- 投稿日:2020-10-26T23:00:27+09:00
JSエコシステムぶらり探訪(4): npmとコマンドライン
前回に続きnpmの機能について扱います。今回はnpmとコマンドラインツールとの関わりを中心に見ていきます。
注意: Windowsとそれ以外では、npmのフォルダ配置は異なります。Windowsでの挙動についてはnpm-foldersを参照してください。
グローバルインストール
npmは通常、Node.jsの配布物に同梱されていますが、yarnは同梱されていません。yarnを使う場合は次のようなコマンドを実行します。
npm install -g yarnこれによって以下のような効果が発生します。
$PREFIX/lib/node_modules/yarn以下にyarnの中身がインストールされる。$PREFIX/lib/node_modules/yarn/node_modules以下にyarnの依存関係がインストールされる。$PREFIX/binにシンボリックリンクyarn,yarnpkgが生成される。どちらも../lib/node_modules/yarn/bin/yarn.jsを参照している。
- これはyarnの
package.jsonの "bin" フィールドの記述に基づいて生成される
$PREFIX/binにはNode.jsの実行バイナリ (node) も入っているので、Node.jsが使えている時点でここにPATHは通っていると仮定してよさそうです。
$PREFIX/lib/node_modules/yarn/bin/yarn.jsは実行可能属性が付与されていて、冒頭は以下のようになっています。1#!/usr/bin/env node /* eslint-disable no-var */ /* eslint-disable flowtype/require-valid-file-annotation */ 'use strict';つまり、nodeにパスが通った状態で
yarnを実行するとnode $PREFIX/bin/yarnが実行されます。Node.jsはモジュール解決前にシンボリックリンクを解決する2ので、これはnode $PREFIX/lib/node_modules/yarn/bin/yarn.jsと同じ意味になります。 (yarn.jsを起点にrequireが解決される。)
npm install -gのインストール先は$PREFIX/lib/node_modulesであって$PREFIX/lib/nodeではありません。Node.jsの探索ルールに含まれているのは前者ではなく後者です3から、これによってライブラリをインストールしてもrequireから使われることはありません。yarnの場合
npm install -gのかわりにyarn global addを使います。- インストール先はnpmとは異なり、バイナリは
~/.yarn/binに、パッケージ本体は~/.config/yarn/globalにそれぞれインストールされます。そのため、npmと違い、node用のパスとは別にPATHを通しておく必要があります。- また、上記のインストール先はyarnでは変更可能です。
npm installの古い挙動
-gをつけない場合、npm installはローカルインストールの挙動になります。npm v4までは、npm installはデフォルトでは
./node_modulesへの展開のみを行い、package.jsonを更新しませんでした。そのため、npm install -Sと書くのが一般的でした。npm v5以降では-Sが自動的に仮定されます。アプリケーションのローカルインストール, yarn exec, npx
現代のJavaScript開発ではprettier, eslint, typescript (tsc), webpackなど多くのCLIツールを使います。これらはグローバルインストールすることもできますが、以下のような懸念があります。
- これらのツールのバージョンが開発者ごとにバラバラだと、再現性の低いトラブルに遭遇しやすくなる。
- eslintやwebpackはプラグインも含めて使うことが多く、これらを含めた全てのパッケージを個別にインストールさせるのはセットアップの手間につながる。
このため、プロジェクトで使うアプリケーションは
package.jsonに指定してローカルインストールほうが主流になっています。方法は簡単で、ライブラリと同様にnpm install (-S)またはyarn addするだけです。グローバルインストール時には
$PREFIX/bin以下にシンボリックリンクが作成されますが、ローカルインストールの場合は同様に./node_modules/.bin以下にシンボリックリンクが作成されます。通常このディレクトリにはPATHは通っておらず、 ローカルインストールされたアプリケーションは、通常のコマンドと同様に呼び出すことはできないため、npm/yarnを経由して使います。以下のコマンドを経由して使われるのが一般的でしょう。
npx(npm exec) /yarn execnpm run/npm run-scripts/yarn run(runが省略された場合も含む)yarn exec
yarn execはyarn共通のセットアップを行ったあと所与のコマンドを実行します。このセットアップにはPATHの設定が含まれているため、ローカルインストールされたアプリケーションの実行が可能です。yarn exec prettier -w 'src/**/*.js'npx /
npm exec
npx/npm execもyarn execと同様の目的で使用することができますが、ローカルインストールされたパッケージがない場合は自動的にnpmレジストリからパッケージを探し、一時的にインストールしてから実行します。npx prettier -w 'src/**/*.js'
prettierがない状態で上記を実行すると、一時的なインストールが行われます。~/.npm/_npx/以下にprettierへの依存が記述されたダミーパッケージが作られ、そこでnpm installが行われてからローカルパッケージが実行されます。
npx/npm execをサポートするバージョンは以下の通りです。
npm execはnpm v7以降に存在します。挙動はnpxとほぼ同じです。npxはnpm v5.2.0以降に同梱されていますが、独立したnpxパッケージとしても提供されています。
- v5.2.0~v6に同梱されている
npxの実装はlibnpxパッケージを使っているため、npxパッケージと共通です。- v7に同梱されている
npxはnpm execのエイリアスです。yarn v2 (berry) にはこれに対応する
yarn dlxが組み込まれていますが、本記事では詳しくは述べません。scripts
npm run/npm run-script/yarn runはpackage.jsonに記述されたスクリプトを実行します。つまり、 npm/yarnには簡易的なタスクランナーとしての機能があるといえます。package.json{ "scripts": { "build": "tsc", "test": "jest", "fmt": "prettier -w src/**/*.ts" } }
npm runはnpm run-scriptのエイリアスです。また、曖昧性がない場合はyarn runのrunは省略できます。 (yarn build/yarn fmtなど)
scripts内のスクリプトは./node_modules/.binにパスが通った状態で実行されるため、node_modules/.bin/webpackのように明示する必要はありません。npm/yarnの管理下でコマンドが実行されるときは、PATH以外にも
NODEやnpm_lifecycle_event,npm_config_registryなどいくつかの環境変数がセットされます。これについてはnpm-run-scriptやnpm-configなどのマニュアルを参照してください。
npm run/yarn runともに、後続引数はスクリプト文字列の末尾に連結されます。たとえば、package.json{ "scripts": { "lint": "eslint 'src/**/*.ts'" } }という記述があるとき、
yarn lint --fixはeslint 'src/**/*.ts' --fixを実行します。ライフサイクルスクリプト
scriptsで定義されるスクリプトの中には特別な意味を持つものがあります。これらをライフサイクルスクリプト (lifecycle scripts) と呼びます。ライフサイクルスクリプトを使うとnpmの処理にフックをかけることができます。ライフサイクルスクリプトのうち重要なのは以下の2種類です。
- prepublish / prepublishOnly / prepare / prepack / postpack / publish / postpublish ... パッケージをレジストリに上げるときに呼ばれます。
- preinstall / install / postinstall ... パッケージがインストールされるときに呼ばれます。「依存関係として」「ローカルパッケージとして」「アプリケーションとして」の区別を問いません。
原則として、「preのついているフック」→「フック対象の処理」→「接頭辞なしのフック」→「postのついているフック」の順で呼ばれます。たとえばinstallの場合、以下の順番に呼ばれます4。
preinstallフック- npmが行うインストール処理
installフックpostinstallフック上記の重要なライフサイクルスクリプトの関係をまとめたのが以下の図です。
ただし、prepublish以下のフックは様々な事情からサポート状況がまちまちです。以下の表を参照してください。
npm2 npm3 npm4 npm5 npm6 npm7 yarn prepublish (pack / publish) ○ ○ ○ ○ ○ ○※1 prepublish (git install) ○ prepublish (local install) ○ ○ ○ ○ ○ ○ ○ prepare (pack / publish) ○ ○ ○ ○※2 prepare (git install) ○ ○ ○ prepare (local install) ○ ○ ○ ○ ○ prepublishOnly ○ ○ ○ ○ ○ prepack / postpack (pack / publish) ○ ○ ○ ○ prepack / postpack (git install) ○ ○ × × (pre-, post-)shrinkwrap ○ ○ ※ バグと思われるものには×をつけている
※1 prepublishはyarn publishでは実行されるがyarn packでは実行されない
※2 npm7では、pack/publish内のprepareはprepackの直前ではなく直後に実行されるこれらの状況を踏まえて、以下のようにスクリプトを配置するのがよいでしょう。
- トランスパイルが必要なパッケージではトランスパイルを
prepackで行う。ただし、git依存関係のprepack呼び出しは現時点でnpm/yarnともに盛大にバグっているので、将来的なバグ修正に期待するしかないでしょう。- ネイティブパッケージのビルドは
installで行う。その他、npmが規定するライフサイクルスクリプトとして以下があります。
- preuninstall, uninstall, postuninstall ...
npm uninstallにフックします。- preversion, version, postversion ...
npm versionにフックします。- preshrinkwrap, shrinkwrap, postshrinkwrap ...
npm shrinkwrapにフックします。- pretest, test, posttest ...
npm testのときに呼ばれます。- prestart, start, poststart ...
npm startのときに呼ばれます。- prestop, stop, poststop ...
npm stopのときに呼ばれます。- prerestart, restart, postrestart ...
npm restartのときに呼ばれます。また、
npm run/yarn runも実際にはpre/postスクリプトを実行します。たとえばnpm run buildはprebuild,build,postbuildの3つのスクリプトを実行することになります。 (preprebuildなどは実行しません) 上に挙げたうちtest/start/stop/restartは単にnpm runのrunを省略できるケースともみなせます。また、npmにはいくつか既定のスクリプトが存在します。
start:node server.js(server.jsというファイルがある場合のみ)install:node-gyp rebuild(binding.gypというファイルがあり、install/preinstallがどちらも定義されていない場合のみ)restart:stopしてからstartするのがデフォルトの挙動です。なお、yarn v2 (berry) ではライフサイクルスクリプトの扱いが大幅に整理されていて、使えるスクリプトも限定されているようです。詳しくはLifecycle Scriptsを参照してください。
npm link / yarn link
npm/yarnはデフォルトではシンボリックリンクを使いませんが、シンボリックリンク操作のためのコマンドとして
npm link/yarn linkが存在しています。主に以下の2つの用途があります。
- 開発中のコマンドラインアプリケーションをグローバルに利用可能な状態にする (
npm linkのみ)- 開発中のライブラリを別のパッケージから利用可能な状態にする (
npm link/yarn link)アプリケーションのリンク
package.jsonのあるディレクトリでnpm linkを無引数で実行すると$PREFIX/lib/node_modules以下に作業中のパッケージ (カレントディレクトリ) へのシンボリックリンクが作成されます。また、$PREFIX/binに対応するシンボリックリンクが作成されます。これらのディレクトリはnpm install -gが使用しているものと同じなので、実質的にローカルパッケージのコマンドをグローバルに利用可能な状態にしていることになります。無引数の
npm linkは「シンボリックリンクであること」以外はnpm install -gと同じなので、npm uninstall -g <パッケージ名>で元に戻せます。 (なお、npm unlinkはnpm uninstallのエイリアスです)ライブラリのリンク (npm link)
npm linkにパッケージ名を引数にして実行すると、$PREFIX/lib/node_modules/$package_nameが指していたディレクトリへのシンボリックリンクが./node_modules/$package_nameとして作成されます。 (元々./node_modules/$package_nameに展開されていたファイルは消滅します)このコマンドは通常、「無引数の
npm link」と組み合わせて以下のように使うことが想定されています。cd /path/to/foo1 npm link cd /path/to/bar1 npm link foo1 # foo1 は/path/too/foo1/package.jsonに記載のパッケージ名 # 以降はbar1は /path/to/foo1のソースを参照するようになるこの操作の正しい取り消し方法はわかりませんが、以下のようにすると良さそうです。なお、
npm unlinkはnpm uninstallのエイリアスであり、npm linkの逆を行ってくれるわけではありません。npm uninstall --no-save $package_name npm install --forceライブラリのリンク (yarn link)
yarn linkも同様の目的で使うことができます。
- 無引数の
yarn linkは~/.config/yarn/link/$package_nameというシンボリックリンクを作成します。- 引数つきの
yarn link $package_nameは./node_modules/$package_nameを消し、~/.config/yarn/link/$package_nameへのシンボリックリンクで置き換えます。
npm linkが作成するシンボリックリンクは直接参照ですが、yarn linkが作成するシンボリックリンクは間接参照になるようです。使い方は
npm linkと同じです。cd /path/to/foo1 yarn link cd /path/to/bar1 yarn link foo1 # foo1 は/path/too/foo1/package.jsonに記載のパッケージ名 # 以降はbar1は /path/to/foo1のソースを参照するようになる
yarn linkを取り消すには以下のようにします。 (npmとは異なり、yarn unlinkはlinkの逆をするためのコマンドです)yarn unlink
yarn link $package_nameを取り消すには以下のようにします。yarn unlink foo1 # foo1 はyarn linkしていた依存関係のパッケージ名 yarn install --forcelinkの問題点
linkを使うと、利用側パッケージの動作を確認しながらライブラリを編集できるようになります。しかしNode.jsの
requireの挙動上、linkした依存関係は通常の依存関係とは異なる挙動をすることがあります。これは以下の2つの理由によります。
- 依存元パッケージの
node_modulesを参照できないこと。- ライブラリ側の
node_modulesが優先されてしまうこと。上記の理由により、以下のような現象が発生する可能性があります。
- 間接依存関係のバージョンが一致しない。 (ライブラリ側が使うバージョンはライブラリ側の
package-lock.json/yarn.lockに基づいて決まるため)- peerDependenciesに書かれたパッケージが見つからない。 (peerDependenciesは依存元パッケージ側の
node_modulesに存在するため)- 間接依存関係のバージョンが同じで、巻き上げの条件を満たしていても、二重requireが発生する。
node_modulesを用いた古典的なパッケージ管理を使っている限り、これらを綺麗に解決するのは難しいですが、 1. については--preserve-symlinksオプションを使うことで緩和できる可能性があります。Node.jsは通常シンボリックリンクを明示的に展開しますが、--preserve-symlinksが指定されたときはこの挙動がスキップされます。これにより、../node_modulesや../../node_modulesを参照するときの親ディレクトリの計算結果が変化し、ライブラリ側から依存元パッケージのnode_modulesがrequireできるようになります。gulp / grunt
package.jsonのscriptsでは賄いきれないような複雑な処理 (タスク定義の共通化や依存管理) を定義したい場合は、GulpやGruntのようなタスクランナーを使うことができるようです5。ただし、JavaScriptのプロジェクトで行う必要があるタスクは典型的なもの (トランスパイルやバンドリング) が多く、TypeScriptやWebpackなどそれぞれのツールが依存管理を含めたパイプラインを提供しているため、これらで済んでしまうことも多いでしょう。まとめ
npm install -g/yarn global addを使うと、パッケージをグローバルにインストールし、CLIツールとして使うことができる。npm install/yarn addで追加したパッケージもnode_modules/.binにPATHを通すことでCLIツールとして使うことができる。npm/yarnの内部で呼ばれるコマンドはこのディレクトリにPATHが通った状態で呼ばれる。yarn exec/npx/npm execを使うと、任意のコマンドをnode_modules/.binにPATHが通った状態で実行することができる。また、npx/npm execに存在しないコマンドを渡した場合は、自動インストールが行われる。npm run(npm run-script) /yarn runを使うと、package.jsonのscriptsに登録されたコマンドを実行できる。yarn runのrunは省略できる。scriptsの中には特別なコマンド名がいくつかあり、npm/yarnの特定の処理にフックすることができる。どのフックが呼ばれるかはバージョンによる挙動の違いが激しいので注意が必要。
- ネイティブ拡張のビルドが必要な場合は
installかpostinstallで行うのがよい。- トランスパイルは
prepackで行うのがよいが、現状ではnpm/yarnともにバグがあってあまりうまく動かない。npm link/yarn linkを使うと、別のディレクトリにあるパッケージを直接使うことができる。アプリケーションの動作を確認しながらライブラリの開発するのに有用だが、依存解決の観点からはlinkによって異なる挙動をする可能性があるため、注意が必要。npm run/yarn runは単なるスクリプト実行機能しかないので、Makefileのようなより複雑なタスク管理が必要ならGulpやGruntなどのタスクランナーを使うのがよい。ただし、トランスパイルやアセットのビルドなど典型的なものであれば、Webpackなどそれに特化したツールで目的を達成できることも多い。次回はモジュールバンドラーの基本的な役割と実装について、webpackを例に説明します。

- 投稿日:2020-10-26T21:21:35+09:00
【Linebot】ピストルズと自然な会話をできるbotを作った話【初心者向け】
概要
少し前に毎日天気予報を通知したり、結婚記念日などの特定の日付にメッセージを送るbotを作りました。
今回はこのbotを改良し、自然な会話ができるようにしてみました。
(参考)
https://qiita.com/ko_seven/items/66cbccced520e0530cdf会話のロジック自体は自作ではなく、A3RTのSmall Talk APIというリクルートが開発しているAPIサービスを活用します。
利用にお金はかからず、APIキーの発行だけで良いので非常に手軽です。デモ環境もあるので興味ある方はお試しあれ。
(参考)
https://a3rt.recruit-tech.co.jp/product/talkAPI/Herokuの環境構築とLineアカウントの用意について
以前記念日を通知してくれるbotを作った際のことを以下の記事にまとめています。
こちらを参照ください。
https://qiita.com/ko_seven/items/66cbccced520e0530cdf返信する部分のロジックについて
webhookを通して返信をする部分をIndex.js
smallTalkのAPIを使う部分をsmalltalk.js
としてファイルを分ける。それぞれのソースは以下の通り。
以下のサイトを参考にさせていただきました。
(参考)
https://qiita.com/Illly/items/350d6631495ef8aea652index.js// ----------------------------------------------------------------------------- // モジュールのインポート const server = require("express")(); const line = require("@line/bot-sdk"); // Messaging APIのSDKをインポート var request = require('request'); const smallTalk = require('./smalltalk'); // smallTalk.js 後述 // ----------------------------------------------------------------------------- // パラメータ設定 const line_config = { channelAccessToken: process.env.LINE_ACCESS_TOKEN, // 環境変数からアクセストークンをセットしています channelSecret: process.env.LINE_CHANNEL_SECRET // 環境変数からChannel Secretをセットしています }; const actoken = process.env.LINE_ACCESS_TOKEN; // ----------------------------------------------------------------------------- // Webサーバー設定 server.listen(process.env.PORT || 3000); // ----------------------------------------------------------------------------- // APIコールのためのクライアントインスタンスを作成 const bot = new line.Client(line_config); // ルーター設定 server.post('/bot/webhook', line.middleware(line_config), (req, res, next) => { // 先行してLINE側にステータスコード200でレスポンスする。 res.sendStatus(200); Promise .all(req.body.events.map(handleEvent)) .then((result) => res.json(result)); }); //イベント処理関数 function handleEvent(event){ if (event.type !== 'message' || event.message.type !== 'text') { return bot.replyMessage(event.replyToken, { type: "text", text: "ちょっと何をいっているかわからないです" }); }else if (event.type == "message" && event.message.type == "text") { console.log(event.message.text); //返信処理 const userText = event.message.text; // ユーザーの送ってくれたテキスト smallTalk(userText) //ユーザが送ったテキストを引数にいれてsmallTalkを呼ぶ .then((smallTalkRes) => { return bot.replyMessage(event.replyToken, { type: "text", text: smallTalkRes }); }) .catch((err) => { return bot.replyMessage(event.replyToken, { type: "text", text: 'err' }); }) }else{ return bot.replyMessage(event.replyToken, { type: "text", text: "ちょっと何をいっているかわからないです" }); } }index.js// パッケージのインポート const request = require('request'); // Talk APIを利用するためにPOSTするURLとAPI Key const smallTalkApiKey = '******'; const smallTalkRequestUrl = 'https://api.a3rt.recruit-tech.co.jp/talk/v1/smalltalk'; // 以下のfunctionをモジュール化 // 引数はユーザーからのテキスト module.exports = function(userText){ // Talk APIが受け付けるリクエスト情報 const smallTalkRequestOption = { url: smallTalkRequestUrl, form: { apikey: smallTalkApiKey, query: userText } }; // Promiseを返す return new Promise((resolve, reject) => { // POST リクエストを送信する request.post(smallTalkRequestOption, function(err, res, body){ if(err){ reject(err); } // Talk APIから受け取ったstring型のレスポンスをJavaScript Objectにする const bodyObj = JSON.parse(body); // .results[0].replyはTalk APIからの返信 if(bodyObj.results[0].reply){ resolve(bodyObj.results[0].reply); // 返信がある場合はそれをresolve } else { reject('Invalid response from smallTalk'); // ない場合はreject } }); }); }これだけです。超絶簡単ですね。
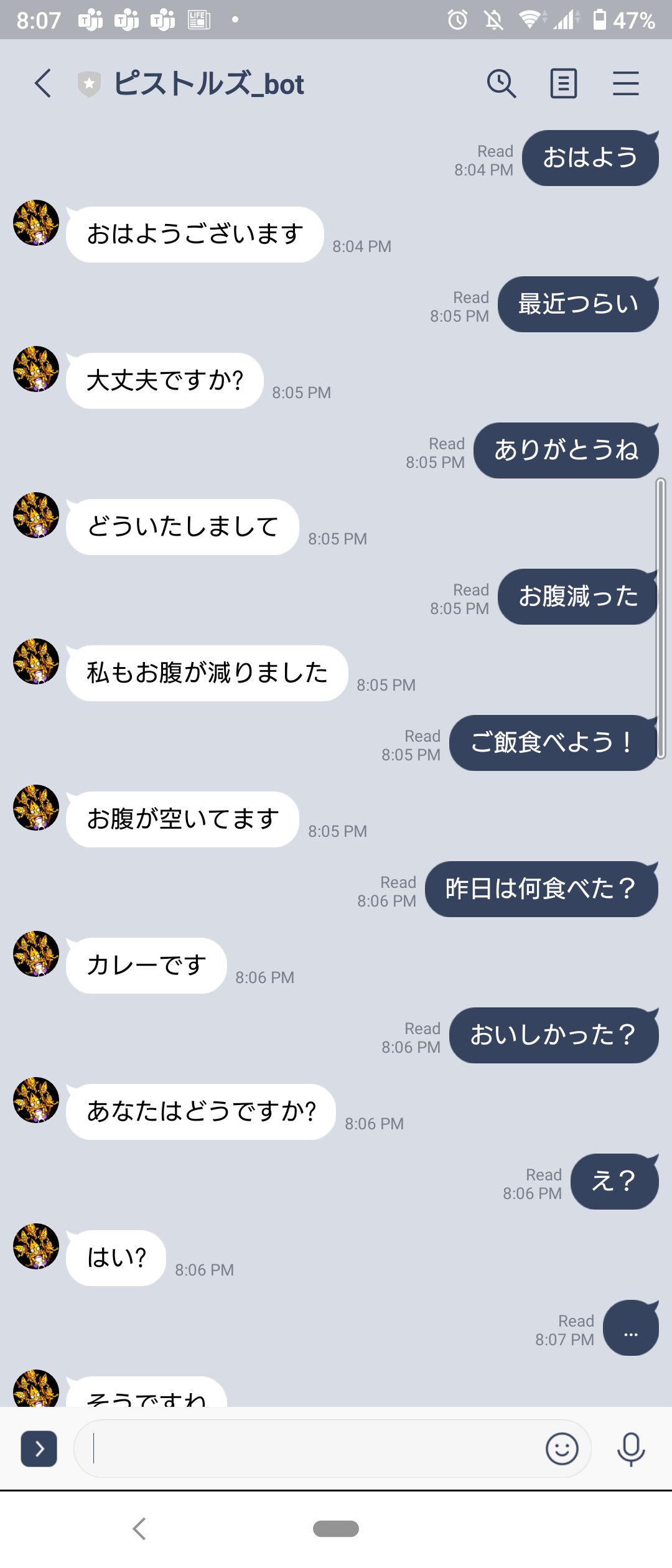
完成したもの
Lineのアイコンは個人的に好きなジョジョ5部よりピストルズを採用。
ちょっと後半の会話は変な空気になってしまいましたが、まぁ自然な会話ができているようですね。
ピストルズが結構礼儀正しい子になっちゃったのは違和感ありますが、そこはご愛嬌ということで。。。まとめ
自然言語処理を活用したbotって作る前はすごく難しいそうなイメージを持っていましたが、いざやってみると超簡単でした。
会話を行う機械学習の部分を自作するとなるともっと大変なんでしょうが、ある程度のレベルであれば適切に外部サービスを利用するほうがコスパがよいですね。
ちなみにAPIの処理上仕方ないのですが、画像やスタンプなどでは反応できませんし、英語でも会話という会話はできません。
そのうちマルチ言語対応したモデルも広く普及するのかしら。
- 投稿日:2020-10-26T21:18:13+09:00
【JavaScript】開発を行う前に整理しておきたい言葉
「言語」、「フレームワーク」、「ミドルウエア」、「ライブラリー」、「テンプレートエンジン」など様々な言葉には意味がある。
今回は「JavaScript」と「Node.js」について整理した。■ JavaScriptとNode.jsについて
JavaScript:JavaScriptはブラウザ上で動くために開発されたプログラミング言語。
Node.js:サーバサイドのJavaScript。■ Node.jsの特徴と強み
・サーバーサイドのJavaScript
⇢今まではフロントエンドでJavaScript、サーバーサイドでPHP、Pythonなどを使用することが一般的。
Node.jsを活用することでサーバーサイドもJavaScriptで記入することが出来る。
・シングルスレッド
⇢Node.jsは複数の処理を同時に行うマルチスレッドではない。Node.jsはシングルスレッドである。
マルチスレッドのようにリクエストごとにスレッドが立ち上がる処理方式ではない。
前の処理が終わっていないと次の処理が始まらない。
・ノンブロッキングI/O
⇢ノンブロッキングI/Oの特徴は結果を待たないで処理を進めることが出来る点。
⇢「シングルスレッド」と「ノンブロッキングI/O」を組み合わせたNode.jsは従来方式よりも効率的に処理を行うことが出来る。
※従来方式は「マルチスレッド」と「ブロッキングI/O」の組み合わせ。
ブロッキングI/Oは、I/Oが完了するまで次の処理に進まない。■ 言葉のイメージ
・値:データの中身
・型:データの入力形式
・変数:データを入れる箱
・関数:プログラムに処理させるふるまい
・引数:受け渡しを行う値■ 定義と使用区分の振り分け
・言語:Javascript、Node.jsなど
⇢PCに下す命令言語
・フレームワーク:Express、AngularJS、など
⇢JavaScriptを使用してWebサイト開発やWebアプリケーションを開発する際の土台として機能するソフト
・ミドルウェア:nginx、MySQL、PostgreSQL、など
⇢OS(オペレーティングシステム)とアプリケーションソフトの中間役割を担うソフト
・ライブラリー:React、jQuery、Vue、など
(node.jsで言うと)express-session、express-validator、など
⇢使用頻度の高い機能や効果などのプログラムをまとめたもの
・テンプレートエンジン:ejs、pugなど
⇢テンプレートと呼ばれるHTMLのひな形を元にプログラムで加工し、画面に出力するためのライブラリ。■ 変数の宣言
Javascriptでは変数名の入力する前に変数の宣言を行う。
使用するものは3種類。
var:変数を宣言し、ある値に初期化することもできる。
let:スコープのローカル変数を宣言し、ある値に初期化することもできる。
const:スコープで読み取り専用の名前付き定数を宣言する。■ データの型
Javascriptで主に使用するデータの型は以下の通り
▼基本型
・真偽値(Boolean): trueまたはfalseのデータ型
・数値(Number): 42 や 3.14159 などの数値のデータ型
・巨大な整数(BigInt): ES2020から追加された9007199254740992nなどの任意精度の整数のデータ型
・文字列(String): "JavaScript" などの文字列のデータ型
・undefined: 値が未定義であることを意味するデータ型
・null: 値が存在しないことを意味するデータ型
・シンボル(Symbol): ES2015から追加された一意で不変な値のデータ型
▼複合型
・プリミティブ型以外のデータ
・オブジェクト、配列、関数、正規表現、Dateなど■ 連想配列とは
・1~5はいずれも連想配列。
連想配列とはキーとバリューで成り立っている。【例】
// 1 var obj = { hoge: 'hoge' }; // 2 var obj = { 'hoge': 'hoge' }; // 3 var obj = {}; obj.hoge = 'hoge'; // 4 var obj = {}; obj['hoge'] = 'hoge'; // 5 var obj = new Object(); obj.hoge = 'hoge'; // 呼び出し方法はいずれも下記の通り obj.hoge■ 配列とは
・1~6いずれも配列。【例】
// 1 var array = ['hoge', 'fuga']; // 2 var array = new Array('hoge', 'fuga'); // 3 var array = Array('hoge', 'fuga'); // 4 var array = []; array[0] = 'hoge'; array[1] = 'fuga'; // 5 var array = []; array['0'] = 'hoge' array['1'] = 'hoge' // 6 var array = { 0: 'hoge', 1: 'fuga', length: 2 }; array.__proto__ = Array.prototype;■ MDN 文法とデータ型
https://developer.mozilla.org/ja/docs/Web/JavaScript/Guide/Grammar_and_types■ スコープ
JavaScriptでは関数の中で定義された変数やオブジェクトは関数の外からアクセスすることができない。
関数の中で定義された変数やオブジェクトを操作したい場合は同じ関数の中で処理を記述する必要がある。【例-1】
function hoge(){ var x = 0; } hoge(); console.log(x);⇢この場合console.log(x);でエラーとなる。変数xはhoge関数の中で定義されているため。
【例-2】
function hoge(){ var x = 0; console.log(x); } hoge();⇢この場合、エラーとならない。
■関数の定義
・関数の定義を行い、定義した関数を使用する。// 関数を定義する function 関数名(仮引数){ 実施したい処理内容 } // 関数を使用する 関数名();【例】
// add関数が定義される function add(a, b) { return a + b; } // add関数を出力する console.log(add(1, 2)); // この場合「add関数」と「log関数」が使用されている。・javascriptでは関数を変数に代入することができる。
つまりjavascriptでは関数も値。// addFunction変数にadd関数を代入 const addFunction = function add(a, b) { return a + b; } // addFunction変数を出力 console.log(addFunction(1, 2)); // 定義した関数を変数に入れることも出来る const addFunction = add;・Javascriptで関数は値。関数を複数回使用することもできる。
関数を受け取る関数を「高階関数」と呼ぶ。// 関数を2回実行する関数の作成 function toDoTwin(func) { func(); // 1回目の関数 func(); // 2回目の関数 } // Hello Worldが2回呼び出される toDoTwin(function() { console.log('Hello World'); });【例題】
配列を受け取って配列の末尾に数値3を加える関数を作る。
※配列に追加する関数は[].push(数値)で入れられる。【例】
var arr = [1,2] // 関数は動詞。キャメル型を使用。 function addNum(arr) { arr.push(3) return arr; }; addNum();※キャメル型の入力形式は下記参照。
https://qiita.com/am_nimitz3/items/7b01af53751dba5d8fb1■ 初期値について
function add(num1=0, num2=0){ return num1 + num2; } ① add (1,2); ② add (1); ③ add (); // 初期値を設定して関数を実行した場合、引数が入っていなくても関数を実行させることが出来る。 // ※初期値はなるべく空にしないこと。空にするのであれば仮引数の最後に設定する。この場合は引数が入っていないため、②、③がエラーとなる。
function add(num1, num2){ return num1 + num2; } ① add (1,2); ② add (1); ③ add ();■ 配列の中に入っているデータを関数で使用すること
function a (num1, num2){ var result = num1 + num2; return result; } var x = 1; var y = 2; var sum; sum= a(x,y); console.log(sum);・処理順序
varが宣言され、変数xが定義される。
変数xに1が代入される。
varが宣言され、変数yが定義される。
変数yに2が代入される。varが宣言され、変数sumが定義される。
変数sumが呼び出される。
関数aが呼び出される。
戻り値1,2が関数aに代入される。
戻り値1,2が足されて、変数resultに代入される。console.log関数で変数sumを呼び出す。
■ 連想配列に入っている値を取り出して関数を使用する
var data = { num1 = 1; num2 = 2; }; function b(data){ var result = data.num1 + data.num2; return result; } B(data); // ここでのポイントは連想配列のデータ呼び出し方法。 // 「変数名.キー」で呼び出すことが出来る。↓修正中
■ コールバック関数とは
シンプルに言うと「高階関数に渡すための関数」。
【例】setTimeout(function() { console.log('Hello World'); }, 2000);⇢この場合、2000ミリ秒後に「Hello World」と出力させる
■ 非同期処理とイベントとコールバック関数
非同期処理は「書いた順に動く」というプログラムの基本とは違う動きになる。「書かれているコードを今は飛ばして後で実行して」という矛盾した状況になる。JavaScriptの多くの非同期処理は、これを以下のような方法で実現。
・非同期処理関数はコールバック関数を受け取る高階関数にする
・利用者は「終わったら実行したい処理」をコールバック関数として渡す
・非同期処理関数は処理が終わったらコールバック関数を呼び出す非同期処理はコードを複雑化させてしまうため、非同期処理を簡単に扱うことができる、Promiseやasync/awaitという機能がある。
【例】
setTimeout() => { console.log('hello'), 500); console.log('world!'); };「world」が先に表示され、500ミリ秒が経過してから「hello」が表示される。
非同期処理では、実行順序はコード通りにはならない。
- 投稿日:2020-10-26T21:18:13+09:00
【JavaScript】開発を行う前に整理しておきたい言葉の定義
「言語」、「フレームワーク」、「ミドルウエア」、「ライブラリー」、「テンプレートエンジン」など様々な言葉には意味がある。
今回は「JavaScript」と「Node.js」について整理した。■ JavaScriptとNode.jsについて
JavaScript:JavaScriptはブラウザ上で動くために開発されたプログラミング言語。
Node.js:サーバサイドのJavaScript。■ Node.jsの特徴と強み
・サーバーサイドのJavaScript
⇢今まではフロントエンドでJavaScript、サーバーサイドでPHP、Pythonなどを使用することが一般的。
Node.jsを活用することでサーバーサイドもJavaScriptで記入することが出来る。
・シングルスレッド
⇢Node.jsは複数の処理を同時に行うマルチスレッドではない。Node.jsはシングルスレッドである。
マルチスレッドのようにリクエストごとにスレッドが立ち上がる処理方式ではない。
前の処理が終わっていないと次の処理が始まらない。
・ノンブロッキングI/O
⇢ノンブロッキングI/Oの特徴は結果を待たないで処理を進めることが出来る点。
⇢「シングルスレッド」と「ノンブロッキングI/O」を組み合わせたNode.jsは従来方式よりも効率的に処理を行うことが出来る。
※従来方式は「マルチスレッド」と「ブロッキングI/O」の組み合わせ。
ブロッキングI/Oは、I/Oが完了するまで次の処理に進まない。■ 言葉のイメージ
・値:データの中身
・型:データの入力形式
・変数:データを入れる箱
・関数:プログラムに処理させるふるまい
・引数:受け渡しを行う値■ 定義と使用区分の振り分け
・言語:Javascript、Node.jsなど
⇢PCに下す命令言語
・フレームワーク:Express、AngularJS、など
⇢JavaScriptを使用してWebサイト開発やWebアプリケーションを開発する際の土台として機能するソフト
・ミドルウェア:nginx、MySQL、PostgreSQL、など
⇢OS(オペレーティングシステム)とアプリケーションソフトの中間役割を担うソフト
・ライブラリー:React、jQuery、Vue、など
(node.jsで言うと)express-session、express-validator、など
⇢使用頻度の高い機能や効果などのプログラムをまとめたもの
・テンプレートエンジン:ejs、pugなど
⇢テンプレートと呼ばれるHTMLのひな形を元にプログラムで加工し、画面に出力するためのライブラリ。■ 変数の宣言
Javascriptでは変数名の入力する前に変数の宣言を行う。
使用するものは3種類。
var:変数を宣言し、ある値に初期化することもできる。
let:スコープのローカル変数を宣言し、ある値に初期化することもできる。
const:スコープで読み取り専用の名前付き定数を宣言する。■ データの型
Javascriptで主に使用するデータの型は以下の通り
▼基本型
・真偽値(Boolean): trueまたはfalseのデータ型
・数値(Number): 42 や 3.14159 などの数値のデータ型
・巨大な整数(BigInt): ES2020から追加された9007199254740992nなどの任意精度の整数のデータ型
・文字列(String): "JavaScript" などの文字列のデータ型
・undefined: 値が未定義であることを意味するデータ型
・null: 値が存在しないことを意味するデータ型
・シンボル(Symbol): ES2015から追加された一意で不変な値のデータ型
▼複合型
・プリミティブ型以外のデータ
・オブジェクト、配列、関数、正規表現、Dateなど■ MDN 文法とデータ型
https://developer.mozilla.org/ja/docs/Web/JavaScript/Guide/Grammar_and_types■ スコープ
JavaScriptでは関数の中で定義された変数やオブジェクトは関数の外からアクセスすることができない。
関数の中で定義された変数やオブジェクトを操作したい場合は同じ関数の中で処理を記述する必要がある。【例-1】
function hoge(){ var x = 0; } hoge(); console.log(x);⇢この場合console.log(x);でエラーとなる。変数xはhoge関数の中で定義されているため。
【例-2】
function hoge(){ var x = 0; console.log(x); } hoge();⇢この場合、エラーとならない。
■関数の定義
・関数の定義を行い、定義した関数を使用する。// 関数を定義する function 関数名(仮引数){ 実施したい処理内容 } // 関数を使用する 関数名();【例】
// add関数が定義される function add(a, b) { return a + b; } // add関数を出力する console.log(add(1, 2)); // この場合「add関数」と「log関数」が使用されている。・javascriptでは関数を変数に代入することができる。
つまりjavascriptでは関数も値。// addFunction変数にadd関数を代入 const addFunction = function add(a, b) { return a + b; } // addFunction変数を出力 console.log(addFunction(1, 2)); // 定義した関数を変数に入れることも出来る const addFunction = add;・Javascriptで関数は値。関数を複数回使用することもできる。
関数を受け取る関数を「高階関数」と呼ぶ。// 関数を2回実行する関数の作成 function toDoTwin(func) { func(); // 1回目の関数 func(); // 2回目の関数 } // Hello Worldが2回呼び出される toDoTwin(function() { console.log('Hello World'); });【例題】
配列を受け取って配列の末尾に数値3を加える関数を作る。
※配列に追加する関数は[].push(数値)で入れられる。【例】
var arr = [1,2] // 関数は動詞。キャメル型を使用。 function addNum(arr) { arr.push(3) return arr; }; addNum();※キャメル型の入力形式は下記参照。
https://qiita.com/am_nimitz3/items/7b01af53751dba5d8fb1■ 初期値について
function add(num1=0, num2=0){ return num1 + num2; } ① add (1,2); ② add (1); ③ add (); // 初期値を設定して関数を実行した場合、引数が入っていなくても関数を実行させることが出来る。 // ※初期値はなるべく空にしないこと。空にするのであれば仮引数の最後に設定する。この場合は引数が入っていないため、②、③がエラーとなる。
function add(num1, num2){ return num1 + num2; } ① add (1,2); ② add (1); ③ add ();↓修正中
■ コールバック関数とは
シンプルに言うと「高階関数に渡すための関数」。
【例】setTimeout(function() { console.log('Hello World'); }, 2000);⇢この場合、2000ミリ秒後に「Hello World」と出力させる
■ 非同期処理とイベントとコールバック関数
非同期処理は「書いた順に動く」というプログラムの基本とは違う動きになる。「書かれているコードを今は飛ばして後で実行して」という矛盾した状況になる。JavaScriptの多くの非同期処理は、これを以下のような方法で実現。
・非同期処理関数はコールバック関数を受け取る高階関数にする
・利用者は「終わったら実行したい処理」をコールバック関数として渡す
・非同期処理関数は処理が終わったらコールバック関数を呼び出す非同期処理はコードを複雑化させてしまうため、非同期処理を簡単に扱うことができる、Promiseやasync/awaitという機能がある。
【例】
setTimeout() => { console.log('hello'), 500); console.log('world!'); };「world」が先に表示され、500ミリ秒が経過してから「hello」が表示される。
非同期処理では、実行順序はコード通りにはならない。
- 投稿日:2020-10-26T01:13:01+09:00
TypeScript + Jestでfsをモックする
TypeScriptでライブラリを作っていて、ユニットテスト内でfsをモックしようとしたときにやり方がわからず苦労したので残しておきます。
環境
Node.js
v12.18.1
TypeScript
4.0.3
Jest
26.6.0
背景
GrafanaをWeb API経由で管理するライブラリのユニットテスト内でファイルを扱っていました。
以下のようなテスト対象のクラスがあるため、fsをユニットテスト内でモックするためにJestのmocking機能を利用しました。Sample.tsexport class Sample { readFile(source: string): string { if (!fs.existsSync(source) { throw new Error(); } else { return fs.readFileSync(source, { encoding: "utf8" }); } } }モッキング方法
方法1
こちらの記事でも取り上げられている方法になります。
しかし、こちらではうまくいきませんでした。Sample.test.tsjest.mock('fs', () => ({ readFileSync: jest.fn(() => `first¥n second¥n third`), })); import * as fs from "fs"; import { Sample } from "./Sample"; describe("Smaple test", () => { beforeEach(() => { // mockClearが定義されていないため、トランスパイルできない fs.readFileSync.mockClear(); fs.existsSync.mockClear(); }); it("ファイルが存在しない", () => { fs.existsSync.mockImplementation(() => false); fs.readFileSync.mockImplementation(() => ""); const sample = new Sample(); expect(() => sample.readFile("foo.txt")).toThrow(); }); it("ファイルが空でない", () => { fs.existsSync.mockImplementation(() => true); fs.readFileSync.mockImplementation(() => "sample"); const sample = new Sample(); const result = sample.readFile("foo.txt"); expect(result).toBe("sample"); }); });方法2
ts-jestの中にあるUtilクラスを使って、モックを行う方法になります。
ts-jestはjestをTypeScript環境でも使うためのパッケージです。Jestの公式ドキュメントでも言及されているので、安心です。使う際に気を付けることは使用しているAPIと同様にmockImplementationを実装する点です。
Sample.test.ts// ここでts-jestのモック作成Utilをインポート import { mocked } from "ts-jest/utils"; // fsをモック jest.mock('fs'); import { Sample } from "./Sample"; describe("Smaple test", () => { it("ファイルが存在しない", () => { // 対象の関数をモックする mocked(fs.existsSync).mockImplementation((_) => false); mocked(fs.readFileSync).mockImplementation((_, __) => "sample"); const sample = new Sample(); expect(() => sample.readFile("foo.txt")).toThrow(); }); it("ファイルが空でない", () => { // 対象の関数をモックする mocked(fs.existsSync).mockImplementation((_) => true); mocked(fs.readFileSync).mockImplementation((_, __) => "sample"); const sample = new Sample(); const result = sample.readFile("foo.txt"); expect(result).toBe("sample"); }); });結論
ts-jestのutilsを使うのがベストです。
毎回、mockImplementationを行う必要がありそうですが(もしかしたらいらないかも)、
テストコード内で共通関数を呼び出すなど工夫をすれば、そこまで気にしないで済みそうです。