- 投稿日:2020-11-13T23:21:07+09:00
AWSはどうやって動いてる?
AWSのwebサーバはどこにあるのか
AWSのwebサーバはデータセンター内に存在している。
データセンターとは
AWSで使用される数千数万のサーバを管理している施設。具体的な所在地は明記されていないが、世界各地に点在している。その拠点がある地域のことをリージョンと呼ぶ。
また、そのデータセンターが隣接した塊をアベイラビリティーゾーンと呼んでいる。団地をアベイラビリティーゾーン、その中の建物の一つがデータセンターだと考えるとわかりやすいかもしれない。
下記はデータセンターの記事。ぴんと来ない方はこちらを見てみるとよい。
https://aws.amazon.com/jp/compliance/data-center/data-centers/ようはAWSとは、データセンターで管理しているサーバの中から一つ、ネットを経由して動かしている。
これがAWSの実体。
- 投稿日:2020-11-13T23:21:07+09:00
AWSの正体
AWSとはAmazonが提供する仮想的にサーバ環境構築をしたり、データを保存したり、データベースを扱えるクラウドコンピューティングサービスである。
仮想化されたことによりコストが最低限に抑えられ、インフラ構築が容易になったが、その代わりその実体が何なのかいまいち掴みきれない。
ここではその仮想化された実体を追う。
AWSのwebサーバはどこにあるのか
そもそも仮想化と言ってはいるが、実体がないわけではない。
AWSのwebサーバはデータセンター内にちゃんと物理的に存在している。データセンターとは
AWSで使用される数千数万のサーバを管理している施設。具体的な所在地は明記されていないが、世界各地に点在している。その拠点がある地域のことをリージョンと呼ぶ。
また、そのデータセンターが隣接した塊をアベイラビリティーゾーンと呼んでいる。団地をアベイラビリティーゾーン、その中の建物の一つがデータセンターだと考えるとわかりやすいかもしれない。
下記はデータセンターの記事。ぴんと来ない方はこちらを見てみるとよい。
https://aws.amazon.com/jp/compliance/data-center/data-centers/ようはAWSとは、データセンターで管理しているサーバの中から一つ、ネットを経由して動かしている。
これがAWSの実体。
- 投稿日:2020-11-13T22:32:45+09:00
【AWS】【初心者】wordpressのブログシステムを構築する(パラシつき) ④
この記事は、【AWS】【初心者】wordpressのブログシステムを構築する(パラシつき) ③
「 https://qiita.com/gbf_abe/items/bc729c19bcc2095de9bf 」の続きです。お詫び
11月入ってお仕事が忙しくなって更新止めてしまいました...(システム作り切って満足しちゃいました)
もうサボらないのでゆるして...前回まででやったこと
順番 内容 ① VPC構築 ② サブネット分割 ③ EC2(パブリック)構築 ④ WebサーバにApacheをインストール ⑤ EC2(プライベート)構築 ⑥ NATゲートウェイ構築 ⑦ DBサーバにMariaDBをインストール ⑧ Webサーバにwordpressをインストール ⑨ 完成(するはず)! ④のApacheインストールまで実施しました。
今回は⑤から始めていきます。事前準備
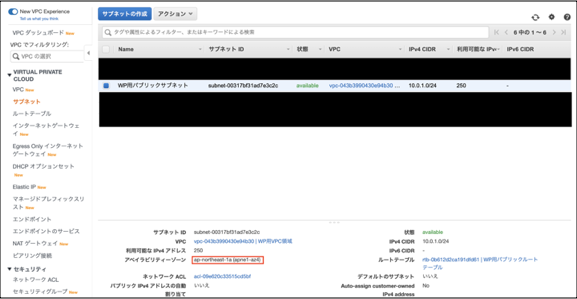
「VPC」>「サブネット」で構築したサブネットのAZ(アベイラビリティーゾーン)を確認します。
プライベートサブネットの構築
「VPC」>「サブネット」>「サブネットの作成」でプライベートサブネットを構築します。
アベイラビリティーゾーンは事前準備で確認したパブリックサブネットのAZを指定しましょう。
VCPは作成したVPCを指定しましょう。(画像バカでけえな...)
スクリーンショット 2020-11-02 16.02.37.pngパラメータ
設定内容 既定値 設定値 名前タグ - WP用プライベートサブネット VPC - WP用VPC領域 アベイラビリティーゾーン 指定なし ap-northeast-1a VPC CIDR 10.0.0.0/16 10.0.0.0/16 IPv4 CIDRブロック - 10.0.2.0/24 EC2 構築
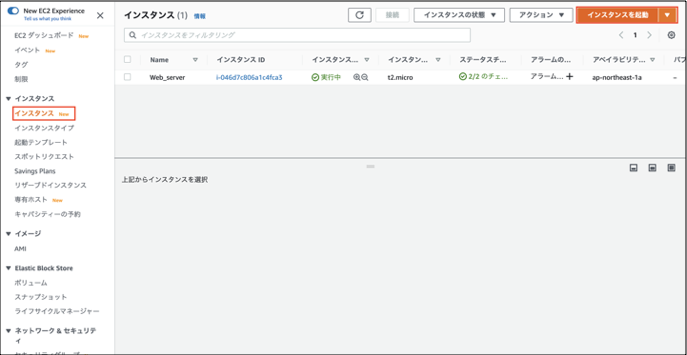
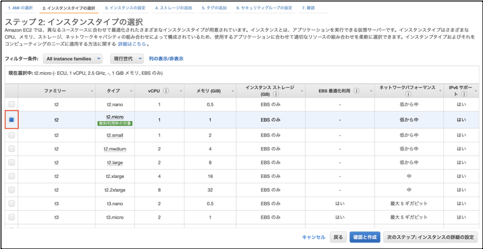
①「EC2」>「インスタンス」>「インスタンスを起動」を選択します。
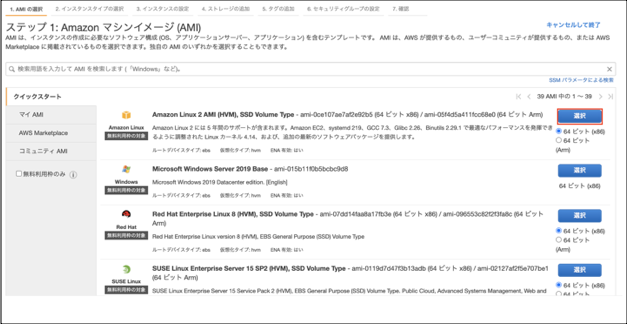
②マシンイメージは「Amazon Linux 2 AMI(HVM),SSD Volume Type」を選択します。
③インスタンスタイプは「t2.micro」を選択します。
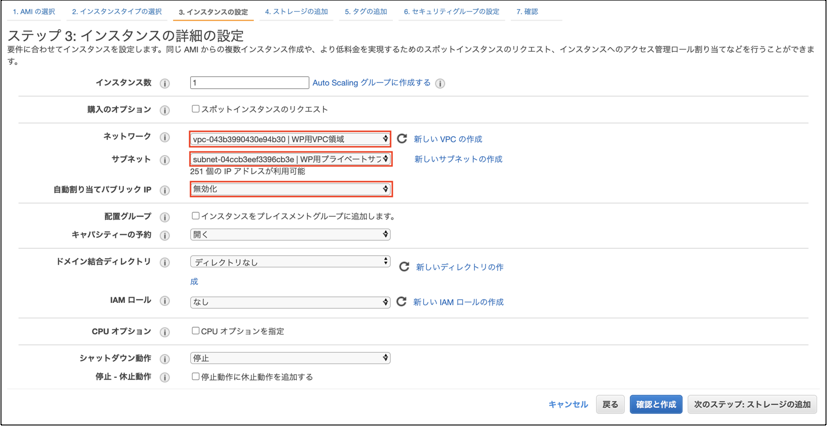
④「ネットワーク」は構築したVPCを選択します。
「サブネット」は構築したプライベートサブネットを選択します。
「自動割り当てパブリックIP」は「(無効化)」を選択します。
「キャパシティーの予約」は「なし(画像は設定値ミスってますが)」を選択します。
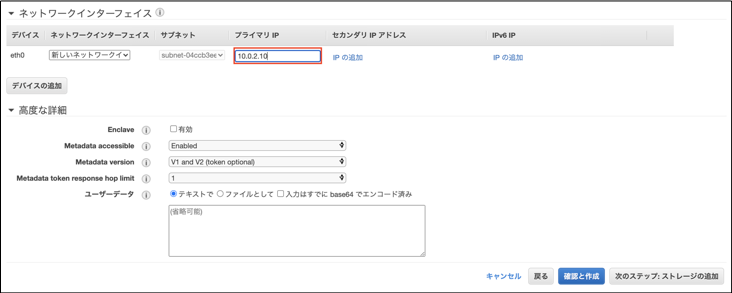
⑤「ネットワークインターフェイス」>「プライマリIP」には「10.0.2.10」と入力します。
⑥ストレージは、既定値のままでOKです。
⑦「タグの追加」は「キー」に「Name」,「値」に「DB_server」と入力します。(任意の名前でいいです)
⑧「セキュリティグループの設定」
「セキュリティグループの割り当て」は「新しいセキュリティグループを作成する」を選択します。
「セキュリティグループ名」に「DB_SG」と入力します。
「タイプ」は「SSH(規定値)」と「MYSQL/Aurora」を選択し、「MYSQL/Aurora」の「ソース」は「任意の場所」を選択します。
「MYSQL/Aurora」のタイプを追加するには「ルールの追加」をクリックすればOKです。
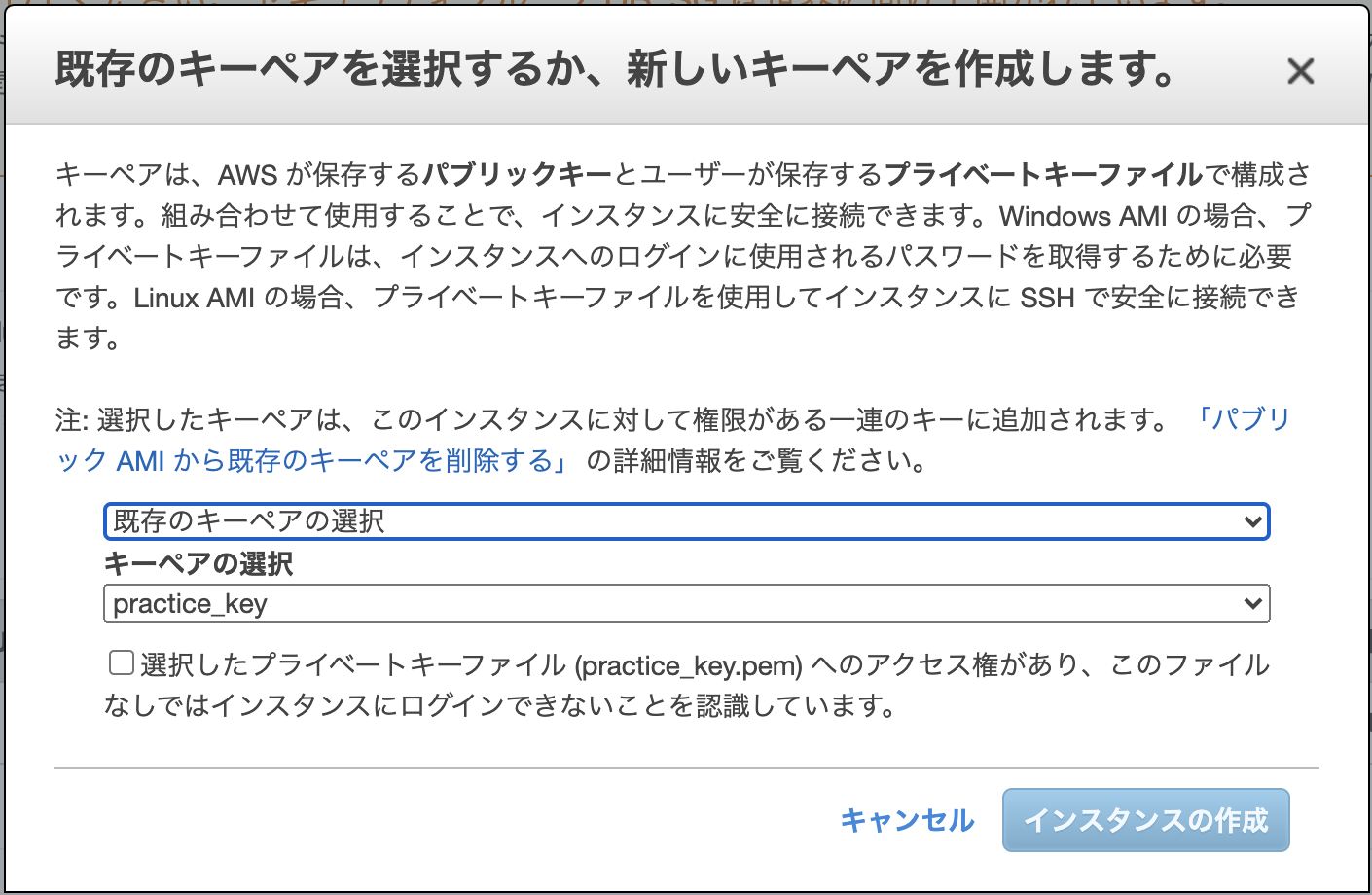
⑦キーペアは既存の物を使いましょう。
「既存のキーペアの選択」を選択し、「キーペアの選択」でWebサーバのEC2構築時に使ったキーペアを選択します。
スクリーンショット 2020-11-02 16.10.27.pngパラメータシート
大項目 設定内容 既定値 設定値 Amazon マシンイメージ(AMI) マシンイメージ - Amazon Linux 2 AMI(HVM),SSD Volume Type インスタンスタイプ タイプ t2.micro t2.micro インスタンスの詳細の設定 ネットワーク デフォルト WP用VPC領域 サブネット 優先順位なし WP用プライベートサブネット 自動割り当てパブリックIP サブネット設定を使用(有効) 無効化 キャパシティーの予約 開く なし ネットワークインターフェイス>プライマリIP 自動的に割り当て 10.0.2.10 タグの追加 キー - Name 値 - DB_server セキュリティグループの設定 セキュリティグループの割り当て 新しいセキュリティグループを作成する 新しいセキュリティグループを作成する セキュリティグループ名 launch-wizard-1 DB_SG タイプ SSH SSH(デフォルト値で問題なし) タイプ - MYSQL/Aurora キーペア 使用するキーペア 既存のキーペアの選択 新しいキーペアの作成 キーペア名 - practice_key(任意のキーペア名) 今回やったこと
順番 内容 ① VPC構築 ② サブネット分割 ③ EC2(パブリック)構築 ④ WebサーバにApacheをインストール ⑤ EC2(プライベート)構築 ⑥ NATゲートウェイ構築 ⑦ DBサーバにMariaDBをインストール ⑧ Webサーバにwordpressをインストール ⑨ 完成(するはず)! 今回は⑤を完了させました。
注意する点としては、プライベートサブネットのAZはパブリックサブネットと同一のAZを指定することぐらいで、
WebサーバのEC2構築と大差ないので、結構簡単にできるかと思います。次回はDBサーバにSSH接続する(scp使うので詰みがちかも)のとNATゲートウェイの構築から始めてきます。
お疲れ様でした。




- 投稿日:2020-11-13T20:44:47+09:00
初心に戻ってAWSでスケーラブルなウェブサイトを作成する
次の通り王道の構成ですが、昔とUIも変わってるということもあり、初心に戻ってAWSでスケーラブルなウェブサイトを作成する基礎の内容です。
1.VPCの作成
「VPCウィザードの起動」より設定を行います。
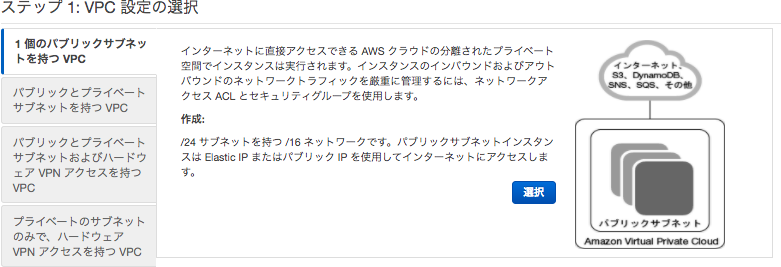
・ステップ 1: VPC 設定の選択
「1 個のパブリックサブネットを持つ VPC」を選択。
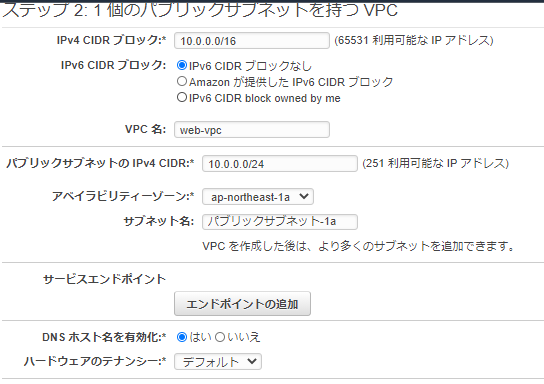
・ステップ 2: ステップ 2: 1 個のパブリックサブネットを持つ VPC
VPC:10.0.0.16 と アベイラビリティーゾーン 1aに パブリックサブネット-1a 10.0.0.0/24 を作成する。
追加で以下のサブネットを作成する。
アベイラビリティーゾーン 1cに パブリックサブネット-1c 10.0.1.0/24
アベイラビリティーゾーン 1aに プライベートサブネット-1a 10.0.2.0/24
アベイラビリティーゾーン 1cに プライベートサブネット-1c 10.0.3.0/24
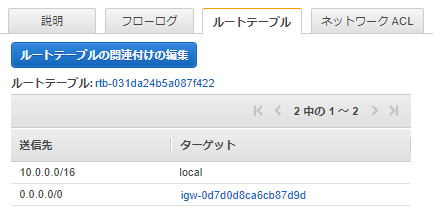
パブリックサブネット-1c のルートテーブルを パブリックサブネット-1a と同じルートテーブルに所属させる。
2.EC2インスタンスの作成(WordPress)
パブリックサブネット-1a に次のユーザーデータを追加し、EC2インスタンスを起動させる。
#!/bin/bash yum -y update amazon-linux-extras install php7.2 -y yum -y install mysql httpd php-mbstring php-xml wget http://ja.wordpress.org/latest-ja.tar.gz -P /tmp/ tar zxvf /tmp/latest-ja.tar.gz -C /tmp cp -r /tmp/wordpress/* /var/www/html/ chown apache:apache -R /var/www/html systemctl enable httpd.service systemctl start httpd.service次のセキュリティグループを開けておく。
・22
・80wordpressが起動するか確認だけしておく。
3.RDSの作成(MySQL)
rds用のセキュリティグループを作成する。
・3306 EC2インスタンスからのアクセスのみを許可する。
DBサブネットグループを作成する。
プライベートサブネット-1a 10.0.2.0/24 と プライベートサブネット-1c 10.0.3.0/24
プライベートサブネット-1a にrdsインスタンス(MySQL)を作成する。
4.ALBの作成
パブリックサブネット-1a 10.0.1.0/24 と パブリックサブネット-1c 10.0.1.0/24 に作成する。
albのセキュリティグループを新しく作成し開けておく。
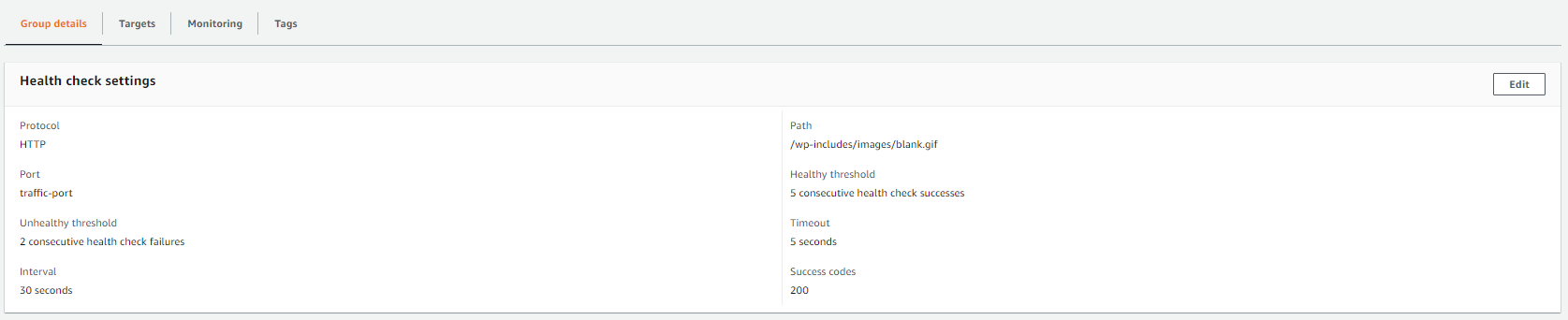
・80ターゲットグループのパスは、次のとおりとする。
/wp-includes/images/blank.gif
【2.EC2インスタンスの作成(WordPress)】で作成したEC2インスタンスをアタッチし、status が healthy になるまで待つ。
alb のDNS名にアクセスし、表示されるか確認する。
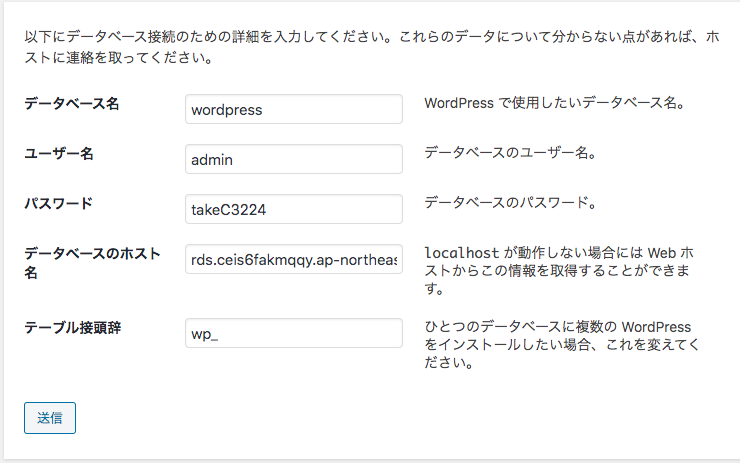
5.WordPressの作成
データベースの設定などWordPressの初期設定を行い、
ELB - EC2 - RDSの構成で作成したブログにアクセスできることを確認する。データベースの接続する為にRDSで作成した、ユーザー名、パスワード、データーベースのホスト名(エンドポイント)を入力する。
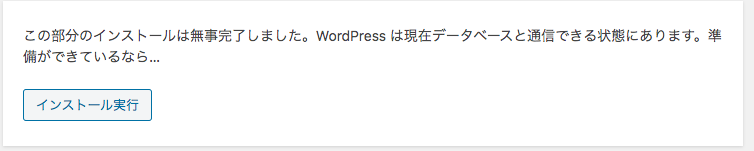
「インストール実行」をクリック。
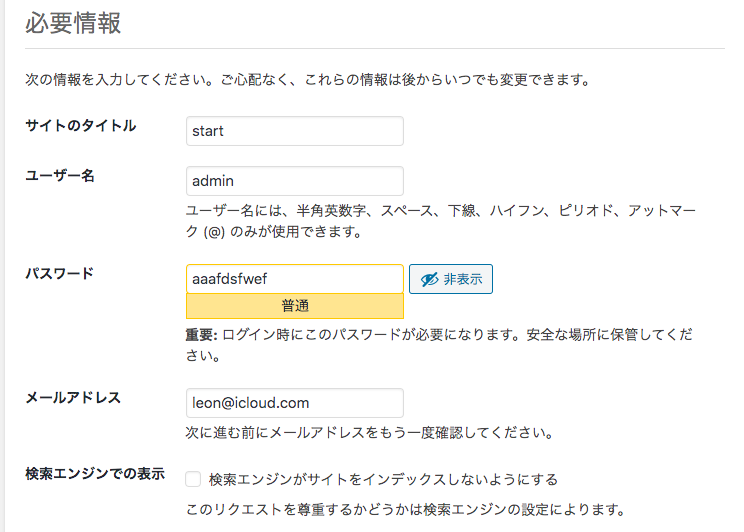
必要事項を入力し、「WordPressをインストール」をクリック。
↑の必要事項で入力した情報で、wordpressにログインできるか表示されるか最後に確認する。
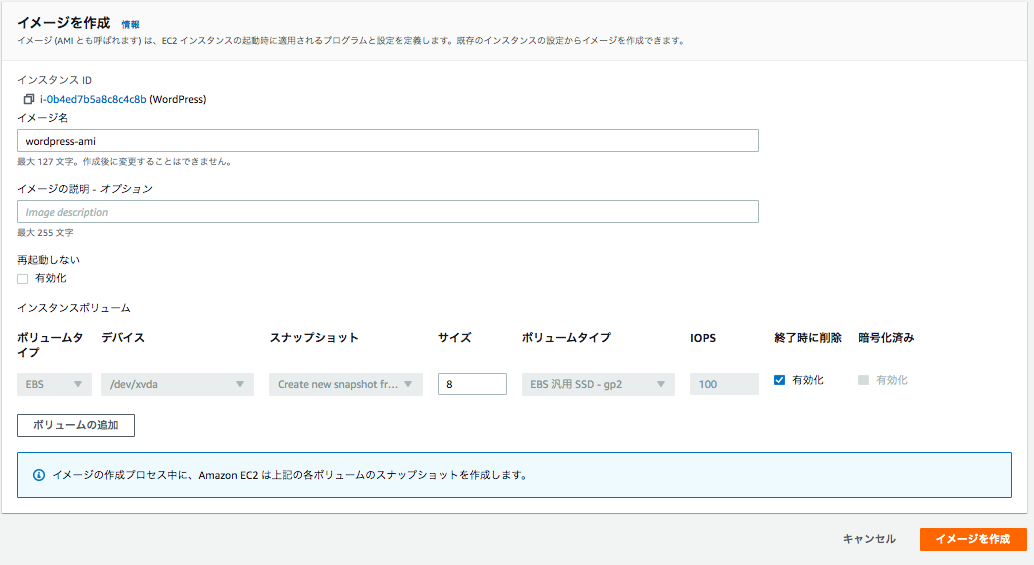
6.AMIの作成と起動
「2.EC2インスタンスの作成(WordPress)」で作成したEC2インスタンスのAMIを作成します。
*1点注意点ですが、「再起動しない」にチェックが入っていません。すなわちイメージの作成中に再起動が発生します。
作成したAMIを使って、パブリックサブネット-1c 10.0.1.0/24にEC2インスタンスを作成する。
ALBのターゲットグループにAMIで作成したEC2インスタンスを追加。
ここまでで、EC2の冗長構成をし、負荷分散がされていることが確認できました。
7.RDSのマルチAZ配置
【3.RDSの作成(MySQL)】で作成したRDSをマルチAZにします。
次から可用性について確認していきます。
8.可用性
ここでは、EC2インスタンスの停止やRDSのフェイルオーバー行い、障害時の動作について確認していきます。
1.「パブリックサブネット-1a 10.0.0.0/24」で作成したEC2インスタンスを停止しても、albのDNS名にアクセスし、表示されるか確認する。
2.RDSを再起動し、albのDNS名にアクセスし、表示されるか確認する。






- 投稿日:2020-11-13T20:00:34+09:00
AWS Lambda Python3.8 から Slack へメッセージを送る設定を terraform で作成する
【個人備忘録】lambdaからslackへメッセージを送るシンプル設定
概要
Slack API へのメッセージ送信に関して
- slackweb ライブラリ は使わない (ローカル環境にライブラリインストールしてあれやこれやがめんどくさい)。
- Python標準ライブラリの urllib を使う。
- Slack API へ渡す情報は、Lambdaの環境変数に設定する。
Terraform での Lambda 作成に関して
- aws provider の バージョンは 2.48.0
- Lambda関数コード(pythonソースコード)は、terraform archive provider の data ソース archive_file を使って zip にしてから、deployする。
送信イメージ
Terraform 設定
- Terraform実行環境 ローカルディレクトリ構成 (MacOS)
├── .terraform │ ├── plugins │ │ └── darwin_amd64 │ │ └── terraform-provider-aws_v2.48.0_x4 ├── post-slack.tf └── source_code └── post-slack └── main.py
- Lambda関数を作成する tf ファイル
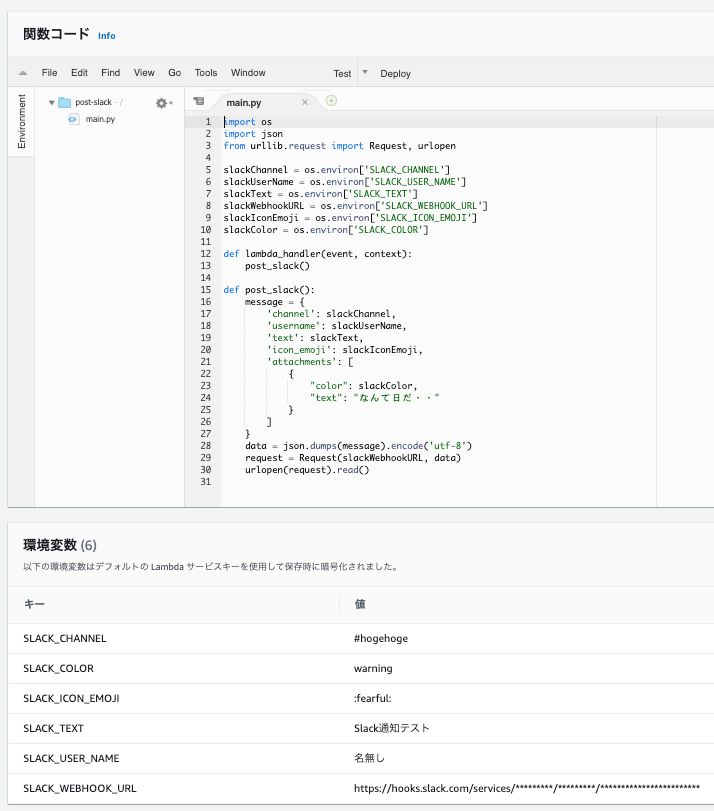
post-slack.tfdata "archive_file" "post-slack" { type = "zip" source_dir = "./source_code/post-slack" output_path = "./source_code/post-slack.zip" } resource "aws_lambda_function" "post-slack" { filename = "${data.archive_file.post-slack.output_path}" function_name = "post-slack" role = "arn:aws:iam::※※※※※※※※※※※※:role/service-role/lambda-basic-execution" handler = "main.lambda_handler" source_code_hash = "${data.archive_file.post-slack.output_base64sha256}" runtime = "python3.8" memory_size = 128 timeout = 300 environment { variables = { SLACK_CHANNEL = "#hogehoge" SLACK_TEXT = "Slack通知テスト" SLACK_USER_NAME = "名無し" SLACK_ICON_EMOJI = ":fearful:" SLACK_COLOR = "warning" SLACK_WEBHOOK_URL = "https://hooks.slack.com/services/※※※※※※※※※/※※※※※※※※※/※※※※※※※※※※※※※※※※※※※※※※※※" } } }
- Lambda に割り当てる IAMロール
lambda-basic-executiondata "aws_iam_policy_document" "lambda-assume-role-policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } } } resource "aws_iam_role" "role_lambda-basic-execution" { name = "lambda-basic-execution" assume_role_policy = data.aws_iam_policy_document.lambda-assume-role-policy.json path = "/service-role/" } resource "aws_iam_role_policy_attachment" "AWSLambdaBasicExecutionRole" { role = aws_iam_role.role_lambda-basic-execution.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" }
- Slack API へメッセージを送信する python コード
source_code/post-slack/main.pyimport os import json from urllib.request import Request, urlopen slackChannel = os.environ['SLACK_CHANNEL'] slackUserName = os.environ['SLACK_USER_NAME'] slackText = os.environ['SLACK_TEXT'] slackWebhookURL = os.environ['SLACK_WEBHOOK_URL'] slackIconEmoji = os.environ['SLACK_ICON_EMOJI'] slackColor = os.environ['SLACK_COLOR'] def lambda_handler(event, context): post_slack() def post_slack(): message = { 'channel': slackChannel, 'username': slackUserName, 'text': slackText, 'icon_emoji': slackIconEmoji, 'attachments': [ { "color": slackColor, "text": "なんて日だ・・" } ] } data = json.dumps(message).encode('utf-8') request = Request(slackWebhookURL, data) urlopen(request).read()terraform plan
terraform plan 初回実行時に次のようなエラーが出た場合は、
$ terraform planError: Could not satisfy plugin requirements Plugin reinitialization required. Please run "terraform init". Plugins are external binaries that Terraform uses to access and manipulate resources. The configuration provided requires plugins which can't be located, don't satisfy the version constraints, or are otherwise incompatible. Terraform automatically discovers provider requirements from your configuration, including providers used in child modules. To see the requirements and constraints from each module, run "terraform providers". Error: provider.archive: no suitable version installed version requirements: "(any version)" versions installed: noneterraform init を実行する
$ terraform initInitializing the backend... Initializing provider plugins... - Checking for available provider plugins... - Downloading plugin for provider "archive" (hashicorp/archive) 2.0.0... The following providers do not have any version constraints in configuration, so the latest version was installed. To prevent automatic upgrades to new major versions that may contain breaking changes, it is recommended to add version = "..." constraints to the corresponding provider blocks in configuration, with the constraint strings suggested below. * provider.archive: version = "~> 2.0" Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.pluginsディレクトリに terraform-provider-aws_v2.48.0_x4 がダウンロードされた
├── .terraform │ ├── plugins │ │ └── darwin_amd64 │ │ ├── terraform-provider-archive_v2.0.0_x5 │ │ └── terraform-provider-aws_v2.48.0_x4terraform apply
$ terraform apply実行後に source_code ディレクトリに post-slack.zip ができる
└── source_code ├── post-slack │ └── main.py └── post-slack.zipAWSマネジメントコンソール で確認
Lambda 関数「post-slack」の設定
テスト実行
テストイベント作成
テスト実行
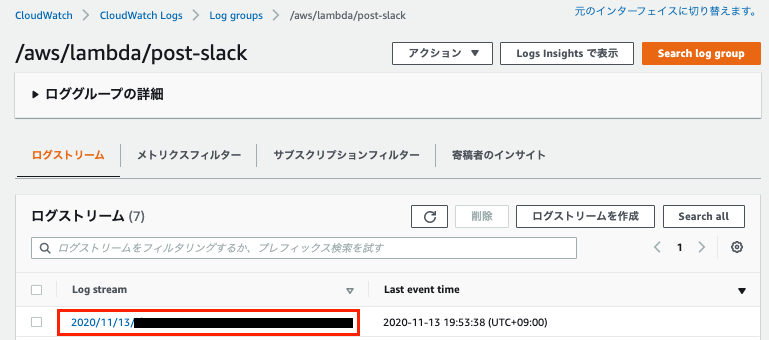
cloudwatch logs ロググループ
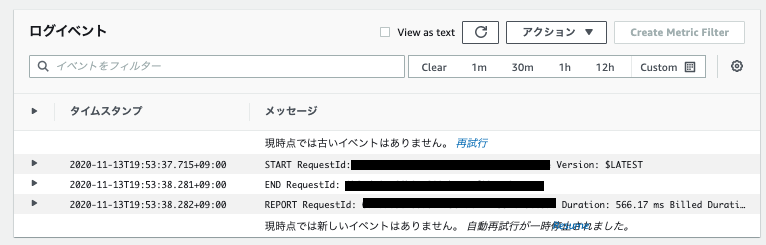
slack通知


- 投稿日:2020-11-13T18:05:38+09:00
AWS の API Gateway (HTTP API) 経由で Lambda に繋いで POST データを処理するメモ
取り急ぎ忘れないようにめもめも。
- POSTパラメータは
event['body']に入っている。- API Gateway の設定で
isBase64Encodedが有効であると、Base64エンコードされるAPIに投げるときにJSONエンコードしたものを渡すと、Base64デコード後にJSONが取れる。
その際は、リクエストクエリのパースではなく、JSONのパース処理を行う。import json import base64 import urllib.parse def lambda_handler(event, context): # POSTパラメータがBASE64でエンコードされているのでデコードする decoded_body = base64.b64decode(event['body']).decode() # POSTパラメータをdict型に変換 post_params = urllib.parse.parse_qs(decoded_body) result = {} result['message'] = 'lambdaからのレスポンス' # POSTされたデータを参照 (配列になっているので注意) result['name'] = post_params['name'][0] result['email'] = post_params['email'][0] return { 'statusCode': 200, 'body': json.dumps(result) }
- 投稿日:2020-11-13T18:00:08+09:00
無限くら寿司ガチャを作ってみた
10月からスタートしたGoToEatキャンペーン皆さんは使用していますか?
農林水産省 GoToEatキャンペーン私はちょくちょく使用していたのですが、なんでも巷で「無限くら寿司」というものが流行っているらしい。
GoToEatでもらえるポイントで食事をして、その食事でまたポイントが貰えるので、くら寿司を何回もお得に食べられるといったものです。(モラル的な話はおいておきます)
くら寿司公式GoToEatキャンペーンページGoToEatでポイントをもらうためには、くら寿司で一人あたりランチは税込み500円、ディナーは税込み1000円以上食事をする必要があります。
そこで、くら寿司のメニューを該当価格を超えるくらいでランダムで表示される「無限くら寿司ガチャ」を作ってみました。作ったwebアプリはこちら↓
無限くら寿司ガチャ今回は「SpringBoot」フレームワークを使用しました。
コード全体はgithubで公開しています↓
https://github.com/yutwoking/eternalKurazushi今後こういったアプリを作成する際の手順としてこの記事を残しておきます。
アプリ作成環境や使用フレームワークなどの前提
- MacBook Pro (13-inch, 2018, Four Thunderbolt 3 Ports)
- macOS Catalina 10.15.6
- Eclipse_2020-09
- Java11
- gradle
- SpringBoot
- Doma2
大まかな流れ
ロジック部分の実装
- くら寿司公式サイトからメニューの読み込み部分
- データベースへの格納・摘出部分
- ガチャロジック部分
SpringBootフレームワーク部分
- build.gradle記述
- ランチャーの作成
- コントローラの作成
- html作成(view作成)
webアプリ公開(AWS)
1. ロジック部分の実装
くら寿司公式サイトからのメニュー読み込み
まずはメニューを公式サイトから読み込みます。
公式メニューサイトのhtmlを解析する必要があります。
Jsoupというライブラリを使用して解析します。Jsoup使用方法参考
https://www.codeflow.site/ja/article/java-with-jsoup解析部分の実装は以下
LoadMenu.javaprivate static List<MenuModel> loadMenuFromSite(String url) throws IOException{ List<MenuModel> models = new LinkedList<>(); Document doc = Jsoup.connect(url).get(); Elements menusBySection = doc.select(".section-body"); for (Element section : menusBySection) { String sectionName = section.select(".menu-section-header h3").text(); if (!StringUtils.isEmpty(sectionName)) { Elements menus = section.select(".menu-list").get(0).select(".menu-item"); for (Element menu : menus) { String name = menu.select(".menu-name").text(); Elements summary = menu.select(".menu-summary li"); if (summary.size() >2) { int price = stringToInt(summary.get(0).select("p").get(0).text()); int kcal = stringToInt(summary.get(0).select("p").get(1).text()); String area = summary.get(1).select("p").get(1).text(); boolean takeout = toBoolean(summary.get(2).select("p").get(1).text()); models.add(new MenuModel(name, price, kcal, area, takeout, sectionName)); } else if (summary.size() == 2) { int price = stringToInt(summary.get(0).select("p").get(0).text()); int kcal = stringToInt(summary.get(0).select("p").get(1).text()); String area = ""; boolean takeout = toBoolean(summary.get(1).select("p").get(1).text()); models.add(new MenuModel(name, price, kcal, area, takeout, sectionName)); } } } } return models; }基本的なJSoupの使用方法としては、
Document doc = Jsoup.connect(url).get();でurlのhtmlを読み込んで、
Elements elements = doc.select(".section-body");のようにselectメソッドを使用して、該当要素を抜き出していきます。
ちょっと実装コードは、if文やfor文がネストしちゃっていて見にくいのは反省。。。
データベースへの格納・摘出部分
次にデータベース周りの実装です。
Doma2 というjavaのDBアクセスフレームワークを使用しています。
Doma2公式はこちらDomaには以下の特徴があります。
・注釈処理を使用して コンパイル時 にコードの生成やコードの検証を行う
・データベース上のカラムの値を振る舞いを持った Java オブジェクトにマッピングできる
・2-way SQL と呼ばれる SQL テンプレートを利用できる
・Java 8 の java.time.LocalDate や java.util.Optional や java.util.stream.Stream を利用できる
・JRE 以外のライブラリへの依存が一切ない個人的にsqlファイルで管理できるところが好きで良く使用しているフレームワークです。
使用方法は公式がまとまっている&日本語なので参考にすると良いです。
実装コードはここでは割愛。
コード全体はgithubで公開しています↓
https://github.com/yutwoking/eternalKurazushiガチャロジック部分
Gacha.javapublic static List<MenuModelForSearch> getResult(Areas area, boolean isLunch){ List<MenuModelForSearch> result = new ArrayList<>(); //thresholdにランチなら500,ディナーなら1000を格納 int threshold = getThreshold(isLunch); //candidatesに全メニューを格納 List<MenuModelForSearch> candidates = MenuCaches.getSingleton().getMenuList(area, isLunch); //取得したメニューの合計金額がthresholdを超えているかチェックし、超えるまでランダムでcandidatesからメニューを加える。 while (isOverThreshold(threshold, result) == false) { addElement(result, candidates); } //最後にランチメニューが含まれているかチェック。ランチメニューが含まれている場合、結果をランチメニューのみにする。 checkIncludeLunchMenu(result); return result; }各メソッドはコード全体を参照してください。
2. SpringBootフレームワーク部分
SpringBootに関しては、以下サイトを参考にしました。
https://qiita.com/gosutesu/items/961b71a95daf3a2bce96
https://qiita.com/opengl-8080/items/eb3bf3b5301bae398cc2
https://note.com/ymzk_jp/n/n272dc9e5c5d3build.gradleの記述
gradleでSpringBootフレームワークを使用できるようにプラグインやライブラリをbuild.gradleに追記します。
今回の実際のbuild.gradleが↓で//spring-boot追記部分とコメントしてある部分を追記しています。
build.gradleplugins { // Apply the java plugin to add support for Java id 'java' // Apply the application plugin to add support for building a CLI application id 'application' id 'eclipse' id 'com.diffplug.eclipse.apt' version '3.25.0' id 'org.springframework.boot' version '2.3.5.RELEASE' //spring-boot追記部分 id 'io.spring.dependency-management' version '1.0.10.RELEASE'//spring-boot追記部分 } version = '2.26.0-SNAPSHOT' ext.dependentVersion = '2.24.0' task copyDomaResources(type: Sync) { from sourceSets.main.resources.srcDirs into compileJava.destinationDir include 'doma.compile.config' include 'META-INF/**/*.sql' include 'META-INF/**/*.script' } compileJava { dependsOn copyDomaResources options.encoding = 'UTF-8' } compileTestJava { options.encoding = 'UTF-8' options.compilerArgs = ['-proc:none'] } repositories { mavenCentral() mavenLocal() maven {url 'https://oss.sonatype.org/content/repositories/snapshots/'} } dependencies { // Use JUnit test framework testImplementation 'junit:junit:4.12' // https://mvnrepository.com/artifact/org.jsoup/jsoup compile group: 'org.jsoup', name: 'jsoup', version: '1.13.1' // https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 compile group: 'org.apache.commons', name: 'commons-lang3', version: '3.11' annotationProcessor "org.seasar.doma:doma:${dependentVersion}" implementation "org.seasar.doma:doma:${dependentVersion}" runtimeOnly 'com.h2database:h2:1.3.175' // https://mvnrepository.com/artifact/org.postgresql/postgresql compile group: 'org.postgresql', name: 'postgresql', version: '42.2.8' // https://mvnrepository.com/artifact/com.zaxxer/HikariCP compile group: 'com.zaxxer', name: 'HikariCP', version: '3.4.1' // https://mvnrepository.com/artifact/javax.inject/javax.inject compile group: 'javax.inject', name: 'javax.inject', version: '1' // https://mvnrepository.com/artifact/io.vavr/vavr compile group: 'io.vavr', name: 'vavr', version: '0.10.2' // https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-thymeleaf compile group: 'org.springframework.boot', name: 'spring-boot-starter-thymeleaf', version: '2.3.5.RELEASE'//spring-boot追記部分 // https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-web compile group: 'org.springframework.boot', name: 'spring-boot-starter-web', version: '2.3.5.RELEASE'//spring-boot追記部分 // https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter compile group: 'org.springframework.boot', name: 'spring-boot-starter', version: '2.3.5.RELEASE'//spring-boot追記部分 } //spring-bootプロジェクトをサービス化するためにbootJarタスクを追記 bootJar { launchScript() } application { // Define the main class for the application mainClassName = 'eternalKurazushi.ServerLuncher' } eclipse { classpath { file { whenMerged { classpath -> classpath.entries.removeAll { it.path == '.apt_generated' } } withXml { provider -> def node = provider.asNode() // specify output path for .apt_generated node.appendNode( 'classpathentry', [ kind: 'src', output: 'bin/main', path: '.apt_generated']) } } } jdt { javaRuntimeName = 'JavaSE-11' } }ランチャーの作成
ServerLuncher.java@SpringBootApplication public class ServerLuncher { public static void main(String[] args) throws Exception { SpringApplication.run(ServerLuncher.class, args); LoadMenu.init(); MenuCaches.getSingleton().load(); } }@SpringBootApplicationアノテーションを付けて、SpringApplication.runを実装するだけでOKです。
LoadMenu.init(); MenuCaches.getSingleton().load();この部分はサーバー起動時にメニューを読み込んでDBに格納し、メモリにもメニューを持つようにしています。
実は今回の構成ならば、DBはいらなかったりもしますが、一応今後拡張した場合(おそらく拡張なんてしないけど)も考えてDBも使用しています。コントローラの作成
FrontController.java@Controller public class FrontController { @RequestMapping("/") public String index() { return "index"; } @RequestMapping(value = "/result", method = RequestMethod.POST) public String getResult(@RequestParam("radio_1") String eatTime, @RequestParam("radio_2") String areaString, Model model) { if (StringUtils.isEmpty(eatTime) || StringUtils.isEmpty(eatTime)) { return "error"; } boolean isLunch = eatTime.equals("ランチ") ? true : false; Areas area = Areas.東日本; if (areaString.equals("西日本")) { area = Areas.西日本; } else if (areaString.equals("九州・沖縄")) { area = Areas.九州; } List<MenuModelForSearch> gachaResult = Gacha.getResult(area, isLunch); model.addAttribute("list", gachaResult); model.addAttribute("sum", getSumString(gachaResult)); model.addAttribute("time", eatTime); model.addAttribute("area", areaString); return "result"; }@Controller アノテーションを使用し、コントローラを実装する。
@RequestMapping アノテーションで対応させるpathを指定する。このへんはjax-rsと似ている。
@RequestParam アノテーションを使用することでhtmlから値を受け取る。model.addAttribute("list", gachaResult);addAttributeによって、htmlに値を渡すことができる。
この例だと、listという変数名でgachaResultの値をhtmlに渡している。return "result";によって、/resources/templates/【Controller の戻り値】.htmlのテンプレートhtmlが返却される。
この例だと、/resources/templates/result.html が読み込まれて返却される。html作成(view作成)
result.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>無限くら寿司ガチャ</title> </head> <body bgcolor=#99FFFF> <div style="text-align: center"> <main> <h1>無限くら寿司ガチャ</h1> <p th:text="${time} + ' / ' + ${area}" class="description"></p> <table border="1" align="center"> <tr> <th>種類</th> <th>商品名</th> <th>価格(税抜き)</th> <th>カロリー</th> <!-- <th>提供エリア</th> <th>お持ち帰り</th> --> </tr> <tr th:each="menu : ${list}"> <td th:text="${menu.type}"></td> <td th:text="${menu.name}"></td> <td th:text="${menu.price} + '円'"></td> <td th:text="${menu.kcal} + 'kcal'"></td> <!-- <td th:text="${menu.area}"></td> <td th:text="${menu.takeout} ? '可' : '不可'"></td> --> </tr> </table> <h3> <p th:text="${sum}" class="sum"></p> </h3> <br> <form method="POST" action="/result"> <input type="hidden" name="radio_1" th:value="${time}"> <input type="hidden" name="radio_2" th:value="${area}"> <div style="margin: 2rem 0rem"> <input type="submit" value="同じ条件でもう一度ガチャを回す" style="width: 250px; height: 50px"> </div> </form> <form method="GET" action="/"> <div style="margin: 2rem 0rem"> <input type="submit" value="戻る"> </div> </form> </main> </div> </body> </html>th:value="${変数名}"
とすることで、コントローラから受け取った値を使用することができる。
formタグを使用して、inputを作成しnameを指定すれば、コントローラに値を渡すことができる。3. webアプリ公開(AWS)
今回はAWSを使用してwebアプリを公開しました。
シンプルなアプリなので使用したのは、
- VPC
- EC2
- RDS
くらいです。
初心者はこの書籍がとても丁寧&練習もできるのでおすすめ。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版最後に
仕事外で何か作成するのは久々でした。
仕事のプログラミングも楽しいけど、プライベートでのプログラミングはまた違った楽しさ(フレームワークの選定や環境作成など)もあるので定期的にスキルアップのためにも行っていきたい。時間があれば以下に取り組みたい。
- 独自ドメインを取得して設定
- コードのリファクタリング
- webアプリの接続プロトコルのhttps化
- この記事では手順をだいぶささっと書いてしまったのでいくつかの記事に分けて一つ一つまとめてみる。
- 投稿日:2020-11-13T15:21:46+09:00
Databricks on AWS - E2 Architecture 概要
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 5日目のエントリーです!
はじめに
AWS 上での Databricks 利用を検討する場合、とりあえず必要十分そうな機能をがそろってる Premium プランで契約、必要に応じて Enterprise プランにアップグレードすればいいかな、と考える方が多いのではないでしょうか?
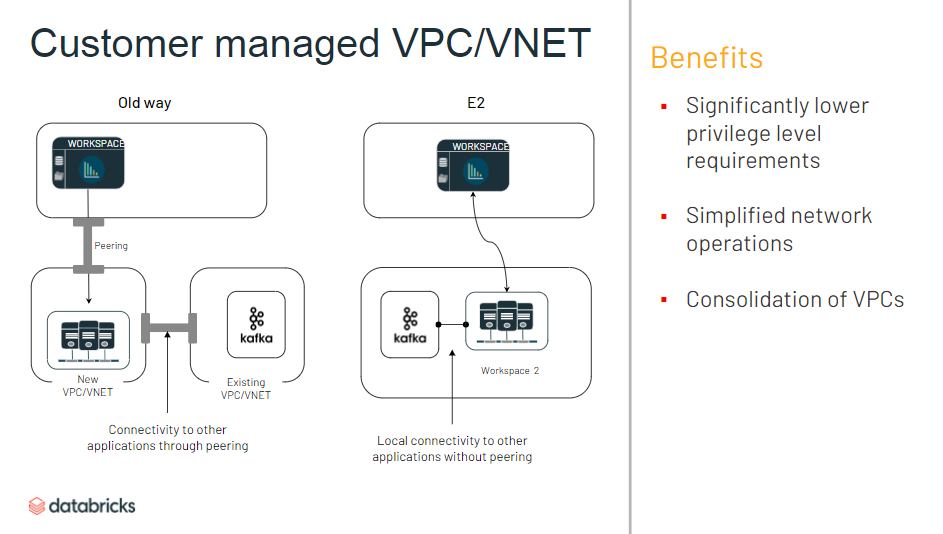
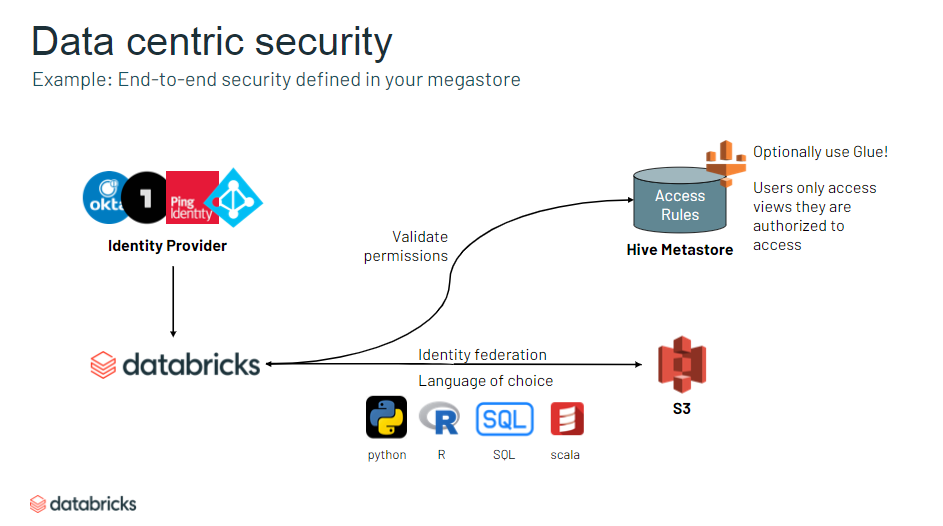
2020年9月に E2 Architecture というものがアナウンスされ、2020年11月末に日本リージョンでも GA されました。リソース管理の利便性やセキュリティ要件などに関する複数のオプションが用意されています。
Databricks on AWS を利用する場合、利用者の AWS リソース(= Control Plane) と Databricks の AWS リソース(= Data Plane) を接続する必要があります。E2 Architecture では後者の構成が随分違うようで、例えば Premium プランから E2 プランへのワークスペース移植には以下工程が発生します。ワークスペースを維持したままの E2 へのアップグレードはできないので注意してください。(2020年12月7日現在)
- メタストアの移植 (スクリプトで実装)
- Permission の設定 (ユーザー数が少ないのであればマニュアルで実装)
よって、
- セキュアな環境構築は必須 and/or その必要性はイメージできる
- 最新機能を使いたい or 将来的に使いたい
という方は 最初から E2 プランを選択したほうが良いよ、というのが本項の趣旨です。
以下のウェビナーに分かりやすい概念図があったので整理しておきます。Features in the new architecture for the Databricks platform on AWS
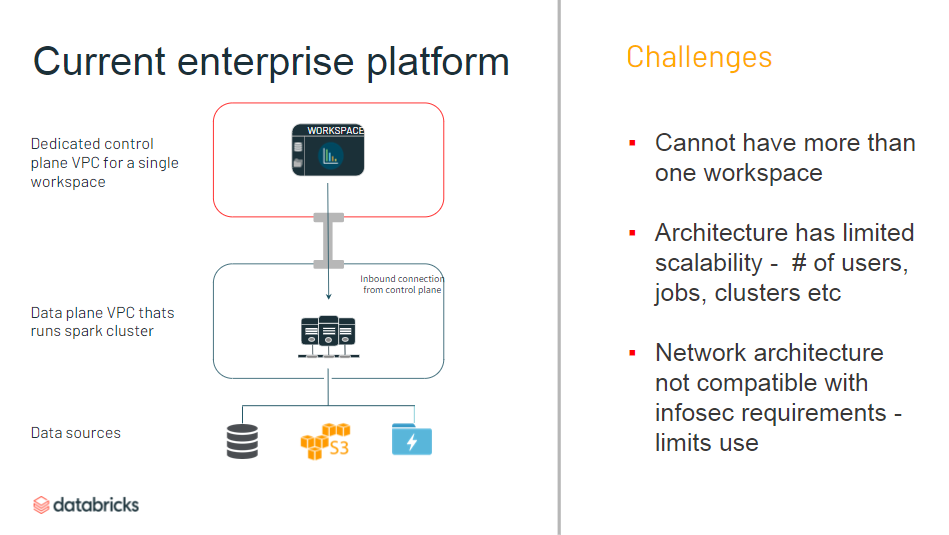
これまでの Enterprise プラン
- 作れるワークスペースは1つのみ
- プロジェクトごとにアクセス制限したい場合は逐一設定する必要
- ユーザー数、ジョブ数、クラスター数などに制限
- InfoSec の制限上、ネットワーク関連で利用制限
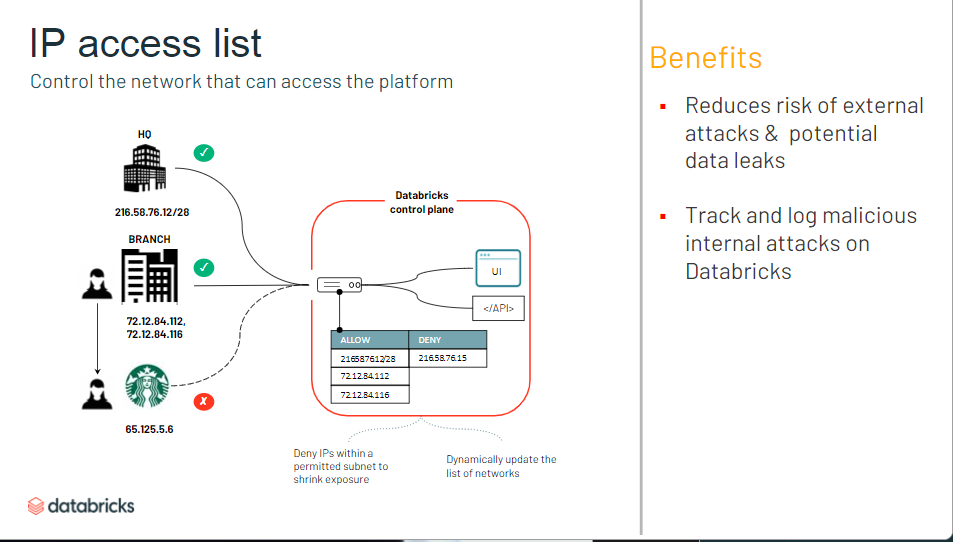
- ワークスペースへの IP アクセス制限ができない
E2 Architecture
以下は一部抜粋です。詳細はこちらを参照のほど。
Databricks architecture overview
なお 2020年12月7日現在、
- E2 アカウント申請
- Databricks 社で承認
- ワークスペース構築
の手順で進める必要があるので注意です。
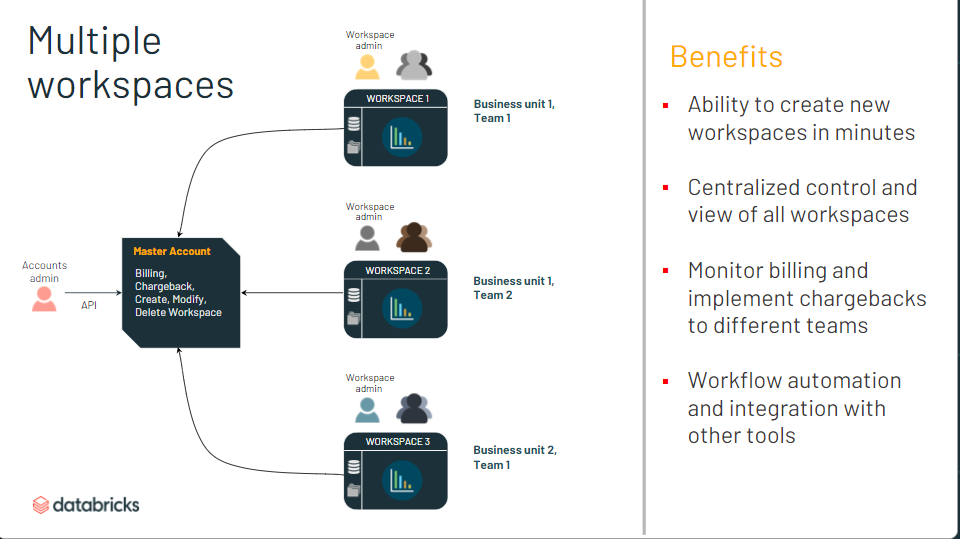
マルチアカウント
- マスターアカウント作って後はAPIで操作すれば、新しいワークスペースを数分で作れる
- AWS 側のリソース (クロスアカウントロールやS3バケット) の構築は必要
- Create a new workspace using the acount API
- 中央集権的に複数ワークスペースを管理。費用もモニター
- アカウントAPI でもろもろの情報取得可能
- GUI での管理コンソールはこれから実装?
- ワークスペースにプレフィックス設定可能
- プロジェクトごとの管理しやくなった
ネットワーク
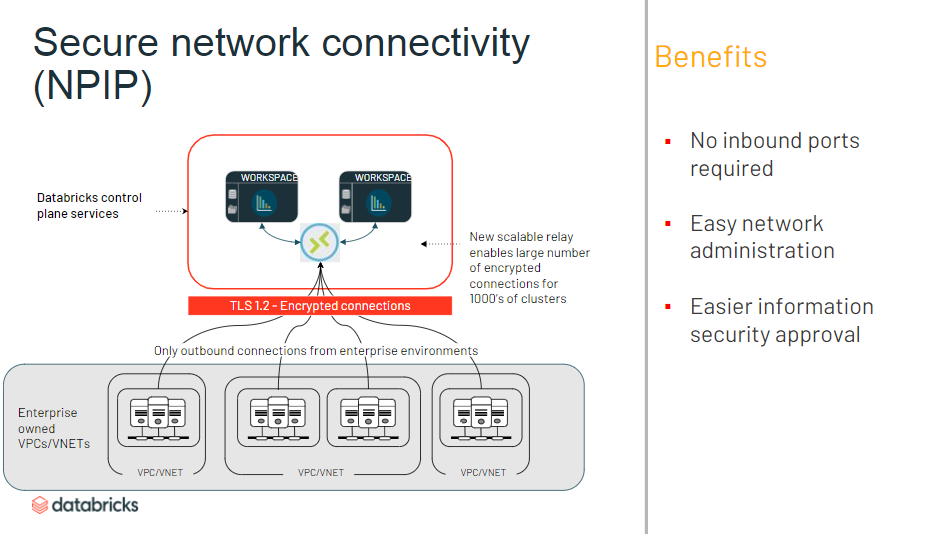
- アウトバウンドのみに制限可能
- ネットワーク管理が簡単に
- 情報セキュリティ認証が簡単に
- コンソールへのIP アクセス制限ができるように
- Databricks 内部からのアタックについてもロギング&トラッキング
- 独自の VPC に Databricks ワークスペースを作成できるように
- Data Plane 側(ユーザー側 AWS リソース) での VPC Peering が簡単に
- 権限付与が細かい粒度で設定可能に
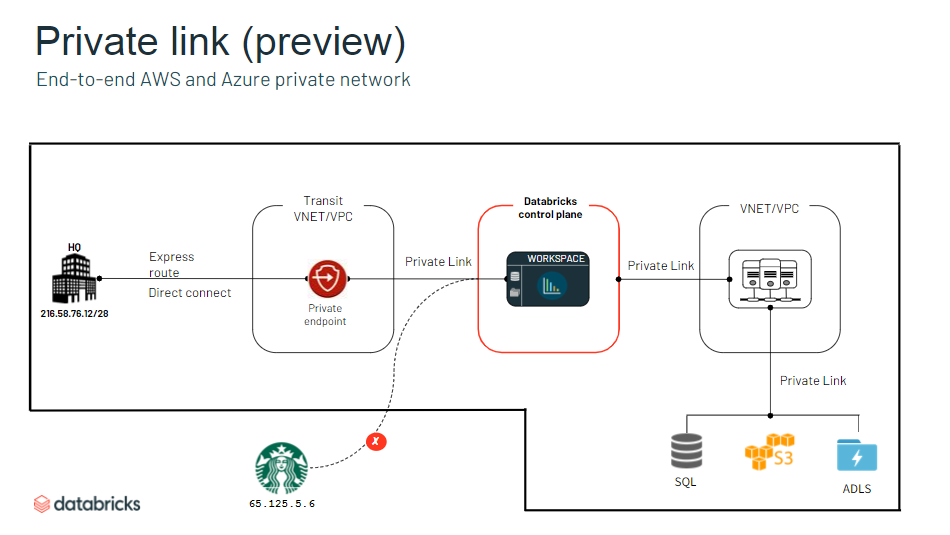
- 閉域網の構築可能
認証
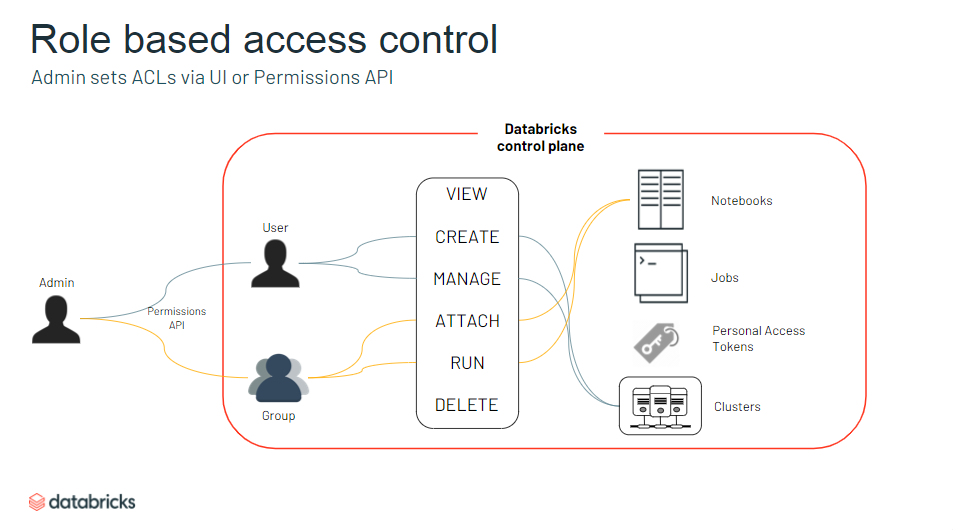
- ワークスペース内オブジェクトへ付与できる権限のバリエーションの増加
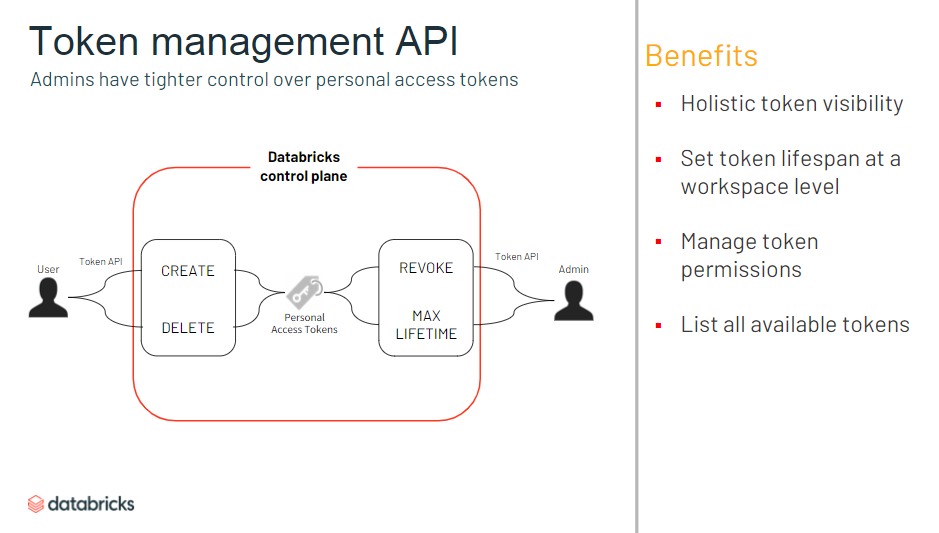
- トークンをいつだれが作ったか、といった情報も管理できるように
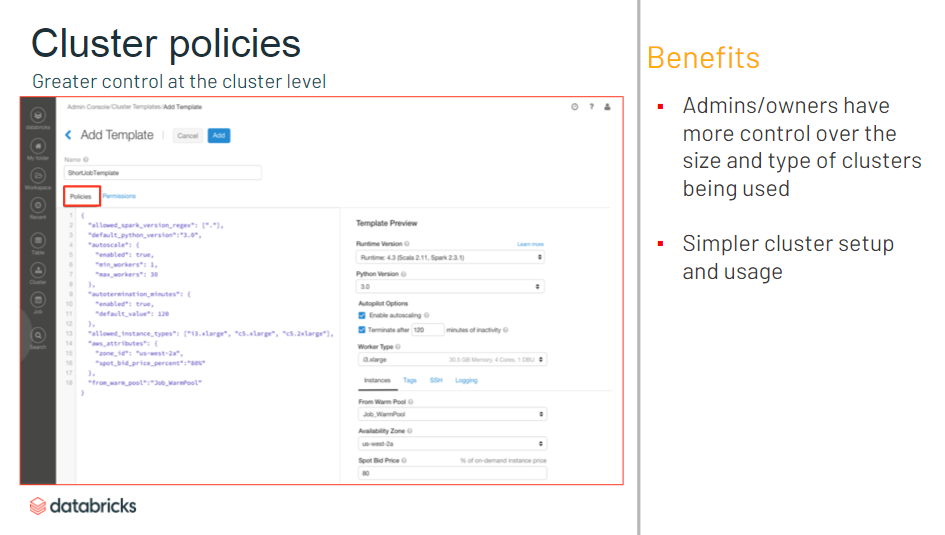
- 一部のオプションのみに制限するような Cluster Policy を JSON で設定可能
- A さんはどんなスペックのクラスタでも作れるけど、B さんは XX DBU 以下のクラスタしか作れない、など
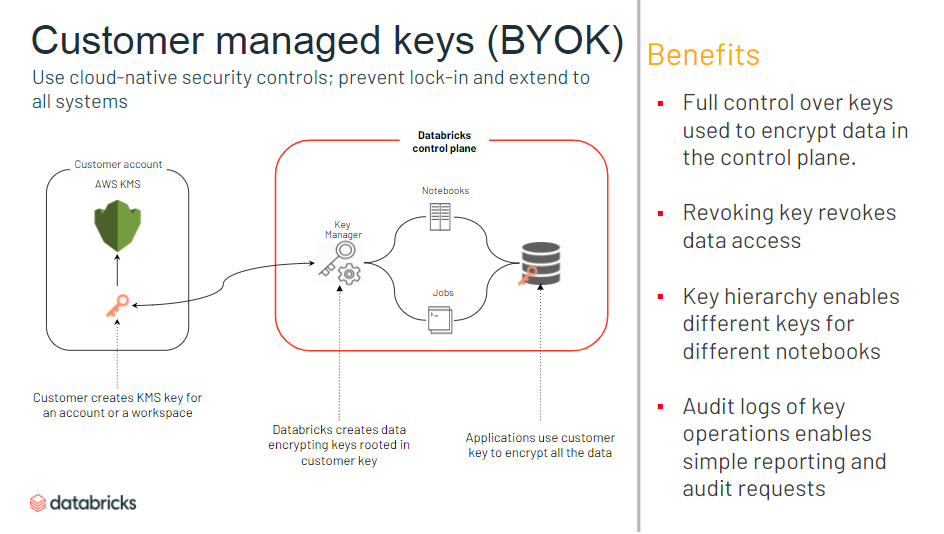
データ保護
- 透過的な認証組めるようになった
- メタストア (Databricks で保持されているメタデータ) の定義に応じてセキュリティレベルを設定可能に
- 顧客管理キーの追加が可能に
- Notebook などのオブジェクトに対するセキュリティを強化
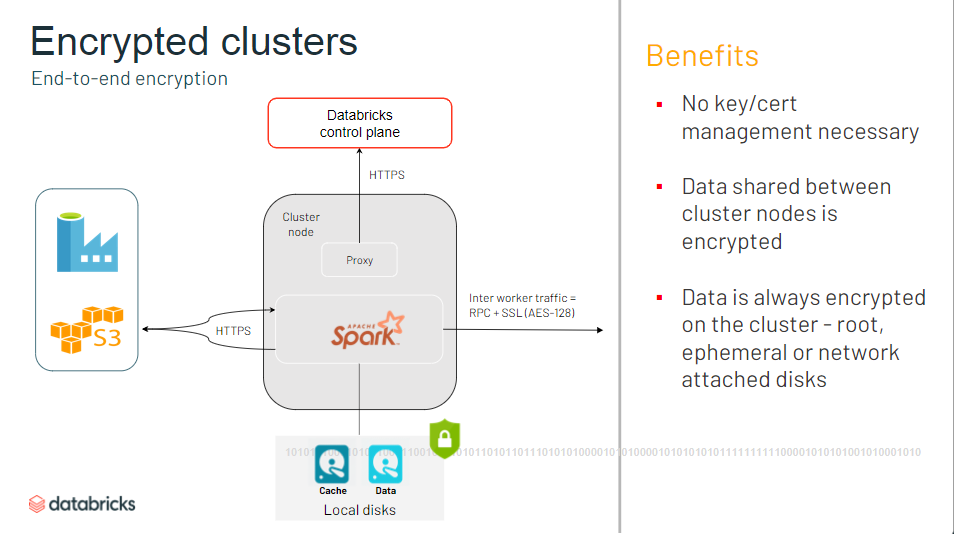
- クラスターに対して、キーや認証の管理が不要に
- クラスタノード間でやり取りされるデータが暗号化
- すべてのノードがプライベートIPのみを持つクラスタを起動可能
セキュリティ
- 以下セキュリティポリシーに準拠

まとめ
E2 Architecture に用意されている機能は使ってくうちに必須要件になってくものが多い印象です。最新機能もここに盛り込まれていくでしょうから最初から E2 プランで進めたほうがよさそうです。

- 投稿日:2020-11-13T14:32:38+09:00
AWS 認定 ソリューションアーキテクト – アソシエイトを受けてきました
結果
合否:合格しました
点数:769(720点が合格ラインなのでギリギリ)
期間:1ヶ月間
1ヶ月間といっても、業務時間のほとんどを資格勉強だったため、他の方よりも勉強時間は長いです。(約170時間)モチベーション
・現在参画している案件にて資格取得を命じられたこと
・資格手当が支給されて、年収が少し上がる
・転職などに有利にはたらく可能性がある
・資格未保持のため、何かが欲しかった前提
AWSは実務未経験で、遊びで触ったことがあります。
そのため、事前知識は少しだけありました(EC2やS3など)勉強方法
・udemyの試験突破講座を見る
・udemyの模擬試験を受け、分からなかった用語をひたすら調べる
詳しくは最後に詳細で書きます試験の感触
難易度:実際の試験<udemyの講座に付随する模擬試験<<udemyの模擬試験問題集
他の方の体験談をみるに、試験回ごとの難易度の差はかなりあるのではないかと思います。
私は難易度の低いラッキーな回に受けることができましたが、運が悪いとudemyの模擬試験問題集レベルになってしまうかもしれません。
難しい問題もありましたが、udemyの問題と一致しているなど答えを確信できる問題が多く、合格点には達しているだろうと思いました。
Auto Scaling、ELB、S3などの問題が多かったです。詳細
以下資格勉強と試験申し込み、試験当日の詳細です。
資格勉強詳細
udemy(各タイトルは変わっている可能性があります)
・これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
・【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)どちらの講座もEdutech Global , inc.の講座です。
udemyの魅力は価格の安さと内容がアップデートされることです。
両講座合わせて3000円とコストパフォーマンスは高いと思います。
ただし、毎月2回ほど開催されているセール時に購入しなければ2万円を超すので、セールを待つ時間の余裕がない方には選べないかもしれません。
内容のアップデートは定期的であるかは分かりませんが、C01からC02に変わった時も対応が早かったようです。
AWSは頻繁に操作画面やサービスのアップデートがあるので、更新のないテキストだとタイミング次第では情報が使えなくなっている可能性があるのではないかと思います。
試験突破講座は実機での操作も含まれています。
また、udemyは返金も手軽にできるので、自分に向いていないと判断すればすぐに切り替えられます。気にしたこと
・Jayendra's Blogの学習パス内に記載されている試験トピック
このトピック全てになんとなくでも答えられるようになれば理解度は十分だと思います。
・FSx、Transit Gateway、Global Acceleratorなどの新出題範囲
特にFSxは出題される確率が高いようで、答えやすい問題が多いので要確認です。
詳しくはこちらの記事を参考にしてください。
・分からない単語はすぐに調べる
chromeの選択した言葉を右クリックから検索を利用してすぐに調べていました。
ブラックベルトを参考にしている方が多いようですが、私には難しかったためQiitaなどを参考にしました。試験申し込み
試験の申し込みはAWS 認定から行いました。
大まかな流れ
・サインイン(日本を選択して普段使用しているAmazonアカウントを入力)、アカウントに移動
↓
・aws training and certificationにてプロフィール情報を入力して、試験の申し込み
↓
・ピアソン VUE を選び、進むままに会場などを選択して、試験日を確定
↓
・登録しているメールアドレスにメールが届く家や職場などで受験するオンライン試験も選択できますが、監視が厳しかったり日本語でやり取りができないことを考えると、自宅から近いテストセンターで受講するのをお勧めします。
また、登録の際に名前を間違えて入力してしまうとテストを受けられないです。
名前の変更はプロフィール画面からでは行えず、メールにて変更を依頼しないといけないので注意しましょう。試験当日の流れ
会場は横浜テストセンターを選び、30分前には会場に到着しました。
受付の方の指示に従い署名などをした後、教室に入って試験を受けました。
身分証明には免許証とクレジットカードを使用しました。
試験中は緊張して、見直しをしたらクリック間違えをしていて焦りました。テストのスコアレポートは試験翌日の夜に開示されたと通知メールがきました。
試験後すぐに合否は判定されるのですが、実際に確認するまではドキドキしました。
スコアレポートにて点数を確認して、報告するべき人に報告して私の試験は終了しました。
試験後当日に書いたメモ(かなり長いです)
試験振り返り
<試験前>
ピアソンVUEの予約をしてメールを受け取った
試験の数日前に会場を下見し、試験当日は業務後急いで向かった
時間には余裕をもつことができて、会場のトイレにもいけた
横浜テストセンターで、18時半と遅い時間だったためか人が少なく質問も受け付けにすぐできる環境だった
受け付けにいって名前を確認し、署名などを求められた(団体名の欄があり質問したがAWSと答えられた)
提出後身分証明(免許証とクレジットカード)と電子署名、試験用の写真撮影を行った
15分前に受付からアナウンス、ロッカーに荷物をすべてしまった
身分証明書はもたずロッカーの鍵は持ち、受け付けからペンとプラスチックのホワイトシートを受け取った
入室し受付から伝えられていた番号の座席へ着席、ログイン情報は入っていてログインをクリック
自分の名前をクリックして写真を確認後、スタートを押し試験スタート
AWSの案内が出て、焦って始めるが、140分の試験時間のうち、最初5分と後5分は承諾やアンケートなどにあてがわれた時間だった
ここでもう少し落ち着けて試験に望めればよかった
案内にそって進め、同意などをしてから試験がスタートした
<試験中>
人も少なくリラックスして受けられた、防音ヘッドホンがあったが利用はしなかった
試験中のトイレの案内などはメモシートの裏に記載されていた
画面は左上に英文表示されるボタン、右上に時間と見直しフラッグ、右下に前・次ボタン
英文表示はポップアップだったため、日本語との比較が簡単にできた
見直しフラッグは旗のマークでクリックすると黄色に変化した
1問選択はボタンクリック、2問選択はボックスクリック
選択肢の文章をクリックしても選択されるため、見返したら1問別の回答を選択していて焦った
2問選択問題で3つ目の選択肢をクリックするとエラーのポップアップが表示された
スクロールの幅が大きくて自分にとっては快適ではなかった
最後の問題の次に行くと見直し画面に移行
見直し終了・フラッグを見直す・全て見直す・未回答を見直すなどの選択肢が下に出る
未回答を見直す選択肢は未回答がないとエラーのポップアップが表示される
全てを見直すと最初からスタート、特定の問題から見直すのはたぶん不可
残り5分でアナウンスが入った
時間制限をオーバーするとどうなるのか分からなかったため、残り1分で見直し終了をクリックした
<試験後>
見直し終了をクリックした後、アンケート回答画面に移行
アンケートは試験を受けた理由など簡単なもので、5分の制限で9問に回答した
回答が終わると未解決の問題が残っていますのようなポップアップが出たが、確認しても未回答はなかったため仕様であると思われる
アンケートが終了すると試験の合否が表示されていた
点数の表示はなく、試験の情報と合否ぐらいだったと思うが安堵でよく覚えていない
終了したら画面が暗くなり、鍵とペンとシートをもって退室、受付に渡した
受付からAWSの試験に関する書類と試験会場の案内をもらい、ロッカーから荷物をもって退室した
試験の詳しい情報は5日以内にサイトに記載され、その旨がメールされる(翌日の夜にきた)
正直メールが送られてくるまで不安は拭えない
デジタルバッジの取得に関するメールもきて、Acclaimのアカウント登録をした
今後はソリューションアーキテクト – プロフェッショナルの取得に向けて学習を進めていきます。
- 投稿日:2020-11-13T13:48:42+09:00
AWS CLIでAmazon CloudWatchのアラームの発砲をテストする
はじめに
ローカルPCからAWS CLIを利用して、Amazon CloudWatchのアラームのステータスを強制的に変更し、Slackなどに発砲するか試験します。
発砲試験のために、アラームに設定している内容を変更するのは、試験内容にはならないことに注意です。
アラームの内容にもよりますが、アラームの数が多いとその分通知が飛ぶため、本来確認すべき内容が分からなくなう可能性があるため、アラーム名を直接指定する形にしています。スクリプト
test_alerm.sh#!/bin/sh cd `dirname $0` test_alerm () { ALERM_NAME=$1 echo "test alerm: ${ALERM_NAME}" aws cloudwatch set-alarm-state \ --alarm-name ${ALERM_NAME} \ --state-value ALARM \ --state-reason '【テストでやんす!!!!】' } test_alerm [アラーム名]
- 投稿日:2020-11-13T12:51:59+09:00
AWSの鍵の管理について
- 投稿日:2020-11-13T12:49:46+09:00
AWSのEBSの再確認
はじめに
今更ですがAWSの基礎の学習をしています。今回は普段(というか今まで全く)気にしていなかった、EBSの動作の再確認をしました。
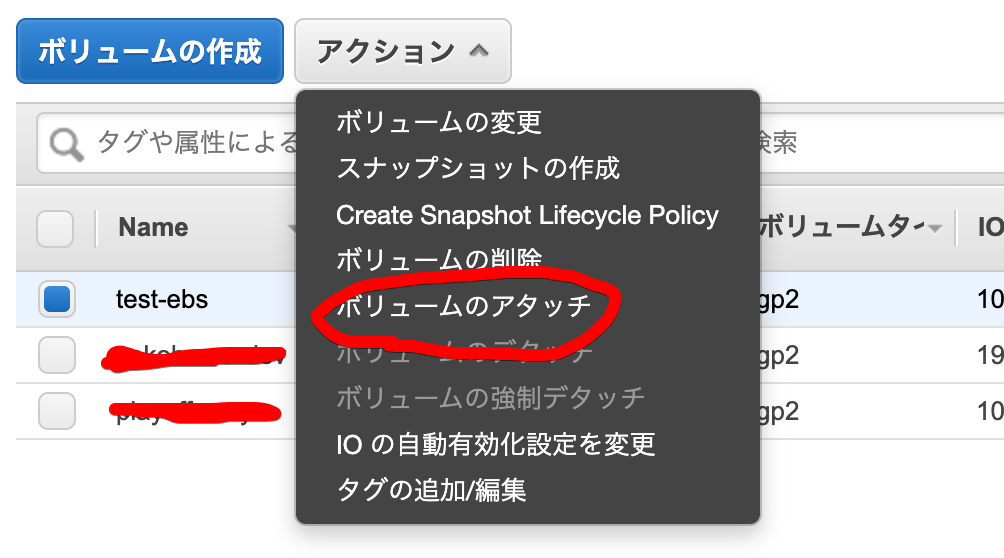
やること
- ボリュームをインスタンスにアタッチして、そのボリュームを他のインスタンスに再アタッチしてちゃんとデータが残っていることを確認する。
- ストレージと言えばS3ばかりだったが、ローカルボリューム(EBS)も保存領域といういみでは使えるということの再確認。
作業の流れ
- ebsの作成
- ebsをインスタンスAにアタッチ
- インスタンスAで、ebsにファイルを作成(hoge.txt)
- インスタンスBに、ebsを再アタッチ
- インスタンスBで、ebs内を確認してhoge.txtがあるかを確認
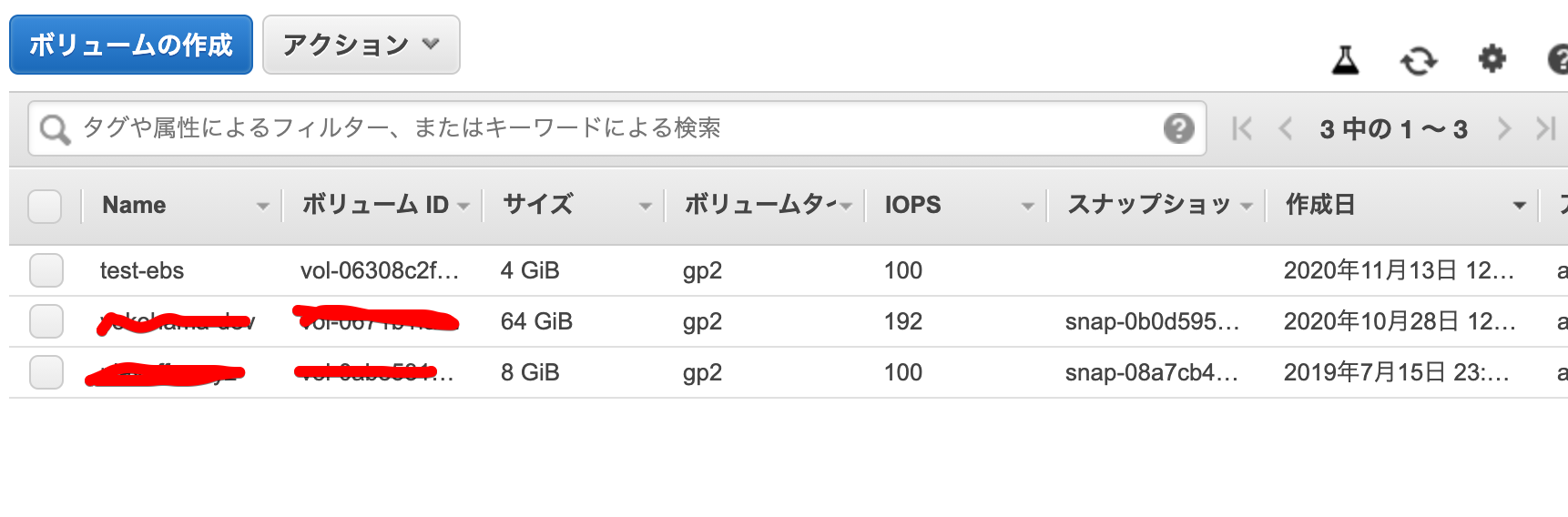
1. ebsの作成
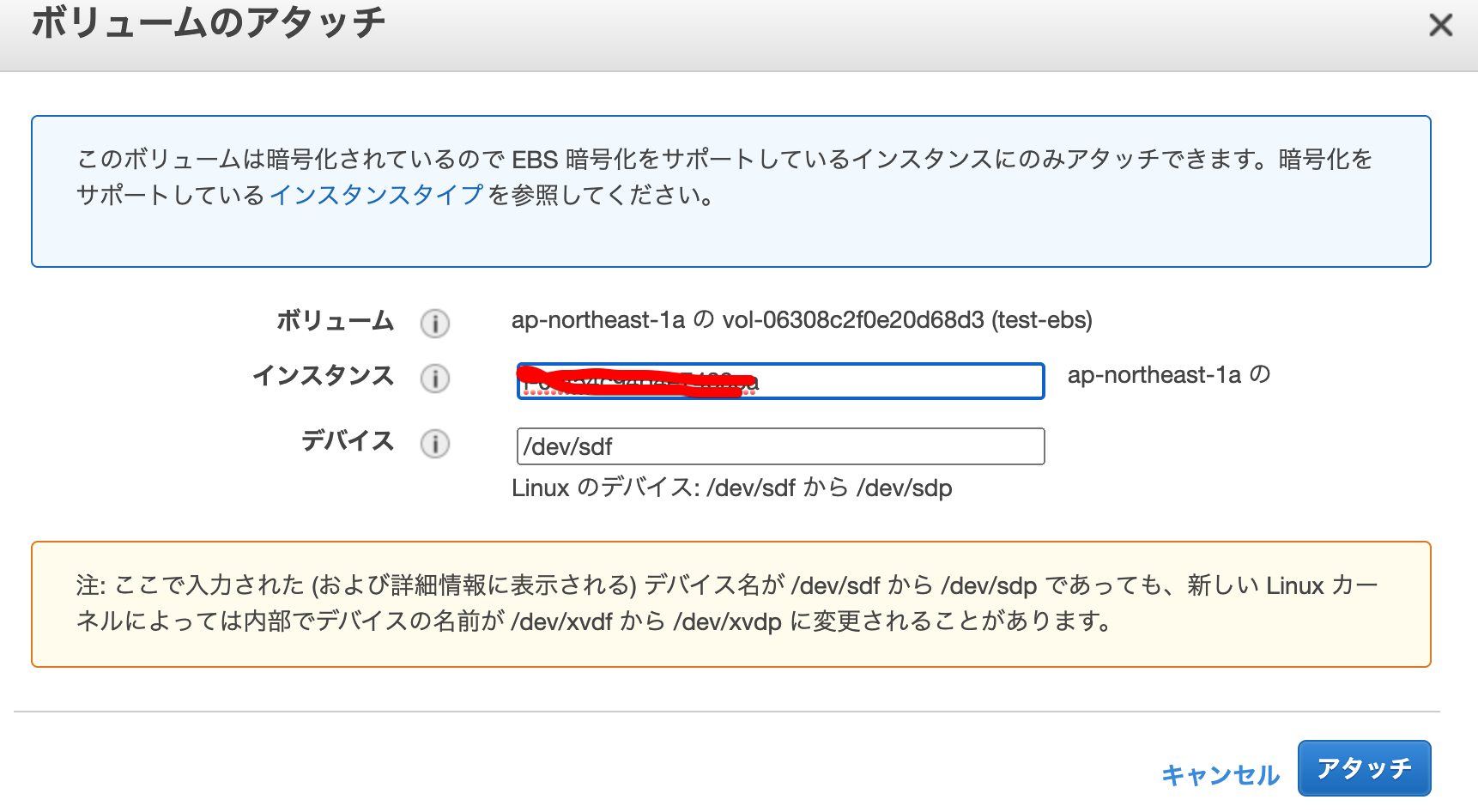
test-ebsを作成しました。4Gで作成をしました。HDDでも、SSDでも何でも大丈夫です。2. ebsをインスタンスAにアタッチ
インスタンスAにアタッチしました。
ボリュームがアタッチされているか確認。インスタンスAにsshします。
Last login: Fri Nov 13 03:16:54 UTC 2020 on pts/0 [root@ip-xxx-xxx-xxx-xxx ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 8G 0 disk └─xvda1 202:1 0 8G 0 part / xvdf 202:80 0 4G 0 disk
xvdfという名前で、4Gがアタッチされていることが確認できました。このデバイスファイルは、/dev/xvdfに存在します。3. インスタンスAで、ebsにファイルを作成(hoge.txt)
ファイルシステムをlinux用にフォーマットします。
[root@ip-xxx-xxx-xxx-xxx ~]# mke2fs /dev/xvdf mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 262144 inodes, 1048576 blocks 52428 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=1073741824 32 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736 Allocating group tables: done Writing inode tables: done Writing superblocks and filesystem accounting information: doneこれでLinuxファイルシステムにマウントができる形になりました。
/mntにマウントします。[root@ip-xxx-xxx-xxx-xxx ~]# mount /dev/xvdf /mnt [root@ip-xxx-xxx-xxx-xxx ~]# ls /mnt/ lost+foundマウントされたことが確認できました。
このボリュームの中にファイルを作成します。
[root@ip-xxx-xxx-xxx-xxx ~]# ce /mnt [root@ip-xxx-xxx-xxx-xxx mnt]# echo hoge > hoge.txt [root@ip-xxx-xxx-xxx-xxx mnt]# cat hoge.txt hoge作成して中身にhogeと記入しました。
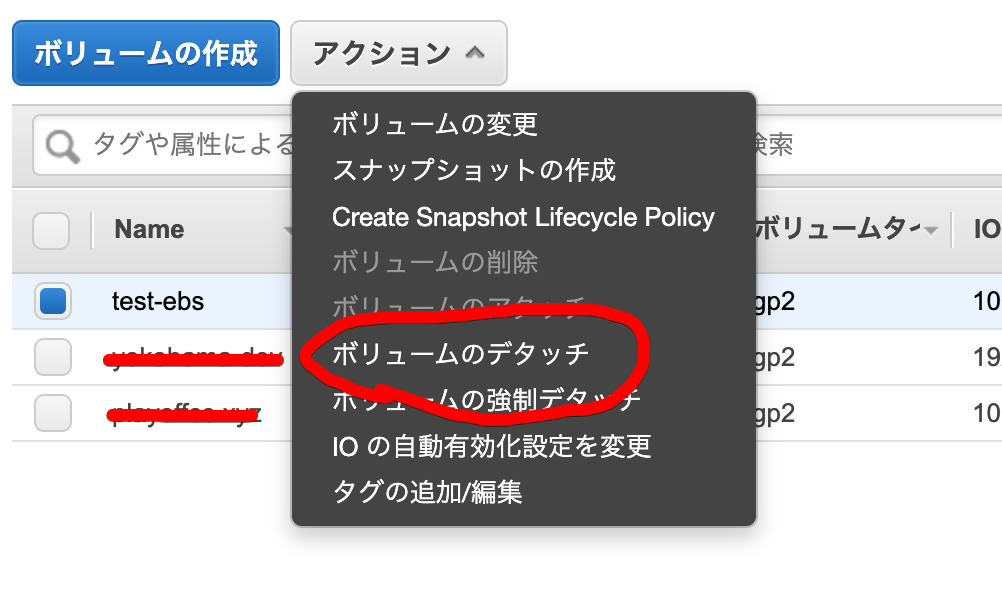
4. インスタンスBに、ebsを再アタッチ
まずは、インスタンスAのボリュームをアンマウントします。
[root@ip-172-31-27-44 ~]# ls /mnt/ hoge.txt lost+found [root@ip-172-31-27-44 ~]# umount /mnt [root@ip-172-31-27-44 ~]# ls /mnt/ [root@ip-172-31-27-44 ~]#
umountしたので、/mntの中身は空になっています。AWSコンソール上でデタッチします。
インスタンスAの時と同じやり方で、ebsをサーバーBにアタッチします。
5. インスタンスBで、ebs内を確認してhoge.txtがあるかを確認
インスタンスBにsshして確認をして、ボリューがアタッチされているかを確認します。
yokohama@ip-yyy-yyy-yyy-yyy [12:41:29 PM] [~] [master *] -> % lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 64G 0 disk └─xvda1 202:1 0 64G 0 part / xvdf 202:80 0 4G 0 disk4Gのやつがされています。デバイスファイル名は、
xvdfでした。マウントして中身を確認します。[root@ip-yyyy-yyyy-yyyy]~# mount /dev/xvdf /mnt [root@ip-yyyy-yyyy-yyyy]~# ls /mnt hoge.txt lost+found [root@ip-yyyy-yyyy-yyyy]~# cat /mnt/hoge.txt hogeマウントしたebsの中には、hoge.txtが存在しており、中身もちゃんと保存されていることが確認できました。
まとめ
使い所は色々とありそうですが、このようにebs内のデータが永続的に保存されていることの確認ができました。
ちなみにこのボリュームを複数のec2にアタッチできたら便利だなと思いましたが、AWSコンソール上でのメニューを確認する限りでは、できないようでした。
あらためて感じますが、20年ぐらい前までは物理的なハードディスクをマザーボードに追加してファイルシステムのフォーマットしてマウントしてましたが、エラスティックな時代だな〜
- 投稿日:2020-11-13T11:59:22+09:00
新しいElastic Load Balancerが来たぞ!
えぇ!?セキュリティアプライアンスでスケーリングを!?
できらぁ!!
Introducing AWS Gateway Load Balancer要約すると、第三者パーティのセキュリティアプライアンス(FortinetとかDeepSecurityとか)が
実装されたELBが使えるよって感じかな。え、ヤバない?
今までインスタンス毎にCloud One Workload Security(旧:Deep Security as a Service)とか入れてたのを、
こいつフロントにかますだけで良くなるってことでしょ?ヤバない?
まだ日本には実装されていないので、シドニーリージョンとかで試してみようかな。
ただ、アプライアンスのライセンス費用がどれくらいかかるのか、それが気になるところ。今後の構成は、[Cloudfront+AWS WAF]-[AWS ゲートウェイロードバランサー]-[EC2]-[RDS]とかで
お手軽セキュア構成とか組めちゃうのかな。【追記】
ドキュメント見たら、
[internet]-[Cloudfront+AWS WAF]-[VPC Endpoint]-[EC2]-[RDS]
|
[AWS ゲートウェイロードバランサー]-[セキュリティアプライアンスEC2群]こんな感じの構成になるぽい。
VPC Endpointで繋いで外も内もトラフィックはAWS GWLBを経由する形に。
- 投稿日:2020-11-13T10:32:18+09:00
[AWS CloudFormation] IoTルールの定義
AWS::IoT::TopicRuleを使用したIoTルール定義構文については公式ドキュメント参照
ただし、以下のように記載されているYAML例がYAMLではなくJSON
英語サイトの場合は、
YAML例はちゃんとYAMLになっている
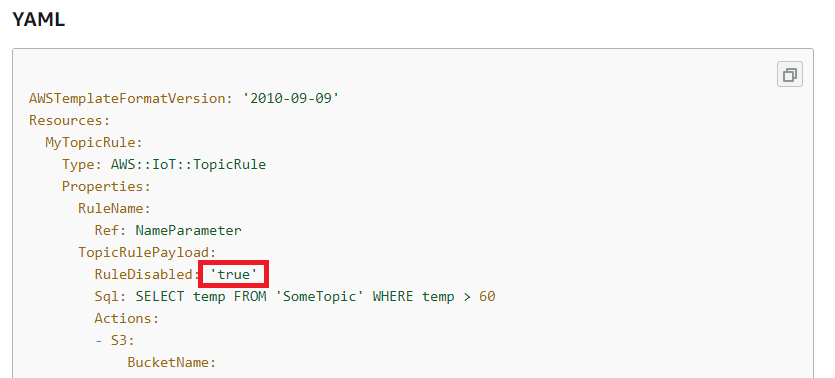
ただし、bool値の箇所が'true'と文字列になっている(ただしくはtrue)等の誤りがあったりするので注意
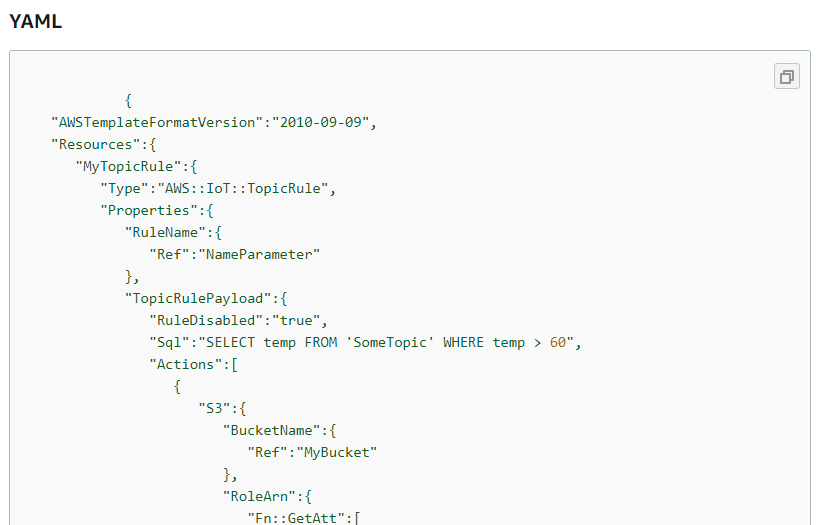
ということで以下が実際のIoTルール定義
# IoTルール EdgeRecvMessageTopicRule: Type: AWS::IoT::TopicRule Properties: TopicRulePayload: RuleDisabled: false Sql: SELECT * FROM '+/info' Actions: # IoTルールに合致した場合に実行するアクション(今回はLambda) - Lambda: FunctionArn: !GetAtt EdgeRecvMessageHook.Arn # IoTルールに合致した場合にフックされるLambda定義 EdgeRecvMessageHook: Type: AWS::Serverless::Function Properties: FunctionName: !Sub '${StackName}_EdgeRecvMessageHook' CodeUri: Edge-Recv-Message/ Handler: function.lambda_handler Runtime: python3.8 # IoTからLambdaを実行する権限付与定義 EdgeRecvMessageHookPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !GetAtt EdgeRecvMessageHook.Arn Principal: iot.amazonaws.comIoTルールの名前について
EdgeRecvMessageTopicRule: Type: AWS::IoT::TopicRule Properties: RuleName: !Sub '${StackName}_EdgeRecvMessage' TopicRulePayload: RuleDisabled: false Sql: SELECT * FROM '+/info' Actions: - Lambda: FunctionArn: !GetAtt EdgeRecvMessageHook.Arn上記のようにスタック名をprefixにした
RuleNameにしようと考えたが、
スタック名に-が入っていたためエラーとなった。IoTルールの名前には
_は使用できるが、-は使用できない。
逆にCloudFormationのスタック名には-は使用できるが、_は使用できない。
ちなみにS3バケット名はスタック名と同様、-は使用できるが、_は使用できない。
RuleNameは必須項目ではないので、自動生成される名前で逃げる手はあり。
自動生成されたルール名にはprefixとしてスタック名から-を除いた文字列が付く。
- 投稿日:2020-11-13T09:53:12+09:00
Principalに指定したリソースがないとIAM Roleの作成に失敗する
概要
AWSでクロスアカウントでアクセスする際にAssumeRoleを行うための設定をします。
例えばアクセス元のアカウントをA、アクセス先のアカウントをBとすると、アカウントBのAWSアカウントにAssumeRoleを許可するためのIAM Roleを作成します。
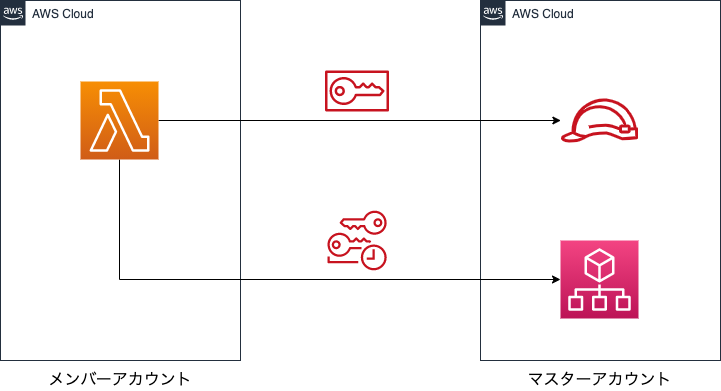
今回、このアカウントBに該当するアカウントで、IAM Roleを作成しようとして失敗しました。オチとしてはタイトルの通りなのですが、なぜ失敗したのか原因を調べたところ、IAMってちゃんと考えられてるな、と感心したので記事にしました。構成
今回はAWS Organizationsでアカウント管理をしている環境において、メンバーアカウントのLambdaからマスターアカウントのOrganizationsサービスが提供しているAPIを実行する場合を例として取り上げたいと思います。Organizationsの部分が例としては少し特殊かと思いますが、基本的にクロスアカウントでAPIを実行する場合は同じような構成になるかと思います。
試したこと
メンバーアカウント側のLambdaの実装は後回しにして、ひとまずマスターアカウント側でIAMRoleを作成するためにCFnで以下のテンプレートを用意しました。
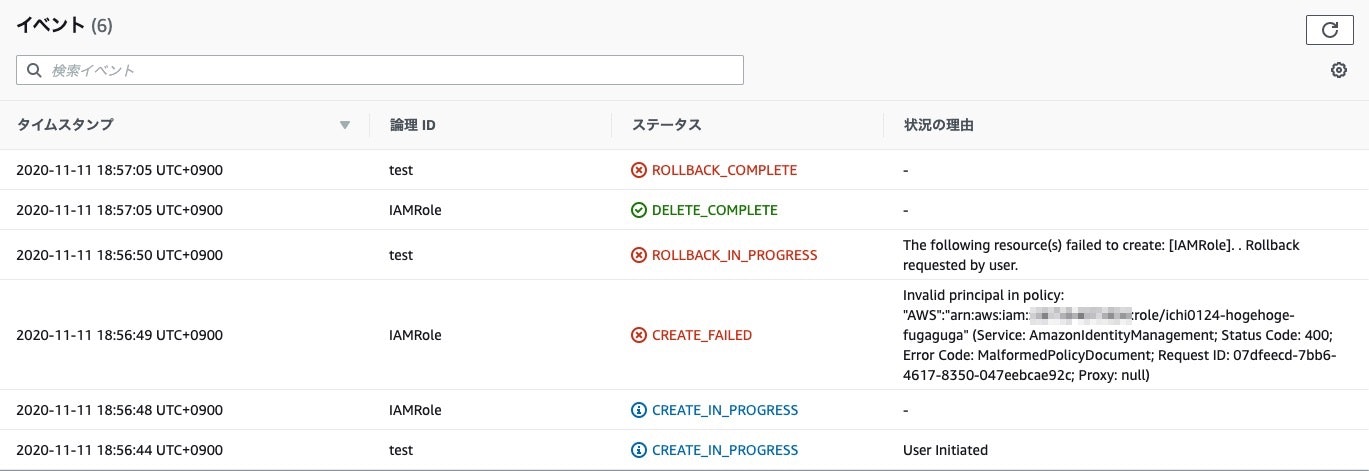
パラメータのMemberAccountIdにはアクセス元のAWSアカウント番号が入ります。AWSTemplateFormatVersion: '2010-09-09' Parameters: PrincipalOrgID: Type: 'String' MemberAccountId: Type: 'String' Resources: IAMRole: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: '2008-10-17' Statement: - Effect: 'Allow' Principal: AWS: !Sub 'arn:aws:iam::${MemberAccountId}:role/ichi0124-hogehoge-fugafuga' Action: 'sts:AssumeRole' Policies: - PolicyDocument: Version: 2012-10-17' Statement: - Effect: 'Allow' Action: - 'organizations:DescribeAccount' Resource: !Sub 'arn:aws:organizations::${AWS::AccountId}:account/${PrincipalOrgID}/${MemberAccountId}' PolicyName: 'get-organizations' RoleName: !Sub 'organizational-information-for-${MemberAccountId}'マスターアカウントでこのテンプレートからCFnスタックを作成し、これでメンバーアカウント側の実装に集中できるぞ、と思ったのですが、作成時にエラーが発生しました。エラー内容は以下の通りです。
エラーの原因
Invalid principal in policyとイベントにあるのでprincipalの定義を中心にCFnテンプレートを見返したのですが、書き方的にはおかしいところはなかったため、ドキュメントを読み返しました。そして、こちらのドキュメントにたどり着きました。注目すべきは以下の記載です。
ロールのPrincipal要素に、特定のIAMロールを指し示すARNが含まれている場合、そのARNはポリシーを保存するときにロールの一意のプリンシパルIDに変換されます
今回エラーになった原因は、Principal要素に記載したIAMロールのARNをプリンシパルIDに変換しようとしたが、対象のIAMロールが存在しないために変換に失敗した、ということになります。明記はされていませんでしたが、Principal要素に記載したARNをプリンシパルIDに変換する際に実体が存在するかどうかの確認をIAMロールの作成時に行っているようです。この事実を知りませんでした。
なぜこのような仕様になっているか
これについては以下の記載に集約されていました。
ロールを削除して再作成することにより、誰かがそのユーザーの特権をエスカレートするリスクを緩和できます。通常、この ID はコンソールには表示されません。これは、信頼ポリシーが表示されるときに、ロールの ARN への逆変換が行われるためです。ただし、ロールを削除すると、関係が壊れます。ロールを再作成した場合でも、ポリシーは適用されません。これは、新しいロールは信頼ポリシーに保存されている ID と一致しない新しいプリンシパル ID を持っているためです。この場合、プリンシパル ID はコンソールに表示されます。これは、AWS が有効な ARN に ID をマッピングできなくなるためです。その結果、信頼ポリシーの Principal エレメントで参照されているロールを削除して再作成する場合は、ロールを編集して正しくなくなったプリンシパル ID を正しい ARN に置き換える必要があります。ポリシーを保存するときに、ARN は再びロールの新しいプリンシパル ID に変換されます。
概要をかいつまむと、単純にIAMロールのARNの文字列をチェックする場合だとロールを同名で再作成することで意図しない誰かに権限を奪われるリスクがある。しかし、ARNを独自のプリンシパルIDに変換することで、再作成時には同名のIAMロールであっても別のプリンシパルIDに変換されるため、上記の可能性を潰すことができる、ということのようです。
おわりに
今回初めて知ったことではありますが、この動作仕様はかなり重要なもので、なるほどと思いました。
色々と考えて作られており、知らないうちに守られているんだなということを実感しました。
- 投稿日:2020-11-13T09:34:51+09:00
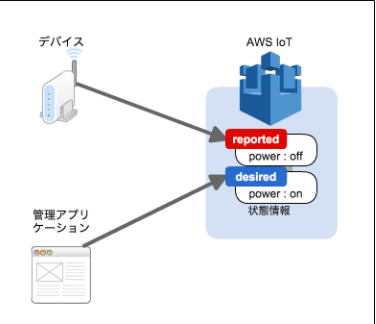
AWS IoT Core の シャドウ機能についての調査まとめ
シャドウ概要
AWS IoT Coreでは、ラズパイなどのエッジ端末をモノ(Thing)として登録し、その状態を保持する機能を持っています。この「状態(state)」がシャドウ(shadow)です。
アプリケーションでは、この状態の変更を通してデバイスを操作します。
状態には”reported”、”desired”の2つの要素が存在します。
- ”desired”: アプリケーションとして期待する状態を示すのに使用します。アプリケーションで状態の変更要求を出す場合は、この状態を更新します。
- “reported”: デバイス自身がどういった状態なのかを示すのに使用します。この状態を変更するのは基本的にはデバイス自身です。
具体例
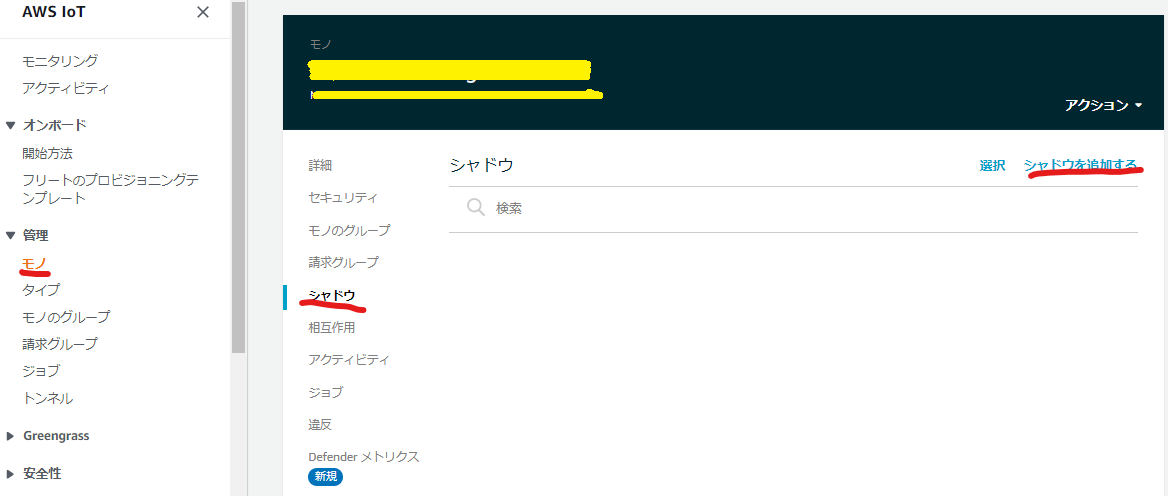
下記例は、AWSコンソールからシャドウを追加し、シャドウの内容を確認した結果です。
IoT Core > [モノ]タブ > 表示されたモノを選択 > [シャドウ]タブ > シャドウを追加するボタン押下
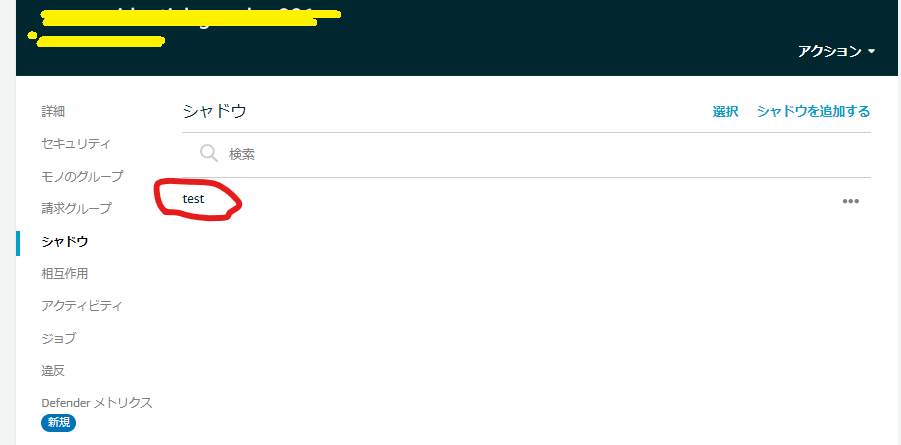
シャドウ名の入力欄が表示されるので、任意(今回は「test」)で入力し、シャドウを追加する。
追加されたシャドウを選択する。
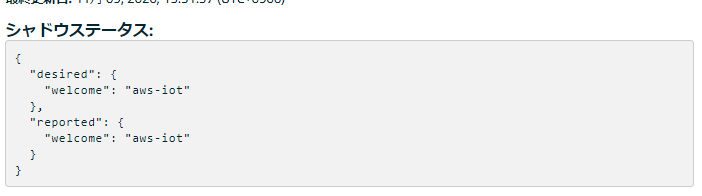
下記の通り、前述したdesired、reportedの状態が表示されている。
アプリケーションからの状態変更があったと想定して、コンソールでdesired側の"welcome"の値を"aiueo"変更すると、シャドウステータスが下記のように変化する。
deltaとは、状態に差異がある箇所を抽出し、表示してくれるもの
{ "desired": { "welcome": "aiueo" }, "reported": { "welcome": "aws-iot" }, "delta": { "welcome": "aiueo" } }
- 次にエッジから状態変更があったと想定して、コンソールでreportedの"welcome"の値を"oeuia"変更すると、シャドウステータスが下記のように変化する。
まだ状態が一致していないため、deltaは表示されたままとなる。
{ "desired": { "welcome": "aiueo" }, "reported": { "welcome": "oeiua" }, "delta": { "welcome": "aiueo" } }
- 最後に、コンソールでreportedの"welcome"の値を"aiueo"変更し状態を一致させると、シャドウステータスが下記のように変化する。
状態が一致するとdeltaが消える。
{ "desired": { "welcome": "aiueo" }, "reported": { "welcome": "aiueo" } }状態はjson形式で管理されるため、例えば下記のように、複数の情報を持つことができ、また配列なども保持することが可能。
そのため、例えば、1つのシャドウで1つのエッジにぶら下がっている複数のデバイス(照明やエアコンなど)の複数の状態(電源ON/OFF、温度など)を管理することも可能です。
(複数のシャドウで管理することも可能ですが、1つのシャドウで管理することもできます。という意味です。)"desired": { "welcome": "aws-iot", "device": [ { "type": "light", "id": "1", "connect": true, "power": "on" }, { "type": "aircon", "id": "2", "connect": true, "ondo": "20" } ] },シャドウの種類
名前なしシャドウ
前述の例では、シャドウに名前を決めていたが、名前なしでシャドウを作ることもできる。
AWSコンソールで作成する場合、前述の例の名前決定箇所で名前を入力しなければ生成される。
公式サイトによると、あらかじめ1つしかシャドウを利用しないことが決まっているのであれば、名前なしシャドウを利用すると良いらしいが、既に複数のシャドウを使用する可能性があるのであれば、後述する名前付きシャドウを利用した方が良いとのこと。
拡張性を考えるなら、名前付きシャドウを使う方が良いとの理解。
[メリット]
- 名前が無いため、利用する側(エッジやLambda)が名前を知らなくてもアクセスできる。(単純)
[デメリット]
- 名前がないため、1つしか作ることができない。
名前付きシャドウ
前述の例で記載した通り、名前を指定したシャドウ。
[メリット]
- シャドウ内で複数の状態(例えば、電源ON/OFF、温度など)を管理することもできるが、複数の名前付きシャドウを作成し、個々に管理することが可能。
[デメリット]
- 基本的(*)にはエッジ端末が直接IoT Coreからシャドウの一覧を取得することはできないため、あらかじめ名前は決めておく必要がある。
(*)Sigv4(IAMユーザのアクセスキーとシークレットキーがあれば、取得可能だが、クライアント証明書では取得することができなかった)
シャドウへのアクセス方法
シャドウへの制御は、名前付きシャドウ と 名前なしシャドウでそれぞれ異なり、それぞれで、
GET、UPDATE、DELETEの3種類の制御が可能。
GETは、指定したシャドウの状態を取得
UPDATEは、指定したシャドウの状態を更新(desired、reportedのどちらを更新するか選択できる)
DELETEは、指定したシャドウの削除
エッジ側からのアクセス方法
<余談>AWS のnodejsのサンプルコードにシャドウに関するサンプルはなかったため、pythonのサンプルを元にnodejsに実装して確認してみた。
前述の通り、シャドウの制御は3つしかないので比較的簡単に実装できる。AWS SDKの"aws-iot-device-sdk-v2"をインポートするとiotshadowというオブジェクトがある。
そのオブジェクトの提供関数に、シャドウの名前付き、名前なしでそれぞれGET、UPDATE、DELETEの関数が提供されているため、それを用いる。
なお、指定したシャドウの状態が変化した場合にコールバック関数を登録できる関数もある。
//シャドウクライアント生成。connectionはMQTTのコネクションオブジェクト let shadow = new iotshadow.IotShadowClient(this.connection); // GET関数コール const getNamShadow: iotshadow.model.GetNamedShadowRequest = { thingName: client_id, //モノの名前 shadowName: shadowName, //シャドウの名前 }; await shadow.publishGetNamedShadow(getNamShadow, mqtt.QoS.AtLeastOnce);AWS側からのアクセス方法
Lambda経由でIoT CoreにMQTTメッセージを送信することで行う。
IoT CoreへMQTTメッセージを送信するSDK(boto3)が提供されているため、それを用いる。
GET、UPDATE、DELETE制御は、それぞれTopicを指定し行う。
名前付きシャドウの場合、下記のようにTopicにモノの名前、シャドウ名を含めMQTTメッセージを送信し、受信を待つ。
iot = boto3.client('iot-data') topic = f'$aws/things/{thingName}/shadow/name/{shadowName}/update' response = iot.get_thing_shadow(thingName=thingName, shadowName=shadowName)Topicについては、公式サイト参照
補足
シャドウをあらかじめ生成していなくても、UPDATE時になければ新規生成される。
最後に
シャドウの状態は、AWS IoT Coreで管理されるため、例えばエッジの電源が落ちていても状態は残り続けます。
そのため、エッジ端末が起動していなかったとしても、シャドウの更新をしておけば、エッジ起動時にシャドウの状態に合わせて、更新後の状態にエッジを動作させる。といったことが可能になります。
シャドウが無いとエッジの状態を管理するための状態をストレージに持つ必要があるので、シャドウはとても便利に思いました。参考URL
・概要
https://hub.appirio.jp/tech-blog/device-management-through-aws-iot-shadow
https://dev.classmethod.jp/articles/aws-iot-things-shadow/
・シャドウ動かしてみた
https://iotnews.jp/archives/6599
・シャドウサンプル
https://dev.classmethod.jp/articles/aws-iot-things-shadow/
・公式サイト
- 投稿日:2020-11-13T01:13:47+09:00
DynamoDB オンデマンドモード ≠ エラーなしのアクセスし放題
問題
DynamoDB をオンデマンドモードにして運用していればテーブルへのアクセス集中による対処(スロットリング)は気にしなくても良い。 というのは間違った認識である。
オンデマンドの DynamoDB テーブルを使用していますが、まだスロットルされています。なぜでしょうか? にあるように、例えオンデマンドモードであってもスロットリングは発生する。
そもそもリクエスト単位って何?
ここの説明に書いてある「リクエスト単位」というのは何を意味するのだろうか? 読み込み・書き込みがあるが、今回は書き込み側に絞ってみていく。
定義は ここ に書いてある。 同ページ内に書き込みキャパシティ単位(WCU)の説明もあるので混同に注意。
書き込みリクエスト単位 (Write Request Unit, WRU)
One write request unit represents one write for an item up to 1 KB in size. If you need to write an item that is larger than 1 KB, DynamoDB needs to consume additional write request units. Transactional write requests require 2 write request units to perform one write for items up to 1 KB. The total number of write request units required depends on the item size. For example, if your item size is 2 KB, you require 2 write request units to sustain one write request or 4 write request units for a transactional write request.
要約すると以下の通り。
- 「どれだけ使ったか(=課金に関する値)」を意味する
- ap-northeast-1 の場合は 100 万 WRU あたり 1.4269 USD (記事執筆時点)
- 1WRUは 最大1KB のデータを 1つ 書き込んだことを意味する
- 1KBより大きいデータを書き込むときは、1つ上のサイズに切り上げた分のWRUを消費する (1.5KBのデータなら2 WRU)
- トランザクションで書き込むときはさらに2倍
各種ドキュメントを探してもこういう結果になるのだが、この定義だと オンデマンドの DynamoDB テーブルを使用していますが、まだスロットルされています。なぜでしょうか? で説明されている
テーブルの各パーティションは、最大 3,000 の読み取りリクエスト単位または 1,000 の書き込みリクエスト単位、またはその両方を線形的に組み合わせることができます。
という内容を説明できない。 素直に読むと "1000件しか書き込みができない" となってしまう。
なので、おそらくではあるが、これらの文脈では per second が省略されている とみてよいと思う。 というのも、いくつかの記事を見る中では、WRU/sec などとして用いられていたためである。
- https://tarepan.hatenablog.com/entry/2018/02/12/AWS_DynamoDB
- https://pages.awscloud.com/rs/112-TZM-766/images/Session%204%20-%2020200825_CyberZ_OPENRECTV_Purpose-Built-Databases-Week-v2.pdf
なので、定義のページを読んでも読み取れないので不安ではあるが、
- 文章で書き込みリクエスト単位の数値が提供されている場合、それは1秒間に書き込み処理できる最大数である (/secが省略されている)
と、捉えることとする。
それを踏まえると、AWS アカウントのオンデマンドのデフォルトでは、40,000 RRU / 40,000 WRU となっている ため、秒間に 40,000 単位の読み込み・書き込みに対応しているが、上限緩和をしない限りはいくらうまく使ったとしても、これ以上の速度で処理を行えないということではある。
調査するに至ったきっかけ
今回出くわしたのは「同一パーティション の大量のデータ書き込みを SQS + Lambda の組み合わせで遅延処理で実施」した。 その結果スロットリングが発生してデータが書き込めない状況が発生した。
テーブル自体は最初からオンデマンドで作成しており、このデータ書き込みが発生するまではほとんどアクセスがない状態だったので、2倍に引き上げたところで性能が追い付かず、また、同一パーティションの書き込みだったので同一シャードにのみ負荷をかけることとなり、結果として上述で示されていた限界よりもかなり小さい 300 ~ 500 WRU / sec あたりでスロットリングの発生を確認した。 少し調整して、100 ~ 125 WRU / sec あたりを維持することでスロットリングは発生しなくなった。ここを動的に調整しようと思うと、トラブルシューティングの記事にならって 、 Provisionモードで事前に高いCapacity Unitを持つテーブルを作成し、これをOn-Demandに変更する 方法や、30分前からウォームアップをしてトラフィックピークを予見する といった方法がある。
ただ今回自分が起こした問題については「同一パーティション」にしてしまったことがそもそもの問題である。 この手の処理で並列投入する予定はなかったが必要になってしまった。
ので、「DynamoDBをオンデマンドで使っているから、スロットリングによってエラーが返ってくることはない」と誤った認識で開発するのではなく、大量書き込み・読み込みが行われるかをちゃんと設計段階で考慮して使わなければならない。
- 投稿日:2020-11-13T00:41:20+09:00
AWS SQS FIFOの並列動作について書いておく
AWS SQSではグループIDが異なれば並列で動くのか?
標準SQSであれば受信可能なメッセージから極力FIFOで処理されていきますが、基本的には順序保証なくどんどん消化されます。
トリガーにLambdaが設定されていれば、複数のLambdaインスタンスにより処理されていきます。ではFIFOはどうなのか?
FIFOはグループID単位で順序を保証します。
ではグループIDが異なっていればどうなるか?例えば
1番目 グループID:A 8:00:01にキュー登録
2番目 グループID:A 8:00:02にキュー登録
3番目 グループID:B 8:00:03にキュー登録
4番目 グループID:C 8:00:04にキュー登録とした場合。
トリガーのLambdaは10秒処理がかかるとします。この場合は
1番目→3番目→4番目→2番目の順でメッセージを取得していきます。
このとき、3番目の実行タイミングは1番目が実行中のときに開始しますので、8:00:03に処理開始します。
4番目も同じく、8:00:04に処理を開始します。
2番目のキューは1番目の処理が完了してから動作するため、8:00:11秒から動作します。相変わらずわかりにくい公式ドキュメント
https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/FIFO-queues.html
プロデューサーとか言われても。。。
ということで
FIFOだからグループIDが別であっても先入れしたメッセージが取得して終わらなければ、次のメッセージ取得はブロッキングされてしまうのではと言う不安、ありますよね。
実際に動作させてみたところ、前述のような動作することが確認できました。
ただ実際のところグループIDが別れていれば並行してメッセージが取得されるかと言われると、それは言い切れないかもしれません。というのもSQSトリガーのLambdaは初期状態では5インスタンスしかありません。
メッセージの増加に従いスケールしていき、最終的には上限の同時期同数に達します。
ただ増加はそこまで急激ではなく、メッセージの増加量に追いつかないケースが考えられます。その場合はおそらくスロットリング。。。
