- 投稿日:2020-10-26T22:35:35+09:00
Paiza Python 入門編1プログラミングを学ぶ
PaizaでPython3の基本文法が完全無料なのでまとめました。
01Pythonとは?
・Pythonとは
素早く効果的にシステムを開発できるように用に作られた
汎用プログラミング言語・Pythonで、なにができるのか
本格的なWebサービスの開発
機械学習・AI、科学計算、統計解析・採用例
Google,Youtube,Instagram,Dropboxなど・pythonの特徴
スクリプト言語で開発しやすい
様々な分野のライブラリがある。
-機械学習 -ビックデータ解析
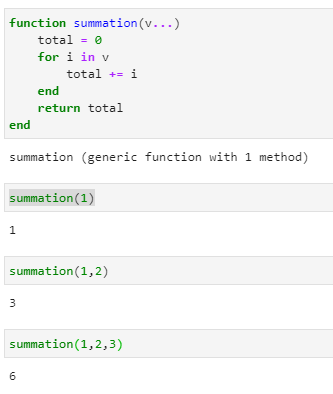
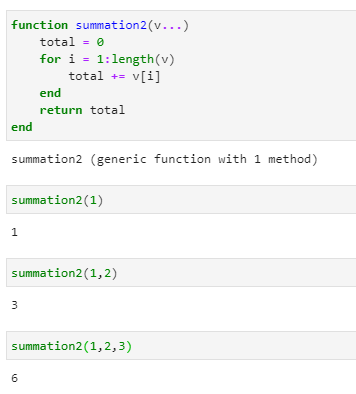
誰が書いても、同じような書き方になる02Pythonでプログラミングを書いてみよう
lssson.py#hello worldを表示する print("hello")間違いやすいポイント
- スペースが全角文字になっている。
- ダブルクォーテーションが全角文字になっている。
- 関数名が、全て半角小文字で記述されていない。
- (× Print、 ○ print)関数とは
Pythonでは、この「print」のような命令を「関数」と呼んでいます。プログラミングでは、「print」のような関数で、コンピュータに対して動作を指示していきます。「print」と書くと、文字を表示するのだなとPythonが理解して、そのとおり動いてくれるのです。
プログラミング言語は、このような関数をたくさん持っています。各関数がどのように動作をするか、プログラミング言語ごとに決まっています。
演習
1〜4「エラー箇所を正しく修正しよう」
5「指定された文字を出力しよう」1.ダブルクォーテーション(")が全角
lesson.pyprint(”hello paizaラーニング”) print("hello paizaラーニング")2.1つ目のダブルクォーテーションが全角
lesson.pyprint(”hello paizaラーニング") print("hello paizaラーニング")3.2つ目がシングルクォーテーションになっている
lesson.pyprint("hello paizaラーニング') print("hello paizaラーニング")4.Printが大文字になっている
lesson.pyPrint("hello paizaラーニング") print("hello paizaラーニング")5.自分で書いてみよう
lesson.pyprint("ハロー、paizaラーニング")03コメントでプログラムを見やすく!
・「#」を使ってコメントを書こう!
・プログラムをコメントにすることをコメントアウトという
・shift + 7 = シングルクォート (')
・シングルクォート3つで、囲むことで、複数行のコメントアウトができる
lssson.py#コメント(この行は無視されます) print("hello world") #プログラムをコメントにすることを「コメントアウト」という #print("hello world") #シングルクォート3つで、囲むことで、複数行のコメントアウトができる ''' print("hello world") print("hello world") print("hello world") '''演習
1.「コメントアウトしてみよう」
最初の行をコメントアウトして。2番目の行だけ表示されるようにするlesson.py#print("勇者は、荒野を歩いていた") print("モンスターがあらわれた")2.「コメントアウトしてみよう」
期待する出力値だけ、出力しようlesson.pyprint("勇者は、荒野を歩いていた") #print("A:モンスターがあらわれた") print("勇者は、すごい剣を手にいれた") ''' print("A:ドラゴンがあらわれた") print("A:魔王があらわれた") ''' print("勇者は、世界を救った")04HTMLを表示してみよう
・html表示をする
lesson.pyprint("<h1>hello world</h1>") print("<p><世界の皆さん") print("<b>こんにちは</b></p>")・複数行でprint関数を扱う
シンングルクォーテーション(')3個で、複数行を扱うことができます。lesson.pyprint('''<h1>hello world</h1> <p>世界の皆さん、 <b>こんにちは</b></p>''')・print関数で改行したくない場合
文字列を「,」で区切ります。
この場合、出力された文字列は、スペースで区切られます。lessson.pyprint("<h1>hello world</h1>", "<p>世界の皆さん、", "<b>こんにちは</b></p>")もうひとつの方法は、カッコの中に「, end=""」を追加します。
lesson.pyprint("<h1>hello world</h1>", end="") print("<p>世界の皆さん、", end="") print("<b>こんにちは</b></p>", end="")・「,end="%"」とすると、「%」で文字が区切られる
lesson.pyprint("<h1>hello world</h1>", end="%") print("<p>世界の皆さん、", end="%") print("<b>こんにちは</b></p>", end="%")演習
1.「HTMLとして出力してみよう」
lesson.pyprint("<p>勇者は、荒野を歩いていた</p>")2.モンスターを太字にしてみよう
lssson.pyprint('''勇者は、荒野を歩いていた <b>モンスター</b>があらわれた''' )05変数を使えるようになろう
lesson.pyplayer="勇者" #変数にデータを代入した print(player)lesson.pyplayer="戦士" print(player + "は、荒野を歩いていた") print(player + "は、モンスターと戦った") print(player + "は、モンスターを倒した")変数の名前のつけ方
Pythonで変数(ローカル変数)の名前は、次のルールに従って付けます。・最初の1文字目:英文字または、「」(アンダーバー)
・2文字目以降 :英文字・数字「」(アンダーバー)変数名の例:
○ player 1文字目が、英小文字
○ weapon 1文字目が、「」(アンダーバー)
○ player01 2文字目以降に数字
○ redDragon 2文字目以降に英大文字× 1player 1文字目に数字は使えない
× class 重複なお、「print」のように、Pythonで使われる関数名などは、
あらかじめ予約されている言葉なので変数名には利用できない文字列の中で変数を利用する方法
文字データを格納した変数と文字列は、「+」記号で連結できます。lesson.pyplayer = "戦士" print(player + "は、荒野を歩いていた")演習
1.演習課題「変数の文字列を連結してみよう」
lesson.pyplayer = "勇者" print(player+"は、レベルアップした")2.演習課題「間違いを修正してみよう」
lesson.pyplayer1 = "勇者" print(player1 + "の体力が回復した")3.演習課題「間違いを修正してみよう Vol.2」
lesson.pyteam = "勇者と戦士" print(team + "の体力が回復した")4.演習課題「変数の文字を出力する」
lesson.pyplayer = "勇者" print(player + "は、荒野を歩いていた") print(player + "は、モンスターと戦った") print(player +"は、モンスターをたおした")06サイコロを作ろう
・str():数値を、数を表す文字に変換する関数です
https://docs.python.org/ja/3/library/functions.html#func-strlesson.pynumber = 300 print("スライムが" + number + "匹現れた") #これだと、表示されない print("スライムが" + str(number)+"匹現れた") #nnumberをstrで数字を文字データに変換するランダム関数を使おう
・random関数:0から1までの間で、ランダムな数値を返す・randomモジュール
https://docs.python.org/ja/3/library/random.htmllesson.pyimport random #ランダムモジュールをインポート number=random.random() print("スライムが" + str(number) + "匹現れた")・randint関数:指定した引数の範囲で、ランダムな整数の値を返す
lesson.py#1〜100までの数値でランダムに表示されるようにしたい import random number=random.randint(1,100) print("スライムが" + str(number) + "匹現れた") #10〜20までの数値でランダムに表示されるようにしたい import random number=random.randint(1,20) print("スライムが" + str(number) + "匹現れた")引数とは
関数の引数(ひきすう)とは、関数に与えるデータです。
引数は、関数に続くカッコの中に記述します。引数が複数ある場合は、「,」(コンマ)で区切ります。引数の例
print(data)のdata
str(number)のnumber戻り値とは
関数の戻り値(もどりち)とは、関数の処理結果のデータです。返り値と呼ぶ場合もあります。random.randint(0, 10)という関数を呼び出すと、0から10までのランダムな数が戻り値となります。
演習
1.「1〜6のサイコロを作る」
lesson.pyimport random number=random.randint(1,6) print("サイコロの目は"+ str(number) + "です。")2.「モンスターに与えるダメージを出力」
55〜99のランダムな数字の範囲lesson.pyimport random number=random.randint(50,99) print("モンスターに、"+ str(number) + "のダメージを与えた。")07演算子で計算してみよう
lesson.pynumber = 100 + 20 print(number +30) print(number) + たす * 掛ける / 割る % 余り演習
1.計算してみよう
lesson.pynumber = 1234*5678/2 print(number)2.変数で計算してみよう
lesson.pya = 31 b = 17 # 以下に、aとbのかけ算し、結果を出力するコードを書いてください print(a*b)3.余りを計算してみよう
lesson.pyx = 8 y = 5 # 以下に、xをyで割ったときの余りを計算し、結果を出力するコードを書いてください print(8%5)4.カッコをつけて計算してみよう
lesson.pynumber=(1234+5678)*3 print(number)値段の計算をしてみよう
lesson.pyapple_price=350 apple_num=5 print("りんごの単価" + str(apple_price) + "円") print("りんごを買う数" + str(apple_num) + "個") total=apple_price*apple_num print("合計金額" + str(total) + "円") #個数を1〜10にしたいのでrandom関数をインポートする import random apple_num=random.randint(1,10) print("りんごを買う数" + str(apple_num) + "個") total=apple_price * apple_num print("合計金額" + str(total) + "円") #単価を100〜300にしたい apple_price=random.randint(1,3)*100 print("りんごの単価" + str(apple_price) + "円") total=apple_price * apple_num print("合計金額" + str(total) + "円")演習
strで囲むの忘れていた
lesson.py# coding: utf-8 import random number = random.randint(1, 10) # 匹数 1 ~ 10 print("体重100キロのスライムが" + str(number) + "匹あらわれた") # 合計体重 = 匹数 x 100 total=number*100 print("スライムの合計体重は"+str(total)+"キロです")09データの型を覚えよう
lesson.pynumber = 100 #数値 strings = "paiza" #文字列(ダブルクォーテーションで囲む) print(number) print(strings) #文字同士を連結するときも + が使える ```lesson.py strings ="ハロー" + "paiza" print(strings) #number = "100" + "30" #print(number) #str関数でnumber変数を文字列に変える print(str(number)+strings) #string型で一次的に変わっただけ print(number + 20)演習
1.エラー箇所を正しく修正しよう
lesson.pyx = 50 print(x - 10)2.エラー箇所を正しく修正しよう2
lesson.pya = "モンスターが" b = "あらわれた" print(a + b)3.エラー箇所を正しく修正しよう3
期待する値
0123456789lesson.pya = "01234" b = "56789" print(a + b)
- 投稿日:2020-10-26T22:25:30+09:00
MacOS Catalinaに更新後、Xcode Command Line ToolsのインストールしてPython 2.7系から3.7系に変更(bash)
- MacOS Catalina
- Python 2.7.17
- bash
MacOS MojaveからCatalinaにバージョンアップしたところ、numpyがimportできなくなりました。
この状況を改善しつつ、併せて、Python 2系が、2020年1月でサポート終了とのことで遅ればせながらこの機会に 3.7.7 にバージョンアップしました。やり方を備忘録として、本記事に記します。numpyがインポートできないことを示すエラーメッセージ
$ python abc.py Traceback (most recent call last): File "abc.py", line 3, in <module> import numpy as np ModuleNotFoundError: No module named 'numpy'Pythonのインストールを試みるもエラー
そこで、Python 3.7.7をインストールしてみようと試みましたが、エラーが表示されました。
$ pyenv install 3.7.7 (略) xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrunQiitaの他の方の記事に、異なるバージョンのOSにおける同様の事例紹介を見つけました。
macOSアップデート後の『xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools)...』の対処法Xcode Command Line Toolsのインストール
Xcode Command Line Toolsが必要ということでインストールしました。
私の環境の場合、次のやり方でうまく進むことができました。$ softwareupdate --list Software Update Tool Finding available software Software Update found the following new or updated software: * Label: Command Line Tools for Xcode-12.1 Title: Command Line Tools for Xcode, Version: 12.1, Size: 431272K, Recommended: YES, $ softwareupdate --install -a Software Update Tool Finding available software Downloading Command Line Tools for Xcode Downloaded Command Line Tools for Xcode Installing Command Line Tools for Xcode Done with Command Line Tools for Xcode Done.pyenvのバージョンと .bash_profileの内容確認
このとき、pyenvのバージョンは次の通りです。
$ pyenv --version pyenv 1.2.17.bash_profile の中には以下のような記述が含まれていました。
(略) PYENV_ROOT="${HOME}/.pyenv" if [ -d "${PYENV_ROOT}" ]; then export PATH=${PYENV_ROOT}/bin:$PATH eval "$(pyenv init -)" fi (略)Python 3.7.7のインストール
あらためて、Python3.7.7をインストールしてみましたが、今度はインストールが完了しました。
$ pyenv install 3.7.7 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.7.tar.xz... -> https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tar.xz Installing Python-3.7.7... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.7 to /Users/ecru/.pyenv/versions/3.7.7pyenv でインストールされている Python のバージョンを確かめます。そして、3.7.7をglobalに設定します。
$ pyenv versions system * 2.7.17 (set by /Users/ecru/.pyenv/version) 3.7.7 $ pyenv global 3.7.7 $ python -V Python 3.7.7こちらで、numpyがインポートできないことを示すエラーメッセージは表示されなくなり、abc.pyがターミナルで実行できるようになりました。
備忘録は以上です。
- 投稿日:2020-10-26T22:25:30+09:00
MacOS X Catalinaに更新後、Xcode Command Line ToolsのインストールしてPython 2.7系から3.7系に変更(bash)
- MacOS X Catalina
- Python 2.7.17
- bash
MacOS X MojaveからCatalinaにバージョンアップしたところ、numpyがimportできなくなりました。
この状況を改善しつつ、併せて、Python 2系が、2020年1月でサポート終了とのことで遅ればせながらこの機会に 3.7.7 にバージョンアップしました。やり方を備忘録として、本記事に記します。numpyがインポートできないことを示すエラーメッセージ
$ python abc.py Traceback (most recent call last): File "abc.py", line 3, in <module> import numpy as np ModuleNotFoundError: No module named 'numpy'Pythonのインストールを試みるもエラー
そこで、Python 3.7.7をインストールしてみようと試みましたが、エラーが表示されました。
$ pyenv install 3.7.7 (略) xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrunQiitaの他の方の記事に、異なるバージョンのOSにおける同様の事例紹介を見つけました。
macOSアップデート後の『xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools)...』の対処法Xcode Command Line Toolsのインストール
Xcode Command Line Toolsが必要ということでインストールしました。
私の環境の場合、次のやり方でうまく進むことができました。$ softwareupdate --list Software Update Tool Finding available software Software Update found the following new or updated software: * Label: Command Line Tools for Xcode-12.1 Title: Command Line Tools for Xcode, Version: 12.1, Size: 431272K, Recommended: YES, $ softwareupdate --install -a Software Update Tool Finding available software Downloading Command Line Tools for Xcode Downloaded Command Line Tools for Xcode Installing Command Line Tools for Xcode Done with Command Line Tools for Xcode Done.pyenvのバージョンと .bash_profileの内容確認
このとき、pyenvのバージョンは次の通りです。
$ pyenv --version pyenv 1.2.17.bash_profile の中には以下のような記述が含まれていました。
(略) PYENV_ROOT="${HOME}/.pyenv" if [ -d "${PYENV_ROOT}" ]; then export PATH=${PYENV_ROOT}/bin:$PATH eval "$(pyenv init -)" fi (略)Python 3.7.7のインストール
あらためて、Python3.7.7をインストールしてみましたが、今度はインストールが完了しました。
$ pyenv install 3.7.7 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.7.tar.xz... -> https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tar.xz Installing Python-3.7.7... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.7 to /Users/ecru/.pyenv/versions/3.7.7pyenv でインストールされている Python のバージョンを確かめます。そして、3.7.7をglobalに設定します。
$ pyenv versions system * 2.7.17 (set by /Users/ecru/.pyenv/version) 3.7.7 $ pyenv global 3.7.7 $ python -V Python 3.7.7こちらで、numpyがインポートできないことを示すエラーメッセージは表示されなくなり、abc.pyがターミナルで実行できるようになりました。
備忘録は以上です。
- 投稿日:2020-10-26T21:54:27+09:00
Python学習5日目
日付の操作
目的:日付を思うように操作する
今後スクレイピングで出力したcsvの日付を操作するときに必要だと思ったから。
この記事で得られること
・応用で現在時刻を使用して、作成するcsv名に日付を指定することができる
・csvファイルに記入されているcsvの操作
・date型をstring型にまたその逆もしかり現在の時刻を出力する
test.pyfrom datetime import datetime now = datetime.now() print(now) -----result----- 2020-10-26 20:39:01.825495文字列を日付に変更する方法
test.pyfrom datetime import datetime # 2018/11/11 も同様にできる str_date = '2018年11月11日' #strptimeは文字列を日付に #strftimeは日付を文字列に one_date = datetime.strptime(str_date, '%Y年%m月%d日') print(one_date) -----result----- 2018-11-11 00:00:00過去未来の日付操作
test.pyfrom datetime import datetime from datetime import timedelta str_date = '2018/11/11' base_date = datetime.strptime(str_date, '%Y/%m/%d') print(base_date) -----result----- 2018-11-11 00:00:00 ---------------- #10日前 before_10days = base_date - timedelta(days=10) #10日後 before_10days = base_date - timedelta(days=10) print(before_10days) -----result----- 2018-11-01 00:00:00csvを使用した日付の操作
day.csv2016-10-01 2016-10-02 2016-10-03 2016-10-04 2016-10-05 2016-10-06 2016-10-07 2016-10-08 2016-10-09 2016-10-10 2016-10-11 2016-10-12 2016-10-13 2016-10-14day.pyfrom datetime import datetime #csv読み込み with open('day.csv', encoding='utf-8') as f: for row in f: day = datetime.strptime(row.rstrip(), '%Y-%m-%d') print(f'{day:%Y/%m/%d}') -----result----- 2016/10/02 2016/10/03 2016/10/04 2016/10/05 2016/10/06 2016/10/07 2016/10/08 2016/10/09 2016/10/10 2016/10/11 2016/10/12 2016/10/13 2016/10/14Python機能
Python3.8の新機能
f'{ 式=}'式そのもの出力ができるようになった。
書式を出力する場合 f'{ 式=:書式}'csvから該当する日付を出力する
test.pyfrom datetime import datetime from datetime import timedelta main_date ='2016-10-12' #文字列→日付に base_day = datetime.strptime(main_date,'%Y-%m-%d') #一週間前の日付 before_7days = base_day - timedelta(days=7) #csvファイルを選択 with open('day.csv', encoding='utf-8') as f: for row in f: # 文字列→日付 行末の改行を削除 day = datetime.strptime(row.rstrip(), '%Y-%m-%d') #print(day) #2016-10-02 00:00:00 #2016-10-03 00:00:00 #~ #2016-10-14 00:00:00 #2016-10-12 から7日間該当するものを表示 if before_7days <= day < base_day: #Y/m/d 形式で print(f'{day:%Y/%m/%d}') -----reult----- 2016/10/05 2016/10/06 2016/10/07 2016/10/08 2016/10/09 2016/10/10 2016/10/11
- 投稿日:2020-10-26T21:47:38+09:00
LEGO Mindstorms 51515 Python Programing
新型マインドストーム発売!!!
2020年10月15日にLEGO MINDSTORMS 51515が発売されましたが、残念なことに日本では発売されませんでした……。悔しかったのでUK Amazonで販売していないか探したところ、思った以上に安く売られていたので購入しちゃいました。
とりあえずPython使えるか確認
アプリ画面です。コードのところをクリックして新プロジェクトを押してみると、どうやらまだBETA版のようです。
プロジェクト画面
右側中央の本のマークを押すとナレッジベースが開きます。とりあえず今色々読んでます。
スマートハブと接続して右下の再生ボタンを押すと小さなビープ音が鳴りました。
BETA版ですが普通に楽しめそうです。色々楽しめそう
初めてMINDSTORMSに触れたので、歴代モデルがどのようなものかわかりませんが、どうやら録音した音や編集などもできるみたいです。
LEGOで遊びながらプログラミングも出来ちゃう最高のアイテムだと思います、今後も時間があればマインドストームネタを投稿したいと思います!




- 投稿日:2020-10-26T21:15:33+09:00
pandas.DataFrameの任意の列がユニークの行をいろいろやってみる
- 環境
- macOS Catalina バージョン10.15.7
- Python 3.8.5
- pandas 1.1.3
サンプルデータはCSVから読み込んだこんなデータ。
このデータの[ID]列に着目してユニークの行をいろいろやってみる。if __name__ == '__main__': df = pandas.read_csv('CSV.csv') print(df) # ID 日付 開始 終了 # 0 20.0 10/14 9:00 18:00 # 1 16.0 10/15 10:00 19:00 # 2 39.0 10/16 11:00 20:00 # 3 NaN 10/17 12:00 21:00 # 4 47.0 10/18 20:00 22:00 # 5 29.0 10/19 11:00 12:00 # 6 62.0 10/20 15:00 17:00 # 7 NaN 10/21 16:00 18:00 # 8 16.0 10/22 17:00 19:00 # 9 3.0 10/23 18:00 20:00 # 10 16.0 10/24 19:00 21:00 # 11 20.0 10/25 20:00 21:00
行
番号ID 日付 ... [ID]列が重複
している行0 20.0 10/14 ... o 1 16.0 10/15 ... o 2 39.0 10/16 ... 3 NaN 10/17 ... o 4 47.0 10/18 ... 5 29.0 10/19 ... 6 62.0 10/20 ... 7 NaN 10/21 ... o 8 16.0 10/22 ... o 9 3.0 10/23 ... 10 16.0 10/24 ... o 11 20.0 10/25 ... o 任意の列のユニークな件数を取得する
# NaNを含む場合 print(df.nunique(dropna=False)['ID']) # 8 # NaNを除いた場合 print(df.nunique()['ID']) # 7任意の列でユニークにしたときの値と件数を取得する
- 参考
違い groupby value_counts 備考 列見出し あり なし ソート 列の値 頻度 sort=Falseにすれば並びは同じ # NaNを含む場合 print(df.groupby('ID', dropna=False).size()) # ID # 3.0 1 # 16.0 3 # 20.0 2 # 29.0 1 # 39.0 1 # 47.0 1 # 62.0 1 # NaN 2 # dtype: int64 print(df['ID'].value_counts(dropna=False)) # 16.0 3 # NaN 2 # 20.0 2 # 3.0 1 # 62.0 1 # 29.0 1 # 47.0 1 # 39.0 1 # Name: ID, dtype: int64 # NaNを除いた場合 print(df.groupby('ID', sort=False).size()) print(df['ID'].value_counts(sort=False)) # 20.0 2 # 16.0 3 # 39.0 1 # 47.0 1 # 29.0 1 # 62.0 1 # 3.0 1 # Name: ID, dtype: int64重複している行の値と件数を取得する
# NaNを含む場合 val_con = df.groupby('ID', dropna=False).size() print(val_con[val_con >= 2]) # ID # 16.0 3 # 20.0 2 # NaN 2 # dtype: int64 # NaNを除いた場合 val_con = df['ID'].value_counts() print(val_con[val_con >= 2]) # 16.0 3 # 20.0 2 # Name: ID, dtype: int64任意の列が重複している行を判定する
- 参考
# NaNを含む場合 print(df.duplicated(subset=['ID'])) # 0 False # 1 False # 2 False # 3 False # 4 False # 5 False # 6 False # 7 True # 8 True # 9 False # 10 True # 11 True # dtype: bool # NaNを除いた場合 print(df.dropna(subset=['ID']).duplicated(subset=['ID'])) # 0 False # 1 False # 2 False # 4 False # 5 False # 6 False # 8 True # 9 False # 10 True # 11 True # dtype: bool
duplicatedは、デフォルトで重複した最初の行がFalseになる(keep='first')。
keepに指定する値によって重複した行のどこがFalseになるかが変わる。
keepの値 ID keep='first'
(デフォルト)keep='last' keep=False 0 20 False True True 1 16 False True True 2 False False False 3 NaN False True True 4 False False False 5 False False False 6 False False False 7 NaN True False True 8 16 True True True 9 False False False 10 16 True False True 11 20 True False True 任意の列が重複しているか判定する
# df.shape[0]で全件数が取得できる if df.shape[0] == df.nunique()['ID']: print('ID列の値は一意') else: print('ID列は一意ではない')任意の列が重複している行を取得する
# NaNを含む場合 print(df[df.duplicated(subset=['ID'])]) # ID 日付 開始 終了 # 0 20.0 10/14 9:00 18:00 # 1 16.0 10/15 10:00 19:00 # 3 NaN 10/17 12:00 21:00 # 7 NaN 10/21 16:00 18:00 # 8 16.0 10/22 17:00 19:00 # 10 16.0 10/24 19:00 21:00 # 11 20.0 10/25 20:00 21:00 # NaNを除いた場合 df_dropna = df.dropna(subset=['ID']) print(df_dropna[df_dropna.duplicated(subset=['ID'], keep=False)]) # ID 日付 開始 終了 # 0 20.0 10/14 9:00 18:00 # 1 16.0 10/15 10:00 19:00 # 8 16.0 10/22 17:00 19:00 # 10 16.0 10/24 19:00 21:00 # 11 20.0 10/25 20:00 21:00
- 投稿日:2020-10-26T21:03:29+09:00
【python】アルファベットを数字に変更
- 投稿日:2020-10-26T20:36:37+09:00
Heroku上にてPythonをPHP上で動かしてみた話
Qiita初投稿です。
今回は下手なところで3時間くらいつまずいた「Heroku上にてPythonをPHP上で動かす」方法を備忘録的に残したいと思います。
脳死で書いています。誤字脱字は温厚な目で見てくれると嬉しいです。思い立ち
最初はWebページにスクレイピングの情報を掲載できればいいかなーとか思っていました。
でもスクレイピングってPythonで書けば簡単じゃーん!とかいって始まったのが地獄の門の入り口でした。Pythonでスクレイピングする
取り合えずトップニュースを取得すればいいかなと思い、以下のコードを記述しました。
# coding: utf-8 import requests from bs4 import BeautifulSoup # 現在のトップニュースのページIDを取得する toppage_url = "https://news.yahoo.co.jp/" html = requests.get(toppage_url) soup = BeautifulSoup(html.content, "html.parser") topic_element = soup.select_one("li.topicsListItem") news_link = topic_element.find("a").get("href") news_id = int(str(news_link).replace("https://news.yahoo.co.jp/pickup/","")) # ニュースのトピック情報を取得する news_url = f"https://news.yahoo.co.jp/pickup/{news_id}" html = requests.get(news_url) soup = BeautifulSoup(html.content, "html.parser") news_element = soup.select_one("p.pickupMain_articleSummary") print(news_element.text)PHPでexec()を利用しPythonの出力を取得する
execでコマンドラインのコマンドを実行し、出力を変数に入れることができます。PHPを以下のように書きます。
<?php header("Content-type: text/html; charset=utf-8"); ?> <!doctype html> <html lang="ja"> <head> <meta charset="utf-8"> <title>Python-PHP</title> </head> <body> <?php exec("export LANG=ja_JP.UTF-8"); exec('python news.py', $output); echo '<p>',$output[0],'</p>'; return false; ?> </body> </html>重要なことは、exec("export LANG=ja_JP.UTF-8");の部分。
※日本語が出力される場合、utf-8を明示しないと文字化けすることがあります。日本語嫌い。
1行目はとりあえずレスポンスヘッダにも書いたほうがいいかなーとか思って付けました。必要性はわからないです文字コードのお話
先ほどからちょくちょくでているUTF-8。今回の苦戦の1つ目になります。
PHPは基本的に文字コードはUTF-8で書くべきとされています。
Pythonの出力もutf-8で統一する必要があり、最初の頃はそこで詰まっていました。(Python側がShift-JISだった)いざHerokuへDeploy!のはずがエラーの嵐
さあできた!デプロイして様子を見よう!とデプロイしてURLを開いてみると…
\\ 現在Herokuはリクエストを処理できません //
はい。ここでエラーです。デプロイには成功してるのにナンデ状態になりました。
結論から申し上げますと、Heroku上でPHPとPythonの両方を同時に動かす場合、2つのBuildPackが必要になります。
こんな感じで設定しましょう。今回はWebページがメインのため、順番はPHP->Pythonの順になります。これで大丈夫だろう!こんどこそ!とデプロイしようとすると、
\\ Deploy failed //
うーんこの。今度は何・・・とlogを漁ると、以下のような内容がありました。
-----> App not compatible with buildpack: https://buildpack-registry.s3.amazonaws.com/buildpacks/heroku/python.tgz More info: https://devcenter.heroku.com/articles/buildpacks#detection-failure ! Push failedこれを検索すると、Pythonアプリケーションのために必要となるファイルが無いとのこと。
それじゃあ作成しましょう。今回のPythonのコードに必要なものを詰めて以下のとおり:#requirement.txt beautifulsoup4==4.9.1 requests==2.24.0#runtime.txt python-3.7.7これでデプロイするとうまく行きました。
完走した乾燥
文字コードとHerokuの環境構築に悩まされた一日を過ごしました。日本語嫌い。
ちなみにXAMPPでテスト環境を作ってみたらHerokuよりも文字コードに関して悩まされました。
今回はとりあえず表示に成功したのでよしとします。参考資料
BuildPackが必要であることを知らされたサイト
https://stackoverflow.com/questions/12126439/run-python-and-php-in-a-single-heroku-app-procfilePythonのHeroku上での実行環境を整えるために必要なファイルを知ったサイト
https://teratail.com/questions/258801(密かに起きてたエラー対処に役立ったサイト)
デプロイ後にcode=H14 desc="No web processes running"
https://qiita.com/rebi/items/efd1c36f0a9e46222d80

- 投稿日:2020-10-26T20:24:21+09:00
GitActionからAzureAppServiceにデプロイする
はじめに
QiitaAzure投稿キャンペーン中で、良い機会なのでGitHubのリポジトリをAzureにデプロイする方法についてまとめました。
Deploy to AzureというVSCodeのエクステンションを使用すると驚くほど簡単にできました。構成
リポジトリにGitHub、デプロイする先にAzureのAppServiceを使用します。
GitHubからAzureへの連携にはGitHubのActionを使用しますが、基本的にVSCodeのエクステンションが勝手にしてくれるため、はじめての人でも楽にできます。手順
- GitHubのプロジェクトを作成
- AzureのAppServiceのリソースを作成
- GitHubのActionのworkflowを作成
- ソースをpush(デプロイ)
手順詳細
1. GitHubのプロジェクトを作成
GitHubのリポジトリを作成します。特に必要な設定はいらないので省略します。
2. AzureのAppServiceのリソースを作成
デプロイ先のAppServiceのリソースを作成します。基本的にはAzureポータルで作成することになります。
2.1. ポータルにログインしてAppServiceの画面まで移動します。
2.2. AppServiceの画面から追加ボタンを押して、リソース作成画面に移動します。
2.3. リソースの作成に必要な情報を入力します。
※インスタンスの詳細については、アプリに影響を与えるため注意してください
ちゃんと作成できるとこのような画面が表示されます。
3. GitHubのActionのworkflowを作成
GitHubのActionに使用するyamlファイルを手で書くのは手間なのでVSCodeのエクステンションを使用します。
リポジトリをクローンしてソースを追加する
GitHubのリポジトリをクローンしてデプロイしたいソースを追加します。
※pythonをデプロイしたいときはrequirements.txtを読み取ってインストールするのでpython -m pip freeze > requirements.txtコマンドでpipを吐き出しておいてくださいDeploy to Azureのインストール
VSCodeのDeploy to Azureというエクステンションを使用するとGitHubのActionのyamlを自動的に生成してくれます。
1からyamlを作るのは手間なのでDeploy to Azureをインストールします。
GitHubのAccessTokenの取得
Deploy to Azureに必要なため、以下のGitHub Docsの通りに、AccessTokenを取得します。
https://docs.github.com/ja/free-pro-team@latest/github/authenticating-to-github/creating-a-personal-access-tokenGitHub Actions を制御するyamlの生成
3.1. クローンしたディレクトリをVSCodeで開いてCtr + Shift + Pでコマンドパレットを開き、Deploy to Azure:Configure CI/CD Pipelineコマンドを実行します。
3.2. GitHubのAccessTokenを聞かれるので事前に取得したAccessTokenを入れます。
3.3. Webサービスの環境とサブスクリプションを聞かれるので入れます。
3.4. 4つめの入力項目が2で作成したAzureのAppServiceのリソース名になっているはずなのでそれを選択します。ここまで入力すると開いているディレクトリ内に
.github\workflows\workflow.ymlができているはずです。yamlの修正
環境によっては、v1のアクションが使えない可能性があるため、
azure/webapps-deploy@v1をazure/webapps-deploy@v2に修正します。4. ソースをpush(デプロイ)
ここまで、作成したすべてをGitHubのリポジトリに反映させます。
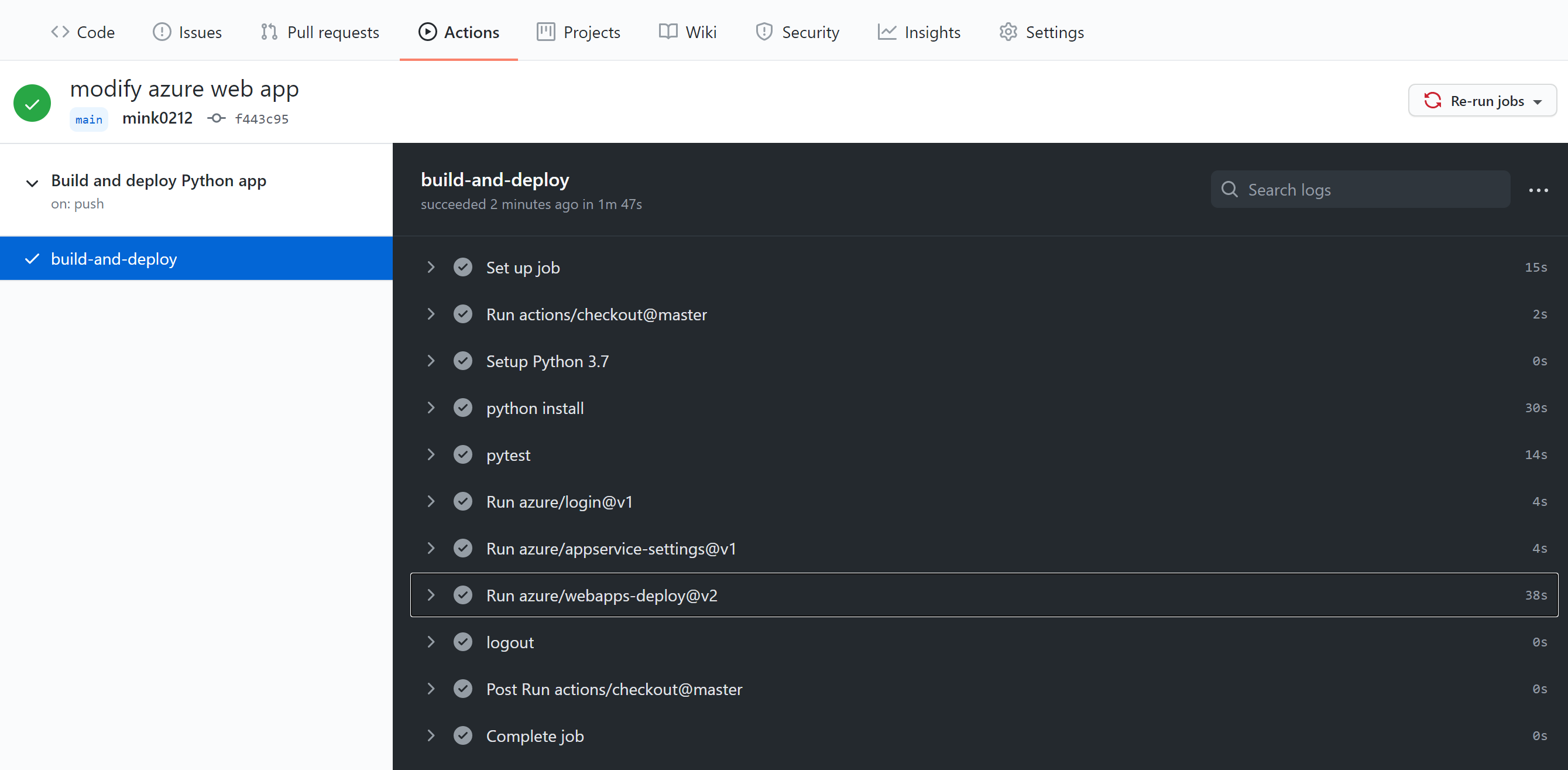
ソースをpushしたタイミングで、GitHubのActionがyamlを読み込みデプロイまで実行してくれます。Actionの途中経過を見たいときは、GitHubの対象のリポジトリを選択して、ActionsタブをクリックするとコミットメッセージでActionのworkflowが走っています。
以下のようになれば完了です。
その他
このyamlにコードを追加すれば、テストの自動化もできるようになります。ちなみに、テストが失敗するとActionが止まりデプロイされません。
以下はpytestを実行したときに追加した例workflow.yml- name: pytest working-directory: . run: | pip install pytest pip install -r requirements.txt python -m pytestおわりに
Azureのデプロイ方法をまとめました。AzureにDevOps starterというここで書いたものを全てGUIでできる機能もありますが、デフォルトがpython2だったことやダッシュボードなどなど不要なものまでついてきたため、自分の好きにできるこの方法をまとめました。





- 投稿日:2020-10-26T19:24:21+09:00
AnacondaをWindowa10にインストール
はじめに
当方IT、ソフトウェア畑ではなくハードウェア畑出身です。
ですので、プログラミングらしいものと言えば、エクセルの関数くらいしか使えないレベルで、
正直「Python?なにそれおいしいの?」と言った、超ド級の初心者です。
(よって専門の方からすると正確ではない解釈、適切ではない内容があるかもしれませんがご容赦ください)そんな僕ですが、
①日常的によくあるデータ収集、前処理、分析の自動化、高速化を行いたい
②仕事の幅を広げたい(というよりこのままだと仕事の幅が狭まりそうで怖い・・・)
③自分の子供たちに教えてあげたいと思い、2020年の春頃からかなり牛歩ですが、Pythonを勉強しています。
というわけで今回は、始めの一歩であるPython環境を構築する上でお手軽な、
Anacondaのインストールを実行していきたいと思います。0.Anacondaとは?
Anacondaとは、Python及びPythonでよく利用されるライブラリ(いくつかの関数をパッケージ化したもの)を
まとめてインストールしてくれるもので、手っ取り早くPython環境の構築が可能です。
その後のライブラリの追加や管理なども行いやすく、フリー(無料)であることなどから、
幅広いユーザーに利用されています。1.Anacondaのダウンロード
では、まずは こちら にアクセスしてください。
ページ下部にWindows版のダウンロードリンクありますので、該当する方(32bit or 64bit)をクリックし、任意の場所にダウンロードしてください。
(ご自身のbit数の確認方法は こちら から)
ファイル容量が大きいのでダウンロードには数分以上かかると思いますので、完了までしばらく待ちます。
2.Anacondaのインストール
ダウンロードが完了したら、ダウンロードファイルをダブルクリックし、実行します。
以下のような画面出てきたら、
Nextをクリック
規約内容に同意できれば
I Agreeをクリック
Just Meを選択し、Nextをクリック
(ログインユーザーだけでなく、PCを共用している全ユーザーで利用可能にしたい場合はAll Usersを選択)
インストールするディレクトリを指定。
任意で書き込み、またはデフォルト設定で問題なければNextをクリック
初めてPythonをインストールする場合は、上段にもチェックを入れて、
Installをクリックしてください。
Not recommended(非推奨)と書かれており、文字が赤くなりますが、気にしなくて大丈夫です。
インストールが始まりますので、数分~数十分待ちます。
問題なくインストールできれば、以下のような画像が出てきますので、
Next->Finishとクリックしてください。
※チュートリアルなど資料ページを開くにチェックが入っていますので、不要な場合はチェックを外してください。
おわりに
以上でAnacondaのダウンロード->インストールが完了です!








- 投稿日:2020-10-26T19:24:21+09:00
AnacondaをWindows10にインストール
はじめに
当方IT、ソフトウェア畑ではなくハードウェア畑出身です。
ですので、プログラミングらしいものと言えば、エクセルの関数くらいしか使えないレベルで、
正直「Python?なにそれおいしいの?」と言った、超ド級の初心者です。
(よって専門の方からすると正確ではない解釈、適切ではない内容があるかもしれませんが、
その際はご指摘、アドバイスをいただけると幸いです。)そんな僕ですが、
①日常的によくあるデータ収集、前処理、分析の自動化、高速化を行いたい
②仕事の幅を広げたい(というよりこのままだと仕事の幅が狭まりそうで怖い・・・)
③自分の子供たちに教えてあげたいと思い、2020年の春頃からかなり牛歩ですが、Pythonを勉強しています。
というわけで今回は、始めの一歩であるPython環境を構築する上でお手軽な、
Anacondaのインストールを実行していきたいと思います。0.Anacondaとは?
Anacondaとは、Python及びPythonでよく利用されるライブラリ(いくつかの関数をパッケージ化したもの)を
まとめてインストールしてくれるもので、手っ取り早くPython環境の構築が可能です。
その後のライブラリの追加や管理なども行いやすく、フリー(無料)であることなどから、
幅広いユーザーに利用されています。1.Anacondaのダウンロード
では、まずは こちら にアクセスしてください。
ページ下部にWindows版のダウンロードリンクありますので、該当する方(32bit or 64bit)をクリックし、任意の場所にダウンロードしてください。
(ご自身のbit数の確認方法は こちら から)
ファイル容量が大きいのでダウンロードには数分以上かかると思いますので、完了までしばらく待ちます。
2.Anacondaのインストール
ダウンロードが完了したら、ダウンロードファイルをダブルクリックし、実行します。
以下のような画面出てきたら、
Nextをクリック
規約内容に同意できれば
I Agreeをクリック
Just Meを選択し、Nextをクリック
(ログインユーザーだけでなく、PCを共用している全ユーザーで利用可能にしたい場合はAll Usersを選択)
インストールするディレクトリを指定。
任意で書き込み、またはデフォルト設定で問題なければNextをクリック
初めてPythonをインストールする場合は、上段にもチェックを入れて、
Installをクリックしてください。
Not recommended(非推奨)と書かれており、文字が赤くなりますが、気にしなくて大丈夫です。
インストールが始まりますので、数分~数十分待ちます。
問題なくインストールできれば、以下のような画像が出てきますので、
Next->Finishとクリックしてください。
※チュートリアルなど資料ページを開くにチェックが入っていますので、不要な場合はチェックを外してください。
おわりに
以上でAnacondaのダウンロード->インストールが完了です!
- 投稿日:2020-10-26T19:14:46+09:00
# PythonでVlookup的な事をやってみた#2
---目的---
在庫情報など日々変わる数値をデータベースから読み込んで指定のデータに流し込んで
指定フォーマットで書き出しする。使用インタープリタ:Python3.8
---投稿者の作業環境---
Windows10Pro 64Bitコード
#!/usr/bin/env python # -*- coding: utf-8 -*- ###使用モジュール### import sqlite3 import pandas as pd import datetime ######タイムスタンプの取得 ThisDate = datetime.datetime.today().strftime("%Y%m%d") #CurStocks <<参照元の在庫マスタのデータベースを入れるデータフレーム用の変数 ######在庫情報マスタを在庫参照元データフレームに変換 #ここでは、在庫参照元のデータをSQlite3形式のファイルから引っ張ってますが、 #お好きなな形式をPandasでデータフレーム変換してください。 dbpath = 'C:/参照元/在庫SQLite/Zaiko.db' conn = sqlite3.connect(dbpath) cursor = conn.cursor() cursor=cursor.execute('SELECT * FROM TurnOver_Data') CurStocks = pd.DataFrame(cursor.fetchall()) CurStocks.columns=["index", "商品名", "商品CD", "バーコード", "在庫"] conn.close() #(備考)↑上記のやり方「cursor.fetchall()」だと # カラムのタイトルが抜けてしまうので、後から足してます。 #参照元のデータは上記のカラムタイトルという前提で。 ######流し込み先のSqlite形式のファイルを用意 print("●在庫連絡ファイルの更新") dbpath = 'C:/流し込み先/得意先_在庫FMT.db' conn = sqlite3.connect(dbpath) df_files=("C:/流し込み先ベースファイル/得意先_在庫FMT.xlsx") #エクセルファイルで別で流し込み先のリストを作ってますが、これは対象アイテムが増えた時など #メンテしやすいようにエクセルファイルでベースのリストを作っておいて書き換えるというやり方の為 df = pd.read_excel(df_files,encoding="cp932") Chlist = (df["JAN"].transpose()) #df["JAN"].transpose()<<「JAN」のデータを1件つづ読み込めるように変換してます。 #流し込み先のカラムに読み取りキーとなる「JAN」というタイトルをつけてます。 ######在庫参照用のデータを回して順次参照していく。 for item in Chlist: CurStocksult = CurStocks.query('バーコード == @item') #ここでさっき作った参照元のデータフレームのキーとなるJANコードを参照して回していきます。 #参照元カラム:「バーコード」 流し込み先:「JAN」というカラムのタイトル #ここで参照元のデータフレームから1件つづ読み取りを行っていきます。 if len(CurStocksult) >= 1: #在庫数カウント:参照元フレームに当該JANがある場合は、当該データ位置を参照 CurStocksult = (CurStocksult.iat[0, 3]) # インデックス番号の取得(2次配列のリストのデータ位置) DFindex=int(df.query('JAN == @item').index.astype("int64").values[0]) if(CurStocksult) < 3 : Buf = 0 df.iat[DFindex, 7] = "欠品" else: Buf=CurStocksult df.iat[DFindex, 7] = "" df.iat[DFindex, 6]=Buf df.iat[DFindex, 8]=ThisDate # 流し込み先の6列が在庫列、7列目がフラグ欄、8列目が更新したタイムスタンプという設定 df.to_sql("Stock_Data", conn, if_exists="replace") df.to_csv('C:/更新した在庫データ.csv') #SqliteとCSVを更新。 conn.close() print("●更新を完了しました") del df del df_files詰まったポイント等
1:ループ処理用のリストの作成
Chlist = (df["JAN"].transpose())
流し込み先のリストを1件づつ処理するために、流し込み先のキーとなるリストを
ループで回せるように変換したところ2:インデックス番号の取得
DFindex=int(df.query('JAN == @item').index.astype("int64").values[0])
2次配列のリストのデータ位置(Y軸?)を取得するための変換処理
- 投稿日:2020-10-26T18:53:49+09:00
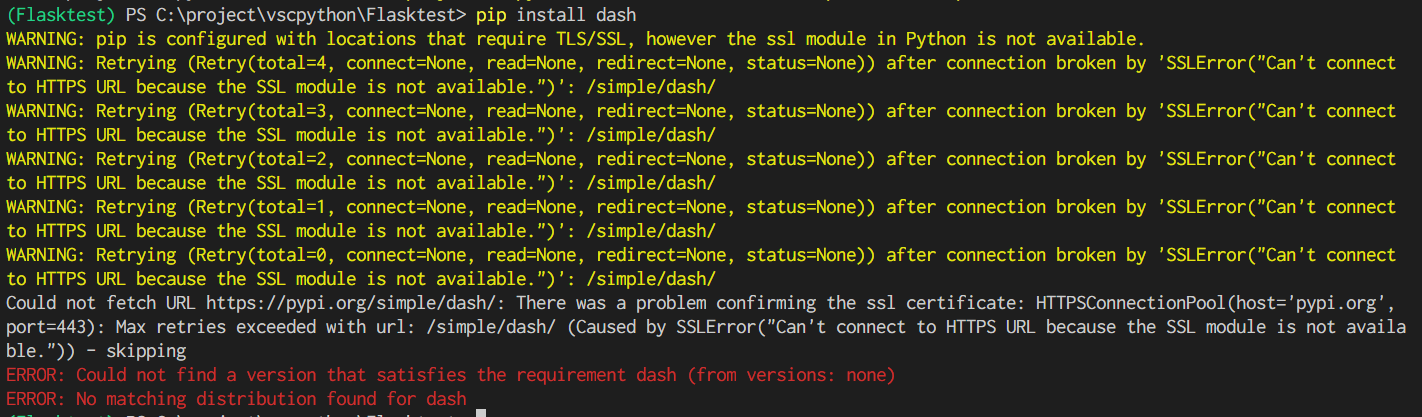
Windows10, miniconda, VScode環境で pipでSSLエラーが出た時の対処
背景
新Win10 PCにMiniconda(ver 4.9.0), VScode(ver 1.50.1)を入れて
pythonのコーディング環境を構築しようとしたら、以下のエラーが出てpipが通らなかったため、四苦八苦して解決させたのでその備忘録。
*正しいやり方かどうかわかりません。状態
VScodeでvenvを使って仮想環境構築後、pip install をしようとするとエラーで通らない。
解決
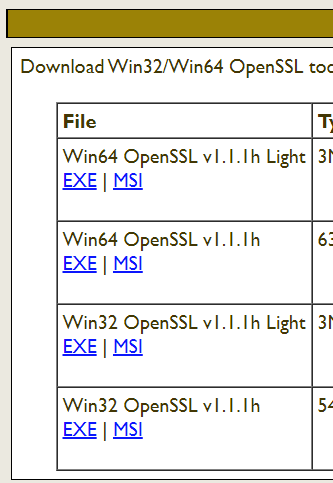
OpenSSLインストール
Win10にOpenSSLをインストール。図のWin32 OpenSSL v1.1.1h Light
OpenSSLのpathを通す
OpenSSLの中身を入れ替える
インストール先のC:\Program Files (x86)\OpenSSL-Win32\binの中身を、
minicondaインストール先フォルダのopensslに入れ替える
例)
C:\Users\[ユーザー名]\miniconda3\pkgs\openssl-1.1.1g-he774522_1\Library\binの中身を上記OpenSSLインストール先へコピーpipが通るか確認
書いてる途中、
\miniconda3\pkgs\openssl-1.1.1g-he774522_1\Library\binを単にpath通したら解決するんじゃ・・・?と思ってしまった。以上です。

- 投稿日:2020-10-26T18:35:06+09:00
プログラミング技術を使って、自分ができることは
技術を何につかうか考えると、コード演習だけでは見えていませんでした。
現時点で、わかったことが2つあります。
1、ディクショナリ型のデータを使って、情報を管理する。
2、jsonは、Webアプリケーションからデータ取得に使われる。
3、Pythonで、jsonをインポートし、従業員情報の管理をする。例)idや名前などimport json j = { "employee": [ {"id": 111,"name": "John"}, {"id": 222,"name": "Elle"} ] } print(j) a = json.dumps(j) print(json.dumps(a)) with open('test.json','w') as f: json.dump(j,f) with open('test.json','r') as f: print(json.load(f)) #ファイル内で、出力したファイルの読み書きを行う。エイジャックスを使ったページの要素の取得です。
該当するソースコード
$.ajax({ url: "./information.json", dataType: "json" }) .done(function(json){ var idx = 0; var $info = $(".info__list .item"); $info.find("time").text(json[idx].date); $info.find("p").text(json[idx].value); setInterval(function(){ if(idx === json.length -1){ idx = 0; } else { idx = idx + 1; } $info.css("opacity",0); setTimeout(function(){ $info.find("time").text(json[idx].date); $info.find("p").text(json[idx].value); $info.css("opacity",1); },500); },5000) });最後にデータの取得について
Webページの情報の取得をrequestsというサードパーティーできるようです。
JavaScriptの情報の取得コードについても調べてみます。
- 投稿日:2020-10-26T18:27:56+09:00
Djangoでfixtureを使ってユーザーモデルと紐づくサンプルデータを投入する方法
目標
Djangoで親モデルのuserモデルと子モデルであるbookモデルを作成したい。
前提
あらかじめsuperuserは作成している。(id:1)
そのため2番目のユーザーとしてsampleuserを作成し、そのユーザーに2つの子モデルを紐づけている結果
アプリのディレクトリにfixtureディレクトリを作成し、以下のように記入。
注意点として、ユーザーモデルのパスワードは下に記述した方法などでわかったハッシュ化した値をいれなければならない。fixtures/sample.json[ { "model":"アプリ名.user", "fields":{ "id":"2", "username":"sampleuser", "password":"ハッシュ化された文字列" } }, { "model":"アプリ名.book", "fields":{ "user":"2", "title":"サンプルの本1", "author":"不明", "price":"0" } }, { "model":"アプリ名.book", "fields":{ "user":"2", "title":"Sapiens", "author":"Yuval Noah Harari", "price":"32767" } } ]パスワードをハッシュ化する方法
コンソールを起動して、make_passwordをよびだすと、値がわかる
python manage.py shell >>> from django.contrib.auth.hashers import make_password >>> make_password('test') >>> ハッシュ化された値参考文献
https://stackoverflow.com/questions/34321075/how-to-add-superuser-in-django-from-fixture/34322435
- 投稿日:2020-10-26T17:41:39+09:00
自然言語処理3 単語の連続性
Aidemy 2020/10/30
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は自然言語処理の3つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・単語の連続性の前準備
単語辞書の作成
・「単語の連続性の分析」を行うために、その前準備として、単語データを数値化する。
・データセットを分かち書きした後、単語ごとにIDを付与して数値化するために、まずはIDを設定した単語辞書(リスト)を作成する。このうち、単語の出現数の多い順に連番を付けたいので、単語の出現数をカウントして降順に並べ替える。・単語の出現数のカウントはCounter()とitertools.chain()を使って行う。
Counter(itertools.chain(*カウントする単語データのリスト))・Counter()は要素の個数を数えるが、結果が多次元で返ってくるので、各要素に個別にアクセスできない。これを、itertools.chain()を使うことで一次元に戻す、ということを行っている。このitertools.chain()に渡す多次元リストには「*」をつける。
・降順に並べ替えるのは、most_common(n)を使う。nを指定すると、大きい順からその個数分のタプルを返す。
・ここまで行ったら、並べ替えた出現数リストの一つ一つにIDを付与して空の辞書に格納することで単語辞書が作れる。
・コード
単語データを数値データに変換する
・辞書を作成したら、目的であった「データセットを数値化する」ということを行う。
・前項で作った単語辞書のID部分を参照して、発話データセット「wakatiO」を数値データのみの「wakatiO_n」という新しい配列に変換する。・そのコードが以下のようになる。
・このコードは後ろから見ていくとわかりやすい。まず「for waka in wakatiO」の部分は、データセット「wakatiO」の各単語リスト(一文ずつで分かれている)をwakaに格納したことを示す。次に「for word in waka」はその単語リストを各単語に分け、wordに格納したことを表す。
・そして、その各単語について「dic_inv[word]」で辞書のIDを参照して「wakatiO_n」に格納していることを表している。単語の連続性から特徴抽出
N-gram
・N-gramは、テキストからトピックを抽出するときに使われるモデルのことであり、テキストを連続したN個の文字に分割するという方法を使う。
・N個の分割について、「あいうえお」という文字列があるとすると、N=1の「1-gram」なら「あ|い|う|え|お」と分割され、「2-gram」なら「あい|いう|うえ|えお」と分割される。
・「自然言語処理2」で出てきた「単語文書行列」でもトピックを抽出するということを行ったが、あちらが「単語の共起性(同じ文中に出現するか)」を表すのに対し、N-gramは「単語の連続性(どの順番で出現するか)」を表す。・N-gramの作成にはメソッドがあるわけではないので、文字列のリストに対して、繰り返し処理で空のリストに分割したものを格納するという手法をとる。
list = [] word = ['いい','天気','です','ね','。'] #3-gramモデルの作成 for i range(len(word)-2): list.append([word[i],word[i+1],word[i+2]]) print(list) #[['いい','天気','です']['天気','です','ね']['です','ね','。']]・「len(word)-2」の部分は、その下の「i+2」がwordの長さを超えないように同じ数字を指定する。
2-gramリストの作成
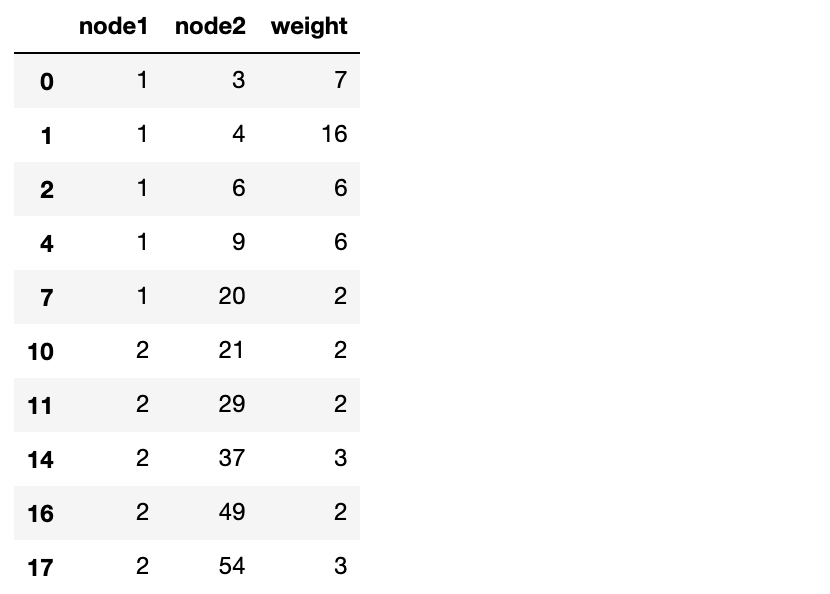
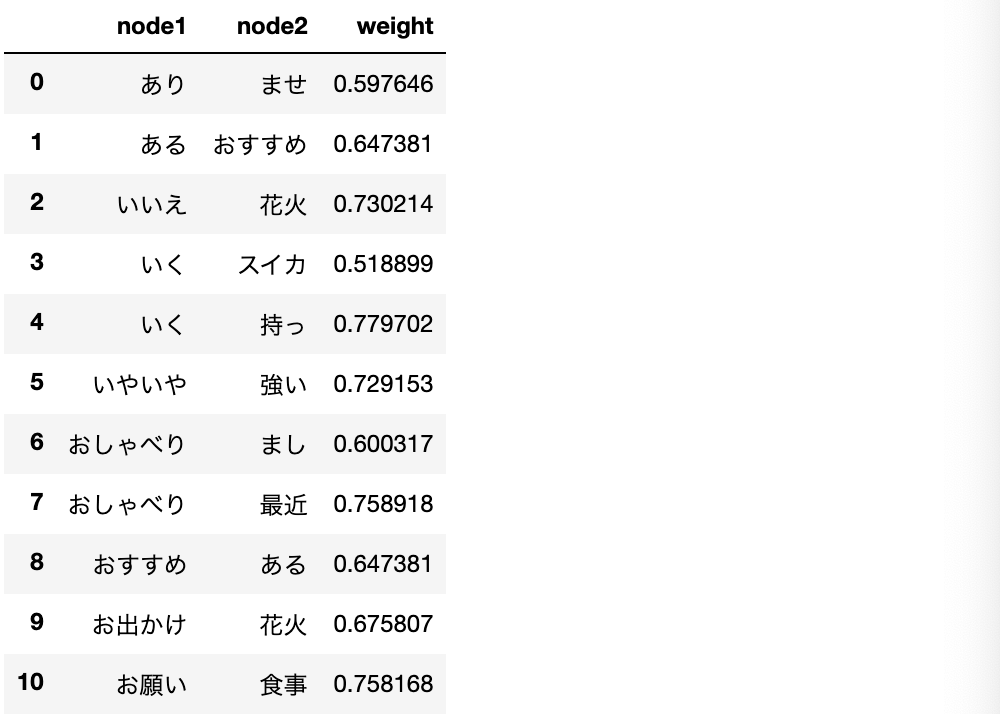
・上記N-gramについて、「wakatiO_n」から、2-gramリストを作成することで、二つのノードの出現回数(重み)を計算する。
・作成方法は、まず「wakatiO_n」に2-gramモデルを適用して2-gram配列「bigramO」を作成する。それをDataFrameに変換(df_bigramO)して「'node1'と'node2'」(連続値を算出する二つのノード)でグループ化(groupby())し、最後に「sum()」で出現数を合計して完成。・コード
※groupby()の「as_index=False」は、キーをindexでなくcolumnに出力するということを指定している。つまり、何も指定しないと、キーであるnode1はindexとして出力されてしまうため、columnであるnode2と同じように出力されない。これを回避するために、このように指定している。
・出力結果
2-gramネットワークの作成
・Chapter2では単語の類似度をエッジ(重み)として無向グラフを作成した。今回は、単語ペアの出現回数をエッジ(重み)として有向グラフを作成する。作成元のデータは、前項で作ったdf_bigramOである。
・有向グラフとは、エッジに「向き」の概念があるものを指す。単語ペアの出現回数については、「出現順」つまり「どちらの単語が先か」という情報にも意味があるのが有向グラフである。
・作成方法は無向グラフの時と全く同じで、nx.from_pandas_edgelist()の引数に「nx.DiGraph」と指定するだけで良い。・コード
・結果
2-gramネットワークの特徴
・前のChapterと同様に、グラフだけを見ても特徴がわかりにくいので、「平均クラスタ係数」や「媒介中心性」を計算して定量的に特徴を把握する。
・(復習)平均クラスタ係数はnx.average_clustering()、媒介中心性はnx.betweenness_centrality()で求める。各単語の影響を見る
・各単語がどう影響しあっているかを見るには、「次数分布」というものを可視化することで行う。
・有向グラフのときは「他の単語から影響を受ける」入次数と「他の単語に影響を与える」出次数に分けられる。
・入次数はin_degree(weight)メソッドを使って調べる。(node番号,入次数)の形で返ってくる。
・同様に、出次数はout_degree(weight)メソッドを使って調べる。・コード
・結果
まとめ
・単語の連続性から特徴を把握するには、まず発話テキストを分かち書きし、そこから単語辞書を作成することで、データを数値に変換する。
・数値に変換したデータをN-gramリストに変換して各単語の組み合わせの出現回数を計算し、そこから有向グラフを作成する。
・有向グラフのままだと特徴がわかりにくいので、「平均クラスタ係数」や「媒介中心性」を計算して定量的に特徴を把握する。
・また、次数分布をすることで定量的な特徴を可視化できる。今回は以上です。最後まで読んでいただき、ありがとうございました。

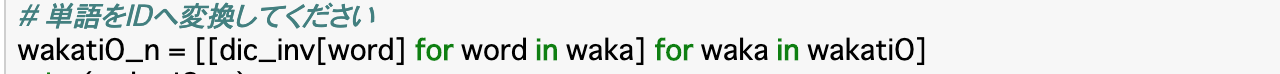




- 投稿日:2020-10-26T17:41:15+09:00
自然言語処理2 単語の類似性
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、 の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・単語の類似性について
・発話の特徴を知る単語の類似性
発話データの内容を形態素分析
・今回は、コーパスの発話データに対して、「単語の類似性」から「発話の特徴」を学習するということを行っていく。そのために、まずは「単語の類似性」を取得しなければならない。
・この項では、「単語の類似性」を取得する前処理を行っていく。具体的には、フラグが「O」、すなわち発話データのうち、自然な発話のみを形態素解析する。・手順
①「自然言語処理1 分析データの抽出」で作成した「df_label_text」のうち、フラグが「O」のもののみ抽出する。(df_label_text_O)
②抽出したdf_label_text_O(NumPy配列)を「.tolist()」でPythonのリストに変換し、それを一行ずつre.sub()で数字、アルファベットを除去。(reg_row)
③reg_rowをJanomeで形態素解析する。このうち、表層系(単語)だけを「morpO」というリストに追加する。・コード
単語文書行列
・単語文書行列とは、単語データを数値データに変換する手法の一つである。
・これは、文書に出現する単語の頻度を数値化したものである。この単語文書行列を実行するために、形態素解析で文書を単語ごとに分けるということを行っていた。
・実行には、scikit-learnのCountVectorizer()を使う。
・デフォルトだと2文字以上でないと単語として認識されないが、日本語の場合1文字でも意味をなす単語は存在するので、このような時は上記引数に「token_pattern='(?u)\b\w+\b'」と入力する。・CountVectorizer()オブジェクト(CV)に対して、CV.fit_transform('単語文書行列にする文字列')というふうにすると単語の出現回数を配列にすることができる。
・以下のコードでは、前項の「morpO」を単語文書行列に変換し、さらにこれをndarray配列に変換し、DataFrameで表している。
※「get_feature_names()」で、学習した単語が配列になって格納される。
・コードの出力結果(一部のみ)
重みあり単語文書行列
・以上の単語文書行列では、「私」や「です」などの普遍的な単語の出現頻度がどうしても多くなってしまう。このままだと、特定の文書にのみ出現する単語が重要視されず、適切に「発話の特徴」を抽出できない。
・このような場合に、「どの文書でも出てくるような普遍的な単語の重みを小さくし、特定の文書にのみ出てくる単語の重みを大きくする」といった手法を用いて単語文書行列を作ることが多くあり、これを「重みあり単語文書行列」という。
・この時の重みを決定づける値は、単語の出現頻度(TF)にIDFという値をかけた「TF-IDF」が利用される。
・IDFは総文書数とその単語の出現する文書数の比によって算出され、出現する文書数が少ないほどIDFの値が大きくなる。すなわち、重み(TF-IDF)が大きくなる。・重みあり単語文書行列の実行は以下のように行う。
TfidfVectorizer(use_idf=)
・「use_idf」にはTrueorFalseを指定し「重み付けにidfを使うかどうか」を指定する。
・また、CountVectorizer()と同様に、1文字でも単語として扱いたい時は「token_pattern」を指定する。・あとはCountVectorizer()と同じように「fit_transform()」で単語の出現回数を配列にすることができる。
単語の類似度を計算
・今回は単語の出現の仕方の類似度を特徴量とした教師なしモデルを作成する。
・単語の類似度を計算する方法はベクトル同士の類似度であるコサイン類似度など様々なものが存在するが、今回は各列間の相関係数を計算することで類似度を測る。
・相関係数を計算するには、DataFrame.corr()メソッドを使う。このために、先述のコードではDataFrameに変換していた。発話の特徴を分析する
類似度リストの作成
・前項で算出した相関係数が特徴量となるので、これを使って定量的に分析していく。
・まずは相関係数を行列形式からリスト形式に変換する。これには、DataFrame.stack()メソッドを使う。(stack()は列から行、unstack()は行から列に変換)・以下のコードの手順
①重み単語文書行列を作成した上で、その相関係数を計算した行列を作成したとして(corr_matrixO)、それをリスト形式に変換する。(corr_stackO)
②このうち、正の相関がある(類似していると言える)組を抽出するため、相関係数が「0.5~1.0」であるindex(単語の組)とvalue(相関係数の値)を抽出し、連結して表示。・実行結果(一部のみ)
類似度ネットワークの作成
・類似度ネットワークとは、平たく言えば類似度の関係をグラフ化して可視化したものである。
・前項で作成した類似度リストを可視化する時は「無向グラフ(無向ネットワーク)」というものを使う。
・無向のグラフの作成はNetworkXと呼ばれるライブラリを使う。これを「nx」でインポートしたとすると、
nx.from_pandas_edgelist(df,source,target,edge_attr,create_using)
で作成することができる。
・各引数について
df:グラフの元となるDataFrame
source:相関の一方(ソースノード)の列名
target:相関のもう一方(対象ノード)の列名
edge_attr:それぞれのデータの重み(エッジ)
create_using:グラフのタイプ(無向ならnx.Graph)・作成したグラフは、pos = nx.spling_layout(グラフ)で最適な表示位置を計算し、nx.draw_networkx(グラフ,pos)で描画、あとはplt.show()で表示できる。
・前項で作成した「df_corlistO」をグラフにする。
・グラフ
類似度ネットワークの特徴
・グラフを出力することはできたが、上記のグラフでは一見して特徴を把握するのは難しい。
・そのため、新しく指標を設けて定量的に判断していく。
・このときに使われる指標は様々あるが、ここでは詳しくは説明しない。今回使う指標は「平均クラスタ係数」と「媒介中心性」と呼ばれるものである。
・クラスタ係数は単語間の繋がりの密度を示し、この平均が高ければ、ネットワーク全体も密になっていると言える。媒介中心性は一つの「ノード(相関の組の一方)」が全てのノード間の最短経路に幾つ含まれるかを示す値であり、値が大きいほど情報を効率的に伝える際に利用されることが多い、すなわち媒介性と中心性の高いノードであると言える。・平均クラスタ係数の計算は以下のように行う。
nx.average_clustering(グラフ,weight=None)
・weightには重み(エッジ)を指定する。Noneだと各エッジの重みは1になる。・媒介中心性の計算は以下のように行う。
nx.betweenness_centrality(グラフ,weight=None)・コード
類似度ネットワークのトピックを抽出
・類似度ネットワーク全体は、複数の部分ネットワーク(コミュニティ)が集まってできている。
・この時のコミュニティの各ノードは密になっているため、コミュニティを抽出するということは類似度の高いネットワークを抽出するということになる。
・部分ネットワークに分割するには、「モジュラリティ」と呼ばれる指標を使う。細かい計算式は省略する。
・モジュラリティを用いたコミュニティの抽出は以下のように行う。
greedy_modularity_communities(グラフ,weight=None)
まとめ
・単語文書行列に変換することで、単語データを数値データに変換することができる。多くの場合、重みありで行われる。
・数値データに変換したことで、各データの相関係数を求めることができる。これにより、単語同士の類似度を算出できる。
・この類似度をリスト化し、ネットワークを作ることで可視化が可能になり、これにモジュラリティという指標を使うことでトピック抽出ができ、これによって類似度の高いネットワークが抽出できる。今回は以上です。最後まで読んでいただき、ありがとうございました。






- 投稿日:2020-10-26T17:40:49+09:00
自然言語処理1 形態素解析
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、自然言語処理の一つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・自然言語処理とは
・テキストコーパスについて
・形態素解析について自然言語処理について
・「自然言語」とは、人間が普段使う、話し言葉/書き言葉のことである。これをコンピュータに処理させることを「自然言語処理」という。
・人間が使う自然言語には曖昧な表現が含まれることがあるが、コンピュータはこれを「解釈」することはできない。
・コンピュータが自然言語を処理するには、自然言語を数値に変換する必要がある。
・自然言語処理は、機械翻訳や音声認識、情報検索などに利用される。コーパス
・コーパスとは、自然言語の文書をまとめたデータである。多くの言語のサポートしており、日本語版も存在する。
・今回は「雑談対話コーパス」というものを使用する。
・データは100セットの雑談データ「init100」ディレクトリと1046セットの雑談データ「rest1046」ディレクトリに分かれている。今回は「init100」
の方を使う。
・ファイル構造については「JSON形式」で提供されている。「質問データ(人の発話)」と「回答データ(システムの発話)」に分けられる。
・これらのデータはファイル内の「turns」キーに格納されている。このうち「utterance」が発話データ、「speaker」が「U」なら人、「S」ならシステムの発話になる。
・また、システムの発話データには「breakdown」というフラグが設定されている。これは、システムの発話が自然かを判定するものになっている。「O」は自然、「T」は不自然、「X」は極めて不自然(破綻)を表す。このフラグは一つの回答に対して複数付与される。
・コーパスの内部
コーパスの読み込み/データの抽出
・コーパスの読み込みは普通のファイルの読み込みと同様、「open()」で開く。読み込みについては、ファイルがJSON型式なので、「json.load()」で読み込む。
・読み込んだファイルに対し、取得したいデータのキーを指定することで、データを抽出することができる。・会話IDを取得
#話者と発話内容を抽出し、表示 for turn in json_data['turns']: print("{}:{}".format(turn['speaker'],turn['utterance']))分析データの抽出
・ここからは「自然な会話」を分析していく。すなわちbreakdownを使用していくので、まずは「人の発話内容」と「システムの発話のフラグ」を取得する。
・このとき、データを取得すると重複したデータが発生してしまうため、drop_duplicates()を使用して重複したデータを削除する。このとき渡せるのはDataframeのデータであるため、取得したものはdfに変換する必要がある。・コード
・上記コードでは、まず前項と同じ方法で発話データが格納されている「turns」から「発話ターンNo」「話者ID」「発話内容」を取得し、さらに「発話内容(utterance)」から、「人の発話内容」と「システムの発話のフラグ」を取得し、それをlabel_listというリストに入れている。最後にそれをDataFrameに変形し、重複するデータを削除している。
形態素解析
形態素解析とは
・形態素解析とは、自然言語処理の手法の一つで、文章を単語(形態素)で分割し、品詞を分類する手法である。
・例えば「こんにちは、んがょぺです!」なら「こんにちは / 、 / 私 / は / んがょぺ / です / !」となる。
・形態素解析の実行ツールには、MeCabやJanomeといったものがある。MeCab
・形態素解析をMeCabで行う。使用方法は以下の通り。
k = MeCab.Tagger('出力モードの指定')としたkに対し、
k.parse('形態素解析を行う文字列')として実行する。具体的には、以下の通り。
・また、Tagger()に設定するモードについて、何も指定しなければ上記のように出力されるが、「'-Owakati'」とすると、単語(形態素)ごとに空白で区切るだけの「分かち書き」で出力される。
・他にも、読みだけが出力される「'-Oyomi'」などのモードも存在する。Janome
・Janomeで形態素解析を行う時は、t = Tokenizer()でオブジェクトを作ってから、t.tokenize('形態素解析を行う文字列')で実行できる。
・また分かち書きの時は、この第二引数に「wakati=True」とすれば良い。・その他の機能として、品詞でフィルターをかけることができる。
・特定の品詞のみ取得したい時はPOSKeepFilter(['品詞'])
・特定の品詞を除外したい時はPOSStopFilter(['品詞'])・Analyzer()を使えば、ここまでの処理と、形態素解析を行う文章の前処理を同時に行うことができる。
・渡す引数は、(前処理,Tokenizerオブジェクト(t),フィルター)である。
・前処理の部分は、Unicode文字列の表記揺れを正規化するUnicodeNormalizeCharFilter()などがある。ちなみにこれは全角のアルファベットやカタカナを半角に統一するなどの正規化を行う。
・また、ときに前処理を行わない場合であっても第一引数は省略できないので、そのような時は「[]」とだけ記述する。
・残り二つの引数には、先述したオブジェクトとフィルターを設定すれば良い。・Analyzer()の実行は以下のように行う。
テキストの正規化
・形態素解析は、使用する辞書に依存するため、辞書に載っていない単語が出てくると解析が不自然になる恐れがある。
・このようなときの対策法は二種類ある。一つ目がユーザー辞書を用意する方法である。(ただしここでは説明しない)
・もう一つの方法が「テキストの正規化」である。これは、前処理として、テキストの不要な記号を削除したり、表記を統一するというものである。・例えば、文章に「,」と「、」が混在しているときにどちらかに統一したり、「りんご」と「林檎」の表記もどちらかに統一したり、といった具合である。
・この正規化を行う文字列の指定は、「正規表現」を使って行う。
・具体的には、re.sub("取り除く文字列","変換後の文字列","取り除くテキスト")で行い、ここで指定する部分を正規表現で記述する。
・正規表現についてはここでは詳しく扱わない。(Qiitaにいろいろな記事があるので、そちらを参照)・コード(「私は商品Aを10個買います。」のうち、英数字を除外する)
まとめ
・自然言語処理では、コンピュータに自然言語を数値として処理させることで行うことができる。
・コーパスは、自然言語の文書をまとめたデータである。
・形態素解析は、自然言語処理の手法の一つで、文章を単語(形態素)で分割し、品詞を分類する手法である。
・形態素解析は「MeCab」や「Janome」で行うことができる。
・形態素解析は使う辞書に依存するので、辞書が判断できるよう、正規表現などを使って前処理することが重要である。今回は以上です。最後まで読んでいただき、ありがとうございました。






- 投稿日:2020-10-26T13:42:41+09:00
googleでpython例文を逆引きする際の検索雑音を除去
TL;DR
Chromeに"Personal Blocklist(not by Google)"プラグインを入れたら作業が捗ったこと。
はじめに
私の場合、高年齢かつpython初心者なので、pythonのパッケージや構文が覚えられない。
そこで、googleで逆引きを多用してなんとかごまかしている。「python pandas csvを読み込む」
「python datetimeフォーマット変換」
とか。そんなかんじで。python使い始めて3年くらいなるけど、未だにこんなことしてる。だいたいこんなかんじでよかったのだけれど、逆引き検索した結果、最初に出てくるページがあまりわかりやすくなく、内容も的を射ていないということに気が付いた。
考えてみると、検索した結果最初に出てくるページは、内容が最適という訳ではなく、SEO対策が最も優れているというだけであるため当然の結末というか、さすがに使いづらい。このままでは、作業効率も落ちるのでなんとかしたい。
Personal Blocklistプラグインで低品質サイトのブロック
Chromeの機能拡張Personal Blocklist(not by Google)を導入した。
かつては、googleご本尊による、"Personal Blocklist (by Google)"という機能拡張があったらしいが、今はなくなっている。
Personal Blocklist(not by Google)をインストールすると、検索結果毎に「xxxxxをブロックする」というリンクが付加されるようになる。このリンクをクリックすると、以降そのページがあったサイトは検索結果からブロックされる。
あくまで、私個人の例ではあるが、
note.nkmk.me
techacademy.jp
の2サイトをブロックしたところ、pythonの逆引きにおける意図しない「はずれのクリック」は減った。# こんなことしなくても、qiita.comのサイト内検索で十分という気もする。
まとめ
少なくともpythonの逆引き用途では、Personal Blocklist(not by Google)でトップサイトをブロックすることで、作業効率は上がり、ストレスが減った。
- 投稿日:2020-10-26T13:00:25+09:00
pythonのグローバル変数を操作するときの話
グローバル変数とローカル変数
pythonで実装中に何度かつまずいたので、自分用にメモ。
このコードが以下の結果を返すことは理解できる。x = 1 def func1(): print(x) def func2(): x = "hoge" print(x) func1() func2() >>> 1 >>> hogepythonでは変数を参照するとき、ローカルスコープ内部で宣言されていない場合グローバルスコープを参照しに行く。
また、ローカルスコープで変数を書き換える前に変数が宣言されていない場合エラーを返す。
def func3(): y += 1 y = 5 print(y) func3() >>> Traceback (most recent call last): >>> File "/test.py", line 8, in <test> >>> func3() >>> File "/test.py", line 4, in func3 >>> y += 1 >>> UnboundLocalError: local variable 'y' referenced before assignmentここまでは理解していたが、グローバル変数が絡むと途端に混乱してしまった。
つまり、グローバル変数として宣言されている変数を操作する場合は明示的に宣言せねばならず、普通にかくとエラーが返ってくる。x = 1 def func4(): x += 1 #この時点ではまだxを参照できない x = 5 #この段階でローカルスコープに変数xが追加される print(x) func4() >>> Traceback (most recent call last): >>> File "/test.py", line 8, in <test> >>> func4() >>> File "/test.py", line 4, in func4 >>> x += 1 >>> UnboundLocalError: local variable 'x' referenced before assignmentじゃあどうしたらいいの
解決方法は簡単で、グローバル変数を使う時はちゃんとグローバル変数であることを明示しましょうねって話。
x = 1 def func5(): global x #グローバル変数であることを明示 x += 1 print(x) def func6(): x = 10 #ローカル変数であることを明示 x += 1 print(x) func5() func6() >>> 2 >>> 11
- 投稿日:2020-10-26T11:49:33+09:00
【初学者向け】演習(kaggle:Merucari)
今回は研修の一環で、過去のkaggleコンペに取り組みましたので
簡単にまとめてみました。・Mercari Price Suggestion Challenge
メルカリの商品情報から、Ridge回帰を用いて価格を予想していきます。
1. モジュールの用意
import numpy as np import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import LabelBinarizer from scipy.sparse import csr_matrix, hstack from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_log_error
2. データの準備
データを読み込みます。
train = pd.read_csv('train.tsv', sep='\t') test = pd.read_csv('test.tsv', sep='\t')データ数を確認しておきます。
print(train.shape) print(test.shape) # (1482535, 8) # (693359, 7)train データと test データを結合します。
all_data = pd.concat([train, test]) all_data.head()
データの基本情報を確認します。
all_data.info(null_counts=True) ''' <class 'pandas.core.frame.DataFrame'> Int64Index: 2175894 entries, 0 to 693358 Data columns (total 9 columns): brand_name 1247687 non-null object category_name 2166509 non-null object item_condition_id 2175894 non-null int64 item_description 2175890 non-null object name 2175894 non-null object price 1482535 non-null float64 shipping 2175894 non-null int64 test_id 693359 non-null float64 train_id 1482535 non-null float64 dtypes: float64(3), int64(2), object(4) memory usage: 166.0+ MB '''各列データのユニーク数(重複をカウントしない)を調べます。
print(all_data.brand_name.nunique()) print(all_data.category_name.nunique()) print(all_data.name.nunique()) print(all_data.item_description.nunique()) # 5289 # 1310 # 1750617 # 1862037
3. 前処理
データを各列ごとに前処理していきます。
今回は文字データが多いので、BoWベクトル や TF-IDF を用いて、データを整えていきます。
その際、他のラベルエンコーディングする特徴量については、データ量が大きくなりすぎてしまうため
疎行列(成分に 0 が多い行列=スパース行列)に変換して、圧縮をしておきます。# name cv = CountVectorizer() name = cv.fit_transform(all_data.name)# item_description all_data.item_description.fillna(value='null', inplace=True) tv = TfidfVectorizer() item_description = tv.fit_transform(all_data.item_description)# category_name all_data.category_name.fillna(value='null', inplace=True) lb = LabelBinarizer(sparse_output=True) category_name = lb.fit_transform(all_data.category_name)# brand_name all_data.brand_name.fillna(value='null', inplace=True) brand_name = lb.fit_transform(all_data.brand_name)# item_condition_id, shipping onehot_cols = ['item_condition_id', 'shipping'] onehot_data = csr_matrix(pd.get_dummies(all_data[onehot_cols], sparse=True))最後に、これらのデータを結合し、疎行列データに変換しておきます。
X_sparse = hstack((name, item_description, category_name, brand_name, onehot_data)).tocsr()
4. モデルの作成
結合データ all_data について
train データには目的変数がありますが、test データにはないので
X のデータ量を y と同じサイズ(= tran データの行数)にしておきます。nrows = train.shape[0] X = X_sparse[:nrows]y(価格データ)にはデータにばらつきがあり、予測結果に影響を及ぼしてしまうため
標準化でも良いですが、今回は対数変換をしておきます。尚、y の値が 0 でも問題ないように、$\log(y+1)$ で変換を行います。
y = np.log1p(train.price) y[:5] ''' 0 2.397895 1 3.970292 2 2.397895 3 3.583519 4 3.806662 Name: price, dtype: float64 '''X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)ridge = Ridge() ridge.fit(X_train, y_train) ''' Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001) '''
5. 性能評価
y_pred = ridge.predict(X_test)今回は RMSE(コンペ用に少し改良)の指標で評価します。
モデリングする前に y を対数変換したので、モデリング後で元に戻す必要がありますが
評価式の中で、その処理を行っています。def rmse(y_test, y_pred): return np.sqrt(mean_squared_log_error(np.expm1(y_test), np.expm1(y_pred)))rmse(y_test, y_pred) # 0.4745184301527575以上より、メルカリの商品情報から価格予測をし、評価することができました。
今回は初学者の方に向けて、記事をまとめさせていただきましたが
少しでも参考になったようでしたら、LGBTをしていただけますと幸いです。ご精読いただきありがとうございました。

- 投稿日:2020-10-26T11:49:33+09:00
【初学者向け】演習(kaggle:merucari)
今回は研修の一環で、過去のkaggleコンペに取り組みましたので
簡単にまとめてみました。・Mercari Price Suggestion Challenge
メルカリの商品情報から、Ridge回帰を用いて価格を予想していきます。
1. モジュールの用意
import numpy as np import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import LabelBinarizer from scipy.sparse import csr_matrix, hstack from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_log_error
2. データの準備
データを読み込みます。
train = pd.read_csv('train.tsv', sep='\t') test = pd.read_csv('test.tsv', sep='\t')データ数を確認しておきます。
print(train.shape) print(test.shape) # (1482535, 8) # (693359, 7)train データと test データを結合します。
all_data = pd.concat([train, test]) all_data.head()
データの基本情報を確認します。
all_data.info(null_counts=True) ''' <class 'pandas.core.frame.DataFrame'> Int64Index: 2175894 entries, 0 to 693358 Data columns (total 9 columns): brand_name 1247687 non-null object category_name 2166509 non-null object item_condition_id 2175894 non-null int64 item_description 2175890 non-null object name 2175894 non-null object price 1482535 non-null float64 shipping 2175894 non-null int64 test_id 693359 non-null float64 train_id 1482535 non-null float64 dtypes: float64(3), int64(2), object(4) memory usage: 166.0+ MB '''各列データのユニーク数(重複をカウントしない)を調べます。
print(all_data.brand_name.nunique()) print(all_data.category_name.nunique()) print(all_data.name.nunique()) print(all_data.item_description.nunique()) # 5289 # 1310 # 1750617 # 1862037
3. 前処理
データを各列ごとに前処理していきます。
今回は文字データが多いので、BoWベクトル や TF-IDF を用いて、データを整えていきます。
その際、他のラベルエンコーディングする特徴量については、データ量が大きくなりすぎてしまうため
疎行列(成分に 0 が多い行列=スパース行列)に変換して、圧縮をしておきます。# name cv = CountVectorizer() name = cv.fit_transform(all_data.name)# item_description all_data.item_description.fillna(value='null', inplace=True) tv = TfidfVectorizer() item_description = tv.fit_transform(all_data.item_description)# category_name all_data.category_name.fillna(value='null', inplace=True) lb = LabelBinarizer(sparse_output=True) category_name = lb.fit_transform(all_data.category_name)# brand_name all_data.brand_name.fillna(value='null', inplace=True) brand_name = lb.fit_transform(all_data.brand_name)# item_condition_id, shipping onehot_cols = ['item_condition_id', 'shipping'] onehot_data = csr_matrix(pd.get_dummies(all_data[onehot_cols], sparse=True))最後に、これらのデータを結合し、疎行列データに変換しておきます。
X_sparse = hstack((name, item_description, category_name, brand_name, onehot_data)).tocsr()
4. モデルの作成
結合データ all_data について
train データには目的変数がありますが、test データにはないので
X のデータ量を y と同じサイズ(= tran データの行数)にしておきます。nrows = train.shape[0] X = X_sparse[:nrows]y(価格データ)にはデータにばらつきがあり、予測結果に影響を及ぼしてしまうため
標準化でも良いですが、今回は対数変換をしておきます。尚、y の値が 0 でも問題ないように、$\log(y+1)$ で変換を行います。
y = np.log1p(train.price) y[:5] ''' 0 2.397895 1 3.970292 2 2.397895 3 3.583519 4 3.806662 Name: price, dtype: float64 '''X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)ridge = Ridge() ridge.fit(X_train, y_train) ''' Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001) '''
5. 性能評価
y_pred = ridge.predict(X_test)今回は RMSE(コンペ用に少し改良)の指標で評価します。
モデリングする前に y を対数変換したので、モデリング後で元に戻す必要がありますが
評価式の中で、その処理を行っています。def rmse(y_test, y_pred): return np.sqrt(mean_squared_log_error(np.expm1(y_test), np.expm1(y_pred)))rmse(y_test, y_pred) # 0.4745184301527575以上より、メルカリの商品情報から価格予測をし、評価することができました。
今回は初学者の方に向けて、記事をまとめさせていただきましたが
少しでも参考になったようでしたら、LGBTをしていただけますと幸いです。ご精読いただきありがとうございました。
- 投稿日:2020-10-26T11:37:45+09:00
PySimpleGUI + Matplotlib でパラメータを変更しながらグラフを表示する
はじめに
関数からグラフを書く場合、パラメータを変更しながらグラフの様子を見たいことがあります。
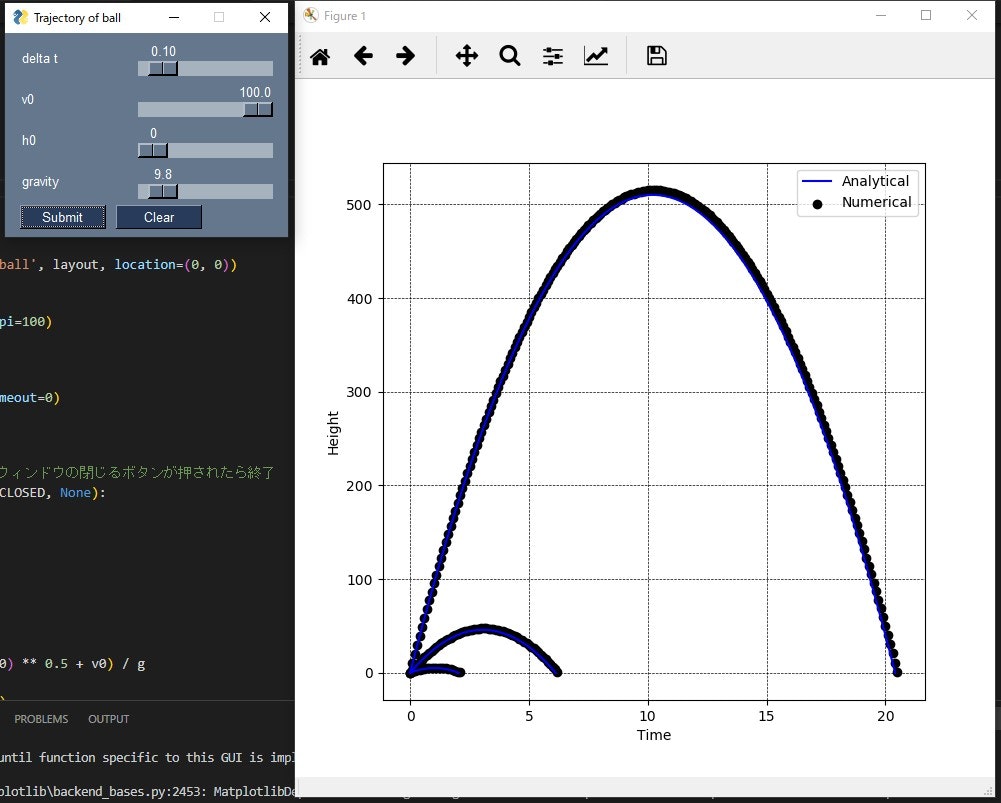
例として、下記文献にある、ボールを垂直に投げ上げた時のボール座標の解析解と数値解の比較について、パラメータを変更しながら確認できるようにしました。ここでは、v0 = 10, 30, 100でのグラフを描写しています。
GUI の表示
時間幅:Δt, 初速度:v0, 初期高さ:h0, 重力加速度:gをスライダで変更できるようにします。
スライダで変数を変更後、Submitボタンでグラフを描写、Clearボタンでグラフを削除するようにします。import numpy as np from matplotlib import pyplot as plt import PySimpleGUI as sg layout = [ [ sg.Text( 'delta t', size=(13, 1) ), sg.Slider( (0.01, 1), 0.1, 0.01, orientation='h', size=(15, 15), key='-DELTA T-', enable_events=True ) ], [ sg.Text( 'v0', size=(13, 1) ), sg.Slider( (0.01, 100), 10, 0.1, orientation='h', size=(15, 15), key='-V0-', enable_events=True ) ], [ sg.Text( 'h0', size=(13, 1) ), sg.Slider( (0, 100), 0, 1, orientation='h', size=(15, 15), key='-H0-', enable_events=True ) ], [ sg.Text( 'gravity', size=(13, 1) ), sg.Slider( (0.1, 100), 9.8, 0.1, orientation='h', size=(15, 15), key='-G-', enable_events=True ) ], [ sg.Button( 'Submit', size=(10, 1) ), sg.Button( 'Clear', size=(10, 1) ) ] ] window = sg.Window('Trajectory of ball', layout, location=(0, 0))グラフの表示
matplotlibでグラフを表示します。plt.figureとfig.add_subplot()でグラフ領域を作成したのち、メインループを回します。
GUIのイベントを監視し、submitボタンを押すと、スライダから値を読み取り、グラフを表示するようにしています。また、plt.pause()を使用することで、更新可能なグラフを表示させています。fig = plt.figure(figsize=(7, 7), dpi=100) ax = fig.add_subplot(111) while True: event, values = window.read(timeout=0) if event == "__TIMEOUT__": continue # Exitボタンが押されたら、またはウィンドウの閉じるボタンが押されたら終了 elif event in ('Exit', sg.WIN_CLOSED, None): break elif event == 'Submit': dt = values['-DELTA T-'] v0 = values['-V0-'] g = values['-G-'] h0 = values['-H0-'] t1 = ((v0 ** 2 + 2 * g * h0) ** 0.5 + v0) / g t = np.linspace(0, t1, 100) h = -0.5 * g * t ** 2 + v0 * t + h0 la, = plt.plot(t, h, color='blue') # ########################################################## t = 0 h = h0 # h = 0まで描写に変更 while h >= 0: ln = plt.scatter(t, h, marker='o', c='black') h += (-g * t + v0) * dt t += dt # グラフの描写 ax.set_xlabel('Time') ax.set_ylabel('Height') ax.grid(color='black', linestyle='dashed', linewidth=0.5) ax.legend(handles=[la, ln], labels=['Analytical', 'Numerical']) plt.pause(0.1) # ########################################################## elif event == 'Clear': plt.clf() ax = fig.add_subplot(111) plt.pause(0.1)
- 投稿日:2020-10-26T11:24:39+09:00
毎朝自動で体温を入力・送信してくれるプログラムを作る【備忘録】
はじめに
初投稿です。
今回は、学校で毎日GoogleFormsで体温入力等をしないといけなくなって、めんどくs....
いや、入力する時間がないので、毎日6:00〜8:30の間にランダムで送信してくれて、しかも体温も36.4~36.6の間のどれかを送信してくれるプログラムを作ってみました。実行環境
- Python3系
- discord.py
- requests
- テスト用のForms
本題
作成にあたって、こちらの記事を参考にしながら作りました。
あと、GoogleFormの質問の識別番号の取得は今回は割愛します。jsonファイルの作成
form_urlには、送信をしたFormのURLを入れ、entryの中には、取得した質問の識別番号を入れていきます。
質問の数に合わせて、ans_7みたいに増やしていってください。
outputの中には、質問に対する答えを書いていきます。ans_1とans_4は毎日値が変わるので適当に値を入れてください。
ここでは、適当にNoneと入れています。cfg.json{ "form_url": "https://docs.google.com/forms/d/e/1FAIpQLSc93lIQ3Aob93cwjx6HSRbuC8V7NT59UfUPhlw6AlkGtZ6CXQ/", "entry": { "ans_1": 964244932, "ans_2": 888214820, "ans_3": 23055831, "ans_4": 10832147, "ans_5": 1720496078, "ans_6": 2017707777 }, "output":{ "ans_1": "None", "ans_2": "2A", "ans_3": "8", "ans_4": "None", "ans_5": "元気です", "ans_6": "いない" } }jsonファイルの作成はこんな感じです。
メインプログラムの作成
今回は、Discordと連携して、ちゃんと送信されたかなどのログを特定のDiscordチャンネルに送信していきます。
完成したプログラムはこんな感じになっています。bot.py# -*- coding: utf-8 -*- import discord from discord import Embed from discord.ext import tasks from datetime import datetime import os import requests import random import json TOKEN = os.environ["TOKEN"] client = discord.Client(intents=discord.Intents.all()) # 次回送信予定時刻を06:00-8:30までの間でランダムに設定 def setting_time_set(): setting_time_h = random.randint(6, 8) if setting_time_h == 8: setting_time_m = random.randint(0, 30) else: setting_time_m = random.randint(0, 59) setting_time = f"{setting_time_h:02}:{setting_time_m:02}" return setting_time def set_tem(): choice_list = ["36.4", "36.5", "36.6"] choice_ans = random.choice(choice_list) # 36.4-36.6までの間でランダムに選択 return choice_ans time_set = setting_time_set() # 起動時に初回の次回送信時刻を設定 tem_set = set_tem() # Embedの関数 async def template_embed(message, title, name_1, name_2, value_1, color, description=None): ch = client.get_channel(message) embed_time = datetime.now().strftime("%Y年%m月%d日-%H:%M") embed = Embed(title=title, description=description, color=color) embed.add_field(name=name_1, value=f"{value_1}", inline=True) embed.add_field(name=name_2, value=f"{tem_set}", inline=True) embed.set_footer(text=f"{embed_time}") await ch.send("<@ユーザーID>") await ch.send(embed=embed) @client.event async def on_ready(): await template_embed(message=768274673984208926, title="起動ログ", name_1="次回の送信予定時刻", value_1=time_set, name_2="送信予定の体温", color=discord.Color.orange()) @client.event async def on_message(message): if message.content == "/reset": await reset(message) if message.content == "/now": await now(message) async def reset(message): global time_set global tem_set time_set = setting_time_set() tem_set = set_tem() await template_embed(message=768274673984208926, title="リセットされました", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.purple()) await template_embed(message=message.channel.id, title="リセットされました", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.purple()) async def now(message): await template_embed(message=message.channel.id, title="現在の状況", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.greyple()) @tasks.loop(seconds=60) async def loop(): global time_set global tem_set now_t = datetime.now().strftime('%H:%M') print(f"現在の時刻:{now_t}/送信予定時刻:{time_set}/送信予定体温:{tem_set}") if now_t == time_set: # 送信予定時刻になった? dt_now = datetime.now().strftime("%Y-%m-%d") # 現在時刻を2020-01-01の形で取得、dt_nowに格納 file_name = "cfg.json" with open(file_name, "r", encoding="utf-8")as f: cfg = json.load(f) cfg["output"]["ans_1"] = f"{dt_now}" cfg["output"]["ans_4"] = f"{tem_set}" params = {"entry.{}".format(cfg["entry"][k]): cfg["output"][k] for k in cfg["entry"].keys()} res = requests.get(cfg["form_url"] + "formResponse", params=params) if res.status_code == 200: await template_embed(message=768274673984208926, title="ログ情報", description=f"[URL]({res.url})", name_1="完了状態", name_2="送信された体温", value_1="成功しました", color=discord.Color.green()) else: res.raise_for_status() await template_embed(message=768274673984208926, title="ログ情報", name_1="完了状態", name_2="送信予定だった体温", value_1="エラーが発生しました。", color=discord.Color.red()) else: if now_t == "21:00": time_set = setting_time_set() tem_set = set_tem() await template_embed(message=768274673984208926, title="送信時刻更新のお知らせ", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.blue()) loop.start() client.run(TOKEN)順を追って説明していきます。
まずは、この部分ですが、送信時間を6:00~8:30の間でランダムに発行してsetting_timeにreturnし、その後体温をランダムに選んでchoice_ansにreturnしています。
その下の処理は、初回起動時に送信時刻と体温を設定しています。更にその下の処理は、Embedの生成処理を行っています。# 次回送信予定時刻を06:00-8:30までの間でランダムに設定 def setting_time_set(): setting_time_h = random.randint(6, 8) if setting_time_h == 8: setting_time_m = random.randint(0, 30) else: setting_time_m = random.randint(0, 59) setting_time = f"{setting_time_h:02}:{setting_time_m:02}" return setting_time def set_tem(): choice_list = ["36.4", "36.5", "36.6"] choice_ans = random.choice(choice_list) # 36.4-36.6までの間でランダムに選択 return choice_ans time_set = setting_time_set() # 起動時に初回の次回送信時刻を設定 tem_set = set_tem() # Embedの関数 async def template_embed(message, title, name_1, name_2, value_1, color, description=None): ch = client.get_channel(message) embed_time = datetime.now().strftime("%Y年%m月%d日-%H:%M") embed = Embed(title=title, description=description, color=color) embed.add_field(name=name_1, value=f"{value_1}", inline=True) embed.add_field(name=name_2, value=f"{tem_set}", inline=True) embed.set_footer(text=f"{embed_time}") await ch.send("<@ユーザーID>") await ch.send(embed=embed)次に
メイン処理の方を解説していきます。
@client.event async def on_ready(): await template_embed(message=768274673984208926, title="起動ログ", name_1="次回の送信予定時刻", value_1=time_set, name_2="送信予定の体温", color=discord.Color.orange())起動時に、特定のチャンネルに起動ログを送信していきます。
@client.event async def on_message(message): if message.content == "/reset": await reset(message) if message.content == "/now": await now(message) async def reset(message): global time_set global tem_set time_set = setting_time_set() tem_set = set_tem() await template_embed(message=768274673984208926, title="リセットされました", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.purple()) await template_embed(message=message.channel.id, title="リセットされました", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.purple()) async def now(message): await template_embed(message=message.channel.id, title="現在の状況", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.greyple())ここでは、送信時間と体温をリセットできるリセットコマンドと、現在の状態を確認できるコマンドの処理です。
@tasks.loop(seconds=60) async def loop(): global time_set global tem_set now_t = datetime.now().strftime('%H:%M') # 現在時刻を取得 print(f"現在の時刻:{now_t}/送信予定時刻:{time_set}/送信予定体温:{tem_set}") if now_t == time_set: # 送信予定時刻になった? dt_now = datetime.now().strftime("%Y-%m-%d") # 現在時刻を2020-01-01の形で取得、dt_nowに格納 file_name = "cfg.json" with open(file_name, "r", encoding="utf-8")as f: cfg = json.load(f) cfg["output"]["ans_1"] = f"{dt_now}" # 今日の年、月、日をans_1に上書き cfg["output"]["ans_4"] = f"{tem_set}" # 体温をans_4に上書き params = {"entry.{}".format(cfg["entry"][k]): cfg["output"][k] for k in cfg["entry"].keys()} res = requests.get(cfg["form_url"] + "formResponse", params=params) if res.status_code == 200: # 正常に送信された場合 await template_embed(message=768274673984208926, title="ログ情報", description=f"[URL]({res.url})", name_1="完了状態", name_2="送信された体温", value_1="成功しました", color=discord.Color.green()) else: # 送信できなかった場合 res.raise_for_status() await template_embed(message=768274673984208926, title="ログ情報", name_1="完了状態", name_2="送信予定だった体温", value_1="エラーが発生しました。", color=discord.Color.red()) else: if now_t == "21:00": time_set = setting_time_set() tem_set = set_tem() await template_embed(message=768274673984208926, title="送信時刻更新のお知らせ", name_1="次回の送信予定時刻", name_2="送信予定の体温", value_1=time_set, color=discord.Color.blue())ここでは、
tasks.loop()を使用して60秒間隔に現在時刻と送信予定時刻の確認を行い、一致したら送信処理を行っています。
そして、一致しなかった場合は、現在時刻とリセット時刻が一致しているかを確認し、リセット時刻であればリセット処理をしています。最後に
初投稿というのもあり、かなりグダグダですが、ご了承ください。
完成したコードは、Githubに上げているので、使用する際はご自由に....
最後の方、かなり解説を省略したんですが、参考になれば幸いです。※完全にネタ投稿です。実際に実行させるかさせないかは自己責任でお願いします。それによって先生に怒られたとしても責任は負いません。
参考
- 投稿日:2020-10-26T10:00:27+09:00
「ゼロから作るDeep Learning」自習メモ(その12) ディープラーニング
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その11 ←
8.1.1 よりディープなネットワークへ
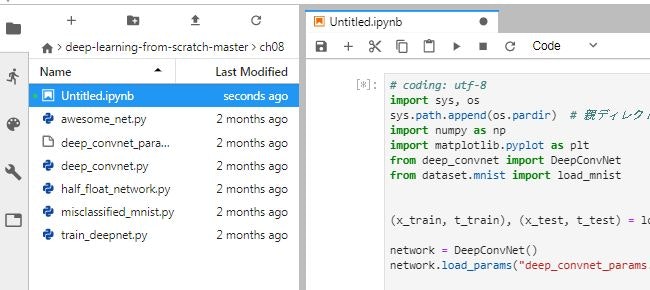
P243で、ネットワークの定義はフォルダch08内のdeep_convnet.py、訓練用のコードは、train_deepnet.py 、学習済みの重みパラメータはdeep_conv_net_params.pkl、と説明してありますが、重みパラメータを読み込んでテストデータを処理するプログラムは misclassified_mnist.py です。
このプログラムはフォルダch08にJupyterNoteを作って実行できるようになっています。
baseディレクトリ上で実行しようとすると、deep_convert.pyとdeep_conv_net_params.pklの置き場所や呼び出しのあたりをいろいろ変更しないといけなくなります。misclassified_mnist.pyの実行結果
DeepConvNetクラスの内容は、これまで説明があったものばかりで、改めて内容を確認する必要はないかと思います。
で、
今回はこのクラスを使って、Kaggleの犬猫データセットを処理してみようかと。
Kaggleの猫と犬のデータセット
データの内容
下記サイトからダウンロード
https://www.microsoft.com/en-us/download/details.aspx?id=54765フォルダ PetImages の下にあるフォルダ Cat と Dog に、画像が入っています。
0.jpg から 12499.jpg とファイル名が連番になっています。
犬、猫それぞれ 12500枚 ずつの画像があるということになります。
画像はカラーで、大きさはそれぞれ違っています。
この画像の1枚0.jpgをNumPy配列に格納して内容を見てみると(375, 500, 3)
(高さ, 幅, 色)の3次元の配列として格納されています。
色が 0は赤、1が緑、2が青 です。
メモ6の2ではグレースケールに変換しましたが、今回は3色、3チャンネルのデータに変換します。画像の大きさをそろえて、処理できる形式に変換する
画像データを チャンネル3、高さ80、幅80の配列にします。
import os import glob from PIL import Image import numpy as np dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset' catfiles = glob.glob(dataset_dir + '/Cat/*.jpg') dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg') fsize = 80 for f in catfiles: try: lblA = 0 pad_u, pad_d, pad_l, pad_r = 0,0,0,0 img = Image.open(f) w,h=img.size if w>h: imgr = img.resize((fsize, int(h*fsize/w))) wr,hr = imgr.size pad_u = int((fsize - hr)/2) pad_d = fsize - hr - pad_u else: imgr = img.resize((int(w*fsize/h),fsize)) wr,hr = imgr.size pad_l = int((fsize - wr)/2) pad_r = fsize - wr - pad_l imgtr = np.array(imgr).transpose(2,0,1) imgA = np.pad(imgtr, [(0, 0),(pad_u,pad_d),(pad_l,pad_r)], 'constant') imgA = imgA.tolist() except Exception as e: print(f+" : " + str(e))PILで読み込んだ画像ファイルの情報
img = Image.open(f) print(img.format, img.size, img.mode)JPEG (500, 375) RGB
ファイルのサイズが(幅、高さ)となっています。
これをnumpy配列に変換すると、こうなります。imgA = np.array(img) print(imgA.size, imgA.shape)562500 (375, 500, 3)
(高さ、幅、色)となっています。
これをふまえて、画像のサイズを80×80にresizeし、次元の軸を入れ替えて、チャンネル3、高さ80、幅80の配列にします。ところが、上のプログラムでフォルダ内のファイルを連続処理していると、こんなエラーが発生します。
C:\Users\021133/dataset/Cat\10125.jpg : axes don't match array
C:\Users\021133/dataset/Cat\10501.jpg : axes don't match array
C:\Users\021133/dataset/Cat\1074.jpg : Python int too large to convert to C ssize_t
C:\Users\021133/dataset/Cat\666.jpg : cannot identify image fileどうも、transpose(2,0,1)あたりで、次元の軸があってないようです。
1074.jpgはメモ6の2で処理した時にもエラーになっています。ファイル読み込み時にエラーになっているようです。
666.jpgは、0バイトで空ファイルです。10125.jpgを調べて見ると
img=Image.open(dataset_dir + '/10125.jpg') print(img.format, img.size, img.mode) imgA = np.array(img) print(imgA.size, imgA.shape,imgA.ndim)GIF (259, 346) P
89614 (346, 259) 2ビューアで見た限りではカラーの画像で問題なく表示されています。問題は、P パレットモードとなっているからのようです。そこで読み込み方法を修正してみました。
img=Image.open(dataset_dir + '/10501.jpg').convert('RGB') print(img.format, img.size, img.mode) imgA = np.array(img) print(imgA.size, imgA.shape,imgA.ndim)None (400, 299) RGB
358800 (299, 400, 3) 3どうやらこれでいけそうです。
問題のファイル CAt 1074.jpg 5127.jpg 666.jpg Dog 11702.jpg 829.jpg 8366.jpg を別のフォルダに移動させ、メモリーエラーを回避するためにテストデータを100件、訓練データを4000件に絞ることにしました。
import os import glob import numpy as np from PIL import Image dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset' catfiles = glob.glob(dataset_dir + '/Cat/*.jpg') dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg') fsize = 80 tsl = [] tsi = [] trl = [] tri = [] tst_count = 0 trn_count = 0 count = 0 for f in catfiles: try: lblA = 0 img = Image.open(f).convert('RGB') w,h=img.size pad_u, pad_d, pad_l, pad_r = 0,0,0,0 if w>h: imgr = img.resize((fsize, int(h*fsize/w))) wr,hr = imgr.size pad_u = int((fsize - hr)/2) pad_d = fsize - hr - pad_u else: imgr = img.resize((int(w*fsize/h),fsize)) wr,hr = imgr.size pad_l = int((fsize - wr)/2) pad_r = fsize - wr - pad_l imgtr = np.array(imgr).transpose(2,0,1) imgA = np.pad(imgtr, [(0, 0),(pad_u,pad_d),(pad_l,pad_r)], 'constant') imgA = imgA.tolist() except Exception as e: print(f+" : " + str(e)) if count < 50: tsl.append(lblA) tsi.append(imgA) tst_count += 1 elif count < 2050: trl.append(lblA) tri.append(imgA) trn_count += 1 else: break count += 1 count = 0 for f in dogfiles: try: lblA = 1 img = Image.open(f).convert('RGB') w,h=img.size pad_u, pad_d, pad_l, pad_r = 0,0,0,0 if w>h: imgr = img.resize((fsize, int(h*fsize/w))) wr,hr = imgr.size pad_u = int((fsize - hr)/2) pad_d = fsize - hr - pad_u else: imgr = img.resize((int(w*fsize/h),fsize)) wr,hr = imgr.size pad_l = int((fsize - wr)/2) pad_r = fsize - wr - pad_l imgtr = np.array(imgr).transpose(2,0,1) imgA = np.pad(imgtr, [(0, 0),(pad_u,pad_d),(pad_l,pad_r)], 'constant') imgA = imgA.tolist() except Exception as e: print(f+" : " + str(e)) if count < 50: tsl.append(lblA) tsi.append(imgA) tst_count += 1 elif count < 2050: trl.append(lblA) tri.append(imgA) trn_count += 1 else: break count += 1 dataset = {} dataset['test_label'] = np.array(tsl, dtype=np.uint8) dataset['test_img'] = np.array(tsi, dtype=np.uint8) dataset['train_label'] = np.array(trl, dtype=np.uint8) dataset['train_img'] = np.array(tri, dtype=np.uint8) import pickle save_file = dataset_dir + '/catdog.pkl' with open(save_file, 'wb') as f: pickle.dump(dataset, f, -1)dataset['test_img'].shape(100, 3, 80, 80)
dataset['train_img'].shape(4000, 3, 80, 80)
DeepConvNetクラス
DeepConvNetクラスのコードは、フォルダch08内のdeep_convnet.pyにありますが、これには(1,28,28)の入力に合わせた部分があるようです。
def __init__(self, input_dim=(1, 28, 28), conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1}, conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, hidden_size=50, output_size=10):input_dim=(1, 28, 28)は当然ですが、これはパラメータとして別の値を与えればいいので、問題ではありません。問題となるのは重みW7のサイズです。
# 重みの初期化=========== # 各層のニューロンひとつあたりが、前層のニューロンといくつのつながりがあるか(TODO:自動で計算する) pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size]) weight_init_scales = np.sqrt(2.0 / pre_node_nums) # ReLUを使う場合に推奨される初期値ここは、各層で使うフィルタの チャネル×高×横 を指定すればいいのですが、入力データが(3,80,80)になることで、こうなります。
pre_node_nums = np.array([3*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*10*10, hidden_size])重み W7 のサイズもこうなってましたが、
self.params['W7'] = weight_init_scales[6] * np.random.randn(64*4*4, hidden_size)こう変えないと、プログラムがうまく動きません。
self.params['W7'] = weight_init_scales[6] * np.random.randn(64*10*10, hidden_size)どうして、10×10なのかと言うと、これは入力データの 高×横 が元になっているから。
今回の入力データは 80×80 ですが、これが途中でpooling層を1回通ると半分のサイズになります。
このクラス定義では3回通るので 80 → 40 → 20 → 10 になります。
元のプログラムの 4×4 というのも 28 → 14 → 7 → 4 ということです。学習処理
import sys, os import pickle import numpy as np from common.functions import * from common.optimizer import * from deep_convnet import DeepConvNet def to_one_hot(label): t = np.zeros((label.size, 2)) for i in range(label.size): t[i][label[i]] = 1 return t dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset' mnist_file = dataset_dir + '/catdog.pkl' with open(mnist_file, 'rb') as f: dataset = pickle.load(f) x_train = dataset['train_img'] t_train = to_one_hot(dataset['train_label']) # ハイパーパラメータ iters_num = 30 train_size = x_train.shape[0] batch_size = 12 learning_rate = 0.1 train_loss_list = [] network = DeepConvNet( input_dim=(3, 80, 80), conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1}, conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, hidden_size=50, output_size=2) optimizer = Adam(lr=learning_rate) for i in range(iters_num): # ミニバッチの取得 batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配の計算 grads = network.gradient(x_batch, t_batch) optimizer.update(network.params, grads) #学習経過の記録 loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) # networkオブジェクトを、pickleで保存する。保存したオブジェクトは、推論処理で使う import pickle save_file = dataset_dir + '/catdogA.pkl' with open(save_file, 'wb') as f: pickle.dump(network, f, -1)これで一応、プログラムは動きましたが、実際には学習できていません。推論処理してみても、正解率が50%になりません。
やはり、1バッチで訓練するデータ数がたったの12件というのがいけないのでしょうか?
でも、これ以上処理するとメモリーエラーになってしまいます。network.layers[common.layers.Convolution at 0x3610030,
common.layers.Relu at 0xbad8170,
common.layers.Convolution at 0xbabf990,
common.layers.Relu at 0xbabf870,
common.layers.Pooling at 0xbabf950,
common.layers.Convolution at 0xbabf430,
common.layers.Relu at 0xbabf0f0,
common.layers.Convolution at 0xbabf230,
common.layers.Relu at 0xbabf570,
common.layers.Pooling at 0xbabf130,
common.layers.Convolution at 0xbabf4d0,
common.layers.Relu at 0xbabf1f0,
common.layers.Convolution at 0xbabf210,
common.layers.Relu at 0xbabf190,
common.layers.Pooling at 0xbabf9f0,
common.layers.Affine at 0xbabf970,
common.layers.Relu at 0xbabf270,
common.layers.Dropout at 0xbabf9b0,
common.layers.Affine at 0xbabf470,
common.layers.Dropout at 0xbabf370]print(x_batch.shape) print(network.params['W1'].shape) print(network.params['W2'].shape) print(network.params['W3'].shape) print(network.params['W4'].shape) print(network.params['W5'].shape) print(network.params['W6'].shape) print(network.params['W7'].shape) print(network.params['W8'].shape)(12, 3, 80, 80)
(16, 3, 3, 3)
(16, 16, 3, 3)
(32, 16, 3, 3)
(32, 32, 3, 3)
(64, 32, 3, 3)
(64, 64, 3, 3)
(6400, 50)
(50, 2)推論処理
# テストデータで評価 import numpy as np import sys, os import pickle from deep_convnet import DeepConvNet dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset' mnist_file = dataset_dir + '/catdog.pkl' with open(mnist_file, 'rb') as f: dataset = pickle.load(f) x_test = dataset['test_img'] t_test = dataset['test_label'] test_size = 10 test_mask = np.random.choice(100, test_size) x = x_test[test_mask] t = t_test[test_mask] #network = DeepConvNet() weight_file = dataset_dir + '/catdogA.pkl' with open(weight_file, 'rb') as f: network = pickle.load(f) y = network.predict(x) accuracy_cnt = 0 for i in range(len(y)): p= np.argmax(y[i]) if p == t[i]: accuracy_cnt += 1 print("Accuracy:" + str(float(accuracy_cnt) / len(x)))Accuracy:0.5
import matplotlib.pyplot as plt class_names = ['cat', 'dog'] def showImg(x): example = x.transpose(1,2,0) plt.figure() plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(example, cmap=plt.cm.binary) plt.show() return for i in range(test_size): c = t[i] print("正解 " + str(c) + " " + class_names[c]) p = np.argmax(y[i]) v = y[p] print("判定 " + str(p) + " " + class_names[p] + " " + str(v) ) showImg(x[i])
判定結果の確率が非常に小さい値になっています。やはり、正常に処理されていないのでしょう。
とは言え、すぐにメモリエラーになる環境ではテストを繰り返すのも厳しいし・・・重みの内容を見てみた
import numpy as np import matplotlib.pyplot as plt dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset' def filter_show(filters, nx=8, margin=3, scale=10): """ c.f. https://gist.github.com/aidiary/07d530d5e08011832b12#file-draw_weight-py """ FN, C, FH, FW = filters.shape ny = int(np.ceil(FN / nx)) fig = plt.figure() fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05) for i in range(FN): ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[]) ax.imshow(filters[i][0], cmap=plt.cm.binary, interpolation='nearest') plt.show() #network = DeepConvNet() weight_file = dataset_dir + '/catdogA.pkl' with open(weight_file, 'rb') as f: network = pickle.load(f) filter_show(network.params['W1'])W1
W2
パターンがあるようには見えません。
その11 ←
参考にしたサイト




- 投稿日:2020-10-26T09:58:21+09:00
「ゼロから作るDeep Learning」自習メモ(その10の2)重みの初期値
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その10 ← →その11
MNIST データセットによる更新手法の比較 で使っているソースコードch06/optimizer_compare_mnist.py を少し変えて、初期値の設定方法を何通りかためしてみた。
# coding: utf-8 import os import sys sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import matplotlib.pyplot as plt from dataset.mnist import load_mnist from common.util import smooth_curve from common.multi_layer_net import MultiLayerNet from common.optimizer import * # 0:MNISTデータの読み込み========== (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True) train_size = x_train.shape[0] batch_size = 128 max_iterations = 2000 # 1:実験の設定========== optimizers = {} optimizers['SGD'] = SGD() optimizers['Momentum'] = Momentum() optimizers['AdaGrad'] = AdaGrad() optimizers['Adam'] = Adam() #optimizers['RMSprop'] = RMSprop() networks = {} train_loss = {} for key in optimizers.keys(): networks[key] = MultiLayerNet( input_size=784, hidden_size_list=[100, 100, 100, 100], output_size=10, activation='relu',weight_init_std='relu', weight_decay_lambda=0) train_loss[key] = [] # 2:訓練の開始========== for i in range(max_iterations): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] for key in optimizers.keys(): grads = networks[key].gradient(x_batch, t_batch) optimizers[key].update(networks[key].params, grads) loss = networks[key].loss(x_batch, t_batch) train_loss[key].append(loss) #テストデータで評価 x = x_test t = t_test for key in optimizers.keys(): network = networks[key] y = network.predict(x) accuracy_cnt = 0 for i in range(len(x)): p= np.argmax(y[i]) if p == t[i]: accuracy_cnt += 1 print(key + " Accuracy:" + str(float(accuracy_cnt) / len(x)))活性化関数に'relu'を指定、「Heの初期値」を設定
activation='relu', weight_init_std='he',テストデータを処理した結果
SGD Accuracy:0.9325
Momentum Accuracy:0.966
AdaGrad Accuracy:0.9707
Adam Accuracy:0.972活性化関数に'sigmoid'を指定、「Xavierの初期値」を設定
activation='sigmoid', weight_init_std='xavier',テストデータを処理した結果
SGD Accuracy:0.1135
Momentum Accuracy:0.1028
AdaGrad Accuracy:0.9326
Adam Accuracy:0.9558SGDとMomentumが、ひどく認識率が落ちたので、バッチの回数を10000にしてみた。
SGD Accuracy:0.1135
Momentum Accuracy:0.9262
AdaGrad Accuracy:0.9617
Adam Accuracy:0.9673
Momentumの認識率はそこそこまで上がったが、SGDはまったくダメ。
活性化関数に'relu'を指定、標準偏差が0.01 の正規分布を初期値に設定
activation='relu', weight_init_std=0.01,テストデータを処理した結果
SGD Accuracy:0.1135
Momentum Accuracy:0.1135
AdaGrad Accuracy:0.9631
Adam Accuracy:0.9713SGDとMomentumは、まったく学習できていないようだ。

- 投稿日:2020-10-26T07:31:08+09:00
Windows + Docker 環境で venv を使う[Python]
エラー
通常の方法でコンテナにマウントして使おうとするとエラーが吐かれる。
$ python -m venv .venv Error: [Errno 71] Protocol error: 'lib' -> '/app/.venv/lib64'原因
venv の使用時にシンボリックリンクを発行していて、ローカルのマウント時にこれを共有してしまっていることが原因
解決方法
DockerでVolumeをマウントするとき一部を除外する方法 を使って、シンボリックリンクが張られる箇所とのマウントから除外する。
下記のコマンドでは、{作業ディレクトリ}/.venv/ 配下にシンボリックリンクが貼られることになるので、ここを除外する。
python -m venv .venvdocker-compose.yml の一部
version: "3.7" services: app: ... volumes: - {作業ディレクトリ}/.venv/docker-compose.yml
全体のサンプル
version: "3.7" services: app: build: ./app/ working_dir: /app volumes: - ./app:/app:cached - /app/__pycache__ - /app/.venv/ - /app/.tox/ # tox 用 environment: - FLASK_ENV=development ports: - "5000:5000"参考
- 投稿日:2020-10-26T06:47:14+09:00
応用情報技術者試験の受験体験記
はじめに
先週、応用情報技術者試験を受験してきました。
今年は新型コロナウイルスの影響で4月試験が中止となってしまったため、
10月試験の一発勝負になってしまいました。備忘録としてその体験記を記しておきます。
学習方法なども追々整理して行けたらと思います。
応用情報技術者試験とは
情報処理技術者試験の試験区分です。
レベル3に該当して、ソフトウェア、システム開発に関する幅広い知識が問われます。
ITエンジニアとしてのレベルアップを図るには、応用情報技術者試験がお勧めです。技術から管理、経営まで、幅広い知識と応用力が身に付き、システム開発、IT基盤構築などの局面で、高いパフォーマンスを発揮することができます。
公式より引用
なぜ受験しようと思ったか
ずっと応用情報はレベルが高く、未経験の自分には敷居が高いかと思っていたのですが、
ネットで調べるうちに未経験でも合格されている方や未経験者向けの勉強法なども公開されていたので
愚直に信じて挑戦することにしました。合格したかどうかはともかく基本情報が開催を延期されたことを踏まえると
応用情報を受験しておいて良かったかもしれません。各問題について
午前問題、午後問題ともに例年並みなっだように感じました。
また、午後問題では新型コロナウイルスに触れるなど、世情が反映された仕上がりになっていたように思います。午前問題
午前問題は基本的に例年通りでした。
私が参考にした勉強法で「午前は過去問演習が全てだ」みたいなことが書かれたので、
午前対策ではひたすら過去問演習を行っていました。そのおかげかそれほど難しいと感じなかったです。
解答速報による自己採点でも75%overだったのでおそらく大丈夫でしょう。
変わった問題としては
「インデントの深さでコードブロックを指定する仕様を持つ言語はどれか」
みたいな出題がされてました。私はPythonistaなので解答できましたが、各言語仕様について問われてもやや戸惑う気がするのですがどうなんでしょう...
あと「レベニューシェア」「プライスライニング」「パテントプール」など今試験で初出しとなる単語もちらほらあったように思いました。
(私が過去問を追いきれてないだけかもしれません...)午後問題
午後問題では補足の紙が配られて、大問9, 10に「ただし、新型コロナウイルス感染症の影響は考慮しないものとする」という文言を追加する訂正が記載されていました。
それ以外は特に特殊なところはなかった気がします。
必須選択のセキュリティでは何度か過去問でも出題歴のあるメールセキュリティについて問われました。
また、大問2では「AI」という単語が出ていて近年の注目を反映したものになっていました。
問8システム開発でアジャイル開発が題材にされていたのは、
アジャイル開発、スクラム開発が市民権を取りつつある状況を表している気がしました。会場の様子について
当然ですが多くの方がマスクをしていました。
マスクをしたまま試験に臨まないと行けないのは足枷な気もしますが、応用情報は相対評価なのであんまり関係ないかもしれませんね。
- 投稿日:2020-10-26T06:02:49+09:00
Julia早引きノート[10]関数 (2)応用編
関数 (2)応用編(書き方例)
note10◆型指定 # 引数はInt型(整数)を指定、返り値はFloat64(実数)を指定 function comsumption_tax(price::Int)::Float64 tax_rate = 1.08 return tax_rate * price end ◆型指定(一行表示) comsumption_tax(price::Int)::Float64 = tax_rate * price ◆可変長引数 ■例文1 function summation(v...) total = 0 for i in v total += v end return total end ■例文2 function summation2(v::Int...) total = 0 for i = 1:length(v) total += v[i] end return total end ◆オプショナル引数 # 引数の初期値を予め設定(下例:v2の初期値を100に設定) function foptional(v1, v2=100) total = v1 + v2 return total end ◆キーワード引数 # 区切り文字に;(セミコロン)を使用(詳細は下部の解説を参照) function car(length, width; color="white", price=10000) println("special car:") println(" lenth x width = ", length, " x ", width) println(" color = ", color) println(" price = ", price) end ◆匿名関数 ■例文1 # 引数は1つのみ指定可 price = x -> x * 1.08 ■例文2 # 複数行の場合は、begin~endで囲う nebiki = x -> begin price = x * 0.9 return price * 1.08 end解説
(1)型指定
型の指定は必須ではありませんが、指定することも可能です。
引数だけの型指定でも構いませんし、返り値だけの型指定でも構いません。
型が一致しない関数を呼び出すとエラーが発生します。(2)可変長引数
◆要約
①引数の数を変えて使用することができます。
②設定できる引数は、最後の引数だけです。
③2つ以上の引数を可変長にすることもできません。
④可変長引数に型指定設定できます。①引数の数を変えて使用することができます。
下図の例では、引数が1つ、2つ、3つの場合です。
引数に設定する値はリスト(配列)として取り出しますので、以下のようにループ部分を書くこともできます。
②設定できる引数は、最後の引数だけです。
以下のような書き方はできません。note10function summation(v..., x) ...③2つ以上の引数を可変長にすることもできません。
④可変長引数に型指定設定できます。
可変長引数に型指定をする場合は、以下のように設定します。note10function summation(v::Int...) ...(3)オプショナル引数
◆要約
①引数の初期値を予め設定しておくことができます。
②複数の引数をオプショナルに指定することができます。
③オプショナル引数は引数の末尾にまとめて書きます。①引数の初期値を予め設定しておくことができます。
引数の値が省略された場合はこの初期値が適用されます。
②複数の引数をオプショナルに指定することができます。
③オプショナル引数は引数の末尾にまとめて書きます。
以下のような書き方はできません。note10function foptional(v2=10, v1) ...(4)キーワード引数
複数の引数のうち、特定の引数の値を特に設定したい場合に使用します。
以下の例では初めの2つの引数は通常の引数で、さらに、複数ある引数のうちpriceの値を設定した例です。
通常の引数とキーワード引数の区切りに ; (セミコロン)を使用する点に注意して下さい。
(5)匿名関数
アロー関数によく似た関数です。
◆要約
①引数は一つのみ指定できます。
②複数行の処理を定義する場合は、begin~endで囲みます。①引数は一つのみ指定できます。
引数を複数設定することはできません。
②複数行の処理を定義する場合は、begin~endで囲みます。
以下の例では2行の処理を行っています。
もくじ
Julia早引きノート[01]変数・定数の使い方
Julia早引きノート[02]算術式、演算子
Julia早引きノート[03]複素数
Julia早引きノート[04]正規表現
Julia早引きノート[05]if文
Julia早引きノート[06]ループ処理
Julia早引きノート[07]try, catch, finally
Julia早引きノート[08]変数の型(Int, Float, Bool, Char, String)
Julia早引きノート[09]関数 (1)基本編
Julia早引きノート[10]関数 (2)応用編(※引き続きコンテンツを増やしていきます)
関連情報
Julia - 公式ページ
https://julialang.org/
https://julia-doc-ja.readthedocs.io/ja/latest/index.html
https://qiita.com/ttlabo/items/b05bb43d06239f968035
https://docs.julialang.org/en/v1/base/math/ご意見など
ご意見、間違い訂正などございましたらお寄せ下さい。