets" elif rp==0 and rt ==0: print("NO") sys.exit() elif rt==1: sword="filter:retweets" elif rp==1: sword="filter:replies" return sword pat=eval_pattern(use_type)+" "+uselang #config読み込み関数と実行 def a(n): return n+1 def f(k): k = list(map(a, k)) return k def g(n,m): b=[] for _ in range(n): m=f(m) b.append(m) return b #連番リスト生成 def validate(text): if re.search(r'(.)\1{1,}', text): return False elif re.search(r'(..)\1{1,}', text): return False elif re.search(r'(...)\1{1,}', text): return False elif re.search(r'(...)\1{1,}', text): return False elif re.search(r'(....)\1{1,}', text): return False else: return True #重複を調べる関数 def eval_what_nosp(c,i): no_term=[] no_start=[] no_in=[] koyu_meisi=[] if re.findall(r"[「」、。)(『』&@_;【/<>,!】\/@]", c[0]): no_term.append(i) no_start.append(i) no_in.append(i) if len(c) == 4: if "接尾" in c[3]: no_start.append(i) if "固有名詞" in c[3]: koyu_meisi.append(i) if c[3]=="名詞-非自立-一般": no_term.append(i) no_start.append(i) no_in.append(i) if "助詞" in c[3]: no_term.append(i) no_start.append(i) #no_in.append(i) if c[3]=="助詞-連体化": no_start.append(i) if c[3]=="助詞": no_start.append(i) if "お" in c[2]: if c[3]=="名詞-サ変接続": no_term.append(i) no_start.append(i) no_in.append(i) if len(c) == 6: if c[4]=="サ変スル": no_start.append(i) if c[3]=="動詞-非自立": no_start.append(i) if "接尾" in c[3]: no_start.append(i) if c[3]=="助動詞": if c[2]=="た": no_start.append(i) no_in.append(i) if c[3]=="助動詞": if c[2]=="ない": no_start.append(i) if c[3]=="助動詞": if "連用" in c[5]: no_term.append(i) no_start.append(i) if c[2]=="する": if c[3]=="動詞-自立": if c[5]=="連用形": no_start.append(i) no_in.append(i) if c[2]=="なる": if c[3]=="動詞-自立": no_start.append(i) no_in.append(i) if c[2]=="てる": if c[3]=="動詞-非自立": no_start.append(i) no_in.append(i) if c[2]=="です": if c[3]=="助動詞": no_start.append(i) no_in.append(i) if c[2]=="ちゃう": if c[3]=="動詞-非自立": no_start.append(i) no_in.append(i) if c[2]=="ある": if c[3]=="動詞-自立": no_term.append(i) no_start.append(i) no_in.append(i) if c[2]=="助動詞": if c[3]=="特殊ダ": no_term.append(i) no_start.append(i) no_in.append(i) if c[2]=="ます": if c[3]=="助動詞": no_term.append(i) no_start.append(i) no_in.append(i) if "連用" in c[5]: no_term.append(i) if c[5]=="体言接続": no_start.append(i) if c[2]=="くれる": if c[3]=="動詞-非自立": no_start.append(i) no_in.append(i) x="" y="" z="" koyu="" if no_term: x=no_term[0] if no_start: y=no_start[0] if no_in: z=no_in[0] if koyu_meisi: koyu=koyu_meisi[0] #print("koyu",koyu) koyu=int(koyu) return x,y,z,koyu small=[] nodouble=[] seq="" def process(ty,tw,un,tagg): global all global seq global small global nodouble tw=tw.replace("\n"," ") sent_write.write(str(tw)) sent_write.write("\n") parselist=m_owaka.parse(tw) parsesplit=parselist.split() parseocha=m_ocha.parse(tw) l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')] nodouble=[] no_term=[] no_start=[] no_in=[] km_l=[] for i, block in enumerate(l): c=block.split('\t') #sent_write.write("\n") #sent_write.write(str(c)) #sent_write.write("\n") #print(str(c)) ha,hi,hu,km=eval_what_nosp(c,i) no_term.append(ha) no_start.append(hi) no_in.append(hu) km_l.append(km) #分かち 書き 完成 if km_l[0]: for r in km_l: strin=parsesplit[r] if not strin in nodouble: all.append([strin,un]) nodouble.append(strin) for s in range(2,8): #2から8の連鎖。 #重くする代わりに精度を上げられるので重要 num=g(len(parsesplit)-s+1,range(-1,s-1)) for nr in num: #1つの文章に対しての2-8連鎖の全通り #print(no_term) if not len(set(nr) & set(no_in)): if not nr[-1] in no_term: if not nr[0] in no_start: small=[] #print(str(parsesplit)) for nr2 in nr: #print(nr2,parsesplit[nr2]) #中の配列をインデックスとした位置にある単語をsmallに追加 small.append(parsesplit[nr2]) seq="".join(small) judge_whole=0 bad_direct_word=["みたいな","\'mat","I\'mat"] #if "" in seq: # judge_whole=1 #if "" in seq: # judge_whole=1 for bd in bad_direct_word: if seq==bd: judge_whole=1 break parselist=m_owaka.parse(seq) l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')] for n in range(len(l)): if len(l[n].split("\t"))==6: if l[n].split("\t")[3]=="動詞-自立": if len(l[n+1].split("\t"))==6: if l[n+1].split("\t")[3]: judge_whole=1 break if judge_whole==0: if validate(seq) and len(seq) > 3 and not re.findall(r'[「」、。『』/\\/@]', seq): if not seq in nodouble: #連続回避 all.append([seq,un]) nodouble.append(seq) #print("正常に追加",seq) #同じ単語を2度集計しない else: #print("既に含まれています",seq) pass else: #print("除外",seq) pass else: #print("始まりがno_startです",seq) pass else: #print("終わりがno_termです",seq) pass #print("\n") #print(parsesplit) #print(l) if tagg: print("tagg",tagg) for sta in tagg: all.append(["#"+str(sta),un]) #tagを含める N=1 #取得ツイート数 def print_varsize(): import types print("{}{: >15}{}{: >10}{}".format('|','Variable Name','|',' Size','|')) print(" -------------------------- ") for k, v in globals().items(): if hasattr(v, 'size') and not k.startswith('_') and not isinstance(v,types.ModuleType): print("{}{: >15}{}{: >10}{}".format('|',k,'|',str(v.size),'|')) elif hasattr(v, '__len__') and not k.startswith('_') and not isinstance(v,types.ModuleType): print("{}{: >15}{}{: >10}{}".format('|',k,'|',str(len(v)),'|')) def collect_count(): global all global deadline hh=[] tueall=[] #print("alllll",all) freshtime=int(time.time()*1000)-200000 deadline=-1 #import pdb; pdb.set_trace() #print(N_time) print(len(N_time)) for b in N_time: if int(b[1]) < freshtime: deadline=b[0] print("dead",deadline) dellist=[] if not deadline ==-1: for b in N_time: print("b",b) if int(b[0]) < int(deadline): dellist.append(b) for d in dellist: N_time.remove(d) #print(N_time) #import pdb; pdb.set_trace() #time.sleep(2) #import pdb; pdb.set_trace() for a in all: if int(a[1]) > freshtime: #取得したいツイート数/45*1000の値を引く。今は5000/45*1000=112000 tueall.append(a[0]) #print("tuealllappend"*10) #print(tueall) else: all.remove(a) #print("allremove",a) #import pdb; pdb.set_trace() c = collections.Counter(tueall) c=c.most_common() #print("c",c) #print(c) for r in c: if r and r[1]>1: hh.append([str(r[0]),str(r[1])]) k=str(hh).replace("[]","") freq_write=open("custam_freq.txt","w",encoding="utf-8-sig", errors='ignore') freq_write.write(str(k)) #import pdb; pdb.set_trace() oldunix=N_time[0][1] newunix=N_time[-1][1] dato=str(datetime.datetime.fromtimestamp(oldunix/1000)).replace(":","-") datn=str(datetime.datetime.fromtimestamp(newunix/1000)).replace(":","-") dato=dato.replace(" ","_") datn=datn.replace(" ","_") #print(dato,datn) #import pdb; pdb.set_trace() freq_writea=open("trenddata/custam_freq-"+dato+"-"+datn+"--"+str(len(N_time))+".txt","w",encoding="utf-8-sig", errors='ignore') freq_writea.write(str(k)) #import pdb; pdb.set_trace() freq_write_tue=open("custam_freq_tue.txt","w",encoding="utf-8-sig", errors='ignore') freq_write_tue.write(str(all)) #print(c) def remove_emoji(src_str): return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI) def deEmojify(inputString): return inputString.encode('ascii', 'ignore').decode('ascii') def get_tag(tw,text_content): taglist=[] entities=eval(str(tw.entities))["hashtags"] for e in entities: text=e["text"] taglist.append(text) for _ in range(len(taglist)+2): for s in taglist: text_content=re.sub(s,"",text_content) #text_content=re.sub(r"#(.+?)+ ","",text_content) return taglist,text_content def get_time(id): two_raw=format(int(id),'016b').zfill(64) unixtime = int(two_raw[:-22],2) + 1288834974657 unixtime_th = datetime.datetime.fromtimestamp(unixtime/1000) tim = str(unixtime_th).replace(" ","_")[:-3] return tim,unixtime non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), '') N_time=[] def gather(tweet,type,tweet_type,removed_text): global N global N_all global lagtime global all_time global all global auth global N_time if get_time(tweet.id): tim,unix=get_time(tweet.id) else: exit #細かいツイート時間を取得 #original_text=tweet.text nowtime=time.time() tweet_pertime=str(round(N/(nowtime-all_time),1)) lag=str(round(nowtime-unix/1000,1)) #ラグを計算 lang=lang_dict[tweet.lang] print(N_all,N,tweet_pertime,"/s","+"+lag,tim,type,tweet_type,lang) #情報表示。(全ツイート、処理ツイート、処理速度、ラグ、実時間、入手経路、ツイートタイプ、言語) print(removed_text.replace("\n"," ")) taglist,tag_removed_text=get_tag(tweet,removed_text) #import pdb; pdb.set_trace() #print(type(tweet)) #import pdb; pdb.set_trace() #タグを除く noemoji=remove_emoji(tag_removed_text) try: process(tweet_type,tag_removed_text,unix,taglist) N_time.append([N,unix]) print("trt",tag_removed_text) except Exception as pe: print("process error") print(pe) #import pdb; pdb.set_trace() #実処理に送る surplus=N%1000 if surplus==0: #sumprocess() try: collect_count() except Exception as eeee: print(eeee) #exit #集計しよう cft_read=open("custam_freq.txt","r",encoding="utf-8-sig") cft_read=cft_read.read() cft_read=eval(cft_read) max_freq=cft_read[0][1] #最大値 allen=inita(max_freq,cft_read) #同じ頻度のトレンドでまとめたリストにする。 finf=notwo(allen) #重複する文字列、重複するトレンドを探して削除する siage(finf) #それをnew_freqとして書き込む print_varsize() #メモリ情報を表示 N=N+1 #streaming本体 def judge_tweet_type(tweet): text = re.sub("https?://[\w/:%#\$&\?\(\)~\.=\+\-]+","",tweet.text) if tweet.in_reply_to_status_id_str : text=re.sub(r"@[a-zA-Z0-9_]* ","",text) text=re.sub(r"@[a-zA-Z0-9_]","",text) return "reply",text else: head= str(tweet.text).split(":") if len(head) >= 2 and "RT" in head[0]: text=re.sub(r"RT @[a-zA-Z0-9_]*: ","",text) return "retwe",text else: return "tweet",text badword=["質問箱","マシュマロを投げ合おう","質問がじゃんじゃん届く","参戦","配信","@","フォロー","応募","スマホRPG","ガチャ","S4live","キャンペーン","ドリフトスピリッツ","プレゼント","協力ライブ","完全無料で相談受付中","おみくじ","当たるチャンス","GET","ゲット","shindanmaker","当たる","抽選"] N_all=0 def gather_pre(tweet,type): global N_all N_all=N_all+1 #ここを通過する全ツイート数カウント go=0 for b in badword: if b in tweet.text: go=1 break #テキスト内にbadwordがあるか判断、0で含まれないからGO判断 if go == 0: if tweet.lang=="ja": tweet_type,removed_text=judge_tweet_type(tweet) #ツイートタイプを判断 if tweet_type=="tweet": try: gather(tweet,type,tweet_type,removed_text) #print(type(tweet)) #gather処理に送る。 except Exception as eee: #gather("あ","あ","あ","あ") #import pdb; pdb.set_trace() pass lagtime=0 def search(last_id): #print(pat) global pat time_search =time.time() for status in apiapp.search(q=pat,count="100",result_type="recent",since_id=last_id): #searchで最後に取得したツイートよりも新しいツイートを取得 gather_pre(status,"search") #search本体 interval = 2.16 #search呼び出し間隔 #min2 trysearch=0 #search呼び出し回数 class StreamingListener(tweepy.StreamListener): def on_status(self, status): global time_search global trysearch gather_pre(status,"stream") time_stream=time.time() time_stream-time_search % interval if time_stream-time_search-interval>interval*trysearch: #一定時間(interbal)ごとにsearchを実行する。 last_id=status.id #executor = concurrent.futures.ThreadPoolExecutor(max_workers=8) #executor.submit(search(last_id)) #並列処理を試す場合 search(last_id) trysearch=trysearch+1 #streaming本体 def carry(): listener = StreamingListener() streaming = tweepy.Stream(auth, listener) streaming.sample() #stream呼び出し関数 time_search =time.time() #searchを最後に実行した時間だがstream前に定義 executor = concurrent.futures.ThreadPoolExecutor(max_workers=8) #並列定義 all_time=time.time() #実行開始時間定義 try: carry() except Exception as e: import pdb; pdb.set_trace() print(e) #import pdb; pdb.set_trace() pass #except Exception as ee: #print(ee) #import pdb; pdb.set_trace() #carry本体とエラー処理下は意味トレンドのプログラムですが、絶賛作業中なので、自信をもってオススメできます()。シソーラスから持ってくる部分は自分が書いたものではないですが、残しておきます。
imi_trend.pyfrom bs4 import BeautifulSoup import collections import concurrent.futures import datetime import emoji import itertools import MeCab from nltk import Tree import os from pathlib import Path from pytz import timezone import re import spacy import subprocess import sys import time import tweepy import unidic2ud import unidic2ud.cabocha as CaboCha from urllib.error import HTTPError, URLError from urllib.parse import quote_plus from urllib.request import urlopen m=MeCab.Tagger("-d ./unidic-cwj-2.3.0") os.remove("bunrui01.csv") os.remove("all_tweet_text.txt") os.remove("all_kakari_imi.txt") bunrui01open=open("bunrui01.csv","a",encoding="utf-8") textopen=open("all_tweet_text.txt","a",encoding="utf-8") akiopen=open("all_kakari_imi.txt","a",encoding="utf-8") catedic={} with open('categori.txt') as f: a=f.read() aa=a.split("\n") b=[] bunrui01open.write(",,,") for i, j in enumerate(aa): catedic[j]=i bunrui01open.write(str(j)) bunrui01open.write(",") bunrui01open.write("\n") print(catedic) with open('./BunruiNo_LemmaID_ansi_user.csv') as f: a=f.read() aa=a.split(",\n") b=[] for bb in aa: if len(bb.split(","))==2: b.append(bb.split(",")) word_origin_num_to_cate=dict(b) with open('./cate_rank2.csv') as f: a=f.read() aa=a.split("\n") b=[] for bb in aa: if len(bb.split(","))==2: b.append(bb.split(",")) cate_rank=dict(b) class Synonym: def getSy(self, word, target_url, css_selector): try: # アクセスするURLに日本語が含まれているのでエンコード self.__url = target_url + quote_plus(word, encoding='utf-8') # アクセスしてパース self.__html = urlopen(self.__url) self.__soup = BeautifulSoup(self.__html, "lxml") result = self.__soup.select_one(css_selector).text return result except HTTPError as e: print(e.reason) except URLError as e: print(e.reason) sy = Synonym() alist = ["選考"] # 検索する先は「日本語シソーラス 連想類語辞典」を使用 target = "https://renso-ruigo.com/word/" selector = "#content > div.word_t_field > div" #for item in alist: # print(sy.getSy(item, target, selector)) consumer_key = "" consumer_secret = "" access_token = "" access_token_secret = "" auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) authapp = tweepy.AppAuthHandler(consumer_key,consumer_secret) apiapp = tweepy.API(authapp) #認証(ここではapi) def remove_emoji(src_str): return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI) def get_tag(tw,text_content): taglist=[] entities=eval(str(tw.entities))["hashtags"] for e in entities: text=e["text"] taglist.append(text) for _ in range(len(taglist)+2): for s in taglist: text_content=re.sub(s,"",text_content) #text_content=re.sub(r"#(.+?)+ ","",text_content) return taglist,text_content def get_swap_dict(d): return {v: k for k, v in d.items()} def xcut(asub,a): asub.append(a[0]) a=a[1:len(a)] return asub,a def ycut(asub,a): asub.append(a[0]) a=a[1:len(a)] return asub,a def bunruikugiri(lastx,lasty): hoge=[] #import pdb; pdb.set_trace() editx=[] edity=[] for _ in range(500): edity,lasty=ycut(edity,lasty) #target=sum(edity) for _ in range(500): target=sum(edity) #rint("sum",sum(editx),"target",target) if sum(editx)<target: editx,lastx=xcut(editx,lastx) elif sum(editx)>target: edity,lasty=ycut(edity,lasty) else: hoge.append(editx) editx=[] edity=[] if lastx==[] and lasty==[]: return hoge break all_appear_cate=[] all_unfound_word=[] all_kumiawase=[] nn=1 all_kakari_imi=[] def process(tw,ty): global nn wordnum_toword={} catenum_wordnum={} word_origin_num=[] mozisu=[] try: tw=re.sub("https?://[\w/:%#\$&\?\(\)~\.=\+\-]+","",tw) tw=tw.replace("#","") tw=tw.replace(",","") tw=tw.replace("\u3000","") #文字数合わせのため重要 tw=re.sub(re.compile("[!-/:-@[-`{-~]"), '', tw) parseocha=m.parse(tw) print(tw) l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')] bunrui_miti_sentence=[] for i, block in enumerate(l): if len(block.split('\t')) > 1: c=block.split('\t') d=c[1].split(",") #単語の処理過程 print(d,len(d)) if len(d)>9: if d[10] in ["する"]: word_origin_num.append(d[10]) bunrui_miti_sentence.append(d[8]) mozisu.append(len(d[8])) elif d[-1] in word_origin_num_to_cate: word_origin_num.append(int(d[-1])) wordnum_toword[int(d[-1])]=d[8] bunrui_miti_sentence.append(word_origin_num_to_cate[str(d[-1])]) mozisu.append(len(d[8])) else: #print("nai",d[8]) #未知語の表示 all_unfound_word.append(d[10]) bunrui_miti_sentence.append(d[8]) mozisu.append(len(c[0])) else: mozisu.append(len(c[0])) all_unfound_word.append(c[0]) bunrui_miti_sentence.append(c[0]) #else: # mozisu.append(l[]) #print("kouho",word_origin_num,"\n") #単語をオリジナル番号に #print(tw) #意味分類と未知語で作った文を見るなら for s in bunrui_miti_sentence: print(s," ",end="") print("\n") stn=0 cmd = "echo "+str(tw)+" | cabocha -f1" cmdtree="echo "+str(tw)+" | cabocha " proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE,shell=True) proctree = subprocess.Popen(cmdtree, stdout=subprocess.PIPE, stderr=subprocess.PIPE,shell=True) proc=proc.communicate()[0].decode('cp932') proctree=proctree.communicate()[0].decode('cp932') print(proctree) proclist=proc.split("\n") #print(proc) #f1情報 #print(proclist) #リスト化情報 procnumlist=[] wordlis=[] eachword="" num=0 for p in proclist: if p[0]=="*": f=p.split(" ")[1] t=p.split(" ")[2].replace("D","") procnumlist.append([f,t]) if eachword: wordlis.append([num,eachword]) num=num+1 eachword="" elif p=="EOS\r": wordlis.append([num,eachword]) num=num+1 eachword="" break else: #print("aaaaa",p.split("\t")[0]) eachword=eachword+p.split("\t")[0] tunagari_num_dict=dict(procnumlist) print(tunagari_num_dict) bunsetu_num_word=dict(wordlis) #print(bunsetu_num_word) bunsetu_mozisu=[] for v in bunsetu_num_word.values(): bunsetu_mozisu.append(len(v)) if sum(bunsetu_mozisu) != sum(mozisu): return #print("mozisu",mozisu) #print("bunsetumozi",bunsetu_mozisu) res=bunruikugiri(mozisu,bunsetu_mozisu) #print("res",res) nnn=0 small_cateandcharlist=[] big_cateandcharlist=[] for gc in res: for _ in range(len(gc)): print(bunrui_miti_sentence[nnn],end=" ") if bunrui_miti_sentence[nnn] in list(catedic.keys()): small_cateandcharlist.append(bunrui_miti_sentence[nnn]) nnn=nnn+1 #未知語や助詞も同じものだとみなされているからmecabnegold辞書使えそう if small_cateandcharlist==[]: big_cateandcharlist.append(["null"]) else: big_cateandcharlist.append(small_cateandcharlist) small_cateandcharlist=[] print("\n") #print("bcacl",big_cateandcharlist) twewtnai_kakari_imi=[] if len(big_cateandcharlist)>1 and len(big_cateandcharlist)==len(bunsetu_num_word): #係り受け、形態素解析の区切りが一致しない for kk, vv in tunagari_num_dict.items(): if vv != "-1": for aaw in big_cateandcharlist[int(kk)]: for bbw in big_cateandcharlist[int(vv)]: twewtnai_kakari_imi.append([aaw,bbw]) if not "順位記号" in str([aaw,bbw]): if not "null" in str([aaw,bbw]): if not "数記号" in str([aaw,bbw]): if not "事柄" in str([aaw,bbw]): all_kakari_imi.append(str([aaw,bbw])) akiopen.write(str([aaw,bbw])) else: break else: return akiopen.write("\n") akiopen.write(str(bunrui_miti_sentence)) akiopen.write("\n") akiopen.write(str(tw)) akiopen.write("\n") print("tki",twewtnai_kakari_imi) tweetnai_cate=[] word_cate_num=[] for k in word_origin_num: if str(k) in word_origin_num_to_cate: ram=word_origin_num_to_cate[str(k)] print(ram,cate_rank[ram],end="") tweetnai_cate.append(ram) all_appear_cate.append(ram) word_cate_num.append(catedic[ram]) catenum_wordnum[catedic[ram]]=int(k) stn=stn+1 else: if k in ["する"]: all_appear_cate.append(k) tweetnai_cate.append(k) print("\n") #print(tweetnai_cate) #import pdb; pdb.set_trace() for k in tweetnai_cate: if k in catedic: aac=catedic[k] #print("gyaku",word_cate_num) #print("wt",wordnum_toword) #print("cw",catenum_wordnum) bunrui01open.write(str(tw)) bunrui01open.write(",") bunrui01open.write(str(tim)) bunrui01open.write(",") bunrui01open.write(str(unix)) bunrui01open.write(",") ps=0 for tt in list(range(544)): if int(tt) in word_cate_num: a=catenum_wordnum[tt] #かてごりから単語番号 bunrui01open.write(str(wordnum_toword[a])) #単語番号から単語 bunrui01open.write(",") ps=ps+1 else: bunrui01open.write("0,") bunrui01open.write("end") bunrui01open.write("\n") textopen.write(str(nn)) textopen.write(" ") textopen.write(tw) textopen.write("\n") nn=nn+1 #全ての通りを入れる for k in list(itertools.combinations(tweetnai_cate,2)): all_kumiawase.append(k) except Exception as ee: print(ee) import pdb; pdb.set_trace() pass def judge_tweet_type(tweet): if tweet.in_reply_to_status_id_str: return "reply" else: head= str(tweet.text).split(":") if len(head) >= 2 and "RT" in head[0]: return "retwe" else: return "tweet" #リプ、リツイート、ツイートか判断 def get_time(id): two_raw=format(int(id),'016b').zfill(64) unixtime = int(two_raw[:-22],2) + 1288834974657 unixtime_th = datetime.datetime.fromtimestamp(unixtime/1000) tim = str(unixtime_th).replace(" ","_")[:-3] return tim,unixtime #idからツイート時間 N=1 def gather(tweet,type,tweet_typea): global all_appear_cate global N global all_time global tim global unix tim,unix=get_time(tweet.id) original_text=tweet.text.replace("\n","") taglist,original_text=get_tag(tweet,original_text) nowtime=time.time() tweet_pertime=str(round(N/(nowtime-all_time),1)) lag=str(round(nowtime-unix/1000,1)) #lang=lang_dict[tweet.lang] try: process(remove_emoji(original_text),tweet_typea,) except Exception as e: print(e) #import pdb; pdb.set_trace() pass print(N,tweet_pertime,"/s","+"+lag,tim,type,tweet_typea) N=N+1 if N%500==0: ccdd=collections.Counter(all_appear_cate).most_common() for a in ccdd: print(a) #ccdd=collections.Counter(all_unfound_word).most_common() #for a in ccdd: # print("ない",a) ccdd=collections.Counter(all_kumiawase).most_common(300) for a in ccdd: print(a) ccdd=collections.Counter(all_kakari_imi).most_common(300) for a in ccdd: print("all_kakari_imi",a) #import pdb; pdb.set_trace() #streamとsearchの全ツイートが集まる def pre_gather(tw,ty): #print(ty) # if "http://utabami.com/TodaysTwitterLife" in tw.text: print(tw.text) if ty=="stream": tweet_type=judge_tweet_type(tw) if tw.lang=="ja" and tweet_type=="tweet": gather(tw,ty,tweet_type) elif ty=="search": gather(tw,ty,"tweet") def search(last_id): time_search =time.time() for status in apiapp.search(q="filter:safe OR -filter:safe -filter:retweets -filter:replies lang:ja",count="100",result_type="recent",since_id=last_id): pre_gather(status,"search") #search本体 class StreamingListener(tweepy.StreamListener): def on_status(self, status): global time_search global trysearch pre_gather(status,"stream") time_stream=time.time() time_stream-time_search % interval if time_stream-time_search-interval>interval*trysearch: last_id=status.id #executor = concurrent.futures.ThreadPoolExecutor(max_workers=2) #executor.submit(search(last_id)) search(last_id) trysearch=trysearch+1 #streaming本体 def carry(): listener = StreamingListener() streaming = tweepy.Stream(auth, listener) streaming.sample() interval = 2.1 trysearch=0 time_search =time.time() #executor = concurrent.futures.ThreadPoolExecutor(max_workers=2) all_time=time.time() try: #executor.submit(carry) carry() except Exception as er: print(er) import pdb; pdb.set_trace() pass
500ツイートごとに、
単純な意味の出現数
2-gramの意味の出現数
2-gram間の係り受けのある意味連続?の出現数
また全てに、
ツイート本文、Unidic解析情報、CaboCha係り受け、意味分類との置き換えなどあります。bunrui01.csvー横軸に544の意味分類、縦軸にツイートで、0は存在しない、1は該当する単語となるよう書き込むcsvです
all_tweet_textー処理ツイートとそれが何番目か
all_kakari_imiー係り受け意味ペア、意味分類置き換え、本文
categori.txtー544の意味分類を記したtxtで実行時にindexで辞書を作ります。
BunruiNo_LemmaID_ansi_user.csvーは詳しくはhttps://pj.ninjal.ac.jp/corpus_center/goihyo.html
を見れば分かるのですが、単語オリジナルNoと意味分類の対応表です。
cate_rank2.csvーある時に作った意味分類の出現順辞書です。他の変数の説明はまた後ほど、、
自分のメモ用で、分かる人は頑張って理解してというくらいなのでこれくらいにします。
- 投稿日:2020-11-16T17:35:20+09:00
FirebaseでiOSのプッシュ通知を実装
始めに
iOS アプリでプッシュ通知機能を実装しようと思ったら、想定より苦戦したので、振り返ってみようと思います。
Firebase プロジェクトを作成する
Firebase コンソールで [プロジェクトを追加] をクリックし、 [プロジェクト名] を選択して、新しいプロジェクト名を入力します。
アプリを Firebase に登録する
- Firebase プロジェクトを作成したら、プロジェクトに iOS アプリを追加できます。 Firebase コンソールから、 [プロジェクトページ] に移動して、中央にある iOS アイコンをクリックして設定ワークフローを起動します。
- アプリのバンドル ID を [iOS バンドル ID] フィールドに入力します。このバンドル ID を探すには、 XCode でアプリを開き、最上位のディレクトリの [General] タブにアクセスします。[bundle identifier] フィールドの値が iOS バンドル ID です(例: com.atsushi-uchida.NewsTwit)。
Firebase 構成ファイルを追加する
- [Download GoogleService-Info.plist] をクリックして、Firebase iOS 構成ファイル(GoogleService-Info.plist)を取得します。
- 構成ファイルを Xcode プロジェクトのルートに移動します。メッセージが表示されたら、構成ファイルをすべてのターゲットに追加するオプションを選択します。
アプリに Firebase SDK を追加する
Firebase ライブラリのインストールにはCocoaPodsを使用することをおすすめします。
・ Podfile がない場合は作成します。$ cd your-project-directory$ pod init・ アプリで使用したいポッドを Podfile に追加します。たとえば、アナリティクスの場合は次のようになります。
$ pod 'Firebase/Analytics'これにより、iOS アプリで Firebase を稼働させるために必要なライブラリが、Firebase 向け Google アナリティクスとともに追加されます。
・ ポッドをインストールし、.xcworkspace ファイルを開いて Xcode でプロジェクトを確認します。
$ pod install$ open your-project.xcworkspace・ 注意!!!一度でも、CocoaPods でポッドをインストールをした事がある場合は、インストールではアップデートにします。
$ pod update2回目以降も、インストールを使用すると、依存性でエラーになる事が多いです。
証明書を発行編に移ります
プッシュ通知を送るために作成するもの・しておくことは以下の7つあります。
- CSRファイルの作成 ※初回作成すれば後は同じものを使いますので改めて作成不要です
- 開発用証明書(.cer)の作成 ※初回作成すれば後は同じものを使いますので改めて作成不要です
- AppIDの作成
- 端末の登録
- プロビショニングプロファイルの作成
- APNs用証明書(.cer)の作成
- APNs用証明書(.p12)の作成
1. CSRファイルの作成
- キーチェーンアクセスを開きます
- 「キーチェーンアクセス」>「証明書アシスタント」>「認証局に証明書を要求」をクリックします
- 「ユーザーのメールアドレス」を入力します
- (「通称」はそのまま、「CAのメールアドレス」は空欄でOK)
- 「要求の処理」は「ディスクに保存」を選択し「鍵ペア情報を設定」にチェックを入れます
- 「続ける」をクリックします
- 保存先の選択が出るので任意の場所を選択し「保存」をクリックします
- 「鍵ペア情報」画面を確認して「続ける」をクリックします
- 「設定結果」画面が出るので「完了」をクリックします
2. 開発用証明書(.cer)の作成
- Apple Developer Programにログインします
- 「Certificates, Identifiers & Profiles」をクリックします
- 「Certificates」をクリックし、「Certificates」の隣にある「+」をクリックします
- 「Create a New Certificate」画面が表示されるので設定していきます
- 「iOS App Development」にチェックをいれ、右上の方の「Continue」をクリックします
- 「Choose File」をクリックして、1.で作成した「CSRファイルの作成」を選択し、「Continue」をクリックします
- 開発者用証明書が作成されるので、「Download」をクリックして書き出しておきます
- 開発用証明書(.cer)の作成は完了です
3. App ID の作成
- 2. 「開発用証明書(.cer)の作成」の作業がスキップだった場合は、Apple Developer Programにログインして、「Certificates, Identifiers & Profiles」をクリックします(※2.の画像参照)
- 「Identifiers」の右の「+」をクリックします
- 「Register a New Identifier」が表示されるので「App IDs」にチェックをいれ、右上の方の「Continue」をクリックします
- 「Description」にアプリの概要を記入します 例) TestPushApp
- 「Bundle ID」では「Explicit」を選択し、「Bundle ID」を入力します 6「Wildcard」を選択するとプッシュ通知が利用できないので注意!
- 「Bundle ID」は アプリ側で同じものを設定します ので必ず控えておきましょう!
- 下にスクロールして「Capabilities」の「Push Notifications」にチェックを入れます
- これを忘れるとプッシュ通知が利用できないので注意!
- 「Continue」をクリックします
- 確認画面が表示されるので「Push Notifications」にチェックが入っている事を確認して「Register」をクリックします
- これでApp ID 作成は完了です
4. 端末の登録
- 「Devices」をクリックして、「Devices」の隣にある「+」をクリックします
- 「Platform」は「iOS, tvOS, WatchOS」に選択します
- 端末の「Device Name」と「Device ID(UDID)」を入力します
- 「Device Name」は自由に設定できます
- 「Device ID(UDID)」はXcodeを使うと確認し易いです
- Mac に端末を接続し、Xcodeを起動します
- 「Window」>「Devices and Simulators」をクリックします
- 「identifier」としてUDIDが確認できます
- 記入できたら「Continue」をクリックします
- 次の画面で端末情報を確認して「Register」をクリックします
- これで端末登録は完了です
5. プロビショニングプロファイルの作成
- 「Profiles」をクリックして、「Profiles」の隣にある「+」をクリックします
- 「Development」の「iOS App Development」を選択し、「Continue」をクリックします
- 利用する App ID、開発用証明書、端末をそれぞれ紐付けていきます
- 3.「App ID の作成」で作成したApp IDを選択し、「Continue」をクリックします
- 2.「開発用証明書(.cer)の作成」で作成した(あるいは既存の) 開発用証明書 を選択し、「Continue」をクリックします
- 4.「端末の登録」で登録した(あるいは既存の)端末を選択し、「Continue」をクリックします
- 最後に「Provisioning Profile Name」にファイル名入力します 例) TestPushApp Provisioning Profiles
- 紐付けを確認し「Generate」をクリックします
- プロビショニングプロファイルがが作成されるので、「Download」をクリックして書き出しておきます
- プロビショニングプロファイルの作成は完了です
6. APNs用証明書(.cer)の作成
- 「Certificates」をクリックして、「Certificates」の隣にある「+」をクリックします
- 2.「開発用証明書(.cer)の作成」で開発用証明書を作成したときとは異なり、下にスクロールし、「Service」の「Apple Push Notification service SSL (Sandbox)」をチェックに入れます
- 「Continue」をクリックします
- 3.「App ID の作成」で作成した App ID を選択し、「Continue」をクリックします
- 1.「CSRファイルの作成」で作成した(あるいは既存の)CSRファイルを選択し、「Continue」をクリックします
- APNs用証明書(.cer) が作成されるので、「Download」をクリックして書き出しておきます
- APNs用証明書(.cer) の作成は完了です
7. APNs用証明書(.p12) の作成
- 6.「APNs用証明書(.cer)の作成」で作成した「APNs用証明書(.cer)」をダブルクリックしてキーチェーンアクセスを開きます
- APNs用証明書(.cer) の左にある三角マークをクリックして開きます
- APNs用証明書(.cer) ファイルには鍵がセットされています
- APNs用証明書(.p12) を書き出すには、開いた状態で 鍵ではなく証明書の上で右クリック をして「~を書き出す…」をクリックします
- ファイル名「名前」と保存先「場所」を指定して「保存」をクリックします
- パスワードを求められますが、 何も入力しない で「OK」をクリックします
- この後、システム側にパスワードを求められる場合があります。対応してください。
- APNs用証明書(.p12) が書き出されます
- APNs用証明書(.p12) 作成は完了です
- これですべて必要なファイルが作成できました
FirebaseのCloud MessagingにAPNs証明書を登録
- 次にFirebaseの設定画面に移動します。
- Firebase Consoleの対象のプロジェクトの画面左上部の歯車のアイコンを選択して、プロジェクトの設定を選択します。
- SettingメニューのCloud Messagingを選択します。
- 画面スクロールしIOSアプリの設定のAPNs証明書の開発用APNs証明書のアプロードを選択します。
- ファイルをアップロードをクリックし、7. 「APNs用証明書(.p12) の作成」で作成したAPNs証明書を選択してップロードを選択します。
- こちらでアップロードが完了すればFirebaseの設定は完了です。
XcodeのSigningを設定
- 次にXcodeの設定を行います。Xcodeのこちらの画面を開き、Signing & Capabilityを選択します。
- まずAutomatically manage signingのチェックを外し、Provisioning Profileに5. 「プロビショニングプロファイルの作成」で作成したProvisioning Profileを設定します。
- 次に+CapabilityをクリックしてPush NortificationsをSigningのした後にドラッグアンドドロップします。
- 同様にBackgroundModeもドラックアンドドロップします。
- Background ModeのRemote nortificationsにチェックを入れます。こちらでXcodeの設定は完了です。
AppDelegate.swiftに通知の許可やDeviceの登録する処理を実装
最後にAppDelegateに処理を書いて終わりになります。
実装箇所は4箇所です。
1. import
2. didFinishLaunchingWithOptions
3. AppDelegateのクラス内
4. UNUserNotificationCenterDelegateのExtensionimport UIKit import Firebase import FirebaseMessaging import UserNotifications @UIApplicationMain class AppDelegate: UIResponder, UIApplicationDelegate { func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool { // Override point for customization after application launch. FirebaseApp.configure() if #available(iOS 10.0, *) { // For iOS 10 display notification (sent via APNS) UNUserNotificationCenter.current().delegate = self let authOptions: UNAuthorizationOptions = [.alert, .badge, .sound] UNUserNotificationCenter.current().requestAuthorization( options: authOptions, completionHandler: {_, _ in }) } else { let settings: UIUserNotificationSettings = UIUserNotificationSettings(types: [.alert, .badge, .sound], categories: nil) application.registerUserNotificationSettings(settings) } application.registerForRemoteNotifications() return true } // MARK: UISceneSession Lifecycle func application(_ application: UIApplication, configurationForConnecting connectingSceneSession: UISceneSession, options: UIScene.ConnectionOptions) -> UISceneConfiguration { // Called when a new scene session is being created. // Use this method to select a configuration to create the new scene with. return UISceneConfiguration(name: "Default Configuration", sessionRole: connectingSceneSession.role) } func application(_ application: UIApplication, didDiscardSceneSessions sceneSessions: Set<UISceneSession>) { // Called when the user discards a scene session. // If any sessions were discarded while the application was not running, this will be called shortly after application:didFinishLaunchingWithOptions. // Use this method to release any resources that were specific to the discarded scenes, as they will not return. } func application(_ application: UIApplication, didReceiveRemoteNotification userInfo: [AnyHashable: Any]) { // Print message ID. if let messageID = userInfo["gcm.message_id"] { print("Message ID: \(messageID)") } // Print full message. print(userInfo) } func application(_ application: UIApplication, didReceiveRemoteNotification userInfo: [AnyHashable: Any], fetchCompletionHandler completionHandler: @escaping (UIBackgroundFetchResult) -> Void) { // Print message ID. if let messageID = userInfo["gcm.message_id"] { print("Message ID: \(messageID)") } // Print full message. print(userInfo) completionHandler(UIBackgroundFetchResult.newData) } } @available(iOS 10, *) extension AppDelegate : UNUserNotificationCenterDelegate { func userNotificationCenter(_ center: UNUserNotificationCenter, willPresent notification: UNNotification, withCompletionHandler completionHandler: @escaping (UNNotificationPresentationOptions) -> Void) { let userInfo = notification.request.content.userInfo if let messageID = userInfo["gcm.message_id"] { print("Message ID: \(messageID)") } print(userInfo) completionHandler([]) } func userNotificationCenter(_ center: UNUserNotificationCenter, didReceive response: UNNotificationResponse, withCompletionHandler completionHandler: @escaping () -> Void) { let userInfo = response.notification.request.content.userInfo if let messageID = userInfo["gcm.message_id"] { print("Message ID: \(messageID)") } print(userInfo) completionHandler() } }コピペでできると思いますので、そのように実装してください。
こちらでコードの設定も完了です。
アプリを実機に接続して、アプリを起動し、通知の許可のダイアログが出ると思うので許可した状態で置いておいてください。(通知の許可がないと通知が届きません。+リモートの通知は実機でないと届かないです。)Cloud Messagingより通知を送信する
- あとは通知を送信するだけです!Firebase Console左メニューよりCloud Messagingを選択します。
- Send your firdt messageをクリックし、通知する内容を入力します。(適当で大丈夫です。) 次へをクリックします。
- アプリを選択から自分のアプリを選択して次へをクリックします。
- スケジュールは細かく設定できますが、今は現在で大丈夫です。次へをクリックします。
- コンバージョンイベントは特に何も設定せず次へをクリックします。
- 最後は通知音のON、OFFやIOSバッチ(アプリ右上につく赤い丸いやつ)の数量など細かく設定できます。設定はお任せします。問題なければ確認をクリックします。
- 最後に公開をクリックすると通知はが発送され、実機に通知が届きます。
- 以上で設定と通知が完了しました。
プッシュ通知が正しく配信されない場合
- 書類の作成順序を間違えている
- 途中で作成した書類を編集した
- 開発用証明書が複数作成されている
- CSRファイルが複数作成されている
- AppIDを作成時に「Push Notifications」にチェックを入れ忘れている
- 実機でアプリが開きっぱになっていないか確認(アプリが開いてると届かないです。)
- 通知の許可がうまくできていない可能性あるので、アプリを一度削除して再インストールする
- Info.plistに変な設定をしていないか確認する。(記事によってはInfo.plistに設定が必要と書いてありますが特に必要ないです。)
Firebase Admin SDKを使ったPush通知
Firebase Cloud Messaging (FCM)を利用して、サーバからスマホへのPush通知を試してみました。サーバからFirebase経由でPush通知を送信する方法を書いていきます。
Firebase Admin SDKをインストール
$ pip install firebase-adminサービス アカウントを認証して Firebase サービスへのアクセスを承認するには、秘密鍵ファイルを JSON 形式で生成する必要があります。
Firebase consoleからfirebase接続用の鍵ファイルを取得
- Firebase コンソールの左上にある歯車マークを押して、プロジェクトの設定画面を開きます。
- この画面から「サービスアカウント」のタブをクリックします。
- 「新しい秘密鍵の生成」ボタンを押すと、秘密鍵のファイルがダウンロードされます。
- キーを含む JSON ファイルを安全に保管します。
特定のスマホにPush通知
特定のスマホ(YOUR_REGISTRATION_TOKEN)へPush通知を送信します。
コードは以下です。path/to/serviceAccountKey.jsonは、ダウンロードした秘密鍵のファイルを指定します。import firebase_admin from firebase_admin import credentials from firebase_admin import messaging cred = credentials.Certificate("path/to/serviceAccountKey.json") firebase_admin.initialize_app(cred) # This registration token comes from the client FCM SDKs. registration_token = 'YOUR_REGISTRATION_TOKEN' # See documentation on defining a message payload. message = messaging.Message( notification=messaging.Notification( title='test server', body='test server message', ), token=registration_token, ) # Send a message to the device corresponding to the provided # registration token. response = messaging.send(message) # Response is a message ID string. print('Successfully sent message:', response)トピックに参加しているスマホにPush通知
特定のトピックに参加している複数のスマホにPush通知する方法です。
例えば、"weather"のトピックに参加しているスマホにPush通知するときは、メッセージの作成部分を以下のように変更します。
具体的には、tokenの部分をtopicに変更するだけです。message = messaging.Message( notification=messaging.Notification( title='test server', body='test server message', ), topic='weather', )iosでトピックへの参加は、AppDelegate.swiftに以下のようなコードで実現できます。
Messaging.messaging().subscribe(toTopic: "weather") { error in print("Subscribed to weather topic") }応用編 アイコン右上の数字(バッジ表示)をつける
今までは、タイトルとメッセージのみでしたが、バッジ処理(アイコン右上の数字)もつけてみようと思います。
以下のようなコードで実現できます。import firebase_admin from firebase_admin import credentials from firebase_admin import messaging cred = credentials.Certificate("path/to/serviceAccountKey.json") firebase_admin.initialize_app(cred) notification = messaging.Notification( title='test server', body='test server message', ) topic='weather' apns = messaging.APNSConfig( payload = messaging.APNSPayload( aps = messaging.Aps(badge = 1) # ここがバックグランド通知に必要な部分 ) ) message = messaging.Message( notification=notification, apns=apns, topic=topic, ) response = messaging.send(message) print('Successfully sent message:', response)終わりに
振り返ってみましたが、かなりの文字数になってしまいました。
それほど、大変ってことですかね?
長文を読んでくれて、ありがとうございました。
以下が参考にさせて頂いたリンクになります。
1. Firebase を iOS プロジェクトに追加する
2. 【Swift5】リモートプッシュ通知の実装方法
3. プッシュ通知に必要な証明書の作り方2020
4. Firebase Admin SDKを使ったPush通知
- 投稿日:2020-11-16T16:57:48+09:00
[Python]決定木の理論と実装を徹底解説してみた
はじめに
今回は、決定木の理論についてまとめていきます。
お付き合い頂ければ幸いです。
理論編
それでは最初に、決定木の理論についてまとめていきます。
決定木の概要
決定木の可視化すると以下のようになります。
今回はirisデータセットによる分類を
scikit-learnのexport_graphvizを用いて可視化しました。
決定木とは、上の画像のようにデータをある条件に従って分割することにより、データの分類または回帰のモデルを作成するアルゴリズムです。分類を行う分類木と回帰を行う回帰木を総称して決定木と呼びます。
かなりシンプルなアルゴリズムのため、他の複雑なアルゴリズムと比較すると精度は出にくい傾向にあります。
しかし、モデルの解釈性が非常に高いです。
モデルの見た目が上の図のように木のように見えることから、決定木と呼ばれています。
代表的なアルゴリズムに
CARTやC5.0などがあります。アルゴリズムについてはこちらの記事を参考にしてください。
ここでは、ニクラス分類を繰り返し行う
CARTのアルゴリズムを取り扱っていきます。決定木の基準について
ここまでで決定木のおおよその概要をつかめたと思います。
ここでは、分類木と回帰木の枝分かれの基準について考えていきます。
分類木の基準
それでは、分類木はどのような判断基準に従って枝分かれさせていくのかを考えていきましょう。
結論から書くと、分類は
不純度が最小になるような分割をする、という基準に基づいて特徴量や閾値を決めています。
不純度とはどれくらい多くのクラスが混じりあっているかを数値にしたもので、誤分類率やジニ指数、交差エントロピー誤差を用いて表されます。一つのノードに一つのクラスの観測地がある状態のとき、不純度は0になります。回帰木の基準
回帰木は、平均二乗誤差で表されるコスト関数を定義し、そのコスト関数の重み付き和が最小となるように特徴量や閾値を選択します。
数式について
分類木
不純度を数式を用いて表してみましょう。以下の図について考えます。
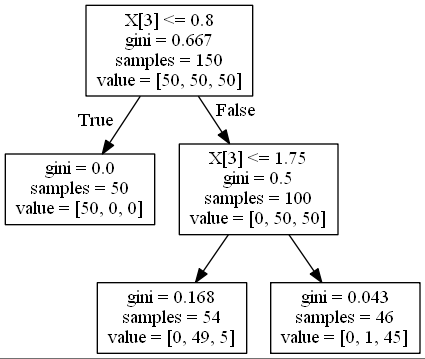
$N_m$個の観測値を持つ領域$R_m$におけるクラスkの観測値の割合を以下のように定義します。
\hat{p}_{mk} = \frac{1}{N_m} \sum_{x_i\in R_m}^{}I(y_i = k)図の上から三番目の段に注目します。mは領域の番号を表しており、m=1で
gini=0.168の領域を表し、m=2でgini=0.043の領域を表しています。kはクラスラベルを表していて、今回はvalueの部分の左からクラス1、クラス2、クラス3と定義しています。数式にすると難しそうですが、実際に計算すると以下のようになります。
\hat{p}_{11} = \frac{0}{54} \quad \hat{p}_{12} = \frac{49}{54} \quad \hat{p}_{13} = \frac{5}{54}なんとなく数式の意味が理解できたでしょうか。
この$\hat{p}$を用いて、以下の三つの関数で不純度を表現します。
誤分類率
\frac{1}{N_m} \sum_{x_i\in R_m}^{}I(y_i \neq k(m)) = 1-\hat{p}_{mk}ジニ指数
1 - \sum_{k=1}^{K}\hat{p}_{mk}交差エントロピー誤差
-\sum_{k=1}^{K}\hat{p}_{mk}log\hat{p}_{mk}
sklearnで標準で用いる不純度の関数はジニ指数になっているので、実際にジニ指数を計算してみましょう。
三段目の不純度をジニ指数を用いて計算します。
左の
gini=0.168のノードのジニ指数は以下の式になりますね。1 - (\frac{0}{54})^2 - (\frac{49}{54})^2 - (\frac{5}{54})^2 = 0.168当然答えは0.168になります。上の式がsklearnが内部で行っている計算式になります。ついでに右の
gini=0.043のノードの計算も行いましょう。1 - (\frac{0}{46})^2 - (\frac{1}{46})^2 - (\frac{45}{46})^2 = 0.043こちらも一致しましたね。それでは、それぞれのにデータの重みをかけることで全体の不純度を計算しましょう。以下の式になります。
\frac{54}{100} ×0.168 + \frac{46}{100} ×0.043 = 0.111これで全体の不純度が導出できました。決定木はこの不純度を小さくするような特徴量や閾値を選択することにより、モデルを構築しています。
回帰木
回帰木において、コスト関数を以下のように定義します。
\hat{c}_m = \frac{1}{N_m}\sum_{x_i \in R_m}^{}y_i\\ Q_m(T) = \frac{1}{N_m} \sum_{x_i \in R_m}(y_i - \hat{c}_m)^2$\hat{c}_m$がそのノードに含まれる観測値の平均を表しているので、コスト関数は平均二乗誤差となります。
このコスト関数はそれぞれのノードについて計算されるため、そのコスト関数の重み付き和が最小となるように特徴量や閾値を設定します。
実装編
ここまでで、分類木と回帰木の理論が理解できたと思います。
それでは、これから決定木の実装を行っていきましょう。
分類木の実装
それでは分類木を実装しています。
まず、分類するデータを作成します。
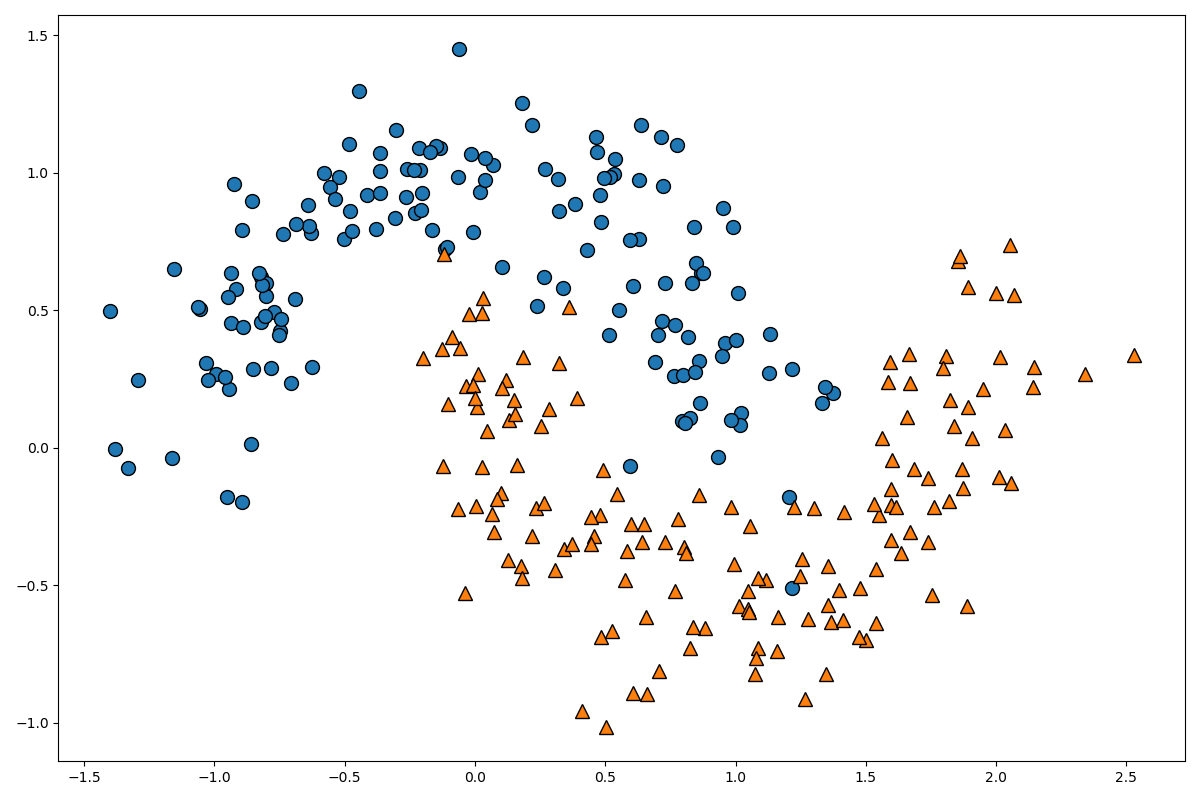
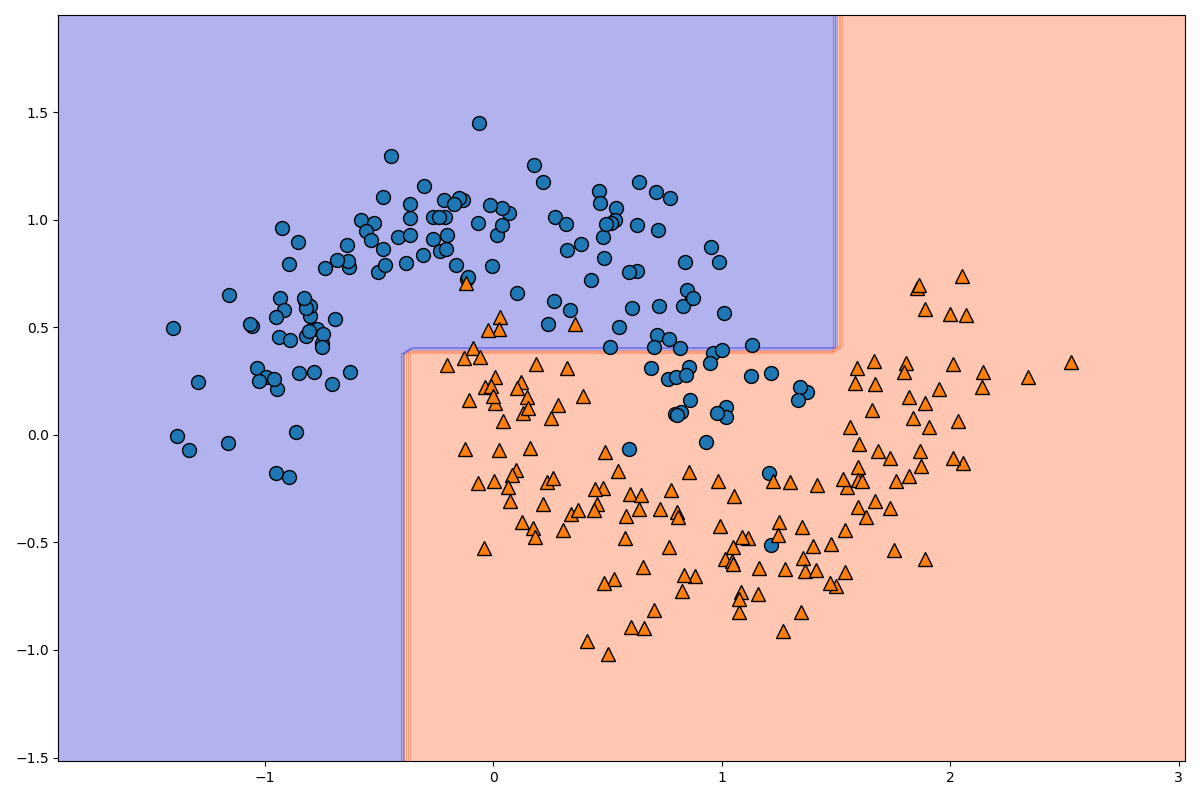
from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_graphviz from matplotlib.colors import ListedColormap import graphviz moons = make_moons(n_samples=300, noise=0.2, random_state=0) X = moons[0] Y = moons[1] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0, stratify=Y) plt.figure(figsize=(12, 8)) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.show()
このデータを分類するモデルを作成していきます。
以下のコードです。
clf_model = DecisionTreeClassifier(max_depth=3) clf_model.fit(X_train, Y_train) print(clf_model.score(X_test, Y_test))0.8933333333333333
そこそこの精度がでましたね。
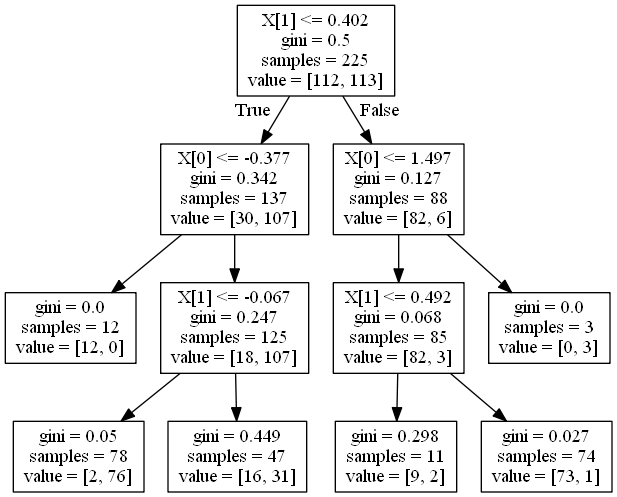
この分類木のモデルを可視化してみましょう。以下のコードです。
dot_data = export_graphviz(clf_model) graph = graphviz.Source(dot_data) graph.render('moon-tree', format='png')
graphvizを用いた可視化については、こちらの記事を参考にしてください。このように、決定木はモデルの解釈性が非常に高いです。今回のモデルでは
max_depth=3としたため、深さが3のモデルになっています。分類後のモデルを可視化してみましょう。以下のコードです。
plt.figure(figsize=(12, 8)) _x1 = np.linspace(X[:, 0].min() - 0.5, X[:, 0].max() + 0.5, 100) _x2 = np.linspace(X[:, 1].min() - 0.5, X[:, 1].max() + 0.5, 100) x1, x2 = np.meshgrid(_x1, _x2) X_stack = np.hstack((x1.ravel().reshape(-1, 1), x2.ravel().reshape(-1, 1))) y_pred = clf_model.predict(X_stack).reshape(x1.shape) custom_cmap = ListedColormap(['mediumblue', 'orangered']) plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.show()
格子点を用いて色を変化させる方法についてはこちらの記事を参考にしてください。
_x1と_x2でx軸方向とy軸方向の格子点の領域を指定し、x1, x2 = np.meshgrid(_x1, _x2)で格子点を作成しています。
X_stack = np.hstack((x1.ravel().reshape(-1, 1), x2.ravel().reshape(-1, 1)))の部分で100×100の格子点を一次元配列に変化させた後、10000×1の二次元配列に変換し、水平方向に結合して10000×2のデータに変換しています。
y_pred = clf_model.predict(X_stack).reshape(x1.shape)の部分で10000×2のデータを0と1のデータに変換し、それを100×100のデータに変換しています。データを分離する線の片側が0でもう一方が1になります。
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)の部分で、等高線を描画します。色をcmap=custom_cmapで指定しています。ここまでで分類木の実装は終了です。
回帰木の実装
それでは回帰木の実装を行いましょう。
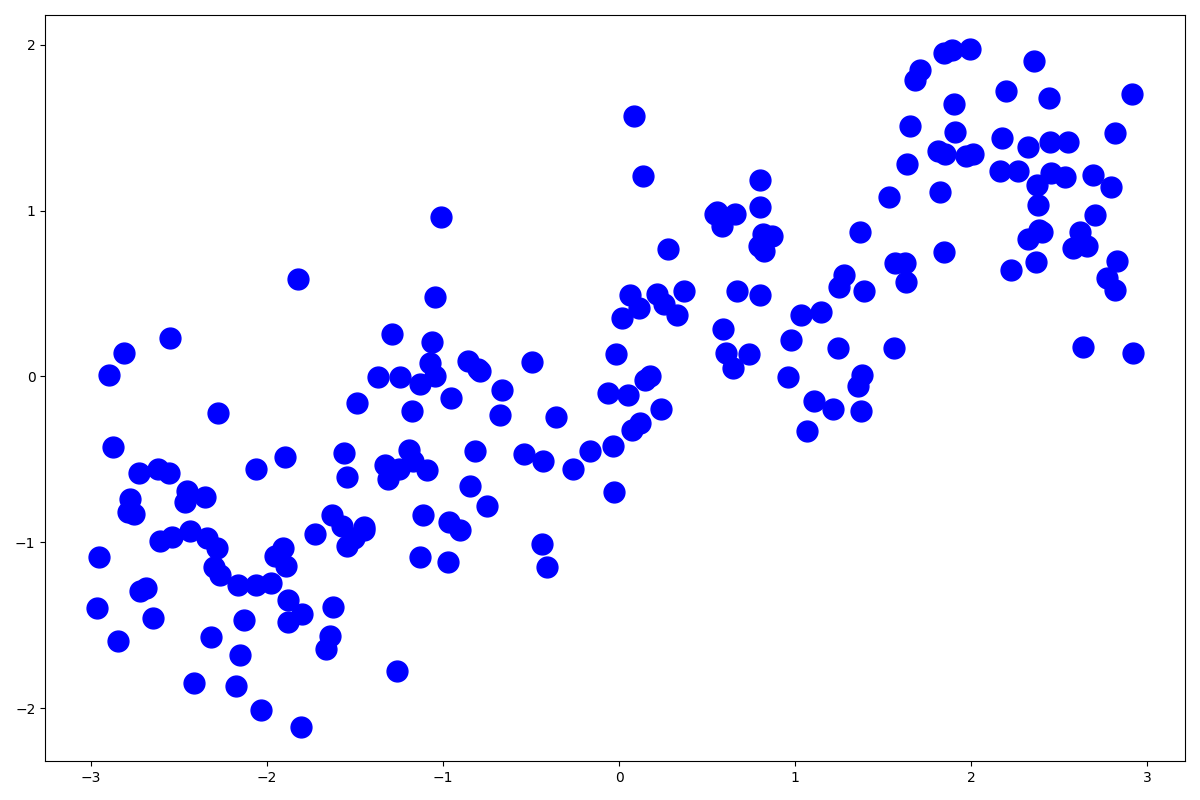
データを準備して描画してみましょう。
import mglearn from sklearn.tree import DecisionTreeRegressor import numpy as np import matplotlib.pyplot as plt from sklearn.tree import export_graphviz import graphviz X, Y = mglearn.datasets.make_wave(n_samples=200) plt.figure(figsize=(12, 8)) plt.plot(X, Y, 'bo', ms=15) plt.show()
このようなデータになっています。それではモデルを作成しましょう。
tree_reg_model = DecisionTreeRegressor(max_depth=3) tree_reg_model.fit(X, Y) print(tree_reg_model.score(X, Y))0.7755211625482443
scoreで$R^2$を表示させることができます。score(self, X, y[, sample_weight]) Returns the coefficient of determination R^2 of the prediction.
あまり精度はよくありませんね。
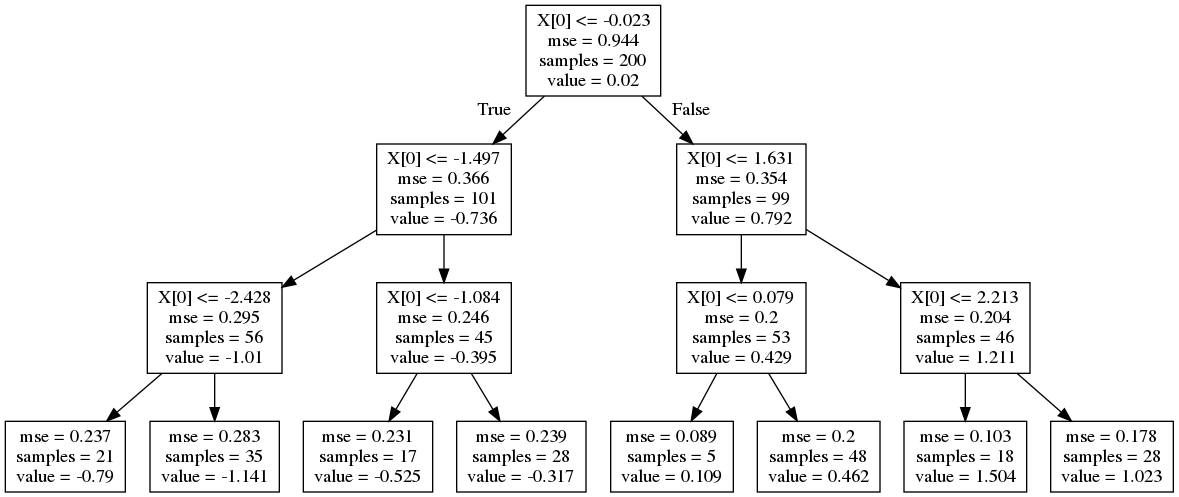
次のコードでモデルを可視化してみましょう。
dot_data = export_graphviz(tree_reg_model) graph = graphviz.Source(dot_data) graph.render('wave-tree', format='png')
このように、回帰木は(決定木もそうですが)モデルの解釈性がとても良いですね。
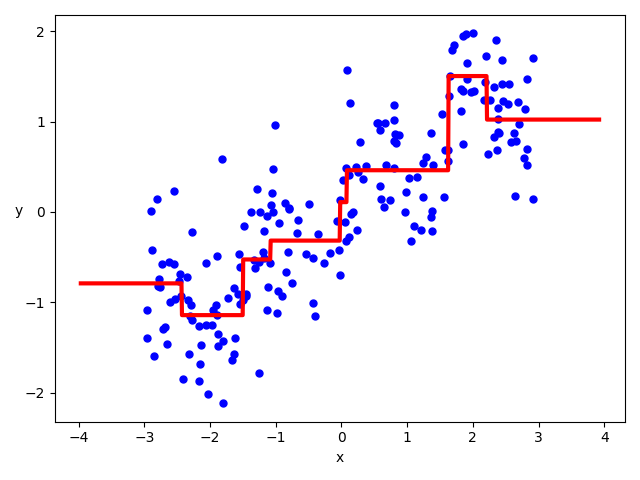
それでは、次のコードで回帰直線を図示してみましょう。
X1 = np.linspace(X.min() - 1, X.max() + 1, 1000).reshape(-1, 1) y_pred = tree_reg_model.predict(X1) plt.xlabel('x', fontsize=10) plt.ylabel('y', fontsize=10, rotation=-0) plt.plot(X, Y, 'bo', ms=5) plt.plot(X1, y_pred, 'r-', linewidth=3) plt.show()
図示してみてわかる通り、あまり正しくはありませんね。
深さを指定せずに実装
それでは、次は深さを実装せずに実装してみましょう。
深さを指定しない以外は同じなので、同じ手順は関数にまとめましょう。
import mglearn from sklearn.tree import DecisionTreeRegressor import numpy as np import matplotlib.pyplot as plt from sklearn.tree import export_graphviz import graphviz X, Y = mglearn.datasets.make_wave(n_samples=200) tree_reg_model_2 = DecisionTreeRegressor() tree_reg_model_2.fit(X, Y) print(tree_reg_model_2.score(X, Y))1.0
$R^2$が1になりました。いったいどのようなモデルになっているのでしょうか。以下で分岐を図示しましょう。
def graph_export(model): dot_data = export_graphviz(model) graph = graphviz.Source(dot_data) graph.render('test', format='png') graph_export(tree_reg_model_2)
恐ろしいほどの分岐になりました。もう、どのように分岐しているか読めませんね。
次のコードでモデルを図示しましょう。
def plot_regression_predictions(tree_reg, x, y): x1 = np.linspace(x.min() - 1, x.max() + 1, 500).reshape(-1, 1) y_pred = tree_reg.predict(x1) plt.xlabel('x', fontsize=10) plt.ylabel('y', fontsize=10, rotation=-0) plt.plot(x, y, 'bo', ms=5) plt.plot(x1, y_pred, 'r-', linewidth=1) plt.show() plot_regression_predictions(tree_reg_model_2, X, Y)
上の図を見て頂ければ分かりますが、これは明らかに過学習になっていますね。
これでは未知のデータを予測することができないので、適切に木の深さを設定する大切さが理解できると思います。
終わりに
今回はここまでになります。
ここまでお付き合い頂きありがとうございました。


- 投稿日:2020-11-16T15:31:03+09:00
強化学習3 動的計画法・TD手法
Aidemy 2020/11/16
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、強化学習の3つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・動的計画法について
・TD手法について動的計画法
動的計画法とは
・Chapter2ではベルマン方程式を使って最適な方策を見つけるということを説明したが、このChapterでは実際にこれを行っていく。
・環境のモデルが「マルコフ決定過程(MDP)」で完全に与えられているとするとき、最適な方策を求める手法を「動的計画法(DP)」という。方策評価
・手法$\pi$をとった時の価値関数$V^\pi(s)$を計算することを方策評価という。実行方法は以下の通り。
・まず方策を更新する際の閾値$\epsilon$を事前に設定する。そして方策$\pi$を入力し、$V(s)$を全ての状態において0と仮定し、更新時に全ての状態の差分が閾値よりも小さくするために、「$\delta$」を定義しておく。
・ここまで定義したら、全ての状態sについて、「v=$V(s)$」として、ベルマン方程式で「$V(s)$」を計算する。更新量を比較するために、あらかじめ定義しておいた「$\delta$」を「$\max(\delta,|v-V(s)|)$」に更新し、これが「$\epsilon$」を下回ったらその時点で計算を終了し、「$V(s)$」を「$V^\pi(s)$」の近似解と仮定して出力する。
・以上についてのコードが以下である。
・方策評価を行う関数「policy_evaluation()」について、引数には「方策pi、状態states、閾値epsilon」を渡す。
・はじめに「$\delta=0$」を定義する。そして、ここからは全ての状態sについて上記手法を行なっていく。まずは「v=V.copy()」で変数「v」に価値関数Vを代入する。また、次の計算で算出される「V[s]」を格納する変数「x」も用意しておく。
・「for (p, s1) in T(s, pi[s]):」について、「p」はエピソードTで得られる「そのActionを起こす確率($\pi(a|s)$)」で、「s1」は「遷移先のState(after_state)」である。これらを使ってベルマン方程式(Chapter2の公式参照)で$V(s)$を計算する。これを「x」に代入する。
・この$V(s)$と$v(s)$を使った上記の式で「$\delta$」を計算し、閾値「$\epsilon$」を下回ったら価値関数の近似値「V」を返す。・実行部分
・実行部分を見てみると、「policy_evaluation()」の「v」部分に当たるVと、引数で渡すpiを定義している。関数を適用した結果、StateAの価値関数とStateBの価値関数がそれぞれ算出されている。
方策反復
・前項の価値評価によって算出された「$V^\pi(s)$」において、greedy手法をとるような方策を「$\pi'$」とすると、「$V^\pi(s)$ < $V^{\pi'}(s)$」となることが知られており、これを価値改善という。
・この価値改善と価値評価を繰り返すことで、最適価値関数を導出することができる。このことを方策反復という。
・価値改善を行う関数「policy_iteration()」のコードは以下のようになる。
・上記コードについて、まずは価値関数Vと方策piを初期化する。これを行なったら、Vについて、Chapter2で作成した関数「policy_evaluation()」で方策評価を行う。同時に、「policy_flag=True」とする。
・各状態sについて、更新したVを使ってゲルマン方程式で方策piを算出し、これに従ってactionをソートする。そして、方策が被ってなければpiにactionを格納してループを継続する。これが終了したら方策piを返す。・実行部分
・方策反復関数「policy_iteration()」は方策piを返すので、この実行結果は「StateAの時ActionXを取り、StateBの時ActionXをとる」という方策を表している。
価値反復
・前項の方策反復は、方策piを計算するために毎回全ての状態について価値関数を計算し直すことを複数回おこなわなければならず、状態が増えるほど計算量も多くなってしまう。これを解決するのが「価値反復」という手法である。
・価値反復では、価値vを計算するために各状態sについて、価値関数を直接求めて更新する手法を取るので、価値関数の計算は一度で済む。
・以下は価値反復関数「value_iteration()」のコードである。
・この関数について、まずは状態価値Vを今までと同様に初期化する。方策反復と違って方策piは考慮されないので、piの初期化を行う必要はない。次に、各行動について、方策評価を行って計算される$V(s)$の最大値を更新する。
・最後に、この$V(s)$から最も報酬が得られる行動を計算し、方策「pi」として返す。この時の最も報酬が得られる行動は前項の方策反復の時と同じように計算できる。・実行部分
TD手法
TD手法とは
・以上の手法は動的計画法であり、状態遷移確率Pがあらかじめわかっていければならない。逆に、状態遷移確率がわかっていない時はChapter1で学んだように、実際に集めた報酬からこれを推定していく必要がある。
・この推定方法として「TD手法」というものがある。TimeDifferanceの略で、最終結果を見ずに現在の推定値を利用して次の推定値を更新するという方法で行われる。
・TD法には、「Sarsa」「Q-learning」_といった手法がある。・以降は、以下の「環境2」を使っていく。
・開始地点は図の「start」のマス、終点は「+1」または「-1」のマス、黒いマスは遷移不可で、隣のマスの上下左右に動くことができる。また、8割の確率で、選択した通りに遷移することができるが、1割で選択した向きの90度時計回りに遷移し、残り1割で反時計回りに遷移する。報酬は、終点のマスはその点数、それ以外のマスは「-0.04」であるとする。
・以下のコードは、スタート地点から「上に二つ、右に三つ」進もうとした時の位置を出力する関数である。
・新しい環境を使うので、まずはそれを定義する。エピソードを定義する関数「T()」は、「take_single_action()」で使用するため、0列目がprobabilily,1列目がnext_stateの配列を返すように定義する。また、next_stateの状態を変化させるため、stateとdirectionから移動先を定義する「go()」も作成する。
・遷移確率に基づいて次の状態を決定する関数である「take_single_action()」はここでも使用する。上記「T()」で定義した「遷移確率」がxを越えるまで「次の状態」を更新し、更新が終了した時点での報酬を設定する。
・最後に、実際に「今いるstateから上に2回右に3回」移動する関数「move()」を作成する。actionsとして、0列目が上下の動き、1列目が左右の動きを定義し、0列目について2回take_single_actionで移動し、同様に1列目について3回移動してstateを更新する。・実行部分
・環境についてはそれぞれのマスを定義している。初期地と終点も定義し、move()を使うことで移動後のstateがわかる。
Sarsa
・SarsaはTD手法の一つで、ベルマン方程式を試行錯誤しながら解いていくものである。価値反復などでは$V(s)$を使っていたが、ここでは行動価値関数$Q(s,a)$を使用する。このQ関数は[全ての状態×全ての行動]の配列で表す。
・この時の「全ての状態」について、環境2では、取りうる状態は11通り、「全ての行動」は上下左右の4通りである。よってQ関数は11×4の配列にしたいのだが、状態は座標で表されるため、これをうまく表現できない。よって、状態の部分は「x座標×10 + y座標×1」で対応させる。・具体的なコードは以下の通り。(前項と重複する箇所は省略)
・「get_action()」は、後で定義するQ関数(q_table)の最大値によって行動を決定する関数である。この時渡される「t_state」は、先述した「座標を変換したstate」である。
・「take_single_action()」は今までのものと用途は同じだが、返される値として、rewardが設定されていない場合、すなわち行動先が壁や障害物で移動できない時は、その場に止まると言う意味で、状態「state」とreward「-0.04」を返し、rewardが設定されているマスにいるときは「next_state」とそのrewardを返す。
・「update_qtable()」は実際に行動価値関数Qを算出し、更新する関数である。この更新の時に使われる公式は以下である。
$$Q(s,a) += \alpha[r + \gamma Q(s',a') - Q(s,a)]$$・この$\alpha$は学習率であり、事前に設定しておく必要がある。今回は「0.4」で設定する。また、割引率$\gamma$は「0.8」とする。また、この時渡される状態も、「座標を変換したstate」とする。計算自体は公式通りに行えば良い。
・最後に、状態「state」を「座標を変換したstate」にする「trans_state()」関数を作成する。・実行部分
・Sarsaを実行するにあたり、まずは行動価値関数Qを初期化する。今回はエピソード数は500、時間ステップは最大1000回とし、またエピソードの終了条件として「5回連続で平均報酬が0.7以上」を設定するため、これを管理する配列も準備する。環境などは前項と同じ。
・次に、500回の各エピソードについて、(終了条件を満たすまで)以降の全てを繰り返す。
・まずはstateを初期化する。これに基づいて、Q関数に渡す「t_state」、行動「action」を計算する。それぞれ「trans_state()」「get_action()」関数を使用する。
・次に、エピソード中の各時間ステップについて「take_single_action()」で、行動aを行なった場合の次の状態s'と報酬rを取得し、報酬を累積していく。また、状態s'についてもQ関数に渡す「t_next_state」、行動「next_action」を計算する。
・これらを「update_qtable()」に渡して、行動価値関数を更新する。また、次の時間ステップに行くためにstateやactionも更新する。
・最終的に終点についたら、そのエピソードは終了し、次のエピソードに移動する。移動する前に、エピソード終了条件である報酬について「total_reward_vec」を更新し、それを出力する。同様に、終了したエピソードの番号と、それが何ステップで終了したかを出力する。
・もしこの「total_reward_vec」の最小値が0.7を超えたらエピソードの繰り返しも終了する。・実行結果(一部のみ)
・実行結果をみてみると、報酬が「0.2」であったエピソードが直近5エピソードから除外され、全ての報酬が0.7を超えたエピソード21+1で終了している。
Sarsaでのε-greedy手法の実装
・前項の手法では、Q関数の最大値のみを選択していたが、これではより優れた手法を見逃す恐れがある。これを避けるために、ε-greedy手法を使って新しい手法を探索していく。
・Chapter1でもε-greedy手法を使ったが、少し変えて使用する。今回は、「episodeが早いうちはεを大きくして探索の割合を増やし、episodeが進むにつれてεの値を小さくして探索を狭めていく」というやり方を使う。式としては以下のものを使う。
$$\epsilon = 0.5 * (1 / ( episode + 1)) $$・具体的なコードは以下の通りで、「get_action()」部分だけが異なる。
・上記関数について、まずは「epsilon」を上の式で算出。このepsilonが一様乱数「np.random.uniform(0,1)」以下であれば、前項と同様にQ関数の最大値に基づいて次の行動を決定し、そうでなければランダムに次の行動を決定することとしている。
・実行部分
・実行部分についてもほとんど前項と違いはないが、初めに定義している「action」は乱数が絡むget_action()を適用せず、Q関数の最大値を使って決定している。next_actionについてはこの関数を使用している。
Q学習
・Sarsaとは別のTD手法として「Q学習」と言うものがある。Sarsaと基本的には同じで、違う点について、各時間ステップの処理において、次の行動を決定してからQ関数の更新を行うのがSarsaであるのに対して、Q関数の更新を行ってから次の行動を決めるのがQ学習である。
・よって、関数「update_Qtable()」には「next_action」は渡さず、その代わりにnext_stateにおけるQ関数の最大値「next_max_q」_を算出し、これを使ってQ関数を更新する。これ以外はSarsaと全く同じ。
まとめ
・環境のモデルがマルコフ決定過程で完全に与えられているとき、Chapter2のベルマン方程式を使って最適な方策を最適な方策を求める手法のことを「動的計画法(DP)」という。
・ある手法$\pi$をとったときの価値関数$V^\pi(s)$を計算することを方策評価という。また、greedy手法をとったときの方策の方が価値関数は大きくなることが知られており、これを価値改善という。評価と改善を繰り返すことで最適な手法を見つけることができ、これを方策反復という。
・方策反復の応用として、方策ではなく価値を計算するために価値関数を更新する手法のことを価値反復という。これにより、価値関数の計算量が大幅に減らせる。
・方策反復や価値反復は動的計画法で、状態遷移率が与えられたモデルにのみ使用できるため、これが与えられていないモデルに対しては、TD手法というものを使用する。TD手法にはSarsaやQ学習がある。
・SarsaやQ学習はベルマン方程式により、行動価値関数Qを算出することで最適な方策を考える。今回は以上です。最後まで読んでいただき、ありがとうございました。

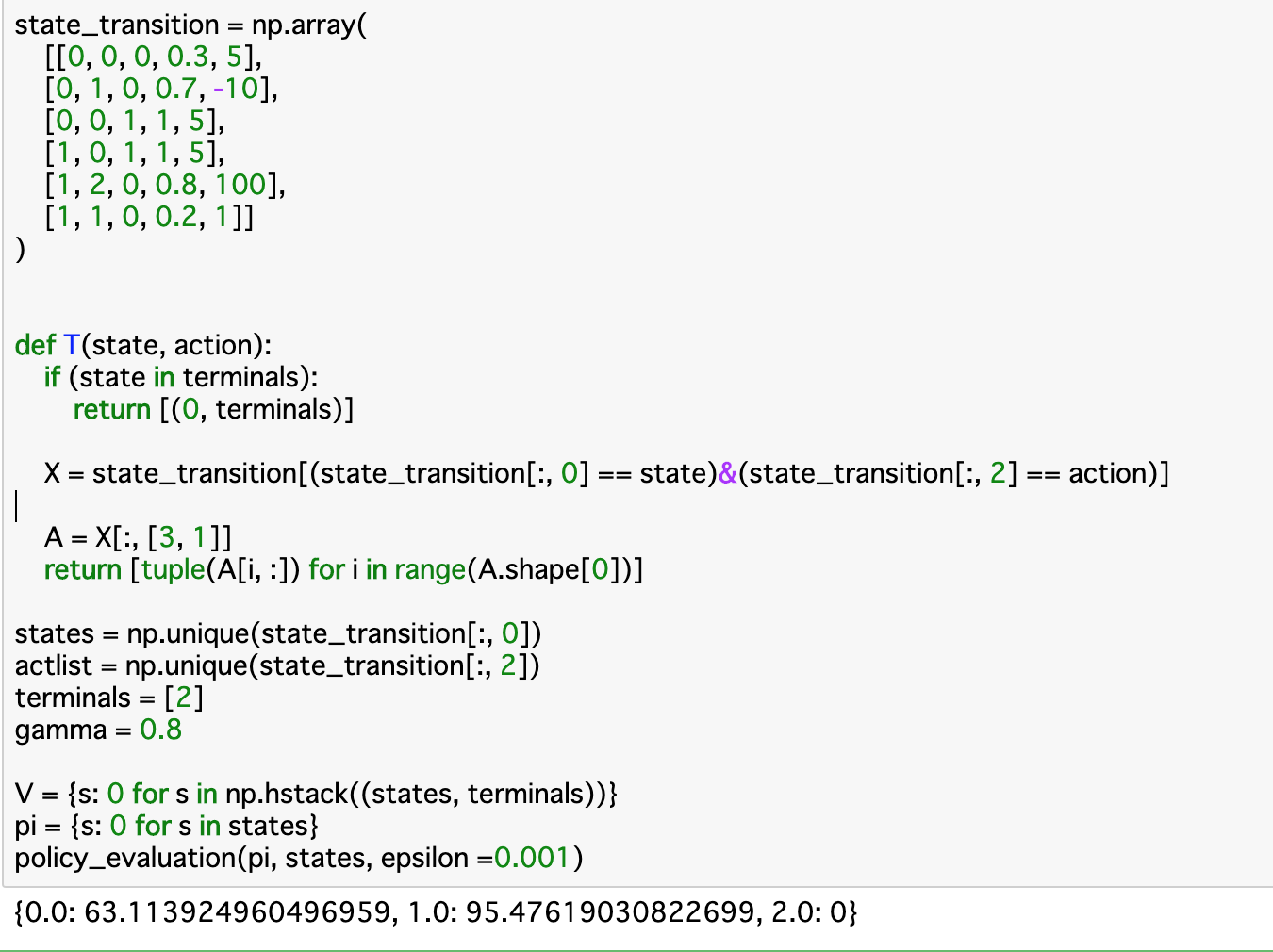




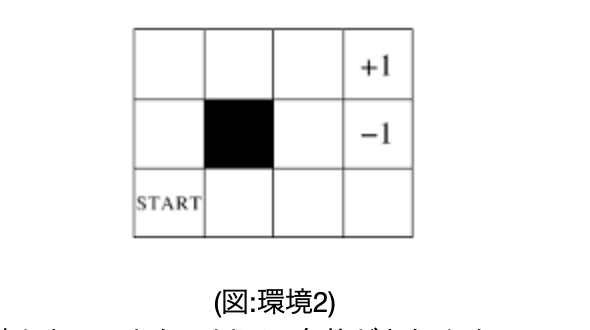










- 投稿日:2020-11-16T14:50:29+09:00
Google Colabで Turtle と遊ぶ
はじめに
当記事は筆者がPyhonの勉強に利用しているGoogle ColabでTurtleの使い方の忘却メモです
Turtleとは
本家サイトより:タートルグラフィックス
タートルグラフィックスは子供向けのプログラミングに入門でよく用いられます。 タートルグラフィックスは Wally Feurzeig, Seymour Papert, Cynthia Solomon が 1967に開発したオリジナルの Logo プログラミング言語の一部分です。
要はPythonを使用してお絵描きが簡単にできるフレームワークです
Java屋さん的にはライブラリのように感じますが。。。Google Colabでは、そのままTurtleで遊べない
ということでColabTurtleを使用します!
世の中には同じようなことを考えて便利なものを作ってくれる人がいます(多謝使い方
いたってシンプル!
以下のコードを実行するだけGoogle Colaboratory!pip3 install ColabTurtleあとは以下のようにコードを書いていけば遊べます
Google Colaboratoryfrom ColabTurtle.Turtle import * initializeTurtle() forward(10) left(10) forward(20) left(10)
- 投稿日:2020-11-16T14:48:23+09:00
ド素人がVisualStudioでFlaskを利用した時のTIPS
Flaskのインストールまでは割愛します。
Flaskの初期構成
スタートファイル(runserver.py)
初期設定ではスタートアップファイルがrunserver.pyになっています。
『app.run』関数を実行してアプリを起動させること”だけ”がこのrunserver.pyファイルの役割です。
ソリューションエクスプローラーの『201114FlaskScraping』フォルダの直下に『init.py』というファイルがあります。この名前のファイルを作っておくと、_201114FlaskScrapingをパッケージとしてインポートできるようになります。
『runserver.py』は『201114FlaskScrapingというパッケージ』をインポートして、それを起動させているだけ、ということです。
「from _201114FlaskScraping import app」runserver.py""" This script runs the _201114FlaskScraping application using a development server. """ from os import environ from _201114FlaskScraping import app if __name__ == '__main__': HOST = environ.get('SERVER_HOST', 'localhost') try: PORT = int(environ.get('SERVER_PORT', '5555')) except ValueError: PORT = 5555 app.run(HOST, PORT)init.pyの役割
init.pyの主な役割は2つあります。
①pythonスクリプトがあるディレクトリを表す
②必要なモジュールをimportするなどの初期化処理を記載し,初期化__init__.py""" The flask application package. """ from flask import Flask app = Flask(__name__) import _201114FlaskScraping.viewsルーティング
view.py""" Routes and views for the flask application. """ from datetime import datetime from flask import render_template from _201114FlaskScraping import app @app.route('/') @app.route('/home') def home(): """Renders the home page.""" return render_template( 'index.html', title='Home Page', year=datetime.now().year, ) @app.route('/contact') def contact(): """Renders the contact page.""" return render_template( 'contact.html', title='Contact', year=datetime.now().year, message='Your contact page.' ) @app.route('/about') def about(): """Renders the about page.""" return render_template( 'about.html', title='About', year=datetime.now().year, message='Your application description page.' )form/inputでサーバーサイドに値を渡す
「method="POST" action="/about"」にしてサーバーへ投げる
index.html<form method="POST" action="/about"> <label>テキスト:</label> <input type="text" class="form-control" id="name" name="name" placeholder="Name"> <button type="submit">送信</button> </form>「@app.route('/about',methods=['POST'])」として受け取る
views.py@app.route('/about',methods=['POST']) def about(): """Renders the about page.""" return render_template( 'about.html', title='About', year=datetime.now().year, message='Your application description page.' )/aboutページが表示される
Flaskの機能を追加していく方向性
基本的な方針は『views.py』に機能を増やしていくことです。
ただ、プログラムが煩雑になるので「BluePrint」をつかっていくとのこと...(続く
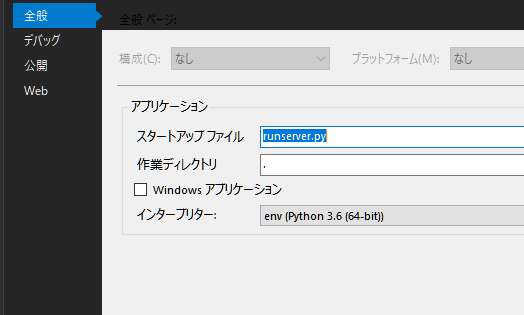

- 投稿日:2020-11-16T14:38:16+09:00
【Python】機械学習における学習結果(モデル)の保存
はじめに
前回の記事で、機械学習の簡単なプログラムに触れてみました。
前回の記事のようなとても小規模なデータは実際には使われません。
機械学習は基本的にはデータが多い方が有利なので、通常はとても大規模なデータになってしまいます。
データが多いと、当然学習にも多くの時間を要します。
知らないとびっくりするかもしれませんが、1週間PCを放置して学習させるなどが当たり前にあります。
このような長時間の学習を、プログラム実行毎にしていては実用性も何もありません。
そこで、学習結果をモデルとして保存し、実際のプログラムではそのモデルを使用する形で実行することで、時間を短縮できます。
今回は、「保存プログラム」と「モデルを用いた予測プログラム」を作成していこうと思います。なにをやっているかわからないと言う人は、前回の記事を参照してください。
環境
python 3.8.5
scikit-learn 0.231ソースコード(モデルの保存)
コードには前回の記事で使用したものを一部流用しています。
save_model.pyimport numpy as np from sklearn import svm import pickle #csvファイルの読み込み npArray = np.loadtxt("data.csv", delimiter = ",", dtype = "float") # 説明変数の格納 x = npArray[:, 0:4] #目的変数の格納 y = npArray[:, 4:5].ravel() #学習手法にSVMを選択 clf = svm.SVC() #学習 clf.fit(x,y) #学習モデルの保存 with open('model.pickle', mode='wb') as f: pickle.dump(clf,f,protocol=2)ソースコード(保存したモデルの使用)
open_model.pyimport pickle # モデルのオープン with open('model.pickle', mode='rb') as f: clf = pickle.load(f) # 評価データ weather = [[9,0,7.9,6.5]] # モデルを用いた予測 ans = clf.predict(weather) if ans == 0: print("晴れです") if ans == 1: print("曇りです") if ans == 2: print("雨です")実行結果
$ python3 open_model.py 晴れですおわりに
お疲れ様でした。
このように学習したモデルを保存することで、実行毎に学習させることなく、データの評価や、予測ができるようになります。
現在、世の中で言われているAIというのは「プログラム」+「学習データ」の2つがセットで作られ、運用されています。
集めてきたデータで作成した学習モデルを見ると、大規模なプログラムを作るのとはまた違った喜びがありますね。
それでは、また。
- 投稿日:2020-11-16T14:13:27+09:00
Pandasで上位n番目までの値を得る
Pandasで上位n番目までの値を得る
やること
Pandasで上位n番目までの値を得る | 自調自考の旅という記事を発見しました。
PandasのDataFrameを使ってデータを処理すると、maxやminといったメソッドを用いて簡単に各カラムの最大値や最小値を得ることが出来ます。しかしながら、現時点(pandas ver 1.1.2)では、2番目の最大値や最小値、3番目の最大値や最小値、、、といった値を得る機能は備わっていません。[……]そこで本記事では、なるべく少ない行数でかけて、かつ以下図のイメージのようにDataFrameの各カラムの上位n番目までの値を得られるようなスクリプトを紹介します。
つまり、以下のようなデータフレーム
dfがあったときに、import numpy as np import pandas as pd np.random.seed(0) df = pd.DataFrame(np.random.permutation(50).reshape(10, 5)) df
0 1 2 3 4 0 28 11 10 41 2 1 27 38 31 22 4 2 33 35 26 34 18 3 7 14 45 48 29 4 15 30 32 16 42 5 20 43 8 13 25 6 5 17 40 49 1 7 12 37 24 6 23 8 36 21 19 9 39 9 46 3 0 47 44 各列に対して上位(あるいは下位)3つを抜き出して、以下のようなデータフレームを取得するような関数・メソッドがpandasにはないということです。
0 1 2 3 4 1 46 43 45 49 44 2 36 38 40 48 42 3 33 37 32 47 39 方針
いま例に挙げているデータフレーム
dfはすべての列が同じデータ型になっていますが、実際のデータは列毎にデータ型が違うことがおおいので、df.apply()で列毎に処理することを考えます。つまり、以下のようなシリーズ
sを渡して、
0 0 28 1 27 2 33 3 7 4 15 5 20 6 5 7 12 8 36 9 46 以下のようなシリーズが返却される関数を作っていきます。
0 1 46 2 36 3 33 方法
引用した記事では、以下のような関数が示されています。なお、オプション引数は以下のとおりです。
topnum: 取得する件数。デフォルトは3。getmin:Trueにすると昇順で取得。デフォルトは降順。getindex:Trueにすると値ではなくインデックスを返す。def getmax(series, topnum=3, getmin=False, getindex=False): if getindex is False: series = (series.sort_values(ascending=getmin).head(topnum) .reset_index(drop=True)) series.index += 1 return series else: return series.sort_values(ascending=getmin).head(topnum).indexこの方法は、まずシリーズ全体をソートしたのちに、上側を取得する、そしてインデックスを1始まりにするために、インデックスをリセットした後に1を加えるという作業を行っています。
しかし、これはないでしょう。
pandasでシリーズから上位n件を取得するには、
pd.Series.nlargset()メソッド(およびpd.Series.nsmallest()メソッド)が最適解です。%timeit df[0].sort_values(ascending=False).head(3) %timeit df[0].nlargest(3)
0 9 46 8 36 2 33 299 µs ± 9.43 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 153 µs ± 1.58 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)速度も倍違います(なお、速度を考えるとNumPyを使うことも考えに入れられますが、コードの簡潔さがやや失われます)。
1始まりの連番インデックスをつけるのについてもかなり冗長です。直接1始まりの連番を設定すればいいところ、0始まりのインデックスにしてから1を足しています。
np.arange()やrange()を使うことを思いつくでしょうが、pd.RangeIndex()を使いましょう。test_s = pd._testing.makeStringSeries(10000) %timeit s2 = test_s.reset_index(drop=True); s2.index += 1 %timeit s2 = test_s.set_axis(range(1, len(test_s)+1)) %timeit s2 = test_s.set_axis(np.arange(1, len(test_s)+1)) %timeit s2 = test_s.set_axis(pd.RangeIndex(1, len(test_s)+1))109 µs ± 2.98 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 40.2 µs ± 1.02 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 64.7 µs ± 1.49 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 39.8 µs ± 931 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)結論
そういうわけで以下のようになります。
def getmax_rev(series, topnum=3, getmin=False, getindex=False): out = series.nsmallest(topnum) if getmin else series.nlargest(topnum) return out.index if getindex else out.set_axis(pd.RangeIndex(1, topnum+1))
- 投稿日:2020-11-16T13:59:33+09:00
Django(ジャンゴ)のインストール
Anacondaのインストール
https://www.anaconda.com/Anacondaをインストールしたら、Anaconda Navigatorを開く
Anaconda Navigatorの左のメニューから「Environments」を選択し、Createでディレクトリを作成する。(今回は「myapp」として話を進めることとする。)
myappを作成したら、「▶」をクリックして「Open Terminal」を選択する。
(myapp) C:\Users\yourname>この状態でcmd.exeが起動できたら、次のコマンドを実行して、Djangoをインストールする。
pip3 install djangopipでDjangoをインストールできたら、次のコマンドを実行して、アプリケーションを作成する。
django-admin startproject [your-app-name]このコマンドでDjangoのアプリケーションのディレクトリが作成される。
(myapp) C:\Users\yourname>django-admin startproject mydjangoapp_webもし、上のような状態で
django-adminコマンドを実行した場合はC:\Users\yourname直下にmydjango_webというディレクトリが作成されることになるので、適宜、フォルダを作成したいディレクトリに移動すること。
ファイル 内容 __init__.py Djangoプロジェクトを実行するときの初期化処理を行うスクリプトファイル settings.py プロジェクトの設定情報を記述したファイル urls.py プロジェクトで使うURL(Webでアクセスするときのアドレス)を管理するファイル wsgi.py Webアプリケーションのメインプログラムとなる部分 アプリの起動
Anaconda Navigatorから起動したcmd.exeで次のコマンドを実行する
python manage.py runserver上記コマンドを実行後、インターネットブラウザで
localhost:8000にアクセスする。ローカルサーバーを終了するには、Ctrl+Cを押す。参考
- Python Django 超入門[第1版第1刷], 掌田津耶野, 2018-06-15
- 投稿日:2020-11-16T12:31:32+09:00
Pythonで進捗表示したい!
概要
時間のかかる処理を実行した時、応答がないと「今どれくらい処理が進んでいるのか」「というか動いているのか」などなど、不安になることってありませんか?ありますよね?そう、あるんですよ(3段活用)。
ということでループ処理の進捗状況を表示する方法を覚書しておきます。↓↓↓ちなみにこんな感じです↓↓↓
何かの役に立ちましたらぜひLGTM・ストック・コメントいただけると嬉しいです。目次
パッケージ
tqdmの利用進捗表示の王道(だと勝手に思ってます)、
tqdmをまずは紹介しておきます。
使い方は非常に簡単、importしてループに次のように組み込むだけです。tqdm_test.py%!pip install tqdm import tqdm import numpy as np for i in tqdm.tqdm(range(int(1e7))): np.pi*np.piこれで次のように表示されます。
便利ですね〜
tqdm.tqdm()に渡すのはイテラブル(ループ処理可能)なオブジェクトなので、他にもリストやらディクショナリやら文字列やらを渡すことができます。
ただし、注意点としてループ処理の中に標準出力であるtqdm_test.py%!pip install tqdm import tqdm import numpy as np for i in tqdm.tqdm(range(int(1e7))): np.pi*np.pi if i % 1e6 == 0: print(i)
同じ理屈で、ループのネスト(入れ子)に対してtqdm.tqdm関数で進捗表示するとひどいことになります。tqdm_test.pyimport tqdm for t in tqdm.tqdm(range(10)): for i in tqdm.tqdm(range(int(1e6))): np.pi*np.pi
こういうの、ごくまれに不便なんですよね...皆さんもそんな経験ありませんか?ありますよね?そう、あるんですよ(3段活用)。
ということで自分でなんとかしてみましょう。自分で作ってみる
少なくともPythonにおいて、標準出力された文字列がプログラムの制御から離れるのは改行された時点なのだそうです。
逆に言えば改行さえしなければ標準出力後もプログラムで操作可能ということです。progress.pyfor i in range(int(1e7)): if i % 1e4 == 0: print("\r", i, end="") np.pi*np.pi
この\rとend=""によって標準出力後もプログラムがその制御権を握り続けることができるようになります。
end=""は、\n(改行)が指定されています。そのため、end=""とすることで空文字を追加する(という言い方は変ですが)ように変更すると改行されず、したがってプログラムで標準出力を弄ることが可能となるわけです。
ここでも登場しましたが、バックスラッシュから始まる\rや\nはエスケープシーケンスといい、文字列の中に含めたい特殊な制御を可能とする文字列群となっています。エスケープシーケンス
エスケープシーケンスは前述の通り、文字列に特殊な制御を施したい時に使用される文字列群のことを言います。代表的なものは以下の表の通りです。
エスケープシーケンス 効果 \b バックスペース \n 改行 \t タブ \r 行の先頭に戻る 処理的にはバックスラッシュがエスケープシーケンス記述の始まりを表しており、その後に続く文字列に対応した制御文や文字コードに変換されています。
そのため、ダブルクオテーション"などの文字列そのものの制御文に利用されている文字列を出力させる時にも利用されます。test_esc.pyprint("\"") print("\'") print("\\")一応この機能を用いてUnicodeで文字列を読み込ませることも可能ですが、まあそんなことをすることはないでしょう。
test_esc.py# Hello world! print("\x48\x65\x6c\x6c\x6f\x20\x77\x6f\x72\x6c\x64\x21")プログレスバーを作ってみる
ではエスケープシーケンス
\rを利用してプログレスバーを自作してみましょう。progress.pyimport time for i in range(50): print("\r[" + "#"*i + "]", end="") time.sleep(0.1)
とりあえずプログレスバーと呼べるものはできましたね!ちなみに、なぜかはわかりませんがformat関数を利用するとエスケープシーケンスが機能しません。
このままだと味気ないのでもっといろいろ工夫してみましょう。progress.pyimport time epoch = 50 for i in range(epoch): bar = "="*i + (">" if i < epoch-1 else "=") + " "*(epoch-i-1) print("\r[" + bar + "]", "{}/{}".format(i+1, epoch), end="") time.sleep(0.1)解説としては、まず
barという変数にプログレスバーの本体文字列を書きます。
コードではプログレスバーの長さを固定するためにスペースで穴埋めをしたり、先頭は矢印にしたりしています。他にも、
tqdmではできなかったネストについても、自分で定義するだけですのでなんとでもできます。progress.pyimport time t_epoch = 10 i_epoch = 50 lap_time = -1 start_time = time.time() for t in range(t_epoch): t_per = int((t+1)/t_epoch*i_epoch) for i in range(i_epoch): i_per = int((i+1)/i_epoch*i_epoch) if i_per <= t_per: bar = ("progress:[" + "X"*i_per + "\\"*(t_per-i_per) + " "*(i_epoch-t_per) + "]") else: bar = ("progress:[" + "X"*t_per + "/"*(i_per-t_per) + " "*(i_epoch-i_per) + "]") time.sleep(1e-2) elapsed_time = time.time() - start_time print("\r" + bar, "{}s/{}s".format( int(elapsed_time), int(lap_time*t_epoch) if lap_time > 0 else int(elapsed_time*(i_epoch/(i+1))*t_epoch)), end="") lap_time = (time.time() - start_time)/(t+1)
いきなり複雑になってしまいましたね...解説します。
t_perやi_perというのはtのループやiのループでの進捗状況を文字列で表示するために必要な文字数を計算して保持しています。
barはプログレスバーそのものですが
tのループは\という文字列で進捗状況を表すiのループは/という文字列で進捗状況を表す- 重なる部分は
Xという文字列で進捗状況を表すというふうになるようにプログラムしています。バックスラッシュはエスケープシーケンスの開始文字なので
"\\"とする必要がありますね。
lap_timeはiのループ1周分にかかる時間を保持しています。平均を取ってより正確な値が出るようにしています。elapsed_timeは現在までの経過時間です。progress.pyint(lap_time*t_epoch) if lap_time > 0 else int(elapsed_time*(i_epoch/(i+1))*t_epoch))の部分ですが、
lap_timeが計算されている場合はそちらを、そうでない(つまりiのループに初めて入った時)場合は経過時間からラップタイムを推測して表示するようにしています。これはあくまで一例ですので、皆さんもいろいろと考えてみてください。
発展:ANSIエスケープコード
ここまでの話は「改行があると標準出力を上書きできない」と言っていましたが、実は改行があっても操作可能だったりします。その方法がANSIエスケープコードです。
progress.pyimport time epoch = 25 print(" "*(epoch-10) + "彡ノノハミ ⌒ミ") print(" "*(epoch-11) + " (´・ω・`)ω・`) 今だ!オラごと撃て!") print(" "*(epoch-13) + " ⊂∩ ∩つ )") print(" "*(epoch-10) + "/ 〈 〈") print(" "*(epoch-11) + " ( /⌒`J ⌒し'") print("\n\n") print(" "*(epoch-1) + "ノ") print(" "*(epoch-4) + "彡 ノ") print(" "*(epoch-6) + "ノ") print(" "*(epoch-8) + "ノノ ミ ノノ") print() print(" "*(epoch-11) + "(´;ω;`)ω^`) クソがあああああああ!!!") print(" "*(epoch-13) + " ⊂∩ ∩つ )") print(" "*(epoch-10) + "/ 〈 〈") print(" "*(epoch-11) + " ( /⌒`J ⌒し'") print("\033[6A") for i in range(epoch): bar = "弌"*i + "⊃" + " "*(epoch-i-1) print("\rにア" + bar + "]", "{}/{}".format(i+1, epoch), end="") time.sleep(0.1) print() print("\033[5B")
個人情報の隠し方が雑なのはスルーしてください笑
皆さんご存知?のドラゴンボールの名シーン、ラディッツ戦のパロディAAです。(なんか見つけたので使いました)
AAの部分を表示するためのコードはまあ見ての通りです。ただ、予め全てのAAを出力してあることに注意です。
そしてprogress.pyprint("\033[6A")によって予め開けておいた
progress.pyprint(" "*(epoch-8) + "ノノ ミ ノノ") print() print(" "*(epoch-11) + "(´;ω;`)ω^`) クソがあああああああ!!!")の空行部分に移動し魔貫光殺法をこれまでの要領で表示させています。
最後にprogress.pyprint() print("\033[5B")で魔貫光殺法を改行し標準出力の最後の行まで移動しています。
さて、謎のコードが出てきていますが、これがANSIエスケープコードです。
Pythonでは次の表のANSIエスケープコードがあります。
ANSIエスケープコード 効果 \033[nA カーソルを上にn行移動 \033[nB カーソルを下にn行移動 \033[nC カーソルを右にn移動 \033[nD カーソルを左にn移動 \033[nE カーソルを下にn行移動した後、その行の先頭に移動 \033[nF カーソルを上にn行移動した後、その行の先頭に移動 \033[nG カーソルを左端から数えてn番目の位置に移動 \033[n;mH カーソルをコンソール上端から数えてn行目、左端から数えてmの位置に移動 \033[nJ n=0のときはカーソルより後ろの文字列(以降の行を含む)を全て削除、n=1のときはカーソルより前の文字列(以前の行を含む)を削除、n=2のときは全文字列(出力された全て)を削除 \033[nK n=0のときはカーソルより後ろの文字列を削除、n=1のときはカーソルより前の文字列を削除、n=2のときは行全体を削除Pythonでは動かないかもしれません。\033[nS n行分コンソールを次にスクロール \033[nT n行分コンソールを前にスクロール \033[n;mf Hのときと同じくカーソル移動 \033[nm SGR: Select Graphic Renditionコマンド。グラッフィック制御を行う。詳細はこちら なんのこっちゃ、という方は最初の4つくらいだけ使えるようにしておきましょう。
このANSIコードを利用することでさっきみたいな自由度の高い操作が可能となります。ちなみにこのANSIコードは多分ターミナルなどのコンソールを利用した場合のみ使用できるっぽいので、jupyter notebookなどでは
\rでの単行プログレスバーで我慢しましょう。おわりに
ということで意外と複雑な標準出力のお話を覚書しておきました。まあプログレスバーを自作する必要のある人はそうそういなさそうですが...
まあこういう機能を利用すればいろいろ遊べる、ということでいいでしょうきっと。参考



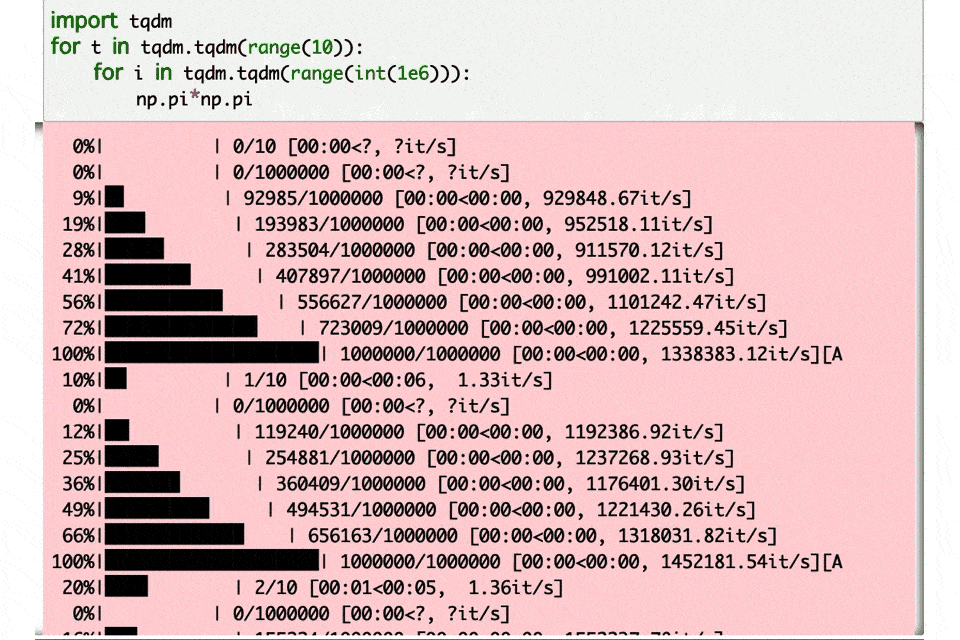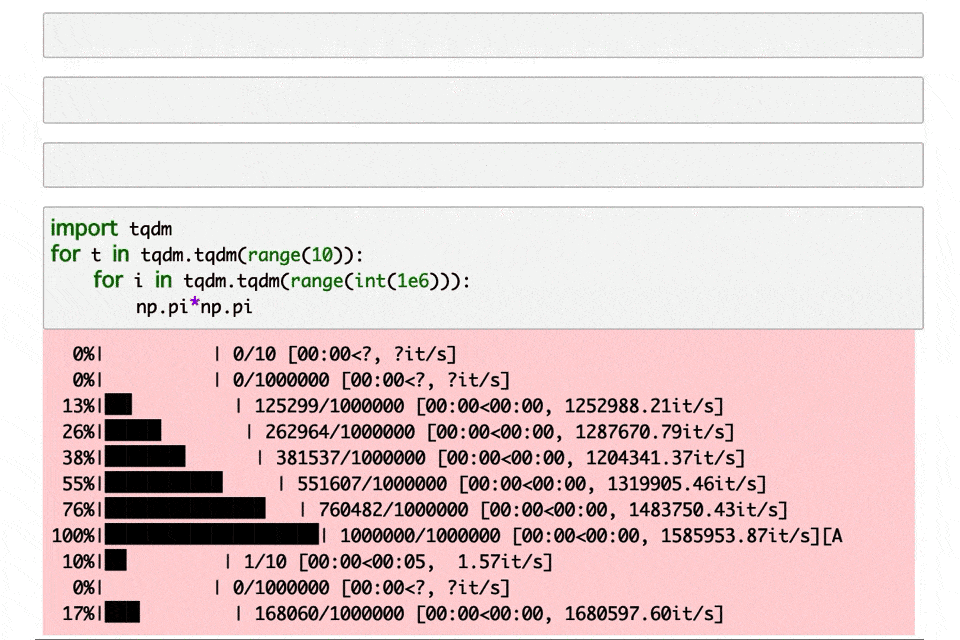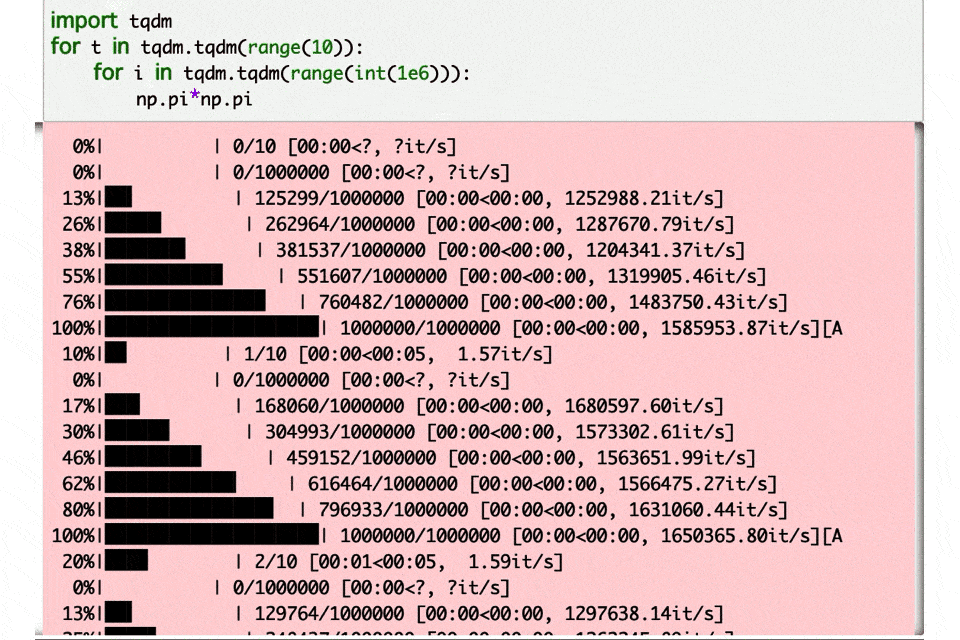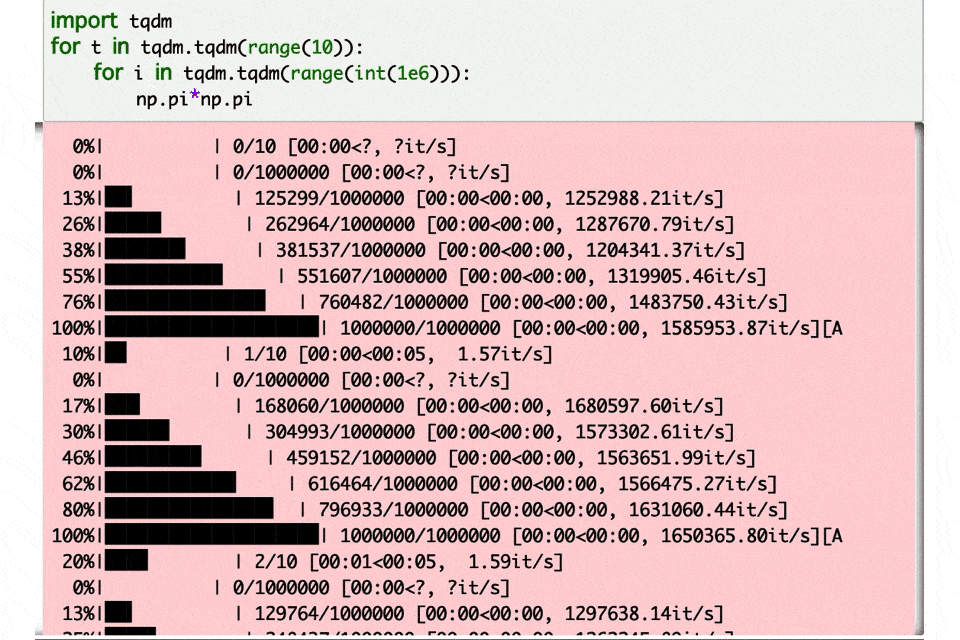



- 投稿日:2020-11-16T11:59:04+09:00
sqlalchemy での API化に必須なコード
sqlalchemy での API化に必須なコード
https://python5.com/q/dqtofqqq
お・ま・じ・な・い (滝川クリステル調に)
items = [{column: value for column, value in rowproxy.items()} for rowproxy in items]
- 投稿日:2020-11-16T10:45:17+09:00
mnistの教師なし学習で分類してみた【PCA、t-SNE、k-means】
はじめに
教師なし学習は一般的に教師あり学習と比較すると精度が落ちますが、その代わりに様々なメリットがあります。具体的に教師なし学習が役に立つシーンとして
- パターンがあまりわかっていないデータ
- 時間的に変動するデータ
- 十分にラベルがついていないデータなどが挙げられます。
教師なし学習ではデータそのものから、データの背後にある構造を学習します。これによってラベルのついていないデータをより多く活用できるので、新たなアプリケーションへの道が開けるかもしれません。
この記事では、mnistのデータを教師なし学習により分類の実装例を紹介します。
手法は主成分分析とt-SNE、k-means法を用います。
続編の記事では、オートエンコーダを用いた分類にもチャレンジしてみたいと考えています。この記事でやること
- mnistデータを教師なし学習で分類
- PCA + k-means法による分類の実装と評価
- PCA+t-SNE + k-means法による分類の実装と評価ライブラリのインポート
import random import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np from sklearn.decomposition import PCA from sklearn.cluster import KMeans from sklearn.metrics import confusion_matrix from sklearn.manifold import TSNEデータの準備
mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() #正規化 train_images = (train_images - train_images.min()) / (train_images.max() - train_images.min()) test_images = (test_images - test_images.min()) / (test_images.max() - test_images.min()) train_images.shape,test_images.shape主成分分析による画像の分類
mnistのデータは28*28=784次元のデータとなっています。このくらいであればぎりぎりそのままでもk-means法を適用することができそうですが、分類する前に次元削減をするのが有効です。そうすることで、計算量をへらすことが可能です。
次元削減の手法として主成分分析(PCA)を用います。そしてPCAで次元削減されたデータに対して、k-means法を適用してデータを分類していきます。
主成分分析の実行
df_train = pd.DataFrame(train_images.reshape(train_images.shape[0],28*28)) pca = PCA() pca.fit(df_train) feature = pca.transform(df_train) #二次元で可視化 plt.scatter(feature[:,0],feature[:,1],alpha=0.8,c=train_labels)主成分の第一成分と第二成分で可視化した結果がこちらです。
0~9の10個のクラスタで色分けしています。
なんとなく分類できているようにも見えますが...かなり重なっている部分が多いですね。
次に、第何成分までを用いてk-meansを適用するかを考えていきます。
そのためにそれぞれの成分の寄与率を可視化します。#寄与率の変化 ev_ratio = pca.explained_variance_ratio_ ev_ratio = np.hstack([0,ev_ratio.cumsum()]) df_ratio = pd.DataFrame({"components":range(len(ev_ratio)), "ratio":ev_ratio}) plt.plot(ev_ratio) plt.xlabel("components") plt.ylabel("explained variance ratio") plt.xlim([0,50]) plt.scatter(range(len(ev_ratio)),ev_ratio)結果をみると第100成分までで90%以上のデータが復元できることがわかります。
いろいろ実験するとわかりますが、分類するときは10成分もあれば十分でした。(下に記す評価方法で実験しました)
このことから、第10成分までを用いてk-means法を適用して分類してみます。
次元数が少ないほど計算数が減るので、少ないほうが好ましいですね。k-means法による分類
まずはk-means法を適用します。
クラスタが10個あることがわかっているので、まずは10個に分類してみます。KM = KMeans(n_clusters = 10) result = KM.fit(feature[:,:9])分類結果の評価
まずは、分類結果を混同行列で表示します。
df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) df_eval.columns = df_eval.idxmax() df_eval = df_eval.sort_index(axis=1) df_eval分類してクラスタの中で最も多かった正解ラベルのものを予測ラベルとしました。
例えば、クラスタNo.0に0が100個、1が20個、4が10個含まれていたらこれは0を予測している、といった具合ですね。結果をみると、0と予測しているクラスタと1と予測しているクラスタが2つあることがわかりますね。
つまり主成分分析とk-means法では10個の数字に上手に分類するのは難しかったと考えられます。
それでは、いくつのクラスタに分類するのが最適なのかを考えていきます。
当たり前のことですが、クラスタ数が多ければクラスタの中は似たものが多くなりますが解釈が難しくなる。逆に少なければ、解釈は簡単ですがクラスタの中にいろんなデータが含まれることになります。なので、クラスタ数は少ないけどできるだけ似たようなデータを含んだ分類がいいですね。
ここでは正解データがわかっているので、クラスタの中で最も多いラベルを正解ラベルとして、正解ラベルの数が最も多くなるようなクラスタ数を見つけたいと思います。なので評価指標を、正解ラベルとなった数/全体の数とします。
#クラスタの中のデータの最も多いラベルを正解ラベルとしてそれが多くなるようなクラスタ数を探索 eval_acc_list=[] for i in range(5,15): KM = KMeans(n_clusters = i) result = KM.fit(feature[:,:9]) df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) eval_acc = df_eval.max().sum()/df_eval.sum().sum() eval_acc_list.append(eval_acc) plt.plot(range(5,15),eval_acc_list) plt.xlabel("The number of cluster") plt.ylabel("accuracy")クラスタ数を5~15に変化させた場合の結果です。
クラスタ数が増えるほど同質性が増えており、accuracyが上がっていますね。
どこが最適か、というのは目的によりますが、クラスタ数10程度が解釈性を考えると良さそうです。つまり、PCAのみでは10個のラベルにきれいにわけるのは難しいということになりました。
そこで、次はt-SNEという手法を組み合わせたいと思います。PCA+t-SNEによる分類
t-SNEの実行
PCAのみでは10個に分類するのが難しかったので、PCAとt-SNEを組み合わせて分類をしてみます。
t-SNEは原理がなかなか難しそうな手法です(自分もよくわかっていない)。
詳しい解説があるサイトを参考文献に乗せておきます。t-SNEは計算時間がかかる手法なので、PCAで次元削減した10次元の10000個のデータの分類を行います。
可視化するとまあまあいい感じに分類できていそうな気もします。tsne = TSNE(n_components=2).fit_transform(feature[:10000,:9]) #可視化 for i in range(10): idx = np.where(train_labels[:10000]==i) plt.scatter(tsne[idx,0],tsne[idx,1],label=i) plt.legend(loc='upper left',bbox_to_anchor=(1.05,1))
k-meansによる分類と評価
つぎに、k-means法で分類して、混同行列を表示します。
#tsneしたものをkmeansで分類 KM = KMeans(n_clusters = 10) result = KM.fit(tsne) df_eval = pd.DataFrame(confusion_matrix(train_labels[:10000],result.labels_)) df_eval.columns = df_eval.idxmax() df_eval = df_eval.sort_index(axis=1) df_eval
たまたまかもしれませんが、10個のラベルに上手に分かれています。良かったよかった。
この表をみていると、「4」と「9」を間違って分類していることが多いのがわかります。
実際にt-SNEの結果を可視化した散布図をみても4と9は近いところにありますね。この学習方法では4と9が似ているものと学習していることがわかります。
なんで似てると考えているのかは不明ですが、なんだが面白いですね。最後にクラスタ数ごとのaccuracyの評価を行います。
クラスタ数10のときaccuracyは0.6となっています。
PCAのみのときよりやや高い結果となっていますね。#クラスタの中のデータの最も多いラベルを正解ラベルとしてそれが多くなるようなクラスタ数を探索 eval_acc_list=[] for i in range(5,15): KM = KMeans(n_clusters = i) result = KM.fit(feature[:,:9]) df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) eval_acc = df_eval.max().sum()/df_eval.sum().sum() eval_acc_list.append(eval_acc) plt.plot(range(5,15),eval_acc_list) plt.xlabel("The number of cluster") plt.ylabel("accuracy")
終わりに
mnistを題材としてPCAとt-SNEによる次元削減と可視化、k-meansによる分類と評価について実装しました。
ラベルのないデータは世の中に溢れているのでなかなか有用そうな手法です。参考になりましたらLGTM等していただけると励みになります。
参考文献
t-SNE を用いた次元圧縮方法のご紹介
https://blog.albert2005.co.jp/2015/12/02/tsne/t-SNEを理解して可視化力を高める
https://qiita.com/g-k/items/120f1cf85ff2ceae4aba
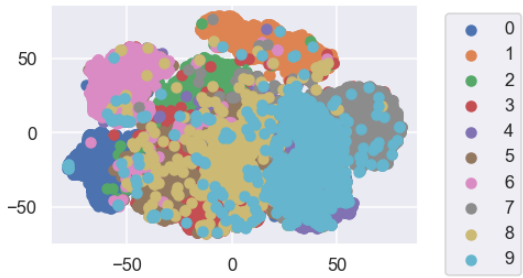

- 投稿日:2020-11-16T10:45:17+09:00
mnistの数字たちを教師なし学習で分類してみた【PCA、t-SNE、k-means】
はじめに
教師なし学習は一般的に教師あり学習と比較すると精度が落ちますが、その代わりに様々なメリットがあります。具体的に教師なし学習が役に立つシーンとして
- パターンがあまりわかっていないデータ
- 時間的に変動するデータ
- 十分にラベルがついていないデータなどが挙げられます。
教師なし学習ではデータそのものから、データの背後にある構造を学習します。これによってラベルのついていないデータをより多く活用できるので、新たなアプリケーションへの道が開けるかもしれません。
この記事では、mnistのデータを教師なし学習により分類の実装例を紹介します。
手法は主成分分析とt-SNE、k-means法を用います。
続編の記事では、オートエンコーダを用いた分類にもチャレンジしてみたいと考えています。この記事でやること
- mnistデータを教師なし学習で分類
- PCA + k-means法による分類の実装と評価
- PCA+t-SNE + k-means法による分類の実装と評価ライブラリのインポート
import random import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np from sklearn.decomposition import PCA from sklearn.cluster import KMeans from sklearn.metrics import confusion_matrix from sklearn.manifold import TSNEデータの準備
mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() #正規化 train_images = (train_images - train_images.min()) / (train_images.max() - train_images.min()) test_images = (test_images - test_images.min()) / (test_images.max() - test_images.min()) train_images.shape,test_images.shape一応可視化します。見覚えのある数字たちですね。
# ランダムに可視化 fig, ax = plt.subplots(4,5,figsize=[8,6]) ax_f = ax.flatten() for ax_i in ax_f: idx = random.choice(range(train_images.shape[0])) ax_i.imshow(train_images[idx,:,:]) ax_i.grid(False) ax_i.tick_params(labelbottom=False,labelleft=False)
主成分分析による画像の分類
mnistのデータは28*28=784次元のデータとなっています。このくらいであればぎりぎりそのままでもk-means法を適用することができそうですが、分類する前に次元削減をするのが有効です。そうすることで、計算量をへらすことが可能です。
次元削減の手法として主成分分析(PCA)を用います。そしてPCAで次元削減されたデータに対して、k-means法を適用してデータを分類していきます。
主成分分析の実行
df_train = pd.DataFrame(train_images.reshape(train_images.shape[0],28*28)) pca = PCA() pca.fit(df_train) feature = pca.transform(df_train) #二次元で可視化 plt.scatter(feature[:,0],feature[:,1],alpha=0.8,c=train_labels)主成分の第一成分と第二成分で可視化した結果がこちらです。
0~9の10個のクラスタで色分けしています。
なんとなく分類できているようにも見えますが...かなり重なっている部分が多いですね。
次に、第何成分までを用いてk-meansを適用するかを考えていきます。
そのためにそれぞれの成分の寄与率を可視化します。#寄与率の変化 ev_ratio = pca.explained_variance_ratio_ ev_ratio = np.hstack([0,ev_ratio.cumsum()]) df_ratio = pd.DataFrame({"components":range(len(ev_ratio)), "ratio":ev_ratio}) plt.plot(ev_ratio) plt.xlabel("components") plt.ylabel("explained variance ratio") plt.xlim([0,50]) plt.scatter(range(len(ev_ratio)),ev_ratio)結果をみると第100成分までで90%以上のデータが復元できることがわかります。
いろいろ実験するとわかりますが、分類するときは10成分もあれば十分でした。(下に記す評価方法で実験しました)
このことから、第10成分までを用いてk-means法を適用して分類してみます。
次元数が少ないほど計算数が減るので、少ないほうが好ましいですね。k-means法による分類
まずはk-means法を適用します。
クラスタが10個あることがわかっているので、まずは10個に分類してみます。KM = KMeans(n_clusters = 10) result = KM.fit(feature[:,:9])分類結果の評価
まずは、分類結果を混同行列で表示します。
df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) df_eval.columns = df_eval.idxmax() df_eval = df_eval.sort_index(axis=1) df_eval分類してクラスタの中で最も多かった正解ラベルのものを予測ラベルとしました。
例えば、クラスタNo.0に0が100個、1が20個、4が10個含まれていたらこれは0を予測している、といった具合ですね。結果をみると、0と予測しているクラスタと1と予測しているクラスタが2つあることがわかりますね。
つまり主成分分析とk-means法では10個の数字に上手に分類するのは難しかったと考えられます。
それでは、いくつのクラスタに分類するのが最適なのかを考えていきます。
当たり前のことですが、クラスタ数が多ければクラスタの中は似たものが多くなりますが解釈が難しくなる。逆に少なければ、解釈は簡単ですがクラスタの中にいろんなデータが含まれることになります。なので、クラスタ数は少ないけどできるだけ似たようなデータを含んだ分類がいいですね。
ここでは正解データがわかっているので、クラスタの中で最も多いラベルを正解ラベルとして、正解ラベルの数が最も多くなるようなクラスタ数を見つけたいと思います。なので評価指標を、正解ラベルとなった数/全体の数とします。
#クラスタの中のデータの最も多いラベルを正解ラベルとしてそれが多くなるようなクラスタ数を探索 eval_acc_list=[] for i in range(5,15): KM = KMeans(n_clusters = i) result = KM.fit(feature[:,:9]) df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) eval_acc = df_eval.max().sum()/df_eval.sum().sum() eval_acc_list.append(eval_acc) plt.plot(range(5,15),eval_acc_list) plt.xlabel("The number of cluster") plt.ylabel("accuracy")クラスタ数を5~15に変化させた場合の結果です。
クラスタ数が増えるほど同質性が増えており、accuracyが上がっていますね。
どこが最適か、というのは目的によりますが、クラスタ数10程度が解釈性を考えると良さそうです。つまり、PCAのみでは10個のラベルにきれいにわけるのは難しいということになりました。
そこで、次はt-SNEという手法を組み合わせたいと思います。PCA+t-SNEによる分類
t-SNEの実行
PCAのみでは10個に分類するのが難しかったので、PCAとt-SNEを組み合わせて分類をしてみます。
t-SNEは原理がなかなか難しそうな手法です(自分もよくわかっていない)。
詳しい解説があるサイトを参考文献に乗せておきます。t-SNEは計算時間がかかる手法なので、PCAで次元削減した10次元の10000個のデータの分類を行います。
可視化するとまあまあいい感じに分類できていそうな気もします。tsne = TSNE(n_components=2).fit_transform(feature[:10000,:9]) #可視化 for i in range(10): idx = np.where(train_labels[:10000]==i) plt.scatter(tsne[idx,0],tsne[idx,1],label=i) plt.legend(loc='upper left',bbox_to_anchor=(1.05,1))
k-meansによる分類と評価
つぎに、k-means法で分類して、混同行列を表示します。
#tsneしたものをkmeansで分類 KM = KMeans(n_clusters = 10) result = KM.fit(tsne) df_eval = pd.DataFrame(confusion_matrix(train_labels[:10000],result.labels_)) df_eval.columns = df_eval.idxmax() df_eval = df_eval.sort_index(axis=1) df_eval
たまたまかもしれませんが、10個のラベルに上手に分かれています。良かったよかった。
この表をみていると、「4」と「9」を間違って分類していることが多いのがわかります。
実際にt-SNEの結果を可視化した散布図をみても4と9は近いところにありますね。この学習方法では4と9が似ているものと学習していることがわかります。
なんで似てると考えているのかは不明ですが、なんだが面白いですね。最後にクラスタ数ごとのaccuracyの評価を行います。
クラスタ数10のときaccuracyは0.6となっています。
PCAのみのときよりやや高い結果となっていますね。#クラスタの中のデータの最も多いラベルを正解ラベルとしてそれが多くなるようなクラスタ数を探索 eval_acc_list=[] for i in range(5,15): KM = KMeans(n_clusters = i) result = KM.fit(feature[:,:9]) df_eval = pd.DataFrame(confusion_matrix(train_labels,result.labels_)) eval_acc = df_eval.max().sum()/df_eval.sum().sum() eval_acc_list.append(eval_acc) plt.plot(range(5,15),eval_acc_list) plt.xlabel("The number of cluster") plt.ylabel("accuracy")
終わりに
mnistを題材としてPCAとt-SNEによる次元削減と可視化、k-meansによる分類と評価について実装しました。
ラベルのないデータは世の中に溢れているのでなかなか有用そうな手法です。参考になりましたらLGTM等していただけると励みになります。
参考文献
t-SNE を用いた次元圧縮方法のご紹介
https://blog.albert2005.co.jp/2015/12/02/tsne/t-SNEを理解して可視化力を高める
https://qiita.com/g-k/items/120f1cf85ff2ceae4aba
- 投稿日:2020-11-16T09:32:36+09:00
Glue Studio【AWS】
はじめに
この記事では、2020年9月23日にリリースされた Glue Studio を利用して GUI ベースで Glue ジョブの作成と実行そしてモニタリングを行います。
AWS Glue
AWS Glue は、Apache Spark のパワーを使用して分析用のデータセットを準備および処理するサーバーレス環境を提供します。
AWS Glue Documentation
Optimize memory management in AWS GlueAWS Glue Studio
AWS Glue Studio は、AWS Glue の新しいビジュアルインターフェースです。これにより、抽出、変換、読み込み (ETL) デベロッパーは、AWS Glue ETL ジョブを簡単に作成、実行、および監視できるようになります。シンプルなビジュアルインターフェイスを使用して、データを移動および変換し、AWS Glue で実行するジョブを作成できるようになりました。次に、AWS Glue Studio のジョブ実行ダッシュボードを使用して ETL 実行を監視し、ジョブが意図したとおりに動作していることを確認できます
AWS Big Data Blog の Making ETL easier with AWS Glue Studio を参考にして Glue Studio でのジョブの作成と実行を行います。
1. Start creating a Job
1. Click either the Jobs on the navigation panel or Create and manage jobs, and start creating a job.
2. Choose the Blank graph and click the Create button.
2. Adding Data source
3. Choose the (+) icon.
On the Node properties tab,
4. For Name, enter input.
5. For Node type, choose S3(Glue Data Catalog table with S3 as the data source.).
On the Data source properties - S3 tab,
(make a Data Catalog with Crawler beforehand)
6. For Database, pyspark_input
7. For Table, titanic_data_csv
8. For Partition predicate, leave blank.
On the Output schema tab,
9. Check the Schema.
3. Adding Transform
10. Choose the input node.
11. Choose the (+) icon.
On the Node properties tab,
12. For Name, enter transform.
13. For Node type, choose the Custom transform.
14. For Node parents, choose the input.
On the Transform tab,
15. For Code block, write Python code of PySpark.
On the Output schema tab,
16. Check the Schema.
By adding Custom transform, a next node to receive the DynamicFrameCollection is added automatically.On the Node properties tab,
17. For Name, enter receive (The word "recieve" is spelled wrong.)
18. For Node type, choose the SelectFromCollection.
19. For Node parents, choose the transform.
4. Adding Data target
20. Choose the receive node.
21. Choose the (+) icon.On the Node properties tab,
22. For Name, enter output.
23. For Node type, choose the S3(Output data directly in an S3 bucket.).
24. For Node parents, choose the receive.
On the Data target properties - S3,
25. For Format, choose the CSV.
26. For Compression Type, None.
27. For S3 Target Location, enter S3 location in the format s3://bucket/prefix/object/ with a trailing slash (/).
28. For Partition, leave blank.
On the Output schema tab,
29. Check the Schema.
5. Script
6. Configuring the job
30. IAM Role: AmazonS3FullAccess / AWSGlueConsoleFullAccess
31. For Job Bookmark, choose Disable.
32. For Number of retries, optionally enter 1.
33. Choose save.
34. When the job is saved, choose Run.
7. Monitoring the job
35. In the AWS Glue Studio navigation panel, choose Monitoring.
35. In the Glue console, check the Glue Job.
ジョブの作成と実行そしてモニタリングを行うことができました。
以上で主題は終了しましたが、実際に Glue というサービスを利用することでどのようなことが出来るのかを簡単に示しておきます。
このアーキテクチャは、Glue を利用したバッチ処理を行うデータ処理基盤の例です。
1. S3にデータが置かれることがCloudWatchのトリガーとなり、CloudWatchが
ターゲットとするStep Functionsが起動
2. Step FunctionsはLambdaから関数を受け取り、GlueのクローラとPySparkの
ジョブをS3に対し実行
3. PySparkにより変換されたデータをS3に出力まとめ
Glue Studio を利用して GUI ベースで Glue ジョブの作成と実行を行ってみました。

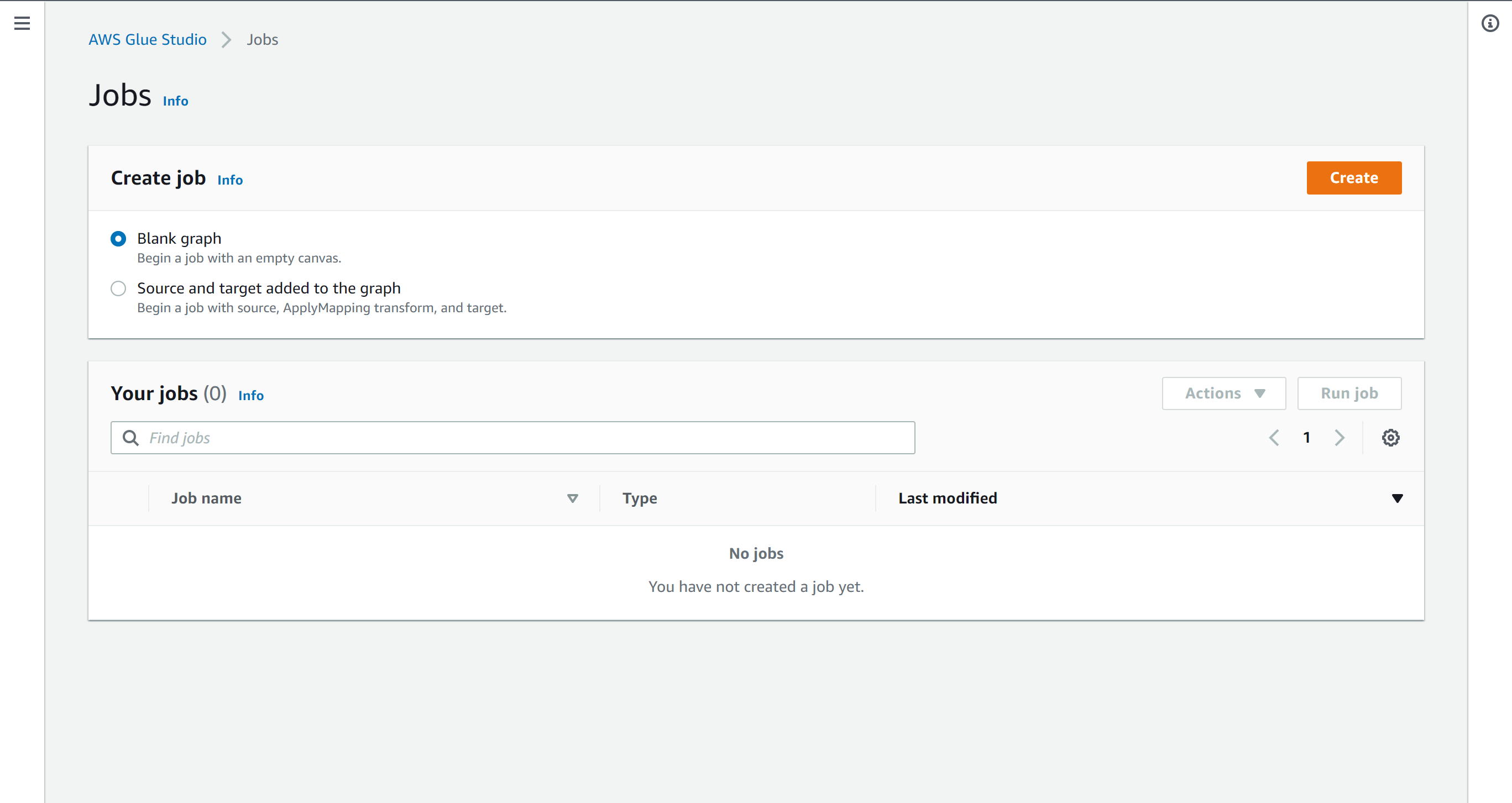


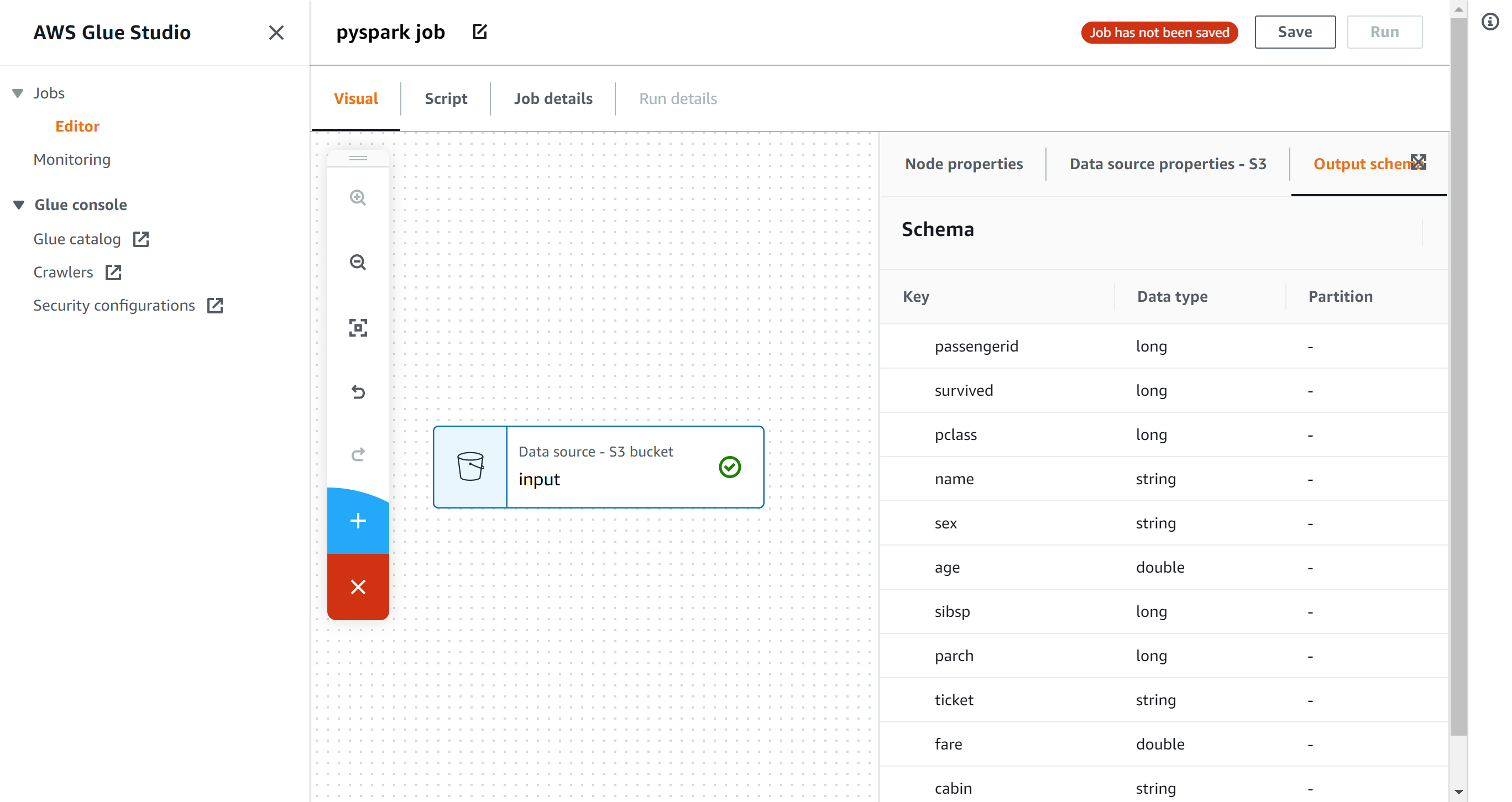
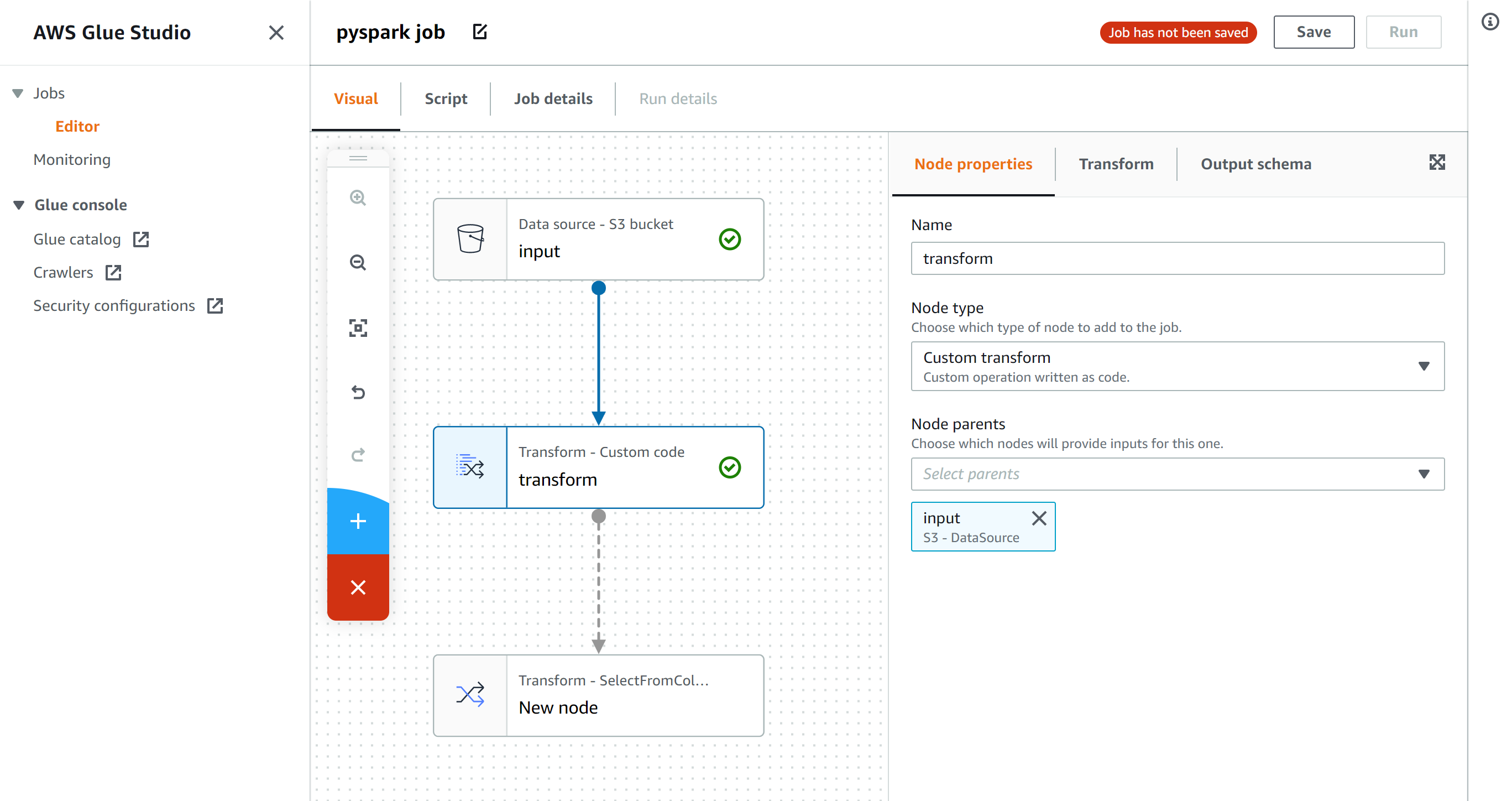
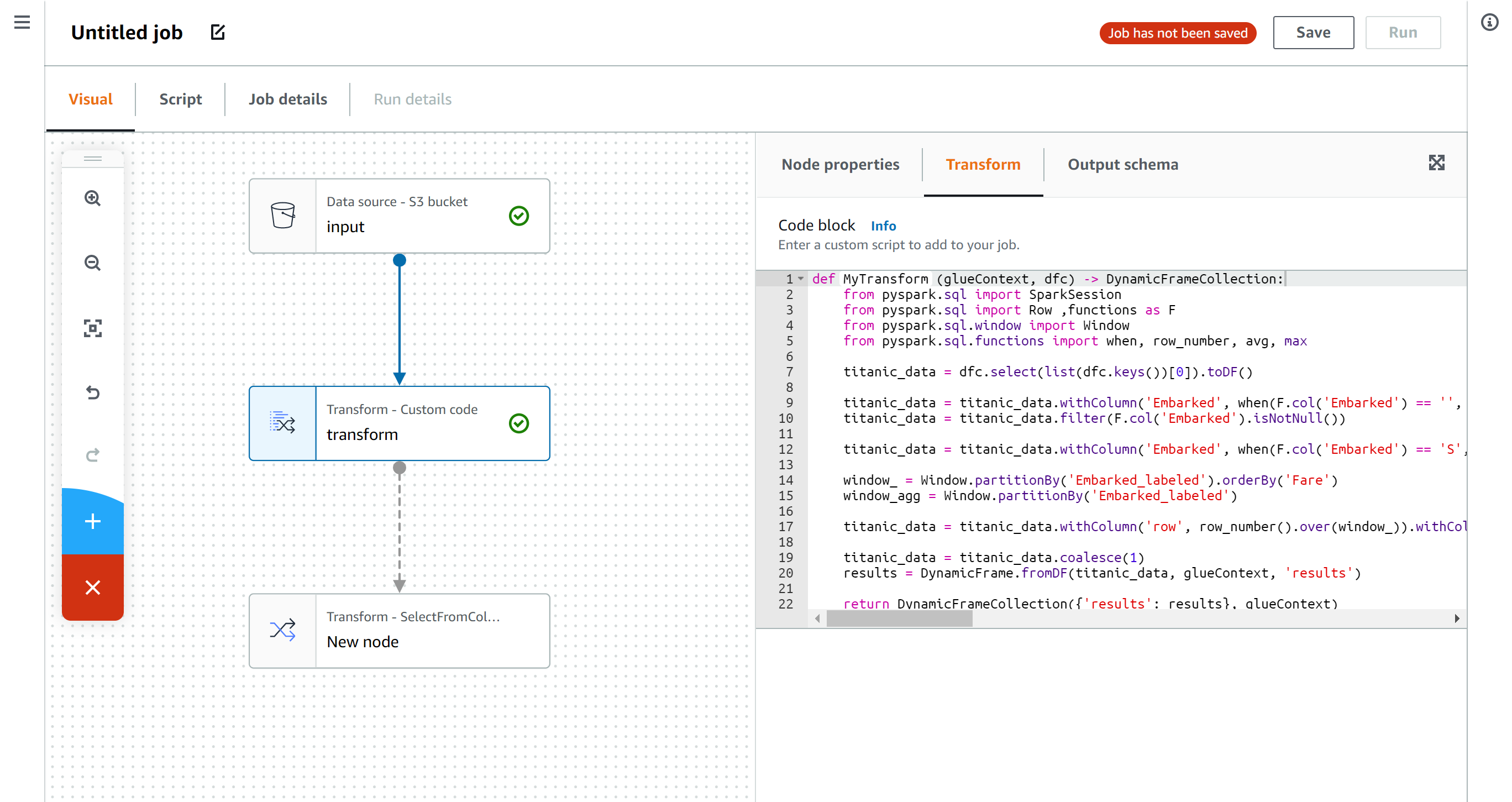
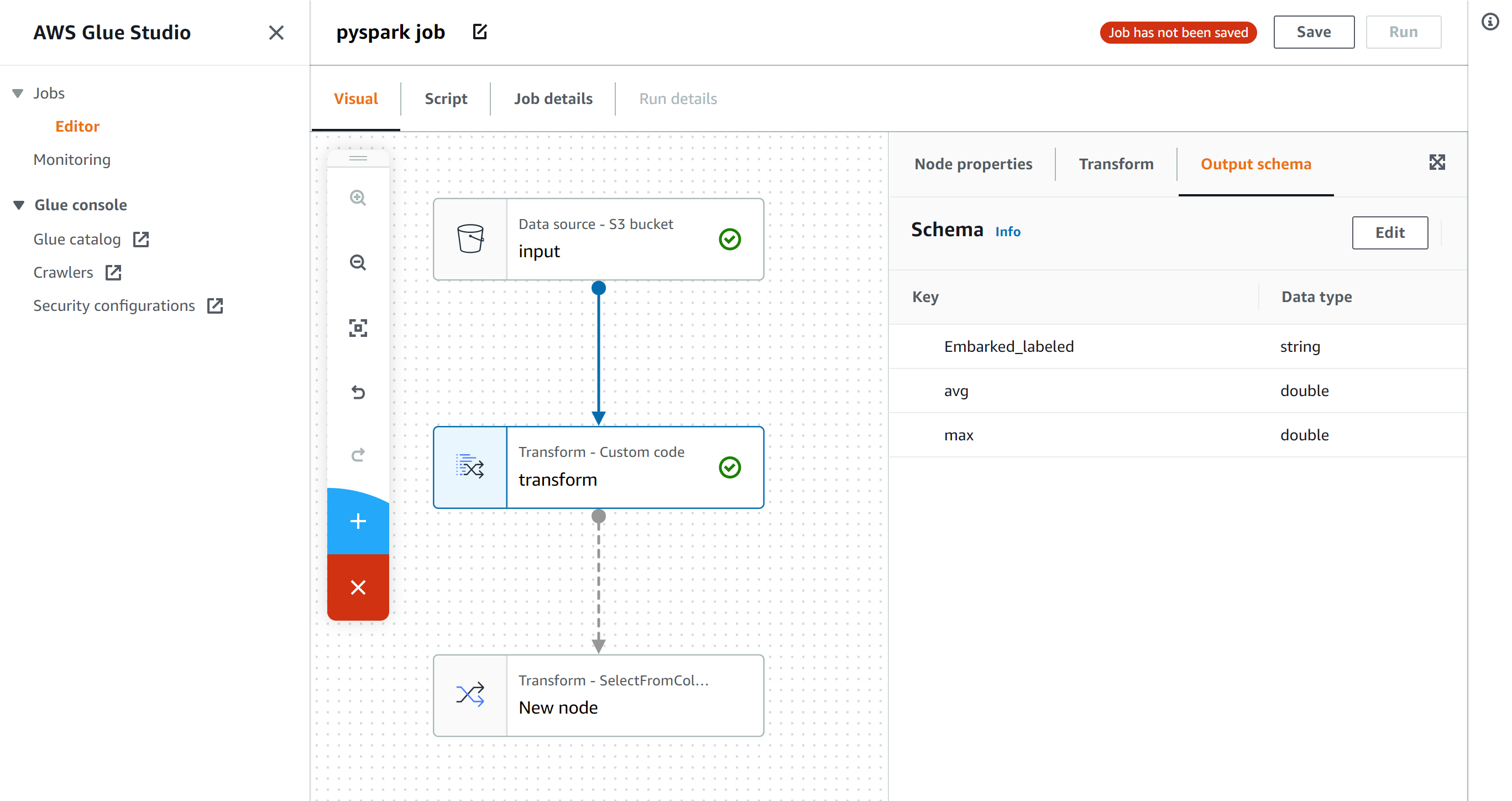
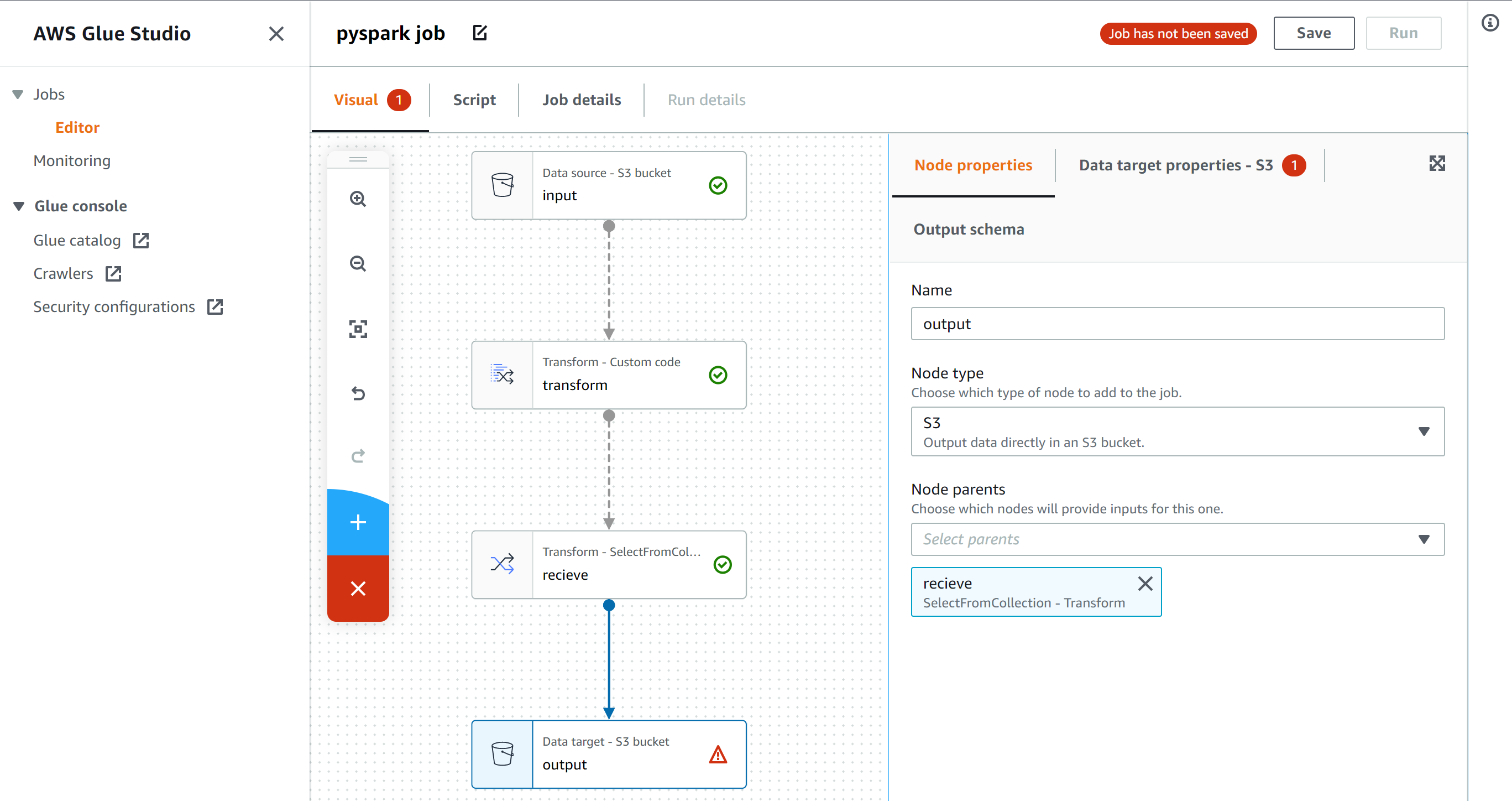
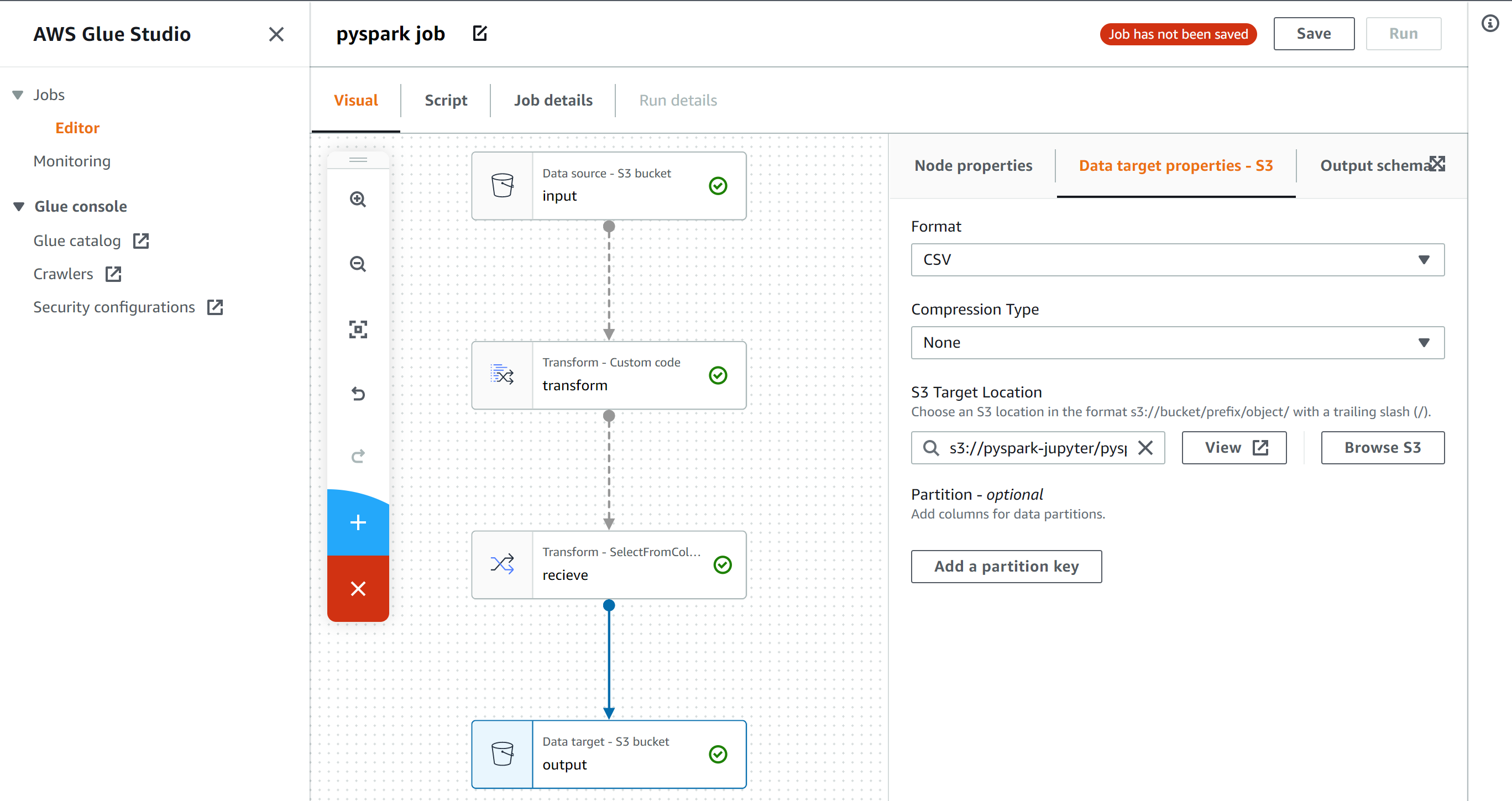
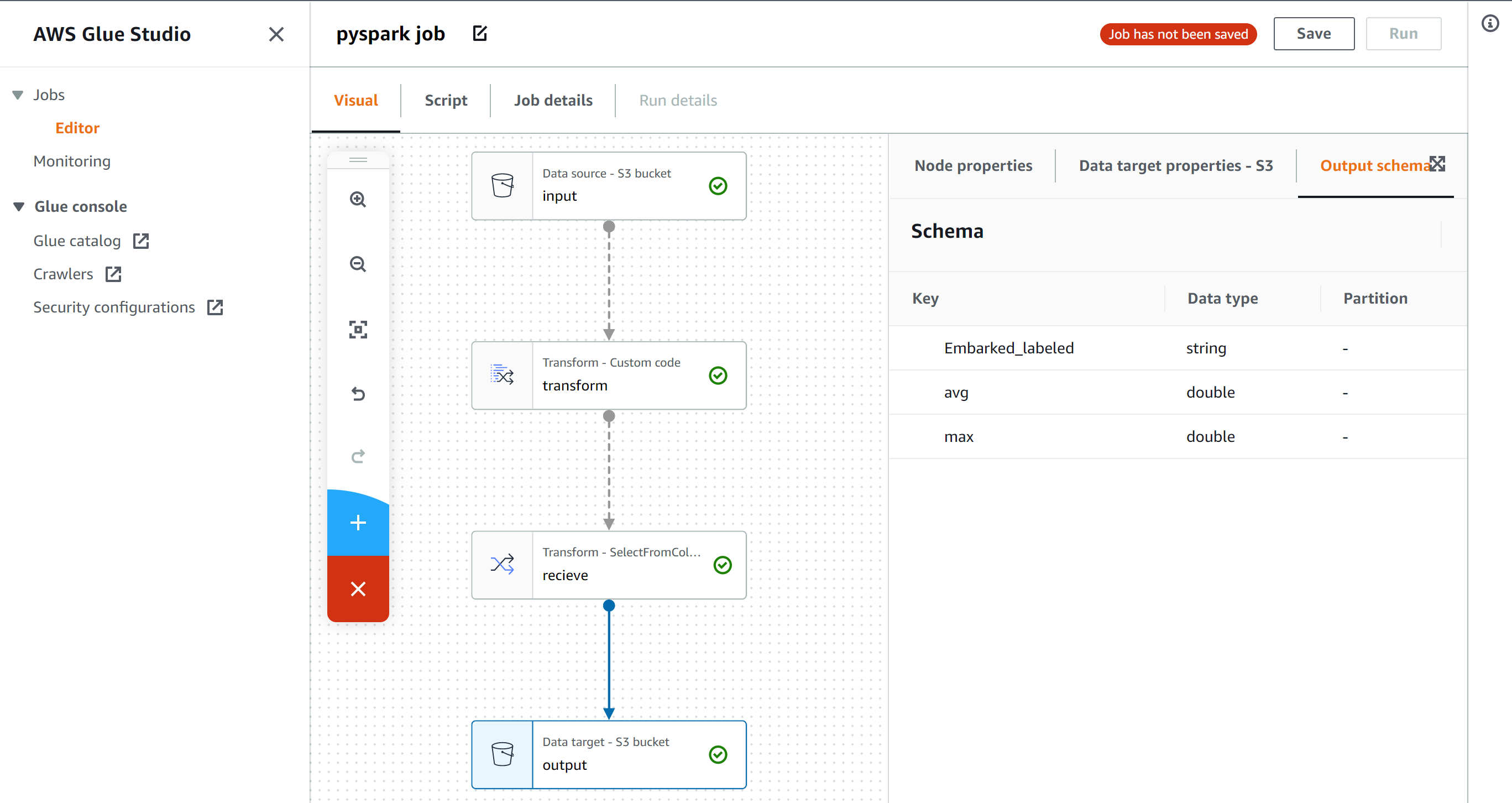
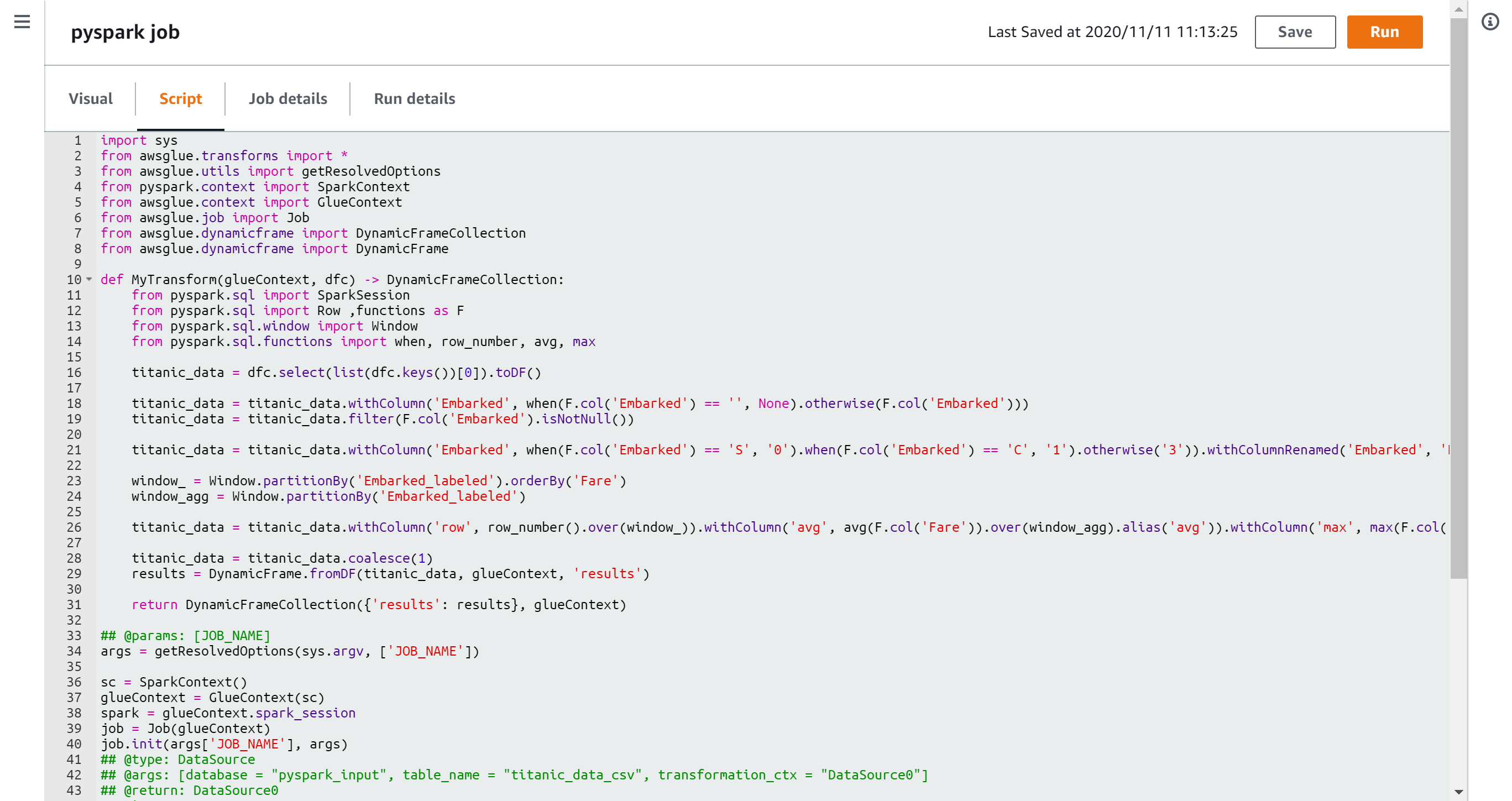

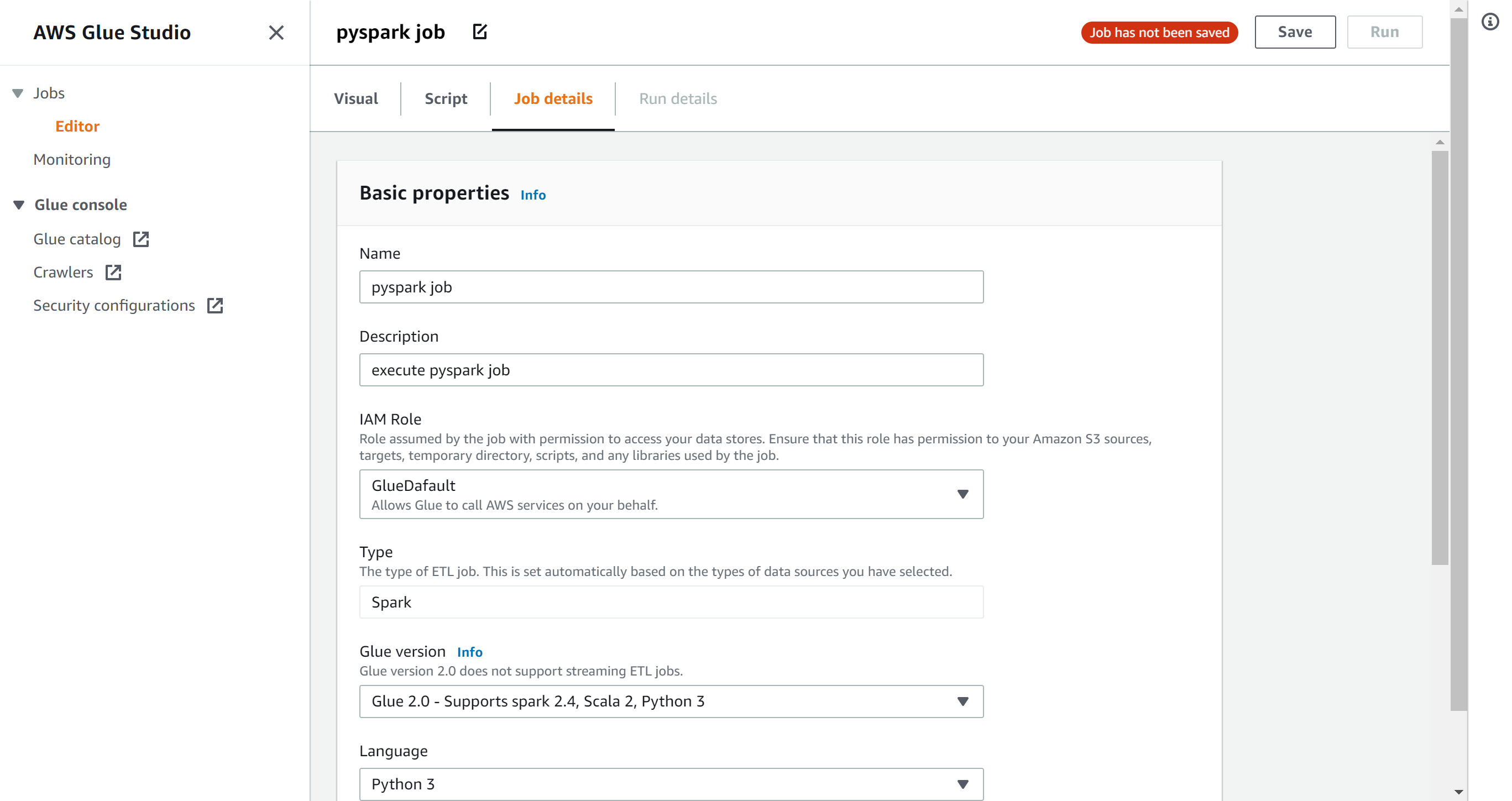
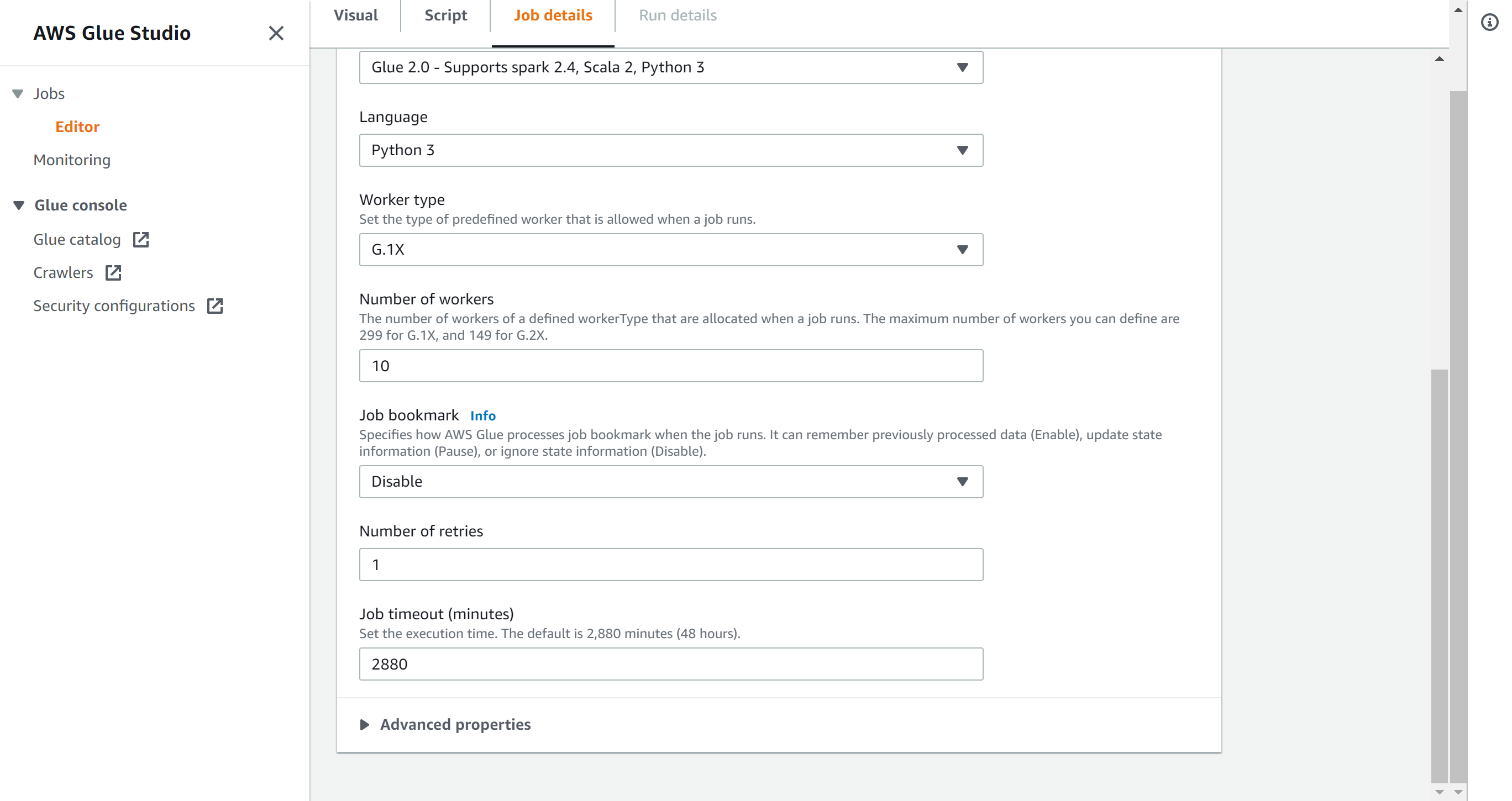
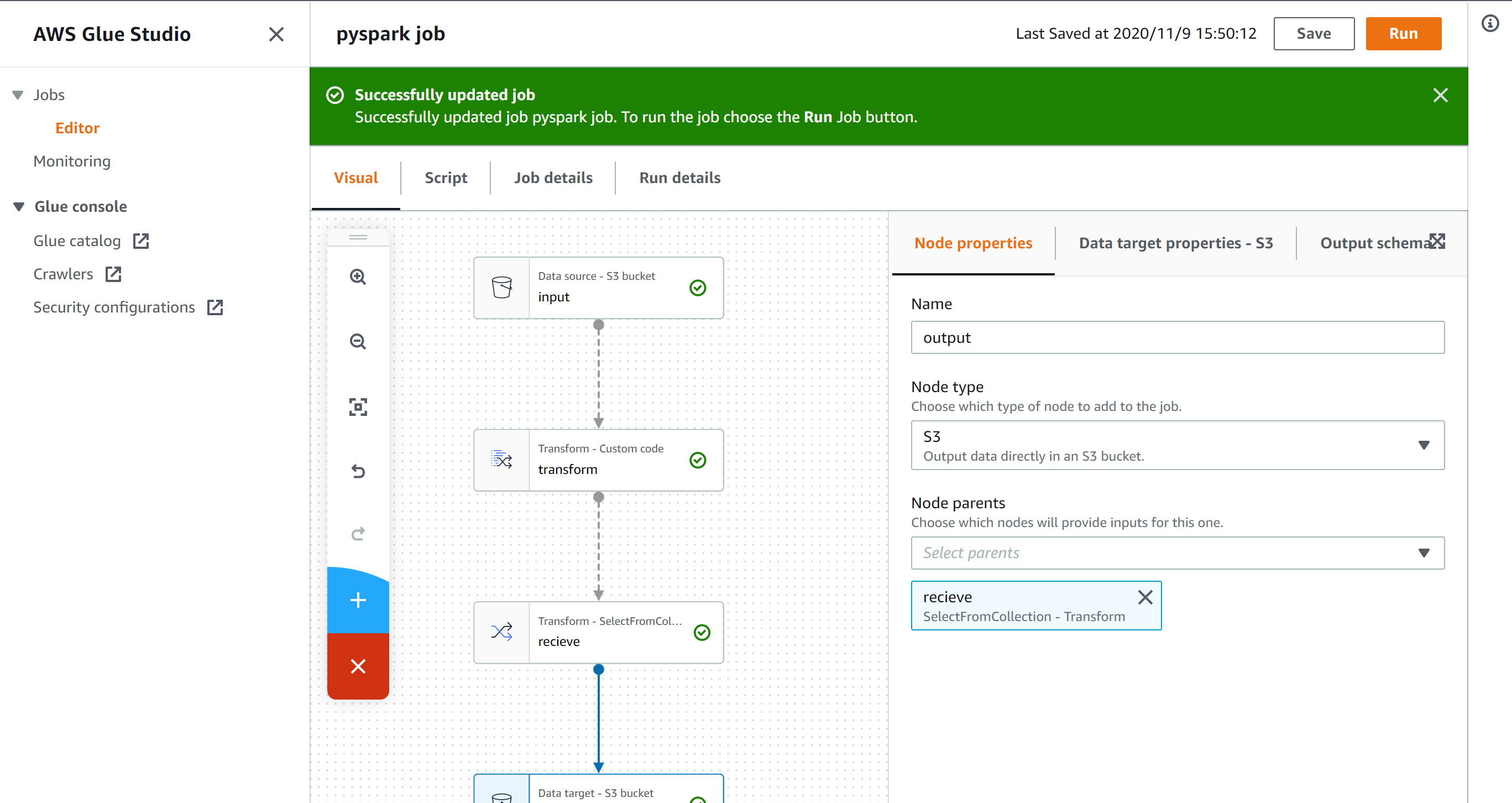
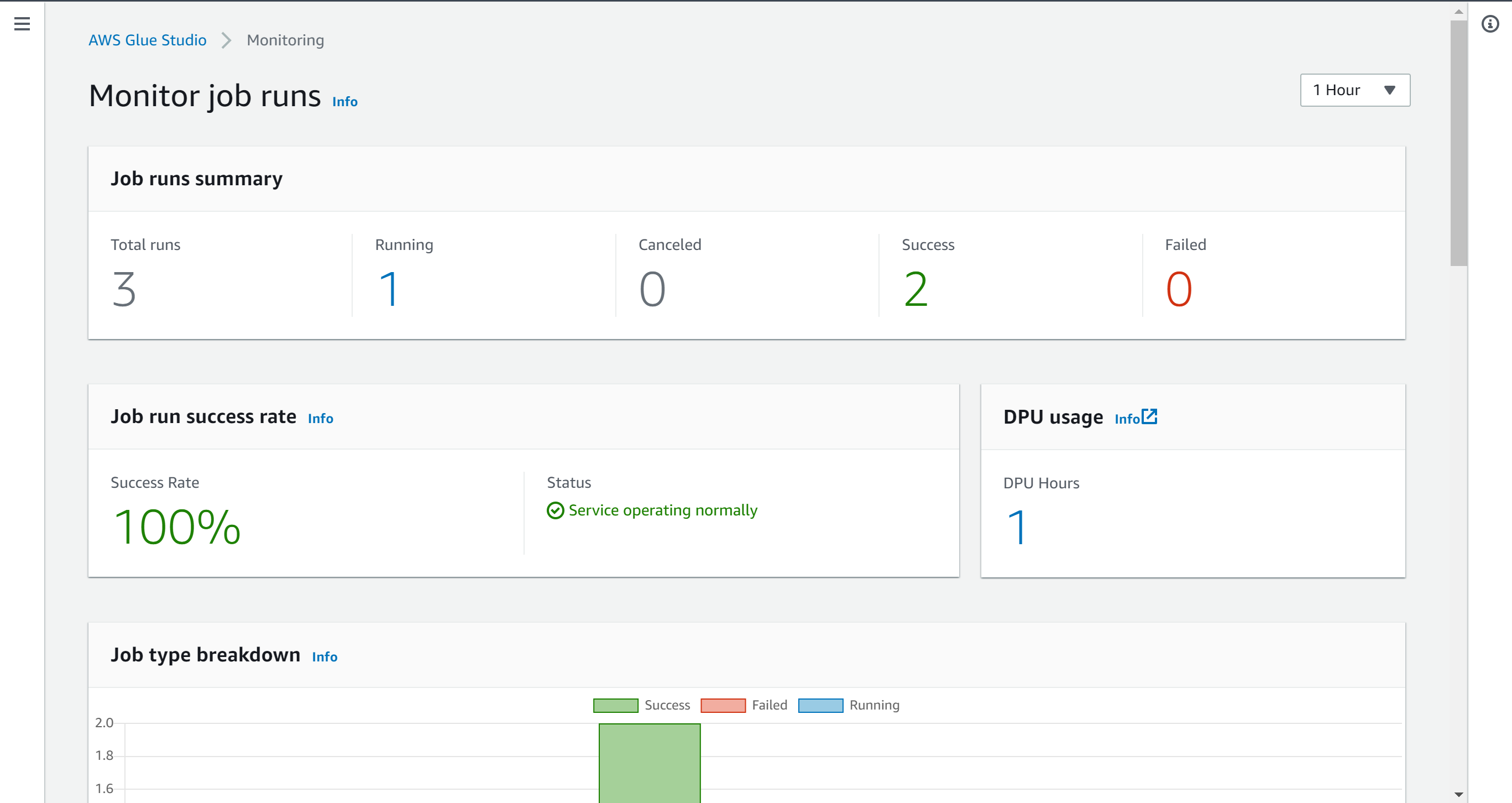
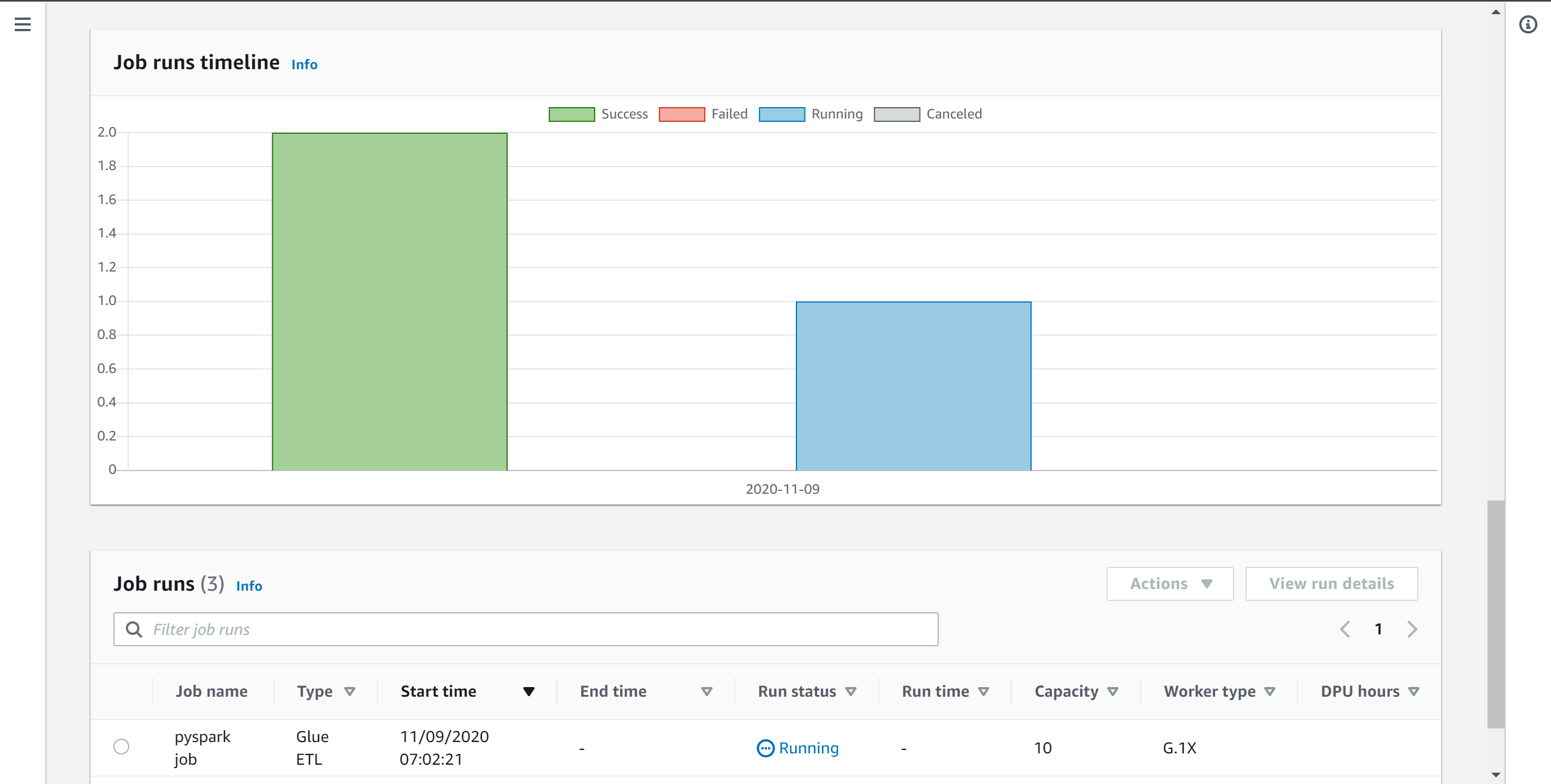
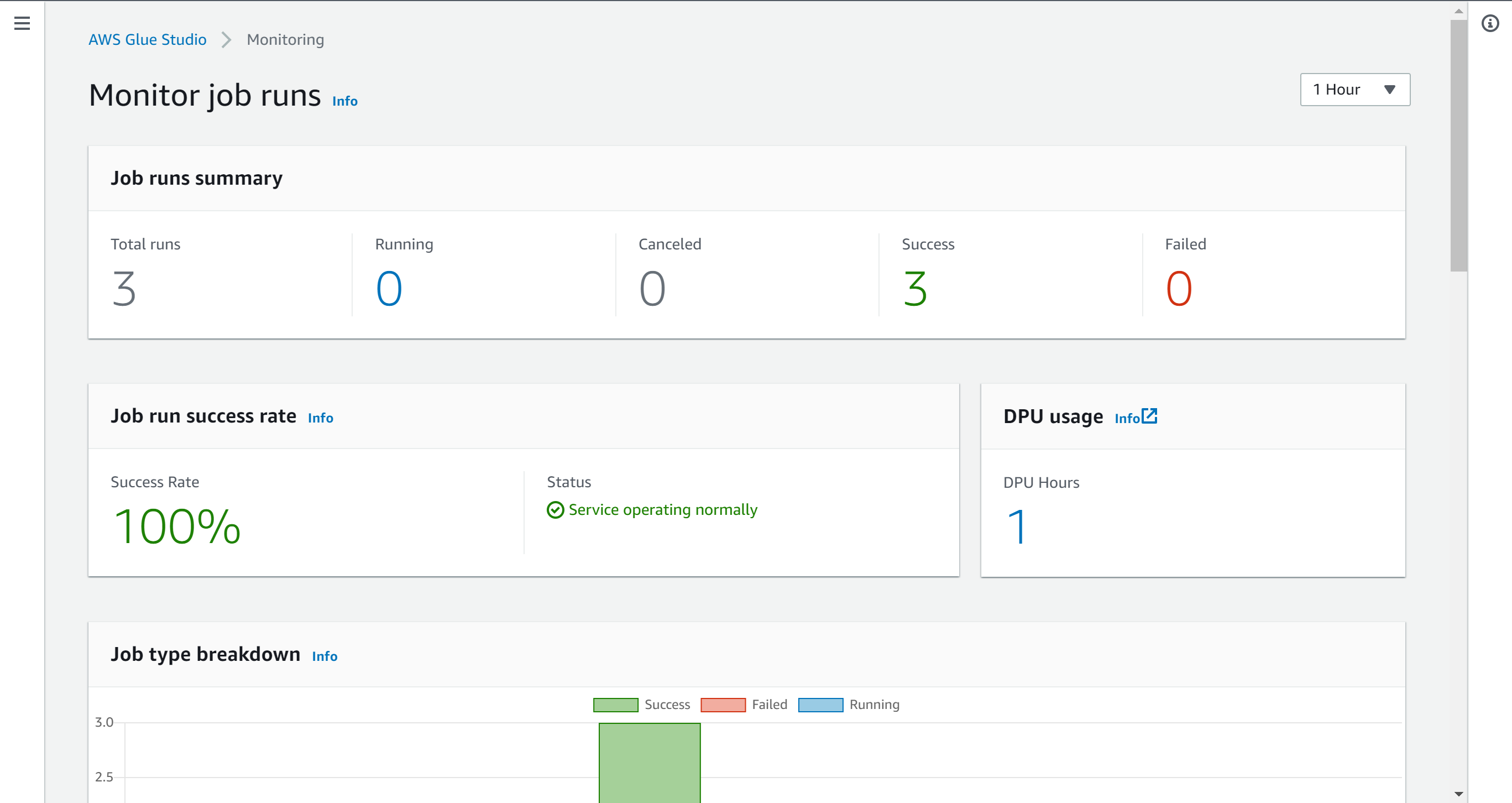
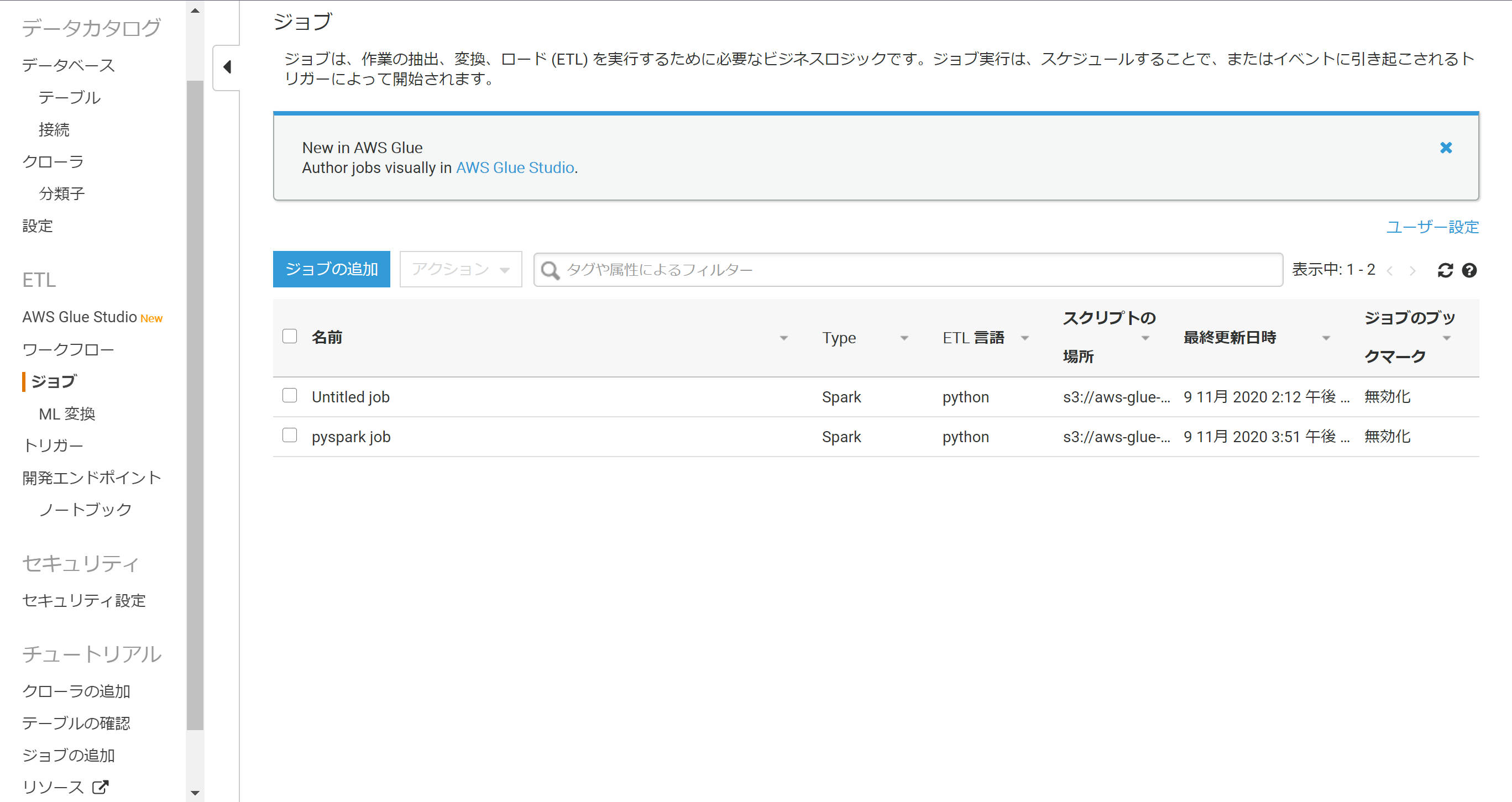
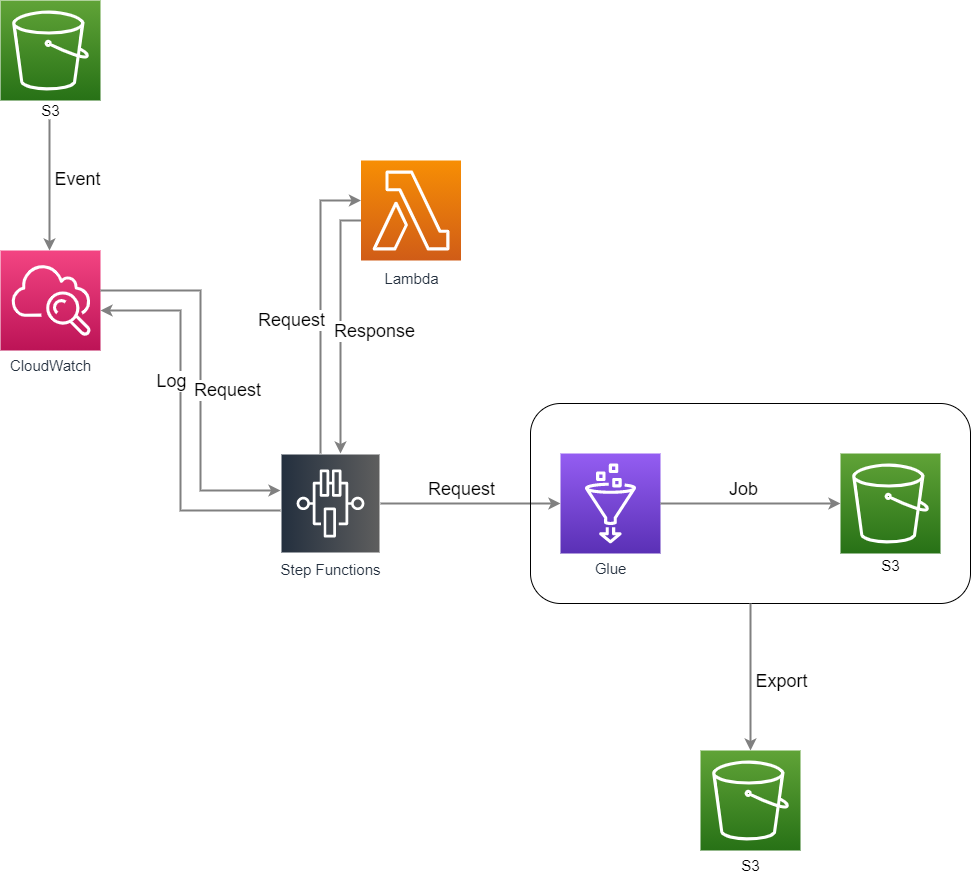
- 投稿日:2020-11-16T09:07:04+09:00
【Kaggle初心者向け】Titanic(LightGBM)
■ はじめに
今回は下記コンペに、LigthGBMで取り組みましたので
簡単にまとめてみました。【概要】
・Titanic: Machine Learning from Disaster
・沈没する船「タイタニック号」の乗客情報をもとに、助かる人とそうでない人について判別する【対象とする読者】
・Kaggle初心の方
・LightGBMの基礎コードについて学びたい方
1. モジュールの用意
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split import lightgbm as lgb from sklearn.metrics import roc_curve, roc_auc_score from sklearn.metrics import accuracy_score, f1_score from sklearn.metrics import confusion_matrix, classification_report
2. データの準備
train = pd.read_csv('train.csv') test = pd.read_csv('test.csv') print(train.shape) print(test.shape) # (891, 12) # (418, 11)train.head()
【データ項目】
・PassengerId:乗客ID
・Survived:生存したかどうか(0:助からない、1:助かる)
・Pclass – チケットのクラス(1:上層クラス、2:中級クラス、3:下層クラス)
・Name:乗客の名前
・Sex:性別
・Age:年齢
・SibSp:船に同乗している兄弟・配偶者の数
・parch:船に同乗している親・子供の数
・ticket:チケット番号
・fare:料金
・cabin:客室番号
・Embarked:船に乗った港(C:Cherbourg、Q:Queenstown、S:Southampton)test.head()
testデータの乗客番号(PassengerId)を保存しておきます。PassengerId = test['PassengerId']実際にはtrainデータのみでモデルの作成を行いますが
train・testデータをまとめて前処理したいので、結合を考えます。trainデータは項目が1つ多い(目的変数:Survived)ので分離します。
y = train['Survived'] train = train[[col for col in train.columns if col != 'Survived']] print(train.shape) print(test.shape) # (891, 11) # (418, 11)これでtrain データとtest データの項目(特徴量)数が同じになったので、結合します。
X_total = pd.concat([train, test], axis=0) print(X_total.shape) X_total.head() # (1309, 11)
3. 前処理
まず、欠損値がどの程度あるのかを確認します。
print(X_total.isnull().sum()) ''' PassengerId 0 Pclass 0 Name 0 Sex 0 Age 263 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 1014 Embarked 2 dtype: int64 '''LightGBMでは、文字列データのままモデルの作成が可能なため
数値変換は行わずに前処理をしていきます。X_total.fillna(value=-999, inplace=True) print(X_total.isnull().sum()) ''' PassengerId 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 0 Embarked 0 dtype: int64 '''ここで、文字列データのカラム(以降、カテゴリカル)を調べます。
categorical_col = [col for col in X_total.columns if X_total[col].dtype == 'object'] print('categorical_col:', categorical_col) # categorical_col: ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']各カテゴリカルのデータ型を調べます。
for i in X_total[categorical_col]: print('{}: {}'.format(i, X_total[i].dtype)) ''' Name: object Sex: object Ticket: object Cabin: object Embarked: object '''LightGBMは、文字列データのままモデリングできますが
object型ではなくcategory型にする必要があるため、データ型を変換していきます。for i in categorical_col: X_total[i] = X_total[i].astype("category")全体データ(X_total)のデータ型を見ておきます。
for i in X_total.columns: print('{}: {}'.format(i, X_total[i].dtype)) ''' PassengerId: int64 Pclass: int64 Name: category Sex: category Age: float64 SibSp: int64 Parch: int64 Ticket: category Fare: float64 Cabin: category Embarked: category '''
4. モデルの作成
trainデータのみでモデルを作成したいですが
X_totalはtestデータも含んでしまっているため、必要な部分のみを抽出します。train_rows = train.shape[0] X = X_total[:train_rows] print(X.shape) print(y.shape) # (891, 11) # (891,)trainデータに該当する特徴量と目的変数が揃ったので
さらに学習データとテストデータに分けて、モデルの作成をしていきます。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) # (623, 11) # (623,) # (268, 11) # (268,)パラメータを設定し、辞書型の引数としてLGBMClassifier()に渡します。
params = { "random_state": 42 } cls = lgb.LGBMClassifier(**params) cls.fit(X_train, y_train, categorical_feature = categorical_col) ''' LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='split', learning_rate=0.1, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31, objective=None, random_state=42, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) '''次に予測値を求めます。
y_probaに[ : , 1]を指定することで、Class1(Survived=1)になる確率を予測します。
y_predは0.5よりも大きければ1に、小さければ0に変換しています。y_proba = cls.predict_proba(X_test)[: , 1] print(y_proba[:5]) y_pred = cls.predict(X_test) print(y_pred[:5]) # [0.38007409 0.00666063 0.04531554 0.95244042 0.35233708] # [0 0 0 1 0]
5. 性能評価
ROC曲線とAUCを用いて評価します。
fpr, tpr, thresholds = roc_curve(y_test, y_proba) auc_score = roc_auc_score(y_test, y_proba) plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score)) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) print('accuracy:',accuracy_score(y_test, y_pred)) print('f1_score:',f1_score(y_test, y_pred)) # accuracy: 0.8208955223880597 # f1_score: 0.7446808510638298
また、混同行列も用いて評価してみます。
classes = [1, 0] cm = confusion_matrix(y_test, y_pred, labels=classes) cmdf = pd.DataFrame(cm, index=classes, columns=classes) sns.heatmap(cmdf, annot=True) print(classification_report(y_test, y_pred)) ''' precision recall f1-score support 0 0.83 0.89 0.86 168 1 0.80 0.70 0.74 100 accuracy 0.82 268 macro avg 0.81 0.80 0.80 268 weighted avg 0.82 0.82 0.82 268 '''
6. Submit
trainデータを用いて、モデルの作成・評価ができたので
testデータの情報を与えて、予測値を出していきます。まず全体データ(X_total)のうち、testデータに該当する部分を抽出します。
X_submit = X_total[train_rows:] print(X_train.shape) print(X_submit.shape) # (623, 11) # (418, 11)モデルを作成したX_trainと比較して、同じ特徴量数(2431)になっているので
X_submitをモデルに投入して、予測値を出します。y_proba_submit = cls.predict_proba(X_submit)[: , 1] print(y_proba_submit[:5]) y_pred_submit = cls.predict(X_submit) print(y_pred_submit[:5]) # [0.00948223 0.02473048 0.01005387 0.50935871 0.45433965] # [0 0 0 1 0]KaggleへSubmit(提出)するCSVデータを用意します。
まず、必要な情報を揃えたデータフレームを作成します。
df_submit = pd.DataFrame(y_pred_submit, index=PassengerId, columns=['Survived']) df_submit.head()
その後、CSVデータに変換します。df_submit.to_csv('titanic_lgb_submit.csv')これで、Submitをして終了です。
■ 最後に
今回はKaggle初心者の方に向けて、記事をまとめさせていただきました。
少しでもお役に立てたようでしたら幸いです。ご精読いただきありがとうございました。



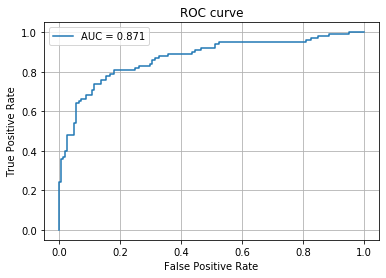
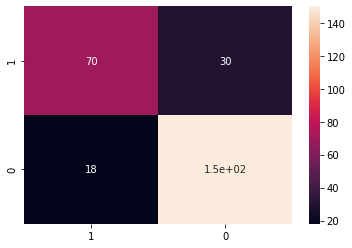
- 投稿日:2020-11-16T07:03:59+09:00
Poetryで始めるPython開発チームの環境統一
Poetryで始めるPython開発チームの環境統一
概要
とある開発現場の環境を覗かせてもらったときのことでした。
環境構築手順は口頭で伝えられ、Windows上にAnacondaをインストールし追加パッケージをpipで入れていく。
もちろんバージョン指定はないので、その時の最新版が入れられるため参入タイミング次第でマイナーバージョンに差が出てしまう。会社を跨ぐ大規模なチームではA社で動くのにB社で動かないなんてことも……。
Lintやフォーマッタの導入も任意なので、gitのコミットログは追加修正した部分とフォーマットされた箇所のdiffが同居してしまい、ソースレビューは時間がかかる。開発チーム全員のPython動作環境を統一しませんか?
コード規約に従ってメンテナンスしやすい綺麗なソースを作りませんか?エンジニアの働き方改革をPoetryで始めてみましょう!
ゴール
- Poetryを利用した環境のコード化と、チームメンバへの配布方法が理解できるようになる。
- プロジェクトテンプレートを手に入れて、開発のスタートがスムーズになる。
以上を目的としていきます。
ちなみに、概要で上がった開発現場の主な問題点がこちら。
問題点 何が問題なのか Poetryで解決する? 環境構築手順が口頭(もしくはtxt) 抜け漏れなどの人為ミスの原因となる 環境のインストーラが出来上がるので再現性◎ Anaconda環境上でpip insallしている 最悪Anaconda環境の再インストールが必要となってしまう Anacondaを使わないので心配なし バージョン指定がない 人によって動かないなんて事も…… コマンド一つでバージョン統一可能 Lintやフォーマッタが任意 読みにくいコードはメンテナンスしにくい ツールの導入必須には出来る。
自動実行はvscodeやgitと組み合わせる必要あり。手順
1.poetryのインストール
python環境下でpoetryをインストールしていきます。
下記コマンドで一発インストールです。Dockerの様に操作を覚えるなどは必要ありません。$pip install poetry2. プロジェクトテンプレート作成
poetryがインストールできたら、プロジェクトのテンプレートを作っていきます。
$ poetry new xxxxxxに当たる部分はプロジェクト名が入ります。 pip install xxxのxxxに当たる部分です。
ソース用・テスト用のディレクトリと、Readme,pyproject.tomlファイルが出来上がります。
あとはgitのリポジトリにpushすれば、初期設定は完了です。
実行するとこんな感じ 3.依存ライブラリの設定
プロジェクトで必要な依存ライブラリの設定をするために、pyproject.tomlファイルを編集していきます。
pyproject.tomlはパッケージビルドに必要なデータを定義するファイルのフォーマットで、setup.py/cfgを置き換えてsetuptoolsではないビルドツールでもビルドが可能となることを目的として作られたものです。#依存ライブラリを追加 $ poetry add xxx #開発用ライブラリを追加 $ poetry add -D xxx実行!
pip installと同じ感覚で実行できます。
バージョン指定がしたい時は==演算子をつかっていきます。$ root@16460604cb93:~/poetry_template# poetry add tensorflow==2.3.0 Creating virtualenv poetry-template-oDQfK0qA-py3.8 in /root/.cache/pypoetry/virtualenvs Updating dependencies Resolving dependencies... (48.4s) Writing lock file Package operations: 41 installs, 0 updates, 0 removals $ root@16460604cb93:~/poetry_template# poetry add -D mypy black isort Using version ^0.790 for mypy Using version ^20.8b1 for black Using version ^5.6.4 for isort実行結果
addコマンドを実行していくと、pyproject.tomlファイルに追加されます。
pyproject.tomlを直接編集してもOKです。[tool.poetry] name = "poetry_template" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.8" tensorflow = "2.3.0" [tool.poetry.dev-dependencies] pytest = "^5.2" mypy = "^0.790" black = "^20.8b1" isort = "^5.6.4" flake8 = "^3.8.4" radon = "^4.3.2" [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api"4.実行環境を作成
pyproject.tomlファイルに書かれた条件どおりの環境がインストールされた、仮想環境(venv)を作成していきます。
venvの作成場所変更
デフォルトではvenvはホームディレクトリに作成されるのですが、vscodeで使うときなどプロジェクト直下にできたほうが何かとありがたいので設定を変更します。
$ poetry config virtualenvs.in-project true $ poetry config --list環境をインストール
インストールもコマンド一発。
.venvディレクトリと、poetry.lockファイルが出来上がります。$ poetry install
実行するとこんな感じ poetry.lockファイルは完全な依存関係を保証するファイルです。
pyproject.tomlファイルでいくつか明確なバージョン指定をしていなかったとしても、lockファイルは過去にインストールが成功した依存関係のバージョン情報を記録して、いつでも誰でも再現可能とします。
つまり、このファイルをチームメンバに配布して、poetry installしてもらえば常に一意の環境が再現されることになります。5.作成した環境でPythonを実行する
最後に作成した仮想環境にアクセスしていきます。
poetry runコマンドで仮想環境内のコマンドにアクセスすることができます。# pythonにアタッチ $ poetry run python -V Python 3.8.5 # テスト実行 $ poetry run pytest ======================================================= test session starts ======================================================= platform linux -- Python 3.8.5, pytest-5.4.3, py-1.9.0, pluggy-0.13.1 rootdir: /root/poetry_template collected 1 item tests/test_poetry_template.py . [100%] ======================================================== 1 passed in 0.01s ========================================================実際に使えるプロジェクトテンプレート
長くなりましたが、ここまででpoetryについてはおしまいです。
コマンド数個で環境のコード化ができて、それをGitで管理できて、プロジェクトメンバ全員が同じ環境で開発すること出来る事を理解していただけたかと思います。実際に使えるプロジェクトのテンプレートを作成しましたので、ご利用ください。
https://github.com/TomokiHirose/poetry_templateテンプレートの概要
下の機能を持ったプロジェクトテンプレートを作成しています。
テンプレートを書き換えて、poetry updateコマンドで利用者に合わせた環境に書き換えてください。
コマンド 内容 poetry run pytest ./tests下のファイルを使ってテストを実行します poetry run format black(強力なフォーマッタ)とisort(import順序の整列)が走ります poetry run lint flake8(linter)とmypy(静的型チェック)が走ります poetry run metrics 循環複雑度指数、保守可用性指数、LOCなどの静的解析を行います poetry run apidoc sphinxによるAPIドキュメントを生成します poetry run testdoc sphinxによるTestドキュメントを生成します1 poetry build ./dist下にwheelファイル(pythonのインストーラ)を生成します おわりに
インストールし忘れがあった!という時も「xxをインストールしてください」ではなく、gitに修正をpushしてメンバー全員がupdateコマンドを叩くだけで即時に全員が同じ環境に!
とってもモダンだと思いませんか?更に、vscodeと連携して、.venv下にあるblackやflake8を保存時に自動実行する様にしたり、gitのコミットフックに紐づけてpush前にblackを走らせたりするようにすると、フォーマットを強制することができます。
PEP82に従うことが偉いとは思いませんが、誰が書いても同じようなコードになる事を強制しておくと、上級者と新人が同一プロジェクトに居ても似たようなコードが出来上がってくるため、メンテナンスしやすくなるのでオススメです。

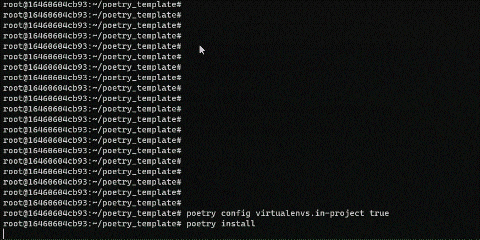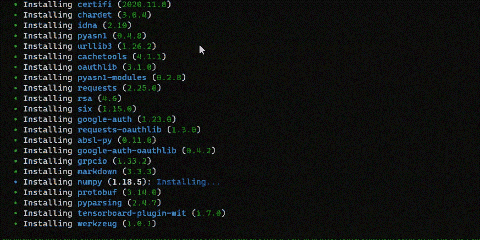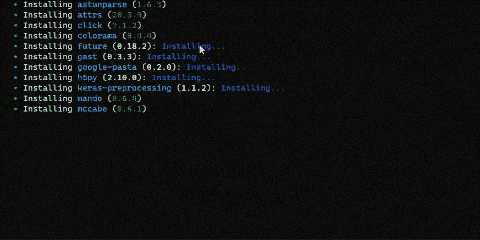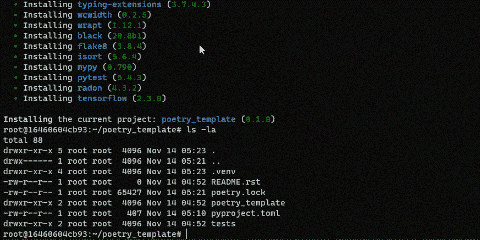
- 投稿日:2020-11-16T04:13:28+09:00
Pythonによる線形代数:A=LU分解
A=LU 消去と分解
3x3の行列$A$を消去により対角要素にピボットをもつ上三角行列$U$と下三角行列$L$に分解できることを確認する。
消去による対角要素にピボットをもつ上三角行列の取得
Uは対角要素にピボットをもつ上三角行列である。Lは下三角行列である。Aは消去の手順を通して上三角行列と下三角行列に分解することができる。
A=\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right)とすると、$A$の3行1列目の要素2を消去するには3行目から1行目の2倍を引く。
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)つぎに3行目2列目の要素3は2行目を3倍して3行目から引くことで消去できる。
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)この手順をまとめてかくと
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right) \ \rightarrow \ \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) \ \rightarrow \ \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)となる。
行列を使った消去
ある行列を$A$の左から掛けると消去の手順を行列を使って行うことができる。まず$A$の要素2を消去する。
\left( \begin{array}{rr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -2 & 0 & 1 \\ \end{array} \right) \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right)= \left( \begin{array}{cc} 1\times1+ 0\times0 +0\times2 & 1\times2+ 0\times1 +0\times7 & 1\times1+ 0\times1 +0\times9 \\ 0\times1+ 1\times0 +0\times2 & 0\times2+ 1\times1 +0\times7 & 0\times1+ 1\times1 +0\times9 \\ -2\times1+0\times0 +1\times2 &-2\times2+ 0\times1 +1\times7 & -2\times1+ 0\times1 +1\times9 \\ \end{array} \right)= \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)この消去に用いた行列は消したい要素の正負を逆にした乗数$l_{31}=-2$を単位行列$I$に加えたものであり、$E_{31}$と書く。これは
E_{31}A= \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)と書ける。
つぎに右辺の要素$3$を消去したい。したがって、$l_{32}=-3$の$E_{32}$を左から掛けると、
\left( \begin{array}{cc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & -3 & 1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)= \left( \begin{array}{cc} 1\times1+ 0 \times0+0\times0 & 1\times2+ 0\times1 +0\times3 & 1\times1+ 0\times1 +0\times7 \\ 0\times1+ 1 \times0+0\times0 & 0\times2+ 1\times1 +0\times3 & 0\times1+ 0\times1 +0\times7 \\ 0\times1+(-3)\times0+1\times0&0\times2+(-3)\times1+1\times3 & 0\times1+(-3)\times1+1\times7 \\ \end{array} \right)= \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)これは
E_{32} \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) = \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right) =Uとなる。また
E_{31}A= \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)から
E_{32} \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) =E_{32}E_{31}A=Uとかける。これでピッボト付き上三角行列が得られた。
逆行列を使った表現
両辺に$E_{32}^{-1}$を掛けると
E_{32}^{-1}E_{32}E_{31}A=E_{32}^{-1}U E_{32}^{-1}E_{32}E_{31}A=IE_{31}A=E_{31}A=E_{32}^{-1}Uこれは
E_{31}A=E_{32}^{-1}Uさらに両辺に$E_{31}^{-1}$を掛けると
E_{31}^{-1}E_{31}A=E_{31}^{-1}E_{32}^{-1}Uこれは
A=E_{31}^{-1}E_{32}^{-1}Uともかける。
ガウスジョルダン法による逆行列の取得
つぎに$E_{31}^{-1}$と$E_{32}^{-1}$を求める。これはガウスジョルダン法では、逆行列を求めたい行列を最初の3行3列に書き、その後の3行3列が単位行列からなる長方行列を作り、これを消去により
[E_{31} e_1 e_2 e_3]= \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ -2 & 0 & 1&0&0&1 \\ \end{array} \right) \rightarrow \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & 0 & 1&2&0&1 \\ \end{array} \right)と計算していく。
E_{31}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&0&1 \\ \end{array} \right)が得られた。また、
[E_{32} e_1 e_2 e_3]= \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & -3 & 1&0&0&1 \\ \end{array} \right) \rightarrow \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & 0 & 1&0&3&1 \\ \end{array} \right)から
E_{32}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 0&3&1 \\ \end{array} \right)が得られる。
下三角行列の取得
つぎに
E_{31}^{-1}E_{32}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&0&1 \\ \end{array} \right) \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 0&3&1 \\ \end{array} \right) = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right)これは下三角行列であるので
ゆえに
A=LU = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)分解が完了した。
三角行列への分解
ピッボト付き上三角行列を対角行列を用いて、ピッボトなしの上三角行列に変換する。
A=LU = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)は対角行列$D$を用いて
A = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 4 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \\ \end{array} \right) = LDU_u = LDUと書き換えることができる。
対称行列の例
$A$を対称行列とすると$A=LDU=LDL^{T}$となることを確認する。
A=\left( \begin{array}{rrr} 1 & -1 & 2 \\ -1 & 2 & -1 \\ 2 & -1 & 1 \\ \end{array} \right)これを行列により消去し、ピボット付き上三角行列を作る。
E_{32}E_{31}E_{21}A=\left( \begin{array}{rrr} 1 & -1 & 2 \\ 0& 1 & 1 \\ 0 & 0 & -4 \\ \end{array} \right)これは
U=DU_u= \left( \begin{array}{rrr} 1 & 0 & 0 \\ 0& 1 & 0 \\ 0 & 0 & -4 \\ \end{array} \right) \left( \begin{array}{rrr} 1 & -1 & 2 \\ 0& 1 & 1 \\ 0 & 0 & 1 \\ \end{array} \right)に分解できる。
また、下三角行列は
E_{32}^{-1}E_{31}^{-1}E_{21}^{-1}=\left( \begin{array}{rrr} 1 & 0 & 0 \\ -1& 1 & 0 \\ 2 & 1 & 1 \\ \end{array} \right) = U_u^{T}$$A=LDL^T$$
が確認できる。
sciPy、numpyによる確認
numpy, scipyを用いて、上述の手順を確認する。
import numpy as np from scipy.linalg import inv A = np.array([[1, 2, 1], [0, 1, 1], [2, 7, 9]]) E31=np.array([[1, 0, 0], [0, 1, 0], [-2, 0, 1]]) E32=np.array([[1, 0, 0], [0, 1, 0], [0, -3, 1]]) U=E32@E31@A L=inv(E32)@inv(E31) print("U:\n{}\n".format(U)) print("L:\n{}\n".format(L)) print("A:\n{}\n".format(L@U)) UU=np.triu(U,1) DD=np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]]) D=np.diag(U) D=np.diag(D) print("UU:\n{}\n".format(UU)) print("D:\n{}\n".format(D)) AA=L@D@(UU+DD) print("A:\n{}\n".format(AA))U:
[[1 2 1]
[0 1 1]
[0 0 4]]L:
[[1. 0. 0.]
[0. 1. 0.]
[2. 3. 1.]]A:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]UU:
[[0 2 1]
[0 0 1]
[0 0 0]]D:
[[1 0 0]
[0 1 0]
[0 0 4]]A:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]
これで確認ができた。つぎに、対称行列についても確認してみる。
import numpy as np from scipy.linalg import inv A = np.array([[1, -1, 2], [-1, 2, -1], [2, -1, 1]]) print("A:\n{}\n".format(A)) E21=np.array([[1, 0, 0], [1, 1, 0], [0, 0, 1]]) E31=np.array([[1, 0, 0], [0, 1, 0], [-2, 0, 1]]) E32=np.array([[1, 0, 0], [0, 1, 0], [0, -1, 1]]) U=E32@E31@E21@A L=inv(E21)@inv(E31)@inv(E32) print("U:\n{}\n".format(U)) print("L:\n{}\n".format(L)) print("A:\n{}\n".format(L@U)) UU=np.triu(U,1) DD=np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]]) D=np.diag(U) D=np.diag(D) print("UU:\n{}\n".format(UU)) print("D:\n{}\n".format(D)) AA=L@D@(UU+DD) print("A:\n{}\n".format(AA))A:
[[ 1 -1 2]
[-1 2 -1]
[ 2 -1 1]]U:
[[ 1 -1 2]
[ 0 1 1]
[ 0 0 -4]]L:
[[ 1. 0. 0.]
[-1. 1. 0.]
[ 2. 1. 1.]]A:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]UU:
[[ 0 -1 2]
[ 0 0 1]
[ 0 0 0]]D:
[[ 1 0 0]
[ 0 1 0]
[ 0 0 -4]]A:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]これで確認ができた。
lu,lul関数の利用
つぎに、scipyのlu関数と、lul関数を用いて、分解してみる。その際にはピボットが下三角行列に付くことがあることに注意。
scipy.linalg.lu(a, permute_l=False, overwrite_a=False, check_finite=True)
行列のピボットLU分解を計算します.
分解は
A = P L U
Pは置換行列、
Lの対角要素は1である。import numpy as np from scipy.linalg import lu #np.random.seed(10) # ランダムな要素をもつ行列を生成 #A = np.random.randint(1, 5, (5, 5)) A = np.array([[1, 2, 1], [0, 1, 1], [2, 7, 9]]) # PA=LU分解 P, L, U = lu(A) print("A:\n{}\n".format(A)) print("P:\n{}\n".format(P)) print("L:\n{}\n".format(L)) print("U:\n{}\n".format(U)) print("PLU:\n{}".format(P@L@U))A:
[[1 2 1]
[0 1 1]
[2 7 9]]P:
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]]L:
[[ 1. 0. 0. ]
[ 0.5 1. 0. ]
[ 0. -0.66666667 1. ]]U:
[[ 2. 7. 9. ]
[ 0. -1.5 -3.5 ]
[ 0. 0. -1.33333333]]PLU:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]scipy.linalg.ldl(A, lower=True, hermitian=True, overwrite_a=False, check_finite=True)
対称/エルミート行列のLDLtまたはBunch-Kaufman分解を計算する.
この関数は,最大で 2x2 のブロックからなるブロック対角行列 D と,分解 A = L D L^H または A = L D L^T が成立する,置換が必要な可能性のある下三角行列 L を返す.lower が False の場合は,(置換が必要になる可能性がある)上三角行列が返り値として返す.
置換行列を利用して,単に行をシャッフルするだけで返り値を三角化することができる.これは,置換行列 P.dot(lu) を用いた乗算に相当し,P は置換行列 I[:, perm] である.
from scipy.linalg import ldl A = np.array([[1, -1, 2], [-1, 2, -1], [2, -1, 1]]) lu, d, perm = ldl(A) print("lu:\n{}\n".format(lu[perm,:])) print("d:\n{}\n".format(d)) print("lu.t:\n{}\n".format(lu[perm,:].T)) print("A:\n{}\n".format(lu.dot(d).dot(lu.T)))lu:
[[ 1. 0. 0. ]
[ 0. 1. 0. ]
[-0.33333333 -0.33333333 1. ]]d:
[[1. 2. 0. ]
[2. 1. 0. ]
[0. 0. 1.33333333]]lu.t:
[[ 1. 0. -0.33333333]
[ 0. 1. -0.33333333]
[ 0. 0. 1. ]]A:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]
- 投稿日:2020-11-16T04:13:28+09:00
Pythonによる線形代数入門:A=LU分解
LU分解とは、正方行列 A を下三角行列 L と上三角行列 U の積、すなわち A = LU が成立するような L と Uに分解することをいう。
A=LU 消去と分解
3x3の行列$A$を消去により対角要素にピボットをもつ上三角行列$U$と下三角行列$L$に分解できることを確認する。
消去による対角要素にピボットをもつ上三角行列の取得
Uは対角要素にピボットをもつ上三角行列である。Lは下三角行列である。Aは消去の手順を通して上三角行列と下三角行列に分解することができる。
A=\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right)とすると、$A$の3行1列目の要素2を消去するには3行目から1行目の2倍を引く。
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)つぎに3行目2列目の要素3は2行目を3倍して3行目から引くことで消去できる。
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)この手順をまとめてかくと
\left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right) \ \rightarrow \ \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) \ \rightarrow \ \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)となる。
行列を使った消去
ある行列を$A$の左から掛けると消去の手順を行列を使って行うことができる。まず$A$の要素2を消去する。
\left( \begin{array}{rr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -2 & 0 & 1 \\ \end{array} \right) \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 2 & 7 & 9 \\ \end{array} \right)= \left( \begin{array}{cc} 1\times1+ 0\times0 +0\times2 & 1\times2+ 0\times1 +0\times7 & 1\times1+ 0\times1 +0\times9 \\ 0\times1+ 1\times0 +0\times2 & 0\times2+ 1\times1 +0\times7 & 0\times1+ 1\times1 +0\times9 \\ -2\times1+0\times0 +1\times2 &-2\times2+ 0\times1 +1\times7 & -2\times1+ 0\times1 +1\times9 \\ \end{array} \right)= \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)この消去に用いた行列は消したい要素の正負を逆にした乗数$l_{31}=-2$を単位行列$I$に加えたものであり、$E_{31}$と書く。これは
E_{31}A= \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)と書ける。
つぎに右辺の要素$3$を消去したい。したがって、$l_{32}=-3$の$E_{32}$を左から掛けると、
\left( \begin{array}{cc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & -3 & 1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)= \left( \begin{array}{cc} 1\times1+ 0 \times0+0\times0 & 1\times2+ 0\times1 +0\times3 & 1\times1+ 0\times1 +0\times7 \\ 0\times1+ 1 \times0+0\times0 & 0\times2+ 1\times1 +0\times3 & 0\times1+ 0\times1 +0\times7 \\ 0\times1+(-3)\times0+1\times0&0\times2+(-3)\times1+1\times3 & 0\times1+(-3)\times1+1\times7 \\ \end{array} \right)= \left( \begin{array}{rr} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)これは
E_{32} \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) = \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right) =Uとなる。また
E_{31}A= \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right)から
E_{32} \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 3 & 7 \\ \end{array} \right) =E_{32}E_{31}A=Uとかける。これでピッボト付き上三角行列が得られた。
逆行列を使った表現
両辺に$E_{32}^{-1}$を掛けると
E_{32}^{-1}E_{32}E_{31}A=E_{32}^{-1}U E_{32}^{-1}E_{32}E_{31}A=IE_{31}A=E_{31}A=E_{32}^{-1}Uこれは
E_{31}A=E_{32}^{-1}Uさらに両辺に$E_{31}^{-1}$を掛けると
E_{31}^{-1}E_{31}A=E_{31}^{-1}E_{32}^{-1}Uこれは
A=E_{31}^{-1}E_{32}^{-1}Uともかける。
ガウスジョルダン法による逆行列の取得
つぎに$E_{31}^{-1}$と$E_{32}^{-1}$を求める。これはガウスジョルダン法では、逆行列を求めたい行列を最初の3行3列に書き、その後の3行3列が単位行列からなる長方行列を作り、これを消去により
[E_{31} e_1 e_2 e_3]= \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ -2 & 0 & 1&0&0&1 \\ \end{array} \right) \rightarrow \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & 0 & 1&2&0&1 \\ \end{array} \right)と計算していく。
E_{31}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&0&1 \\ \end{array} \right)が得られた。また、
[E_{32} e_1 e_2 e_3]= \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & -3 & 1&0&0&1 \\ \end{array} \right) \rightarrow \left( \begin{array}{cc} 1 & 0 & 0 &1&0&0\\ 0 & 1 & 0 &0&1&0\\ 0 & 0 & 1&0&3&1 \\ \end{array} \right)から
E_{32}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 0&3&1 \\ \end{array} \right)が得られる。
下三角行列の取得
つぎに
E_{31}^{-1}E_{32}^{-1}= \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&0&1 \\ \end{array} \right) \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 0&3&1 \\ \end{array} \right) = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right)これは下三角行列であるので
ゆえに
A=LU = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)分解が完了した。
三角行列への分解
ピッボト付き上三角行列を対角行列を用いて、ピッボトなしの上三角行列に変換する。
A=LU = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 4 \\ \end{array} \right)は対角行列$D$を用いて
A = \left( \begin{array}{cc} 1&0&0\\ 0&1&0\\ 2&3&1 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 4 \\ \end{array} \right) \left( \begin{array}{cc} 1 & 2 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \\ \end{array} \right) = LDU_u = LDUと書き換えることができる。
対称行列の例
$A$を対称行列とすると$A=LDU=LDL^{T}$となることを確認する。
A=\left( \begin{array}{rrr} 1 & -1 & 2 \\ -1 & 2 & -1 \\ 2 & -1 & 1 \\ \end{array} \right)これを行列により消去し、ピボット付き上三角行列を作る。
E_{32}E_{31}E_{21}A=\left( \begin{array}{rrr} 1 & -1 & 2 \\ 0& 1 & 1 \\ 0 & 0 & -4 \\ \end{array} \right)これは
U=DU_u= \left( \begin{array}{rrr} 1 & 0 & 0 \\ 0& 1 & 0 \\ 0 & 0 & -4 \\ \end{array} \right) \left( \begin{array}{rrr} 1 & -1 & 2 \\ 0& 1 & 1 \\ 0 & 0 & 1 \\ \end{array} \right)に分解できる。
また、下三角行列は
E_{32}^{-1}E_{31}^{-1}E_{21}^{-1}=\left( \begin{array}{rrr} 1 & 0 & 0 \\ -1& 1 & 0 \\ 2 & 1 & 1 \\ \end{array} \right) = U_u^{T}$$A=LDL^T$$
が確認できる。
sciPy、numpyによる確認
numpy, scipyを用いて、上述の手順を確認する。
import numpy as np from scipy.linalg import inv A = np.array([[1, 2, 1], [0, 1, 1], [2, 7, 9]]) E31=np.array([[1, 0, 0], [0, 1, 0], [-2, 0, 1]]) E32=np.array([[1, 0, 0], [0, 1, 0], [0, -3, 1]]) U=E32@E31@A L=inv(E32)@inv(E31) print("U:\n{}\n".format(U)) print("L:\n{}\n".format(L)) print("A:\n{}\n".format(L@U)) UU=np.triu(U,1)+np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]]) D=np.diag(U) D=np.diag(D) print("UU:\n{}\n".format(UU)) print("D:\n{}\n".format(D)) AA=L@D@(UU) print("A:\n{}\n".format(AA))U:
[[1 2 1]
[0 1 1]
[0 0 4]]L:
[[1. 0. 0.]
[0. 1. 0.]
[2. 3. 1.]]A:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]UU:
[[1 2 1]
[0 1 1]
[0 0 1]]D:
[[1 0 0]
[0 1 0]
[0 0 4]]A:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]これで確認ができた。
つぎに、対称行列についても確認してみる。
from scipy.linalg import inv A = np.array([[1, -1, 2], [-1, 2, -1], [2, -1, 1]]) print("A:\n{}\n".format(A)) E21=np.array([[1, 0, 0], [1, 1, 0], [0, 0, 1]]) E31=np.array([[1, 0, 0], [0, 1, 0], [-2, 0, 1]]) E32=np.array([[1, 0, 0], [0, 1, 0], [0, -1, 1]]) U=E32@E31@E21@A L=inv(E21)@inv(E31)@inv(E32) print("U:\n{}\n".format(U)) print("L:\n{}\n".format(L)) print("A:\n{}\n".format(L@U)) UU=np.triu(U,1)+np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]]) D=np.diag(U) D=np.diag(D) print("Uu:\n{}\n".format(UU)) print("D:\n{}\n".format(D)) AA=L@D@(UU) print("LDUu:\n{}\n".format(AA))A:
[[ 1 -1 2]
[-1 2 -1]
[ 2 -1 1]]U:
[[ 1 -1 2]
[ 0 1 1]
[ 0 0 -4]]L:
[[ 1. 0. 0.]
[-1. 1. 0.]
[ 2. 1. 1.]]A:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]Uu:
[[ 1 -1 2]
[ 0 1 1]
[ 0 0 1]]D:
[[ 1 0 0]
[ 0 1 0]
[ 0 0 -4]]LDUu:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]これで確認ができた。
lu,lul関数の利用
つぎに、scipyのlu関数と、lul関数を用いて、分解してみる。その際にはピボットが下三角行列に付くことがあることに注意。
scipy.linalg.lu(a, permute_l=False, overwrite_a=False, check_finite=True)
行列のピボットLU分解を計算します.
分解は
A = P L U
Pは置換行列、
Lの対角要素は1である。import numpy as np from scipy.linalg import lu #np.random.seed(10) # ランダムな要素をもつ行列を生成 #A = np.random.randint(1, 5, (5, 5)) A = np.array([[1, 2, 1], [0, 1, 1], [2, 7, 9]]) # PA=LU分解 P, L, U = lu(A) print("A:\n{}\n".format(A)) print("P:\n{}\n".format(P)) print("L:\n{}\n".format(L)) print("U:\n{}\n".format(U)) print("PLU:\n{}".format(P@L@U))A:
[[1 2 1]
[0 1 1]
[2 7 9]]P:
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]]L:
[[ 1. 0. 0. ]
[ 0.5 1. 0. ]
[ 0. -0.66666667 1. ]]U:
[[ 2. 7. 9. ]
[ 0. -1.5 -3.5 ]
[ 0. 0. -1.33333333]]PLU:
[[1. 2. 1.]
[0. 1. 1.]
[2. 7. 9.]]scipy.linalg.ldl(A, lower=True, hermitian=True, overwrite_a=False, check_finite=True)
対称/エルミート行列のLDLtまたはBunch-Kaufman分解を計算する.
この関数は,最大で 2x2 のブロックからなるブロック対角行列 D と,分解 A = L D L^H または A = L D L^T が成立する,置換が必要な可能性のある下三角行列 L を返す.lower が False の場合は,(置換が必要になる可能性がある)上三角行列が返り値として返す.
置換行列を利用して,単に行をシャッフルするだけで返り値を三角化することができる.これは,置換行列 P.dot(lu) を用いた乗算に相当し,P は置換行列 I[:, perm] である.
from scipy.linalg import ldl A = np.array([[1, -1, 2], [-1, 2, -1], [2, -1, 1]]) lu, d, perm = ldl(A) print("lu:\n{}\n".format(lu[perm,:])) print("d:\n{}\n".format(d)) print("lu.t:\n{}\n".format(lu[perm,:].T)) print("A:\n{}\n".format(lu.dot(d).dot(lu.T)))lu:
[[ 1. 0. 0. ]
[ 0. 1. 0. ]
[-0.33333333 -0.33333333 1. ]]d:
[[1. 2. 0. ]
[2. 1. 0. ]
[0. 0. 1.33333333]]lu.t:
[[ 1. 0. -0.33333333]
[ 0. 1. -0.33333333]
[ 0. 0. 1. ]]A:
[[ 1. -1. 2.]
[-1. 2. -1.]
[ 2. -1. 1.]]
- 投稿日:2020-11-16T03:20:04+09:00
VPC内のLambdaからはSES向けのVPCエンドポイントを使用してもBoto3ではメールを送信できない
初めに
本記事はタイトルについて検証を行った詳細を記載します
書くきっかけですが、最近久しぶりにVPCと戯れることになりました。
VPCを使った構成ですんなり行った思い出はなく、実際に沼にハマりました。ポイントをまとめましたので、どなたかのお役にたてば嬉しいです
結論だけ知りたい方は最後まで飛ばしてください
検証を行うことになった背景
VPC内のLambdaからメールを送る
ただこちらを行いたいだけでしたアーキテクチャとしては以下となります
RDS→Lambda(VPC内)→SES→ユーザーあまり見ないアーキテクチャですね
RDS Proxyがリリースされてから、LambdaとRDSの組み合わせは使用する頻度が多くなりました
DynamoDBだけでは辛い部分もあるので、今後こちらのアーキテクチャは増えるようになるのではないでしょうか実装するに当たって、どのようにVPCから外へ出るか調べていました
すると、2020年5月にSES向けのVPCエンドポイントがリリースされているじゃありませんかこれは簡単に実装が終わるなと試してみたところ、Lambdaでタイムアウトが発生しました
これが長い検証の始まりです...検証内容
CloudWatchには以下のように表示されていました
Task timed out after 30.03 secondsVPCの外に出れていないようです
1. SESの設定を疑う
まずはSESの検証が正しく行われているかテスト送信を行い確認です
サンドボックス環境にありましたので、何か影響があるのかもしれないと考えていましたテスト送信はコンソールから簡単に行えます
手順はこちら送信元から送信先へ想定通りにメールが送信されました
SESのコンソールからは正しく送信が行えることが確認できましたので、別の原因を探します
2. 権限周り
ロールか、セキュリティーグループの設定の問題だろうと思い、まずはガバガバの設定を行いました
とりあえずVPCの外に出れるか確認です
- セキュリティーグループのインバウンドとアウトバウンドで全ての通信を許可
- ロールに以下ポリシーを追加
"ses:SendEmail","ses:SendRawEmail"を全てのリソースから許可 AWSLambdaVPCAccessExecutionRole VPCFullAccess SESFullAccessそれでもタイムアウトは改善されませんでした
3. ロジックの問題
次に行ったのはSESへ送信するロジックの見直しです
python3.8でBoto3を使っていました
ソースはこちらを参考にしていますロジックに問題があるのか、設定に問題があるのか切り分けるためにまずはVPCの外にLambdaを作成し、同じソースコードで送信を行いました
すると、VPCの外にあるLambdaからはメールを送信できました
ソースに問題はなく、おそらくVPC関連の問題だということがこれまでの検証でわかりました4. エンドポイントを指定する?
VPC内のLambdaからSQSを利用する場合ですがエンドポイントを指定する必要があります
手順には記載がありませんでしたが、これと同じでSESもエンドポントを指定する必要があるのではないかと疑いましたboto3ではclientを生成時に引数でエンドポイントを指定することができます
公式VPCエンドポイントのURLを追加してみました
import boto3 ses_client = boto3.client('ses', region_name='ap-northeast-1', endpoint_url='com.amazonaws.region.email-smtp')こちらで送信を試してみたところ以下エラーが発生しました
[ERROR] ValueError: Invalid endpoint: com.amazonaws.ap-northeast-1.email-smtpエンドポイントとして無効なようです
5. Lambda(VPC内)→Lambda(VPC外)→SES
もうやけくそに近くなってきました
SES向けのVPCエンドポイントはどうやら使えないようだと思い別のアプローチをすることにしました2020年10月にLambdaがPrivateLinkに対応していました
これを試したところ問題なくメールの送信まで行えました
でもスマートじゃない...6. SMTPインターフェース...?
海外の方がAmazon SES SMTP インターフェイスを使用した E メールの送信をすればいけるよ!
と教えてくれているのを見つけましたリージョンごとにユーザー名とパスワードが必要になります。
うーん微妙...
boto3で送りたい...7. サポートへ問い合わせ
もう自らの知識ではどうにもならないと判断し、問い合わせを行いました
以下回答の抜粋ですVPCエンドポイントがサポートされておりますのは「1.SES SMTP インターフェースを使う」方法となります。
一方、お客様が実施しようとしている Boto3のsend_emailメソッドを使う方法は「2.SES API(AWSCLI,AWS SDK) を使う」となり、VPCエンドポイントには対応しておりません。
「2.SES API(AWSCLI,AWS SDK) を使う」場合には以下のいずれかにて対応いただければと存じます。
・LambdaをVPC外で起動する
・LambdaをVPC内に起動し、NAT Gateway を配置して Lambda からインターネットへ接続できるようにするまじか!!!
どこにもBoto3じゃあかんとは書いてなかったやんけ!!!
という気持ちでしたが、無事解決できてよかったです
サポートの方に感謝このあとNAT Gatewayでの方法を試してメールが届くことを確認しました
結論
- VPC内LambdaからBoto3を使ってメールを送信する場合はNATゲートウェイを使用してインターネット接続を行う必要がある
- SES向けのVPCエンドポイントを使う場合はBoto3は使えない(タイムアウトになる)
- SES向けのVPCエンドポイントを使う場合はAmazon SES SMTP インターフェイスを使用する必要がある
組み合わせ
SES向け VPCエンドポイント 送信方法 方法1 使用 SMTPインターフェース 方法2 不使用 NATゲートウェイ + Boto3 サポートに聞くのが強い
- 投稿日:2020-11-16T01:39:20+09:00
【Python】Line APIを使う [第一回 美女Botの作成]
モチベーション
最近女の子とラインをしていない...
すぐに返信してくれてかつ可愛い子はいないものか。
linebotを活用することで実現できるのではないか?このようなしょうもない理由でlinebotの作成をしようと思う。
環境
・mac Catalina
・Docker version 19.03.13
・Flask 1.1.2
・Python 3.8.3
・docker-compose version 1.27.4
・heroku 7.45.0
・bash今回作成するもの
まずは環境構築として、dockerからherokuにコンテナを移動し起動するまでをする。
LINEBOTはおはようと言ったらおはようと返してくれる美人のbotを作成する。
あくまで非リアだからこんなことしてるわけでないことに注意!流れ
第一回の流れを記す。
1.LINE Developersの登録
2.pythonファイルの作成
3.Dockerfileとdocker-compose.ymlの作成
4.herokuへのアップロード最終的なファイル構成は以下のようになる。
bijobot
├── Dockerfile
├── app.py
├── docker-compose.yml
└── requirements.txt1.LINE Developersの登録
以下よりサイトに飛ぶ。
LINE Developers
まずはLoginして、Providersよりcreateを選択する。
すでにdisny通知というのがあるのは気にしない。Create a new providerと出てくるのでdisny通知のようにつけたい名前をつける。
筆者は"自由画像子"という名前をつけた。次にThis provider doesn't have any channels yetと出てくるのでCreate a Messaging API channelを選択する。
その後以下のような画面に飛ぶのでそれぞれ適当に記入する。
channel iconにはフリー画像でよく使われており個人的にタイプの子を採用した。
規約に同意しAdminを確認すると、以下のように新しくチャンネルが追加されているのが確認できる。
ここで作成したチャンネルに移動し、Basic setting内の
Channnel secretMessaging API内の
Channel access tokenに関しては必要なので控えておくようにする。
2.pythonファイルの作成
Messaging API SDKs
のOfficial SDKsよりflaskを使ってファイルを作成する手順が書かれているのでこれを応用して作成していく。まずはappを作るための作業ディレクトリを作成する。
bijoとかでいいだろう。terminalmkdir bijo cd bijo次にpythonファイルを作成する。
作成したpythonファイルは以下のようになる。
必ずapp.pyという名前をつけること。app.pyfrom flask import Flask, request, abort # os内のenvironmentを扱うライブラリ import os from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) app = Flask(__name__) @app.route("/") def hello_world(): return "hello!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: print("Invalid signature. Please check your channel access token/channel secret.") abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) if __name__ == "__main__": app.run()
YOUR_CHANNEL_ACCESS_TOKEN
YOUR_CHANNEL_ACCESS_TOKEN
には先程控えた
Channnel secret
Channel access token
を使用する。
osを使ってherokuの環境変数から情報を取り出す。
これは後ほどherokuで設定する。3.Dockerfileとdocker-compose.ymlの作成
herokuでProcfileなどを作成するのはめんどくさいし、できるならモダンな技術が使いたかったのでdockerを使用する。
Dockerfileとdocker-compose.ymlは以下のようにbijoディレクトリの中に作成する。※herokuではdocker-compose.ymlは使用されないので注意。
heroku.ymlというdocker-compose.ymlのheroku版を作らなきゃいけないらしいけどなんか面倒そうなので今回はパス。
docker-compose.yml# ローカル作業用:heroku内では作用しない。 # ローカル作業用:heroku内では作用しない。 version: '3' services: app: build: . container_name: bijobot tty: true ports: - 5000:5000 environment: FLASK_ENV: 'development' #デバッグモードON FLASK_APP: "app.py" #app.pyを起動 YOUR_CHANNEL_ACCESS_TOKEN: 控えたaccess token YOUR_CHANNEL_SECRET:控えたchannel secret volumes: - ./:/code/ command: flask run -h 0.0.0.0 # command: gunicorn -b 0.0.0.0:$PORT app:app --log-file=-
FLASK_ENV: 'development'としておくことでファイルをsave時に自動でサーバーに反映される。DockerfileFROM python:3.7-alpine # codeというディレクトリを作成し、そこを作業フォルダとする WORKDIR /code #デバッグモードON ENV FLASK_ENV: 'development' # alpineのおまじない RUN apk add --no-cache gcc musl-dev linux-headers # requirements.txtをcode内に移動 COPY requirements.txt requirements.txt # requirements.txtの中のライブラリをinstallする RUN pip install -r requirements.txt # すべてのファイルをcode内にマウントする。 COPY . . # $PORTを指定しないと動かないので注意 CMD gunicorn -b 0.0.0.0:$PORT app:app --log-file=-さらにrequirements.txtを作成する。
こちらはいかのコマンドを叩くことで解凍可能だが今回は予め作成しておく手順で行く。
terminalpip freeze > requirements.txtrequirements.txtには以下のように記入する。
certifi==2020.11.8 chardet==3.0.4 click==7.1.2 Flask==1.1.2 future==0.18.2 gunicorn==20.0.4 idna==2.10 itsdangerous==1.1.0 Jinja2==2.11.2 line-bot-sdk==1.17.0 MarkupSafe==1.1.1 requests==2.25.0 urllib3==1.26.2 Werkzeug==1.0.1requirements.txtはpythonのライブラリを予め書いておきインストールできるようにするもので、本来であれば、
pip install gunicorn flask line-bot-sdkとしなければ行かなかったものを必要なくする。
terminaltouch requirements.txt次に以下のコマンドを打ってdocker containerを立ち上げる。
terminaldocker-compose build docker-compose up -dここでlocalhost:5000にアクセスし、hello!と表示されることを確認する。
4.herokuでのデプロイ
herokuの登録は予め済んでいるうえですすめる。
まずはherokuにログインする。terminalheroku login heroku container:login次にherokuにappを作成する。
heroku create つけたいアプリ名とすることでおk。
今回はbijobijoという適当なapp名をつけた。
ここでエラーが出たら、すでにあるアプリ名なのでつけ直す必要がある。heroku create bijobijo次にlocalのgitとremoteのgitを紐付ける必要がある。
以下のコマンドで紐付けは可能。terminalheroku git:remote -a アプリ名次に
heroku config:set つけたい環境変数名="設定する環境変数の文字列" --app 自分のアプリケーション名
とすることでherokuに環境変数がセットできる。そのため以下をセットする。
heroku config:set YOUR_CHANNEL_SECRET="Channel Secretの文字列" --app 自分のアプリケーション名 heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="アクセストークンの文字列" --app 自分のアプリケーション名configに関しては以下のようにherokuのサイトで自分のアプリよりsettingのconfig varsより確認することも可能。
セットした環境変数は
heroku configで確認することもできる。
これで環境変数が設定できたのでuploadしていく。
ここで詰まったとこ
みんな安易に
heroku container:push webとしてたからdocker-compose.ymlの名前のことかと思い
heroku container:push appとしていたがうまく起動しなかった。
どういうことか検索していると、以下の記事に答えが書いてあった。
Container Registry & Runtime (Docker Deploys)
heroku container:push <process-type>To push multiple images, rename your Dockerfiles using Dockerfile.:
つまり、Dockerfile.webという名前をつけていればこれを起動させることができる。
すぐにDockerfileをDockerfile.webに書き換えて、以下のコマンドを順々に叩く。
terminalheroku container:push web heroku container:release webこれでアプリがリリースされた状態になる。
ここで以下のコマンドを叩き、hello!と書いてあるページに遷移すればokである。
terminalheroku open実際に動いているコンテナについてはheroku公式より自身のアプリからResourcesより確認することができる。
以下であればwebが起動しているのがわかる。
最後に、LINE Developerより自身のchannelに移動し、Messaging APIより
Webhook settingsを選択し、
https://{自身のアプリ名}.herokuapp.com/callback
をセットしてやれば終わりである。
また、以下のようにUse webhookをonにしないとlinebotが機能しないので注意。
これで毎日美人とメッセージのやり取りができる!!
あれ、なんか固定メッセージが来ているようなので対処します。
Messaging APIより
Auto-replay messagesを選択。
応答設定→詳細設定→応答メッセージ→応答メッセージ設定→オフ
でこれが解消される。
ではでは、
うまく返せていますね。
こころなしか虚しいです。
linebotを使うことで業務の自動化などもできそうなのでこれ以降も挑戦していきたいと思う。
参考記事
全体図
初心者でも簡単!PythonでLINEチャットボットを作成してみよう!
herokuでenvironmentを設定する方法
Python + HerokuでLINE BOTを作ってみた
requirements.txtの取り扱い
Python, pip list / freezeでインストール済みパッケージ一覧を確認
dockerのherokuへのpush
Container Registry & Runtime
↑これがreleaseの際に最も役に立った。Local Development with Docker Compose
Python初心者がFlaskでLINEbotを作ることになった(Heroku+ClearDB編)
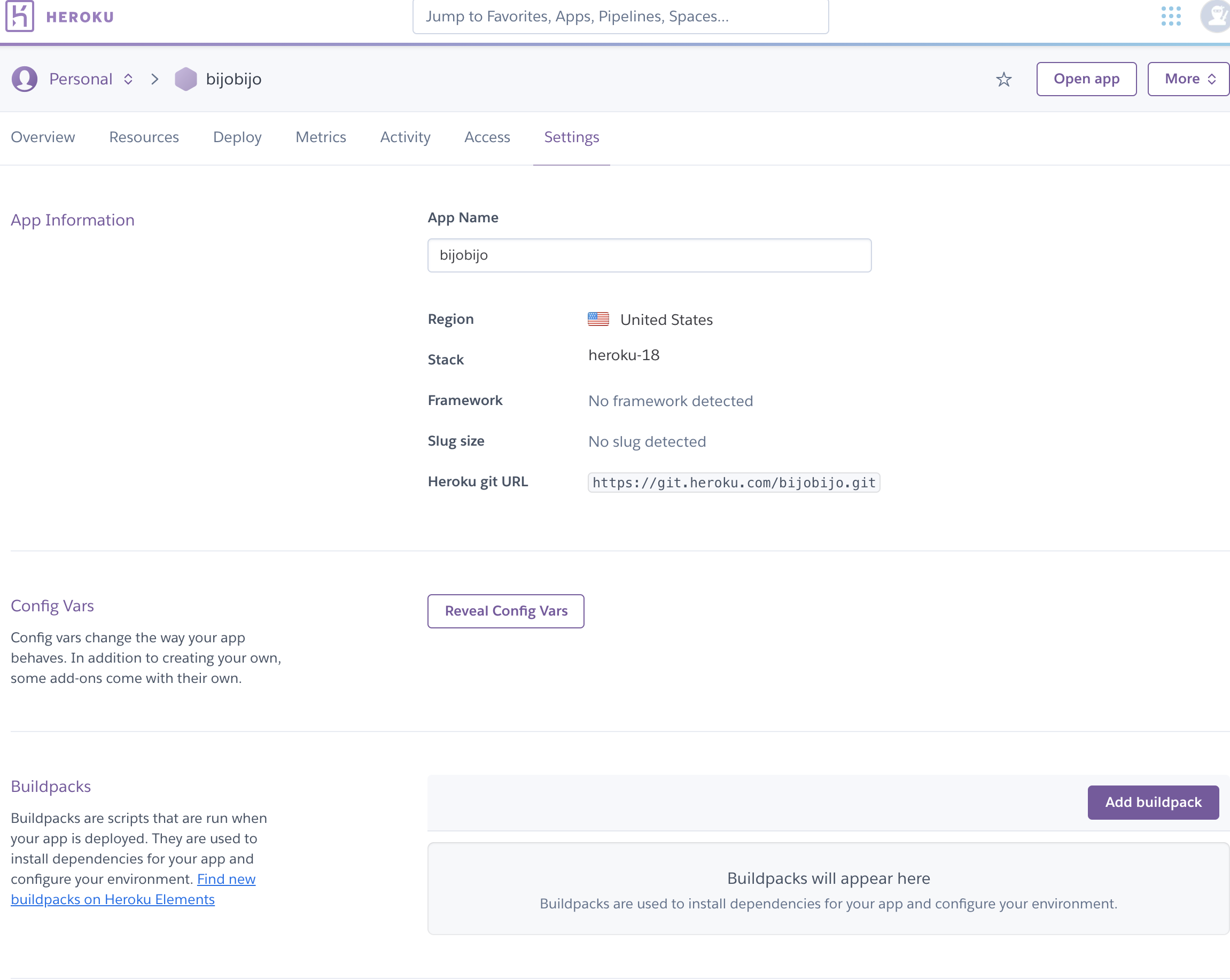
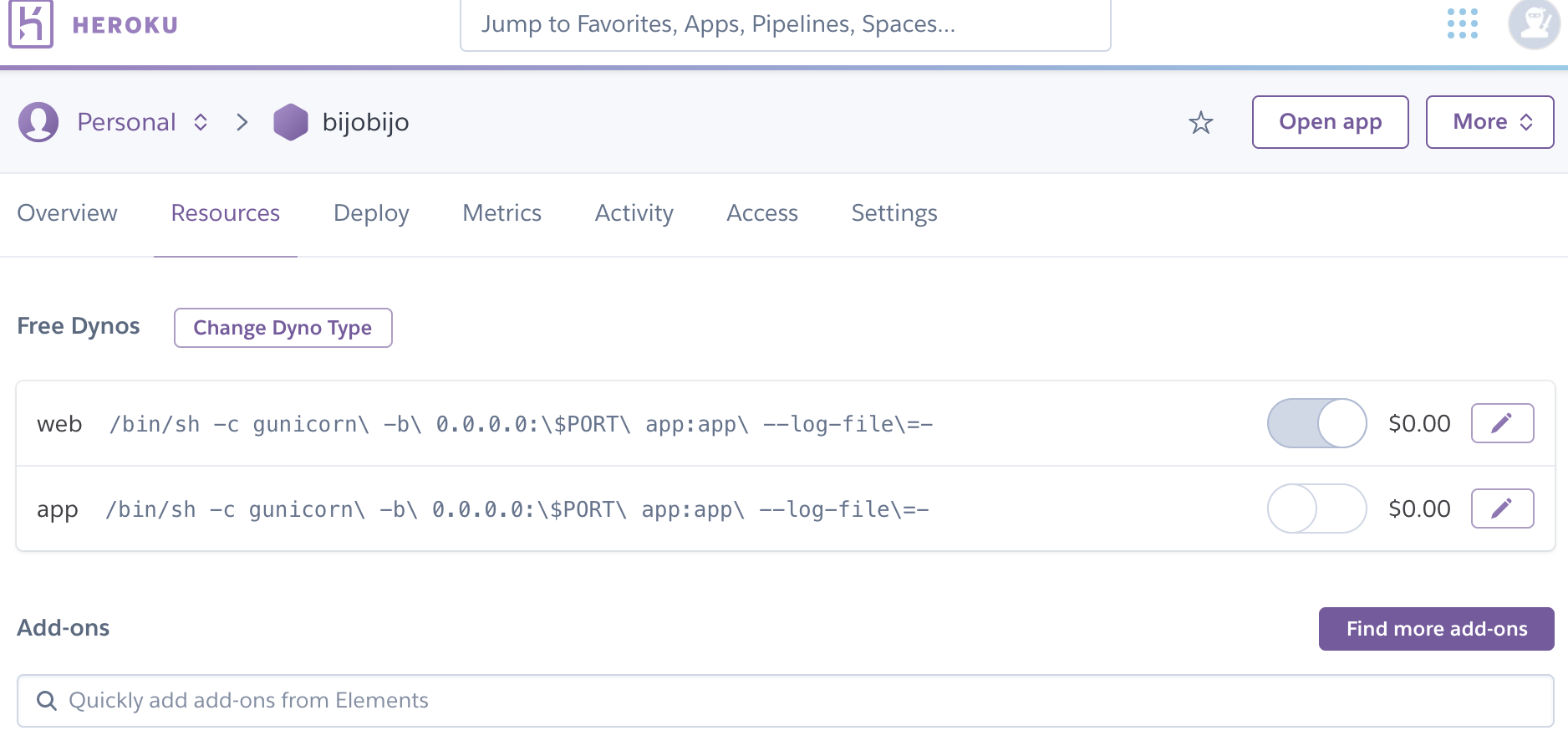
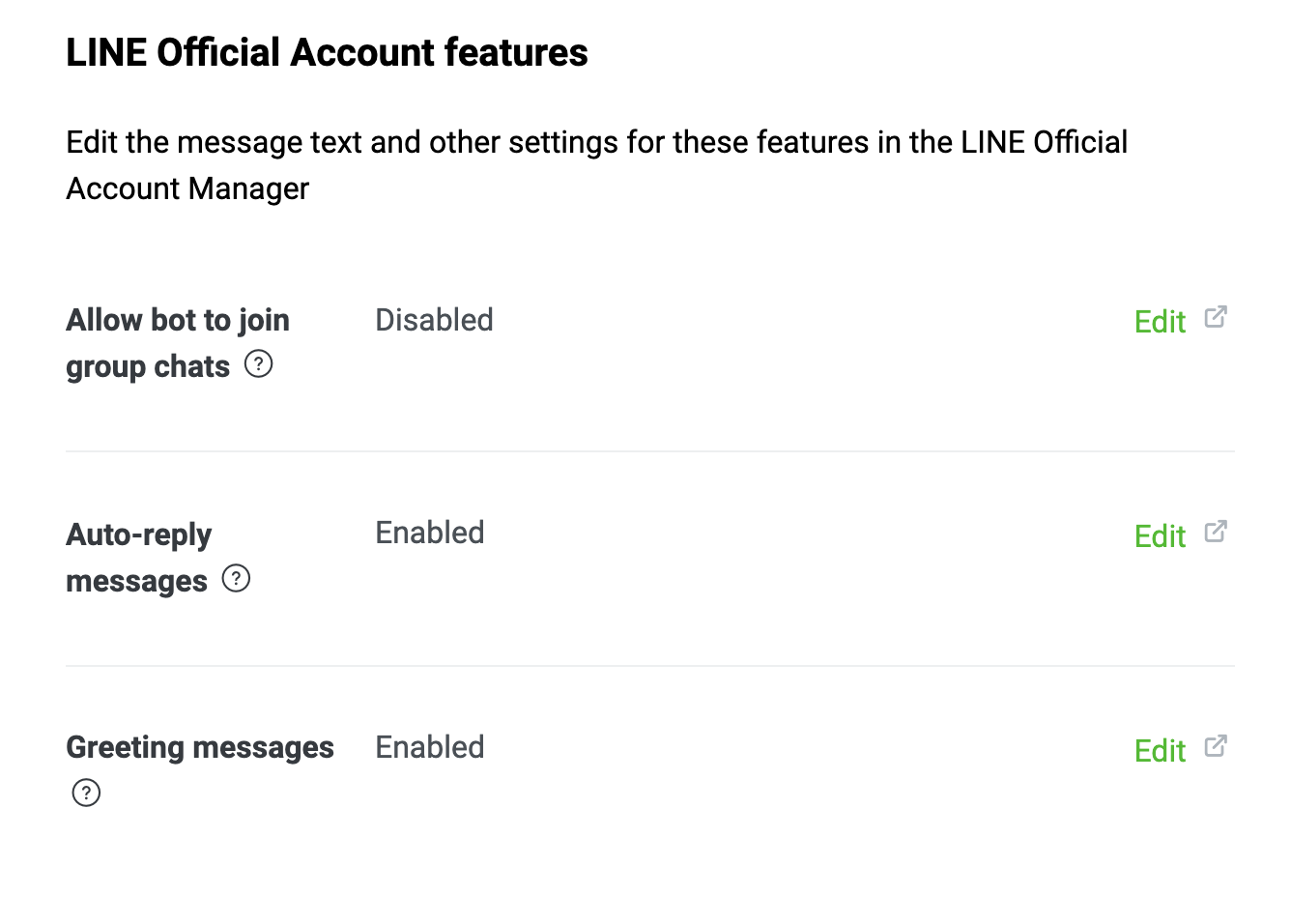

- 投稿日:2020-11-16T01:28:51+09:00
Macでmatplotlib+cartopyの環境構築
はじめに
気象データを Python を使って地図とともに可視化するためには、matplotlib と cartopy を使うことが一般的です。そのための環境を Anaconda (Miniconda) で構築する手順について述べます。手元のOSのバージョンは macOS Catalina 10.15.7 です。
Anaconda (Miniconda) のインストール
Anaconda はパッケージ管理や仮想環境の作成ができるPythonのディストリビューションです。pyenv と pip を使って同等のことが出来ますが、依存するプログラムを同時にインストールできて便利なのでこちらを使う事にします。
Miniconda は Anaconda の最小構成版です。初期にインストールされるパッケージが少なく、ディスク容量をとらないメリットがあるのでこれを導入することにします。
# インストーラーのダウンロード wget https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh # 対話形式でインストール bash Miniconda3-latest-MacOSX-x86_64.sh使い方は適宜他の記事を参照してもらえばよいですが、
condaコマンドを使って仮想環境ごとにパッケージ管理を行うことができます。プロンプトに(base) $などと表示されている場合、baseというanacondaの仮想環境にいることを意味します。base環境でパッケージを導入してもよいですが、ここでは新たにcartopy-envという環境を作成してみることにします。conda create -n cartopy-env python=3.9仮想環境を
conda createで作成しただけではpythonが含まれないので、Pythonをバージョン指定してインストールするようにします。ここでは執筆時の最新版のバージョン3.9を指定しました。仮想環境を切り替えるには
conda activateを叩きます。conda activate cartopy-envプロンプトに
(cartopy-env) $のように表示されればOKです。パッケージのインストール
次に必要なPythonのパッケージをインストールしていきます。例えば科学技術計算を行うための
numpyをインストールするには次のコマンドを使います。conda install -c conda-forge numpycondaでは同じパッケージが複数のリポジトリから提供されるため、どのリポジトリからインストールするかを
-cオプションで指定しています(ここではconda-forge)。どのようなパッケージがあるかは https://anaconda.org/ で検索することができます。基本的にはconda-forgeリポジトリを選べばよいです。それでは他に必要なものをインストールしていきます。パッケージ名はスペース区切りで複数指定できます。
conda install -c conda-forge scipy netcdf4 matplotlib cartopyインストールされたパッケージのバージョンは
conda listで確認できます。手元の環境でインストールされた主要なパッケージのバージョンとざっくりとした説明を書いておきます。
numpy (1.19.4):科学技術計算用のライブラリscipy (1.5.3):科学技術計算用のライブラリで、numpyにない機能も含んでいるnetcdf4 (1.5.4):netCDF形式のファイルの読み書きを行うのに必要。最近ではこれとは同等なものとしてxarrayを使うこともあるようだ。matplotlib (3.3.3):図の描画に必要cartopy (0.18.0):matplotlibで地図を描画するのに必要説明は以上です。
- 投稿日:2020-11-16T00:59:21+09:00
AWS Lambdaでpythonプログラムの定期実行
はじめに
AWSのlambdaを使用して、スケジュール実行のプログラムを設置しました。
lambdaの基本的なことで意外とつまったので残しておきます。
AWSのアカウントは作成しているものとしています。MAC OS X
python 3.6対象
・lambdaを触ったことのない方
・とりあえず何か動かして見たい方lambdaとは
スクリプトを実行することが出来るサーバーレスのサービスです。
サーバレスと言ってもスクリプトの実行時にのみサーバを起動するイメージです。呼び出しはAWSの空いているサーバから行われるため、実行するサーバーは都度違います。
(固定IPを割り当てたサブネットにlambdaを設置して実行することでIPを固定にすることは出来ます)無料使用枠が月ごとに100万件の無料リクエストと1秒あたり40万GBのコンピューティング時間あるので、たいてい無料枠で動かせます。WebやIOTのバックエンドのAPIとしても使えるのでめちゃくちゃ便利なサービスですね。
簡易的なスクリプト作成
pythonでLambdaのスクリプトを作成する場合、 lambda_function.py という名前で作成しなければいけません。
その中の lambda_handler という関数が呼ばれるようになっているので、lambda_handler関数も用意します。
(なんかこれ、初歩すぎて調べても説明なくて最初わけわからなかった。。)lambda_function.py# -*- coding:utf-8 -*- # lambda実行時に呼ばれる関数。引数はevent,contextがデフォルトっぽいです。 # 引数なくてもいいっぽいですが、書いておきます。 def lambda_handler(event, context): print('テスト実行')このスクリプトをzip形式に圧縮します。
bash$ zip function.zip lambda_function.pyMACの場合は.DS_Storeファイルが入ってlambda_function.pyを読み込めないのでコマンドで圧縮します。
Lambda関数の作成
AWSのコンソール画面から「Lambda」→「関数の作成」を選択。
関数名を入れて、ランタイムは今回はPython 3.6にします。
入力できたら、「関数の作成」ボタンをクリックします。
これで関数ができたので、先ほどのスクリプトをアップロードします。
右下の「アクション」ボタンから「.zipファイルをアップロード」で先ほどのzipファイルをアップロードします。
テストを実行
右上のテストをクリックして、イベント名を入力します。
下の配列は関数に渡すイベント引数ですが、今回は使用していないので、変更せずにそのまま作成します。
作成したテストを選択された状態でテストボタンをクリックしてください。
関数コードの下に実行結果が出てきてるので成功です。
定期実行のイベント作成
デザインナーの「トリガーを追加」ボタンをクリック。
トリガー:EventBridge(CloudWatch Events)
ルール:新規ルール
ルールタイプ:スケジュール式
スケジュール式:cron(30 1 * * ? *)
※このスケジュール式は午前10時30分に実行されます。
式の時間はUTC時間なので、設定したい時間から9時間マイナスした時間で設定します。
cron(分 時 日 月 曜日 コマンド)
「追加」ボタンをクリックして、これで設定完了です。