Last login: Fri Nov 13 03:16:54 UTC 2020 on pts/0
[root@ip-xxx-xxx-xxx-xxx ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdf 202:80 0 4G 0 disk
[root@ip-xxx-xxx-xxx-xxx ~]# mke2fs /dev/xvdf
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
262144 inodes, 1048576 blocks
52428 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1073741824
32 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
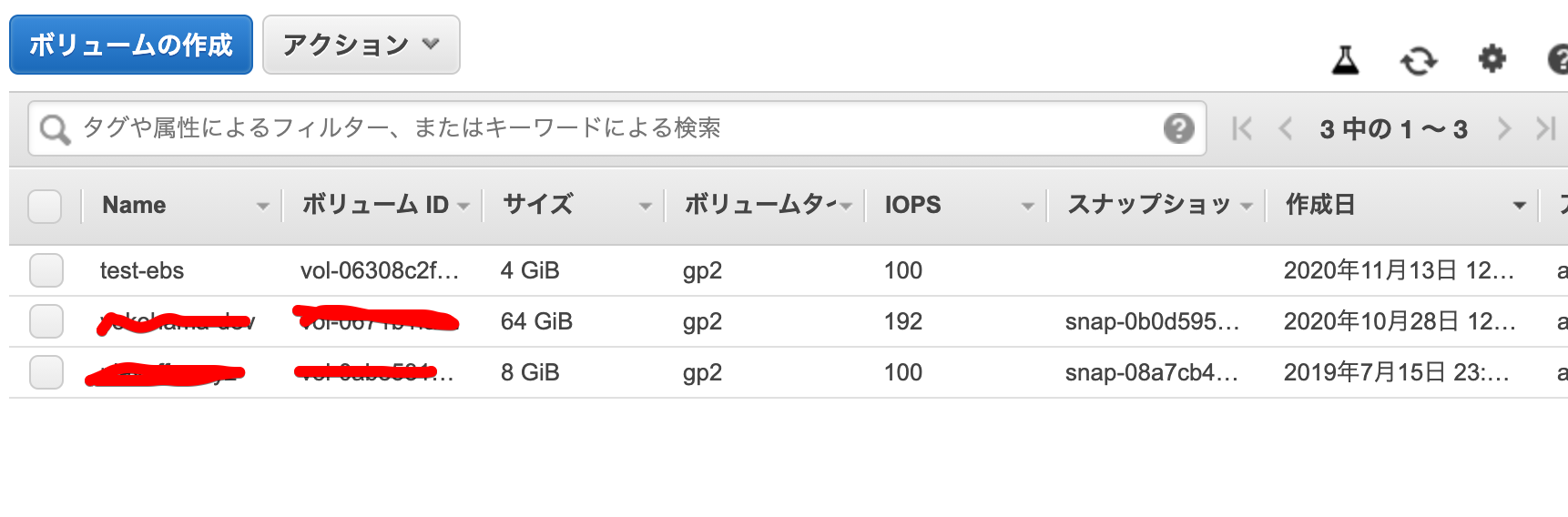
これでLinuxファイルシステムにマウントができる形になりました。
/mntにマウントします。
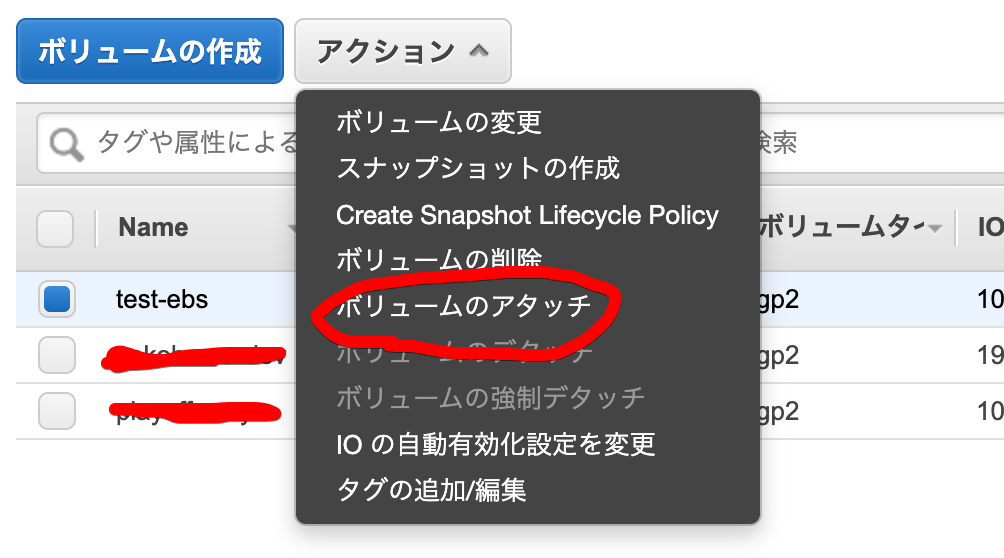
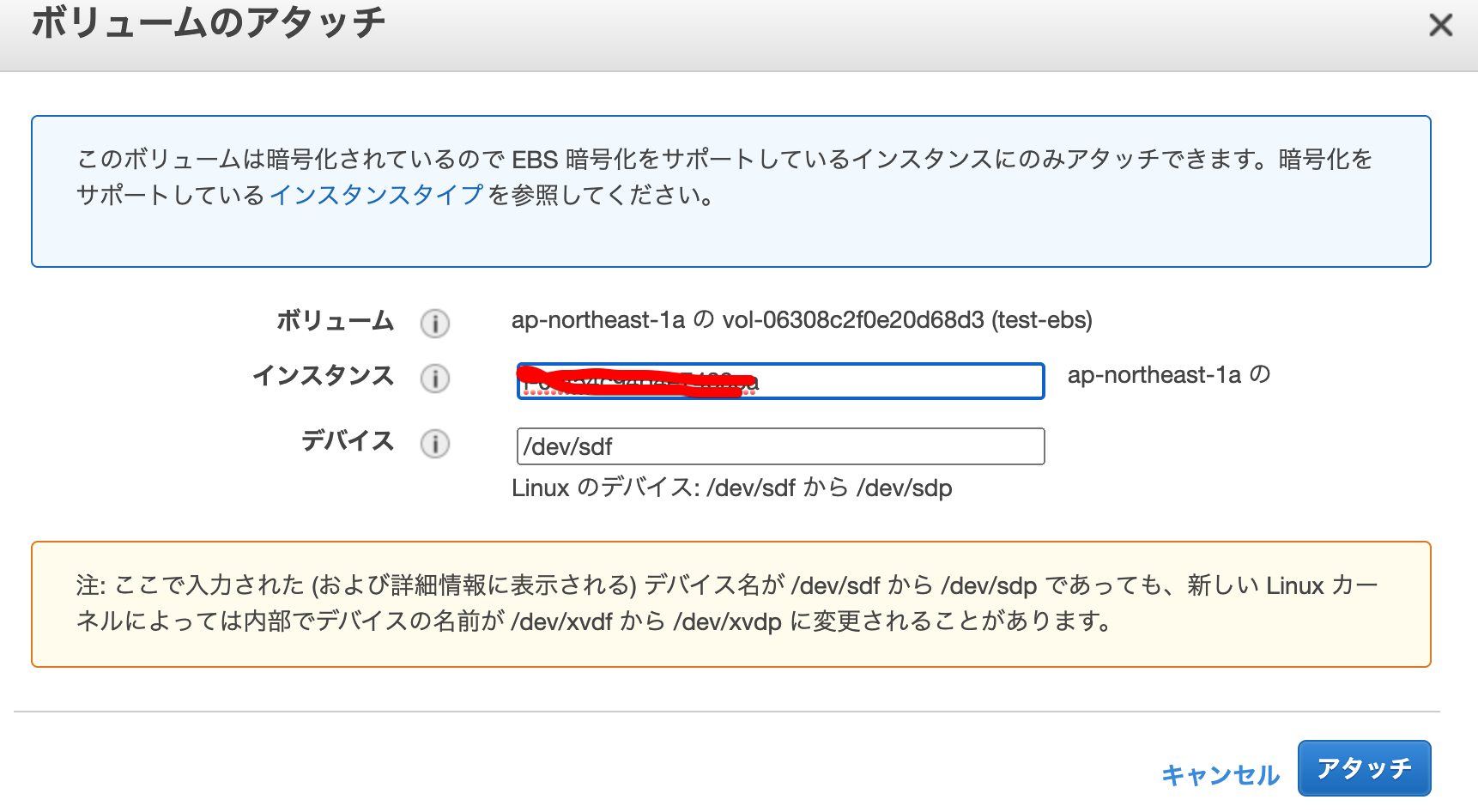
[root@ip-xxx-xxx-xxx-xxx ~]# mount /dev/xvdf /mnt
[root@ip-xxx-xxx-xxx-xxx ~]# ls /mnt/
lost+found
ls -1 | while read LINE
do
PREFECTURE=${LINE}
ls -1 "${PREFECTURE}" | while read LINE2
do
CITY="${LINE2}"
ls -1 "${PREFECTURE}"/"${LINE2}" | while read LINE3
do
FILE="${LINE3}"
echo "${PREFECTURE}"/"${CITY}"/"${FILE}"
done
done
done
ls -1 | while read LINE
do
PREFECTURE=${LINE}
ls -1 "${PREFECTURE}" | while read LINE2
do
CITY="${LINE2}"
ls -1 "${PREFECTURE}"/"${LINE2}" | while read LINE3
do
FILE="${LINE3}"
echo "${PREFECTURE}"/"${CITY}"/"${FILE}"
done
done
done