- 投稿日:2020-10-26T23:09:35+09:00
Redmine(スクラム、アジャイルプラグイン)の環境構築備忘録
Redmineの環境を作成する機会があったのでメモ
- Dockerを使用
- https化はLet’s Encrypt(https-portal)を使用
- Redmineのバージョンは最新バージョン(4.1.1)
- MySQLを使用
docker-compose(パスワードやドメイン名は適宜設定してください)
docker-compose.ymlversion: '3' services: redmine: image: redmine:4.1.1 restart: always container_name: redmine_container environment: REDMINE_DB_MYSQL: mysql REDMINE_DB_DATABASE: redmine REDMINE_DB_USERNAME: redmine REDMINE_DB_PASSWORD: redmine REDMINE_DB_ENCODING: utf8mb4 VIRTUAL_HOST: <設定したいドメイン名> expose: - 3000 volumes: - ./redmine/files:/usr/src/redmine/files - ./redmine/log:/usr/src/redmine/log - ./redmine/plugins:/usr/src/redmine/plugins - ./redmine/public/themes:/usr/src/redmine/public/themes depends_on: - mysql mysql: image: mysql:5.7 container_name: mysql restart: always environment: TZ: Asia/Tokyo MYSQL_ROOT_PASSWORD: redmine MYSQL_DATABASE: redmine MYSQL_USER: redmine MYSQL_PASSWORD: redmine volumes: - ./mysql-data:/var/lib/mysql command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_bin https-portal: image: steveltn/https-portal:latest ports: - '80:80' - '443:443' links: - redmine restart: always environment: DOMAINS: '<設定したいドメイン名> -> http://redmine_container:3000' STAGE: 'production' #FORCE_RENEW: 'true' volumes: - ./certs:/var/lib/https-portalhttps-portalとは??
- Let’s Encryptを使用したSSL証明書の取得を簡単に設定することができる。
- https://github.com/SteveLTN/https-portal/blob/master/README.md
STAGE
- production...SSL証明書を取得しに行く
- local...オレオレ証明書を設定
FORCE_RENEW
- 基本使わない
- 強制的に証明書を発行する
- Let’s Encryptには制限があるので注意
volumes
- 証明書を永続化するために、
/var/lib/https-portalをボリュームに設定するScrum Redmine pluginのインストール
1. Redmineのpluginディレクトリにプラグインを格納する
- サンプルのdocker-compose.ymlのpluginディレクトリは
./redmine/plugins
- https://redmine.ociotec.com/projects/redmine-plugin-scrum/files
2. Redmineのコンテナ内に入り以下のコマンドを実行
$ RAILS_ENV=production bundle exec rake redmine:plugins:migrate3. Redmine上でプラグインの設定
参考
- 公式のインストール手順
Redmine Agile plugin (Light version)のインストール
1. 公式サイトから無料のLightプランをダウンロード
2. Redmineのpluginディレクトリにプラグインを格納する
- サンプルのdocker-compose.ymlのpluginディレクトリは
./redmine/plugins3. Redmineのコンテナ内に入り以下のコマンドを実行
$ bundle install --without development test --no-deployment $ bundle exec rake redmine:plugins NAME=redmine_agile RAILS_ENV=production参考
- 公式のインストール手順
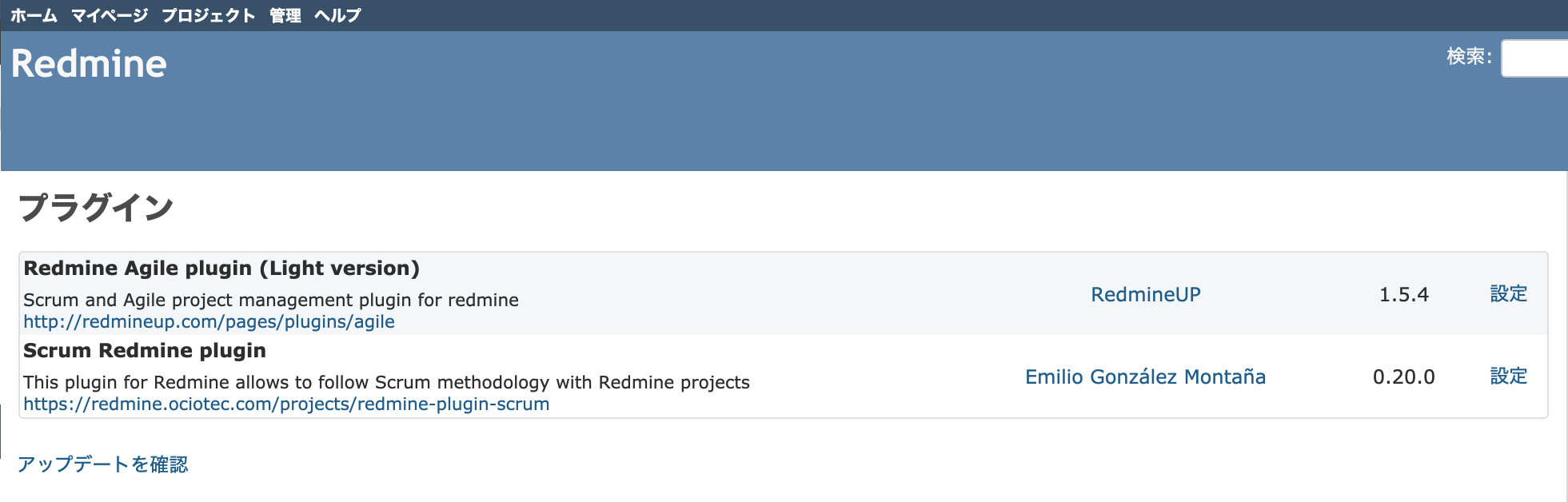
インストールが完了したらRedmineのプラグインページが表示される
- 投稿日:2020-10-26T22:43:46+09:00
mysqlをdockerで起動しておきたい時のdocker-compose.yml
(1)
docker-compose.ymlを作成するdocker-compose.ymlversion: "3.8" services: db: image: mysql:5.7 # mysqlのバージョンを指定する container_name: docker_mysql ports: - "3307:3306" # DBを起動するポートを指定する environment: - MYSQL_USER=root - MYSQL_PASSWORD= - MYSQL_ROOT_PASSWORD= - MYSQL_ALLOW_EMPTY_PASSWORD=yes # パスワード無しを許可する volumes: - mysql-db-data:/var/lib/mysql # データの永続化 tty: true # コンテナを起動し続ける volumes: mysql-db-data: driver: local(2) mysqlを起動する
docker-compose up -d(3) mysqlに接続する
mysql -u root -h 127.0.0.1 -P 3307
- 投稿日:2020-10-26T22:22:03+09:00
【Laravel】composer require時のメモリ不足エラーの対処法【Docker】
概要
Docker環境でcomposerインストール時に表題のエラーが発生しました。
ググっていくつかの方法を試しましたが解決に至るまで少し時間を要したので備忘として残しておきます。環境
Docker:19.03.8
Laravel:6.19.1エラー内容
Fatal error: Allowed memory size of 1610612736 bytes exhausted (tried to allocate 327680 bytes) in phar:///usr/bin/composer/src/Composer/DependencyResolver/Decisions.php on line 196メモリ不足でインストールできないエラーです。
解決方法
1.以下を実行しappコンテナに入る
make app //もしくは docker-compose exec app bash2.以下でインストール
php -d memory_limit=-1 /usr/bin/composer require fruitcake/laravel-cors-dはdefineの略で、php.iniで指定できる設定値を明示的に設定できるようです。
PHPコマンドラインオプションこのオプションにより php.ini で指定できる設定ディレクティブに カスタム値を設定することができます。構文は以下のようになります。
-d configuration_directive[=value]-d memory_limit=-1とすることで、メモリlimitを無制限で実行することができます。
- 投稿日:2020-10-26T22:19:13+09:00
dockerイメージとDockerfileのFROMを詳しく
dockerイメージとDockerfileのFROMを詳しく
dockerのDockerfileについて軽く読み流していたが、きちんと理解するには以下のことを改めて問う必要があるように思った。dockerイメージとは何者で、Dockerfileとは何者で、そのDockerfileに記述されるFROMとは何者か。
Dockerfileとは
Dockerfile のベスト・プラクティス Docker-docs-ja 19.03 ドキュメント
Dockerfile はイメージを構築するために必要な全ての命令を、順番通りに記述したテキストファイルです。
知っている人にはdocker版のMakefileといえば通りが良いかもしれない。
dockerのイメージを構築するための手順を特定の書式と命令群に則り、順番通りに記述したものだ。要するにdockerイメージという環境の構築をテキストファイルに落とし込んだものと言う事になる。レイヤとは
Dockerfile の命令に相当する読み込み専用のレイヤによって、 Docker イメージは構成されます。それぞれのレイヤは直前のレイヤから変更した差分であり、これらのレイヤは積み重なっています。唐突に出てきたレイヤとは何か。
FROM ubuntu:18.04
COPY . /app
RUN make /app
CMD python /app/app.py
これらの命令ごとに1つのレイヤを作成します、とある。
イメージを実行し、コンテナを生成すると、元のレイヤ上に新しい 書き込み可能なレイヤ(writable layer) (これが「コンテナ・レイヤ」です)を追加します。実行中のコンテナに対する全ての変更、たとえば新しいファイル書き込み、既存ファイルの編集、ファイルの削除などは、この書き込み可能なコンテナ・レイヤ内に記述されます。
上の例でいえば「ubuntu:18.04」レイヤに「COPY . /app」「RUN make /app」で新しいレイヤを追加、さらに「CMD python /app/app.py」でpython で/app/app.pyが実行されたイメージを作ると言う事になる。「ubuntu:18.04」レイヤに他のレイヤが積み重なったという表現はわかりやすいかもしれない。build とは
一言で言えば、指定したDockerfile に従ってdockerイメージを構築するコマンドだ。これも知っている人にはdocker版のmakeコマンドと言えば通りがいいかもしれない。
mkdir myproject && cd myproject
echo "hello" > hello
echo -e "FROM busybox\nCOPY /hello /\nRUN cat /hello" > Dockerfile
docker build -t helloapp:v1 .
上記の例でいえば、BusyBoxを使ってをcatで「helloファイル」を表示するイメージを構築するDockerfileを吐き出し、そのDockerfileに従ってdockerイメージを構築している。Dockerfile のFROMとは
Dockerfile のFROMとは何か。
FROM ubuntu:18.04
COPY . /app
RUN make /app
CMD python /app/app.py
先ほどのこの例においてFROM は 「ubuntu:18.04 の Docker イメージからレイヤを作成」と解説されている。
mkdir myproject && cd myproject
echo "hello" > hello
echo -e "FROM busybox\nCOPY /hello /\nRUN cat /hello" > Dockerfile
docker build -t helloapp:v1 .
こちらの例ではFROM は busyboxが指定されている。もちろん、busyboxもdockerイメージがあり、単にFROM busyboxと指定すれば、latest(最新)のイメージが指定される。FROM ubuntu:18.04の場合
FROM ubuntu:18.04の場合はどうか。FROM busyboxと「:」の指定が無い場合はlatest(最新)となるが、「:」を付けるとどうなるか。
FROMについて解説をみよう。
FROM <image> [AS <name>]
または
FROM <image>[:<tag>] [AS <name>]
または
FROM <image>[@<digest>] [AS <name>]
オプションとして、新たなビルドステージに対しては名前をつけることができます。 これは FROM 命令の AS name により行います。 この名前は後続の FROM や COPY --from= 命令において利用することができ、このビルドステージにおいてビルドされたイメージを参照します。
tag と digest の設定はオプションです。 これを省略した場合、デフォルトである latest タグが指定されたものとして扱われます。 tag の値に合致するものがなければ、エラーが返されます。
と言う事で、FROM ubuntu:18.04と指定した場合は、ubuntuの18.04タグのイメージが指定されることになる。
具体的にubuntuのDocker Imagesの18.04を見ると、どの様にubuntu:18.04のdockerイメージが作られているのか、Dockerfileをみることができる。
FROM scratch
ADD ubuntu-bionic-core-cloudimg-amd64-root.tar.gz /
中略
RUN mkdir -p /run/systemd && echo 'docker' > /run/systemd/container
CMD ["/bin/bash"]
ベースとなるdockerイメージがないので、FROM scratchで始まっていることに注目してほしい。公式の推奨FROM
Dockerfile のベスト・プラクティス Docker-docs-ja 19.03 ドキュメントのFROMの説明において、推奨が記載されている。
可能なら常に、イメージの土台には最新の公式イメージを利用します。私たちの推奨は Alpine イメージ です。これは非常にコントロールされながら、容量が小さい(現時点で 5MB 以下) Linux ディストリビューションです。Alpine イメージとは
完全なパッケージインデックスとわずか5MBのサイズを備えたAlpineLinuxに基づく最小限のDockerイメージ!と謳われているのが、Alpine イメージだ。さらに「他のBusyBoxベースのイメージよりもはるかに完全なパッケージリポジトリにアクセスできます。これにより、Alpine Linuxは、ユーティリティや本番アプリケーションの優れたイメージベースになります。」とのこと。実際にAlpine イメージを採用している例として、先日取り上げたウェブサーバーソフトであるcaddyを挙げてみる。latest(最新)のcaddyのDockerfileをみると「FROM alpine:3.12」から始まっている。alpineは現在「3.12.1, 3.12, 3」をlatestとしている。
まとめで詳しく
dockerイメージとは何者で、Dockerfileとは何者で、そのDockerfileに記述されるFROMとは何者か。
dockerイメージとは指定したDockerfile に従ってbuild コマンドによって構築されたdockerコンテナ用イメージ。
Dockerfileとはdockerイメージを構築するために必要な全ての命令を、順番通りに記述したテキストファイル。
FROMとはDockerfileに記載する土台となるもの。通常はdockerイメージを指定するが、無ければFROM scratchと書く。公式推奨はFROM Alpine。
- 投稿日:2020-10-26T18:52:16+09:00
[Docker / mysql] Can't connect to local MySQL server through socket
Docker で mysql server 立てようとしたら
Can't connect to local MySQL server through socketって言われました。なんだかわからないまま、解決するのに結構時間かかってしまったので、残しておきます。
結論
docker runでは、末尾に[COMMAND]という option を指定できるが、mysql サーバ (container) を立てる時には指定してはいけない、ということです。docker run [OPTIONS] IMAGE[:TAG|@DIGEST] [COMMAND] [ARG...]
- OK な例
docker run -d --name mydb --rm -p 3306:3306 mysql:5.7 # してから docker exec -it /bin/bash # host mysql -u root -p # container
- ダメな例
docker run -d --name mydb --rm -p 3306:3306 mysql:5.7 /bin/bash ^^^^^^^^^ これをしちゃダメ!!チョット 詳細 (未完成)
まず、
docker runするとき、[COMMAND]の部分は optional です。(つまり、あってもなくても良い)次に、docker image の話を少しします。
docker image は
Dockerfileを作ってdocker buildを行うことにより作ることができます。
そしてこの build された image から container を起動できる、という流れになっています。イメージ図[Dockerfile] === docker build ==> [image] === docker run ===> [container]通常、起動直後に実行されるコマンドは、上記のような
Dockerfileの最後あたりにCMD ["command"]という形で指定されますThis command is optional because the person who created the IMAGE may have already provided a default COMMAND using the Dockerfile CMD instruction.
これはもちろん、 image の作者が、意図的に、CMD を用いて、実行するコマンドを指定している可能性があります。つまり、起動した container がきちんとサービスとしての振る舞いを行うために
CMD ["command"]を書いている可能性がある、ということです。しかし、docker run の時に、あなたが指定した
[COMMAND] optionは、この Dockerfile で作者が指定した CMD をオーバーライドして、新たなコマンドの実行を指定してしまうらしいです。As the operator (the person running a container from the image), you can override that CMD instruction just by specifying a new COMMAND.
CMD (default command or options) ?
なので、mysql container が通常起動された時に実行される (はず) の、このコマンドが実行されないため、mysql server に接続できない、というのが原因であると考えています。
先のリンクにある、CMD 部分をを見て、こう思った方がいるかもしれません。
mysql/5.7/DockerfileCMD ["mysqld"]「じゃあ、docker container が立ち上がった時に
mysqldコマンドを実行すればいいんじゃね?」つまりこうするわけです# ダメな例 (host) $ docker run -d --name mydb --rm -p 3306:3306 mysql:5.7 /bin/bash (container) # mysqld実際私もそう思いました。試しました。ダメでした ?
「タイムスタンプがどうのこうの」と言われてしまい、うまくいきません...
( 調査中です... ご存知の方、いらっしゃいましたらご教示ください... )
- 投稿日:2020-10-26T17:35:26+09:00
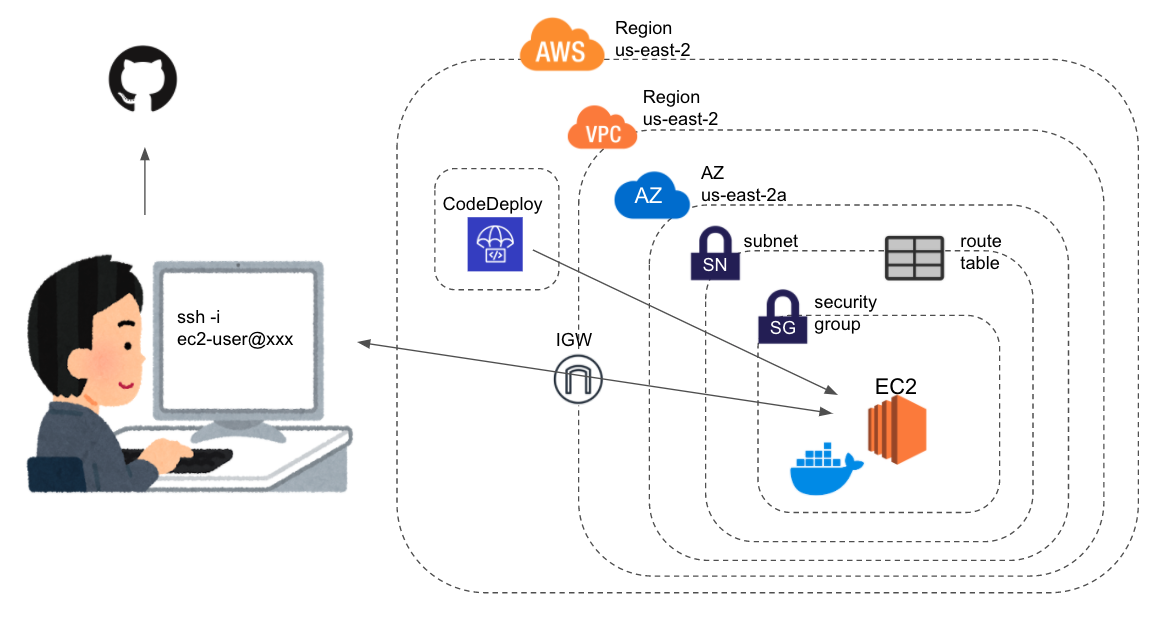
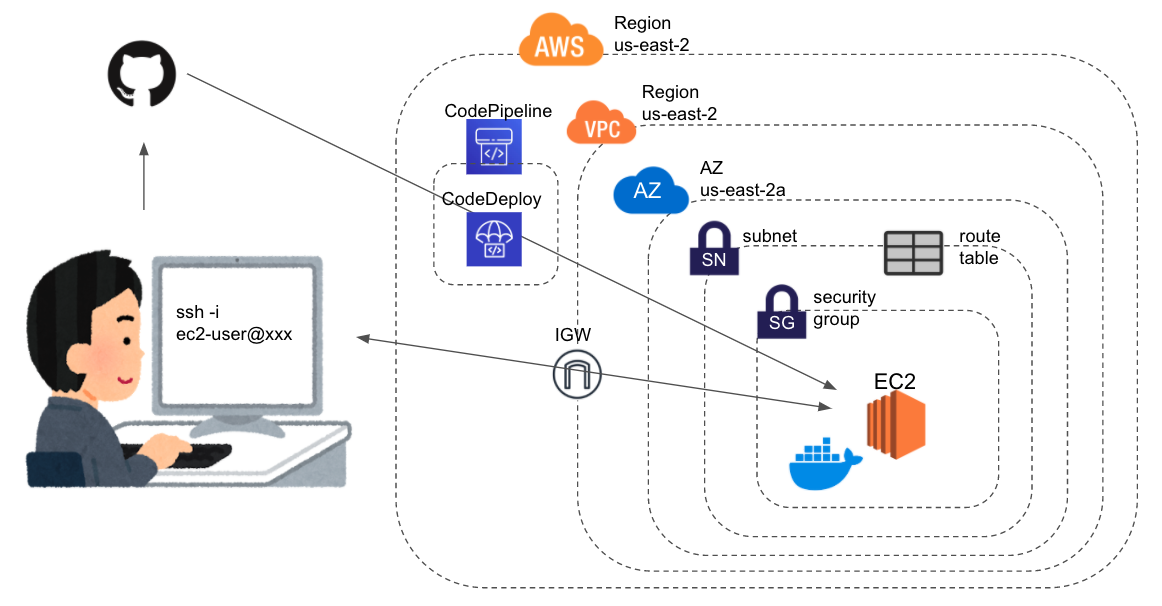
初学者によるDocker理解まとめ⑥ 〜CodeDeployとCodePipelineを使ってEC2インスタンスにdockerコンテナを自動デプロイするまで〜
はじめに
ようやくDockerを学び始めたので自分の理解をまとめておく。
やったこと
- 前回の続き
- 前回はgithubのレポジトリを
git cloneし、updateの度にgit pull+docker-compose upしていた。- 上記の一連の動作を
CodeDeployを使って置換するCodePipelineを使って上記一連の流れを自動化する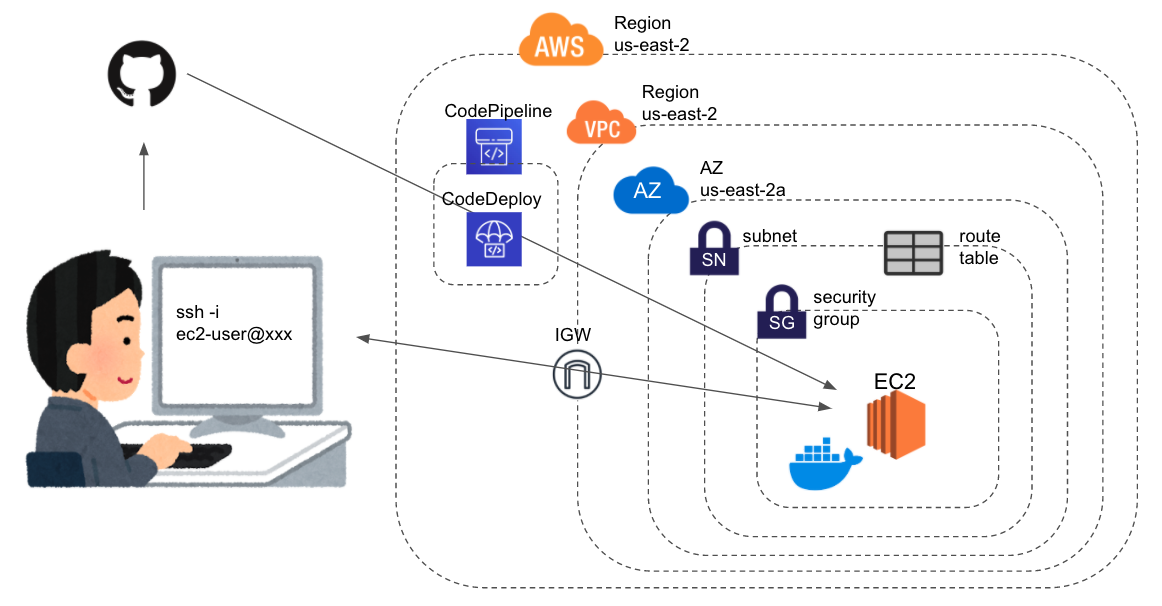
そして今回もdockerはあまり関係ありません。。
前提
前々回の時点でEC2インスタンスを起動して
dockerとdocker-composeをインストールできている状態。
手順
- EC2インスタンスに
CodeDeployエージェントをインストールAWSCodeDeployRoleポリシーをアタッチしたIAMロールを作成し、EC2インスタンスにアタッチCodeDeployの設定
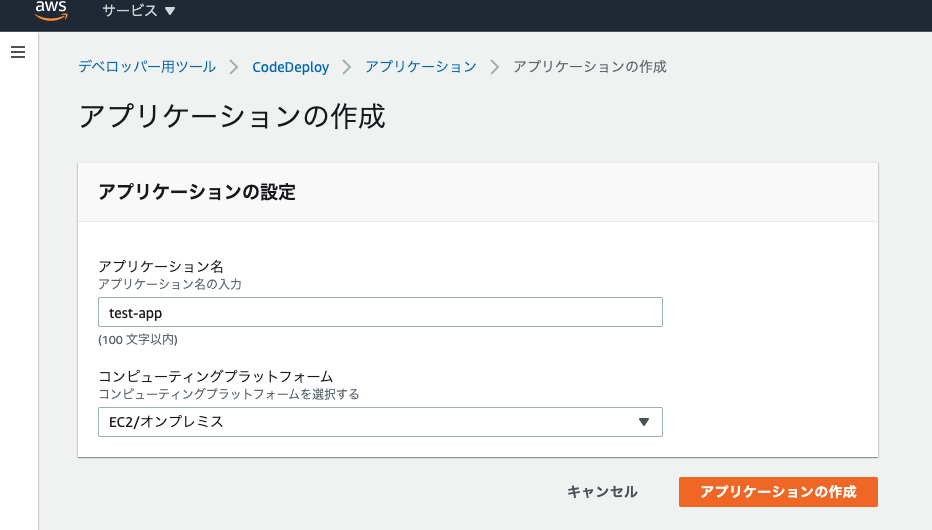
- アプリケーションの作成
- デプロイメントグループの作成
appspec.ymlとApplicationStart.bashの作成- デプロイの作成
CodePipelineの設定EC2インスタンスに
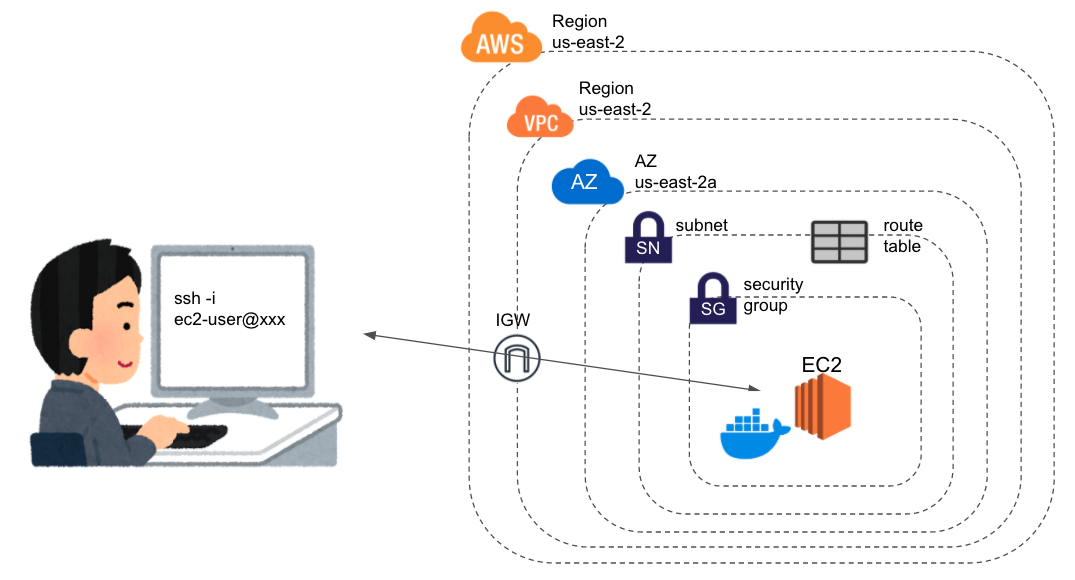
CodeDeployエージェントをインストール# まずはEC2にログイン ssh -i "ec2-key.pem" ec2-user@XXX.YYY.ZZZ.XXX # インストール sudo yum update sudo yum install ruby sudo yum install wget cd /home/ec2-user # ここは環境ごとにbucket-nameとregion-identifierを変更する wget https://bucket-name.s3.region-identifier.amazonaws.com/latest/install chmod +x ./install sudo ./install auto sudo service codedeploy-agent statusちなみに、上記をインスタンス起動設定のユーザーデータに記載しておけば、AutoScallingなどのインスタンス作成時に自動的に実行される。今回は関係ないけど。
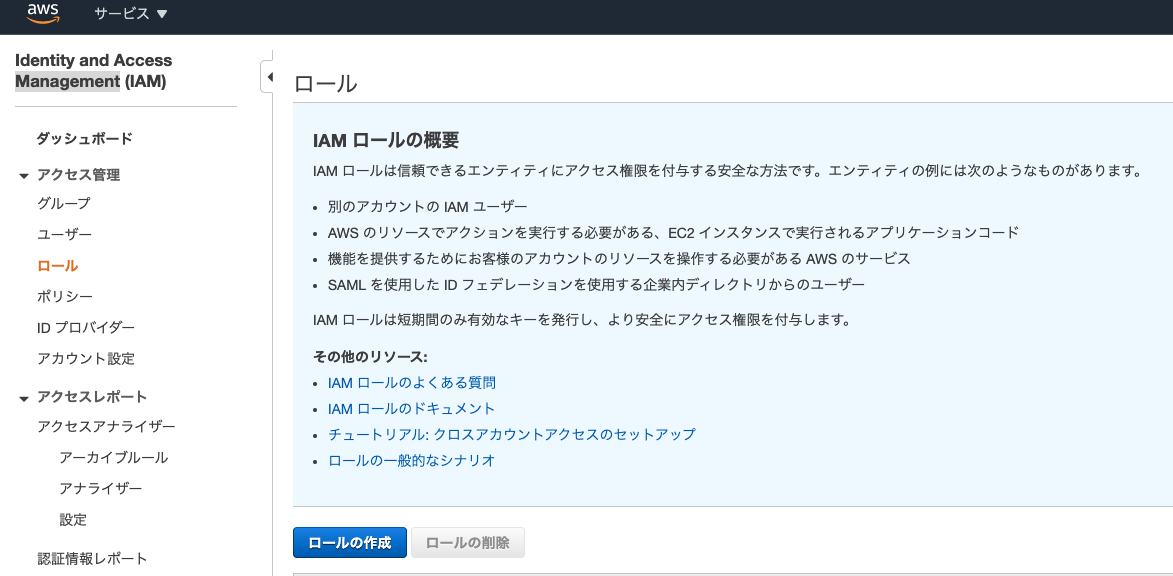
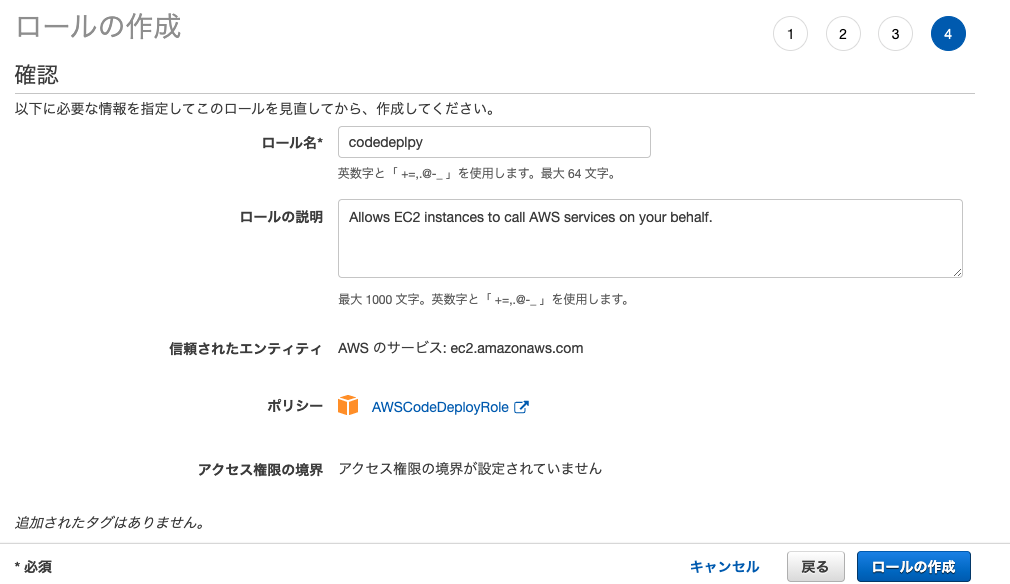
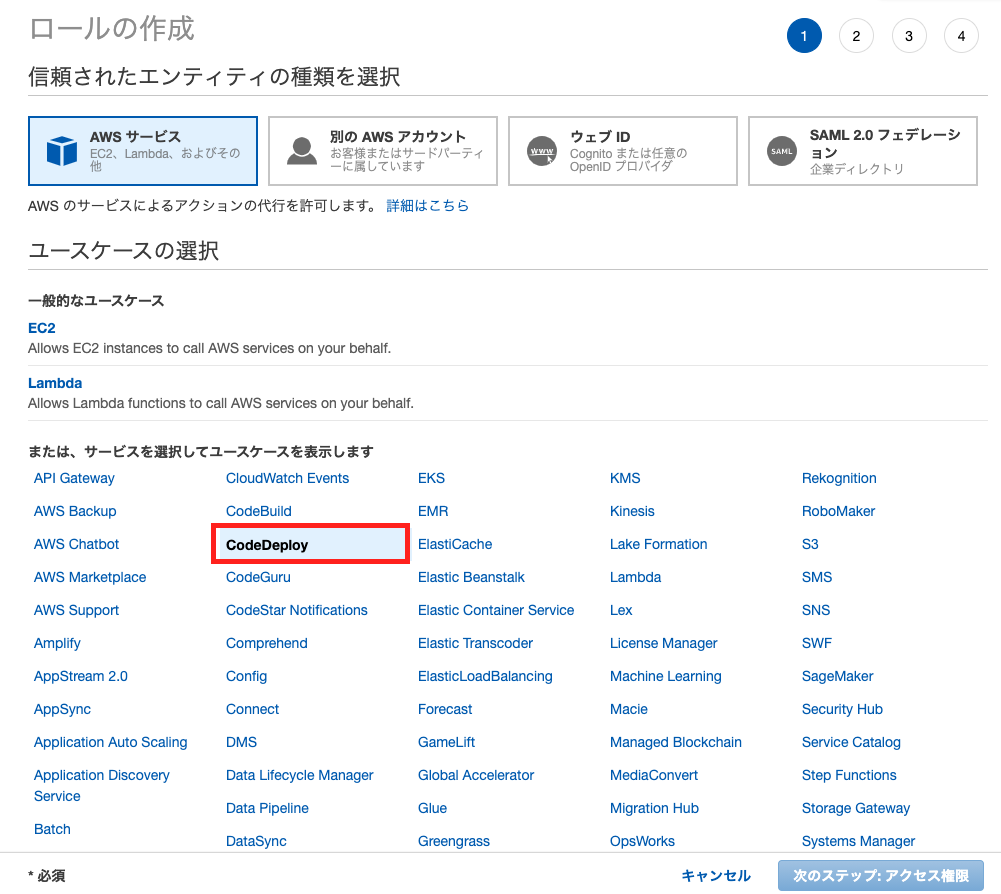
AWSCodeDeployRoleポリシーをアタッチしたIAMロールを作成し、EC2インスタンスにアタッチまずはIAMコンソールからロールの作成を選択
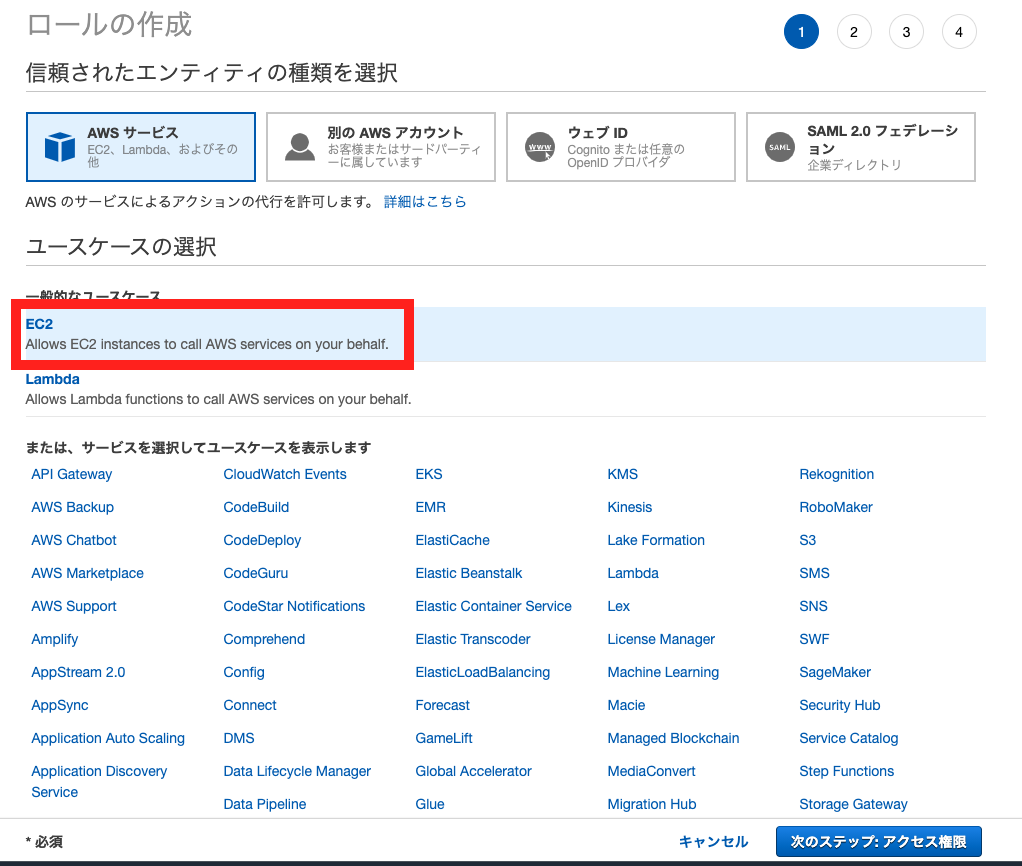
エンティティとしてEC2を選択
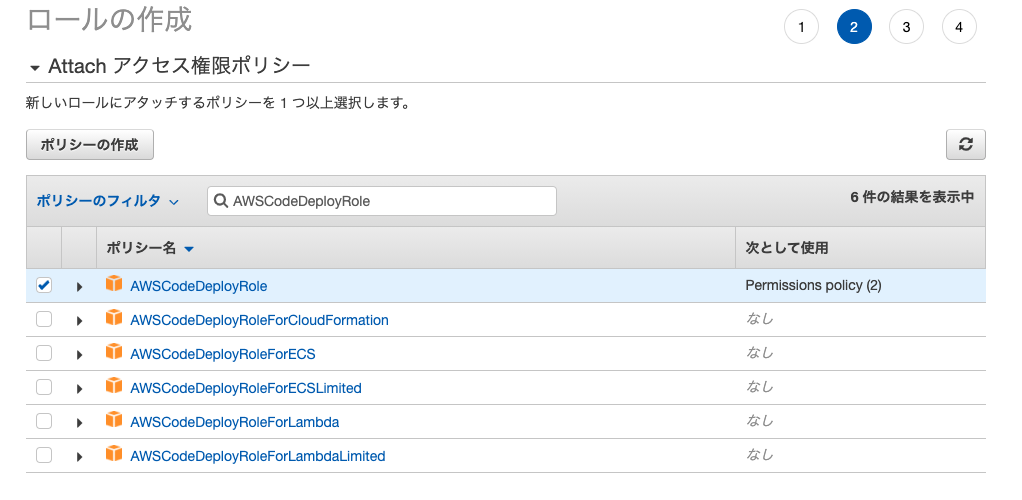
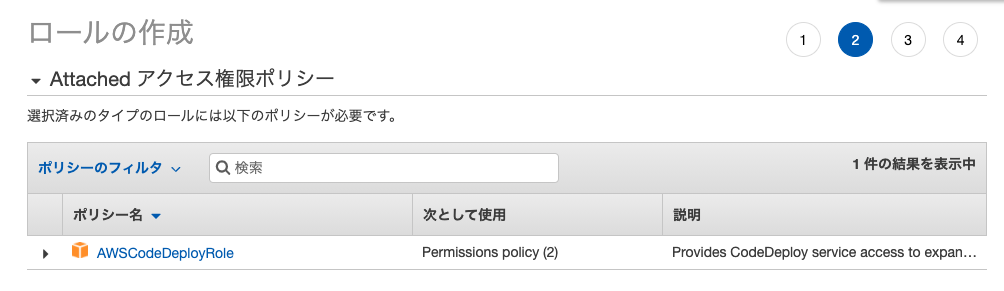
AWSCodeDeployRoleポリシーをアタッチ
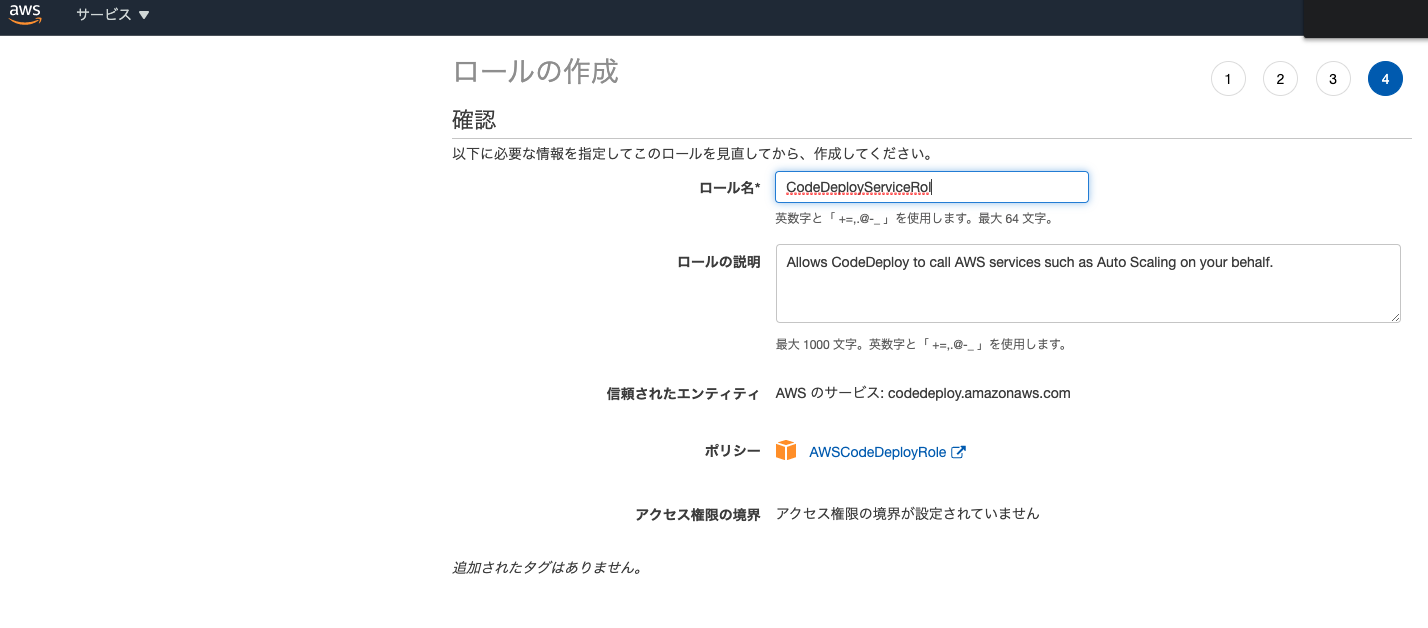
適当なタグとロール名をつけて、ロールを作成
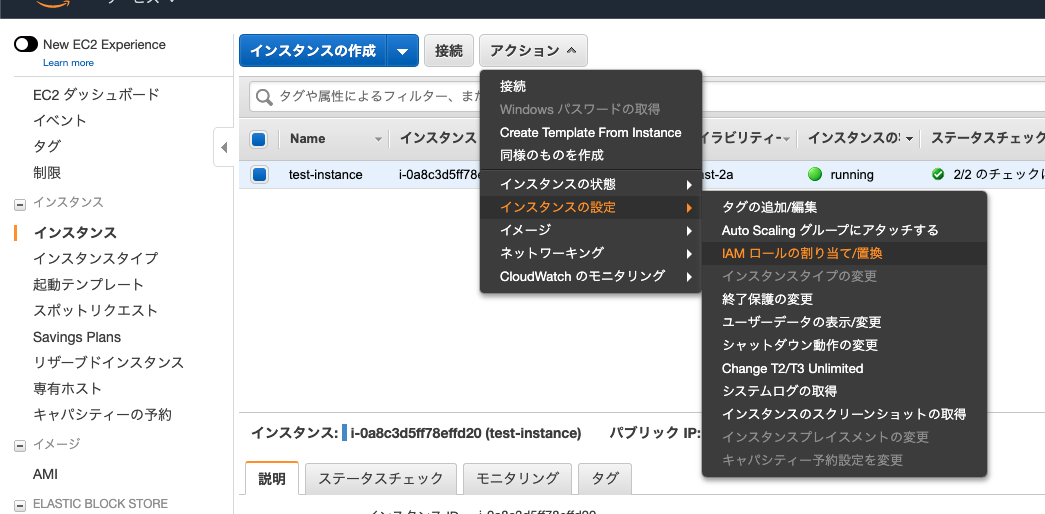
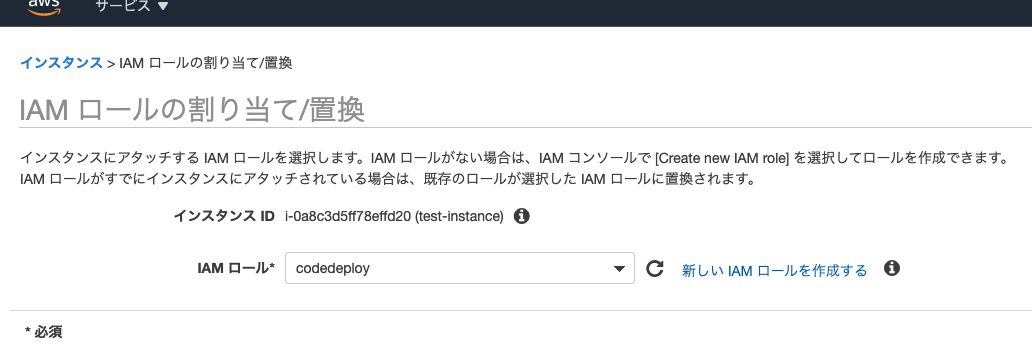
EC2インスタンスに作成したロールをアタッチ
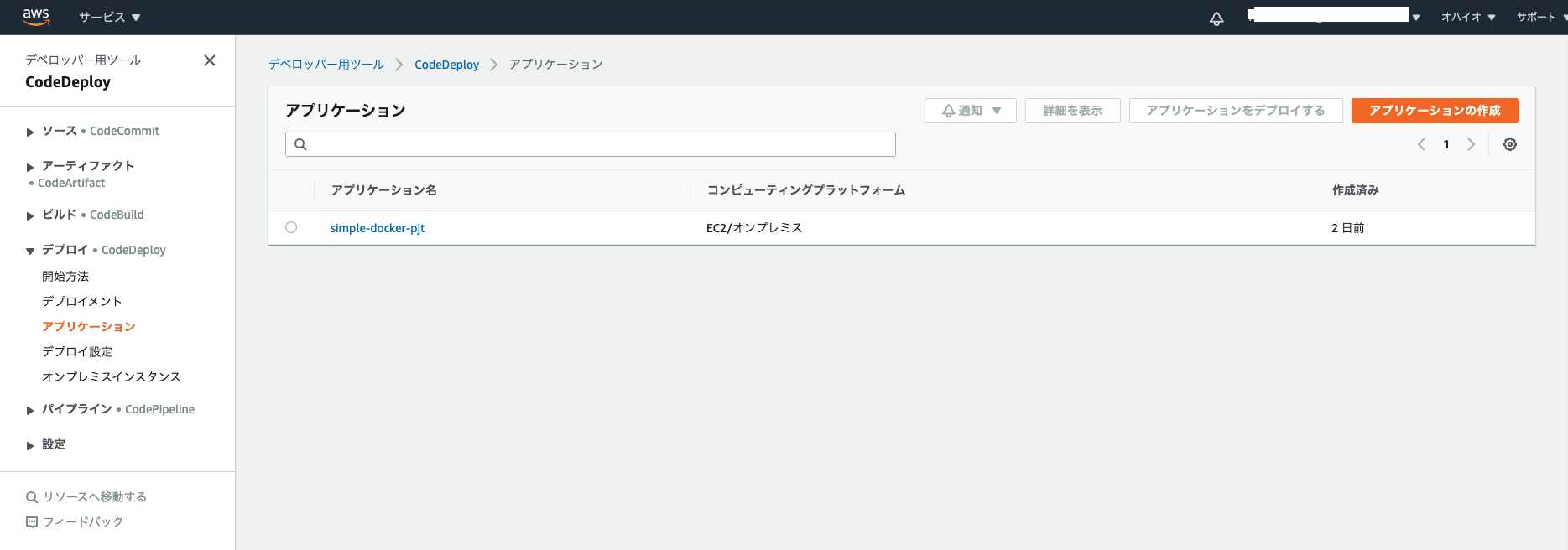
CodeDeployの設定まずはCodeDeployコンソール
アプリケーションの設定
プラットフォームはEC2を選択
CodeDeployのためのロールを作成
先ほどのEC2のためのロール作成と同じ手順。
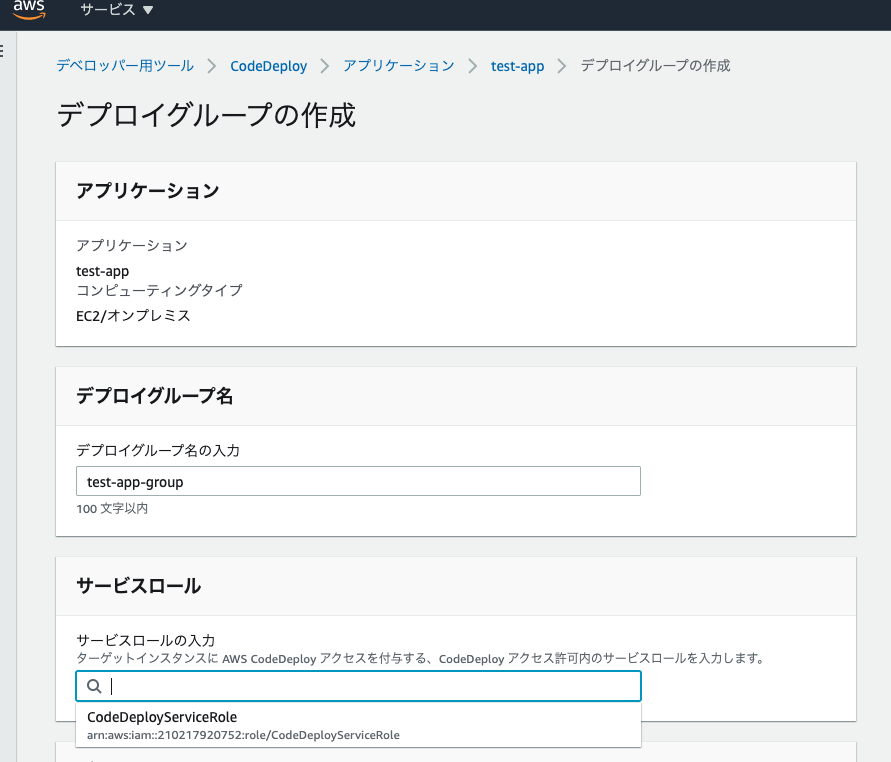
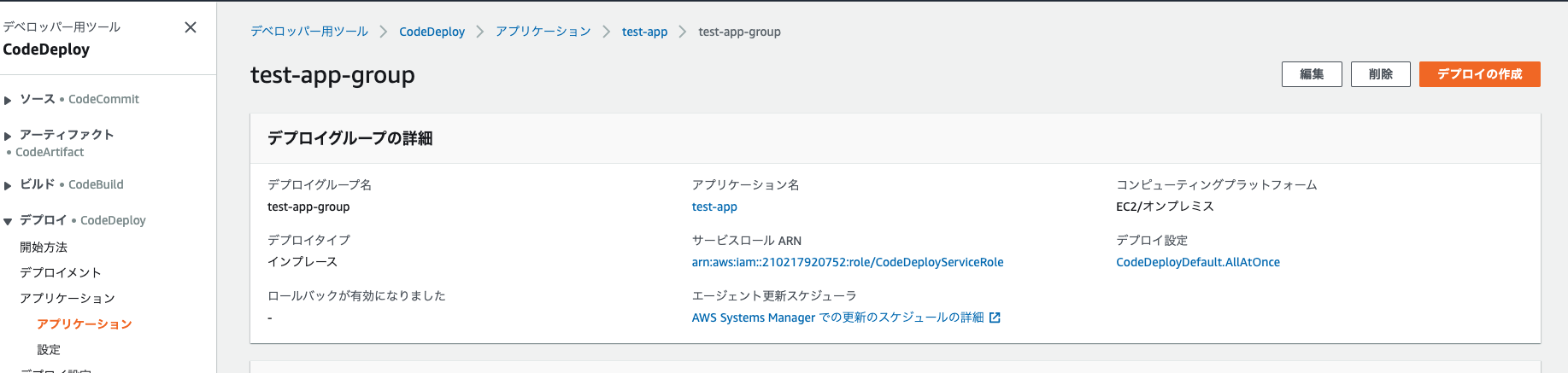
作成したアプリケーションに、デプロイグループを作成
デプロイグループ名は適当に。
サービスロールは先ほど作成したCodeDeployのためのロールをアタッチ。
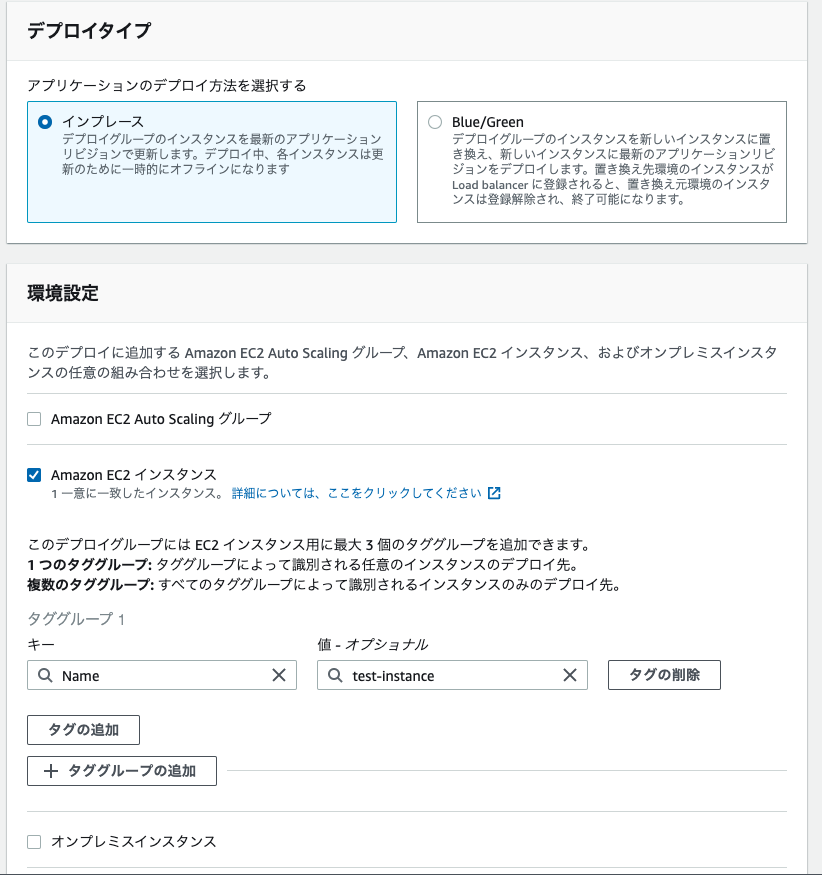
デプロイタイプはインプレースを選択。
環境設定はEC"インスタンスを設定。
ここでは、どのEC2にデプロイするかを判定するためにタグを使う。選択したタグをもつ全てのEC2にデプロイされる。
同時にいくつものEC2にデプロイするためには便利。
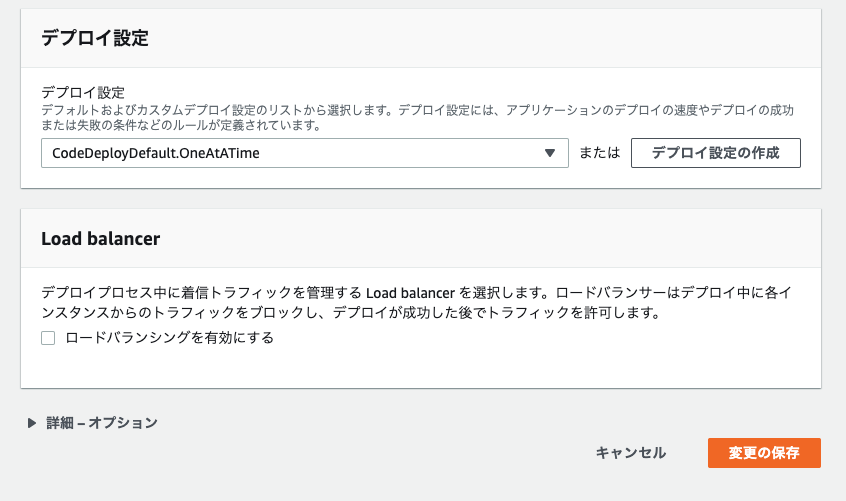
デプロイ設定はデフォルトを指定。
今回はLoad balancerを使わない。
appspec.ymlとApplicationStart.bashの作成gitレポジトリと連携させてコードをデプロイするのだが、ソースコードに加え、どうやってデプロイするかを記述したファイルをgitレポジトリのルートディレクトリに保存する必要がある。そしてファイル名は
appspec.ymlで固定。
具体的な書き方はこちらやこちらの記事を参照させていただいた。
ありがとうございます。appspec.ymlversion: 0.0 os: linux files: - source: / destination: /home/ec2-user/simple-docker-pjt runas: ec2-user permissions: - object: / pattern: '**' owner: ec2-user group: ec2-user hooks: ApplicationStart: - location: scripts/ApplicationStart.bash runas: ec2-userまた、
appspec.ymlにしたがって、EC2にコードをコピーインストールした後、実際にdocker-compose upをする必要がある。
それをApplicationStart.bashに記述する。
くれぐれもdocker-compose up -dの-dの部分にお気をつけください。バックグラウンドで実行しないと、永遠にデプロイが終わりません。/scripts/ApplicationStart.bash#!/bin/bash -e cd /home/ec2-user/simple-docker-pjt sudo systemctl start docker docker-compose up -dデプロイの作成
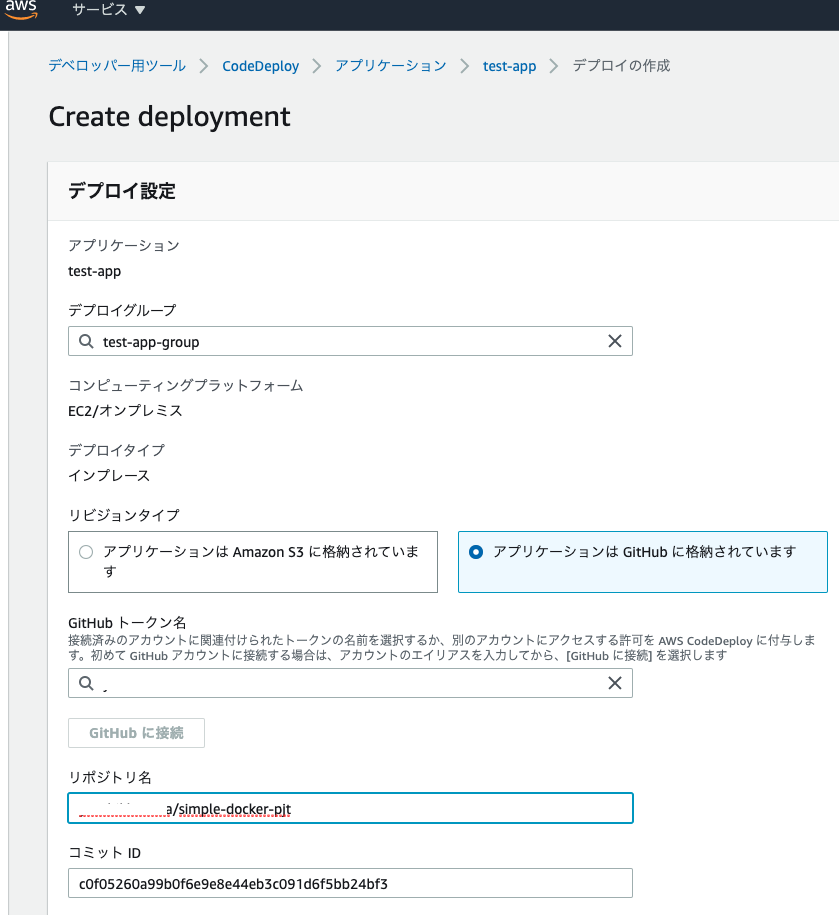
アプリケーションを選択し、「デプロイの作成」、をクリック。
「リビジョンタイプ」にgithubを選択し、トークン名として自分のアカウント名を記入。そして接続する。
また、接続先のレポジトリ名とデプロイしたい任意の時点のコミットIDを指定する。
これでデプロイを作成すれば、問題なくデプロイできるはず。ここまで来ました。
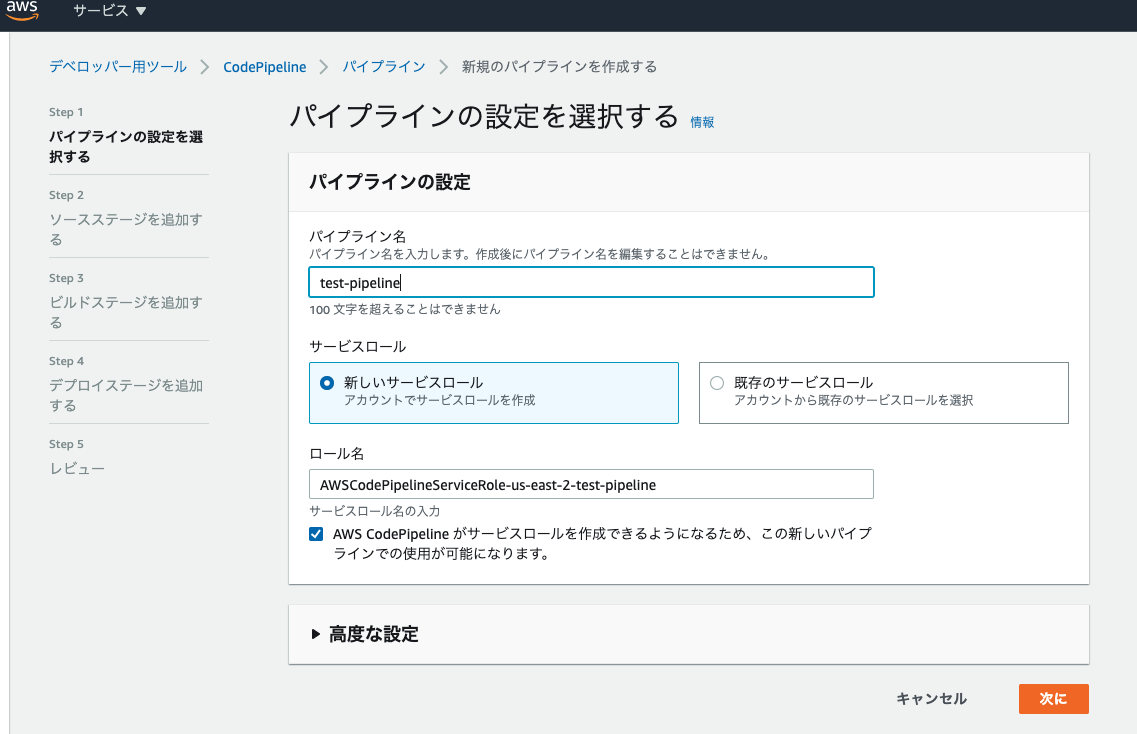
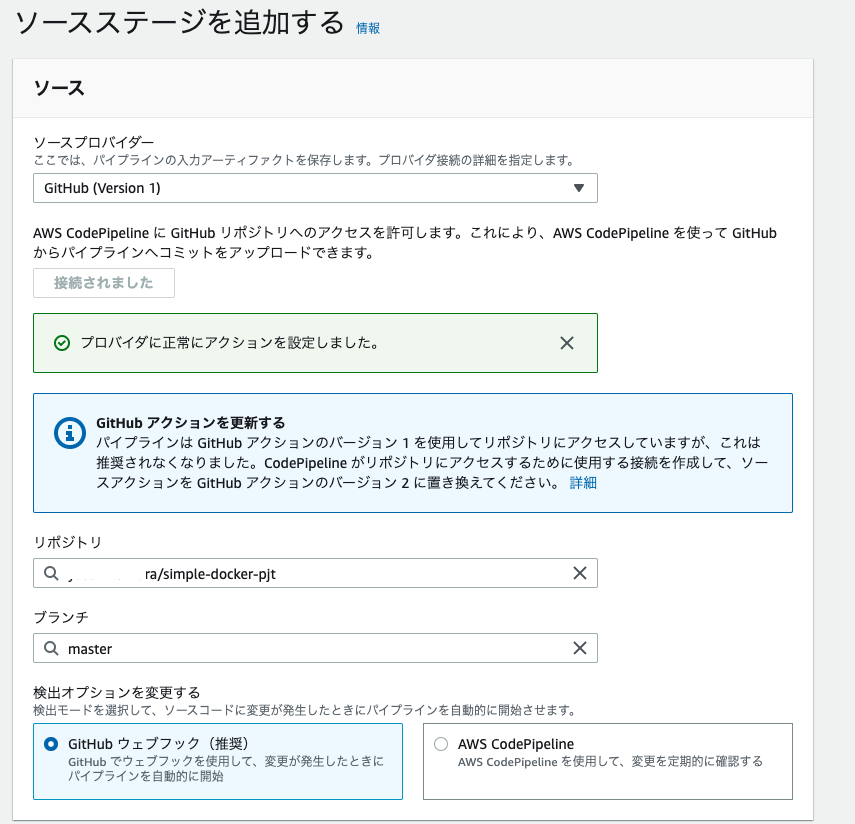
CodePipelineの設定パイプラインを作成する
CodePipelineのコンソールから新しいパイプラインを作成する。
パイプライン名を適当に設定すると、自動でサービスロール名も設定される。
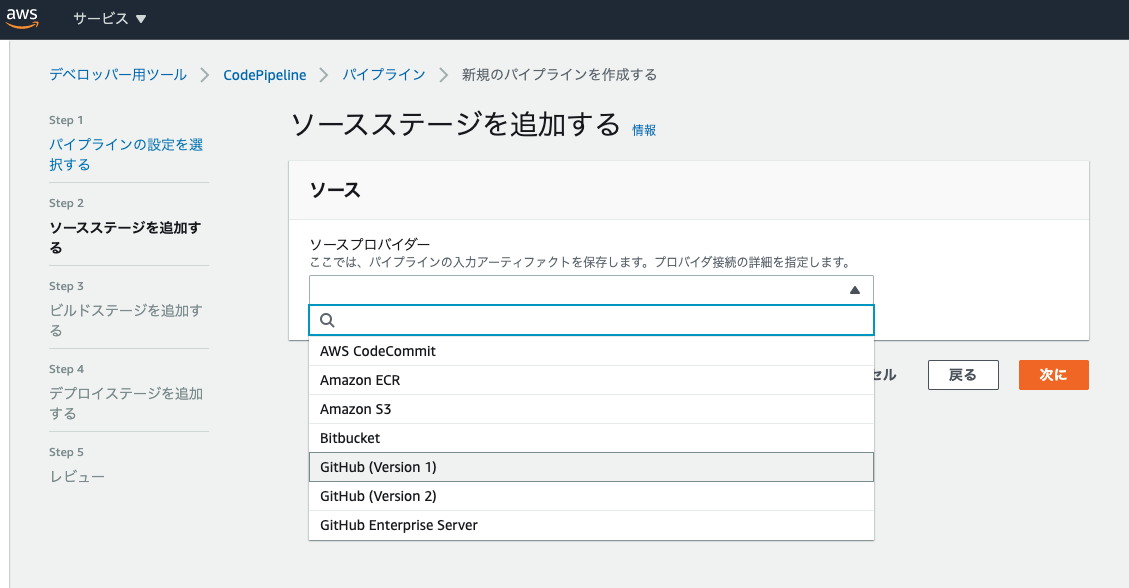
ソースステージはgithub(ver.1)を選択し、自分のアカウントに接続する。
レポジトリとブランチを選択する。
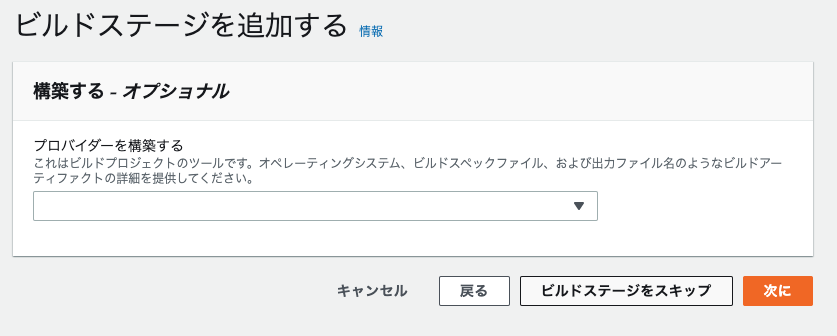
ビルドステージは(今回はビルド不要の言語なので)スキップする
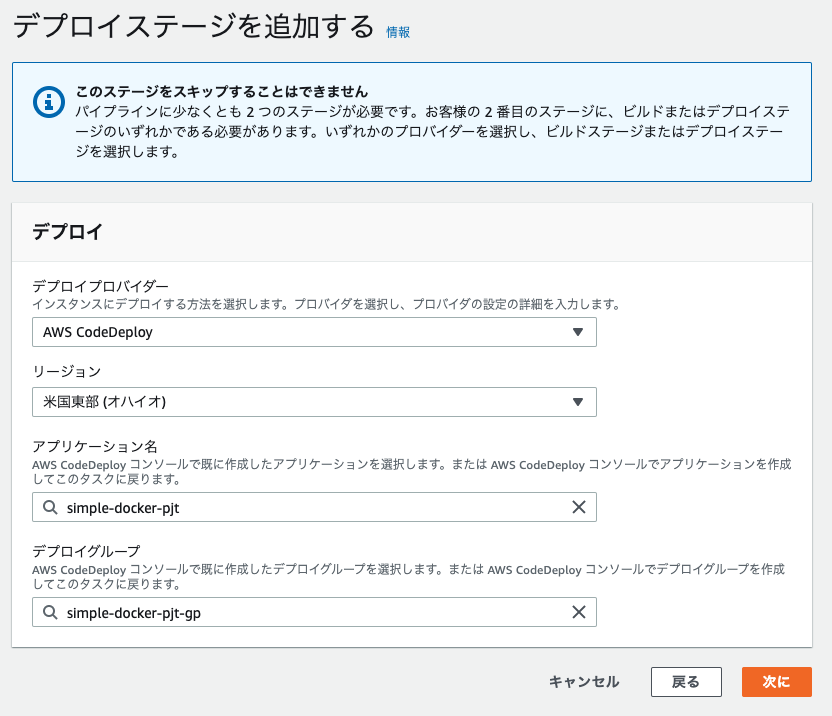
デプロイプロバイダーは
CodeDeployを選択し、先ほど作成したアプリケーションとデプロイグループを選択する。
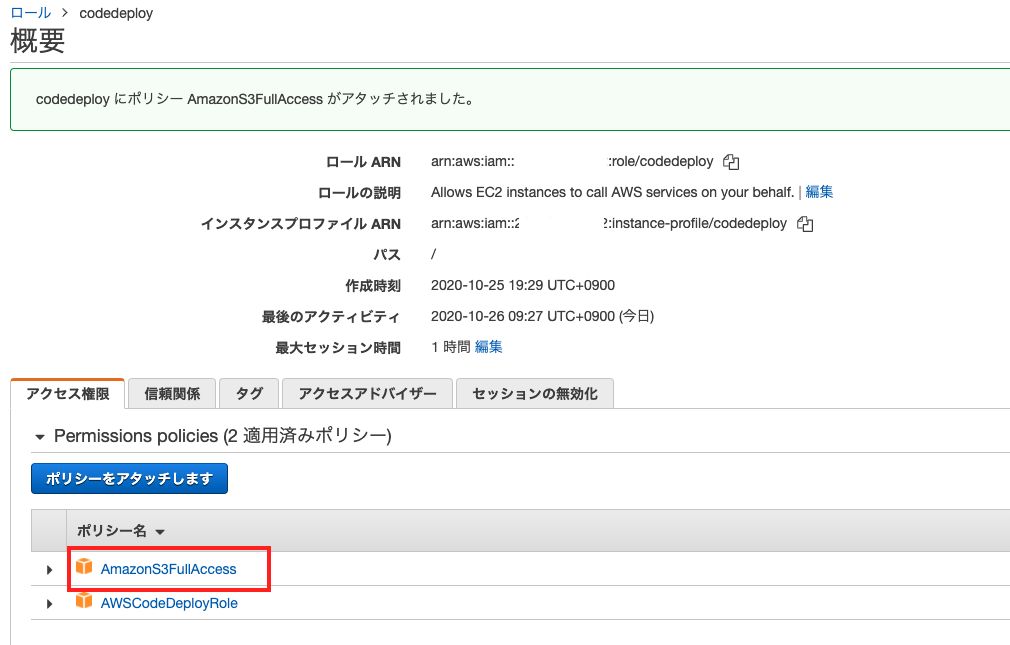
EC2にS3へのアクセス権限を追加する。
EC2がCodePipelineを利用するためには、S3へのアクセスが必要となる。
そのため、先ほどEC2にアタッチしたロールにAmazonS3FullAccessポリシーを追加でアタッチする。
これで設定ができました。
gitにコードをpushすると自動的にEC2にデプロイされます。
参考サイト
くろかわさんのyoutube。いつも参考にさせていただいております。
https://youtu.be/8mPm7jolnVk
- 投稿日:2020-10-26T16:33:02+09:00
すでにあるDockerfileからGPU対応させた話
はじめに
この記事は、機械学習させようと思ったDockerfileおよびdocker-composeファイルがGPUに対応していなかったので、その原因と対策という話になります。
とはいえ、自分はdockerを調べ始めて1ヶ月ほどしかたっておらず、いくつか間違った知識があるかもしれないので、ご了承くださいm(_ _)m環境
- Ubuntu 18.04
- docker 19.03.11
- docker-compose 1.17.1 -> 1.20.1
- nvidia-docker、cuda等はホストOSにインストール済み
- tensorflow 2.1.0
対象となる人
- dockerをGPU対応させたい人
- GPU対応できてるか知りたい人
使用したDockerfileとdocker-compose.yml
今回使おうとしたのはとある書籍のサンプルプロジェクトなので、すべてを載せることはできませんが、最低限の部分だけ記述しておきます。
DockerfileFROM continuumio/miniconda3:latest COPY environment.yml /tmp/ RUN conda update -y -n base conda \ && conda env create -f /tmp/environment.yml \ && conda clean -y -t \ && rm /tmp/environment.yml ENV PATH /opt/conda/envs/tf/bin:$PATHdocker-compose.ymlversion: "3" services: tf: build: context: ../ dockerfile: ./docker/Dockerfile container_name: tf image: tf ports: - "8888:8888" volumes: - ../:/tf command: /opt/conda/envs/tf/bin/jupyter notebook --ip='0.0.0.0' --port=8888 --no-browserやりたいこととしては、minicondaを使用してenvironment.ymlからpython環境を作成し、docker-composeでjupyter notebookを起動させるといったものです。
environment.ymlにはtensorflow2.1やjupyterなどが含まれています。しかし、このままではGPUを認識してくれません。
GPUが認識されているかどうかの検証方法
GPUが使えるかどうかにはいくつか方法があるので、ここでまとめておきます。これらをdockerコンテナ内で実行することで、GPUが使えるか調べることができます。
nvidia-smi
物理デバイスとしてGPUが認識できているか確認する方法です。dockerからGPUを使えるようになっていれば基本的にコマンドを受けつけてくれると思います。
tf.config.list_physical_devices('GPU')
これはpythonで実行するやつです。tensorflowをimportしてから使用してください。
これを実行すると、GPUが使えればそのリストが返ってきます。この時、使用できない場合は様々なwarningが出てくるので、これを手掛かりに原因を掴むことができます。tf.test.is_gpu_available()
これもpythonの関数です。こちらはTrue/Falseで返ってくる以外は上の関数と同じです。
※ lspci | grep -i nvidia
調べるとこの方法もよく出てくるのですが、docker内だとこのコマンドが使用できなかったです。最小限の構成だからでしょうか...?
GPUが使えない原因
使いたいDockerコンテナに対し、上記のコマンドを試したところ、すべてGPUを認識していない結果となりました。
すごく調べて調査した結果、大きく分けて以下の3つの理由があることがわかりました。
- docker-composeがGPUに対応しきれていない
- CUDAやcudnnがdockerコンテナ内に含まれていない
- tensorflowがCUDAなどを認識していない
それでは、1つずつ詳しくみていきます。
docker-composeのGPU対応
すでにnvidia-docker(nvidia-container-toolkit)がホストOSにインストールされている前提でお話しします。
dockerは19.03からgpusオプションに対応し、--gpus allとすることで物理的にGPUデバイスを認識しnvidia-smiが使用できるようになります。
しかし、docker-composeはgpusタグに対応していません。そこでruntimeタグを使用してGPU対応させます。docker-composeでgpu対応する方法はこちらの記事など、「docker-compose GPU」で検索かければたくさん出てきますが、やり方がいくつか異なっていたりして難しいと思います。
確認すべき要点は以下の通りです。
- docker-composeのバージョンを1.19以上にする
- runtimeタグが使用できるようになります
- docker-compose.ymlのversionタグを確認する
- docker-composeのバージョンとの対応によって使えない場合があります。最新版ならなんとかなるかもしれません。
- /etc/docker/daemon.jsonの中身を確認する
- nvidia関連の設定が書かれていれば問題ありません
- docker-composeに
runtime: nvidiaを記述する- environmentタグに
NVIDIA_VISIBLE_DEVICES=allやNVIDIA_DRIVER_CAPABILITIES=allを記述する
- NVIDIA_VISIBLE_DEVICESは使用するGPUデバイスを指定し、NVIDIA_DRIVER_CAPABILITIESはGPUの使用方法(?)を指定します。computeやutilityなど最低限の指定でも問題ないかもです。
これらの確認・変更を行って、docker-composeで立ち上げたコンテナ内でnvidia-smiを使用すると、うまくいけばnvidia-smiが使用できると思います。
CUDAやcudnnの対応
ここからの問題に対する調査が非常に苦労しました。
dockerおよびdocker-composeでのGPU対応は、あくまで物理デバイスとしてのGPUを認識させるだけで、GPU計算ができるようになるわけではありません。
したがって、CUDAやcudnnがdockerコンテナにインストールされていなければなりません。
ほとんどのサンプルでは、nvidia/cudaというイメージや、tensorflowイメージなどを使用していますが、これらのコンテナにはCUDAが含まれています。しかし、minicondaのようなほとんどのイメージについてはGPUに対応していないのではないかと思います。正直、この対策としては、ベースとなるDockerイメージによって異なると思います。
自分の環境では、minicondaベースをやめ、nvidia/cudaをベースにし、RUNでminicondaをインストールしました。
もしベースとなるイメージにcudaやcudnnが含まれているタグや関連するイメージがあれば、dockerhubからそれを選択するべきだと思います。
もしnvidia/cudaをベースにできないし、cudaのあるバージョンもないということであれば、Dockerfile内でcudaやcudnnを追加する方法しかないように思います。
Dockerfileにどのように書いたらいいかは分からないので、詳しい人に聞いてください...
愚直にやると、キャッシュ等が残ってしまい軽量とはいえなくなる可能性があります。tensorflowのCUDA認識
CUDAやcudnnのあるバージョンを見つけたところ悪いのですが、tensorflowには対応するCUDAやcudnnがインストールされている必要があります。少しでもバージョンが異なると動かない可能性があります。対応するCUDAのバージョンを含むDockerイメージにしてください。(参考:Tensorflowのビルド構成)
さらにここから、場合によってはせっかく入ったのにtensorflowが見つけてくれないという場合があります。これは、LD_LIBRARY_PATHという環境変数にcuda関係のファイルへのパスが含まれていない可能性があります。
find / -name libcu*のように検索することで、全ファイルからlibcudartやlibcurandなどのファイルが見つかると思います。それらが入っているフォルダをLD_LIBRARY_PATHに追加してください。先ほどの方法でtensorflowがGPUを認識したら成功です!おめでとうございます。
おまけ:tensorRTについて
自分の環境ではそうなのですが、tensorflowをimportするタイミングでいくつかのwarningが出ます。そこではtensorRTが使えないといった旨が記載されています。
これは決してtensorflowが使えないというわけではなく、GPU計算をさらに高速化させるtensorRTが含まれていないことを意味しています。なので、もし出てしまった場合でも問題なくGPUを認識してくれると思います。おわりに
自分の経験をつらつらと書いただけなので参考にならなかったかもしれません...
そもそも、最初からtensorflow-gpuのdockerイメージをベースにすればこのような問題は起こりにくく、しかもgpuタグを付けなくてもGPUを認識してくれるので、できることならそのようなイメージから始めることをオススメします。
- 投稿日:2020-10-26T16:33:02+09:00
すでにあるDockerfileをGPU対応させた話
はじめに
この記事は、機械学習させようと思ったDockerfileおよびdocker-composeファイルがGPUに対応していなかったので、その原因と対策という話になります。
とはいえ、自分はdockerを調べ始めて1ヶ月ほどしかたっておらず、いくつか間違った知識があるかもしれないので、ご了承くださいm(_ _)m環境
- Ubuntu 18.04
- docker 19.03.11
- docker-compose 1.17.1 -> 1.20.1
- nvidia-docker、cuda等はホストOSにインストール済み
- tensorflow 2.1.0
対象となる人
- dockerをGPU対応させたい人
- GPU対応できてるか知りたい人
使用したDockerfileとdocker-compose.yml
今回使おうとしたのはとある書籍のサンプルプロジェクトなので、すべてを載せることはできませんが、最低限の部分だけ記述しておきます。
DockerfileFROM continuumio/miniconda3:latest COPY environment.yml /tmp/ RUN conda update -y -n base conda \ && conda env create -f /tmp/environment.yml \ && conda clean -y -t \ && rm /tmp/environment.yml ENV PATH /opt/conda/envs/tf/bin:$PATHdocker-compose.ymlversion: "3" services: tf: build: context: ../ dockerfile: ./docker/Dockerfile container_name: tf image: tf ports: - "8888:8888" volumes: - ../:/tf command: /opt/conda/envs/tf/bin/jupyter notebook --ip='0.0.0.0' --port=8888 --no-browserやりたいこととしては、minicondaを使用してenvironment.ymlからpython環境を作成し、docker-composeでjupyter notebookを起動させるといったものです。
environment.ymlにはtensorflow2.1やjupyterなどが含まれています。しかし、このままではGPUを認識してくれません。
GPUが認識されているかどうかの検証方法
GPUが使えるかどうかにはいくつか方法があるので、ここでまとめておきます。これらをdockerコンテナ内で実行することで、GPUが使えるか調べることができます。
nvidia-smi
物理デバイスとしてGPUが認識できているか確認する方法です。dockerからGPUを使えるようになっていれば基本的にコマンドを受けつけてくれると思います。
tf.config.list_physical_devices('GPU')
これはpythonで実行するやつです。tensorflowをimportしてから使用してください。
これを実行すると、GPUが使えればそのリストが返ってきます。この時、使用できない場合は様々なwarningが出てくるので、これを手掛かりに原因を掴むことができます。tf.test.is_gpu_available()
これもpythonの関数です。こちらはTrue/Falseで返ってくる以外は上の関数と同じです。
※ lspci | grep -i nvidia
調べるとこの方法もよく出てくるのですが、docker内だとこのコマンドが使用できなかったです。最小限の構成だからでしょうか...?
GPUが使えない原因
使いたいDockerコンテナに対し、上記のコマンドを試したところ、すべてGPUを認識していない結果となりました。
すごく調べて調査した結果、大きく分けて以下の3つの理由があることがわかりました。
- docker-composeがGPUに対応しきれていない
- CUDAやcudnnがdockerコンテナ内に含まれていない
- tensorflowがCUDAなどを認識していない
それでは、1つずつ詳しくみていきます。
docker-composeのGPU対応
すでにnvidia-docker(nvidia-container-toolkit)がホストOSにインストールされている前提でお話しします。
dockerは19.03からgpusオプションに対応し、--gpus allとすることで物理的にGPUデバイスを認識しnvidia-smiが使用できるようになります。
しかし、docker-composeはgpusタグに対応していません。そこでruntimeタグを使用してGPU対応させます。docker-composeでgpu対応する方法はこちらの記事など、「docker-compose GPU」で検索かければたくさん出てきますが、やり方がいくつか異なっていたりして難しいと思います。
確認すべき要点は以下の通りです。
- docker-composeのバージョンを1.19以上にする
- runtimeタグが使用できるようになります
- docker-compose.ymlのversionタグを確認する
- docker-composeのバージョンとの対応によって使えない場合があります。最新版ならなんとかなるかもしれません。
- /etc/docker/daemon.jsonの中身を確認する
- nvidia関連の設定が書かれていれば問題ありません
- docker-composeに
runtime: nvidiaを記述する- environmentタグに
NVIDIA_VISIBLE_DEVICES=allやNVIDIA_DRIVER_CAPABILITIES=allを記述する
- NVIDIA_VISIBLE_DEVICESは使用するGPUデバイスを指定し、NVIDIA_DRIVER_CAPABILITIESはGPUの使用方法(?)を指定します。computeやutilityなど最低限の指定でも問題ないかもです。
これらの確認・変更を行って、docker-composeで立ち上げたコンテナ内でnvidia-smiを使用すると、うまくいけばnvidia-smiが使用できると思います。
CUDAやcudnnの対応
ここからの問題に対する調査が非常に苦労しました。
dockerおよびdocker-composeでのGPU対応は、あくまで物理デバイスとしてのGPUを認識させるだけで、GPU計算ができるようになるわけではありません。
したがって、CUDAやcudnnがdockerコンテナにインストールされていなければなりません。
ほとんどのサンプルでは、nvidia/cudaというイメージや、tensorflowイメージなどを使用していますが、これらのコンテナにはCUDAが含まれています。しかし、minicondaのようなほとんどのイメージについてはGPUに対応していないのではないかと思います。正直、この対策としては、ベースとなるDockerイメージによって異なると思います。
自分の環境では、minicondaベースをやめ、nvidia/cudaをベースにし、RUNでminicondaをインストールしました。
もしベースとなるイメージにcudaやcudnnが含まれているタグや関連するイメージがあれば、dockerhubからそれを選択するべきだと思います。
もしnvidia/cudaをベースにできないし、cudaのあるバージョンもないということであれば、Dockerfile内でcudaやcudnnを追加する方法しかないように思います。
Dockerfileにどのように書いたらいいかは分からないので、詳しい人に聞いてください...
愚直にやると、キャッシュ等が残ってしまい軽量とはいえなくなる可能性があります。tensorflowのCUDA認識
CUDAやcudnnのあるバージョンを見つけたところ悪いのですが、tensorflowには対応するCUDAやcudnnがインストールされている必要があります。少しでもバージョンが異なると動かない可能性があります。対応するCUDAのバージョンを含むDockerイメージにしてください。(参考:Tensorflowのビルド構成)
さらにここから、場合によってはせっかく入ったのにtensorflowが見つけてくれないという場合があります。これは、LD_LIBRARY_PATHという環境変数にcuda関係のファイルへのパスが含まれていない可能性があります。
find / -name libcu*のように検索することで、全ファイルからlibcudartやlibcurandなどのファイルが見つかると思います。それらが入っているフォルダをLD_LIBRARY_PATHに追加してください。先ほどの方法でtensorflowがGPUを認識したら成功です!おめでとうございます。
おまけ:tensorRTについて
自分の環境ではそうなのですが、tensorflowをimportするタイミングでいくつかのwarningが出ます。そこではtensorRTが使えないといった旨が記載されています。
これは決してtensorflowが使えないというわけではなく、GPU計算をさらに高速化させるtensorRTが含まれていないことを意味しています。なので、もし出てしまった場合でも問題なくGPUを認識してくれると思います。おわりに
自分の経験をつらつらと書いただけなので参考にならなかったかもしれません...
そもそも、最初からtensorflow-gpuのdockerイメージをベースにすればこのような問題は起こりにくく、しかもgpuタグを付けなくてもGPUを認識してくれるので、できることならそのようなイメージから始めることをオススメします。
- 投稿日:2020-10-26T16:01:28+09:00
【0からCircleCIに挑戦】AWSのECR・ECSを理解する
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためCircleCIを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからCircleCIに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
AWSのECR・ECSを理解する。実際にECRとECSを使ってアプリケーションを手動でデプロイしてみる。
【関連記事】
【0からCircleCIに挑戦】CircleCIの基礎を学ぶ
【0からCircleCIに挑戦】自動テストを構築する(Rails6.0・mysql8.0・Rspec)
【0からCircleCIに挑戦】AWSのECR・ECSを理解する
【0からCircleCIに挑戦】CircleCI・AWS(ECR・ECS)で自動デプロイ環境
ruby 2.6.6
rails 6.0
db: mysql 8.0
test: rspec目次
- ECRとは何か
- ECSとは何か
- 実際にAWSでECR・ECSデプロイする
1.ECRとは何か
ECRについて
ECRとは「Elastic Container Registry」の略で、AWS上のコンテナイメージ管理システムのことです。Dockerを使ったことがある人ならDockerHubというクラウドレジストリサービスを知っていると思いますが、簡単にいうとECRはAWS版のDokcerHubです。
ECRはAWSでコンテナを使ってデプロイする際、非常に便利なサービスです。もちろんDockerHubを使って運用することもできますが、本番環境でAWSを使う際はECRを使ったほうが管理が簡単になります。またECRはAmazonが管理しているサービスなので安全性も保証されています。
ECRに関しては概念も用語も特に新しいものはなく、DockerHubを使ったことがあるならばすぐ理解できるでしょう。
2.ECSとはなにか
ECSについて
ECSとは「Elastic Container Service」の略で、AWS上のコンテナの実行・管理システムです。実は前述のECRもECSの一種のサービスといえます。ECSはAWS上で簡単にコンテナを起動させたり、停止させたり、管理したりできるシステムのことです。
もしコンテナを使ってアプリケーションをAWSの本番環境にデプロイしたい場合はECSは必須のサービスといえるでしょう。ただ少し独特の概念や用語があり、とっかかりにくいところもあります。なのでまずはECS独特の用語や概念を理解しましょう。
ECSの概念・用語について
クラスター
Amazon ECS クラスターは、タスクまたはサービスの論理グループです。 EC2 を使用してタスクまたはサービスを実行している場合、クラスターはコンテナインスタンスのグループ化でもあります。 キャパシティープロバイダーを使用している場合、クラスターはキャパシティープロバイダーの論理的なグループでもあります。
AWSの公式では上記のように書かれています。ECSではEC2サーバーを使ってコンテナを実行しており、そのEC2サーバーは1つのプロジェクトに対し単体のこともあれば複数にわたることもあります。クラスターとはこのプロジェクトに対するEC2のまとまりのことをいいます。
サービス
Amazon ECS サービスを使用すると、Amazon ECS クラスター内で、タスク定義の指定した数のインスタンスを同時に実行して維持できます。タスクが何らかの理由で失敗または停止した場合、Amazon ECS サービススケジューラは、タスク定義の別のインスタンスを起動してそれに置き換え、サービスで必要数のタスクを維持します。
サービスで必要数のタスクを維持することに加えて、オプションでロードバランサーの背後でサービスを実行することもできます。ロードバランサーは、サービスに関連付けられたタスク間でトラフィックを分散させます。AWSの公式では上記のように書かれています。サービスと言う概念は非常に分かりづらいですが、簡単にいうとコンテナとロードバランサーを結びつけたり、どのタスク定義をコンテナに適応させるかを管理することです。サービスに関しては実際に手を動かしながら設定を進めていくとわかりやすいかと思います。
タスク
タスクとは、関連するコンテナの集合体です。少し分かりにくいので具体例で説明します。railsアプリケーションのコンテナ構成は,webサーバー + アプリケーションサーバーの2つであるこが多いですが、どちらかのコンテナが欠けている場合アプリケーションは起動しません。このようにアプリケーションの起動に関連し合うコンテナをAWS上ではタスクといいます。
AWSではコンテナを起動するためにタスクの設定をする必要があり、それをタスク定義と呼んでいます。
3. 実際にAWSでECR・ECSデプロイする
※AWSのVPC,ELB,RDSは設定済み、開発環境でDockerfile作成済みという前提です。
AWSに関しては、【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
Dockerに関しては、【0からDockerに挑戦】Dockerを使ってnginx・puma・rails6.0・mysqlの開発環境を構築する
で詳しく書いてありますので、AWSやDockerについて不明であれば参照してください。ファイル構成
今回は既存のアプリケーションを使います。ファイル構成は下記です。
Desktop/
├ webapp/
├ containers
└ nginx
└ Dockerfile
└ nginx.conf
├ enviroment
└ db.env
├ Dockerfile
├ docker-compose.yml
├ Gemfile
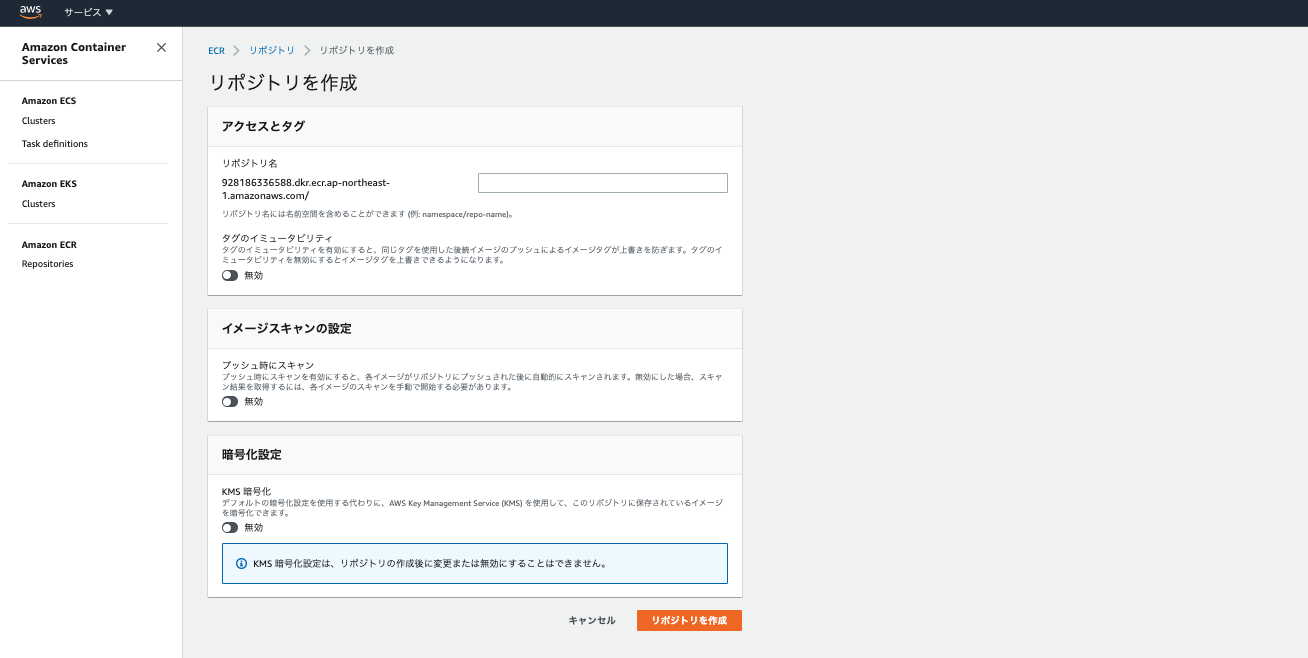
├ Gemfile.lockECRでレポジトリを作成する
AWSのメニューでECRと検索すると、ECRが出てくると思います(※実際ECSの中にECRの項目があります)。そしてリポジトリの作成を押します。そうすると下記画面になりますので、リポジトリ名に好きな名前を入力します。リポジトリはDockerfile分必要ですので、nginx用とapp用の2種類作ります。データベースに関してはRDSを使用するので不要です。
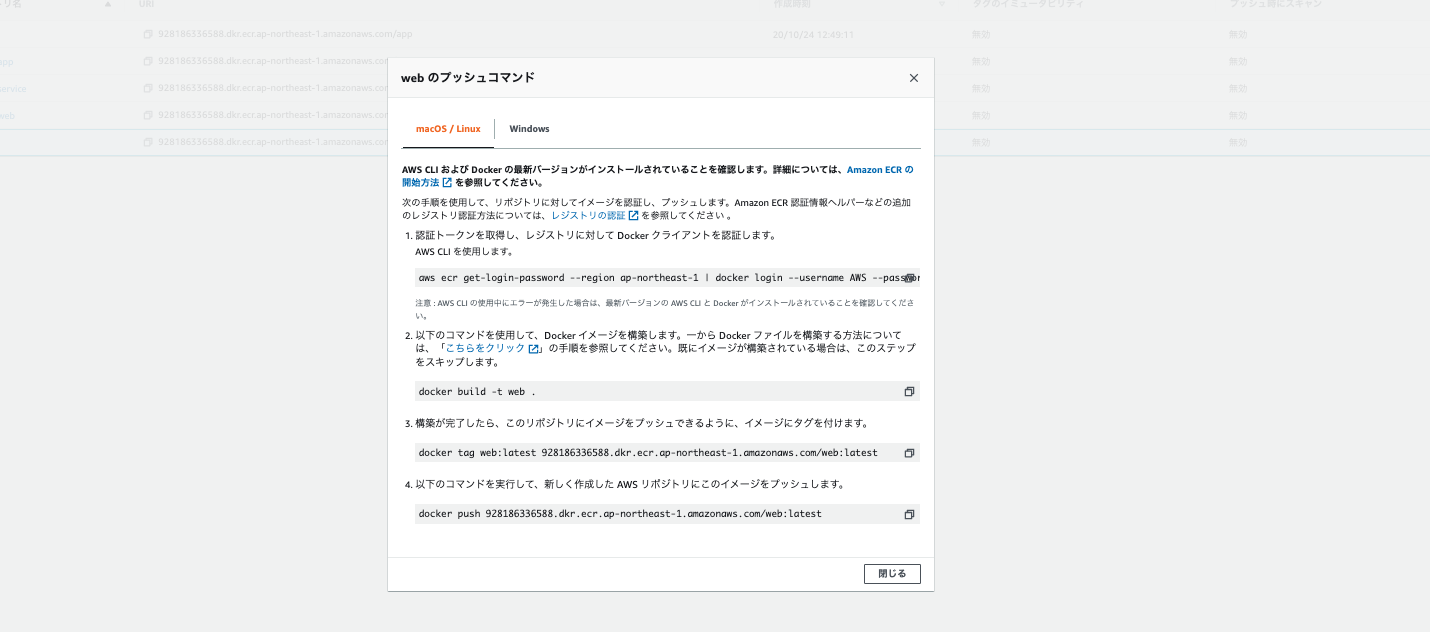
次にECRメニュー上に作成したリポジトリが表示されますので、それを選択して右上にあるプッシュコマンドの表示を押しましょう。下記のように4つのコマンドが表示されますので、それをコピーしてターミナルで実行してください。
※2つめのコマンドはDockerfileのある位置を指定する必要がありますので、今回は下記のように変更する必要がありますターミナル(nginx用) docker build -t nginx -f ./container/nginx/Dockerfile . (app用) docker build -t app .※またAmazonCLIを入れていない場合はエラーが発生します。その場合は下記を入力してから実行してください。
ターミナル$ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" $ unzip awscli-bundle.zip $ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws以上でECRの設定は完了です。プッシュコマンド表示のコマンドはイメージを構築して、ECRにイメージをプッシュするという内容です。つまりこれでローカルのDockerイメージがAWS上に保存されたということになります。
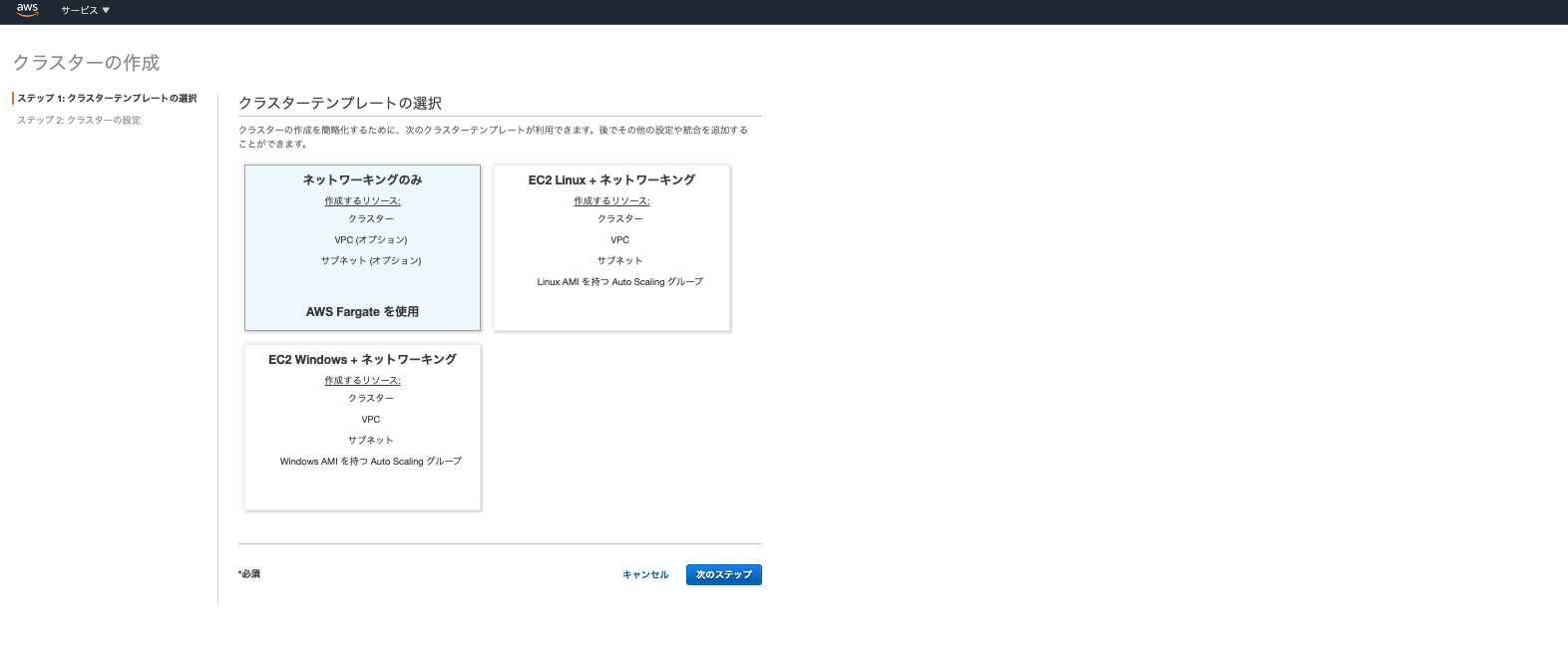
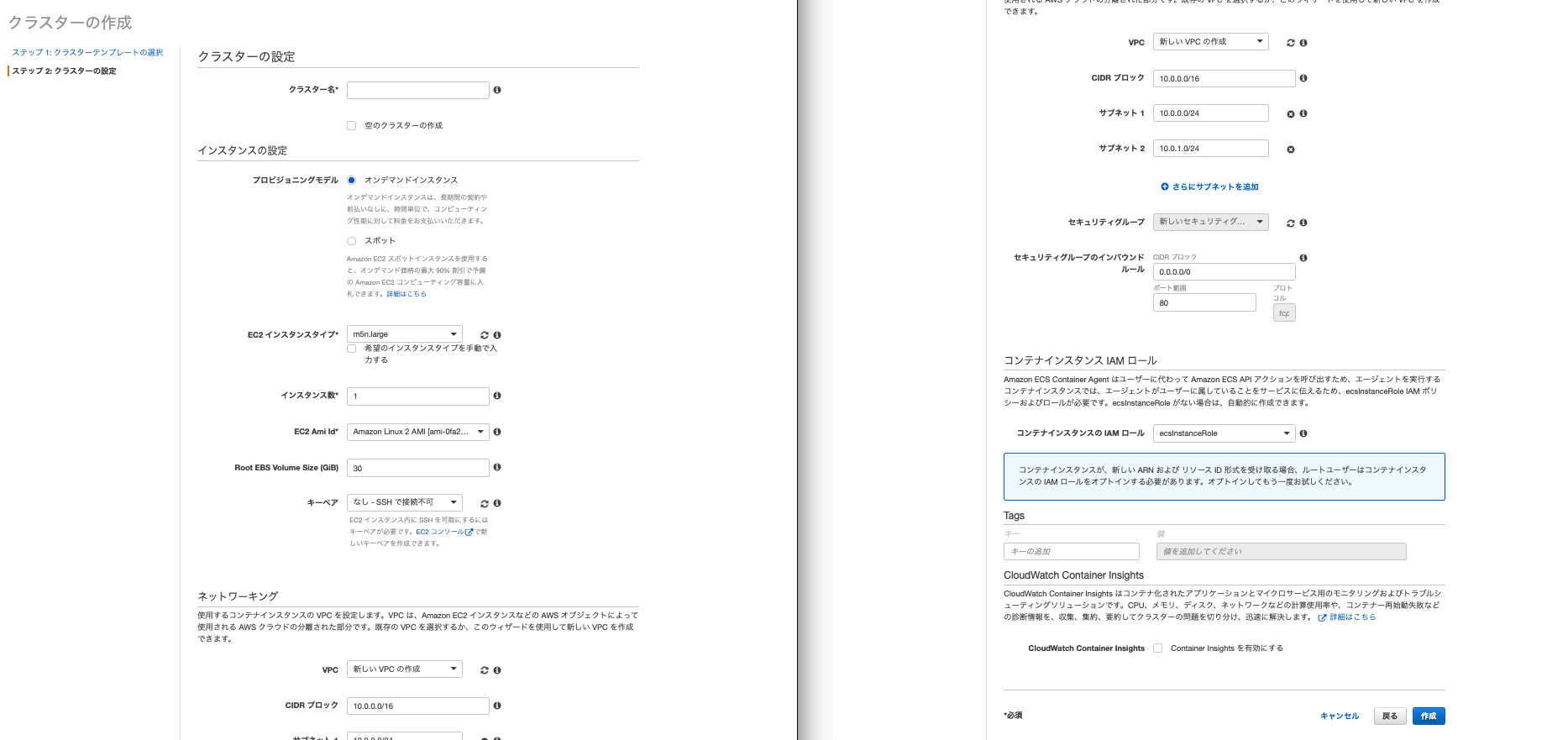
ECSでクラスタを作成する
クラスター作成
次に左側のメニューからECSのクラスターを選び、クラスターを作成をクリックします。そうすると下記画面が表示されます。
ここは「EC2 Linux + ネットワーキング」を選びます。次に設定の詳細が出てきます。
(※「AWS Fargate」については後述します)
設定でいじるところだけ説明します。
- クラスター名はわかりやすい名前を設定してください。
- EC2インスタンスタイプは「t2.micro」をにします。これ以外を選択すると無料枠ではなくなってしまうので注意してください。
- インスタンス数は1にします。
- キーペアはいつもEC2にログインしている時に使っているものを選びます。デフォルトのままだとECSから作成されたEC2にSSHで接続できません。
- ネットワーキングは作成済みのVPC、サブネットはVPCのなかのパブリックサブネット、セキュリティグループはパブリックサブネットで使っているセキュリティグループを選びます。他の触れていないところはデフォルトで問題ないです。以上クラスターの完成です。
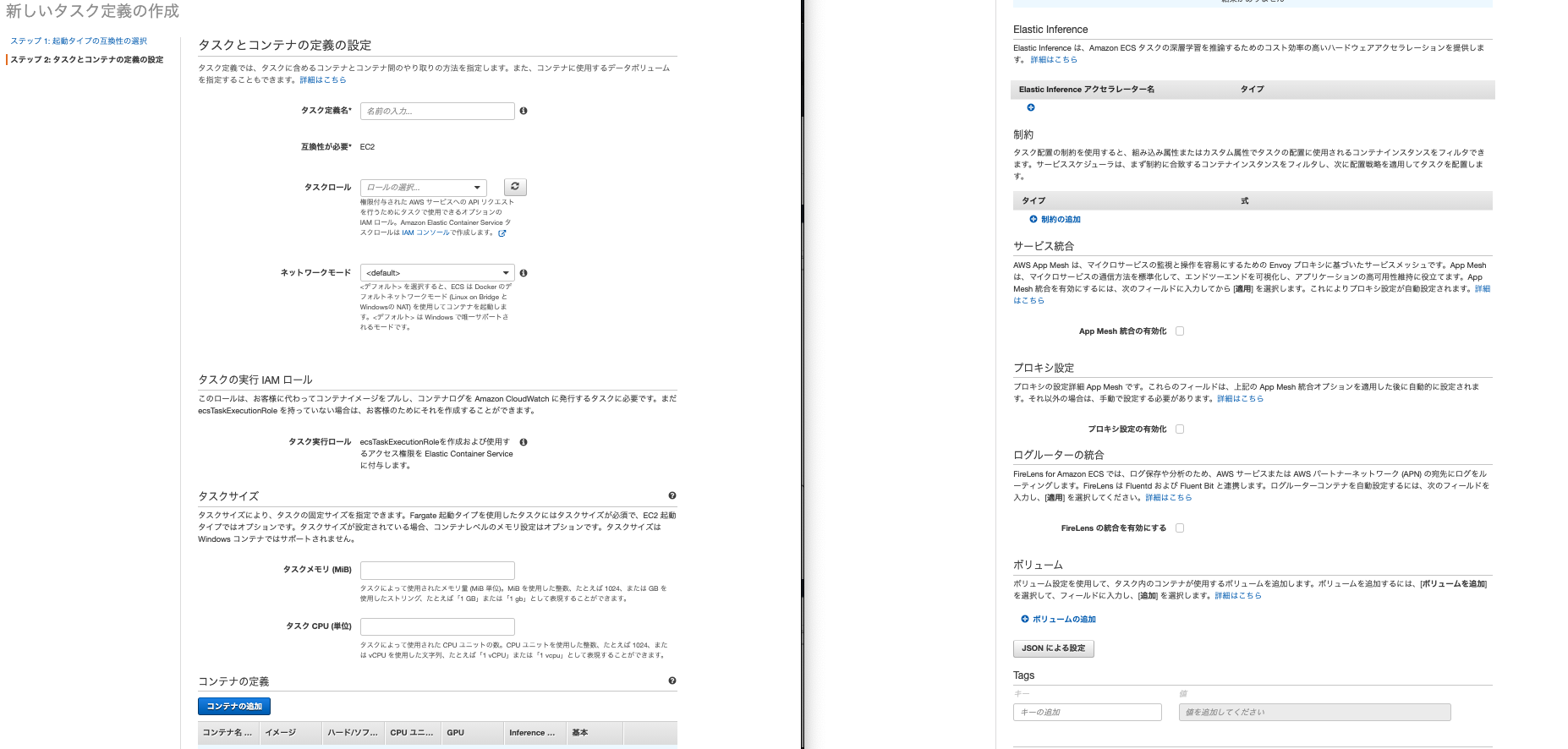
タスク作成
左側のメニューからタスク定義を選択します。起動タイプの互換性の選択という画面が表示されるのでEC2を選択します(※Fargateについては後述します)。そうすると下記設定画面がでてきます。
こちらも設定いじるところだけ説明します。
- タスク定義はわかりやすい名前を入力します。
- ネットワークモードはbridgeを選択します。ちなみにこれはdockerコンテナで使われるネットワークの種類です
- 一番下のボリュームの追加をクリックします。名前はわかりやすい名前、ボリュームタイプをDockerにしてください。他の2つはデフォルトのlocal,taskのままでOKです。ちなみにボリュームとはDockerのデータを永続する場所のことを差します。
- タスクサイズは今回は両方512で設定します。
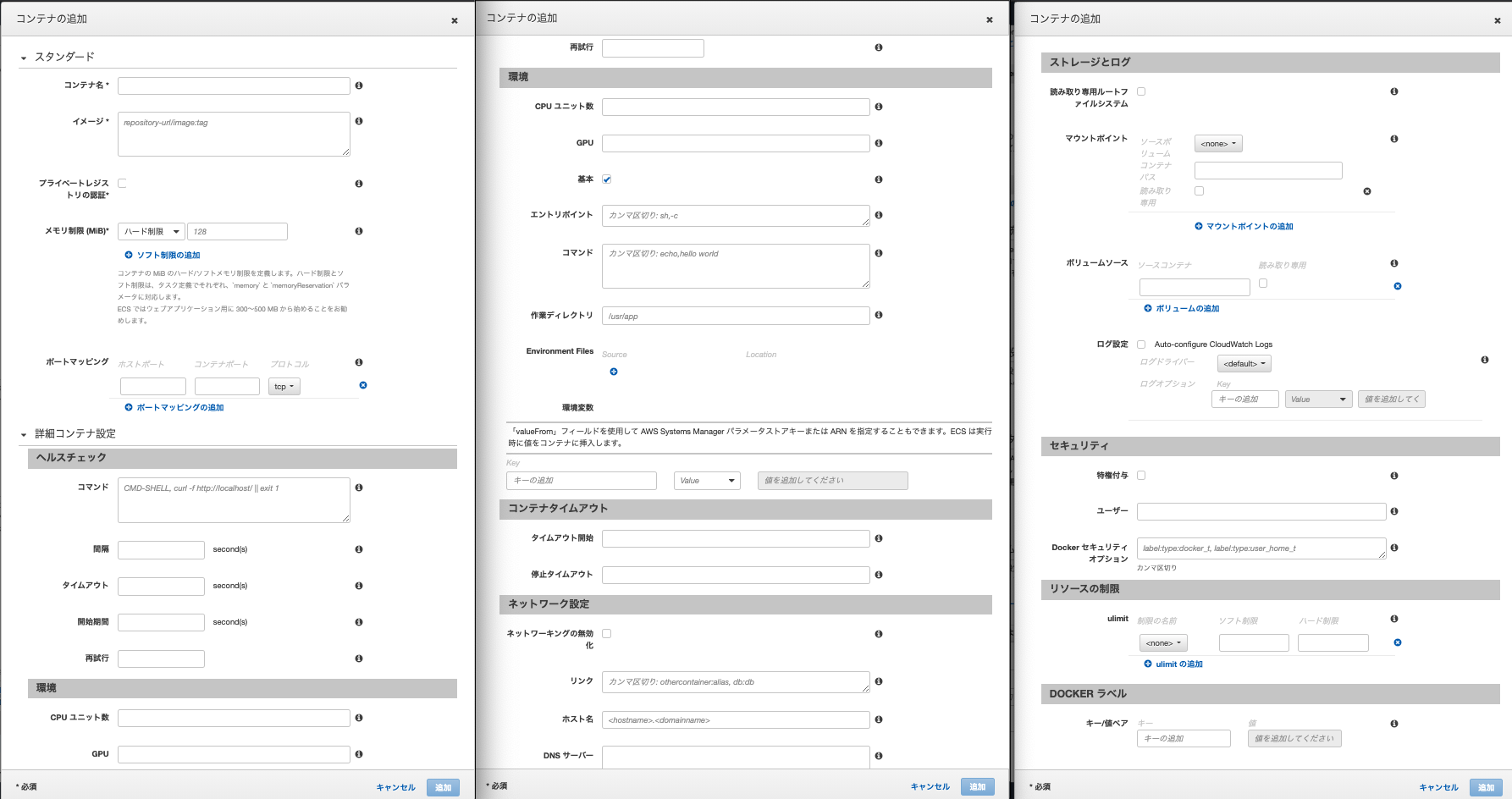
- 真ん中にあるコンテナ追加をクリックします。今回はnginx用とapp用の2つのコンテナが必要があります。ここは少し入力するところが多いのです。
- コンテナ名はわかりやすい名前を入れてください。
- イメージはECRのURIをいれます。nginxであれば、先程ECRにプッシュしたnginxのイメージのURIをいれます。URIはECRのメニューから確認できます。
- ポートマッピングはnginxであれば0:80,appであれば0:3000を入力します。※Dockerのポートの設定と同じですね。
- appのみですが、環境変数を設定します。たとえばRDSのパスワードであればKeyに「RDS_PASSWORD」を入力、値に設定したパスワードを入力します。appに必要な環境変数をここに全て入力してください。
- 他はデフォルトでOKです。
これでコンテナを2つを追加し、タスク定義の作成をクリックしましょう。これでタスクの完成です。
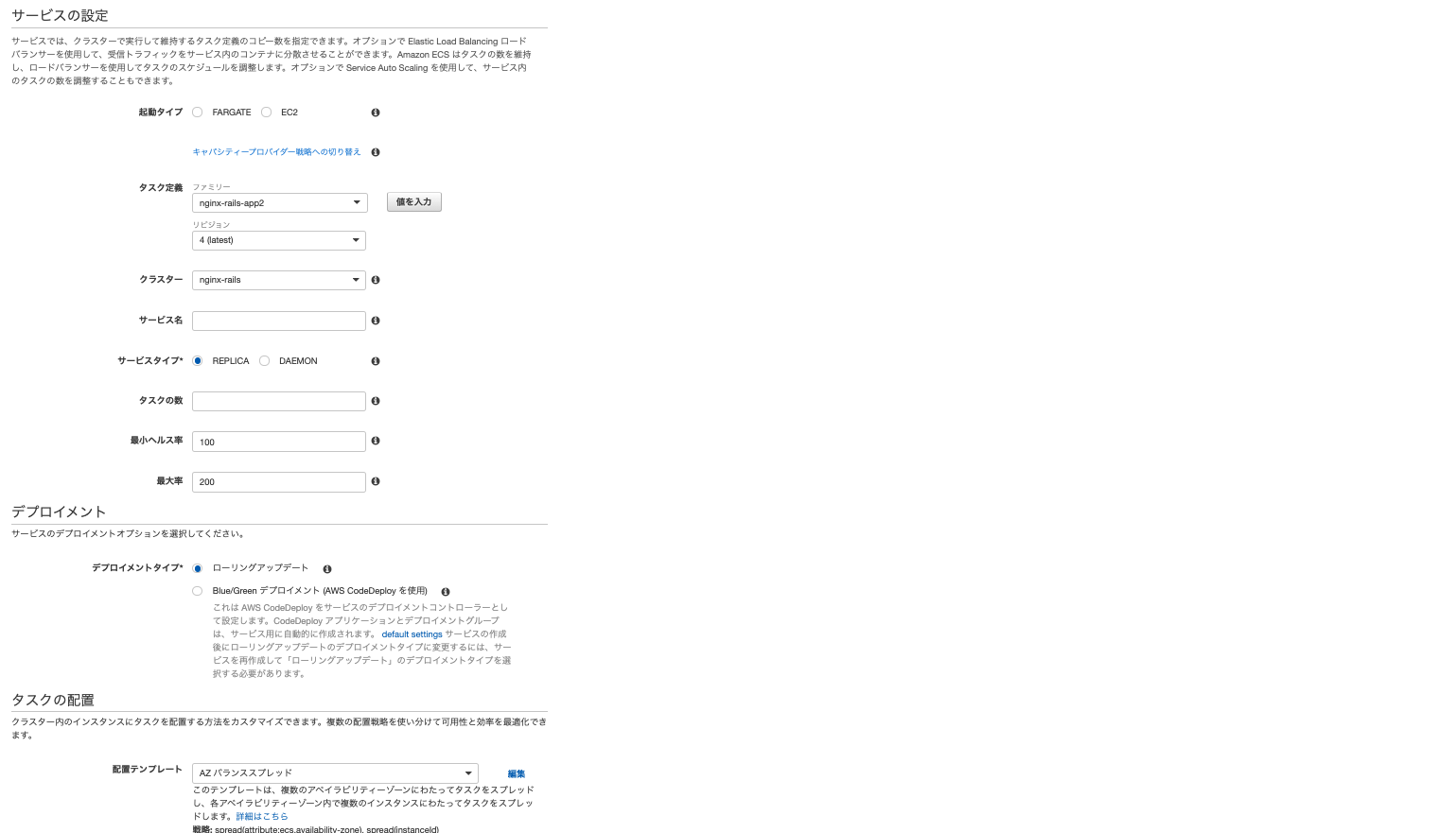
サービスの追加
左のメニューでECSのクラスターを選択し、先程作成したクラスターをクリックします。詳細画面が現れ、下部にメニューが表示されます。そのメニューの中からサービスを選び、作成ボタンを押してください。
- 起動タイプはEC2を選択します
- タスク定義は先程作成したタスクを選びます。
- サービスはわかりやすい名前をつけてください。
- タスクの数は2にします。ここはコンテナの数にあわせます。
- あとはデフォルトで大丈夫です
上記入力が完了したら次のステップを押します。すると下記画面が現れます。
- ロードバランシングは「Application Load Balancer」を選択します。そうするとロードバランサー名を選択する箇所が現れるので、作成済みのロードバランサーを選びましょう
- 次にロードバランス用のコンテナの「web:0:80」(デフォルト)をロードバランサーに追加を押します。そうするとターゲットグループ名を選択するところが表示されるので、ロードバランサー作成時に作ったターゲットグループ名を選択しましょう。
上記入力が終わったら次のステップを押します。そのあとも設定が続きますがデフォルトのままでOKです。これでサービスも完成です。
ECSをsshで接続・ブラウザでアクセス
今までで準備が完了しました。sshでECSに接続し、コンテナがあるか確認します。ECSメニューのクラスターから作成したクラスターを選択し、下部のメニューからECSインスタンスをクリックします。EC2インスタンスという項目があるので、そこからECSを通して作成したEC2が確認できます。そのEC2のプライベートipをコピーしてターミナルで下記を入力します。
ターミナル$ ssh -i [キーペアの] ec2-user@[パブリックIP] (成功するとこんな感じで表示されます) ast login: Sat Oct 24 10:28:34 2020 from 56.97.30.125.dy.iij4u.or.jp __| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/ For documentation, visit http://aws.amazon.com/documentation/ecsあとは「docker ps」や[docker image」でコンテナやイメージを確認しましょう。おそらく今まで作成したものが現れるはずです。
最後にコンテナの中に入りデータベース作成し、マイグレーションをしましょう。ターミナル$ docker exec -it [コンテナのID] bash $ rails db:create $ rails db:migrateこれでブラウザでアプリケーションが表示されるようになったと思います。
ブラウザで確認するにはEC2メニューからロードバランサーを選択し、サービスの作成時に指定したロードバランサーのDNS名をブラウザに入力します。以上で完了です。
※「AWS Fargate」とは簡単にいうと、EC2で管理・運用していたコンテナをAWSが自動でやってくれる仕組みのことです。こちら料金がかかってしまいますが、運用コストが大幅に下がります。今後はFargateが主流になる可能性が高いです。ただ個人のポートフォリオであればEC2でも大差ないかと思います。
おさらいですがおおまかな流れは下記です
ECRにdockerイメージを登録 → クラスターを作成(一番大きな箱) →タスクの定義(コンテナの関係の定義) → サービスの作成(クラスターとタスクを結びつける、ロードバランサーとコンテナの設定) → 完成次回記事ではECSとCircleCIを結びつけて、実際に自動デプロイを構築します。
まとめ・感想
ECSが独特すぎて苦労しましたが、実際に扱ってみると便利さに気づきました。AWS・Docker・CircleCIすべての知識が必要になってくるので、今まで自分が書いてきた記事を参考にしつつ自動デプロイを設定できればと思います。
参考
【書籍】
『CircleCI実践入門──CI/CDがもたらす開発速度と品質の両立 浦井 誠人 (著), 大竹 智也 (著), 金 洋国 (著) 』【qiita】
『いまさらだけどCircleCIに入門したので分かりやすくまとめてみた』
『【CircleCI】Railsアプリに導入(設定ファイルについて)』
『初心者でもできる! ECS × ECR × CircleCIでRailsアプリケーションをコンテナデプロイ』【その他サイト】
『CircleCI Orbsを使ってECR/ECSへ自動デプロイする』

- 投稿日:2020-10-26T15:39:00+09:00
DockerでのFlaskサーバーの作成
Elasticsearchへデータを送るFlaskサーバーを作成する必要があったので、docker-composeを使用して構築
ディレクトリ構成
fl/
├ Dockerfile
├ docker-compose.yml
└ src/
├app.py
└requirements.txt最初にDockerfileの記載
pythonのバージョン、プロジェクトディレクトリ、必要なライブラリを記載したファイルの設定FROM python:3.6 ARG project_dir=/projects/ ADD src/requirements.txt $project_dir WORKDIR $project_dir RUN pip install -r requirements.txt次にdocker-compose.ymlを記載
portの設定とflask runのコマンドを記載
--with-thredsはマルチスレッドで動かすかどうかを設定するオプションdocker-compose.ymlversion: '3' services: flask: build: . ports: - "6000:6000" volumes: - "./src:/projects" tty: true environment: TZ: Asia/Tokyo command: flask run --host 0.0.0.0 --port 6000 --with-threadsrequirements.txtの記載
pipでインストールするライブラリを記載requirements.txtflask elasticsearch実際のサーバーを記載
app.pyfrom flask import Flask, jsonify, request from elasticsearch import Elasticsearch from datetime import datetime app = Flask(__name__) #Elasticsearchのホストとポートとインデックス名 host = "192.168.xx" port = "9200" index_name = "XXXXX" @app.route('/', methods=['POST']) #URLのパスを記載、またPOSTのみ許可 def insert(): data = json.loads(request.data) #flaskに投げられたデータを取得 doc = { "location" : data["location"] } es = Elasticsearch( hosts = [{'host': host, 'port' : port}] ) res = es.index(index=index_name, body=doc) if __name__ == '__main__': app.run()fl/ディレクトリに移動し、
$ docker-compose up -d --buildで起動
修正等で、一度落としたい場合は
$ docker-compose down --rmi all --volumesでイメージ事削除可能
- 投稿日:2020-10-26T15:27:56+09:00
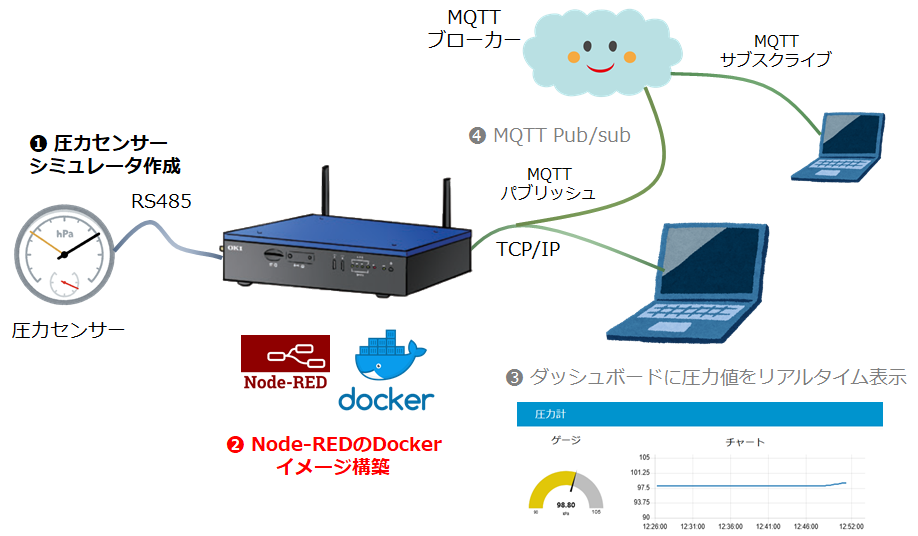
OKI AE2100 & Node-REDでローコードIoTしてみた。その2 構築編
DockerでローコードIoTプラットフォーム構築編
はじめに
これはOKIの「AIエッジコンピューター」と呼ばれる AE2100 というゲートウェイ製品にNode-REDを載せて、ローコードIoTのプラットフォームにしようという記事のその2、DockerでローコードIoTプラットフォーム構築編 になります。
その1 PythonでRS-485シミュレータ準備編
その2 DockerでローコードIoTプラットフォーム構築編 (本記事)
その3 Node-REDでローコードIoT実践編 1 ダッシュボード作成
その4 Node-REDでローコードIoT実践編 2 MQTT Pub/Sub前回の記事では、Windows 10 PC で動作する RS-485シミュレータを Python で作成しました。
今回はいよいよ AE2100 で Node-REDを立ち上げます。
内容としては、ほとんどDockerの作業になります。Dockerfile を作り、Dockerコマンドを数回たたくと、 AE2100 で Node-RED が立ち上がります。
こんなことやります
図の ❷ のNode-REDをインストールしたDockerイメージを作成します。
Dockerイメージの構築
SSH で AE2100 にログインして Bash 上で作業します。
Dockerfile
AE2100 で実行するDockerコンテナのイメージを作成するDockerfileです。
これだけでOKです。DockerfileFROM nodered/node-red:1.1.3-minimal USER root RUN apk add python3 make g++ linux-headers RUN npm install node-red-node-serialport node-red-dashboardこのファイルの内容ですが、まずFROM命令でベースとなるイメージを、Docker Hub にある nodered/node-red の最小イメージ 1.1.3-minimal に指定します。
そしてこの Alpine Linuxベースのイメージに root になって、Node-REDのシリアル通信ドライバのビルドに必要な以下の4つのパッケージを apk add します。
- python3
- make
- g++
- linux-headers
最後に、今回の作業に必要な以下の2つのNode-REDライブラリをここで npm install してしまいます。
- node-red-node-serialport
- node-red-dashboard
node-red-node-serialport は今回 AE2100 上の Node-RED で RS-485 を使うためのライブラリです。
このライブラリは名前が示す通り、RS-232C/RS-485/RS-422等シリアル通信機能をNode-REDに追加するライブラリになります。通常、RS-232C通信で良く使われるライブラリですが、RS-485でも問題なく使えました(マルチドロップは試していません)。node-red-dashboard はNode-REDで簡易ダッシュボードを作成するためのライブラリです。
非常によく利用されており、アップデートも頻繁に行われています。
本文執筆時のバージョンはそれぞれ 3.23.3 と 0.11.0 でした。この2つのライブラリはNode-REDが立ち上がってからインストールしても良いのですが、今回必須ということで、イメージの中に組み込んでしまいます。
Docker イメージのビルド
それでは AE2100 でイメージをビルドしてみます。
上記のDockerfileがあるディレクトリで以下を実行します。AE2100-Shell# docker build --tag node-red_v1:appf . : Successfully built 3691865b0133 Successfully tagged node-red_v1:appfnode-red-node-serialport のC++モジュールのビルドが始まると何やら赤字のログがたくさん出力されますが、"Successfully build..." が出れば大丈夫でしょう。
これで "node-red_v1:appf" のタグ名が付いたイメージができました。
公式のMinimalイメージ194MBに、もろもろ追加されて、計441MBのイメージになりました。。。
しかし 32GB の eMMC を搭載する AE2100 にとってはまだまだ余裕たっぷりです。Docker コンテナの実行
コンテナの立ち上げです!
Node-REDにアクセスする1880番ポートとMQTT用の1883番ポートをそのままコンテナで使えるようにします。
AE2100 の RS-485 のデバイスファイルは /dev/ttyRS485 です。これもそのままコンテナで使えるようにします。
そして AE2100 ホストの /home/root/.node-red ディレクトリをコンテナの /data にボリュームマウントして、Node-REDの設定ファイルやフローは AE2100 ホスト側のファイルシステムに保存するようにします。
Node-RED のフローやライブラリは頻繁に更新されますからね。# docker run -it -p 1880:1880 -p 1883:1883 --device=/dev/ttyRS485:/dev/ttyRS485 -v /home/root/.node-red:/data --name node-red-1 node-red_v1:appf > node-red-docker@1.1.3 start /usr/src/node-red > node $NODE_OPTIONS node_modules/node-red/red.js $FLOWS "--userDir" "/data" 8 Sep 23:27:27 - [info] Welcome to Node-RED =================== 8 Sep 23:27:27 - [info] Node-RED version: v1.1.3 8 Sep 23:27:27 - [info] Node.js version: v10.22.0 8 Sep 23:27:27 - [info] Linux 4.14.67-intel-pk-standard x64 LE 8 Sep 23:27:27 - [info] Loading palette nodes 8 Sep 23:27:29 - [info] Dashboard version 2.23.3 started at /ui 8 Sep 23:27:29 - [info] Settings file : /data/settings.js 8 Sep 23:27:29 - [info] Context store : 'default' [module=memory] 8 Sep 23:27:29 - [info] User directory : /data 8 Sep 23:27:29 - [warn] Projects disabled : editorTheme.projects.enabled=false 8 Sep 23:27:29 - [info] Flows file : /data/flows.json 8 Sep 23:27:29 - [info] Creating new flow file 8 Sep 23:27:29 - [warn] --------------------------------------------------------------------- Your flow credentials file is encrypted using a system-generated key. If the system-generated key is lost for any reason, your credentials file will not be recoverable, you will have to delete it and re-enter your credentials. You should set your own key using the 'credentialSecret' option in your settings file. Node-RED will then re-encrypt your credentials file using your chosen key the next time you deploy a change. --------------------------------------------------------------------- 8 Sep 23:27:29 - [info] Server now running at http://127.0.0.1:1880/ 8 Sep 23:27:29 - [info] Starting flows 8 Sep 23:27:29 - [info] Started flowsエラーなしに立ち上がったでしょうか?
Docker コマンドで確認してみますか。# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 122cd69c5b65 node-red_v1:appf "npm start --cache /…" 15 seconds ago Up 14 seconds (health: starting) 0.0.0.0:1880->1880/tcp, 0.0.0.0:1883->1883/tcp node-red-1実行時 "--name" オプションで指定した "node-red-1" という名前で動作しているようです。
Node-RED の実行確認
それでは PC のWebブラウザでこの Node-RED に接続してみましょう。
URLは以下のようになります。http://AE2100のIPアドレス:1880
おなじみのフローエディタが表示されるはずです。
ネットワーク・パレットを見ると、一番下に "serial in"、"serial out"、"serial request" の3つのノードが追加されています。Dockerfile 内に記述した RUN 命令でインストールされた node-red-node-serialport ライブラリです。
MinimalのイメージでもMQTTやWebSocketのノードがあるのはさすがNode-REDですね。
ローコードIoT開発プラットフォームなので当然ですか。パレットの一番下 dashboard も Dockerfile 内でインストールしたライブラリ node-red-dashboard のノード達です。
先に少し説明しましたが、これにより本当に簡単にちょっとしたダッシュボードを作ることができ、デバッグ支援にも使えるし、必須ともいえる外部ライブラリではないでしょうか。
さいごに
以上で AE2100 ローコードIoT開発プラットフォームの完成です!
Node-RED が立ち上がってしまえば、Node-RED 経験者にはこれ以上説明することはないのですが、せっかくなので、Node-RED 初心者向けにIoTらしい簡単な実践編の記事を書くことにしました。
まずは RS-485シミュレータからセンサーデータを取り込んで、Webブラウザ上の簡易ダッシュボードに表示するアプリを作成します。

- 投稿日:2020-10-26T14:02:19+09:00
【Docker】コンテナにソースコードをバインドマウントしている時のビルド方法
はじめに
前提
Dockerの基本的な操作等については触れません。
バインドマウントを利用して、アプリのソースコードをコンテナ内にマウントして開発している状況を想定しています。大まかな流れ
- まず結論
- バインドマウントとは
- 順を追ってビルド方法を確認していく
- おまけ
- 感想
当記事のゴール
バインドマウントの特徴を理解し、アプリのソースごとビルドして、イメージ化出来るようになる。
まず結論
開発時にソースコードをコンテナにバインドマウントするのはよくある手法だが、デプロイなどの際にソースコードを含めてイメージ化するには一工夫する必要がある。
その方法は拍子抜けするほどシンプルだが、別途ビルド用のDockerfileを用意し、明示的にソースをCOPYすればいい。
(自分で調べていて、「ほんとにこんなシンプルな話なの・・・?」と思わず疑ってしまった。)
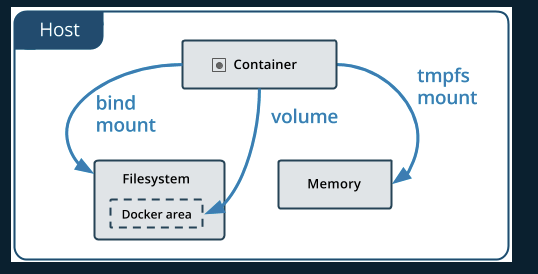
バインドマウントとは
Dockerで使えるボリュームのマウントタイプは主に3つある。
それぞれの違いを完結に説明すると
- ボリューム
- Dockerによって管理される領域に対してマウントする
- 複数のコンテナが共有可能
- バインドマウント
- ホスト上のパスに対してマウントさせる
- ホストとコンテナ、相互に読み書きが出来てしまう
- tmpfsマウント
- ホストのメモリ上に保存される
- コンテナが起動している間のみ、コンテナが利用するもの
- 一時的な状態や機密情報などを保存する
また、ボリュームとバインドマウントには以下のような特徴もある
公式のストレージ概要から引用バインドマウントとボリュームを使う際のヒント
バインドマウントとボリュームのどちらかを用いる場合には、以下のことを忘れないでください。コンテナー内のディレクトリに 空のボリューム をマウントしようとしていて、そのディレクトリ内にファイルやディレクトリが存在する場合、そのファイルやディレクトリはボリューム内にコピーされます。 コンテナー起動時に指定したボリュームがまだ存在していなかった場合は、空のボリュームが生成されます。 コンテナーの求めに応じて事前にデータを提供しておく方法として用いられます。
コンテナー内のディレクトリに バインドマウントか、空ではないボリューム をマウントしようとしていて、そのディレクトリ内にファイルやディレクトリが存在する場合、マウントによってそのファイルやディレクトリは隠れてしまいます。 それはたとえば、Linux マシン上の /mnt にファイルを保存した後に、/mnt に対して USB ドライブをマウントしたような場合と同じです。 /mnt に存在していた内容は USB ドライブの内容によって隠されてしまい、USB ドライブがアンマウントされるまで続きます。 隠されてしまったファイルは、削除されるわけでなく変更もされません。 しかしバインドマウントやボリュームがアンマウントされない限り、アクセスすることはできません。
順を追ってビルド方法を確認していく
シチュエーション
シンプルにNginxコンテナを構築し、ソースコードをコンテナにマウントさせ開発を行っていると想定する。
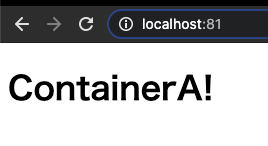
下記にサンプルのディレクトリ構成とDockerfileを示す。ディレクトリ構成project-directory/ └html/ └index.html └DockerfileDockerfileFROM nginx COPY ./html /usr/share/nginx/html EXPOSE 80index.html<!DOCTYPE html> <head> <title>ContainerA</title> </head> <body> <h1>ContainerA!</h1> </body>下記のコマンドでソースコードがバインドマウントされたNginxコンテナを作る
docker run --name containerA --mount type=bind,source=(pwd)/html,target=/usr/share/nginx/html -d -p 81:80 nginx
コマンド解説
DockerHub公式リポジトリのnginxイメージをベースに、以下のオプションでコンテナを作成する
--nameでコンテナ名を指定--mountでボリュームをマウント
- ボリュームには旧来のオプションとして
-v or --volumeもあるが、公式で--mountを推奨しているので従うtypeはマウントタイプを指定(今回はバインドマウントなのでbind)sourceはマウント元のパスを指定(ホスト)targetはマウント先のパスを指定(コンテナ内)-dでデタッチモード(バックグラウンドで起動)-pでポートフォワードを設定
- ホストの
localhost:81に対して、コンテナ内のloclahost:80を紐付けるhttp://localhost:81 にアクセスして、画面を表示してみる
下記のような画面が表示される
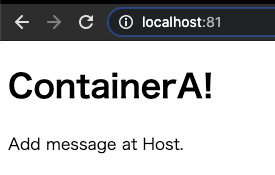
文言を追加して、コンテナ内に反映されることを確認する
index.html<!DOCTYPE html> ~省略~ <body> <h1>ContainerA!</h1> <p>Add message at Host.</p> </body>再度読み込むと、追加した文言が表示されている。
これで、ホストとコンテナが確実にバインドマウントされていることも確認できた。
Dockerfileをビルドし、ソースごとイメージ化する
docker build -t build_with_bind_data ./※
Dockerfileが存在するディレクトリで実行する
↓は実行結果
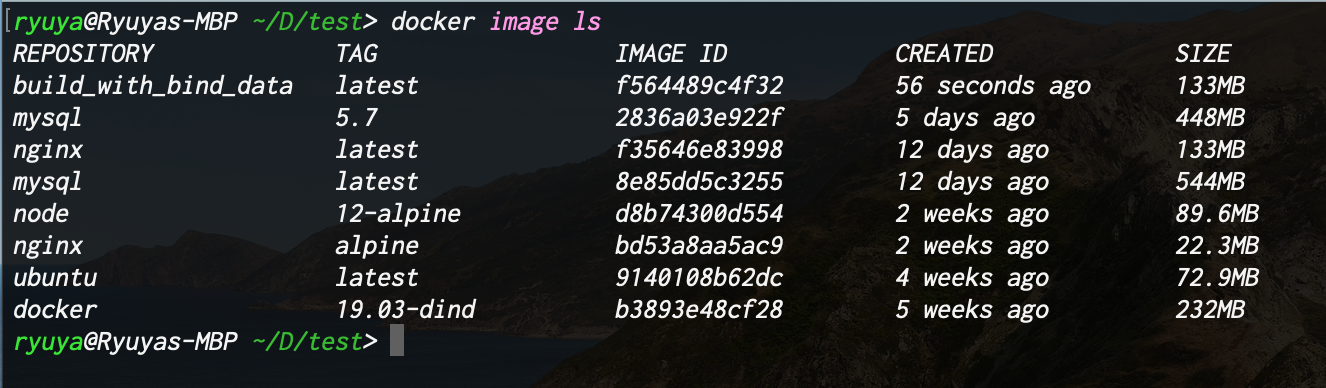
ビルドされたイメージを確認する
docker image ls下記のように
build_with_bind_dataというイメージがビルドされている
ビルドしたイメージを元にコンテナを作成し、ソースも含められているか確認する
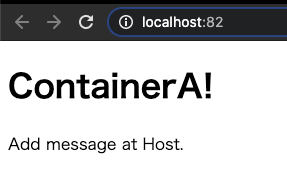
docker run --name containerB -d -p 82:80 build_with_bind_data
http://localhost:82 にアクセスすると
ContaierAで表示させていたものと全く一緒なのが確認できた。
一応、containerB内部のソースも確認しておくと
docker exec containerB bash -c "cat /usr/share/nginx/html/index.html"ビルド時に、
COPYコマンドによって、指定のディレクトリ/ファイルがコピーされていることが分かる。
おまけ
COMMITコマンドでコンテナはイメージ化出来るが、ボリュームマウントのデータは含まれない
COMMITコマンドでイメージを固めたくなるが、これはあくまでコンテナ内部での設定や変更をイメージ化するものであり、コンテナにボリュームマウント1されたデータは、コミットで作成されたイメージには含まれない、という点に注意する。
なので、ビルド時にCOPYコマンドでアプリのソースコードを配置する必要がある。
感想
多分内容としては初歩的なものです。
今までのDockerを使ってきた経験として、ビルドしてイメージを管理する機会が無かったので、ソースを含めたイメージ化の具体的な手法がわからず、苦戦しました。
COMMITコマンドの特徴に気づかず、「なんでコミットしてもソースが含まれないんだ!?」なんて風に驚いていました。
が、公式の解説等をじっくり読んで自分なりに理解を深められたので、忘れないように記事に残しました。
マウントタイプが、ボリューム/バインドマウント/tmpfsマウントのいずれか。 ↩



- 投稿日:2020-10-26T12:36:22+09:00
9.Docker (ホストとコンテナの関係)
ファイルシステムの共有
コンテナのファイルシステムは、ホストのファイルシステムとは独立しているが、「-v」オプションでコンテナからホストのファイルシステムにアクセスできるようになる。
ホストのファイルシステムをコンテナにマウントする。
ファイルシステムをマウントすることによって、あたかもホストのファイルシステムがコンテナのファイルシステムにあるかのように振舞うことができる。
(実際にはコンテナ内にはない。コンテナにおくと大きくなってしまう。)開発環境でコードはホストに置いて、コードを実行する時にコンテナを使うという使い方が多い。
基本的に開発を進める時は、コードのスクリプトやデータはホストに置き、コンテナには置かないのが一般的。
docker run -v [host/path]:[container/path]
ファイルへのアクセス権限
ユーザーIDとグループIDを指定してコンテナをrunする
コンテナからホストのファイルシステムにアクセスできると、ファイルへのアクセス権限が問題になる。
「-u」オプションをつけることによって、ユーザーのIDやグループのIDを指定してコンテナを立てれる。
それによって、ホストのユーザーのIDやグループのIDの権限がそのままコンテナにも適用される。※共有サーバーを立てる時は必須
docker run -u $(id -u):$(id -g)
id -u : ユーザーID
id -g : グループID
$ : コマンドの返り値が「-u」に指定されるポートをつなげる
ホストのポートをコンテナのポートに繋げる
ポート ・・・ プロセスがデータ通信する時に使う物
IPアドレスやホスト名は建物の住所、ポートは部屋番号のようなイメージ外からホストのwebサーバーやwebサービスにアクセスする時に、ホストの名前やIPアドレスに加えて、ポートを指定することによって、ホストのwebサーバー、webサービスにアクセスできる。
もしwebサーバーやwebサービスがコンテナの上で動いていた場合、ホストのポートとコンテナのポートを繋げる(パブリッシュする)ことによって、外からコンテナのポートにアクセスできる。docker run -p [host_port]:[container_port]
docker run -p 8888:8888コンピューターリソースの上限
ホストの中に複数のコンテナがあった場合に一つのコンテナで、メモリを全て使ったりすると、システムずべてが落ちる可能性がある。
それを避けるために、各コンテナに対して「cpu」や「メモリ」の上限を指定できる。※共有サーバーを立てる時やデータ解析をする時などは必須
docker run --cpus [#ofCPUs] --memory [byte]
[#ofCPUs] ・・・ コンテナがアクセスできる上限のCPUを設定
[byte] ・・・ コンテナがアクセスできる上限のメモリを設定コンテナの詳細を表示する
dockerのコンテナの情報が一覧で表示される。
docker inspect [container] | grep -i [something]
docker inspectで表示される内容は量が多く、すぐに必要な情報にアクセスできない
grep -i [something]で、「CPU」や「メモリ」「環境変数(env)」など指定した文字列に関係するdockr inspectのみ表示する。-i ・・・ ignore、大文字小文字を無視する
最後に
この記事は、かめさん( https://twitter.com/usdatascientist?s=21 )のudemyのdocker講座の( https://www.udemy.com/share/103aTRAEMfeVhaTXoB/ )書き起こしです。
※あくまで、自分のための書き残しとして投稿しているので、講座と異なる部分を含んでいる可能性があります。
かめさんのブログ( https://datawokagaku.com/docker_lecture/ )
- 投稿日:2020-10-26T12:07:52+09:00
Docker × Rails × RSpecで開発環境で’Could not find ’****’ in any of the sources’が出た時の対処方法
【Rails】Docker × Rails × RSpecの開発環境で’Could not find ’****’ in any of the sources’が出た時の対処方法
Gemfilegroup :development, :test do ~ 以下追加 ~ gem 'rspec-rails' gem 'factory_bot_rails' endGemfileを更新したのでdockerコマンドでbundle install実行
$ docker-compose run web bundle exec rails g rspec:installエラーメッセージ
Could not find diff-lcs-1.4.4 in any of the sources Run `bundle install` to install missing gems.色んな記事を参照させてもらって実行してみるもなかなかうまくいかず・・・
解決方法
いろいろググっている内にキャッシュで bundle install が実行されないていない場合がある?という記事を見させていただき、早速実行しました
$ docker-compose build --no-cache実行結果
$ docker-compose run web bundle exec rails g rspec:install Creating app_run ... done Running via Spring preloader in process 64 create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb見事クリエイトに成功
原因
docker-compose build しても cache が有効になっていて設定変更が反映されてうまく動作しないことがあるので、開発中にGemfileを更新した時は
$ docker-compose build --no-cacheで実行する方がいいとのことです
まとめ
spring stop関連の記事が多かったため解決するのに時間がかかってしまった点が反省点。でも初学者だからこそこの積み重ねが大事とも感じました
参考
以下の記事参考にさせていただきました!ありがとうございました!
Dockerでコンテナ内にbundle installされない問題の解決法
docker をキャッシュを使わないでビルドする
- 投稿日:2020-10-26T11:48:51+09:00
最強のLaravel開発環境(Docker)を日本時間にする
はじめに(開発環境構築)
https://qiita.com/ucan-lab/items/5fc1281cd8076c8ac9f4
こちらの神リポジトリをcloneし、利用しようとしたときに、
TimeZoneがUTCだったため、日本時間に修正した際の備忘録となります。下記構成内のDockerfileを修正します。
コンテナを立ち上げたことがあるものに対して実施する際には、
コンテナ停止時にDockerfileを修正し、再ビルドを実施してください。ディレクトリ構成
├── backend # Laravelプロジェクトのルートディレクトリ ├── infra │ └── docker │ ├── mysql │ │ ├── Dockerfile │ │ └── my.cnf │ ├── nginx │ │ ├── Dockerfile │ │ └── default.conf │ └── php │ ├── Dockerfile │ ├── php-fpm.d │ │ └── zzz-www.conf => unixドメインソケットの設定ファイル │ └── php.ini ├── Makefile └── docker-compose.ymlmysql
修正箇所
docker-laravel\infra\docker\mysql\Dockerfile# ENV TZを変更する(4行目付近) # ENV TZ=UTC \ ENV TZ=Asia/Tokyo \確認方法
build、コンテナ立ち上げ(up)が完了後、の作業になります。
shell$ make db # $ docker-compose exec db bash (上記makeコマンドの内容) root@XXXXXXX:# mysql -u root -p -h 127.0.0.1 Enter password: secret # Dockerfileに記載されている8行目付近のPWを記入してください。 # MYSQL_ROOT_PASSWORD=secret #  ̄ ̄ ̄ ̄ mysql> show variables like '%time_zone%'; +------------------+--------+ | Variable_name | Value | +------------------+--------+ | system_time_zone | JST | | time_zone | SYSTEM | +------------------+--------+ 2 rows in set (0.01 sec)system_time_zoneにJSTが表示されれば問題ありません。
nginx
修正箇所
docker-laravel\infra\docker\nginx\Dockerfile# ENV TZを変更する(6行目付近) # ENV TZ=UTC ENV TZ=Asia/Tokyo確認方法
build、コンテナ立ち上げ(up)が完了後、の作業になります。
shell$ make web # $ docker-compose exec web ash (上記makeコマンドの内容) /work/backend# date現在時間が表示されれば問題ありません。
php
修正箇所
docker-laravel\infra\docker\php\Dockerfile# timezone environmentを変更する(5行目付近) # ENV TZ=UTC \ # locale # LANG=en_US.UTF-8 \ # LANGUAGE=en_US:en \ # LC_ALL=en_US.UTF-8 \ ENV TZ=Asia/Tokyo \ # locale LANG=ja_JP.UTF-8 \ LANGUAGE=ja_JP:ja \ LC_ALL=ja_JP.UTF-8 \docker-laravel\infra\docker\php\Dockerfile# localの設定を変更(36行目付近) # locale-gen en_US.UTF-8 && \ # localedef -f UTF-8 -i en_US en_US.UTF-8 && \ locale-gen ja_JP.UTF-8 && \ localedef -f UTF-8 -i ja_JP ja_JP.UTF-8 && \確認方法
build、コンテナ立ち上げ(up)が完了後、の作業になります。
shell$ make app # $ docker-compose exec app bash (上記makeコマンドの内容) root@XXXXXXX:/work/backend# php -r 'echo date("Y/m/d H:i:s"),PHP_EOL;'現在時間が表示されれば問題ありません。
最後に
以上で対応完了となります。
誰かの一助になれば幸いです。誤りやもっと良い改修方法があればコメントにてご教示いただけますと幸いです。
よろしくお願いいたします。
- 投稿日:2020-10-26T11:31:04+09:00
[解決] RailsでWebpacker::Manifest::MissingEntryError
はじめに
RailsのWebpacker::Manifest::MissingEntryErrorは、初学者あるあるらしい。
でもすぐ解決できた。発生した場面
Rails6,MySQLをDockerで環境構築した.
↓
"yay, you are on rails!"
↓
早速書き始めて、root ディレクトリを変えたり、viewを書いたりして、ブラウザで確認。
↓
Webpacker::Manifest::MissingEntryError解決方法
qiita.rbbundle exec rails webpacker:install他の方法
https://github.com/rails/webpacker/issues/1730
https://blog.yuhiisk.com/archive/2018/04/24/rails-error-collection.html#Webpacker
- 投稿日:2020-10-26T08:55:47+09:00
phpモジュールにbrotli入れてbrコンテンツを使う!!
ブラウザーのコンテンツの圧縮でよく聞いているのがgzipだと思います。今回UberEatsで使用しようとしたAPIがJson形式だけど、拡張子が「.json.br」でbrotliで圧縮されてそれをそのままだと利用できなかったので、それを解決する方法をまとめた内容です。
Brotliとは
簡単に調べると「https://hackers-high.com/linux/brotli-installation-effect/」でこんな感じで説明されています。
brotliは2015年に発表され、その後Googleによってアップデートされたデータ圧縮アルゴリズムです。
httpにおける圧縮アルゴリズムとして使われることを主な目的としています。従来から広く使われているgzipと比較して、圧縮率が向上していながら、圧縮/伸長速度は同程度を維持しています。ただし、SSL/TLSが必須となっています。どの程度圧縮率が向上しているのかは、Brotilの効果を参照。
圧縮に辞書を併用しているのが特徴で、辞書には"<div/>"、"before"、"普通"などの頻繁に使われるHTMLタグや各言語の表現が約1万語入っており、圧縮をより効率的にしています。
ブラウザーの開発ツール等で見える以下のHeader情報brのことです。
accept-encoding: gzip, deflate, br対応状況
Fedora / CentOS / RHEL
Remi's RPM repositoryを利用して「php-brotli」の名前でインストールが可能です。
centosの例 # yum install -y php-brotliその他
Remi's RPM repositoryを利用出来ない場合はbuildしてインストールします。
# git clone --recursive --depth=1 https://github.com/kjdev/php-ext-brotli.git # cd php-ext-brotli # phpize # ./configure # make # make install設定
php.ini及モジュールのディレクトリーに設定ファイルを作成します。
extension=brotli.soDockerイメージのphp-fpm
インストールする際にはインストール前に「apt-get update」が必要があります。
FROM php:7.1-fpm ... RUN apt-get update && apt-get install -y git && \ git clone --recursive --depth=1 https://github.com/kjdev/php-ext-brotli.git && \ cd php-ext-brotli && \ phpize && \ ./configure && \ make && \ make install && \ printf '%s\n' 'extension=brotli.so' >> /usr/local/etc/php/conf.d/brotli.ini && \ rm -rf php-ext-brotli ...確認
phpのメソードについて:https://github.com/kjdev/php-ext-brotli
$compressed = brotli_compress('Compresstest'); $uncompressed = brotli_uncompress($compressed); echo $uncompressed;
- 投稿日:2020-10-26T08:16:32+09:00
"Docker-compose" で "Rails6" の安定的な開発環境構築マニュアル
本記事の目的
Docker・Rails初心者である私が
Docker-composeを使用しRails6の環境構築を行った際
御見識ある方に情報を提供頂き、無事に環境構築する事ができました。
しかしながら、構築内容で実行している内容が初心者の私には非常に理解しづらく、
Rails5での環境構築時と違い処理事項を間違えると環境構築できませんでした。
環境構築にあたり、ポイントが複数あると思います。本記事では自身が相談し、回答頂いた事項を元に
- 環境構築時のコードを分解解説し自身の学習と知識定着を行う
- 自身の忘備録と今後の環境構築時のマニュアルとして使う
- 他の方に少しでも参考資料として役立ててもらえればとの意図
上記を目的にまとめました。
初心者ゆえに間違いがあるかもしれませんが、お気づきの点がありましたら、
ご指摘頂けますと幸いです。
少しでも参考になりましたら LGTM 頂けると感激です。この記事で作成する環境
Docker-compose
- Web
- Ruby version:2.7〜
- Rails version:6.0.3.4〜
- db
- PostgreSQL version: 12.4〜
とりあえず使いたい方
早々に使ってみて構築したい方は下記GitHubリポジトリに公開しております。
READMEに手順記載しておりますが、下記のコマンドを順に実行して下さい。
- 下記サイトのREADMEより
git clone <Project name>の実行cd <Project name>でプロジェクトディレクトリ移動./qs setupコマンド実行*下記サイトのREADMEを参照して実行をお願いします。
Rails6-QSコマンド完了まで20分ぐらいかかります。
辛抱強くお待ち願います。(笑)
終わるとブラウザでlocalhost:3000を叩けばお馴染みのRails初期画面が現れます。
DockerのDashboardにもプロジェクト名の中にweb,dbのコンテナがあるはずです。この記事で作成するもの
- Dockerfile
- Docker-compose.yml
- シェルスクリプト(sample.bash)
*公開リポジトリはqs(クイックスタートの略)と名前をしております。- .gitignore
- Gemfile
- database.yml
①Dockerfileの作成
まずはDockerfileから作成を行なっていきます。
Dockerfileの作成にあたっては
- 公式のサイト
Docker Quickstart- Docker Docs
Docker Docs上記のサイトの説明がわかりやすく整備されています。
Dockerfileで定義されたイメージを使って作成されるコンテナは、可能ならばエフェメラル(短命;ephemeral)にすべきです。私たちの「エフェメラル」とは、停止・破棄可能であり、明らかに最小のセットアップで構築して使えることを意味します。上記サイト引用の通り
Dockerfileは最小のセットアップで構築する事を目指しております。
以降で今回作成するDockerfileを項目毎に説明していきます。ファイルの構成
Rubyバージョンの指定 Version:2.7
FROM ruby:2.7rails consoleで日本語を使う為に必要
ENV LANG C.UTF-8警告非表示・リッスンポート設定
- DEBCONFの警告をなくすための設定
[Ubuntu manual] http://manpages.ubuntu.com/manpages/bionic/man7/debconf.7.html- apt-keyコマンドによって出る警告防止の為
- Dockerのマウント領域に生成されるファイルが、
キャッシュディレクトリの書き込み権限が無くてエラーを吐くケースがあリます。
XDG_CACHE_HOMEに書き込み権限のあるディレクトリを指定してますが、
どうもRailsのみの使用では発生しなさそうです。
問題なければ外してもいいと思います。- コンテナが接続用にリッスンするポート
ENV DEBCONF_NOWARNINGS yes ENV APT_KEY_DONT_WARN_ON_DANGEROUS_USAGE yes ENV XDG_CACHE_HOME /tmp EXPOSE 3000コンテナパッケージインストール
- apt-get とapt-get install-y でキャッシュ利用されず最新バージョンのパッケージを使用できる。
- ビルドツールのインストール
- PostgreSQL対応に必要です。
- vimのインストール*
- lessコマンド(linux)を追加する為に指定しています。*
- オープンソースのツールパッケージgraphvizを使う為*
*印部分は使わない場合は削除してもいいと思います。
RUN apt-get update -qq && apt-get install -y \ build-essential \ libpq-dev \ vim \ less \ graphvizyarnのインストール
Rails6よりWebpackが標準となったので、yanrインストールがないとエラーが発生します。
- https対処の為
apt-transport-httpsでパッケージをインストールしています。- その後のコマンドはyarnのインストールです。
RUN apt-get install apt-transport-https RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - RUN echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list RUN apt-get update && apt-get install -y yarnワークディレクトリの作成
# setting work directory RUN mkdir /app WORKDIR /app環境変数設定
- スクリプトやコンテナに入ったときに使う為
ENV HOME /appGemfile作成
COPY Gemfile /app/Gemfile
上記全てを記載すると下記の内容になると思います。
(*部分的にコメント追記しております。)# use ruby version 2.7 FROM ruby:2.7 # using japanese on rails console ENV LANG C.UTF-8 # remove warn ENV DEBCONF_NOWARNINGS yes ENV APT_KEY_DONT_WARN_ON_DANGEROUS_USAGE yes ENV XDG_CACHE_HOME /tmp EXPOSE 3000 # install package to docker container RUN apt-get update -qq && apt-get install -y \ build-essential \ libpq-dev \ vim \ less \ graphviz # install yarn RUN apt-get install apt-transport-https RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - RUN echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list RUN apt-get update && apt-get install -y yarn # setting work directory RUN mkdir /app WORKDIR /app # setting environment value ENV HOME /app # executing bundle install COPY Gemfile /app/Gemfile②Docker-compose.yml ファイルの作成
docker-composeのversion指定
現状は3です。
version: '3'service作成
- image
データベース・webなどを指定します。
今回使われそうなdbredischromeweb: &appspringsolagraphを指定しました。
必要に応じて削除等して修正頂ければと思います。- port
ポートの設定(一般的に設定されるポート内容で作成しております。)- volume
マウント設定。db等Dockerコンテナ削除後に抹消しては困るデータの格納先の指定です。- build
Dockerfile等があるパスを示しますが、基本は.でカレントディレクトリとなります。
補足的事項
shm_size
selenium-chromeを使用した場合メモリ不足なる事あるので少し増やしています。.:
docker-composeの機能でボリュームの読み込みを高速化するために使用しています。<<: *app
webサービスの設定をspringに継承しています。tty: true
コンテナを起動し続ける設定- ポート設定について
左側がホスト側のポートで、右側がコンテナ側のポートとなります。
これも上記全て記載してまとめると下記の通りとなります。
version: '3' services: db: image: postgres ports: - "5432:5432" volumes: - data:/var/lib/postgresql/data:cached environment: POSTGRES_PASSWORD: postgres redis: image: redis ports: - "6379:6379" command: redis-server --appendonly yes volumes: - redis-data:/data:cached chrome: image: selenium/standalone-chrome ports: - "4444:4444" web: &app build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/app:cached - bundle:/usr/local/bundle:cached - /app/.git environment: HOME: /app RAILS_ENV: development ports: - "3000:3000" tty: true links: - db spring: <<: *app command: bundle exec spring server ports: [] solargraph: <<: *app command: bundle exec solargraph socket --host=0.0.0.0 --port=7658 ports: - "8091:7658" links: [] volumes: bundle: driver: local data: driver: local redis-data: driver: local③スクリプト作成
シェルスクリプトで実行内容をまとめておきます。こうする事により
Dockerfileを「停止・破棄可能であり、明らかに最小のセットアップで構築して使えること」が実現できます。シェルスクリプトとは、Unixコマンドを実行するために使用されるものです。シェルスクリプトの基本抜粋
シャルスクリプトの解説記事ではありませんが、自身が対象シェルスクリプトを理解する為に基本事項を抜粋し記載します。
記事作成とシェル動作の理解にあたり下記サイトを参考にさせて頂きました。
[初心者向けシェルスクリプトの基本コマンドの紹介]
https://qiita.com/zayarwinttun/items/0dae4cb66d8f4bd2a337
[シェルスクリプトリファレンス]
https://shellscript.sunone.me/
宣言
#!/bin/bash
シェルスクリプトの宣言を行うために必要。
#!/bin/shの書き方もありますが、bashの独自機能を使う場合はshではNGとなります。
参考にしたサイト:https://sechiro.hatenablog.com/entry/20120806/1344267619
特にこだわりがなければ、#!/bin/bash とするといいと思われます。コメントアウト
先頭に#をつけるだけです。出力
echoで出力if条件
ifの基本の書き方はif [ 条件 ] then コマンド fiです。- 条件が真の場合
thenの次のコマンドを実行します。- 違う条件の場合
elif [ 条件2 ]を確認します。- 真の条件がない場合
elseの次のコマンドを実行して終了します。elseがない場合は、そのまま終了します。引数の取り方
変数をアクセスする時変数名の前に$を入れます。あるいは$入れて変数を{}で囲みます。
-e
特殊テキストをエスケープ
$*
全部の引数をまとめて1つとして処理。同じような処理に$@があります。
ダブルコーテーションで囲なければ$@と同じであるが、囲むと引数毎に出力するか、
まとめて一つの引数で出力するかの違いがあります。
$1
1番目の引数
$0
スクリプト名関数
シェルスクリプトでは、関数を書いて引用することができます
Function () {
echo
}終了処理
スクリプトを途中で終了するにはexitコマンドに数字を与えます。Swith
switchの基本の書き方はcase 変数 in 条件・値) コマンド ;; esacです。
条件・値が変数と合う場合次のコマンドを実行します。シェルスクリプト構成の概要
- 最初にdocker-composeのコマンドをフルパスでdcに指定します。
- dockerがインストールしていない場合はインストールをするようにメッセージが出ます。
- それぞれの変数に値を格納します(rm, app, db, app_name)
- echoで$1のコマンド値を実行
- $1は関数で与えられた値(関数によってはswitch構文で展開)される与えられたコマンドを処理する形になります。
- $0でスクリプト名を記載しhelpとして使用できるようにしています。
上記内容で、各種コマンドや設定事項を入れ込んだスクリプトファイルを作成すると下記の通りとなります。
qs.bashdc=$(which docker-compose) # docker-compose command with full path if [[ -x "$dc" ]]; then : else echo "Please install Docker before run this command." exit 2 fi rm="--rm" # To destroy a container app="web" # describe $application service name from docker-compose.yml db="db" # describe database service name from docker-compose.yml app_name=$(pwd | awk -F "/" '{ print $NF }') # get project dir name # define container name app_container="${app_name}_${app}_1" db_container="${app_name}_${db}_1" echoing() { echo "========================================================" echo "$1" echo "========================================================" } rm_pids() { if [ -f "tmp/pids/server.pid" ]; then rm -f tmp/pids/server.pid fi } create_project() { echoing "Exec Bundle Install for executing rails new command" compose_build $app bundle_cmd install echoing "Exec rails new with postgresql and webpack" bundle_exec rails new . -f -d=postgresql $* echoing "Update config/database.yml" mv database.yml config/database.yml echoing "Exec db create" bundle_exec rails db:create echoing "docker-compose up" compose_up $app echo "You can access to localhost:3000" } init_services() { echoing "Building containers" $dc down -v $dc build --no-cache $app bundle_cmd install if [ "--webpack" == "$1" ]; then run_yarn install fi rails_cmd db:migrate:reset rails_cmd db:seed rm_pids $dc up $app } compose_up() { echoing "Create and start containers $*" rm_pids $dc up -d "$1" } compose_down() { echoing "Stop and remove containers $*" $dc down $* } compose_build() { echoing "Build containers $*" $dc build $* } compose_start() { echoing "Start services $*" rm_pids $dc start $* } compose_stop() { echoing "Stop services $*" $dc stop $* } compose_restart() { echoing "Restart services $*" $dc restart $* } compose_ps() { echoing "Showing running containers" $dc ps } logs() { echoing "Logs $*" $dc logs -f $1 } invoke_bash() { $dc run $rm -u root $1 bash } invoke_run() { renv="" if [ -n "$RAILS_ENV" ]; then renv="-e RAILS_ENV=$RAILS_ENV " fi if [ -n "$TRUNCATE_LOGS" ]; then renv="$renv -e TRUNCATE_LOGS=$TRUNCATE_LOGS " fi dbenv="" if [ -n "$DISABLE_DATABASE_ENVIRONMENT_CHECK" ]; then dbenv="-e DISABLE_DATABASE_ENVIRONMENT_CHECK=$DISABLE_DATABASE_ENVIRONMENT_CHECK " fi $dc run $rm ${renv}${dbenv}$* } run_app() { invoke_run $app $* } run_db() { invoke_run $db $* } run_spring() { $dc exec spring $* } run_solargraph() { invoke_run solargraph $* } rails_server() { rm_pids # $dc run $rm ${renv}--service-ports $app rails s -p 3000 -b 0.0.0.0 $dc run $rm --service-ports $app bundle exec foreman start -f Procfile.dev } rails_db() { case "$1" in set) rails_cmd db:migrate ;; up) rails_cmd db:migrate:up VERSION="$2" ;; down) rails_cmd db:migrate:down VERSION="$2" ;; reset) rails_cmd db:reset ;; *) rails_cmd db:migrate:status ;; esac } spring_db() { case "$1" in set) spring_cmd rake db:migrate ;; up) spring_cmd rake db:migrate:up VERSION="$2" ;; down) spring_cmd rake db:migrate:down VERSION="$2" ;; reset) spring_cmd rake db:reset ;; *) spring_cmd rake db:migrate:status ;; esac } spring_dive() { $dc exec spring bash } rails_cmd() { bundle_exec rails $* } rake_cmd() { bundle_exec rake $* } rspec_cmd() { $dc start chrome bundle_exec rspec $* } test_cmd() { bundle_exec test $* } bundle_cmd() { run_app bundle $* } bundle_exec() { run_app bundle exec $* } rubocop_cmd() { bundle_exec rubocop $* } rails_console() { bundle_exec rails c $* } spring_cmd() { run_spring spring $* } solargraph_cmd() { run_solargraph solargraph $* } rake_reset_db() { echoing "Running reset db" compose_stop $app DISABLE_DATABASE_ENVIRONMENT_CHECK=1 rake_cmd "db:reset" rake_cmd "db:fdw:setup" RAILS_ENV=test rake_cmd "db:fdw:setup" compose_up $app } db_console() { # from config/database.yml database="development" username="postgres" port="5432" run_db psql -h $db_container -p $port -U $username $database } db_dump() { # from config/database.yml database="development" username="postgres" port="5432" tm=$(date +\%Y\%m\%d-\%H\%M) dump_file=tmp/dbdump-${dbname}-${tm}.dump echoing "Dump database $dbname data to $dump_file" run_db pg_dump -h $db_container -p $port -U $username --disable-triggers $database >$dump_file echo "done" } run_yarn() { run_app bin/yarn $* } run_npm() { run_app npm $* } run_webpack() { run_app webpack $* } cmd=$1 shift case "$cmd" in setup) create_project $* && exit 0 ;; init) init_services $* && exit 0 ;; ps) compose_ps && exit 0 ;; up) compose_up $* && compose_ps && exit 0 ;; build) compose_build $* && exit 0 ;; start) compose_start $* && exit 0 ;; stop) compose_stop $* && exit 0 ;; restart) compose_restart $* && exit 0 ;; down) compose_down $* && exit 0 ;; logs) logs $* ;; bash) invoke_bash $* ;; run) invoke_run $* ;; server) rails_server $* ;; rails) rails_cmd $* ;; db) rails_db $* ;; cons) rails_console $* ;; rake) rake_cmd $* ;; rspec) rspec_cmd $* ;; test) test_cmd $* ;; bundle) bundle_cmd $* ;; rubocop) rubocop_cmd $* ;; reset-db) rake_reset_db ;; psql) db_console $* ;; db-dump) db_dump $* ;; yarn) run_yarn $* ;; npm) run_npm $* ;; webpack) run_webpack $* ;; spring) spring_cmd $* ;; sdb) spring_db $* ;; sdive) spring_dive $* ;; solargraph) solargraph_cmd $* ;; *) read -d '' help <<-EOF Usage: $0 command Service: setup Create new rails application init Initialize backend services then run ps Show status of services up Create service containers and start backend services down Stop backend services and remove service containers start Start services stop Stop services logs [options] default: none. View output from containers bash [service] invoke bash run [service] [command] run command in given container App: server Run rails server rails [args] Run rails command in application container rake [args] Run rake command in application container db [args] Run rails db command you can use set(migrate), up, down, reset, other is status ex: ./qs db set #running rails db:migrate ./qs db up 2019010101 #running rails db:migrate:up VERSION=2019010101 rspec [args] Run rspec command in application container test [args] Run Minitest command in application container bundle [args] Run bundle command in application container cons Run rails console rubocop [args] Run rubocop yarn Run yarn command in application container npm Run npm command in application container webpack Run webpack command in application container Spring spring Exec spring command in Spring container sdive Into spring container sdb [args] Run rails db command you can use set(migrate), up, down, reset, other is status ex: ./qs db set #running rails db:migrate ./qs db up 2019010101 #running rails db:migrate:up VERSION=2019010101 Solargraph solargraph Run solargraph command in Spring container DB: reset-db reset database in DB container psql launch psql console in DB container pg-dump dump database data as sql file in DB container EOF echo "$help" exit 2 ;; esacその他作成ファイル
その他の設定ファイルですが、一般的な構築で作成しておりますので説明は割愛致します。
補足的な事項として、DBとしてPostgreSQLを選んでおります。
理由としてMySQLではRails6.0よりバリデータのエラーが発生する事があり設定を追加する必要がある為です。
この点に関してはMySQLを使用する場合は設定を行えばいいのですが、
PostgreSQLでは設定不要の為、こちらをDBとして採用しています。
詳細は下記サイトを参照ください。
Rails 6.0で"Uniqueness validator will no longer enforce case sensitive comparison in Rails 6.1."という警告が出たときの対処法database.ymldefault: &default adapter: postgresql encoding: utf8 min_messages: WARNING host: db port: 5432 username: postgres password: postgres pool: 5 timeout: 5000 stats_execution_limit: 10 development: <<: *default database: development test: <<: *default database: test production: <<: *default database: productionGemfile
source 'https://rubygems.org' gem 'rails', '~> 6.0'.gitignore
.bash_history .bundle .solargraph .atom .vscode .viminfoあとがき
ローカルでのRails6の開発環境構築はhomebrewでrbenvなどを使いながら
それほど大きな工数がかからなかった印象ですが、安定的なコンテナでの開発環境の構築は、
Docker公式サイトでもRails5での記載で、Rails6での構築は難しい印象でした。また公式サイトのQuickStartでは実行コマンドがDockerfileに記載されており、
出来る限り最小のセットアップで記載する場合、シェルスクリプトへ分けた方が
開発環境としてメンテナンス性も含めいいと考えられます。
*本番環境はDockerfileが変わる可能性も含めこの記事を読了頂きありがとうございました。何らか開発の助けになれば幸いです。
最後に、この記事をまとめるにあたり多くの協力とご助言を賜りました。
ありがとうございました。参照サイト・資料元
Quickstart Compose and Rails
Dockerfileのベストプラクティス
Bashスクリプト実行サンプル
新しいLinuxの教科書 SB Creative
- 投稿日:2020-10-26T07:31:08+09:00
Windows + Docker 環境で venv を使う[Python]
エラー
通常の方法でコンテナにマウントして使おうとするとエラーが吐かれる。
$ python -m venv .venv Error: [Errno 71] Protocol error: 'lib' -> '/app/.venv/lib64'原因
venv の使用時にシンボリックリンクを発行していて、ローカルのマウント時にこれを共有してしまっていることが原因
解決方法
DockerでVolumeをマウントするとき一部を除外する方法 を使って、シンボリックリンクが張られる箇所とのマウントから除外する。
下記のコマンドでは、{作業ディレクトリ}/.venv/ 配下にシンボリックリンクが貼られることになるので、ここを除外する。
python -m venv .venvdocker-compose.yml の一部
version: "3.7" services: app: ... volumes: - {作業ディレクトリ}/.venv/docker-compose.yml
全体のサンプル
version: "3.7" services: app: build: ./app/ working_dir: /app volumes: - ./app:/app:cached - /app/__pycache__ - /app/.venv/ - /app/.tox/ # tox 用 environment: - FLASK_ENV=development ports: - "5000:5000"参考
- 投稿日:2020-10-26T06:42:02+09:00
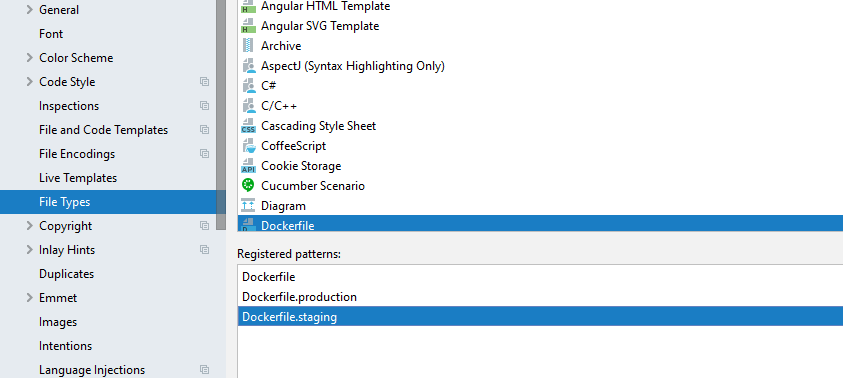
PycharmでDockerfile.productionのようなファイルをSyntax Highlightする方法
Pycharmはデフォルト設定ではDockerfile.productionのようにDockerfileの後に文字列があるとSyntax Highlightをしなくなっています。これをハイライトさせるには次のように、Pycharm > Preferences > Editor > File Typesを選び、Dockerfileを選び、「Register patterns」に"Dockerfile.production"を設定します。
"Dockerfile.production"がHighlightされるようになりました。
他にも"Dockerfile.prod"や"Dockerfile.なんちゃら"を追加したいのですが、全て個別に入力するのは面倒なので、"Dockerfile.*"を入れると、他のDockerfileのシンタックスハイライトもできるようになります。
- 投稿日:2020-10-26T03:16:58+09:00
初心者向けCI/CD実践 - Part3 - 開発プロジェクトの準備編
CI/CD環境を構築
本連載は、「CI/CDを実践してみたい」という超初心者向けの内容となっています
enterpriseレベルやproductionレベルの導入に際して、「CI/CDとは?」という感覚をつかむものとなれば幸いです。
利用するツール等はこちらで選定していますので、別のツールを利用する場合は、適宜お調べください。
大まかな内容としては、以下のようなフローとなります
- 環境構築
- CI/CDツールの構築
- 開発プロジェクトの準備<-今回はここを説明
- GitHubにプロジェクトデータを登録
- Jenkins Pluginのインストール
- 手動ビルド
- CI/CDツールとその他ツールの併用例
- テストツールとの協調
- インスペクションツールとの協調
概要
GitHubのリモート、ローカルレポジトリの設定- Jenkins Pluginの自動インストール
- ジョブの作成、実行、結果の確認
GitHubにプロジェクトデータの登録
CI/CDツールの利用例を理解するにあたって、Jenkins実践入門のモデルプロジェクトを利用させていただく
最初にプロジェクトデータの登録を行う
(事前にGitHubアカウントの作成とログインを済ませておく)
下図の通り、リンク先で右上Forkボタンをクリック
すると、自分のレポジトリ内に
<GitHubアカウント>/Jenkins_Practical_Guide_3rd_Editionが現れる
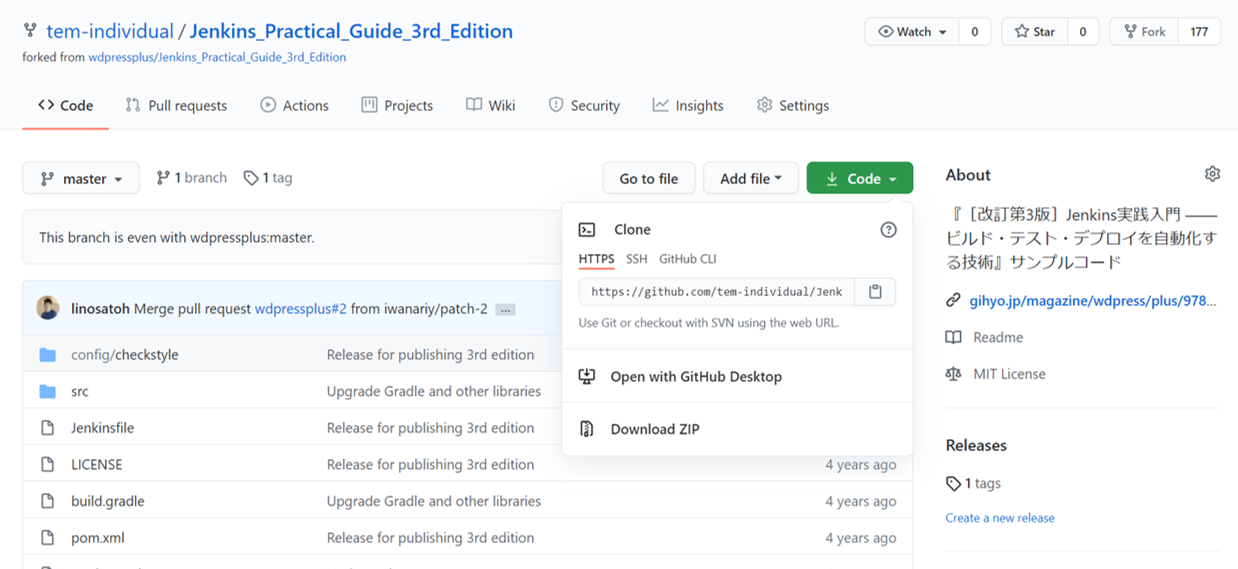
続いて、プロジェクトデータをローカルレポジトリで取得する
リモートレジストリ上で
<GitHubアカウント>/Jenkins_Practical_Guide_3rd_Editionをクリックした後、リモートレジストリ上のブランチを指すリンクをコピーする
terminal上で以下のコマンドを実行
$ pwd $ mkdir <demo用directory> //demo開発用のdirectryを適宜作成 $ cd <demo用directory> $ git clone https://github.com/tem-individual/Jenkins_Practical_Guide_3rd_Edition.git sampleproject以下のようになっていれば、成功
$ cd sampleproject $ ls -a . .. .git Jenkinsfile LICENSE build.gradle config pom.xml readme.md src $ cat .git/config [core] repositoryformatversion = 0 filemode = true bare = false logallrefupdates = true [remote "origin"] url = https://github.com/<GitHubアカウント>/Jenkins_Practical_Guide_3rd_Edition.git fetch = +refs/heads/*:refs/remotes/origin/* [branch "master"] remote = origin merge = refs/heads/masterPluginのインストール
今回のdemo開発では、下記4つのpluginをインストールします
- JaCoCo Plugin
- Checkstyle Plugin
- FindBugs Plugin
- StepCounter Plugin
Jenkins Pluginのインストール方法は2通りあります
- アップデートサイトを経由したインストール
- 自分でダウンロードしてインストール
注意
「自分でダウンロードしてインストール」を実施する際は、インストールするJenkins Pluginの依存性を確認する必要性がある。
「アップデートサイトを経由したインストール」では、依存性のあるその他のPluginも考慮して自動でインストールしてくれるので、基本的には前者を選択インターネットアクセスが可能な環境なので、前者で実施
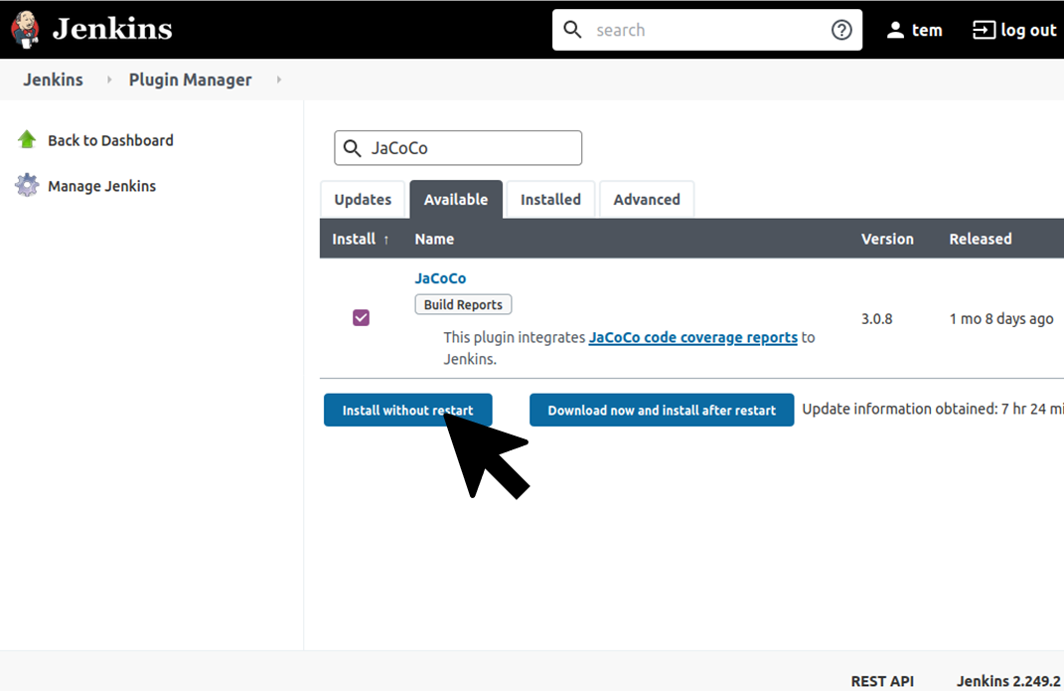
手順はこちら
1. Jenkins dashboard
2. 左ペインのJenkinsの管理
3. 中央ペインのPluginの管理
4.利用可能タブの選択
5. 検索窓にJaCoCoと入力し以下のようにインストール
top pageに戻った後、その他Pluginも同様にインストール
手動ビルドの実施
では、実際にJenkinsを利用していきましょう
手動ビルド以外の様々な操作は次回以降で紹介していきます実施フローは以下の通り
1. ジョブの設定
1. 新規ジョブの作成
2. VCSの設定
3. ビルド・トリガの設定
4. ビルドタスクの設定
5. ビルド後の処理の設定
2. ビルドの実行
3. リリース対象物の保存ジョブの設定
「新規ジョブの作成」
dashboard >新規ジョブの作成>
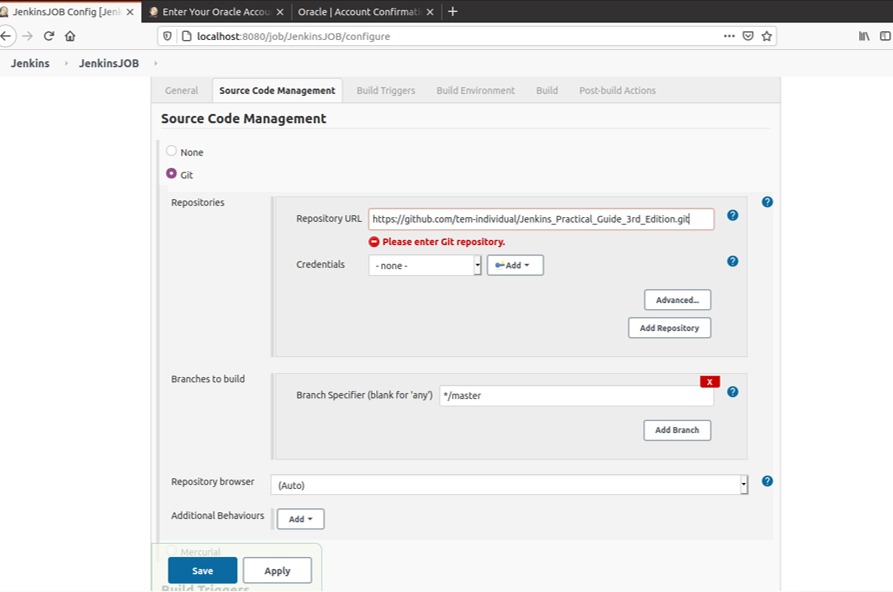
Item名を"JenkinsJOB"とし、FreeStyle projectを選択しOKをクリック「VCSの設定」
以下の図のように入力
また、GitHubのプロジェクトがprivacyの場合、Credentialを入力する必要がある
(今回はpublishプロジェクトをForkしているので入力不要)
「ビルド・トリガの設定」
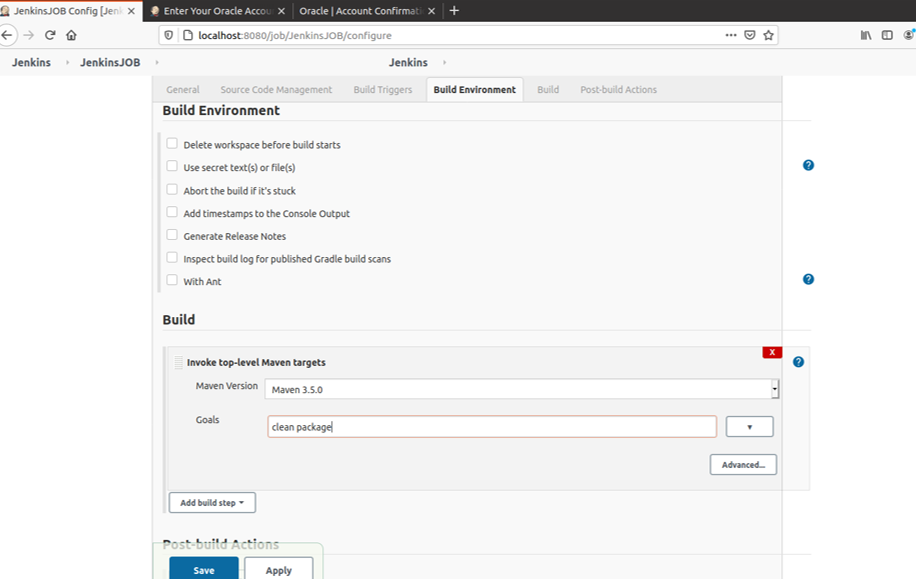
手動ビルドのため、今回は設定しない「ビルドタスクの設定」
以下の図のように入力し、「保存」をクリック
「ビルド後の処理の設定」
手動ビルドのため、今回は設定しないビルドの実行
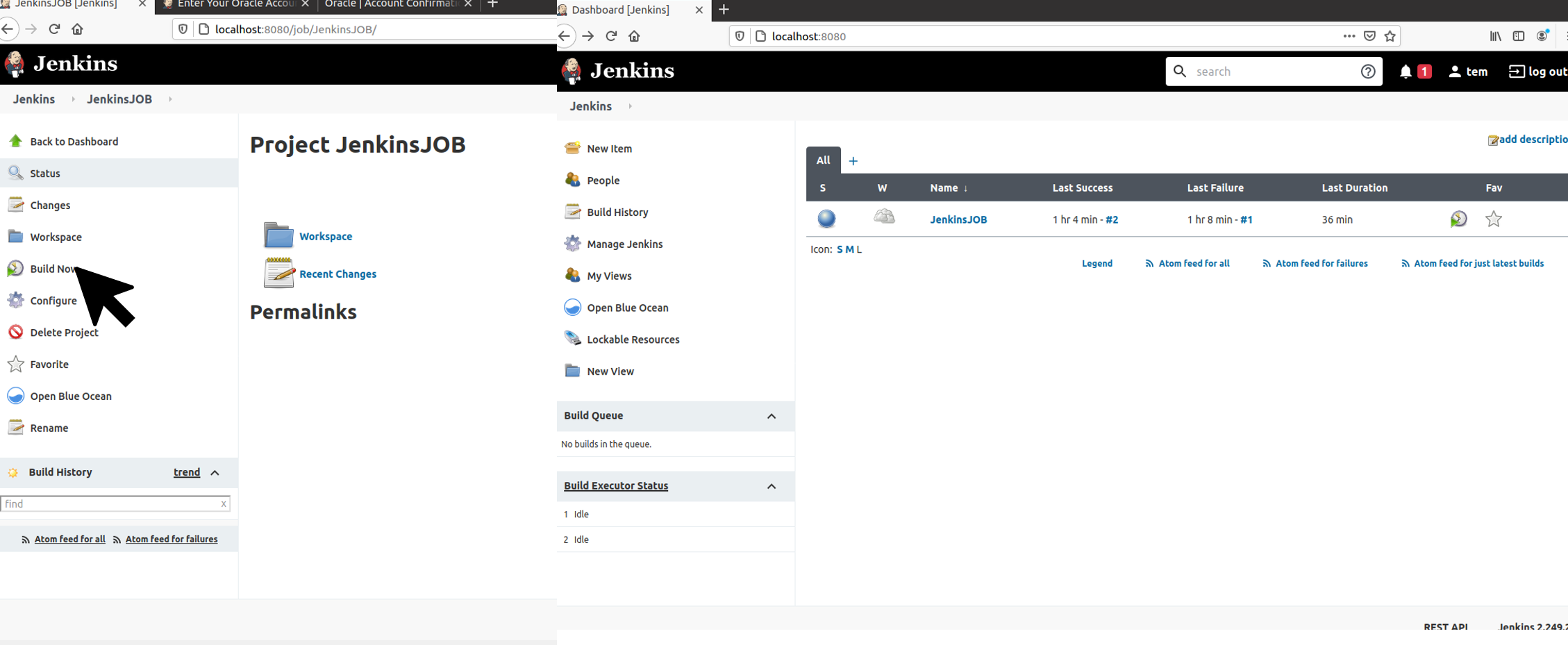
下図の通りBuild Nowを選択すると、ビルドが実行される
ビルド結果が成功していれば、赤枠で囲まれた通り●※1になる※1
● : 問題なし
● : ビルドは成功。テスト結果やコード解析に問題あり
● : ビルドの失敗
● : ビルド未実行ビルドの履歴や特定のビルド情報を確認する際は
1. dashboard
2. 左ペインのビルド履歴
- ビルド履歴の一覧を確認できる
4. 特定のビルドをクリック
-Workspaceからはプロジェクトの中身をディレクトリ構成で確認可能
-Recent Changeからは直近の変更点のみを確認可能
- その他、誰が実行したか、テスト結果等を確認できるリリース対象物の保存
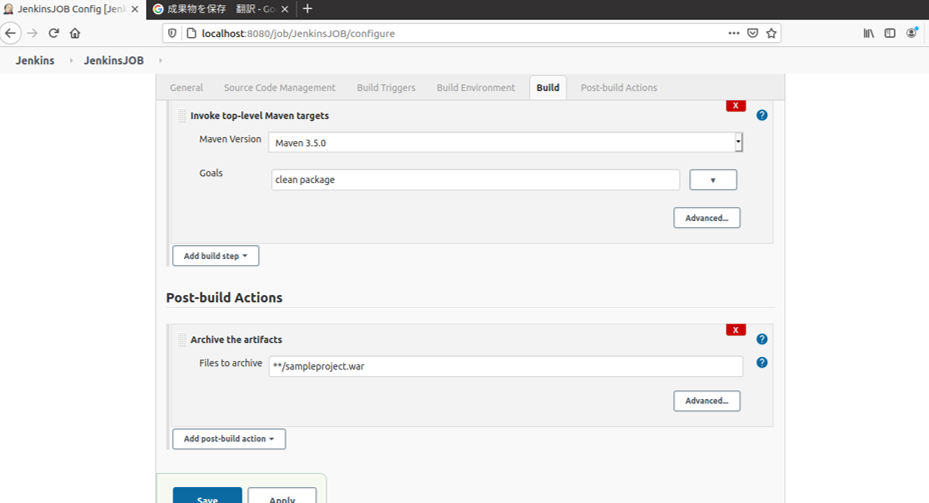
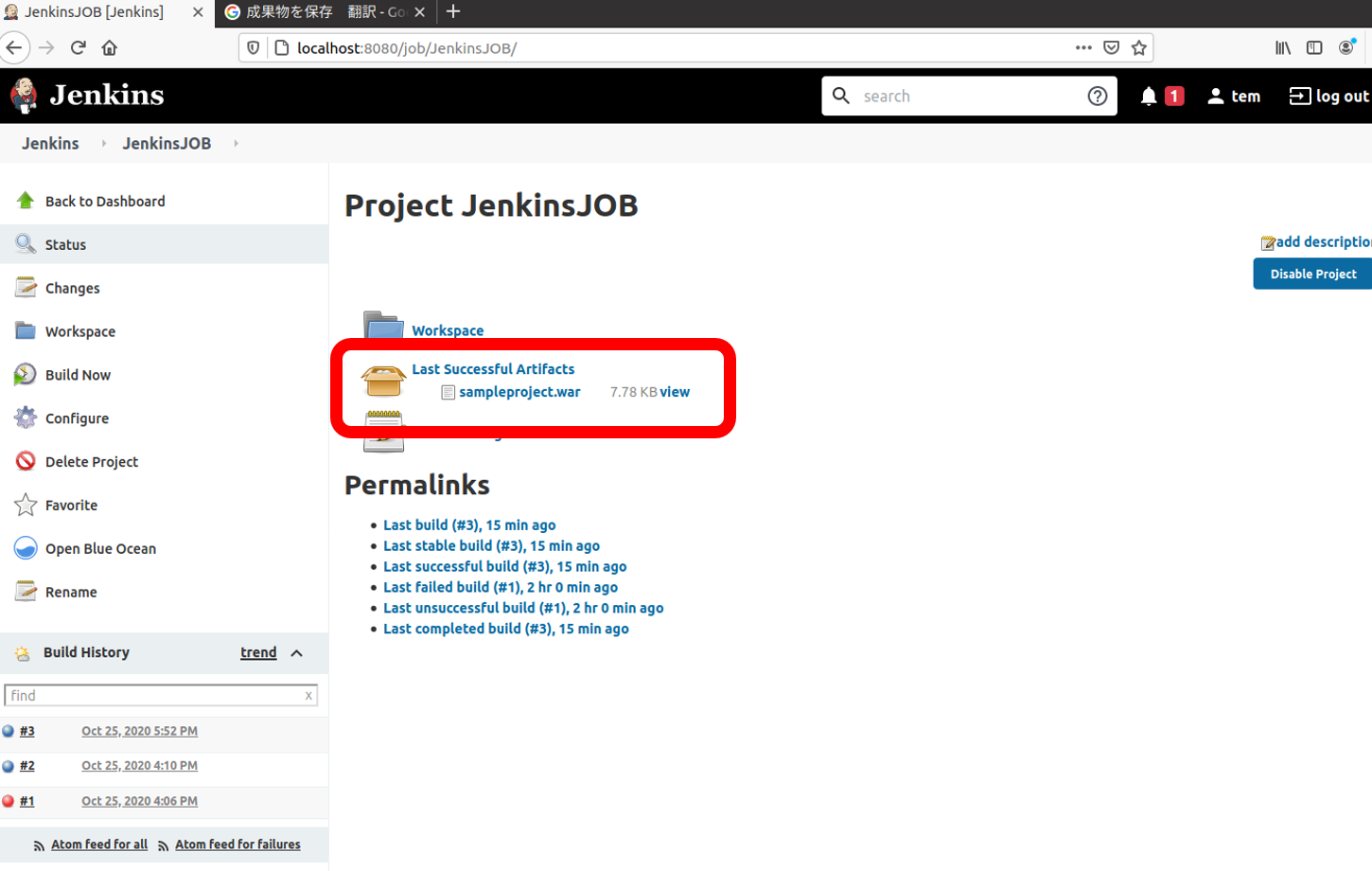
最後に、リリース対象物をまとめて簡単に確認できる場所に配置する設定を行う"JenkinsJOB"等の特定のジョブを選択 >
設定>ビルド後の処理にて成果物保存を選択しパスを指定
ビルドを実行すると、dashboardやホスト上に
sampleproject.warが作成される
$ sudo su - $ cd /var/lib/docker/volumes/jenkins-data/_data/workspace/JenkinsJOB/target $ ls checkstyle-cachefile checkstyle-result.xml findbugsXml.xml generated-test-sources maven-archiver sampleproject-1.0.0 surefire-reports checkstyle-checker.xml classes generated-sources jacoco.exec maven-status sampleproject.war test-classes