- 投稿日:2020-10-27T23:16:32+09:00
YAMAHA RTX1200 でAWS サイト間VPN接続の構築
YAMAHA RTX1200 でAWS サイト間VPN接続の構築
にわかSEがAWSで遊んでると突然「VPN接続ぐらいできるよね?」みたいな感じで案件アサインされました(笑)。
Client VPN ならさくっと設定したことあります...(震え声)
とにかく検証しないと始まらないので、会社に転がっていたYAMAHA RTX1200 でサイト間VPN接続を検証してみます。今回のゴール
VPN接続したルータ配下にPCを接続し、VPC内のTest-ServerにプライベートIPアドレスでRDP接続できるようにする。
前提条件
- 固定グローバルIPアドレス×1 の契約がある
- PPPoEが設定できるルータがある ※今回はYAMAHA RTX1200 を使います
- VPN接続しようしているAWS VPCに既存VPGは存在しない
- ISP接続情報(PPPoE接続するためのユーザIDやPW)が分かる
- RTX1200の設定はCLIで行います
1. ですがAWS サイト間VPN接続は動的IPでは設定できませんので固定IP必須です。
3. ですがAWS VPCの仕様上、1つのVPCにアタッチできるVPGは1つだけなので
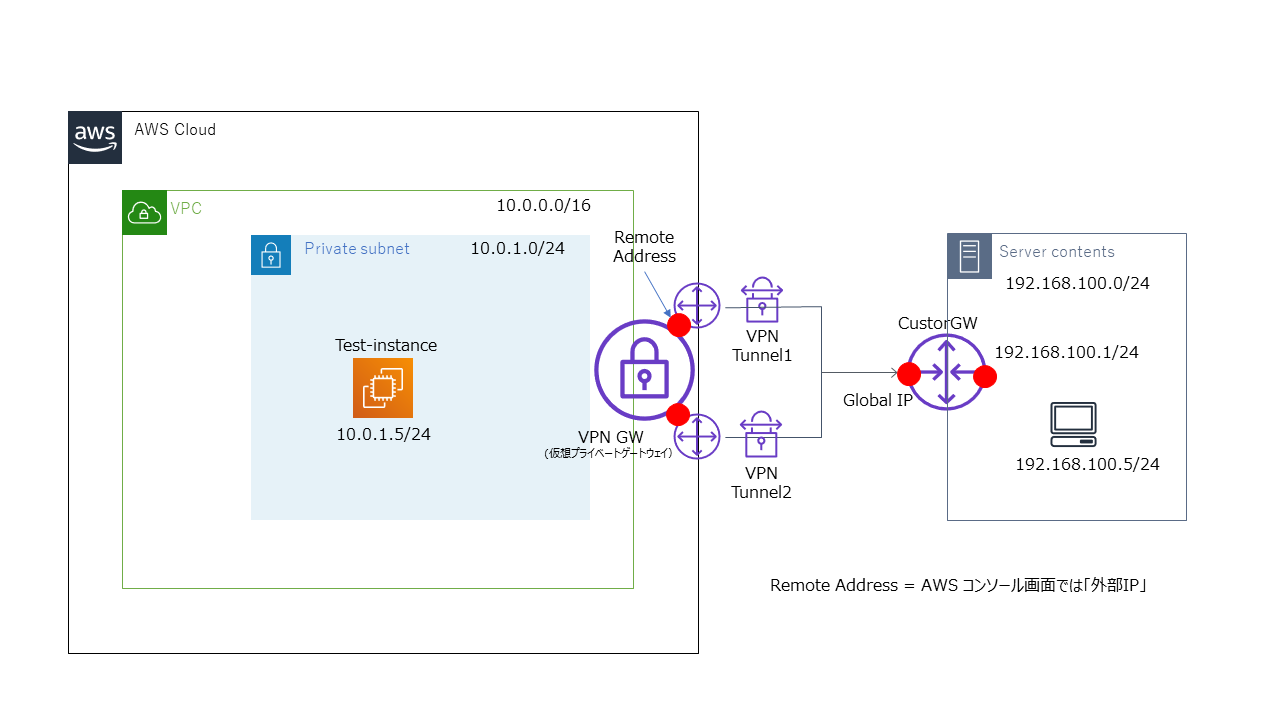
複数のVPN接続を設定することはできないです。サイト間VPNの接続構成図
※調べてみたところ、接続構成図的にはこんな感じになるようです。(間違ってたらコメント下さると幸いです)設定手順
- VPCを作成する
- Test用インスタンスを作成する ※RDP可能にしておく
- カスタマーゲートウェイの設定
- 仮想プライベートゲートウェイの設定
- VPCのルーティング設定
- セキュリティグループの設定
- VPN接続を作成する
- ルータ設定コンフィグをAWSからDLする
- YAMAHA RTX1200 の基本設定(IFやPPPoE、フィルター設定など)
- YAMAHA RTX1200のBGP、IPsecの設定
- RDPでの接続テスト
実際にやってみた
1と2は本記事のメインではないので割愛します。それでは3から設定していきます。
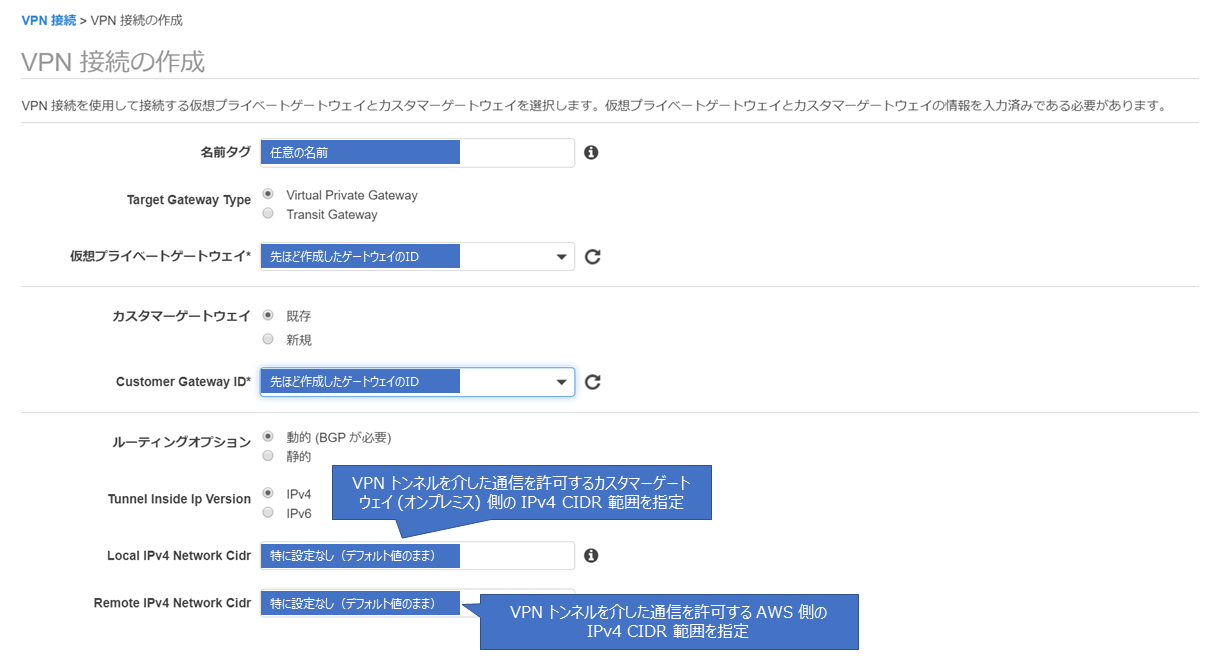
VPCの設定画面から「カスタマーゲートウェイ」を選択します。
名前は任意のものを記入し、IPアドレスは固定グローバルIPを記入します。今回は動的ルーティングで設定しますのでルーティングは「動的」を選択します。
その他は特に設定不要です。
記入できたら「カスタマーゲートウェイの作成」を選択して、作成します。次に仮想プライベートゲートウェイを作成します。
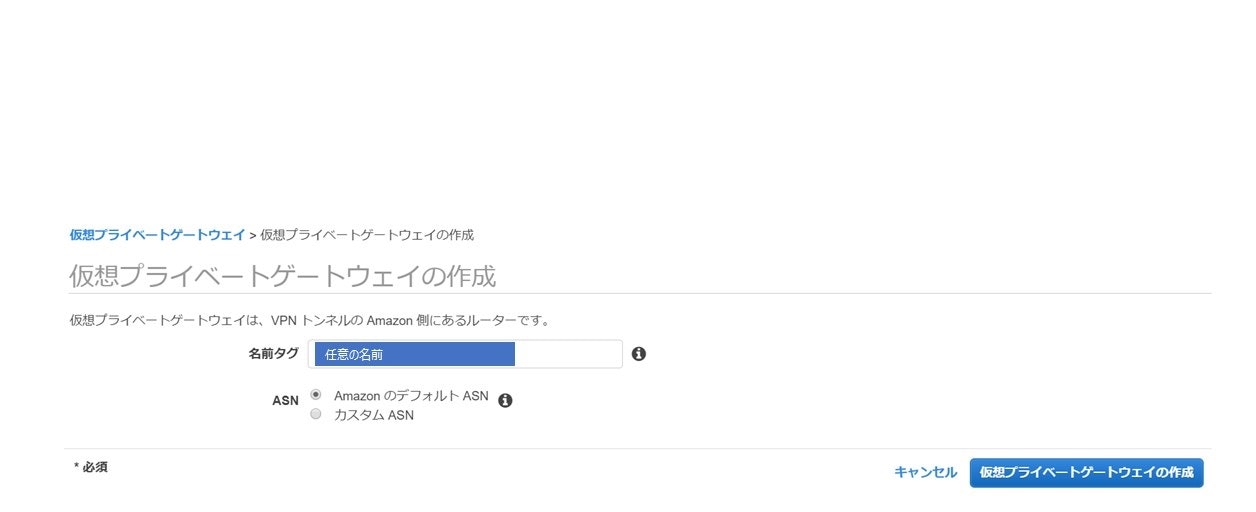
同じくVPCの設定画面から「仮想プライベートゲートウェイ」を選択します。
名前は任意のものを記入し、ASN番号はデフォルト(65000)のままでOKです。
記入ができれば、「作成」まで進めます。各種ゲートウェイが作成できたところで、VPN接続を構築する前にローカル環境からアクセスできるようにセキュリティグループ設定とルーティング設定を行います。
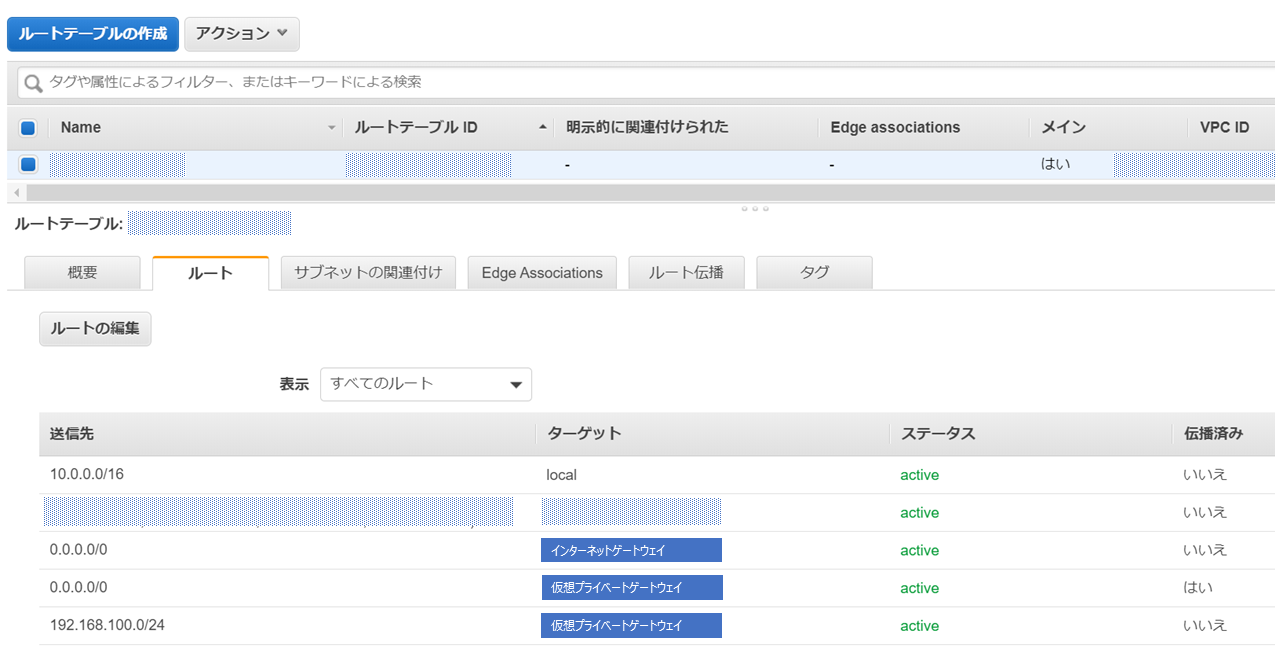
まずルーティングの設定ですが、VPCの管理画面でVPGをアタッチ予定のVPCを選択し、「ルートの編集」で
ローカル側への通信(宛先が192.168.100.0/24)への通信をVPGへ向けるルーティングを追記します。
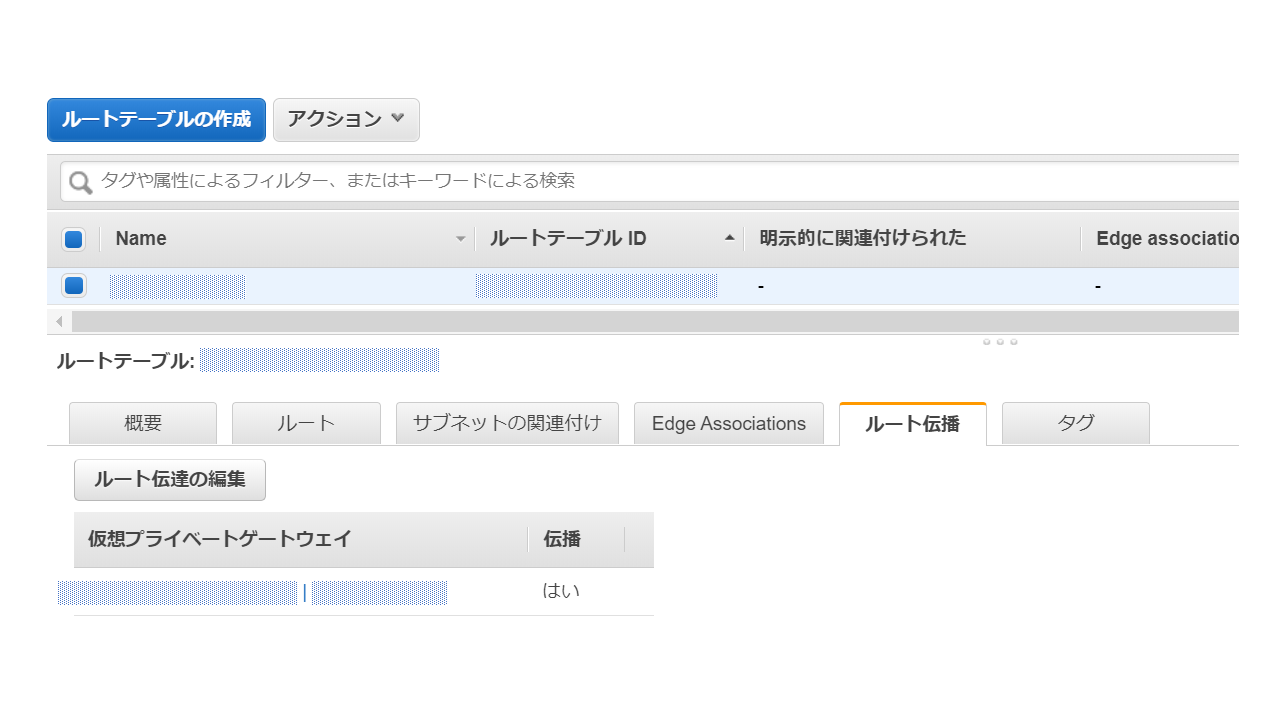
※0.0.0.0/0 をVPGへルーティングする設定は自動で登録されていました続いてAWS側のルート情報がVPG経由でオンプレ側に広告されるように「ルート伝播」の項目を設定します。
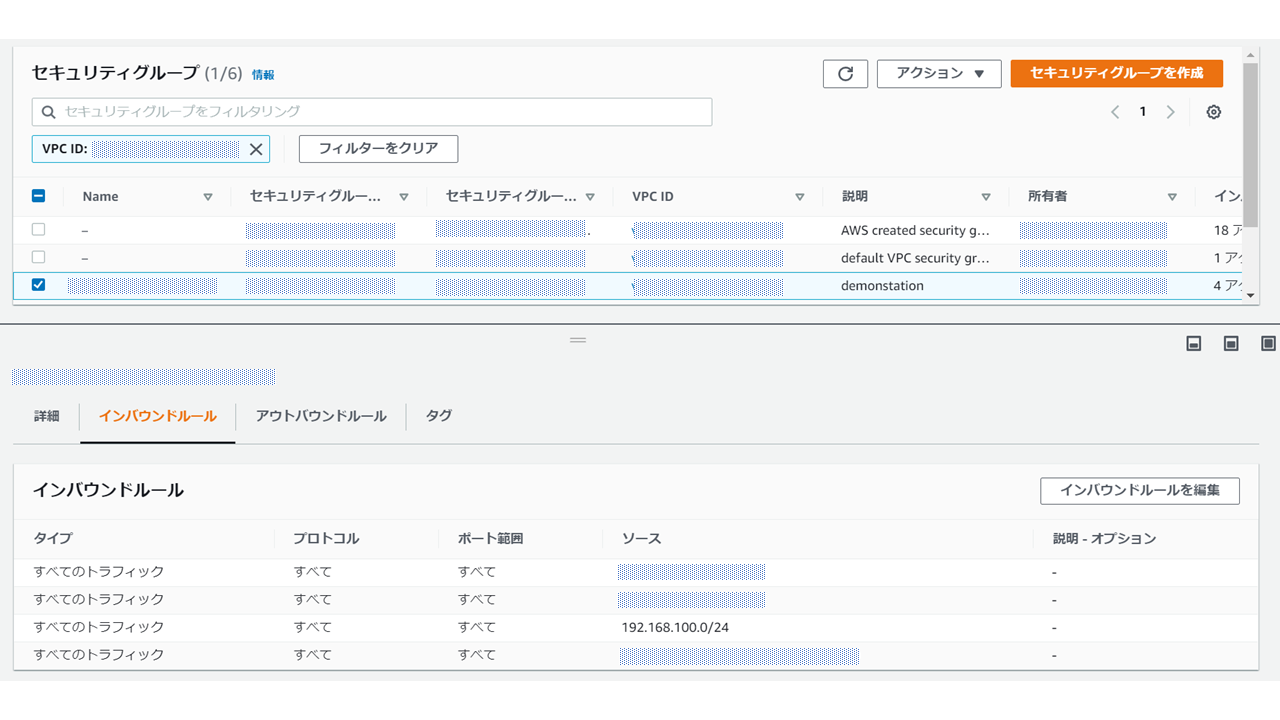
「ルート伝播」のタグを選択し、「ルート伝播の編集」から伝播するに☑をいれます。次にローカル側からAWS VPC内のインスタンスにアクセスできるようにセキュリティグループを編集していきます。
今回はインバウンドルールにローカル側のアドレスセグメント(192.168.100.0/24)の通過許可設定をします。ではAWS側の通信設定とゲートウェイは出来たので、実際にVPN接続を構築していきます。
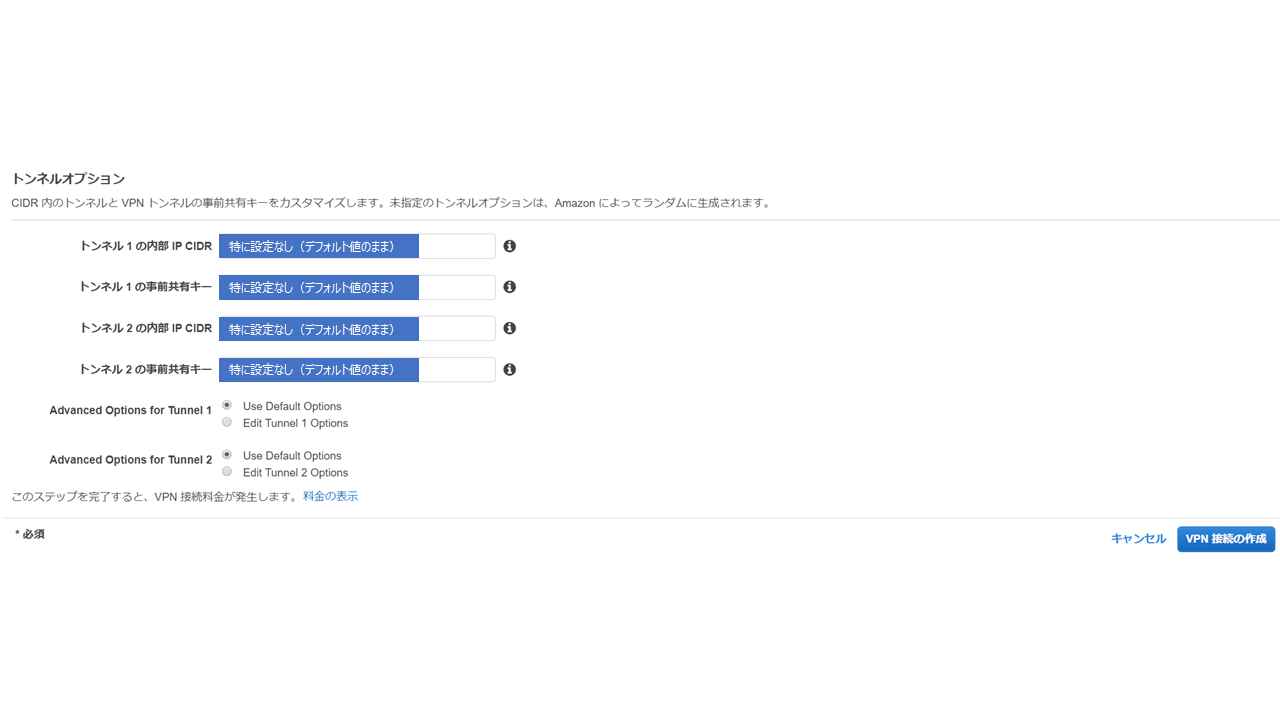
VPCの管理画面から「サイト間VPN」を選択し、以下のように必要事項を登録していきます。
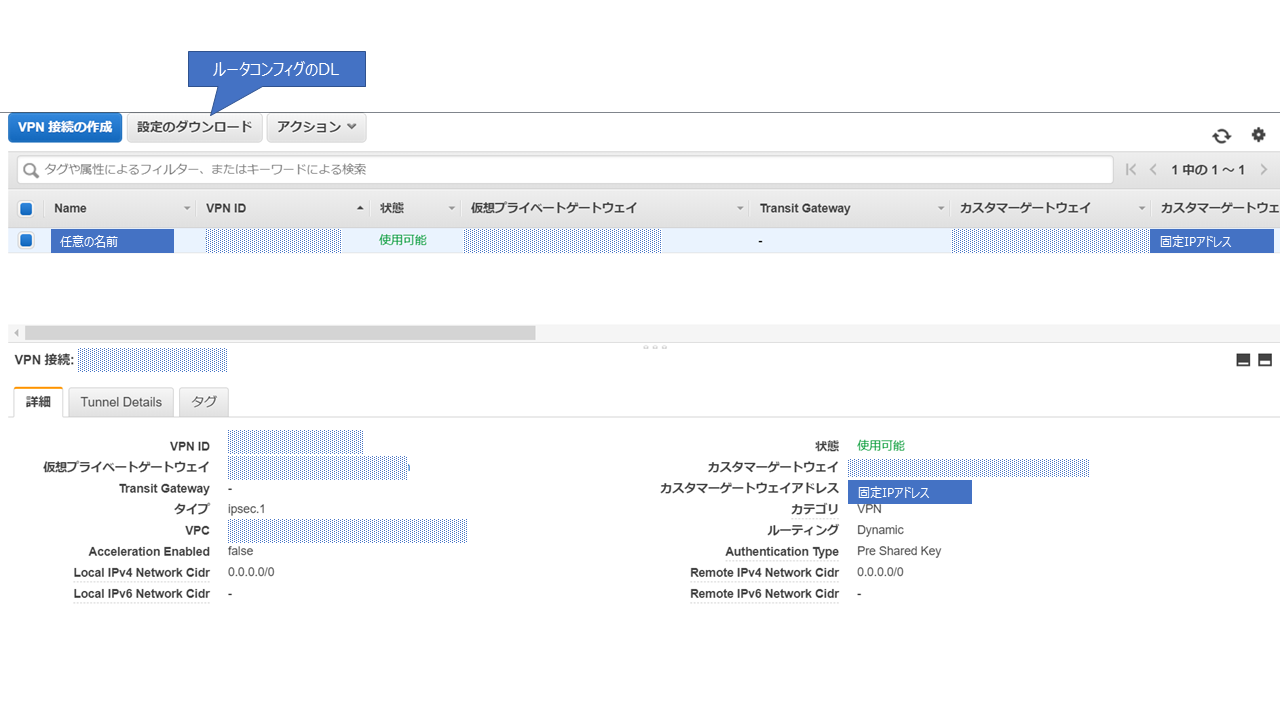
VPN接続設定後の画面は以下のような形になります。
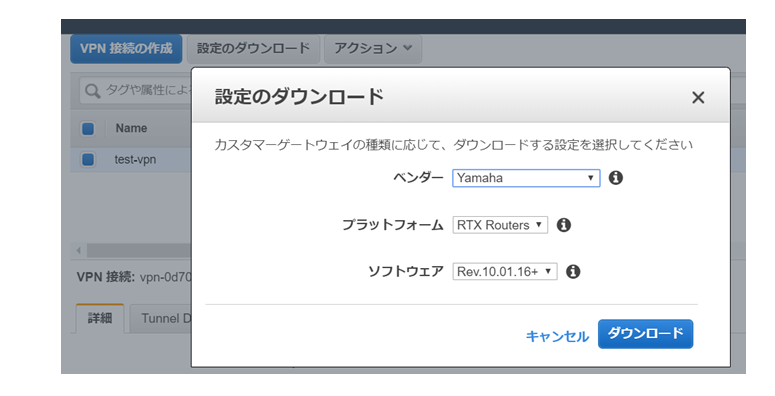
登録が完了すると利用するルータに合わせて、ルータコンフィグをDLできるようになりますのでDLしておきます。
これでAWS側の設定は完了です。ここからはYAMAHA RTX1200 側に必要な設定を投入をしていきます。
まずRTX1200 の基本的な設定を投入していきます。
基本的にベンダー公式情報の通りにやれば設定できるようになってます。
ネット上の情報だと一部修正が必要と書かれている記事もありますが2020年10月時点で
上述の前提条件で設定するはアレンジなしで設定できました。# RTX1200 Rev.10.01.78 (Wed Nov 13 16:29:42 2019) ip route default gateway pp 1 filter 500000 gateway pp 1 ip lan1 address 192.168.100.1/24 pp select 1 pp always-on on pppoe use lan2 pppoe auto disconnect off pp auth accept pap chap pp auth myname (ISPへ接続するID) (ISPへ接続するパスワード) ppp lcp mru on 1454 ppp ipcp msext on ppp ccp type none ip pp address (ルーターのグローバルIPアドレス) ip pp secure filter in 200003 200020 200021 200022 200023 200024 200025 200030 200032 200080 200081 ip pp secure filter out 200013 200020 200021 200022 200023 200024 200025 200026 200027 200099 dynamic 200080 200081 200082 200083 200084 200085 200098 200099 ip pp nat descriptor 1000 pp enable 1 ip filter 200000 reject 10.0.0.0/8 * * * * ip filter 200001 reject 172.16.0.0/12 * * * * ip filter 200002 reject 192.168.0.0/16 * * * * ip filter 200003 reject 192.168.100.0/24 * * * * ip filter 200010 reject * 10.0.0.0/8 * * * ip filter 200011 reject * 172.16.0.0/12 * * * ip filter 200012 reject * 192.168.0.0/16 * * * ip filter 200013 reject * 192.168.100.0/24 * * * ip filter 200020 reject * * udp,tcp 135 * ip filter 200021 reject * * udp,tcp * 135 ip filter 200022 reject * * udp,tcp netbios_ns-netbios_ssn * ip filter 200023 reject * * udp,tcp * netbios_ns-netbios_ssn ip filter 200024 reject * * udp,tcp 445 * ip filter 200025 reject * * udp,tcp * 445 ip filter 200026 restrict * * tcpfin * www,21,nntp ip filter 200027 restrict * * tcprst * www,21,nntp ip filter 200030 pass * 192.168.100.0/24 icmp * * ip filter 200031 pass * 192.168.100.0/24 established * * ip filter 200032 pass * 192.168.100.0/24 tcp * ident ip filter 200033 pass * 192.168.100.0/24 tcp ftpdata * ip filter 200034 pass * 192.168.100.0/24 tcp,udp * domain ip filter 200035 pass * 192.168.100.0/24 udp domain * ip filter 200036 pass * 192.168.100.0/24 udp * ntp ip filter 200037 pass * 192.168.100.0/24 udp ntp * ip filter 200080 pass * 192.168.100.1 udp * 500 ip filter 200081 pass * 192.168.100.1 esp * * ip filter 200098 reject-nolog * * established ip filter 200099 pass * * * * * ip filter 500000 restrict * * * * * ip filter dynamic 200080 * * ftp ip filter dynamic 200081 * * domain ip filter dynamic 200082 * * www ip filter dynamic 200083 * * smtp ip filter dynamic 200084 * * pop3 ip filter dynamic 200085 * * submission ip filter dynamic 200098 * * tcp ip filter dynamic 200099 * * udp nat descriptor type 1000 masquerade nat descriptor address outer 1000 (ルーターのグローバルIPアドレス) nat descriptor masquerade static 1000 1 192.168.100.1 udp 500 nat descriptor masquerade static 1000 2 192.168.100.1 esp dns server (ISPから指定されたDNSサーバーのIPアドレス) dns private address spoof on dhcp service server dhcp server rfc2131 compliant except remain-silent dhcp scope 1 192.168.100.2-192.168.100.191/24続いてAWSからDLしたコンフィグ情報で#がついていない行をコピペで投入していきます。
tunnel select 1 ipsec ike encryption 1 aes-cbc ipsec ike group 1 modp1024 ipsec ike hash 1 sha ipsec ike pre-shared-key 1 text (事前共有キー) ipsec tunnel 201 ipsec sa policy 201 1 esp aes-cbc sha-hmac ipsec ike duration ipsec-sa 1 3600 ipsec ike pfs 1 on ipsec tunnel outer df-bit clear ipsec ike keepalive use 1 on dpd 10 3 ipsec ike local address 1 (固定グローバルIP) ipsec ike remote address 1 (外部IP) ip tunnel address (内部IP CIDR) ip tunnel remote address (内部IP CIDR) ipsec ike local id 1 0.0.0.0/0 ipsec ike remote id 1 0.0.0.0/0 ip tunnel tcp mss limit 1379 tunnel enable 1 tunnel select none ipsec auto refresh on bgp use on bgp autonomous-system 65000 bgp neighbor 1 64512 (内部IP CIDR) hold-time=30 local-address=(内部IP CIDR) bgp import filter 1 equal 0.0.0.0/0 bgp import 64512 static filter 1 bgp configure refresh tunnel select 2 ipsec ike encryption 2 aes-cbc ipsec ike group 2 modp1024 ipsec ike hash 2 sha ipsec ike pre-shared-key 2 text (事前共有キー) ipsec tunnel 202 ipsec sa policy 202 2 esp aes-cbc sha-hmac ipsec ike duration ipsec-sa 2 3600 ipsec ike pfs 2 on ipsec tunnel outer df-bit clear ipsec ike keepalive use 2 on dpd 10 3 ipsec ike local address 2 (固定グローバルIP) ipsec ike remote address 2 (外部IP) ip tunnel address (内部IP CIDR) ip tunnel remote address (内部IP CIDR) ipsec ike local id 2 0.0.0.0/0 ipsec ike remote id 2 0.0.0.0/0 ip tunnel tcp mss limit 1379 tunnel enable 2 tunnel select none ipsec auto refresh on bgp use on bgp autonomous-system 65000 bgp neighbor 2 64512 (内部IP CIDR) hold-time=30 local-address=(内部IP CIDR) bgp import filter 1 equal 0.0.0.0/0 bgp import 64512 static filter 1 bgp configure refresh ipsec ike local address 1 192.168.100.1 ipsec ike local address 2 192.168.100.1これでルータ側のコンフィグ投入も完了です。
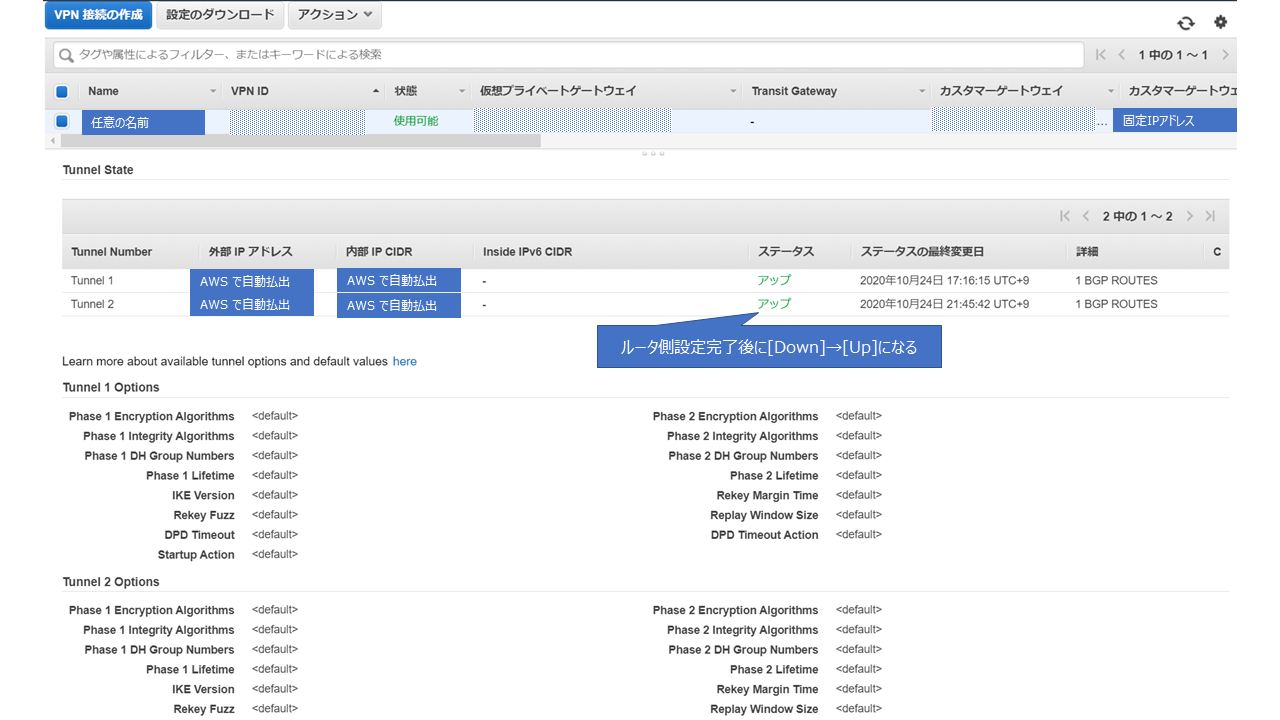
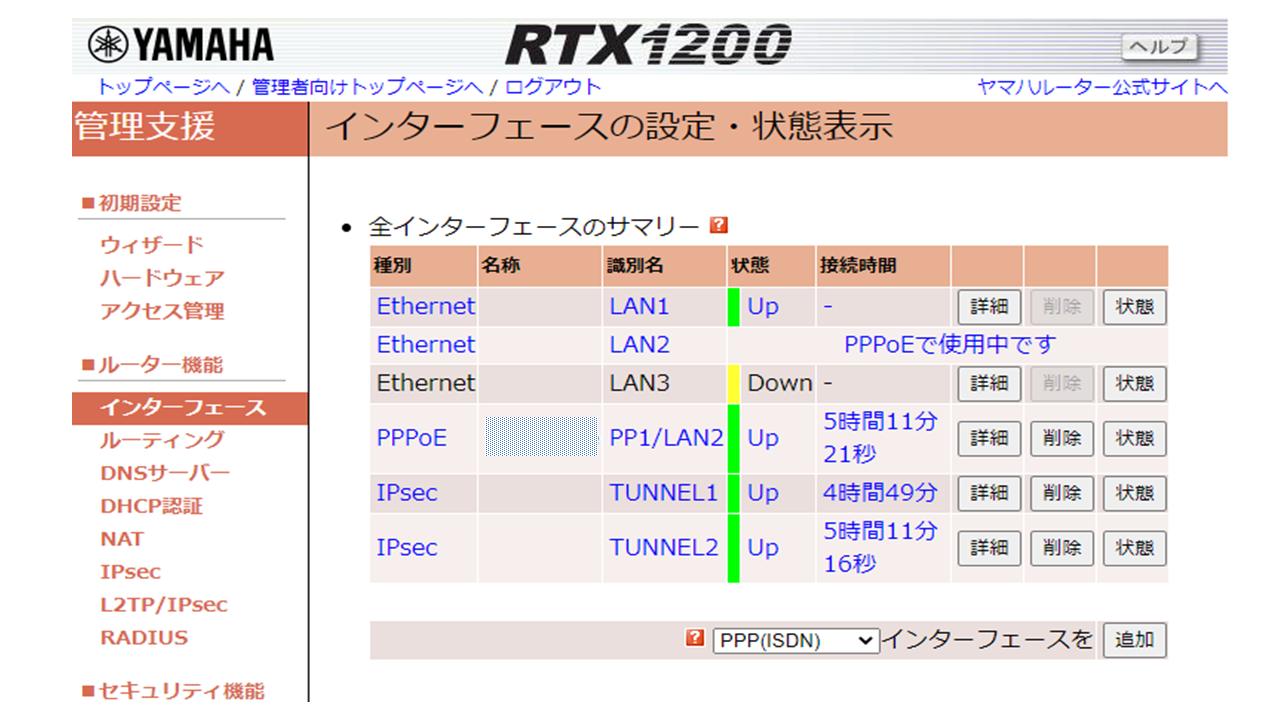
ルータ配下にPCを接続して、今のルータ設定状態をGUIで確認してみましょう!
YAMAHA RTX1200 のデフォルト設定では、ルータとPCをLANケーブルでつないで、Webブラウザーでhttp://192.168.100.1/ でルータ管理画面(GUI)にアクセスできます。
LAN1 に別IPアドレスを割り当てた場合はその適宜変更してください。
PPPoEを設定したLan2と2つ設定したIPsecのTunnelのステータスがUpになっていればOKです。
AWSのサイト間VPNではデフォルトで2本IPsecを設定する形になります。最後にPCからAWS VPC上のTest-ServerにプライベートIPでRDPできるか確認しましょう!
無事RDP接続できれば、VPN接続できていますd(`・ω・’)
終わりに
どういうわけか、みんなYAMAHAは設定簡単だよ~って言います(笑)
未経験者からするとよく分からんコマンドが並んでいて、この設定であっているか凄い不安になりますが、基本的にコピペと公式の指示通りにすれば接続できます。初心者に優しいというのは重要です!参考ページ


- 投稿日:2020-10-27T22:23:45+09:00
[AWS】MFAの有効化とSSH接続
AWSの利用を開始した際、すぐにやっておきたいのは
ルートユーザの保護です。今回はルートユーザのMFA有効化などによる保護、作業用アカウントの作成とSSH接続までをやってみます。
ルートユーザのMFA有効化
MFAの詳細は以下AWSの公式サイトを参照。
AWS での多要素認証 (MFA) の使用MFA(多要素認証)を利用するとログインに認証済デバイスが必要となるため
セキュリティがぐっと高くなります。ここではルートユーザだけMFAを有効化しますが
全ユーザでMFAを有効化しておくことをお勧めします。
MFAデバイスにはいくつか種類がありますが、仮想MFAデバイスを利用することが
多いと思いますので今回は仮想MFAデバイス(Android端末)を利用します。1.ナビゲーションバーの右側で、使用するアカウント名を選択し、「マイセキュリティ資格情報」を選択
2.多要素認証(MFA)項目の中にある「MFA有効化」をクリックし、次のウィザードで続行を押下
3.QRコードを表示し、Androidで立ち上げた仮想MAFアプリでスキャンする
4.アプリで表示される連続するMFAコードを2つ入力する(時間経過すると自動でMFAコードは切り替わる)これでMFAデバイスの有効化は完了です。
次回のログイン時からはアカウントIDとパスワードに加えてMFAコードが必要となります。注意点
セキュリティは向上しますが、MFAデバイスの故障や紛失が起きるとログインが出来なくなります。
アカウントに登録している電話とEメールで回避が可能なので、
アカウント情報には正しいものを入力して起きましょう。これをしておかないとAWSサポートへの
連絡が必要となりかなり手間がかかります。以上
- 投稿日:2020-10-27T22:07:41+09:00
AWS SAMを用いてローカルでLambdaを開発する時に独自の環境変数をどう扱うか
はじめに
この記事は、AWS SAMを用いてLambda関数の実装をローカルで行う際に、
ユーザ独自の環境変数をどう扱うかについてハマってしまったことをまとめた記事です。
Lamnda関数を通してTwitterAPIを用いてツイートを送信する処理を実装したのですが、ローカルでの実行時にAPIキーなどを扱う時に苦労しました。
これが正解かどうかは確かではありませんが、ローカルでの検証や実行を行う際のやり方の一つではないかと思います。godotenvが使えない…?
今回、Lambda関数はGolangを用いて開発をしました。
Golangにおいて環境変数を読み込む時は、godotenvというオープンソースパッケージを用いて.envファイルから環境変数を読み込んでいます。.envHOGE_ACCESS_TOKEN="" HOGE_ACCESS_TOKEN_SECRET=""main.goerr := godotenv.Load()しかし、AWS SAMを用いて開発をした場合、この
.envファイルを読み込むのには少し癖があるそうです。
というのも、AWS SAMを用いて開発をした場合、SAM側はLambdaを実行している時だけDockerコンテナを立ち上げるため、通常go run main.goコマンドを使ってプログラムを実行するだけで読み込めた.envファイルが読み込めない場合がほとんどです。
※こちらについて、僕なりに.envファイルをDocker Lambdaで読み込む方法を調べましたが、良い方法を見つけることが出来ませんでした?環境変数を定義するJSONから読み込む
SAMのドキュメントを読んでみると、
--env-varsという環境変数を読み込むためのオプションが用意されています。
環境変数ファイルとは何かというのをさらに調べたところ、Lambda関数に定義されている環境変数をJSON形式で書くことによって、それらを上書きできるというものらしいです。
Lambda関数の環境変数の定義はAWSのコンソール上からも定義が出来るので、それらをJSONで管理しているものと考えて良いでしょう。ドキュメントによると、JSONは以下のように定義が出来ます。
env.json{ "Your function name": { "TABLE_NAME": "hoge", "BUCKET_NAME": "fuga" } }今回私はTwitterのAPIキーをこの
env.jsonに記載しました。
なおこのJSONファイルは、.gitignoreに含めることをオススメします。リポジトリにはenv.sample.json的な名前をつけた空っぽのファイルをpushしましょう。env.json{ "Your function name": { "TWITTER_API_KEY": "hogehoge", "TWITTER_SECRET_KEY": "fugafuga" } }template.yamlから定義済み環境変数を読み込む
env.jsonに定義したファイルを、今度はLambda関数に読み込ませます。
SAM templateを用いてLambda関数を生成した場合、template.yamlというファイルが生成されていると思います。こちらのyamlファイルの
ParameterセクションにAPIキーのフィールドを定義します。template.yamlDescription: > Sample function Params: TwitterAPIKey: Type: String TwitterSecretKey: Type: String受け取ったAPIキーを、
Resourcesセクションの中でこのlambda関数の環境変数として設定をします。template.yamlResources: SampleFunction: Type: AWS::Serverless::Function Properties: Environment: Variables: TWITTER_API_KEY: !Refs TwitterAPIKey TWITTER_SECRET_KEY: !Refs TwitterSecretKeyコードから環境変数を読み込み、実行
読み込まれた環境変数は、
os.Getenv()を使ってコード上から呼び出すことが可能です。main.go// getCredential TwitterAPIを取得する func getCredential() *anaconda.TwitterApi { return anaconda.NewTwitterApiWithCredentials( os.Getenv("TWITTER_ACCESS_TOKEN"), os.Getenv("TWITTER_ACCESS_TOKEN_SECRET"), ) }忘れてはならないのが、
sam local invokeコマンドを使って実行する際に--env-varsオプションをつけて実行することです。sam build; sam local invoke SampleFnuction \ --env-vars env.jsonまとめ
godotenvを使って環境変数を読み込む方法を見つけられなかったので、JSONファイルから独自の環境変数を定義して読み込むやり方を採用しましたが、これよりも良い方法が何かしらあると思っています。実際に、aws-sam-cliのissueにも、dotenvファイルを読み込むオプションを作らないかという提案が上がっているのを見つけました。
feat(init): load .env file at startup of sam local #1355
現状、sam-cliを使って
.envファイルをローカルで読み込む方法は無さそうなので、しばらくは今回紹介したやり方で運用をしようかと思います。参考

- 投稿日:2020-10-27T21:21:19+09:00
AWS CloudFormationを動かすためのAWS CLIの設定
はじめに
AWS CloudFormationを動かすための事前準備として、AWS CLIの設定が必要です。
設定方法
Amazon Linux 2
※デフォルトでAWS CLIが利用できます。
- AdministratorAccessポリシー関連付けたIAMロールを作成し、EC2インスタンスにアタッチします。
- ~/.bashrcに
AWS_DEFAULT_REGION=ap-northeast-1を追記します。source ~/.bashrcを実行してください。Mac
brew install awscliを実行し、AWS CLIをインストールします。- IAMユーザーを作成し、アクセスキーとシークレットキーを発行しましす。
aws configureを実行します。ターミナル$ aws configure AWS Access Key ID [None]: {アクセスキー} AWS Secret Access Key [None]: {シークレットアクセスキー} Default region name [None]: ap-northeast-1 Default output format [None]: json
- 投稿日:2020-10-27T20:29:36+09:00
これでスポットリクエストのキャンセルし忘れとさらばだ!
概要
開発環境にEC2のスポットインスタンスを利用することはよくあると思います。その中でも「永続的リクエスト」を使っているとついついインスタンスだけを「終了」し、スポットリクエストをキャンセルし忘れることありませんか?リクエスト有効期間内であれば、自動的に同じタイプのインスタンスがゾンビのごとくのように再作成され、無駄な課金が発生します。
インスタンスの削除時にスポットリクエストからキャンセルするように運用手順で決めていてもついつい忘れがちなので、自動化する方法を紹介します。前提条件のまとめ
- スポットインスタンスを使用している
- 永続的リクエストである
- リクエスト有効期限内である
構成
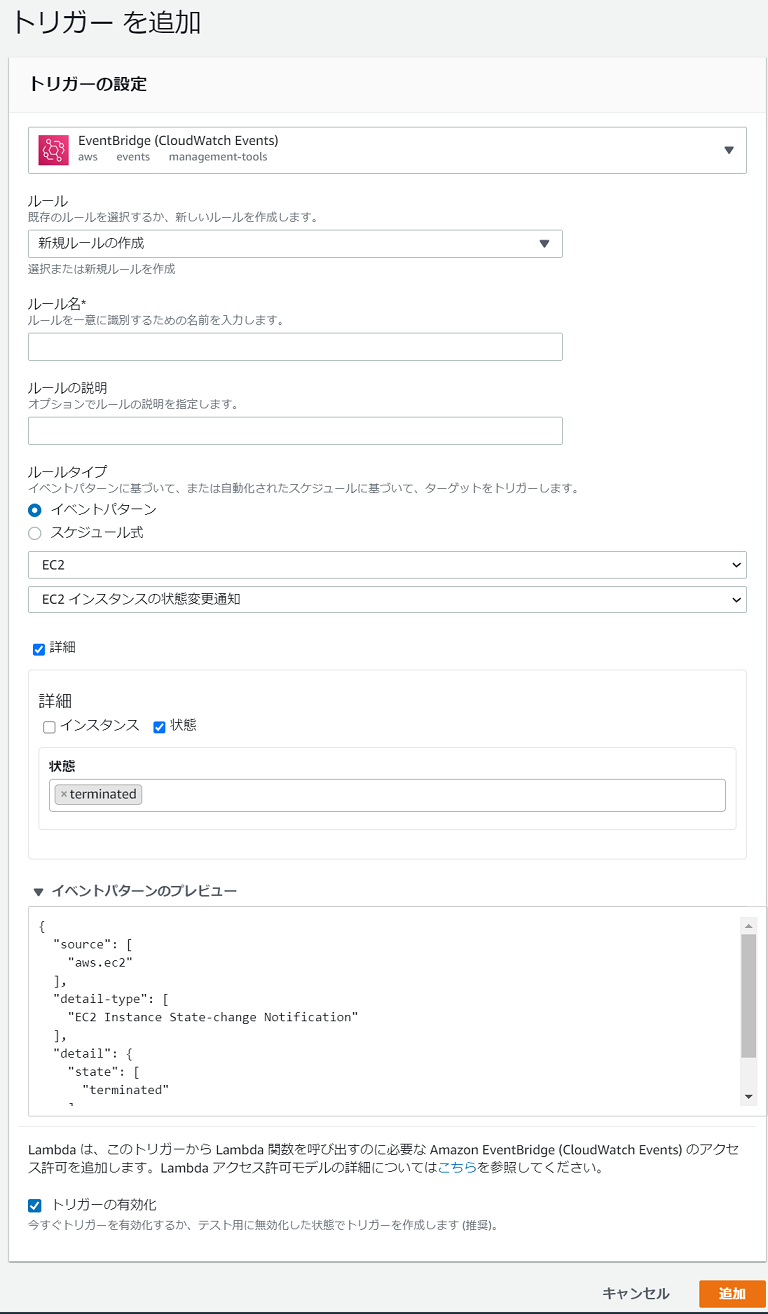
EventBridgeを使用することで、インスタンス終了イベント時に指定したLambdaを実行し、スポットリクエストをキャンセルします。
EventBridge
イベントとしてインスタンスの状態変更通知で「Terminated」を追加します。
eventbridge.json{ "detail-type": [ "EC2 Instance State-change Notification" ], "source": [ "aws.ec2" ], "detail": { "state": [ "terminated" ] } }Lambda
Lambdaにアタッチされているロールに以下の権限(インスタンスの情報取得、スポットリクエストのキャンセル)を含めればOKです。
role.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:CancelSpotInstanceRequests", "ec2:DescribeInstances" ], "Resource": "*" } ] }EventBridgeから渡される変数は以下になります。
同時に複数のインスタンスを削除した場合でも、1つずつのイベントとして送られますので、
Lambda側では基本的に単数を想定した実装でよいでしょう。event.json{ "version": "0", "id": "xxxxxxxxxxxxxxxxxxxxxx", "detail-type": "EC2 Instance State-change Notification", "source": "aws.ec2", "account": "xxxxxxxxxx", "time": "2020-10-26T09:28:11Z", "region": "ap-northeast-1", "resources": [ "arn:aws:ec2:ap-northeast-1:xxxxxx:instance/i-xxxxxxxxxxxx" ], "detail": { "instance-id": "i-xxxxxxxxxxxx", "state": "terminated" } }eventのinstance-idからインスタンスの情報を取得し、関連するスポットリクエストをキャンセルする。
cancle_spotrequest.pyimport json import boto3 def lambda_handler(event, context): ''' EC2インスタンス削除時に関連するスポットリクエストをキャンセルする ''' print('--------event----------') print(event) print('------------------') client = boto3.client('ec2') event_detail = event['detail'] if event_detail['state'] != 'terminated': return # インスタンスIDで終了済みのスポットインスタンスを取得する response = client.describe_instances( Filters=[{ 'Name': 'instance-state-name', 'Values': ['terminated'] },{ 'Name': 'instance-lifecycle', 'Values': ['spot'] }], InstanceIds=[event_detail['instance-id']] ) # 対象がなければ、終了 if len(response['Reservations']) <= 0: return spot_request_id = '' for reservations in response['Reservations']: for ins in reservations['Instances']: spot_request_id = ins['SpotInstanceRequestId'] print('--------cancel id----------') print(spot_request_id) print('------------------') # スポットリクエストをキャンセル client.cancel_spot_instance_requests(SpotInstanceRequestIds=[spot_request_id])

- 投稿日:2020-10-27T18:31:05+09:00
データストア(データベース)における汎用的な機能分類について
概要
データストアの製品選定を行う際に、データストアに求められる機能を分類してみました。
この機能分類を分解していき、製品間で比較することを想定しております。データストアとは、データベースだけでなく、データレイク(ストレージ)を含めることを想定しております。
私が考えているデータストアとしては、データ分析基盤における概念モデル(リファレンスアーキテクチャ)の下記を含むことを想定しております。
- ストレージ
- オペレーショナルデータストア (ODS)
- データレイク
- データ統合サービス
- データウェアハウス(DWH)【分析データストア(コールドパス)】
- 分析データストア(ホットパス)
- セマンティックデータモデル
- データ仮想化ソリューション
- クエリエンジン
データ分析基盤における概念モデル(リファレンスアーキテクチャ)については下記の記事をご確認ください。
データストアの機能
データストアの機能分類
# 第一分類 機能分類 A 機能要件 接続の提供 B 機能要件 メタデータ定義 C 機能要件 データ品質保証 D 機能要件 データ蓄積 E 機能要件 データの問い合わせ F 機能要件 プログラミング G 機能要件 オーケストレーション H 機能要件 クエリ最適化 I 機能要件 データ活用 J 機能要件 データ書き込み K 機能要件 データ取込 V 非機能要件 運用保守性 W 非機能要件 セキュリティ X 非機能要件 拡張性 Y 非機能要件 回復性 Z 非機能要件 可用性 データストアの機能詳細
# 第一分類 機能分類_1 機能分類_2 機能項目 A010 機能要件 接続の提供 エンドポイントの利用 エンドポイントの利用 A020 機能要件 接続の提供 APIの利用 ODBCによるデータ処理 A030 機能要件 接続の提供 APIの利用 JDBCによるデータ処理 A040 機能要件 接続の提供 APIの利用 REST APIによるデータ処理 A050 機能要件 接続の提供 APIの利用 SDKによるデータ処理 A060 機能要件 接続の提供 APIの利用 CLIによるデータ処理 B010 機能要件 メタデータ定義 DDL(Data Definition Language) DDLの利用 B020 機能要件 メタデータ定義 サポートしているデータ型 サポートしているデータ型 B030 機能要件 メタデータ定義 動的スキーマ 動的スキーマの利用 B040 機能要件 メタデータ定義 データカタログから配信されたスキーマの利用 データカタログから配信されたスキーマの利用 B050 機能要件 メタデータ定義 データベースオブジェクトの定義 複数のインスタンスの定義 B060 機能要件 メタデータ定義 データベースオブジェクトの定義 複数のデータベースの定義 B070 機能要件 メタデータ定義 データベースオブジェクトの定義 複数のスキーマの定義 B080 機能要件 メタデータ定義 データベースオブジェクトの制約 マルチバイト文字のオブジェクトでの利用 B090 機能要件 メタデータ定義 外部データストアオブジェクトの定義 外部データストアの参照 C010 機能要件 データ品質保証 制約の利用 一意性制約 C020 機能要件 データ品質保証 制約の利用 NOT NULL制約 C030 機能要件 データ品質保証 制約の利用 主キー制約 C040 機能要件 データ品質保証 制約の利用 参照整合性(外部キー)制約 C050 機能要件 データ品質保証 制約の利用 チェック制約 C060 機能要件 データ品質保証 制約の利用 エッジ制約 C070 機能要件 データ品質保証 データプロファイル データプロファイル D010 機能要件 データ蓄積 サポートしているデータストアモデル サポートしているデータストアモデル D020 機能要件 データ蓄積 サポートしているデータ保持方針 サポートしているデータ保持方針 D030 機能要件 データ蓄積 サポートしているトランザクション分離レベル サポートしているトランザクション分離レベル D040 機能要件 データ蓄積 サポートしているデータモデルリング技法 サポートしているデータモデルリング技法 D050 機能要件 データ蓄積 サポートしているデータ形式 構造化データのデータ蓄積 D060 機能要件 データ蓄積 サポートしているデータ形式 半構造化データのデータ蓄積 D070 機能要件 データ蓄積 サポートしているデータ形式 非構造化データのデータ蓄積 D080 機能要件 データ蓄積 データの変更管理 データのバージョニング(タイムトラベル) D090 機能要件 データ蓄積 データの変更管理 変更データキャプチャ D100 機能要件 データ蓄積 HTAP(Hybrid transactional/analytical processing)の対応 OLTP型データストアにて分析用クエリが利用可能な領域への自動蓄積 E010 機能要件 データの問い合わせ クエリ実行方法 SQLによるクエリ実行方法 E020 機能要件 データの問い合わせ クエリ実行方法 REST APIによるクエリ実行方法 E030 機能要件 データの問い合わせ クエリ実行方法 GraphQLによるクエリ実行方法 E040 機能要件 データの問い合わせ クエリ実行方法 SDKによるクエリ実行方法 E050 機能要件 データの問い合わせ サポートしているデータ形式 構造化データへのクエリ E060 機能要件 データの問い合わせ サポートしているデータ形式 半構造化データへのクエリ E070 機能要件 データの問い合わせ サポートしているデータ形式 非構造化データへのクエリ E080 機能要件 データの問い合わせ 外部データストアへのクエリ 外部データストアへのクエリ実行 E090 機能要件 データの問い合わせ 外部データストアへのクエリ サポートしている外部データストアのファイル形式 F010 機能要件 プログラミング ユーザー定義関数 ユーザー定義関数の利用 F020 機能要件 プログラミング 動的SQL 動的SQLの利用 F030 機能要件 プログラミング ストアードプロシージャ ストアードプロシージャの利用 F040 機能要件 プログラミング トリガー トリガーの利用 F050 機能要件 プログラミング ビュー ビューの利用 F060 機能要件 プログラミング ビュー 外部テーブルを含むビューの利用 F070 機能要件 プログラミング 外部APIの利用 外部REST APIの利用 F080 機能要件 プログラミング 外部ライブラリーの利用 外部ライブラリーの利用 G010 機能要件 オーケストレーション パイプライン定義 他プロセス実行 G020 機能要件 オーケストレーション パイプライン定義 パイプライン定義 G030 機能要件 オーケストレーション プロセスコントロール パイプライントリガー登録 G040 機能要件 オーケストレーション プロセスコントロール パイプライン実行ログ保持 G050 機能要件 オーケストレーション プロセスコントロール パイプラインアラート G060 機能要件 オーケストレーション プロセスコントロール パイプライン処理のエラー時の再実行 H010 機能要件 クエリ最適化 インデックスの利用 クラスター化インデックスの設定 H020 機能要件 クエリ最適化 インデックスの利用 非クラスター化インデックスの設定 H030 機能要件 クエリ最適化 データ保持方法の最適化 列ストアインデックスの設定 H040 機能要件 クエリ最適化 マテリアルビューの利用 マテリアルビュー(単一テーブルの集計結果を保持)の設定 H050 機能要件 クエリ最適化 マテリアルビューの利用 マテリアルビュー(複数テーブルの結合後の集計結果を保持)の設定 H060 機能要件 クエリ最適化 マテリアルビューの利用 マテリアルビュー(外部データストア)の設定 H070 機能要件 クエリ最適化 パーティションの利用 水平的パーティション分割(シャーディング)の設定 H080 機能要件 クエリ最適化 パーティションの利用 垂直的パーティション分割の設定 H090 機能要件 クエリ最適化 水平的パーティション分割の設定方法 レンジ(範囲)パーティションの設定 H100 機能要件 クエリ最適化 水平的パーティション分割の設定方法 リストパーティションの設定 H110 機能要件 クエリ最適化 水平的パーティション分割の設定方法 ハッシュパーティションの設定 H120 機能要件 クエリ最適化 テーブルの分散方法 ラウンドロビン分散テーブル H130 機能要件 クエリ最適化 テーブルの分散方法 ハッシュ分散テーブル H140 機能要件 クエリ最適化 テーブルの分散方法 レプリケート テーブル H150 機能要件 クエリ最適化 リソースの再利用 結果セットキャッシュの利用 H160 機能要件 クエリ最適化 リソースの最適化 データの統計情報更新 H170 機能要件 クエリ最適化 リソースの最適化 ワークロード管理 H180 機能要件 クエリ最適化 ストレージ最適化 インデックスの最適化 H190 機能要件 クエリ最適化 ストレージ最適化 データ配置の最適化(VACUUM) H200 機能要件 クエリ最適化 パフォーマンスの自動チューニング インデックスの自動設定 H210 機能要件 クエリ最適化 パフォーマンスの自動チューニング マテリアルビューの自動設定 H220 機能要件 クエリ最適化 パフォーマンスの自動チューニング データの統計情報の自動更新 H230 機能要件 クエリ最適化 パフォーマンスの自動チューニング パーティションの自動設定 I010 機能要件 データ活用 可視化 可視化の実施 I020 機能要件 データ活用 統計解析 統計解析の実施 I030 機能要件 データ活用 シミュレーション シミュレーションの実施 J010 機能要件 データ書き込み データの更新方法 全件更新 J020 機能要件 データ書き込み データの更新方法 差分更新 J030 機能要件 データ書き込み データの更新方法 増分更新 J040 機能要件 データ書き込み データの更新方法 履歴保持型差分更新 J050 機能要件 データ書き込み 連携タイミング(レイテンシー)に応じた処理 バッチ処理により書き込み J060 機能要件 データ書き込み 連携タイミング(レイテンシー)に応じた処理 準リアルタイムとイベント駆動により書き込み J070 機能要件 データ書き込み 連携タイミング(レイテンシー)に応じた処理 リアルタイム(低レイテンシまたはストリーミング)による書き込み J080 機能要件 データ書き込み データ書き込みの最適化 データの一括書き込み J090 機能要件 データ書き込み データ書き込みの最適化 ストレージからの並列書き込み K010 機能要件 データ取込 データレプリケーション トランザクションレプリケーション K020 機能要件 データ取込 データレプリケーション データ同期 K030 機能要件 データ取込 他データストアへのデータ取込 外部ストレージへのエクスポート K040 機能要件 データ取込 他データストアへのデータ取込 ODBCによるデータ取込 K050 機能要件 データ取込 他データストアへのデータ取込 JDBCによるデータ取込 K060 機能要件 データ取込 他データストアへのデータ取込 REST APIによるデータ取込 K070 機能要件 データ取込 他データストアへのデータ取込 CLIによるデータ取込 V010 非機能要件 運用保守性 運用支援 スキーマのバージョン管理 V020 非機能要件 運用保守性 リリース支援 スキーマの差分反映 V030 非機能要件 運用保守性 リリース支援 データベース定義の自動差分反映 V040 非機能要件 運用保守性 リリース支援 ソフトウェアのバージョン管理 V050 非機能要件 運用保守性 パフォーマンス監視 クエリの発行履歴の保持 V060 非機能要件 運用保守性 パフォーマンス監視 クエリ実行時のリソース利用情報の保持 V070 非機能要件 運用保守性 パフォーマンス監視 クエリ実行時の実行計画の保持 V080 非機能要件 運用保守性 パフォーマンス監視 パフォーマンスに関するアラート W010 非機能要件 セキュリティ 認証 基本認証の利用 W020 非機能要件 セキュリティ 認証 多要素認証の実施 W030 非機能要件 セキュリティ 認証 多段階認証の実施 W040 非機能要件 セキュリティ 認証 外部IDサービスの利用 W050 非機能要件 セキュリティ データストアシステムへの権限付与 SQL命令(DDL、DCL)相当に対する実行の権限付与 W060 非機能要件 セキュリティ データストアシステムへの権限付与 オブジェクト(スキーマ)一覧の閲覧の権限付与 W070 非機能要件 セキュリティ データストアシステムへの権限付与 子オブジェクトへの継承の権限付与 W080 非機能要件 セキュリティ データストアシステムへの権限付与 データ参照の権限付与 W090 非機能要件 セキュリティ データストアシステムへの権限付与 データ挿入・更新・削除の権限付与 W100 非機能要件 セキュリティ データストアシステムへの権限付与 データストアに対するデータアクセス者の認証による権限付与 W110 非機能要件 セキュリティ データへの権限付与 ルールベースによる行レベルセキュリティ W120 非機能要件 セキュリティ データへの権限付与 データ権限(認可)テーブルを利用した行レベルセキュリティ W130 非機能要件 セキュリティ データへの権限付与 列への参照権限付与による列レベルセキュリティ W140 非機能要件 セキュリティ データへの権限付与 永続データマスキングによる列レベルセキュリティ W150 非機能要件 セキュリティ データへの権限付与 動的データマスキングによる列レベルセキュリティ W160 非機能要件 セキュリティ 物理的なセキュリティ W170 非機能要件 セキュリティ 監視 監査ログデータの生成 W180 非機能要件 セキュリティ 境界 セキュリティ監視サービスの利用 W190 非機能要件 セキュリティ ネットワーク ファイヤーウォールの設定 W200 非機能要件 セキュリティ アプリケーション W210 非機能要件 セキュリティ データ データの暗号化 X010 非機能要件 拡張性 データ容量の拡張 データ容量の拡張 X020 非機能要件 拡張性 同時実行数 同時実行数 X030 非機能要件 拡張性 コンピューティングリソースの拡張 スケールアップ (垂直方向のスケーリング) X040 非機能要件 拡張性 コンピューティングリソースの拡張 ノードのスケールアウト (水平方向のスケーリング) X050 非機能要件 拡張性 コンピューティングリソースの拡張 クラスターのスケールアウト (水平方向のスケーリング) X060 非機能要件 拡張性 コンピューティングリソースの拡張 コンピューティングリソースのマルチ化 Y010 非機能要件 回復性 偶発的なリソース削除への対応 偶発的なリソース削除への対応 Y020 非機能要件 回復性 データセンターの一部に対する障害対応 データセンターの一部に対する障害対応 Y030 非機能要件 回復性 データセンター全体に対する障害対応 データセンター全体に対する障害対応 Y040 非機能要件 回復性 バックアップ 自動バックアップ Y050 非機能要件 回復性 バックアップ 手動バックアップ Y060 非機能要件 回復性 バックアップ バックアップファイルのエクスポート Y070 非機能要件 回復性 バックアップ バックアップからの復元 Y080 非機能要件 回復性 バックアップ ポイントインタイムリストア Z010 非機能要件 可用性 可用性の最適化 フォールトレランス Z020 非機能要件 可用性 サービスレベルアグリーメント サービス レベル アグリーメント Z030 非機能要件 可用性 計画的なメンテナンスへの対応 計画的なメンテナンスへの対応 Z040 非機能要件 可用性 データセンターの一部に対する障害対応 データセンターの一部に対する障害対応 Z050 非機能要件 可用性 データセンター全体に対する障害対応 データセンター全体に対する障害対応 前提知識
データストアモデル一覧
# データストアモデル 1 リレーショナル型データベース 2 キーバリュー型データベース 3 ドキュメント型データベース 4 グラフ型データベース 5 データ分析型データベース 6 列指向型データベース 7 検索エンジン型データベース 8 時系列データベース 9 空間データベース 10 オブジェクトストレージ 11 ファイル共有ストレージ データモデル一覧
# データモデル 1 リレーショナルモデリング(3NF) 2 データヴォールトモデリング(DV) 3 ディメンションナルモデリング(DM) 4 第一正規形(大福帳)モデリング(1NF) 5 NoSQL データ保持方針
# データの保持方針 説明 代表的なサービス 1 メモリとストレージの最適利用型 データをシステムが管理しているストレージに保持しておき、必要に応じてメモリに展開して処理する方法。 PostgreSQL、Spark 2 OLTP最適化インメモリ型 データの書き込みとデータの読み込みに最適化できるようにデータをメモリに保持しておき処理する方法。 SAP HANA、Redis 3 クエリ最適化インメモリ型 データの読み込みに最適化できるようにデータをメモリに保持しておき処理する方法。 Power BIデータセット 4 ストレージ集中型 データをストレージに保持しておき、最小減のメモリのみ利用するように、中間結果をストレージに保存しながら処理する方法。 Hadoop データ処理の類型
# データ処理分類 データ処理分類 説明 1 データ抽出 データ抽出 ソースのデータストアからデータを抽出する処理。 2 データ変換 データ変換 データを変換する処理。 3 データ変換 データのメタデータ変換 データのメタデータ(データ型、データの構造化等)を実施する処理。 4 データ変換 データのフィルタリング 指定の条件のみのデータに変換する処理。 5 データ変換 データの並び替え データの並び替えを実施する処理。 6 データ変換 データの結合 複数のデータを結合する処理。 7 データ変換 データの集計 データを集計する処理。 8 データ変換 データのユニオン データをユニオンする処理。 9 データ変換 分析関数(Parttition BY句相当機能)の利用 分析関数(Parttition BY句相当機能)を利用する機能。 10 データ変換 データクレンジング 現在のデータの品質を改善する処理 11 データ変換 データ強化 参照データとのマッピングや変換仕様の実装を行うことで、データの付加によるデータの品質を改善する処理。 12 データ取込 データ取込 ターゲットのデータストアにデータを取り込む処理。 13 データの問い合わせ データの問い合わせ 内部で管理しているストレージからデータを読み込む処理。 14 データ書き込み データ書き込み 内部で管理しているストレージにデータを書き込む処理。
- 投稿日:2020-10-27T16:38:26+09:00
Amazon EC2のインスタンスにプロキシサーバーを構築する方法
はじめに
自分専用のProxyサーバーを構築しました。
その手順を書き残しておきますので参考になれば幸いです。目次
・環境
・Elastic IPの設定
・Squidのインストール
・Squidの設定
・AWSセキュリティグループの設定
・クライアント(自宅PC)の設定
・終わりに環境
AWSのインスタンスは以下のものを使用しました。
・Red Hat Enterprise Linux 8(無料版)Elastic IPの設定
インスタンスを作成したら、IPアドレスを固定します。
(これをしないと、起動するたびにIPが変わって面倒です。)方法は以下のURLを参考にしてください。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/elastic-ip-addresses-eip.htmlSquidのインストール
インスタンスにSSH接続して以下のコマンドを実施します。
①Squidのインストールsudo yum install -y squid②Squidの起動
sudo systemctl enable squid③ステータスの確認(squid.serviceがenabledであること)
sudo systemctl list-unit-files -t service | grep squidSquidの設定
squid.confを以下のように修正します。
①ファイルの修正sudo vim /etc/squid/squid.conf②追記する内容
# 接続したいIPアドレスを指定(複数指定可能) acl myip src [IPアドレス1]/32 acl myip src [IPアドレス2]/32 # 接続したいIPを許可 http_access allow myip自宅PCのグローバルIPは以下のサイトで調べられます。
https://www.cman.jp/network/support/go_access.cgi③Squidのリロード
sudo systemctl reload squidAWSセキュリティグループの設定
インスタンスのファイヤーウォールの設定を行います。
デフォルトではSSH接続のポートしか開いていないので、
Proxy用のポートも解放します。(デフォルトだと3128)設定方法は以下のURLを参照してください。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/working-with-security-groups.html#adding-security-group-rule設定は以下のようにします。
タイプ:カスタムTCPルール
プロトコル:TCP
ポート範囲:3128
ソース:自分のPCのグローバルIP/32
説明:TCP for Proxy(これはなんでもいいです。)AWSコンソールのセキュリティグループを選択。
クライアント(自宅PC)の設定
Proxyを指定します。
設定⇒ネットワークとインターネット⇒プロキシ
プロキシサーバーを使うをオンにする。
アドレス:インスタンスのIP
ポート:3128終わりに
とりあえずこれらを実施して動きました。
IPを調べてみたらちゃんとProxyサーバーのIPになってます。参考にしたサイト
https://blog.officekoma.co.jp/2020/04/aws-ec2linux.html
- 投稿日:2020-10-27T14:25:03+09:00
AWS 認定 ソリューションアーキテクト – アソシエイトに合格しました
はじめに
AWS SAAに1発合格しましたので、学習方法・反省点をまとめました。
プロフィールは以下の通りです。
- 年齢:23歳(新卒2年目)
- 会社:元請けSIer
- 職業:システムエンジニア
- 備考:AWS実務経験無し
学習履歴
以下3つの教材で学習対策を行いました。
学習の際に、実際のAWSスキルも養いたかったため、ポートフォリオ作成と並行しつつ、
AWS SAA学習を実施しました。これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
- 良かった点
- ハンズオン形式で学習出来る
- AWSの主要サービスを一通り学習出来る
- 模擬テストを受験出来る
AWS WEB問題集で学習しよう
- 良かった点
- 問題数がかなり豊富
- スキマ時間に取り組むことが出来る
- 基礎固めに最適な難易度
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
- 良かった点
- 難易度が本試験に近い
- 6回分模擬試験に取り組むことが出来る
- スキマ時間に取り組むことが出来る
最後に
合格後に感じたこと
- Web系企業への転職の際に、アピールポイントになる
- AWSのサービス・用語をほぼ理解出来る
反省点
- 受験直前は、自然と暗記が多くなってしまった
- 実務経験が無いため、イメージしにくい問題が多かった

- 投稿日:2020-10-27T11:31:44+09:00
KubernetesにおいてのAWSリソースのアクセス管理
はじめに
Kubernetesは、マシンを最大限に活用できるオープンソースのコンテナオーケストレーションシステムです。 ただし、Kubernetesを使用すると、さまざまなAmazon Webサービス(AWS)へのポッドのアクセスを管理するという問題が発生します。 この記事では、特定のツールを使用してこれらの問題を克服する方法について説明します。 カバーする記事の内容は次のとおりです。
- アクセスの管理が問題になる理由
- Kube2iamを介したアクセスの管理
- KIAMを介したアクセスの管理
- サービスアカウントのIAMロール(IRSA)
AWSサービスへのアクセスの管理が問題になるのはなぜなのか?
想像してみてください。Kubernetesノードは、AWSDynamoDBテーブルへのアクセスを必要とするアプリケーションポッドをホストしています。一方、同じノード上の別のポッドは、AWSS3バケットにアクセスする必要があります。両方のアプリケーションが正しく機能するには、KubernetesワーカーノードがDynamoDBテーブルとS3バケットの両方に同時にアクセスする必要があります。
ここで、これが何百ものポッドで発生し、すべてがさまざまなAWSリソースへのアクセスを必要とすることを考えてみてください。ポッドは、複数の異なるAWSサービスに同時にアクセスする必要があるGovernorateクラスターで常にスケジュールされています...これがたくさんあるのです!
これを解決する1つの方法は、Kubernetesノード(つまりポッド)にすべてのAWSリソースへのアクセスを許可することです。ただし、これにより、システムは潜在的な攻撃者の標的になりやすくなります。単一のポッドまたはノードが侵害された場合、攻撃者はAWSインフラストラクチャ全体にアクセスできるようになります。これを回避するには、Kube2iam、Kiam、IAM IRSAなどのツールを使用して、KubernetesポッドからAWSリソースへのアクセスを改善できます。すべてのアクセスAPI呼び出しと認証メトリックは、Prometheusによってプルされ、Grafanaで視覚化できます。 Prometheus / Grafanaパーツを自分で試してみたい場合は、MetricFireの[無料デモを予約}(https://www.metricfire.com/demo-japan/?utm_source=blog&utm_medium=Qiita&utm_campaign=Japan&utm_content=Kubernetes%20on%20AWS%20Resources)して、ご相談ください。
Kube2iamを使用した実装へ
全体的なアーキテクチャ
Kube2iamは、クラスターにDaemonSetとしてデプロイされます。 したがって、Kube2iamのポッドは、Kubernetesクラスターのすべてのワーカーノードで実行されるようにスケジュールされます。 別のポッドがリソースにアクセスするためにAWSAPI呼び出しを行うと、その呼び出しはそのノードで実行されているKube2iamポッドによってインターセプトされます。 次に、Kube2iamは、ポッドにリソースにアクセスするための適切な資格情報が割り当てられていることを確認します。
また、ポッド仕様でIDおよびアクセス管理(IAM)の役割を指定する必要があります。 内部的には、Kube2iamポッドは、発信者のIAMロールの一時的な資格情報を取得し、それらを発信者に返します。 基本的に、すべてのAmazon Elastic Compute Cloud(EC2)メタデータAPI呼び出しはプロキシになります。 (Kube2iamポッドは、EC2メタデータAPI呼び出しを実行できるように、ホストネットワーキングを有効にして実行する必要があります。)
実装
IAMロールの作成と添付
- 必要なAWSリソース(たとえば、AWS S3バケット)にアクセスできるmy-roleという名前のIAMロールを作成します。
- 次の手順に従って、ロールとKubernetesワーカーノードにアタッチされているロールの間の信頼関係を有効にします。 (Kubernetes APIワーカーに関連付けられているロールのアクセス許可が非常に制限されていることを確認してください。すべてのAPI呼び出しまたはアクセス要求は、ノードで実行されているコンテナーによって行われ、Kube2iamを使用して資格情報を受け取るため、ワーカーノードのIAMロールにアクセスする必要はありません。 多数のAWSリソース。)
a. AWSコンソールで新しく作成された役割に移動し、[Trust relationships]タブを選択します
b. [Edit Trust relationships]をクリックします
c. ポリシーに次のコンテンツを追加します。{ "Sid": "", "Effect": "Allow", "Principal": { "AWS": "<ARN_KUBERNETES_NODES_IAM_ROLE>" }, "Action": "sts:AssumeRole" }d. ノードプールIAMロールの「Assume role」を有効にします。 次のコンテンツをノードIAMポリシーに追加します。
{ "Sid": "", "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": [ "arn:aws:iam::810085094893:instance-profile/*" ] }3.IAMロールの名前を注釈としてデプロイメントに追加します。
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: mydeployment namespace: default spec: ... minReadySeconds: 5 template: annotations: iam.amazonaws.com/role: my-role spec: containers: ...Kube2iamのデプロイ
- Kube2iamポッドで使用するサービスアカウントClusterRoleおよびClusterRoleBindingを作成します。 ClusterRoleには、すべてのAPIグループの下にある名前名とポッドへの「get」、「watch」、および「list」アクセスが必要です。 以下のマニフェストを使用して、それらを作成できます。
--- apiVersion: v1 kind: ServiceAccount metadata: name: kube2iam namespace: kube-system --- apiVersion: v1 kind: List items: - apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: kube2iam rules: - apiGroups: [""] resources: ["namespaces","pods"] verbs: ["get","watch","list"] - apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: kube2iam subjects: - kind: ServiceAccount name: kube2iam namespace: kube-system roleRef: kind: ClusterRole name: kube2iam apiGroup: rbac.authorization.k8s.io ---2.以下のマニフェストを使用して、Kube2iamDaemonSetをデプロイします。
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: kube2iam labels: app: kube2iam namespace: kube-system spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: kube2iam spec: hostNetwork: true serviceAccount: kube2iam containers: - image: jtblin/kube2iam:latest name: kube2iam args: - "--auto-discover-base-arn" - "--iptables=true" - "--host-ip=$(HOST_IP)" - "--host-interface=cali+" - "--verbose" - "--debug" env: - name: HOST_IP valueFrom: fieldRef: fieldPath: status.podIP ports: - containerPort: 8181 hostPort: 8181 name: http securityContext: privileged: true ---注:Kube2iamコンテナーは、引数--iptables = trueおよび--host-ip = $(HOST_IP)を使用して、特権モードでtrueとして実行されています。
... securityContext: privileged: true ...次の設定は、他のポッドで実行されているコンテナがEC2メタデータAPIに直接アクセスして、AWSリソースへの不要なアクセスを取得するのを防ぎます。 169.254.169.254へのトラフィックは、Dockerコンテナーのプロキシにする必要があります。 または、各Kubernetesワーカーノードで次のコマンドを実行することで、これを適用できます。
iptables \ --append PREROUTING \ --protocol tcp \ --destination 169.254.169.254 \ --dport 80 \ --in-interface docker0 \ --jump DNAT \ --table nat \ --to-destination `curl 169.254.169.254/latest/meta-data/local-ipv4`:8181テストポッドからのアクセスのテスト
Kube2iamデプロイメントとIAM設定が機能するかどうかを確認するために、アノテーションとして指定されたIAMロールを使用してテストポッドをデプロイできます。 すべてが機能する場合は、どのIAMノードがポッドに接続されているかを確認できるはずです。 これは、EC2メタデータAPIにクエリを実行することで簡単に確認できます。 以下のマニフェストを使用してテストポッドをデプロイしましょう。
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: access-test namespace: default spec: replicas: 1 selector: matchLabels: app: access-test minReadySeconds: 5 template: metadata: labels: app: access-test annotations: iam.amazonaws.com/role: my-role spec: containers: - name: access-test image: "iotapi322/worker:v4"作成したテストポッドで次のコマンドを実行します。
curl 169.254.169.254/latest/meta-data/iam/security-credentials/このAPIへの応答としてmyroleを取得する必要があります。
API呼び出しがインターセプトされる方法とタイミングをより深く理解するために、そのノードで実行されているKube2iamポッドのログを調整することを強くお勧めします。 セットアップが期待どおりに機能したら、ロギングバックエンドへの攻撃を回避するために、Kube2iamデプロイメントで詳細度をオフにする必要があります。
Kiam
Kube2iamには非常に役立ちますが、Kiamが解決しようとしている2つの主要な問題があります。
負荷状態でのデータ競合:アプリケーションの負荷が非常に高く、クラスター内に複数のポッドがある場合、Kube2iamがそれらのポッドに誤った資格情報を返すことがあります。 GitHubの問題はここで参照できます。
事前フェッチ認証情報:コンテナがポッドでの起動を処理する前に、アクセス認証情報がポッド仕様で指定されたIAMロールに割り当てられます。 以前に資格情報を割り当てることにより、Kiamは開始待ち時間を短縮し、信頼性を向上させます。
Kiamの追加機能は次のとおりです。
- 構造化ロギングを使用して、ポッド名、ロール、アクセスキーIDなどを使用したElacsticsearch、Logstash、Kibana(ELK)セットアップへの統合を改善します。
- 応答時間、キャッシュヒット率などを追跡するためのメトリックの使用。これらのメトリックは、Prometheusによって簡単にスクレイピングされ、Grafana上にレンダリングされます。
全体的なアーキテクチャ
Kiamは、エージェントサーバーアーキテクチャに基づいています。
- Kiam Agent:これは、ポッドがAWSメタデータAPIにアクセスできないようにするために、通常はDaemonSetとしてデプロイされるプロセスです。 代わりに、Kiamエージェントは認証情報要求をインターセプトして他のすべてを渡すHTTPプロキシを実行します。
- Kiamサーバー:このプロセスは、Kubernetes APIサーバーを接続してポッドを監視し、AWS Security Token Service(STS)と通信して認証情報を要求する役割を果たします。 また、ポッドを実行することで現在使用されているロールの資格情報のキャッシュを維持し、資格情報が数分ごとに更新され、ポッドが必要になる前に保存されるようにします。
実装
Kube2iamと同様に、ポッドがIAMロールの認証情報を取得するには、そのロールをデプロイメントマニフェストのアノテーションとして指定する必要があります。 さらに、適切なアノテーションを使用して、特定の名前空間内に割り当てることができるIAMロールを指定する必要があります。 これによりセキュリティが強化され、IAMロールの制御を微調整できます。
IAMロールの作成とアタッチ
AWSリソースへの適切なアクセス権を持つkiam-serverという名前のIAMロールを作成します。
次の手順に従って、kiam-serverロールとKubernetesマスターノードにアタッチされたロールの間のTrust relationshipsを有効にします。 (Kubernetes APIワーカーに関連付けられているロールの権限が非常に制限されていることを確認してください。すべてのAPI呼び出しまたはアクセスリクエストはノードで実行されているコンテナによって行われ、Kiamを使用して認証情報を受け取ります。ワーカーノードのIAMロールは多くのアクセス権を必要としません。 AWSリソース。)
a. AWSコンソールで新しく作成されたロールに移動し、[Trust relationships]タブを選択します。
b. [Edit Trust relationships]をクリックします。
c. 次のコンテンツをポリシーに追加します。
{ "Sid": "", "Effect": "Allow", "Principal": { "AWS": "<ARN_KUBERNETES_MASTER_IAM_ROLE>" }, "Action": "sts:AssumeRole" }3.インラインポリシーをkiam-serverロールに追加します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": "*" } ] }
- AWSリソースへの適切なアクセス権を持つIAMロール(my-role)を作成します。
5.新しく作成されたロールとKiamサーバーロールの間のTrust relationshipsを有効にします。
そうするために:
a. AWSコンソールで新しく作成されたロールに移動し、[Trust relationships]を選択します
b. [Edit Trust relationships]をクリックします
c. 次のコンテンツをポリシーに追加します。
{ "Sid": "", "Effect": "Allow", "Principal": { "AWS": "<ARN_KIAM-SERVER_IAM_ROLE>" }, "Action": "sts:AssumeRole" }6.マスタープールIAMロールの「Assume role」を有効にします。 次のコンテンツをインラインポリシーとしてマスターIAMロールに追加します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": "<ARN_KIAM-SERVER_IAM_ROLE>" } ]Kiamエージェントとサーバー間のすべての通信はTLS暗号化されています。 これにより、セキュリティが強化されます。 これを行うには、最初にcert-managerをKubernetesクラスターにデプロイし、エージェントとサーバー間の通信用の証明書を生成する必要があります。
CertManagerの展開と証明書の生成
1.カスタムリソース定義リソースを個別にインストールします。
kubectl apply -f https://raw.githubusercontent.com/jetstack/cert-manager/release-0.8/deploy/manifests/00-crds.yaml2.cert-managerの名前空間を作成します。
kubectl create namespace cert-manager
- cert-manager名前空間にラベルを付けて、リソース検証を無効にします。
kubectl label namespace cert-manager certmanager.k8s.io/disable-validation=true
- JetstackHelmリポジトリを追加します。
helm repo add jetstack https://charts.jetstack.io5.ローカルHelmチャートリポジトリキャッシュを更新します。
helm repo update6.cert-managerヘルムチャートをインストールします。
helm install --name cert-manager --namespace cert-manager --version v0.8.0 jetstack/cert-managerKiamエージェントサーバーTLSのCA秘密鍵と自己署名証明書を生成
1.CRTファイルを生成します。
openssl genrsa -out ca.key 2048 openssl req -x509 -new -nodes -key ca.key -subj "/CN=kiam" -out kiam.cert -days 3650 -reqexts v3_req -extensions v3_ca -out ca.crt2.CAキーペアをシークレットとしてKubernetesに保存します。
kubectl create secret tls kiam-ca-key-pair \ --cert=ca.crt \ --key=ca.key \ --namespace=cert-manager3.クラスター発行者をデプロイし、証明書を発行します。
a. Kiam名前空間を作成します
apiVersion: v1 kind: Namespace metadata: name: kiam annotations: iam.amazonaws.com/permitted: ".*" ---b. クラスター発行者をデプロイし、証明書を発行します。
apiVersion: certmanager.k8s.io/v1alpha1 kind: ClusterIssuer metadata: name: kiam-ca-issuer namespace: kiam spec: ca: secretName: kiam-ca-key-pair --- apiVersion: certmanager.k8s.io/v1alpha1 kind: Certificate metadata: name: kiam-agent namespace: kiam spec: secretName: kiam-agent-tls issuerRef: name: kiam-ca-issuer kind: ClusterIssuer commonName: kiam --- apiVersion: certmanager.k8s.io/v1alpha1 kind: Certificate metadata: name: kiam-server namespace: kiam spec: secretName: kiam-server-tls issuerRef: name: kiam-ca-issuer kind: ClusterIssuer commonName: kiam dnsNames: - kiam-server - kiam-server:443 - localhost - localhost:443 - localhost:9610 ---4.証明書が正しく発行されているかどうかをテストします。
kubectl -n kiam get secret kiam-agent-tls -o yaml kubectl -n kiam get secret kiam-server-tls -o yamlリソースに注釈を付ける
1.IAMロールの名前をアノテーションとしてデプロイに追加します。
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: mydeployment namespace: default spec: ... minReadySeconds: 5 template: annotations: iam.amazonaws.com/role: my-role spec: containers: ...2.ポッドが実行される名前空間に役割注釈を追加します。 Kube2iamでこれを行う必要はありません。
apiVersion: v1 kind: Namespace metadata: name: default annotations: iam.amazonaws.com/permitted: ".*"デフォルトでは、ロールは許可されません。 上記の正規表現を使用してすべての役割を許可したり、名前空間ごとに特定の役割を指定したりすることもできます。
Kiamエージェントとサーバーのデプロイ
Kiamサーバー
以下のマニフェストは、以下をデプロイします。
- Kubernetesマスターノードで実行されるKiamServer DaemonSet(上記で作成したTLSシークレットを使用するように構成します)
- Kiamサーバーサービス
- Kiamサーバーに必要なサービスアカウント、ClusterRoleおよびClusterRoleBinding
--- kind: ServiceAccount apiVersion: v1 metadata: name: kiam-server namespace: kiam --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: kiam-read rules: - apiGroups: - "" resources: - namespaces - pods verbs: - watch - get - list --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: kiam-read roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kiam-read subjects: - kind: ServiceAccount name: kiam-server namespace: kiam --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: kiam-write rules: - apiGroups: - "" resources: - events verbs: - create - patch --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: kiam-write roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kiam-write subjects: - kind: ServiceAccount name: kiam-server namespace: kiam --- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: namespace: kiam name: kiam-server spec: updateStrategy: type: RollingUpdate template: metadata: labels: app: kiam role: server spec: tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule serviceAccountName: kiam-server nodeSelector: kubernetes.io/role: master volumes: - name: ssl-certs hostPath: nodeSelector: nodeSelector: kubernetes.io/role: master volumes: - name: ssl-certs hostPath: path: /etc/ssl/certs - name: tls secret: secretName: kiam-server-tls containers: - name: kiam image: quay.io/uswitch/kiam:b07549acf880e3a064e6679f7147d34738a8b789 imagePullPolicy: Always command: - /kiam args: - server - --level=info - --bind=0.0.0.0:443 - --cert=/etc/kiam/tls/tls.crt - --key=/etc/kiam/tls/tls.key - --ca=/etc/kiam/tls/ca.crt - --role-base-arn-autodetect - --assume-role-arn=<KIAM_SERVER_ROLE_ARN> - --sync=1m volumeMounts: - mountPath: /etc/ssl/certs name: ssl-certs - mountPath: /etc/kiam/tls name: tls livenessProbe: exec: command: - /kiam - health - --cert=/etc/kiam/tls/tls.crt - --key=/etc/kiam/tls/tls.key - --ca=/etc/kiam/tls/ca.crt - --server-address=localhost:443 - --gateway-timeout-creation=1s - --timeout=5s initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: - /kiam - health - --cert=/etc/kiam/tls/tls.crt - --key=/etc/kiam/tls/tls.key - --ca=/etc/kiam/tls/ca.crt - --server-address=localhost:443 - --gateway-timeout-creation=1s - --timeout=5s initialDelaySeconds: 3 periodSeconds: 10 timeoutSeconds: 10 --- apiVersion: v1 kind: Service metadata: name: kiam-server namespace: kiam spec: clusterIP: None selector: app: kiam role: server ports: - name: grpclb port: 443 targetPort: 443 protocol: TCP注意:
ここに配置されているスケジューラー許容値とノードセレクターは、KiamポッドがKiamマスターノードでのみスケジュールされるようにします。 これが、KiamサーバーのIAMロールとKubernetesマスターノードにアタッチされたIAMロール(上記)の間の信頼関係を有効にする理由です。
... tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule ...... nodeSelector: kubernetes.io/role: master ....
kiam-serverロールARNは、Kiamサーバーコンテナーへの引数として提供されます。 上記のマニフェストのフィールドを、作成したロールのARNに更新してください。
Kiamサーバー用に作成されたClusterRoleとClusterRoleBindingは、効果的に動作するために必要な最小限のアクセス許可をサーバーに付与します。 変更する前によく検討してください。
cert-manager証明書を使用して作成したシークレットに従って、SSL証明書へのパスが正しく設定されていることを確認してください。 これは、KiamサーバーとKiamエージェントポッド間の安全な通信を確立するために重要です。
Kiam Agent
以下に示すマニフェストは、Kubernetesワーカーノードでのみ実行される次のKiam AgentDaemonSetをデプロイします。
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: namespace: kiam name: kiam-agent spec: template: metadata: labels: app: kiam role: agent spec: hostNetwork: true dnsPolicy: ClusterFirstWithHostNet volumes: - name: ssl-certs hostPath: path: /etc/ssl/certs - name: tls secret: secretName: kiam-agent-tls - name: xtables hostPath: path: /run/xtables.lock type: FileOrCreate containers: - name: kiam securityContext: capabilities: add: ["NET_ADMIN"] image: quay.io/uswitch/kiam:b07549acf880e3a064e6679f7147d34738a8b789 imagePullPolicy: Always command: - /kiam args: - agent - --iptables - --host-interface=cali+ - --json-log - --port=8181 - --cert=/etc/kiam/tls/tls.crt - --key=/etc/kiam/tls/tls.key - --ca=/etc/kiam/tls/ca.crt - --server-address=kiam-server:443 - --gateway-timeout-creation=30s env: - name: HOST_IP valueFrom: fieldRef: fieldPath: status.podIP volumeMounts: - mountPath: /etc/ssl/certs name: ssl-certs - mountPath: /etc/kiam/tls name: tls - mountPath: /var/run/xtables.lock name: xtables livenessProbe: httpGet: path: /ping port: 8181 initialDelaySeconds: 3 periodSeconds: 3Kiamエージェントも、Kube2iamと同様に、ホストネットワークをtrueに設定して実行されることに注意してください。 また、Kiamエージェントのコンテナに対する引数の1つは、KiamサーバーにアクセスするためのKiamサービスの名前です(この場合はkiam-server:443)。したがって、Kiamエージェントをデプロイする前にKiamサーバーをデプロイする必要があります。
また、コンテナ引数--gateway-timeout-creationは、エージェントが接続を試行する前にKiamサーバーポッドが起動するまでの待機期間を定義します。 ポッドがKubernetesクラスターに表示されるまでにかかる時間に応じて調整できます。 理想的には、30秒の待機期間で十分です。
テスト
KiamとKube2iamのセットアップをテストするプロセスは同じです。 テストポッドを使用してメタデータをカールし、割り当てられた役割を確認できます。 デプロイメントと名前空間の両方に適切な注釈が付けられていることを確認してください。
サービスアカウントのIAMロール(IRSA)
最近、AWSは、ポッドがAWSリソースにアクセスできるようにする独自のサービスをリリースしました。サービスアカウントのIAMロール(IRSA)です。 ロールはサービスアカウントで認証されるため、そのサービスアカウントが接続されているすべてのポッドで共有できます。 このサービスは、AWSEKSとKOPSベースのインストールの両方で利用できます。 あなたはそれについては、こちらをご確認ください。
まとめ
このブログで取り上げているツールは、KubernetesポッドからAWSリソースへのアクセスを管理するのに役立ち、すべてに長所と短所があります。
Kube2IAMは実装が最も簡単ですが、セットアップが簡単なため効率が低下し、高負荷状態では確実に動作しない可能性があります。大きなトラフィックサージが発生しない非本番環境またはシナリオに適しています。
IAM IRSAはKube2iamよりも多くの作業を必要としますが、Amazonの詳細なドキュメントを考えると、実装が簡単な場合があります。非常に最近であるため、この記事の執筆時点では、業界でIRSAの実装が十分ではありません。
KIAMの実装では、cert-managerを実行する必要があり、Kube2iamとは異なり、デプロイメントとともに名前空間に注釈を付ける必要があります。とにかく、Kiamを使用することを強くお勧めします。これは、証明書マネージャーを実行するためのリソースがあり、マスターノードがそれらで実行されているDaemonSetを処理できるようになっている場合にすべての場合に使用できるためです。この投稿で提供されているマニフェストを使用することで、セットアップがシームレスになり、本番環境に対応できるようになります。
Prometheusを搭載したGrafanaダッシュボードでメトリックを視覚化してみたい場合は、今すぐMetricFireのデモにサインアップして、どの監視ソリューションが効果的かについて直接お問い合わせください。
それでは、またの記事で!

- 投稿日:2020-10-27T10:04:31+09:00
AWS lambda でgoogle spread sheetを操作したくなったのでやってみた [その2]
概要
前回の記事の続きです。
前回は下半分を作成したので今回は上半分を作成していきます
serverless framework 環境
動作環境
npm (6.14.8) : 古くなければ...
serverless (2.8.0) : 2.x.x系であれば
python (3.8.2) :3.8系であれば構成
以下、serverless frameworkを知っている方、pythonがなんとなくわかる方向けに
説明は省いております。ご参考程度にご覧ください。functions/layers/serverless.yml # 構成ファイル functions/layers/package.json # パッケージ関連 functions/layers/requirements.txt # パッケージ関連 functions/layers/python/util.py # 共通関数 functions/main/serverless.yml # 構成ファイル functions/main/handler.py # lambda のメインパッケージが多くなったらlayersを作っておくのが便利です。
参照 Aws Lambda レイヤー各モジュールの説明
functions/layers/serverless.yml
service: goole-test-layer frameworkVersion: "2" plugins: - serverless-python-requirements custom: defaultStage: dev pythonRequirements: dockerizePip: true layer: true provider: name: aws runtime: python3.8 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 environment: TZ: Asia/Tokyo package: exclude: - ./node_modules/** # パケージのある場所を定義 layers: LayersCommon: path: "./" #pythonというフォルダに入れておくと共通関数としてlambda側から呼び出し可能になります compatibleRuntimes: - python3.8 resources: Outputs: PythonRequirementsLambdaLayerExport: Value: Ref: PythonRequirementsLambdaLayer ## function側の設定で使います LayersCommonLambdaLayerExport: Value: Ref: LayersCommonLambdaLayer ## function側の設定で使いますfunctions/layers/package.json
{ "name": "sample", "description": "", "version": "0.1.0", "dependencies": {}, "devDependencies": { "serverless-python-requirements": "^5.1.0" } }functions/layers/requirements.txt
boto3 botocore gspread oauth2clientfunctions/main/serverless.yml
service: goole-test frameworkVersion: "2" custom: defaultStage: dev sampleS3BucketName: Fn::Join: - "" - - ${self:service}- - ${self:provider.stage}- - Ref: AWS::AccountId ## layerの設定[packege] requirements_service: goole-test-layer requirements_export: PythonRequirementsLambdaLayerExport requirements_layer: ${cf:${self:custom.requirements_service}-${self:provider.stage}.${self:custom.requirements_export}} ## layerの設定[common] layers_common_service: goole-test-layer layers_common_export: LayersCommonLambdaLayerExport layers_common: ${cf:${self:custom.layers_common_service}-${self:provider.stage}.${self:custom.layers_common_export}} provider: name: aws runtime: python3.8 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 logRetentionInDays: 30 environment: KEYNAME : "/google/access_key" # 作成したkeyの保管場所 iamRoleStatements: - Effect: "Allow" Action: - "s3:ListBucket" - "s3:GetObject" - "s3:PutObject" Resource: - Fn::Join: ["", ["arn:aws:s3:::", { "Ref": "S3Bucket" }]] - Fn::Join: ["", ["arn:aws:s3:::", { "Ref": "S3Bucket" }, "/*"]] - Effect: Allow Action: - secretsmanager:GetSecretValue Resource: - "*" # secretsmanagerのarnを指定すればより権限制御が可能 functions: google_test: handler: handler.google_test memorySize: 512 timeout: 900 layers: - ${self:custom.requirements_layer} - ${self:custom.layers_common} events: - s3: # とりあえず良く使うS3のcreateオブジェクトを設定 bucket: Ref: S3Bucket event: s3:ObjectCreated:* existing: true rules: - suffix: .csv resources: Resources: S3Bucket: # S3を作成 Type: AWS::S3::Bucket Properties: BucketName: ${self:custom.sampleS3BucketName}functions/main/hander.py
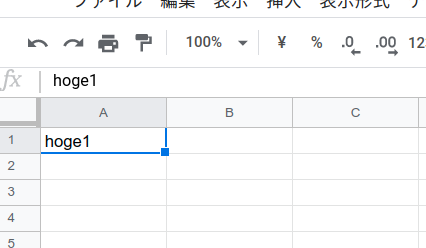
横着して全部1モジュールに書いていますが、関数ごとにファイルの分割等は行ってください・・・import json import os import boto3 from botocore.exceptions import ClientError import base64 import gspread from oauth2client.service_account import ServiceAccountCredentials def get_secret(): # これはSecrets Managerを作成するときのサンプルコードのほぼそのままです try: secret = None decoded_binary_secret = None secret_name = os.environ['KEYNAME'] region_name = "ap-northeast-1" # Create a Secrets Manager client session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name=region_name ) get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: if e.response['Error']['Code'] == 'DecryptionFailureException': raise e elif e.response['Error']['Code'] == 'InternalServiceErrorException': raise e elif e.response['Error']['Code'] == 'InvalidParameterException': raise e elif e.response['Error']['Code'] == 'InvalidRequestException': raise e elif e.response['Error']['Code'] == 'ResourceNotFoundException': raise e else: if 'SecretString' in get_secret_value_response: secret = get_secret_value_response['SecretString'] else: decoded_binary_secret = base64.b64decode( get_secret_value_response['SecretBinary']) # Your code goes here. return decoded_binary_secret.decode() def connect_gspread(jsonf, key): scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name( jsonf, scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = key worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 return worksheet def google_test(event, context): #APIにはファイルで渡すので/tmpに出力しましょう。 jsonf = "/tmp/google-access.json" with open(jsonf, mode='w') as f: f.write(get_secret()) spread_sheet_key = '1o3xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' ws = connect_gspread(jsonf, spread_sheet_key) # A1 セルにhoge1って入れます ws.update_cell(1, 1, "hoge1") body = { "message": "{} !".format("finished ."), "input": event } response = { "statusCode": 200, "body": json.dumps(body) } return responseデプロイ
## layersからデプロイする cd functions/layers npm install pip install -r requirements.txt sls deploy ## main関数をデプロイする cd functions/main sls deploy実行!!!
無事A1セルにhoge1がはいりました!
ということでAWS lambdaからspread sheetを更新できました。
まあ、GASで書けばいいんじゃん?っていうツッコミもありますが、こんなことがしたくなってしまったかたは
ご参考までにしていただけると幸いです。ではよいAWSライフを!
- 投稿日:2020-10-27T10:02:16+09:00
AWS lambda でgoogle spread sheetを操作したくなったのでやってみた [その1]
概要
表題そのままなのですが、google spread sheet って、なんかGAS(Google Apps Script)で操作する。
そんな固定観念があったんですが、今回はAWS lambda (Python)で操作したくなったのでやってみました。別にGCPだけでも完結しますが、、、
AWS慣れているので使いたかった。それだけです(笑)構成
構成はシンプルです。
GCP側で作成した認証情報は、暗号化してAWS Secrets Managerに保持します。
lambdaのコードに認証key直書きとかはやめたほうが吉...準備
GCP側の認証を作成する
AWSでいうところのIAMのkeyを作成する感じです。
まずはGCPのコンソールに入って適当なプロジェクトを作成し
- APIとサービス-> ライブラリ よりAPIの有効
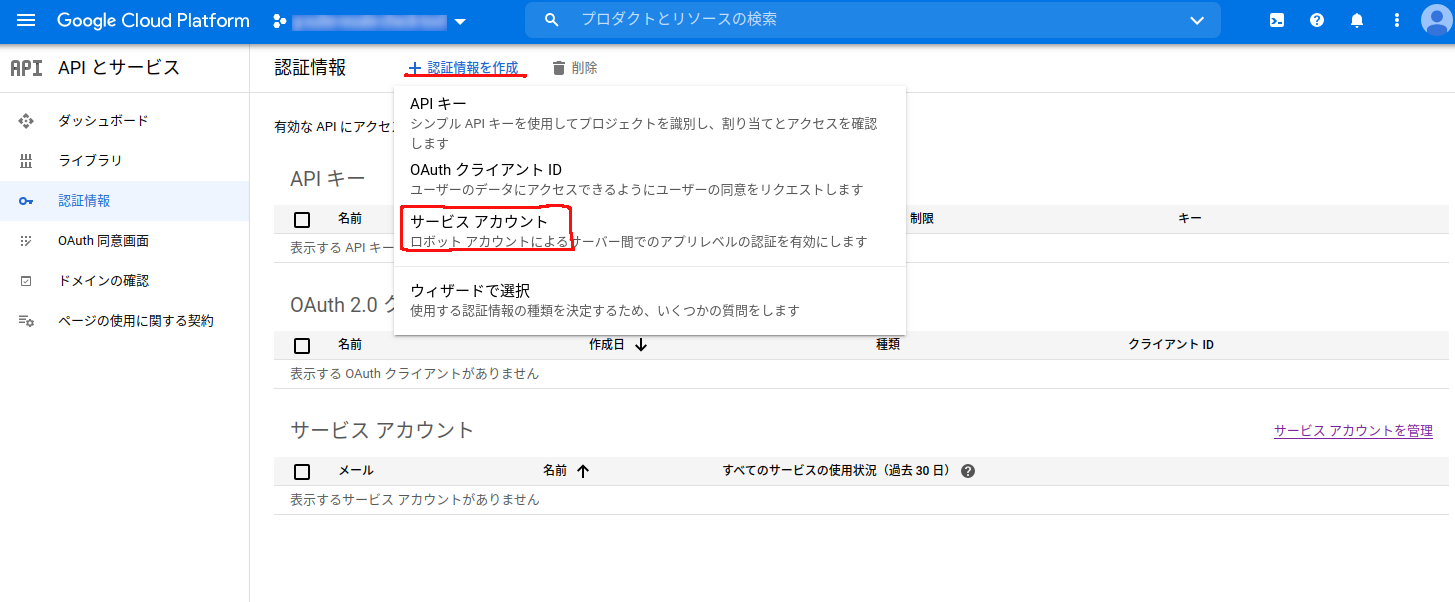
- APIとサービス-> 認証情報-> サービスアカウントの作成
を行います。
APIとサービス-> ライブラリ よりAPIの有効にする
APIとサービス-> 認証情報-> サービスアカウントを作成
サービスアカウント名をきかれます。
大事なのはサービスアカウントIDです。
他人がみてわかりやすい名前にしましょうw
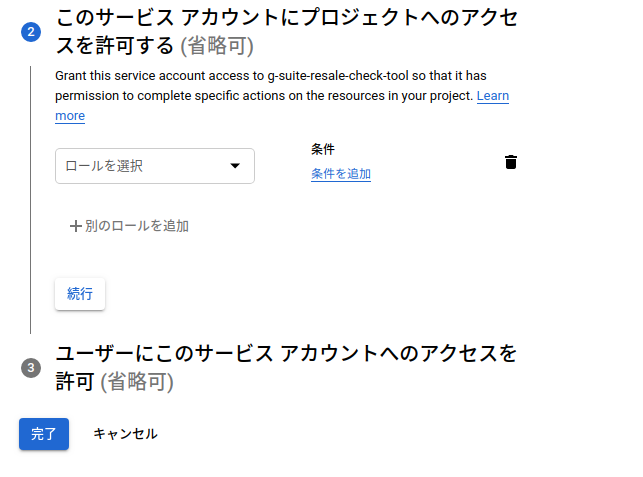
2.3 は省略可能なので省略。
※細かいアクセス制限とかしたい方は設定してください。
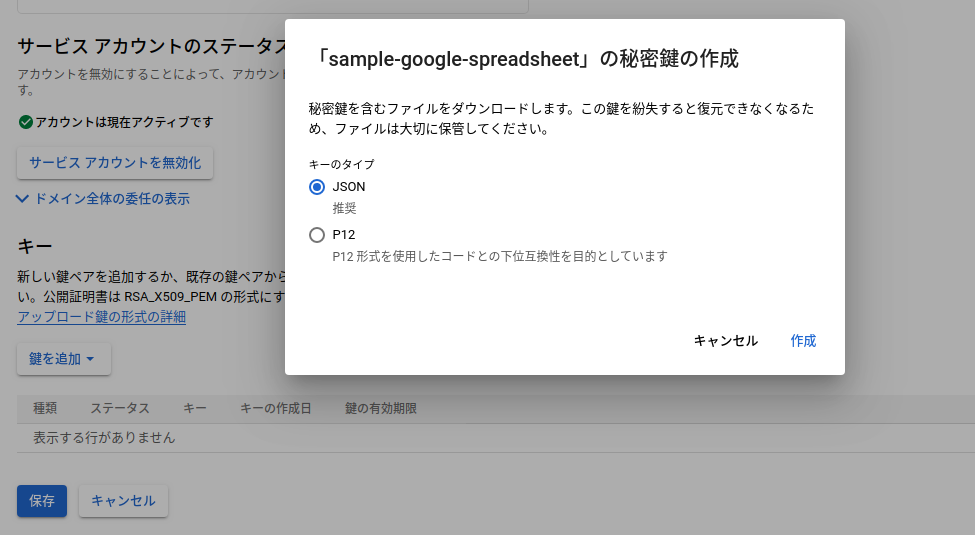
これが完了すると、サービスアカウントの箇所にメールアドレスみたいのができるので編集をおします。
編集の中から鍵を追加とあるので押すとjsonかP12かと選択がでてくるので、みんな大好きjsonを選択すると
ローカルにjsonがダウンロードされます。 これで認証keyの作成完了です。
(これがAWSいうcredential.jsonですね)[注意!!]これが漏れると外部からアクセスされる可能性があるのでgithubとかに置くのはやめましょうね!
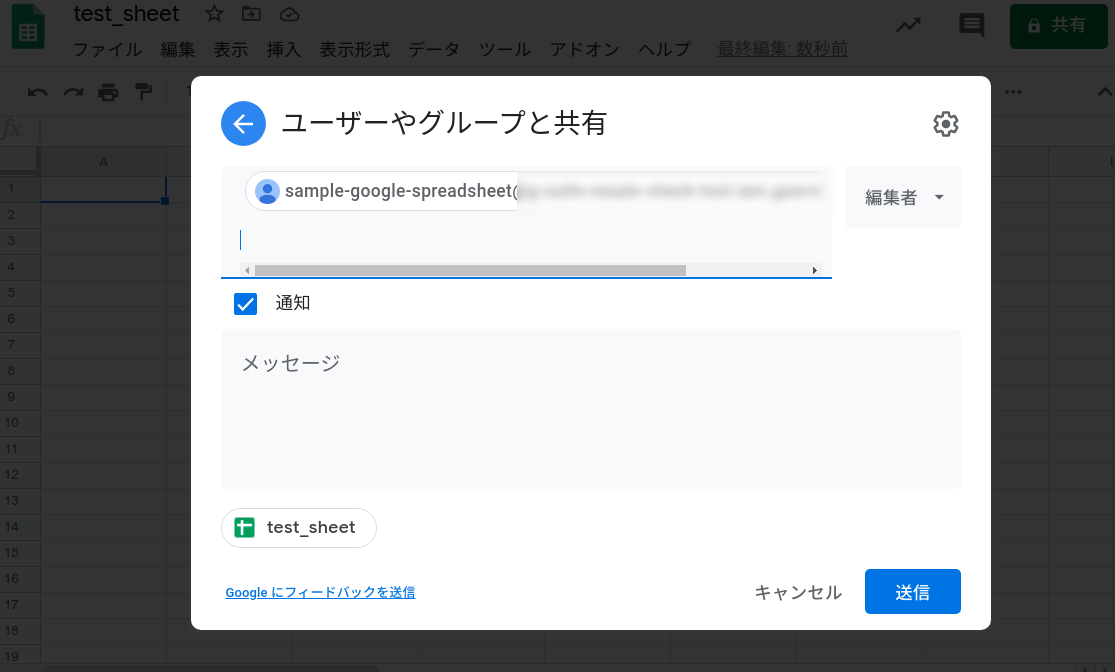
更新するスプレットシートの準備
先程のサービスアカウントID(メアドっぽくなっているやつ)を共有するユーザとして設定します。
AWS 側の準備
AWS Secrets Manager
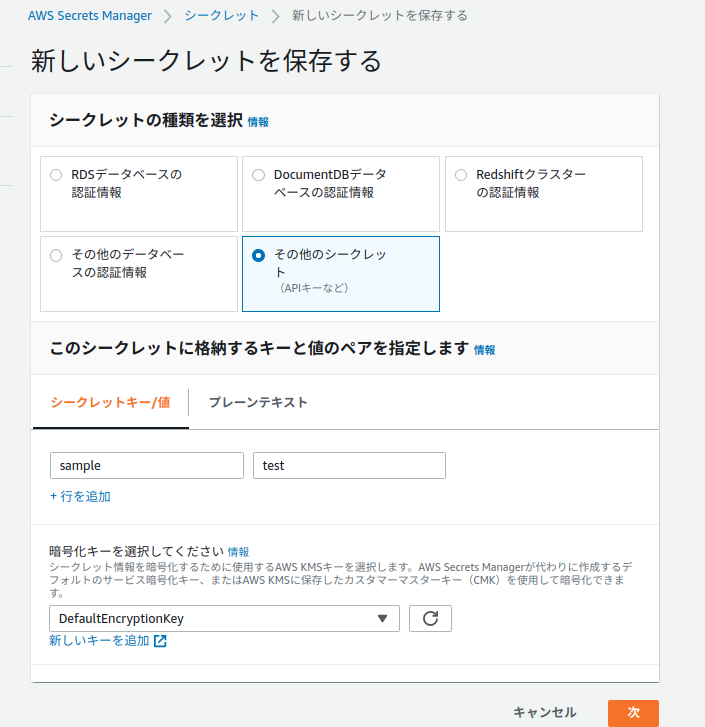
keyを保管する場所を作成しましょう。
cloudformationで自動で作成することもできますが、ここでは手で作成しています。
※ちなみに
system managerのキーストアでも同じようなkeyの保管ができますが、
今回はAWS Secrets Managerです。まずは枠だけ作るの シークレットの種類を選択 は
その他のシークレットを選びましょう。
値は適当に入れておいてください(ここではsampla: test)と入れています。
それでは先程のkey(今はgoogle_key.jsonにリネームしています)をbase64に変換して
AWS cliをつかってkeyに登録していきます。
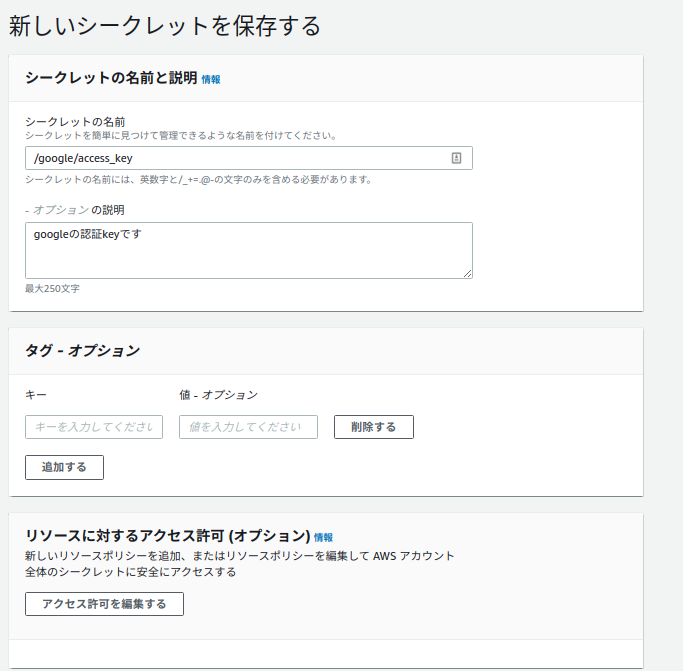
(※profileの向き先に注意してくださいw)$ cat google_key.json | base64 > base64.json aws secretsmanager update-secret --secret-id "/google/access_key" --secret-binary fileb://base64.json--secret-binaryを指定することによって暗号化された状態で登録することになります。
※これを指定するとコンソールから値が見れないという利点があります。
もっとセキュリティを強化したい方はKMSを利用ください。こんな感じでGCP側とAWS側の準備が完成です。
次回:
AWS lambda でgoogle spread sheetを操作したくなったのでやってみた (その2)次回はlambda側の作成をしていきます!!!
では、良いAWSライフを!!




- 投稿日:2020-10-27T01:14:45+09:00
SIEM on Amazon Elasticsearch Serviceを利用する
https://aws.amazon.com/jp/blogs/news/siem-on-amazon-elasticsearch-service/
AWSの方がセキュリティ観点の可視化とログ分析の解決策を公開しました。このようなサービスは大変お高い印象がありますが、AWSのサービス上で構築するため規模に合わせた課金額になります。(ログ量に比例するため小規模のシステムでも導入できるはず)
aws-samples / siem-on-amazon-elasticsearch
https://github.com/aws-samples/siem-on-amazon-elasticsearchログの可視化と分析においてログ出力/蓄積/サービスごとに重複したログの消し込みなど導入までにやらなければならないことが非常に多いですが、CloudFormationのテンプレートをデプロイすれば利用準備が整い、専用のS3バケットにログを書き込むことであらかじめ用意してあるダッシュボードで可視化できるようになります。
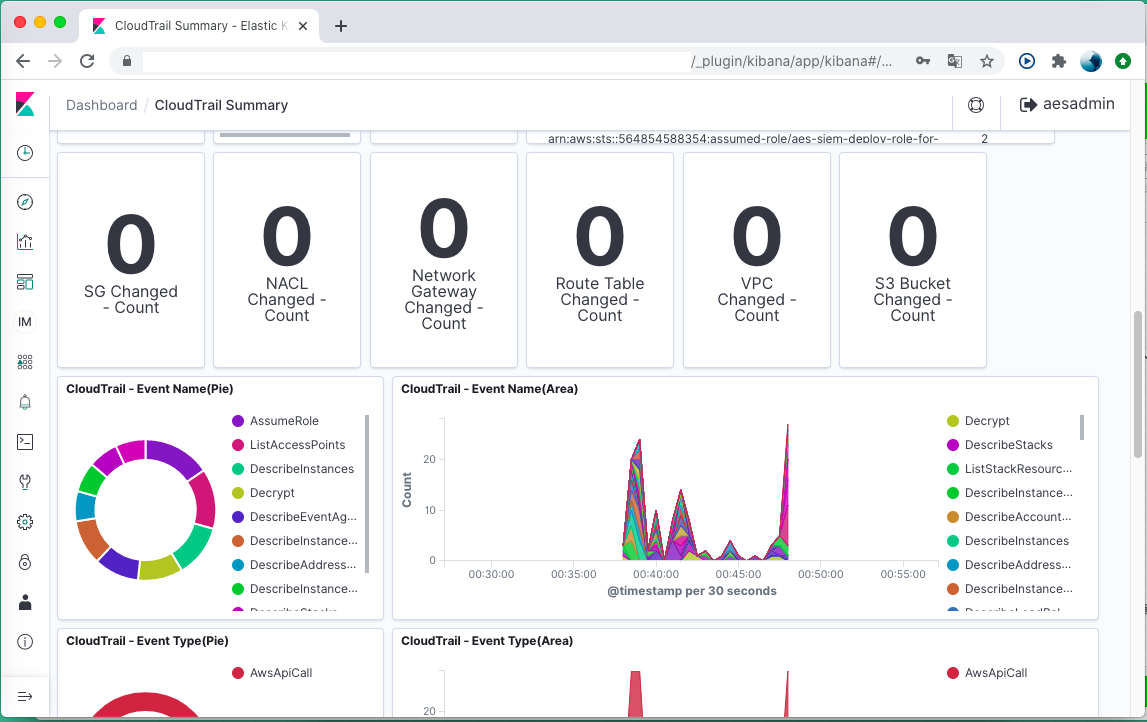
以下はCloudtrailのテンプレを使った可視化
デフォルトでもセキュリティ関連のイベントがいつ/どれだけ起きているか?可視化できます
単純にダッシュボードを表示するだけでも、クロスアカウント環境下において全体像の可視化に利用できるかと思います。ただより効率的に運用するにはもう少し鳴らしてノウハウをためる必要があるかと思いました。いろいろなログを蓄積して可視化を進めていきます!
- 投稿日:2020-10-27T00:08:12+09:00
【AWS入門】RDSによるMySQL環境の構築
【AWS入門】EC2インスタンス上に.NET Core + nginx環境を構築の続きです。
今回はRDSを使用したMySQLインスタンスをAWS上に構築し、EC2インスタンス上に配置されたWebアプリから接続するところまでをご紹介しようと思います。
環境
MySQL 8.0.20
RDSインスタンスの作成
まずはRDSインスタンスを作成していきましょう。
以下手順でRDSのコンソールを開き、データベースの作成メニューを開いてください。
- AWSマネジメントコンソールにログイン
- 「サービス」の「すべてのサービス」に
RDSを入力- RDSへのリンクが表示されるので押下
- RDSコンソールが表示されるので、「データベースの作成」を押下
以降各セクションごとに説明します。
データベースの作成方法
簡単作成でも問題ありませんが、今回は練習の意味で標準作成を選択します。
エンジンのオプション
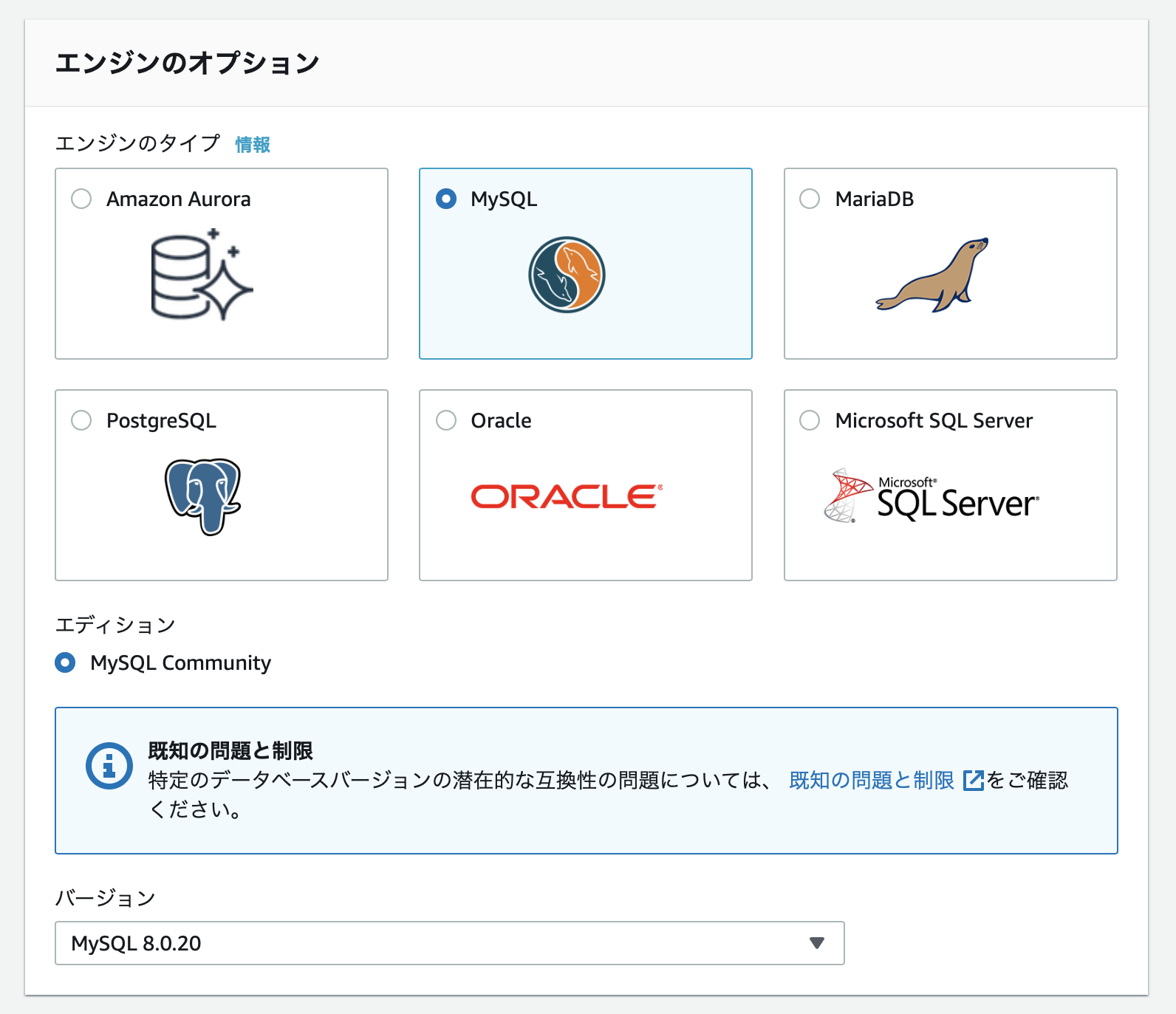
MySQLを選択します。
バージョンは8.0.20にしました。
テンプレート
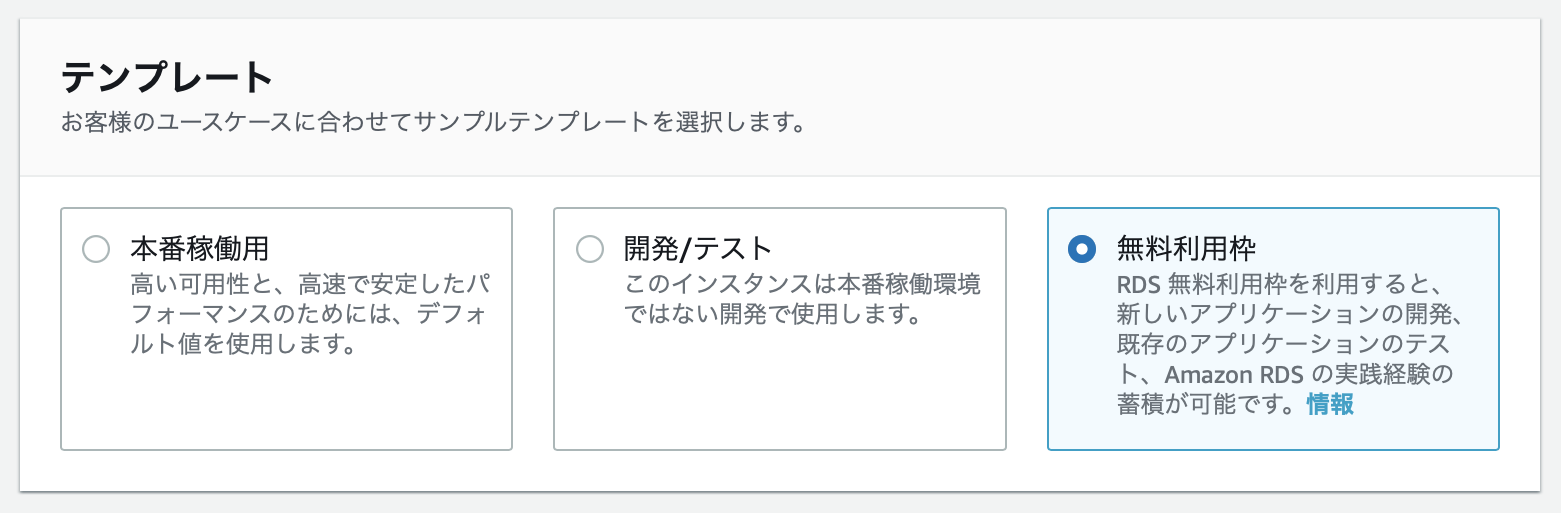
今回は勉強用なので、無料利用枠を使用します。
設定
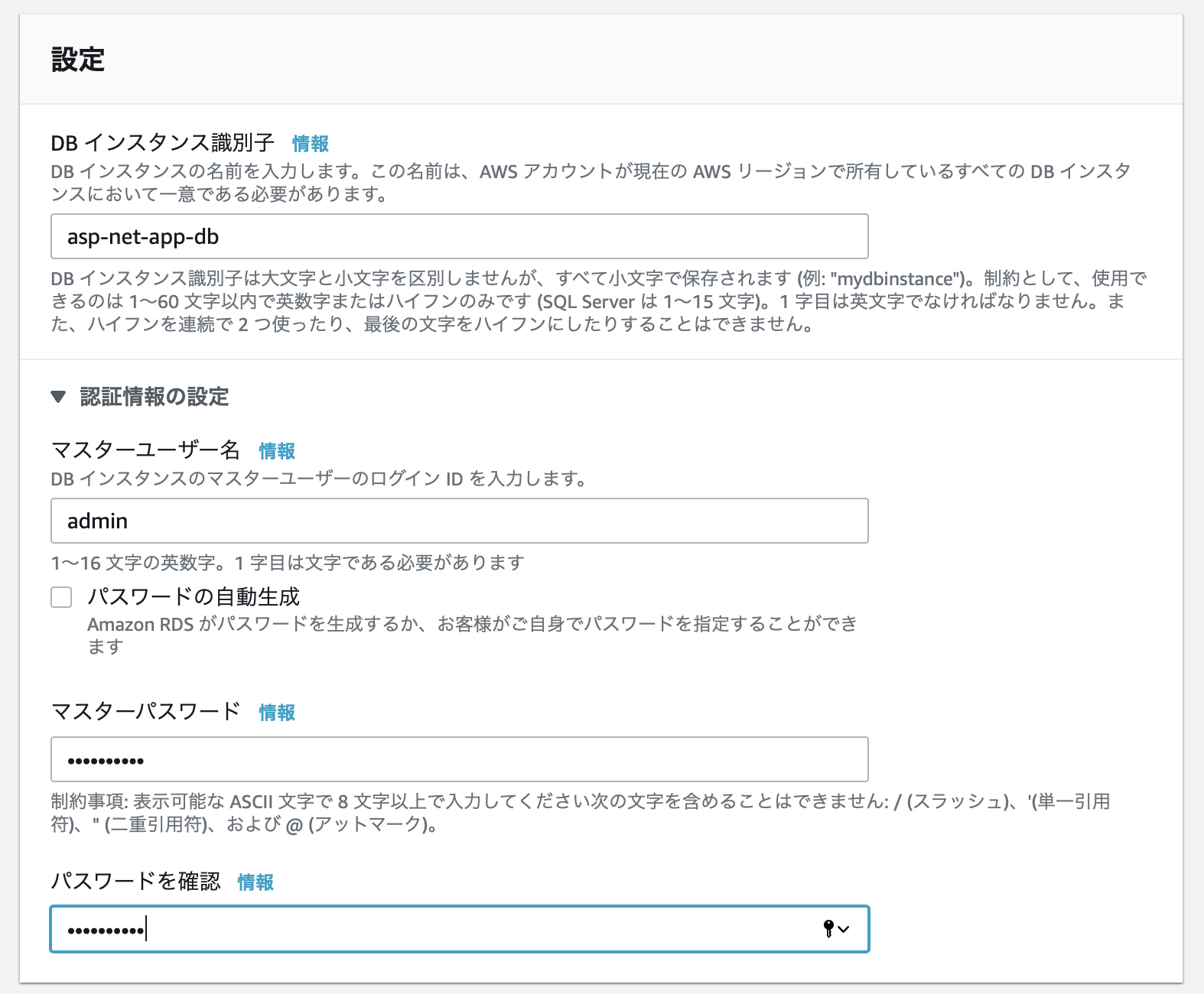
MySQLに接続するマスターユーザの情報を入力します。
今回はインスタンス名をasp-net-app-db、ユーザ名はデフォルトのadminに設定しました。
パスワードは適宜設定してください。また、ユーザ名とパスワードは後ほど接続文字列を設定する際に利用するので、どこかに書き留めておいてください。
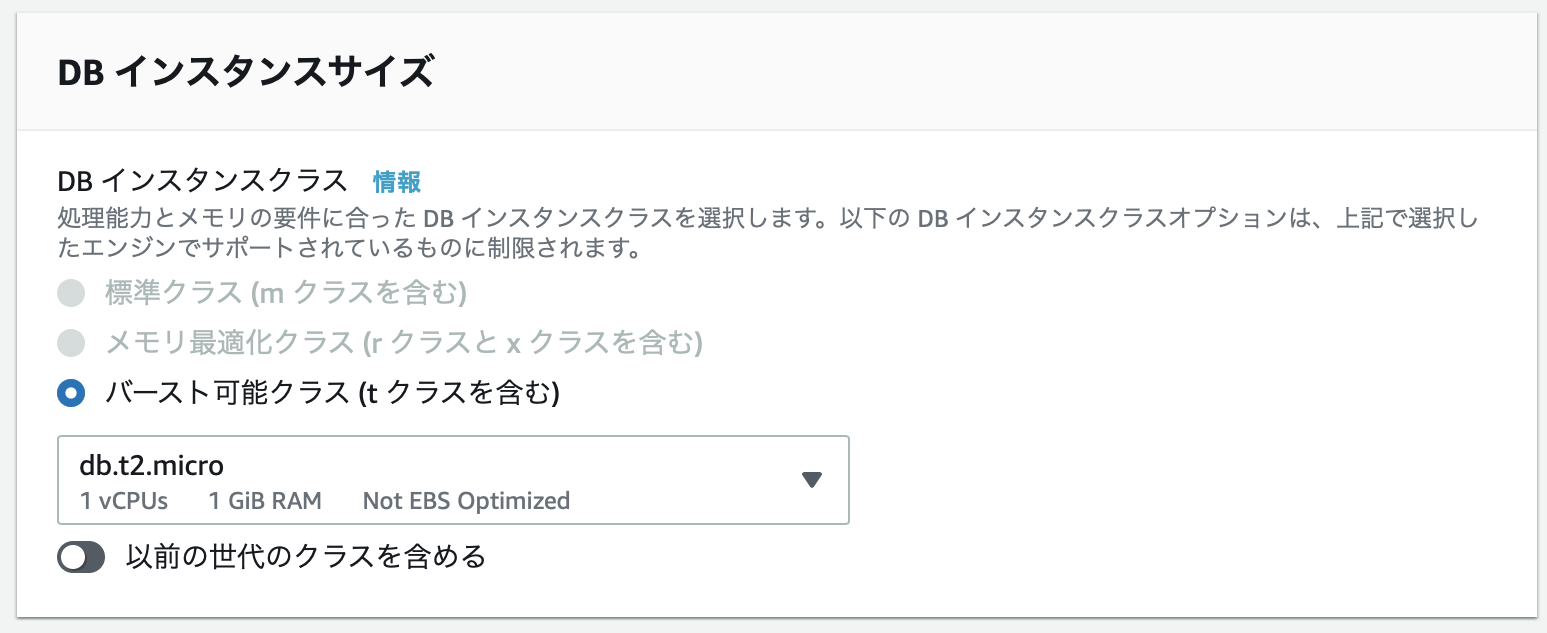
DB インスタンスサイズ
無料枠なのでdb.t2.microのみ有効です。
そのまま進みましょう。
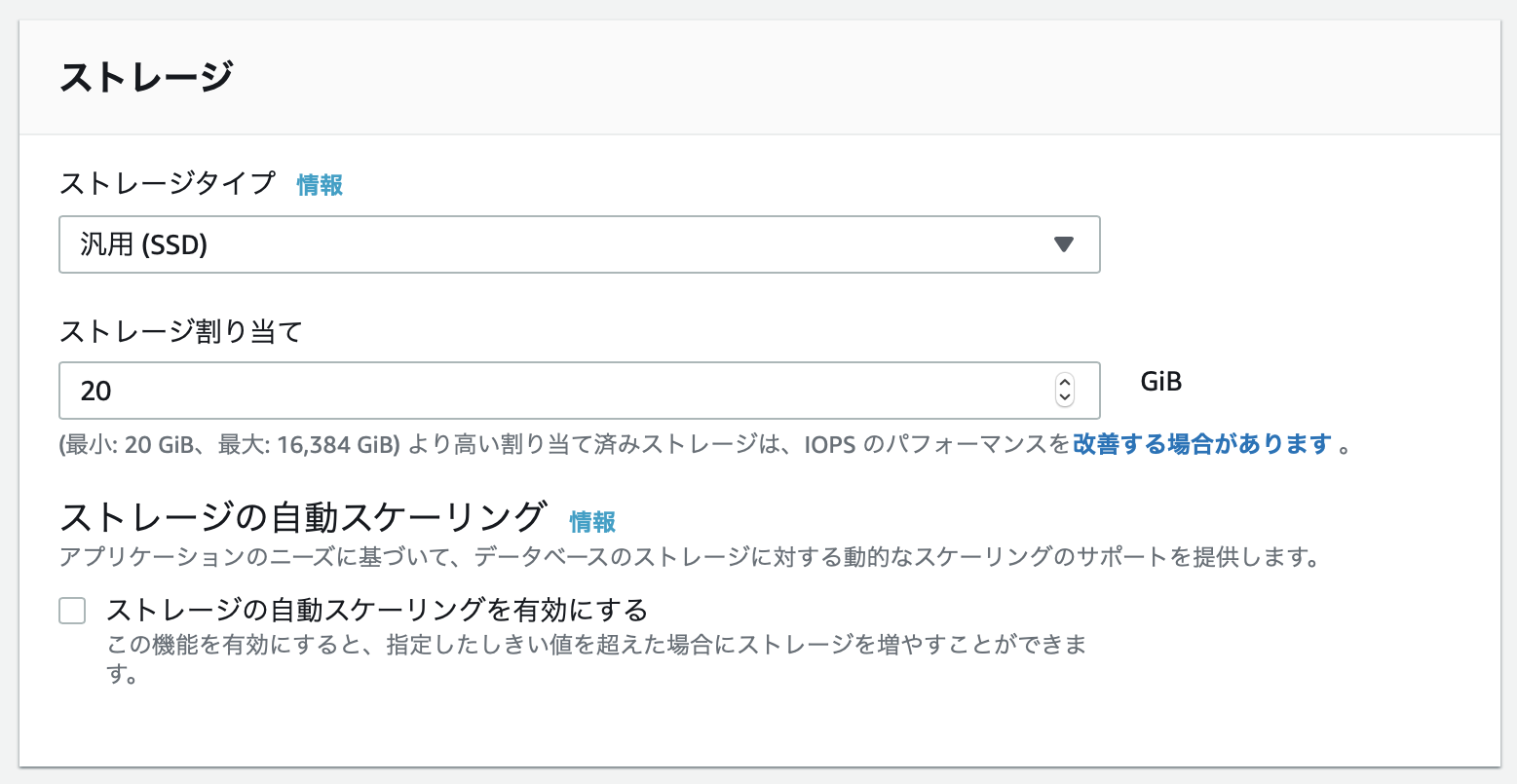
ストレージ
ストレージタイプ、ストレージ割り当てはそれぞれデフォルト値でOKです。
ストレージの自動スケーリングについては、万が一なにか起こった場合にスケールされるのを防ぐため、一応チェックを外しておきました。
可用性と耐久性
このセクションは無料枠の場合特に設定できる項目がないので次に進みます。
接続
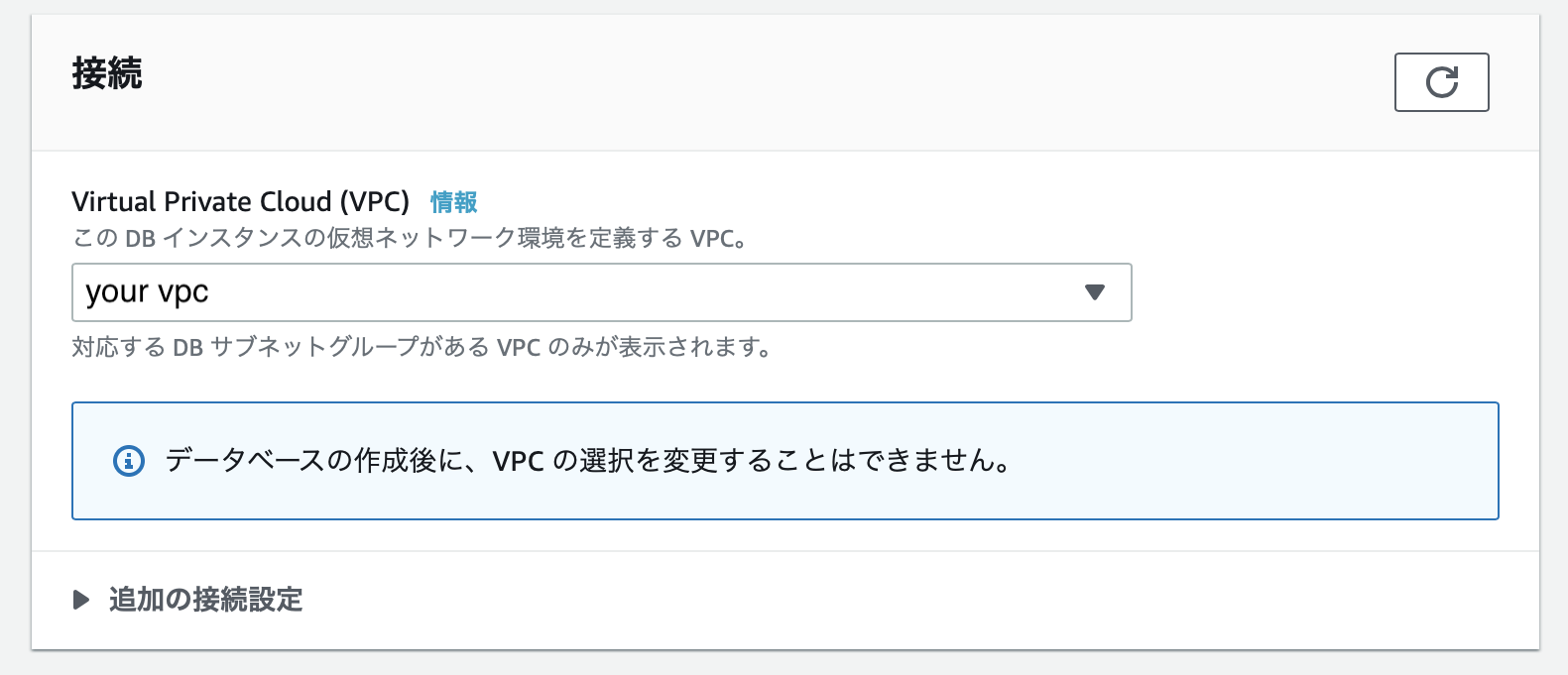
RDSのインスタンスを配置するVPCを選択してください。
要件として、VPC内に別々のアベイラビリティゾーンに属するサブネットが最低2つ必要です。
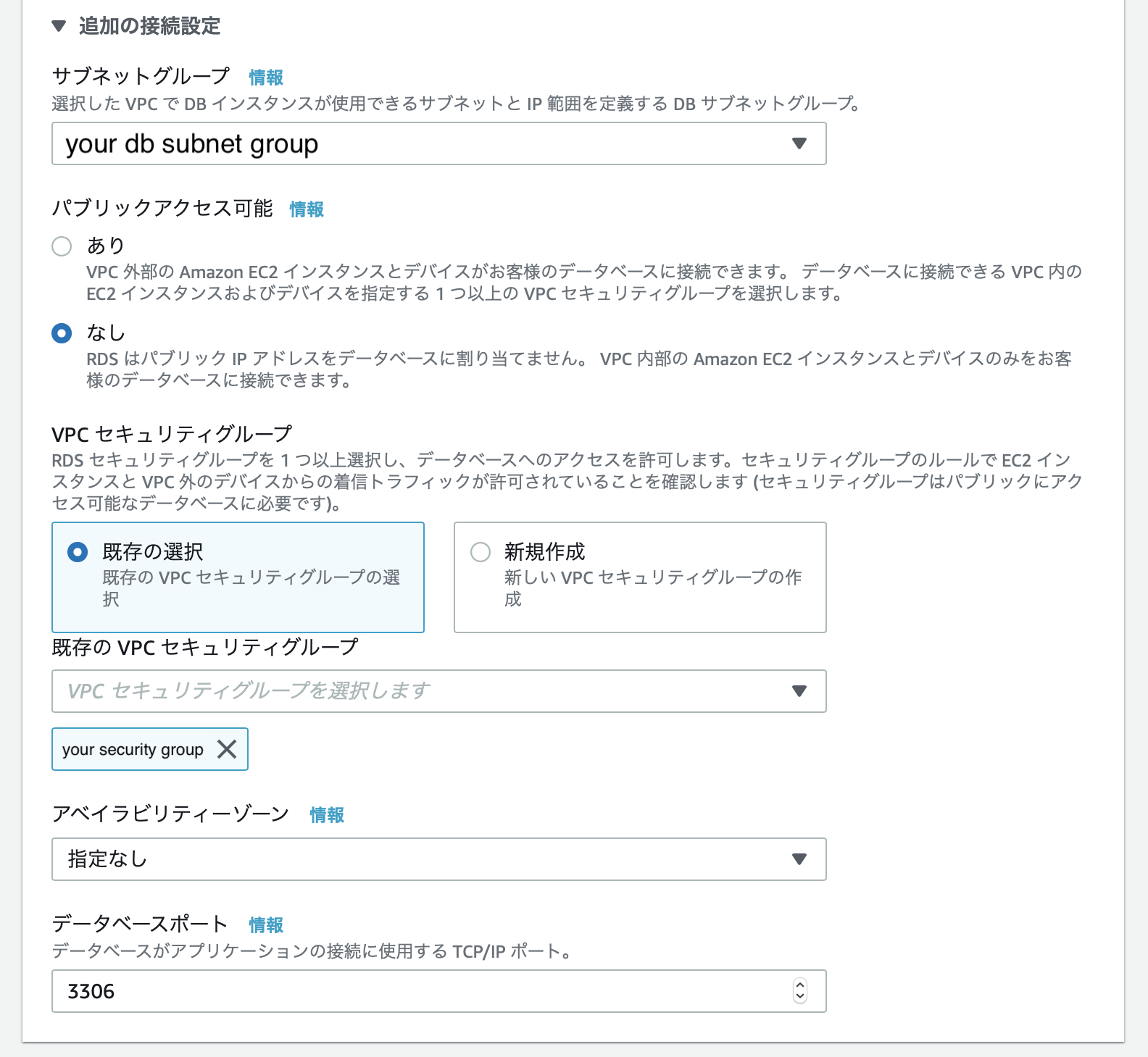
次に、追加の接続設定を編集していきます。
設定名 設定値 サブネットグループ デフォルト値 パブリックアクセス可能 なし VPCセキュリティグループ 事前に作成したセキュリティグループ アベイラビリティゾーン 指定なし データベースポート 3306 ※VPCセキュリティグループについてはポート3306が開いている必要があります。
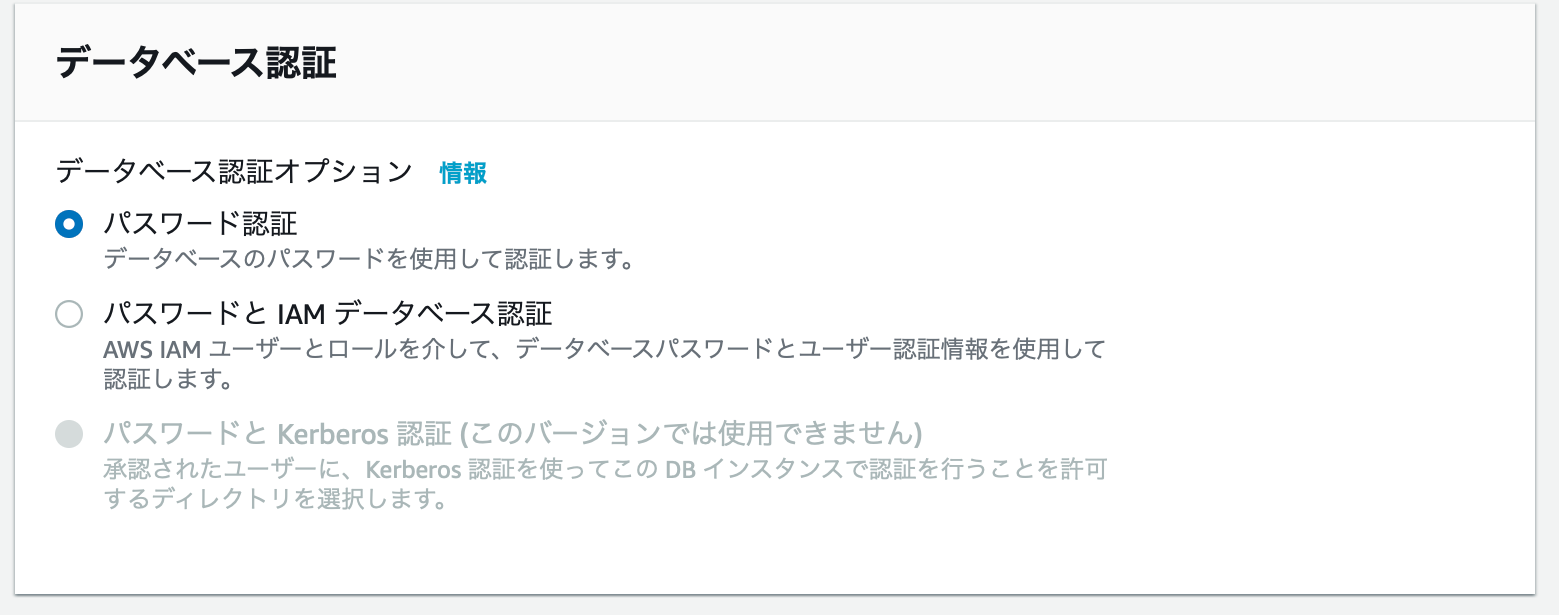
データベース認証
パスワード認証を設定します。
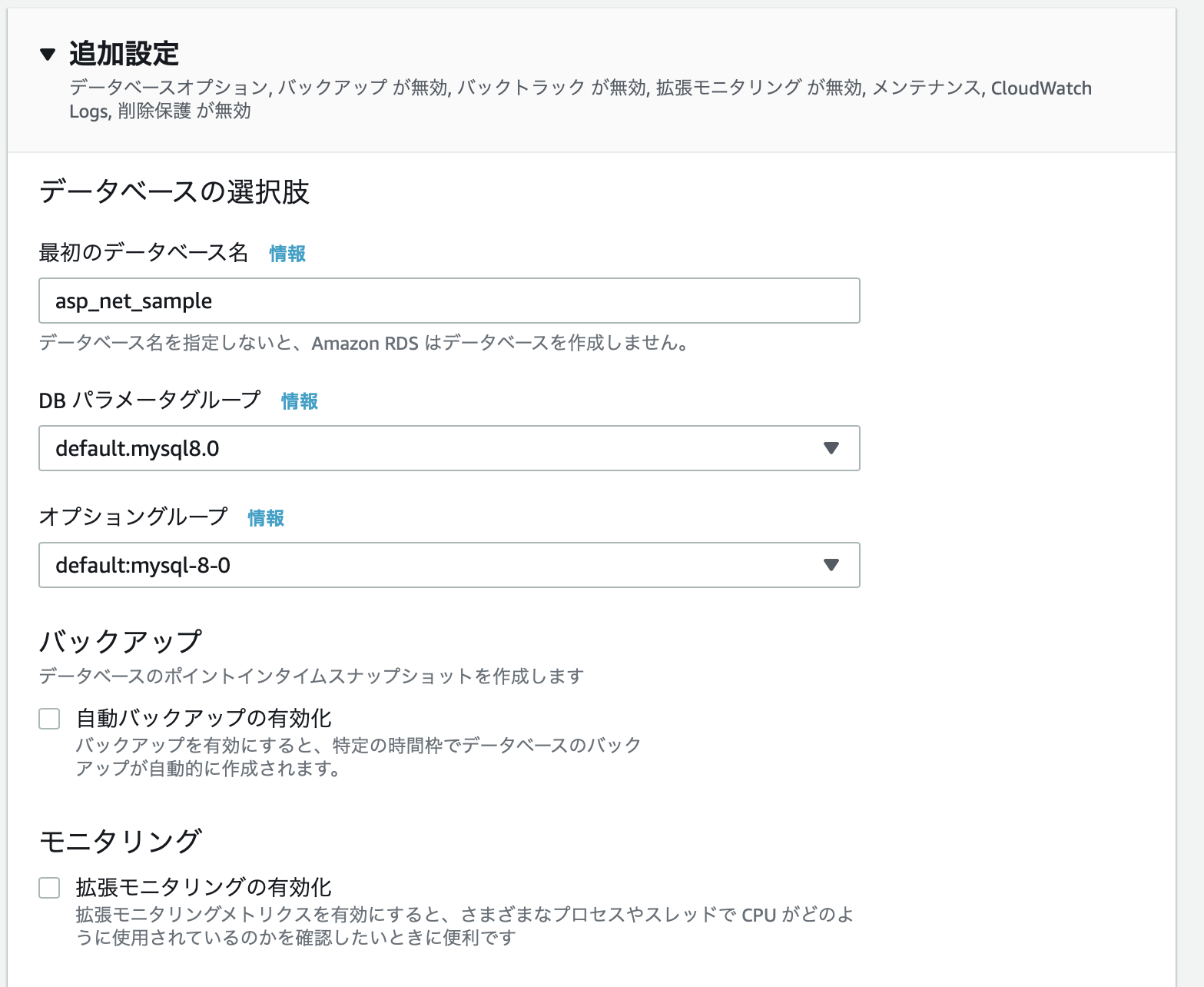
追加設定
最初のデータベース名に
asp_net_sampleを入力し、それ以外は全て無効に設定します。
設定後、データベースの作成を押下するとインスタンスの作成が開始されます。
接続文字列をServiceの環境変数に記述
最後に前回作成したアプリケーションからRDSインスタンスを参照できるように、Serviceの環境変数を編集します。
EC2インスタンスにSSH後、以下コマンドを実行します。
$ sudo vim /etc/systemd/system/kestrel-asp-net-app.service #Environment=ASPNETCORE_ENVIRONMENT=Production以下に追加 Environment=DB_CONNECTION_STRING=server=サーバのエンドポイント;uid=admin;pwd=パスワード;database=asp_net_sample Environment=ELASTIC_SEARCH_SERVER=http://localhost:9200設定後、以下コマンドを実行します。
$ sudo service nginx restart確認
ローカルマシンにて
http://サーバIP/をブラウザで開いてください。
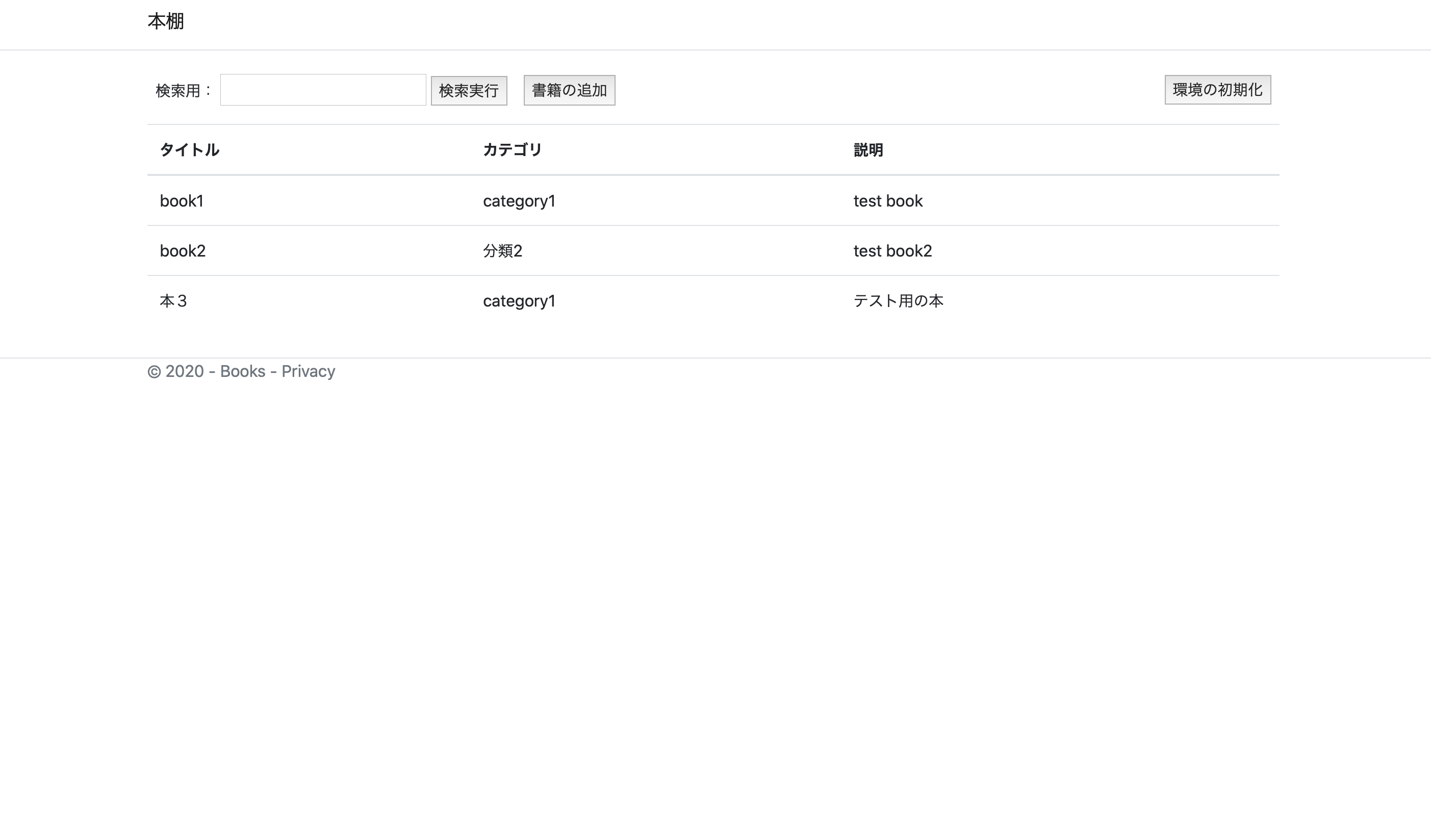
RDSインスタンスが作成されたばかりでテーブルが存在していないので、環境の初期化を押下します。
以下のような画面が表示されれば正常に動作しています。
次回
Elasticsearchと連携 -> 作成中...