- 投稿日:2020-10-26T23:32:45+09:00
AWS 認定 高度なネットワーキング合格に向けた知識メモ
はじめに
AWSを触るようになって早1年。先日鬼弁の甲斐もあってAWS 認定セキュリティに合格することができました。
次に何を受験しようか悩んでいたものの、社内にはすでにSAPの取得者がワンサカいて面白くない。。。
のでとりあえず認定〇〇シリーズを攻めていこうと思いネットワークの勉強を始めたのですがとてつもなく知識不足(特にDX接続)でしたので勉強したことをまとめてみます。今回勉強したサービス目次
1.Direct Connect
2.内容い
3.内容ろ
4.内容は
5.おわりに1. Direct Connect
2. 内容い
3. 内容ろ
4. 内容は
5. おわりに
- 投稿日:2020-10-26T23:32:45+09:00
知識メモ
はじめに
AWSを触るようになって早1年。先日鬼弁の甲斐もあってAWS 認定セキュリティに合格することができました。
次に何を受験しようか悩んでいたものの、社内にはすでにSAPの取得者がワンサカいて面白くない。。。
のでとりあえず認定〇〇シリーズを攻めていこうと思いネットワークの勉強を始めたのですがとてつもなく知識不足(特にDX接続)でしたので勉強したことをまとめてみます。1. Direct Connect周り
aaaa
a
a
a
- 投稿日:2020-10-26T21:39:40+09:00
SAP模擬試験1
- 投稿日:2020-10-26T21:37:52+09:00
【OpenShift Container Platform】oc login時のトークン更新
概要
今回はOpenShift Container Platform(以降OCP)の
oc loginコマンドを実行時にセッションを確立するために使用されるトークンの動きが気になったので、調べた結果を記載する。前提
- 検証環境:OpenShift Container Platform 4.3 on AWS
- 作業端末:OCPデプロイ先のVPCのパブリックサブネット内にあるEC2 Amazon Linux2インスタンス
この作業端末にはOCPクラスタに接続するための設定情報kubeconfigファイルが格納されている。結論
結論から言うと、CLIのログインコマンド
# oc login -u <user_name> -p <passwd>を使用し、OCPにログインを行うと、OCPの認証情報が格納されているkubeconfigファイルの以下の部分のトークンが更新される。
- name: <user_name>/api-myopenshift-test-com:6443 user: token: **************************検証
1. 作業端末にsshでログイン
ssh ec2-user@<remote-ip> -i <private-key-file>2. rootユーザーにスイッチ
$ sudo su -3. OCPにログイン前のkubeconfigのトークンの値を確認
# less <your-dir>/kubeconfig (一部抜粋) - name: <user_name>/api-myopenshift-test-com:6443 user: token: nFKg1Clp00jQYBYJl-kPgvkU0wNN15-papWTeGLILCQ
<your-dir>はkubeconfigが格納されているディレクトリ4. kubeconfigを環境変数としてexport
# export KUBECONFIG=<your-dir>/kubeconfigこれを行うことで、格納されている認証情報を用いてocコマンドを実行できる。
5. oc login実行
# oc login -u <user_name> -p <passwd>6. 再度トークンを確認
# less <your-dir>/kubeconfig (一部抜粋) - name: <user_name>/api-myopenshift-test-com:6443 user: token: OTn3jUv5oonEx2wgUwE2pPJQxx68pvIomO2NrBBL5fAこのように、
oc login毎にトークンが更新される。以上、読んでいただきありがとうございました。
- 投稿日:2020-10-26T21:37:52+09:00
【OpenShift Container Platform】oc loginのセッショントークン
概要
今回はOpenShift Container Platform(以降OCP)の
oc loginコマンドを実行時にセッションを確立するために使用されるトークンの動きが気になったので、調べた結果だけを記載する。前提
- 検証環境:OpenShift Container Platform 3.4 on AWS
- 作業端末:OCPデプロイ先のVPCのパブリックサブネット内にあるEC2 Amazon Linux2インスタンス
この作業端末にはOCPクラスタに接続するための設定情報kubeconfigファイルが格納されている。結論
結論から言うと、CLIのログインコマンド
# oc login -u <user_name> -p <passwd>を使用し、OCPにログインを行うと、OCPの認証情報が格納されているkubeconfigファイルの以下の部分のトークンが更新される。
- name: admin-usr/api-myopenshift-test-com:6443 user: token: **************************検証
1. 作業端末にsshでログイン
ssh ec2-user@<remote-ip> -i <private-key-file>2. rootユーザーにスイッチ
$ sudo su -3. OCPにログイン前のkubeconfigのトークンの値を確認
# less <your-dir>/kubeconfig (一部抜粋) - name: admin-usr/api-myopenshift-test-com:6443 user: token: nFKg1Clp00jQYBYJl-kPgvkU0wNN15-papWTeGLILCQ
<your-dir>はkubeconfigが格納されているディレクトリ4. kubeconfigを環境変数としてexport
# export KUBECONFIG=<your-dir>/kubeconfigこれを行うことで、格納されている認証情報を用いてocコマンドを実行できる。
5. oc login実行
# oc login -u <user_name> -p <passwd>6. 再度トークンを確認
# less <your-dir>/kubeconfig (一部抜粋) - name: admin-usr/api-myopenshift-test-com:6443 user: token: OTn3jUv5oonEx2wgUwE2pPJQxx68pvIomO2NrBBL5fAこのように、
oc login毎にトークンが更新される。以上、読んでいただきありがとうございました。
- 投稿日:2020-10-26T21:17:01+09:00
【0からCircleCIに挑戦】CircleCI・AWS(ECR・ECS)で自動デプロイ
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためCircleCIを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからCircleCIに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
git push → CircleCI自動テスト(※実装済み) → テスト合格&masterブランチの場合自動デプロイ
【関連記事】
【0からCircleCIに挑戦】CircleCIの基礎を学ぶ
【0からCircleCIに挑戦】自動テストを構築する(Rails6.0・mysql8.0・Rspec)
【0からCircleCIに挑戦】AWSのECR・ECSを理解する
【0からCircleCIに挑戦】CircleCI・AWS(ECR・ECS)で自動デプロイ環境
ruby 2.6.6
rails 6.0
db: mysql 8.0
test: rspec手順
- 全体図の確認
- CircleCIの設定
- .circleci/config.ymlの記述
1. 全体図の確認
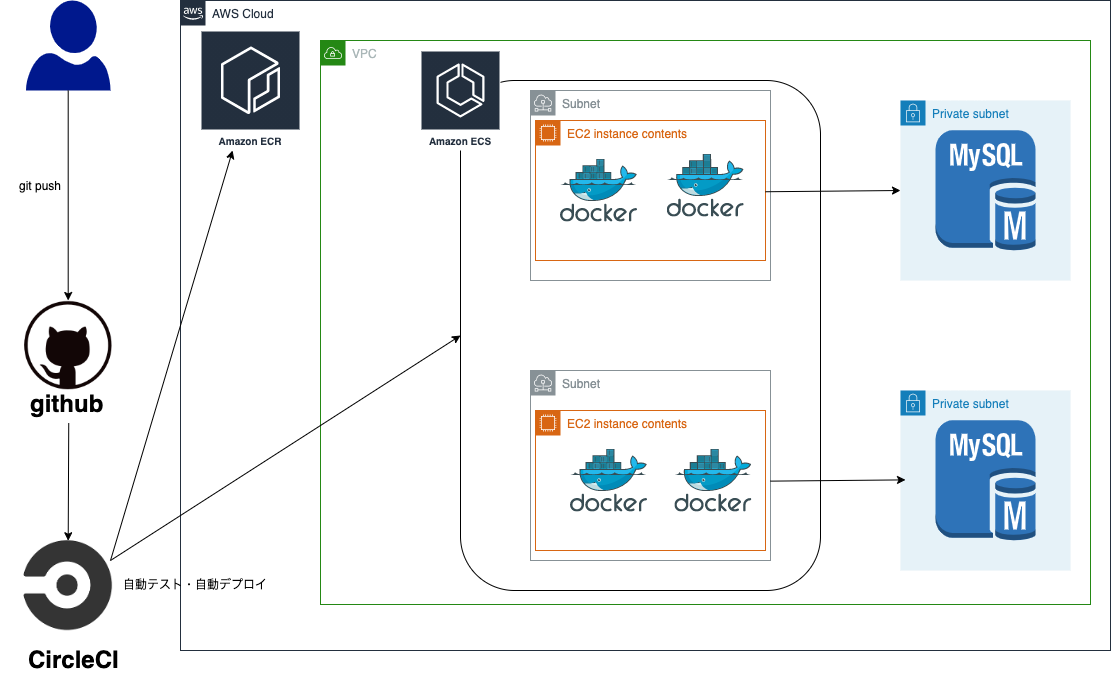
まずAWS全体がどうなるかを確認します。
流れを確認すると、
git pushする→そうするとCircleCI上で自動テストが走る →自動テストが成功した場合自動デプロイ開始 → ECRにイメージを保存 →そのイメージをもとにECSでEC2上にコンテナを作成という流れになります。ちなみにEC2内のコンテナはnginxとapp用の2種類でapp用のコンテナはRDSと連携しています。
2. CircleCIの設定
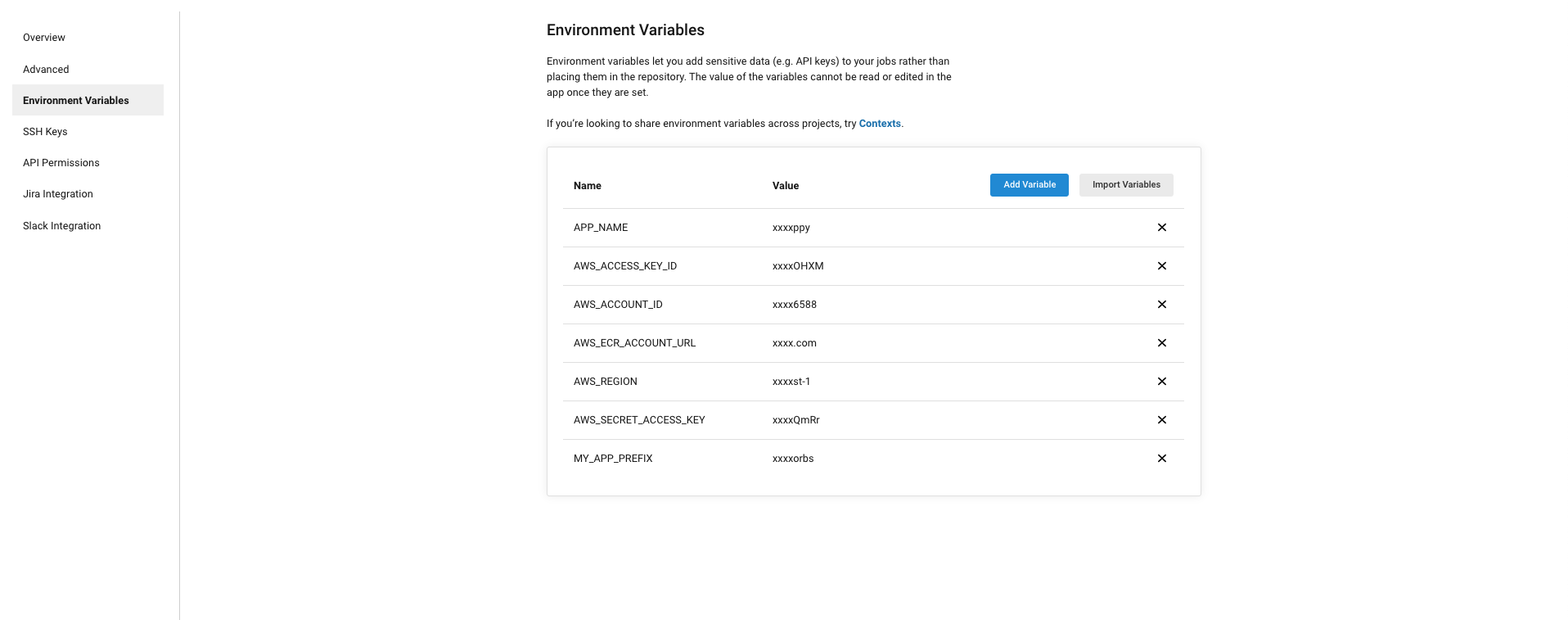
githubとCircleCIの連携は済んでいるという前提で、ダッシュボードから該当のプロジェクトを選択します。そうすると右上に「project settings」があるのでそれを選択します。左のメニューから「Environment Variables」を選択すると下記画面が表示されます。ここでは環境変数を設定することができます。
具体的に設定内容は下記になります。
Namw value APP_NAME 'アプリケーションの名前' AWS_ACCESS_KEY_ID IAMのアクセスkey AWS_ACCOUNT_ID IAMのアクセスID AWS_ECR_ACCOUNT_URL ECRのURIの「~.com」の部分 AWS_REGION 使用しているリージョン AWS_SECRET_ACCESS_KEY IAMのシークレットkey
3. .circleci/config.ymlの記述
.circleci/config.ymlversion: 2.1 jobs: test: docker: - image: circleci/ruby:2.6.6-node-browsers environment: RAILS_ENV: 'test' MYSQL_HOST: 127.0.0.1 MYSQL_USERNAME: 'root' MYSQL_PASSWORD: '' MYSQL_PORT: 3306 - image: circleci/mysql:8.0 command: mysqld --default-authentication-plugin=mysql_native_password environment: MYSQL_ALLOW_EMPTY_PASSWORD: 'true' MYSQL_ROOT_HOST: '%' working_directory: ~/repo steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} - run: mv config/database.yml.ci config/database.yml - run: bundle exec rake db:create - run: bundle exec rake db:schema:load - run: name: RSpec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/models/users_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results orbs: aws-ecr: circleci/aws-ecr@6.5.0 aws-ecs: circleci/aws-ecs@1.3.0 workflows: test: jobs: - test deploy-web: jobs: - aws-ecr/build-and-push-image: filters: branches: only: master account-url: AWS_ECR_ACCOUNT_URL create-repo: true dockerfile: containers/nginx/Dockerfile repo: "${APP_NAME}_web" region: AWS_REGION tag: "${CIRCLE_SHA1}" - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "nginx-rails-app2" cluster-name: "nginx-rails" service-name: "ecs-rails" container-image-name-updates: 'container=web,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${APP_NAME}_web:${CIRCLE_SHA1}' deploy-app: jobs: - aws-ecr/build-and-push-image: filters: branches: only: master account-url: AWS_ECR_ACCOUNT_URL create-repo: true dockerfile: docker/Dockerfile repo: "${APP_NAME}_app" region: AWS_REGION tag: "${CIRCLE_SHA1}" - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "nginx-rails-app2" cluster-name: "nginx-rails" service-name: "ecs-rails" container-image-name-updates: 'container=app,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${APP_NAME}_app:${CIRCLE_SHA1}'少し長いですが1つ1つ説明します。
- version ~ orbsの前までは自動テストの記事の際に説明したので省略します。
- orbsは一連の処理をまとめたパッケージのことでした。すなわち今回の「aws-ecr: circleci/aws-ecr」「aws-ecs: circleci/aws-ecs」はそれぞれCircleCIが用意した、AWSのECRにイメージを簡単に保存できるようにしたパッケージ、またはAWSのECSを簡単に設定できるパッケージを呼び出していることになります。
- workflowは複数のジョブの処理を制御するものでした。今回は3つのワークフローがあります(test,deploy-web,deploy-app)。それぞれ異なる環境であり、異なるコンテナのため3つに分けました。
- 最初の「test」ワークフローは上に書いてあるテストジョブを実行しています。
- 「deploy-web」ワークフローはnginxのコンテナに関するワークフローです。2つのジョブ(『aws-ecr/build-and-push-image:』と『- aws-ecs/deploy-service-update:』)を実行しています。
- 『aws-ecr/build-and-push-image:』はorbsで「aws-ecr: circleci/aws-ecr」を呼び出すことによって使える様になるジョブです。イメージをリポジトリにプッシュするジョブです。なのでジョブ以下でどのイメージをどういう設定でプッシュするかを記載します。
- 「filters: ~ only: master」と設定することで、masterブランチ以外でgit pushされた際はデプロイしない設定になっています。
- 「account-url ~ region」までの設定は直感的にわかるかと思います。前回の記事でECRにイメージをプッシュしましたが、それをもとにリージョンやURLを設定します。※実際に入力するのは環境変数名ですが、、、
- tag: "${CIRCLE_SHA1}"は環境変数ですが、CircleCIが勝手に用意してくれるものです。ちなみに「SHA1」はSSL通信などに使われるハッシュ関数です。ここでは安全にプッシュ・そしてプッシュ内容に印をつけるために、ジョブの最後につけるおまじないと考えればよいでしょう。
- 『 - aws-ecs/deploy-service-update:』はorbsで「aws-ecs: circleci/aws-ecs」を呼び出すことによって使えるようになったジョブです。ecsでコンテナを起動・更新するためのジョブです。なのでジョブ以下でタスクやサービスの設定をします。
- 「require」で依存関係を示します。上述のECRへのイメージのプッシュが完了してから行う必要があるからです。
- 「family」はタスク名、「cluster-name」はクラスター名、「service-name」サービス名です。ちなみにこちらは予め設定した名前を使いましょう。今回は前回の記事で作成したクラスター名などを指定します。 ※ここで自分はエラー起こりましたが、どうやら新規にタスクやクラスターをつくることはできなくて、既存のものをアップデートする形でデプロイするらしいです。updateって書いてあるから当たり前っちゃ当たり前ですが、、、、
- container-image-name-updatesでコンテナ名と使用するイメージとタグを指定しています
- 「deploy-app」も基本的に「deploy-web」と同じ構成です。
上記でファイルの設定は完了です。あとはgit pushして完了です。おそらく下記のようにテストとデプロイに成功するはずです。
(ご覧のように私は27回失敗しました。)
あと余談ですが、ECS設定したことでドメイン名とSSL通信について再設定が必要そうです。そちらに関しては改めて記事を書きたいと思います。現状HTTPのみなので不便ですね、、、、
まとめ・感想
もしかすると今後進めて行く上で修正が必要かもしれませんが、一度設定できたのであとはそれを基に調整するだけで色々とできそうです。ただ勉強していくうちにterraformに興味ももったので、terraformも実装して記事書きたいです。
参考
【書籍】
『CircleCI実践入門──CI/CDがもたらす開発速度と品質の両立 浦井 誠人 (著), 大竹 智也 (著), 金 洋国 (著) 』【qiita】
『いまさらだけどCircleCIに入門したので分かりやすくまとめてみた』
『【CircleCI】Railsアプリに導入(設定ファイルについて)』
『初心者でもできる! ECS × ECR × CircleCIでRailsアプリケーションをコンテナデプロイ』【その他サイト】
『CircleCI Orbsを使ってECR/ECSへ自動デプロイする』

- 投稿日:2020-10-26T20:59:18+09:00
【Amazon RDS】データベース作成時にエラー
RDSでデータベース作成時にエラーとなったので対処方法メモ
データベース作成前の状態
VPC
名前 IPv4 CIDR my-vpc 10.0.0.0/16 サブネット
名前 IPv4 CIDRブロック アベイラビリティゾーン public-subnet 10.0.1.0/24 ap-northeast-1c private-subnet 10.0.2.0/24 ap-northeast-1c セキュリティーグループ
名前 インバウンドルール 用途 sample-web-sg SSH(22)とHTTP(80)を許可 EC2用 データベース作成の設定情報
- マルチ AZ 配置:スタンバイインスタンスを作成しないでください
- VPC:my-vpc
- パブリックアクセス可能:なし
- VPCセキュリティグループ:新規作成
- セキュリティグループ名:sample-db-sg
- アベイラビリティゾーン:ap-northeast-1c
エラー内容
ご指定になった DB インスタンス choreslist-db の作成リクエストは実行されませんでした。
DB Subnet Group doesn't meet availability zone coverage requirement. Please add subnets to cover at least 2 availability zones. Current coverage: 1 (Service: AmazonRDS; Status Code: 400; Error Code: DBSubnetGroupDoesNotCoverEnoughAZs; Request ID: 1099fafb-cfe1-423e-a872-fac67560dd39; Proxy: null)原因
RDSではアベイラビリティゾーンが別のサブネットが2つ用意する必要がある
対処方法
- サブネットをもう1つ作成する
名前 IPv4 CIDRブロック アベイラビリティゾーン public-subnet 10.0.1.0/24 ap-northeast-1c private-subnet 10.0.2.0/24 ap-northeast-1c private-subnet2 10.0.3.0/24 ap-northeast-1a
- サブネット作成後にデーターベースを再度作成
OK
- 投稿日:2020-10-26T20:00:50+09:00
MACローカルで公開鍵を作りたい時備忘録(AWSとか用に)
- 投稿日:2020-10-26T18:28:48+09:00
【資格】AWS クラウドプラクティショナー
- 投稿日:2020-10-26T18:01:18+09:00
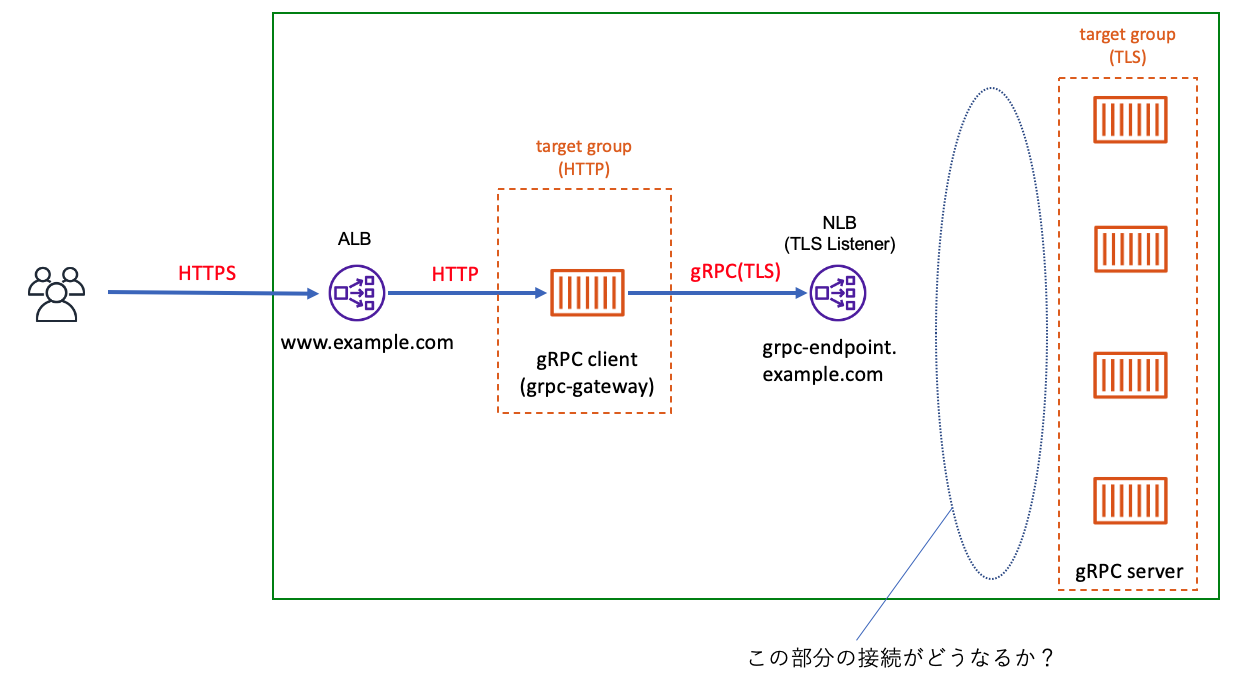
AWSのNLBだけでgRPCの負荷分散ができなかった話
2020/5 に Network Loadbalancer(NLB) が TLS ALPN ポリシーに対応しました。
これに伴い「 envoy とか使わなくても NLB だけで gRPC の負荷分散できんじゃね?」という記事はあるものの、実際に試しているものはなかったので、書きました。作った構成
別件で、たまたま gRPC-gateway の環境を作っていたため、それを少しカスタマイズして利用しました。
ユーザリクエストが、ALBを経由して grpc-gatewayに着弾します。
gRCP Gatewayでは、HTTPリクエストをgRPCリクエストに変換して、gRPC Serverに渡します。gRPC Serverに直接接続するのではなく、前段に内部用 NLB を作成して、 gRPC gateway - NLB - gRCP server という経路にしています。今回は、gRPC Gateway も gRPC Serverも Fargate で作成しました。
NLBは、バックエンドに均等に分散されるように スティッキーセッションを無効にし、クロスゾーン負荷分散を有効にしています。検証した点
ALBに対してひたすらHTTPを送って、gRPC Gateway から gRPC Serverへのアクセス状況を見ました。
gRPC Serverは、gRPC リクエストがあると、標準出力にシンプルなログを吐くようになっています。
なので、接続状況は、ログを見て判断する形になっています。検証
負荷テストの実施
こちらは アクセス元のグローバルIPアドレスを複数にしたかったため、こちらのAWS 負荷テストソリューションを使いました。
CloudFormatiotテンプレートをデプロイするだけで、分散HTTPテスト環境が作れます。
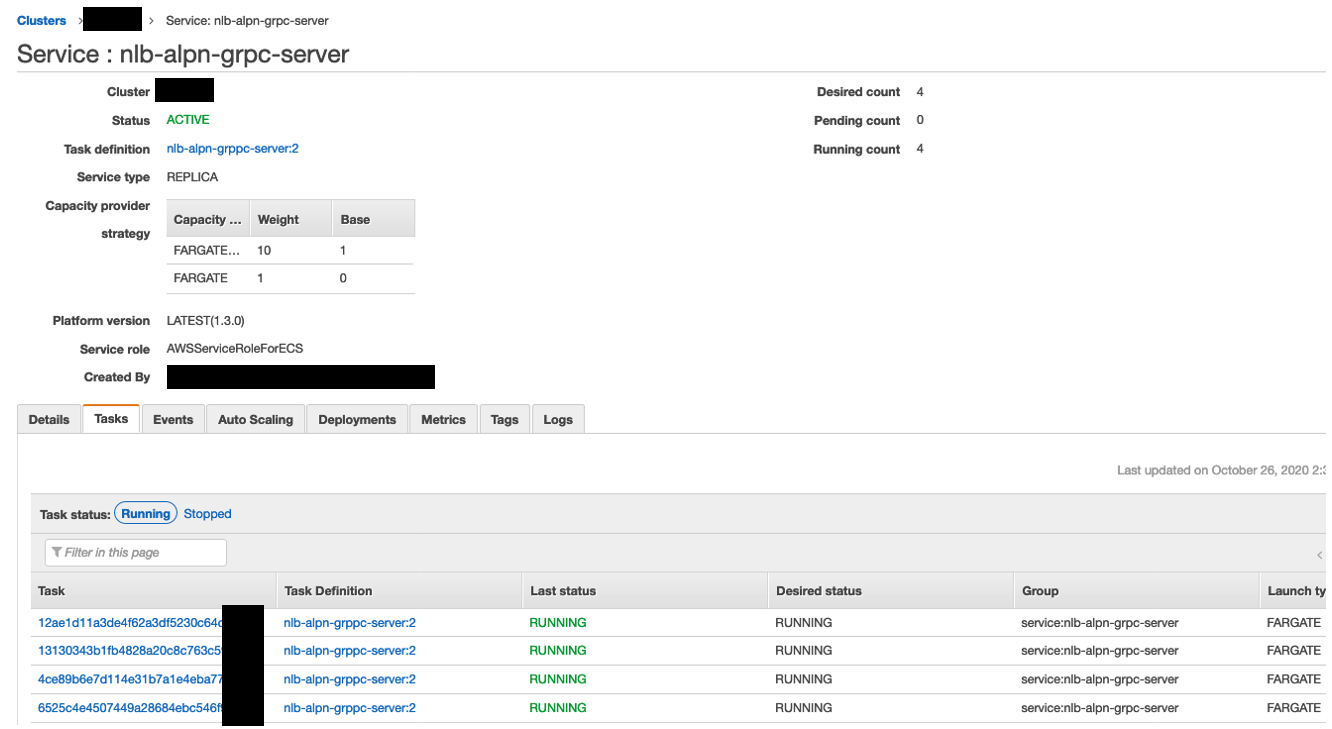
こちらに、負荷テスト先のURLを指定して、1時間 約1000アクセス/秒な負荷を与えました。Fargate、NLB、Target Group の状況
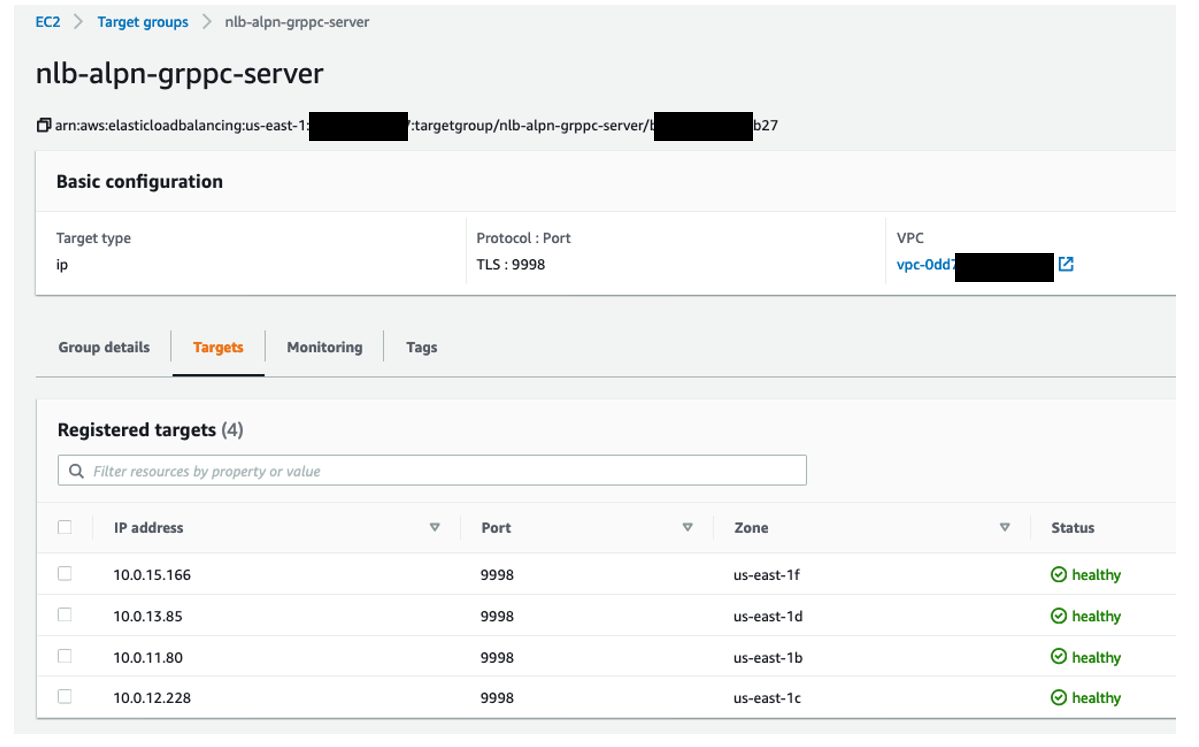
前述の通り、gRPC Server は内部用NLBの背後に、4つのFargateが動いています。
Target Group は、ALPNを利用する場合は、TLSプロトコルを指定する必要があります。
(この環境では、 port 9998 を gRPC用のポートにしています)
TLSリスナーなので、NLBでTLSを終端し、バックエンドには gRPC 平文(cleartext, h2c)で流すといったことはできません。
ログの確認
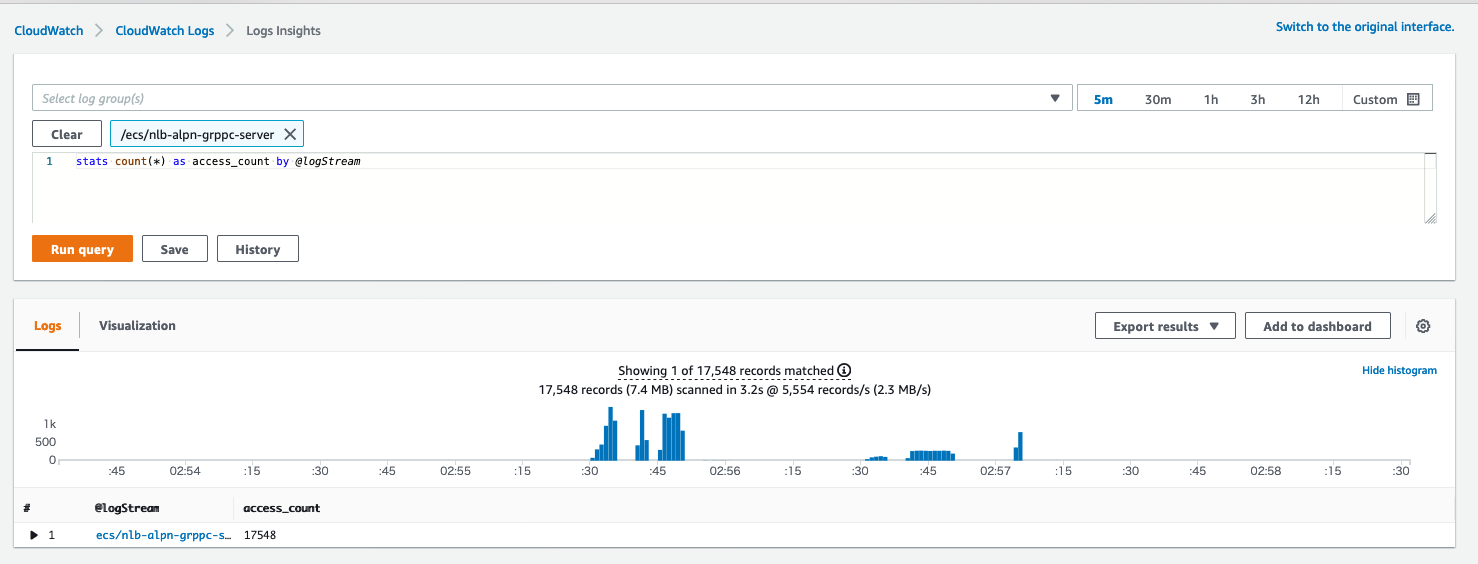
負荷テスト中もしくは後に、CloudWatch Logs Insightsでログが出力されていることを確認しました。
gRPC sever は、gRPC リクエストがあると、以下のようなログを吐きます(ログの中身の解説は本質ではないので説明は行わないのですが、1ログ = 1 gRPC リクエスト になっています)
{"Level":"INFO","Time":"2020-10-23T18:47:02.459Z","Caller":"zap/options.go:203","Msg":"finished unary call with code OK","grpc.start_time":"2020-10-23T18:47:02Z","system":"grpc","span.kind":"server","grpc.service":"grpc.health.v1.Health","grpc.method":"Check","access.ClientIp":"10.0.11.199:38104","access.Useragent":"grpc-go/1.27.0","access.AuthToken":"","grpc.code":"OK","grpc.time_ms":0.05900000035762787}こんな感じで、gRPC リクエストは、バックエンドの Fargate に飛んでいることが分かります。
ただ、今回の検証は、バックエンドへのgRPC リクエストが負荷されるかの確認なので、
CloudWatch logs insighs でクエリを発行して、タスク(コンテナ)ごとリクエスト数の集計を行いました。負荷分散状況の確認
実行した CloudWatch logs insighs のクエリ
stats count(*) as access_count by @logStream以下のように、Fargate は4つ(4つのタスク)が存在しているにも関わらず、1つのタスクにしか、ログがありません。
つまり、gRPCリクエストは1つのFargateに集中し、他の3つFargate には gRPCリクエスト が一切来ていないことが分かりました。
もし、負荷分散されていれば、4つのタスクに均等にリクエスト数が分散されているはずです。
ここで、検証の目的である
「NLBだけでgRPCの負荷分散ができるかどうか」という疑問に対して、「できない」という検証結果になった事がわかりました。考察
なぜ負荷分散できないのか
NLBは ALPNに対応したからといって、あくまでも責務はL4だからに尽きると思います。
つまり、NLBはTLSの処理はできるものの、gRPC(HTTP2)については何もしない(というより理解しないので)、バックエンドに張ったコネクションをずっと利用するようになっているような気がします。これは、NLBは悪いのではなく、NLBの機能から見て、当たり前な動きだと思います。なぜ envoy だと負荷分散できるのか
envoyは L7 まで見てくれます。つまり、リクエストがgRPCかどうか判断でき、中身を見て、リクエストごとに接続先を負荷分散することが可能です。
これについては、ここにも記載されています。envoy は Connectionベースではなく。リクエストベースで負荷分散すると。(この言葉を使うと、NLB は Connection ベースでの負荷を行っているという感じでしょうか。なので、1 Connectを使い回す gRPCでは負荷分散ができないと)その他
現時点での仕様では、target group は、TLSプロトコルが必須になり、サーバ証明書をアプリ側に埋め込む必要があります。ただ、実際 gRPC Clientから見ると、接続先は NLB なので、ACMにimport した証明書が必要になります。つまり、NLB用にも証明書が必要で、gRPC サーバにも証明書が必要になります。

- 投稿日:2020-10-26T17:31:43+09:00
WinSCPでAmazon S3にアクセス
Windowsで比較的広く使われているオープンソースのSCPクライアントに「WinSCP」がある。WinSCPはSCPのほかにもSFTP、FTPS等のプロトコルに対応していたが、AWSのオブジェクトストレージサービスであるAmazon S3にも2018年の5.12.12 RCで対応、5.13で安定版に組込まれた。
- WinSCPとは :: WinSCP
- Amazon S3クライアント機能を搭載した、オープンソースのWindows対応FTPクライアント「WinSCP 5.13」リリース。FTPサーバのようにAmazon S3を操作 - Publickey
管理コンソールからのS3アクセスはSSHやFTPポートを介さずHTTPSアクセスのみでできるので、境界型セキュリティ中心の企業環境でも比較的利用しやすいのだけど、大量の作業を行うときにはExplorerライクなGUIアプリが好まれることがある。WinSCPでのS3アクセスは両方のニーズを満たせるし、境界型セキュリティな会社には大抵あるプロキシ(しばしば認証プロキシ)経由でも使えたので、意外とこれが有用な場面もあるかと思う。
S3アクセスの設定
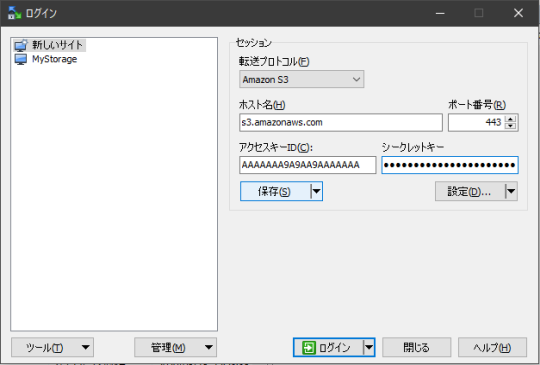
Amazon S3への接続は、以下のような設定になる。転送プロトコルとして
SCPなどとの代わりにAmazon S3を選択する。ホスト名とポート番号は、通常は変更不要。アクセスキーIDとシークレットキーに、AWS CLI等で使用するアクセスキーとシークレットキーを入力。
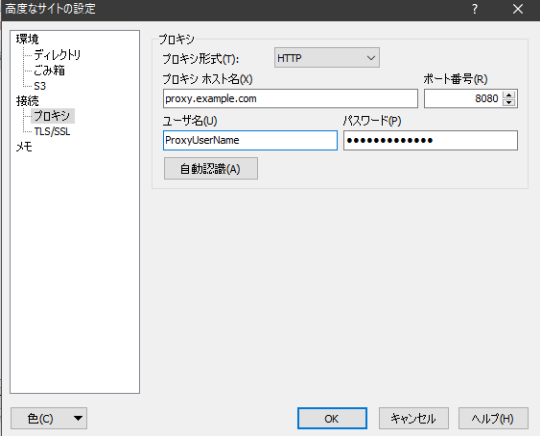
HTTPプロキシを経由する場合、「設定」ボタンから設定画面に進む。左のメニューから「プロキシ」を選び、プロキシサーバーのホスト名とポート番号、認証が必要であればユーザー名とパスワードを指定する。
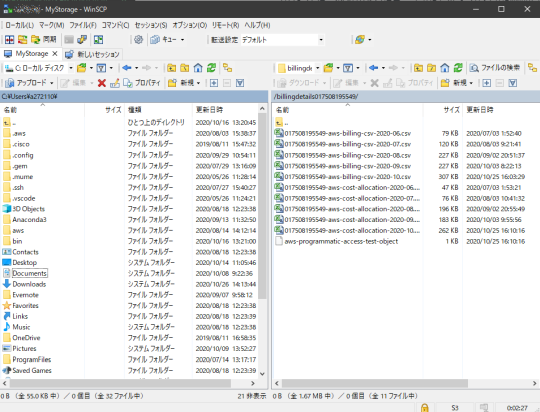
設定は保存しておく。その後「ログイン」を行うと、該当アカウントのS3の「ルート」として、バケット一覧が表示される。
あとはSFTPやFTP、FTPS接続時と同じように、エクスプローラー感覚で利用できる。バケット内に入ると、管理コンソールでしているようにディレクトリ感覚でパスを移動しファイル感覚でオブジェクトを操作できる。
ロール切替には(おそらく)未対応
WinSCPは設定可能項目を見る限り、残念ながらロール切替(スイッチロール)してアクセスするといった機能はなさそうに思われる。Windows用のS3クライアントとしては、例えばS3 browserがあるが、こちらも同様でロール切替の設定はない。他にもS3をWindowsにマウントできるようにする商用製品等があるが、ロール切替に対応したものは見つけることができなかった。
ロール切替を前提とするならAWS CLIやAWS Tool for PowerShell等を使う、GUIが必須であればロールではなくIAMユーザーでS3にアクセスできるように権限設定をする、という割り切りが早道だと思われる。
- 投稿日:2020-10-26T17:28:08+09:00
AWSSAAに受かった時の嬉しさを書く
はじめに
今の自分のスキル感
- 実務4ヶ月程度(メインはバックエンド)
- AWSたまに触るぐらい(超主要なサービスは理解していた)
まだまだ駆け出しひよっこエンジニアになります。
10月末にAWSSAAの試験を受けてきました。(2回目)
前回(1度目)は9月末に受けましたが、見事に撃沈しました。
その時の勉強した事や自分のスキルレベルやスコアは前回の記事をご覧ください。落ちて感じた事
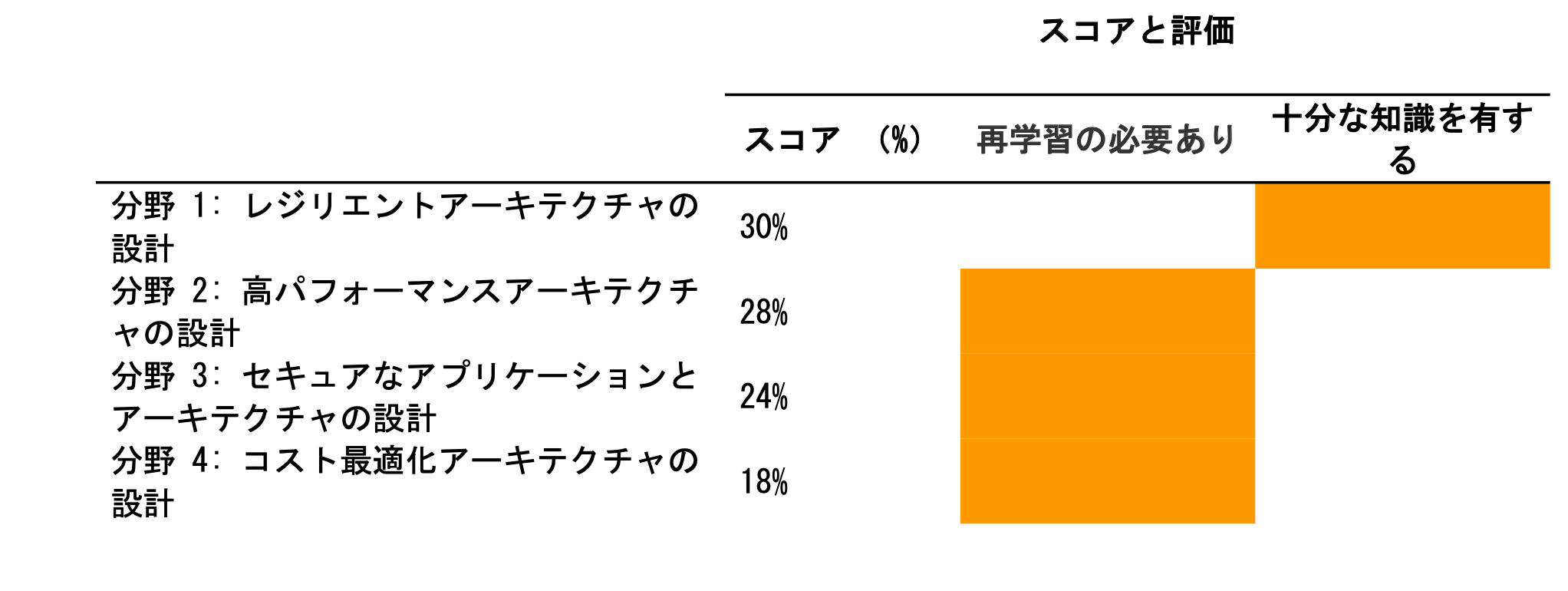
下記が前回の試験結果になります
どうして自分は落ちたのか自分のスコアの結果を見て考えました。
前回の記事にも書きましたが、問題で問われている部分をきちんと理解できなかったのも結構大きいポイントでした。
どういうことかというと、求められるアーキテクチャ設計によって選ぶ答えは変わります。
求めているものが、可用性なのか、コストなのか、パフォーマンスなのかを意識しながら、問題を解くことが大事だと、この結果を見て思いました。
あとはサービス単体の知識不足もあったと思います。落ちてから勉強したこと
落ちてから勉強したことは以下の2点になります。
上記のゴールドプラン(記事を書いた時点では期間:60日、金額:3880円(税抜き))で契約し、#80〜#138の問題集を1.5週ぐらいやりました。
一問一答形式なので、空いた時間にやりやすかったです。
ちょこちょこ本番レベルの難易度の問題もあるので、いい訓練にはなるかなと思います。上記の問題集を念のため、再度もう一周程度やりました。(4週目)
試験問題も更新されていたりするので、見たことない問題もありました。
模擬試験1 4回目:80%
模擬試験2 4回目:89%
模擬試験3 4回目:81%
模擬試験4 4回目:81%
模擬試験5 4回目:70%
模擬試験6 4回目:76%あとは間違えた部分を書籍を読んでサービスの内容を確認したり、記事を読んだりしてもう一度おさらいしました。
試験当日
1回受けていたので、2回目は少しだけ簡単に感じました。
あとは求められている事はなにか(可用性、セキュリティ、パフォーマンス、コストなど)をずっと意識して問題を解きました。
意識しながら、サービスの内容がある程度頭に入っていると自ずと答えに辿りつけた感じでした。試験を解き終わって、アンケートに答えて、緊張の瞬間でしたが、目の前には・・・合格の文字がありました。
以下のような結果が数時間経って送られてきました。(まあまあギリギリでしたが、良しとしよう)
最後に
資格取得までの勉強期間は約2ヶ月程度(一日2時間ぐらいで)でした!
AWSSAA資格が取れて本当によかったです!!!!
1000倍返しもできてかなりスッキリしました!!!資格取っても意味ないという人もいますが、勉強することによってある程度のAWSの知識が身につくのも事実ですし、パブリッククラウドの知識が求められるのが当たり前の時代において、取っておいて損はないかなと思います。
資格があるだけで一定程度の知識があるという証明にもなります。この記事がAWSSAAに資格取得したい人の参考になれば幸いです!
ここまで読んでいただいてありがとうございました!



- 投稿日:2020-10-26T16:01:28+09:00
【0からCircleCIに挑戦】AWSのECR・ECSを理解する
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためCircleCIを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからCircleCIに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
AWSのECR・ECSを理解する。実際にECRとECSを使ってアプリケーションを手動でデプロイしてみる。
【関連記事】
【0からCircleCIに挑戦】CircleCIの基礎を学ぶ
【0からCircleCIに挑戦】自動テストを構築する(Rails6.0・mysql8.0・Rspec)
【0からCircleCIに挑戦】AWSのECR・ECSを理解する
【0からCircleCIに挑戦】CircleCI・AWS(ECR・ECS)で自動デプロイ環境
ruby 2.6.6
rails 6.0
db: mysql 8.0
test: rspec目次
- ECRとは何か
- ECSとは何か
- 実際にAWSでECR・ECSデプロイする
1.ECRとは何か
ECRについて
ECRとは「Elastic Container Registry」の略で、AWS上のコンテナイメージ管理システムのことです。Dockerを使ったことがある人ならDockerHubというクラウドレジストリサービスを知っていると思いますが、簡単にいうとECRはAWS版のDokcerHubです。
ECRはAWSでコンテナを使ってデプロイする際、非常に便利なサービスです。もちろんDockerHubを使って運用することもできますが、本番環境でAWSを使う際はECRを使ったほうが管理が簡単になります。またECRはAmazonが管理しているサービスなので安全性も保証されています。
ECRに関しては概念も用語も特に新しいものはなく、DockerHubを使ったことがあるならばすぐ理解できるでしょう。
2.ECSとはなにか
ECSについて
ECSとは「Elastic Container Service」の略で、AWS上のコンテナの実行・管理システムです。実は前述のECRもECSの一種のサービスといえます。ECSはAWS上で簡単にコンテナを起動させたり、停止させたり、管理したりできるシステムのことです。
もしコンテナを使ってアプリケーションをAWSの本番環境にデプロイしたい場合はECSは必須のサービスといえるでしょう。ただ少し独特の概念や用語があり、とっかかりにくいところもあります。なのでまずはECS独特の用語や概念を理解しましょう。
ECSの概念・用語について
クラスター
Amazon ECS クラスターは、タスクまたはサービスの論理グループです。 EC2 を使用してタスクまたはサービスを実行している場合、クラスターはコンテナインスタンスのグループ化でもあります。 キャパシティープロバイダーを使用している場合、クラスターはキャパシティープロバイダーの論理的なグループでもあります。
AWSの公式では上記のように書かれています。ECSではEC2サーバーを使ってコンテナを実行しており、そのEC2サーバーは1つのプロジェクトに対し単体のこともあれば複数にわたることもあります。クラスターとはこのプロジェクトに対するEC2のまとまりのことをいいます。
サービス
Amazon ECS サービスを使用すると、Amazon ECS クラスター内で、タスク定義の指定した数のインスタンスを同時に実行して維持できます。タスクが何らかの理由で失敗または停止した場合、Amazon ECS サービススケジューラは、タスク定義の別のインスタンスを起動してそれに置き換え、サービスで必要数のタスクを維持します。
サービスで必要数のタスクを維持することに加えて、オプションでロードバランサーの背後でサービスを実行することもできます。ロードバランサーは、サービスに関連付けられたタスク間でトラフィックを分散させます。AWSの公式では上記のように書かれています。サービスと言う概念は非常に分かりづらいですが、簡単にいうとコンテナとロードバランサーを結びつけたり、どのタスク定義をコンテナに適応させるかを管理することです。サービスに関しては実際に手を動かしながら設定を進めていくとわかりやすいかと思います。
タスク
タスクとは、関連するコンテナの集合体です。少し分かりにくいので具体例で説明します。railsアプリケーションのコンテナ構成は,webサーバー + アプリケーションサーバーの2つであるこが多いですが、どちらかのコンテナが欠けている場合アプリケーションは起動しません。このようにアプリケーションの起動に関連し合うコンテナをAWS上ではタスクといいます。
AWSではコンテナを起動するためにタスクの設定をする必要があり、それをタスク定義と呼んでいます。
3. 実際にAWSでECR・ECSデプロイする
※AWSのVPC,ELB,RDSは設定済み、開発環境でDockerfile作成済みという前提です。
AWSに関しては、【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
Dockerに関しては、【0からDockerに挑戦】Dockerを使ってnginx・puma・rails6.0・mysqlの開発環境を構築する
で詳しく書いてありますので、AWSやDockerについて不明であれば参照してください。ファイル構成
今回は既存のアプリケーションを使います。ファイル構成は下記です。
Desktop/
├ webapp/
├ containers
└ nginx
└ Dockerfile
└ nginx.conf
├ enviroment
└ db.env
├ Dockerfile
├ docker-compose.yml
├ Gemfile
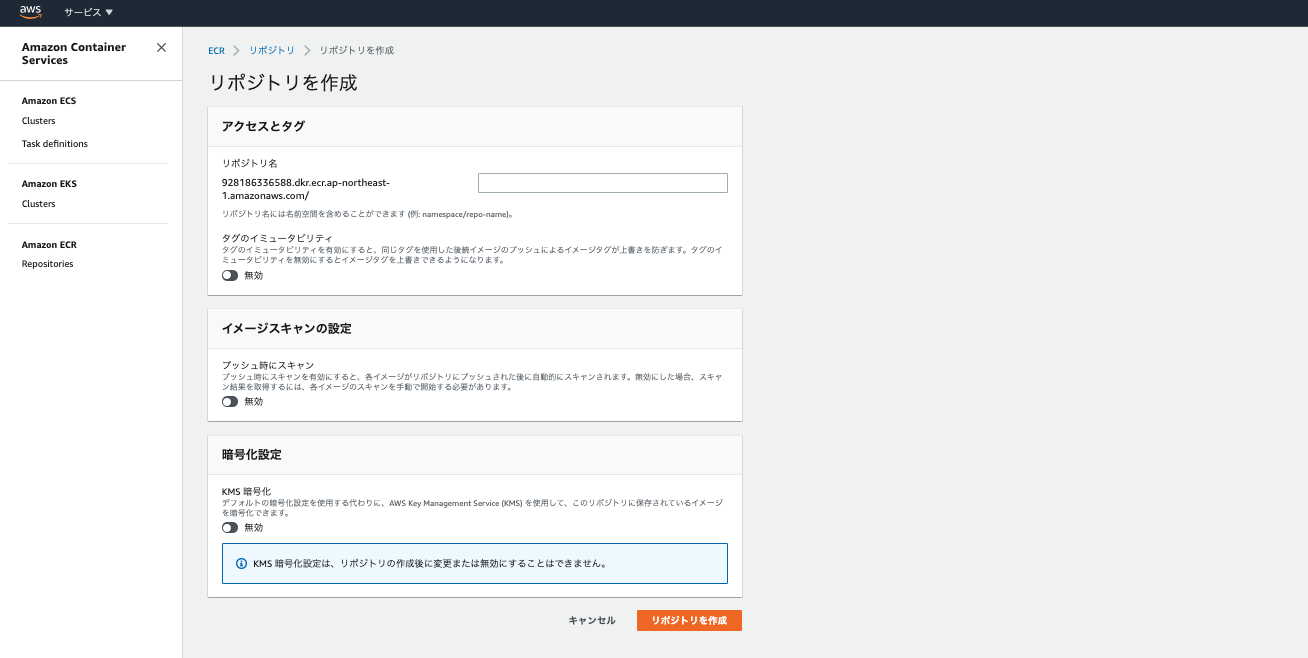
├ Gemfile.lockECRでレポジトリを作成する
AWSのメニューでECRと検索すると、ECRが出てくると思います(※実際ECSの中にECRの項目があります)。そしてリポジトリの作成を押します。そうすると下記画面になりますので、リポジトリ名に好きな名前を入力します。リポジトリはDockerfile分必要ですので、nginx用とapp用の2種類作ります。データベースに関してはRDSを使用するので不要です。
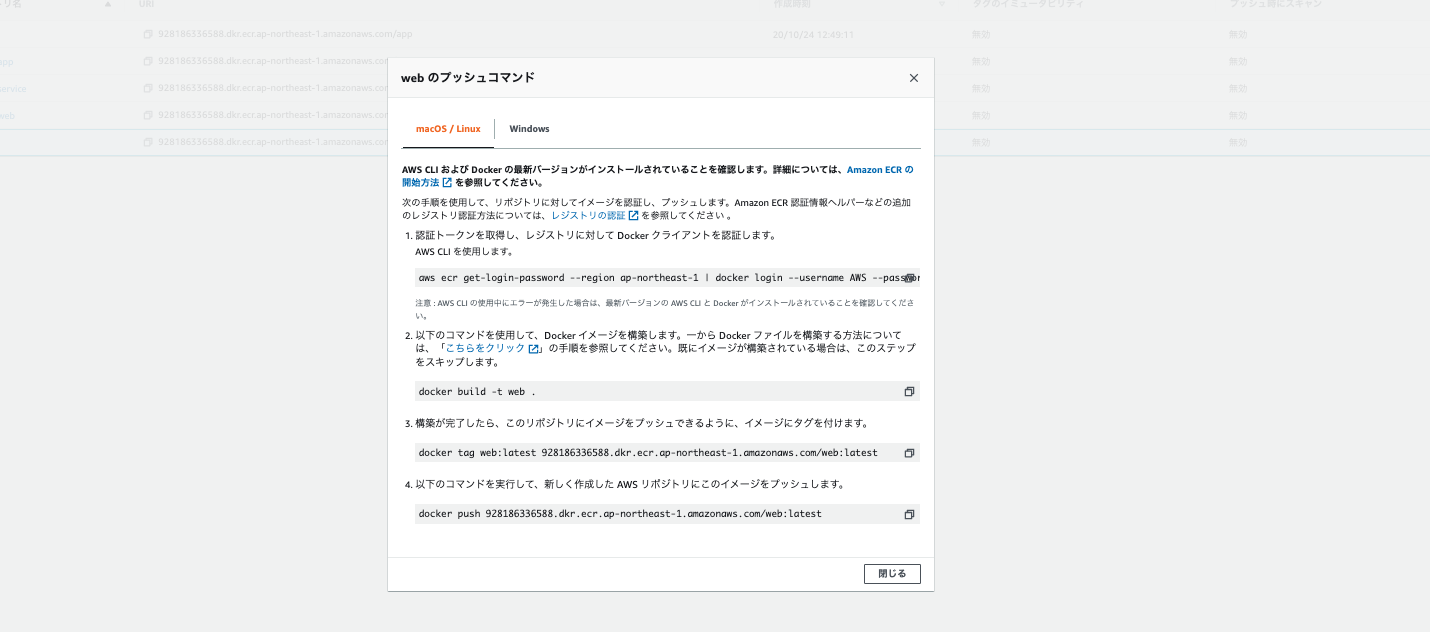
次にECRメニュー上に作成したリポジトリが表示されますので、それを選択して右上にあるプッシュコマンドの表示を押しましょう。下記のように4つのコマンドが表示されますので、それをコピーしてターミナルで実行してください。
※2つめのコマンドはDockerfileのある位置を指定する必要がありますので、今回は下記のように変更する必要がありますターミナル(nginx用) docker build -t nginx -f ./container/nginx/Dockerfile . (app用) docker build -t app .※またAmazonCLIを入れていない場合はエラーが発生します。その場合は下記を入力してから実行してください。
ターミナル$ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" $ unzip awscli-bundle.zip $ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws以上でECRの設定は完了です。プッシュコマンド表示のコマンドはイメージを構築して、ECRにイメージをプッシュするという内容です。つまりこれでローカルのDockerイメージがAWS上に保存されたということになります。
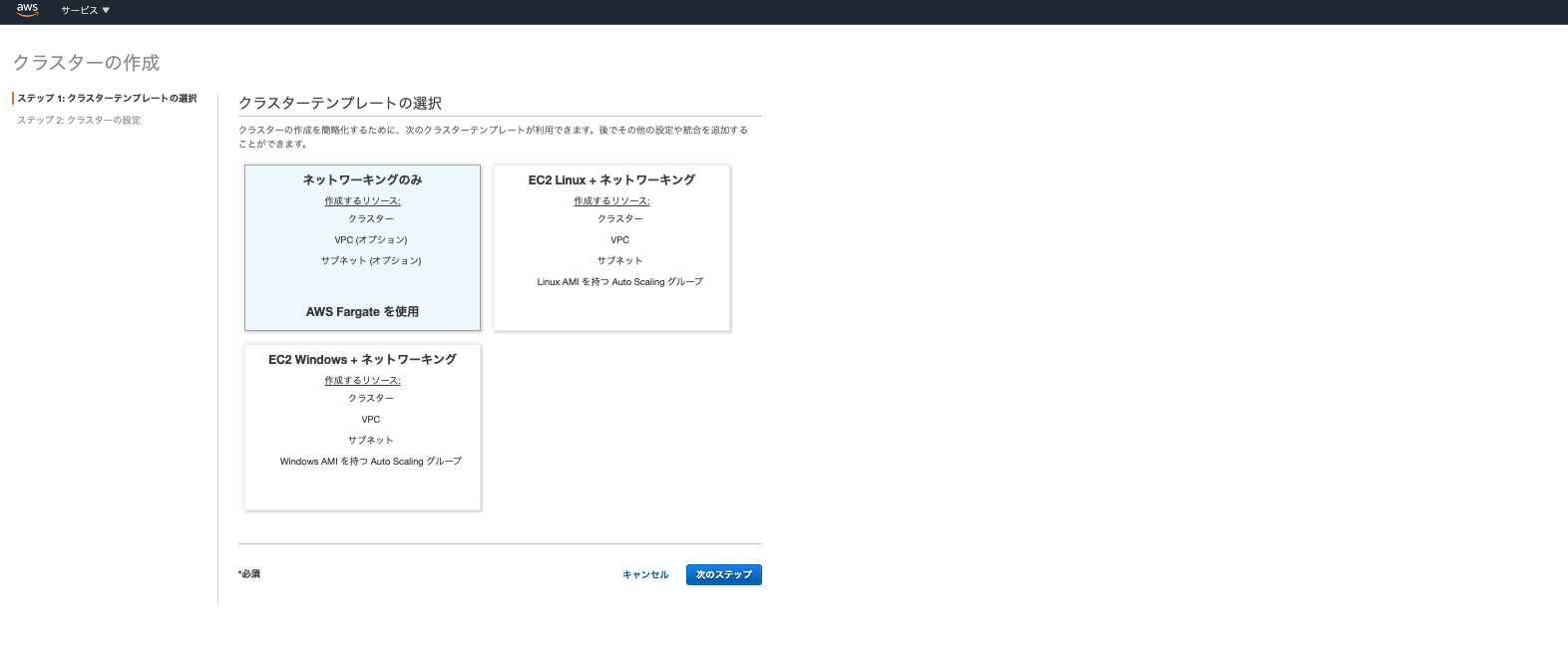
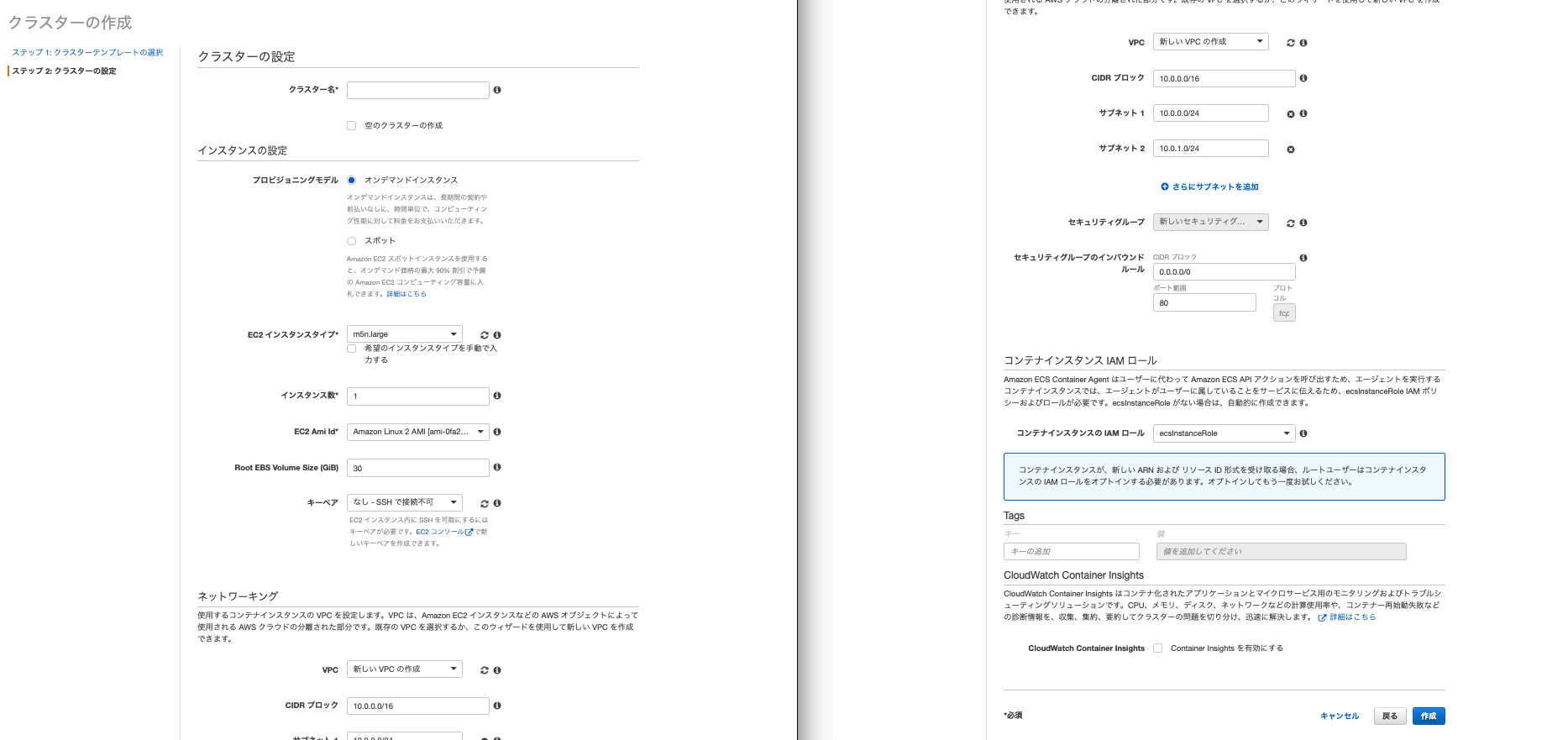
ECSでクラスタを作成する
クラスター作成
次に左側のメニューからECSのクラスターを選び、クラスターを作成をクリックします。そうすると下記画面が表示されます。
ここは「EC2 Linux + ネットワーキング」を選びます。次に設定の詳細が出てきます。
(※「AWS Fargate」については後述します)
設定でいじるところだけ説明します。
- クラスター名はわかりやすい名前を設定してください。
- EC2インスタンスタイプは「t2.micro」をにします。これ以外を選択すると無料枠ではなくなってしまうので注意してください。
- インスタンス数は1にします。
- キーペアはいつもEC2にログインしている時に使っているものを選びます。デフォルトのままだとECSから作成されたEC2にSSHで接続できません。
- ネットワーキングは作成済みのVPC、サブネットはVPCのなかのパブリックサブネット、セキュリティグループはパブリックサブネットで使っているセキュリティグループを選びます。他の触れていないところはデフォルトで問題ないです。以上クラスターの完成です。
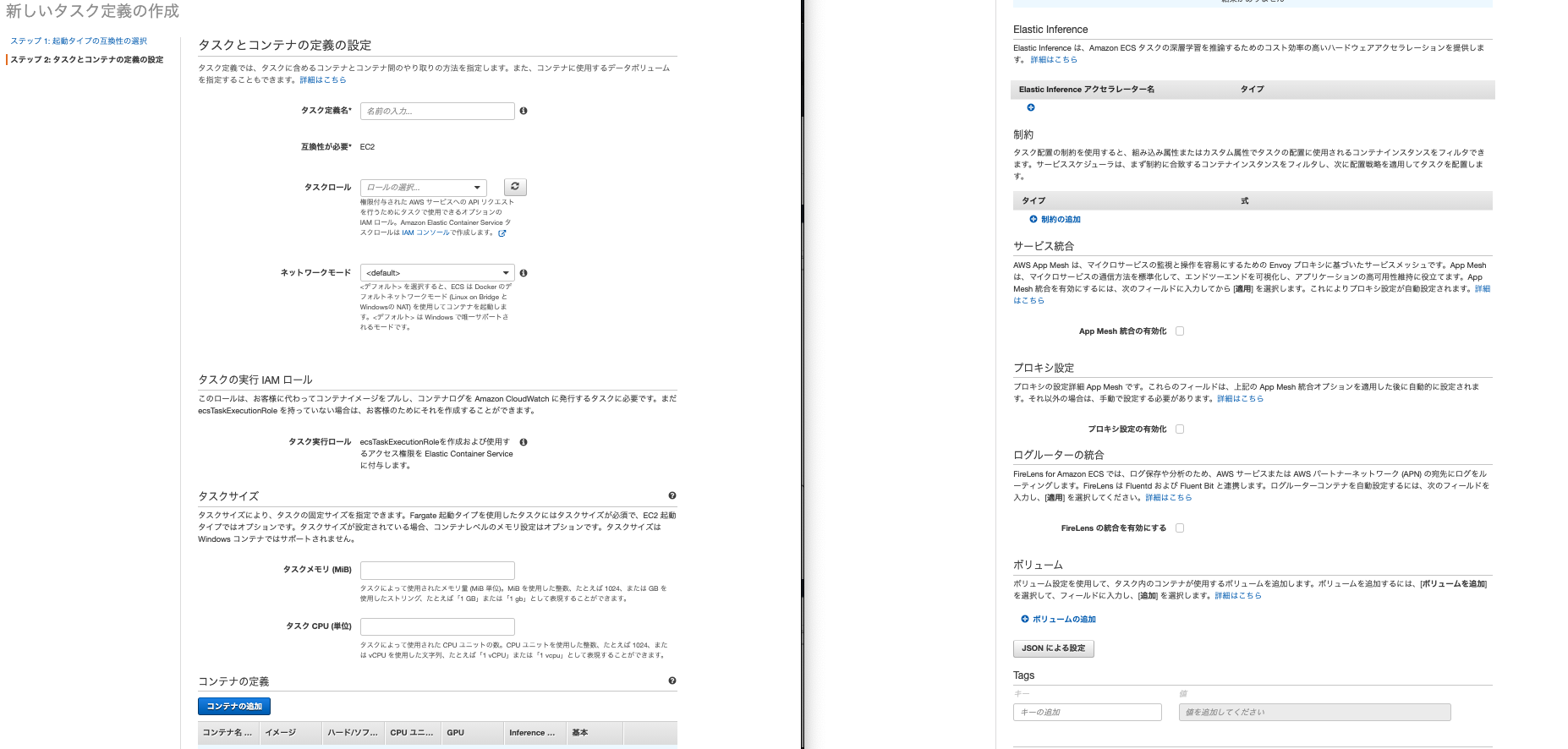
タスク作成
左側のメニューからタスク定義を選択します。起動タイプの互換性の選択という画面が表示されるのでEC2を選択します(※Fargateについては後述します)。そうすると下記設定画面がでてきます。
こちらも設定いじるところだけ説明します。
- タスク定義はわかりやすい名前を入力します。
- ネットワークモードはbridgeを選択します。ちなみにこれはdockerコンテナで使われるネットワークの種類です
- 一番下のボリュームの追加をクリックします。名前はわかりやすい名前、ボリュームタイプをDockerにしてください。他の2つはデフォルトのlocal,taskのままでOKです。ちなみにボリュームとはDockerのデータを永続する場所のことを差します。
- タスクサイズは今回は両方512で設定します。
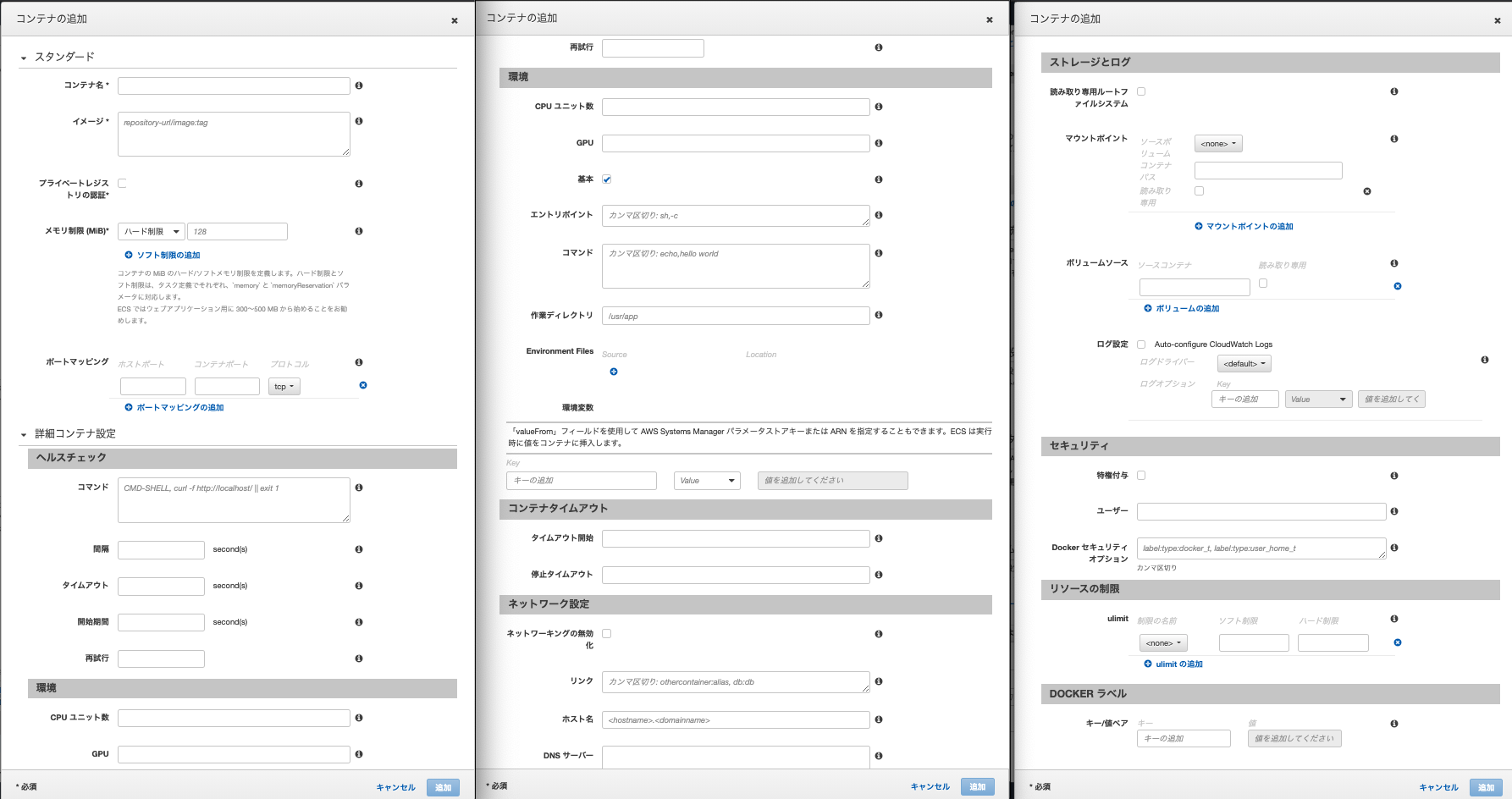
- 真ん中にあるコンテナ追加をクリックします。今回はnginx用とapp用の2つのコンテナが必要があります。ここは少し入力するところが多いのです。
- コンテナ名はわかりやすい名前を入れてください。
- イメージはECRのURIをいれます。nginxであれば、先程ECRにプッシュしたnginxのイメージのURIをいれます。URIはECRのメニューから確認できます。
- ポートマッピングはnginxであれば0:80,appであれば0:3000を入力します。※Dockerのポートの設定と同じですね。
- appのみですが、環境変数を設定します。たとえばRDSのパスワードであればKeyに「RDS_PASSWORD」を入力、値に設定したパスワードを入力します。appに必要な環境変数をここに全て入力してください。
- 他はデフォルトでOKです。
これでコンテナを2つを追加し、タスク定義の作成をクリックしましょう。これでタスクの完成です。
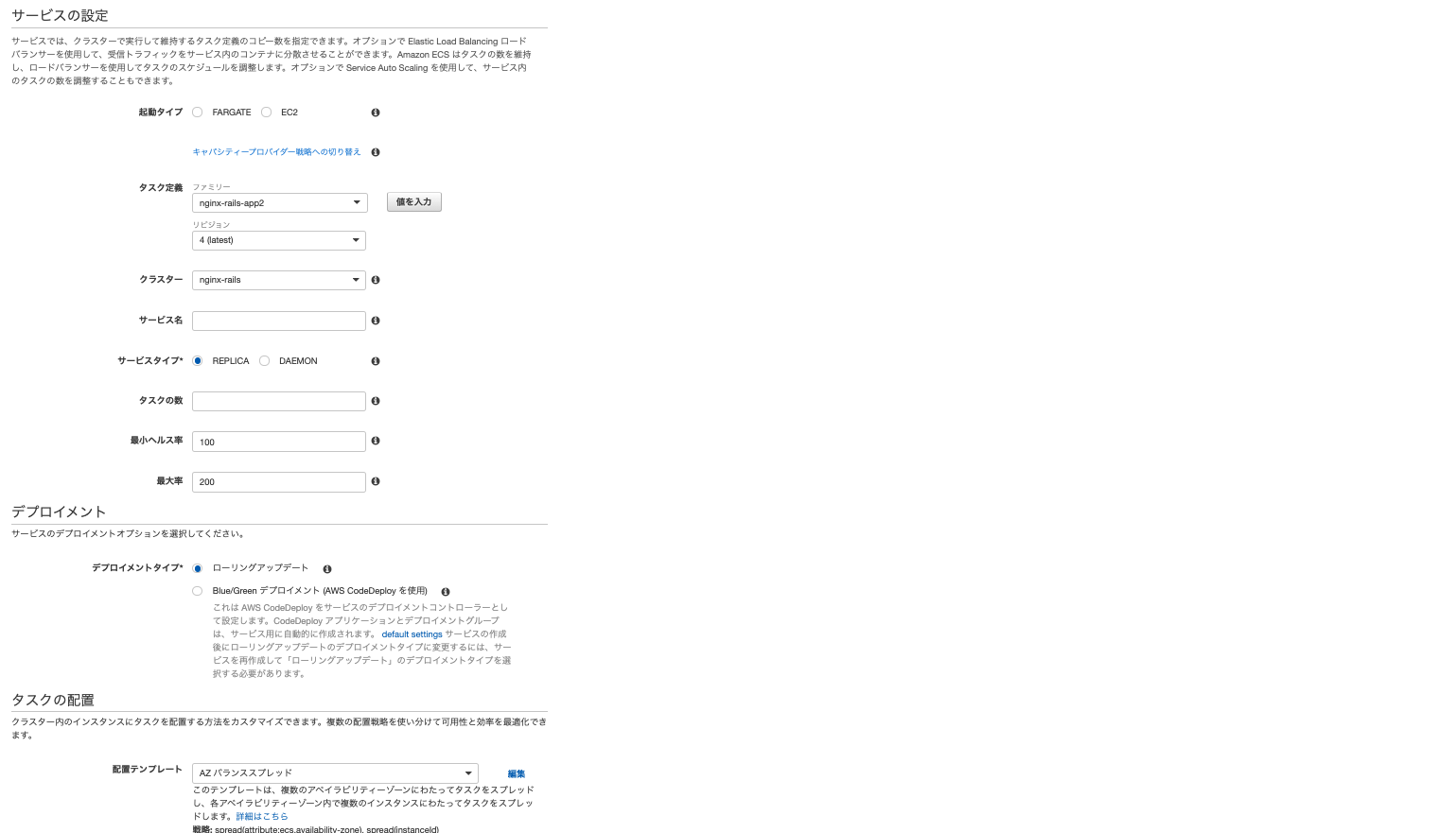
サービスの追加
左のメニューでECSのクラスターを選択し、先程作成したクラスターをクリックします。詳細画面が現れ、下部にメニューが表示されます。そのメニューの中からサービスを選び、作成ボタンを押してください。
- 起動タイプはEC2を選択します
- タスク定義は先程作成したタスクを選びます。
- サービスはわかりやすい名前をつけてください。
- タスクの数は2にします。ここはコンテナの数にあわせます。
- あとはデフォルトで大丈夫です
上記入力が完了したら次のステップを押します。すると下記画面が現れます。
- ロードバランシングは「Application Load Balancer」を選択します。そうするとロードバランサー名を選択する箇所が現れるので、作成済みのロードバランサーを選びましょう
- 次にロードバランス用のコンテナの「web:0:80」(デフォルト)をロードバランサーに追加を押します。そうするとターゲットグループ名を選択するところが表示されるので、ロードバランサー作成時に作ったターゲットグループ名を選択しましょう。
上記入力が終わったら次のステップを押します。そのあとも設定が続きますがデフォルトのままでOKです。これでサービスも完成です。
ECSをsshで接続・ブラウザでアクセス
今までで準備が完了しました。sshでECSに接続し、コンテナがあるか確認します。ECSメニューのクラスターから作成したクラスターを選択し、下部のメニューからECSインスタンスをクリックします。EC2インスタンスという項目があるので、そこからECSを通して作成したEC2が確認できます。そのEC2のプライベートipをコピーしてターミナルで下記を入力します。
ターミナル$ ssh -i [キーペアの] ec2-user@[パブリックIP] (成功するとこんな感じで表示されます) ast login: Sat Oct 24 10:28:34 2020 from 56.97.30.125.dy.iij4u.or.jp __| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/ For documentation, visit http://aws.amazon.com/documentation/ecsあとは「docker ps」や[docker image」でコンテナやイメージを確認しましょう。おそらく今まで作成したものが現れるはずです。
最後にコンテナの中に入りデータベース作成し、マイグレーションをしましょう。ターミナル$ docker exec -it [コンテナのID] bash $ rails db:create $ rails db:migrateこれでブラウザでアプリケーションが表示されるようになったと思います。
ブラウザで確認するにはEC2メニューからロードバランサーを選択し、サービスの作成時に指定したロードバランサーのDNS名をブラウザに入力します。以上で完了です。
※「AWS Fargate」とは簡単にいうと、EC2で管理・運用していたコンテナをAWSが自動でやってくれる仕組みのことです。こちら料金がかかってしまいますが、運用コストが大幅に下がります。今後はFargateが主流になる可能性が高いです。ただ個人のポートフォリオであればEC2でも大差ないかと思います。
おさらいですがおおまかな流れは下記です
ECRにdockerイメージを登録 → クラスターを作成(一番大きな箱) →タスクの定義(コンテナの関係の定義) → サービスの作成(クラスターとタスクを結びつける、ロードバランサーとコンテナの設定) → 完成次回記事ではECSとCircleCIを結びつけて、実際に自動デプロイを構築します。
まとめ・感想
ECSが独特すぎて苦労しましたが、実際に扱ってみると便利さに気づきました。AWS・Docker・CircleCIすべての知識が必要になってくるので、今まで自分が書いてきた記事を参考にしつつ自動デプロイを設定できればと思います。
参考
【書籍】
『CircleCI実践入門──CI/CDがもたらす開発速度と品質の両立 浦井 誠人 (著), 大竹 智也 (著), 金 洋国 (著) 』【qiita】
『いまさらだけどCircleCIに入門したので分かりやすくまとめてみた』
『【CircleCI】Railsアプリに導入(設定ファイルについて)』
『初心者でもできる! ECS × ECR × CircleCIでRailsアプリケーションをコンテナデプロイ』【その他サイト】
『CircleCI Orbsを使ってECR/ECSへ自動デプロイする』

- 投稿日:2020-10-26T15:27:05+09:00
AWSのEC2インスタンス上に.NET Core + nginx環境を構築
.NET Core + MySQL + Elasticsearch(Nest)構成でクリーンアーキテクチャなバックエンド開発 の続きです。
今回はAWSのEC2インスタンス上にWebアプリを配置後、nginxでリバースプロキシするところまでをご紹介しようと思います。
はじめに
ネットワーク構築とEC2インスタンスの作成が済んでいることが前提となります。
その部分に関しては以下書籍で勉強しましたので合わせてご紹介します。
Amazon Web Services 基礎からのネットワーク&サーバー環境
- Amazon Linux 2 AMI (HVM), SSD Volume Type
- t2.micro
ソースコード
https://github.com/t-ash0410/asp.net-core-sample
1. EC2インスタンスにnginxのインストール
まずはnginxをインストールしましょう。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo yum -y update $ sudo amazon-linux-extras install nginx1 $ sudo service nginx start以上を実施した後、ローカルマシンのブラウザにて
http://サーバIPに接続し、以下のような画面が表示されれば成功です。
$ sudo amazon-linux-extras install nginx1
このコマンドについてですが、EC2インスタンス上でnginxをインストールしようとするとこのコマンドを使ってねという案内が表示されました。
amazon-linux-extrasについてはこちらで紹介されています。2. nginxにリバースプロキシ設定
次にnginxにリバースプロキシの設定をしていきます。
nginxのコンフィグファイルを編集するため、EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo vim /etc/nginx/nginx.confコンフィグファイルの内容を以下のように編集します。
server { # ここから location / { proxy_pass http://localhost:5000/; } # ここまで追加 }以下コマンドでコンフィグファイルの内容が正しいか確認します。
$ sudo nginx -t #これが出力されればOK nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful編集完了後、設定を反映させるためnginxを再起動します。
$ sudo service nginx restartもう一度、ローカルマシンのブラウザにて
http://サーバIPに接続してみましょう。
現状ではポート5000にてアプリケーションを起動していないため、以下のような画面が表示されればOKです。
3. EC2インスタンスに.NET Core Runtimeのインストール
続いて、.NET Coreアプリケーション実行のために、.NET Core Runtimeをインストールしていきます。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo rpm -Uvh https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm $ sudo yum install -y aspnetcore-runtime-3.1runtimeが正常にインストールされたかを確認します。
$ dotnet -h #これが出力されればOK It was not possible to find any installed .NET Core SDKs Did you mean to run .NET Core SDK commands? Install a .NET Core SDK from: https://aka.ms/dotnet-download Usage: dotnet [host-options] [path-to-application] path-to-application: The path to an application .dll file to execute. host-options: --additionalprobingpath <path> Path containing probing policy and assemblies to probe for. --depsfile <path> Path to <application>.deps.json file. --runtimeconfig <path> Path to <application>.runtimeconfig.json file. --fx-version <version> Version of the installed Shared Framework to use to run the application. --roll-forward <value> Roll forward to framework version (LatestPatch, Minor, LatestMinor, Major, LatestMajor, Disable) --additional-deps <path> Path to additional deps.json file. --list-runtimes Display the installed runtimes --list-sdks Display the installed SDKs Common Options: -h|--help Displays this help. --info Display .NET Core information.4. EC2インスタンスに.NET Coreアプリケーションをデプロイ
続いては.NET Coreアプリケーションのデプロイまでを一気にやっていきます。
まずは、アプリケーションをデプロイするディレクトリを作成しましょう。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo mkdir -p /var/www/asp-net-app $ sudo chown ec2-user /var/www/asp-net-app
次に、アプリケーションを発行します。
ローカルマシンで以下コマンドを実行してください。$ cd アプリケーションのルートディレクトリ/app/Web $ dotnet publish -c Release # これが表示されればOK Microsoft (R) Build Engine version 16.7.0+7fb82e5b2 for .NET Copyright (C) Microsoft Corporation. All rights reserved. Determining projects to restore... All projects are up-to-date for restore. Lib -> アプリケーションのルートディレクトリ/app/Lib/bin/Release/netcoreapp3.1/Lib.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/Web.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/Web.Views.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/publish/
続いて、発行されたアプリケーションをデプロイしましょう。
以下コマンドをローカルマシンにて実行します。$ scp -i "pemファイル" -r アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/publish/* ec2-user@サーバアドレス:/var/www/asp-net-app # ファイルの転送状況が表示されていればOK
ここまででアプリケーションのデプロイが完了しました。
確認のため、EC2インスタンスにSSHして以下を実行してみましょう。$ dotnet /var/www/asp-net-app/Web.dll次に、ローカルマシンのブラウザで
http://サーバIP/health/checkを表示してみます。
以下のようなレスポンスが返却されればサーバ上でアプリケーションの実行に成功しています。
5. サービスにアプリケーションを追加
以上の手順でEC2上にて.NET Coreアプリケーションを実行することに成功しましたが、このままだと実行ユーザがSSHでログインしたユーザになっているので、ログアウトするとアプリが停止してしまいます。
そんなWebアプリケーションは聞いたことがないので、nginxにアプリケーションの管理を任せ、ログアウト後も実行を継続させましょう。
まずは追加するサービスの構成ファイルを作成します。
以下コマンドを実行しましょう。$ sudo vim /etc/systemd/system/kestrel-asp-net-app.service [Unit] Description=Service file for book app. [Service] WorkingDirectory=/var/www/asp-net-app ExecStart=/usr/bin/dotnet /var/www/asp-net-app/Web.dll Restart=always RestartSec=10 SyslogIdentifier=dotnet-example User=nginx Environment=ASPNETCORE_ENVIRONMENT=Production [Install] WantedBy=multi-user.target
次に、作成したサービスをsystemctlに登録します。
以下コマンドを実行しましょう。$ sudo systemctl enable kestrel-asp-net-app.service $ sudo systemctl start kestrel-asp-net-app.service以下コマンドで正常に起動しているかの確認ができます。
反映まで数秒かかる場合がありますので、焦らずに確認していきましょう。$ systemctl status kestrel-asp-net-app.service #これが表示されればOK kestrel-asp-net-app.service - Service file for book app. Loaded: loaded (/etc/systemd/system/kestrel-asp-net-app.service; enabled; vendor preset: disabled) Active: active (running) since 日 2020-10-25 19:14:25 UTC; 11h ago Main PID: 9868 (dotnet) CGroup: /system.slice/kestrel-asp-net-app.service └─9868 /usr/bin/dotnet /var/www/asp-net-app/publish/Web.dll
以上でサービスへの登録が完了し、ログアウト後もサービスを続けることが可能になりました。
確認のため、SSH接続を終了し、ローカルマシンにてhttp://サーバIP/health/checkにアクセスしてみましょう。
{message:"ok"}が表示されれば正常にアプリケーションが動作しています。link
MS Nginx 搭載の Linux で ASP.NET Core をホストする
次回
EC2上で動作する.NET CoreアプリケーションにRDSを追加 -> 作成中...


- 投稿日:2020-10-26T15:27:05+09:00
【AWS入門】EC2インスタンス上に.NET Core + nginx環境を構築
.NET Core + MySQL + Elasticsearch(Nest)構成でクリーンアーキテクチャなバックエンド開発 の続きです。
今回はAWSのEC2インスタンス上にWebアプリを配置後、nginxでリバースプロキシするところまでをご紹介しようと思います。
はじめに
ネットワーク構築とEC2インスタンスの作成が済んでいることが前提となります。
その部分に関しては以下書籍で勉強しましたので合わせてご紹介します。
Amazon Web Services 基礎からのネットワーク&サーバー環境
- Amazon Linux 2 AMI (HVM), SSD Volume Type
- t2.micro
ソースコード
https://github.com/t-ash0410/asp.net-core-sample
1. EC2インスタンスにnginxのインストール
まずはnginxをインストールしましょう。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo yum -y update $ sudo amazon-linux-extras install nginx1 $ sudo service nginx start以上を実施した後、ローカルマシンのブラウザにて
http://サーバIPに接続し、以下のような画面が表示されれば成功です。
$ sudo amazon-linux-extras install nginx1
このコマンドについてですが、EC2インスタンス上でnginxをインストールしようとするとこのコマンドを使ってねという案内が表示されました。
amazon-linux-extrasについてはこちらで紹介されています。2. nginxにリバースプロキシ設定
次にnginxにリバースプロキシの設定をしていきます。
nginxのコンフィグファイルを編集するため、EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo vim /etc/nginx/nginx.confコンフィグファイルの内容を以下のように編集します。
server { # ここから location / { proxy_pass http://localhost:5000/; } # ここまで追加 }以下コマンドでコンフィグファイルの内容が正しいか確認します。
$ sudo nginx -t #これが出力されればOK nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful編集完了後、設定を反映させるためnginxを再起動します。
$ sudo service nginx restartもう一度、ローカルマシンのブラウザにて
http://サーバIPに接続してみましょう。
現状ではポート5000にてアプリケーションを起動していないため、以下のような画面が表示されればOKです。
3. EC2インスタンスに.NET Core Runtimeのインストール
続いて、.NET Coreアプリケーション実行のために、.NET Core Runtimeをインストールしていきます。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo rpm -Uvh https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm $ sudo yum install -y aspnetcore-runtime-3.1runtimeが正常にインストールされたかを確認します。
$ dotnet -h #これが出力されればOK It was not possible to find any installed .NET Core SDKs Did you mean to run .NET Core SDK commands? Install a .NET Core SDK from: https://aka.ms/dotnet-download Usage: dotnet [host-options] [path-to-application] path-to-application: The path to an application .dll file to execute. host-options: --additionalprobingpath <path> Path containing probing policy and assemblies to probe for. --depsfile <path> Path to <application>.deps.json file. --runtimeconfig <path> Path to <application>.runtimeconfig.json file. --fx-version <version> Version of the installed Shared Framework to use to run the application. --roll-forward <value> Roll forward to framework version (LatestPatch, Minor, LatestMinor, Major, LatestMajor, Disable) --additional-deps <path> Path to additional deps.json file. --list-runtimes Display the installed runtimes --list-sdks Display the installed SDKs Common Options: -h|--help Displays this help. --info Display .NET Core information.4. EC2インスタンスに.NET Coreアプリケーションをデプロイ
続いては.NET Coreアプリケーションのデプロイまでを一気にやっていきます。
まずは、アプリケーションをデプロイするディレクトリを作成しましょう。
EC2インスタンスにSSHして、以下コマンドを実行します。$ sudo mkdir -p /var/www/asp-net-app $ sudo chown ec2-user /var/www/asp-net-app
次に、アプリケーションを発行します。
ローカルマシンで以下コマンドを実行してください。$ cd アプリケーションのルートディレクトリ/app/Web $ dotnet publish -c Release # これが表示されればOK Microsoft (R) Build Engine version 16.7.0+7fb82e5b2 for .NET Copyright (C) Microsoft Corporation. All rights reserved. Determining projects to restore... All projects are up-to-date for restore. Lib -> アプリケーションのルートディレクトリ/app/Lib/bin/Release/netcoreapp3.1/Lib.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/Web.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/Web.Views.dll Web -> アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/publish/
続いて、発行されたアプリケーションをデプロイしましょう。
以下コマンドをローカルマシンにて実行します。$ scp -i "pemファイル" -r アプリケーションのルートディレクトリ/app/Web/bin/Release/netcoreapp3.1/publish/* ec2-user@サーバアドレス:/var/www/asp-net-app # ファイルの転送状況が表示されていればOK
ここまででアプリケーションのデプロイが完了しました。
確認のため、EC2インスタンスにSSHして以下を実行してみましょう。$ dotnet /var/www/asp-net-app/Web.dll次に、ローカルマシンのブラウザで
http://サーバIP/health/checkを表示してみます。
以下のようなレスポンスが返却されればサーバ上でアプリケーションの実行に成功しています。
5. サービスにアプリケーションを追加
以上の手順でEC2上にて.NET Coreアプリケーションを実行することに成功しましたが、このままだと実行ユーザがSSHでログインしたユーザになっているので、ログアウトするとアプリが停止してしまいます。
そんなWebアプリケーションは聞いたことがないので、nginxにアプリケーションの管理を任せ、ログアウト後も実行を継続させましょう。
まずは追加するサービスの構成ファイルを作成します。
以下コマンドを実行しましょう。$ sudo vim /etc/systemd/system/kestrel-asp-net-app.service [Unit] Description=Service file for book app. [Service] WorkingDirectory=/var/www/asp-net-app ExecStart=/usr/bin/dotnet /var/www/asp-net-app/Web.dll Restart=always RestartSec=10 SyslogIdentifier=dotnet-example User=nginx Environment=ASPNETCORE_ENVIRONMENT=Production [Install] WantedBy=multi-user.target
次に、作成したサービスをsystemctlに登録します。
以下コマンドを実行しましょう。$ sudo systemctl enable kestrel-asp-net-app.service $ sudo systemctl start kestrel-asp-net-app.service以下コマンドで正常に起動しているかの確認ができます。
反映まで数秒かかる場合がありますので、焦らずに確認していきましょう。$ systemctl status kestrel-asp-net-app.service #これが表示されればOK kestrel-asp-net-app.service - Service file for book app. Loaded: loaded (/etc/systemd/system/kestrel-asp-net-app.service; enabled; vendor preset: disabled) Active: active (running) since 日 2020-10-25 19:14:25 UTC; 11h ago Main PID: 9868 (dotnet) CGroup: /system.slice/kestrel-asp-net-app.service └─9868 /usr/bin/dotnet /var/www/asp-net-app/publish/Web.dll
以上でサービスへの登録が完了し、ログアウト後もサービスを続けることが可能になりました。
確認のため、SSH接続を終了し、ローカルマシンにてhttp://サーバIP/health/checkにアクセスしてみましょう。
{message:"ok"}が表示されれば正常にアプリケーションが動作しています。link
MS Nginx 搭載の Linux で ASP.NET Core をホストする
次回
- 投稿日:2020-10-26T14:18:55+09:00
データ分析基盤におけるデータレイクでの保持ファイル形式、および、インターフェースファイルの形式について
概要
データ分析基盤にてよく用いられるファイル形式を整理します。
データ分析基盤で用いるファイル形式と利用指針
番号 フォーマット 説明 データ分析基盤での利用推奨 1 区切り型テキストファイル(CSV、TSV) カンマ区切り、あるいは、タブ区切りによりデータを保持したファイルフォーマットであり、容易に利用できる。データストアに取り込む際には、最も高速に取り込むことができることが多い。 データレイク:×
業務システム:〇
バッチレイヤーへの連携時:◎
サービスレイヤーへの連携時:◎
リアルタイム処理時:〇
データ連携サービス:〇
クエリエンジン:×2 json システムで利用されるデータ形式。 × 3 xml システムで利用されるデータ形式。 × 4 Apache Parquet 列指向のデータ形式。スキーマの自動読み込みが可能。 データレイク:〇
業務システム:×
バッチレイヤーへの連携時:〇
サービスレイヤーへの連携時:×
リアルタイム処理時:×
データ連携サービス:〇
クエリエンジン:◎5 Delta Lake ACID特性などを保持させなどのParquetを拡張させたデータ形式。データレイクにおけるスタンダードとなりそうなファイル形式。ただし、利用するサービスで対応しているか確認する必要がある。 データレイク:◎
業務システム:×
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:〇
データ連携サービス:〇
クエリエンジン:〇6 Apache Avro スキーマ情報を保持しており、システム間でデータ交換を行うための行指向のデータ形式。 データレイク:×
業務システム:×
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:◎
データ連携サービス:×
クエリエンジン:×7 ORC Hiveの処理に最適化された列指向のデータ形式。 × 8 Common Data Model 標準の共通データ モデル形式のスキーマ化されたデータとして保存するデータ形式。 データレイク:×
業務システム:◎
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:×
データ連携サービス:〇
クエリエンジン:×Q&A
- 投稿日:2020-10-26T10:08:01+09:00
AWS S3 Macローカルのディレクトリを任意のバケットに同期する
目的
- AWSのS3の任意のバケットにMacローカルのディレクトリを同期する方法をまとめる
実施環境
- ハードウェア環境
項目 情報 OS macOS Catalina(10.15.5) ハードウェア MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) プロセッサ 2 GHz クアッドコアIntel Core i5 メモリ 32 GB 3733 MHz LPDDR4 グラフィックス Intel Iris Plus Graphics 1536 MB
- S3
- 下記の方法でバケットを作成した。
必要なもの
- バケット作成をしたAWSアカウントのアクセスキーとシークレットアクセスキー(AWSのユーザアカウント登録時にダウンロードされたCSVに記載されている、シークレットアクセスキーは再確認方法がなかったはずなのでCSVを紛失したなら新たにアカウント作成したほうが早いかもしれない。)
前提情報
- 本説明で実行するコマンドはMacのターミナルで実行するものとする。
詳細
- 下記にアクセスする。
- 「AWS CLIの最新バージョンの場合:」のリンクをクリックする。
- インストールされた「AWSCLIV2.pkg」をダブルクリックで開く。
- 「続ける」をクリックする。
- 内容を確認して「続ける」をクリックする。
- 使用許諾契約の内容を確認して問題ない場合「続ける」をクリックする。
- インストール先はお好みのものを選んで「続ける」をクリックする。
- インストール先が決定したら「インストール」をクリックする。
- インストールが完了したら「閉じる」をクリックする。
下記コマンドを実行してAWSアカウントの情報を入力する。
$ aws configure下記のように設定内容を入力してEnterを押下する。
> AWS Access Key ID [None]: AWSアカウントのアクセスキーを入力する > AWS Secret Access Key [None]: AWSアカウントのシークレットアクセスキーを入力する > Default region name [None]: ap-northeast-1と入力する > Default output format [None]: 何も入力しない下記コマンドを実行してMacの
~/ディレクトリにtestディレクトリを作成する。$ mkdir ~/test下記コマンドを実行して
~/testディレクトリにtest.txtファイルを作成する。$ touch ~/test/test.txt下記コマンドを実行してMacのローカルの
~/testディレクトリをS3のバケットに同期する。設定がうまく行っていればtest.txtが指定したバケットの直下にアップロードされる。$ aws s3 sync ~/test s3://同期先のバケット名同期先のバケットのtestディレクトリ直下にMacローカルのtest.txtをアップロードしたい場合は下記を実行する。
$ aws s3 sync ~/test s3://同期先のバケット名/test参考文献
- 投稿日:2020-10-26T10:03:05+09:00
AWS Certified Advanced Networking - Specialty 合格記録
この記事
AWS Advanced Networking Specialty を取得したので
学習内容と感想を記録します。about me
インフラエンジニアで、AWS関連のインフラ構築や保守を3年くらい経験しています。
ネットワークに関してはこの業界でインフラをやることになったきっかけでもあり
その昔研修でルータ設定とサーバ構築を併せて行ったことはあります。
クラウドの業務が大半なのでオンプレ業務経験はそこまでないです。AWS資格は
2019 Solution Architect Associate (7月) SysOps Administrator Associate (9月) Solution Architect Professional (11月) Developer Associate (12月) 2020 DevOps Engineer Professional (3月) Security Specialty(5月) Advanced Networking(10月)という順で取得しました。
Networkingの資格は一番とりたかったAWSの資格なので
今回はとても嬉しい結果となりました。about ANS試験
AWS 認定 高度なネットワーキング – 専門知識
https://aws.amazon.com/jp/certification/certified-advanced-networking-specialty/試験対策でやったこと
試験ガイドとサンプル問題
毎度ここが超重要です。
「試験ガイドとサンプル問題」はまず目を通します。
↑リンク先「試験ガイド」「サンプル問題」また、この試験は模擬試験はなかったと思います。
注意すべき点は試験ガイドのこの部分です。
分野 1: 大規模なハイブリッド IT ネットワークアーキテクチャを設計し、実装する
ハイブリッド、つまりオンプレも出る前提なので、ネットワークの知識は絶対に避けられないものですね。
23%を占めています。具体的には、いろんなサイトの模擬試験をやればわかると思いますが
基本的なポートやプロトコル、ルーティングのルールなど、クラウドのみに依存しない知識が必要とされます。ソリューションアーキテクト分野のVPC分野はもちろん被っているので、そこからさらに深く学びたいところです。
また、試験ガイドにもあるとおり
DirectConnectやRoute53などは必須部分となるので集中的に学習が必要です。AWS公式ドキュメントによる対策
こちらで学習しました。
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
※Networking & Content Delivery 部分全てネットワーキング - AWS Answers
https://aws.amazon.com/jp/answers/networking/APNブログの、各ネットワーキング関連の記事
例:AWS PrivateLink
https://aws.amazon.com/jp/blogs/apn/reviewing-dns-mechanisms-for-routing-traffic-and-enabling-failover-for-aws-privatelink-deployments/Udemy
問題集を100%になるまで解きました。
自分に足りない知識がわかるので随時ドキュメントを調べていきます。
https://www.udemy.com/course/aws-certified-advanced-networking-specialty-practice-tests-/結果今回は使用しませんでしたが、Route53やVPCリソースも実務経験が少ない場合は
こちらのハンズオンがあればイメージしやすいなと感じました。
https://www.udemy.com/course/awsnetworking/DirectConnect
DXについてはほぼ触った事がない状態だったので
ルーティングの知識はこちらの資料を参考にさせていただきました。
非常に頭の整理ができました。ありがとうございました。
https://www.slideshare.net/skikuchi/akibaaws-vgwNetwork
出る/出ない関係なく、私が補ったのは主にこの辺りでした。
AWSの中で何をやってくれてるの・・・?という疑問から、ネットワークを再度学習しました。
難しいことまで覚えるのではなく、この技術が中でどんなことをしてくれてるのかイメージするのは重要かと思います。・ルーティング
https://www.infraexpert.com/study/study19.html
※AWS側
https://docs.aws.amazon.com/vpc/latest/userguide/what-is-amazon-vpc.html・VLAN
https://www.infraexpert.com/study/vlanz1.html・VRF
https://www.infraexpert.com/study/mpls5.html・Squidとプロキシ
https://www.designet.co.jp/faq/term/?id=c3F1aWQ・BFD
https://www.infraexpert.com/study/routing11.html・MPLS
https://www.infraexpert.com/study/mpls1.htmlこれらのワードのきっかけは、主に試験ガイドや問題集からです。
推奨される一般的な IT の知識
他にも、ルートテーブルやDirectConnectのアーキテクチャで
頻繁に出てくるような技術を学習しました。Tips
パブリック仮想インターフェース?
仮装プライベートゲートウェイ?
Transit VPC?
Private Link ...?みたいな状態だと確実に落ちるので、そこの知識を
具体的なアーキテクチャを踏まえて整理することが大事だと感じました。ソリューションアーキテクトプロフェッショナルの時みたいに、
広範囲であっちもこっちも。。という試験範囲ではないので、そういう意味では取り組みやすい…結果&まとめ
一度目の試験の時は、Tipsのような状態に試験日になったので完全にアウトでしたが、
二度目の今回は全て知識の穴埋めをし終えて余裕を持って合格しました。当日、鼻炎が酷くかなりバッドコンディションでしたが、コーヒーで乗り越えました。
いつもの試験日のルーティンに助けられた気がします。ANS試験はSolution Architectの資格の知識が有効だったと感じます。
試験対策としての学習時間は40-50時間程度でした。全体的に、英語ドキュメントや英語の情報が多く見受けられたので
やっぱり英語って大事だなと感じました。。また、今回で7個目のAWS資格を取得することができました。
受けていて感じることは、資格の学習は、AWSでは特に知識をつけるための入り口(きっかけ)になるということです。
試験取得後はベースの知識はあるので、その状態でホワイトペーパーやベストプラクティスを改めて読み直し、
自分で検証をしてしっかり頭に入れる流れが今のところ一番効果的だなと感じます。..というのも、知識ゼロの時に立派なホワイトペーパーを読んでも正直全然頭に入らなかったからです。
資格用の問題演習や、いきなりのハンズオンから入る方がまだ頭に入るなと感じました。ちょうど私はここ数ヶ月で、半年ほど前に取得したSecurity資格の知識を実際に活用する場面があったりしたので、
その際にドキュメントやホワイトペーパーを読み直し、より詳しく頭に入れることができている気がします。次の試験
Database Specialtyを取ります。
データベースに弱いので、少し辛い思いをしそうですが頑張ります。この記事が何かのお役に立てられれば幸いです。
ありがとうございました!Qiitaへの記録
SAA
https://qiita.com/shinon_uk/items/5525178bf98034676b2fSOP
https://qiita.com/shinon_uk/items/e60bcb946b49bf5cabdaSAP
・合格編
https://qiita.com/shinon_uk/items/c6b599d1cd3000e84d59
・失敗編(資料集め)
https://qiita.com/shinon_uk/items/ba839ba048ba439cc3ffDVA
https://qiita.com/shinon_uk/items/8015953c792ef4bc7223
- 投稿日:2020-10-26T09:42:11+09:00
EC2のCPU使用率が上がらない件
起きたこと
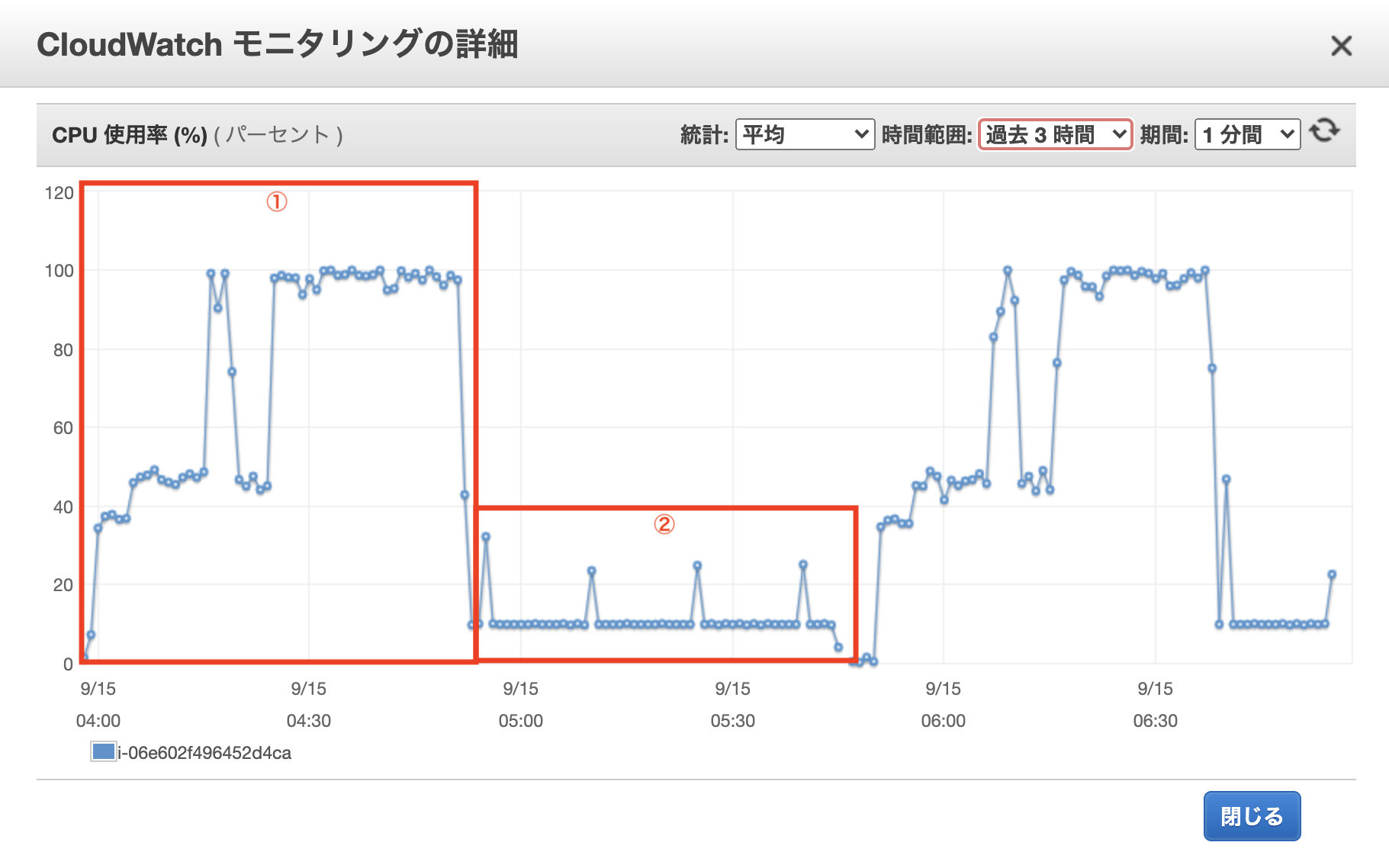
EC2(インスタンスタイプ:t2.micro)で重たい処理を走らせた所、途中までは下図①のようにCPU使用率が100 %まで上がるものの、その先で下図②のように10 %から上がらず処理に時間がかかりました。
プロセスも終了していないし、メモリやネットワーク、RDSなどの使用率も確認したがボトルネックになっているような箇所は見受けられませんでした。
キーワード
- CPUクレジット
- ベースライン使用率
- Unlimitedモード
t2の挙動
公式説明
t2の説明文にはこのように書いてあります。
ベースラインから必要に応じてバースト可能な汎用インスタンスタイプ
私はこの一文を「ベースライン = CPU使用率100 %」と解釈したため、通常使用でもCPU使用率100 %を発揮でき、必要に応じてオートスケール可能なのだという思い込みをしていました。
CPUクレジットとベースライン
t2およびt3インスタンスにはCPUクレジットという概念があります。
CPUクレジット残高が0のとき、各インスタンスごとに決められたベースライン使用率で稼働します。例としてt2.microではベースライン使用率が10 %なので、
CPUクレジット残高が0のとき起きたことに掲載した画像の②のように10 %を超えた稼働ができなくなります。CPUクレジット1つは、1vCPUのCPU使用率を1分間100%まで上げることができます。
例として、
- 1vCPUのCPU使用率50% -> 2分間で1クレジットを消費
- 2vCPUのCPU使用率50% -> 1分間で1クレジットを消費
※ 実際にはCPUクレジットは整数値ではなくミリ秒単位で消費計算がされます。
Unlimitedモード
t3ではデフォルトでUnlimitedモードがONにされています。
これはCPUクレジットが枯渇してもベースライン使用率を超えた稼働を可能にするものですが、当然その分は課金が必要になります。CPUクレジットの獲得
CPUクレジットは2つの方法で獲得することができます。
- 起動クレジット (t2のみ)
- 経時獲得クレジット
t2インスタンスは停止・再起動によってCPUクレジットの持ち越しができません。
その代わり、起動時に起動クレジットがもらえます。
t2.microの場合は30クレジットです。一方で経時獲得クレジットは起動している間、インスタンスタイプによって決められた割合だけ時間経過でもらえるクレジットです。
t2.microの場合は6クレジット/時です。※ 消費と同様に、実際にはCPUクレジットは整数値ではなくミリ秒単位で獲得計算がされます。
CPUクレジットの保有と消費
CPUクレジットは経時獲得量が消費量を上回る時、残高が増えていきますが保有できる上限が決まっています。
上限数はインスタンスタイプによって異なりますが、 24時間で獲得可能なクレジット数 と同値です。また、t2の起動クレジットと経時獲得クレジットは見た目上区別されていませんが、消費の優先度や獲得上限などでは区別されています。
区別1 保有可能上限は別管理
上記でCPUクレジットの保有可能上限を24時間で獲得可能なクレジット数と述べましたが、これは経時獲得クレジットの上限で起動クレジットは別カウントされます。
そのため、起動してからクレジットを一切消費しなかった場合、保有できる最大値は保有できる最大値 = 起動クレジット + 経時獲得クレジットの上限
になります。
区別2 起動クレジットから消費される
起動クレジットと経時獲得クレジットの両方が存在しているとき、起動クレジットを消費し、起動クレジットが枯渇してから経時獲得クレジットを消費し始めます。
おまけ:ベースライン使用率の本質と計算方法
ベースライン使用率は本質的には 「CPUクレジットの獲得数と消費数が釣り合うCPU使用率」 です。
ためしにt2.microとt2.largeを例にベースライン使用率を計算してみましょう。
t2.microのベースライン使用率
t2.microは1vCPUで1時間に6クレジットを獲得できます。
そのため1vCPUが1時間で6クレジットを消費するようなCPU使用率を計算すればOKです。60分あたり6クレジット消費可能
-> 1分あたり0.1クレジット消費可能
-> 0.1 = 10%(ベースライン使用率)ということで、10%の使用率が算出されました。
t2.largeのベースライン使用率
t2.largeは2vCPUで1時間に36クレジットを獲得できます。
t2.microと同様に計算をしますが、複数vCPUなためベースライン使用率の算出のためにはvCPU数で割る必要があります。60分あたり36クレジット消費可能 / 2vCPU
-> 1分あたり0.6クレジット消費可能 / 2vCPU
-> 0.6 / 2vCPU = 60% / 2vCPU
-> 1vCPUあたり30%(ベースライン使用率)最後に
t2インスタンスは気軽に使えて便利ではありますが、制約も大きく、できることには限りがありますね。
AWSはこのあたりのバランス感覚が非常に優れているな、と改めて痛感しました。
- 投稿日:2020-10-26T09:11:18+09:00
AWSでIAMユーザを使い捨てにする
はじめに
私が所属するaslead DevOpsチームでは、日々変化するユーザの開発サーバ構成に対して、セキュリティを保ちつつ開発業務の効率化・自動化ができないかを検討しています。
この記事では、AWSにログインして作業するIAMユーザの扱い方についてご紹介します。AWSの中でもセキュリティの基礎となる重要サービスであり、ユーザの棚卸しや権限の管理に時間を割かれているチームも多いのではないでしょうか。
そこで、Hashicorp社が提供しているVaultを利用し、作業のタイミングでIAMユーザを作成し、終わったら削除するアプローチを考えてみます。IAMユーザの作成自体はVaultの標準機能ですが、複数アカウントの権限制御ができるスイッチロールとの組み合わせを提案します。Vaultとは
公式サイトより、Vaultは主に以下のような機能を持っています。
- Secret Management:様々な環境のパスワードのライフサイクルを管理する
- Data Encryption:データの暗号化/複合化を行う(データ自体は保持せず、変換だけ)
- Identity-based Access:同一人物の様々な環境上のアカウントを一つに取りまとめる
本記事ではSecret Managementに分類される機能を取り扱います。
想定するIAMユーザ運用
以下のようなAWSの不正利用のリスクがある運用ケースを想定し、解消を試みてみます。
- チームから移動したメンバのIAMユーザは手動で削除している
- 強い権限を持った、アクセスキーが固定の機械ユーザがいる
- アクセスキーの発行操作に特に制限をかけていない
Vaultによる解決策
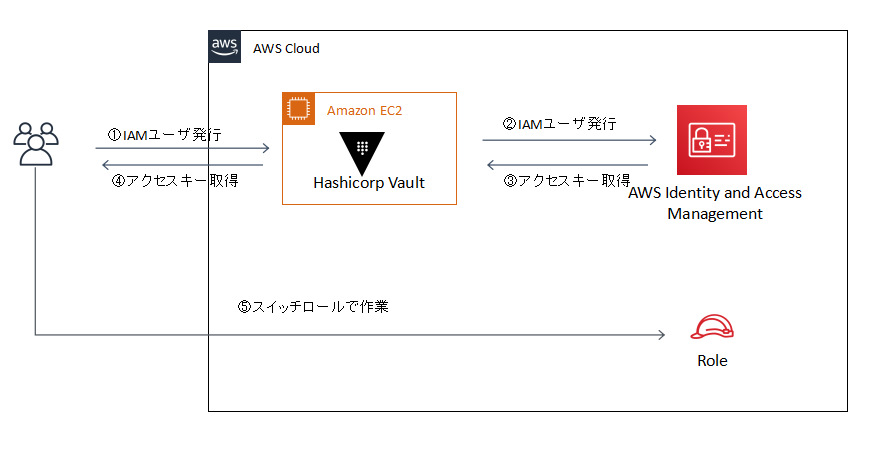
上記のリスクに対し、今回はAWS Secret EngineでIAMユーザを作成し、スイッチロールで作業するアプローチをとってみます。
これにより、以下のようなメリットがもたらされます。
- Vault以外に固定のIAMユーザが不要になり、IAMユーザの管理が容易になる
- 利用時のみ機械ユーザを作成することで、アクセスキーの流出リスクを低減できる
- Vault側でLDAPなどと組み合わせれば、アクセスキー(IAMユーザ)の発行を制御できる
以下では具体的にVaultを構築し、発行したIAMユーザでスイッチロールする部分について実装していきます。なお、上記では作業対象のAWSアカウント上にVaultを構築していますが、異なるAWSアカウントに対してもIAMユーザの発行が可能です。
実装
実装する環境
今回は以下の環境で実装を行います。
AWS上でVaultを構築していますが、ローカルでも確認可能な内容になっています。
- Vault:ver1.5.4
- OS:Amazon Linux 2
- IaaS:AWS EC2サービス
OS部分の構築
本記事の主な解説対象ではないため、割愛します。
Acrovision社の記事などが参考になるかと思います。以降は、Vaultが稼働するOSを
vaultというホスト名で作成した前提で進みます。Vaultのインストール
2020/07/24より、Linuxレポジトリからの取得が可能になりましたので、こちらを利用して
vaultに対してインストールしていきます。$ sudo yum install -y yum-utils Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 Package yum-utils-1.1.31-46.amzn2.0.1.noarch already installed and latest version Nothing to do $ sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo Loaded plugins: extras_suggestions, langpacks, priorities, update-motd adding repo from: https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo grabbing file https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo to /etc/yum.repos.d/hashicorp.repo repo saved to /etc/yum.repos.d/hashicorp.repo $ sudo yum install -y vault ~中略~ Complete!説明の簡便のため、起動は開発者モードで行います。
-dev-listen-addressはvaultのIPアドレスを含めて下さい。EC2の場合は下記のようにメタデータから取得することができます。$ vault server -dev -dev-root-token-id="root" -dev-listen-address="$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4):8200" ==> Vault server configuration: Api Address: http://172.31.39.141:8200 Cgo: disabled Cluster Address: https://172.31.39.141:8201 Go Version: go1.14.7 Listener 1: tcp (addr: "172.31.39.141:8200", cluster address: "172.31.39.141:8201", max_request_duration: "1m30s", max_request_size: "33554432", tls: "disabled") Log Level: info Mlock: supported: true, enabled: false Recovery Mode: false Storage: inmem Version: Vault v1.5.4 Version Sha: 1a730771ec70149293efe91e1d283b10d255c6d1 ~中略~ ==> Vault server started! Log data will stream in below: ~省略~ブラウザから
Api Addressに記載されたアドレス(上記ではhttp://172.31.39.141:8200)にアクセスし、下記のようにログイン画面が表示されればインストールと起動は完了です。
IAMユーザの発行
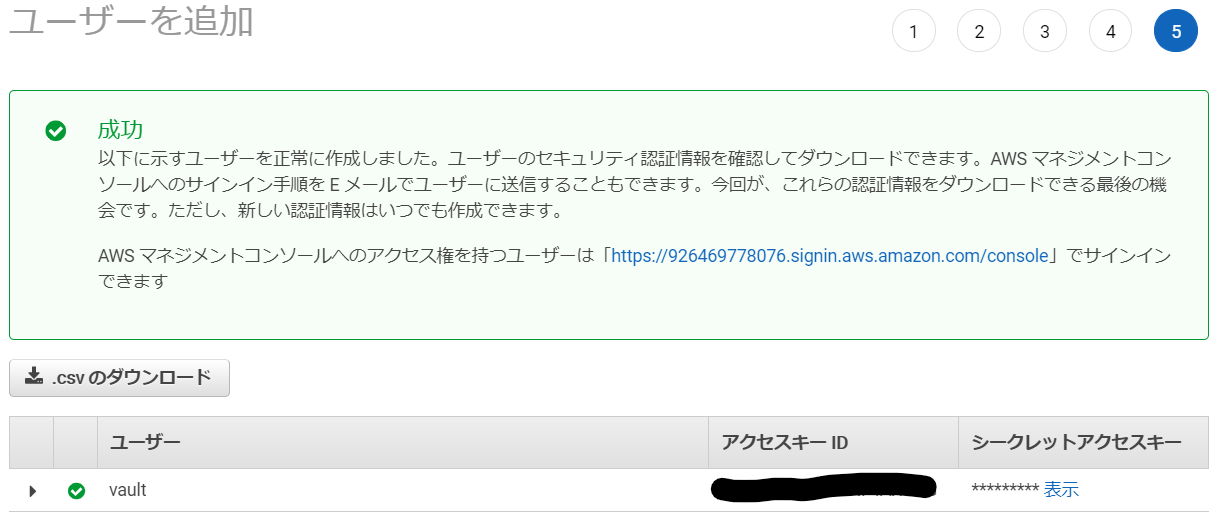
AWS管理コンソールの作業
Vaultが利用するIAMユーザを作成します。ここでは
vaultという名称にしています。
作成の際、以下のようにIAMの操作権限を付与してください。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "iam:*", "Resource": "*" } ] }IAMユーザが作成されたら、アクセスキーIDとシークレットアクセスキーを控えておきます。
Vaultの作業
IAMユーザの発行にはAWS Secret Engineという機能を利用します。
新規でvaultのターミナルを開き、AWS Secret Engineを有効化します。
access_keyとsecret_keyには先ほどIAMユーザを作成したときに控えておいた値を入れます。$ export VAULT_ADDR="http://$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4):8200" $ vault secrets enable -path=aws aws Success! Enabled the aws secrets engine at: aws/ $ vault write aws/config/root \ access_key=XXXXXXXXXXXXXXX \ secret_key=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX \ region=ap-northeast-1作成するIAMユーザにはロールという単位で権限を付与します。このロールも作成していきます。
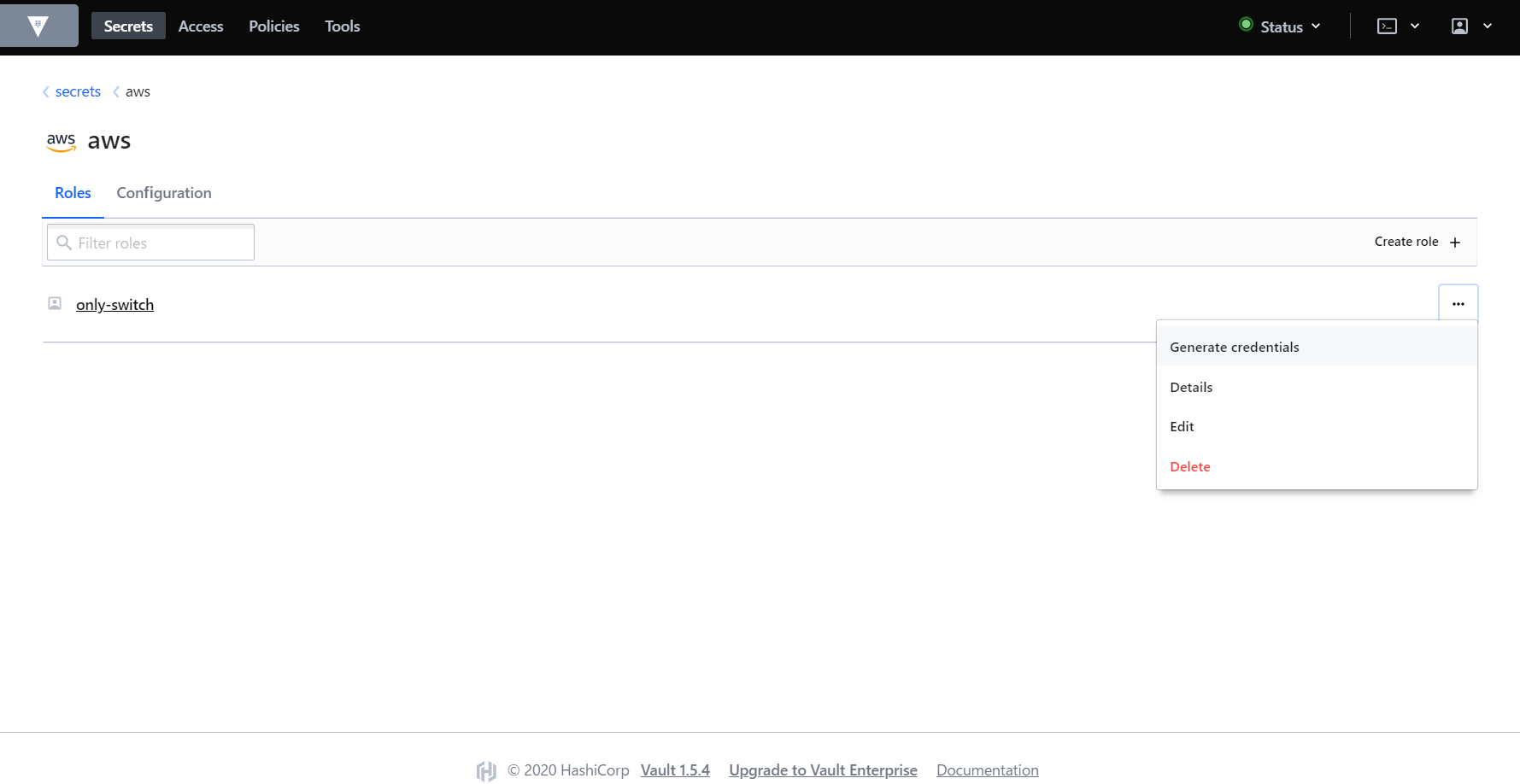
今回はスイッチロールを利用するため、以下のようなonly-switchというロールを作成します。$ vault write aws/roles/only-switch \ credential_type=iam_user \ policy_document=-<<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": "*" } ] } EOF Success! Data written to: aws/roles/only-switchブラウザから
vaultサーバに8200ポートでアクセスし、Tokenにrootを入力してログインします。ログイン後、Secrets>awsにアクセスすると、only-switchのロールが表示されているはずです。右の三点リーダからGenerate credentialsを選択します。
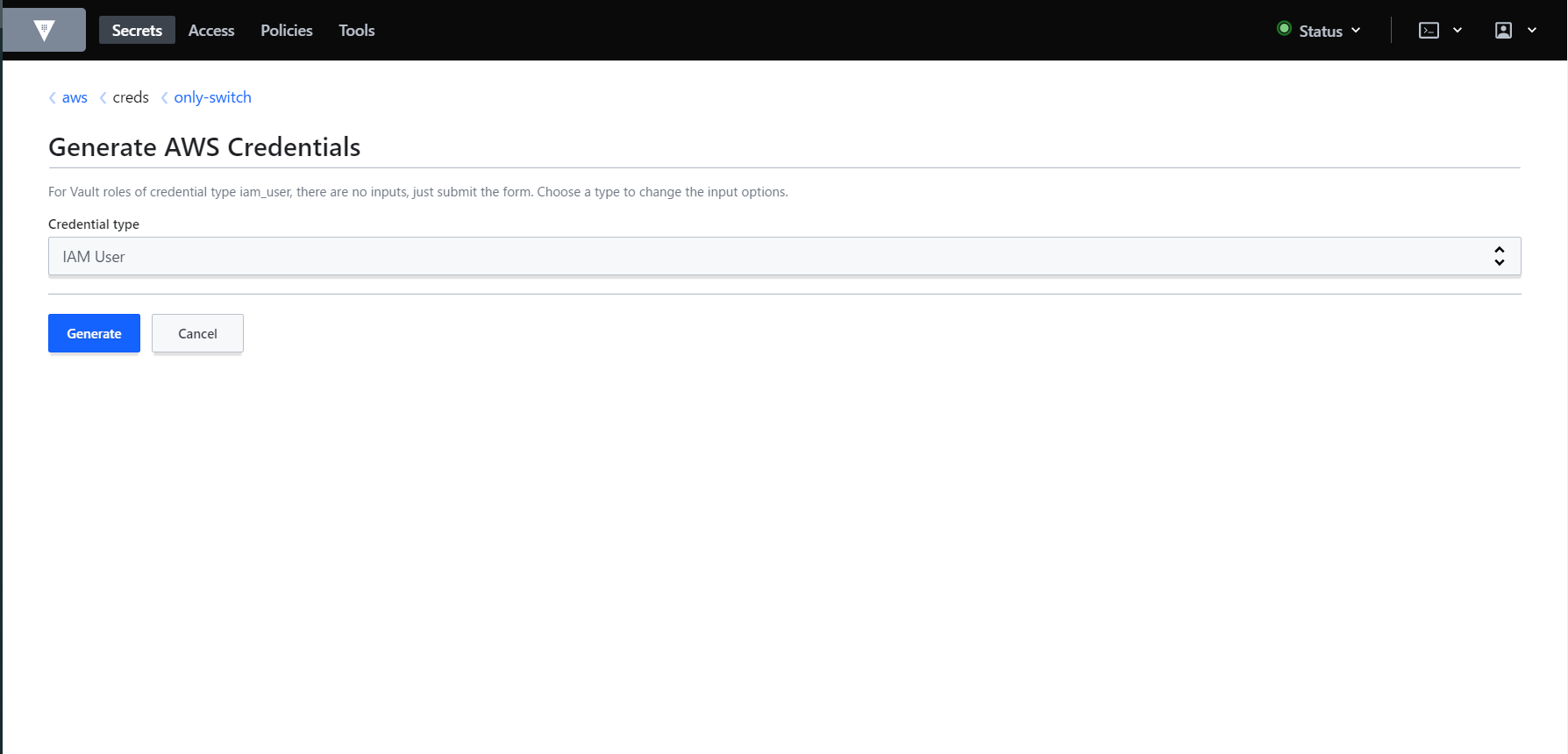
Credential typeはIAM Userを選択したまま、Generateをクリックします。
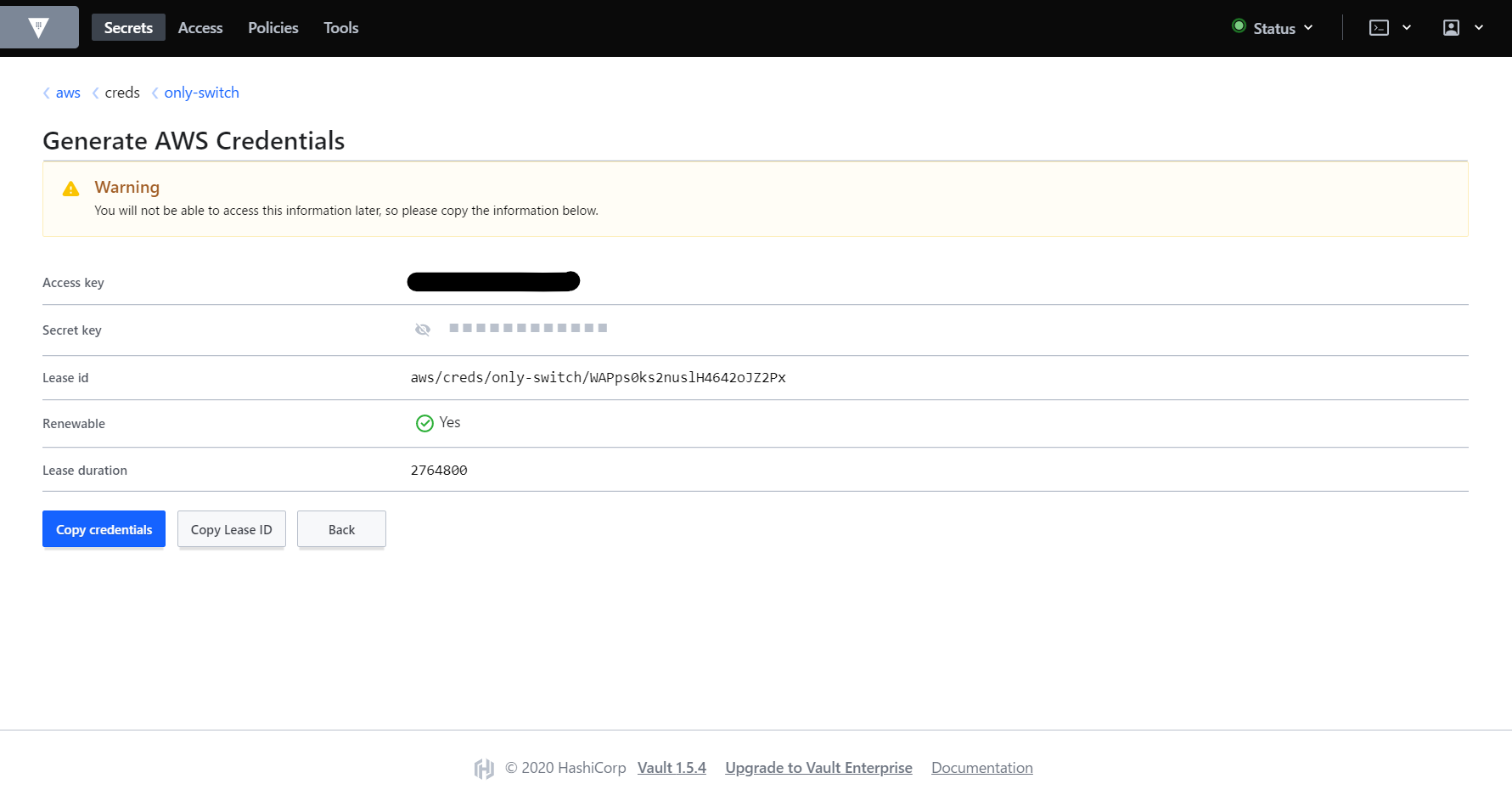
IAMユーザが作成されました。アクセスキーIDとシークレットアクセスキーは画面遷移すると参照できなくなってしまうため控えておきます。
Lease durationで表示されているのがこのIAMユーザの有効期間です。本記事では割愛しますが、デフォルトの2,764,800秒(32日間)から60秒まで短くすることができます。
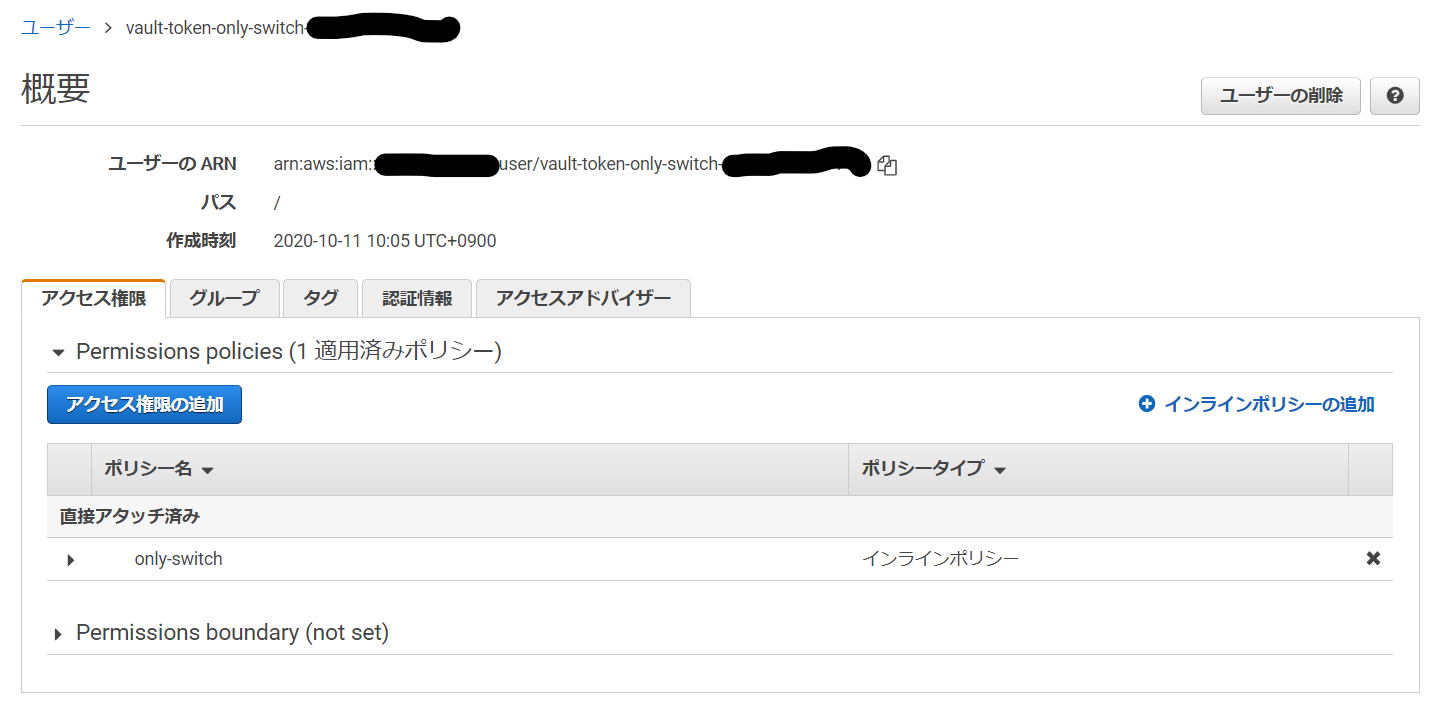
AWS管理コンソールでも確認すると、
only-switchというポリシーが直接アタッチされたIAMユーザが作成されていることが確認できます。
スイッチロールでの作業
ここまでの手順で作成したIAMユーザに様々な権限をロールとして付与していくことでAWSの不正利用のリスクは低減できるのですが、既に複数のAWSアカウントでIAMロールを用意して運用されているケースが多いかと思います。
Vaultで作成したIAMユーザでスイッチロールを可能にするすることで、複数アカウントの権限制御に対処します。
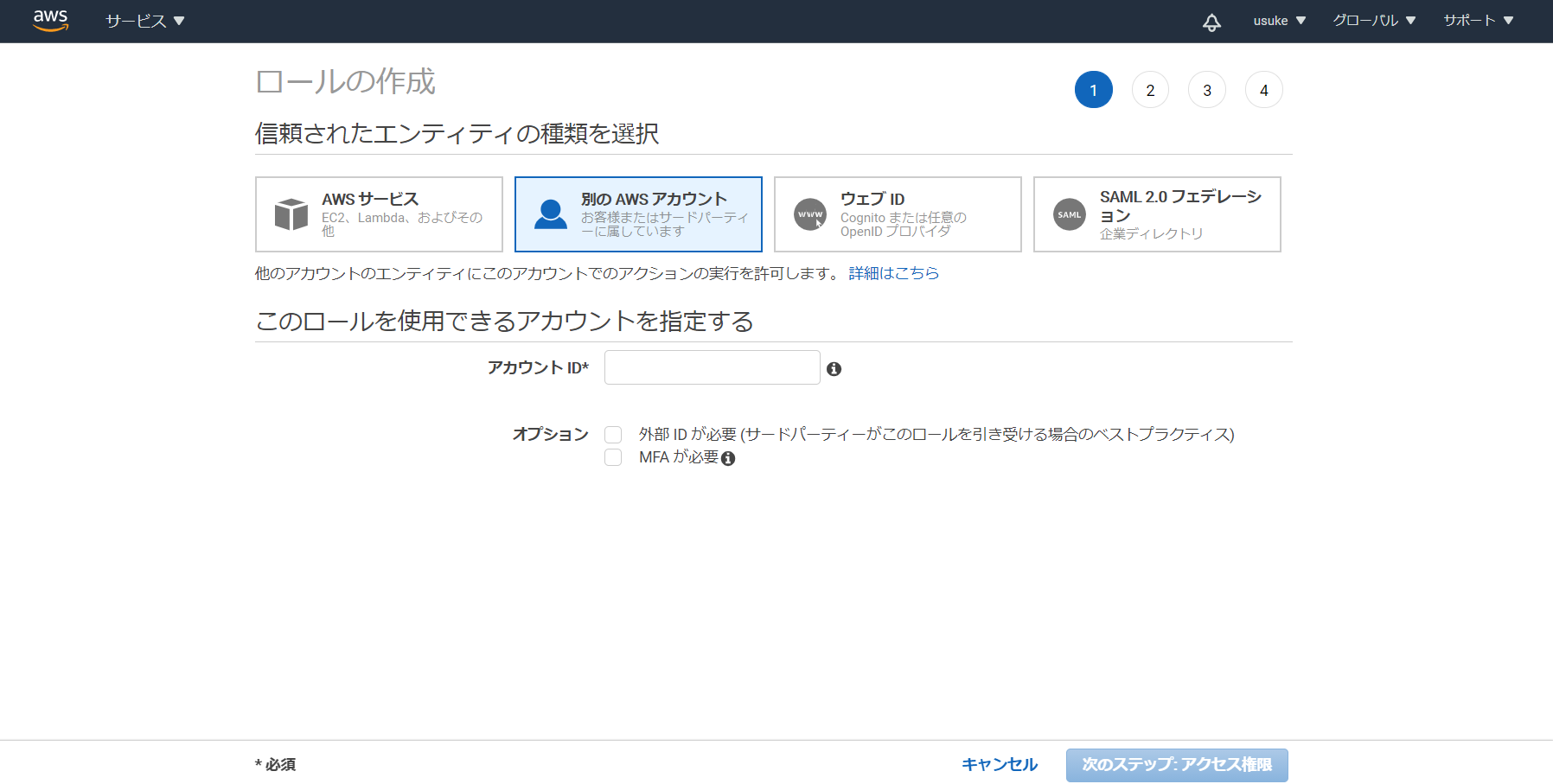
AWSの公式ドキュメントをもとに実装していきます。AWS管理コンソールの作業
例えばIAMの操作を行うロールを作成することを想定し、
IAM-Adminという名前で以下のようなポリシーを作成します。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:*" ], "Resource": "*" } ] }
IAM-Adminという名前でロールを作成します。信頼されたエンティティは別のAWSアカウントを指定し、アカウントIDにはVaultがIAMユーザを作成するAWSアカウントのIDを入力してください。
ポリシーは先ほど作成しIAM-Adminポリシーをアタッチします。
IAMロールが作成されたら、ロールARNを控えておきます。
AWS CLIの作業
AWS CLIをインストールしていない方は公式ドキュメントをもとにインストールして下さい。
aws configureで作成したIAMユーザのアクセスキーIDとシークレットアクセスキーを設定します。$aws configure AWS Access Key ID []: XXXXXXXXXXXXXXXXXXXXXX AWS Secret Access Key []: YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY Default region name []:ap-northeast-1 Default output format []:json
.aws/configファイルにiamadminというプロファイルを追記し、IAM-AdminロールのARNを設定します。[profile iamidmin] role_arn = arn:aws:iam::XXXXXXXXXXXX:role/IAM-Admin source_profile = default動作検証として、以下のように
IAM-Adminの情報が取得できればスイッチロールは成功です。$aws iam get-role --role-name IAM-Admin --profile iamadmin { "Role": { "Path": "/", "RoleName": "IAM-Admin", ~~中略~~ } }
--profile iamadmin無しで実行するとエラーとなり、作成されたIAMユーザの認証情報だけでは権限がないことが確認できます。$aws iam get-role --role-name IAM-Admin An error occurred (AccessDenied) when calling the GetRole operation: User: arn:aws:iam::XXXXXXXXXXXXX:user/vault-token-only-switch-XXXXXXXXXXXXXXX is not authorized to perform: iam:GetRole on resource: role IAM-Adminまとめ
本記事で伝えたかったことは以下の2点です。
- Hashicorp VaultでIAMユーザを使い捨てにすることでアクセスキーの流出リスクを低減できる
- スイッチロールと組み合わせることで既存のIAMロール運用から少ない修正で適用することができる

- 投稿日:2020-10-26T08:44:26+09:00
CIS AWS Foundations Benchmark v1.3.0 の変更点
はじめに
2020/8/7 に CIS AWS Foundations Benchmark が v1.3.0 に更新されたため、
2018年にリリースされた v1.2.0 からの変更点を確認しました。
項目レベルの変更点で、参照ドキュメント追加などの細かなアップデートは除きます。CIS AWS Foundations Benchmark とは
米国の非営利団体である CIS (Center for Internet Secuirty) が公開している
AWS アカウントの基本的なセキュリティを実装するための技術的なベストプラクティスです。
CIS は 各種 OS、サーバー、クラウド環境などを強化するためのガイドラインとして
140 以上の CIS Benchmark を発行されており、PCI DSS などのコンプライアンス要件で
業界標準のベストプラクティスとの記載があった場合などに参照されます。CIS AWS Foundations Benchmark は CIS のサイトから PDF 形式でダウンロードできます。
ライセンスは CC BY-NC-SA (Creative Commons Attribution-NonCommercial-ShareAlike) です。https://www.cisecurity.org/benchmark/amazon_web_services/
以降の項目名以外の記載は私の私見や所感などを含むもので、CIS Benchmark 記載の
内容ではありませんのでご注意ください。
完全な内容は CIS AWS Foundations Benchmark v1.3.0 の PDF をご参照ください。
参照ドキュメント等の変更も含む、すべての Change History が記載されています。Assessment Status
ベンチマークの各項目には以下の Assessment Status (評価ステータス) が含まれています。
Automated:
このステータスは準拠状況の評価を完全に自動化できることを表します。Manual:
このステータスは準拠状況の評価を完全に自動化することができず、一部またはすべてに
手動による確認が必要となることを表します。これらのステータスは v1.2.0 における Scoring Information (Scored/Not Scored) が
置き換えられたものです。
AWS Foundations Benchmark に限らず、他の CIS Benchmark でも同様の変更が行われています。1 Identity and Access Management
新たに追加された項目
5 項目が新たに追加されています。
1.13 Ensure there is only one active access key available for any single IAM user (Automated)
参考訳: 単一の IAM ユーザーに対して利用可能なアクティブなアクセスキーは 1 つだけであることを確認するIAM ユーザー毎に最大2つまでアクセスキーを発行できますが、これはキーのローテーションに
使用すべきもので、常に複数のキーが有効な状態を許可すべきではありません。1.19 Ensure that all the expired SSL/TLS certificates stored in AWS IAM are removed (Automated)
参考訳: AWS IAM に保存されている有効期限切れの SSL/TLS 証明書をすべて削除することを確認するサーバー証明書の保存とデプロイに対応したサービスとして、ACM と IAM が存在しますが、
ACM がサポートされていないリージョンを除いて、 IAM を証明書マネージャーとして
使用することは推奨されていません。https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_server-certs.html
IAM を証明書マネージャーとして使用している場合には、失効した SSL/TLS 証明書が
すべて削除されていることを確認する必要があります。1.20 Ensure that S3 Buckets are configured with 'Block public access (bucket settings)' (Automated)
参考訳: S3 バケットが「パブリックアクセスをブロックする (バケット設定)」に設定されていることを確認するブロックパブリックアクセスはアカウントレベルの設定とバケットレベルの設定があります。
どちらか、あるいは両方の設定を行うかはデータの機密性やユースケース等に基づいて
組織的に判断すべき内容です。ベンチマーク内では監査、是正手順についてどちらも両方の手法が記載されています。
1.21 Ensure that IAM Access analyzer is enabled (Automated)
参考訳: IAM Access analyzer が有効になっていることを確認するIAM Access Analyzer を使用すると、外部エンティティ (別アカウントのユーザーやロール、
AWS サービス等) と共有されている S3 バケットや IAM ロール、KMS キーなどのリソースを
識別できるため、意図しないアクセスを特定できます。IAM Access Analyzer はリージョナルサービスであるため、アカウント内のすべての
環境を分析するには対象のリソースを使用している各リージョンで
アナライザーを有効化する必要があります。1.22 Ensure IAM users are managed centrally via identity federation or AWS Organizations for multi-account environments (Manual)
参考訳: マルチアカウント環境の場合、IAM ユーザを ID フェデレーションまたは AWS Organizations を介して一元管理するようにするマルチアカウント環境では外部 IdP や AWS Organization を利用し、
IAM ユーザーの管理を一元化することで複雑さを軽減することができます。削除された項目
※ v1.2.0 における項目番号です
- 1.5 Ensure IAM password policy requires at least one uppercase letter
- 1.6 Ensure IAM password policy require at least one lowercase letter
- 1.7 Ensure IAM password policy require at least one symbol
- 1.8 Ensure IAM password policy require at least one number
- 1.11 Ensure IAM password policy expires passwords within 90 days or less
パスワードに関連する推奨項目が多く削除されているのは
CIS / DISA のガイダンスに一致させるようにするためのようです。変更があった項目
1.7 Eliminate use of the root user for administrative and daily tasks (Automated)
v1.2.0 の 1.1 Avoid the use of the "root" account から項目名が変更されています。
1.15 Ensure IAM Users Receive Permissions Only Through Groups (Automated)
v1.2.0 の 1.16 Ensure IAM policies are attached only to groups or roles から
項目名が変更されています。
また対象にインラインポリシーを含むよう監査手順が変更されています。1.16 Ensure IAM policies that allow full ":" administrative privileges are not attached (Automated)
v1.2.0 の 1.22 Ensure IAM policies that allow full ":" administrative privileges are not created
がアタッチされているポリシーのみを監査対象とするように変更され
項目名もそれに合わせて変更されました。上記以外の既存の項目についても項番の順序が細かく入れ替わっていますが、詳細は割愛します。
2 Storage
ストレージに関連する推奨項目が 2 Storage として新規追加され、
以降の Logging, Monitoring, Networking は一つずつ項番がずれています2.1.1 Ensure all S3 buckets employ encryption-at-rest (Manual)
参考訳: すべての S3 バケットに保存時の暗号化が採用されていることを確認するバケットのデフォルト暗号化設定が AES-256 または AWS-KMS であることを確認します。
2.1.2 Ensure S3 Bucket Policy allows HTTPS requests (Manual)
参考訳: S3 バケットポリシーが HTTPS リクエストを許可していることを確認する以下のようなバケットポリシーを適用してオブジェクトへのアクセスを
HTTPS 経由でのみ許可し、HTTP リクエストを明示的に拒否する必要があります。{ "Sid": "<optional>", "Effect": "Deny", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<bucket_name>/*", "Condition": { "Bool": { "aws:SecureTransport": "false" } } }2.2.1 Ensure EBS volume encryption is enabled (Manual)
参考訳: EBS ボリュームの暗号化が有効になっていることを確認するEBS 暗号化機能をオプトインし、すべての新しい EBS ボリュームとスナップショットについて
デフォルトの暗号化が有効になるように設定します。デフォルト暗号化設定を変更しても、既存のボリュームには影響しません。
またデフォルト暗号化を有効にすると、暗号化をサポートしていない
旧世代のインスタンスタイプを起動できなくなります。
(C3、cr1.8xlarge、G2、I2、M3、およびR3 を除く)3 Logging
新たに追加された項目
3.10 Ensure that Object-level logging for write events is enabled for S3 bucket (Automated)
参考訳: S3 バケットの書き込みイベントのオブジェクトレベルロギングが有効になっていることを確認する3.11 Ensure that Object-level logging for read events is enabled for S3 bucket (Automated)
参考訳: S3 バケットの読み取りイベントのオブジェクトレベルロギングが有効になっていることを確認するCloudTrail のオブジェクトレベルロギングに関する項目が追加されています。
証跡のデフォルト設定では GetObject や DeleteObject などのデータイベントを記録しないため
S3 バケットに対してオブジェクトレベルのロギングを有効にすることが推奨されます。4 Monitoring
新たに追加された項目
4.15 Ensure a log metric filter and alarm exists for AWS Organizations changes (Automated)
参考訳: AWS Organizationsの変更に対してログメトリックフィルタとアラームが存在することを確認するAWS Organizations 内の予期せぬ変更をモニタリングすることで不要な変更を
発見、修正することができます。以下のフィルタパターンでメトリクスフィルタを設定し、
有効な SNS Topic にサブスクライブします。{ ($.eventSource = organizations.amazonaws.com) && (($.eventName = "AcceptHandshake") || ($.eventName = "AttachPolicy") || ($.eventName = "CreateAccount") || ($.eventName = "CreateOrganizationalUnit") || ($.eventName= "CreatePolicy") || ($.eventName = "DeclineHandshake") || ($.eventName = "DeleteOrganization") || ($.eventName = "DeleteOrganizationalUnit") || ($.eventName = "DeletePolicy") || ($.eventName = "DetachPolicy") || ($.eventName = "DisablePolicyType") || ($.eventName = "EnablePolicyType") || ($.eventName = "InviteAccountToOrganization") || ($.eventName = "LeaveOrganization") || ($.eventName = "MoveAccount") || ($.eventName = "RemoveAccountFromOrganization") || ($.eventName = "UpdatePolicy") || ($.eventName ="UpdateOrganizationalUnit")) }変更があった項目
4.1 Ensure a log metric filter and alarm exist for unauthorized API calls (Automated)
HeadBucketイベントを除外するようにメトリクスフィルタのフィルタパターンが変更されています。
{ ($.errorCode = "*UnauthorizedOperation") || ($.errorCode = "AccessDenied*") || ($.sourceIPAddress!="delivery.logs.amazonaws.com") || ($.eventName!="HeadBucket") }4.2 Ensure a log metric filter and alarm exist for Management Console sign-in without MFA (Automated)
SSO 環境下を考慮したフィルタパターンが追加されています。
{ ($.eventName = "ConsoleLogin") && ($.additionalEventData.MFAUsed != "Yes") && ($.userIdentity.type = "IAMUser") && ($.responseElements.ConsoleLogin = "Success") }5 Networking
新たに追加された項目
5.1 Ensure no Network ACLs allow ingress from 0.0.0.0/0 to remote server administration ports (Automated)
参考訳: ネットワーク ACL が 0.0.0.0/0 からリモートサーバー管理ポートへの侵入を許可しないようにする22番ポート (SSH) や 3389 番ポート (RDP) などのリモートサーバ管理ポートへの
パブリックアクセスは Attack Surface (攻撃対象領域) を不必要に増加させるため
無制限アクセスを許可しないように設定します。変更があった項目
5.2 Ensure no security groups allow ingress from 0.0.0.0/0 to remote server administration ports (Automated)
v1.2.0 の
4.1 Ensure no security groups allow ingress from 0.0.0.0/0 to port 22 と
4.2 Ensure no security groups allow ingress from 0.0.0.0/0 to port 3389
が統合されて、1つの項目になりました。AWS Security Hub の対応状況
2020年10月末時点で、Security Hub の セキュリティ標準機能では
CIS AWS Foundations Benchmark v1.3.0 に準拠したルールでのチェックに対応していません。参考
CIS Benchmarks September 2020 Update
https://www.cisecurity.org/blog/cis-benchmarks-september-2020-update/以上です。
参考なれば幸いです。
- 投稿日:2020-10-26T06:36:33+09:00
AWS CloudFormationでVPCを構築しよう
はじめに
AWS CloudFormationを利用してVPC構築のテンプレートのサンプルです。
テンプレートの概要が分からない場合は、はじめてのAWS CloudFormationテンプレートを理解するを参考にすると良いです。
コードはGitHubにもあります。
今回は、akane というシステムの dev 環境を想定しています。
ディレクトリ構成akane (システム) └─ network (スタック) ├─ network.yml (CFnテンプレート) └─ dev-parameters.json (dev環境のパラメータ)AWS リソース構築内容
- VPC (10.0.0.0/16)
実行環境の準備
Amazon Linux 2
※デフォルトでAWS CLIが利用できます。
- AdministratorAccessポリシー関連付けたIAMロールを作成し、EC2インスタンスにアタッチします。
- ~/bashrcに
AWS_DEFAULT_REGION=ap-northeast-1を追記します。source ~./bashrcを実行してください。Mac
brew install awscliを実行し、AWS CLIをインストールします。- IAMユーザーを作成し、アクセスキーとシークレットキーを発行しまし。
aws configureを実行します。ターミナル$ aws configure AWS Access Key ID [None]: {アクセスキー} AWS Secret Access Key [None]: {シークレットアクセスキー} Default region name [None]: ap-northeast-1 Default output format [None]: jsonAWS リソース構築手順
下記を実行してスタックを作成
./create.sh下記を実行してスタックを削除
./delete.shVPC構築テンプレート
network.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Network For Akane # Metadata: Parameters: SystemName: Type: String AllowedPattern: '[a-zA-Z0-9-]*' EnvType: Description: Environment type. Type: String AllowedValues: [all, dev, stg, prod] ConstraintDescription: must specify all, dev, stg, or prod. VPCCidrBlock: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/16 # Mappings: # Conditions # Transform Resources: # VPC作成 akaneVPC: Type: AWS::EC2::VPC Properties: CidrBlock: !Ref VPCCidrBlock EnableDnsSupport: true EnableDnsHostnames: true InstanceTenancy: default Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType} - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType Outputs: akaneVPC: Value: !Ref akaneVPC Export: Name: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType}dev-parameters.json{ "Parameters": [ { "ParameterKey": "SystemName", "ParameterValue": "akane" }, { "ParameterKey": "EnvType", "ParameterValue": "dev" }, { "ParameterKey": "VPCCidrBlock", "ParameterValue": "10.0.0.0/16" } ] }create.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev STACK_NAME=network aws cloudformation create-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} \ --template-body file://./${SYSTEM_NAME}/${STACK_NAME}/${STACK_NAME}.yml \ --cli-input-json file://./${SYSTEM_NAME}/${STACK_NAME}/${ENV_TYPE}-parameters.jsondelete.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev STACK_NAME=network aws cloudformation delete-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME}
- 投稿日:2020-10-26T02:43:14+09:00
【AWS】【初心者】wordpressのブログシステムを構築する(パラシつき) ②
【AWS】【初心者】wordpressのブログシステムを構築する(パラシつき) ①
https://qiita.com/gbf_abe/items/3d6a4c5e6406ff460e1f の続きです。前回までにやったこと
前回はIAMユーザーが請求情報を確認できる設定とIAMユーザーの作成をしました。
順番 内容 ① VPC構築 ② サブネット分割 ③ EC2(パブリック)構築 ④ WebサーバにApacheをインストール ⑤ EC2(プライベート)構築 ⑥ NATゲートウェイ構築 ⑦ DBサーバにMariaDBをインストール ⑧ Webサーバにwordpressをインストール ⑨ 完成(するはず)! ↑こんな流れをご案内したかと思うので、進捗0ですね...
今日やること
①のVPCの作成からやっていきます。
今回もよろしくお願いします。
パラメータシート的なものは自己満足で書いているので、無視した方がわかりやすいかもしれませんVPC構築
「10.0.0.0/16」のVPC領域を作成します。
前回作成したIAMユーザーでログインしてください。リージョンの選択
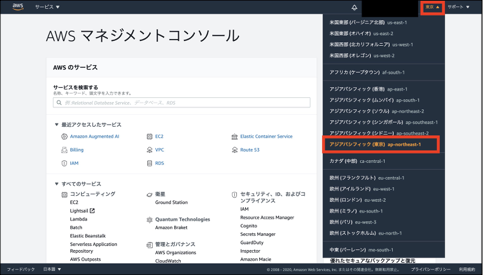
VPCはAWSのサーバを借りて構築する仮想のネットワークなんですが、
借りるサーバ群がある地域を選ぶことができます。今回は東京リージョンを選びます。①上部タブの地域が書かれている箇所を選択する。
②アジアパシフィック(東京)を選択する。
パラメータシート
設定内容 既定値 設定値 リージョン (不明) アジアパシフィック(東京) ap-northeast-1 VPC作成
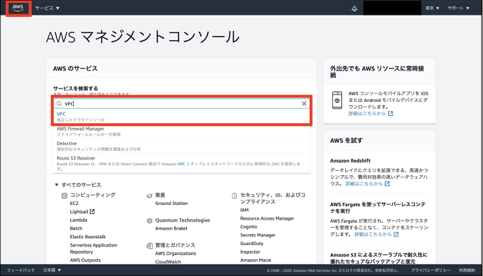
①左上のAWSのマーク(ホーム)をクリックし、検索欄に「VPC」と入力します。
②検索結果の一番上の「VPC」を選択します。
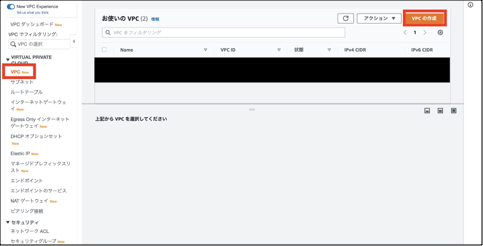
③「VPC」を選択し、「VPCの作成」をクリックします。(既にVPCが用意されているかと思いますが、それは使いません。)
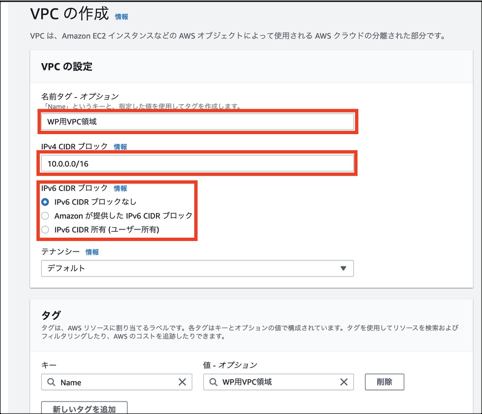
④「名前タグ-オプション」にVPC領域であることが分かる任意の名前を入力します。
「IPv4 CIDRブロック」には「10.0.0.0/16」を指定します。
「IPv6 CIDRブロック」は、IPv6を使用しないため「IPv6 CIDRブロックなし」を選択します。
(
宣言してしまったので)例のアレVPCの作成
大項目 設定内容 既定値 設定値 名前タグ-オプション 名前タグ-オプション - WP用VPC領域 IPv4 CIDRブロック IPv4 CIDRブロック - 10.0.0.0/16 IPv6 CIDRブロック IPv6 CIDRブロック IPv6 CIDRブロックなし IPv6 CIDRブロックなし タグ キー - (自動設定)Name 値-オプション - (自動設定)WP用VPC領域 ここまで、リージョンを選択し、VPCを構築しました。
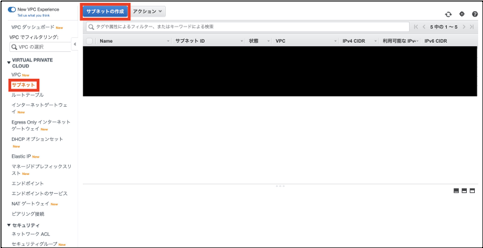
次の手順では、webサーバを配置するためのパブリックサブネットをリージョン内に構築します。①「VPC」>「サブネット」を選択します。
②「サブネットの作成」を選択します。
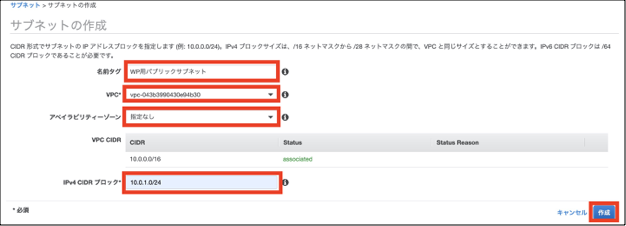
③「名前タグ」にパブリックサブネットであることが分かる任意の名前を入力します。
「VPC」は先ほど構築したVPCを選択します。(2枚目の画像を参照してください)
「アベイラリティーゾーン」は自動で決定されるので、特に指定は必要ないです。
「IPv4 CIDRブロック」には「10.0.1.0/24」を指定します。
「作成」をクリックします。これでパブリックサブネットは完成です。
例のやつ(サブネットの作成)
大項目 設定内容 既定値 設定値 名前タグ 名前タグ - WP用パブリックサブネット VPC VPC - VPC構築時まで不明(WP用VPC領域を選択) アベイラビリティーゾーン アベイラビリティーゾーン 指定なし 指定なし(自動選択される) VPC CIDR VPC CIDR - (自動で決定) IPv4 CIDRブロック IPv4 CIDRブロック - 10.0.1.0/24 インターネットゲートウェイの構築
このVPCとサブネットは今のままだとインターネットに接続できないので、インターネットに接続する設定を行い、その設定をVPCに紐付けます。
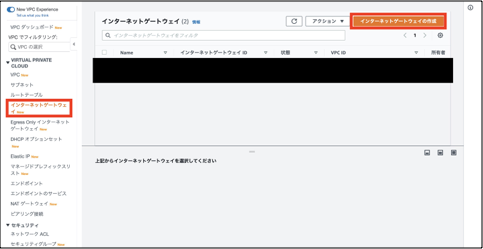
①「VPC」>「インターネットゲートウェイ」を選択し、「インターネットゲートウェイの作成」を選択します。
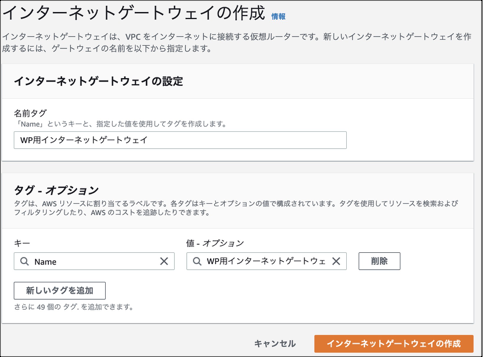
②「名前タグ」にインターネットゲートウェイを示すことがわかる任意の名前を入力します。
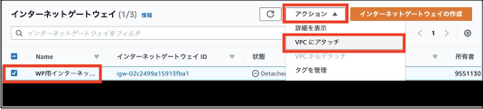
「タグ」の「キー」と「値-オプション」は自動で決まるので特段設定は必要ありません。
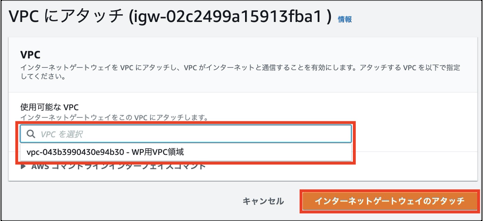
③構築したインターネットゲートウェイを選択し、「アクション」>「VPCにアタッチ」を選択します。
④「使用可能なVPC」で構築したVPCを選択します。
⑤「インターネットゲートウェイのアタッチ」を選択します。
⑥コンソール画面で、インターネットゲートウェイの状態が「Attached」になっていれば成功です。例のアレ
インターネットゲートウェイ
大項目 設定内容 既定値 設定値 名前タグ 名前タグ - WP用インターネットゲートウェイ タグ-オプション Name - WP用インターネットゲートウェイ VPCにアタッチ
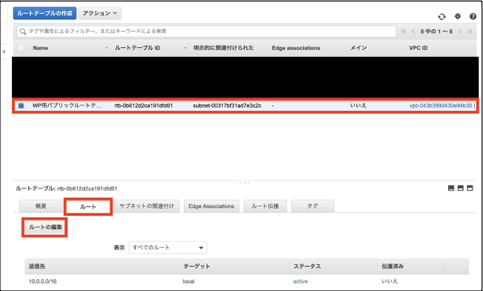
設定内容 既定値 設定値 使用可能なVPC - VPC構築時まで不明(WP用VPC領域を選択) ルートテーブル
ルートテーブルを新規構築し、サブネットと紐付け、ルートテーブルにインターネットゲートウェイを追加することで
パブリックサブネットがインターネットと通信できるようになる、という仕組みです(ここ間違ってるかも)ルートテーブルを構築していきましょう。
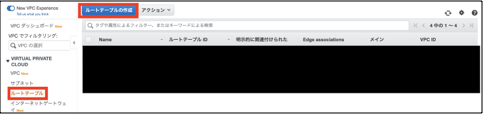
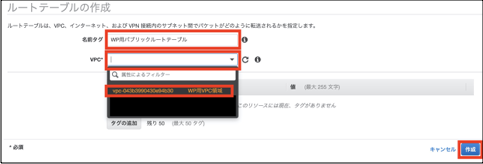
①「VPC」>「ルートテーブル」を選択し。「ルートテーブルの作成」を選択します。
②「名前タグ」にパブリックルートテーブルを示すことがわかる任意の名前を入力します。
③「VPC」は今回構築したVPCを選択します。
④「作成」をクリックします。
パラメータシート
設定内容 既定値 設定値 名前タグ - WP用パブリックルートテーブル VPC - VPC構築時まで不明(WP用VPC領域を選択) タグの追加 - - パブリックサブネットとの紐付け
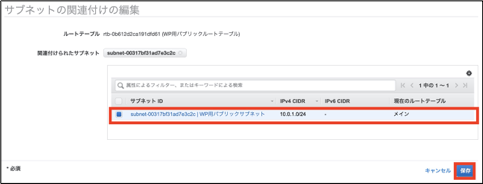
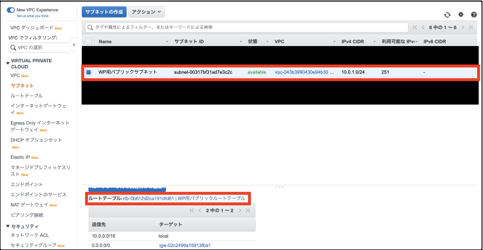
まず、新規作成したルートテーブルをパブリックサブネットに紐付けます。
①作成されたルートテーブルを選択し、「サブネットの関連付け」>「サブネットの関連付けの編集」をクリックします。
②割り当てたいサブネットにチェックをつけます。(この場合WP用パブリックサブネット)
③「保存」をクリックします。
パラメータシート(サブネット関連付けの編集)
設定内容 既定値 設定値 WP用パブリックサブネット □ ■ ルートテーブルをサブネットに割り当てる
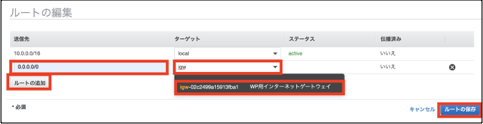
①作成したルートテーブルを選択した状態で、「ルート」>「ルートの編集」を選択します。
②(若干端折ってます)「ルートの追加」を選択
③「送信先」に「0.0.0.0」を入力
④「ターゲット」に構築したインターネットゲートウェイを選択
(素直に出てこなかった覚えがあるので、「igw」とかで検索するといいです)
⑤「ルートの追加」を選択します。
ルートの編集(新規ルートのみの記載)
大項目 設定内容 既定値 設定値 local 送信先 10.0.0.0/16 10.0.0.0/16 ターゲット local local ステータス active active 伝播済み いいえ いいえ インターネットゲートウェイ 送信先 - 0.0.0.0 ターゲット - インターネットゲートウェイ構築時まで不明(WP用インターネットゲートウェイを選択) ステータス - - 伝播済み いいえ いいえ 「VPC」>「サブネット」で構築したパブリックサブネットを選択します。
タブ「ルートテーブル」を確認し、ルートテーブルが構築したパブリックルートテーブルになっていれば完了です。
ひとまずお疲れ様でした。
今回の手順で、「10.0.0.0/16」のVPCを構築し、VPCをサブネットに分割、webサーバを配置するパブリックセグメントを構築しました。
さらに、VPCでインターネット接続ができるようにインターネットゲートウェイを構築し、VPCと紐付けました。
そして最後に、ルートテーブルを新規作成し、パブリックサブネットに紐付け、インターネットゲートウェイを割り当てることでパブリックサブネットのインターネット接続を可能にしました。次回はwebサーバの構築から始めます。長くなってしまいましたが最後までご覧いただきありがとうございました。
参考文献
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版
https://amzn.to/3mqfImv
- 投稿日:2020-10-26T02:39:58+09:00
【AWS】【初心者】wordpressのブログシステムを構築する(パラシつき) ①
よくある入門編
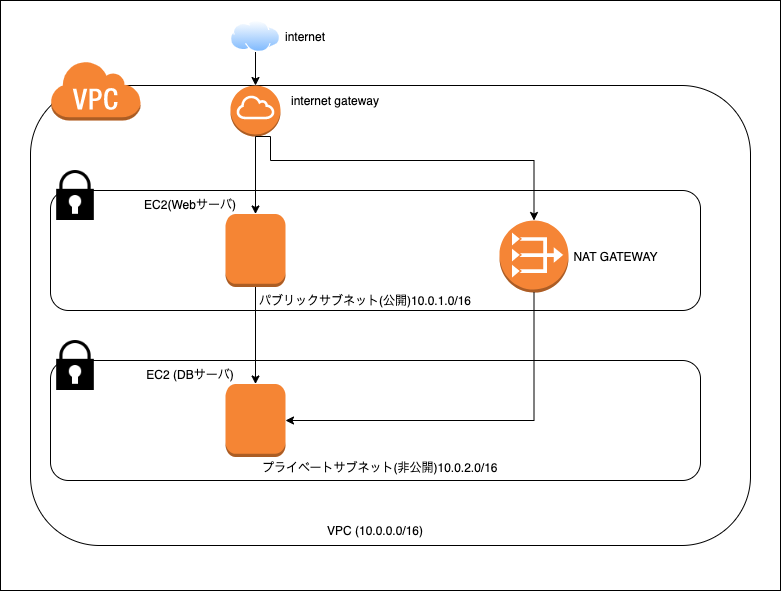
順番 内容 ① VPC構築 ② サブネット分割 ③ EC2(パブリック)構築 ④ WebサーバにApacheをインストール ⑤ EC2(プライベート)構築 ⑥ NATゲートウェイ構築 ⑦ DBサーバにMariaDBをインストール ⑧ Webサーバにwordpressをインストール ⑨ 完成(するはず)! という流れを予定しています、入門編でとりあえずやるアレです。
(おそらく)他の方と違う点
レガシーブラックSIer勤務の意地を見せたいと思っているので、パラメータ管理を徹底しようと思っています。
本当は卍Excel卍でやりたいですが、さすがにアレなのでやめます。Markdown勉強したいので。
とはいえ、新卒半年の人間なので至らない点も多いかと思いますが、温かく見守っていただけると身に余る僥倖です。断っておくべきであろうこと
やりながら手順書いてるので、途中で詰む可能性があります。
完全に詰んだら更新止まるかもしれませんが、今のところ動かせる予定ではいます。完成予定のシステム構成図
draw.io初めて使ったからこの構成図描くのに2時間近くかかったなんて言えない
前置きが長くなりましたが、早速作っていきましょう【構築する前に】 IAMユーザーを作ろう
最初にログインしてるrootユーザーは権限が強すぎるので、権限が制限されたIAMユーザーという作業用のユーザーを作成します。
請求情報の設定
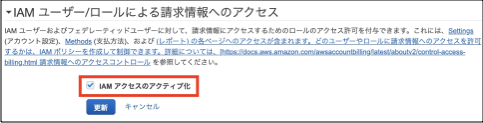
画面上部のタブに表示されている自分のユーザー名をクリックし、「マイアカウント」を選択します。
IAMユーザー/ロールによる請求情報へのアクセス
今回はIAMユーザーが請求情報を見れるように設定したいので、以下のように設定します。
項目 規定値 設定値 IAMアクセスのアクティブ化 ■ ■
請求情報についての設定が完了したので、IAMユーザーを作成していきましょう。IAMユーザーの作成
①AWSマネジメントコンソールの「サービス」をクリックし、「IAM」と検索します。
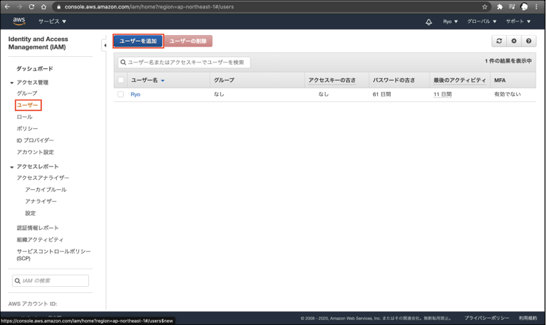
②「ユーザー」>「ユーザーを追加」をクリックします。
③「ユーザー名」にIAMのユーザー名を入力します。
「アクセスの種類」は、今回はGUIでの操作がメインになるので「AWSマネジメントコンソールへのアクセス」を選択します。
「コンソールのパスワード」は、「カスタムパスワード」を選択し、任意のパスワードを入力します。
「パスワードのリセットが必要」はチェックを外しておきます。
「次のステップ:アクセス権限」をクリックします。
④「アクセス許可の設定」は「既存のポリシーを直接アタッチ」を選択します。
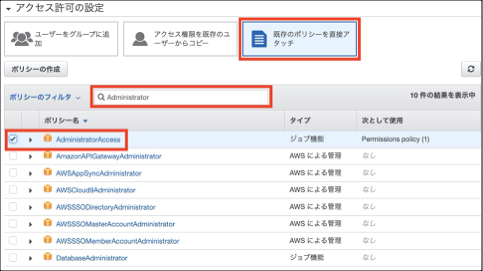
「ポリシーのフィルタ」で「Administrator」と検索します。
「AdministratorAccess」を選択します。(IAMのベストプラクティスには反しますが、今回は勉強用なのでOKとします)
⑤「タグの追加(オプション)」は必要がないので設定しません。
⑥確認画面が出ます。「OK」を選択します。
⑦IAMユーザーの追加が成功すると、以下のようなメッセージが表示されます。
記載されているリンクをブックマークに登録するなどして控えておきましょう。
(パラメータシート)ユーザーを追加
大項目 設定項目 規定値 設定値 ユーザー詳細の設定 ユーザー名 - test-user AWS アクセスの種類を選択 アクセスの種類 プログラムによるアクセス □ □ AWSマネジメントコンソールへのアクセス □ ■ コンソールのパスワード 自動生成パスワード ⚫︎ ⚪︎ カスタムパスワード ⚪︎ ⚫︎ パスワードのリセットが必要 パスワードのリセットが必要 ■ □ アクセス許可の設定 ユーザーをグループに追加 既存のポリシーを直接アタッチ アクセス権限の境界の設定 アクセス権限の境界を設定せずにuserを作成する ⚫︎ ⚫︎ アクセス権限の境界を使用してuserの最大アクセス権限を制御する ⚪︎ ⚪︎ タグの追加(オプション) キー - - 値 - - ↑宣言したからにはパラメータシート的なのを一応書いてます。
無視でOKですここまで、IAMユーザーの請求情報に関する権限を設定し、IAMユーザーを作成しました。
長くなってしまったので、次回からはVPCの構築に入っていきます。参考文献
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版
https://amzn.to/3mqfImv