- 投稿日:2020-10-27T23:50:11+09:00
京急線の時刻表をスクレイピング
はじめに
職場を出た際に、スマホから自動でツイートする機能はできましたので、
次は職場の最寄り駅の発車時刻や遅延情報を表示したいです。
そうすれば、時間があるから寄り道しようとか、時間がないからすたすた歩こうとかできますよね。時刻表を取得するAPIに、「駅すぱあとWebサービス」がありますが、有料です。
「駅すぱあとWebサービス」
https://docs.ekispert.com/v1/それでは自分で作ればいいじゃないかと思い、色々調べたところ、興味深い記事が出てきました。
ブログ「入鋏省略」:時刻表スクレイピングツールに対する考え
https://nkth.info/blog/dia_scraping/サーバに負担をかけずに時刻表情報を抽出し、個人利用する分には問題ないそうです。
よって、スクレイピングによって、時刻表と遅延情報を取得して行きます。
私は京急線で通勤しているので、今回は京急線に絞っていきます。本記事では、スクレイピングによって京急線の発車時刻と遅延情報を取得します。
本記事の目指すことろ↑想定と実行環境
今回の想定は下記のとおりです。
使用鉄道路線:京急本線
職場最寄り駅:黄金町駅(私の住所とは一切関係ありません。)
使用列車:普通列車下り実行環境:
Ubuntu18.04LTS(将来的にはAndroidかAWSを想定)
Python 3.6.9環境構築
スクレイピング用で有名なライブラリにbeautifulsoupがあります。
Code Zine:PythonでHTMLを解析してデータ収集してみる? スクレイピングが最初からわかる『Python 2年生』
https://codezine.jp/article/detail/12230しかし、京急線時刻表の場合、beautifulsoupではうまく取得できません。
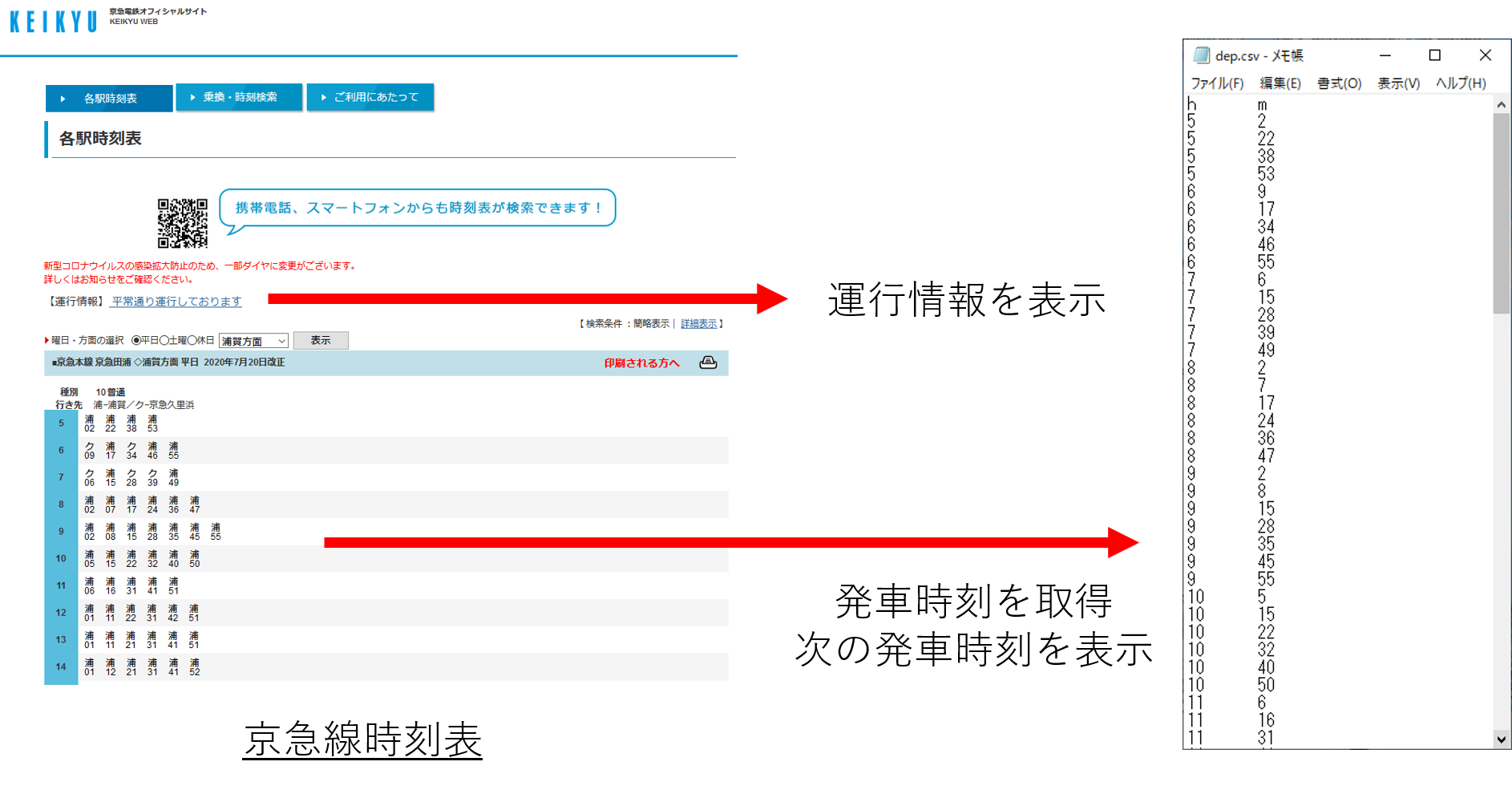
試しにbeautifulsoupで取得したデータは下記のとおりです。取得データ<html> <head> <title>京急本線:京急田浦駅時刻表</title> <meta content="max-age=1" http-equiv="Cache-Control"/> </head> <body> ★検索結果<br/> 京急本線<br/> 京急田浦駅時刻表<br/> 浦賀方面<br/> 平日のダイヤ<br/> 23:04 浦賀 <font color="#000000">普通</font><br/> 23:17 浦賀 <font color="#000000">普通</font><br/> 23:27 浦賀 <font color="#000000">普通</font><br/> 23:40 浦賀 <font color="#000000">普通</font><br/> 23:52 浦賀 <font color="#000000">普通</font><br/> 0:04 浦賀 <font color="#000000">普通</font><br/> 0:23 浦賀 <font color="#000000">普通</font><br/> 2020/7/20現在<br/> <hr/> <a href="T5?uid=27329&dir=38&path=2020102623438741&slCode=250-40&time=2125&d=2&dw=0&date=&pFlg=2&reFlg=0&USR=IM">↑前時間</a><br/> <a accesskey="1" href="T3?uid=27329&dir=38&path=2020102623438741&sf=%8B%9E%8B%7D%93%63%89%59&sfCode=2053&slCode=250-40&d=2&time=2300&dw=0&USR=IM">1.方面/時刻選択へ</a><br/> <hr width="80%"/> 全国の駅の時刻表は<a href="http://1069.jp/">駅探★時刻表</a>へ<hr width="80%"/> <a accesskey="8" href="/transit/norikae/T1?USR=IM&sf=%8B%9E%8B%7D%93%63%89%59">8.駅の時刻表トップ</a><br/> <a accesskey="9" href="http://www.keikyu.co.jp/m/index.html">9.トップへ</a><br/> <center>(C)KEIKYU</center> </body> </html>ダイヤが一部しか表示されません。
これは京急のWebサーバはブラウザが描画するための情報しか送っておらず、
ブラウザで見える情報≠サーバから帰ってきたデータ
だそうです。GAMMASOFT:requestsで取得できないWebページをスクレイピングする方法
https://gammasoft.jp/blog/how-to-download-web-page-created-javascript/そこで、上記記事のとおり、「requests-html」を使用して、ブラウザが処理した後のページ情報を取得します。
下記コマンドを入力し、「requests-html」をインストールします。requests-htmlのインストール$ pip install requests #requests-htmlの依存ライブラリ $ pip install requests-htmlサンプルファイルを改造し、京急線の時刻表で、京急線田浦駅、普通下りのURLを指定、ブラウザで処理したのちにソースを取得します。
req.pyfrom requests_html import HTMLSession url = "https://norikae.keikyu.co.jp/transit/norikae/T5?uid=34683&dir=7&path=202010272317801&USR=PC&dw=0&slCode=250-28&d=2&rsf=%89%A9%8B%E0%92%AC" #京急線 黄金町駅 下り普通のURL # セッション開始 session = HTMLSession() r = session.get(url) # ブラウザエンジンでHTMLを生成させる r.html.render()#ブラウザでHTMLを生成 print(r.text)#ブラウザで生成したHTMLを出力初回起動時のみ、勝手に「chromium」がインストールされます。
初回実行時の様子$ python req.py [W:pyppeteer.chromium_downloader] start chromium download. Download may take a few minutes. 100%|████████████████████████████████████████████████████████| 108773488/108773488 [00:09<00:00, 11116758.16it/s] [W:pyppeteer.chromium_downloader] chromium download done.無事にページ情報が出力されることを確認します。
(全部表示すると長すぎるので省略します。)ちなみに下記コマンドだけで、平常通り運行しているか分かります。
$ python req.py | grep 運行情報 -A 1 #検索文字列「運行情報」が含まれる行と、その次の行を出力 <div style="font-size: larger;">【運行情報】<a href="https://unkou.keikyu.co.jp/?from=top" target="_blank"> 平常通り運行しておりますやっとページ情報が取得できたので、スクレイピングしていきます。
下記プログラムを作成します。
詳細はコメントを見てください。
git-hubでもあげました。
https://github.com/zakuzakuzaki/zaki-aws/blob/main/station/koganecho.pykoganecho.py""" 京急線普通列車のの運行状況、発車時刻を取得・表示するプログラム。 urlにお好きな駅を指定してください。 """ from requests_html import HTMLSession import datetime url = "https://norikae.keikyu.co.jp/transit/norikae/T5?uid=80&dir=8&path=2020102719268885&USR=PC&dw=0&slCode=250-28&d=2&rsf=%89%A9%8B%E0%92%AC" #京急線黄金町駅下り普通列車のURL # セッション開始 session = HTMLSession() r = session.get(url) # ブラウザエンジンでHTMLを生成させる r.html.render() #運行情報を取得 #改行単位でsplit #参考URL:https://karupoimou.hatenablog.com/entry/2019/07/08/112734 page = r.text.split("\n") for i in range(len(page)): p = page[i] if "運行情報" in p: info = page[i+1]#「運行情報」文字列の次の行に内容が書いてある. #時刻表(時間)を取得 hour = r.html.find(".side01") hour_list = [] for h in hour: hour_list.append(int(h.text)) train = hour_list[0]#始発時間を取得 #時刻表(分)を取得 minute = r.html.find(".min1001") minute_list = [] for m in minute: minute_list.append(int(m.text)) del minute_list[0]#最初と最後の要素は時刻ではないので削除 del minute_list[-1]#同上 #時刻表を格納するための2次元配列の初期化 num = len(minute_list) dep = [[0 for i in range(2)] for j in range(num)] #時刻表の構築作業 for i in range(num): if i>0 and minute_list[i-1] > minute_list[i]: train+=1 dep[i] = (train, minute_list[i]) #print(dep)#時刻表の確認 #現在時刻を取得 #参考URL:https://note.nkmk.me/python-datetime-now-today/ now_time = datetime.datetime.now() now_hour = now_time.hour now_minute = now_time.minute #print(now_hour, now_minute)#現在時刻の確認 #現在時刻から最も近い発車時刻を取得 next=0 now_i=0 for i in range(num):#始発電車から1つずつ探していく. if dep[i][0]==now_hour:#現在時刻(時間)と比較 now_i = i if dep[i][1]>now_minute:#現在時刻(分)と比較 next = i break if next==0:#分がHitしなかった場合の処理 next=now_i+1 #結果出力 print("今日もおつかれさまでした.") print("京急線は"+ info) print("次の発車は") for i in range(3): if next+i>=num: next = -1 print("〜終電〜") print(str(dep[next+i][0]).zfill(2)+":"+str(dep[next+i][1]).zfill(2))#発車時刻を表示上記プログラムは下記記事を参考に参考しました。
・文字列抽出
なろう分析記録:【Pythonサンプルコード】スクレイピングで「特定の文字列を含む行」だけを抽出したい時の簡単な方法を解説
https://karupoimou.hatenablog.com/entry/2019/07/08/112734・現在時刻を取得
Pythonで現在時刻・日付・日時を取得:https://note.nkmk.me/python-datetime-now-today/テスト
実行結果は下記の通りです。
$ python koganecho.py 今日もおつかれさまでした. 京急線は平常通り運行しております 次の発車は 23:22 23:35 23:45無事、運行状況と次の列車の発車時間を表示させることができました。
駅(URL)を変えても正常に動作することを確認しました。おわりに
退社時を想定して、職場の最寄り駅の発車時刻と遅延情報を表示できました。
はじめてスクレイピングしましたが、結構楽しいですね。
ただ、pythonコードが汚いので、もう少し綺麗にできたらいいなと思います。
ちなみに今回は普通列車のみでしたが、抽出するclassを変更すれば、他の列車でも対応可能です。
複数列車の指定が時間かかりそうだったので、今回はパスしました。車種とclassの対応(横浜駅時刻表より)<span class="syasyu1004"><span class="min1004">10</span>快特</span> <span class="syasyu1003"><span class="min1003">10</span>特急</span> <span class="syasyu1010"><span class="min1010">10</span>エアポート急行</span> <span class="syasyu1001"><span class="min1001">10</span>普通</span>上記ページのURL(横浜駅浦賀方面時刻表)
https://norikae.keikyu.co.jp/transit/norikae/T5?uid=22537&dir=34&path=2020102723533416&USR=PC&dw=0&slCode=250-25&d=2&rsf=%89%A1%95%6C
- 投稿日:2020-10-27T23:37:15+09:00
CPLEX Python API 自作マニュアル LP編
動機
Python上でCPLEXを使いたいけど英語のマニュアルしかないし、いちいち調べるのも面倒だから自分で日本語のマニュアルを書いてしまえという理由から。
あくまでも自分用なので網羅してるわけではないのでご了承を。
またプログラムについてはjupyter notebookで記述することを想定しています。以下のサイトをもとにしています。
[公式CPLEX Python API Reference Manual]
https://www.ibm.com/support/knowledgecenter/en/SSSA5P_12.8.0/ilog.odms.cplex.help/refpythoncplex/html/cplex-module.html参考記事
[PythonでIBMの最適化ソルバ CPLEXを使う]
https://qiita.com/__leopardus__/items/93cac0f97cb22151983a環境
- MacBook Pro macOS Catalina
- Anaconda
- CPLEX_Studio1210 Academic版
LP(線形計画問題)
今回はLPを解く際に必要なものを中心に記述していきます(jupyter notebook形式)。
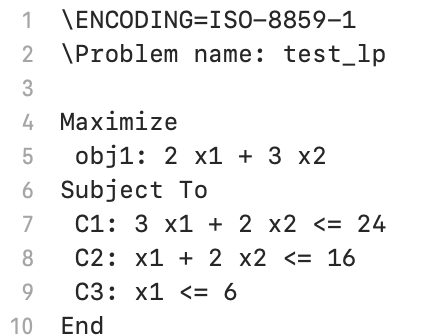
以下の問題を例にプログラミングしていきます。
$$
\begin{align}
\max\ \ &2x_1+3x_2 \\
\text{s.t.}\ \ &3x_1+2x_2 \leq 24 \\
&x_1+2x_2 \leq 16 \\
&x_1 \leq 6 \\
&x_1 \geq 0,x_2 \geq 0
\end{align}
$$問題設定
import cplexまず最適化問題のインスタンスをつくります。
lp = cplex.Cplex()これで何もデータを持たない空の問題ができました。
次にこの問題がLP(線形計画問題)であることを設定します。lp.set_problem_type(lp.problem_type.LP)LP以外の最適化問題にする場合は上記の関数の引数を
lp.problem_type.MILPや
lp.problem_type.QPなどにすることで対応させることができます。今回はLPなので
lp.problem_type.LPを代入しています。
次に目的関数について最大化か最小化かを指定します。
デフォルトでは"minimize"つまり最小化問題になっていますが今回は"maximize"最大化に設定します。lp.objective.set_sense(lp.objective.sense.maximize)なくてもいいですが問題に名前をつけます。
lp.set_problem_name("test_lp")ここまででLPについての大枠の設定が完了しました。
変数の設定
次に変数の設定を行います。
lp.variables.add(names=["x1","x2"],lb=[0,0])変数を新たに加える場合は上記のaddという関数を用いますが、addの引数は
objlbubtypesnamescolumnsの6種類があります。それぞれの説明は次のとおりです。
obj
目的関数が線形の場合に限るが、目的関数の変数の係数をリストで渡すことができる。 今回の場合はobj=[2,3]のようにすると目的関数を設定できる。lbub
変数の下限(lb)および上限(ub)を指定できる。デフォルトは下限は0上限はNoneとなっている。types
変数のタイプを指定できる。指定の仕方は次のとおり。
- 整数:
lp.variables.type.integerもしくは'I'- バイナリ変数:
lp.variables.type.binaryもしくは'B'- 連続変数:
lp.variables.type.continuousもしくは'C'- 半整数:
lp.variables.type.semi_integerもしくは'N'- 半連続:
lp.variables.type.semi_continuousもしくは'S'
ただしtypesを指定すると、すべての変数を連続に指定しても問題の型がMIPになるので注意names
変数の名前を指定できる。columns
制約式を設定できるらしいが複雑そうなので省略。目的関数・制約式の記述
目的関数を設定します。
lp.objective.set_linear("x1",2) lp.objective.set_linear("x2",3)もしくは
lp.objective.set_linear([(0,2),(1,3)])上記のように引数は
(変数名,係数)か(変数番号,係数)で与え、変数ごとに個別に設定してもまとめて設定しても良いです。
次に制約式の記述をします。lp.linear_constraints.add(names=["C1","C2","C3"], lin_expr=[cplex.SparsePair(ind=["x1","x2"],val=[3,2]), cplex.SparsePair(ind=["x1","x2"],val=[1,2]), cplex.SparsePair(ind=["x1","x2"],val=[1,0])], senses=["L","L","L"], rhs=[24,16,6])もしくは
lp.linear_constraints.add(names=["C1","C2","C3"], lin_expr=[[["x1","x2"],[3,2]], [["x1","x2"],[1,2]], [["x1","x2"],[1,0]]], senses=["L","L","L"], rhs=[24,16,6])線形の制約を追加する場合はlinear_constraints.addという関数を用いる必要がありますが、これも変数同様複数の引数が設定されています。
names
制約式の名前を設定できる。lin_expr
制約式の左辺の部分を指定する。形はSparsePairか行列形式のリストを与える。rhs
制約式の右辺の部分を指定する。senses
制約式の左辺と右辺の関係を表す等号あるいは不等号を指定する。 記号と指定すべき文字の対応は以下のとおり。
- $\leq$:
'L'- $\geq$:
'G'- $=$:
'E'- 範囲制約:
'R'
range_values
範囲制約の値を指定できる。求解
問題の定義ができたのでいよいよ求解しますが、その前にこれまで定義してきた問題を出力してみます。
lp.write("test.lp")
出力したファイルを見ると正しく問題が定義できています。
正しく定義できたところで解を求めます。lp.solve()最適化の結果、最適解が得られたかどうかを表示します。
print(lp.solution.get_status_string())出力:
optimal
となり、最適解が得られています。
最適解と最適値を表示します。print(lp.solution.get_values()) print(lp.solution.get_objective_value())出力:
[4.0, 6.0]
26.0
となって正しく解が得られました。次回
次回があるか分かりませんがQPを取り扱いたいと思います。
コード
import cplex lp = cplex.Cplex() lp.set_problem_type(lp.problem_type.LP) lp.objective.set_sense(lp.objective.sense.maximize) lp.set_problem_name("test_lp") lp.variables.add(names=["x1","x2"],lb=[0.0,0.0]) lp.objective.set_linear([("x1",2),("x2",3)]) lp.linear_constraints.add(names=["C1","C2","C3"], lin_expr=[[["x1","x2"],[3,2]], [["x1","x2"],[1,2]], [["x1","x2"],[1,0]]], senses=["L","L","L"], rhs=[24,16,6]) lp.write("test.lp") lp.solve() print(lp.solution.get_status_string()) print(lp.solution.get_values()) print(lp.solution.get_objective_value())
- 投稿日:2020-10-27T23:05:02+09:00
フォルダ内のcsvファイルを全て読み込み
概要
csvファイルが時期毎や属性毎に分かれていたりする場合があり、それらのファイルを一行で読み込めるようにするべく、実装しました。
目的の機能は以下の通りです。
・フォルダ内のcsvファイルを全て読み込む。
・指定の文字を含むcsvファイルのみ対象とすることも出来るようにする。
・下位ディレクトリも含められるようにする。実行環境
・Windows10 64bit
・Python 3.8.3
・pandas 0.25.3
・seaborn 0.11.0実装
1.データ準備
irisデータ(150件)を4分割して、csvファイルとして保存(Eドライブ直下の"main"フォルダ)。また、"main"フォルダ内の”sub”フォルダにも同じファイルを保存。
import seaborn as sns data = sns.load_dataset('iris') import os os.makedirs(r'E:\main', exist_ok=True) for i in range(4): st = int(0 if i==0 else (len(data)/4)*i) en = int((len(data)/4)*(i+1)) data.iloc[st:en].to_csv(r'E:\main\iris{}.csv'.format(i), encoding='cp932', index=False) os.makedirs(r'E:\main\sub', exist_ok=True) for i in range(4): st = int(0 if i==0 else (len(data)/4)*i) en = int((len(data)/4)*(i+1)) data.iloc[st:en].to_csv(r'E:\main\sub\iris{}.csv'.format(i+4), encoding='cp932', index=False)2.csvファイル読み込み
結果としては、以下の関数にて実装しました。
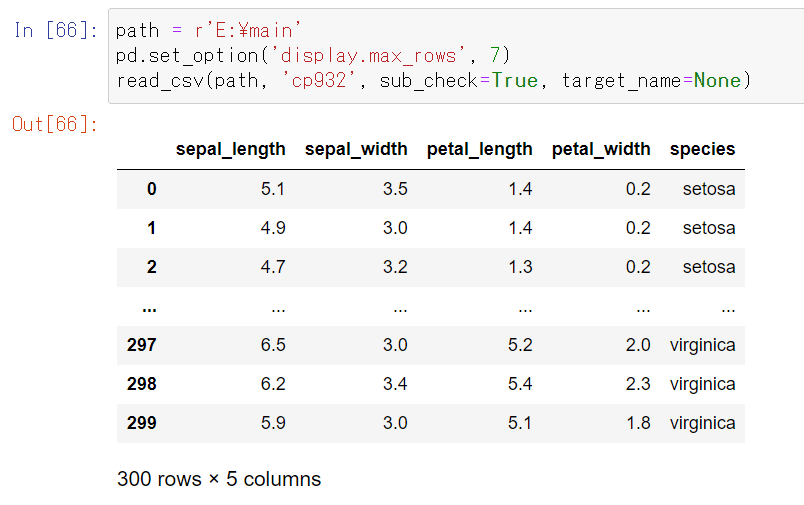
import glob import pandas as pd def read_csv(path, encode, sub_check=False, target_name=None): #フォルダ内全てのcsvファイルのパスをlistで取得 #sub_check=Trueならサブフォルダまで対象 target_files = glob.glob(path+r'\**\*.csv', recursive=True) if sub_check else glob.glob(path+r'\*.csv') #結合後のファイル格納用 merged_file = pd.DataFrame() #対象のcsvファイルを全て結合 for filepath in target_files: #ファイル名に指定の文字を含まなければ対象外とする filename = filepath.split('\\')[-1] if target_name!=None and target_name not in filename: continue #一つのcsvファイルを読み込み input_file = pd.read_csv(filepath, encoding=encode, sep=",", engine='python') #一つのcsvファイルを今までに読み込んだcsvファイルへ結合 merged_file = pd.concat([merged_file, input_file], axis=0) #結合後のDataFrameのindexをリセット merged_file = merged_file.reset_index(drop=True) return merged_file動作確認
1.一つのフォルダ内のcsvファイル読み込み
一つのフォルダ内のcsvファイル(150件)を全て読み込めました。
2.一つのフォルダ内のcsvファイルで指定ファイルのみ読み込み
target_nameに"1"を指定すると、名前に”1”を含むcsvファイル(38件)を読み込めました。
3.下位ディレクトリも含めてファイル読み込み
sub_check=Trueとすれば、下位ディレクトリの"sub"フォルダも含めて、csvファイル(300件)を全て読み込めました。
以上、閲覧頂きありがとうございました。


- 投稿日:2020-10-27T22:59:54+09:00
【git】git stash の使い方を具体例を使ってわかりやすくしてみた
はじめに
Git Hubを使用するときに、次のようなことありませんか。
プルリクして他の人に確認をしてもらっている時にそのプルリクの内容を使用して開発を続けたい。
作業するブランチを間違えて本来作業したいブランチにその作業した内容を反映させたい。
そんなときにstashというコマンドが便利のなので使用例と共に紹介していこうと思います。
git初心者のためもっと便利な方法がありましたら指摘してただけると幸いです。前提として
- git hub の基本的な使い方(comit,push,pullなど)が分かっていること
私の使用している環境
- pc:macOS Catalina 10.15.7
- 統合開発環境:atom version1.50.0
stashについて
stashとは・・・
一言で言うとコミットからの変更履歴をstash listに避難(保持)ができるコマンドです。具体例を使用して説明していきます。
大まかな手順をまとめておきます。
- 手順①Aブランチをつくってtest1.pyプルリクエスト
- 手順②プルリクエスト後Aブランチのままtest1.pyに内容を追加
- 手順③test1.pyに追加した内容をgit stash listに避難させる
- 手順④git stash list でstashした内容の確認
- 手順⑤新しいブランチを作成(Bブランチ作成)
- 手順⑥リモートの内容をBブランチにpullする(Aブランチの状態によってpullしてくる箇所が異なる)
- 手順⑦git stash listの内容を反映することができるコマンドを確認
- 手順⑧git stash listの内容を反映する
手順①Aブランチをつくってtest1.pyプルリクエスト
masterブランチからAブランチを作成後、以下のファイルをコミットしてプルリクエストをした。
test1.py# 最初のコミット print("test1")次にプルリクエストを待っている間にコミットしたファイルを使用したい。
手順②プルリクエスト後Aブランチのままtest1.pyに内容を追加
Aブランチのままtest1.pyに以下の内容を追加した。
test1.py# 最初のコミット print("test1") # 内容の追加 print("test2")保存をすると画像みたいにunstagedの箇所にtest1.pyの変更が反映される。
次にこの追加した内容を違うブランチに反映したい。
同じブランチでそのままコミットすることも可能ですが、基本的に相手に確認してもらっている最中にコミットするのはあまり気持ちのいいものではないので避けたい。今回の例は追加のみでしたが実際は手順①でプルリクしている箇所の間違いに気づいて修正することも考えられます。(相手からすると途中までみてたのに勝手に内容変えられると最初から見ないといけないじゃないかクソが!となってしまします。笑)
手順③test1.pyに追加した内容をgit stash listに避難させる
変更内容を避難させる。
ターミナル(windowsの場合はコマンドプロンプト)にてgit stashコマンドを実行します。するとAブランチにあるtest1.pyファイルは以下のようになります。ターミナルgit stash<実行後>
test1.py# 最初のコミット print("test1")手順①でコミットした時のファイルの内容に戻ります。言い方を変えると手順②で追加した内容を
git stash listに避難させています。unstagedの箇所にあったtest1.pyの変更もなくなります。(以下の画像のようになります。)
手順④git stash list を確認するコマンドの確認
避難させたgit stash listを確認する。使用するコマンドは以下のとおりです。
①
git stash list(内容)
git stash listを確認できます。
(使用例)ターミナルgit stash list <以下実行結果> stash@{0}: WIP on branch_name: commit_id2 commit_comment2上の
stash@{0}に先ほど避難させた内容が入っています。この0はstash listの0番目だよってことを示しています。複数ある場合はこの数字によって使用したいstash listを指定します。実行しても何も起きない場合はgit stash list がないことを示します。
※git stash listにsatsh@{0}があるときにgit stash listコマンドを実行すると実行前のstash@{0}はstash@{1}となる。新たにstashされた内容がstash@{0}となる。{}の中の数字が小さいほど新しいstash listの内容である。②
git stash show stash@{0} -p(内容)
git stash list の退避内容が確認できます。stash@{0}の中の0はgit stash list が複数ある際にどのstash listを確認したいかを指定するものです。-pの部分は--patchでも代用可能です。(使用例)
ターミナルgit stash show stash@{0} -p <以下実行結果> # 最初のコミット print("test1") + +# 内容の追加 +print("test2")③
git diff stash@{0}(内容)git stash list のdiff(差分)を表示できます。言葉での説明はわかりにくいので使用例をみてください。
(使用例)
ターミナルgit diff stash@{0} <以下実行結果> # 最初のコミット print("test1") - -# 内容の追加 -print("test2")手順⑤新しいブランチを作成(Bブランチ作成)
反映をさせる前に新しいブランチを作ります。ここではmasterブランチからBブランチを作ります。
手順⑥リモートの内容をBブランチにpullする(Aブランチの状態によってpullしてくる箇所が異なる)
Bブランチ作成後に、リモートの内容をpullするのですが、Aブランチのプルリクがマージされているのか、されていないのかでpullしてくる箇所が変わってきます。
1.マージされている場合
git pull origin masterによりリモートのmasterブランチの内容をBブランチに反映させる。その時のtest1.pyの内容は以下のとおりである。test1.py# 最初のコミット print("test1")2.マージされていない場合
git pull origin Aによりプルリク中のAブランチの内容を反映させる。これでもtest1.pyのAブランチの内容をBブランチに反映させることができる。反映内容は上記と同様。test1.py# 最初のコミット print("test1")※注意
2の方法によりpullしてきた箇所を修正すると、AブランチのプルリクがマージされたあとBブランチのプルリクをマージしようとするとコンフリクトしてしまいます。コンフリクトしても都度解消すれば特に問題はありません。
pullしてきた箇所を修正せず追加のみだとコンフリクトはおきません。(補足)Aブランチの内容をBブランチにpullしたいときにAブランチに複数のコミットがあり、その中の1つの内容を反映させたい場合があると思います。その時は
git cherry-pickという便利なコマンドがあります。cherry-pickについて知りたい方は以下のurlでわかりやすく説明されている方がおられますのでそちらを参考にしてください。[git]他ブランチの作業を自分のブランチに持ってくる方法まとめ
手順⑦git stash listの内容を反映することができるコマンドを確認
反映ができるコマンドは主に2つあります。
○1つ目
git stash apply stash@{0}こっちは反映した後にgit stash listはそのまま残ります。
○2つ目
git stash pop stash@{0}こっちは反映した後にgit stash list を削除されます。
{}の中の数字は整数を入れてどのstash listの内容を反映するのかを指定します。
stash listを指定しない場合は、デフォルトでstash@{0}指定されます。手順⑧git stash listの内容を反映する
手順⑦で確認した
git stash popコマンドにより避難させた内容を以下のとおり反映します。ターミナルgit stash pop stash@{0}実行後のtest1.pyファイル
test1.py# 最初のコミット print("test1") # 内容の追加 print("test2")これで手順①でプルリク後からの変更内容をBブランチに反映することができました。
このあとにgit stash listを実行してもstash@{0}はありません。git stash apply stash@{0}により実行した場合だとstash@{0}は残っています。参照url
- 投稿日:2020-10-27T22:25:05+09:00
気象庁レーダー毎極座標GPVのGRIBをnetCDF(CF/Radial 規約)に変換する
TL;DR
変換プログラムをGitHubに置いておくので自己責任でどうぞ。
はじめに
降水現象を調べるときに、気象庁(JMA)のレーダーデータを使いたいことがあります。通常は、1kmメッシュ全国合成レーダーエコー強度GPVや解析雨量)などの複数のレーダーからの情報を加工して作られた降水量の空間2次元データを使うことが多いでしょう。しかし降水の3次元の空間分布を調べるといった凝ったことをする場合、レーダーを中心とする仰角別の極座標格子に反射強度が格納されたレーダー毎極座標データを扱う必要があります。
このデータは他の気象庁のデータと同じくGRIB2形式で格納されており、テンプレート3.50120や4.51022といったJMA独自のテンプレートが使われていることが特徴としてあげられます(配信資料に関する仕様 No.13702を参照)。そのため、NCLやGrADSといった描画ソフトでそのままの形で読み出して描画することはできません。
描画する一つのやり方として、NICTの気象庁極座標レーダーデータのダウンロードサイトにあるサンプルプログラムを利用する方法があります。このサンプルプログラムには、wgrib2でJMA独自のテンプレートを読めるようにするパッチ、パッチを当てたwgrib2を使って変換したプレーンバイナリからレーダーサイトを中心とした直交座標に変換するCのプログラム、変換後のデータを描画するGrADSスクリプトが含まれています。
一方で、最近ではPyARTやwradlibといったPythonでのレーダーデータの解析ツールが充実してきています。これらのツールは、当然ながら独自テンプレートのGRIBを読んでくれるはずはなく、CF/Radial規約のnetCDF形式などにデータを変換して読み込ませる必要があります。このような変換プログラムを公開している人はいないようなので、作成しました。
変換プログラムの作成
基本的に配信資料に関する仕様 No.13702とCfRadial Data File Formatを見比べて変換するコードを書くだけです。今回はPythonのnetCDF4パッケージを使いました。いくつかポイントを記しておきます。
GRIBの第1節(識別節)・第3節(格子系定義節)・第4節(プロダクト定義節)はPythonでバイナリを読み出しました。第5節(資料表現節)と第7節(資料節)のランレングス圧縮されたデータについては、Pythonで解凍するコードを書くのが面倒なので、wgrib2でプレーンバイナリに変換してそれを読み込んでいます。プレーンバイナリへの出力はJMA独自テンプレートは関係しないため、通常のwgrib2でもエラーになりません。もちろん外部プログラムへの依存性が気になる人は、ランレングスの解凍をPythonで書くこともできると思います。
CfRadial Data File Formatの2.3節を読めば分かる通り、データの格納方法には Regular 2-D storage と Staggered 2-D storage の2種類があります。前者は時間によらずレンジ方向のビン数が一定な場合で、反射強度などの変数はrangeとtimeの2次元配列として格納されます。後者はレンジ方向のビン数が時間によって可変な場合で、反射強度などの変数は1次元配列して格納され、各時刻のレンジ方向のビン数と位置についてはray_n_gatesとray_start_indexに格納されます。レーダー毎極座標データの場合は仰角によってレンジ方向のビン数が可変なため、はじめは Staggered 2-D storage を使おうと思いました。しかし出力したnetCDFがPyARTで上手く読み込めなかったので、Regular 2-D storage にして値がないところは_FillValueで埋めました。
2020年から気象庁のレーダーが順次更新されていて、執筆時点では東京レーダーが更新されました。この更新の目玉は二重偏波化ですが、隠れた改善点としてボリュームスキャン(上から下まで全ての仰角で3次元的にスキャンすること)にかかる時間が10分から5分になることが挙げられます。GRIB2のデータは引き続き10分で1つのため、1ファイルに2つのボリュームスキャンが含まれることになります。CF/Radial規約を読むと1ファイルに1ボリュームのようなので(本当かは自信がない)、1つのGRIBから2つのnetCDFを生成したい場合がありそうです。そこで、GRIBの格納されているデータの番号(何番目の仰角かに対応)を指定して切り出せるようにしました。
作成した変換プログラムはGitHubにMITライセンスで置いておきます。
変換したデータの描画
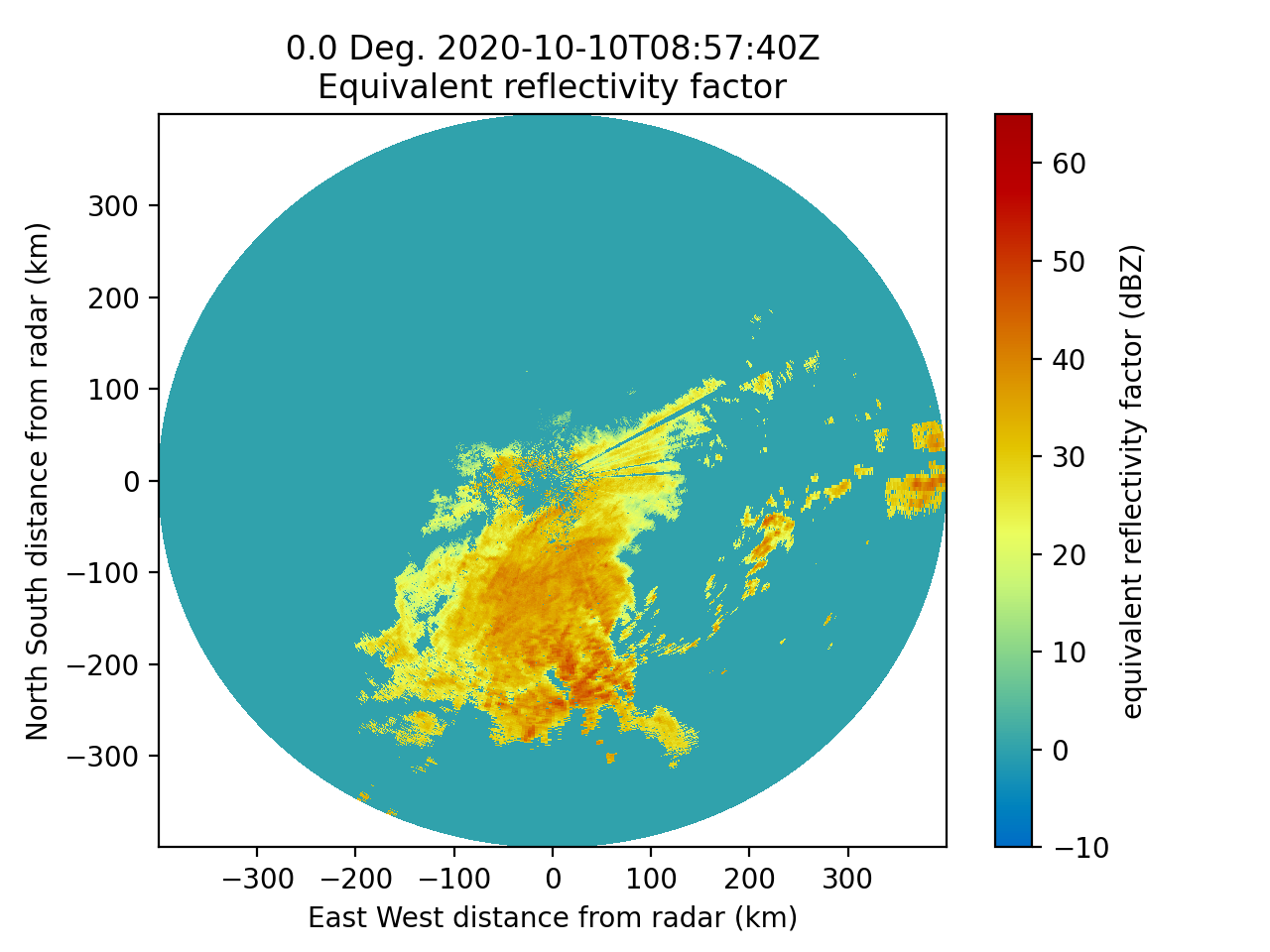
本題から外れますが、出力されたデータをPyARTで図を描くとこんな感じになります。実質4行で最低限の図が描けるのは便利ですね。
draw.pyimport matplotlib.pyplot as plt import pyart radar = pyart.io.read_cfradial('./work/RS47695.nc') display = pyart.graph.RadarDisplay(radar) display.plot('DBZ', sweep=29) plt.show()
- 投稿日:2020-10-27T21:37:00+09:00
Pythonエンジニア認定データ分析試験に合格してきた
難しくはないが知識の整理になった
【注意】本記事では試験に出題された内容を直接書いていません。
タイトルの通り合格しました。
Python CDA合格証明 試験結果 Pythonエンジニア認定試験には基礎試験とデータ分析試験があります(2020/10/27現在)。少なくともデータ分析試験はそこまで難しくありませんが、普段はデバッグもできるし、不安になった文法はネットで調べることができますが、試験では何も見ることができません。真面目に対策もしなかったので間違いも多かったようです。以下ではこの試験を受ける上で確認すべき内容をいくつか紹介します。
数学・統計
まず、指数対数や正弦余弦などの関数、ベクトル・行列、微分・積分は必須項目です。僕は理系なのでこの試験に向けて特に勉強したことはありません。確率統計についても、例えば度数分布表に関してはmatplotlibで扱うax.histの返り値により出力できるなど、データ分析に欠かせない内容です。
rangeとかnumpyとか
以下の出力など、間違いなく答えられますでしょうか。僕は不安になる時があります。
Question 1~4import numpy as np # Question 1 q1 = range(1, 10, 1) print( q1 ) # Question 2 q2 = np.arange(1, 10, 1) print( q2 ) # Question 3 q3 = np.arange(1.0, 10.0, 0.1) print( q3 ) # Question 4 q4 = [ len( q1 ), len( q2 ), len( q3 ) ] print( [ f'q{i+1} length = {a}' for i, a in enumerate(q4)] ) # print( q4 )
答えq1~q4(ブラウザによってはデフォで表示されてるかも)
# Answer for Question 1 range(1, 10) # Answer for Question 2 9 # Answer for Question 3 [1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9] # Answer for Question 4 90Question 5~8
# Question 5 q5 = [ i for i in range(1, 10, 3) ] print( q5 ) q6 = q5[-1] print( q6 ) # Question 7, Which range is true? # 1<=q7<=9 or 1<=q7<=10 or 2<=q7<=9 or 2<=q7<=10 ? #q7 = [ random.randint(1, 10) for i in range(100) ] q7 = random.randint(1, 10) print( q7 ) # Question 8, Which range is true? # 1<=q8<=9 or 1<=q8<=10 or 2<=q8<=9 or 2<=q8<=10 ? #q8 = [ random.randrange(1, 10) for i in range(100)] q8 = random.randrange(1, 10) print(q8)
答えq5~q8(ブラウザによってはデフォで表示されてるかも)
# Answer for Question 5 [1, 4, 7] # Answer for Question 6 7 # Answer for Question 7 #ex) 9 1<=q7<=10 # Answer for Question 8 #ex) 4 1<=q8<=9軽く上記の解説(range)
Pythonでは普通x = range(a, b)を使うとa <= x < bとなります。Numpyの場合でもq2 = np.arange(1, 10, 1)のように10を含まないようになります。スライスも同様です。
しかしq7 = random.randint(1, 10)のような場合にはrangeではないので1から10(10を含む)ということになります。
こういうものがq5 = [ i for i in range(1, 10, 3) ]のようにステップを含んだり、q3 = np.arange(1.0, 10.0, 0.1)のようにnumpyや小数となったりすれば、Pythonに慣れていない人は混乱するかもしれません。よく使いこんで、頭の中で結果を出力できるようにしましょう。正規表現
使ったことない人は"| (または)"と"? (0または1回)"の使い方くらいは押さえておきましょう。
import re prog = re.compile('Mori(i|mori)t(a)?k(a)?y(o)?s(hi)?', re.IGNORECASE) ret = prog.search('Moriitkys') print(ret[0]) ret = prog.search('Moritkys') print(ret[0]) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-48-3f281450d109> in <module>() 4 print(ret[0]) 5 ret = prog.search('Moritkys') ----> 6 print(ret[0]) TypeError: 'NoneType' object is not subscriptable上記のように、(i|mori)の場合はどちらか必ず含む必要があります。一方、t(a)?の場合許される文字列は"t"か"ta"のどちらかのみです。
Pandas
データ分析試験の特色というのでしょうか。Pandasの細かい部分は正確に暗記できていますでしょうか。
例えば、データフレームにおけるlocとilocの違いを確認します。import pandas as pd df = pd.DataFrame([[101, "a", True],[102, "b", False],[103, "c", False]]) df.index = ["01", "02", "03"] df.columns = ["A", "B", "C"] a1 = df.loc["03", "A"] a2 = df.iloc[2, 0] print(a1, a2)
答え(ブラウザによってはデフォで表示されてるかも)
いずれも103が出力です。要素の指定ではdf.locの場合はindexやcolumnsで、df.ilocの場合は0番目からの数値で指定します。これも参考書には載っている内容なので、試験に出るとすれば暗記しておく必要があります。
その他、df.headでは頭から何行のデータをとるか、とか、欠損値処理(dropnaやfillna)の詳細など、確認事項は多いです。
Matplotlib
気が向いたら何かまとめますが、例えばグラフのスタイル、タイトルの設定のようなところもテキストには書いてあるので、確認しておく必要があります。特に、グラフの種類(ax.bar, ax.scatter, ax.hist, ax.boxplot, ax.pie, など)においてはデータ分析という試験表題の通り必須項目です。
機械学習
機械学習には様々な手法があります。決定木、主成分分析、NN、など。データ分析者なら当然すべて使いこなせているはず。とはいえ普段あまり使わない手法はアルゴリズムや手法の説明、scikit-learnなどを見なおしておく必要があると思います。
参考書では教師あり学習と教師なし学習がごちゃごちゃになっているような気がしたので(そんなことないですかね)、どれが教師あり・なしなのか自分でまとめて勉強してもいいかもしれません。機械学習の諸々まとめ
・データ前処理(欠損値処理、特徴量の正規化など)
欠損値処理については上述のPandasによる欠損値処理などが紹介されています。詳細は参考書を確認してください。
特徴量正規化は確率統計などの知識が必要となります(分散正規化、最大正規化など)。
また、前処理ではデータの特徴量選択や外れ値除外も重要(試験範囲外?)になってきますが、とりあえずは参考書に載っている内容を確認すべきです。・教師あり学習
参考書ではサポートベクタマシン(sklearn.svmのSVC)、線形回帰モデル(sklearn.linear_modelのLinearRegression)、について解説されていますので、詳細はそちらを確認してください。・教師なし学習
参考書では決定木(sklearn.treeのDecisionTreeClassifier)、ランダムフォレスト(sklearn.ensembleのRandomForestClassifier)、次元削減(sklearn.decompositionのPCA)、クラスタリング(sklearn.clusterのKMeans、sklearn.clusterのAgglomerativeClustering)、について解説されていますので、詳細はそちらを確認してください。・強化学習
参考書には概要説明しか出てきません。・変数エンコーディング
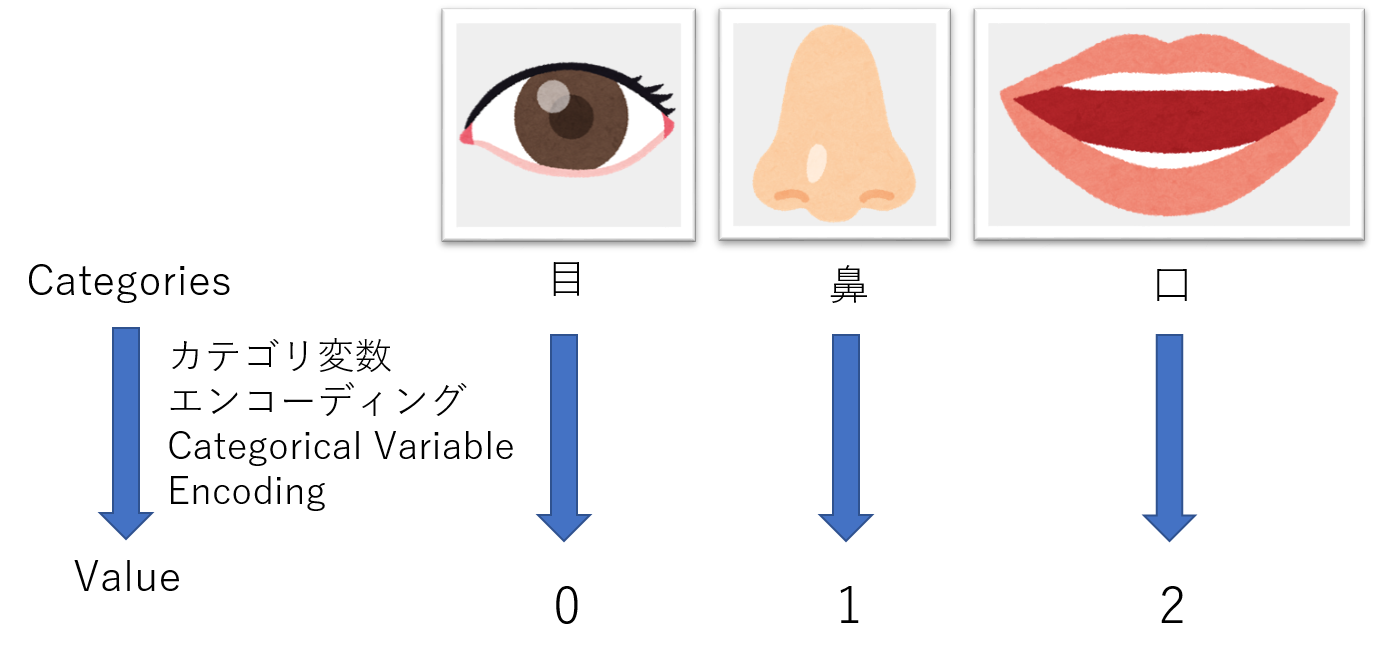
【カテゴリ変数エンコーディング】
人間は自分たちの住む世界を認識しやすいように、物体に対して名前を付けています。例えば人間の頭部前方に二つ付いた光を受容する感覚器のことを"目"と呼び、人間の頭部前方に付いた嗅覚・呼吸のための器官を"鼻"と呼びます。このように文字型によって解釈される対象でも、計算によって分類したい場合には入力や出力を数列(数値)としなければなりません。その数値と実際の対象を対応付けるための作業がカテゴリ変数エンコーディングです。
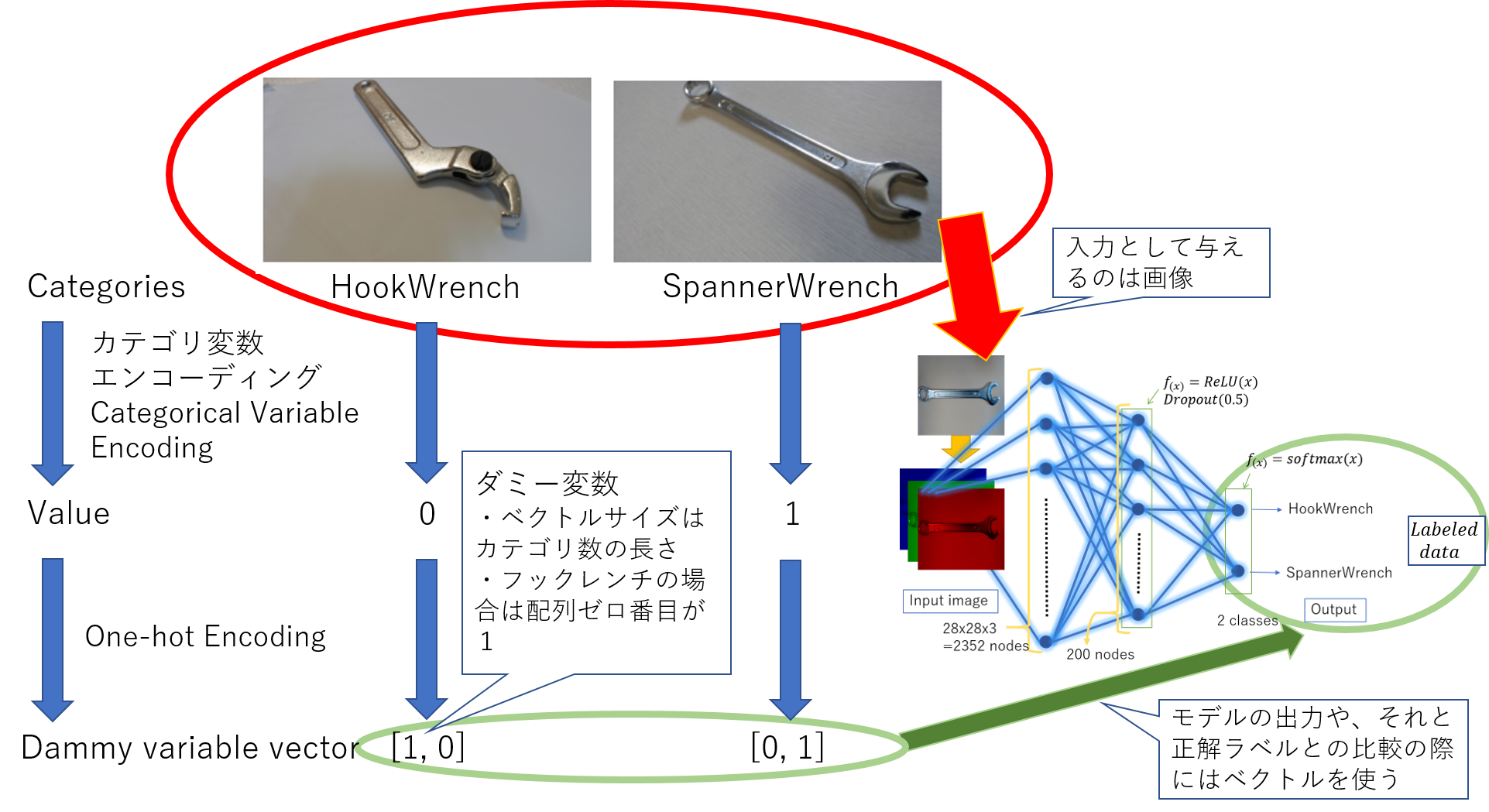
カテゴリ変数エンコーディングの概念図 具体的に、僕が以前作ったプログラムではどこがカテゴリ変数エンコーディングか説明します。
カテゴリ変数エンコーディング、One-hotエンコーディングの概念図 以下のページはPyTorchやKerasを使ってフックレンチとスパナレンチを分類したときの記事です。
https://qiita.com/moriitkys/items/316fcca8d83dfa706597
この場合、GitHub(GitHub-moriitkys/MyOwnNN)のMyOwnNN_pytorch.ipynbのプログラムの1セル56行目で実行している辞書の代入がカテゴリ変数エンコーディングです。#How many classes are in "dataset" folder categories = [i for i in os.listdir(os.getcwd().replace("/mylib", "") + "/dataset")] categories_idx = {}#ex) HookWrench:0, SpannerWrench:1 for i, name in enumerate(categories): categories_idx[name] = i nb_classes = len(categories)#ex) nb_classes=2この場合、フックレンチを0、スパナレンチを1として変換しています。
カテゴリ変数エンコーディングはsklean.preprocessingの方法が参考書で紹介されています。【One-hotエンコーディング】
これも計算によって目的の結果を得るために必要な作業です。機械学習では入力や出力を配列として扱った方が便利な場合が多いので、スカラ値のデータセットも配列として変換する必要があります。
例えば、スパナレンチ:0とフックレンチ:1の2カテゴリーがある場合、スパナレンチを[1, 0]、フックレンチを[0, 1]として変換します。具体的に、僕が以前作ったプログラムではどこがカテゴリ変数エンコーディングか説明します。3セル13から16行目付近がOne-hotエンコーディングです。
y_train1=np_utils.to_categorical(y_train,nb_classes) y_val1=np_utils.to_categorical(y_val,nb_classes)One-hotエンコーディングはskleanとpandasの二つの方法が参考書で紹介されています。
・モデルの評価
【分類の評価指標】
理解はできますが暗記しているかというと心もとないので、まとめておきました。この説明も参考書に載っているので、そちらを確認しておくといいと思います。
正例 負例 正例と予測 TP FP 負例と予測 FN TN TP (True Positive): 正例と予測して実際に正例
FP (False Positive): 正例と予測したが実際は負例
FN (False Negative): 負例と予測したが実際は正例
TN (True Negative): 負例と予測して実際は負例適合率:正例と予測したデータのうち、実際に正例の割合。
・適合率の式 P=TP/(TP+FP)
・適合率は予測クラスの間違いをいかに小さくできたかの指標と考えられる
再現率:実際の正例のうち、正例と予測したものの割合。
・再現率の式 R=TP/(TP+FN)
・再現率と適合率はトレードオフな関係
F値:適合率と再現率の調和平均。
・F=2PR/(P+R)
・PとRのバランスが良くなるような指標
正解率:予測と実績が一致したデータの割合
・正解率の式 A=(TP+TN)/(TP+FP)【予測確率の正確さ】
知ってれば何の問題もありませんが、参考書ではROC曲線について述べられています(sklearn.metricsのroc_curve)。まとめ
ちゃんと勉強すべきです。模試暗記みたいなことはできなさそうかなと思います。参考書の暗記も役に立つかもしれませんが、理解しておくべきです。
参考書
Pythonによるあたらしいデータ分析の教科書(寺田学、辻真吾、鈴木たかのり、福島真太郎)
本記事の著者
moriitkys 森井隆禎
ロボットを作ります。
AI・Robotics・3DGraphicsに興味があります。最近はいかにしてお金を稼ぐかを考え、そのお金でハードをそろえようと企んでいます。
資格・認定:G検定、Pythonエンジニア認定データ分析試験、AI実装検定A級、TOEIC:810(2019/01/13)


- 投稿日:2020-10-27T21:20:23+09:00
【CRUD】【Django】PythonフレームワークDjangoを使ってCRUDサイトを作成する~4~
シリーズ一覧(全記事完成したら更新していきます)
フロントエンドの作成準備
フロントエンド作成に必要なフォルダを作成する
HTML,JavaScript,CSSはstaticファイルと呼ばれます。
なのでディレクトリ名はstaticとし、crud配下(blog,configと同じ階層)に作成します。
さらに、static配下にimages,js,css,fontsフォルダを作成します。続いて、ststicフォルダを読み込む設定を入れていきます。
/crudconfig/settings.pyimport os STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]フロントエンドのダウンロード
以下サイトからフロントエンドの公開コードをダウンロードします。
「JACK FREE CSS TEMPLATE」からDOWNLOADを押して、zipを解答します。
フロントエンドの取り込み
ダウンロードしたフロンドエンドのテンプレートをDjangoに取り込む
解凍したimages,js,css,fonts配下のファイルはstatic配下のimages,js,cssフォルダ内へ、
解凍したindex.htmlの内容はtemplates/blog配下のhome.htmlファイル内へコピーします。リンクをDjango形式に置き換える
※完成版は末尾参照
先ほど作成したstaticディレクトリ配下へのリンクをDjango形式で記述します。
hrefリンクは以下のように書き換えます。/crud/blog/templates/blog/home.html<link rel="stylesheet" href="css/bootstrap.min.css"> ↓ <link rel="stylesheet" type="text/css" href="{% static 'css/bootstrap.min.css' %}">srcリンクは以下のように書き換えます。
/crud/blog/templates/blog/home.html<script src="js/jquery.min.js"></script> ↓ <script src="{% static 'js/jquery.min.js' %}"></script> <div class="loader"><img src="images/loading.gif" alt="" /></div> ↓ <div class="loader"><img src="{% static 'images/loading.gif' %}" alt="" /></div>サーバを起動する
python manage.py runserver「http://127.0.0.1:8000/」を開きます。
「JACK FREE CSS TEMPLATE」のデモ画面と同じ画面が表示されれば成功です。
また、JavaScriptによる動きもあることを確認しましょう。BLOGアプリを実装する
ではさっそくアプリを実装したいと思います。home.htmlに以下を追記します。
※完成版は末尾参照/crud/blog/templates/blog/home.html{% for post in posts %} <div class="row"> <div class="col-md-6"> <h1>{{ post.title }} <span>{{ post.author }}</span></h1> <p>{{ post.date_posted }}</p> <p>{{ post.content }}</p> </div> <div class="col-md-6"> <img src="{% static 'images/blog1.png' %}" alt="#" /> </div> </div> {% endfor %}本日はここまでです。
本記事の完成版
画面スクショ
HTMLファイル
/crud/blog/templates/blog/home.html{% load static %} <!DOCTYPE html> <html lang="en"> <head> <!-- basic --> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <!-- mobile metas --> <meta name="viewport" content="width=device-width, initial-scale=1"> <meta name="viewport" content="initial-scale=1, maximum-scale=1"> <!-- site metas --> <title>Jack Blogger</title> <meta name="keywords" content=""> <meta name="description" content=""> <meta name="author" content=""> <!-- bootstrap css --> <link rel="stylesheet" type="text/css" href="{% static 'css/bootstrap.min.css' %}"> <!-- style css --> <link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}"> <!-- Responsive--> <link rel="stylesheet" type="text/css" href="{% static 'css/responsive.css' %}"> <!-- fevicon --> <link rel="icon" href="{% static 'images/fevicon.png' %}" type="image/gif" /> <!-- Scrollbar Custom CSS --> <link rel="stylesheet" type="text/css" href="{% static 'css/jquery.mCustomScrollbar.min.css' %}"> <!-- Tweaks for older IEs--> <!--[if lt IE 9]> <script src="https://oss.maxcdn.com/html5shiv/3.7.3/html5shiv.min.js"></script> <script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script><![endif]--> </head> <!-- body --> <body class="main-layout"> <!-- loader --> <div class="loader_bg"> <div class="loader"><img src="{% static 'images/loading.gif' %}" alt="" /></div> </div> <!-- end loader --> <!-- header --> <header> <!-- header inner --> <div class="container-fluid"> <div class="row"> <div class="col-lg-3 logo_section"> <div class="full"> <div class="center-desk"> <div class="logo"> <a href="index.html"><img src="{% static 'images/logo.png' %}" alt="#"></a> </div> </div> </div> </div> <div class="col-lg-9"> <div class="menu-area"> <div class="limit-box"> <nav class="main-menu"> <ul class="menu-area-main"> <li class="active"> <a href="index.html">Home</a> </li> <li> <a href="about.html">About</a> </li> <li> <a href="marketing.html">Marketing</a> </li> <li> <a href="blog.html">Blog</a> </li> <li> <a href="contact.html">Contact us</a> </li> <li> <a href="#">Login</a> </li> <li> <a href="#">Register</a> </li> <li> <a href="#"><img src="{% static 'images/search_icon.png' %}" alt="#" /></a> </li> </ul> </nav> </div> </div> </div> </div> </div> <!-- end header inner --> </header> <!-- end header --> <!-- revolution slider --> <div class="banner-slider"> <div class="container-fluid"> <div class="row"> <div class="col-md-7"> <div id="slider_main" class="carousel slide" data-ride="carousel"> <!-- The slideshow --> <div class="carousel-inner"> <div class="carousel-item active"> <img src="{% static 'images/slider_1.png' %}" alt="#" /> </div> <div class="carousel-item"> <img src="{% static 'images/slider_1.png' %}" alt="#" /> </div> </div> <!-- Left and right controls --> <a class="carousel-control-prev" href="#slider_main" data-slide="prev"> <i class="fa fa-angle-left" aria-hidden="true"></i> </a> <a class="carousel-control-next" href="#slider_main" data-slide="next"> <i class="fa fa-angle-right" aria-hidden="true"></i> </a> </div> </div> <div class="col-md-5"> <div class="full slider_cont_section"> <h4>More Featured in</h4> <h3>Jack Blogger</h3> <p>It is a long established fact that a reader will be distracted by the readable content of a page when looking at its layout. The point of using Lorem Ipsum is that it has a more-or-less normal distribution of letters, as opposed to using 'Content here, content here', making it look</p> <div class="button_section"> <a href="about.html">Read More</a> <a href="contact.html">Contact Us</a> </div> </div> </div> </div> </div> </div> <!-- end revolution slider --> <!-- section --> <div class="section layout_padding"> <div class="container"> <div class="row"> <div class="col-md-12"> <div class="heading"> <h3>BLOG</h3> </div> </div> </div> {% for post in posts %} <div class="row"> <div class="col-md-6"> <h1>{{ post.title }} <span>{{ post.author }}</span></h1> <p>{{ post.date_posted }}</p> <p>{{ post.content }}</p> </div> <div class="col-md-6"> <img src="{% static 'images/blog1.png' %}" alt="#" /> </div> </div> {% endfor %} <div class="row margin_top_30"> <div class="col-md-12"> <div class="button_section full center margin_top_30"> <a style="margin:0;" href="about.html">Read More</a> </div> </div> </div> </div> </div> <!-- end section --> <!-- section --> <div class="section layout_padding dark_bg"> <div class="container"> <div class="row"> <div class="col-md-12"> <div class="heading"> <h3>Marketing</h3> </div> </div> </div> <div class="row"> <div class="col-md-6"> <img src="{% static 'images/marketing_img.png' %}" alt="#" /> </div> <div class="col-md-6"> <div class="full blog_cont"> <h3 class="white_font">Where can I get some</h3> <h5 class="grey_font">March 19 2019 5 READ</h5> <p class="white_font">There are many variations of passages of Lorem Ipsum available, but the majority have suffered alteration in some form, by injected humour, or randomised words which don't look even slightly believable. If you are going to use a passage of Lorem Ipsum, you need to be sure there isn't anything embarrassing hidden in the middle of text. All the Lorem Ipsum generators on the Internet tend to repeat predefined chunks as necessary, making this the first true generator on the Internet. It uses a dictionary of over 200 Latin words, combined g to use a passage of Lorem Ipsum, you need to be sure there isn't anything embarrassing hidden in the middle of text. All the Lorem Ipsum generators on the Internet tend to repeat predefined chunks as necessary, making this the first true generator..</p> </div> </div> </div> </div> </div> <!-- end section --> <!-- section --> <section class="layout_padding"> <div class="container"> <div class="row"> <div class="col-md-12"> <div class="heading" style="padding-left: 15px;padding-right: 15px;"> <h4 style="border-bottom: solid #333 1px;">Comments / 2</h4> </div> </div> </div> <div class="row"> <div class="col-md-12"> <div class="full comment_blog_line"> <div class="row"> <div class="col-md-1"> <img src="{% static 'images/c_1.png' %}" alt="#" /> </div> <div class="col-md-9"> <div class="full contact_text"> <h3>Veniam</h3> <h4>Posted on Jan 10 / 2017 at 06:53 am</h4> <p>Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat. </p> </div> </div> <div class="col-md-2"> <a class="reply_bt" href="#">Reply</a> </div> </div> </div> <div class="full comment_blog_line"> <div class="row"> <div class="col-md-1"> <img src="{% static 'images/c_2.png' %}" alt="#" /> </div> <div class="col-md-9"> <div class="full contact_text"> <h3>Jack</h3> <h4>Posted on Jan 10 / 2017 at 06:53 am</h4> <p>Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat. </p> </div> </div> <div class="col-md-2"> <a class="reply_bt" href="#">Reply</a> </div> </div> </div> </div> </div> <div class="row margin_top_30"> <div class="col-md-12 margin_top_30"> <div class="heading" style="padding-left: 15px;padding-right: 15px;"> <h4>Post : Your Comment</h4> </div> </div> </div> <div class="row"> <div class="col-md-12"> <div class="full comment_form"> <form action="index.html"> <fieldset> <div class="col-md-12"> <div class="row"> <div class="col-md-6"> <input type="text" name="name" placeholder="Name" required="#" /> <input type="email" name="email" placeholder="Email" required="#" /> </div> <div class="col-md-6"> <textarea placeholder="Comment"></textarea> </div> </div> <div class="row margin_top_30"> <div class="col-md-12"> <div class="center"> <button>Send</button> </div> </div> </div> </div> </fieldset> </form> </div> </div> </div> </div> </section> <!-- end section --> <!-- section --> <div class="section layout_padding blog_blue_bg light_silver"> <div class="container"> <div class="row"> <div class="col-md-8 offset-md-2"> <div class="heading"> <h3>Blog</h3> </div> </div> </div> <div class="row"> <div class="col-md-8 offset-md-2"> <div class="full"> <div class="big_blog"> <img class="img-responsive" src="{% static 'images/blog_1.png' %}" alt="#" /> </div> <div class="blog_cont_2"> <h3>Why do we use it</h3> <p class="sublittle">March 19 2019 5 READ</p> <p>It is a long established fact that a reader will be distracted by the readable content of a page when looking at its layout. The point of using Lorem Ipsum is that it has a more-or-less normal distribution of letters as opposed to using Content here content here making..</p> </div> </div> </div> </div> </div> </div> <!-- end section --> <!-- footer --> <footer> <div class="container"> <div class="row"> <div class="col-lg-4 col-md-6"> <a href="#"><img src="{% static 'images/footer_logo.png' %}" alt="#" /></a> <ul class="contact_information"> <li><span><img src="{% static 'images/location_icon.png' %}" alt="#" /></span><span class="text_cont">London 145<br>United Kingdom</span></li> <li><span><img src="{% static 'images/phone_icon.png' %}" alt="#" /></span><span class="text_cont">987 654 3210<br>987 654 3210</span></li> <li><span><img src="{% static 'images/mail_icon.png' %}" alt="#" /></span><span class="text_cont">demo@gmail.com<br>support@gmail.com</span></li> </ul> <ul class="social_icon"> <li><a href="#"><i class="fa fa-facebook"></i></a></li> <li><a href="#"><i class="fa fa-twitter"></i></a></li> <li><a href="#"><i class="fa fa-linkedin"></i></a></li> <li><a href="#"><i class="fa fa-google-plus"></i></a></li> </ul> </div> <div class="col-lg-2 col-md-6"> <div class="footer_links"> <h3>Quick link</h3> <ul> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Home</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Features</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Evens</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Markrting</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Blog</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Testimonial</a></li> <li><a href="#"><i class="fa fa-angle-right" aria-hidden="true"></i> Contact</a></li> </ul> </div> </div> <div class="col-lg-3 col-md-6"> <div class="footer_links"> <h3>Instagram</h3> <ol> <li><img class="img-responsive" src="{% static 'images/footer_blog.png' %}" alt="#" /></li> <li><img class="img-responsive" src="{% static 'images/footer_blog.png' %}" alt="#" /></li> <li><img class="img-responsive" src="{% static 'images/footer_blog.png' %}" alt="#" /></li> <li><img class="img-responsive" src="{% static 'images/footer_blog.png' %}" alt="#" /></li> </ol> </div> </div> <div class="col-lg-3 col-md-6"> <div class="footer_links"> <h3>Contact us</h3> <form action="index.html"> <fieldset> <div class="field"> <input type="text" name="name" placeholder="Your Name" required="" /> </div> <div class="field"> <input type="email" name="email" placeholder="Email" required="" /> </div> <div class="field"> <input type="text" name="subject" placeholder="Subject" required="" /> </div> <div class="field"> <textarea placeholder="Message"></textarea> </div> <div class="field"> <div class="center"> <button class="reply_bt">Send</button> </div> </div> </fieldset> </form> </div> </div> </div> </div> </footer> <div class="cpy"> <div class="container"> <div class="row"> <div class="col-md-12"> <p>Copyright © 2019 Design by <a href="https://html.design/">Free Html Templates</a></p> </div> </div> </div> </div> <!-- end footer --> <!-- Javascript files--> <script src="{% static 'js/jquery.min.js' %}"></script> <script src="{% static 'js/popper.min.js' %}"></script> <script src="{% static 'js/bootstrap.bundle.min.js' %}"></script> <script src="{% static 'js/jquery-3.0.0.min.js' %}"></script> <script src="{% static 'js/plugin.js' %}"></script> <!-- Scrollbar Js Files --> <script src="{% static 'js/jquery.mCustomScrollbar.concat.min.js' %}"></script> <script src="{% static 'js/custom.js' %}"></script> </body> </html>
- 投稿日:2020-10-27T21:08:27+09:00
【Python】一定期間の日時(datetime型)のリスト作成
注意事項
- 自分用の簡単なまとめであり,説明はほとんどありません.
- 内容は時間があるときに補充します.
入力と出力
- 入力:開始日と終了日(str型)
- 出力:配列(各要素はdatetime型)
使用コード
import datetime def list_date(start_date='2020-01-01', end_date='2020-01-31'): # str型をdatetime型に変換する. date_start = datetime.datetime.strptime(start_date, '%Y-%m-%d') date_end = datetime.datetime.strptime(end_date, '%Y-%m-%d') # 開始日と終了日の間隔を計算する. days = (date_end - date_start).days # 間隔の分だけfor文を回し,日を追加する. tmp_date = start_date date = [tmp_date] for i in range(days): tmp_date += datetime.timedelta(days=1) date.append(tmp_date) return date使用例
date = list_date(start_date='2020-01-01', end_date='2020-01-05') print(date)実行結果[datetime.datetime(2020 1, 1, 0, 0), datetime.datetime(2020 1, 2, 0, 0), datetime.datetime(2020 1, 3, 0, 0), datetime.datetime(2020 1, 4, 0, 0), datetime.datetime(2020 1, 5, 0, 0)]
- 投稿日:2020-10-27T20:01:02+09:00
Pythonでcsvに書き込みを行う
目的:テキストファイル等に、何かを書き込みたい場合に使用する
# 'w'について ('test.csv', 'w', encoding='utf-8')
表記 概要 r 読み込み w 新規で書き込み a 追記で書き込み r+ 追記の書き込み読み込みファイルが存在しない場合はエラーになる w+ 新規の書き込みと読み込みファイルがない場合作成 a+ 追記の書き込みと読み込み、ファイルがない場合作成 Hello Worldと書き込みを行う
hello.py# with open('test.csv', 'w', encoding='utf-8') as f: f.write('Hello World\n') print('書き込みました。') -----result------ 書き込みました。test.csvHellor World複数の行を出力するときの処理
lang.pylang = ['SQL', 'Java', 'Ruby', 'PHP', 'Python'] with open('lang.csv', 'w', encoding = 'utf-8') as f: for item in lang: f.write(item + '\n') print('書き込みしました。')実行結果
lang.csvSQL Java Ruby PHP Python応用 日付の操作
time.pyfrom datetime import datetime now = datetime.now() #print(now) 2020-10-27 19:56:15.019242 str_now = f'{now:%Y/%m/%d %H:%M}' #print(str_now) 2020/10/27 19:56 with open('time.csv', 'w', encoding='utf-8') as f: f.write(str_now + ' - 休日\n') print('書き込みました。')実行結果
time.csv2020/10/27 20:00 - 休日
- 投稿日:2020-10-27T20:01:02+09:00
Python6日目
csvに書き込みを行う
目的:テキストファイル等に、何かを書き込みたい場合に使用する
# 'w'について ('test.csv', 'w', encoding='utf-8')
表記 概要 r 読み込み w 新規で書き込み a 追記で書き込み r+ 追記の書き込み読み込みファイルが存在しない場合はエラーになる w+ 新規の書き込みと読み込みファイルがない場合作成 a+ 追記の書き込みと読み込み、ファイルがない場合作成 Hello Worldと書き込みを行う
hello.py# with open('test.csv', 'w', encoding='utf-8') as f: f.write('Hello World\n') print('書き込みました。') -----result------ 書き込みました。test.csvHellor World複数の行を出力するときの処理
lang.pylang = ['SQL', 'Java', 'Ruby', 'PHP', 'Python'] with open('lang.csv', 'w', encoding = 'utf-8') as f: for item in lang: f.write(item + '\n') print('書き込みしました。')実行結果
lang.csvSQL Java Ruby PHP Python応用 日付の操作
time.pyfrom datetime import datetime now = datetime.now() #print(now) 2020-10-27 19:56:15.019242 str_now = f'{now:%Y/%m/%d %H:%M}' #print(str_now) 2020/10/27 19:56 with open('time.csv', 'w', encoding='utf-8') as f: f.write(str_now + ' - 休日\n') print('書き込みました。')実行結果
time.csv2020/10/27 20:00 - 休日
- 投稿日:2020-10-27T19:26:51+09:00
Anacondaが「大規模な企業」での商用利用では有償になっていた
TL;DR
Pythonを利用した機械学習の環境構築を行うために有用なAnacondaというソフトがあります。このソフトにはリポジトリに含まれるバイナリが高速、依存関係を解決しやすいなどの利点を持っています。
このソフトについて2020年4月30日に利用規約の改定があり、商用利用時の費用について条件が変更され、環境によっては有償となっていましたので内容をまとめます。
? 確かなところは公式サイトの原文(利用規約、発表)をご参照ください。
? 記載間違いなどはご指摘いただけると幸いです。まとめ
結論から記載すると以下となります。
- 200人以上の従業員を抱えた企業での利用は有償。
- 商用利用でも小規模利用であれば個人版(Anaconda Individual Edition)を利用可能。
- 個人利用、研究用は今まで通り。
個人利用、研究用、小規模な企業であれば利用に問題はありませんし、商用利用が必要となる条件の企業でも利点(リポジトリに含まれるバイナリが高速、依存関係を解決しやすい)を考慮して商用版を購入するという選択肢も当然ありだと思います。
製品種別(2020年10月27日時点)
- Anaconda Individual Edition(個人版)
- Anaconda Commercial Edition(商用版)
- Anaconda Team Edition
- Anaconda Enterprise Edition
経緯
2020年4月30日の発表にて、利用規約を改定しAnacondaの商用利用の条件が変わったことが説明されています。
Anacondaがメンテしているリポジトリに対して「多量の商用利用」のトラフィックがあり、リポジトリを大規模に商業的に使用する場合、またはその周りに商用ソフトウェア/サービスを構築する場合などの商用利用には、Anacondaがサービスを持続するための商用リポジトリの購入依頼する必要が出てきた、とのことです。
? 実際のところ、トラフィックコストの増加への対応とリポジトリを維持して継続したサービスを行うためには必要なコストだと思います。
有償、無償の条件
2020年4月30日の発表には以下の記載があります。
This does not apply to non-commercial users (e.g. students, academics, hobbyists). Even if you are using Anaconda for commercial purposes, if you are just doing small one-off research projects or just learning data science, this is no real burden to our systems, and these changes do not apply to you either.
日本語訳(DeepL利用):
非営利目的のユーザー(学生、学術関係者、趣味の人など)には適用されません。あなたが商業目的でAnacondaを使用している場合でも、小規模な単発の研究プロジェクトやデータサイエンスを学ぶだけであれば、これは私たちのシステムには実質的な負担にはならず、これらの変更はあなたにも適用されません。
また規約では以下のように記載されています。
To avoid confusion, “commercial activities” are any use of the Repository which is NOT:
- use solely by an individual using for personal, non-business purposes,
- use by a student or employee of an educational institution in connection with educational activities,
- use by an employee or volunteer on behalf of a non-profit institution in connection with the provision of charitable services, or
- use by entities in common control with each other with fewer than 200 employees in aggregate.日本語訳(DeepL利用):
混乱を避けるために、「商業活動」とは、リポジトリを使用していないものを指します。
- 個人が個人的な非ビジネス目的で使用する場合。
- 教育機関の学生または職員が教育活動に関連して使用すること。
- 慈善サービスの提供に関連して、非営利団体の従業員やボランティアが使用する場合、または
- 従業員の総数が200人未満の共通支配下にある事業体が使用すること。これらをまとめると以下となると思います。
区分 条件 無償 - 個人が個人的に使用する場合に限り、業務以外の目的で使用することができます。
- 教育機関の学生または職員が教育活動に関連して使用すること。
- 慈善サービスの提供に関連して、非営利団体の従業員やボランティアが使用する場合、または
- 従業員の総数が200人未満の共通支配下にある事業体が使用すること。有償 "無償"に記載した以外の条件でリポジトリを使用する場合 Redditなどでの議論
2020年9月12日の投稿で、AnacondaのCEOも交えて議論が行われています。
AnacondaのCEOが、商用利用でも小規模利用であれば個人版(Anaconda Individual Edition)を利用してもよい旨の投稿を行っています。
この中でMiniCondaは問題ないのでは、という記載もありますが本当に問題ないかは定かではありません。
参考資料
公式
ブログ、掲示板等
- 投稿日:2020-10-27T19:26:51+09:00
Anacondaが「大規模な」商用利用では有償になっていた
TL;DR
Pythonを利用した機械学習の環境構築を行うために有用なAnacondaというソフトがあります。このソフトはリポジトリに含まれるバイナリが高速、依存関係を解決しやすいなどの利点を持っています。
このソフトについて2020年4月30日に利用規約の改定があり、商用利用時の費用の条件が変更され、環境によっては有償となっていましたので内容をまとめます。
? 確かなところは公式サイトの原文(利用規約、発表)をご参照ください。
? 記載間違いなどはご指摘いただけると幸いです。まとめ
結論から記載すると以下となります。
- 200人以上の従業員を抱えた企業での利用は有償。
- 商用利用でも小規模利用であれば個人版(Anaconda Individual Edition)を利用可能。
- 個人利用、研究用は今まで通り。
個人利用、研究用、小規模な商用利用であれば問題はありませんし、有償のライセンスが必要となる条件の企業でも利点(リポジトリに含まれるバイナリが高速、依存関係を解決しやすい)を考慮して商用版を購入するという選択肢も当然ありだと思います。
製品種別(2020年10月27日時点)
- Anaconda Individual Edition(個人版)
- Anaconda Commercial Edition(商用版)
- Anaconda Team Edition
- Anaconda Enterprise Edition
経緯
2020年4月30日の発表にて、利用規約を改定しAnacondaの商用利用の条件が変わったことが説明されています。
Anacondaがメンテしているリポジトリに対して「多量の商用利用」のトラフィックがあり、リポジトリを大規模に商業的に使用する場合、またはその周りに商用ソフトウェア/サービスを構築する場合などの商用利用には、Anacondaがサービスを持続するための商用リポジトリの購入を依頼する必要が出てきた、とのことです。
? 実際のところ、トラフィックコストの増加への対応とリポジトリを維持して継続したサービスを行うためには必要なコストだと思います。
有償、無償の条件
2020年4月30日の発表には以下の記載があります。
This does not apply to non-commercial users (e.g. students, academics, hobbyists). Even if you are using Anaconda for commercial purposes, if you are just doing small one-off research projects or just learning data science, this is no real burden to our systems, and these changes do not apply to you either.
日本語訳(DeepL利用):
非営利目的のユーザー(学生、学術関係者、趣味の人など)には適用されません。あなたが商業目的でAnacondaを使用している場合でも、小規模な単発の研究プロジェクトやデータサイエンスを学ぶだけであれば、これは私たちのシステムには実質的な負担にはならず、これらの変更はあなたにも適用されません。
また規約では以下のように記載されています。
To avoid confusion, “commercial activities” are any use of the Repository which is NOT:
- use solely by an individual using for personal, non-business purposes,
- use by a student or employee of an educational institution in connection with educational activities,
- use by an employee or volunteer on behalf of a non-profit institution in connection with the provision of charitable services, or
- use by entities in common control with each other with fewer than 200 employees in aggregate.日本語訳(DeepL利用、一部修正):
混乱を避けるために、「商業活動」とは、以下以外でリポジトリを使用しているものを指します。
- 個人が個人的な非ビジネス目的で使用する場合。
- 教育機関の学生または職員が教育活動に関連して使用すること。
- 慈善サービスの提供に関連して、非営利団体の従業員やボランティアが使用する場合、または
- 従業員の総数が200人未満の共通支配下にある事業体が使用すること。これらをまとめると以下となると思います。
区分 条件 無償 - 個人が個人的に使用する場合に限り、業務以外の目的で使用することができます。
- 教育機関の学生または職員が教育活動に関連して使用すること。
- 慈善サービスの提供に関連して、非営利団体の従業員やボランティアが使用する場合、または
- 従業員の総数が200人未満の共通支配下にある事業体が使用すること。有償 "無償"に記載した以外の条件でリポジトリを使用する場合 Redditなどでの議論
2020年9月12日の投稿で、AnacondaのCEOも交えて議論が行われています。
AnacondaのCEOが、商用利用でも小規模利用であれば個人版(Anaconda Individual Edition)を利用してもよい旨の投稿を行っています。
この中でMiniCondaは問題ないのでは、という記載もありますが本当に問題ないかは定かではありません。
参考資料
公式
ブログ、掲示板等
- 投稿日:2020-10-27T19:08:13+09:00
生データのフーリエ変換
離散フーリエ変換を生データで解析してみた
機械学習をする際に必要な特徴量を時系列データからフーリエ変換し、求めました。
周期関数を自動で作成して解析する記事はいくつかあったのですが実データに対しどのように対処すればいいのか手間取ったので備忘録も兼ねて作成します。また、概念や用語の理解も含めてまとめてみます。
大雑把な理解なため曖昧かもしれません。間違いがあればご指摘お願いします。理論
離散フーリエ変換(DFT)
簡単にフーリエ変換についてまとめると、
時間領域に対する時系列データの周期的な信号を周波数領域におけるスペクトルに変換したもの
になります。
また、窓関数(一般的なものはハミング窓)を適用することで強制的に周期的なものとみなす。高速フーリエ変換(FFT)
高速フーリエ変換は、離散フーリエ変換の中でもデータ数が2の冪乗であった場合に高速に計算ができるものを指す。
式やアルゴリズムの詳細は、理解してませんが膨大なデータな場合、0埋めなどをしてデータ数を2の冪乗に揃えると計算速度の向上が見込めるでしょう。実装
まず、生データをそのままフーリエ変換します。
ここでは、Numpyのfftを用います。
https://numpy.org/doc/stable/reference/generated/numpy.fft.fft.html
FFTは高速フーリエ変換のことですが、numpyに値を渡すとき2のべき乗じゃなくてもフーリエ変換されます。
つまり、2のべき乗のときはFFT、2のべき乗でないときはDFTが実行されていると考えられます。
今回のデータは30fpsの1秒間のデータ
すなわち、サンプルデータ30をフーリエ変換してみます。
今回はあるcsvファイルのある1列30行をデータとして扱います。データの取り出し# 必要なライブラリの import import numpy as np # データのロード data = np.loadtxt('____.csv', delimiter=',', dtype=float) features = data[0:30,0:1] features[0:30,0:1]解析したい30データがfeaturesに取り込まれました。
ちなみに、features内のデータは以下のような配列のデータになっている。featuresarray([[0.32640783],[0.32772677],[0.32963271],[0.32872528],[0.33125733],[0.3250282 ],[0.33900562],[0.33105499],[0.33294834],[0.34554142],[0.33217829],[0.33006385],[0.33765947],[0.33173415],[0.33826796][0.34325231],[0.35284764],[0.34785128],[0.349527 ],[0.34782048],[0.35720176],[0.36520328],[0.37276383],[0.37766436],[0.37410199],[0.37990772],[0.38644416],[0.38045958],[0.37864619],[0.39122537]])関連記事を参考にしながら実装を進めた。
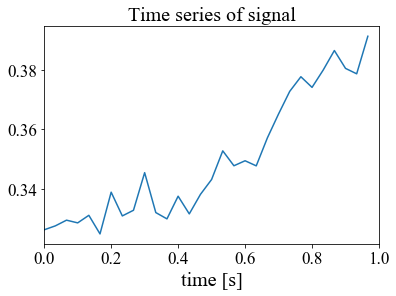
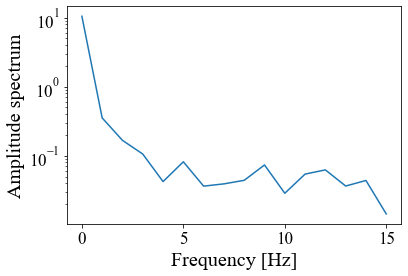
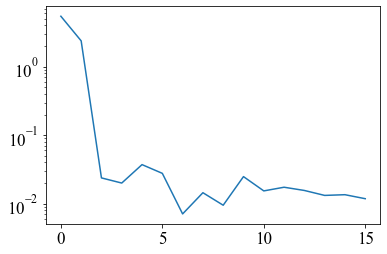
実装コードと結果が以下となる。main# サンプリング周波数 rate = 30 # [1/s] # サンプル時刻 [s] t = np.arange(0, 1, 1/rate) # 信号 signal = np.ravel(features[0:30,0:1]) plt.plot(t, signal) plt.xlim(0, 1) plt.xlabel('time [s]', fontsize=20) plt.title('Time series of signal', fontsize=20) plt.show() #print(np.ravel(signal)) # power spectrum p = np.abs(np.fft.rfft(signal)) hammingWindow = np.hamming(30) # ハミング窓 plt.plot(t, hammingWindow*signal) plt.show() p2 = np.abs(np.fft.rfft(hammingWindow*signal)) # サンプリングレート(の逆数)を与えると各成分の周波数を返す f = np.fft.rfftfreq(signal.size, d=1./rate) print(p) print(np.fft.rfft(hammingWindow*signal),p2) plt.xlabel("Frequency [Hz]", fontsize=20) plt.ylabel("Amplitude spectrum", fontsize=20) plt.yscale("log") plt.plot(f, p) plt.show() plt.yscale("log") plt.plot(f, p2) plt.show() # 高速フーリエ変換 F = np.fft.fft(hammingWindow*signal) # 振幅スペクトルを計算 Amp = np.abs(F) freq = np.linspace(0, 1.0/0.03, 30) # 周波数軸 print(np.fft.rfft(signal)) plt.plot(freq, Amp) plt.show()結果
まず、時間領域におけるデータ(features)をグラフ化した。
見れば分かるが、周期性がない、、、
一応実装が目的なのでこのまま進めていく。
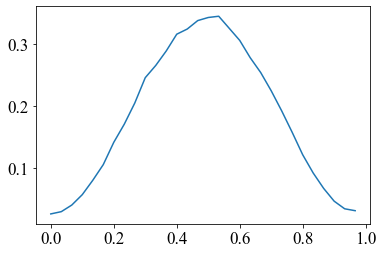
また、周期性を持たせるハミング窓を適応した形がこのようなものとなる。
周期っぽくなっている
次に窓関数をかけていないものとかけたものをフーリエ変換して振幅スペクトルにしたものは以下のようになった。
左軸は対数グラフで取っている。
似たような振幅スペクトルを得られた。以上、フーリエ変換を行い振幅スペクトルを求めた。
パワースペクトルは振幅スペクトルの二乗であるのでパワースペクトルが欲しい場合、振幅スペクトルを二乗すればいい。以下、振幅スペクトルを求めるに至ってフーリエ変換の用語とnumpyがややこしかったので整理しておく。
np.fft.fft:実部と虚部のフーリエ変換結果を返す
np.fft.rfft:実部のみ返す(np.fft.fftの1/2の配列)よって、abs(np.fft.fft)、abs(np.fft.rfft)では、大きさは同じであるが帰ってくる長さが違う。
np.fft.rfftはnp.fft.fftの半分である。複素共役の関係なため不要ではある。F(w):フーリエスペクトル(フーリエ変換したもの)
|F(w)| = np.abs(F(w)):振幅スペクトル(F(w)の絶対値)
|F(w)|^2 = F(w)*(F(w)の共役複素数):パワースペクトル、振幅スペクトルの二乗、電力(パワー)の次元を持つため
エクセル(Exel)のフーリエ解析
実は、エクセルのデータ解析のツールにフーリエ解析が搭載されている。
numpyと同様であるか検証を行ったところnp.fft.fftと同じ実部と虚部が返ってきた。
プログラムを組むのを面倒な時はそっちの方がいいのかもしれない。
ただし、実部と虚部まじりな点であり振幅スペクトルを求めるためには新たに計算が必要なである。
また、エクセルでは、データ数は2のべき乗でないと実行不可なため注意。逆フーリエ変換
低周波成分がグラフ形状に大きな概形を成していると考えらえ、高周波成分はノイズが多いということが
文献調査をしている中でみられた。
そのため、フーリエ変換した結果の低周波成分0Hz~2Hzのスペクトルのみを逆フーリエ変換すれば、
元のデータに近いグラフを描けるのではないかと考え、実装した。
先ほどrfftしたものの先頭3つのデータ」はそのままで他を0としている。irfftplt.plot(t, np.fft.irfft([1.04921492e+01+0.j,8.98589353e-02+0.34154378j,-6.04938542e-02+0.15582535j,0,0,0,0,0,0,0,0,0,0,0,0,0])) plt.show()結果
元データのグラフと見比べると似た形になっている。
よって、再現できたと言える。参考文献
https://ja.wikipedia.org/wiki/離散フーリエ変換
https://numpy.org/doc/stable/reference/generated/numpy.fft.fft.html
https://kyotogeopython.zawawahoge.com/html/基礎編/Numpyの基礎(7)便利なライブラリ群.html
https://aidiary.hatenablog.com/entry/20110716/1310824587
https://www.geidai.ac.jp/~marui/r_program/spectrum.html
- 投稿日:2020-10-27T18:30:02+09:00
スクレイピングしたデータをCSVに保存してみた!
はじめに
最近スクレイピングに関して学んで実装をして見ました。今回作成したのは「CiNii Articles - 日本の論文をさがす - 国立情報学研究所」でキーワードを入力し、そのキーワードにヒットした論文の「タイトル」「著者」「論文掲載媒体」をすべて取得しCSVに保存するというものです。
スクレイピングの学習を行う上でいい勉強になったので記事にして見ました。スクレイピングの学習をしている方に役立つことを願っています!コード
以下が自分自身が作成したコードになります。説明に関してはコードと一緒に書いてあるのでそれを見ていただければと思います。また、実際に「CiNii Articles - 日本の論文をさがす - 国立情報学研究所」のサイトに行って、Chromeの検証機能を使用し実際にHTMLの構造を見ながら行うと理解が深まると思います。
今回このコードを「search.py」として保存しました。import sys import os import requests import pandas as pd from bs4 import BeautifulSoup import re def main(): url ='https://ci.nii.ac.jp/search?q={}&count=200'.format(sys.argv[1]) res = requests.get(url) soup = BeautifulSoup(res.content , "html.parser") #検索件数を調べる。 #textには'\n検索結果\n\t\n\t0件\n\t'こんな感じのデータが入っている。 search_count_result = soup.find_all("h1" , {"class":"heading"})[0].text #正規表現を使用して検索件数を取得 pattern = '[0-9]+' result = re.search(pattern, search_count_result) #検索結果がない場合はここで関数は終了 search_count = int(result.group()) if search_count == 0: return print('検索結果はございません。') print('検索件数は' + str(search_count) + '件です。') #データを保存するディレクトリの作成。 try: os.makedirs(sys.argv[1]) print("新しいディレクトリが作成されました。") except FileExistsError: print("すでに存在しているディレクトリになります。") #すべての検索結果を取得する為、forの回数を取得する。 #今回は200件ごとに表示を行うようにしたため200に設定しています。 if search_count // 200 == 0: times = 1 elif search_count % 200 == 0: times = search_count // 200 else: times = search_count // 200 + 1 #著者・タイトル・掲載媒体を一気に取得 title_list = [] author_list = [] media_list = [] #ここで空白文字の削除を行うための処理 escape = str.maketrans({"\n":'',"\t":''}) for time in range(times): #urlを取得 count = 1 + 200 * time #search?q={}ここに検索したいキーワードが入ります。 #count=200&start={} 200ごとにカウントし、何番目から表示するかを入力しています。 url ='https://ci.nii.ac.jp/search?q={}&count=200&start={}'.format(sys.argv[1], count) print(url) res = requests.get(url) soup = BeautifulSoup(res.content , "html.parser") for paper in soup.find_all("dl", {"class":"paper_class"}):#1つの論文ごとにループを回す。 #タイトルの取得 title_list.append(paper.a.text.translate(escape)) #著者の取得 author_list.append(paper.find('p' , {'class':"item_subData item_authordata"}).text.translate(escape)) #掲載媒体の取得 media_list.append(paper.find('p' , {'class':"item_extraData item_journaldata"}).text.translate(escape)) #データフレームにしてCSVで保存する。 jurnal = pd.DataFrame({"Title":title_list , "Author":author_list , "Media":media_list}) #文字化けを防ぐためにエンコーディングを行っている。 jurnal.to_csv(str(sys.argv[1] + '/' + str(sys.argv[1]) + '.csv'),encoding='utf_8_sig') print('ファイルを作成しました。') print(jurnal.head()) if __name__ == '__main__': # モジュールを直接実行した時だけ、実行したいコード main()実装してみた。
実際に作成したものを実装してみました。
まずターミナルに以下のように打ち込みます。
今回は機械学習を検索のキーワードとして入力しました。
機械学習というところに自分自身が検索したいキーワードを入力する形になります。python search.py 機械学習上手くいくと以下のようになります。
CSVの中身はこのような形になります。
最後に
いかがだったでしょうか?
私自身スクレイピングの学習をしたのは三日前ぐらいですが、コードは汚いものの実装するだけであれば比較的簡単に行うことが出来ました。
まだまだ、勉強することもあると思うので引き続き頑張りたいと思います。
- 投稿日:2020-10-27T18:18:29+09:00
PyTorchでRTX 3090を使う
※2020/10/24日時点の情報です。
課題
PyTorch 1.6では,現状RTX 3080/3090に対応しておらず,以下のようなエラーを吐きます。
GeForce RTX 3090 with CUDA capability sm_86 is not compatible with the current PyTorch installation.対処方法
対処方法は,開発版のPyTorch 1.8を入れることです。
pip install --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cu110/torch_nightly.htmlcu110となっていますが,cuda11.1を使っていても動くので問題ありません。
バージョン情報
NVIDIA-SMI 455.23.05 Driver Version: 455.23.05 CUDA Version: 11.1/Ubuntu 20.04
結果
以前は2070 SUPERを使っていたのですが,学習速度が3倍程度早くなりました。あと,jaxは普通に動きました。
Ref.
- 投稿日:2020-10-27T17:40:53+09:00
Paiza Python 入門編2:条件分岐、比較演算子を学ぶ
PaizaでPython3が完全無料なのでまとめました。
01:数値が一致した場合、メッセージを表示
lesson.py''' if 条件式: #条件式が成り立った時の処理 ''' number=1 if number == 1: #左辺等辺が等しかったら、代入とは区別する print("スキ!")lesson.pynumber=2 if number == 1: #左辺等辺が等しかったら、代入とは区別する print("スキ!")なにも表示されない
lesson.pynumber=2 if number == 1: #左辺等辺が等しかったら、代入とは区別する print("スキ!") else: #条件式が成立しなかったときの処理 print("キライ!")キライと表示される
lesson.py#ランダムでスキ、キライを表示させる import random number=random.randint(1,2) if number == 1: #左辺等辺が等しかったら、代入とは区別する print("スキ!") else: #条件式が成立しなかったときの処理 print("キライ!")演習
1.順位が1位だったら「おめでとう」としよう
lesson.py# if文による条件分岐 import random number = random.randint(1, 3) print("あなたの順位は" + str(number) + "位です") # ここにif文を追加する if number ==1: print("おめでとう")2.順位が2位以下だったら「あと少し」と表示
lesson.py# if文による条件分岐 import random number = random.randint(1,5) print("あなたの順位は" + str(number) + "位です") # ここにif文を追加する if number == 1: print("おめでとう") else: print("あと少し")3.間違い探し1
==でないlesson.py# if文による条件分岐 import random number = random.randint(1, 3) * 100 print("あなたの得点は" + str(number) + "ポイントです") if number == 300: print("おめでとう")4.間違い探し2
:が足りないlesson.py# coding: utf-8 # if文による条件分岐 import random number = random.randint(1,3) * 100 print("あなたの得点は" + str(number) + "ポイントです") if number == 300: print("おめでとう") else: print("ざんねん")02:複数の条件を組み合わせてみよう
条件式を2つ以上使うには?→elifを使う
lesson.py# if文による条件分岐 elif文 number = 1 if number == 1: print( "スキ!") #条件式が成立したときの処理 elif 条件式2: #条件式2が成立したときの処理 else: print( "キライ") #条件式が成立しなかったときの処理「どちらでもない」という条件分岐をelifで書く
lesson.py# if文による条件分岐 elif文 number = 2 if number == 1: print( "スキ!") #条件式が成立したときの処理 elif number == 2; print("どちらでもない")#条件式2が成立したときの処理 else: print( "キライ") #条件式が成立しなかったときの処理演習
1.順位に合わせてメッセージを表示する
lesson.py# coding: utf-8 # if文による条件分岐 import random number = random.randint(1, 5) print("あなたの順位は" + str(number) + "位です") # ここにif文を追加する if number==1: print("おめでとう") elif number==2: print("あと少し") else : print("よくがんばったね")2.間違い探し
誤字が多かった
lesson.py# if文による条件分岐 import random number = random.randint(1, 5) print("あなたの順位は" + str(number) + "位です") if number == 1: print("おめでとう") elif number == 2: print("あと少し") else: print("よくがんばったね")03比較演算子で条件を分岐しよう
lesson.pya == b :aはbと等しい a > b :aはbより大きい a < b :aはbより小さい a >= b :aはb以上 a <= b :aはb以下 a != b :aはbと等しくないlesson.pynumber = 2 if number > 1: print("スキ!") #条件式が成立したときの処理lesson.py# if文による条件分岐 比較演算子 time = 12 if time > 1: print("午前中") #条件式が成立したときの処理 elif time ==12: print("正午!") elif time >12: print("午後")演習
1.飲酒可能な年齢か判定する
lesson.pyimport random age = random.randint(18, 22) # ageに、何才かを18~22の範囲でランダムに代入 text = "" if age>= 20: text = "飲酒可能" #条件が成り立ったときの処理 # 条件が成り立ったときの処理 else: text = "飲酒不可" #それ以外だったときの処理 # それ以外だったときの処理 print(str(age) + "才は" + text)2.間違い修正:入賞圏内か判別する
lesson.py# coding: utf-8 import random place = random.randint(1, 12) #placeに、何位かを1~12でランダムに代入 print(str(place) + "位", end="") if place <= 6: print("入賞") # 条件が成り立ったときの処理 else: print("入賞圏外") # それ以外だったときの処理3.間違い修正:成人判別
lesson.pyimport random age = random.randint(15, 25) # ageに、何才かを15~25の範囲でランダムに代入 print(str(age) + "才", end="") if age >= 20: print("成人です") # 条件が成り立ったときの処理 else: print("未成年です") # それ以外だったときの処理04:おみくじを作ってみよう
lesson.pyimport random omikuji = random.randint(1,10) print(omikuji) if omikuji ==1: print("大吉") elif omikuji ==2: print("中吉") elif omikuji <=4:#3,4 print("小吉") elif omikuji <=7: print("凶") #5,6,7 else: print("大凶")演習
omikuji の中には、1~100までの数字がランダムで
代入されます。omikuji の数字が30~100の時は「omikujiの中身は○○なので大吉」と表示、
omikuji の数字が29以下の時は「omikujiの中身は○○なので大凶」と表示する。lesson.pyimport random omikuji = random.randint(1, 100) if omikuji >=30: print("omikujiの中身は" + str(omikuji) + "なので大吉") else: print("omikujiの中身は" + str(omikuji) + "なので大凶")05:RPGのクリティカルヒットを再現
lesson.pyimport random hit =random.randint(1,10) #print(hit) if hit < 6 : print("スライムに、" + str(hit) + "のダメージを与えた") else: print("クリティカルヒット!スライムに、100ダメージを与えた!")06:西暦から平成何年か求めてみよう
lesson.py# 西暦年から平成年を求める import datetime seireki=2015 #seireki=atetime.date.today().yearとすると、現在から引いた数になる print("西暦" + str(seireki)+ "年は",end="") #西暦年から西暦年を計算する #平成一年とは1989年。その差は、1988 #西暦年 - 1988 =平成*年 #例:西暦1989 - 1988 =平成1年 #例:西暦2015 - 1988 =平成27年 heisei = seireki -1988 print("平成"+str(heisei) +"年です")演習
1.西暦年を昭和年にしてみよう
lesson.py# 西暦を昭和年に変換 import random seireki = random.randint(1926, 1988) #西暦年 print("西暦" + str(seireki) + "年は", end = "") # 昭和年を計算 showa = seireki-1925 # 昭和年を出力 print("昭和" + str(showa) + "年です")2.西暦年を令和年に変換してみよう
lesson.py# 西暦を令和年に変換 import random ad_year = random.randint(2019, 2099) #西暦年 print("西暦" + str(ad_year) + "年は", end = "") # 令和年を計算 era_year = ad_year-2018 # 令和年を出力 print("令和" + str(era_year) + "年です")
- 投稿日:2020-10-27T17:40:40+09:00
sqlacodegenを使って既存のMySQLサーバからSQLAlchemyのテーブル定義を生成する
まっさらなAmazonLinux2でやるときの手順です
実行環境
OS: AmazonLinux2 (Linux version 4.14.193-149.317.amzn2.x86_64)
python: Python 2.7.18やること
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py pip install sqlacodegen pymysql sqlacodegen mysql+pymysql://user:password@sqlhost/dbnameオプション:
--outfile
--tables
これで標準出力に全テーブルのSQLAlchemy定義が出力されます公式サイトには
oursqlというのを使うと書いてありますが、この環境では下記エラーが出るためpymysqlを使います
https://pypi.org/project/sqlacodegen/Traceback (most recent call last): File "/home/ec2-user/.local/bin/sqlacodegen", line 8, in <module> sys.exit(main()) File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlacodegen/main.py", line 44, in main engine = create_engine(args.url) File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlalchemy/engine/__init__.py", line 500, in create_engine return strategy.create(*args, **kwargs) File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlalchemy/engine/strategies.py", line 61, in create entrypoint = u._get_entrypoint() File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlalchemy/engine/url.py", line 172, in _get_entrypoint cls = registry.load(name) File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlalchemy/util/langhelpers.py", line 254, in load loader = self.auto_fn(name) File "/home/ec2-user/.local/lib/python2.7/site-packages/sqlalchemy/dialects/__init__.py", line 32, in _auto_fn dialect, driver = name.split(".") ValueError: too many values to unpack
- 投稿日:2020-10-27T16:38:15+09:00
ArduinoとラズパイでIoTラジコンカー
はじめに
この記事を書こうと思った理由
・備忘録を書きたかった
・Qiitaを使ってみたかった私にとって初投稿の記事であり、人様にとっては読みづらいかもしれませんがご了承ください。
また、かなり適当に作っているので近いうちに作り直そうと思います。使用した環境
・windows10
・ubuntu18.04
・AWS
・MQTTwindows10でarduinoのプログラムスケッチ、書き込みを行う
ubuntuでラズパイとssh接続し、ラズパイを操作
AWSをMQTTブローカーとして使用
通信プロトコルはMQTTMQTTについて
この記事ではMQTTについての説明は省略
MQTTについては他にわかりやすく解説しているサイトが多くあるのでそちらを参考にしてください。使用したもの
・Arduino
・Raspberry Pi 3 Model B
・usbケーブル(AruinoとRaspiをシリアル通信させるために使用)
・モバイルバッテリー、usbケーブル(ラズパイに電源供給するために使用)
・電池ボックス(アマゾンで購入)
・モータードライバ(スイッチサイエンスで購入)
・タミヤ楽しい工作シリーズダブルギヤボックス(アマゾンで購入)
・タミヤ楽しい工作シリーズナロータイヤセット58mm(アマゾンで購入)ハードウェアの準備
・アマゾンで届いた段ボールを適当な大きさに切ってモーターと電池ボックスを置き、
モータの上にはモータードライバを両面テープで固定。
さらにその上にarduinoとラズパイをテープで固定。・とりあえず動けばいいという考えで作ってます。(近いうちきれいに作り直します)
ソフトウェアの準備
MQTTのパラメータ
トピック mqtt_RC
メッセージ 動作 w 前進 a 左旋回 d 右旋回 s 停止 b 後進 f 終了 Arduinoのプログラム
arduinoはラズパイからシリアル通信で送られてくる信号に応じてモーターを制御する。
mqtt_RC_arduino.inoconst int MA1 = 10; const int MA2 = 11; const int MB1 = 12; const int MB2 = 13; int com = 0; void setup() { Serial.begin(9600); pinMode(MA1,OUTPUT); pinMode(MA2,OUTPUT); pinMode(MB1,OUTPUT); pinMode(MB2,OUTPUT); } void loop() { while(true){ if(Serial.available() > 0){ com = Serial.read(); Serial.println(com); } if(com == 'w'){ motor_forward(); delay(1000); } else if(com =='d'){ motor_righit(); delay(1000); } else if(com =='a'){ motor_left(); delay(1000); } else if(com =='s'){ motor_stop(); delay(1000); } else if(com =='b'){ motor_back(); delay(1000); } else if(com =='f'){ break; } } } void motor_forward(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); } void motor_back(){ digitalWrite(MA1,LOW); digitalWrite(MA2,HIGH); digitalWrite(MB1,LOW); digitalWrite(MB2,HIGH); Serial.println("back"); } void motor_stop(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("motor stop"); } void motor_righit(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("righit"); } void motor_left(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); Serial.println("left"); }ラズパイのプログラム
ラズパイはmqtt通信でpubliserから送られてくるメッセージを受信しそれをシリアル通信でarduinoに送る。
シリアル通信でarduinoと接続するラズパイのポートと、mqttブローカーのアドレスは自分で調べて入力する。mqtt_RC_raspi.pyimport sys from time import sleep import paho.mqtt.client as mqtt import serial # ------------------------------------------------------------------ sys.stderr.write("*** 通信開始 ***\n") ser = serial.Serial('接続するarduinoのポートを入力',9600) host = 'ブローカーのアドレスを入力' port = 1883 topic = 'mqtt_RC' def on_connect(client, userdata, flags, respons_code): print('status {0}'.format(respons_code)) client.subscribe(topic) def on_message(client, userdata, msg): st = str(msg.payload,'utf-8') print(st) if st == "w": print("go_straight") ser.write(b'w') elif st == "s": print("stop") ser.write(b's') elif st == "d": ser.write(b'd') print("turn_righit") elif st == "a": ser.write(b'a') print("turn_left") elif st == "b": ser.write(b'b') print("go_back") elif st =="f": print("fin") client.disconnect() if __name__ == '__main__': client = mqtt.Client(protocol=mqtt.MQTTv311) client.on_connect = on_connect client.on_message = on_message client.connect(host, port=port, keepalive=60) client.loop_forever() sys.stderr.write("*** 終了 ***\n")MQTTのpublisherについて
メッセージの送信はスマホにmqtt通信でpublishiやsubsclibeできるアプリがあるのでそれを使用してpublishすれば制御することができる。今回はパソコンでpublisihするプログラムを作成し、パソコンをコントローラとて動作させた。
結果
ノートパソコンのターミナルでpublishするプログラムを動かし、実際にラジコンとして動作させることができた。体感的には全くラグを感じなかった。


- 投稿日:2020-10-27T16:38:15+09:00
ArduinoとRaspiでMQTTラジコンカー
はじめに
この記事を書こうと思った理由
・備忘録を書きたかった
・Qiitaを使ってみたかった私にとって初投稿の記事であり、人様にとっては読みづらいかもしれませんがご了承ください。
また、かなり適当に作っているので近いうちに作り直そうと思います。使用した環境
・windows10
・ubuntu18.04
・AWSwindows10でarduinoのプログラムスケッチ、書き込みを行う
ubuntuでラズパイとssh接続し、ラズパイを操作
AWSをMQTTブローカーとして使用MQTTについて
この記事ではMQTTについての説明は省略
MQTTについては他にわかりやすく解説しているサイトが多くあるのでそちらを参考にしてください。使用したもの
・Arduino
・Raspberry Pi 3 Model B
・usbケーブル(AruinoとRaspiをシリアル通信させるために使用)
・モバイルバッテリー、usbケーブル(Raspiに電源供給するために使用)
・電池ボックス(アマゾンで購入)
・モータードライバ(スイッチサイエンスで購入)
・タミヤ楽しい工作シリーズダブルギヤボックス(アマゾンで購入)
・タミヤ楽しい工作シリーズナロータイヤセット58mm(アマゾンで購入)ハードウェアの製作
・アマゾンで届いた段ボールを適当な大きさに切ってモーターと電池ボックスを置き、
モータの上にはモータードライバを両面テープで固定。
さらにその上にarduinoとraspiをテープで固定。・とりあえず動けばいいという考えで作ってます。(近いうちきれいに作り直します)
ソフトウェア
MQTTのパラメータ
トピック mqtt_RC
メッセージ 動作 w 前進 a 左旋回 d 右旋回 s 停止 b 後進 f 終了 Arduinoのプログラム
arduinoはraspiからシリアル通信で送られてくる信号に応じてモーターを制御する。
mqtt_RC_arduino.inoconst int MA1 = 10; const int MA2 = 11; const int MB1 = 12; const int MB2 = 13; int com = 0; void setup() { Serial.begin(9600); pinMode(MA1,OUTPUT); pinMode(MA2,OUTPUT); pinMode(MB1,OUTPUT); pinMode(MB2,OUTPUT); } void loop() { while(true){ if(Serial.available() > 0){ com = Serial.read(); Serial.println(com); } if(com == 'w'){ motor_forward(); delay(1000); } else if(com =='d'){ motor_righit(); delay(1000); } else if(com =='a'){ motor_left(); delay(1000); } else if(com =='s'){ motor_stop(); delay(1000); } else if(com =='b'){ motor_back(); delay(1000); } else if(com =='f'){ break; } } } void motor_forward(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); } void motor_back(){ digitalWrite(MA1,LOW); digitalWrite(MA2,HIGH); digitalWrite(MB1,LOW); digitalWrite(MB2,HIGH); Serial.println("back"); } void motor_stop(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("motor stop"); } void motor_righit(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("righit"); } void motor_left(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); Serial.println("left"); }Raspiのプログラム
raspiはmqtt通信でpubliserから送られてくるメッセージを受信しそれをシリアル通信でarduinoに送る
接続するarduinoのポートとblokerのアドレスは自分で調べて入力するmqtt_RC_raspi.pyimport sys from time import sleep import paho.mqtt.client as mqtt import serial # ------------------------------------------------------------------ sys.stderr.write("*** 通信開始 ***\n") ser = serial.Serial('接続するarduinoのポート',9600) host = 'ブローカーのアドレス' port = 1883 topic = 'mqtt_RC' def on_connect(client, userdata, flags, respons_code): print('status {0}'.format(respons_code)) client.subscribe(topic) def on_message(client, userdata, msg): st = str(msg.payload,'utf-8') print(st) if st == "w": print("go_straight") ser.write(b'w') elif st == "s": print("stop") ser.write(b's') elif st == "d": ser.write(b'd') print("turn_righit") elif st == "a": ser.write(b'a') print("turn_left") elif st == "b": ser.write(b'b') print("go_back") elif st =="f": print("fin") client.disconnect() if __name__ == '__main__': client = mqtt.Client(protocol=mqtt.MQTTv311) client.on_connect = on_connect client.on_message = on_message client.connect(host, port=port, keepalive=60) client.loop_forever() sys.stderr.write("*** 終了 ***\n")mqttのpublisherについて
メッセージの送信はスマホにmqtt通信でpublishiやsubsclibeできるアプリがあるのでそれを使用してpublishすれば制御することができます。
- 投稿日:2020-10-27T16:38:15+09:00
ArduinoとラズパイでMQTTラジコンカー
はじめに
この記事を書こうと思った理由
・備忘録を書きたかった
・Qiitaを使ってみたかった私にとって初投稿の記事であり、人様にとっては読みづらいかもしれませんがご了承ください。
また、かなり適当に作っているので近いうちに作り直そうと思います。使用した環境
・windows10
・ubuntu18.04
・AWSwindows10でarduinoのプログラムスケッチ、書き込みを行う
ubuntuでラズパイとssh接続し、ラズパイを操作
AWSをMQTTブローカーとして使用MQTTについて
この記事ではMQTTについての説明は省略
MQTTについては他にわかりやすく解説しているサイトが多くあるのでそちらを参考にしてください。使用したもの
・Arduino
・Raspberry Pi 3 Model B
・usbケーブル(AruinoとRaspiをシリアル通信させるために使用)
・モバイルバッテリー、usbケーブル(ラズパイに電源供給するために使用)
・電池ボックス(アマゾンで購入)
・モータードライバ(スイッチサイエンスで購入)
・タミヤ楽しい工作シリーズダブルギヤボックス(アマゾンで購入)
・タミヤ楽しい工作シリーズナロータイヤセット58mm(アマゾンで購入)ハードウェアの準備
・アマゾンで届いた段ボールを適当な大きさに切ってモーターと電池ボックスを置き、
モータの上にはモータードライバを両面テープで固定。
さらにその上にarduinoとラズパイをテープで固定。・とりあえず動けばいいという考えで作ってます。(近いうちきれいに作り直します)
ソフトウェアの準備
MQTTのパラメータ
トピック mqtt_RC
メッセージ 動作 w 前進 a 左旋回 d 右旋回 s 停止 b 後進 f 終了 Arduinoのプログラム
arduinoはラズパイからシリアル通信で送られてくる信号に応じてモーターを制御する。
mqtt_RC_arduino.inoconst int MA1 = 10; const int MA2 = 11; const int MB1 = 12; const int MB2 = 13; int com = 0; void setup() { Serial.begin(9600); pinMode(MA1,OUTPUT); pinMode(MA2,OUTPUT); pinMode(MB1,OUTPUT); pinMode(MB2,OUTPUT); } void loop() { while(true){ if(Serial.available() > 0){ com = Serial.read(); Serial.println(com); } if(com == 'w'){ motor_forward(); delay(1000); } else if(com =='d'){ motor_righit(); delay(1000); } else if(com =='a'){ motor_left(); delay(1000); } else if(com =='s'){ motor_stop(); delay(1000); } else if(com =='b'){ motor_back(); delay(1000); } else if(com =='f'){ break; } } } void motor_forward(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); } void motor_back(){ digitalWrite(MA1,LOW); digitalWrite(MA2,HIGH); digitalWrite(MB1,LOW); digitalWrite(MB2,HIGH); Serial.println("back"); } void motor_stop(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("motor stop"); } void motor_righit(){ digitalWrite(MA1,HIGH); digitalWrite(MA2,LOW); digitalWrite(MB1,LOW); digitalWrite(MB2,LOW); Serial.println("righit"); } void motor_left(){ digitalWrite(MA1,LOW); digitalWrite(MA2,LOW); digitalWrite(MB1,HIGH); digitalWrite(MB2,LOW); Serial.println("left"); }ラズパイのプログラム
ラズパイはmqtt通信でpubliserから送られてくるメッセージを受信しそれをシリアル通信でarduinoに送る。
シリアル通信でarduinoと接続するラズパイのポートと、mqttブローカーのアドレスは自分で調べて入力する。mqtt_RC_raspi.pyimport sys from time import sleep import paho.mqtt.client as mqtt import serial # ------------------------------------------------------------------ sys.stderr.write("*** 通信開始 ***\n") ser = serial.Serial('接続するarduinoのポートを入力',9600) host = 'ブローカーのアドレスを入力' port = 1883 topic = 'mqtt_RC' def on_connect(client, userdata, flags, respons_code): print('status {0}'.format(respons_code)) client.subscribe(topic) def on_message(client, userdata, msg): st = str(msg.payload,'utf-8') print(st) if st == "w": print("go_straight") ser.write(b'w') elif st == "s": print("stop") ser.write(b's') elif st == "d": ser.write(b'd') print("turn_righit") elif st == "a": ser.write(b'a') print("turn_left") elif st == "b": ser.write(b'b') print("go_back") elif st =="f": print("fin") client.disconnect() if __name__ == '__main__': client = mqtt.Client(protocol=mqtt.MQTTv311) client.on_connect = on_connect client.on_message = on_message client.connect(host, port=port, keepalive=60) client.loop_forever() sys.stderr.write("*** 終了 ***\n")MQTTのpublisherについて
メッセージの送信はスマホにmqtt通信でpublishiやsubsclibeできるアプリがあるのでそれを使用してpublishすれば制御することができる。今回はパソコンでpublisihするプログラムを作成し、パソコンをコントローラとて動作させた。
結果
ノートパソコンのターミナルでpublishするプログラムを動かし、実際にラジコンとして動作させることができた。体感的には全くラグを感じなかった。
- 投稿日:2020-10-27T15:20:31+09:00
「ゼロから作るDeep Learning」自習メモ(その13) Google Colaboratoryを使ってみる
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その12 ←
自分のパソコンでJupyterLabを動かして学習してきましたが、メモリーエラーが多発するようになり、先に進めなくなりました。
で
GoogleのColaboratoryを試してみようかと思います。
Colaboratory
Colaboratory という英単語はないようです。と言う事は、Googleが自社のサービスにつけた名前というわけで、
コラボ collaborate + 実験室 laboratory
からの造語なんでしょうか。
co + laboratory とすると、読み方は コラボラトリー でいいのかな?
コラボの意味を強調して
collabora(te) + (labora)tory と考えればコラボレイトリーという読み方もありうるけど、 l がひとつ多くなるし。Qiita にもたくさん投稿されている
ということで、ぼちぼち行ってみます。
やっぱり、ドライブのフォルダやファイルの構成が気になる
これまで、いろいろやってみて思うのは、プログラムを実行する時には、たくさんのライブラリや入力ファイルやpklファイルを参照するということ。
なので、それらをgoogle drive 上に作成、参照するために、フォルダとファイルの構成や、それらの指定の仕方を最初に押さえておかないといけません。パスを通す
とりあえず、ドライブをマウントしてから、ライブラリやファイルがあるフォルダへのパスを通しておけば問題なさそうです。
# ドライブのマウント from google.colab import drive drive.mount('/content/drive')#パスの追加 import sys sys.path.append('/content/drive/My Drive/Colab Notebook/deep_learning/common') sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset')#これまでJupyterLabでフォルダdatasetにあるライブラリを指定するときはこうしてた from dataset.mnist import load_mnist #パスを通しておけばこれでいい from mnist import load_mnistいろいろ関連する関数を試してみた
import os print(os.getcwd()) #カレントディレクトリ print(os.pardir) #親ディレクトリ print(os.path.dirname(os.path.abspath(__file__))) #このスクリプトファイルがあるディレクトリを返すはずだが、対話モードではエラーになる/content
..
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
2 print(os.getcwd()) #カレントディレクトリ
3 print(os.pardir)
----> 4 print(os.path.dirname(os.path.abspath(_file_)))
5
NameError: name '_file_' is not definedJupyterLab や Colaboratory のような対話モードでは _file_ が使えないそうです。
しかし、ファイル名をつけて保存したスクリプトの中からは使えるようです。
なので、次のスクリプトはきちんと動きます。# coding: utf-8 import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import numpy as np from mnist import load_mnist import matplotlib.pyplot as plt def showImg(x): example = x.reshape((28, 28)) plt.figure() plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(example, cmap=plt.cm.binary) plt.show() return (x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False) img = x_train[1] label = t_train[1] print(img.shape) # (784,) img = img.reshape(28, 28) # 形状を元の画像サイズに変形 print(img.shape) # (28, 28) print(label) # 0 showImg(img)(784,)
(28, 28)
0importされたmnist.pyの中では、このようにファイルを指定しています
mnist.pyでmnistデータのディレクトリをセットしているスクリプトdataset_dir = os.path.dirname(os.path.abspath(__file__)) save_file = dataset_dir + "/mnist.pkl"mnist.py があるフォルダ'/content/drive/My Drive/Colab Notebooks/deep_learning/dataset' から mnist.pkl を読み込めます。
対話モードでファイルを指定する場合は、絶対パスを指定したほうが無難そう
# coding: utf-8 import matplotlib.pyplot as plt from matplotlib.image import imread img = imread('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset/lena.png') # 画像の読み込み plt.imshow(img) plt.show()なんとか動きそうなので、本の中のプログラムを実際に動かして確認してから、
重くて動かせなかった犬猫写真の判別をやってみようかと思います。その12 ←
参考にしたサイト
Google ColaboratoryでGoogle Drive上の.pyファイルをインポート
fileを使用しても実行中のスクリプトのディレクトリ名を取得できない理由を調べる
- 投稿日:2020-10-27T14:50:26+09:00
Pythonのオブジェクトでの代入と変更
概要
Pythonでモヤモヤしていたのでテスト。
詳しくは、元記事(https://qiita.com/yuta0801/items/f8690a6e129c594de5fb )を参照ください。
(私は挙動を知りたいだけなので、参照渡しがどうとか言われても興味がありません。また今度勉強します。)内容
tmp.pyobj = {'arr': ['hoge']} print(obj) arr = obj['arr'] obj['arr'] = [] print(obj) print(arr)output{'arr': ['hoge']} {'arr': []} ['hoge']蛇足
tmp.pyobj = {'arr': ['hoge']} print(obj) arr = obj['arr'] arr.append('fuga') print(obj) print(arr) obj['arr'] = [] print(obj) print(arr)output{'arr': ['hoge']} {'arr': ['hoge', 'fuga']} ['hoge', 'fuga'] {'arr': []} ['hoge', 'fuga']すっきりした
- 投稿日:2020-10-27T14:48:37+09:00
djangorestframework-jwtでユーザー認証とトークン認証を簡単で実現する
中国の開発者です。東京浜松町で1年ぐらい働いたことがありました。どうぞよろしくお願いします。
djangorestframework-jwtの紹介
djangorestframework-jwtはDjangoのパッケージとして、ユーザー認証とトークン認証が簡単で実現できます。
この記事はdjangorestframework-jwtを使ってAPIの作る方法を伝えます。
インストール
この二つのライリブラリが必要です。
$ pip install djangorestframework $ pip install djangorestframework-jwtコーティング
①これらのコードをsettings.pyに改修、或は追加する
settings.pyimport datetime INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', # <-- 追加する 'my_app' ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'corsheaders.middleware.CorsMiddleware', 'django.middleware.common.CommonMiddleware', # 'django.middleware.csrf.CsrfViewMiddleware', <-- コメントする 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] # 認証用のフレームワーク REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': ( 'rest_framework.permissions.IsAuthenticated' ), 'DEFAULT_AUTHENTICATION_CLASSES': ( 'rest_framework_jwt.authentication.JSONWebTokenAuthentication', 'rest_framework.authentication.BasicAuthentication', 'rest_framework.authentication.SessionAuthentication' ) } JWT_AUTH = { # トークンの有効時間を設定する 'JWT_EXPIRATION_DELTA': datetime.timedelta(seconds=60 * 60 * 2) }②urls.pyにコードを挿入する
ここには2つのAPIがあります。
userLoginはユーザー登録認証用APIです。フロントエンドはPOSTでユーザー名とパスワードをバックエンドに送って、登録してから、トークンを取得するAPIです。(ユーザーとパスワードはdjango adminのスーパーユーザーを使っていいです。)
getInfoはユーザー登録後、トークンを使って情報を取得するAPIです。
urls.pyfrom django.urls import path from my_app import views urlpatterns = [ path('userLogin/', views.user_login), path('getInfo/', views.get_info) ]③views.pyにコードを挿入する
views.pyimport json from django.http import JsonResponse from django.contrib.auth import authenticate, login from rest_framework.decorators import api_view, authentication_classes, permission_classes from rest_framework.permissions import IsAuthenticated from rest_framework_jwt.authentication import JSONWebTokenAuthentication from rest_framework_jwt.settings import api_settings def user_login(request): obj = json.loads(request.body) username = obj.get('username', None) password = obj.get('password', None) if username is None or password is None: return JsonResponse({'code': 500, 'message': '请求参数错误'}) is_login = authenticate(request, username=username, password=password) if is_login is None: return JsonResponse({'code': 500, 'message': '账号或密码错误'}) login(request, is_login) jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER payload = jwt_payload_handler(is_login) token = jwt_encode_handler(payload) return JsonResponse( { 'code': 200, 'message': '登録成功', 'data': {'token': token} } ) # APIにトークン認証を付与した @api_view(['GET']) @permission_classes((IsAuthenticated,)) @authentication_classes((JSONWebTokenAuthentication,)) def get_info(request): data = 'some info' return JsonResponse( { 'code': 200, 'message': 'success', 'data': data } )フロントエンドはAPIをどう使用する
まず、POSTでuserLoginを使用して、トークンを取得する。
次、GetでgetInfoを使用して、HeadersのAuthorizationパラメータにJWT + 先ほど取得したトークンを指定してリクウェストする。
フロントエンドの例token = 'abcdefg123456789' authorization = 'JWT' + tokenこうすると、getInfoはリクウェストできます。
- 投稿日:2020-10-27T14:31:17+09:00
Anaconda環境における仮想環境の作成
はじめに
Pythonをインストールして
venvのコマンドより仮想環境の作成をしていたが、Anaconda(科学計算のためのオープンソースディストリビューション)を使った方が異なるPythonバージョンの環境作成ができるし、視覚的にも操作しやすいらしいので、本記事ではAnacondaで仮想環境の作成を試してみる。実行環境
【ローカルPC環境-OS】
・Windows 10 Pro【ソフト・パッケージ】
・Anaconda3-2020.07-Windows-x86_64今回やること
1.Anacondaのインストール
2.仮想環境の作成1.Anacondaのインストール
まずは以下のサイトのから自分のPCに合うインストーラーをダウンロード。
https://www.anaconda.com/products/individual
※自分のPCは Windows なので下図の赤枠をダウンロード。
ダウンロードした [.exe] ファイルを実行
起動してからは以下の流れ。・セットアップ画面 ⇒ 『NEXT』をクリック
・ライセンス契約 ⇒ 『I Agree』をクリック
・インストールタイプの選択 ⇒ 『NEXT』をクリック ※デフォルト "Just Me" でOK
・インストール場所 ⇒ 適当に決めて『NEXT』をクリック ※デフォルトOK
・インストールオプション ⇒ 何もチェックを付けずに『NEXT』をクリック
※インストールが完了したら『NEXT』・『FINISH』などをクリックして終了。Anacondaの起動
【Anaconda Navigator】をクリックして起動すればOK
2.仮想環境の作成
左側メニューの [Environments] を開き、『Create』をクリック。
ポップアップ画面が出てくるので、仮想環境の名前とパッケージを決めたら『Create』をクリックして環境を作成する。
補足
デフォルトではPythonもRも1つのバージョンしか入ってないなかったが、異なるバージョンの環境を作ることも可能。
【Anaconda Prompt】を起動して、以下のコマンドを実施すれば別バージョンのPythonがインストールされた環境が作成できる。
conda create -n 【環境の名前】 python=【バージョン】 # 実際のコマンド例 conda create -n test_py36 python3.6Navigatorから確認してみると、Python3.6が入った環境が作成されている。
まとめ
確かに簡単に仮想環境を作れたし、異なるバージョンの環境作成も問題なさそうなので、しばらくはAnacondaを使ってみようと思う。
使っていく中で何か不都合があったら、またメモを残します。。



- 投稿日:2020-10-27T13:42:58+09:00
boto3のClientAPIのレスポンスをデータクラスで定義する
はじめに
お勉強の為にboto3を弄ってました。
boto3を利用して得たリソースの情報はデータクラスに格納して参照した方がいい(理由は後述)と考えたので知見として記事にしときます。boto3ってなんだ!?
簡潔に説明するとpythonでAWSリソースを操作するためのSDKです。
低レベル(client)APIと高レベルAPI(resorce)に分別されます。
関連記事は他に無限にあるので、詳しく知りたい方はそちらをどうぞ。今回は低レベルAPIを使用します。
データクラスってなんだ!?
__init__()等のクラスに紐づく特殊なメソッドを動的に付与してくれるデコレータを提供してくれます。
以下のようなコンストラクタを持ったクラスを
class Wanchan_Nekochan(): def __init__(self, cat:str, dog:str): self.cat =cat self.dog = dogこのようなコンストラクタが無いスマートな記述ができるようになります
@dataclass class Wanchan_Nekochan(): cat: str dog: strhttps://docs.python.org/ja/3/library/dataclasses.html
類似機能を持ったnamedtupleと比較する場合、以下のような差別点があります。
・namedtupleはインスタンス生成後にイミュータブル(編集不可)状態となる。
dataclassはデフォルトではミュータブル(編集可)だが、引数のfrozenをtrueで渡すと
イミュータブルとなる。
・dataclassはデータの読み取りが少し早い(要検証)演習
今回はS3のバケット一覧を取得する為、S3.Clientクラスのlist_buckets()メソッドを使用します。
(参考)公式リファレンス
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html#S3.Client.list_bucketsレスポンスの定義は以下の辞書型です。
{ 'Buckets': [ { 'Name': 'string', 'CreationDate': datetime }, ], 'Owner': { 'DisplayName': 'string', 'ID': 'string' }, "ResponseMetadata": { "RequestId": str, "HTTPStatusCode": int, "HTTPHeaders": dict, "RetryAttempts": int } }帰ってきたレスポンスから情報を取得する際には以下のようにキーを文字列で指定することになります。
s3_client = session.client('s3') data=s3_client.list_buckets() status_code = data["ResponseMetadata"]["HTTPStatusCode"] display_name = data["Owner"]["DisplayName"]文字列によるキー指定の為、IDEによる入力補完機能が使えないのでスペルミスの危険性がある、そのデータの持つ型が何か参照するまでわからない等の困った問題が存在します。
予めレスポンスの定義をdataclassとして定義しておけばドットアクセスが可能なので、入力補完が可能になったり、mypyによる型ヒントをゴリッゴリに利用できるようになります。
こりゃdataclass使わない理由ないっすね!!!
という事で...
とりあえずソース
from dataclasses import dataclass from typing import List from datetime import datetime import boto3 from dacite import from_dict session = boto3.session.Session(profile_name='s3_test') # BasesClientは何回もAPI投げるのを避ける為グローバルスコープに置いて # シングルトンで実装する s3_client = session.client('s3') @dataclass class Boto3_Response(): RequestId: str HostId: str HTTPStatusCode: int HTTPHeaders: Dict RetryAttempts: int @dataclass class Inner_Owner(): DisplayName: str ID: str @dataclass class Inner_Buckets(): Name: str CreationDate: datetime @dataclass class S3_LIST(): ResponseMetadata: Boto3_Response Owner: Inner_Owner Buckets: List[Inner_Buckets] @classmethod def make_s3_name_list(cls): return from_dict(data_class=cls, data=s3_client.list_buckets()) s3_list_response = S3_LIST.make_s3_name_list() # ステータスコード print(s3_list_response.ResponseMetadata.HTTPStatusCode) #200 # オーナー名 print(s3_list_response.Owner.DisplayName) # nikujaga-kun # ID print(s3_list_response.Owner.ID) # バケット一覧 print(*[bucket.Name for bucket in s3_list_response.Buckets])以下解説
from dacite import from_dictここでdaciteなるサードパーティーライブラリをインポートしています。
dacite(筆者は"でして"と読んでます)は簡潔に言うとネストしたデータクラスに辞書型を渡してインスタンス生成する為のライブラリです。
https://pypi.org/project/dacite/@dataclass class Boto3_Response(): RequestId: str HostId: str HTTPStatusCode: int HTTPHeaders: Dict RetryAttempts: int @dataclass class Inner_Owner(): DisplayName: str ID: str @dataclass class Inner_Buckets(): Name: str CreationDate: datetime @dataclass class S3_LIST(): ResponseMetadata: Boto3_Response Owner: Inner_Owner Buckets: List[Inner_Buckets] @classmethod def make_s3_name_list(cls): return from_dict(data_class=cls, data=s3_client.list_buckets())上記S3_LISTの定義において、別のデータクラスであるBoto3_Response,Inner_Owner,Inner_Bucketsを属性の型としてそれぞれ定義しています。
daciteのfrom_dictを利用せずに、そのままlist_bucketsのレスポンスをアンパックでS3_LISTに渡すと@classmethod def make_s3_name_list(cls): return cls(**s3_client.list_buckets())このような形になるわけですが、クラスインスタンスでなく辞書型で渡している為そんな属性無いと怒られます。
s3_list_response = S3_LIST.make_s3_name_list() # ここでAttributeErrorで怒られる print(s3_list_response.ResponseMetadata.HTTPStatusCode) # 'dict' object has no attribute 'HTTPStatusCode'組込だけでここらへんを上手いことやろうとすると、それなりに大変なので、
よしなにやってくれるライブラリとしてdaciteを利用しています。
巨人の肩には無限に乗るべき。最後に
dataclassはいいぞ
- 投稿日:2020-10-27T13:37:24+09:00
プログラミング超絶初心者の学習履歴
はじめに
僕は自動車のハードウェア設計が専門で、プログラミングらしいものはエクセルの関数や簡単なマクロを使う程度(web上に公開されているものを少しだけ加工して使うレベル)で、苦手意識も強く避けて来たというのが正直なところでした。
しかしここ何年かはデータ収集・処理・分析が主業務となり、「あぁプログラミングができれば・・・」
と思うことが多くなったため、
重い腰を上げて、2020年の春からボチボチと勉強を始めています。
僕の場合は"データ”に関する自動化や高度化を行いたかっため、
Pythonを軸としてプログラミングの世界に飛び込むことにしました。以下、自分の記録 兼 もしかし僕のような ”非IT畑の方” の参考になるかも
ということでボチボチ学習歴を記載していこうと思います。ちなみに、”どういう順序で学ぶべきか?”ということは全く考えず、
興味の赴くままに、行き当たりばったり学んでいるので、参考にはならない可能性が高いですがご容赦ください笑Python学習記録
時期 内容 詳細 2020年3月頃 意を決してTechgym(プログラミング教室)へ とにかく自己コントロールができないので、無理矢理勉強せざるを得ない状況を作ろうと、2時間ほどの無料講習会に参加。Techgymの特徴は文法などは基本的に教えず、いきなり課題を与えられる点。最低限のヒントが提示され、それを参考にどうコードを書くべきか自分で考える→書く→また考える→どうしてもわからなければ回答を見る、のくり返しで学習していく。やりたいコト、作りたいモノをまず定め、それに必要な知識を優先的に付けるスタイルで、とにかく実践力重視。個人的には、 いきなり”Pyhtonとは?”的な講義ではなく、簡単でもコードを書いて実行→目的を達成ということを体験できて、とてもいいスタートになったと思います。教室に通うことも考えましたがコロナにより断念。 2020年3月頃 Udemyで動画を爆買い 本を読みながら勉強というのが大の苦手で、動画での勉強を選択。"Python" "初級" "入門"などのキーワードで評価が高く面白そうなものを5本ほど購入。定価だと5万円分くらいでしょうが、常にセール価格の気がするので実際は1万円ほどで購入できたと思います。 2020年4月頃 Udemyで学習を開始 あるあるですが、動画を購入した時点がかなり満足してしまい、2週間ほど放置。これじゃいかんと奮い立って一番面白そうだと思った【ゼロから始めるデータ分析】というコースを視聴。”ゼロから”の名に相応しく、Anacondaの導入から説明が入るので、超絶初心者の自分にぴったりでした。こちらのコースはTechgymと近いスタイルで、文法などの説明はあまりなく、”この時はこういうコードを書きました。ではこうしたい時はどうしたらいいでしょう?考えてみてください”というスタイルで、個人的には楽しく学習を続けられました。動画そのものは8時間くらいだったと思いますが、自分で考えたり写経したりする時間があるので実際には倍の16時間程かけて学習を終えたと思います。 2020年4月頃 Udemyで学習を開始 その2 一つ目のコースを終えたことで「なんかできるかも」と謎の自信が湧いてしまい、次は飛び級気味に【人工知能・機械学習】のコースの視聴を開始。前半はよかったのですが、後半に入るとひたすら写経が続く感じで、”なぜこう書くんだろう? 今どういう処理をしているんだろう?”とブラックボックス度合いが高くなり、学習意欲が低下してきました。14時間の動画を8時間程見たところで、”あーちょっと疲れた”となり、Udemyをそっ閉じしました。 2020年5月頃 さくらインターネットの無料プログラミング教材で勉強スタート Udemyの経験から”さすがに少しは基本的な記述方法や構文は理解しとかないときついな”と思っていたら、さくらインターネットさんが丁度教科書的なドキュメントを無料公開してくれていて、それを完全に写経しながら理解していくという形で、基礎中の基礎を学んでいきました。これによって超絶初心者から超初心者にアップグレードされたような気がします。
- 投稿日:2020-10-27T13:34:34+09:00
深層学習でスナックの売り上げ予測
ブログの目的
機械学習の勉強を始めて早1ヶ月が経ちました。理解が進むにつれて、実際の社会の中のデータで機械学習のモデルを構築してみたいという気持ちがふつふつと湧き上がってきています。そこで今回は母親が経営しているスナックの売り上げ深層学習を使って予測してみます。
また、このブログで、自分の復習&これから機械学習を勉強する人への良い教材の2つを実現できたら良いなと思っています^^機械学習とは?
まずは機械学習についてです。機械学習とは簡単に言うと、「大量のデータから反復的に学習して、そこに潜むパターンを探し出すこと」と言えます。機械学習のアルゴリズムの種類は本当にたくさんありますが、この根幹の部分は全てにおいて共通していました。なので、すべてに共通している実装の大まかな流れを把握しておくとGOODだと思います。機械学習の簡単な流れは以下のようになっています。
1.データ収集
2.データの前処理(重複や欠損データ等を取り除いて、データの精度を高める。)
3.機械学習の手法でデータを学習
4.テストデータで性能をテスト3の部分がデータを基にして機械学習のモデルに学習させるフェーズです。ここで多くの手法やアルゴリズムが登場するので、学習していてとても楽しかったですね。
しかし、意外とAI開発者の力量が試されるフェーズは2のデータの前処理だったりするそうです。機械学習のモデルに対して、質の良いデータを与えるほど、質の良いモデル構築につながります。今回のブログでもこの部分を特に注意して実装していくつもりです。時系列データ解析について
今回の「スナックの売り上げ予測のモデル構築」は、時系列データ解析に該当します。時系列データとは、時間の経過と共に変化するデータのことを指します。このようなデータを解析する時系列データ解析は、会社の売り上げや商品の売り上げの予測にも応用できるので、ビジネスシーンでもとても重要な分析技術とされています。
時系列解析と一口に言っても、その解析手法にはいろいろあります。今回のブログではその中でも深層学習の手法を応用したアルゴリズムを使用していきます。深層学習(ディープラーニング)とは
深層学習とは、機械学習の手法の一つです。この深層学習を理解するために、まずはニューラルネットワークについての理解が必要です。
ニューラルネットワークとは、脳の情報伝達の仕組みを応用した機械学習の手法一つです。ニューラルネットワークは入力層、中間層、出力層の3層で構成されています。すべての層において、入力されたデータ値が、適切な重みをかけられて次の層に出力されます。そのプロセスを繰り返しながら、入力層から入力された値が中間層を介して出力層に出力されます。
(https://www.sbbit.jp/article/cont1/33345より引用)
そして、深層学習とは、このニューラルネットワークの中間層を多く重ねて設計された機械学習モデルのことを指します。
今回解析するデータの種類は時系列データですが、このデータに関しても深層学習を使用した解析が可能です。時系列データを解析する深層学習モデルとして、RNN(Recurrent Neural Network)とLSTM(Long-short-term-memory)の2つのニューラルネットワークを紹介します。
RNN(Recurrent Neural Network)
RNNとは、深層学習によって時系列データを解析する機械学習アルゴリズムの一つです。中間層において、前の時点のデータを現時点の入力として自己ループすることがRNNの特徴です。これによってRNNでは、中間層におけるデータ同士の前後の文脈を保持したまま、情報の伝達が可能になります。そして、この性質が、時間の概念を持つデータの学習を可能にしました。
(https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67caより引用)RNNの欠点
深層学習で時系列データの解析を可能にしたRNNですが、実は性能がそれほど高くはありません。その原因はRNNのループ構造によって活性化関数が何度も乗算されることにあります。時間の経過と共に、繰り返し活性化関数が乗算されることで、勾配の値が収束する勾配消失or演算量が指数的に増加する勾配爆発が起きてしまうのです。その結果、適切なデータ処理が難しくなってしまいます。また、これらの理由から、長期間の時系列データの学習にはRNNは向いていないことが分かります。
この欠点を解決した深層学習モデルが次に紹介するLSTM(Long-short-term-momory)です。LSTM(Long-short-term-memory)
LSTMモデルでは、中間層のセルをLSTMブロックに置き換えることで、RNNの持つ「長期間の記憶を保持しながら学習できない」という欠点を克服しています。LETMブロックの基本的な構成は以下です。
・CEC:過去のデータを保存するユニット
・入力ゲート:前のユニットの入力の重みを調整するゲート
・出力ゲート:前のユニットの出力の重みを調整するゲート
・忘却ゲート:過去の情報が入っているCECの中身をどの程度残すかを調整するゲート
(https://sagantaf.hatenablog.com/entry/2019/06/04/225239より引用)LSTMでは、上述したゲートの機能によって、セルの状態に応じた情報の削除・追加が可能です。入力・出力の重みを調整・セル内のデータの調整によって、RNNの欠点であった勾配消失と勾配爆発の問題を解消しています。よって、長期間の時系列データ解析にも適応することができます。
今回のスナックの売り上げを予測するモデル構築では、このLSTMアルゴリズムを使用して深層学習の機械学習モデルを構築していきます。それでは実際にモデル構築をしていきます。開発環境
OS: Windows10 python環境: Jupyter Notebookファイル構成
Forecast- |-Forecast.py(pythonファイル) |-sales_data- |-各種CSVファイルモデル構築の流れ
モデル構築の流れは先ほど紹介した以下の流れです。
1.データ収集
2.データの前処理(重複や欠損データ等を取り除いて、データの精度を高める。)
3.機械学習の手法でデータを学習
4.テストデータで性能をテスト0.必要モジュール
まずは必要なモジュールをimportします。実行環境に以下のコードを書きます。
Forecast.pyimport numpy as np import pandas as pd import matplotlib.pyplot as plt import math from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error1.データ収集
まずはデータ収集です。必死のお願いの末、母親が経営しているスナックの売り上げデータをゲットしました。月ごとの売り上げをまとめた2013-2019年のエクセルデータの形を整えてCSV形式に出力します。実際のデータファイルは以下のGoogle Sheetsからデータを閲覧できます。
https://docs.google.com/spreadsheets/d/1-eOPORhaGfSCdXCScSsBsM586yXkt3e_xbOlG2K6zN8/edit?usp=sharing
Forecast.py#CSVファイルをDataFrame形式で読み込みます。 df_2019 = pd.read_csv('./sales_data/2019_sales.csv') df_2018 = pd.read_csv('./sales_data/2018_sales.csv') df_2017 = pd.read_csv('./sales_data/2017_sales.csv') df_2016 = pd.read_csv('./sales_data/2016_sales.csv') df_2015 = pd.read_csv('./sales_data/2015_sales.csv') df_2014 = pd.read_csv('./sales_data/2014_sales.csv') df_2013 = pd.read_csv('./sales_data/2013_sales.csv') #読み込んだDataFrameを結合して、一つのDataFrameにします。 df_sales_concat = pd.concat([df_2013, df_2014, df_2015,df_2016,df_2017,df_2018,df_2019], axis=0) #使用するFrameDataのインデックスを作成します。 index = pd.date_range("2013-01", "2019-12-31", freq='M') df_sales_concat.index = index #不必要なDataFrameの列を削除します。 del df_sales_concat['month'] #モデル構築で使用する実際の売り上げデータのみをdataset変数に格納します。 dataset = df_sales_concat.values dataset = dataset.astype('float32')2.データの前処理(データセットの作成)
次にデータの前処理です。具体的にはモデル構築に使用するデータセットを作成していきます。
Forecast.py# トレーニングデータとテストデータに分ける。比率は2:1=トレーニング:テストです。 train_size = int(len(dataset) * 0.67) train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] # データのスケーリング。 #トレーニングデータを元にしたデータ標準化のためのインスタンスを作成しています。 scaler = MinMaxScaler(feature_range=(0, 1)) scaler_train = scaler.fit(train) train = scaler_train.transform(train) test = scaler_train.transform(test) # データの作成 look_back =1 train_X, train_Y = create_dataset(train, look_back) test_X, test_Y = create_dataset(test, look_back) # データの整形 train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)3.LSTMモデルの構築と学習
構築
Forecast.pymodel = Sequential() model.add(LSTM(64, return_sequences=True, input_shape=(look_back, 1))) model.add(LSTM(32)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') ###学習 model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=2)以上でデータセットからLSTMモデルによる機械学習が完了しました。次に結果をグラフにプロットするための処理です。
Forecast.py# 予測データの作成 train_predict = model.predict(train_X) test_predict = model.predict(test_X) # スケールしたデータを基に戻す。標準化された値を実際の予測値に変換します。 train_predict = scaler_train.inverse_transform(train_predict) train_Y = scaler_train.inverse_transform([train_Y]) test_predict = scaler_train.inverse_transform(test_predict) test_Y = scaler_train.inverse_transform([test_Y]) # 予測精度の計算 train_score = math.sqrt(mean_squared_error(train_Y[0], train_predict[:, 0])) print(train_score) print('Train Score: %.2f RMSE' % (train_score)) test_score = math.sqrt(mean_squared_error(test_Y[0], test_predict[:, 0])) print('Test Score: %.2f RMSE' % (test_score)) # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict次は実際のデータをグラフにプロットしていきます。
Forecast.py# グラフのメタ情報を出力する plt.title("monthly-sales") plt.xlabel("time(month)") plt.ylabel("sales") #データをプロットする plt.plot(dataset, label='sales_dataset', c='green') plt.plot(train_predict_plot, label='train_data', c='red') plt.plot(test_predict_plot, label='test_data', c='blue') #y軸の目盛りを調整する plt.yticks([500000, 600000, 700000, 800000, 900000, 1000000, 1100000]) #グラフをプロットする plt.legend() plt.show()4.結果
結果として出力されたグラフが下になります。なんとなく傾向は予測できていますが、実測値と大きく外れている点が多く見受けられます。LSTMのモデルの良さの基準になるRMSEに関してもTrain Score: 94750.73 RMSE, Test Score: 115472.92 RMSEとなり、いまいちの結果でした。。
考察
結果としては、「売り上げの傾向を掴むことができたが、実測値と予測値とのずれを埋めることができなかった」です。パラメータであるloop_back, epochs, batch_sizeのいろいろなパターンを試しましたが、特に性能が上がることはなかったです。。。
原因としては、データの少なさとばらつきに原因があったのかなと思います。機械学習モデルの構築には、データが命であるということを身にしみて感じました。
しかし、何はともあれ、一か月の機械学習の復習と初学者への良い教材にはなったかと思います。これから機械学習エンジニアとしてレベルアップできるように、さらに精進していきます!今回使用した全コード
Forecast.pyimport numpy as np import pandas as pd import matplotlib.pyplot as plt import math from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # データセットの作成 def create_dataset(dataset, look_back): data_X, data_Y = [], [] for i in range(look_back, len(dataset)): data_X.append(dataset[i-look_back:i, 0]) data_Y.append(dataset[i, 0]) return np.array(data_X), np.array(data_Y) df_2019 = pd.read_csv('./sales_data/2019_sales.csv') df_2018 = pd.read_csv('./sales_data/2018_sales.csv') df_2017 = pd.read_csv('./sales_data/2017_sales.csv') df_2016 = pd.read_csv('./sales_data/2016_sales.csv') df_2015 = pd.read_csv('./sales_data/2015_sales.csv') df_2014 = pd.read_csv('./sales_data/2014_sales.csv') df_2013 = pd.read_csv('./sales_data/2013_sales.csv') df_sales_concat = pd.concat([df_2013, df_2014, df_2015,df_2016,df_2017,df_2018,df_2019], axis=0) index = pd.date_range("2013-01", "2019-12-31", freq='M') df_sales_concat.index = index del df_sales_concat['month'] dataset = df_sales_concat.values dataset = dataset.astype('float32') # トレーニングデータとテストデータに分ける train_size = int(len(dataset) * 0.67) train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] # データのスケーリング scaler = MinMaxScaler(feature_range=(0, 1)) scaler_train = scaler.fit(train) train = scaler_train.transform(train) test = scaler_train.transform(test) # データの作成 look_back =1 train_X, train_Y = create_dataset(train, look_back) test_X, test_Y = create_dataset(test, look_back) # データの整形 train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1) # LSTMモデルの作成と学習 model = Sequential() model.add(LSTM(64, return_sequences=True, input_shape=(look_back, 1))) model.add(LSTM(32)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=2) # 予測データの作成 train_predict = model.predict(train_X) test_predict = model.predict(test_X) # スケールしたデータを基に戻す。 train_predict = scaler_train.inverse_transform(train_predict) train_Y = scaler_train.inverse_transform([train_Y]) test_predict = scaler_train.inverse_transform(test_predict) test_Y = scaler_train.inverse_transform([test_Y]) # 予測精度の計算 train_score = math.sqrt(mean_squared_error(train_Y[0], train_predict[:, 0])) print(train_score) print('Train Score: %.2f RMSE' % (train_score)) test_score = math.sqrt(mean_squared_error(test_Y[0], test_predict[:, 0])) print('Test Score: %.2f RMSE' % (test_score)) # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict # データのプロット plt.title("monthly-sales") plt.xlabel("time(month)") plt.ylabel("sales") plt.plot(dataset, label='sales_dataset', c='green') plt.plot(train_predict_plot, label='train_data', c='red') plt.plot(test_predict_plot, label='test_data', c='blue') plt.yticks([500000, 600000, 700000, 800000, 900000, 1000000, 1100000]) plt.legend() plt.show()
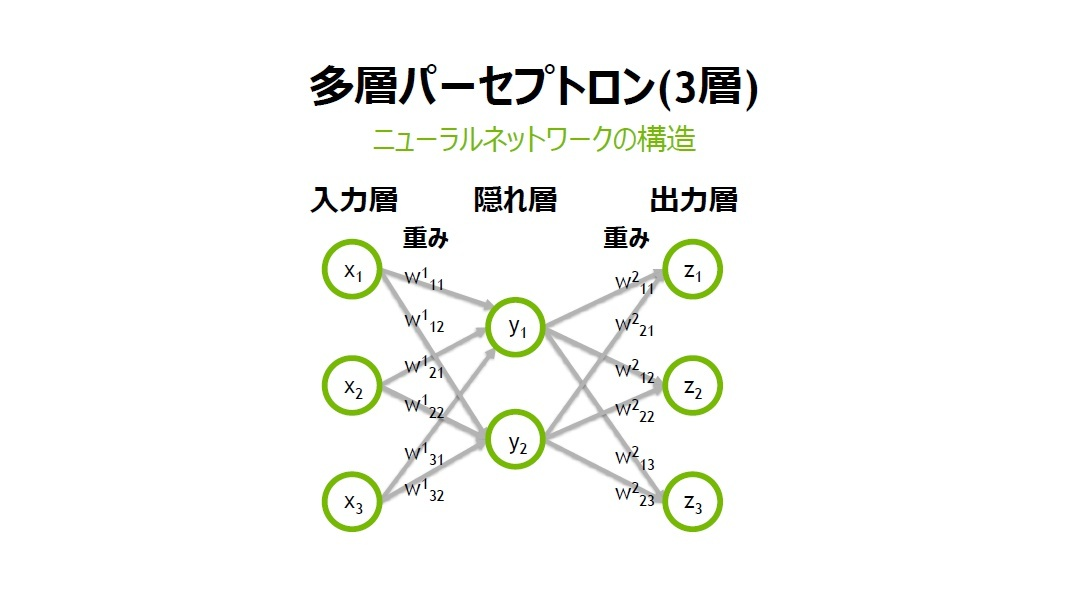

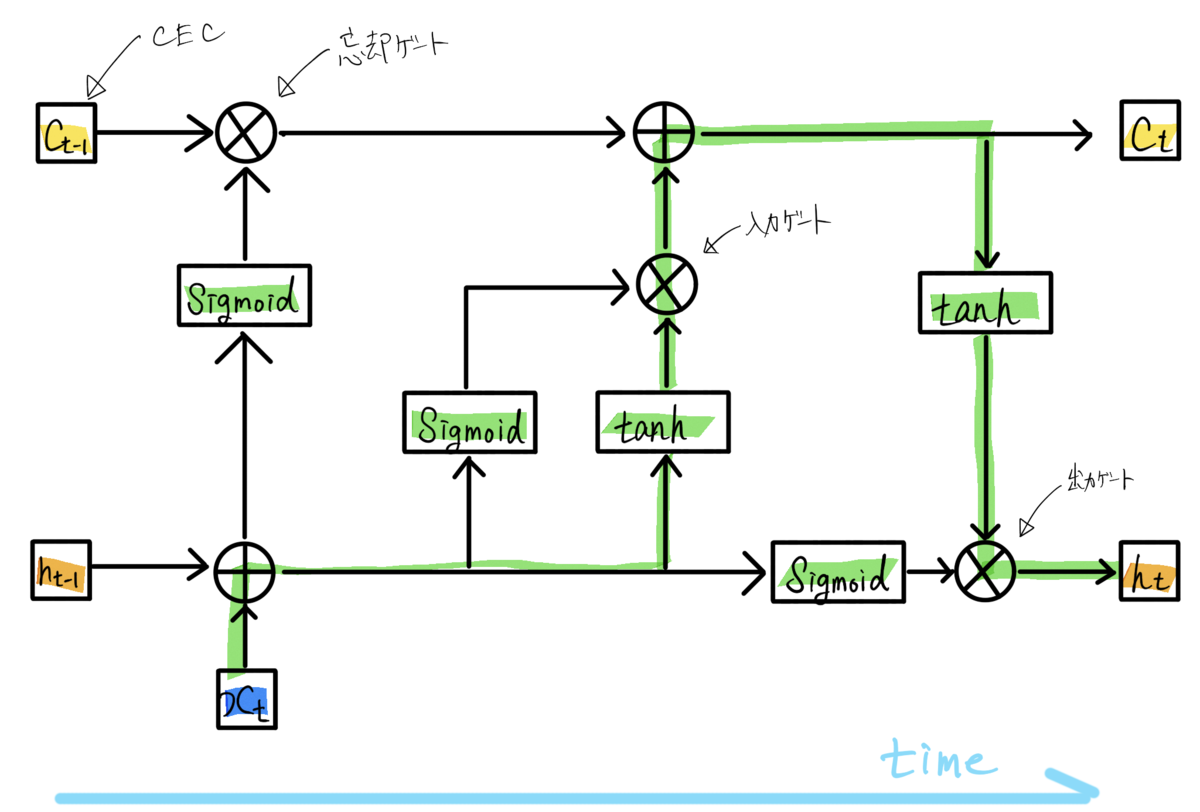
- 投稿日:2020-10-27T12:36:17+09:00
macでpython実行時に方向キーを押すと"^[[A^[[B^[[C^[[D"となってしまう対処法
環境
macOS:Catalina 10.15.7
python:3.8.5
VScode:1.50.1問題点
VScodeのterminalにてpython実行時に、方向キーを押すと、"^[[A^[[B^[[C^[[D"と入力されてしまい、過去に一度入力した値でももう一度入力しなければいけなかった。
^[[A^[[B^[[C^[[D解決策
今回は、「rlwrap」を導入することによってこの問題を回避します。
導入にあたって、「homebrew」を使用しますが、今回はこの「Homebrew」のインストールは割愛させていただきます。(Homebrewのインストールに関しての記事は既にたくさんあるため。)手順
まず、「command+space」で「Terminal」と検索し、Terminal を起動。
そこで以下のように入力します。brew install rlwrap特に問題なければ、「rlwrap」がインストールされているはずなので、正常にインストールされたかを確認します。
$ rlwrap -v rlwrap 0.43こんな感じでバージョンが表示されれば大丈夫です。
あとは、pythonを実行する時に
$ rlwrap python a.pyと前に付け加えるだけです!
(python以外の言語では試していないのでわかりません!
ごめんなさい!)おまけ
VScodeを使用している人だけにはなりますが、便利な設定がありますので紹介させていただきます。
まず、拡張機能の「Code Runner」をインストールします。
この拡張機能は対応している言語の実行を、再生ボタンを押すか、ショートカットキーでできるようになるため、非常に楽になる機能です。
インストールができたら、歯車のマークをクリックし、一番下の「Extention Settings」を選択します。
次に、「User」と「Workspace」とあると思いますが、
「User」の中の「Run in Terminal」にチェックを付けます。
次に、「Workspace」の方を選択します。
そして「Code-runner:Executor Map」という欄の中の「Edit in settings.json」をクリックします。
開いたsettings.json の中を探すと以下のようなコードがありますので、、
settings.json"python": "python -u",これを次のように書き換えて保存します。
settings.json"python": "rlwrap python -u",こうすることで、「Code Runner」でpythonを実行した際にも自動で「rlwrap」がつくので、毎回入力せずに済みます。
- 投稿日:2020-10-27T10:50:10+09:00
AtCoder Regular Contest 106 復習
今回の成績
今回の感想
Dの解く時間が足りなかったです…(10分後くらいに通った)。C問題で読み落としていた部分に気付きかずに時間を使いすぎました…。
悔しいものの青diff(ほぼ黄diff)にコンテスト中に手がかかったのは初だと思うので、これを良い兆候と捉えてより精進しようと思います。(DominoQualityもか…)
A問題
TLにも余裕があるので適当に全探索します。A,Bのいずれもあまり大きな数になりません。
クエリで繰り返し判定をすることが要求されればもう少し面白いかもしれません。
A.pyn=int(input()) x3,x5=[3],[5] while True: if x3[-1]*3<n: x3.append(x3[-1]*3) else: break while True: if x5[-1]*5<n: x5.append(x5[-1]*5) else: break x3,x5=[i for i in x3 if i<n],[i for i in x5 if i<n] y3,y5=set(x3),set(x5) #print(y3,y5) for i in y3: if n-i in y5: a,b=i,n-i ans1,ans2=0,0 while a!=1: a//=3 ans1+=1 while b!=1: b//=5 ans2+=1 print(ans1,ans2) exit() print(-1)B問題
操作回数を最小にするなども求められていないので、任意の頂点の$a_i,b_i$の和が等しければ良いのではと思ったのですが、グラフが非連結である場合に気づきました。
いずれにせよ、連結な頂点同士の間では$a$の値をうまく調整できるので、それぞれの連結成分に含まれる頂点の$a_i,b_i$の和が等しいというのが条件になります。UnionFindを使えば実装も難しくありません。
B.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //以下、素集合と木は同じものを表す class UnionFind{ public: vector<ll> parent; //parent[i]はiの親 vector<ll> siz; //素集合のサイズを表す配列(1で初期化) map<ll,vector<ll>> group; //集合ごとに管理する(key:集合の代表元、value:集合の要素の配列) ll n; //要素数 //コンストラクタ UnionFind(ll n_):n(n_),parent(n_),siz(n_,1){ //全ての要素の根が自身であるとして初期化 for(ll i=0;i<n;i++){parent[i]=i;} } //データxの属する木の根を取得(経路圧縮も行う) ll root(ll x){ if(parent[x]==x) return x; return parent[x]=root(parent[x]);//代入式の値は代入した変数の値なので、経路圧縮できる } //xとyの木を併合 void unite(ll x,ll y){ ll rx=root(x);//xの根 ll ry=root(y);//yの根 if(rx==ry) return;//同じ木にある時 //小さい集合を大きい集合へと併合(ry→rxへ併合) if(siz[rx]<siz[ry]) swap(rx,ry); siz[rx]+=siz[ry]; parent[ry]=rx;//xとyが同じ木にない時はyの根ryをxの根rxにつける } //xとyが属する木が同じかを判定 bool same(ll x,ll y){ ll rx=root(x); ll ry=root(y); return rx==ry; } //xの素集合のサイズを取得 ll size(ll x){ return siz[root(x)]; } //素集合をそれぞれグループ化 void grouping(){ //経路圧縮を先に行う REP(i,n)root(i); //mapで管理する(デフォルト構築を利用) REP(i,n)group[parent[i]].PB(i); } //素集合系を削除して初期化 void clear(){ REP(i,n){parent[i]=i;} siz=vector<ll>(n,1); group.clear(); } }; signed main(){ //小数の桁数の出力指定 //cout<<fixed<<setprecision(10); //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,m;cin>>n>>m; vector<ll> a(n);REP(i,n)cin>>a[i]; vector<ll> b(n);REP(i,n)cin>>b[i]; UnionFind uf(n); REP(i,m){ ll c,d;cin>>c>>d; uf.unite(c-1,d-1); } uf.grouping(); FORA(i,uf.group){ ll s=0; FORA(j,i.S){ s+=(a[j]-b[j]); } if(s!=0){ cout<<"No"<<endl; return 0; } } cout<<"Yes"<<endl; }C問題
成り立つ場合を満たす構築はすぐにできた(15分くらい)のですが、問題文の成り立たない場合は-1を出力するという文章を完全に読み落としていて無駄な時間を過ごしていました。
まず、成り立たない場合の条件を確認します。ここで、題意の二人は区間スケジューリング問題を解いており前者は正しく解けているので最大の個数の区間を選ぶことができています。したがって、$M \geqq 0$が必ず成り立ち、$M<0$の場合は-1を出力します。
よって、以降では$M \geqq 0$のときの構築を考えます。区間スケジューリング問題を解いたことのある人ならわかるように、$L_i$の昇順で選ぶ場合は最小の$L_i$の区間が長い区間のパターンで$R_i$の昇順で選ぶ場合よりも明らかに少ない区間の個数しか選ぶことができません。図で表すなら下図です。
上図では先ほど述べた最小の$L_i$で長い区間が$l$個の区間を内包するとしています。このとき、前者は$n-1$個の区間を選べ、後者は$n-l$個の区間しか選べません。よって、この時$m=l-1$となります。また、$0 \leqq l \leqq n-1$となりますが、$l=0$のときは$m=0$なので、$1 \leqq l \leqq n-1 \leftrightarrow 0 \leqq m \leqq n-2$の時は構築をすることができます。また、$m=n-1,n$のときは構築ができていませんが、両者とも一つ以上の区間を選択することができるので$m=n$は成り立たず、$m=n-1$のときは高橋くんが$n$個の区間,青木くんが$1$個の区間を選択する場合ですが、高橋くんが$n$個の区間を選択するときはいずれの区間も重ならないので青木くんも$n$個の区間を選ぶことができます。
また、上記では$n=1,m=0$の場合を考慮できていないので、注意が必要です。これは$m=0$の場合は重ならない区間を並べるだけでできるので、$m=0$を先に場合分けすることでも回避できます。
上図をそのまま実装するだけで実装はそこまで難しくないと思います。
C.pyn,m=map(int,input().split()) if n==1 and m==0: print(1,2) exit() if m==n or m==n-1 or m<0: print(-1) exit() ans=[[1,10**7]] for i in range(m+1): ans.append([2*(i+1),2*(i+1)+1]) for i in range(n-m-2): ans.append([10**7+2*(i+1),10**7+2*(i+1)+1]) #print(ans) for i in ans: print(i[0],i[1])D問題
式変形をガチャガチャやるだけでそこまで難しくもないので、D問題の方が簡単だと感じました。コンテスト中は見た目に気圧されていたのですが、残り20分の時に思いついて実装するも間に合いませんでした。
まず、総和の問題でただの多項式なのでそれぞれの$A_i$の寄与などに注目することを考えました。すると、$(A_L+A_R)^x$を展開したくなるので、二項定理により展開すれば、以下のようになります。
$(A_L+A_ R)^x=_xC_0 A_L^x+_xC_1 A_L^{x-1} A_R+…+_xC_x A_R^x$
ここで、ある$A_i$の寄与を考えると、$A_i$は自身以外の全ての数と$(A_L,A_R)$の組になるので、上式を利用すれば、二項定理で展開して出てくるそれぞれの項について以下のようになります。(✳︎)
$_xC_0:A_i^{x}(A_1^0+…+A_{i-1}^0+A_{i+1}^0+…+A_{n}^0)$
$_xC_1:A_i^{x-1}(A_1^1+…+A_{i-1}^1+A_{i+1}^1+…+A_{n}^1)$
↓
$_xC_{x-1}:A_i^{1}(A_1^{x-1}+…+A_{i-1}^{x-1}+A_{i+1}^{x-1}+…+A_{n}^{x-1})$
$_xC_{x}:A_i^{0}(A_1^{x}+…+A_{i-1}^{x}+A_{i+1}^{x}+…+A_{n}^{x})$また、このまま実装すると、$_xC_i$を前計算しておいたとしても$x$の候補が$k$通り,$A_i$の候補が$n$通り,上記のそれぞれの二項係数で$x+1$通り,$(\ )$内の計算で$n$回などとなり、愚直にやっても間に合わなそうです。そこで、いくつか前計算をするという前提のもとでさらに式をまとめることを考えます。
すなわち、任意の$A_i$についてそれぞれの二項係数$_xC_i$での和を取ることを考えます。すると、下図のようになります。
よって、この和をまとめると$(A_1^{x-i}+A_2^{x-i}+…+A_n^{x-i}) \times (A_1^{i}+A_2^{i}+…+A_n^{i})-(A_1^{x}+A_2^{x}+…+A_n^{x})$になります(対称性から考えれば自然な気がします)。
したがって、二項係数の前計算を行うだけでなく、$y[i]:=(A_1^i+A_2^i+…+A_n^i)$の前計算を$i=0$~$k$で行えば($O(nk)$)、$_xC_i$での和は$O(1)$で求めることができます。したがって、それぞれの$x$での答えを求めるのに全体の計算量は$O(k^2)$となります。
以上より、全体の計算量は$O(n+nk+k^2)=O(k(k+n))$となり、十分高速です。
(✳︎)…ここ以降は$1 \leqq L \leqq n-1,L+1 \leqq R \leqq n$ではなく、$1 \leqq L,R \leqq N,L \neq R$という条件を考えていますが、対称性より最終的な答えを1/2するだけで良いです。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 998244353 //10^9+7:合同式の法 #define MAXR 1000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 template<ll mod> class modint{ public: ll val=0; //コンストラクタ modint(ll x=0){while(x<0)x+=mod;val=x%mod;} //コピーコンストラクタ modint(const modint &r){val=r.val;} //算術演算子 modint operator -(){return modint(-val);} //単項 modint operator +(const modint &r){return modint(*this)+=r;} modint operator -(const modint &r){return modint(*this)-=r;} modint operator *(const modint &r){return modint(*this)*=r;} modint operator /(const modint &r){return modint(*this)/=r;} //代入演算子 modint &operator +=(const modint &r){ val+=r.val; if(val>=mod)val-=mod; return *this; } modint &operator -=(const modint &r){ if(val<r.val)val+=mod; val-=r.val; return *this; } modint &operator *=(const modint &r){ val=val*r.val%mod; return *this; } modint &operator /=(const modint &r){ ll a=r.val,b=mod,u=1,v=0; while(b){ ll t=a/b; a-=t*b;swap(a,b); u-=t*v;swap(u,v); } val=val*u%mod; if(val<0)val+=mod; return *this; } //等価比較演算子 bool operator ==(const modint& r){return this->val==r.val;} bool operator <(const modint& r){return this->val<r.val;} bool operator !=(const modint& r){return this->val!=r.val;} }; using mint = modint<MOD>; //入出力ストリーム istream &operator >>(istream &is,mint& x){//xにconst付けない ll t;is >> t; x=t; return (is); } ostream &operator <<(ostream &os,const mint& x){ return os<<x.val; } //累乗 mint modpow(const mint &a,ll n){ if(n==0)return 1; mint t=modpow(a,n/2); t=t*t; if(n&1)t=t*a; return t; } //二項係数の計算 mint fac[MAXR+1],finv[MAXR+1],inv[MAXR+1]; //テーブルの作成 void COMinit() { fac[0]=fac[1]=1; finv[0]=finv[1]=1; inv[1]=1; FOR(i,2,MAXR){ fac[i]=fac[i-1]*mint(i); inv[i]=-inv[MOD%i]*mint(MOD/i); finv[i]=finv[i-1]*inv[i]; } } //演算部分 mint COM(ll n,ll k){ if(n<k)return 0; if(n<0 || k<0)return 0; return fac[n]*finv[k]*finv[n-k]; } signed main(){ //小数の桁数の出力指定 //cout<<fixed<<setprecision(10); //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); COMinit(); ll n,k;cin>>n>>k; vector<ll> a(n);REP(i,n)cin>>a[i]; //po vector<vector<mint>> po(n,vector<mint>(k+1,0)); REP(i,n){ po[i][0]=1; REP(j,k){ po[i][j+1]=po[i][j]*a[i]; } } vector<mint> y(k+1,0); REP(i,k+1){ REP(j,n){ y[i]+=po[j][i]; } } vector<mint> ans(k,0); FOR(x,1,k){ mint ans_sub=0; REP(j,x+1){ ans_sub+=(COM(x,j)*((y[x-j])*(y[j])-y[x])); } ans[x-1]+=ans_sub; } REP(i,k){ cout<<ans[i]/2<<endl; } }E問題以降

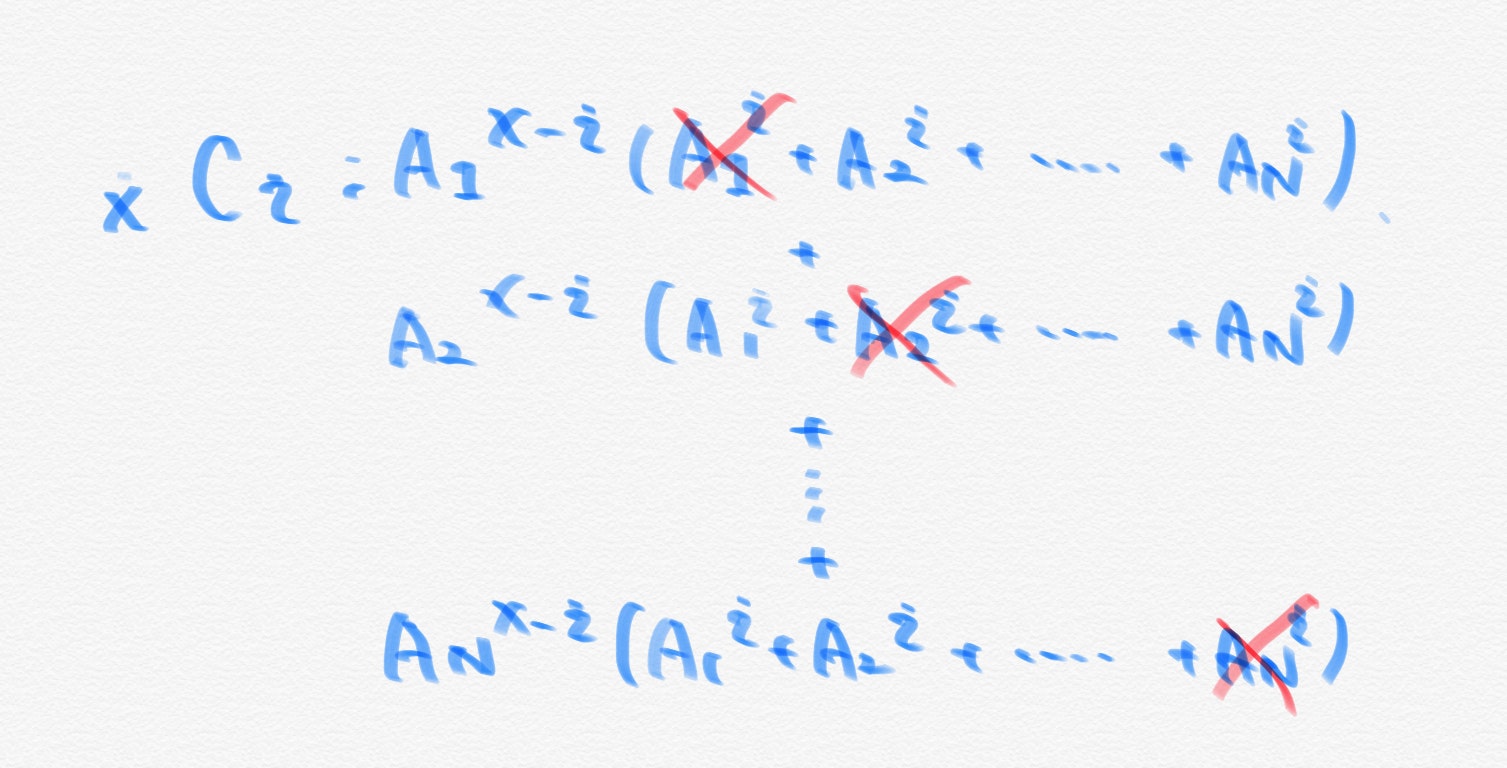
- 投稿日:2020-10-27T10:49:05+09:00
【AtCoder】エイシング C - XYZ Triplets
エイシング プログラミング コンテスト 2020のC問題です。
苦戦したので、失敗したコードと共に振り返ってみました。失敗1(TLE)
n=int(input()) def f_count(j): count=0 for x in range(1,j): for y in range(1,j): for z in range(1,j): if x**2+y**2+z**2+x*y+y*z+z*x==j: count+=1 return count for i in range(1,n+1): print(f_count(i))f(n)を求める関数f_count(j)を定義して、jに1~nまで代入して、出力する方法です。
時間超過になったので、zを消したりしてみましたが、それでも時間超過になりました。
<ポイント1>
解答を見てみると、nの最大値は10**4。x,y,zは二乗しているから、x,y,zの最大値は100より小さい。
<ポイント2>
f(1)の時、x,y,zを1~100まで全探索する → f(2)の時、x,y,zを1~100まで全探索する…としていては、時間がかかる。
失敗2
N=int(input()) #f(N)を入れるリスト ans_list=[0]*N for x in range(1,100): for y in range(1,100): for z in range(1,100): s=x**2+y**2+z**2+x*y+y*z+z*x if s<=N: ans_list[s]+=1 for i in range(1,N+1): print(ans_list[i])<結果>IndexError: list index out of range
x, y, zに1~100まで代入して、x*2+y2+z*2+x*y+y*z+z*xの値を計算し、結果をリストans_listに入れていきました。
しかし、範囲を間違えました。ans_list[0]=[], ans_list[1]=f(1), ans_list[N-1]=f(N-1)としてしまったため、f(N)がリストに入らなくなってしまいました。
正解1
N=int(input()) max_x=int(N**0.5) ans_list=[0]*N for x in range(1,max_x): for y in range(1,max_x): for z in range(1,max_x): s=x**2+y**2+z**2+x*y+y*z+z*x if s<=N: ans_list[s-1]+=1 for i in range(N): print(ans_list[i])ans_list[s-1]+=1にしました。
正解2
n=int(input()) keys=[i for i in range(1,n+1)] values=[0 for i in range(1,n+1)] dic=dict(zip(keys,values)) for x in range(1,100): for y in range(1,100): for z in range(1,100): num=x**2+y**2+z**2+x*y+y*z+z*x if 1<=num<=n: dic[num]+=1 for key in dic: value=dic[key] print(value)正解1は、リストのインデックスとf(n)のnがズレるのがすっきりしなかったので、辞書にしてみました。