- 投稿日:2020-11-13T23:25:26+09:00
【OpenCV/Python】OpenCVで細胞の画像解析をやってみた
はじめに
仕事柄、細胞の画像を撮影することが多く、細胞画像をPython版OpenCVで解析してみた。
備忘録的な意味も込めて。
今回は、培養容器接着面を培養細胞が覆った割合(細胞占有面積率、あるいはコンフルエンシー)、いわゆる「細胞のコンフル」を求めてみる。
要するに、顕微鏡画像の中の細胞の占有率を、画像解析によって数値化する。
ご意見や、もっとこうしたほうがいいなどあればコメントお願いします。
使用する画像
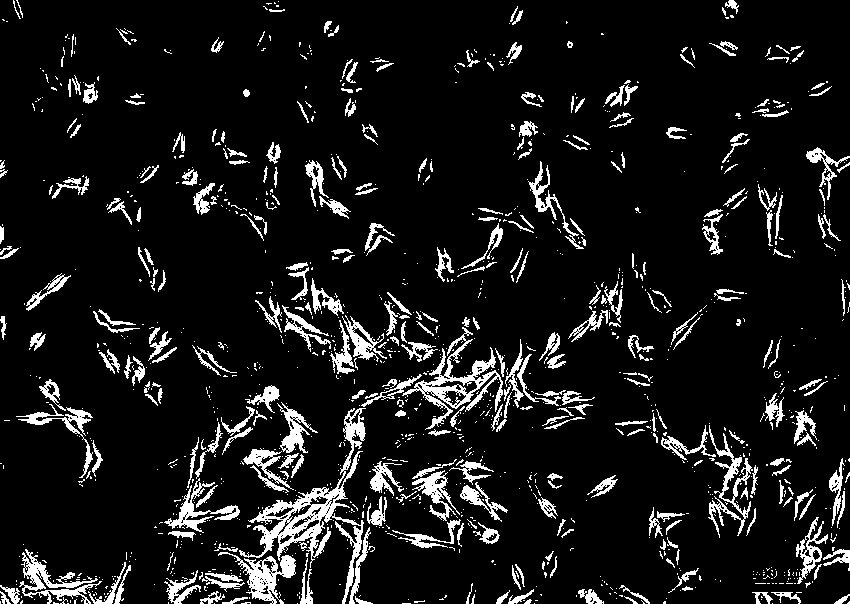
間葉系幹細胞(MSC)と呼ばれる細胞の顕微鏡写真。
ぱっと見、コンフル(画像中の細胞の占有率)は30~40%程度というところでしょうか。
必要なパッケージ
Pythonを使って画像解析するため、OpenCVライブラリを読み込む。
それと、NumPyも読み込んでおく。
# ライブラリ import cv2 import numpy as np画像の読み込みとグレースケール化
imread()関数で画像データをカラーで読み込んで、cvtColor()関数でグレースケール化する。
cvtColor()関数の第一引数は入力画像(カラー画像)。
imread()関数で取得したデータは BGR 形式なので、cv2.COLOR_BGR2GRAYを第2引数に指定する。# カラー画像の読み込み img = cv2.imread('cell.jpg', 1) # グレースケール化 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)画像を二値化する
画像を二値化する。
つまり、画素値がしきい値より大きければある値(白)を割り当て、そうでなければ別の値(黒)を割り当てる。
二値化には、いろいろな方法があるらしいが、「大津の二値化」というものを使ってみた。
二値化するにはthreshold()関数を使う。
threshold()関数の第1引数は入力画像でグレースケール画像でないといけない。
第2引数はしきい値で、画素値を識別するために使う。
第3引数は最大値でしきい値以上の値を持つ画素に対して割り当てられる値。
前述の通り、OpenCVはいくつかのしきい値処理の方法があり、第4引数にて指定する。
今回は「大津の二値化」を使うため、cv2.THRESH_BINARY+cv2.THRESH_OTSUとする。# 大津の二値化 ret,th = cv2.threshold(img_gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)threshold()関数は2つの戻り値を返す。
2つ目の戻り値thが、二値化画像となる。モルフォロジー変換(膨張)
画像のノイズを除去するためにモルフォロジー変換(膨張)を行う。
カーネルのサイズ(今回は5×5サイズ)に依存して物体の境界付近の全画素が黒(0)から白(1)になって消える。
カーネル内に画素値が ‘1’ の画素が一つでも含まれれば、出力画像の注目画素の画素値を ‘1’ になる。# カーネルの設定 kernel = np.ones((5,5),np.uint8) # モルフォロジー変換(膨張) th_dilation = cv2.dilate(th,kernel,iterations = 1)モルフォロジー変換前(th)
モルフォロジー変換後(th_dilation)
細胞内の黒い領域を白い領域に変換できた。
輪郭抽出
モルフォロジー変換によりノイズを除去した画像をもとに輪郭を抽出する。
輪郭を抽出するにはfindContours()関数を使う。
findContours()関数の第1引数は輪郭抽出に使う画像。
第2引数は抽出モード、第3引数は輪郭の近似方法を指定する。findContours()関数の戻り値である
contoursは各輪郭の座標データがNumpyのarray形式で収められている。
contoursを使って、drawContours()関数により元画像に輪郭を描画する。全輪郭を描画する時はdrawContours()関数の第3引数を
-1に指定する。# 輪郭抽出 contours, hierarchy = cv2.findContours(th_dilation, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) # 輪郭を元画像に描画 img_contour = cv2.drawContours(img, contours, -1, (0, 255, 0), 3)白黒面積の計算
.sizeで全体の画素数を取得する。countNonZero()関数で白領域、つまり細胞領域の画素数を取得する。
全体の画素数 - 白領域を計算し、黒領域(細胞以外の領域)の画素数を取得する。
最後にそれぞれの割合を表示する。
# 全体の画素数 whole_area = th_dilation.size # 白部分の画素数 white_area = cv2.countNonZero(th_dilation) # 黒部分の画素数 black_area = whole_area - white_area # それぞれの割合を表示 print('White_Area =' + str(white_area / whole_area * 100) + ' %') print('Black_Area =' + str(black_area / whole_area * 100) + ' %')結果
White_Area =26.266264121542658 % Black_Area =73.73373587845734 %細胞のコンフルは大体30%という結果となった。
画像の表示
最後に、輪郭を加えた元の画像と輪郭抽出に用いた画像を表示する。
# 画像の表示 cv2.imshow('img', img) cv2.imshow('th_dilation', th_dilation) cv2.waitKey(0) cv2.destroyAllWindows()結果
元画像+輪郭(img)
輪郭抽出に使った画像(th_dilation)
最終的なスクリプト
# ライブラリ import cv2 import numpy as np # カラー画像の読み込み img = cv2.imread('cell.jpg', 1) # グレースケール化 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 大津の二値化 ret,th = cv2.threshold(img_gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) # カーネルの設定 kernel = np.ones((5,5),np.uint8) # モルフォロジー変換(膨張) th_dilation = cv2.dilate(th,kernel,iterations = 1) # 輪郭抽出 contours, hierarchy = cv2.findContours(th_dilation, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) # 輪郭を元画像に描画 img_contour = cv2.drawContours(img, contours, -1, (0, 255, 0), 3) # 全体の画素数 whole_area = th_dilation.size # 白領域の画素数 white_area = cv2.countNonZero(th_dilation) # 黒領域の画素数 black_area = whole_area - white_area # それぞれの割合を表示 print('White_Area =' + str(white_area / whole_area * 100) + ' %') print('Black_Area =' + str(black_area / whole_area * 100) + ' %') # 画像の表示 cv2.imshow('img', img) cv2.imshow('th_dilation', th_dilation) cv2.waitKey(0) cv2.destroyAllWindows()




- 投稿日:2020-11-13T23:23:14+09:00
yukicoder contest 274 参戦記
yukicoder contest 274 参戦記
A 1285 ゴミ捨て
小さい順でも大きい順でもいいので一つづつ重ねれるかをチェックして行けばいいだけ.
from heapq import heappush, heapreplace N, *A = map(int, open(0).read().split()) A.sort() q = [A[0]] for a in A[1:]: if a <= q[0] + 1: heappush(q, a) else: heapreplace(q, a) print(len(q))B 1286 Stone Skipping
1回も跳ねないと x、1回跳ねると 3/2 * x、2回跳ねると 7/4 * x、3回跳ねると 15/8 * x、n回跳ねると (2n+1-1)/2n * x となる. D≦1018 なので60回も跳ねるとそれ以降は飛距離が伸びなくなる. なので、60回、59回、……、1回跳ねた場合の答えがあるかを調べていけば良い. 切り捨ての影響があるので、適当に前後±100くらいをチェックしたら AC した.
D = int(input()) def f(x): result = 0 while x != 0: result += x x //= 2 if result >= D: break return result for i in range(60, 0, -1): t = D * (2 ** (i - 1)) // (2 ** i - 1) for j in range(-100, 100): if t + j < 0: continue if f(t + j) == D: print(t + j) exit()
- 投稿日:2020-11-13T22:47:42+09:00
ALDA実行メモ
https://github.com/ZJULearning/ALDA
これを実行。データは下記。
https://github.com/notfolder/svhnsplitしたので、catで結合して使う。
pip freeze結果
asn1crypto==0.24.0 certifi==2018.1.18 chardet==3.0.4 cryptography==2.1.4 dataclasses==0.7 future==0.18.2 idna==2.6 imageio==2.1.2 keyring==10.6.0 keyrings.alt==3.0 numpy==1.14.6 Pillow==5.3.0 protobuf==3.13.0 pycrypto==2.6.1 pygobject==3.26.1 pyxdg==0.25 requests==2.18.4 SecretStorage==2.3.1 six==1.11.0 ssh-import-id==5.7 tensorboardX==1.4 torch==1.7.0 torchsummary==1.5.1 torchvision==0.8.1 tqdm==4.26.0 typing-extensions==3.7.4.3 urllib3==1.22Dockerfileはこれ。vscode-server.tgzは無くてよし
FROM nvidia/cuda:10.0-base-ubuntu18.04 # sshサーバをインストールします RUN apt-get update && apt-get install -y openssh-server # これが無いとsshdが起動しないっぽい RUN mkdir /var/run/sshd # sshのrootでのアクセスを許可します。ただし、パスワードでのアクセスは無効 RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin prohibit-password/' /etc/ssh/sshd_config # ホスト側にある公開鍵をイメージ側に登録します COPY id_rsa.pub /root/.ssh/authorized_keys # add sudo user RUN groupadd -g 1000 notfolder && \ useradd -g notfolder -G sudo -m -s /bin/bash notfolder RUN echo 'Defaults visiblepw' >> /etc/sudoers RUN echo 'notfolder ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers #COPY id_rsa.pub /home/notfolder/.ssh/authorized_keys RUN mkdir -p /home/notfolder/.ssh COPY id_rsa.pub /home/notfolder/.ssh/authorized_keys RUN chown 1000:1000 -R /home/notfolder RUN chmod 700 /home/notfolder/.ssh RUN apt-get update && apt-get install -y python3 && \ apt-get install -y python3-pip && \ update-alternatives --install /usr/bin/python python /usr/bin/python3 0 && \ update-alternatives --set python /usr/bin/python3 && \ update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 0 && \ update-alternatives --set pip /usr/bin/pip3 && \ pip install --upgrade pip COPY vscode-server.tgz /tmp/ RUN tar -zxf /tmp/vscode-server.tgz -C /home/notfolder/ COPY requirements.txt /tmp/ RUN pip install -r /tmp/requirements.txt EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"]nvidia-smiは下記。
$ nvidia-smi Fri Nov 13 22:46:44 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 GeForce RTX 2070 Off | 00000000:04:00.0 Off | N/A | | 29% 35C P0 20W / 175W | 0MiB / 7982MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
- 投稿日:2020-11-13T21:42:02+09:00
【1】UbuntuにAnacondaで構築するTensorFlow-GPU環境構築〜GPUスペック確認編〜
TensorFlowのGPU版(tensorflow-gpu)を動かすために必要なこととは?
- Deep Learningを行う計算力(compute capability)のある比較的新しいGPU(nVidia社製)を搭載していること?今ここ
- GPUの適切なドライバが入っていて、使用可能な状態になっていること
- tensorflow-gpuやGPUのドライバ(CUDA)、Deep Learning用のライブラリ(cuDNN)をインストールする環境を作るため、Anacondaがインストールされていること
- Pythonや必要なライブラリがバージョンの互換性を持っていること
この記事のゴール
tensorflow-gpuを動かすことができるGPUが搭載されているのかを確認し、これ以降のステップに進めるかどうかを判断する。
クリアするべき二つの条件
そのためには以下の二つの条件を満たしているかを確認していきます。
条件1: nVidia社製のGPUを搭載していること
条件2: コンピュータのGPUがTensorFlowの要求する計算力(compute capability)を満たすこと条件1の確認手順
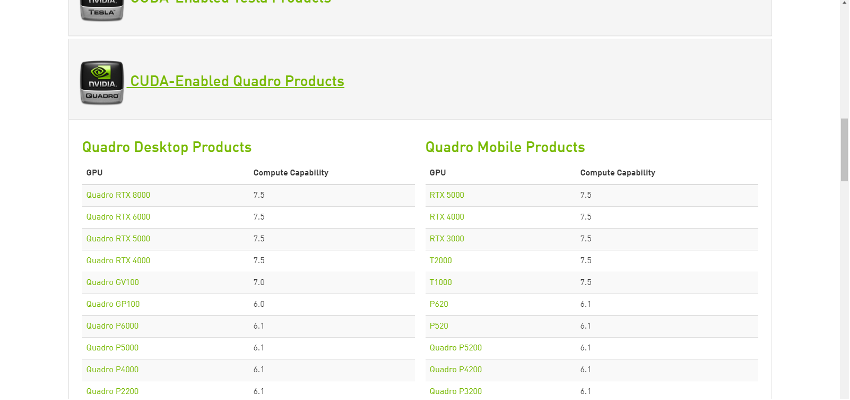
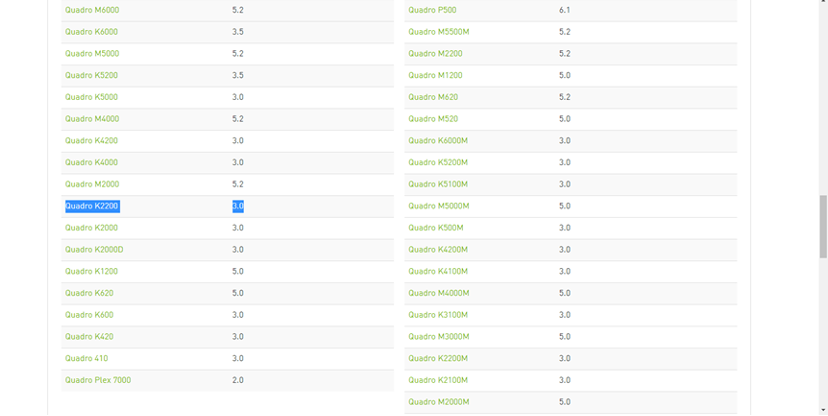
条件1から確認していく。そもそも、nVidia社製のGPUが搭載されているかを確認するので、次のようにコマンドを実行する。結果、このコンピュータに搭載されているGPUはnVidia社製のQuadro K2200だと判明(条件1をクリア)。
$ lspci | grep -i nvidia 02:00.0 VGA compatible controller: NVIDIA Corporation GM107GL [Quadro K2200] (rev a2) 02:00.1 Audio device: NVIDIA Corporation Device 0fbc (rev a1)条件2の確認手順
次に条件2の確認に入る。以下のページからcompute capabilityを見ておく(tensorflow-gpuを動かすにはcompute capability3.0以上が必要)。
先のコマンドでGPUはQuadroシリーズの製品だと分かったので、CUDA-Enabled Quadro Productsのボタンをクリックして表を表示させる。
該当の行を探す。
結果、Quadro K2200はcompute capabilityが3.0であることが判明(条件2をクリア)。
もしcompute capabilityが不足していたら
これ以降の環境構築をこなせたとしてもGPUでの計算はできません。そのときは本当にGPUを用いなくてはならないほどの計算なのかを再検討しましょう。必要ならcompute capabilityを満たすGPUを購入しましょう。
二つの条件がクリアできたら
環境構築に取り掛かっていきます。次の記事ではGPUのドライバーをインストールしてきます。
- 投稿日:2020-11-13T21:39:13+09:00
AxisのPTZカメラをROS上で制御してみた
経緯
AxisのPTZカメラをROS上で動かす機会があったので、その手順をまとめてみました。PTZ(パンチルトズーム)カメラとは、パン(左右)、チルト(上下)、ズーム(拡大)の制御ができるカメラのことです。
axis_cameraについて
最初は、PTZも含めたカメラ制御ができるpython-onvifを使おうとしたのですが、Axisのカメラに対応していなかったので、他の方法を探すことにしました。そこで見つけたのがaxis_cameraでした。axis_cameraはAxisのカメラ制御用のROSパッケージです。とても便利ですが、python2で書かれているので注意が必要です。近いうちに自分でpython3に書き換えたものを作って、また記事にしようと思います。
環境
- AXIS M5525-E PTZ Network Camera
- Ubuntu 18.04
- ROS Melodic
- python2.7
手順
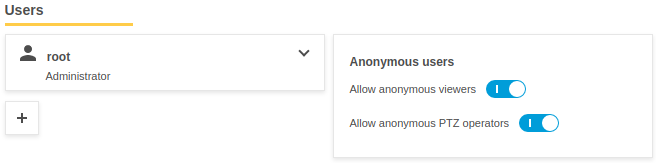
まず、準備としてaxisのデフォルトの権限がrootなので、ptz制御できるようにanonymousに変えておきます。Axisのカメラ設定画面の右下のSettings->System->Usersといくと下のようなページに行くので、Anonymous usersをONにします。
次にgithubからソースコードを落としてきて、ROSを動かしていきます。
$ git clone https://github.com/ros-drivers/axis_camera.git $ cd axis_camera $ roscore別のターミナルを開いて、下のコマンドを実行します。
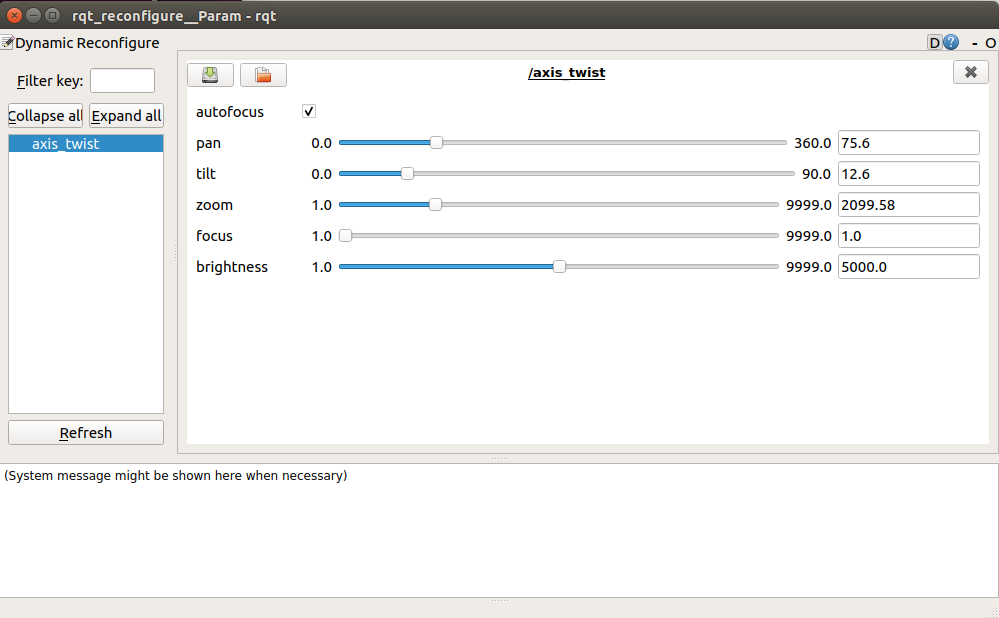
$ rosrun axis_camera axis_ptz.py _hostname:=IP_ADDRESS_OF_YOUR_CAMERAaxis_cameraはROSのDynamic Reconfigureを使ってGUI上でPTZ制御ができるようになっています。
別のターミナルを開き、下のコマンドを実行します。$ rosrun rqt_reconfigure rqt_reconfigureすると、下のようなGUIが出現します。それぞれのスライドバーを動かすことで、PTZ制御ができます。
デフォルトだと、tiltが動作しなかったので、PTZ.cfgの中のtiltの設定値を変更しました。それぞれの項目はgen.add()の後ろの3つに初期値、最小値、最大値の順で並んでいます。
#!/usr/bin/env python PACKAGE = "axis_camera" from dynamic_reconfigure.parameter_generator_catkin import * gen = ParameterGenerator() #gen.add("speed_control", bool_t, 0, "Speed control (true) or absolute position control (false)", False) gen.add("autofocus", bool_t, 0, "Autofocus", True) gen.add("pan", double_t, 0, "Pan value in degrees (or percent in absolute mode)", 0, -180, 180) // tiltの値を-45,-90,0から0,0,90に変えている gen.add("tilt", double_t, 0, "Tilt value in degrees (or percent in absolute mode)", 0, 0, 90) gen.add("zoom", double_t, 0, "Zoom value", 1, 1, 9999) gen.add("focus", double_t, 0, "Focus", 1, 1, 9999) gen.add("brightness", double_t, 0, "Brightness", 1, 1, 9999) exit(gen.generate(PACKAGE, "axis_camera", "PTZ"))まとめ
Axisのカメラであれば、簡単にROS上で動かすことができました。PTZカメラは動かすだけでも楽しいので、是非買ってみてください!家での使い道はあんまり無いと思いますが(笑)。
参考文献
- 投稿日:2020-11-13T21:37:55+09:00
pythonのbool型は遅い
言いたいこと
競技プログラミングにおいてTrue/Falseをbool型で扱うのは遅いです。
int型を使いましょう。概要
何かフラグを用意して、それによって処理を分岐させることはよくあると思います。
f = 1とする人も
f = Trueとする人もいるかと思いますが、どちらも同じ事が起きると期待しますよね。
しかし、実際は実行速度に差がでます。
正確に言うと、真偽値の判定に差がは無く、書き換えで差が出ます。これは後ほど語ります。
実験
以下のコードで比較してみます。
実行環境はatcoderのコードテストでPyPy3(3.7.0)です。int.pyf = 1 for i in range(10**9): if f: f = 0 else: f = 1bool.pyf = True for i in range(10**9): if f: f = False else: f = True結果はこのようになりました。(複数回やってもだいたいこんな感じです)
コード 実行時間 メモリ int.py 2423 ms 25640 KB bool.py 7439 ms 25612 KB 思ったより差がデカくないですか!?
実行速度が厳しい問題だと、これだけでもTLEの危険が高まります。
(実際、これでABC182 Eでハマりました)考察
ということで、あくまでpythonで競技プログラミングをやる場合の話ですが、フラグを使いたい場合にはbool型ではなくint型を使うようにしましょう。
いろいろ実験してみましたが、速度の差に影響があるのは真偽値判定ではなく値の書き換えのようでした。
詳しい理屈はわかりませんが、int型の方が機械にとっては素直に扱いやすいといったところ?フラグとして使うからには書き換えが前提になるかと思いますので注意が必要です。
例えば途中でフラグを立てたらそれ以降立てっぱなしという場合であれば、速度に差は出ないはずです。
コロコロと立てたり折ったりする場合にはこんなつまらない理由でTLEしてしまうかもしれません。とくにこだわりがなければint型を使うことをおすすめします。
おまけ
strでもやってみました。
str.pya = "True" for i in range(10**9): if a == "True": a = "False" else: a = "True"結果は以下の通りです。さすがに一番遅いですね。
実行時間 メモリ 8183 ms 25612 KB
- 投稿日:2020-11-13T21:37:55+09:00
pypyのbool型は遅い
修正
最初「pythonのbool型は遅い」とのタイトルで公開しておりましたが、記事の内容が当てはまるのはpypyを使う場合のみであり、誤りでした。
誤った情報を流してしまい、申し訳ありません。言いたいこと
競技プログラミングでpypyを利用する時、True/Falseをbool型で扱うのは遅いです。
int型を使いましょう。概要
何かフラグを用意して、それによって処理を分岐させることはよくあると思います。
f = 1とする人も
f = Trueとする人もいるかと思いますが、どちらも同じ事が起きると期待しますよね。
しかし、実際は実行速度に差がでます。
正確に言うと、真偽値の判定に差がは無く、書き換えで差が出ます。これは後ほど語ります。
実験
以下のコードで比較してみます。
実行環境はatcoderのコードテストでPyPy3(3.7.0)です。int.pyf = 1 for i in range(10**9): if f: f = 0 else: f = 1bool.pyf = True for i in range(10**9): if f: f = False else: f = True結果はこのようになりました。(複数回やってもだいたいこんな感じです)
コード 実行時間 メモリ int.py 2423 ms 25640 KB bool.py 7439 ms 25612 KB 思ったより差がデカくないですか!?
実行速度が厳しい問題だと、これだけでもTLEの危険が高まります。
(実際、これでABC182 Eでハマりました)考察
ということで、あくまで競技プログラミングでpypyを使う場合の話ですが、フラグを使いたい場合にはbool型ではなくint型を使うようにしましょう。
いろいろ実験してみましたが、速度の差に影響があるのは真偽値判定ではなく値の書き換えのようでした。
フラグとして使うからには書き換えが前提になるかと思いますので注意が必要です。
例えば途中でフラグを立てたらそれ以降立てっぱなしという場合であれば、速度に差は出ないはずです。
コロコロと立てたり折ったりする場合にはこんなつまらない理由でTLEしてしまうかもしれません。とくにこだわりがなければint型を使うことをおすすめします。
おまけ
strでもやってみました。
str.pya = "True" for i in range(10**9): if a == "True": a = "False" else: a = "True"結果は以下の通りです。さすがに一番遅いですね。
実行時間 メモリ 8183 ms 25612 KB 追記
python3で実行した場合は誤差の範囲内でした。
@shiracums さん、ご指摘ありがとうございました。
- 投稿日:2020-11-13T21:20:46+09:00
[Blender×Python] マテリアルをマスターしよう!!
目次
0.マテリアルを追加する方法
1.ガラスのマテリアルをつくってみよう!!
2.メタリックをつくってみよう!!
3.テキストを追加しよう!!
4.英単語※今回は解説が少ないので、サンプルコードだけでまとめてはいません。
0.マテリアルを追加する方法
0-1.マテリアルを追加していく手順
①新しいマテリアルをつくる
②ノードを使えるようにする
③オブジェクトを追加する
④ノードの値を設定する
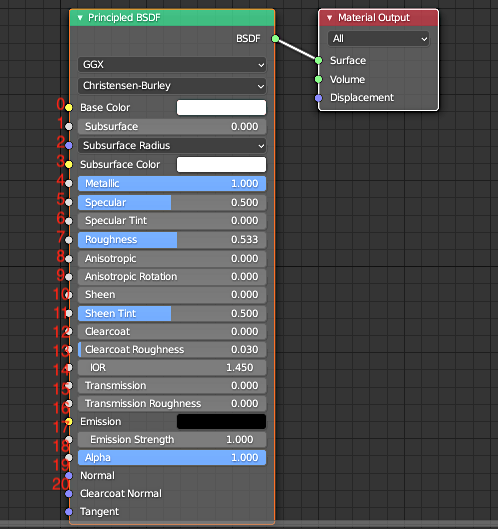
⑤オブジェクトにマテリアルを適応する0-2.Principled BSDFの中身
◯それぞれの項目は0から順番に数字が割り当てられています。
Base Color→0
Subsurface→1
:
Metallic→4
:
Roughness→7
:
Transmission→15のようになっています。
◯これを利用して
nodes["Principled BSDF"].inputs[0]のようにして指定していきます。1.ガラスのマテリアルをつくってみよう!!
◯シンプルなガラスのico_sphereを作るプログラム
import bpy #新しいマテリアルをつくる material_glass = bpy.data.materials.new('Green') #ノードを使えるようにする material_glass.use_nodes = True #オブジェクトを追加する bpy.ops.mesh.primitive_ico_sphere_add(subdivisions=1, enter_editmode=False, align='WORLD', location=(0, 0, 0), scale=(1, 1, 1)) #ノードの値を設定していく #変数p_BSDFをつくって書く量を減らす p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/7→roughness(=粗さ)/15→transmission(=伝播) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = (0, 1, 0, 1) p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass)
◯ガラスの立方体を3次元的に並べるプログラム
import bpy for i in range(0,5): for j in range(0,5): for k in range(0,5): #新規マテリアルをつくる material_glass = bpy.data.materials.new('Red') #ノードを使えるようにする material_glass.use_nodes = True bpy.ops.mesh.primitive_cube_add( size=0.8, #それぞれ縦、横、高さを決める location=(i, j, k), ) p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] p_BSDF.inputs[0].default_value = (1, 0, 0, 1) p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 bpy.context.object.data.materials.append(material_glass)
2.メタリックをつくってみよう!!
◯メタリックのico_spehreを並べるプログラム
import bpy #6回処理を繰り返す for i in range(0,6): #新規マテリアルをつくる material_glass = bpy.data.materials.new('Blue') #ノードを使えるようにする material_glass.use_nodes = True #ico_sphereを追加する関数 bpy.ops.mesh.primitive_ico_sphere_add( #どんどん滑らかにしていく subdivisions=i+1, location=(i, 0, 0), scale=(0.7, 0.7, 0.7) ) p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/4→Metallic(=金属)/7→roughness(=粗さ) p_BSDF.inputs[0].default_value = (0, 0, 1, 0.5) p_BSDF.inputs[4].default_value = 1 p_BSDF.inputs[7].default_value = 0 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass)
◯少しずつ色を変えていくプログラム
処理を繰り返す度に変化するiを色に代入することで色を少しずつ変化させることができます。
import bpy import math import random for i in range(0,10): #0から1までのランダムな値を変数numに代入する num = random.random() material_glass = bpy.data.materials.new('Blue') material_glass.use_nodes = True bpy.ops.mesh.primitive_torus_add( #180(度)×0~1のランダムな値 rotation=(math.pi * num, math.pi * num, 0), major_segments=64, minor_segments=3, major_radius=10-i, minor_radius=0.1, ) p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] p_BSDF.inputs[4].default_value = 1 p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[0].default_value = (0, 0, 1 - i/10, 1) bpy.context.object.data.materials.append(material_glass)
3.テキストを追加しよう!!
3-1.テキストの追加方法
◯シンプルなテキストの入力を行います。
import bpy #テキストを追加して編集モードで編集できるようにする bpy.ops.object.text_add(enter_editmode = True,location = (0,0,0)) #初期テキストを削除する bpy.ops.font.delete(type = 'PREVIOUS_WORD') #テキストを入力する bpy.ops.font.text_insert(text = 'Blender') #編集モードを終了する bpy.ops.object.editmode_toggle()
3-1.メタリックなテキストをつくる
◯テキストにメタリックのマテリアルを組み合わせます。
import bpy material_glass = bpy.data.materials.new('Blue') #ノードを使えるようにする material_glass.use_nodes = True #テキストを追加して編集モードで編集できるようにする bpy.ops.object.text_add(enter_editmode = True,location = (0,0,0)) #初期テキストを削除する bpy.ops.font.delete(type = 'PREVIOUS_WORD') #テキストを入力する bpy.ops.font.text_insert(text = 'Blender') #編集モードを終了する bpy.ops.object.editmode_toggle() #ノードをいじる p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] p_BSDF.inputs[4].default_value = 1 p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[0].default_value = (0, 0, 1, 1) bpy.context.object.data.materials.append(material_glass)
4.英単語
英単語 訳 material 素材 default デフォルト/既定 value 値 append 加える object もの、物体 edit 編集 type 種類 delete 消去 toggle 切り替え operation(ops) 運用 add 追加 segment 区分、分割 insert 挿入する input 取得する、入手する previous 以前の、前の principled 原理、原則 subdivision 細分化






- 投稿日:2020-11-13T20:04:04+09:00
fastTextがさらにすごい!「Yahoo!ニュース」クラスタリング 〜教師なし学習編〜
前回はYahooニュースの記事データに対して、fastTextのtrain_supervisedメソッドを使って教師あり学習を行い、クラスタリングを行いました。
今回はfastTextのtrain_unsupervisedメソッドを使って教師なし学習を行い、前回の様に綺麗にクラスタリングできるか分析してみましょう。開発環境
- Docker
- JupyterLab
実装スタート
①ライブラリ読み込み
②utility.pyと言うファイルを作成して、今まで作成した関数を格納しています。そこから、今回必要な関数を読み込みます。
③YN関数を使ってYahooニュースの記事を取得します。約10で500記事ほど取得できます。この関数はこちらで紹介しています。# ① import pandas as pd, numpy as np from sklearn.model_selection import train_test_split import fasttext from sklearn import preprocessing from sklearn.decomposition import PCA import matplotlib.pyplot as plt import japanize_matplotlib import re# ② import utility as util wakati = util.wakati M2A = util.MecabMorphologicalAnalysis YN = util.YahooNews cos_sim = util.cos_sim# ③ df = YN(1000) # df = pd.read_csv('./YahooNews.csv') # すでにデータを取得済の場合は読み込んで分析スタート! df[====================] 502記事
title category text 0 パナ 22年に持ち株会社へ移行 経済 ブルームバーグ パナソニックは13日2022年4月から持ち株会社体制に移行すると発表した社名... 1 全国で1700人超感染 過去最多 国内 Nippon News NetworkNNN新型コロナウイルスの13日一日の新たな感染者はN... 2 眞子さまの結婚 両陛下も尊重 国内 宮内庁は13日秋篠宮ご夫妻の長女眞子さまと国際基督教大学ICU時代の同級生小室圭さん29と... 3 トランプ氏 子の助言分かれる 国際 CNN 米大統領選で敗北が確実となったトランプ大統領が次の一手の戦略を練るなか同氏の最も信頼... 4 国交相「GoTo延長したい」 国内 CopyrightC Japan News Network All rights reser... ... ... ... ... 497 バイデン氏 国民向けTV演説へ 国際 AFP時事米民主党の大統領候補ジョーバイデンJoe Biden氏が6日夜日本時間7日午前国民... 498 全米各地で衝突や暴動警戒 国際 All Nippon NewsNetworkANN アメリカでは大統領選挙の勝者が確定しない... 499 日中ビジネス往来 再開で合意 国内 日中両政府が新型コロナウイルス対策のため制限しているビジネス関係者らの往来を今月中旬にも再... 500 大統領選 ジョージア再集計へ 国際 AFP時事更新米大統領選で民主党のジョーバイデンJoe Biden氏が共和党のドナルドトラン... 501 IOCバッハ会長 15日に来日へ スポーツ 来夏に延期された東京五輪パラリンピックをめぐり国際オリンピック委員会IOCのトーマスバッハ... 502 rows × 3 columns
subwordについて
前回は触れなかったのですが、今回はfastTextの大きな特徴であるsubwordを考慮してみようと思います。
subwordとは単語をさらに細かな「部分語」に分割して単語の関連性を捉えようと言うものです。
例えば「Go」と「Going」の様な共通部分を持つ語句について、その関連性を学習できます。
subwordを適応すると精度が上がったので使用しようと思います。逆にカタカタ語に対しては弊害もある様です。
train_supervisedやtrain_unsupervisedの引数にmaxnとminnを渡すことで実装できます。
train_supervisedとtrain_unsupervisedでデフォルト値が異なります。詳しくはGitHubへ。教師あり学習(train_supervised)
まずは、比較のために前回の内容を一気に実行。
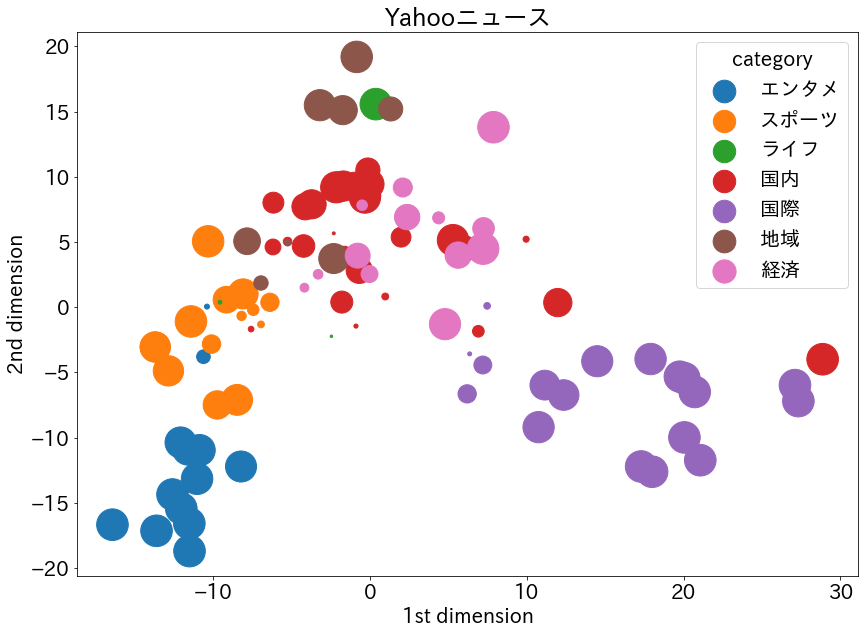
# カテゴリと本文をそれぞれリストに格納 cat_lst = ['__label__' + cat for cat in df.category] text_lst = [M2A(text, mecab=wakati) for text in df.text] # trainとvalidに分割 text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # trainファイルとvalidファイル作成 with open('./s_train', mode='w') as f: for i in range(len(text_train)): f.write(cat_train[i] + ' '+ text_train[i]) with open('./s_valid', mode='w') as f: for i in range(len(text_valid)): f.write(cat_valid[i] + ' ' + text_valid[i]) # モデルの学習 model = fasttext.train_supervised(input='./s_train', lr=0.5, epoch=500, minn=3, maxn=5, wordNgrams=3, loss='ova', dim=300, bucket=200000) # モデルの精度を確認 # print("TrainData:", model.test('./s_news_train')) print("ValidData:", model.test('./s_valid')) # validデータを使って2次元プロットの準備 with open("./s_valid") as f: l_strip = [s.strip() for s in f.readlines()] # strip()を利用することにより改行文字除去 labels = [] texts = [] sizes = [] for t in l_strip: labels.append(re.findall('__label__(.*?) ', t)[0]) texts.append(re.findall(' (.*)', t)[0]) sizes.append(model.predict(re.findall(' (.*)', t))[1][0][0]) # validの記事本文からベクトル生成 vectors = [] for t in texts: vectors.append(model.get_sentence_vector(t)) # numpyに変換 vectors = np.array(vectors) labels = np.array(labels) sizes = np.array(sizes) # 標準化 ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # 次元削減 pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] # プロット x0, y0, z0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1], sizes[labels=='エンタメ']*1000 x1, y1, z1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1], sizes[labels=='スポーツ']*1000 x2, y2, z2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1], sizes[labels=='ライフ']*1000 x3, y3, z3 = feature[labels=='国内', 0], feature[labels=='国内', 1], sizes[labels=='国内']*1000 x4, y4, z4 = feature[labels=='国際', 0], feature[labels=='国際', 1], sizes[labels=='国際']*1000 x5, y5, z5 = feature[labels=='地域', 0], feature[labels=='地域', 1], sizes[labels=='地域']*1000 x6, y6, z6 = feature[labels=='経済', 0], feature[labels=='経済', 1], sizes[labels=='経済']*1000 plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=z0) plt.scatter(x1, y1, label="スポーツ", s=z1) plt.scatter(x2, y2, label="ライフ", s=z2) plt.scatter(x3, y3, label="国内", s=z3) plt.scatter(x4, y4, label="国際", s=z4) plt.scatter(x5, y5, label="地域", s=z5) plt.scatter(x6, y6, label="経済", s=z6) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()ValidData: (101, 0.801980198019802, 0.801980198019802)
教師なし学習(train_unsupervised)
データの準備
教師なし学習にはラベルが必要ないので、学習するためのデータは分かち書きしておくだけでOKです。
①カテゴリはcat_lstへ、文章はM2A関数で分かち書きしてtext_lstへそれぞれ格納します。
②trainデータとvalidデータに分割します。
③文章はファイルに保存しておきます。# ① cat_lst = [cat for cat in df.category] text_lst = [M2A(text, mecab=wakati) for text in df.text] # ② text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # ③ with open('./u_train', mode='w') as f: for i in range(len(text_train)): f.write(text_train[i]) with open('./u_valid', mode='w') as f: for i in range(len(text_valid)): f.write(text_valid[i])モデルの学習
教師なし学習は
train_unsupervisedを使用します。model = fasttext.train_unsupervised('./u_train', epoch=500, lr=0.01, minn=3, maxn=5, dim=300)trainデータ分析
文章ベクトルの類似度比較
学習済モデルを使用して、記事内容の類似度を算出しましょう。
①get_sentence_vectorメソッドを使用して学習済モデルから文章ベクトルを生成します。
②記事のカテゴリと本文を表示。
③上で読み込んだcos_sim関数を用いてコサイン類似度を算出。# ① vectors = [] for t in text_train: vectors.append(model.get_sentence_vector(t.strip())) # ② print("<{}>".format(cat_train[0])) print(text_train[0][:200], end="\n\n") print("<{}>".format(cat_train[1])) print(text_train[1][:200], end="\n\n") print("<{}>".format(cat_train[2])) print(text_train[2][:200], end="\n\n") # ③ print("<{}><{}>".format(cat_train[0], cat_train[1]), cos_sim(vectors[0], vectors[1])) print("<{}><{}>".format(cat_train[1], cat_train[2]), cos_sim(vectors[1], vectors[2])) print("<{}><{}>".format(cat_train[0], cat_train[2]), cos_sim(vectors[0], vectors[2]))<国内> 政府 の 新型コロナ ウイルス対策 分科会 の 尾身茂 会長 地域医療機能推進機構 理事長 は 9日 緊急 で 記者会見 を 開き 感染 が 全国的 に 見 て も 増加 し て いる の は 間違い ない 減少 要因 を 早急 に 強め なけれ ば いま は 徐々に だ が 急速 な 拡大 傾向 に 至る 可能性 が 高い と 訴え た そして 政府 へ の 緊急 提言 として 1 いま まで <国内> 昨年7月 の 参院選 を めぐり 公職選挙法違反 買収 の 罪 に 問わ れ た 参院 議員 河井案里 被告 47 の 被告人 質問 が 13日 午前 東京地裁 で 始まっ た 案 里 議員 は 地元 議員 ら に 現金 を 渡し た こと について 当選 祝い や 陣中 見舞い だっ た と 初公判 で 述べ た 主張 を 繰り返し 違法性 が ない と 訴え た スーツ姿 の 案 里 議員 は <国際> AFP 時事 更新 ドナルドトランプ Donald Trump 米大統領 は 9日 ツイッター Twitter へ の 投稿 で マークエスパー Mark Esper 国防長官 を 解任 し た こと を 明らか に し た 大統領選 で の 敗北 を 認め ない トランプ氏 へ の 対応 に 追わ れる 政権 に さらなる 揺さぶり が かけ られ た トランプ氏 は 投稿 で マークエスパー <国内><国内> 0.91201633 <国内><国際> 0.9294117 <国内><国際> 0.92017622次元プロット
いよいよ2次元にプロットしてみましょう。
①ベクトルとラベルをそれぞれnumpy配列に変換
②ベクトルを標準化
③ベクトルをPCAを用いて次元削減
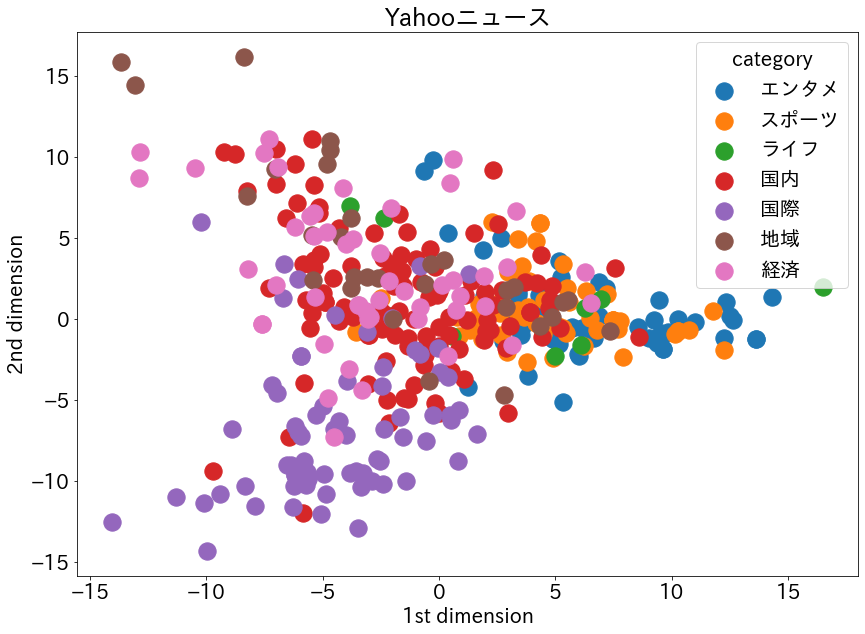
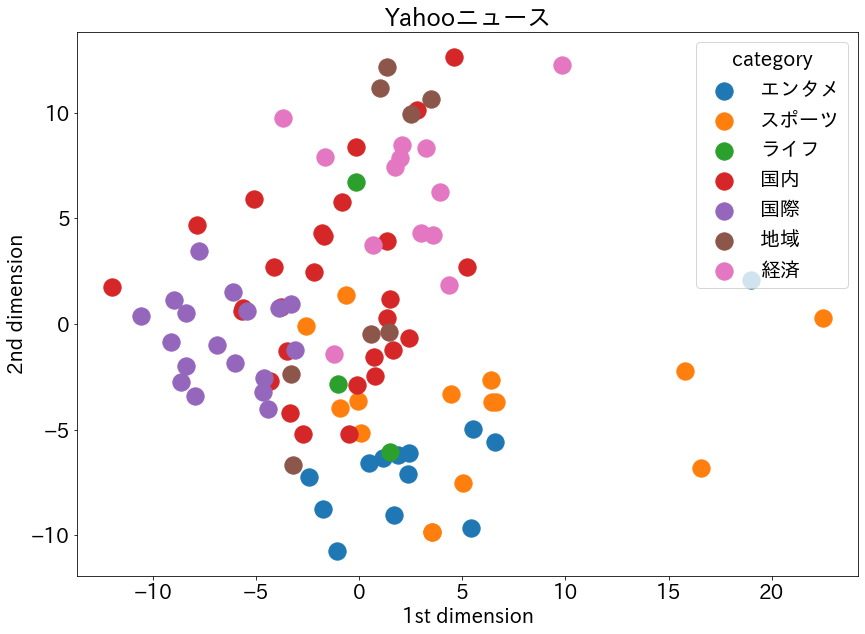
④matplotlibでプロット。train_supervisedと異なり、予測に対する確率を取得できないので、全てのプロットのサイズは同じ。# ① vectors = np.array(vectors) labels = np.array(cat_train) # ② ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # ③ pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] # ④ x0, y0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1] x1, y1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1] x2, y2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1] x3, y3 = feature[labels=='国内', 0], feature[labels=='国内', 1] x4, y4 = feature[labels=='国際', 0], feature[labels=='国際', 1] x5, y5 = feature[labels=='地域', 0], feature[labels=='地域', 1] x6, y6 = feature[labels=='経済', 0], feature[labels=='経済', 1] plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=300) plt.scatter(x1, y1, label="スポーツ", s=300) plt.scatter(x2, y2, label="ライフ", s=300) plt.scatter(x3, y3, label="国内", s=300) plt.scatter(x4, y4, label="国際", s=300) plt.scatter(x5, y5, label="地域", s=300) plt.scatter(x6, y6, label="経済", s=300) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
validデータ分析
次に、validデータをクラスタリングしてみます。
内容はtrainデータ分析と同じですので解説を省略します。vectors = [] for t in text_valid: vectors.append(model.get_sentence_vector(t.strip())) print("<{}>".format(cat_valid[0])) print(text_valid[0][:200], end="\n\n") print("<{}>".format(cat_valid[1])) print(text_valid[1][:200], end="\n\n") print("<{}>".format(cat_valid[2])) print(text_valid[2][:200], end="\n\n") print("<{}><{}>".format(cat_valid[0], cat_valid[1]), cos_sim(vectors[0], vectors[1])) print("<{}><{}>".format(cat_valid[1], cat_valid[2]), cos_sim(vectors[1], vectors[2])) print("<{}><{}>".format(cat_valid[0], cat_valid[2]), cos_sim(vectors[0], vectors[2]))<経済> 近畿日本ツーリスト など を 傘下 に 持つ KNT ― CT ホールディングス HD は 11日 希望退職 など で グループ 従業員 約 7000人 の 3分の1 を 2025年 3月 まで に 削減 する と 発表 し た 個人旅行 を 扱う 全国 138 の 店舗 も 3分の2 を 22年 3月 まで に 閉鎖 する 新型コロナウイルス 感染拡大 に 伴う 旅行 需要 の 激減 で 業績 <地域> 北海道 の 新型コロナウイルス へ の 感染者 が 11月9日 過去最多 200人 を 超える 見通し と なっ た こと が わかり まし た 5日 連続 の 100人 超 が ついに 200人 台 へ の 到達 見込み と なり 感染拡大 が 止まり ませ ん 新た な クラスター が 確認 さ れ て いる と み られ ます 北海道 で は 5日 に 119人 の 感染者 が 確認 さ れ <経済> 日立製作所 は 9日 年末年始 の 休暇 の 分散 取得 など を 求める 政府 の 方針 を 受け 12月28日 来年 1月8日 まで を 対象 期間 と し 有休 取得 を 促す と 発表 し た 通常 は 12月30日 から 1月3日 まで グループ会社 の 社員 を 含む 約 15万人 が 対象 で 社内 の 年末年始 行事 や 不要不急 の 会議 の 開催 を 避け 休暇 を 取得 し <経済><地域> 0.9284181 <地域><経済> 0.90896636 <経済><経済> 0.9533808vectors = np.array(vectors) labels = np.array(cat_valid) ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] x0, y0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1] x1, y1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1] x2, y2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1] x3, y3 = feature[labels=='国内', 0], feature[labels=='国内', 1] x4, y4 = feature[labels=='国際', 0], feature[labels=='国際', 1] x5, y5 = feature[labels=='地域', 0], feature[labels=='地域', 1] x6, y6 = feature[labels=='経済', 0], feature[labels=='経済', 1] plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=300) plt.scatter(x1, y1, label="スポーツ", s=300) plt.scatter(x2, y2, label="ライフ", s=300) plt.scatter(x3, y3, label="国内", s=300) plt.scatter(x4, y4, label="国際", s=300) plt.scatter(x5, y5, label="地域", s=300) plt.scatter(x6, y6, label="経済", s=300) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
考察
教師あり学習
- subwordを採用したことで、前回記事の時よりさらに精度が向上しました。0.75→0.80
- 前回同様、1次元目では「エンタメ」と「スポーツ」は重なる部分が多いが、2次元目でしっかり分かれている。「エンタメ」と「スポーツ」が近い位置にあるのは納得。
- 「国際」と「国内」もしっかり分かれており、その間に「経済」がある。前回同様これも納得。
- 前回記事において「地域」ははっきりしていなかったが、今回は2次元方向に特徴が強く出ている。
- 全体として前回よりもはっきり分類された感じがします。
教師なし学習
trainデータ
- カテゴリごとに重なっている部分が多い。
- 「国際」と「国内」はしっかり分かれている。
- 「経済」は「国際」と「国内」の間にあると言うのがお決まりのパターンであったが、今回は広い範囲にプロットされてしまっている。
- 「エンタメ」と「スポーツ」はかなりの部分が重なっているが、一次元方向において「エンタメ」が若干右より、「スポーツ」が左に位置した。
- 「地域」は「国際」と重なる部分がほとんどなく、これは納得。「国内」、「経済」とかなりの部分が重なっている。
validデータ
- 重なっている部分が少なく、全体として綺麗に分類された。
- 中央に「国内」があり、左側に「国際」、中央上に「経済」と言う配置になった。今までとは随分違う。
- 今回も「スポーツ」と「エンタメ」はかなり近い位置にあるが、若干「スポーツ」が広い範囲に分布した。
- 「地域」は2つに分かれている。この傾向は、教師あり学習の方でも見て取れるため、何かの基準があるかもしれない。
今回は教師なし学習で分析を行いましたが、割と綺麗に分類が成功していて驚きました。
ラベルがないので、文章の中から「国際」っぽさや「スポーツ」っぽさを取得できていると言うことになります。実際にモデルがどの様な特徴を取得して、ベクトル作成に反映させているのか非常に気になります。
fastTextについてさらに深掘りしてみたくなりました!!!参考文献
Yahoo!ニュース
fastText
Facebookが公開したfastTextのインストールと使用方法について解説
fastTextのsubword(部分語)の弊害
fastText tutorial(Word representations)
GitHub (fastText/python)
fastTextがすごい!「Yahoo!ニュース」をクラスタリング
- 投稿日:2020-11-13T20:04:04+09:00
fastTextがかなりすごい!「Yahoo!ニュース」クラスタリング 〜教師なし学習編〜
前回はYahooニュースの記事データに対して、fastTextのtrain_supervisedメソッドを使って教師あり学習を行い、クラスタリングを行いました。
今回はfastTextのtrain_unsupervisedメソッドを使って教師なし学習を行い、前回の様に綺麗にクラスタリングできるか分析してみましょう。開発環境
- Docker
- JupyterLab
実装スタート
①ライブラリ読み込み
②utility.pyと言うファイルを作成して、今まで作成した関数を格納しています。そこから、今回必要な関数を読み込みます。
③YN関数を使ってYahooニュースの記事を取得します。約10で500記事ほど取得できます。この関数はこちらで紹介しています。# ① import pandas as pd, numpy as np from sklearn.model_selection import train_test_split import fasttext from sklearn import preprocessing from sklearn.decomposition import PCA import matplotlib.pyplot as plt import japanize_matplotlib import re# ② import utility as util wakati = util.wakati M2A = util.MecabMorphologicalAnalysis YN = util.YahooNews cos_sim = util.cos_sim# ③ df = YN(1000) # df = pd.read_csv('./YahooNews.csv') # すでにデータを取得済の場合は読み込んで分析スタート! df[====================] 502記事
title category text 0 パナ 22年に持ち株会社へ移行 経済 ブルームバーグ パナソニックは13日2022年4月から持ち株会社体制に移行すると発表した社名... 1 全国で1700人超感染 過去最多 国内 Nippon News NetworkNNN新型コロナウイルスの13日一日の新たな感染者はN... 2 眞子さまの結婚 両陛下も尊重 国内 宮内庁は13日秋篠宮ご夫妻の長女眞子さまと国際基督教大学ICU時代の同級生小室圭さん29と... 3 トランプ氏 子の助言分かれる 国際 CNN 米大統領選で敗北が確実となったトランプ大統領が次の一手の戦略を練るなか同氏の最も信頼... 4 国交相「GoTo延長したい」 国内 CopyrightC Japan News Network All rights reser... ... ... ... ... 497 バイデン氏 国民向けTV演説へ 国際 AFP時事米民主党の大統領候補ジョーバイデンJoe Biden氏が6日夜日本時間7日午前国民... 498 全米各地で衝突や暴動警戒 国際 All Nippon NewsNetworkANN アメリカでは大統領選挙の勝者が確定しない... 499 日中ビジネス往来 再開で合意 国内 日中両政府が新型コロナウイルス対策のため制限しているビジネス関係者らの往来を今月中旬にも再... 500 大統領選 ジョージア再集計へ 国際 AFP時事更新米大統領選で民主党のジョーバイデンJoe Biden氏が共和党のドナルドトラン... 501 IOCバッハ会長 15日に来日へ スポーツ 来夏に延期された東京五輪パラリンピックをめぐり国際オリンピック委員会IOCのトーマスバッハ... 502 rows × 3 columns
subwordについて
前回は触れなかったのですが、今回はfastTextの大きな特徴であるsubwordを考慮してみようと思います。
subwordとは単語をさらに細かな「部分語」に分割して単語の関連性を捉えようと言うものです。
例えば「Go」と「Going」の様な共通部分を持つ語句について、その関連性を学習できます。
subwordを適応すると精度が上がったので使用しようと思います。逆にカタカタ語に対しては弊害もある様です。
train_supervisedやtrain_unsupervisedの引数にmaxnとminnを渡すことで実装できます。
train_supervisedとtrain_unsupervisedでデフォルト値が異なります。詳しくはGitHubへ。教師あり学習(train_supervised)
まずは、比較のために前回の内容を一気に実行。
# カテゴリと本文をそれぞれリストに格納 cat_lst = ['__label__' + cat for cat in df.category] text_lst = [M2A(text, mecab=wakati) for text in df.text] # trainとvalidに分割 text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # trainファイルとvalidファイル作成 with open('./s_train', mode='w') as f: for i in range(len(text_train)): f.write(cat_train[i] + ' '+ text_train[i]) with open('./s_valid', mode='w') as f: for i in range(len(text_valid)): f.write(cat_valid[i] + ' ' + text_valid[i]) # モデルの学習 model = fasttext.train_supervised(input='./s_train', lr=0.5, epoch=500, minn=3, maxn=5, wordNgrams=3, loss='ova', dim=300, bucket=200000) # モデルの精度を確認 # print("TrainData:", model.test('./s_news_train')) print("ValidData:", model.test('./s_valid')) # validデータを使って2次元プロットの準備 with open("./s_valid") as f: l_strip = [s.strip() for s in f.readlines()] # strip()を利用することにより改行文字除去 labels = [] texts = [] sizes = [] for t in l_strip: labels.append(re.findall('__label__(.*?) ', t)[0]) texts.append(re.findall(' (.*)', t)[0]) sizes.append(model.predict(re.findall(' (.*)', t))[1][0][0]) # validの記事本文からベクトル生成 vectors = [] for t in texts: vectors.append(model.get_sentence_vector(t)) # numpyに変換 vectors = np.array(vectors) labels = np.array(labels) sizes = np.array(sizes) # 標準化 ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # 次元削減 pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] # プロット x0, y0, z0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1], sizes[labels=='エンタメ']*1000 x1, y1, z1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1], sizes[labels=='スポーツ']*1000 x2, y2, z2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1], sizes[labels=='ライフ']*1000 x3, y3, z3 = feature[labels=='国内', 0], feature[labels=='国内', 1], sizes[labels=='国内']*1000 x4, y4, z4 = feature[labels=='国際', 0], feature[labels=='国際', 1], sizes[labels=='国際']*1000 x5, y5, z5 = feature[labels=='地域', 0], feature[labels=='地域', 1], sizes[labels=='地域']*1000 x6, y6, z6 = feature[labels=='経済', 0], feature[labels=='経済', 1], sizes[labels=='経済']*1000 plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=z0) plt.scatter(x1, y1, label="スポーツ", s=z1) plt.scatter(x2, y2, label="ライフ", s=z2) plt.scatter(x3, y3, label="国内", s=z3) plt.scatter(x4, y4, label="国際", s=z4) plt.scatter(x5, y5, label="地域", s=z5) plt.scatter(x6, y6, label="経済", s=z6) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()ValidData: (101, 0.801980198019802, 0.801980198019802)
教師なし学習(train_unsupervised)
データの準備
教師なし学習にはラベルが必要ないので、学習するためのデータは分かち書きしておくだけでOKです。
①カテゴリはcat_lstへ、文章はM2A関数で分かち書きしてtext_lstへそれぞれ格納します。
②trainデータとvalidデータに分割します。
③文章はファイルに保存しておきます。# ① cat_lst = [cat for cat in df.category] text_lst = [M2A(text, mecab=wakati) for text in df.text] # ② text_train, text_valid, cat_train, cat_valid = train_test_split( text_lst, cat_lst, test_size=0.2, random_state=0, stratify=cat_lst ) # ③ with open('./u_train', mode='w') as f: for i in range(len(text_train)): f.write(text_train[i]) with open('./u_valid', mode='w') as f: for i in range(len(text_valid)): f.write(text_valid[i])モデルの学習
教師なし学習は
train_unsupervisedを使用します。model = fasttext.train_unsupervised('./u_train', epoch=500, lr=0.01, minn=3, maxn=5, dim=300)trainデータ分析
文章ベクトルの類似度比較
学習済モデルを使用して、記事内容の類似度を算出しましょう。
①get_sentence_vectorメソッドを使用して学習済モデルから文章ベクトルを生成します。
②記事のカテゴリと本文を表示。
③上で読み込んだcos_sim関数を用いてコサイン類似度を算出。# ① vectors = [] for t in text_train: vectors.append(model.get_sentence_vector(t.strip())) # ② print("<{}>".format(cat_train[0])) print(text_train[0][:200], end="\n\n") print("<{}>".format(cat_train[1])) print(text_train[1][:200], end="\n\n") print("<{}>".format(cat_train[2])) print(text_train[2][:200], end="\n\n") # ③ print("<{}><{}>".format(cat_train[0], cat_train[1]), cos_sim(vectors[0], vectors[1])) print("<{}><{}>".format(cat_train[1], cat_train[2]), cos_sim(vectors[1], vectors[2])) print("<{}><{}>".format(cat_train[0], cat_train[2]), cos_sim(vectors[0], vectors[2]))<国内> 政府 の 新型コロナ ウイルス対策 分科会 の 尾身茂 会長 地域医療機能推進機構 理事長 は 9日 緊急 で 記者会見 を 開き 感染 が 全国的 に 見 て も 増加 し て いる の は 間違い ない 減少 要因 を 早急 に 強め なけれ ば いま は 徐々に だ が 急速 な 拡大 傾向 に 至る 可能性 が 高い と 訴え た そして 政府 へ の 緊急 提言 として 1 いま まで <国内> 昨年7月 の 参院選 を めぐり 公職選挙法違反 買収 の 罪 に 問わ れ た 参院 議員 河井案里 被告 47 の 被告人 質問 が 13日 午前 東京地裁 で 始まっ た 案 里 議員 は 地元 議員 ら に 現金 を 渡し た こと について 当選 祝い や 陣中 見舞い だっ た と 初公判 で 述べ た 主張 を 繰り返し 違法性 が ない と 訴え た スーツ姿 の 案 里 議員 は <国際> AFP 時事 更新 ドナルドトランプ Donald Trump 米大統領 は 9日 ツイッター Twitter へ の 投稿 で マークエスパー Mark Esper 国防長官 を 解任 し た こと を 明らか に し た 大統領選 で の 敗北 を 認め ない トランプ氏 へ の 対応 に 追わ れる 政権 に さらなる 揺さぶり が かけ られ た トランプ氏 は 投稿 で マークエスパー <国内><国内> 0.91201633 <国内><国際> 0.9294117 <国内><国際> 0.92017622次元プロット
いよいよ2次元にプロットしてみましょう。
①ベクトルとラベルをそれぞれnumpy配列に変換
②ベクトルを標準化
③ベクトルをPCAを用いて次元削減
④matplotlibでプロット。train_supervisedと異なり、予測に対する確率を取得できないので、全てのプロットのサイズは同じ。# ① vectors = np.array(vectors) labels = np.array(cat_train) # ② ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) # ③ pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] # ④ x0, y0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1] x1, y1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1] x2, y2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1] x3, y3 = feature[labels=='国内', 0], feature[labels=='国内', 1] x4, y4 = feature[labels=='国際', 0], feature[labels=='国際', 1] x5, y5 = feature[labels=='地域', 0], feature[labels=='地域', 1] x6, y6 = feature[labels=='経済', 0], feature[labels=='経済', 1] plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=300) plt.scatter(x1, y1, label="スポーツ", s=300) plt.scatter(x2, y2, label="ライフ", s=300) plt.scatter(x3, y3, label="国内", s=300) plt.scatter(x4, y4, label="国際", s=300) plt.scatter(x5, y5, label="地域", s=300) plt.scatter(x6, y6, label="経済", s=300) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
validデータ分析
次に、validデータをクラスタリングしてみます。
内容はtrainデータ分析と同じですので解説を省略します。vectors = [] for t in text_valid: vectors.append(model.get_sentence_vector(t.strip())) print("<{}>".format(cat_valid[0])) print(text_valid[0][:200], end="\n\n") print("<{}>".format(cat_valid[1])) print(text_valid[1][:200], end="\n\n") print("<{}>".format(cat_valid[2])) print(text_valid[2][:200], end="\n\n") print("<{}><{}>".format(cat_valid[0], cat_valid[1]), cos_sim(vectors[0], vectors[1])) print("<{}><{}>".format(cat_valid[1], cat_valid[2]), cos_sim(vectors[1], vectors[2])) print("<{}><{}>".format(cat_valid[0], cat_valid[2]), cos_sim(vectors[0], vectors[2]))<経済> 近畿日本ツーリスト など を 傘下 に 持つ KNT ― CT ホールディングス HD は 11日 希望退職 など で グループ 従業員 約 7000人 の 3分の1 を 2025年 3月 まで に 削減 する と 発表 し た 個人旅行 を 扱う 全国 138 の 店舗 も 3分の2 を 22年 3月 まで に 閉鎖 する 新型コロナウイルス 感染拡大 に 伴う 旅行 需要 の 激減 で 業績 <地域> 北海道 の 新型コロナウイルス へ の 感染者 が 11月9日 過去最多 200人 を 超える 見通し と なっ た こと が わかり まし た 5日 連続 の 100人 超 が ついに 200人 台 へ の 到達 見込み と なり 感染拡大 が 止まり ませ ん 新た な クラスター が 確認 さ れ て いる と み られ ます 北海道 で は 5日 に 119人 の 感染者 が 確認 さ れ <経済> 日立製作所 は 9日 年末年始 の 休暇 の 分散 取得 など を 求める 政府 の 方針 を 受け 12月28日 来年 1月8日 まで を 対象 期間 と し 有休 取得 を 促す と 発表 し た 通常 は 12月30日 から 1月3日 まで グループ会社 の 社員 を 含む 約 15万人 が 対象 で 社内 の 年末年始 行事 や 不要不急 の 会議 の 開催 を 避け 休暇 を 取得 し <経済><地域> 0.9284181 <地域><経済> 0.90896636 <経済><経済> 0.9533808vectors = np.array(vectors) labels = np.array(cat_valid) ss = preprocessing.StandardScaler() vectors_std = ss.fit_transform(vectors) pca = PCA() pca.fit(vectors_std) feature = pca.transform(vectors_std) feature = feature[:, :2] x0, y0 = feature[labels=='エンタメ', 0], feature[labels=='エンタメ', 1] x1, y1 = feature[labels=='スポーツ', 0], feature[labels=='スポーツ', 1] x2, y2 = feature[labels=='ライフ', 0], feature[labels=='ライフ', 1] x3, y3 = feature[labels=='国内', 0], feature[labels=='国内', 1] x4, y4 = feature[labels=='国際', 0], feature[labels=='国際', 1] x5, y5 = feature[labels=='地域', 0], feature[labels=='地域', 1] x6, y6 = feature[labels=='経済', 0], feature[labels=='経済', 1] plt.figure(figsize=(14, 10)) plt.rcParams["font.size"]=20 plt.scatter(x0, y0, label="エンタメ", s=300) plt.scatter(x1, y1, label="スポーツ", s=300) plt.scatter(x2, y2, label="ライフ", s=300) plt.scatter(x3, y3, label="国内", s=300) plt.scatter(x4, y4, label="国際", s=300) plt.scatter(x5, y5, label="地域", s=300) plt.scatter(x6, y6, label="経済", s=300) plt.title("Yahooニュース") plt.xlabel('1st dimension') plt.ylabel('2nd dimension') plt.legend(title="category") plt.show()
考察
教師あり学習
- subwordを採用したことで、前回記事の時よりさらに精度が向上しました。0.75→0.80
- 前回同様、1次元目では「エンタメ」と「スポーツ」は重なる部分が多いが、2次元目でしっかり分かれている。「エンタメ」と「スポーツ」が近い位置にあるのは納得。
- 「国際」と「国内」もしっかり分かれており、その間に「経済」がある。前回同様これも納得。
- 前回記事において「地域」ははっきりしていなかったが、今回は2次元方向に特徴が強く出ている。
- 全体として前回よりもはっきり分類された感じがします。
教師なし学習
trainデータ
- カテゴリごとに重なっている部分が多い。
- 「国際」と「国内」はしっかり分かれている。
- 「経済」は「国際」と「国内」の間にあると言うのがお決まりのパターンであったが、今回は広い範囲にプロットされてしまっている。
- 「エンタメ」と「スポーツ」はかなりの部分が重なっているが、一次元方向において「エンタメ」が若干右より、「スポーツ」が左に位置した。
- 「地域」は「国際」と重なる部分がほとんどなく、これは納得。「国内」、「経済」とかなりの部分が重なっている。
validデータ
- 重なっている部分が少なく、全体として綺麗に分類された。
- 中央に「国内」があり、左側に「国際」、中央上に「経済」と言う配置になった。今までとは随分違う。
- 今回も「スポーツ」と「エンタメ」はかなり近い位置にあるが、若干「スポーツ」が広い範囲に分布した。
- 「地域」は2つに分かれている。この傾向は、教師あり学習の方でも見て取れるため、何かの基準があるかもしれない。
今回は教師なし学習で分析を行いましたが、割と綺麗に分類が成功していて驚きました。
ラベルがないので、文章の中から「国際」っぽさや「スポーツ」っぽさを取得できていると言うことになります。実際にモデルがどの様な特徴を取得して、ベクトル作成に反映させているのか非常に気になります。
fastTextについてさらに深掘りしてみたくなりました!!!参考文献
Yahoo!ニュース
fastText
Facebookが公開したfastTextのインストールと使用方法について解説
fastTextのsubword(部分語)の弊害
fastText tutorial(Word representations)
GitHub (fastText/python)
fastTextがすごい!「Yahoo!ニュース」をクラスタリング
- 投稿日:2020-11-13T19:53:58+09:00
C#でjsonを読み込み辞書型に変換(強引)
お久しぶりです。
Qiitaの皆さん、お久しぶりです。
前回からかなり時間がアイてしまいましたが、あれから念願の新しいパソコンを購入しました。
そしてPythonにも飽きてきたので、C#に手を出してみることにしました。ふと思ったjsonの読み込みについて
私は以前、Pythonでjsonを使用して設定ファイルやデータをイチイチに定義しなければならないものをjsonに格納して便利に使っていたので、ぜひC#でも使いたいと思い模索しました。
薄々気づいてはいましたが、Pythonはなんて素晴らしいライブラリを取り揃えているのかと思い知らされることになりました。json読み込みのコード
hoge.json{ "hoge": "hoge1", "hogehoge": "hoge2", "hogehogehoge": "hoge3" }Pythonでのjsonの読み込みはjsonライブラリを使用しますが
import json def load_json(filename): with open(filename) as files: load = json.load(files) return loadこのように関数を一つ定義してしまえば、辞書型で帰ってくるので
result = load_json("hoge.json") hoge1 = result["hoge"] hoge2 = result["hogehoge"] hoge3 = result["hogehogehoge"] print(hoge1) print(hoge2) print(hoge3) print(type(hoge1)) print(type(hoge2)) print(type(hoge3))hoge1 hoge2 hoge3 <class 'str'> <class 'str'> <class 'str'>こうすると簡単にstrやintで帰ってきますので、あとは煮るなり焼くなりすれば簡単に使うことができますが
(ガバコードデゴメンネ)C#の場合
using System; using System.IO; using System.Text; using System.Text.Json; namespace ConsoleApp2 { class Program { public static string ReadAllLine(string filePath, string encodingName) { StreamReader sr = new StreamReader(filePath, Encoding.GetEncoding(encodingName)); string allLine = sr.ReadToEnd(); sr.Close(); return allLine; } class hogejson { public string hoge { get; set; } public string hogehoge { get; set; } public string hogehogehoge { get; set; } } static void Main(string[] args) { string readjson = ReadAllLine("hoge.json", "utf-8"); hogejson jsonData = JsonSerializer.Deserialize<hogejson>(readjson); string hoge = jsonData.hoge; string hogehoge = jsonData.hogehoge; string hogehogehoge = jsonData.hogehogehoge; Console.WriteLine(hoge); Console.WriteLine(hogehoge); Console.WriteLine(hogehogehoge); Console.WriteLine(hoge.GetType()); Console.WriteLine(hogehoge.GetType()); Console.WriteLine(hogehogehoge.GetType()); } } }hoge1 hoge2 hoge3 System.String System.String System.Stringこんな感じで記載しないとうまく読み込まないのですが、一番個人的に面倒なのが
「jsonのクラスを作らないといけない」
のと
「メソッド(Pythonでいう関数(若干違うけど))作った時わかりにくい!
ことが引っかかりました。なぜこんなことになってしまったのか
Pythonは先程の関数で帰ってくる返り値は辞書型に対してC#は特定の返り値を指定しなければなりません。
このため、Pythonでは辞書型で帰ってくるのでhoge = result["hoge"]とresultに指定定するだけでkeyである「hoge」のvalue「hoge1」を取り出すことができますが
対してC#は、例えば「hoge.json」のkeyである「hoge」のvalueが「hoge1」であったとき、クラス「hogejson」のhogeにstring型(str)でセットされます。
逆にこれをint型や別の型でセットしようとしてもできません。なぜなら、クラスhogeの返り値はstringと決めているからです。
そのためPythonでよくお世話になった辞書型に返り値には指定されていないため、仮に返り値を"勝手"に辞書型に指定しても他の「hogehoge」や「hogehogehoge」のkeyはおろかvalueの情報すらありません(自己解釈)ほんじゃあ辞書型に返ってくるように作ろう!笑
探してみたところ、C#には「Dictionaryクラス」というものが存在するようで、それでPythonの辞書型と同じように使えるみたいです。
なら話は早いです、hoge.jsonのkeyとvalueを辞書型に詰め込めるよう試行錯誤を繰り返してできたのがこちらです。
using System; using System.Collections.Generic; using System.IO; using System.Text; using System.Text.Json; namespace ConsoleApp2 { class library { // ファイル読み込み public string ReadAllLine(string filePath, string encodingName) { StreamReader sr = new StreamReader(filePath, Encoding.GetEncoding(encodingName)); string allLine = sr.ReadToEnd(); sr.Close(); return allLine; } // List型をDictionary型に強引に変換する public static Dictionary<string, string> ListInDictionary(string[] left, string[] right) { // 一致したとき if (left.Length == right.Length) { var result = new Dictionary<string, string>(); // leftのListの数の分だけforを回す for (int i = 0; i < left.Length; i++) { // resultに辞書を追加 result.Add(left[i], right[i]); } return result; } // 不一致のとき else { return null; } } class hogejson { public string hoge { get; set; } public string hogehoge { get; set; } public string hogehogehoge { get; set; } } //hoge.jsonを読み込むためのメソッド public Dictionary<string, string> GetHogejson(string filename) { try { string jsonfile = ReadAllLine(filename, "utf-8"); hogejson jsonData = JsonSerializer.Deserialize<hogejson>(jsonfile); string[] json_key = { "hoge", "hogehoge", "hogehogehoge" }; string[] json_value = { jsonData.hoge, jsonData.hogehoge, jsonData.hogehogehoge }; var result = ListInDictionary(json_key, json_value); return result; } // jsonが読み込めない時 catch (JsonException) { return null; } } } class Program { static void Main(string[] args) { library Library = new library(); Dictionary<string, string> gethogejson = Library.GetHogejson("hoge.json"); string hoge, hogehoge, hogehogehoge; hoge = gethogejson["hoge"]; hogehoge = gethogejson["hogehoge"]; hogehogehoge = gethogejson["hogehogehoge"]; Console.WriteLine(hoge); Console.WriteLine(hogehoge); Console.WriteLine(hogehogehoge); Console.WriteLine(hoge.GetType()); Console.WriteLine(hogehoge.GetType()); Console.WriteLine(hogehogehoge.GetType()); } } }...自分でも感じた、強引すぎると...
問題点
- valueがint型だろうとなんだろうとstring型にしてresult(辞書型)に格納する。
- 結局jsonデータのクラスを指定しなければならないので、根本的な解決には至っていない。
- とりあえず思いついた発想と知恵で強引に作ったので、見られたら怒られるくらいのガバコード
個人的にはPythonのように使えるのが一番ありがたいですが、あまりに強引すぎて怒られるような気がします。
ちなみに結果は
hoge1 hoge2 hoge3 System.String System.String System.Stringこんなふうに表示されます。
最後に
この方法よりこっちのほうが使いやすいよ!
ガバすぎだろもっとこうするべきだ等あれば、ご遠慮無くぜひコメントまで!
結構真剣に困っていたので、また時間があれば改良してみます。久々に書ききりました。
おやすみなさい。引用元
https://usefuledge.com/csharp-json.html
https://json2csharp.com/ (先程のjsonデータクラスをjsonデータをもとに作ってくれるサイト、めっちゃ便利)
Thank you!!!!!
- 投稿日:2020-11-13T19:53:58+09:00
C#でjsonを読み込み・そして辞書型に変換(強引)
お久しぶりです。
Qiitaの皆さん、お久しぶりです。
前回からかなり時間が空きすぎましたが、あれから念願の新しいパソコンを購入しました。
そしてPythonにも飽きてきたので、C#に手を出してみることにしました。理解するメモとして書き残しておきます。
ガバな点はご容赦ください。ふと思ったjsonの読み込みについて
私は以前、Pythonでjsonを使用して設定ファイルやデータをイチイチに定義しなければならないものをjsonに格納して便利に使っていたので、ぜひC#でも使いたいと思い模索しました。
薄々気づいてはいましたが、Pythonはなんて素晴らしいライブラリを取り揃えているのかと思い知らされることになりました。json読み込みのコード
hoge.json{ "hoge": "hoge1", "hogehoge": "hoge2", "hogehogehoge": "hoge3" }Pythonでのjsonの読み込みはjsonライブラリを使用しますが
import json def load_json(filename): with open(filename) as files: load = json.load(files) return loadこのように関数を一つ定義してしまえば、辞書型で帰ってくるので
result = load_json("hoge.json") hoge1 = result["hoge"] hoge2 = result["hogehoge"] hoge3 = result["hogehogehoge"] print(hoge1) print(hoge2) print(hoge3) print(type(hoge1)) print(type(hoge2)) print(type(hoge3))hoge1 hoge2 hoge3 <class 'str'> <class 'str'> <class 'str'>こうすると簡単にstrやintで帰ってきますので、あとは煮るなり焼くなりすれば簡単に使うことができますが
(ガバコードデゴメンネ)C#の場合
using System; using System.IO; using System.Text; using System.Text.Json; namespace ConsoleApp2 { class Program { public static string ReadAllLine(string filePath, string encodingName) { StreamReader sr = new StreamReader(filePath, Encoding.GetEncoding(encodingName)); string allLine = sr.ReadToEnd(); sr.Close(); return allLine; } class hogejson { public string hoge { get; set; } public string hogehoge { get; set; } public string hogehogehoge { get; set; } } static void Main(string[] args) { string readjson = ReadAllLine("hoge.json", "utf-8"); hogejson jsonData = JsonSerializer.Deserialize<hogejson>(readjson); string hoge = jsonData.hoge; string hogehoge = jsonData.hogehoge; string hogehogehoge = jsonData.hogehogehoge; Console.WriteLine(hoge); Console.WriteLine(hogehoge); Console.WriteLine(hogehogehoge); Console.WriteLine(hoge.GetType()); Console.WriteLine(hogehoge.GetType()); Console.WriteLine(hogehogehoge.GetType()); } } }hoge1 hoge2 hoge3 System.String System.String System.Stringこんな感じで記載しないとうまく読み込まないのですが、一番個人的に面倒なのが
「jsonのクラスを作らないといけない」
のと
「メソッド(Pythonでいう関数(若干違うけど))作った時わかりにくい!
ことが引っかかりました。なぜこんなことになってしまったのか
Pythonは先程の関数で帰ってくる返り値は辞書型に対してC#は特定の返り値を指定しなければなりません。
このため、Pythonでは辞書型で帰ってくるのでhoge = result["hoge"]とresultに指定定するだけでkeyである「hoge」のvalue「hoge1」を取り出すことができますが
対してC#は、例えば「hoge.json」のkeyである「hoge」のvalueが「hoge1」であったとき、クラス「hogejson」のhogeにstring型(str)でセットされます。
逆にこれをint型や別の型でセットしようとしてもできません。なぜなら、クラスhogeの返り値はstringと決めているからです。
そのためPythonでよくお世話になった辞書型に返り値には指定されていないため、仮に返り値を"勝手"に辞書型に指定しても他の「hogehoge」や「hogehogehoge」のkeyはおろかvalueの情報すらありません(自己解釈)ほんじゃあ辞書型に返ってくるように作ろう!笑
探してみたところ、C#には「Dictionaryクラス」というものが存在するようで、それでPythonの辞書型と同じように使えるみたいです。
なら話は早いです、hoge.jsonのkeyとvalueを辞書型に詰め込めるよう試行錯誤を繰り返してできたのがこちらです。
using System; using System.Collections.Generic; using System.IO; using System.Text; using System.Text.Json; namespace ConsoleApp2 { class library { // ファイル読み込み public string ReadAllLine(string filePath, string encodingName) { StreamReader sr = new StreamReader(filePath, Encoding.GetEncoding(encodingName)); string allLine = sr.ReadToEnd(); sr.Close(); return allLine; } // List型をDictionary型に強引に変換する public static Dictionary<string, string> ListInDictionary(string[] left, string[] right) { // 一致したとき if (left.Length == right.Length) { var result = new Dictionary<string, string>(); // leftのListの数の分だけforを回す for (int i = 0; i < left.Length; i++) { // resultに辞書を追加 result.Add(left[i], right[i]); } return result; } // 不一致のとき else { return null; } } class hogejson { public string hoge { get; set; } public string hogehoge { get; set; } public string hogehogehoge { get; set; } } //hoge.jsonを読み込むためのメソッド public Dictionary<string, string> GetHogejson(string filename) { try { string jsonfile = ReadAllLine(filename, "utf-8"); hogejson jsonData = JsonSerializer.Deserialize<hogejson>(jsonfile); string[] json_key = { "hoge", "hogehoge", "hogehogehoge" }; string[] json_value = { jsonData.hoge, jsonData.hogehoge, jsonData.hogehogehoge }; var result = ListInDictionary(json_key, json_value); return result; } // jsonが読み込めない時 catch (JsonException) { return null; } } } class Program { static void Main(string[] args) { library Library = new library(); Dictionary<string, string> gethogejson = Library.GetHogejson("hoge.json"); string hoge, hogehoge, hogehogehoge; hoge = gethogejson["hoge"]; hogehoge = gethogejson["hogehoge"]; hogehogehoge = gethogejson["hogehogehoge"]; Console.WriteLine(hoge); Console.WriteLine(hogehoge); Console.WriteLine(hogehogehoge); Console.WriteLine(hoge.GetType()); Console.WriteLine(hogehoge.GetType()); Console.WriteLine(hogehogehoge.GetType()); } } }...自分でも感じた、強引すぎると...
問題点
- valueがint型だろうとなんだろうとstring型にしてresult(辞書型)に格納する。
- 結局jsonデータのクラスを指定しなければならないので、根本的な解決には至っていない。
- とりあえず思いついた発想と知恵で強引に作ったので、見られたら怒られるくらいのガバコード
個人的にはPythonのように使えるのが一番ありがたいですが、あまりに強引すぎて怒られるような気がします。
ちなみに結果は
hoge1 hoge2 hoge3 System.String System.String System.Stringこんなふうに表示されます。
最後に
この方法より「こうしたほうがいいよ~・
ガバすぎこれを使え」等あれば、ご遠慮無くぜひコメントまで!
結構真剣に困っていたので、また時間があれば改良してみます。追記
これなんなんですかね?よく出てきて動かなくなります。
こうなるともう保存して起動し直すしかないのでめっちゃ不便です。久々に書き切りました。
おやすみなさい。引用元
https://usefuledge.com/csharp-json.html
https://json2csharp.com/ (先程のjsonデータクラスをjsonデータをもとに作ってくれるサイト、めっちゃ便利)
Thank you!!!!!

- 投稿日:2020-11-13T19:50:09+09:00
4年間ほどデータエンジニアをしてみたので所感や知見を雑多に書き出してみる
4年ほどデータエンジニアをしてみて、いろいろ振り返りつつ実際に経験してみて得られた所感や知見を上長から許可もいただいたので雑多に記事にまとめてみます。
注意書き
- ゲーム業界の話です。web業界では色々話が変わってくるところも多いかもしれませんし、同じ業界でも会社によって様々だと思います。
- ここに書いたことが他の環境ではうまくいかないケースも多々あると思います。異論も色々あると思います。状況に合わせたイレギュラーなことも結構やっています。一つの事例程度としてお考えください。
- ポエム成分を含むかもしれません。
集計やETLの全ての処理は冪等性を極力担保する
集計やらETLの対応はツールやサービスのGUIだったり、自前でPythonなどのコードやSQLを書いたりと様々だと思いますが、すべての処理で冪等性が担保できているということが大事です(任意の過去のデータも含め、何度集計などを流しても同じ集計結果になる状態)。
冪等性参考 : 冪等性とは「同じ操作を何度繰り返しても、同じ結果が得られる性質」のこと
基本的には後述するように念入りにチェックなどをするものの、多くの対応をしていると一部にミスが見つかったりも発生しうるものになります。
また、何らかの影響で日々の集計などが一部の処理が通らないといったケースが発生することも、頻繁にはありませんが数か月に1回くらいは発生しています。
そういった場合に過去の日付に対して処理を流しなおしが必要になることもあれば、直近のデータに対して処理を流し直す必要が出てきたりします。
そのようなケースが発生したときに、ごく一部でも冪等性が担保されていないところがあると大分しんどいことになりえます(大半の処理は冪等性が担保されるのが一般的ですが、ごく一部定期処理の中に担保されていないものが混じっているケースなど)。
しっかり気を付けていても大量に処理があると「え、そこで引っかかるの?」といったことも発生しますし、ログ側の都合で巻き込まれる形で流し直しになりうるケースも起こり得ます。
なので処理を書く際には「障害は起きるもの」として対応し、「過去の処理を流し直す場合どのくらいで対応できるだろうか?」といったことを意識しておくといいと思います。
日々のチェックの処理を面倒臭がらずに仕込んでおくと後が楽
データ基盤だと、大半のケースでは時系列的なデータを持つことが大半だと思います。
毎日多くのデータが蓄積されていきます。うちはデータ基盤は各プロジェクト横断的に対応しているので、新しい社内のプロジェクトがリリースされたら増加ペースが早くなります。古いプロジェクトが終了した場合でも過去の分析をしたい・・・という要望を考えると終了プロジェクトのデータも消さずに残す形で運用していきます。
結果としては非常に長期の期間のデータを扱う必要が出てきます。ゲーム業界だとスマホゲームとかだと開発3年、運用5年といった長期にプロジェクトがなるケースも珍しくは無くなってきました(開発費の高騰などの影響も含め)。
そういった状況で、集計などの処理が「後々になってからミスが見つかった」みたいなケースが発生すると、結構対応が面倒なことになります。
特に追加した処理を反映してからミスに気づくのが数か月後とか、年単位で経過していると大分対応に時間が持っていかれるケースがあります(特に利用頻度が低いデータだと、目に見えづらいことも絡んで気づくのが遅れたりします)。
そういったケースをなるべく減らして楽をするために、チェック用のスクリプトなどはしっかりさせておくと後々の負担がぐぐっと減ります。
弊社のデータ基盤の場合、集計処理やETLの多くをPythonとデータサイエンス方面のライブラリに頼っています(ETLなどでBigQueryやAthenaでのSQLを大量に書くといったことは少な目)が、基本的にはほぼほぼの行カバレッジを確保する形で集計処理などに対する単体テストは書いています。
SQLやら外部サービスなどを使う場合でも、ミスしていないかのチェック用にスクリプトを書いたりは大切かなと思います。また、デイリーなどで「集計結果大丈夫だよね?」といったことを確認するための様々なチェック処理が流れるようにしています。
他にも「送っていただいているログ側が何だかおかしいぞ?」といったことのチェックも色々入れたりもしています(なんらか引っかかったらチャットに通知し、早い段階でプロジェクト側に連絡をしたり等ができるようにしています。データソースで問題がありそうであればプロジェクト側の方が気づくよりも先に気づけるくらいが理想)。
加えて集計後のものに対する検算対応であったり、プロジェクトのドメイン知識が浅かったりもするので「この集計結果、違和感ないでしょうか?」みたいなことをプロジェクトに張り付いている分析担当の方に確認していただいたりなど、多重にチェックを入れたりもしていました(プロジェクト固有の数値の感覚は、プロジェクト側の方の方が鋭かったりもするため)。
若干チェックに力を入れすぎ・・・と感じられるかもしれませんが、前述のように長期間経過してからミスに気づくと結構地獄です。
また、修正を入れるときも各プロジェクトへの説明が必要になったり、今までの意思決定が誤った数字によるものになってしまう恐れもあります。
そういったリスクを加味すると、チェックは「やりすぎ」くらいが結局長期的には楽になったりします。なんだかんだそれくらいチェックしていてもミスするときはミスしますが、データ基盤の仕事を始めたころのチェックが甘い時と比べれば大分負担が減っています。
速度は大事
いくらチェックなどを頑張っていても、ミスやエラーなどが発生するときは発生します。
また、途中で追加の要望をいただいたりすることも結構あります。
そのようなケースで数か月、場合によっては年単位の処理の流し直しが発生することも結構あります(特に要望系は障害などと比べると結構多く発生しますし、会社への貢献という面でいうとなるべく要望に対応すべきとは考えています。差し込みタスクとなってしんどい時もありますが)。
流し直しが必要になった時に、冪等性などが担保されていても処理速度が遅いと辛いことになります。
仮に1日分で必要な処理が1分くらいで終わるとしても、1か月分で約30分、1年分で約6時間。
3年分とかの依頼が来ると結構辛いです(一方で案外そういった年単位の依頼は来たりします)。
なるべく楽をするためにも一日分の処理をなるべく速くしたいところです。データレイクやDWHなどは速いものを利用する(BigQueryなりS3なりで)、パーティションの利用などはきっちりとやる、PythonスクリプトやSQLなどで遅くならないように注意する、事前に細かく速度を計測しておく、知らないうちにログが大きくなっているデータセットでパフォーマンス的に問題を抱えていないかなどを継続的にチェックする、アラートの仕組みを整えておくなど、配慮すべき点は様々です。
年経過でPython界隈も色々改善しているライブラリが出てきたりもしていますので、そういった新しいものに少しずつ切り替えていくといったことをすることもあります(PandasやNumPyを良く使っていたコードの箇所で、DaskやVaexを検討するなど)。
諸々の処理のコードなどの保守性も意識する
※注記 : プロダクション環境のスクリプトなどの話となります。例えばJupyterのノートブックなどもそうですが、色々試行錯誤したいタイミングでテストだ、Lintだ、docstringだ・・・と(使い捨てのノートブックなどで)気にするのは非効率なケースも多く、そういったものは以降の節では含みません。
- notebookはあくまでもアドホックな「らくがき帳」「試行錯誤するためのサンドボックス」である*12
- 「よっしゃこれはイケるぞ!」ってなった段階でちゃんとしたプロダクトのコード(テストコードを含める)に落とし込むべき
データ分析者たちのコードレビュー #とは - 散らかったJupyter notebookを片付けるかどうするか問題を考える
集計やETLの処理などは日々増えていきます。弊社の場合、集計以外の内製・補助的なツール部分・施策やRCTの実行など諸々を全て含めるとデータ基盤のプロジェクトがこの記事を書いている時点でファーストコミットから7年目、10000弱のコミット、Pythonのdocstringやテストなども含めたスクリプトが約36万行ありました。
ゲーム業界の各プロジェクトが長期戦がデフォルトな件・且つ弊社の場合データ基盤が各プロジェクト横断的に担当しているため、社内の中でも大分長期プロジェクトになっています(多くのベンチャーが10年未満で無くなることを考えると、1つのプロジェクトで7年って大分長く感じます・・・)。
そうなってくると人の異動なども勿論発生しますし、半年前のスクリプトなどは自分が書いたものでも記憶が曖昧になってきたりもします。他の人からみても自分が後で読み返しても、瞬時に内容を把握できる読みやすいスクリプトやSQLなどである必要があります。
長時間かければ読めるという状態だと、スクリプトやらが膨大になってくると作業効率的に辛くなってきます。なるべく瞬時に理解できるという状態が理想です。
特にデータエンジニアという職種は会社の規模にもよりますが、通常のゲームクライアントのエンジニアさんやweb業界でのフロントエンジニアさん、サーバー・インフラエンジニアさん達と比べると少人数になりがちです。
数人といったケースや、場合によってはベンチャーなどで人数が少ないフェーズでは1人、もしくは専任のデータエンジニアが0人でサーバーサイドの方が兼任というケースも結構あるかもしれません。なるべく人数が少なくても効率良く仕事をさばけるようにすることが大切です。
読みやすいコードにするため、Pythonのスクリプトであればdocstringをしっかりと書く・1つの関数で循環的複雑度(or認知的複雑度)などが高くならないようにしたり行数を短くしたりして、テストなどが書きやすいものを多くする・各種Lintを利用する・型アノテーションを利用する・他の方の事前のレビューを挟むといったことが挙げられます。
データセット(データレイクやDWHなど)であればメタデータをしっかり保守するという点も含みます。
普通のプロジェクトで必要になるものに似たようなものが多めですが、集計やETLのコードでも長く保守するものは同様にコードを綺麗に読みやすくするためのものは可能であれば導入しておくといいと思います。
弊社のケースであれば、以下のようにやっています。
docstring
基本的に全てのコードに対してNumPyスタイルのdocstringを書く形で進めています。
この辺りの書き方は自分でも以前記事にしているので、同僚の方にそちらを確認いただいたりしています。[Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
また、「うっかり書き忘れていた」「コード書き換えていたらうっかり引数などのdocstringがずれていた」といったケースも結構発生します。Pythonスクリプトでテストを基本的に書く形で保守している都合、気軽に変更がデプロイできるのでコードの頻繁な変更も入ったりしており、その分docstringとコードの内実がずれたりが発生しがちです。
この辺りは人の目だとミスを見落としたりしがちなので、本番反映される前にCI的にdocstringのLintを通してからデプロイされていく形で運用しています。
NumPyスタイルのdocstringのLintは要件に合うものが見つからなかったため自作しています。
NumPyスタイルのdocstringをチェックしてくれるLintを作りました。
プロジェクトの途中からこのLintを入れたのですが、docstringの記事を自分で書いておきながらLintをプロジェクトのスクリプトに反映したら自分で書いたコードでも結構Lintに引っかかる点が見つかりました。人の目に頼らずにLintを通る環境にしておくことが大事です(自戒)。
また、複数人で作業する際にもLint任せでdocstringの不足やずれなどのチェックがレビューで不要になったのでその辺りも負担が減って良かったなと思っています。
循環的複雑度(or 認知的複雑度)や行数について
ifやらtry-exceptやらforやらがたくさん入れ子になっていたり、1つの関数やメソッドがとても長いと読むのが大変ですしテストを書くのもハードモードになってきます。
スクリプトだけでなく、他人が読んだり引き継いだりするのが無理ゲーに感じられる複雑なSQLも同様です。
そういったスクリプトを避けるために、循環的複雑度(cyclomatic complexity)という指標があります。
循環的複雑度とは、ソフトウェア測定法の一種である。Thomas McCabe が開発したもので、プログラムの複雑度を測るのに使われる。プログラムのソースコードから、線形的に独立した経路の数を直接数える。
循環的複雑度 - Wikipedia以下の記事が循環的複雑度について分かりやすくまとめていらっしゃいます。
記事にある通りifやらforやらが関数内などで増えていけばその分読むのが辛く、テストなども書きづらくなってきます。体感的には関数1つで複雑度5以下、docstringなどを除いた行数40行以内くらいのものが大半になっていると快適だなぁと感じています。
ただし、テストの書きやすさに関してはprivateのものに対してもテストを書くか / 書かないかによっても変わってきます(publicのものにだけテストを書く場合はprivateのものを細かく関数分割してもあまりメリットが少ないなど)。
privateのものにテストを書くかどうかは、privateのものにテストが書きやすい言語かどうかなども絡んできますし、プロジェクトごとの選択次第でどちらが正解というものでもないと思っています。
Pythonの場合はprivateの場合は関数名やメソッド名の先頭にアンダースコアを付けるだけの運用(Pylanceなどでprivateのものに対してチェックの挙動が変わったりはするものの、実際には外部からはアクセスができます)となるため、テストモジュール側からもprivateのものへのアクセスはでき簡単にテストは書けるので書く形で運用しています。
複雑度の低いprivateのものに細かくテストを書くことで、個々のテストの関数がシンプルになりますし、問題が出た時に問題箇所の特定が素早くできるなどのメリットは享受できています。この辺りはプロジェクトに応じてベストなやり方を選択ください。
弊社プロジェクトの現状ですと明確にLintで縛ったりはしていませんが、ぱっと見で複雑度が高そうであれば直したりレビューでコメントしたりといった形で運用しています(近いうちにLintの導入を検討する、といったissueは登録されている段階)。
Lintなどで運用する場合には循環的複雑度をチェックしてくれるflake8のプラグインなどもあります。
また、JupyterLabなどであればLanguage Server Protocol用の拡張機能などで組み込まれていたりもします。
- Language Server Protocol integration for Jupyter(Lab)
- ついにJupyterLabの入力補完??Tab押さずに補完してくれるjupyterlab-lspを試してみた
また、循環的複雑度よりかはもっと新しいもので、認知的複雑度(cognitive complexity)という指標も存在します。
Cognitive Complexity でコードの複雑さを定量的に計測しよう
たとえば、
if ... : if ... : if ...: for ... : ...といったコードと
if ... : return if ... : return if ... : return for ... : ...みたいなコードでは、循環的複雑度では複雑度が同じですが、人からすると前者の方が読みづらいコードになります。認知的複雑度だと人にとっての感覚に近い形で複雑度がカウントされるので、前者の方が数値が高くなります。
flake8の拡張機能のものも含めて、ライブラリはいくつかPyPI(pip)に登録されています。
各種Lint
弊社のプロジェクトの場合、ETLやら集計などのを扱うPythonスクリプトに関してはコードを綺麗にしたりスタイル統一のために以下のLintを導入しており、一通りのLintを通ってから本番にスクリプトが反映される形で運用しています。
- autoflake -> 使われていないimportやローカル変数などの自動削除
- autopep8 -> 修正ができる範囲での自動のPEP8を準拠する形へのスクリプト変換
- isort -> PEP8に準じる形でのimportの整形
- flake8 -> autoflake、autopep8、isortを通しても引っかかるPEP8の点のチェック
- numdoclint -> 前述のdocstringチェック用
Blackなど含め、他にも色々Lintは世の中にありますのでプロジェクトに合わせて好きなものを選択いただければいいと思います。
PEP8に関しては以前記事を書いているので、そちらを同僚の方に共有したりしています。
[Pythonコーディング規約]PEP8を読み解く](https://qiita.com/simonritchie/items/bb06a7521ae6560738a7)
Lintでどのように更新されたり引っかかったりするのかを日々見ていると、「規約的にどのように書くべきなのか」「このルール間違って認識していた」といったことに気づけて勉強になります。
また、コードスタイルが強制的に統一されていくので、複数人で作業しても似たようなコードになってきて他人のコードでも読みやすくなります(人による癖などが減り、プロジェクト全体で統一感が増します)。
Lintに任せられるところはチェックを省けるので、コードレビューなどでの負担も減ります。
途中からLintを加えていくのもアリ
既にスクリプトなどが稼働中の場合、途中からLintを入れるのに抵抗がある・・・といったケースもあるかもしれません。
弊社のプロジェクトでも、私は途中からプロジェクトに参加しましたが、当時はLintが導入されていませんでした。
各種Lintは途中から入れたのですが、以下のように入れていきました。
- モジュール(スクリプトファイル)単位で、各Lintで有効にするものを設定できるようにします。
- テストの追加が終わっているモジュールに対して、問題が無さそうであればLintを有効にする設定を追加します。
- Lint有効化の設定がされたモジュールのLint反映結果がテストを通ることを確認します。
- テストが無いモジュールに関してはLintの追加を後回しにします。
- ※現在はほぼほぼのテストカバレッジが確保されていますが、当時はテストが無いモジュールもかなり存在していました。
- ※テストが無いモジュールに関しては、Lint有効化よりも先にテストを追加する方を優先します。
こうすることで日々少しずつLint設定が有効化されたモジュールが増えていく形となり、一気にLint反映・・・とならない(小出しに変更が細かくデプロイされていく)ですし、テストを通っているので一層安心して進めることができます。
また、小出しにLintを導入できる形にしたので、新しいLintの追加なども気持ち的なハードルが下がり、複数のLintの導入に繋がっています。
加えて、日々各Lintの有効化されているモジュール数のカバレッジを通知するようにしたり、各Lintで有効化されていないモジュールはどれなのかがすぐに確認できるようにしていました。
少しずつLintのカバレッジが高くなっていく推移を毎日眺めつつ過ごすのも、闇雲に進めるよりも進捗が分かりやすくて気持ち的にプラスに働いた気がします。
型アノテーション
Pythonなどが静的型付け言語ではないので、型を書かなくても動きますが、やはり型情報を書いてリアルタイムにチェックなどが走っていると、事前にミスに結構気づくことができます。
もしPythonなどを結構使われている場合には、積極的に利用するとより堅牢・保守しやすいスクリプトになります。このあたりの型アノテーションは以前記事を書いたり、他の方が書かれていたりするので引用やリンクだけ貼っておきます。
Python は、動的型付けを備えているから楽しいという部分もあるかもしれませんが、全体を見通しにくくなる場合があります。
...
静的型チェックの鍵は、規模です。プロジェクトが大きくなればなるほど、静的型チェックの必要性を感じるようになります(最終的には必須になります)。
...
型チェッカーは大小問わず多くのバグを見つけます。「None」 値などの特別な条件の処理が忘れられているような場合が、よくある例です。
Python の型チェックが 400 万行に到達するまで
- Pythonではじまる、型のある世界
- 入力補完を充実させ、より堅牢なPythonコードのための型アノテーションとPyright入門
- [Python]PylanceのVS Code拡張機能をさっそく使ってみた。
- Pythonで型を極める【Python 3.9対応】
なお、最近の3.9や3.10のPythonバージョンでも色々型アノテーション関係のアップデートが入っています。もしアップデートが現実的な場合には新しいPythonバージョンの方が色々便利だと思います。
データセットのメタデータ
データレイクやDWHなどのデータに対するメタデータ(テーブル説明やらカラム説明やら、データ更新タイミング、補正の入ったタイミングの情報など)の資料の保守は大切です。
普段の作業で資料がないと結構データの把握で時間がかかってしんどいですし、データを誤解して集計をミスするといったリスクも高まります。
新たにアサインされた方のキャッチアップのしやすさ的にも、しっかりログなどに更新が入ったタイミングで資料をアップデートしていくことが大切です。
メタデータの資料が無いと謎のテーブルがたくさん量産されている、削除していいのか判断が難しい、ディスクコスト的に無駄が多い・・・といったことも発生するかもしれません(集計用の中間テーブルなどで)。
この辺りはクラウドサービス側でも用意されていたりもしますし、うまいこと保守できればやりやすい形でいいと思います。ただし共有サーバーにエクセルで資料を置くといった対応は保守されなくなるケースが経験的に多めです(n=4くらい)。
エクセルでの保守が厳しそうであれば、「更新が楽」「開くのに時間がかからない」「ファイルが乱立しない」「検索のUXが良い」「できたらバージョン管理して欲しい」辺りを意識しつつ良さそうなサービスやツールなどを選択するといいと思います。
ごく短時間で更新が終わらせられるといった点が、ちゃんと保守されるかどうかに絡んでくるので検索してすぐ見つかる・すぐ開けるといった点も大事です。
弊社の場合、会社の都合でGCPのBigQueryではなくAWS環境を使っているのです(その辺りは後々触れます)。
Athenaなども利用しつつ、同じデータソースでS3をマウントしたりしてPython(PandasやらDaskなど)でも直接扱えるようにしています(SQLだけでなくPythonを使って色々できると楽なので)。
また、データの扱いもDjangoのORM的に扱え(内部でDaskなどを使いつつ)、モデルを追加する(DWH的なところにテーブルを追加する際など)には「メタデータを追加しないとモデルが定義できない」形にしてあります(且つ、モデルを追加するとAthena側でのテーブル生成やパーティション更新などが自動でされるようにしてあります)。
モデルを指定するとメタデータのマークダウンが出力できるようにもしてあり、これによってDWH環境にテーブルを追加する際にメタデータの追加を忘れるといったことが無い形で運用ができています。
プロジェクトごとの個別のデータ基盤にするべきか?社内横断的なデータ基盤にするべきか?の話
プロジェクトごとに個別にデータ基盤やらBIなどの環境を組むか、もしくは独立したデータ基盤のチームが担当して、各プロジェクト共通の基盤にするべきか?というトピックが話に出ることがあります。
これに関しては様々な意見があるでしょうし、私もいまだに正解がどちらなのか分かっていません。弊社だと横断的に共通基盤で対応しており、個別に作るケースを経験したことがありませんので参考程度となりますが、個人の主観によるメリット・デメリットに触れておきます。
共通基盤にする場合のメリット
ぱっと思いつくもので以下のようなメリットがあります。
- 2個目以降のプロジェクトの対応が楽
- 人やプロジェクトによる些細な集計の違いによるズレが起きづらい
- 他のプロジェクトのログで、まだ試していないものの傾向が調べられる
- 人のプロジェクト異動の際の学習コストを抑えられる
それぞれ細かく触れていきます。
2個目以降のプロジェクトの対応が楽
弊社の場合ゲーム業界なので、各プロジェクトで共通で確認が必要なKPIというものが色々存在します。
それらの集計のコードは各プロジェクトで共通で回してあり、可視化なども含め共通コードで処理されています。
そのため新規プロジェクトの対応依頼が来たときにはデータレイクなどに送っていただいているログを参照してETLを行い、各プロジェクト共通のフォーマットのテーブルを追加するだけで様々なKPIの可視化まで含めたダッシュボードやその他のBIツール上の機能の対応が終わります。楽です。
特にゲーム業界だとリリース直後に広告などを頑張ったりする都合、リリーススケジュールがずらすのが難しかったりするものの、一方でデータレイクのデータ対応が結構リリースギリギリになったりもするケースがあるのでリリース前にさくっと対応が終わるというのは大切です。
また、既に他のプロジェクトで経験を積んだメンバーが他プロジェクトも担当することになるので、「どんなKPIが必要なのか」「どんな作業が必要なのか」「どんなことに気を付ける必要があるのか(リセマラユーザーやらbotやら不正ユーザーやら)」といった点で経験値が溜まっているというメリットもあります。
人やプロジェクトによる些細な集計の違いによるズレが起きづらい
集計などをする方が各プロジェクトで別だと、ちょっとした集計の差やログの差で結果が結構ずれてしまいます。
例えばAプロジェクトではリセマラやbotの判定を〇〇する形でやっているけど、Bプロジェクトでは××の形で集計している、といった類のものです。
密にコミュニケーションを取らないと人によってKPIの細かい定義の差が発生することもあります。
また、密にコミュニケーションを取っていても〇〇のフィルタリングを入れるタイミングがAさんとBさんで微妙に違ったため数値が合わない・・・といったことも発生したりで、ちょっとしたSQLやスクリプトの内容の差でずれたりもします。
このズレは世間が思っている以上に発生しやすく、ぴったり合わせるのは大分骨の折れる作業になります(特に複雑な集計になるほど)。
また、ズレていると会社としての意思決定のミスにも繋がりかねません。
(例 : AプロジェクトはROASの数値が良かったのでAプロジェクトに広告費を多く使ったものの、実はAプロジェクトの方が有利な集計内容になっていて本当はBプロジェクトの方が広告回収効率が良かった等)ズレた時に「なんでずれているの?」と各所から質問が来たりもしますがその説明も結構負担になります。
データエンジニアリソースが不足しがちなことを考えると、この辺りのコミュニケーションコストの負担はなるべく抑えてるためにも、大部分の集計コードやSQLなどは各プロジェクトで共通化できるとズレが少なくできて楽です。
人のプロジェクト異動の際の学習コストを抑えられる
これはまあ・・・会社でツールやサービスを統一すればいい話ではありますが、一方で日頃新しくイケてそうなツールやサービスなどがどんどん生まれているのも事実です。
「新しいプロジェクトでは〇〇を使ってみよう」という話が出るのも良くあることですし、そういった新しいものを積極的に試すことも大切だと思います。
一方で日々忙しくしているブロデューサーの方やプランナーの方からすると、ツールの使い方の勉強時間はなるべく抑えて企画などを考えるのに注力したい・・・という意見もあるかもしれません。
各プロジェクトであまりに使うツールやサービスがばらばらになりすぎると、異動時のキャッチアップが少し大変かもしれません。
共通基盤・共通ツールだとその辺りの学習コストが抑えられますし、過去のプロジェクトでのツール上での設定や記述なども使いまわしたりもすることができます。
ただし古いものを使い続けることになりがちなので、この節の内容に関しては光と闇の両面がありそうです。
他のプロジェクトのログで、まだ試していないものの傾向が調べられる
共通の基盤・同じフォーマットのログデータなどを揃えておくと、リリース前のプロジェクトや未リリースの施策などで、別のリリース済みのプロジェクトの内容や施策結果がどうだったかなどを他部署の方が分析したりといった利用もすることができます。
実際にAプロジェクトの方がBプロジェクトの数値を見たり分析をしたりといったことは弊社でも見受けられます。
すぐに複数プロジェクトで比較したりもできるため、例えば役員の方が横断的に比較したいといったときにさくっと切り替えが出来るなどのメリットもあります。
共通基盤にする場合のデメリット
デメリットの方は以下のものがぱっと思いつきました。こちらもそれぞれ詳しく触れていきます。
- 技術が固定化されがちで、新しい言語やライブラリへのアップデートが大変 / 新しいサービスの利用がやりづらい
- プロジェクトが増えてくると、少人数のチームで回すのが大変になってきそう
技術が固定化されがちで、新しい言語やライブラリへのアップデートが大変 / 新しいサービスの利用がやりづらい
新しいプロジェクトでは過去のしがらみが少ないので新しい技術やサービスなどを試してみる・・・という選択肢が取りやすくなります。
また、プロジェクトの終了に伴い基盤も停止させたりする場合には保守の負担も減ります。
一方で共通基盤とすると、年数経過でデータ量・データの種類・スクリプトやSQL・可視化結果などがどんどん増えていきます。
弊社もたくさんのPythonスクリプトがありますが、動いているそれらを維持したまま新しいバージョンにしたり、古いデータ環境を切り落としてもっと優れて安いものに引っ越ししたり・・・といったことは必要になったりします。中々骨の折れる作業です。
そういった移行作業などの際に前述したテストをしっかり書いているかどうかが結構響いてきます(というよりもテストが無い場合・もしくはカバレッジが低い場合移行が出来る気がしません)。
稼働中のものになるべく障害やダウンタイム的な影響を出さずに切り替えや切り落としなどを進めていく上では、ストラングラーパターン的な対応をしたりしていますが、新規プロジェクトで新しいサービスの利用を進めるケースよりも負担が大きいことは間違いありません。
結果的には共通基盤にすることで基盤の寿命が長くなり、古い部分が結構出てきてしまったり、新しくする人的リソースが確保できなくなる(そこまで手が回らない)可能性は出てきます。
便利そうなツールやサービスは新しいものがどんどん出てきていますし、同じクラウドでも新しいサービスが日々出てきています(特にAWSはサービス多すぎ感が強い)。
もしくはプロジェクトの海外展開で、中国展開が必要だけどGCPの中国リージョンが無いからAWSにしようとか、逆に今後はGCPの便利な機能を使ってGCPメインにしていこうとか、Office関係と連携を楽にするためにAzureメインにしようといったようなクラウド自体の引っ越しも起こり得るかもしれません。
BigQueryだけGCP、他AWSみたいな選択は多いと思いますが、会社の管理面などの都合でマルチクラウドではなくAWS/GCPどれかに統一しようとかそういった選択をする会社もあると思います。
これらを加味すると、切り替えや新しいものの利用が気軽にできないというのはデメリットに感じます。
プロジェクトが増えてくると、少人数のチームで回すのが大変になってきそう
複数プロジェクトを横断的に対応していると、質問や要望などで多方面からチャットが飛んできます。
各プロジェクトのプロデューサー・ディレクター・プランナーの方々からの質問や要望であったり、マーケの方からのものだったり、役員の方からの質問や依頼だったり、各プロジェクトのエンジニアさんとのやりとりだったりと様々です。
プロジェクトが増えてもデータエンジニアが増えればまあ何とかなるかもしれませんが(あまりに人数が多くなったらチーム分けたりは必要になるかもしれませんが)、基本的にはプロジェクトが増えたタイミングでデータエンジニアが増えたり・・・はしないことが多いと思います。基本的には今の人的リソースで何とかするといったケースが多いと思います。
また、プロジェクトが増えなくても日々データが積みあがって増えていったり、集計のスクリプトが増えていったりもします。
今の所私はほとんど残業せずに、有給などもしっかり取る形で過ごせていますが、今後のプロジェクト増などで状況が変わってくる可能性もあります。負担が各プロジェクトに分散せずに、共通基盤部分に集中していってしまうというのは一応デメリットではあるかもしれません。
使い方研修をしなくても色々な人に使ってもらえるUIを目指す
話は変わってUIなどの話です。元々デザインの学校を出てデザイナーのお仕事をしたり、ゲームのクライアントエンジニアをしていて「演出こだわるの楽しい!」といった経歴なので、弊社の場合BIツール部分が内製になっておりUIや見せ方にこだわるのは楽しい作業です(ちなみに同僚の方も元ゲームクライアントの方でセンスが凄いという・・・)。
BIツールが使いづらいUIだと中々社内の利用率が上がってくれません。研修などをして使い方を覚えていただく・・・というのも良いのですが、入社や退職などによる人の異動もあり頻繁に研修を入れるというのも、人数の少ないデータエンジニアで回そうとすると大変です。
UI面では以下のような点を意識しています。
大事な各プロジェクト共通の様々なKPIのダッシュボードはページを開くだけで理解・利用できるようにする
なんだかんだ重要なKPIダッシュボードは開くだけで大半を理解できて利用できる状態が理想です。
なんでもかんでも詰め込めばいいというものでもありませんし(大事なデータが見えづらくなる等の面で)、逆に足りなくて俯瞰しづらいといった状況も良くありません。
皆さん日々忙しくお仕事されているので、1ページで色々大切な数字や可視化部分が過不足なく俯瞰できることが大切です。
このダッシュボードは利用率が高く、職種も様々な方がアクセスしています(役員・プロデューサー・ディレクター・プランナー・マーケ・エンジニア・デザインナー・バックオフィスの方など)。
探索的にデータを深堀りしたり分析したりされている方も勿論いらっしゃいますが、利用率的にはここがやはり大きいのでしっかり力を割くべきところでもあります。
分かりやすく、見えやすいデザインのUIにしたり、統一感のある配色にしたりなどこだわりたいところです。また、定性的な感覚になってしまいますがあまりにデザインが古臭すぎてもよくない気がする(ユーザーからしたら、このツールは技術力的に信用できるのか・・?と感じられてしまったり)のでその辺りも初心者っぽい作りに見えないようにある程度はしっかりしておきたいところです。
非デザイナーの方でも、ノンデザイナーズ・デザインブックといった昔からあるロングセラー本も含め色々本が出ていますしそういった領域を学んでみても面白いかもしれません。
また、会社によってはカラーユニバーサルデザイン的に可視化の配色をこだわったりも有益かもしれません。
この辺りはGoogleの方が書かれたStorytelling with Data: A Data Visualization Guide for Business Professionalsとかのベストセラー本なども参考になるかもしれません(ちなみにノンデザイナーズ・デザインブックに出てくるような内容はこちらにも出てきます)。
国内だと先日バズっていたGoodpatchさんの決算資料に対する記事の【パワポ研の決算資料探訪①】Goodpatch社の決算説明資料はシンプルが故に美しいなども良くできていて素敵で参考になりました。
複雑な機能でもなるべく分かりやすくするように頑張る
ダッシュボードだけでは勿論不足していて、データを深堀りしていったりが必要な方々もいらっしゃいます。
そういった方のために、SQLやスクリプトを書かなくてもGUI操作だけで色々条件を変えて集計したり自動でマスタ連携してくれたり、さくっと可視化したりが出来るようにしてあります。
Metabaseのクエリビルダー的なものに少し傾向が近いかもしれません。OSSのデータ可視化ツール「Metabase」が超使いやすい
一方で、ページを開けば使えるダッシュボードとは異なり設定のUIはどうしても多くなってしまうので、ユーザーにとっては使いづらくなってしまいがちです。
そのため、なるべく使い方研修やらを入れなくても使えるように、各UIにマウスオーバーするとヘルプを表示してくれたり、詳細なヘルプも各UIパーツの右上のアイコンをクリックすれば表示できるといったように「なるべくヘルプを身近な存在にする」という点は意識しています。
別ページで長々とヘルプのページを追加する・・・というのも悪くはないのですが、検索で探したり他のページに遷移したりに時間がかかるのも良くありませんし、大抵の場合皆さんご自身の仕事を忙しく担当されているので、ヘルプが遠いと大抵のケースで読まれません。
ヘルプが読まれないと質問がデータエンジニアに飛んできて良くありません。その辺りはなるべく親切に・・・というところは心がけています(まだまだ改善点は残っていますが・・・)。
また、年数経過で、様々な要望などに対応していった結果UI要素が増えていって初見のときの難しさなどを招いたりもするので、BIツールの各機能の利用状況などを確認して使われていない機能の切り落としを行ってシンプルにするという対応も大切です(分析基盤自体の分析と改善を行ったり等)。
日本語のUIは意外と馬鹿にできない
会社にもよりますが、BIツールのUIが日本語で、お知らせやヘルプもしっかりと日本語で確認できるといったことは社内の利用率を上げる上で大切かもと思っています。
エンジニアとして仕事をしていると「UI別に英語でもいいよね」と感じてしまいがちですが、非エンジニアの方がユーザーとなるため、ユーザーフレンドリーという面でいうとできたら日本語UIのものだと利用率の改善的にいいかなという印象ではあります(英語でよく分からないUIがあると敬遠されがちになったり等)。
各部署の方が英語に抵抗の無い方である会社であれば特に意識する必要はありませんが、そうでは無い場合は日本語対応しているツールやサービスを検討するというのもいいかもしれません。
なるべく社内の利用者の方の要望をスピード感を持って反映していく
BIツール部分などを内製している都合、機能やデータなどに対して要望をいただくことも結構あります。
差し込みタスクになったりするのでしんどい時もありますが、そういった要望を出してくださる方は結構ヘビーユーザーになってくれたりするのでなるべく要望に答え、スピーディーに対応していきたいところです(数か月後に対応などだと遅すぎで、施策などのためにすぐ欲しいといったケースも結構あります)。
外部のOSSやらサービスだと中々すぐに変更を加えたり要望を受け入れてもらったりは難しいケースも多いと思いますが、この辺りが素早く対応できるのは内製の強みではありますし楽しさでもあります。
ライトなものであれば要望をいただいてから数時間で、コードを書いてLintやテストなどが通るのを確認して本番反映・・・とできることもあります。
弊社も例に漏れずごく少人数のデータエンジニアのチームで回していますが、細かくアップデートで1日平均3デプロイくらいはしているのでペース的には悪くはないかなという感じではあります。
この辺りのデグレなどを抑えつつ長期プロジェクトでスピード感を落とさないためにもテストやLintの仕組みの有無が響いてきます。
SQLをユーザーの多くの方に学んでもらうのは正解か分かっていない
データの民主化、素晴らしい事だと思います。各社員がSQLを書いて分析するというのも素敵に思います。クックパッドさんみたいにデザイナーも分析するといったケースや、ワークマンさんの各社員が分析のスキルを身に付けるというのもいい話に思います。
他にも、社内の方からも「プランナーがSQLなどで分析できるようになってスキルアップすることは良いことだ」という話も聞いて、そういったところは特に反対意見も違和感もありません。
一方で、全員がSQLを書けて分析が出来るものを目指す・・・というのも100%正しいとも限らない・・・という所感も最近しています。
きっかけはとある社内のディレクターの方がおっしゃっていた「退職や異動などでSQLやスクリプトを引き継ぐのが厳しいので今後はGUI完結で進めていきたい」というものになります。
たしかに普段からSQLやらスクリプトやらを書いている私でも複雑なSQLやスクリプトなどを引継ぎで渡されてしまうとちょっと辛いと感じることもありますし、普段SQLを書かれていない方からすると引継ぎなどが大変そう・・・というのは想像できます。
そういったことを加味して「BIツールはGUIで自動化など含めなるべく完結できるようにしようか・・・」という気持ちが強くなっています。
エクセルで複雑で謎のスクリプトなどが組まれていて、作った方は退職済みだけど触らないといけない・・・とかに似たようなケースと言えるかもしれません。
以下の記事も参考になります。
みんなSQLが書けることを自慢している会社もあるけれど、本当にそれでいいのだろうか
データの民主化が悪と言うつもりはなくて、「何となく良さそうだから中途半端に手を出す」というのがあまり良くない結果になるかも、という印象です。
データの民主化を進めるにしても、
- ちゃんと業務時間でしっかり研修を(場合によっては復習として繰り替えし)やる余裕がある会社
- 保守の難しい謎のSQLが大量生産されないようにしたり、集計ミスを減らすためにSQLレビューのプロセスなどを整備する
- 会社の評価や昇進などの面で、SQLや分析などのものを組み込む
辺りがしっかりとしているといいかなぁと思っています。環境やら制度やらが整っていないと、Redash環境とかを整備しても中々社内利用が進まないかもとは社内で話しています。
AWSのデータ基盤もそこまで悪くはない
世の中の多くのケースではGCPのBigQueryを使うケースが多いと思いますが、弊社データ基盤は大人の都合(他の社内のプロジェクトがほぼAWSで統一されていたり等)でAWSで組まれています。
個人的にはGCPのBigQueryなどのサービスの本もAWSのAthenaなどの本も当時両方読んで、AWSとGCPのイベントもそれぞれ参加はしていたので、BigQuery推しではありましたがどちらでもOKという感じだったところ、各プロジェクトがほぼAWSだったので分析基盤もAWSを利用して組まれる流れとなりました。
データレイクやDWH(データマート)などはS3で、AthenaでSQLを投げたりS3をマウントしてPandasやDask(Vaexなどの利用も検討中)などで利用したりもしています。
世間的には「とりあえずBigQuery」という印象も受けますし、それも正解だと思いますが、実際にAWSで何年か運用してみたところまあAWSでも普通に回せるな・・・という印象は受けています。
Lake Formationなどの便利そうなものもAWSのイベントで結構目につくようになってきましたし、S3のアップデートなども結構入っています。国内のゲーム会社さんの事例でも、SageMakerなども目立ってきました。
Athena(S3)などは圧縮後のデータサイズでコストが扱われる(ディスクコストも、クエリスキャンコストも)形ですし、楽をするためのライフサイクル関係のアップデートなども出てきています。Pythonで扱うためにバイナリ(HDF5やParquetなど)を置きやすいというのも便利ではありますし、データ消失などのリスクに関してもS3のイレブンナインの耐久性と長い歴史というのは信頼が置けます。
なにより、少し前に開催されていたAWSのイベントで知りましたが、フォートナイトやPUBGなどの分析基盤もAWSというのは安心できます。
※日本だとモンストやFGO、ポケモンGoなどの方が知名度があるかもしれませんが、2018年や2019年の世界のゲーム売上だとトップの方で、ユーザー数も膨大(ログの規模もきっと恐ろしいレベル)です。
まあでも自由に選ばせていただけるならBigQueryを選びそうな気がします。エクセルなどの非構造化データをETLなどで扱うのは結構辛い
仕事の大半の扱うデータに関しては処理しやすい構造化データです。
一方で、社内でコントロールがしにくい契約先の企業から送られてくるレポートなどがエクセルなどのフォーマットになっているケースがありました。
一応PythonなどでもエクセルやらPDF操作用のライブラリも色々ありますが、実際やってみると大分しんどかったです。というのも、会社ごとにフォーマットがばらばらで、同じ会社からのエクセルレポートでもフォーマットやファイル名・シート名がばらばらだったり、データが開始する箇所がばらばらだったり・・・と、やってみると分岐される条件が膨大になりました(且つ、すでに年単位でエクセルファイルが大量に溜まっていたりが発覚したりと・・・)。
結局、手を出したはいいもののかなりの労力が必要になりましたしETL対応している間に契約が終了になったりと、辛い経験だけで終わりました。
非構造化データのETLなどは安請負せずに相当な覚悟を持って受けるべきだなと反省しました。
基盤の利用状況のアクセスログを取っているとモチベに繋がる
データ基盤自体が他のプロジェクトのログを使って分析する環境ではありますが、分析基盤自体の社内の方の利用状況などもログを取って色々見てみるとプラスになることがあります。例えば以下のようなメリットが挙げられます。
- どの機能がよく使われているのかが分かるので、注力すべき点が分かる。
- 逆にどの機能があまり使われておらず、切り落としてUIをシンプルにできそうかが分かる。
- 利用者の増加や色々な部署の方が使ってくれたりしているのが分かり、闇雲にデータ基盤やデータ整備の仕事をしているよりもモチベが維持しやすい。
基盤やBIツール環境も整えて終わりではなく、ログを見て常に改善のサイクルを回していけたらいいなと思います(気合を入れてダッシュボードなどを用意しても、全然利用されないと辛いですし)。
施策とかにまで手を出せるといいかもしれない
データエンジニアリングの領域では無い気もするのですが、以前の上司の方が色々部署間の調整をしてくださったり改善の指摘をしてくださったり、同僚の方がAWSでの連携などを対応してくださったりして、分析基盤から社内のプロジェクトに対して施策が実行できるようにしたりも比較的最近のアップデートとして入ったりしました。
アプリ側のアップデート無しで「RCT(ABテスト)での施策実行」 → 「ログ蓄積」 → 「MCMCなども使った効果の色々な可視化」といった一連のものを基盤環境で完結できるようにしてみたりしたのですが、結構試験的なものでしたが案外アリだなという印象を受けました。
RCT実施の前には連絡を入れたり社内プロジェクト側の方に確認と許可をいただいたりは必要ですが、多くの領域をコントロールできるようになると機動力高く対応できたりして快適に思います。
これが複数部署絡んで部署間の調整がたくさん必要になったり、アプリ側のアップデートが必要にすると敬遠されてしまったり(皆さん忙しいですし)と大変です。
且つ、最終的にはRCT的に明確に数値改善の効果が出たりもした(何度も何度も調整したり変えたりは必要になりましたが)ので、数値が出ると後々の説得などをするのもやりやすいかなぁと。
外部の部署のメンバーが分析などをしても「分析・提案したけど施策や実験まで中々落とし込んでもらえない」「分析が無駄になってしまった」みたいなケースは結構あると思っていまして、逆にプロジェクト内の方だと「エンジニアリングにあまり詳しくない」とか「分析にそこまで精通していない」といったケースもあると思います。
そういった面でも施策まで全部セットでコントロール下におけるというのは今後も少しずつやっていきたいところです。
古いシステムへの敬意を
社内の分析基盤関係のプロジェクトが7年目とかになっていますが、それだけの年数があると、初期のころのものなどが結構長期的に悪影響を出したりといったケースも結構あります。
私の方も途中からの参加・引き継ぎだったので結構苦い思いもしています。前任の方が部署にいない状態で、一人情シスならぬ一人データエンジニアで対応しないといけないといったケースを体験して、ブラックボックス化しているものも苦労しつつも色々触ってきました(今は幸い、凄腕の同僚の方に恵まれています)。
しかしながらこれだけ長いこと(社内の中でもトップレベルに長いのではという印象)使われてきたというのは素晴らしいことですし、「如何にしてなるべく安全に改善していくか」といったところなども含めとても勉強になっています(中々できない経験だなと)。
どうか先人を否定しないようにしてください。その開発者は無茶ぶりされながらも奮闘した新人だったかもしれませんし、その頃には今となっては周知のベストプラクティスが存在しなかったのかもしれません。何より「役に立たないコードより、役に立つクソコード」は一つの真実です。
ブラックボックス化したデータ基盤を作りなおすことを決意した貴方へここまで長期に続いてることに敬意を表しつつ、たくさん問題があるということは改善し放題です。諸々を新しくしたりより良くできたりすると中々嬉しいですし楽しいので、案外そこまで悲観しなくてもいいのかもしれません。
※比較的ポジティブにお仕事ができているのは、技術とコードのところや仕事の進め方などの選択はほぼほぼ裁量があるという環境なのも大きいかもしれません。
データエンジニアの仕事を担当してみて、大分成長できた気はする
データエンジニアチーム、社内の中では少人数のチームになりがちです。少人数だと自分で色々な分野を扱わないといけなくなります。
弊社の場合エンジニアでも申請すればCreative Cloudなどは使わせてくれるのと、BIツール部分などは内製していたりするので、デザインツールを扱って自分達でデザインカンプを作ったりお洒落にしたりまでしている(これはこれで楽しい)ので、その辺りまで含めれると大分広い技術を扱っている気がします。書きだすと今の所以下のような感じでしょうか。
- Linux関係(CentOS・Ubuntu)
- Python関係
- Python界隈のライブラリ(NumPy・Pandas・Dask・matplotlib・Jupyter・scikit-learn・PyMC・Django・たまにディープラーニング方面のものなど)
- webサーバー関係(Nginx・gunicornなど)
- Docker関係
- クラウド関係(AWSメイン・稀にGCP。S3・EC2・Athena・Aurora(移行検討中)・Firehose・etc)
- DB関係(RDS・NoSQL)
- HTML・CSS・jsなどのフロント関係(古いのでTypeScript移行検討中)。D3.jsなども。
- CI/CD周りのツール群
- 監視系のツール群
- Adobeを中心としたデザインツール
担当するまではゲームのクライアントエンジニアなどをしていてサーバーサイドやらインフラ周りなどは別のエンジニアさんが担当してくださっていたので、一人データエンジニア担当になった時には「Linux聞いたことはあるけど(言葉通りに)ナニモワカラナイ」「Django?なにそれ美味しいの?」状態でした。
※当時はDjangoの和書もほとんどないタイミングでした。人間、必要に駆られるととても成長できるような気がしていて、デザイナーからエンジニアのお仕事をし始めたころもそうですが結構知らないことが多い領域に飛び込んでみるのもたまにはいいなと思いました。
気が付いたらPython関係は大分詳しくなった気もしますし、Qiita関係もたくさん勉強でアウトプットしてこれた気もします。
自分で色々な技術を触れるというだけでなく、独立部隊としての側面が強く技術選択なども自分達に裁量が結構あります。
他にも朝の始業前に諸々の膨大なデータに対して大量の処理をなるべく落ちずに安定して流れきっている必要があったりと、パフォーマンスやプチSRE的な(あくまでライトな範囲ですが)ところも必要になったりもします。
データエンジニアリングだけでなく、ビジネス的な知見もある程度身に付いたり、データサイエンス方面もある程度勉強する機会に恵まれたりもしています。
この辺りはデータ界隈で有名なゆずたそさんも記事にしていらっしゃいますが、私も同感なところもあり色々技術的にチャレンジができたり勉強すべきところが山ほどあるというのは楽しいし合っているかもなぁとは思っています。
趣味開発ではなかなか接する機会のない規模のデータを捌くことになります。 ISUCONでのパフォーマンスチューニングや、アドテク・動画配信の基盤担当者に近いモチベーションかもしれません。
「多少作りが悪くても動けば良し」というわけにはいきません。 それゆえか少数精鋭チームで技術力の高い人たちが集まっているように思います。
データ基盤エンジニアの面白さ地味で泥臭い面も多々あり向き不向きはあると思いますが、個人的にはデータ基盤のお仕事も中々いいなぁという所感です。
長期の開発・保守を担当してみて
頻繁に転職したり新しいプロジェクトに異動させてもらったりも(実際に過去に異動などを何度か経験してみて)学べることは色々あると思います。
一方で、長期的にプロジェクトをどんどん良くして、Developer Experienceを高めていくというのも面白いなぁとここ最近感じています。
少人数のチームということもあり、良くない実装や保守しづらいものを追加してしまうとそのままダイレクトに自分に帰ってきます。
和田卓人さんのスライドでも触れられているように、長期プロジェクトで深くまで携わって改善や機能追加などを対応していくという選択もアリなのかなと。
今後考えていること
データの民主化をして複雑なSQLやスクリプトが量産されると保守がつらい(それに、非エンジニアの方の学習コストを抑えたいという声も聞いたりしているのでGUIベースでなるべく完結できるようにしたい)一方で、分析の柔軟性も確保したい(ただし現状のGUIベースだと結構辛い)ので、将来的にUnrealEngineのブループリント的なビジュアルスクリプティングで柔軟且つ設定が分かりやすくシンプルなものの機能を追加したいな・・・と考えています。
ブループリント例 :
AzureMLのようなものが近いかもしれません。
AzureMLは機械学習をこれから勉強する人にとって最高の環境だった
余談
勢いに任せて色々書きましたが、色々賛否両論あると思います。自身の知識も経験も足りておらず、いまだに色々試行錯誤している感じは否めないのであくまで参考程度にお願いします。

- 投稿日:2020-11-13T19:32:17+09:00
TouchDesignerとReSpeakerで音カメラを作った話
TouchDesignerの学習のため、ReSpeakerを使って音カメラを作った。
ReSpeakerでSSL(Sound Source Localization)を行い、音の到来方向へエフェクトを入れることで、音を可視化したらおもしろいかもしれないと思って製作した。
これを音カメラと呼ぶことにした。TouchDesigner側
これはずっと悩みだったんですが、こういうビジュアルプログラミング系の製作物って、Qiitaでどう共有したら見やすいんですかねぇ…?
とりあえず今回は画像で行きます。内容はいたってシンプルです。
videodeviceinでカメラからの画像を読みこみ、そこに以下のようなgif画像を位置を指定して重ねているだけです。
SSLは生のPythonでやっているので、そのプロセスから結果をOSCで受けています。
ReSpeaker側
ReSpeakerはv2.0を使いました。1.0も持っていて、そっちの方が精度でそうなんですが、何故か手元のWindows10で接続できなかったため断念しました。以前はつながったのに…
ReSpeaker v2.0
https://github.com/respeaker/usb_4_mic_arrayこちらのライブラリから、DoA(Direction of Arrival)というのを行っているところから、音源方向の値のみを抽出してOSCで送信します。
ファームウェアの書き込みとかで結構ハマるので注意。
因みに、今回はPython側でやっていますが、マイクアレイ単体でも音源方向のLEDが点灯するので、デバイス側でも音源方向の推定はやっている模様。
パッと見はこちらの方が精度がよさげなので、そのデータが吸い出せるならそっちを使った方がいいかもしれない。doa.pyfrom pythonosc import osc_message_builder from pythonosc import udp_client from tuning import Tuning import usb.core import usb.util import time osc_client = udp_client.SimpleUDPClient('127.0.0.1', 50000) from infi.devicemanager import DeviceManager dm = DeviceManager() devices = dm.all_devices for i in devices: try: print ('{} : address: {}, bus: {}, location: {}'.format(i.friendly_name, i.address, i.bus_number, i.location)) except Exception: pass import usb.backend.libusb1 backend = usb.backend.libusb1.get_backend(find_library=lambda x: "./libusb-1.0.dll") dev = usb.core.find(idVendor=0x2886, idProduct=0x0018) direction = 0 if dev: Mic_tuning = Tuning(dev) direction = Mic_tuning.direction print(Mic_tuning.direction) while True: try: if direction != Mic_tuning.direction: direction = Mic_tuning.direction osc_client.send_message("/direction", direction) print(direction) time.sleep(0.5) except KeyboardInterrupt: breakセッティング
マイクアレイの原点と、カメラの原点が一致するように配置する。
カメラは今回はlogicoolのc920というwebカメラを使用した。
カメラの画角は事前に調べておくこと。
動作確認
動かしてみるとこんな感じ。
少しラグがあるが、スマホを追いかけてエフェクトが入るのがわかるだろうか。
— hatbot (@hatbot3) November 13, 2020また、手近なところでホチキスをカチカチ鳴らした動画がこちら。
— hatbot (@hatbot3) November 13, 2020今回はマイクアレイが平面的な配置だったため一次元的なエフェクトだが、マイクアレイを立体的に配置したり、ReSpeakerを二台使うなどすると、スポット的にエフェクトを入れることもできるはず。
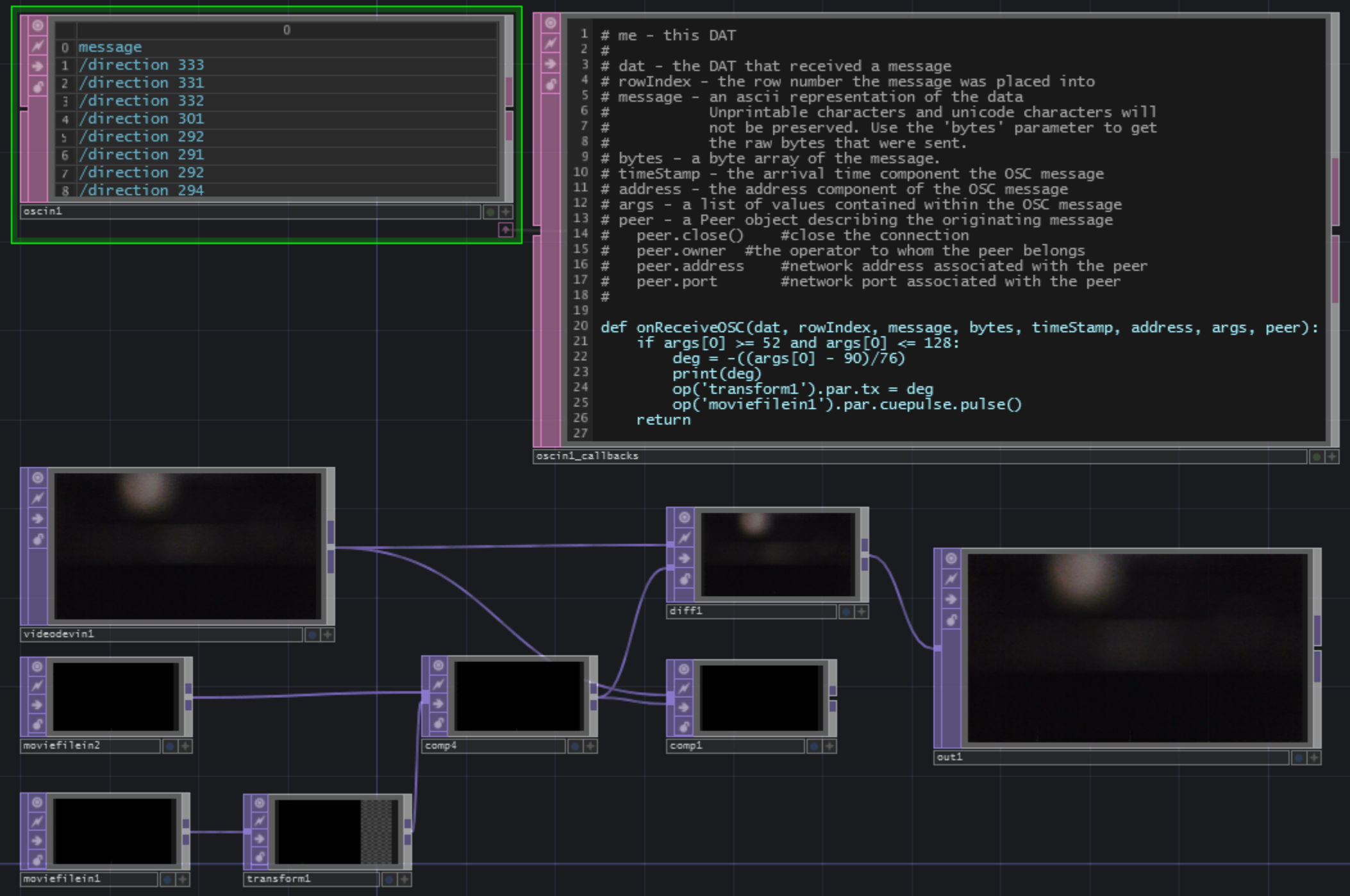


- 投稿日:2020-11-13T19:27:19+09:00
操作ログ整形ツールを作る 4日目
操作ログ整形ツールを作る 1日目, 2日目
操作ログ整形ツールを作る 3日目CSVを読み込んだらエラーが出ましたよ
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byteCSVはこんな(マスクしています)
oplog20201112.csvユーザーID,クライアント名,WindowsログインID,端末ID,IP Address,MAC Address,ドメイン名,ログイン時刻,ログアウト時刻,ログインステータス,アクション,機能名,実行ファイル名(シェル),引数(コマンドライン),実行時刻,実行状態 "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","ジョブ監視","Job.exe","-context:*****","2020/11/12 13:19:23","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","メインメニュー","Companyxx.exe","-cfg","2020/11/12 13:18:56","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","システム設定","Maintenance.exe","-context:*****","2020/11/12 13:19:19","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","svc.sh","userid/password","2020/11/12 13:19:32","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","test.sh","userid/password 0 0","2020/11/12 13:19:29","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","test.sh","userid/password 0 0","2020/11/12 13:19:30","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","バッチジョブ","mst13","out.sh","userid/password %JAVA% 0","2020/11/12 13:19:31","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","ジョブ管理","quevw.exe","-context:*****","2020/11/12 13:19:20","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","batchjob jobid:498298","test.sh","userid/password 0 0","2020/11/12 13:19:56","成功" "all","client-name","works","client-name","xx.xx.xx.xx","xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx xx-xx-xx-xx-xx-xx ","123-456","2020/11/12 13:18:56","2020/11/12 13:23:38","成功","プログラム","batchjob jobid:498301","svc.sh","userid/password","2020/11/12 13:21:39","成功"まあ日本語含まれてたしね。エンコードが必要。
https://techacademy.jp/magazine/21128
全然関係ないけど
Python 新型コロナのcsvファイルを題材にpandasでデータ処理する
というのもあって面白そう。
一旦確認のためテキストをUTF-8にエディタで変えたら読込成功。
お、これこのまま日時カラムでソートしてみる?firstpandas.pyimport pandas as pd df = pd.read_csv('oplog20201112.csv') print(df) df_s = df.sort_values('実行時刻') print(df_s)結果、結構普通に実行時刻でソートしてくれた。なるほど。
CSVを別名で保存してみよう。このページに戻る。
https://note.nkmk.me/python-pandas-to-csv/firstpandas.pyimport pandas as pd df = pd.read_csv('oplog20201112.csv') # print(df) df_s = df.sort_values('実行時刻') # print(df_s) df_s.to_csv('out.csv')これに先程のエンコード問題を以下で対処。
https://note.sngklab.jp/?p=435firstpandas.pyimport pandas as pd df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS") print(df) df_s = df.sort_values('実行時刻') print(df_s) df_s.to_csv('out.csv')実行時刻カラムを一番左に持ってきたい
続いてカラムを動かす方法。
https://note.nkmk.me/python-pandas-reindex/見たまんま、それらしくなりました。
firstpandas.pyimport pandas as pd df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS") # print(df) df_s = df.sort_values('実行時刻') # print(df_s) df_s = df_s.reindex(columns=['実行時刻', '機能名', 'ユーザーID', 'クライアント名', 'WindowsログインID', '端末ID', 'ログイン時刻', 'ログアウト時刻']) df_s.to_csv('out.csv')ツールの配布
作ったものをどうやって使いやすくすればいいのかも見ておきたい。
pyintallerというものがあるんだな。set path=C:\Users\works\AppData\Local\Programs\Python\Python39\Scripts;%path%が先に必要なので注意。
コマンドプロンプトでC:\workspaces\playground>pyinstaller firstpandas.py --onefile 67 INFO: PyInstaller: 4.0 67 INFO: Python: 3.9.0 69 INFO: Platform: Windows-10-10.0.19041-SP0 70 INFO: wrote C:\workspaces\playground\firstpandas.spec (後略)とすると無事Exeができました。
- 投稿日:2020-11-13T18:24:18+09:00
Python でクラスオブジェクトをJSON形式にする・戻す
Pythonで,自分で定義したクラスのオブジェクトを Json 形式にする (encode) 方法とJson形式から戻す (decode) 方法のメモ.
参考にしたページ:
* Pythonのjsonモジュールドキュメント
* How to use custom Python JSON serializers and deserializers to automatically roundtrip complex types例
こんなクラスを例にする.
import json from datetime import date class MyA: def __init__(self, i=0, d=date.today()): self.i = i # int型 self.d = d # date型Jsonデータ
まず始めに,オブジェクトをどのような形式でJsonデータにするのかを考えなくてはならない.MyA オブジェクトは,
'i'と'd'をキーとした object にするのが自然に思える.また,date型のデータは,文字列にしても良いが,手っ取り早く toordinal メソッドで整数にしてしまおう.するとたとえばa = MyA(i=100, d=date(year=2345, month=6, day=12))と定義した a は,
{"i": 100, "d": 856291}というJsonデータに変換されることになる.これでも良いこともあるだろうが,しかし,これでは,デコードするときに,どの型に戻せば良いかわからなくて面倒になる.そこで,'_type'というキーにクラス名を格納し,値は'value'というキーに格納する.その結果として,Jsonデータは次のようになる:{ "_type": "MyA", "value": {"i": 100, "d": { "_type": "date", "value": 856291}}}エンコード
Python の json ライブラリの dump や dumps コマンドは,cls という引数をとる.ここに,自分で定義したエンコーダを指定することができる.JSONEncoder というのが普通使われるクラスなので,これをベースとして自分のエンコーダを作る.実際に必要なことは,default というメソッドの再定義である.
class MyEncoder(json.JSONEncoder): def default(self, o): if isinstance(o, date): return {'_type': 'date', 'value': o.toordinal()} if isinstance(o, MyA): return {'_type': 'MyA', 'value': o.__dict__} return json.JSONEncoder.default(self, o)ご覧のように,各クラスが直接見ているところだけ書けばよくて,再帰するのはライブラリがよしなにやってくれる.(MyAクラスのオブジェクトのときには,返すものは辞書であって,そこには date型のデータが設定されていても良い.)
次のように実行できる.
a = MyA(100, date(year=2345, month=6, day=12)) js = json.dumps(a, cls=MyEncoder) print(js)実行結果:
{"_type": "MyA", "value": {"i": 100, "d": {"_type": "date", "value": 856291}}}デコード
こちらも,JSONDecoderというクラスをベースにデコーダを作る.今度は,親クラスであるJSONDecoderのオブジェクトが作成される際に,object_hook という変数に渡す関数の中で,必要なデコードが行われるように書く.以下のような具合である:
class MyDecoder(json.JSONDecoder): def __init__(self, *args, **kwargs): json.JSONDecoder.__init__(self, object_hook=self.object_hook, *args, **kwargs) def object_hook(self, o): if '_type' not in o: return o type = o['_type'] if type == 'date': return date.fromordinal(o['value']) elif type == 'MyA': return MyA(**o['value'])object_hook の o としては,普通にデコードされた結果が渡ってくる.上の例だと
'_type'だの'value'だのをキーに持つ辞書が来るので,それを適切なクラスのオブジェクトに作り替えるようにコードを書けば良い.ここでもまた,再帰処理のことは考えなくても大丈夫.エンコードの時の実行に引き続いてやってみる:
b = json.loads(js, cls=MyDecoder) print(b.i, b.d)実行結果:
100 2345-06-12
- 投稿日:2020-11-13T18:05:38+09:00
AWS の API Gateway (HTTP API) 経由で Lambda に繋いで POST データを処理するメモ
取り急ぎ忘れないようにめもめも。
- POSTパラメータは
event['body']に入っている。- API Gateway の設定で
isBase64Encodedが有効であると、Base64エンコードされるAPIに投げるときにJSONエンコードしたものを渡すと、Base64デコード後にJSONが取れる。
その際は、リクエストクエリのパースではなく、JSONのパース処理を行う。import json import base64 import urllib.parse def lambda_handler(event, context): # POSTパラメータがBASE64でエンコードされているのでデコードする decoded_body = base64.b64decode(event['body']).decode() # POSTパラメータをdict型に変換 post_params = urllib.parse.parse_qs(decoded_body) result = {} result['message'] = 'lambdaからのレスポンス' # POSTされたデータを参照 (配列になっているので注意) result['name'] = post_params['name'][0] result['email'] = post_params['email'][0] return { 'statusCode': 200, 'body': json.dumps(result) }
- 投稿日:2020-11-13T17:33:20+09:00
python+SCOOP分散コンピューティングはWindows PCでは出来ない
はじめに
Windows上でSCOOPというPythonのライブラリで分散コンピューティングを試したときのメモです。
SCOOPはタスク分散のためのPythonライブラリで、Windowsのパッケージ管理ツールのScoopとは別物。ややこしいです。
並列とか分散とかは素人のため、偉い人がやれと言うからには出来るものと信じて色々調べたのですが結果できなかったので、自分と同じ無駄足を踏むものが出ないよう残します。できない理由
SCOOPによる複数台PCでの分散実行では、処理の中で
os.getpgrp()
という関数を呼び出します。これがUnixでしか使えないため、エラーになってしまいます。
Windows Subsystem for Linuxを使えば、それ上ではgetpgrp()を使えるのですが、あくまでLinux上での実行になってしまうためWindowsでの分散実行にはならないです。
自PC内での並列実行は可能なため騙されそうになりましたが、つまり
--host <host>
を指定するとエラーになります。やったこと
以下参考のため試した手順を残します。
準備
インスタンスの用意
- AWSにEC2のインスタンスを二つ用意
- 接続元と接続先
- 今回は二つとも「Windows Server 2019」
- Windows Server 2016だとOpenSSHの用意が手動になる
- どちらも固定IPを発行
- 接続先となるインスタンスのセキュリティグループのインバウンドルールに「SSH」を全アドレスOKで追加(面倒なので)
- フォルダの表示設定で「ファイル名拡張子」「隠しファイル」にチェック
SSH接続(公開鍵認証)の用意
- OpenSSH サーバー機能の追加
- 設定→アプリ→オプション機能の管理→機能の追加→「OpenSSH サーバー」をインストール
- サービスからOpenSSHを「開始」し、スタートアップの種類を「自動」に変更
- ファイアウォールの「受信の規則」で「新しい規則...」をポート番号「22」で追加
- 念のためインスタンス間でSSH通信ができることを確認
ssh Administrator@<もう一方のインスタンスのIP>
でログインができるかどうか、タイムアウトせず、パスワードを求められるかどうかを確認- 公開鍵通信の設定
- インスタンス間でSSHの公開鍵による通信ができるように設定する
- 接続元のインスタンスでssh-keygenで秘密鍵・公開鍵のペアを作成
- 公開鍵(***.pub)を接続先インスタンスの.sshフォルダ直下に置いて、「authorized_keys」にリネーム
- .sshフォルダは特別なことをしなければ「C:\Users\Administrator\.ssh」にあるはず
- 今回は1個目なのでリネームとしたが、2個目以降はauthorized_keysの中に追記していくこと
- 接続先の「C:\ProgramData\ssh\sshd_config」ファイルの最後の2行(Administratorsがどうとか書いてる行)を「#」でコメントアウトし、OpenSSHを再起動
- configファイルの作成
- 接続元のインスタンスで「.ssh\config」を作成し、以下のように接続名・接続先を定義する
- Host以外にインデントがあるのは複数の接続先を記述した際の読みやすさのためなので面倒なら下げなくてOK
- 今回の例では
ssh test
で接続が成功すればOKHost <任意の名称> HostName <接続先のIPアドレス> User <任意のユーザー> Port <使用したいポート> IdentityFile <自分が持っている秘密鍵のパス> --- 以下は今回の例 --- Host test HostName **.***.***.*** User Administrator Port 22 IdentityFile C:/Users/Administrator/.ssh/id_rsabuild tools for visual studio 2019のインストール
- 公式ページの画面下の方にある「Visual Studio 2019のツール」を開く
- Build Tools for Visual Studio 2019をダウンロードして実行
- C++ Build Toolsにチェック
- この時画面右側に現れるチェックリスト下にあるMSVC140,141の二つにもチェックを入れて「インストール」
Pythonの用意
- pythonをインストール
- 最新版の3.9.0を使用した
- anaconda等を使用せず直でインストール
- ライブラリのインストール
- pip install pyzmq
- SCOOPの公式マニュアルにはダウンロードして来いと書いてますがURLのファイルかなり古いです…
- pip install scoop
- 分散したいpythonプログラムを用意
- 公式マニュアルの
map_doc.pyをコピペ- 並列実行したい関数は
furures.map(分散したい関数, ←の関数に渡したい引数)で指定map_doc.pyfrom __future__ import print_function from scoop import futures def helloWorld(value): return "Hello World from Future #{0}".format(value) if __name__ == "__main__": returnValues = list(futures.map(helloWorld, range(16))) print("\n".join(returnValues))試行
ここまで出来たらあとは公式マニュアルの通りに
python -m scoop -n 8 map_doc.py
これだと自PC内での並列実行であり普通に成功してしまうので
python -m scoop -n 8 --host test map_doc.py
こうすると以下のエラーが出て失敗してしまいます。
このエラーの最後に書いてあるAttributeError: module 'os' has no attribute 'getpgrp'が失敗の原因です。無いものは無いです。b'Traceback (most recent call last):\r\n File "C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python39\\lib\\runpy.py", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File "C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python39\\lib\\runpy.py", line 87, in _run_code\r\n exec(code, run_globals)\r\n File "C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python39\\lib\\site-packages\\scoop\\broker\\__main__.py", line 65, in <module>\r\n sys.stdout.write(str(os.getpgrp()) + "\\n")\r\nAttributeError: module \'os\' has no attribute \'getpgrp\'\r\n'最後に
諦めかけてきたころ他の人に相談してみると「分散コンピューティングとかやりたいときは将来的にスパコンでも使ってみる、みたいなパターンが多いからそもそもLinux前提でプログラム書くよ、Windowsではあんまりやらないよ」的なコメントいただきました。そういうことらしいです。
今回WindowsでやりたかったのはWindows PC上で動くことが前提で書かれてるプログラムを並列実行したかったからなのですが、OSに関数が無いものは無いということで仕方ないです。参考リンク
https://scoop.readthedocs.io/en/0.7/index.html
https://docs.python.org/ja/3/library/os.html
http://fx-kirin.com/python/python-scoop/
https://www.server-world.info/query?os=Windows_Server_2019&p=ssh&f=3
- 投稿日:2020-11-13T17:11:06+09:00
PythonとGASでAtCoderのContest予定をGoogleCalendar上に作成する
初めに
AtCoderのコンテストが不定期に開催されているが、時々予定に入れ忘れたりして、家族に迷惑をかけそうだったので自動化することにした(できるかは分からない)。
実行にはGoogleColaboratoryを使用した。
プログラミング初心者なのでコードが煩雑だったり間違ってたりするかもしれません。ごめんなさい。AtCoderからGoogleCalendarまで
手順
- AtCoderからPythonのrequestsやBeautifulSoupなどを使ってスクレイピング
- スクレイピングしたデータをPythonのgspreadなどを使いGoogleSpreadSheetsにまとめる
- GoogleSpreadSheetsからGASを使ってGoogleCalendarに予定を作成
1. スクレイピング
実際のコード
AtCoderの開催予定コンテストの名前、開催日、リンクのみを、AtCoderホームページの「コンテスト一覧」から取得してlistにする。from bs4 import BeautifulSoup # BeautifulSoupのインポート import requests # requestsのインポート import datetime import re url = "https://atcoder.jp/contests/" response = requests.get(url).text soup = BeautifulSoup(response, 'html.parser') # BeautifulSoupの初期化 tags = soup.select("tbody a") # tbody下のaタグを全て選択 l=[] l_n=[] l_link=[] l_n1=[] now=datetime.datetime.now().strftime('%Y-%m-%d %H:%M') # 現在の年、月、日、時間を取得 for i in tags: l.append(i.text) # aタグ内のテキストを取得 l.append(i.get("href")) # aタグに付いてるリンクを取得 l.remove("practice contest") l.remove("/contests/practice") l.remove("AtCoder Library Practice Contest") l.remove("/contests/practice2") l=[l[i:i + 4] for i in range(0,len(l), 4)] for i in range(len(l)): l[i][0]=l[i][0][0:16] del l[i][1] if (l[i][0][0:4] > now[0:4]) or (l[i][0][0:4] == now[0:4] and l[i][0][5:7] > now[5:7]) or (l[i][0][0:4] == now[0:4] and l[i][0][5:7] == now[5:7] and l[i][0][8:10] >= now[8:10]): # 過去のコンテストをリストから削除 l_n.append(l[i]) for i in range(len(l_n)): l_link.append("https://atcoder.jp"+l_n[i][2]) # 相対リンクを絶対リンクに変更コンテストの開始時間、終了時間、Ratedやペナルティなどは取得しづらかったので、それぞれのリンクに飛んで取得した。
for i in l_link: url_n=i response_n = requests.get(url_n).text soup_n = BeautifulSoup(response_n, 'html.parser') # BeautifulSoupの初期化 tags2=soup_n.select("span.mr-2")+soup_n.select("small.contest-duration") # Ratedやペナルティ、開催時間などを取得 for j in tags2: l_n1.append(j.text) l_n1=[l_n1[i:i + 4] for i in range(0,len(l_n1), 4)] for i in range(len(l_n1)): l_n1[i][1]=l_n1[i][1][13:] l_n1[i][1]=l_n1[i][1].replace("-","~") l_n1[i][2]=l_n1[i][2][9:] l_n1[i][3]=re.sub("\n","",l_n1[i][3]) l_n1[i][3]=re.sub("\t","",l_n1[i][3]) l_n1[i][3]=l_n1[i][3][54:60] del l_n1[i][0] for i in range(len(l_n)): l_n[i]+=l_n1[i](参考:https://dividable.net/programming/python/python-scraping)
2. データをスプレッドシートへ
取得したデータをスプレッドシートに貼り付ける。
from google.colab import auth from oauth2client.client import GoogleCredentials import gspread auth.authenticate_user() gc = gspread.authorize(GoogleCredentials.get_application_default()) worksheet = gc.open('AtCoderNewContestList').get_worksheet(0) # AtCoderNewContestListという名前のスプレッドシートの1シート目を指定 for i in range(len(l_n)): if worksheet.update_acell("B"+str(i+2),l_n[i][1]) in worksheet.range('B2:B10'): # コンテストがもう追加されていたら処理をしない continue else: worksheet.update_acell("B"+str(i+2),l_n[i][1]) worksheet.update_acell("C"+str(i+2), l_n[i][0][0:4]+"/"+l_n[i][0][5:7]+"/"+l_n[i][0][8:10]) worksheet.update_acell("D"+str(i+2),l_n[i][0][11:]) worksheet.update_acell("E"+str(i+2),l_n[i][-1]) worksheet.update_acell("F"+str(i+2),l_n[i][3]) worksheet.update_acell("G"+str(i+2),l_n[i][4]) worksheet.update_acell("H"+str(i+2),"https://atcoder.jp"+l_n[i][2]) worksheet.update_acell("A"+str(i+2),"")結果が以下。
割とうまくいっている。3. GASで予定を追加
GASを使ってGoogleCalendarに予定を追加する。
諸々の事情から、新しいGoogleアカウントを作って、作成したスプレッドシートにアクセス、GASでデータを抜き取り予定を作成、とすることにした。
ら、初めに作ったアカウントにアクセスできなくなった。なんで?
スプレッドシートの「ツール」から「スクリプトエディタ」を選択するとGASのコードが書ける。
(GASはコードの内容は理解できるが書けはしないので、下のサイトのコードをコピーして編集した。)
(参考:https://qiita.com/cazimayaa/items/5fdfbc060dff7a11ee15)function myFunction() { // 今選択中のスプレッドシートのシートを取得 var sheet = SpreadsheetApp.getActiveSheet(); // 取得したシートから、セルの中身を取得 var values = sheet.getDataRange().getValues(); var calendar = CalendarApp.getDefaultCalendar(); // ※var i の0番目はヘッダーになるので、1からスタートします。 for (var i = 1; i < values.length; i++) { var status = values[i][0]; if ( status != "済" // 連携の欄が済になっていなかったら処理を行う ) { // 予定日 var date = values[i][2]; // 開始時間 var startTime = values[i][3]; var startDateTime = new Date(date.getFullYear(), date.getMonth(), date.getDate(), startTime.getHours(), startTime.getMinutes(), 0); // 終了時間 var endTime = values[i][4]; var endDateTime = new Date(date.getFullYear(), date.getMonth(), date.getDate(), endTime.getHours(), endTime.getMinutes(), 0); // タイトル var title = values[i][1]+values[i][8]; var options = { description: values[i][7] } // var event = calendar.createEvent(title, startDateTime, endDateTime); // 引数にoptionsを追加するだけ var event = calendar.createEvent(title, startDateTime, endDateTime, options); // カレンダーへ登録 sheet.getRange(i + 1, 1).setValue("済"); // 連携の欄を済にする } } }このままでもいいかもしれないが、スプレッドシートが更新されたらカレンダーも連動させたいので、トリガーを設定する。(参考:https://auto-worker.com/blog/?p=1646)
「現在のプロジェクトのトリガー」から、シート変更時に関数を実行するようにする。実行後
カレンダー
スプレッドシート
やったぜ。4. 補足
本当は定期的にPythonのコードを自動で実行させたかったが、面倒くさそうなのでやめておいた。
- 投稿日:2020-11-13T15:48:38+09:00
「ゼロから作るDeep Learning」自習メモ(その17)DeepConvNet を Keras で構築してみた
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その16 ←
DeepConvNet
本のP241から説明されている DeepConvNet を Keras で構築してみます。
レイヤがやたら多くなって、そこんとこがディープなんだろうとは思いますが、これでどうして認識精度が上がるのか、まったくわかっていません。
が
見本のスクリプトをまねて動かすことはできるわけで、
やってみました。
from google.colab import drive drive.mount('/content/drive') import sys, os sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/common') sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset') # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from keras.layers import Dense, Activation, Flatten, Conv2D, MaxPooling2D, Dropout # ヘルパーライブラリのインポート import numpy as np import matplotlib.pyplot as plt from mnist import load_mnist # データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(flatten=False) X_train = x_train.transpose(0,2,3,1) X_test = x_test.transpose(0,2,3,1)input_shape=(28,28,1) filter_num = 16 filter_size = 3 filter_stride = 1 filter_num2 = 32 filter_num3 = 64 pool_size_h=2 pool_size_w=2 pool_stride=2 d_rate = 0.5 hidden_size=100 output_size=10 model = keras.Sequential(name="DeepConvNet") model.add(keras.Input(shape=input_shape)) model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(keras.layers.Flatten()) model.add(Dense(hidden_size, activation="relu", kernel_initializer='he_normal')) model.add(Dropout(d_rate)) model.add(Dense(output_size)) model.add(Dropout(d_rate)) model.add(Activation("softmax")) #モデルのコンパイル model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])padding="same" という指定を入れることで、入力画像のサイズと同じサイズの出力画像になります。
model.summary()Model: "DeepConvNet"
Layer (type) Output Shape Param #
conv2d (Conv2D) (None, 28, 28, 16) 160
conv2d_1 (Conv2D) (None, 28, 28, 16) 2320
max_pooling2d (MaxPooling2D) (None, 14, 14, 16) 0
conv2d_2 (Conv2D) (None, 14, 14, 32) 4640
conv2d_3 (Conv2D) (None, 14, 14, 32) 9248
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 32) 0
conv2d_4 (Conv2D) (None, 7, 7, 64) 18496
conv2d_5 (Conv2D) (None, 7, 7, 64) 36928
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 64) 0
flatten (Flatten) (None, 576) 0
dense (Dense) (None, 100) 57700
dropout (Dropout) (None, 100) 0
dense_1 (Dense) (None, 10) 1010
dropout_1 (Dropout) (None, 10) 0
activation (Activation) (None, 10) 0
Total params: 130,502
Trainable params: 130,502
Non-trainable params: 0model.fit(X_train, t_train, epochs=5, batch_size=128) test_loss, test_acc = model.evaluate(X_test, t_test, verbose=2) print('\nTest accuracy:', test_acc)313/313 - 6s - loss: 0.0313 - accuracy: 0.9902
Test accuracy: 0.9901999831199646ちゃんと動いているようです。
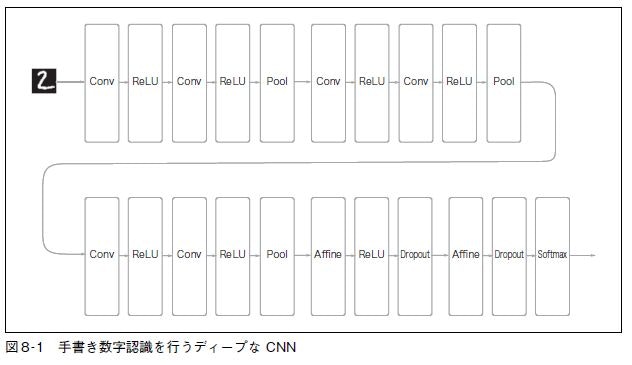
- 投稿日:2020-11-13T14:10:51+09:00
Pythonの簡易HTTPサーバでブラウザキャッシュを無効にするには
簡易HTTPサーバ http.server
ローカルにあるHTMLファイルにブラウザからアクセスするための簡易的なHTTPサーバは、Pythonがあれば以下のコマンドで起動できます。
$ python -m http.server 8080 Serving HTTP on 0.0.0.0 port 8080 (http://0.0.0.0:8080/) ...このコマンドを実行し、同じPCのブラウザで http://localhost:8080/ にアクセスすれば、カレントディレクトリにある index.html が表示されます。
困ったこと
ブラウザにキャッシュが効いてリロードしてもブラウザが簡易HTTPサーバにリクエストしてくれないときがあり、ローカルファイルを編集してもブラウザで確認できなくて困るケースがありました。ブラウザからキャッシュを消せばいいのですが、手間です。
そこで、簡易HTTPサーバからのレスポンスにキャッシュの有効期限0を含めるようにしました。
キャッシュ無効のPythonスクリプト
import http.server import sys port = int(sys.argv[1]) class NoCacheHTTPRequestHandler(http.server.SimpleHTTPRequestHandler): def end_headers(self): self.send_header('Cache-Control', 'max-age=0') self.send_header('Expires', '0') super().end_headers() httpServer = http.server.HTTPServer(('', port), NoCacheHTTPRequestHandler) httpServer.serve_forever()
server.pyなどの名前でこのスクリプトを保存すると、以下のコマンドでサーバが起動します。$ python server.py 8080レスポンスヘッダはcurlコマンドでも確認できます。別のターミナルを開いて実行します。
$ curl -I http://localhost:8080/ HTTP/1.0 200 OK Server: SimpleHTTP/0.6 Python/3.8.3 Date: Thu, 12 Nov 2020 13:31:44 GMT Content-type: text/html Content-Length: 1178 Last-Modified: Thu, 12 Nov 2020 13:21:38 GMT Cache-Control: max-age=0 Expires: 0ブラウザでも毎回リクエストを送信してくれるようになり、ローカルファイルの変更がすぐに反映されるようになりました。
バージョン情報
$ python --version Python 3.8.3
- 投稿日:2020-11-13T13:19:36+09:00
psycopg2でpd.DataFrameからインサートする
こちらの記事を参考にしてインサートを試みましたが躓いたので書き記します。大方同じなのですが、文字列挿入で二つ困ったところがありました。
日本語文字列を挿入する時のエンコーディングエラーとバックスラッシュを含んだ文字列のエンコーディングエラーです。実装
from io import StringIO from typing import List import pandas as pd import psycopg2 class Client: def __init__(self, dsn: str) -> None: """ Arguments: dsn(str): 'postgresql://{username}:{password}@{hostname}:{port}/{dbname}' """ self._cur = None self._conn = psycopg2.connect(dsn) self._conn.set_client_encoding('UTF8') self._cur = self._conn.cursor() def __del__(self) -> None: if self._cur is not None: self._cur.close() self._conn.close() def insert(self, table: str, values: pd.DataFrame) -> None: buf = StringIO() df.to_csv(buf, sep='\t', na_rep='\\N', index=False, header=False) buf.seek(0) columns = df.columns.values.tolist() self._cur.copy_from(buf, table, columns=columns) self._conn.commit()今回は発生しませんでしたが、
pd.DataFrameでNULLABLEな整数型を扱う場合もエラーになる可能性があるようです。
参照: https://qiita.com/hoto17296/items/b6c90db4b9bcdb7b6d78日本語のエンコーディングの問題
set_client_encoding('UTF8')で解決
参考: https://www.psycopg.org/docs/connection.html#connection.set_client_encodingバックスラッシュの問題
これは外から実装してしまいましたが、次のようにして回避しました。
ここではaというカラムが文字列だとしますimport os df = get_dataframe() # 任意の方法でデータフレームを取得 df.a = df.a.str.replace('\\', '\\\\') client = Client(os.environ.get('POSTGRES_DSN') client.insert(table, df)他の実装
上では
copy_fromを用いましたが、copy_expertを使う場合は次のように書けます。cur.copy_expert( f""" COPY {table}( {','.join(columns)} ) FROM STDIN WITH DELIMITER AS ' ' NULL AS '\\N' ENCODING 'utf8' """, buf, )こちらではクエリの中でエンコーディングを指定しているため、
set_client_encoding('UTF8')は不要です。参考: https://www.psycopg.org/docs/cursor.html#cursor.copy_expert
- 投稿日:2020-11-13T11:49:32+09:00
「ゼロから作るDeep Learning」自習メモ(その16)SimpleConvNet を Keras で構築してみた
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その15← → その17
Google Colab がふつうに使えるので、この本の内容を TensorFlow でやってみることにします。
TensorFlow のサイト https://www.tensorflow.org/?hl=ja の初心者向けチュートリアル「はじめてのニューラルネットワーク」をやって、本の5章めくらいまではカバーできたかと思います。
なので、7章のSimpleConvNetに相当するものを keras で構築してみようと思います。Conv1D ? 2D ? 3D ?
畳み込みには Convナントカ を使うんだろうな、というのは察しがつくのですが、1D 2D 3D と種類があって、 D はたぶん Dimension 次元 のことなんでしょうから、画像の処理は2次元 2D でいい、ということなんでしょうか?
そういうことなら、それでいいんですが、が
1次元って、どんなものがあるの? 3次元って?
ということが気になります。1D は時系列データ等で
Keras Documentationより
このレイヤーを第一層に使う場合,キーワード引数としてinput_shape(整数のタプルかNone.例えば10個の128次元ベクトルの場合ならば(10, 128),任意個数の128次元ベクトルの場合は(None, 128))を指定してください.ということです
こんな例がありました。
時系列予測を一次元畳み込みを使って解く
時系列データに対する1次元畳み込み層の出力を可視化2D は画像等で
このレイヤーをモデルの第1層に使うときはキーワード引数input_shape (整数のタプル,サンプル軸を含まない)を指定してください. 例えば,data_format="channels_last"のとき,128x128 RGB画像ではinput_shape=(128, 128, 3)となります.
3D は高さを含めた空間等で
このレイヤーをモデルの第一層に使うときはキーワード引数input_shape (整数のタプル,サンプル軸を含まない)を指定してください. 例えばdata_format="channels_last"の場合,シングルチャネルの128x128x128の立体はinput_shape=(128, 128, 128, 1)です.
空間内での移動方向のデータも3次元になるので、こんな例がありました。
加速度センサーで行動分類Conv2D Convolution2D
パラメータ
filters, 畳み込みにおける出力フィルタの数
kernel_size, 畳み込みフィルタの幅と高さを指定します. 単一の整数の場合は正方形のカーネルになります
strides=(1, 1), 畳み込みの縦と横のストライドをそれぞれ指定できます.単一の整数の場合は幅と高さが同様のストライドになります
padding='valid', "valid"か"same"のどちらかを指定します
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargsdata_format
"channels_last"(デフォルト)か"channels_first"のどちらかを指定します.これは入力における次元の順序です. "channels_last"の場合,入力のshapeは"(batch, height, width, channels)"となり,"channels_first"の場合は"(batch, channels, height, width)"となります.これ、逆に考えると、Keras では channels_last 入力のshapeが(batch, height, width, channels) というのがデフォルトだよ、と言っているわけです。
で
注意しないといけないのが、「ゼロから作るDeep Learning」で扱っているMNISTデータは、(batch, channels, height, width) channels_first だということ。
ところが、このパラメータに "channels_first" を指定しても、エラーが出てしまいます。
結局、データを channels_last に変換して処理する事にしました。padding については、こちらを参照しました→ Tensorflow - padding = VALID/SAMEの違いについて
SimpleConvNet
本のP229から説明されている SimpleConvNet を Keras で構築してみます。
Google Drive に保存している MNISTデータを使うので、ドライブのマウントやドライブにあるフォルダへのパスを定義します。
from google.colab import drive drive.mount('/content/drive') import sys, os sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/common') sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset')# TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from keras.layers import Dense, Activation, Flatten, Conv2D, MaxPooling2D # ヘルパーライブラリのインポート import numpy as np import matplotlib.pyplot as pltドライブに保存してあるMNISTデータを読み込みます。
from mnist import load_mnist # データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(flatten=False) x_train.shape(60000, 1, 28, 28)
(batch, channels, height, width) channels_first の形式です。
これを(batch, height, width, channels) channels_last に変換します。X_train = x_train.transpose(0,2,3,1) X_test = x_test.transpose(0,2,3,1) X_train.shape(60000, 28, 28, 1)
channel_last になりました。
また、ラベル t_train は整数の目的値なので、損失関数には sparse_categorical_crossentropyを使います。「ゼロから作るDeep Learning」P230
図7-23 に示すように、ネットワークの構成は、「Convolution - ReLU - Pooling - Affine - ReLU - Affine - Softmax」という流れです。
これをKerasで構築しました。活性化関数に relu を使うので、重みの初期値には he_normal を使っています。
input_shape=(28,28,1) filter_num = 30 filter_size = 5 filter_stride = 1 pool_size_h=2 pool_size_w=2 pool_stride=2 hidden_size=100 output_size=10 model = keras.Sequential(name="SimpleConvNet") model.add(Conv2D(filter_num, filter_size, activation="relu", strides=filter_stride, kernel_initializer='he_normal', input_shape=input_shape)) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(Flatten()) model.add(Dense(hidden_size, activation="relu", kernel_initializer='he_normal')) model.add(keras.layers.Dense(output_size, activation="softmax")) #モデルのコンパイル model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) model.summary()Model: SimpleConvNet
Layer (type) Output Shape Param
conv2d (Conv2D) (None, 24, 24, 30) 780
max_pooling2d (MaxPooling2D) (None, 12, 12, 30) 0
flatten (Flatten) (None, 4320) 0
dense (Dense) (None, 100) 432100
dense_1 (Dense) (None, 10) 1010
Total params: 433,890
Trainable params: 433,890
Non-trainable params: 0モデルを訓練します。
model.fit(X_train, t_train, epochs=5, batch_size=128)Epoch 1/5
469/469 [==============================] - 27s 58ms/step - loss: 0.2050 - accuracy: 0.9404
Epoch 2/5
469/469 [==============================] - 27s 57ms/step - loss: 0.0614 - accuracy: 0.9819
Epoch 3/5
469/469 [==============================] - 26s 56ms/step - loss: 0.0411 - accuracy: 0.9875
Epoch 4/5
469/469 [==============================] - 27s 58ms/step - loss: 0.0315 - accuracy: 0.9903
Epoch 5/5
469/469 [==============================] - 27s 57ms/step - loss: 0.0251 - accuracy: 0.9927
tensorflow.python.keras.callbacks.History at 0x7f5167581748かなり高い正解率になりました。
#予測する predictions = model.predict(X_test) class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] def plot_image(i, predictions_array, t_label, img): predictions_array = predictions_array[i] img = img[i].reshape((28, 28)) true_label = t_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, t_label): predictions_array = predictions_array[i] true_label = t_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue') # X個のテスト画像、予測されたラベル、正解ラベルを表示します。 # 正しい予測は青で、間違った予測は赤で表示しています。 num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, t_test, X_test) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, t_test) plt.show()
かなり難しい9番目の 5 もちゃんと判別できました。
レイヤーを個々に積み上げていく書き方もあります。
model = keras.Sequential(name="SimpleConvNet") model.add(keras.Input(shape=input_shape)) model.add(keras.layers.Convolution2D(filter_num, filter_size, strides=filter_stride, kernel_initializer='he_normal')) model.add(keras.layers.Activation(tf.nn.relu)) model.add(keras.layers.MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(hidden_size)) model.add(keras.layers.Activation(tf.nn.relu)) model.add(keras.layers.Dense(output_size)) model.add(keras.layers.Activation(tf.nn.softmax))
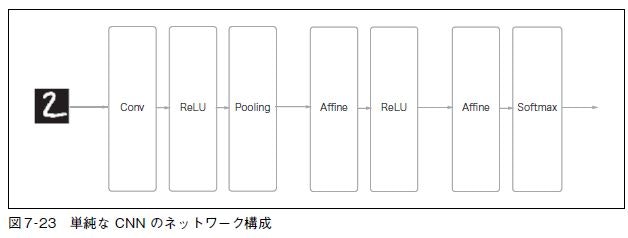

- 投稿日:2020-11-13T11:10:17+09:00
pythonで折れ線グラフと目盛線
ごく稀に必要になるので,自分用にメモ
モンテカルロ法を例に
import random import math result = [] in_circle = 0 out_circle = 0 for i in range( 100000 ): x = random.uniform( -1.0, 1.0 ) y = random.uniform( -1.0, 1.0 ) distance = math.sqrt( x ** 2 + y ** 2 ) if distance <= 1: in_circle += 1 else: out_circle += 1 result.append( ( in_circle / ( in_circle + out_circle ) ) * 4)import numpy as np import matplotlib.pyplot as plt plt.figure(figsize=(28,21)) plt.plot(range(1, len(result)+1), result, "-o") plt.ylabel('area') plt.xlabel('num of experiments') plt.xticks(np.arange(0, len(result) + 1, 10000)) plt.yticks(np.arange(0, 4.5, 0.1)) plt.plot([0, len(result)], [math.pi, math.pi], "red", linestyle='solid') plt.grid() plt.show()
- 投稿日:2020-11-13T08:16:53+09:00
DeepChemのGraphGatherLayerをPyTorchのカスタムレイヤーで実装する
はじめに
GraphConvLayer, GraphPoolLayerに続いて、DeepChem の GraphGatherLayer を Pytorch のカスタムレイヤーで実装してみた。
環境
- DeepChem 2.3
- PyTorch 1.7.0
ソース
DeepChemのGraphGatherLayerをPyTorchに移植し、前回のGraphConvLayerの出力結果を、作成したGraphPoolLayerに食わせてみた。
import torch from torch.utils import data from deepchem.feat.graph_features import ConvMolFeaturizer from deepchem.feat.mol_graphs import ConvMol import torch.nn as nn import numpy as np from torch_scatter import scatter_max def unsorted_segment_sum(data, segment_ids, num_segments): # segment_ids is a 1-D tensor repeat it to have the same shape as data if len(segment_ids.shape) == 1: s = torch.prod(torch.tensor(data.shape[1:])).long() segment_ids = segment_ids.repeat_interleave(s).view(segment_ids.shape[0], *data.shape[1:]) shape = [num_segments] + list(data.shape[1:]) tensor = torch.zeros(*shape).scatter_add(0, segment_ids, data.float()) tensor = tensor.type(data.dtype) return tensor class GraphConv(nn.Module): def __init__(self, in_channel, out_channel, min_deg=0, max_deg=10, activation=lambda x: x ): super().__init__() self.in_channel = in_channel self.out_channel = out_channel self.min_degree = min_deg self.max_degree = max_deg num_deg = 2 * self.max_degree + (1 - self.min_degree) self.W_list = [ nn.Parameter(torch.Tensor( np.random.normal(size=(in_channel, out_channel))).double()) for k in range(num_deg)] self.b_list = [ nn.Parameter(torch.Tensor(np.zeros(out_channel)).double()) for k in range(num_deg)] def forward(self, atom_features, deg_slice, deg_adj_lists): #print("deg_adj_list") #print(deg_adj_lists) W = iter(self.W_list) b = iter(self.b_list) # Sum all neighbors using adjacency matrix deg_summed = self.sum_neigh(atom_features, deg_adj_lists) # Get collection of modified atom features new_rel_atoms_collection = (self.max_degree + 1 - self.min_degree) * [None] for deg in range(1, self.max_degree + 1): # Obtain relevant atoms for this degree rel_atoms = deg_summed[deg - 1] # Get self atoms begin = deg_slice[deg - self.min_degree, 0] size = deg_slice[deg - self.min_degree, 1] self_atoms = torch.narrow(atom_features, 0, int(begin), int(size)) # Apply hidden affine to relevant atoms and append rel_out = torch.matmul(rel_atoms, next(W)) + next(b) self_out = torch.matmul(self_atoms, next(W)) + next(b) out = rel_out + self_out new_rel_atoms_collection[deg - self.min_degree] = out # Determine the min_deg=0 case if self.min_degree == 0: deg = 0 begin = deg_slice[deg - self.min_degree, 0] size = deg_slice[deg - self.min_degree, 1] self_atoms = torch.narrow(atom_features, 0, int(begin), int(size)) # Only use the self layer out = torch.matmul(self_atoms, next(W)) + next(b) new_rel_atoms_collection[deg - self.min_degree] = out # Combine all atoms back into the list #print(new_rel_atoms_collection) atom_features = torch.cat(new_rel_atoms_collection, 0) return atom_features def sum_neigh(self, atoms, deg_adj_lists): """Store the summed atoms by degree""" deg_summed = self.max_degree * [None] for deg in range(1, self.max_degree + 1): index = torch.tensor(deg_adj_lists[deg - 1], dtype=torch.int64) gathered_atoms = atoms[index] # Sum along neighbors as well as self, and store summed_atoms = torch.sum(gathered_atoms, 1) deg_summed[deg - 1] = summed_atoms return deg_summed class GraphPool(nn.Module): def __init__(self, min_degree=0, max_degree=10): super().__init__() self.min_degree = min_degree self.max_degree = max_degree def forward(self, atom_features, deg_slice, deg_adj_lists): # Perform the mol gather deg_maxed = (self.max_degree + 1 - self.min_degree) * [None] # Tensorflow correctly processes empty lists when using concat for deg in range(1, self.max_degree + 1): # Get self atoms begin = deg_slice[deg - self.min_degree, 0] size = deg_slice[deg - self.min_degree, 1] self_atoms = torch.narrow(atom_features, 0, int(begin), int(size)) # Expand dims self_atoms = torch.unsqueeze(self_atoms, 1) # always deg-1 for deg_adj_lists index = torch.tensor(deg_adj_lists[deg - 1], dtype=torch.int64) gathered_atoms = atom_features[index] gathered_atoms = torch.cat([self_atoms, gathered_atoms], 1) if gathered_atoms.shape[0] > 0: maxed_atoms = torch.max(gathered_atoms, 1)[0] else: maxed_atoms = torch.Tensor([]) deg_maxed[deg - self.min_degree] = maxed_atoms if self.min_degree == 0: begin = deg_slice[0, 0] size = deg_slice[0, 1] self_atoms = torch.narrow(atom_features, 0, int(begin), int(size)) deg_maxed[0] = self_atoms return torch.cat(deg_maxed, 0) class GraphGather(nn.Module): def __init__(self, batch_size): super().__init__() self.batch_size = batch_size def forward(self, atom_features, membership): assert self.batch_size > 1, "graph_gather requires batches larger than 1" sparse_reps = unsorted_segment_sum(atom_features, membership, self.batch_size) max_reps = scatter_max(atom_features, membership, dim=0) mol_features = torch.cat([sparse_reps, max_reps[0]], 1) return mol_features class GCNDataset(data.Dataset): def __init__(self, smiles_list, label_list): self.smiles_list = smiles_list self.label_list = label_list def __len__(self): return len(self.smiles_list) def __getitem__(self, index): return self.smiles_list[index], self.label_list[index] def gcn_collate_fn(batch): from rdkit import Chem cmf = ConvMolFeaturizer() mols = [] labels = [] for sample, label in batch: mols.append(Chem.MolFromSmiles(sample)) labels.append(torch.tensor(label)) conv_mols = cmf.featurize(mols) multiConvMol = ConvMol.agglomerate_mols(conv_mols) atom_feature = torch.tensor(multiConvMol.get_atom_features(), dtype=torch.float64) deg_slice = torch.tensor(multiConvMol.deg_slice, dtype=torch.float64) membership = torch.tensor(multiConvMol.membership, dtype=torch.int64) deg_adj_lists = [] for i in range(1, len(multiConvMol.get_deg_adjacency_lists())): deg_adj_lists.append(multiConvMol.get_deg_adjacency_lists()[i]) return atom_feature, deg_slice, membership, deg_adj_lists, labels def main(): dataset = GCNDataset(["CCC", "CCCC", "CCCCC"], [1, 0, 1]) dataloader = data.DataLoader(dataset, batch_size=3, shuffle=False, collate_fn =gcn_collate_fn) gc = GraphConv(75, 20) gp = GraphPool() gt = GraphGather(3) for atom_feature, deg_slice, membership, deg_adj_lists, labels in dataloader: print("atom_feature") print(atom_feature) print("deg_slice") print(deg_slice) print("membership") print(membership) print("result") gc_out = gc(atom_feature, deg_slice, deg_adj_lists) gp_out = gp(gc_out, deg_slice, deg_adj_lists) #print(gp_out) gt_out = gt(gp_out, membership) print(gt_out) if __name__ == "__main__": main()結果
はい、どん。
とりあえず、結果の形状は、分子数 x 40次元であり、原子が分子に集約されていることが分かる。
相変わらずこのホワイトボックス感がいいね(毎回コメントが全く同じで手抜き)。
今回は、TensorFlowのunsorted_segment_sumとunsorted_segment_max演算を移植するのに超苦労した。検証はこれからということで。tensor([[ 7.7457, 2.1970, 22.1151, 1.8238, 7.5860, 15.5079, -1.3865, 5.3634, 0.3872, 24.7713, 30.9865, 13.0032, 5.8331, 12.8195, 9.2520, 16.4660, -8.8977, 10.5881, 16.8875, 3.6356, 2.5819, 0.7323, 7.3717, 0.6079, 2.5287, 5.1693, -0.4622, 1.7878, 0.1291, 8.2571, 10.3288, 4.3344, 1.9444, 4.2732, 3.0840, 5.4887, -2.9659, 3.5294, 5.6292, 1.2119], [12.4624, 16.9705, 26.8321, 4.3047, 17.4027, 23.3370, -1.8487, 7.1511, 0.2538, 23.2520, 25.0874, 17.3375, 7.7775, 9.7369, 8.3362, 20.8373, -4.3081, 14.1175, 17.6781, 6.4011, 3.1156, 4.2426, 6.7080, 1.0762, 4.3507, 5.8342, -0.4622, 1.7878, 0.0634, 5.8130, 6.2718, 4.3344, 1.9444, 2.4342, 2.0840, 5.2093, -1.0770, 3.5294, 4.4195, 1.6003], [17.1790, 31.7441, 33.5401, 8.6282, 27.2195, 31.1660, -4.6301, 4.2145, -1.0452, 29.0650, 31.3592, 15.0395, 14.6857, 12.1711, 10.4202, 26.0466, 3.5187, 10.4842, 22.0976, 9.1667, 3.6493, 7.7530, 6.7080, 2.1586, 6.1727, 6.4992, -0.4622, 1.7878, 0.0634, 5.8130, 6.2718, 4.3344, 3.5990, 2.4342, 2.0840, 5.2093, 1.8909, 3.5294, 4.4195, 1.9887]], dtype=torch.float64, grad_fn=<CatBackward>)参考
- 投稿日:2020-11-13T05:50:17+09:00
dataframeでの関数適用のサンプルです。
- 投稿日:2020-11-13T03:44:04+09:00
xarray を用いたデータ解析
xarray を用いたデータ解析
以前の記事
で紹介したxarrayを用いたデータ解析について、もう少し実用的な面から紹介します。
著者について
2017年から、pydata xarray の開発メンバー。
ここ最近はもっぱらユーザーですが、たまにバグ修正のPRを送ったりしています。本業で行うほぼ全てのデータ解析に xarray を使っています。
想定している読者について
numpy についてある程度知っている(np.ndarray を使った操作・演算ができる)ことを想定しています。
本記事の構成
この記事では、もう一度 xarray のデータモデルを紹介したあと、基本的な操作であるインデクシングについて述べます。
このインデクシングが xarray の本質だと言っても良いかもしれません。その後、インデクシングの逆操作である concat を紹介します。
これらを踏まえた上で、実際にデータを作ることを考えた時、どのようなデータ構成にしておけば xarray での解析が容易になるか紹介します。
データの保存・読み込みや、dask を使った out-of-memory 処理についても少し述べます。
なお、本記事はGoogle collaboratoryを使って執筆しています。
こちらからコピーしてもらうことで、誰でも実行・トレースできます。xarray のデータモデル
概要
xarray を一言で述べると、 座標軸付きの多次元配列 です。numpy の nd-array と、pandas の pd.Series を合わせたものだと考えてもよいかもしれません。
使い方に慣れてくると、データ解析の途中で座標のことを考えなくてよくなるので非常に便利です。
一方で、使い方が少し独特であり、学習コストが高いとよく言われます。
この記事は、その学習コストを少しでも低くすることを目指しています。xarray には大きく2つのクラスがあります。1つは xarray.DataArray で、もう一つは xarray.Dataset です。
それらについて紹介します。なお、これは 多次元データ解析ライブラリ xarray で述べた内容とほぼ同一です。
xarray.DataArray
座標軸付きの多次元配列 である xarray.DataArray を紹介します。オブジェクトの作り方については後に述べますが、まずは xarray.tutorial にあるデータを用いて説明します。
import numpy as np import xarray as xrdata = xr.tutorial.open_dataset('air_temperature')['air'] data<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> [3869000 values with dtype=float32] Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]ここで、
dataは3次元の xr.DataArray インスタンスです。なお、xarray のオフィシャルな略語はxrです。
dataを表示すると、上記のようなサマリが表示されます。一番上の行の(time: 2920, lat: 25, lon: 53)は、格納されている配列の次元名およびその要素数を表しています。このように、xarray では 各次元に名前をつけて扱います(オフィシャルなドキュメントでは label と呼ばれています)。
1軸目が
time軸、2軸目がlat軸、3軸目がlon軸です。
このように名前をつけておくことで、軸の順番を気にしなくてよくなります。さらに、それぞれの軸には座標値が付加されています。座標のリストが
Coordinatesセクションに表示されます。
このデータでは、time,lat,lonの全ての軸に座標がついています。また、その他のデータも添付できます。それらは
Attributesセクションにあります。インデクシングの節で詳しく述べますが、座標軸がついていることで所望の範囲のデータを直感的に取得することができます。例えば 2014年8月30日のデータが欲しい場合、
data.sel(time='2014-08-30')<xarray.DataArray 'air' (time: 4, lat: 25, lon: 53)> array([[[270.29 , 270.29 , ..., 258.9 , 259.5 ], [273. , 273.1 , ..., 262.6 , 264.19998], ..., [299.5 , 298.79 , ..., 299. , 298.5 ], [299.29 , 299.29 , ..., 299.9 , 300. ]], [[269.9 , 270.1 , ..., 258.6 , 259.5 ], [273. , 273.29 , ..., 262.5 , 265. ], ..., [299.19998, 298.9 , ..., 298.5 , 298. ], [299.4 , 299.69998, ..., 299.19998, 299.6 ]], [[270.4 , 270.69998, ..., 261.29 , 261.9 ], [273. , 273.6 , ..., 266.4 , 268.6 ], ..., [297.9 , 297.6 , ..., 298.29 , 298.29 ], [298.69998, 298.69998, ..., 299.1 , 299.4 ]], [[270. , 270.4 , ..., 266. , 266.19998], [273. , 273.9 , ..., 268.1 , 269.69998], ..., [298.5 , 298.29 , ..., 298.69998, 299. ], [299.1 , 299.19998, ..., 299.5 , 299.69998]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2014-08-30 ... 2014-08-30T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]のようにできます。ここで
.selメソッドは座標軸を用いてデータを選ぶために用います。.sel(time='2014-08-30')は、time軸を参照して'2014-08-30'であるデータを選んでくることに相当します。DataArray に関する演算
DataArray は np.ndarray のような多次元配列でもあるので、np.ndarrayに対するような演算を行うことができます。
data * 2<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> array([[[482.4 , 485. , 487. , ..., 465.59998, 471. , 477.19998], [487.59998, 489. , 489.4 , ..., 465.59998, 470.59998, 478.59998], [500. , 499.59998, 497.78 , ..., 466.4 , 472.78 , 483.4 ], ..., [593.2 , 592.39996, 592.8 , ..., 590.8 , 590.2 , 589.39996], [591.8 , 592.39996, 593.58 , ..., 591.8 , 591.8 , 590.39996], [592.58 , 593.58 , 594.2 , ..., 593.8 , 593.58 , 593.2 ]], [[484.19998, 485.4 , 486.19998, ..., 464. , 467.19998, 471.59998], [487.19998, 488.19998, 488.4 , ..., 462. , 465. , 471.4 ], [506.4 , 505.78 , 504.19998, ..., 461.59998, 466.78 , 477. ], ... [587.38 , 587.77997, 590.77997, ..., 590.18 , 589.38 , 588.58 ], [592.58 , 594.38 , 595.18 , ..., 590.58 , 590.18 , 588.77997], [595.58 , 596.77997, 596.98 , ..., 591.38 , 590.98 , 590.38 ]], [[490.18 , 488.58 , 486.58 , ..., 483.37997, 482.97998, 483.58 ], [499.78 , 498.58 , 496.78 , ..., 479.18 , 480.58 , 483.37997], [525.98 , 524.38 , 522.77997, ..., 479.78 , 485.18 , 492.58 ], ..., [587.58 , 587.38 , 590.18 , ..., 590.58 , 590.18 , 589.38 ], [592.18 , 593.77997, 594.38 , ..., 591.38 , 591.38 , 590.38 ], [595.38 , 596.18 , 596.18 , ..., 592.98 , 592.38 , 591.38 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00直感的にそうあるべきなように、掛け算はアレイデータに対してのみ行われ、座標軸データは変更されずにそのまま保持されます。
アレイ以外で保持できるデータ
アレイデータ以外に、Coordinate を保持できることを述べました。Coordinateデータは以下のように分類できます。
- dimension coordinate
- non-dimension coordinate
- scalar coordinate
Dimension coordinate
これは、前節で Coordinate として紹介したものです。dimensionの名前(前節のデータでは
time,lon,lat)と同じ名前を持っています。Non-dimension coordinate
dimension とは異なる名前の座標も保持できます。どういう場面でそれが必要・便利になるかは後ほど説明しますが、基本的には 保持されているけど演算されないデータ だと理解すれば良いと思います。
Scalar coordinate
座標軸になりうるスカラーを保持できます。これもよく使うデータタイプですが、ひとまずは Non-dimension coordinate のように演算されないけど保持されているデータだと思っておけば良いと思います。
基本的なメソッド
np.ndarray にある基本的なメソッドを有しています。
.shape: 形状を返します.size: 合計の大きさを返します.ndim: 次元数を返しますそのほか、
.sizes: 次元名と大きさの連想配列(辞書型)を返します型に関するもの
.dtype: 配列の型を返します.astype(): 配列の型を変更します.real: 全データの実部を返します.imag: 全データの虚部を返しますDataArrayからnp.ndarrayに変換する。
DataArrayの中には、np.ndarray が収納されています。
(補足ですが、実際はnp.ndarray 以外の多次元配列も格納できます。)
.dataとすることで、中身の配列にアクセスできます。
(なお、.valuesでは中身の配列がどんなオブジェクトであれ np.ndarray に変換して返してくれます。)type(data.data), data.shape(numpy.ndarray, (2920, 25, 53))座標軸情報を取り出す
座標軸オブジェクトは、辞書のように
[]内に軸名を渡すことで取り出すことができます。data['lat']<xarray.DataArray 'lat' (lat: 25)> array([75. , 72.5, 70. , 67.5, 65. , 62.5, 60. , 57.5, 55. , 52.5, 50. , 47.5, 45. , 42.5, 40. , 37.5, 35. , 32.5, 30. , 27.5, 25. , 22.5, 20. , 17.5, 15. ], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 Attributes: standard_name: latitude long_name: Latitude units: degrees_north axis: Y取り出したものも DataArray オブジェクトになります。
xarray.Dataset
DataArrayを複数まとめたオブジェクトがDatasetです。
data = xr.tutorial.open_dataset('air_temperature') data['mean_temperature'] = data['air'].mean('time') data<xarray.Dataset> Dimensions: (lat: 25, lon: 53, time: 2920) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69 mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502 Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...この例では、
dataはairとmean_temperatureの2つのDataArrayを保持しています。
それらはData variablesというセクションに書かれています。
airは (time,lon,lat) 次元を持つ3次元配列mean_temperatureは (lon,lat) 次元を持つ2次元配列です。
保持するDataArrayは、座標軸を共有できます。そのため、以下のように複数のDataArrayに対して同時にインデクシングすることが可能です。
data.sel(lat=70, method='nearest')<xarray.Dataset> Dimensions: (lon: 53, time: 2920) Coordinates: lat float32 70.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lon) float32 250.0 249.79999 ... 242.59 246.29 mean_temperature (lon) float32 264.7681 264.3271 ... 253.58247 257.71475 Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...保持されている DataArray は、異なる次元(Dimension)を持っていてもかまいません。軸が共通かどうかは、軸の名前で判断します。そのため、共通でないけど同じ名前の座標軸をもたせるということはできません。
Datasetから DataArray を取得するには、辞書のようにDataArrayの名前をキーとして渡せばよいです。
da = data['air'] da<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> array([[[241.2 , 242.5 , ..., 235.5 , 238.59999], [243.79999, 244.5 , ..., 235.29999, 239.29999], ..., [295.9 , 296.19998, ..., 295.9 , 295.19998], [296.29 , 296.79 , ..., 296.79 , 296.6 ]], [[242.09999, 242.7 , ..., 233.59999, 235.79999], [243.59999, 244.09999, ..., 232.5 , 235.7 ], ..., [296.19998, 296.69998, ..., 295.5 , 295.1 ], [296.29 , 297.19998, ..., 296.4 , 296.6 ]], ..., [[245.79 , 244.79 , ..., 243.98999, 244.79 ], [249.89 , 249.29 , ..., 242.48999, 244.29 ], ..., [296.29 , 297.19 , ..., 295.09 , 294.38998], [297.79 , 298.38998, ..., 295.49 , 295.19 ]], [[245.09 , 244.29 , ..., 241.48999, 241.79 ], [249.89 , 249.29 , ..., 240.29 , 241.68999], ..., [296.09 , 296.88998, ..., 295.69 , 295.19 ], [297.69 , 298.09 , ..., 296.19 , 295.69 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]DataArray のインスタンス化
ここでは、DataArray オブジェクトを作る方法について説明します。
最も簡単な方法は、
np.ndarrayとそれぞれの軸名を与える方法です。xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'])<xarray.DataArray (x: 3, y: 4)> array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) Dimensions without coordinates: x, y上記の例では、3x4 要素を持つ DataArrayを作成しています。1つ目の次元の名前が
xで、2つ目の次元がyです。座標軸を与えるには、
coordsキーワードに対して辞書型で指定します。xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'], coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4]})<xarray.DataArray (x: 3, y: 4)> array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) Coordinates: * x (x) int64 0 1 2 * y (y) float64 0.1 0.2 0.3 0.4non-dimension coordinate を含めるためには、それが依存する軸名を指定しないといけません。そのために、辞書型の引数(コロンの右側)をタプルにします。1つ目の要素が依存する軸名で、2つ目が配列本体です。
xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'], coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4], 'z': ('x', ['a', 'b', 'c'])})<xarray.DataArray (x: 3, y: 4)> array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) Coordinates: * x (x) int64 0 1 2 * y (y) float64 0.1 0.2 0.3 0.4 z (x) <U1 'a' 'b' 'c'ここで、non-dimension coordinate
zはx軸上に定義されたものです。scalar coordinate も
coordsに渡します。xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'], coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4], 'scalar': 3})<xarray.DataArray (x: 3, y: 4)> array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) Coordinates: * x (x) int64 0 1 2 * y (y) float64 0.1 0.2 0.3 0.4 scalar int64 3scalar coordinate は、どの次元にも属していないことがわかります。
軸情報の他に、attribute や DataArray の名前も渡すことができます。ただし、attribute は演算の途中で失われてしまうので、まとめてファイルに保存したいものなどを入れる程度にしたほうがよいかもしれません。
このあたりは後で説明する、保存のためのデータ構造の章で説明したいと思います。
インデクシング
.isel,.sel,.interp,.reindexインデクシングは、最も基本的かつ本質的な操作です。それをシンプルにするために xarray の開発がスタートしたと言っても過言ではないと思います。
xarray では、位置ベースインデクシングと座標軸ベースのインデクシングが可能です。
位置ベースインデクシング
.iselこれは、np.ndarray などの一般的な配列に対するインデクシングと同様のものです。
data[i,j,k]のようにカギカッコの中に整数を引数として与えます。
引数は、 配列の中の要素の位置 を示すものです。da[0, :4, 3]<xarray.DataArray 'air' (lat: 4)> array([244. , 244.2 , 247.5 , 266.69998], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 lon float32 207.5 time datetime64[ns] 2013-01-01 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]上記の書き方だと、各次元の位置(例えば
time軸が一番最初の軸で、というようなもの)を覚えておく必要があります。解析ごとにそれらを覚えておくというのは意外と大変です。以下のような書き方をすると、軸の名前だけを覚えておけばよいことになります
da.isel(time=0, lat=slice(0, 4), lon=3)<xarray.DataArray 'air' (lat: 4)> array([244. , 244.2 , 247.5 , 266.69998], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 lon float32 207.5 time datetime64[ns] 2013-01-01 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]このように、
.isel()メソッドの引数にキーワード形式で軸名を入れ、それに対応するインデックスをイコールの後に与えます。なお、範囲を指定するときは明示的にスライス(
slice(0, 4))を使う必要があります。座標ベースインデクシング
.sel実際のデータ解析では、興味のある範囲は座標で指定されることが多いと思います。xarray では
.selメソッドを用いることで実現できます。da.sel(time='2013-01-01', lat=slice(75, 60))<xarray.DataArray 'air' (time: 4, lat: 7, lon: 53)> array([[[241.2 , 242.5 , ..., 235.5 , 238.59999], [243.79999, 244.5 , ..., 235.29999, 239.29999], ..., [272.1 , 270.9 , ..., 275.4 , 274.19998], [273.69998, 273.6 , ..., 274.19998, 275.1 ]], [[242.09999, 242.7 , ..., 233.59999, 235.79999], [243.59999, 244.09999, ..., 232.5 , 235.7 ], ..., [269.19998, 268.5 , ..., 275.5 , 274.69998], [272.1 , 272.69998, ..., 275.79 , 276.19998]], [[242.29999, 242.2 , ..., 236.09999, 238.7 ], [244.59999, 244.39 , ..., 232. , 235.7 ], ..., [273. , 273.5 , ..., 275.29 , 274.29 ], [275.5 , 275.9 , ..., 277.4 , 277.6 ]], [[241.89 , 241.79999, ..., 235.5 , 237.59999], [246.29999, 245.29999, ..., 231.5 , 234.5 ], ..., [273.29 , 272.6 , ..., 277.6 , 276.9 ], [274.1 , 274. , ..., 279.1 , 279.9 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 62.5 60.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2013-01-01T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]
.iselの場合と同様に、キーワードに軸名、イコールの後にほしい座標の値を与えます。
sliceオブジェクトも使うことができます。その場合は、sliceの引数に実数を入れればよいです。ただし、
.selメソッドにはいくつか注意点があります。おおよその座標値を用いたい時
.selメソッドにはオプションmethod,toleranceがあります。最もよく使う
methodはnearestだと思います。これは、最も近い座標値を用いてインデクシングしてくれます。da.sel(lat=76, method='nearest')<xarray.DataArray 'air' (time: 2920, lon: 53)> array([[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999], [242.09999, 242.7 , 243.09999, ..., 232. , 233.59999, 235.79999], [242.29999, 242.2 , 242.29999, ..., 234.29999, 236.09999, 238.7 ], ..., [243.48999, 242.98999, 242.09 , ..., 244.18999, 244.48999, 244.89 ], [245.79 , 244.79 , 243.48999, ..., 243.29 , 243.98999, 244.79 ], [245.09 , 244.29 , 243.29 , ..., 241.68999, 241.48999, 241.79 ]], dtype=float32) Coordinates: lat float32 75.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]座標軸ベースのインデクシングが働かない時
座標軸は自由度があるので、うまくインデクシングできない場合があります。例えば以下のようなケースが該当します。
座標軸が単調増加・単調減少でないとき
da.sortby('lat')のようにsortbyメソッドでその軸方向にソートできます。座標軸に Nan が含まれている時
da.isel(lat=~da['lat'].isnull())のように、Nanでない座標を返すisnullメソッドを併用することで、その座標値をスキップした配列を作れます座標軸に重複値があるとき
da.isel(lat=np.unique(da['lat'], return_index=True)[1])とすると、重複座標に対応する部分をスキップした配列を作れます補間
.interpインデクシングと同じようなシンタックスで補間が可能です。
da.interp(lat=74)<xarray.DataArray 'air' (time: 2920, lon: 53)> array([[242.23999321, 243.29999998, 243.9799988 , ..., 232.79998779, 235.41999512, 238.87998962], [242.69999081, 243.25999451, 243.53999329, ..., 231.60000001, 233.1599945 , 235.75999145], [243.21998903, 243.07599789, 242.97999266, ..., 232.69998783, 234.45999444, 237.49999702], ..., [245.72999275, 245.38999009, 244.68999648, ..., 242.74999088, 243.20999146, 244.00999451], [247.42999566, 246.58999336, 245.48999023, ..., 242.4899933 , 243.38999027, 244.58999329], [247.00999749, 246.28999329, 245.32999587, ..., 240.84999084, 241.00999144, 241.74999085]]) Coordinates: * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 lat int64 74 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]条件によるインデクシング
xr.where複雑な条件を満たすデータだけを選びたいときがあります。例えば上記の例だと、
timeがある曜日の時だけ選びたいairがある値以上のものだけを選びたいとかです。
選択結果が一次元のとき、例えばある曜日を選択するときなどは、Bool型の一次元配列を
.iselメソッドに渡すことで実現できます。import datetime # 週末だけを選びます is_weekend = da['time'].dt.dayofweek.isin([5, 6]) is_weekend<xarray.DataArray 'dayofweek' (time: 2920)> array([False, False, False, ..., False, False, False]) Coordinates: * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00# bool型を.isel メソッドに渡します。 da.isel(time=is_weekend)<xarray.DataArray 'air' (time: 832, lat: 25, lon: 53)> array([[[248.59999, 246.89 , ..., 245.7 , 246.7 ], [256.69998, 254.59999, ..., 248. , 250.09999], ..., [296.69998, 296. , ..., 295. , 294.9 ], [297. , 296.9 , ..., 296.79 , 296.69998]], [[245.09999, 243.59999, ..., 249.89 , 251.39 ], [254. , 251.79999, ..., 247.79999, 250.89 ], ..., [296.79 , 296.19998, ..., 294.6 , 294.69998], [297.19998, 296.69998, ..., 296.29 , 296.6 ]], ..., [[242.39 , 241.79999, ..., 247.59999, 247.29999], [247.18999, 246.09999, ..., 253.29999, 254.29999], ..., [294.79 , 295.29 , ..., 297.69998, 297.6 ], [296.38998, 297.19998, ..., 298.19998, 298.29 ]], [[249.18999, 248. , ..., 244.09999, 242.5 ], [254.5 , 253. , ..., 251. , 250.59999], ..., [294.88998, 295.19998, ..., 298. , 297.29 ], [296.1 , 296.88998, ..., 298.5 , 298.29 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-05 ... 2014-12-28T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]多次元配列のデータをもとに選択を行いたいとき、選んだ後の配列の形状を定義できないので、選ばない要素をNanで置き換えるとよいでしょう。
そういうときにはwhere関数が使えます。da.where(da > 270)<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> array([[[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 , 294.69998], [295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 , 295.19998], [296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 , 296.6 ]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ... [293.69 , 293.88998, 295.38998, ..., 295.09 , 294.69 , 294.29 ], [296.29 , 297.19 , 297.59 , ..., 295.29 , 295.09 , 294.38998], [297.79 , 298.38998, 298.49 , ..., 295.69 , 295.49 , 295.19 ]], [[ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], [ nan, nan, nan, ..., nan, nan, nan], ..., [293.79 , 293.69 , 295.09 , ..., 295.29 , 295.09 , 294.69 ], [296.09 , 296.88998, 297.19 , ..., 295.69 , 295.69 , 295.19 ], [297.69 , 298.09 , 298.09 , ..., 296.49 , 296.19 , 295.69 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]ここでは、
da > 270に当てはまらない要素をnp.nanで置き換えています。発展的なインデクシング
これまで基本的なインデクシングを紹介しましたが、xarray では発展的なインデクシングも可能です。
この図のように、多次元配列の中から別の配列を切り出すことができます。
オフィシャルドキュメントでは Advanced indexingと呼んでいます。
これを実現するためには、引数として渡す配列を DataArrayとして定義します。そのとき、それらの配列の次元を新しく作成する配列の次元にしておきます。
上の図に沿うと、新しい次元は
zなので、z上のDataArrayを定義します。lon_new = xr.DataArray([60, 61, 62], dims=['z'], coords={'z': ['a', 'b', 'c']}) lat_new = xr.DataArray([16, 46, 76], dims=['z'], coords={'z': ['a', 'b', 'c']})これらを
.selメソッドの引数として渡すと(lon, lat)がそれぞれ[(60, 16), (61, 46), (62, 76)]のもの(に最も近いもの)を選んできてくれます。da.sel(lon=lon_new, lat=lat_new, method='nearest')<xarray.DataArray 'air' (time: 2920, z: 3)> array([[296.29 , 280. , 241.2 ], [296.29 , 279.19998, 242.09999], [296.4 , 278.6 , 242.29999], ..., [298.19 , 279.99 , 243.48999], [297.79 , 279.69 , 245.79 ], [297.69 , 279.79 , 245.09 ]], dtype=float32) Coordinates: lat (z) float32 15.0 45.0 75.0 lon (z) float32 200.0 200.0 200.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 * z (z) <U1 'a' 'b' 'c' Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]新たに得られた配列は、もはや
lon,lat軸には依存していなくて、zに依存していることがわかります。また、同様の方法を補間にも用いることができます。
da.interp(lon=lon_new, lat=lat_new)<xarray.DataArray 'air' (time: 2920, z: 3)> array([[nan, nan, nan], [nan, nan, nan], [nan, nan, nan], ..., [nan, nan, nan], [nan, nan, nan], [nan, nan, nan]]) Coordinates: * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 lon (z) int64 60 61 62 lat (z) int64 16 46 76 * z (z) <U1 'a' 'b' 'c' Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]データの結合
xr.concat複数の xarray オブジェクトを結合させたいこともよくあります。
例えば、色々なパラメータで得られた実験データ・シミュレーションデータを合わせて解析したいときとかでしょうか。これは
np.concatenate,np.stackに相当する関数です。
インデクシングの逆操作だと思うとわかりやすいと思います。シンタックスは
xr.concat([data1, data2, ..., ], dim='dim')です。
最初の引数として、複数の DataArray (もしくは Dataset)を渡します。
2つ目の引数として、結合の方向を指定します。
結合方向によって、 concatenate 動作と stack 動作に分けられます。既存の軸を指定する(concatenate動作)
xr.concat関数の基本的な操作は、既存の軸方向に複数の DataArray をつなげることができます。例えば以下の2つの DataArray
da0 = da.isel(time=slice(0, 10)) da1 = da.isel(time=slice(10, None)) da0<xarray.DataArray 'air' (time: 10, lat: 25, lon: 53)> array([[[241.2 , 242.5 , ..., 235.5 , 238.59999], [243.79999, 244.5 , ..., 235.29999, 239.29999], ..., [295.9 , 296.19998, ..., 295.9 , 295.19998], [296.29 , 296.79 , ..., 296.79 , 296.6 ]], [[242.09999, 242.7 , ..., 233.59999, 235.79999], [243.59999, 244.09999, ..., 232.5 , 235.7 ], ..., [296.19998, 296.69998, ..., 295.5 , 295.1 ], [296.29 , 297.19998, ..., 296.4 , 296.6 ]], ..., [[244.79999, 244.39 , ..., 242.7 , 244.79999], [246.7 , 247.09999, ..., 237.79999, 240.2 ], ..., [297.79 , 297.19998, ..., 296.4 , 295.29 ], [297.9 , 297.69998, ..., 297.19998, 297. ]], [[243.89 , 243.79999, ..., 240.29999, 242.59999], [245.5 , 245.79999, ..., 236.59999, 239. ], ..., [297.6 , 297. , ..., 295.6 , 295. ], [298.1 , 297.69998, ..., 296.79 , 297.1 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2013-01-03T06:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]を
time方向につなげることで、もとのデータを復元できます。xr.concat([da0, da1], dim='time')<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> array([[[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999], [243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999, 239.29999], [250. , 249.79999, 248.89 , ..., 233.2 , 236.39 , 241.7 ], ..., [296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 , 294.69998], [295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 , 295.19998], [296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 , 296.6 ]], [[242.09999, 242.7 , 243.09999, ..., 232. , 233.59999, 235.79999], [243.59999, 244.09999, 244.2 , ..., 231. , 232.5 , 235.7 ], [253.2 , 252.89 , 252.09999, ..., 230.79999, 233.39 , 238.5 ], ... [293.69 , 293.88998, 295.38998, ..., 295.09 , 294.69 , 294.29 ], [296.29 , 297.19 , 297.59 , ..., 295.29 , 295.09 , 294.38998], [297.79 , 298.38998, 298.49 , ..., 295.69 , 295.49 , 295.19 ]], [[245.09 , 244.29 , 243.29 , ..., 241.68999, 241.48999, 241.79 ], [249.89 , 249.29 , 248.39 , ..., 239.59 , 240.29 , 241.68999], [262.99 , 262.19 , 261.38998, ..., 239.89 , 242.59 , 246.29 ], ..., [293.79 , 293.69 , 295.09 , ..., 295.29 , 295.09 , 294.69 ], [296.09 , 296.88998, 297.19 , ..., 295.69 , 295.69 , 295.19 ], [297.69 , 298.09 , 298.09 , ..., 296.49 , 296.19 , 295.69 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]ここで、
time軸も同じように復元されていることにも気をつけてください。新しい軸を指定する (stack 動作)
例えば以下のように2つのDataArrayがあるとします。
da0 = da.isel(time=0) da1 = da.isel(time=1) da0<xarray.DataArray 'air' (lat: 25, lon: 53)> array([[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999], [243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999, 239.29999], [250. , 249.79999, 248.89 , ..., 233.2 , 236.39 , 241.7 ], ..., [296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 , 294.69998], [295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 , 295.19998], [296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 , 296.6 ]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 time datetime64[ns] 2013-01-01 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]これを、
time軸方向に結合するには以下のようにします。xr.concat([da0, da1], dim='time')<xarray.DataArray 'air' (time: 2, lat: 25, lon: 53)> array([[[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999], [243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999, 239.29999], [250. , 249.79999, 248.89 , ..., 233.2 , 236.39 , 241.7 ], ..., [296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 , 294.69998], [295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 , 295.19998], [296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 , 296.6 ]], [[242.09999, 242.7 , 243.09999, ..., 232. , 233.59999, 235.79999], [243.59999, 244.09999, 244.2 , ..., 231. , 232.5 , 235.7 ], [253.2 , 252.89 , 252.09999, ..., 230.79999, 233.39 , 238.5 ], ..., [296.4 , 295.9 , 296.19998, ..., 295.4 , 295.1 , 294.79 ], [296.19998, 296.69998, 296.79 , ..., 295.6 , 295.5 , 295.1 ], [296.29 , 297.19998, 297.4 , ..., 296.4 , 296.4 , 296.6 ]]], dtype=float32) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 2013-01-01T06:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]このように、
da0,da1にtimeという scalar coordinate が存在している場合、その方向につなげることで
(dim='time'というようにdimキーワードに名前を指定することで)、time軸を新たな座標軸(dimension coordinate)にすることができます。ほかにも、
dimキーワードにDataArrayを与えることで、その名前の座標軸を新しく作ることも可能です。ファイルIO
xarray のもう一つのメリットは、DataArray や Dataset などのデータを無矛盾・自己完結的に保存できることです。
いくつかファイルフォーマットをサポートしていますが、最も使いやすいのは netCDF でしょう。Wikipedia にも説明があります。
NetCDFは、コンピュータの機種に依存しないバイナリ形式であり(機種非依存)、データを配列として読み書きすることができ(配列指向)、さらにデータに加えそのデータに関するに関する説明を格納できる(自己記述的)という特徴がある。NetCDFは、オープンな地理情報標準を策定する国際的なコンソーシアムである、Open Geospatial Consortiumにおける国際標準である。
現在、バージョン3と4がメンテナンスされていますが、バージョン4を使っておくほうが無難でしょう。
バージョン4はHDF5の標準に準拠していますので、通常の HDF5 リーダでも内容を読み込むことができます。なお、正式な拡張子は
.ncです。netCDF 形式でファイルを保存・読み込みをする
netCDF 形式で保存するためには、 パッケージ
netcdf4が必要です。pip install netcdf4もしくは
bash
conda install netcdf4
を実行してシステムにインストールしておきましょう。xarray オブジェクトを netCDF 形式で保存するには、
.to_netcdfメソッドを実行します。data.to_netcdf('test.nc')/home/keisukefujii/miniconda3/envs/xarray/lib/python3.7/site-packages/ipykernel_launcher.py:1: SerializationWarning: saving variable air with floating point data as an integer dtype without any _FillValue to use for NaNs """Entry point for launching an IPython kernel.これで、現在のパスに
test.ncが保存されたと思います。逆に、保存されたファイルを読み込むためには、
xr.load_datasetを行います。xr.load_dataset('test.nc')<xarray.Dataset> Dimensions: (lat: 25, lon: 53, time: 2920) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69 mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502 Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...このように、配列の部分だけでなく、軸の名前、座標の値、
attributesにあるその他の情報まで保存されていることがわかります。
scipy.io.netcdfに関する注意xarray の
.to_netcdfは、デフォルトではnetcdf4ライブラリを使いますが、システムにインストールされていない場合、scipy.io.netcdfを使います。 ただしscipy.io.netcdfでサポートされているのはバージョン3で、バージョン4では互換性がないので混乱の元になります。システムに
netcdf4をインストールするのを忘れないようにしましょう。
もしくは、.to_netcdf('test.nc', engine='netcdf4')というように、陽に使うパッケージを指定することもできます。Out-of-memory 配列
netCDF 形式のファイルはランダム読み込みができます。そのため、ファイルのある部分のデータだけを使いたいというようなときは、全てのデータをまずハードディスクから読み込むのではなく、必要なときに読み込むようにすれば効率がよいでしょう。
特に、メモリに格納できないくらい大きなサイズのファイルを扱うときは、そういった処理が本質的に重要になってきます。
これを out-of-memory 処理と呼びます。xarray における out-of-memory 処理は結構重要な昨日と位置づけられていて、様々な実装が進んでいます。
その詳細はまた別の記事で紹介することにして、ここでは最も基本的な内容だけを述べようと思います。読み込み時に
load_datasetではなくopen_datasetをすることで、out-of-memory 処理が行われます。unloaded_data = xr.open_dataset('test.nc') unloaded_data<xarray.Dataset> Dimensions: (lat: 25, lon: 53, time: 2920) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lat, lon) float32 ... mean_temperature (lat, lon) float32 ... Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...
Data variablesのところを見てもらうと、例えばairのところに数字が入っておらず、単に...となっていることがわかります。これはデータが読み込まれていないことを示しています。
ただし座標軸は常に読み込まれるので、上記のインデクシング作業はこのまま可能です。unloaded_data['air'].sel(lat=60, method='nearest')<xarray.DataArray 'air' (time: 2920, lon: 53)> [154760 values with dtype=float32] Coordinates: lat float32 60.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: long_name: 4xDaily Air temperature at sigma level 995 units: degK precision: 2 GRIB_id: 11 GRIB_name: TMP var_desc: Air temperature dataset: NMC Reanalysis level_desc: Surface statistic: Individual Obs parent_stat: Other actual_range: [185.16 322.1 ]変数を選んだり、インデクシングしたりしてもまだロードされません。
演算されたり、.dataや.valuesが呼ばれるとメモリに初めてロードされることになります。明示的にロードするには、
.compute()メソッドを使っても良いと思います。unloaded_data.compute()<xarray.Dataset> Dimensions: (lat: 25, lon: 53, time: 2920) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69 mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502 Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...注意
open_dataset,open_dataarrayでは、ファイルをロックし今後の読み込みに備えます。そのため、別のプログラムで同じ名前のファイルを触るとエラーが起こります。例えば、時間のかかる計算の結果を
.ncファイルとしてその都度出力しているときを考えます。途中経過を見たいと思ってopen_datasetで開くと、その後そのファイルに書き込もうとすると失敗します。
失敗して止まるだけならましですが、既存のデータを壊してしまうことも多いようです。
この out-of-memory 処理は注意して使う必要があります。以下のように、
with文を使うと、確実にファイルを閉じてロックを解除してくれます。with xr.open_dataset('test.nc') as f: print(f)<xarray.Dataset> Dimensions: (lat: 25, lon: 53, time: 2920) Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Data variables: air (time, lat, lon) float32 ... mean_temperature (lat, lon) float32 ... Attributes: Conventions: COARDS title: 4x daily NMC reanalysis (1948) description: Data is from NMC initialized reanalysis\n(4x/day). These a... platform: Model references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...おすすめデータ構造
上記のように、netcdf 形式でデータを保存しておくと xarray でスムースにデータ解析を行うことができます。
実験やシミュレーションなどでデータを作成する時には、その後の解析のことを考えたデータ構造を作っておいて、それを含めた netcdf 形式で保存しておくとよいでしょう。以下を抑えたデータにしておくことをお勧めします。
- 座標軸データも保存する
- 実験時刻やスキャンするパラメータは、
attributesではなくscalar coordinateとするattributesには変化させないもの(実験に使った機器の情報や、データに関する説明文など) を入れるとよいでしょう。実験の場合、以下のような構造で保存すれば良いと思います。
from datetime import datetime# これをカメラで撮影した画像データだとします。 raw_data = np.arange(512 * 2048).reshape(512, 2048) # 画像のx軸・y軸の座標です。 x = np.arange(512) y = np.arange(2048) # 画像の各ピクセルに対する位置データ r = 300.0 X = r * np.cos(x / 512)[:, np.newaxis] + r * np.sin(y / 2048) Y = r * np.sin(x / 512)[:, np.newaxis] - r * np.cos(y / 2048) # 実験で使ったパラメータ p0 = 3.0 p1 = 'normal' # 実験時刻 now = datetime.now() data = xr.DataArray( raw_data, dims=['x', 'y'], coords={'x': x, 'y': y, 'X': (('x', 'y'), X), 'Y': (('x', 'y'), Y), 'p0': p0, 'p1': p1, 'datetime': now}, attrs={'camera type': 'flash 4', 'about': 'Example of the recommended data structure.'}) data<xarray.DataArray (x: 512, y: 2048)> array([[ 0, 1, 2, ..., 2045, 2046, 2047], [ 2048, 2049, 2050, ..., 4093, 4094, 4095], [ 4096, 4097, 4098, ..., 6141, 6142, 6143], ..., [1042432, 1042433, 1042434, ..., 1044477, 1044478, 1044479], [1044480, 1044481, 1044482, ..., 1046525, 1046526, 1046527], [1046528, 1046529, 1046530, ..., 1048573, 1048574, 1048575]]) Coordinates: * x (x) int64 0 1 2 3 4 5 6 7 8 ... 504 505 506 507 508 509 510 511 * y (y) int64 0 1 2 3 4 5 6 7 ... 2041 2042 2043 2044 2045 2046 2047 X (x, y) float64 300.0 300.1 300.3 300.4 ... 414.7 414.8 414.9 414.9 Y (x, y) float64 -300.0 -300.0 -300.0 -300.0 ... 89.66 89.79 89.91 p0 float64 3.0 p1 <U6 'normal' datetime datetime64[ns] 2020-11-13T03:31:56.219372 Attributes: camera type: flash 4 about: Example of the recommended data structure.実験中に変わりうるものを scalar coordinate にまとめておくことで、後にそれらに対する依存性を知りたい時にも解析が容易になります。
その他の有用な関数・メソッド
Reduction
.sum,.mean, etc
np.sum,np.meanなどの reduction 処理はメソッドとして提供されています。
例えばnp.sumでは、どの軸方向に足し合わせるかを指定できます。xarray では同様に、軸を軸名として指定できます。data = xr.tutorial.open_dataset('air_temperature')['air'] data.sum('lat')<xarray.DataArray 'air' (time: 2920, lon: 53)> array([[6984.9497, 6991.6606, 6991.5303, ..., 6998.77 , 7007.8804, 7016.5605], [6976.4307, 6988.45 , 6993.2407, ..., 6994.3906, 7006.7505, 7019.941 ], [6975.2603, 6982.02 , 6988.77 , ..., 6992.0503, 7004.9404, 7020.3506], ..., [6990.7505, 6998.3496, 7013.3496, ..., 6995.05 , 7008.6504, 7019.4497], [6984.95 , 6991.6504, 7007.949 , ..., 6994.15 , 7008.55 , 7020.8506], [6981.75 , 6983.85 , 6997.0503, ..., 6985.6494, 6999.2495, 7012.0493]], dtype=float32) Coordinates: * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00このようにある軸方向に足し合わせを行えば、その方向の座標軸がなくなります。
他の座標軸は残っています。なお、
.sumなどを実行する場合、デフォルトではnp.sumではなくnp.nansumが呼ばれ、Nanをスキップした計算が行われます。
Nanをスキップしてほしくない場合(np.nansumではなくnp.sumを使いたい場合)は、skipna=Falseを与える必要があります。描画
.plot
DataArrayにはplotメソッドが備わっており、データの内容を簡単に可視化することができます。data.sel(time='2014-08-30 08:00', method='nearest').plot()<matplotlib.collections.QuadMesh at 0x7f9a98557310>
論文・報告の最終的な図を作るためというよりは、簡易的なものと思っておいたほうがよいかもしれませんが、Jupyter や Ipython などでデータを可視化して理解しながら解析を進めるために使うには非常に便利です。
- 投稿日:2020-11-13T02:35:23+09:00
PythonからFortranサブルーチンを呼び出す時の多次元配列のアクセス順(ctypeslibとf2py)
はじめに
Pythonで多次元配列に対してfor文を回して複雑な処理をしたい事がありますが(大気海洋分野ではデータが多次元配列で表されることが多いです)、そうした場合しばしば実行時間が長くなり困ることがあります。これを解決する高速化方法は様々ですが、流体計算でよく使われるFortranでサブルーチンを書いて、それをPythonから呼び出すことは一つの解決方法です。PythonからFortranのサブルーチンを呼び出す方法には、numpy.ctypeslibを使う方法とf2pyを使う方法の大きく2つがあります。両者で多次元配列のアクセス順が異なりますが、日本語でまとめられているページが見つからなかったので、記事を書きました。
実行環境は以下の通りです。
- macOS 10.15.7 Catalina
- Python 3.7.7 (conda 4.9.0)
- NumPy 1.19.2
- f2py version 2
- gfortran (gcc) 10.2.0 (Homebrew)
PythonとFortranでの多次元配列の扱いの違い
基礎的な話なので、既知の場合はこの節を読み飛ばして大丈夫です。
プログラミング言語で多次元配列が扱われますが、メモリ上では1次元方向に並べて配置されます。その際、どのように格納されるかは言語によって異なります。以下のコードでは、メモリ上に配置された順番で配列の要素に値0を書き込んでいます。
loop.pyimport numpy as np nk = 2 nj = 3 ni = 4 array = np.empty((nk, nj, ni), dtype=np.float32, order="C") for k in range(nk): for j in range(nj): for i in range(ni): array[k, j, i] = 0loop.f90integer(4), parameter :: nk = 2, nj = 3, ni = 4 real(4), dimension(ni, nj, nk) :: array do k = 1, nk do j = 1, nj do i = 1, ni array(i, j, k) = 0 end do end do end doPython(正確にはnumpyの配列の
order="C"の場合)では[k, j, i]、Fortranでは(i, j, k)の順になっている点が違います(それぞれ、行優先と列優先と呼ばれたりします)。メモリ上の格納順にアクセスするか飛び飛びにアクセスするかは、特に配列のサイズが大きくなると実行時間に影響します。numpy.ctypeslibを使う場合
例として、numpyの2次元配列をFortranにサブルーチンに渡し、それを2倍したものを返すコードを書いてみます(3次元以上の場合についても同様です)。コードの詳細についてはここでは解説しないので、知りたい場合は例えば Fortran, C言語 との連携 など他の記事を見てください。
doubling1.pyfrom ctypes import POINTER, c_int32, c_void_p import numpy as np libDoubling = np.ctypeslib.load_library("doubling1.so", ".") libDoubling.doubling.argtypes = [ np.ctypeslib.ndpointer(dtype=np.float32), np.ctypeslib.ndpointer(dtype=np.float32), POINTER(c_int32), POINTER(c_int32), ] libDoubling.doubling.restype = c_void_p nj = 2 ni = 3 vin = np.empty((nj, ni), dtype=np.float32, order="C") vin[0, 0] = 1 vin[0, 1] = 2 vin[0, 2] = 3 vin[1, 0] = 4 vin[1, 1] = 5 vin[1, 2] = 6 vout = np.empty((nj, ni), dtype=np.float32, order="C") _nj = POINTER((c_int32))(c_int32(nj)) _ni = POINTER((c_int32))(c_int32(ni)) libDoubling.doubling(vin, vout, _ni, _nj) print(vin) # [[1. 2. 3.] # [4. 5. 6.]] print(vout) # [[ 2. 4. 6.] # [ 8. 10. 12.]]doubling1.f90! gfortran -Wall -cpp -fPIC -shared doubling1.f90 -o doubling1.so subroutine doubling(vin, vout, ni, nj) bind(C) use, intrinsic :: ISO_C_BINDING implicit none integer(c_int32_t), intent(in) :: ni, nj real(c_float), dimension(ni, nj), intent(in) :: vin real(c_float), dimension(ni, nj), intent(out) :: vout integer(c_int32_t) :: i, j do j = 1, nj do i = 1, ni vout(i, j) = vin(i, j) * 2 end do end do end subroutine doublingFortranのサブルーチン(共有ライブラリ)の引数にはポインタが渡されます。PythonとFortranでインデックスが
[j, i]と(i, j)と逆になりますが、メモリ上にデータがどういう順番で格納されているかを考えれば、素直に理解できるはずです。f2pyを使う場合
次にf2pyを使い、先ほどと同様のコードを書いてみます。これについても詳細は解説しませんが、例えば f2pyでnumpyの配列を扱う といった記事が参考になると思います。
doubling2.f90! f2py -c --fcompiler=gfortran -m doubling2 doubling2.f90 subroutine doubling2(vin, vout, ni, nj) implicit none integer(4), intent(in) :: ni, nj real(4), dimension(nj, ni), intent(in) :: vin real(4), dimension(nj, ni), intent(out) :: vout integer(4) :: i, j do j = 1, nj do i = 1, ni vout(j, i) = vin(j, i) * 2 end do end do end subroutine doubling2doubling2.pyimport numpy as np import doubling2 nj = 2 ni = 3 vin = np.empty((nj, ni), dtype=np.float32, order="C") vin[0, 0] = 1 vin[0, 1] = 2 vin[0, 2] = 3 vin[1, 0] = 4 vin[1, 1] = 5 vin[1, 2] = 6 vout = np.empty((nj, ni), dtype=np.float32, order="C") vout = doubling2.doubling2(vin, ni, nj) print(vin) # [[1. 2. 3.] # [4. 5. 6.]] print(vout) # [[ 2. 4. 6.] # [ 8. 10. 12.]]f2pyを使う場合は、Pythonの
[j, i]はそのままFortranでも(j, i)とすればOKです。コード上の見た目が同じになるメリットがありますが、doubling2.f90の中のdo文では、配列のアクセス順がメモリ上のデータ格納順と対応しなくなるというデメリットがあります。これを解決するにはどうすれば良いでしょうか? つまりFortran側のコードをdoubling1.f90と同じく、メモリ上のデータ格納順にアクセスするようにしたいわけです。
doubling3.f90! f2py -c --fcompiler=gfortran -m doubling3 doubling3.f90 subroutine doubling3(vin, vout, ni, nj) implicit none integer(4), intent(in) :: ni, nj real(4), dimension(ni, nj), intent(in) :: vin real(4), dimension(ni, nj), intent(out) :: vout integer(4) :: i, j do j = 1, nj do i = 1, ni vout(i, j) = vin(i, j) * 2 end do end do end subroutine doubling3numpyの配列の
order引数をデフォルトの"C"ではなく"F"にすることで、メモリ上の格納順を逆にすることが出来ることを思いつくかもしれません。しかし、これではこの問題は解決しません。すなわち、doubling2.pyでorder="C"をorder="F"に変えたとしても、対応するFortranコードは依然としてdoubling2.f90であり、doubling3.f90を使うとエラーになるということです。解決策は、f2py — prevent array reordering - Stack Overflowにあるとおり、
T属性を用いて配列を転置することです。doubling3.pyimport numpy as np import doubling3 nj = 2 ni = 3 vin = np.empty((nj, ni), dtype=np.float32, order="C") vin[0, 0] = 1 vin[0, 1] = 2 vin[0, 2] = 3 vin[1, 0] = 4 vin[1, 1] = 5 vin[1, 2] = 6 _vout = np.empty((nj, ni), dtype=np.float32, order="C") _vout = doubling3.doubling3(vin.T, ni, nj) vout = _vout.T print(vin) # [[1. 2. 3.] # [4. 5. 6.]] print(vout) # [[ 2. 4. 6.] # [ 8. 10. 12.]]例えば「netCDF4ライブラリを用いてGPVを読み込み、それをFortranのサブルーチンで効率良く処理した後、matplotlib+cartopyなどで描画する」といった用途の場合、この方法がよいと思います。"お節介"を回避するために転置するのは面倒ですが、それを含めてもnumpy.ctypeslibを使う場合と比べると記述量は少なく、f2pyのほうが使い勝手がよいように思います。
- 投稿日:2020-11-13T01:44:53+09:00
ロケーション名を入力すると、施設の種類や住所etc.を返すGeocodingツール
(コード) Python3
loc_geocoding.py# coding: utf-8 import time, argparse, datetime from pprint import pprint import pandas as pd import numpy as np # コマンドライン引数を受け取る parser = argparse.ArgumentParser() # コマンドライン引数を1つだけ受け取る parser.add_argument('-loc', '--location_name', default='東京駅', help='興味のある場所または施設の名称を入力して下さい。') args = parser.parse_args() location = str(args.location_name) print("\n\n入力されたロケーション名: ", args.location_name, "\n") import geocoder data = geocoder.osm(location, timeout=5.0) output_dict = {} if data.ok: data_json = data.json # 種別 try: pprint(data_json["raw"]["category"]) output_dict.update({"種別" : data_json["raw"]["category"]}) except: pass # 表示名 try: pprint(data_json["raw"]["display_name"]) output_dict.update({"表示名" : data_json["raw"]["display_name"]}) except: pass # オフィス名 try: pprint(data_json["raw"]["address"]["office"]) output_dict.update({"オフィス名" : data_json["raw"]["office"]}) except: pass # 緯度 try: pprint(data_json["lat"]) output_dict.update({"緯度" : data_json["lat"]}) except: pass # 経度 try: pprint(data_json["lng"]) output_dict.update({"経度" : data_json["lat"]}) except: pass # 国名 try: pprint(data_json["raw"]["address"]["country"]) output_dict.update({"国名" : data_json["raw"]["address"]["country"]}) except: pass # 郵便番号 try: pprint(data_json["raw"]["address"]["postcode"]) output_dict.update({"郵便番号" : data_json["raw"]["address"]["postcode"]}) except: pass # 都道府県名 try: print(data_json['city']) output_dict.update({"都道府県名" : data_json['city']}) except: pass # 街区名 try: pprint(data_json["raw"]["address"]["quarter"]) output_dict.update({"街区名" : data_json["raw"]["address"]["quarter"]}) except: pass # ストリート名 try: pprint(data_json["raw"]["address"]["road"]) output_dict.update({"ストリート名" : data_json["raw"]["address"]["road"]}) except: pass # 番地 try: pprint(data_json["raw"]["address"]["house_number"]) output_dict.update({"番地" : data_json["raw"]["address"]["house_number"]}) except: pass # 住所(全体) try: pprint(data_json["address"]) output_dict.update({"住所(全体)" : data_json["address"]}) except: pass #tmp = ["属性名: {key} 値 : {value}".format(key=k, value=v) for k,v in data_json.items()] # #tmp = ["{key} : {value}".format(key=k, value=v) for k,v in data_json.items()] #tmp_df = pd.DataFrame(data_json.values(), index=data_json.keys()) print("""\n\n==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ====================================================================================\n""") output_df = pd.DataFrame(output_dict.values(), index=output_dict.keys()) else: print("そのロケーションは見つかりませんでした。") print("DataFrameオブジェクトに格納された情報") print(output_df)( 実行方法 )
Terminal$ python3 loc_geocoding.py -h usage: loc_geocoding.py [-h] [-loc LOCATION_NAME] optional arguments: -h, --help show this help message and exit -loc LOCATION_NAME, --location_name LOCATION_NAME 興味のある場所または施設の名称を入力して下さい。 $( 実行例 )
東京タワー
Terminal$ python3 loc_geocoding.py -loc '東京タワー' 入力されたロケーション名: 東京タワー 'tourism' '東京タワー, 東京タワー通り, 麻布, 南青山6, 東京都, 港区, 105-0011, 日本 (Japan)' 35.65858645 139.74544005796224 '日本 (Japan)' '105-0011' 東京都 '麻布' '東京タワー通り' '東京タワー, 東京タワー通り, 麻布, 南青山6, 東京都, 港区, 105-0011, 日本 (Japan)' ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 tourism 表示名 東京タワー, 東京タワー通り, 麻布, 南青山6, 東京都, 港区, 105-0011, 日... 緯度 35.6586 経度 35.6586 国名 日本 (Japan) 郵便番号 105-0011 都道府県名 東京都 街区名 麻布 ストリート名 東京タワー通り 住所(全体) 東京タワー, 東京タワー通り, 麻布, 南青山6, 東京都, 港区, 105-0011, 日... $米国大使館
Terminal$ python3 loc_geocoding.py -loc '米国大使館' 入力されたロケーション名: 米国大使館 'office' 'U.S. Embassy Tokyo, 5, 泉通り, 六本木, 東京都, 港区, 107-8420, 日本 (Japan)' 'U.S. Embassy Tokyo' 35.668439449999994 139.7433025345327 '日本 (Japan)' '107-8420' 東京都 '六本木' '泉通り' '5' 'U.S. Embassy Tokyo, 5, 泉通り, 六本木, 東京都, 港区, 107-8420, 日本 (Japan)' ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 office 表示名 U.S. Embassy Tokyo, 5, 泉通り, 六本木, 東京都, 港区, 107-... 緯度 35.6684 経度 35.6684 国名 日本 (Japan) 郵便番号 107-8420 都道府県名 東京都 街区名 六本木 ストリート名 泉通り 番地 5 住所(全体) U.S. Embassy Tokyo, 5, 泉通り, 六本木, 東京都, 港区, 107-... $東京大学
Terminal$ python3 loc_geocoding.py -loc '東京大学' 入力されたロケーション名: 東京大学 'tourism' '情報学環オープンスタジオ, 1, 合格通り, 文京区, 113-8654, 日本 (Japan)' 35.7114214 139.7612027 '日本 (Japan)' '113-8654' 文京区 '合格通り' '1' '情報学環オープンスタジオ, 1, 合格通り, 文京区, 113-8654, 日本 (Japan)' ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 tourism 表示名 情報学環オープンスタジオ, 1, 合格通り, 文京区, 113-8654, 日本 (Japan) 緯度 35.7114 経度 35.7114 国名 日本 (Japan) 郵便番号 113-8654 都道府県名 文京区 ストリート名 合格通り 番地 1 住所(全体) 情報学環オープンスタジオ, 1, 合格通り, 文京区, 113-8654, 日本 (Japan) $ラーメン二郎
Terminal$ python3 loc_geocoding.py -loc 'ラーメン二郎' 入力されたロケーション名: ラーメン二郎 'amenity' 'ラーメン二郎\u3000ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市, 188-0001, 日本 (Japan)' 35.7499086 139.5434758 '日本 (Japan)' '188-0001' 西東京市 '北原町' '谷戸新道' '3-27-24' 'ラーメン二郎\u3000ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市, 188-0001, 日本 (Japan)' ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 amenity 表示名 ラーメン二郎 ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市... 緯度 35.7499 経度 35.7499 国名 日本 (Japan) 郵便番号 188-0001 都道府県名 西東京市 街区名 北原町 ストリート名 谷戸新道 番地 3-27-24 住所(全体) ラーメン二郎 ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市... $White House
Terminal$ python3 loc_geocoding.py -loc 'White House' 入力されたロケーション名: White House 'historic' ('White House, 1600, Pennsylvania Avenue Northwest, Washington, District of ' 'Columbia, 20500, United States of America') 38.8976998 -77.03655315 'United States of America' '20500' Washington 'Pennsylvania Avenue Northwest' '1600' ('White House, 1600, Pennsylvania Avenue Northwest, Washington, District of ' 'Columbia, 20500, United States of America') ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 historic 表示名 White House, 1600, Pennsylvania Avenue Northwe... 緯度 38.8977 経度 38.8977 国名 United States of America 郵便番号 20500 都道府県名 Washington ストリート名 Pennsylvania Avenue Northwest 番地 1600 住所(全体) White House, 1600, Pennsylvania Avenue Northwe... $ロケーション名が、1単語の場合は、single quotation記号「'」で囲む必要はありません。White Hoseのように複数単語の場合は、「'」が必要になります。
ラーメン二郎
Terminal$ python3 loc_geocoding.py -loc ラーメン二郎 入力されたロケーション名: ラーメン二郎 'amenity' 'ラーメン二郎\u3000ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市, 188-0001, 日本 (Japan)' 35.7499086 139.5434758 '日本 (Japan)' '188-0001' 西東京市 '北原町' '谷戸新道' '3-27-24' 'ラーメン二郎\u3000ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市, 188-0001, 日本 (Japan)' ==================================================================================== ロケーション情報をDataFrameオブジェクトに格納します。 ==================================================================================== DataFrameオブジェクトに格納された情報 0 種別 amenity 表示名 ラーメン二郎 ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市... 緯度 35.7499 経度 35.7499 国名 日本 (Japan) 郵便番号 188-0001 都道府県名 西東京市 街区名 北原町 ストリート名 谷戸新道 番地 3-27-24 住所(全体) ラーメン二郎 ひばりヶ丘駅前店, 3-27-24, 谷戸新道, 北原町, 田無町, 西東京市...White House
Terminal$ python3 loc_geocoding.py -loc White House usage: loc_geocoding.py [-h] [-loc LOCATION_NAME] loc_geocoding.py: error: unrecognized arguments: House $
- 投稿日:2020-11-13T01:43:52+09:00
Don't work Python with OpenCV on AMD Ryzen CPU on WSL2 Ubuntu 18.04 And 20.04
MAIN BOARD
ASUSTek COMPUTER INC.
PRIME X570-PRO
Rev X.0xCPU
AMD Ryzen 7 3700XMEM
G.Skill DDR4 3600GPU
RTX 3900It's looks like this error.
Don't work.$ python >>>import cv2 WARNING: CPU random generator seem to be failing, disable hardware random number generation WARNING: RDRND generated: 0xffffffff 0xffffffff 0xffffffff 0xffffffffI update bios. It's fatal.
It's working update after.
My computer use PRIME X570-PRO BIOS 0602. I set up PRIME X570-PRO BIOS 2802.Type "help", "copyright", "credits" or "license" for more information. >>> import cv2 >>>